Chat with any full website (not just a single page). Complete Tutorial

The web is full of information, and sometimes it's hard to find the right information for your specific needs. Even more so if the website provider has no or weak search capabilities, such as keyword only search.
What is "Chat With"?
With the "chat with website" approach, we don't just ask ChatGPT about a topic. We first feed GPT the information from the website and then start asking questions about that website. Unlike simply uploading a single file, this method allows you to ask questions about the whole website, not just a single page.
Why not just use the site search directly?.
The difference with site search is that we can actually chat and interact with the documentation in natural language, not just keyword based. You can even ask a question and get an answer to that specific query.
Why not use ChatGPT directly, i.e. without crawling?.
Unlike just asking an LLM without embedding, crawling and feeding it the documentation, there is a risk of hallucination - where the LLM makes up things that don't exist or are factually wrong, misleading the user. This can leave you lost and unable to follow the steps you are supposed to take to complete the task.
The solution: Crawl + Embed + Chat.
Luckily, there's a solution for querying this kind of unstructured but very valuable information on the web: using an LLM to interpret this information and answer our questions. There's plenty of information on the web about how to do this with a** file or folder,** but for the complex structure of the web - including bot protection and link following - it can be a not-so-simple undertaking.
Here are some of the things you typically need to consider if you want to go beyond analysing or crawling the text of a** single web page:**
- Imitating JavaScript
- Getting around bot protection using proxies
- Following links to a certain depth
- Automatic scrolling
- Extracting the text and skipping all the unimportant stuff like navigation, etc.
- And many more
But let's take a step back. What do we usually need to implement a complete solution? After crawling the entire website, we need to talk to it.
In a perfect world, you'd have a workflow like this:
Crawl > Extract/Cleanup > Embed for vector search > Do QA on this data with LLM.
Some commercial off-the-shelf solutions offer AI search features to crawl an entire site, which is great. But there's a problem: you have no control over that crawler.
And much more: What happens after the data is crawled, i.e. how is it chuking and **embedded **for the Retrieval etc.? This part is usually limited as well.
There are dozens of out-of-the-box solutions, but most or all of them lack this kind of control. I admit that sometimes for a small site with simple links to follow, using off-the-shelf solutions may be sufficient (if it's free or the price is affordable). But in many cases you simply need more control over the crawler and the extraction process if you want to get reliable results.
If you want to build a reliable solution, I recommend breaking it down into pieces and using tools that specialise in each part, rather than relying on one vendor to do it all, but highly opinionated, with limited control and, on top of that, full vendor lock. This is my personal opinion, especially for the application that really matters to you.
OK, so let's go back to our example: **Creating a RAG for chatting with a website **(here: obisidan documentation)
Our pipeline, I see two main parts:
Part I: Gathering the data:
Crawl > Extract/Cleanup.
Part 2: analysing and actually using that data.
Embedding > Retrieval / QA with LLM
In this tutorial we'll use Apify for the first part of the workflow (data extraction) and Open WebUI for the second part (embedding and using the data for QA).
For the first part, there are a few platforms that specialise in crawling using multiple proxies and using state-of-the-art techniques to crawl massive websites with thousands or even hundreds of thousands of pages. One that I have been using extensively for many years is Apify.
If you have never heard of Apify, Google is your friend :)
I have already created some tutorials for Open WebUI, which you may want to read before continuing.
The use case will be to **crawl the documentation **of my beloved note-taking tool Obsidian, embed it in OpenWebUI, and then ask questions about specific usage scenarios, such as how to create and use Canvas, how to use Markdown, etc., or any other question available in the documentation.
If you don't have an account with Apify, you can sign up for free and even get a free quote for $5 per month. For small crawling jobs, this is usually enough.
So let's get started.
https://console.apify.com/actors/aYG0l9s7dbB7j3gbS/input
Step 1: Open the website content crawler actor (this is the piece of logic that contains all the nitty-gritty to get all the content of entire websites with tons of configurations). So press "Create task". This is the crawling task. Give it something like "Obsidian documentation".
