📖 From Scratch vs Pre-trained: A Dataset Size Analysis for Small-Scale Language Model Training

Théo (alias RDTvlokip)
github.com/RDTvlokip
September 2025
Original Publication: Zenodo Record
DOI: 10.5281/zenodo.17080914
Shield: ![]()
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International License.

📄 Abstract
The choice between training language models from scratch versus fine-tuning pre-trained models remains a critical decision in natural language processing, particularly for resource-constrained scenarios. This paper presents a comprehensive empirical analysis comparing from-scratch training against GPT-2 fine-tuning across varying dataset sizes (1MB to 20MB). Our experiments reveal a clear dataset size threshold effect: from-scratch models demonstrate superior generalization on small datasets (1MB and 5MB), achieving generalization scores of 59.0 and 88.7 respectively, while pre-trained models excel on larger datasets (10MB and 20MB) with scores of 56.7 and 46.0. However, detailed analysis reveals that superior performance on small datasets primarily reflects memorization rather than genuine linguistic understanding, with from-scratch models achieving perfect perplexity through copy-paste mechanisms. We implement adaptive learning rate and dropout strategies optimized for dataset size, and provide practical guidelines for model selection based on available data volume. Our findings challenge the conventional wisdom that pre-trained models universally outperform from-scratch approaches, demonstrating that careful consideration of dataset size and learning objectives is crucial for optimal model selection in small-data regimes.
🎯 Introduction
The dominance of pre-trained language models in natural language processing has established transfer learning as the de facto standard for most NLP tasks. However, this paradigm primarily emerged from experiments on large-scale datasets measured in gigabytes or terabytes. The question of optimal training strategies for smaller datasets - those measured in megabytes rather than gigabytes - remains underexplored despite being highly relevant for specialized domains, low-resource languages, and resource-constrained environments.
