

Upload folder using huggingface_hub
Browse files- assets/CogVideoX-LoRA.webm +0 -0
- assets/contribute.md +16 -0
- assets/contribute_zh.md +16 -0
- assets/dataset_zh.md +72 -0
- assets/lora_2b.png +0 -0
- assets/lora_5b.png +0 -0
- assets/output_altar.mp4 +0 -0
- assets/output_cup.mp4 +0 -0
- assets/output_marble.mp4 +0 -0
- assets/output_vase.mp4 +0 -0
- assets/sft_2b.png +0 -0
- assets/sft_5b.png +0 -0
- assets/slaying-ooms.png +0 -0
- assets/tests/metadata.csv +2 -0
- assets/tests/prompts.txt +1 -0
- assets/tests/prompts_multi.txt +2 -0
- assets/tests/videos.txt +1 -0
- assets/tests/videos/hiker.mp4 +0 -0
- assets/tests/videos/hiker_tiny.mp4 +0 -0
- assets/tests/videos_multi.txt +2 -0
assets/CogVideoX-LoRA.webm
ADDED
|
Binary file (483 kB). View file
|
|
|
assets/contribute.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributions Welcome
|
| 2 |
+
|
| 3 |
+
This project is in a very early stage, and we welcome contributions from everyone. We hope to receive contributions and support in the following areas:
|
| 4 |
+
|
| 5 |
+
1. Support for more models. In addition to CogVideoX models, we also highly encourage contributions supporting other models.
|
| 6 |
+
2. Support for richer datasets. In our example, we used a Disney video generation dataset, but we hope to support more datasets as the current one is too limited for deeper fine-tuning exploration.
|
| 7 |
+
3. Anything in `TODO` we mention in our README.md
|
| 8 |
+
|
| 9 |
+
## How to Submit
|
| 10 |
+
|
| 11 |
+
We welcome you to create a new PR and describe the corresponding contribution. We will review it as soon as possible.
|
| 12 |
+
|
| 13 |
+
## Naming Conventions
|
| 14 |
+
|
| 15 |
+
- Please use English for naming, avoid using pinyin or other languages. All comments should be in English.
|
| 16 |
+
- Strictly follow PEP8 conventions, and use underscores to separate words. Please avoid using names like a, b, c.
|
assets/contribute_zh.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 欢迎你们的贡献
|
| 2 |
+
|
| 3 |
+
本项目属于非常初级的阶段,欢迎大家进行贡献。我们希望在以下方面得到贡献和支持:
|
| 4 |
+
|
| 5 |
+
1. 支持更多的模型,除了 CogVideoX 模型之外的模型,我们也非常支持。
|
| 6 |
+
2. 更丰富的数据集支持。在我们的例子中,我们使用了一个 Disney 视频生成数据集,但是我们希望能够支持更多的数据集,这个数据集太少了,并不足以进行更深的微调探索。
|
| 7 |
+
3. 任何我们在README中`TODO`提到的内容。
|
| 8 |
+
|
| 9 |
+
## 提交方式
|
| 10 |
+
|
| 11 |
+
我们欢迎您直接创建一个新的PR,并说明对应的贡献,我们将第一时间查看。
|
| 12 |
+
|
| 13 |
+
## 命名规范
|
| 14 |
+
|
| 15 |
+
- 请使用英文命名,不要使用拼音或者其他语言命名。所有的注释均使用英文。
|
| 16 |
+
- 请严格遵循 PEP8 规范,使用下划线分割单词。请勿使用 a,b,c 这样的命名。
|
assets/dataset_zh.md
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 数据集格式
|
| 2 |
+
|
| 3 |
+
### 提示词数据集要求
|
| 4 |
+
|
| 5 |
+
创建 `prompt.txt` 文件,文件应包含逐行分隔的提示。请注意,提示必须是英文,并且建议使用 [提示润色脚本](https://github.com/THUDM/CogVideo/blob/main/inference/convert_demo.py) 进行润色。或者可以使用 [CogVideo-caption](https://huggingface.co/THUDM/cogvlm2-llama3-caption) 进行数据标注:
|
| 6 |
+
|
| 7 |
+
```
|
| 8 |
+
A black and white animated sequence featuring a rabbit, named Rabbity Ribfried, and an anthropomorphic goat in a musical, playful environment, showcasing their evolving interaction.
|
| 9 |
+
A black and white animated sequence on a ship’s deck features a bulldog character, named Bully Bulldoger, showcasing exaggerated facial expressions and body language...
|
| 10 |
+
...
