Spaces:
Runtime error

Runtime error
Upload 168 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .editorconfig +8 -0
- .flake8 +6 -0
- .gitattributes +1 -0
- .github/FUNDING.yml +1 -0
- .github/preview.png +3 -0
- .github/workflows/ci.yml +58 -0
- .gitignore +6 -0
- LICENSE.md +3 -0
- README.md +60 -12
- facefusion.ico +0 -0
- facefusion.ini +115 -0
- facefusion.py +10 -0
- facefusion/__init__.py +0 -0
- facefusion/app_context.py +16 -0
- facefusion/args.py +134 -0
- facefusion/audio.py +139 -0
- facefusion/choices.py +97 -0
- facefusion/common_helper.py +72 -0
- facefusion/config.py +92 -0
- facefusion/content_analyser.py +126 -0
- facefusion/core.py +483 -0
- facefusion/date_helper.py +28 -0
- facefusion/download.py +163 -0
- facefusion/execution.py +139 -0
- facefusion/exit_helper.py +26 -0
- facefusion/face_analyser.py +124 -0
- facefusion/face_classifier.py +131 -0
- facefusion/face_detector.py +314 -0
- facefusion/face_helper.py +234 -0
- facefusion/face_landmarker.py +222 -0
- facefusion/face_masker.py +217 -0
- facefusion/face_recognizer.py +84 -0
- facefusion/face_selector.py +91 -0
- facefusion/face_store.py +53 -0
- facefusion/ffmpeg.py +230 -0
- facefusion/filesystem.py +160 -0
- facefusion/hash_helper.py +32 -0
- facefusion/inference_manager.py +63 -0
- facefusion/installer.py +93 -0
- facefusion/jobs/__init__.py +0 -0
- facefusion/jobs/job_helper.py +15 -0
- facefusion/jobs/job_list.py +34 -0
- facefusion/jobs/job_manager.py +260 -0
- facefusion/jobs/job_runner.py +106 -0
- facefusion/jobs/job_store.py +27 -0
- facefusion/json.py +22 -0
- facefusion/logger.py +80 -0
- facefusion/memory.py +21 -0
- facefusion/metadata.py +17 -0
- facefusion/model_helper.py +11 -0
.editorconfig
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
root = true
|
| 2 |
+
|
| 3 |
+
[*]
|
| 4 |
+
end_of_line = lf
|
| 5 |
+
insert_final_newline = true
|
| 6 |
+
indent_size = 4
|
| 7 |
+
indent_style = tab
|
| 8 |
+
trim_trailing_whitespace = true
|
.flake8
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[flake8]
|
| 2 |
+
select = E3, E4, F, I1, I2
|
| 3 |
+
per-file-ignores = facefusion.py:E402, install.py:E402
|
| 4 |
+
plugins = flake8-import-order
|
| 5 |
+
application_import_names = facefusion
|
| 6 |
+
import-order-style = pycharm
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
.github/preview.png filter=lfs diff=lfs merge=lfs -text
|
.github/FUNDING.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
custom: [ buymeacoffee.com/facefusion, ko-fi.com/facefusion ]
|
.github/preview.png
ADDED

|
Git LFS Details
|
.github/workflows/ci.yml
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: ci
|
| 2 |
+
|
| 3 |
+
on: [ push, pull_request ]
|
| 4 |
+
|
| 5 |
+
jobs:
|
| 6 |
+
lint:
|
| 7 |
+
runs-on: ubuntu-latest
|
| 8 |
+
steps:
|
| 9 |
+
- name: Checkout
|
| 10 |
+
uses: actions/checkout@v4
|
| 11 |
+
- name: Set up Python 3.12
|
| 12 |
+
uses: actions/setup-python@v5
|
| 13 |
+
with:
|
| 14 |
+
python-version: '3.12'
|
| 15 |
+
- run: pip install flake8
|
| 16 |
+
- run: pip install flake8-import-order
|
| 17 |
+
- run: pip install mypy
|
| 18 |
+
- run: flake8 facefusion.py install.py
|
| 19 |
+
- run: flake8 facefusion tests
|
| 20 |
+
- run: mypy facefusion.py install.py
|
| 21 |
+
- run: mypy facefusion tests
|
| 22 |
+
test:
|
| 23 |
+
strategy:
|
| 24 |
+
matrix:
|
| 25 |
+
os: [ macos-latest, ubuntu-latest, windows-latest ]
|
| 26 |
+
runs-on: ${{ matrix.os }}
|
| 27 |
+
steps:
|
| 28 |
+
- name: Checkout
|
| 29 |
+
uses: actions/checkout@v4
|
| 30 |
+
- name: Set up FFmpeg
|
| 31 |
+
uses: AnimMouse/setup-ffmpeg@v1
|
| 32 |
+
- name: Set up Python 3.12
|
| 33 |
+
uses: actions/setup-python@v5
|
| 34 |
+
with:
|
| 35 |
+
python-version: '3.12'
|
| 36 |
+
- run: python install.py --onnxruntime default --skip-conda
|
| 37 |
+
- run: pip install pytest
|
| 38 |
+
- run: pytest
|
| 39 |
+
report:
|
| 40 |
+
needs: test
|
| 41 |
+
runs-on: ubuntu-latest
|
| 42 |
+
steps:
|
| 43 |
+
- name: Checkout
|
| 44 |
+
uses: actions/checkout@v4
|
| 45 |
+
- name: Set up FFmpeg
|
| 46 |
+
uses: FedericoCarboni/setup-ffmpeg@v3
|
| 47 |
+
- name: Set up Python 3.12
|
| 48 |
+
uses: actions/setup-python@v5
|
| 49 |
+
with:
|
| 50 |
+
python-version: '3.12'
|
| 51 |
+
- run: python install.py --onnxruntime default --skip-conda
|
| 52 |
+
- run: pip install coveralls
|
| 53 |
+
- run: pip install pytest
|
| 54 |
+
- run: pip install pytest-cov
|
| 55 |
+
- run: pytest tests --cov facefusion
|
| 56 |
+
- run: coveralls --service github
|
| 57 |
+
env:
|
| 58 |
+
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
.gitignore
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
.assets
|
| 3 |
+
.caches
|
| 4 |
+
.jobs
|
| 5 |
+
.idea
|
| 6 |
+
.vscode
|
LICENSE.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT license
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Henry Ruhs
|
README.md
CHANGED
|
@@ -1,12 +1,60 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FaceFusion
|
| 2 |
+
==========
|
| 3 |
+
|
| 4 |
+
> Industry leading face manipulation platform.
|
| 5 |
+
|
| 6 |
+
[](https://github.com/facefusion/facefusion/actions?query=workflow:ci)
|
| 7 |
+
[](https://coveralls.io/r/facefusion/facefusion)
|
| 8 |
+

|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
Preview
|
| 12 |
+
-------
|
| 13 |
+
|
| 14 |
+
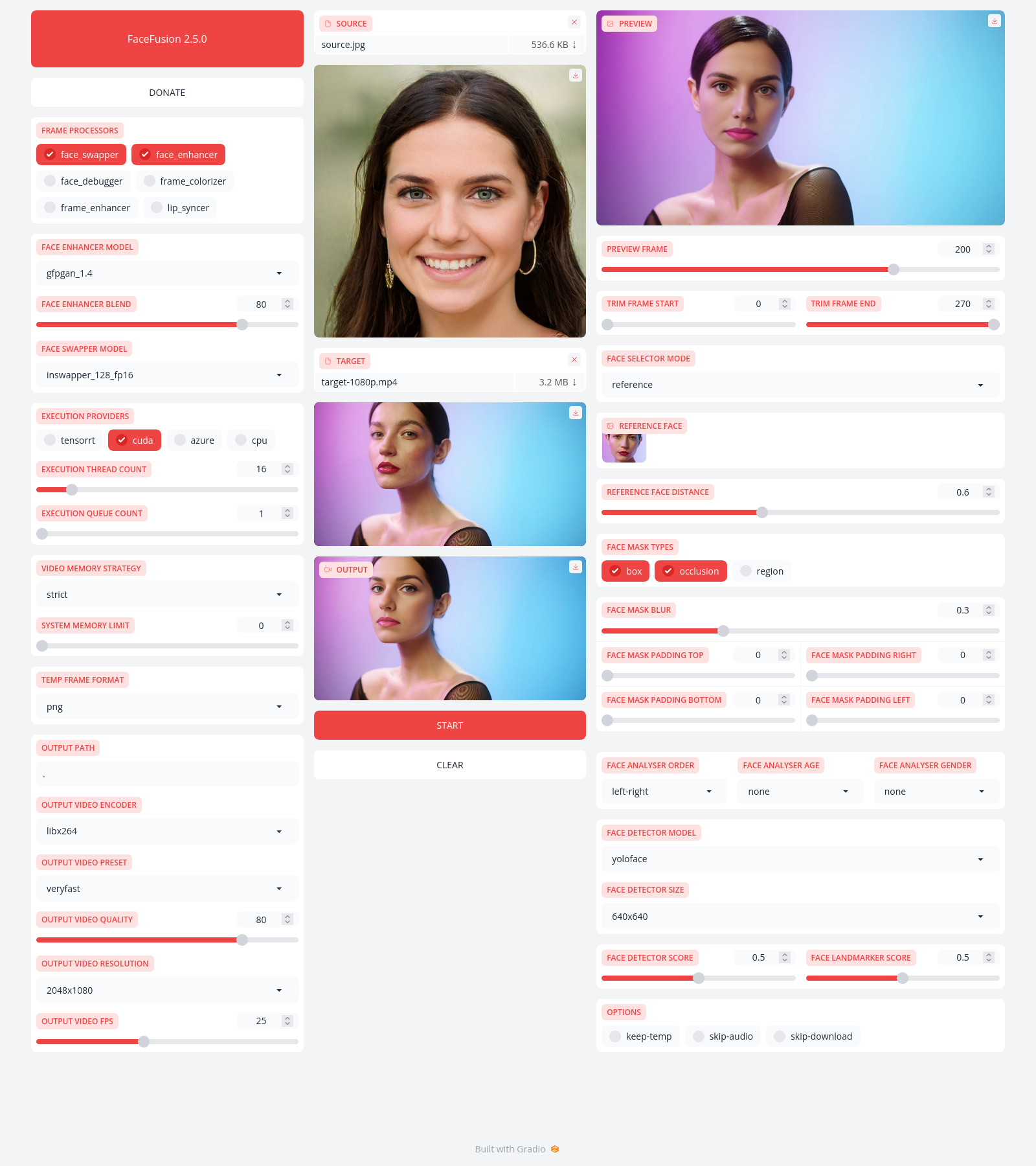
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
Installation
|
| 18 |
+
------------
|
| 19 |
+
|
| 20 |
+
Be aware, the [installation](https://docs.facefusion.io/installation) needs technical skills and is not recommended for beginners. In case you are not comfortable using a terminal, our [Windows Installer](http://windows-installer.facefusion.io) and [macOS Installer](http://macos-installer.facefusion.io) get you started.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
Usage
|
| 24 |
+
-----
|
| 25 |
+
|
| 26 |
+
Run the command:
|
| 27 |
+
|
| 28 |
+
```
|
| 29 |
+
python facefusion.py [commands] [options]
|
| 30 |
+
|
| 31 |
+
options:
|
| 32 |
+
-h, --help show this help message and exit
|
| 33 |
+
-v, --version show program's version number and exit
|
| 34 |
+
|
| 35 |
+
commands:
|
| 36 |
+
run run the program
|
| 37 |
+
headless-run run the program in headless mode
|
| 38 |
+
batch-run run the program in batch mode
|
| 39 |
+
force-download force automate downloads and exit
|
| 40 |
+
job-list list jobs by status
|
| 41 |
+
job-create create a drafted job
|
| 42 |
+
job-submit submit a drafted job to become a queued job
|
| 43 |
+
job-submit-all submit all drafted jobs to become a queued jobs
|
| 44 |
+
job-delete delete a drafted, queued, failed or completed job
|
| 45 |
+
job-delete-all delete all drafted, queued, failed and completed jobs
|
| 46 |
+
job-add-step add a step to a drafted job
|
| 47 |
+
job-remix-step remix a previous step from a drafted job
|
| 48 |
+
job-insert-step insert a step to a drafted job
|
| 49 |
+
job-remove-step remove a step from a drafted job
|
| 50 |
+
job-run run a queued job
|
| 51 |
+
job-run-all run all queued jobs
|
| 52 |
+
job-retry retry a failed job
|
| 53 |
+
job-retry-all retry all failed jobs
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
Documentation
|
| 58 |
+
-------------
|
| 59 |
+
|
| 60 |
+
Read the [documentation](https://docs.facefusion.io) for a deep dive.
|
facefusion.ico
ADDED
|
|
facefusion.ini
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[paths]
|
| 2 |
+
temp_path =
|
| 3 |
+
jobs_path =
|
| 4 |
+
source_paths =
|
| 5 |
+
target_path =
|
| 6 |
+
output_path =
|
| 7 |
+
|
| 8 |
+
[patterns]
|
| 9 |
+
source_pattern =
|
| 10 |
+
target_pattern =
|
| 11 |
+
output_pattern =
|
| 12 |
+
|
| 13 |
+
[face_detector]
|
| 14 |
+
face_detector_model =
|
| 15 |
+
face_detector_size =
|
| 16 |
+
face_detector_angles =
|
| 17 |
+
face_detector_score =
|
| 18 |
+
|
| 19 |
+
[face_landmarker]
|
| 20 |
+
face_landmarker_model =
|
| 21 |
+
face_landmarker_score =
|
| 22 |
+
|
| 23 |
+
[face_selector]
|
| 24 |
+
face_selector_mode =
|
| 25 |
+
face_selector_order =
|
| 26 |
+
face_selector_age_start =
|
| 27 |
+
face_selector_age_end =
|
| 28 |
+
face_selector_gender =
|
| 29 |
+
face_selector_race =
|
| 30 |
+
reference_face_position =
|
| 31 |
+
reference_face_distance =
|
| 32 |
+
reference_frame_number =
|
| 33 |
+
|
| 34 |
+
[face_masker]
|
| 35 |
+
face_occluder_model =
|
| 36 |
+
face_parser_model =
|
| 37 |
+
face_mask_types =
|
| 38 |
+
face_mask_blur =
|
| 39 |
+
face_mask_padding =
|
| 40 |
+
face_mask_regions =
|
| 41 |
+
|
| 42 |
+
[frame_extraction]
|
| 43 |
+
trim_frame_start =
|
| 44 |
+
trim_frame_end =
|
| 45 |
+
temp_frame_format =
|
| 46 |
+
keep_temp =
|
| 47 |
+
|
| 48 |
+
[output_creation]
|
| 49 |
+
output_image_quality =
|
| 50 |
+
output_image_resolution =
|
| 51 |
+
output_audio_encoder =
|
| 52 |
+
output_video_encoder =
|
| 53 |
+
output_video_preset =
|
| 54 |
+
output_video_quality =
|
| 55 |
+
output_video_resolution =
|
| 56 |
+
output_video_fps =
|
| 57 |
+
skip_audio =
|
| 58 |
+
|
| 59 |
+
[processors]
|
| 60 |
+
processors =
|
| 61 |
+
age_modifier_model =
|
| 62 |
+
age_modifier_direction =
|
| 63 |
+
deep_swapper_model =
|
| 64 |
+
deep_swapper_morph =
|
| 65 |
+
expression_restorer_model =
|
| 66 |
+
expression_restorer_factor =
|
| 67 |
+
face_debugger_items =
|
| 68 |
+
face_editor_model =
|
| 69 |
+
face_editor_eyebrow_direction =
|
| 70 |
+
face_editor_eye_gaze_horizontal =
|
| 71 |
+
face_editor_eye_gaze_vertical =
|
| 72 |
+
face_editor_eye_open_ratio =
|
| 73 |
+
face_editor_lip_open_ratio =
|
| 74 |
+
face_editor_mouth_grim =
|
| 75 |
+
face_editor_mouth_pout =
|
| 76 |
+
face_editor_mouth_purse =
|
| 77 |
+
face_editor_mouth_smile =
|
| 78 |
+
face_editor_mouth_position_horizontal =
|
| 79 |
+
face_editor_mouth_position_vertical =
|
| 80 |
+
face_editor_head_pitch =
|
| 81 |
+
face_editor_head_yaw =
|
| 82 |
+
face_editor_head_roll =
|
| 83 |
+
face_enhancer_model =
|
| 84 |
+
face_enhancer_blend =
|
| 85 |
+
face_enhancer_weight =
|
| 86 |
+
face_swapper_model =
|
| 87 |
+
face_swapper_pixel_boost =
|
| 88 |
+
frame_colorizer_model =
|
| 89 |
+
frame_colorizer_size =
|
| 90 |
+
frame_colorizer_blend =
|
| 91 |
+
frame_enhancer_model =
|
| 92 |
+
frame_enhancer_blend =
|
| 93 |
+
lip_syncer_model =
|
| 94 |
+
|
| 95 |
+
[uis]
|
| 96 |
+
open_browser =
|
| 97 |
+
ui_layouts =
|
| 98 |
+
ui_workflow =
|
| 99 |
+
|
| 100 |
+
[execution]
|
| 101 |
+
execution_device_id =
|
| 102 |
+
execution_providers =
|
| 103 |
+
execution_thread_count =
|
| 104 |
+
execution_queue_count =
|
| 105 |
+
|
| 106 |
+
[download]
|
| 107 |
+
download_providers =
|
| 108 |
+
download_scope =
|
| 109 |
+
|
| 110 |
+
[memory]
|
| 111 |
+
video_memory_strategy =
|
| 112 |
+
system_memory_limit =
|
| 113 |
+
|
| 114 |
+
[misc]
|
| 115 |
+
log_level =
|
facefusion.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
os.environ['OMP_NUM_THREADS'] = '1'
|
| 6 |
+
|
| 7 |
+
from facefusion import core
|
| 8 |
+
|
| 9 |
+
if __name__ == '__main__':
|
| 10 |
+
core.cli()
|
facefusion/__init__.py
ADDED
|
File without changes
|
facefusion/app_context.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from facefusion.typing import AppContext
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def detect_app_context() -> AppContext:
|
| 8 |
+
frame = sys._getframe(1)
|
| 9 |
+
|
| 10 |
+
while frame:
|
| 11 |
+
if os.path.join('facefusion', 'jobs') in frame.f_code.co_filename:
|
| 12 |
+
return 'cli'
|
| 13 |
+
if os.path.join('facefusion', 'uis') in frame.f_code.co_filename:
|
| 14 |
+
return 'ui'
|
| 15 |
+
frame = frame.f_back
|
| 16 |
+
return 'cli'
|
facefusion/args.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from facefusion import state_manager
|
| 2 |
+
from facefusion.filesystem import is_image, is_video, list_directory
|
| 3 |
+
from facefusion.jobs import job_store
|
| 4 |
+
from facefusion.normalizer import normalize_fps, normalize_padding
|
| 5 |
+
from facefusion.processors.core import get_processors_modules
|
| 6 |
+
from facefusion.typing import ApplyStateItem, Args
|
| 7 |
+
from facefusion.vision import create_image_resolutions, create_video_resolutions, detect_image_resolution, detect_video_fps, detect_video_resolution, pack_resolution
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def reduce_step_args(args : Args) -> Args:
|
| 11 |
+
step_args =\
|
| 12 |
+
{
|
| 13 |
+
key: args[key] for key in args if key in job_store.get_step_keys()
|
| 14 |
+
}
|
| 15 |
+
return step_args
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def reduce_job_args(args : Args) -> Args:
|
| 19 |
+
job_args =\
|
| 20 |
+
{
|
| 21 |
+
key: args[key] for key in args if key in job_store.get_job_keys()
|
| 22 |
+
}
|
| 23 |
+
return job_args
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def collect_step_args() -> Args:
|
| 27 |
+
step_args =\
|
| 28 |
+
{
|
| 29 |
+
key: state_manager.get_item(key) for key in job_store.get_step_keys() #type:ignore[arg-type]
|
| 30 |
+
}
|
| 31 |
+
return step_args
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def collect_job_args() -> Args:
|
| 35 |
+
job_args =\
|
| 36 |
+
{
|
| 37 |
+
key: state_manager.get_item(key) for key in job_store.get_job_keys() #type:ignore[arg-type]
|
| 38 |
+
}
|
| 39 |
+
return job_args
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def apply_args(args : Args, apply_state_item : ApplyStateItem) -> None:
|
| 43 |
+
# general
|
| 44 |
+
apply_state_item('command', args.get('command'))
|
| 45 |
+
# paths
|
| 46 |
+
apply_state_item('temp_path', args.get('temp_path'))
|
| 47 |
+
apply_state_item('jobs_path', args.get('jobs_path'))
|
| 48 |
+
apply_state_item('source_paths', args.get('source_paths'))
|
| 49 |
+
apply_state_item('target_path', args.get('target_path'))
|
| 50 |
+
apply_state_item('output_path', args.get('output_path'))
|
| 51 |
+
# patterns
|
| 52 |
+
apply_state_item('source_pattern', args.get('source_pattern'))
|
| 53 |
+
apply_state_item('target_pattern', args.get('target_pattern'))
|
| 54 |
+
apply_state_item('output_pattern', args.get('output_pattern'))
|
| 55 |
+
# face detector
|
| 56 |
+
apply_state_item('face_detector_model', args.get('face_detector_model'))
|
| 57 |
+
apply_state_item('face_detector_size', args.get('face_detector_size'))
|
| 58 |
+
apply_state_item('face_detector_angles', args.get('face_detector_angles'))
|
| 59 |
+
apply_state_item('face_detector_score', args.get('face_detector_score'))
|
| 60 |
+
# face landmarker
|
| 61 |
+
apply_state_item('face_landmarker_model', args.get('face_landmarker_model'))
|
| 62 |
+
apply_state_item('face_landmarker_score', args.get('face_landmarker_score'))
|
| 63 |
+
# face selector
|
| 64 |
+
apply_state_item('face_selector_mode', args.get('face_selector_mode'))
|
| 65 |
+
apply_state_item('face_selector_order', args.get('face_selector_order'))
|
| 66 |
+
apply_state_item('face_selector_age_start', args.get('face_selector_age_start'))
|
| 67 |
+
apply_state_item('face_selector_age_end', args.get('face_selector_age_end'))
|
| 68 |
+
apply_state_item('face_selector_gender', args.get('face_selector_gender'))
|
| 69 |
+
apply_state_item('face_selector_race', args.get('face_selector_race'))
|
| 70 |
+
apply_state_item('reference_face_position', args.get('reference_face_position'))
|
| 71 |
+
apply_state_item('reference_face_distance', args.get('reference_face_distance'))
|
| 72 |
+
apply_state_item('reference_frame_number', args.get('reference_frame_number'))
|
| 73 |
+
# face masker
|
| 74 |
+
apply_state_item('face_occluder_model', args.get('face_occluder_model'))
|
| 75 |
+
apply_state_item('face_parser_model', args.get('face_parser_model'))
|
| 76 |
+
apply_state_item('face_mask_types', args.get('face_mask_types'))
|
| 77 |
+
apply_state_item('face_mask_blur', args.get('face_mask_blur'))
|
| 78 |
+
apply_state_item('face_mask_padding', normalize_padding(args.get('face_mask_padding')))
|
| 79 |
+
apply_state_item('face_mask_regions', args.get('face_mask_regions'))
|
| 80 |
+
# frame extraction
|
| 81 |
+
apply_state_item('trim_frame_start', args.get('trim_frame_start'))
|
| 82 |
+
apply_state_item('trim_frame_end', args.get('trim_frame_end'))
|
| 83 |
+
apply_state_item('temp_frame_format', args.get('temp_frame_format'))
|
| 84 |
+
apply_state_item('keep_temp', args.get('keep_temp'))
|
| 85 |
+
# output creation
|
| 86 |
+
apply_state_item('output_image_quality', args.get('output_image_quality'))
|
| 87 |
+
if is_image(args.get('target_path')):
|
| 88 |
+
output_image_resolution = detect_image_resolution(args.get('target_path'))
|
| 89 |
+
output_image_resolutions = create_image_resolutions(output_image_resolution)
|
| 90 |
+
if args.get('output_image_resolution') in output_image_resolutions:
|
| 91 |
+
apply_state_item('output_image_resolution', args.get('output_image_resolution'))
|
| 92 |
+
else:
|
| 93 |
+
apply_state_item('output_image_resolution', pack_resolution(output_image_resolution))
|
| 94 |
+
apply_state_item('output_audio_encoder', args.get('output_audio_encoder'))
|
| 95 |
+
apply_state_item('output_video_encoder', args.get('output_video_encoder'))
|
| 96 |
+
apply_state_item('output_video_preset', args.get('output_video_preset'))
|
| 97 |
+
apply_state_item('output_video_quality', args.get('output_video_quality'))
|
| 98 |
+
if is_video(args.get('target_path')):
|
| 99 |
+
output_video_resolution = detect_video_resolution(args.get('target_path'))
|
| 100 |
+
output_video_resolutions = create_video_resolutions(output_video_resolution)
|
| 101 |
+
if args.get('output_video_resolution') in output_video_resolutions:
|
| 102 |
+
apply_state_item('output_video_resolution', args.get('output_video_resolution'))
|
| 103 |
+
else:
|
| 104 |
+
apply_state_item('output_video_resolution', pack_resolution(output_video_resolution))
|
| 105 |
+
if args.get('output_video_fps') or is_video(args.get('target_path')):
|
| 106 |
+
output_video_fps = normalize_fps(args.get('output_video_fps')) or detect_video_fps(args.get('target_path'))
|
| 107 |
+
apply_state_item('output_video_fps', output_video_fps)
|
| 108 |
+
apply_state_item('skip_audio', args.get('skip_audio'))
|
| 109 |
+
# processors
|
| 110 |
+
available_processors = [ file.get('name') for file in list_directory('facefusion/processors/modules') ]
|
| 111 |
+
apply_state_item('processors', args.get('processors'))
|
| 112 |
+
for processor_module in get_processors_modules(available_processors):
|
| 113 |
+
processor_module.apply_args(args, apply_state_item)
|
| 114 |
+
# uis
|
| 115 |
+
apply_state_item('open_browser', args.get('open_browser'))
|
| 116 |
+
apply_state_item('ui_layouts', args.get('ui_layouts'))
|
| 117 |
+
apply_state_item('ui_workflow', args.get('ui_workflow'))
|
| 118 |
+
# execution
|
| 119 |
+
apply_state_item('execution_device_id', args.get('execution_device_id'))
|
| 120 |
+
apply_state_item('execution_providers', args.get('execution_providers'))
|
| 121 |
+
apply_state_item('execution_thread_count', args.get('execution_thread_count'))
|
| 122 |
+
apply_state_item('execution_queue_count', args.get('execution_queue_count'))
|
| 123 |
+
# download
|
| 124 |
+
apply_state_item('download_providers', args.get('download_providers'))
|
| 125 |
+
apply_state_item('download_scope', args.get('download_scope'))
|
| 126 |
+
# memory
|
| 127 |
+
apply_state_item('video_memory_strategy', args.get('video_memory_strategy'))
|
| 128 |
+
apply_state_item('system_memory_limit', args.get('system_memory_limit'))
|
| 129 |
+
# misc
|
| 130 |
+
apply_state_item('log_level', args.get('log_level'))
|
| 131 |
+
# jobs
|
| 132 |
+
apply_state_item('job_id', args.get('job_id'))
|
| 133 |
+
apply_state_item('job_status', args.get('job_status'))
|
| 134 |
+
apply_state_item('step_index', args.get('step_index'))
|
facefusion/audio.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from typing import Any, List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy
|
| 5 |
+
import scipy
|
| 6 |
+
from numpy._typing import NDArray
|
| 7 |
+
|
| 8 |
+
from facefusion.ffmpeg import read_audio_buffer
|
| 9 |
+
from facefusion.filesystem import is_audio
|
| 10 |
+
from facefusion.typing import Audio, AudioFrame, Fps, Mel, MelFilterBank, Spectrogram
|
| 11 |
+
from facefusion.voice_extractor import batch_extract_voice
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@lru_cache(maxsize = 128)
|
| 15 |
+
def read_static_audio(audio_path : str, fps : Fps) -> Optional[List[AudioFrame]]:
|
| 16 |
+
return read_audio(audio_path, fps)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def read_audio(audio_path : str, fps : Fps) -> Optional[List[AudioFrame]]:
|
| 20 |
+
sample_rate = 48000
|
| 21 |
+
channel_total = 2
|
| 22 |
+
|
| 23 |
+
if is_audio(audio_path):
|
| 24 |
+
audio_buffer = read_audio_buffer(audio_path, sample_rate, channel_total)
|
| 25 |
+
audio = numpy.frombuffer(audio_buffer, dtype = numpy.int16).reshape(-1, 2)
|
| 26 |
+
audio = prepare_audio(audio)
|
| 27 |
+
spectrogram = create_spectrogram(audio)
|
| 28 |
+
audio_frames = extract_audio_frames(spectrogram, fps)
|
| 29 |
+
return audio_frames
|
| 30 |
+
return None
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
@lru_cache(maxsize = 128)
|
| 34 |
+
def read_static_voice(audio_path : str, fps : Fps) -> Optional[List[AudioFrame]]:
|
| 35 |
+
return read_voice(audio_path, fps)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def read_voice(audio_path : str, fps : Fps) -> Optional[List[AudioFrame]]:
|
| 39 |
+
sample_rate = 48000
|
| 40 |
+
channel_total = 2
|
| 41 |
+
chunk_size = 240 * 1024
|
| 42 |
+
step_size = 180 * 1024
|
| 43 |
+
|
| 44 |
+
if is_audio(audio_path):
|
| 45 |
+
audio_buffer = read_audio_buffer(audio_path, sample_rate, channel_total)
|
| 46 |
+
audio = numpy.frombuffer(audio_buffer, dtype = numpy.int16).reshape(-1, 2)
|
| 47 |
+
audio = batch_extract_voice(audio, chunk_size, step_size)
|
| 48 |
+
audio = prepare_voice(audio)
|
| 49 |
+
spectrogram = create_spectrogram(audio)
|
| 50 |
+
audio_frames = extract_audio_frames(spectrogram, fps)
|
| 51 |
+
return audio_frames
|
| 52 |
+
return None
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def get_audio_frame(audio_path : str, fps : Fps, frame_number : int = 0) -> Optional[AudioFrame]:
|
| 56 |
+
if is_audio(audio_path):
|
| 57 |
+
audio_frames = read_static_audio(audio_path, fps)
|
| 58 |
+
if frame_number in range(len(audio_frames)):
|
| 59 |
+
return audio_frames[frame_number]
|
| 60 |
+
return None
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def get_voice_frame(audio_path : str, fps : Fps, frame_number : int = 0) -> Optional[AudioFrame]:
|
| 64 |
+
if is_audio(audio_path):
|
| 65 |
+
voice_frames = read_static_voice(audio_path, fps)
|
| 66 |
+
if frame_number in range(len(voice_frames)):
|
| 67 |
+
return voice_frames[frame_number]
|
| 68 |
+
return None
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def create_empty_audio_frame() -> AudioFrame:
|
| 72 |
+
mel_filter_total = 80
|
| 73 |
+
step_size = 16
|
| 74 |
+
audio_frame = numpy.zeros((mel_filter_total, step_size)).astype(numpy.int16)
|
| 75 |
+
return audio_frame
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def prepare_audio(audio : Audio) -> Audio:
|
| 79 |
+
if audio.ndim > 1:
|
| 80 |
+
audio = numpy.mean(audio, axis = 1)
|
| 81 |
+
audio = audio / numpy.max(numpy.abs(audio), axis = 0)
|
| 82 |
+
audio = scipy.signal.lfilter([ 1.0, -0.97 ], [ 1.0 ], audio)
|
| 83 |
+
return audio
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def prepare_voice(audio : Audio) -> Audio:
|
| 87 |
+
sample_rate = 48000
|
| 88 |
+
resample_rate = 16000
|
| 89 |
+
|
| 90 |
+
audio = scipy.signal.resample(audio, int(len(audio) * resample_rate / sample_rate))
|
| 91 |
+
audio = prepare_audio(audio)
|
| 92 |
+
return audio
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def convert_hertz_to_mel(hertz : float) -> float:
|
| 96 |
+
return 2595 * numpy.log10(1 + hertz / 700)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def convert_mel_to_hertz(mel : Mel) -> NDArray[Any]:
|
| 100 |
+
return 700 * (10 ** (mel / 2595) - 1)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def create_mel_filter_bank() -> MelFilterBank:
|
| 104 |
+
mel_filter_total = 80
|
| 105 |
+
mel_bin_total = 800
|
| 106 |
+
sample_rate = 16000
|
| 107 |
+
min_frequency = 55.0
|
| 108 |
+
max_frequency = 7600.0
|
| 109 |
+
mel_filter_bank = numpy.zeros((mel_filter_total, mel_bin_total // 2 + 1))
|
| 110 |
+
mel_frequency_range = numpy.linspace(convert_hertz_to_mel(min_frequency), convert_hertz_to_mel(max_frequency), mel_filter_total + 2)
|
| 111 |
+
indices = numpy.floor((mel_bin_total + 1) * convert_mel_to_hertz(mel_frequency_range) / sample_rate).astype(numpy.int16)
|
| 112 |
+
|
| 113 |
+
for index in range(mel_filter_total):
|
| 114 |
+
start = indices[index]
|
| 115 |
+
end = indices[index + 1]
|
| 116 |
+
mel_filter_bank[index, start:end] = scipy.signal.windows.triang(end - start)
|
| 117 |
+
return mel_filter_bank
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def create_spectrogram(audio : Audio) -> Spectrogram:
|
| 121 |
+
mel_bin_total = 800
|
| 122 |
+
mel_bin_overlap = 600
|
| 123 |
+
mel_filter_bank = create_mel_filter_bank()
|
| 124 |
+
spectrogram = scipy.signal.stft(audio, nperseg = mel_bin_total, nfft = mel_bin_total, noverlap = mel_bin_overlap)[2]
|
| 125 |
+
spectrogram = numpy.dot(mel_filter_bank, numpy.abs(spectrogram))
|
| 126 |
+
return spectrogram
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def extract_audio_frames(spectrogram : Spectrogram, fps : Fps) -> List[AudioFrame]:
|
| 130 |
+
mel_filter_total = 80
|
| 131 |
+
step_size = 16
|
| 132 |
+
audio_frames = []
|
| 133 |
+
indices = numpy.arange(0, spectrogram.shape[1], mel_filter_total / fps).astype(numpy.int16)
|
| 134 |
+
indices = indices[indices >= step_size]
|
| 135 |
+
|
| 136 |
+
for index in indices:
|
| 137 |
+
start = max(0, index - step_size)
|
| 138 |
+
audio_frames.append(spectrogram[:, start:index])
|
| 139 |
+
return audio_frames
|
facefusion/choices.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import List, Sequence
|
| 3 |
+
|
| 4 |
+
from facefusion.common_helper import create_float_range, create_int_range
|
| 5 |
+