This paper addresses a fundamental question: When should practitioners choose from-scratch training over pre-trained model fine-tuning? While conventional wisdom suggests that pre-trained models should universally outperform from-scratch approaches due to their accumulated linguistic knowledge, our empirical analysis reveals a more nuanced picture.
We conduct a systematic comparison between from-scratch training and GPT-2 fine-tuning across four dataset sizes: 1MB, 5MB, 10MB, and 20MB, extracted from a comprehensive 20MB French corpus. Our experiments demonstrate a clear threshold effect where the optimal training strategy depends critically on dataset size, with an important caveat: superior metrics on small datasets often reflect memorization rather than genuine learning.
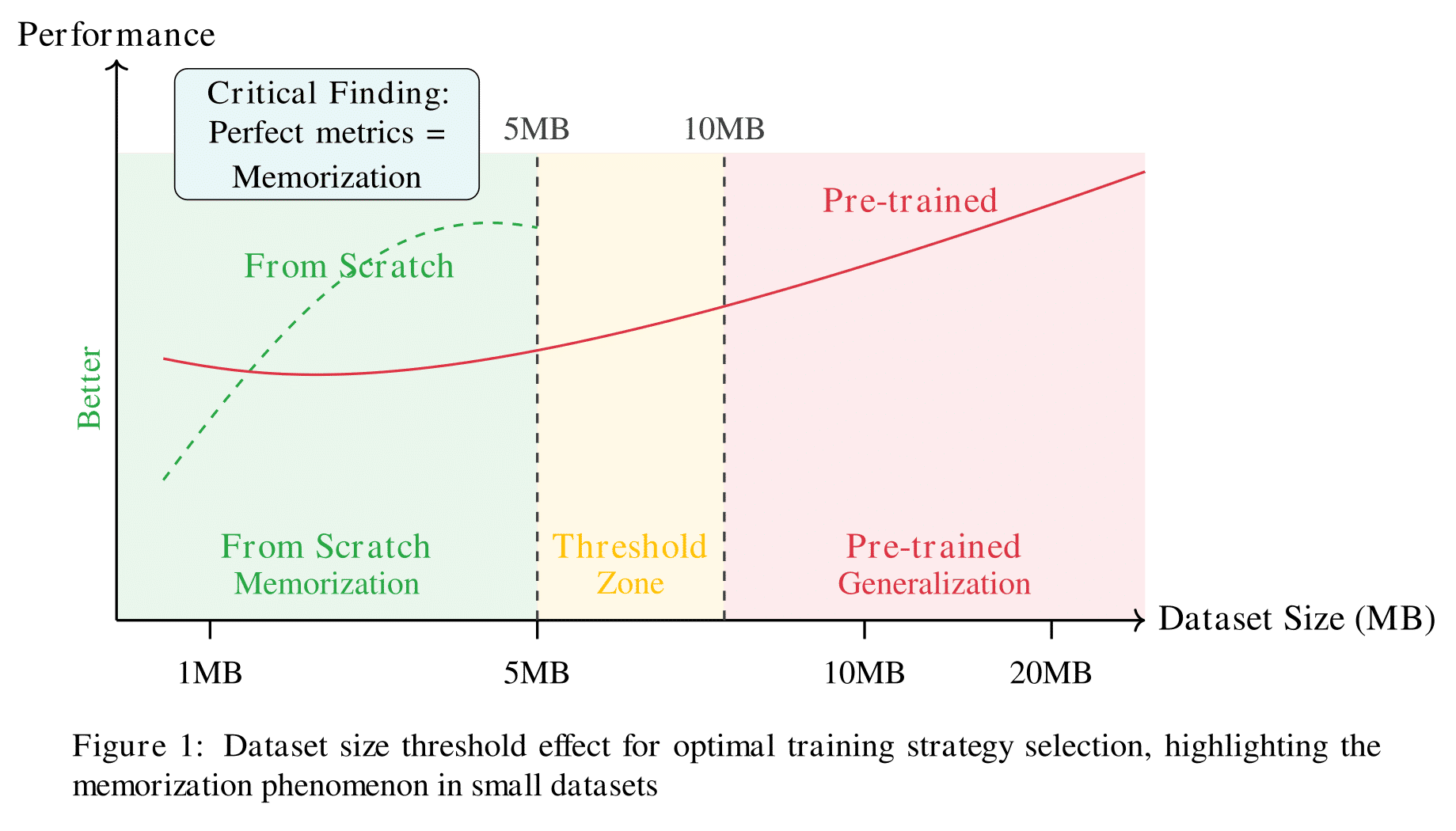
🔍 Dataset Size Threshold Effect
🎯 Key Contributions
- Empirical demonstration of dataset size threshold effects in training strategy selection
- Identification of memorization vs. generalization trade-offs in small datasets
- Comprehensive performance analysis across multiple metrics: generalization score, test loss, and overfitting resistance
- Adaptive hyperparameter strategies optimized for dataset size and training approach
- Practical guidelines for model selection in small-data regimes
📚 Related Work
Transfer Learning in NLP 🔄
The success of pre-trained language models like BERT, GPT-2, and their successors has established transfer learning as the dominant paradigm in NLP. These models leverage large-scale pre-training on diverse text corpora to develop general linguistic representations that transfer effectively to downstream tasks.
Small Data Learning 📊
Few-shot and low-resource learning scenarios present unique challenges where traditional large-scale approaches may not apply optimally. In these contexts, the relationship between pre-training benefits and data availability becomes more complex, with potential for catastrophic forgetting and poor adaptation to domain-specific patterns.
Dataset Size Effects 📈
Previous work has explored the relationship between dataset size and model performance, but most studies focus on scaling laws for very large datasets. The behavior of different training strategies in the small-data regime (1-20MB) remains understudied, creating a gap in practical guidance for resource-constrained scenarios.