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
### 视频数据集要求
|
| 14 |
+
|
| 15 |
+
该框架支持的分辨率和帧数需要满足以下条件:
|
| 16 |
+
|
| 17 |
+
- **支持的分辨率(宽 * 高)**:
|
| 18 |
+
- 任意分辨率且必须能被32整除。例如,`720 * 480`, `1920 * 1020` 等分辨率。
|
| 19 |
+
|
| 20 |
+
- **支持的帧数(Frames)**:
|
| 21 |
+
- 必须是 `4 * k` 或 `4 * k + 1`(例如:16, 32, 49, 81)
|
| 22 |
+
|
| 23 |
+
所有的视频建议放在一个文件夹中。
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
接着,创建 `videos.txt` 文件。 `videos.txt` 文件应包含逐行分隔的视频文件路径。请注意,路径必须相对于 `--data_root` 目录。格式如下:
|
| 27 |
+
|
| 28 |
+
```
|
| 29 |
+
videos/00000.mp4
|
| 30 |
+
videos/00001.mp4
|
| 31 |
+
...
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
对于有兴趣了解更多细节的开发者,您可以查看相关的 `BucketSampler` 代码。
|
| 35 |
+
|
| 36 |
+
### 数据集结构
|
| 37 |
+
|
| 38 |
+
您的数据集结构应如下所示,通过运行`tree`命令,你能看到:
