Spaces:
Sleeping

Sleeping
Add Dockerfile and project files
Browse files- .gitattributes +3 -34
- .gitignore +0 -0
- Dockerfile +21 -0
- README.md +175 -9
- app.py +63 -0
- chatbot.log +0 -0
- data/emotion_dataset.csv +3 -0
- error.log +0 -0
- models/__pycache__/chatbot_model.cpython-312.pyc +0 -0
- models/bert_emotion_model/config.json +3 -0
- models/bert_emotion_model/id_to_label.json +3 -0
- models/bert_emotion_model/label_to_id.json +3 -0
- models/bert_emotion_model/model.safetensors +3 -0
- models/bert_emotion_model/special_tokens_map.json +3 -0
- models/bert_emotion_model/tokenizer.json +3 -0
- models/bert_emotion_model/tokenizer_config.json +3 -0
- models/bert_emotion_model/training_args.bin +3 -0
- models/bert_emotion_model/vocab.txt +0 -0
- models/chatbot_model.py +227 -0
- models/responses.json +3 -0
- requirements.txt +0 -0
- static/css/styles.css +360 -0
- static/img/1.png +0 -0
- static/img/bot-avatar.png +0 -0
- static/img/chatbot1.png +0 -0
- static/img/chatbot2.png +0 -0
- static/img/index.png +0 -0
- static/js/scripts.js +116 -0
- templates/chatbot.html +60 -0
- templates/index.html +53 -0
- train_model.py +216 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,4 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
|
| 27 |
-
*.
|
| 28 |
-
*.
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.csv filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.gitignore
ADDED
|
Binary file (34 Bytes). View file
|
|
|
Dockerfile
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Usa una imagen base de Python
|
| 2 |
+
FROM python:3.9-slim
|
| 3 |
+
|
| 4 |
+
# Establecer el directorio de trabajo
|
| 5 |
+
WORKDIR /app
|
| 6 |
+
|
| 7 |
+
# Copiar el archivo de requerimientos
|
| 8 |
+
COPY requirements.txt /app
|
| 9 |
+
|
| 10 |
+
# Instalar dependencias
|
| 11 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 12 |
+
|
| 13 |
+
# Copiar el resto del código
|
| 14 |
+
COPY . /app
|
| 15 |
+
|
| 16 |
+
# Hugging Face Spaces asigna un puerto en la variable $PORT
|
| 17 |
+
# Ajusta tu Flask para usar ese puerto (ver más abajo).
|
| 18 |
+
EXPOSE 7860
|
| 19 |
+
|
| 20 |
+
# Usar gunicorn para producción (puerto = 7860 por convención en Spaces)
|
| 21 |
+
CMD ["gunicorn", "app:app", "--bind", "0.0.0.0:7860"]
|
README.md
CHANGED
|
@@ -1,11 +1,177 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
---
|
| 10 |
|
| 11 |
-
|
|
|
|
|
|
| 1 |
+
# Chatbot de Salud Mental - Versión 1.0
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
<img src="static/img/1.png" alt="Pantalla de Inicio" width="250">
|
| 5 |
+
<br>
|
| 6 |
+
<em>Logo del Chatbot de Salud Mental</em>
|
| 7 |
+
</div>
|
| 8 |
+
|
| 9 |
+
## Descripción del Proyecto
|
| 10 |
+
Este proyecto es un chatbot **orientado a la salud mental** que, mediante **Procesamiento de Lenguaje Natural (PLN)**, analiza los mensajes ingresados por los usuarios (ya sea por **texto** o **audio**) para predecir su estado emocional y generar respuestas de apoyo o contestaciones acordes.
|
| 11 |
+
|
| 12 |
+
- **Interacción por voz**: El usuario puede hablar (speech-to-text) y recibir la respuesta en audio (text-to-speech).
|
| 13 |
+
- **Emociones limitadas**: Actualmente detecta 11 emociones básicas, pero se planea mejorar en futuras versiones (2.0).
|
| 14 |
+
- **Versión 1.0**: Implementación básica y experimental; **no** sustituye asesoramiento profesional.
|
| 15 |
+
|
| 16 |
+
## Tecnologías Utilizadas
|
| 17 |
+
- **Python**: Flask (backend web), Transformers, PyTorch
|
| 18 |
+
- **BERT** (Bidirectional Encoder Representations from Transformers)
|
| 19 |
+
- **Procesamiento de Lenguaje Natural (PLN)**
|
| 20 |
+
- **Reconocimiento de Voz** (SpeechRecognition en el navegador)
|
| 21 |
+
- **Síntesis de Texto a Voz** (pyttsx3/pydub)
|
| 22 |
+
- **HTML, CSS, JavaScript** (Frontend)
|
| 23 |
+
|
| 24 |
+
## Arquitectura del Chatbot
|
| 25 |
+
|
| 26 |
+
El pipeline principal que sigue este proyecto es:
|
| 27 |
+
|
| 28 |
+
```text
|
| 29 |
+
-> Speech Recognition -> Natural Language Understanding -> Dialog Manager <-> Task Manager
|
| 30 |
+
Text-to-Speech Synthesis <- Natural Language Generation <- Dialog Manager
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
1. **Speech Recognition**: El usuario habla y el navegador convierte el audio a texto (Web Speech API).
|
| 34 |
+
2. **Natural Language Understanding**: El texto se envía a Flask, donde BERT analiza la emoción.
|
| 35 |
+
3. **Dialog Manager**: Gestiona la lógica de la conversación y decide la respuesta.
|
| 36 |
+
4. **Text-to-Speech Synthesis**: El chatbot genera un archivo de audio que se devuelve al navegador.
|
| 37 |
+
|
| 38 |
+
## Emociones Detectadas
|
| 39 |
+
El modelo (fine-tuned en BERT) reconoce las siguientes emociones:
|
| 40 |
+
|
| 41 |
+
- FELICIDAD
|
| 42 |
+
- NEUTRAL
|
| 43 |
+
- DEPRESIÓN
|
| 44 |
+
- ANSIEDAD
|
| 45 |
+
- ESTRÉS
|
| 46 |
+
- EMERGENCIA
|
| 47 |
+
- CONFUSIÓN
|
| 48 |
+
- IRA
|
| 49 |
+
- MIEDO
|
| 50 |
+
- SORPRESA
|
| 51 |
+
- DISGUSTO
|
| 52 |
+
|
| 53 |
+
Se utilizó un dataset de ~500 muestras para cada emoción (total ~5500 filas).
|
| 54 |
+
|
| 55 |
+
# Capturas de Pantalla
|
| 56 |
+
|
| 57 |
+
**Página de Inicio**
|
| 58 |
+
<div align="center"> <img src="static/img/index.png" alt="Página de Inicio" width="1000"> <br> <em>Página de inicio del Chatbot de Salud Mental</em> </div>
|
| 59 |
+
|
| 60 |
+
**Interfaz del Chatbot**
|
| 61 |
+
<div align="center"> <img src="static/img/chatbot1.png" alt="Interfaz del Chatbot" width="1000"> <br> <em>Interfaz del Chatbot</em> </div>
|
| 62 |
+
|
| 63 |
+
**Reconocimiento de Voz Activado**
|
| 64 |
+
<div align="center"> <img src="static/img/chatbot2.png" alt="Reconocimiento de Voz Activado" width="1000"> <br> <em>Indicador de grabación de voz</em> </div>
|
| 65 |
+
|
| 66 |
+
## Estructura del Proyecto
|
| 67 |
+
|
| 68 |
+
```text
|
| 69 |
+
ChatBot/
|
| 70 |
+
├── conversations/
|
| 71 |
+
├── data/
|
| 72 |
+
│ └── emotion_dataset.csv
|
| 73 |
+
├── models/
|
| 74 |
+
│ ├── bert_emotion_model/
|
| 75 |
+
│ │ ├── checkpoint-1600
|
| 76 |
+
│ │ ├── checkpoint-1650
|
| 77 |
+
│ │ ├── config.json
|
| 78 |
+
│ │ ├── model.safetensors
|
| 79 |
+
│ │ ├── special_tokens_map.json
|
| 80 |
+
│ │ ├── tokenizer.json
|
| 81 |
+
│ │ ├── tokenizer_config.json
|
| 82 |
+
│ │ ├── training_args.bin
|
| 83 |
+
│ │ └── vocab.txt
|
| 84 |
+
│ ├── chatbot_model.py
|
| 85 |
+
│ └── responses.json
|
| 86 |
+
├── static/
|
| 87 |
+
│ ├── audio/
|
| 88 |
+
│ ├── css/
|
| 89 |
+
│ │ └── styles.css
|
| 90 |
+
│ ├── img/
|
| 91 |
+
│ └── js/
|
| 92 |
+
│ └── scripts.js
|
| 93 |
+
├── templates/
|
| 94 |
+
│ ├── chatbot.html
|
| 95 |
+
│ └── index.html
|
| 96 |
+
├── app.py
|
| 97 |
+
├── chatbot.log
|
| 98 |
+
├── error.log
|
| 99 |
+
├── requirements.txt
|
| 100 |
+
└── train_model.py
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
## Instalación y Configuración
|
| 104 |
+
|
| 105 |
+
### 1. Clonar el repositorio con Git LFS
|
| 106 |
+
Si el proyecto usa archivos grandes (como modelos BERT), asegúrate de tener Git LFS instalado antes de clonar el repositorio.
