How to build an incremental Web Crawler with Apify


I've been working with Apify for a while now, and it's an incredible platform for extracting all kinds of web data, whether it's Twitter feeds, documents, or just about anything else.
In the real world, the challenge doesn't end with crawling a website once. Websites are constantly being updated with new content, such as classifieds or articles, so how do you keep up with these changes? Typically, you have two periodic approaches that differ mainly in their frequency:
Standard periodic crawls, say once per week: This method involves crawling the entire site at regular, but less frequent, intervals. Pros: You capture all changes and updates. Cons: Data may become outdated between crawls, although less resource-intensive than frequent crawls.
High-frequency periodic crawls, e.g. daily: In this approach, you crawl the entire site more frequently to capture updates as they happen. Pros: You keep your data more current with minimal delay. Cons: This method can be very expensive and inefficient due to the repeated scraping of the entire site.
****So is there a more efficient way to manage this?****
Fortunately, there is. With Apify, you can now focus on crawling only the updated pages, drastically reducing the amount of data you scrape while keeping your information up to date. In this guide, I'll show you step-by-step how to implement this more efficient approach and explore use cases where this method can save you time and resources.
How it Works
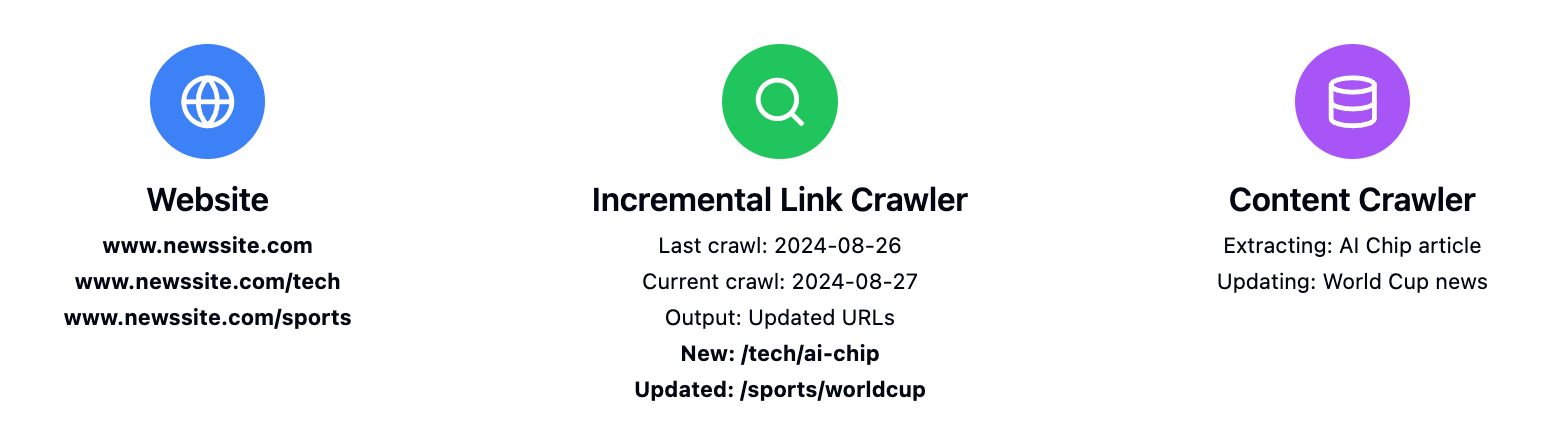
The Incremental Web Crawler takes two main inputs:
url: the website you want to monitordaysAgo: the number of days back you want to search for updates (default is 1 day)
Example
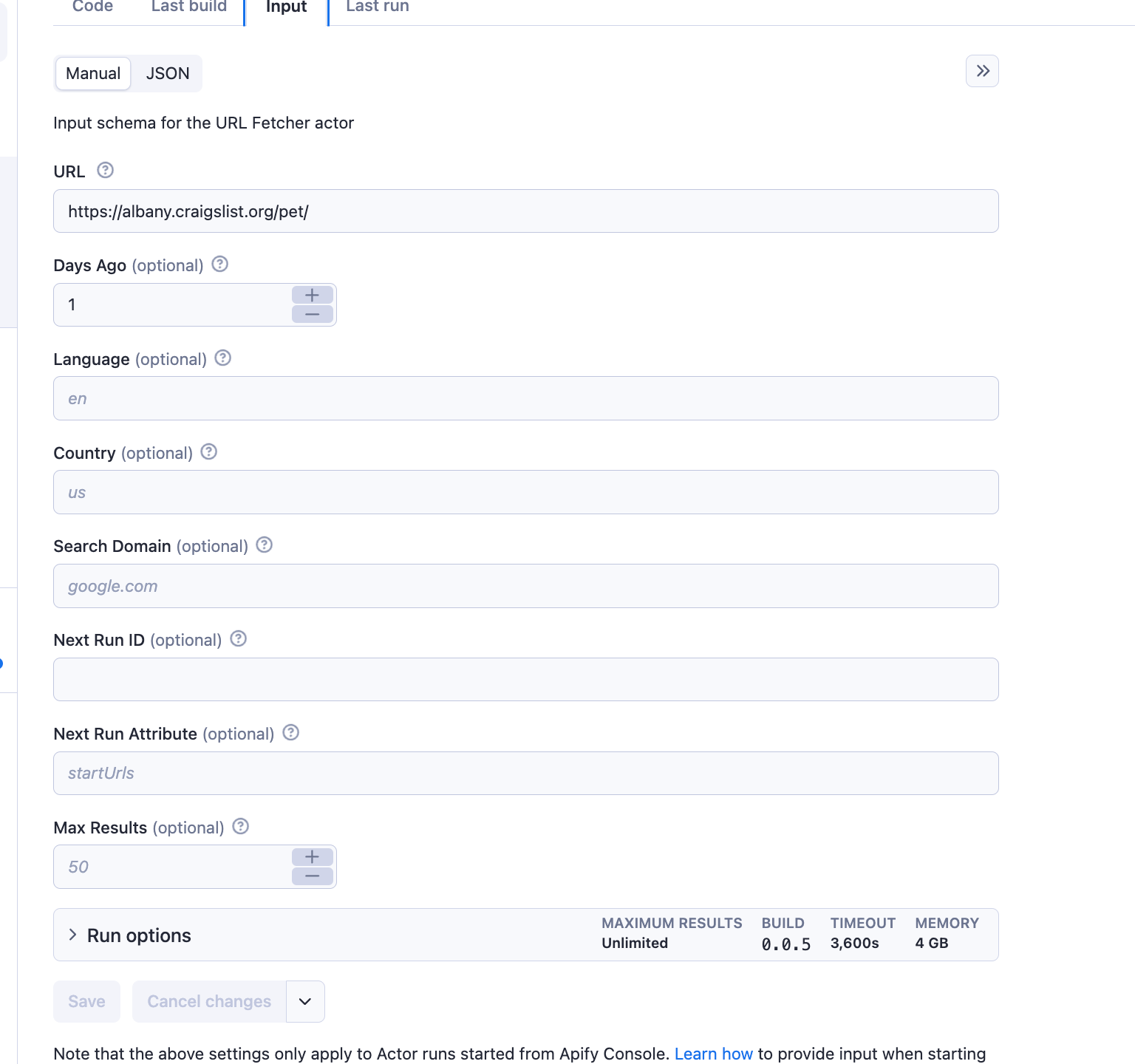
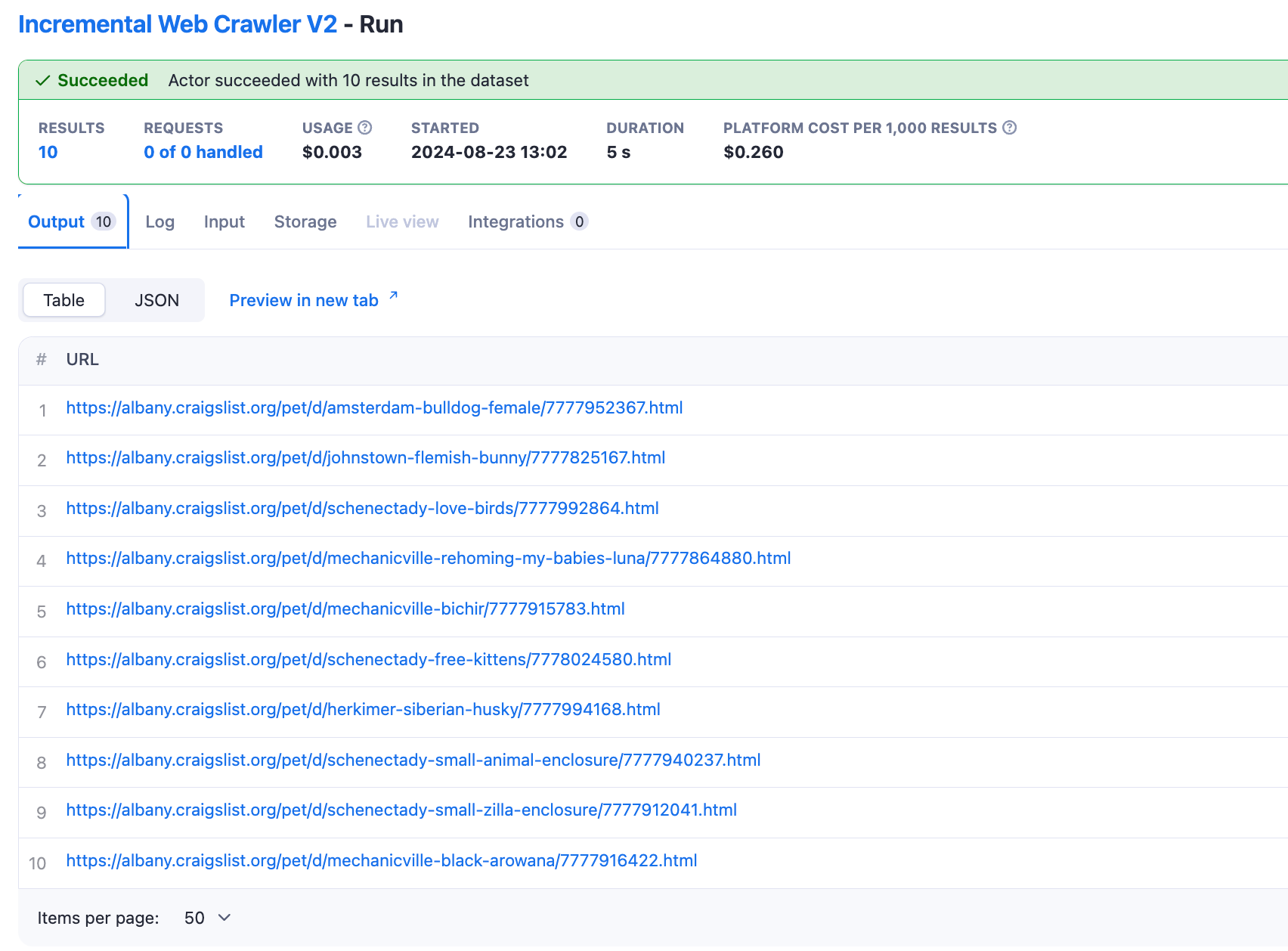
The crawler will then identify pages that have been added or updated within the specified time frame and return a list of URLs pointing to the newly added or updated pages.
**Integration with other actors **, e.g. apify/website-content-crawler
The user creates a task for the next actor and passes the task ID to the incremental crawler, who calls the task after finding updated links.
nextRunId: ID for the subsequent task (optional)nextRunAttribute: attribute to update in the next run (default is 'startUrls', optional)
Example Configurations
Basic Setup example
{"url": "https://www.example-news-site.com","daysAgo": 2,"maxResults": 100}
Advanced Setup with Follow-Up Task
{...."nextRunId": "your-task-id","nextRunAttribute": "startUrls"}
Tips for Optimal Results
- Use a moving window to ensure you capture all relevant updates. For example, set
daysAgoto 2 or 3 days for daily crawls, or 8 or 9 days for weekly crawls.
For more information on using the Incremental Link Crawler, please refer to the documentation.