

Upload 4 files
Browse files
docs/source/zh/tutorials/inspect_runs.md
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 使用 OpenTelemetry 检查运行记录
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
> [!TIP]
|
| 6 |
+
> 如果您是初次构建Agent,建议先阅读 [Agent 入门指南](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
|
| 7 |
+
|
| 8 |
+
## 为什么需要记录Agent运行?
|
| 9 |
+
|
| 10 |
+
调试Agent运行过程具有挑战性。
|
| 11 |
+
|
| 12 |
+
验证运行是否正常进行很困难,因为Agent的工作流程本身具有 [设计上的不可预测性](../conceptual_guides/intro_agents)(如果可预测,直接使用传统代码即可)。
|
| 13 |
+
|
| 14 |
+
检查运行记录同样困难:多步骤的Agent往往会快速在控制台生成大量日志,而大多数错误只是"LLM 低级错误"类型的问题,通常LLM会在后续步骤中通过生成更好的代码或工具调用来自我修正。
|
| 15 |
+
|
| 16 |
+
因此,在生产环境中使用监控工具记录Agent运行过程,对于后续检查和分析至关重要!
|
| 17 |
+
|
| 18 |
+
我们采用 [OpenTelemetry](https://opentelemetry.io/) 标准来实现Agent运行监控。
|
| 19 |
+
|
| 20 |
+
这意味着您只需添加少量监控代码,即可在正常运行Agent时自动记录所有信息到监控平台。以下是在不同OpenTelemetry后端实现此功能的示例:
|
| 21 |
+
|
| 22 |
+
在监控平台上的展示效果如下:
|
| 23 |
+
|
| 24 |
+
<div class="flex justify-center">
|
| 25 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/smolagents/inspect_run_phoenix.gif"/>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## 使用 Arize AI Phoenix 配置遥测
|
| 30 |
+
|
| 31 |
+
首先安装必要的软件包。这里我们选择安装 [Arize AI 的 Phoenix](https://github.com/Arize-ai/phoenix) 作为日志收集和检查方案,您也可以使用其他兼容 OpenTelemetry 的平台来完成收集与检查工作。
|
| 32 |
+
|
| 33 |
+
```shell
|
| 34 |
+
pip install 'smolagents[telemetry]'
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
接着在后台运行日志收集器:
|
| 38 |
+
|
| 39 |
+
```shell
|
| 40 |
+
python -m phoenix.server.main serve
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
最后配置 `SmolagentsInstrumentor` 来追踪Agent活动,并将追踪数据发送至 Phoenix 默认端点:
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
from phoenix.otel import register
|
| 47 |
+
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
|
| 48 |
+
|
| 49 |
+
register()
|
| 50 |
+
SmolagentsInstrumentor().instrument()
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
完成上述配置后,即可正常运行您的Agent!
|
| 54 |
+
|
| 55 |
+
```py
|
| 56 |
+
from smolagents import (
|
| 57 |
+
CodeAgent,
|
| 58 |
+
ToolCallingAgent,
|
| 59 |
+
WebSearchTool,
|
| 60 |
+
VisitWebpageTool,
|
| 61 |
+
InferenceClientModel,
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
model = InferenceClientModel()
|
| 65 |
+
|
| 66 |
+
search_agent = ToolCallingAgent(
|
| 67 |
+
tools=[WebSearchTool(), VisitWebpageTool()],
|
| 68 |
+
model=model,
|
| 69 |
+
name="search_agent",
|
| 70 |
+
description="This is an agent that can do web search.",
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
manager_agent = CodeAgent(
|
| 74 |
+
tools=[],
|
| 75 |
+
model=model,
|
| 76 |
+
managed_agents=[search_agent],
|
| 77 |
+
)
|
| 78 |
+
manager_agent.run(
|
| 79 |
+
"If the US keeps its 2024 growth rate, how many years will it take for the GDP to double?"
|
| 80 |
+
)
|
| 81 |
+
```
|
| 82 |
+
Voilà!
|
| 83 |
+
|
| 84 |
+
此时访问 `http://0.0.0.0:6006/projects/` 即可查看运行记录:
|
| 85 |
+
|
| 86 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/smolagents/inspect_run_phoenix.png">
|
| 87 |
+
|
| 88 |
+
如图所示,CodeAgent 调用了其托管的 ToolCallingAgent(注:托管Agent也可以是另一个 CodeAgent)执行美国2024年经济增长率的网络搜索。托管Agent返回报告后,管理Agent根据结果计算出经济翻倍周期!是不是很智能?
