

add the ONNX-TensorRT way of model conversion
Browse files- README.md +43 -0
- configs/inference_trt.json +10 -0
- configs/metadata.json +2 -1
- docs/README.md +43 -0
README.md
CHANGED
|
@@ -71,6 +71,33 @@ Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducib
|
|
| 71 |
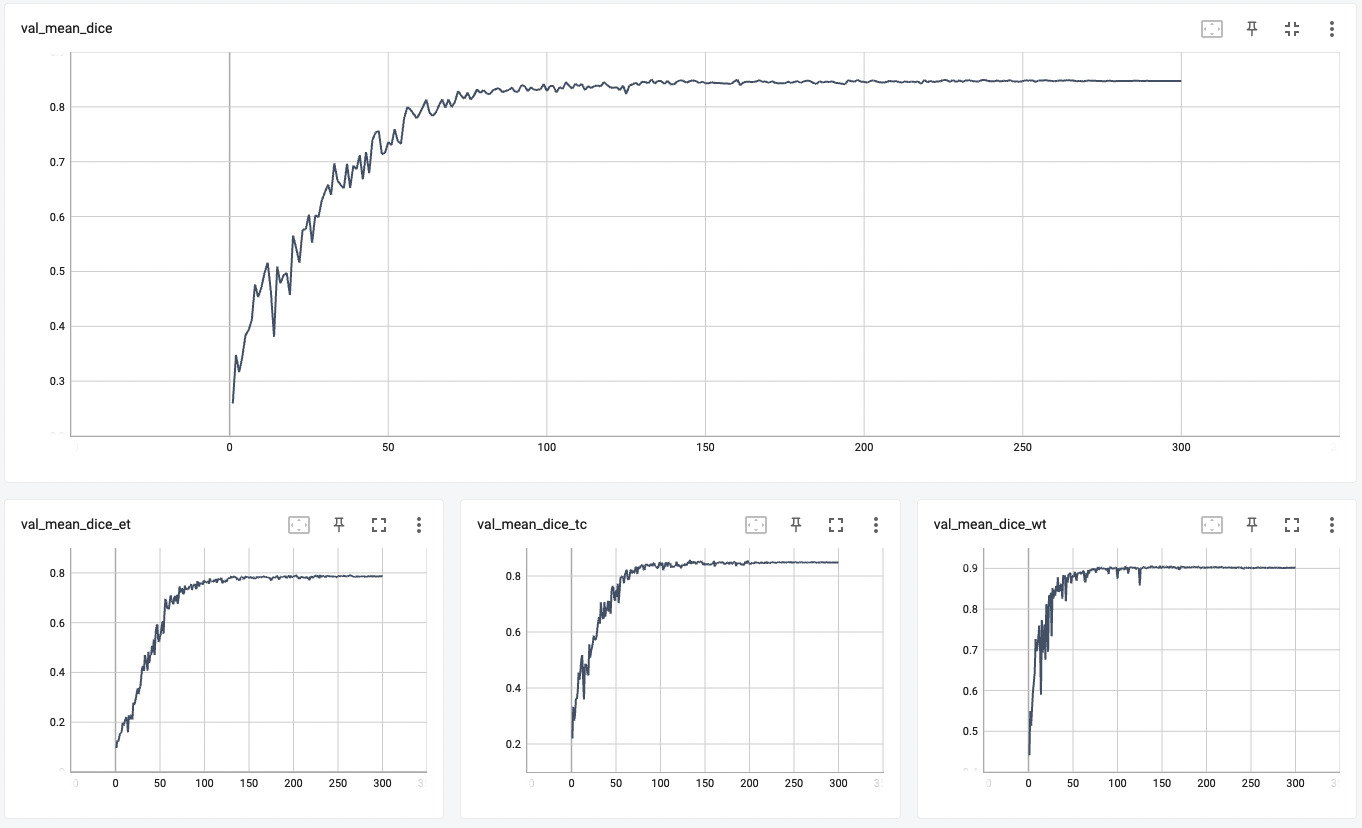
#### Validation Dice
|
| 72 |
|
| 73 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
## MONAI Bundle Commands
|
| 75 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 76 |
|
|
@@ -102,6 +129,22 @@ python -m monai.bundle run --config_file "['configs/train.json','configs/evaluat
|
|
| 102 |
python -m monai.bundle run --config_file configs/inference.json
|
| 103 |
```
|
| 104 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 105 |
# References
|
| 106 |
[1] Myronenko, Andriy. "3D MRI brain tumor segmentation using autoencoder regularization." International MICCAI Brainlesion Workshop. Springer, Cham, 2018. https://arxiv.org/abs/1810.11654.
|
| 107 |
|
|
|
|
| 71 |
#### Validation Dice
|
| 72 |

|
| 73 |
|
| 74 |
+
#### TensorRT speedup
|
| 75 |
+
The `brats_mri_segmentation` bundle supports the TensorRT acceleration through the ONNX-TensorRT way. The table below shows the speedup ratios benchmarked on an A100 80G GPU.
|
| 76 |
+
|
| 77 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 78 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 79 |
+
| model computation | 5.49 | 4.36 | 2.35 | 2.09 | 1.26 | 2.34 | 2.63 | 2.09 |
|
| 80 |
+
| end2end | 592.01 | 434.59 | 395.73 | 394.93 | 1.36 | 1.50 | 1.50 | 1.10 |
|
| 81 |
+
|
| 82 |
+
Where:
|
| 83 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 84 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 85 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 86 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 87 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 88 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 89 |
+
|
| 90 |
+
Currently, this model can only be accelerated through the ONNX-TensorRT way and the Torch-TensorRT way will come soon.
|
| 91 |
+
|
| 92 |
+
This result is benchmarked under:
|
| 93 |
+
- TensorRT: 8.5.3+cuda11.8
|
| 94 |
+
- Torch-TensorRT Version: 1.4.0
|
| 95 |
+
- CPU Architecture: x86-64
|
| 96 |
+
- OS: ubuntu 20.04
|
| 97 |
+
- Python version:3.8.10
|
| 98 |
+
- CUDA version: 12.0
|
| 99 |
+
- GPU models and configuration: A100 80G
|
| 100 |
+
|
| 101 |
## MONAI Bundle Commands
|
| 102 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 103 |
|
|
|
|
| 129 |
python -m monai.bundle run --config_file configs/inference.json
|
| 130 |
```
|
| 131 |
|
| 132 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 133 |
+
|
| 134 |
+
```bash
|
| 135 |
+
python -m monai.bundle trt_export --net_id network_def \
|
| 136 |
+
--filepath models/model_trt.ts --ckpt_file models/model.pt \
|
| 137 |
+
--meta_file configs/metadata.json --config_file configs/inference.json \
|
| 138 |
+
--precision <fp32/fp16> --input_shape "[1, 4, 240, 240, 160]" --use_onnx "True" \
|
| 139 |
+
--use_trace "True"
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
#### Execute inference with the TensorRT model:
|
| 143 |
+
|
| 144 |
+
```
|
| 145 |
+
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
# References
|
| 149 |
[1] Myronenko, Andriy. "3D MRI brain tumor segmentation using autoencoder regularization." International MICCAI Brainlesion Workshop. Springer, Cham, 2018. https://arxiv.org/abs/1810.11654.