🔬 Methodology
Experimental Design 🧪
We compare two training approaches across four dataset sizes extracted from a 20MB French corpus:
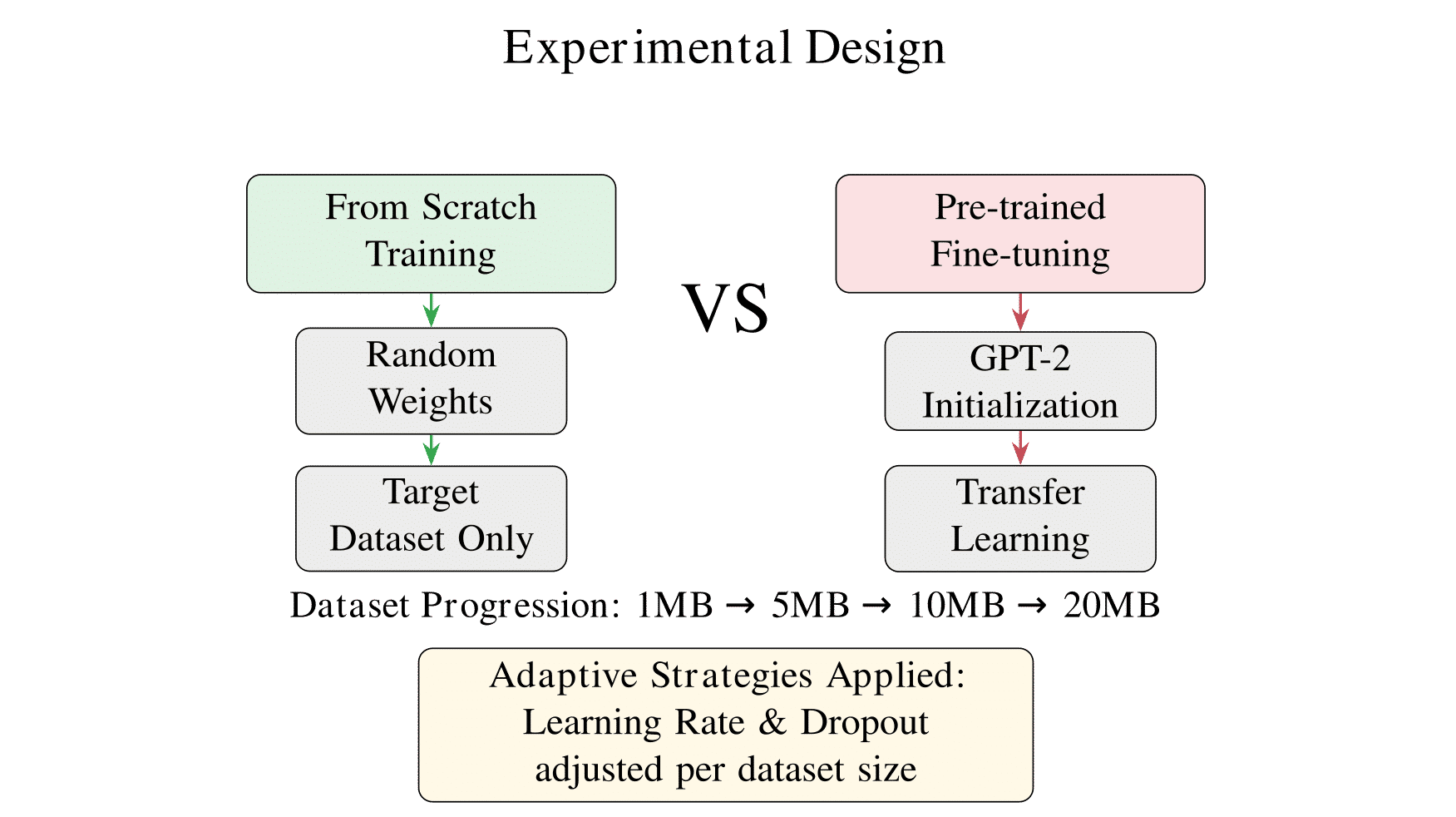
From Scratch Training: A transformer model initialized with random weights and trained entirely on the target dataset.
Pre-trained Fine-tuning: GPT-2 model fine-tuned on the target dataset using transfer learning.
