Meet Yi-Coder: A Small but Mighty LLM for Code







Introduction
Yi-Coder is a series of open-source code large language models (LLMs) that deliver state-of-the-art coding performance with fewer than 10 billion parameters.
Available in two sizes—1.5B and 9B parameters—Yi-Coder offers both base and chat versions, designed for efficient inference and flexible training. Notably, Yi-Coder-9B builds upon Yi-9B with an additional 2.4T high-quality tokens, meticulously sourced from a repository-level code corpus on GitHub and code-related data filtered from CommonCrawl.
Key features of Yi-Coder include:
Continue pretrained on 2.4 Trillion high-quality tokens over 52 major programming languages.
Long-context modeling: A maximum context window of 128K tokens enables project-level code comprehension and generation.
Small but mighty: Yi-Coder-9B outperforms other models with under 10 billion parameters, such as CodeQwen1.5 7B and CodeGeex4 9B, and even achieves performance on par with DeepSeek-Coder 33B.

The demo idea was inspired by: https://github.com/nutlope/llamacoder
Yi-Coder Delivers Impressive Coding Performance
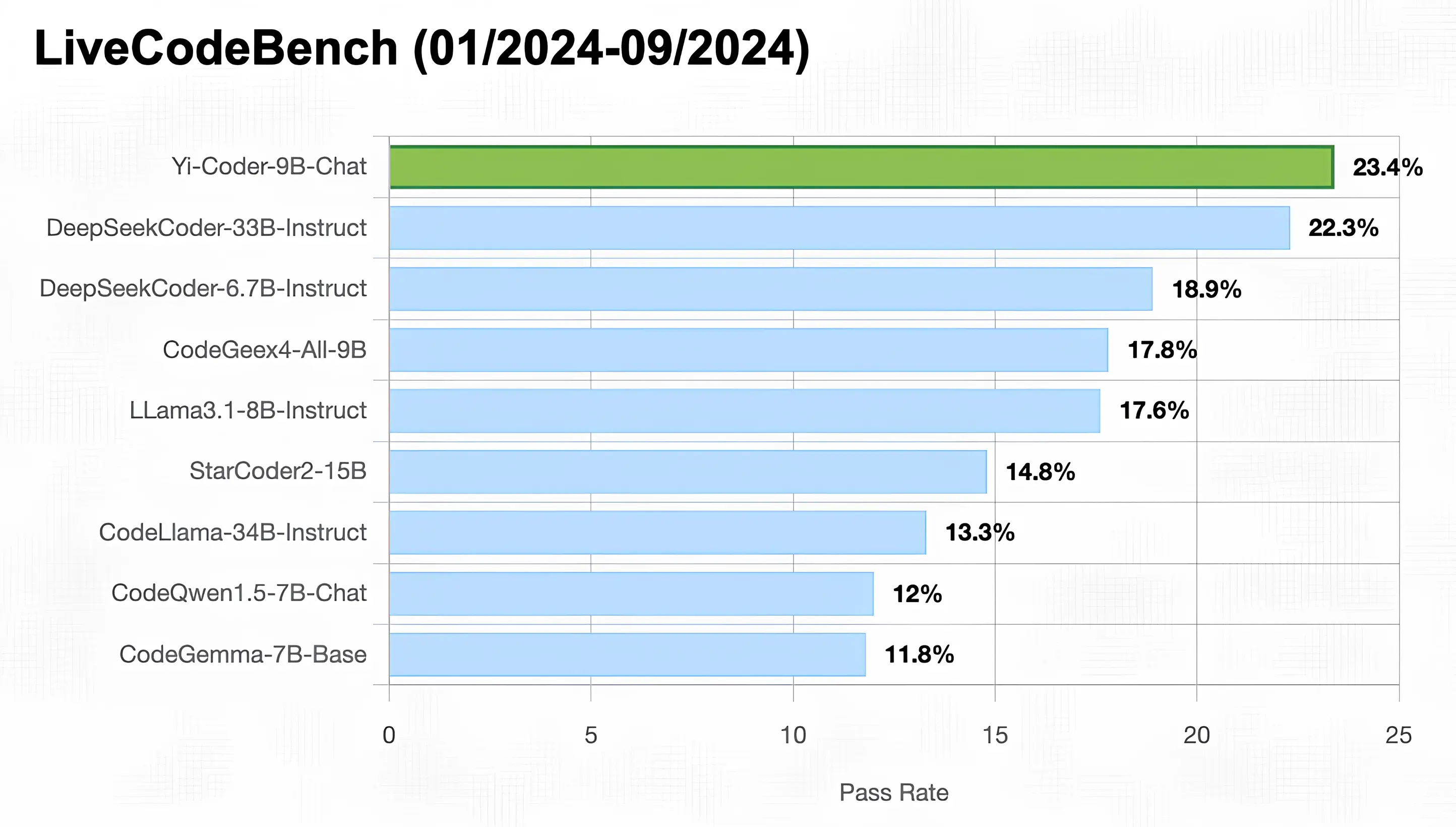
LiveCodeBench
LiveCodeBench is a publicly available platform designed to provide comprehensive and fair evaluation on competitive programming for LLMs. It collects new problems in real-time from competitive platforms such as LeetCode, AtCoder, and CodeForces, forming a dynamic and comprehensive benchmark library. To ensure no data contamination, since Yi-Coder's training data cutoff was at the end of 2023, we selected problems from January to September 2024 for testing.
