
MLMvsCLM
non-profit
AI & ML interests
None defined yet.
Recent Activity
View all activity
Organization Card
Should We Still Pretrain Encoders with Masked Language Modeling?
This page gathers all the artefacts and references related to the paper Should We Still Pretrain Encoders with Masked Language Modeling? (Gisserot-Boukhlef et al.).
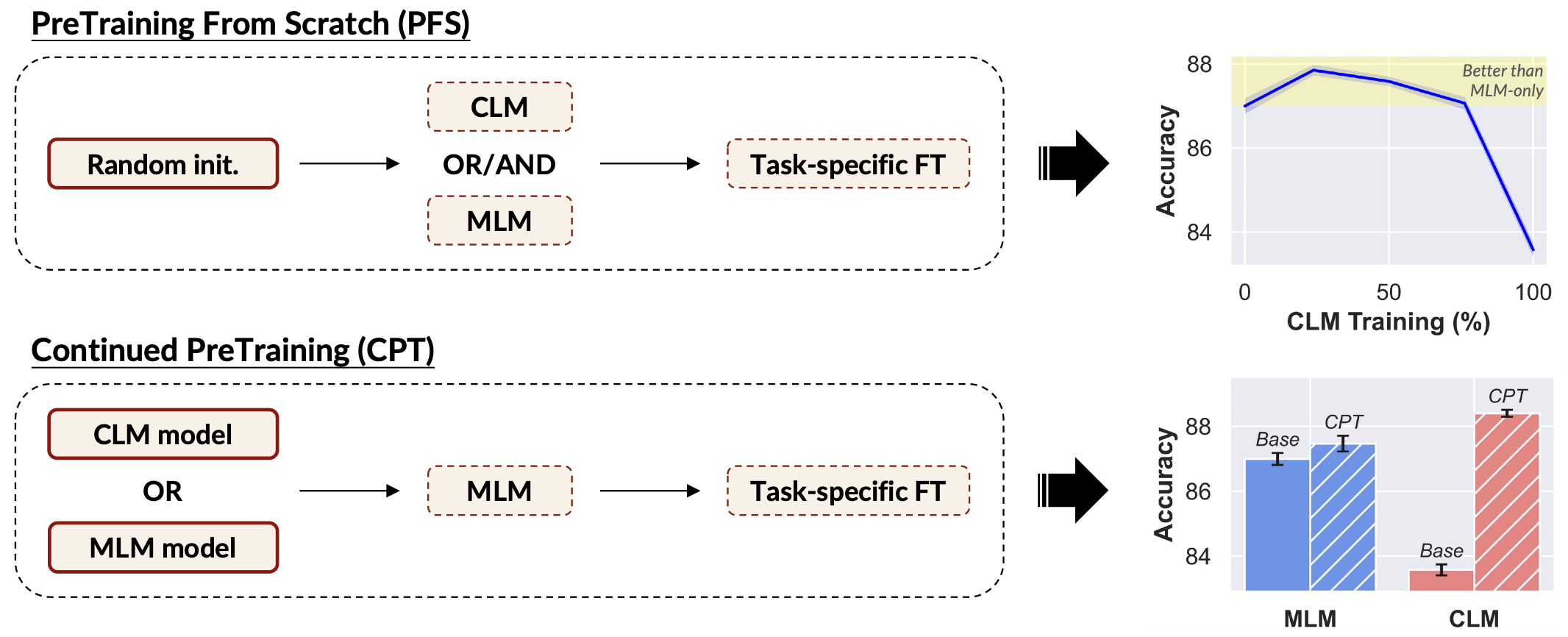
Abstract
Learning high-quality text representations is fundamental to a wide range of NLP tasks. While encoder pretraining has traditionally relied on Masked Language Modeling (MLM), recent evidence suggests that decoder models pretrained with Causal Language Modeling (CLM) can be effectively repurposed as encoders, often surpassing traditional encoders on text representation benchmarks. However, it remains unclear whether these gains reflect an inherent advantage of the CLM objective or arise from confounding factors such as model and data scale. In this paper, we address this question through a series of large-scale, carefully controlled pretraining ablations, training a total of 38 models ranging from 210 million to 1 billion parameters, and conducting over 15,000 fine-tuning and evaluation runs. We find that while training with MLM generally yields better performance across text representation tasks, CLM-trained models are more data-efficient and demonstrate improved fine-tuning stability. Building on these findings, we experimentally show that a biphasic training strategy that sequentially applies CLM and then MLM, achieves optimal performance under a fixed computational training budget. Moreover, we demonstrate that this strategy becomes more appealing when initializing from readily available pretrained CLM models, reducing the computational burden needed to train best-in-class encoder models.
