MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
MobileCLIP was introduced in MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
(CVPR 2024), by Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel.
This repository contains the MobileCLIP-S2 checkpoint for timm.
Highlights
- Our smallest variant
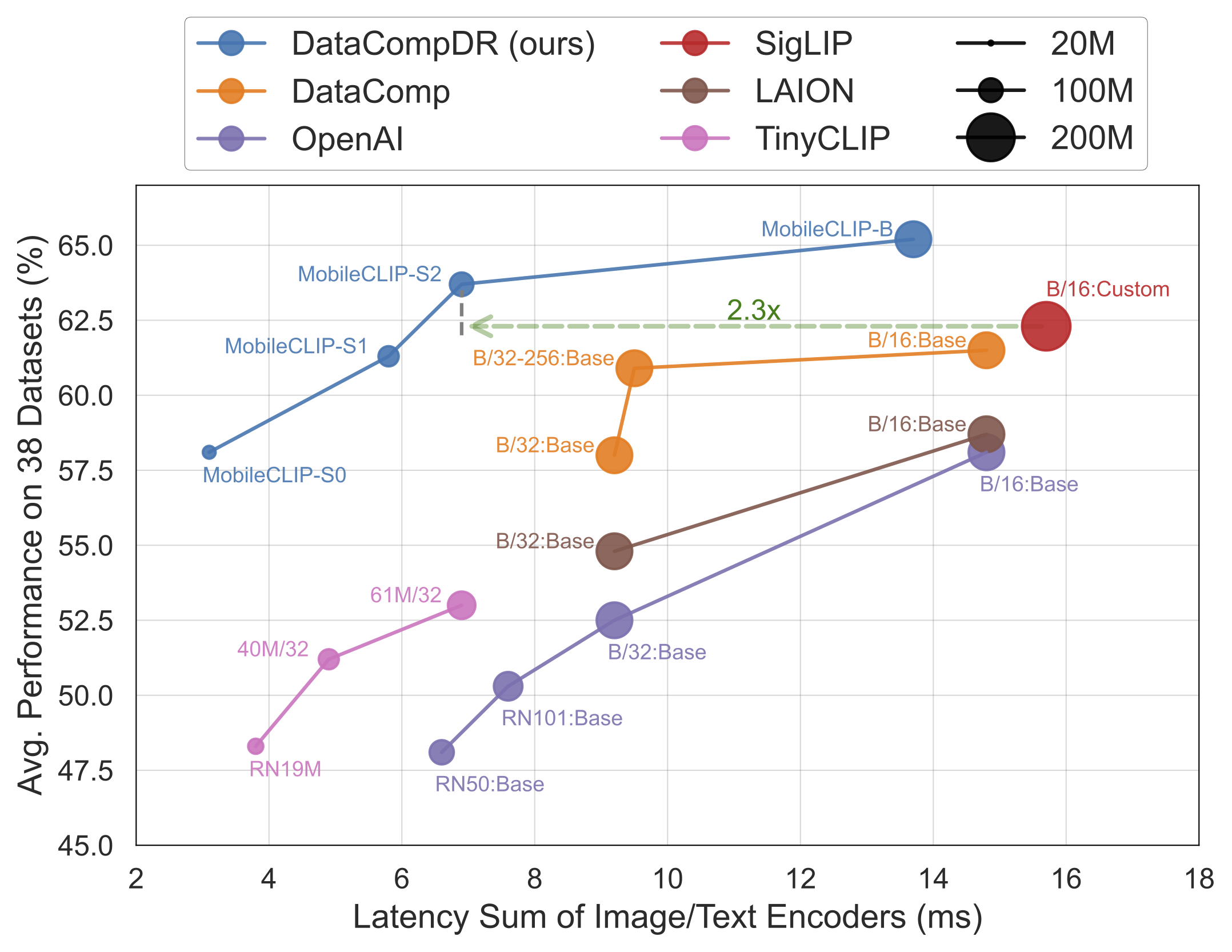
MobileCLIP-S0 obtains similar zero-shot performance as OpenAI's ViT-B/16 model while being 4.8x faster and 2.8x smaller.
MobileCLIP-S2 obtains better avg zero-shot performance than SigLIP's ViT-B/16 model while being 2.3x faster and 2.1x smaller, and trained with 3x less seen samples.MobileCLIP-B(LT) attains zero-shot ImageNet performance of 77.2% which is significantly better than recent works like DFN and SigLIP with similar architectures or even OpenAI's ViT-L/14@336.
Checkpoints
| Model |
# Seen
Samples (B) |
# Params (M)
(img + txt) |
Latency (ms)
(img + txt) |
IN-1k Zero-Shot
Top-1 Acc. (%) |
Avg. Perf. (%)
on 38 datasets |
| MobileCLIP-S0 |
13 |
11.4 + 42.4 |
1.5 + 1.6 |
67.8 |
58.1 |
| MobileCLIP-S1 |
13 |
21.5 + 63.4 |
2.5 + 3.3 |
72.6 |
61.3 |
| MobileCLIP-S2 |
13 |
35.7 + 63.4 |
3.6 + 3.3 |
74.4 |
63.7 |
| MobileCLIP-B |
13 |
86.3 + 63.4 |
10.4 + 3.3 |
76.8 |
65.2 |
| MobileCLIP-B (LT) |
36 |
86.3 + 63.4 |
10.4 + 3.3 |
77.2 |
65.8 |