As illustrated in the figure below, Yi-Coder-9B-Chat achieved an impressive 23.4% pass rate, making it the only model with under 10B parameters to exceed 20%. This performance surpasses:
- DeepSeek-Coder-33B-Instruct (abbreviated as DS-Coder) at 22.3%
- CodeGeex4-All-9B at 17.8%
- CodeLLama-34B-Instruct at 13.3%
- CodeQwen1.5-7B-Chat at 12%
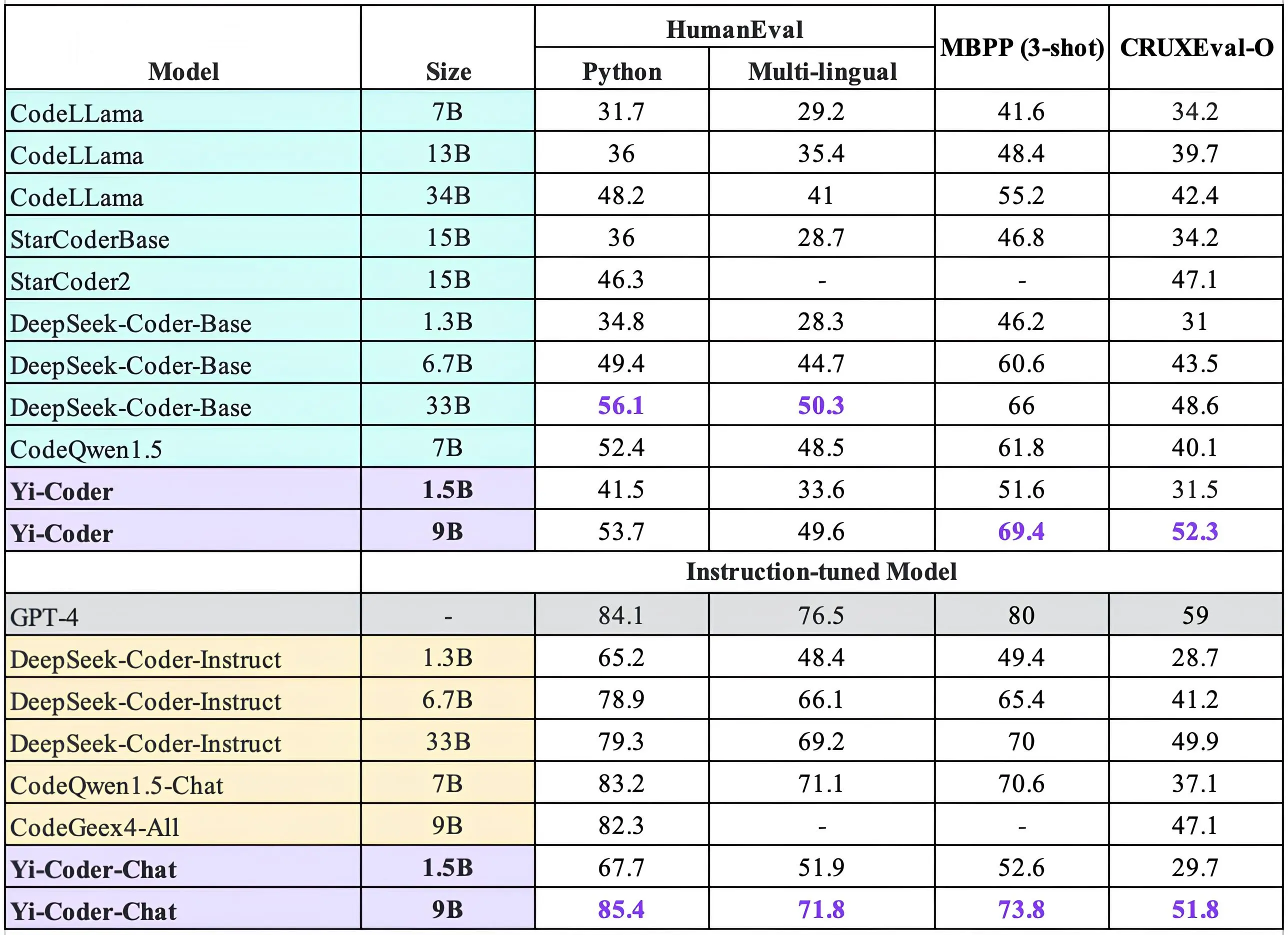
HumanEval, MBPP and CRUXEval-O
In addition to contest-level evaluations, we also selected popular benchmarks such as HumanEval, MBPP, and CRUXEval-O to assess the model's basic code generation and reasoning abilities. The evaluation results shown below indicate that Yi-Coder has achieved outstanding performance across these three tasks. Specifically, Yi-Coder-9B-Chat achieved pass rates of 85.4% on HumanEval and 73.8% on MBPP, surpassing other code LLMs. Moreover, Yi-Coder 9B became the first open-source code LLM to surpass 50% accuracy on CRUXEval-O.
