
filename
stringlengths 7
56
| text
stringlengths 257
90.2k
⌀ |
|---|---|
perf_train_cpu_many.md
|
# Efficient Training on Multiple CPUs
When training on a single CPU is too slow, we can use multiple CPUs. This guide focuses on PyTorch-based DDP enabling distributed CPU training efficiently.
## Intel® oneCCL Bindings for PyTorch
[Intel® oneCCL](https://github.com/oneapi-src/oneCCL) (collective communications library) is a library for efficient distributed deep learning training implementing such collectives like allreduce, allgather, alltoall. For more information on oneCCL, please refer to the [oneCCL documentation](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html) and [oneCCL specification](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html).
Module `oneccl_bindings_for_pytorch` (`torch_ccl` before version 1.12) implements PyTorch C10D ProcessGroup API and can be dynamically loaded as external ProcessGroup and only works on Linux platform now
Check more detailed information for [oneccl_bind_pt](https://github.com/intel/torch-ccl).
### Intel® oneCCL Bindings for PyTorch installation:
Wheel files are available for the following Python versions:
| Extension Version | Python 3.6 | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 |
| :---------------: | :--------: | :--------: | :--------: | :--------: | :---------: |
| 1.13.0 | | √ | √ | √ | √ |
| 1.12.100 | | √ | √ | √ | √ |
| 1.12.0 | | √ | √ | √ | √ |
| 1.11.0 | | √ | √ | √ | √ |
| 1.10.0 | √ | √ | √ | √ | |
pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu
where `{pytorch_version}` should be your PyTorch version, for instance 1.13.0.
Check more approaches for [oneccl_bind_pt installation](https://github.com/intel/torch-ccl).
Versions of oneCCL and PyTorch must match.
oneccl_bindings_for_pytorch 1.12.0 prebuilt wheel does not work with PyTorch 1.12.1 (it is for PyTorch 1.12.0)
PyTorch 1.12.1 should work with oneccl_bindings_for_pytorch 1.12.100
## Intel® MPI library
Use this standards-based MPI implementation to deliver flexible, efficient, scalable cluster messaging on Intel® architecture. This component is part of the Intel® oneAPI HPC Toolkit.
oneccl_bindings_for_pytorch is installed along with the MPI tool set. Need to source the environment before using it.
for Intel® oneCCL >= 1.12.0
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
for Intel® oneCCL whose version < 1.12.0
torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os.path.abspath(os.path.dirname(torch_ccl.__file__)))")
source $torch_ccl_path/env/setvars.sh
#### IPEX installation:
IPEX provides performance optimizations for CPU training with both Float32 and BFloat16, you could refer [single CPU section](./perf_train_cpu).
The following "Usage in Trainer" takes mpirun in Intel® MPI library as an example.
## Usage in Trainer
To enable multi CPU distributed training in the Trainer with the ccl backend, users should add **`--ddp_backend ccl`** in the command arguments.
Let's see an example with the [question-answering example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
The following command enables training with 2 processes on one Xeon node, with one process running per one socket. The variables OMP_NUM_THREADS/CCL_WORKER_COUNT can be tuned for optimal performance.
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=127.0.0.1
mpirun -n 2 -genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex
The following command enables training with a total of four processes on two Xeons (node0 and node1, taking node0 as the main process), ppn (processes per node) is set to 2, with one process running per one socket. The variables OMP_NUM_THREADS/CCL_WORKER_COUNT can be tuned for optimal performance.
In node0, you need to create a configuration file which contains the IP addresses of each node (for example hostfile) and pass that configuration file path as an argument.
```shell script
cat hostfile
xxx.xxx.xxx.xxx #node0 ip
xxx.xxx.xxx.xxx #node1 ip
Now, run the following command in node0 and **4DDP** will be enabled in node0 and node1 with BF16 auto mixed precision:
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 4 -ppn 2 \
-genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex \
--bf16
|
bertology.md
|
# BERTology
There is a growing field of study concerned with investigating the inner working of large-scale transformers like BERT
(that some call "BERTology"). Some good examples of this field are:
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
https://arxiv.org/abs/1905.05950
- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
Manning: https://arxiv.org/abs/1906.04341
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
In order to help this new field develop, we have included a few additional features in the BERT/GPT/GPT-2 models to
help people access the inner representations, mainly adapted from the great work of Paul Michel
(https://arxiv.org/abs/1905.10650):
- accessing all the hidden-states of BERT/GPT/GPT-2,
- accessing all the attention weights for each head of BERT/GPT/GPT-2,
- retrieving heads output values and gradients to be able to compute head importance score and prune head as explained
in https://arxiv.org/abs/1905.10650.
To help you understand and use these features, we have added a specific example script: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) while extract information and prune a model pre-trained on
GLUE.
|
training.md
|
# Fine-tune a pretrained model
[[open-in-colab]]
There are significant benefits to using a pretrained model. It reduces computation costs, your carbon footprint, and allows you to use state-of-the-art models without having to train one from scratch. 🤗 Transformers provides access to thousands of pretrained models for a wide range of tasks. When you use a pretrained model, you train it on a dataset specific to your task. This is known as fine-tuning, an incredibly powerful training technique. In this tutorial, you will fine-tune a pretrained model with a deep learning framework of your choice:
* Fine-tune a pretrained model with 🤗 Transformers [`Trainer`].
* Fine-tune a pretrained model in TensorFlow with Keras.
* Fine-tune a pretrained model in native PyTorch.
## Prepare a dataset
Before you can fine-tune a pretrained model, download a dataset and prepare it for training. The previous tutorial showed you how to process data for training, and now you get an opportunity to put those skills to the test!
Begin by loading the [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full) dataset:
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset["train"][100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularlythat takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
As you now know, you need a tokenizer to process the text and include a padding and truncation strategy to handle any variable sequence lengths. To process your dataset in one step, use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process#map) method to apply a preprocessing function over the entire dataset:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
If you like, you can create a smaller subset of the full dataset to fine-tune on to reduce the time it takes:
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
## Train
At this point, you should follow the section corresponding to the framework you want to use. You can use the links
in the right sidebar to jump to the one you want - and if you want to hide all of the content for a given framework,
just use the button at the top-right of that framework's block!
## Train with PyTorch Trainer
🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] API supports a wide range of training options and features such as logging, gradient accumulation, and mixed precision.
Start by loading your model and specify the number of expected labels. From the Yelp Review [dataset card](https://huggingface.co/datasets/yelp_review_full#data-fields), you know there are five labels:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
You will see a warning about some of the pretrained weights not being used and some weights being randomly
initialized. Don't worry, this is completely normal! The pretrained head of the BERT model is discarded, and replaced with a randomly initialized classification head. You will fine-tune this new model head on your sequence classification task, transferring the knowledge of the pretrained model to it.
### Training hyperparameters
Next, create a [`TrainingArguments`] class which contains all the hyperparameters you can tune as well as flags for activating different training options. For this tutorial you can start with the default training [hyperparameters](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments), but feel free to experiment with these to find your optimal settings.
Specify where to save the checkpoints from your training:
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
### Evaluate
[`Trainer`] does not automatically evaluate model performance during training. You'll need to pass [`Trainer`] a function to compute and report metrics. The [🤗 Evaluate](https://huggingface.co/docs/evaluate/index) library provides a simple [`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy) function you can load with the [`evaluate.load`] (see this [quicktour](https://huggingface.co/docs/evaluate/a_quick_tour) for more information) function:
>>> import numpy as np
>>> import evaluate
>>> metric = evaluate.load("accuracy")
Call [`~evaluate.compute`] on `metric` to calculate the accuracy of your predictions. Before passing your predictions to `compute`, you need to convert the logits to predictions (remember all 🤗 Transformers models return logits):
>>> def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
If you'd like to monitor your evaluation metrics during fine-tuning, specify the `evaluation_strategy` parameter in your training arguments to report the evaluation metric at the end of each epoch:
>>> from transformers import TrainingArguments, Trainer
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
### Trainer
Create a [`Trainer`] object with your model, training arguments, training and test datasets, and evaluation function:
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
Then fine-tune your model by calling [`~transformers.Trainer.train`]:
>>> trainer.train()
## Train a TensorFlow model with Keras
You can also train 🤗 Transformers models in TensorFlow with the Keras API!
### Loading data for Keras
When you want to train a 🤗 Transformers model with the Keras API, you need to convert your dataset to a format that
Keras understands. If your dataset is small, you can just convert the whole thing to NumPy arrays and pass it to Keras.
Let's try that first before we do anything more complicated.
First, load a dataset. We'll use the CoLA dataset from the [GLUE benchmark](https://huggingface.co/datasets/glue),
since it's a simple binary text classification task, and just take the training split for now.
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
dataset = dataset["train"] # Just take the training split for now
Next, load a tokenizer and tokenize the data as NumPy arrays. Note that the labels are already a list of 0 and 1s,
so we can just convert that directly to a NumPy array without tokenization!
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
# Tokenizer returns a BatchEncoding, but we convert that to a dict for Keras
tokenized_data = dict(tokenized_data)
labels = np.array(dataset["label"]) # Label is already an array of 0 and 1
Finally, load, [`compile`](https://keras.io/api/models/model_training_apis/#compile-method), and [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) the model. Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
from transformers import TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
# Load and compile our model
model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased")
# Lower learning rates are often better for fine-tuning transformers
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tokenized_data, labels)
You don't have to pass a loss argument to your models when you `compile()` them! Hugging Face models automatically
choose a loss that is appropriate for their task and model architecture if this argument is left blank. You can always
override this by specifying a loss yourself if you want to!
This approach works great for smaller datasets, but for larger datasets, you might find it starts to become a problem. Why?
Because the tokenized array and labels would have to be fully loaded into memory, and because NumPy doesn’t handle
“jagged” arrays, so every tokenized sample would have to be padded to the length of the longest sample in the whole
dataset. That’s going to make your array even bigger, and all those padding tokens will slow down training too!
### Loading data as a tf.data.Dataset
If you want to avoid slowing down training, you can load your data as a `tf.data.Dataset` instead. Although you can write your own
`tf.data` pipeline if you want, we have two convenience methods for doing this:
- [`~TFPreTrainedModel.prepare_tf_dataset`]: This is the method we recommend in most cases. Because it is a method
on your model, it can inspect the model to automatically figure out which columns are usable as model inputs, and
discard the others to make a simpler, more performant dataset.
- [`~datasets.Dataset.to_tf_dataset`]: This method is more low-level, and is useful when you want to exactly control how
your dataset is created, by specifying exactly which `columns` and `label_cols` to include.
Before you can use [`~TFPreTrainedModel.prepare_tf_dataset`], you will need to add the tokenizer outputs to your dataset as columns, as shown in
the following code sample:
def tokenize_dataset(data):
# Keys of the returned dictionary will be added to the dataset as columns
return tokenizer(data["text"])
dataset = dataset.map(tokenize_dataset)
Remember that Hugging Face datasets are stored on disk by default, so this will not inflate your memory usage! Once the
columns have been added, you can stream batches from the dataset and add padding to each batch, which greatly
reduces the number of padding tokens compared to padding the entire dataset.
>>> tf_dataset = model.prepare_tf_dataset(dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer)
Note that in the code sample above, you need to pass the tokenizer to `prepare_tf_dataset` so it can correctly pad batches as they're loaded.
If all the samples in your dataset are the same length and no padding is necessary, you can skip this argument.
If you need to do something more complex than just padding samples (e.g. corrupting tokens for masked language
modelling), you can use the `collate_fn` argument instead to pass a function that will be called to transform the
list of samples into a batch and apply any preprocessing you want. See our
[examples](https://github.com/huggingface/transformers/tree/main/examples) or
[notebooks](https://huggingface.co/docs/transformers/notebooks) to see this approach in action.
Once you've created a `tf.data.Dataset`, you can compile and fit the model as before:
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tf_dataset)
## Train in native PyTorch
[`Trainer`] takes care of the training loop and allows you to fine-tune a model in a single line of code. For users who prefer to write their own training loop, you can also fine-tune a 🤗 Transformers model in native PyTorch.
At this point, you may need to restart your notebook or execute the following code to free some memory:
del model
del trainer
torch.cuda.empty_cache()
Next, manually postprocess `tokenized_dataset` to prepare it for training.
1. Remove the `text` column because the model does not accept raw text as an input:
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
2. Rename the `label` column to `labels` because the model expects the argument to be named `labels`:
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
3. Set the format of the dataset to return PyTorch tensors instead of lists:
>>> tokenized_datasets.set_format("torch")
Then create a smaller subset of the dataset as previously shown to speed up the fine-tuning:
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
### DataLoader
Create a `DataLoader` for your training and test datasets so you can iterate over batches of data:
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
Load your model with the number of expected labels:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
### Optimizer and learning rate scheduler
Create an optimizer and learning rate scheduler to fine-tune the model. Let's use the [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) optimizer from PyTorch:
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
Create the default learning rate scheduler from [`Trainer`]:
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
)
Lastly, specify `device` to use a GPU if you have access to one. Otherwise, training on a CPU may take several hours instead of a couple of minutes.
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
Get free access to a cloud GPU if you don't have one with a hosted notebook like [Colaboratory](https://colab.research.google.com/) or [SageMaker StudioLab](https://studiolab.sagemaker.aws/).
Great, now you are ready to train! 🥳
### Training loop
To keep track of your training progress, use the [tqdm](https://tqdm.github.io/) library to add a progress bar over the number of training steps:
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
### Evaluate
Just like how you added an evaluation function to [`Trainer`], you need to do the same when you write your own training loop. But instead of calculating and reporting the metric at the end of each epoch, this time you'll accumulate all the batches with [`~evaluate.add_batch`] and calculate the metric at the very end.
>>> import evaluate
>>> metric = evaluate.load("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
## Additional resources
For more fine-tuning examples, refer to:
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) includes scripts
to train common NLP tasks in PyTorch and TensorFlow.
- [🤗 Transformers Notebooks](notebooks) contains various notebooks on how to fine-tune a model for specific tasks in PyTorch and TensorFlow.
|
tf_xla.md
|
# XLA Integration for TensorFlow Models
[[open-in-colab]]
Accelerated Linear Algebra, dubbed XLA, is a compiler for accelerating the runtime of TensorFlow Models. From the [official documentation](https://www.tensorflow.org/xla):
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes.
Using XLA in TensorFlow is simple – it comes packaged inside the `tensorflow` library, and it can be triggered with the `jit_compile` argument in any graph-creating function such as [`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs). When using Keras methods like `fit()` and `predict()`, you can enable XLA simply by passing the `jit_compile` argument to `model.compile()`. However, XLA is not limited to these methods - it can also be used to accelerate any arbitrary `tf.function`.
Several TensorFlow methods in 🤗 Transformers have been rewritten to be XLA-compatible, including text generation for models such as [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [T5](https://huggingface.co/docs/transformers/model_doc/t5) and [OPT](https://huggingface.co/docs/transformers/model_doc/opt), as well as speech processing for models such as [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper).
While the exact amount of speed-up is very much model-dependent, for TensorFlow text generation models inside 🤗 Transformers, we noticed a speed-up of ~100x. This document will explain how you can use XLA for these models to get the maximum amount of performance. We’ll also provide links to additional resources if you’re interested to learn more about the benchmarks and our design philosophy behind the XLA integration.
## Running TF functions with XLA
Let us consider the following model in TensorFlow:
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
The above model accepts inputs having a dimension of `(10, )`. We can use the model for running a forward pass like so:
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
In order to run the forward pass with an XLA-compiled function, we’d need to do:
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
The default `call()` function of the `model` is used for compiling the XLA graph. But if there’s any other model function you want to compile into XLA that’s also possible with:
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
## Running a TF text generation model with XLA from 🤗 Transformers
To enable XLA-accelerated generation within 🤗 Transformers, you need to have a recent version of `transformers` installed. You can install it by running:
```bash
pip install transformers --upgrade
And then you can run the following code:
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
As you can notice, enabling XLA on `generate()` is just a single line of code. The rest of the code remains unchanged. However, there are a couple of gotchas in the above code snippet that are specific to XLA. You need to be aware of those to realize the speed-ups that XLA can bring in. We discuss these in the following section.
## Gotchas to be aware of
When you are executing an XLA-enabled function (like `xla_generate()` above) for the first time, it will internally try to infer the computation graph, which is time-consuming. This process is known as [“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing).
You might notice that the generation time is not fast. Successive calls of `xla_generate()` (or any other XLA-enabled function) won’t have to infer the computation graph, given the inputs to the function follow the same shape with which the computation graph was initially built. While this is not a problem for modalities with fixed input shapes (e.g., images), you must pay attention if you are working with variable input shape modalities (e.g., text).
To ensure `xla_generate()` always operates with the same input shapes, you can specify the `padding` arguments when calling the tokenizer.
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
This way, you can ensure that the inputs to `xla_generate()` will always receive inputs with the shape it was traced with and thus leading to speed-ups in the generation time. You can verify this with the code below:
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
On a Tesla T4 GPU, you can expect the outputs like so:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
The first call to `xla_generate()` is time-consuming because of tracing, but the successive calls are orders of magnitude faster. Keep in mind that any change in the generation options at any point with trigger re-tracing and thus leading to slow-downs in the generation time.
We didn’t cover all the text generation options 🤗 Transformers provides in this document. We encourage you to read the documentation for advanced use cases.
## Additional Resources
Here, we leave you with some additional resources if you want to delve deeper into XLA in 🤗 Transformers and in general.
* [This Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) provides an interactive demonstration if you want to fiddle with the XLA-compatible encoder-decoder (like [T5](https://huggingface.co/docs/transformers/model_doc/t5)) and decoder-only (like [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)) text generation models.
* [This blog post](https://huggingface.co/blog/tf-xla-generate) provides an overview of the comparison benchmarks for XLA-compatible models along with a friendly introduction to XLA in TensorFlow.
* [This blog post](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) discusses our design philosophy behind adding XLA support to the TensorFlow models in 🤗 Transformers.
* Recommended posts for learning more about XLA and TensorFlow graphs in general:
* [XLA: Optimizing Compiler for Machine Learning](https://www.tensorflow.org/xla)
* [Introduction to graphs and tf.function](https://www.tensorflow.org/guide/intro_to_graphs)
* [Better performance with tf.function](https://www.tensorflow.org/guide/function)
|
run_scripts.md
|
# Train with a script
Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
## Setup
To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
For older versions of the example scripts, click on the toggle below:
Examples for older versions of 🤗 Transformers
v4.5.1
v4.4.2
v4.3.3
v4.2.2
v4.1.1
v4.0.1
v3.5.1
v3.4.0
v3.3.1
v3.2.0
v3.1.0
v3.0.2
v2.11.0
v2.10.0
v2.9.1
v2.8.0
v2.7.0
v2.6.0
v2.5.1
v2.4.0
v2.3.0
v2.2.0
v2.1.1
v2.0.0
v1.2.0
v1.1.0
v1.0.0
Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
```bash
git checkout tags/v3.5.1
After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
```bash
pip install -r requirements.txt
## Run a script
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset with the [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
## Distributed training and mixed precision
The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
- Add the `fp16` argument to enable mixed precision.
- Set the number of GPUs to use with the `nproc_per_node` argument.
```bash
python -m torch.distributed.launch \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
TensorFlow scripts utilize a [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) for distributed training, and you don't need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
## Run a script on a TPU
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the [XLA](https://www.tensorflow.org/xla) deep learning compiler (see [here](https://github.com/pytorch/xla/blob/master/README.md) for more details). To use a TPU, launch the `xla_spawn.py` script and use the `num_cores` argument to set the number of TPU cores you want to use.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) for training on TPUs. To use a TPU, pass the name of the TPU resource to the `tpu` argument.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
## Run a script with 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don't already have it:
> Note: As Accelerate is rapidly developing, the git version of accelerate must be installed to run the scripts
```bash
pip install git+https://github.com/huggingface/accelerate
Instead of the `run_summarization.py` script, you need to use the `run_summarization_no_trainer.py` script. 🤗 Accelerate supported scripts will have a `task_no_trainer.py` file in the folder. Begin by running the following command to create and save a configuration file:
```bash
accelerate config
Test your setup to make sure it is configured correctly:
```bash
accelerate test
Now you are ready to launch the training:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
## Use a custom dataset
The summarization script supports custom datasets as long as they are a CSV or JSON Line file. When you use your own dataset, you need to specify several additional arguments:
- `train_file` and `validation_file` specify the path to your training and validation files.
- `text_column` is the input text to summarize.
- `summary_column` is the target text to output.
A summarization script using a custom dataset would look like this:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
## Test a script
It is often a good idea to run your script on a smaller number of dataset examples to ensure everything works as expected before committing to an entire dataset which may take hours to complete. Use the following arguments to truncate the dataset to a maximum number of samples:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
Not all example scripts support the `max_predict_samples` argument. If you aren't sure whether your script supports this argument, add the `-h` argument to check:
```bash
examples/pytorch/summarization/run_summarization.py -h
## Resume training from checkpoint
Another helpful option to enable is resuming training from a previous checkpoint. This will ensure you can pick up where you left off without starting over if your training gets interrupted. There are two methods to resume training from a checkpoint.
The first method uses the `output_dir previous_output_dir` argument to resume training from the latest checkpoint stored in `output_dir`. In this case, you should remove `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
The second method uses the `resume_from_checkpoint path_to_specific_checkpoint` argument to resume training from a specific checkpoint folder.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
## Share your model
All scripts can upload your final model to the [Model Hub](https://huggingface.co/models). Make sure you are logged into Hugging Face before you begin:
```bash
huggingface-cli login
Then add the `push_to_hub` argument to the script. This argument will create a repository with your Hugging Face username and the folder name specified in `output_dir`.
To give your repository a specific name, use the `push_to_hub_model_id` argument to add it. The repository will be automatically listed under your namespace.
The following example shows how to upload a model with a specific repository name:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
|
generation_strategies.md
|
# Text generation strategies
Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and
more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text
and vision-to-text. Some of the models that can generate text include
GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
Check out a few examples that use [`~transformers.generation_utils.GenerationMixin.generate`] method to produce
text outputs for different tasks:
* [Text summarization](./tasks/summarization#inference)
* [Image captioning](./model_doc/git#transformers.GitForCausalLM.forward.example)
* [Audio transcription](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
Note that the inputs to the generate method depend on the model's modality. They are returned by the model's preprocessor
class, such as AutoTokenizer or AutoProcessor. If a model's preprocessor creates more than one kind of input, pass all
the inputs to generate(). You can learn more about the individual model's preprocessor in the corresponding model's documentation.
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
that the `generate()` method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
and make it more coherent.
This guide describes:
* default generation configuration
* common decoding strategies and their main parameters
* saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
## Default text generation configuration
A decoding strategy for a model is defined in its generation configuration. When using pre-trained models for inference
within a [`pipeline`], the models call the `PreTrainedModel.generate()` method that applies a default generation
configuration under the hood. The default configuration is also used when no custom configuration has been saved with
the model.
When you load a model explicitly, you can inspect the generation configuration that comes with it through
`model.generation_config`:
thon
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
Printing out the `model.generation_config` reveals only the values that are different from the default generation
configuration, and does not list any of the default values.
The default generation configuration limits the size of the output combined with the input prompt to a maximum of 20
tokens to avoid running into resource limitations. The default decoding strategy is greedy search, which is the simplest decoding strategy that picks a token with the highest probability as the next token. For many tasks
and small output sizes this works well. However, when used to generate longer outputs, greedy search can start
producing highly repetitive results.
## Customize text generation
You can override any `generation_config` by passing the parameters and their values directly to the [`generate`] method:
thon
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the
commonly adjusted parameters include:
- `max_new_tokens`: the maximum number of tokens to generate. In other words, the size of the output sequence, not
including the tokens in the prompt. As an alternative to using the output's length as a stopping criteria, you can choose
to stop generation whenever the full generation exceeds some amount of time. To learn more, check [`StoppingCriteria`].
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
distribution over the entire vocabulary with various strategy-specific adjustments.
- `num_return_sequences`: the number of sequence candidates to return for each input. This option is only available for
the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding
strategies like greedy search and contrastive search return a single output sequence.
## Save a custom decoding strategy with your model
If you would like to share your fine-tuned model with a specific generation configuration, you can:
* Create a [`GenerationConfig`] class instance
* Specify the decoding strategy parameters
* Save your generation configuration with [`GenerationConfig.save_pretrained`], making sure to leave its `config_file_name` argument empty
* Set `push_to_hub` to `True` to upload your config to the model's repo
thon
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
>>> generation_config = GenerationConfig(
max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
)
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
You can also store several generation configurations in a single directory, making use of the `config_file_name`
argument in [`GenerationConfig.save_pretrained`]. You can later instantiate them with [`GenerationConfig.from_pretrained`]. This is useful if you want to
store several generation configurations for a single model (e.g. one for creative text generation with sampling, and
one for summarization with beam search). You must have the right Hub permissions to add configuration files to a model.
thon
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
>>> translation_generation_config = GenerationConfig(
num_beams=4,
early_stopping=True,
decoder_start_token_id=0,
eos_token_id=model.config.eos_token_id,
pad_token=model.config.pad_token_id,
)
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']
## Streaming
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible with any instance
from a class that has the following methods: `put()` and `end()`. Internally, `put()` is used to push new tokens and
`end()` is used to flag the end of text generation.
The API for the streamer classes is still under development and may change in the future.
In practice, you can craft your own streaming class for all sorts of purposes! We also have basic streaming classes
ready for you to use. For example, you can use the [`TextStreamer`] class to stream the output of `generate()` into
your screen, one word at a time:
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
## Decoding strategies
Certain combinations of the `generate()` parameters, and ultimately `generation_config`, can be used to enable specific
decoding strategies. If you are new to this concept, we recommend reading [this blog post that illustrates how common decoding strategies work](https://huggingface.co/blog/how-to-generate).
Here, we'll show some of the parameters that control the decoding strategies and illustrate how you can use them.
### Greedy Search
[`generate`] uses greedy search decoding by default so you don't have to pass any parameters to enable it. This means the parameters `num_beams` is set to 1 and `do_sample=False`.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
### Contrastive search
The contrastive search decoding strategy was proposed in the 2022 paper [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417).
It demonstrates superior results for generating non-repetitive yet coherent long outputs. To learn how contrastive search
works, check out [this blog post](https://huggingface.co/blog/introducing-csearch).
The two main parameters that enable and control the behavior of contrastive search are `penalty_alpha` and `top_k`:
thon
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']
### Multinomial sampling
As opposed to greedy search that always chooses a token with the highest probability as the
next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution over the entire
vocabulary given by the model. Every token with a non-zero probability has a chance of being selected, thus reducing the
risk of repetition.
To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
thon
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']
### Beam-search decoding
Unlike greedy search, beam-search decoding keeps several hypotheses at each time step and eventually chooses
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
### Beam-search multinomial sampling
As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
thon
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'
### Diverse beam search decoding
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
thon
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
"The Permaculture Design Principles are a set of universal design principles "
"that can be applied to any location, climate and culture, and they allow us to design "
"the most efficient and sustainable human habitation and food production systems. "
"Permaculture is a design system that encompasses a wide variety of disciplines, such "
"as ecology, landscape design, environmental science and energy conservation, and the "
"Permaculture design principles are drawn from these various disciplines. Each individual "
"design principle itself embodies a complete conceptual framework based on sound "
"scientific principles. When we bring all these separate principles together, we can "
"create a design system that both looks at whole systems, the parts that these systems "
"consist of, and how those parts interact with each other to create a complex, dynamic, "
"living system. Each design principle serves as a tool that allows us to integrate all "
"the separate parts of a design, referred to as elements, into a functional, synergistic, "
"whole system, where the elements harmoniously interact and work together in the most "
"efficient way possible."
)
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'
This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation.md).
### Assisted Decoding
Assisted decoding is a modification of the decoding strategies above that uses an assistant model with the same
tokenizer (ideally a much smaller model) to greedily generate a few candidate tokens. The main model then validates
the candidate tokens in a single forward pass, which speeds up the decoding process. Currently, only greedy search
and sampling are supported with assisted decoding, and doesn't support batched inputs. To learn more about assisted
decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
To enable assisted decoding, set the `assistant_model` argument with a model.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
When using assisted decoding with sampling methods, you can use the `temperature` argument to control the randomness
just like in multinomial sampling. However, in assisted decoding, reducing the temperature will help improving latency.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']
|
multilingual.md
|
# Multilingual models for inference
[[open-in-colab]]
There are several multilingual models in 🤗 Transformers, and their inference usage differs from monolingual models. Not *all* multilingual model usage is different though. Some models, like [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), can be used just like a monolingual model. This guide will show you how to use multilingual models whose usage differs for inference.
## XLM
XLM has ten different checkpoints, only one of which is monolingual. The nine remaining model checkpoints can be split into two categories: the checkpoints that use language embeddings and those that don't.
### XLM with language embeddings
The following XLM models use language embeddings to specify the language used at inference:
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
Language embeddings are represented as a tensor of the same shape as the `input_ids` passed to the model. The values in these tensors depend on the language used and are identified by the tokenizer's `lang2id` and `id2lang` attributes.
In this example, load the `xlm-clm-enfr-1024` checkpoint (Causal language modeling, English-French):
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
The `lang2id` attribute of the tokenizer displays this model's languages and their ids:
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
Next, create an example input:
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
Set the language id as `"en"` and use it to define the language embedding. The language embedding is a tensor filled with `0` since that is the language id for English. This tensor should be the same size as `input_ids`.
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, , 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
Now you can pass the `input_ids` and language embedding to the model:
>>> outputs = model(input_ids, langs=langs)
The [run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) script can generate text with language embeddings using the `xlm-clm` checkpoints.
### XLM without language embeddings
The following XLM models do not require language embeddings during inference:
- `xlm-mlm-17-1280` (Masked language modeling, 17 languages)
- `xlm-mlm-100-1280` (Masked language modeling, 100 languages)
These models are used for generic sentence representations, unlike the previous XLM checkpoints.
## BERT
The following BERT models can be used for multilingual tasks:
- `bert-base-multilingual-uncased` (Masked language modeling + Next sentence prediction, 102 languages)
- `bert-base-multilingual-cased` (Masked language modeling + Next sentence prediction, 104 languages)
These models do not require language embeddings during inference. They should identify the language from the
context and infer accordingly.
## XLM-RoBERTa
The following XLM-RoBERTa models can be used for multilingual tasks:
- `xlm-roberta-base` (Masked language modeling, 100 languages)
- `xlm-roberta-large` (Masked language modeling, 100 languages)
XLM-RoBERTa was trained on 2.5TB of newly created and cleaned CommonCrawl data in 100 languages. It provides strong gains over previously released multilingual models like mBERT or XLM on downstream tasks like classification, sequence labeling, and question answering.
## M2M100
The following M2M100 models can be used for multilingual translation:
- `facebook/m2m100_418M` (Translation)
- `facebook/m2m100_1.2B` (Translation)
In this example, load the `facebook/m2m100_418M` checkpoint to translate from Chinese to English. You can set the source language in the tokenizer:
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
Tokenize the text:
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
M2M100 forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
## MBart
The following MBart models can be used for multilingual translation:
- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
- `facebook/mbart-large-cc25`
In this example, load the `facebook/mbart-large-50-many-to-many-mmt` checkpoint to translate Finnish to English. You can set the source language in the tokenizer:
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
Tokenize the text:
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
MBart forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
|
community.md
|
# Community
This page regroups resources around 🤗 Transformers developed by the community.
## Community resources:
| Resource | Description | Author |
|:----------|:-------------|------:|
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learned/revised using [Anki ](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
## Community notebooks:
| Notebook | Description | Author | |
|:----------|:-------------|:-------------|------:|
| [Fine-tune a pre-trained Transformer to generate lyrics](https://github.com/AlekseyKorshuk/huggingartists) | How to generate lyrics in the style of your favorite artist by fine-tuning a GPT-2 model | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
| [Train T5 in Tensorflow 2 ](https://github.com/snapthat/TF-T5-text-to-text) | How to train T5 for any task using Tensorflow 2. This notebook demonstrates a Question & Answer task implemented in Tensorflow 2 using SQUAD | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
| [Train T5 on TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | How to train T5 on SQUAD with Transformers and Nlp | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
| [Fine-tune T5 for Classification and Multiple Choice](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | How to fine-tune T5 for classification and multiple choice tasks using a text-to-text format with PyTorch Lightning | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
| [Fine-tune DialoGPT on New Datasets and Languages](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | How to fine-tune the DialoGPT model on a new dataset for open-dialog conversational chatbots | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
| [Long Sequence Modeling with Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | How to train on sequences as long as 500,000 tokens with Reformer | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
| [Fine-tune BART for Summarization](https://github.com/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) | How to fine-tune BART for summarization with fastai using blurr | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) |
| [Fine-tune a pre-trained Transformer on anyone's tweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | How to generate tweets in the style of your favorite Twitter account by fine-tuning a GPT-2 model | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
| [Optimize 🤗 Hugging Face models with Weights & Biases](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | A complete tutorial showcasing W&B integration with Hugging Face | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
| [Pretrain Longformer](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | How to build a "long" version of existing pretrained models | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
| [Fine-tune Longformer for QA](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | How to fine-tune longformer model for QA task | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
| [Evaluate Model with 🤗nlp](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | How to evaluate longformer on TriviaQA with `nlp` | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
| [Fine-tune T5 for Sentiment Span Extraction](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | How to fine-tune T5 for sentiment span extraction using a text-to-text format with PyTorch Lightning | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
| [Fine-tune DistilBert for Multiclass Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | How to fine-tune DistilBert for multiclass classification with PyTorch | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
|[Fine-tune BERT for Multi-label Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|How to fine-tune BERT for multi-label classification using PyTorch|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
|[Fine-tune T5 for Summarization](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|How to fine-tune T5 for summarization in PyTorch and track experiments with WandB|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
|[Speed up Fine-Tuning in Transformers with Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|How to speed up fine-tuning by a factor of 2 using dynamic padding / bucketing|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|[Pretrain Reformer for Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| How to train a Reformer model with bi-directional self-attention layers | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|[Expand and Fine Tune Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| How to increase vocabulary of a pretrained SciBERT model from AllenAI on the CORD dataset and pipeline it. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| How to fine-tune BlenderBotSmall for summarization on a custom dataset, using the Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|[Fine-tune Electra and interpret with Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | How to fine-tune Electra for sentiment analysis and interpret predictions with Captum Integrated Gradients | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|[fine-tune a non-English GPT-2 Model with Trainer class](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | How to fine-tune a non-English GPT-2 Model with Trainer class | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|[Fine-tune a DistilBERT Model for Multi Label Classification task](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | How to fine-tune a DistilBERT Model for Multi Label Classification task | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|[Fine-tune ALBERT for sentence-pair classification](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | How to fine-tune an ALBERT model or another BERT-based model for the sentence-pair classification task | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
|[Fine-tune Roberta for sentiment analysis](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | How to fine-tune a Roberta model for sentiment analysis | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
|[Evaluating Question Generation Models](https://github.com/flexudy-pipe/qugeev) | How accurate are the answers to questions generated by your seq2seq transformer model? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
|[Classify text with DistilBERT and Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | How to fine-tune DistilBERT for text classification in TensorFlow | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
|[Leverage BERT for Encoder-Decoder Summarization on CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | How to warm-start a *EncoderDecoderModel* with a *bert-base-uncased* checkpoint for summarization on CNN/Dailymail | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
|[Leverage RoBERTa for Encoder-Decoder Summarization on BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | How to warm-start a shared *EncoderDecoderModel* with a *roberta-base* checkpoint for summarization on BBC/XSum | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
|[Fine-tune TAPAS on Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | How to fine-tune *TapasForQuestionAnswering* with a *tapas-base* checkpoint on the Sequential Question Answering (SQA) dataset | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
|[Evaluate TAPAS on Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | How to evaluate a fine-tuned *TapasForSequenceClassification* with a *tapas-base-finetuned-tabfact* checkpoint using a combination of the 🤗 datasets and 🤗 transformers libraries | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
|[Fine-tuning mBART for translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | How to fine-tune mBART using Seq2SeqTrainer for Hindi to English translation | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
|[Fine-tune LayoutLM on FUNSD (a form understanding dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | How to fine-tune *LayoutLMForTokenClassification* on the FUNSD dataset for information extraction from scanned documents | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
|[Fine-Tune DistilGPT2 and Generate Text](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | How to fine-tune DistilGPT2 and generate text | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
|[Fine-Tune LED on up to 8K tokens](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | How to fine-tune LED on pubmed for long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
|[Evaluate LED on Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | How to effectively evaluate LED on long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
|[Fine-tune LayoutLM on RVL-CDIP (a document image classification dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | How to fine-tune *LayoutLMForSequenceClassification* on the RVL-CDIP dataset for scanned document classification | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
|[Wav2Vec2 CTC decoding with GPT2 adjustment](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | How to decode CTC sequence with language model adjustment | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
|[Fine-tune BART for summarization in two languages with Trainer class](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | How to fine-tune BART for summarization in two languages with Trainer class | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
|[Evaluate Big Bird on Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | How to evaluate BigBird on long document question answering on Trivia QA | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
| [Create video captions using Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | How to create YouTube captions from any video by transcribing the audio with Wav2Vec | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
| [Fine-tune the Vision Transformer on CIFAR-10 using PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and PyTorch Lightning | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
| [Fine-tune the Vision Transformer on CIFAR-10 using the 🤗 Trainer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and the 🤗 Trainer | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
| [Evaluate LUKE on Open Entity, an entity typing dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | How to evaluate *LukeForEntityClassification* on the Open Entity dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
| [Evaluate LUKE on TACRED, a relation extraction dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | How to evaluate *LukeForEntityPairClassification* on the TACRED dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
| [Evaluate LUKE on CoNLL-2003, an important NER benchmark](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | How to evaluate *LukeForEntitySpanClassification* on the CoNLL-2003 dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
| [Evaluate BigBird-Pegasus on PubMed dataset](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | How to evaluate *BigBirdPegasusForConditionalGeneration* on PubMed dataset | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
| [Speech Emotion Classification with Wav2Vec2](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | How to leverage a pretrained Wav2Vec2 model for Emotion Classification on the MEGA dataset | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
| [Detect objects in an image with DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | How to use a trained *DetrForObjectDetection* model to detect objects in an image and visualize attention | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
| [Fine-tune DETR on a custom object detection dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | How to fine-tune *DetrForObjectDetection* on a custom object detection dataset | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
| [Finetune T5 for Named Entity Recognition](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | How to fine-tune *T5* on a Named Entity Recognition Task | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
|
task_summary.md
|
# What 🤗 Transformers can do
🤗 Transformers is a library of pretrained state-of-the-art models for natural language processing (NLP), computer vision, and audio and speech processing tasks. Not only does the library contain Transformer models, but it also has non-Transformer models like modern convolutional networks for computer vision tasks. If you look at some of the most popular consumer products today, like smartphones, apps, and televisions, odds are that some kind of deep learning technology is behind it. Want to remove a background object from a picture taken by your smartphone? This is an example of a panoptic segmentation task (don't worry if you don't know what this means yet, we'll describe it in the following sections!).
This page provides an overview of the different speech and audio, computer vision, and NLP tasks that can be solved with the 🤗 Transformers library in just three lines of code!
## Audio
Audio and speech processing tasks are a little different from the other modalities mainly because audio as an input is a continuous signal. Unlike text, a raw audio waveform can't be neatly split into discrete chunks the way a sentence can be divided into words. To get around this, the raw audio signal is typically sampled at regular intervals. If you take more samples within an interval, the sampling rate is higher, and the audio more closely resembles the original audio source.
Previous approaches preprocessed the audio to extract useful features from it. It is now more common to start audio and speech processing tasks by directly feeding the raw audio waveform to a feature encoder to extract an audio representation. This simplifies the preprocessing step and allows the model to learn the most essential features.
### Audio classification
Audio classification is a task that labels audio data from a predefined set of classes. It is a broad category with many specific applications, some of which include:
* acoustic scene classification: label audio with a scene label ("office", "beach", "stadium")
* acoustic event detection: label audio with a sound event label ("car horn", "whale calling", "glass breaking")
* tagging: label audio containing multiple sounds (birdsongs, speaker identification in a meeting)
* music classification: label music with a genre label ("metal", "hip-hop", "country")
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
### Automatic speech recognition
Automatic speech recognition (ASR) transcribes speech into text. It is one of the most common audio tasks due partly to speech being such a natural form of human communication. Today, ASR systems are embedded in "smart" technology products like speakers, phones, and cars. We can ask our virtual assistants to play music, set reminders, and tell us the weather.
But one of the key challenges Transformer architectures have helped with is in low-resource languages. By pretraining on large amounts of speech data, finetuning the model on only one hour of labeled speech data in a low-resource language can still produce high-quality results compared to previous ASR systems trained on 100x more labeled data.
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
## Computer vision
One of the first and earliest successful computer vision tasks was recognizing images of zip code numbers using a [convolutional neural network (CNN)](glossary#convolution). An image is composed of pixels, and each pixel has a numerical value. This makes it easy to represent an image as a matrix of pixel values. Each particular combination of pixel values describes the colors of an image.
Two general ways computer vision tasks can be solved are:
1. Use convolutions to learn the hierarchical features of an image from low-level features to high-level abstract things.
2. Split an image into patches and use a Transformer to gradually learn how each image patch is related to each other to form an image. Unlike the bottom-up approach favored by a CNN, this is kind of like starting out with a blurry image and then gradually bringing it into focus.
### Image classification
Image classification labels an entire image from a predefined set of classes. Like most classification tasks, there are many practical use cases for image classification, some of which include:
* healthcare: label medical images to detect disease or monitor patient health
* environment: label satellite images to monitor deforestation, inform wildland management or detect wildfires
* agriculture: label images of crops to monitor plant health or satellite images for land use monitoring
* ecology: label images of animal or plant species to monitor wildlife populations or track endangered species
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
### Object detection
Unlike image classification, object detection identifies multiple objects within an image and the objects' positions in an image (defined by the bounding box). Some example applications of object detection include:
* self-driving vehicles: detect everyday traffic objects such as other vehicles, pedestrians, and traffic lights
* remote sensing: disaster monitoring, urban planning, and weather forecasting
* defect detection: detect cracks or structural damage in buildings, and manufacturing defects
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
### Image segmentation
Image segmentation is a pixel-level task that assigns every pixel in an image to a class. It differs from object detection, which uses bounding boxes to label and predict objects in an image because segmentation is more granular. Segmentation can detect objects at a pixel-level. There are several types of image segmentation:
* instance segmentation: in addition to labeling the class of an object, it also labels each distinct instance of an object ("dog-1", "dog-2")
* panoptic segmentation: a combination of semantic and instance segmentation; it labels each pixel with a semantic class **and** each distinct instance of an object
Segmentation tasks are helpful in self-driving vehicles to create a pixel-level map of the world around them so they can navigate safely around pedestrians and other vehicles. It is also useful for medical imaging, where the task's finer granularity can help identify abnormal cells or organ features. Image segmentation can also be used in ecommerce to virtually try on clothes or create augmented reality experiences by overlaying objects in the real world through your camera.
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
### Depth estimation
Depth estimation predicts the distance of each pixel in an image from the camera. This computer vision task is especially important for scene understanding and reconstruction. For example, in self-driving cars, vehicles need to understand how far objects like pedestrians, traffic signs, and other vehicles are to avoid obstacles and collisions. Depth information is also helpful for constructing 3D representations from 2D images and can be used to create high-quality 3D representations of biological structures or buildings.
There are two approaches to depth estimation:
* stereo: depths are estimated by comparing two images of the same image from slightly different angles
* monocular: depths are estimated from a single image
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
## Natural language processing
NLP tasks are among the most common types of tasks because text is such a natural way for us to communicate. To get text into a format recognized by a model, it needs to be tokenized. This means dividing a sequence of text into separate words or subwords (tokens) and then converting these tokens into numbers. As a result, you can represent a sequence of text as a sequence of numbers, and once you have a sequence of numbers, it can be input into a model to solve all sorts of NLP tasks!
### Text classification
Like classification tasks in any modality, text classification labels a sequence of text (it can be sentence-level, a paragraph, or a document) from a predefined set of classes. There are many practical applications for text classification, some of which include:
* sentiment analysis: label text according to some polarity like `positive` or `negative` which can inform and support decision-making in fields like politics, finance, and marketing
* content classification: label text according to some topic to help organize and filter information in news and social media feeds (`weather`, `sports`, `finance`, etc.)
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
### Token classification
In any NLP task, text is preprocessed by separating the sequence of text into individual words or subwords. These are known as [tokens](/glossary#token). Token classification assigns each token a label from a predefined set of classes.
Two common types of token classification are:
* named entity recognition (NER): label a token according to an entity category like organization, person, location or date. NER is especially popular in biomedical settings, where it can label genes, proteins, and drug names.
* part-of-speech tagging (POS): label a token according to its part-of-speech like noun, verb, or adjective. POS is useful for helping translation systems understand how two identical words are grammatically different (bank as a noun versus bank as a verb).
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
{
"entity": pred["entity"],
"score": round(pred["score"], 4),
"index": pred["index"],
"word": pred["word"],
"start": pred["start"],
"end": pred["end"],
}
for pred in preds
]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
### Question answering
Question answering is another token-level task that returns an answer to a question, sometimes with context (open-domain) and other times without context (closed-domain). This task happens whenever we ask a virtual assistant something like whether a restaurant is open. It can also provide customer or technical support and help search engines retrieve the relevant information you're asking for.
There are two common types of question answering:
* extractive: given a question and some context, the answer is a span of text from the context the model must extract
* abstractive: given a question and some context, the answer is generated from the context; this approach is handled by the [`Text2TextGenerationPipeline`] instead of the [`QuestionAnsweringPipeline`] shown below
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
question="What is the name of the repository?",
context="The name of the repository is huggingface/transformers",
)
>>> print(
f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
)
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
### Summarization
Summarization creates a shorter version of a text from a longer one while trying to preserve most of the meaning of the original document. Summarization is a sequence-to-sequence task; it outputs a shorter text sequence than the input. There are a lot of long-form documents that can be summarized to help readers quickly understand the main points. Legislative bills, legal and financial documents, patents, and scientific papers are a few examples of documents that could be summarized to save readers time and serve as a reading aid.
Like question answering, there are two types of summarization:
* extractive: identify and extract the most important sentences from the original text
* abstractive: generate the target summary (which may include new words not in the input document) from the original text; the [`SummarizationPipeline`] uses the abstractive approach
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
"In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
)
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
### Translation
Translation converts a sequence of text in one language to another. It is important in helping people from different backgrounds communicate with each other, help translate content to reach wider audiences, and even be a learning tool to help people learn a new language. Along with summarization, translation is a sequence-to-sequence task, meaning the model receives an input sequence and returns a target output sequence.
In the early days, translation models were mostly monolingual, but recently, there has been increasing interest in multilingual models that can translate between many pairs of languages.
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
### Language modeling
Language modeling is a task that predicts a word in a sequence of text. It has become a very popular NLP task because a pretrained language model can be finetuned for many other downstream tasks. Lately, there has been a lot of interest in large language models (LLMs) which demonstrate zero- or few-shot learning. This means the model can solve tasks it wasn't explicitly trained to do! Language models can be used to generate fluent and convincing text, though you need to be careful since the text may not always be accurate.
There are two types of language modeling:
* causal: the model's objective is to predict the next token in a sequence, and future tokens are masked
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
* masked: the model's objective is to predict a masked token in a sequence with full access to the tokens in the sequence
>>> text = "Hugging Face is a community-based open-source for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
{
"score": round(pred["score"], 4),
"token": pred["token"],
"token_str": pred["token_str"],
"sequence": pred["sequence"],
}
for pred in preds
]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
## Multimodal
Multimodal tasks require a model to process multiple data modalities (text, image, audio, video) to solve a particular problem. Image captioning is an example of a multimodal task where the model takes an image as input and outputs a sequence of text describing the image or some properties of the image.
Although multimodal models work with different data types or modalities, internally, the preprocessing steps help the model convert all the data types into embeddings (vectors or list of numbers that holds meaningful information about the data). For a task like image captioning, the model learns relationships between image embeddings and text embeddings.
### Document question answering
Document question answering is a task that answers natural language questions from a document. Unlike a token-level question answering task which takes text as input, document question answering takes an image of a document as input along with a question about the document and returns an answer. Document question answering can be used to parse structured documents and extract key information from it. In the example below, the total amount and change due can be extracted from a receipt.
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/2/image/image.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
question="What is the total amount?",
image=image,
)
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
Hopefully, this page has given you some more background information about all the types of tasks in each modality and the practical importance of each one. In the next [section](tasks_explained), you'll learn **how** 🤗 Transformers work to solve these tasks.
|
chat_templating.md
|
# Templates for Chat Models
## Introduction
An increasingly common use case for LLMs is **chat**. In a chat context, rather than continuing a single string
of text (as is the case with a standard language model), the model instead continues a conversation that consists
of one or more **messages**, each of which includes a **role**, like "user" or "assistant", as well as message text.
Much like tokenization, different models expect very different input formats for chat. This is the reason we added
**chat templates** as a feature. Chat templates are part of the tokenizer. They specify how to convert conversations,
represented as lists of messages, into a single tokenizable string in the format that the model expects.
Let's make this concrete with a quick example using the `BlenderBot` model. BlenderBot has an extremely simple default
template, which mostly just adds whitespace between rounds of dialogue:
thon
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!"
Notice how the entire chat is condensed into a single string. If we use `tokenize=True`, which is the default setting,
that string will also be tokenized for us. To see a more complex template in action, though, let's use the
`mistralai/Mistral-7B-Instruct-v0.1` model.
thon
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
>>> chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
"[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today? [INST] I'd like to show off how chat templating works! [/INST]"
Note that this time, the tokenizer has added the control tokens [INST] and [/INST] to indicate the start and end of
user messages (but not assistant messages!). Mistral-instruct was trained with these tokens, but BlenderBot was not.
## How do I use chat templates?
As you can see in the example above, chat templates are easy to use. Simply build a list of messages, with `role`
and `content` keys, and then pass it to the [`~PreTrainedTokenizer.apply_chat_template`] method. Once you do that,
you'll get output that's ready to go! When using chat templates as input for model generation, it's also a good idea
to use `add_generation_prompt=True` to add a [generation prompt](#what-are-generation-prompts).
Here's an example of preparing input for `model.generate()`, using the `Zephyr` assistant model:
thon
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
This will yield a string in the input format that Zephyr expects.
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate
<|user|>
How many helicopters can a human eat in one sitting?
<|assistant|>
Now that our input is formatted correctly for Zephyr, we can use the model to generate a response to the user's question:
thon
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
This will yield:
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate
<|user|>
How many helicopters can a human eat in one sitting?
<|assistant|>
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
Arr, 'twas easy after all!
## Is there an automated pipeline for chat?
Yes, there is: [`ConversationalPipeline`]. This pipeline is designed to make it easy to use chat models. Let's try
the `Zephyr` example again, but this time using the pipeline:
thon
from transformers import pipeline
pipe = pipeline("conversational", "HuggingFaceH4/zephyr-7b-beta")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
print(pipe(messages))
```text
Conversation id: 76d886a0-74bd-454e-9804-0467041a63dc
system: You are a friendly chatbot who always responds in the style of a pirate
user: How many helicopters can a human eat in one sitting?
assistant: Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
[`ConversationalPipeline`] will take care of all the details of tokenization and calling `apply_chat_template` for you -
once the model has a chat template, all you need to do is initialize the pipeline and pass it the list of messages!
## What are "generation prompts"?
You may have noticed that the `apply_chat_template` method has an `add_generation_prompt` argument. This argument tells
the template to add tokens that indicate the start of a bot response. For example, consider the following chat:
thon
messages = [
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "Can I ask a question?"}
]
Here's what this will look like without a generation prompt, using the ChatML template we saw in the Zephyr example:
thon
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
"""
And here's what it looks like **with** a generation prompt:
thon
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
"""
Note that this time, we've added the tokens that indicate the start of a bot response. This ensures that when the model
generates text it will write a bot response instead of doing something unexpected, like continuing the user's
message. Remember, chat models are still just language models - they're trained to continue text, and chat is just a
special kind of text to them! You need to guide them with the appropriate control tokens so they know what they're
supposed to be doing.
Not all models require generation prompts. Some models, like BlenderBot and LLaMA, don't have any
special tokens before bot responses. In these cases, the `add_generation_prompt` argument will have no effect. The exact
effect that `add_generation_prompt` has will depend on the template being used.
## Can I use chat templates in training?
Yes! We recommend that you apply the chat template as a preprocessing step for your dataset. After this, you
can simply continue like any other language model training task. When training, you should usually set
`add_generation_prompt=False`, because the added tokens to prompt an assistant response will not be helpful during
training. Let's see an example:
thon
from transformers import AutoTokenizer
from datasets import Dataset
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
chat1 = [
{"role": "user", "content": "Which is bigger, the moon or the sun?"},
{"role": "assistant", "content": "The sun."}
]
chat2 = [
{"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
{"role": "assistant", "content": "A bacterium."}
]
dataset = Dataset.from_dict({"chat": [chat1, chat2]})
dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
print(dataset['formatted_chat'][0])
And we get:
```text
<|user|>
Which is bigger, the moon or the sun?
<|assistant|>
The sun.
From here, just continue training like you would with a standard language modelling task, using the `formatted_chat` column.
## Advanced: How do chat templates work?
The chat template for a model is stored on the `tokenizer.chat_template` attribute. If no chat template is set, the
default template for that model class is used instead. Let's take a look at the template for `BlenderBot`:
thon
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> tokenizer.default_chat_template
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
That's kind of intimidating. Let's add some newlines and indentation to make it more readable. Note that the first
newline after each block as well as any preceding whitespace before a block are ignored by default, using the
Jinja `trim_blocks` and `lstrip_blocks` flags. However, be cautious - although leading whitespace on each
line is stripped, spaces between blocks on the same line are not. We strongly recommend checking that your template
isn't printing extra spaces where it shouldn't be!
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ ' ' }}
{% endif %}
{{ message['content'] }}
{% if not loop.last %}
{{ ' ' }}
{% endif %}
{% endfor %}
{{ eos_token }}
If you've never seen one of these before, this is a [Jinja template](https://jinja.palletsprojects.com/en/3.1.x/templates/).
Jinja is a templating language that allows you to write simple code that generates text. In many ways, the code and
syntax resembles Python. In pure Python, this template would look something like this:
thon
for idx, message in enumerate(messages):
if message['role'] == 'user':
print(' ')
print(message['content'])
if not idx == len(messages) - 1: # Check for the last message in the conversation
print(' ')
print(eos_token)
Effectively, the template does three things:
1. For each message, if the message is a user message, add a blank space before it, otherwise print nothing.
2. Add the message content
3. If the message is not the last message, add two spaces after it. After the final message, print the EOS token.
This is a pretty simple template - it doesn't add any control tokens, and it doesn't support "system" messages, which
are a common way to give the model directives about how it should behave in the subsequent conversation.
But Jinja gives you a lot of flexibility to do those things! Let's see a Jinja template that can format inputs
similarly to the way LLaMA formats them (note that the real LLaMA template includes handling for default system
messages and slightly different system message handling in general - don't use this one in your actual code!)
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<>\\n' + message['content'] + '\\n<>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ ' ' + message['content'] + ' ' + eos_token }}
{% endif %}
{% endfor %}
Hopefully if you stare at this for a little bit you can see what this template is doing - it adds specific tokens based
on the "role" of each message, which represents who sent it. User, assistant and system messages are clearly
distinguishable to the model because of the tokens they're wrapped in.
## Advanced: Adding and editing chat templates
### How do I create a chat template?
Simple, just write a jinja template and set `tokenizer.chat_template`. You may find it easier to start with an
existing template from another model and simply edit it for your needs! For example, we could take the LLaMA template
above and add "[ASST]" and "[/ASST]" to assistant messages:
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<>\\n' + message['content'].strip() + '\\n<>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
{% endif %}
{% endfor %}
Now, simply set the `tokenizer.chat_template` attribute. Next time you use [`~PreTrainedTokenizer.apply_chat_template`], it will
use your new template! This attribute will be saved in the `tokenizer_config.json` file, so you can use
[`~utils.PushToHubMixin.push_to_hub`] to upload your new template to the Hub and make sure everyone's using the right
template for your model!
thon
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
The method [`~PreTrainedTokenizer.apply_chat_template`] which uses your chat template is called by the [`ConversationalPipeline`] class, so
once you set the correct chat template, your model will automatically become compatible with [`ConversationalPipeline`].
### What are "default" templates?
Before the introduction of chat templates, chat handling was hardcoded at the model class level. For backwards
compatibility, we have retained this class-specific handling as default templates, also set at the class level. If a
model does not have a chat template set, but there is a default template for its model class, the `ConversationalPipeline`
class and methods like `apply_chat_template` will use the class template instead. You can find out what the default
template for your tokenizer is by checking the `tokenizer.default_chat_template` attribute.
This is something we do purely for backward compatibility reasons, to avoid breaking any existing workflows. Even when
the class template is appropriate for your model, we strongly recommend overriding the default template by
setting the `chat_template` attribute explicitly to make it clear to users that your model has been correctly configured
for chat, and to future-proof in case the default templates are ever altered or deprecated.
### What template should I use?
When setting the template for a model that's already been trained for chat, you should ensure that the template
exactly matches the message formatting that the model saw during training, or else you will probably experience
performance degradation. This is true even if you're training the model further - you will probably get the best
performance if you keep the chat tokens constant. This is very analogous to tokenization - you generally get the
best performance for inference or fine-tuning when you precisely match the tokenization used during training.
If you're training a model from scratch, or fine-tuning a base language model for chat, on the other hand,
you have a lot of freedom to choose an appropriate template! LLMs are smart enough to learn to handle lots of different
input formats. Our default template for models that don't have a class-specific template follows the
[ChatML format](https://github.com/openai/openai-python/blob/main/chatml.md), and this is a good, flexible choice for many use-cases. It looks like this:
{% for message in messages %}
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
If you like this one, here it is in one-liner form, ready to copy into your code. The one-liner also includes
handy support for "generation prompts" - see the next section for more!
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
This template wraps each message in `<|im_start|>` and `<|im_end|>` tokens, and simply writes the role as a string, which
allows for flexibility in the roles you train with. The output looks like this:
```text
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm doing great!<|im_end|>
The "user", "system" and "assistant" roles are the standard for chat, and we recommend using them when it makes sense,
particularly if you want your model to operate well with [`ConversationalPipeline`]. However, you are not limited
to these roles - templating is extremely flexible, and any string can be a role.
### I want to add some chat templates! How should I get started?
If you have any chat models, you should set their `tokenizer.chat_template` attribute and test it using
[`~PreTrainedTokenizer.apply_chat_template`], then push the updated tokenizer to the Hub. This applies even if you're
not the model owner - if you're using a model with an empty chat template, or one that's still using the default class
template, please open a [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to the model repository so that this attribute can be set properly!
Once the attribute is set, that's it, you're done! `tokenizer.apply_chat_template` will now work correctly for that
model, which means it is also automatically supported in places like `ConversationalPipeline`!
By ensuring that models have this attribute, we can make sure that the whole community gets to use the full power of
open-source models. Formatting mismatches have been haunting the field and silently harming performance for too long -
it's time to put an end to them!
## Advanced: Template writing tips
If you're unfamiliar with Jinja, we generally find that the easiest way to write a chat template is to first
write a short Python script that formats messages the way you want, and then convert that script into a template.
Remember that the template handler will receive the conversation history as a variable called `messages`. Each
message is a dictionary with two keys, `role` and `content`. You will be able to access `messages` in your template
just like you can in Python, which means you can loop over it with `{% for message in messages %}` or access
individual messages with, for example, `{{ messages[0] }}`.
You can also use the following tips to convert your code to Jinja:
### For loops
For loops in Jinja look like this:
{% for message in messages %}
{{ message['content'] }}
{% endfor %}
Note that whatever's inside the {{ expression block }} will be printed to the output. You can use operators like
`+` to combine strings inside expression blocks.
### If statements
If statements in Jinja look like this:
{% if message['role'] == 'user' %}
{{ message['content'] }}
{% endif %}
Note how where Python uses whitespace to mark the beginnings and ends of `for` and `if` blocks, Jinja requires you
to explicitly end them with `{% endfor %}` and `{% endif %}`.
### Special variables
Inside your template, you will have access to the list of `messages`, but you can also access several other special
variables. These include special tokens like `bos_token` and `eos_token`, as well as the `add_generation_prompt`
variable that we discussed above. You can also use the `loop` variable to access information about the current loop
iteration, for example using `{% if loop.last %}` to check if the current message is the last message in the
conversation. Here's an example that puts these ideas together to add a generation prompt at the end of the
conversation if add_generation_prompt is `True`:
{% if loop.last and add_generation_prompt %}
{{ bos_token + 'Assistant:\n' }}
{% endif %}
### Notes on whitespace
As much as possible, we've tried to get Jinja to ignore whitespace outside of {{ expressions }}. However, be aware
that Jinja is a general-purpose templating engine, and it may treat whitespace between blocks on the same line
as significant and print it to the output. We **strongly** recommend checking that your template isn't printing extra
spaces where it shouldn't be before you upload it!
|
perf_torch_compile.md
|
# Optimize inference using torch.compile()
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
## Benefits of torch.compile
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
## Benchmarking code
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
### Image Classification with ViT
thon
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
#### Object Detection with DETR
thon
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
#### Image Segmentation with Segformer
thon
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
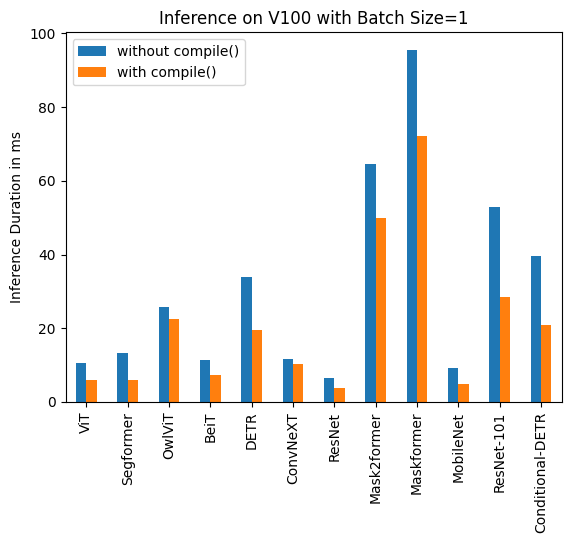
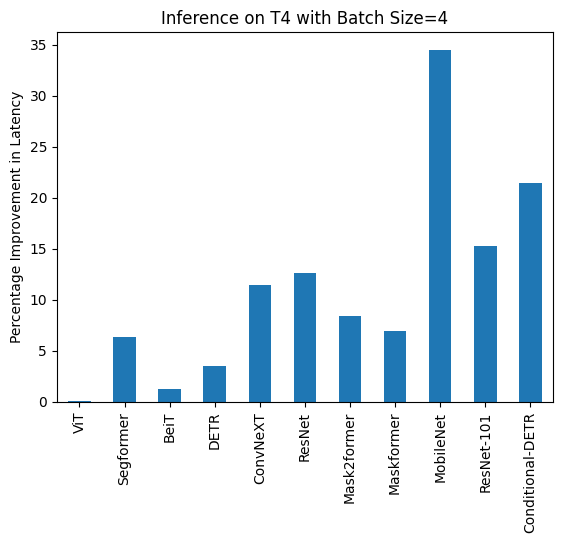
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
hpo_train.md
|
# Hyperparameter Search using Trainer API
🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] provides API for hyperparameter search. This doc shows how to enable it in example.
## Hyperparameter Search backend
[`Trainer`] supports four hyperparameter search backends currently:
[optuna](https://optuna.org/), [sigopt](https://sigopt.com/), [raytune](https://docs.ray.io/en/latest/tune/index.html) and [wandb](https://wandb.ai/site/sweeps).
you should install them before using them as the hyperparameter search backend
```bash
pip install optuna/sigopt/wandb/ray[tune]
## How to enable Hyperparameter search in example
Define the hyperparameter search space, different backends need different format.
For sigopt, see sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter), it's like following:
>>> def sigopt_hp_space(trial):
return [
{"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
{
"categorical_values": ["16", "32", "64", "128"],
"name": "per_device_train_batch_size",
"type": "categorical",
},
]
For optuna, see optuna [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py), it's like following:
>>> def optuna_hp_space(trial):
return {
"learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
"per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
}
Optuna provides multi-objective HPO. You can pass `direction` in `hyperparameter_search` and define your own compute_objective to return multiple objective values. The Pareto Front (`List[BestRun]`) will be returned in hyperparameter_search, you should refer to the test case `TrainerHyperParameterMultiObjectOptunaIntegrationTest` in [test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py). It's like following
>>> best_trials = trainer.hyperparameter_search(
direction=["minimize", "maximize"],
backend="optuna",
hp_space=optuna_hp_space,
n_trials=20,
compute_objective=compute_objective,
)
For raytune, see raytune [object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html), it's like following:
>>> def ray_hp_space(trial):
return {
"learning_rate": tune.loguniform(1e-6, 1e-4),
"per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
}
For wandb, see wandb [object_parameter](https://docs.wandb.ai/guides/sweeps/configuration), it's like following:
>>> def wandb_hp_space(trial):
return {
"method": "random",
"metric": {"name": "objective", "goal": "minimize"},
"parameters": {
"learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
"per_device_train_batch_size": {"values": [16, 32, 64, 128]},
},
}
Define a `model_init` function and pass it to the [`Trainer`], as an example:
>>> def model_init(trial):
return AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
Create a [`Trainer`] with your `model_init` function, training arguments, training and test datasets, and evaluation function:
>>> trainer = Trainer(
model=None,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
model_init=model_init,
data_collator=data_collator,
)
Call hyperparameter search, get the best trial parameters, backend could be `"optuna"`/`"sigopt"`/`"wandb"`/`"ray"`. direction can be`"minimize"` or `"maximize"`, which indicates whether to optimize greater or lower objective.
You could define your own compute_objective function, if not defined, the default compute_objective will be called, and the sum of eval metric like f1 is returned as objective value.
>>> best_trial = trainer.hyperparameter_search(
direction="maximize",
backend="optuna",
hp_space=optuna_hp_space,
n_trials=20,
compute_objective=compute_objective,
)
## Hyperparameter search For DDP finetune
Currently, Hyperparameter search for DDP is enabled for optuna and sigopt. Only the rank-zero process will generate the search trial and pass the argument to other ranks.
|
glossary.md
|
# Glossary
This glossary defines general machine learning and 🤗 Transformers terms to help you better understand the
documentation.
## A
### attention mask
The attention mask is an optional argument used when batching sequences together.
This argument indicates to the model which tokens should be attended to, and which should not.
For example, consider these two sequences:
thon
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "This is a short sequence."
>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
The encoded versions have different lengths:
thon
>>> len(encoded_sequence_a), len(encoded_sequence_b)
(8, 19)
Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
of the second one, or the second one needs to be truncated down to the length of the first one.
In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
it to pad like this:
thon
>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
thon
>>> padded_sequences["input_ids"]
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`], `1` indicates a
value that should be attended to, while `0` indicates a padded value. This attention mask is in the dictionary returned
by the tokenizer under the key "attention_mask":
thon
>>> padded_sequences["attention_mask"]
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
### autoencoding models
See [encoder models](#encoder-models) and [masked language modeling](#masked-language-modeling-mlm)
### autoregressive models
See [causal language modeling](#causal-language-modeling) and [decoder models](#decoder-models)
## B
### backbone
The backbone is the network (embeddings and layers) that outputs the raw hidden states or features. It is usually connected to a [head](#head) which accepts the features as its input to make a prediction. For example, [`ViTModel`] is a backbone without a specific head on top. Other models can also use [`VitModel`] as a backbone such as [DPT](model_doc/dpt).
## C
### causal language modeling
A pretraining task where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence but using a mask inside the model to hide the future tokens at a certain timestep.
### channel
Color images are made up of some combination of values in three channels - red, green, and blue (RGB) - and grayscale images only have one channel. In 🤗 Transformers, the channel can be the first or last dimension of an image's tensor: [`n_channels`, `height`, `width`] or [`height`, `width`, `n_channels`].
### connectionist temporal classification (CTC)
An algorithm which allows a model to learn without knowing exactly how the input and output are aligned; CTC calculates the distribution of all possible outputs for a given input and chooses the most likely output from it. CTC is commonly used in speech recognition tasks because speech doesn't always cleanly align with the transcript for a variety of reasons such as a speaker's different speech rates.
### convolution
A type of layer in a neural network where the input matrix is multiplied element-wise by a smaller matrix (kernel or filter) and the values are summed up in a new matrix. This is known as a convolutional operation which is repeated over the entire input matrix. Each operation is applied to a different segment of the input matrix. Convolutional neural networks (CNNs) are commonly used in computer vision.
## D
### DataParallel (DP)
Parallelism technique for training on multiple GPUs where the same setup is replicated multiple times, with each instance
receiving a distinct data slice. The processing is done in parallel and all setups are synchronized at the end of each training step.
Learn more about how DataParallel works [here](perf_train_gpu_many#dataparallel-vs-distributeddataparallel).
### decoder input IDs
This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
way specific to each model.
Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In such models,
passing the `labels` is the preferred way to handle training.
Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
### decoder models
Also referred to as autoregressive models, decoder models involve a pretraining task (called causal language modeling) where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence with a mask to hide future tokens at a certain timestep.
### deep learning (DL)
Machine learning algorithms which uses neural networks with several layers.