from facefusion.typing import Angle, DownloadProvider, DownloadProviderSet, DownloadScope, ExecutionProvider, ExecutionProviderSet, FaceDetectorModel, FaceDetectorSet, FaceLandmarkerModel, FaceMaskRegion, FaceMaskRegionSet, FaceMaskType, FaceOccluderModel, FaceParserModel, FaceSelectorMode, FaceSelectorOrder, Gender, JobStatus, LogLevel, LogLevelSet, OutputAudioEncoder, OutputVideoEncoder, OutputVideoPreset, Race, Score, TempFrameFormat, UiWorkflow, VideoMemoryStrategy
|
| 6 |
+
|
| 7 |
+
face_detector_set : FaceDetectorSet =\
|
| 8 |
+
{
|
| 9 |
+
'many': [ '640x640' ],
|
| 10 |
+
'retinaface': [ '160x160', '320x320', '480x480', '512x512', '640x640' ],
|
| 11 |
+
'scrfd': [ '160x160', '320x320', '480x480', '512x512', '640x640' ],
|
| 12 |
+
'yoloface': [ '640x640' ]
|
| 13 |
+
}
|
| 14 |
+
face_detector_models : List[FaceDetectorModel] = list(face_detector_set.keys())
|
| 15 |
+
face_landmarker_models : List[FaceLandmarkerModel] = [ 'many', '2dfan4', 'peppa_wutz' ]
|
| 16 |
+
face_selector_modes : List[FaceSelectorMode] = [ 'many', 'one', 'reference' ]
|
| 17 |
+
face_selector_orders : List[FaceSelectorOrder] = [ 'left-right', 'right-left', 'top-bottom', 'bottom-top', 'small-large', 'large-small', 'best-worst', 'worst-best' ]
|
| 18 |
+
face_selector_genders : List[Gender] = [ 'female', 'male' ]
|
| 19 |
+
face_selector_races : List[Race] = [ 'white', 'black', 'latino', 'asian', 'indian', 'arabic' ]
|
| 20 |
+
face_occluder_models : List[FaceOccluderModel] = [ 'xseg_1', 'xseg_2' ]
|
| 21 |
+
face_parser_models : List[FaceParserModel] = [ 'bisenet_resnet_18', 'bisenet_resnet_34' ]
|
| 22 |
+
face_mask_types : List[FaceMaskType] = [ 'box', 'occlusion', 'region' ]
|
| 23 |
+
face_mask_region_set : FaceMaskRegionSet =\
|
| 24 |
+
{
|
| 25 |
+
'skin': 1,
|
| 26 |
+
'left-eyebrow': 2,
|
| 27 |
+
'right-eyebrow': 3,
|
| 28 |
+
'left-eye': 4,
|
| 29 |
+
'right-eye': 5,
|
| 30 |
+
'glasses': 6,
|
| 31 |
+
'nose': 10,
|
| 32 |
+
'mouth': 11,
|
| 33 |
+
'upper-lip': 12,
|
| 34 |
+
'lower-lip': 13
|
| 35 |
+
}
|
| 36 |
+
face_mask_regions : List[FaceMaskRegion] = list(face_mask_region_set.keys())
|
| 37 |
+
temp_frame_formats : List[TempFrameFormat] = [ 'bmp', 'jpg', 'png' ]
|
| 38 |
+
output_audio_encoders : List[OutputAudioEncoder] = [ 'aac', 'libmp3lame', 'libopus', 'libvorbis' ]
|
| 39 |
+
output_video_encoders : List[OutputVideoEncoder] = [ 'libx264', 'libx265', 'libvpx-vp9', 'h264_nvenc', 'hevc_nvenc', 'h264_amf', 'hevc_amf', 'h264_qsv', 'hevc_qsv', 'h264_videotoolbox', 'hevc_videotoolbox' ]
|
| 40 |
+
output_video_presets : List[OutputVideoPreset] = [ 'ultrafast', 'superfast', 'veryfast', 'faster', 'fast', 'medium', 'slow', 'slower', 'veryslow' ]
|
| 41 |
+
|
| 42 |
+
image_template_sizes : List[float] = [ 0.25, 0.5, 0.75, 1, 1.5, 2, 2.5, 3, 3.5, 4 ]
|
| 43 |
+
video_template_sizes : List[int] = [ 240, 360, 480, 540, 720, 1080, 1440, 2160, 4320 ]
|
| 44 |
+
|
| 45 |
+
execution_provider_set : ExecutionProviderSet =\
|
| 46 |
+
{
|
| 47 |
+
'cpu': 'CPUExecutionProvider',
|
| 48 |
+
'coreml': 'CoreMLExecutionProvider',
|
| 49 |
+
'cuda': 'CUDAExecutionProvider',
|
| 50 |
+
'directml': 'DmlExecutionProvider',
|
| 51 |
+
'openvino': 'OpenVINOExecutionProvider',
|
| 52 |
+
'rocm': 'ROCMExecutionProvider',
|
| 53 |
+
'tensorrt': 'TensorrtExecutionProvider'
|
| 54 |
+
}
|
| 55 |
+
execution_providers : List[ExecutionProvider] = list(execution_provider_set.keys())
|
| 56 |
+
download_provider_set : DownloadProviderSet =\
|
| 57 |
+
{
|
| 58 |
+
'github':
|
| 59 |
+
{
|
| 60 |
+
'url': 'https://github.com',
|
| 61 |
+
'path': '/facefusion/facefusion-assets/releases/download/{base_name}/{file_name}'
|
| 62 |
+
},
|
| 63 |
+
'huggingface':
|
| 64 |
+
{
|
| 65 |
+
'url': 'https://huggingface.co',
|
| 66 |
+
'path': '/facefusion/{base_name}/resolve/main/{file_name}'
|
| 67 |
+
}
|
| 68 |
+
}
|
| 69 |
+
download_providers : List[DownloadProvider] = list(download_provider_set.keys())
|
| 70 |
+
download_scopes : List[DownloadScope] = [ 'lite', 'full' ]
|
| 71 |
+
|
| 72 |
+
video_memory_strategies : List[VideoMemoryStrategy] = [ 'strict', 'moderate', 'tolerant' ]
|
| 73 |
+
|
| 74 |
+
log_level_set : LogLevelSet =\
|
| 75 |
+
{
|
| 76 |
+
'error': logging.ERROR,
|
| 77 |
+
'warn': logging.WARNING,
|
| 78 |
+
'info': logging.INFO,
|
| 79 |
+
'debug': logging.DEBUG
|
| 80 |
+
}
|
| 81 |
+
log_levels : List[LogLevel] = list(log_level_set.keys())
|
| 82 |
+
|
| 83 |
+
ui_workflows : List[UiWorkflow] = [ 'instant_runner', 'job_runner', 'job_manager' ]
|
| 84 |
+
job_statuses : List[JobStatus] = [ 'drafted', 'queued', 'completed', 'failed' ]
|
| 85 |
+
|
| 86 |
+
execution_thread_count_range : Sequence[int] = create_int_range(1, 32, 1)
|
| 87 |
+
execution_queue_count_range : Sequence[int] = create_int_range(1, 4, 1)
|
| 88 |
+
system_memory_limit_range : Sequence[int] = create_int_range(0, 128, 4)
|
| 89 |
+
face_detector_angles : Sequence[Angle] = create_int_range(0, 270, 90)
|
| 90 |
+
face_detector_score_range : Sequence[Score] = create_float_range(0.0, 1.0, 0.05)
|
| 91 |
+
face_landmarker_score_range : Sequence[Score] = create_float_range(0.0, 1.0, 0.05)
|
| 92 |
+
face_mask_blur_range : Sequence[float] = create_float_range(0.0, 1.0, 0.05)
|
| 93 |
+
face_mask_padding_range : Sequence[int] = create_int_range(0, 100, 1)
|
| 94 |
+
face_selector_age_range : Sequence[int] = create_int_range(0, 100, 1)
|
| 95 |
+
reference_face_distance_range : Sequence[float] = create_float_range(0.0, 1.5, 0.05)
|
| 96 |
+
output_image_quality_range : Sequence[int] = create_int_range(0, 100, 1)
|
| 97 |
+
output_video_quality_range : Sequence[int] = create_int_range(0, 100, 1)
|
facefusion/common_helper.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import platform
|
| 2 |
+
from typing import Any, Optional, Sequence
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def is_linux() -> bool:
|
| 6 |
+
return platform.system().lower() == 'linux'
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def is_macos() -> bool:
|
| 10 |
+
return platform.system().lower() == 'darwin'
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def is_windows() -> bool:
|
| 14 |
+
return platform.system().lower() == 'windows'
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def create_int_metavar(int_range : Sequence[int]) -> str:
|
| 18 |
+
return '[' + str(int_range[0]) + '..' + str(int_range[-1]) + ':' + str(calc_int_step(int_range)) + ']'
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def create_float_metavar(float_range : Sequence[float]) -> str:
|
| 22 |
+
return '[' + str(float_range[0]) + '..' + str(float_range[-1]) + ':' + str(calc_float_step(float_range)) + ']'
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def create_int_range(start : int, end : int, step : int) -> Sequence[int]:
|
| 26 |
+
int_range = []
|
| 27 |
+
current = start
|
| 28 |
+
|
| 29 |
+
while current <= end:
|
| 30 |
+
int_range.append(current)
|
| 31 |
+
current += step
|
| 32 |
+
return int_range
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def create_float_range(start : float, end : float, step : float) -> Sequence[float]:
|
| 36 |
+
float_range = []
|
| 37 |
+
current = start
|
| 38 |
+
|
| 39 |
+
while current <= end:
|
| 40 |
+
float_range.append(round(current, 2))
|
| 41 |
+
current = round(current + step, 2)
|
| 42 |
+
return float_range
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def calc_int_step(int_range : Sequence[int]) -> int:
|
| 46 |
+
return int_range[1] - int_range[0]
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def calc_float_step(float_range : Sequence[float]) -> float:
|
| 50 |
+
return round(float_range[1] - float_range[0], 2)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def cast_int(value : Any) -> Optional[Any]:
|
| 54 |
+
try:
|
| 55 |
+
return int(value)
|
| 56 |
+
except (ValueError, TypeError):
|
| 57 |
+
return None
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def cast_float(value : Any) -> Optional[Any]:
|
| 61 |
+
try:
|
| 62 |
+
return float(value)
|
| 63 |
+
except (ValueError, TypeError):
|
| 64 |
+
return None
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_first(__list__ : Any) -> Any:
|
| 68 |
+
return next(iter(__list__), None)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def get_last(__list__ : Any) -> Any:
|
| 72 |
+
return next(reversed(__list__), None)
|
facefusion/config.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from configparser import ConfigParser
|
| 2 |
+
from typing import Any, List, Optional
|
| 3 |
+
|
| 4 |
+
from facefusion import state_manager
|
| 5 |
+
from facefusion.common_helper import cast_float, cast_int
|
| 6 |
+
|
| 7 |
+
CONFIG = None
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def get_config() -> ConfigParser:
|
| 11 |
+
global CONFIG
|
| 12 |
+
|
| 13 |
+
if CONFIG is None:
|
| 14 |
+
CONFIG = ConfigParser()
|
| 15 |
+
CONFIG.read(state_manager.get_item('config_path'), encoding = 'utf-8')
|
| 16 |
+
return CONFIG
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def clear_config() -> None:
|
| 20 |
+
global CONFIG
|
| 21 |
+
|
| 22 |
+
CONFIG = None
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def get_str_value(key : str, fallback : Optional[str] = None) -> Optional[str]:
|
| 26 |
+
value = get_value_by_notation(key)
|
| 27 |
+
|
| 28 |
+
if value or fallback:
|
| 29 |
+
return str(value or fallback)
|
| 30 |
+
return None
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def get_int_value(key : str, fallback : Optional[str] = None) -> Optional[int]:
|
| 34 |
+
value = get_value_by_notation(key)
|
| 35 |
+
|
| 36 |
+
if value or fallback:
|
| 37 |
+
return cast_int(value or fallback)
|
| 38 |
+
return None
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_float_value(key : str, fallback : Optional[str] = None) -> Optional[float]:
|
| 42 |
+
value = get_value_by_notation(key)
|
| 43 |
+
|
| 44 |
+
if value or fallback:
|
| 45 |
+
return cast_float(value or fallback)
|
| 46 |
+
return None
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def get_bool_value(key : str, fallback : Optional[str] = None) -> Optional[bool]:
|
| 50 |
+
value = get_value_by_notation(key)
|
| 51 |
+
|
| 52 |
+
if value == 'True' or fallback == 'True':
|
| 53 |
+
return True
|
| 54 |
+
if value == 'False' or fallback == 'False':
|
| 55 |
+
return False
|
| 56 |
+
return None
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def get_str_list(key : str, fallback : Optional[str] = None) -> Optional[List[str]]:
|
| 60 |
+
value = get_value_by_notation(key)
|
| 61 |
+
|
| 62 |
+
if value or fallback:
|
| 63 |
+
return [ str(value) for value in (value or fallback).split(' ') ]
|
| 64 |
+
return None
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_int_list(key : str, fallback : Optional[str] = None) -> Optional[List[int]]:
|
| 68 |
+
value = get_value_by_notation(key)
|
| 69 |
+
|
| 70 |
+
if value or fallback:
|
| 71 |
+
return [ cast_int(value) for value in (value or fallback).split(' ') ]
|
| 72 |
+
return None
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def get_float_list(key : str, fallback : Optional[str] = None) -> Optional[List[float]]:
|
| 76 |
+
value = get_value_by_notation(key)
|
| 77 |
+
|
| 78 |
+
if value or fallback:
|
| 79 |
+
return [ cast_float(value) for value in (value or fallback).split(' ') ]
|
| 80 |
+
return None
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def get_value_by_notation(key : str) -> Optional[Any]:
|
| 84 |
+
config = get_config()
|
| 85 |
+
|
| 86 |
+
if '.' in key:
|
| 87 |
+
section, name = key.split('.')
|
| 88 |
+
if section in config and name in config[section]:
|
| 89 |
+
return config[section][name]
|
| 90 |
+
if key in config:
|
| 91 |
+
return config[key]
|
| 92 |
+
return None
|
facefusion/content_analyser.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
from facefusion import inference_manager, state_manager, wording
|
| 8 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources, resolve_download_url
|
| 9 |
+
from facefusion.filesystem import resolve_relative_path
|
| 10 |
+
from facefusion.thread_helper import conditional_thread_semaphore
|
| 11 |
+
from facefusion.typing import DownloadScope, Fps, InferencePool, ModelOptions, ModelSet, VisionFrame
|
| 12 |
+
from facefusion.vision import detect_video_fps, get_video_frame, read_image
|
| 13 |
+
|
| 14 |
+
PROBABILITY_LIMIT = 0.80
|
| 15 |
+
RATE_LIMIT = 10
|
| 16 |
+
STREAM_COUNTER = 0
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@lru_cache(maxsize = None)
|
| 20 |
+
def create_static_model_set(download_scope : DownloadScope) -> ModelSet:
|
| 21 |
+
return\
|
| 22 |
+
{
|
| 23 |
+
'open_nsfw':
|
| 24 |
+
{
|
| 25 |
+
'hashes':
|
| 26 |
+
{
|
| 27 |
+
'content_analyser':
|
| 28 |
+
{
|
| 29 |
+
'url': resolve_download_url('models-3.0.0', 'open_nsfw.hash'),
|
| 30 |
+
'path': resolve_relative_path('../.assets/models/open_nsfw.hash')
|
| 31 |
+
}
|
| 32 |
+
},
|
| 33 |
+
'sources':
|
| 34 |
+
{
|
| 35 |
+
'content_analyser':
|
| 36 |
+
{
|
| 37 |
+
'url': resolve_download_url('models-3.0.0', 'open_nsfw.onnx'),
|
| 38 |
+
'path': resolve_relative_path('../.assets/models/open_nsfw.onnx')
|
| 39 |
+
}
|
| 40 |
+
},
|
| 41 |
+
'size': (224, 224),
|
| 42 |
+
'mean': [ 104, 117, 123 ]
|
| 43 |
+
}
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_inference_pool() -> InferencePool:
|
| 48 |
+
model_sources = get_model_options().get('sources')
|
| 49 |
+
return inference_manager.get_inference_pool(__name__, model_sources)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def clear_inference_pool() -> None:
|
| 53 |
+
inference_manager.clear_inference_pool(__name__)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_model_options() -> ModelOptions:
|
| 57 |
+
return create_static_model_set('full').get('open_nsfw')
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def pre_check() -> bool:
|
| 61 |
+
model_hashes = get_model_options().get('hashes')
|
| 62 |
+
model_sources = get_model_options().get('sources')
|
| 63 |
+
|
| 64 |
+
return conditional_download_hashes(model_hashes) and conditional_download_sources(model_sources)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def analyse_stream(vision_frame : VisionFrame, video_fps : Fps) -> bool:
|
| 68 |
+
global STREAM_COUNTER
|
| 69 |
+
|
| 70 |
+
STREAM_COUNTER = STREAM_COUNTER + 1
|
| 71 |
+
if STREAM_COUNTER % int(video_fps) == 0:
|
| 72 |
+
return analyse_frame(vision_frame)
|
| 73 |
+
return False
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def analyse_frame(vision_frame : VisionFrame) -> bool:
|
| 77 |
+
vision_frame = prepare_frame(vision_frame)
|
| 78 |
+
probability = forward(vision_frame)
|
| 79 |
+
|
| 80 |
+
return probability > PROBABILITY_LIMIT
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def forward(vision_frame : VisionFrame) -> float:
|
| 84 |
+
content_analyser = get_inference_pool().get('content_analyser')
|
| 85 |
+
|
| 86 |
+
with conditional_thread_semaphore():
|
| 87 |
+
probability = content_analyser.run(None,
|
| 88 |
+
{
|
| 89 |
+
'input': vision_frame
|
| 90 |
+
})[0][0][1]
|
| 91 |
+
|
| 92 |
+
return probability
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def prepare_frame(vision_frame : VisionFrame) -> VisionFrame:
|
| 96 |
+
model_size = get_model_options().get('size')
|
| 97 |
+
model_mean = get_model_options().get('mean')
|
| 98 |
+
vision_frame = cv2.resize(vision_frame, model_size).astype(numpy.float32)
|
| 99 |
+
vision_frame -= numpy.array(model_mean).astype(numpy.float32)
|
| 100 |
+
vision_frame = numpy.expand_dims(vision_frame, axis = 0)
|
| 101 |
+
return vision_frame
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
@lru_cache(maxsize = None)
|
| 105 |
+
def analyse_image(image_path : str) -> bool:
|
| 106 |
+
vision_frame = read_image(image_path)
|
| 107 |
+
return analyse_frame(vision_frame)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
@lru_cache(maxsize = None)
|
| 111 |
+
def analyse_video(video_path : str, trim_frame_start : int, trim_frame_end : int) -> bool:
|
| 112 |
+
video_fps = detect_video_fps(video_path)
|
| 113 |
+
frame_range = range(trim_frame_start, trim_frame_end)
|
| 114 |
+
rate = 0.0
|
| 115 |
+
counter = 0
|
| 116 |
+
|
| 117 |
+
with tqdm(total = len(frame_range), desc = wording.get('analysing'), unit = 'frame', ascii = ' =', disable = state_manager.get_item('log_level') in [ 'warn', 'error' ]) as progress:
|
| 118 |
+
for frame_number in frame_range:
|
| 119 |
+
if frame_number % int(video_fps) == 0:
|
| 120 |
+
vision_frame = get_video_frame(video_path, frame_number)
|
| 121 |
+
if analyse_frame(vision_frame):
|
| 122 |
+
counter += 1
|
| 123 |
+
rate = counter * int(video_fps) / len(frame_range) * 100
|
| 124 |
+
progress.update()
|
| 125 |
+
progress.set_postfix(rate = rate)
|
| 126 |
+
return rate > RATE_LIMIT
|
facefusion/core.py
ADDED
|
@@ -0,0 +1,483 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import itertools
|
| 2 |
+
import shutil
|
| 3 |
+
import signal
|
| 4 |
+
import sys
|
| 5 |
+
from time import time
|
| 6 |
+
|
| 7 |
+
import numpy
|
| 8 |
+
|
| 9 |
+
from facefusion import content_analyser, face_classifier, face_detector, face_landmarker, face_masker, face_recognizer, logger, process_manager, state_manager, voice_extractor, wording
|
| 10 |
+
from facefusion.args import apply_args, collect_job_args, reduce_job_args, reduce_step_args
|
| 11 |
+
from facefusion.common_helper import get_first
|
| 12 |
+
from facefusion.content_analyser import analyse_image, analyse_video
|
| 13 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources
|
| 14 |
+
from facefusion.exit_helper import conditional_exit, graceful_exit, hard_exit
|
| 15 |
+
from facefusion.face_analyser import get_average_face, get_many_faces, get_one_face
|
| 16 |
+
from facefusion.face_selector import sort_and_filter_faces
|
| 17 |
+
from facefusion.face_store import append_reference_face, clear_reference_faces, get_reference_faces
|
| 18 |
+
from facefusion.ffmpeg import copy_image, extract_frames, finalize_image, merge_video, replace_audio, restore_audio
|
| 19 |
+
from facefusion.filesystem import filter_audio_paths, is_image, is_video, list_directory, resolve_file_pattern
|
| 20 |
+
from facefusion.jobs import job_helper, job_manager, job_runner
|
| 21 |
+
from facefusion.jobs.job_list import compose_job_list
|
| 22 |
+
from facefusion.memory import limit_system_memory
|
| 23 |
+
from facefusion.processors.core import get_processors_modules
|
| 24 |
+
from facefusion.program import create_program
|
| 25 |
+
from facefusion.program_helper import validate_args
|
| 26 |
+
from facefusion.statistics import conditional_log_statistics
|
| 27 |
+
from facefusion.temp_helper import clear_temp_directory, create_temp_directory, get_temp_file_path, get_temp_frame_paths, move_temp_file
|
| 28 |
+
from facefusion.typing import Args, ErrorCode
|
| 29 |
+
from facefusion.vision import get_video_frame, pack_resolution, read_image, read_static_images, restrict_image_resolution, restrict_trim_frame, restrict_video_fps, restrict_video_resolution, unpack_resolution
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def cli() -> None:
|
| 33 |
+
signal.signal(signal.SIGINT, lambda signal_number, frame: graceful_exit(0))
|
| 34 |
+
program = create_program()
|
| 35 |
+
|
| 36 |
+
if validate_args(program):
|
| 37 |
+
args = vars(program.parse_args())
|
| 38 |
+
apply_args(args, state_manager.init_item)
|
| 39 |
+
|
| 40 |
+
if state_manager.get_item('command'):
|
| 41 |
+
logger.init(state_manager.get_item('log_level'))
|
| 42 |
+
route(args)
|
| 43 |
+
else:
|
| 44 |
+
program.print_help()
|
| 45 |
+
else:
|
| 46 |
+
hard_exit(2)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def route(args : Args) -> None:
|
| 50 |
+
system_memory_limit = state_manager.get_item('system_memory_limit')
|
| 51 |
+
if system_memory_limit and system_memory_limit > 0:
|
| 52 |
+
limit_system_memory(system_memory_limit)
|
| 53 |
+
if state_manager.get_item('command') == 'force-download':
|
| 54 |
+
error_code = force_download()
|
| 55 |
+
return conditional_exit(error_code)
|
| 56 |
+
if state_manager.get_item('command') in [ 'job-list', 'job-create', 'job-submit', 'job-submit-all', 'job-delete', 'job-delete-all', 'job-add-step', 'job-remix-step', 'job-insert-step', 'job-remove-step' ]:
|
| 57 |
+
if not job_manager.init_jobs(state_manager.get_item('jobs_path')):
|
| 58 |
+
hard_exit(1)
|
| 59 |
+
error_code = route_job_manager(args)
|
| 60 |
+
hard_exit(error_code)
|
| 61 |
+
if not pre_check():
|
| 62 |
+
return conditional_exit(2)
|
| 63 |
+
if state_manager.get_item('command') == 'run':
|
| 64 |
+
import facefusion.uis.core as ui
|
| 65 |
+
|
| 66 |
+
if not common_pre_check() or not processors_pre_check():
|
| 67 |
+
return conditional_exit(2)
|
| 68 |
+
for ui_layout in ui.get_ui_layouts_modules(state_manager.get_item('ui_layouts')):
|
| 69 |
+
if not ui_layout.pre_check():
|
| 70 |
+
return conditional_exit(2)
|
| 71 |
+
ui.init()
|
| 72 |
+
ui.launch()
|
| 73 |
+
if state_manager.get_item('command') == 'headless-run':
|
| 74 |
+
if not job_manager.init_jobs(state_manager.get_item('jobs_path')):
|
| 75 |
+
hard_exit(1)
|
| 76 |
+
error_core = process_headless(args)
|
| 77 |
+
hard_exit(error_core)
|
| 78 |
+
if state_manager.get_item('command') == 'batch-run':
|
| 79 |
+
if not job_manager.init_jobs(state_manager.get_item('jobs_path')):
|
| 80 |
+
hard_exit(1)
|
| 81 |
+
error_core = process_batch(args)
|
| 82 |
+
hard_exit(error_core)
|
| 83 |
+
if state_manager.get_item('command') in [ 'job-run', 'job-run-all', 'job-retry', 'job-retry-all' ]:
|
| 84 |
+
if not job_manager.init_jobs(state_manager.get_item('jobs_path')):
|
| 85 |
+
hard_exit(1)
|
| 86 |
+
error_code = route_job_runner()
|
| 87 |
+
hard_exit(error_code)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def pre_check() -> bool:
|
| 91 |
+
if sys.version_info < (3, 10):
|
| 92 |
+
logger.error(wording.get('python_not_supported').format(version = '3.10'), __name__)
|
| 93 |
+
return False
|
| 94 |
+
if not shutil.which('curl'):
|
| 95 |
+
logger.error(wording.get('curl_not_installed'), __name__)
|
| 96 |
+
return False
|
| 97 |
+
if not shutil.which('ffmpeg'):
|
| 98 |
+
logger.error(wording.get('ffmpeg_not_installed'), __name__)
|
| 99 |
+
return False
|
| 100 |
+
return True
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def common_pre_check() -> bool:
|
| 104 |
+
common_modules =\
|
| 105 |
+
[
|
| 106 |
+
content_analyser,
|
| 107 |
+
face_classifier,
|
| 108 |
+
face_detector,
|
| 109 |
+
face_landmarker,
|
| 110 |
+
face_masker,
|
| 111 |
+
face_recognizer,
|
| 112 |
+
voice_extractor
|
| 113 |
+
]
|
| 114 |
+
|
| 115 |
+
return all(module.pre_check() for module in common_modules)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def processors_pre_check() -> bool:
|
| 119 |
+
for processor_module in get_processors_modules(state_manager.get_item('processors')):
|
| 120 |
+
if not processor_module.pre_check():
|
| 121 |
+
return False
|
| 122 |
+
return True
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def force_download() -> ErrorCode:
|
| 126 |
+
common_modules =\
|
| 127 |
+
[
|
| 128 |
+
content_analyser,
|
| 129 |
+
face_classifier,
|
| 130 |
+
face_detector,
|
| 131 |
+
face_landmarker,
|
| 132 |
+
face_masker,
|
| 133 |
+
face_recognizer,
|
| 134 |
+
voice_extractor
|
| 135 |
+
]
|
| 136 |
+
available_processors = [ file.get('name') for file in list_directory('facefusion/processors/modules') ]
|
| 137 |
+
processor_modules = get_processors_modules(available_processors)
|
| 138 |
+
|
| 139 |
+
for module in common_modules + processor_modules:
|
| 140 |
+
if hasattr(module, 'create_static_model_set'):
|
| 141 |
+
for model in module.create_static_model_set(state_manager.get_item('download_scope')).values():
|
| 142 |
+
model_hashes = model.get('hashes')
|
| 143 |
+
model_sources = model.get('sources')
|
| 144 |
+
|
| 145 |
+
if model_hashes and model_sources:
|
| 146 |
+
if not conditional_download_hashes(model_hashes) or not conditional_download_sources(model_sources):
|
| 147 |
+
return 1
|
| 148 |
+
|
| 149 |
+
return 0
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def route_job_manager(args : Args) -> ErrorCode:
|
| 153 |
+
if state_manager.get_item('command') == 'job-list':
|
| 154 |
+
job_headers, job_contents = compose_job_list(state_manager.get_item('job_status'))
|
| 155 |
+
|
| 156 |
+
if job_contents:
|
| 157 |
+
logger.table(job_headers, job_contents)
|
| 158 |
+
return 0
|
| 159 |
+
return 1
|
| 160 |
+
if state_manager.get_item('command') == 'job-create':
|
| 161 |
+
if job_manager.create_job(state_manager.get_item('job_id')):
|
| 162 |
+
logger.info(wording.get('job_created').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 163 |
+
return 0
|
| 164 |
+
logger.error(wording.get('job_not_created').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 165 |
+
return 1
|
| 166 |
+
if state_manager.get_item('command') == 'job-submit':
|
| 167 |
+
if job_manager.submit_job(state_manager.get_item('job_id')):
|
| 168 |
+
logger.info(wording.get('job_submitted').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 169 |
+
return 0
|
| 170 |
+
logger.error(wording.get('job_not_submitted').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 171 |
+
return 1
|
| 172 |
+
if state_manager.get_item('command') == 'job-submit-all':
|
| 173 |
+
if job_manager.submit_jobs():
|
| 174 |
+
logger.info(wording.get('job_all_submitted'), __name__)
|
| 175 |
+
return 0
|
| 176 |
+
logger.error(wording.get('job_all_not_submitted'), __name__)
|
| 177 |
+
return 1
|
| 178 |
+
if state_manager.get_item('command') == 'job-delete':
|
| 179 |
+
if job_manager.delete_job(state_manager.get_item('job_id')):
|
| 180 |
+
logger.info(wording.get('job_deleted').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 181 |
+
return 0
|
| 182 |
+
logger.error(wording.get('job_not_deleted').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 183 |
+
return 1
|
| 184 |
+
if state_manager.get_item('command') == 'job-delete-all':
|
| 185 |
+
if job_manager.delete_jobs():
|
| 186 |
+
logger.info(wording.get('job_all_deleted'), __name__)
|
| 187 |
+
return 0
|
| 188 |
+
logger.error(wording.get('job_all_not_deleted'), __name__)
|
| 189 |
+
return 1
|
| 190 |
+
if state_manager.get_item('command') == 'job-add-step':
|
| 191 |
+
step_args = reduce_step_args(args)
|
| 192 |
+
|
| 193 |
+
if job_manager.add_step(state_manager.get_item('job_id'), step_args):
