

Update README.md
Browse files
README.md
CHANGED
|
@@ -6,69 +6,23 @@ base_model:
|
|
| 6 |
- Qwen/Qwen2.5-1.5B-Instruct
|
| 7 |
library_name: transformers
|
| 8 |
---
|
| 9 |
-
#
|
| 10 |
|
| 11 |
<!-- Provide a quick summary of what the model is/does. -->
|
| 12 |
|
| 13 |
-
|
| 14 |
|
| 15 |
-
|
| 16 |
|
| 17 |
-
|
| 18 |
|
| 19 |
-
|
| 20 |
|
| 21 |
|
| 22 |
-
|
| 23 |
-
- **
|
| 24 |
-
- **
|
| 25 |
-
- **
|
| 26 |
-
- **Model type:** [More Information Needed]
|
| 27 |
-
- **Language(s) (NLP):** [More Information Needed]
|
| 28 |
-
- **License:** [More Information Needed]
|
| 29 |
-
- **Finetuned from model [optional]:** [More Information Needed]
|
| 30 |
-
|
| 31 |
-
### Model Sources [optional]
|
| 32 |
-
|
| 33 |
-
<!-- Provide the basic links for the model. -->
|
| 34 |
-
|
| 35 |
-
- **Repository:** [More Information Needed]
|
| 36 |
-
- **Paper [optional]:** [More Information Needed]
|
| 37 |
-
- **Demo [optional]:** [More Information Needed]
|
| 38 |
-
|
| 39 |
-
## Uses
|
| 40 |
-
|
| 41 |
-
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 42 |
-
|
| 43 |
-
### Direct Use
|
| 44 |
-
|
| 45 |
-
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 46 |
-
|
| 47 |
-
[More Information Needed]
|
| 48 |
-
|
| 49 |
-
### Downstream Use [optional]
|
| 50 |
-
|
| 51 |
-
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 52 |
-
|
| 53 |
-
[More Information Needed]
|
| 54 |
-
|
| 55 |
-
### Out-of-Scope Use
|
| 56 |
-
|
| 57 |
-
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 58 |
-
|
| 59 |
-
[More Information Needed]
|
| 60 |
-
|
| 61 |
-
## Bias, Risks, and Limitations
|
| 62 |
-
|
| 63 |
-
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 64 |
-
|
| 65 |
-
[More Information Needed]
|
| 66 |
-
|
| 67 |
-
### Recommendations
|
| 68 |
-
|
| 69 |
-
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 70 |
-
|
| 71 |
-
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 72 |
|
| 73 |
## How to Get Started with the Model
|
| 74 |
|
|
@@ -183,123 +137,13 @@ print(processor.batch_decode(cont, skip_special_tokens=True))
|
|
| 183 |
|
| 184 |
### Training Data
|
| 185 |
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
[More Information Needed]
|
| 189 |
-
|
| 190 |
-
### Training Procedure
|
| 191 |
-
|
| 192 |
-
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 193 |
-
|
| 194 |
-
#### Preprocessing [optional]
|
| 195 |
-
|
| 196 |
-
[More Information Needed]
|
| 197 |
-
|
| 198 |
-
|
| 199 |
-
#### Training Hyperparameters
|
| 200 |
-
|
| 201 |
-
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 202 |
-
|
| 203 |
-
#### Speeds, Sizes, Times [optional]
|
| 204 |
-
|
| 205 |
-
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 206 |
-
|
| 207 |
-
[More Information Needed]
|
| 208 |
-
|
| 209 |
-
## Evaluation
|
| 210 |
-
|
| 211 |
-
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 212 |
-
|
| 213 |
-
### Testing Data, Factors & Metrics
|
| 214 |
-
|
| 215 |
-
#### Testing Data
|
| 216 |
-
|
| 217 |
-
<!-- This should link to a Dataset Card if possible. -->
|
| 218 |
-
|
| 219 |
-
[More Information Needed]
|
| 220 |
-
|
| 221 |
-
#### Factors
|
| 222 |
-
|
