
--update base
Browse files
README.md
CHANGED
|
@@ -1,101 +1,119 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
-
|
| 29 |
-
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
base_model:
|
| 6 |
+
- hexgrad/Kokoro-82M
|
| 7 |
+
- Qwen/Qwen2.5-0.5B-Instruct
|
| 8 |
+
- openai/whisper-tiny.en
|
| 9 |
+
- pyannote/segmentation-3.0
|
| 10 |
+
pipeline_tag: audio-to-audio
|
| 11 |
+
tags:
|
| 12 |
+
- speech-to-speech,
|
| 13 |
+
- conversational-ai,
|
| 14 |
+
- voice-chat,
|
| 15 |
+
- realtime,
|
| 16 |
+
- on-device
|
| 17 |
+
- cpu
|
| 18 |
+
---
|
| 19 |
+
# On Device Speech to Speech Conversational AI
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
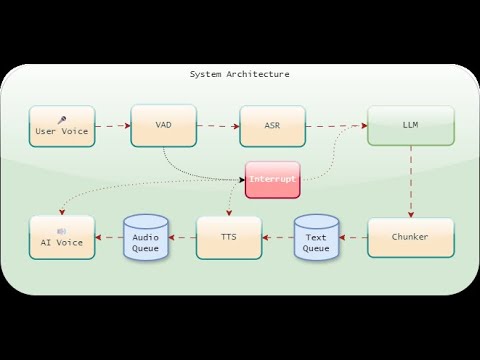
This is realtime on-device speech-to-speech AI model. It used a series to tools to achieve that. It uses a combination of voice activity detection, speech recognition, language models, and text-to-speech synthesis to create a seamless and responsive conversational AI experience. The system is designed to run on-device, ensuring low latency and minimal data usage.
|
| 23 |
+
|
| 24 |
+
<h2 style="color: yellow;">HOW TO RUN IT</h2>
|
| 25 |
+
|
| 26 |
+
1. **Prerequisites:**
|
| 27 |
+
- Install Python 3.8+ (tested with 3.12)
|
| 28 |
+
- Install [eSpeak NG](https://github.com/espeak-ng/espeak-ng/releases/tag/1.52.0) (required for voice synthesis)
|
| 29 |
+
- Install Ollama from https://ollama.ai/
|
| 30 |
+
|
| 31 |
+
2. **Setup:**
|
| 32 |
+
- Clone the repository `git clone https://github.com/asiff00/On-Device-Speech-to-Speech-Conversational-AI.git`
|
| 33 |
+
- Run `git lfs pull` to download the models and voices
|
| 34 |
+
- Copy `.env.template` to `.env`
|
| 35 |
+
- Add your HuggingFace token to `.env`
|
| 36 |
+
- Tweak other parameters in `.env`, if needed [Optional]
|
| 37 |
+
- Install requirements: `pip install -r requirements.txt`
|
| 38 |
+
- Add any missing packages if not already installed `pip install <package_name>`
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
4. **Run Ollama:**
|
| 42 |
+
- Start Ollama service
|
| 43 |
+
- Run: `ollama run qwen2.5:0.5b-instruct-q8_0` or any other model of your choice
|
| 44 |
+
|
| 45 |
+
5. **Start Application:**
|
| 46 |
+
- Run: `python speech_to_speech.py`
|
| 47 |
+
- Wait for initialization (models loading)
|
| 48 |
+
- Start talking when you see "Voice Chat Bot Ready"
|
| 49 |
+
- Long press `Ctrl+C` to stop the application
|
| 50 |
+
</details>
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
We basically put a few models together to work in a multi-threaded architecture, where each component operates independently but is integrated through a queue management system to ensure performance and responsiveness.
|
| 54 |
+
|
| 55 |
+
## The flow works as follows: Loop (VAD -> Whisper -> LM -> TextChunker -> TTS)
|
| 56 |
+
To achieve that we use:
|
| 57 |
+
- **Voice Activity Detection**: Pyannote:pyannote/segmentation-3.0
|
| 58 |
+
- **Speech Recognition**: Whisper:whisper-tiny.en (OpenAI)
|
| 59 |
+
- **Language Model**: LM Studio/Ollama with qwen2.5:0.5b-instruct-q8_0
|
| 60 |
+
- **Voice Synthesis**: Kokoro:hexgrad/Kokoro-82M (Version 0.19, 16bit)
|
| 61 |
+
|
| 62 |
+
We use custom text processing and queues to manage data, with separate queues for text and audio. This setup allows the system to handle heavy tasks without slowing down. We also use an interrupt mechanism allowing the user to interrupt the AI at any time. This makes the conversation feel more natural and responsive rather than just a generic TTS engine.
|
| 63 |
+
|
| 64 |
+
## Demo Video:
|
| 65 |
+
A demo video is uploaded here. Either click on the thumbnail or click on the YouTube link: [https://youtu.be/x92FLnwf-nA](https://youtu.be/x92FLnwf-nA).
|
| 66 |
+
|
| 67 |
+
[](https://youtu.be/x92FLnwf-nA)
|
| 68 |
+
|
| 69 |
+
## Performance:
|
| 70 |
+

|
| 71 |
+
|
| 72 |
+
I ran this test on an AMD Ryzen 5600G, 16 GB, SSD, and No-GPU setup, achieving consistent ~2s latency. On average, it takes around 1.5s for the system to respond to a user query from the point the user says the last word. Although I haven't tested this on a GPU, I believe testing on a GPU would significantly improve performance and responsiveness.