|
| 194 |
+
logger.info(wording.get('job_step_added').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 195 |
+
return 0
|
| 196 |
+
logger.error(wording.get('job_step_not_added').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 197 |
+
return 1
|
| 198 |
+
if state_manager.get_item('command') == 'job-remix-step':
|
| 199 |
+
step_args = reduce_step_args(args)
|
| 200 |
+
|
| 201 |
+
if job_manager.remix_step(state_manager.get_item('job_id'), state_manager.get_item('step_index'), step_args):
|
| 202 |
+
logger.info(wording.get('job_remix_step_added').format(job_id = state_manager.get_item('job_id'), step_index = state_manager.get_item('step_index')), __name__)
|
| 203 |
+
return 0
|
| 204 |
+
logger.error(wording.get('job_remix_step_not_added').format(job_id = state_manager.get_item('job_id'), step_index = state_manager.get_item('step_index')), __name__)
|
| 205 |
+
return 1
|
| 206 |
+
if state_manager.get_item('command') == 'job-insert-step':
|
| 207 |
+
step_args = reduce_step_args(args)
|
| 208 |
+
|
| 209 |
+
if job_manager.insert_step(state_manager.get_item('job_id'), state_manager.get_item('step_index'), step_args):
|
| 210 |
+
logger.info(wording.get('job_step_inserted').format(job_id = state_manager.get_item('job_id'), step_index = state_manager.get_item('step_index')), __name__)
|
| 211 |
+
return 0
|
| 212 |
+
logger.error(wording.get('job_step_not_inserted').format(job_id = state_manager.get_item('job_id'), step_index = state_manager.get_item('step_index')), __name__)
|
| 213 |
+
return 1
|
| 214 |
+
if state_manager.get_item('command') == 'job-remove-step':
|
| 215 |
+
if job_manager.remove_step(state_manager.get_item('job_id'), state_manager.get_item('step_index')):
|
| 216 |
+
logger.info(wording.get('job_step_removed').format(job_id = state_manager.get_item('job_id'), step_index = state_manager.get_item('step_index')), __name__)
|
| 217 |
+
return 0
|
| 218 |
+
logger.error(wording.get('job_step_not_removed').format(job_id = state_manager.get_item('job_id'), step_index = state_manager.get_item('step_index')), __name__)
|
| 219 |
+
return 1
|
| 220 |
+
return 1
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def route_job_runner() -> ErrorCode:
|
| 224 |
+
if state_manager.get_item('command') == 'job-run':
|
| 225 |
+
logger.info(wording.get('running_job').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 226 |
+
if job_runner.run_job(state_manager.get_item('job_id'), process_step):
|
| 227 |
+
logger.info(wording.get('processing_job_succeed').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 228 |
+
return 0
|
| 229 |
+
logger.info(wording.get('processing_job_failed').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 230 |
+
return 1
|
| 231 |
+
if state_manager.get_item('command') == 'job-run-all':
|
| 232 |
+
logger.info(wording.get('running_jobs'), __name__)
|
| 233 |
+
if job_runner.run_jobs(process_step):
|
| 234 |
+
logger.info(wording.get('processing_jobs_succeed'), __name__)
|
| 235 |
+
return 0
|
| 236 |
+
logger.info(wording.get('processing_jobs_failed'), __name__)
|
| 237 |
+
return 1
|
| 238 |
+
if state_manager.get_item('command') == 'job-retry':
|
| 239 |
+
logger.info(wording.get('retrying_job').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 240 |
+
if job_runner.retry_job(state_manager.get_item('job_id'), process_step):
|
| 241 |
+
logger.info(wording.get('processing_job_succeed').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 242 |
+
return 0
|
| 243 |
+
logger.info(wording.get('processing_job_failed').format(job_id = state_manager.get_item('job_id')), __name__)
|
| 244 |
+
return 1
|
| 245 |
+
if state_manager.get_item('command') == 'job-retry-all':
|
| 246 |
+
logger.info(wording.get('retrying_jobs'), __name__)
|
| 247 |
+
if job_runner.retry_jobs(process_step):
|
| 248 |
+
logger.info(wording.get('processing_jobs_succeed'), __name__)
|
| 249 |
+
return 0
|
| 250 |
+
logger.info(wording.get('processing_jobs_failed'), __name__)
|
| 251 |
+
return 1
|
| 252 |
+
return 2
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def process_headless(args : Args) -> ErrorCode:
|
| 256 |
+
job_id = job_helper.suggest_job_id('headless')
|
| 257 |
+
step_args = reduce_step_args(args)
|
| 258 |
+
|
| 259 |
+
if job_manager.create_job(job_id) and job_manager.add_step(job_id, step_args) and job_manager.submit_job(job_id) and job_runner.run_job(job_id, process_step):
|
| 260 |
+
return 0
|
| 261 |
+
return 1
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
def process_batch(args : Args) -> ErrorCode:
|
| 265 |
+
job_id = job_helper.suggest_job_id('batch')
|
| 266 |
+
step_args = reduce_step_args(args)
|
| 267 |
+
job_args = reduce_job_args(args)
|
| 268 |
+
source_paths = resolve_file_pattern(job_args.get('source_pattern'))
|
| 269 |
+
target_paths = resolve_file_pattern(job_args.get('target_pattern'))
|
| 270 |
+
|
| 271 |
+
if job_manager.create_job(job_id):
|
| 272 |
+
if source_paths and target_paths:
|
| 273 |
+
for index, (source_path, target_path) in enumerate(itertools.product(source_paths, target_paths)):
|
| 274 |
+
step_args['source_paths'] = [ source_path ]
|
| 275 |
+
step_args['target_path'] = target_path
|
| 276 |
+
step_args['output_path'] = job_args.get('output_pattern').format(index = index)
|
| 277 |
+
if not job_manager.add_step(job_id, step_args):
|
| 278 |
+
return 1
|
| 279 |
+
if job_manager.submit_job(job_id) and job_runner.run_job(job_id, process_step):
|
| 280 |
+
return 0
|
| 281 |
+
|
| 282 |
+
if not source_paths and target_paths:
|
| 283 |
+
for index, target_path in enumerate(target_paths):
|
| 284 |
+
step_args['target_path'] = target_path
|
| 285 |
+
step_args['output_path'] = job_args.get('output_pattern').format(index = index)
|
| 286 |
+
if not job_manager.add_step(job_id, step_args):
|
| 287 |
+
return 1
|
| 288 |
+
if job_manager.submit_job(job_id) and job_runner.run_job(job_id, process_step):
|
| 289 |
+
return 0
|
| 290 |
+
return 1
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
def process_step(job_id : str, step_index : int, step_args : Args) -> bool:
|
| 294 |
+
clear_reference_faces()
|
| 295 |
+
step_total = job_manager.count_step_total(job_id)
|
| 296 |
+
step_args.update(collect_job_args())
|
| 297 |
+
apply_args(step_args, state_manager.set_item)
|
| 298 |
+
|
| 299 |
+
logger.info(wording.get('processing_step').format(step_current = step_index + 1, step_total = step_total), __name__)
|
| 300 |
+
if common_pre_check() and processors_pre_check():
|
| 301 |
+
error_code = conditional_process()
|
| 302 |
+
return error_code == 0
|
| 303 |
+
return False
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def conditional_process() -> ErrorCode:
|
| 307 |
+
start_time = time()
|
| 308 |
+
for processor_module in get_processors_modules(state_manager.get_item('processors')):
|
| 309 |
+
if not processor_module.pre_process('output'):
|
| 310 |
+
return 2
|
| 311 |
+
conditional_append_reference_faces()
|
| 312 |
+
if is_image(state_manager.get_item('target_path')):
|
| 313 |
+
return process_image(start_time)
|
| 314 |
+
if is_video(state_manager.get_item('target_path')):
|
| 315 |
+
return process_video(start_time)
|
| 316 |
+
return 0
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def conditional_append_reference_faces() -> None:
|
| 320 |
+
if 'reference' in state_manager.get_item('face_selector_mode') and not get_reference_faces():
|
| 321 |
+
source_frames = read_static_images(state_manager.get_item('source_paths'))
|
| 322 |
+
source_faces = get_many_faces(source_frames)
|
| 323 |
+
source_face = get_average_face(source_faces)
|
| 324 |
+
if is_video(state_manager.get_item('target_path')):
|
| 325 |
+
reference_frame = get_video_frame(state_manager.get_item('target_path'), state_manager.get_item('reference_frame_number'))
|
| 326 |
+
else:
|
| 327 |
+
reference_frame = read_image(state_manager.get_item('target_path'))
|
| 328 |
+
reference_faces = sort_and_filter_faces(get_many_faces([ reference_frame ]))
|
| 329 |
+
reference_face = get_one_face(reference_faces, state_manager.get_item('reference_face_position'))
|
| 330 |
+
append_reference_face('origin', reference_face)
|
| 331 |
+
|
| 332 |
+
if source_face and reference_face:
|
| 333 |
+
for processor_module in get_processors_modules(state_manager.get_item('processors')):
|
| 334 |
+
abstract_reference_frame = processor_module.get_reference_frame(source_face, reference_face, reference_frame)
|
| 335 |
+
if numpy.any(abstract_reference_frame):
|
| 336 |
+
abstract_reference_faces = sort_and_filter_faces(get_many_faces([ abstract_reference_frame ]))
|
| 337 |
+
abstract_reference_face = get_one_face(abstract_reference_faces, state_manager.get_item('reference_face_position'))
|
| 338 |
+
append_reference_face(processor_module.__name__, abstract_reference_face)
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
def process_image(start_time : float) -> ErrorCode:
|
| 342 |
+
if analyse_image(state_manager.get_item('target_path')):
|
| 343 |
+
return 3
|
| 344 |
+
# clear temp
|
| 345 |
+
logger.debug(wording.get('clearing_temp'), __name__)
|
| 346 |
+
clear_temp_directory(state_manager.get_item('target_path'))
|
| 347 |
+
# create temp
|
| 348 |
+
logger.debug(wording.get('creating_temp'), __name__)
|
| 349 |
+
create_temp_directory(state_manager.get_item('target_path'))
|
| 350 |
+
# copy image
|
| 351 |
+
process_manager.start()
|
| 352 |
+
temp_image_resolution = pack_resolution(restrict_image_resolution(state_manager.get_item('target_path'), unpack_resolution(state_manager.get_item('output_image_resolution'))))
|
| 353 |
+
logger.info(wording.get('copying_image').format(resolution = temp_image_resolution), __name__)
|
| 354 |
+
if copy_image(state_manager.get_item('target_path'), temp_image_resolution):
|
| 355 |
+
logger.debug(wording.get('copying_image_succeed'), __name__)
|
| 356 |
+
else:
|
| 357 |
+
logger.error(wording.get('copying_image_failed'), __name__)
|
| 358 |
+
process_manager.end()
|
| 359 |
+
return 1
|
| 360 |
+
# process image
|
| 361 |
+
temp_file_path = get_temp_file_path(state_manager.get_item('target_path'))
|
| 362 |
+
for processor_module in get_processors_modules(state_manager.get_item('processors')):
|
| 363 |
+
logger.info(wording.get('processing'), processor_module.__name__)
|
| 364 |
+
processor_module.process_image(state_manager.get_item('source_paths'), temp_file_path, temp_file_path)
|
| 365 |
+
processor_module.post_process()
|
| 366 |
+
if is_process_stopping():
|
| 367 |
+
process_manager.end()
|
| 368 |
+
return 4
|
| 369 |
+
# finalize image
|
| 370 |
+
logger.info(wording.get('finalizing_image').format(resolution = state_manager.get_item('output_image_resolution')), __name__)
|
| 371 |
+
if finalize_image(state_manager.get_item('target_path'), state_manager.get_item('output_path'), state_manager.get_item('output_image_resolution')):
|
| 372 |
+
logger.debug(wording.get('finalizing_image_succeed'), __name__)
|
| 373 |
+
else:
|
| 374 |
+
logger.warn(wording.get('finalizing_image_skipped'), __name__)
|
| 375 |
+
# clear temp
|
| 376 |
+
logger.debug(wording.get('clearing_temp'), __name__)
|
| 377 |
+
clear_temp_directory(state_manager.get_item('target_path'))
|
| 378 |
+
# validate image
|
| 379 |
+
if is_image(state_manager.get_item('output_path')):
|
| 380 |
+
seconds = '{:.2f}'.format((time() - start_time) % 60)
|
| 381 |
+
logger.info(wording.get('processing_image_succeed').format(seconds = seconds), __name__)
|
| 382 |
+
conditional_log_statistics()
|
| 383 |
+
else:
|
| 384 |
+
logger.error(wording.get('processing_image_failed'), __name__)
|
| 385 |
+
process_manager.end()
|
| 386 |
+
return 1
|
| 387 |
+
process_manager.end()
|
| 388 |
+
return 0
|
| 389 |
+
|
| 390 |
+
|
| 391 |
+
def process_video(start_time : float) -> ErrorCode:
|
| 392 |
+
trim_frame_start, trim_frame_end = restrict_trim_frame(state_manager.get_item('target_path'), state_manager.get_item('trim_frame_start'), state_manager.get_item('trim_frame_end'))
|
| 393 |
+
if analyse_video(state_manager.get_item('target_path'), trim_frame_start, trim_frame_end):
|
| 394 |
+
return 3
|
| 395 |
+
# clear temp
|
| 396 |
+
logger.debug(wording.get('clearing_temp'), __name__)
|
| 397 |
+
clear_temp_directory(state_manager.get_item('target_path'))
|
| 398 |
+
# create temp
|
| 399 |
+
logger.debug(wording.get('creating_temp'), __name__)
|
| 400 |
+
create_temp_directory(state_manager.get_item('target_path'))
|
| 401 |
+
# extract frames
|
| 402 |
+
process_manager.start()
|
| 403 |
+
temp_video_resolution = pack_resolution(restrict_video_resolution(state_manager.get_item('target_path'), unpack_resolution(state_manager.get_item('output_video_resolution'))))
|
| 404 |
+
temp_video_fps = restrict_video_fps(state_manager.get_item('target_path'), state_manager.get_item('output_video_fps'))
|
| 405 |
+
logger.info(wording.get('extracting_frames').format(resolution = temp_video_resolution, fps = temp_video_fps), __name__)
|
| 406 |
+
if extract_frames(state_manager.get_item('target_path'), temp_video_resolution, temp_video_fps, trim_frame_start, trim_frame_end):
|
| 407 |
+
logger.debug(wording.get('extracting_frames_succeed'), __name__)
|
| 408 |
+
else:
|
| 409 |
+
if is_process_stopping():
|
| 410 |
+
process_manager.end()
|
| 411 |
+
return 4
|
| 412 |
+
logger.error(wording.get('extracting_frames_failed'), __name__)
|
| 413 |
+
process_manager.end()
|
| 414 |
+
return 1
|
| 415 |
+
# process frames
|
| 416 |
+
temp_frame_paths = get_temp_frame_paths(state_manager.get_item('target_path'))
|
| 417 |
+
if temp_frame_paths:
|
| 418 |
+
for processor_module in get_processors_modules(state_manager.get_item('processors')):
|
| 419 |
+
logger.info(wording.get('processing'), processor_module.__name__)
|
| 420 |
+
processor_module.process_video(state_manager.get_item('source_paths'), temp_frame_paths)
|
| 421 |
+
processor_module.post_process()
|
| 422 |
+
if is_process_stopping():
|
| 423 |
+
return 4
|
| 424 |
+
else:
|
| 425 |
+
logger.error(wording.get('temp_frames_not_found'), __name__)
|
| 426 |
+
process_manager.end()
|
| 427 |
+
return 1
|
| 428 |
+
# merge video
|
| 429 |
+
logger.info(wording.get('merging_video').format(resolution = state_manager.get_item('output_video_resolution'), fps = state_manager.get_item('output_video_fps')), __name__)
|
| 430 |
+
if merge_video(state_manager.get_item('target_path'), state_manager.get_item('output_video_resolution'), state_manager.get_item('output_video_fps')):
|
| 431 |
+
logger.debug(wording.get('merging_video_succeed'), __name__)
|
| 432 |
+
else:
|
| 433 |
+
if is_process_stopping():
|
| 434 |
+
process_manager.end()
|
| 435 |
+
return 4
|
| 436 |
+
logger.error(wording.get('merging_video_failed'), __name__)
|
| 437 |
+
process_manager.end()
|
| 438 |
+
return 1
|
| 439 |
+
# handle audio
|
| 440 |
+
if state_manager.get_item('skip_audio'):
|
| 441 |
+
logger.info(wording.get('skipping_audio'), __name__)
|
| 442 |
+
move_temp_file(state_manager.get_item('target_path'), state_manager.get_item('output_path'))
|
| 443 |
+
else:
|
| 444 |
+
source_audio_path = get_first(filter_audio_paths(state_manager.get_item('source_paths')))
|
| 445 |
+
if source_audio_path:
|
| 446 |
+
if replace_audio(state_manager.get_item('target_path'), source_audio_path, state_manager.get_item('output_path')):
|
| 447 |
+
logger.debug(wording.get('replacing_audio_succeed'), __name__)
|
| 448 |
+
else:
|
| 449 |
+
if is_process_stopping():
|
| 450 |
+
process_manager.end()
|
| 451 |
+
return 4
|
| 452 |
+
logger.warn(wording.get('replacing_audio_skipped'), __name__)
|
| 453 |
+
move_temp_file(state_manager.get_item('target_path'), state_manager.get_item('output_path'))
|
| 454 |
+
else:
|
| 455 |
+
if restore_audio(state_manager.get_item('target_path'), state_manager.get_item('output_path'), state_manager.get_item('output_video_fps'), trim_frame_start, trim_frame_end):
|
| 456 |
+
logger.debug(wording.get('restoring_audio_succeed'), __name__)
|
| 457 |
+
else:
|
| 458 |
+
if is_process_stopping():
|
| 459 |
+
process_manager.end()
|
| 460 |
+
return 4
|
| 461 |
+
logger.warn(wording.get('restoring_audio_skipped'), __name__)
|
| 462 |
+
move_temp_file(state_manager.get_item('target_path'), state_manager.get_item('output_path'))
|
| 463 |
+
# clear temp
|
| 464 |
+
logger.debug(wording.get('clearing_temp'), __name__)
|
| 465 |
+
clear_temp_directory(state_manager.get_item('target_path'))
|
| 466 |
+
# validate video
|
| 467 |
+
if is_video(state_manager.get_item('output_path')):
|
| 468 |
+
seconds = '{:.2f}'.format((time() - start_time))
|
| 469 |
+
logger.info(wording.get('processing_video_succeed').format(seconds = seconds), __name__)
|
| 470 |
+
conditional_log_statistics()
|
| 471 |
+
else:
|
| 472 |
+
logger.error(wording.get('processing_video_failed'), __name__)
|
| 473 |
+
process_manager.end()
|
| 474 |
+
return 1
|
| 475 |
+
process_manager.end()
|
| 476 |
+
return 0
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
def is_process_stopping() -> bool:
|
| 480 |
+
if process_manager.is_stopping():
|
| 481 |
+
process_manager.end()
|
| 482 |
+
logger.info(wording.get('processing_stopped'), __name__)
|
| 483 |
+
return process_manager.is_pending()
|
facefusion/date_helper.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datetime import datetime, timedelta
|
| 2 |
+
from typing import Optional, Tuple
|
| 3 |
+
|
| 4 |
+
from facefusion import wording
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def get_current_date_time() -> datetime:
|
| 8 |
+
return datetime.now().astimezone()
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def split_time_delta(time_delta : timedelta) -> Tuple[int, int, int, int]:
|
| 12 |
+
days, hours = divmod(time_delta.total_seconds(), 86400)
|
| 13 |
+
hours, minutes = divmod(hours, 3600)
|
| 14 |
+
minutes, seconds = divmod(minutes, 60)
|
| 15 |
+
return int(days), int(hours), int(minutes), int(seconds)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def describe_time_ago(date_time : datetime) -> Optional[str]:
|
| 19 |
+
time_ago = datetime.now(date_time.tzinfo) - date_time
|
| 20 |
+
days, hours, minutes, _ = split_time_delta(time_ago)
|
| 21 |
+
|
| 22 |
+
if timedelta(days = 1) < time_ago:
|
| 23 |
+
return wording.get('time_ago_days').format(days = days, hours = hours, minutes = minutes)
|
| 24 |
+
if timedelta(hours = 1) < time_ago:
|
| 25 |
+
return wording.get('time_ago_hours').format(hours = hours, minutes = minutes)
|
| 26 |
+
if timedelta(minutes = 1) < time_ago:
|
| 27 |
+
return wording.get('time_ago_minutes').format(minutes = minutes)
|
| 28 |
+
return wording.get('time_ago_now')
|
facefusion/download.py
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
| 3 |
+
import subprocess
|
| 4 |
+
from functools import lru_cache
|
| 5 |
+
from typing import List, Optional, Tuple
|
| 6 |
+
from urllib.parse import urlparse
|
| 7 |
+
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
import facefusion.choices
|
| 11 |
+
from facefusion import logger, process_manager, state_manager, wording
|
| 12 |
+
from facefusion.filesystem import get_file_size, is_file, remove_file
|
| 13 |
+
from facefusion.hash_helper import validate_hash
|
| 14 |
+
from facefusion.typing import DownloadProvider, DownloadSet
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def open_curl(args : List[str]) -> subprocess.Popen[bytes]:
|
| 18 |
+
commands = [ shutil.which('curl'), '--silent', '--insecure', '--location' ]
|
| 19 |
+
commands.extend(args)
|
| 20 |
+
return subprocess.Popen(commands, stdin = subprocess.PIPE, stdout = subprocess.PIPE)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def conditional_download(download_directory_path : str, urls : List[str]) -> None:
|
| 24 |
+
for url in urls:
|
| 25 |
+
download_file_name = os.path.basename(urlparse(url).path)
|
| 26 |
+
download_file_path = os.path.join(download_directory_path, download_file_name)
|
| 27 |
+
initial_size = get_file_size(download_file_path)
|
| 28 |
+
download_size = get_static_download_size(url)
|
| 29 |
+
|
| 30 |
+
if initial_size < download_size:
|
| 31 |
+
with tqdm(total = download_size, initial = initial_size, desc = wording.get('downloading'), unit = 'B', unit_scale = True, unit_divisor = 1024, ascii = ' =', disable = state_manager.get_item('log_level') in [ 'warn', 'error' ]) as progress:
|
| 32 |
+
commands = [ '--create-dirs', '--continue-at', '-', '--output', download_file_path, url ]
|
| 33 |
+
open_curl(commands)
|
| 34 |
+
current_size = initial_size
|
| 35 |
+
progress.set_postfix(download_providers = state_manager.get_item('download_providers'), file_name = download_file_name)
|
| 36 |
+
|
| 37 |
+
while current_size < download_size:
|
| 38 |
+
if is_file(download_file_path):
|
| 39 |
+
current_size = get_file_size(download_file_path)
|
| 40 |
+
progress.update(current_size - progress.n)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
@lru_cache(maxsize = None)
|
| 44 |
+
def get_static_download_size(url : str) -> int:
|
| 45 |
+
commands = [ '-I', url ]
|
| 46 |
+
process = open_curl(commands)
|
| 47 |
+
lines = reversed(process.stdout.readlines())
|
| 48 |
+
|
| 49 |
+
for line in lines:
|
| 50 |
+
__line__ = line.decode().lower()
|
| 51 |
+
if 'content-length:' in __line__:
|
| 52 |
+
_, content_length = __line__.split('content-length:')
|
| 53 |
+
return int(content_length)
|
| 54 |
+
|
| 55 |
+
return 0
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
@lru_cache(maxsize = None)
|
| 59 |
+
def ping_static_url(url : str) -> bool:
|
| 60 |
+
commands = [ '-I', url ]
|
| 61 |
+
process = open_curl(commands)
|
| 62 |
+
process.communicate()
|
| 63 |
+
return process.returncode == 0
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def conditional_download_hashes(hashes : DownloadSet) -> bool:
|
| 67 |
+
hash_paths = [ hashes.get(hash_key).get('path') for hash_key in hashes.keys() ]
|
| 68 |
+
|
| 69 |
+
process_manager.check()
|
| 70 |
+
_, invalid_hash_paths = validate_hash_paths(hash_paths)
|
| 71 |
+
if invalid_hash_paths:
|
| 72 |
+
for index in hashes:
|
| 73 |
+
if hashes.get(index).get('path') in invalid_hash_paths:
|
| 74 |
+
invalid_hash_url = hashes.get(index).get('url')
|
| 75 |
+
if invalid_hash_url:
|
| 76 |
+
download_directory_path = os.path.dirname(hashes.get(index).get('path'))
|
| 77 |
+
conditional_download(download_directory_path, [ invalid_hash_url ])
|
| 78 |
+
|
| 79 |
+
valid_hash_paths, invalid_hash_paths = validate_hash_paths(hash_paths)
|
| 80 |
+
|
| 81 |
+
for valid_hash_path in valid_hash_paths:
|
| 82 |
+
valid_hash_file_name, _ = os.path.splitext(os.path.basename(valid_hash_path))
|
| 83 |
+
logger.debug(wording.get('validating_hash_succeed').format(hash_file_name = valid_hash_file_name), __name__)
|
| 84 |
+
for invalid_hash_path in invalid_hash_paths:
|
| 85 |
+
invalid_hash_file_name, _ = os.path.splitext(os.path.basename(invalid_hash_path))
|
| 86 |
+
logger.error(wording.get('validating_hash_failed').format(hash_file_name = invalid_hash_file_name), __name__)
|
| 87 |
+
|
| 88 |
+
if not invalid_hash_paths:
|
| 89 |
+
process_manager.end()
|
| 90 |
+
return not invalid_hash_paths
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def conditional_download_sources(sources : DownloadSet) -> bool:
|
| 94 |
+
source_paths = [ sources.get(source_key).get('path') for source_key in sources.keys() ]
|
| 95 |
+
|
| 96 |
+
process_manager.check()
|
| 97 |
+
_, invalid_source_paths = validate_source_paths(source_paths)
|
| 98 |
+
if invalid_source_paths:
|
| 99 |
+
for index in sources:
|
| 100 |
+
if sources.get(index).get('path') in invalid_source_paths:
|
| 101 |
+
invalid_source_url = sources.get(index).get('url')
|
| 102 |
+
if invalid_source_url:
|
| 103 |
+
download_directory_path = os.path.dirname(sources.get(index).get('path'))
|
| 104 |
+
conditional_download(download_directory_path, [ invalid_source_url ])
|
| 105 |
+
|
| 106 |
+
valid_source_paths, invalid_source_paths = validate_source_paths(source_paths)
|
| 107 |
+
|
| 108 |
+
for valid_source_path in valid_source_paths:
|
| 109 |
+
valid_source_file_name, _ = os.path.splitext(os.path.basename(valid_source_path))
|
| 110 |
+
logger.debug(wording.get('validating_source_succeed').format(source_file_name = valid_source_file_name), __name__)
|
| 111 |
+
for invalid_source_path in invalid_source_paths:
|
| 112 |
+
invalid_source_file_name, _ = os.path.splitext(os.path.basename(invalid_source_path))
|
| 113 |
+
logger.error(wording.get('validating_source_failed').format(source_file_name = invalid_source_file_name), __name__)
|
| 114 |
+
|
| 115 |
+
if remove_file(invalid_source_path):
|
| 116 |
+
logger.error(wording.get('deleting_corrupt_source').format(source_file_name = invalid_source_file_name), __name__)
|
| 117 |
+
|
| 118 |
+
if not invalid_source_paths:
|
| 119 |
+
process_manager.end()
|
| 120 |
+
return not invalid_source_paths
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def validate_hash_paths(hash_paths : List[str]) -> Tuple[List[str], List[str]]:
|
| 124 |
+
valid_hash_paths = []
|
| 125 |
+
invalid_hash_paths = []
|
| 126 |
+
|
| 127 |
+
for hash_path in hash_paths:
|
| 128 |
+
if is_file(hash_path):
|
| 129 |
+
valid_hash_paths.append(hash_path)
|
| 130 |
+
else:
|
| 131 |
+
invalid_hash_paths.append(hash_path)
|
| 132 |
+
return valid_hash_paths, invalid_hash_paths
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def validate_source_paths(source_paths : List[str]) -> Tuple[List[str], List[str]]:
|
| 136 |
+
valid_source_paths = []
|
| 137 |
+
invalid_source_paths = []
|
| 138 |
+
|
| 139 |
+
for source_path in source_paths:
|
| 140 |
+
if validate_hash(source_path):
|
| 141 |
+
valid_source_paths.append(source_path)
|
| 142 |
+
else:
|
| 143 |
+
invalid_source_paths.append(source_path)
|
| 144 |
+
return valid_source_paths, invalid_source_paths
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def resolve_download_url(base_name : str, file_name : str) -> Optional[str]:
|
| 148 |
+
download_providers = state_manager.get_item('download_providers')
|
| 149 |
+
|
| 150 |
+
for download_provider in download_providers:
|
| 151 |
+
if ping_download_provider(download_provider):
|
| 152 |
+
return resolve_download_url_by_provider(download_provider, base_name, file_name)
|
| 153 |
+
return None