|
| 107 |
+
```bash
|
| 108 |
+
# Instalar Git LFS (si no lo tienes)
|
| 109 |
+
git lfs install
|
| 110 |
+
|
| 111 |
+
# Clonar el repositorio
|
| 112 |
+
git clone https://github.com/tu-usuario/ChatBot-MentalHealth.git
|
| 113 |
+
cd ChatBot-MentalHealth
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
### 2. Crear un entorno virtual y activarlo
|
| 117 |
+
```bash
|
| 118 |
+
python -m venv venv
|
| 119 |
+
# En Windows
|
| 120 |
+
venv\Scripts\activate
|
| 121 |
+
# En macOS/Linux
|
| 122 |
+
source venv/bin/activate
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
### 3. Instalar dependencias
|
| 126 |
+
```bash
|
| 127 |
+
pip install -r requirements.txt
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
### 4. Ejecutar la aplicación
|
| 131 |
+
```bash
|
| 132 |
+
python app.py
|
| 133 |
+
```
|
| 134 |
+
La aplicación se ejecutará en [http://127.0.0.1:5000/](http://127.0.0.1:5000/).
|
| 135 |
+
|
| 136 |
+
## Ejemplo de Código (`train_model.py`)
|
| 137 |
+
|
| 138 |
+
```python
|
| 139 |
+
class CustomTrainer(Trainer):
|
| 140 |
+
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
|
| 141 |
+
labels = inputs.get("labels").to(model.device)
|
| 142 |
+
outputs = model(**inputs)
|
| 143 |
+
logits = outputs.get("logits")
|
| 144 |
+
loss = custom_loss(labels, logits) # Pérdida con class_weights
|
| 145 |
+
return (loss, outputs) if return_outputs else loss
|
| 146 |
+
|
| 147 |
+
def custom_loss(labels, logits):
|
| 148 |
+
loss_fct = torch.nn.CrossEntropyLoss(weight=class_weights)
|
| 149 |
+
return loss_fct(logits, labels)
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
De esta forma, cada emoción recibe un peso distinto, mitigando el riesgo de que el modelo ignore las clases menos representadas.
|
| 153 |
+
|
| 154 |
+
## Flujo de Uso de los Archivos en el Proyecto
|
| 155 |
+
|
| 156 |
+
1. **Cargar el Modelo**: Los pesos del modelo están en `model.safetensors` junto con `config.json`, `tokenizer.json`, etc.
|
| 157 |
+
2. **Tokenización**: Se convierte la entrada (texto) en tokens con el tokenizer de BERT (`tokenizer.json`, `vocab.txt`).
|
| 158 |
+
3. **Inferencia**: El texto del usuario se procesa con BERT para predecir la emoción y generar una respuesta.
|
| 159 |
+
4. **Respuesta**: Se envía el texto de vuelta al navegador y, si se activa la síntesis de voz, se genera un archivo de audio.
|
| 160 |
+
|
| 161 |
+
## Notas Finales
|
| 162 |
+
|
| 163 |
+
- Esta versión (1.0) es experimental y **no** sustituye asesoramiento profesional en salud mental.
|
| 164 |
+
- Se recomienda seguir refinando el modelo, incorporar más emociones y ampliar la base de datos.
|
| 165 |
+
- En caso de emergencia o situación de riesgo, busca ayuda de un profesional de la salud mental.
|
| 166 |
+
|
| 167 |
+
## Colaboradores
|
| 168 |
+
- **Nicolás Ceballos Brito** (@Nico2603)
|
| 169 |
+
- **Juan Alejandro Urueña Serna** (@Uruena2603)
|
| 170 |
+
- **Camilo Castañeda Yepes** (@camCy)
|
| 171 |
+
|
| 172 |
+
Para cualquier duda o sugerencia, contáctame en: **[email protected]**
|
| 173 |
+
|
| 174 |
---
|
| 175 |
|
| 176 |
+
¡Gracias por probar el Chatbot de Salud Mental!
|
| 177 |
+
Si deseas contribuir, siéntete libre de hacer un **fork** y enviar tus **pull requests**.
|
app.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import logging
|
| 3 |
+
from flask import Flask, render_template, request, jsonify
|
| 4 |
+
from models.chatbot_model import MentalHealthChatbot
|
| 5 |
+
|
| 6 |
+
app = Flask(__name__)
|
| 7 |
+
|
| 8 |
+
# Configurar el registro de errores
|
| 9 |
+
logging.basicConfig(
|
| 10 |
+
level=logging.ERROR,
|
| 11 |
+
format='%(asctime)s %(levelname)s %(name)s %(threadName)s : %(message)s',
|
| 12 |
+
handlers=[
|
| 13 |
+
logging.FileHandler("error.log"),
|
| 14 |
+
logging.StreamHandler()
|
| 15 |
+
]
|
| 16 |
+
)
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
# Crear una instancia del chatbot con el modelo fine-tuned
|
| 20 |
+
try:
|
| 21 |
+
chatbot = MentalHealthChatbot(model_path='models/bert_emotion_model')
|
| 22 |
+
except Exception as e:
|
| 23 |
+
logger.error(f"Error al inicializar el chatbot: {e}")
|
| 24 |
+
raise
|
| 25 |
+
|
| 26 |
+
@app.route('/')
|
| 27 |
+
def index():
|
| 28 |
+
try:
|
| 29 |
+
return render_template('index.html')
|
| 30 |
+
except Exception as e:
|
| 31 |
+
logger.error(f"Error al renderizar index.html: {e}")
|
| 32 |
+
return "Error al cargar la página de inicio.", 500
|
| 33 |
+
|
| 34 |
+
@app.route('/chatbot')
|
| 35 |
+
def chatbot_page():
|
| 36 |
+
try:
|
| 37 |
+
return render_template('chatbot.html')
|
| 38 |
+
except Exception as e:
|
| 39 |
+
logger.error(f"Error al renderizar chatbot.html: {e}")
|
| 40 |
+
return "Error al cargar la página del chatbot.", 500
|
| 41 |
+
|
| 42 |
+
@app.route('/get_response', methods=['POST'])
|
| 43 |
+
def get_bot_response():
|
| 44 |
+
try:
|
| 45 |
+
user_input = request.form.get('message', '').strip()
|
| 46 |
+
if not user_input:
|
| 47 |
+
logger.warning("Mensaje vacío recibido del usuario.")
|
| 48 |
+
return jsonify({'response': "Por favor, ingresa un mensaje.", 'audio_path': None}), 400
|
| 49 |
+
|
| 50 |
+
response_data = chatbot.generate_response(user_input)
|
| 51 |
+
response_text = response_data.get('text', "Lo siento, no pude procesar tu mensaje.")
|
| 52 |
+
audio_path = response_data.get('audio_path', '')
|
| 53 |
+
|
| 54 |
+
return jsonify({'response': response_text, 'audio_path': audio_path})
|
| 55 |
+
|
| 56 |
+
except Exception as e:
|
| 57 |
+
logger.error(f"Error en /get_response: {e}")
|
| 58 |
+
return jsonify({'response': "Lo siento, ha ocurrido un error al procesar tu solicitud.", 'audio_path': None}), 500
|
| 59 |
+
|
| 60 |
+
if __name__ == '__main__':
|
| 61 |
+
# Ajustamos para leer la variable de entorno PORT (o usar 7860 por defecto)
|
| 62 |
+
port = int(os.environ.get("PORT", 7860))
|
| 63 |
+
app.run(host="0.0.0.0", port=port, debug=True)
|
chatbot.log
ADDED
|
File without changes
|
data/emotion_dataset.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cdfc2e577dd8f636ef0895a70c1fc88ed85796cd4ca49be762f889222e1ebab9
|
| 3 |
+
size 262199
|
error.log
ADDED
|
File without changes
|
models/__pycache__/chatbot_model.cpython-312.pyc
ADDED
|
Binary file (13.6 kB). View file
|
|
|
models/bert_emotion_model/config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d577c1a895af38eaee44acbbacebcd5ddc8131b8c86bf83a61900a970a0e6b0e
|
| 3 |
+
size 1232
|
models/bert_emotion_model/id_to_label.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62e6445c3c0aaedbbc923a3833b7782e1a470158bb3ee33a64f6fe686f3242ed
|
| 3 |
+
size 197
|
models/bert_emotion_model/label_to_id.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e7f224ae7d4fbb6aa8c2306d0bcd8a5f0af01b585105d726e102995e25f78850
|
| 3 |
+
size 175
|
models/bert_emotion_model/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e8fe35a11a5154074d70a3a5c49d56eaea4a6e136cd2c491ca7077a452d3fc9c
|
| 3 |
+
size 439460892
|
models/bert_emotion_model/special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d5b662e421ea9fac075174bb0688ee0d9431699900b90662acd44b2a350503a
|
| 3 |
+
size 695
|
models/bert_emotion_model/tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:19b81454892d4fea517c4b3451266e52f17fa67c18897d362c7a3436b5cd6ee9
|
| 3 |
+
size 729452
|
models/bert_emotion_model/tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b1db878ac84c4485192c8ec713e90bfde5025001d8cf521e6329610bf782707a
|
| 3 |
+
size 1237
|
models/bert_emotion_model/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:88327331d4c1c4db61b98f5a6a232d2b6c026d7d331d0f550e63332421a63d89
|
| 3 |
+
size 5240
|
models/bert_emotion_model/vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/chatbot_model.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import BertForSequenceClassification, BertTokenizer
|
| 3 |
+
import numpy as np
|
| 4 |
+
import re
|
| 5 |
+
from datetime import datetime
|
| 6 |
+
import os
|
| 7 |
+
import logging
|
| 8 |
+
from typing import Tuple, Dict, Any
|
| 9 |
+
import json
|
| 10 |
+
import pyttsx3
|
| 11 |
+
|
| 12 |
+
class MentalHealthChatbot:
|
| 13 |
+
def __init__(self, model_path: str = 'models/bert_emotion_model'):
|
| 14 |
+
"""
|
| 15 |
+
Inicializa el chatbot con el modelo BERT fine-tuned y configuraciones necesarias.
