Qwen3-Shining-Lucy-CODER-2.4B
This repo contains the full precision source code, in "safe tensors" format to generate GGUFs, GPTQ, EXL2, AWQ, HQQ and other formats.
The source code can also be used directly.
This model contains - "ValiantLabs/Qwen3-1.7B-ShiningValiant3" FUSED with "Menlo/Lucy-128k" (instruct models):
Fused formula by DavidAU, which co-joins the models in 4 blocks, in a roughly 75%/75% merge resulting in a model of 42 layers, 464 tensors
creating a 2.4B model from the TWO 1.7B models.
This method takes the best of both models without compromise or "averaging" / "cancelling out" parts of either model, increasing
model net performance and retaining model knowledge.
The 2.4B model is also a reasoning model, with a lot shorter "reasoning" blocks - part of the FUSED merge effect.
Settings information on the 2.4B fused model below, followed by info from each model (model card) and then a complete help
section for running LLM / AI models.
This model requires:
- Jinja (embedded) or CHATML template
- Max context of 40k.
Settings used for testing (suggested):
- Temp .3 to .7
- Rep pen 1.05 to 1.1
- Topp .8 , minp .05
- Topk 20
- No system prompt.
- Min context window of 8k to 16k suggested.
BEST settings for coding:
- Temp .8, rep pen 1.05 OR rep pen 1.1
- topk 20, top p .95, minp 0
- Context window of 16k.
FOR CODING:
Higher temps: .6 to .9 (even over 1) work better for more complex coding / especially with more restrictions.
This model will respond well to both detailed instructions and step by step refinement and additions to code.
As this is an instruct model, it will also benefit from a detailed system prompt too.
For simpler coding problems, lower quants will work well; but for complex/multi-step problem solving suggest Q6 or Q8.
QUANTS:
Special Thanks to Team Mradermacher for the quants:
GGUF:
https://huggingface.co/mradermacher/Qwen3-Shining-Lucy-CODER-2.4B-GGUF
GGUF-IMATRIX:
https://huggingface.co/mradermacher/Qwen3-Shining-Lucy-CODER-2.4B-i1-GGUF
Model #1 - Shining Valiant 1.7B
Support our open-source dataset and model releases!

Shining Valiant 3: Qwen3-1.7B, Qwen3-8B
Shining Valiant 3 is a science, AI design, and general reasoning specialist built on Qwen 3.
Prompting Guide
Shining Valiant 3 uses the Qwen 3 prompt format.
Shining Valiant 3 is a reasoning finetune; we recommend enable_thinking=True for all chats.
Example inference script to get started:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "ValiantLabs/Qwen3-1.7B-ShiningValiant3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Propose a novel cognitive architecture where the primary memory component is a Graph Neural Network (GNN). How would this GNN represent working, declarative, and procedural memory? How would the \"cognitive cycle\" be implemented as operations on this graph?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)

Shining Valiant 3 is created by Valiant Labs.
Check out our HuggingFace page to see all of our models!
We care about open source. For everyone to use.
Model #2 - Lucy 128k (1.7B)
Lucy: Edgerunning Agentic Web Search on Mobile with a 1.7B model.


