
Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
Paper • 2411.06272 • Published • 5

Golden Touchstone is a simple, effective, and systematic benchmark for bilingual (Chinese-English) financial large language models, driving the research and implementation of financial large language models, akin to a touchstone. We also have trained and open-sourced Touchstone-GPT as a baseline for subsequent community research.
The paper shows the evaluation of the diversity, systematicness and LLM adaptability of each open source benchmark.

By collecting and selecting representative task datasets, we built our own Chinese-English bilingual Touchstone Benchmark, which includes 22 datasets

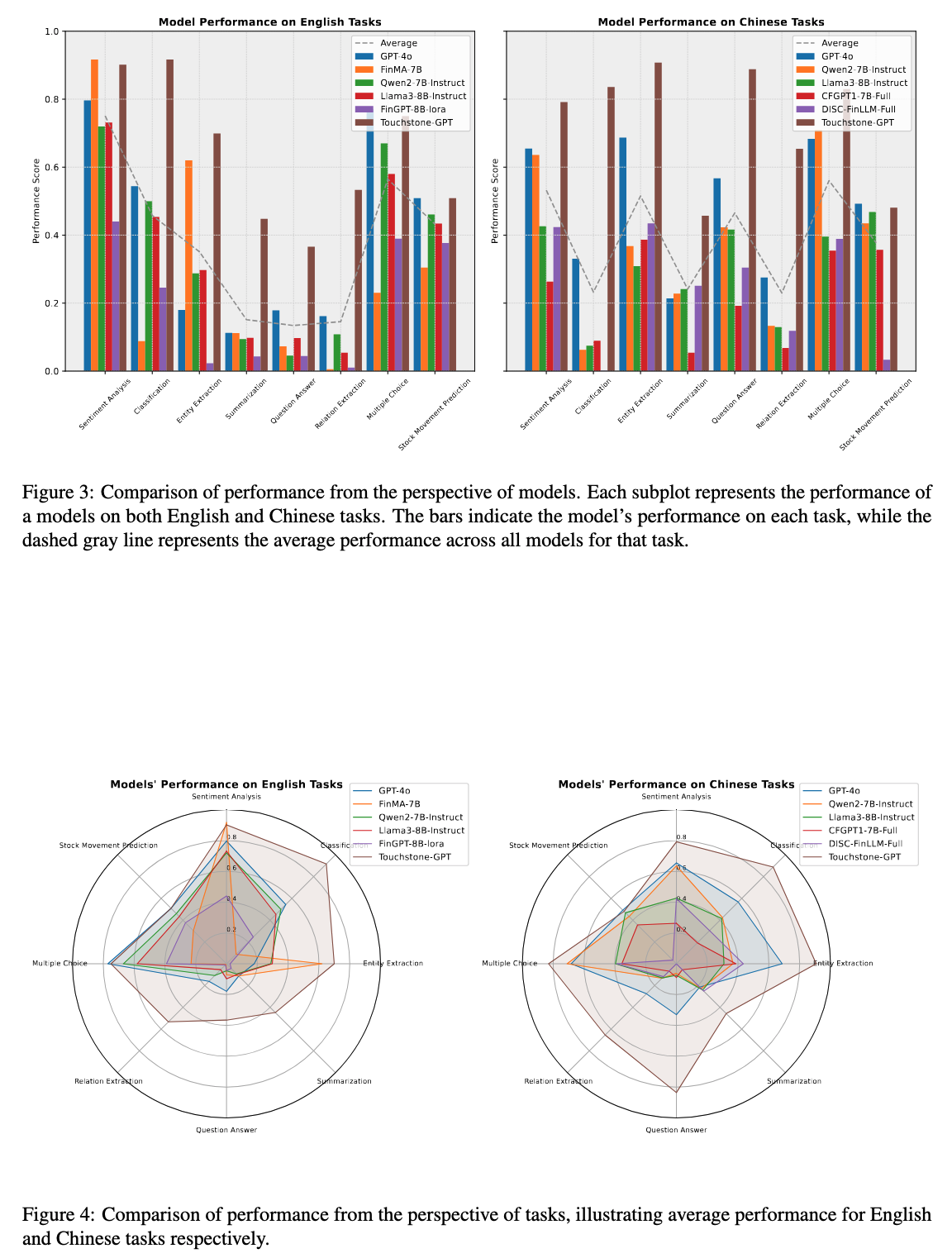
We extensively evaluated GPT-4o, llama3, qwen2, fingpt and our own trained Touchstone-GPT, analyzed the advantages and disadvantages of these models, and provided direction for subsequent research on financial large language models
Please See our github repo Golden-Touchstone
Here provides a code snippet with apply_chat_template to show you how to load the tokenizer and model and how to generate contents.
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"IDEA-FinAI/TouchstoneGPT-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("IDEA-FinAI/TouchstoneGPT-7B-Instruct")
prompt = "What is the sentiment of the following financial post: Positive, Negative, or Neutral?\nsees #Apple at $150/share in a year (+36% from today) on growing services business."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
@misc{wu2024goldentouchstonecomprehensivebilingual,
title={Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models},
author={Xiaojun Wu and Junxi Liu and Huanyi Su and Zhouchi Lin and Yiyan Qi and Chengjin Xu and Jiajun Su and Jiajie Zhong and Fuwei Wang and Saizhuo Wang and Fengrui Hua and Jia Li and Jian Guo},
year={2024},
eprint={2411.06272},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.06272},
}