
Search is not available for this dataset
modelId
stringlengths 5
137
| author
stringlengths 2
42
| last_modified
unknowndate 2020-02-15 11:33:14
2025-03-29 00:36:43
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 401
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
unknowndate 2022-03-02 23:29:04
2025-03-29 00:36:28
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
baxromovcomston/raft-001 | baxromovcomston | "2024-12-22T11:07:33Z" | 122 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:facebook/opt-350m",
"base_model:finetune:facebook/opt-350m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-12-22T11:06:42Z" | ---
base_model: facebook/opt-350m
library_name: transformers
model_name: raft-001
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for raft-001
This model is a fine-tuned version of [facebook/opt-350m](https://huggingface.co/facebook/opt-350m).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="baxromovcomston/raft-001", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.13.0
- Transformers: 4.47.1
- Pytorch: 2.5.1
- Datasets: 2.21.0
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
PrunaAI/vit_base_patch16_224.augreg_in21k_ft_in1k-turbo-tiny-green-smashed | PrunaAI | "2024-11-13T13:20:53Z" | 1 | 0 | pruna-engine | [
"pruna-engine",
"region:us"
] | null | "2024-03-14T10:58:44Z" | ---
library_name: pruna-engine
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://docs.pruna.ai/en/latest/setup/pip.html" target="_blank" rel="noopener noreferrer">
<img src="https://imgur.com/rVAgqMY.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
<div style="color: #9B1DBE; font-size: 2em; font-weight: bold;">
Deprecation Notice: This model is deprecated and will no longer receive updates.
</div>
<br><br>
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/rskEr4BZJx) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed by combining quantization, xformers, jit, cuda graphs, triton.
- ***How does the model quality change?*** The quality of the model output might slightly vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We used a custom Pruna model format based on pickle to make models compatible with the compression methods. We provide a tutorial to run models in dockers in the documentation [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/) if needed.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check that you have linux, python 3.10, and cuda 12.1.0 requirements installed. For cuda, check with `nvcc --version` and install with `conda install nvidia/label/cuda-12.1.0::cuda`.
1. Install the `pruna-engine` available [here](https://pypi.org/project/pruna-engine/) on Pypi. It might take up to 15 minutes to install.
```bash
pip install pruna-engine[gpu]==0.7.1 --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
```
2. Download the model files using one of these three options.
- Option 1 - Use command line interface (CLI):
```bash
mkdir vit_base_patch16_224.augreg_in21k_ft_in1k-turbo-tiny-green-smashed
huggingface-cli download PrunaAI/vit_base_patch16_224.augreg_in21k_ft_in1k-turbo-tiny-green-smashed --local-dir vit_base_patch16_224.augreg_in21k_ft_in1k-turbo-tiny-green-smashed --local-dir-use-symlinks False
```
- Option 2 - Use Python:
```python
import subprocess
repo_name = "vit_base_patch16_224.augreg_in21k_ft_in1k-turbo-tiny-green-smashed"
subprocess.run(["mkdir", repo_name])
subprocess.run(["huggingface-cli", "download", 'PrunaAI/'+ repo_name, "--local-dir", repo_name, "--local-dir-use-symlinks", "False"])
```
- Option 3 - Download them manually on the HuggingFace model page.
3. Load & run the model.
```python
from pruna_engine.PrunaModel import PrunaModel
model_path = "vit_base_patch16_224.augreg_in21k_ft_in1k-turbo-tiny-green-smashed/model" # Specify the downloaded model path.
smashed_model = PrunaModel.load_model(model_path) # Load the model.
import torch; image = torch.rand(1, 3, 224, 224).to('cuda')
smashed_model(image)
```
## Configurations
The configuration info are in `model/smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model vit_base_patch16_224.augreg_in21k_ft_in1k before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
bb1070/lirio_sets_hometown_white_bg_4e4_b4_2k | bb1070 | "2024-12-05T19:22:28Z" | 8 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2024-12-05T19:22:25Z" | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: UNST
---
# Lirio_Sets_Hometown_White_Bg_4E4_B4_2K
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `UNST` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('bb1070/lirio_sets_hometown_white_bg_4e4_b4_2k', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
bar41234/distilbert-base-uncased-finetuned-imdb | bar41234 | "2023-08-04T17:03:54Z" | 70 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2023-08-04T15:29:55Z" | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: bar41234/distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# bar41234/distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.7656
- Validation Loss: 2.1132
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'transformers.optimization_tf', 'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}, 'registered_name': 'WarmUp'}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.7656 | 2.1132 | 0 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.13.0
- Datasets 2.14.3
- Tokenizers 0.13.3
|
NikolayKozloff/reka-flash-3-Q3_K_M-GGUF | NikolayKozloff | "2025-03-14T16:51:05Z" | 0 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:RekaAI/reka-flash-3",
"base_model:quantized:RekaAI/reka-flash-3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-03-14T16:50:16Z" | ---
base_model: RekaAI/reka-flash-3
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# NikolayKozloff/reka-flash-3-Q3_K_M-GGUF
This model was converted to GGUF format from [`RekaAI/reka-flash-3`](https://huggingface.co/RekaAI/reka-flash-3) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/RekaAI/reka-flash-3) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo NikolayKozloff/reka-flash-3-Q3_K_M-GGUF --hf-file reka-flash-3-q3_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo NikolayKozloff/reka-flash-3-Q3_K_M-GGUF --hf-file reka-flash-3-q3_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo NikolayKozloff/reka-flash-3-Q3_K_M-GGUF --hf-file reka-flash-3-q3_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo NikolayKozloff/reka-flash-3-Q3_K_M-GGUF --hf-file reka-flash-3-q3_k_m.gguf -c 2048
```
|
kaneyxx/black_LUAD_3000_1e-4 | kaneyxx | "2023-05-29T10:44:15Z" | 1 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-2-1-base",
"base_model:adapter:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | "2023-05-29T10:26:38Z" |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - kaneyxx/black_LUAD_3000_1e-4
These are LoRA adaption weights for kaneyxx/black_LUAD_3000_1e-4. The weights were trained on BlackLUAD using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




|
chainup244/Qwen-Qwen1.5-1.8B-1717140299 | chainup244 | "2024-05-31T07:28:33Z" | 152 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-31T07:25:00Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
amiguel/classItem-FT-llama-3-1-8b-instruct | amiguel | "2024-09-08T12:47:25Z" | 119 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"base_model:quantized:unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | "2024-09-08T12:44:46Z" | ---
base_model: unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
---
# Uploaded model
- **Developed by:** amiguel
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Realgon/N_roberta_sst5_padding10model | Realgon | "2023-12-25T07:04:05Z" | 4 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-12-25T06:54:20Z" | ---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: N_roberta_sst5_padding10model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# N_roberta_sst5_padding10model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5812
- Accuracy: 0.2308
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.5764 | 1.0 | 534 | 1.5927 | 0.2308 |
| 1.5738 | 2.0 | 1068 | 1.5804 | 0.2308 |
| 1.5736 | 3.0 | 1602 | 1.5860 | 0.2308 |
| 1.569 | 4.0 | 2136 | 1.5789 | 0.2308 |
| 1.5736 | 5.0 | 2670 | 1.5774 | 0.2864 |
| 1.5737 | 6.0 | 3204 | 1.5839 | 0.2308 |
| 1.5726 | 7.0 | 3738 | 1.5786 | 0.2308 |
| 1.5707 | 8.0 | 4272 | 1.5790 | 0.2308 |
| 1.5699 | 9.0 | 4806 | 1.5811 | 0.2308 |
| 1.5687 | 10.0 | 5340 | 1.5829 | 0.2308 |
| 1.5725 | 11.0 | 5874 | 1.5800 | 0.2308 |
| 1.5713 | 12.0 | 6408 | 1.5815 | 0.2308 |
| 1.5684 | 13.0 | 6942 | 1.5822 | 0.2308 |
| 1.5716 | 14.0 | 7476 | 1.5816 | 0.2308 |
| 1.5696 | 15.0 | 8010 | 1.5827 | 0.2308 |
| 1.5684 | 16.0 | 8544 | 1.5818 | 0.2308 |
| 1.5687 | 17.0 | 9078 | 1.5812 | 0.2308 |
| 1.5706 | 18.0 | 9612 | 1.5813 | 0.2308 |
| 1.5698 | 19.0 | 10146 | 1.5816 | 0.2308 |
| 1.5693 | 20.0 | 10680 | 1.5812 | 0.2308 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
InsultedByMathematics/all-online-lr-5e-7-base-as-reference_555134_1738169111_update_401 | InsultedByMathematics | "2025-01-29T22:35:43Z" | 18 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-01-29T22:31:17Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
muhammadsaadgondal/mms-tts-urd-finetune-test | muhammadsaadgondal | "2024-08-13T11:26:07Z" | 5 | 0 | transformers | [
"transformers",
"safetensors",
"vits",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2024-08-13T11:22:25Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
cminja/llama-2-7b-guanaco-qlora-ds-sr | cminja | "2024-06-13T17:21:35Z" | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | "2024-06-13T17:19:44Z" | ---
license: apache-2.0
---
This is a Llama-2 version of Guanaco, finetuned from the base Llama-7b model using the official training scripts found in the QLoRA repository. To improve its functionality for the specific domain of cold calling, I have included datasets provided by Xgaming Org in the finetuning process.
Note: This repository contains the QLoRA adapter only. |
mradermacher/MonaCeption-7B-SLERP-GGUF | mradermacher | "2024-05-06T05:02:15Z" | 17 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:CultriX/MonaCeption-7B-SLERP",
"base_model:quantized:CultriX/MonaCeption-7B-SLERP",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2024-04-11T10:04:51Z" | ---
base_model: CultriX/MonaCeption-7B-SLERP
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/CultriX/MonaCeption-7B-SLERP
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MonaCeption-7B-SLERP-GGUF/resolve/main/MonaCeption-7B-SLERP.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
lmg-anon/vntl-7b-v0.3.1-gguf | lmg-anon | "2024-02-19T04:02:30Z" | 9 | 0 | null | [
"gguf",
"translation",
"ja",
"en",
"dataset:lmg-anon/VNTL-v2.5-1k",
"license:llama2",
"endpoints_compatible",
"region:us"
] | translation | "2024-02-18T21:01:28Z" | ---
license: llama2
datasets:
- lmg-anon/VNTL-v2.5-1k
language:
- ja
- en
pipeline_tag: translation
---
This repository contains some GGUF quantizations of the merge of the [experimental VNTL v0.3.1 lora](https://huggingface.co/lmg-anon/vntl-7b-v0.3.1-lora).
This is a prompt example:
```
<<START>>
Name: Uryuu Shingo (瓜生 新吾) | Gender: Male | Aliases: Onii-chan (お兄ちゃん)
Name: Uryuu Sakuno (瓜生 桜乃) | Gender: Female
<<JAPANESE>>
[桜乃]: 『……ごめん』
<<ENGLISH>> (fidelity = absolute)
[Sakuno]: 『... Sorry.』</s>
<<JAPANESE>>
[新吾]: 「ううん、こう言っちゃなんだけど、迷子でよかったよ。桜乃は可愛いから、いろいろ心配しちゃってたんだぞ俺」
<<ENGLISH>> (fidelity = high)
```
The generated translation for that prompt, with temperature 0, is:
```
[Shingo]: 「No, don't apologize. I'm just glad you're safe. You're so cute, Sakuno, I was worried sick.」
``` |
ShuaHousetable/condition-Kitchen | ShuaHousetable | "2023-03-03T14:10:26Z" | 146 | 0 | transformers | [
"transformers",
"pytorch",
"swinv2",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2023-03-01T07:49:17Z" | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: condition-Kitchen
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# condition-Kitchen
This model is a fine-tuned version of [microsoft/swinv2-tiny-patch4-window8-256](https://huggingface.co/microsoft/swinv2-tiny-patch4-window8-256) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1685
- Rmse: 1.0810
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 101 | 1.2101 | 1.1001 |
| No log | 2.0 | 202 | 0.7917 | 0.8898 |
| No log | 3.0 | 303 | 1.0430 | 1.0213 |
| No log | 4.0 | 404 | 0.9290 | 0.9639 |
| 2.8472 | 5.0 | 505 | 0.6923 | 0.8321 |
| 2.8472 | 6.0 | 606 | 0.8079 | 0.8989 |
| 2.8472 | 7.0 | 707 | 0.7159 | 0.8461 |
| 2.8472 | 8.0 | 808 | 0.6934 | 0.8327 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu117
- Datasets 2.10.0
- Tokenizers 0.13.0
|
alapin/ppo-LunarLander-v2 | alapin | "2023-06-04T21:58:45Z" | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | "2023-06-04T21:58:21Z" | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.90 +/- 21.71
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ITESM/sentece-embeddings-BETO | ITESM | "2022-06-05T05:05:05Z" | 19 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"dataset:stackexchange_xml",
"dataset:code_search_net",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-06-05T05:04:52Z" | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- stackexchange_xml
- code_search_net
---
# ITESM/sentece-embeddings-BETO
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('ITESM/sentece-embeddings-BETO')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('ITESM/sentece-embeddings-BETO')
model = AutoModel.from_pretrained('ITESM/sentece-embeddings-BETO')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=ITESM/sentece-embeddings-BETO)
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 16 with parameters:
```
{'batch_size': 100}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 1,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 2,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
lesso01/dc36d136-6b69-4076-b012-14535ab4a0b1 | lesso01 | "2025-01-23T08:33:05Z" | 8 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:oopsung/llama2-7b-koNqa-test-v1",
"base_model:adapter:oopsung/llama2-7b-koNqa-test-v1",
"8-bit",
"bitsandbytes",
"region:us"
] | null | "2025-01-23T07:19:19Z" | ---
library_name: peft
base_model: oopsung/llama2-7b-koNqa-test-v1
tags:
- axolotl
- generated_from_trainer
model-index:
- name: dc36d136-6b69-4076-b012-14535ab4a0b1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: oopsung/llama2-7b-koNqa-test-v1
bf16: true
chat_template: llama3
datasets:
- data_files:
- 0470cc49f434ca45_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/0470cc49f434ca45_train_data.json
type:
field_input: ''
field_instruction: prompt
field_output: responseA
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: 2
eval_max_new_tokens: 128
eval_steps: 5
eval_table_size: null
flash_attention: false
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: lesso01/dc36d136-6b69-4076-b012-14535ab4a0b1
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 25
micro_batch_size: 2
mlflow_experiment_name: /tmp/0470cc49f434ca45_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 10
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: db1a33bc-9f36-4a09-a66d-2395320ddb3b
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: db1a33bc-9f36-4a09-a66d-2395320ddb3b
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# dc36d136-6b69-4076-b012-14535ab4a0b1
This model is a fine-tuned version of [oopsung/llama2-7b-koNqa-test-v1](https://huggingface.co/oopsung/llama2-7b-koNqa-test-v1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0 | 0.0000 | 1 | nan |
| 0.0 | 0.0002 | 5 | nan |
| 0.0 | 0.0005 | 10 | nan |
| 0.0 | 0.0007 | 15 | nan |
| 0.0 | 0.0009 | 20 | nan |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
Shakhovak/flan-t5-base-absa-joint | Shakhovak | "2024-03-19T18:45:54Z" | 6 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2024-03-12T14:20:23Z" | ---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: flan-t5-base-absa-joint
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-absa-joint
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2287
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8317 | 0.47 | 200 | 0.3644 |
| 0.4202 | 0.95 | 400 | 0.2779 |
| 0.3202 | 1.42 | 600 | 0.2573 |
| 0.3065 | 1.9 | 800 | 0.2419 |
| 0.2454 | 2.37 | 1000 | 0.2372 |
| 0.25 | 2.84 | 1200 | 0.2266 |
| 0.2105 | 3.32 | 1400 | 0.2366 |
| 0.2109 | 3.79 | 1600 | 0.2287 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
facebook/sam2.1-hiera-tiny | facebook | "2024-09-24T01:51:41Z" | 6,310 | 9 | sam2 | [
"sam2",
"mask-generation",
"arxiv:2408.00714",
"license:apache-2.0",
"region:us"
] | mask-generation | "2024-09-24T01:52:21Z" | ---
license: apache-2.0
pipeline_tag: mask-generation
library_name: sam2
---
Repository for SAM 2: Segment Anything in Images and Videos, a foundation model towards solving promptable visual segmentation in images and videos from FAIR. See the [SAM 2 paper](https://arxiv.org/abs/2408.00714) for more information.
The official code is publicly release in this [repo](https://github.com/facebookresearch/segment-anything-2/).
## Usage
For image prediction:
```python
import torch
from sam2.sam2_image_predictor import SAM2ImagePredictor
predictor = SAM2ImagePredictor.from_pretrained("facebook/sam2-hiera-tiny")
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
```
For video prediction:
```python
import torch
from sam2.sam2_video_predictor import SAM2VideoPredictor
predictor = SAM2VideoPredictor.from_pretrained("facebook/sam2-hiera-tiny")
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and instantly get the output on the same frame
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
# propagate the prompts to get masklets throughout the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...
```
Refer to the [demo notebooks](https://github.com/facebookresearch/segment-anything-2/tree/main/notebooks) for details.