## E
### encoder models
Also known as autoencoding models, encoder models take an input (such as text or images) and transform them into a condensed numerical representation called an embedding. Oftentimes, encoder models are pretrained using techniques like [masked language modeling](#masked-language-modeling-mlm), which masks parts of the input sequence and forces the model to create more meaningful representations.
## F
### feature extraction
The process of selecting and transforming raw data into a set of features that are more informative and useful for machine learning algorithms. Some examples of feature extraction include transforming raw text into word embeddings and extracting important features such as edges or shapes from image/video data.
### feed forward chunking
In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
`bert-base-uncased`).
For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, , [batch_size, config.hidden_size]_n`
individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n =
sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
**equivalent** result.
For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the number of output
embeddings that are computed in parallel and thus defines the trade-off between memory and time complexity. If
`chunk_size` is set to 0, no feed forward chunking is done.
### finetuned models
Finetuning is a form of transfer learning which involves taking a pretrained model, freezing its weights, and replacing the output layer with a newly added [model head](#head). The model head is trained on your target dataset.
See the [Fine-tune a pretrained model](https://huggingface.co/docs/transformers/training) tutorial for more details, and learn how to fine-tune models with 🤗 Transformers.
## H
### head
The model head refers to the last layer of a neural network that accepts the raw hidden states and projects them onto a different dimension. There is a different model head for each task. For example:
* [`GPT2ForSequenceClassification`] is a sequence classification head - a linear layer - on top of the base [`GPT2Model`].
* [`ViTForImageClassification`] is an image classification head - a linear layer on top of the final hidden state of the `CLS` token - on top of the base [`ViTModel`].
* [`Wav2Vec2ForCTC`] ia a language modeling head with [CTC](#connectionist-temporal-classification-(CTC)) on top of the base [`Wav2Vec2Model`].
## I
### image patch
Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in its configuration.
### inference
Inference is the process of evaluating a model on new data after training is complete. See the [Pipeline for inference](https://huggingface.co/docs/transformers/pipeline_tutorial) tutorial to learn how to perform inference with 🤗 Transformers.
### input IDs
The input ids are often the only required parameters to be passed to the model as input. They are token indices,
numerical representations of tokens building the sequences that will be used as input by the model.
Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
thon
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence = "A Titan RTX has 24GB of VRAM"
The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
thon
>>> tokenized_sequence = tokenizer.tokenize(sequence)
The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
is added for "RA" and "M":
thon
>>> print(tokenized_sequence)
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding
the sentence to the tokenizer, which leverages the Rust implementation of [🤗
Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
thon
>>> inputs = tokenizer(sequence)
The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
token indices are under the key `input_ids`:
thon
>>> encoded_sequence = inputs["input_ids"]
>>> print(encoded_sequence)
[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
IDs the model sometimes uses.
If we decode the previous sequence of ids,
thon
>>> decoded_sequence = tokenizer.decode(encoded_sequence)
we will see
thon
>>> print(decoded_sequence)
[CLS] A Titan RTX has 24GB of VRAM [SEP]
because this is the way a [`BertModel`] is going to expect its inputs.
## L
### labels
The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
predictions and the expected value (the label).
These labels are different according to the model head, for example:
- For sequence classification models, ([`BertForSequenceClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of the entire sequence.
- For token classification models, ([`BertForTokenClassification`]), the model expects a tensor of dimension
`(batch_size, seq_length)` with each value corresponding to the expected label of each individual token.
- For masked language modeling, ([`BertForMaskedLM`]), the model expects a tensor of dimension `(batch_size,
seq_length)` with each value corresponding to the expected label of each individual token: the labels being the token
ID for the masked token, and values to be ignored for the rest (usually -100).
- For sequence to sequence tasks, ([`BartForConditionalGeneration`], [`MBartForConditionalGeneration`]), the model
expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences
associated with each input sequence. During training, both BART and T5 will make the appropriate
`decoder_input_ids` and decoder attention masks internally. They usually do not need to be supplied. This does not
apply to models leveraging the Encoder-Decoder framework.
- For image classification models, ([`ViTForImageClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of each individual image.
- For semantic segmentation models, ([`SegformerForSemanticSegmentation`]), the model expects a tensor of dimension
`(batch_size, height, width)` with each value of the batch corresponding to the expected label of each individual pixel.
- For object detection models, ([`DetrForObjectDetection`]), the model expects a list of dictionaries with a
`class_labels` and `boxes` key where each value of the batch corresponds to the expected label and number of bounding boxes of each individual image.
- For automatic speech recognition models, ([`Wav2Vec2ForCTC`]), the model expects a tensor of dimension `(batch_size,
target_length)` with each value corresponding to the expected label of each individual token.
Each model's labels may be different, so be sure to always check the documentation of each model for more information
about their specific labels!
The base models ([`BertModel`]) do not accept labels, as these are the base transformer models, simply outputting
features.
### large language models (LLM)
A generic term that refers to transformer language models (GPT-3, BLOOM, OPT) that were trained on a large quantity of data. These models also tend to have a large number of learnable parameters (e.g. 175 billion for GPT-3).
## M
### masked language modeling (MLM)
A pretraining task where the model sees a corrupted version of the texts, usually done by
masking some tokens randomly, and has to predict the original text.
### multimodal
A task that combines texts with another kind of inputs (for instance images).
## N
### Natural language generation (NLG)
All tasks related to generating text (for instance, [Write With Transformers](https://transformer.huggingface.co/), translation).
### Natural language processing (NLP)
A generic way to say "deal with texts".
### Natural language understanding (NLU)
All tasks related to understanding what is in a text (for instance classifying the
whole text, individual words).
## P
### pipeline
A pipeline in 🤗 Transformers is an abstraction referring to a series of steps that are executed in a specific order to preprocess and transform data and return a prediction from a model. Some example stages found in a pipeline might be data preprocessing, feature extraction, and normalization.
For more details, see [Pipelines for inference](https://huggingface.co/docs/transformers/pipeline_tutorial).
### PipelineParallel (PP)
Parallelism technique in which the model is split up vertically (layer-level) across multiple GPUs, so that only one or
several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline
and working on a small chunk of the batch. Learn more about how PipelineParallel works [here](perf_train_gpu_many#from-naive-model-parallelism-to-pipeline-parallelism).
### pixel values
A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from an image processor.
### pooling
An operation that reduces a matrix into a smaller matrix, either by taking the maximum or average of the pooled dimension(s). Pooling layers are commonly found between convolutional layers to downsample the feature representation.
### position IDs
Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in the
list of tokens.
They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
absolute positional embeddings.
Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
### preprocessing
The task of preparing raw data into a format that can be easily consumed by machine learning models. For example, text is typically preprocessed by tokenization. To gain a better idea of what preprocessing looks like for other input types, check out the [Preprocess](https://huggingface.co/docs/transformers/preprocessing) tutorial.
### pretrained model
A model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods involve a
self-supervised objective, which can be reading the text and trying to predict the next word (see [causal language
modeling](#causal-language-modeling)) or masking some words and trying to predict them (see [masked language
modeling](#masked-language-modeling-mlm)).
Speech and vision models have their own pretraining objectives. For example, Wav2Vec2 is a speech model pretrained on a contrastive task which requires the model to identify the "true" speech representation from a set of "false" speech representations. On the other hand, BEiT is a vision model pretrained on a masked image modeling task which masks some of the image patches and requires the model to predict the masked patches (similar to the masked language modeling objective).
## R
### recurrent neural network (RNN)
A type of model that uses a loop over a layer to process texts.
### representation learning
A subfield of machine learning which focuses on learning meaningful representations of raw data. Some examples of representation learning techniques include word embeddings, autoencoders, and Generative Adversarial Networks (GANs).
## S
### sampling rate
A measurement in hertz of the number of samples (the audio signal) taken per second. The sampling rate is a result of discretizing a continuous signal such as speech.
### self-attention
Each element of the input finds out which other elements of the input they should attend to.
### self-supervised learning
A category of machine learning techniques in which a model creates its own learning objective from unlabeled data. It differs from [unsupervised learning](#unsupervised-learning) and [supervised learning](#supervised-learning) in that the learning process is supervised, but not explicitly from the user.
One example of self-supervised learning is [masked language modeling](#masked-language-modeling-mlm), where a model is passed sentences with a proportion of its tokens removed and learns to predict the missing tokens.
### semi-supervised learning
A broad category of machine learning training techniques that leverages a small amount of labeled data with a larger quantity of unlabeled data to improve the accuracy of a model, unlike [supervised learning](#supervised-learning) and [unsupervised learning](#unsupervised-learning).
An example of a semi-supervised learning approach is "self-training", in which a model is trained on labeled data, and then used to make predictions on the unlabeled data. The portion of the unlabeled data that the model predicts with the most confidence gets added to the labeled dataset and used to retrain the model.
### sequence-to-sequence (seq2seq)
Models that generate a new sequence from an input, like translation models, or summarization models (such as
[Bart](model_doc/bart) or [T5](model_doc/t5)).
### Sharded DDP
Another name for the foundational [ZeRO](#zero-redundancy-optimizer--zero-) concept as used by various other implementations of ZeRO.
### stride
In [convolution](#convolution) or [pooling](#pooling), the stride refers to the distance the kernel is moved over a matrix. A stride of 1 means the kernel is moved one pixel over at a time, and a stride of 2 means the kernel is moved two pixels over at a time.
### supervised learning
A form of model training that directly uses labeled data to correct and instruct model performance. Data is fed into the model being trained, and its predictions are compared to the known labels. The model updates its weights based on how incorrect its predictions were, and the process is repeated to optimize model performance.
## T
### Tensor Parallelism (TP)
Parallelism technique for training on multiple GPUs in which each tensor is split up into multiple chunks, so instead of
having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. Shards gets
processed separately and in parallel on different GPUs and the results are synced at the end of the processing step.
This is what is sometimes called horizontal parallelism, as the splitting happens on horizontal level.
Learn more about Tensor Parallelism [here](perf_train_gpu_many#tensor-parallelism).
### token
A part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a
punctuation symbol.
### token Type IDs
Some models' purpose is to do classification on pairs of sentences or question answering.
These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT model
builds its two sequence input as such:
thon
>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
arguments (and not a list, like before) like this:
thon
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "HuggingFace is based in NYC"
>>> sequence_b = "Where is HuggingFace based?"
>>> encoded_dict = tokenizer(sequence_a, sequence_b)
>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
which will return:
thon
>>> print(decoded)
[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
This is enough for some models to understand where one sequence ends and where another begins. However, other models,
such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
the two types of sequence in the model.
The tokenizer returns this mask as the "token_type_ids" entry:
thon
>>> encoded_dict["token_type_ids"]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the second
sequence, corresponding to the "question", has all its tokens represented by a `1`.
Some models, like [`XLNetModel`] use an additional token represented by a `2`.
### transfer learning
A technique that involves taking a pretrained model and adapting it to a dataset specific to your task. Instead of training a model from scratch, you can leverage knowledge obtained from an existing model as a starting point. This speeds up the learning process and reduces the amount of training data needed.
### transformer
Self-attention based deep learning model architecture.
## U
### unsupervised learning
A form of model training in which data provided to the model is not labeled. Unsupervised learning techniques leverage statistical information of the data distribution to find patterns useful for the task at hand.
## Z
### Zero Redundancy Optimizer (ZeRO)
Parallelism technique which performs sharding of the tensors somewhat similar to [TensorParallel](#tensorparallel--tp-),
except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need
to be modified. This method also supports various offloading techniques to compensate for limited GPU memory.
Learn more about ZeRO [here](perf_train_gpu_many#zero-data-parallelism).
|
troubleshooting.md
|
# Troubleshoot
Sometimes errors occur, but we are here to help! This guide covers some of the most common issues we've seen and how you can resolve them. However, this guide isn't meant to be a comprehensive collection of every 🤗 Transformers issue. For more help with troubleshooting your issue, try:
1. Asking for help on the [forums](https://discuss.huggingface.co/). There are specific categories you can post your question to, like [Beginners](https://discuss.huggingface.co/c/beginners/5) or [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9). Make sure you write a good descriptive forum post with some reproducible code to maximize the likelihood that your problem is solved!
2. Create an [Issue](https://github.com/huggingface/transformers/issues/new/choose) on the 🤗 Transformers repository if it is a bug related to the library. Try to include as much information describing the bug as possible to help us better figure out what's wrong and how we can fix it.
3. Check the [Migration](migration) guide if you use an older version of 🤗 Transformers since some important changes have been introduced between versions.
For more details about troubleshooting and getting help, take a look at [Chapter 8](https://huggingface.co/course/chapter8/1?fw=pt) of the Hugging Face course.
## Firewalled environments
Some GPU instances on cloud and intranet setups are firewalled to external connections, resulting in a connection error. When your script attempts to download model weights or datasets, the download will hang and then timeout with the following message:
ValueError: Connection error, and we cannot find the requested files in the cached path.
Please try again or make sure your Internet connection is on.
In this case, you should try to run 🤗 Transformers on [offline mode](installation#offline-mode) to avoid the connection error.
## CUDA out of memory
Training large models with millions of parameters can be challenging without the appropriate hardware. A common error you may encounter when the GPU runs out of memory is:
CUDA out of memory. Tried to allocate 256.00 MiB (GPU 0; 11.17 GiB total capacity; 9.70 GiB already allocated; 179.81 MiB free; 9.85 GiB reserved in total by PyTorch)
Here are some potential solutions you can try to lessen memory use:
- Reduce the [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) value in [`TrainingArguments`].
- Try using [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps) in [`TrainingArguments`] to effectively increase overall batch size.
Refer to the Performance [guide](performance) for more details about memory-saving techniques.
## Unable to load a saved TensorFlow model
TensorFlow's [model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) method will save the entire model - architecture, weights, training configuration - in a single file. However, when you load the model file again, you may run into an error because 🤗 Transformers may not load all the TensorFlow-related objects in the model file. To avoid issues with saving and loading TensorFlow models, we recommend you:
- Save the model weights as a `h5` file extension with [`model.save_weights`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) and then reload the model with [`~TFPreTrainedModel.from_pretrained`]:
>>> from transformers import TFPreTrainedModel
>>> from tensorflow import keras
>>> model.save_weights("some_folder/tf_model.h5")
>>> model = TFPreTrainedModel.from_pretrained("some_folder")
- Save the model with [`~TFPretrainedModel.save_pretrained`] and load it again with [`~TFPreTrainedModel.from_pretrained`]:
>>> from transformers import TFPreTrainedModel
>>> model.save_pretrained("path_to/model")
>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
## ImportError
Another common error you may encounter, especially if it is a newly released model, is `ImportError`:
ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
For these error types, check to make sure you have the latest version of 🤗 Transformers installed to access the most recent models:
```bash
pip install transformers --upgrade
## CUDA error: device-side assert triggered
Sometimes you may run into a generic CUDA error about an error in the device code.
RuntimeError: CUDA error: device-side assert triggered
You should try to run the code on a CPU first to get a more descriptive error message. Add the following environment variable to the beginning of your code to switch to a CPU:
>>> import os
>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
Another option is to get a better traceback from the GPU. Add the following environment variable to the beginning of your code to get the traceback to point to the source of the error:
>>> import os
>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
## Incorrect output when padding tokens aren't masked
In some cases, the output `hidden_state` may be incorrect if the `input_ids` include padding tokens. To demonstrate, load a model and tokenizer. You can access a model's `pad_token_id` to see its value. The `pad_token_id` may be `None` for some models, but you can always manually set it.
>>> from transformers import AutoModelForSequenceClassification
>>> import torch
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
>>> model.config.pad_token_id
0
The following example shows the output without masking the padding tokens:
>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[ 0.1317, -0.1683]], grad_fn=)
Here is the actual output of the second sequence:
>>> input_ids = torch.tensor([[7592]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[-0.1008, -0.4061]], grad_fn=)
Most of the time, you should provide an `attention_mask` to your model to ignore the padding tokens to avoid this silent error. Now the output of the second sequence matches its actual output:
By default, the tokenizer creates an `attention_mask` for you based on your specific tokenizer's defaults.
>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
>>> output = model(input_ids, attention_mask=attention_mask)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[-0.1008, -0.4061]], grad_fn=)
🤗 Transformers doesn't automatically create an `attention_mask` to mask a padding token if it is provided because:
- Some models don't have a padding token.
- For some use-cases, users want a model to attend to a padding token.
## ValueError: Unrecognized configuration class XYZ for this kind of AutoModel
Generally, we recommend using the [`AutoModel`] class to load pretrained instances of models. This class
can automatically infer and load the correct architecture from a given checkpoint based on the configuration. If you see
this `ValueError` when loading a model from a checkpoint, this means the Auto class couldn't find a mapping from
the configuration in the given checkpoint to the kind of model you are trying to load. Most commonly, this happens when a
checkpoint doesn't support a given task.
For instance, you'll see this error in the following example because there is no GPT2 for question answering:
>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("gpt2-medium")
>>> model = AutoModelForQuestionAnswering.from_pretrained("gpt2-medium")
ValueError: Unrecognized configuration class for this kind of AutoModel: AutoModelForQuestionAnswering.
Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig,
|
accelerate.md
|
# Distributed training with 🤗 Accelerate
As models get bigger, parallelism has emerged as a strategy for training larger models on limited hardware and accelerating training speed by several orders of magnitude. At Hugging Face, we created the [🤗 Accelerate](https://huggingface.co/docs/accelerate) library to help users easily train a 🤗 Transformers model on any type of distributed setup, whether it is multiple GPU's on one machine or multiple GPU's across several machines. In this tutorial, learn how to customize your native PyTorch training loop to enable training in a distributed environment.
## Setup
Get started by installing 🤗 Accelerate:
```bash
pip install accelerate
Then import and create an [`~accelerate.Accelerator`] object. The [`~accelerate.Accelerator`] will automatically detect your type of distributed setup and initialize all the necessary components for training. You don't need to explicitly place your model on a device.
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
## Prepare to accelerate
The next step is to pass all the relevant training objects to the [`~accelerate.Accelerator.prepare`] method. This includes your training and evaluation DataLoaders, a model and an optimizer:
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
## Backward
The last addition is to replace the typical `loss.backward()` in your training loop with 🤗 Accelerate's [`~accelerate.Accelerator.backward`]method:
>>> for epoch in range(num_epochs):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
As you can see in the following code, you only need to add four additional lines of code to your training loop to enable distributed training!
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
## Train
Once you've added the relevant lines of code, launch your training in a script or a notebook like Colaboratory.
### Train with a script
If you are running your training from a script, run the following command to create and save a configuration file:
```bash
accelerate config
Then launch your training with:
```bash
accelerate launch train.py
### Train with a notebook
🤗 Accelerate can also run in a notebook if you're planning on using Colaboratory's TPUs. Wrap all the code responsible for training in a function, and pass it to [`~accelerate.notebook_launcher`]:
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
For more information about 🤗 Accelerate and its rich features, refer to the [documentation](https://huggingface.co/docs/accelerate).
|
index.md
|
# 🤗 Transformers
State-of-the-art Machine Learning for [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), and [JAX](https://jax.readthedocs.io/en/latest/).
🤗 Transformers provides APIs and tools to easily download and train state-of-the-art pretrained models. Using pretrained models can reduce your compute costs, carbon footprint, and save you the time and resources required to train a model from scratch. These models support common tasks in different modalities, such as:
📝 **Natural Language Processing**: text classification, named entity recognition, question answering, language modeling, summarization, translation, multiple choice, and text generation.
🖼️ **Computer Vision**: image classification, object detection, and segmentation.
🗣️ **Audio**: automatic speech recognition and audio classification.
🐙 **Multimodal**: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
🤗 Transformers support framework interoperability between PyTorch, TensorFlow, and JAX. This provides the flexibility to use a different framework at each stage of a model's life; train a model in three lines of code in one framework, and load it for inference in another. Models can also be exported to a format like ONNX and TorchScript for deployment in production environments.
Join the growing community on the [Hub](https://huggingface.co/models), [forum](https://discuss.huggingface.co/), or [Discord](https://discord.com/invite/JfAtkvEtRb) today!
## If you are looking for custom support from the Hugging Face team
## Contents
The documentation is organized into five sections:
- **GET STARTED** provides a quick tour of the library and installation instructions to get up and running.
- **TUTORIALS** are a great place to start if you're a beginner. This section will help you gain the basic skills you need to start using the library.
- **HOW-TO GUIDES** show you how to achieve a specific goal, like finetuning a pretrained model for language modeling or how to write and share a custom model.
- **CONCEPTUAL GUIDES** offers more discussion and explanation of the underlying concepts and ideas behind models, tasks, and the design philosophy of 🤗 Transformers.
- **API** describes all classes and functions:
- **MAIN CLASSES** details the most important classes like configuration, model, tokenizer, and pipeline.
- **MODELS** details the classes and functions related to each model implemented in the library.
- **INTERNAL HELPERS** details utility classes and functions used internally.
## Supported models and frameworks
The table below represents the current support in the library for each of those models, whether they have a Python
tokenizer (called "slow"). A "fast" tokenizer backed by the 🤗 Tokenizers library, whether they have support in Jax (via
Flax), PyTorch, and/or TensorFlow.
| Model | PyTorch support | TensorFlow support | Flax Support |
|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
| [LED](model_doc/led) | ✅ | ✅ | ❌ |
| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
| [UnivNet](model_doc/univnet) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
|
add_new_model.md
|
# How to add a model to 🤗 Transformers?
The 🤗 Transformers library is often able to offer new models thanks to community contributors. But this can be a challenging project and requires an in-depth knowledge of the 🤗 Transformers library and the model to implement. At Hugging Face, we're trying to empower more of the community to actively add models and we've put together this guide to walk you through the process of adding a PyTorch model (make sure you have [PyTorch installed](https://pytorch.org/get-started/locally/)).
If you're interested in implementing a TensorFlow model, take a look at the [How to convert a 🤗 Transformers model to TensorFlow](add_tensorflow_model) guide!
Along the way, you'll:
- get insights into open-source best practices
- understand the design principles behind one of the most popular deep learning libraries
- learn how to efficiently test large models
- learn how to integrate Python utilities like `black`, `ruff`, and `make fix-copies` to ensure clean and readable code
A Hugging Face team member will be available to help you along the way so you'll never be alone. 🤗 ❤️
To get started, open a [New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml) issue for the model you want to see in 🤗 Transformers. If you're not especially picky about contributing a specific model, you can filter by the [New model label](https://github.com/huggingface/transformers/labels/New%20model) to see if there are any unclaimed model requests and work on it.
Once you've opened a new model request, the first step is to get familiar with 🤗 Transformers if you aren't already!
## General overview of 🤗 Transformers
First, you should get a general overview of 🤗 Transformers. 🤗 Transformers is a very opinionated library, so there is a
chance that you don't agree with some of the library's philosophies or design choices. From our experience, however, we
found that the fundamental design choices and philosophies of the library are crucial to efficiently scale 🤗
Transformers while keeping maintenance costs at a reasonable level.
A good first starting point to better understand the library is to read the [documentation of our philosophy](philosophy). As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over-abstraction
- Duplicating code is not always bad if it strongly improves the readability or accessibility of a model
- Model files are as self-contained as possible so that when you read the code of a specific model, you ideally only
have to look into the respective `modeling_.py` file.
In our opinion, the library's code is not just a means to provide a product, *e.g.* the ability to use BERT for
inference, but also as the very product that we want to improve. Hence, when adding a model, the user is not only the
person who will use your model, but also everybody who will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library design.
### Overview of models
To successfully add a model, it is important to understand the interaction between your model and its config,
[`PreTrainedModel`], and [`PretrainedConfig`]. For exemplary purposes, we will
call the model to be added to 🤗 Transformers `BrandNewBert`.
Let's take a look:
As you can see, we do make use of inheritance in 🤗 Transformers, but we keep the level of abstraction to an absolute
minimum. There are never more than two levels of abstraction for any model in the library. `BrandNewBertModel`
inherits from `BrandNewBertPreTrainedModel` which in turn inherits from [`PreTrainedModel`] and
that's it. As a general rule, we want to make sure that a new model only depends on
[`PreTrainedModel`]. The important functionalities that are automatically provided to every new
model are [`~PreTrainedModel.from_pretrained`] and
[`~PreTrainedModel.save_pretrained`], which are used for serialization and deserialization. All of the
other important functionalities, such as `BrandNewBertModel.forward` should be completely defined in the new
`modeling_brand_new_bert.py` script. Next, we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit from `BrandNewBertModel`, but rather uses `BrandNewBertModel`
as a component that can be called in its forward pass to keep the level of abstraction low. Every new model requires a
configuration class, called `BrandNewBertConfig`. This configuration is always stored as an attribute in
[`PreTrainedModel`], and thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`:
thon
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
Similar to the model, the configuration inherits basic serialization and deserialization functionalities from
[`PretrainedConfig`]. Note that the configuration and the model are always serialized into two
different formats - the model to a *pytorch_model.bin* file and the configuration to a *config.json* file. Calling
[`~PreTrainedModel.save_pretrained`] will automatically call
[`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
### Code style
When coding your new model, keep in mind that Transformers is an opinionated library and we have a few quirks of our
own regarding how code should be written :-)
1. The forward pass of your model should be fully written in the modeling file while being fully independent of other
models in the library. If you want to reuse a block from another model, copy the code and paste it with a
`# Copied from` comment on top (see [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
for a good example and [there](pr_checks#check-copies) for more documentation on Copied from).
2. The code should be fully understandable, even by a non-native English speaker. This means you should pick
descriptive variable names and avoid abbreviations. As an example, `activation` is preferred to `act`.
One-letter variable names are strongly discouraged unless it's an index in a for loop.
3. More generally we prefer longer explicit code to short magical one.
4. Avoid subclassing `nn.Sequential` in PyTorch but subclass `nn.Module` and write the forward pass, so that anyone
using your code can quickly debug it by adding print statements or breaking points.
5. Your function signature should be type-annotated. For the rest, good variable names are way more readable and
understandable than type annotations.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
## Step-by-step recipe to add a model to 🤗 Transformers
Everyone has different preferences of how to port a model so it can be very helpful for you to take a look at summaries
of how other contributors ported models to Hugging Face. Here is a list of community blog posts on how to port a model:
1. [Porting GPT2 Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for the new 🤗 Transformers model already exist
somewhere in 🤗 Transformers. Take some time to find similar, already existing models and tokenizers you can copy
from. [grep](https://www.gnu.org/software/grep/) and [rg](https://github.com/BurntSushi/ripgrep) are your
friends. Note that it might very well happen that your model's tokenizer is based on one model implementation, and
your model's modeling code on another one. *E.g.* FSMT's modeling code is based on BART, while FSMT's tokenizer code
is based on XLM.
- It's more of an engineering challenge than a scientific challenge. You should spend more time creating an
efficient debugging environment rather than trying to understand all theoretical aspects of the model in the paper.
- Ask for help, when you're stuck! Models are the core component of 🤗 Transformers so we at Hugging Face are more
than happy to help you at every step to add your model. Don't hesitate to ask if you notice you are not making
progress.
In the following, we try to give you a general recipe that we found most useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add a model and can be used by you as a To-Do
List:
☐ (Optional) Understood the model's theoretical aspects
☐ Prepared 🤗 Transformers dev environment
☐ Set up debugging environment of the original repository
☐ Created script that successfully runs the `forward()` pass using the original repository and checkpoint
☐ Successfully added the model skeleton to 🤗 Transformers
☐ Successfully converted original checkpoint to 🤗 Transformers checkpoint
☐ Successfully ran `forward()` pass in 🤗 Transformers that gives identical output to original checkpoint
☐ Finished model tests in 🤗 Transformers
☐ Successfully added tokenizer in 🤗 Transformers
☐ Run end-to-end integration tests
☐ Finished docs
☐ Uploaded model weights to the Hub
☐ Submitted the pull request
☐ (Optional) Added a demo notebook
To begin with, we usually recommend starting by getting a good theoretical understanding of `BrandNewBert`. However,
if you prefer to understand the theoretical aspects of the model *on-the-job*, then it is totally fine to directly dive
into the `BrandNewBert`'s code-base. This option might suit you better if your engineering skills are better than
your theoretical skill, if you have trouble understanding `BrandNewBert`'s paper, or if you just enjoy programming
much more than reading scientific papers.
### 1. (Optional) Theoretical aspects of BrandNewBert
You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
effectively re-implement the model in 🤗 Transformers. That being said, you don't have to spend too much time on the
theoretical aspects, but rather focus on the practical ones, namely:
- What type of model is *brand_new_bert*? BERT-like encoder-only model? GPT2-like decoder-only model? BART-like
encoder-decoder model? Look at the [model_summary](model_summary) if you're not familiar with the differences between those.
- What are the applications of *brand_new_bert*? Text classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model that makes it different from BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers models](https://huggingface.co/transformers/#contents) is most
similar to *brand_new_bert*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word piece tokenizer? Is it the same tokenizer as used
for BERT or BART?
After you feel like you have gotten a good overview of the architecture of the model, you might want to write to the
Hugging Face team with any questions you might have. This might include questions regarding the model's architecture,
its attention layer, etc. We will be more than happy to help you.
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the ‘Fork' button on the
repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
3. Set up a development environment, for instance by running the following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
which should be enough for most use cases. You can then return to the parent directory
```bash
cd ..
4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
instructions on https://pytorch.org/get-started/locally/.
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
5. To port *brand_new_bert*, you will also need access to its original repository:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
### 3.-4. Run a pretrained checkpoint using the original repository
At first, you will work on the original *brand_new_bert* repository. Often, the original implementation is very
“researchy”. Meaning that documentation might be lacking and the code can be difficult to understand. But this should
be exactly your motivation to reimplement *brand_new_bert*. At Hugging Face, one of our main goals is to *make people
stand on the shoulders of giants* which translates here very well into taking a working model and rewriting it to make
it as **accessible, user-friendly, and beautiful** as possible. This is the number-one motivation to re-implement
models into 🤗 Transformers - trying to make complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the original repository.
Successfully running the official pretrained model in the original repository is often **the most difficult** step.
From our experience, it is very important to spend some time getting familiar with the original code-base. You need to
figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions are required for a simple forward pass. Usually,
you only have to reimplement those functions.
- Be able to locate the important components of the model: Where is the model's class? Are there model sub-classes,
*e.g.* EncoderModel, DecoderModel? Where is the self-attention layer? Are there multiple different attention layers,
*e.g.* *self-attention*, *cross-attention*?
- How can you debug the model in the original environment of the repo? Do you have to add *print* statements, can you
work with an interactive debugger like *ipdb*, or should you use an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, you can **efficiently** debug code in the original
repository! Also, remember that you are working with an open-source library, so do not hesitate to open an issue, or
even a pull request in the original repository. The maintainers of this repository are most likely very happy about
someone looking into their code!
At this point, it is really up to you which debugging environment and strategy you prefer to use to debug the original
model. We strongly advise against setting up a costly GPU environment, but simply work on a CPU both when starting to
dive into the original repository and also when starting to write the 🤗 Transformers implementation of the model. Only
at the very end, when the model has already been successfully ported to 🤗 Transformers, one should verify that the
model also works as expected on GPU.
In general, there are two possible debugging environments for running the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell execution which can be helpful to better split
logical components from one another and to have faster debugging cycles as intermediate results can be stored. Also,
notebooks are often easier to share with other contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we strongly recommend you work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not used to working with them you will have to spend
some time adjusting to the new programming environment and you might not be able to use your known debugging tools
anymore, like `ipdb`.
For each code-base, a good first step is always to load a **small** pretrained checkpoint and to be able to reproduce a
single forward pass using a dummy integer vector of input IDs as an input. Such a script could look like this (in
pseudocode):
thon
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
Next, regarding the debugging strategy, there are generally a few from which to choose from:
- Decompose the original model into many small testable components and run a forward pass on each of those for
verification
- Decompose the original model only into the original *tokenizer* and the original *model*, run a forward pass on
those, and use intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other is advantageous depending on the original code
base.
If the original code-base allows you to decompose the model into smaller sub-components, *e.g.* if the original
code-base can easily be run in eager mode, it is usually worth the effort to do so. There are some important advantages
to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging Face implementation, you can verify automatically
for each component individually that the corresponding component of the 🤗 Transformers implementation matches instead
of relying on visual comparison via print statements
- it can give you some rope to decompose the big problem of porting a model into smaller problems of just porting
individual components and thus structure your work better
- separating the model into logical meaningful components will help you to get a better overview of the model's design
and thus to better understand the model
- at a later stage those component-by-component tests help you to ensure that no regression occurs as you continue
changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) integration checks for ELECTRA
gives a nice example of how this can be done.
However, if the original code-base is very complex or only allows intermediate components to be run in a compiled mode,
it might be too time-consuming or even impossible to separate the model into smaller testable sub-components. A good
example is [T5's MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) library which is
very complex and does not offer a simple way to decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often the same that you should start to debug the
starting layers first and the ending layers last.
It is recommended that you retrieve the output, either by print statements or sub-component functions, of the following
layers in the following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole BrandNewBert Model
Input IDs should thereby consists of an array of integers, *e.g.* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional float arrays and can look like this:
[[
[-0.1465, -0.6501, 0.1993, , 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, , -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, , -0.3662, 0.6091, 0.7648],
,
[-0.5613, -0.6332, 0.4324, , -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, , -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, , -0.3339, 0.6533, 0.8694]]],
We expect that every model added to 🤗 Transformers passes a couple of integration tests, meaning that the original
model and the reimplemented version in 🤗 Transformers have to give the exact same output up to a precision of 0.001!
Since it is normal that the exact same model written in different libraries can give a slightly different output
depending on the library framework, we accept an error tolerance of 1e-3 (0.001). It is not enough if the model gives
nearly the same output, they have to be almost identical. Therefore, you will certainly compare the intermediate
outputs of the 🤗 Transformers version multiple times against the intermediate outputs of the original implementation of
*brand_new_bert* in which case an **efficient** debugging environment of the original repository is absolutely
important. Here is some advice to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original repository written in PyTorch? Then you should
probably take the time to write a longer script that decomposes the original model into smaller sub-components to
retrieve intermediate values. Is the original repository written in Tensorflow 1? Then you might have to rely on
TensorFlow print operations like [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to output
intermediate values. Is the original repository written in Jax? Then make sure that the model is **not jitted** when
running the forward pass, *e.g.* check-out [this link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the checkpoint, the faster your debug cycle
becomes. It is not efficient if your pretrained model is so big that your forward pass takes more than 10 seconds.
In case only very large checkpoints are available, it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights for comparison with the 🤗 Transformers version
of your model
- Make sure you are using the easiest way of calling a forward pass in the original repository. Ideally, you want to
find the function in the original repository that **only** calls a single forward pass, *i.e.* that is often called
`predict`, `evaluate`, `forward` or `__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.* to generate text, like `autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's *forward* pass. If the original repository shows examples where
you have to input a string, then try to find out where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly write a small script yourself or change the
original code so that you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in training mode, which often causes the model to yield
random outputs due to multiple dropout layers in the model. Make sure that the forward pass in your debugging
environment is **deterministic** so that the dropout layers are not used. Or use *transformers.utils.set_seed*
if the old and new implementations are in the same framework.
The following section gives you more specific details/tips on how you can do this for *brand_new_bert*.
### 5.-14. Port BrandNewBert to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into the clone of your 🤗 Transformers' fork:
```bash
cd transformers
In the special case that you are adding a model whose architecture exactly matches the model architecture of an
existing model you only have to add a conversion script as described in [this section](#write-a-conversion-script).
In this case, you can just re-use the whole model architecture of the already existing model.
Otherwise, let's start generating a new model. You have two choices here:
- `transformers-cli add-new-model-like` to add a new model like an existing one
- `transformers-cli add-new-model` to add a new model from our template (will look like BERT or Bart depending on the type of model you select)
In both cases, you will be prompted with a questionnaire to fill in the basic information of your model. The second command requires to install `cookiecutter`, you can find more information on it [here](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the time to open a “Work in progress (WIP)” pull
request, *e.g.* “[WIP] Add *brand_new_bert*”, in 🤗 Transformers so that you and the Hugging Face team can work
side-by-side on integrating the model into 🤗 Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_brand_new_bert
2. Commit the automatically generated code:
```bash
git add .
git commit
3. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
4. Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
future changes.
6. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
In the following, whenever you have made some progress, don't forget to commit your work and push it to your account so
that it shows in the pull request. Additionally, you should make sure to update your work with the current main from
time to time by doing:
```bash
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your implementation should be asked in your PR and
discussed/solved in the PR. This way, the Hugging Face team will always be notified when you are committing new code or
if you have a question. It is often very helpful to point the Hugging Face team to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the “Files changed” tab where you see all of your changes, go to a line regarding which you
want to ask a question, and click on the “+” symbol to add a comment. Whenever a question or problem has been solved,
you can click on the “Resolve” button of the created comment.
In the same way, the Hugging Face team will open comments when reviewing your code. We recommend asking most questions
on GitHub on your PR. For some very general questions that are not very useful for the public, feel free to ping the
Hugging Face team by Slack or email.
**5. Adapt the generated models code for brand_new_bert**
At first, we will focus only on the model itself and not care about the tokenizer. All the relevant code should be
found in the generated files `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` and
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` will either have the same architecture as BERT if
it's an encoder-only model or BART if it's an encoder-decoder model. At this point, you should remind yourself what
you've learned in the beginning about the theoretical aspects of the model: *How is the model different from BERT or
BART?*". Implement those changes which often means changing the *self-attention* layer, the order of the normalization
layer, etc… Again, it is often useful to look at the similar architecture of already existing models in Transformers to
get a better feeling of how your model should be implemented.
**Note** that at this point, you don't have to be very sure that your code is fully correct or clean. Rather, it is
advised to add a first *unclean*, copy-pasted version of the original code to
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` until you feel like all the necessary code is
added. From our experience, it is much more efficient to quickly add a first version of the required code and
improve/correct the code iteratively with the conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers implementation of *brand_new_bert*, *i.e.* the
following command should work:
thon
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
The above command will create a model according to the default parameters as defined in `BrandNewBertConfig()` with
random weights, thus making sure that the `init()` methods of all components works.
Note that all random initialization should happen in the `_init_weights` method of your `BrandnewBertPreTrainedModel`
class. It should initialize all leaf modules depending on the variables of the config. Here is an example with the
BERT `_init_weights` method:
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
You can have some more custom schemes if you need a special initialization for some modules. For instance, in
`Wav2Vec2ForPreTraining`, the last two linear layers need to have the initialization of the regular PyTorch `nn.Linear`
but all the other ones should use an initialization as above. This is coded like this:
def _init_weights(self, module):
"""Initialize the weights"""
if isinstnace(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
The `_is_hf_initialized` flag is internally used to make sure we only initialize a submodule once. By setting it to
`True` for `module.project_q` and `module.project_hid`, we make sure the custom initialization we did is not overridden later on,
the `_init_weights` function won't be applied to them.
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the checkpoint you used to debug *brand_new_bert* in
the original repository to a checkpoint compatible with your just created 🤗 Transformers implementation of
*brand_new_bert*. It is not advised to write the conversion script from scratch, but rather to look through already
existing conversion scripts in 🤗 Transformers for one that has been used to convert a similar model that was written in
the same framework as *brand_new_bert*. Usually, it is enough to copy an already existing conversion script and
slightly adapt it for your use case. Don't hesitate to ask the Hugging Face team to point you to a similar already
existing conversion script for your model.
- If you are porting a model from TensorFlow to PyTorch, a good starting point might be BERT's conversion script [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- If you are porting a model from PyTorch to PyTorch, a good starting point might be BART's conversion script [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
In the following, we'll quickly explain how PyTorch models store layer weights and define layer names. In PyTorch, the
name of a layer is defined by the name of the class attribute you give the layer. Let's define a dummy model in
PyTorch, called `SimpleModel` as follows:
thon
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
Now we can create an instance of this model definition which will fill all weights: `dense`, `intermediate`,
`layer_norm` with random weights. We can print the model to see its architecture
thon
model = SimpleModel()
print(model)
This will print out the following:
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
We can see that the layer names are defined by the name of the class attribute in PyTorch. You can print out the weight
values of a specific layer:
thon
print(model.dense.weight.data)
to see that the weights were randomly initialized
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
In the conversion script, you should fill those randomly initialized weights with the exact weights of the
corresponding layer in the checkpoint. *E.g.*
thon
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
While doing so, you must verify that each randomly initialized weight of your PyTorch model and its corresponding
pretrained checkpoint weight exactly match in both **shape and name**. To do so, it is **necessary** to add assert
statements for the shape and print out the names of the checkpoints weights. E.g. you should add statements like:
thon
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
Besides, you should also print out the names of both weights to make sure they match, *e.g.*
thon
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
If either the shape or the name doesn't match, you probably assigned the wrong checkpoint weight to a randomly
initialized layer of the 🤗 Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the config parameters in `BrandNewBertConfig()` that
do not exactly match those that were used for the checkpoint you want to convert. However, it could also be that
PyTorch's implementation of a layer requires the weight to be transposed beforehand.
Finally, you should also check that **all** required weights are initialized and print out all checkpoint weights that
were not used for initialization to make sure the model is correctly converted. It is completely normal, that the
conversion trials fail with either a wrong shape statement or a wrong name assignment. This is most likely because either
you used incorrect parameters in `BrandNewBertConfig()`, have a wrong architecture in the 🤗 Transformers
implementation, you have a bug in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of the checkpoint are correctly loaded in the
Transformers model. Having correctly loaded the checkpoint into the 🤗 Transformers implementation, you can then save
the model under a folder of your choice `/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
thon
model.save_pretrained("/path/to/converted/checkpoint/folder")
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗 Transformers implementation, you should now make
sure that the forward pass is correctly implemented. In [Get familiar with the original repository](#34-run-a-pretrained-checkpoint-using-the-original-repository), you have already created a script that runs a forward
pass of the model using the original repository. Now you should write an analogous script using the 🤗 Transformers
implementation instead of the original one. It should look as follows:
thon
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
It is very likely that the 🤗 Transformers implementation and the original model implementation don't give the exact
same output the very first time or that the forward pass throws an error. Don't be disappointed - it's expected! First,
you should make sure that the forward pass doesn't throw any errors. It often happens that the wrong dimensions are
used leading to a *Dimensionality mismatch* error or that the wrong data type object is used, *e.g.* `torch.long`
instead of `torch.float32`. Don't hesitate to ask the Hugging Face team for help, if you don't manage to solve
certain errors.
The final part to make sure the 🤗 Transformers implementation works correctly is to ensure that the outputs are
equivalent to a precision of `1e-3`. First, you should ensure that the output shapes are identical, *i.e.*
`outputs.shape` should yield the same value for the script of the 🤗 Transformers implementation and the original
implementation. Next, you should make sure that the output values are identical as well. This one of the most difficult
parts of adding a new model. Common mistakes why the outputs are not identical are:
- Some layers were not added, *i.e.* an *activation* layer was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure *model.training is False* and that no dropout
layer is falsely activated during the forward pass, *i.e.* pass *self.training* to [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass of the original implementation and the 🤗
Transformers implementation side-by-side and check if there are any differences. Ideally, you should debug/print out
intermediate outputs of both implementations of the forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original implementation. First, make sure that the
hard-coded `input_ids` in both scripts are identical. Next, verify that the outputs of the first transformation of
the `input_ids` (usually the word embeddings) are identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two implementations, which should point you to the bug
in the 🤗 Transformers implementation. From our experience, a simple and efficient way is to add many print statements
in both the original implementation and 🤗 Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the same values for intermediate presentations.
When you're confident that both implementations yield the same output, verify the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with the most difficult part! Congratulations - the
work left to be done should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is very much possible that the model does not yet
fully comply with the required design. To make sure, the implementation is fully compatible with 🤗 Transformers, all
common tests should pass. The Cookiecutter should have automatically added a test file for your model, probably under
the same `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`. Run this test file to verify that all common
tests pass:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
Having fixed all common tests, it is now crucial to ensure that all the nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at specific tests of *brand_new_bert*
- b) Future changes to your model will not break any important feature of the model.
At first, integration tests should be added. Those integration tests essentially do the same as the debugging scripts
you used earlier to implement the model to 🤗 Transformers. A template of those model tests has already added by the
Cookiecutter, called `BrandNewBertModelIntegrationTests` and only has to be filled out by you. To ensure that those
tests are passing, run
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
ways:
- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
special features of *brand_new_bert* should work.
- Future contributors can quickly test changes to the model by running those special tests.
**9. Implement the tokenizer**
Next, we should add the tokenizer of *brand_new_bert*. Usually, the tokenizer is equivalent to or very similar to an
already existing tokenizer of 🤗 Transformers.
It is very important to find/extract the original tokenizer file and to manage to load this file into the 🤗
Transformers' implementation of the tokenizer.
To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
thon
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
You might have to take a deeper look again into the original repository to find the correct tokenizer function or you
might even have to do changes to your clone of the original repository to only output the `input_ids`. Having written
a functional tokenization script that uses the original repository, an analogous script for 🤗 Transformers should be
created. It should look similar to this:
thon
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
When both `input_ids` yield the same values, as a final step a tokenizer test file should also be added.
Analogous to the modeling test files of *brand_new_bert*, the tokenization test files of *brand_new_bert* should
contain a couple of hard-coded integration tests.
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end integration tests using both the model and the
tokenizer to `tests/models/brand_new_bert/test_modeling_brand_new_bert.py` in 🤗 Transformers.
Such a test should show on a meaningful
text-to-text sample that the 🤗 Transformers implementation works as expected. A meaningful text-to-text sample can
include *e.g.* a source-to-target-translation pair, an article-to-summary pair, a question-to-answer pair, etc… If none
of the ported checkpoints has been fine-tuned on a downstream task it is enough to simply rely on the model tests. In a
final step to ensure that the model is fully functional, it is advised that you also run all tests on GPU. It can
happen that you forgot to add some `.to(self.device)` statements to internal tensors of the model, which in such a
test would show in an error. In case you have no access to a GPU, the Hugging Face team can take care of running those
tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *brand_new_bert* is added - you're almost done! The only thing left to add is
a nice docstring and a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/brand_new_bert.md` that you should fill out. Users of your model will usually first look at
this page before using your model. Hence, the documentation must be understandable and concise. It is very useful for
the community to add some *Tips* to show how the model should be used. Don't hesitate to ping the Hugging Face team
regarding the docstrings.
Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *brand_new_bert*. At this point, you should correct some potential
incorrect code style by running:
```bash
make style
and verify that your coding style passes the quality check:
```bash
make quality
There are a couple of other very strict design tests in 🤗 Transformers that might still be failing, which shows up in
the tests of your pull request. This is often because of some missing information in the docstring or some incorrect
naming. The Hugging Face team will surely help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having ensured that the code works correctly. With all
tests passing, now it's a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the model hub and add a model card for each
uploaded model checkpoint. You can get familiar with the hub functionalities by reading our [Model sharing and uploading Page](model_sharing). You should work alongside the Hugging Face team here to decide on a fitting name for each
checkpoint and to get the required access rights to be able to upload the model under the author's organization of
*brand_new_bert*. The `push_to_hub` method, present in all models in `transformers`, is a quick and efficient way to push your checkpoint to the hub. A little snippet is pasted below:
thon
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("/brand_new_bert")
It is worth spending some time to create fitting model cards for each checkpoint. The model cards should highlight the
specific characteristics of this particular checkpoint, *e.g.* On which dataset was the checkpoint
pretrained/fine-tuned on? On what down-stream task should the model be used? And also include some code on how to
correctly use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how *brand_new_bert* can be used for inference and/or
fine-tuned on a downstream task. This is not mandatory to merge your PR, but very useful for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is getting your PR merged into main. Usually, the
Hugging Face team should have helped you already at this point, but it is worth taking some time to give your finished
PR a nice description and eventually add comments to your code, if you want to point out certain design choices to your
reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work! Having completed a model addition is a major
contribution to Transformers and the whole NLP community. Your code and the ported pre-trained models will certainly be
used by hundreds and possibly even thousands of developers and researchers. You should be proud of your work and share
your achievements with the community.
**You have made another model that is super easy to access for everyone in the community! 🤯**
|
benchmarks.md
|
# Benchmarks
Hugging Face's Benchmarking tools are deprecated and it is advised to use external Benchmarking libraries to measure the speed
and memory complexity of Transformer models.
[[open-in-colab]]
Let's take a look at how 🤗 Transformers models can be benchmarked, best practices, and already available benchmarks.
A notebook explaining in more detail how to benchmark 🤗 Transformers models can be found [here](https://github.com/huggingface/notebooks/tree/main/examples/benchmark.ipynb).
## How to benchmark 🤗 Transformers models
The classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] allow to flexibly benchmark 🤗 Transformers models. The benchmark classes allow us to measure the _peak memory usage_ and _required time_ for both _inference_ and _training_.
Hereby, _inference_ is defined by a single forward pass, and _training_ is defined by a single forward pass and
backward pass.
The benchmark classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] expect an object of type [`PyTorchBenchmarkArguments`] and
[`TensorFlowBenchmarkArguments`], respectively, for instantiation. [`PyTorchBenchmarkArguments`] and [`TensorFlowBenchmarkArguments`] are data classes and contain all relevant configurations for their corresponding benchmark class. In the following example, it is shown how a BERT model of type _bert-base-cased_ can be benchmarked.
>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments
>>> args = PyTorchBenchmarkArguments(models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512])
>>> benchmark = PyTorchBenchmark(args)
>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments
>>> args = TensorFlowBenchmarkArguments(
models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
)
>>> benchmark = TensorFlowBenchmark(args)
Here, three arguments are given to the benchmark argument data classes, namely `models`, `batch_sizes`, and
`sequence_lengths`. The argument `models` is required and expects a `list` of model identifiers from the
[model hub](https://huggingface.co/models) The `list` arguments `batch_sizes` and `sequence_lengths` define
the size of the `input_ids` on which the model is benchmarked. There are many more parameters that can be configured
via the benchmark argument data classes. For more detail on these one can either directly consult the files
`src/transformers/benchmark/benchmark_args_utils.py`, `src/transformers/benchmark/benchmark_args.py` (for PyTorch)
and `src/transformers/benchmark/benchmark_args_tf.py` (for Tensorflow). Alternatively, running the following shell
commands from root will print out a descriptive list of all configurable parameters for PyTorch and Tensorflow
respectively.
```bash
python examples/pytorch/benchmarking/run_benchmark.py --help
An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
>>> results = benchmark.run()
>>> print(results)
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base-uncased 8 8 0.006
bert-base-uncased 8 32 0.006
bert-base-uncased 8 128 0.018
bert-base-uncased 8 512 0.088
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base-uncased 8 8 1227
bert-base-uncased 8 32 1281
bert-base-uncased 8 128 1307
bert-base-uncased 8 512 1539
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.4.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 08:58:43.371351
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```bash
python examples/tensorflow/benchmarking/run_benchmark_tf.py --help
An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
>>> results = benchmark.run()
>>> print(results)
>>> results = benchmark.run()
>>> print(results)
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base-uncased 8 8 0.005
bert-base-uncased 8 32 0.008
bert-base-uncased 8 128 0.022
bert-base-uncased 8 512 0.105
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base-uncased 8 8 1330
bert-base-uncased 8 32 1330
bert-base-uncased 8 128 1330
bert-base-uncased 8 512 1770
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: Tensorflow
- use_xla: False
- framework_version: 2.2.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:26:35.617317
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
By default, the _time_ and the _required memory_ for _inference_ are benchmarked. In the example output above the first
two sections show the result corresponding to _inference time_ and _inference memory_. In addition, all relevant
information about the computing environment, _e.g._ the GPU type, the system, the library versions, etc are printed
out in the third section under _ENVIRONMENT INFORMATION_. This information can optionally be saved in a _.csv_ file
when adding the argument `save_to_csv=True` to [`PyTorchBenchmarkArguments`] and
[`TensorFlowBenchmarkArguments`] respectively. In this case, every section is saved in a separate
_.csv_ file. The path to each _.csv_ file can optionally be defined via the argument data classes.
Instead of benchmarking pre-trained models via their model identifier, _e.g._ `bert-base-uncased`, the user can
alternatively benchmark an arbitrary configuration of any available model class. In this case, a `list` of
configurations must be inserted with the benchmark args as follows.
>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments, BertConfig
>>> args = PyTorchBenchmarkArguments(
models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
)
>>> config_base = BertConfig()
>>> config_384_hid = BertConfig(hidden_size=384)
>>> config_6_lay = BertConfig(num_hidden_layers=6)
>>> benchmark = PyTorchBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
>>> benchmark.run()
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base 8 128 0.006
bert-base 8 512 0.006
bert-base 8 128 0.018
bert-base 8 512 0.088
bert-384-hid 8 8 0.006
bert-384-hid 8 32 0.006
bert-384-hid 8 128 0.011
bert-384-hid 8 512 0.054
bert-6-lay 8 8 0.003
bert-6-lay 8 32 0.004
bert-6-lay 8 128 0.009
bert-6-lay 8 512 0.044
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base 8 8 1277
bert-base 8 32 1281
bert-base 8 128 1307
bert-base 8 512 1539
bert-384-hid 8 8 1005
bert-384-hid 8 32 1027
bert-384-hid 8 128 1035
bert-384-hid 8 512 1255
bert-6-lay 8 8 1097
bert-6-lay 8 32 1101
bert-6-lay 8 128 1127
bert-6-lay 8 512 1359
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.4.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:35:25.143267
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments, BertConfig
>>> args = TensorFlowBenchmarkArguments(
models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
)
>>> config_base = BertConfig()
>>> config_384_hid = BertConfig(hidden_size=384)
>>> config_6_lay = BertConfig(num_hidden_layers=6)
>>> benchmark = TensorFlowBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
>>> benchmark.run()
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base 8 8 0.005
bert-base 8 32 0.008
bert-base 8 128 0.022
bert-base 8 512 0.106
bert-384-hid 8 8 0.005
bert-384-hid 8 32 0.007
bert-384-hid 8 128 0.018
bert-384-hid 8 512 0.064
bert-6-lay 8 8 0.002
bert-6-lay 8 32 0.003
bert-6-lay 8 128 0.0011
bert-6-lay 8 512 0.074
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base 8 8 1330
bert-base 8 32 1330
bert-base 8 128 1330
bert-base 8 512 1770
bert-384-hid 8 8 1330
bert-384-hid 8 32 1330
bert-384-hid 8 128 1330
bert-384-hid 8 512 1540
bert-6-lay 8 8 1330
bert-6-lay 8 32 1330
bert-6-lay 8 128 1330
bert-6-lay 8 512 1540
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: Tensorflow
- use_xla: False
- framework_version: 2.2.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:38:15.487125
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
Again, _inference time_ and _required memory_ for _inference_ are measured, but this time for customized configurations
of the `BertModel` class. This feature can especially be helpful when deciding for which configuration the model
should be trained.
## Benchmark best practices
This section lists a couple of best practices one should be aware of when benchmarking a model.
- Currently, only single device benchmarking is supported. When benchmarking on GPU, it is recommended that the user
specifies on which device the code should be run by setting the `CUDA_VISIBLE_DEVICES` environment variable in the
shell, _e.g._ `export CUDA_VISIBLE_DEVICES=0` before running the code.
- The option `no_multi_processing` should only be set to `True` for testing and debugging. To ensure accurate
memory measurement it is recommended to run each memory benchmark in a separate process by making sure
`no_multi_processing` is set to `True`.
- One should always state the environment information when sharing the results of a model benchmark. Results can vary
heavily between different GPU devices, library versions, etc., so that benchmark results on their own are not very
useful for the community.
## Sharing your benchmark
Previously all available core models (10 at the time) have been benchmarked for _inference time_, across many different
settings: using PyTorch, with and without TorchScript, using TensorFlow, with and without XLA. All of those tests were
done across CPUs (except for TensorFlow XLA) and GPUs.
The approach is detailed in the [following blogpost](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) and the results are
available [here](https://docs.google.com/spreadsheets/d/1sryqufw2D0XlUH4sq3e9Wnxu5EAQkaohzrJbd5HdQ_w/edit?usp=sharing).
With the new _benchmark_ tools, it is easier than ever to share your benchmark results with the community
- [PyTorch Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/pytorch/benchmarking/README.md).
- [TensorFlow Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/benchmarking/README.md).
|
debugging.md
|
# Debugging
## Multi-GPU Network Issues Debug
When training or inferencing with `DistributedDataParallel` and multiple GPU, if you run into issue of inter-communication between processes and/or nodes, you can use the following script to diagnose network issues.
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
For example to test how 2 GPUs interact do:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
If both processes can talk to each and allocate GPU memory each will print an OK status.
For more GPUs or nodes adjust the arguments in the script.
You will find a lot more details inside the diagnostics script and even a recipe to how you could run it in a SLURM environment.
An additional level of debug is to add `NCCL_DEBUG=INFO` environment variable as follows:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
This will dump a lot of NCCL-related debug information, which you can then search online if you find that some problems are reported. Or if you're not sure how to interpret the output you can share the log file in an Issue.
## Underflow and Overflow Detection
This feature is currently available for PyTorch-only.
For multi-GPU training it requires DDP (`torch.distributed.launch`).
This feature can be used with any `nn.Module`-based model.
If you start getting `loss=NaN` or the model inhibits some other abnormal behavior due to `inf` or `nan` in
activations or weights one needs to discover where the first underflow or overflow happens and what led to it. Luckily
you can accomplish that easily by activating a special module that will do the detection automatically.
If you're using [`Trainer`], you just need to add:
```bash
--debug underflow_overflow
to the normal command line arguments, or pass `debug="underflow_overflow"` when creating the
[`TrainingArguments`] object.
If you're using your own training loop or another Trainer you can accomplish the same with:
thon
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
[`~debug_utils.DebugUnderflowOverflow`] inserts hooks into the model that immediately after each
forward call will test input and output variables and also the corresponding module's weights. As soon as `inf` or
`nan` is detected in at least one element of the activations or weights, the program will assert and print a report
like this (this was caught with `google/mt5-small` under fp16 mixed precision):
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
The example output has been trimmed in the middle for brevity.
The second column shows the value of the absolute largest element, so if you have a closer look at the last few frames,
the inputs and outputs were in the range of `1e4`. So when this training was done under fp16 mixed precision the very
last step overflowed (since under `fp16` the largest number before `inf` is `64e3`). To avoid overflows under
`fp16` the activations must remain way below `1e4`, because `1e4 * 1e4 = 1e8` so any matrix multiplication with
large activations is going to lead to a numerical overflow condition.
At the very start of the trace you can discover at which batch number the problem occurred (here `Detected inf/nan during batch_number=0` means the problem occurred on the first batch).
Each reported frame starts by declaring the fully qualified entry for the corresponding module this frame is reporting
for. If we look just at this frame:
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
Here, `encoder.block.2.layer.1.layer_norm` indicates that it was a layer norm for the first layer, of the second
block of the encoder. And the specific calls of the `forward` is `T5LayerNorm`.
Let's look at the last few frames of that report:
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
The last frame reports for `Dropout.forward` function with the first entry for the only input and the second for the
only output. You can see that it was called from an attribute `dropout` inside `DenseReluDense` class. We can see
that it happened during the first layer, of the 2nd block, during the very first batch. Finally, the absolute largest
input elements was `6.27e+04` and same for the output was `inf`.
You can see here, that `T5DenseGatedGeluDense.forward` resulted in output activations, whose absolute max value was
around 62.7K, which is very close to fp16's top limit of 64K. In the next frame we have `Dropout` which renormalizes
the weights, after it zeroed some of the elements, which pushes the absolute max value to more than 64K, and we get an
overflow (`inf`).
As you can see it's the previous frames that we need to look into when the numbers start going into very large for fp16
numbers.
Let's match the report to the code from `models/t5/modeling_t5.py`:
thon
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
Now it's easy to see the `dropout` call, and all the previous calls as well.
Since the detection is happening in a forward hook, these reports are printed immediately after each `forward`
returns.
Going back to the full report, to act on it and to fix the problem, we need to go a few frames up where the numbers
started to go up and most likely switch to the `fp32` mode here, so that the numbers don't overflow when multiplied
or summed up. Of course, there might be other solutions. For example, we could turn off `amp` temporarily if it's
enabled, after moving the original `forward` into a helper wrapper, like so:
thon
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
Since the automatic detector only reports on inputs and outputs of full frames, once you know where to look, you may
want to analyse the intermediary stages of any specific `forward` function as well. In such a case you can use the
`detect_overflow` helper function to inject the detector where you want it, for example:
thon
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
You can see that we added 2 of these and now we track if `inf` or `nan` for `forwarded_states` was detected
somewhere in between.
Actually, the detector already reports these because each of the calls in the example above is a `nn.Module`, but
let's say if you had some local direct calculations this is how you'd do that.
Additionally, if you're instantiating the debugger in your own code, you can adjust the number of frames printed from
its default, e.g.:
thon
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
### Specific batch absolute min and max value tracing
The same debugging class can be used for per-batch tracing with the underflow/overflow detection feature turned off.
Let's say you want to watch the absolute min and max values for all the ingredients of each `forward` call of a given
batch, and only do that for batches 1 and 3. Then you instantiate this class as:
thon
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
And now full batches 1 and 3 will be traced using the same format as the underflow/overflow detector does.
Batches are 0-indexed.
This is helpful if you know that the program starts misbehaving after a certain batch number, so you can fast-forward
right to that area. Here is a sample truncated output for such configuration:
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[]
Here you will get a huge number of frames dumped - as many as there were forward calls in your model, so it may or may
not what you want, but sometimes it can be easier to use for debugging purposes than a normal debugger. For example, if
a problem starts happening at batch number 150. So you can dump traces for batches 149 and 150 and compare where
numbers started to diverge.
You can also specify the batch number after which to stop the training, with:
thon
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
|
model_memory_anatomy.md
|
# Model training anatomy
To understand performance optimization techniques that one can apply to improve efficiency of model training
speed and memory utilization, it's helpful to get familiar with how GPU is utilized during training, and how compute
intensity varies depending on an operation performed.
Let's start by exploring a motivating example of GPU utilization and the training run of a model. For the demonstration,
we'll need to install a few libraries:
```bash
pip install transformers datasets accelerate nvidia-ml-py3
The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar
with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
Then, we create some dummy data: random token IDs between 100 and 30000 and binary labels for a classifier.
In total, we get 512 sequences each with length 512 and store them in a [`~datasets.Dataset`] with PyTorch format.
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
"labels": np.random.randint(0, 1, (dataset_size)),
}
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")
To print summary statistics for the GPU utilization and the training run with the [`Trainer`] we define two helper functions:
>>> from pynvml import *
>>> def print_gpu_utilization():
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
info = nvmlDeviceGetMemoryInfo(handle)
print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
print(f"Time: {result.metrics['train_runtime']:.2f}")
print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
print_gpu_utilization()
Let's verify that we start with a free GPU memory:
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.
That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on
your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by
the user. When a model is loaded to the GPU the kernels are also loaded, which can take up 1-2GB of memory. To see how
much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.
We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
## Load Model
First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check
how much space just the weights use.
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.
We can see that the model weights alone take up 1.3 GB of GPU memory. The exact number depends on the specific
GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an
optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result
as with `nvidia-smi` CLI:
```bash
nvidia-smi
```bash
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2 On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can
start training the model and see how the GPU memory consumption changes. First, we set up a few standard training
arguments:
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
If you plan to run multiple experiments, in order to properly clear the memory between experiments, restart the Python
kernel between experiments.
## Memory utilization at vanilla training
Let's use the [`Trainer`] and train the model without using any GPU performance optimization techniques and a batch size of 4:
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size
can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our
model's needs and not to the GPU limitations. What's interesting is that we use much more memory than the size of the model.
To understand a bit better why this is the case let's have a look at a model's operations and memory needs.
## Anatomy of Model's Operations
Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
1. **Tensor Contractions**
Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
2. **Statistical Normalizations**
Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
3. **Element-wise Operators**
These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
This knowledge can be helpful to know when analyzing performance bottlenecks.
This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
## Anatomy of Model's Memory
We've seen that training the model uses much more memory than just putting the model on the GPU. This is because there
are many components during training that use GPU memory. The components on GPU memory are the following:
1. model weights
2. optimizer states
3. gradients
4. forward activations saved for gradient computation
5. temporary buffers
6. functionality-specific memory
A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory. For
inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per
model parameter for mixed precision inference, plus activation memory.
Let's look at the details.
**Model Weights:**
- 4 bytes * number of parameters for fp32 training
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
**Optimizer States:**
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
**Gradients**
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
**Forward Activations**
- size depends on many factors, the key ones being sequence length, hidden size and batch size.
There are the input and output that are being passed and returned by the forward and the backward functions and the
forward activations saved for gradient computation.
**Temporary Memory**
Additionally, there are all kinds of temporary variables which get released once the calculation is done, but in the
moment these could require additional memory and could push to OOM. Therefore, when coding it's crucial to think
strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
**Functionality-specific memory**
Then, your software could have special memory needs. For example, when generating text using beam search, the software
needs to maintain multiple copies of inputs and outputs.
**`forward` vs `backward` Execution Speed**
For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates
into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually
bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward
(e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward,
and writes once, gradInput).
As you can see, there are potentially a few places where we could save GPU memory or speed up operations.
Now that you understand what affects GPU utilization and computation speed, refer to
the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) documentation page to learn about
performance optimization techniques.
|
tflite.md
|
# Export to TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) is a lightweight framework for deploying machine learning models
on resource-constrained devices, such as mobile phones, embedded systems, and Internet of Things (IoT) devices.
TFLite is designed to optimize and run models efficiently on these devices with limited computational power, memory, and
power consumption.
A TensorFlow Lite model is represented in a special efficient portable format identified by the `.tflite` file extension.
🤗 Optimum offers functionality to export 🤗 Transformers models to TFLite through the `exporters.tflite` module.
For the list of supported model architectures, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/tflite/overview).
To export a model to TFLite, install the required dependencies:
```bash
pip install optimum[exporters-tf]
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model),
or view help in command line:
```bash
optimum-cli export tflite --help
To export a model's checkpoint from the 🤗 Hub, for example, `bert-base-uncased`, run the following command:
```bash
optimum-cli export tflite --model bert-base-uncased --sequence_length 128 bert_tflite/
You should see the logs indicating progress and showing where the resulting `model.tflite` is saved, like this:
```bash
Validating TFLite model
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub.
|
performance.md
|
# Performance and Scalability
Training large transformer models and deploying them to production present various challenges.
During training, the model may require more GPU memory than available or exhibit slow training speed. In the deployment
phase, the model can struggle to handle the required throughput in a production environment.
This documentation aims to assist you in overcoming these challenges and finding the optimal setting for your use-case.
The guides are divided into training and inference sections, as each comes with different challenges and solutions.
Within each section you'll find separate guides for different hardware configurations, such as single GPU vs. multi-GPU
for training or CPU vs. GPU for inference.
Use this document as your starting point to navigate further to the methods that match your scenario.
## Training
Training large transformer models efficiently requires an accelerator such as a GPU or TPU. The most common case is where
you have a single GPU. The methods that you can apply to improve training efficiency on a single GPU extend to other setups
such as multiple GPU. However, there are also techniques that are specific to multi-GPU or CPU training. We cover them in
separate sections.
* [Methods and tools for efficient training on a single GPU](perf_train_gpu_one): start here to learn common approaches that can help optimize GPU memory utilization, speed up the training, or both.
* [Multi-GPU training section](perf_train_gpu_many): explore this section to learn about further optimization methods that apply to a multi-GPU settings, such as data, tensor, and pipeline parallelism.
* [CPU training section](perf_train_cpu): learn about mixed precision training on CPU.
* [Efficient Training on Multiple CPUs](perf_train_cpu_many): learn about distributed CPU training.
* [Training on TPU with TensorFlow](perf_train_tpu_tf): if you are new to TPUs, refer to this section for an opinionated introduction to training on TPUs and using XLA.
* [Custom hardware for training](perf_hardware): find tips and tricks when building your own deep learning rig.
* [Hyperparameter Search using Trainer API](hpo_train)
## Inference
Efficient inference with large models in a production environment can be as challenging as training them. In the following
sections we go through the steps to run inference on CPU and single/multi-GPU setups.
* [Inference on a single CPU](perf_infer_cpu)
* [Inference on a single GPU](perf_infer_gpu_one)
* [Multi-GPU inference](perf_infer_gpu_one)
* [XLA Integration for TensorFlow Models](tf_xla)
## Training and inference
Here you'll find techniques, tips and tricks that apply whether you are training a model, or running inference with it.
* [Instantiating a big model](big_models)
* [Troubleshooting performance issues](debugging)
## Contribute
This document is far from being complete and a lot more needs to be added, so if you have additions or corrections to
make please don't hesitate to open a PR or if you aren't sure start an Issue and we can discuss the details there.
When making contributions that A is better than B, please try to include a reproducible benchmark and/or a link to the
source of that information (unless it comes directly from you).
|
tokenizer_summary.md
|
# Summary of the tokenizers
[[open-in-colab]]
On this page, we will have a closer look at tokenization.
As we saw in [the preprocessing tutorial](preprocessing), tokenizing a text is splitting it into words or
subwords, which then are converted to ids through a look-up table. Converting words or subwords to ids is
straightforward, so in this summary, we will focus on splitting a text into words or subwords (i.e. tokenizing a text).
More specifically, we will look at the three main types of tokenizers used in 🤗 Transformers: [Byte-Pair Encoding
(BPE)](#byte-pair-encoding), [WordPiece](#wordpiece), and [SentencePiece](#sentencepiece), and show examples
of which tokenizer type is used by which model.
