

[fix]: fix the pic link of benchmark
Browse files
README.md
CHANGED
|
@@ -1,100 +1,100 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
language:
|
| 4 |
-
- zh
|
| 5 |
-
- en
|
| 6 |
-
pipeline_tag: text-generation
|
| 7 |
-
library_name: transformers
|
| 8 |
-
---
|
| 9 |
-
<div align="center">
|
| 10 |
-
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
|
| 11 |
-
</div>
|
| 12 |
-
|
| 13 |
-
<p align="center">
|
| 14 |
-
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
|
| 15 |
-
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
|
| 16 |
-
</p>
|
| 17 |
-
<p align="center">
|
| 18 |
-
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
|
| 19 |
-
</p>
|
| 20 |
-
|
| 21 |
-
## What's New
|
| 22 |
-
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
|
| 23 |
-
|
| 24 |
-
## MiniCPM4 Series
|
| 25 |
-
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
|
| 26 |
-
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
|
| 27 |
-
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
|
| 28 |
-
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
|
| 29 |
-
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
|
| 30 |
-
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
|
| 31 |
-
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
|
| 32 |
-
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width. (**<-- you are here**)
|
| 33 |
-
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
|
| 34 |
-
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
|
| 35 |
-
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
|
| 36 |
-
|
| 37 |
-
## Introduction
|
| 38 |
-
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
|
| 39 |
-
- Improvements of the training method
|
| 40 |
-
- Searching hyperparameters with a wind-tunnel on a small model.
|
| 41 |
-
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
|
| 42 |
-
- High parameter efficiency
|
| 43 |
-
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
|
| 44 |
-
|
| 45 |
-
## Usage
|
| 46 |
-
### Inference with Transformers
|
| 47 |
-
BitCPM4's parameters are stored in a fake-quantized format, which supports direct inference within the Huggingface framework.
|
| 48 |
-
```python
|
| 49 |
-
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 50 |
-
import torch
|
| 51 |
-
|
| 52 |
-
path = "openbmb/BitCPM4-0.5B"
|
| 53 |
-
device = "cuda"
|
| 54 |
-
|
| 55 |
-
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
|
| 56 |
-
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
|
| 57 |
-
|
| 58 |
-
messages = [
|
| 59 |
-
{"role": "user", "content": "推荐5个北京的景点。"},
|
| 60 |
-
]
|
| 61 |
-
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device)
|
| 62 |
-
|
| 63 |
-
model_outputs = model.generate(
|
| 64 |
-
model_inputs,
|
| 65 |
-
max_new_tokens=1024,
|
| 66 |
-
top_p=0.7,
|
| 67 |
-
temperature=0.7
|
| 68 |
-
)
|
| 69 |
-
|
| 70 |
-
output_token_ids = [
|
| 71 |
-
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
|
| 72 |
-
]
|
| 73 |
-
|
| 74 |
-
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
|
| 75 |
-
print(responses)
|
| 76 |
-
```
|
| 77 |
-
|
| 78 |
-
## Evaluation Results
|
| 79 |
-
BitCPM4's performance is comparable with other full-precision models in same model size.
|
| 80 |
-
 License.
|
| 90 |
-
|
| 91 |
-
## Citation
|
| 92 |
-
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
|
| 93 |
-
|
| 94 |
-
```bibtex
|
| 95 |
-
@article{minicpm4,
|
| 96 |
-
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
|
| 97 |
-
author={MiniCPM Team},
|
| 98 |
-
year={2025}
|
| 99 |
-
}
|
| 100 |
-
```
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
library_name: transformers
|
| 8 |
+
---
|
| 9 |
+
<div align="center">
|
| 10 |
+
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
|
| 11 |
+
</div>
|
| 12 |
+
|
| 13 |
+
<p align="center">
|
| 14 |
+
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
|
| 15 |
+
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
|
| 16 |
+
</p>
|
| 17 |
+
<p align="center">
|
| 18 |
+
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
|
| 19 |
+
</p>
|
| 20 |
+
|
| 21 |
+
## What's New
|
| 22 |
+
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
|
| 23 |
+
|
| 24 |
+
## MiniCPM4 Series
|
| 25 |
+
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
|
| 26 |
+
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
|
| 27 |
+
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
|
| 28 |
+
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
|
| 29 |
+
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
|
| 30 |
+
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
|
| 31 |
+
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
|
| 32 |
+
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width. (**<-- you are here**)
|
| 33 |
+
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
|
| 34 |
+
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
|
| 35 |
+
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
|
| 36 |
+
|
| 37 |
+
## Introduction
|
| 38 |
+
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
|
| 39 |
+
- Improvements of the training method
|
| 40 |
+
- Searching hyperparameters with a wind-tunnel on a small model.
|
| 41 |
+
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
|
| 42 |
+
- High parameter efficiency
|
| 43 |
+
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
|
| 44 |
+
|
| 45 |
+
## Usage
|
| 46 |
+
### Inference with Transformers
|
| 47 |
+
BitCPM4's parameters are stored in a fake-quantized format, which supports direct inference within the Huggingface framework.
|
| 48 |
+
```python
|
| 49 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 50 |
+
import torch
|
| 51 |
+
|
| 52 |
+
path = "openbmb/BitCPM4-0.5B"
|
| 53 |
+
device = "cuda"
|
| 54 |
+
|
| 55 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
|
| 56 |
+
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
|
| 57 |
+
|
| 58 |
+
messages = [
|
| 59 |
+
{"role": "user", "content": "推荐5个北京的景点。"},
|
| 60 |
+
]
|
| 61 |
+
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device)
|
| 62 |
+
|
| 63 |
+
model_outputs = model.generate(
|
| 64 |
+
model_inputs,
|
| 65 |
+
max_new_tokens=1024,
|
| 66 |
+
top_p=0.7,
|
| 67 |
+
temperature=0.7
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
output_token_ids = [
|
| 71 |
+
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
|
| 75 |
+
print(responses)
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
## Evaluation Results
|
| 79 |
+
BitCPM4's performance is comparable with other full-precision models in same model size.
|
| 80 |
+
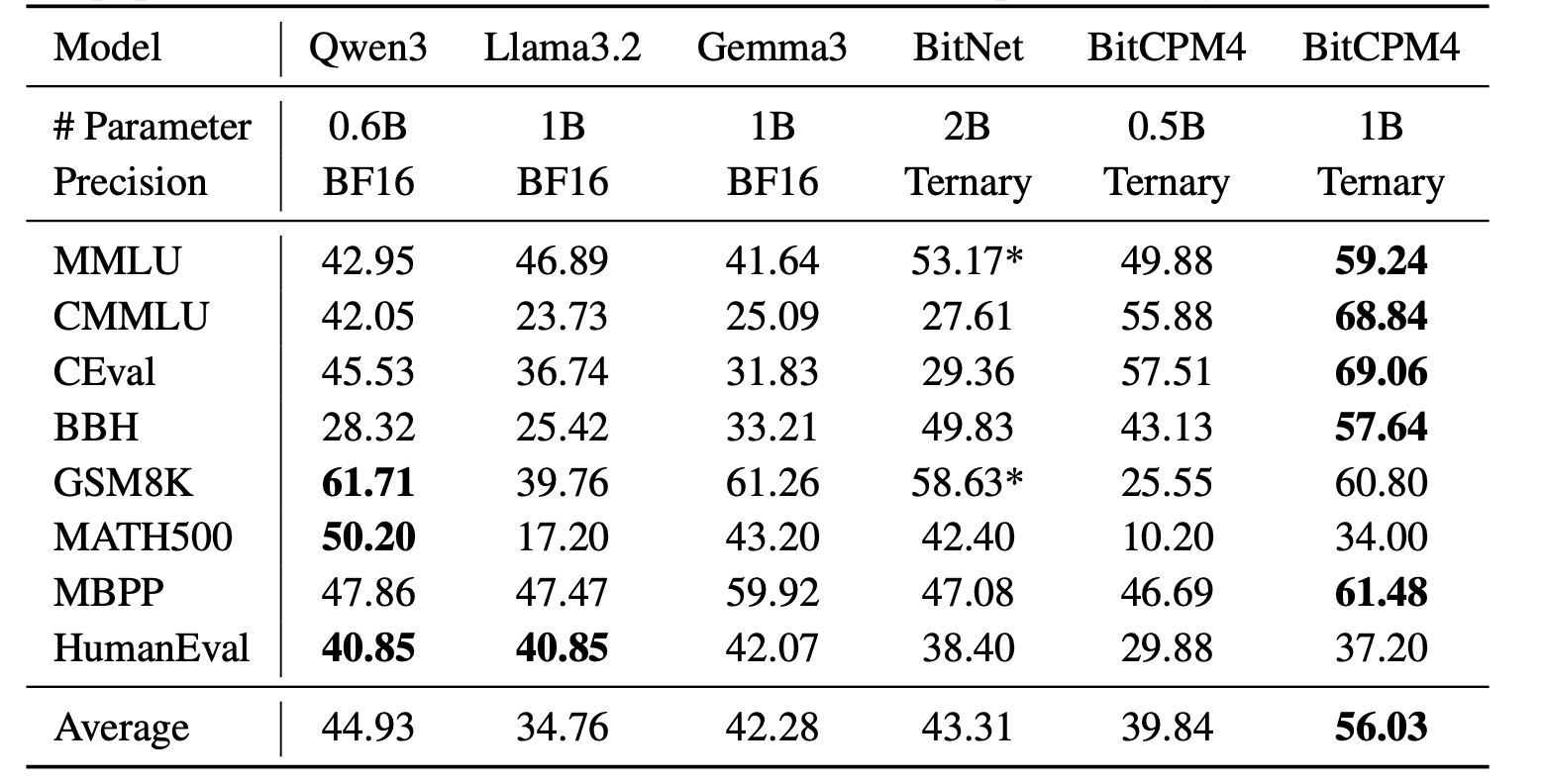
|
| 81 |
+
|
| 82 |
+
## Statement
|
| 83 |
+
- As a language model, MiniCPM generates content by learning from a vast amount of text.
|
| 84 |
+
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
|
| 85 |
+
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
|
| 86 |
+
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
|
| 87 |
+
|
| 88 |
+
## LICENSE
|
| 89 |
+
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
|
| 90 |
+
|
| 91 |
+
## Citation
|
| 92 |
+
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
|
| 93 |
+
|
| 94 |
+
```bibtex
|
| 95 |
+
@article{minicpm4,
|
| 96 |
+
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
|
| 97 |
+
author={MiniCPM Team},
|
| 98 |
+
year={2025}
|
| 99 |
+
}
|
| 100 |
+
```
|