|
| 16 |
+
Args:
|
| 17 |
+
model_path: Ruta al modelo fine-tuned
|
| 18 |
+
"""
|
| 19 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 20 |
+
|
| 21 |
+
# Configuración del logging
|
| 22 |
+
self.logger = logging.getLogger(__name__)
|
| 23 |
+
self.logger.setLevel(logging.INFO)
|
| 24 |
+
handler = logging.FileHandler('chatbot.log')
|
| 25 |
+
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
|
| 26 |
+
handler.setFormatter(formatter)
|
| 27 |
+
if not self.logger.handlers:
|
| 28 |
+
self.logger.addHandler(handler)
|
| 29 |
+
|
| 30 |
+
try:
|
| 31 |
+
self.logger.info("Cargando el tokenizador y el modelo BERT fine-tuned...")
|
| 32 |
+
|
| 33 |
+
# Crear carpeta para guardar historiales si no existe
|
| 34 |
+
os.makedirs('conversations', exist_ok=True)
|
| 35 |
+
|
| 36 |
+
self.tokenizer = BertTokenizer.from_pretrained(model_path)
|
| 37 |
+
self.model = BertForSequenceClassification.from_pretrained(model_path).to(self.device)
|
| 38 |
+
|
| 39 |
+
# Cargar respuestas predefinidas
|
| 40 |
+
self.load_responses()
|
| 41 |
+
|
| 42 |
+
# Inicializar el historial de conversación
|
| 43 |
+
self.conversation_history = []
|
| 44 |
+
|
| 45 |
+
self.logger.info("Chatbot inicializado correctamente.")
|
| 46 |
+
except Exception as e:
|
| 47 |
+
self.logger.error(f"Error al cargar el modelo: {str(e)}")
|
| 48 |
+
raise e
|
| 49 |
+
|
| 50 |
+
def load_responses(self):
|
| 51 |
+
"""Carga las respuestas predefinidas desde un archivo JSON."""
|
| 52 |
+
try:
|
| 53 |
+
with open('models/responses.json', 'r', encoding='utf-8') as f:
|
| 54 |
+
self.responses = json.load(f)
|
| 55 |
+
self.logger.info("Respuestas cargadas desde 'responses.json'.")
|
| 56 |
+
except FileNotFoundError:
|
| 57 |
+
self.logger.error("Archivo 'responses.json' no encontrado. Asegúrate de que el archivo existe en la ruta especificada.")
|
| 58 |
+
raise
|
| 59 |
+
except json.JSONDecodeError as e:
|
| 60 |
+
self.logger.error(f"Error al decodificar 'responses.json': {str(e)}")
|
| 61 |
+
raise
|
| 62 |
+
|
| 63 |
+
def preprocess_text(self, text: str) -> str:
|
| 64 |
+
"""Preprocesa el texto de entrada."""
|
| 65 |
+
try:
|
| 66 |
+
text = text.lower()
|
| 67 |
+
text = re.sub(r'[^\w\s]', '', text)
|
| 68 |
+
return text.strip()
|
| 69 |
+
except Exception as e:
|
| 70 |
+
self.logger.error(f"Error al preprocesar el texto: {str(e)}")
|
| 71 |
+
return text
|
| 72 |
+
|
| 73 |
+
def detect_emergency(self, text: str) -> bool:
|
| 74 |
+
"""Detecta si el mensaje indica una emergencia de salud mental."""
|
| 75 |
+
try:
|
| 76 |
+
emergency_keywords = [
|
| 77 |
+
'suicidar', 'morir', 'muerte', 'matar', 'dolor',
|
| 78 |
+
'ayuda', 'emergencia', 'crisis', 'grave'
|
| 79 |
+
]
|
| 80 |
+
return any(keyword in text.lower() for keyword in emergency_keywords)
|
| 81 |
+
except Exception as e:
|
| 82 |
+
self.logger.error(f"Error al detectar emergencia: {str(e)}")
|
| 83 |
+
return False
|
| 84 |
+
|
| 85 |
+
def get_emotion_prediction(self, text: str) -> Tuple[str, float]:
|
| 86 |
+
"""Predice la emoción del texto usando el modelo fine-tuned."""
|
| 87 |
+
# Asegúrate de que el orden de las etiquetas coincide con el del entrenamiento
|
| 88 |
+
emotion_labels = ['FELICIDAD', 'NEUTRAL', 'DEPRESIÓN', 'ANSIEDAD', 'ESTRÉS',
|
| 89 |
+
'EMERGENCIA', 'CONFUSIÓN', 'IRA', 'MIEDO', 'SORPRESA', 'DISGUSTO']
|
| 90 |
+
|
| 91 |
+
try:
|
| 92 |
+
inputs = self.tokenizer.encode_plus(
|
| 93 |
+
text,
|
| 94 |
+
add_special_tokens=True,
|
| 95 |
+
max_length=128,
|
| 96 |
+
padding='max_length',
|
| 97 |
+
truncation=True,
|
| 98 |
+
return_tensors='pt'
|
| 99 |
+
).to(self.device)
|
| 100 |
+
|
| 101 |
+
with torch.no_grad():
|
| 102 |
+
outputs = self.model(**inputs)
|
| 103 |
+
probs = torch.softmax(outputs.logits, dim=1)
|
| 104 |
+
predicted_class = torch.argmax(probs, dim=1).item()
|
| 105 |
+
confidence = probs[0][predicted_class].item()
|
| 106 |
+
|
| 107 |
+
emotion = emotion_labels[predicted_class]
|
| 108 |
+
self.logger.info(f"Emoción predicha: {emotion} con confianza {confidence:.2f}")
|
| 109 |
+
return emotion, confidence
|
| 110 |
+
|
| 111 |
+
except Exception as e:
|
| 112 |
+
self.logger.error(f"Error en la predicción de emoción: {str(e)}")
|
| 113 |
+
return 'CONFUSIÓN', 0.0
|
| 114 |
+
|
| 115 |
+
def generate_response(self, user_input: str) -> Dict[str, Any]:
|
| 116 |
+
"""Genera una respuesta basada en el input del usuario."""
|
| 117 |
+
try:
|
| 118 |
+
# Preprocesar texto
|
| 119 |
+
processed_text = self.preprocess_text(user_input)
|
| 120 |
+
self.logger.info(f"Texto procesado: {processed_text}")
|
| 121 |
+
|
| 122 |
+
# Verificar emergencia
|
| 123 |
+
if self.detect_emergency(processed_text):
|
| 124 |
+
emotion = 'EMERGENCIA'
|
| 125 |
+
confidence = 1.0
|
| 126 |
+
self.logger.info("Emergencia detectada en el mensaje del usuario.")
|
| 127 |
+
else:
|
| 128 |
+
# Predecir emoción
|
| 129 |
+
emotion, confidence = self.get_emotion_prediction(processed_text)
|
| 130 |
+
|
| 131 |
+
# Seleccionar respuesta
|
| 132 |
+
responses = self.responses.get(emotion, self.responses.get('CONFUSIÓN', ["Lo siento, no he entendido tu mensaje."]))
|
| 133 |
+
|
| 134 |
+
response = np.random.choice(responses)
|
| 135 |
+
self.logger.info(f"Respuesta seleccionada: {response}")
|
| 136 |
+
|
| 137 |
+
# Generar audio
|
| 138 |
+
audio_path = self.generate_audio(response)
|
| 139 |
+
|
| 140 |
+
# Actualizar historial
|
| 141 |
+
self.update_conversation_history(user_input, response, emotion)
|
| 142 |
+
|
| 143 |
+
# Guardar historial después de actualizar
|
| 144 |
+
self.save_conversation_history()
|
| 145 |
+
|
| 146 |
+
return {
|
| 147 |
+
'text': response,
|
| 148 |
+
'audio_path': audio_path,
|
| 149 |
+
'emotion': emotion,
|
| 150 |
+
'confidence': confidence,
|
| 151 |
+
'timestamp': datetime.now().isoformat()
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
except Exception as e:
|
| 155 |
+
self.logger.error(f"Error al generar respuesta: {str(e)}")
|
| 156 |
+
return {
|
| 157 |
+
'text': "Lo siento, ha ocurrido un error. ¿Podrías intentarlo de nuevo?",
|
| 158 |
+
'audio_path': None,
|
| 159 |
+
'emotion': 'ERROR',
|
| 160 |
+
'confidence': 0.0,
|
| 161 |
+
'timestamp': datetime.now().isoformat()
|
| 162 |
+
}
|
| 163 |
+
|
| 164 |
+
def generate_audio(self, text: str) -> str:
|
| 165 |
+
"""Genera el audio para la respuesta y devuelve la URL accesible para el cliente."""