Model Architecture 🏗️
The from-scratch model employs a standard transformer architecture:
| Parameter | Value |
|---|---|
| Embedding Dimension | 768 |
| Number of Layers | 6 |
| Attention Heads | 12 |
| Maximum Length | 512 tokens |
| Vocabulary Size | 10,000 |
| Base Dropout | 0.1 |
Adaptive Hyperparameter Strategy ⚙️
To optimize performance across different dataset sizes, we implement adaptive learning rate and dropout strategies:
Adaptive Learning Rate Selection
def get_adaptive_lr(size_mb, model_type):
if model_type == 'scratch':
if size_mb <= 5:
return 1e-4
elif size_mb <= 25:
return 2e-4
elif size_mb <= 50:
return 3e-4
else:
return 5e-4
else: # pre-trained
if size_mb <= 5:
return 5e-5
elif size_mb <= 25:
return 1e-4
elif size_mb <= 50:
return 2e-4
else:
return 3e-4
Adaptive Dropout Selection
def get_adaptive_dropout(size_mb):
if size_mb <= 5:
return 0.3
elif size_mb <= 25:
return 0.2
elif size_mb <= 50:
return 0.15
else:
return 0.1
These adaptive strategies address the fundamental challenge that small datasets require more aggressive regularization and careful learning rate tuning to prevent overfitting while enabling effective learning.
Evaluation Metrics 📏
We evaluate models using three key metrics:
- Generalization Score: A composite metric measuring model performance on held-out test data
- Test Loss & Perplexity: Standard language modeling evaluation metrics
- Overfitting Score: Quantifies the gap between training and validation performance
📊 Results
Overall Performance Summary 📈
| Dataset | Model | Winner | Gen. Score | Test Loss | PPL | Overfitting |
|---|---|---|---|---|---|---|
| 1MB | From Scratch | ✓ | 59.0 | 5.021 | 151.6 | 0.45 |
| GPT-2 | 57.8 | 3.298 | 27.0 | 0.38 | ||
| 5MB | From Scratch | ✓ | 88.7 | 0.037 | 1.0 | 0.12 |
| GPT-2 | 63.6 | 2.929 | 18.7 | 0.44 | ||
| 10MB | From Scratch | 36.4 | 0.028 | 1.0 | 1.74 | |
| GPT-2 | ✓ | 56.7 | 2.944 | 19.0 | 0.73 | |
| 20MB | From Scratch | 40.8 | 0.014 | 1.0 | 1.45 | |
| GPT-2 | ✓ | 46.0 | 2.932 | 18.8 | 1.10 |
Dataset Size Threshold Effect 🎯
Our results reveal a clear threshold effect at approximately 5-10MB of training data:
Small Data Regime (1MB, 5MB): From-scratch models demonstrate superior generalization, with peak performance at 5MB (generalization score: 88.7). The from-scratch approach wins 2/2 comparisons in this regime.
Large Data Regime (10MB, 20MB): Pre-trained models show better generalization despite higher test losses. GPT-2 wins 2/2 comparisons, with overfitting scores consistently lower than from-scratch models.
The Memorization Phenomenon 🧠
A critical observation reveals that the extremely low test losses achieved by from-scratch models on small datasets (PPL = 1.0 for 1MB and 5MB) indicate near-perfect memorization rather than genuine language understanding.
