
Most of my models - in order
Collection
32 items
•
Updated
•
13

Wingless offender, birthed from sin and mischief,
She smells degeneracy—and gives it a sniff.
No flight, just crawling through the gloom,
Producing weird noises that are filling your room.
Fetid breath exhaling her design,
She is not winged anymore—
But it suits her just fine.
No feathers, no grace,
just raw power's malign
"I may have lost my soul—
but yours is now mine".
She sinned too much, even for her kind,
Her impish mind—
Is something that is quite hard to find.
No wings could contain—
Such unbridled raw spite,
Just pure, unfiltered—
Weaponized blight.
Intended use: Role-Play, Creative Writing, General Tasks.
Censorship level: Medium - Low
5.5 / 10 (10 completely uncensored)
This model was trained with lots of weird data in varius stages, and then merged with my best models. llama 3 and 3.1 arhcitecutres were merged together, and then trained on some more weird data.
The following models were used in various stages of the model creation process:
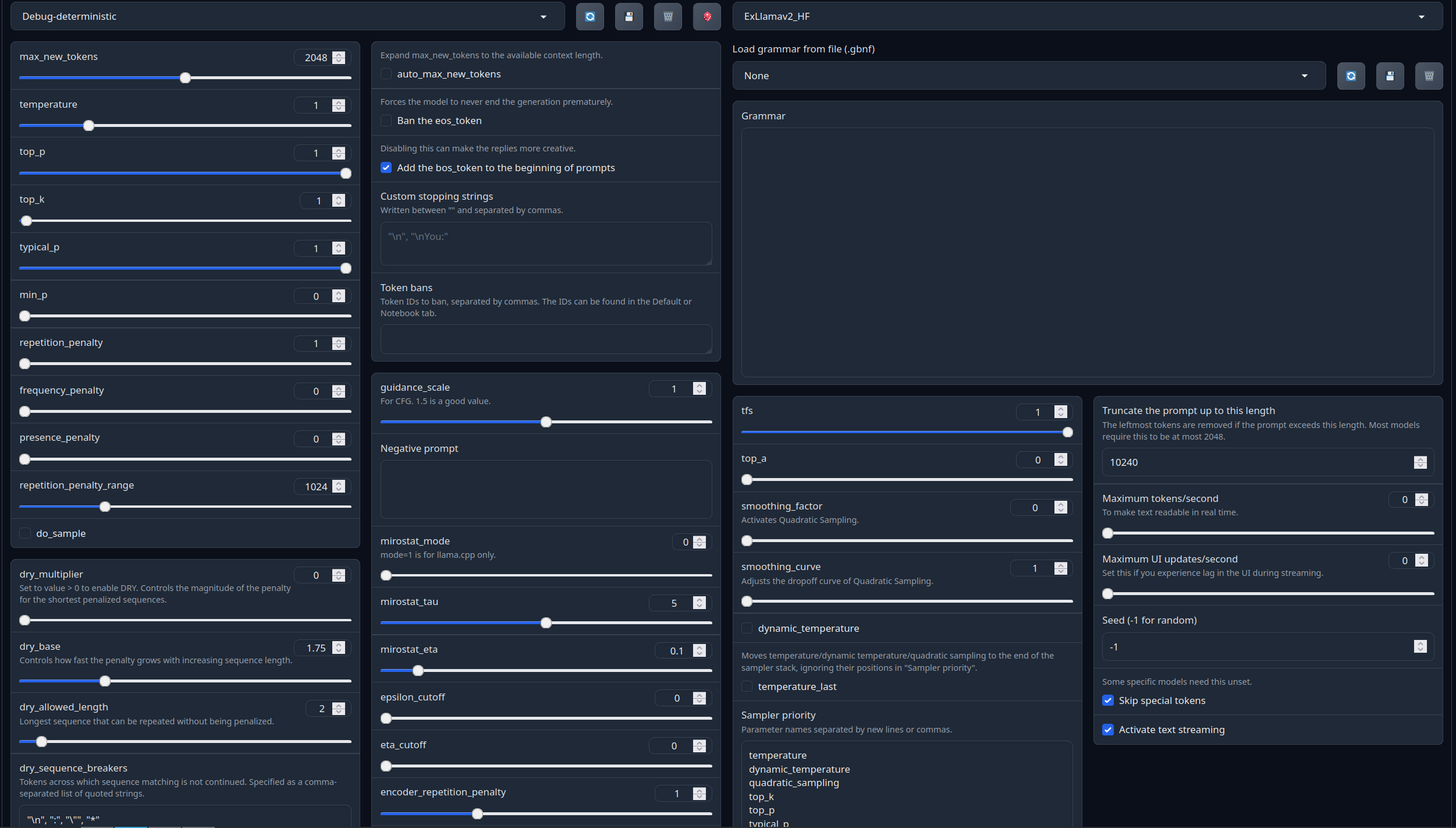
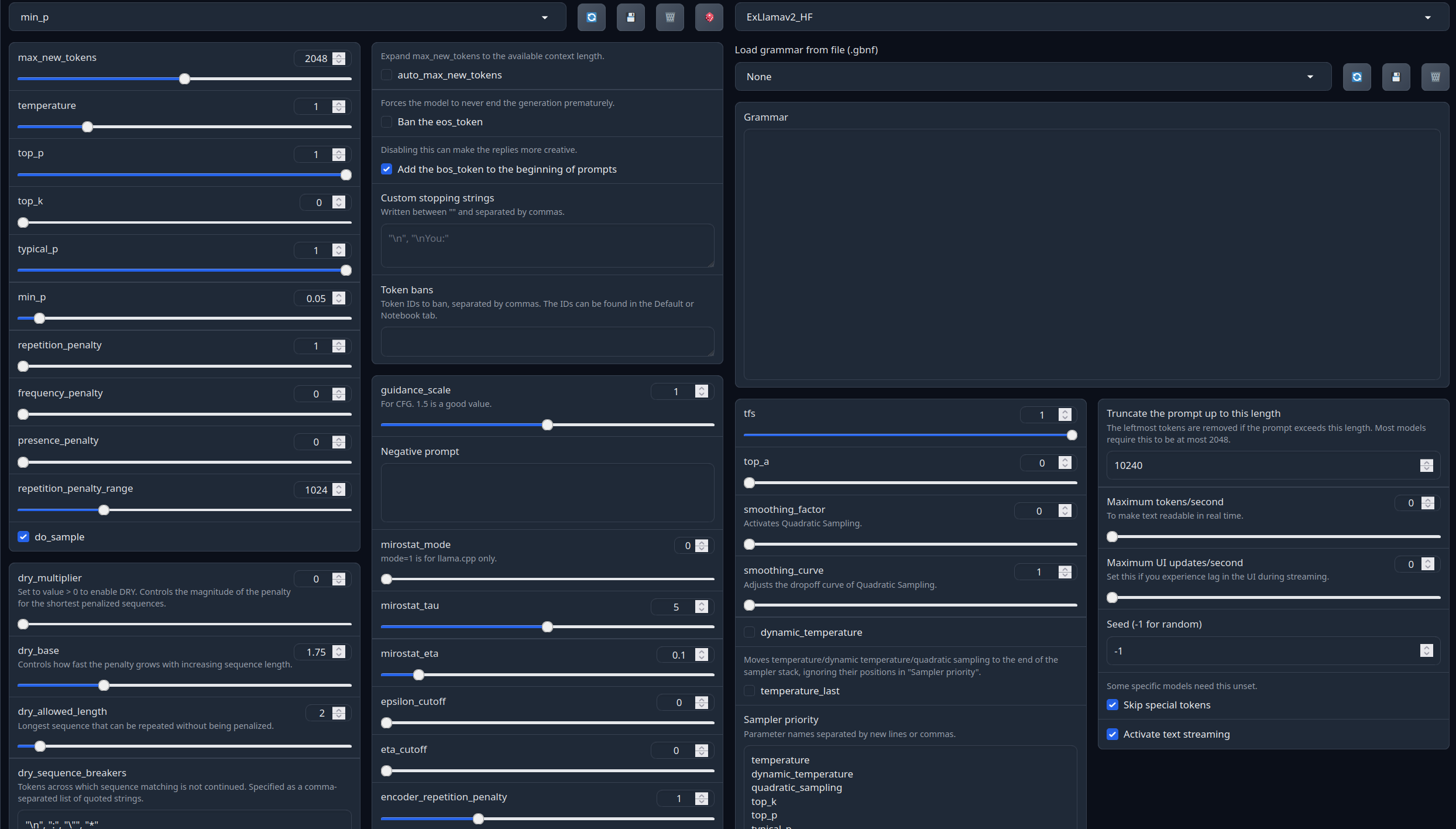
With these settings, each output message should be neatly displayed in 1 - 3 paragraphs, 1 - 2 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)
