File size: 8,915 Bytes
042770c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 |
# ================================================
# GEM Model Trainer & Evaluator - Callable Version
# ================================================
import torch
import torch.quantization
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification, get_linear_schedule_with_warmup
from sklearn.cluster import MiniBatchKMeans
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
import numpy as np
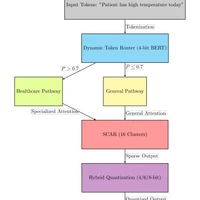
def run_gem_pipeline(
dataset,
model_name="bert-base-uncased",
num_classes=77,
num_epochs=3,
batch_size=16,
learning_rate=2e-5,
max_seq_length=128,
gradient_accum_steps=2,
cluster_size=256,
threshold=0.65
):
"""
Runs the GEM model training & evaluation pipeline on a custom dataset.
Args:
dataset: HuggingFace DatasetDict or custom dataset (must have 'train' and 'test').
model_name: Name of the transformer model.
num_classes: Number of output classes.
num_epochs: Training epochs.
batch_size: Batch size for dataloaders.
learning_rate: Learning rate for optimizer.
max_seq_length: Max sequence length for tokenizer.
gradient_accum_steps: Gradient accumulation steps.
cluster_size: Number of clusters for routing.
threshold: Routing threshold.
Returns:
final_accuracy: Final evaluation accuracy on test set.
avg_loss: Average training loss.
"""
# ========================
# Config
# ========================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
hidden_size = 768
num_heads = 12
# ========================
# Tokenizer & Dataloaders
# ========================
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_fn(examples):
return tokenizer(
examples['text'],
padding='max_length',
truncation=True,
max_length=max_seq_length
)
dataset = dataset.map(tokenize_fn, batched=True)
def collate_fn(batch):
return {
'input_ids': torch.stack([torch.tensor(x['input_ids']) for x in batch]),
'attention_mask': torch.stack([torch.tensor(x['attention_mask']) for x in batch]),
'labels': torch.tensor([x['label'] for x in batch])
}
train_loader = DataLoader(
dataset['train'],
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn
)
test_loader = DataLoader(
dataset['test'],
batch_size=batch_size,
collate_fn=collate_fn
)
# ========================
# GEM Model (Modular)
# ========================
class QuantizedBERT(nn.Module):
def __init__(self):
super().__init__()
self.bert = AutoModel.from_pretrained(model_name)
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, input_ids, attention_mask=None):
outputs = self.bert(input_ids, attention_mask=attention_mask)
return self.dequant(self.quant(outputs.last_hidden_state))
class TokenRouter(nn.Module):
def __init__(self):
super().__init__()
self.clusterer = MiniBatchKMeans(n_clusters=cluster_size)
self.W_r = nn.Parameter(torch.randn(num_classes, hidden_size))
self.threshold = threshold
def forward(self, x):
cluster_input = x.detach().cpu().numpy().reshape(-1, x.shape[-1])
cluster_ids = self.clusterer.fit_predict(cluster_input)
cluster_ids = torch.tensor(cluster_ids, device=device).reshape(x.shape[:2])
domain_logits = torch.einsum('bsh,nh->bsn', x, self.W_r.to(x.device))
domain_probs = F.softmax(domain_logits, dim=-1)
routing_mask = (domain_probs.max(-1).values > self.threshold).long()
return domain_probs, routing_mask, cluster_ids
class SCAR(nn.Module):
def __init__(self):
super().__init__()
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
self.qkv = nn.Linear(hidden_size, 3 * hidden_size)
self.out = nn.Linear(hidden_size, hidden_size)
def create_mask(self, cluster_ids, routing_mask):
cluster_mask = (cluster_ids.unsqueeze(-1) == cluster_ids.unsqueeze(-2))
domain_mask = (routing_mask.unsqueeze(-1) == routing_mask.unsqueeze(-2))
return cluster_mask | domain_mask
def forward(self, x, cluster_ids, routing_mask):
B, N, _ = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) / np.sqrt(self.head_dim)
mask = self.create_mask(cluster_ids, routing_mask).unsqueeze(1)
attn = attn.masked_fill(~mask, -1e9)
attn = F.softmax(attn, dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
return self.out(x)
class GEM(nn.Module):
def __init__(self):
super().__init__()
self.bert = QuantizedBERT()
self.router = TokenRouter()
self.scar = SCAR()
self.classifier = nn.Linear(hidden_size, num_classes)
self.teacher = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=num_classes
).eval().to(device).requires_grad_(False)
def forward(self, input_ids, attention_mask=None):
x = self.bert(input_ids, attention_mask)
domain_probs, routing_mask, cluster_ids = self.router(x)
x = self.scar(x, cluster_ids, routing_mask)
return self.classifier(x[:, 0, :])
def qakp_loss(self, outputs, labels, input_ids):
task_loss = F.cross_entropy(outputs, labels)
quant_error = F.mse_loss(self.bert.quant(self.bert.dequant(outputs)), outputs)
with torch.no_grad():
teacher_logits = self.teacher(input_ids).logits
kd_loss = F.kl_div(
F.log_softmax(outputs, dim=-1),
F.softmax(teacher_logits, dim=-1),
reduction='batchmean'
)
return task_loss + 0.3 * quant_error + 0.7 * kd_loss
# ========================
# Training Setup
# ========================
model = GEM().to(device)
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model, device_ids=list(range(torch.cuda.device_count())))
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=100,
num_training_steps=len(train_loader) * num_epochs
)
# ========================
# Training Loop
# ========================
model.train()
avg_loss = 0
for epoch in range(num_epochs):
total_loss = 0
for step, batch in enumerate(tqdm(train_loader)):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = model.module.qakp_loss(outputs, labels, input_ids) if hasattr(model, 'module') else model.qakp_loss(outputs, labels, input_ids)
loss.backward()
if (step + 1) % gradient_accum_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch+1}/{num_epochs} | Avg Loss: {avg_loss:.4f}")
# ========================
# Evaluation Loop
# ========================
model.eval()
correct = total = 0
with torch.no_grad():
for batch in tqdm(test_loader):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
preds = outputs.argmax(dim=-1)
correct += (preds == labels).sum().item()
total += labels.size(0)
final_accuracy = 100 * correct / total
print(f"Final Accuracy: {final_accuracy:.2f}%")
return {
'accuracy': final_accuracy,
'average_loss': avg_loss
} |