
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/model-cards#model-card-metadata)
Leap-0
This repository contains the implementation of a lightweight, modified version of the GPT architecture Leap-0 trained from scratch using FineWeb-Edu, an open-source dataset. The project demonstrates the design, training, and optimization of a custom natural language model on local hardware.
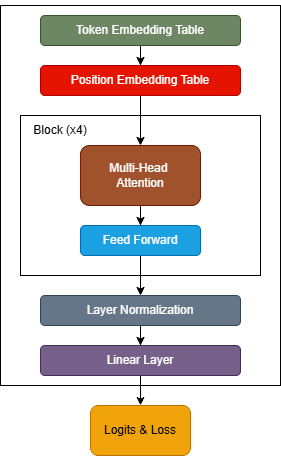
Figure 1: Architecture of Leap
Features
- Custom GPT Architecture: A miniaturized version of the GPT model tailored for efficient training on limited hardware.
- Local Training: Complete model training executed on local resources, enabling cost-effective development.
- Open-Source Datasets: Trained using publicly available FineWeb-Edu dataset to ensure accessibility and reproducibility.
- Scalable Design: Architecture optimized for experimentation and scalability while maintaining resource efficiency.
Implementation Details
Model Architecture
- A streamlined GPT-based architecture designed for reduced complexity and improved training efficiency.
- Incorporates modifications to parameter scaling to suit resource-constrained environments.
Training
- Training executed locally on NVIDIA GeForce RTX 4500 ada 24GB GPU, leveraging PyTorch.
Testing
- A simple Streamlit UI created for testing generation capability of the model.
Model Architecture
Configuration
- Sequence Length: 512 tokens
- Vocabulary Size: 48,951 tokens
- Includes 50,000 BPE merges, 256 special byte tokens, and 1
<|endoftext|>token.
- Includes 50,000 BPE merges, 256 special byte tokens, and 1
- Number of Layers: 4 transformer blocks
- Attention Heads: 8 per block
- Embedding Dimension: 512
- Dropout: 0.1
Components
Embeddings:
- Word Embeddings (
wte): Learnable token embeddings of sizen_embd. - Position Embeddings (
wpe): Learnable positional embeddings for sequences up toblock_size.
- Word Embeddings (
Transformer Blocks:
- A stack of 4 transformer blocks, each comprising:
- Multi-head self-attention mechanisms.
- Feedforward networks for feature transformation.
- A stack of 4 transformer blocks, each comprising:
Output Head:
- Linear Layer (
lm_head): Maps hidden states to logits for token predictions. - Implements weight sharing between token embeddings (
wte) and output projection for parameter efficiency.
- Linear Layer (
Layer Normalization:
- Final layer normalization (
ln_f) ensures stable optimization.
- Final layer normalization (
Current Status:
- Dataset Used: FineWeb-Edu (18.5 GB) entirely.
- Training Steps: 5000
- Time Taken: ~ 7 hours
- File format: .pt
Requirements
- Python 3.8+
- PyTorch 2.0+ or TensorFlow 2.10+
- CUDA-enabled GPU with at least 4GB VRAM (recommended)
- Dependencies listed in
requirements.txt - Note: Different OS support different versions of PyTorch/Tensorflow to use CUDA (local GPU). Install only after verifying for your OS.
- Downloads last month
- 3
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support