


using to build tf great ;)

Hieu Lam
lamhieu
AI & ML interests
.-.
Recent Activity
updated a Space about 2 months ago
lamhieu/lightweight-embeddings updated a Space about 2 months ago
lamhieu/docsifer updated a Space about 2 months ago
lamhieu/docsiferOrganizations


replied to their post 9 months ago
replied to their post 9 months ago
go ahead and create something interesting ;)
posted an update 9 months ago
Post
2802
🚀 Introducing the xLLMs Dataset Collection
The xLLMs project is a growing suite of multilingual and multimodal dialogue datasets designed to train and evaluate advanced conversational LLMs. Each dataset focuses on a specific capability — from long-context reasoning and factual grounding to STEM explanations, math Q&A, and polite multilingual interaction.
🌍 Explore the full collection on Hugging Face:
👉 lamhieu/xllms-66cdfe34307bb2edc8c6df7d
💬 Highlight: xLLMs – Dialogue Pubs
A large-scale multilingual dataset built from document-guided synthetic dialogues (Wikipedia, WikiHow, and technical sources). It’s ideal for training models on long-context reasoning, multi-turn coherence, and tool-augmented dialogue across 9 languages.
👉 lamhieu/xllms_dialogue_pubs
🧠 Designed for:
- Long-context and reasoning models
- Multilingual assistants
- Tool-calling and structured response learning
All datasets are open for research and development use — free, transparent, and carefully curated to improve dialogue model quality.
The xLLMs project is a growing suite of multilingual and multimodal dialogue datasets designed to train and evaluate advanced conversational LLMs. Each dataset focuses on a specific capability — from long-context reasoning and factual grounding to STEM explanations, math Q&A, and polite multilingual interaction.
🌍 Explore the full collection on Hugging Face:
👉 lamhieu/xllms-66cdfe34307bb2edc8c6df7d
💬 Highlight: xLLMs – Dialogue Pubs
A large-scale multilingual dataset built from document-guided synthetic dialogues (Wikipedia, WikiHow, and technical sources). It’s ideal for training models on long-context reasoning, multi-turn coherence, and tool-augmented dialogue across 9 languages.
👉 lamhieu/xllms_dialogue_pubs
🧠 Designed for:
- Long-context and reasoning models
- Multilingual assistants
- Tool-calling and structured response learning
All datasets are open for research and development use — free, transparent, and carefully curated to improve dialogue model quality.


- 4 replies
replied to their post 11 months ago
At the company where I work, we always use paid tools to build features and support tools such as Copilot, OpenAI APIs, Gemini, Vertex, and so on. But for example, with Copilot, it’s very difficult to know whether they don’t use enterprise data for training. Of course, we always see those ‘terms’ stated, but you know, the data passes through so many layers.
posted an update 11 months ago
Post
482
Copilot, Cursor and all those new AI-driven extensions are rising fast — they can read your codebase, optimize logic, and even automate whole workflows. But here’s the flip side: once these tools start peeking into .env files, nodes, and source code, the risk of leaking critical keys or sensitive info becomes very real.
So yeah, we’re coding faster than ever, but are we also opening the door to a whole new wave of vulnerabilities?
👉 Is this the hidden threat waiting to hit the next era of “vibe-coding”?
So yeah, we’re coding faster than ever, but are we also opening the door to a whole new wave of vulnerabilities?
👉 Is this the hidden threat waiting to hit the next era of “vibe-coding”?

- 2 replies
posted an update about 1 year ago
Post
247
(tiếng Việt bên dưới ⬇️)
🔍 AI is redefining the search experience.
From the limits of keyword-based search to the power of NLP, conversational AI, and personalization — search is no longer just typing and filtering, but understanding intent.
This slide deck shares key insights, real-world use cases, and recommendations for e-commerce and retail businesses — especially in food & FMCG:
- 📈 Higher conversions
- 🛒 Better shopping experience
- 🚀 Stronger, future-ready brand positioning
Check it out here:
👉 https://docs.google.com/presentation/d/1_Ix_jmK-kbOV_Ayi5SNbzhfwpmpenDmtBub9ucR2xGI/edit?usp=sharing
💬 Open to discuss if you’re exploring AI-powered search!
