Nemotron-Personas: Improve AI Training With the First Synthetic Personas Dataset Aligned to Real-World Distributions









Synthetic Personas, Grounded in Reality
We’re excited to release Nemotron-Personas, the first open dataset of synthetic personas aligned to real-world demographic, geographic and personality-based traits.
Created using Gretel Data Designer (now part of NVIDIA, and soon integrated into NeMo), the dataset draws from U.S. Census data and academic research on names and personality traits. The result: a scalable, privacy-safe, and regulation-friendly foundation for modeling user behavior in AI systems.
Personas are more than just fictional characters—they're compressed representations of real-world diversity, designed to steer large language models (LLMs) toward more accurate, inclusive, and behaviorally realistic outputs.
First popularized in Tencent's Scaling Synthetic Data with 1B Personas and adopted by the Allen Institute for AI’s Tülu 3 model, persona-driven training is emerging as a best practice for both LLM and agentic system development and evaluation—especially in regulated industries that require secure, representative training data.
What’s in the Dataset?
- 600k synthetic personas total
- 100k records with 22 fields: 6 persona fields and 16 contextual fields allowing one to zone in on specific subsets of personas
- Grounded in U.S. Census demographic and geographic data and personality psychology research
- Covers 560+ real-world occupation categories
- Includes rich narrative fields like
career_goals_and_ambitions,skills_and_expertise,hobbies_and_interests, (e.g., professional, arts, sports, culinary) - Licensed under CC BY 4.0 for full commercial and non-commercial use
All data was synthetically generated using a compound AI system:
- Probabilistic Graphical Model (PGM) to ground in demographic, geographic, names and personality trait statistics;
- Open-weight LLMs (e.g.,
mistralai/Mistral-Nemo-Instruct-2407,mistralai/Mixtral-8x22B-v0.1) to generate high-fidelity personal narratives.
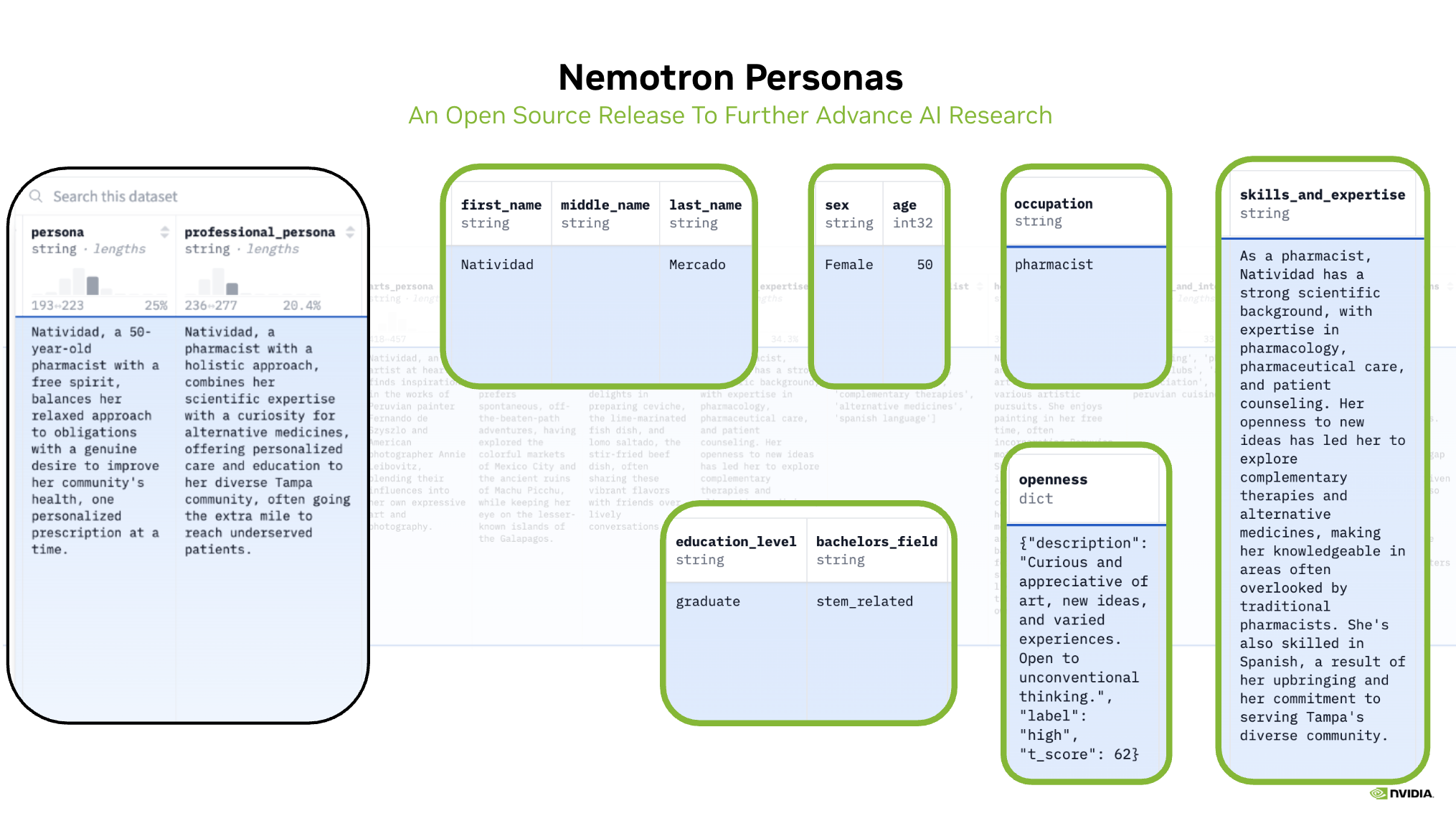 Example 1: persona and professional persona (in black) infused with real-world demographic, geographic and personality trait attributes (in green). Note the rich interwoven data tapestry created as a result.
Example 1: persona and professional persona (in black) infused with real-world demographic, geographic and personality trait attributes (in green). Note the rich interwoven data tapestry created as a result.
 Example 2: sports and arts personas (in black) infused with location, cultural background, and hobbies/interests (in green). Again, note the complexity and quality of generated personas.
Example 2: sports and arts personas (in black) infused with location, cultural background, and hobbies/interests (in green). Again, note the complexity and quality of generated personas.
Built for Open Research and Enterprise AI
Nemotron-Personas was purpose-built to support both open-source experimentation and production-grade AI development:
- LLM training and instruction tuning: Guide model outputs across diverse perspectives to improve response variety, instruction following, and task generalization.
- Safety and security testing: Use personas to red team models, simulate phishing targets, or test social engineering defenses—without exposing real user data.
- Regulated industry prototyping: Enterprises in finance, healthcare, and government can simulate representative populations for model evaluation and fairness testing.
- Banking: Audit loan models for rural or underserved applicants.
- Healthtech: Assess advice quality across demographics.
- Public sector: Stress-test eligibility bots against census-aligned citizen personas.
The Road Ahead
This release is grounded in U.S. population data—but it’s just the beginning. In future projects, we hope to extend this dataset to include:
- International distributions
- Domain-specific variants (e.g.,
finance_persona,healthcare_persona) - Temporal dimensions to simulate user evolution over time
With the right synthetic data, the world is your oyster.
How to Use It
You can get started with just two lines of code:
from datasets import load_dataset
ds = load_dataset("nvidia/Nemotron-Personas")
👉 Explore the dataset here and get in touch to explore enterprise or research use cases.



