---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen3-1.7B
pipeline_tag: text-generation
library_name: transformers
---
# Lucy-128k GGUF Models
## Model Generation Details
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`c82d48ec`](https://github.com/ggerganov/llama.cpp/commit/c82d48ec23fb8749c341d0838f6891fd5f6b6da0).
---
## Quantization Beyond the IMatrix
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
Click here to get info on choosing the right GGUF model format
---
# Lucy: Edgerunning Agentic Web Search on Mobile with a 1.7B model.
[](https://github.com/menloresearch/deep-research)
[](https://opensource.org/licenses/Apache-2.0)
**Authors:** [Alan Dao](https://scholar.google.com/citations?user=eGWws2UAAAAJ&hl=en), [Bach Vu Dinh](https://scholar.google.com/citations?user=7Lr6hdoAAAAJ&hl=vi), [Alex Nguyen](https://github.com/nguyenhoangthuan99), [Norapat Buppodom](https://scholar.google.com/citations?user=utfEThsAAAAJ&hl=th&authuser=1)

## Overview
Lucy is a compact but capable 1.7B model focused on agentic web search and lightweight browsing. Built on [Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B), Lucy inherits deep research capabilities from larger models while being optimized to run efficiently on mobile devices, even with CPU-only configurations.
We achieved this through machine-generated task vectors that optimize thinking processes, smooth reward functions across multiple categories, and pure reinforcement learning without any supervised fine-tuning.
## What Lucy Excels At
- **🔍 Strong Agentic Search**: Powered by MCP-enabled tools (e.g., Serper with Google Search)
- **🌐 Basic Browsing Capabilities**: Through Crawl4AI (MCP server to be released), Serper,...
- **📱 Mobile-Optimized**: Lightweight enough to run on CPU or mobile devices with decent speed
- **🎯 Focused Reasoning**: Machine-generated task vectors optimize thinking processes for search tasks
## Evaluation
Following the same MCP benchmark methodology used for [Jan-Nano](https://huggingface.co/Menlo/Jan-nano) and [Jan-Nano-128k](https://huggingface.co/Menlo/Jan-nano-128k), Lucy demonstrates impressive performance despite being only a 1.7B model, achieving higher accuracy than DeepSeek-v3 on [SimpleQA](https://openai.com/index/introducing-simpleqa/).
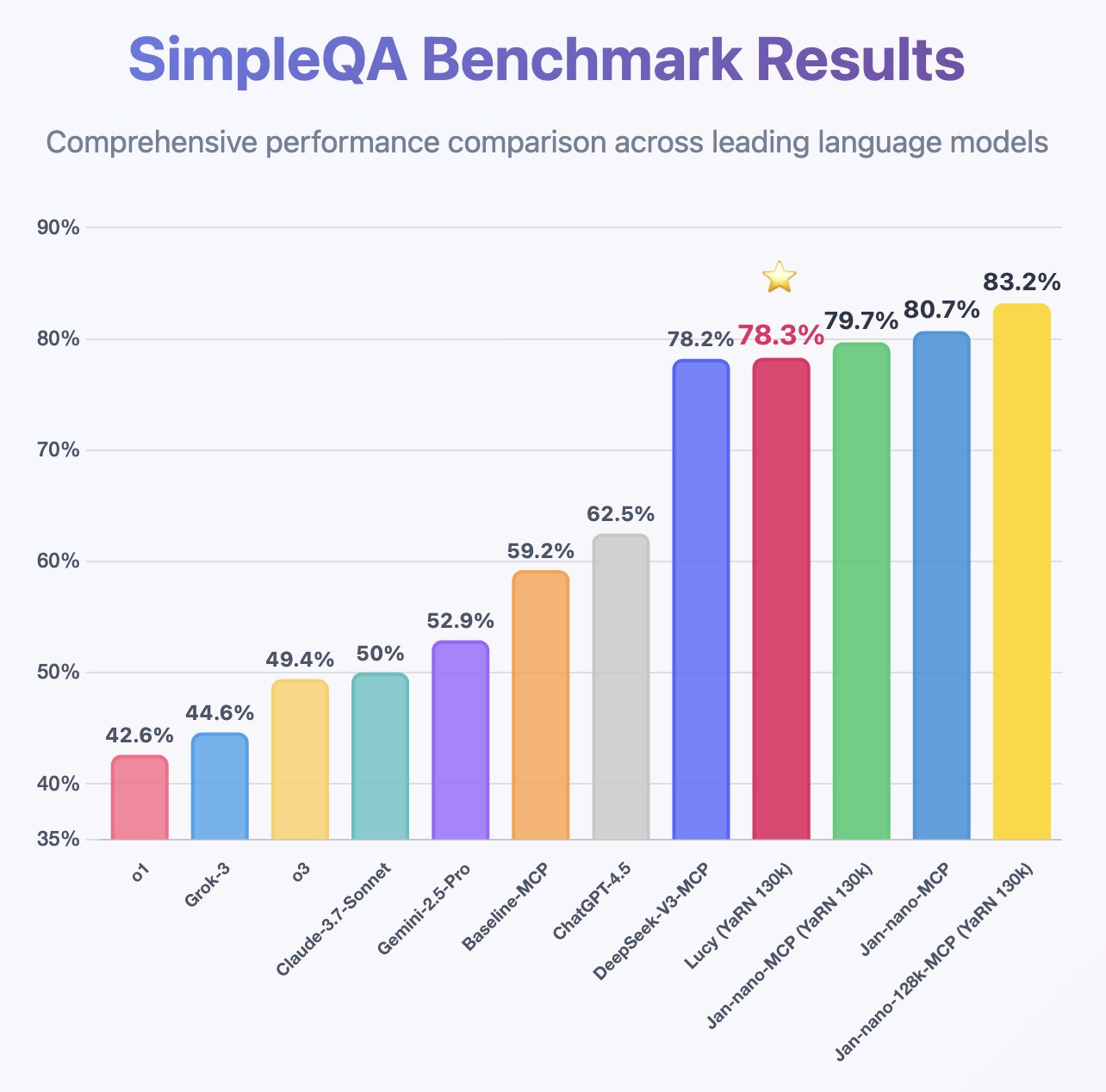
## 🖥️ How to Run Locally
Lucy can be deployed using various methods including vLLM, llama.cpp, or through local applications like Jan, LMStudio, and other compatible inference engines. The model supports integration with search APIs and web browsing tools through the MCP.
### Deployment
Deploy using VLLM:
```bash
vllm serve Menlo/Lucy-128k \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--rope-scaling '{"rope_type":"yarn","factor":3.2,"original_max_position_embeddings":40960}' --max-model-len 131072
```
Or `llama-server` from `llama.cpp`:
```bash
llama-server ... --rope-scaling yarn --rope-scale 3.2 --yarn-orig-ctx 40960
```
### Recommended Sampling Parameters
```yaml
Temperature: 0.7
Top-p: 0.9
Top-k: 20
Min-p: 0.0
```
## 🤝 Community & Support
- **Discussions**: [HuggingFace Community](https://huggingface.co/Menlo/Lucy-128k/discussions)
## 📄 Citation
**Paper (coming soon)**: *Lucy: edgerunning agentic web search on mobile with machine generated task vectors.*
---
# 🚀 If you find these models useful
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a [Quantum Network Monitor Agent](https://readyforquantum.com/Download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) to run the .net code on. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