|
| 166 |
+
try:
|
| 167 |
+
filename = f"response_{datetime.now().strftime('%Y%m%d_%H%M%S_%f')}.mp3"
|
| 168 |
+
file_path = os.path.join('static', 'audio', filename)
|
| 169 |
+
os.makedirs(os.path.dirname(file_path), exist_ok=True)
|
| 170 |
+
|
| 171 |
+
engine = pyttsx3.init()
|
| 172 |
+
|
| 173 |
+
# Configurar la voz en español (ajusta el índice o usa el id de la voz)
|
| 174 |
+
voices = engine.getProperty('voices')
|
| 175 |
+
for voice in voices:
|
| 176 |
+
if 'Spanish' in voice.name or 'Español' in voice.name:
|
| 177 |
+
engine.setProperty('voice', voice.id)
|
| 178 |
+
break
|
| 179 |
+
else:
|
| 180 |
+
self.logger.warning("No se encontró una voz en español. Usando la voz predeterminada.")
|
| 181 |
+
|
| 182 |
+
# Configurar la velocidad del habla si es necesario
|
| 183 |
+
rate = engine.getProperty('rate')
|
| 184 |
+
engine.setProperty('rate', rate - 50) # Ajusta el valor según tus necesidades
|
| 185 |
+
|
| 186 |
+
# Guardar el audio en el archivo especificado
|
| 187 |
+
engine.save_to_file(text, file_path)
|
| 188 |
+
engine.runAndWait()
|
| 189 |
+
|
| 190 |
+
self.logger.info(f"Audio generado y guardado en {file_path}")
|
| 191 |
+
|
| 192 |
+
# Devolver la ruta relativa que el cliente puede usar
|
| 193 |
+
return f"/static/audio/{filename}"
|
| 194 |
+
except Exception as e:
|
| 195 |
+
self.logger.error(f"Error al generar audio: {str(e)}")
|
| 196 |
+
return None
|
| 197 |
+
|
| 198 |
+
def update_conversation_history(self, user_input: str, response: str, emotion: str):
|
| 199 |
+
"""Actualiza el historial de conversación."""
|
| 200 |
+
try:
|
| 201 |
+
self.conversation_history.append({
|
| 202 |
+
'user_input': user_input,
|
| 203 |
+
'response': response,
|
| 204 |
+
'emotion': emotion,
|
| 205 |
+
'timestamp': datetime.now().isoformat()
|
| 206 |
+
})
|
| 207 |
+
|
| 208 |
+
# Mantener solo las últimas 10 conversaciones
|
| 209 |
+
if len(self.conversation_history) > 10:
|
| 210 |
+
self.conversation_history.pop(0)
|
| 211 |
+
|
| 212 |
+
self.logger.info("Historial de conversación actualizado.")
|
| 213 |
+
except Exception as e:
|
| 214 |
+
self.logger.error(f"Error al actualizar el historial de conversación: {str(e)}")
|
| 215 |
+
|
| 216 |
+
def save_conversation_history(self):
|
| 217 |
+
"""Guarda el historial de conversación en un archivo."""
|
| 218 |
+
try:
|
| 219 |
+
filename = f"conversations/chat_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
|
| 220 |
+
os.makedirs(os.path.dirname(filename), exist_ok=True)
|
| 221 |
+
|
| 222 |
+
with open(filename, 'w', encoding='utf-8') as f:
|
| 223 |
+
json.dump(self.conversation_history, f, ensure_ascii=False, indent=2)
|
| 224 |
+
|
| 225 |
+
self.logger.info(f"Historial de conversación guardado en {filename}")
|
| 226 |
+
except Exception as e:
|
| 227 |
+
self.logger.error(f"Error al guardar el historial: {str(e)}")
|
models/responses.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:83a5d8720e08ce62a1ab51997deda4dbefc3191f19b0237caddd4d7e0d9dd0c1
|
| 3 |
+
size 123983
|
requirements.txt
ADDED
|
Binary file (2.29 kB). View file
|
|
|
static/css/styles.css
ADDED
|
@@ -0,0 +1,360 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Variables globales */
|
| 2 |
+
:root {
|
| 3 |
+
--primary-color: #128C7E;
|
| 4 |
+
--secondary-color: #25D366;
|
| 5 |
+
--background-color: #E5DDD5;
|
| 6 |
+
--chat-bg: #DCF8C6;
|
| 7 |
+
--bot-chat-bg: #FFFFFF;
|
| 8 |
+
--text-color: #333333;
|
| 9 |
+
}
|
| 10 |
+
|
| 11 |
+
/* Estilos generales */
|
| 12 |
+
* {
|
| 13 |
+
box-sizing: border-box;
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
body {
|
| 17 |
+
background-color: var(--background-color);
|
| 18 |
+
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
|
| 19 |
+
margin: 0;
|
| 20 |
+
padding: 0;
|
| 21 |
+
height: 100vh;
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
/* Contenedor principal del chat */
|
| 25 |
+
.chat-container {
|
| 26 |
+
display: flex;
|
| 27 |
+
flex-direction: column;
|
| 28 |
+
max-width: 650px;
|
| 29 |
+
margin: 20px auto; /* Margen ajustado para centrar */
|
| 30 |
+
height: calc(100vh - 40px);
|
| 31 |
+
background-color: var(--background-color);
|
| 32 |
+
padding: 0;
|
| 33 |
+
border: 1px solid #ccc;
|
| 34 |
+
border-radius: 15px;
|
| 35 |
+
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1);
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
/* Header del chat */
|
| 39 |
+
.chat-header {
|
| 40 |
+
background-color: var(--primary-color);
|
| 41 |
+
color: white;
|
| 42 |
+
padding: 15px;
|
| 43 |
+
display: flex;
|
| 44 |
+
align-items: center;
|
| 45 |
+
flex-shrink: 0;
|
| 46 |
+
width: 100%;
|
| 47 |
+
border-top-left-radius: 15px;
|
| 48 |
+
border-top-right-radius: 15px;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
/* Ajustar el avatar del bot */
|
| 52 |
+
.chat-header img {
|
| 53 |
+
width: 80px; /* Aumentar el tamaño del avatar */
|
| 54 |
+
height: 80px;
|
| 55 |
+
border-radius: 50%;
|
| 56 |
+
margin-right: 15px;
|
| 57 |
+
position: relative;
|
| 58 |
+
left: 10px; /* Mover el avatar 10px hacia la izquierda */
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
/* Área de mensajes */
|
| 62 |
+
.chatbox {
|
| 63 |
+
flex-grow: 1;
|
| 64 |
+
overflow-y: auto;
|
| 65 |
+
padding: 20px; /* Añadir padding uniforme */
|
| 66 |
+
background-color: var(--background-color);
|
| 67 |
+
scroll-behavior: smooth;
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
/* Estilos de los mensajes */
|
| 71 |
+
.message {
|
| 72 |
+
/* Propiedades existentes */
|
| 73 |
+
max-width: 65%;
|
| 74 |
+
margin: 10px 0;
|
| 75 |
+
padding: 10px 15px;
|
| 76 |
+
position: relative;
|
| 77 |
+
clear: both;
|
| 78 |
+
animation: messageIn 0.3s ease-out;
|
| 79 |
+
|
| 80 |
+
/* Nuevas propiedades */
|
| 81 |
+
border: 1px solid #ccc; /* Borde gris claro */
|
| 82 |
+
border-radius: 10px; /* Esquinas redondeadas */
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
.user-message {
|
| 86 |
+
background-color: var(--chat-bg);
|
| 87 |
+
float: right;
|
| 88 |
+
border-radius: 15px 0 15px 15px;
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
.bot-message {
|
| 92 |
+
background-color: var(--bot-chat-bg);
|
| 93 |
+
float: left;
|
| 94 |
+
border-radius: 0 15px 15px 15px;
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
/* Área de entrada de mensaje */
|
| 98 |
+
.input-group {
|
| 99 |
+
background-color: #F0F0F0;
|
| 100 |
+
padding: 10px; /* Añadir padding uniforme */
|
| 101 |
+
display: flex;
|
| 102 |
+
align-items: center;
|
| 103 |
+
gap: 10px;
|
| 104 |
+
flex-shrink: 0;
|
| 105 |
+
width: 100%; /* Asegurar que ocupe el 100% del contenedor */
|
| 106 |
+
border-bottom-left-radius: 15px; /* Esquinas redondeadas inferiores */
|
| 107 |
+
