
Speech Enhancement Model
このモデルは日本語と英語で小規模に学習された音声復元モデルです。 SSLモデルとしてmHuBERT-147を用い、VocoderとしてHiFi-GANを用いました。 HiFi-GANに関してはssl-vocoderの実装を使って学習しました。
このモデルはMiipher-2の再現を目指して実装されましたが、学習の規模も使用している事前学習済みモデルも大きく異なります。 ノイズの除去は上手く動きますが、話者性が大きく変動するモデルとなっています。 また、計算資源の都合で学習も十分に行えていません。 Miipher-1の再現実装であるWataru-Nakata/miipherとの比較評価結果を載せているので参考にしてください。
| degraded | enhanced |
|---|---|
|
|
Model Components
1. Parallel Adapter
- Architecture: Lightweight feedforward network inserted into mHuBERT-147
- Target Layer: Layer 6
- Hidden Dimension: 768
2. Lightning SSL-Vocoder
- Architecture: HiFi-GAN based vocoder with PyTorch Lightning
- Input: SSL features from enhanced mHuBERT
- Output: High-quality audio at 22050Hz


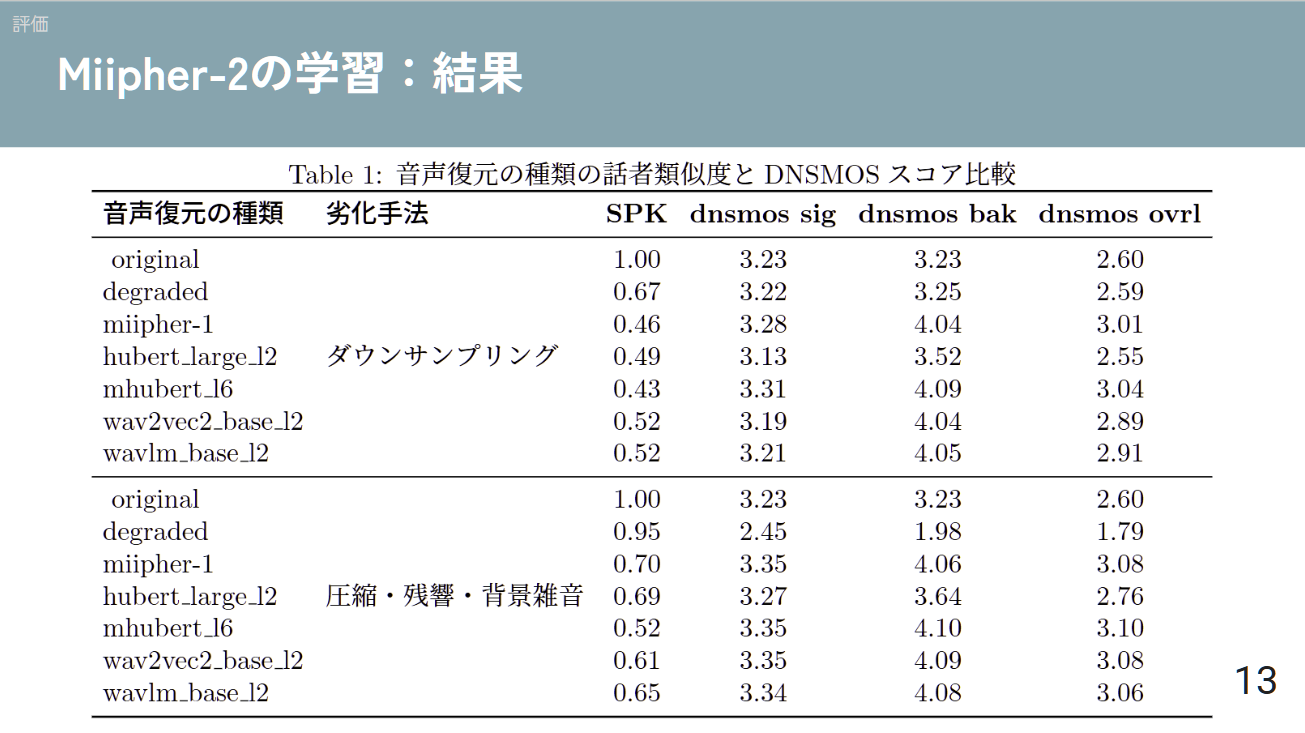
Model Performance
- Target: Speech enhancement from noisy/degraded audio
- Training Data: JVS & LibriTTS-R
Usage
学習および推論コードは以下のリポジトリにあります。
https://github.com/Atotti/miipher-2
HugginFace Spaces上にデモを用意しました。Web上から使えます。
https://huggingface.co/spaces/Atotti/miipher-2-HuBERT-HiFi-GAN-v0.1
License
Apache-2.0
- Downloads last month
- 66
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support