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
dataset
|
| 42 |
+
├── prompt.txt
|
| 43 |
+
├── videos.txt
|
| 44 |
+
├── videos
|
| 45 |
+
├── videos/00000.mp4
|
| 46 |
+
├── videos/00001.mp4
|
| 47 |
+
├── ...
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
### 使用数据集
|
| 51 |
+
|
| 52 |
+
当使用此格式时,`--caption_column` 应为 `prompt.txt`,`--video_column` 应为 `videos.txt`。如果您的数据存储在 CSV
|
| 53 |
+
文件中,也可以指定 `--dataset_file` 为 CSV 文件的路径,`--caption_column` 和 `--video_column` 为 CSV
|
| 54 |
+
文件中的实际列名。请参考 [test_dataset](../tests/test_dataset.py) 文件中的一些简单示例。
|
| 55 |
+
|
| 56 |
+
例如,使用 [这个](https://huggingface.co/datasets/Wild-Heart/Disney-VideoGeneration-Dataset) Disney 数据集进行微调。下载可通过🤗
|
| 57 |
+
Hugging Face CLI 完成:
|
| 58 |
+
|
| 59 |
+
```
|
| 60 |
+
huggingface-cli download --repo-type dataset Wild-Heart/Disney-VideoGeneration-Dataset --local-dir video-dataset-disney
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
该数据集已按照预期格式准备好,可直接使用。但是,直接使用视频数据集可能会导致较小 VRAM 的 GPU 出现
|
| 64 |
+
OOM(内存不足),因为它需要加载 [VAE](https://huggingface.co/THUDM/CogVideoX-5b/tree/main/vae)
|
| 65 |
+
(将视频编码为潜在空间)和大型 [T5-XXL](https://huggingface.co/google/t5-v1_1-xxl/)
|
| 66 |
+
|
| 67 |
+
文本编码器。为了降低内存需求,您可以使用 `training/prepare_dataset.py` 脚本预先计算潜在变量和嵌入。
|
| 68 |
+
|
| 69 |
+
填写或修改 `prepare_dataset.sh` 中的参数并执行它以获得预先计算的潜在变量和嵌入(请确保指定 `--save_latents_and_embeddings`
|
| 70 |
+
以保存预计算的工件)。如果准备图像到视频的训练,请确保传递 `--save_image_latents`,它对沙子进行编码,将图像潜在值与视频一起保存。
|
| 71 |
+
在训练期间使用这些工件时,确保指定 `--load_tensors` 标志,否则将直接使用视频并需要加载文本编码器和
|
| 72 |
+
VAE。该脚本还支持 PyTorch DDP,以便可以使用多个 GPU 并行编码大型数据集(修改 `NUM_GPUS` 参数)。