border-bottom-right-radius: 15px;
|
| 108 |
+
border-top: 1px solid #ccc; /* Borde superior para separar del chat */
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
/* Campo de entrada */
|
| 112 |
+
.input-group input {
|
| 113 |
+
flex: 1;
|
| 114 |
+
padding: 12px;
|
| 115 |
+
margin: 0 10px; /* Margen horizontal para mantener la separación */
|
| 116 |
+
border: none;
|
| 117 |
+
border-radius: 25px;
|
| 118 |
+
background-color: white;
|
| 119 |
+
font-size: 16px;
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
/* Botones de acción */
|
| 123 |
+
.action-button {
|
| 124 |
+
background-color: var(--primary-color);
|
| 125 |
+
color: white;
|
| 126 |
+
border: none;
|
| 127 |
+
border-radius: 50%;
|
| 128 |
+
width: 45px;
|
| 129 |
+
height: 45px;
|
| 130 |
+
display: flex;
|
| 131 |
+
align-items: center;
|
| 132 |
+
justify-content: center;
|
| 133 |
+
cursor: pointer;
|
| 134 |
+
transition: background-color 0.3s ease;
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
.action-button:hover {
|
| 138 |
+
background-color: var(--secondary-color);
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
/* Animaciones */
|
| 142 |
+
@keyframes messageIn {
|
| 143 |
+
from {
|
| 144 |
+
opacity: 0;
|
| 145 |
+
transform: translateY(20px);
|
| 146 |
+
}
|
| 147 |
+
to {
|
| 148 |
+
opacity: 1;
|
| 149 |
+
transform: translateY(0);
|
| 150 |
+
}
|
| 151 |
+
}
|
| 152 |
+
|
| 153 |
+
/* Scroll personalizado */
|
| 154 |
+
.chatbox::-webkit-scrollbar {
|
| 155 |
+
width: 6px;
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
.chatbox::-webkit-scrollbar-track {
|
| 159 |
+
background: #f1f1f1;
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
.chatbox::-webkit-scrollbar-thumb {
|
| 163 |
+
background: #888;
|
| 164 |
+
border-radius: 3px;
|
| 165 |
+
}
|
| 166 |
+
|
| 167 |
+
/* Estilos responsivos para el chat */
|
| 168 |
+
@media (max-width: 768px) {
|
| 169 |
+
.chat-container {
|
| 170 |
+
max-width: 100%;
|
| 171 |
+
padding: 0 10px;
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
.message {
|
| 175 |
+
max-width: 85%;
|
| 176 |
+
}
|
| 177 |
+
}
|
| 178 |
+
|
| 179 |
+
/* Indicador de escritura */
|
| 180 |
+
#typingIndicator p {
|
| 181 |
+
display: inline-block;
|
| 182 |
+
}
|
| 183 |
+
|
| 184 |
+
.dot-one, .dot-two, .dot-three {
|
| 185 |
+
animation: blink 1.4s infinite both;
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
.dot-one {
|
| 189 |
+
animation-delay: 0s;
|
| 190 |
+
}
|
| 191 |
+
|
| 192 |
+
.dot-two {
|
| 193 |
+
animation-delay: 0.2s;
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
.dot-three {
|
| 197 |
+
animation-delay: 0.4s;
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
@keyframes blink {
|
| 201 |
+
0% {
|
| 202 |
+
opacity: 0;
|
| 203 |
+
}
|
| 204 |
+
20% {
|
| 205 |
+
opacity: 1;
|
| 206 |
+
}
|
| 207 |
+
100% {
|
| 208 |
+
opacity: 0;
|
| 209 |
+
}
|
| 210 |
+
}
|
| 211 |
+
|
| 212 |
+
/* Indicador de grabación */
|
| 213 |
+
.recording-indicator {
|
| 214 |
+
position: fixed;
|
| 215 |
+
bottom: 100px;
|
| 216 |
+
right: 20px;
|
| 217 |
+
background-color: var(--primary-color);
|
| 218 |
+
color: white;
|
| 219 |
+
padding: 10px 15px;
|
| 220 |
+
border-radius: 25px;
|
| 221 |
+
display: flex;
|
| 222 |
+
align-items: center;
|
| 223 |
+
gap: 10px;
|
| 224 |
+
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
|
| 225 |
+
}
|
| 226 |
+
|
| 227 |
+
.recording-indicator i {
|
| 228 |
+
animation: pulse 1s infinite;
|
| 229 |
+
}
|
| 230 |
+
|
| 231 |
+
@keyframes pulse {
|
| 232 |
+
0% {
|
| 233 |
+
opacity: 0.7;
|
| 234 |
+
}
|
| 235 |
+
50% {
|
| 236 |
+
opacity: 1;
|
| 237 |
+
}
|
| 238 |
+
100% {
|
| 239 |
+
opacity: 0.7;
|
| 240 |
+
}
|
| 241 |
+
}
|
| 242 |
+
|
| 243 |
+
/* Estilos para la página de inicio */
|
| 244 |
+
.landing-page {
|
| 245 |
+
background-color: #f0f2f5;
|
| 246 |
+
min-height: 100vh;
|
| 247 |
+
display: flex;
|
| 248 |
+
align-items: center;
|
| 249 |
+
justify-content: center;
|
| 250 |
+
}
|
| 251 |
+
|
| 252 |
+
.landing-container {
|
| 253 |
+
width: 100%;
|
| 254 |
+
max-width: 1200px;
|
| 255 |
+
padding: 20px;
|
| 256 |
+
}
|
| 257 |
+
|
| 258 |
+
.welcome-card {
|
| 259 |
+
background: white;
|
| 260 |
+
border-radius: 20px;
|
| 261 |
+
padding: 40px;
|
| 262 |
+
text-align: center;
|
| 263 |
+
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
.logo-container {
|
| 267 |
+
margin-bottom: 30px;
|
| 268 |
+
}
|
| 269 |
+
|
| 270 |
+
.logo {
|
| 271 |
+
max-width: 100px; /* Aumentado de 120px a 200px */
|
| 272 |
+
height: auto;
|
| 273 |
+
}
|
| 274 |
+
|
| 275 |
+
.features {
|
| 276 |
+
display: flex;
|
| 277 |
+
justify-content: center;
|
| 278 |
+
gap: 40px;
|
| 279 |
+
margin: 40px 0;
|
| 280 |
+
flex-wrap: wrap;
|
| 281 |
+
}
|
| 282 |
+
|
| 283 |
+
.feature-item {
|
| 284 |
+
text-align: center;
|
| 285 |
+
flex: 1;
|
| 286 |
+
min-width: 200px;
|
| 287 |
+
}
|
| 288 |
+
|
| 289 |
+
.feature-item i {
|
| 290 |
+
font-size: 2.5rem;
|
| 291 |
+
color: var(--primary-color);
|
| 292 |
+
margin-bottom: 15px;
|
| 293 |
+
}
|
| 294 |
+
|
| 295 |
+
.welcome-text {
|
| 296 |
+
font-size: 1.2rem;
|
| 297 |
+
color: #666;
|
| 298 |
+
margin: 30px 0;
|
| 299 |
+
max-width: 600px;
|
| 300 |
+
margin-left: auto;
|
| 301 |
+
margin-right: auto;
|
| 302 |
+
}
|
| 303 |
+
|
| 304 |
+
.start-chat-btn {
|
| 305 |
+
display: inline-block;
|
| 306 |
+
background-color: var(--primary-color);
|
| 307 |
+
color: white;
|
| 308 |
+
padding: 15px 30px;
|
| 309 |
+
border-radius: 30px;
|
| 310 |
+
text-decoration: none;
|
| 311 |
+
font-size: 1.2rem;
|
| 312 |
+
margin: 20px 0;
|
| 313 |
+
transition: background-color 0.3s ease;
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
.start-chat-btn:hover {
|
| 317 |
+
background-color: var(--secondary-color);
|
| 318 |
+
text-decoration: none;
|
| 319 |
+
}
|
| 320 |
+
|
| 321 |
+
.start-chat-btn i {
|
| 322 |
+
margin-right: 10px;
|
| 323 |
+
}
|
| 324 |
+
|
| 325 |
+
.disclaimer {
|
| 326 |
+
margin-top: 30px;
|
| 327 |
+
padding: 15px;
|
| 328 |
+
background-color: #f8f9fa;
|
| 329 |
+
border-radius: 10px;
|
| 330 |
+
font-size: 0.9rem;
|
| 331 |
+
color: #666;
|
| 332 |
+
display: flex;
|
| 333 |
+
align-items: center;
|
| 334 |
+
justify-content: center;
|
| 335 |
+
gap: 10px;
|
| 336 |
+
}
|
| 337 |
+
|
| 338 |
+
.disclaimer i {
|
| 339 |
+
color: var(--primary-color);
|
| 340 |
+
}
|
| 341 |
+
|
| 342 |
+
/* Estilos responsivos para la página de inicio */
|
| 343 |
+
@media (max-width: 768px) {
|
| 344 |
+
.welcome-card {
|
| 345 |
+
padding: 20px;
|
| 346 |
+
}
|
| 347 |
+
|
| 348 |
+
.features {
|
| 349 |
+
flex-direction: column;
|
| 350 |
+
gap: 20px;
|
| 351 |
+
}
|
| 352 |
+
|
| 353 |
+
.feature-item {
|
| 354 |
+
min-width: 100%;
|
| 355 |
+
}
|
| 356 |
+
|
| 357 |
+
.logo {