Note that on each model page, you can look at the documentation of the associated tokenizer to know which tokenizer
type was used by the pretrained model. For instance, if we look at [`BertTokenizer`], we can see
that the model uses [WordPiece](#wordpiece).
## Introduction
Splitting a text into smaller chunks is a task that is harder than it looks, and there are multiple ways of doing so.
For instance, let's look at the sentence `"Don't you love 🤗 Transformers? We sure do."`
A simple way of tokenizing this text is to split it by spaces, which would give:
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
This is a sensible first step, but if we look at the tokens `"Transformers?"` and `"do."`, we notice that the
punctuation is attached to the words `"Transformer"` and `"do"`, which is suboptimal. We should take the
punctuation into account so that a model does not have to learn a different representation of a word and every possible
punctuation symbol that could follow it, which would explode the number of representations the model has to learn.
Taking punctuation into account, tokenizing our exemplary text would give:
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
Better. However, it is disadvantageous, how the tokenization dealt with the word `"Don't"`. `"Don't"` stands for
`"do not"`, so it would be better tokenized as `["Do", "n't"]`. This is where things start getting complicated, and
part of the reason each model has its own tokenizer type. Depending on the rules we apply for tokenizing a text, a
different tokenized output is generated for the same text. A pretrained model only performs properly if you feed it an
input that was tokenized with the same rules that were used to tokenize its training data.
[spaCy](https://spacy.io/) and [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) are two popular
rule-based tokenizers. Applying them on our example, *spaCy* and *Moses* would output something like:
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
As can be seen space and punctuation tokenization, as well as rule-based tokenization, is used here. Space and
punctuation tokenization and rule-based tokenization are both examples of word tokenization, which is loosely defined
as splitting sentences into words. While it's the most intuitive way to split texts into smaller chunks, this
tokenization method can lead to problems for massive text corpora. In this case, space and punctuation tokenization
usually generates a very big vocabulary (the set of all unique words and tokens used). *E.g.*, [Transformer XL](model_doc/transformerxl) uses space and punctuation tokenization, resulting in a vocabulary size of 267,735!
Such a big vocabulary size forces the model to have an enormous embedding matrix as the input and output layer, which
causes both an increased memory and time complexity. In general, transformers models rarely have a vocabulary size
greater than 50,000, especially if they are pretrained only on a single language.
So if simple space and punctuation tokenization is unsatisfactory, why not simply tokenize on characters?
While character tokenization is very simple and would greatly reduce memory and time complexity it makes it much harder
for the model to learn meaningful input representations. *E.g.* learning a meaningful context-independent
representation for the letter `"t"` is much harder than learning a context-independent representation for the word
`"today"`. Therefore, character tokenization is often accompanied by a loss of performance. So to get the best of
both worlds, transformers models use a hybrid between word-level and character-level tokenization called **subword**
tokenization.
## Subword tokenization
Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller
subwords, but rare words should be decomposed into meaningful subwords. For instance `"annoyingly"` might be
considered a rare word and could be decomposed into `"annoying"` and `"ly"`. Both `"annoying"` and `"ly"` as
stand-alone subwords would appear more frequently while at the same time the meaning of `"annoyingly"` is kept by the
composite meaning of `"annoying"` and `"ly"`. This is especially useful in agglutinative languages such as Turkish,
where you can form (almost) arbitrarily long complex words by stringing together subwords.
Subword tokenization allows the model to have a reasonable vocabulary size while being able to learn meaningful
context-independent representations. In addition, subword tokenization enables the model to process words it has never
seen before, by decomposing them into known subwords. For instance, the [`~transformers.BertTokenizer`] tokenizes
`"I have a new GPU!"` as follows:
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]
Because we are considering the uncased model, the sentence was lowercased first. We can see that the words `["i", "have", "a", "new"]` are present in the tokenizer's vocabulary, but the word `"gpu"` is not. Consequently, the
tokenizer splits `"gpu"` into known subwords: `["gp" and "##u"]`. `"##"` means that the rest of the token should
be attached to the previous one, without space (for decoding or reversal of the tokenization).
As another example, [`~transformers.XLNetTokenizer`] tokenizes our previously exemplary text as follows:
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
We'll get back to the meaning of those `"▁"` when we look at [SentencePiece](#sentencepiece). As one can see,
the rare word `"Transformers"` has been split into the more frequent subwords `"Transform"` and `"ers"`.
Let's now look at how the different subword tokenization algorithms work. Note that all of those tokenization
algorithms rely on some form of training which is usually done on the corpus the corresponding model will be trained
on.
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/gpt) which uses
Spacy and ftfy, to count the frequency of each word in the training corpus.
After pre-tokenization, a set of unique words has been created and the frequency with which each word occurred in the
training data has been determined. Next, BPE creates a base vocabulary consisting of all symbols that occur in the set
of unique words and learns merge rules to form a new symbol from two symbols of the base vocabulary. It does so until
the vocabulary has attained the desired vocabulary size. Note that the desired vocabulary size is a hyperparameter to
define before training the tokenizer.
As an example, let's assume that after pre-tokenization, the following set of words including their frequency has been
determined:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
Consequently, the base vocabulary is `["b", "g", "h", "n", "p", "s", "u"]`. Splitting all words into symbols of the
base vocabulary, we obtain:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
BPE then counts the frequency of each possible symbol pair and picks the symbol pair that occurs most frequently. In
the example above `"h"` followed by `"u"` is present _10 + 5 = 15_ times (10 times in the 10 occurrences of
`"hug"`, 5 times in the 5 occurrences of `"hugs"`). However, the most frequent symbol pair is `"u"` followed by
`"g"`, occurring _10 + 5 + 5 = 20_ times in total. Thus, the first merge rule the tokenizer learns is to group all
`"u"` symbols followed by a `"g"` symbol together. Next, `"ug"` is added to the vocabulary. The set of words then
becomes
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
BPE then identifies the next most common symbol pair. It's `"u"` followed by `"n"`, which occurs 16 times. `"u"`,
`"n"` is merged to `"un"` and added to the vocabulary. The next most frequent symbol pair is `"h"` followed by
`"ug"`, occurring 15 times. Again the pair is merged and `"hug"` can be added to the vocabulary.
At this stage, the vocabulary is `["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]` and our set of unique words
is represented as
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
Assuming, that the Byte-Pair Encoding training would stop at this point, the learned merge rules would then be applied
to new words (as long as those new words do not include symbols that were not in the base vocabulary). For instance,
the word `"bug"` would be tokenized to `["b", "ug"]` but `"mug"` would be tokenized as `["", "ug"]` since
the symbol `"m"` is not in the base vocabulary. In general, single letters such as `"m"` are not replaced by the
`""` symbol because the training data usually includes at least one occurrence of each letter, but it is likely
to happen for very special characters like emojis.
As mentioned earlier, the vocabulary size, *i.e.* the base vocabulary size + the number of merges, is a hyperparameter
to choose. For instance [GPT](model_doc/gpt) has a vocabulary size of 40,478 since they have 478 base characters
and chose to stop training after 40,000 merges.
#### Byte-level BPE
A base vocabulary that includes all possible base characters can be quite large if *e.g.* all unicode characters are
considered as base characters. To have a better base vocabulary, [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) uses bytes
as the base vocabulary, which is a clever trick to force the base vocabulary to be of size 256 while ensuring that
every base character is included in the vocabulary. With some additional rules to deal with punctuation, the GPT2's
tokenizer can tokenize every text without the need for the symbol. [GPT-2](model_doc/gpt) has a vocabulary
size of 50,257, which corresponds to the 256 bytes base tokens, a special end-of-text token and the symbols learned
with 50,000 merges.
### WordPiece
WordPiece is the subword tokenization algorithm used for [BERT](model_doc/bert), [DistilBERT](model_doc/distilbert), and [Electra](model_doc/electra). The algorithm was outlined in [Japanese and Korean
Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) and is very similar to
BPE. WordPiece first initializes the vocabulary to include every character present in the training data and
progressively learns a given number of merge rules. In contrast to BPE, WordPiece does not choose the most frequent
symbol pair, but the one that maximizes the likelihood of the training data once added to the vocabulary.
So what does this mean exactly? Referring to the previous example, maximizing the likelihood of the training data is
equivalent to finding the symbol pair, whose probability divided by the probabilities of its first symbol followed by
its second symbol is the greatest among all symbol pairs. *E.g.* `"u"`, followed by `"g"` would have only been
merged if the probability of `"ug"` divided by `"u"`, `"g"` would have been greater than for any other symbol
pair. Intuitively, WordPiece is slightly different to BPE in that it evaluates what it _loses_ by merging two symbols
to ensure it's _worth it_.
### Unigram
Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
conjunction with [SentencePiece](#sentencepiece).
At each training step, the Unigram algorithm defines a loss (often defined as the log-likelihood) over the training
data given the current vocabulary and a unigram language model. Then, for each symbol in the vocabulary, the algorithm
computes how much the overall loss would increase if the symbol was to be removed from the vocabulary. Unigram then
removes p (with p usually being 10% or 20%) percent of the symbols whose loss increase is the lowest, *i.e.* those
symbols that least affect the overall loss over the training data. This process is repeated until the vocabulary has
reached the desired size. The Unigram algorithm always keeps the base characters so that any word can be tokenized.
Because Unigram is not based on merge rules (in contrast to BPE and WordPiece), the algorithm has several ways of
tokenizing new text after training. As an example, if a trained Unigram tokenizer exhibits the vocabulary:
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
`"hugs"` could be tokenized both as `["hug", "s"]`, `["h", "ug", "s"]` or `["h", "u", "g", "s"]`. So which one
to choose? Unigram saves the probability of each token in the training corpus on top of saving the vocabulary so that
the probability of each possible tokenization can be computed after training. The algorithm simply picks the most
likely tokenization in practice, but also offers the possibility to sample a possible tokenization according to their
probabilities.
Those probabilities are defined by the loss the tokenizer is trained on. Assuming that the training data consists of
the words \\(x_{1}, \dots, x_{N}\\) and that the set of all possible tokenizations for a word \\(x_{i}\\) is
defined as \\(S(x_{i})\\), then the overall loss is defined as
$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
### SentencePiece
All tokenization algorithms described so far have the same problem: It is assumed that the input text uses spaces to
separate words. However, not all languages use spaces to separate words. One possible solution is to use language
specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer).
To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
algorithm to construct the appropriate vocabulary.
The [`XLNetTokenizer`] uses SentencePiece for example, which is also why in the example earlier the
`"▁"` character was included in the vocabulary. Decoding with SentencePiece is very easy since all tokens can just be
concatenated and `"▁"` is replaced by a space.
All transformers models in the library that use SentencePiece use it in combination with unigram. Examples of models
using SentencePiece are [ALBERT](model_doc/albert), [XLNet](model_doc/xlnet), [Marian](model_doc/marian), and [T5](model_doc/t5).
|
perf_infer_cpu.md
|
# CPU inference
With some optimizations, it is possible to efficiently run large model inference on a CPU. One of these optimization techniques involves compiling the PyTorch code into an intermediate format for high-performance environments like C++. The other technique fuses multiple operations into one kernel to reduce the overhead of running each operation separately.
You'll learn how to use [BetterTransformer](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) for faster inference, and how to convert your PyTorch code to [TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html). If you're using an Intel CPU, you can also use [graph optimizations](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features.html#graph-optimization) from [Intel Extension for PyTorch](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/index.html) to boost inference speed even more. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime or OpenVINO (if you're using an Intel CPU).
## BetterTransformer
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention).
BetterTransformer is not supported for all models. Check this [list](https://huggingface.co/docs/optimum/bettertransformer/overview#supported-models) to see if a model supports BetterTransformer.
Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
Enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder")
model.to_bettertransformer()
## TorchScript
TorchScript is an intermediate PyTorch model representation that can be run in production environments where performance is important. You can train a model in PyTorch and then export it to TorchScript to free the model from Python performance constraints. PyTorch [traces](https://pytorch.org/docs/stable/generated/torch.jit.trace.html) a model to return a [`ScriptFunction`] that is optimized with just-in-time compilation (JIT). Compared to the default eager mode, JIT mode in PyTorch typically yields better performance for inference using optimization techniques like operator fusion.
For a gentle introduction to TorchScript, see the [Introduction to PyTorch TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html) tutorial.
With the [`Trainer`] class, you can enable JIT mode for CPU inference by setting the `--jit_mode_eval` flag:
```bash
python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
--jit_mode_eval
For PyTorch >= 1.14.0, JIT-mode could benefit any model for prediction and evaluaion since the dict input is supported in `jit.trace`.
For PyTorch < 1.14.0, JIT-mode could benefit a model if its forward parameter order matches the tuple input order in `jit.trace`, such as a question-answering model. If the forward parameter order does not match the tuple input order in `jit.trace`, like a text classification model, `jit.trace` will fail and we are capturing this with the exception here to make it fallback. Logging is used to notify users.
## IPEX graph optimization
Intel® Extension for PyTorch (IPEX) provides further optimizations in JIT mode for Intel CPUs, and we recommend combining it with TorchScript for even faster performance. The IPEX [graph optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html) fuses operations like Multi-head attention, Concat Linear, Linear + Add, Linear + Gelu, Add + LayerNorm, and more.
To take advantage of these graph optimizations, make sure you have IPEX [installed](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html):
```bash
pip install intel_extension_for_pytorch
Set the `--use_ipex` and `--jit_mode_eval` flags in the [`Trainer`] class to enable JIT mode with the graph optimizations:
```bash
python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
--use_ipex \
--jit_mode_eval
## 🤗 Optimum
Learn more details about using ORT with 🤗 Optimum in the [Optimum Inference with ONNX Runtime](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/models) guide. This section only provides a brief and simple example.
ONNX Runtime (ORT) is a model accelerator that runs inference on CPUs by default. ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers, without making too many changes to your code. You only need to replace the 🤗 Transformers `AutoClass` with its equivalent [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and load a checkpoint in the ONNX format.
For example, if you're running inference on a question answering task, load the [optimum/roberta-base-squad2](https://huggingface.co/optimum/roberta-base-squad2) checkpoint which contains a `model.onnx` file:
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2")
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
onnx_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = "What's my name?"
context = "My name is Philipp and I live in Nuremberg."
pred = onnx_qa(question, context)
If you have an Intel CPU, take a look at 🤗 [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) which supports a variety of compression techniques (quantization, pruning, knowledge distillation) and tools for converting models to the [OpenVINO](https://huggingface.co/docs/optimum/intel/inference) format for higher performance inference.
|
create_a_model.md
|
# Create a custom architecture
An [`AutoClass`](model_doc/auto) automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an `AutoClass` to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an `AutoClass`. Learn how to:
- Load and customize a model configuration.
- Create a model architecture.
- Create a slow and fast tokenizer for text.
- Create an image processor for vision tasks.
- Create a feature extractor for audio tasks.
- Create a processor for multimodal tasks.
## Configuration
A [configuration](main_classes/configuration) refers to a model's specific attributes. Each model configuration has different attributes; for instance, all NLP models have the `hidden_size`, `num_attention_heads`, `num_hidden_layers` and `vocab_size` attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
Get a closer look at [DistilBERT](model_doc/distilbert) by accessing [`DistilBertConfig`] to inspect it's attributes:
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
[`DistilBertConfig`] displays all the default attributes used to build a base [`DistilBertModel`]. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
- Try a different activation function with the `activation` parameter.
- Use a higher dropout ratio for the attention probabilities with the `attention_dropout` parameter.
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
Pretrained model attributes can be modified in the [`~PretrainedConfig.from_pretrained`] function:
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
Once you are satisfied with your model configuration, you can save it with [`~PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory:
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
To reuse the configuration file, load it with [`~PretrainedConfig.from_pretrained`]:
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the [configuration](main_classes/configuration) documentation for more details.
## Model
The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. This means models are compatible with each of their respective framework's usage.
Load your custom configuration attributes into the model:
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with [`~PreTrainedModel.from_pretrained`]:
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
Load your custom configuration attributes into the model:
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with [`~TFPreTrainedModel.from_pretrained`]:
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
### Model heads
At this point, you have a base DistilBERT model which outputs the *hidden states*. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can't use DistilBERT for a sequence-to-sequence task like translation).
For example, [`DistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`DistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
For example, [`TFDistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`TFDistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
## Tokenizer
The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to its Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
Not every model supports a fast tokenizer. Take a look at this [table](index#supported-frameworks) to check if a model has fast tokenizer support.
If you trained your own tokenizer, you can create one from your *vocabulary* file:
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model's tokenizer. You need to use a pretrained model's vocabulary if you are using a pretrained model, otherwise the inputs won't make sense. Create a tokenizer with a pretrained model's vocabulary with the [`DistilBertTokenizer`] class:
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
Create a fast tokenizer with the [`DistilBertTokenizerFast`] class:
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable this behavior by setting `use_fast=False` in `from_pretrained`.
## Image Processor
An image processor processes vision inputs. It inherits from the base [`~image_processing_utils.ImageProcessingMixin`] class.
To use, create an image processor associated with the model you're using. For example, create a default [`ViTImageProcessor`] if you are using [ViT](model_doc/vit) for image classification:
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default image processor parameters.
Modify any of the [`ViTImageProcessor`] parameters to create your custom image processor:
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
## Feature Extractor
A feature extractor processes audio inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`SequenceFeatureExtractor`] class for processing audio inputs.
To use, create a feature extractor associated with the model you're using. For example, create a default [`Wav2Vec2FeatureExtractor`] if you are using [Wav2Vec2](model_doc/wav2vec2) for audio classification:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
Modify any of the [`Wav2Vec2FeatureExtractor`] parameters to create your custom feature extractor:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
## Processor
For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps processing classes such as a feature extractor and a tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
Create a feature extractor to handle the audio inputs:
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
Create a tokenizer to handle the text inputs:
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, image processor, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
|
model_sharing.md
|
# Share a model
The last two tutorials showed how you can fine-tune a model with PyTorch, Keras, and 🤗 Accelerate for distributed setups. The next step is to share your model with the community! At Hugging Face, we believe in openly sharing knowledge and resources to democratize artificial intelligence for everyone. We encourage you to consider sharing your model with the community to help others save time and resources.
In this tutorial, you will learn two methods for sharing a trained or fine-tuned model on the [Model Hub](https://huggingface.co/models):
- Programmatically push your files to the Hub.
- Drag-and-drop your files to the Hub with the web interface.
To share a model with the community, you need an account on [huggingface.co](https://huggingface.co/join). You can also join an existing organization or create a new one.
## Repository features
Each repository on the Model Hub behaves like a typical GitHub repository. Our repositories offer versioning, commit history, and the ability to visualize differences.
The Model Hub's built-in versioning is based on git and [git-lfs](https://git-lfs.github.com/). In other words, you can treat one model as one repository, enabling greater access control and scalability. Version control allows *revisions*, a method for pinning a specific version of a model with a commit hash, tag or branch.
As a result, you can load a specific model version with the `revision` parameter:
>>> model = AutoModel.from_pretrained(
"julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
)
Files are also easily edited in a repository, and you can view the commit history as well as the difference:

## Setup
Before sharing a model to the Hub, you will need your Hugging Face credentials. If you have access to a terminal, run the following command in the virtual environment where 🤗 Transformers is installed. This will store your access token in your Hugging Face cache folder (`~/.cache/` by default):
```bash
huggingface-cli login
If you are using a notebook like Jupyter or Colaboratory, make sure you have the [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) library installed. This library allows you to programmatically interact with the Hub.
```bash
pip install huggingface_hub
Then use `notebook_login` to sign-in to the Hub, and follow the link [here](https://huggingface.co/settings/token) to generate a token to login with:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Convert a model for all frameworks
To ensure your model can be used by someone working with a different framework, we recommend you convert and upload your model with both PyTorch and TensorFlow checkpoints. While users are still able to load your model from a different framework if you skip this step, it will be slower because 🤗 Transformers will need to convert the checkpoint on-the-fly.
Converting a checkpoint for another framework is easy. Make sure you have PyTorch and TensorFlow installed (see [here](installation) for installation instructions), and then find the specific model for your task in the other framework.
Specify `from_tf=True` to convert a checkpoint from TensorFlow to PyTorch:
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
Specify `from_pt=True` to convert a checkpoint from PyTorch to TensorFlow:
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
Then you can save your new TensorFlow model with its new checkpoint:
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
If a model is available in Flax, you can also convert a checkpoint from PyTorch to Flax:
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
"path/to/awesome-name-you-picked", from_pt=True
)
## Push a model during training
Sharing a model to the Hub is as simple as adding an extra parameter or callback. Remember from the [fine-tuning tutorial](training), the [`TrainingArguments`] class is where you specify hyperparameters and additional training options. One of these training options includes the ability to push a model directly to the Hub. Set `push_to_hub=True` in your [`TrainingArguments`]:
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
Pass your training arguments as usual to [`Trainer`]:
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
After you fine-tune your model, call [`~transformers.Trainer.push_to_hub`] on [`Trainer`] to push the trained model to the Hub. 🤗 Transformers will even automatically add training hyperparameters, training results and framework versions to your model card!
>>> trainer.push_to_hub()
Share a model to the Hub with [`PushToHubCallback`]. In the [`PushToHubCallback`] function, add:
- An output directory for your model.
- A tokenizer.
- The `hub_model_id`, which is your Hub username and model name.
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
)
Add the callback to [`fit`](https://keras.io/api/models/model_training_apis/), and 🤗 Transformers will push the trained model to the Hub:
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
## Use the `push_to_hub` function
You can also call `push_to_hub` directly on your model to upload it to the Hub.
Specify your model name in `push_to_hub`:
>>> pt_model.push_to_hub("my-awesome-model")
This creates a repository under your username with the model name `my-awesome-model`. Users can now load your model with the `from_pretrained` function:
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
If you belong to an organization and want to push your model under the organization name instead, just add it to the `repo_id`:
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
The `push_to_hub` function can also be used to add other files to a model repository. For example, add a tokenizer to a model repository:
>>> tokenizer.push_to_hub("my-awesome-model")
Or perhaps you'd like to add the TensorFlow version of your fine-tuned PyTorch model:
>>> tf_model.push_to_hub("my-awesome-model")
Now when you navigate to your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
For more details on how to create and upload files to a repository, refer to the Hub documentation [here](https://huggingface.co/docs/hub/how-to-upstream).
## Upload with the web interface
Users who prefer a no-code approach are able to upload a model through the Hub's web interface. Visit [huggingface.co/new](https://huggingface.co/new) to create a new repository:

From here, add some information about your model:
- Select the **owner** of the repository. This can be yourself or any of the organizations you belong to.
- Pick a name for your model, which will also be the repository name.
- Choose whether your model is public or private.
- Specify the license usage for your model.
Now click on the **Files** tab and click on the **Add file** button to upload a new file to your repository. Then drag-and-drop a file to upload and add a commit message.

## Add a model card
To make sure users understand your model's capabilities, limitations, potential biases and ethical considerations, please add a model card to your repository. The model card is defined in the `README.md` file. You can add a model card by:
* Manually creating and uploading a `README.md` file.
* Clicking on the **Edit model card** button in your model repository.
Take a look at the DistilBert [model card](https://huggingface.co/distilbert-base-uncased) for a good example of the type of information a model card should include. For more details about other options you can control in the `README.md` file such as a model's carbon footprint or widget examples, refer to the documentation [here](https://huggingface.co/docs/hub/models-cards).
|
fast_tokenizers.md
|
# Use tokenizers from 🤗 Tokenizers
The [`PreTrainedTokenizerFast`] depends on the [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 Tokenizers library can be
loaded very simply into 🤗 Transformers.
Before getting in the specifics, let's first start by creating a dummy tokenizer in a few lines:
thon
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = []
>>> tokenizer.train(files, trainer)
We now have a tokenizer trained on the files we defined. We can either continue using it in that runtime, or save it to
a JSON file for future re-use.
## Loading directly from the tokenizer object
Let's see how to leverage this tokenizer object in the 🤗 Transformers library. The
[`PreTrainedTokenizerFast`] class allows for easy instantiation, by accepting the instantiated
*tokenizer* object as an argument:
thon
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
page](main_classes/tokenizer) for more information.
## Loading from a JSON file
In order to load a tokenizer from a JSON file, let's first start by saving our tokenizer:
thon
>>> tokenizer.save("tokenizer.json")
The path to which we saved this file can be passed to the [`PreTrainedTokenizerFast`] initialization
method using the `tokenizer_file` parameter:
thon
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
page](main_classes/tokenizer) for more information.
|
perf_hardware.md
|
# Custom hardware for training
The hardware you use to run model training and inference can have a big effect on performance. For a deep dive into GPUs make sure to check out Tim Dettmer's excellent [blog post](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/).
Let's have a look at some practical advice for GPU setups.
## GPU
When you train bigger models you have essentially three options:
- bigger GPUs
- more GPUs
- more CPU and NVMe (offloaded to by [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
Let's start at the case where you have a single GPU.
### Power and Cooling
If you bought an expensive high end GPU make sure you give it the correct power and sufficient cooling.
**Power**:
Some high end consumer GPU cards have 2 and sometimes 3 PCI-E 8-Pin power sockets. Make sure you have as many independent 12V PCI-E 8-Pin cables plugged into the card as there are sockets. Do not use the 2 splits at one end of the same cable (also known as pigtail cable). That is if you have 2 sockets on the GPU, you want 2 PCI-E 8-Pin cables going from your PSU to the card and not one that has 2 PCI-E 8-Pin connectors at the end! You won't get the full performance out of your card otherwise.
Each PCI-E 8-Pin power cable needs to be plugged into a 12V rail on the PSU side and can supply up to 150W of power.
Some other cards may use a PCI-E 12-Pin connectors, and these can deliver up to 500-600W of power.
Low end cards may use 6-Pin connectors, which supply up to 75W of power.
Additionally you want the high-end PSU that has stable voltage. Some lower quality ones may not give the card the stable voltage it needs to function at its peak.
And of course the PSU needs to have enough unused Watts to power the card.
**Cooling**:
When a GPU gets overheated it will start throttling down and will not deliver full performance and it can even shutdown if it gets too hot.
It's hard to tell the exact best temperature to strive for when a GPU is heavily loaded, but probably anything under +80C is good, but lower is better - perhaps 70-75C is an excellent range to be in. The throttling down is likely to start at around 84-90C. But other than throttling performance a prolonged very high temperature is likely to reduce the lifespan of a GPU.
Next let's have a look at one of the most important aspects when having multiple GPUs: connectivity.
### Multi-GPU Connectivity
If you use multiple GPUs the way cards are inter-connected can have a huge impact on the total training time. If the GPUs are on the same physical node, you can run:
nvidia-smi topo -m
and it will tell you how the GPUs are inter-connected. On a machine with dual-GPU and which are connected with NVLink, you will most likely see something like:
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X NV2 0-23 N/A
GPU1 NV2 X 0-23 N/A
on a different machine w/o NVLink we may see:
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X PHB 0-11 N/A
GPU1 PHB X 0-11 N/A
The report includes this legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
So the first report `NV2` tells us the GPUs are interconnected with 2 NVLinks, and the second report `PHB` we have a typical consumer-level PCIe+Bridge setup.
Check what type of connectivity you have on your setup. Some of these will make the communication between cards faster (e.g. NVLink), others slower (e.g. PHB).
Depending on the type of scalability solution used, the connectivity speed could have a major or a minor impact. If the GPUs need to sync rarely, as in DDP, the impact of a slower connection will be less significant. If the GPUs need to send messages to each other often, as in ZeRO-DP, then faster connectivity becomes super important to achieve faster training.
#### NVlink
[NVLink](https://en.wikipedia.org/wiki/NVLink) is a wire-based serial multi-lane near-range communications link developed by Nvidia.
Each new generation provides a faster bandwidth, e.g. here is a quote from [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf):
> Third-Generation NVLink®
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
So the higher `X` you get in the report of `NVX` in the output of `nvidia-smi topo -m` the better. The generation will depend on your GPU architecture.
Let's compare the execution of a gpt2 language model training over a small sample of wikitext.
The results are:
| NVlink | Time |
| ----- | ---: |
| Y | 101s |
| N | 131s |
You can see that NVLink completes the training ~23% faster. In the second benchmark we use `NCCL_P2P_DISABLE=1` to tell the GPUs not to use NVLink.
Here is the full benchmark code and outputs:
```bash
# DDP w/ NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
|
pr_checks.md
|
# Checks on a Pull Request
When you open a pull request on 🤗 Transformers, a fair number of checks will be run to make sure the patch you are adding is not breaking anything existing. Those checks are of four types:
- regular tests
- documentation build
- code and documentation style
- general repository consistency
In this document, we will take a stab at explaining what those various checks are and the reason behind them, as well as how to debug them locally if one of them fails on your PR.
Note that, ideally, they require you to have a dev install:
```bash
pip install transformers[dev]
or for an editable install:
```bash
pip install -e .[dev]
inside the Transformers repo. Since the number of optional dependencies of Transformers has grown a lot, it's possible you don't manage to get all of them. If the dev install fails, make sure to install the Deep Learning framework you are working with (PyTorch, TensorFlow and/or Flax) then do
```bash
pip install transformers[quality]
or for an editable install:
```bash
pip install -e .[quality]
## Tests
All the jobs that begin with `ci/circleci: run_tests_` run parts of the Transformers testing suite. Each of those jobs focuses on a part of the library in a certain environment: for instance `ci/circleci: run_tests_pipelines_tf` runs the pipelines test in an environment where TensorFlow only is installed.
Note that to avoid running tests when there is no real change in the modules they are testing, only part of the test suite is run each time: a utility is run to determine the differences in the library between before and after the PR (what GitHub shows you in the "Files changes" tab) and picks the tests impacted by that diff. That utility can be run locally with:
```bash
python utils/tests_fetcher.py
from the root of the Transformers repo. It will:
1. Check for each file in the diff if the changes are in the code or only in comments or docstrings. Only the files with real code changes are kept.
2. Build an internal map that gives for each file of the source code of the library all the files it recursively impacts. Module A is said to impact module B if module B imports module A. For the recursive impact, we need a chain of modules going from module A to module B in which each module imports the previous one.
3. Apply this map on the files gathered in step 1, which gives us the list of model files impacted by the PR.
4. Map each of those files to their corresponding test file(s) and get the list of tests to run.
When executing the script locally, you should get the results of step 1, 3 and 4 printed and thus know which tests are run. The script will also create a file named `test_list.txt` which contains the list of tests to run, and you can run them locally with the following command:
```bash
python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
Just in case anything slipped through the cracks, the full test suite is also run daily.
## Documentation build
The `build_pr_documentation` job builds and generates a preview of the documentation to make sure everything looks okay once your PR is merged. A bot will add a link to preview the documentation in your PR. Any changes you make to the PR are automatically updated in the preview. If the documentation fails to build, click on **Details** next to the failed job to see where things went wrong. Often, the error is as simple as a missing file in the `toctree`.
If you're interested in building or previewing the documentation locally, take a look at the [`README.md`](https://github.com/huggingface/transformers/tree/main/docs) in the docs folder.
## Code and documentation style
Code formatting is applied to all the source files, the examples and the tests using `black` and `ruff`. We also have a custom tool taking care of the formatting of docstrings and `rst` files (`utils/style_doc.py`), as well as the order of the lazy imports performed in the Transformers `__init__.py` files (`utils/custom_init_isort.py`). All of this can be launched by executing
```bash
make style
The CI checks those have been applied inside the `ci/circleci: check_code_quality` check. It also runs `ruff`, that will have a basic look at your code and will complain if it finds an undefined variable, or one that is not used. To run that check locally, use
```bash
make quality
This can take a lot of time, so to run the same thing on only the files you modified in the current branch, run
```bash
make fixup
This last command will also run all the additional checks for the repository consistency. Let's have a look at them.
## Repository consistency
This regroups all the tests to make sure your PR leaves the repository in a good state, and is performed by the `ci/circleci: check_repository_consistency` check. You can locally run that check by executing the following:
```bash
make repo-consistency
This checks that:
- All objects added to the init are documented (performed by `utils/check_repo.py`)
- All `__init__.py` files have the same content in their two sections (performed by `utils/check_inits.py`)
- All code identified as a copy from another module is consistent with the original (performed by `utils/check_copies.py`)
- All configuration classes have at least one valid checkpoint mentioned in their docstrings (performed by `utils/check_config_docstrings.py`)
- All configuration classes only contain attributes that are used in corresponding modeling files (performed by `utils/check_config_attributes.py`)
- The translations of the READMEs and the index of the doc have the same model list as the main README (performed by `utils/check_copies.py`)
- The auto-generated tables in the documentation are up to date (performed by `utils/check_table.py`)
- The library has all objects available even if not all optional dependencies are installed (performed by `utils/check_dummies.py`)
- All docstrings properly document the arguments in the signature of the object (performed by `utils/check_docstrings.py`)
Should this check fail, the first two items require manual fixing, the last four can be fixed automatically for you by running the command
```bash
make fix-copies
Additional checks concern PRs that add new models, mainly that:
- All models added are in an Auto-mapping (performed by `utils/check_repo.py`)
- All models are properly tested (performed by `utils/check_repo.py`)
### Check copies
Since the Transformers library is very opinionated with respect to model code, and each model should fully be implemented in a single file without relying on other models, we have added a mechanism that checks whether a copy of the code of a layer of a given model stays consistent with the original. This way, when there is a bug fix, we can see all other impacted models and choose to trickle down the modification or break the copy.
If a file is a full copy of another file, you should register it in the constant `FULL_COPIES` of `utils/check_copies.py`.
This mechanism relies on comments of the form `# Copied from xxx`. The `xxx` should contain the whole path to the class of function which is being copied below. For instance, `RobertaSelfOutput` is a direct copy of the `BertSelfOutput` class, so you can see [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L289) it has a comment:
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
Note that instead of applying this to a whole class, you can apply it to the relevant methods that are copied from. For instance [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L598) you can see how `RobertaPreTrainedModel._init_weights` is copied from the same method in `BertPreTrainedModel` with the comment:
# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
Sometimes the copy is exactly the same except for names: for instance in `RobertaAttention`, we use `RobertaSelfAttention` insted of `BertSelfAttention` but other than that, the code is exactly the same. This is why `# Copied from` supports simple string replacements with the follwoing syntax: `Copied from xxx with foo->bar`. This means the code is copied with all instances of `foo` being replaced by `bar`. You can see how it used [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L304C1-L304C86) in `RobertaAttention` with the comment:
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
Note that there shouldn't be any spaces around the arrow (unless that space is part of the pattern to replace of course).
You can add several patterns separated by a comma. For instance here `CamemberForMaskedLM` is a direct copy of `RobertaForMaskedLM` with two replacements: `Roberta` to `Camembert` and `ROBERTA` to `CAMEMBERT`. You can see [here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929) this is done with the comment:
# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
If the order matters (because one of the replacements might conflict with a previous one), the replacements are executed from left to right.
If the replacements change the formatting (if you replace a short name by a very long name for instance), the copy is checked after applying the auto-formatter.
Another way when the patterns are just different casings of the same replacement (with an uppercased and a lowercased variants) is just to add the option `all-casing`. [Here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237) is an example in `MobileBertForSequenceClassification` with the comment:
# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
In this case, the code is copied from `BertForSequenceClassification` by replacing:
- `Bert` by `MobileBert` (for instance when using `MobileBertModel` in the init)
- `bert` by `mobilebert` (for instance when defining `self.mobilebert`)
- `BERT` by `MOBILEBERT` (in the constant `MOBILEBERT_INPUTS_DOCSTRING`)
|
perf_train_tpu.md
|
# Training on TPUs
Note: Most of the strategies introduced in the [single GPU section](perf_train_gpu_one) (such as mixed precision training or gradient accumulation) and [multi-GPU section](perf_train_gpu_many) are generic and apply to training models in general so make sure to have a look at it before diving into this section.
This document will be completed soon with information on how to train on TPUs.
|
serialization.md
|
# Export to ONNX
Deploying 🤗 Transformers models in production environments often requires, or can benefit from exporting the models into
a serialized format that can be loaded and executed on specialized runtimes and hardware.
🤗 Optimum is an extension of Transformers that enables exporting models from PyTorch or TensorFlow to serialized formats
such as ONNX and TFLite through its `exporters` module. 🤗 Optimum also provides a set of performance optimization tools to train
and run models on targeted hardware with maximum efficiency.
This guide demonstrates how you can export 🤗 Transformers models to ONNX with 🤗 Optimum, for the guide on exporting models to TFLite,
please refer to the [Export to TFLite page](tflite).
## Export to ONNX
[ONNX (Open Neural Network eXchange)](http://onnx.ai) is an open standard that defines a common set of operators and a
common file format to represent deep learning models in a wide variety of frameworks, including PyTorch and
TensorFlow. When a model is exported to the ONNX format, these operators are used to
construct a computational graph (often called an _intermediate representation_) which
represents the flow of data through the neural network.
By exposing a graph with standardized operators and data types, ONNX makes it easy to
switch between frameworks. For example, a model trained in PyTorch can be exported to
ONNX format and then imported in TensorFlow (and vice versa).
Once exported to ONNX format, a model can be:
- optimized for inference via techniques such as [graph optimization](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) and [quantization](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization).
- run with ONNX Runtime via [`ORTModelForXXX` classes](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort),
which follow the same `AutoModel` API as the one you are used to in 🤗 Transformers.
- run with [optimized inference pipelines](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines),
which has the same API as the [`pipeline`] function in 🤗 Transformers.
🤗 Optimum provides support for the ONNX export by leveraging configuration objects. These configuration objects come
ready-made for a number of model architectures, and are designed to be easily extendable to other architectures.
For the list of ready-made configurations, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/onnx/overview).
There are two ways to export a 🤗 Transformers model to ONNX, here we show both:
- export with 🤗 Optimum via CLI.
- export with 🤗 Optimum with `optimum.onnxruntime`.
### Exporting a 🤗 Transformers model to ONNX with CLI
To export a 🤗 Transformers model to ONNX, first install an extra dependency:
```bash
pip install optimum[exporters]
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli),
or view help in command line:
```bash
optimum-cli export onnx --help
To export a model's checkpoint from the 🤗 Hub, for example, `distilbert-base-uncased-distilled-squad`, run the following command:
```bash
optimum-cli export onnx --model distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
You should see the logs indicating progress and showing where the resulting `model.onnx` is saved, like this:
```bash
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub and provide the `--task` argument.
You can review the list of supported tasks in the [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/task_manager).
If `task` argument is not provided, it will default to the model architecture without any task specific head.
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
The resulting `model.onnx` file can then be run on one of the [many
accelerators](https://onnx.ai/supported-tools.html#deployModel) that support the ONNX
standard. For example, we can load and run the model with [ONNX
Runtime](https://onnxruntime.ai/) as follows:
thon
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
>>> outputs = model(**inputs)
The process is identical for TensorFlow checkpoints on the Hub. For instance, here's how you would
export a pure TensorFlow checkpoint from the [Keras organization](https://huggingface.co/keras-io):
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
### Exporting a 🤗 Transformers model to ONNX with `optimum.onnxruntime`
Alternative to CLI, you can export a 🤗 Transformers model to ONNX programmatically like so:
thon
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> model_checkpoint = "distilbert_base_uncased_squad"
>>> save_directory = "onnx/"
>>> # Load a model from transformers and export it to ONNX
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
>>> # Save the onnx model and tokenizer
>>> ort_model.save_pretrained(save_directory)
>>> tokenizer.save_pretrained(save_directory)
### Exporting a model for an unsupported architecture
If you wish to contribute by adding support for a model that cannot be currently exported, you should first check if it is
supported in [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview),
and if it is not, [contribute to 🤗 Optimum](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)
directly.
### Exporting a model with `transformers.onnx`
`tranformers.onnx` is no longer maintained, please export models with 🤗 Optimum as described above. This section will be removed in the future versions.
To export a 🤗 Transformers model to ONNX with `tranformers.onnx`, install extra dependencies:
```bash
pip install transformers[onnx]
Use `transformers.onnx` package as a Python module to export a checkpoint using a ready-made configuration:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
This exports an ONNX graph of the checkpoint defined by the `--model` argument. Pass any checkpoint on the 🤗 Hub or one that's stored locally.
The resulting `model.onnx` file can then be run on one of the many accelerators that support the ONNX standard. For example,
load and run the model with ONNX Runtime as follows:
thon
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
The required output names (like `["last_hidden_state"]`) can be obtained by taking a look at the ONNX configuration of
each model. For example, for DistilBERT we have:
thon
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
The process is identical for TensorFlow checkpoints on the Hub. For example, export a pure TensorFlow checkpoint like so:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
To export a model that's stored locally, save the model's weights and tokenizer files in the same directory (e.g. `local-pt-checkpoint`),
then export it to ONNX by pointing the `--model` argument of the `transformers.onnx` package to the desired directory:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
|
installation.md
|
# Installation
Install 🤗 Transformers for whichever deep learning library you're working with, setup your cache, and optionally configure 🤗 Transformers to run offline.
🤗 Transformers is tested on Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, and Flax. Follow the installation instructions below for the deep learning library you are using:
* [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) installation instructions.
* [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
## Install with pip
You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
Start by creating a virtual environment in your project directory:
```bash
python -m venv .env
Activate the virtual environment. On Linux and MacOs:
```bash
source .env/bin/activate
Activate Virtual environment on Windows
```bash
.env/Scripts/activate
Now you're ready to install 🤗 Transformers with the following command:
```bash
pip install transformers
For CPU-support only, you can conveniently install 🤗 Transformers and a deep learning library in one line. For example, install 🤗 Transformers and PyTorch with:
```bash
pip install 'transformers[torch]'
🤗 Transformers and TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
M1 / ARM Users
You will need to install the following before installing TensorFLow 2.0
brew install cmake
brew install pkg-config
🤗 Transformers and Flax:
```bash
pip install 'transformers[flax]'
Finally, check if 🤗 Transformers has been properly installed by running the following command. It will download a pretrained model:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
Then print out the label and score:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
## Install from source
Install 🤗 Transformers from source with the following command:
```bash
pip install git+https://github.com/huggingface/transformers
This command installs the bleeding edge `main` version rather than the latest `stable` version. The `main` version is useful for staying up-to-date with the latest developments. For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet. However, this means the `main` version may not always be stable. We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day. If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
Check if 🤗 Transformers has been properly installed by running the following command:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
## Editable install
You will need an editable install if you'd like to:
* Use the `main` version of the source code.
* Contribute to 🤗 Transformers and need to test changes in the code.
Clone the repository and install 🤗 Transformers with the following commands:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
These commands will link the folder you cloned the repository to and your Python library paths. Python will now look inside the folder you cloned to in addition to the normal library paths. For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/transformers/`.
You must keep the `transformers` folder if you want to keep using the library.
Now you can easily update your clone to the latest version of 🤗 Transformers with the following command:
```bash
cd ~/transformers/
git pull
Your Python environment will find the `main` version of 🤗 Transformers on the next run.
## Install with conda
Install from the conda channel `huggingface`:
```bash
conda install -c huggingface transformers
## Cache setup
Pretrained models are downloaded and locally cached at: `~/.cache/huggingface/hub`. This is the default directory given by the shell environment variable `TRANSFORMERS_CACHE`. On Windows, the default directory is given by `C:\Users\username\.cache\huggingface\hub`. You can change the shell environment variables shown below - in order of priority - to specify a different cache directory:
1. Shell environment variable (default): `HUGGINGFACE_HUB_CACHE` or `TRANSFORMERS_CACHE`.
2. Shell environment variable: `HF_HOME`.
3. Shell environment variable: `XDG_CACHE_HOME` + `/huggingface`.
🤗 Transformers will use the shell environment variables `PYTORCH_TRANSFORMERS_CACHE` or `PYTORCH_PRETRAINED_BERT_CACHE` if you are coming from an earlier iteration of this library and have set those environment variables, unless you specify the shell environment variable `TRANSFORMERS_CACHE`.
## Offline mode
Run 🤗 Transformers in a firewalled or offline environment with locally cached files by setting the environment variable `TRANSFORMERS_OFFLINE=1`.
Add [🤗 Datasets](https://huggingface.co/docs/datasets/) to your offline training workflow with the environment variable `HF_DATASETS_OFFLINE=1`.
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en
This script should run without hanging or waiting to timeout because it won't attempt to download the model from the Hub.
You can also bypass loading a model from the Hub from each [`~PreTrainedModel.from_pretrained`] call with the [`local_files_only`] parameter. When set to `True`, only local files are loaded:
from transformers import T5Model
model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
### Fetch models and tokenizers to use offline
Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
* Download a file through the user interface on the [Model Hub](https://huggingface.co/models) by clicking on the ↓ icon.

* Use the [`PreTrainedModel.from_pretrained`] and [`PreTrainedModel.save_pretrained`] workflow:
1. Download your files ahead of time with [`PreTrainedModel.from_pretrained`]:
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
2. Save your files to a specified directory with [`PreTrainedModel.save_pretrained`]:
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
3. Now when you're offline, reload your files with [`PreTrainedModel.from_pretrained`] from the specified directory:
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
* Programmatically download files with the [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) library:
1. Install the `huggingface_hub` library in your virtual environment:
```bash
python -m pip install huggingface_hub
2. Use the [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) function to download a file to a specific path. For example, the following command downloads the `config.json` file from the [T0](https://huggingface.co/bigscience/T0_3B) model to your desired path:
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
Once your file is downloaded and locally cached, specify it's local path to load and use it:
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
See the [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) section for more details on downloading files stored on the Hub.
|
notebooks.md
| null |
perf_train_tpu_tf.md
|
# Training on TPU with TensorFlow
If you don't need long explanations and just want TPU code samples to get started with, check out [our TPU example notebook!](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)
### What is a TPU?
A TPU is a **Tensor Processing Unit.** They are hardware designed by Google, which are used to greatly speed up the tensor computations within neural networks, much like GPUs. They can be used for both network training and inference. They are generally accessed through Google’s cloud services, but small TPUs can also be accessed directly for free through Google Colab and Kaggle Kernels.
Because [all TensorFlow models in 🤗 Transformers are Keras models](https://huggingface.co/blog/tensorflow-philosophy), most of the methods in this document are generally applicable to TPU training for any Keras model! However, there are a few points that are specific to the HuggingFace ecosystem (hug-o-system?) of Transformers and Datasets, and we’ll make sure to flag them up when we get to them.
### What kinds of TPU are available?
New users are often very confused by the range of TPUs, and the different ways to access them. The first key distinction to understand is the difference between **TPU Nodes** and **TPU VMs.**
When you use a **TPU Node**, you are effectively indirectly accessing a remote TPU. You will need a separate VM, which will initialize your network and data pipeline and then forward them to the remote node. When you use a TPU on Google Colab, you are accessing it in the **TPU Node** style.
Using TPU Nodes can have some quite unexpected behaviour for people who aren’t used to them! In particular, because the TPU is located on a physically different system to the machine you’re running your Python code on, your data cannot be local to your machine - any data pipeline that loads from your machine’s internal storage will totally fail! Instead, data must be stored in Google Cloud Storage where your data pipeline can still access it, even when the pipeline is running on the remote TPU node.
If you can fit all your data in memory as `np.ndarray` or `tf.Tensor`, then you can `fit()` on that data even when using Colab or a TPU Node, without needing to upload it to Google Cloud Storage.
**🤗Specific Hugging Face Tip🤗:** The methods `Dataset.to_tf_dataset()` and its higher-level wrapper `model.prepare_tf_dataset()` , which you will see throughout our TF code examples, will both fail on a TPU Node. The reason for this is that even though they create a `tf.data.Dataset` it is not a “pure” `tf.data` pipeline and uses `tf.numpy_function` or `Dataset.from_generator()` to stream data from the underlying HuggingFace `Dataset`. This HuggingFace `Dataset` is backed by data that is on a local disc and which the remote TPU Node will not be able to read.
The second way to access a TPU is via a **TPU VM.** When using a TPU VM, you connect directly to the machine that the TPU is attached to, much like training on a GPU VM. TPU VMs are generally easier to work with, particularly when it comes to your data pipeline. All of the above warnings do not apply to TPU VMs!
This is an opinionated document, so here’s our opinion: **Avoid using TPU Node if possible.** It is more confusing and more difficult to debug than TPU VMs. It is also likely to be unsupported in future - Google’s latest TPU, TPUv4, can only be accessed as a TPU VM, which suggests that TPU Nodes are increasingly going to become a “legacy” access method. However, we understand that the only free TPU access is on Colab and Kaggle Kernels, which uses TPU Node - so we’ll try to explain how to handle it if you have to! Check the [TPU example notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) for code samples that explain this in more detail.
### What sizes of TPU are available?
A single TPU (a v2-8/v3-8/v4-8) runs 8 replicas. TPUs exist in **pods** that can run hundreds or thousands of replicas simultaneously. When you use more than a single TPU but less than a whole pod (for example, a v3-32), your TPU fleet is referred to as a **pod slice.**
When you access a free TPU via Colab, you generally get a single v2-8 TPU.
### I keep hearing about this XLA thing. What’s XLA, and how does it relate to TPUs?
XLA is an optimizing compiler, used by both TensorFlow and JAX. In JAX it is the only compiler, whereas in TensorFlow it is optional (but mandatory on TPU!). The easiest way to enable it when training a Keras model is to pass the argument `jit_compile=True` to `model.compile()`. If you don’t get any errors and performance is good, that’s a great sign that you’re ready to move to TPU!
Debugging on TPU is generally a bit harder than on CPU/GPU, so we recommend getting your code running on CPU/GPU with XLA first before trying it on TPU. You don’t have to train for long, of course - just for a few steps to make sure that your model and data pipeline are working like you expect them to.
XLA compiled code is usually faster - so even if you’re not planning to run on TPU, adding `jit_compile=True` can improve your performance. Be sure to note the caveats below about XLA compatibility, though!
**Tip born of painful experience:** Although using `jit_compile=True` is a good way to get a speed boost and test if your CPU/GPU code is XLA-compatible, it can actually cause a lot of problems if you leave it in when actually training on TPU. XLA compilation will happen implicitly on TPU, so remember to remove that line before actually running your code on a TPU!
### How do I make my model XLA compatible?
In many cases, your code is probably XLA-compatible already! However, there are a few things that work in normal TensorFlow that don’t work in XLA. We’ve distilled them into three core rules below:
**🤗Specific HuggingFace Tip🤗:** We’ve put a lot of effort into rewriting our TensorFlow models and loss functions to be XLA-compatible. Our models and loss functions generally obey rule #1 and #2 by default, so you can skip over them if you’re using `transformers` models. Don’t forget about these rules when writing your own models and loss functions, though!
#### XLA Rule #1: Your code cannot have “data-dependent conditionals”
What that means is that any `if` statement cannot depend on values inside a `tf.Tensor`. For example, this code block cannot be compiled with XLA!
thon
if tf.reduce_sum(tensor) > 10:
tensor = tensor / 2.0
This might seem very restrictive at first, but most neural net code doesn’t need to do this. You can often get around this restriction by using `tf.cond` (see the documentation [here](https://www.tensorflow.org/api_docs/python/tf/cond)) or by removing the conditional and finding a clever math trick with indicator variables instead, like so:
thon
sum_over_10 = tf.cast(tf.reduce_sum(tensor) > 10, tf.float32)
tensor = tensor / (1.0 + sum_over_10)
This code has exactly the same effect as the code above, but by avoiding a conditional, we ensure it will compile with XLA without problems!
#### XLA Rule #2: Your code cannot have “data-dependent shapes”
What this means is that the shape of all of the `tf.Tensor` objects in your code cannot depend on their values. For example, the function `tf.unique` cannot be compiled with XLA, because it returns a `tensor` containing one instance of each unique value in the input. The shape of this output will obviously be different depending on how repetitive the input `Tensor` was, and so XLA refuses to handle it!
In general, most neural network code obeys rule #2 by default. However, there are a few common cases where it becomes a problem. One very common one is when you use **label masking**, setting your labels to a negative value to indicate that those positions should be ignored when computing the loss. If you look at NumPy or PyTorch loss functions that support label masking, you will often see code like this that uses [boolean indexing](https://numpy.org/doc/stable/user/basics.indexing.html#boolean-array-indexing):
thon
label_mask = labels >= 0
masked_outputs = outputs[label_mask]
masked_labels = labels[label_mask]
loss = compute_loss(masked_outputs, masked_labels)
mean_loss = torch.mean(loss)
This code is totally fine in NumPy or PyTorch, but it breaks in XLA! Why? Because the shape of `masked_outputs` and `masked_labels` depends on how many positions are masked - that makes it a **data-dependent shape.** However, just like for rule #1, we can often rewrite this code to yield exactly the same output without any data-dependent shapes.
thon
label_mask = tf.cast(labels >= 0, tf.float32)
loss = compute_loss(outputs, labels)
loss = loss * label_mask # Set negative label positions to 0
mean_loss = tf.reduce_sum(loss) / tf.reduce_sum(label_mask)
Here, we avoid data-dependent shapes by computing the loss for every position, but zeroing out the masked positions in both the numerator and denominator when we calculate the mean, which yields exactly the same result as the first block while maintaining XLA compatibility. Note that we use the same trick as in rule #1 - converting a `tf.bool` to `tf.float32` and using it as an indicator variable. This is a really useful trick, so remember it if you need to convert your own code to XLA!
#### XLA Rule #3: XLA will need to recompile your model for every different input shape it sees
This is the big one. What this means is that if your input shapes are very variable, XLA will have to recompile your model over and over, which will create huge performance problems. This commonly arises in NLP models, where input texts have variable lengths after tokenization. In other modalities, static shapes are more common and this rule is much less of a problem.
How can you get around rule #3? The key is **padding** - if you pad all your inputs to the same length, and then use an `attention_mask`, you can get the same results as you’d get from variable shapes, but without any XLA issues. However, excessive padding can cause severe slowdown too - if you pad all your samples to the maximum length in the whole dataset, you might end up with batches consisting endless padding tokens, which will waste a lot of compute and memory!
There isn’t a perfect solution to this problem. However, you can try some tricks. One very useful trick is to **pad batches of samples up to a multiple of a number like 32 or 64 tokens.** This often only increases the number of tokens by a small amount, but it hugely reduces the number of unique input shapes, because every input shape now has to be a multiple of 32 or 64. Fewer unique input shapes means fewer XLA compilations!
**🤗Specific HuggingFace Tip🤗:** Our tokenizers and data collators have methods that can help you here. You can use `padding="max_length"` or `padding="longest"` when calling tokenizers to get them to output padded data. Our tokenizers and data collators also have a `pad_to_multiple_of` argument that you can use to reduce the number of unique input shapes you see!
### How do I actually train my model on TPU?
Once your training is XLA-compatible and (if you’re using TPU Node / Colab) your dataset has been prepared appropriately, running on TPU is surprisingly easy! All you really need to change in your code is to add a few lines to initialize your TPU, and to ensure that your model and dataset are created inside a `TPUStrategy` scope. Take a look at [our TPU example notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) to see this in action!
### Summary
There was a lot in here, so let’s summarize with a quick checklist you can follow when you want to get your model ready for TPU training:
- Make sure your code follows the three rules of XLA
- Compile your model with `jit_compile=True` on CPU/GPU and confirm that you can train it with XLA
- Either load your dataset into memory or use a TPU-compatible dataset loading approach (see [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))
- Migrate your code either to Colab (with accelerator set to “TPU”) or a TPU VM on Google Cloud
- Add TPU initializer code (see [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))
- Create your `TPUStrategy` and make sure dataset loading and model creation are inside the `strategy.scope()` (see [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))
- Don’t forget to take `jit_compile=True` out again when you move to TPU!
- 🙏🙏🙏🥺🥺🥺
- Call model.fit()
- You did it!
|
llm_tutorial_optimization.md
|
# Optimizing LLMs for Speed and Memory
[[open-in-colab]]
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
In this guide, we will go over the effective techniques for efficient LLM deployment:
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
## 1. Lower Precision
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
```bash
!pip install transformers accelerate bitsandbytes optimum
thon
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
In this guide, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
thon
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
thon
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
**Output**:
Here is a Python function that transforms bytes to Giga bytes:\n\nthon\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
Nice, we can now directly use the result to convert bytes into Gigabytes.
thon
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
thon
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
**Output**:
```bash
29.0260648727417
Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(, torch_dtype=)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
Let's define a `flush()` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
thon
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
Let's call it now for the next experiment.
thon
flush()
In the recent version of the accelerate library, you can also use an utility method called `release_memory()`
thon
from accelerate.utils import release_memory
#
release_memory(model)
Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
- 1. Quantize all weights to the target precision
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
$$ Y = X * W $$
are changed to
$$ Y = X * \text{dequantize}(W) $$
for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
the [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library is installed.
```bash
!pip install bitsandbytes
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
thon
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
Now, let's run our example again and measure the memory usage.
thon
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
**Output**:
Here is a Python function that transforms bytes to Giga bytes:\n\nthon\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
thon
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
**Output**:
15.219234466552734
Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
We delete the models and flush the memory again.
thon
del model
del pipe
thon
flush()
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
thon
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
**Output**:
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
thon
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
**Output**:
9.543574333190918
Just 9.5GB! That's really not a lot for a >15 billion parameter model.
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
thon
del model
del pipe
thon
flush()
Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
## 2. Flash Attention
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\\( \mathbf{X} = (\mathbf{x}_1, \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
Let's look at a practical example.
Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
In the following, we use a system prompt that will make OctoCoder a better coding assistant.
thon
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
For demonstration purposes, we duplicate the system prompt by ten so that the input length is long enough to observe Flash Attention's memory savings.
We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
thon
long_prompt = 10 * system_prompt + prompt
We instantiate our model again in bfloat16 precision.
thon
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
thon
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
**Output**:
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
`
We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
Let's measure the peak GPU memory requirement.
thon
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
**Output**:
```bash
37.668193340301514
As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
We call `flush()` to free GPU memory for our next experiment.
thon
flush()
For comparison, let's run the same function, but enable Flash Attention instead.
To do so, we convert the model to [BetterTransformers](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is based on Flash Attention.
thon
model.to_bettertransformer()
Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
**Output**:
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
Let's measure the memory consumption one last time.
thon
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
**Output**:
32.617331981658936
And we're almost back to our original 29GB peak GPU memory from the beginning.
We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
flush()
For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
## 3. Architectural Innovations
So far we have looked into improving computational and memory efficiency by:
- Casting the weights to a lower precision format
- Replacing the self-attention algorithm with a more memory- and compute efficient version
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
- Retrieval augmented Questions Answering,
- Summarization,
- Chat
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
- The positional embeddings
- The key-value cache
Let's go over each component in more detail
### 3.1 Improving positional embeddings of LLMs
Self-attention puts each token in relation to each other's tokens.
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:

Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
> By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
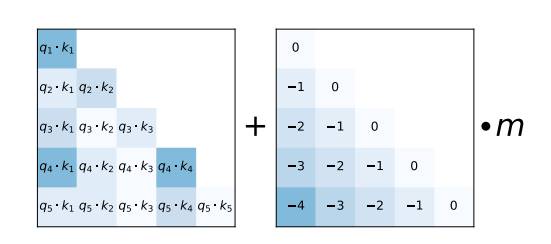
As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
### 3.2 The key-value cache
Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
thon
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
**Output**:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
As we can see every time we increase the text input tokens by the just sampled token.
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
thon
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
**Output**:
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
Using the key-value cache has two advantages:
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation).
Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
#### 3.2.1 Multi-round conversation
The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
In this chat, the LLM runs auto-regressive decoding twice:
1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
thon
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
**Output**:
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number of
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
thon
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
**Output**:
7864320000
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
#### 3.2.2 Multi-Query-Attention (MQA)
[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
#### 3.2.3 Grouped-Query-Attention (GQA)
[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
## Conclusion
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
|
philosophy.md
|
# Philosophy
🤗 Transformers is an opinionated library built for:
- machine learning researchers and educators seeking to use, study or extend large-scale Transformers models.
- hands-on practitioners who want to fine-tune those models or serve them in production, or both.
- engineers who just want to download a pretrained model and use it to solve a given machine learning task.
The library was designed with two strong goals in mind:
1. Be as easy and fast to use as possible:
- We strongly limited the number of user-facing abstractions to learn, in fact, there are almost no abstractions,
just three standard classes required to use each model: [configuration](main_classes/configuration),
[models](main_classes/model), and a preprocessing class ([tokenizer](main_classes/tokenizer) for NLP, [image processor](main_classes/image_processor) for vision, [feature extractor](main_classes/feature_extractor) for audio, and [processor](main_classes/processors) for multimodal inputs).
- All of these classes can be initialized in a simple and unified way from pretrained instances by using a common
`from_pretrained()` method which downloads (if needed), caches and
loads the related class instance and associated data (configurations' hyperparameters, tokenizers' vocabulary,
and models' weights) from a pretrained checkpoint provided on [Hugging Face Hub](https://huggingface.co/models) or your own saved checkpoint.
- On top of those three base classes, the library provides two APIs: [`pipeline`] for quickly
using a model for inference on a given task and [`Trainer`] to quickly train or fine-tune a PyTorch model (all TensorFlow models are compatible with `Keras.fit`).
- As a consequence, this library is NOT a modular toolbox of building blocks for neural nets. If you want to
extend or build upon the library, just use regular Python, PyTorch, TensorFlow, Keras modules and inherit from the base
classes of the library to reuse functionalities like model loading and saving. If you'd like to learn more about our coding philosophy for models, check out our [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy) blog post.
2. Provide state-of-the-art models with performances as close as possible to the original models:
- We provide at least one example for each architecture which reproduces a result provided by the official authors
of said architecture.
- The code is usually as close to the original code base as possible which means some PyTorch code may be not as
*pytorchic* as it could be as a result of being converted TensorFlow code and vice versa.
A few other goals:
- Expose the models' internals as consistently as possible:
- We give access, using a single API, to the full hidden-states and attention weights.
- The preprocessing classes and base model APIs are standardized to easily switch between models.
- Incorporate a subjective selection of promising tools for fine-tuning and investigating these models:
- A simple and consistent way to add new tokens to the vocabulary and embeddings for fine-tuning.
- Simple ways to mask and prune Transformer heads.
- Easily switch between PyTorch, TensorFlow 2.0 and Flax, allowing training with one framework and inference with another.
## Main concepts
The library is built around three types of classes for each model:
- **Model classes** can be PyTorch models ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)), Keras models ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) or JAX/Flax models ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) that work with the pretrained weights provided in the library.
- **Configuration classes** store the hyperparameters required to build a model (such as the number of layers and hidden size). You don't always need to instantiate these yourself. In particular, if you are using a pretrained model without any modification, creating the model will automatically take care of instantiating the configuration (which is part of the model).
- **Preprocessing classes** convert the raw data into a format accepted by the model. A [tokenizer](main_classes/tokenizer) stores the vocabulary for each model and provide methods for encoding and decoding strings in a list of token embedding indices to be fed to a model. [Image processors](main_classes/image_processor) preprocess vision inputs, [feature extractors](main_classes/feature_extractor) preprocess audio inputs, and a [processor](main_classes/processors) handles multimodal inputs.
All these classes can be instantiated from pretrained instances, saved locally, and shared on the Hub with three methods:
- `from_pretrained()` lets you instantiate a model, configuration, and preprocessing class from a pretrained version either
provided by the library itself (the supported models can be found on the [Model Hub](https://huggingface.co/models)) or
stored locally (or on a server) by the user.
- `save_pretrained()` lets you save a model, configuration, and preprocessing class locally so that it can be reloaded using
`from_pretrained()`.
- `push_to_hub()` lets you share a model, configuration, and a preprocessing class to the Hub, so it is easily accessible to everyone.
|
perf_train_gpu_one.md
|
# Methods and tools for efficient training on a single GPU
This guide demonstrates practical techniques that you can use to increase the efficiency of your model's training by
optimizing memory utilization, speeding up the training, or both. If you'd like to understand how GPU is utilized during
training, please refer to the [Model training anatomy](model_memory_anatomy) conceptual guide first. This guide
focuses on practical techniques.
If you have access to a machine with multiple GPUs, these approaches are still valid, plus you can leverage additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
When training large models, there are two aspects that should be considered at the same time:
* Data throughput/training time
* Model performance
Maximizing the throughput (samples/second) leads to lower training cost. This is generally achieved by utilizing the GPU
as much as possible and thus filling GPU memory to its limit. If the desired batch size exceeds the limits of the GPU memory,
the memory optimization techniques, such as gradient accumulation, can help.
However, if the preferred batch size fits into memory, there's no reason to apply memory-optimizing techniques because they can
slow down the training. Just because one can use a large batch size, does not necessarily mean they should. As part of
hyperparameter tuning, you should determine which batch size yields the best results and then optimize resources accordingly.
The methods and tools covered in this guide can be classified based on the effect they have on the training process:
| Method/tool | Improves training speed | Optimizes memory utilization |
|:-----------------------------------------------------------|:------------------------|:-----------------------------|
| [Batch size choice](#batch-size-choice) | Yes | Yes |
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
| [Mixed precision training](#mixed-precision-training) | Yes | (No) |
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
| [Data preloading](#data-preloading) | Yes | No |
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
| [torch.compile](#using-torchcompile) | Yes | No |
Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a
large model and a small batch size, the memory use will be larger.
You can combine the above methods to get a cumulative effect. These techniques are available to you whether you are
training your model with [`Trainer`] or writing a pure PyTorch loop, in which case you can [configure these optimizations
with 🤗 Accelerate](#using-accelerate).
If these methods do not result in sufficient gains, you can explore the following options:
* [Look into building your own custom Docker container with efficient softare prebuilds](#efficient-software-prebuilds)
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention)
Finally, if all of the above is still not enough, even after switching to a server-grade GPU like A100, consider moving
to a multi-GPU setup. All these approaches are still valid in a multi-GPU setup, plus you can leverage additional parallelism
techniques outlined in the [multi-GPU section](perf_train_gpu_many).
## Batch size choice
To achieve optimal performance, start by identifying the appropriate batch size. It is recommended to use batch sizes and
input/output neuron counts that are of size 2^N. Often it's a multiple of 8, but it can be
higher depending on the hardware being used and the model's dtype.
For reference, check out NVIDIA's recommendation for [input/output neuron counts](
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and
[batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size) for
fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)
define the multiplier based on the dtype and the hardware. For instance, for fp16 data type a multiple of 8 is recommended, unless
it's an A100 GPU, in which case use multiples of 64.
For parameters that are small, consider also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization).
This is where tiling happens and the right multiplier can have a significant speedup.
## Gradient Accumulation
The **gradient accumulation** method aims to calculate gradients in smaller increments instead of computing them for the
entire batch at once. This approach involves iteratively calculating gradients in smaller batches by performing forward
and backward passes through the model and accumulating the gradients during the process. Once a sufficient number of
gradients have been accumulated, the model's optimization step is executed. By employing gradient accumulation, it
becomes possible to increase the **effective batch size** beyond the limitations imposed by the GPU's memory capacity.
However, it is important to note that the additional forward and backward passes introduced by gradient accumulation can
slow down the training process.
You can enable gradient accumulation by adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]:
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
In the above example, your effective batch size becomes 4.
Alternatively, use 🤗 Accelerate to gain full control over the training loop. Find the 🤗 Accelerate example
[further down in this guide](#using-accelerate).
While it is advised to max out GPU usage as much as possible, a high number of gradient accumulation steps can
result in a more pronounced training slowdown. Consider the following example. Let's say, the `per_device_train_batch_size=4`
without gradient accumulation hits the GPU's limit. If you would like to train with batches of size 64, do not set the
`per_device_train_batch_size` to 1 and `gradient_accumulation_steps` to 64. Instead, keep `per_device_train_batch_size=4`
and set `gradient_accumulation_steps=16`. This results in the same effective batch size while making better use of
the available GPU resources.
For additional information, please refer to batch size and gradient accumulation benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
## Gradient Checkpointing
Some large models may still face memory issues even when the batch size is set to 1 and gradient accumulation is used.
This is because there are other components that also require memory storage.
Saving all activations from the forward pass in order to compute the gradients during the backward pass can result in
significant memory overhead. The alternative approach of discarding the activations and recalculating them when needed
during the backward pass, would introduce a considerable computational overhead and slow down the training process.
**Gradient checkpointing** offers a compromise between these two approaches and saves strategically selected activations
throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. For
an in-depth explanation of gradient checkpointing, refer to [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9).
To enable gradient checkpointing in the [`Trainer`], pass the corresponding a flag to [`TrainingArguments`]:
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
Alternatively, use 🤗 Accelerate - find the 🤗 Accelerate example [further in this guide](#using-accelerate).
While gradient checkpointing may improve memory efficiency, it slows training by approximately 20%.
## Mixed precision training
**Mixed precision training** is a technique that aims to optimize the computational efficiency of training models by
utilizing lower-precision numerical formats for certain variables. Traditionally, most models use 32-bit floating point
precision (fp32 or float32) to represent and process variables. However, not all variables require this high precision
level to achieve accurate results. By reducing the precision of certain variables to lower numerical formats like 16-bit
floating point (fp16 or float16), we can speed up the computations. Because in this approach some computations are performed
in half-precision, while some are still in full precision, the approach is called mixed precision training.
Most commonly mixed precision training is achieved by using fp16 (float16) data types, however, some GPU architectures
(such as the Ampere architecture) offer bf16 and tf32 (CUDA internal data type) data types. Check
out the [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) to learn more about
the differences between these data types.
### fp16
The main advantage of mixed precision training comes from saving the activations in half precision (fp16).
Although the gradients are also computed in half precision they are converted back to full precision for the optimization
step so no memory is saved here.