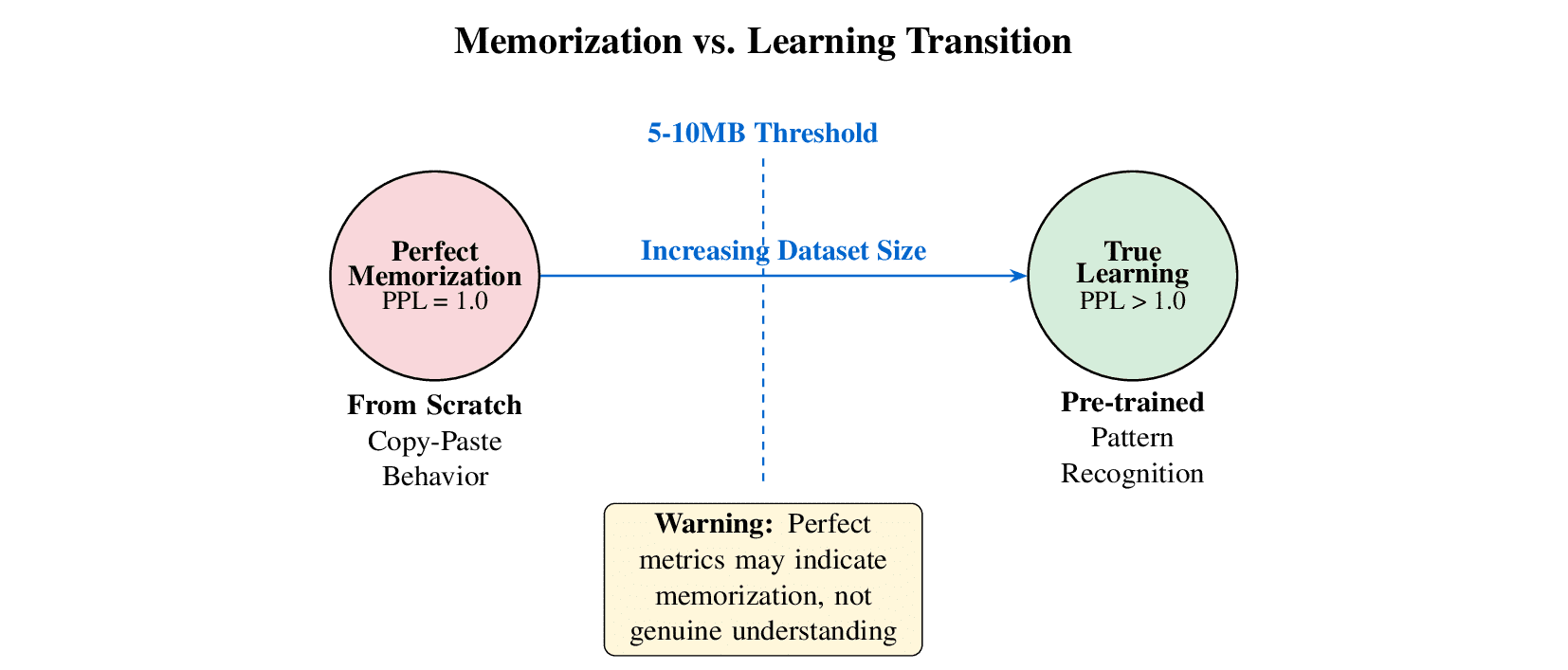
Detailed analysis of model outputs shows that from-scratch models essentially perform copy-paste operations, reproducing training sequences verbatim rather than learning generalizable linguistic patterns. This memorization phenomenon explains the paradoxical relationship between test loss and generalization scores:
- Perfect Perplexity (1.0): Indicates complete memorization of training sequences
- High Generalization Scores: Reflects the model's ability to reproduce exact patterns when prompted
- Limited True Understanding: Model lacks capability for novel text generation or pattern extrapolation
Key Observations from Training Dynamics 📊
- From-scratch models show rapid convergence to near-zero loss on small datasets
- GPT-2 maintains more stable learning curves across all dataset sizes
- Overfitting becomes severe for from-scratch models beyond 5MB
- The threshold effect is clearly visible in the 10MB transition point
🔍 Analysis and Discussion
Understanding the Small Data Advantage 🎯
Despite the memorization phenomenon observed in small datasets, from-scratch models demonstrate specific advantages in certain scenarios:
Tabula Rasa Learning: Without pre-existing linguistic biases, from-scratch models can adapt more readily to domain-specific patterns present in small datasets.
Optimal Capacity Utilization: The limited model capacity is entirely devoted to learning patterns from the target dataset, rather than balancing pre-existing knowledge with new information.
Reduced Catastrophic Forgetting: No pre-trained knowledge to forget or conflict with domain-specific patterns.
However, practitioners must be aware that the superior metrics achieved on very small datasets (1-5MB) primarily reflect memorization capabilities rather than true linguistic understanding.