---
🔍 AI đang tái định nghĩa trải nghiệm tìm kiếm.
Từ giới hạn của tìm kiếm theo từ khóa đến sức mạnh của NLP, AI đàm thoại và cá nhân hóa — tìm kiếm không còn chỉ là gõ rồi lọc, mà là hiểu đúng nhu cầu.
Slide deck này chia sẻ góc nhìn tổng quan, ví dụ thực tiễn và khuyến nghị cụ thể cho doanh nghiệp TMĐT, bán lẻ — đặc biệt trong ngành thực phẩm & FMCG:
- 📈 Tăng chuyển đổi
- 🛒 Trải nghiệm mua sắm tốt hơn
- 🚀 Xây dựng thương hiệu hiện đại, dẫn đầu xu hướng
Xem tại đây:
👉 https://docs.google.com/presentation/d/1_Ix_jmK-kbOV_Ayi5SNbzhfwpmpenDmtBub9ucR2xGI/edit?usp=sharing
💬 Rất sẵn lòng trao đổi nếu bạn quan tâm ứng dụng AI vào doanh nghiệp!
🔍 AI is redefining the search experience.
From the limits of keyword-based search to the power of NLP, conversational AI, and personalization — search is no longer just typing and filtering, but understanding intent.
This slide deck shares key insights, real-world use cases, and recommendations for e-commerce and retail businesses — especially in food & FMCG:
- 📈 Higher conversions
- 🛒 Better shopping experience
- 🚀 Stronger, future-ready brand positioning
Check it out here:
👉 https://docs.google.com/presentation/d/1_Ix_jmK-kbOV_Ayi5SNbzhfwpmpenDmtBub9ucR2xGI/edit?usp=sharing
💬 Open to discuss if you’re exploring AI-powered search!
---
🔍 AI đang tái định nghĩa trải nghiệm tìm kiếm.
Từ giới hạn của tìm kiếm theo từ khóa đến sức mạnh của NLP, AI đàm thoại và cá nhân hóa — tìm kiếm không còn chỉ là gõ rồi lọc, mà là hiểu đúng nhu cầu.
Slide deck này chia sẻ góc nhìn tổng quan, ví dụ thực tiễn và khuyến nghị cụ thể cho doanh nghiệp TMĐT, bán lẻ — đặc biệt trong ngành thực phẩm & FMCG:
- 📈 Tăng chuyển đổi
- 🛒 Trải nghiệm mua sắm tốt hơn
- 🚀 Xây dựng thương hiệu hiện đại, dẫn đầu xu hướng
Xem tại đây:
👉 https://docs.google.com/presentation/d/1_Ix_jmK-kbOV_Ayi5SNbzhfwpmpenDmtBub9ucR2xGI/edit?usp=sharing
💬 Rất sẵn lòng trao đổi nếu bạn quan tâm ứng dụng AI vào doanh nghiệp!
posted an update over 1 year ago
Post
1677
Power Up RAG, Virtual Assistants, and Perplexity Alternatives! 🚀
🔗 Docsifer + Lightweight Embeddings API = The perfect duo for next-gen solutions!
- 📄 Docsifer: Seamlessly convert PDFs, Word, JSON, and URLs to Markdown—ideal for building clean, structured knowledge bases.
- ✨ Lightweight Embeddings API: Create multilingual and multimodal embeddings for fast, accurate search, reranking, and understanding.
🤖 Build smarter RAG pipelines, enhance virtual assistants, or craft powerful Perplexity-like applications with this free, production-ready combo.
👉 Start optimizing today:
- Docsifer: lamhieu/docsifer
- Lightweight Embeddings API: lamhieu/lightweight-embeddings
💡 Faster insights. Better recommendations. Global reach. 🚀
🔗 Docsifer + Lightweight Embeddings API = The perfect duo for next-gen solutions!
- 📄 Docsifer: Seamlessly convert PDFs, Word, JSON, and URLs to Markdown—ideal for building clean, structured knowledge bases.
- ✨ Lightweight Embeddings API: Create multilingual and multimodal embeddings for fast, accurate search, reranking, and understanding.
🤖 Build smarter RAG pipelines, enhance virtual assistants, or craft powerful Perplexity-like applications with this free, production-ready combo.