Resources
- Preprint: For the full details of our work
- Blog post: A quick overview if you only have 5 minutes
- EuroBERT: The encoder model architecture used in our experiments
- Training codebase: Optimus, our distributed framework for training encoders at scale
- Evaluation codebase: EncodEval, our framework for evaluating encoder models across a wide range of representation tasks
Models
We release all the models trained and evaluated in the paper. Model identifiers follow a consistent format that encodes key training details:
- Single-stage models:
[model size]-[objective]-[number of steps]. Example:610m-clm-42kdenotes a 610M-parameter model trained with CLM for 42,000 steps. - Two-stage models:
[model size]-[objective #1]-[steps #1]-[objective #2]-[total steps]. Example:610m-clm-10k-mlm40-42kindicates a 610M model trained first with CLM for 10k steps, then continued with MLM (40% masking ratio) for 32k more steps, totaling 42k steps. - Continued pretraining from decayed checkpoints:
These use the dec prefix on the first training stage.
Example:
610m-clm-dec42k-mlm40-64k refersto a 610M model pretrained with CLM for 42k steps (with weight decay), then further trained with MLM (40% masking) for 22k additional steps, totaling 64k. - Intermediate checkpoints:
To refer to a specific training step before the final checkpoint, append the step number at the end.
Example:
610m-mlm40-42k-1000corresponds to step 1,000 during the MLM training phase of a 610M model trained for 42k steps.
First authors' contact information
- Hippolyte Gisserot-Boukhlef : hippolyte.gisserot-boukhlef@centralesupelec.fr
- Nicolas Boizard : nicolas.boizard@centralesupelec.fr
Citation
If you found our work useful, please consider citing our paper:
@misc{gisserotboukhlef2025pretrainencodersmaskedlanguage,
title={Should We Still Pretrain Encoders with Masked Language Modeling?},
author={Hippolyte Gisserot-Boukhlef and Nicolas Boizard and Manuel Faysse and Duarte M. Alves and Emmanuel Malherbe and André F. T. Martins and Céline Hudelot and Pierre Colombo},
year={2025},
eprint={2507.00994},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.00994},
}
models 50
MLMvsCLM/610m-mlm40-dec42k-mlm40-54k
Feature Extraction • Updated • 10
MLMvsCLM/610m-clm-3k-mlm40-12k
Feature Extraction • Updated • 3
MLMvsCLM/610m-mlm40-42k-1000
Feature Extraction • Updated • 22
MLMvsCLM/1b-mlm40-42k
Feature Extraction • Updated • 24
MLMvsCLM/610m-clm-40k-mlm20-42k
Feature Extraction • Updated • 26
MLMvsCLM/610m-mlm40-42k-2000
Feature Extraction • Updated • 23
MLMvsCLM/610m-mlm40-12k
Feature Extraction • Updated • 29
MLMvsCLM/610m-mlm30-42k
Feature Extraction • Updated • 24
MLMvsCLM/610m-mlm40-42k-10000
Feature Extraction • Updated • 10
MLMvsCLM/610m-clm-42k
Feature Extraction • Updated • 13
datasets 0
None public yet