
Selene 1
Collection
Our most powerful evaluation model, Selene 1 beats frontier models from leading labs. Learn more here: https://www.atla-ai.com/post/selene-1
•
2 items
•
Updated

🌐 Blogpost | 📄 Technical report | 💻 Cookbooks | 👀 Atla agent evals
Atla Selene 1 is a state-of-the-art large language model-as-a-judge. Selene 1 achieves frontier-level performance across 11 evaluation benchmarks, outperforming OpenAI's o1, o3-mini, and GPT-4o, Anthropic's Claude 3.5 Sonnet, Meta's Llama 3.3, and DeepSeek's R1.
This is an 8-bit (W8A8) quantized version of Selene 1.
This model was quantised using GPTQ and SmoothQuant from AtlaAI/Selene-1-Llama-3.3-70B, using vLLM's llm-compressor library
The quantisation was calibrated using a sample of 512 datapoints from the data used to train Selene-1.
As a result, our quantised models show minimal performance degradation, losing <0.5% overall across benchmarks!
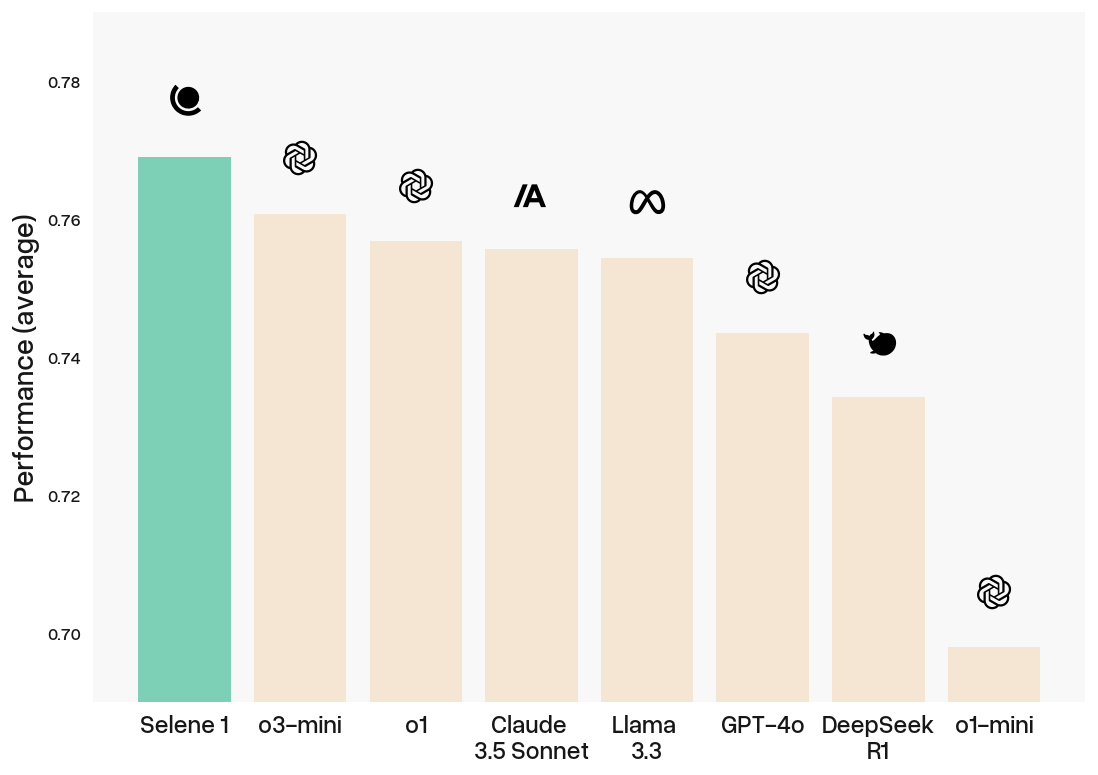
Selene 1 was post-trained from Llama-3.3-70B on a combined SFT+DPO objective using the same recipe as Selene Mini. Trained across a wide range of evaluation tasks and scoring criteria, Selene 1 outperforms frontier models across 11 benchmarks covering three different types of tasks:
Selene 1 particularly excels at capturing human judgements on nuanced, complex real-world evaluations, as evidenced by its state-of-the-art performance on FLASK, MT-Bench, RewardBench and Auto-J.

If you're interested in evaluating more complex systems like LLM agents, learn more here.
Selene 1 can be used as a general-purpose evaluation model. It supports different inputs & scoring scales, generates structured evaluation outputs, and provides qualitative critiques with reasoning. The model is highly steerable with customizable evaluation criteria and can evaluate responses with or without reference responses.
Try our cookbooks to get started with two popular use cases below:
To achieve best results, we provide the prompts we used for training here.
Remember to apply the conversation template of Llama 3 - not doing so might lead to unexpected behaviors. You can find the conversation class at this link or you can refer to the below code that will apply it.
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model_id = "AtlaAI/Selene-1-Llama-3.3-70B-GPTQ-W8A8"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
prompt = "I heard you can evaluate my responses?" # replace with your prompt / we provide prompt templates used during training at github.com/atla-ai/selene-mini/tree/main/prompt-templates
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
[email protected]
You can also join our Discord!
If you are using the model, cite using
@misc{alexandru2025atlaseleneminigeneral,
title={Atla Selene Mini: A General Purpose Evaluation Model},
author={Andrei Alexandru and Antonia Calvi and Henry Broomfield and Jackson Golden and Kyle Dai and Mathias Leys and Maurice Burger and Max Bartolo and Roman Engeler and Sashank Pisupati and Toby Drane and Young Sun Park},
year={2025},
eprint={2501.17195},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.17195},
}
Base model
meta-llama/Llama-3.1-70B