While mixed precision training results in faster computations, it can also lead to more GPU memory being utilized, especially for small batch sizes.
This is because the model is now present on the GPU in both 16-bit and 32-bit precision (1.5x the original model on the GPU).
To enable mixed precision training, set the `fp16` flag to `True`:
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
If you prefer to use 🤗 Accelerate, find the 🤗 Accelerate example [further in this guide](#using-accelerate).
### BF16
If you have access to an Ampere or newer hardware you can use bf16 for mixed precision training and evaluation. While
bf16 has a worse precision than fp16, it has a much bigger dynamic range. In fp16 the biggest number you can have
is `65535` and any number above that will result in an overflow. A bf16 number can be as large as `3.39e+38` (!) which
is about the same as fp32 - because both have 8-bits used for the numerical range.
You can enable BF16 in the 🤗 Trainer with:
thon
training_args = TrainingArguments(bf16=True, **default_args)
### TF32
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead
of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total. It's "magical" in the sense that
you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput
improvement. All you need to do is to add the following to your code:
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
CUDA will automatically switch to using tf32 instead of fp32 where possible, assuming that the used GPU is from the Ampere series.
According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/), the
majority of machine learning training workloads show the same perplexity and convergence with tf32 training as with fp32.
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
You can enable this mode in the 🤗 Trainer:
thon
TrainingArguments(tf32=True, **default_args)
tf32 can't be accessed directly via `tensor.to(dtype=torch.tf32)` because it is an internal CUDA data type. You need `torch>=1.7` to use tf32 data types.
For additional information on tf32 vs other precisions, please refer to the following benchmarks:
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
## Flash Attention 2
You can speedup the training throughput by using Flash Attention 2 integration in transformers. Check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2) to learn more about how to load a model with Flash Attention 2 modules.
## Optimizer choice
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
`adamw_apex_fused`, `adamw_anyprecision`, `adafactor`, or `adamw_bnb_8bit`. More optimizers can be plugged in via a third-party implementation.
Let's take a closer look at two alternatives to AdamW optimizer:
1. `adafactor` which is available in [`Trainer`]
2. `adamw_bnb_8bit` is also available in Trainer, but a third-party integration is provided below for demonstration.
For comparison, for a 3B-parameter model, like “t5-3b”:
* A standard AdamW optimizer will need 24GB of GPU memory because it uses 8 bytes for each parameter (8*3 => 24GB)
* Adafactor optimizer will need more than 12GB. It uses slightly more than 4 bytes for each parameter, so 4*3 and then some extra.
* 8bit BNB quantized optimizer will use only (2*3) 6GB if all optimizer states are quantized.
### Adafactor
Adafactor doesn't store rolling averages for each element in weight matrices. Instead, it keeps aggregated information
(sums of rolling averages row- and column-wise), significantly reducing its footprint. However, compared to Adam,
Adafactor may have slower convergence in certain cases.
You can switch to Adafactor by setting `optim="adafactor"` in [`TrainingArguments`]:
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training)
you can notice up to 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of
Adafactor can be worse than Adam.
### 8-bit Adam
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization
means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the
idea behind mixed precision training.
To use `adamw_bnb_8bit`, you simply need to set `optim="adamw_bnb_8bit"` in [`TrainingArguments`]:
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
However, we can also use a third-party implementation of the 8-bit optimizer for demonstration purposes to see how that can be integrated.
First, follow the installation guide in the GitHub [repo](https://github.com/TimDettmers/bitsandbytes) to install the `bitsandbytes` library
that implements the 8-bit Adam optimizer.
Next you need to initialize the optimizer. This involves two steps:
* First, group the model's parameters into two groups - one where weight decay should be applied, and the other one where it should not. Usually, biases and layer norm parameters are not weight decayed.
* Then do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
Finally, pass the custom optimizer as an argument to the `Trainer`:
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training),
you can expect to get about a 3x memory improvement and even slightly higher throughput as using Adafactor.
### multi_tensor
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations
with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner, take a look at this GitHub [issue](https://github.com/huggingface/transformers/issues/9965).
## Data preloading
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it
can handle. By default, everything happens in the main process, and it might not be able to read the data from disk fast
enough, and thus create a bottleneck, leading to GPU under-utilization. Configure the following arguments to reduce the bottleneck:
- `DataLoader(pin_memory=True, )` - ensures the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
- `DataLoader(num_workers=4, )` - spawn several workers to preload data faster. During training, watch the GPU utilization stats; if it's far from 100%, experiment with increasing the number of workers. Of course, the problem could be elsewhere, so many workers won't necessarily lead to better performance.
When using [`Trainer`], the corresponding [`TrainingArguments`] are: `dataloader_pin_memory` (`True` by default), and `dataloader_num_workers` (defaults to `0`).
## DeepSpeed ZeRO
DeepSpeed is an open-source deep learning optimization library that is integrated with 🤗 Transformers and 🤗 Accelerate.
It provides a wide range of features and optimizations designed to improve the efficiency and scalability of large-scale
deep learning training.
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don't need to use DeepSpeed
as it'll only slow things down. However, if the model doesn't fit onto a single GPU or you can't fit a small batch, you can
leverage DeepSpeed ZeRO + CPU Offload, or NVMe Offload for much larger models. In this case, you need to separately
[install the library](main_classes/deepspeed#installation), then follow one of the guides to create a configuration file
and launch DeepSpeed:
* For an in-depth guide on DeepSpeed integration with [`Trainer`], review [the corresponding documentation](main_classes/deepspeed), specifically the
[section for a single GPU](main_classes/deepspeed#deployment-with-one-gpu). Some adjustments are required to use DeepSpeed in a notebook; please take a look at the [corresponding guide](main_classes/deepspeed#deployment-in-notebooks).
* If you prefer to use 🤗 Accelerate, refer to [🤗 Accelerate DeepSpeed guide](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed).
## Using torch.compile
PyTorch 2.0 introduced a new compile function that doesn't require any modification to existing PyTorch code but can
optimize your code by adding a single line of code: `model = torch.compile(model)`.
If using [`Trainer`], you only need `to` pass the `torch_compile` option in the [`TrainingArguments`]:
thon
training_args = TrainingArguments(torch_compile=True, **default_args)
`torch.compile` uses Python's frame evaluation API to automatically create a graph from existing PyTorch programs. After
capturing the graph, different backends can be deployed to lower the graph to an optimized engine.
You can find more details and benchmarks in [PyTorch documentation](https://pytorch.org/get-started/pytorch-2.0/).
`torch.compile` has a growing list of backends, which can be found in by calling `torchdynamo.list_backends()`, each of which with its optional dependencies.
Choose which backend to use by specifying it via `torch_compile_backend` in the [`TrainingArguments`]. Some of the most commonly used backends are:
**Debugging backends**:
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
**Training & inference backends**:
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
**Inference-only backend**s:
* `dynamo.optimize("ofi")` - Uses Torchscript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
* `dynamo.optimize("fx2trt")` - Uses NVIDIA TensorRT for inference optimizations. [Read more](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
For an example of using `torch.compile` with 🤗 Transformers, check out this [blog post on fine-tuning a BERT model for Text Classification using the newest PyTorch 2.0 features](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)
## Using 🤗 Accelerate
With [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) you can use the above methods while gaining full
control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications.
Suppose you have combined the methods in the [`TrainingArguments`] like so:
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method.
When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)
we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call.
During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)
call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same [8-bit optimizer](#8-bit-adam) from the earlier example.
Finally, we can add the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see
how gradient accumulation works: we normalize the loss, so we get the average at the end of accumulation and once we have
enough steps we run the optimization.
Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the
benefit of more flexibility in the training loop. For a full documentation of all features have a look at the
[Accelerate documentation](https://huggingface.co/docs/accelerate/index).
## Efficient Software Prebuilds
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuilt with the cuda toolkit
which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
At times, additional efforts may be required to pre-build some components. For instance, if you're using libraries like `apex` that
don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated.
To address these scenarios PyTorch and NVIDIA released a new version of NGC docker container which already comes with
everything prebuilt. You just need to install your programs on it, and it will run out of the box.
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
To find the docker image version you want start [with PyTorch release notes](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/),
choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's
components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go
to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
Next follow the instructions to download and deploy the docker image.
## Mixture of Experts
Some recent papers reported a 4-5x training speedup and a faster inference by integrating
Mixture of Experts (MoE) into the Transformer models.
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the
number of parameters by an order of magnitude without increasing training costs.
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function
that trains each expert in a balanced way depending on the input token's position in a sequence.

(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude
larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or
hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the
memory requirements moderately as well.
Most related papers and implementations are built around Tensorflow/TPUs:
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
## Using PyTorch native attention and Flash Attention
PyTorch 2.0 released a native [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA),
that allows using fused GPU kernels such as [memory-efficient attention](https://arxiv.org/abs/2112.05682) and [flash attention](https://arxiv.org/abs/2205.14135).
After installing the [`optimum`](https://github.com/huggingface/optimum) package, the relevant internal modules can be
replaced to use PyTorch's native attention with:
thon
model = model.to_bettertransformer()
Once converted, train the model as usual.
The PyTorch-native `scaled_dot_product_attention` operator can only dispatch to Flash Attention if no `attention_mask` is provided.
By default, in training mode, the BetterTransformer integration **drops the mask support and can only be used for training that does not require a padding mask for batched training**. This is the case, for example, during masked language modeling or causal language modeling. BetterTransformer is not suited for fine-tuning models on tasks that require a padding mask.
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
|
testing.md
|
# Testing
Let's take a look at how 🤗 Transformers models are tested and how you can write new tests and improve the existing ones.
There are 2 test suites in the repository:
1. `tests` -- tests for the general API
2. `examples` -- tests primarily for various applications that aren't part of the API
## How transformers are tested
1. Once a PR is submitted it gets tested with 9 CircleCi jobs. Every new commit to that PR gets retested. These jobs
are defined in this [config file](https://github.com/huggingface/transformers/tree/main/.circleci/config.yml), so that if needed you can reproduce the same
environment on your machine.
These CI jobs don't run `@slow` tests.
2. There are 3 jobs run by [github actions](https://github.com/huggingface/transformers/actions):
- [torch hub integration](https://github.com/huggingface/transformers/tree/main/.github/workflows/github-torch-hub.yml): checks whether torch hub
integration works.
- [self-hosted (push)](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-push.yml): runs fast tests on GPU only on commits on
`main`. It only runs if a commit on `main` has updated the code in one of the following folders: `src`,
`tests`, `.github` (to prevent running on added model cards, notebooks, etc.)
- [self-hosted runner](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-scheduled.yml): runs normal and slow tests on GPU in
`tests` and `examples`:
```bash
RUN_SLOW=1 pytest tests/
RUN_SLOW=1 pytest examples/
The results can be observed [here](https://github.com/huggingface/transformers/actions).
## Running tests
### Choosing which tests to run
This document goes into many details of how tests can be run. If after reading everything, you need even more details
you will find them [here](https://docs.pytest.org/en/latest/usage.html).
Here are some most useful ways of running tests.
Run all:
```console
pytest
or:
```bash
make test
Note that the latter is defined as:
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/
which tells pytest to:
- run as many test processes as they are CPU cores (which could be too many if you don't have a ton of RAM!)
- ensure that all tests from the same file will be run by the same test process
- do not capture output
- run in verbose mode
### Getting the list of all tests
All tests of the test suite:
```bash
pytest --collect-only -q
All tests of a given test file:
```bash
pytest tests/test_optimization.py --collect-only -q
### Run a specific test module
To run an individual test module:
```bash
pytest tests/utils/test_logging.py
### Run specific tests
Since unittest is used inside most of the tests, to run specific subtests you need to know the name of the unittest
class containing those tests. For example, it could be:
```bash
pytest tests/test_optimization.py::OptimizationTest::test_adam_w
Here:
- `tests/test_optimization.py` - the file with tests
- `OptimizationTest` - the name of the class
- `test_adam_w` - the name of the specific test function
If the file contains multiple classes, you can choose to run only tests of a given class. For example:
```bash
pytest tests/test_optimization.py::OptimizationTest
will run all the tests inside that class.
As mentioned earlier you can see what tests are contained inside the `OptimizationTest` class by running:
```bash
pytest tests/test_optimization.py::OptimizationTest --collect-only -q
You can run tests by keyword expressions.
To run only tests whose name contains `adam`:
```bash
pytest -k adam tests/test_optimization.py
Logical `and` and `or` can be used to indicate whether all keywords should match or either. `not` can be used to
negate.
To run all tests except those whose name contains `adam`:
```bash
pytest -k "not adam" tests/test_optimization.py
And you can combine the two patterns in one:
```bash
pytest -k "ada and not adam" tests/test_optimization.py
For example to run both `test_adafactor` and `test_adam_w` you can use:
```bash
pytest -k "test_adam_w or test_adam_w" tests/test_optimization.py
Note that we use `or` here, since we want either of the keywords to match to include both.
If you want to include only tests that include both patterns, `and` is to be used:
```bash
pytest -k "test and ada" tests/test_optimization.py
### Run `accelerate` tests
Sometimes you need to run `accelerate` tests on your models. For that you can just add `-m accelerate_tests` to your command, if let's say you want to run these tests on `OPT` run:
```bash
RUN_SLOW=1 pytest -m accelerate_tests tests/models/opt/test_modeling_opt.py
### Run documentation tests
In order to test whether the documentation examples are correct, you should check that the `doctests` are passing.
As an example, let's use [`WhisperModel.forward`'s docstring](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py#L1017-L1035):
thon
r"""
Returns:
Example:
thon
>>> import torch
>>> from transformers import WhisperModel, WhisperFeatureExtractor
>>> from datasets import load_dataset
>>> model = WhisperModel.from_pretrained("openai/whisper-base")
>>> feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-base")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
>>> input_features = inputs.input_features
>>> decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
>>> last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
>>> list(last_hidden_state.shape)
[1, 2, 512]
```"""
Just run the following line to automatically test every docstring example in the desired file:
```bash
pytest --doctest-modules
If the file has a markdown extention, you should add the `--doctest-glob="*.md"` argument.
### Run only modified tests
You can run the tests related to the unstaged files or the current branch (according to Git) by using [pytest-picked](https://github.com/anapaulagomes/pytest-picked). This is a great way of quickly testing your changes didn't break
anything, since it won't run the tests related to files you didn't touch.
```bash
pip install pytest-picked
```bash
pytest --picked
All tests will be run from files and folders which are modified, but not yet committed.
### Automatically rerun failed tests on source modification
[pytest-xdist](https://github.com/pytest-dev/pytest-xdist) provides a very useful feature of detecting all failed
tests, and then waiting for you to modify files and continuously re-rerun those failing tests until they pass while you
fix them. So that you don't need to re start pytest after you made the fix. This is repeated until all tests pass after
which again a full run is performed.
```bash
pip install pytest-xdist
To enter the mode: `pytest -f` or `pytest --looponfail`
File changes are detected by looking at `looponfailroots` root directories and all of their contents (recursively).
If the default for this value does not work for you, you can change it in your project by setting a configuration
option in `setup.cfg`:
```ini
[tool:pytest]
looponfailroots = transformers tests
or `pytest.ini`/``tox.ini`` files:
```ini
[pytest]
looponfailroots = transformers tests
This would lead to only looking for file changes in the respective directories, specified relatively to the ini-file’s
directory.
[pytest-watch](https://github.com/joeyespo/pytest-watch) is an alternative implementation of this functionality.
### Skip a test module
If you want to run all test modules, except a few you can exclude them by giving an explicit list of tests to run. For
example, to run all except `test_modeling_*.py` tests:
```bash
pytest *ls -1 tests/*py | grep -v test_modeling*
### Clearing state
CI builds and when isolation is important (against speed), cache should be cleared:
```bash
pytest --cache-clear tests
### Running tests in parallel
As mentioned earlier `make test` runs tests in parallel via `pytest-xdist` plugin (`-n X` argument, e.g. `-n 2`
to run 2 parallel jobs).
`pytest-xdist`'s `--dist=` option allows one to control how the tests are grouped. `--dist=loadfile` puts the
tests located in one file onto the same process.
Since the order of executed tests is different and unpredictable, if running the test suite with `pytest-xdist`
produces failures (meaning we have some undetected coupled tests), use [pytest-replay](https://github.com/ESSS/pytest-replay) to replay the tests in the same order, which should help with then somehow
reducing that failing sequence to a minimum.
### Test order and repetition
It's good to repeat the tests several times, in sequence, randomly, or in sets, to detect any potential
inter-dependency and state-related bugs (tear down). And the straightforward multiple repetition is just good to detect
some problems that get uncovered by randomness of DL.
#### Repeat tests
- [pytest-flakefinder](https://github.com/dropbox/pytest-flakefinder):
```bash
pip install pytest-flakefinder
And then run every test multiple times (50 by default):
```bash
pytest --flake-finder --flake-runs=5 tests/test_failing_test.py
This plugin doesn't work with `-n` flag from `pytest-xdist`.
There is another plugin `pytest-repeat`, but it doesn't work with `unittest`.
#### Run tests in a random order
```bash
pip install pytest-random-order
Important: the presence of `pytest-random-order` will automatically randomize tests, no configuration change or
command line options is required.
As explained earlier this allows detection of coupled tests - where one test's state affects the state of another. When
`pytest-random-order` is installed it will print the random seed it used for that session, e.g:
```bash
pytest tests
[]
Using --random-order-bucket=module
Using --random-order-seed=573663
So that if the given particular sequence fails, you can reproduce it by adding that exact seed, e.g.:
```bash
pytest --random-order-seed=573663
[]
Using --random-order-bucket=module
Using --random-order-seed=573663
It will only reproduce the exact order if you use the exact same list of tests (or no list at all). Once you start to
manually narrowing down the list you can no longer rely on the seed, but have to list them manually in the exact order
they failed and tell pytest to not randomize them instead using `--random-order-bucket=none`, e.g.:
```bash
pytest --random-order-bucket=none tests/test_a.py tests/test_c.py tests/test_b.py
To disable the shuffling for all tests:
```bash
pytest --random-order-bucket=none
By default `--random-order-bucket=module` is implied, which will shuffle the files on the module levels. It can also
shuffle on `class`, `package`, `global` and `none` levels. For the complete details please see its
[documentation](https://github.com/jbasko/pytest-random-order).
Another randomization alternative is: [`pytest-randomly`](https://github.com/pytest-dev/pytest-randomly). This
module has a very similar functionality/interface, but it doesn't have the bucket modes available in
`pytest-random-order`. It has the same problem of imposing itself once installed.
### Look and feel variations
#### pytest-sugar
[pytest-sugar](https://github.com/Frozenball/pytest-sugar) is a plugin that improves the look-n-feel, adds a
progressbar, and show tests that fail and the assert instantly. It gets activated automatically upon installation.
```bash
pip install pytest-sugar
To run tests without it, run:
```bash
pytest -p no:sugar
or uninstall it.
#### Report each sub-test name and its progress
For a single or a group of tests via `pytest` (after `pip install pytest-pspec`):
```bash
pytest --pspec tests/test_optimization.py
#### Instantly shows failed tests
[pytest-instafail](https://github.com/pytest-dev/pytest-instafail) shows failures and errors instantly instead of
waiting until the end of test session.
```bash
pip install pytest-instafail
```bash
pytest --instafail
### To GPU or not to GPU
On a GPU-enabled setup, to test in CPU-only mode add `CUDA_VISIBLE_DEVICES=""`:
```bash
CUDA_VISIBLE_DEVICES="" pytest tests/utils/test_logging.py
or if you have multiple gpus, you can specify which one is to be used by `pytest`. For example, to use only the
second gpu if you have gpus `0` and `1`, you can run:
```bash
CUDA_VISIBLE_DEVICES="1" pytest tests/utils/test_logging.py
This is handy when you want to run different tasks on different GPUs.
Some tests must be run on CPU-only, others on either CPU or GPU or TPU, yet others on multiple-GPUs. The following skip
decorators are used to set the requirements of tests CPU/GPU/TPU-wise:
- `require_torch` - this test will run only under torch
- `require_torch_gpu` - as `require_torch` plus requires at least 1 GPU
- `require_torch_multi_gpu` - as `require_torch` plus requires at least 2 GPUs
- `require_torch_non_multi_gpu` - as `require_torch` plus requires 0 or 1 GPUs
- `require_torch_up_to_2_gpus` - as `require_torch` plus requires 0 or 1 or 2 GPUs
- `require_torch_tpu` - as `require_torch` plus requires at least 1 TPU
Let's depict the GPU requirements in the following table:
| n gpus | decorator |
|--------+--------------------------------|
| `>= 0` | `@require_torch` |
| `>= 1` | `@require_torch_gpu` |
| `>= 2` | `@require_torch_multi_gpu` |
| `< 2` | `@require_torch_non_multi_gpu` |
| `< 3` | `@require_torch_up_to_2_gpus` |
For example, here is a test that must be run only when there are 2 or more GPUs available and pytorch is installed:
thon no-style
@require_torch_multi_gpu
def test_example_with_multi_gpu():
If a test requires `tensorflow` use the `require_tf` decorator. For example:
thon no-style
@require_tf
def test_tf_thing_with_tensorflow():
These decorators can be stacked. For example, if a test is slow and requires at least one GPU under pytorch, here is
how to set it up:
thon no-style
@require_torch_gpu
@slow
def test_example_slow_on_gpu():
Some decorators like `@parametrized` rewrite test names, therefore `@require_*` skip decorators have to be listed
last for them to work correctly. Here is an example of the correct usage:
thon no-style
@parameterized.expand()
@require_torch_multi_gpu
def test_integration_foo():
This order problem doesn't exist with `@pytest.mark.parametrize`, you can put it first or last and it will still
work. But it only works with non-unittests.
Inside tests:
- How many GPUs are available:
thon
from transformers.testing_utils import get_gpu_count
n_gpu = get_gpu_count() # works with torch and tf
### Testing with a specific PyTorch backend or device
To run the test suite on a specific torch device add `TRANSFORMERS_TEST_DEVICE="$device"` where `$device` is the target backend. For example, to test on CPU only:
```bash
TRANSFORMERS_TEST_DEVICE="cpu" pytest tests/utils/test_logging.py
This variable is useful for testing custom or less common PyTorch backends such as `mps`. It can also be used to achieve the same effect as `CUDA_VISIBLE_DEVICES` by targeting specific GPUs or testing in CPU-only mode.
Certain devices will require an additional import after importing `torch` for the first time. This can be specified using the environment variable `TRANSFORMERS_TEST_BACKEND`:
```bash
TRANSFORMERS_TEST_BACKEND="torch_npu" pytest tests/utils/test_logging.py
Alternative backends may also require the replacement of device-specific functions. For example `torch.cuda.manual_seed` may need to be replaced with a device-specific seed setter like `torch.npu.manual_seed` to correctly set a random seed on the device. To specify a new backend with backend-specific device functions when running the test suite, create a Python device specification file in the format:
import torch
import torch_npu
# !! Further additional imports can be added here !!
# Specify the device name (eg. 'cuda', 'cpu', 'npu')
DEVICE_NAME = 'npu'
# Specify device-specific backends to dispatch to.
# If not specified, will fallback to 'default' in 'testing_utils.py`
MANUAL_SEED_FN = torch.npu.manual_seed
EMPTY_CACHE_FN = torch.npu.empty_cache
DEVICE_COUNT_FN = torch.npu.device_count
This format also allows for specification of any additional imports required. To use this file to replace equivalent methods in the test suite, set the environment variable `TRANSFORMERS_TEST_DEVICE_SPEC` to the path of the spec file.
Currently, only `MANUAL_SEED_FN`, `EMPTY_CACHE_FN` and `DEVICE_COUNT_FN` are supported for device-specific dispatch.
### Distributed training
`pytest` can't deal with distributed training directly. If this is attempted - the sub-processes don't do the right
thing and end up thinking they are `pytest` and start running the test suite in loops. It works, however, if one
spawns a normal process that then spawns off multiple workers and manages the IO pipes.
Here are some tests that use it:
- [test_trainer_distributed.py](https://github.com/huggingface/transformers/tree/main/tests/trainer/test_trainer_distributed.py)
- [test_deepspeed.py](https://github.com/huggingface/transformers/tree/main/tests/deepspeed/test_deepspeed.py)
To jump right into the execution point, search for the `execute_subprocess_async` call in those tests.
You will need at least 2 GPUs to see these tests in action:
```bash
CUDA_VISIBLE_DEVICES=0,1 RUN_SLOW=1 pytest -sv tests/test_trainer_distributed.py
### Output capture
During test execution any output sent to `stdout` and `stderr` is captured. If a test or a setup method fails, its
according captured output will usually be shown along with the failure traceback.
To disable output capturing and to get the `stdout` and `stderr` normally, use `-s` or `--capture=no`:
```bash
pytest -s tests/utils/test_logging.py
To send test results to JUnit format output:
```bash
py.test tests --junitxml=result.xml
### Color control
To have no color (e.g., yellow on white background is not readable):
```bash
pytest --color=no tests/utils/test_logging.py
### Sending test report to online pastebin service
Creating a URL for each test failure:
```bash
pytest --pastebin=failed tests/utils/test_logging.py
This will submit test run information to a remote Paste service and provide a URL for each failure. You may select
tests as usual or add for example -x if you only want to send one particular failure.
Creating a URL for a whole test session log:
```bash
pytest --pastebin=all tests/utils/test_logging.py
## Writing tests
🤗 transformers tests are based on `unittest`, but run by `pytest`, so most of the time features from both systems
can be used.
You can read [here](https://docs.pytest.org/en/stable/unittest.html) which features are supported, but the important
thing to remember is that most `pytest` fixtures don't work. Neither parametrization, but we use the module
`parameterized` that works in a similar way.
### Parametrization
Often, there is a need to run the same test multiple times, but with different arguments. It could be done from within
the test, but then there is no way of running that test for just one set of arguments.
thon
# test_this1.py
import unittest
from parameterized import parameterized
class TestMathUnitTest(unittest.TestCase):
@parameterized.expand(
[
("negative", -1.5, -2.0),
("integer", 1, 1.0),
("large fraction", 1.6, 1),
]
)
def test_floor(self, name, input, expected):
assert_equal(math.floor(input), expected)
Now, by default this test will be run 3 times, each time with the last 3 arguments of `test_floor` being assigned the
corresponding arguments in the parameter list.
and you could run just the `negative` and `integer` sets of params with:
```bash
pytest -k "negative and integer" tests/test_mytest.py
or all but `negative` sub-tests, with:
```bash
pytest -k "not negative" tests/test_mytest.py
Besides using the `-k` filter that was just mentioned, you can find out the exact name of each sub-test and run any
or all of them using their exact names.
```bash
pytest test_this1.py --collect-only -q
and it will list:
```bash
test_this1.py::TestMathUnitTest::test_floor_0_negative
test_this1.py::TestMathUnitTest::test_floor_1_integer
test_this1.py::TestMathUnitTest::test_floor_2_large_fraction
So now you can run just 2 specific sub-tests:
```bash
pytest test_this1.py::TestMathUnitTest::test_floor_0_negative test_this1.py::TestMathUnitTest::test_floor_1_integer
The module [parameterized](https://pypi.org/project/parameterized/) which is already in the developer dependencies
of `transformers` works for both: `unittests` and `pytest` tests.
If, however, the test is not a `unittest`, you may use `pytest.mark.parametrize` (or you may see it being used in
some existing tests, mostly under `examples`).
Here is the same example, this time using `pytest`'s `parametrize` marker:
thon
# test_this2.py
import pytest
@pytest.mark.parametrize(
"name, input, expected",
[
("negative", -1.5, -2.0),
("integer", 1, 1.0),
("large fraction", 1.6, 1),
],
)
def test_floor(name, input, expected):
assert_equal(math.floor(input), expected)
Same as with `parameterized`, with `pytest.mark.parametrize` you can have a fine control over which sub-tests are
run, if the `-k` filter doesn't do the job. Except, this parametrization function creates a slightly different set of
names for the sub-tests. Here is what they look like:
```bash
pytest test_this2.py --collect-only -q
and it will list:
```bash
test_this2.py::test_floor[integer-1-1.0]
test_this2.py::test_floor[negative--1.5--2.0]
test_this2.py::test_floor[large fraction-1.6-1]
So now you can run just the specific test:
```bash
pytest test_this2.py::test_floor[negative--1.5--2.0] test_this2.py::test_floor[integer-1-1.0]
as in the previous example.
### Files and directories
In tests often we need to know where things are relative to the current test file, and it's not trivial since the test
could be invoked from more than one directory or could reside in sub-directories with different depths. A helper class
`transformers.test_utils.TestCasePlus` solves this problem by sorting out all the basic paths and provides easy
accessors to them:
- `pathlib` objects (all fully resolved):
- `test_file_path` - the current test file path, i.e. `__file__`
- `test_file_dir` - the directory containing the current test file
- `tests_dir` - the directory of the `tests` test suite
- `examples_dir` - the directory of the `examples` test suite
- `repo_root_dir` - the directory of the repository
- `src_dir` - the directory of `src` (i.e. where the `transformers` sub-dir resides)
- stringified paths---same as above but these return paths as strings, rather than `pathlib` objects:
- `test_file_path_str`
- `test_file_dir_str`
- `tests_dir_str`
- `examples_dir_str`
- `repo_root_dir_str`
- `src_dir_str`
To start using those all you need is to make sure that the test resides in a subclass of
`transformers.test_utils.TestCasePlus`. For example:
thon
from transformers.testing_utils import TestCasePlus
class PathExampleTest(TestCasePlus):
def test_something_involving_local_locations(self):
data_dir = self.tests_dir / "fixtures/tests_samples/wmt_en_ro"
If you don't need to manipulate paths via `pathlib` or you just need a path as a string, you can always invoked
`str()` on the `pathlib` object or use the accessors ending with `_str`. For example:
thon
from transformers.testing_utils import TestCasePlus
class PathExampleTest(TestCasePlus):
def test_something_involving_stringified_locations(self):
examples_dir = self.examples_dir_str
### Temporary files and directories
Using unique temporary files and directories are essential for parallel test running, so that the tests won't overwrite
each other's data. Also we want to get the temporary files and directories removed at the end of each test that created
them. Therefore, using packages like `tempfile`, which address these needs is essential.
However, when debugging tests, you need to be able to see what goes into the temporary file or directory and you want
to know it's exact path and not having it randomized on every test re-run.
A helper class `transformers.test_utils.TestCasePlus` is best used for such purposes. It's a sub-class of
`unittest.TestCase`, so we can easily inherit from it in the test modules.
Here is an example of its usage:
thon
from transformers.testing_utils import TestCasePlus
class ExamplesTests(TestCasePlus):
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir()
This code creates a unique temporary directory, and sets `tmp_dir` to its location.
- Create a unique temporary dir:
thon
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir()
`tmp_dir` will contain the path to the created temporary dir. It will be automatically removed at the end of the
test.
- Create a temporary dir of my choice, ensure it's empty before the test starts and don't empty it after the test.
thon
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir("./xxx")
This is useful for debug when you want to monitor a specific directory and want to make sure the previous tests didn't
leave any data in there.
- You can override the default behavior by directly overriding the `before` and `after` args, leading to one of the
following behaviors:
- `before=True`: the temporary dir will always be cleared at the beginning of the test.
- `before=False`: if the temporary dir already existed, any existing files will remain there.
- `after=True`: the temporary dir will always be deleted at the end of the test.
- `after=False`: the temporary dir will always be left intact at the end of the test.
In order to run the equivalent of `rm -r` safely, only subdirs of the project repository checkout are allowed if
an explicit `tmp_dir` is used, so that by mistake no `/tmp` or similar important part of the filesystem will
get nuked. i.e. please always pass paths that start with `./`.
Each test can register multiple temporary directories and they all will get auto-removed, unless requested
otherwise.
### Temporary sys.path override
If you need to temporary override `sys.path` to import from another test for example, you can use the
`ExtendSysPath` context manager. Example:
thon
import os
from transformers.testing_utils import ExtendSysPath
bindir = os.path.abspath(os.path.dirname(__file__))
with ExtendSysPath(f"{bindir}/.."):
from test_trainer import TrainerIntegrationCommon # noqa
### Skipping tests
This is useful when a bug is found and a new test is written, yet the bug is not fixed yet. In order to be able to
commit it to the main repository we need make sure it's skipped during `make test`.
Methods:
- A **skip** means that you expect your test to pass only if some conditions are met, otherwise pytest should skip
running the test altogether. Common examples are skipping windows-only tests on non-windows platforms, or skipping
tests that depend on an external resource which is not available at the moment (for example a database).
- A **xfail** means that you expect a test to fail for some reason. A common example is a test for a feature not yet
implemented, or a bug not yet fixed. When a test passes despite being expected to fail (marked with
pytest.mark.xfail), it’s an xpass and will be reported in the test summary.
One of the important differences between the two is that `skip` doesn't run the test, and `xfail` does. So if the
code that's buggy causes some bad state that will affect other tests, do not use `xfail`.
#### Implementation
- Here is how to skip whole test unconditionally:
thon no-style
@unittest.skip("this bug needs to be fixed")
def test_feature_x():
or via pytest:
thon no-style
@pytest.mark.skip(reason="this bug needs to be fixed")
or the `xfail` way:
thon no-style
@pytest.mark.xfail
def test_feature_x():
Here's how to skip a test based on internal checks within the test:
thon
def test_feature_x():
if not has_something():
pytest.skip("unsupported configuration")
or the whole module:
thon
import pytest
if not pytest.config.getoption("--custom-flag"):
pytest.skip("--custom-flag is missing, skipping tests", allow_module_level=True)
or the `xfail` way:
thon
def test_feature_x():
pytest.xfail("expected to fail until bug XYZ is fixed")
- Here is how to skip all tests in a module if some import is missing:
thon
docutils = pytest.importorskip("docutils", minversion="0.3")
- Skip a test based on a condition:
thon no-style
@pytest.mark.skipif(sys.version_info < (3,6), reason="requires python3.6 or higher")
def test_feature_x():
or:
thon no-style
@unittest.skipIf(torch_device == "cpu", "Can't do half precision")
def test_feature_x():
or skip the whole module:
thon no-style
@pytest.mark.skipif(sys.platform == 'win32', reason="does not run on windows")
class TestClass():
def test_feature_x(self):
More details, example and ways are [here](https://docs.pytest.org/en/latest/skipping.html).
### Slow tests
The library of tests is ever-growing, and some of the tests take minutes to run, therefore we can't afford waiting for
an hour for the test suite to complete on CI. Therefore, with some exceptions for essential tests, slow tests should be
marked as in the example below:
thon no-style
from transformers.testing_utils import slow
@slow
def test_integration_foo():
Once a test is marked as `@slow`, to run such tests set `RUN_SLOW=1` env var, e.g.:
```bash
RUN_SLOW=1 pytest tests
Some decorators like `@parameterized` rewrite test names, therefore `@slow` and the rest of the skip decorators
`@require_*` have to be listed last for them to work correctly. Here is an example of the correct usage:
thon no-style
@parameteriz ed.expand()
@slow
def test_integration_foo():
As explained at the beginning of this document, slow tests get to run on a scheduled basis, rather than in PRs CI
checks. So it's possible that some problems will be missed during a PR submission and get merged. Such problems will
get caught during the next scheduled CI job. But it also means that it's important to run the slow tests on your
machine before submitting the PR.
Here is a rough decision making mechanism for choosing which tests should be marked as slow:
If the test is focused on one of the library's internal components (e.g., modeling files, tokenization files,
pipelines), then we should run that test in the non-slow test suite. If it's focused on an other aspect of the library,
such as the documentation or the examples, then we should run these tests in the slow test suite. And then, to refine
this approach we should have exceptions:
- All tests that need to download a heavy set of weights or a dataset that is larger than ~50MB (e.g., model or
tokenizer integration tests, pipeline integration tests) should be set to slow. If you're adding a new model, you
should create and upload to the hub a tiny version of it (with random weights) for integration tests. This is
discussed in the following paragraphs.
- All tests that need to do a training not specifically optimized to be fast should be set to slow.
- We can introduce exceptions if some of these should-be-non-slow tests are excruciatingly slow, and set them to
`@slow`. Auto-modeling tests, which save and load large files to disk, are a good example of tests that are marked
as `@slow`.
- If a test completes under 1 second on CI (including downloads if any) then it should be a normal test regardless.
Collectively, all the non-slow tests need to cover entirely the different internals, while remaining fast. For example,
a significant coverage can be achieved by testing with specially created tiny models with random weights. Such models
have the very minimal number of layers (e.g., 2), vocab size (e.g., 1000), etc. Then the `@slow` tests can use large
slow models to do qualitative testing. To see the use of these simply look for *tiny* models with:
```bash
grep tiny tests examples
Here is a an example of a [script](https://github.com/huggingface/transformers/tree/main/scripts/fsmt/fsmt-make-tiny-model.py) that created the tiny model
[stas/tiny-wmt19-en-de](https://huggingface.co/stas/tiny-wmt19-en-de). You can easily adjust it to your specific
model's architecture.
It's easy to measure the run-time incorrectly if for example there is an overheard of downloading a huge model, but if
you test it locally the downloaded files would be cached and thus the download time not measured. Hence check the
execution speed report in CI logs instead (the output of `pytest --durations=0 tests`).
That report is also useful to find slow outliers that aren't marked as such, or which need to be re-written to be fast.
If you notice that the test suite starts getting slow on CI, the top listing of this report will show the slowest
tests.
### Testing the stdout/stderr output
In order to test functions that write to `stdout` and/or `stderr`, the test can access those streams using the
`pytest`'s [capsys system](https://docs.pytest.org/en/latest/capture.html). Here is how this is accomplished:
thon
import sys
def print_to_stdout(s):
print(s)
def print_to_stderr(s):
sys.stderr.write(s)
def test_result_and_stdout(capsys):
msg = "Hello"
print_to_stdout(msg)
print_to_stderr(msg)
out, err = capsys.readouterr() # consume the captured output streams
# optional: if you want to replay the consumed streams:
sys.stdout.write(out)
sys.stderr.write(err)
# test:
assert msg in out
assert msg in err
And, of course, most of the time, `stderr` will come as a part of an exception, so try/except has to be used in such
a case:
thon
def raise_exception(msg):
raise ValueError(msg)
def test_something_exception():
msg = "Not a good value"
error = ""
try:
raise_exception(msg)
except Exception as e:
error = str(e)
assert msg in error, f"{msg} is in the exception:\n{error}"
Another approach to capturing stdout is via `contextlib.redirect_stdout`:
thon
from io import StringIO
from contextlib import redirect_stdout
def print_to_stdout(s):
print(s)
def test_result_and_stdout():
msg = "Hello"
buffer = StringIO()
with redirect_stdout(buffer):
print_to_stdout(msg)
out = buffer.getvalue()
# optional: if you want to replay the consumed streams:
sys.stdout.write(out)
# test:
assert msg in out
An important potential issue with capturing stdout is that it may contain `\r` characters that in normal `print`
reset everything that has been printed so far. There is no problem with `pytest`, but with `pytest -s` these
characters get included in the buffer, so to be able to have the test run with and without `-s`, you have to make an
extra cleanup to the captured output, using `re.sub(r'~.*\r', '', buf, 0, re.M)`.
But, then we have a helper context manager wrapper to automatically take care of it all, regardless of whether it has
some `\r`'s in it or not, so it's a simple:
thon
from transformers.testing_utils import CaptureStdout
with CaptureStdout() as cs:
function_that_writes_to_stdout()
print(cs.out)
Here is a full test example:
thon
from transformers.testing_utils import CaptureStdout
msg = "Secret message\r"
final = "Hello World"
with CaptureStdout() as cs:
print(msg + final)
assert cs.out == final + "\n", f"captured: {cs.out}, expecting {final}"
If you'd like to capture `stderr` use the `CaptureStderr` class instead:
thon
from transformers.testing_utils import CaptureStderr
with CaptureStderr() as cs:
function_that_writes_to_stderr()
print(cs.err)
If you need to capture both streams at once, use the parent `CaptureStd` class:
thon
from transformers.testing_utils import CaptureStd
with CaptureStd() as cs:
function_that_writes_to_stdout_and_stderr()
print(cs.err, cs.out)
Also, to aid debugging test issues, by default these context managers automatically replay the captured streams on exit
from the context.
### Capturing logger stream
If you need to validate the output of a logger, you can use `CaptureLogger`:
thon
from transformers import logging
from transformers.testing_utils import CaptureLogger
msg = "Testing 1, 2, 3"
logging.set_verbosity_info()
logger = logging.get_logger("transformers.models.bart.tokenization_bart")
with CaptureLogger(logger) as cl:
logger.info(msg)
assert cl.out, msg + "\n"
### Testing with environment variables
If you want to test the impact of environment variables for a specific test you can use a helper decorator
`transformers.testing_utils.mockenv`
thon
from transformers.testing_utils import mockenv
class HfArgumentParserTest(unittest.TestCase):
@mockenv(TRANSFORMERS_VERBOSITY="error")
def test_env_override(self):
env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None)
At times an external program needs to be called, which requires setting `PYTHONPATH` in `os.environ` to include
multiple local paths. A helper class `transformers.test_utils.TestCasePlus` comes to help:
thon
from transformers.testing_utils import TestCasePlus
class EnvExampleTest(TestCasePlus):
def test_external_prog(self):
env = self.get_env()
# now call the external program, passing `env` to it
Depending on whether the test file was under the `tests` test suite or `examples` it'll correctly set up
`env[PYTHONPATH]` to include one of these two directories, and also the `src` directory to ensure the testing is
done against the current repo, and finally with whatever `env[PYTHONPATH]` was already set to before the test was
called if anything.
This helper method creates a copy of the `os.environ` object, so the original remains intact.
### Getting reproducible results
In some situations you may want to remove randomness for your tests. To get identical reproducible results set, you
will need to fix the seed:
thon
seed = 42
# python RNG
import random
random.seed(seed)
# pytorch RNGs
import torch
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
# numpy RNG
import numpy as np
np.random.seed(seed)
# tf RNG
tf.random.set_seed(seed)
### Debugging tests
To start a debugger at the point of the warning, do this:
```bash
pytest tests/utils/test_logging.py -W error::UserWarning --pdb
## Working with github actions workflows
To trigger a self-push workflow CI job, you must:
1. Create a new branch on `transformers` origin (not a fork!).
2. The branch name has to start with either `ci_` or `ci-` (`main` triggers it too, but we can't do PRs on
`main`). It also gets triggered only for specific paths - you can find the up-to-date definition in case it
changed since this document has been written [here](https://github.com/huggingface/transformers/blob/main/.github/workflows/self-push.yml) under *push:*
3. Create a PR from this branch.
4. Then you can see the job appear [here](https://github.com/huggingface/transformers/actions/workflows/self-push.yml). It may not run right away if there
is a backlog.
## Testing Experimental CI Features
Testing CI features can be potentially problematic as it can interfere with the normal CI functioning. Therefore if a
new CI feature is to be added, it should be done as following.
1. Create a new dedicated job that tests what needs to be tested
2. The new job must always succeed so that it gives us a green ✓ (details below).
3. Let it run for some days to see that a variety of different PR types get to run on it (user fork branches,
non-forked branches, branches originating from github.com UI direct file edit, various forced pushes, etc. - there
are so many) while monitoring the experimental job's logs (not the overall job green as it's purposefully always
green)
4. When it's clear that everything is solid, then merge the new changes into existing jobs.
That way experiments on CI functionality itself won't interfere with the normal workflow.
Now how can we make the job always succeed while the new CI feature is being developed?
Some CIs, like TravisCI support ignore-step-failure and will report the overall job as successful, but CircleCI and
Github Actions as of this writing don't support that.
So the following workaround can be used:
1. `set +euo pipefail` at the beginning of the run command to suppress most potential failures in the bash script.
2. the last command must be a success: `echo "done"` or just `true` will do
Here is an example:
```yaml
- run:
name: run CI experiment
command: |
set +euo pipefail
echo "setting run-all-despite-any-errors-mode"
this_command_will_fail
echo "but bash continues to run"
# emulate another failure
false
# but the last command must be a success
echo "during experiment do not remove: reporting success to CI, even if there were failures"
For simple commands you could also do:
```bash
cmd_that_may_fail || true
Of course, once satisfied with the results, integrate the experimental step or job with the rest of the normal jobs,
while removing `set +euo pipefail` or any other things you may have added to ensure that the experimental job doesn't
interfere with the normal CI functioning.
This whole process would have been much easier if we only could set something like `allow-failure` for the
experimental step, and let it fail without impacting the overall status of PRs. But as mentioned earlier CircleCI and
Github Actions don't support it at the moment.
You can vote for this feature and see where it is at these CI-specific threads:
- [Github Actions:](https://github.com/actions/toolkit/issues/399)
- [CircleCI:](https://ideas.circleci.com/ideas/CCI-I-344)
|
custom_models.md
|
# Sharing custom models
The 🤗 Transformers library is designed to be easily extensible. Every model is fully coded in a given subfolder
of the repository with no abstraction, so you can easily copy a modeling file and tweak it to your needs.
If you are writing a brand new model, it might be easier to start from scratch. In this tutorial, we will show you
how to write a custom model and its configuration so it can be used inside Transformers, and how you can share it
with the community (with the code it relies on) so that anyone can use it, even if it's not present in the 🤗
Transformers library.
We will illustrate all of this on a ResNet model, by wrapping the ResNet class of the
[timm library](https://github.com/rwightman/pytorch-image-models) into a [`PreTrainedModel`].
## Writing a custom configuration
Before we dive into the model, let's first write its configuration. The configuration of a model is an object that
will contain all the necessary information to build the model. As we will see in the next section, the model can only
take a `config` to be initialized, so we really need that object to be as complete as possible.
In our example, we will take a couple of arguments of the ResNet class that we might want to tweak. Different
configurations will then give us the different types of ResNets that are possible. We then just store those arguments,
after checking the validity of a few of them.
thon
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
The three important things to remember when writing you own configuration are the following:
- you have to inherit from `PretrainedConfig`,
- the `__init__` of your `PretrainedConfig` must accept any kwargs,
- those `kwargs` need to be passed to the superclass `__init__`.
The inheritance is to make sure you get all the functionality from the 🤗 Transformers library, while the two other
constraints come from the fact a `PretrainedConfig` has more fields than the ones you are setting. When reloading a
config with the `from_pretrained` method, those fields need to be accepted by your config and then sent to the
superclass.
Defining a `model_type` for your configuration (here `model_type="resnet"`) is not mandatory, unless you want to
register your model with the auto classes (see last section).
With this done, you can easily create and save your configuration like you would do with any other model config of the
library. Here is how we can create a resnet50d config and save it:
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
This will save a file named `config.json` inside the folder `custom-resnet`. You can then reload your config with the
`from_pretrained` method:
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
You can also use any other method of the [`PretrainedConfig`] class, like [`~PretrainedConfig.push_to_hub`] to
directly upload your config to the Hub.
## Writing a custom model
Now that we have our ResNet configuration, we can go on writing the model. We will actually write two: one that
extracts the hidden features from a batch of images (like [`BertModel`]) and one that is suitable for image
classification (like [`BertForSequenceClassification`]).
As we mentioned before, we'll only write a loose wrapper of the model to keep it simple for this example. The only
thing we need to do before writing this class is a map between the block types and actual block classes. Then the
model is defined from the configuration by passing everything to the `ResNet` class:
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
For the model that will classify images, we just change the forward method:
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
In both cases, notice how we inherit from `PreTrainedModel` and call the superclass initialization with the `config`
(a bit like when you write a regular `torch.nn.Module`). The line that sets the `config_class` is not mandatory, unless
you want to register your model with the auto classes (see last section).
If your model is very similar to a model inside the library, you can re-use the same configuration as this model.
You can have your model return anything you want, but returning a dictionary like we did for
`ResnetModelForImageClassification`, with the loss included when labels are passed, will make your model directly
usable inside the [`Trainer`] class. Using another output format is fine as long as you are planning on using your own
training loop or another library for training.
Now that we have our model class, let's create one:
resnet50d = ResnetModelForImageClassification(resnet50d_config)
Again, you can use any of the methods of [`PreTrainedModel`], like [`~PreTrainedModel.save_pretrained`] or
[`~PreTrainedModel.push_to_hub`]. We will use the second in the next section, and see how to push the model weights
with the code of our model. But first, let's load some pretrained weights inside our model.
In your own use case, you will probably be training your custom model on your own data. To go fast for this tutorial,
we will use the pretrained version of the resnet50d. Since our model is just a wrapper around it, it's going to be
easy to transfer those weights:
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
Now let's see how to make sure that when we do [`~PreTrainedModel.save_pretrained`] or [`~PreTrainedModel.push_to_hub`], the
code of the model is saved.
## Sending the code to the Hub
This API is experimental and may have some slight breaking changes in the next releases.
First, make sure your model is fully defined in a `.py` file. It can rely on relative imports to some other files as
long as all the files are in the same directory (we don't support submodules for this feature yet). For our example,
we'll define a `modeling_resnet.py` file and a `configuration_resnet.py` file in a folder of the current working
directory named `resnet_model`. The configuration file contains the code for `ResnetConfig` and the modeling file
contains the code of `ResnetModel` and `ResnetModelForImageClassification`.
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
The `__init__.py` can be empty, it's just there so that Python detects `resnet_model` can be use as a module.
If copying a modeling files from the library, you will need to replace all the relative imports at the top of the file
to import from the `transformers` package.
Note that you can re-use (or subclass) an existing configuration/model.
To share your model with the community, follow those steps: first import the ResNet model and config from the newly
created files:
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
Then you have to tell the library you want to copy the code files of those objects when using the `save_pretrained`
method and properly register them with a given Auto class (especially for models), just run:
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
Note that there is no need to specify an auto class for the configuration (there is only one auto class for them,
[`AutoConfig`]) but it's different for models. Your custom model could be suitable for many different tasks, so you
have to specify which one of the auto classes is the correct one for your model.
Use `register_for_auto_class()` if you want the code files to be copied. If you instead prefer to use code on the Hub from another repo,
you don't need to call it. In cases where there's more than one auto class, you can modify the `config.json` directly using the
following structure:
"auto_map": {
"AutoConfig": "--",
"AutoModel": "--",
"AutoModelFor": "--",
},
Next, let's create the config and models as we did before:
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
Now to send the model to the Hub, make sure you are logged in. Either run in your terminal:
```bash
huggingface-cli login
or from a notebook:
from huggingface_hub import notebook_login
notebook_login()
You can then push to your own namespace (or an organization you are a member of) like this:
resnet50d.push_to_hub("custom-resnet50d")
On top of the modeling weights and the configuration in json format, this also copied the modeling and
configuration `.py` files in the folder `custom-resnet50d` and uploaded the result to the Hub. You can check the result
in this [model repo](https://huggingface.co/sgugger/custom-resnet50d).
See the [sharing tutorial](model_sharing) for more information on the push to Hub method.
## Using a model with custom code
You can use any configuration, model or tokenizer with custom code files in its repository with the auto-classes and
the `from_pretrained` method. All files and code uploaded to the Hub are scanned for malware (refer to the [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) documentation for more information), but you should still
review the model code and author to avoid executing malicious code on your machine. Set `trust_remote_code=True` to use
a model with custom code:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
It is also strongly encouraged to pass a commit hash as a `revision` to make sure the author of the models did not
update the code with some malicious new lines (unless you fully trust the authors of the models).
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
Note that when browsing the commit history of the model repo on the Hub, there is a button to easily copy the commit
hash of any commit.
## Registering a model with custom code to the auto classes
If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
get the custom models (contrarily to automatically downloading the model code from the Hub).
As long as your config has a `model_type` attribute that is different from existing model types, and that your model
classes have the right `config_class` attributes, you can just add them to the auto classes like this:
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
of your custom config, and the first argument used when registering your custom models to any auto model class needs
to match the `config_class` of those models.
|
big_models.md
|
# Instantiating a big model
When you want to use a very big pretrained model, one challenge is to minimize the use of the RAM. The usual workflow
from PyTorch is:
1. Create your model with random weights.
2. Load your pretrained weights.
3. Put those pretrained weights in your random model.
Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you get out of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instantiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
In this guide, we explore the solutions Transformers offer to deal with this issue. Note that this is an area of active development, so the APIs explained here may change slightly in the future.
## Sharded checkpoints
Since version 4.18.0, model checkpoints that end up taking more than 10GB of space are automatically sharded in smaller pieces. In terms of having one single checkpoint when you do `model.save_pretrained(save_dir)`, you will end up with several partial checkpoints (each of which being of size < 10GB) and an index that maps parameter names to the files they are stored in.
You can control the maximum size before sharding with the `max_shard_size` parameter, so for the sake of an example, we'll use a normal-size models with a small shard size: let's take a traditional BERT model.
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
If you save it using [`~PreTrainedModel.save_pretrained`], you will get a new folder with two files: the config of the model and its weights:
>>> import os
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir)
print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model.bin']
Now let's use a maximum shard size of 200MB:
>>> with tempfile.TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir, max_shard_size="200MB")
print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
On top of the configuration of the model, we see three different weights files, and an `index.json` file which is our index. A checkpoint like this can be fully reloaded using the [`~PreTrainedModel.from_pretrained`] method:
>>> with tempfile.TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir, max_shard_size="200MB")
new_model = AutoModel.from_pretrained(tmp_dir)
The main advantage of doing this for big models is that during step 2 of the workflow shown above, each shard of the checkpoint is loaded after the previous one, capping the memory usage in RAM to the model size plus the size of the biggest shard.
Behind the scenes, the index file is used to determine which keys are in the checkpoint, and where the corresponding weights are stored. We can load that index like any json and get a dictionary:
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir, max_shard_size="200MB")
with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
The metadata just consists of the total size of the model for now. We plan to add other information in the future:
>>> index["metadata"]
{'total_size': 433245184}
The weights map is the main part of this index, which maps each parameter name (as usually found in a PyTorch model `state_dict`) to the file it's stored in:
>>> index["weight_map"]
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
If you want to directly load such a sharded checkpoint inside a model without using [`~PreTrainedModel.from_pretrained`] (like you would do `model.load_state_dict()` for a full checkpoint) you should use [`~modeling_utils.load_sharded_checkpoint`]:
>>> from transformers.modeling_utils import load_sharded_checkpoint
>>> with tempfile.TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir, max_shard_size="200MB")
load_sharded_checkpoint(model, tmp_dir)
## Low memory loading
Sharded checkpoints reduce the memory usage during step 2 of the workflow mentioned above, but in order to use that model in a low memory setting, we recommend leveraging our tools based on the Accelerate library.
Please read the following guide for more information: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
|
attention.md
|
# Attention mechanisms
Most transformer models use full attention in the sense that the attention matrix is square. It can be a big
computational bottleneck when you have long texts. Longformer and reformer are models that try to be more efficient and
use a sparse version of the attention matrix to speed up training.
## LSH attention
[Reformer](#reformer) uses LSH attention. In the softmax(QK^t), only the biggest elements (in the softmax
dimension) of the matrix QK^t are going to give useful contributions. So for each query q in Q, we can consider only
the keys k in K that are close to q. A hash function is used to determine if q and k are close. The attention mask is
modified to mask the current token (except at the first position), because it will give a query and a key equal (so
very similar to each other). Since the hash can be a bit random, several hash functions are used in practice
(determined by a n_rounds parameter) and then are averaged together.
## Local attention
[Longformer](#longformer) uses local attention: often, the local context (e.g., what are the two tokens to the
left and right?) is enough to take action for a given token. Also, by stacking attention layers that have a small
window, the last layer will have a receptive field of more than just the tokens in the window, allowing them to build a
representation of the whole sentence.
Some preselected input tokens are also given global attention: for those few tokens, the attention matrix can access
all tokens and this process is symmetric: all other tokens have access to those specific tokens (on top of the ones in
their local window). This is shown in Figure 2d of the paper, see below for a sample attention mask:
Using those attention matrices with less parameters then allows the model to have inputs having a bigger sequence
length.
## Other tricks
### Axial positional encodings
[Reformer](#reformer) uses axial positional encodings: in traditional transformer models, the positional encoding
E is a matrix of size \\(l\\) by \\(d\\), \\(l\\) being the sequence length and \\(d\\) the dimension of the
hidden state. If you have very long texts, this matrix can be huge and take way too much space on the GPU. To alleviate
that, axial positional encodings consist of factorizing that big matrix E in two smaller matrices E1 and E2, with
dimensions \\(l_{1} \times d_{1}\\) and \\(l_{2} \times d_{2}\\), such that \\(l_{1} \times l_{2} = l\\) and
\\(d_{1} + d_{2} = d\\) (with the product for the lengths, this ends up being way smaller). The embedding for time
step \\(j\\) in E is obtained by concatenating the embeddings for timestep \\(j \% l1\\) in E1 and \\(j // l1\\)
in E2.
|
pipeline_tutorial.md
|
# Pipelines for inference
The [`pipeline`] makes it simple to use any model from the [Hub](https://huggingface.co/models) for inference on any language, computer vision, speech, and multimodal tasks. Even if you don't have experience with a specific modality or aren't familiar with the underlying code behind the models, you can still use them for inference with the [`pipeline`]! This tutorial will teach you to:
* Use a [`pipeline`] for inference.
* Use a specific tokenizer or model.
* Use a [`pipeline`] for audio, vision, and multimodal tasks.
Take a look at the [`pipeline`] documentation for a complete list of supported tasks and available parameters.
## Pipeline usage
While each task has an associated [`pipeline`], it is simpler to use the general [`pipeline`] abstraction which contains
all the task-specific pipelines. The [`pipeline`] automatically loads a default model and a preprocessing class capable
of inference for your task. Let's take the example of using the [`pipeline`] for automatic speech recognition (ASR), or
speech-to-text.
1. Start by creating a [`pipeline`] and specify the inference task:
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
2. Pass your input to the [`pipeline`]. In the case of speech recognition, this is an audio input file:
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
Not the result you had in mind? Check out some of the [most downloaded automatic speech recognition models](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
on the Hub to see if you can get a better transcription.
Let's try the [Whisper large-v2](https://huggingface.co/openai/whisper-large) model from OpenAI. Whisper was released
2 years later than Wav2Vec2, and was trained on close to 10x more data. As such, it beats Wav2Vec2 on most downstream
benchmarks. It also has the added benefit of predicting punctuation and casing, neither of which are possible with
Wav2Vec2.
Let's give it a try here to see how it performs:
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
Now this result looks more accurate! For a deep-dive comparison on Wav2Vec2 vs Whisper, refer to the [Audio Transformers Course](https://huggingface.co/learn/audio-course/chapter5/asr_models).
We really encourage you to check out the Hub for models in different languages, models specialized in your field, and more.
You can check out and compare model results directly from your browser on the Hub to see if it fits or
handles corner cases better than other ones.
And if you don't find a model for your use case, you can always start [training](training) your own!
If you have several inputs, you can pass your input as a list:
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
Pipelines are great for experimentation as switching from one model to another is trivial; however, there are some ways to optimize them for larger workloads than experimentation. See the following guides that dive into iterating over whole datasets or using pipelines in a webserver:
of the docs:
* [Using pipelines on a dataset](#using-pipelines-on-a-dataset)
* [Using pipelines for a webserver](./pipeline_webserver)
## Parameters
[`pipeline`] supports many parameters; some are task specific, and some are general to all pipelines.
In general, you can specify parameters anywhere you want:
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber() # This will use `my_parameter=1`.
out = transcriber(, my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber() # This will go back to using `my_parameter=1`.
Let's check out 3 important ones:
### Device
If you use `device=n`, the pipeline automatically puts the model on the specified device.
This will work regardless of whether you are using PyTorch or Tensorflow.
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
If the model is too large for a single GPU and you are using PyTorch, you can set `device_map="auto"` to automatically
determine how to load and store the model weights. Using the `device_map` argument requires the 🤗 [Accelerate](https://huggingface.co/docs/accelerate)
package:
```bash
pip install --upgrade accelerate
The following code automatically loads and stores model weights across devices:
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
Note that if `device_map="auto"` is passed, there is no need to add the argument `device=device` when instantiating your `pipeline` as you may encounter some unexpected behavior!
### Batch size
By default, pipelines will not batch inference for reasons explained in detail [here](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching). The reason is that batching is not necessarily faster, and can actually be quite slower in some cases.
But if it works in your use case, you can use:
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
This runs the pipeline on the 4 provided audio files, but it will pass them in batches of 2
to the model (which is on a GPU, where batching is more likely to help) without requiring any further code from you.
The output should always match what you would have received without batching. It is only meant as a way to help you get more speed out of a pipeline.
Pipelines can also alleviate some of the complexities of batching because, for some pipelines, a single item (like a long audio file) needs to be chunked into multiple parts to be processed by a model. The pipeline performs this [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching) for you.
### Task specific parameters
All tasks provide task specific parameters which allow for additional flexibility and options to help you get your job done.
For instance, the [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] method has a `return_timestamps` parameter which sounds promising for subtitling videos:
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
As you can see, the model inferred the text and also outputted **when** the various sentences were pronounced.
There are many parameters available for each task, so check out each task's API reference to see what you can tinker with!
For instance, the [`~transformers.AutomaticSpeechRecognitionPipeline`] has a `chunk_length_s` parameter which is helpful
for working on really long audio files (for example, subtitling entire movies or hour-long videos) that a model typically
cannot handle on its own:
thon
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening
If you can't find a parameter that would really help you out, feel free to [request it](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
## Using pipelines on a dataset
The pipeline can also run inference on a large dataset. The easiest way we recommend doing this is by using an iterator:
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
The iterator `data()` yields each result, and the pipeline automatically
recognizes the input is iterable and will start fetching the data while
it continues to process it on the GPU (this uses [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) under the hood).
This is important because you don't have to allocate memory for the whole dataset
and you can feed the GPU as fast as possible.
Since batching could speed things up, it may be useful to try tuning the `batch_size` parameter here.
The simplest way to iterate over a dataset is to just load one from 🤗 [Datasets](https://github.com/huggingface/datasets/):
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
## Using pipelines for a webserver
Creating an inference engine is a complex topic which deserves it's own
page.
[Link](./pipeline_webserver)
## Vision pipeline
Using a [`pipeline`] for vision tasks is practically identical.
Specify your task and pass your image to the classifier. The image can be a link, a local path or a base64-encoded image. For example, what species of cat is shown below?

>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
## Text pipeline
Using a [`pipeline`] for NLP tasks is practically identical.
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
"I have a problem with my iphone that needs to be resolved asap!!",
candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
)
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
## Multimodal pipeline
The [`pipeline`] supports more than one modality. For example, a visual question answering (VQA) task combines text and image. Feel free to use any image link you like and a question you want to ask about the image. The image can be a URL or a local path to the image.
For example, if you use this [invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
question="What is the invoice number?",
)
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
To run the example above you need to have [`pytesseract`](https://pypi.org/project/pytesseract/) installed in addition to 🤗 Transformers:
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
## Using `pipeline` on large models with 🤗 `accelerate`:
You can easily run `pipeline` on large models using 🤗 `accelerate`! First make sure you have installed `accelerate` with `pip install accelerate`.
First load your model using `device_map="auto"`! We will use `facebook/opt-1.3b` for our example.
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
You can also pass 8-bit loaded models if you install `bitsandbytes` and add the argument `load_in_8bit=True`
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
Note that you can replace the checkpoint with any of the Hugging Face model that supports large model loading such as BLOOM!
|
custom_tools.md
|
# Custom Tools and Prompts
If you are not aware of what tools and agents are in the context of transformers, we recommend you read the
[Transformers Agents](transformers_agents) page first.
Transformers Agents is an experimental API that is subject to change at any time. Results returned by the agents
can vary as the APIs or underlying models are prone to change.
Creating and using custom tools and prompts is paramount to empowering the agent and having it perform new tasks.
In this guide we'll take a look at:
- How to customize the prompt
- How to use custom tools
- How to create custom tools
## Customizing the prompt
As explained in [Transformers Agents](transformers_agents) agents can run in [`~Agent.run`] and [`~Agent.chat`] mode.
Both the `run` and `chat` modes underlie the same logic. The language model powering the agent is conditioned on a long
prompt and completes the prompt by generating the next tokens until the stop token is reached.
The only difference between the two modes is that during the `chat` mode the prompt is extended with
previous user inputs and model generations. This allows the agent to have access to past interactions,
seemingly giving the agent some kind of memory.
### Structure of the prompt
Let's take a closer look at how the prompt is structured to understand how it can be best customized.
The prompt is structured broadly into four parts.
- 1. Introduction: how the agent should behave, explanation of the concept of tools.
- 2. Description of all the tools. This is defined by a `<>` token that is dynamically replaced at runtime with the tools defined/chosen by the user.
- 3. A set of examples of tasks and their solution
- 4. Current example, and request for solution.
To better understand each part, let's look at a shortened version of how the `run` prompt can look like:
````text
I will ask you to perform a task, your job is to come up with a series of simple commands in Python that will perform the task.
[]
You can print intermediate results if it makes sense to do so.
Tools:
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
- image_captioner: This is a tool that generates a description of an image. It takes an input named `image` which should be the image to the caption and returns a text that contains the description in English.
[]
Task: "Answer the question in the variable `question` about the image stored in the variable `image`. The question is in French."
I will use the following tools: `translator` to translate the question into English and then `image_qa` to answer the question on the input image.
Answer:
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(image=image, question=translated_question)
print(f"The answer is {answer}")
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
[]
Task: "Draw me a picture of rivers and lakes"
I will use the following
`
The introduction (the text before *"Tools:"*) explains precisely how the model shall behave and what it should do.
This part most likely does not need to be customized as the agent shall always behave the same way.
The second part (the bullet points below *"Tools"*) is dynamically added upon calling `run` or `chat`. There are
exactly as many bullet points as there are tools in `agent.toolbox` and each bullet point consists of the name
and description of the tool:
```text
- :
Let's verify this quickly by loading the document_qa tool and printing out the name and description.
from transformers import load_tool
document_qa = load_tool("document-question-answering")
print(f"- {document_qa.name}: {document_qa.description}")
which gives:
```text
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
We can see that the tool name is short and precise. The description includes two parts, the first explaining
what the tool does and the second states what input arguments and return values are expected.
A good tool name and tool description are very important for the agent to correctly use it. Note that the only
information the agent has about the tool is its name and description, so one should make sure that both
are precisely written and match the style of the existing tools in the toolbox. In particular make sure the description
mentions all the arguments expected by name in code-style, along with the expected type and a description of what they
are.
Check the naming and description of the curated Transformers tools to better understand what name and
description a tool is expected to have. You can see all tools with the [`Agent.toolbox`] property.
The third part includes a set of curated examples that show the agent exactly what code it should produce
for what kind of user request. The large language models empowering the agent are extremely good at
recognizing patterns in a prompt and repeating the pattern with new data. Therefore, it is very important
that the examples are written in a way that maximizes the likelihood of the agent to generating correct,
executable code in practice.
Let's have a look at one example:
````text
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
`
The pattern the model is prompted to repeat has three parts: The task statement, the agent's explanation of
what it intends to do, and finally the generated code. Every example that is part of the prompt has this exact
pattern, thus making sure that the agent will reproduce exactly the same pattern when generating new tokens.
The prompt examples are curated by the Transformers team and rigorously evaluated on a set of
[problem statements](https://github.com/huggingface/transformers/blob/main/src/transformers/tools/evaluate_agent.py)
to ensure that the agent's prompt is as good as possible to solve real use cases of the agent.
The final part of the prompt corresponds to:
```text
Task: "Draw me a picture of rivers and lakes"
I will use the following
is a final and unfinished example that the agent is tasked to complete. The unfinished example
is dynamically created based on the actual user input. For the above example, the user ran:
agent.run("Draw me a picture of rivers and lakes")
The user input - *a.k.a* the task: *"Draw me a picture of rivers and lakes"* is cast into the
prompt template: "Task: \n\n I will use the following". This sentence makes up the final lines of the
prompt the agent is conditioned on, therefore strongly influencing the agent to finish the example
exactly in the same way it was previously done in the examples.
Without going into too much detail, the chat template has the same prompt structure with the
examples having a slightly different style, *e.g.*:
````text
[]
=====
Human: Answer the question in the variable `question` about the image stored in the variable `image`.
Assistant: I will use the tool `image_qa` to answer the question on the input image.
answer = image_qa(text=question, image=image)
print(f"The answer is {answer}")
Human: I tried this code, it worked but didn't give me a good result. The question is in French
Assistant: In this case, the question needs to be translated first. I will use the tool `translator` to do this.
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(text=translated_question, image=image)
print(f"The answer is {answer}")
=====
[]
`
Contrary, to the examples of the `run` prompt, each `chat` prompt example has one or more exchanges between the
*Human* and the *Assistant*. Every exchange is structured similarly to the example of the `run` prompt.
The user's input is appended to behind *Human:* and the agent is prompted to first generate what needs to be done
before generating code. An exchange can be based on previous exchanges, therefore allowing the user to refer
to past exchanges as is done *e.g.* above by the user's input of "I tried **this** code" refers to the
previously generated code of the agent.
Upon running `.chat`, the user's input or *task* is cast into an unfinished example of the form:
```text
Human: \n\nAssistant:
which the agent completes. Contrary to the `run` command, the `chat` command then appends the completed example
to the prompt, thus giving the agent more context for the next `chat` turn.
Great now that we know how the prompt is structured, let's see how we can customize it!
### Writing good user inputs
While large language models are getting better and better at understanding users' intentions, it helps
enormously to be as precise as possible to help the agent pick the correct task. What does it mean to be
as precise as possible?