|
| 89 |
+
|
| 90 |
+
## 使用 Langfuse 配置遥测
|
| 91 |
+
|
| 92 |
+
本部分演示如何通过 `SmolagentsInstrumentor` 使用 **Langfuse** 监控和调试 Hugging Face **smolagents**。
|
| 93 |
+
|
| 94 |
+
> **Langfuse 是什么?** [Langfuse](https://langfuse.com) 是面向LLM工程的开源平台,提供AI Agent的追踪与监控功能,帮助开发者调试、分析和优化产品。该平台通过原生集成、OpenTelemetry 和 SDKs 与各类工具框架对接。
|
| 95 |
+
|
| 96 |
+
### 步骤 1: 安装依赖
|
| 97 |
+
|
| 98 |
+
```python
|
| 99 |
+
%pip install smolagents
|
| 100 |
+
%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
### 步骤 2: 配置环境变量
|
| 104 |
+
|
| 105 |
+
设置 Langfuse API 密钥,并配置 OpenTelemetry 端点将追踪数据发送至 Langfuse。通过注册 [Langfuse Cloud](https://cloud.langfuse.com) 或 [自托管 Langfuse](https://langfuse.com/self-hosting) 获取 API 密钥。
|
| 106 |
+
|
| 107 |
+
同时需添加 [Hugging Face 令牌](https://huggingface.co/settings/tokens) (`HF_TOKEN`) 作为环境变量:
|
| 108 |
+
```python
|
| 109 |
+
import os
|
| 110 |
+
import base64
|
| 111 |
+
|
| 112 |
+
LANGFUSE_PUBLIC_KEY="pk-lf-..."
|
| 113 |
+
LANGFUSE_SECRET_KEY="sk-lf-..."
|
| 114 |
+
LANGFUSE_AUTH=base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
|
| 115 |
+
|
| 116 |
+
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel" # EU data region
|
| 117 |
+
# os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://us.cloud.langfuse.com/api/public/otel" # US data region
|
| 118 |
+
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
|
| 119 |
+
|
| 120 |
+
# your Hugging Face token
|
| 121 |
+
os.environ["HF_TOKEN"] = "hf_..."
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
### 步骤 3: 初始化 `SmolagentsInstrumentor`
|
| 125 |
+
|
| 126 |
+
在应用程序代码执行前初始化 `SmolagentsInstrumentor`。配置 `tracer_provider` 并添加 span processor 将追踪数据导出至 Langfuse。`OTLPSpanExporter()` 会自动使用环境变量中配置的端点和请求头。
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
from opentelemetry.sdk.trace import TracerProvider
|
| 131 |
+
|
| 132 |
+
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
|
| 133 |
+
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
|
| 134 |
+
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
|
| 135 |
+
|
| 136 |
+
trace_provider = TracerProvider()
|
| 137 |
+
trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
|
| 138 |
+
|
| 139 |
+
SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
### 步骤 4: 运行 smolagent
|
| 143 |
+
|
| 144 |
+
```python
|
| 145 |
+
from smolagents import (
|
| 146 |
+
CodeAgent,
|
| 147 |
+
ToolCallingAgent,
|
| 148 |
+
WebSearchTool,
|
| 149 |
+
VisitWebpageTool,
|
| 150 |
+
InferenceClientModel,
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
model = InferenceClientModel(
|
| 154 |
+
model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
search_agent = ToolCallingAgent(
|
| 158 |
+
tools=[WebSearchTool(), VisitWebpageTool()],
|
| 159 |
+
model=model,
|
| 160 |
+
name="search_agent",
|
| 161 |
+
description="This is an agent that can do web search.",
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
manager_agent = CodeAgent(
|
| 165 |
+
tools=[],
|
| 166 |
+
model=model,
|
| 167 |
+
managed_agents=[search_agent],
|
| 168 |
+
)
|
| 169 |
+
manager_agent.run(
|
| 170 |
+
"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?"