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def ping_download_provider(download_provider : DownloadProvider) -> bool:
|
| 157 |
+
download_provider_value = facefusion.choices.download_provider_set.get(download_provider)
|
| 158 |
+
return ping_static_url(download_provider_value.get('url'))
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def resolve_download_url_by_provider(download_provider : DownloadProvider, base_name : str, file_name : str) -> Optional[str]:
|
| 162 |
+
download_provider_value = facefusion.choices.download_provider_set.get(download_provider)
|
| 163 |
+
return download_provider_value.get('url') + download_provider_value.get('path').format(base_name = base_name, file_name = file_name)
|
facefusion/execution.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import shutil
|
| 2 |
+
import subprocess
|
| 3 |
+
import xml.etree.ElementTree as ElementTree
|
| 4 |
+
from functools import lru_cache
|
| 5 |
+
from typing import Any, List, Optional
|
| 6 |
+
|
| 7 |
+
from onnxruntime import get_available_providers, set_default_logger_severity
|
| 8 |
+
|
| 9 |
+
import facefusion.choices
|
| 10 |
+
from facefusion.typing import ExecutionDevice, ExecutionProvider, ValueAndUnit
|
| 11 |
+
|
| 12 |
+
set_default_logger_severity(3)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def has_execution_provider(execution_provider : ExecutionProvider) -> bool:
|
| 16 |
+
return execution_provider in get_available_execution_providers()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_available_execution_providers() -> List[ExecutionProvider]:
|
| 20 |
+
inference_execution_providers = get_available_providers()
|
| 21 |
+
available_execution_providers = []
|
| 22 |
+
|
| 23 |
+
for execution_provider, execution_provider_value in facefusion.choices.execution_provider_set.items():
|
| 24 |
+
if execution_provider_value in inference_execution_providers:
|
| 25 |
+
available_execution_providers.append(execution_provider)
|
| 26 |
+
|
| 27 |
+
return available_execution_providers
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def create_inference_execution_providers(execution_device_id : str, execution_providers : List[ExecutionProvider]) -> List[Any]:
|
| 31 |
+
inference_execution_providers : List[Any] = []
|
| 32 |
+
|
| 33 |
+
for execution_provider in execution_providers:
|
| 34 |
+
if execution_provider == 'cuda':
|
| 35 |
+
inference_execution_providers.append((facefusion.choices.execution_provider_set.get(execution_provider),
|
| 36 |
+
{
|
| 37 |
+
'device_id': execution_device_id,
|
| 38 |
+
'cudnn_conv_algo_search': 'DEFAULT' if is_geforce_16_series() else 'EXHAUSTIVE'
|
| 39 |
+
}))
|
| 40 |
+
if execution_provider == 'tensorrt':
|
| 41 |
+
inference_execution_providers.append((facefusion.choices.execution_provider_set.get(execution_provider),
|
| 42 |
+
{
|
| 43 |
+
'device_id': execution_device_id,
|
| 44 |
+
'trt_engine_cache_enable': True,
|
| 45 |
+
'trt_engine_cache_path': '.caches',
|
| 46 |
+
'trt_timing_cache_enable': True,
|
| 47 |
+
'trt_timing_cache_path': '.caches',
|
| 48 |
+
'trt_builder_optimization_level': 5
|
| 49 |
+
}))
|
| 50 |
+
if execution_provider == 'openvino':
|
| 51 |
+
inference_execution_providers.append((facefusion.choices.execution_provider_set.get(execution_provider),
|
| 52 |
+
{
|
| 53 |
+
'device_type': 'GPU' if execution_device_id == '0' else 'GPU.' + execution_device_id,
|
| 54 |
+
'precision': 'FP32'
|
| 55 |
+
}))
|
| 56 |
+
if execution_provider in [ 'directml', 'rocm' ]:
|
| 57 |
+
inference_execution_providers.append((facefusion.choices.execution_provider_set.get(execution_provider),
|
| 58 |
+
{
|
| 59 |
+
'device_id': execution_device_id
|
| 60 |
+
}))
|
| 61 |
+
if execution_provider == 'coreml':
|
| 62 |
+
inference_execution_providers.append(facefusion.choices.execution_provider_set.get(execution_provider))
|
| 63 |
+
|
| 64 |
+
if 'cpu' in execution_providers:
|
| 65 |
+
inference_execution_providers.append(facefusion.choices.execution_provider_set.get('cpu'))
|
| 66 |
+
|
| 67 |
+
return inference_execution_providers
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def is_geforce_16_series() -> bool:
|
| 71 |
+
execution_devices = detect_static_execution_devices()
|
| 72 |
+
product_names = ('GeForce GTX 1630', 'GeForce GTX 1650', 'GeForce GTX 1660')
|
| 73 |
+
|
| 74 |
+
return any(execution_device.get('product').get('name').startswith(product_names) for execution_device in execution_devices)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def run_nvidia_smi() -> subprocess.Popen[bytes]:
|
| 78 |
+
commands = [ shutil.which('nvidia-smi'), '--query', '--xml-format' ]
|
| 79 |
+
return subprocess.Popen(commands, stdout = subprocess.PIPE)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
@lru_cache(maxsize = None)
|
| 83 |
+
def detect_static_execution_devices() -> List[ExecutionDevice]:
|
| 84 |
+
return detect_execution_devices()
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def detect_execution_devices() -> List[ExecutionDevice]:
|
| 88 |
+
execution_devices : List[ExecutionDevice] = []
|
| 89 |
+
|
| 90 |
+
try:
|
| 91 |
+
output, _ = run_nvidia_smi().communicate()
|
| 92 |
+
root_element = ElementTree.fromstring(output)
|
| 93 |
+
except Exception:
|
| 94 |
+
root_element = ElementTree.Element('xml')
|
| 95 |
+
|
| 96 |
+
for gpu_element in root_element.findall('gpu'):
|
| 97 |
+
execution_devices.append(
|
| 98 |
+
{
|
| 99 |
+
'driver_version': root_element.findtext('driver_version'),
|
| 100 |
+
'framework':
|
| 101 |
+
{
|
| 102 |
+
'name': 'CUDA',
|
| 103 |
+
'version': root_element.findtext('cuda_version')
|
| 104 |
+
},
|
| 105 |
+
'product':
|
| 106 |
+
{
|
| 107 |
+
'vendor': 'NVIDIA',
|
| 108 |
+
'name': gpu_element.findtext('product_name').replace('NVIDIA', '').strip()
|
| 109 |
+
},
|
| 110 |
+
'video_memory':
|
| 111 |
+
{
|
| 112 |
+
'total': create_value_and_unit(gpu_element.findtext('fb_memory_usage/total')),
|
| 113 |
+
'free': create_value_and_unit(gpu_element.findtext('fb_memory_usage/free'))
|
| 114 |
+
},
|
| 115 |
+
'temperature':
|
| 116 |
+
{
|
| 117 |
+
'gpu': create_value_and_unit(gpu_element.findtext('temperature/gpu_temp')),
|
| 118 |
+
'memory': create_value_and_unit(gpu_element.findtext('temperature/memory_temp'))
|
| 119 |
+
},
|
| 120 |
+
'utilization':
|
| 121 |
+
{
|
| 122 |
+
'gpu': create_value_and_unit(gpu_element.findtext('utilization/gpu_util')),
|
| 123 |
+
'memory': create_value_and_unit(gpu_element.findtext('utilization/memory_util'))
|
| 124 |
+
}
|
| 125 |
+
})
|
| 126 |
+
|
| 127 |
+
return execution_devices
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def create_value_and_unit(text : str) -> Optional[ValueAndUnit]:
|
| 131 |
+
if ' ' in text:
|
| 132 |
+
value, unit = text.split(' ')
|
| 133 |
+
|
| 134 |
+
return\
|
| 135 |
+
{
|
| 136 |
+
'value': int(value),
|
| 137 |
+
'unit': str(unit)
|
| 138 |
+
}
|
| 139 |
+
return None
|
facefusion/exit_helper.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import signal
|
| 2 |
+
import sys
|
| 3 |
+
from time import sleep
|
| 4 |
+
|
| 5 |
+
from facefusion import process_manager, state_manager
|
| 6 |
+
from facefusion.temp_helper import clear_temp_directory
|
| 7 |
+
from facefusion.typing import ErrorCode
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def hard_exit(error_code : ErrorCode) -> None:
|
| 11 |
+
signal.signal(signal.SIGINT, signal.SIG_IGN)
|
| 12 |
+
sys.exit(error_code)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def conditional_exit(error_code : ErrorCode) -> None:
|
| 16 |
+
if state_manager.get_item('command') == 'headless-run':
|
| 17 |
+
hard_exit(error_code)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def graceful_exit(error_code : ErrorCode) -> None:
|
| 21 |
+
process_manager.stop()
|
| 22 |
+
while process_manager.is_processing():
|
| 23 |
+
sleep(0.5)
|
| 24 |
+
if state_manager.get_item('target_path'):
|
| 25 |
+
clear_temp_directory(state_manager.get_item('target_path'))
|
| 26 |
+
hard_exit(error_code)
|
facefusion/face_analyser.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import numpy
|
| 4 |
+
|
| 5 |
+
from facefusion import state_manager
|
| 6 |
+
from facefusion.common_helper import get_first
|
| 7 |
+
from facefusion.face_classifier import classify_face
|
| 8 |
+
from facefusion.face_detector import detect_faces, detect_rotated_faces
|
| 9 |
+
from facefusion.face_helper import apply_nms, convert_to_face_landmark_5, estimate_face_angle, get_nms_threshold
|
| 10 |
+
from facefusion.face_landmarker import detect_face_landmarks, estimate_face_landmark_68_5
|
| 11 |
+
from facefusion.face_recognizer import calc_embedding
|
| 12 |
+
from facefusion.face_store import get_static_faces, set_static_faces
|
| 13 |
+
from facefusion.typing import BoundingBox, Face, FaceLandmark5, FaceLandmarkSet, FaceScoreSet, Score, VisionFrame
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def create_faces(vision_frame : VisionFrame, bounding_boxes : List[BoundingBox], face_scores : List[Score], face_landmarks_5 : List[FaceLandmark5]) -> List[Face]:
|
| 17 |
+
faces = []
|
| 18 |
+
nms_threshold = get_nms_threshold(state_manager.get_item('face_detector_model'), state_manager.get_item('face_detector_angles'))
|
| 19 |
+
keep_indices = apply_nms(bounding_boxes, face_scores, state_manager.get_item('face_detector_score'), nms_threshold)
|
| 20 |
+
|
| 21 |
+
for index in keep_indices:
|
| 22 |
+
bounding_box = bounding_boxes[index]
|
| 23 |
+
face_score = face_scores[index]
|
| 24 |
+
face_landmark_5 = face_landmarks_5[index]
|
| 25 |
+
face_landmark_5_68 = face_landmark_5
|
| 26 |
+
face_landmark_68_5 = estimate_face_landmark_68_5(face_landmark_5_68)
|
| 27 |
+
face_landmark_68 = face_landmark_68_5
|
| 28 |
+
face_landmark_score_68 = 0.0
|
| 29 |
+
face_angle = estimate_face_angle(face_landmark_68_5)
|
| 30 |
+
|
| 31 |
+
if state_manager.get_item('face_landmarker_score') > 0:
|
| 32 |
+
face_landmark_68, face_landmark_score_68 = detect_face_landmarks(vision_frame, bounding_box, face_angle)
|
| 33 |
+
if face_landmark_score_68 > state_manager.get_item('face_landmarker_score'):
|
| 34 |
+
face_landmark_5_68 = convert_to_face_landmark_5(face_landmark_68)
|
| 35 |
+
|
| 36 |
+
face_landmark_set : FaceLandmarkSet =\
|
| 37 |
+
{
|
| 38 |
+
'5': face_landmark_5,
|
| 39 |
+
'5/68': face_landmark_5_68,
|
| 40 |
+
'68': face_landmark_68,
|
| 41 |
+
'68/5': face_landmark_68_5
|
| 42 |
+
}
|
| 43 |
+
face_score_set : FaceScoreSet =\
|
| 44 |
+
{
|
| 45 |
+
'detector': face_score,
|
| 46 |
+
'landmarker': face_landmark_score_68
|
| 47 |
+
}
|
| 48 |
+
embedding, normed_embedding = calc_embedding(vision_frame, face_landmark_set.get('5/68'))
|
| 49 |
+
gender, age, race = classify_face(vision_frame, face_landmark_set.get('5/68'))
|
| 50 |
+
faces.append(Face(
|
| 51 |
+
bounding_box = bounding_box,
|
| 52 |
+
score_set = face_score_set,
|
| 53 |
+
landmark_set = face_landmark_set,
|
| 54 |
+
angle = face_angle,
|
| 55 |
+
embedding = embedding,
|
| 56 |
+
normed_embedding = normed_embedding,
|
| 57 |
+
gender = gender,
|
| 58 |
+
age = age,
|
| 59 |
+
race = race
|
| 60 |
+
))
|
| 61 |
+
return faces
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def get_one_face(faces : List[Face], position : int = 0) -> Optional[Face]:
|
| 65 |
+
if faces:
|
| 66 |
+
position = min(position, len(faces) - 1)
|
| 67 |
+
return faces[position]
|
| 68 |
+
return None
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def get_average_face(faces : List[Face]) -> Optional[Face]:
|
| 72 |
+
embeddings = []
|
| 73 |
+
normed_embeddings = []
|
| 74 |
+
|
| 75 |
+
if faces:
|
| 76 |
+
first_face = get_first(faces)
|
| 77 |
+
|
| 78 |
+
for face in faces:
|
| 79 |
+
embeddings.append(face.embedding)
|
| 80 |
+
normed_embeddings.append(face.normed_embedding)
|
| 81 |
+
|
| 82 |
+
return Face(
|
| 83 |
+
bounding_box = first_face.bounding_box,
|
| 84 |
+
score_set = first_face.score_set,
|
| 85 |
+
landmark_set = first_face.landmark_set,
|
| 86 |
+
angle = first_face.angle,
|
| 87 |
+
embedding = numpy.mean(embeddings, axis = 0),
|
| 88 |
+
normed_embedding = numpy.mean(normed_embeddings, axis = 0),
|
| 89 |
+
gender = first_face.gender,
|
| 90 |
+
age = first_face.age,
|
| 91 |
+
race = first_face.race
|
| 92 |
+
)
|
| 93 |
+
return None
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def get_many_faces(vision_frames : List[VisionFrame]) -> List[Face]:
|
| 97 |
+
many_faces : List[Face] = []
|
| 98 |
+
|
| 99 |
+
for vision_frame in vision_frames:
|
| 100 |
+
if numpy.any(vision_frame):
|
| 101 |
+
static_faces = get_static_faces(vision_frame)
|
| 102 |
+
if static_faces:
|
| 103 |
+
many_faces.extend(static_faces)
|
| 104 |
+
else:
|
| 105 |
+
all_bounding_boxes = []
|
| 106 |
+
all_face_scores = []
|
| 107 |
+
all_face_landmarks_5 = []
|
| 108 |
+
|
| 109 |
+
for face_detector_angle in state_manager.get_item('face_detector_angles'):
|
| 110 |
+
if face_detector_angle == 0:
|
| 111 |
+
bounding_boxes, face_scores, face_landmarks_5 = detect_faces(vision_frame)
|
| 112 |
+
else:
|
| 113 |
+
bounding_boxes, face_scores, face_landmarks_5 = detect_rotated_faces(vision_frame, face_detector_angle)
|
| 114 |
+
all_bounding_boxes.extend(bounding_boxes)
|
| 115 |
+
all_face_scores.extend(face_scores)
|
| 116 |
+
all_face_landmarks_5.extend(face_landmarks_5)
|
| 117 |
+
|
| 118 |
+
if all_bounding_boxes and all_face_scores and all_face_landmarks_5 and state_manager.get_item('face_detector_score') > 0:
|
| 119 |
+
faces = create_faces(vision_frame, all_bounding_boxes, all_face_scores, all_face_landmarks_5)
|
| 120 |
+
|
| 121 |
+
if faces:
|
| 122 |
+
many_faces.extend(faces)
|
| 123 |
+
set_static_faces(vision_frame, faces)
|
| 124 |
+
return many_faces
|
facefusion/face_classifier.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from typing import List, Tuple
|
| 3 |
+
|
| 4 |
+
import numpy
|
| 5 |
+
|
| 6 |
+
from facefusion import inference_manager
|
| 7 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources, resolve_download_url
|
| 8 |
+
from facefusion.face_helper import warp_face_by_face_landmark_5
|
| 9 |
+
from facefusion.filesystem import resolve_relative_path
|
| 10 |
+
from facefusion.thread_helper import conditional_thread_semaphore
|
| 11 |
+
from facefusion.typing import Age, DownloadScope, FaceLandmark5, Gender, InferencePool, ModelOptions, ModelSet, Race, VisionFrame
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@lru_cache(maxsize = None)
|
| 15 |
+
def create_static_model_set(download_scope : DownloadScope) -> ModelSet:
|
| 16 |
+
return\
|
| 17 |
+
{
|
| 18 |
+
'fairface':
|
| 19 |
+
{
|
| 20 |
+
'hashes':
|
| 21 |
+
{
|
| 22 |
+
'face_classifier':
|
| 23 |
+
{
|
| 24 |
+
'url': resolve_download_url('models-3.0.0', 'fairface.hash'),
|
| 25 |
+
'path': resolve_relative_path('../.assets/models/fairface.hash')
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
'sources':
|
| 29 |
+
{
|
| 30 |
+
'face_classifier':
|
| 31 |
+
{
|
| 32 |
+
'url': resolve_download_url('models-3.0.0', 'fairface.onnx'),
|
| 33 |
+
'path': resolve_relative_path('../.assets/models/fairface.onnx')
|
| 34 |
+
}
|
| 35 |
+
},
|
| 36 |
+
'template': 'arcface_112_v2',
|
| 37 |
+
'size': (224, 224),
|
| 38 |
+
'mean': [ 0.485, 0.456, 0.406 ],
|
| 39 |
+
'standard_deviation': [ 0.229, 0.224, 0.225 ]
|
| 40 |
+
}
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_inference_pool() -> InferencePool:
|
| 45 |
+
model_sources = get_model_options().get('sources')
|
| 46 |
+
return inference_manager.get_inference_pool(__name__, model_sources)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def clear_inference_pool() -> None:
|
| 50 |
+
inference_manager.clear_inference_pool(__name__)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def get_model_options() -> ModelOptions:
|
| 54 |
+
return create_static_model_set('full').get('fairface')
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def pre_check() -> bool:
|
| 58 |
+
model_hashes = get_model_options().get('hashes')
|
| 59 |
+
model_sources = get_model_options().get('sources')
|
| 60 |
+
|
| 61 |
+
return conditional_download_hashes(model_hashes) and conditional_download_sources(model_sources)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def classify_face(temp_vision_frame : VisionFrame, face_landmark_5 : FaceLandmark5) -> Tuple[Gender, Age, Race]:
|
| 65 |
+
model_template = get_model_options().get('template')
|
| 66 |
+
model_size = get_model_options().get('size')
|
| 67 |
+
model_mean = get_model_options().get('mean')
|
| 68 |
+
model_standard_deviation = get_model_options().get('standard_deviation')
|
| 69 |
+
crop_vision_frame, _ = warp_face_by_face_landmark_5(temp_vision_frame, face_landmark_5, model_template, model_size)
|
| 70 |
+
crop_vision_frame = crop_vision_frame.astype(numpy.float32)[:, :, ::-1] / 255
|
| 71 |
+
crop_vision_frame -= model_mean
|
| 72 |
+
crop_vision_frame /= model_standard_deviation
|
| 73 |
+
crop_vision_frame = crop_vision_frame.transpose(2, 0, 1)
|
| 74 |
+
crop_vision_frame = numpy.expand_dims(crop_vision_frame, axis = 0)
|
| 75 |
+
gender_id, age_id, race_id = forward(crop_vision_frame)
|
| 76 |
+
gender = categorize_gender(gender_id[0])
|
| 77 |
+
age = categorize_age(age_id[0])
|
| 78 |
+
race = categorize_race(race_id[0])
|
| 79 |
+
return gender, age, race
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def forward(crop_vision_frame : VisionFrame) -> Tuple[List[int], List[int], List[int]]:
|
| 83 |
+
face_classifier = get_inference_pool().get('face_classifier')
|
| 84 |
+
|
| 85 |
+
with conditional_thread_semaphore():
|
| 86 |
+
race_id, gender_id, age_id = face_classifier.run(None,
|
| 87 |
+
{
|
| 88 |
+
'input': crop_vision_frame
|
| 89 |
+
})
|
| 90 |
+
|
| 91 |
+
return gender_id, age_id, race_id
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def categorize_gender(gender_id : int) -> Gender:
|
| 95 |
+
if gender_id == 1:
|
| 96 |
+
return 'female'
|
| 97 |
+
return 'male'
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def categorize_age(age_id : int) -> Age:
|
| 101 |
+
if age_id == 0:
|
| 102 |
+
return range(0, 2)
|
| 103 |
+
if age_id == 1:
|
| 104 |
+
return range(3, 9)
|
| 105 |
+
if age_id == 2:
|
| 106 |
+
return range(10, 19)
|
| 107 |
+
if age_id == 3:
|
| 108 |
+
return range(20, 29)
|
| 109 |
+
if age_id == 4:
|
| 110 |
+
return range(30, 39)
|
| 111 |
+
if age_id == 5:
|
| 112 |
+
return range(40, 49)
|
| 113 |
+
if age_id == 6:
|
| 114 |
+
return range(50, 59)
|
| 115 |
+
if age_id == 7:
|
| 116 |
+
return range(60, 69)
|
| 117 |
+
return range(70, 100)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def categorize_race(race_id : int) -> Race:
|
| 121 |
+
if race_id == 1:
|
| 122 |
+
return 'black'
|
| 123 |
+
if race_id == 2:
|
| 124 |
+
return 'latino'
|
| 125 |
+
if race_id == 3 or race_id == 4:
|
| 126 |
+
return 'asian'
|
| 127 |
+
if race_id == 5:
|
| 128 |
+
return 'indian'
|
| 129 |
+
if race_id == 6:
|
| 130 |
+
return 'arabic'
|
| 131 |
+
return 'white'
|
facefusion/face_detector.py
ADDED
|
@@ -0,0 +1,314 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Tuple
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy
|
| 5 |
+
from charset_normalizer.md import lru_cache
|
| 6 |
+
|
| 7 |
+
from facefusion import inference_manager, state_manager
|
| 8 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources, resolve_download_url
|
| 9 |
+
from facefusion.face_helper import create_rotated_matrix_and_size, create_static_anchors, distance_to_bounding_box, distance_to_face_landmark_5, normalize_bounding_box, transform_bounding_box, transform_points
|
| 10 |
+
from facefusion.filesystem import resolve_relative_path
|
| 11 |
+
from facefusion.thread_helper import thread_semaphore
|
| 12 |
+
from facefusion.typing import Angle, BoundingBox, Detection, DownloadScope, DownloadSet, FaceLandmark5, InferencePool, ModelSet, Score, VisionFrame
|
| 13 |
+
from facefusion.vision import resize_frame_resolution, unpack_resolution
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
@lru_cache(maxsize = None)
|
| 17 |
+
def create_static_model_set(download_scope : DownloadScope) -> ModelSet:
|
| 18 |
+
return\
|
| 19 |
+
{
|
| 20 |
+
'retinaface':
|
| 21 |
+
{
|
| 22 |
+
'hashes':
|
| 23 |
+
{
|
| 24 |
+
'retinaface':
|
| 25 |
+
{
|
| 26 |
+
'url': resolve_download_url('models-3.0.0', 'retinaface_10g.hash'),
|
| 27 |
+
'path': resolve_relative_path('../.assets/models/retinaface_10g.hash')
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
'sources':
|
| 31 |
+
{
|
| 32 |
+
'retinaface':
|
| 33 |
+
{
|
| 34 |
+
'url': resolve_download_url('models-3.0.0', 'retinaface_10g.onnx'),
|
| 35 |
+
'path': resolve_relative_path('../.assets/models/retinaface_10g.onnx')
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
},
|
| 39 |
+
'scrfd':
|
| 40 |
+
{
|
| 41 |
+
'hashes':
|
| 42 |
+
{
|
| 43 |
+
'scrfd':
|
| 44 |
+
{
|
| 45 |
+
'url': resolve_download_url('models-3.0.0', 'scrfd_2.5g.hash'),
|
| 46 |
+
'path': resolve_relative_path('../.assets/models/scrfd_2.5g.hash')
|
| 47 |
+
}
|
| 48 |
+
},
|
| 49 |
+
'sources':
|
| 50 |
+
{
|
| 51 |
+
'scrfd':
|
| 52 |
+
{
|
| 53 |
+
'url': resolve_download_url('models-3.0.0', 'scrfd_2.5g.onnx'),
|
| 54 |
+
'path': resolve_relative_path('../.assets/models/scrfd_2.5g.onnx')
|
| 55 |
+
}
|
| 56 |
+
}
|
| 57 |
+
},
|
| 58 |
+
'yoloface':
|
| 59 |
+
{
|
| 60 |
+
'hashes':
|
| 61 |
+
{
|
| 62 |
+
'yoloface':
|
| 63 |
+
{
|
| 64 |
+
'url': resolve_download_url('models-3.0.0', 'yoloface_8n.hash'),
|
| 65 |
+
'path': resolve_relative_path('../.assets/models/yoloface_8n.hash')
|
| 66 |
+
}
|
| 67 |
+
},
|
| 68 |
+
'sources':
|
| 69 |
+
{
|
| 70 |
+
'yoloface':
|
| 71 |
+
{
|
| 72 |
+
'url': resolve_download_url('models-3.0.0', 'yoloface_8n.onnx'),
|
| 73 |
+
'path': resolve_relative_path('../.assets/models/yoloface_8n.onnx')
|
| 74 |
+
}
|
| 75 |
+
}
|
| 76 |
+
}
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def get_inference_pool() -> InferencePool:
|
| 81 |
+
_, model_sources = collect_model_downloads()
|
| 82 |
+
return inference_manager.get_inference_pool(__name__, model_sources)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def clear_inference_pool() -> None:
|
| 86 |
+
inference_manager.clear_inference_pool(__name__)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def collect_model_downloads() -> Tuple[DownloadSet, DownloadSet]:
|
| 90 |
+
model_hashes = {}
|
| 91 |
+
model_sources = {}
|
| 92 |
+
model_set = create_static_model_set('full')
|
| 93 |
+
|
| 94 |
+
if state_manager.get_item('face_detector_model') in [ 'many', 'retinaface' ]:
|
| 95 |
+
model_hashes['retinaface'] = model_set.get('retinaface').get('hashes').get('retinaface')
|
| 96 |
+
model_sources['retinaface'] = model_set.get('retinaface').get('sources').get('retinaface')
|
| 97 |
+
|
| 98 |
+
if state_manager.get_item('face_detector_model') in [ 'many', 'scrfd' ]:
|
| 99 |
+
model_hashes['scrfd'] = model_set.get('scrfd').get('hashes').get('scrfd')
|
| 100 |
+
model_sources['scrfd'] = model_set.get('scrfd').get('sources').get('scrfd')
|
| 101 |
+
|
| 102 |
+
if state_manager.get_item('face_detector_model') in [ 'many', 'yoloface' ]:
|
| 103 |
+
model_hashes['yoloface'] = model_set.get('yoloface').get('hashes').get('yoloface')
|
| 104 |
+
model_sources['yoloface'] = model_set.get('yoloface').get('sources').get('yoloface')
|
| 105 |
+
|
| 106 |
+
return model_hashes, model_sources
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def pre_check() -> bool:
|
| 110 |
+
model_hashes, model_sources = collect_model_downloads()
|
| 111 |
+
|
| 112 |
+
return conditional_download_hashes(model_hashes) and conditional_download_sources(model_sources)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def detect_faces(vision_frame : VisionFrame) -> Tuple[List[BoundingBox], List[Score], List[FaceLandmark5]]:
|
| 116 |
+
all_bounding_boxes : List[BoundingBox] = []
|
| 117 |
+
all_face_scores : List[Score] = []
|
| 118 |
+
all_face_landmarks_5 : List[FaceLandmark5] = []
|
| 119 |
+
|
| 120 |
+
if state_manager.get_item('face_detector_model') in [ 'many', 'retinaface' ]:
|
| 121 |
+
bounding_boxes, face_scores, face_landmarks_5 = detect_with_retinaface(vision_frame, state_manager.get_item('face_detector_size'))
|
| 122 |
+
all_bounding_boxes.extend(bounding_boxes)
|
| 123 |
+
all_face_scores.extend(face_scores)
|
| 124 |
+
all_face_landmarks_5.extend(face_landmarks_5)
|
| 125 |
+
|
| 126 |
+
if state_manager.get_item('face_detector_model') in [ 'many', 'scrfd' ]:
|
| 127 |
+
bounding_boxes, face_scores, face_landmarks_5 = detect_with_scrfd(vision_frame, state_manager.get_item('face_detector_size'))
|
| 128 |
+
all_bounding_boxes.extend(bounding_boxes)
|
| 129 |
+
all_face_scores.extend(face_scores)
|
| 130 |
+
all_face_landmarks_5.extend(face_landmarks_5)
|
| 131 |
+
|
| 132 |
+
if state_manager.get_item('face_detector_model') in [ 'many', 'yoloface' ]:
|
| 133 |
+
bounding_boxes, face_scores, face_landmarks_5 = detect_with_yoloface(vision_frame, state_manager.get_item('face_detector_size'))
|
| 134 |
+
all_bounding_boxes.extend(bounding_boxes)
|
| 135 |
+
all_face_scores.extend(face_scores)
|
| 136 |
+
all_face_landmarks_5.extend(face_landmarks_5)
|
| 137 |
+
|
| 138 |
+
all_bounding_boxes = [ normalize_bounding_box(all_bounding_box) for all_bounding_box in all_bounding_boxes ]
|
| 139 |
+
return all_bounding_boxes, all_face_scores, all_face_landmarks_5
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def detect_rotated_faces(vision_frame : VisionFrame, angle : Angle) -> Tuple[List[BoundingBox], List[Score], List[FaceLandmark5]]:
|
| 143 |
+
rotated_matrix, rotated_size = create_rotated_matrix_and_size(angle, vision_frame.shape[:2][::-1])
|
| 144 |
+
rotated_vision_frame = cv2.warpAffine(vision_frame, rotated_matrix, rotated_size)
|
| 145 |
+
rotated_inverse_matrix = cv2.invertAffineTransform(rotated_matrix)
|
| 146 |
+
bounding_boxes, face_scores, face_landmarks_5 = detect_faces(rotated_vision_frame)
|
| 147 |
+
bounding_boxes = [ transform_bounding_box(bounding_box, rotated_inverse_matrix) for bounding_box in bounding_boxes ]
|
| 148 |
+
face_landmarks_5 = [ transform_points(face_landmark_5, rotated_inverse_matrix) for face_landmark_5 in face_landmarks_5 ]
|
| 149 |
+
return bounding_boxes, face_scores, face_landmarks_5