The agent sees a list of tool names and their description in its prompt. The more tools are added the
more difficult it becomes for the agent to choose the correct tool and it's even more difficult to choose
the correct sequences of tools to run. Let's look at a common failure case, here we will only return
the code to analyze it.
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.run("Show me a tree", return_code=True)
gives:
```text
==Explanation from the agent==
I will use the following tool: `image_segmenter` to create a segmentation mask for the image.
==Code generated by the agent==
mask = image_segmenter(image, prompt="tree")
which is probably not what we wanted. Instead, it is more likely that we want an image of a tree to be generated.
To steer the agent more towards using a specific tool it can therefore be very helpful to use important keywords that
are present in the tool's name and description. Let's have a look.
agent.toolbox["image_generator"].description
```text
'This is a tool that creates an image according to a prompt, which is a text description. It takes an input named `prompt` which contains the image description and outputs an image.
The name and description make use of the keywords "image", "prompt", "create" and "generate". Using these words will most likely work better here. Let's refine our prompt a bit.
agent.run("Create an image of a tree", return_code=True)
gives:
```text
==Explanation from the agent==
I will use the following tool `image_generator` to generate an image of a tree.
==Code generated by the agent==
image = image_generator(prompt="tree")
Much better! That looks more like what we want. In short, when you notice that the agent struggles to
correctly map your task to the correct tools, try looking up the most pertinent keywords of the tool's name
and description and try refining your task request with it.
### Customizing the tool descriptions
As we've seen before the agent has access to each of the tools' names and descriptions. The base tools
should have very precise names and descriptions, however, you might find that it could help to change the
the description or name of a tool for your specific use case. This might become especially important
when you've added multiple tools that are very similar or if you want to use your agent only for a certain
domain, *e.g.* image generation and transformations.
A common problem is that the agent confuses image generation with image transformation/modification when
used a lot for image generation tasks, *e.g.*
agent.run("Make an image of a house and a car", return_code=True)
returns
```text
==Explanation from the agent==
I will use the following tools `image_generator` to generate an image of a house and `image_transformer` to transform the image of a car into the image of a house.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
house_car_image = image_transformer(image=car_image, prompt="A house")
which is probably not exactly what we want here. It seems like the agent has a difficult time
to understand the difference between `image_generator` and `image_transformer` and often uses the two together.
We can help the agent here by changing the tool name and description of `image_transformer`. Let's instead call it `modifier`
to disassociate it a bit from "image" and "prompt":
agent.toolbox["modifier"] = agent.toolbox.pop("image_transformer")
agent.toolbox["modifier"].description = agent.toolbox["modifier"].description.replace(
"transforms an image according to a prompt", "modifies an image"
)
Now "modify" is a strong cue to use the new image processor which should help with the above prompt. Let's run it again.
agent.run("Make an image of a house and a car", return_code=True)
Now we're getting:
```text
==Explanation from the agent==
I will use the following tools: `image_generator` to generate an image of a house, then `image_generator` to generate an image of a car.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
which is definitely closer to what we had in mind! However, we want to have both the house and car in the same image. Steering the task more toward single image generation should help:
agent.run("Create image: 'A house and car'", return_code=True)
```text
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="A house and car")
Agents are still brittle for many use cases, especially when it comes to
slightly more complex use cases like generating an image of multiple objects.
Both the agent itself and the underlying prompt will be further improved in the coming
months making sure that agents become more robust to a variety of user inputs.
### Customizing the whole prompt
To give the user maximum flexibility, the whole prompt template as explained in [above](#structure-of-the-prompt)
can be overwritten by the user. In this case make sure that your custom prompt includes an introduction section,
a tool section, an example section, and an unfinished example section. If you want to overwrite the `run` prompt template,
you can do as follows:
template = """ [] """
agent = HfAgent(your_endpoint, run_prompt_template=template)
Please make sure to have the `<>` string and the `<>` defined somewhere in the `template` so that the agent can be aware
of the tools, it has available to it as well as correctly insert the user's prompt.
Similarly, one can overwrite the `chat` prompt template. Note that the `chat` mode always uses the following format for the exchanges:
```text
Human: <>
Assistant:
Therefore it is important that the examples of the custom `chat` prompt template also make use of this format.
You can overwrite the `chat` template at instantiation as follows.
template = """ [] """
agent = HfAgent(url_endpoint=your_endpoint, chat_prompt_template=template)
Please make sure to have the `<>` string defined somewhere in the `template` so that the agent can be aware
of the tools, it has available to it.
In both cases, you can pass a repo ID instead of the prompt template if you would like to use a template hosted by someone in the community. The default prompts live in [this repo](https://huggingface.co/datasets/huggingface-tools/default-prompts) as an example.
To upload your custom prompt on a repo on the Hub and share it with the community just make sure:
- to use a dataset repository
- to put the prompt template for the `run` command in a file named `run_prompt_template.txt`
- to put the prompt template for the `chat` command in a file named `chat_prompt_template.txt`
## Using custom tools
In this section, we'll be leveraging two existing custom tools that are specific to image generation:
- We replace [huggingface-tools/image-transformation](https://huggingface.co/spaces/huggingface-tools/image-transformation),
with [diffusers/controlnet-canny-tool](https://huggingface.co/spaces/diffusers/controlnet-canny-tool)
to allow for more image modifications.
- We add a new tool for image upscaling to the default toolbox:
[diffusers/latent-upscaler-tool](https://huggingface.co/spaces/diffusers/latent-upscaler-tool) replace the existing image-transformation tool.
We'll start by loading the custom tools with the convenient [`load_tool`] function:
from transformers import load_tool
controlnet_transformer = load_tool("diffusers/controlnet-canny-tool")
upscaler = load_tool("diffusers/latent-upscaler-tool")
Upon adding custom tools to an agent, the tools' descriptions and names are automatically
included in the agents' prompts. Thus, it is imperative that custom tools have
a well-written description and name in order for the agent to understand how to use them.
Let's take a look at the description and name of `controlnet_transformer`:
print(f"Description: '{controlnet_transformer.description}'")
print(f"Name: '{controlnet_transformer.name}'")
gives
```text
Description: 'This is a tool that transforms an image with ControlNet according to a prompt.
It takes two inputs: `image`, which should be the image to transform, and `prompt`, which should be the prompt to use to change it. It returns the modified image.'
Name: 'image_transformer'
The name and description are accurate and fit the style of the [curated set of tools](./transformers_agents#a-curated-set-of-tools).
Next, let's instantiate an agent with `controlnet_transformer` and `upscaler`:
tools = [controlnet_transformer, upscaler]
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=tools)
This command should give you the following info:
```text
image_transformer has been replaced by as provided in `additional_tools`
The set of curated tools already has an `image_transformer` tool which is hereby replaced with our custom tool.
Overwriting existing tools can be beneficial if we want to use a custom tool exactly for the same task as an existing tool
because the agent is well-versed in using the specific task. Beware that the custom tool should follow the exact same API
as the overwritten tool in this case, or you should adapt the prompt template to make sure all examples using that
tool are updated.
The upscaler tool was given the name `image_upscaler` which is not yet present in the default toolbox and is therefore simply added to the list of tools.
You can always have a look at the toolbox that is currently available to the agent via the `agent.toolbox` attribute:
print("\n".join([f"- {a}" for a in agent.toolbox.keys()]))
```text
- document_qa
- image_captioner
- image_qa
- image_segmenter
- transcriber
- summarizer
- text_classifier
- text_qa
- text_reader
- translator
- image_transformer
- text_downloader
- image_generator
- video_generator
- image_upscaler
Note how `image_upscaler` is now part of the agents' toolbox.
Let's now try out the new tools! We will re-use the image we generated in [Transformers Agents Quickstart](./transformers_agents#single-execution-run).
from diffusers.utils import load_image
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png"
)
Let's transform the image into a beautiful winter landscape:
image = agent.run("Transform the image: 'A frozen lake and snowy forest'", image=image)
```text
==Explanation from the agent==
I will use the following tool: `image_transformer` to transform the image.
==Code generated by the agent==
image = image_transformer(image, prompt="A frozen lake and snowy forest")
The new image processing tool is based on ControlNet which can make very strong modifications to the image.
By default the image processing tool returns an image of size 512x512 pixels. Let's see if we can upscale it.
image = agent.run("Upscale the image", image)
```text
==Explanation from the agent==
I will use the following tool: `image_upscaler` to upscale the image.
==Code generated by the agent==
upscaled_image = image_upscaler(image)
The agent automatically mapped our prompt "Upscale the image" to the just added upscaler tool purely based on the description and name of the upscaler tool
and was able to correctly run it.
Next, let's have a look at how you can create a new custom tool.
### Adding new tools
In this section, we show how to create a new tool that can be added to the agent.
#### Creating a new tool
We'll first start by creating a tool. We'll add the not-so-useful yet fun task of fetching the model on the Hugging Face
Hub with the most downloads for a given task.
We can do that with the following code:
thon
from huggingface_hub import list_models
task = "text-classification"
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
print(model.id)
For the task `text-classification`, this returns `'facebook/bart-large-mnli'`, for `translation` it returns `'t5-base`.
How do we convert this to a tool that the agent can leverage? All tools depend on the superclass `Tool` that holds the
main attributes necessary. We'll create a class that inherits from it:
thon
from transformers import Tool
class HFModelDownloadsTool(Tool):
pass
This class has a few needs:
- An attribute `name`, which corresponds to the name of the tool itself. To be in tune with other tools which have a
performative name, we'll name it `model_download_counter`.
- An attribute `description`, which will be used to populate the prompt of the agent.
- `inputs` and `outputs` attributes. Defining this will help the python interpreter make educated choices about types,
and will allow for a gradio-demo to be spawned when we push our tool to the Hub. They're both a list of expected
values, which can be `text`, `image`, or `audio`.
- A `__call__` method which contains the inference code. This is the code we've played with above!
Here's what our class looks like now:
thon
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = (
"This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub. "
"It takes the name of the category (such as text-classification, depth-estimation, etc), and "
"returns the name of the checkpoint."
)
inputs = ["text"]
outputs = ["text"]
def __call__(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
We now have our tool handy. Save it in a file and import it from your main script. Let's name this file
`model_downloads.py`, so the resulting import code looks like this:
thon
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
In order to let others benefit from it and for simpler initialization, we recommend pushing it to the Hub under your
namespace. To do so, just call `push_to_hub` on the `tool` variable:
thon
tool.push_to_hub("hf-model-downloads")
You now have your code on the Hub! Let's take a look at the final step, which is to have the agent use it.
#### Having the agent use the tool
We now have our tool that lives on the Hub which can be instantiated as such (change the user name for your tool):
thon
from transformers import load_tool
tool = load_tool("lysandre/hf-model-downloads")
In order to use it in the agent, simply pass it in the `additional_tools` parameter of the agent initialization method:
thon
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run(
"Can you read out loud the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?"
)
which outputs the following:
```text
==Code generated by the agent==
model = model_download_counter(task="text-to-video")
print(f"The model with the most downloads is {model}.")
audio_model = text_reader(model)
==Result==
The model with the most downloads is damo-vilab/text-to-video-ms-1.7b.
and generates the following audio.
| **Audio** |
|------------------------------------------------------------------------------------------------------------------------------------------------------|
| |
Depending on the LLM, some are quite brittle and require very exact prompts in order to work well. Having a well-defined
name and description of the tool is paramount to having it be leveraged by the agent.
### Replacing existing tools
Replacing existing tools can be done simply by assigning a new item to the agent's toolbox. Here's how one would do so:
thon
from transformers import HfAgent, load_tool
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.toolbox["image-transformation"] = load_tool("diffusers/controlnet-canny-tool")
Beware when replacing tools with others! This will also adjust the agent's prompt. This can be good if you have a better
prompt suited for the task, but it can also result in your tool being selected way more than others or for other
tools to be selected instead of the one you have defined.
## Leveraging gradio-tools
[gradio-tools](https://github.com/freddyaboulton/gradio-tools) is a powerful library that allows using Hugging
Face Spaces as tools. It supports many existing Spaces as well as custom Spaces to be designed with it.
We offer support for `gradio_tools` by using the `Tool.from_gradio` method. For example, we want to take
advantage of the `StableDiffusionPromptGeneratorTool` tool offered in the `gradio-tools` toolkit so as to
improve our prompts and generate better images.
We first import the tool from `gradio_tools` and instantiate it:
thon
from gradio_tools import StableDiffusionPromptGeneratorTool
gradio_tool = StableDiffusionPromptGeneratorTool()
We pass that instance to the `Tool.from_gradio` method:
thon
from transformers import Tool
tool = Tool.from_gradio(gradio_tool)
Now we can manage it exactly as we would a usual custom tool. We leverage it to improve our prompt
` a rabbit wearing a space suit`:
thon
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run("Generate an image of the `prompt` after improving it.", prompt="A rabbit wearing a space suit")
The model adequately leverages the tool:
```text
==Explanation from the agent==
I will use the following tools: `StableDiffusionPromptGenerator` to improve the prompt, then `image_generator` to generate an image according to the improved prompt.
==Code generated by the agent==
improved_prompt = StableDiffusionPromptGenerator(prompt)
print(f"The improved prompt is {improved_prompt}.")
image = image_generator(improved_prompt)
Before finally generating the image:
gradio-tools requires *textual* inputs and outputs, even when working with different modalities. This implementation
works with image and audio objects. The two are currently incompatible, but will rapidly become compatible as we
work to improve the support.
## Future compatibility with Langchain
We love Langchain and think it has a very compelling suite of tools. In order to handle these tools,
Langchain requires *textual* inputs and outputs, even when working with different modalities.
This is often the serialized version (i.e., saved to disk) of the objects.
This difference means that multi-modality isn't handled between transformers-agents and langchain.
We aim for this limitation to be resolved in future versions, and welcome any help from avid langchain
users to help us achieve this compatibility.
We would love to have better support. If you would like to help, please
[open an issue](https://github.com/huggingface/transformers/issues/new) and share what you have in mind.
|
perplexity.md
|
# Perplexity of fixed-length models
[[open-in-colab]]
Perplexity (PPL) is one of the most common metrics for evaluating language models. Before diving in, we should note
that the metric applies specifically to classical language models (sometimes called autoregressive or causal language
models) and is not well defined for masked language models like BERT (see [summary of the models](model_summary)).
Perplexity is defined as the exponentiated average negative log-likelihood of a sequence. If we have a tokenized
sequence \\(X = (x_0, x_1, \dots, x_t)\\), then the perplexity of \\(X\\) is,
$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{
When working with approximate models, however, we typically have a constraint on the number of tokens the model can
process. The largest version of [GPT-2](model_doc/gpt2), for example, has a fixed length of 1024 tokens, so we
cannot calculate \\(p_\theta(x_t|x_{
This is quick to compute since the perplexity of each segment can be computed in one forward pass, but serves as a poor
approximation of the fully-factorized perplexity and will typically yield a higher (worse) PPL because the model will
have less context at most of the prediction steps.
Instead, the PPL of fixed-length models should be evaluated with a sliding-window strategy. This involves repeatedly
sliding the context window so that the model has more context when making each prediction.
This is a closer approximation to the true decomposition of the sequence probability and will typically yield a more
favorable score. The downside is that it requires a separate forward pass for each token in the corpus. A good
practical compromise is to employ a strided sliding window, moving the context by larger strides rather than sliding by
1 token a time. This allows computation to proceed much faster while still giving the model a large context to make
predictions at each step.
## Example: Calculating perplexity with GPT-2 in 🤗 Transformers
Let's demonstrate this process with GPT-2.
thon
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
device = "cuda"
model_id = "gpt2-large"
model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
We'll load in the WikiText-2 dataset and evaluate the perplexity using a few different sliding-window strategies. Since
this dataset is small and we're just doing one forward pass over the set, we can just load and encode the entire
dataset in memory.
thon
from datasets import load_dataset
test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
With 🤗 Transformers, we can simply pass the `input_ids` as the `labels` to our model, and the average negative
log-likelihood for each token is returned as the loss. With our sliding window approach, however, there is overlap in
the tokens we pass to the model at each iteration. We don't want the log-likelihood for the tokens we're just treating
as context to be included in our loss, so we can set these targets to `-100` so that they are ignored. The following
is an example of how we could do this with a stride of `512`. This means that the model will have at least 512 tokens
for context when calculating the conditional likelihood of any one token (provided there are 512 preceding tokens
available to condition on).
thon
import torch
from tqdm import tqdm
max_length = model.config.n_positions
stride = 512
seq_len = encodings.input_ids.size(1)
nlls = []
prev_end_loc = 0
for begin_loc in tqdm(range(0, seq_len, stride)):
end_loc = min(begin_loc + max_length, seq_len)
trg_len = end_loc - prev_end_loc # may be different from stride on last loop
input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
target_ids = input_ids.clone()
target_ids[:, :-trg_len] = -100
with torch.no_grad():
outputs = model(input_ids, labels=target_ids)
# loss is calculated using CrossEntropyLoss which averages over valid labels
# N.B. the model only calculates loss over trg_len - 1 labels, because it internally shifts the labels
# to the left by 1.
neg_log_likelihood = outputs.loss
nlls.append(neg_log_likelihood)
prev_end_loc = end_loc
if end_loc == seq_len:
break
ppl = torch.exp(torch.stack(nlls).mean())
Running this with the stride length equal to the max input length is equivalent to the suboptimal, non-sliding-window
strategy we discussed above. The smaller the stride, the more context the model will have in making each prediction,
and the better the reported perplexity will typically be.
When we run the above with `stride = 1024`, i.e. no overlap, the resulting PPL is `19.44`, which is about the same
as the `19.93` reported in the GPT-2 paper. By using `stride = 512` and thereby employing our striding window
strategy, this jumps down to `16.45`. This is not only a more favorable score, but is calculated in a way that is
closer to the true autoregressive decomposition of a sequence likelihood.
|
model_summary.md
|
# The Transformer model family
Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
## Computer vision
### Convolutional network
For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://arxiv.org/abs/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
### Encoder[[cv-encoder]]
The [Vision Transformer (ViT)](model_doc/vit) opened the door to computer vision tasks without convolutions. ViT uses a standard Transformer encoder, but its main breakthrough was how it treated an image. It splits an image into fixed-size patches and uses them to create an embedding, just like how a sentence is split into tokens. ViT capitalized on the Transformers' efficient architecture to demonstrate competitive results with the CNNs at the time while requiring fewer resources to train. ViT was soon followed by other vision models that could also handle dense vision tasks like segmentation as well as detection.
One of these models is the [Swin](model_doc/swin) Transformer. It builds hierarchical feature maps (like a CNN 👀 and unlike ViT) from smaller-sized patches and merges them with neighboring patches in deeper layers. Attention is only computed within a local window, and the window is shifted between attention layers to create connections to help the model learn better. Since the Swin Transformer can produce hierarchical feature maps, it is a good candidate for dense prediction tasks like segmentation and detection. The [SegFormer](model_doc/segformer) also uses a Transformer encoder to build hierarchical feature maps, but it adds a simple multilayer perceptron (MLP) decoder on top to combine all the feature maps and make a prediction.
Other vision models, like BeIT and ViTMAE, drew inspiration from BERT's pretraining objective. [BeIT](model_doc/beit) is pretrained by *masked image modeling (MIM)*; the image patches are randomly masked, and the image is also tokenized into visual tokens. BeIT is trained to predict the visual tokens corresponding to the masked patches. [ViTMAE](model_doc/vitmae) has a similar pretraining objective, except it must predict the pixels instead of visual tokens. What's unusual is 75% of the image patches are masked! The decoder reconstructs the pixels from the masked tokens and encoded patches. After pretraining, the decoder is thrown away, and the encoder is ready to be used in downstream tasks.
### Decoder[[cv-decoder]]
Decoder-only vision models are rare because most vision models rely on an encoder to learn an image representation. But for use cases like image generation, the decoder is a natural fit, as we've seen from text generation models like GPT-2. [ImageGPT](model_doc/imagegpt) uses the same architecture as GPT-2, but instead of predicting the next token in a sequence, it predicts the next pixel in an image. In addition to image generation, ImageGPT could also be finetuned for image classification.
### Encoder-decoder[[cv-encoder-decoder]]
Vision models commonly use an encoder (also known as a backbone) to extract important image features before passing them to a Transformer decoder. [DETR](model_doc/detr) has a pretrained backbone, but it also uses the complete Transformer encoder-decoder architecture for object detection. The encoder learns image representations and combines them with object queries (each object query is a learned embedding that focuses on a region or object in an image) in the decoder. DETR predicts the bounding box coordinates and class label for each object query.
## Natural language processing
### Encoder[[nlp-encoder]]
[BERT](model_doc/bert) is an encoder-only Transformer that randomly masks certain tokens in the input to avoid seeing other tokens, which would allow it to "cheat". The pretraining objective is to predict the masked token based on the context. This allows BERT to fully use the left and right contexts to help it learn a deeper and richer representation of the inputs. However, there was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a new pretraining recipe that includes training for longer and on larger batches, randomly masking tokens at each epoch instead of just once during preprocessing, and removing the next-sentence prediction objective.
The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://arxiv.org/abs/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
However, most Transformer models continued to trend towards more parameters, leading to new models focused on improving training efficiency. [ALBERT](model_doc/albert) reduces memory consumption by lowering the number of parameters in two ways: separating the larger vocabulary embedding into two smaller matrices and allowing layers to share parameters. [DeBERTa](model_doc/deberta) added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention is computed from these separate vectors instead of a single vector containing the word and position embeddings. [Longformer](model_doc/longformer) also focused on making attention more efficient, especially for processing documents with longer sequence lengths. It uses a combination of local windowed attention (attention only calculated from fixed window size around each token) and global attention (only for specific task tokens like `[CLS]` for classification) to create a sparse attention matrix instead of a full attention matrix.
### Decoder[[nlp-decoder]]
[GPT-2](model_doc/gpt2) is a decoder-only Transformer that predicts the next word in the sequence. It masks tokens to the right so the model can't "cheat" by looking ahead. By pretraining on a massive body of text, GPT-2 became really good at generating text, even if the text is only sometimes accurate or true. But GPT-2 lacked the bidirectional context from BERT's pretraining, which made it unsuitable for certain tasks. [XLNET](model_doc/xlnet) combines the best of both BERT and GPT-2's pretraining objectives by using a permutation language modeling objective (PLM) that allows it to learn bidirectionally.
After GPT-2, language models grew even bigger and are now known as *large language models (LLMs)*. LLMs demonstrate few- or even zero-shot learning if pretrained on a large enough dataset. [GPT-J](model_doc/gptj) is an LLM with 6B parameters and trained on 400B tokens. GPT-J was followed by [OPT](model_doc/opt), a family of decoder-only models, the largest of which is 175B and trained on 180B tokens. [BLOOM](model_doc/bloom) was released around the same time, and the largest model in the family has 176B parameters and is trained on 366B tokens in 46 languages and 13 programming languages.
### Encoder-decoder[[nlp-encoder-decoder]]
[BART](model_doc/bart) keeps the original Transformer architecture, but it modifies the pretraining objective with *text infilling* corruption, where some text spans are replaced with a single `mask` token. The decoder predicts the uncorrupted tokens (future tokens are masked) and uses the encoder's hidden states to help it. [Pegasus](model_doc/pegasus) is similar to BART, but Pegasus masks entire sentences instead of text spans. In addition to masked language modeling, Pegasus is pretrained by gap sentence generation (GSG). The GSG objective masks whole sentences important to a document, replacing them with a `mask` token. The decoder must generate the output from the remaining sentences. [T5](model_doc/t5) is a more unique model that casts all NLP tasks into a text-to-text problem using specific prefixes. For example, the prefix `Summarize:` indicates a summarization task. T5 is pretrained by supervised (GLUE and SuperGLUE) training and self-supervised training (randomly sample and drop out 15% of tokens).
## Audio
### Encoder[[audio-encoder]]
[Wav2Vec2](model_doc/wav2vec2) uses a Transformer encoder to learn speech representations directly from raw audio waveforms. It is pretrained with a contrastive task to determine the true speech representation from a set of false ones. [HuBERT](model_doc/hubert) is similar to Wav2Vec2 but has a different training process. Target labels are created by a clustering step in which segments of similar audio are assigned to a cluster which becomes a hidden unit. The hidden unit is mapped to an embedding to make a prediction.
### Encoder-decoder[[audio-encoder-decoder]]
[Speech2Text](model_doc/speech_to_text) is a speech model designed for automatic speech recognition (ASR) and speech translation. The model accepts log mel-filter bank features extracted from the audio waveform and pretrained autoregressively to generate a transcript or translation. [Whisper](model_doc/whisper) is also an ASR model, but unlike many other speech models, it is pretrained on a massive amount of ✨ labeled ✨ audio transcription data for zero-shot performance. A large chunk of the dataset also contains non-English languages, meaning Whisper can also be used for low-resource languages. Structurally, Whisper is similar to Speech2Text. The audio signal is converted to a log-mel spectrogram encoded by the encoder. The decoder generates the transcript autoregressively from the encoder's hidden states and the previous tokens.
## Multimodal
### Encoder[[mm-encoder]]
[VisualBERT](model_doc/visual_bert) is a multimodal model for vision-language tasks released shortly after BERT. It combines BERT and a pretrained object detection system to extract image features into visual embeddings, passed alongside text embeddings to BERT. VisualBERT predicts the masked text based on the unmasked text and the visual embeddings, and it also has to predict whether the text is aligned with the image. When ViT was released, [ViLT](model_doc/vilt) adopted ViT in its architecture because it was easier to get the image embeddings this way. The image embeddings are jointly processed with the text embeddings. From there, ViLT is pretrained by image text matching, masked language modeling, and whole word masking.
[CLIP](model_doc/clip) takes a different approach and makes a pair prediction of (`image`, `text`) . An image encoder (ViT) and a text encoder (Transformer) are jointly trained on a 400 million (`image`, `text`) pair dataset to maximize the similarity between the image and text embeddings of the (`image`, `text`) pairs. After pretraining, you can use natural language to instruct CLIP to predict the text given an image or vice versa. [OWL-ViT](model_doc/owlvit) builds on top of CLIP by using it as its backbone for zero-shot object detection. After pretraining, an object detection head is added to make a set prediction over the (`class`, `bounding box`) pairs.
### Encoder-decoder[[mm-encoder-decoder]]
Optical character recognition (OCR) is a long-standing text recognition task that typically involves several components to understand the image and generate the text. [TrOCR](model_doc/trocr) simplifies the process using an end-to-end Transformer. The encoder is a ViT-style model for image understanding and processes the image as fixed-size patches. The decoder accepts the encoder's hidden states and autoregressively generates text. [Donut](model_doc/donut) is a more general visual document understanding model that doesn't rely on OCR-based approaches. It uses a Swin Transformer as the encoder and multilingual BART as the decoder. Donut is pretrained to read text by predicting the next word based on the image and text annotations. The decoder generates a token sequence given a prompt. The prompt is represented by a special token for each downstream task. For example, document parsing has a special `parsing` token that is combined with the encoder hidden states to parse the document into a structured output format (JSON).
## Reinforcement learning
### Decoder[[rl-decoder]]
The Decision and Trajectory Transformer casts the state, action, and reward as a sequence modeling problem. The [Decision Transformer](model_doc/decision_transformer) generates a series of actions that lead to a future desired return based on returns-to-go, past states, and actions. For the last *K* timesteps, each of the three modalities are converted into token embeddings and processed by a GPT-like model to predict a future action token. [Trajectory Transformer](model_doc/trajectory_transformer) also tokenizes the states, actions, and rewards and processes them with a GPT architecture. Unlike the Decision Transformer, which is focused on reward conditioning, the Trajectory Transformer generates future actions with beam search.
|
sagemaker.md
|
# Run training on Amazon SageMaker
The documentation has been moved to [hf.co/docs/sagemaker](https://huggingface.co/docs/sagemaker). This page will be removed in `transformers` 5.0.
### Table of Content
- [Train Hugging Face models on Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
- [Deploy Hugging Face models to Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
|
contributing.md
| null |
perf_train_cpu.md
|
# Efficient Training on CPU
This guide focuses on training large models efficiently on CPU.
## Mixed precision with IPEX
IPEX is optimized for CPUs with AVX-512 or above, and functionally works for CPUs with only AVX2. So, it is expected to bring performance benefit for Intel CPU generations with AVX-512 or above while CPUs with only AVX2 (e.g., AMD CPUs or older Intel CPUs) might result in a better performance under IPEX, but not guaranteed. IPEX provides performance optimizations for CPU training with both Float32 and BFloat16. The usage of BFloat16 is the main focus of the following sections.
Low precision data type BFloat16 has been natively supported on the 3rd Generation Xeon® Scalable Processors (aka Cooper Lake) with AVX512 instruction set and will be supported on the next generation of Intel® Xeon® Scalable Processors with Intel® Advanced Matrix Extensions (Intel® AMX) instruction set with further boosted performance. The Auto Mixed Precision for CPU backend has been enabled since PyTorch-1.10. At the same time, the support of Auto Mixed Precision with BFloat16 for CPU and BFloat16 optimization of operators has been massively enabled in Intel® Extension for PyTorch, and partially upstreamed to PyTorch master branch. Users can get better performance and user experience with IPEX Auto Mixed Precision.
Check more detailed information for [Auto Mixed Precision](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html).
### IPEX installation:
IPEX release is following PyTorch, to install via pip:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 1.13 | 1.13.0+cpu |
| 1.12 | 1.12.300+cpu |
| 1.11 | 1.11.200+cpu |
| 1.10 | 1.10.100+cpu |
pip install intel_extension_for_pytorch== -f https://developer.intel.com/ipex-whl-stable-cpu
Check more approaches for [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html).
### Usage in Trainer
To enable auto mixed precision with IPEX in Trainer, users should add `use_ipex`, `bf16` and `no_cuda` in training command arguments.
Take an example of the use cases on [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
- Training with IPEX using BF16 auto mixed precision on CPU:
python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--use_ipex \
--bf16 --no_cuda
### Practice example
Blog: [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids)
|
transformers_agents.md
|
# Transformers Agents
Transformers Agents is an experimental API which is subject to change at any time. Results returned by the agents
can vary as the APIs or underlying models are prone to change.
Transformers version v4.29.0, building on the concept of *tools* and *agents*. You can play with in
[this colab](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj).
In short, it provides a natural language API on top of transformers: we define a set of curated tools and design an
agent to interpret natural language and to use these tools. It is extensible by design; we curated some relevant tools,
but we'll show you how the system can be extended easily to use any tool developed by the community.
Let's start with a few examples of what can be achieved with this new API. It is particularly powerful when it comes
to multimodal tasks, so let's take it for a spin to generate images and read text out loud.
agent.run("Caption the following image", image=image)
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| | A beaver is swimming in the water |
---
agent.run("Read the following text out loud", text=text)
| **Input** | **Output** |
|-------------------------------------------------------------------------------------------------------------------------|----------------------------------------------|
| A beaver is swimming in the water | your browser does not support the audio element.
---
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|----------------|
| | ballroom foyer |
## Quickstart
Before being able to use `agent.run`, you will need to instantiate an agent, which is a large language model (LLM).
We provide support for openAI models as well as opensource alternatives from BigCode and OpenAssistant. The openAI
models perform better (but require you to have an openAI API key, so cannot be used for free); Hugging Face is
providing free access to endpoints for BigCode and OpenAssistant models.
To start with, please install the `agents` extras in order to install all default dependencies.
```bash
pip install transformers[agents]
To use openAI models, you instantiate an [`OpenAiAgent`] after installing the `openai` dependency:
```bash
pip install openai
from transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="")
To use BigCode or OpenAssistant, start by logging in to have access to the Inference API:
from huggingface_hub import login
login("")
Then, instantiate the agent
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
This is using the inference API that Hugging Face provides for free at the moment. If you have your own inference
endpoint for this model (or another one) you can replace the URL above with your URL endpoint.
StarCoder and OpenAssistant are free to use and perform admirably well on simple tasks. However, the checkpoints
don't hold up when handling more complex prompts. If you're facing such an issue, we recommend trying out the OpenAI
model which, while sadly not open-source, performs better at this given time.
You're now good to go! Let's dive into the two APIs that you now have at your disposal.
### Single execution (run)
The single execution method is when using the [`~Agent.run`] method of the agent:
agent.run("Draw me a picture of rivers and lakes.")
It automatically selects the tool (or tools) appropriate for the task you want to perform and runs them appropriately. It
can perform one or several tasks in the same instruction (though the more complex your instruction, the more likely
the agent is to fail).
agent.run("Draw me a picture of the sea then transform the picture to add an island")
Every [`~Agent.run`] operation is independent, so you can run it several times in a row with different tasks.
Note that your `agent` is just a large-language model, so small variations in your prompt might yield completely
different results. It's important to explain as clearly as possible the task you want to perform. We go more in-depth
on how to write good prompts [here](custom_tools#writing-good-user-inputs).
If you'd like to keep a state across executions or to pass non-text objects to the agent, you can do so by specifying
variables that you would like the agent to use. For example, you could generate the first image of rivers and lakes,
and ask the model to update that picture to add an island by doing the following:
thon
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)
This can be helpful when the model is unable to understand your request and mixes tools. An example would be:
agent.run("Draw me the picture of a capybara swimming in the sea")
Here, the model could interpret in two ways:
- Have the `text-to-image` generate a capybara swimming in the sea
- Or, have the `text-to-image` generate capybara, then use the `image-transformation` tool to have it swim in the sea
In case you would like to force the first scenario, you could do so by passing it the prompt as an argument:
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")
### Chat-based execution (chat)
The agent also has a chat-based approach, using the [`~Agent.chat`] method:
agent.chat("Generate a picture of rivers and lakes")
agent.chat("Transform the picture so that there is a rock in there")
This is an interesting approach when you want to keep the state across instructions. It's better for experimentation,
but will tend to be much better at single instructions rather than complex instructions (which the [`~Agent.run`]
method is better at handling).
This method can also take arguments if you would like to pass non-text types or specific prompts.
### ⚠️ Remote execution
For demonstration purposes and so that it could be used with all setups, we had created remote executors for several
of the default tools the agent has access for the release. These are created using
[inference endpoints](https://huggingface.co/inference-endpoints).
We have turned these off for now, but in order to see how to set up remote executors tools yourself,
we recommend reading the [custom tool guide](./custom_tools).
### What's happening here? What are tools, and what are agents?
#### Agents
The "agent" here is a large language model, and we're prompting it so that it has access to a specific set of tools.
LLMs are pretty good at generating small samples of code, so this API takes advantage of that by prompting the
LLM gives a small sample of code performing a task with a set of tools. This prompt is then completed by the
task you give your agent and the description of the tools you give it. This way it gets access to the doc of the
tools you are using, especially their expected inputs and outputs, and can generate the relevant code.
#### Tools
Tools are very simple: they're a single function, with a name, and a description. We then use these tools' descriptions
to prompt the agent. Through the prompt, we show the agent how it would leverage tools to perform what was
requested in the query.
This is using brand-new tools and not pipelines, because the agent writes better code with very atomic tools.
Pipelines are more refactored and often combine several tasks in one. Tools are meant to be focused on
one very simple task only.
#### Code-execution?!
This code is then executed with our small Python interpreter on the set of inputs passed along with your tools.
We hear you screaming "Arbitrary code execution!" in the back, but let us explain why that is not the case.
The only functions that can be called are the tools you provided and the print function, so you're already
limited in what can be executed. You should be safe if it's limited to Hugging Face tools.
Then, we don't allow any attribute lookup or imports (which shouldn't be needed anyway for passing along
inputs/outputs to a small set of functions) so all the most obvious attacks (and you'd need to prompt the LLM
to output them anyway) shouldn't be an issue. If you want to be on the super safe side, you can execute the
run() method with the additional argument return_code=True, in which case the agent will just return the code
to execute and you can decide whether to do it or not.
The execution will stop at any line trying to perform an illegal operation or if there is a regular Python error
with the code generated by the agent.
### A curated set of tools
We identify a set of tools that can empower such agents. Here is an updated list of the tools we have integrated
in `transformers`:
- **Document question answering**: given a document (such as a PDF) in image format, answer a question on this document ([Donut](./model_doc/donut))
- **Text question answering**: given a long text and a question, answer the question in the text ([Flan-T5](./model_doc/flan-t5))
- **Unconditional image captioning**: Caption the image! ([BLIP](./model_doc/blip))
- **Image question answering**: given an image, answer a question on this image ([VILT](./model_doc/vilt))
- **Image segmentation**: given an image and a prompt, output the segmentation mask of that prompt ([CLIPSeg](./model_doc/clipseg))
- **Speech to text**: given an audio recording of a person talking, transcribe the speech into text ([Whisper](./model_doc/whisper))
- **Text to speech**: convert text to speech ([SpeechT5](./model_doc/speecht5))
- **Zero-shot text classification**: given a text and a list of labels, identify to which label the text corresponds the most ([BART](./model_doc/bart))
- **Text summarization**: summarize a long text in one or a few sentences ([BART](./model_doc/bart))
- **Translation**: translate the text into a given language ([NLLB](./model_doc/nllb))
These tools have an integration in transformers, and can be used manually as well, for example:
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
### Custom tools
While we identify a curated set of tools, we strongly believe that the main value provided by this implementation is
the ability to quickly create and share custom tools.
By pushing the code of a tool to a Hugging Face Space or a model repository, you're then able to leverage the tool
directly with the agent. We've added a few
**transformers-agnostic** tools to the [`huggingface-tools` organization](https://huggingface.co/huggingface-tools):
- **Text downloader**: to download a text from a web URL
- **Text to image**: generate an image according to a prompt, leveraging stable diffusion
- **Image transformation**: modify an image given an initial image and a prompt, leveraging instruct pix2pix stable diffusion
- **Text to video**: generate a small video according to a prompt, leveraging damo-vilab
The text-to-image tool we have been using since the beginning is a remote tool that lives in
[*huggingface-tools/text-to-image*](https://huggingface.co/spaces/huggingface-tools/text-to-image)! We will
continue releasing such tools on this and other organizations, to further supercharge this implementation.
The agents have by default access to tools that reside on [`huggingface-tools`](https://huggingface.co/huggingface-tools).
We explain how to you can write and share your tools as well as leverage any custom tool that resides on the Hub in [following guide](custom_tools).
### Code generation
So far we have shown how to use the agents to perform actions for you. However, the agent is only generating code
that we then execute using a very restricted Python interpreter. In case you would like to use the code generated in
a different setting, the agent can be prompted to return the code, along with tool definition and accurate imports.
For example, the following instruction
thon
agent.run("Draw me a picture of rivers and lakes", return_code=True)
returns the following code
thon
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")
that you can then modify and execute yourself.
|
torchscript.md
|
# Export to TorchScript
This is the very beginning of our experiments with TorchScript and we are still
exploring its capabilities with variable-input-size models. It is a focus of interest to
us and we will deepen our analysis in upcoming releases, with more code examples, a more
flexible implementation, and benchmarks comparing Python-based codes with compiled
TorchScript.
According to the [TorchScript documentation](https://pytorch.org/docs/stable/jit.html):
> TorchScript is a way to create serializable and optimizable models from PyTorch code.
There are two PyTorch modules, [JIT and
TRACE](https://pytorch.org/docs/stable/jit.html), that allow developers to export their
models to be reused in other programs like efficiency-oriented C++ programs.
We provide an interface that allows you to export 🤗 Transformers models to TorchScript
so they can be reused in a different environment than PyTorch-based Python programs.
Here, we explain how to export and use our models using TorchScript.
Exporting a model requires two things:
- model instantiation with the `torchscript` flag
- a forward pass with dummy inputs
These necessities imply several things developers should be careful about as detailed
below.
## TorchScript flag and tied weights
The `torchscript` flag is necessary because most of the 🤗 Transformers language models
have tied weights between their `Embedding` layer and their `Decoding` layer.
TorchScript does not allow you to export models that have tied weights, so it is
necessary to untie and clone the weights beforehand.
Models instantiated with the `torchscript` flag have their `Embedding` layer and
`Decoding` layer separated, which means that they should not be trained down the line.
Training would desynchronize the two layers, leading to unexpected results.
This is not the case for models that do not have a language model head, as those do not
have tied weights. These models can be safely exported without the `torchscript` flag.
## Dummy inputs and standard lengths
The dummy inputs are used for a models forward pass. While the inputs' values are
propagated through the layers, PyTorch keeps track of the different operations executed
on each tensor. These recorded operations are then used to create the *trace* of the
model.
The trace is created relative to the inputs' dimensions. It is therefore constrained by
the dimensions of the dummy input, and will not work for any other sequence length or
batch size. When trying with a different size, the following error is raised:
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
We recommended you trace the model with a dummy input size at least as large as the
largest input that will be fed to the model during inference. Padding can help fill the
missing values. However, since the model is traced with a larger input size, the
dimensions of the matrix will also be large, resulting in more calculations.
Be careful of the total number of operations done on each input and follow the
performance closely when exporting varying sequence-length models.
## Using TorchScript in Python
This section demonstrates how to save and load models as well as how to use the trace
for inference.
### Saving a model
To export a `BertModel` with TorchScript, instantiate `BertModel` from the `BertConfig`
class and then save it to disk under the filename `traced_bert.pt`:
thon
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
### Loading a model
Now you can load the previously saved `BertModel`, `traced_bert.pt`, from disk and use
it on the previously initialised `dummy_input`:
thon
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
### Using a traced model for inference
Use the traced model for inference by using its `__call__` dunder method:
thon
traced_model(tokens_tensor, segments_tensors)
## Deploy Hugging Face TorchScript models to AWS with the Neuron SDK
AWS introduced the [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
instance family for low cost, high performance machine learning inference in the cloud.
The Inf1 instances are powered by the AWS Inferentia chip, a custom-built hardware
accelerator, specializing in deep learning inferencing workloads. [AWS
Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) is the SDK for
Inferentia that supports tracing and optimizing transformers models for deployment on
Inf1. The Neuron SDK provides:
1. Easy-to-use API with one line of code change to trace and optimize a TorchScript
model for inference in the cloud.
2. Out of the box performance optimizations for [improved
cost-performance](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>).
3. Support for Hugging Face transformers models built with either
[PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
or
[TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
### Implications
Transformers models based on the [BERT (Bidirectional Encoder Representations from
Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert)
architecture, or its variants such as
[distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) and
[roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) run best on
Inf1 for non-generative tasks such as extractive question answering, sequence
classification, and token classification. However, text generation tasks can still be
adapted to run on Inf1 according to this [AWS Neuron MarianMT
tutorial](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
More information about models that can be converted out of the box on Inferentia can be
found in the [Model Architecture
Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia)
section of the Neuron documentation.
### Dependencies
Using AWS Neuron to convert models requires a [Neuron SDK
environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide)
which comes preconfigured on [AWS Deep Learning
AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
### Converting a model for AWS Neuron
Convert a model for AWS NEURON using the same code from [Using TorchScript in
Python](torchscript#using-torchscript-in-python) to trace a `BertModel`. Import the
`torch.neuron` framework extension to access the components of the Neuron SDK through a
Python API:
thon
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
You only need to modify the following line:
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
This enables the Neuron SDK to trace the model and optimize it for Inf1 instances.
To learn more about AWS Neuron SDK features, tools, example tutorials and latest
updates, please see the [AWS NeuronSDK
documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
|
perf_train_special.md
|
# Training on Specialized Hardware
Note: Most of the strategies introduced in the [single GPU section](perf_train_gpu_one) (such as mixed precision training or gradient accumulation) and [multi-GPU section](perf_train_gpu_many) are generic and apply to training models in general so make sure to have a look at it before diving into this section.
This document will be completed soon with information on how to train on specialized hardware.
|
autoclass_tutorial.md
|
# Load pretrained instances with an AutoClass
With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an `AutoClass` automatically infers and loads the correct architecture from a given checkpoint. The `from_pretrained()` method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
Remember, architecture refers to the skeleton of the model and checkpoints are the weights for a given architecture. For example, [BERT](https://huggingface.co/bert-base-uncased) is an architecture, while `bert-base-uncased` is a checkpoint. Model is a general term that can mean either architecture or checkpoint.
In this tutorial, learn to:
* Load a pretrained tokenizer.
* Load a pretrained image processor
* Load a pretrained feature extractor.
* Load a pretrained processor.
* Load a pretrained model.
## AutoTokenizer
Nearly every NLP task begins with a tokenizer. A tokenizer converts your input into a format that can be processed by the model.
Load a tokenizer with [`AutoTokenizer.from_pretrained`]:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
Then tokenize your input as shown below:
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
## AutoImageProcessor
For vision tasks, an image processor processes the image into the correct input format.
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
## AutoFeatureExtractor
For audio tasks, a feature extractor processes the audio signal the correct input format.
Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
"ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
)
## AutoProcessor
Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires an image processor to handle images and a tokenizer to handle text; a processor combines both of them.
Load a processor with [`AutoProcessor.from_pretrained`]:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
## AutoModel
Finally, the `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
Easily reuse the same checkpoint to load an architecture for a different task:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
For PyTorch models, the `from_pretrained()` method uses `torch.load()` which internally uses `pickle` and is known to be insecure. In general, never load a model that could have come from an untrusted source, or that could have been tampered with. This security risk is partially mitigated for public models hosted on the Hugging Face Hub, which are [scanned for malware](https://huggingface.co/docs/hub/security-malware) at each commit. See the [Hub documentation](https://huggingface.co/docs/hub/security) for best practices like [signed commit verification](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg) with GPG.
TensorFlow and Flax checkpoints are not affected, and can be loaded within PyTorch architectures using the `from_tf` and `from_flax` kwargs for the `from_pretrained` method to circumvent this issue.
Generally, we recommend using the `AutoTokenizer` class and the `AutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
Finally, the `TFAutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`TFAutoModelForSequenceClassification.from_pretrained`]:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
Easily reuse the same checkpoint to load an architecture for a different task:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, image processor, feature extractor and processor to preprocess a dataset for fine-tuning.
|
perf_train_gpu_many.md
|
# Efficient Training on Multiple GPUs
If training a model on a single GPU is too slow or if the model's weights do not fit in a single GPU's memory, transitioning
to a multi-GPU setup may be a viable option. Prior to making this transition, thoroughly explore all the strategies covered
in the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) as they are universally applicable
to model training on any number of GPUs. Once you have employed those strategies and found them insufficient for your
case on a single GPU, consider moving to multiple GPUs.
Transitioning from a single GPU to multiple GPUs requires the introduction of some form of parallelism, as the workload
must be distributed across the resources. Multiple techniques can be employed to achieve parallelism, such as data
parallelism, tensor parallelism, and pipeline parallelism. It's important to note that there isn't a one-size-fits-all
solution, and the optimal settings depend on the specific hardware configuration you are using.
This guide offers an in-depth overview of individual types of parallelism, as well as guidance on ways to combine
techniques and choosing an appropriate approach. For step-by-step tutorials on distributed training, please refer to
the [🤗 Accelerate documentation](https://huggingface.co/docs/accelerate/index).
While the main concepts discussed in this guide are likely applicable across frameworks, here we focus on
PyTorch-based implementations.
Before diving deeper into the specifics of each technique, let's go over the rough decision process when training
large models on a large infrastructure.
## Scalability strategy
Begin by estimating how much vRAM is required to train your model. For models hosted on the 🤗 Hub, use our
[Model Memory Calculator](https://huggingface.co/spaces/hf-accelerate/model-memory-usage), which gives you
accurate calculations within a few percent margin.
**Parallelization strategy for a single Node / multi-GPU setup**
When training a model on a single node with multiple GPUs, your choice of parallelization strategy can significantly
impact performance. Here's a breakdown of your options:
**Case 1: Your model fits onto a single GPU**
If your model can comfortably fit onto a single GPU, you have two primary options:
1. DDP - Distributed DataParallel
2. ZeRO - depending on the situation and configuration used, this method may or may not be faster, however, it's worth experimenting with it.
**Case 2: Your model doesn't fit onto a single GPU:**
If your model is too large for a single GPU, you have several alternatives to consider:
1. PipelineParallel (PP)
2. ZeRO
3. TensorParallel (TP)
With very fast inter-node connectivity (e.g., NVLINK or NVSwitch) all three strategies (PP, ZeRO, TP) should result in
similar performance. However, without these, PP will be faster than TP or ZeRO. The degree of TP may also
make a difference. It's best to experiment with your specific setup to determine the most suitable strategy.
TP is almost always used within a single node. That is TP size <= GPUs per node.
**Case 3: Largest layer of your model does not fit onto a single GPU**
1. If you are not using ZeRO, you have to use TensorParallel (TP), because PipelineParallel (PP) alone won't be sufficient to accommodate the large layer.
2. If you are using ZeRO, additionally adopt techniques from the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one).
**Parallelization strategy for a multi-Node / multi-GPU setup**
* When you have fast inter-node connectivity (e.g., NVLINK or NVSwitch) consider using one of these options:
1. ZeRO - as it requires close to no modifications to the model
2. A combination of PipelineParallel(PP) with TensorParallel(TP) and DataParallel(DP) - this approach will result in fewer communications, but requires significant changes to the model
* When you have slow inter-node connectivity and still low on GPU memory:
1. Employ a combination of DataParallel(DP) with PipelineParallel(PP), TensorParallel(TP), and ZeRO.
In the following sections of this guide we dig deeper into how these different parallelism methods work.
## Data Parallelism
Even with only 2 GPUs, you can readily leverage the accelerated training capabilities offered by PyTorch's built-in features,
such as `DataParallel` (DP) and `DistributedDataParallel` (DDP). Note that
[PyTorch documentation](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html) recommends to prefer
`DistributedDataParallel` (DDP) over `DataParallel` (DP) for multi-GPU training as it works for all models.
Let's take a look at how these two methods work and what makes them different.
### DataParallel vs DistributedDataParallel
To understand the key differences in inter-GPU communication overhead between the two methods, let's review the processes per batch:
[DDP](https://pytorch.org/docs/master/notes/ddp.html):
- At the start time the main process replicates the model once from GPU 0 to the rest of GPUs
- Then for each batch:
1. Each GPU directly consumes its mini-batch of data.
2. During `backward`, once the local gradients are ready, they are averaged across all processes.
[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
For each batch:
1. GPU 0 reads the batch of data and then sends a mini-batch to each GPU.
2. The up-to-date model is replicated from GPU 0 to each GPU.
3. `forward` is executed, and output from each GPU is sent to GPU 0 to compute the loss.
4. The loss is distributed from GPU 0 to all GPUs, and `backward` is run.
5. Gradients from each GPU are sent to GPU 0 and averaged.
Key differences include:
1. DDP performs only a single communication per batch - sending gradients, while DP performs five different data exchanges per batch.
DDP copies data using [torch.distributed](https://pytorch.org/docs/master/distributed.html), while DP copies data within
the process via Python threads (which introduces limitations associated with GIL). As a result, **`DistributedDataParallel` (DDP) is generally faster than `DataParallel` (DP)** unless you have slow GPU card inter-connectivity.
2. Under DP, GPU 0 performs significantly more work than other GPUs, resulting in GPU under-utilization.
3. DDP supports distributed training across multiple machines, whereas DP does not.
This is not an exhaustive list of differences between DP and DDP, however, other nuances are out of scope of this guide.
You can get a deeper understanding of these methods by reading this [article](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/).
Let's illustrate the differences between DP and DDP with an experiment. We'll benchmark the differences between DP and
DDP with an added context of NVLink presence:
* Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`).
* Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`.
To disable the NVLink feature on one of the benchmarks, we use `NCCL_P2P_DISABLE=1`.
Here is the benchmarking code and outputs:
**DP**
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
**DDP w/ NVlink**
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
**DDP w/o NVlink**
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
Here are the same benchmarking results gathered in a table for convenience:
| Type | NVlink | Time |
| :----- | ----- | ---: |
| 2:DP | Y | 110s |
| 2:DDP | Y | 101s |
| 2:DDP | N | 131s |
As you can see, in this case DP is ~10% slower than DDP with NVlink, but ~15% faster than DDP without NVlink.
The real difference will depend on how much data each GPU needs to sync with the others - the more there is to sync,
the more a slow link will impede the overall runtime.
## ZeRO Data Parallelism
ZeRO-powered data parallelism (ZeRO-DP) is illustrated in the following diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/).
While it may appear complex, it is a very similar concept to `DataParallel` (DP). The difference is that instead of
replicating the full model parameters, gradients and optimizer states, each GPU stores only a slice of it. Then, at
run-time when the full layer parameters are needed just for the given layer, all GPUs synchronize to give each other
parts that they miss.
To illustrate this idea, consider a simple model with 3 layers (La, Lb, and Lc), where each layer has 3 parameters.
Layer La, for example, has weights a0, a1 and a2:
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
If we have 3 GPUs, ZeRO-DP splits the model onto 3 GPUs like so:
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
In a way, this is the same horizontal slicing as tensor parallelism, as opposed to Vertical
slicing, where one puts whole layer-groups on different GPUs. Now let's see how this works:
Each of these GPUs will get the usual mini-batch as it works in DP:
x0 => GPU0
x1 => GPU1
x2 => GPU2
The inputs are passed without modifications as if they would be processed by the original model.
First, the inputs get to the layer `La`. What happens at this point?
On GPU0: the x0 mini-batch requires the a0, a1, a2 parameters to do its forward path through the layer, but the GPU0 has only a0.
It will get a1 from GPU1 and a2 from GPU2, bringing all the pieces of the model together.
In parallel, GPU1 gets another mini-batch - x1. GPU1 has the a1 parameter, but needs a0 and a2, so it gets those from GPU0 and GPU2.
Same happens to GPU2 that gets the mini-batch x2. It gets a0 and a1 from GPU0 and GPU1.
This way each of the 3 GPUs gets the full tensors reconstructed and makes a forward pass with its own mini-batch.
As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation.
The reconstruction is done efficiently via a pre-fetch.
Then the whole process is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La.
This mechanism is similar to an efficient group backpacking strategy: person A carries the tent, person B carries the stove,
and person C carries the axe. Each night they all share what they have with others and get from others what they don't have,
and in the morning they pack up their allocated type of gear and continue on their way. This is what ZeRO DP/Sharded DDP is.
Compare this strategy to the simple one where each person has to carry their own tent, stove and axe (similar to
DataParallel (DP and DDP) in PyTorch), which would be far more inefficient.
While reading the literature on this topic you may encounter the following synonyms: Sharded, Partitioned.
If you pay close attention the way ZeRO partitions the model's weights - it looks very similar to tensor parallelism
which will be discussed later. This is because it partitions/shards each layer's weights, unlike vertical model parallelism
which is discussed next.
Implementations:
- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) ZeRO-DP stages 1+2+3
- [`Accelerate` integration](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed)
- [`transformers` integration](main_classes/trainer#trainer-integrations)
## From Naive Model Parallelism to Pipeline Parallelism
To explain Pipeline parallelism, we'll first look into Naive Model Parallelism (MP), also known as Vertical MP. This approach
involves distributing groups of model layers across multiple GPUs by assigning specific layers to specific GPUs with `.to()`.
As data flows through these layers, it is moved to the same GPU as the layer, while the other layers remain untouched.
We refer to this Model parallelism as "Vertical" because of how models are typically visualized. For example, the
following diagram shows an 8-layer model split vertically into two slices, placing layers 0-3 onto
GPU0 and 4-7 to GPU1:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
In this example, when data moves from layer 0 to 3, it's no different from regular forward pass. However, passing data
from layer 3 to 4 requires moving it from GPU0 to GPU1, introducing a communication overhead. If the participating
GPUs are on the same compute node (e.g. same physical machine) this copying is fast, but if the GPUs are distributed
across different compute nodes (e.g. multiple machines), the communication overhead could be substantially greater.
Following that, layers 4 to 7 work as they would in the original model. Upon completion of the 7th layer, there is often
a need to send the data back to layer 0 where the labels are (or alternatively send the labels to the last layer). Now the loss can be
computed and the optimizer can do its work.
Naive Model Parallelism comes several shortcomings:
- **All but one GPU are idle at any given moment**: if 4 GPUs are used, it's nearly identical to quadrupling the amount of memory of a single GPU, and ignoring the rest of the hardware.
- **Overhead in data transfer between devices**: E.g. 4x 6GB cards will be able to accommodate the same size as 1x 24GB card using naive MP, but a single 24GB card will complete the training faster, because it doesn't have the data copying overhead. But, say, if you have 40GB cards and need to fit a 45GB model you can with 4x 40GB cards (but barely because of the gradient and optimizer states)
- **Copying shared embeddings**: Shared embeddings may need to get copied back and forth between GPUs.
Now that you are familiar with how the naive approach to model parallelism works and its shortcomings, let's look at Pipeline Parallelism (PP).
PP is almost identical to a naive MP, but it solves the GPU idling problem by chunking the incoming batch into micro-batches
and artificially creating a pipeline, which allows different GPUs to concurrently participate in the computation process.
The following illustration from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)
shows the naive MP on the top, and PP on the bottom:
At the bottom of the diagram, you can observe that the Pipeline Parallelism (PP) approach minimizes the number of idle
GPU zones, referred to as 'bubbles'. Both parts of the diagram show a parallelism level of degree 4, meaning that 4 GPUs
are involved in the pipeline. You can see that there's a forward path of 4 pipe stages (F0, F1, F2 and F3) followed by
a backward path in reverse order (B3, B2, B1, and B0).
PP introduces a new hyperparameter to tune - `chunks`, which determines how many data chunks are sent in a sequence
through the same pipe stage. For example, in the bottom diagram you can see `chunks=4`. GPU0 performs the same
forward path on chunk 0, 1, 2 and 3 (F0,0, F0,1, F0,2, F0,3) and then it waits for other GPUs to do complete their work.
Only when the other GPUs begin to complete their work, GPU0 starts to work again doing the backward path for chunks
3, 2, 1 and 0 (B0,3, B0,2, B0,1, B0,0).
Note that this is the same concept as gradient accumulation steps. PyTorch uses `chunks`, while DeepSpeed refers
to the same hyperparameter as gradient accumulation steps.
Because of the chunks, PP introduces the notion of micro-batches (MBS). DP splits the global data batch size into
mini-batches, so if you have a DP degree of 4, a global batch size of 1024 gets split up into 4 mini-batches of
256 each (1024/4). And if the number of `chunks` (or GAS) is 32 we end up with a micro-batch size of 8 (256/32). Each
Pipeline stage works with a single micro-batch at a time. To calculate the global batch size of the DP + PP setup,
use the formula: `mbs * chunks * dp_degree` (`8 * 32 * 4 = 1024`).
With `chunks=1` you end up with the naive MP, which is inefficient. With a large `chunks` value you end up with
tiny micro-batch sizes which is also inefficient. For this reason, we encourage to experiment with the `chunks` value to
find the one that leads to the most efficient GPUs utilization.
You may notice a bubble of "dead" time on the diagram that can't be parallelized because the last `forward` stage
has to wait for `backward` to complete the pipeline. The purpose of finding the best value for `chunks` is to enable a high
concurrent GPU utilization across all participating GPUs which translates to minimizing the size of the bubble.
Pipeline API solutions have been implemented in:
- PyTorch
- DeepSpeed
- Megatron-LM
These come with some shortcomings:
- They have to modify the model quite heavily, because Pipeline requires one to rewrite the normal flow of modules into a `nn.Sequential` sequence of the same, which may require changes to the design of the model.
- Currently the Pipeline API is very restricted. If you had a bunch of Python variables being passed in the very first stage of the Pipeline, you will have to find a way around it. Currently, the pipeline interface requires either a single Tensor or a tuple of Tensors as the only input and output. These tensors must have a batch size as the very first dimension, since pipeline is going to chunk the mini batch into micro-batches. Possible improvements are being discussed here https://github.com/pytorch/pytorch/pull/50693
- Conditional control flow at the level of pipe stages is not possible - e.g., Encoder-Decoder models like T5 require special workarounds to handle a conditional encoder stage.
- They have to arrange each layer so that the output of one layer becomes an input to the other layer.
More recent solutions include:
- Varuna
- Sagemaker
We have not experimented with Varuna and SageMaker but their papers report that they have overcome the list of problems
mentioned above and that they require smaller changes to the user's model.
Implementations:
- [PyTorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - this is implemented based on the Hugging Face Transformers.
🤗 Transformers status: as of this writing none of the models supports full-PP. GPT2 and T5 models have naive MP support.
The main obstacle is being unable to convert the models to `nn.Sequential` and have all the inputs to be Tensors. This
is because currently the models include many features that make the conversion very complicated, and will need to be removed to accomplish that.
DeepSpeed and Megatron-LM integrations are available in [🤗 Accelerate](https://huggingface.co/docs/accelerate/main/en/usage_guides/deepspeed)
Other approaches:
DeepSpeed, Varuna and SageMaker use the concept of an [Interleaved Pipeline](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)
Here the bubble (idle time) is further minimized by prioritizing backward passes. Varuna further attempts to improve the
schedule by using simulations to discover the most efficient scheduling.
OSLO has pipeline parallelism implementation based on the Transformers without `nn.Sequential` conversion.
## Tensor Parallelism
In Tensor Parallelism, each GPU processes a slice of a tensor and only aggregates the full tensor for operations requiring it.
To describe this method, this section of the guide relies on the concepts and diagrams from the [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
paper: [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
The main building block of any transformer is a fully connected `nn.Linear` followed by a nonlinear activation `GeLU`.
The dot dot-product part of it, following the Megatron's paper notation, can be written as `Y = GeLU(XA)`, where `X` is
an input vector, `Y` is the output vector, and `A` is the weight matrix.
If we look at the computation in matrix form, you can see how the matrix multiplication can be split between multiple GPUs:
If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel,
then we will end up with `N` output vectors `Y_1, Y_2, , Y_n` which can be fed into `GeLU` independently:
Using this principle, we can update a multi-layer perceptron of arbitrary depth, without the need for any synchronization
between GPUs until the very end, where we need to reconstruct the output vector from shards. The Megatron-LM paper authors
provide a helpful illustration for that:
Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having
multiple independent heads!
Special considerations: TP requires very fast network, and therefore it's not advisable to do TP across more than one node.
Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use
nodes that have at least 8 GPUs.
This section is based on the original much more [detailed TP overview](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530).
by [@anton-l](https://github.com/anton-l).
Alternative names:
- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/training/#model-parallelism)
Implementations:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation, as it's very model-specific
- [parallelformers](https://github.com/tunib-ai/parallelformers) (only inference at the moment)
- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) has the tensor parallelism implementation based on the Transformers.
SageMaker combines TP with DP for a more efficient processing.
🤗 Transformers status:
- core: not yet implemented in the core
- but if you want inference [parallelformers](https://github.com/tunib-ai/parallelformers) provides this support for most of our models. So until this is implemented in the core you can use theirs. And hopefully training mode will be supported too.
- Deepspeed-Inference also supports our BERT, GPT-2, and GPT-Neo models in their super-fast CUDA-kernel-based inference mode, see more [here](https://www.deepspeed.ai/tutorials/inference-tutorial/)
🤗 Accelerate integrates with [TP from Megatron-LM](https://huggingface.co/docs/accelerate/v0.23.0/en/usage_guides/megatron_lm).
## Data Parallelism + Pipeline Parallelism
The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates
how one can combine DP with PP.
Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there is just GPUs 0
and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP.
And GPU1 does the same by enlisting GPU3 to its aid.
Since each dimension requires at least 2 GPUs, here you'd need at least 4 GPUs.
Implementations:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers status: not yet implemented
## Data Parallelism + Pipeline Parallelism + Tensor Parallelism
To get an even more efficient training a 3D parallelism is used where PP is combined with TP and DP. This can be seen in the following diagram.
This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
Since each dimension requires at least 2 GPUs, here you'd need at least 8 GPUs.
Implementations:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeed also includes an even more efficient DP, which they call ZeRO-DP.
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers status: not yet implemented, since we have no PP and TP.
## ZeRO Data Parallelism + Pipeline Parallelism + Tensor Parallelism
One of the main features of DeepSpeed is ZeRO, which is a super-scalable extension of DP. It has already been
discussed in [ZeRO Data Parallelism](#zero-data-parallelism). Normally it's a standalone feature that doesn't require PP or TP.
But it can be combined with PP and TP.
When ZeRO-DP is combined with PP (and optionally TP) it typically enables only ZeRO stage 1 (optimizer sharding).
While it's theoretically possible to use ZeRO stage 2 (gradient sharding) with Pipeline Parallelism, it will have negative
performance impacts. There would need to be an additional reduce-scatter collective for every micro-batch to aggregate
the gradients before sharding, which adds a potentially significant communication overhead. By nature of Pipeline Parallelism,
small micro-batches are used and instead the focus is on trying to balance arithmetic intensity (micro-batch size) with
minimizing the Pipeline bubble (number of micro-batches). Therefore those communication costs are going to impact the performance.
In addition, there are already fewer layers than normal due to PP and so the memory savings won't be huge. PP already
reduces gradient size by ``1/PP``, and so gradient sharding savings on top of that are less significant than pure DP.
ZeRO stage 3 is not a good choice either for the same reason - more inter-node communications required.
And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
Implementations:
- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
- [OSLO](https://github.com/tunib-ai/oslo)
Important papers:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
https://arxiv.org/abs/2201.11990)
🤗 Transformers status: not yet implemented, since we have no PP and TP.
## FlexFlow
[FlexFlow](https://github.com/flexflow/FlexFlow) also solves the parallelization problem in a slightly different approach.
Paper: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
It performs a sort of 4D Parallelism over Sample-Operator-Attribute-Parameter.
1. Sample = Data Parallelism (sample-wise parallel)
2. Operator = Parallelize a single operation into several sub-operations
3. Attribute = Data Parallelism (length-wise parallel)
4. Parameter = Model Parallelism (regardless of dimension - horizontal or vertical)
Examples:
* Sample
Let's take 10 batches of sequence length 512. If we parallelize them by sample dimension into 2 devices, we get 10 x 512 which becomes be 5 x 2 x 512.
* Operator
If we perform layer normalization, we compute std first and mean second, and then we can normalize data.
Operator parallelism allows computing std and mean in parallel. So if we parallelize them by operator dimension into 2
devices (cuda:0, cuda:1), first we copy input data into both devices, and cuda:0 computes std, cuda:1 computes mean at the same time.
* Attribute
We have 10 batches of 512 length. If we parallelize them by attribute dimension into 2 devices, 10 x 512 will be 10 x 2 x 256.
* Parameter
It is similar with tensor model parallelism or naive layer-wise model parallelism.
The significance of this framework is that it takes resources like (1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3)
fast-intra-connect/slow-inter-connect and it automatically optimizes all these algorithmically deciding which
parallelisation to use where.
One very important aspect is that FlexFlow is designed for optimizing DNN parallelizations for models with static and
fixed workloads, since models with dynamic behavior may prefer different parallelization strategies across iterations.
So the promise is very attractive - it runs a 30min simulation on the cluster of choice and it comes up with the best
strategy to utilise this specific environment. If you add/remove/replace any parts it'll run and re-optimize the plan
for that. And then you can train. A different setup will have its own custom optimization.
🤗 Transformers status: Transformers models are FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py),
which is a prerequisite for FlexFlow, however, changes are required on the FlexFlow side to make it work with Transformers models.
|
quicktour.md
|
# Quick tour
[[open-in-colab]]
Get up and running with 🤗 Transformers! Whether you're a developer or an everyday user, this quick tour will help you get started and show you how to use the [`pipeline`] for inference, load a pretrained model and preprocessor with an [AutoClass](./model_doc/auto), and quickly train a model with PyTorch or TensorFlow. If you're a beginner, we recommend checking out our tutorials or [course](https://huggingface.co/course/chapter1/1) next for more in-depth explanations of the concepts introduced here.
Before you begin, make sure you have all the necessary libraries installed:
```bash
!pip install transformers datasets
You'll also need to install your preferred machine learning framework:
```bash
pip install torch
```bash
pip install tensorflow
## Pipeline
The [`pipeline`] is the easiest and fastest way to use a pretrained model for inference. You can use the [`pipeline`] out-of-the-box for many tasks across different modalities, some of which are shown in the table below:
For a complete list of available tasks, check out the [pipeline API reference](./main_classes/pipelines).
| **Task** | **Description** | **Modality** | **Pipeline identifier** |
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|-----------------------------------------------|
| Text classification | assign a label to a given sequence of text | NLP | pipeline(task=“sentiment-analysis”) |
| Text generation | generate text given a prompt | NLP | pipeline(task=“text-generation”) |
| Summarization | generate a summary of a sequence of text or document | NLP | pipeline(task=“summarization”) |
| Image classification | assign a label to an image | Computer vision | pipeline(task=“image-classification”) |
| Image segmentation | assign a label to each individual pixel of an image (supports semantic, panoptic, and instance segmentation) | Computer vision | pipeline(task=“image-segmentation”) |
| Object detection | predict the bounding boxes and classes of objects in an image | Computer vision | pipeline(task=“object-detection”) |
| Audio classification | assign a label to some audio data | Audio | pipeline(task=“audio-classification”) |
| Automatic speech recognition | transcribe speech into text | Audio | pipeline(task=“automatic-speech-recognition”) |
| Visual question answering | answer a question about the image, given an image and a question | Multimodal | pipeline(task=“vqa”) |
| Document question answering | answer a question about the document, given a document and a question | Multimodal | pipeline(task="document-question-answering") |
| Image captioning | generate a caption for a given image | Multimodal | pipeline(task="image-to-text") |
Start by creating an instance of [`pipeline`] and specifying a task you want to use it for. In this guide, you'll use the [`pipeline`] for sentiment analysis as an example:
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
The [`pipeline`] downloads and caches a default [pretrained model](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) and tokenizer for sentiment analysis. Now you can use the `classifier` on your target text:
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
If you have more than one input, pass your inputs as a list to the [`pipeline`] to return a list of dictionaries:
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
The [`pipeline`] can also iterate over an entire dataset for any task you like. For this example, let's choose automatic speech recognition as our task:
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
Load an audio dataset (see the 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart#audio) for more details) you'd like to iterate over. For example, load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset:
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
You need to make sure the sampling rate of the dataset matches the sampling
rate [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) was trained on:
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
The audio files are automatically loaded and resampled when calling the `"audio"` column.