|
| 171 |
+
)
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
### 步骤 5: 在 Langfuse 中查看追踪记录
|
| 175 |
+
|
| 176 |
+
运行Agent后,您可以在 [Langfuse](https://cloud.langfuse.com) 平台查看 smolagents 应用生成的追踪记录。这些记录会详细展示LLM的交互步骤,帮助您调试和优化AI代理。
|
| 177 |
+
|
| 178 |
+
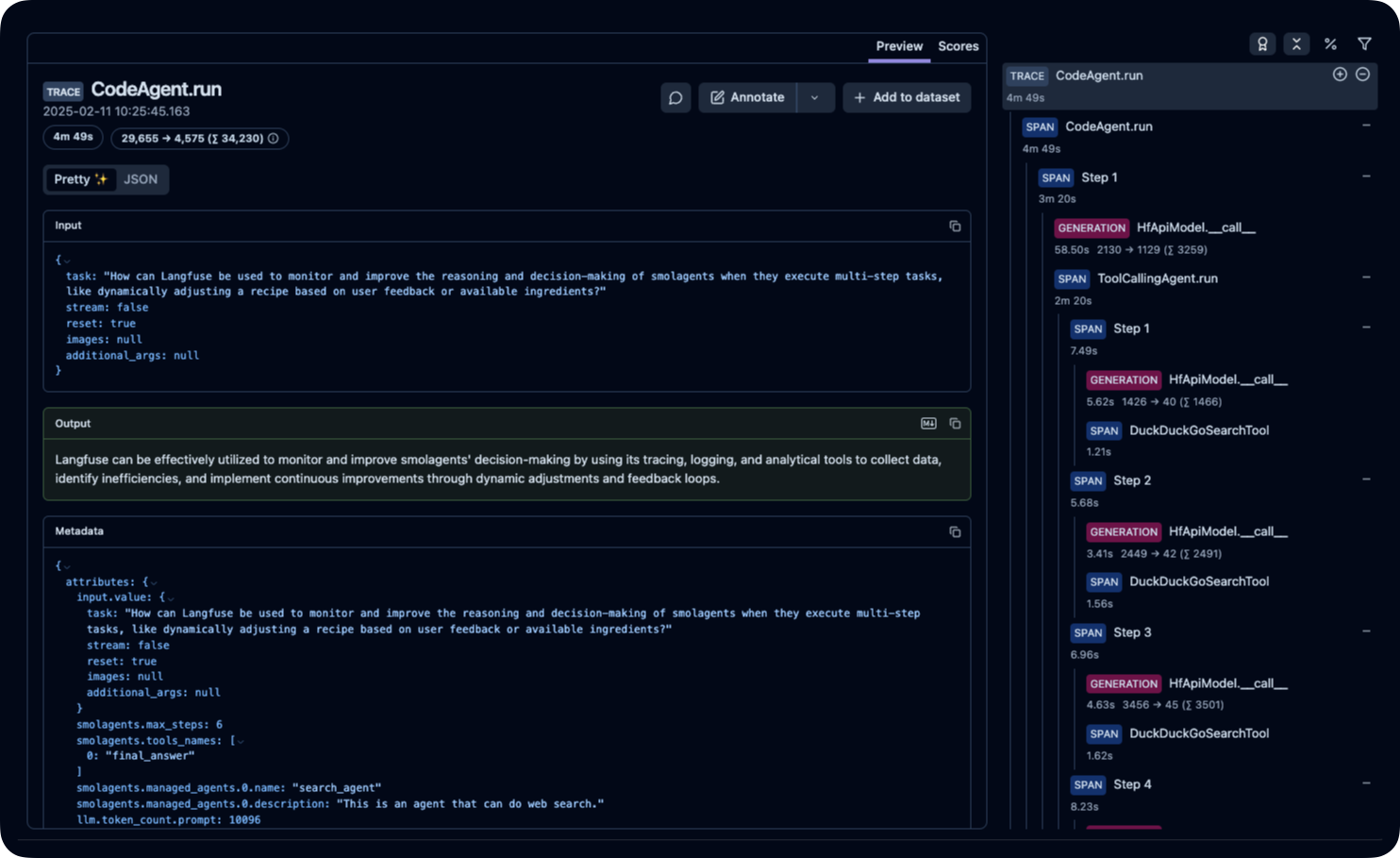
|
| 179 |
+
|
| 180 |
+
_[Langfuse 公开示例追踪](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_
|
docs/source/zh/tutorials/memory.md
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 📚 管理Agent的记忆
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
归根结底,Agent可以定义为由几个简单组件构成:它拥有工具、提示词。最重要的是,它具备对过往步骤的记忆,能够追溯完整的规划、执行和错误历史。
|
| 6 |
+
|
| 7 |
+
### 回放Agent的记忆
|
| 8 |
+
|
| 9 |
+
我们提供了多项功能来审查Agent的过往运行记录。
|
| 10 |
+
|
| 11 |
+
您可以通过插装(instrumentation)在可视化界面中查看Agent的运行过程,该界面支持对特定步骤进行缩放操作,具体方法参见[插装指南](./inspect_runs)。
|
| 12 |
+
|
| 13 |
+
您也可以使用`agent.replay()`方法实现回放:
|
| 14 |
+
|
| 15 |
+
当Agent完成运行后:
|
| 16 |
+
```py
|
| 17 |
+
from smolagents import InferenceClientModel, CodeAgent
|
| 18 |
+
|
| 19 |
+
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=0)
|
| 20 |
+
|
| 21 |
+
result = agent.run("What's the 20th Fibonacci number?")
