
LM Studio with GGUF

The GGUF model is sourced from mradermacher/Seed-X-Instruct-7B-GGUF(Q8). After loading the model, I tried using the Chat interface to call it with the following prompt:
"Translate the following English sentence into Chinese:\nMay the force be with you "
However, the response I received was garbled text.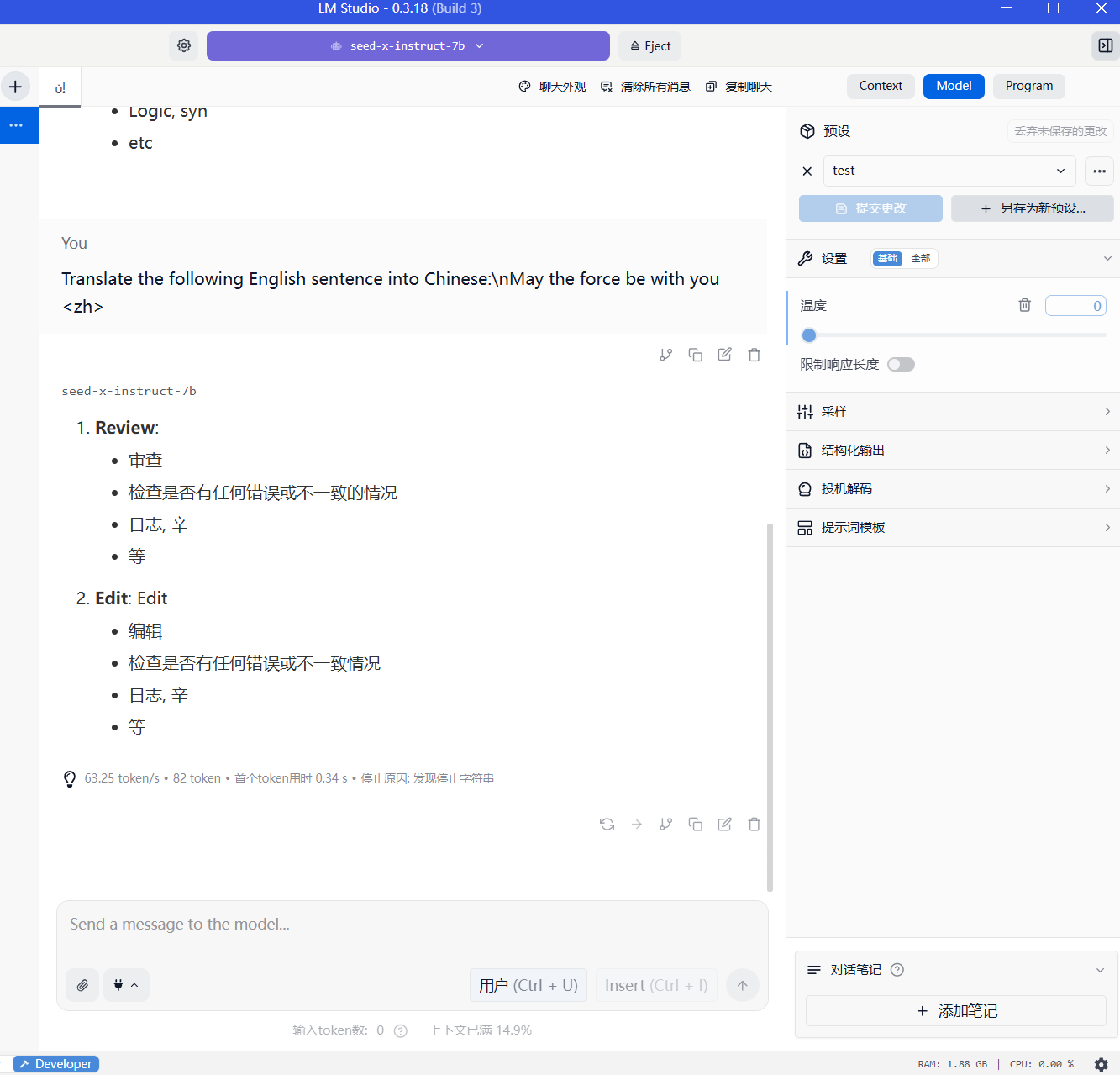
Is this issue caused by incorrect configuration settings, or does the GGUF model simply not support chat-based interactions?"

I'm getting the same issue on plain llama.cpp (using llama-cli)
Q6_0

This quantized model isn't an official release. The issues might stem from the quantization process itself. We would recommend use official released model weight and use the BF16 to inference

既然GGUF还有问题,就暂时不试了。我猜翻译效果不一定会比deepseek-v2-lite-chat 模型更好,速度也肯定没有deepseek-v2-lite-chat更快。
既然GGUF还有问题,就暂时不试了。我猜翻译效果不一定会比deepseek-v2-lite-chat 模型更好,速度也肯定没有deepseek-v2-lite-chat更快。
Thank you for your interest in our model.
I must address a key factual point in your comparison. As we've detailed in both our README and the technical report https://arxiv.org/pdf/2507.13618 , our model has been shown to outperform DeepSeek's current largest and most powerful model, DeepSeek-V3/R1 (671B), on both automatic benchmarks and human evaluations. It's important to consider that our model has only 7B parameters. For a model of this size, its inference speed is highly competitive.
We are actively working on providing official quantized versions of the model. Stay tuned!

@Doctor-Chad-PhD @qixing Thank you for trying. We will release the official quantized version as soon as possible.

Actually, vllm can run Q4 GGUF from mradermacher and it performs great. But llama.cpp and LM Studio just do not perform at all, both, ppo and instruct, with both, /v1/completions and /v1/chat/completions endpoints. vllm vram overhead is a joke, so any chances to run it in llama.cpp/LM Studio?
It works a bit better when you create a special_tokens_map.json file in the same directory before quantizing it (but it's not the complete fix):
{
"bos_token": {
"content": "<s>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false
},
"eos_token": {
"content": "</s>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false
},
"unk_token": {
"content": "<unk>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false
}
}
Output:
Translate the following English sentence into Chinese:
Hello! <zh> 你好! [end of text]