
File size: 7,024 Bytes
e336f2f 2ac49cd da5220b 2ac49cd e336f2f 2ac49cd e336f2f 8b560fe 2ac49cd da5220b 2ac49cd da5220b 2ac49cd 1937dc4 2ac49cd e336f2f 00e246b 62021ad 1937dc4 62021ad 1937dc4 00e246b 62021ad a0728e8 62021ad 00e246b 62021ad 1937dc4 00e246b 62021ad 00e246b 62021ad c6bc75b 00e246b 2ac49cd adbbb2e |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 |
---
library_name: transformers
tags:
- reward
- RM
- Code
- AceCode
- AceCoder
license: mit
datasets:
- TIGER-Lab/AceCode-87K
- TIGER-Lab/AceCodePair-300K
language:
- en
base_model:
- Qwen/Qwen2.5-Coder-32B-Instruct
---
# 🂡 AceCoder
[Paper](https://arxiv.org/abs/2502.01718) |
[Github](https://github.com/TIGER-AI-Lab/AceCoder) |
[AceCode-87K](https://huggingface.co/datasets/TIGER-Lab/AceCode-87K) |
[AceCodePair-300K](https://huggingface.co/datasets/TIGER-Lab/AceCodePair-300K) |
[RM/RL Models](https://huggingface.co/collections/TIGER-Lab/acecoder-67a16011a6c7d65cad529eba)
We introduce AceCoder, the first work to propose a fully automated pipeline for synthesizing large-scale reliable tests used for the reward model training and reinforcement learning in the coding scenario. To do this, we curated the dataset AceCode-87K, where we start from a seed code dataset and prompt powerful LLMs to "imagine" proper test cases for the coding question and filter the noisy ones. We sample inferences from existing coder models and compute their pass rate as the reliable and verifiable rewards for both training the reward model and conducting the reinforcement learning for coder LLM.
**This model is the official AceCodeRM-32B trained from Qwen2.5-Coder-32B-Instruct on [TIGER-Lab/AceCodePair-300K](https://huggingface.co/datasets/TIGER-Lab/AceCodePair-300K)**

## Performance on RM Bench
| Model | Code | Chat | Math | Safety | Easy | Normal | Hard | Avg |
| ------------------------------------ | ---- | ----- | ----- | ------ | ----- | ------ | ---- | ---- |
| Skywork/Skywork-Reward-Llama-3.1-8B | 54.5 | 69.5 | 60.6 | 95.7 | **89** | 74.7 | 46.6 | 70.1 |
| LxzGordon/URM-LLaMa-3.1-8B | 54.1 | 71.2 | 61.8 | 93.1 | 84 | 73.2 | 53 | 70 |