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def detect_with_retinaface(vision_frame : VisionFrame, face_detector_size : str) -> Tuple[List[BoundingBox], List[Score], List[FaceLandmark5]]:
|
| 153 |
+
bounding_boxes = []
|
| 154 |
+
face_scores = []
|
| 155 |
+
face_landmarks_5 = []
|
| 156 |
+
feature_strides = [ 8, 16, 32 ]
|
| 157 |
+
feature_map_channel = 3
|
| 158 |
+
anchor_total = 2
|
| 159 |
+
face_detector_width, face_detector_height = unpack_resolution(face_detector_size)
|
| 160 |
+
temp_vision_frame = resize_frame_resolution(vision_frame, (face_detector_width, face_detector_height))
|
| 161 |
+
ratio_height = vision_frame.shape[0] / temp_vision_frame.shape[0]
|
| 162 |
+
ratio_width = vision_frame.shape[1] / temp_vision_frame.shape[1]
|
| 163 |
+
detect_vision_frame = prepare_detect_frame(temp_vision_frame, face_detector_size)
|
| 164 |
+
detection = forward_with_retinaface(detect_vision_frame)
|
| 165 |
+
|
| 166 |
+
for index, feature_stride in enumerate(feature_strides):
|
| 167 |
+
keep_indices = numpy.where(detection[index] >= state_manager.get_item('face_detector_score'))[0]
|
| 168 |
+
|
| 169 |
+
if numpy.any(keep_indices):
|
| 170 |
+
stride_height = face_detector_height // feature_stride
|
| 171 |
+
stride_width = face_detector_width // feature_stride
|
| 172 |
+
anchors = create_static_anchors(feature_stride, anchor_total, stride_height, stride_width)
|
| 173 |
+
bounding_box_raw = detection[index + feature_map_channel] * feature_stride
|
| 174 |
+
face_landmark_5_raw = detection[index + feature_map_channel * 2] * feature_stride
|
| 175 |
+
|
| 176 |
+
for bounding_box in distance_to_bounding_box(anchors, bounding_box_raw)[keep_indices]:
|
| 177 |
+
bounding_boxes.append(numpy.array(
|
| 178 |
+
[
|
| 179 |
+
bounding_box[0] * ratio_width,
|
| 180 |
+
bounding_box[1] * ratio_height,
|
| 181 |
+
bounding_box[2] * ratio_width,
|
| 182 |
+
bounding_box[3] * ratio_height,
|
| 183 |
+
]))
|
| 184 |
+
|
| 185 |
+
for score in detection[index][keep_indices]:
|
| 186 |
+
face_scores.append(score[0])
|
| 187 |
+
|
| 188 |
+
for face_landmark_5 in distance_to_face_landmark_5(anchors, face_landmark_5_raw)[keep_indices]:
|
| 189 |
+
face_landmarks_5.append(face_landmark_5 * [ ratio_width, ratio_height ])
|
| 190 |
+
|
| 191 |
+
return bounding_boxes, face_scores, face_landmarks_5
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def detect_with_scrfd(vision_frame : VisionFrame, face_detector_size : str) -> Tuple[List[BoundingBox], List[Score], List[FaceLandmark5]]:
|
| 195 |
+
bounding_boxes = []
|
| 196 |
+
face_scores = []
|
| 197 |
+
face_landmarks_5 = []
|
| 198 |
+
feature_strides = [ 8, 16, 32 ]
|
| 199 |
+
feature_map_channel = 3
|
| 200 |
+
anchor_total = 2
|
| 201 |
+
face_detector_width, face_detector_height = unpack_resolution(face_detector_size)
|
| 202 |
+
temp_vision_frame = resize_frame_resolution(vision_frame, (face_detector_width, face_detector_height))
|
| 203 |
+
ratio_height = vision_frame.shape[0] / temp_vision_frame.shape[0]
|
| 204 |
+
ratio_width = vision_frame.shape[1] / temp_vision_frame.shape[1]
|
| 205 |
+
detect_vision_frame = prepare_detect_frame(temp_vision_frame, face_detector_size)
|
| 206 |
+
detection = forward_with_scrfd(detect_vision_frame)
|
| 207 |
+
|
| 208 |
+
for index, feature_stride in enumerate(feature_strides):
|
| 209 |
+
keep_indices = numpy.where(detection[index] >= state_manager.get_item('face_detector_score'))[0]
|
| 210 |
+
|
| 211 |
+
if numpy.any(keep_indices):
|
| 212 |
+
stride_height = face_detector_height // feature_stride
|
| 213 |
+
stride_width = face_detector_width // feature_stride
|
| 214 |
+
anchors = create_static_anchors(feature_stride, anchor_total, stride_height, stride_width)
|
| 215 |
+
bounding_box_raw = detection[index + feature_map_channel] * feature_stride
|
| 216 |
+
face_landmark_5_raw = detection[index + feature_map_channel * 2] * feature_stride
|
| 217 |
+
|
| 218 |
+
for bounding_box in distance_to_bounding_box(anchors, bounding_box_raw)[keep_indices]:
|
| 219 |
+
bounding_boxes.append(numpy.array(
|
| 220 |
+
[
|
| 221 |
+
bounding_box[0] * ratio_width,
|
| 222 |
+
bounding_box[1] * ratio_height,
|
| 223 |
+
bounding_box[2] * ratio_width,
|
| 224 |
+
bounding_box[3] * ratio_height,
|
| 225 |
+
]))
|
| 226 |
+
|
| 227 |
+
for score in detection[index][keep_indices]:
|
| 228 |
+
face_scores.append(score[0])
|
| 229 |
+
|
| 230 |
+
for face_landmark_5 in distance_to_face_landmark_5(anchors, face_landmark_5_raw)[keep_indices]:
|
| 231 |
+
face_landmarks_5.append(face_landmark_5 * [ ratio_width, ratio_height ])
|
| 232 |
+
|
| 233 |
+
return bounding_boxes, face_scores, face_landmarks_5
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def detect_with_yoloface(vision_frame : VisionFrame, face_detector_size : str) -> Tuple[List[BoundingBox], List[Score], List[FaceLandmark5]]:
|
| 237 |
+
bounding_boxes = []
|
| 238 |
+
face_scores = []
|
| 239 |
+
face_landmarks_5 = []
|
| 240 |
+
face_detector_width, face_detector_height = unpack_resolution(face_detector_size)
|
| 241 |
+
temp_vision_frame = resize_frame_resolution(vision_frame, (face_detector_width, face_detector_height))
|
| 242 |
+
ratio_height = vision_frame.shape[0] / temp_vision_frame.shape[0]
|
| 243 |
+
ratio_width = vision_frame.shape[1] / temp_vision_frame.shape[1]
|
| 244 |
+
detect_vision_frame = prepare_detect_frame(temp_vision_frame, face_detector_size)
|
| 245 |
+
detection = forward_with_yoloface(detect_vision_frame)
|
| 246 |
+
detection = numpy.squeeze(detection).T
|
| 247 |
+
bounding_box_raw, score_raw, face_landmark_5_raw = numpy.split(detection, [ 4, 5 ], axis = 1)
|
| 248 |
+
keep_indices = numpy.where(score_raw > state_manager.get_item('face_detector_score'))[0]
|
| 249 |
+
|
| 250 |
+
if numpy.any(keep_indices):
|
| 251 |
+
bounding_box_raw, face_landmark_5_raw, score_raw = bounding_box_raw[keep_indices], face_landmark_5_raw[keep_indices], score_raw[keep_indices]
|
| 252 |
+
|
| 253 |
+
for bounding_box in bounding_box_raw:
|
| 254 |
+
bounding_boxes.append(numpy.array(
|
| 255 |
+
[
|
| 256 |
+
(bounding_box[0] - bounding_box[2] / 2) * ratio_width,
|
| 257 |
+
(bounding_box[1] - bounding_box[3] / 2) * ratio_height,
|
| 258 |
+
(bounding_box[0] + bounding_box[2] / 2) * ratio_width,
|
| 259 |
+
(bounding_box[1] + bounding_box[3] / 2) * ratio_height,
|
| 260 |
+
]))
|
| 261 |
+
|
| 262 |
+
face_scores = score_raw.ravel().tolist()
|
| 263 |
+
face_landmark_5_raw[:, 0::3] = (face_landmark_5_raw[:, 0::3]) * ratio_width
|
| 264 |
+
face_landmark_5_raw[:, 1::3] = (face_landmark_5_raw[:, 1::3]) * ratio_height
|
| 265 |
+
|
| 266 |
+
for face_landmark_5 in face_landmark_5_raw:
|
| 267 |
+
face_landmarks_5.append(numpy.array(face_landmark_5.reshape(-1, 3)[:, :2]))
|
| 268 |
+
|
| 269 |
+
return bounding_boxes, face_scores, face_landmarks_5
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def forward_with_retinaface(detect_vision_frame : VisionFrame) -> Detection:
|
| 273 |
+
face_detector = get_inference_pool().get('retinaface')
|
| 274 |
+
|
| 275 |
+
with thread_semaphore():
|
| 276 |
+
detection = face_detector.run(None,
|
| 277 |
+
{
|
| 278 |
+
'input': detect_vision_frame
|
| 279 |
+
})
|
| 280 |
+
|
| 281 |
+
return detection
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def forward_with_scrfd(detect_vision_frame : VisionFrame) -> Detection:
|
| 285 |
+
face_detector = get_inference_pool().get('scrfd')
|
| 286 |
+
|
| 287 |
+
with thread_semaphore():
|
| 288 |
+
detection = face_detector.run(None,
|
| 289 |
+
{
|
| 290 |
+
'input': detect_vision_frame
|
| 291 |
+
})
|
| 292 |
+
|
| 293 |
+
return detection
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
def forward_with_yoloface(detect_vision_frame : VisionFrame) -> Detection:
|
| 297 |
+
face_detector = get_inference_pool().get('yoloface')
|
| 298 |
+
|
| 299 |
+
with thread_semaphore():
|
| 300 |
+
detection = face_detector.run(None,
|
| 301 |
+
{
|
| 302 |
+
'input': detect_vision_frame
|
| 303 |
+
})
|
| 304 |
+
|
| 305 |
+
return detection
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
def prepare_detect_frame(temp_vision_frame : VisionFrame, face_detector_size : str) -> VisionFrame:
|
| 309 |
+
face_detector_width, face_detector_height = unpack_resolution(face_detector_size)
|
| 310 |
+
detect_vision_frame = numpy.zeros((face_detector_height, face_detector_width, 3))
|
| 311 |
+
detect_vision_frame[:temp_vision_frame.shape[0], :temp_vision_frame.shape[1], :] = temp_vision_frame
|
| 312 |
+
detect_vision_frame = (detect_vision_frame - 127.5) / 128.0
|
| 313 |
+
detect_vision_frame = numpy.expand_dims(detect_vision_frame.transpose(2, 0, 1), axis = 0).astype(numpy.float32)
|
| 314 |
+
return detect_vision_frame
|
facefusion/face_helper.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from typing import List, Sequence, Tuple
|
| 3 |
+
|
| 4 |
+
import cv2
|
| 5 |
+
import numpy
|
| 6 |
+
from cv2.typing import Size
|
| 7 |
+
|
| 8 |
+
from facefusion.typing import Anchors, Angle, BoundingBox, Distance, FaceDetectorModel, FaceLandmark5, FaceLandmark68, Mask, Matrix, Points, Scale, Score, Translation, VisionFrame, WarpTemplate, WarpTemplateSet
|
| 9 |
+
|
| 10 |
+
WARP_TEMPLATES : WarpTemplateSet =\
|
| 11 |
+
{
|
| 12 |
+
'arcface_112_v1': numpy.array(
|
| 13 |
+
[
|
| 14 |
+
[ 0.35473214, 0.45658929 ],
|
| 15 |
+
[ 0.64526786, 0.45658929 ],
|
| 16 |
+
[ 0.50000000, 0.61154464 ],
|
| 17 |
+
[ 0.37913393, 0.77687500 ],
|
| 18 |
+
[ 0.62086607, 0.77687500 ]
|
| 19 |
+
]),
|
| 20 |
+
'arcface_112_v2': numpy.array(
|
| 21 |
+
[
|
| 22 |
+
[ 0.34191607, 0.46157411 ],
|
| 23 |
+
[ 0.65653393, 0.45983393 ],
|
| 24 |
+
[ 0.50022500, 0.64050536 ],
|
| 25 |
+
[ 0.37097589, 0.82469196 ],
|
| 26 |
+
[ 0.63151696, 0.82325089 ]
|
| 27 |
+
]),
|
| 28 |
+
'arcface_128_v2': numpy.array(
|
| 29 |
+
[
|
| 30 |
+
[ 0.36167656, 0.40387734 ],
|
| 31 |
+
[ 0.63696719, 0.40235469 ],
|
| 32 |
+
[ 0.50019687, 0.56044219 ],
|
| 33 |
+
[ 0.38710391, 0.72160547 ],
|
| 34 |
+
[ 0.61507734, 0.72034453 ]
|
| 35 |
+
]),
|
| 36 |
+
'dfl_whole_face': numpy.array(
|
| 37 |
+
[
|
| 38 |
+
[ 0.35342266, 0.39285716 ],
|
| 39 |
+
[ 0.62797622, 0.39285716 ],
|
| 40 |
+
[ 0.48660713, 0.54017860 ],
|
| 41 |
+
[ 0.38839287, 0.68750011 ],
|
| 42 |
+
[ 0.59821427, 0.68750011 ]
|
| 43 |
+
]),
|
| 44 |
+
'ffhq_512': numpy.array(
|
| 45 |
+
[
|
| 46 |
+
[ 0.37691676, 0.46864664 ],
|
| 47 |
+
[ 0.62285697, 0.46912813 ],
|
| 48 |
+
[ 0.50123859, 0.61331904 ],
|
| 49 |
+
[ 0.39308822, 0.72541100 ],
|
| 50 |
+
[ 0.61150205, 0.72490465 ]
|
| 51 |
+
]),
|
| 52 |
+
'mtcnn_512': numpy.array(
|
| 53 |
+
[
|
| 54 |
+
[ 0.36562865, 0.46733799 ],
|
| 55 |
+
[ 0.63305391, 0.46585885 ],
|
| 56 |
+
[ 0.50019127, 0.61942959 ],
|
| 57 |
+
[ 0.39032951, 0.77598822 ],
|
| 58 |
+
[ 0.61178945, 0.77476328 ]
|
| 59 |
+
]),
|
| 60 |
+
'styleganex_384': numpy.array(
|
| 61 |
+
[
|
| 62 |
+
[ 0.42353745, 0.52289879 ],
|
| 63 |
+
[ 0.57725008, 0.52319972 ],
|
| 64 |
+
[ 0.50123859, 0.61331904 ],
|
| 65 |
+
[ 0.43364461, 0.68337652 ],
|
| 66 |
+
[ 0.57015325, 0.68306005 ]
|
| 67 |
+
])
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def estimate_matrix_by_face_landmark_5(face_landmark_5 : FaceLandmark5, warp_template : WarpTemplate, crop_size : Size) -> Matrix:
|
| 72 |
+
normed_warp_template = WARP_TEMPLATES.get(warp_template) * crop_size
|
| 73 |
+
affine_matrix = cv2.estimateAffinePartial2D(face_landmark_5, normed_warp_template, method = cv2.RANSAC, ransacReprojThreshold = 100)[0]
|
| 74 |
+
return affine_matrix
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def warp_face_by_face_landmark_5(temp_vision_frame : VisionFrame, face_landmark_5 : FaceLandmark5, warp_template : WarpTemplate, crop_size : Size) -> Tuple[VisionFrame, Matrix]:
|
| 78 |
+
affine_matrix = estimate_matrix_by_face_landmark_5(face_landmark_5, warp_template, crop_size)
|
| 79 |
+
crop_vision_frame = cv2.warpAffine(temp_vision_frame, affine_matrix, crop_size, borderMode = cv2.BORDER_REPLICATE, flags = cv2.INTER_AREA)
|
| 80 |
+
return crop_vision_frame, affine_matrix
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def warp_face_by_bounding_box(temp_vision_frame : VisionFrame, bounding_box : BoundingBox, crop_size : Size) -> Tuple[VisionFrame, Matrix]:
|
| 84 |
+
source_points = numpy.array([ [ bounding_box[0], bounding_box[1] ], [bounding_box[2], bounding_box[1] ], [ bounding_box[0], bounding_box[3] ] ]).astype(numpy.float32)
|
| 85 |
+
target_points = numpy.array([ [ 0, 0 ], [ crop_size[0], 0 ], [ 0, crop_size[1] ] ]).astype(numpy.float32)
|
| 86 |
+
affine_matrix = cv2.getAffineTransform(source_points, target_points)
|
| 87 |
+
if bounding_box[2] - bounding_box[0] > crop_size[0] or bounding_box[3] - bounding_box[1] > crop_size[1]:
|
| 88 |
+
interpolation_method = cv2.INTER_AREA
|
| 89 |
+
else:
|
| 90 |
+
interpolation_method = cv2.INTER_LINEAR
|
| 91 |
+
crop_vision_frame = cv2.warpAffine(temp_vision_frame, affine_matrix, crop_size, flags = interpolation_method)
|
| 92 |
+
return crop_vision_frame, affine_matrix
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def warp_face_by_translation(temp_vision_frame : VisionFrame, translation : Translation, scale : float, crop_size : Size) -> Tuple[VisionFrame, Matrix]:
|
| 96 |
+
affine_matrix = numpy.array([ [ scale, 0, translation[0] ], [ 0, scale, translation[1] ] ])
|
| 97 |
+
crop_vision_frame = cv2.warpAffine(temp_vision_frame, affine_matrix, crop_size)
|
| 98 |
+
return crop_vision_frame, affine_matrix
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def paste_back(temp_vision_frame : VisionFrame, crop_vision_frame : VisionFrame, crop_mask : Mask, affine_matrix : Matrix) -> VisionFrame:
|
| 102 |
+
inverse_matrix = cv2.invertAffineTransform(affine_matrix)
|
| 103 |
+
temp_size = temp_vision_frame.shape[:2][::-1]
|
| 104 |
+
inverse_mask = cv2.warpAffine(crop_mask, inverse_matrix, temp_size).clip(0, 1)
|
| 105 |
+
inverse_vision_frame = cv2.warpAffine(crop_vision_frame, inverse_matrix, temp_size, borderMode = cv2.BORDER_REPLICATE)
|
| 106 |
+
paste_vision_frame = temp_vision_frame.copy()
|
| 107 |
+
paste_vision_frame[:, :, 0] = inverse_mask * inverse_vision_frame[:, :, 0] + (1 - inverse_mask) * temp_vision_frame[:, :, 0]
|
| 108 |
+
paste_vision_frame[:, :, 1] = inverse_mask * inverse_vision_frame[:, :, 1] + (1 - inverse_mask) * temp_vision_frame[:, :, 1]
|
| 109 |
+
paste_vision_frame[:, :, 2] = inverse_mask * inverse_vision_frame[:, :, 2] + (1 - inverse_mask) * temp_vision_frame[:, :, 2]
|
| 110 |
+
return paste_vision_frame
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
@lru_cache(maxsize = None)
|
| 114 |
+
def create_static_anchors(feature_stride : int, anchor_total : int, stride_height : int, stride_width : int) -> Anchors:
|
| 115 |
+
y, x = numpy.mgrid[:stride_height, :stride_width][::-1]
|
| 116 |
+
anchors = numpy.stack((y, x), axis = -1)
|
| 117 |
+
anchors = (anchors * feature_stride).reshape((-1, 2))
|
| 118 |
+
anchors = numpy.stack([ anchors ] * anchor_total, axis = 1).reshape((-1, 2))
|
| 119 |
+
return anchors
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def create_rotated_matrix_and_size(angle : Angle, size : Size) -> Tuple[Matrix, Size]:
|
| 123 |
+
rotated_matrix = cv2.getRotationMatrix2D((size[0] / 2, size[1] / 2), angle, 1)
|
| 124 |
+
rotated_size = numpy.dot(numpy.abs(rotated_matrix[:, :2]), size)
|
| 125 |
+
rotated_matrix[:, -1] += (rotated_size - size) * 0.5 #type:ignore[misc]
|
| 126 |
+
rotated_size = int(rotated_size[0]), int(rotated_size[1])
|
| 127 |
+
return rotated_matrix, rotated_size
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def create_bounding_box(face_landmark_68 : FaceLandmark68) -> BoundingBox:
|
| 131 |
+
min_x, min_y = numpy.min(face_landmark_68, axis = 0)
|
| 132 |
+
max_x, max_y = numpy.max(face_landmark_68, axis = 0)
|
| 133 |
+
bounding_box = normalize_bounding_box(numpy.array([ min_x, min_y, max_x, max_y ]))
|
| 134 |
+
return bounding_box
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def normalize_bounding_box(bounding_box : BoundingBox) -> BoundingBox:
|
| 138 |
+
x1, y1, x2, y2 = bounding_box
|
| 139 |
+
x1, x2 = sorted([ x1, x2 ])
|
| 140 |
+
y1, y2 = sorted([ y1, y2 ])
|
| 141 |
+
return numpy.array([ x1, y1, x2, y2 ])
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def transform_points(points : Points, matrix : Matrix) -> Points:
|
| 145 |
+
points = points.reshape(-1, 1, 2)
|
| 146 |
+
points = cv2.transform(points, matrix) #type:ignore[assignment]
|
| 147 |
+
points = points.reshape(-1, 2)
|
| 148 |
+
return points
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def transform_bounding_box(bounding_box : BoundingBox, matrix : Matrix) -> BoundingBox:
|
| 152 |
+
points = numpy.array(
|
| 153 |
+
[
|
| 154 |
+
[ bounding_box[0], bounding_box[1] ],
|
| 155 |
+
[ bounding_box[2], bounding_box[1] ],
|
| 156 |
+
[ bounding_box[2], bounding_box[3] ],
|
| 157 |
+
[ bounding_box[0], bounding_box[3] ]
|
| 158 |
+
])
|
| 159 |
+
points = transform_points(points, matrix)
|
| 160 |
+
x1, y1 = numpy.min(points, axis = 0)
|
| 161 |
+
x2, y2 = numpy.max(points, axis = 0)
|
| 162 |
+
return normalize_bounding_box(numpy.array([ x1, y1, x2, y2 ]))
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
def distance_to_bounding_box(points : Points, distance : Distance) -> BoundingBox:
|
| 166 |
+
x1 = points[:, 0] - distance[:, 0]
|
| 167 |
+
y1 = points[:, 1] - distance[:, 1]
|
| 168 |
+
x2 = points[:, 0] + distance[:, 2]
|
| 169 |
+
y2 = points[:, 1] + distance[:, 3]
|
| 170 |
+
bounding_box = numpy.column_stack([ x1, y1, x2, y2 ])
|
| 171 |
+
return bounding_box
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def distance_to_face_landmark_5(points : Points, distance : Distance) -> FaceLandmark5:
|
| 175 |
+
x = points[:, 0::2] + distance[:, 0::2]
|
| 176 |
+
y = points[:, 1::2] + distance[:, 1::2]
|
| 177 |
+
face_landmark_5 = numpy.stack((x, y), axis = -1)
|
| 178 |
+
return face_landmark_5
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def scale_face_landmark_5(face_landmark_5 : FaceLandmark5, scale : Scale) -> FaceLandmark5:
|
| 182 |
+
face_landmark_5_scale = face_landmark_5 - face_landmark_5[2]
|
| 183 |
+
face_landmark_5_scale *= scale
|
| 184 |
+
face_landmark_5_scale += face_landmark_5[2]
|
| 185 |
+
return face_landmark_5_scale
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def convert_to_face_landmark_5(face_landmark_68 : FaceLandmark68) -> FaceLandmark5:
|
| 189 |
+
face_landmark_5 = numpy.array(
|
| 190 |
+
[
|
| 191 |
+
numpy.mean(face_landmark_68[36:42], axis = 0),
|
| 192 |
+
numpy.mean(face_landmark_68[42:48], axis = 0),
|
| 193 |
+
face_landmark_68[30],
|
| 194 |
+
face_landmark_68[48],
|
| 195 |
+
face_landmark_68[54]
|
| 196 |
+
])
|
| 197 |
+
return face_landmark_5
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def estimate_face_angle(face_landmark_68 : FaceLandmark68) -> Angle:
|
| 201 |
+
x1, y1 = face_landmark_68[0]
|
| 202 |
+
x2, y2 = face_landmark_68[16]
|
| 203 |
+
theta = numpy.arctan2(y2 - y1, x2 - x1)
|
| 204 |
+
theta = numpy.degrees(theta) % 360
|
| 205 |
+
angles = numpy.linspace(0, 360, 5)
|
| 206 |
+
index = numpy.argmin(numpy.abs(angles - theta))
|
| 207 |
+
face_angle = int(angles[index] % 360)
|
| 208 |
+
return face_angle
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
def apply_nms(bounding_boxes : List[BoundingBox], face_scores : List[Score], score_threshold : float, nms_threshold : float) -> Sequence[int]:
|
| 212 |
+
normed_bounding_boxes = [ (x1, y1, x2 - x1, y2 - y1) for (x1, y1, x2, y2) in bounding_boxes ]
|
| 213 |
+
keep_indices = cv2.dnn.NMSBoxes(normed_bounding_boxes, face_scores, score_threshold = score_threshold, nms_threshold = nms_threshold)
|
| 214 |
+
return keep_indices
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
def get_nms_threshold(face_detector_model : FaceDetectorModel, face_detector_angles : List[Angle]) -> float:
|
| 218 |
+
if face_detector_model == 'many':
|
| 219 |
+
return 0.1
|
| 220 |
+
if len(face_detector_angles) == 2:
|
| 221 |
+
return 0.3
|
| 222 |
+
if len(face_detector_angles) == 3:
|
| 223 |
+
return 0.2
|
| 224 |
+
if len(face_detector_angles) == 4:
|
| 225 |
+
return 0.1
|
| 226 |
+
return 0.4
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def merge_matrix(matrices : List[Matrix]) -> Matrix:
|
| 230 |
+
merged_matrix = numpy.vstack([ matrices[0], [ 0, 0, 1 ] ])
|
| 231 |
+
for matrix in matrices[1:]:
|
| 232 |
+
matrix = numpy.vstack([ matrix, [ 0, 0, 1 ] ])
|
| 233 |
+
merged_matrix = numpy.dot(merged_matrix, matrix)
|
| 234 |
+
return merged_matrix[:2, :]
|
facefusion/face_landmarker.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from typing import Tuple
|
| 3 |
+
|
| 4 |
+
import cv2
|
| 5 |
+
import numpy
|
| 6 |
+
|
| 7 |
+
from facefusion import inference_manager, state_manager
|
| 8 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources, resolve_download_url
|
| 9 |
+
from facefusion.face_helper import create_rotated_matrix_and_size, estimate_matrix_by_face_landmark_5, transform_points, warp_face_by_translation
|
| 10 |
+
from facefusion.filesystem import resolve_relative_path
|
| 11 |
+
from facefusion.thread_helper import conditional_thread_semaphore
|
| 12 |
+
from facefusion.typing import Angle, BoundingBox, DownloadScope, DownloadSet, FaceLandmark5, FaceLandmark68, InferencePool, ModelSet, Prediction, Score, VisionFrame
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@lru_cache(maxsize = None)
|
| 16 |
+
def create_static_model_set(download_scope : DownloadScope) -> ModelSet:
|
| 17 |
+
return\
|
| 18 |
+
{
|
| 19 |
+
'2dfan4':
|
| 20 |
+
{
|
| 21 |
+
'hashes':
|
| 22 |
+
{
|
| 23 |
+
'2dfan4':
|
| 24 |
+
{
|
| 25 |
+
'url': resolve_download_url('models-3.0.0', '2dfan4.hash'),
|
| 26 |
+
'path': resolve_relative_path('../.assets/models/2dfan4.hash')
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
'sources':
|
| 30 |
+
{
|
| 31 |
+
'2dfan4':
|
| 32 |
+
{
|
| 33 |
+
'url': resolve_download_url('models-3.0.0', '2dfan4.onnx'),
|
| 34 |
+
'path': resolve_relative_path('../.assets/models/2dfan4.onnx')
|
| 35 |
+
}
|
| 36 |
+
},
|
| 37 |
+
'size': (256, 256)
|
| 38 |
+
},
|
| 39 |
+
'peppa_wutz':
|
| 40 |
+
{
|
| 41 |
+
'hashes':
|
| 42 |
+
{
|
| 43 |
+
'peppa_wutz':
|
| 44 |
+
{
|
| 45 |
+
'url': resolve_download_url('models-3.0.0', 'peppa_wutz.hash'),
|
| 46 |
+
'path': resolve_relative_path('../.assets/models/peppa_wutz.hash')
|
| 47 |
+
}
|
| 48 |
+
},
|
| 49 |
+
'sources':
|
| 50 |
+
{
|
| 51 |
+
'peppa_wutz':
|
| 52 |
+
{
|
| 53 |
+
'url': resolve_download_url('models-3.0.0', 'peppa_wutz.onnx'),
|
| 54 |
+
'path': resolve_relative_path('../.assets/models/peppa_wutz.onnx')
|
| 55 |
+
}
|
| 56 |
+
},
|
| 57 |
+
'size': (256, 256)
|
| 58 |
+
},
|
| 59 |
+
'fan_68_5':
|
| 60 |
+
{
|
| 61 |
+
'hashes':
|
| 62 |
+
{
|
| 63 |
+
'fan_68_5':
|
| 64 |
+
{
|
| 65 |
+
'url': resolve_download_url('models-3.0.0', 'fan_68_5.hash'),
|
| 66 |
+
'path': resolve_relative_path('../.assets/models/fan_68_5.hash')
|
| 67 |
+
}
|
| 68 |
+
},
|
| 69 |
+
'sources':
|
| 70 |
+
{
|
| 71 |
+
'fan_68_5':
|
| 72 |
+
{
|
| 73 |
+
'url': resolve_download_url('models-3.0.0', 'fan_68_5.onnx'),
|
| 74 |
+
'path': resolve_relative_path('../.assets/models/fan_68_5.onnx')
|
| 75 |
+
}
|
| 76 |
+
}
|
| 77 |
+
}
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def get_inference_pool() -> InferencePool:
|
| 82 |
+
_, model_sources = collect_model_downloads()
|
| 83 |
+
return inference_manager.get_inference_pool(__name__, model_sources)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def clear_inference_pool() -> None:
|
| 87 |
+
inference_manager.clear_inference_pool(__name__)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def collect_model_downloads() -> Tuple[DownloadSet, DownloadSet]:
|
| 91 |
+
model_set = create_static_model_set('full')
|
| 92 |
+
model_hashes =\
|
| 93 |
+
{
|
| 94 |
+
'fan_68_5': model_set.get('fan_68_5').get('hashes').get('fan_68_5')
|
| 95 |
+
}
|
| 96 |
+
model_sources =\
|
| 97 |
+
{
|
| 98 |
+
'fan_68_5': model_set.get('fan_68_5').get('sources').get('fan_68_5')
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
if state_manager.get_item('face_landmarker_model') in [ 'many', '2dfan4' ]:
|
| 102 |
+
model_hashes['2dfan4'] = model_set.get('2dfan4').get('hashes').get('2dfan4')
|
| 103 |
+
model_sources['2dfan4'] = model_set.get('2dfan4').get('sources').get('2dfan4')
|
| 104 |
+
|
| 105 |
+
if state_manager.get_item('face_landmarker_model') in [ 'many', 'peppa_wutz' ]:
|
| 106 |
+
model_hashes['peppa_wutz'] = model_set.get('peppa_wutz').get('hashes').get('peppa_wutz')
|
| 107 |
+
model_sources['peppa_wutz'] = model_set.get('peppa_wutz').get('sources').get('peppa_wutz')
|
| 108 |
+
|
| 109 |
+
return model_hashes, model_sources
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def pre_check() -> bool:
|
| 113 |
+
model_hashes, model_sources = collect_model_downloads()
|
| 114 |
+
|
| 115 |
+
return conditional_download_hashes(model_hashes) and conditional_download_sources(model_sources)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def detect_face_landmarks(vision_frame : VisionFrame, bounding_box : BoundingBox, face_angle : Angle) -> Tuple[FaceLandmark68, Score]:
|
| 119 |
+
face_landmark_2dfan4 = None
|
| 120 |
+
face_landmark_peppa_wutz = None
|
| 121 |
+
face_landmark_score_2dfan4 = 0.0
|
| 122 |
+
face_landmark_score_peppa_wutz = 0.0
|
| 123 |
+
|
| 124 |
+
if state_manager.get_item('face_landmarker_model') in [ 'many', '2dfan4' ]:
|
| 125 |
+
face_landmark_2dfan4, face_landmark_score_2dfan4 = detect_with_2dfan4(vision_frame, bounding_box, face_angle)
|
| 126 |
+
|
| 127 |
+
if state_manager.get_item('face_landmarker_model') in [ 'many', 'peppa_wutz' ]:
|
| 128 |
+
face_landmark_peppa_wutz, face_landmark_score_peppa_wutz = detect_with_peppa_wutz(vision_frame, bounding_box, face_angle)
|
| 129 |
+
|
| 130 |
+
if face_landmark_score_2dfan4 > face_landmark_score_peppa_wutz - 0.2:
|
| 131 |
+
return face_landmark_2dfan4, face_landmark_score_2dfan4
|
| 132 |
+
return face_landmark_peppa_wutz, face_landmark_score_peppa_wutz
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def detect_with_2dfan4(temp_vision_frame: VisionFrame, bounding_box: BoundingBox, face_angle: Angle) -> Tuple[FaceLandmark68, Score]:
|
| 136 |
+
model_size = create_static_model_set('full').get('2dfan4').get('size')
|
| 137 |
+
scale = 195 / numpy.subtract(bounding_box[2:], bounding_box[:2]).max().clip(1, None)
|
| 138 |
+
translation = (model_size[0] - numpy.add(bounding_box[2:], bounding_box[:2]) * scale) * 0.5
|
| 139 |
+
rotated_matrix, rotated_size = create_rotated_matrix_and_size(face_angle, model_size)
|
| 140 |
+
crop_vision_frame, affine_matrix = warp_face_by_translation(temp_vision_frame, translation, scale, model_size)
|
| 141 |
+
crop_vision_frame = cv2.warpAffine(crop_vision_frame, rotated_matrix, rotated_size)
|
| 142 |
+
crop_vision_frame = conditional_optimize_contrast(crop_vision_frame)
|
| 143 |
+
crop_vision_frame = crop_vision_frame.transpose(2, 0, 1).astype(numpy.float32) / 255.0
|
| 144 |
+
face_landmark_68, face_heatmap = forward_with_2dfan4(crop_vision_frame)
|
| 145 |
+
face_landmark_68 = face_landmark_68[:, :, :2][0] / 64 * 256
|
| 146 |
+
face_landmark_68 = transform_points(face_landmark_68, cv2.invertAffineTransform(rotated_matrix))
|
| 147 |
+
face_landmark_68 = transform_points(face_landmark_68, cv2.invertAffineTransform(affine_matrix))
|
| 148 |
+
face_landmark_score_68 = numpy.amax(face_heatmap, axis = (2, 3))
|
| 149 |
+
face_landmark_score_68 = numpy.mean(face_landmark_score_68)
|
| 150 |
+
face_landmark_score_68 = numpy.interp(face_landmark_score_68, [ 0, 0.9 ], [ 0, 1 ])
|
| 151 |
+
return face_landmark_68, face_landmark_score_68
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def detect_with_peppa_wutz(temp_vision_frame : VisionFrame, bounding_box : BoundingBox, face_angle : Angle) -> Tuple[FaceLandmark68, Score]:
|
| 155 |
+
model_size = create_static_model_set('full').get('peppa_wutz').get('size')
|
| 156 |
+
scale = 195 / numpy.subtract(bounding_box[2:], bounding_box[:2]).max().clip(1, None)
|
| 157 |
+
translation = (model_size[0] - numpy.add(bounding_box[2:], bounding_box[:2]) * scale) * 0.5
|
| 158 |
+
rotated_matrix, rotated_size = create_rotated_matrix_and_size(face_angle, model_size)
|
| 159 |
+
crop_vision_frame, affine_matrix = warp_face_by_translation(temp_vision_frame, translation, scale, model_size)
|
| 160 |
+
crop_vision_frame = cv2.warpAffine(crop_vision_frame, rotated_matrix, rotated_size)
|
| 161 |
+
crop_vision_frame = conditional_optimize_contrast(crop_vision_frame)
|
| 162 |
+
crop_vision_frame = crop_vision_frame.transpose(2, 0, 1).astype(numpy.float32) / 255.0
|
| 163 |
+
crop_vision_frame = numpy.expand_dims(crop_vision_frame, axis = 0)
|
| 164 |
+
prediction = forward_with_peppa_wutz(crop_vision_frame)
|
| 165 |
+
face_landmark_68 = prediction.reshape(-1, 3)[:, :2] / 64 * model_size[0]
|
| 166 |
+
face_landmark_68 = transform_points(face_landmark_68, cv2.invertAffineTransform(rotated_matrix))
|
| 167 |
+
face_landmark_68 = transform_points(face_landmark_68, cv2.invertAffineTransform(affine_matrix))
|
| 168 |
+
face_landmark_score_68 = prediction.reshape(-1, 3)[:, 2].mean()
|
| 169 |
+
face_landmark_score_68 = numpy.interp(face_landmark_score_68, [ 0, 0.95 ], [ 0, 1 ])
|
| 170 |
+
return face_landmark_68, face_landmark_score_68
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def conditional_optimize_contrast(crop_vision_frame : VisionFrame) -> VisionFrame:
|
| 174 |
+
crop_vision_frame = cv2.cvtColor(crop_vision_frame, cv2.COLOR_RGB2Lab)
|
| 175 |
+
if numpy.mean(crop_vision_frame[:, :, 0]) < 30: #type:ignore[arg-type]
|
| 176 |
+
crop_vision_frame[:, :, 0] = cv2.createCLAHE(clipLimit = 2).apply(crop_vision_frame[:, :, 0])
|
| 177 |
+
crop_vision_frame = cv2.cvtColor(crop_vision_frame, cv2.COLOR_Lab2RGB)
|
| 178 |
+
return crop_vision_frame
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def estimate_face_landmark_68_5(face_landmark_5 : FaceLandmark5) -> FaceLandmark68:
|
| 182 |
+
affine_matrix = estimate_matrix_by_face_landmark_5(face_landmark_5, 'ffhq_512', (1, 1))
|
| 183 |
+
face_landmark_5 = cv2.transform(face_landmark_5.reshape(1, -1, 2), affine_matrix).reshape(-1, 2)
|
| 184 |
+
face_landmark_68_5 = forward_fan_68_5(face_landmark_5)
|
| 185 |
+
face_landmark_68_5 = cv2.transform(face_landmark_68_5.reshape(1, -1, 2), cv2.invertAffineTransform(affine_matrix)).reshape(-1, 2)
|
| 186 |
+
return face_landmark_68_5
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def forward_with_2dfan4(crop_vision_frame : VisionFrame) -> Tuple[Prediction, Prediction]:
|
| 190 |
+
face_landmarker = get_inference_pool().get('2dfan4')
|
| 191 |
+
|
| 192 |
+
with conditional_thread_semaphore():
|
| 193 |
+
prediction = face_landmarker.run(None,
|
| 194 |
+
{
|
| 195 |
+
'input': [ crop_vision_frame ]
|
| 196 |
+
})
|
| 197 |
+
|
| 198 |
+
return prediction
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def forward_with_peppa_wutz(crop_vision_frame : VisionFrame) -> Prediction:
|
| 202 |
+
face_landmarker = get_inference_pool().get('peppa_wutz')
|
| 203 |
+
|
| 204 |
+
with conditional_thread_semaphore():
|
| 205 |
+
prediction = face_landmarker.run(None,
|
| 206 |
+
{
|
| 207 |
+
'input': crop_vision_frame
|
| 208 |
+
})[0]
|
| 209 |
+
|
| 210 |
+
return prediction
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def forward_fan_68_5(face_landmark_5 : FaceLandmark5) -> FaceLandmark68:
|
| 214 |
+
face_landmarker = get_inference_pool().get('fan_68_5')
|
| 215 |
+
|
| 216 |
+
with conditional_thread_semaphore():
|
| 217 |
+
face_landmark_68_5 = face_landmarker.run(None,
|
| 218 |
+
{
|
| 219 |
+
'input': [ face_landmark_5 ]
|
| 220 |
+
})[0][0]
|
| 221 |
+
|
| 222 |
+
return face_landmark_68_5
|
facefusion/face_masker.py
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from typing import List, Tuple
|
| 3 |
+
|
| 4 |
+
import cv2
|
| 5 |
+
import numpy
|
| 6 |
+
from cv2.typing import Size
|
| 7 |
+
|
| 8 |
+
import facefusion.choices
|
| 9 |
+
from facefusion import inference_manager, state_manager
|
| 10 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources, resolve_download_url
|
| 11 |
+
from facefusion.filesystem import resolve_relative_path
|
| 12 |
+
from facefusion.thread_helper import conditional_thread_semaphore
|
| 13 |
+
from facefusion.typing import DownloadScope, DownloadSet, FaceLandmark68, FaceMaskRegion, InferencePool, Mask, ModelSet, Padding, VisionFrame
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
@lru_cache(maxsize = None)
|
| 17 |
+
def create_static_model_set(download_scope : DownloadScope) -> ModelSet:
|
| 18 |
+
return\
|
| 19 |
+
{
|
| 20 |
+
'xseg_1':
|
| 21 |
+
{
|
| 22 |
+
'hashes':
|
| 23 |
+
{
|
| 24 |
+
'face_occluder':
|
| 25 |
+
{
|
| 26 |
+
'url': resolve_download_url('models-3.1.0', 'xseg_1.hash'),
|
| 27 |
+
'path': resolve_relative_path('../.assets/models/xseg_1.hash')
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
'sources':
|
| 31 |
+
{
|
| 32 |
+
'face_occluder':
|
| 33 |
+
{
|
| 34 |
+
'url': resolve_download_url('models-3.1.0', 'xseg_1.onnx'),
|
| 35 |
+
'path': resolve_relative_path('../.assets/models/xseg_1.onnx')
|
| 36 |
+
}
|
| 37 |
+
},
|
| 38 |
+
'size': (256, 256)
|
| 39 |
+
},
|
| 40 |
+
'xseg_2':
|
| 41 |
+
{
|
| 42 |
+
'hashes':
|
| 43 |
+
{
|
| 44 |
+
'face_occluder':
|
| 45 |
+
{
|
| 46 |
+
'url': resolve_download_url('models-3.1.0', 'xseg_2.hash'),
|
| 47 |
+
'path': resolve_relative_path('../.assets/models/xseg_2.hash')
|
| 48 |
+
}
|
| 49 |
+
},
|
| 50 |
+
'sources':
|
| 51 |
+
{
|
| 52 |
+
'face_occluder':
|
| 53 |
+
{
|
| 54 |
+
'url': resolve_download_url('models-3.1.0', 'xseg_2.onnx'),
|
| 55 |
+
'path': resolve_relative_path('../.assets/models/xseg_2.onnx')
|
| 56 |
+
}
|
| 57 |
+
},
|
| 58 |
+
'size': (256, 256)
|
| 59 |
+
},
|
| 60 |
+
'bisenet_resnet_18':
|
| 61 |
+
{
|
| 62 |
+
'hashes':
|
| 63 |
+
{
|
| 64 |
+
'face_parser':
|
| 65 |
+
{
|
| 66 |
+
'url': resolve_download_url('models-3.1.0', 'bisenet_resnet_18.hash'),
|
| 67 |
+
'path': resolve_relative_path('../.assets/models/bisenet_resnet_18.hash')
|
| 68 |
+
}
|
| 69 |
+
},
|
| 70 |
+
'sources':
|
| 71 |
+
{
|
| 72 |
+
'face_parser':
|
| 73 |
+
{
|
| 74 |
+
'url': resolve_download_url('models-3.1.0', 'bisenet_resnet_18.onnx'),
|
| 75 |
+
'path': resolve_relative_path('../.assets/models/bisenet_resnet_18.onnx')
|
| 76 |
+
}
|
| 77 |
+
},
|
| 78 |
+
'size': (512, 512)
|
| 79 |
+
},
|
| 80 |
+
'bisenet_resnet_34':
|
| 81 |
+
{
|
| 82 |
+
'hashes':
|
| 83 |
+
{
|
| 84 |
+
'face_parser':
|
| 85 |
+
{
|
| 86 |
+
'url': resolve_download_url('models-3.0.0', 'bisenet_resnet_34.hash'),
|
| 87 |
+
'path': resolve_relative_path('../.assets/models/bisenet_resnet_34.hash')
|
| 88 |
+
}
|
| 89 |
+
},
|
| 90 |
+
'sources':
|
| 91 |
+
{
|
| 92 |
+
'face_parser':
|
| 93 |
+
{
|
| 94 |
+
'url': resolve_download_url('models-3.0.0', 'bisenet_resnet_34.onnx'),
|
| 95 |
+
'path': resolve_relative_path('../.assets/models/bisenet_resnet_34.onnx')
|
| 96 |
+
}
|
| 97 |
+
},
|
| 98 |
+
'size': (512, 512)
|
| 99 |
+
}
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def get_inference_pool() -> InferencePool:
|
| 104 |
+
_, model_sources = collect_model_downloads()
|
| 105 |
+
return inference_manager.get_inference_pool(__name__, model_sources)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def clear_inference_pool() -> None:
|
| 109 |
+
inference_manager.clear_inference_pool(__name__)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def collect_model_downloads() -> Tuple[DownloadSet, DownloadSet]:
|
| 113 |
+
model_hashes = {}
|
| 114 |
+
model_sources = {}
|
| 115 |
+
model_set = create_static_model_set('full')
|
| 116 |
+
|
| 117 |
+
if state_manager.get_item('face_occluder_model') == 'xseg_1':
|
| 118 |
+
model_hashes['xseg_1'] = model_set.get('xseg_1').get('hashes').get('face_occluder')
|
| 119 |
+
model_sources['xseg_1'] = model_set.get('xseg_1').get('sources').get('face_occluder')
|
| 120 |
+
|
| 121 |
+
if state_manager.get_item('face_occluder_model') == 'xseg_2':
|
| 122 |
+
model_hashes['xseg_2'] = model_set.get('xseg_2').get('hashes').get('face_occluder')
|
| 123 |
+
model_sources['xseg_2'] = model_set.get('xseg_2').get('sources').get('face_occluder')
|
| 124 |
+
|
| 125 |
+
if state_manager.get_item('face_parser_model') == 'bisenet_resnet_18':
|
| 126 |
+
model_hashes['bisenet_resnet_18'] = model_set.get('bisenet_resnet_18').get('hashes').get('face_parser')
|
| 127 |
+
model_sources['bisenet_resnet_18'] = model_set.get('bisenet_resnet_18').get('sources').get('face_parser')
|
| 128 |
+
|
| 129 |
+
if state_manager.get_item('face_parser_model') == 'bisenet_resnet_34':
|
| 130 |
+
model_hashes['bisenet_resnet_34'] = model_set.get('bisenet_resnet_34').get('hashes').get('face_parser')
|
| 131 |
+
model_sources['bisenet_resnet_34'] = model_set.get('bisenet_resnet_34').get('sources').get('face_parser')
|
| 132 |
+
|
| 133 |
+
return model_hashes, model_sources
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def pre_check() -> bool:
|
| 137 |
+
model_hashes, model_sources = collect_model_downloads()
|
| 138 |
+
|
| 139 |
+
return conditional_download_hashes(model_hashes) and conditional_download_sources(model_sources)
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
@lru_cache(maxsize = None)
|
| 143 |
+
def create_static_box_mask(crop_size : Size, face_mask_blur : float, face_mask_padding : Padding) -> Mask:
|
| 144 |
+
blur_amount = int(crop_size[0] * 0.5 * face_mask_blur)
|
| 145 |
+
blur_area = max(blur_amount // 2, 1)
|
| 146 |
+
box_mask : Mask = numpy.ones(crop_size).astype(numpy.float32)
|
| 147 |
+
box_mask[:max(blur_area, int(crop_size[1] * face_mask_padding[0] / 100)), :] = 0
|
| 148 |
+
box_mask[-max(blur_area, int(crop_size[1] * face_mask_padding[2] / 100)):, :] = 0
|
| 149 |
+
box_mask[:, :max(blur_area, int(crop_size[0] * face_mask_padding[3] / 100))] = 0
|
| 150 |
+
box_mask[:, -max(blur_area, int(crop_size[0] * face_mask_padding[1] / 100)):] = 0
|
| 151 |
+
if blur_amount > 0:
|
| 152 |
+
box_mask = cv2.GaussianBlur(box_mask, (0, 0), blur_amount * 0.25)
|
| 153 |
+
return box_mask
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def create_occlusion_mask(crop_vision_frame : VisionFrame) -> Mask:
|
| 157 |
+
face_occluder_model = state_manager.get_item('face_occluder_model')
|
| 158 |
+
model_size = create_static_model_set('full').get(face_occluder_model).get('size')
|
| 159 |
+
prepare_vision_frame = cv2.resize(crop_vision_frame, model_size)
|
| 160 |
+
prepare_vision_frame = numpy.expand_dims(prepare_vision_frame, axis = 0).astype(numpy.float32) / 255
|
| 161 |
+
prepare_vision_frame = prepare_vision_frame.transpose(0, 1, 2, 3)
|
| 162 |
+
occlusion_mask = forward_occlude_face(prepare_vision_frame)
|
| 163 |
+
occlusion_mask = occlusion_mask.transpose(0, 1, 2).clip(0, 1).astype(numpy.float32)
|
| 164 |
+
occlusion_mask = cv2.resize(occlusion_mask, crop_vision_frame.shape[:2][::-1])
|
| 165 |
+
occlusion_mask = (cv2.GaussianBlur(occlusion_mask.clip(0, 1), (0, 0), 5).clip(0.5, 1) - 0.5) * 2
|
| 166 |
+
return occlusion_mask
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def create_region_mask(crop_vision_frame : VisionFrame, face_mask_regions : List[FaceMaskRegion]) -> Mask:
|
| 170 |
+
face_parser_model = state_manager.get_item('face_parser_model')
|
| 171 |
+
model_size = create_static_model_set('full').get(face_parser_model).get('size')
|
| 172 |
+
prepare_vision_frame = cv2.resize(crop_vision_frame, model_size)
|
| 173 |
+
prepare_vision_frame = prepare_vision_frame[:, :, ::-1].astype(numpy.float32) / 255
|
| 174 |
+
prepare_vision_frame = numpy.subtract(prepare_vision_frame, numpy.array([ 0.485, 0.456, 0.406 ]).astype(numpy.float32))
|
| 175 |
+
prepare_vision_frame = numpy.divide(prepare_vision_frame, numpy.array([ 0.229, 0.224, 0.225 ]).astype(numpy.float32))
|
| 176 |
+
prepare_vision_frame = numpy.expand_dims(prepare_vision_frame, axis = 0)
|
| 177 |
+
prepare_vision_frame = prepare_vision_frame.transpose(0, 3, 1, 2)
|
| 178 |
+
region_mask = forward_parse_face(prepare_vision_frame)
|
| 179 |
+
region_mask = numpy.isin(region_mask.argmax(0), [ facefusion.choices.face_mask_region_set.get(face_mask_region) for face_mask_region in face_mask_regions ])
|
| 180 |
+
region_mask = cv2.resize(region_mask.astype(numpy.float32), crop_vision_frame.shape[:2][::-1])
|
| 181 |
+
region_mask = (cv2.GaussianBlur(region_mask.clip(0, 1), (0, 0), 5).clip(0.5, 1) - 0.5) * 2
|
| 182 |
+
return region_mask
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def create_mouth_mask(face_landmark_68 : FaceLandmark68) -> Mask:
|
| 186 |
+
convex_hull = cv2.convexHull(face_landmark_68[numpy.r_[3:14, 31:36]].astype(numpy.int32))
|
| 187 |
+
mouth_mask : Mask = numpy.zeros((512, 512)).astype(numpy.float32)
|
| 188 |
+
mouth_mask = cv2.fillConvexPoly(mouth_mask, convex_hull, 1.0) #type:ignore[call-overload]
|
| 189 |
+
mouth_mask = cv2.erode(mouth_mask.clip(0, 1), numpy.ones((21, 3)))
|
| 190 |
+
mouth_mask = cv2.GaussianBlur(mouth_mask, (0, 0), sigmaX = 1, sigmaY = 15)
|
| 191 |
+
return mouth_mask
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def forward_occlude_face(prepare_vision_frame : VisionFrame) -> Mask:
|
| 195 |
+
face_occluder_model = state_manager.get_item('face_occluder_model')
|
| 196 |
+
face_occluder = get_inference_pool().get(face_occluder_model)
|
| 197 |
+
|
| 198 |
+
with conditional_thread_semaphore():
|
| 199 |
+
occlusion_mask : Mask = face_occluder.run(None,
|
| 200 |
+
{
|
| 201 |
+
'input': prepare_vision_frame
|
| 202 |
+
})[0][0]
|
| 203 |
+
|
| 204 |
+
return occlusion_mask
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def forward_parse_face(prepare_vision_frame : VisionFrame) -> Mask:
|
| 208 |
+
face_parser_model = state_manager.get_item('face_parser_model')
|
| 209 |
+
face_parser = get_inference_pool().get(face_parser_model)
|
| 210 |
+
|
| 211 |
+
with conditional_thread_semaphore():
|
| 212 |
+
region_mask : Mask = face_parser.run(None,
|
| 213 |
+
{
|
| 214 |
+
'input': prepare_vision_frame
|
| 215 |
+
})[0][0]
|
| 216 |
+
|
| 217 |
+
return region_mask
|
facefusion/face_recognizer.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
from typing import Tuple
|
| 3 |
+
|
| 4 |
+
import numpy
|
| 5 |
+
|
| 6 |
+
from facefusion import inference_manager
|
| 7 |
+
from facefusion.download import conditional_download_hashes, conditional_download_sources, resolve_download_url
|
| 8 |
+
from facefusion.face_helper import warp_face_by_face_landmark_5
|
| 9 |
+
from facefusion.filesystem import resolve_relative_path
|
| 10 |
+
from facefusion.thread_helper import conditional_thread_semaphore
|
| 11 |
+
from facefusion.typing import DownloadScope, Embedding, FaceLandmark5, InferencePool, ModelOptions, ModelSet, VisionFrame
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@lru_cache(maxsize = None)
|
| 15 |
+
def create_static_model_set(download_scope : DownloadScope) -> ModelSet:
|
| 16 |
+
return\
|
| 17 |
+
{
|
| 18 |
+
'arcface':
|
| 19 |
+
{
|
| 20 |
+
'hashes':
|
| 21 |
+
{
|
| 22 |
+
'face_recognizer':
|
| 23 |
+
{
|
| 24 |
+
'url': resolve_download_url('models-3.0.0', 'arcface_w600k_r50.hash'),
|
| 25 |
+
'path': resolve_relative_path('../.assets/models/arcface_w600k_r50.hash')
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
'sources':
|
| 29 |
+
{
|
| 30 |
+
'face_recognizer':
|
| 31 |
+
{
|
| 32 |
+
'url': resolve_download_url('models-3.0.0', 'arcface_w600k_r50.onnx'),
|
| 33 |
+
'path': resolve_relative_path('../.assets/models/arcface_w600k_r50.onnx')
|
| 34 |
+
}
|
| 35 |
+
},
|
| 36 |
+
'template': 'arcface_112_v2',
|
| 37 |
+
'size': (112, 112)
|
| 38 |
+
}
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def get_inference_pool() -> InferencePool:
|
| 43 |
+
model_sources = get_model_options().get('sources')
|
| 44 |
+
return inference_manager.get_inference_pool(__name__, model_sources)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def clear_inference_pool() -> None:
|
| 48 |
+
inference_manager.clear_inference_pool(__name__)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def get_model_options() -> ModelOptions:
|
| 52 |
+
return create_static_model_set('full').get('arcface')
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def pre_check() -> bool:
|
| 56 |
+
model_hashes = get_model_options().get('hashes')
|
| 57 |
+
model_sources = get_model_options().get('sources')
|
| 58 |
+
|
| 59 |
+
return conditional_download_hashes(model_hashes) and conditional_download_sources(model_sources)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def calc_embedding(temp_vision_frame : VisionFrame, face_landmark_5 : FaceLandmark5) -> Tuple[Embedding, Embedding]:
|
| 63 |
+
model_template = get_model_options().get('template')
|
| 64 |
+
model_size = get_model_options().get('size')
|
| 65 |
+
crop_vision_frame, matrix = warp_face_by_face_landmark_5(temp_vision_frame, face_landmark_5, model_template, model_size)
|
| 66 |
+
crop_vision_frame = crop_vision_frame / 127.5 - 1
|
| 67 |
+
crop_vision_frame = crop_vision_frame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32)
|
| 68 |
+
crop_vision_frame = numpy.expand_dims(crop_vision_frame, axis = 0)
|
| 69 |
+
embedding = forward(crop_vision_frame)
|
| 70 |
+
embedding = embedding.ravel()
|
| 71 |
+
normed_embedding = embedding / numpy.linalg.norm(embedding)
|
| 72 |
+
return embedding, normed_embedding
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def forward(crop_vision_frame : VisionFrame) -> Embedding:
|
| 76 |
+
face_recognizer = get_inference_pool().get('face_recognizer')
|
| 77 |
+
|
| 78 |
+
with conditional_thread_semaphore():
|
| 79 |
+
embedding = face_recognizer.run(None,
|
| 80 |
+
{
|
| 81 |
+
'input': crop_vision_frame
|
| 82 |
+
})[0]
|
| 83 |
+
|
| 84 |
+
return embedding
|
facefusion/face_selector.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
import numpy
|
| 4 |
+
|
| 5 |
+
from facefusion import state_manager
|
| 6 |
+
from facefusion.typing import Face, FaceSelectorOrder, FaceSet, Gender, Race
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def find_similar_faces(faces : List[Face], reference_faces : FaceSet, face_distance : float) -> List[Face]:
|
| 10 |
+
similar_faces : List[Face] = []
|
| 11 |
+
|
| 12 |
+
if faces and reference_faces:
|
| 13 |
+
for reference_set in reference_faces:
|
| 14 |
+
if not similar_faces:
|
| 15 |
+
for reference_face in reference_faces[reference_set]:
|
| 16 |
+
for face in faces:
|
| 17 |
+
if compare_faces(face, reference_face, face_distance):
|
| 18 |
+
similar_faces.append(face)
|
| 19 |
+
return similar_faces
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def compare_faces(face : Face, reference_face : Face, face_distance : float) -> bool:
|
| 23 |
+
current_face_distance = calc_face_distance(face, reference_face)
|
| 24 |
+
return current_face_distance < face_distance
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def calc_face_distance(face : Face, reference_face : Face) -> float:
|
| 28 |
+
if hasattr(face, 'normed_embedding') and hasattr(reference_face, 'normed_embedding'):
|
| 29 |
+
return 1 - numpy.dot(face.normed_embedding, reference_face.normed_embedding)
|
| 30 |
+
return 0
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def sort_and_filter_faces(faces : List[Face]) -> List[Face]:
|
| 34 |
+
if faces:
|
| 35 |
+
if state_manager.get_item('face_selector_order'):
|
| 36 |
+
faces = sort_faces_by_order(faces, state_manager.get_item('face_selector_order'))
|
| 37 |
+
if state_manager.get_item('face_selector_gender'):
|
| 38 |
+
faces = filter_faces_by_gender(faces, state_manager.get_item('face_selector_gender'))
|
| 39 |
+
if state_manager.get_item('face_selector_race'):
|
| 40 |
+
faces = filter_faces_by_race(faces, state_manager.get_item('face_selector_race'))
|
| 41 |
+
if state_manager.get_item('face_selector_age_start') or state_manager.get_item('face_selector_age_end'):
|
| 42 |
+
faces = filter_faces_by_age(faces, state_manager.get_item('face_selector_age_start'), state_manager.get_item('face_selector_age_end'))
|
| 43 |
+
return faces
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def sort_faces_by_order(faces : List[Face], order : FaceSelectorOrder) -> List[Face]:
|
| 47 |
+
if order == 'left-right':
|
| 48 |
+
return sorted(faces, key = lambda face: face.bounding_box[0])
|
| 49 |
+
if order == 'right-left':
|
| 50 |
+
return sorted(faces, key = lambda face: face.bounding_box[0], reverse = True)
|
| 51 |
+
if order == 'top-bottom':
|
| 52 |
+
return sorted(faces, key = lambda face: face.bounding_box[1])
|
| 53 |
+
if order == 'bottom-top':
|
| 54 |
+
return sorted(faces, key = lambda face: face.bounding_box[1], reverse = True)
|
| 55 |
+
if order == 'small-large':
|
| 56 |
+
return sorted(faces, key = lambda face: (face.bounding_box[2] - face.bounding_box[0]) * (face.bounding_box[3] - face.bounding_box[1]))
|
| 57 |
+
if order == 'large-small':
|
| 58 |
+
return sorted(faces, key = lambda face: (face.bounding_box[2] - face.bounding_box[0]) * (face.bounding_box[3] - face.bounding_box[1]), reverse = True)
|
| 59 |
+
if order == 'best-worst':
|
| 60 |
+
return sorted(faces, key = lambda face: face.score_set.get('detector'), reverse = True)
|
| 61 |
+
if order == 'worst-best':
|
| 62 |
+
return sorted(faces, key = lambda face: face.score_set.get('detector'))
|
| 63 |
+
return faces
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def filter_faces_by_gender(faces : List[Face], gender : Gender) -> List[Face]:
|
| 67 |
+
filter_faces = []
|
| 68 |
+
|
| 69 |
+
for face in faces:
|
| 70 |
+
if face.gender == gender:
|
| 71 |
+
filter_faces.append(face)
|
| 72 |
+
return filter_faces
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def filter_faces_by_age(faces : List[Face], face_selector_age_start : int, face_selector_age_end : int) -> List[Face]:
|
| 76 |
+
filter_faces = []
|
| 77 |
+
age = range(face_selector_age_start, face_selector_age_end)
|
| 78 |
+
|
| 79 |
+
for face in faces:
|
| 80 |
+
if set(face.age) & set(age):
|
| 81 |
+
filter_faces.append(face)
|
| 82 |
+
return filter_faces
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def filter_faces_by_race(faces : List[Face], race : Race) -> List[Face]:
|
| 86 |
+
filter_faces = []
|
| 87 |
+
|
| 88 |
+
for face in faces:
|
| 89 |
+
if face.race == race:
|
| 90 |
+
filter_faces.append(face)
|
| 91 |
+
return filter_faces
|
facefusion/face_store.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
from typing import List, Optional
|
| 3 |
+
|
| 4 |
+
import numpy
|
| 5 |
+
|
| 6 |
+
from facefusion.typing import Face, FaceSet, FaceStore, VisionFrame
|
| 7 |
+
|
| 8 |
+
FACE_STORE : FaceStore =\
|
| 9 |
+
{
|
| 10 |
+
'static_faces': {},
|
| 11 |
+
'reference_faces': {}
|
| 12 |
+
}
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_face_store() -> FaceStore:
|
| 16 |
+
return FACE_STORE
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_static_faces(vision_frame : VisionFrame) -> Optional[List[Face]]:
|
| 20 |
+
frame_hash = create_frame_hash(vision_frame)
|
| 21 |
+
if frame_hash in FACE_STORE['static_faces']:
|
| 22 |
+
return FACE_STORE['static_faces'][frame_hash]
|
| 23 |
+
return None
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def set_static_faces(vision_frame : VisionFrame, faces : List[Face]) -> None:
|
| 27 |
+
frame_hash = create_frame_hash(vision_frame)
|
| 28 |
+
if frame_hash:
|
| 29 |
+
FACE_STORE['static_faces'][frame_hash] = faces
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def clear_static_faces() -> None:
|
| 33 |
+
FACE_STORE['static_faces'] = {}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def create_frame_hash(vision_frame : VisionFrame) -> Optional[str]:
|
| 37 |
+
return hashlib.sha1(vision_frame.tobytes()).hexdigest() if numpy.any(vision_frame) else None
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def get_reference_faces() -> Optional[FaceSet]:
|
| 41 |
+
if FACE_STORE['reference_faces']:
|
| 42 |
+
return FACE_STORE['reference_faces']
|
| 43 |
+
return None
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def append_reference_face(name : str, face : Face) -> None:
|
| 47 |
+
if name not in FACE_STORE['reference_faces']:
|
| 48 |
+
FACE_STORE['reference_faces'][name] = []
|
| 49 |
+
FACE_STORE['reference_faces'][name].append(face)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def clear_reference_faces() -> None:
|
| 53 |
+
FACE_STORE['reference_faces'] = {}
|
facefusion/ffmpeg.py
ADDED
|
@@ -0,0 +1,230 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
| 3 |
+
import subprocess
|
| 4 |
+
import tempfile
|
| 5 |
+
from typing import List, Optional
|
| 6 |
+
|
| 7 |
+
import filetype
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
from facefusion import logger, process_manager, state_manager, wording
|
| 11 |
+
from facefusion.filesystem import remove_file
|
| 12 |
+
from facefusion.temp_helper import get_temp_file_path, get_temp_frame_paths, get_temp_frames_pattern
|
| 13 |
+
from facefusion.typing import AudioBuffer, Fps, OutputVideoPreset, UpdateProgress
|
| 14 |
+
from facefusion.vision import count_trim_frame_total, detect_video_duration, restrict_video_fps
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def run_ffmpeg_with_progress(args: List[str], update_progress : UpdateProgress) -> subprocess.Popen[bytes]:
|
| 18 |
+
log_level = state_manager.get_item('log_level')
|
| 19 |
+
commands = [ shutil.which('ffmpeg'), '-hide_banner', '-nostats', '-loglevel', 'error', '-progress', '-' ]
|
| 20 |
+
commands.extend(args)
|
| 21 |
+
process = subprocess.Popen(commands, stderr = subprocess.PIPE, stdout = subprocess.PIPE)
|
| 22 |
+
|
| 23 |
+
while process_manager.is_processing():
|
| 24 |
+
try:
|
| 25 |
+
|
| 26 |
+
while __line__ := process.stdout.readline().decode().lower():
|
| 27 |
+
if 'frame=' in __line__:
|
| 28 |
+
_, frame_number = __line__.split('frame=')
|
| 29 |
+
update_progress(int(frame_number))
|
| 30 |
+
|
| 31 |
+
if log_level == 'debug':
|
| 32 |
+
log_debug(process)
|
| 33 |
+
process.wait(timeout = 0.5)
|
| 34 |
+
except subprocess.TimeoutExpired:
|
| 35 |
+
continue
|
| 36 |
+
return process
|
| 37 |
+
|
| 38 |
+
if process_manager.is_stopping():
|
| 39 |
+
process.terminate()
|
| 40 |
+
return process
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def run_ffmpeg(args : List[str]) -> subprocess.Popen[bytes]:
|
| 44 |
+
log_level = state_manager.get_item('log_level')
|
| 45 |
+
commands = [ shutil.which('ffmpeg'), '-hide_banner', '-nostats', '-loglevel', 'error' ]
|
| 46 |
+
commands.extend(args)
|
| 47 |
+
process = subprocess.Popen(commands, stderr = subprocess.PIPE, stdout = subprocess.PIPE)
|
| 48 |
+
|
| 49 |
+
while process_manager.is_processing():
|
| 50 |
+
try:
|
| 51 |
+
if log_level == 'debug':
|
| 52 |
+
log_debug(process)
|
| 53 |
+
process.wait(timeout = 0.5)
|
| 54 |
+
except subprocess.TimeoutExpired:
|
| 55 |
+
continue
|
| 56 |
+
return process
|
| 57 |
+
|
| 58 |
+
if process_manager.is_stopping():
|
| 59 |
+
process.terminate()
|
| 60 |
+
return process
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def open_ffmpeg(args : List[str]) -> subprocess.Popen[bytes]:
|
| 64 |
+
commands = [ shutil.which('ffmpeg'), '-loglevel', 'quiet' ]
|
| 65 |
+
commands.extend(args)
|
| 66 |
+
return subprocess.Popen(commands, stdin = subprocess.PIPE, stdout = subprocess.PIPE)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def log_debug(process : subprocess.Popen[bytes]) -> None:
|
| 70 |
+
_, stderr = process.communicate()
|
| 71 |
+
errors = stderr.decode().split(os.linesep)
|
| 72 |
+
|
| 73 |
+
for error in errors:
|
| 74 |
+
if error.strip():
|
| 75 |
+
logger.debug(error.strip(), __name__)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def extract_frames(target_path : str, temp_video_resolution : str, temp_video_fps : Fps, trim_frame_start : int, trim_frame_end : int) -> bool:
|
| 79 |
+
extract_frame_total = count_trim_frame_total(target_path, trim_frame_start, trim_frame_end)
|
| 80 |
+
temp_frames_pattern = get_temp_frames_pattern(target_path, '%08d')
|
| 81 |
+
commands = [ '-i', target_path, '-s', str(temp_video_resolution), '-q:v', '0' ]
|
| 82 |
+
|
| 83 |
+
if isinstance(trim_frame_start, int) and isinstance(trim_frame_end, int):
|
| 84 |
+
commands.extend([ '-vf', 'trim=start_frame=' + str(trim_frame_start) + ':end_frame=' + str(trim_frame_end) + ',fps=' + str(temp_video_fps) ])
|
| 85 |
+
elif isinstance(trim_frame_start, int):
|
| 86 |
+
commands.extend([ '-vf', 'trim=start_frame=' + str(trim_frame_start) + ',fps=' + str(temp_video_fps) ])
|
| 87 |
+
elif isinstance(trim_frame_end, int):
|
| 88 |
+
commands.extend([ '-vf', 'trim=end_frame=' + str(trim_frame_end) + ',fps=' + str(temp_video_fps) ])
|
| 89 |
+
else:
|
| 90 |
+
commands.extend([ '-vf', 'fps=' + str(temp_video_fps) ])
|
| 91 |
+
commands.extend([ '-vsync', '0', temp_frames_pattern ])
|
| 92 |
+
|
| 93 |
+
with tqdm(total = extract_frame_total, desc = wording.get('extracting'), unit = 'frame', ascii = ' =', disable = state_manager.get_item('log_level') in [ 'warn', 'error' ]) as progress:
|
| 94 |
+
process = run_ffmpeg_with_progress(commands, lambda frame_number: progress.update(frame_number - progress.n))
|
| 95 |
+
return process.returncode == 0
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def merge_video(target_path : str, output_video_resolution : str, output_video_fps: Fps) -> bool:
|
| 99 |
+
output_video_encoder = state_manager.get_item('output_video_encoder')
|
| 100 |
+
output_video_quality = state_manager.get_item('output_video_quality')
|
| 101 |
+
output_video_preset = state_manager.get_item('output_video_preset')
|
| 102 |
+
merge_frame_total = len(get_temp_frame_paths(target_path))
|
| 103 |
+
temp_video_fps = restrict_video_fps(target_path, output_video_fps)
|
| 104 |
+
temp_file_path = get_temp_file_path(target_path)
|
| 105 |
+
temp_frames_pattern = get_temp_frames_pattern(target_path, '%08d')
|
| 106 |
+
is_webm = filetype.guess_mime(target_path) == 'video/webm'
|
| 107 |
+
|
| 108 |
+
if is_webm:
|
| 109 |
+
output_video_encoder = 'libvpx-vp9'
|
| 110 |
+
commands = [ '-r', str(temp_video_fps), '-i', temp_frames_pattern, '-s', str(output_video_resolution), '-c:v', output_video_encoder ]
|
| 111 |
+
if output_video_encoder in [ 'libx264', 'libx265' ]:
|
| 112 |
+
output_video_compression = round(51 - (output_video_quality * 0.51))
|
| 113 |
+
commands.extend([ '-crf', str(output_video_compression), '-preset', output_video_preset ])
|
| 114 |
+
if output_video_encoder in [ 'libvpx-vp9' ]:
|
| 115 |
+
output_video_compression = round(63 - (output_video_quality * 0.63))
|
| 116 |
+
commands.extend([ '-crf', str(output_video_compression) ])
|
| 117 |
+
if output_video_encoder in [ 'h264_nvenc', 'hevc_nvenc' ]:
|
| 118 |
+
output_video_compression = round(51 - (output_video_quality * 0.51))
|
| 119 |
+
commands.extend([ '-cq', str(output_video_compression), '-preset', map_nvenc_preset(output_video_preset) ])
|
| 120 |
+
if output_video_encoder in [ 'h264_amf', 'hevc_amf' ]:
|
| 121 |
+
output_video_compression = round(51 - (output_video_quality * 0.51))
|
| 122 |
+
commands.extend([ '-qp_i', str(output_video_compression), '-qp_p', str(output_video_compression), '-quality', map_amf_preset(output_video_preset) ])
|
| 123 |
+
if output_video_encoder in [ 'h264_videotoolbox', 'hevc_videotoolbox' ]:
|
| 124 |
+
commands.extend([ '-q:v', str(output_video_quality) ])
|
| 125 |
+
commands.extend([ '-vf', 'framerate=fps=' + str(output_video_fps), '-pix_fmt', 'yuv420p', '-colorspace', 'bt709', '-y', temp_file_path ])
|
| 126 |
+
|
| 127 |
+
with tqdm(total = merge_frame_total, desc = wording.get('merging'), unit = 'frame', ascii = ' =', disable = state_manager.get_item('log_level') in [ 'warn', 'error' ]) as progress:
|
| 128 |
+
process = run_ffmpeg_with_progress(commands, lambda frame_number: progress.update(frame_number - progress.n))
|
| 129 |
+
return process.returncode == 0
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def concat_video(output_path : str, temp_output_paths : List[str]) -> bool:
|
| 133 |
+
output_audio_encoder = state_manager.get_item('output_audio_encoder')
|
| 134 |
+
concat_video_path = tempfile.mktemp()
|
| 135 |
+
|
| 136 |
+
with open(concat_video_path, 'w') as concat_video_file:
|
| 137 |
+
for temp_output_path in temp_output_paths:
|
| 138 |
+
concat_video_file.write('file \'' + os.path.abspath(temp_output_path) + '\'' + os.linesep)
|
| 139 |
+
concat_video_file.flush()
|
| 140 |
+
concat_video_file.close()
|
| 141 |
+
commands = [ '-f', 'concat', '-safe', '0', '-i', concat_video_file.name, '-c:v', 'copy', '-c:a', output_audio_encoder, '-y', os.path.abspath(output_path) ]
|
| 142 |
+
process = run_ffmpeg(commands)
|
| 143 |
+
process.communicate()
|
| 144 |
+
remove_file(concat_video_path)
|
| 145 |
+
return process.returncode == 0
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def copy_image(target_path : str, temp_image_resolution : str) -> bool:
|
| 149 |
+
temp_file_path = get_temp_file_path(target_path)
|
| 150 |
+
temp_image_compression = calc_image_compression(target_path, 100)
|
| 151 |
+
commands = [ '-i', target_path, '-s', str(temp_image_resolution), '-q:v', str(temp_image_compression), '-y', temp_file_path ]
|
| 152 |
+
return run_ffmpeg(commands).returncode == 0
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def finalize_image(target_path : str, output_path : str, output_image_resolution : str) -> bool:
|
| 156 |
+
output_image_quality = state_manager.get_item('output_image_quality')
|
| 157 |
+
temp_file_path = get_temp_file_path(target_path)
|
| 158 |
+
output_image_compression = calc_image_compression(target_path, output_image_quality)
|
| 159 |
+
commands = [ '-i', temp_file_path, '-s', str(output_image_resolution), '-q:v', str(output_image_compression), '-y', output_path ]
|
| 160 |
+
return run_ffmpeg(commands).returncode == 0
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def calc_image_compression(image_path : str, image_quality : int) -> int:
|
| 164 |
+
is_webp = filetype.guess_mime(image_path) == 'image/webp'
|
| 165 |
+
if is_webp:
|
| 166 |
+
image_quality = 100 - image_quality
|
| 167 |
+
return round(31 - (image_quality * 0.31))
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def read_audio_buffer(target_path : str, sample_rate : int, channel_total : int) -> Optional[AudioBuffer]:
|
| 171 |
+
commands = [ '-i', target_path, '-vn', '-f', 's16le', '-acodec', 'pcm_s16le', '-ar', str(sample_rate), '-ac', str(channel_total), '-' ]
|
| 172 |
+
process = open_ffmpeg(commands)
|
| 173 |
+
audio_buffer, _ = process.communicate()
|
| 174 |
+
if process.returncode == 0:
|
| 175 |
+
return audio_buffer
|
| 176 |
+
return None
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def restore_audio(target_path : str, output_path : str, output_video_fps : Fps, trim_frame_start : int, trim_frame_end : int) -> bool:
|
| 180 |
+
output_audio_encoder = state_manager.get_item('output_audio_encoder')
|
| 181 |
+
temp_file_path = get_temp_file_path(target_path)
|
| 182 |
+
temp_video_duration = detect_video_duration(temp_file_path)
|
| 183 |
+
commands = [ '-i', temp_file_path ]
|
| 184 |
+
|
| 185 |
+
if isinstance(trim_frame_start, int):
|
| 186 |
+
start_time = trim_frame_start / output_video_fps
|
| 187 |
+
commands.extend([ '-ss', str(start_time) ])
|
| 188 |
+
if isinstance(trim_frame_end, int):
|
| 189 |
+
end_time = trim_frame_end / output_video_fps
|
| 190 |
+
commands.extend([ '-to', str(end_time) ])
|
| 191 |
+
commands.extend([ '-i', target_path, '-c:v', 'copy', '-c:a', output_audio_encoder, '-map', '0:v:0', '-map', '1:a:0', '-t', str(temp_video_duration), '-y', output_path ])
|
| 192 |
+
return run_ffmpeg(commands).returncode == 0
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def replace_audio(target_path : str, audio_path : str, output_path : str) -> bool:
|
| 196 |
+
output_audio_encoder = state_manager.get_item('output_audio_encoder')
|
| 197 |
+
temp_file_path = get_temp_file_path(target_path)
|
| 198 |
+
temp_video_duration = detect_video_duration(temp_file_path)
|
| 199 |
+
commands = [ '-i', temp_file_path, '-i', audio_path, '-c:v', 'copy', '-c:a', output_audio_encoder, '-t', str(temp_video_duration), '-y', output_path ]
|
| 200 |
+
return run_ffmpeg(commands).returncode == 0
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def map_nvenc_preset(output_video_preset : OutputVideoPreset) -> Optional[str]:
|
| 204 |
+
if output_video_preset in [ 'ultrafast', 'superfast', 'veryfast', 'faster', 'fast' ]:
|
| 205 |
+
return 'fast'
|
| 206 |
+
if output_video_preset == 'medium':
|
| 207 |
+
return 'medium'
|
| 208 |
+
if output_video_preset in [ 'slow', 'slower', 'veryslow' ]:
|
| 209 |
+
return 'slow'
|
| 210 |
+
return None
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def map_amf_preset(output_video_preset : OutputVideoPreset) -> Optional[str]:
|
| 214 |
+
if output_video_preset in [ 'ultrafast', 'superfast', 'veryfast' ]:
|
| 215 |
+
return 'speed'
|
| 216 |
+
if output_video_preset in [ 'faster', 'fast', 'medium' ]:
|
| 217 |
+
return 'balanced'
|
| 218 |
+
if output_video_preset in [ 'slow', 'slower', 'veryslow' ]:
|
| 219 |
+
return 'quality'
|
| 220 |
+
return None
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def map_qsv_preset(output_video_preset : OutputVideoPreset) -> Optional[str]:
|
| 224 |
+
if output_video_preset in [ 'ultrafast', 'superfast', 'veryfast', 'faster', 'fast' ]:
|
| 225 |
+
return 'fast'
|
| 226 |
+
if output_video_preset == 'medium':
|
| 227 |
+
return 'medium'
|
| 228 |
+
if output_video_preset in [ 'slow', 'slower', 'veryslow' ]:
|
| 229 |
+
return 'slow'
|
| 230 |
+
return None
|
facefusion/filesystem.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import os
|
| 3 |
+
import shutil
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from typing import List, Optional
|
| 6 |
+
|
| 7 |
+
import filetype
|
| 8 |
+
|
| 9 |
+
from facefusion.common_helper import is_windows
|
| 10 |
+
from facefusion.typing import File
|
| 11 |
+
|
| 12 |
+
if is_windows():
|
| 13 |
+
import ctypes
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_file_size(file_path : str) -> int:
|
| 17 |
+
if is_file(file_path):
|
| 18 |
+
return os.path.getsize(file_path)
|
| 19 |
+
return 0
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def same_file_extension(file_paths : List[str]) -> bool:
|
| 23 |
+
file_extensions : List[str] = []
|
| 24 |
+
|
| 25 |
+
for file_path in file_paths:
|
| 26 |
+
_, file_extension = os.path.splitext(file_path.lower())
|
| 27 |
+
|
| 28 |
+
if file_extensions and file_extension not in file_extensions:
|
| 29 |
+
return False
|
| 30 |
+
file_extensions.append(file_extension)
|
| 31 |
+
return True
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def is_file(file_path : str) -> bool:
|
| 35 |
+
return bool(file_path and os.path.isfile(file_path))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def is_directory(directory_path : str) -> bool:
|
| 39 |
+
return bool(directory_path and os.path.isdir(directory_path))
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def in_directory(file_path : str) -> bool:
|
| 43 |
+
if file_path and not is_directory(file_path):
|
| 44 |
+
return is_directory(os.path.dirname(file_path))
|
| 45 |
+
return False
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def is_audio(audio_path : str) -> bool:
|
| 49 |
+
return is_file(audio_path) and filetype.helpers.is_audio(audio_path)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def has_audio(audio_paths : List[str]) -> bool:
|
| 53 |
+
if audio_paths:
|
| 54 |
+
return any(is_audio(audio_path) for audio_path in audio_paths)
|
| 55 |
+
return False
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def is_image(image_path : str) -> bool:
|
| 59 |
+
return is_file(image_path) and filetype.helpers.is_image(image_path)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def has_image(image_paths: List[str]) -> bool:
|
| 63 |
+
if image_paths:
|
| 64 |
+
return any(is_image(image_path) for image_path in image_paths)
|
| 65 |
+
return False
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def is_video(video_path : str) -> bool:
|
| 69 |
+
return is_file(video_path) and filetype.helpers.is_video(video_path)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def filter_audio_paths(paths : List[str]) -> List[str]:
|
| 73 |
+
if paths:
|
| 74 |
+
return [ path for path in paths if is_audio(path) ]
|
| 75 |
+
return []
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def filter_image_paths(paths : List[str]) -> List[str]:
|
| 79 |
+
if paths:
|
| 80 |
+
return [ path for path in paths if is_image(path) ]
|
| 81 |
+
return []
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def resolve_relative_path(path : str) -> str:
|
| 85 |
+
return os.path.abspath(os.path.join(os.path.dirname(__file__), path))
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def sanitize_path_for_windows(full_path : str) -> Optional[str]:
|
| 89 |
+
buffer_size = 0
|
| 90 |
+
|
| 91 |
+
while True:
|
| 92 |
+
unicode_buffer = ctypes.create_unicode_buffer(buffer_size)
|
| 93 |
+
buffer_limit = ctypes.windll.kernel32.GetShortPathNameW(full_path, unicode_buffer, buffer_size) #type:ignore[attr-defined]
|
| 94 |
+
|
| 95 |
+
if buffer_size > buffer_limit:
|
| 96 |
+
return unicode_buffer.value
|
| 97 |
+
if buffer_limit == 0:
|
| 98 |
+
return None
|
| 99 |
+
buffer_size = buffer_limit
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def copy_file(file_path : str, move_path : str) -> bool:
|
| 103 |
+
if is_file(file_path):
|
| 104 |
+
shutil.copy(file_path, move_path)
|
| 105 |
+
return is_file(move_path)
|
| 106 |
+
return False
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def move_file(file_path : str, move_path : str) -> bool:
|
| 110 |
+
if is_file(file_path):
|
| 111 |
+
shutil.move(file_path, move_path)
|
| 112 |
+
return not is_file(file_path) and is_file(move_path)
|
| 113 |
+
return False
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def remove_file(file_path : str) -> bool:
|
| 117 |
+
if is_file(file_path):
|
| 118 |
+
os.remove(file_path)
|
| 119 |
+
return not is_file(file_path)
|
| 120 |
+
return False
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def create_directory(directory_path : str) -> bool:
|
| 124 |
+
if directory_path and not is_file(directory_path):
|
| 125 |
+
Path(directory_path).mkdir(parents = True, exist_ok = True)
|
| 126 |
+
return is_directory(directory_path)
|
| 127 |
+
return False
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def list_directory(directory_path : str) -> Optional[List[File]]:
|
| 131 |
+
if is_directory(directory_path):
|
| 132 |
+
file_paths = sorted(os.listdir(directory_path))
|
| 133 |
+
files: List[File] = []
|
| 134 |
+
|
| 135 |
+
for file_path in file_paths:
|
| 136 |
+
file_name, file_extension = os.path.splitext(file_path)
|
| 137 |
+
|
| 138 |
+
if not file_name.startswith(('.', '__')):
|
| 139 |
+
files.append(
|
| 140 |
+
{
|
| 141 |
+
'name': file_name,
|
| 142 |
+
'extension': file_extension,
|
| 143 |
+
'path': os.path.join(directory_path, file_path)
|
| 144 |
+
})
|
| 145 |
+
|
| 146 |
+
return files
|
| 147 |
+
return None
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def resolve_file_pattern(file_pattern : str) -> List[str]:
|
| 151 |
+
if in_directory(file_pattern):
|
| 152 |
+
return sorted(glob.glob(file_pattern))
|
| 153 |
+
return []
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def remove_directory(directory_path : str) -> bool:
|
| 157 |
+
if is_directory(directory_path):
|
| 158 |
+
shutil.rmtree(directory_path, ignore_errors = True)
|
| 159 |
+
return not is_directory(directory_path)
|
| 160 |
+
return False
|
facefusion/hash_helper.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import zlib
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
from facefusion.filesystem import is_file
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def create_hash(content : bytes) -> str:
|
| 9 |
+
return format(zlib.crc32(content), '08x')
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def validate_hash(validate_path : str) -> bool:
|
| 13 |
+
hash_path = get_hash_path(validate_path)
|
| 14 |
+
|
| 15 |
+
if is_file(hash_path):
|
| 16 |
+
with open(hash_path, 'r') as hash_file:
|
| 17 |
+
hash_content = hash_file.read().strip()
|
| 18 |
+
|
| 19 |
+
with open(validate_path, 'rb') as validate_file:
|
| 20 |
+
validate_content = validate_file.read()
|
| 21 |
+
|
| 22 |
+
return create_hash(validate_content) == hash_content
|
| 23 |
+
return False
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_hash_path(validate_path : str) -> Optional[str]:
|
| 27 |
+
if is_file(validate_path):
|
| 28 |
+
validate_directory_path, _ = os.path.split(validate_path)
|
| 29 |
+
validate_file_name, _ = os.path.splitext(_)
|
| 30 |
+
|
| 31 |
+
return os.path.join(validate_directory_path, validate_file_name + '.hash')
|
| 32 |
+
return None
|
facefusion/inference_manager.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from time import sleep
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
from onnxruntime import InferenceSession
|
| 5 |
+
|
| 6 |
+
from facefusion import process_manager, state_manager
|
| 7 |
+
from facefusion.app_context import detect_app_context
|
| 8 |
+
from facefusion.execution import create_inference_execution_providers
|
| 9 |
+
from facefusion.thread_helper import thread_lock
|
| 10 |
+
from facefusion.typing import DownloadSet, ExecutionProvider, InferencePool, InferencePoolSet
|
| 11 |
+
|
| 12 |
+
INFERENCE_POOLS : InferencePoolSet =\
|
| 13 |
+
{
|
| 14 |
+
'cli': {}, #type:ignore[typeddict-item]
|
| 15 |
+
'ui': {} #type:ignore[typeddict-item]
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_inference_pool(model_context : str, model_sources : DownloadSet) -> InferencePool:
|
| 20 |
+
global INFERENCE_POOLS
|
| 21 |
+
|
| 22 |
+
with thread_lock():
|
| 23 |
+
while process_manager.is_checking():
|
| 24 |
+
sleep(0.5)
|
| 25 |
+
app_context = detect_app_context()
|
| 26 |
+
inference_context = get_inference_context(model_context)
|
| 27 |
+
|
| 28 |
+
if app_context == 'cli' and INFERENCE_POOLS.get('ui').get(inference_context):
|
| 29 |
+
INFERENCE_POOLS['cli'][inference_context] = INFERENCE_POOLS.get('ui').get(inference_context)
|
| 30 |
+
if app_context == 'ui' and INFERENCE_POOLS.get('cli').get(inference_context):
|
| 31 |
+
INFERENCE_POOLS['ui'][inference_context] = INFERENCE_POOLS.get('cli').get(inference_context)
|
| 32 |
+
if not INFERENCE_POOLS.get(app_context).get(inference_context):
|
| 33 |
+
INFERENCE_POOLS[app_context][inference_context] = create_inference_pool(model_sources, state_manager.get_item('execution_device_id'), state_manager.get_item('execution_providers'))
|
| 34 |
+
|
| 35 |
+
return INFERENCE_POOLS.get(app_context).get(inference_context)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def create_inference_pool(model_sources : DownloadSet, execution_device_id : str, execution_providers : List[ExecutionProvider]) -> InferencePool:
|
| 39 |
+
inference_pool : InferencePool = {}
|
| 40 |
+
|
| 41 |
+
for model_name in model_sources.keys():
|
| 42 |
+
inference_pool[model_name] = create_inference_session(model_sources.get(model_name).get('path'), execution_device_id, execution_providers)
|
| 43 |
+
return inference_pool
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def clear_inference_pool(model_context : str) -> None:
|
| 47 |
+
global INFERENCE_POOLS
|
| 48 |
+
|
| 49 |
+
app_context = detect_app_context()
|
| 50 |
+
inference_context = get_inference_context(model_context)
|
| 51 |
+
|
| 52 |
+
if INFERENCE_POOLS.get(app_context).get(inference_context):
|
| 53 |
+
del INFERENCE_POOLS[app_context][inference_context]
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def create_inference_session(model_path : str, execution_device_id : str, execution_providers : List[ExecutionProvider]) -> InferenceSession:
|
| 57 |
+
inference_execution_providers = create_inference_execution_providers(execution_device_id, execution_providers)
|
| 58 |
+
return InferenceSession(model_path, providers = inference_execution_providers)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_inference_context(model_context : str) -> str:
|
| 62 |
+
inference_context = model_context + '.' + '_'.join(state_manager.get_item('execution_providers'))
|
| 63 |
+
return inference_context
|
facefusion/installer.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
| 3 |
+
import signal
|
| 4 |
+
import subprocess
|
| 5 |
+
import sys
|
| 6 |
+
import tempfile
|
| 7 |
+
from argparse import ArgumentParser, HelpFormatter
|
| 8 |
+
from typing import Dict, Tuple
|
| 9 |
+
|
| 10 |
+
from facefusion import metadata, wording
|
| 11 |
+
from facefusion.common_helper import is_linux, is_macos, is_windows
|
| 12 |
+
|
| 13 |
+
ONNXRUNTIMES : Dict[str, Tuple[str, str]] = {}
|
| 14 |
+
|
| 15 |
+
if is_macos():
|
| 16 |
+
ONNXRUNTIMES['default'] = ('onnxruntime', '1.20.1')
|
| 17 |
+
else:
|
| 18 |
+
ONNXRUNTIMES['default'] = ('onnxruntime', '1.20.1')
|
| 19 |
+
ONNXRUNTIMES['cuda'] = ('onnxruntime-gpu', '1.20.1')
|
| 20 |
+
ONNXRUNTIMES['openvino'] = ('onnxruntime-openvino', '1.20.0')
|
| 21 |
+
if is_linux():
|
| 22 |
+
ONNXRUNTIMES['rocm'] = ('onnxruntime-rocm', '1.19.0')
|
| 23 |
+
if is_windows():
|
| 24 |
+
ONNXRUNTIMES['directml'] = ('onnxruntime-directml', '1.17.3')
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def cli() -> None:
|
| 28 |
+
signal.signal(signal.SIGINT, lambda signal_number, frame: sys.exit(0))
|
| 29 |
+
program = ArgumentParser(formatter_class = lambda prog: HelpFormatter(prog, max_help_position = 50))
|
| 30 |
+
program.add_argument('--onnxruntime', help = wording.get('help.install_dependency').format(dependency = 'onnxruntime'), choices = ONNXRUNTIMES.keys(), required = True)
|
| 31 |
+
program.add_argument('--skip-conda', help = wording.get('help.skip_conda'), action = 'store_true')
|
| 32 |
+
program.add_argument('-v', '--version', version = metadata.get('name') + ' ' + metadata.get('version'), action = 'version')
|
| 33 |
+
run(program)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def run(program : ArgumentParser) -> None:
|
| 37 |
+
args = program.parse_args()
|
| 38 |
+
has_conda = 'CONDA_PREFIX' in os.environ
|
| 39 |
+
onnxruntime_name, onnxruntime_version = ONNXRUNTIMES.get(args.onnxruntime)
|
| 40 |
+
|
| 41 |
+
if not args.skip_conda and not has_conda:
|
| 42 |
+
sys.stdout.write(wording.get('conda_not_activated') + os.linesep)
|
| 43 |
+
sys.exit(1)
|
| 44 |
+
|
| 45 |
+
subprocess.call([ shutil.which('pip'), 'install', '-r', 'requirements.txt', '--force-reinstall' ])
|
| 46 |
+
|
| 47 |
+
if args.onnxruntime == 'rocm':
|
| 48 |
+
python_id = 'cp' + str(sys.version_info.major) + str(sys.version_info.minor)
|
| 49 |
+
|
| 50 |
+
if python_id in [ 'cp310', 'cp312' ]:
|
| 51 |
+
