
Qwen2.5-Omni
Collection
End-to-End Omni (text, audio, image, video, and natural speech interaction) model based Qwen2.5
•
7 items
•
Updated
•
114
Qwen2.5-Omni is an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner.
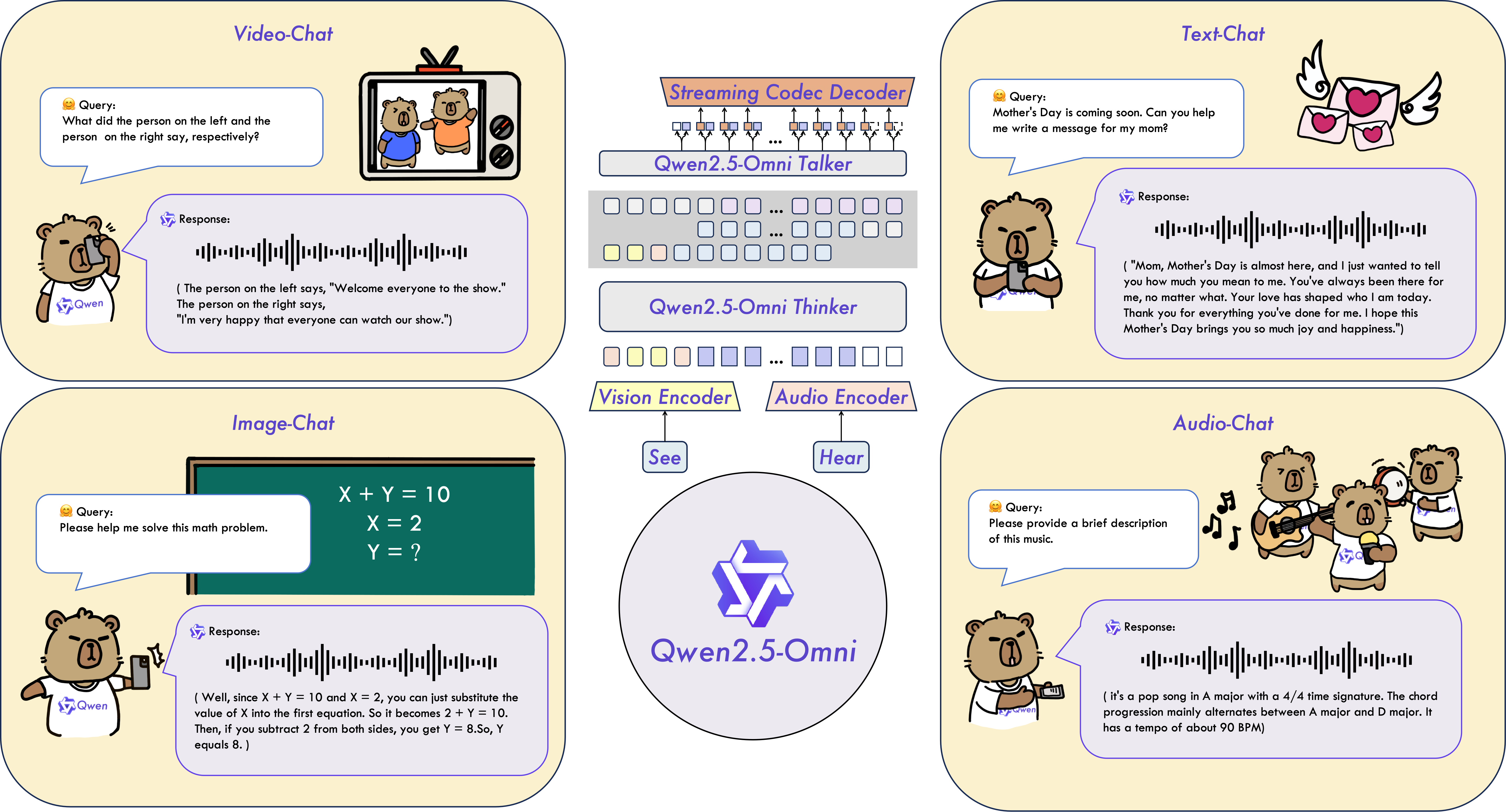
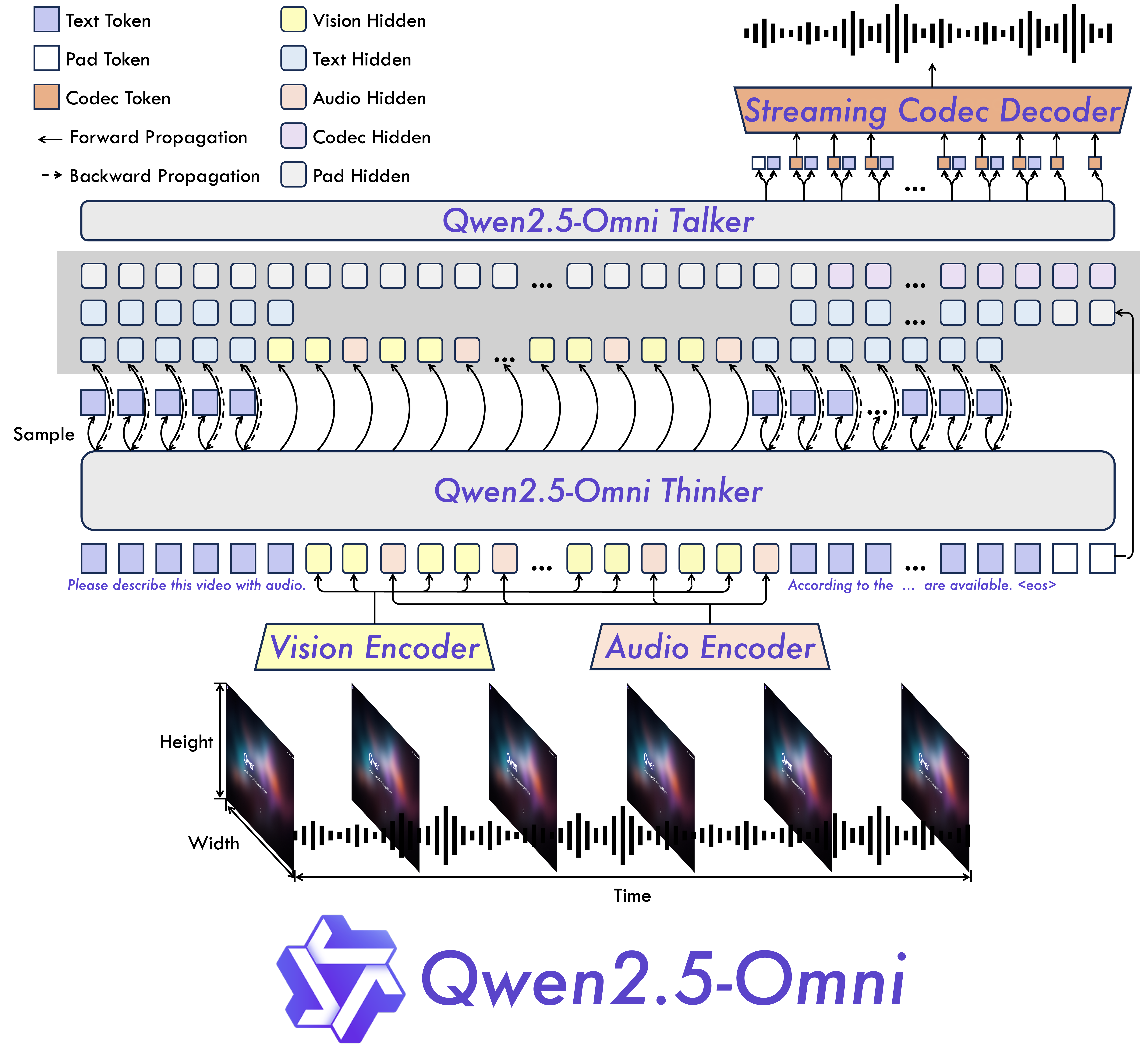
Omni and Novel Architecture: We propose Thinker-Talker architecture, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time-aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
Real-Time Voice and Video Chat: Architecture designed for fully real-time interactions, supporting chunked input and immediate output.