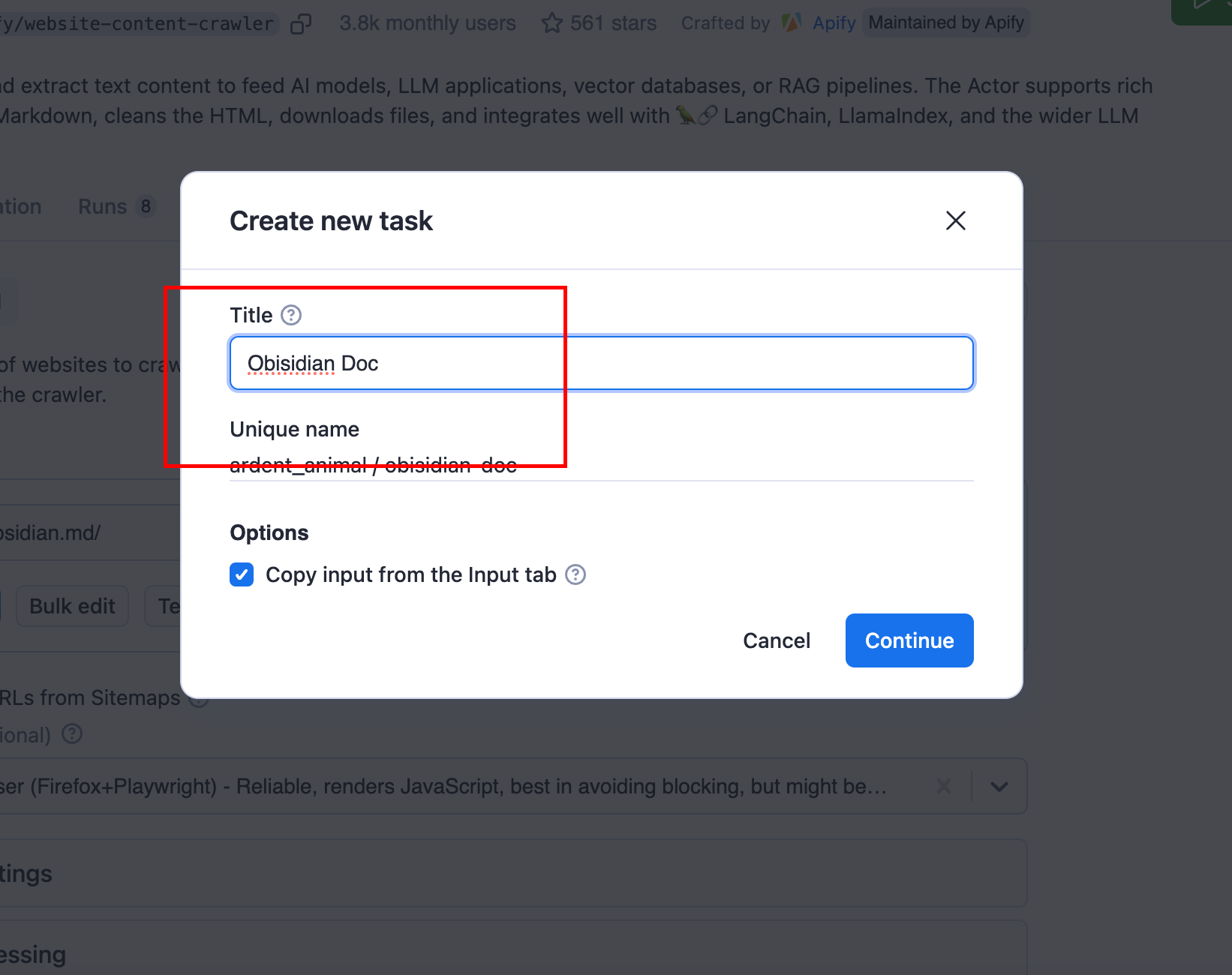
Then set some basic configuration for the start URL.