👉 Start optimizing today:
- Docsifer: lamhieu/docsifer
- Lightweight Embeddings API: lamhieu/lightweight-embeddings
💡 Faster insights. Better recommendations. Global reach. 🚀

- 1 reply
posted an update over 1 year ago
Post
1025
🚀 Docsifer: Convert Anything to Markdown! 📝
Transform your files into Markdown with Docsifer—your all-in-one tool for diverse formats like PDF, Word, Excel, JSON, HTML, CSV, ZIP, and even audio/images. Supports URL-to-Markdown too! 🔗✨
🌟 Why Docsifer?
- Multi-Format: Convert virtually any document type.
- Flexible & Accurate: Powered by MarkItDown and optional LLMs for advanced text extraction.
- Privacy-First: No data storage—only minimal anonymous stats.
- Open Source: Transparent and community-driven.
- Production-Ready: Docker, API, and interactive playground on Hugging Face Spaces.
👉 Try it out or contribute:
🌐 Hugging Face: lamhieu/docsifer
💻 GitHub: https://github.com/lh0x00/docsifer
Convert smarter. Collaborate better. Start now! 🚀
Transform your files into Markdown with Docsifer—your all-in-one tool for diverse formats like PDF, Word, Excel, JSON, HTML, CSV, ZIP, and even audio/images. Supports URL-to-Markdown too! 🔗✨
🌟 Why Docsifer?
- Multi-Format: Convert virtually any document type.
- Flexible & Accurate: Powered by MarkItDown and optional LLMs for advanced text extraction.
- Privacy-First: No data storage—only minimal anonymous stats.
- Open Source: Transparent and community-driven.
- Production-Ready: Docker, API, and interactive playground on Hugging Face Spaces.
👉 Try it out or contribute:
🌐 Hugging Face: lamhieu/docsifer
💻 GitHub: https://github.com/lh0x00/docsifer
Convert smarter. Collaborate better. Start now! 🚀
posted an update over 1 year ago
Post
1890
Unlock seamless document conversion with Docsifer, powered by MarkItDown at its core! 🚀 Effortlessly transform PDFs, Word, Excel, images, audio, HTML, and more into clean, structured Markdown—perfect for developers, writers, and content creators. With optional LLM-enhanced extraction and robust format support, Docsifer ensures accuracy, speed, and privacy.
🌟 Try it now and experience professional-grade Markdown conversion: lamhieu/docsifer
🌟 Try it now and experience professional-grade Markdown conversion: lamhieu/docsifer
posted an update over 1 year ago
Post
2274
🚀 Unlock the power of a completely free, unlimited multilingual API!
🌐 The Lightweight Embeddings API offers state-of-the-art text and image embeddings, advanced reranking, and seamless support for over 100 languages — no limits, no restrictions.
🌟 Try it now: lamhieu/lightweight-embeddings
🌐 The Lightweight Embeddings API offers state-of-the-art text and image embeddings, advanced reranking, and seamless support for over 100 languages — no limits, no restrictions.
🌟 Try it now: lamhieu/lightweight-embeddings
reacted to m-ric's post with 🔥 almost 2 years ago
Post
1187
Emu3: Next-token prediction conquers multimodal tasks 🔥
This is the most important research in months: we’re now very close to having a single architecture to handle all modalities. The folks at Beijing Academy of Artificial Intelligence (BAAI) just released Emu3, a single model that handles text, images, and videos all at once.
𝗪𝗵𝗮𝘁'𝘀 𝘁𝗵𝗲 𝗯𝗶𝗴 𝗱𝗲𝗮𝗹?
🌟 Emu3 is the first model to truly unify all these different types of data (text, images, video) using just one simple trick: predicting the next token.
And it’s only 8B, but really strong:
🖼️ For image generation, it's matching the best specialized models out there, like SDXL.
👁️ In vision tasks, it's outperforming top models like LLaVA-1.6-7B, which is a big deal for a model that wasn't specifically designed for this.
🎬 It's the first to nail video generation without using complicated diffusion techniques.
𝗛𝗼𝘄 𝗱𝗼𝗲𝘀 𝗶𝘁 𝘄𝗼𝗿𝗸?