|
| 358 |
+
max-width: 150px; /* Ajuste para dispositivos móviles */
|
| 359 |
+
}
|
| 360 |
+
}
|
static/img/1.png
ADDED

|
static/img/bot-avatar.png
ADDED
|
|
static/img/chatbot1.png
ADDED

|
static/img/chatbot2.png
ADDED

|
static/img/index.png
ADDED
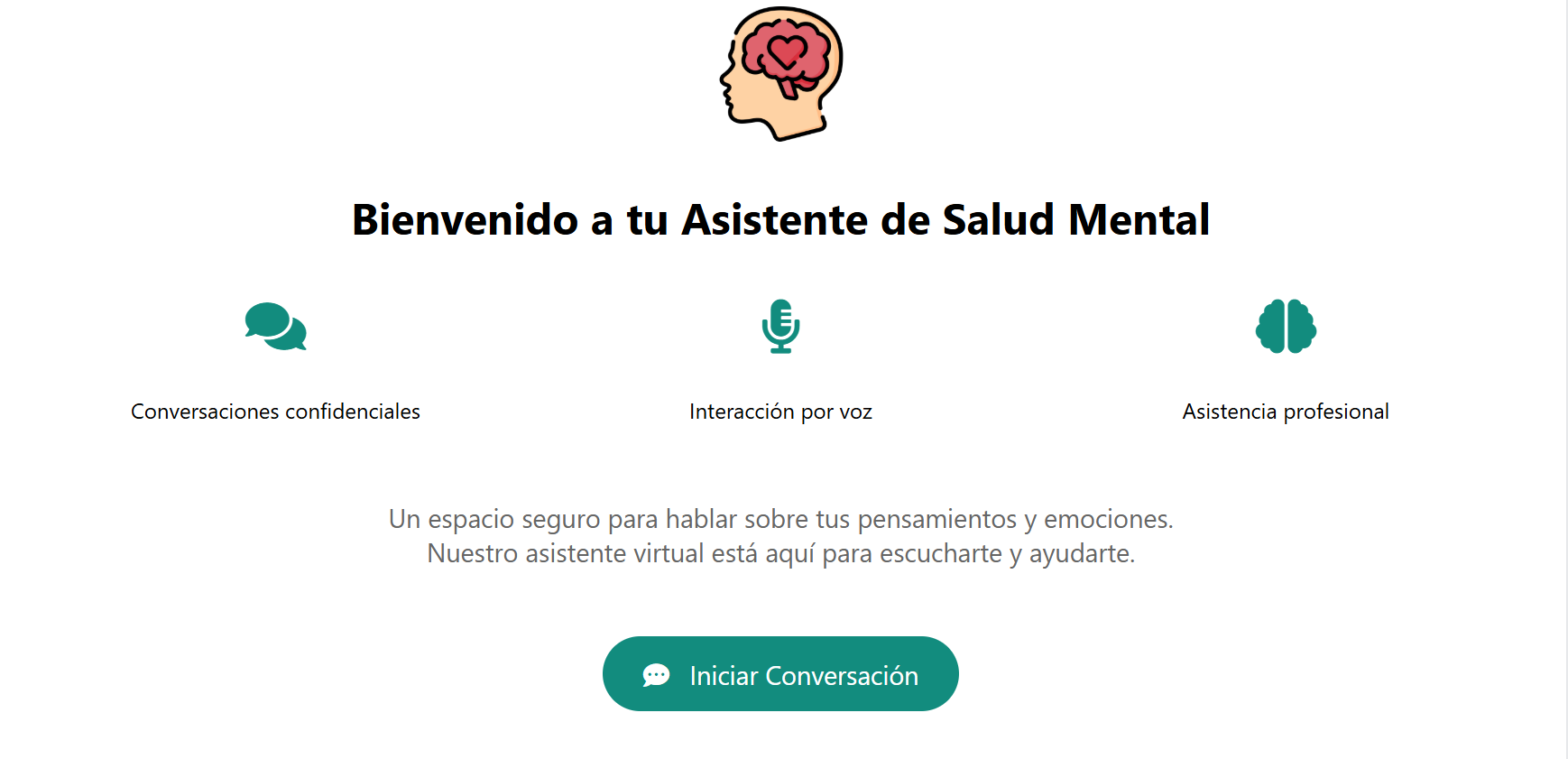
|
static/js/scripts.js
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
document.addEventListener('DOMContentLoaded', () => {
|
| 2 |
+
const sendButton = document.getElementById('send');
|
| 3 |
+
const messageInput = document.getElementById('message');
|
| 4 |
+
const voiceButton = document.getElementById('voice');
|
| 5 |
+
const chatbox = document.getElementById('chatbox');
|
| 6 |
+
const recordingIndicator = document.getElementById('recordingIndicator');
|
| 7 |
+
|
| 8 |
+
sendButton.addEventListener('click', sendMessage);
|
| 9 |
+
messageInput.addEventListener('keypress', (e) => {
|
| 10 |
+
if (e.key === 'Enter') sendMessage();
|
| 11 |
+
});
|
| 12 |
+
voiceButton.addEventListener('click', startRecognition);
|
| 13 |
+
|
| 14 |
+
function sendMessage() {
|
| 15 |
+
const message = messageInput.value.trim();
|
| 16 |
+
if (message === '') return;
|
| 17 |
+
|
| 18 |
+
addMessageToChatbox('Usuario', message);
|
| 19 |
+
messageInput.value = '';
|
| 20 |
+
toggleInput(false);
|
| 21 |
+
|
| 22 |
+
// Mostrar indicador de carga
|
| 23 |
+
addTypingIndicator();
|
| 24 |
+
|
| 25 |
+
fetch('/get_response', {
|
| 26 |
+
method: 'POST',
|
| 27 |
+
body: new URLSearchParams({'message': message}),
|
| 28 |
+
})
|
| 29 |
+
.then(response => response.ok ? response.json() : response.json().then(err => Promise.reject(err)))
|
| 30 |
+
.then(data => {
|
| 31 |
+
removeTypingIndicator();
|
| 32 |
+
addMessageToChatbox('Asistente', data.response);
|
| 33 |
+
playResponse(data.audio_path);
|
| 34 |
+
})
|
| 35 |
+
.catch(error => {
|
| 36 |
+
removeTypingIndicator();
|
| 37 |
+
console.error('Error:', error);
|
| 38 |
+
addMessageToChatbox('Asistente', error.response || 'Lo siento, ha ocurrido un error al procesar tu solicitud.');
|
| 39 |
+
})
|
| 40 |
+
.finally(() => {
|
| 41 |
+
toggleInput(true);
|
| 42 |
+
});
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
function addMessageToChatbox(sender, message) {
|
| 46 |
+
const messageDiv = document.createElement('div');
|
| 47 |
+
messageDiv.className = sender === 'Usuario' ? 'message user-message' : 'message bot-message';
|
| 48 |
+
messageDiv.innerHTML = `<p>${message}</p>`;
|
| 49 |
+
chatbox.appendChild(messageDiv);
|
| 50 |
+
chatbox.scrollTop = chatbox.scrollHeight;
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
function addTypingIndicator() {
|
| 54 |
+
const typingIndicator = document.createElement('div');
|
| 55 |
+
typingIndicator.id = 'typingIndicator';
|
| 56 |
+
typingIndicator.className = 'message bot-message';
|
| 57 |
+
typingIndicator.innerHTML = '<p>Escribiendo<span class="dot-one">.</span><span class="dot-two">.</span><span class="dot-three">.</span></p>';
|
| 58 |
+
chatbox.appendChild(typingIndicator);
|
| 59 |
+
chatbox.scrollTop = chatbox.scrollHeight;
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
function removeTypingIndicator() {
|
| 63 |
+
const typingIndicator = document.getElementById('typingIndicator');
|
| 64 |
+
if (typingIndicator) {
|
| 65 |
+
chatbox.removeChild(typingIndicator);
|
| 66 |
+
}
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
function startRecognition() {
|
| 70 |
+
if (!('webkitSpeechRecognition' in window)) {
|
| 71 |
+
alert('Tu navegador no soporta reconocimiento de voz.');
|
| 72 |
+
return;
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
const recognition = new webkitSpeechRecognition();
|
| 76 |
+
recognition.lang = 'es-ES';
|
| 77 |
+
recognition.start();
|
| 78 |
+
|
| 79 |
+
if (recordingIndicator) {
|
| 80 |
+
recordingIndicator.style.display = 'block';
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
recognition.onresult = (event) => {
|
| 84 |
+
const transcript = event.results[0][0].transcript;
|
| 85 |
+
messageInput.value = transcript;
|
| 86 |
+
sendMessage();
|
| 87 |
+
};
|
| 88 |
+
|
| 89 |
+
recognition.onerror = (event) => {
|
| 90 |
+
console.error('Error en el reconocimiento de voz:', event.error);
|
| 91 |
+
alert('Ocurrió un error durante el reconocimiento de voz: ' + event.error);
|
| 92 |
+
};
|
| 93 |
+
|
| 94 |
+
recognition.onend = () => {
|
| 95 |
+
if (recordingIndicator) {
|
| 96 |
+
recordingIndicator.style.display = 'none';
|
| 97 |
+
}
|
| 98 |
+
};
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
function playResponse(audioPath) {
|
| 102 |
+
if (audioPath) {
|
| 103 |
+
console.log('Reproduciendo audio desde:', audioPath);
|
| 104 |
+
const audio = new Audio(audioPath);
|
| 105 |
+
audio.play().catch(error => {
|
| 106 |
+
console.error('Error al reproducir el audio:', error);
|
| 107 |
+
});
|
| 108 |
+
}
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
function toggleInput(enable) {
|
| 112 |
+
messageInput.disabled = !enable;
|
| 113 |
+
sendButton.disabled = !enable;
|
| 114 |
+
voiceButton.disabled = !enable;
|
| 115 |
+
}
|
| 116 |
+
});
|
templates/chatbot.html
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html lang="es">
|
| 3 |
+
<head>
|
| 4 |
+
<!-- Metadatos y enlaces a estilos y scripts -->
|
| 5 |
+
<meta charset="UTF-8">
|
| 6 |
+
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
| 7 |
+
<title>Chatbot de Salud Mental | Chat</title>
|
| 8 |
+
<!-- Estilos -->
|
| 9 |
+
<link rel="stylesheet" href="{{ url_for('static', filename='css/styles.css') }}">
|
| 10 |
+
<!-- Font Awesome -->
|
| 11 |
+
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.4/css/all.min.css">
|
| 12 |
+
</head>
|
| 13 |
+
<body>
|
| 14 |
+
<!-- Contenedor principal del chat -->
|
| 15 |
+
<div class="chat-container">
|
| 16 |
+
<!-- Header del chat -->
|
| 17 |
+
<div class="chat-header">
|
| 18 |
+
<img src="{{ url_for('static', filename='img/bot-avatar.png') }}" alt="Bot Avatar" class="bot-avatar">
|
| 19 |
+
<div class="chat-info">
|
| 20 |
+
<h2>Asistente de Salud Mental</h2>
|
| 21 |
+
<p class="status">En línea</p>
|
| 22 |
+
</div>
|
| 23 |
+
</div>
|
| 24 |
+
|
| 25 |
+
<!-- Área de mensajes -->
|
| 26 |
+
<div class="chatbox" id="chatbox">
|
| 27 |
+
<!-- Mensaje de bienvenida -->
|
| 28 |
+
<div class="message bot-message">
|
| 29 |
+
<p>¡Hola! Soy tu asistente virtual especializado en salud mental. ¿En qué puedo ayudarte hoy?</p>
|
| 30 |
+
</div>
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
<!-- Área de entrada -->
|
| 34 |
+
<div class="input-group">
|
| 35 |
+
<input type="text"
|
| 36 |
+
id="message"
|
| 37 |
+
class="form-control message-input"
|
| 38 |
+
placeholder="Escribe un mensaje o presiona el micrófono para hablar..."