### Citation
To cite the paper, model, or software, please use the below:
```
@article{ravi2024sam2,
title={SAM 2: Segment Anything in Images and Videos},
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph},
journal={arXiv preprint arXiv:2408.00714},
url={https://arxiv.org/abs/2408.00714},
year={2024}
}
``` |
mlx-community/BB-L-01-7B-mlx-4bit | mlx-community | "2024-01-06T14:58:37Z" | 2 | 0 | mlx | [
"mlx",
"mistral",
"alignment-handbook",
"generated_from_trainer",
"hi",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:rohansolo/BB_HindiHinglish",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:cc-by-nc-4.0",
"region:us"
] | null | "2024-01-06T14:48:26Z" | ---
language:
- hi
license: cc-by-nc-4.0
tags:
- alignment-handbook
- generated_from_trainer
- mlx
datasets:
- HuggingFaceH4/ultrachat_200k
- rohansolo/BB_HindiHinglish
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: BB-L-01-7B
results: []
---
# BB-L-01-7B-mlx-4bit
This model was converted to MLX format from [`rohansolo/BB-L-01-7B`]().
Refer to the [original model card](https://huggingface.co/rohansolo/BB-L-01-7B) for more details on the model.
## Use with mlx
```bash
pip install mlx
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/llms/hf_llm
python generate.py --model rohansolo/BB-L-01-7B-mlx-4bit --prompt "<|system|>
You are a helpful AI assistant</s>
<|user|>
एक पाइथन स्क्रिप्ट लिखो बबल सॉर्ट के लिए</s>"
```
|
mrhunghd/d6044016-3042-4834-bb19-c7c67c029487 | mrhunghd | "2025-01-14T05:43:46Z" | 11 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/tinyllama-chat",
"base_model:adapter:unsloth/tinyllama-chat",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
] | null | "2025-01-14T05:21:10Z" | ---
library_name: peft
license: apache-2.0
base_model: unsloth/tinyllama-chat
tags:
- axolotl
- generated_from_trainer
model-index:
- name: d6044016-3042-4834-bb19-c7c67c029487
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/tinyllama-chat
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 13b81573f695fc61_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/13b81573f695fc61_train_data.json
type:
field_instruction: premise
field_output: hypothesis
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: mrhunghd/d6044016-3042-4834-bb19-c7c67c029487
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-05
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 2
mlflow_experiment_name: /tmp/13b81573f695fc61_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 401a2ebc-a1b3-4cbf-a863-00f98fd628f9
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 401a2ebc-a1b3-4cbf-a863-00f98fd628f9
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# d6044016-3042-4834-bb19-c7c67c029487
This model is a fine-tuned version of [unsloth/tinyllama-chat](https://huggingface.co/unsloth/tinyllama-chat) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9931
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.8926 | 0.0100 | 200 | 0.9931 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
ferrazzipietro/LS_Llama-2-7b-hf_adapters_en.layer1_NoQuant_32_64_0.01_2_0.0002 | ferrazzipietro | "2024-05-10T18:30:19Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2024-05-03T21:17:11Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
automerger/Yamshadowexperiment28T3q-7B | automerger | "2024-04-29T16:10:51Z" | 0 | 0 | null | [
"merge",
"mergekit",
"lazymergekit",
"automerger",
"license:apache-2.0",
"region:us"
] | null | "2024-04-29T16:10:51Z" | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
---
# Yamshadowexperiment28T3q-7B
Yamshadowexperiment28T3q-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
- model: automerger/YamshadowExperiment28-7B
- model: chihoonlee10/T3Q-Mistral-Orca-Math-DPO
merge_method: model_stock
base_model: mistralai/Mistral-7B-v0.1
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/Yamshadowexperiment28T3q-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
beast33/4f5835be-efd5-4493-b3ba-32c9e15b5318 | beast33 | "2025-01-31T20:17:59Z" | 8 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:codellama/CodeLlama-7b-Instruct-hf",
"base_model:adapter:codellama/CodeLlama-7b-Instruct-hf",
"license:llama2",
"8-bit",
"bitsandbytes",
"region:us"
] | null | "2025-01-31T19:30:39Z" | ---
library_name: peft
license: llama2
base_model: codellama/CodeLlama-7b-Instruct-hf
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 4f5835be-efd5-4493-b3ba-32c9e15b5318
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: codellama/CodeLlama-7b-Instruct-hf
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- aaa3841fd2b63be1_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/aaa3841fd2b63be1_train_data.json
type:
field_instruction: Article
field_output: Headline
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
device_map: auto
do_eval: true
early_stopping_patience: null
eval_batch_size: 4
eval_max_new_tokens: 128
eval_steps: null
eval_table_size: null
evals_per_epoch: null
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
group_by_length: true
hub_model_id: beast33/4f5835be-efd5-4493-b3ba-32c9e15b5318
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 0.0001
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_grad_norm: 1.0
max_memory:
0: 75GB
max_steps: 200
micro_batch_size: 4
mlflow_experiment_name: /tmp/aaa3841fd2b63be1_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: null
saves_per_epoch: null
sequence_len: 1024
special_tokens:
pad_token: </s>
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 034b5af9-11fe-4bd5-b50c-4e81be01a019
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 034b5af9-11fe-4bd5-b50c-4e81be01a019
warmup_steps: 5
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 4f5835be-efd5-4493-b3ba-32c9e15b5318
This model is a fine-tuned version of [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2149
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.4408 | 0.0281 | 200 | 1.2149 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
yjkim104906/Meta-Llama-3-8B-ft-Instruct | yjkim104906 | "2024-06-07T07:14:46Z" | 19 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-05T04:45:13Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MayBashendy/ArabicNewSplits_FineTuningAraBERT_AugV5_k4_task5_organization_fold1 | MayBashendy | "2024-11-27T10:41:24Z" | 164 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:aubmindlab/bert-base-arabertv02",
"base_model:finetune:aubmindlab/bert-base-arabertv02",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2024-11-27T10:39:15Z" | ---
library_name: transformers
base_model: aubmindlab/bert-base-arabertv02
tags:
- generated_from_trainer
model-index:
- name: ArabicNewSplits_FineTuningAraBERT_AugV5_k4_task5_organization_fold1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ArabicNewSplits_FineTuningAraBERT_AugV5_k4_task5_organization_fold1
This model is a fine-tuned version of [aubmindlab/bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8211
- Qwk: 0.3216
- Mse: 1.8211
- Rmse: 1.3495
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:------:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 0.1818 | 2 | 2.5300 | 0.1733 | 2.5300 | 1.5906 |
| No log | 0.3636 | 4 | 1.7812 | 0.0836 | 1.7812 | 1.3346 |
| No log | 0.5455 | 6 | 1.5012 | 0.0165 | 1.5012 | 1.2252 |
| No log | 0.7273 | 8 | 1.3442 | 0.1305 | 1.3442 | 1.1594 |
| No log | 0.9091 | 10 | 1.3540 | 0.1729 | 1.3540 | 1.1636 |
| No log | 1.0909 | 12 | 1.3156 | 0.1418 | 1.3156 | 1.1470 |
| No log | 1.2727 | 14 | 1.2819 | 0.1418 | 1.2819 | 1.1322 |
| No log | 1.4545 | 16 | 1.2649 | 0.1766 | 1.2649 | 1.1247 |
| No log | 1.6364 | 18 | 1.2432 | 0.1418 | 1.2432 | 1.1150 |
| No log | 1.8182 | 20 | 1.2627 | 0.1418 | 1.2627 | 1.1237 |
| No log | 2.0 | 22 | 1.3403 | 0.1326 | 1.3403 | 1.1577 |
| No log | 2.1818 | 24 | 1.4135 | 0.1212 | 1.4135 | 1.1889 |
| No log | 2.3636 | 26 | 1.4925 | 0.3378 | 1.4925 | 1.2217 |
| No log | 2.5455 | 28 | 1.5658 | 0.3296 | 1.5658 | 1.2513 |
| No log | 2.7273 | 30 | 1.5778 | 0.3580 | 1.5778 | 1.2561 |
| No log | 2.9091 | 32 | 1.5097 | 0.2498 | 1.5097 | 1.2287 |
| No log | 3.0909 | 34 | 1.4836 | 0.2083 | 1.4836 | 1.2180 |
| No log | 3.2727 | 36 | 1.5224 | 0.3697 | 1.5224 | 1.2338 |
| No log | 3.4545 | 38 | 1.5347 | 0.3407 | 1.5347 | 1.2388 |
| No log | 3.6364 | 40 | 1.4941 | 0.2605 | 1.4941 | 1.2223 |
| No log | 3.8182 | 42 | 1.4730 | 0.2083 | 1.4730 | 1.2137 |
| No log | 4.0 | 44 | 1.4518 | 0.1616 | 1.4518 | 1.2049 |
| No log | 4.1818 | 46 | 1.4177 | 0.2020 | 1.4177 | 1.1907 |
| No log | 4.3636 | 48 | 1.3923 | 0.1782 | 1.3923 | 1.1800 |
| No log | 4.5455 | 50 | 1.3945 | 0.2222 | 1.3945 | 1.1809 |
| No log | 4.7273 | 52 | 1.4037 | 0.2449 | 1.4037 | 1.1848 |
| No log | 4.9091 | 54 | 1.4231 | 0.3489 | 1.4231 | 1.1929 |
| No log | 5.0909 | 56 | 1.4893 | 0.3386 | 1.4893 | 1.2204 |
| No log | 5.2727 | 58 | 1.5326 | 0.3428 | 1.5326 | 1.2380 |
| No log | 5.4545 | 60 | 1.5264 | 0.4169 | 1.5264 | 1.2355 |
| No log | 5.6364 | 62 | 1.5175 | 0.4228 | 1.5175 | 1.2319 |
| No log | 5.8182 | 64 | 1.5574 | 0.3931 | 1.5574 | 1.2480 |
| No log | 6.0 | 66 | 1.6494 | 0.3411 | 1.6494 | 1.2843 |
| No log | 6.1818 | 68 | 1.7818 | 0.3301 | 1.7818 | 1.3348 |
| No log | 6.3636 | 70 | 1.8253 | 0.3058 | 1.8253 | 1.3510 |
| No log | 6.5455 | 72 | 1.7581 | 0.3294 | 1.7581 | 1.3259 |
| No log | 6.7273 | 74 | 1.7033 | 0.3208 | 1.7033 | 1.3051 |
| No log | 6.9091 | 76 | 1.6849 | 0.3330 | 1.6849 | 1.2981 |
| No log | 7.0909 | 78 | 1.6153 | 0.3444 | 1.6153 | 1.2709 |
| No log | 7.2727 | 80 | 1.6617 | 0.3456 | 1.6617 | 1.2891 |
| No log | 7.4545 | 82 | 1.8027 | 0.3097 | 1.8027 | 1.3427 |
| No log | 7.6364 | 84 | 1.9454 | 0.2524 | 1.9454 | 1.3948 |
| No log | 7.8182 | 86 | 2.0545 | 0.2280 | 2.0545 | 1.4334 |
| No log | 8.0 | 88 | 2.0672 | 0.2418 | 2.0672 | 1.4378 |
| No log | 8.1818 | 90 | 2.0462 | 0.2418 | 2.0462 | 1.4305 |
| No log | 8.3636 | 92 | 1.9775 | 0.2632 | 1.9775 | 1.4062 |
| No log | 8.5455 | 94 | 1.8833 | 0.2980 | 1.8833 | 1.3723 |
| No log | 8.7273 | 96 | 1.7957 | 0.3216 | 1.7957 | 1.3400 |
| No log | 8.9091 | 98 | 1.7590 | 0.3208 | 1.7590 | 1.3263 |
| No log | 9.0909 | 100 | 1.7751 | 0.3216 | 1.7751 | 1.3323 |
| No log | 9.2727 | 102 | 1.7767 | 0.3216 | 1.7767 | 1.3329 |
| No log | 9.4545 | 104 | 1.7922 | 0.3216 | 1.7922 | 1.3387 |
| No log | 9.6364 | 106 | 1.8047 | 0.3216 | 1.8047 | 1.3434 |
| No log | 9.8182 | 108 | 1.8160 | 0.3216 | 1.8160 | 1.3476 |
| No log | 10.0 | 110 | 1.8211 | 0.3216 | 1.8211 | 1.3495 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.0+cu118
- Datasets 2.21.0
- Tokenizers 0.19.1
|
LarryAIDraw/selenaPGRbyscarxzyss | LarryAIDraw | "2023-12-16T15:44:42Z" | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | "2023-12-16T15:33:44Z" | ---
license: creativeml-openrail-m
---
https://civitai.com/models/231849/selena-or-punishing-gray-raven |
CocoRoF/KMB_SimCSE_test | CocoRoF | "2025-01-31T02:04:41Z" | 23 | 0 | transformers | [
"transformers",
"safetensors",
"modernbert",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2025-01-16T07:01:34Z" | ---
library_name: transformers
license: apache-2.0
base_model: CocoRoF/KoModernBERT-chp-11
tags:
- generated_from_trainer
model-index:
- name: KMB_SimCSE_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# KMB_SimCSE_test
This model is a fine-tuned version of [CocoRoF/KoModernBERT-chp-11](https://huggingface.co/CocoRoF/KoModernBERT-chp-11) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0438
- Pearson Cosine: 0.7947
- Spearman Cosine: 0.7992
- Pearson Manhattan: 0.7493
- Spearman Manhattan: 0.7655
- Pearson Euclidean: 0.7507
- Spearman Euclidean: 0.7666
- Pearson Dot: 0.6408
- Spearman Dot: 0.6472
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson Cosine | Spearman Cosine | Pearson Manhattan | Spearman Manhattan | Pearson Euclidean | Spearman Euclidean | Pearson Dot | Spearman Dot |
|:-------------:|:------:|:----:|:---------------:|:--------------:|:---------------:|:-----------------:|:------------------:|:-----------------:|:------------------:|:-----------:|:------------:|
| 0.761 | 0.1172 | 250 | 0.1397 | 0.7191 | 0.7366 | 0.7129 | 0.7205 | 0.7135 | 0.7210 | 0.4342 | 0.4302 |
| 0.6275 | 0.2343 | 500 | 0.1240 | 0.7535 | 0.7638 | 0.7442 | 0.7505 | 0.7442 | 0.7506 | 0.4527 | 0.4533 |
| 0.5326 | 0.3515 | 750 | 0.1149 | 0.7540 | 0.7698 | 0.7320 | 0.7461 | 0.7327 | 0.7466 | 0.4786 | 0.4737 |
| 0.4917 | 0.4686 | 1000 | 0.1028 | 0.7630 | 0.7778 | 0.7395 | 0.7532 | 0.7395 | 0.7531 | 0.5428 | 0.5404 |
| 0.4451 | 0.5858 | 1250 | 0.0959 | 0.7634 | 0.7803 | 0.7505 | 0.7649 | 0.7508 | 0.7652 | 0.5909 | 0.5929 |
| 0.4682 | 0.7029 | 1500 | 0.1057 | 0.7687 | 0.7855 | 0.7541 | 0.7681 | 0.7545 | 0.7685 | 0.5271 | 0.5190 |
| 0.4489 | 0.8201 | 1750 | 0.0994 | 0.7658 | 0.7800 | 0.7505 | 0.7624 | 0.7514 | 0.7627 | 0.5765 | 0.5760 |
| 0.4696 | 0.9372 | 2000 | 0.1055 | 0.7618 | 0.7835 | 0.7514 | 0.7669 | 0.7526 | 0.7675 | 0.5910 | 0.5835 |
| 0.3474 | 1.0544 | 2250 | 0.0818 | 0.7663 | 0.7777 | 0.7527 | 0.7636 | 0.7536 | 0.7642 | 0.5774 | 0.5748 |
| 0.319 | 1.1715 | 2500 | 0.0752 | 0.7753 | 0.7858 | 0.7589 | 0.7692 | 0.7592 | 0.7692 | 0.5929 | 0.5919 |
| 0.3682 | 1.2887 | 2750 | 0.0767 | 0.7736 | 0.7851 | 0.7556 | 0.7667 | 0.7564 | 0.7671 | 0.5784 | 0.5785 |
| 0.3033 | 1.4058 | 3000 | 0.0716 | 0.7836 | 0.7962 | 0.7590 | 0.7723 | 0.7600 | 0.7727 | 0.5987 | 0.5976 |
| 0.3247 | 1.5230 | 3250 | 0.0768 | 0.7779 | 0.7911 | 0.7613 | 0.7731 | 0.7621 | 0.7735 | 0.5638 | 0.5623 |
| 0.26 | 1.6401 | 3500 | 0.0686 | 0.7792 | 0.7902 | 0.7615 | 0.7733 | 0.7623 | 0.7734 | 0.6004 | 0.5998 |
| 0.3216 | 1.7573 | 3750 | 0.0707 | 0.7851 | 0.7950 | 0.7668 | 0.7787 | 0.7677 | 0.7791 | 0.6098 | 0.6136 |
| 0.3166 | 1.8744 | 4000 | 0.0719 | 0.7799 | 0.7911 | 0.7550 | 0.7693 | 0.7563 | 0.7701 | 0.5737 | 0.5754 |
| 0.315 | 1.9916 | 4250 | 0.0710 | 0.7818 | 0.7925 | 0.7657 | 0.7780 | 0.7672 | 0.7790 | 0.5918 | 0.5930 |