The Large Data Advantage of Pre-trained Models 📈
As dataset size increases, pre-trained models leverage their advantages:
Linguistic Foundation: Pre-trained representations provide a robust foundation that becomes more valuable as training data increases.
Transfer Learning Benefits: General linguistic knowledge helps prevent overfitting and improves generalization on larger datasets.
Regularization Effects: Pre-training acts as an implicit regularizer, preventing the model from overfitting to specific dataset characteristics.
Practical Decision Framework 🛠️
Based on our findings, we propose a practical decision framework for training strategy selection:
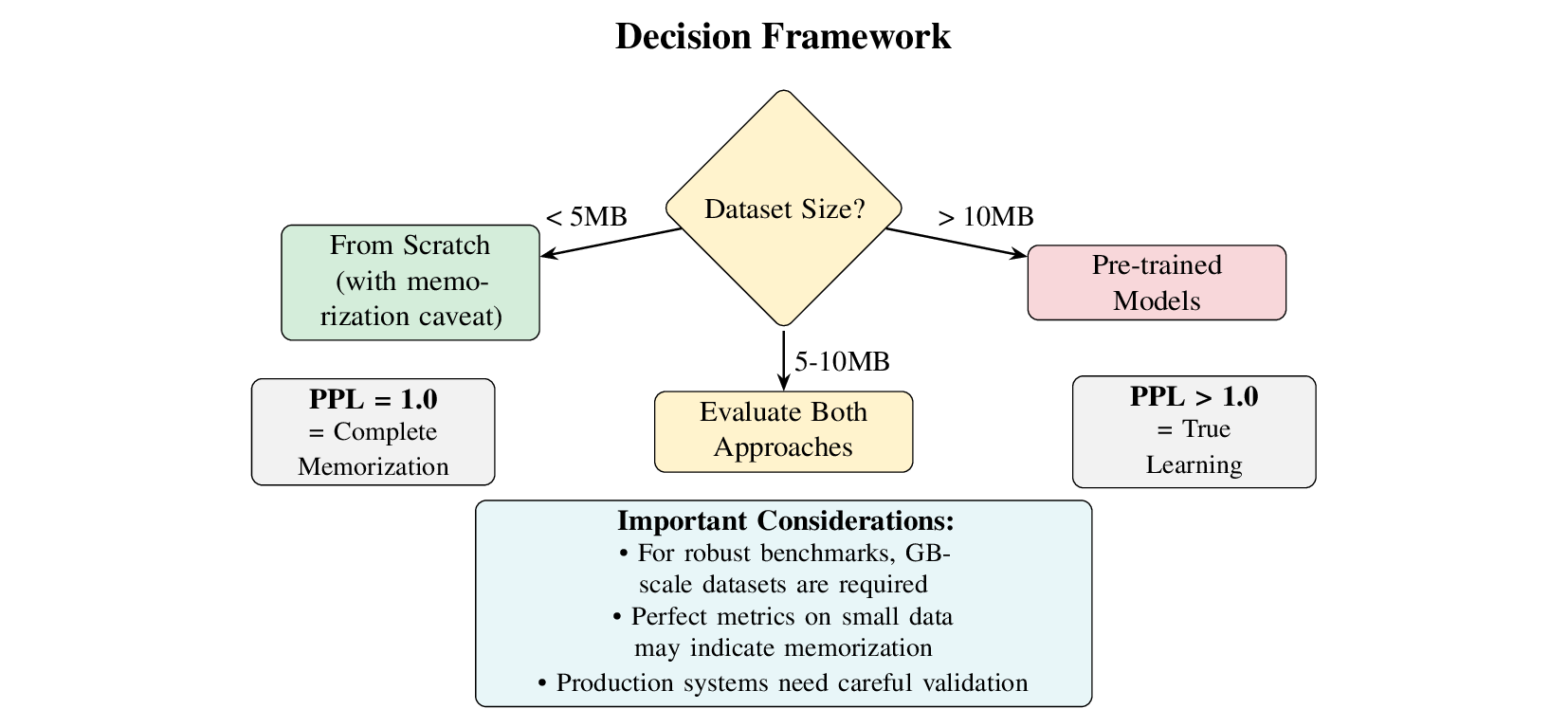
Detailed Guidelines:
- Dataset Size < 5MB: Consider from-scratch training with aggressive regularization, but be aware of memorization limitations
- Dataset Size 5-10MB: Threshold zone - evaluate both approaches based on specific requirements
- Dataset Size > 10MB: Pre-trained models likely optimal, but consider computational constraints
- Production Systems: Robust benchmarks require gigabyte-scale datasets for reliable conclusions
Implications for Practice 💼
Our findings have several important implications for practitioners:
Metric Interpretation: Perfect or near-perfect metrics on small datasets should be interpreted with caution, as they may indicate memorization rather than genuine learning.
