Datasets:

Tasks:
Visual Question Answering
Modalities:
Text
Formats:
json
Languages:
English
Size:
10K - 100K
License:
| license: mit | |
| task_categories: | |
| - visual-question-answering | |
| language: | |
| - en | |
| # VLM 3TP Data Processing | |
| This document outlines the steps for processing VLM 3TP data, focusing on datasets with ground truth annotations. | |
| ## Table of Contents | |
| - [VLM 3TP Data Processing](#vlm-3tp-data-processing) | |
| - [Table of Contents](#table-of-contents) | |
| - [Quick Start: Mono3DRefer Preprocessing Workflow](#quick-start-mono3drefer-preprocessing-workflow) | |
| - [1. Datasets with Ground Truth Annotations](#1-datasets-with-ground-truth-annotations) | |
| - [Downloading Raw Data](#downloading-raw-data) | |
| - [2. Data Preprocessing Details](#2-data-preprocessing-details) | |
| - [Input Data Requirements](#input-data-requirements) | |
| - [Preprocessing Pipeline](#preprocessing-pipeline) | |
| - [Output Metadata Format](#output-metadata-format) | |
| - [3. Downstream Task Generation (QA)](#3-downstream-task-generation-qa) | |
| - [VSI-Bench Task Details](#vsi-bench-task-details) | |
| - [3D Fundamental Tasks (VSI-Bench)](#3d-fundamental-tasks-vsi-bench) | |
| - [Metric Estimation Tasks (VSI-Bench)](#metric-estimation-tasks-vsi-bench) | |
| - [Measurement Tasks (VSI-Bench)](#measurement-tasks-vsi-bench) | |
| ## Quick Start: Mono3DRefer Preprocessing Workflow | |
| We provide a complete, end-to-end workflow for processing the ScanNet dataset, from raw data to the final QA pairs. This includes detailed steps and command-line examples for each stage of the process. For the full guide, please refer to the documentation at [`src/metadata_generation/Mono3DRefer/README.md`](src/metadata_generation/Mono3DRefer/README.md). | |
| ## 1. Datasets with Ground Truth Annotations | |
| ### Downloading Raw Data | |
| Follow the instructions from the respective repositories to download the raw datasets: | |
| - **Mono3DRefer**: Download data to `data/Mono3DRefer`. Follow instructions at [Mono3DVG](https://github.com/ZhanYang-nwpu/Mono3DVG). | |
| The basic 2D visual knowledge is essential for the 3D spatial understanding. The general 2D visual grounding looks like this: | |
|  | |
| ## 2. Data Preprocessing Details | |
| This section outlines the general pipeline for preprocessing 3D scene data for tasks. The goal is to extract structured metadata from raw inputs, which can then be used to generate diverse question-answering (QA) datasets. | |
| ### Input Data Requirements | |
| The preprocessing pipeline requires the following types of data for each scene: | |
| 1. **Calibration Data**: The intrinsic parameters of the camera of the scene (e.g., from `.txt` files), typically containing focal length `fx`, `fy` and principal point `cx`, `cy`. | |
| 2. **Color Images**: RGB images of the scene (e.g., from `.jpg` or `.png` files). | |
| ### Preprocessing Pipeline | |
| The core preprocessing involves generating metadata files: | |
| 1. **Metadata Generation:** | |
| - Processes the Sampled Frame Data (Color) and Camera Calibration Data. | |
| - Extracts object annotations such as: | |
| - Category. | |
| - 2D bounding boxes (xmin, ymin, xmax, ymax) in image coordinates. | |
| - 3D size (width, height, length) in real-world units (e.g., meters). | |
| - 3D location (x, y, z) in real-world coordinates. | |
| - rotation_y and angle. | |
| - occlusion and truncation levels. | |
| - Typically saves this information in a structured format like JSON (e.g., `metadata.json`). | |
| ### Output Metadata Format | |
| The specific structure of the output metadata JSON files, based on the current implementation (e.g., `metadata.py`), is as follows: | |
| 1. **`metadata.json`:** | |
| A JSON file containing a dictionary where keys are scene IDs (e.g., "000000"). Each scene ID maps to a dictionary with the following structure: | |
| ```json | |
| { | |
| "scene_id": { | |
| "camera_intrinsics": [ // 3 x 4 matrix | |
| [fx, 0, cx, Tx], | |
| [0, fy, cy, Ty], | |
| [0, 0, 1, 0] | |
| ], | |
| "frames": [ | |
| { | |
| "frame_id": 0, // Integer frame index/number from sampled data | |
| "file_path_color": "images/000000.png", // Relative path to color image within processed dir | |
| "objects": [ | |
| { | |
| "instance_id": 0, // Unique instance ID for the object | |
| "category": "Car", // Object category | |
| "bbox_2d": [xmin, ymin, xmax, ymax], // 2D bounding box in image coordinates | |
| "size_3d": [height, width, length], // 3D size in meters | |
| "location_3d": [x, y, z], // 3D location of center of object's upper plane in meters | |
| "rotation_y": rotation_y, // Rotation around Y-axis in radians, face to camera is [0, pi], instead [0, -pi] | |
| "angle": angle, // Viewing angle in radians | |
| "occlusion": occlusion_level, // Occlusion level (0-3) | |
| "truncation": truncation_level, // Truncation level (0-1) | |
| "center_3d": [x_center, y_center, z_center], // 3D center coordinates in meters | |
| "center_3d_proj_2d": [x_center_2d, y_center_2d], // 2D projection of 3D center in image coordinates | |
| "depth": depth_value, // Object's depth from the camera in meters | |
| "corners_3d": [ // 8 corners of the 3D bounding box in meters | |
| [x1, y1, z1], | |
| [x2, y2, z2], | |
| ... | |
| [x8, y8, z8] | |
| ], | |
| "corners_3d_proj_2d": [ // 2D projections of the 8 corners in image coordinates | |
| [x1_2d, y1_2d], | |
| [x2_2d, y2_2d], | |
| ... | |
| [x8_2d, y8_2d] | |
| ], | |
| "descriptions": [ // Optional list of textual descriptions for the object | |
| "This vehicle is ...", | |
| "The vehicle ...", | |
| ] | |
| }, | |
| ... // other objects | |
| ], | |
| }, | |
| ... // other frames | |
| ], | |
| }, | |
| ... // other scenes | |
| } | |
| ``` | |
| ## 3. Downstream Task Generation (QA) | |
| This section details the Question-Answering (QA) tasks. Inspired by the VSI-Bench, a benchmark for visual spatial intelligence, from "Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces". We hope to involve this intelligence to more complicated scene, the monocular visual grounding. Without external sptatial knowledge, like cloud points or depth maps, we assume the advenced vision-language models, already understand the 2D spatial information, can implicitly cultivate the perception ablity of 3D spatia cues based on the monocular image and calibration data. | |
| ### VSI-Bench Task Details | |
| **Task Summary Table (VSI-Bench)** | |
| | Task Name | Task Category | Answer Type | | |
| | :------------------ | :---------------- | :-------------- | | |
| | Object Count | Fundamental | Multiple Choice | | |
| | Ind Object Size | Fundamental | Multiple Choice | | |
| | Ind Object Depth | Fundamental | Multiple Choice | | |
| | Ind Object Rotation | Fundamental | Multiple Choice | | |
| | Ind Object 3D BBox | Fundamental | JSON | | |
| | Object 3D BBox | Fundamental | JSON | | |
| | Ind Object Detect | Metric Estimation | JSON | | |
| | Object 3D Detect | Metric Estimation | JSON | | |
| | Object Center Dist | Measurement | Multiple Choice | | |
| | Object Min Dist | Measurement | Multiple Choice | | |
| #### 3D Fundamental Tasks (VSI-Bench) | |
| These tasks extend the advenced vision-language models' capabilities to understand basic 3D spatial properties of objects in a scene. | |
|  | |
| - **Indicted Object 3D Attributes:** Asks the basic 3D attributes of the indicated object by box range, point coord, or description indicator. | |
| - **QA Generation (`get_ind_obj_size_qa.py`, `...depth_qa.py`, `...ry_qa.py`, `...3dBbox_qa.py`):** This task generates multiple-choice questions asking about the 3D size, depth, rotation_y of an indicated object. And asking for the 3D bounding box coordinates of an indicated object in JSON format. | |
| - **Indicator Types:** The indicated object is specified using three types, including object's bounding box range, object's center point coordinate, or object's textual description. | |
| - **Answer Types:** The answers are provided in two formats: multiple-choice (for size, depth, rotation_y) and JSON (for 3D bounding box coordinates). | |
| - **Object Count:** Asks for the total number of instances of a specific object category (e.g., "How many cars are there?"). | |
| - **QA Generation (`get_obj_count_qa.py`):** This task generates multiple-choice questions based on `metadata.json`. It iterates through the `object_counts` for each object type in the scene. For categories with more than one instance, it formulates a question. The correct answer is the actual count from the metadata. The other three distractor options are generated by adding small, random offsets to the correct answer, creating a four-choice question. | |
| - **Object 3D Bbox:** Asks for the 3D coordinates of the eight corners of a specific category of objects, visualizing the ablity of 3D spatial understanding. | |
| - **QA Generation (`get_obj_3dBbox_qa.py`):** For all categories in the scene, this task generates random combinations of categories for each question. The answer is provided in JSON format, detailing the 3D coordinates of the eight corners of the bounding boxes in image coordinates. | |
| #### Metric Estimation Tasks (VSI-Bench) | |
| These tasks require estimating quantitative metrics based on existing 3D Object detection benchmarks. | |
| - **Indicted Object 3D Detection:** Asks the indicated object's 3D size and position to estimate the 3D grounding performance with 3D BBox IoU metric. | |
| - **QA Generation (`get_ind_obj_3dIou_qa.py`):** This task generates questions asking for the 3D size and position of an indicated object in JSON format. | |
| - **Indicator Types:** The indicated object is specified using by object's textual description. For each object, there are multiple descriptions available to choose from. We keep all generated QA pairs with different descriptions for the same object to enhance the diversity of the dataset. | |
| - **Answer Types:** The answers are provided in JSON format. | |
| - **Ambiguity Filtering:** To ensure clarity, the script excludes cases where the objects are inappropriately spaced (too close or too far) based on occlusion and truncation levels. | |
| - **Multiple Objects 3D Detection:** Asks for the all 3D attributes (category, angle, 2D bbox, 3D size, 3D location, rotation_y) of all objects in the scene to evaluate the 3D detection performance with KITTI 3D AP metric. | |
| - **QA Generation (`get_obj_3dDetect_qa.py`):** (Implementation in progress) | |
| #### Measurement Tasks (VSI-Bench) | |
| These tasks involve measuring spatial relationships between objects in the scene. | |
| 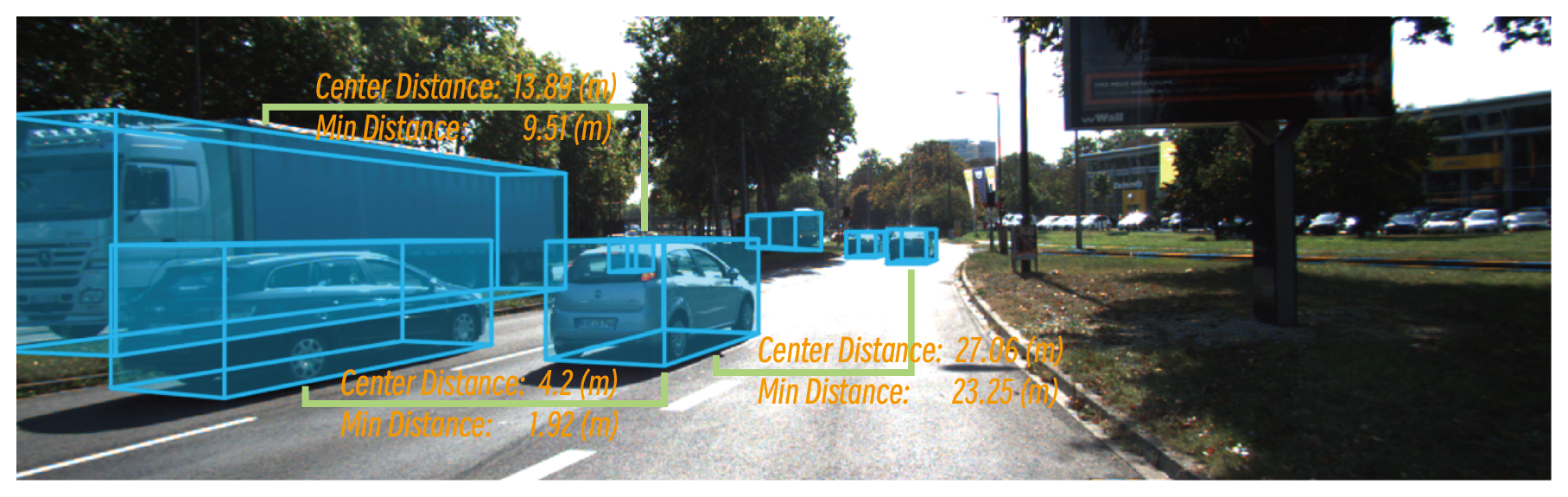 | |
| - **Object Center Distance:** Asks for the distance between the centers of two specified objects. | |
| - **QA Generation (`get_obj_center_distance_qa.py`):** This task generates multiple-choice questions asking for the distance between the centers of two specified objects. The correct answer is calculated using the Euclidean distance formula based on the 3D coordinates of the object centers. The other three distractor options are generated by adding small, random offsets to the correct answer, creating a four-choice question. | |
| - **Indicator Types:** The two objects are specified using their object's textual description. | |
| - **Answer Types:** The answers are provided in multiple-choice format. | |
| - **Object Minimum Distance:** Asks for the minimum distance between the bounding boxes of two specified objects. | |
| - **QA Generation (`get_obj_min_distance_qa.py`):** This task generates multiple-choice questions asking for the minimum distance between the bounding boxes of two specified objects. The correct answer is calculated using a specialized function that computes the minimum distance between two 3D bounding boxes, considering their dimensions and orientations. The other three distractor options are generated by adding small, random offsets to the correct answer, creating a four-choice question. | |
| - **Indicator Types:** The two objects are specified using their object's textual description. | |
| - **Answer Types:** The answers are provided in multiple-choice format. |