🧩 Emu3 uses a special tokenizer (SBER-MoVQGAN) to turn images and video clips into sequences of 4,096 tokens.
🔗 Then, it treats everything - text, images, and videos - as one long series of tokens to predict.
🔮 During training, it just tries to guess the next token, whether that's a word, part of an image, or a video frame.
𝗖𝗮𝘃𝗲𝗮𝘁𝘀 𝗼𝗻 𝘁𝗵𝗲 𝗿𝗲𝘀𝘂𝗹𝘁𝘀:
👉 In image generation, Emu3 beats SDXL, but it’s also much bigger (8B vs 3.5B). It would be more difficult to beat the real diffusion GOAT FLUX-dev.
👉 In vision, authors also don’t show a comparison against all the current SOTA models like Qwen-VL or Pixtral.
This approach is exciting because it's simple (next token prediction) and scalable(handles all sorts of data)!
Read the paper 👉 Emu3: Next-Token Prediction is All You Need (2409.18869)
This is the most important research in months: we’re now very close to having a single architecture to handle all modalities. The folks at Beijing Academy of Artificial Intelligence (BAAI) just released Emu3, a single model that handles text, images, and videos all at once.
𝗪𝗵𝗮𝘁'𝘀 𝘁𝗵𝗲 𝗯𝗶𝗴 𝗱𝗲𝗮𝗹?
🌟 Emu3 is the first model to truly unify all these different types of data (text, images, video) using just one simple trick: predicting the next token.
And it’s only 8B, but really strong:
🖼️ For image generation, it's matching the best specialized models out there, like SDXL.
👁️ In vision tasks, it's outperforming top models like LLaVA-1.6-7B, which is a big deal for a model that wasn't specifically designed for this.
🎬 It's the first to nail video generation without using complicated diffusion techniques.
𝗛𝗼𝘄 𝗱𝗼𝗲𝘀 𝗶𝘁 𝘄𝗼𝗿𝗸?
🧩 Emu3 uses a special tokenizer (SBER-MoVQGAN) to turn images and video clips into sequences of 4,096 tokens.
🔗 Then, it treats everything - text, images, and videos - as one long series of tokens to predict.
🔮 During training, it just tries to guess the next token, whether that's a word, part of an image, or a video frame.
𝗖𝗮𝘃𝗲𝗮𝘁𝘀 𝗼𝗻 𝘁𝗵𝗲 𝗿𝗲𝘀𝘂𝗹𝘁𝘀:
👉 In image generation, Emu3 beats SDXL, but it’s also much bigger (8B vs 3.5B). It would be more difficult to beat the real diffusion GOAT FLUX-dev.
👉 In vision, authors also don’t show a comparison against all the current SOTA models like Qwen-VL or Pixtral.
This approach is exciting because it's simple (next token prediction) and scalable(handles all sorts of data)!
Read the paper 👉 Emu3: Next-Token Prediction is All You Need (2409.18869)
reacted to singhsidhukuldeep's post with 👍 almost 2 years ago
Post
1666
Just wrapped up a deep dive into the latest lecture on building LLMs, such as ChatGPT, from @Stanford CS229 course. Here are my top takeaways:
🔍 Understanding the Components: LLMs like ChatGPT, Claude, and others are more than just neural networks; they are a complex blend of architecture, training loss, data evaluation, and systems. Knowing how these components work together is key to improving and scaling these models.
📊 Scaling Matters: Performance improves predictably with more data, bigger models, and greater computational power. However, balancing these factors is crucial to avoid overfitting and resource waste.
📈 Data is King: LLMs are trained on trillions of tokens scraped from the internet, but the quality of this data matters immensely. Rigorous filtering and deduplication processes are essential to maintaining data integrity.
🏗️ Pre-Training vs. Post-Training: While pre-training equips the model with general knowledge, post-training (like RLHF) fine-tunes it to follow human-like responses, reducing toxic outputs and improving alignment with human values.
🌐 Reinforcement Learning from Human Feedback (RLHF): This technique allows LLMs to maximize outputs that align with human preferences, making models more reliable and accurate.
💡 Why It Matters: Understanding these processes not only helps us appreciate the complexity behind our everyday AI tools but also highlights the challenges and opportunities in the ever-evolving field of AI.