|
| 73 |
+
|
| 74 |
+
## How do we reduce latency?
|
| 75 |
+
### Priority based text chunking
|
| 76 |
+
We capitalize on the streaming output of the language model to reduce latency. Instead of waiting for the entire response to be generated, we process and deliver each chunk of text as soon as they become available, form phrases, and send it to the TTS engine queue. We play the audio as soon as it becomes available. This way, the user gets a very fast response, while the rest of the response is being generated.
|
| 77 |
+
|
| 78 |
+
Our custom `TextChunker` analyzes incoming text streams from the language model and splits them into chunks suitable for the voice synthesizer. It uses a combination of sentence breaks (like periods, question marks, and exclamation points) and semantic breaks (like "and", "but", and "however") to determine the best places to split the text, ensuring natural-sounding speech output.
|
| 79 |
+
|
| 80 |
+
The `TextChunker` maintains a set of break points:
|
| 81 |
+
- **Sentence breaks**: `.`, `!`, `?` (highest priority)
|
| 82 |
+
- **Semantic breaks** with priority levels:
|
| 83 |
+
- Level 4: `however`, `therefore`, `furthermore`, `moreover`, `nevertheless`
|
| 84 |
+
- Level 3: `while`, `although`, `unless`, `since`
|
| 85 |
+
- Level 2: `and`, `but`, `because`, `then`
|
| 86 |
+
- **Punctuation breaks**: `;` (4), `:` (4), `,` (3), `-` (2)
|
| 87 |
+
|
| 88 |
+
When processing text, the `TextChunker` uses a priority-based system:
|
| 89 |
+
1. Looks for sentence-ending punctuation first (highest priority 5)
|
| 90 |
+
2. Checks for semantic break words with their associated priority levels
|
| 91 |
+
3. Falls back to punctuation marks with lower priorities
|
| 92 |
+
4. Splits at target word count if no natural breaks are found
|
| 93 |
+
|
| 94 |
+
The text chunking method significantly reduces perceived latency by processing and delivering the first chunk of text as soon as it becomes available. Let's consider a hypothetical system where the language model generates responses at a certain rate. If we imagine a scenario where the model produces a response of N words at a rate of R words per second, waiting for the complete response would introduce a delay of N/R seconds before any audio is produced. With text chunking, the system can start processing the first M words as soon as they are ready (after M/R seconds), while the remaining words continue to be generated. This means the user hears the initial part of the response in just M/R seconds, while the rest streams in naturally.
|
| 95 |
+
|
| 96 |
+
### Leading filler word LLM Prompting
|
| 97 |
+
We use a another little trick in the LLM prompt to speed up the system’s first response. We ask the LLM to start its reply with filler words like “umm,” “so,” or “well.” These words have a special role in language: they create natural pauses and breaks. Since these are single-word responses, they take only milliseconds to convert to audio. When we apply our chunking rules, the system splits the response at the filler word (e.g., “umm,”) and sends that tiny chunk to the TTS engine. This lets the bot play the audio for “umm” almost instantly, reducing perceived latency. The filler words act as natural “bridges” to mask processing delays. Even a short “umm” gives the illusion of a fluid conversation, while the system works on generating the rest of the response in the background. Longer chunks after the filler word might take more time to process, but the initial pause feels intentional and human-like.
|
| 98 |
+
|
| 99 |
+
We have fallback plans for cases when the LLM fails to start its response with fillers. In those cases, we put hand breaks at 2 to 5 words, which comes with a cost of a bit of choppiness at the beginning but that feels less painful than the system taking a long time to give the first response.
|
| 100 |
+
|
| 101 |
+
**In practice,** this approach can reduce perceived latency by up to 50-70%, depending on the length of the response and the speed of the language model. For example, in a typical conversation where responses average 15-20 words, our techniques can bring the initial response time down from 1.5-2 seconds to just `0.5-0.7` seconds, making the interaction feel much more natural and immediate.
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
## Resources
|
| 106 |
+
This project utilizes the following resources:
|
| 107 |
+
* **Text-to-Speech Model:** [Kokoro](https://huggingface.co/hexgrad/Kokoro-82M)
|
| 108 |
+
* **Speech-to-Text Model:** [Whisper](https://huggingface.co/openai/whisper-tiny.en)
|
| 109 |
+
* **Voice Activity Detection Model:** [Pyannote](https://huggingface.co/pyannote/segmentation-3.0)
|
| 110 |
+
* **Large Language Model Server:** [Ollama](https://ollama.ai/)
|
| 111 |
+
* **Fallback Text-to-Speech Engine:** [eSpeak NG](https://github.com/espeak-ng/espeak-ng/releases/tag/1.52.0)
|
| 112 |
+
|
| 113 |
+
## Acknowledgements
|
| 114 |
+
This project draws inspiration and guidance from the following articles and repositories, among others:
|
| 115 |
+
* [Realtime speech to speech conversation with MiniCPM-o](https://github.com/OpenBMB/MiniCPM-o)
|
| 116 |
+
* [A Comparative Guide to OpenAI and Ollama APIs](https://medium.com/@zakkyang/a-comparative-guide-to-openai-and-ollama-apis-with-cheathsheet-5aae6e515953)
|
| 117 |
+
* [Building Production-Ready TTS with Kokoro-82M](https://medium.com/@simeon.emanuilov/kokoro-82m-building-production-ready-tts-with-82m-parameters-unfoldai-98e36ff286b9)
|
| 118 |
+
* [Kokoro-82M: The Best TTS Model in Just 82 Million Parameters](https://medium.com/data-science-in-your-pocket/kokoro-82m-the-best-tts-model-in-just-82-million-parameters-512b4ba4f94c)
|
| 119 |
+
* [StyleTTS2 Model Implementation](https://github.com/yl4579/StyleTTS2/blob/main/models.py)
|