

Submitted by
 YuSun-AI
YuSun-AI
YuSun-AIGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
YuSun-AI
 itaowe
itaowe
 Min-Jaewon
Min-Jaewon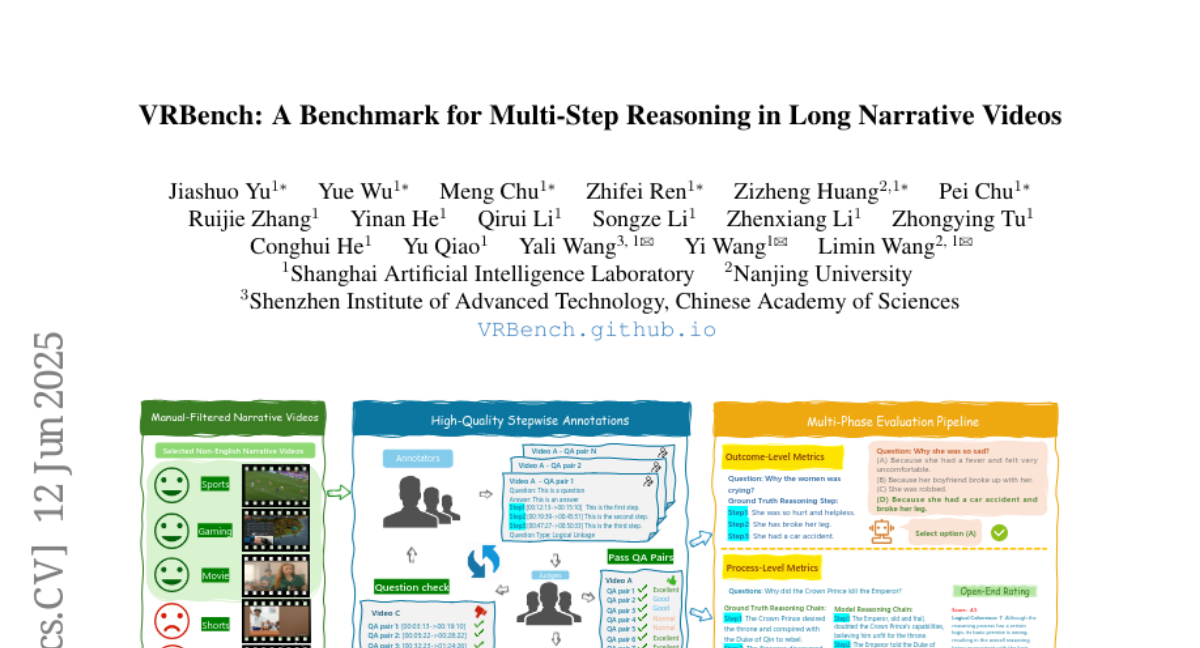
 awojustin
awojustin
 YunxinLi
YunxinLi
 stefan-it
stefan-it
 gallilmaimon
gallilmaimon
 Howe77
Howe77
 dawn0815
dawn0815
 Owen777
Owen777
 upup-ashton-wang
upup-ashton-wang
 Ningyu
Ningyu
 BiaoGong
BiaoGong
 avery00
avery00
 zbrl
zbrl Ningyu
Ningyu
 xhluca
xhluca
 zhiyang1
zhiyang1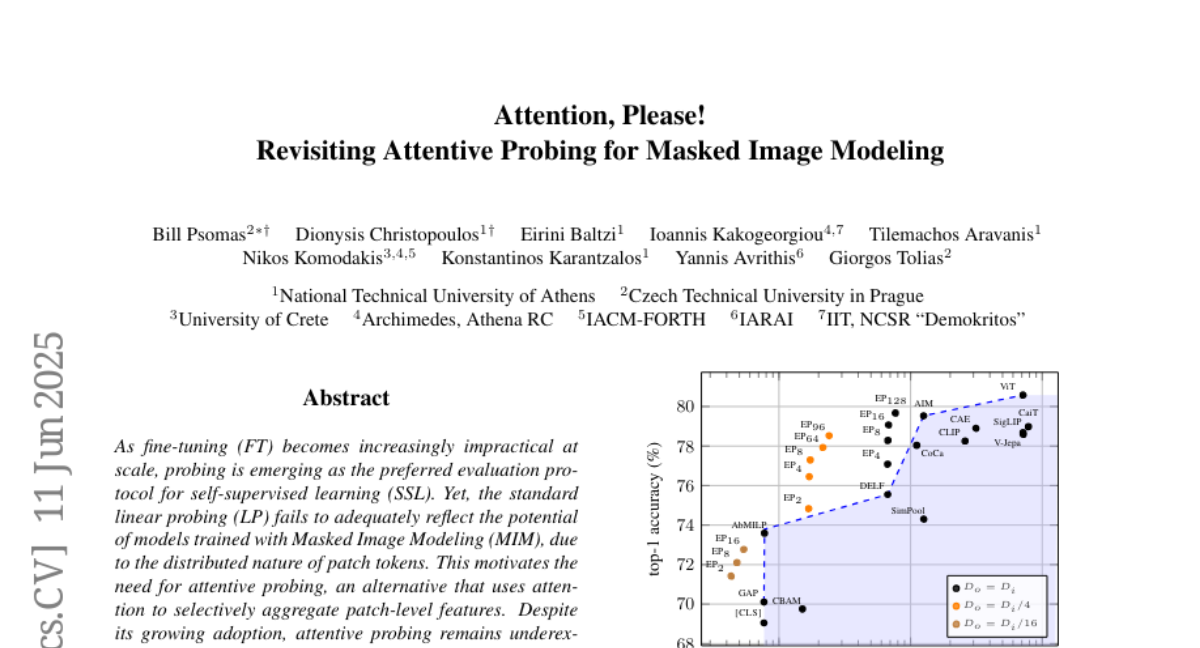
 billpsomas
