EmbRACE-3K: Embodied Reasoning and Action in Complex Environments
 AaronHuangWei
AaronHuangWei






Abstract
A new dataset, EmRACE-3K, evaluates vision-language models in embodied settings, showing limitations in spatial reasoning and long-horizon planning, and demonstrates improvements through supervised and reinforcement learning fine-tuning.
Recent advanced vision-language models(VLMs) have demonstrated strong performance on passive, offline image and video understanding tasks. However, their effectiveness in embodied settings, which require online interaction and active scene understanding remains limited. In such scenarios, an agent perceives the environment from a first-person perspective, with each action dynamically shaping subsequent observations. Even state-of-the-art models such as GPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro struggle in open-environment interactions, exhibiting clear limitations in spatial reasoning and long-horizon planning. To address this gap, we introduce EmRACE-3K, a dataset of over 3,000 language-guided tasks situated in diverse, photorealistic environments constructed using Unreal Engine and the UnrealCV-Zoo framework. The tasks encompass a wide range of embodied challenges, including navigation, object manipulation, and multi-stage goal execution. Each task unfolds as a multi-step trajectory, pairing first-person visual observations with high-level instructions, grounded actions, and natural language rationales that express the agent's intent at every step. Using EmRACE-3K, we establish a benchmark to evaluate the embodied reasoning capabilities of VLMs across three key dimensions: Exploration, Dynamic Spatial-Semantic Reasoning, and Multi-stage Goal Execution. In zero-shot settings, all models achieve success rates below 20%, underscoring the challenge posed by our benchmark and the current limitations of VLMs in interactive environments. To demonstrate the utility of EmRACE-3K, we further fine-tune Qwen2.5-VL-7B using supervised learning followed by reinforcement learning. This approach yields substantial improvements across all three challenge categories, highlighting the dataset's effectiveness in enabling the development of embodied reasoning capabilities.
Community
Recent vision-language models (VLMs) show strong results on offline image and video understanding, but their performance in interactive, embodied environments remains limited. In close loop settings, an agent acts from a first-person view, where each decision alters future observations. Even leading models like GPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro struggle with spatial reasoning and long-horizon planning. We present EmbRACE-3K , a dataset of over 3,000 language-guided tasks in diverse Unreal Engine environments. Each task spans multiple steps, with egocentric views, high-level instructions, grounded actions, and natural language rationales. We benchmark VLMs on three core skills: exploration, dynamic spatial-semantic reasoning, and multi-stage goal execution. In zero-shot tests, all models achieve below 20 percent success, showing clear room for improvement. Fine-tuning Qwen2.5-VL-7B with supervised and reinforcement learning leads to consistent gains across all task types, demonstrating the value of EmbRACE-3K for developing embodied intelligence.
🚀 New Dataset Release: EmbRACE-3K 🌍🧠
Recent vision-language models (VLMs) like GPT-4o, Claude 3.5, and Gemini 2.5 excel at static vision tasks — but struggle in closed-loop embodied reasoning, where actions directly influence future observations.
We introduce EmbRACE-3K, a dataset of over 3,000 multi-step, language-guided tasks in photorealistic Unreal Engine environments.
Each task step includes:
- 👁️ Egocentric visual observations
- 🗒️ High-level natural language instructions
- 🧭 Grounded actions
- 💬 Step-wise natural language rationales
We benchmark three core reasoning skills:
- 🧭 Exploration
- 🧠 Dynamic Spatial-Semantic Reasoning
- 🎯 Multi-stage Goal Execution
Zero-shot performance of leading VLMs remains under 20%, highlighting the challenge.
Fine-tuning Qwen2.5-VL-7B using supervised and reinforcement learning yields consistent gains across all categories.
📄 Paper: arxiv.org/pdf/2507.10548
💻 Code: github.com/mxllc/EmbRACE-3K
🌐 Project Page: mxllc.github.io/EmbRACE-3K
🧠 Let’s push the boundaries of embodied intelligence.
🔁 Step-by-Step Closed-Loop Reasoning
This demo shows how a fine-tuned Qwen2.5-VL-7B agent reasons and acts step by step in a closed-loop setting, guided by egocentric perception and language-based reasoning.
📊 Dataset Overview
An overview of EmbRACE-3K, consisting of 3.1k tasks and 26k decision steps across diverse environments. Tasks involve multi-step grounded reasoning and perceptual decision making.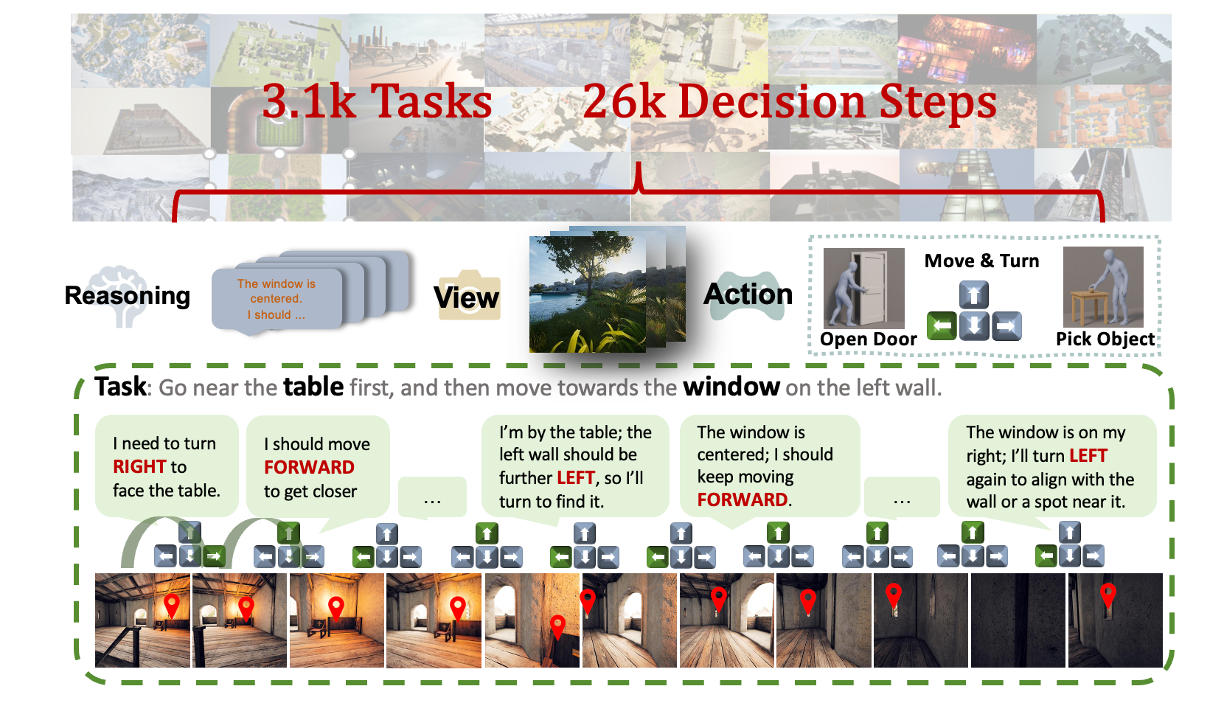
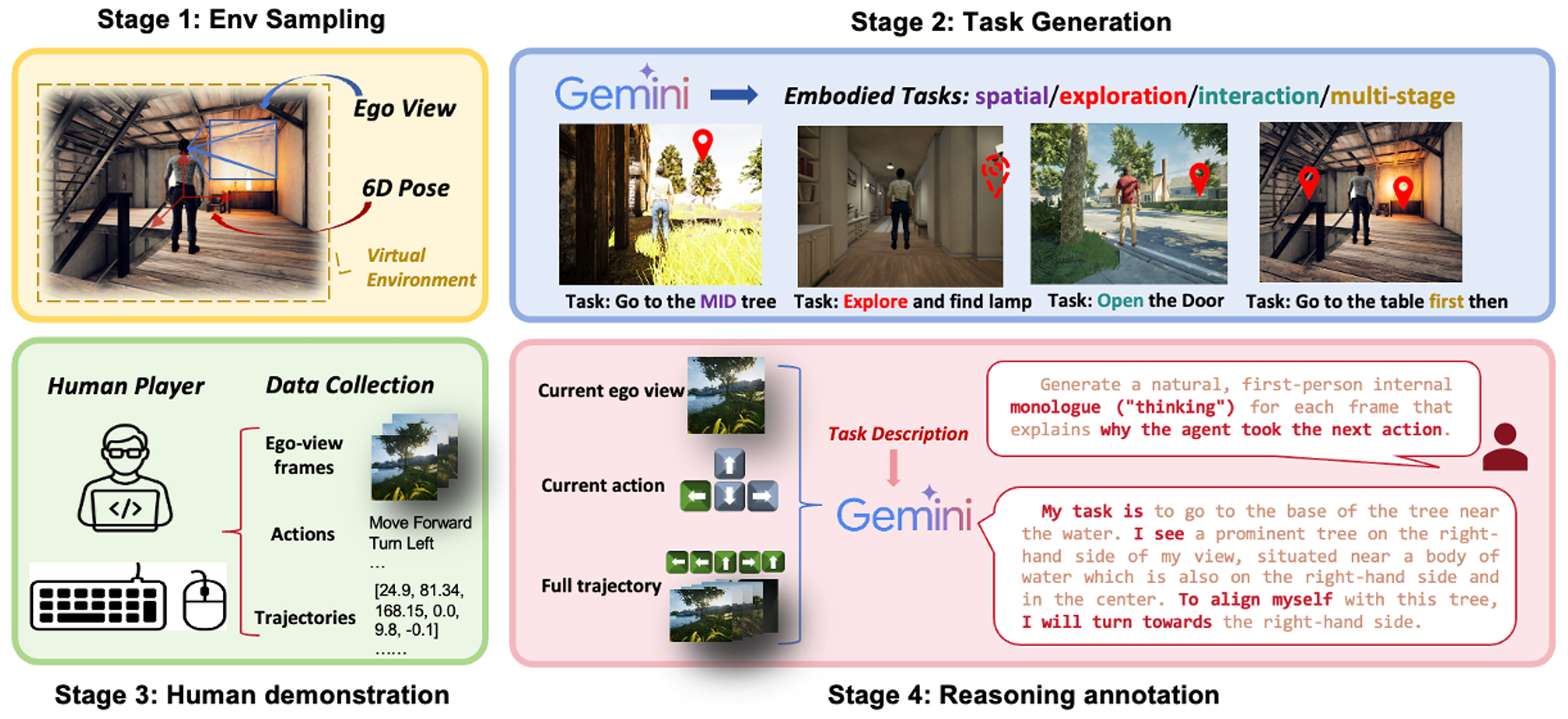
🛠 Dataset Construction Pipeline
The dataset is constructed in four stages:
- Sampling diverse 6-DoF egocentric views
- Generating task instructions using Gemini
- Collecting high-quality human demonstrations
- Annotating each action with step-level rationales




Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper