
Add figure & links to approx. scripts
Browse files
README.md
CHANGED
|
@@ -104,6 +104,10 @@ model-index:
|
|
| 104 |
|
| 105 |
This is a [Cross Encoder](https://www.sbert.net/docs/cross_encoder/usage/usage.html) model finetuned from [answerdotai/ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base) using the [sentence-transformers](https://www.SBERT.net) library. It computes scores for pairs of texts, which can be used for text reranking and semantic search.
|
| 106 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 107 |
## Model Details
|
| 108 |
|
| 109 |
### Model Description
|
|
|
|
| 104 |
|
| 105 |
This is a [Cross Encoder](https://www.sbert.net/docs/cross_encoder/usage/usage.html) model finetuned from [answerdotai/ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base) using the [sentence-transformers](https://www.SBERT.net) library. It computes scores for pairs of texts, which can be used for text reranking and semantic search.
|
| 106 |
|
| 107 |
+
See [training_gooaq_bce.py](https://github.com/UKPLab/sentence-transformers/blob/feat/cross_encoder_trainer/examples/cross_encoder/training/rerankers/training_gooaq_bce.py) for roughly the training script for this model. I only updated the dataset to trivia-qa, used the first 1000 samples as the evaluation dataset, and the remaining samples are used in the training dataset. This script is also described in the [Cross Encoder > Training Overview](https://sbert.net/docs/cross_encoder/training_overview.html) documentation and the [Training and Finetuning Reranker Models with Sentence Transformers v4](https://huggingface.co/blog/train-reranker) blogpost.
|
| 108 |
+
|
| 109 |
+
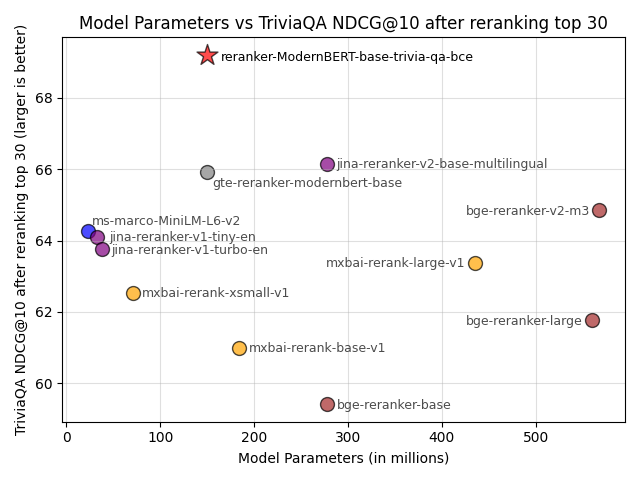
|
| 110 |
+
|
| 111 |
## Model Details
|
| 112 |
|
| 113 |
### Model Description
|