Extract the raw waveform arrays from the first 4 samples and pass it as a list to the pipeline:
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
For larger datasets where the inputs are big (like in speech or vision), you'll want to pass a generator instead of a list to load all the inputs in memory. Take a look at the [pipeline API reference](./main_classes/pipelines) for more information.
### Use another model and tokenizer in the pipeline
The [`pipeline`] can accommodate any model from the [Hub](https://huggingface.co/models), making it easy to adapt the [`pipeline`] for other use-cases. For example, if you'd like a model capable of handling French text, use the tags on the Hub to filter for an appropriate model. The top filtered result returns a multilingual [BERT model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) finetuned for sentiment analysis you can use for French text:
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
Use [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] to load the pretrained model and it's associated tokenizer (more on an `AutoClass` in the next section):
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
Use [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] to load the pretrained model and it's associated tokenizer (more on an `TFAutoClass` in the next section):
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
Specify the model and tokenizer in the [`pipeline`], and now you can apply the `classifier` on French text:
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
If you can't find a model for your use-case, you'll need to finetune a pretrained model on your data. Take a look at our [finetuning tutorial](./training) to learn how. Finally, after you've finetuned your pretrained model, please consider [sharing](./model_sharing) the model with the community on the Hub to democratize machine learning for everyone! 🤗
## AutoClass
Under the hood, the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] classes work together to power the [`pipeline`] you used above. An [AutoClass](./model_doc/auto) is a shortcut that automatically retrieves the architecture of a pretrained model from its name or path. You only need to select the appropriate `AutoClass` for your task and it's associated preprocessing class.
Let's return to the example from the previous section and see how you can use the `AutoClass` to replicate the results of the [`pipeline`].
### AutoTokenizer
A tokenizer is responsible for preprocessing text into an array of numbers as inputs to a model. There are multiple rules that govern the tokenization process, including how to split a word and at what level words should be split (learn more about tokenization in the [tokenizer summary](./tokenizer_summary)). The most important thing to remember is you need to instantiate a tokenizer with the same model name to ensure you're using the same tokenization rules a model was pretrained with.
Load a tokenizer with [`AutoTokenizer`]:
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
Pass your text to the tokenizer:
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
The tokenizer returns a dictionary containing:
* [input_ids](./glossary#input-ids): numerical representations of your tokens.
* [attention_mask](.glossary#attention-mask): indicates which tokens should be attended to.
A tokenizer can also accept a list of inputs, and pad and truncate the text to return a batch with uniform length:
>>> pt_batch = tokenizer(
["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
>>> tf_batch = tokenizer(
["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
padding=True,
truncation=True,
max_length=512,
return_tensors="tf",
)
Check out the [preprocess](./preprocessing) tutorial for more details about tokenization, and how to use an [`AutoImageProcessor`], [`AutoFeatureExtractor`] and [`AutoProcessor`] to preprocess image, audio, and multimodal inputs.
### AutoModel
🤗 Transformers provides a simple and unified way to load pretrained instances. This means you can load an [`AutoModel`] like you would load an [`AutoTokenizer`]. The only difference is selecting the correct [`AutoModel`] for the task. For text (or sequence) classification, you should load [`AutoModelForSequenceClassification`]:
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
See the [task summary](./task_summary) for tasks supported by an [`AutoModel`] class.
Now pass your preprocessed batch of inputs directly to the model. You just have to unpack the dictionary by adding `**`:
>>> pt_outputs = pt_model(**pt_batch)
The model outputs the final activations in the `logits` attribute. Apply the softmax function to the `logits` to retrieve the probabilities:
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
🤗 Transformers provides a simple and unified way to load pretrained instances. This means you can load an [`TFAutoModel`] like you would load an [`AutoTokenizer`]. The only difference is selecting the correct [`TFAutoModel`] for the task. For text (or sequence) classification, you should load [`TFAutoModelForSequenceClassification`]:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
See the [task summary](./task_summary) for tasks supported by an [`AutoModel`] class.
Now pass your preprocessed batch of inputs directly to the model. You can pass the tensors as-is:
>>> tf_outputs = tf_model(tf_batch)
The model outputs the final activations in the `logits` attribute. Apply the softmax function to the `logits` to retrieve the probabilities:
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
All 🤗 Transformers models (PyTorch or TensorFlow) output the tensors *before* the final activation
function (like softmax) because the final activation function is often fused with the loss. Model outputs are special dataclasses so their attributes are autocompleted in an IDE. The model outputs behave like a tuple or a dictionary (you can index with an integer, a slice or a string) in which case, attributes that are None are ignored.
### Save a model
Once your model is fine-tuned, you can save it with its tokenizer using [`PreTrainedModel.save_pretrained`]:
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
When you are ready to use the model again, reload it with [`PreTrainedModel.from_pretrained`]:
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
Once your model is fine-tuned, you can save it with its tokenizer using [`TFPreTrainedModel.save_pretrained`]:
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
When you are ready to use the model again, reload it with [`TFPreTrainedModel.from_pretrained`]:
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
One particularly cool 🤗 Transformers feature is the ability to save a model and reload it as either a PyTorch or TensorFlow model. The `from_pt` or `from_tf` parameter can convert the model from one framework to the other:
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
## Custom model builds
You can modify the model's configuration class to change how a model is built. The configuration specifies a model's attributes, such as the number of hidden layers or attention heads. You start from scratch when you initialize a model from a custom configuration class. The model attributes are randomly initialized, and you'll need to train the model before you can use it to get meaningful results.
Start by importing [`AutoConfig`], and then load the pretrained model you want to modify. Within [`AutoConfig.from_pretrained`], you can specify the attribute you want to change, such as the number of attention heads:
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
Create a model from your custom configuration with [`AutoModel.from_config`]:
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
Create a model from your custom configuration with [`TFAutoModel.from_config`]:
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
Take a look at the [Create a custom architecture](./create_a_model) guide for more information about building custom configurations.
## Trainer - a PyTorch optimized training loop
All models are a standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) so you can use them in any typical training loop. While you can write your own training loop, 🤗 Transformers provides a [`Trainer`] class for PyTorch, which contains the basic training loop and adds additional functionality for features like distributed training, mixed precision, and more.
Depending on your task, you'll typically pass the following parameters to [`Trainer`]:
1. You'll start with a [`PreTrainedModel`] or a [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
2. [`TrainingArguments`] contains the model hyperparameters you can change like learning rate, batch size, and the number of epochs to train for. The default values are used if you don't specify any training arguments:
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
output_dir="path/to/save/folder/",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
)
3. Load a preprocessing class like a tokenizer, image processor, feature extractor, or processor:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
4. Load a dataset:
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
5. Create a function to tokenize the dataset:
>>> def tokenize_dataset(dataset):
return tokenizer(dataset["text"])
Then apply it over the entire dataset with [`~datasets.Dataset.map`]:
>>> dataset = dataset.map(tokenize_dataset, batched=True)
6. A [`DataCollatorWithPadding`] to create a batch of examples from your dataset:
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
Now gather all these classes in [`Trainer`]:
>>> from transformers import Trainer
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
) # doctest: +SKIP
When you're ready, call [`~Trainer.train`] to start training:
>>> trainer.train() # doctest: +SKIP
For tasks - like translation or summarization - that use a sequence-to-sequence model, use the [`Seq2SeqTrainer`] and [`Seq2SeqTrainingArguments`] classes instead.
You can customize the training loop behavior by subclassing the methods inside [`Trainer`]. This allows you to customize features such as the loss function, optimizer, and scheduler. Take a look at the [`Trainer`] reference for which methods can be subclassed.
The other way to customize the training loop is by using [Callbacks](./main_classes/callbacks). You can use callbacks to integrate with other libraries and inspect the training loop to report on progress or stop the training early. Callbacks do not modify anything in the training loop itself. To customize something like the loss function, you need to subclass the [`Trainer`] instead.
## Train with TensorFlow
All models are a standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) so they can be trained in TensorFlow with the [Keras](https://keras.io/) API. 🤗 Transformers provides the [`~TFPreTrainedModel.prepare_tf_dataset`] method to easily load your dataset as a `tf.data.Dataset` so you can start training right away with Keras' [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) and [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) methods.
1. You'll start with a [`TFPreTrainedModel`] or a [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model):
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
2. Load a preprocessing class like a tokenizer, image processor, feature extractor, or processor:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
3. Create a function to tokenize the dataset:
>>> def tokenize_dataset(dataset):
return tokenizer(dataset["text"]) # doctest: +SKIP
4. Apply the tokenizer over the entire dataset with [`~datasets.Dataset.map`] and then pass the dataset and tokenizer to [`~TFPreTrainedModel.prepare_tf_dataset`]. You can also change the batch size and shuffle the dataset here if you'd like:
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
) # doctest: +SKIP
5. When you're ready, you can call `compile` and `fit` to start training. Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
>>> model.fit(tf_dataset) # doctest: +SKIP
## What's next?
Now that you've completed the 🤗 Transformers quick tour, check out our guides and learn how to do more specific things like writing a custom model, fine-tuning a model for a task, and how to train a model with a script. If you're interested in learning more about 🤗 Transformers core concepts, grab a cup of coffee and take a look at our Conceptual Guides!
|
pad_truncation.md
|
# Padding and truncation
Batched inputs are often different lengths, so they can't be converted to fixed-size tensors. Padding and truncation are strategies for dealing with this problem, to create rectangular tensors from batches of varying lengths. Padding adds a special **padding token** to ensure shorter sequences will have the same length as either the longest sequence in a batch or the maximum length accepted by the model. Truncation works in the other direction by truncating long sequences.
In most cases, padding your batch to the length of the longest sequence and truncating to the maximum length a model can accept works pretty well. However, the API supports more strategies if you need them. The three arguments you need to are: `padding`, `truncation` and `max_length`.
The `padding` argument controls padding. It can be a boolean or a string:
- `True` or `'longest'`: pad to the longest sequence in the batch (no padding is applied if you only provide
a single sequence).
- `'max_length'`: pad to a length specified by the `max_length` argument or the maximum length accepted
by the model if no `max_length` is provided (`max_length=None`). Padding will still be applied if you only provide a single sequence.
- `False` or `'do_not_pad'`: no padding is applied. This is the default behavior.
The `truncation` argument controls truncation. It can be a boolean or a string:
- `True` or `'longest_first'`: truncate to a maximum length specified by the `max_length` argument or
the maximum length accepted by the model if no `max_length` is provided (`max_length=None`). This will
truncate token by token, removing a token from the longest sequence in the pair until the proper length is
reached.
- `'only_second'`: truncate to a maximum length specified by the `max_length` argument or the maximum
length accepted by the model if no `max_length` is provided (`max_length=None`). This will only truncate
the second sentence of a pair if a pair of sequences (or a batch of pairs of sequences) is provided.
- `'only_first'`: truncate to a maximum length specified by the `max_length` argument or the maximum
length accepted by the model if no `max_length` is provided (`max_length=None`). This will only truncate
the first sentence of a pair if a pair of sequences (or a batch of pairs of sequences) is provided.
- `False` or `'do_not_truncate'`: no truncation is applied. This is the default behavior.
The `max_length` argument controls the length of the padding and truncation. It can be an integer or `None`, in which case it will default to the maximum length the model can accept. If the model has no specific maximum input length, truncation or padding to `max_length` is deactivated.
The following table summarizes the recommended way to setup padding and truncation. If you use pairs of input sequences in any of the following examples, you can replace `truncation=True` by a `STRATEGY` selected in
`['only_first', 'only_second', 'longest_first']`, i.e. `truncation='only_second'` or `truncation='longest_first'` to control how both sequences in the pair are truncated as detailed before.
| Truncation | Padding | Instruction |
|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
| no truncation | no padding | `tokenizer(batch_sentences)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True)` or |
| | | `tokenizer(batch_sentences, padding='longest')` |
| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length')` |
| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
| | padding to a multiple of a value | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8) |
| truncation to max model input length | no padding | `tokenizer(batch_sentences, truncation=True)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
| | padding to specific length | Not possible |
| truncation to specific length | no padding | `tokenizer(batch_sentences, truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
| | padding to max model input length | Not possible |
| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
|
preprocessing.md
|
# Preprocess
[[open-in-colab]]
Before you can train a model on a dataset, it needs to be preprocessed into the expected model input format. Whether your data is text, images, or audio, they need to be converted and assembled into batches of tensors. 🤗 Transformers provides a set of preprocessing classes to help prepare your data for the model. In this tutorial, you'll learn that for:
* Text, use a [Tokenizer](./main_classes/tokenizer) to convert text into a sequence of tokens, create a numerical representation of the tokens, and assemble them into tensors.
* Speech and audio, use a [Feature extractor](./main_classes/feature_extractor) to extract sequential features from audio waveforms and convert them into tensors.
* Image inputs use a [ImageProcessor](./main_classes/image) to convert images into tensors.
* Multimodal inputs, use a [Processor](./main_classes/processors) to combine a tokenizer and a feature extractor or image processor.
`AutoProcessor` **always** works and automatically chooses the correct class for the model you're using, whether you're using a tokenizer, image processor, feature extractor or processor.
Before you begin, install 🤗 Datasets so you can load some datasets to experiment with:
```bash
pip install datasets
## Natural Language Processing
The main tool for preprocessing textual data is a [tokenizer](main_classes/tokenizer). A tokenizer splits text into *tokens* according to a set of rules. The tokens are converted into numbers and then tensors, which become the model inputs. Any additional inputs required by the model are added by the tokenizer.
If you plan on using a pretrained model, it's important to use the associated pretrained tokenizer. This ensures the text is split the same way as the pretraining corpus, and uses the same corresponding tokens-to-index (usually referred to as the *vocab*) during pretraining.
Get started by loading a pretrained tokenizer with the [`AutoTokenizer.from_pretrained`] method. This downloads the *vocab* a model was pretrained with:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
Then pass your text to the tokenizer:
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
The tokenizer returns a dictionary with three important items:
* [input_ids](glossary#input-ids) are the indices corresponding to each token in the sentence.
* [attention_mask](glossary#attention-mask) indicates whether a token should be attended to or not.
* [token_type_ids](glossary#token-type-ids) identifies which sequence a token belongs to when there is more than one sequence.
Return your input by decoding the `input_ids`:
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
As you can see, the tokenizer added two special tokens - `CLS` and `SEP` (classifier and separator) - to the sentence. Not all models need
special tokens, but if they do, the tokenizer automatically adds them for you.
If there are several sentences you want to preprocess, pass them as a list to the tokenizer:
>>> batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
### Pad
Sentences aren't always the same length which can be an issue because tensors, the model inputs, need to have a uniform shape. Padding is a strategy for ensuring tensors are rectangular by adding a special *padding token* to shorter sentences.
Set the `padding` parameter to `True` to pad the shorter sequences in the batch to match the longest sequence:
>>> batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
The first and third sentences are now padded with `0`'s because they are shorter.
### Truncation
On the other end of the spectrum, sometimes a sequence may be too long for a model to handle. In this case, you'll need to truncate the sequence to a shorter length.
Set the `truncation` parameter to `True` to truncate a sequence to the maximum length accepted by the model:
>>> batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
Check out the [Padding and truncation](./pad_truncation) concept guide to learn more different padding and truncation arguments.
### Build tensors
Finally, you want the tokenizer to return the actual tensors that get fed to the model.
Set the `return_tensors` parameter to either `pt` for PyTorch, or `tf` for TensorFlow:
>>> batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
>>> batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': ,
'token_type_ids': ,
'attention_mask': }
## Audio
For audio tasks, you'll need a [feature extractor](main_classes/feature_extractor) to prepare your dataset for the model. The feature extractor is designed to extract features from raw audio data, and convert them into tensors.
Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a feature extractor with audio datasets:
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
Access the first element of the `audio` column to take a look at the input. Calling the `audio` column automatically loads and resamples the audio file:
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, , -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
This returns three items:
* `array` is the speech signal loaded - and potentially resampled - as a 1D array.
* `path` points to the location of the audio file.
* `sampling_rate` refers to how many data points in the speech signal are measured per second.
For this tutorial, you'll use the [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) model. Take a look at the model card, and you'll learn Wav2Vec2 is pretrained on 16kHz sampled speech audio. It is important your audio data's sampling rate matches the sampling rate of the dataset used to pretrain the model. If your data's sampling rate isn't the same, then you need to resample your data.
1. Use 🤗 Datasets' [`~datasets.Dataset.cast_column`] method to upsample the sampling rate to 16kHz:
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
2. Call the `audio` column again to resample the audio file:
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
Next, load a feature extractor to normalize and pad the input. When padding textual data, a `0` is added for shorter sequences. The same idea applies to audio data. The feature extractor adds a `0` - interpreted as silence - to `array`.
Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
Pass the audio `array` to the feature extractor. We also recommend adding the `sampling_rate` argument in the feature extractor in order to better debug any silent errors that may occur.
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
Just like the tokenizer, you can apply padding or truncation to handle variable sequences in a batch. Take a look at the sequence length of these two audio samples:
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
Create a function to preprocess the dataset so the audio samples are the same lengths. Specify a maximum sample length, and the feature extractor will either pad or truncate the sequences to match it:
>>> def preprocess_function(examples):
audio_arrays = [x["array"] for x in examples["audio"]]
inputs = feature_extractor(
audio_arrays,
sampling_rate=16000,
padding=True,
max_length=100000,
truncation=True,
)
return inputs
Apply the `preprocess_function` to the first few examples in the dataset:
>>> processed_dataset = preprocess_function(dataset[:5])
The sample lengths are now the same and match the specified maximum length. You can pass your processed dataset to the model now!
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
## Computer vision
For computer vision tasks, you'll need an [image processor](main_classes/image_processor) to prepare your dataset for the model.
Image preprocessing consists of several steps that convert images into the input expected by the model. These steps
include but are not limited to resizing, normalizing, color channel correction, and converting images to tensors.
Image preprocessing often follows some form of image augmentation. Both image preprocessing and image augmentation
transform image data, but they serve different purposes:
* Image augmentation alters images in a way that can help prevent overfitting and increase the robustness of the model. You can get creative in how you augment your data - adjust brightness and colors, crop, rotate, resize, zoom, etc. However, be mindful not to change the meaning of the images with your augmentations.
* Image preprocessing guarantees that the images match the model’s expected input format. When fine-tuning a computer vision model, images must be preprocessed exactly as when the model was initially trained.
You can use any library you like for image augmentation. For image preprocessing, use the `ImageProcessor` associated with the model.
Load the [food101](https://huggingface.co/datasets/food101) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use an image processor with computer vision datasets:
Use 🤗 Datasets `split` parameter to only load a small sample from the training split since the dataset is quite large!
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) feature:
>>> dataset[0]["image"]
Load the image processor with [`AutoImageProcessor.from_pretrained`]:
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
First, let's add some image augmentation. You can use any library you prefer, but in this tutorial, we'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module. If you're interested in using another data augmentation library, learn how in the [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) or [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb).
1. Here we use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain together a couple of
transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html).
Note that for resizing, we can get the image size requirements from the `image_processor`. For some models, an exact height and
width are expected, for others only the `shortest_edge` is defined.
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
>>> size = (
image_processor.size["shortest_edge"]
if "shortest_edge" in image_processor.size
else (image_processor.size["height"], image_processor.size["width"])
)
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values)
as its input. `ImageProcessor` can take care of normalizing the images, and generating appropriate tensors.
Create a function that combines image augmentation and image preprocessing for a batch of images and generates `pixel_values`:
>>> def transforms(examples):
images = [_transforms(img.convert("RGB")) for img in examples["image"]]
examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
return examples
In the example above we set `do_resize=False` because we have already resized the images in the image augmentation transformation,
and leveraged the `size` attribute from the appropriate `image_processor`. If you do not resize images during image augmentation,
leave this parameter out. By default, `ImageProcessor` will handle the resizing.
If you wish to normalize images as a part of the augmentation transformation, use the `image_processor.image_mean`,
and `image_processor.image_std` values.
3. Then use 🤗 Datasets[`~datasets.Dataset.set_transform`] to apply the transforms on the fly:
>>> dataset.set_transform(transforms)
4. Now when you access the image, you'll notice the image processor has added `pixel_values`. You can pass your processed dataset to the model now!
>>> dataset[0].keys()
Here is what the image looks like after the transforms are applied. The image has been randomly cropped and it's color properties are different.
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
For tasks like object detection, semantic segmentation, instance segmentation, and panoptic segmentation, `ImageProcessor`
offers post processing methods. These methods convert model's raw outputs into meaningful predictions such as bounding boxes,
or segmentation maps.
### Pad
In some cases, for instance, when fine-tuning [DETR](./model_doc/detr), the model applies scale augmentation at training
time. This may cause images to be different sizes in a batch. You can use [`DetrImageProcessor.pad`]
from [`DetrImageProcessor`] and define a custom `collate_fn` to batch images together.
>>> def collate_fn(batch):
pixel_values = [item["pixel_values"] for item in batch]
encoding = image_processor.pad(pixel_values, return_tensors="pt")
labels = [item["labels"] for item in batch]
batch = {}
batch["pixel_values"] = encoding["pixel_values"]
batch["pixel_mask"] = encoding["pixel_mask"]
batch["labels"] = labels
return batch
## Multimodal
For tasks involving multimodal inputs, you'll need a [processor](main_classes/processors) to prepare your dataset for the model. A processor couples together two processing objects such as as tokenizer and feature extractor.
Load the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub) for more details on how to load a dataset) to see how you can use a processor for automatic speech recognition (ASR):
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
For ASR, you're mainly focused on `audio` and `text` so you can remove the other columns:
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
Now take a look at the `audio` and `text` columns:
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
Remember you should always [resample](preprocessing#audio) your audio dataset's sampling rate to match the sampling rate of the dataset used to pretrain a model!
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
Load a processor with [`AutoProcessor.from_pretrained`]:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
1. Create a function to process the audio data contained in `array` to `input_values`, and tokenize `text` to `labels`. These are the inputs to the model:
>>> def prepare_dataset(example):
audio = example["audio"]
example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
return example
2. Apply the `prepare_dataset` function to a sample:
>>> prepare_dataset(lj_speech[0])
The processor has now added `input_values` and `labels`, and the sampling rate has also been correctly downsampled to 16kHz. You can pass your processed dataset to the model now!
|
llm_tutorial.md
|
# Generation with LLMs
[[open-in-colab]]
LLMs, or Large Language Models, are the key component behind text generation. In a nutshell, they consist of large pretrained transformer models trained to predict the next word (or, more precisely, token) given some input text. Since they predict one token at a time, you need to do something more elaborate to generate new sentences other than just calling the model -- you need to do autoregressive generation.
Autoregressive generation is the inference-time procedure of iteratively calling a model with its own generated outputs, given a few initial inputs. In 🤗 Transformers, this is handled by the [`~generation.GenerationMixin.generate`] method, which is available to all models with generative capabilities.
This tutorial will show you how to:
* Generate text with an LLM
* Avoid common pitfalls
* Next steps to help you get the most out of your LLM
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
## Generate text
A language model trained for [causal language modeling](tasks/language_modeling) takes a sequence of text tokens as input and returns the probability distribution for the next token.
"Forward pass of an LLM"
A critical aspect of autoregressive generation with LLMs is how to select the next token from this probability distribution. Anything goes in this step as long as you end up with a token for the next iteration. This means it can be as simple as selecting the most likely token from the probability distribution or as complex as applying a dozen transformations before sampling from the resulting distribution.
"Autoregressive generation iteratively selects the next token from a probability distribution to generate text"
The process depicted above is repeated iteratively until some stopping condition is reached. Ideally, the stopping condition is dictated by the model, which should learn when to output an end-of-sequence (`EOS`) token. If this is not the case, generation stops when some predefined maximum length is reached.
Properly setting up the token selection step and the stopping condition is essential to make your model behave as you'd expect on your task. That is why we have a [`~generation.GenerationConfig`] file associated with each model, which contains a good default generative parameterization and is loaded alongside your model.
Let's talk code!
If you're interested in basic LLM usage, our high-level [`Pipeline`](pipeline_tutorial) interface is a great starting point. However, LLMs often require advanced features like quantization and fine control of the token selection step, which is best done through [`~generation.GenerationMixin.generate`]. Autoregressive generation with LLMs is also resource-intensive and should be executed on a GPU for adequate throughput.
First, you need to load the model.
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
)
You'll notice two flags in the `from_pretrained` call:
- `device_map` ensures the model is moved to your GPU(s)
- `load_in_4bit` applies [4-bit dynamic quantization](main_classes/quantization) to massively reduce the resource requirements
There are other ways to initialize a model, but this is a good baseline to begin with an LLM.
Next, you need to preprocess your text input with a [tokenizer](tokenizer_summary).
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
The `model_inputs` variable holds the tokenized text input, as well as the attention mask. While [`~generation.GenerationMixin.generate`] does its best effort to infer the attention mask when it is not passed, we recommend passing it whenever possible for optimal results.
After tokenizing the inputs, you can call the [`~generation.GenerationMixin.generate`] method to returns the generated tokens. The generated tokens then should be converted to text before printing.
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
Finally, you don't need to do it one sequence at a time! You can batch your inputs, which will greatly improve the throughput at a small latency and memory cost. All you need to do is to make sure you pad your inputs properly (more on that below).
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']
And that's it! In a few lines of code, you can harness the power of an LLM.
## Common pitfalls
There are many [generation strategies](generation_strategies), and sometimes the default values may not be appropriate for your use case. If your outputs aren't aligned with what you're expecting, we've created a list of the most common pitfalls and how to avoid them.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
)
### Generated output is too short/long
If not specified in the [`~generation.GenerationConfig`] file, `generate` returns up to 20 tokens by default. We highly recommend manually setting `max_new_tokens` in your `generate` call to control the maximum number of new tokens it can return. Keep in mind LLMs (more precisely, [decoder-only models](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)) also return the input prompt as part of the output.
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
### Incorrect generation mode
By default, and unless specified in the [`~generation.GenerationConfig`] file, `generate` selects the most likely token at each iteration (greedy decoding). Depending on your task, this may be undesirable; creative tasks like chatbots or writing an essay benefit from sampling. On the other hand, input-grounded tasks like audio transcription or translation benefit from greedy decoding. Enable sampling with `do_sample=True`, and you can learn more about this topic in this [blog post](https://huggingface.co/blog/how-to-generate).
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'
### Wrong padding side
LLMs are [decoder-only](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt) architectures, meaning they continue to iterate on your input prompt. If your inputs do not have the same length, they need to be padded. Since LLMs are not trained to continue from pad tokens, your input needs to be left-padded. Make sure you also don't forget to pass the attention mask to generate!
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
### Wrong prompt
Some models and tasks expect a certain input prompt format to work properly. When this format is not applied, you will get a silent performance degradation: the model kinda works, but not as well as if you were following the expected prompt. More information about prompting, including which models and tasks need to be careful, is available in this [guide](tasks/prompting). Let's see an example with a chat LLM, which makes use of [chat templating](chat_templating):
thon
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
"HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
)
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a thug",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎
## Further resources
While the autoregressive generation process is relatively straightforward, making the most out of your LLM can be a challenging endeavor because there are many moving parts. For your next steps to help you dive deeper into LLM usage and understanding:
### Advanced generate usage
1. [Guide](generation_strategies) on how to control different generation methods, how to set up the generation configuration file, and how to stream the output;
2. [Guide](chat_templating) on the prompt template for chat LLMs;
3. [Guide](tasks/prompting) on to get the most of prompt design;
4. API reference on [`~generation.GenerationConfig`], [`~generation.GenerationMixin.generate`], and [generate-related classes](internal/generation_utils).
### LLM leaderboards
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), which focuses on the quality of the open-source models;
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), which focuses on LLM throughput.
### Latency, throughput and memory utilization
1. [Guide](llm_tutorial_optimization) on how to optimize LLMs for speed and memory;
2. [Guide](main_classes/quantization) on quantization such as bitsandbytes and autogptq, which shows you how to drastically reduce your memory requirements.
### Related libraries
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), a production-ready server for LLMs;
2. [`optimum`](https://github.com/huggingface/optimum), an extension of 🤗 Transformers that optimizes for specific hardware devices.
|
perf_infer_gpu_one.md
|
# GPU inference
GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia GPUs.
The majority of the optimizations described here also apply to multi-GPU setups!
## FlashAttention-2
FlashAttention-2 is experimental and may change considerably in future versions.
[FlashAttention-2](https://huggingface.co/papers/2205.14135) is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
1. additionally parallelizing the attention computation over sequence length
2. partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
FlashAttention-2 supports inference with Llama, Mistral, Falcon and Bark models. You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
Before you begin, make sure you have FlashAttention-2 installed (see the [installation](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features) guide for more details about prerequisites):
```bash
pip install flash-attn --no-build-isolation
To enable FlashAttention-2, add the `use_flash_attention_2` parameter to [`~AutoModelForCausalLM.from_pretrained`]:
thon
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
use_flash_attention_2=True,
)
FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`, and it only runs on Nvidia GPUs. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
FlashAttention-2 can be combined with other optimization techniques like quantization to further speedup inference. For example, you can combine FlashAttention-2 with 8-bit or 4-bit quantization:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
use_flash_attention_2=True,
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
use_flash_attention_2=True,
)
### Expected speedups
You can benefit from considerable speedups for inference, especially for inputs with long sequences. However, since FlashAttention-2 does not support computing attention scores with padding tokens, you must manually pad/unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
To overcome this, you should use FlashAttention-2 without padding tokens in the sequence during training (by packing a dataset or [concatenating sequences](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516) until reaching the maximum sequence length).
For a single forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
For a single forward pass on [meta-llama/Llama-7b-hf](https://hf.co/meta-llama/Llama-7b-hf) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
But for larger sequence lengths, you can expect even more speedup benefits:
FlashAttention is more memory efficient, meaning you can train on much larger sequence lengths without running into out-of-memory issues. You can potentially reduce memory usage up to 20x for larger sequence lengths. Take a look at the [flash-attention](https://github.com/Dao-AILab/flash-attention) repository for more details.
## BetterTransformer
Check out our benchmarks with BetterTransformer and scaled dot product attention in the [Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0](https://pytorch.org/blog/out-of-the-box-acceleration/) and learn more about the fastpath execution in the [BetterTransformer](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) blog post.
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention (SDPA)](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention), and it calls optimized kernels like [FlashAttention](https://huggingface.co/papers/2205.14135) under the hood.
Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
Then you can enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
thon
model = model.to_bettertransformer()
You can return the original Transformers model with the [`~PreTrainedModel.reverse_bettertransformer`] method. You should use this before saving your model to use the canonical Transformers modeling:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")
### FlashAttention
SDPA can also call FlashAttention kernels under the hood. FlashAttention can only be used for models using the `fp16` or `bf16` dtype, so make sure to cast your model to the appropriate dtype before using it.
To enable FlashAttention or to check whether it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
# convert the model to BetterTransformer
model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
If you see a bug with the traceback below, try using nightly version of PyTorch which may have broader coverage for FlashAttention:
```bash
RuntimeError: No available kernel. Aborting execution.
# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
## bitsandbytes
bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
Make sure you have bitsnbytes and 🤗 Accelerate installed:
```bash
# these versions support 8-bit and 4-bit
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
# install Transformers
pip install transformers
### 4-bit
To load a model in 4-bit for inference, use the `load_in_4bit` parameter. The `device_map` parameter is optional, but we recommend setting it to `"auto"` to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment.
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 600MB of memory to the first GPU and 1GB of memory to the second GPU:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
### 8-bit
If you're curious and interested in learning more about the concepts underlying 8-bit quantization, read the [Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes](https://huggingface.co/blog/hf-bitsandbytes-integration) blog post.
To load a model in 8-bit for inference, use the `load_in_8bit` parameter. The `device_map` parameter is optional, but we recommend setting it to `"auto"` to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment:
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
If you're loading a model in 8-bit for text generation, you should use the [`~transformers.GenerationMixin.generate`] method instead of the [`Pipeline`] function which is not optimized for 8-bit models and will be slower. Some sampling strategies, like nucleus sampling, are also not supported by the [`Pipeline`] for 8-bit models. You should also place all inputs on the same device as the model:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 1GB of memory to the first GPU and 2GB of memory to the second GPU:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
Feel free to try running a 11 billion parameter [T5 model](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing) or the 3 billion parameter [BLOOM model](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing) for inference on Google Colab's free tier GPUs!
## 🤗 Optimum
Learn more details about using ORT with 🤗 Optimum in the [Accelerated inference on NVIDIA GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#accelerated-inference-on-nvidia-gpus) guide. This section only provides a brief and simple example.
ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and specify the `provider` parameter which can be set to either [`CUDAExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#cudaexecutionprovider) or [`TensorrtExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#tensorrtexecutionprovider). If you want to load a model that was not yet exported to ONNX, you can set `export=True` to convert your model on-the-fly to the ONNX format :
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)
Now you're free to use the model for inference:
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")
## Combine optimizations
It is often possible to combine several of the optimization techniques described above to get the best inference performance possible for your model. For example, you can load a model in 4-bit, and then enable BetterTransformer with FlashAttention:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
# enable BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
pipeline_webserver.md
|
# Using pipelines for a webserver
Creating an inference engine is a complex topic, and the "best" solution
will most likely depend on your problem space. Are you on CPU or GPU? Do
you want the lowest latency, the highest throughput, support for
many models, or just highly optimize 1 specific model?
There are many ways to tackle this topic, so what we are going to present is a good default
to get started which may not necessarily be the most optimal solution for you.
The key thing to understand is that we can use an iterator, just like you would [on a
dataset](pipeline_tutorial#using-pipelines-on-a-dataset), since a webserver is basically a system that waits for requests and
treats them as they come in.
Usually webservers are multiplexed (multithreaded, async, etc..) to handle various
requests concurrently. Pipelines on the other hand (and mostly the underlying models)
are not really great for parallelism; they take up a lot of RAM, so it's best to give them all the available resources when they are running or it's a compute-intensive job.
We are going to solve that by having the webserver handle the light load of receiving
and sending requests, and having a single thread handling the actual work.
This example is going to use `starlette`. The actual framework is not really
important, but you might have to tune or change the code if you are using another
one to achieve the same effect.
Create `server.py`:
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
Now you can start it with:
```bash
uvicorn server:app
And you can query it:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},]
And there you go, now you have a good idea of how to create a webserver!
What is really important is that we load the model only **once**, so there are no copies
of the model on the webserver. This way, no unnecessary RAM is being used.
Then the queuing mechanism allows you to do fancy stuff like maybe accumulating a few
items before inferring to use dynamic batching:
The code sample below is intentionally written like pseudo-code for readability.
Do not run this without checking if it makes sense for your system resources!
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
Again, the proposed code is optimized for readability, not for being the best code.
First of all, there's no batch size limit which is usually not a
great idea. Next, the timeout is reset on every queue fetch, meaning you could
wait much more than 1ms before running the inference (delaying the first request
by that much).
It would be better to have a single 1ms deadline.
This will always wait for 1ms even if the queue is empty, which might not be the
best since you probably want to start doing inference if there's nothing in the queue.
But maybe it does make sense if batching is really crucial for your use case.
Again, there's really no one best solution.
## Few things you might want to consider
### Error checking
There's a lot that can go wrong in production: out of memory, out of space,
loading the model might fail, the query might be wrong, the query might be
correct but still fail to run because of a model misconfiguration, and so on.
Generally, it's good if the server outputs the errors to the user, so
adding a lot of `try..except` statements to show those errors is a good
idea. But keep in mind it may also be a security risk to reveal all those errors depending
on your security context.
### Circuit breaking
Webservers usually look better when they do circuit breaking. It means they
return proper errors when they're overloaded instead of just waiting for the query indefinitely. Return a 503 error instead of waiting for a super long time or a 504 after a long time.
This is relatively easy to implement in the proposed code since there is a single queue.
Looking at the queue size is a basic way to start returning errors before your
webserver fails under load.
### Blocking the main thread
Currently PyTorch is not async aware, and computation will block the main
thread while running. That means it would be better if PyTorch was forced to run
on its own thread/process. This wasn't done here because the code is a lot more
complex (mostly because threads and async and queues don't play nice together).
But ultimately it does the same thing.
This would be important if the inference of single items were long (> 1s) because
in this case, it means every query during inference would have to wait for 1s before
even receiving an error.
### Dynamic batching
In general, batching is not necessarily an improvement over passing 1 item at
a time (see [batching details](./main_classes/pipelines#pipeline-batching) for more information). But it can be very effective
when used in the correct setting. In the API, there is no dynamic
batching by default (too much opportunity for a slowdown). But for BLOOM inference -
which is a very large model - dynamic batching is **essential** to provide a decent experience for everyone.
|
peft.md
|
# Load adapters with 🤗 PEFT
[[open-in-colab]]
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it. The adapters are trained to learn task-specific information. This approach has been shown to be very memory-efficient with lower compute usage while producing results comparable to a fully fine-tuned model.
Adapters trained with PEFT are also usually an order of magnitude smaller than the full model, making it convenient to share, store, and load them.
The adapter weights for a OPTForCausalLM model stored on the Hub are only ~6MB compared to the full size of the model weights, which can be ~700MB.
If you're interested in learning more about the 🤗 PEFT library, check out the [documentation](https://huggingface.co/docs/peft/index).
## Setup
Get started by installing 🤗 PEFT:
```bash
pip install peft
If you want to try out the brand new features, you might be interested in installing the library from source:
```bash
pip install git+https://github.com/huggingface/peft.git
## Supported PEFT models
🤗 Transformers natively supports some PEFT methods, meaning you can load adapter weights stored locally or on the Hub and easily run or train them with a few lines of code. The following methods are supported:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
If you want to use other PEFT methods, such as prompt learning or prompt tuning, or about the 🤗 PEFT library in general, please refer to the [documentation](https://huggingface.co/docs/peft/index).
## Load a PEFT adapter
To load and use a PEFT adapter model from 🤗 Transformers, make sure the Hub repository or local directory contains an `adapter_config.json` file and the adapter weights, as shown in the example image above. Then you can load the PEFT adapter model using the `AutoModelFor` class. For example, to load a PEFT adapter model for causal language modeling:
1. specify the PEFT model id
2. pass it to the [`AutoModelForCausalLM`] class
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
You can load a PEFT adapter with either an `AutoModelFor` class or the base model class like `OPTForCausalLM` or `LlamaForCausalLM`.
You can also load a PEFT adapter by calling the `load_adapter` method:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
## Load in 8bit or 4bit
The `bitsandbytes` integration supports 8bit and 4bit precision data types, which are useful for loading large models because it saves memory (see the `bitsandbytes` integration [guide](./quantization#bitsandbytes-integration) to learn more). Add the `load_in_8bit` or `load_in_4bit` parameters to [`~PreTrainedModel.from_pretrained`] and set `device_map="auto"` to effectively distribute the model to your hardware:
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
## Add a new adapter
You can use [`~peft.PeftModel.add_adapter`] to add a new adapter to a model with an existing adapter as long as the new adapter is the same type as the current one. For example, if you have an existing LoRA adapter attached to a model:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
To add a new adapter:
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
Now you can use [`~peft.PeftModel.set_adapter`] to set which adapter to use:
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
## Enable and disable adapters
Once you've added an adapter to a model, you can enable or disable the adapter module. To enable the adapter module:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
To disable the adapter module:
model.disable_adapters()
output = model.generate(**inputs)
## Train a PEFT adapter
PEFT adapters are supported by the [`Trainer`] class so that you can train an adapter for your specific use case. It only requires adding a few more lines of code. For example, to train a LoRA adapter:
If you aren't familiar with fine-tuning a model with [`Trainer`], take a look at the [Fine-tune a pretrained model](training) tutorial.
1. Define your adapter configuration with the task type and hyperparameters (see [`~peft.LoraConfig`] for more details about what the hyperparameters do).
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
2. Add adapter to the model.
model.add_adapter(peft_config)
3. Now you can pass the model to [`Trainer`]!
trainer = Trainer(model=model, )
trainer.train()
To save your trained adapter and load it back:
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
## Add additional trainable layers to a PEFT adapter
You can also fine-tune additional trainable adapters on top of a model that has adapters attached by passing `modules_to_save` in your PEFT config. For example, if you want to also fine-tune the lm_head on top of a model with a LoRA adapter:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
modules_to_save=["lm_head"],
)
model.add_adapter(lora_config)
|
add_new_pipeline.md
|
# How to create a custom pipeline?
In this guide, we will see how to create a custom pipeline and share it on the [Hub](hf.co/models) or add it to the
🤗 Transformers library.
First and foremost, you need to decide the raw entries the pipeline will be able to take. It can be strings, raw bytes,
dictionaries or whatever seems to be the most likely desired input. Try to keep these inputs as pure Python as possible
as it makes compatibility easier (even through other languages via JSON). Those will be the `inputs` of the
pipeline (`preprocess`).
Then define the `outputs`. Same policy as the `inputs`. The simpler, the better. Those will be the outputs of
`postprocess` method.
Start by inheriting the base class `Pipeline` with the 4 methods needed to implement `preprocess`,
`_forward`, `postprocess`, and `_sanitize_parameters`.
thon
from transformers import Pipeline
class MyPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
return preprocess_kwargs, {}, {}
def preprocess(self, inputs, maybe_arg=2):
model_input = Tensor(inputs["input_ids"])
return {"model_input": model_input}
def _forward(self, model_inputs):
# model_inputs == {"model_input": model_input}
outputs = self.model(**model_inputs)
# Maybe {"logits": Tensor()}
return outputs
def postprocess(self, model_outputs):
best_class = model_outputs["logits"].softmax(-1)
return best_class
The structure of this breakdown is to support relatively seamless support for CPU/GPU, while supporting doing
pre/postprocessing on the CPU on different threads
`preprocess` will take the originally defined inputs, and turn them into something feedable to the model. It might
contain more information and is usually a `Dict`.
`_forward` is the implementation detail and is not meant to be called directly. `forward` is the preferred
called method as it contains safeguards to make sure everything is working on the expected device. If anything is
linked to a real model it belongs in the `_forward` method, anything else is in the preprocess/postprocess.
`postprocess` methods will take the output of `_forward` and turn it into the final output that was decided
earlier.
`_sanitize_parameters` exists to allow users to pass any parameters whenever they wish, be it at initialization
time `pipeline(., maybe_arg=4)` or at call time `pipe = pipeline(); output = pipe(., maybe_arg=4)`.
The returns of `_sanitize_parameters` are the 3 dicts of kwargs that will be passed directly to `preprocess`,
`_forward`, and `postprocess`. Don't fill anything if the caller didn't call with any extra parameter. That
allows to keep the default arguments in the function definition which is always more "natural".
A classic example would be a `top_k` argument in the post processing in classification tasks.
thon
>>> pipe = pipeline("my-new-task")
>>> pipe("This is a test")
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
>>> pipe("This is a test", top_k=2)
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
`_sanitize_parameters` to allow this new parameter.
thon
def postprocess(self, model_outputs, top_k=5):
best_class = model_outputs["logits"].softmax(-1)
# Add logic to handle top_k
return best_class
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
postprocess_kwargs = {}
if "top_k" in kwargs:
postprocess_kwargs["top_k"] = kwargs["top_k"]
return preprocess_kwargs, {}, postprocess_kwargs
Try to keep the inputs/outputs very simple and ideally JSON-serializable as it makes the pipeline usage very easy
without requiring users to understand new kinds of objects. It's also relatively common to support many different types
of arguments for ease of use (audio files, which can be filenames, URLs or pure bytes)
## Adding it to the list of supported tasks
To register your `new-task` to the list of supported tasks, you have to add it to the `PIPELINE_REGISTRY`:
thon
from transformers.pipelines import PIPELINE_REGISTRY
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
)
You can specify a default model if you want, in which case it should come with a specific revision (which can be the name of a branch or a commit hash, here we took `"abcdef"`) as well as the type:
thon
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
default={"pt": ("user/awesome_model", "abcdef")},
type="text", # current support type: text, audio, image, multimodal
)
## Share your pipeline on the Hub
To share your custom pipeline on the Hub, you just have to save the custom code of your `Pipeline` subclass in a
python file. For instance, let's say we want to use a custom pipeline for sentence pair classification like this:
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
The implementation is framework agnostic, and will work for PyTorch and TensorFlow models. If we have saved this in
a file named `pair_classification.py`, we can then import it and register it like this:
from pair_classification import PairClassificationPipeline
from transformers.pipelines import PIPELINE_REGISTRY
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
PIPELINE_REGISTRY.register_pipeline(
"pair-classification",
pipeline_class=PairClassificationPipeline,
pt_model=AutoModelForSequenceClassification,
tf_model=TFAutoModelForSequenceClassification,
)
Once this is done, we can use it with a pretrained model. For instance `sgugger/finetuned-bert-mrpc` has been
fine-tuned on the MRPC dataset, which classifies pairs of sentences as paraphrases or not.
from transformers import pipeline
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
Then we can share it on the Hub by using the `save_pretrained` method in a `Repository`:
from huggingface_hub import Repository
repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
classifier.save_pretrained("test-dynamic-pipeline")
repo.push_to_hub()
This will copy the file where you defined `PairClassificationPipeline` inside the folder `"test-dynamic-pipeline"`,
along with saving the model and tokenizer of the pipeline, before pushing everything into the repository
`{your_username}/test-dynamic-pipeline`. After that, anyone can use it as long as they provide the option
`trust_remote_code=True`:
from transformers import pipeline
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
## Add the pipeline to 🤗 Transformers
If you want to contribute your pipeline to 🤗 Transformers, you will need to add a new module in the `pipelines` submodule
with the code of your pipeline, then add it to the list of tasks defined in `pipelines/__init__.py`.
Then you will need to add tests. Create a new file `tests/test_pipelines_MY_PIPELINE.py` with examples of the other tests.
The `run_pipeline_test` function will be very generic and run on small random models on every possible
architecture as defined by `model_mapping` and `tf_model_mapping`.
This is very important to test future compatibility, meaning if someone adds a new model for
`XXXForQuestionAnswering` then the pipeline test will attempt to run on it. Because the models are random it's
impossible to check for actual values, that's why there is a helper `ANY` that will simply attempt to match the
output of the pipeline TYPE.
You also *need* to implement 2 (ideally 4) tests.
- `test_small_model_pt` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_tf`.
- `test_small_model_tf` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_pt`.
- `test_large_model_pt` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
- `test_large_model_tf` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
|
tasks_explained.md
|
# How 🤗 Transformers solve tasks
In [What 🤗 Transformers can do](task_summary), you learned about natural language processing (NLP), speech and audio, computer vision tasks, and some important applications of them. This page will look closely at how models solve these tasks and explain what's happening under the hood. There are many ways to solve a given task, some models may implement certain techniques or even approach the task from a new angle, but for Transformer models, the general idea is the same. Owing to its flexible architecture, most models are a variant of an encoder, decoder, or encoder-decoder structure. In addition to Transformer models, our library also has several convolutional neural networks (CNNs), which are still used today for computer vision tasks. We'll also explain how a modern CNN works.
To explain how tasks are solved, we'll walk through what goes on inside the model to output useful predictions.
- [Wav2Vec2](model_doc/wav2vec2) for audio classification and automatic speech recognition (ASR)
- [Vision Transformer (ViT)](model_doc/vit) and [ConvNeXT](model_doc/convnext) for image classification
- [DETR](model_doc/detr) for object detection
- [Mask2Former](model_doc/mask2former) for image segmentation
- [GLPN](model_doc/glpn) for depth estimation
- [BERT](model_doc/bert) for NLP tasks like text classification, token classification and question answering that use an encoder
- [GPT2](model_doc/gpt2) for NLP tasks like text generation that use a decoder
- [BART](model_doc/bart) for NLP tasks like summarization and translation that use an encoder-decoder
Before you go further, it is good to have some basic knowledge of the original Transformer architecture. Knowing how encoders, decoders, and attention work will aid you in understanding how different Transformer models work. If you're just getting started or need a refresher, check out our [course](https://huggingface.co/course/chapter1/4?fw=pt) for more information!
## Speech and audio
[Wav2Vec2](model_doc/wav2vec2) is a self-supervised model pretrained on unlabeled speech data and finetuned on labeled data for audio classification and automatic speech recognition.
This model has four main components:
1. A *feature encoder* takes the raw audio waveform, normalizes it to zero mean and unit variance, and converts it into a sequence of feature vectors that are each 20ms long.
2. Waveforms are continuous by nature, so they can't be divided into separate units like a sequence of text can be split into words. That's why the feature vectors are passed to a *quantization module*, which aims to learn discrete speech units. The speech unit is chosen from a collection of codewords, known as a *codebook* (you can think of this as the vocabulary). From the codebook, the vector or speech unit, that best represents the continuous audio input is chosen and forwarded through the model.
3. About half of the feature vectors are randomly masked, and the masked feature vector is fed to a *context network*, which is a Transformer encoder that also adds relative positional embeddings.
4. The pretraining objective of the context network is a *contrastive task*. The model has to predict the true quantized speech representation of the masked prediction from a set of false ones, encouraging the model to find the most similar context vector and quantized speech unit (the target label).
Now that wav2vec2 is pretrained, you can finetune it on your data for audio classification or automatic speech recognition!
### Audio classification
To use the pretrained model for audio classification, add a sequence classification head on top of the base Wav2Vec2 model. The classification head is a linear layer that accepts the encoder's hidden states. The hidden states represent the learned features from each audio frame which can have varying lengths. To create one vector of fixed-length, the hidden states are pooled first and then transformed into logits over the class labels. The cross-entropy loss is calculated between the logits and target to find the most likely class.
Ready to try your hand at audio classification? Check out our complete [audio classification guide](tasks/audio_classification) to learn how to finetune Wav2Vec2 and use it for inference!
### Automatic speech recognition
To use the pretrained model for automatic speech recognition, add a language modeling head on top of the base Wav2Vec2 model for [connectionist temporal classification (CTC)](glossary#connectionist-temporal-classification-ctc). The language modeling head is a linear layer that accepts the encoder's hidden states and transforms them into logits. Each logit represents a token class (the number of tokens comes from the task vocabulary). The CTC loss is calculated between the logits and targets to find the most likely sequence of tokens, which are then decoded into a transcription.
Ready to try your hand at automatic speech recognition? Check out our complete [automatic speech recognition guide](tasks/asr) to learn how to finetune Wav2Vec2 and use it for inference!
## Computer vision
There are two ways to approach computer vision tasks:
1. Split an image into a sequence of patches and process them in parallel with a Transformer.
2. Use a modern CNN, like [ConvNeXT](model_doc/convnext), which relies on convolutional layers but adopts modern network designs.
A third approach mixes Transformers with convolutions (for example, [Convolutional Vision Transformer](model_doc/cvt) or [LeViT](model_doc/levit)). We won't discuss those because they just combine the two approaches we examine here.
ViT and ConvNeXT are commonly used for image classification, but for other vision tasks like object detection, segmentation, and depth estimation, we'll look at DETR, Mask2Former and GLPN, respectively; these models are better suited for those tasks.
### Image classification
ViT and ConvNeXT can both be used for image classification; the main difference is that ViT uses an attention mechanism while ConvNeXT uses convolutions.
#### Transformer
[ViT](model_doc/vit) replaces convolutions entirely with a pure Transformer architecture. If you're familiar with the original Transformer, then you're already most of the way toward understanding ViT.
The main change ViT introduced was in how images are fed to a Transformer:
1. An image is split into square non-overlapping patches, each of which gets turned into a vector or *patch embedding*. The patch embeddings are generated from a convolutional 2D layer which creates the proper input dimensions (which for a base Transformer is 768 values for each patch embedding). If you had a 224x224 pixel image, you could split it into 196 16x16 image patches. Just like how text is tokenized into words, an image is "tokenized" into a sequence of patches.
2. A *learnable embedding* - a special `[CLS]` token - is added to the beginning of the patch embeddings just like BERT. The final hidden state of the `[CLS]` token is used as the input to the attached classification head; other outputs are ignored. This token helps the model learn how to encode a representation of the image.
3. The last thing to add to the patch and learnable embeddings are the *position embeddings* because the model doesn't know how the image patches are ordered. The position embeddings are also learnable and have the same size as the patch embeddings. Finally, all of the embeddings are passed to the Transformer encoder.
4. The output, specifically only the output with the `[CLS]` token, is passed to a multilayer perceptron head (MLP). ViT's pretraining objective is simply classification. Like other classification heads, the MLP head converts the output into logits over the class labels and calculates the cross-entropy loss to find the most likely class.
Ready to try your hand at image classification? Check out our complete [image classification guide](tasks/image_classification) to learn how to finetune ViT and use it for inference!
#### CNN
This section briefly explains convolutions, but it'd be helpful to have a prior understanding of how they change an image's shape and size. If you're unfamiliar with convolutions, check out the [Convolution Neural Networks chapter](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb) from the fastai book!
[ConvNeXT](model_doc/convnext) is a CNN architecture that adopts new and modern network designs to improve performance. However, convolutions are still at the core of the model. From a high-level perspective, a [convolution](glossary#convolution) is an operation where a smaller matrix (*kernel*) is multiplied by a small window of the image pixels. It computes some features from it, such as a particular texture or curvature of a line. Then it slides over to the next window of pixels; the distance the convolution travels is known as the *stride*.
A basic convolution without padding or stride, taken from A guide to convolution arithmetic for deep learning.
You can feed this output to another convolutional layer, and with each successive layer, the network learns more complex and abstract things like hotdogs or rockets. Between convolutional layers, it is common to add a pooling layer to reduce dimensionality and make the model more robust to variations of a feature's position.
ConvNeXT modernizes a CNN in five ways:
1. Change the number of blocks in each stage and "patchify" an image with a larger stride and corresponding kernel size. The non-overlapping sliding window makes this patchifying strategy similar to how ViT splits an image into patches.
2. A *bottleneck* layer shrinks the number of channels and then restores it because it is faster to do a 1x1 convolution, and you can increase the depth. An inverted bottleneck does the opposite by expanding the number of channels and shrinking them, which is more memory efficient.
3. Replace the typical 3x3 convolutional layer in the bottleneck layer with *depthwise convolution*, which applies a convolution to each input channel separately and then stacks them back together at the end. This widens the network width for improved performance.
4. ViT has a global receptive field which means it can see more of an image at once thanks to its attention mechanism. ConvNeXT attempts to replicate this effect by increasing the kernel size to 7x7.
5. ConvNeXT also makes several layer design changes that imitate Transformer models. There are fewer activation and normalization layers, the activation function is switched to GELU instead of ReLU, and it uses LayerNorm instead of BatchNorm.
The output from the convolution blocks is passed to a classification head which converts the outputs into logits and calculates the cross-entropy loss to find the most likely label.
### Object detection
[DETR](model_doc/detr), *DEtection TRansformer*, is an end-to-end object detection model that combines a CNN with a Transformer encoder-decoder.
1. A pretrained CNN *backbone* takes an image, represented by its pixel values, and creates a low-resolution feature map of it. A 1x1 convolution is applied to the feature map to reduce dimensionality and it creates a new feature map with a high-level image representation. Since the Transformer is a sequential model, the feature map is flattened into a sequence of feature vectors that are combined with positional embeddings.
2. The feature vectors are passed to the encoder, which learns the image representations using its attention layers. Next, the encoder hidden states are combined with *object queries* in the decoder. Object queries are learned embeddings that focus on the different regions of an image, and they're updated as they progress through each attention layer. The decoder hidden states are passed to a feedforward network that predicts the bounding box coordinates and class label for each object query, or `no object` if there isn't one.
DETR decodes each object query in parallel to output *N* final predictions, where *N* is the number of queries. Unlike a typical autoregressive model that predicts one element at a time, object detection is a set prediction task (`bounding box`, `class label`) that makes *N* predictions in a single pass.
3. DETR uses a *bipartite matching loss* during training to compare a fixed number of predictions with a fixed set of ground truth labels. If there are fewer ground truth labels in the set of *N* labels, then they're padded with a `no object` class. This loss function encourages DETR to find a one-to-one assignment between the predictions and ground truth labels. If either the bounding boxes or class labels aren't correct, a loss is incurred. Likewise, if DETR predicts an object that doesn't exist, it is penalized. This encourages DETR to find other objects in an image instead of focusing on one really prominent object.
An object detection head is added on top of DETR to find the class label and the coordinates of the bounding box. There are two components to the object detection head: a linear layer to transform the decoder hidden states into logits over the class labels, and a MLP to predict the bounding box.
Ready to try your hand at object detection? Check out our complete [object detection guide](tasks/object_detection) to learn how to finetune DETR and use it for inference!
### Image segmentation
[Mask2Former](model_doc/mask2former) is a universal architecture for solving all types of image segmentation tasks. Traditional segmentation models are typically tailored towards a particular subtask of image segmentation, like instance, semantic or panoptic segmentation. Mask2Former frames each of those tasks as a *mask classification* problem. Mask classification groups pixels into *N* segments, and predicts *N* masks and their corresponding class label for a given image. We'll explain how Mask2Former works in this section, and then you can try finetuning SegFormer at the end.
There are three main components to Mask2Former:
1. A [Swin](model_doc/swin) backbone accepts an image and creates a low-resolution image feature map from 3 consecutive 3x3 convolutions.
2. The feature map is passed to a *pixel decoder* which gradually upsamples the low-resolution features into high-resolution per-pixel embeddings. The pixel decoder actually generates multi-scale features (contains both low- and high-resolution features) with resolutions 1/32, 1/16, and 1/8th of the original image.
3. Each of these feature maps of differing scales is fed successively to one Transformer decoder layer at a time in order to capture small objects from the high-resolution features. The key to Mask2Former is the *masked attention* mechanism in the decoder. Unlike cross-attention which can attend to the entire image, masked attention only focuses on a certain area of the image. This is faster and leads to better performance because the local features of an image are enough for the model to learn from.
4. Like [DETR](tasks_explained#object-detection), Mask2Former also uses learned object queries and combines them with the image features from the pixel decoder to make a set prediction (`class label`, `mask prediction`). The decoder hidden states are passed into a linear layer and transformed into logits over the class labels. The cross-entropy loss is calculated between the logits and class label to find the most likely one.
The mask predictions are generated by combining the pixel-embeddings with the final decoder hidden states. The sigmoid cross-entropy and dice loss is calculated between the logits and the ground truth mask to find the most likely mask.
Ready to try your hand at object detection? Check out our complete [image segmentation guide](tasks/semantic_segmentation) to learn how to finetune SegFormer and use it for inference!
### Depth estimation
[GLPN](model_doc/glpn), *Global-Local Path Network*, is a Transformer for depth estimation that combines a [SegFormer](model_doc/segformer) encoder with a lightweight decoder.
1. Like ViT, an image is split into a sequence of patches, except these image patches are smaller. This is better for dense prediction tasks like segmentation or depth estimation. The image patches are transformed into patch embeddings (see the [image classification](#image-classification) section for more details about how patch embeddings are created), which are fed to the encoder.
2. The encoder accepts the patch embeddings, and passes them through several encoder blocks. Each block consists of attention and Mix-FFN layers. The purpose of the latter is to provide positional information. At the end of each encoder block is a *patch merging* layer for creating hierarchical representations. The features of each group of neighboring patches are concatenated, and a linear layer is applied to the concatenated features to reduce the number of patches to a resolution of 1/4. This becomes the input to the next encoder block, where this whole process is repeated until you have image features with resolutions of 1/8, 1/16, and 1/32.
3. A lightweight decoder takes the last feature map (1/32 scale) from the encoder and upsamples it to 1/16 scale. From here, the feature is passed into a *Selective Feature Fusion (SFF)* module, which selects and combines local and global features from an attention map for each feature and then upsamples it to 1/8th. This process is repeated until the decoded features are the same size as the original image. The output is passed through two convolution layers and then a sigmoid activation is applied to predict the depth of each pixel.
## Natural language processing
The Transformer was initially designed for machine translation, and since then, it has practically become the default architecture for solving all NLP tasks. Some tasks lend themselves to the Transformer's encoder structure, while others are better suited for the decoder. Still, other tasks make use of both the Transformer's encoder-decoder structure.
### Text classification
[BERT](model_doc/bert) is an encoder-only model and is the first model to effectively implement deep bidirectionality to learn richer representations of the text by attending to words on both sides.
1. BERT uses [WordPiece](tokenizer_summary#wordpiece) tokenization to generate a token embedding of the text. To tell the difference between a single sentence and a pair of sentences, a special `[SEP]` token is added to differentiate them. A special `[CLS]` token is added to the beginning of every sequence of text. The final output with the `[CLS]` token is used as the input to the classification head for classification tasks. BERT also adds a segment embedding to denote whether a token belongs to the first or second sentence in a pair of sentences.
2. BERT is pretrained with two objectives: masked language modeling and next-sentence prediction. In masked language modeling, some percentage of the input tokens are randomly masked, and the model needs to predict these. This solves the issue of bidirectionality, where the model could cheat and see all the words and "predict" the next word. The final hidden states of the predicted mask tokens are passed to a feedforward network with a softmax over the vocabulary to predict the masked word.
The second pretraining object is next-sentence prediction. The model must predict whether sentence B follows sentence A. Half of the time sentence B is the next sentence, and the other half of the time, sentence B is a random sentence. The prediction, whether it is the next sentence or not, is passed to a feedforward network with a softmax over the two classes (`IsNext` and `NotNext`).
3. The input embeddings are passed through multiple encoder layers to output some final hidden states.
To use the pretrained model for text classification, add a sequence classification head on top of the base BERT model. The sequence classification head is a linear layer that accepts the final hidden states and performs a linear transformation to convert them into logits. The cross-entropy loss is calculated between the logits and target to find the most likely label.
Ready to try your hand at text classification? Check out our complete [text classification guide](tasks/sequence_classification) to learn how to finetune DistilBERT and use it for inference!
### Token classification
To use BERT for token classification tasks like named entity recognition (NER), add a token classification head on top of the base BERT model. The token classification head is a linear layer that accepts the final hidden states and performs a linear transformation to convert them into logits. The cross-entropy loss is calculated between the logits and each token to find the most likely label.
Ready to try your hand at token classification? Check out our complete [token classification guide](tasks/token_classification) to learn how to finetune DistilBERT and use it for inference!
### Question answering
To use BERT for question answering, add a span classification head on top of the base BERT model. This linear layer accepts the final hidden states and performs a linear transformation to compute the `span` start and end logits corresponding to the answer. The cross-entropy loss is calculated between the logits and the label position to find the most likely span of text corresponding to the answer.
Ready to try your hand at question answering? Check out our complete [question answering guide](tasks/question_answering) to learn how to finetune DistilBERT and use it for inference!
💡 Notice how easy it is to use BERT for different tasks once it's been pretrained. You only need to add a specific head to the pretrained model to manipulate the hidden states into your desired output!
### Text generation
[GPT-2](model_doc/gpt2) is a decoder-only model pretrained on a large amount of text. It can generate convincing (though not always true!) text given a prompt and complete other NLP tasks like question answering despite not being explicitly trained to.
1. GPT-2 uses [byte pair encoding (BPE)](tokenizer_summary#bytepair-encoding-bpe) to tokenize words and generate a token embedding. Positional encodings are added to the token embeddings to indicate the position of each token in the sequence. The input embeddings are passed through multiple decoder blocks to output some final hidden state. Within each decoder block, GPT-2 uses a *masked self-attention* layer which means GPT-2 can't attend to future tokens. It is only allowed to attend to tokens on the left. This is different from BERT's [`mask`] token because, in masked self-attention, an attention mask is used to set the score to `0` for future tokens.
2. The output from the decoder is passed to a language modeling head, which performs a linear transformation to convert the hidden states into logits. The label is the next token in the sequence, which are created by shifting the logits to the right by one. The cross-entropy loss is calculated between the shifted logits and the labels to output the next most likely token.
GPT-2's pretraining objective is based entirely on [causal language modeling](glossary#causal-language-modeling), predicting the next word in a sequence. This makes GPT-2 especially good at tasks that involve generating text.
Ready to try your hand at text generation? Check out our complete [causal language modeling guide](tasks/language_modeling#causal-language-modeling) to learn how to finetune DistilGPT-2 and use it for inference!
For more information about text generation, check out the [text generation strategies](generation_strategies) guide!
### Summarization
Encoder-decoder models like [BART](model_doc/bart) and [T5](model_doc/t5) are designed for the sequence-to-sequence pattern of a summarization task. We'll explain how BART works in this section, and then you can try finetuning T5 at the end.
1. BART's encoder architecture is very similar to BERT and accepts a token and positional embedding of the text. BART is pretrained by corrupting the input and then reconstructing it with the decoder. Unlike other encoders with specific corruption strategies, BART can apply any type of corruption. The *text infilling* corruption strategy works the best though. In text infilling, a number of text spans are replaced with a **single** [`mask`] token. This is important because the model has to predict the masked tokens, and it teaches the model to predict the number of missing tokens. The input embeddings and masked spans are passed through the encoder to output some final hidden states, but unlike BERT, BART doesn't add a final feedforward network at the end to predict a word.
2. The encoder's output is passed to the decoder, which must predict the masked tokens and any uncorrupted tokens from the encoder's output. This gives additional context to help the decoder restore the original text. The output from the decoder is passed to a language modeling head, which performs a linear transformation to convert the hidden states into logits. The cross-entropy loss is calculated between the logits and the label, which is just the token shifted to the right.
Ready to try your hand at summarization? Check out our complete [summarization guide](tasks/summarization) to learn how to finetune T5 and use it for inference!
For more information about text generation, check out the [text generation strategies](generation_strategies) guide!
### Translation
Translation is another example of a sequence-to-sequence task, which means you can use an encoder-decoder model like [BART](model_doc/bart) or [T5](model_doc/t5) to do it. We'll explain how BART works in this section, and then you can try finetuning T5 at the end.
BART adapts to translation by adding a separate randomly initialized encoder to map a source language to an input that can be decoded into the target language. This new encoder's embeddings are passed to the pretrained encoder instead of the original word embeddings. The source encoder is trained by updating the source encoder, positional embeddings, and input embeddings with the cross-entropy loss from the model output. The model parameters are frozen in this first step, and all the model parameters are trained together in the second step.
BART has since been followed up by a multilingual version, mBART, intended for translation and pretrained on many different languages.
Ready to try your hand at translation? Check out our complete [translation guide](tasks/summarization) to learn how to finetune T5 and use it for inference!
For more information about text generation, check out the [text generation strategies](generation_strategies) guide!
|
add_tensorflow_model.md
|
# How to convert a 🤗 Transformers model to TensorFlow?
Having multiple frameworks available to use with 🤗 Transformers gives you flexibility to play their strengths when
designing your application, but it implies that compatibility must be added on a per-model basis. The good news is that
adding TensorFlow compatibility to an existing model is simpler than [adding a new model from scratch](add_new_model)!
Whether you wish to have a deeper understanding of large TensorFlow models, make a major open-source contribution, or
enable TensorFlow for your model of choice, this guide is for you.
This guide empowers you, a member of our community, to contribute TensorFlow model weights and/or
architectures to be used in 🤗 Transformers, with minimal supervision from the Hugging Face team. Writing a new model
is no small feat, but hopefully this guide will make it less of a rollercoaster 🎢 and more of a walk in the park 🚶.
Harnessing our collective experiences is absolutely critical to make this process increasingly easier, and thus we
highly encourage that you suggest improvements to this guide!
Before you dive deeper, it is recommended that you check the following resources if you're new to 🤗 Transformers:
- [General overview of 🤗 Transformers](add_new_model#general-overview-of-transformers)
- [Hugging Face's TensorFlow Philosophy](https://huggingface.co/blog/tensorflow-philosophy)
In the remainder of this guide, you will learn what's needed to add a new TensorFlow model architecture, the
procedure to convert PyTorch into TensorFlow model weights, and how to efficiently debug mismatches across ML
frameworks. Let's get started!
Are you unsure whether the model you wish to use already has a corresponding TensorFlow architecture?
Check the `model_type` field of the `config.json` of your model of choice
([example](https://huggingface.co/bert-base-uncased/blob/main/config.json#L14)). If the corresponding model folder in
🤗 Transformers has a file whose name starts with "modeling_tf", it means that it has a corresponding TensorFlow
architecture ([example](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert)).
## Step-by-step guide to add TensorFlow model architecture code
There are many ways to design a large model architecture, and multiple ways of implementing said design. However,
you might recall from our [general overview of 🤗 Transformers](add_new_model#general-overview-of-transformers)
that we are an opinionated bunch - the ease of use of 🤗 Transformers relies on consistent design choices. From
experience, we can tell you a few important things about adding TensorFlow models:
- Don't reinvent the wheel! More often than not, there are at least two reference implementations you should check: the
PyTorch equivalent of the model you are implementing and other TensorFlow models for the same class of problems.
- Great model implementations survive the test of time. This doesn't happen because the code is pretty, but rather
because the code is clear, easy to debug and build upon. If you make the life of the maintainers easy with your
TensorFlow implementation, by replicating the same patterns as in other TensorFlow models and minimizing the mismatch
to the PyTorch implementation, you ensure your contribution will be long lived.