|
| 39 |
+
autocomplete="off">
|
| 40 |
+
|
| 41 |
+
<button class="action-button voice-button" id="voice">
|
| 42 |
+
<i class="fas fa-microphone"></i>
|
| 43 |
+
</button>
|
| 44 |
+
|
| 45 |
+
<button class="action-button send-button" id="send">
|
| 46 |
+
<i class="fas fa-paper-plane"></i>
|
| 47 |
+
</button>
|
| 48 |
+
</div>
|
| 49 |
+
</div>
|
| 50 |
+
|
| 51 |
+
<!-- Indicador de grabación -->
|
| 52 |
+
<div class="recording-indicator" id="recordingIndicator" style="display: none;">
|
| 53 |
+
<i class="fas fa-microphone-alt"></i>
|
| 54 |
+
<span>Grabando...</span>
|
| 55 |
+
</div>
|
| 56 |
+
|
| 57 |
+
<!-- Scripts -->
|
| 58 |
+
<script src="{{ url_for('static', filename='js/scripts.js') }}"></script>
|
| 59 |
+
</body>
|
| 60 |
+
</html>
|
templates/index.html
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html lang="es">
|
| 3 |
+
<head>
|
| 4 |
+
<meta charset="UTF-8">
|
| 5 |
+
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
| 6 |
+
<title>Asistente de Salud Mental | Inicio</title>
|
| 7 |
+
<!-- Estilos -->
|
| 8 |
+
<link rel="stylesheet" href="{{ url_for('static', filename='css/styles.css') }}">
|
| 9 |
+
<!-- Font Awesome -->
|
| 10 |
+
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.4/css/all.min.css">
|
| 11 |
+
<!-- Bootstrap CSS (opcional) -->
|
| 12 |
+
<!-- <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css"> -->
|
| 13 |
+
</head>
|
| 14 |
+
<body class="landing-page">
|
| 15 |
+
<div class="landing-container">
|
| 16 |
+
<div class="welcome-card">
|
| 17 |
+
<div class="logo-container">
|
| 18 |
+
<br><br><br><img src="{{ url_for('static', filename='img/1.png') }}" alt="Logo" class="logo">
|
| 19 |
+
</div>
|
| 20 |
+
<h1>Bienvenido a tu Asistente de Salud Mental</h1>
|
| 21 |
+
<div class="features">
|
| 22 |
+
<div class="feature-item">
|
| 23 |
+
<i class="fas fa-comments"></i>
|
| 24 |
+
<p>Conversaciones confidenciales</p>
|
| 25 |
+
</div>
|
| 26 |
+
<div class="feature-item">
|
| 27 |
+
<i class="fas fa-microphone-alt"></i>
|
| 28 |
+
<p>Interacción por voz</p>
|
| 29 |
+
</div>
|
| 30 |
+
<div class="feature-item">
|
| 31 |
+
<i class="fas fa-brain"></i>
|
| 32 |
+
<p>Asistencia profesional</p>
|
| 33 |
+
</div>
|
| 34 |
+
</div>
|
| 35 |
+
<p class="welcome-text">
|
| 36 |
+
Un espacio seguro para hablar sobre tus pensamientos y emociones.
|
| 37 |
+
Nuestro asistente virtual está aquí para escucharte y ayudarte.
|
| 38 |
+
</p>
|
| 39 |
+
<a href="{{ url_for('chatbot_page') }}" class="start-chat-btn">
|
| 40 |
+
<i class="fas fa-comment-dots"></i>
|
| 41 |
+
Iniciar Conversación
|
| 42 |
+
</a>
|
| 43 |
+
<div class="disclaimer">
|
| 44 |
+
<i class="fas fa-info-circle"></i>
|
| 45 |
+
<p>Este es un asistente virtual y no reemplaza la atención profesional.
|
| 46 |
+
En caso de emergencia, contacta a un profesional de la salud.</p>
|
| 47 |
+
</div>
|
| 48 |
+
</div>
|
| 49 |
+
</div>
|
| 50 |
+
<!-- Scripts opcionales -->
|
| 51 |
+
<!-- <script src="https://code.jquery.com/jquery-3.5.1.min.js"></script> -->
|
| 52 |
+
</body>
|
| 53 |
+
</html>
|
train_model.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from datasets import Dataset
|
| 4 |
+
from transformers import BertTokenizerFast, BertForSequenceClassification, Trainer, TrainingArguments, DataCollatorWithPadding, EarlyStoppingCallback
|
| 5 |
+
from sklearn.model_selection import train_test_split
|
| 6 |
+
from sklearn.utils.class_weight import compute_class_weight
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
import random
|
| 10 |
+
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score
|
| 11 |
+
import json
|
| 12 |
+
|
| 13 |
+
# Establecer la semilla para garantizar reproducibilidad
|
| 14 |
+
def set_seed(seed):
|
| 15 |
+
random.seed(seed)
|
| 16 |
+
np.random.seed(seed)
|
| 17 |
+
torch.manual_seed(seed)
|
| 18 |
+
if torch.cuda.is_available():
|
| 19 |
+
torch.cuda.manual_seed_all(seed)
|
| 20 |
+
|
| 21 |
+
set_seed(42)
|
| 22 |
+
|
| 23 |
+
# Función para cargar datos (simplificada para UTF-8)
|
| 24 |
+
def load_data(file_path):
|
| 25 |
+
data = pd.read_csv(file_path, encoding='utf-8')
|
| 26 |
+
return data
|
| 27 |
+
|
| 28 |
+
# Función para normalizar texto, manteniendo caracteres especiales
|
| 29 |
+
def normalize_text(text):
|
| 30 |
+
if isinstance(text, str):
|
| 31 |
+
return text.strip().upper()
|
| 32 |
+
return text
|
| 33 |
+
|
| 34 |
+
# Función para limpiar y preparar los datos
|
| 35 |
+
def clean_and_prepare_data(data):
|
| 36 |
+
data = data.copy()
|
| 37 |
+
# Eliminar filas con valores nulos
|
| 38 |
+
data = data.dropna(subset=['text', 'label'])
|
| 39 |
+
# Normalizar las etiquetas
|
| 40 |
+
data['label'] = data['label'].apply(normalize_text)
|
| 41 |
+
# Definir las etiquetas esperadas
|
| 42 |
+
emotion_labels = ['FELICIDAD', 'NEUTRAL', 'DEPRESIÓN', 'ANSIEDAD', 'ESTRÉS',
|
| 43 |
+
'EMERGENCIA', 'CONFUSIÓN', 'IRA', 'MIEDO', 'SORPRESA', 'DISGUSTO']
|
| 44 |
+
# Filtrar solo las etiquetas conocidas
|
| 45 |
+
data = data[data['label'].isin(emotion_labels)]
|
| 46 |
+
# Crear el mapeo de etiquetas
|
| 47 |
+
label_to_id = {label: idx for idx, label in enumerate(emotion_labels)}
|
| 48 |
+
data['label'] = data['label'].map(label_to_id)
|
| 49 |
+
# Verificar que no haya valores NaN
|
| 50 |
+
if data['label'].isna().any():
|
| 51 |
+
data = data.dropna(subset=['label'])
|
| 52 |
+
data['label'] = data['label'].astype(int)
|
| 53 |
+
return data, emotion_labels, label_to_id
|
| 54 |
+
|
| 55 |
+
# Función para dividir los datos
|
| 56 |
+
def split_data(data):
|
| 57 |
+
train_texts, val_texts, train_labels, val_labels = train_test_split(
|
| 58 |
+
data['text'], data['label'],
|
| 59 |
+
test_size=0.2,
|
| 60 |
+
stratify=data['label'],
|
| 61 |
+
random_state=42
|
| 62 |
+
)
|
| 63 |
+
return train_texts, val_texts, train_labels, val_labels
|
| 64 |
+
|
| 65 |
+
# Función para calcular los pesos de clase
|
| 66 |
+
def get_class_weights(labels):
|
| 67 |
+
class_weights = compute_class_weight(
|
| 68 |
+
class_weight='balanced',
|
| 69 |
+
classes=np.unique(labels),
|
| 70 |
+
y=labels
|
| 71 |
+
)
|
| 72 |
+
return torch.tensor(class_weights, dtype=torch.float)
|
| 73 |
+
|
| 74 |
+
# Función para tokenizar los datos (sin padding, ya que lo maneja el data collator)
|
| 75 |
+
def tokenize_data(tokenizer, texts, labels):
|
| 76 |
+
dataset = Dataset.from_dict({'text': texts.tolist(), 'label': labels.tolist()})
|
| 77 |
+
dataset = dataset.map(lambda batch: tokenizer(batch['text'], truncation=True, max_length=128), batched=True)
|
| 78 |
+
return dataset
|
| 79 |
+
|
| 80 |
+
# Función de pérdida personalizada que incorpora los pesos de clase
|
| 81 |
+
def custom_loss(labels, logits):
|
| 82 |
+
loss_fct = torch.nn.CrossEntropyLoss(weight=class_weights)
|
| 83 |
+
return loss_fct(logits, labels)
|
| 84 |
+
|
| 85 |
+
# Clase CustomTrainer para usar la función de pérdida personalizada
|
| 86 |
+
from transformers import Trainer
|
| 87 |
+
|
| 88 |
+
class CustomTrainer(Trainer):
|
| 89 |
+
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
|
| 90 |
+
labels = inputs.get("labels").to(model.device)
|
| 91 |
+
# Realizar el forward pass
|
| 92 |
+
outputs = model(**inputs)
|
| 93 |
+
logits = outputs.get("logits")
|
| 94 |
+
# Calcular la pérdida personalizada
|
| 95 |
+
loss = custom_loss(labels, logits)
|
| 96 |
+
return (loss, outputs) if return_outputs else loss
|
| 97 |
+
|
| 98 |
+
# Función para calcular métricas de evaluación
|
| 99 |
+
def compute_metrics(eval_pred):
|
| 100 |
+
logits, labels = eval_pred
|
| 101 |
+
predictions = np.argmax(logits, axis=-1)
|
| 102 |
+
labels = labels.astype(int)
|
| 103 |
+
predictions = predictions.astype(int)
|
| 104 |
+
accuracy = accuracy_score(labels, predictions)
|
| 105 |
+
f1 = f1_score(labels, predictions, average='weighted')
|
| 106 |
+
precision = precision_score(labels, predictions, average='weighted')
|
| 107 |
+
recall = recall_score(labels, predictions, average='weighted')
|
| 108 |
+
return {
|
| 109 |
+
'accuracy': accuracy,
|
| 110 |
+
'f1': f1,
|
| 111 |
+
'precision': precision,
|
| 112 |
+
'recall': recall
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
# Función para predecir la etiqueta de un texto dado
|
| 116 |
+
def predict(text):
|
| 117 |
+
# Tokenizar el texto
|
| 118 |
+
inputs = tokenizer(text, return_tensors='pt', truncation=True, max_length=128)
|
| 119 |
+
inputs = {k: v.to(device) for k, v in inputs.items()}
|
| 120 |
+
# Realizar la predicción
|
| 121 |
+
model.eval()
|
| 122 |
+
with torch.no_grad():
|
| 123 |
+
outputs = model(**inputs)
|
| 124 |
+
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 125 |
+
predicted_class = torch.argmax(probs, dim=-1).item()
|
| 126 |
+
label = id_to_label.get(predicted_class, "Etiqueta desconocida")
|
| 127 |
+
return label
|
| 128 |
+
|
| 129 |
+
if __name__ == '__main__':
|
| 130 |
+
# Configurar el dispositivo
|
| 131 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 132 |
+
print(f"\nUsando dispositivo: {device}")
|
| 133 |
+
|
| 134 |
+
# Ruta del archivo CSV
|
| 135 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 136 |
+
input_file = os.path.join(current_dir, 'data', 'emotion_dataset.csv')
|
| 137 |
+
|
| 138 |
+
# Paso 1: Cargar y preparar los datos
|
| 139 |
+
data = load_data(input_file)
|
| 140 |
+
data, emotion_labels, label_to_id = clean_and_prepare_data(data)
|
| 141 |
+
id_to_label = {v: k for k, v in label_to_id.items()}
|
| 142 |
+
|
| 143 |
+
# Paso 2: Dividir los datos
|
| 144 |
+
train_texts, val_texts, train_labels, val_labels = split_data(data)
|
| 145 |
+
|
| 146 |
+
# Paso 3: Calcular los pesos de clase
|
| 147 |
+
class_weights = get_class_weights(train_labels).to(device)
|
| 148 |
+
|
| 149 |
+
# Paso 4: Configurar el tokenizer
|
| 150 |
+
tokenizer = BertTokenizerFast.from_pretrained('dccuchile/bert-base-spanish-wwm-cased')
|
| 151 |
+
|
| 152 |
+
# Paso 5: Tokenizar los datos
|
| 153 |
+
train_dataset = tokenize_data(tokenizer, train_texts, train_labels)
|
| 154 |
+
val_dataset = tokenize_data(tokenizer, val_texts, val_labels)
|
| 155 |
+
|
| 156 |
+
# Paso 6: Configurar el data collator
|
| 157 |
+
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
|
| 158 |
+
|
| 159 |
+
# Paso 7: Configurar el modelo
|
| 160 |
+
model = BertForSequenceClassification.from_pretrained(
|
| 161 |
+
'dccuchile/bert-base-spanish-wwm-cased',
|
| 162 |
+
num_labels=len(emotion_labels)
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
# Paso 8: Configurar el entrenamiento
|
| 166 |
+
training_args = TrainingArguments(
|
| 167 |
+
output_dir='./models/bert_emotion_model',
|
| 168 |
+
num_train_epochs=5,
|
| 169 |
+
per_device_train_batch_size=16,
|
| 170 |
+
per_device_eval_batch_size=16,
|
| 171 |
+
learning_rate=2e-5,
|
| 172 |
+
lr_scheduler_type='linear',
|
| 173 |
+
warmup_steps=500,
|
| 174 |
+
eval_steps=500,
|
| 175 |
+
save_steps=500,
|
| 176 |
+
save_total_limit=1,
|
| 177 |
+
evaluation_strategy="steps",
|
| 178 |
+
save_strategy="steps",
|
| 179 |
+
logging_dir='./logs',
|
| 180 |
+
logging_steps=100,
|
| 181 |
+
load_best_model_at_end=True,
|
| 182 |
+
metric_for_best_model='eval_loss',
|
| 183 |
+
report_to="none"
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
# Paso 9: Crear el entrenador personalizado
|
| 187 |
+
trainer = CustomTrainer(
|
| 188 |
+
model=model,
|
| 189 |
+
args=training_args,
|
| 190 |
+
train_dataset=train_dataset,
|
| 191 |
+
eval_dataset=val_dataset,
|
| 192 |
+
tokenizer=tokenizer,
|
| 193 |
+
compute_metrics=compute_metrics,
|
| 194 |
+
data_collator=data_collator,
|
| 195 |
+
callbacks=[EarlyStoppingCallback(early_stopping_patience=2)]
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
# Paso 10: Entrenar el modelo
|
| 199 |
+
trainer.train()
|
| 200 |
+
|
| 201 |
+
# Paso 11: Guardar el modelo y el tokenizer
|
| 202 |
+
trainer.save_model('./models/bert_emotion_model')
|
| 203 |
+
tokenizer.save_pretrained('./models/bert_emotion_model')
|
| 204 |
+
|
| 205 |
+
# Paso 12: Guardar los mapeos de etiquetas
|
| 206 |
+
with open('./models/bert_emotion_model/label_to_id.json', 'w') as f:
|
| 207 |
+
json.dump(label_to_id, f)
|
| 208 |
+
with open('./models/bert_emotion_model/id_to_label.json', 'w') as f:
|
| 209 |
+
json.dump(id_to_label, f)
|
| 210 |
+
|
| 211 |
+
print("\nModelo entrenado y guardado exitosamente.")
|
| 212 |
+
|
| 213 |
+
# Paso 13: Probar el modelo con un ejemplo
|
| 214 |
+
sample_text = "Me siento muy feliz hoy"
|
| 215 |
+
print(f"Texto: {sample_text}")
|
| 216 |
+
print(f"Predicción: {predict(sample_text)}")
|