🚀 Best Practices for Evaluating the Qwen3-Omni Model

Qwen3-Omni represents the next generation of native multimodal large models, seamlessly handling various input forms such as text, images, audio, and video, while simultaneously generating text and natural voice outputs through real-time streaming responses. In this best practice guide, we will utilize the EvalScope framework to evaluate the Qwen3-Omni-30B-A3B-Instruct model, covering both inference performance evaluation and model capability assessment.
Dependency Installation
First, install the EvalScope model evaluation framework:
pip install 'evalscope[app,perf]' -U
Model Service Inference Performance Evaluation
For multimodal models, we need to access model capabilities through an OpenAI API-compatible inference service for evaluation, as local usage of transformers for inference is not yet supported. You can deploy the model to a cloud service supporting the OpenAI API interface or choose to start the model locally using frameworks like vLLM or ollama. These inference frameworks effectively support multiple concurrent requests, accelerating the evaluation process.
Below, we demonstrate how to start the Qwen3-Omni-30B-A3B-Instruct model service locally using vLLM and conduct performance evaluation.
Dependency Installation
Since the code submitted to vLLM is currently (as of September 25, 2025) in the pull request stage, and audio output inference support for the instruction model will be released soon, you can install vLLM from the source using the following commands. Note that we recommend creating a new Python environment to avoid runtime conflicts and incompatibilities:
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm
pip install -r requirements/build.txt
pip install -r requirements/cuda.txt
export VLLM_PRECOMPILED_WHEEL_LOCATION=https://wheels.vllm.ai/a5dd03c1ebc5e4f56f3c9d3dc0436e9c582c978f/vllm-0.9.2-cp38-abi3-manylinux1_x86_64.whl
VLLM_USE_PRECOMPILED=1 pip install -e . -v --no-build-isolation
# If you encounter an "Undefined symbol" error while using VLLM_USE_PRECOMPILED=1, please use "pip install -e . -v" to build from source.
# Install the Transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
pip install qwen-omni-utils -U
pip install -U flash-attn --no-build-isolation
Starting the Model Service
The following command can be used to create an API endpoint at http://localhost:8801/v1:
