
license: apache-2.0
datasets:
- hadyelsahar/ar_res_reviews
language:
- ar
metrics:
- accuracy
- precision
- recall
- f1
base_model:
- aubmindlab/bert-base-arabertv02
pipeline_tag: text-classification
tags:
- arabic
- sentiment-analysis
- transformers
- huggingface
- bert
- restaurants
- fine-tuning
- nlp
inference: true
🍽️ Arabic Restaurant Review Sentiment Analysis 🚀
📌 Overview
This fine-tuned AraBERT model classifies Arabic restaurant reviews as Positive or Negative.
It is based on aubmindlab/bert-base-arabertv2 and fine-tuned using Hugging Face Transformers.
🔥 Why This Model?
✅ Trained on Real Restaurant Reviews from the Hugging Face Dataset.
✅ Fine-tuned with Full Training (not LoRA or Adapters).
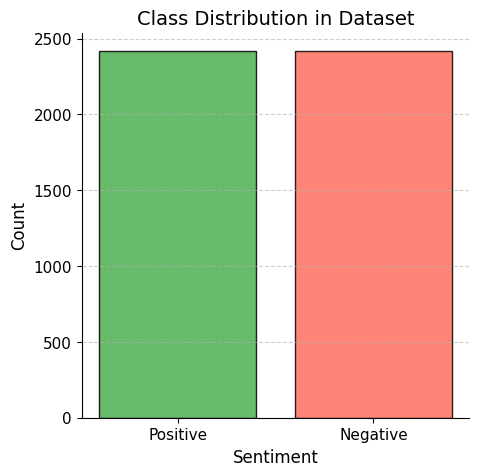
✅ Balanced Dataset (2418 Positive vs. 2418 Negative Reviews).
✅ High Accuracy & Performance for Sentiment Analysis in Arabic.
🚀 Try the Model Now!
Run inference directly from the Hugging Face Space:

📥 Dataset & Preprocessing
- Dataset Source:
hadyelsahar/ar_res_reviews - Text Cleaning:
- Removed non-Arabic text, special characters, and extra spaces.
- Normalized Arabic characters (
إ, أ, آ → ا,ة → ه). - Balanced Positive & Negative sentiment distribution.
- Tokenization:
- Used AraBERT tokenizer (
aubmindlab/bert-base-arabertv2).
- Used AraBERT tokenizer (
- Train-Test Split:
- 80% Training | 20% Testing.
🏋️ Training & Performance
The model was fine-tuned using Hugging Face Transformers with the following hyperparameters:
📊 Final Model Results
| Metric | Score |
|---|---|
| Eval Loss | 0.354245 |
| Accuracy | 87.40% |
| Precision | 85.28% |
| Recall | 86.33% |
| F1-score | 85.81% |
⚙️ Training Configuration
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=4,
weight_decay=1,
learning_rate=1e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
fp16=True,
save_total_limit=2,
gradient_accumulation_steps=2,
load_best_model_at_end=True,
max_grad_norm=1.0,
metric_for_best_model="eval_loss",
greater_is_better=False,
)
💡 Usage
1️⃣ Quick Inference using pipeline()
from transformers import pipeline
model_name = "Abduuu/ArabReview-Sentiment"
sentiment_pipeline = pipeline("text-classification", model=model_name)
review = "الطعام كان رائعًا والخدمة ممتازة!"
result = sentiment_pipeline(review)
print(result)
✅ Example Output:
[{'label': 'Positive', 'score': 0.91551274061203}]
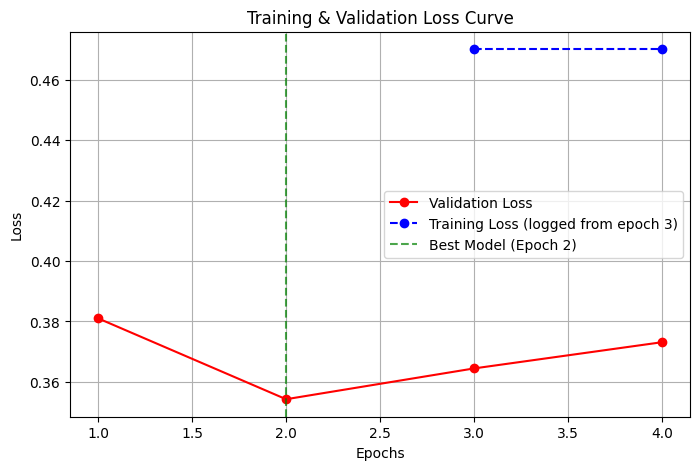
📉 Training & Validation Loss Curve
The model was trained for 4 epochs, and the best model was selected at Epoch 2 (lowest validation loss).
📊 Dataset Class Distribution
For questions or collaborations, feel free to reach out! 🚀