
Upload 2 files
Browse files
README.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fine-tuned BERT-based model to accurately translate Weiss Schwarz cards.
|
| 2 |
+
### Model on HuggingFace here: https://huggingface.co/EricZ0u/WeissTranslate
|
| 3 |
+
|
| 4 |
+
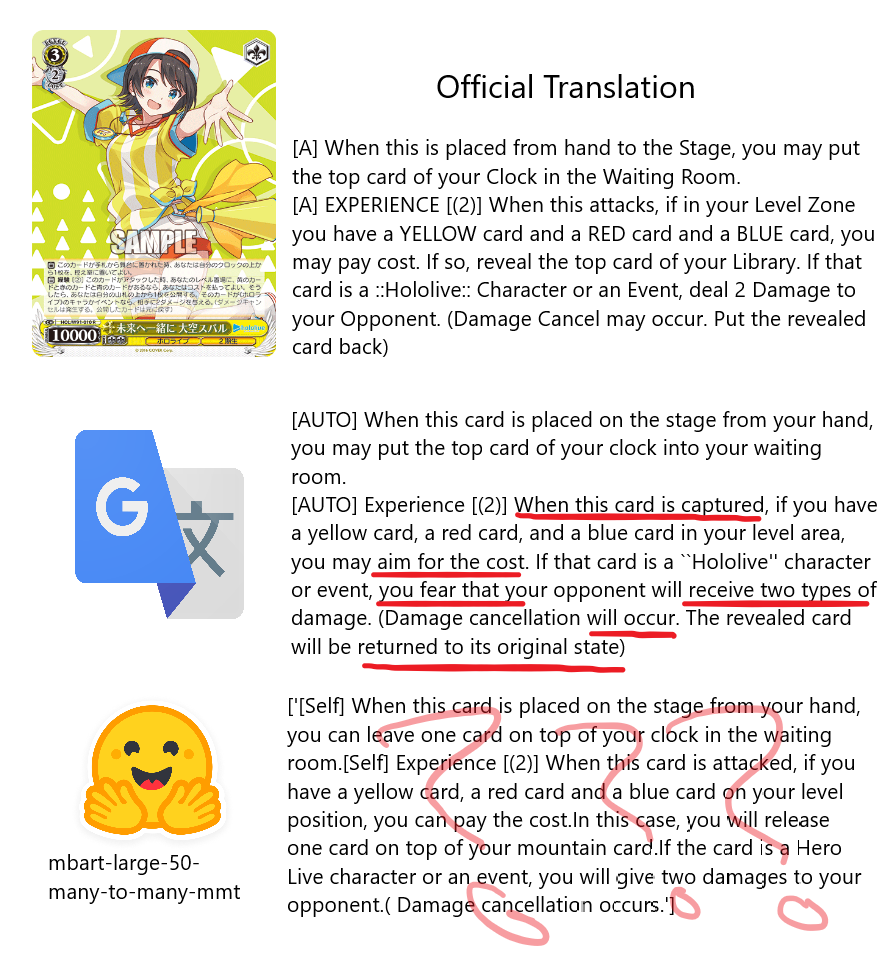
Weiss Schwarz is a trading card game by Japanese company Bushiroad. It plays cards out of a 50-card deck where each card will have a number of lengthy, specifically-worded effects. This makes the game known for being very beginner-unfriendly, sometimes referred to as a "paragraph reading simulator". This is made worse by the fact that many sets in the game are exclusively printed in the Japanese language, so the choices are to either print out a thick stack of translations, memorize every card, or fumble with google translate(Makes wording very weird and confusing, especially for new players). I'm aiming to build a bert-based model that can accurately translate Japanese cards so the wording is the same as their english counterparts. I plan to add a function to tag card effects to make them easier to search, and hopefully integrate this all into an app to image translate cards instantly.
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
### 6/6/24
|
| 8 |
+
Did some more training with a slightly larger pool of data(40 training, 10 validation). I'm not using a defined metric(like BLEU) just yet, but going by eye the translations are a lot cleaner than the model I started with, "focus" is now BRAINSTORM and "mountain札" is now library. A lot better! There are still some wonky bits though, like "backup" is "skull sword"??. I definitely need to expand the dataset, but besides that I do want to tweak the hyperparameters. I'm on Google Colab Pro already, but their A100 instances are never available and I can't go past a batch size of 8 on their L4 instances. While it should theoretically be enough, I do want to try going on AWS to get more freedom.
|
| 9 |
+
### 6/5/24
|
| 10 |
+
Worked on getting a large corpus of training data. I'm going to need multiple series-worth of data as no one set has an instance of every effect in the game. The current solution is taking a list of the english translations for a whole set(looks like this https://www.heartofthecards.com/translations/hololive_production_booster_pack.html) off of heartofthecards, extracting the text to a .txt, then using a simple python script to populate the english part of the JSON for training. As I couldn't find a sheet of card text like this for Japanese, I just manually copy/pasted data in. It was pretty quick, but if I need more data in the future I might need to use some Japanese search engines to find an easily scrapeable list of Japanese card effects.
|
| 11 |
+
### 6/4/24
|
| 12 |
+
Started training. I chose to do the data in JSON, and gathered some quick data to do an initial proof of concept. First issue I ran into was that the instance was running out of RAM and crashing while training. I solved this by decreasing the batch size from 16 to 8 and increasing the learning rate accordingly . There was also a weird issue with accelerate, with it being up to date but colab not recognizing that it was up to date. The solution I found for this on HF forums was just to pip update it, then restart the runtime and then not pip any other packages. Weird, but worked.
|
| 13 |
+
### 6/3/24
|
| 14 |
+
Exploring models to retrain. There weren't many specific Japanese to English models on huggingface, so I settled on using "facebook/mbart-large-50-many-to-many-mmt", which seems to be pretty popular. It uses 50 languages, so I will just take the tokenizer for Japanese and do the fine tuning on that
|
lol.png
ADDED
|