|
assets/lora_2b.png
ADDED
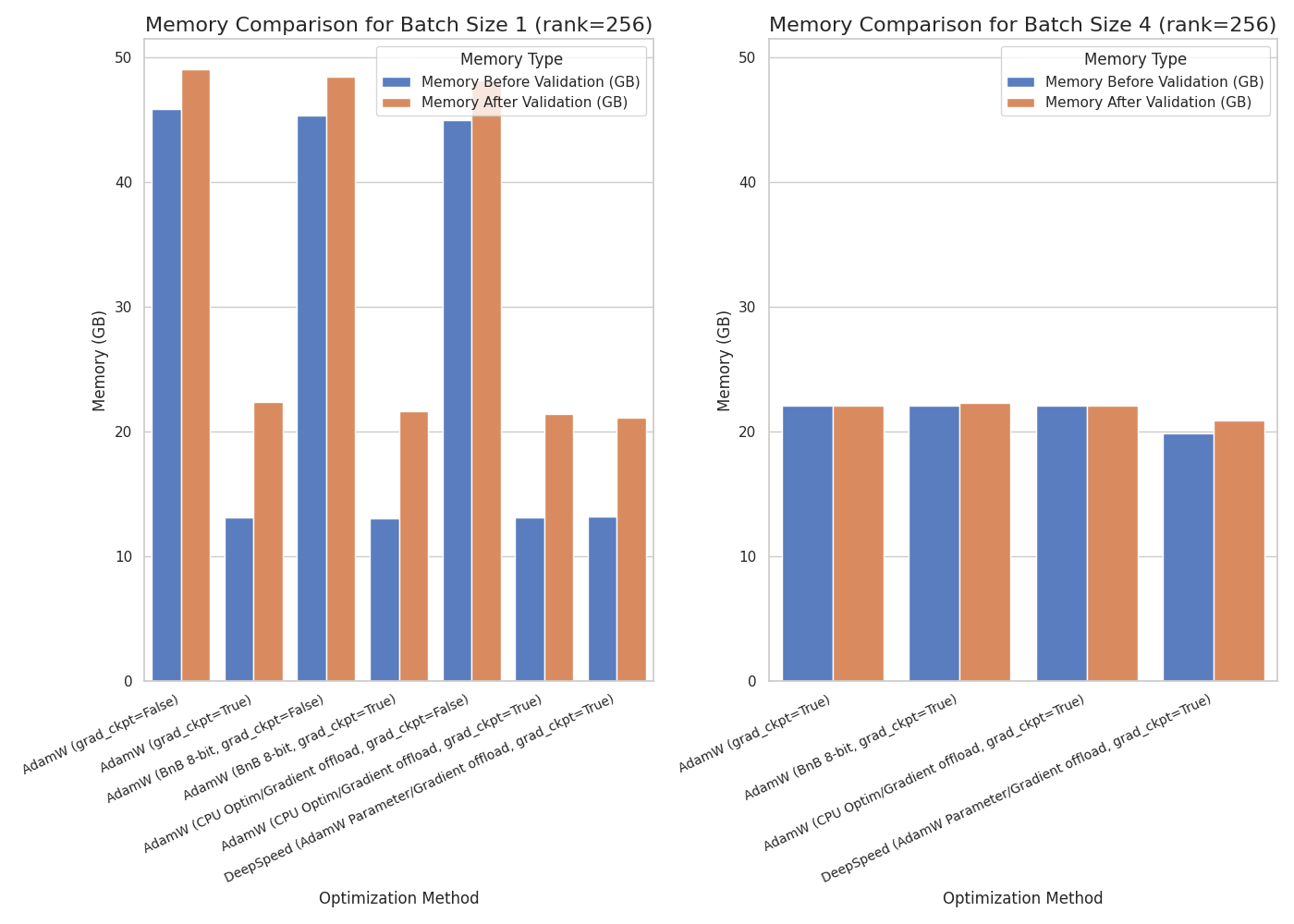
|
assets/lora_5b.png
ADDED
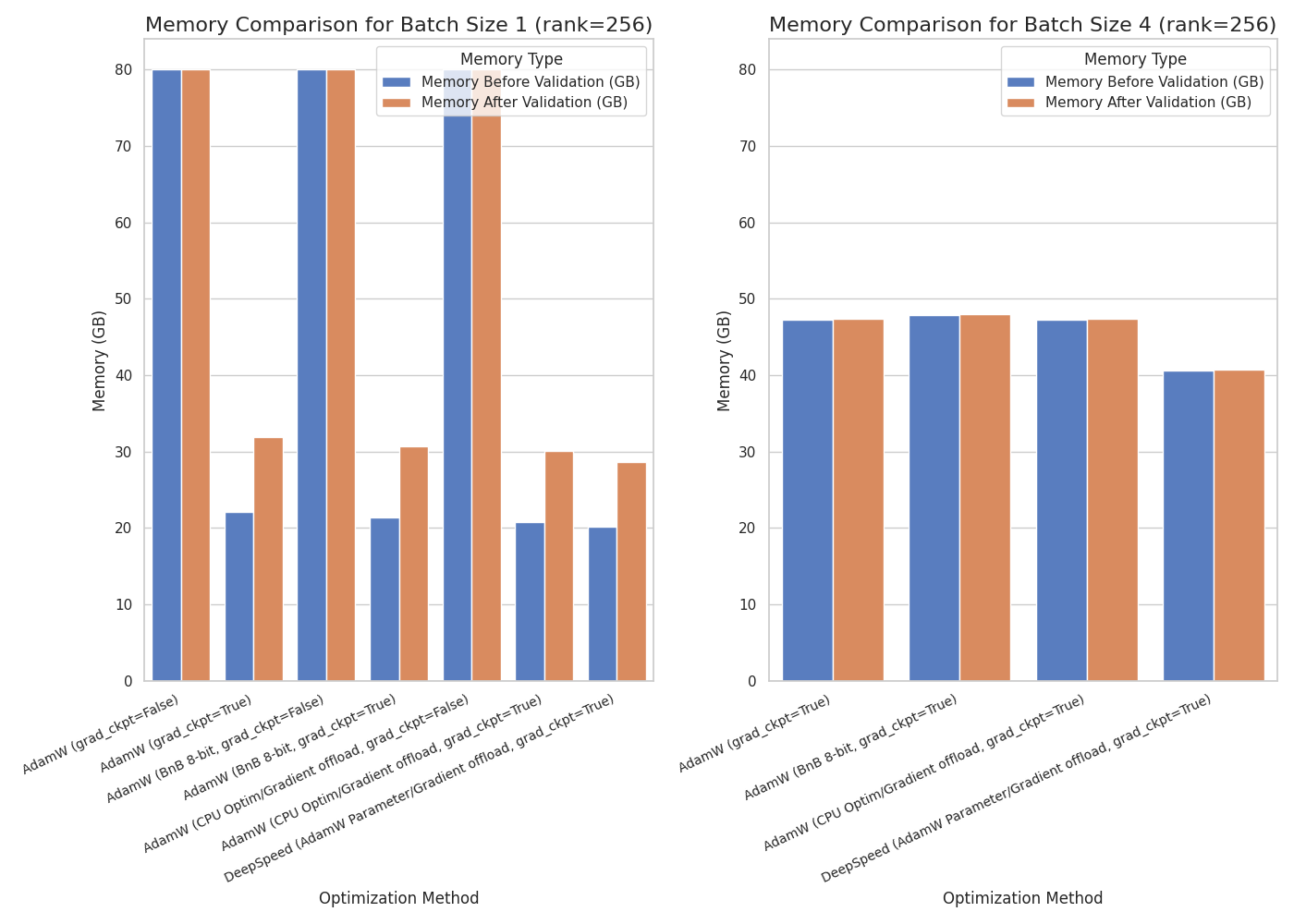
|
assets/output_altar.mp4
ADDED
|
Binary file (562 kB). View file
|
|
|
assets/output_cup.mp4
ADDED
|
Binary file (414 kB). View file
|
|
|
assets/output_marble.mp4
ADDED
|
Binary file (469 kB). View file
|
|
|
assets/output_vase.mp4
ADDED
|
Binary file (568 kB). View file
|
|
|
assets/sft_2b.png
ADDED
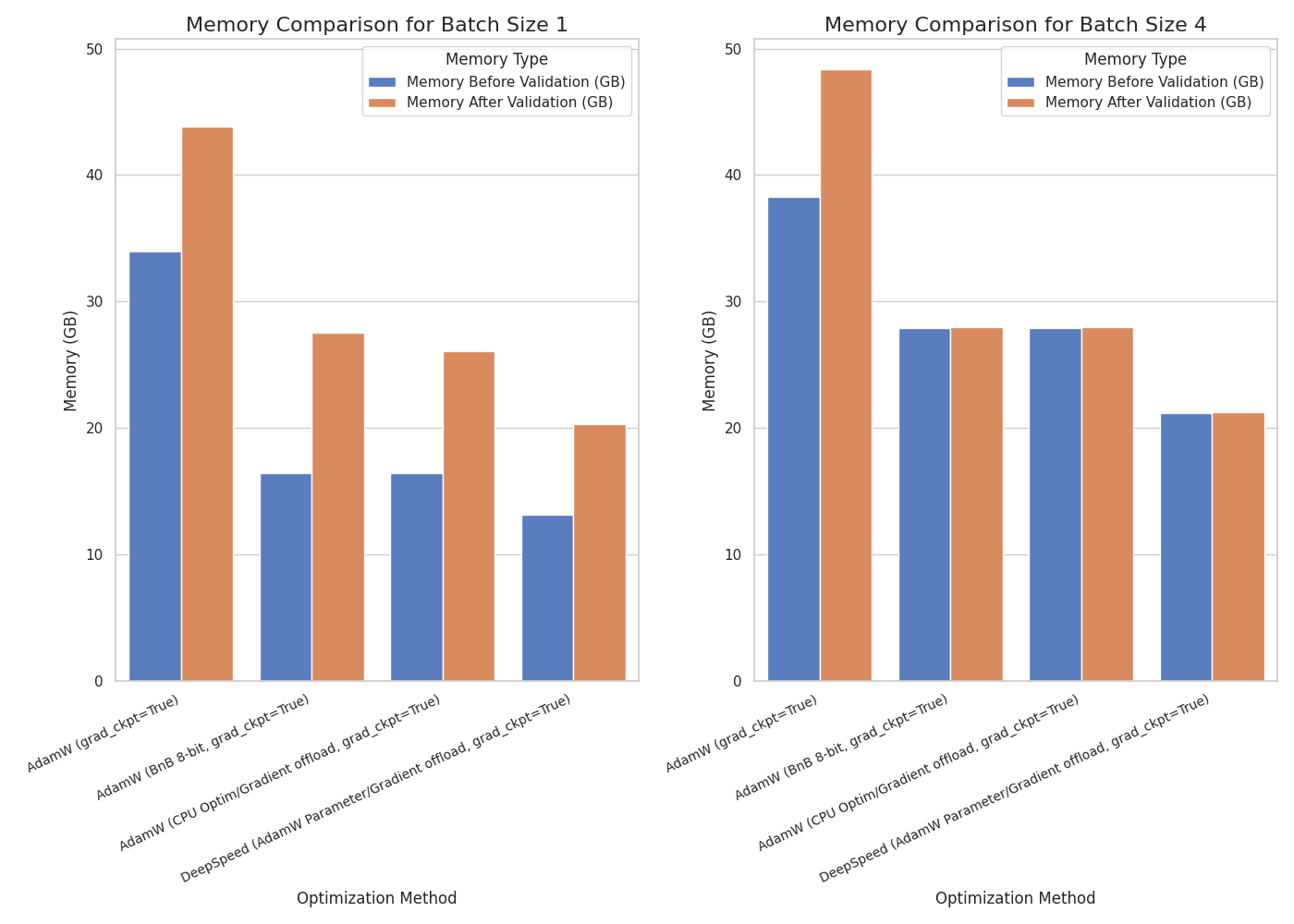
|
assets/sft_5b.png
ADDED
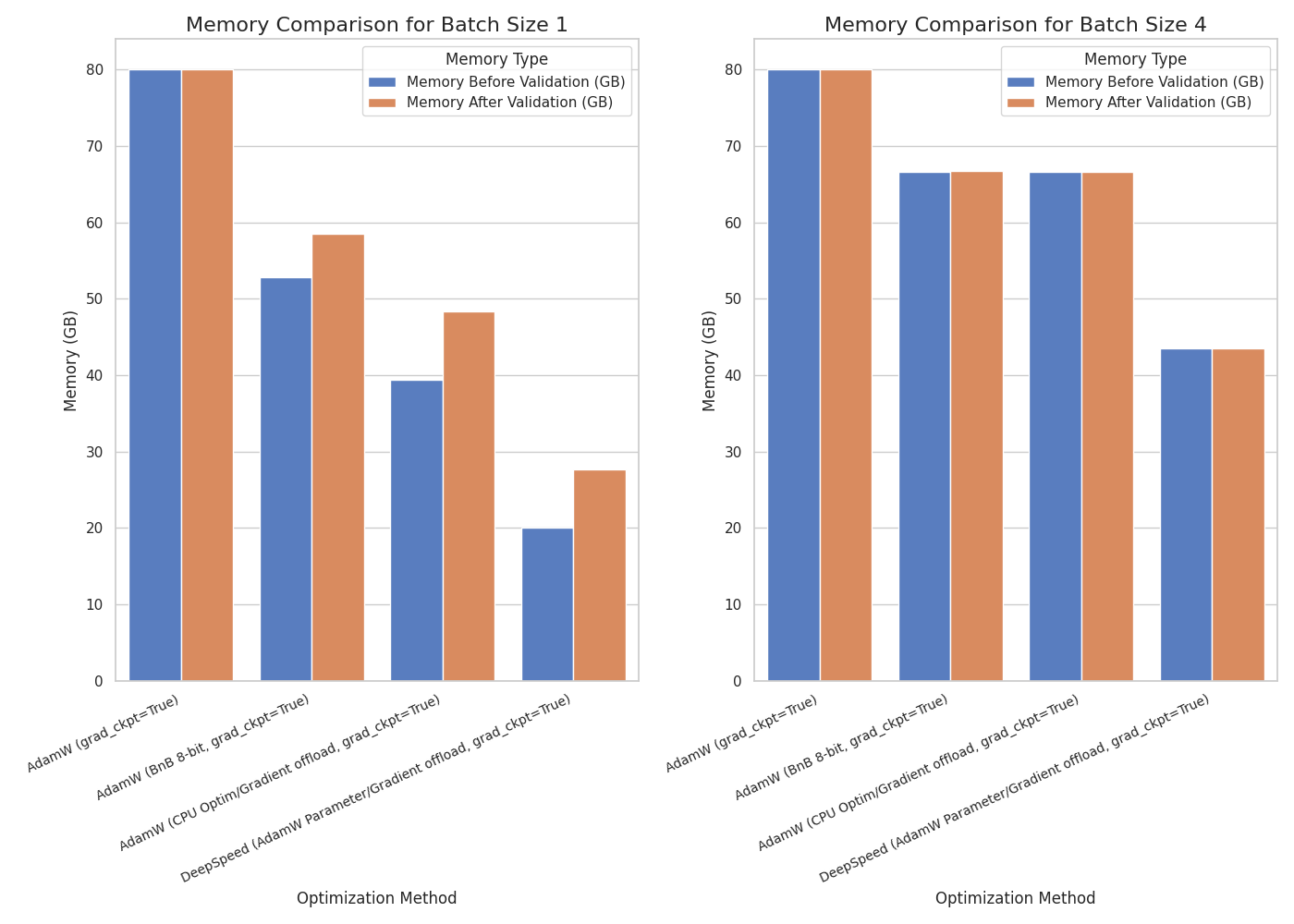
|
assets/slaying-ooms.png
ADDED

|
assets/tests/metadata.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
video,caption
|
| 2 |
+
"videos/hiker.mp4","""A hiker standing at the top of a mountain, triumphantly, high quality"""
|
assets/tests/prompts.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
A hiker standing at the top of a mountain, triumphantly, high quality
|
assets/tests/prompts_multi.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
A hiker standing at the top of a mountain, triumphantly, high quality
|
| 2 |
+
A hiker standing at the top of a mountain, triumphantly, high quality
|
assets/tests/videos.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
videos/hiker.mp4
|
assets/tests/videos/hiker.mp4
ADDED
|
Binary file (266 kB). View file
|
|
|
assets/tests/videos/hiker_tiny.mp4
ADDED
|
Binary file (71 kB). View file
|
|
|
assets/tests/videos_multi.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
videos/hiker.mp4
|
| 2 |
+
videos/hiker_tiny.mp4
|