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
若要回放最近一次运行,只需使用:
|
| 25 |
+
```py
|
| 26 |
+
agent.replay()
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
### 动态修改Agent的记忆
|
| 30 |
+
|
| 31 |
+
许多高级应用场景需要对Agent的记忆进行动态修改。
|
| 32 |
+
|
| 33 |
+
您可以通过以下方式访问Agent的记忆:
|
| 34 |
+
|
| 35 |
+
```py
|
| 36 |
+
from smolagents import ActionStep
|
| 37 |
+
|
| 38 |
+
system_prompt_step = agent.memory.system_prompt
|
| 39 |
+
print("The system prompt given to the agent was:")
|
| 40 |
+
print(system_prompt_step.system_prompt)
|
| 41 |
+
|
| 42 |
+
task_step = agent.memory.steps[0]
|
| 43 |
+
print("\n\nThe first task step was:")
|
| 44 |
+
print(task_step.task)
|
| 45 |
+
|
| 46 |
+
for step in agent.memory.steps:
|
| 47 |
+
if isinstance(step, ActionStep):
|
| 48 |
+
if step.error is not None:
|
| 49 |
+
print(f"\nStep {step.step_number} got this error:\n{step.error}\n")
|
| 50 |
+
else:
|
| 51 |
+
print(f"\nStep {step.step_number} got these observations:\n{step.observations}\n")
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
使用`agent.memory.get_full_steps()`可获取完整步骤字典数据。
|
| 55 |
+
|
| 56 |
+
您还可以通过步骤回调(step callbacks)实现记忆的动态修改。
|
| 57 |
+
|
| 58 |
+
步骤回调函数可通过参数直接访问`agent`对象,因此能够访问所有记忆步骤并根据需要进行修改。例如,假设您正在监控网页浏览Agent每个步骤的屏幕截图,希望保留最新截图同时删除旧步骤的图片以节省token消耗。
|
| 59 |
+
|
| 60 |
+
可参考以下代码示例:
|
| 61 |
+
_注:此代码片段不完整,部分导入语句和对象定义已精简,完整代码请访问[原始脚本](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py)_
|
| 62 |
+
|
| 63 |
+
```py
|
| 64 |
+
import helium
|
| 65 |
+
from PIL import Image
|
| 66 |
+
from io import BytesIO
|
| 67 |
+
from time import sleep
|
| 68 |
+
|
| 69 |
+
def update_screenshot(memory_step: ActionStep, agent: CodeAgent) -> None:
|
| 70 |
+
sleep(1.0) # Let JavaScript animations happen before taking the screenshot
|
| 71 |
+
driver = helium.get_driver()
|
| 72 |
+
latest_step = memory_step.step_number
|
| 73 |
+
for previous_memory_step in agent.memory.steps: # Remove previous screenshots from logs for lean processing
|
| 74 |
+
if isinstance(previous_memory_step, ActionStep) and previous_memory_step.step_number <= latest_step - 2:
|
| 75 |
+
previous_memory_step.observations_images = None
|
| 76 |
+
png_bytes = driver.get_screenshot_as_png()
|
| 77 |
+
image = Image.open(BytesIO(png_bytes))
|
| 78 |
+
memory_step.observations_images = [image.copy()]
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
最后在初始化Agent时,将此函数传入`step_callbacks`参数:
|
| 82 |
+
|
| 83 |
+
```py
|
| 84 |
+
CodeAgent(
|
| 85 |
+
tools=[WebSearchTool(), go_back, close_popups, search_item_ctrl_f],
|
| 86 |
+
model=model,
|
| 87 |
+
additional_authorized_imports=["helium"],
|
| 88 |
+
step_callbacks=[update_screenshot],
|
| 89 |
+
max_steps=20,
|
| 90 |
+
verbosity_level=2,
|
| 91 |
+
)
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
请访问我们的 [vision web browser code](https://github.com/huggingface/smolagents/blob/main/src/smolagents/vision_web_browser.py) 查看完整可运行示例。
|
| 95 |
+
|
| 96 |
+
### 分步运行 Agents
|
| 97 |
+
|
| 98 |
+
当您需要处理耗时数天的工具调用时,这种方式特别有用:您可以逐步执行Agents。这还允许您在每一步更新记忆。
|
| 99 |
+
|
| 100 |
+
```py
|
| 101 |
+
from smolagents import InferenceClientModel, CodeAgent, ActionStep, TaskStep
|
| 102 |
+
|
| 103 |
+
agent = CodeAgent(tools=[], model=InferenceClientModel(), verbosity_level=1)
|
| 104 |
+
print(agent.memory.system_prompt)
|
| 105 |
+
|
| 106 |
+
task = "What is the 20th Fibonacci number?"
|
| 107 |
+
|
| 108 |
+
# You could modify the memory as needed here by inputting the memory of another agent.
|
| 109 |
+
# agent.memory.steps = previous_agent.memory.steps
|
| 110 |
+
|
| 111 |
+
# Let's start a new task!
|
| 112 |
+
agent.memory.steps.append(TaskStep(task=task, task_images=[]))
|
| 113 |
+
|
| 114 |
+
final_answer = None
|
| 115 |
+
step_number = 1
|
| 116 |
+
while final_answer is None and step_number <= 10:
|
| 117 |
+
memory_step = ActionStep(
|
| 118 |
+
step_number=step_number,
|
| 119 |
+
observations_images=[],
|
| 120 |
+
)
|
| 121 |
+
# Run one step.
|
| 122 |
+
final_answer = agent.step(memory_step)
|
| 123 |
+
agent.memory.steps.append(memory_step)
|
| 124 |
+
step_number += 1
|
| 125 |
+
|
| 126 |
+
# Change the memory as you please!
|
| 127 |
+
# For instance to update the latest step:
|
| 128 |
+
# agent.memory.steps[-1] = ...
|
| 129 |
+
|
| 130 |
+
print("The final answer is:", final_answer)
|
| 131 |
+
```
|
docs/source/zh/tutorials/secure_code_execution.md
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 安全代码执行
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
> [!TIP]
|
| 6 |
+
> 如果你是第一次构建 agent,请先阅读 [agent 介绍](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
|
| 7 |
+
|
| 8 |
+
### 代码智能体
|
| 9 |
+
|
| 10 |
+
[多项](https://huggingface.co/papers/2402.01030) [研究](https://huggingface.co/papers/2411.01747) [表明](https://huggingface.co/papers/2401.00812),让大语言模型用代码编写其动作(工具调用)比当前标准的工具调用格式要好得多,目前行业标准是 "将动作写成包含工具名称和参数的 JSON" 的各种变体。
|
| 11 |
+
|
| 12 |
+
为什么代码更好?因为我们专门为计算机执行的动作而设计编程语言。如果 JSON 片段是更好的方式,那么这个工具包就应该是用 JSON 片段编写的,魔鬼就会嘲笑我们。
|
| 13 |
+
|
| 14 |
+
代码就是表达计算机动作的更好方式。它具有更好的:
|
| 15 |
+
- **组合性**:你能像定义 Python 函数那样,在 JSON 动作中嵌套其他 JSON 动作,或者定义一组 JSON 动作以便以后重用吗?
|
| 16 |
+
- **对象管理**:你如何在 JSON 中存储像 `generate_image` 这样的动作的输出?
|
| 17 |
+
- **通用性**:代码是为了简单地表达任何可以让计算机做的事情而构建的。
|
| 18 |
+
- **在 LLM 训练语料库中的表示**:天赐良机,为什么不利用已经包含在 LLM 训练语料库中的大量高质量动作呢?
|
| 19 |
+
|
| 20 |
+
下图展示了这一点,取自 [可执行代码动作引出更好的 LLM 智能体](https://huggingface.co/papers/2402.01030)。
|
| 21 |
+
|
| 22 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/code_vs_json_actions.png">
|
| 23 |
+
|
| 24 |
+
这就是为什么我们强调提出代码智能体,在本例中是 Python 智能体,这意味着我们要在构建安全的 Python 解释器上投入更多精力。
|
| 25 |
+
|
| 26 |
+
### 本地 Python 解释器
|
| 27 |
+
|
| 28 |
+
默认情况下,`CodeAgent` 会在你的环境中运行 LLM 生成的代码。
|
| 29 |
+
这个执行不是由普通的 Python 解释器完成的:我们从零开始重新构建了一个更安全的 `LocalPythonExecutor`。
|
| 30 |
+
这个解释器通过以下方式设计以确保安全:
|
| 31 |
+
- 将导入限制为用户显式传递的列表
|
| 32 |
+
- 限制操作次数以防止无限循环和资源膨胀
|
| 33 |
+
- 不会执行任何未预定义的操作
|
| 34 |
+
|
| 35 |
+
我们已经在许多用例中使用了这个解释器,从未观察到对环境造成任何损害。
|
| 36 |
+
|
| 37 |
+
然而,这个解决方案并不是万无一失的:可以想象,如果 LLM 被微调用于恶意操作,仍然可能损害你的环境。例如,如果你允许像 `Pillow` 这样无害的包处理图像,LLM 可能会生成数千张图像保存以膨胀你的硬盘。
|
| 38 |
+
如果你自己选择了 LLM 引擎,这当然不太可能,但它可能会发生。
|
| 39 |
+
|
| 40 |
+
所以如果你想格外谨慎,可以使用下面描述的远程代码执行选项。
|
| 41 |
+
|
| 42 |
+
### E2B 代码执行器
|
| 43 |
+
|
| 44 |
+
为了最大程度的安全性,你可以使用我们与 E2B 的集成在沙盒环境中运行代码。这是一个远程执行服务,可以在隔离的容器中运行你的代码,使代码无法影响你的本地环境。
|
| 45 |
+
|
| 46 |
+
为此,你需要设置你的 E2B 账户并在环境变量中设置 `E2B_API_KEY`。请前往 [E2B 快速入门文档](https://e2b.dev/docs/quickstart) 了解更多信息。
|
| 47 |
+
|
| 48 |
+
然后你可以通过 `pip install e2b-code-interpreter python-dotenv` 安装它。
|
| 49 |
+
|
| 50 |
+
现在你已经准备好了!
|
| 51 |
+
|
| 52 |
+
要将代码执行器设置为 E2B,只需在初始化 `CodeAgent` 时传递标志 `executor_type="e2b"`。
|
| 53 |
+
请注意,你应该将所有工具的依赖项添加到 `additional_authorized_imports` 中,以便执行器安装它们。
|
| 54 |
+
|
| 55 |
+
```py
|
| 56 |
+
from smolagents import CodeAgent, VisitWebpageTool, InferenceClientModel
|
| 57 |
+
agent = CodeAgent(
|
| 58 |
+
tools = [VisitWebpageTool()],
|
| 59 |
+
model=InferenceClientModel(),
|
| 60 |
+
additional_authorized_imports=["requests", "markdownify"],
|
| 61 |
+
executor_type="e2b"
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
agent.run("What was Abraham Lincoln's preferred pet?")
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
目前 E2B 代码执行暂不兼容多 agent——因为把 agent 调用放在应该在远程执行的代码块里,是非常混乱的。但我们正在努力做到这件事!
|
docs/source/zh/tutorials/tools.md
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 工具
|
| 2 |
+
|
| 3 |
+
[[open-in-colab]]
|
| 4 |
+
|
| 5 |
+
在这里,我们将学习高级工具的使用。
|
| 6 |
+
|
| 7 |
+
> [!TIP]
|
| 8 |
+
> 如果你是构建 agent 的新手,请确保先阅读 [agent 介绍](../conceptual_guides/intro_agents) 和 [smolagents 导览](../guided_tour)。
|
| 9 |
+
|
| 10 |
+
- [工具](#工具)
|
| 11 |
+
- [什么是工具,如何构建一个工具?](#什么是工具如何构建一个工具)
|
| 12 |
+
- [将你的工具分享到 Hub](#将你的工具分享到-hub)
|
| 13 |
+
- [将 Space 导入为工具](#将-space-导入为工具)
|
| 14 |
+
- [使用 LangChain 工具](#使用-langchain-工具)
|
| 15 |
+
- [管理你的 agent 工具箱](#管理你的-agent-工具箱)
|
| 16 |
+
- [使用工具集合](#使用工具集合)
|
| 17 |
+
|
| 18 |
+
### 什么是工具,如何构建一个工具?
|
| 19 |
+
|
| 20 |
+
工具主要是 LLM 可以在 agent 系统中使用的函数。
|
| 21 |
+
|
| 22 |
+
但要使用它,LLM 需要被提供一个 API:名称、工具描述、输入类型和描述、输出类型。
|
| 23 |
+
|
| 24 |
+
所以它不能仅仅是一个函数。它应该是一个类。
|
| 25 |
+
|
| 26 |
+
因此,核心上,工具是一个类,它包装了一个函数,并带有帮助 LLM 理解如何使用它的元数据。
|
| 27 |
+
|
| 28 |
+
以下是它的结构:
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
from smolagents import Tool
|
| 32 |
+
|
| 33 |
+
class HFModelDownloadsTool(Tool):
|
| 34 |
+
name = "model_download_counter"
|
| 35 |
+
description = """
|
| 36 |
+
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
|
| 37 |
+
It returns the name of the checkpoint."""
|
| 38 |
+
inputs = {
|
| 39 |
+
"task": {
|
| 40 |
+
"type": "string",
|
| 41 |
+
"description": "the task category (such as text-classification, depth-estimation, etc)",
|
| 42 |
+
}
|
| 43 |
+
}
|
| 44 |
+
output_type = "string"
|
| 45 |
+
|
| 46 |
+
def forward(self, task: str):
|
| 47 |
+
from huggingface_hub import list_models
|
| 48 |
+
|
| 49 |
+
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
|
| 50 |
+
return model.id
|
| 51 |
+
|
| 52 |
+
model_downloads_tool = HFModelDownloadsTool()
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
自定义工具继承 [`Tool`] 以继承有用的方法。子类还定义了:
|
| 56 |
+
- 一个属性 `name`,对应于工具本身的名称。名称通常描述工具的功能。由于代码返回任务中下载量最多的模型,我们将其命名为 `model_download_counter`。
|
| 57 |
+
- 一个属性 `description`,用于填充 agent 的系统提示。
|
| 58 |
+
- 一个 `inputs` 属性,它是一个带有键 `"type"` 和 `"description"` 的字典。它包含帮助 Python 解释器对输入做出明智选择的信息。
|
| 59 |
+
- 一个 `output_type` 属性,指定输出类型。`inputs` 和 `output_type` 的类型应为 [Pydantic 格式](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema),它们可以是以下之一:[`~AUTHORIZED_TYPES`]。
|
| 60 |
+
- 一个 `forward` 方法,包含要执行的推理代码。
|
| 61 |
+
|
| 62 |
+
这就是它在 agent 中使用所需的全部内容!
|
| 63 |
+
|
| 64 |
+
还有另一种构建工具的方法。在 [guided_tour](../guided_tour) 中,我们使用 `@tool` 装饰器实现了一个工具。[`tool`] 装饰器是定义简单工具的推荐方式,但有时你需要更多:在类中使用多个方法以获得更清晰的代码,或使用额外的类属性。
|
| 65 |
+
|
| 66 |
+
在这种情况下,你可以通过如上所述继承 [`Tool`] 来构建你的工具。
|
| 67 |
+
|
| 68 |
+
### 将你的工具分享到 Hub
|
| 69 |
+
|
| 70 |
+
你可以通过调用 [`~Tool.push_to_hub`] 将你的自定义工具分享到 Hub。确保你已经在 Hub 上为其创建了一个仓库,并且使用的是具有读取权限的 token。
|
| 71 |
+
|
| 72 |
+
```python
|
| 73 |
+
model_downloads_tool.push_to_hub("{your_username}/hf-model-downloads", token="<YOUR_HUGGINGFACEHUB_API_TOKEN>")
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
为了使推送到 Hub 正常工作,你的工具需要遵守一些规则:
|
| 77 |
+
- 所有方法都是自包含的,例如使用来自其参数中的变量。
|
| 78 |
+
- 根据上述要点,**所有导入应直接在工具的函数中定义**,否则在尝试使用 [`~Tool.save`] 或 [`~Tool.push_to_hub`] 调用你的自定义工具时会出现错误。
|
| 79 |
+
- 如果你继承了 `__init__` 方法,除了 `self` 之外,你不能给它任何其他参数。这是因为在特定工具实例初始化期间设置的参数很难跟踪,这阻碍了将它们正确分享到 Hub。无论如何,创建特定类的想法是你已经可以为任何需要硬编码的内容设置类属性(只需在 `class YourTool(Tool):` 行下直接设置 `your_variable=(...)`)。当然,你仍然可以通过将内容分配给 `self.your_variable` 在代码中的任何地方创建类属性。
|
| 80 |
+
|
| 81 |
+
一旦你的工具被推送到 Hub,你就可以查看它。[这里](https://huggingface.co/spaces/m-ric/hf-model-downloads) 是我推送的 `model_downloads_tool`。它有一个漂亮的 gradio 界面。
|
| 82 |
+
|
| 83 |
+
在深入工具文件时,你可以发现所有工具的逻辑都在 [tool.py](https://huggingface.co/spaces/m-ric/hf-model-downloads/blob/main/tool.py) 下。这是你可以检查其他人分享的工具的地方。
|
| 84 |
+
|
| 85 |
+
然后你可以使用 [`load_tool`] 加载工具或使用 [`~Tool.from_hub`] 创建它,并将其传递给 agent 中的 `tools` 参数。
|
| 86 |
+
由于运行工具意味着运行自定义代码,你需要确保你信任该仓库,因此我们需要传递 `trust_remote_code=True` 来从 Hub 加载工具。
|
| 87 |
+
|
| 88 |
+
```python
|
| 89 |
+
from smolagents import load_tool, CodeAgent
|
| 90 |
+
|
| 91 |
+
model_download_tool = load_tool(
|
| 92 |
+
"{your_username}/hf-model-downloads",
|
| 93 |
+
trust_remote_code=True
|
| 94 |
+
)
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
### 将 Space 导入为工具
|
| 98 |
+
|
| 99 |
+
你可以使用 [`Tool.from_space`] 方法直接从 Hub 导入一个 Space 作为工具!
|
| 100 |
+
|
| 101 |
+
你只需要提供 Hub 上 Space 的 id、它的名称和一个帮助你的 agent 理解工具功能的描述。在底层,这将使用 [`gradio-client`](https://pypi.org/project/gradio-client/) 库来调用 Space。
|
| 102 |
+
|
| 103 |
+
例如,让我们从 Hub 导入 [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) Space 并使用它生成一张图片。
|
| 104 |
+
|
| 105 |
+
```python
|
| 106 |
+
image_generation_tool = Tool.from_space(
|
| 107 |
+
"black-forest-labs/FLUX.1-schnell",
|
| 108 |
+
name="image_generator",
|
| 109 |
+
description="Generate an image from a prompt"
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
image_generation_tool("A sunny beach")
|
| 113 |
+
```
|
| 114 |
+
瞧,这是你的图片!🏖️
|
| 115 |
+
|
| 116 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sunny_beach.webp">
|
| 117 |
+
|
| 118 |
+
然后你可以像使用任何其他工具一样使用这个工具。例如,让我们改进提示 `A rabbit wearing a space suit` 并生成它的图片。
|
| 119 |
+
|
| 120 |
+
```python
|
| 121 |
+
from smolagents import CodeAgent, InferenceClientModel
|
| 122 |
+
|
| 123 |
+
model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
|
| 124 |
+
agent = CodeAgent(tools=[image_generation_tool], model=model)
|
| 125 |
+
|
| 126 |
+
agent.run(
|
| 127 |
+
"Improve this prompt, then generate an image of it.", additional_args={'user_prompt': 'A rabbit wearing a space suit'}
|
| 128 |
+
)
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
```text
|
| 132 |
+
=== Agent thoughts:
|
| 133 |
+
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
|
| 134 |
+
|
| 135 |
+
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
|
| 136 |
+
>>> Agent is executing the code below:
|
| 137 |
+
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
|
| 138 |
+
final_answer(image)
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit_spacesuit_flux.webp">
|
| 142 |
+
|
| 143 |
+
这得有多酷?🤩
|
| 144 |
+
|
| 145 |
+
### 使用 LangChain 工具
|
| 146 |
+
|
| 147 |
+
我们喜欢 Langchain,并认为它有一套非常吸引人的工具。
|
| 148 |
+
要从 LangChain 导入工具,请使用 `from_langchain()` 方法。
|
| 149 |
+
|
| 150 |
+
以下是如何使用它来重现介绍中的搜索结果,使用 LangChain 的 web 搜索工具。
|
| 151 |
+
这个工具需要 `pip install langchain google-search-results -q` 才能正常工作。
|
| 152 |
+
```python
|
| 153 |
+
from langchain.agents import load_tools
|
| 154 |
+
|
| 155 |
+
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
|
| 156 |
+
|
| 157 |
+
agent = CodeAgent(tools=[search_tool], model=model)
|
| 158 |
+
|
| 159 |
+
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
### 管理你的 agent 工具箱
|
| 163 |
+
|
| 164 |
+
你可以通过添加或替换工具来管理 agent 的工具箱。
|
| 165 |
+
|
| 166 |
+
让我们将 `model_download_tool` 添加到一个仅使用默认工具箱初始化的现有 agent 中。
|
| 167 |
+
|
| 168 |
+
```python
|
| 169 |
+
from smolagents import InferenceClientModel
|
| 170 |
+
|
| 171 |
+
model = InferenceClientModel(model_id="Qwen/Qwen2.5-Coder-32B-Instruct")
|
| 172 |
+
|
| 173 |
+
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
|
| 174 |
+
agent.tools[model_download_tool.name] = model_download_tool
|
| 175 |
+
```
|
| 176 |
+
现在我们可以利用新工具:
|
| 177 |
+
|
| 178 |
+
```python
|
| 179 |
+
agent.run(
|
| 180 |
+
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?"
|
| 181 |
+
)
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
> [!TIP]
|
| 186 |
+
> 注意不要向 agent 添加太多工具:这可能会让较弱的 LLM 引擎不堪重负。
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
### 使用工具集合
|
| 190 |
+
|
| 191 |
+
你可以通过使用 ToolCollection 对象来利用工具集合,使用你想要使用的集合的 slug。
|
| 192 |
+
然后将它们作为列表传递给 agent 初始化,并开始使用它们!
|
| 193 |
+
|
| 194 |
+
```py
|
| 195 |
+
from smolagents import ToolCollection, CodeAgent
|
| 196 |
+
|
| 197 |
+
image_tool_collection = ToolCollection.from_hub(
|
| 198 |
+
collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f",
|
| 199 |
+
token="<YOUR_HUGGINGFACEHUB_API_TOKEN>"
|
| 200 |
+
)
|
| 201 |
+
agent = CodeAgent(tools=[*image_tool_collection.tools], model=model, add_base_tools=True)
|
| 202 |
+
|
| 203 |
+
agent.run("Please draw me a picture of rivers and lakes.")
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
为了加快启动速度,工具仅在 agent 调用时加载。
|