

Submitted by
 KaitaoSong
KaitaoSong
KaitaoSongGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
KaitaoSong
 NeoZ123
NeoZ123
 Swtheking
Swtheking
 gmlwns5176
gmlwns5176
 tianbaoxiexxx
tianbaoxiexxx
 PY007
PY007
 Vinnnf
Vinnnf
 Wa2erGo
Wa2erGo
 zlzheng
zlzheng
 Cierra0506
Cierra0506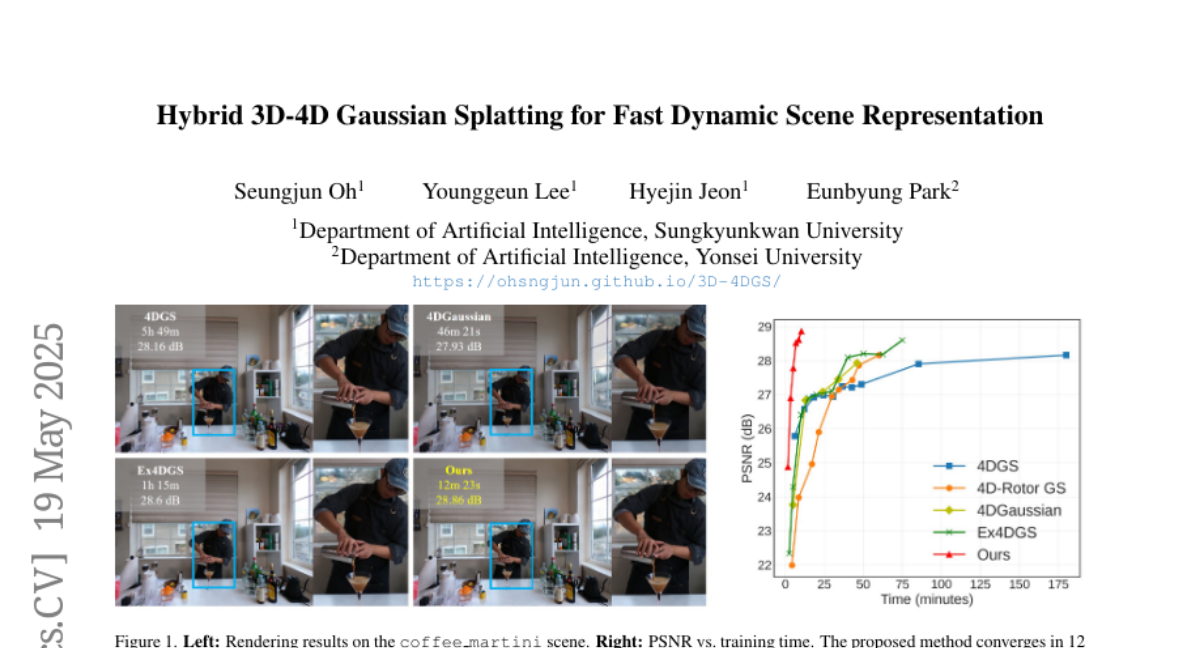
 ohseungjun
ohseungjun
 Sangsang
Sangsang
 Zkkkai
Zkkkai
 yuhuixu
yuhuixu
 lytang
lytang
 lixiaoxi45
lixiaoxi45
 Dreamer312
Dreamer312
 zszhong
zszhong
 Vasily
Vasily
 merlerm
merlerm
 amphora
amphora
 Doreamonzzz
Doreamonzzz
 Tyrannosaurus
Tyrannosaurus
 gentaiscool
gentaiscool
 vincentkoc
vincentkoc
 Harold328
Harold328
 yanboding
yanboding
 Paulmzr
Paulmzr
 Krystalan
Krystalan
 mgvz
mgvz
 Harahan
Harahan
 xuyige
xuyige
 Ksgk-fy
Ksgk-fy
 minwoosun
minwoosun
 zhilinw
zhilinw
 AndreiArhire
AndreiArhire
 JitaiHao
JitaiHao
 PChemGuy
PChemGuy
 lekssays
lekssays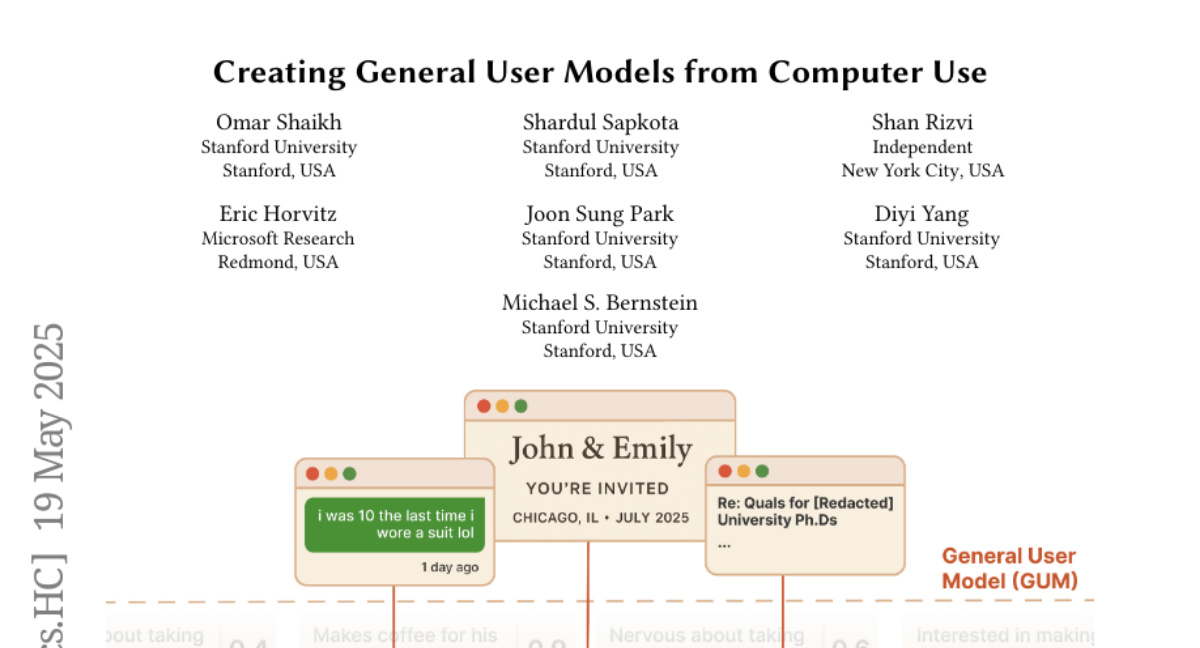
 oshaikh13
oshaikh13 PChemGuy
PChemGuy
 MahtaFetrat
MahtaFetrat
 dnoever
dnoever







































































