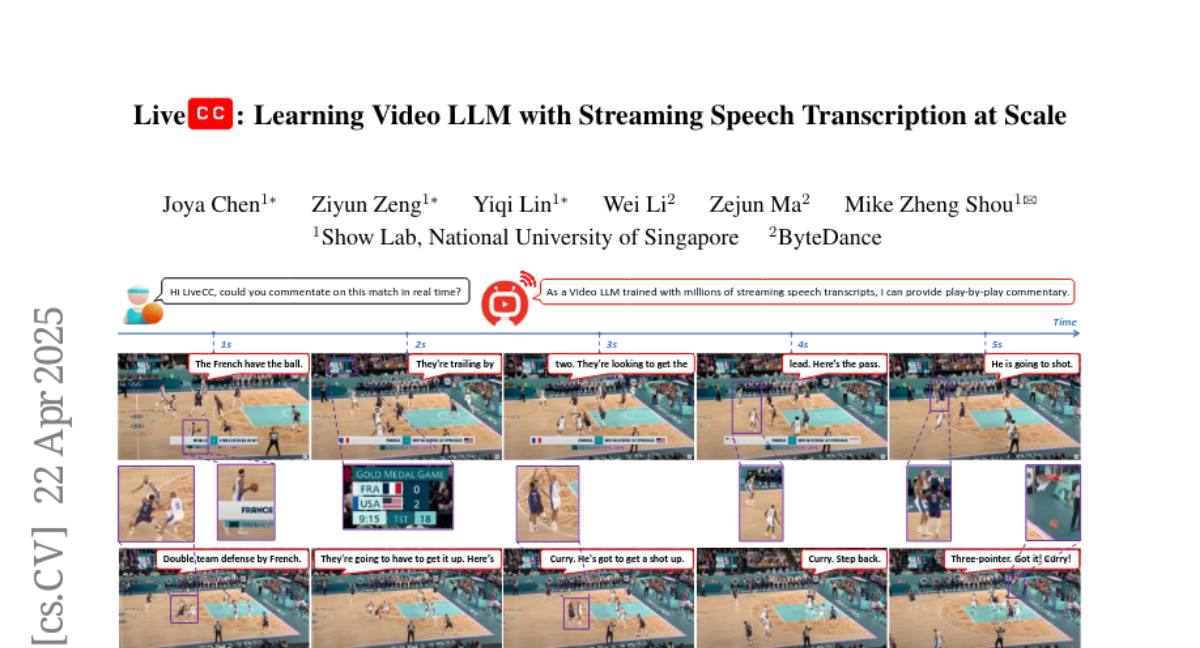
Learning Video LLM with Streaming Speech Transcription at Scale (CVPR 2025)
Joya Chen
chenjoya
AI & ML interests
Video LLM
Recent Activity
liked a model about 5 hours ago
nvidia/AnyFlow-FAR-Wan2.1-1.3B-Diffusers updated a dataset about 5 hours ago
DataTransfer111/marker upvoted a paper about 2 months ago
Mixture-of-Depths AttentionOrganizations