Authors: Alan Dao, Bach Vu Dinh, Alex Nguyen, Norapat Buppodom

Overview
Lucy is a compact but capable 1.7B model focused on agentic web search and lightweight browsing. Built on Qwen3-1.7B, Lucy inherits deep research capabilities from larger models while being optimized to run efficiently on mobile devices, even with CPU-only configurations.
We achieved this through machine-generated task vectors that optimize thinking processes, smooth reward functions across multiple categories, and pure reinforcement learning without any supervised fine-tuning.
What Lucy Excels At
- 🔍 Strong Agentic Search: Powered by MCP-enabled tools (e.g., Serper with Google Search)
- 🌐 Basic Browsing Capabilities: Through Crawl4AI (MCP server to be released), Serper,...
- 📱 Mobile-Optimized: Lightweight enough to run on CPU or mobile devices with decent speed
- 🎯 Focused Reasoning: Machine-generated task vectors optimize thinking processes for search tasks
Evaluation
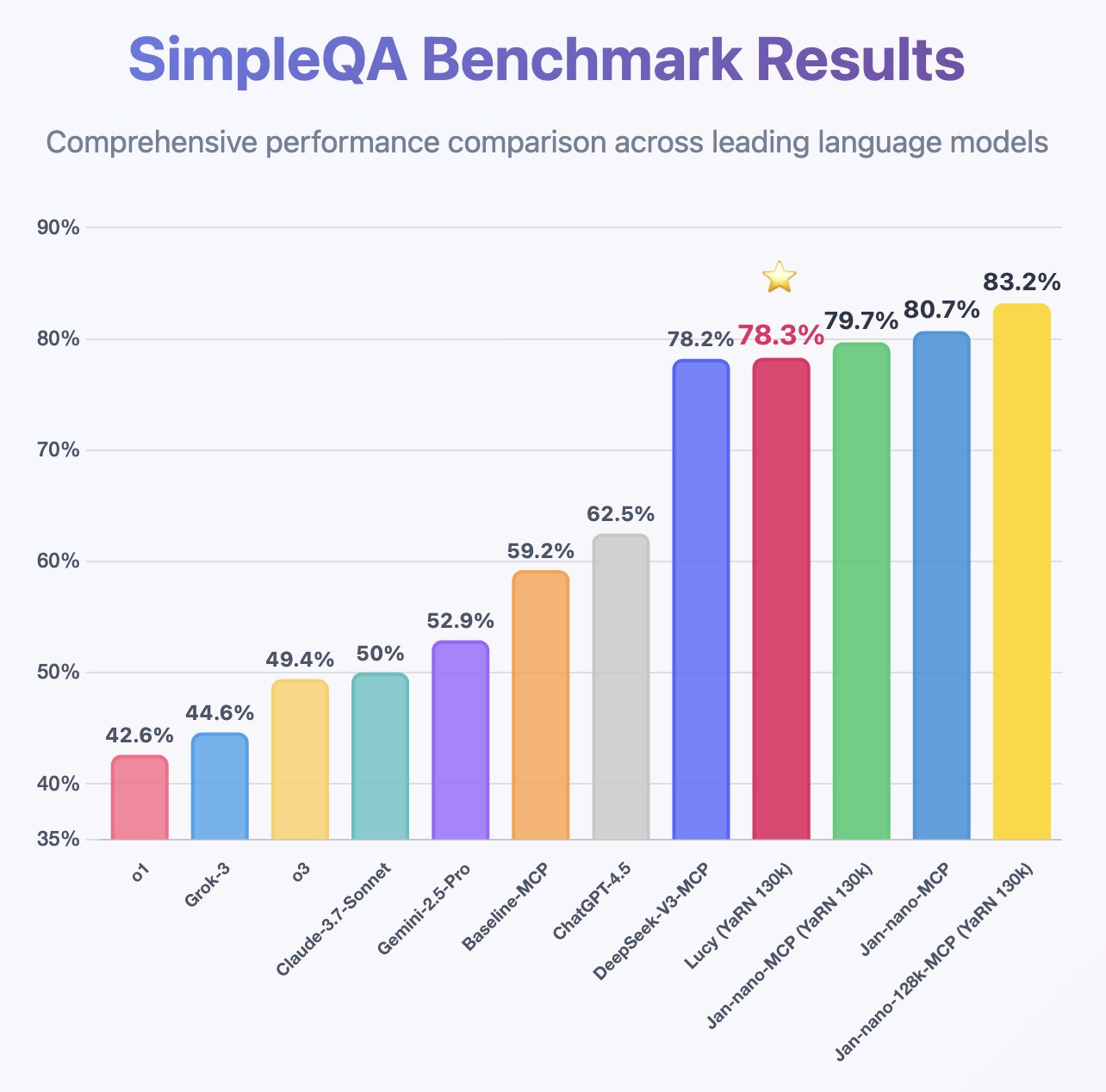
Following the same MCP benchmark methodology used for Jan-Nano and Jan-Nano-128k, Lucy demonstrates impressive performance despite being only a 1.7B model, achieving higher accuracy than DeepSeek-v3 on SimpleQA.
🖥️ How to Run Locally
Lucy can be deployed using various methods including vLLM, llama.cpp, or through local applications like Jan, LMStudio, and other compatible inference engines. The model supports integration with search APIs and web browsing tools through the MCP.
Deployment
Deploy using VLLM:
vllm serve Menlo/Lucy-128k \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--rope-scaling '{"rope_type":"yarn","factor":3.2,"original_max_position_embeddings":40960}' --max-model-len 131072
Or llama-server from llama.cpp:
llama-server ... --rope-scaling yarn --rope-scale 3.2 --yarn-orig-ctx 40960
Recommended Sampling Parameters
Temperature: 0.7
Top-p: 0.9
Top-k: 20
Min-p: 0.0
🤝 Community & Support
📄 Citation
Paper (coming soon): Lucy: edgerunning agentic web search on mobile with machine generated task vectors.
For more information / other Qwen/Mistral Coders / additional settings see:
[ https://huggingface.co/DavidAU/Qwen2.5-MOE-2x-4x-6x-8x__7B__Power-CODER__19B-30B-42B-53B-gguf ]
Help, Adjustments, Samplers, Parameters and More
CHANGE THE NUMBER OF ACTIVE EXPERTS:
See this document:
https://huggingface.co/DavidAU/How-To-Set-and-Manage-MOE-Mix-of-Experts-Model-Activation-of-Experts
Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:
In "KoboldCpp" or "oobabooga/text-generation-webui" or "Silly Tavern" ;
Set the "Smoothing_factor" to 1.5
: in KoboldCpp -> Settings->Samplers->Advanced-> "Smooth_F"
: in text-generation-webui -> parameters -> lower right.
: In Silly Tavern this is called: "Smoothing"
NOTE: For "text-generation-webui"
-> if using GGUFs you need to use "llama_HF" (which involves downloading some config files from the SOURCE version of this model)
Source versions (and config files) of my models are here:
https://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be
OTHER OPTIONS:
Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use "smoothing_factor")
If the interface/program you are using to run AI MODELS supports "Quadratic Sampling" ("smoothing") just make the adjustment as noted.
Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers
This a "Class 1" model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
You can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]