- Ask for help when you're stuck! The 🤗 Transformers team is here to help, and we've probably found solutions to the same
problems you're facing.
Here's an overview of the steps needed to add a TensorFlow model architecture:
1. Select the model you wish to convert
2. Prepare transformers dev environment
3. (Optional) Understand theoretical aspects and the existing implementation
4. Implement the model architecture
5. Implement model tests
6. Submit the pull request
7. (Optional) Build demos and share with the world
### 1.-3. Prepare your model contribution
**1. Select the model you wish to convert**
Let's start off with the basics: the first thing you need to know is the architecture you want to convert. If you
don't have your eyes set on a specific architecture, asking the 🤗 Transformers team for suggestions is a great way to
maximize your impact - we will guide you towards the most prominent architectures that are missing on the TensorFlow
side. If the specific model you want to use with TensorFlow already has a TensorFlow architecture implementation in
🤗 Transformers but is lacking weights, feel free to jump straight into the
[weight conversion section](#adding-tensorflow-weights-to-hub)
of this page.
For simplicity, the remainder of this guide assumes you've decided to contribute with the TensorFlow version of
*BrandNewBert* (the same example as in the [guide](add_new_model) to add a new model from scratch).
Before starting the work on a TensorFlow model architecture, double-check that there is no ongoing effort to do so.
You can search for `BrandNewBert` on the
[pull request GitHub page](https://github.com/huggingface/transformers/pulls?q=is%3Apr) to confirm that there is no
TensorFlow-related pull request.
**2. Prepare transformers dev environment**
Having selected the model architecture, open a draft PR to signal your intention to work on it. Follow the
instructions below to set up your environment and open a draft PR.
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the 'Fork' button on the
repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
3. Set up a development environment, for instance by running the following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install TensorFlow then do:
```bash
pip install -e ".[quality]"
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
4. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_tf_brand_new_bert
5. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
6. Add an empty `.py` file in `transformers/src/models/brandnewbert/` named `modeling_tf_brandnewbert.py`. This will
be your TensorFlow model file.
7. Push the changes to your account using:
```bash
git add .
git commit -m "initial commit"
git push -u origin add_tf_brand_new_bert
8. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
future changes.
9. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
Now you have set up a development environment to port *BrandNewBert* to TensorFlow in 🤗 Transformers.
**3. (Optional) Understand theoretical aspects and the existing implementation**
You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
effectively re-implement the model in 🤗 Transformers using TensorFlow. That being said, you don't have to spend too
much time on the theoretical aspects, but rather focus on the practical ones, namely the existing model documentation
page (e.g. [model docs for BERT](model_doc/bert)).
After you've grasped the basics of the models you are about to implement, it's important to understand the existing
implementation. This is a great chance to confirm that a working implementation matches your expectations for the
model, as well as to foresee technical challenges on the TensorFlow side.
It's perfectly natural that you feel overwhelmed with the amount of information that you've just absorbed. It is
definitely not a requirement that you understand all facets of the model at this stage. Nevertheless, we highly
encourage you to clear any pressing questions in our [forum](https://discuss.huggingface.co/).
### 4. Model implementation
Now it's time to finally start coding. Our suggested starting point is the PyTorch file itself: copy the contents of
`modeling_brand_new_bert.py` inside `src/transformers/models/brand_new_bert/` into
`modeling_tf_brand_new_bert.py`. The goal of this section is to modify the file and update the import structure of
🤗 Transformers such that you can import `TFBrandNewBert` and
`TFBrandNewBert.from_pretrained(model_repo, from_pt=True)` successfully loads a working TensorFlow *BrandNewBert* model.
Sadly, there is no prescription to convert a PyTorch model into TensorFlow. You can, however, follow our selection of
tips to make the process as smooth as possible:
- Prepend `TF` to the name of all classes (e.g. `BrandNewBert` becomes `TFBrandNewBert`).
- Most PyTorch operations have a direct TensorFlow replacement. For example, `torch.nn.Linear` corresponds to
`tf.keras.layers.Dense`, `torch.nn.Dropout` corresponds to `tf.keras.layers.Dropout`, etc. If you're not sure
about a specific operation, you can use the [TensorFlow documentation](https://www.tensorflow.org/api_docs/python/tf)
or the [PyTorch documentation](https://pytorch.org/docs/stable/).
- Look for patterns in the 🤗 Transformers codebase. If you come across a certain operation that doesn't have a direct
replacement, the odds are that someone else already had the same problem.
- By default, keep the same variable names and structure as in PyTorch. This will make it easier to debug, track
issues, and add fixes down the line.
- Some layers have different default values in each framework. A notable example is the batch normalization layer's
epsilon (`1e-5` in [PyTorch](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html#torch.nn.BatchNorm2d)
and `1e-3` in [TensorFlow](https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization)).
Double-check the documentation!
- PyTorch's `nn.Parameter` variables typically need to be initialized within TF Layer's `build()`. See the following
example: [PyTorch](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_vit_mae.py#L212) /
[TensorFlow](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_tf_vit_mae.py#L220)
- If the PyTorch model has a `#copied from ` on top of a function, the odds are that your TensorFlow model can also
borrow that function from the architecture it was copied from, assuming it has a TensorFlow architecture.
- Assigning the `name` attribute correctly in TensorFlow functions is critical to do the `from_pt=True` weight
cross-loading. `name` is almost always the name of the corresponding variable in the PyTorch code. If `name` is not
properly set, you will see it in the error message when loading the model weights.
- The logic of the base model class, `BrandNewBertModel`, will actually reside in `TFBrandNewBertMainLayer`, a Keras
layer subclass ([example](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L719)).
`TFBrandNewBertModel` will simply be a wrapper around this layer.
- Keras models need to be built in order to load pretrained weights. For that reason, `TFBrandNewBertPreTrainedModel`
will need to hold an example of inputs to the model, the `dummy_inputs`
([example](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L916)).
- If you get stuck, ask for help - we're here to help you! 🤗
In addition to the model file itself, you will also need to add the pointers to the model classes and related
documentation pages. You can complete this part entirely following the patterns in other PRs
([example](https://github.com/huggingface/transformers/pull/18020/files)). Here's a list of the needed manual
changes:
- Include all public classes of *BrandNewBert* in `src/transformers/__init__.py`
- Add *BrandNewBert* classes to the corresponding Auto classes in `src/transformers/models/auto/modeling_tf_auto.py`
- Add the lazy loading classes related to *BrandNewBert* in `src/transformers/utils/dummy_tf_objects.py`
- Update the import structures for the public classes in `src/transformers/models/brand_new_bert/__init__.py`
- Add the documentation pointers to the public methods of *BrandNewBert* in `docs/source/en/model_doc/brand_new_bert.md`
- Add yourself to the list of contributors to *BrandNewBert* in `docs/source/en/model_doc/brand_new_bert.md`
- Finally, add a green tick ✅ to the TensorFlow column of *BrandNewBert* in `docs/source/en/index.md`
When you're happy with your implementation, run the following checklist to confirm that your model architecture is
ready:
1. All layers that behave differently at train time (e.g. Dropout) are called with a `training` argument, which is
propagated all the way from the top-level classes
2. You have used `#copied from ` whenever possible
3. `TFBrandNewBertMainLayer` and all classes that use it have their `call` function decorated with `@unpack_inputs`
4. `TFBrandNewBertMainLayer` is decorated with `@keras_serializable`
5. A TensorFlow model can be loaded from PyTorch weights using `TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`
6. You can call the TensorFlow model using the expected input format
### 5. Add model tests
Hurray, you've implemented a TensorFlow model! Now it's time to add tests to make sure that your model behaves as
expected. As in the previous section, we suggest you start by copying the `test_modeling_brand_new_bert.py` file in
`tests/models/brand_new_bert/` into `test_modeling_tf_brand_new_bert.py`, and continue by making the necessary
TensorFlow replacements. For now, in all `.from_pretrained()` calls, you should use the `from_pt=True` flag to load
the existing PyTorch weights.
After you're done, it's time for the moment of truth: run the tests! 😬
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
The most likely outcome is that you'll see a bunch of errors. Don't worry, this is expected! Debugging ML models is
notoriously hard, and the key ingredient to success is patience (and `breakpoint()`). In our experience, the hardest
problems arise from subtle mismatches between ML frameworks, for which we have a few pointers at the end of this guide.
In other cases, a general test might not be directly applicable to your model, in which case we suggest an override
at the model test class level. Regardless of the issue, don't hesitate to ask for help in your draft pull request if
you're stuck.
When all tests pass, congratulations, your model is nearly ready to be added to the 🤗 Transformers library! 🎉
### 6.-7. Ensure everyone can use your model
**6. Submit the pull request**
Once you're done with the implementation and the tests, it's time to submit a pull request. Before pushing your code,
run our code formatting utility, `make fixup` 🪄. This will automatically fix any formatting issues, which would cause
our automatic checks to fail.
It's now time to convert your draft pull request into a real pull request. To do so, click on the "Ready for
review" button and add Joao (`@gante`) and Matt (`@Rocketknight1`) as reviewers. A model pull request will need
at least 3 reviewers, but they will take care of finding appropriate additional reviewers for your model.
After all reviewers are happy with the state of your PR, the final action point is to remove the `from_pt=True` flag in
`.from_pretrained()` calls. Since there are no TensorFlow weights, you will have to add them! Check the section
below for instructions on how to do it.
Finally, when the TensorFlow weights get merged, you have at least 3 reviewer approvals, and all CI checks are
green, double-check the tests locally one last time
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
and we will merge your PR! Congratulations on the milestone 🎉
**7. (Optional) Build demos and share with the world**
One of the hardest parts about open-source is discovery. How can the other users learn about the existence of your
fabulous TensorFlow contribution? With proper communication, of course! 📣
There are two main ways to share your model with the community:
- Build demos. These include Gradio demos, notebooks, and other fun ways to show off your model. We highly
encourage you to add a notebook to our [community-driven demos](https://huggingface.co/docs/transformers/community).
- Share stories on social media like Twitter and LinkedIn. You should be proud of your work and share
your achievement with the community - your model can now be used by thousands of engineers and researchers around
the world 🌍! We will be happy to retweet your posts and help you share your work with the community.
## Adding TensorFlow weights to 🤗 Hub
Assuming that the TensorFlow model architecture is available in 🤗 Transformers, converting PyTorch weights into
TensorFlow weights is a breeze!
Here's how to do it:
1. Make sure you are logged into your Hugging Face account in your terminal. You can log in using the command
`huggingface-cli login` (you can find your access tokens [here](https://huggingface.co/settings/tokens))
2. Run `transformers-cli pt-to-tf --model-name foo/bar`, where `foo/bar` is the name of the model repository
containing the PyTorch weights you want to convert
3. Tag `@joaogante` and `@Rocketknight1` in the 🤗 Hub PR the command above has just created
That's it! 🎉
## Debugging mismatches across ML frameworks 🐛
At some point, when adding a new architecture or when creating TensorFlow weights for an existing architecture, you
might come across errors complaining about mismatches between PyTorch and TensorFlow. You might even decide to open the
model architecture code for the two frameworks, and find that they look identical. What's going on? 🤔
First of all, let's talk about why understanding these mismatches matters. Many community members will use 🤗
Transformers models out of the box, and trust that our models behave as expected. When there is a large mismatch
between the two frameworks, it implies that the model is not following the reference implementation for at least one
of the frameworks. This might lead to silent failures, in which the model runs but has poor performance. This is
arguably worse than a model that fails to run at all! To that end, we aim at having a framework mismatch smaller than
`1e-5` at all stages of the model.
As in other numerical problems, the devil is in the details. And as in any detail-oriented craft, the secret
ingredient here is patience. Here is our suggested workflow for when you come across this type of issues:
1. Locate the source of mismatches. The model you're converting probably has near identical inner variables up to a
certain point. Place `breakpoint()` statements in the two frameworks' architectures, and compare the values of the
numerical variables in a top-down fashion until you find the source of the problems.
2. Now that you've pinpointed the source of the issue, get in touch with the 🤗 Transformers team. It is possible
that we've seen a similar problem before and can promptly provide a solution. As a fallback, scan popular pages
like StackOverflow and GitHub issues.
3. If there is no solution in sight, it means you'll have to go deeper. The good news is that you've located the
issue, so you can focus on the problematic instruction, abstracting away the rest of the model! The bad news is
that you'll have to venture into the source implementation of said instruction. In some cases, you might find an
issue with a reference implementation - don't abstain from opening an issue in the upstream repository.
In some cases, in discussion with the 🤗 Transformers team, we might find that fixing the mismatch is infeasible.
When the mismatch is very small in the output layers of the model (but potentially large in the hidden states), we
might decide to ignore it in favor of distributing the model. The `pt-to-tf` CLI mentioned above has a `--max-error`
flag to override the error message at weight conversion time.
|
tasks/audio_classification.md
|
# Audio classification
[[open-in-colab]]
Audio classification - just like with text - assigns a class label output from the input data. The only difference is instead of text inputs, you have raw audio waveforms. Some practical applications of audio classification include identifying speaker intent, language classification, and even animal species by their sounds.
This guide will show you how to:
1. Finetune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to classify speaker intent.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load MInDS-14 dataset
Start by loading the MInDS-14 dataset from the 🤗 Datasets library:
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
Split the dataset's `train` split into a smaller train and test set with the [`~datasets.Dataset.train_test_split`] method. This'll give you a chance to experiment and make sure everything works before spending more time on the full dataset.
>>> minds = minds.train_test_split(test_size=0.2)
Then take a look at the dataset:
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 450
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 113
})
})
While the dataset contains a lot of useful information, like `lang_id` and `english_transcription`, you'll focus on the `audio` and `intent_class` in this guide. Remove the other columns with the [`~datasets.Dataset.remove_columns`] method:
>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
Take a look at an example now:
>>> minds["train"][0]
{'audio': {'array': array([ 0. , 0. , 0. , , -0.00048828,
-0.00024414, -0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 8000},
'intent_class': 2}
There are two fields:
- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
- `intent_class`: represents the class id of the speaker's intent.
To make it easier for the model to get the label name from the label id, create a dictionary that maps the label name to an integer and vice versa:
>>> labels = minds["train"].features["intent_class"].names
>>> label2id, id2label = dict(), dict()
>>> for i, label in enumerate(labels):
label2id[label] = str(i)
id2label[str(i)] = label
Now you can convert the label id to a label name:
>>> id2label[str(2)]
'app_error'
## Preprocess
The next step is to load a Wav2Vec2 feature extractor to process the audio signal:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
The MInDS-14 dataset has a sampling rate of 8000khz (you can find this information in it's [dataset card](https://huggingface.co/datasets/PolyAI/minds14)), which means you'll need to resample the dataset to 16000kHz to use the pretrained Wav2Vec2 model:
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ,
-2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 16000},
'intent_class': 2}
Now create a preprocessing function that:
1. Calls the `audio` column to load, and if necessary, resample the audio file.
2. Checks if the sampling rate of the audio file matches the sampling rate of the audio data a model was pretrained with. You can find this information in the Wav2Vec2 [model card](https://huggingface.co/facebook/wav2vec2-base).
3. Set a maximum input length to batch longer inputs without truncating them.
>>> def preprocess_function(examples):
audio_arrays = [x["array"] for x in examples["audio"]]
inputs = feature_extractor(
audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
)
return inputs
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by setting `batched=True` to process multiple elements of the dataset at once. Remove the columns you don't need, and rename `intent_class` to `label` because that's the name the model expects:
>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
>>> import numpy as np
>>> def compute_metrics(eval_pred):
predictions = np.argmax(eval_pred.predictions, axis=1)
return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load Wav2Vec2 with [`AutoModelForAudioClassification`] along with the number of expected labels, and the label mappings:
>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
>>> num_labels = len(id2label)
>>> model = AutoModelForAudioClassification.from_pretrained(
"facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_mind_model",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=3e-5,
per_device_train_batch_size=32,
gradient_accumulation_steps=4,
per_device_eval_batch_size=32,
num_train_epochs=10,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_minds["train"],
eval_dataset=encoded_minds["test"],
tokenizer=feature_extractor,
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
For a more in-depth example of how to finetune a model for audio classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an audio file you'd like to run inference on. Remember to resample the sampling rate of the audio file to match the sampling rate of the model if you need to!
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for audio classification with your model, and pass your audio file to it:
>>> from transformers import pipeline
>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
>>> classifier(audio_file)
[
{'score': 0.09766869246959686, 'label': 'cash_deposit'},
{'score': 0.07998877018690109, 'label': 'app_error'},
{'score': 0.0781070664525032, 'label': 'joint_account'},
{'score': 0.07667109370231628, 'label': 'pay_bill'},
{'score': 0.0755252093076706, 'label': 'balance'}
]
You can also manually replicate the results of the `pipeline` if you'd like:
Load a feature extractor to preprocess the audio file and return the `input` as PyTorch tensors:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
Pass your inputs to the model and return the logits:
>>> from transformers import AutoModelForAudioClassification
>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
>>> with torch.no_grad():
logits = model(**inputs).logits
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a label:
>>> import torch
>>> predicted_class_ids = torch.argmax(logits).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'cash_deposit'
|
tasks/prompting.md
|
# LLM prompting guide
[[open-in-colab]]
Large Language Models such as Falcon, LLaMA, etc. are pretrained transformer models initially trained to predict the
next token given some input text. They typically have billions of parameters and have been trained on trillions of
tokens for an extended period of time. As a result, these models become quite powerful and versatile, and you can use
them to solve multiple NLP tasks out of the box by instructing the models with natural language prompts.
Designing such prompts to ensure the optimal output is often called "prompt engineering". Prompt engineering is an
iterative process that requires a fair amount of experimentation. Natural languages are much more flexible and expressive
than programming languages, however, they can also introduce some ambiguity. At the same time, prompts in natural language
are quite sensitive to changes. Even minor modifications in prompts can lead to wildly different outputs.
While there is no exact recipe for creating prompts to match all cases, researchers have worked out a number of best
practices that help to achieve optimal results more consistently.
This guide covers the prompt engineering best practices to help you craft better LLM prompts and solve various NLP tasks.
You'll learn:
- [Basics of prompting](#basic-prompts)
- [Best practices of LLM prompting](#best-practices-of-llm-prompting)
- [Advanced prompting techniques: few-shot prompting and chain-of-thought](#advanced-prompting-techniques)
- [When to fine-tune instead of prompting](#prompting-vs-fine-tuning)
Prompt engineering is only a part of the LLM output optimization process. Another essential component is choosing the
optimal text generation strategy. You can customize how your LLM selects each of the subsequent tokens when generating
the text without modifying any of the trainable parameters. By tweaking the text generation parameters, you can reduce
repetition in the generated text and make it more coherent and human-sounding.
Text generation strategies and parameters are out of scope for this guide, but you can learn more about these topics in
the following guides:
* [Generation with LLMs](../llm_tutorial)
* [Text generation strategies](../generation_strategies)
## Basics of prompting
### Types of models
The majority of modern LLMs are decoder-only transformers. Some examples include: [LLaMA](../model_doc/llama),
[Llama2](../model_doc/llama2), [Falcon](../model_doc/falcon), [GPT2](../model_doc/gpt2). However, you may encounter
encoder-decoder transformer LLMs as well, for instance, [Flan-T5](../model_doc/flan-t5) and [BART](../model_doc/bart).
Encoder-decoder-style models are typically used in generative tasks where the output **heavily** relies on the input, for
example, in translation and summarization. The decoder-only models are used for all other types of generative tasks.
When using a pipeline to generate text with an LLM, it's important to know what type of LLM you are using, because
they use different pipelines.
Run inference with decoder-only models with the `text-generation` pipeline:
thon
>>> from transformers import pipeline
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> generator = pipeline('text-generation', model = 'gpt2')
>>> prompt = "Hello, I'm a language model"
>>> generator(prompt, max_length = 30)
[{'generated_text': "Hello, I'm a language model expert, so I'm a big believer in the concept that I know very well and then I try to look into"}]
To run inference with an encoder-decoder, use the `text2text-generation` pipeline:
thon
>>> text2text_generator = pipeline("text2text-generation", model = 'google/flan-t5-base')
>>> prompt = "Translate from English to French: I'm very happy to see you"
>>> text2text_generator(prompt)
[{'generated_text': 'Je suis très heureuse de vous rencontrer.'}]
### Base vs instruct/chat models
Most of the recent LLM checkpoints available on 🤗 Hub come in two versions: base and instruct (or chat). For example,
[`tiiuae/falcon-7b`](https://huggingface.co/tiiuae/falcon-7b) and [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct).
Base models are excellent at completing the text when given an initial prompt, however, they are not ideal for NLP tasks
where they need to follow instructions, or for conversational use. This is where the instruct (chat) versions come in.
These checkpoints are the result of further fine-tuning of the pre-trained base versions on instructions and conversational data.
This additional fine-tuning makes them a better choice for many NLP tasks.
Let's illustrate some simple prompts that you can use with [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)
to solve some common NLP tasks.
### NLP tasks
First, let's set up the environment:
```bash
pip install -q transformers accelerate
Next, let's load the model with the appropriate pipeline (`"text-generation"`):
thon
>>> from transformers import pipeline, AutoTokenizer
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> model = "tiiuae/falcon-7b-instruct"
>>> tokenizer = AutoTokenizer.from_pretrained(model)
>>> pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto",
)
Note that Falcon models were trained using the `bfloat16` datatype, so we recommend you use the same. This requires a recent
version of CUDA and works best on modern cards.
Now that we have the model loaded via the pipeline, let's explore how you can use prompts to solve NLP tasks.
#### Text classification
One of the most common forms of text classification is sentiment analysis, which assigns a label like "positive", "negative",
or "neutral" to a sequence of text. Let's write a prompt that instructs the model to classify a given text (a movie review).
We'll start by giving the instruction, and then specifying the text to classify. Note that instead of leaving it at that, we're
also adding the beginning of the response - `"Sentiment: "`:
thon
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Classify the text into neutral, negative or positive.
Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
Sentiment:
"""
>>> sequences = pipe(
prompt,
max_new_tokens=10,
)
>>> for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Classify the text into neutral, negative or positive.
Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
Sentiment:
Positive
As a result, the output contains a classification label from the list we have provided in the instructions, and it is a correct one!
You may notice that in addition to the prompt, we pass a `max_new_tokens` parameter. It controls the number of tokens the
model shall generate, and it is one of the many text generation parameters that you can learn about
in [Text generation strategies](../generation_strategies) guide.
#### Named Entity Recognition
Named Entity Recognition (NER) is a task of finding named entities in a piece of text, such as a person, location, or organization.
Let's modify the instructions in the prompt to make the LLM perform this task. Here, let's also set `return_full_text = False`
so that output doesn't contain the prompt:
thon
>>> torch.manual_seed(1) # doctest: +IGNORE_RESULT
>>> prompt = """Return a list of named entities in the text.
Text: The Golden State Warriors are an American professional basketball team based in San Francisco.
Named entities:
"""
>>> sequences = pipe(
prompt,
max_new_tokens=15,
return_full_text = False,
)
>>> for seq in sequences:
print(f"{seq['generated_text']}")
- Golden State Warriors
- San Francisco
As you can see, the model correctly identified two named entities from the given text.
#### Translation
Another task LLMs can perform is translation. You can choose to use encoder-decoder models for this task, however, here,
for the simplicity of the examples, we'll keep using Falcon-7b-instruct, which does a decent job. Once again, here's how
you can write a basic prompt to instruct a model to translate a piece of text from English to Italian:
thon
>>> torch.manual_seed(2) # doctest: +IGNORE_RESULT
>>> prompt = """Translate the English text to Italian.
Text: Sometimes, I've believed as many as six impossible things before breakfast.
Translation:
"""
>>> sequences = pipe(
prompt,
max_new_tokens=20,
do_sample=True,
top_k=10,
return_full_text = False,
)
>>> for seq in sequences:
print(f"{seq['generated_text']}")
A volte, ho creduto a sei impossibili cose prima di colazione.
Here we've added a `do_sample=True` and `top_k=10` to allow the model to be a bit more flexible when generating output.
#### Text summarization
Similar to the translation, text summarization is another generative task where the output **heavily** relies on the input,
and encoder-decoder models can be a better choice. However, decoder-style models can be used for this task as well.
Previously, we have placed the instructions at the very beginning of the prompt. However, the very end of the prompt can
also be a suitable location for instructions. Typically, it's better to place the instruction on one of the extreme ends.
thon
>>> torch.manual_seed(3) # doctest: +IGNORE_RESULT
>>> prompt = """Permaculture is a design process mimicking the diversity, functionality and resilience of natural ecosystems. The principles and practices are drawn from traditional ecological knowledge of indigenous cultures combined with modern scientific understanding and technological innovations. Permaculture design provides a framework helping individuals and communities develop innovative, creative and effective strategies for meeting basic needs while preparing for and mitigating the projected impacts of climate change.
Write a summary of the above text.
Summary:
"""
>>> sequences = pipe(
prompt,
max_new_tokens=30,
do_sample=True,
top_k=10,
return_full_text = False,
)
>>> for seq in sequences:
print(f"{seq['generated_text']}")
Permaculture is an ecological design mimicking natural ecosystems to meet basic needs and prepare for climate change. It is based on traditional knowledge and scientific understanding.
#### Question answering
For question answering task we can structure the prompt into the following logical components: instructions, context, question, and
the leading word or phrase (`"Answer:"`) to nudge the model to start generating the answer:
thon
>>> torch.manual_seed(4) # doctest: +IGNORE_RESULT
>>> prompt = """Answer the question using the context below.
Context: Gazpacho is a cold soup and drink made of raw, blended vegetables. Most gazpacho includes stale bread, tomato, cucumbers, onion, bell peppers, garlic, olive oil, wine vinegar, water, and salt. Northern recipes often include cumin and/or pimentón (smoked sweet paprika). Traditionally, gazpacho was made by pounding the vegetables in a mortar with a pestle; this more laborious method is still sometimes used as it helps keep the gazpacho cool and avoids the foam and silky consistency of smoothie versions made in blenders or food processors.
Question: What modern tool is used to make gazpacho?
Answer:
"""
>>> sequences = pipe(
prompt,
max_new_tokens=10,
do_sample=True,
top_k=10,
return_full_text = False,
)
>>> for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Modern tools are used, such as immersion blenders
#### Reasoning
Reasoning is one of the most difficult tasks for LLMs, and achieving good results often requires applying advanced prompting techniques, like
[Chain-of-though](#chain-of-thought).
Let's try if we can make a model reason about a simple arithmetics task with a basic prompt:
thon
>>> torch.manual_seed(5) # doctest: +IGNORE_RESULT
>>> prompt = """There are 5 groups of students in the class. Each group has 4 students. How many students are there in the class?"""
>>> sequences = pipe(
prompt,
max_new_tokens=30,
do_sample=True,
top_k=10,
return_full_text = False,
)
>>> for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result:
There are a total of 5 groups, so there are 5 x 4=20 students in the class.
Correct! Let's increase the complexity a little and see if we can still get away with a basic prompt:
thon
>>> torch.manual_seed(6) # doctest: +IGNORE_RESULT
>>> prompt = """I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My partner then bought 6 more muffins and ate 2. How many muffins do we now have?"""
>>> sequences = pipe(
prompt,
max_new_tokens=10,
do_sample=True,
top_k=10,
return_full_text = False,
)
>>> for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result:
The total number of muffins now is 21
This is a wrong answer, it should be 12. In this case, this can be due to the prompt being too basic, or due to the choice
of model, after all we've picked the smallest version of Falcon. Reasoning is difficult for models of all sizes, but larger
models are likely to perform better.
## Best practices of LLM prompting
In this section of the guide we have compiled a list of best practices that tend to improve the prompt results:
* When choosing the model to work with, the latest and most capable models are likely to perform better.
* Start with a simple and short prompt, and iterate from there.
* Put the instructions at the beginning of the prompt, or at the very end. When working with large context, models apply various optimizations to prevent Attention complexity from scaling quadratically. This may make a model more attentive to the beginning or end of a prompt than the middle.
* Clearly separate instructions from the text they apply to - more on this in the next section.
* Be specific and descriptive about the task and the desired outcome - its format, length, style, language, etc.
* Avoid ambiguous descriptions and instructions.
* Favor instructions that say "what to do" instead of those that say "what not to do".
* "Lead" the output in the right direction by writing the first word (or even begin the first sentence for the model).
* Use advanced techniques like [Few-shot prompting](#few-shot-prompting) and [Chain-of-thought](#chain-of-thought)
* Test your prompts with different models to assess their robustness.
* Version and track the performance of your prompts.
## Advanced prompting techniques
### Few-shot prompting
The basic prompts in the sections above are the examples of "zero-shot" prompts, meaning, the model has been given
instructions and context, but no examples with solutions. LLMs that have been fine-tuned on instruction datasets, generally
perform well on such "zero-shot" tasks. However, you may find that your task has more complexity or nuance, and, perhaps,
you have some requirements for the output that the model doesn't catch on just from the instructions. In this case, you can
try the technique called few-shot prompting.
In few-shot prompting, we provide examples in the prompt giving the model more context to improve the performance.
The examples condition the model to generate the output following the patterns in the examples.
Here's an example:
thon
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Text: The first human went into space and orbited the Earth on April 12, 1961.
Date: 04/12/1961
Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
Date:"""
>>> sequences = pipe(
prompt,
max_new_tokens=8,
do_sample=True,
top_k=10,
)
>>> for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Text: The first human went into space and orbited the Earth on April 12, 1961.
Date: 04/12/1961
Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
Date: 09/28/1960
In the above code snippet we used a single example to demonstrate the desired output to the model, so this can be called a
"one-shot" prompting. However, depending on the task complexity you may need to use more than one example.
Limitations of the few-shot prompting technique:
- While LLMs can pick up on the patterns in the examples, these technique doesn't work well on complex reasoning tasks
- Few-shot prompting requires creating lengthy prompts. Prompts with large number of tokens can increase computation and latency. There's also a limit to the length of the prompts.
- Sometimes when given a number of examples, models can learn patterns that you didn't intend them to learn, e.g. that the third movie review is always negative.
### Chain-of-thought
Chain-of-thought (CoT) prompting is a technique that nudges a model to produce intermediate reasoning steps thus improving
the results on complex reasoning tasks.
There are two ways of steering a model to producing the reasoning steps:
- few-shot prompting by illustrating examples with detailed answers to questions, showing the model how to work through a problem.
- by instructing the model to reason by adding phrases like "Let's think step by step" or "Take a deep breath and work through the problem step by step."
If we apply the CoT technique to the muffins example from the [reasoning section](#reasoning) and use a larger model,
such as (`tiiuae/falcon-180B-chat`) which you can play with in the [HuggingChat](https://huggingface.co/chat/),
we'll get a significant improvement on the reasoning result:
```text
Let's go through this step-by-step:
1. You start with 15 muffins.
2. You eat 2 muffins, leaving you with 13 muffins.
3. You give 5 muffins to your neighbor, leaving you with 8 muffins.
4. Your partner buys 6 more muffins, bringing the total number of muffins to 14.
5. Your partner eats 2 muffins, leaving you with 12 muffins.
Therefore, you now have 12 muffins.
## Prompting vs fine-tuning
You can achieve great results by optimizing your prompts, however, you may still ponder whether fine-tuning a model
would work better for your case. Here are some scenarios when fine-tuning a smaller model may be a preferred option:
- Your domain is wildly different from what LLMs were pre-trained on and extensive prompt optimization did not yield sufficient results.
- You need your model to work well in a low-resource language.
- You need the model to be trained on sensitive data that is under strict regulations.
- You have to use a small model due to cost, privacy, infrastructure or other limitations.
In all of the above examples, you will need to make sure that you either already have or can easily obtain a large enough
domain-specific dataset at a reasonable cost to fine-tune a model. You will also need to have enough time and resources
to fine-tune a model.
If the above examples are not the case for you, optimizing prompts can prove to be more beneficial.
|
tasks/asr.md
|
# Automatic speech recognition
[[open-in-colab]]
Automatic speech recognition (ASR) converts a speech signal to text, mapping a sequence of audio inputs to text outputs. Virtual assistants like Siri and Alexa use ASR models to help users everyday, and there are many other useful user-facing applications like live captioning and note-taking during meetings.
This guide will show you how to:
1. Finetune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to transcribe audio to text.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate jiwer
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load MInDS-14 dataset
Start by loading a smaller subset of the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
Split the dataset's `train` split into a train and test set with the [`~Dataset.train_test_split`] method:
>>> minds = minds.train_test_split(test_size=0.2)
Then take a look at the dataset:
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
While the dataset contains a lot of useful information, like `lang_id` and `english_transcription`, you'll focus on the `audio` and `transcription` in this guide. Remove the other columns with the [`~datasets.Dataset.remove_columns`] method:
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
Take a look at the example again:
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , , 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
There are two fields:
- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
- `transcription`: the target text.
## Preprocess
The next step is to load a Wav2Vec2 processor to process the audio signal:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
The MInDS-14 dataset has a sampling rate of 8000kHz (you can find this information in its [dataset card](https://huggingface.co/datasets/PolyAI/minds14)), which means you'll need to resample the dataset to 16000kHz to use the pretrained Wav2Vec2 model:
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
As you can see in the `transcription` above, the text contains a mix of upper and lowercase characters. The Wav2Vec2 tokenizer is only trained on uppercase characters so you'll need to make sure the text matches the tokenizer's vocabulary:
>>> def uppercase(example):
return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
Now create a preprocessing function that:
1. Calls the `audio` column to load and resample the audio file.
2. Extracts the `input_values` from the audio file and tokenize the `transcription` column with the processor.
>>> def prepare_dataset(batch):
audio = batch["audio"]
batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
batch["input_length"] = len(batch["input_values"][0])
return batch
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by increasing the number of processes with the `num_proc` parameter. Remove the columns you don't need with the [`~datasets.Dataset.remove_columns`] method:
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
🤗 Transformers doesn't have a data collator for ASR, so you'll need to adapt the [`DataCollatorWithPadding`] to create a batch of examples. It'll also dynamically pad your text and labels to the length of the longest element in its batch (instead of the entire dataset) so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
Unlike other data collators, this specific data collator needs to apply a different padding method to `input_values` and `labels`:
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
class DataCollatorCTCWithPadding:
processor: AutoProcessor
padding: Union[bool, str] = "longest"
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"][0]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
Now instantiate your `DataCollatorForCTCWithPadding`:
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [word error rate](https://huggingface.co/spaces/evaluate-metric/wer) (WER) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> wer = evaluate.load("wer")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the WER:
>>> import numpy as np
>>> def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load Wav2Vec2 with [`AutoModelForCTC`]. Specify the reduction to apply with the `ctc_loss_reduction` parameter. It is often better to use the average instead of the default summation:
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
"facebook/wav2vec2-base",
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the WER and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_asr_mind_model",
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
learning_rate=1e-5,
warmup_steps=500,
max_steps=2000,
gradient_checkpointing=True,
fp16=True,
group_by_length=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_minds["train"],
eval_dataset=encoded_minds["test"],
tokenizer=processor,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
For a more in-depth example of how to finetune a model for automatic speech recognition, take a look at this blog [post](https://huggingface.co/blog/fine-tune-wav2vec2-english) for English ASR and this [post](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for multilingual ASR.
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an audio file you'd like to run inference on. Remember to resample the sampling rate of the audio file to match the sampling rate of the model if you need to!
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for automatic speech recognition with your model, and pass your audio file to it:
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
The transcription is decent, but it could be better! Try finetuning your model on more examples to get even better results!
You can also manually replicate the results of the `pipeline` if you'd like:
Load a processor to preprocess the audio file and transcription and return the `input` as PyTorch tensors:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
Pass your inputs to the model and return the logits:
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
logits = model(**inputs).logits
Get the predicted `input_ids` with the highest probability, and use the processor to decode the predicted `input_ids` back into text:
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
|
tasks/token_classification.md
|
# Token classification
[[open-in-colab]]
Token classification assigns a label to individual tokens in a sentence. One of the most common token classification tasks is Named Entity Recognition (NER). NER attempts to find a label for each entity in a sentence, such as a person, location, or organization.
This guide will show you how to:
1. Finetune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [WNUT 17](https://huggingface.co/datasets/wnut_17) dataset to detect new entities.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [BROS](../model_doc/bros), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [Phi](../model_doc/phi), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate seqeval
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load WNUT 17 dataset
Start by loading the WNUT 17 dataset from the 🤗 Datasets library:
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17")
Then take a look at an example:
>>> wnut["train"][0]
{'id': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
}
Each number in `ner_tags` represents an entity. Convert the numbers to their label names to find out what the entities are:
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> label_list
[
"O",
"B-corporation",
"I-corporation",
"B-creative-work",
"I-creative-work",
"B-group",
"I-group",
"B-location",
"I-location",
"B-person",
"I-person",
"B-product",
"I-product",
]
The letter that prefixes each `ner_tag` indicates the token position of the entity:
- `B-` indicates the beginning of an entity.
- `I-` indicates a token is contained inside the same entity (for example, the `State` token is a part of an entity like
`Empire State Building`).
- `0` indicates the token doesn't correspond to any entity.
## Preprocess
The next step is to load a DistilBERT tokenizer to preprocess the `tokens` field:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
As you saw in the example `tokens` field above, it looks like the input has already been tokenized. But the input actually hasn't been tokenized yet and you'll need to set `is_split_into_words=True` to tokenize the words into subwords. For example:
>>> example = wnut["train"][0]
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
>>> tokens
['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
However, this adds some special tokens `[CLS]` and `[SEP]` and the subword tokenization creates a mismatch between the input and labels. A single word corresponding to a single label may now be split into two subwords. You'll need to realign the tokens and labels by:
1. Mapping all tokens to their corresponding word with the [`word_ids`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.BatchEncoding.word_ids) method.
2. Assigning the label `-100` to the special tokens `[CLS]` and `[SEP]` so they're ignored by the PyTorch loss function (see [CrossEntropyLoss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html)).
3. Only labeling the first token of a given word. Assign `-100` to other subtokens from the same word.
Here is how you can create a function to realign the tokens and labels, and truncate sequences to be no longer than DistilBERT's maximum input length:
>>> def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples[f"ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
previous_word_idx = None
label_ids = []
for word_idx in word_ids: # Set the special tokens to -100.
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx: # Only label the first token of a given word.
label_ids.append(label[word_idx])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
Now create a batch of examples using [`DataCollatorWithPadding`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [seqeval](https://huggingface.co/spaces/evaluate-metric/seqeval) framework (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric). Seqeval actually produces several scores: precision, recall, F1, and accuracy.
>>> import evaluate
>>> seqeval = evaluate.load("seqeval")
Get the NER labels first, and then create a function that passes your true predictions and true labels to [`~evaluate.EvaluationModule.compute`] to calculate the scores:
>>> import numpy as np
>>> labels = [label_list[i] for i in example[f"ner_tags"]]
>>> def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = seqeval.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
Before you start training your model, create a map of the expected ids to their labels with `id2label` and `label2id`:
>>> id2label = {
0: "O",
1: "B-corporation",
2: "I-corporation",
3: "B-creative-work",
4: "I-creative-work",
5: "B-group",
6: "I-group",
7: "B-location",
8: "I-location",
9: "B-person",
10: "I-person",
11: "B-product",
12: "I-product",
}
>>> label2id = {
"O": 0,
"B-corporation": 1,
"I-corporation": 2,
"B-creative-work": 3,
"I-creative-work": 4,
"B-group": 5,
"I-group": 6,
"B-location": 7,
"I-location": 8,
"B-person": 9,
"I-person": 10,
"B-product": 11,
"I-product": 12,
}
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load DistilBERT with [`AutoModelForTokenClassification`] along with the number of expected labels, and the label mappings:
>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
>>> model = AutoModelForTokenClassification.from_pretrained(
"distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the seqeval scores and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_wnut_model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_wnut["train"],
eval_dataset=tokenized_wnut["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 3
>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
>>> optimizer, lr_schedule = create_optimizer(
init_lr=2e-5,
num_train_steps=num_train_steps,
weight_decay_rate=0.01,
num_warmup_steps=0,
)
Then you can load DistilBERT with [`TFAutoModelForTokenClassification`] along with the number of expected labels, and the label mappings:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained(
"distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
)
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
tokenized_wnut["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_validation_set = model.prepare_tf_dataset(
tokenized_wnut["validation"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
The last two things to setup before you start training is to compute the seqeval scores from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
output_dir="my_awesome_wnut_model",
tokenizer=tokenizer,
)
Then bundle your callbacks together:
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for token classification, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Grab some text you'd like to run inference on:
>>> text = "The Golden State Warriors are an American professional basketball team based in San Francisco."
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for NER with your model, and pass your text to it:
>>> from transformers import pipeline
>>> classifier = pipeline("ner", model="stevhliu/my_awesome_wnut_model")
>>> classifier(text)
[{'entity': 'B-location',
'score': 0.42658573,
'index': 2,
'word': 'golden',
'start': 4,
'end': 10},
{'entity': 'I-location',
'score': 0.35856336,
'index': 3,
'word': 'state',
'start': 11,
'end': 16},
{'entity': 'B-group',
'score': 0.3064001,
'index': 4,
'word': 'warriors',
'start': 17,
'end': 25},
{'entity': 'B-location',
'score': 0.65523505,
'index': 13,
'word': 'san',
'start': 80,
'end': 83},
{'entity': 'B-location',
'score': 0.4668663,
'index': 14,
'word': 'francisco',
'start': 84,
'end': 93}]
You can also manually replicate the results of the `pipeline` if you'd like:
Tokenize the text and return PyTorch tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="pt")
Pass your inputs to the model and return the `logits`:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> with torch.no_grad():
logits = model(**inputs).logits
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
>>> predictions = torch.argmax(logits, dim=2)
>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
Tokenize the text and return TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="tf")
Pass your inputs to the model and return the `logits`:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> logits = model(**inputs).logits
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
|
tasks/image_to_image.md
|
# Image-to-Image Task Guide
[[open-in-colab]]
Image-to-Image task is the task where an application receives an image and outputs another image. This has various subtasks, including image enhancement (super resolution, low light enhancement, deraining and so on), image inpainting, and more.
This guide will show you how to:
- Use an image-to-image pipeline for super resolution task,
- Run image-to-image models for same task without a pipeline.
Note that as of the time this guide is released, `image-to-image` pipeline only supports super resolution task.
Let's begin by installing the necessary libraries.
```bash
pip install transformers
We can now initialize the pipeline with a [Swin2SR model](https://huggingface.co/caidas/swin2SR-lightweight-x2-64). We can then infer with the pipeline by calling it with an image. As of now, only [Swin2SR models](https://huggingface.co/models?sort=trending&search=swin2sr) are supported in this pipeline.
thon
from transformers import pipeline
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pipe = pipeline(task="image-to-image", model="caidas/swin2SR-lightweight-x2-64", device=device)
Now, let's load an image.
thon
from PIL import Image
import requests
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/cat.jpg"
image = Image.open(requests.get(url, stream=True).raw)
print(image.size)
```bash
# (532, 432)
We can now do inference with the pipeline. We will get an upscaled version of the cat image.
thon
upscaled = pipe(image)
print(upscaled.size)
```bash
# (1072, 880)
If you wish to do inference yourself with no pipeline, you can use the `Swin2SRForImageSuperResolution` and `Swin2SRImageProcessor` classes of transformers. We will use the same model checkpoint for this. Let's initialize the model and the processor.
thon
from transformers import Swin2SRForImageSuperResolution, Swin2SRImageProcessor
model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-lightweight-x2-64").to(device)
processor = Swin2SRImageProcessor("caidas/swin2SR-lightweight-x2-64")
`pipeline` abstracts away the preprocessing and postprocessing steps that we have to do ourselves, so let's preprocess the image. We will pass the image to the processor and then move the pixel values to GPU.
thon
pixel_values = processor(image, return_tensors="pt").pixel_values
print(pixel_values.shape)
pixel_values = pixel_values.to(device)
We can now infer the image by passing pixel values to the model.
thon
import torch
with torch.no_grad():
outputs = model(pixel_values)
Output is an object of type `ImageSuperResolutionOutput` that looks like below 👇
(loss=None, reconstruction=tensor([[[[0.8270, 0.8269, 0.8275, , 0.7463, 0.7446, 0.7453],
[0.8287, 0.8278, 0.8283, , 0.7451, 0.7448, 0.7457],
[0.8280, 0.8273, 0.8269, , 0.7447, 0.7446, 0.7452],
,
[0.5923, 0.5933, 0.5924, , 0.0697, 0.0695, 0.0706],
[0.5926, 0.5932, 0.5926, , 0.0673, 0.0687, 0.0705],
[0.5927, 0.5914, 0.5922, , 0.0664, 0.0694, 0.0718]]]],
device='cuda:0'), hidden_states=None, attentions=None)
We need to get the `reconstruction` and post-process it for visualization. Let's see how it looks like.
thon
outputs.reconstruction.data.shape
# torch.Size([1, 3, 880, 1072])
We need to squeeze the output and get rid of axis 0, clip the values, then convert it to be numpy float. Then we will arrange axes to have the shape [1072, 880], and finally, bring the output back to range [0, 255].
thon
import numpy as np
# squeeze, take to CPU and clip the values
output = outputs.reconstruction.data.squeeze().cpu().clamp_(0, 1).numpy()
# rearrange the axes
output = np.moveaxis(output, source=0, destination=-1)
# bring values back to pixel values range
output = (output * 255.0).round().astype(np.uint8)
Image.fromarray(output)
|
tasks/text-to-speech.md
|
# Text to speech
[[open-in-colab]]
Text-to-speech (TTS) is the task of creating natural-sounding speech from text, where the speech can be generated in multiple
languages and for multiple speakers. Several text-to-speech models are currently available in 🤗 Transformers, such as
[Bark](../model_doc/bark), [MMS](../model_doc/mms), [VITS](../model_doc/vits) and [SpeechT5](../model_doc/speecht5).
You can easily generate audio using the `"text-to-audio"` pipeline (or its alias - `"text-to-speech"`). Some models, like Bark,
can also be conditioned to generate non-verbal communications such as laughing, sighing and crying, or even add music.
Here's an example of how you would use the `"text-to-speech"` pipeline with Bark:
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="suno/bark-small")
>>> text = "[clears throat] This is a test and I just took a long pause."
>>> output = pipe(text)
Here's a code snippet you can use to listen to the resulting audio in a notebook:
thon
>>> from IPython.display import Audio
>>> Audio(output["audio"], rate=output["sampling_rate"])
For more examples on what Bark and other pretrained TTS models can do, refer to our
[Audio course](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models).
If you are looking to fine-tune a TTS model, you can currently fine-tune SpeechT5 only. SpeechT5 is pre-trained on a combination of
speech-to-text and text-to-speech data, allowing it to learn a unified space of hidden representations shared by both text
and speech. This means that the same pre-trained model can be fine-tuned for different tasks. Furthermore, SpeechT5
supports multiple speakers through x-vector speaker embeddings.
The remainder of this guide illustrates how to:
1. Fine-tune [SpeechT5](../model_doc/speecht5) that was originally trained on English speech on the Dutch (`nl`) language subset of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) dataset.
2. Use your refined model for inference in one of two ways: using a pipeline or directly.
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install datasets soundfile speechbrain accelerate
Install 🤗Transformers from source as not all the SpeechT5 features have been merged into an official release yet:
```bash
pip install git+https://github.com/huggingface/transformers.git
To follow this guide you will need a GPU. If you're working in a notebook, run the following line to check if a GPU is available:
```bash
!nvidia-smi
We encourage you to log in to your Hugging Face account to upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load the dataset
[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) is a large-scale multilingual speech corpus consisting of
data sourced from 2009-2020 European Parliament event recordings. It contains labelled audio-transcription data for 15
European languages. In this guide, we are using the Dutch language subset, feel free to pick another subset.
Note that VoxPopuli or any other automated speech recognition (ASR) dataset may not be the most suitable
option for training TTS models. The features that make it beneficial for ASR, such as excessive background noise, are
typically undesirable in TTS. However, finding top-quality, multilingual, and multi-speaker TTS datasets can be quite
challenging.
Let's load the data:
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
>>> len(dataset)
20968
20968 examples should be sufficient for fine-tuning. SpeechT5 expects audio data to have a sampling rate of 16 kHz, so
make sure the examples in the dataset meet this requirement:
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
## Preprocess the data
Let's begin by defining the model checkpoint to use and loading the appropriate processor:
>>> from transformers import SpeechT5Processor
>>> checkpoint = "microsoft/speecht5_tts"
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
### Text cleanup for SpeechT5 tokenization
Start by cleaning up the text data. You'll need the tokenizer part of the processor to process the text:
>>> tokenizer = processor.tokenizer
The dataset examples contain `raw_text` and `normalized_text` features. When deciding which feature to use as the text input,
consider that the SpeechT5 tokenizer doesn't have any tokens for numbers. In `normalized_text` the numbers are written
out as text. Thus, it is a better fit, and we recommend using `normalized_text` as input text.
Because SpeechT5 was trained on the English language, it may not recognize certain characters in the Dutch dataset. If
left as is, these characters will be converted to `` tokens. However, in Dutch, certain characters like `à` are
used to stress syllables. In order to preserve the meaning of the text, we can replace this character with a regular `a`.
To identify unsupported tokens, extract all unique characters in the dataset using the `SpeechT5Tokenizer` which
works with characters as tokens. To do this, write the `extract_all_chars` mapping function that concatenates
the transcriptions from all examples into one string and converts it to a set of characters.
Make sure to set `batched=True` and `batch_size=-1` in `dataset.map()` so that all transcriptions are available at once for
the mapping function.
>>> def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
>>> vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
>>> dataset_vocab = set(vocabs["vocab"][0])
>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
Now you have two sets of characters: one with the vocabulary from the dataset and one with the vocabulary from the tokenizer.
To identify any unsupported characters in the dataset, you can take the difference between these two sets. The resulting
set will contain the characters that are in the dataset but not in the tokenizer.
>>> dataset_vocab - tokenizer_vocab
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
To handle the unsupported characters identified in the previous step, define a function that maps these characters to
valid tokens. Note that spaces are already replaced by `▁` in the tokenizer and don't need to be handled separately.
>>> replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
>>> def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
>>> dataset = dataset.map(cleanup_text)
Now that you have dealt with special characters in the text, it's time to shift focus to the audio data.
### Speakers
The VoxPopuli dataset includes speech from multiple speakers, but how many speakers are represented in the dataset? To
determine this, we can count the number of unique speakers and the number of examples each speaker contributes to the dataset.
With a total of 20,968 examples in the dataset, this information will give us a better understanding of the distribution of
speakers and examples in the data.
>>> from collections import defaultdict
>>> speaker_counts = defaultdict(int)
>>> for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1
By plotting a histogram you can get a sense of how much data there is for each speaker.
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.hist(speaker_counts.values(), bins=20)
>>> plt.ylabel("Speakers")
>>> plt.xlabel("Examples")
>>> plt.show()
The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
the data to speakers with between 100 and 400 examples.
>>> def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
Let's check how many speakers remain:
>>> len(set(dataset["speaker_id"]))
42
Let's see how many examples are left:
>>> len(dataset)
9973
You are left with just under 10,000 examples from approximately 40 unique speakers, which should be sufficient.
Note that some speakers with few examples may actually have more audio available if the examples are long. However,
determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
time-consuming process that involves loading and decoding each audio file. As such, we have chosen to skip this step here.
### Speaker embeddings
To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
The speaker embedding is an additional input into the model that captures a particular speaker's voice characteristics.
To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
model from SpeechBrain.
Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
containing the corresponding speaker embedding.
>>> import os
>>> import torch
>>> from speechbrain.pretrained import EncoderClassifier
>>> spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
>>> def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddings
It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
reasonable speaker embeddings for our Dutch dataset, this assumption may not hold true in all cases.
For optimal results, we recommend training an X-vector model on the target speech first. This will ensure that the model
is better able to capture the unique voice characteristics present in the Dutch language.
### Processing the dataset
Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
It should also add the speaker embeddings as an additional input.
>>> def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# strip off the batch dimension
example["labels"] = example["labels"][0]
# use SpeechBrain to obtain x-vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return example
Verify the processing is correct by looking at a single example:
>>> processed_example = prepare_dataset(dataset[0])
>>> list(processed_example.keys())
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
Speaker embeddings should be a 512-element vector:
>>> processed_example["speaker_embeddings"].shape
(512,)
The labels should be a log-mel spectrogram with 80 mel bins.
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.imshow(processed_example["labels"].T)
>>> plt.show()
Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
the y-axis is flipped and the spectrograms appear upside down.
Now apply the processing function to the entire dataset. This will take between 5 and 10 minutes.
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
Remove those examples from the dataset. Here we go even further and to allow for larger batch sizes we remove anything over 200 tokens.
>>> def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
>>> dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
>>> len(dataset)
8259
Next, create a basic train/test split:
>>> dataset = dataset.train_test_split(test_size=0.1)
### Data collator
In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with the special value `-100`. This special value
instructs the model to ignore that part of the spectrogram when calculating the spectrogram loss.
>>> from dataclasses import dataclass
>>> from typing import Any, Dict, List, Union
>>> @dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# collate the inputs and targets into a batch
batch = processor.pad(input_ids=input_ids, labels=label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
batch["labels"] = batch["labels"].masked_fill(batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100)
# not used during fine-tuning
del batch["decoder_attention_mask"]
# round down target lengths to multiple of reduction factor
if model.config.reduction_factor > 1:
target_lengths = torch.tensor([len(feature["input_values"]) for feature in label_features])
target_lengths = target_lengths.new(
[length - length % model.config.reduction_factor for length in target_lengths]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# also add in the speaker embeddings
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batch
In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
multiple of 2.
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)
## Train the model
Load the pre-trained model from the same checkpoint as you used for loading the processor:
>>> from transformers import SpeechT5ForTextToSpeech
>>> model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
The `use_cache=True` option is incompatible with gradient checkpointing. Disable it for training.
>>> model.config.use_cache = False
Define the training arguments. Here we are not computing any evaluation metrics during the training process. Instead, we'll
only look at the loss:
thon
>>> from transformers import Seq2SeqTrainingArguments
>>> training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)
Instantiate the `Trainer` object and pass the model, dataset, and data collator to it.
>>> from transformers import Seq2SeqTrainer
>>> trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)
And with that, you're ready to start training! Training will take several hours. Depending on your GPU,
it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
the `per_device_train_batch_size` incrementally by factors of 2 and increase `gradient_accumulation_steps` by 2x to compensate.
>>> trainer.train()
To be able to use your checkpoint with a pipeline, make sure to save the processor with the checkpoint:
>>> processor.save_pretrained("YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
Push the final model to the 🤗 Hub:
>>> trainer.push_to_hub()
## Inference
### Inference with a pipeline
Great, now that you've fine-tuned a model, you can use it for inference!
First, let's see how you can use it with a corresponding pipeline. Let's create a `"text-to-speech"` pipeline with your
checkpoint:
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")
Pick a piece of text in Dutch you'd like narrated, e.g.:
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
To use SpeechT5 with the pipeline, you'll need a speaker embedding. Let's get it from an example in the test dataset:
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
Now you can pass the text and speaker embeddings to the pipeline, and it will take care of the rest:
>>> forward_params = {"speaker_embeddings": speaker_embeddings}
>>> output = pipe(text, forward_params=forward_params)
>>> output
{'audio': array([-6.82714235e-05, -4.26525949e-04, 1.06134125e-04, ,
-1.22392643e-03, -7.76011671e-04, 3.29112721e-04], dtype=float32),
'sampling_rate': 16000}
You can then listen to the result:
>>> from IPython.display import Audio
>>> Audio(output['audio'], rate=output['sampling_rate'])
### Run inference manually
You can achieve the same inference results without using the pipeline, however, more steps will be required.
Load the model from the 🤗 Hub:
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")
Pick an example from the test dataset obtain a speaker embedding.
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
Define the input text and tokenize it.
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")
Create a spectrogram with your model:
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
Visualize the spectrogram, if you'd like to:
>>> plt.figure()
>>> plt.imshow(spectrogram.T)
>>> plt.show()
Finally, use the vocoder to turn the spectrogram into sound.
>>> with torch.no_grad():
speech = vocoder(spectrogram)
>>> from IPython.display import Audio
>>> Audio(speech.numpy(), rate=16000)
In our experience, obtaining satisfactory results from this model can be challenging. The quality of the speaker
embeddings appears to be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
when using English speaker embeddings. If the synthesized speech sounds poor, try using a different speaker embedding.
Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
capture the voice characteristics of the speaker (compare to the original audio in the example).
Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
see if this improves the results.
Finally, it is essential to consider ethical considerations. Although TTS technology has numerous useful applications, it
may also be used for malicious purposes, such as impersonating someone's voice without their knowledge or consent. Please
use TTS judiciously and responsibly.
|
tasks/question_answering.md
|
# Question answering
[[open-in-colab]]
Question answering tasks return an answer given a question. If you've ever asked a virtual assistant like Alexa, Siri or Google what the weather is, then you've used a question answering model before. There are two common types of question answering tasks:
- Extractive: extract the answer from the given context.
- Abstractive: generate an answer from the context that correctly answers the question.
This guide will show you how to:
1. Finetune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [SQuAD](https://huggingface.co/datasets/squad) dataset for extractive question answering.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [OpenAI GPT-2](../model_doc/gpt2), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [LXMERT](../model_doc/lxmert), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OPT](../model_doc/opt), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [Splinter](../model_doc/splinter), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load SQuAD dataset
Start by loading a smaller subset of the SQuAD dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset
>>> squad = load_dataset("squad", split="train[:5000]")
Split the dataset's `train` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> squad = squad.train_test_split(test_size=0.2)
Then take a look at an example:
>>> squad["train"][0]
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
'id': '5733be284776f41900661182',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'title': 'University_of_Notre_Dame'
}
There are several important fields here:
- `answers`: the starting location of the answer token and the answer text.
- `context`: background information from which the model needs to extract the answer.
- `question`: the question a model should answer.
## Preprocess
The next step is to load a DistilBERT tokenizer to process the `question` and `context` fields:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
There are a few preprocessing steps particular to question answering tasks you should be aware of:
1. Some examples in a dataset may have a very long `context` that exceeds the maximum input length of the model. To deal with longer sequences, truncate only the `context` by setting `truncation="only_second"`.
2. Next, map the start and end positions of the answer to the original `context` by setting
`return_offset_mapping=True`.
3. With the mapping in hand, now you can find the start and end tokens of the answer. Use the [`~tokenizers.Encoding.sequence_ids`] method to
find which part of the offset corresponds to the `question` and which corresponds to the `context`.
Here is how you can create a function to truncate and map the start and end tokens of the `answer` to the `context`:
>>> def preprocess_function(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=384,
truncation="only_second",
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
answer = answers[i]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label it (0, 0)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once. Remove any columns you don't need:
>>> tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
Now create a batch of examples using [`DefaultDataCollator`]. Unlike other data collators in 🤗 Transformers, the [`DefaultDataCollator`] does not apply any additional preprocessing such as padding.
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load DistilBERT with [`AutoModelForQuestionAnswering`]:
>>> from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
>>> model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_qa_model",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_squad["train"],
eval_dataset=tokenized_squad["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_epochs = 2
>>> total_train_steps = (len(tokenized_squad["train"]) // batch_size) * num_epochs
>>> optimizer, schedule = create_optimizer(
init_lr=2e-5,
num_warmup_steps=0,
num_train_steps=total_train_steps,
)
Then you can load DistilBERT with [`TFAutoModelForQuestionAnswering`]:
>>> from transformers import TFAutoModelForQuestionAnswering
>>> model = TFAutoModelForQuestionAnswering("distilbert-base-uncased")
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
tokenized_squad["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_validation_set = model.prepare_tf_dataset(
tokenized_squad["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
The last thing to setup before you start training is to provide a way to push your model to the Hub. This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
output_dir="my_awesome_qa_model",
tokenizer=tokenizer,
)
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=[callback])
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for question answering, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
## Evaluate
Evaluation for question answering requires a significant amount of postprocessing. To avoid taking up too much of your time, this guide skips the evaluation step. The [`Trainer`] still calculates the evaluation loss during training so you're not completely in the dark about your model's performance.
If have more time and you're interested in how to evaluate your model for question answering, take a look at the [Question answering](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing) chapter from the 🤗 Hugging Face Course!
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with a question and some context you'd like the model to predict:
>>> question = "How many programming languages does BLOOM support?"
>>> context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for question answering with your model, and pass your text to it:
>>> from transformers import pipeline
>>> question_answerer = pipeline("question-answering", model="my_awesome_qa_model")
>>> question_answerer(question=question, context=context)
{'score': 0.2058267742395401,
'start': 10,
'end': 95,
'answer': '176 billion parameters and can generate text in 46 languages natural languages and 13'}
You can also manually replicate the results of the `pipeline` if you'd like:
Tokenize the text and return PyTorch tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_qa_model")
>>> inputs = tokenizer(question, context, return_tensors="pt")
Pass your inputs to the model and return the `logits`:
>>> import torch
>>> from transformers import AutoModelForQuestionAnswering
>>> model = AutoModelForQuestionAnswering.from_pretrained("my_awesome_qa_model")
>>> with torch.no_grad():
outputs = model(**inputs)
Get the highest probability from the model output for the start and end positions:
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
Decode the predicted tokens to get the answer:
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens)
'176 billion parameters and can generate text in 46 languages natural languages and 13'
Tokenize the text and return TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_qa_model")
>>> inputs = tokenizer(question, text, return_tensors="tf")
Pass your inputs to the model and return the `logits`:
>>> from transformers import TFAutoModelForQuestionAnswering
>>> model = TFAutoModelForQuestionAnswering.from_pretrained("my_awesome_qa_model")
>>> outputs = model(**inputs)
Get the highest probability from the model output for the start and end positions:
>>> answer_start_index = int(tf.math.argmax(outputs.start_logits, axis=-1)[0])
>>> answer_end_index = int(tf.math.argmax(outputs.end_logits, axis=-1)[0])
Decode the predicted tokens to get the answer:
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens)
'176 billion parameters and can generate text in 46 languages natural languages and 13'
|
tasks/multiple_choice.md
|
# Multiple choice
[[open-in-colab]]
A multiple choice task is similar to question answering, except several candidate answers are provided along with a context and the model is trained to select the correct answer.
This guide will show you how to:
1. Finetune [BERT](https://huggingface.co/bert-base-uncased) on the `regular` configuration of the [SWAG](https://huggingface.co/datasets/swag) dataset to select the best answer given multiple options and some context.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [I-BERT](../model_doc/ibert), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load SWAG dataset
Start by loading the `regular` configuration of the SWAG dataset from the 🤗 Datasets library:
>>> from datasets import load_dataset
>>> swag = load_dataset("swag", "regular")
Then take a look at an example:
>>> swag["train"][0]
{'ending0': 'passes by walking down the street playing their instruments.',
'ending1': 'has heard approaching them.',
'ending2': "arrives and they're outside dancing and asleep.",
'ending3': 'turns the lead singer watches the performance.',
'fold-ind': '3416',
'gold-source': 'gold',
'label': 0,
'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
'sent2': 'A drum line',
'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
'video-id': 'anetv_jkn6uvmqwh4'}
While it looks like there are a lot of fields here, it is actually pretty straightforward:
- `sent1` and `sent2`: these fields show how a sentence starts, and if you put the two together, you get the `startphrase` field.
- `ending`: suggests a possible ending for how a sentence can end, but only one of them is correct.
- `label`: identifies the correct sentence ending.
## Preprocess
The next step is to load a BERT tokenizer to process the sentence starts and the four possible endings:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
The preprocessing function you want to create needs to:
1. Make four copies of the `sent1` field and combine each of them with `sent2` to recreate how a sentence starts.
2. Combine `sent2` with each of the four possible sentence endings.
3. Flatten these two lists so you can tokenize them, and then unflatten them afterward so each example has a corresponding `input_ids`, `attention_mask`, and `labels` field.
>>> ending_names = ["ending0", "ending1", "ending2", "ending3"]
>>> def preprocess_function(examples):
first_sentences = [[context] * 4 for context in examples["sent1"]]
question_headers = examples["sent2"]
second_sentences = [
[f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
]
first_sentences = sum(first_sentences, [])
second_sentences = sum(second_sentences, [])
tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
tokenized_swag = swag.map(preprocess_function, batched=True)
🤗 Transformers doesn't have a data collator for multiple choice, so you'll need to adapt the [`DataCollatorWithPadding`] to create a batch of examples. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
`DataCollatorForMultipleChoice` flattens all the model inputs, applies padding, and then unflattens the results:
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import torch
>>> @dataclass
class DataCollatorForMultipleChoice:
"""
Data collator that will dynamically pad the inputs for multiple choice received.
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
]
flattened_features = sum(flattened_features, [])
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
batch["labels"] = torch.tensor(labels, dtype=torch.int64)
return batch
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import tensorflow as tf
>>> @dataclass
class DataCollatorForMultipleChoice:
"""
Data collator that will dynamically pad the inputs for multiple choice received.
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
]
flattened_features = sum(flattened_features, [])
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="tf",
)
batch = {k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()}
batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
return batch
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
>>> import numpy as np
>>> def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load BERT with [`AutoModelForMultipleChoice`]:
>>> from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
>>> model = AutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_swag_model",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
learning_rate=5e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_swag["train"],
eval_dataset=tokenized_swag["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 2
>>> total_train_steps = (len(tokenized_swag["train"]) // batch_size) * num_train_epochs
>>> optimizer, schedule = create_optimizer(init_lr=5e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
Then you can load BERT with [`TFAutoModelForMultipleChoice`]:
>>> from transformers import TFAutoModelForMultipleChoice
>>> model = TFAutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
>>> tf_train_set = model.prepare_tf_dataset(
tokenized_swag["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
>>> tf_validation_set = model.prepare_tf_dataset(
tokenized_swag["validation"],
shuffle=False,
batch_size=batch_size,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> model.compile(optimizer=optimizer) # No loss argument!
The last two things to setup before you start training is to compute the accuracy from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
output_dir="my_awesome_model",
tokenizer=tokenizer,
)
Then bundle your callbacks together:
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=2, callbacks=callbacks)
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for multiple choice, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text and two candidate answers:
>>> prompt = "France has a bread law, Le Décret Pain, with strict rules on what is allowed in a traditional baguette."
>>> candidate1 = "The law does not apply to croissants and brioche."
>>> candidate2 = "The law applies to baguettes."
Tokenize each prompt and candidate answer pair and return PyTorch tensors. You should also create some `labels`:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_swag_model")
>>> inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="pt", padding=True)
>>> labels = torch.tensor(0).unsqueeze(0)
Pass your inputs and labels to the model and return the `logits`:
>>> from transformers import AutoModelForMultipleChoice
>>> model = AutoModelForMultipleChoice.from_pretrained("my_awesome_swag_model")
>>> outputs = model(**{k: v.unsqueeze(0) for k, v in inputs.items()}, labels=labels)
>>> logits = outputs.logits
Get the class with the highest probability:
>>> predicted_class = logits.argmax().item()
>>> predicted_class
'0'
Tokenize each prompt and candidate answer pair and return TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_swag_model")
>>> inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="tf", padding=True)
Pass your inputs to the model and return the `logits`:
>>> from transformers import TFAutoModelForMultipleChoice
>>> model = TFAutoModelForMultipleChoice.from_pretrained("my_awesome_swag_model")
>>> inputs = {k: tf.expand_dims(v, 0) for k, v in inputs.items()}
>>> outputs = model(inputs)
>>> logits = outputs.logits
Get the class with the highest probability:
>>> predicted_class = int(tf.math.argmax(logits, axis=-1)[0])
>>> predicted_class
'0'
|
tasks/monocular_depth_estimation.md
|
# Monocular depth estimation
Monocular depth estimation is a computer vision task that involves predicting the depth information of a scene from a
single image. In other words, it is the process of estimating the distance of objects in a scene from
a single camera viewpoint.
Monocular depth estimation has various applications, including 3D reconstruction, augmented reality, autonomous driving,
and robotics. It is a challenging task as it requires the model to understand the complex relationships between objects
in the scene and the corresponding depth information, which can be affected by factors such as lighting conditions,
occlusion, and texture.
The task illustrated in this tutorial is supported by the following model architectures:
[DPT](../model_doc/dpt), [GLPN](../model_doc/glpn)
In this guide you'll learn how to:
* create a depth estimation pipeline
* run depth estimation inference by hand
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q transformers
## Depth estimation pipeline
The simplest way to try out inference with a model supporting depth estimation is to use the corresponding [`pipeline`].
Instantiate a pipeline from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=depth-estimation&sort=downloads):
>>> from transformers import pipeline
>>> checkpoint = "vinvino02/glpn-nyu"
>>> depth_estimator = pipeline("depth-estimation", model=checkpoint)
Next, choose an image to analyze:
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/HwBAsSbPBDU/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MzR8fGNhciUyMGluJTIwdGhlJTIwc3RyZWV0fGVufDB8MHx8fDE2Nzg5MDEwODg&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
Pass the image to the pipeline.
>>> predictions = depth_estimator(image)
The pipeline returns a dictionary with two entries. The first one, called `predicted_depth`, is a tensor with the values
being the depth expressed in meters for each pixel.
The second one, `depth`, is a PIL image that visualizes the depth estimation result.
Let's take a look at the visualized result:
>>> predictions["depth"]
## Depth estimation inference by hand
Now that you've seen how to use the depth estimation pipeline, let's see how we can replicate the same result by hand.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=depth-estimation&sort=downloads).