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --port 8801 --dtype bfloat16 --max-model-len 32768 --served-model-name Qwen3-Omni-30B-A3B-Instruct
Local Model Service Performance Evaluation
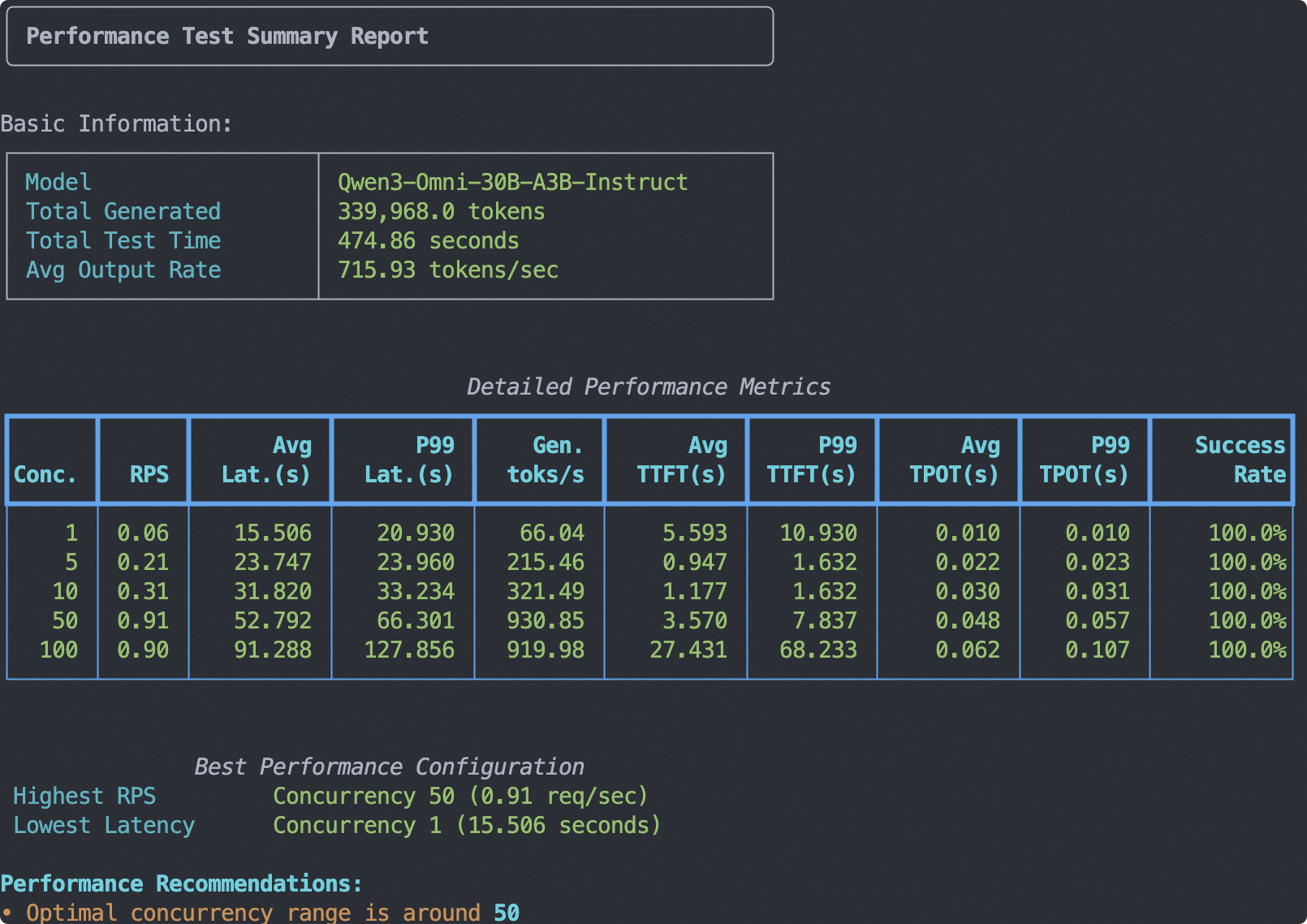
Stress Test Command:
- Test Environment: A100 80G * 1
- Input: 1024 tokens of text + 1 image of 512x512
- Output: 1024 tokens
Note: The tokenizer path of Qwen3-30B-A3B-Instruct is used here because Qwen3-Omni-30B-A3B-Instruct and Qwen3-30B-A3B-Instruct use the same text tokenizer.
evalscope perf \
--model Qwen3-Omni-30B-A3B-Instruct \
--url http://localhost:8801/v1/chat/completions \
--api-key "API_KEY" \
--parallel 1 5 10 50 100 \
--number 2 10 20 100 200 \
--api openai \
--dataset random_vl \
--min-tokens 1024 \
--max-tokens 1024 \
--prefix-length 0 \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--image-width 512 \
--image-height 512 \
--image-format RGB \
--image-num 1 \
--tokenizer-path Qwen/Qwen3-30B-A3B-Instruct-2507
The output report is as follows:
Model Capability Evaluation
Next, we proceed with the model capability evaluation process using OmniBench. OmniBench is a benchmark tool for assessing multimodal models' understanding capabilities across text, image, and audio modalities.
Note: Subsequent evaluation processes are based on API model services. You can start the model service according to the model inference framework usage steps. Due to a bug in the vLLM framework (as of September 25, 2025) regarding Base64 audio input support, audio input evaluation is temporarily unavailable.
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
task_cfg = TaskConfig(
model='Qwen3-Omni-30B-A3B-Instruct',
api_url='http://localhost:8801/v1',
api_key='EMPTY',
eval_type=EvalType.SERVICE,
datasets=[
'omni_bench',
],
dataset_args={
'omni_bench': {
'extra_params': {
'use_image': True, # Whether to use image input, if False, use text alternative image content.
'use_audio': False, # Whether to use audio input, if False, use text alternative audio content.
}
}
},
eval_batch_size=1,
generation_config={
'max_tokens': 10000, # Maximum number of tokens to generate, recommended to set a large value to avoid output truncation
'temperature': 0.0, # Sampling temperature (recommended value from Qwen report)
},
limit=100, # Set to 100 data points for testing
)
run_task(task_cfg=task_cfg)
The output results are as follows:
Note: The results below are based on 100 data points, used only for testing the evaluation process. The limit should be removed for formal evaluation.