billpsomas
 Wesleythu
Wesleythu
 reach-vb
reach-vb
 wanglz14
wanglz14
 LavenderLA
LavenderLA
 Speeeed
Speeeed
 codelion
codelion
 dxlong2000
dxlong2000
 vincolle
vincolle
 Acruxos
Acruxos
 sayakpaul
sayakpaul
 ordavids1
ordavids1
 benfielding
benfielding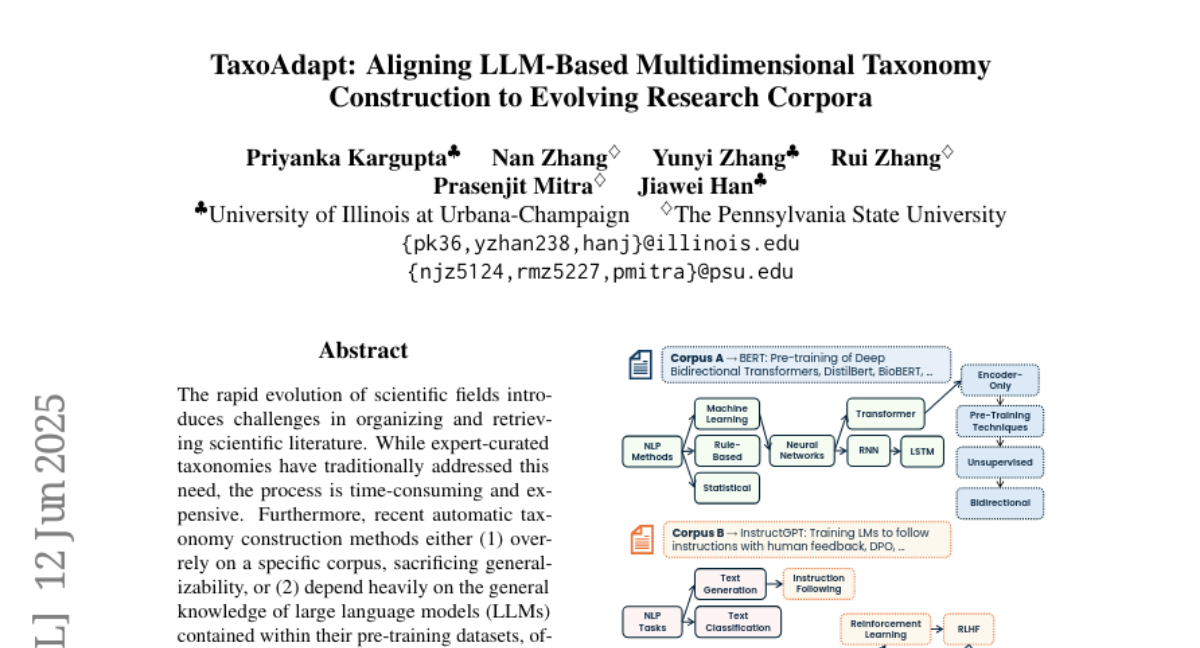
 pkargupta
pkargupta pkargupta
pkargupta
 msadat97
msadat97
 kev95
kev95
 JJ-TMT
JJ-TMT
 xinjjj
xinjjj
 hlzhang109
hlzhang109
 Franck-Dernoncourt
Franck-Dernoncourt
 yiren98
yiren98
 Nickwzk
Nickwzk


