Whether you’re in tech, data science, or just AI-curious, staying updated on these advancements is crucial. LLMs are not just transforming industries; they’re redefining the future of human-computer interaction!
I just realized this was almost 2 hours long...
Link: https://www.youtube.com/watch?v=9vM4p9NN0Ts
🔍 Understanding the Components: LLMs like ChatGPT, Claude, and others are more than just neural networks; they are a complex blend of architecture, training loss, data evaluation, and systems. Knowing how these components work together is key to improving and scaling these models.
📊 Scaling Matters: Performance improves predictably with more data, bigger models, and greater computational power. However, balancing these factors is crucial to avoid overfitting and resource waste.
📈 Data is King: LLMs are trained on trillions of tokens scraped from the internet, but the quality of this data matters immensely. Rigorous filtering and deduplication processes are essential to maintaining data integrity.
🏗️ Pre-Training vs. Post-Training: While pre-training equips the model with general knowledge, post-training (like RLHF) fine-tunes it to follow human-like responses, reducing toxic outputs and improving alignment with human values.
🌐 Reinforcement Learning from Human Feedback (RLHF): This technique allows LLMs to maximize outputs that align with human preferences, making models more reliable and accurate.
💡 Why It Matters: Understanding these processes not only helps us appreciate the complexity behind our everyday AI tools but also highlights the challenges and opportunities in the ever-evolving field of AI.
Whether you’re in tech, data science, or just AI-curious, staying updated on these advancements is crucial. LLMs are not just transforming industries; they’re redefining the future of human-computer interaction!
I just realized this was almost 2 hours long...
Link: https://www.youtube.com/watch?v=9vM4p9NN0Ts


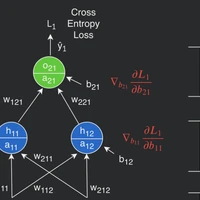
- 3 replies
Sounds interesting but I think there will be a big breakthrough, a new "architecture/methodology/factor/rethinking" for developing large models. That's what I think, I don't know what it is yet, haha.
reacted to m-ric's post with 👍 almost 2 years ago
Post
856
🚀 𝗪𝗵𝗲𝗿𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 𝗹𝗮𝘄𝘀 𝗮𝗿𝗲 𝘁𝗮𝗸𝗶𝗻𝗴 𝘂𝘀 : 𝗯𝘆 𝟮𝟬𝟮𝟴, 𝗔𝗜 𝗖𝗹𝘂𝘀𝘁𝗲𝗿𝘀 𝘄𝗶𝗹𝗹 𝗿𝗲𝗮𝗰𝗵 𝘁𝗵𝗲 𝗽𝗼𝘄𝗲𝗿 𝗰𝗼𝗻𝘀𝘂𝗺𝗽𝘁𝗶𝗼𝗻 𝗼𝗳 𝗲𝗻𝘁𝗶𝗿𝗲 𝗰𝗼𝘂𝗻𝘁𝗿𝗶𝗲𝘀
Reminder : “Scaling laws” are empirical laws saying that if you keep multiplying your compute by x10, your models will mechanically keep getting better and better.
To give you an idea, GPT-3 can barely write sentences, and GPT-4, which only used x15 its amount of compute, already sounds much smarter than some of my friends (although it's not really - or at least I haven't tested them side-by side). So you can imagine how far a x100 over GPT-4 can take us.
🏎️ As a result, tech titans are racing to build the biggest models, and for this they need gigantic training clusters.
The picture below shows the growth of training compute: it is increasing at a steady exponential rate of a x10 every 2 years. So let’s take this progress a bit further:
- 2022: starting training for GPT-4 : 10^26 FLOPs, cost of $100M
- 2024: today, companies start training on much larger clusters like the “super AI cluster” of Elon Musk’s xAI, 10^27 FLOPS, $1B
- 2026 : by then clusters will require 1GW, i.e. around the full power generated by a nuclear reactor
- 2028: we reach cluster prices in the 100 billion dollars, using 10GW, more than the most powerful power stations currently in use in the US. This last size seems crazy, but Microsoft and OpenAI already are planning one.
Will AI clusters effectively reach these crazy sizes where the consume as much as entire countries?
➡️ Three key ingredients of training might be a roadblock to scaling up :
💸 Money: but it’s very unlikely, given the potential market size for AGI, that investors lose interest.
⚡️ Energy supply at a specific location
📚 Training data: we’re already using 15 trillion tokens for Llama-3.1 when Internet has something like 60 trillion.
🤔 I’d be curious to hear your thoughts: do you think we’ll race all the way there?
Reminder : “Scaling laws” are empirical laws saying that if you keep multiplying your compute by x10, your models will mechanically keep getting better and better.
To give you an idea, GPT-3 can barely write sentences, and GPT-4, which only used x15 its amount of compute, already sounds much smarter than some of my friends (although it's not really - or at least I haven't tested them side-by side). So you can imagine how far a x100 over GPT-4 can take us.
🏎️ As a result, tech titans are racing to build the biggest models, and for this they need gigantic training clusters.
The picture below shows the growth of training compute: it is increasing at a steady exponential rate of a x10 every 2 years. So let’s take this progress a bit further:
- 2022: starting training for GPT-4 : 10^26 FLOPs, cost of $100M
- 2024: today, companies start training on much larger clusters like the “super AI cluster” of Elon Musk’s xAI, 10^27 FLOPS, $1B
- 2026 : by then clusters will require 1GW, i.e. around the full power generated by a nuclear reactor
- 2028: we reach cluster prices in the 100 billion dollars, using 10GW, more than the most powerful power stations currently in use in the US. This last size seems crazy, but Microsoft and OpenAI already are planning one.
Will AI clusters effectively reach these crazy sizes where the consume as much as entire countries?
➡️ Three key ingredients of training might be a roadblock to scaling up :
💸 Money: but it’s very unlikely, given the potential market size for AGI, that investors lose interest.
⚡️ Energy supply at a specific location
📚 Training data: we’re already using 15 trillion tokens for Llama-3.1 when Internet has something like 60 trillion.
🤔 I’d be curious to hear your thoughts: do you think we’ll race all the way there?


- 3 replies
posted an update almost 2 years ago
Post
1763
🎯 Ghost 8B Beta 1608: Empowering Your AI Assistant
📦 Unlock the Power of Ghost 8B Beta 1608: Build Your Personal AI Companion
Ghost 8B Beta 1608 empowers you to create a safe and multilingual AI assistant tailored to your needs, directly on your personal computer. 🧑💻 Leverage AI's capabilities within your own space! 🚀 Ghost 8B Beta 1608 is ready to become your AI companion.
~
📦 개인용 AI 보조 도구로 Ghost 8B Beta 1608를 활용하세요!
Ghost 8B Beta 1608, AI의 힘을 활용하여 안전하고 개인화된 언어 지원을 제공하는 AI 보조 도구를 직접 구축할 수 있습니다. 🧑💻 개인 컴퓨터에서 AI의 혜택을 누리세요! 🚀 Ghost 8B Beta 1608는 당신의 AI 파트너가 될 준비가 되어 있습니다.
lamhieu/ghost-8b-beta-8k
ghost-x/ghost-8b-beta-668ead6179f93be717db4542
📦 Unlock the Power of Ghost 8B Beta 1608: Build Your Personal AI Companion
Ghost 8B Beta 1608 empowers you to create a safe and multilingual AI assistant tailored to your needs, directly on your personal computer. 🧑💻 Leverage AI's capabilities within your own space! 🚀 Ghost 8B Beta 1608 is ready to become your AI companion.
~
📦 개인용 AI 보조 도구로 Ghost 8B Beta 1608를 활용하세요!
Ghost 8B Beta 1608, AI의 힘을 활용하여 안전하고 개인화된 언어 지원을 제공하는 AI 보조 도구를 직접 구축할 수 있습니다. 🧑💻 개인 컴퓨터에서 AI의 혜택을 누리세요! 🚀 Ghost 8B Beta 1608는 당신의 AI 파트너가 될 준비가 되어 있습니다.
lamhieu/ghost-8b-beta-8k
ghost-x/ghost-8b-beta-668ead6179f93be717db4542
posted an update almost 2 years ago
Post
3266
🚀 We’re excited to launch Ghost 8B Beta (1608), a top-performing language model with unmatched multilingual support and cost efficiency.