| 223 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 224 |
-
|
| 225 |
-
[More Information Needed]
|
| 226 |
-
|
| 227 |
-
#### Metrics
|
| 228 |
-
|
| 229 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 230 |
-
|
| 231 |
-
[More Information Needed]
|
| 232 |
-
|
| 233 |
-
### Results
|
| 234 |
-
|
| 235 |
-
[More Information Needed]
|
| 236 |
-
|
| 237 |
-
#### Summary
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
## Model Examination [optional]
|
| 242 |
-
|
| 243 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 244 |
-
|
| 245 |
-
[More Information Needed]
|
| 246 |
-
|
| 247 |
-
## Environmental Impact
|
| 248 |
-
|
| 249 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 250 |
-
|
| 251 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 252 |
-
|
| 253 |
-
- **Hardware Type:** [More Information Needed]
|
| 254 |
-
- **Hours used:** [More Information Needed]
|
| 255 |
-
- **Cloud Provider:** [More Information Needed]
|
| 256 |
-
- **Compute Region:** [More Information Needed]
|
| 257 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 258 |
-
|
| 259 |
-
## Technical Specifications [optional]
|
| 260 |
-
|
| 261 |
-
### Model Architecture and Objective
|
| 262 |
-
|
| 263 |
-
[More Information Needed]
|
| 264 |
-
|
| 265 |
-
### Compute Infrastructure
|
| 266 |
-
|
| 267 |
-
[More Information Needed]
|
| 268 |
-
|
| 269 |
-
#### Hardware
|
| 270 |
-
|
| 271 |
-
[More Information Needed]
|
| 272 |
-
|
| 273 |
-
#### Software
|
| 274 |
-
|
| 275 |
-
[More Information Needed]
|
| 276 |
-
|
| 277 |
-
## Citation [optional]
|
| 278 |
-
|
| 279 |
-
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 280 |
-
|
| 281 |
-
**BibTeX:**
|
| 282 |
-
|
| 283 |
-
[More Information Needed]
|
| 284 |
-
|
| 285 |
-
**APA:**
|
| 286 |
-
|
| 287 |
-
[More Information Needed]
|
| 288 |
-
|
| 289 |
-
## Glossary [optional]
|
| 290 |
-
|
| 291 |
-
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 292 |
-
|
| 293 |
-
[More Information Needed]
|
| 294 |
-
|
| 295 |
-
## More Information [optional]
|
| 296 |
-
|
| 297 |
-
[More Information Needed]
|
| 298 |
-
|
| 299 |
-
## Model Card Authors [optional]
|
| 300 |
|
| 301 |
-
[
|
|
|
|
| 302 |
|
| 303 |
-
|
|
|
|
|
|
|
| 304 |
|
| 305 |
[More Information Needed]
|
|
|
|
| 6 |
- Qwen/Qwen2.5-1.5B-Instruct
|
| 7 |
library_name: transformers
|
| 8 |
---
|
| 9 |
+
# Aero-1-Audio
|
| 10 |
|
| 11 |
<!-- Provide a quick summary of what the model is/does. -->
|
| 12 |
|
| 13 |
+
`Aero-1-Audio` is a compact audio model adept at various audio tasks, including speech recognition, audio understanding, and following audio instructions.
|
| 14 |
|
| 15 |
+
1. Built upon the Qwen-2.5-1.5B language model, Aero delivers strong performance across multiple audio benchmarks while remaining parameter-efficient, even compared with larger advanced models like Whisper and Qwen-2-Audio and Phi-4-Multimodal, or commercial services like ElevenLabs/Scribe.
|
| 16 |
|
| 17 |
+
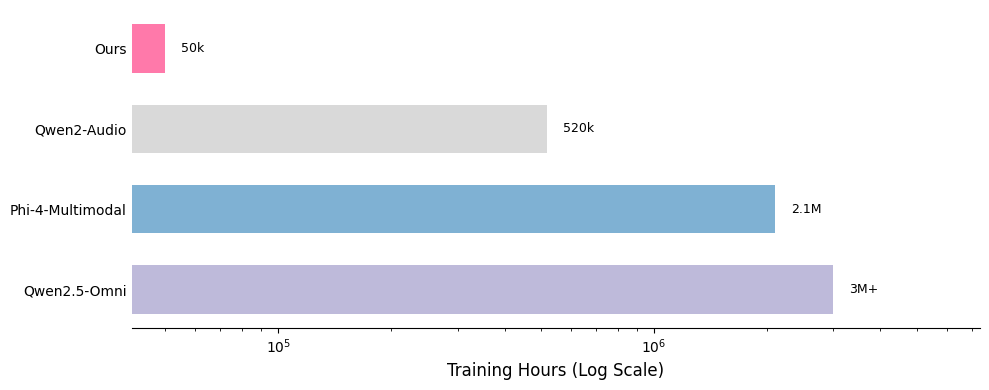
2. Aero is trained within one day on 16 H100 GPUs using just 50k hours of audio data. Our insight suggests that audio model training could be sample efficient with high quality and filtered data.
