
CoQAR: Question Rewriting on CoQA
Paper • 2207.03240 • Published
The viewer is disabled because this dataset repo requires arbitrary Python code execution. Please consider
removing the loading script and relying on automated data support (you can use convert_to_parquet from the datasets library). If this is not possible, please open a discussion for direct help.
YAML Metadata Warning:empty or missing yaml metadata in repo card
Check out the documentation for more information.
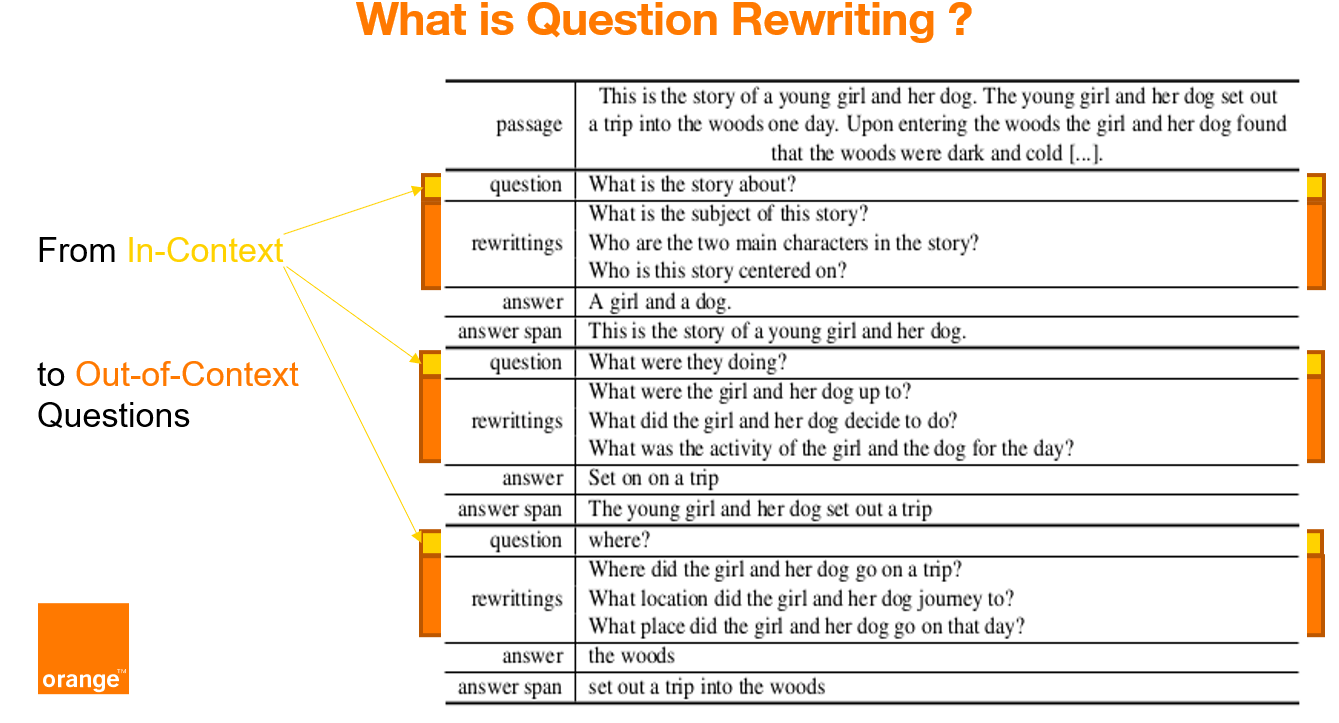
CoQAR is a corpus containing 4.5K conversations from the open-source dataset Conversational Question-Answering dataset CoQA, for a total of 53K follow-up question-answer pairs. In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.
English.
The dataset is composed of several conversations. Each row correspond to one question of one conversation. The fields are the following:
The annotations are published under the licence CC-BY-SA 4.0. The original content of the dataset CoQA is under the distinct licences described below.
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
@inproceedings{brabant-etal-2022-coqar,
title = "{C}o{QAR}: Question Rewriting on {C}o{QA}",
author = "Brabant, Quentin and
Lecorv{\'e}, Gw{\'e}nol{\'e} and
Rojas Barahona, Lina M.",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.13",
pages = "119--126"
}