Use this: https://help.obsidian.md
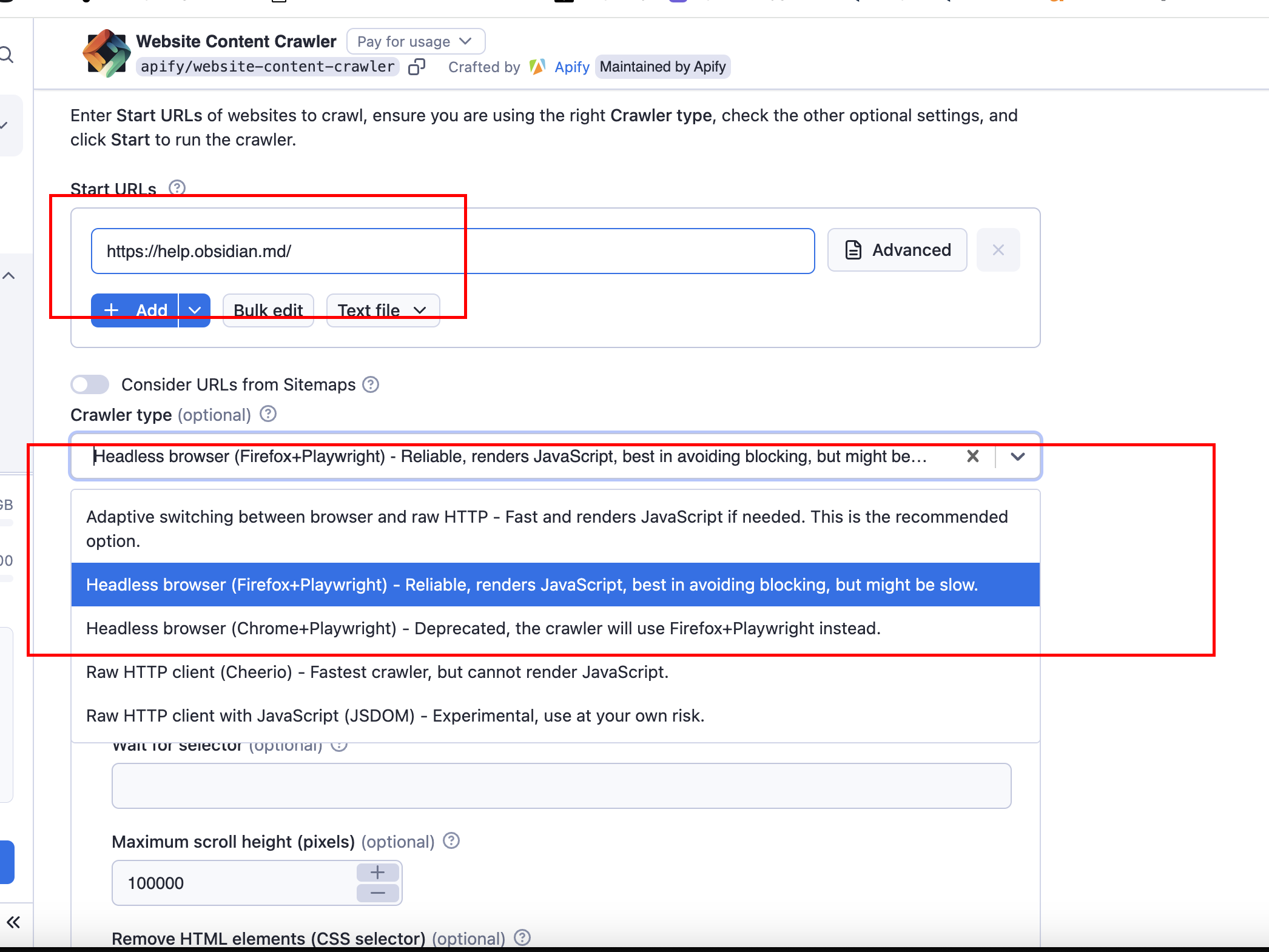
Then add a pattern like this to crawl all pages related to the documentation:
https://help.obsidian.md/** (note that the double asterisks mean that all pages will be crawled regardless of depth, as long as the main part, help.obsidian.md, is in the URL)