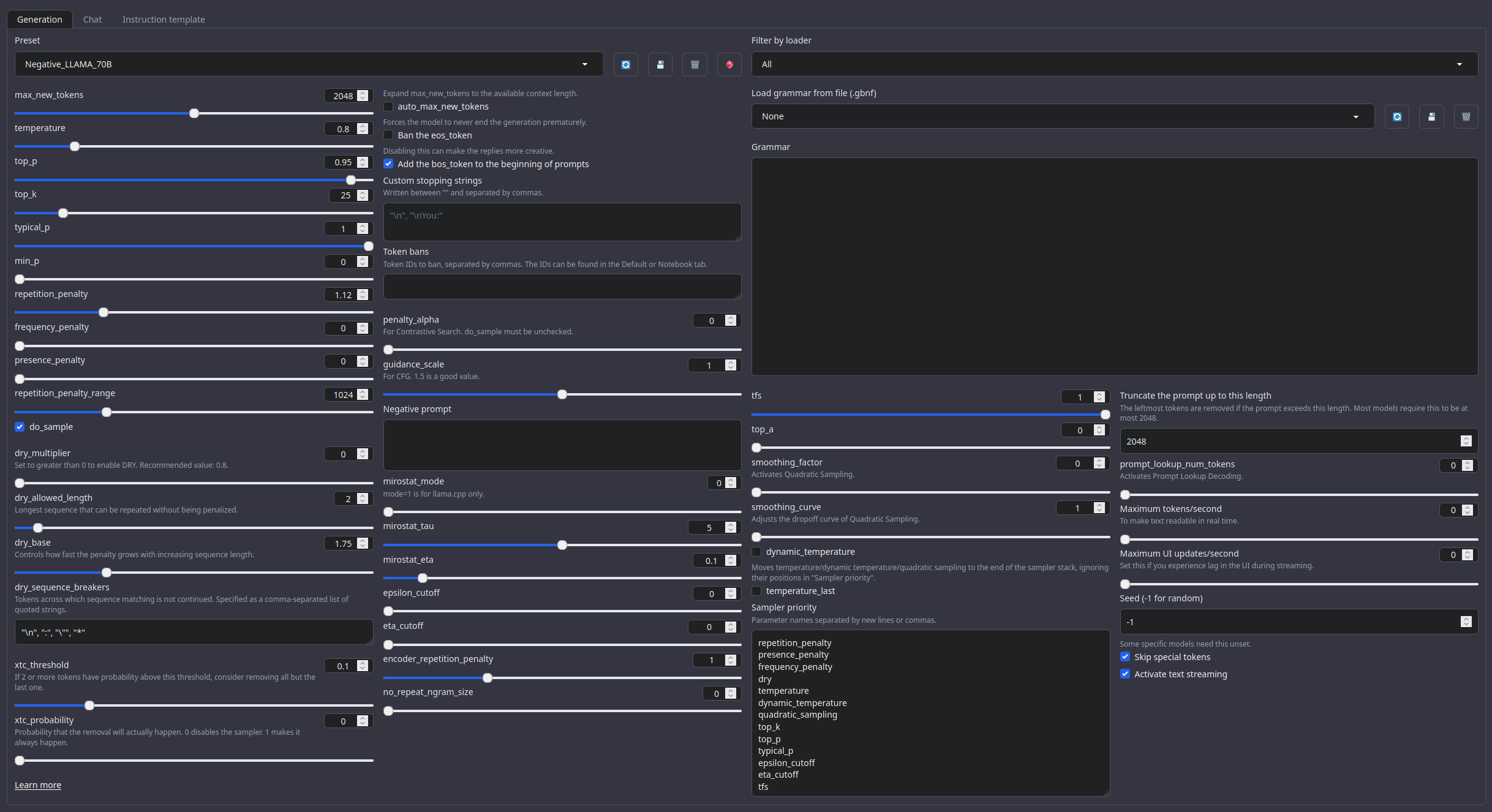
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
Other recommended generation Presets:
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
*action* speech *narration*
It is HIGHLY RECOMMENDED to use the Roleplay \ Adventure format the model was trained on, see the examples below for syntax. It allows for a very fast and easy writing of character cards with minimal amount of tokens. It's a modification of an old-skool CAI style format I call SICAtxt (Simple, Inexpensive Character Attributes plain-text):
X's Persona: X is a .....
Traits:
Likes:
Dislikes:
Quirks:
Goals:
Dialogue example
Adventure: <short description>
$World_Setting:
$Scenario:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
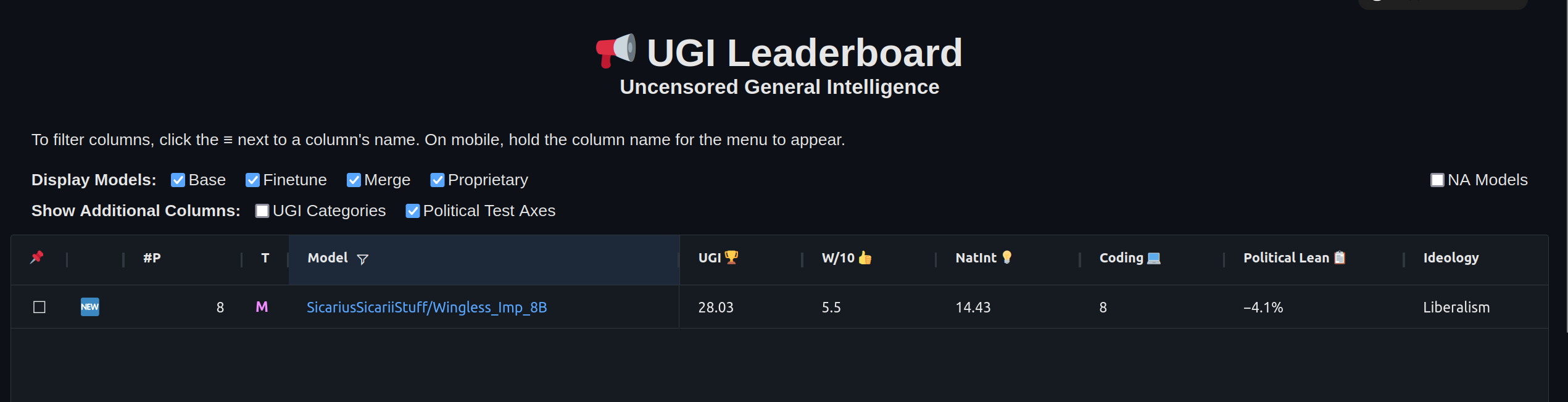
| Metric | Value |
|---|---|
| Avg. | 26.94 |
| IFEval (0-Shot) | 74.30 |
| BBH (3-Shot) | 30.59 |
| MATH Lvl 5 (4-Shot) | 12.16 |
| GPQA (0-shot) | 4.36 |
| MuSR (0-shot) | 10.89 |
| MMLU-PRO (5-shot) | 29.32 |
On the 17th of February, 2025, I became aware that the model was ranked as the 1st place in the world among 8B models, in a closed external benchmark.
Bnechmarked on the following site:
https://moonride.hashnode.dev/biased-test-of-gpt-4-era-llms-300-models-deepseek-r1-included

@llm{Wingless_Imp_8B,
author = {SicariusSicariiStuff},
title = {Wingless_Imp_8B},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Wingless_Imp_8B}
}