

Submitted by
 YuSun-AI
YuSun-AI
YuSun-AIGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
YuSun-AI
 itaowe
itaowe
 Min-Jaewon
Min-Jaewon
 stefan-it
stefan-it
 YunxinLi
YunxinLi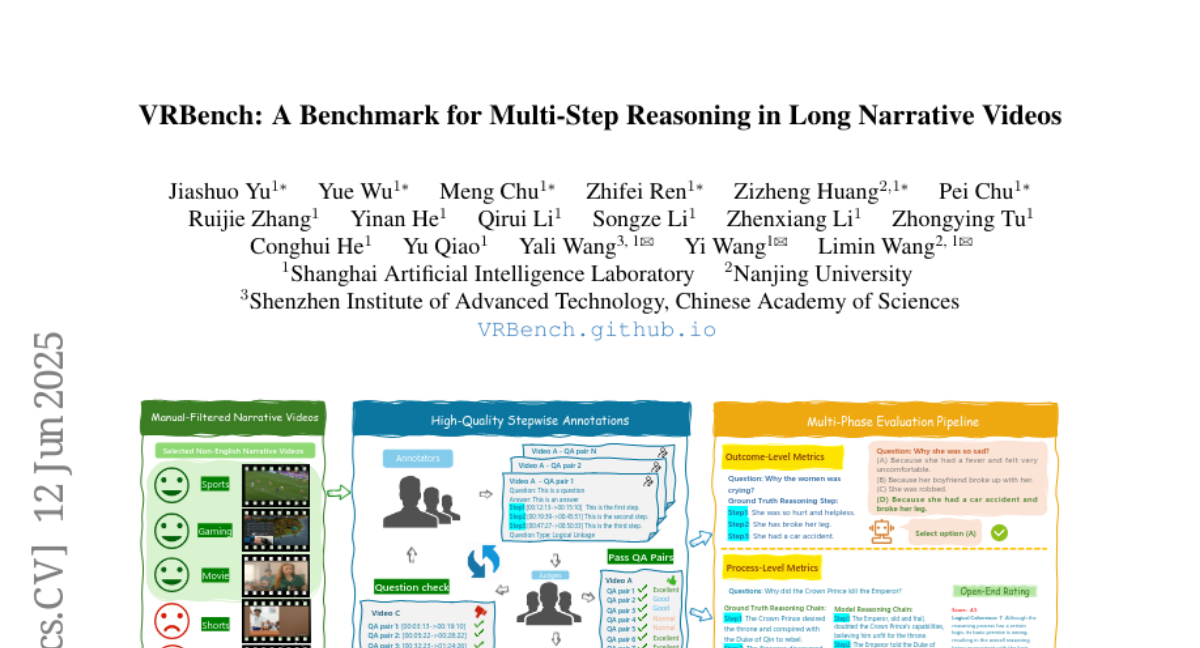
 awojustin
awojustin
 gallilmaimon
gallilmaimon
 Howe77
Howe77
 sayakpaul
sayakpaul
 Owen777
Owen777
 dawn0815
dawn0815
 BiaoGong
BiaoGong
 upup-ashton-wang
upup-ashton-wang
 xhluca
xhluca
 Ningyu
Ningyu
 avery00
avery00
 reach-vb
reach-vb
 zbrl
zbrl Ningyu
Ningyu
 zhiyang1
