Datasets:


Update README.md
Browse files
README.md
CHANGED
|
@@ -32,6 +32,10 @@ task_categories:
|
|
| 32 |
- **Paper:** [Arxiv](TBD)
|
| 33 |
- **Point of Contact:** [Gabriele Sarti](mailto:[email protected])
|
| 34 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
### Dataset Summary
|
| 36 |
|
| 37 |
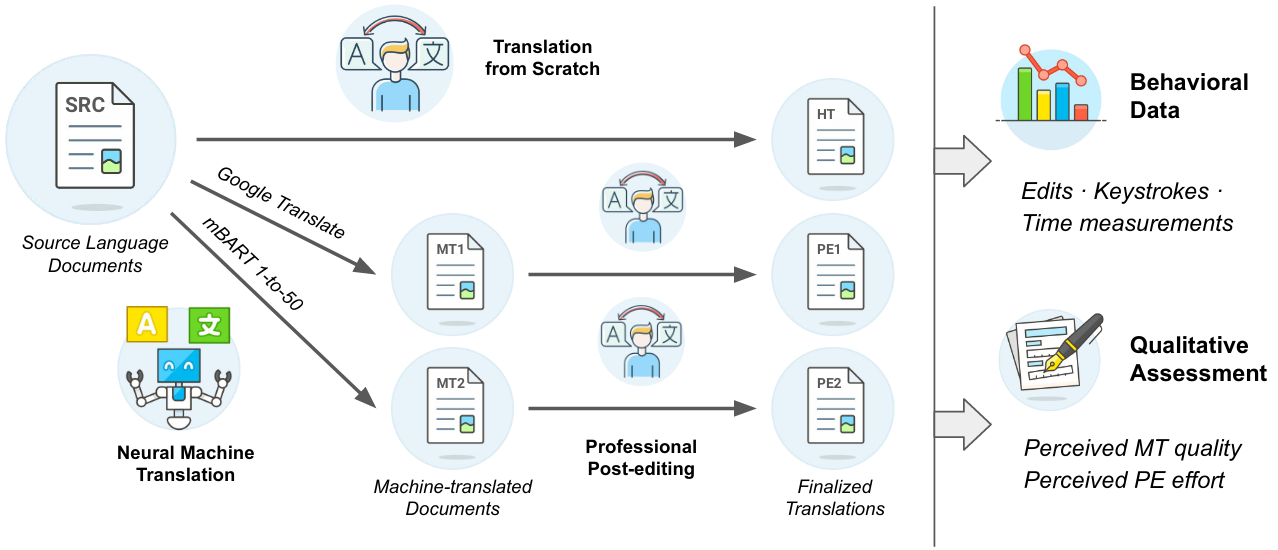
This dataset contains the processed `warmup` and `main` splits of the DivEMT dataset. A sample of documents extracted from the Flores-101 corpus were either translated from scratch or post-edited from an existing automatic translation by a total of 18 professional translators across six typologically diverse languages (Arabic, Dutch, Italian, Turkish, Ukrainian, Vietnamese). During the translation, behavioral data (keystrokes, pauses, editing times) were collected using the [PET](https://github.com/wilkeraziz/PET) platform.
|
|
|
|
| 32 |
- **Paper:** [Arxiv](TBD)
|
| 33 |
- **Point of Contact:** [Gabriele Sarti](mailto:[email protected])
|
| 34 |
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
*For an overview of DivEMT, see our [Paper](https://arxiv.org/abs/2205.12215) and our [Github repository](https://github.com/gsarti/divemt)*
|
| 38 |
+
|
| 39 |
### Dataset Summary
|
| 40 |
|
| 41 |
This dataset contains the processed `warmup` and `main` splits of the DivEMT dataset. A sample of documents extracted from the Flores-101 corpus were either translated from scratch or post-edited from an existing automatic translation by a total of 18 professional translators across six typologically diverse languages (Arabic, Dutch, Italian, Turkish, Ukrainian, Vietnamese). During the translation, behavioral data (keystrokes, pauses, editing times) were collected using the [PET](https://github.com/wilkeraziz/PET) platform.
|