
BioXP-0.5B
BioXP-0.5B is a 🤗 Medical-AI model trained using our two-stage fine-tuning approach:
Supervised Fine-Tuning (SFT): The model was initially fine-tuned on labeled data(MedMCQA) to achieve strong baseline accuracy on multiple-choice medical QA tasks.
Group Relative Policy Optimization (GRPO): In the second stage, GRPO was applied to further align the model with human-like reasoning patterns. This reinforcement learning technique enhances the model’s ability to generate coherent, high-quality explanations and improve answer reliability.
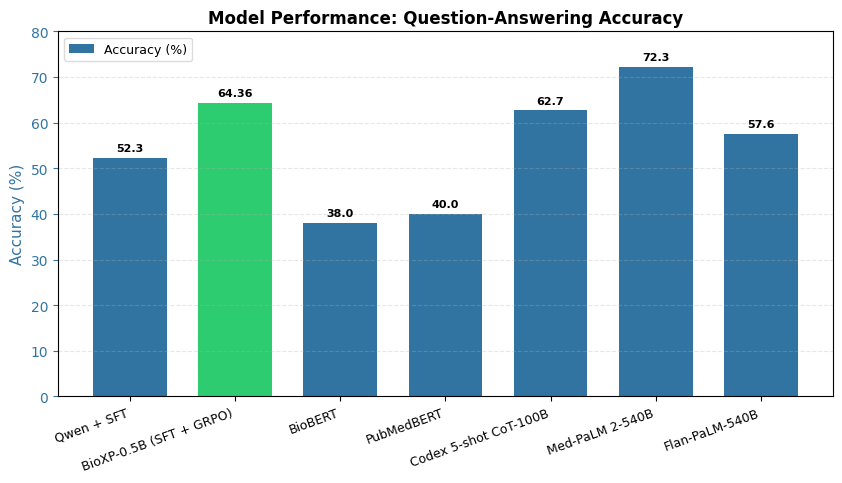
The final model achieves an accuracy of 64.58% on the MedMCQA benchmark.
Model Details
This model is a finetuned version of Qwen/Qwen2.5-0.5B-Instruct, a 0.5 billion parameter language model from the Qwen2 family. The finetuning was performed using SFT following by Group Relative Policy Optimization (GRPO).
- Developed by: Qwen (original model), finetuning by Abaryan
- Funded by : Abaryan
- Shared by : Abaryan
- Model type: Causal Language Model
- Language(s) (NLP): English
- License: MIT
- Finetuned from model: Qwen/Qwen2.5-0.5B-Instruct
Out-of-Scope Use
This model should not be used for generating harmful, biased, or inappropriate content. It's important to be aware of the potential limitations and biases inherited from the base model and the finetuning data.
Bias, Risks, and Limitations
As a large language model, this model may exhibit biases present in the training data. The finetuning process may have amplified or mitigated certain biases. Further evaluation is needed to understand the full extent of these biases and limitations.
How to Get Started with the Model
Use Below Space for a quick demo https://huggingface.co/spaces/rgb2gbr/BioXP-0.5b-v2
You can load this model using the transformers library in Python:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "rgb2gbr/BioXP-0.5B-MedMCQA"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype="auto")
prompt = "Identify the right answer and elaborate your reasoning"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- Downloads last month
- 102