

Submitted by
 lixiaochuan
lixiaochuan
lixiaochuanGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
lixiaochuan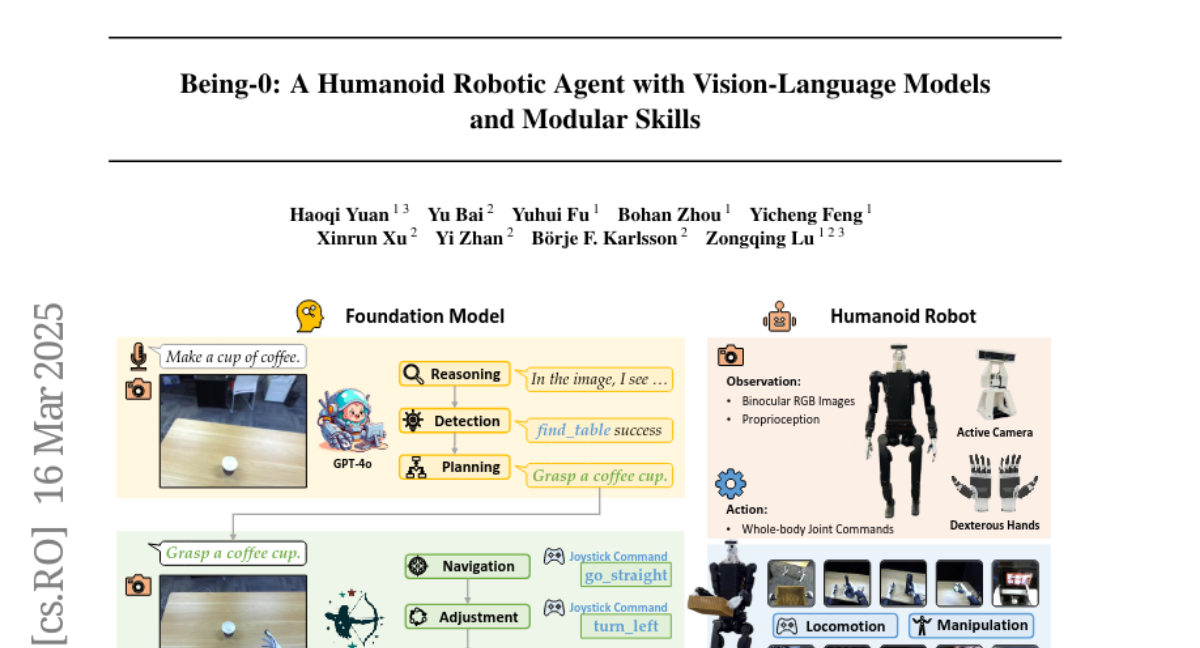
 tellarin
tellarin
 limuloo1999
limuloo1999
 huanngzh
huanngzh
 yyyyyyjjjjzzz
yyyyyyjjjjzzz
 Gh0stAR
Gh0stAR
 akhaliq
akhaliq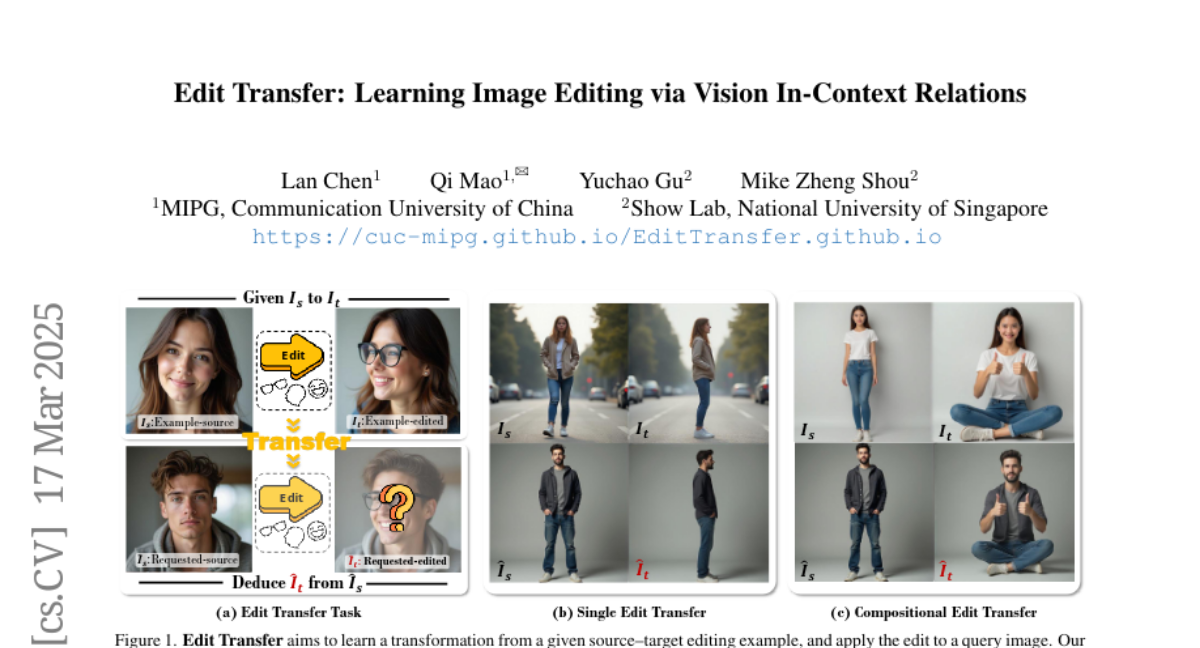
 Orannue
Orannue ZyZcuhk
ZyZcuhk
 jmhb
jmhb
 Lingaaaaaaa
Lingaaaaaaa
 ZhaofengWu
ZhaofengWu
 KevinQHLin
KevinQHLin
 lwpyh
lwpyh ysy31415926
ysy31415926
 fpoiesi
fpoiesi
 Luo-Yihong
Luo-Yihong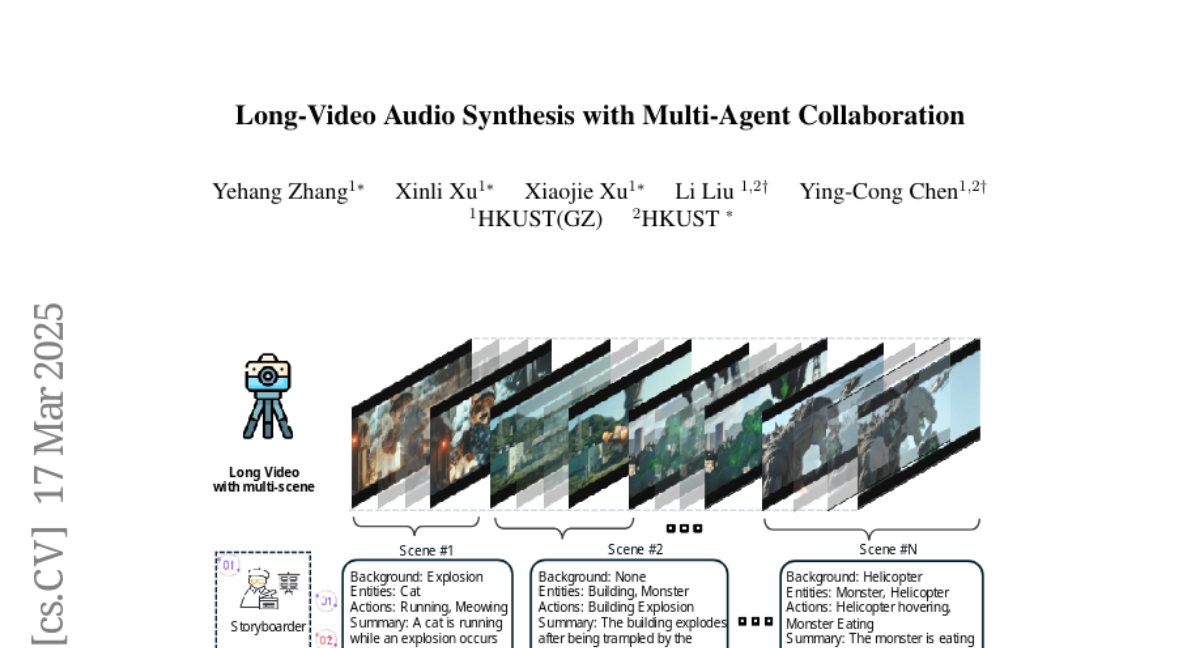
 Buzz-lightyear
Buzz-lightyear
 soarhigh
soarhigh
 zeeshanp
zeeshanp
 k-nick
k-nick
 FQiao
FQiao
 JesseTNRoberts
JesseTNRoberts JesseTNRoberts
JesseTNRoberts
 Sckathach
Sckathach
 zxbsmk
zxbsmk





























