Key Highlights:
- Superior Performance: Outperforms Llama 3.1 8B Instruct, GPT-3.5 Turbo, Claude 3 Opus, GPT-4, and more in winrate scores.
- Expanded Language Support: Now supports 16 languages, including English, Vietnamese, Spanish, Chinese, and more.
- Enhanced Capabilities: Improved math, reasoning, and instruction-following for better task handling.
With two context options (8k and 128k), Ghost 8B Beta is perfect for complex, multilingual applications, balancing power and cost-effectiveness.
🔗 Learn More: https://ghost-x.org/docs/models/ghost-8b-beta
ghost-x/ghost-8b-beta-668ead6179f93be717db4542
Key Highlights:
- Superior Performance: Outperforms Llama 3.1 8B Instruct, GPT-3.5 Turbo, Claude 3 Opus, GPT-4, and more in winrate scores.
- Expanded Language Support: Now supports 16 languages, including English, Vietnamese, Spanish, Chinese, and more.
- Enhanced Capabilities: Improved math, reasoning, and instruction-following for better task handling.
With two context options (8k and 128k), Ghost 8B Beta is perfect for complex, multilingual applications, balancing power and cost-effectiveness.
🔗 Learn More: https://ghost-x.org/docs/models/ghost-8b-beta
ghost-x/ghost-8b-beta-668ead6179f93be717db4542
reacted to Xenova's post with 🔥 almost 2 years ago
Post
15262
I'm excited to announce that Transformers.js V3 is finally available on NPM! 🔥 State-of-the-art Machine Learning for the web, now with WebGPU support! 🤯⚡️
Install it from NPM with:
𝚗𝚙𝚖 𝚒 @𝚑𝚞𝚐𝚐𝚒𝚗𝚐𝚏𝚊𝚌𝚎/𝚝𝚛𝚊𝚗𝚜𝚏𝚘𝚛𝚖𝚎𝚛𝚜
or via CDN, for example: https://v2.scrimba.com/s0lmm0qh1q
Segment Anything demo: webml-community/segment-anything-webgpu
Install it from NPM with:
𝚗𝚙𝚖 𝚒 @𝚑𝚞𝚐𝚐𝚒𝚗𝚐𝚏𝚊𝚌𝚎/𝚝𝚛𝚊𝚗𝚜𝚏𝚘𝚛𝚖𝚎𝚛𝚜
or via CDN, for example: https://v2.scrimba.com/s0lmm0qh1q
Segment Anything demo: webml-community/segment-anything-webgpu



- 5 replies
replied to their post almost 2 years ago
thanks @danielus 🤗
replied to their post almost 2 years ago
@Dihelson @llama-anon @AIWizard76 @danielus
🎉 Ghost 8B Beta Released: Game-Changing Language Model
Ghost 8B Beta is a groundbreaking language model developed with a clear vision: to deliver exceptional multilingual support, superior knowledge capabilities, and all while remaining cost-effective. This model comes in two context length variations, 8k and 128k, ensuring flexibility for various tasks. Moreover, it boasts built-in multilingual functionality, making it a powerful tool for global communication and understanding.
- See detailed article: https://huggingface.co/blog/lamhieu/ghost-8b-beta-released-game-changing-language-mode
- Model card: https://huggingface.co/ghost-x/ghost-8b-beta
- Official website: https://ghost-x.org/docs/models/ghost-8b-beta
replied to their post almost 2 years ago
🎉 Ghost 8B Beta Released: Game-Changing Language Model
Ghost 8B Beta is a groundbreaking language model developed with a clear vision: to deliver exceptional multilingual support, superior knowledge capabilities, and all while remaining cost-effective. This model comes in two context length variations, 8k and 128k, ensuring flexibility for various tasks. Moreover, it boasts built-in multilingual functionality, making it a powerful tool for global communication and understanding.
- See detailed article: https://huggingface.co/blog/lamhieu/ghost-8b-beta-released-game-changing-language-mode
- Model card: https://huggingface.co/ghost-x/ghost-8b-beta
- Official website: https://ghost-x.org/docs/models/ghost-8b-beta