|
| 18 |
|
| 19 |
+
3. Aero can accurately perform ASR and audio understanding on continuous audio inputs up to 15 minutes in length, which we find the scenario is still a challenge for other models.
|
| 20 |
|
| 21 |
|
| 22 |
+
- **Developed by:** [LMMs-Lab]
|
| 23 |
+
- **Model type:** [LLM + Audio Encoder]
|
| 24 |
+
- **Language(s) (NLP):** [English]
|
| 25 |
+
- **License:** [MIT]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
## How to Get Started with the Model
|
| 28 |
|
|
|
|
| 137 |
|
| 138 |
### Training Data
|
| 139 |
|
| 140 |
+
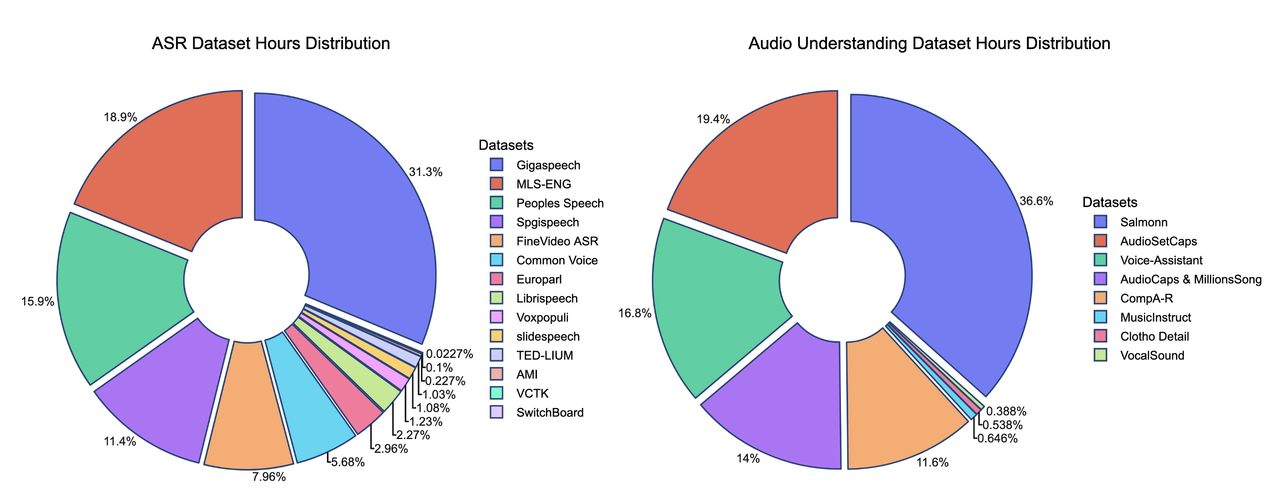
We present the contributions of our data mixture here. Our SFT data mixture includes over 20 publicly available datasets, and comparisons with other models highlight the data's lightweight nature.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 141 |
|
| 142 |
+
[](https://postimg.cc/c6CB0HkF)
|
| 143 |
+
[](https://postimg.cc/XBrf8HBR)
|
| 144 |
|
| 145 |
+
*The hours of some training datasets are estimated and may not be fully accurate
|
| 146 |
+
<br>
|
| 147 |
+
One of the key strengths of our training recipe lies in the quality and quantity of our data. Our training dataset consists of approximately 5 billion tokens, corresponding to around 50,000 hours of audio. Compared to models such as Qwen-Omni and Phi-4, our dataset is over 100 times smaller, yet our model achieves competitive performance. All data is sourced from publicly available open-source datasets, highlighting the sample efficiency of our training approach. A detailed breakdown of our data distribution is provided below, along with comparisons to other models.
|
| 148 |
|
| 149 |
[More Information Needed]
|