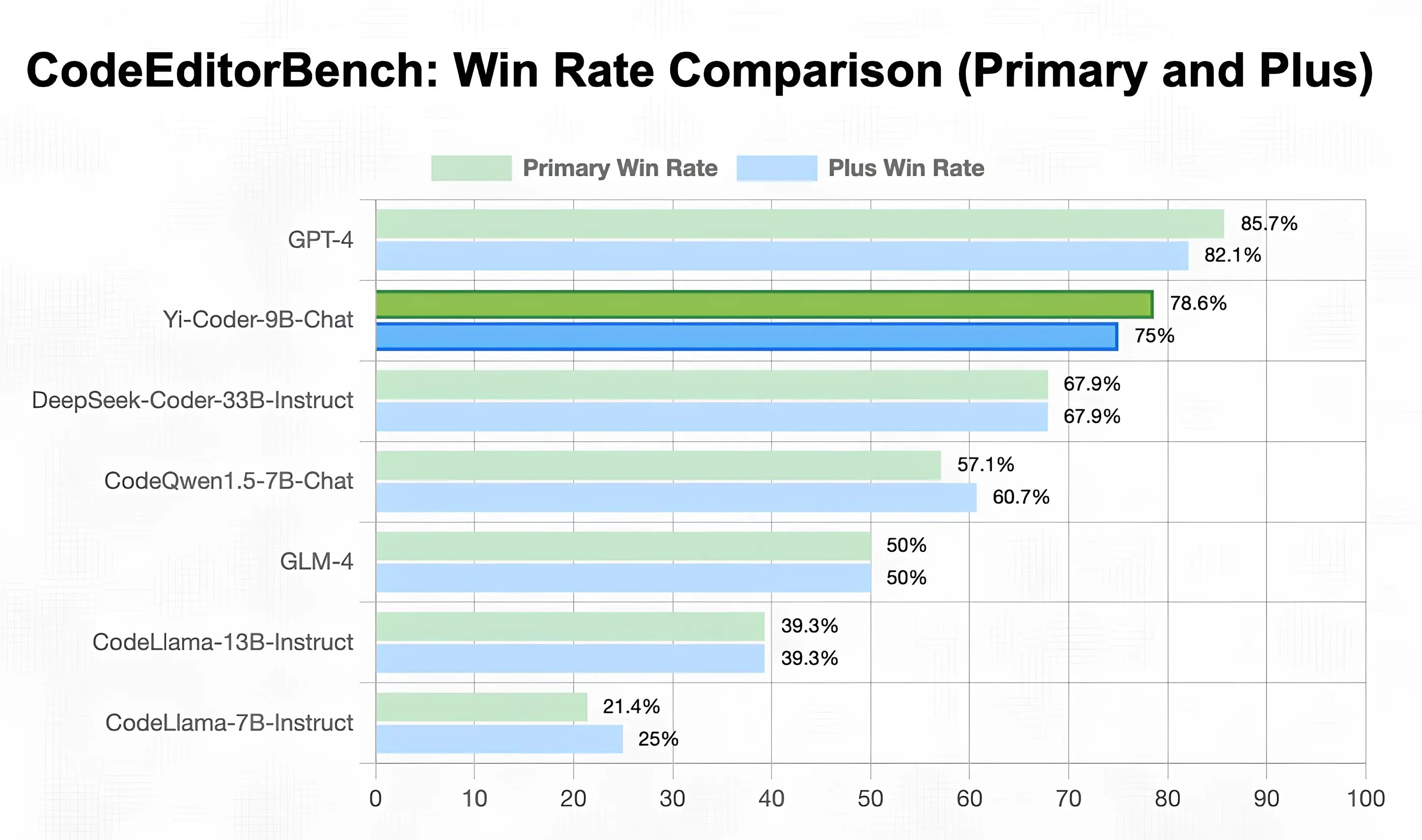
Yi-Coder Excels in Code Editing and Completion
CodeEditorBench
To evaluate Yi-Coder's proficiency in code modification tasks, we utilized CodeEditorBench, covering four key areas: Debugging, Translation, Language Switching, and Code Polishing. As shown in the below chart, Yi-Coder-9B achieves impressive average win rates among open-source code LLMs, consistently outperforming DeepSeek-Coder-33B-Instruct and CodeQwen1.5-7B-Chat across both primary and plus subsets.
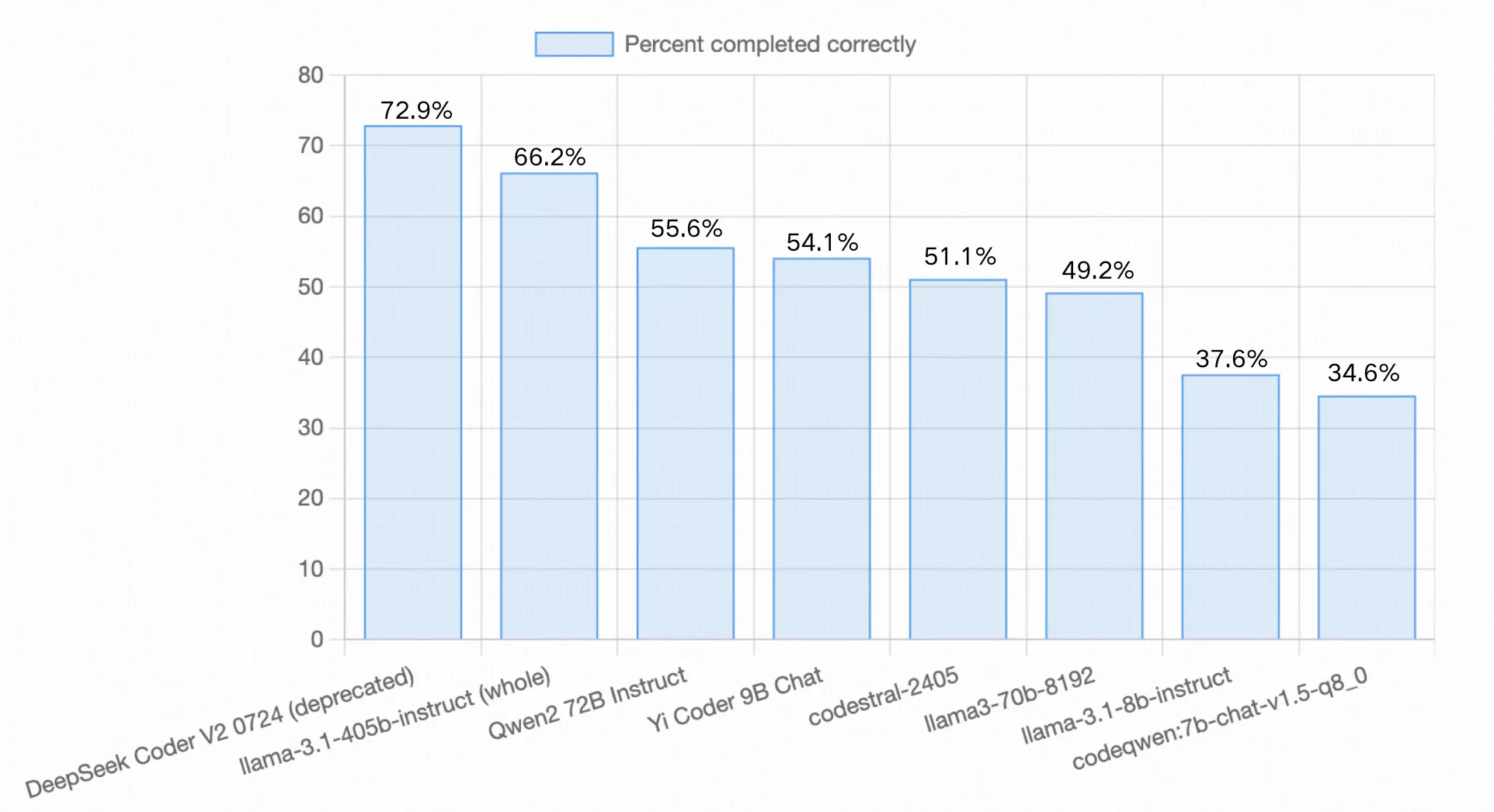
Aider LLM Leaderboards
Aider’s code editing benchmark evaluates an LLM's ability to modify Python source files across 133 coding exercises sourced from Exercism. This assessment not only tests the model's capacity to generate new code but also determines its proficiency in seamlessly integrating that code into pre-existing codebases. Additionally, the model must apply all changes autonomously, without requiring any human guidance during the process.
Following the model release, Yi-Coder-9B-Chat successfully completed 54.1% of the exercises, positioning it between Qwen2-72B Instruct (55.6%) and codestral-2405 (51.1%), largely outperforming models at similar scale such as LLama-3.1-8B-Instruct (37.6%) and CodeQwen1.5-7B-Chat (34.6%).
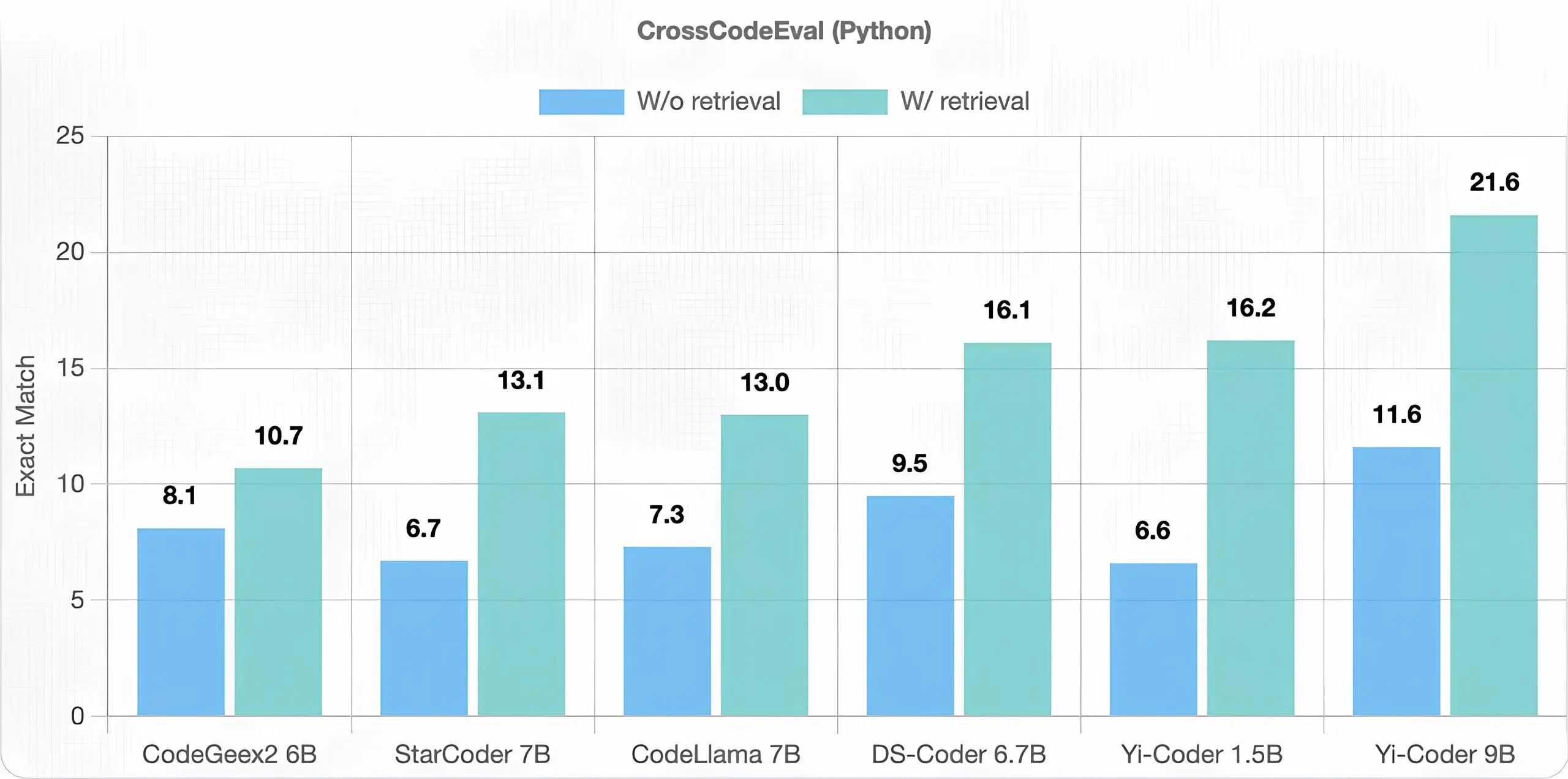
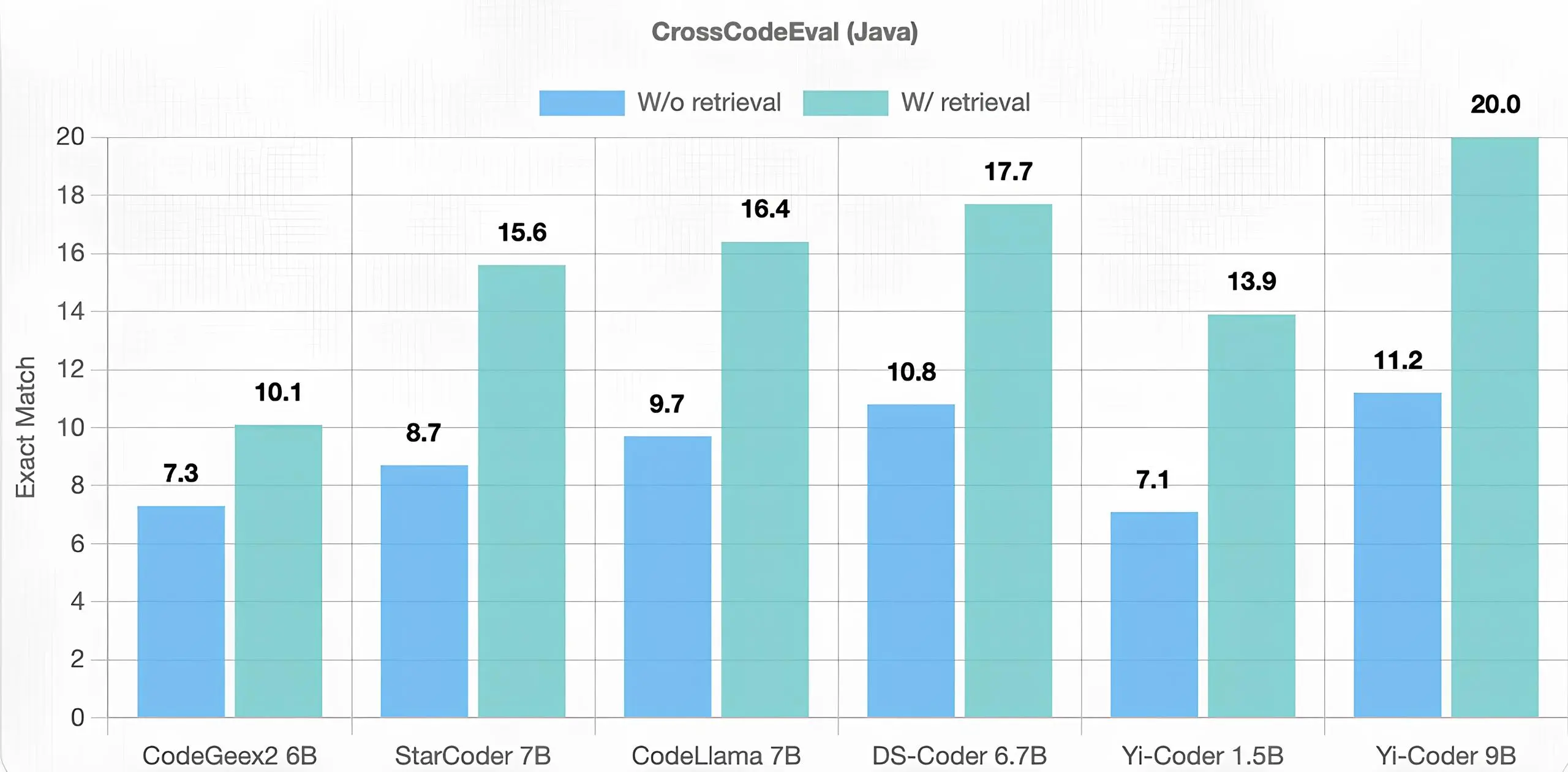
CrossCodeEval
In terms of code completion, a critical use case in modern AI-powered IDE tools, Yi-Coder also demonstrated excellent performance. Unlike code generation, cross-file code completion requires the model to access and understand repositories spanning multiple files, with numerous cross-file dependencies. We considered the CrossCodeEval benchmark for this evaluation under two different scenarios: with and without the retrieval of relevant contexts.
The results in the chart below show that Yi-Coder outperformed other models of similar scale in both retrieval and non-retrieval scenarios for both Python and Java datasets. This success validates that training on software repository-level code corpora with longer context lengths enables Yi-Coder to effectively capture long-term dependencies, thereby contributing to its superior performance.
Yi-Coder is Capable of Modeling 128K Long Contexts
Needle in the code
To test Yi-Coder's long-context modeling capability, we created a synthetic task called "Needle in the code" with a 128K-long sequence, which is twice the length of the 64K-long sequence used in the CodeQwen1.5 evaluation. In this task, a simple customized function is randomly inserted into a long codebase, and the model is tested on whether it can reproduce the function at the end of the codebase. The purpose of this evaluation is to assess whether the LLM can extract key information from long contexts, thereby reflecting its fundamental ability to understand long sequences.
The all-green results in the chart below indicate that Yi-Coder-9B flawlessly completed this task within the 128K length range.

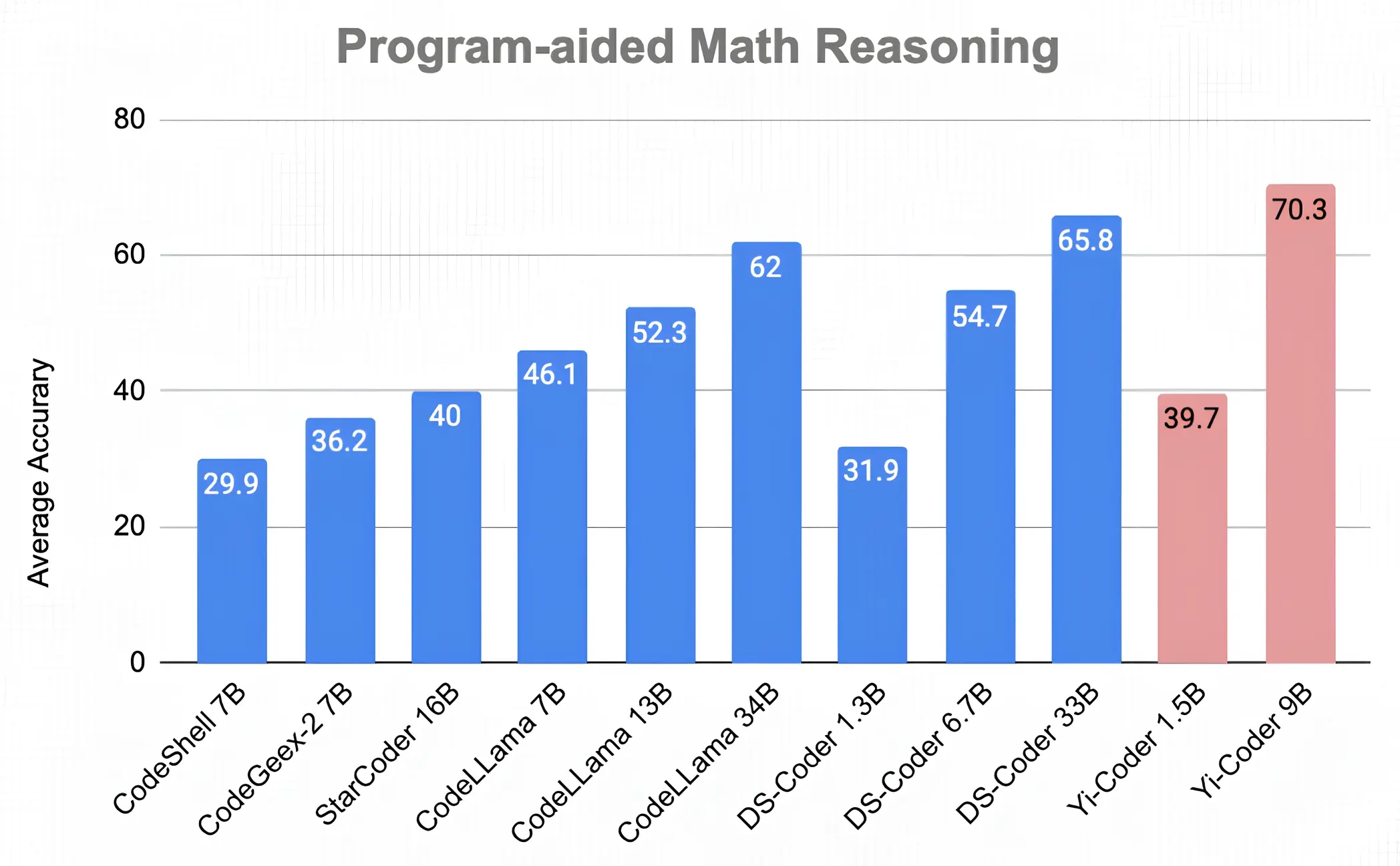
Yi-Coder Shines in Mathematical Reasoning
Program-Aid Math Reasoning
Previous research on DeepSeek-Coder has shown that strong coding capabilities can enhance mathematical reasoning by solving problems through programming. Inspired by this, we evaluated Yi-Coder on 7 math reasoning benchmarks under program-aided settings (i.e., PAL: Program-aided Language Models). In each of these benchmarks, the model is asked to generate a Python program and then return the final answer by executing the program.
The average accuracy scores, presented in the figure below, demonstrate that Yi-Coder-9B achieves a remarkable accuracy of 70.3%, surpassing DeepSeek-Coder-33B's 65.8%.
Conclusion
We have open-sourced Yi-Coder 1.5B/9B, offering both base and chat versions to the community. Despite its relatively small size, Yi-coder showcases remarkable performance across various tasks, including basic and competitive programming, code editing and repo-level completion, long-context comprehension, and mathematical reasoning. We believe Yi-Coder can push the boundaries of small code LLMs, unlocking use cases that could accelerate and transform software development.
Yi-Coder series models are part of the Yi open-source family. To learn more about using Yi-Coder with Transformers, Ollama, vLLM, and other frameworks, please see the Yi-Coder README.
We encourage developers to explore these resources and integrate Yi-Coder into their projects to experience its powerful capabilities firsthand. Join us on Discord or email us at [email protected] for any inquiries or discussions.
Cheers,
DevRel from 01.AI
Citation
@misc{yicoder,
title = {Meet Yi-Coder: A Small but Mighty LLM for Code},
url = {https://01-ai.github.io/blog.html?post=en/2024-09-05-A-Small-but-Mighty-LLM-for-Code.md},
author = {01.AI},
month = {September},
year = {2024}
}