|
| 150 |
|
configs/inference_trt.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"imports": [
|
| 3 |
+
"$import glob",
|
| 4 |
+
"$import os",
|
| 5 |
+
"$import torch_tensorrt"
|
| 6 |
+
],
|
| 7 |
+
"handlers#0#_disabled_": true,
|
| 8 |
+
"network_def": "$torch.jit.load(@bundle_root + '/models/model_trt.ts')",
|
| 9 |
+
"evaluator#amp": false
|
| 10 |
+
}
|
configs/metadata.json
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
-
"version": "0.4.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.4.2": "fix mgpu finalize issue",
|
| 6 |
"0.4.1": "add non-deterministic note",
|
| 7 |
"0.4.0": "adapt to BundleWorkflow interface",
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
+
"version": "0.4.3",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.4.3": "add the ONNX-TensorRT way of model conversion",
|
| 6 |
"0.4.2": "fix mgpu finalize issue",
|
| 7 |
"0.4.1": "add non-deterministic note",
|
| 8 |
"0.4.0": "adapt to BundleWorkflow interface",
|
docs/README.md
CHANGED
|
@@ -64,6 +64,33 @@ Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducib
|
|
| 64 |
#### Validation Dice
|
| 65 |

|
| 66 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 67 |
## MONAI Bundle Commands
|
| 68 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 69 |
|
|
@@ -95,6 +122,22 @@ python -m monai.bundle run --config_file "['configs/train.json','configs/evaluat
|
|
| 95 |
python -m monai.bundle run --config_file configs/inference.json
|
| 96 |
```
|
| 97 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 98 |
# References
|
| 99 |
[1] Myronenko, Andriy. "3D MRI brain tumor segmentation using autoencoder regularization." International MICCAI Brainlesion Workshop. Springer, Cham, 2018. https://arxiv.org/abs/1810.11654.
|
| 100 |
|
|
|
|
| 64 |
#### Validation Dice
|
| 65 |

|
| 66 |
|
| 67 |
+
#### TensorRT speedup
|
| 68 |
+
The `brats_mri_segmentation` bundle supports the TensorRT acceleration through the ONNX-TensorRT way. The table below shows the speedup ratios benchmarked on an A100 80G GPU.
|
| 69 |
+
|
| 70 |
+
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
|
| 71 |
+
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 72 |
+
| model computation | 5.49 | 4.36 | 2.35 | 2.09 | 1.26 | 2.34 | 2.63 | 2.09 |
|
| 73 |
+
| end2end | 592.01 | 434.59 | 395.73 | 394.93 | 1.36 | 1.50 | 1.50 | 1.10 |
|
| 74 |
+
|
| 75 |
+
Where:
|
| 76 |
+
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
|
| 77 |
+
- `end2end` means run the bundle end-to-end with the TensorRT based model.
|
| 78 |
+
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
|
| 79 |
+
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
|
| 80 |
+
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
|
| 81 |
+
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
|
| 82 |
+
|
| 83 |
+
Currently, this model can only be accelerated through the ONNX-TensorRT way and the Torch-TensorRT way will come soon.
|
| 84 |
+
|
| 85 |
+
This result is benchmarked under:
|
| 86 |
+
- TensorRT: 8.5.3+cuda11.8
|
| 87 |
+
- Torch-TensorRT Version: 1.4.0
|
| 88 |
+
- CPU Architecture: x86-64
|
| 89 |
+
- OS: ubuntu 20.04
|
| 90 |
+
- Python version:3.8.10
|
| 91 |
+
- CUDA version: 12.0
|
| 92 |
+
- GPU models and configuration: A100 80G
|
| 93 |
+
|
| 94 |
## MONAI Bundle Commands
|
| 95 |
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
|
| 96 |
|
|
|
|
| 122 |
python -m monai.bundle run --config_file configs/inference.json
|
| 123 |
```
|
| 124 |
|
| 125 |
+
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
|
| 126 |
+
|
| 127 |
+
```bash
|
| 128 |
+
python -m monai.bundle trt_export --net_id network_def \
|
| 129 |
+
--filepath models/model_trt.ts --ckpt_file models/model.pt \
|
| 130 |
+
--meta_file configs/metadata.json --config_file configs/inference.json \
|
| 131 |
+
--precision <fp32/fp16> --input_shape "[1, 4, 240, 240, 160]" --use_onnx "True" \
|
| 132 |
+
--use_trace "True"
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
#### Execute inference with the TensorRT model:
|
| 136 |
+
|
| 137 |
+
```
|
| 138 |
+
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
# References
|
| 142 |
[1] Myronenko, Andriy. "3D MRI brain tumor segmentation using autoencoder regularization." International MICCAI Brainlesion Workshop. Springer, Cham, 2018. https://arxiv.org/abs/1810.11654.
|
| 143 |
|