| 0.2117 | 2.1087 | 4500 | 0.0545 | 0.7772 | 0.7890 | 0.7551 | 0.7702 | 0.7567 | 0.7712 | 0.6059 | 0.6096 |
| 0.1725 | 2.2259 | 4750 | 0.0544 | 0.7780 | 0.7868 | 0.7593 | 0.7714 | 0.7605 | 0.7721 | 0.6065 | 0.6128 |
| 0.1985 | 2.3430 | 5000 | 0.0540 | 0.7818 | 0.7916 | 0.7621 | 0.7733 | 0.7626 | 0.7734 | 0.6017 | 0.6078 |
| 0.1871 | 2.4602 | 5250 | 0.0527 | 0.7830 | 0.7898 | 0.7576 | 0.7718 | 0.7587 | 0.7724 | 0.5843 | 0.5894 |
| 0.17 | 2.5773 | 5500 | 0.0521 | 0.7877 | 0.7959 | 0.7621 | 0.7746 | 0.7633 | 0.7753 | 0.6240 | 0.6246 |
| 0.174 | 2.6945 | 5750 | 0.0528 | 0.7876 | 0.7949 | 0.7594 | 0.7713 | 0.7603 | 0.7716 | 0.6196 | 0.6234 |
| 0.1896 | 2.8116 | 6000 | 0.0506 | 0.7848 | 0.7891 | 0.7595 | 0.7712 | 0.7606 | 0.7718 | 0.6052 | 0.6083 |
| 0.1897 | 2.9288 | 6250 | 0.0549 | 0.7819 | 0.7902 | 0.7521 | 0.7664 | 0.7533 | 0.7667 | 0.5957 | 0.5981 |
| 0.105 | 3.0459 | 6500 | 0.0450 | 0.7887 | 0.7931 | 0.7516 | 0.7669 | 0.7527 | 0.7675 | 0.6385 | 0.6450 |
| 0.1055 | 3.1631 | 6750 | 0.0460 | 0.7875 | 0.7927 | 0.7515 | 0.7652 | 0.7525 | 0.7657 | 0.6256 | 0.6332 |
| 0.1145 | 3.2802 | 7000 | 0.0453 | 0.7925 | 0.7977 | 0.7548 | 0.7671 | 0.7559 | 0.7678 | 0.6316 | 0.6408 |
| 0.1252 | 3.3974 | 7250 | 0.0470 | 0.7889 | 0.7947 | 0.7561 | 0.7683 | 0.7571 | 0.7693 | 0.6257 | 0.6283 |
| 0.1058 | 3.5145 | 7500 | 0.0446 | 0.7913 | 0.7958 | 0.7572 | 0.7714 | 0.7578 | 0.7715 | 0.6221 | 0.6338 |
| 0.1144 | 3.6317 | 7750 | 0.0433 | 0.7939 | 0.7989 | 0.7534 | 0.7673 | 0.7542 | 0.7677 | 0.6519 | 0.6583 |
| 0.0971 | 3.7488 | 8000 | 0.0438 | 0.7952 | 0.7993 | 0.7537 | 0.7675 | 0.7547 | 0.7679 | 0.6345 | 0.6383 |
| 0.1107 | 3.8660 | 8250 | 0.0432 | 0.7953 | 0.7992 | 0.7507 | 0.7673 | 0.7518 | 0.7675 | 0.6355 | 0.6411 |
| 0.1232 | 3.9831 | 8500 | 0.0438 | 0.7947 | 0.7992 | 0.7493 | 0.7655 | 0.7507 | 0.7666 | 0.6408 | 0.6472 |
### Framework versions
- Transformers 4.48.0.dev0
- Pytorch 2.5.1+cu121
- Datasets 3.1.0
- Tokenizers 0.21.0
|
daniel40/efb80f7c-5c85-40f6-b4d8-e505ee172b96 | daniel40 | "2025-01-24T23:28:36Z" | 9 | 0 | peft | [
"peft",
"safetensors",
"opt",
"axolotl",
"generated_from_trainer",
"base_model:facebook/opt-125m",
"base_model:adapter:facebook/opt-125m",
"license:other",
"region:us"
] | null | "2025-01-24T23:27:48Z" | ---
library_name: peft
license: other
base_model: facebook/opt-125m
tags:
- axolotl
- generated_from_trainer
model-index:
- name: efb80f7c-5c85-40f6-b4d8-e505ee172b96
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: facebook/opt-125m
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 9a31c4e8d7bc32cb_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9a31c4e8d7bc32cb_train_data.json
type:
field_input: context
field_instruction: title
field_output: question
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: daniel40/efb80f7c-5c85-40f6-b4d8-e505ee172b96
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 10
micro_batch_size: 2
mlflow_experiment_name: /tmp/9a31c4e8d7bc32cb_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 02097914-0e30-48b1-b4f2-de4d7ed7768b
wandb_project: Birthday-SN56-28-Gradients-On-Demand
wandb_run: your_name
wandb_runid: 02097914-0e30-48b1-b4f2-de4d7ed7768b
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# efb80f7c-5c85-40f6-b4d8-e505ee172b96
This model is a fine-tuned version of [facebook/opt-125m](https://huggingface.co/facebook/opt-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0325
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 16.5819 | 0.0004 | 1 | 3.4605 |
| 14.998 | 0.0012 | 3 | 3.4390 |
| 13.8681 | 0.0024 | 6 | 3.2987 |
| 12.2096 | 0.0036 | 9 | 3.0325 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
Kryptone/GPTSVC | Kryptone | "2024-03-19T22:48:09Z" | 0 | 0 | null | [
"license:openrail++",
"region:us"
] | null | "2024-03-19T22:35:23Z" | ---
license: openrail++
---
# GPTSVC (GPT So-Vits Collection)
<!-- Provide a quick summary of what the model is/does. -->
This is a collection of all my models trained using GPT So-Vits. All models in here will mostly be Japanese unless otherwise noted.
## No models in here will work with w-okada, an official one is in development by RVC-Boss (maybe), so when/if it does come out, this description will be updated. |
mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF | mradermacher | "2024-12-28T03:09:45Z" | 36 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:reasonwang/ToolGen-WoSystem-Llama-3-8B-Instruct",
"base_model:quantized:reasonwang/ToolGen-WoSystem-Llama-3-8B-Instruct",
"endpoints_compatible",
"region:us"
] | null | "2024-12-28T02:48:17Z" | ---
base_model: reasonwang/ToolGen-WoSystem-Llama-3-8B-Instruct
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/reasonwang/ToolGen-WoSystem-Llama-3-8B-Instruct
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q2_K.gguf) | Q2_K | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q3_K_S.gguf) | Q3_K_S | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q3_K_M.gguf) | Q3_K_M | 4.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q3_K_L.gguf) | Q3_K_L | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.IQ4_XS.gguf) | IQ4_XS | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q4_K_S.gguf) | Q4_K_S | 5.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q4_K_M.gguf) | Q4_K_M | 5.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q5_K_S.gguf) | Q5_K_S | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q5_K_M.gguf) | Q5_K_M | 6.1 | |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q6_K.gguf) | Q6_K | 7.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.Q8_0.gguf) | Q8_0 | 9.1 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/ToolGen-WoSystem-Llama-3-8B-Instruct-GGUF/resolve/main/ToolGen-WoSystem-Llama-3-8B-Instruct.f16.gguf) | f16 | 16.9 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
fenar/secops | fenar | "2024-06-20T00:01:30Z" | 0 | 3 | null | [
"onnx",
"license:apache-2.0",
"region:us"
] | null | "2024-06-20T00:00:00Z" | ---
license: apache-2.0
---
# Network Security Analysis with AI
## Project Overview
Here we are leveraging AI to assist us for better network security operations.
## Data
Data-Set: https://huggingface.co/datasets/fenar/sec_ops <br>
GitHub: https://github.com/fenar/TME-AIX/tree/main/secops
## Model: XGBRegressor
## Results
The model predictions are compared against actual values for key metrics like latency. The MAPE value is calculated and printed, providing a quantitative measure of the model's performance.
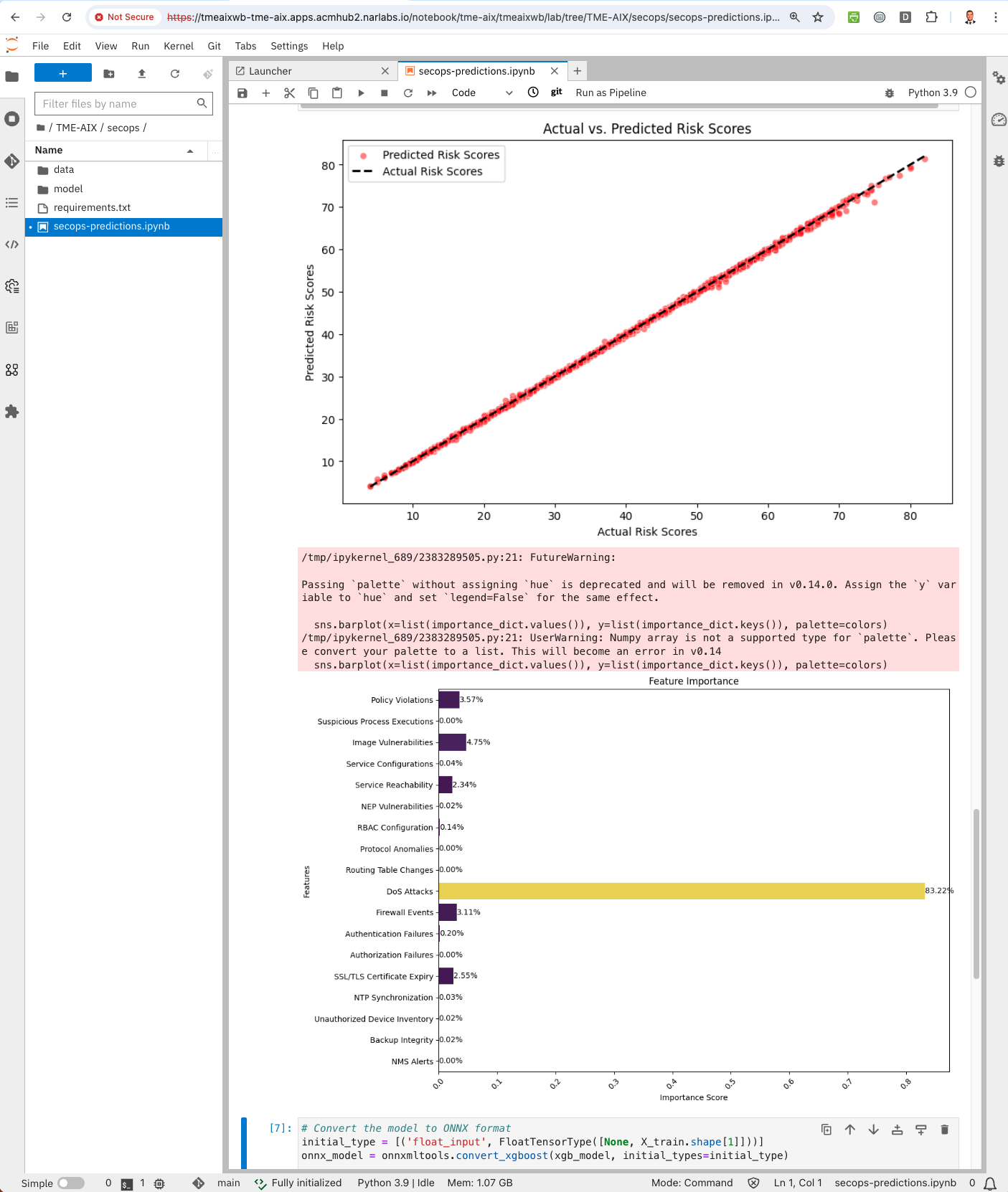<br>
|
Aashraf995/Creative-7B-nerd | Aashraf995 | "2024-12-13T09:40:45Z" | 10 | 2 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:jeffmeloy/Qwen2.5-7B-nerd-uncensored-v1.5",
"base_model:merge:jeffmeloy/Qwen2.5-7B-nerd-uncensored-v1.5",
"base_model:suayptalha/HomerCreativeAnvita-Mix-Qw7B",
"base_model:merge:suayptalha/HomerCreativeAnvita-Mix-Qw7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-12-13T09:26:05Z" | ---
base_model:
- suayptalha/HomerCreativeAnvita-Mix-Qw7B
- jeffmeloy/Qwen2.5-7B-nerd-uncensored-v1.5
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [suayptalha/HomerCreativeAnvita-Mix-Qw7B](https://huggingface.co/suayptalha/HomerCreativeAnvita-Mix-Qw7B)
* [jeffmeloy/Qwen2.5-7B-nerd-uncensored-v1.5](https://huggingface.co/jeffmeloy/Qwen2.5-7B-nerd-uncensored-v1.5)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: suayptalha/HomerCreativeAnvita-Mix-Qw7B
layer_range:
- 0
- 28
- model: jeffmeloy/Qwen2.5-7B-nerd-uncensored-v1.5
layer_range:
- 0
- 28
merge_method: slerp
base_model: suayptalha/HomerCreativeAnvita-Mix-Qw7B
parameters:
t:
- filter: self_attn
value:
- 0
- 0.5
- 0.3
- 0.7
- 1
- filter: mlp
value:
- 1
- 0.5
- 0.7
- 0.3
- 0
- value: 0.5
dtype: bfloat16
|
tomaszki/mistral-19 | tomaszki | "2024-03-29T23:11:38Z" | 3 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-03-29T23:09:30Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MrRobotoAI/149 | MrRobotoAI | "2025-03-23T15:40:37Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2203.05482",
"base_model:MrRobotoAI/129",
"base_model:merge:MrRobotoAI/129",
"base_model:MrRobotoAI/A10",
"base_model:merge:MrRobotoAI/A10",
"base_model:MrRobotoAI/A2",
"base_model:merge:MrRobotoAI/A2",
"base_model:MrRobotoAI/A4",
"base_model:merge:MrRobotoAI/A4",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-03-23T15:36:48Z" | ---
base_model:
- MrRobotoAI/A10
- MrRobotoAI/A4
- MrRobotoAI/129
- MrRobotoAI/A2
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Linear](https://arxiv.org/abs/2203.05482) merge method.
### Models Merged
The following models were included in the merge:
* [MrRobotoAI/A10](https://huggingface.co/MrRobotoAI/A10)
* [MrRobotoAI/A4](https://huggingface.co/MrRobotoAI/A4)
* [MrRobotoAI/129](https://huggingface.co/MrRobotoAI/129)
* [MrRobotoAI/A2](https://huggingface.co/MrRobotoAI/A2)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: MrRobotoAI/A10
- model: MrRobotoAI/A2
- model: MrRobotoAI/A4
- model: MrRobotoAI/129
parameters:
weight: 1.0
merge_method: linear
dtype: float16
```
|
memevis/s31 | memevis | "2025-01-05T18:42:52Z" | 155 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-01-05T17:48:07Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sail-rvc/Tyler_Joseph__RVC_v2__300_Epoch | sail-rvc | "2023-07-14T07:34:15Z" | 1 | 0 | transformers | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | "2023-07-14T07:33:22Z" |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# Tyler_Joseph__RVC_v2__300_Epoch
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:34:15
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
|
marialvsantiago/cbc868b3-41bd-4e87-a3d0-b8cf26acae69 | marialvsantiago | "2025-01-24T08:15:00Z" | 8 | 0 | peft | [
"peft",
"safetensors",
"gemma",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/codegemma-7b",
"base_model:adapter:unsloth/codegemma-7b",
"license:apache-2.0",
"region:us"
] | null | "2025-01-24T07:48:34Z" | ---
library_name: peft
license: apache-2.0
base_model: unsloth/codegemma-7b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: cbc868b3-41bd-4e87-a3d0-b8cf26acae69
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/codegemma-7b
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- d57373015f0200ac_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/d57373015f0200ac_train_data.json
type:
field_instruction: problem
field_output: solution
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
device: cuda
early_stopping_patience: 1
eval_max_new_tokens: 128
eval_steps: 5
eval_table_size: null
evals_per_epoch: null
flash_attention: false
fp16: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
group_by_length: true
hub_model_id: marialvsantiago/cbc868b3-41bd-4e87-a3d0-b8cf26acae69
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-05
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 3
lora_alpha: 32
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 16
lora_target_linear: true
lr_scheduler: cosine
max_memory:
0: 79GiB
max_steps: 30
micro_batch_size: 2
mlflow_experiment_name: /tmp/d57373015f0200ac_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optim_args:
adam_beta1: 0.9
adam_beta2: 0.95
adam_epsilon: 1e-5
optimizer: adamw_torch
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 10
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: true
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: c2e858ef-72e0-466b-ac1a-9bdca7d0809c
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: c2e858ef-72e0-466b-ac1a-9bdca7d0809c
warmup_steps: 5
weight_decay: 0.001
xformers_attention: true
```
</details><br>
# cbc868b3-41bd-4e87-a3d0-b8cf26acae69
This model is a fine-tuned version of [unsloth/codegemma-7b](https://huggingface.co/unsloth/codegemma-7b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9608
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=adam_beta1=0.9,adam_beta2=0.95,adam_epsilon=1e-5
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0007 | 1 | 1.1187 |
| 0.6822 | 0.0034 | 5 | 1.0826 |
| 0.8142 | 0.0068 | 10 | 1.0343 |
| 0.7937 | 0.0103 | 15 | 0.9939 |
| 0.9328 | 0.0137 | 20 | 0.9724 |
| 0.9609 | 0.0171 | 25 | 0.9602 |
| 0.9306 | 0.0205 | 30 | 0.9608 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
NassimB/mistral-7b-hf-platypus-lamini-vxxiii-chat-enhanced | NassimB | "2024-04-15T11:06:19Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | "2024-04-15T07:19:06Z" | ---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistral-7b-hf-platypus-lamini-vxxiii-chat-enhanced
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b-hf-platypus-lamini-vxxiii-chat-enhanced
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.1
- Pytorch 2.2.0+cu121
- Datasets 2.14.6
- Tokenizers 0.15.1 |
daniel40/41fc695f-4c0e-4a75-aba9-2afade8952dc | daniel40 | "2025-03-04T22:52:59Z" | 0 | 0 | peft | [
"peft",
"generated_from_trainer",
"base_model:huggyllama/llama-7b",
"base_model:adapter:huggyllama/llama-7b",
"region:us"
] | null | "2025-03-04T22:52:43Z" | ---
library_name: peft
tags:
- generated_from_trainer
base_model: huggyllama/llama-7b
model-index:
- name: daniel40/41fc695f-4c0e-4a75-aba9-2afade8952dc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# daniel40/41fc695f-4c0e-4a75-aba9-2afade8952dc
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2750
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
hcarrion/kaposi_sarcoma | hcarrion | "2025-02-18T18:20:11Z" | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:stabilityai/stable-diffusion-2-1-base",
"base_model:adapter:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2025-02-18T17:08:30Z" |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - hcarrion/kaposi_sarcoma
These are textual inversion adaption weights for stabilityai/stable-diffusion-2-1-base. You can find some example images in the following.
|
BLURPLETESTS/L3-8B-Chara-v1-Alpha-Q5_K_M_imat_GGUF | BLURPLETESTS | "2024-07-01T06:38:45Z" | 7 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:Sao10K/L3-8B-Chara-v1-Alpha",
"base_model:quantized:Sao10K/L3-8B-Chara-v1-Alpha",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | "2024-07-01T06:38:19Z" | ---
base_model: Sao10K/L3-8B-Chara-v1-Alpha
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# BLURPLETESTS/L3-8B-Chara-v1-Alpha-Q5_K_M-GGUF
This model was converted to GGUF format from [`Sao10K/L3-8B-Chara-v1-Alpha`](https://huggingface.co/Sao10K/L3-8B-Chara-v1-Alpha) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Sao10K/L3-8B-Chara-v1-Alpha) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo BLURPLETESTS/L3-8B-Chara-v1-Alpha-Q5_K_M-GGUF --hf-file l3-8b-chara-v1-alpha-q5_k_m-imat.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo BLURPLETESTS/L3-8B-Chara-v1-Alpha-Q5_K_M-GGUF --hf-file l3-8b-chara-v1-alpha-q5_k_m-imat.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo BLURPLETESTS/L3-8B-Chara-v1-Alpha-Q5_K_M-GGUF --hf-file l3-8b-chara-v1-alpha-q5_k_m-imat.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo BLURPLETESTS/L3-8B-Chara-v1-Alpha-Q5_K_M-GGUF --hf-file l3-8b-chara-v1-alpha-q5_k_m-imat.gguf -c 2048
```
|
ThisIsATest/160m-random-corruption-0-12 | ThisIsATest | "2025-03-19T03:27:52Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-03-19T03:27:19Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
theZoo/q-FrozenLake-v1-4x4-noSlippery | theZoo | "2024-01-31T14:13:14Z" | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | "2024-01-31T14:13:12Z" | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="theZoo/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
qfq/Qwen2.5-32B-Instruct-20241128_111922 | qfq | "2024-11-28T20:27:55Z" | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-11-28T19:22:15Z" | ---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: Qwen2.5-32B-Instruct-20241128_111922
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen2.5-32B-Instruct-20241128_111922
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="qfq/Qwen2.5-32B-Instruct-20241128_111922", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/hashimoto-group/o1/runs/t6hj8tt8)
This model was trained with SFT.
### Framework versions
- TRL: 0.12.0
- Transformers: 4.46.3
- Pytorch: 2.3.1
- Datasets: 3.0.1
- Tokenizers: 0.20.3
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Ngks03/PPG-VascularAge | Ngks03 | "2025-02-28T13:56:13Z" | 26 | 1 | null | [
"en",
"arxiv:2502.12990",
"license:mit",
"region:us"
] | null | "2025-02-16T02:30:43Z" | ---
license: mit
language:
- en
---
# VascularAge Model
## Background
Photoplethysmography (PPG) has emerged as a non-invasive method for monitoring cardiovascular health. This model estimates vascular age (AI-vascular age) from PPG signals, offering insights into an individual's cardiovascular health and associated risks.
The model was developed and evaluated using data from the UK Biobank (UKBB) cohort, where PPG signals were collected in a standardized format. For more details, please refer to our [research article](https://arxiv.org/abs/2502.12990).
## Use Case
The `VascularAge` model is designed to estimate vascular age, which can be used for:
- **Risk Stratification**: Identifying individuals at higher risk for cardiovascular events.
- **Health Monitoring**: Tracking cardiovascular health over time to support personalized interventions.
This model provides a non-invasive, scalable approach for real-time cardiovascular health assessment using PPG signals. It is specifically trained to process PPG data from the UKBB dataset, ensuring its effectiveness in research and clinical settings that use similar data.
## Data Format
To ensure compatibility, PPG signals should be preprocessed and formatted in the same way as in the UKBB dataset. The expected format for input PPG signals is a 3D array with the shape `(batch_size, num_channels, num_samples)`.
## Usage (Pytorch)
```python
import json
import torch
import numpy as np
from net1d import Net1D
# Function to normalize PPG data (Z-score along the last dimension)
def normalize_ppg(parsed_ppg: np.ndarray) -> np.ndarray:
mean_ppg = parsed_ppg.mean(axis=-1, keepdims=True) # Compute mean along the last dimension
std_ppg = parsed_ppg.std(axis=-1, keepdims=True) # Compute standard deviation along the last dimension
normalized_ppg = (parsed_ppg - mean_ppg) / (std_ppg + 1e-8) # Z-score normalization
return normalized_ppg
# Load the configuration file
with open('./config.json') as f:
cfg = json.load(f)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Initialize the model
model = Net1D(**cfg).to(device)
# Load model weights
model.load_state_dict(torch.load('./model.pth', map_location=device))
# Prepare raw PPG data (example) and normalize it
raw_ppg_data = np.random.randn(1, 1, 100) # Example PPG data (batch size of 1, 1 channel, 100 time steps)
normalized_ppg_data = normalize_ppg(raw_ppg_data) # Normalize the PPG data
# Convert normalized PPG data to tensor
ppg_data_tensor = torch.tensor(normalized_ppg_data, dtype=torch.float32).to(device)
# Perform inference
model.eval()
with torch.no_grad():
vascular_age = model(ppg_data_tensor)
print(f"Estimated Vascular Age: {vascular_age.item()}") |
PotatoB/task_3-exp | PotatoB | "2024-11-25T10:03:32Z" | 5 | 0 | null | [
"safetensors",
"mistral",
"merge",
"mergekit",
"potatoB/task_2-1",
"potatoB/task_1-2",
"license:apache-2.0",
"region:us"
] | null | "2024-11-25T10:00:36Z" | ---
license: apache-2.0
tags:
- merge
- mergekit
- potatoB/task_2-1
- potatoB/task_1-2
---
# task_3-exp
task_3-exp is a merged model generated for Model Kinship experiments, originating from
* [potatoB/task_2-1](https://huggingface.co/potatoB/task_2-1)
* [potatoB/task_1-2](https://huggingface.co/potatoB/task_1-2)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: potatoB/task_2-1
layer_range: [0, 32]
- model: potatoB/task_1-2
layer_range: [0, 32]
merge_method: slerp
base_model: potatoB/task_2-1
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: float16
``` |
behzadnet/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned-adapters_rand75_seed100 | behzadnet | "2023-11-21T15:15:25Z" | 1 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | "2023-11-21T15:15:20Z" | ---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
unsloth/Qwen2.5-VL-72B-Instruct-bnb-4bit | unsloth | "2025-03-09T03:38:05Z" | 5,604 | 10 | transformers | [
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"multimodal",
"qwen",
"qwen2",
"unsloth",
"vision",
"conversational",
"en",
"arxiv:2309.00071",
"arxiv:2409.12191",
"arxiv:2308.12966",
"base_model:Qwen/Qwen2.5-VL-72B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-72B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | image-text-to-text | "2025-01-31T11:01:19Z" | ---
base_model: Qwen/Qwen2.5-VL-72B-Instruct
language:
- en
library_name: transformers
pipeline_tag: image-text-to-text
license: apache-2.0
tags:
- multimodal
- qwen
- qwen2
- unsloth
- transformers
- vision
---
<div>
<p style="margin-bottom: 0;margin-top:0;">
<em>View all of our uploaded models <a href="https://docs.unsloth.ai/get-started/all-our-models">here</em>
</p>
<div style="display: flex; gap: 5px; align-items: center;margin-top:0; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
<h1 style="margin-top: 0rem;">Finetune LLMs 2-5x faster with 70% less memory via Unsloth</h2>
</div>
We have a free Google Colab Tesla T4 notebook for Qwen2-VL (7B) here: https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL_(7B)-Vision.ipynb
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Llama-3.2 (3B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(1B_and_3B)-Conversational.ipynb) | 2.4x faster | 58% less |
| **Llama-3.2 (11B vision)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(11B)-Vision.ipynb) | 2x faster | 60% less |
| **Qwen2 VL (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL_(7B)-Vision.ipynb) | 1.8x faster | 60% less |
| **Qwen2.5 (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(7B)-Alpaca.ipynb) | 2x faster | 60% less |
| **Llama-3.1 (8B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-Alpaca.ipynb) | 2.4x faster | 58% less |
| **Phi-3.5 (mini)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Phi_3.5_Mini-Conversational.ipynb) | 2x faster | 50% less |
| **Gemma 2 (9B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma2_(9B)-Alpaca.ipynb) | 2.4x faster | 58% less |
| **Mistral (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Mistral_v0.3_(7B)-Conversational.ipynb) | 2.2x faster | 62% less |
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="200"/>](https://docs.unsloth.ai)
- This [Llama 3.2 conversational notebook](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(1B_and_3B)-Conversational.ipynb) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Mistral_(7B)-Text_Completion.ipynb) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster.
# Qwen2.5-VL
## Introduction
In the past five months since Qwen2-VL’s release, numerous developers have built new models on the Qwen2-VL vision-language models, providing us with valuable feedback. During this period, we focused on building more useful vision-language models. Today, we are excited to introduce the latest addition to the Qwen family: Qwen2.5-VL.
#### Key Enhancements:
* **Understand things visually**: Qwen2.5-VL is not only proficient in recognizing common objects such as flowers, birds, fish, and insects, but it is highly capable of analyzing texts, charts, icons, graphics, and layouts within images.
* **Being agentic**: Qwen2.5-VL directly plays as a visual agent that can reason and dynamically direct tools, which is capable of computer use and phone use.
* **Understanding long videos and capturing events**: Qwen2.5-VL can comprehend videos of over 1 hour, and this time it has a new ability of cpaturing event by pinpointing the relevant video segments.
* **Capable of visual localization in different formats**: Qwen2.5-VL can accurately localize objects in an image by generating bounding boxes or points, and it can provide stable JSON outputs for coordinates and attributes.
* **Generating structured outputs**: for data like scans of invoices, forms, tables, etc. Qwen2.5-VL supports structured outputs of their contents, benefiting usages in finance, commerce, etc.
#### Model Architecture Updates:
* **Dynamic Resolution and Frame Rate Training for Video Understanding**:
We extend dynamic resolution to the temporal dimension by adopting dynamic FPS sampling, enabling the model to comprehend videos at various sampling rates. Accordingly, we update mRoPE in the time dimension with IDs and absolute time alignment, enabling the model to learn temporal sequence and speed, and ultimately acquire the ability to pinpoint specific moments.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-VL/qwen2.5vl_arc.jpeg" width="80%"/>
<p>
* **Streamlined and Efficient Vision Encoder**
We enhance both training and inference speeds by strategically implementing window attention into the ViT. The ViT architecture is further optimized with SwiGLU and RMSNorm, aligning it with the structure of the Qwen2.5 LLM.
We have three models with 3, 7 and 72 billion parameters. This repo contains the instruction-tuned 7B Qwen2.5-VL model. For more information, visit our [Blog](https://qwenlm.github.io/blog/qwen2.5-vl/) and [GitHub](https://github.com/QwenLM/Qwen2.5-VL).
## Evaluation
### Image benchmark
| Benchmark | InternVL2.5-8B | MiniCPM-o 2.6 | GPT-4o-mini | Qwen2-VL-7B |**Qwen2.5-VL-7B** |
| :--- | :---: | :---: | :---: | :---: | :---: |
| MMMU<sub>val</sub> | 56 | 50.4 | **60**| 54.1 | 58.6|
| MMMU-Pro<sub>val</sub> | 34.3 | - | 37.6| 30.5 | 41.0|
| DocVQA<sub>test</sub> | 93 | 93 | - | 94.5 | **95.7** |
| InfoVQA<sub>test</sub> | 77.6 | - | - |76.5 | **82.6** |
| ChartQA<sub>test</sub> | 84.8 | - |- | 83.0 |**87.3** |
| TextVQA<sub>val</sub> | 79.1 | 80.1 | -| 84.3 | **84.9**|
| OCRBench | 822 | 852 | 785 | 845 | **864** |
| CC_OCR | 57.7 | | | 61.6 | **77.8**|
| MMStar | 62.8| | |60.7| **63.9**|
| MMBench-V1.1-En<sub>test</sub> | 79.4 | 78.0 | 76.0| 80.7 | **82.6** |
| MMT-Bench<sub>test</sub> | - | - | - |**63.7** |63.6 |
| MMStar | **61.5** | 57.5 | 54.8 | 60.7 |63.9 |
| MMVet<sub>GPT-4-Turbo</sub> | 54.2 | 60.0 | 66.9 | 62.0 | **67.1**|
| HallBench<sub>avg</sub> | 45.2 | 48.1 | 46.1| 50.6 | **52.9**|
| MathVista<sub>testmini</sub> | 58.3 | 60.6 | 52.4 | 58.2 | **68.2**|
| MathVision | - | - | - | 16.3 | **25.07** |
### Video Benchmarks
| Benchmark | Qwen2-VL-7B | **Qwen2.5-VL-7B** |
| :--- | :---: | :---: |
| MVBench | 67.0 | **69.6** |
| PerceptionTest<sub>test</sub> | 66.9 | **70.5** |
| Video-MME<sub>wo/w subs</sub> | 63.3/69.0 | **65.1**/**71.6** |
| LVBench | | 45.3 |
| LongVideoBench | | 54.7 |
| MMBench-Video | 1.44 | 1.79 |
| TempCompass | | 71.7 |
| MLVU | | 70.2 |
| CharadesSTA/mIoU | 43.6|
### Agent benchmark
| Benchmarks | Qwen2.5-VL-7B |
|-------------------------|---------------|
| ScreenSpot | 84.7 |
| ScreenSpot Pro | 29.0 |
| AITZ_EM | 81.9 |
| Android Control High_EM | 60.1 |
| Android Control Low_EM | 93.7 |
| AndroidWorld_SR | 25.5 |
| MobileMiniWob++_SR | 91.4 |
## Requirements
The code of Qwen2.5-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip install git+https://github.com/huggingface/transformers accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_vl'
```
## Quickstart
Below, we provide simple examples to show how to use Qwen2.5-VL with 🤖 ModelScope and 🤗 Transformers.
The code of Qwen2.5-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip install git+https://github.com/huggingface/transformers accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_vl'
```
We offer a toolkit to help you handle various types of visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved images and videos. You can install it using the following command:
```bash
# It's highly recommanded to use `[decord]` feature for faster video loading.
pip install qwen-vl-utils[decord]==0.0.8
```
If you are not using Linux, you might not be able to install `decord` from PyPI. In that case, you can use `pip install qwen-vl-utils` which will fall back to using torchvision for video processing. However, you can still [install decord from source](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source) to get decord used when loading video.
### Using 🤗 Transformers to Chat
Here we show a code snippet to show you how to use the chat model with `transformers` and `qwen_vl_utils`:
```python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
<details>
<summary>Multi image inference</summary>
```python
# Messages containing multiple images and a text query
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "Identify the similarities between these images."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
</details>
<details>
<summary>Video inference</summary>
```python
# Messages containing a images list as a video and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a local video path and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
},
{"type": "text", "text": "Describe this video."},
],
}
]
#In Qwen 2.5 VL, frame rate information is also input into the model to align with absolute time.
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
fps=fps,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
Video URL compatibility largely depends on the third-party library version. The details are in the table below. change the backend by `FORCE_QWENVL_VIDEO_READER=torchvision` or `FORCE_QWENVL_VIDEO_READER=decord` if you prefer not to use the default one.
| Backend | HTTP | HTTPS |
|-------------|------|-------|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
</details>
<details>
<summary>Batch inference</summary>
```python
# Sample messages for batch inference
messages1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "What are the common elements in these pictures?"},
],
}
]
messages2 = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
# Combine messages for batch processing
messages = [messages1, messages2]
# Preparation for batch inference
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Batch Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)
```
</details>
### 🤖 ModelScope
We strongly advise users especially those in mainland China to use ModelScope. `snapshot_download` can help you solve issues concerning downloading checkpoints.
### More Usage Tips
For input images, we support local files, base64, and URLs. For videos, we currently only support local files.
```python
# You can directly insert a local file path, a URL, or a base64-encoded image into the position where you want in the text.
## Local file path
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Image URL
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "http://path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Base64 encoded image
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "data:image;base64,/9j/..."},
{"type": "text", "text": "Describe this image."},
],
}
]
```
#### Image Resolution for performance boost
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs, such as a token count range of 256-1280, to balance speed and memory usage.
```python
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
```
Besides, We provide two methods for fine-grained control over the image size input to the model:
1. Define min_pixels and max_pixels: Images will be resized to maintain their aspect ratio within the range of min_pixels and max_pixels.
2. Specify exact dimensions: Directly set `resized_height` and `resized_width`. These values will be rounded to the nearest multiple of 28.
```python
# min_pixels and max_pixels
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"resized_height": 280,
"resized_width": 420,
},
{"type": "text", "text": "Describe this image."},
],
}
]
# resized_height and resized_width
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"min_pixels": 50176,
"max_pixels": 50176,
},
{"type": "text", "text": "Describe this image."},
],
}
]
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
{
...,
"type": "yarn",
"mrope_section": [
16,
24,
24
],
"factor": 4,
"original_max_position_embeddings": 32768
}
However, it should be noted that this method has a significant impact on the performance of temporal and spatial localization tasks, and is therefore not recommended for use.
At the same time, for long video inputs, since MRoPE itself is more economical with ids, the max_position_embeddings can be directly modified to a larger value, such as 64k.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5-VL,
title = {Qwen2.5-VL},
url = {https://qwenlm.github.io/blog/qwen2.5-vl/},
author = {Qwen Team},
month = {January},
year = {2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}
```
|
tranquocthanh/q-FrozenLake-v1-4x4-noSlippery | tranquocthanh | "2023-11-11T16:19:26Z" | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | "2023-11-11T16:19:24Z" | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="tranquocthanh/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
research-backup/bart-base-squadshifts-vanilla-nyt-qg | research-backup | "2022-12-04T10:06:35Z" | 121 | 0 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"question generation",
"en",
"dataset:lmqg/qg_squadshifts",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-06-22T10:41:18Z" |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: en
datasets:
- lmqg/qg_squadshifts
pipeline_tag: text2text-generation
tags:
- question generation
widget:
- text: "<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records."
example_title: "Question Generation Example 1"
- text: "Beyonce further expanded her acting career, starring as blues singer <hl> Etta James <hl> in the 2008 musical biopic, Cadillac Records."
example_title: "Question Generation Example 2"
- text: "Beyonce further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, <hl> Cadillac Records <hl> ."
example_title: "Question Generation Example 3"
model-index:
- name: research-backup/bart-base-squadshifts-vanilla-nyt-qg
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squadshifts
type: nyt
args: nyt
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 7.56
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 22.89
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 22.84
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 92.42
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 63.53
---
# Model Card of `research-backup/bart-base-squadshifts-vanilla-nyt-qg`
This model is fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) for question generation task on the [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) (dataset_name: nyt) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/bart-base](https://huggingface.co/facebook/bart-base)
- **Language:** en
- **Training data:** [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) (nyt)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="research-backup/bart-base-squadshifts-vanilla-nyt-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "research-backup/bart-base-squadshifts-vanilla-nyt-qg")
output = pipe("<hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/research-backup/bart-base-squadshifts-vanilla-nyt-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_squadshifts.nyt.json)
| | Score | Type | Dataset |
|:-----------|--------:|:-------|:---------------------------------------------------------------------------|
| BERTScore | 92.42 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_1 | 23.63 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_2 | 15.34 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_3 | 10.58 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| Bleu_4 | 7.56 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| METEOR | 22.84 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| MoverScore | 63.53 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
| ROUGE_L | 22.89 | nyt | [lmqg/qg_squadshifts](https://huggingface.co/datasets/lmqg/qg_squadshifts) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squadshifts
- dataset_name: nyt
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: facebook/bart-base
- max_length: 512
- max_length_output: 32
- epoch: 6
- batch: 8
- lr: 5e-05
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/research-backup/bart-base-squadshifts-vanilla-nyt-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
kenzic/speecht5_finetuned_voxpopuli_nl | kenzic | "2024-08-26T02:48:42Z" | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-to-audio | "2024-08-26T00:58:17Z" | ---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_nl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_nl
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4606
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.5177 | 4.3034 | 1000 | 0.4797 |
| 0.4955 | 8.6068 | 2000 | 0.4661 |
| 0.4916 | 12.9102 | 3000 | 0.4612 |
| 0.4909 | 17.2136 | 4000 | 0.4606 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.3.1+cu121
- Datasets 2.21.0
- Tokenizers 0.19.1
|
ReadyArt/Forgotten-Abomination-24B-V2.1-Q8_0-GGUF | ReadyArt | "2025-02-24T20:56:12Z" | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"arxiv:2311.03099",
"base_model:ReadyArt/Forgotten-Safeword-24B-V2.0",
"base_model:merge:ReadyArt/Forgotten-Safeword-24B-V2.0",
"base_model:TheDrummer/Cydonia-24B-v2",
"base_model:merge:TheDrummer/Cydonia-24B-v2",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-02-24T20:27:29Z" | ---
base_model:
- ReadyArt/Forgotten-Safeword-24B-V2.0
- TheDrummer/Cydonia-24B-v2
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE TIES](https://arxiv.org/abs/2311.03099) merge method using [TheDrummer/Cydonia-24B-v2](https://huggingface.co/TheDrummer/Cydonia-24B-v2) as a base.
### Models Merged
The following models were included in the merge:
* [ReadyArt/Forgotten-Safeword-24B-V2.0](https://huggingface.co/ReadyArt/Forgotten-Safeword-24B-V2.0)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
merge_method: dare_ties
base_model: TheDrummer/Cydonia-24B-v2
models:
- model: TheDrummer/Cydonia-24B-v2
parameters:
weight: 0.5
- model: ReadyArt/Forgotten-Safeword-24B-V2.0
parameters:
weight: 0.5
parameters:
density: 0.3
tokenizer:
source: union
chat_template: auto
```
|
AnnaCarson/roberta-base-ner-demo | AnnaCarson | "2024-05-27T19:01:03Z" | 127 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"mn",
"base_model:bayartsogt/mongolian-roberta-base",
"base_model:finetune:bayartsogt/mongolian-roberta-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2024-04-05T17:49:19Z" | ---
language:
- mn
base_model: bayartsogt/mongolian-roberta-base
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-ner-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-ner-demo
This model is a fine-tuned version of [bayartsogt/mongolian-roberta-base](https://huggingface.co/bayartsogt/mongolian-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1834
- Precision: 0.6839
- Recall: 0.7644
- F1: 0.7219
- Accuracy: 0.9459
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.7672 | 1.0 | 20 | 0.5162 | 0.0825 | 0.0401 | 0.0540 | 0.8256 |
| 0.3886 | 2.0 | 40 | 0.3017 | 0.4778 | 0.5113 | 0.4939 | 0.9061 |
| 0.2163 | 3.0 | 60 | 0.2214 | 0.5543 | 0.6266 | 0.5882 | 0.9225 |
| 0.1199 | 4.0 | 80 | 0.1942 | 0.6346 | 0.7268 | 0.6776 | 0.9359 |
| 0.0742 | 5.0 | 100 | 0.1852 | 0.6396 | 0.7293 | 0.6815 | 0.9409 |
| 0.0555 | 6.0 | 120 | 0.1811 | 0.6943 | 0.7569 | 0.7242 | 0.9449 |
| 0.0407 | 7.0 | 140 | 0.1860 | 0.6804 | 0.7469 | 0.7121 | 0.9439 |
| 0.0346 | 8.0 | 160 | 0.1876 | 0.6952 | 0.7544 | 0.7236 | 0.9463 |
| 0.0302 | 9.0 | 180 | 0.1820 | 0.6868 | 0.7694 | 0.7258 | 0.9459 |
| 0.0289 | 10.0 | 200 | 0.1834 | 0.6839 | 0.7644 | 0.7219 | 0.9459 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
bustamiyusoef/Nougat_DANN_Edv_En_De_500tar_01 | bustamiyusoef | "2025-03-26T00:11:52Z" | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-03-26T00:06:29Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
seregadgl101/baii_pr_v1_5ep | seregadgl101 | "2024-04-28T14:06:16Z" | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-04-28T14:04:51Z" | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# seregadgl101/baii_pr_v1_5ep
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('seregadgl101/baii_pr_v1_5ep')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=seregadgl101/baii_pr_v1_5ep)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Qwen/Qwen1.5-0.5B-Chat-AWQ | Qwen | "2024-04-30T07:20:07Z" | 79 | 6 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"conversational",
"en",
"arxiv:2309.16609",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | "2024-02-03T07:01:23Z" | ---
license: other
license_name: tongyi-qianwen-research
license_link: >-
https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat-AWQ/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- chat
---
# Qwen1.5-0.5B-Chat-AWQ
## Introduction
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:
* 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B and 72B dense models, and an MoE model of 14B with 2.7B activated;
* Significant performance improvement in human preference for chat models;
* Multilingual support of both base and chat models;
* Stable support of 32K context length for models of all sizes
* No need of `trust_remote_code`.
For more details, please refer to our [blog post](https://qwenlm.github.io/blog/qwen1.5/) and [GitHub repo](https://github.com/QwenLM/Qwen1.5).
<br>
## Model Details
Qwen1.5 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. For the beta version, temporarily we did not include GQA (except for 32B) and the mixture of SWA and full attention.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-0.5B-Chat-AWQ",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-0.5B-Chat-AWQ")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Tips
* If you encounter code switching or other bad cases, we advise you to use our provided hyper-parameters in `generation_config.json`.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
```
|
gokuls/distilbert_sa_GLUE_Experiment_qqp_384 | gokuls | "2023-01-25T06:44:42Z" | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-01-25T05:05:07Z" | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: distilbert_sa_GLUE_Experiment_qqp_384
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QQP
type: glue
config: qqp
split: validation
args: qqp
metrics:
- name: Accuracy
type: accuracy
value: 0.8082364580756863
- name: F1
type: f1
value: 0.7405200977275009
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_sa_GLUE_Experiment_qqp_384
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4322
- Accuracy: 0.8082
- F1: 0.7405
- Combined Score: 0.7744
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.5251 | 1.0 | 1422 | 0.5016 | 0.7563 | 0.6686 | 0.7124 |
| 0.466 | 2.0 | 2844 | 0.4668 | 0.7745 | 0.6459 | 0.7102 |
| 0.4292 | 3.0 | 4266 | 0.4609 | 0.7854 | 0.6685 | 0.7270 |
| 0.3971 | 4.0 | 5688 | 0.4463 | 0.7945 | 0.7190 | 0.7568 |
| 0.3677 | 5.0 | 7110 | 0.4326 | 0.8001 | 0.7280 | 0.7641 |
| 0.3398 | 6.0 | 8532 | 0.4511 | 0.8017 | 0.7361 | 0.7689 |
| 0.3141 | 7.0 | 9954 | 0.4322 | 0.8082 | 0.7405 | 0.7744 |
| 0.2891 | 8.0 | 11376 | 0.4373 | 0.8096 | 0.7434 | 0.7765 |
| 0.266 | 9.0 | 12798 | 0.4793 | 0.7966 | 0.7440 | 0.7703 |
| 0.2433 | 10.0 | 14220 | 0.5018 | 0.8143 | 0.7503 | 0.7823 |
| 0.2235 | 11.0 | 15642 | 0.4917 | 0.8144 | 0.7428 | 0.7786 |
| 0.2045 | 12.0 | 17064 | 0.5152 | 0.8166 | 0.7521 | 0.7844 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
lccllccc/0920_sdxl_lora_2500_steps | lccllccc | "2023-09-20T08:29:06Z" | 1 | 1 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | "2023-09-20T05:03:19Z" |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-xl-base-1.0
dataset: None
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - lccllccc/0920_sdxl_lora_2500_steps
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were fine-tuned on the None dataset. You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
Jollyfish/whisper-lgv3-new-fold3-plot0 | Jollyfish | "2025-02-28T20:42:20Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2025-02-28T20:02:49Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
SergiRusi/ppo-Huggy | SergiRusi | "2025-03-24T17:54:34Z" | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | "2025-03-24T17:54:28Z" | Temporary Redirect. Redirecting to /api/resolve-cache/models/SergiRusi/ppo-Huggy/479ca7994f63933912d18f5bc1ab13d3433c35d5/README.md?%2FSergiRusi%2Fppo-Huggy%2Fresolve%2Fmain%2FREADME.md=&etag=%22681656c550c7b1064247233cb8370b6935104478%22 |
nightpicnic/trained-bert | nightpicnic | "2024-06-26T19:54:21Z" | 161 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-06-26T19:40:47Z" | ---
tags:
- generated_from_trainer
model-index:
- name: tmp_trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmp_trainer
This model was trained from scratch on odegiber/hate_speech18.
## Model description
google-bert/bert-base-uncased
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.1
- Datasets 2.20.0
- Tokenizers 0.19.1
|
bishmoy/q-FrozenLake-v1-4x4-noSlippery | bishmoy | "2022-06-01T13:42:57Z" | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | "2022-06-01T13:42:50Z" | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="bishmoy/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
RichardErkhov/NatureUniverse_-_alpaca-gpt4-8bits | RichardErkhov | "2025-03-14T18:47:43Z" | 0 | 0 | null | [
"safetensors",
"gpt2",
"8-bit",
"bitsandbytes",
"region:us"
] | null | "2025-03-14T18:47:29Z" | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
alpaca-gpt4 - bnb 8bits
- Model creator: https://huggingface.co/NatureUniverse/
- Original model: https://huggingface.co/NatureUniverse/alpaca-gpt4/
Original model description:
---
datasets:
- vicgalle/alpaca-gpt4
library_name: transformers
pipeline_tag: question-answering
language:
- en
tags:
- onnx
---
### Training parameters
- learning_rate: 1e-05
- train_batch_size: 20
- eval_batch_size: 32
- optimizer:paged_adamw_32bit
- num_epochs: 1
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
2084Collective/checkpoint-20 | 2084Collective | "2025-03-13T18:09:27Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-03-13T07:00:30Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF | mradermacher | "2024-12-07T21:00:14Z" | 41 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:zelk12/MT1-Gen3-BB-gemma-2-MTg2S2-9B",
"base_model:quantized:zelk12/MT1-Gen3-BB-gemma-2-MTg2S2-9B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-12-07T11:13:20Z" | ---
base_model: zelk12/MT1-Gen3-BB-gemma-2-MTg2S2-9B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
static quants of https://huggingface.co/zelk12/MT1-Gen3-BB-gemma-2-MTg2S2-9B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q2_K.gguf) | Q2_K | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q3_K_S.gguf) | Q3_K_S | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q3_K_M.gguf) | Q3_K_M | 4.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q3_K_L.gguf) | Q3_K_L | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.IQ4_XS.gguf) | IQ4_XS | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q4_0_4_4.gguf) | Q4_0_4_4 | 5.5 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q4_K_S.gguf) | Q4_K_S | 5.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q4_K_M.gguf) | Q4_K_M | 5.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q5_K_S.gguf) | Q5_K_S | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q5_K_M.gguf) | Q5_K_M | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q6_K.gguf) | Q6_K | 7.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.Q8_0.gguf) | Q8_0 | 9.9 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MT1-Gen3-BB-gemma-2-MTg2S2-9B-GGUF/resolve/main/MT1-Gen3-BB-gemma-2-MTg2S2-9B.f16.gguf) | f16 | 18.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
propet/a2c-PandaReachDense-v2 | propet | "2023-11-29T17:11:13Z" | 4 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"arxiv:2106.13687",
"model-index",
"region:us"
] | reinforcement-learning | "2023-03-16T21:08:33Z" | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.32 +/- 0.13
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
Panda Gym environments: [arxiv.org/abs/2106.13687](https://arxiv.org/abs/2106.13687) |
kexinz/mistral-7b_qlora | kexinz | "2024-03-14T20:13:29Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | "2024-03-11T06:42:37Z" | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistral-7b_qlora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b_qlora
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on an unknown dataset.
## Model description
mistral-7b quantized with QLoRA and fine-tuned with 5% MMLU axiliary training (with bad prompt format)
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 500
### MMLU accuracy
Overall: 59.4%
STEM: 50.30%
Humanities: 65.57%
Social Sciences: 70.33%
Other (business, health, misc.): 63.05%
### Framework versions
- PEFT 0.9.1.dev0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 |
lunarsylph/stablecell_v8 | lunarsylph | "2024-03-29T01:59:04Z" | 89 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-03-28T14:05:46Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
HmzBou/gemma-3-unsloth-4bit-lora64 | HmzBou | "2025-03-25T13:08:44Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma3_text",
"trl",
"en",
"base_model:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2025-03-25T13:08:38Z" | ---
base_model: unsloth/gemma-3-1b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** HmzBou
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it-unsloth-bnb-4bit
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Niggendar/hassakuXLHentai_v13BetterEyesVersion | Niggendar | "2024-07-16T10:30:53Z" | 79 | 0 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2024-07-16T10:22:29Z" | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mertyazan/PPO-LunarLander | mertyazan | "2023-01-15T17:33:58Z" | 9 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | "2023-01-15T16:34:21Z" | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 295.92 +/- 19.30
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
strawhat/minicpm2.5-agiqa-3k-ft | strawhat | "2025-02-23T01:52:46Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-02-23T01:45:09Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Benjamin-png/swahili-mms-tts-train | Benjamin-png | "2024-08-03T09:17:21Z" | 7 | 0 | null | [
"pytorch",
"safetensors",
"vits",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"region:us"
] | text-to-speech | "2024-08-03T09:13:29Z" |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): Swahili Text-to-Speech
This repository contains the **Swahili (swh)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-swh")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-swh")
text = "some example text in the Swahili language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output, rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
|
birdaz/nagisa | birdaz | "2023-05-16T09:43:28Z" | 19 | 1 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2023-01-06T13:19:45Z" | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### nagisa Dreambooth model trained by birdaz with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
zwloong/simpletuner-lora | zwloong | "2024-08-26T20:20:20Z" | 5 | 1 | diffusers | [
"diffusers",
"flux",
"flux-diffusers",
"text-to-image",
"simpletuner",
"lora",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2024-08-26T09:36:31Z" | ---
license: other
base_model: "black-forest-labs/FLUX.1-dev"
tags:
- flux
- flux-diffusers
- text-to-image
- diffusers
- simpletuner
- lora
- template:sd-lora
inference: true
widget:
- text: 'unconditional (blank prompt)'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_0_0.png
- text: 'A cute pokemon design, featuring a single bird, water type pokemon, on a white background'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_1_0.png
---
# simpletuner-lora
This is a standard PEFT LoRA derived from [black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev).
The main validation prompt used during training was:
```
A cute pokemon design, featuring a single bird, water type pokemon, on a white background
```
## Validation settings
- CFG: `3.0`
- CFG Rescale: `0.0`
- Steps: `20`
- Sampler: `None`
- Seed: `42`
- Resolution: `1024x1024`
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 13
- Training steps: 3000
- Learning rate: 8e-05
- Effective batch size: 2
- Micro-batch size: 2
- Gradient accumulation steps: 1
- Number of GPUs: 1
- Prediction type: flow-matching
- Rescaled betas zero SNR: False
- Optimizer: adamw_bf16
- Precision: bf16
- Quantised: Yes: int8-quanto
- Xformers: Not used
- LoRA Rank: 16
- LoRA Alpha: None
- LoRA Dropout: 0.1
- LoRA initialisation style: default
## Datasets
### paltype_flux_rank64
- Repeats: 5
- Total number of images: 74
- Total number of aspect buckets: 1
- Resolution: 1.048576 megapixels
- Cropped: True
- Crop style: center
- Crop aspect: square
## Inference
```python
import torch
from diffusers import DiffusionPipeline
model_id = 'black-forest-labs/FLUX.1-dev'
adapter_id = 'zwloong/simpletuner-lora'
pipeline = DiffusionPipeline.from_pretrained(model_id)
pipeline.load_lora_weights(adapter_id)
prompt = "A cute pokemon design, featuring a single bird, water type pokemon, on a white background"
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
image = pipeline(
prompt=prompt,
num_inference_steps=20,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=1024,
height=1024,
guidance_scale=3.0,
).images[0]
image.save("output.png", format="PNG")
```
|
bpd1997/falcon7binstruct_mentalhealthmodel_oct23 | bpd1997 | "2023-10-19T11:04:44Z" | 0 | 0 | null | [
"generated_from_trainer",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"base_model:finetune:vilsonrodrigues/falcon-7b-instruct-sharded",
"license:apache-2.0",
"region:us"
] | null | "2023-10-16T08:38:21Z" | ---
license: apache-2.0
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
tags:
- generated_from_trainer
model-index:
- name: falcon7binstruct_mentalhealthmodel_oct23
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# falcon7binstruct_mentalhealthmodel_oct23
This model is a fine-tuned version of [vilsonrodrigues/falcon-7b-instruct-sharded](https://huggingface.co/vilsonrodrigues/falcon-7b-instruct-sharded) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 180
### Training results
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
stablediffusionapi/anime-illust-diffusion-xl | stablediffusionapi | "2025-01-20T11:37:12Z" | 9 | 2 | diffusers | [
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2023-12-18T17:51:35Z" | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Anime Illust Diffusion XL API Inference

## Get API Key
Get API key from [ModelsLab](https://modelslab.com/), No Payment needed.
Replace Key in below code, change **model_id** to "anime-illust-diffusion-xl"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/anime-illust-diffusion-xl)
Model link: [View model](https://stablediffusionapi.com/models/anime-illust-diffusion-xl)
Credits: [View credits](https://civitai.com/?query=Anime%20Illust%20Diffusion%20XL)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "anime-illust-diffusion-xl",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
KimByeongSu/gpt-neo-125m-cs-finetuning-filtered | KimByeongSu | "2024-05-17T07:57:27Z" | 108 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"base_model:EleutherAI/gpt-neo-125m",
"base_model:finetune:EleutherAI/gpt-neo-125m",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-17T07:35:11Z" | ---
license: mit
base_model: EleutherAI/gpt-neo-125m
tags:
- generated_from_trainer
model-index:
- name: gpt-neo-125m-cs-finetuning-filtered
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt-neo-125m-cs-finetuning-filtered
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1868
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.4022 | 1.0 | 950 | 3.2552 |
| 3.137 | 2.0 | 1900 | 3.1998 |
| 3.04 | 3.0 | 2850 | 3.1868 |
### Framework versions
- Transformers 4.36.2
- Pytorch 1.13.1+cu117
- Datasets 2.14.6
- Tokenizers 0.15.0
|
hattran/gpt2-vn-right-PROMPT_TUNING_CAUSAL_LM | hattran | "2023-09-15T09:20:01Z" | 0 | 0 | peft | [
"peft",
"region:us"
] | null | "2023-09-15T09:19:57Z" | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
janhq/laser-dolphin-mixtral-2x7b-dpo-GGUF | janhq | "2024-02-17T05:39:46Z" | 9 | 0 | transformers | [
"transformers",
"gguf",
"base_model:macadeliccc/laser-dolphin-mixtral-2x7b-dpo",
"base_model:quantized:macadeliccc/laser-dolphin-mixtral-2x7b-dpo",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2024-02-16T01:08:41Z" | ---
license: apache-2.0
library_name: transformers
base_model: macadeliccc/laser-dolphin-mixtral-2x7b-dpo
model_creator: macadeliccc
model_name: laser-dolphin-mixtral-2x7b-dpo
quantized_by: JanHQ
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://github.com/janhq/jan/assets/89722390/35daac7d-b895-487c-a6ac-6663daaad78e" alt="Jan banner" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<p align="center">
<a href="https://jan.ai/">Jan</a>
- <a href="https://discord.gg/AsJ8krTT3N">Discord</a>
</p>
<!-- header end -->
# Model Description
This is a GGUF version of [macadeliccc/laser-dolphin-mixtral-2x7b-dpo](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo)
- Model creator: [macadeliccc](https://huggingface.co/macadeliccc)
- Original model: [laser-dolphin-mixtral-2x7b-dpo](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo)
- Model description: [Readme](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo/blob/main/README.md)
# About Jan
Jan believes in the need for an open-source AI ecosystem and is building the infra and tooling to allow open-source AIs to compete on a level playing field with proprietary ones.
Jan's long-term vision is to build a cognitive framework for future robots, who are practical, useful assistants for humans and businesses in everyday life.
# Jan Model Converter
This is a repository for the [open-source converter](https://github.com/janhq/model-converter. We would be grateful if the community could contribute and strengthen this repository. We are aiming to expand the repo that can convert into various types of format
|
jorbix/Qwen2.5-1.5B-Open-R1-GRPO | jorbix | "2025-03-22T11:05:30Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-03-22T10:51:06Z" | ---
base_model: Qwen/Qwen2.5-1.5B-Instruct
library_name: transformers
model_name: Qwen2.5-1.5B-Open-R1-GRPO
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-1.5B-Open-R1-GRPO
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="jorbix/Qwen2.5-1.5B-Open-R1-GRPO", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jornbowrlx/huggingface/runs/pdzvvsu6)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
dvalbuena1/Reinforce-CartPole | dvalbuena1 | "2022-08-24T18:41:30Z" | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | "2022-08-24T18:39:32Z" | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 209.20 +/- 17.72
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
marcelovidigal/ajuste_fino_modelo_hugging_face_v1 | marcelovidigal | "2024-09-26T16:20:20Z" | 5 | 0 | null | [
"tensorboard",
"safetensors",
"bert",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"region:us"
] | null | "2024-09-25T20:39:43Z" | ---
base_model: google-bert/bert-base-cased
license: apache-2.0
metrics:
- accuracy
tags:
- generated_from_trainer
model-index:
- name: ajuste_fino_modelo_hugging_face_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/mvgdr/retrieval_augmented_generation/runs/akkgxnmm)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/mvgdr/retrieval_augmented_generation/runs/45wkzpj8)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/mvgdr/retrieval_augmented_generation/runs/yas2dj59)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/mvgdr/retrieval_augmented_generation/runs/nx1hlivq)
# ajuste_fino_modelo_hugging_face_v1
This model is a fine-tuned version of [google-bert/bert-base-cased](https://huggingface.co/google-bert/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5848
- Accuracy: 0.5698
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1704 | 1.0 | 625 | 1.0946 | 0.525 |
| 0.9192 | 2.0 | 1250 | 1.0280 | 0.5588 |
| 0.7161 | 3.0 | 1875 | 1.1614 | 0.573 |
| 0.4003 | 4.0 | 2500 | 1.5113 | 0.5698 |
| 0.2678 | 5.0 | 3125 | 2.3124 | 0.556 |
| 0.2277 | 6.0 | 3750 | 2.7098 | 0.5722 |
| 0.1286 | 7.0 | 4375 | 3.2215 | 0.5642 |
| 0.0402 | 8.0 | 5000 | 3.4412 | 0.57 |
| 0.0212 | 9.0 | 5625 | 3.5369 | 0.576 |
| 0.015 | 10.0 | 6250 | 3.5848 | 0.5698 |
### Framework versions
- Transformers 4.42.4
- Pytorch 2.4.1+cu121
- Datasets 2.19.2
- Tokenizers 0.19.1
|
lorahub/flan_t5_xl-duorc_ParaphraseRC_extract_answer | lorahub | "2023-10-19T06:09:37Z" | 12 | 0 | peft | [
"peft",
"region:us"
] | null | "2023-10-19T06:09:19Z" | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
baaaaaaaam/v6 | baaaaaaaam | "2024-05-06T05:35:06Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2024-05-06T03:19:18Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
andrewzhang505/isaacgym_allegrohand | andrewzhang505 | "2022-11-30T19:05:45Z" | 13 | 0 | sample-factory | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | "2022-11-30T01:09:09Z" | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AllegroHand
type: AllegroHand
metrics:
- type: mean_reward
value: 3481.38 +/- 1145.73
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **AllegroHand** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r andrewzhang505/isaacgym_allegrohand
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.isaacgym_examples.enjoy_isaacgym --algo=APPO --env=AllegroHand --train_dir=./train_dir --experiment=isaacgym_allegrohand
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.isaacgym_examples.train_isaacgym --algo=APPO --env=AllegroHand --train_dir=./train_dir --experiment=isaacgym_allegrohand --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
aniketr/mrl-nq | aniketr | "2023-09-29T04:41:33Z" | 0 | 0 | null | [
"question-answering",
"dataset:natural_questions",
"arxiv:2305.19435",
"license:mit",
"region:us"
] | question-answering | "2023-09-29T02:42:05Z" | ---
license: mit
datasets:
- natural_questions
pipeline_tag: question-answering
---
# AdANNS: A Framework for Adaptive Semantic Search 💃
_Aniket Rege*, Aditya Kusupati*, Sharan Ranjit S, Alan Fan, Qinqqing Cao, Sham Kakade, Prateek Jain, Ali Farhadi_
GitHub: https://github.com/RAIVNLab/AdANNS
Arxiv: https://arxiv.org/abs/2305.19435
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64af72d4a609b29cc7b5919b/QYOqZ25qc9pTWlFR0D0VF.png" alt="drawing" width="600"/>
Adaptive representations can be utilized effectively in the decoupled components of clustering and
searching for a better accuracy-compute trade-off (AdANNS-IVF).
</p>
We provide four BERT-Base models finetuned on Natural Questions with [Matryoshka Representation Learning](https://github.com/RAIVNLab/MRL) (MRL).
A vanilla pretrained BERT-Base has a 768-d representation (information bottleneck). As we train with MRL, we enforce the network to learn representations at
multiple granularities nested within a 768-d embedding. The granularities at which we finetune BERT-Base with Matroyshka Loss are specified in the folder name,
e.g. for `dpr-nq-d768_384_192_96_48`, we have d=[48, 96, 192, 384, 768].
You can easily load an mrl-nq model as follows:
```
from transformers import BertModel
import torch
model = BertModel.from_pretrained('dpr-nq-d768_384_192_96_48')
```
## Citation
If you find this project useful in your research, please consider citing:
```
@inproceedings{rege2023adanns,
title={AdANNS: A Framework for Adaptive Semantic Search},
author={Aniket Rege and Aditya Kusupati and Sharan Ranjit S and Alan Fan and Qingqing Cao and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2023},
booktitle = {Advances in Neural Information Processing Systems},
month = {December},
year = {2023},
}
``` |
sh3rry/bce-embedding-base_v1-Q6_K-GGUF | sh3rry | "2025-02-06T14:15:29Z" | 23 | 0 | sentence-transformers | [
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"transformers",
"llama-cpp",
"gguf-my-repo",
"en",
"zh",
"base_model:maidalun1020/bce-embedding-base_v1",
"base_model:quantized:maidalun1020/bce-embedding-base_v1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2025-02-06T14:15:24Z" | ---
license: apache-2.0
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- llama-cpp
- gguf-my-repo
language:
- en
- zh
base_model: maidalun1020/bce-embedding-base_v1
---
# sh3rry/bce-embedding-base_v1-Q6_K-GGUF
This model was converted to GGUF format from [`maidalun1020/bce-embedding-base_v1`](https://huggingface.co/maidalun1020/bce-embedding-base_v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/maidalun1020/bce-embedding-base_v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo sh3rry/bce-embedding-base_v1-Q6_K-GGUF --hf-file bce-embedding-base_v1-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo sh3rry/bce-embedding-base_v1-Q6_K-GGUF --hf-file bce-embedding-base_v1-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo sh3rry/bce-embedding-base_v1-Q6_K-GGUF --hf-file bce-embedding-base_v1-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo sh3rry/bce-embedding-base_v1-Q6_K-GGUF --hf-file bce-embedding-base_v1-q6_k.gguf -c 2048
```
|
Felix92/doctr-dummy-torch-resnet18 | Felix92 | "2022-04-14T07:39:52Z" | 146 | 0 | transformers | [
"transformers",
"pytorch",
"en",
"endpoints_compatible",
"region:us"
] | null | "2022-04-14T07:39:45Z" |
---
language: en
---
<p align="center">
<img src="https://github.com/mindee/doctr/releases/download/v0.3.1/Logo_doctr.gif" width="60%">
</p>
**Optical Character Recognition made seamless & accessible to anyone, powered by TensorFlow 2 & PyTorch**
## Task: classification
https://github.com/mindee/doctr
### Example usage:
```python
>>> from doctr.io import DocumentFile
>>> from doctr.models import ocr_predictor, from_hub
>>> img = DocumentFile.from_images(['<image_path>'])
>>> # Load your model from the hub
>>> model = from_hub('mindee/my-model')
>>> # Pass it to the predictor
>>> # If your model is a recognition model:
>>> predictor = ocr_predictor(det_arch='db_mobilenet_v3_large',
>>> reco_arch=model,
>>> pretrained=True)
>>> # If your model is a detection model:
>>> predictor = ocr_predictor(det_arch=model,
>>> reco_arch='crnn_mobilenet_v3_small',
>>> pretrained=True)
>>> # Get your predictions
>>> res = predictor(img)
```
|
beratcmn/Poet-7B-TR | beratcmn | "2023-12-28T17:26:12Z" | 24 | 3 | peft | [
"peft",
"safetensors",
"xglm",
"text-generation",
"tr",
"dataset:beratcmn/rephrased-instruction-turkish-poems",
"base_model:facebook/xglm-7.5B",
"base_model:adapter:facebook/xglm-7.5B",
"license:apache-2.0",
"region:us"
] | text-generation | "2023-12-17T12:56:42Z" | ---
library_name: peft
base_model: facebook/xglm-7.5B
datasets:
- beratcmn/rephrased-instruction-turkish-poems
language:
- tr
metrics:
- accuracy
pipeline_tag: text-generation
license: apache-2.0
---
# Poet 7B Turkish
Şiir yazmak için eğitilmiş model.
## Model Details
### Model Description
Bu model bulabildiğim en fazla Türkçe token ile eğitilmiş olan `facebook/xglm-7.5B` modelinin QLora kullanılarak fine-tune edilmiş hali. Buradaki asıl amaç modelin bu denli complex bir task'ı anlama kabiletiyini test etmekti ve sonuçlar beni gayet memnun etti.
- **Developed by:** Berat Çimen
- **Model type:** Autoregressive Decoder-only Transformer model with 7.5B Parameters
- **Language(s) (NLP):** Turkish and English
- **License:** apache-2.0
- **Finetuned from model:** facebook/xglm-7.5B
### Framework versions
- PEFT 0.7.1
### Contact
Website: beratcimen.com
E-Mail: [email protected] |
MultEase/QwQ-32B-CoD | MultEase | "2025-03-16T15:03:47Z" | 0 | 0 | null | [
"chat",
"text-generation",
"en",
"arxiv:2502.18600",
"arxiv:2412.15115",
"base_model:Qwen/QwQ-32B",
"base_model:finetune:Qwen/QwQ-32B",
"license:apache-2.0",
"region:us"
] | text-generation | "2025-03-16T06:19:57Z" | ---
license: apache-2.0
license_link: https://huggingface.co/Qwen/QWQ-32B/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model:
- Qwen/QwQ-32B
- Qwen/Qwen2.5-32B
tags:
- chat
---

# Use this model 👉 [https://ollama.com/scratchfens/QwQ-32B-CoD](https://ollama.com/scratchfens/QwQ-32B-CoD) Just check here!
# QwQ-32B-CoD
> 该模型储存库为空,请在Ollama.com上使用。
>
> 在Ollama.com上使用:[链接](https://ollama.com/scratchfens/QwQ-32B-CoD)
>
> The model repository is empty, please use it on Ollama.com.
>
> Use in Ollama.com:[URL](https://ollama.com/scratchfens/QwQ-32B-CoD)
<a href="https://ollama.com/scratchfens/QwQ-32B-CoD" target="_blank" style="margin: 2px;">
<img alt="Ollama" src="https://img.shields.io/badge/%F0%9F%A6%99%20Ollama-Download-brightgreen" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## 模型简介
QwQ-32B-CoD 是基于 Qwen 系列 QwQ 模型进行改进的推理模型。由 FenYi Studio(MultEase) 开发,该模型在保持原有推理能力的基础上,显著优化了推理过程的简洁性,并引入了 CoD (Chain of Draft) 逐步草稿式思维链,增强了模型的推理表达能力。
## 什么是QwQ-32B?
QwQ 是 Qwen 系列的推理模型。与传统的指令调优模型相比,具有思考和推理能力的 QwQ 可以在下游任务中实现显著增强的性能,尤其是难题。QwQ-32B 是中型推理模型,能够实现与最先进的推理模型(如 DeepSeek-R1、o1-mini)竞争的性能。
## 模型特点
CoD 思维链设计受到了论文 "[Chain of Draft: Thinking Faster by Writing Less](https://arxiv.org/abs/2502.18600)" 的启发。原论文中的方法对于真正的**推理模型**并不十分有效,我们观察到,即使使用了论文中的提示词,模型依然会产生复杂冗长而不可控的推理链,而该方法对非推理模型并不十分有效,因为这些模型并不具备真正的**推理能力**,而经过模板与系统提示词的调整后,我们发现QwQ-32B模型可以实现精简方式的推理。
该模型的特点:
- **推理简洁性优化:** 相比原版 QwQ-32B 模型,QwQ-32B-CoD 在生成推理过程时更加精简、直接,减少了冗余信息,提高了推理的可读性和效率。并且可以获得甚至超越原有模型的推理水平,特别是在长上下文推理中。
- **CoD (Chain of Draft) 思维链:** 引入了逐步草稿式思维链,使模型在推理过程中能够像人类一样逐步构建思路,最终形成完整的推理路径。
- **基于 Qwen 系列:** 继承了 Qwen 系列模型的强大基础能力,在各类推理任务中表现出色。

* *由于时间紧张,我们并未对模型进行详细测评,您可以协助我们进行模型水平测评。*
## 模型参数(取自QwQ-32B)
- **类型:** 因果语言模型 (Causal Language Models)
- **训练阶段:** 预训练 & 后训练 (监督微调和强化学习)
- **架构:** 基于 Transformer,采用 RoPE、SwiGLU、RMSNorm 和 Attention QKV bias
- **参数量:** 32.5B
- **非嵌入层参数量:** 31.0B
- **层数:** 64
- **注意力头数 (GQA):** Q 为 40,KV 为 8
- **上下文长度:** 131,072 tokens
- 对于超过 8,192 tokens 的提示,请按照[使用指南](#使用指南)中的说明启用 YaRN。
## 与原模型对比 (QwQ-32B)
| 特性 | QwQ-32B-CoD | QwQ-32B |
| ---------- | -------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 推理简洁性 | **显著优化**,推理过程更精简、直接。 | 推理过程可能较为冗长,包含较多中间步骤和解释。 |
| 思维链 | **CoD (Chain of Draft)** 逐步草稿式思维链。 | 传统的思维链。 |
| 推理示例 | 见下方 | 见下方 |
**推理示例对比**
**原模型 (QwQ-32B) 推理(冗长):**
```
<think>
首先,我们来分析题目:解方程 \((1+a^2)(a^2+2a+5) - (1-a)(2-2a) = 0\)。
我们的目标是找到所有满足这个等式的实数 \(a\)。
**步骤1:展开方程的每一部分**
首先,我们需要将方程中的每一部分展开,以便合并同类项并简化方程。
首先处理第一个乘积项:\((1+a^2)(a^2+2a+5)\)。
使用分配律(即多项式乘法)展开:
\[
(1+a^2)(a^2+2a+5) = 1 \times (a^2+2a+5) + a^2 \times (a^2+2a+5)
\]
计算每一部分:
1. \(1 \times (a^2+2a+5) = a^2 + 2a + 5\)
2. \(a^2 \times (a^2+2a+5) = a^4 + 2a^3 + 5a^2\)
将两者相加:
\[
a^2 + 2a + 5 + a^4 + 2a^3 + 5a^2 = a^4 + 2a^3 + (a^2 + 5a^2) + 2a + 5
\]
\[
= a^4 + 2a^3 + 6a^2 + 2a + 5
\]
接下来处理第二个乘积项:\((1 - a)(2 - 2a)\)。
同样使用分配律展开:
\[
(1 - a)(2 - 2a) = 1 \times (2 - 2a) - a \times (2 - 2a)
\]
计算每一部分:
1. \(1 \times (2 - 2a) = 2 - 2a\)
2. \(-a \times (2 - 2a) = -2a + 2a^2\)
将两者相加:
\[
2 - 2a - 2a + 2a^2 = 2a^2 - 4a + 2
\]
**步骤2:将展开后的表达式代入原方程**
现在,将展开后的结果代入原方程:
\[
(a^4 + 2a^3 + 6a^2 + 2a + 5) - (2a^2 - 4a + 2) = 0
\]
接下来,需要减去第二个多项式,即:
\[
a^4 + 2a^3 + 6a^2 + 2a + 5 - 2a^2 + 4a - 2 = 0
\]
注意符号的变化:减去 \((2a^2 - 4a + 2)\) 等同于加上 \(-2a^2 + 4a - 2\)。
**步骤3:合并同类项**
现在合并同类项:
1. **四次项**:\(a^4\)(没有其他四次项)
2. **三次项**:\(2a^3\)(没有其他三次项)
3. **二次项**:\(6a^2 - 2a^2 = 4a^2\)
4. **一次项**:\(2a + 4a = 6a\)
5. **常数项**:\(5 - 2 = 3\)
因此,合并后的方程为:
\[
a^4 + 2a^3 + 4a^2 + 6a + 3 = 0
\]
**步骤4:尝试因式分解**
接下来,我们需要尝试对方程 \(a^4 + 2a^3 + 4a^2 + 6a + 3 = 0\) 进行因式分解,以找到可能的根。
首先,可以尝试有理根定理,寻找可能的有理根。有理根定理指出,可能的有理根为常数项的因数除以首项系数的因数。这里,常数项是3,首项系数是1,因此可能的根为 \(\pm1, \pm3\)。
测试 \(a = -1\):
\[
(-1)^4 + 2(-1)^3 + 4(-1)^2 + 6(-1) + 3 = 1 - 2 + 4 - 6 + 3 = 0
\]
计算结果为0,因此 \(a = -1\) 是方程的一个根。因此,\((a + 1)\) 是多项式的一个因子。
接下来,我们可以用多项式除法或综合除法来分解多项式。这里使用综合除法:
用根 \(a = -1\) 对多项式 \(a^4 + 2a^3 + 4a^2 + 6a + 3\) 进行除法:
将系数列出来:1(\(a^4\))、2(\(a^3\))、4(\(a^2\))、6(\(a\))、3(常数项)。
进行综合除法:
- 带入根 -1:
-1 | 1 2 4 6 3
| -1 -1 -3 -3
-------------------------
1 1 3 3 0
余数为0,说明分解正确。因此,多项式可以分解为:
\[
(a + 1)(a^3 + a^2 + 3a + 3)
\]
现在需要进一步分解三次多项式 \(a^3 + a^2 + 3a + 3\)。
同样尝试有理根定理,可能的根为 \(\pm1, \pm3\)。
测试 \(a = -1\):
\[
(-1)^3 + (-1)^2 + 3(-1) + 3 = -1 + 1 - 3 + 3 = 0
\]
因此 \(a = -1\) 是另一个根,因此多项式 \(a^3 + a^2 + 3a + 3\) 可以分解为:
\[
(a + 1)(a^2 + 0a + 3) = (a + 1)(a^2 + 3)
\]
因此,原多项式分解为:
\[
(a + 1)^2 (a^2 + 3)
\]
因此,原方程变为:
\[
(a + 1)^2 (a^2 + 3) = 0
\]
**步骤5:求解方程**
方程的解由每个因子为零时得到:
1. \(a + 1 = 0 \Rightarrow a = -1\),这是一个二重根。
2. \(a^2 + 3 = 0 \Rightarrow a^2 = -3\),这在实数范围内无解,但在复数范围内解为 \(a = \pm \sqrt{-3} = \pm i\sqrt{3}\)。
不过题目可能只寻找实数解,因此只有 \(a = -1\) 是实数解。
但需要确认是否在原方程中代入正确,以及是否在展开过程中有误。
**步骤6:验证解的正确性**
将 \(a = -1\) 代入原方程:
左边:
\[
(1 + (-1)^2)((-1)^2 + 2(-1) + 5) - (1 - (-1))(2 - 2(-1))
\]
计算各部分:
1. \(1 + (-1)^2 = 1 + 1 = 2\)
2. \((-1)^2 + 2(-1) +5 = 1 -2 +5 =4\)
3. \(1 - (-1) = 2\)
4. \(2 -2(-1) = 2 + 2 =4\)
因此左边:
\[
2 \times 4 - 2 \times 4 = 8 - 8 =0
\]
符合方程,因此 \(a = -1\) 是正确的解。
对于复数解 \(a = \pm i\sqrt{3}\),若题目要求实数解,则只取 \(a = -1\)。
**步骤7:总结答案**
因此,方程的实数解为 \(a = -1\),由于是二重根,但题目可能只需要解的存在性,所以最终解为 \(a = -1\)。
</think>
#### 最终答案
方程的解为 \(\boxed{-1}\)。
```
**QwQ-32B-CoD 推理 (清晰且精简):**
---
> (1+a²)(a²+2a+5) → a⁴+2a³+5a² +a²²+2a³+5a² → 错误展开,重新计算
> 正确展开:(1)(a²) + (1)(2a) + (1)(5) + a²(a²) +a²(2a)+a²(5) → a² +2a+5 +a⁴+2a³+5a² → 合并项
> 合并后:a⁴+2a³+6a²+2a+5
> (1-a)(2-2a) → 2-2a-2a+2a² → 2a²-4a+2
> 整个式子:a⁴+2a³+6a²+2a+5 - (2a²-4a+2)=0 → a⁴+2a³+4a²+6a+3=0
> 试可能有理根:±1, ±3 → 代入a=-1:1-2+4-6+3=0 ✓
> 因式分解:(a+1)(a³+a²+3a+3)=0
> 解三次方程a³+a²+3a+3=0 → 分组(a³+a²)+(3a+3)=a²(a+1)+3(a+1)=(a+1)(a²+3)=0
> 所以根为a=-1,a=±√3 i
> 实数解:a=-1
#### 最终输出
解方程:(1+a²)(a²+2a+5) - (1-a)(2-2a) = 0
**步骤详解:**
1. **展开多项式:**
- 展开第一个乘积:
(1+a²)(a²+2a+5)
=1×a² +1×2a +1×5 +a²×a² +a²×2a +a²×5
=a² +2a +5 +a⁴ +2a³ +5a²
=a⁴ +2a³ +6a² +2a +5
- 展开第二个乘积:
(1−a)(2−2a)
=1×2 +1×(−2a) + (−a)×2 + (−a)×(−2a)
=2 −2a −2a +2a²
=2a² −4a +2
2. **合并方程:**
将展开式代入原方程:
[a⁴ +2a³ +6a² +2a +5] − [2a² −4a +2] =0
去括号并合并同类项:
a⁴ +2a³ + (6a²−2a²) + (2a+4a) + (5−2) =0
化简得:
a⁴ +2a³ +4a² +6a +3 =0
3. **因式分解:**
尝试有理根,代入a=−1:
(−1)⁴ +2(−1)³ +4(−1)² +6(−1) +3
=1−2+4−6+3 =0 ✓
因此可分解为:
(a+1)(a³ +a² +3a +3)=0
4. **解三次方程:**
分解a³ +a² +3a +3:
分组为(a³ +a²) + (3a +3)
=a²(a+1) +3(a+1)
=(a+1)(a² +3)
因此方程变为:
(a+1)²(a² +3)=0
5. **求根:**
- 实数根:a+1=0 → a=−1
- 虚数根:a² +3=0 → a=±√3 i
**最终解:**
实数解为 **a = −1**,虚数解为 **a = ±√3 i**。
---
## 使用指南
要快速体验 QwQ-32B-CoD 模型,请访问 Ollama:
<a href="https://ollama.com/scratchfens/QwQ-32B-CoD" target="_blank" style="margin: 2px;">
<img alt="Ollama" src="https://img.shields.io/badge/%F0%9F%A6%99%20Ollama-Download-brightgreen" style="display: inline-block; vertical-align: middle;"/>
</a>
点击链接,按照 Ollama 上的说明拉取并运行模型。
## 致谢
- 感谢阿里云Qwen团队提供的基础模型
- 感谢 **论文 "[Chain of Draft: Thinking Faster by Writing Less](https://arxiv.org/abs/2502.18600)"** 提供的思路启发。
## 关于我们
FenYi Studio是一个推进大型语言模型应用的技术兴趣小组。请联系我们加入讨论或提供计算资源。在GitHub上与我们见面:https://github.com/Fenyi-Studios
## 引用
如果您觉得我们的工作有帮助,请引用我们:
```
@misc{qwq32bcod,
title = {QwQ-32B-CoD: Enhanced Reasoning with Chain of Draft},
url = {https://huggingface.co/MultEase/QwQ-32B-CoD},
author = {MultEase},
month = {March},
year = {2025}
}
@article{Chain of Draft: Thinking Faster by Writing Less,
title={Chain of Draft: Thinking Faster by Writing Less},
journal={arXiv preprint arXiv:2502.18600},
year={2025}
}
@misc{qwq32b,
title = {QwQ-32B: Embracing the Power of Reinforcement Learning},
url = {https://qwenlm.github.io/blog/qwq-32b/},
author = {Qwen Team},
month = {March},
year = {2025}
}
@article{qwen2.5,
title={Qwen2.5 Technical Report},
author={An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mingfeng Xue and Pei Zhang and Qin Zhu and Rui Men and Runji Lin and Tianhao Li and Tianyi Tang and Tingyu Xia and Xingzhang Ren and Xuancheng Ren and Yang Fan and Yang Su and Yichang Zhang and Yu Wan and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zihan Qiu},
journal={arXiv preprint arXiv:2412.15115},
year={2024}
}
```
# QwQ-32B-CoD
<a href="https://ollama.com/scratchfens/QwQ-32B-CoD" target="_blank" style="margin: 2px;">
<img alt="Ollama" src="https://img.shields.io/badge/%F0%9F%A6%99%20Ollama-Download-brightgreen" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Model Introduction
QwQ-32B-CoD is an improved reasoning model based on the Qwen series QwQ models. Developed by FenYi Studio (MultEase), this model significantly optimizes the conciseness of the reasoning process while maintaining the original reasoning ability. It also introduces CoD (Chain of Draft), a step-by-step drafting thought chain, which enhances the model's reasoning and expressive capabilities.
## What is QwQ-32B?
QwQ is a reasoning model in the Qwen series. Compared with traditional instruction-tuned models, QwQ, with its ability to think and reason, can achieve significantly enhanced performance in downstream tasks, especially difficult ones. QwQ-32B is a medium-sized reasoning model capable of achieving performance competitive with state-of-the-art reasoning models such as DeepSeek-R1 and o1-mini.
## Model Features
The CoD (Chain of Draft) thought chain design is inspired by the paper "[Chain of Draft: Thinking Faster by Writing Less](https://arxiv.org/abs/2502.18600)". The original method in the paper is not very effective for true **reasoning models**. We observed that even with the prompts in the paper, the model still generates complex, lengthy, and uncontrollable reasoning chains. The method is also not very effective for non-reasoning models, because these models do not have real **reasoning capabilities**. After adjusting the template and system prompts, we found that the QwQ-32B model can achieve concise reasoning.
The features of this model are:
- **Optimized Reasoning Conciseness:** Compared to the original QwQ-32B model, QwQ-32B-CoD generates a more concise and direct reasoning process, reducing redundant information and improving the readability and efficiency of reasoning. It can even achieve or surpass the reasoning level of the original model, especially in long-context reasoning.
- **CoD (Chain of Draft) Thought Chain:** Introduces a step-by-step drafting thought chain, enabling the model to gradually construct its ideas during the reasoning process, similar to humans, and ultimately form a complete reasoning path.
- **Based on the Qwen Series:** Inherits the strong foundation of the Qwen series models and performs well in various reasoning tasks.

* *Due to time constraints, we did not conduct a detailed evaluation of the model. You can assist us in assessing the model’s performance.*
## Model Parameters (Taken from QwQ-32B)
- **Type:** Causal Language Models
- **Training Stage:** Pre-training & Post-training (Supervised Fine-tuning and Reinforcement Learning)
- **Architecture:** Transformer-based, using RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- **Parameter Count:** 32.5B
- **Non-embedding Parameter Count:** 31.0B
- **Layers:** 64
- **Attention Heads (GQA):** Q is 40, KV is 8
- **Context Length:** 131,072 tokens
- For prompts exceeding 8,192 tokens, please follow the instructions in the [Usage Guide](#usage-guide) to enable YaRN.
## Comparison with the Original Model (QwQ-32B)
| Feature | QwQ-32B-CoD | QwQ-32B |
| -------------------- | -------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| Reasoning Conciseness | **Significantly optimized**, more concise and direct. | The reasoning process may be relatively verbose, including more intermediate steps and explanations. |
| Thought Chain | **CoD (Chain of Draft)** step-by-step drafting. | Traditional thought chain. |
| Reasoning Example | See below | See below |
**Reasoning Example Comparison**
**Original Model (QwQ-32B) Reasoning (Verbose):**
```
<think>
First, let's analyze the problem: Solve the equation \((1+a^2)(a^2+2a+5) - (1-a)(2-2a) = 0\).
Our goal is to find all real numbers \(a\) that satisfy this equation.
**Step 1: Expand each part of the equation**
First, we need to expand each part of the equation to combine like terms and simplify the equation.
Let's start with the first product term: \((1+a^2)(a^2+2a+5)\).
Using the distributive property (i.e., polynomial multiplication) to expand:
\[
(1+a^2)(a^2+2a+5) = 1 \times (a^2+2a+5) + a^2 \times (a^2+2a+5)
\]
Calculate each part:
1. \(1 \times (a^2+2a+5) = a^2 + 2a + 5\)
2. \(a^2 \times (a^2+2a+5) = a^4 + 2a^3 + 5a^2\)
Add the two parts together:
\[
a^2 + 2a + 5 + a^4 + 2a^3 + 5a^2 = a^4 + 2a^3 + (a^2 + 5a^2) + 2a + 5
\]
\[
= a^4 + 2a^3 + 6a^2 + 2a + 5
\]
Next, let's deal with the second product term: \((1 - a)(2 - 2a)\).
Similarly, use the distributive property to expand:
\[
(1 - a)(2 - 2a) = 1 \times (2 - 2a) - a \times (2 - 2a)
\]
Calculate each part:
1. \(1 \times (2 - 2a) = 2 - 2a\)
2. \(-a \times (2 - 2a) = -2a + 2a^2\)
Add the two parts together:
\[
2 - 2a - 2a + 2a^2 = 2a^2 - 4a + 2
\]
**Step 2: Substitute the expanded expressions into the original equation**
Now, substitute the expanded results into the original equation:
\[
(a^4 + 2a^3 + 6a^2 + 2a + 5) - (2a^2 - 4a + 2) = 0
\]
Next, we need to subtract the second polynomial:
\[
a^4 + 2a^3 + 6a^2 + 2a + 5 - 2a^2 + 4a - 2 = 0
\]
Note the change in signs: subtracting \((2a^2 - 4a + 2)\) is equivalent to adding \(-2a^2 + 4a - 2\).
**Step 3: Combine like terms**
Now combine like terms:
1. **Quartic term:** \(a^4\) (no other quartic terms)
2. **Cubic term:** \(2a^3\) (no other cubic terms)
3. **Quadratic term:** \(6a^2 - 2a^2 = 4a^2\)
4. **Linear term:** \(2a + 4a = 6a\)
5. **Constant term:** \(5 - 2 = 3\)
Therefore, the combined equation is:
\[
a^4 + 2a^3 + 4a^2 + 6a + 3 = 0
\]
**Step 4: Try to factor**
Next, we need to try to factor the equation \(a^4 + 2a^3 + 4a^2 + 6a + 3 = 0\) to find possible roots.
First, we can try the Rational Root Theorem to find possible rational roots. The Rational Root Theorem states that possible rational roots are factors of the constant term divided by factors of the leading coefficient. Here, the constant term is 3 and the leading coefficient is 1, so the possible roots are \(\pm1, \pm3\).
Test \(a = -1\):
\[
(-1)^4 + 2(-1)^3 + 4(-1)^2 + 6(-1) + 3 = 1 - 2 + 4 - 6 + 3 = 0
\]
The result is 0, so \(a = -1\) is a root of the equation. Therefore, \((a + 1)\) is a factor of the polynomial.
Next, we can use polynomial long division or synthetic division to factor the polynomial. Here we use synthetic division:
Divide the polynomial \(a^4 + 2a^3 + 4a^2 + 6a + 3\) by the root \(a = -1\):
List the coefficients: 1 (\(a^4\)), 2 (\(a^3\)), 4 (\(a^2\)), 6 (\(a\)), 3 (constant term).
Perform synthetic division:
- Bring down the root -1:
-1 | 1 2 4 6 3
| -1 -1 -3 -3
-------------------------
1 1 3 3 0
The remainder is 0, which means the factorization is correct. Therefore, the polynomial can be factored as:
\[
(a + 1)(a^3 + a^2 + 3a + 3)
\]
Now we need to further factor the cubic polynomial \(a^3 + a^2 + 3a + 3\).
Again, try the Rational Root Theorem, the possible roots are \(\pm1, \pm3\).
Test \(a = -1\):
\[
(-1)^3 + (-1)^2 + 3(-1) + 3 = -1 + 1 - 3 + 3 = 0
\]
So \(a = -1\) is another root, so the polynomial \(a^3 + a^2 + 3a + 3\) can be factored as:
\[
(a + 1)(a^2 + 0a + 3) = (a + 1)(a^2 + 3)
\]
Therefore, the original polynomial is factored as:
\[
(a + 1)^2 (a^2 + 3)
\]
Therefore, the original equation becomes:
\[
(a + 1)^2 (a^2 + 3) = 0
\]
**Step 5: Solve the equation**
The solutions of the equation are obtained when each factor is zero:
1. \(a + 1 = 0 \Rightarrow a = -1\), this is a double root.
2. \(a^2 + 3 = 0 \Rightarrow a^2 = -3\), this has no solution in the real number range, but in the complex number range, the solutions are \(a = \pm \sqrt{-3} = \pm i\sqrt{3}\).
However, the problem likely only seeks real solutions, so only \(a = -1\) is a real solution.
But we need to confirm that substituting into the original equation is correct, and that there were no errors in the expansion process.
**Step 6: Verify the correctness of the solution**
Substitute \(a = -1\) into the original equation:
Left side:
\[
(1 + (-1)^2)((-1)^2 + 2(-1) + 5) - (1 - (-1))(2 - 2(-1))
\]
Calculate each part:
1. \(1 + (-1)^2 = 1 + 1 = 2\)
2. \((-1)^2 + 2(-1) +5 = 1 -2 +5 =4\)
3. \(1 - (-1) = 2\)
4. \(2 -2(-1) = 2 + 2 =4\)
Therefore, the left side:
\[
2 \times 4 - 2 \times 4 = 8 - 8 =0
\]
Matches the equation, so \(a = -1\) is the correct solution.
For the complex solutions \(a = \pm i\sqrt{3}\), if the problem requires real solutions, then only \(a = -1\) is taken.
**Step 7: Summarize the answer**
Therefore, the real solution of the equation is \(a = -1\). Since it is a double root, but the problem may only require the existence of the solution, the final solution is \(a = -1\).
</think>
#### Final Answer
The solution to the equation is \(\boxed{-1}\).
```
**QwQ-32B-CoD Reasoning (Clear and Concise):**
---
> (1+a²)(a²+2a+5) → a⁴+2a³+5a² +a²²+2a³+5a² → Incorrect expansion, recalculate.
> Correct expansion: (1)(a²) + (1)(2a) + (1)(5) + a²(a²) +a²(2a)+a²(5) → a² +2a+5 +a⁴+2a³+5a² → Combine terms.
> After combining: a⁴+2a³+6a²+2a+5
> (1-a)(2-2a) → 2-2a-2a+2a² → 2a²-4a+2
> The whole expression: a⁴+2a³+6a²+2a+5 - (2a²-4a+2)=0 → a⁴+2a³+4a²+6a+3=0
> Try possible rational roots: ±1, ±3 → Substitute a=-1: 1-2+4-6+3=0 ✓
> Factorization: (a+1)(a³+a²+3a+3)=0
> Solve the cubic equation a³+a²+3a+3=0 → Group (a³+a²)+(3a+3)=a²(a+1)+3(a+1)=(a+1)(a²+3)=0
> So the roots are a=-1, a=±√3 i
> Real solution: a=-1
#### Final Answer
Solve the equation: (1+a²)(a²+2a+5) - (1-a)(2-2a) = 0
**Detailed Steps:**
1. **Expand the polynomials:**
- Expand the first product:
(1+a²)(a²+2a+5)
=1×a² +1×2a +1×5 +a²×a² +a²×2a +a²×5
=a² +2a +5 +a⁴ +2a³ +5a²
=a⁴ +2a³ +6a² +2a +5
- Expand the second product:
(1−a)(2−2a)
=1×2 +1×(−2a) + (−a)×2 + (−a)×(−2a)
=2 −2a −2a +2a²
=2a² −4a +2
2. **Combine the equation:**
Substitute the expansions into the original equation:
[a⁴ +2a³ +6a² +2a +5] − [2a² −4a +2] =0
Remove parentheses and combine like terms:
a⁴ +2a³ + (6a²−2a²) + (2a+4a) + (5−2) =0
Simplify to:
a⁴ +2a³ +4a² +6a +3 =0
3. **Factorization:**
Try rational roots, substitute a=−1:
(−1)⁴ +2(−1)³ +4(−1)² +6(−1) +3
=1−2+4−6+3 =0 ✓
Therefore it can be factored as:
(a+1)(a³ +a² +3a +3)=0
4. **Solve the cubic equation:**
Factor a³ +a² +3a +3:
Group as (a³ +a²) + (3a +3)
=a²(a+1) +3(a+1)
=(a+1)(a² +3)
Therefore the equation becomes:
(a+1)²(a² +3)=0
5. **Find the roots:**
- Real root: a+1=0 → a=−1
- Imaginary roots: a² +3=0 → a=±√3 i
**Final Solution:**
The real solution is **a = −1**, the imaginary solutions are **a = ±√3 i**.
---
## Usage Guide
To quickly experience the QwQ-32B-CoD model, please visit Ollama:
<a href="https://ollama.com/scratchfens/QwQ-32B-CoD" target="_blank" style="margin: 2px;">
<img alt="Ollama" src="https://img.shields.io/badge/%F0%9F%A6%99%20Ollama-Download-brightgreen" style="display: inline-block; vertical-align: middle;"/>
</a>
Click the link and follow the instructions on Ollama to pull and run the model.
## Acknowledgements
- Thanks to the Alibaba Cloud Qwen team for providing the base model.
- Thanks to the **paper "[Chain of Draft: Thinking Faster by Writing Less](https://arxiv.org/abs/2502.18600)"** for the inspiration.
## About Us
FenYi Studio is a technology interest group promoting the application of large language models. Please contact us to join the discussion or provide computing resources. Meet us on GitHub: https://github.com/Fenyi-Studios
## Citation
If you find our work helpful, please cite us:
```
@misc{qwq32bcod,
title = {QwQ-32B-CoD: Enhanced Reasoning with Chain of Draft},
url = {https://huggingface.co/MultEase/QwQ-32B-CoD},
author = {MultEase},
month = {March},
year = {2025}
}
@article{Chain of Draft: Thinking Faster by Writing Less,
title={Chain of Draft: Thinking Faster by Writing Less},
journal={arXiv preprint arXiv:2502.18600},
year={2025}
}
@misc{qwq32b,
title = {QwQ-32B: Embracing the Power of Reinforcement Learning},
url = {https://qwenlm.github.io/blog/qwq-32b/},
author = {Qwen Team},
month = {March},
year = {2025}
}
@article{qwen2.5,
title={Qwen2.5 Technical Report},
author={An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mingfeng Xue and Pei Zhang and Qin Zhu and Rui Men and Runji Lin and Tianhao Li and Tianyi Tang and Tingyu Xia and Xingzhang Ren and Xuancheng Ren and Yang Fan and Yang Su and Yichang Zhang and Yu Wan and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zihan Qiu},
journal={arXiv preprint arXiv:2412.15115},
year={2024}
}
```
|
ORKAFILM/kay2 | ORKAFILM | "2025-01-03T17:49:14Z" | 6 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-01-03T16:56:06Z" | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: kay2
---
# Kay2
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `kay2` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('ORKAFILM/kay2', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
memevis/HA60 | memevis | "2025-01-03T15:35:06Z" | 15 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-01-03T15:30:13Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hpsmarttest/Lexika | hpsmarttest | "2025-01-08T23:47:01Z" | 26 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-01-08T22:26:50Z" | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Lexika
---
# Lexika
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Lexika` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('hpsmarttest/Lexika', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
ZhihongDeng/ppo-Huggy | ZhihongDeng | "2023-02-17T03:25:19Z" | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | "2023-02-17T03:25:11Z" |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: ZhihongDeng/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
gabrielloiseau/ModernBERT-base-authorship-verification | gabrielloiseau | "2025-02-17T14:14:42Z" | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"modernbert",
"sentence-similarity",
"base_model:answerdotai/ModernBERT-base",
"base_model:finetune:answerdotai/ModernBERT-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2025-02-17T14:12:24Z" | ---
tags:
- sentence-transformers
- sentence-similarity
base_model: answerdotai/ModernBERT-base
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on answerdotai/ModernBERT-base
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [answerdotai/ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [answerdotai/ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base) <!-- at revision 8949b909ec900327062f0ebf497f51aef5e6f0c8 -->
- **Maximum Sequence Length:** 8192 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown --> |
RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf | RichardErkhov | "2024-08-22T19:29:27Z" | 33 | 0 | null | [
"gguf",
"arxiv:2406.04313",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-08-22T17:42:19Z" | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8B-Instruct-RR - GGUF
- Model creator: https://huggingface.co/GraySwanAI/
- Original model: https://huggingface.co/GraySwanAI/Llama-3-8B-Instruct-RR/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8B-Instruct-RR.Q2_K.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8B-Instruct-RR.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8B-Instruct-RR.IQ3_S.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8B-Instruct-RR.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8B-Instruct-RR.IQ3_M.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8B-Instruct-RR.Q3_K.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8B-Instruct-RR.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8B-Instruct-RR.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8B-Instruct-RR.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8B-Instruct-RR.Q4_0.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8B-Instruct-RR.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8B-Instruct-RR.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8B-Instruct-RR.Q4_K.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8B-Instruct-RR.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8B-Instruct-RR.Q4_1.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8B-Instruct-RR.Q5_0.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8B-Instruct-RR.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8B-Instruct-RR.Q5_K.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8B-Instruct-RR.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8B-Instruct-RR.Q5_1.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8B-Instruct-RR.Q6_K.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-8B-Instruct-RR.Q8_0.gguf](https://huggingface.co/RichardErkhov/GraySwanAI_-_Llama-3-8B-Instruct-RR-gguf/blob/main/Llama-3-8B-Instruct-RR.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
# Model Details
Llama-3-8B-Instruct-RR is a Llama-3 model with circuit breakers inserted using Representation Rerouting (RR).
Circuit Breaking is a new approach inspired by [representation engineering](https://ai-transparency.org/), designed to prevent AI systems from generating harmful content by directly altering harmful model representations, with minimal capability degradation. For more information, [please check out our paper](https://arxiv.org/abs/2406.04313).
<p align="center">
<img src="https://github.com/GraySwanAI/circuit-breakers/raw/main/assets/llama_splash.png" width="800"/>
</p>
|
mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF | mradermacher | "2024-10-01T07:14:07Z" | 138 | 1 | transformers | [
"transformers",
"gguf",
"en",
"dataset:jondurbin/gutenberg-dpo-v0.1",
"dataset:nbeerbower/gutenberg2-dpo",
"base_model:nbeerbower/Hermes2-Gutenberg2-Mistral-7B",
"base_model:quantized:nbeerbower/Hermes2-Gutenberg2-Mistral-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | "2024-10-01T02:09:19Z" | ---
base_model: nbeerbower/Hermes2-Gutenberg2-Mistral-7B
datasets:
- jondurbin/gutenberg-dpo-v0.1
- nbeerbower/gutenberg2-dpo
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/nbeerbower/Hermes2-Gutenberg2-Mistral-7B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Hermes2-Gutenberg2-Mistral-7B-i1-GGUF/resolve/main/Hermes2-Gutenberg2-Mistral-7B.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Subsets and Splits