
POLARIS
Overview
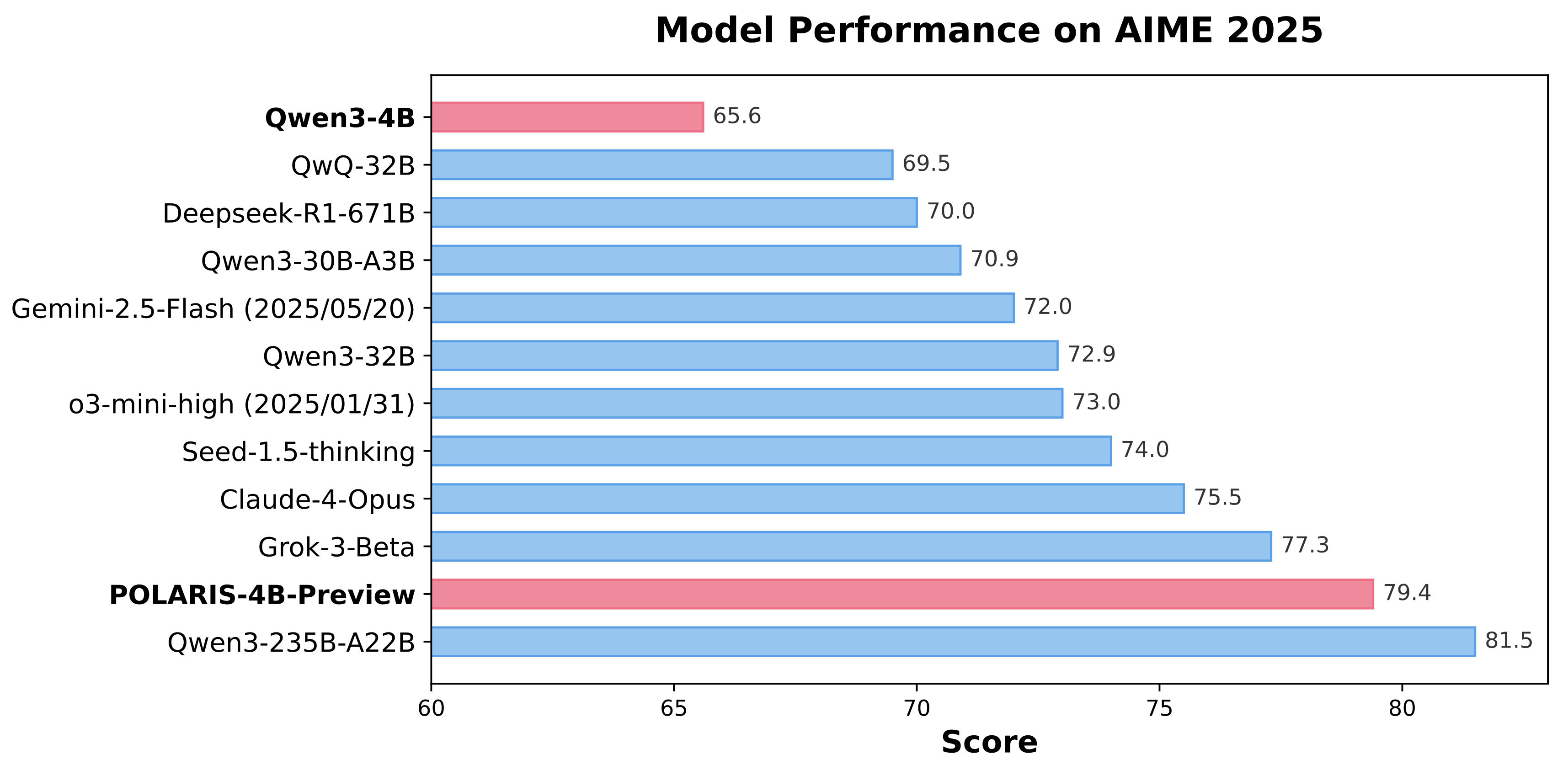
Polaris is an open-source post-training method that uses reinforcement learning (RL) scaling to refine and enhance models with advanced reasoning abilities. Our research shows that even top-tier models like Qwen3-4B can achieve significant improvements on challenging reasoning tasks when optimized with Polaris. By leveraging open-source data and academic-level resources, Polaris pushes the capabilities of open-recipe reasoning models to unprecedented heights. In benchmark tests, our method even surpasses top commercial systems, including Claude-4-Opus, Grok-3-Beta, and o3-mini-high (2025/01/03).