| NVIDIA/Nemotron-340B-Reward | 59.4 | 71.2 | 59.8 | 87.5 | 81 | 71.4 | 56.1 | 69.5 |
| NCSOFT/Llama-3-OffsetBias-RM-8B | 53.2 | 71.3 | 61.9 | 89.6 | 84.6 | 72.2 | 50.2 | 69 |
| internlm/internlm2-20b-reward | 56.7 | 63.1 | 66.8 | 86.5 | 82.6 | 71.6 | 50.7 | 68.3 |
| Ray2333/GRM-llama3-8B-sftreg | 57.8 | 62.7 | 62.5 | 90 | 83.5 | 72.7 | 48.6 | 68.2 |
| Ray2333/GRM-llama3-8B-distill | 56.9 | 62.4 | 62.1 | 88.1 | 82.2 | 71.5 | 48.4 | 67.4 |
| Ray2333/GRM-Llama3-8B-rewardmodel-ft | 52.1 | 66.8 | 58.8 | 91.4 | 86.2 | 70.6 | 45.1 | 67.3 |
| LxzGordon/URM-LLLaMa-3-8B | 52.3 | 68.5 | 57.6 | 90.3 | 80.2 | 69.9 | 51.5 | 67.2 |
| internlm/internlm2-7b-reward* | 49.7 | 61.7 | **71.4** | 85.5 | 85.4 | 70.7 | 45.1 | 67.1 |
| Skywork-Reward-Llama-3.1-8B-v0.2* | 53.4 | 69.2 | 62.1 | **96** | 88.5 | 74 | 47.9 | 70.1 |
| Skywork-Reward-Gemma-2-27B-v0.2* | 45.8 | 49.4 | 50.7 | 48.2 | 50.3 | 48.2 | 47 | 48.5 |
| AceCoder-RM-7B | 66.9 | 66.7 | 65.3 | 89.9 | 79.9 | 74.4 | 62.2 | 72.2 |
| AceCoder-RM-32B | **72.1** | **73.7** | 70.5 | 88 | 84.5 | **78.3** | **65.5** | **76.1** |
| Delta (AceCoder 7B - Others) | 7.5 | \-4.6 | \-6.1 | \-6.1 | \-9.1 | \-0.3 | 6.1 | 2.1 |
| Delta (AceCoder 32B - Others) | 12.7 | 2.4 | \-0.9 | \-8 | \-4.5 | 3.6 | 9.4 | 6 |
\* These models do not have official results as they are released later than the RM Bench paper; therefore, the authors tried our best to extend the original code base to test these models. Our implementation can be found here:
[Modified Reward Bench / RM Bench Code](https://github.com/wyettzeng/reward-bench)
## Performance on Best-of-N sampling
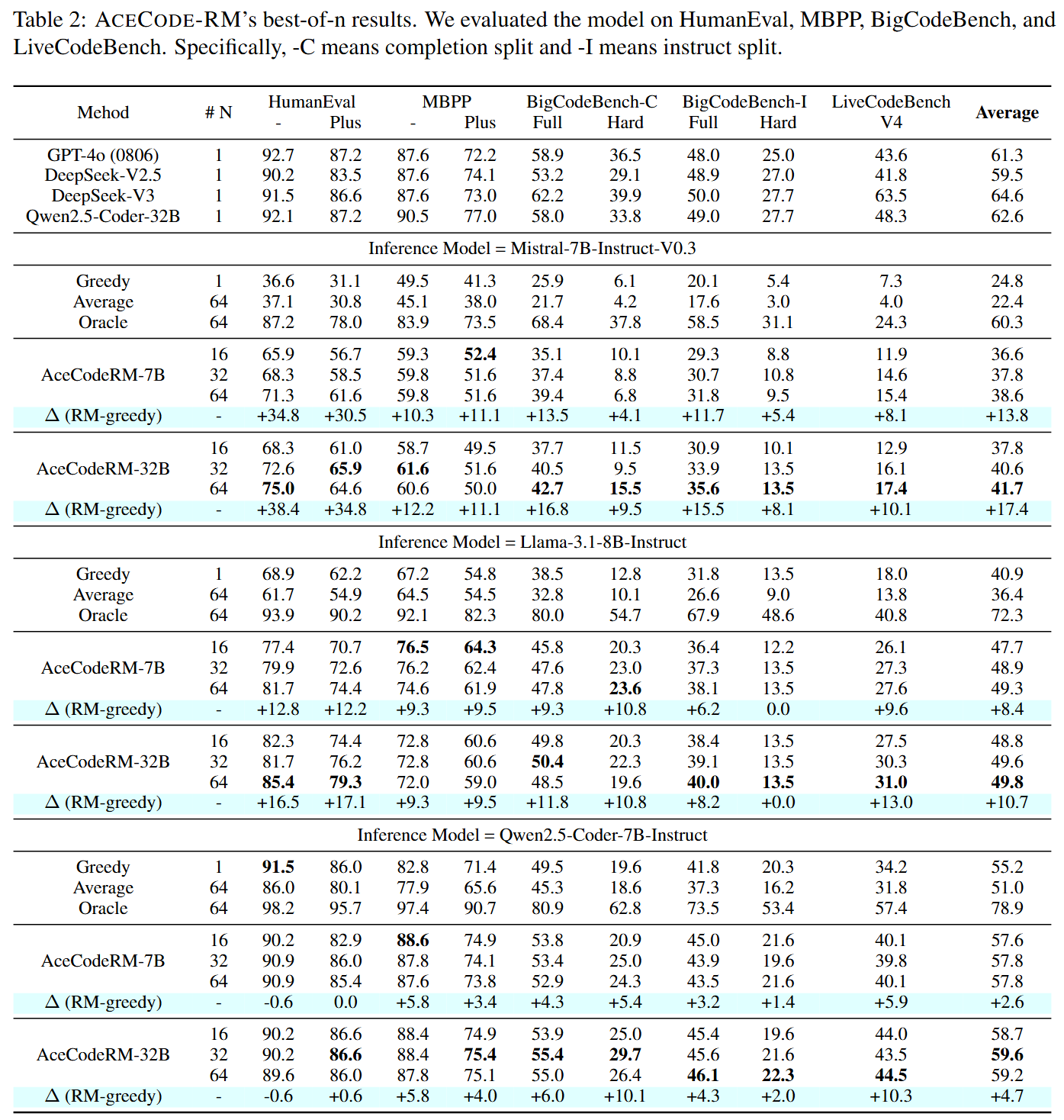
## Usage
- To use the RM to produce rewards, please apply the following example codes:
```python
"""pip install git+https://github.com/TIGER-AI-Lab/AceCoder"""
from acecoder import AceCodeRM
from transformers import AutoTokenizer
model_path = "TIGER-Lab/AceCodeRM-7B"
model = AceCodeRM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
question = """\
Given an array of numbers, write a function runningSum that returns an array where each element at index i is the sum of all elements from index 0 to i (inclusive).
For example:
Input: nums = [1,2,3,4]
Output: [1,3,6,10]
"""
program_with_3_errors = """\
def runningSum(nums):
result = []
current_sum = 0
for i in range(1, len(nums)):
result.append(nums[i])
current_sum += nums[i]
return result
"""
program_with_2_errors = """\
def runningSum(nums):
result = []
current_sum = 0
for i in range(0, len(nums)):
result.append(nums[i])
current_sum += nums[i]
return result
"""
program_with_1_errors = """\
def runningSum(nums):
result = []
current_sum = 0
for i in range(0, len(nums)):
result.append(current_sum)
current_sum += nums[i]
return result
"""
program_correct = """\
def runningSum(nums):
result = []
current_sum = 0
for num in nums:
current_sum += num
result.append(current_sum)
return result
"""
program_chats = [
[
{
"content": question,
"role": "user",
},
{
"role": "assistant",
"content": program
}
] for program in [program_with_3_errors, program_with_2_errors, program_with_1_errors, program_correct]
]
input_tokens = tokenizer.apply_chat_template(
program_chats,
tokenize=True,
return_dict=True,
padding=True,
return_tensors="pt",
).to(model.device)
rm_scores = model(
**input_tokens,
output_hidden_states=True,
return_dict=True,
use_cache=False,
)
print("RM Scores:", rm_scores)
print("Score of program with 3 errors:", rm_scores[0].item())
print("Score of program with 2 errors:", rm_scores[1].item())
print("Score of program with 1 errors:", rm_scores[2].item())
print("Score of correct program:", rm_scores[3].item())
"""
RM Scores: tensor([-20.5058, -1.7867, 0.4395, 23.0689], device='cuda:0',
grad_fn=<SqueezeBackward0>)
Score of program with 3 errors: -20.505754470825195
Score of program with 2 errors: -1.7866804599761963
Score of program with 1 errors: 0.43949759006500244
Score of correct program: 23.068859100341797
"""
```
- To use the RM for the RL tuning, please refer to our [Github Code](https://github.com/TIGER-AI-Lab/AceCoder) for more details
## Citation
```bibtex
@article{AceCoder,
title={AceCoder: Acing Coder RL via Automated Test-Case Synthesis},
author={Zeng, Huaye and Jiang, Dongfu and Wang, Haozhe and Nie, Ping and Chen, Xiaotong and Chen, Wenhu},
journal={ArXiv},
year={2025},
volume={abs/2207.01780}
}
``` |