zhiyang1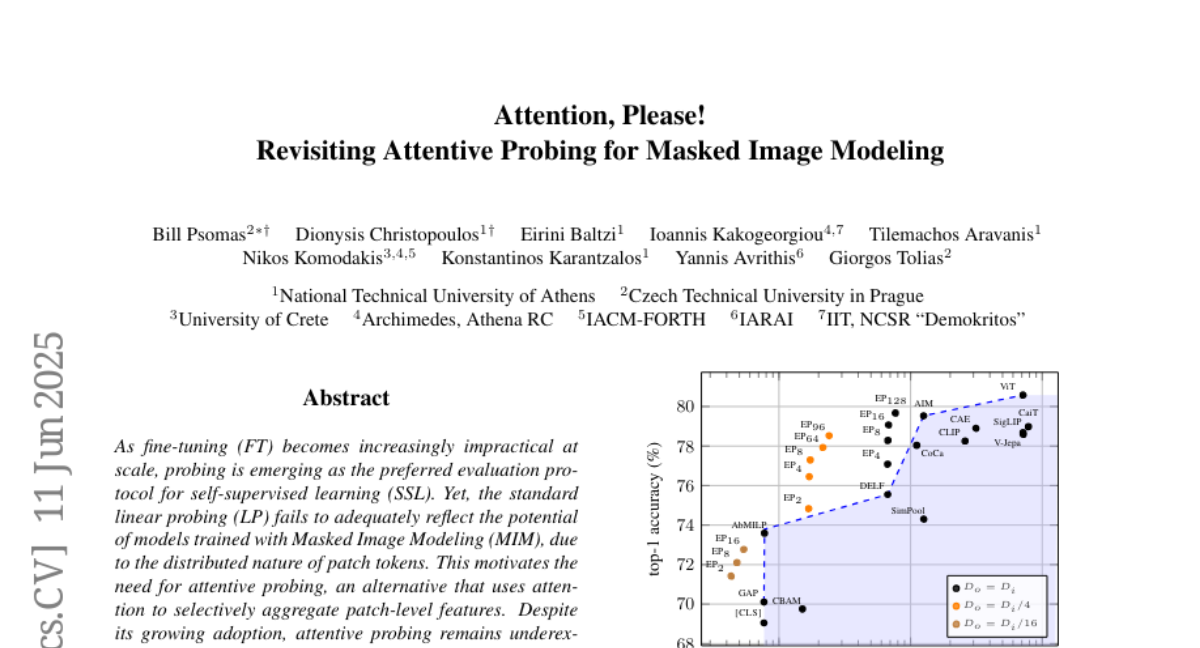
 billpsomas
billpsomas
 LavenderLA
LavenderLA
 Wesleythu
Wesleythu
 Speeeed
Speeeed
 codelion
codelion
 dxlong2000
dxlong2000
 wanglz14
wanglz14
 msadat97
msadat97
 ordavids1
ordavids1
 benfielding
benfielding
 vincolle
vincolle
 kev95
kev95
 Acruxos
Acruxos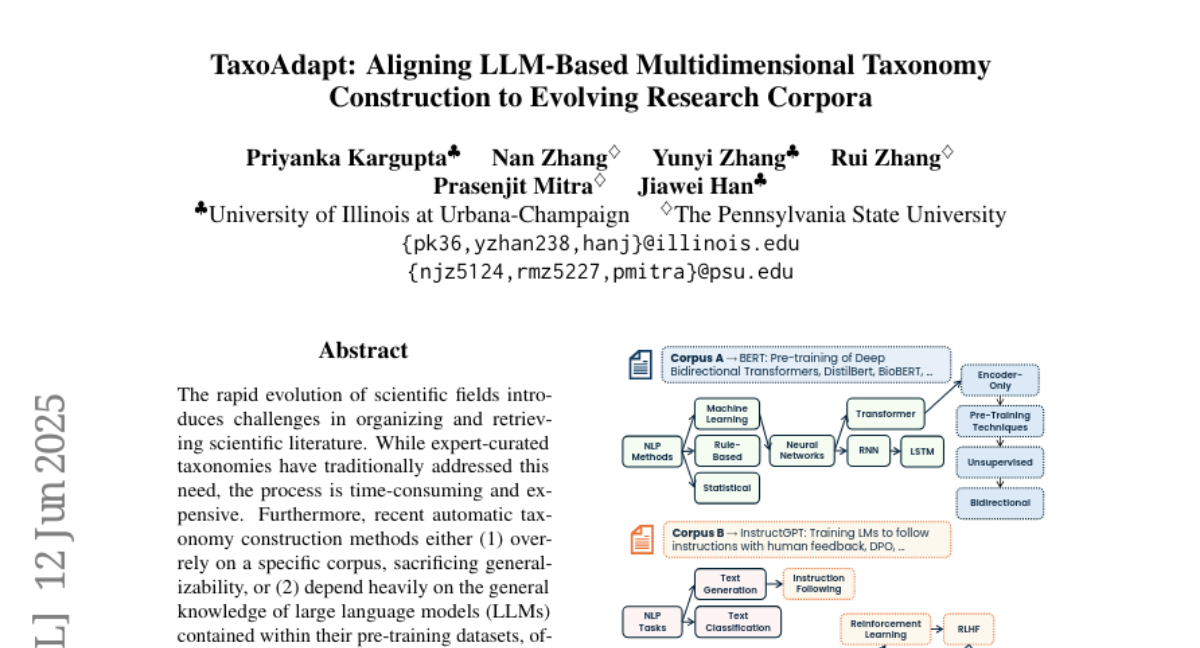
 pkargupta
pkargupta pkargupta
pkargupta
 JJ-TMT
JJ-TMT
 xinjjj
xinjjj
 hlzhang109
hlzhang109
 Franck-Dernoncourt
Franck-Dernoncourt
 yiren98
yiren98
 Nickwzk
Nickwzk



