wheel_name = 'onnxruntime_rocm-' + onnxruntime_version + '-' + python_id + '-' + python_id + '-linux_x86_64.whl'
|
| 52 |
+
wheel_path = os.path.join(tempfile.gettempdir(), wheel_name)
|
| 53 |
+
wheel_url = 'https://repo.radeon.com/rocm/manylinux/rocm-rel-6.3.1/' + wheel_name
|
| 54 |
+
subprocess.call([ shutil.which('curl'), '--silent', '--location', '--continue-at', '-', '--output', wheel_path, wheel_url ])
|
| 55 |
+
subprocess.call([ shutil.which('pip'), 'uninstall', 'onnxruntime', wheel_path, '-y', '-q' ])
|
| 56 |
+
subprocess.call([ shutil.which('pip'), 'install', wheel_path, '--force-reinstall' ])
|
| 57 |
+
os.remove(wheel_path)
|
| 58 |
+
else:
|
| 59 |
+
subprocess.call([ shutil.which('pip'), 'uninstall', 'onnxruntime', onnxruntime_name, '-y', '-q' ])
|
| 60 |
+
subprocess.call([ shutil.which('pip'), 'install', onnxruntime_name + '==' + onnxruntime_version, '--force-reinstall' ])
|
| 61 |
+
|
| 62 |
+
if args.onnxruntime == 'cuda' and has_conda:
|
| 63 |
+
library_paths = []
|
| 64 |
+
|
| 65 |
+
if is_linux():
|
| 66 |
+
if os.getenv('LD_LIBRARY_PATH'):
|
| 67 |
+
library_paths = os.getenv('LD_LIBRARY_PATH').split(os.pathsep)
|
| 68 |
+
|
| 69 |
+
python_id = 'python' + str(sys.version_info.major) + '.' + str(sys.version_info.minor)
|
| 70 |
+
library_paths.extend(
|
| 71 |
+
[
|
| 72 |
+
os.path.join(os.getenv('CONDA_PREFIX'), 'lib'),
|
| 73 |
+
os.path.join(os.getenv('CONDA_PREFIX'), 'lib', python_id, 'site-packages', 'tensorrt_libs')
|
| 74 |
+
])
|
| 75 |
+
library_paths = list(dict.fromkeys([ library_path for library_path in library_paths if os.path.exists(library_path) ]))
|
| 76 |
+
|
| 77 |
+
subprocess.call([ shutil.which('conda'), 'env', 'config', 'vars', 'set', 'LD_LIBRARY_PATH=' + os.pathsep.join(library_paths) ])
|
| 78 |
+
|
| 79 |
+
if is_windows():
|
| 80 |
+
if os.getenv('PATH'):
|
| 81 |
+
library_paths = os.getenv('PATH').split(os.pathsep)
|
| 82 |
+
|
| 83 |
+
library_paths.extend(
|
| 84 |
+
[
|
| 85 |
+
os.path.join(os.getenv('CONDA_PREFIX'), 'Lib'),
|
| 86 |
+
os.path.join(os.getenv('CONDA_PREFIX'), 'Lib', 'site-packages', 'tensorrt_libs')
|
| 87 |
+
])
|
| 88 |
+
library_paths = list(dict.fromkeys([ library_path for library_path in library_paths if os.path.exists(library_path) ]))
|
| 89 |
+
|
| 90 |
+
subprocess.call([ shutil.which('conda'), 'env', 'config', 'vars', 'set', 'PATH=' + os.pathsep.join(library_paths) ])
|
| 91 |
+
|
| 92 |
+
if args.onnxruntime in [ 'directml', 'rocm' ]:
|
| 93 |
+
subprocess.call([ shutil.which('pip'), 'install', 'numpy==1.26.4', '--force-reinstall' ])
|
facefusion/jobs/__init__.py
ADDED
|
File without changes
|
facefusion/jobs/job_helper.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from datetime import datetime
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def get_step_output_path(job_id : str, step_index : int, output_path : str) -> Optional[str]:
|
| 7 |
+
if output_path:
|
| 8 |
+
output_directory_path, _ = os.path.split(output_path)
|
| 9 |
+
output_file_name, output_file_extension = os.path.splitext(_)
|
| 10 |
+
return os.path.join(output_directory_path, output_file_name + '-' + job_id + '-' + str(step_index) + output_file_extension)
|
| 11 |
+
return None
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def suggest_job_id(job_prefix : str = 'job') -> str:
|
| 15 |
+
return job_prefix + '-' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
|
facefusion/jobs/job_list.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datetime import datetime
|
| 2 |
+
from typing import Optional, Tuple
|
| 3 |
+
|
| 4 |
+
from facefusion.date_helper import describe_time_ago
|
| 5 |
+
from facefusion.jobs import job_manager
|
| 6 |
+
from facefusion.typing import JobStatus, TableContents, TableHeaders
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def compose_job_list(job_status : JobStatus) -> Tuple[TableHeaders, TableContents]:
|
| 10 |
+
jobs = job_manager.find_jobs(job_status)
|
| 11 |
+
job_headers : TableHeaders = [ 'job id', 'steps', 'date created', 'date updated', 'job status' ]
|
| 12 |
+
job_contents : TableContents = []
|
| 13 |
+
|
| 14 |
+
for index, job_id in enumerate(jobs):
|
| 15 |
+
if job_manager.validate_job(job_id):
|
| 16 |
+
job = jobs[job_id]
|
| 17 |
+
step_total = job_manager.count_step_total(job_id)
|
| 18 |
+
date_created = prepare_describe_datetime(job.get('date_created'))
|
| 19 |
+
date_updated = prepare_describe_datetime(job.get('date_updated'))
|
| 20 |
+
job_contents.append(
|
| 21 |
+
[
|
| 22 |
+
job_id,
|
| 23 |
+
step_total,
|
| 24 |
+
date_created,
|
| 25 |
+
date_updated,
|
| 26 |
+
job_status
|
| 27 |
+
])
|
| 28 |
+
return job_headers, job_contents
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def prepare_describe_datetime(date_time : Optional[str]) -> Optional[str]:
|
| 32 |
+
if date_time:
|
| 33 |
+
return describe_time_ago(datetime.fromisoformat(date_time))
|
| 34 |
+
return None
|
facefusion/jobs/job_manager.py
ADDED
|
@@ -0,0 +1,260 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from copy import copy
|
| 3 |
+
from typing import List, Optional
|
| 4 |
+
|
| 5 |
+
import facefusion.choices
|
| 6 |
+
from facefusion.date_helper import get_current_date_time
|
| 7 |
+
from facefusion.filesystem import create_directory, is_directory, is_file, move_file, remove_directory, remove_file, resolve_file_pattern
|
| 8 |
+
from facefusion.jobs.job_helper import get_step_output_path
|
| 9 |
+
from facefusion.json import read_json, write_json
|
| 10 |
+
from facefusion.typing import Args, Job, JobSet, JobStatus, JobStep, JobStepStatus
|
| 11 |
+
|
| 12 |
+
JOBS_PATH : Optional[str] = None
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def init_jobs(jobs_path : str) -> bool:
|
| 16 |
+
global JOBS_PATH
|
| 17 |
+
|
| 18 |
+
JOBS_PATH = jobs_path
|
| 19 |
+
job_status_paths = [ os.path.join(JOBS_PATH, job_status) for job_status in facefusion.choices.job_statuses ]
|
| 20 |
+
|
| 21 |
+
for job_status_path in job_status_paths:
|
| 22 |
+
create_directory(job_status_path)
|
| 23 |
+
return all(is_directory(status_path) for status_path in job_status_paths)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def clear_jobs(jobs_path : str) -> bool:
|
| 27 |
+
return remove_directory(jobs_path)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def create_job(job_id : str) -> bool:
|
| 31 |
+
job : Job =\
|
| 32 |
+
{
|
| 33 |
+
'version': '1',
|
| 34 |
+
'date_created': get_current_date_time().isoformat(),
|
| 35 |
+
'date_updated': None,
|
| 36 |
+
'steps': []
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
return create_job_file(job_id, job)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def submit_job(job_id : str) -> bool:
|
| 43 |
+
drafted_job_ids = find_job_ids('drafted')
|
| 44 |
+
steps = get_steps(job_id)
|
| 45 |
+
|
| 46 |
+
if job_id in drafted_job_ids and steps:
|
| 47 |
+
return set_steps_status(job_id, 'queued') and move_job_file(job_id, 'queued')
|
| 48 |
+
return False
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def submit_jobs() -> bool:
|
| 52 |
+
drafted_job_ids = find_job_ids('drafted')
|
| 53 |
+
|
| 54 |
+
if drafted_job_ids:
|
| 55 |
+
for job_id in drafted_job_ids:
|
| 56 |
+
if not submit_job(job_id):
|
| 57 |
+
return False
|
| 58 |
+
return True
|
| 59 |
+
return False
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def delete_job(job_id : str) -> bool:
|
| 63 |
+
return delete_job_file(job_id)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def delete_jobs() -> bool:
|
| 67 |
+
job_ids = find_job_ids('drafted') + find_job_ids('queued') + find_job_ids('failed') + find_job_ids('completed')
|
| 68 |
+
|
| 69 |
+
if job_ids:
|
| 70 |
+
for job_id in job_ids:
|
| 71 |
+
if not delete_job(job_id):
|
| 72 |
+
return False
|
| 73 |
+
return True
|
| 74 |
+
return False
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def find_jobs(job_status : JobStatus) -> JobSet:
|
| 78 |
+
job_ids = find_job_ids(job_status)
|
| 79 |
+
jobs : JobSet = {}
|
| 80 |
+
|
| 81 |
+
for job_id in job_ids:
|
| 82 |
+
jobs[job_id] = read_job_file(job_id)
|
| 83 |
+
return jobs
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def find_job_ids(job_status : JobStatus) -> List[str]:
|
| 87 |
+
job_pattern = os.path.join(JOBS_PATH, job_status, '*.json')
|
| 88 |
+
job_paths = resolve_file_pattern(job_pattern)
|
| 89 |
+
job_paths.sort(key = os.path.getmtime)
|
| 90 |
+
job_ids = []
|
| 91 |
+
|
| 92 |
+
for job_path in job_paths:
|
| 93 |
+
job_id, _ = os.path.splitext(os.path.basename(job_path))
|
| 94 |
+
job_ids.append(job_id)
|
| 95 |
+
return job_ids
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def validate_job(job_id : str) -> bool:
|
| 99 |
+
job = read_job_file(job_id)
|
| 100 |
+
return bool(job and 'version' in job and 'date_created' in job and 'date_updated' in job and 'steps' in job)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def has_step(job_id : str, step_index : int) -> bool:
|
| 104 |
+
step_total = count_step_total(job_id)
|
| 105 |
+
return step_index in range(step_total)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def add_step(job_id : str, step_args : Args) -> bool:
|
| 109 |
+
job = read_job_file(job_id)
|
| 110 |
+
|
| 111 |
+
if job:
|
| 112 |
+
job.get('steps').append(
|
| 113 |
+
{
|
| 114 |
+
'args': step_args,
|
| 115 |
+
'status': 'drafted'
|
| 116 |
+
})
|
| 117 |
+
return update_job_file(job_id, job)
|
| 118 |
+
return False
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def remix_step(job_id : str, step_index : int, step_args : Args) -> bool:
|
| 122 |
+
steps = get_steps(job_id)
|
| 123 |
+
step_args = copy(step_args)
|
| 124 |
+
|
| 125 |
+
if step_index and step_index < 0:
|
| 126 |
+
step_index = count_step_total(job_id) - 1
|
| 127 |
+
|
| 128 |
+
if has_step(job_id, step_index):
|
| 129 |
+
output_path = steps[step_index].get('args').get('output_path')
|
| 130 |
+
step_args['target_path'] = get_step_output_path(job_id, step_index, output_path)
|
| 131 |
+
return add_step(job_id, step_args)
|
| 132 |
+
return False
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def insert_step(job_id : str, step_index : int, step_args : Args) -> bool:
|
| 136 |
+
job = read_job_file(job_id)
|
| 137 |
+
step_args = copy(step_args)
|
| 138 |
+
|
| 139 |
+
if step_index and step_index < 0:
|
| 140 |
+
step_index = count_step_total(job_id) - 1
|
| 141 |
+
|
| 142 |
+
if job and has_step(job_id, step_index):
|
| 143 |
+
job.get('steps').insert(step_index,
|
| 144 |
+
{
|
| 145 |
+
'args': step_args,
|
| 146 |
+
'status': 'drafted'
|
| 147 |
+
})
|
| 148 |
+
return update_job_file(job_id, job)
|
| 149 |
+
return False
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def remove_step(job_id : str, step_index : int) -> bool:
|
| 153 |
+
job = read_job_file(job_id)
|
| 154 |
+
|
| 155 |
+
if step_index and step_index < 0:
|
| 156 |
+
step_index = count_step_total(job_id) - 1
|
| 157 |
+
|
| 158 |
+
if job and has_step(job_id, step_index):
|
| 159 |
+
job.get('steps').pop(step_index)
|
| 160 |
+
return update_job_file(job_id, job)
|
| 161 |
+
return False
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def get_steps(job_id : str) -> List[JobStep]:
|
| 165 |
+
job = read_job_file(job_id)
|
| 166 |
+
|
| 167 |
+
if job:
|
| 168 |
+
return job.get('steps')
|
| 169 |
+
return []
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def count_step_total(job_id : str) -> int:
|
| 173 |
+
steps = get_steps(job_id)
|
| 174 |
+
|
| 175 |
+
if steps:
|
| 176 |
+
return len(steps)
|
| 177 |
+
return 0
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def set_step_status(job_id : str, step_index : int, step_status : JobStepStatus) -> bool:
|
| 181 |
+
job = read_job_file(job_id)
|
| 182 |
+
|
| 183 |
+
if job:
|
| 184 |
+
steps = job.get('steps')
|
| 185 |
+
|
| 186 |
+
if has_step(job_id, step_index):
|
| 187 |
+
steps[step_index]['status'] = step_status
|
| 188 |
+
return update_job_file(job_id, job)
|
| 189 |
+
return False
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def set_steps_status(job_id : str, step_status : JobStepStatus) -> bool:
|
| 193 |
+
job = read_job_file(job_id)
|
| 194 |
+
|
| 195 |
+
if job:
|
| 196 |
+
for step in job.get('steps'):
|
| 197 |
+
step['status'] = step_status
|
| 198 |
+
return update_job_file(job_id, job)
|
| 199 |
+
return False
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def read_job_file(job_id : str) -> Optional[Job]:
|
| 203 |
+
job_path = find_job_path(job_id)
|
| 204 |
+
return read_json(job_path) #type:ignore[return-value]
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def create_job_file(job_id : str, job : Job) -> bool:
|
| 208 |
+
job_path = find_job_path(job_id)
|
| 209 |
+
|
| 210 |
+
if not is_file(job_path):
|
| 211 |
+
job_create_path = suggest_job_path(job_id, 'drafted')
|
| 212 |
+
return write_json(job_create_path, job) #type:ignore[arg-type]
|
| 213 |
+
return False
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
def update_job_file(job_id : str, job : Job) -> bool:
|
| 217 |
+
job_path = find_job_path(job_id)
|
| 218 |
+
|
| 219 |
+
if is_file(job_path):
|
| 220 |
+
job['date_updated'] = get_current_date_time().isoformat()
|
| 221 |
+
return write_json(job_path, job) #type:ignore[arg-type]
|
| 222 |
+
return False
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
def move_job_file(job_id : str, job_status : JobStatus) -> bool:
|
| 226 |
+
job_path = find_job_path(job_id)
|
| 227 |
+
job_move_path = suggest_job_path(job_id, job_status)
|
| 228 |
+
return move_file(job_path, job_move_path)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
def delete_job_file(job_id : str) -> bool:
|
| 232 |
+
job_path = find_job_path(job_id)
|
| 233 |
+
return remove_file(job_path)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def suggest_job_path(job_id : str, job_status : JobStatus) -> Optional[str]:
|
| 237 |
+
job_file_name = get_job_file_name(job_id)
|
| 238 |
+
|
| 239 |
+
if job_file_name:
|
| 240 |
+
return os.path.join(JOBS_PATH, job_status, job_file_name)
|
| 241 |
+
return None
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def find_job_path(job_id : str) -> Optional[str]:
|
| 245 |
+
job_file_name = get_job_file_name(job_id)
|
| 246 |
+
|
| 247 |
+
if job_file_name:
|
| 248 |
+
for job_status in facefusion.choices.job_statuses:
|
| 249 |
+
job_pattern = os.path.join(JOBS_PATH, job_status, job_file_name)
|
| 250 |
+
job_paths = resolve_file_pattern(job_pattern)
|
| 251 |
+
|
| 252 |
+
for job_path in job_paths:
|
| 253 |
+
return job_path
|
| 254 |
+
return None
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
def get_job_file_name(job_id : str) -> Optional[str]:
|
| 258 |
+
if job_id:
|
| 259 |
+
return job_id + '.json'
|
| 260 |
+
return None
|
facefusion/jobs/job_runner.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from facefusion.ffmpeg import concat_video
|
| 2 |
+
from facefusion.filesystem import is_image, is_video, move_file, remove_file
|
| 3 |
+
from facefusion.jobs import job_helper, job_manager
|
| 4 |
+
from facefusion.typing import JobOutputSet, JobStep, ProcessStep
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def run_job(job_id : str, process_step : ProcessStep) -> bool:
|
| 8 |
+
queued_job_ids = job_manager.find_job_ids('queued')
|
| 9 |
+
|
| 10 |
+
if job_id in queued_job_ids:
|
| 11 |
+
if run_steps(job_id, process_step) and finalize_steps(job_id):
|
| 12 |
+
clean_steps(job_id)
|
| 13 |
+
return job_manager.move_job_file(job_id, 'completed')
|
| 14 |
+
clean_steps(job_id)
|
| 15 |
+
job_manager.move_job_file(job_id, 'failed')
|
| 16 |
+
return False
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def run_jobs(process_step : ProcessStep) -> bool:
|
| 20 |
+
queued_job_ids = job_manager.find_job_ids('queued')
|
| 21 |
+
|
| 22 |
+
if queued_job_ids:
|
| 23 |
+
for job_id in queued_job_ids:
|
| 24 |
+
if not run_job(job_id, process_step):
|
| 25 |
+
return False
|
| 26 |
+
return True
|
| 27 |
+
return False
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def retry_job(job_id : str, process_step : ProcessStep) -> bool:
|
| 31 |
+
failed_job_ids = job_manager.find_job_ids('failed')
|
| 32 |
+
|
| 33 |
+
if job_id in failed_job_ids:
|
| 34 |
+
return job_manager.set_steps_status(job_id, 'queued') and job_manager.move_job_file(job_id, 'queued') and run_job(job_id, process_step)
|
| 35 |
+
return False
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def retry_jobs(process_step : ProcessStep) -> bool:
|
| 39 |
+
failed_job_ids = job_manager.find_job_ids('failed')
|
| 40 |
+
|
| 41 |
+
if failed_job_ids:
|
| 42 |
+
for job_id in failed_job_ids:
|
| 43 |
+
if not retry_job(job_id, process_step):
|
| 44 |
+
return False
|
| 45 |
+
return True
|
| 46 |
+
return False
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def run_step(job_id : str, step_index : int, step : JobStep, process_step : ProcessStep) -> bool:
|
| 50 |
+
step_args = step.get('args')
|
| 51 |
+
|
| 52 |
+
if job_manager.set_step_status(job_id, step_index, 'started') and process_step(job_id, step_index, step_args):
|
| 53 |
+
output_path = step_args.get('output_path')
|
| 54 |
+
step_output_path = job_helper.get_step_output_path(job_id, step_index, output_path)
|
| 55 |
+
|
| 56 |
+
return move_file(output_path, step_output_path) and job_manager.set_step_status(job_id, step_index, 'completed')
|
| 57 |
+
job_manager.set_step_status(job_id, step_index, 'failed')
|
| 58 |
+
return False
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def run_steps(job_id : str, process_step : ProcessStep) -> bool:
|
| 62 |
+
steps = job_manager.get_steps(job_id)
|
| 63 |
+
|
| 64 |
+
if steps:
|
| 65 |
+
for index, step in enumerate(steps):
|
| 66 |
+
if not run_step(job_id, index, step, process_step):
|
| 67 |
+
return False
|
| 68 |
+
return True
|
| 69 |
+
return False
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def finalize_steps(job_id : str) -> bool:
|
| 73 |
+
output_set = collect_output_set(job_id)
|
| 74 |
+
|
| 75 |
+
for output_path, temp_output_paths in output_set.items():
|
| 76 |
+
if all(map(is_video, temp_output_paths)):
|
| 77 |
+
if not concat_video(output_path, temp_output_paths):
|
| 78 |
+
return False
|
| 79 |
+
if any(map(is_image, temp_output_paths)):
|
| 80 |
+
for temp_output_path in temp_output_paths:
|
| 81 |
+
if not move_file(temp_output_path, output_path):
|
| 82 |
+
return False
|
| 83 |
+
return True
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def clean_steps(job_id: str) -> bool:
|
| 87 |
+
output_set = collect_output_set(job_id)
|
| 88 |
+
|
| 89 |
+
for temp_output_paths in output_set.values():
|
| 90 |
+
for temp_output_path in temp_output_paths:
|
| 91 |
+
if not remove_file(temp_output_path):
|
| 92 |
+
return False
|
| 93 |
+
return True
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def collect_output_set(job_id : str) -> JobOutputSet:
|
| 97 |
+
steps = job_manager.get_steps(job_id)
|
| 98 |
+
output_set : JobOutputSet = {}
|
| 99 |
+
|
| 100 |
+
for index, step in enumerate(steps):
|
| 101 |
+
output_path = step.get('args').get('output_path')
|
| 102 |
+
|
| 103 |
+
if output_path:
|
| 104 |
+
step_output_path = job_manager.get_step_output_path(job_id, index, output_path)
|
| 105 |
+
output_set.setdefault(output_path, []).append(step_output_path)
|
| 106 |
+
return output_set
|
facefusion/jobs/job_store.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from facefusion.typing import JobStore
|
| 4 |
+
|
| 5 |
+
JOB_STORE : JobStore =\
|
| 6 |
+
{
|
| 7 |
+
'job_keys': [],
|
| 8 |
+
'step_keys': []
|
| 9 |
+
}
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_job_keys() -> List[str]:
|
| 13 |
+
return JOB_STORE.get('job_keys')
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_step_keys() -> List[str]:
|
| 17 |
+
return JOB_STORE.get('step_keys')
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def register_job_keys(step_keys : List[str]) -> None:
|
| 21 |
+
for step_key in step_keys:
|
| 22 |
+
JOB_STORE['job_keys'].append(step_key)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def register_step_keys(job_keys : List[str]) -> None:
|
| 26 |
+
for job_key in job_keys:
|
| 27 |
+
JOB_STORE['step_keys'].append(job_key)
|
facefusion/json.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from json import JSONDecodeError
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
from facefusion.filesystem import is_file
|
| 6 |
+
from facefusion.typing import Content
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def read_json(json_path : str) -> Optional[Content]:
|
| 10 |
+
if is_file(json_path):
|
| 11 |
+
try:
|
| 12 |
+
with open(json_path, 'r') as json_file:
|
| 13 |
+
return json.load(json_file)
|
| 14 |
+
except JSONDecodeError:
|
| 15 |
+
pass
|
| 16 |
+
return None
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def write_json(json_path : str, content : Content) -> bool:
|
| 20 |
+
with open(json_path, 'w') as json_file:
|
| 21 |
+
json.dump(content, json_file, indent = 4)
|
| 22 |
+
return is_file(json_path)
|
facefusion/logger.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from logging import Logger, basicConfig, getLogger
|
| 2 |
+
from typing import Tuple
|
| 3 |
+
|
| 4 |
+
import facefusion.choices
|
| 5 |
+
from facefusion.common_helper import get_first, get_last
|
| 6 |
+
from facefusion.typing import LogLevel, TableContents, TableHeaders
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def init(log_level : LogLevel) -> None:
|
| 10 |
+
basicConfig(format = '%(message)s')
|
| 11 |
+
get_package_logger().setLevel(facefusion.choices.log_level_set.get(log_level))
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_package_logger() -> Logger:
|
| 15 |
+
return getLogger('facefusion')
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def debug(message : str, module_name : str) -> None:
|
| 19 |
+
get_package_logger().debug(create_message(message, module_name))
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def info(message : str, module_name : str) -> None:
|
| 23 |
+
get_package_logger().info(create_message(message, module_name))
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def warn(message : str, module_name : str) -> None:
|
| 27 |
+
get_package_logger().warning(create_message(message, module_name))
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def error(message : str, module_name : str) -> None:
|
| 31 |
+
get_package_logger().error(create_message(message, module_name))
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def create_message(message : str, module_name : str) -> str:
|
| 35 |
+
scopes = module_name.split('.')
|
| 36 |
+
first_scope = get_first(scopes)
|
| 37 |
+
last_scope = get_last(scopes)
|
| 38 |
+
|
| 39 |
+
if first_scope and last_scope:
|
| 40 |
+
return '[' + first_scope.upper() + '.' + last_scope.upper() + '] ' + message
|
| 41 |
+
return message
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def table(headers : TableHeaders, contents : TableContents) -> None:
|
| 45 |
+
package_logger = get_package_logger()
|
| 46 |
+
table_column, table_separator = create_table_parts(headers, contents)
|
| 47 |
+
|
| 48 |
+
package_logger.info(table_separator)
|
| 49 |
+
package_logger.info(table_column.format(*headers))
|
| 50 |
+
package_logger.info(table_separator)
|
| 51 |
+
|
| 52 |
+
for content in contents:
|
| 53 |
+
content = [ value if value else '' for value in content ]
|
| 54 |
+
package_logger.info(table_column.format(*content))
|
| 55 |
+
|
| 56 |
+
package_logger.info(table_separator)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def create_table_parts(headers : TableHeaders, contents : TableContents) -> Tuple[str, str]:
|
| 60 |
+
column_parts = []
|
| 61 |
+
separator_parts = []
|
| 62 |
+
widths = [ len(header) for header in headers ]
|
| 63 |
+
|
| 64 |
+
for content in contents:
|
| 65 |
+
for index, value in enumerate(content):
|
| 66 |
+
widths[index] = max(widths[index], len(str(value)))
|
| 67 |
+
|
| 68 |
+
for width in widths:
|
| 69 |
+
column_parts.append('{:<' + str(width) + '}')
|
| 70 |
+
separator_parts.append('-' * width)
|
| 71 |
+
|
| 72 |
+
return '| ' + ' | '.join(column_parts) + ' |', '+-' + '-+-'.join(separator_parts) + '-+'
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def enable() -> None:
|
| 76 |
+
get_package_logger().disabled = False
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def disable() -> None:
|
| 80 |
+
get_package_logger().disabled = True
|
facefusion/memory.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from facefusion.common_helper import is_macos, is_windows
|
| 2 |
+
|
| 3 |
+
if is_windows():
|
| 4 |
+
import ctypes
|
| 5 |
+
else:
|
| 6 |
+
import resource
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def limit_system_memory(system_memory_limit : int = 1) -> bool:
|
| 10 |
+
if is_macos():
|
| 11 |
+
system_memory_limit = system_memory_limit * (1024 ** 6)
|
| 12 |
+
else:
|
| 13 |
+
system_memory_limit = system_memory_limit * (1024 ** 3)
|
| 14 |
+
try:
|
| 15 |
+
if is_windows():
|
| 16 |
+
ctypes.windll.kernel32.SetProcessWorkingSetSize(-1, ctypes.c_size_t(system_memory_limit), ctypes.c_size_t(system_memory_limit)) #type:ignore[attr-defined]
|
| 17 |
+
else:
|
| 18 |
+
resource.setrlimit(resource.RLIMIT_DATA, (system_memory_limit, system_memory_limit))
|
| 19 |
+
return True
|
| 20 |
+
except Exception:
|
| 21 |
+
return False
|
facefusion/metadata.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
METADATA =\
|
| 4 |
+
{
|
| 5 |
+
'name': 'FaceFusion',
|
| 6 |
+
'description': 'Industry leading face manipulation platform',
|
| 7 |
+
'version': '3.1.1',
|
| 8 |
+
'license': 'MIT',
|
| 9 |
+
'author': 'Henry Ruhs',
|
| 10 |
+
'url': 'https://facefusion.io'
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get(key : str) -> Optional[str]:
|
| 15 |
+
if key in METADATA:
|
| 16 |
+
return METADATA.get(key)
|
| 17 |
+
return None
|
facefusion/model_helper.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import lru_cache
|
| 2 |
+
|
| 3 |
+
import onnx
|
| 4 |
+
|
| 5 |
+
from facefusion.typing import ModelInitializer
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
@lru_cache(maxsize = None)
|
| 9 |
+
def get_static_model_initializer(model_path : str) -> ModelInitializer:
|
| 10 |
+
model = onnx.load(model_path)
|
| 11 |
+
return onnx.numpy_helper.to_array(model.graph.initializer[-1])
|