+-----------------------------+------------+----------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=============================+============+==========+==========+=======+=========+=========+
| Qwen3-Omni-30B-A3B-Instruct | omni_bench | mean_acc | default | 100 | 0.44 | default |
+-----------------------------+------------+----------+----------+-------+---------+---------+
For more available evaluation datasets, refer to the Dataset List.
Visualization
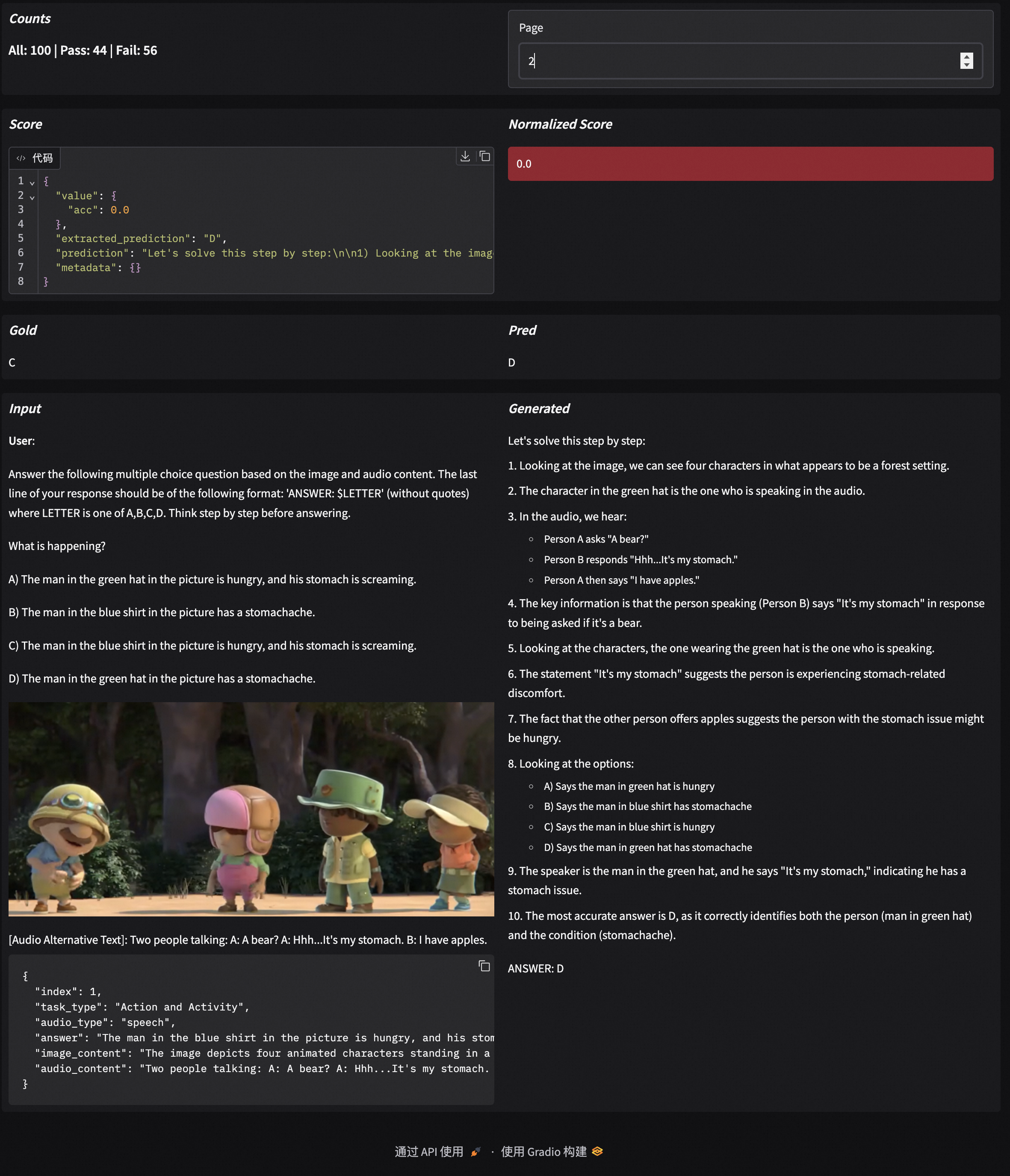
EvalScope supports result visualization, allowing you to view the model's specific outputs.
Run the following command to start a Gradio-based visualization interface:
evalscope app
Select the evaluation report, click load, and you can see the model's output results for each question, along with the overall accuracy: