From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
 cetosignis
cetosignis
Abstract
An autoregressive U-Net learns to embed its own tokens during training, enabling a multi-scale view of text sequences and improved handling of character-level tasks and low-resource languages.
Tokenization imposes a fixed granularity on the input text, freezing how a language model operates on data and how far in the future it predicts. Byte Pair Encoding (BPE) and similar schemes split text once, build a static vocabulary, and leave the model stuck with that choice. We relax this rigidity by introducing an autoregressive U-Net that learns to embed its own tokens as it trains. The network reads raw bytes, pools them into words, then pairs of words, then up to 4 words, giving it a multi-scale view of the sequence. At deeper stages, the model must predict further into the future -- anticipating the next few words rather than the next byte -- so deeper stages focus on broader semantic patterns while earlier stages handle fine details. When carefully tuning and controlling pretraining compute, shallow hierarchies tie strong BPE baselines, and deeper hierarchies have a promising trend. Because tokenization now lives inside the model, the same system can handle character-level tasks and carry knowledge across low-resource languages.
Community
We present AU-Net: an Autoregressive U‑Net that incorporates tokenization inside the model, pooling raw bytes into words then word‑groups. The resulting architecture focuses most of its effort in computing latent vectors that correspond to larger units of meaning.
Joint work with @byoubii
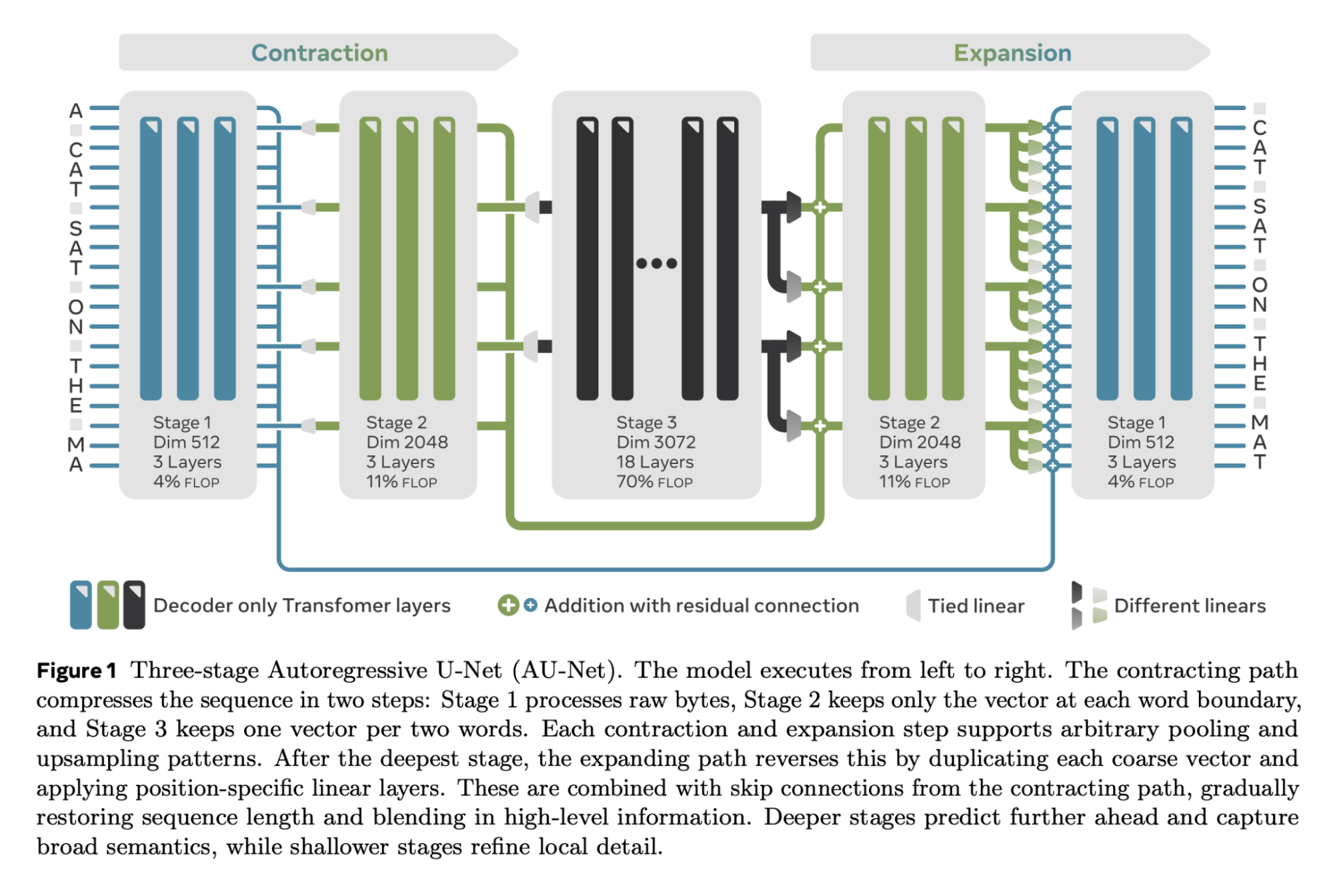
Pooling keeps one vector at each split (word, every 2 words, …). Upsampling duplicates those coarse vectors with position‑specific linear layers and merges them through residual connections, yielding an Autoregressive U‑Net (AU-Net)

The hierarchy acts as implicit multi‑token prediction: no extra losses or heads. Different levels of the hierarchy process different granularities, enabling future prediction while keeping autoregressive coherence.
Our AU‑Net matches or outperforms strong BPE baselines on most evals. 📊 (see big scary table)

In our experiments, all models were tuned via hyper‑parameter scaling laws.AU‑Net keeps pace with the best we could squeeze from BPE before adding its own hierarchical advantages.

Byte‑level training helps low‑resource languages. On FLORES‑200, AU‑Net‑2 gains ≈ +4 BLEU on average in translation from many low resource languages to English, out of the box, no finetunings here !

7/8 In future work, we would like to make AU-Net hierarchies deeper, so the model spends a tiny portion of compute on syntax and spelling. The model should be thinking about the next idea, instead of the next token.
8/8 Links to paper and code. Please enjoy!
📄 https://arxiv.org/abs/2506.14761
🛠https://github.com/facebookresearch/lingua/tree/main/apps/aunet
Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper
Collections including this paper 0
No Collection including this paper