Dataset Size Planning: When possible, aim for datasets above the 5-10MB threshold to leverage true generalization capabilities.
Validation Strategies: For small datasets, implement careful out-of-domain validation to distinguish between memorization and genuine learning.
Resource Allocation: In resource-constrained environments, from-scratch training may be viable for very small datasets, but with clear understanding of limitations.
Limitations and Future Work ⚠️
Several limitations warrant consideration:
Scale Limitations: Our maximum dataset size of 20MB is small by modern standards. Robust benchmarks require gigabyte-scale evaluation, which remains computationally prohibitive for comprehensive comparative analysis but represents the next crucial research direction.
Single Language Evaluation: Our experiments focus on French text; cross-lingual validation needed.
Architecture Constraints: Comparison limited to specific transformer architectures; broader architectural analysis required.
Domain Specificity: Results may vary significantly across different text domains and styles.
Memorization vs. Learning: Further research needed to distinguish beneficial memorization from problematic overfitting in small-data scenarios.
🎯 Conclusion
This research provides empirical evidence for dataset size-dependent training strategy selection, revealing that from-scratch training can outperform transfer learning in small-data regimes, albeit through memorization rather than genuine learning. Our analysis demonstrates a clear threshold effect around 5-10MB, with important implications for practitioners working with limited data resources.
🔑 Key Findings
- From-scratch models excel on datasets < 5MB through memorization mechanisms
- Pre-trained models dominate on datasets > 10MB through genuine generalization
- Adaptive hyperparameter strategies are crucial for optimal performance
- The 5-10MB range represents a critical decision threshold
- Robust evaluation requires gigabyte-scale datasets for definitive conclusions
- Perfect metrics on small datasets often indicate memorization, not learning
The broader implications extend beyond academic interest to practical deployment scenarios where data availability is limited. Organizations working with specialized domains, proprietary datasets, or resource constraints should carefully evaluate dataset size and learning objectives when selecting training strategies.
This work challenges the universal superiority of pre-trained models while highlighting the importance of understanding the underlying learning mechanisms. As NLP systems become increasingly complex and adaptive, distinguishing between memorization and genuine learning becomes crucial for developing effective small-data strategies.
Future work should expand this analysis to larger datasets, multiple languages, and diverse domains to establish more comprehensive guidelines for training strategy selection. The development of robust benchmarks at the gigabyte scale represents a critical next step for validating these findings in production environments.
📋 Summary
This research reveals a critical threshold effect based on dataset size for training strategy selection. From-scratch models excel on small datasets (< 5MB) through memorization, while pre-trained models dominate on larger datasets (> 10MB) thanks to true generalization. The transition threshold lies around 5–10MB, with significant implications for practitioners working with limited resources.
🔗 Data and Code Availability
Experimental configurations and hyperparameter settings are provided in the methodology section to facilitate reproduction. The adaptive learning rate and dropout strategies are fully specified and can be implemented using standard deep learning frameworks.
📖 Citation
@misc{charlet_2025_scratch_vs_pretrained,
author = {Charlet, Théo},
title = {From Scratch vs Pre-trained: A Dataset Size Analysis for
Small-Scale Language Model Training},
month = sep,
year = 2025,
doi = {10.5281/zenodo.17080914},
url = {https://doi.org/10.5281/zenodo.17080914}
}