Polaris's Recipe
- Data Difficulty: Before training, Polaris analyzes and maps the distribution of data difficulty. The dataset should not be overwhelmed by either overly difficult or trivially easy problems. We recommend using a data distribution with a slight bias toward challenging problems, which typically exhibits a mirrored J-shaped distribution.
- Diversity-Based Rollout: We leverage the diversity among rollouts to initialize the sampling temperature, which is then progressively increased throughout the RL training stages.
- Inference-Time Length: Polaris incorporates length extrapolation techniques for generating longer CoT at inference stage. This enables a "train-short, generate-long" paradigm for CoT reasoning, mitigating the computational burden of training with excessively long rollouts .
- Exploration Efficiency: Exploration efficiency in Polaris is enhanced through multi-stage training. However, reducing the model's response length in the first stage poses potential risks. A more conservative approach would be to directly allow the model to "think longer" from the beginning.
The details of our training recipe and analysis can be found in our blog post. The code and data for reproducing our results can be found in our github repo.
Evaluation Results
| Models | AIME24 avg@32 | AIME25 avg@32 | Minerva Math avg@4 | Olympiad Bench avg@4 | AMC23 avg@8 |
|---|---|---|---|---|---|
| DeepScaleR-1.5B | 43.1 | 27.2 | 34.6 | 40.7 | 50.6 |
| Qwen3-1.7B | 48.3 | 36.8 | 34.9 | 55.1 | 75.6 |
POLARIS-1.7B-Preview |
66.9 | 53.0 | 38.9 | 63.8 | 85.8 |
| Deepseek-R1-Distill-Qwen-7B | 55.0 | 39.7 | 36.7 | 56.8 | 81.9 |
| AReal-boba-RL-7B | 61.9 | 48.3 | 39.5 | 61.9 | 86.4 |
| Skywork-OR1-7B-Math | 69.8 | 52.3 | 40.8 | 63.2 | 85.3 |
POLARIS-7B-Preview |
72.6 | 52.6 | 40.2 | 65.4 | 89.0 |
| Deepseek-R1-Distill-Qwen-32B | 72.6 | 54.9 | 42.1 | 59.4 | 84.3 |
| qwen3-32B | 81.4 | 72.9 | 44.2 | 66.7 | 92.4 |
| qwen3-4B | 73.8 | 65.6 | 43.6 | 62.2 | 87.2 |
POLARIS-4B-Preview |
81.2 | 79.4 | 44.0 | 69.1 | 94.8 |
Acknowledgements
The training and evaluation codebase is heavily built on Verl. The reward function in polaris is from DeepScaleR. Our model is trained on top of Qwen3-4B and DeepSeek-R1-Distill-Qwen-7B. Thanks for their wonderful work.
Citation
@misc{Polaris2025,
title = {POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models},
url = {https://hkunlp.github.io/blog/2025/Polaris},
author = {An, Chenxin and Xie, Zhihui and Li, Xiaonan and Li, Lei and Zhang, Jun and Gong, Shansan and Zhong, Ming and Xu, Jingjing and Qiu, Xipeng and Wang, Mingxuan and Kong, Lingpeng}
year = {2025}
}
- Downloads last month
- 684
Model tree for POLARIS-Project/Polaris-4B-Preview
Base model
Qwen/Qwen3-4B-Base