Natural and Robust Speech Generation: Surpassing many existing streaming and non-streaming alternatives, demonstrating superior robustness and naturalness in speech generation.
Strong Performance Across Modalities: Exhibiting exceptional performance across all modalities when benchmarked against similarly sized single-modality models. Qwen2.5-Omni outperforms the similarly sized Qwen2-Audio in audio capabilities and achieves comparable performance to Qwen2.5-VL-7B.
Excellent End-to-End Speech Instruction Following: Qwen2.5-Omni shows performance in end-to-end speech instruction following that rivals its effectiveness with text inputs, evidenced by benchmarks such as MMLU and GSM8K.
This model card introduces a series of enhancements designed to improve the Qwen2.5-Omni-7B's operability on devices with constrained GPU memory. Key optimizations include:
Implemented 4-bit quantization of the Thinker's weights using GPTQ, effectively reducing GPU VRAM usage.
Enhanced the inference pipeline to load model weights on-demand for each module and offload them to CPU memory once inference is complete, preventing peak VRAM usage from becoming excessive.
Converted the token2wav module to support streaming inference, thereby avoiding the pre-allocation of excessive GPU memory.
Adjusted the ODE solver from a second-order (RK4) to a first-order (Euler) method to further decrease computational overhead.
These improvements aim to ensure efficient performance of Qwen2.5-Omni across a range of hardware configurations, particularly those with lower GPU memory availability (RTX3080, 4080, 5070, etc).
Below, we provide simple example to show how to use Qwen2.5-Omni-7B-GPTQ-Int4 with gptqmodel as follows:
pip uninstall transformers
pip install git+https://github.com/huggingface/[email protected]
pip install accelerate
pip install gptqmodel==2.0.0
pip install numpy==2.0.0
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni/low-VRAM-mode/
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_gptq.py
We offer a toolkit to help you handle various types of audio and visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved audio, images and videos. You can install it using the following command and make sure your system has ffmpeg installed:
# It's highly recommended to use `[decord]` feature for faster video loading.
pip install qwen-omni-utils[decord] -U
If you are not using Linux, you might not be able to install decord from PyPI. In that case, you can use pip install qwen-omni-utils -U which will fall back to using torchvision for video processing. However, you can still install decord from source to get decord used when loading video.
The following two tables present a performance comparison and GPU memory consumption between Qwen2.5-Omni-7B-GPTQ-Int4 and Qwen2.5-Omni-7B on specific evaluation benchmarks. The data demonstrates that the GPTQ-Int4 model maintains comparable performance while reducing GPU memory requirements by over 50%+, enabling a broader range of devices to run and experience the high-performance Qwen2.5-Omni-7B model. Notably, the GPTQ-Int4 variant exhibits slightly slower inference speeds compared to the native Qwen2.5-Omni-7B model due to quantization techniques and CPU offload mechanisms.
| Evaluation Set | Task | Metrics | Qwen2.5-Omni-7B | Qwen2.5-Omni-7B-GPTQ-Int4 |
|---|---|---|---|---|
| LibriSpeech test-other | ASR | WER ⬇️ | 3.4 | 3.71 |
| WenetSpeech test-net | ASR | WER ⬇️ | 5.9 | 6.62 |
| Seed-TTS test-hard | TTS (Speaker: Chelsie) | WER ⬇️ | 8.7 | 10.3 |
| MMLU-Pro | Text -> Text | Accuracy ⬆️ | 47.0 | 43.76 |
| OmniBench | Speech -> Text | Accuracy ⬆️ | 56.13 | 53.59 |
| VideoMME | Multimodality -> Text | Accuracy ⬆️ | 72.4 | 68.0 |
| Model | Precision | 15(s) Video | 30(s) Video | 60(s) Video |
|---|---|---|---|---|
| Qwen-Omni-7B | FP32 | 93.56 GB | Not Recommend | Not Recommend |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
| Qwen-Omni-7B | GPTQ-Int4 | 11.64 GB | 17.43 GB | 29.51 GB |
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}