Here we'll use the same checkpoint as before:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> checkpoint = "vinvino02/glpn-nyu"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
>>> model = AutoModelForDepthEstimation.from_pretrained(checkpoint)
Prepare the image input for the model using the `image_processor` that will take care of the necessary image transformations
such as resizing and normalization:
>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
Pass the prepared inputs through the model:
>>> import torch
>>> with torch.no_grad():
outputs = model(pixel_values)
predicted_depth = outputs.predicted_depth
Visualize the results:
>>> import numpy as np
>>> # interpolate to original size
>>> prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
).squeeze()
>>> output = prediction.numpy()
>>> formatted = (output * 255 / np.max(output)).astype("uint8")
>>> depth = Image.fromarray(formatted)
>>> depth
|
tasks/sequence_classification.md
|
# Text classification
[[open-in-colab]]
Text classification is a common NLP task that assigns a label or class to text. Some of the largest companies run text classification in production for a wide range of practical applications. One of the most popular forms of text classification is sentiment analysis, which assigns a label like 🙂 positive, 🙁 negative, or 😐 neutral to a sequence of text.
This guide will show you how to:
1. Finetune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [IMDb](https://huggingface.co/datasets/imdb) dataset to determine whether a movie review is positive or negative.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate accelerate
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load IMDb dataset
Start by loading the IMDb dataset from the 🤗 Datasets library:
>>> from datasets import load_dataset
>>> imdb = load_dataset("imdb")
Then take a look at an example:
>>> imdb["test"][0]
{
"label": 0,
"text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
}
There are two fields in this dataset:
- `text`: the movie review text.
- `label`: a value that is either `0` for a negative review or `1` for a positive review.
## Preprocess
The next step is to load a DistilBERT tokenizer to preprocess the `text` field:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
Create a preprocessing function to tokenize `text` and truncate sequences to be no longer than DistilBERT's maximum input length:
>>> def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True)
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by setting `batched=True` to process multiple elements of the dataset at once:
tokenized_imdb = imdb.map(preprocess_function, batched=True)
Now create a batch of examples using [`DataCollatorWithPadding`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
>>> import numpy as np
>>> def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
Before you start training your model, create a map of the expected ids to their labels with `id2label` and `label2id`:
>>> id2label = {0: "NEGATIVE", 1: "POSITIVE"}
>>> label2id = {"NEGATIVE": 0, "POSITIVE": 1}
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load DistilBERT with [`AutoModelForSequenceClassification`] along with the number of expected labels, and the label mappings:
>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
>>> model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_imdb["train"],
eval_dataset=tokenized_imdb["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
>>> trainer.train()
[`Trainer`] applies dynamic padding by default when you pass `tokenizer` to it. In this case, you don't need to specify a data collator explicitly.
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer
>>> import tensorflow as tf
>>> batch_size = 16
>>> num_epochs = 5
>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
>>> total_train_steps = int(batches_per_epoch * num_epochs)
>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
Then you can load DistilBERT with [`TFAutoModelForSequenceClassification`] along with the number of expected labels, and the label mappings:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
)
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
tokenized_imdb["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_validation_set = model.prepare_tf_dataset(
tokenized_imdb["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
The last two things to setup before you start training is to compute the accuracy from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
output_dir="my_awesome_model",
tokenizer=tokenizer,
)
Then bundle your callbacks together:
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for text classification, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Grab some text you'd like to run inference on:
>>> text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for sentiment analysis with your model, and pass your text to it:
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model")
>>> classifier(text)
[{'label': 'POSITIVE', 'score': 0.9994940757751465}]
You can also manually replicate the results of the `pipeline` if you'd like:
Tokenize the text and return PyTorch tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
>>> inputs = tokenizer(text, return_tensors="pt")
Pass your inputs to the model and return the `logits`:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
>>> with torch.no_grad():
logits = model(**inputs).logits
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
'POSITIVE'
Tokenize the text and return TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
>>> inputs = tokenizer(text, return_tensors="tf")
Pass your inputs to the model and return the `logits`:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
>>> logits = model(**inputs).logits
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a text label:
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
>>> model.config.id2label[predicted_class_id]
'POSITIVE'
|
tasks/semantic_segmentation.md
|
# Image Segmentation
[[open-in-colab]]
Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
In this guide, we will:
1. [Take a look at different types of segmentation](#Types-of-Segmentation),
2. [Have an end-to-end fine-tuning example for semantic segmentation](#Fine-tuning-a-Model-for-Segmentation).
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q datasets transformers evaluate
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Types of Segmentation
Semantic segmentation assigns a label or class to every single pixel in an image. Let's take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as "cat" instead of "cat-1", "cat-2".
We can use transformers' image segmentation pipeline to quickly infer a semantic segmentation model. Let's take a look at the example image.
thon
from transformers import pipeline
from PIL import Image
import requests
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
We will use [nvidia/segformer-b1-finetuned-cityscapes-1024-1024](https://huggingface.co/nvidia/segformer-b1-finetuned-cityscapes-1024-1024).
thon
semantic_segmentation = pipeline("image-segmentation", "nvidia/segformer-b1-finetuned-cityscapes-1024-1024")
results = semantic_segmentation(image)
results
The segmentation pipeline output includes a mask for every predicted class.
```bash
[{'score': None,
'label': 'road',
'mask': },
{'score': None,
'label': 'sidewalk',
'mask': },
{'score': None,
'label': 'building',
'mask': },
{'score': None,
'label': 'wall',
'mask': },
{'score': None,
'label': 'pole',
'mask': },
{'score': None,
'label': 'traffic sign',
'mask': },
{'score': None,
'label': 'vegetation',
'mask': },
{'score': None,
'label': 'terrain',
'mask': },
{'score': None,
'label': 'sky',
'mask': },
{'score': None,
'label': 'car',
'mask': }]
Taking a look at the mask for the car class, we can see every car is classified with the same mask.
thon
results[-1]["mask"]
In instance segmentation, the goal is not to classify every pixel, but to predict a mask for **every instance of an object** in a given image. It works very similar to object detection, where there is a bounding box for every instance, there's a segmentation mask instead. We will use [facebook/mask2former-swin-large-cityscapes-instance](https://huggingface.co/facebook/mask2former-swin-large-cityscapes-instance) for this.
thon
instance_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-instance")
results = instance_segmentation(Image.open(image))
results
As you can see below, there are multiple cars classified, and there's no classification for pixels other than pixels that belong to car and person instances.
```bash
[{'score': 0.999944,
'label': 'car',
'mask': },
{'score': 0.999945,
'label': 'car',
'mask': },
{'score': 0.999652,
'label': 'car',
'mask': },
{'score': 0.903529,
'label': 'person',
'mask': }]
Checking out one of the car masks below.
thon
results[2]["mask"]
Panoptic segmentation combines semantic segmentation and instance segmentation, where every pixel is classified into a class and an instance of that class, and there are multiple masks for each instance of a class. We can use [facebook/mask2former-swin-large-cityscapes-panoptic](https://huggingface.co/facebook/mask2former-swin-large-cityscapes-panoptic) for this.
thon
panoptic_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-panoptic")
results = panoptic_segmentation(Image.open(image))
results
As you can see below, we have more classes. We will later illustrate to see that every pixel is classified into one of the classes.
```bash
[{'score': 0.999981,
'label': 'car',
'mask': },
{'score': 0.999958,
'label': 'car',
'mask': },
{'score': 0.99997,
'label': 'vegetation',
'mask': },
{'score': 0.999575,
'label': 'pole',
'mask': },
{'score': 0.999958,
'label': 'building',
'mask': },
{'score': 0.999634,
'label': 'road',
'mask': },
{'score': 0.996092,
'label': 'sidewalk',
'mask': },
{'score': 0.999221,
'label': 'car',
'mask': },
{'score': 0.99987,
'label': 'sky',
'mask': }]
Let's have a side by side comparison for all types of segmentation.
Seeing all types of segmentation, let's have a deep dive on fine-tuning a model for semantic segmentation.
Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
## Fine-tuning a Model for Segmentation
We will now:
1. Finetune [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) on the [SceneParse150](https://huggingface.co/datasets/scene_parse_150) dataset.
2. Use your fine-tuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[BEiT](../model_doc/beit), [Data2VecVision](../model_doc/data2vec-vision), [DPT](../model_doc/dpt), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [SegFormer](../model_doc/segformer), [UPerNet](../model_doc/upernet)
### Load SceneParse150 dataset
Start by loading a smaller subset of the SceneParse150 dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset
>>> ds = load_dataset("scene_parse_150", split="train[:50]")
Split the dataset's `train` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> ds = ds.train_test_split(test_size=0.2)
>>> train_ds = ds["train"]
>>> test_ds = ds["test"]
Then take a look at an example:
>>> train_ds[0]
{'image': ,
'annotation': ,
'scene_category': 368}
- `image`: a PIL image of the scene.
- `annotation`: a PIL image of the segmentation map, which is also the model's target.
- `scene_category`: a category id that describes the image scene like "kitchen" or "office". In this guide, you'll only need `image` and `annotation`, both of which are PIL images.
You'll also want to create a dictionary that maps a label id to a label class which will be useful when you set up the model later. Download the mappings from the Hub and create the `id2label` and `label2id` dictionaries:
>>> import json
>>> from huggingface_hub import cached_download, hf_hub_url
>>> repo_id = "huggingface/label-files"
>>> filename = "ade20k-id2label.json"
>>> id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename, repo_type="dataset")), "r"))
>>> id2label = {int(k): v for k, v in id2label.items()}
>>> label2id = {v: k for k, v in id2label.items()}
>>> num_labels = len(id2label)
### Preprocess
The next step is to load a SegFormer image processor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn't actually included in the 150 classes, so you'll need to set `reduce_labels=True` to subtract one from all the labels. The zero-index is replaced by `255` so it's ignored by SegFormer's loss function:
>>> from transformers import AutoImageProcessor
>>> checkpoint = "nvidia/mit-b0"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint, reduce_labels=True)
It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting. In this guide, you'll use the [`ColorJitter`](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html) function from [torchvision](https://pytorch.org/vision/stable/index.html) to randomly change the color properties of an image, but you can also use any image library you like.
>>> from torchvision.transforms import ColorJitter
>>> jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into `pixel_values` and annotations to `labels`. For the training set, `jitter` is applied before providing the images to the image processor. For the test set, the image processor crops and normalizes the `images`, and only crops the `labels` because no data augmentation is applied during testing.
>>> def train_transforms(example_batch):
images = [jitter(x) for x in example_batch["image"]]
labels = [x for x in example_batch["annotation"]]
inputs = image_processor(images, labels)
return inputs
>>> def val_transforms(example_batch):
images = [x for x in example_batch["image"]]
labels = [x for x in example_batch["annotation"]]
inputs = image_processor(images, labels)
return inputs
To apply the `jitter` over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.set_transform`] function. The transform is applied on the fly which is faster and consumes less disk space:
>>> train_ds.set_transform(train_transforms)
>>> test_ds.set_transform(val_transforms)
It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting.
In this guide, you'll use [`tf.image`](https://www.tensorflow.org/api_docs/python/tf/image) to randomly change the color properties of an image, but you can also use any image
library you like.
Define two separate transformation functions:
- training data transformations that include image augmentation
- validation data transformations that only transpose the images, since computer vision models in 🤗 Transformers expect channels-first layout
>>> import tensorflow as tf
>>> def aug_transforms(image):
image = tf.keras.utils.img_to_array(image)
image = tf.image.random_brightness(image, 0.25)
image = tf.image.random_contrast(image, 0.5, 2.0)
image = tf.image.random_saturation(image, 0.75, 1.25)
image = tf.image.random_hue(image, 0.1)
image = tf.transpose(image, (2, 0, 1))
return image
>>> def transforms(image):
image = tf.keras.utils.img_to_array(image)
image = tf.transpose(image, (2, 0, 1))
return image
Next, create two preprocessing functions to prepare batches of images and annotations for the model. These functions apply
the image transformations and use the earlier loaded `image_processor` to convert the images into `pixel_values` and
annotations to `labels`. `ImageProcessor` also takes care of resizing and normalizing the images.
>>> def train_transforms(example_batch):
images = [aug_transforms(x.convert("RGB")) for x in example_batch["image"]]
labels = [x for x in example_batch["annotation"]]
inputs = image_processor(images, labels)
return inputs
>>> def val_transforms(example_batch):
images = [transforms(x.convert("RGB")) for x in example_batch["image"]]
labels = [x for x in example_batch["annotation"]]
inputs = image_processor(images, labels)
return inputs
To apply the preprocessing transformations over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.set_transform`] function.
The transform is applied on the fly which is faster and consumes less disk space:
>>> train_ds.set_transform(train_transforms)
>>> test_ds.set_transform(val_transforms)
### Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load an evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [mean Intersection over Union](https://huggingface.co/spaces/evaluate-metric/accuracy) (IoU) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> metric = evaluate.load("mean_iou")
Then create a function to [`~evaluate.EvaluationModule.compute`] the metrics. Your predictions need to be converted to
logits first, and then reshaped to match the size of the labels before you can call [`~evaluate.EvaluationModule.compute`]:
>>> import numpy as np
>>> import torch
>>> from torch import nn
>>> def compute_metrics(eval_pred):
with torch.no_grad():
logits, labels = eval_pred
logits_tensor = torch.from_numpy(logits)
logits_tensor = nn.functional.interpolate(
logits_tensor,
size=labels.shape[-2:],
mode="bilinear",
align_corners=False,
).argmax(dim=1)
pred_labels = logits_tensor.detach().cpu().numpy()
metrics = metric.compute(
predictions=pred_labels,
references=labels,
num_labels=num_labels,
ignore_index=255,
reduce_labels=False,
)
for key, value in metrics.items():
if isinstance(value, np.ndarray):
metrics[key] = value.tolist()
return metrics
>>> def compute_metrics(eval_pred):
logits, labels = eval_pred
logits = tf.transpose(logits, perm=[0, 2, 3, 1])
logits_resized = tf.image.resize(
logits,
size=tf.shape(labels)[1:],
method="bilinear",
)
pred_labels = tf.argmax(logits_resized, axis=-1)
metrics = metric.compute(
predictions=pred_labels,
references=labels,
num_labels=num_labels,
ignore_index=-1,
reduce_labels=image_processor.do_reduce_labels,
)
per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
per_category_iou = metrics.pop("per_category_iou").tolist()
metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
return {"val_" + k: v for k, v in metrics.items()}
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
### Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
You're ready to start training your model now! Load SegFormer with [`AutoModelForSemanticSegmentation`], and pass the model the mapping between label ids and label classes:
>>> from transformers import AutoModelForSemanticSegmentation, TrainingArguments, Trainer
>>> model = AutoModelForSemanticSegmentation.from_pretrained(checkpoint, id2label=id2label, label2id=label2id)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. It is important you don't remove unused columns because this'll drop the `image` column. Without the `image` column, you can't create `pixel_values`. Set `remove_unused_columns=False` to prevent this behavior! The only other required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the IoU metric and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="segformer-b0-scene-parse-150",
learning_rate=6e-5,
num_train_epochs=50,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
save_total_limit=3,
evaluation_strategy="steps",
save_strategy="steps",
save_steps=20,
eval_steps=20,
logging_steps=1,
eval_accumulation_steps=5,
remove_unused_columns=False,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you are unfamiliar with fine-tuning a model with Keras, check out the [basic tutorial](./training#train-a-tensorflow-model-with-keras) first!
To fine-tune a model in TensorFlow, follow these steps:
1. Define the training hyperparameters, and set up an optimizer and a learning rate schedule.
2. Instantiate a pretrained model.
3. Convert a 🤗 Dataset to a `tf.data.Dataset`.
4. Compile your model.
5. Add callbacks to calculate metrics and upload your model to 🤗 Hub
6. Use the `fit()` method to run the training.
Start by defining the hyperparameters, optimizer and learning rate schedule:
>>> from transformers import create_optimizer
>>> batch_size = 2
>>> num_epochs = 50
>>> num_train_steps = len(train_ds) * num_epochs
>>> learning_rate = 6e-5
>>> weight_decay_rate = 0.01
>>> optimizer, lr_schedule = create_optimizer(
init_lr=learning_rate,
num_train_steps=num_train_steps,
weight_decay_rate=weight_decay_rate,
num_warmup_steps=0,
)
Then, load SegFormer with [`TFAutoModelForSemanticSegmentation`] along with the label mappings, and compile it with the
optimizer. Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> from transformers import TFAutoModelForSemanticSegmentation
>>> model = TFAutoModelForSemanticSegmentation.from_pretrained(
checkpoint,
id2label=id2label,
label2id=label2id,
)
>>> model.compile(optimizer=optimizer) # No loss argument!
Convert your datasets to the `tf.data.Dataset` format using the [`~datasets.Dataset.to_tf_dataset`] and the [`DefaultDataCollator`]:
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
>>> tf_train_dataset = train_ds.to_tf_dataset(
columns=["pixel_values", "label"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
>>> tf_eval_dataset = test_ds.to_tf_dataset(
columns=["pixel_values", "label"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
To compute the accuracy from the predictions and push your model to the 🤗 Hub, use [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`KerasMetricCallback`],
and use the [`PushToHubCallback`] to upload the model:
>>> from transformers.keras_callbacks import KerasMetricCallback, PushToHubCallback
>>> metric_callback = KerasMetricCallback(
metric_fn=compute_metrics, eval_dataset=tf_eval_dataset, batch_size=batch_size, label_cols=["labels"]
)
>>> push_to_hub_callback = PushToHubCallback(output_dir="scene_segmentation", tokenizer=image_processor)
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you are ready to train your model! Call `fit()` with your training and validation datasets, the number of epochs,
and your callbacks to fine-tune the model:
>>> model.fit(
tf_train_dataset,
validation_data=tf_eval_dataset,
callbacks=callbacks,
epochs=num_epochs,
)
Congratulations! You have fine-tuned your model and shared it on the 🤗 Hub. You can now use it for inference!
### Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an image for inference:
>>> image = ds[0]["image"]
>>> image
We will now see how to infer without a pipeline. Process the image with an image processor and place the `pixel_values` on a GPU:
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # use GPU if available, otherwise use a CPU
>>> encoding = image_processor(image, return_tensors="pt")
>>> pixel_values = encoding.pixel_values.to(device)
Pass your input to the model and return the `logits`:
>>> outputs = model(pixel_values=pixel_values)
>>> logits = outputs.logits.cpu()
Next, rescale the logits to the original image size:
>>> upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1],
mode="bilinear",
align_corners=False,
)
>>> pred_seg = upsampled_logits.argmax(dim=1)[0]
Load an image processor to preprocess the image and return the input as TensorFlow tensors:
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("MariaK/scene_segmentation")
>>> inputs = image_processor(image, return_tensors="tf")
Pass your input to the model and return the `logits`:
>>> from transformers import TFAutoModelForSemanticSegmentation
>>> model = TFAutoModelForSemanticSegmentation.from_pretrained("MariaK/scene_segmentation")
>>> logits = model(**inputs).logits
Next, rescale the logits to the original image size and apply argmax on the class dimension:
>>> logits = tf.transpose(logits, [0, 2, 3, 1])
>>> upsampled_logits = tf.image.resize(
logits,
# We reverse the shape of `image` because `image.size` returns width and height.
image.size[::-1],
)
>>> pred_seg = tf.math.argmax(upsampled_logits, axis=-1)[0]
To visualize the results, load the [dataset color palette](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51) as `ade_palette()` that maps each class to their RGB values. Then you can combine and plot your image and the predicted segmentation map:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> color_seg = np.zeros((pred_seg.shape[0], pred_seg.shape[1], 3), dtype=np.uint8)
>>> palette = np.array(ade_palette())
>>> for label, color in enumerate(palette):
color_seg[pred_seg == label, :] = color
>>> color_seg = color_seg[, ::-1] # convert to BGR
>>> img = np.array(image) * 0.5 + color_seg * 0.5 # plot the image with the segmentation map
>>> img = img.astype(np.uint8)
>>> plt.figure(figsize=(15, 10))
>>> plt.imshow(img)
>>> plt.show()
|
tasks/object_detection.md
|
# Object detection
[[open-in-colab]]
Object detection is the computer vision task of detecting instances (such as humans, buildings, or cars) in an image. Object detection models receive an image as input and output
coordinates of the bounding boxes and associated labels of the detected objects. An image can contain multiple objects,
each with its own bounding box and a label (e.g. it can have a car and a building), and each object can
be present in different parts of an image (e.g. the image can have several cars).
This task is commonly used in autonomous driving for detecting things like pedestrians, road signs, and traffic lights.
Other applications include counting objects in images, image search, and more.
In this guide, you will learn how to:
1. Finetune [DETR](https://huggingface.co/docs/transformers/model_doc/detr), a model that combines a convolutional
backbone with an encoder-decoder Transformer, on the [CPPE-5](https://huggingface.co/datasets/cppe-5)
dataset.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[Conditional DETR](../model_doc/conditional_detr), [Deformable DETR](../model_doc/deformable_detr), [DETA](../model_doc/deta), [DETR](../model_doc/detr), [Table Transformer](../model_doc/table-transformer), [YOLOS](../model_doc/yolos)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q datasets transformers evaluate timm albumentations
You'll use 🤗 Datasets to load a dataset from the Hugging Face Hub, 🤗 Transformers to train your model,
and `albumentations` to augment the data. `timm` is currently required to load a convolutional backbone for the DETR model.
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the Hub.
When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load the CPPE-5 dataset
The [CPPE-5 dataset](https://huggingface.co/datasets/cppe-5) contains images with
annotations identifying medical personal protective equipment (PPE) in the context of the COVID-19 pandemic.
Start by loading the dataset:
>>> from datasets import load_dataset
>>> cppe5 = load_dataset("cppe-5")
>>> cppe5
DatasetDict({
train: Dataset({
features: ['image_id', 'image', 'width', 'height', 'objects'],
num_rows: 1000
})
test: Dataset({
features: ['image_id', 'image', 'width', 'height', 'objects'],
num_rows: 29
})
})
You'll see that this dataset already comes with a training set containing 1000 images and a test set with 29 images.
To get familiar with the data, explore what the examples look like.
>>> cppe5["train"][0]
{'image_id': 15,
'image': ,
'width': 943,
'height': 663,
'objects': {'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]],
'category': [4, 4, 0, 0]}}
The examples in the dataset have the following fields:
- `image_id`: the example image id
- `image`: a `PIL.Image.Image` object containing the image
- `width`: width of the image
- `height`: height of the image
- `objects`: a dictionary containing bounding box metadata for the objects in the image:
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [COCO format](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) )
- `category`: the object's category, with possible values including `Coverall (0)`, `Face_Shield (1)`, `Gloves (2)`, `Goggles (3)` and `Mask (4)`
You may notice that the `bbox` field follows the COCO format, which is the format that the DETR model expects.
However, the grouping of the fields inside `objects` differs from the annotation format DETR requires. You will
need to apply some preprocessing transformations before using this data for training.
To get an even better understanding of the data, visualize an example in the dataset.
>>> import numpy as np
>>> import os
>>> from PIL import Image, ImageDraw
>>> image = cppe5["train"][0]["image"]
>>> annotations = cppe5["train"][0]["objects"]
>>> draw = ImageDraw.Draw(image)
>>> categories = cppe5["train"].features["objects"].feature["category"].names
>>> id2label = {index: x for index, x in enumerate(categories, start=0)}
>>> label2id = {v: k for k, v in id2label.items()}
>>> for i in range(len(annotations["id"])):
box = annotations["bbox"][i]
class_idx = annotations["category"][i]
x, y, w, h = tuple(box)
draw.rectangle((x, y, x + w, y + h), outline="red", width=1)
draw.text((x, y), id2label[class_idx], fill="white")
>>> image
To visualize the bounding boxes with associated labels, you can get the labels from the dataset's metadata, specifically
the `category` field.
You'll also want to create dictionaries that map a label id to a label class (`id2label`) and the other way around (`label2id`).
You can use them later when setting up the model. Including these maps will make your model reusable by others if you share
it on the Hugging Face Hub.
As a final step of getting familiar with the data, explore it for potential issues. One common problem with datasets for
object detection is bounding boxes that "stretch" beyond the edge of the image. Such "runaway" bounding boxes can raise
errors during training and should be addressed at this stage. There are a few examples with this issue in this dataset.
To keep things simple in this guide, we remove these images from the data.
>>> remove_idx = [590, 821, 822, 875, 876, 878, 879]
>>> keep = [i for i in range(len(cppe5["train"])) if i not in remove_idx]
>>> cppe5["train"] = cppe5["train"].select(keep)
## Preprocess the data
To finetune a model, you must preprocess the data you plan to use to match precisely the approach used for the pre-trained model.
[`AutoImageProcessor`] takes care of processing image data to create `pixel_values`, `pixel_mask`, and
`labels` that a DETR model can train with. The image processor has some attributes that you won't have to worry about:
- `image_mean = [0.485, 0.456, 0.406 ]`
- `image_std = [0.229, 0.224, 0.225]`
These are the mean and standard deviation used to normalize images during the model pre-training. These values are crucial
to replicate when doing inference or finetuning a pre-trained image model.
Instantiate the image processor from the same checkpoint as the model you want to finetune.
>>> from transformers import AutoImageProcessor
>>> checkpoint = "facebook/detr-resnet-50"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
Before passing the images to the `image_processor`, apply two preprocessing transformations to the dataset:
- Augmenting images
- Reformatting annotations to meet DETR expectations
First, to make sure the model does not overfit on the training data, you can apply image augmentation with any data augmentation library. Here we use [Albumentations](https://albumentations.ai/docs/)
This library ensures that transformations affect the image and update the bounding boxes accordingly.
The 🤗 Datasets library documentation has a detailed [guide on how to augment images for object detection](https://huggingface.co/docs/datasets/object_detection),
and it uses the exact same dataset as an example. Apply the same approach here, resize each image to (480, 480),
flip it horizontally, and brighten it:
>>> import albumentations
>>> import numpy as np
>>> import torch
>>> transform = albumentations.Compose(
[
albumentations.Resize(480, 480),
albumentations.HorizontalFlip(p=1.0),
albumentations.RandomBrightnessContrast(p=1.0),
],
bbox_params=albumentations.BboxParams(format="coco", label_fields=["category"]),
)
The `image_processor` expects the annotations to be in the following format: `{'image_id': int, 'annotations': List[Dict]}`,
where each dictionary is a COCO object annotation. Let's add a function to reformat annotations for a single example:
>>> def formatted_anns(image_id, category, area, bbox):
annotations = []
for i in range(0, len(category)):
new_ann = {
"image_id": image_id,
"category_id": category[i],
"isCrowd": 0,
"area": area[i],
"bbox": list(bbox[i]),
}
annotations.append(new_ann)
return annotations
Now you can combine the image and annotation transformations to use on a batch of examples:
>>> # transforming a batch
>>> def transform_aug_ann(examples):
image_ids = examples["image_id"]
images, bboxes, area, categories = [], [], [], []
for image, objects in zip(examples["image"], examples["objects"]):
image = np.array(image.convert("RGB"))[:, :, ::-1]
out = transform(image=image, bboxes=objects["bbox"], category=objects["category"])
area.append(objects["area"])
images.append(out["image"])
bboxes.append(out["bboxes"])
categories.append(out["category"])
targets = [
{"image_id": id_, "annotations": formatted_anns(id_, cat_, ar_, box_)}
for id_, cat_, ar_, box_ in zip(image_ids, categories, area, bboxes)
]
return image_processor(images=images, annotations=targets, return_tensors="pt")
Apply this preprocessing function to the entire dataset using 🤗 Datasets [`~datasets.Dataset.with_transform`] method. This method applies
transformations on the fly when you load an element of the dataset.
At this point, you can check what an example from the dataset looks like after the transformations. You should see a tensor
with `pixel_values`, a tensor with `pixel_mask`, and `labels`.
>>> cppe5["train"] = cppe5["train"].with_transform(transform_aug_ann)
>>> cppe5["train"][15]
{'pixel_values': tensor([[[ 0.9132, 0.9132, 0.9132, , -1.9809, -1.9809, -1.9809],
[ 0.9132, 0.9132, 0.9132, , -1.9809, -1.9809, -1.9809],
[ 0.9132, 0.9132, 0.9132, , -1.9638, -1.9638, -1.9638],
,
[-1.5699, -1.5699, -1.5699, , -1.9980, -1.9980, -1.9980],
[-1.5528, -1.5528, -1.5528, , -1.9980, -1.9809, -1.9809],
[-1.5528, -1.5528, -1.5528, , -1.9980, -1.9809, -1.9809]],
[[ 1.3081, 1.3081, 1.3081, , -1.8431, -1.8431, -1.8431],
[ 1.3081, 1.3081, 1.3081, , -1.8431, -1.8431, -1.8431],
[ 1.3081, 1.3081, 1.3081, , -1.8256, -1.8256, -1.8256],
,
[-1.3179, -1.3179, -1.3179, , -1.8606, -1.8606, -1.8606],
[-1.3004, -1.3004, -1.3004, , -1.8606, -1.8431, -1.8431],
[-1.3004, -1.3004, -1.3004, , -1.8606, -1.8431, -1.8431]],
[[ 1.4200, 1.4200, 1.4200, , -1.6476, -1.6476, -1.6476],
[ 1.4200, 1.4200, 1.4200, , -1.6476, -1.6476, -1.6476],
[ 1.4200, 1.4200, 1.4200, , -1.6302, -1.6302, -1.6302],
,
[-1.0201, -1.0201, -1.0201, , -1.5604, -1.5604, -1.5604],
[-1.0027, -1.0027, -1.0027, , -1.5604, -1.5430, -1.5430],
[-1.0027, -1.0027, -1.0027, , -1.5604, -1.5430, -1.5430]]]),
'pixel_mask': tensor([[1, 1, 1, , 1, 1, 1],
[1, 1, 1, , 1, 1, 1],
[1, 1, 1, , 1, 1, 1],
,
[1, 1, 1, , 1, 1, 1],
[1, 1, 1, , 1, 1, 1],
[1, 1, 1, , 1, 1, 1]]),
'labels': {'size': tensor([800, 800]), 'image_id': tensor([756]), 'class_labels': tensor([4]), 'boxes': tensor([[0.7340, 0.6986, 0.3414, 0.5944]]), 'area': tensor([519544.4375]), 'iscrowd': tensor([0]), 'orig_size': tensor([480, 480])}}
You have successfully augmented the individual images and prepared their annotations. However, preprocessing isn't
complete yet. In the final step, create a custom `collate_fn` to batch images together.
Pad images (which are now `pixel_values`) to the largest image in a batch, and create a corresponding `pixel_mask`
to indicate which pixels are real (1) and which are padding (0).
>>> def collate_fn(batch):
pixel_values = [item["pixel_values"] for item in batch]
encoding = image_processor.pad(pixel_values, return_tensors="pt")
labels = [item["labels"] for item in batch]
batch = {}
batch["pixel_values"] = encoding["pixel_values"]
batch["pixel_mask"] = encoding["pixel_mask"]
batch["labels"] = labels
return batch
## Training the DETR model
You have done most of the heavy lifting in the previous sections, so now you are ready to train your model!
The images in this dataset are still quite large, even after resizing. This means that finetuning this model will
require at least one GPU.
Training involves the following steps:
1. Load the model with [`AutoModelForObjectDetection`] using the same checkpoint as in the preprocessing.
2. Define your training hyperparameters in [`TrainingArguments`].
3. Pass the training arguments to [`Trainer`] along with the model, dataset, image processor, and data collator.
4. Call [`~Trainer.train`] to finetune your model.
When loading the model from the same checkpoint that you used for the preprocessing, remember to pass the `label2id`
and `id2label` maps that you created earlier from the dataset's metadata. Additionally, we specify `ignore_mismatched_sizes=True` to replace the existing classification head with a new one.
>>> from transformers import AutoModelForObjectDetection
>>> model = AutoModelForObjectDetection.from_pretrained(
checkpoint,
id2label=id2label,
label2id=label2id,
ignore_mismatched_sizes=True,
)
In the [`TrainingArguments`] use `output_dir` to specify where to save your model, then configure hyperparameters as you see fit.
It is important you do not remove unused columns because this will drop the image column. Without the image column, you
can't create `pixel_values`. For this reason, set `remove_unused_columns` to `False`.
If you wish to share your model by pushing to the Hub, set `push_to_hub` to `True` (you must be signed in to Hugging
Face to upload your model).
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
output_dir="detr-resnet-50_finetuned_cppe5",
per_device_train_batch_size=8,
num_train_epochs=10,
fp16=True,
save_steps=200,
logging_steps=50,
learning_rate=1e-5,
weight_decay=1e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=True,
)
Finally, bring everything together, and call [`~transformers.Trainer.train`]:
>>> from transformers import Trainer
>>> trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
train_dataset=cppe5["train"],
tokenizer=image_processor,
)
>>> trainer.train()
If you have set `push_to_hub` to `True` in the `training_args`, the training checkpoints are pushed to the
Hugging Face Hub. Upon training completion, push the final model to the Hub as well by calling the [`~transformers.Trainer.push_to_hub`] method.
>>> trainer.push_to_hub()
## Evaluate
Object detection models are commonly evaluated with a set of COCO-style metrics.
You can use one of the existing metrics implementations, but here you'll use the one from `torchvision` to evaluate the final
model that you pushed to the Hub.
To use the `torchvision` evaluator, you'll need to prepare a ground truth COCO dataset. The API to build a COCO dataset
requires the data to be stored in a certain format, so you'll need to save images and annotations to disk first. Just like
when you prepared your data for training, the annotations from the `cppe5["test"]` need to be formatted. However, images
should stay as they are.
The evaluation step requires a bit of work, but it can be split in three major steps.
First, prepare the `cppe5["test"]` set: format the annotations and save the data to disk.
>>> import json
>>> # format annotations the same as for training, no need for data augmentation
>>> def val_formatted_anns(image_id, objects):
annotations = []
for i in range(0, len(objects["id"])):
new_ann = {
"id": objects["id"][i],
"category_id": objects["category"][i],
"iscrowd": 0,
"image_id": image_id,
"area": objects["area"][i],
"bbox": objects["bbox"][i],
}
annotations.append(new_ann)
return annotations
>>> # Save images and annotations into the files torchvision.datasets.CocoDetection expects
>>> def save_cppe5_annotation_file_images(cppe5):
output_json = {}
path_output_cppe5 = f"{os.getcwd()}/cppe5/"
if not os.path.exists(path_output_cppe5):
os.makedirs(path_output_cppe5)
path_anno = os.path.join(path_output_cppe5, "cppe5_ann.json")
categories_json = [{"supercategory": "none", "id": id, "name": id2label[id]} for id in id2label]
output_json["images"] = []
output_json["annotations"] = []
for example in cppe5:
ann = val_formatted_anns(example["image_id"], example["objects"])
output_json["images"].append(
{
"id": example["image_id"],
"width": example["image"].width,
"height": example["image"].height,
"file_name": f"{example['image_id']}.png",
}
)
output_json["annotations"].extend(ann)
output_json["categories"] = categories_json
with open(path_anno, "w") as file:
json.dump(output_json, file, ensure_ascii=False, indent=4)
for im, img_id in zip(cppe5["image"], cppe5["image_id"]):
path_img = os.path.join(path_output_cppe5, f"{img_id}.png")
im.save(path_img)
return path_output_cppe5, path_anno
Next, prepare an instance of a `CocoDetection` class that can be used with `cocoevaluator`.
>>> import torchvision
>>> class CocoDetection(torchvision.datasets.CocoDetection):
def __init__(self, img_folder, image_processor, ann_file):
super().__init__(img_folder, ann_file)
self.image_processor = image_processor
def __getitem__(self, idx):
# read in PIL image and target in COCO format
img, target = super(CocoDetection, self).__getitem__(idx)
# preprocess image and target: converting target to DETR format,
# resizing + normalization of both image and target)
image_id = self.ids[idx]
target = {"image_id": image_id, "annotations": target}
encoding = self.image_processor(images=img, annotations=target, return_tensors="pt")
pixel_values = encoding["pixel_values"].squeeze() # remove batch dimension
target = encoding["labels"][0] # remove batch dimension
return {"pixel_values": pixel_values, "labels": target}
>>> im_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> path_output_cppe5, path_anno = save_cppe5_annotation_file_images(cppe5["test"])
>>> test_ds_coco_format = CocoDetection(path_output_cppe5, im_processor, path_anno)
Finally, load the metrics and run the evaluation.
>>> import evaluate
>>> from tqdm import tqdm
>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> module = evaluate.load("ybelkada/cocoevaluate", coco=test_ds_coco_format.coco)
>>> val_dataloader = torch.utils.data.DataLoader(
test_ds_coco_format, batch_size=8, shuffle=False, num_workers=4, collate_fn=collate_fn
)
>>> with torch.no_grad():
for idx, batch in enumerate(tqdm(val_dataloader)):
pixel_values = batch["pixel_values"]
pixel_mask = batch["pixel_mask"]
labels = [
{k: v for k, v in t.items()} for t in batch["labels"]
] # these are in DETR format, resized + normalized
# forward pass
outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
orig_target_sizes = torch.stack([target["orig_size"] for target in labels], dim=0)
results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to COCO api
module.add(prediction=results, reference=labels)
del batch
>>> results = module.compute()
>>> print(results)
Accumulating evaluation results
DONE (t=0.08s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.352
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.681
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.292
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.168
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.208
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.429
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.274
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.484
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.501
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.323
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.590
These results can be further improved by adjusting the hyperparameters in [`~transformers.TrainingArguments`]. Give it a go!
## Inference
Now that you have finetuned a DETR model, evaluated it, and uploaded it to the Hugging Face Hub, you can use it for inference.
The simplest way to try out your finetuned model for inference is to use it in a [`Pipeline`]. Instantiate a pipeline
for object detection with your model, and pass an image to it:
>>> from transformers import pipeline
>>> import requests
>>> url = "https://i.imgur.com/2lnWoly.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> obj_detector = pipeline("object-detection", model="devonho/detr-resnet-50_finetuned_cppe5")
>>> obj_detector(image)
You can also manually replicate the results of the pipeline if you'd like:
>>> image_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> with torch.no_grad():
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[0]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
Detected Coverall with confidence 0.566 at location [1215.32, 147.38, 4401.81, 3227.08]
Detected Mask with confidence 0.584 at location [2449.06, 823.19, 3256.43, 1413.9]
Let's plot the result:
>>> draw = ImageDraw.Draw(image)
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
x, y, x2, y2 = tuple(box)
draw.rectangle((x, y, x2, y2), outline="red", width=1)
draw.text((x, y), model.config.id2label[label.item()], fill="white")
>>> image
|
tasks/video_classification.md
|
# Video classification
[[open-in-colab]]
Video classification is the task of assigning a label or class to an entire video. Videos are expected to have only one class for each video. Video classification models take a video as input and return a prediction about which class the video belongs to. These models can be used to categorize what a video is all about. A real-world application of video classification is action / activity recognition, which is useful for fitness applications. It is also helpful for vision-impaired individuals, especially when they are commuting.
This guide will show you how to:
1. Fine-tune [VideoMAE](https://huggingface.co/docs/transformers/main/en/model_doc/videomae) on a subset of the [UCF101](https://www.crcv.ucf.edu/data/UCF101.php) dataset.
2. Use your fine-tuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[TimeSformer](../model_doc/timesformer), [VideoMAE](../model_doc/videomae), [ViViT](../model_doc/vivit)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q pytorchvideo transformers evaluate
You will use [PyTorchVideo](https://pytorchvideo.org/) (dubbed `pytorchvideo`) to process and prepare the videos.
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load UCF101 dataset
Start by loading a subset of the [UCF-101 dataset](https://www.crcv.ucf.edu/data/UCF101.php). This will give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from huggingface_hub import hf_hub_download
>>> hf_dataset_identifier = "sayakpaul/ucf101-subset"
>>> filename = "UCF101_subset.tar.gz"
>>> file_path = hf_hub_download(repo_id=hf_dataset_identifier, filename=filename, repo_type="dataset")
After the subset has been downloaded, you need to extract the compressed archive:
>>> import tarfile
>>> with tarfile.open(file_path) as t:
t.extractall(".")
At a high level, the dataset is organized like so:
```bash
UCF101_subset/
train/
BandMarching/
video_1.mp4
video_2.mp4
Archery
video_1.mp4
video_2.mp4
val/
BandMarching/
video_1.mp4
video_2.mp4
Archery
video_1.mp4
video_2.mp4
test/
BandMarching/
video_1.mp4
video_2.mp4
Archery
video_1.mp4
video_2.mp4
The (`sorted`) video paths appear like so:
```bash
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c04.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c06.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c02.avi',
'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c06.avi'
You will notice that there are video clips belonging to the same group / scene where group is denoted by `g` in the video file paths. `v_ApplyEyeMakeup_g07_c04.avi` and `v_ApplyEyeMakeup_g07_c06.avi`, for example.
For the validation and evaluation splits, you wouldn't want to have video clips from the same group / scene to prevent [data leakage](https://www.kaggle.com/code/alexisbcook/data-leakage). The subset that you are using in this tutorial takes this information into account.
Next up, you will derive the set of labels present in the dataset. Also, create two dictionaries that'll be helpful when initializing the model:
* `label2id`: maps the class names to integers.
* `id2label`: maps the integers to class names.
>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
>>> label2id = {label: i for i, label in enumerate(class_labels)}
>>> id2label = {i: label for label, i in label2id.items()}
>>> print(f"Unique classes: {list(label2id.keys())}.")
# Unique classes: ['ApplyEyeMakeup', 'ApplyLipstick', 'Archery', 'BabyCrawling', 'BalanceBeam', 'BandMarching', 'BaseballPitch', 'Basketball', 'BasketballDunk', 'BenchPress'].
There are 10 unique classes. For each class, there are 30 videos in the training set.
## Load a model to fine-tune
Instantiate a video classification model from a pretrained checkpoint and its associated image processor. The model's encoder comes with pre-trained parameters, and the classification head is randomly initialized. The image processor will come in handy when writing the preprocessing pipeline for our dataset.
>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
>>> model_ckpt = "MCG-NJU/videomae-base"
>>> image_processor = VideoMAEImageProcessor.from_pretrained(model_ckpt)
>>> model = VideoMAEForVideoClassification.from_pretrained(
model_ckpt,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
While the model is loading, you might notice the following warning:
```bash
Some weights of the model checkpoint at MCG-NJU/videomae-base were not used when initializing VideoMAEForVideoClassification: [, 'decoder.decoder_layers.1.attention.output.dense.bias', 'decoder.decoder_layers.2.attention.attention.key.weight']
- This IS expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of VideoMAEForVideoClassification were not initialized from the model checkpoint at MCG-NJU/videomae-base and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
The warning is telling us we are throwing away some weights (e.g. the weights and bias of the `classifier` layer) and randomly initializing some others (the weights and bias of a new `classifier` layer). This is expected in this case, because we are adding a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
**Note** that [this checkpoint](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) leads to better performance on this task as the checkpoint was obtained fine-tuning on a similar downstream task having considerable domain overlap. You can check out [this checkpoint](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset) which was obtained by fine-tuning `MCG-NJU/videomae-base-finetuned-kinetics`.
## Prepare the datasets for training
For preprocessing the videos, you will leverage the [PyTorchVideo library](https://pytorchvideo.org/). Start by importing the dependencies we need.
>>> import pytorchvideo.data
>>> from pytorchvideo.transforms import (
ApplyTransformToKey,
Normalize,
RandomShortSideScale,
RemoveKey,
ShortSideScale,
UniformTemporalSubsample,
)
>>> from torchvision.transforms import (
Compose,
Lambda,
RandomCrop,
RandomHorizontalFlip,
Resize,
)
For the training dataset transformations, use a combination of uniform temporal subsampling, pixel normalization, random cropping, and random horizontal flipping. For the validation and evaluation dataset transformations, keep the same transformation chain except for random cropping and horizontal flipping. To learn more about the details of these transformations check out the [official documentation of PyTorchVideo](https://pytorchvideo.org).
Use the `image_processor` associated with the pre-trained model to obtain the following information:
* Image mean and standard deviation with which the video frame pixels will be normalized.
* Spatial resolution to which the video frames will be resized.
Start by defining some constants.
>>> mean = image_processor.image_mean
>>> std = image_processor.image_std
>>> if "shortest_edge" in image_processor.size:
height = width = image_processor.size["shortest_edge"]
>>> else:
height = image_processor.size["height"]
width = image_processor.size["width"]
>>> resize_to = (height, width)
>>> num_frames_to_sample = model.config.num_frames
>>> sample_rate = 4
>>> fps = 30
>>> clip_duration = num_frames_to_sample * sample_rate / fps
Now, define the dataset-specific transformations and the datasets respectively. Starting with the training set:
>>> train_transform = Compose(
[
ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(num_frames_to_sample),
Lambda(lambda x: x / 255.0),
Normalize(mean, std),
RandomShortSideScale(min_size=256, max_size=320),
RandomCrop(resize_to),
RandomHorizontalFlip(p=0.5),
]
),
),
]
)
>>> train_dataset = pytorchvideo.data.Ucf101(
data_path=os.path.join(dataset_root_path, "train"),
clip_sampler=pytorchvideo.data.make_clip_sampler("random", clip_duration),
decode_audio=False,
transform=train_transform,
)
The same sequence of workflow can be applied to the validation and evaluation sets:
>>> val_transform = Compose(
[
ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(num_frames_to_sample),
Lambda(lambda x: x / 255.0),
Normalize(mean, std),
Resize(resize_to),
]
),
),
]
)
>>> val_dataset = pytorchvideo.data.Ucf101(
data_path=os.path.join(dataset_root_path, "val"),
clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
decode_audio=False,
transform=val_transform,
)
>>> test_dataset = pytorchvideo.data.Ucf101(
data_path=os.path.join(dataset_root_path, "test"),
clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
decode_audio=False,
transform=val_transform,
)
**Note**: The above dataset pipelines are taken from the [official PyTorchVideo example](https://pytorchvideo.org/docs/tutorial_classification#dataset). We're using the [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) function because it's tailored for the UCF-101 dataset. Under the hood, it returns a [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) object. `LabeledVideoDataset` class is the base class for all things video in the PyTorchVideo dataset. So, if you want to use a custom dataset not supported off-the-shelf by PyTorchVideo, you can extend the `LabeledVideoDataset` class accordingly. Refer to the `data` API [documentation to](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) learn more. Also, if your dataset follows a similar structure (as shown above), then using the `pytorchvideo.data.Ucf101()` should work just fine.
You can access the `num_videos` argument to know the number of videos in the dataset.
>>> print(train_dataset.num_videos, val_dataset.num_videos, test_dataset.num_videos)
# (300, 30, 75)
## Visualize the preprocessed video for better debugging
>>> import imageio
>>> import numpy as np
>>> from IPython.display import Image
>>> def unnormalize_img(img):
"""Un-normalizes the image pixels."""
img = (img * std) + mean
img = (img * 255).astype("uint8")
return img.clip(0, 255)
>>> def create_gif(video_tensor, filename="sample.gif"):
"""Prepares a GIF from a video tensor.
The video tensor is expected to have the following shape:
(num_frames, num_channels, height, width).
"""
frames = []
for video_frame in video_tensor:
frame_unnormalized = unnormalize_img(video_frame.permute(1, 2, 0).numpy())
frames.append(frame_unnormalized)
kargs = {"duration": 0.25}
imageio.mimsave(filename, frames, "GIF", **kargs)
return filename
>>> def display_gif(video_tensor, gif_name="sample.gif"):
"""Prepares and displays a GIF from a video tensor."""
video_tensor = video_tensor.permute(1, 0, 2, 3)
gif_filename = create_gif(video_tensor, gif_name)
return Image(filename=gif_filename)
>>> sample_video = next(iter(train_dataset))
>>> video_tensor = sample_video["video"]
>>> display_gif(video_tensor)
## Train the model
Leverage [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer) from 🤗 Transformers for training the model. To instantiate a `Trainer`, you need to define the training configuration and an evaluation metric. The most important is the [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments), which is a class that contains all the attributes to configure the training. It requires an output folder name, which will be used to save the checkpoints of the model. It also helps sync all the information in the model repository on 🤗 Hub.
Most of the training arguments are self-explanatory, but one that is quite important here is `remove_unused_columns=False`. This one will drop any features not used by the model's call function. By default it's `True` because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in this case, you need the unused features ('video' in particular) in order to create `pixel_values` (which is a mandatory key our model expects in its inputs).
>>> from transformers import TrainingArguments, Trainer
>>> model_name = model_ckpt.split("/")[-1]
>>> new_model_name = f"{model_name}-finetuned-ucf101-subset"
>>> num_epochs = 4
>>> args = TrainingArguments(
new_model_name,
remove_unused_columns=False,
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
max_steps=(train_dataset.num_videos // batch_size) * num_epochs,
)
The dataset returned by `pytorchvideo.data.Ucf101()` doesn't implement the `__len__` method. As such, we must define `max_steps` when instantiating `TrainingArguments`.
Next, you need to define a function to compute the metrics from the predictions, which will use the `metric` you'll load now. The only preprocessing you have to do is to take the argmax of our predicted logits:
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
**A note on evaluation**:
In the [VideoMAE paper](https://arxiv.org/abs/2203.12602), the authors use the following evaluation strategy. They evaluate the model on several clips from test videos and apply different crops to those clips and report the aggregate score. However, in the interest of simplicity and brevity, we don't consider that in this tutorial.
Also, define a `collate_fn`, which will be used to batch examples together. Each batch consists of 2 keys, namely `pixel_values` and `labels`.
>>> def collate_fn(examples):
# permute to (num_frames, num_channels, height, width)
pixel_values = torch.stack(
[example["video"].permute(1, 0, 2, 3) for example in examples]
)
labels = torch.tensor([example["label"] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}
Then you just pass all of this along with the datasets to `Trainer`:
>>> trainer = Trainer(
model,
args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=image_processor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)
You might wonder why you passed along the `image_processor` as a tokenizer when you preprocessed the data already. This is only to make sure the image processor configuration file (stored as JSON) will also be uploaded to the repo on the Hub.
Now fine-tune our model by calling the `train` method:
>>> train_results = trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
## Inference
Great, now that you have fine-tuned a model, you can use it for inference!
Load a video for inference:
>>> sample_test_video = next(iter(test_dataset))
The simplest way to try out your fine-tuned model for inference is to use it in a [`pipeline`](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.VideoClassificationPipeline). Instantiate a `pipeline` for video classification with your model, and pass your video to it:
>>> from transformers import pipeline
>>> video_cls = pipeline(model="my_awesome_video_cls_model")
>>> video_cls("https://huggingface.co/datasets/sayakpaul/ucf101-subset/resolve/main/v_BasketballDunk_g14_c06.avi")
[{'score': 0.9272987842559814, 'label': 'BasketballDunk'},
{'score': 0.017777055501937866, 'label': 'BabyCrawling'},
{'score': 0.01663011871278286, 'label': 'BalanceBeam'},
{'score': 0.009560945443809032, 'label': 'BandMarching'},
{'score': 0.0068979403004050255, 'label': 'BaseballPitch'}]
You can also manually replicate the results of the `pipeline` if you'd like.
>>> def run_inference(model, video):
# (num_frames, num_channels, height, width)
perumuted_sample_test_video = video.permute(1, 0, 2, 3)
inputs = {
"pixel_values": perumuted_sample_test_video.unsqueeze(0),
"labels": torch.tensor(
[sample_test_video["label"]]
), # this can be skipped if you don't have labels available.
}
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
inputs = {k: v.to(device) for k, v in inputs.items()}
model = model.to(device)
# forward pass
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
return logits
Now, pass your input to the model and return the `logits`:
>>> logits = run_inference(trained_model, sample_test_video["video"])
Decoding the `logits`, we get:
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: BasketballDunk
```
|
tasks/zero_shot_object_detection.md
|
# Zero-shot object detection
[[open-in-colab]]
Traditionally, models used for [object detection](object_detection) require labeled image datasets for training,
and are limited to detecting the set of classes from the training data.
Zero-shot object detection is supported by the [OWL-ViT](../model_doc/owlvit) model which uses a different approach. OWL-ViT
is an open-vocabulary object detector. It means that it can detect objects in images based on free-text queries without
the need to fine-tune the model on labeled datasets.
OWL-ViT leverages multi-modal representations to perform open-vocabulary detection. It combines [CLIP](../model_doc/clip) with
lightweight object classification and localization heads. Open-vocabulary detection is achieved by embedding free-text queries with the text encoder of CLIP and using them as input to the object classification and localization heads.
associate images and their corresponding textual descriptions, and ViT processes image patches as inputs. The authors
of OWL-ViT first trained CLIP from scratch and then fine-tuned OWL-ViT end to end on standard object detection datasets using
a bipartite matching loss.
With this approach, the model can detect objects based on textual descriptions without prior training on labeled datasets.
In this guide, you will learn how to use OWL-ViT:
- to detect objects based on text prompts
- for batch object detection
- for image-guided object detection
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q transformers
## Zero-shot object detection pipeline
The simplest way to try out inference with OWL-ViT is to use it in a [`pipeline`]. Instantiate a pipeline
for zero-shot object detection from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?other=owlvit):
thon
>>> from transformers import pipeline
>>> checkpoint = "google/owlvit-base-patch32"
>>> detector = pipeline(model=checkpoint, task="zero-shot-object-detection")
Next, choose an image you'd like to detect objects in. Here we'll use the image of astronaut Eileen Collins that is
a part of the [NASA](https://www.nasa.gov/multimedia/imagegallery/index.html) Great Images dataset.
>>> import skimage
>>> import numpy as np
>>> from PIL import Image
>>> image = skimage.data.astronaut()
>>> image = Image.fromarray(np.uint8(image)).convert("RGB")
>>> image
Pass the image and the candidate object labels to look for to the pipeline.
Here we pass the image directly; other suitable options include a local path to an image or an image url. We also pass text descriptions for all items we want to query the image for.
>>> predictions = detector(
image,
candidate_labels=["human face", "rocket", "nasa badge", "star-spangled banner"],
)
>>> predictions
[{'score': 0.3571370542049408,
'label': 'human face',
'box': {'xmin': 180, 'ymin': 71, 'xmax': 271, 'ymax': 178}},
{'score': 0.28099656105041504,
'label': 'nasa badge',
'box': {'xmin': 129, 'ymin': 348, 'xmax': 206, 'ymax': 427}},
{'score': 0.2110239565372467,
'label': 'rocket',
'box': {'xmin': 350, 'ymin': -1, 'xmax': 468, 'ymax': 288}},
{'score': 0.13790413737297058,
'label': 'star-spangled banner',
'box': {'xmin': 1, 'ymin': 1, 'xmax': 105, 'ymax': 509}},
{'score': 0.11950037628412247,
'label': 'nasa badge',
'box': {'xmin': 277, 'ymin': 338, 'xmax': 327, 'ymax': 380}},
{'score': 0.10649408400058746,
'label': 'rocket',
'box': {'xmin': 358, 'ymin': 64, 'xmax': 424, 'ymax': 280}}]
Let's visualize the predictions:
>>> from PIL import ImageDraw
>>> draw = ImageDraw.Draw(image)
>>> for prediction in predictions:
box = prediction["box"]
label = prediction["label"]
score = prediction["score"]
xmin, ymin, xmax, ymax = box.values()
draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
draw.text((xmin, ymin), f"{label}: {round(score,2)}", fill="white")
>>> image
## Text-prompted zero-shot object detection by hand
Now that you've seen how to use the zero-shot object detection pipeline, let's replicate the same
result manually.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?other=owlvit).
Here we'll use the same checkpoint as before:
>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
Let's take a different image to switch things up.
>>> import requests
>>> url = "https://unsplash.com/photos/oj0zeY2Ltk4/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTR8fHBpY25pY3xlbnwwfHx8fDE2Nzc0OTE1NDk&force=true&w=640"
>>> im = Image.open(requests.get(url, stream=True).raw)
>>> im
Use the processor to prepare the inputs for the model. The processor combines an image processor that prepares the
image for the model by resizing and normalizing it, and a [`CLIPTokenizer`] that takes care of the text inputs.
>>> text_queries = ["hat", "book", "sunglasses", "camera"]
>>> inputs = processor(text=text_queries, images=im, return_tensors="pt")
Pass the inputs through the model, post-process, and visualize the results. Since the image processor resized images before
feeding them to the model, you need to use the [`~OwlViTImageProcessor.post_process_object_detection`] method to make sure the predicted bounding
boxes have the correct coordinates relative to the original image:
>>> import torch
>>> with torch.no_grad():
outputs = model(**inputs)
target_sizes = torch.tensor([im.size[::-1]])
results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(im)
>>> scores = results["scores"].tolist()
>>> labels = results["labels"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
xmin, ymin, xmax, ymax = box
draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
draw.text((xmin, ymin), f"{text_queries[label]}: {round(score,2)}", fill="white")
>>> im
## Batch processing
You can pass multiple sets of images and text queries to search for different (or same) objects in several images.
Let's use both an astronaut image and the beach image together.
For batch processing, you should pass text queries as a nested list to the processor and images as lists of PIL images,
PyTorch tensors, or NumPy arrays.
>>> images = [image, im]
>>> text_queries = [
["human face", "rocket", "nasa badge", "star-spangled banner"],
["hat", "book", "sunglasses", "camera"],
]
>>> inputs = processor(text=text_queries, images=images, return_tensors="pt")
Previously for post-processing you passed the single image's size as a tensor, but you can also pass a tuple, or, in case
of several images, a list of tuples. Let's create predictions for the two examples, and visualize the second one (`image_idx = 1`).
>>> with torch.no_grad():
outputs = model(**inputs)
target_sizes = [x.size[::-1] for x in images]
results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)
>>> image_idx = 1
>>> draw = ImageDraw.Draw(images[image_idx])
>>> scores = results[image_idx]["scores"].tolist()
>>> labels = results[image_idx]["labels"].tolist()
>>> boxes = results[image_idx]["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
xmin, ymin, xmax, ymax = box
draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
draw.text((xmin, ymin), f"{text_queries[image_idx][label]}: {round(score,2)}", fill="white")
>>> images[image_idx]
## Image-guided object detection
In addition to zero-shot object detection with text queries, OWL-ViT offers image-guided object detection. This means
you can use an image query to find similar objects in the target image.
Unlike text queries, only a single example image is allowed.
Let's take an image with two cats on a couch as a target image, and an image of a single cat
as a query:
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image_target = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000524280.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
Let's take a quick look at the images:
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(1, 2)
>>> ax[0].imshow(image_target)
>>> ax[1].imshow(query_image)
In the preprocessing step, instead of text queries, you now need to use `query_images`:
>>> inputs = processor(images=image_target, query_images=query_image, return_tensors="pt")
For predictions, instead of passing the inputs to the model, pass them to [`~OwlViTForObjectDetection.image_guided_detection`]. Draw the predictions
as before except now there are no labels.
>>> with torch.no_grad():
outputs = model.image_guided_detection(**inputs)
target_sizes = torch.tensor([image_target.size[::-1]])
results = processor.post_process_image_guided_detection(outputs=outputs, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(image_target)
>>> scores = results["scores"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
xmin, ymin, xmax, ymax = box
draw.rectangle((xmin, ymin, xmax, ymax), outline="white", width=4)
>>> image_target
If you'd like to interactively try out inference with OWL-ViT, check out this demo:
|
tasks/language_modeling.md
|
# Causal language modeling
[[open-in-colab]]
There are two types of language modeling, causal and masked. This guide illustrates causal language modeling.
Causal language models are frequently used for text generation. You can use these models for creative applications like
choosing your own text adventure or an intelligent coding assistant like Copilot or CodeParrot.
Causal language modeling predicts the next token in a sequence of tokens, and the model can only attend to tokens on
the left. This means the model cannot see future tokens. GPT-2 is an example of a causal language model.
This guide will show you how to:
1. Finetune [DistilGPT2](https://huggingface.co/distilgpt2) on the [r/askscience](https://www.reddit.com/r/askscience/) subset of the [ELI5](https://huggingface.co/datasets/eli5) dataset.
2. Use your finetuned model for inference.
You can finetune other architectures for causal language modeling following the same steps in this guide.
Choose one of the following architectures:
[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load ELI5 dataset
Start by loading a smaller subset of the r/askscience subset of the ELI5 dataset from the 🤗 Datasets library.
This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
Split the dataset's `train_asks` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> eli5 = eli5.train_test_split(test_size=0.2)
Then take a look at an example:
>>> eli5["train"][0]
{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
'score': [6, 3],
'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
'answers_urls': {'url': []},
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls': {'url': []}}
While this may look like a lot, you're only really interested in the `text` field. What's cool about language modeling
tasks is you don't need labels (also known as an unsupervised task) because the next word *is* the label.
## Preprocess
The next step is to load a DistilGPT2 tokenizer to process the `text` subfield:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to
extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'answers.a_id': ['c3d1aib', 'c3d4lya'],
'answers.score': [6, 3],
'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
'answers_urls.url': [],
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls.url': []}
Each subfield is now a separate column as indicated by the `answers` prefix, and the `text` field is a list now. Instead
of tokenizing each sentence separately, convert the list to a string so you can jointly tokenize them.
Here is a first preprocessing function to join the list of strings for each example and tokenize the result:
>>> def preprocess_function(examples):
return tokenizer([" ".join(x) for x in examples["answers.text"]])
To apply this preprocessing function over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once, and increasing the number of processes with `num_proc`. Remove any columns you don't need:
>>> tokenized_eli5 = eli5.map(
preprocess_function,
batched=True,
num_proc=4,
remove_columns=eli5["train"].column_names,
)
This dataset contains the token sequences, but some of these are longer than the maximum input length for the model.
You can now use a second preprocessing function to
- concatenate all the sequences
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
>>> block_size = 128
>>> def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# Split by chunks of block_size.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
Apply the `group_texts` function over the entire dataset:
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
Now create a batch of examples using [`DataCollatorForLanguageModeling`]. It's more efficient to *dynamically pad* the
sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
Use the end-of-sequence token as the padding token and set `mlm=False`. This will use the inputs as labels shifted to the right by one element:
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
Use the end-of-sequence token as the padding token and set `mlm=False`. This will use the inputs as labels shifted to the right by one element:
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the [basic tutorial](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load DistilGPT2 with [`AutoModelForCausalLM`]:
>>> from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_eli5_clm-model",
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_dataset["train"],
eval_dataset=lm_dataset["test"],
data_collator=data_collator,
)
>>> trainer.train()
Once training is completed, use the [`~transformers.Trainer.evaluate`] method to evaluate your model and get its perplexity:
>>> import math
>>> eval_results = trainer.evaluate()
>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 49.61
Then share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the [basic tutorial](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
Then you can load DistilGPT2 with [`TFAutoModelForCausalLM`]:
>>> from transformers import TFAutoModelForCausalLM
>>> model = TFAutoModelForCausalLM.from_pretrained("distilgpt2")
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
lm_dataset["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_test_set = model.prepare_tf_dataset(
lm_dataset["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
output_dir="my_awesome_eli5_clm-model",
tokenizer=tokenizer,
)
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for causal language modeling, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with a prompt you'd like to generate text from:
>>> prompt = "Somatic hypermutation allows the immune system to"
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for text generation with your model, and pass your text to it:
>>> from transformers import pipeline
>>> generator = pipeline("text-generation", model="my_awesome_eli5_clm-model")
>>> generator(prompt)
[{'generated_text': "Somatic hypermutation allows the immune system to be able to effectively reverse the damage caused by an infection.\n\n\nThe damage caused by an infection is caused by the immune system's ability to perform its own self-correcting tasks."}]
Tokenize the text and return the `input_ids` as PyTorch tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
>>> inputs = tokenizer(prompt, return_tensors="pt").input_ids
Use the [`~transformers.generation_utils.GenerationMixin.generate`] method to generate text.
For more details about the different text generation strategies and parameters for controlling generation, check out the [Text generation strategies](../generation_strategies) page.
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
Decode the generated token ids back into text:
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
["Somatic hypermutation allows the immune system to react to drugs with the ability to adapt to a different environmental situation. In other words, a system of 'hypermutation' can help the immune system to adapt to a different environmental situation or in some cases even a single life. In contrast, researchers at the University of Massachusetts-Boston have found that 'hypermutation' is much stronger in mice than in humans but can be found in humans, and that it's not completely unknown to the immune system. A study on how the immune system"]
Tokenize the text and return the `input_ids` as TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
>>> inputs = tokenizer(prompt, return_tensors="tf").input_ids
Use the [`~transformers.generation_tf_utils.TFGenerationMixin.generate`] method to create the summarization. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text generation strategies](../generation_strategies) page.
>>> from transformers import TFAutoModelForCausalLM
>>> model = TFAutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
>>> outputs = model.generate(input_ids=inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
Decode the generated token ids back into text:
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Somatic hypermutation allows the immune system to detect the presence of other viruses as they become more prevalent. Therefore, researchers have identified a high proportion of human viruses. The proportion of virus-associated viruses in our study increases with age. Therefore, we propose a simple algorithm to detect the presence of these new viruses in our samples as a sign of improved immunity. A first study based on this algorithm, which will be published in Science on Friday, aims to show that this finding could translate into the development of a better vaccine that is more effective for']
|
tasks/masked_language_modeling.md
|
# Masked language modeling
[[open-in-colab]]
Masked language modeling predicts a masked token in a sequence, and the model can attend to tokens bidirectionally. This
means the model has full access to the tokens on the left and right. Masked language modeling is great for tasks that
require a good contextual understanding of an entire sequence. BERT is an example of a masked language model.
This guide will show you how to:
1. Finetune [DistilRoBERTa](https://huggingface.co/distilroberta-base) on the [r/askscience](https://www.reddit.com/r/askscience/) subset of the [ELI5](https://huggingface.co/datasets/eli5) dataset.
2. Use your finetuned model for inference.
You can finetune other architectures for masked language modeling following the same steps in this guide.
Choose one of the following architectures:
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [CamemBERT](../model_doc/camembert), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ESM](../model_doc/esm), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MRA](../model_doc/mra), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [Perceiver](../model_doc/perceiver), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [TAPAS](../model_doc/tapas), [Wav2Vec2](../model_doc/wav2vec2), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load ELI5 dataset
Start by loading a smaller subset of the r/askscience subset of the ELI5 dataset from the 🤗 Datasets library. This'll
give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
Split the dataset's `train_asks` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> eli5 = eli5.train_test_split(test_size=0.2)
Then take a look at an example:
>>> eli5["train"][0]
{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
'score': [6, 3],
'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
'answers_urls': {'url': []},
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls': {'url': []}}
While this may look like a lot, you're only really interested in the `text` field. What's cool about language modeling tasks is you don't need labels (also known as an unsupervised task) because the next word *is* the label.
## Preprocess
For masked language modeling, the next step is to load a DistilRoBERTa tokenizer to process the `text` subfield:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to e
xtract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'answers.a_id': ['c3d1aib', 'c3d4lya'],
'answers.score': [6, 3],
'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
'answers_urls.url': [],
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls.url': []}
Each subfield is now a separate column as indicated by the `answers` prefix, and the `text` field is a list now. Instead
of tokenizing each sentence separately, convert the list to a string so you can jointly tokenize them.
Here is a first preprocessing function to join the list of strings for each example and tokenize the result:
>>> def preprocess_function(examples):
return tokenizer([" ".join(x) for x in examples["answers.text"]])
To apply this preprocessing function over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once, and increasing the number of processes with `num_proc`. Remove any columns you don't need:
>>> tokenized_eli5 = eli5.map(
preprocess_function,
batched=True,
num_proc=4,
remove_columns=eli5["train"].column_names,
)
This dataset contains the token sequences, but some of these are longer than the maximum input length for the model.
You can now use a second preprocessing function to
- concatenate all the sequences
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
>>> block_size = 128
>>> def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# Split by chunks of block_size.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
return result
Apply the `group_texts` function over the entire dataset:
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
Now create a batch of examples using [`DataCollatorForLanguageModeling`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
Use the end-of-sequence token as the padding token and specify `mlm_probability` to randomly mask tokens each time you iterate over the data:
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
Use the end-of-sequence token as the padding token and specify `mlm_probability` to randomly mask tokens each time you iterate over the data:
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15, return_tensors="tf")
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load DistilRoBERTa with [`AutoModelForMaskedLM`]:
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("distilroberta-base")
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_eli5_mlm_model",
evaluation_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_dataset["train"],
eval_dataset=lm_dataset["test"],
data_collator=data_collator,
)
>>> trainer.train()
Once training is completed, use the [`~transformers.Trainer.evaluate`] method to evaluate your model and get its perplexity:
>>> import math
>>> eval_results = trainer.evaluate()
>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 8.76
Then share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
Then you can load DistilRoBERTa with [`TFAutoModelForMaskedLM`]:
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("distilroberta-base")
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
lm_dataset["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_test_set = model.prepare_tf_dataset(
lm_dataset["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
output_dir="my_awesome_eli5_mlm_model",
tokenizer=tokenizer,
)
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for masked language modeling, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text you'd like the model to fill in the blank with, and use the special `` token to indicate the blank:
>>> text = "The Milky Way is a galaxy."
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for fill-mask with your model, and pass your text to it. If you like, you can use the `top_k` parameter to specify how many predictions to return:
>>> from transformers import pipeline
>>> mask_filler = pipeline("fill-mask", "stevhliu/my_awesome_eli5_mlm_model")
>>> mask_filler(text, top_k=3)
[{'score': 0.5150994658470154,
'token': 21300,
'token_str': ' spiral',
'sequence': 'The Milky Way is a spiral galaxy.'},
{'score': 0.07087188959121704,
'token': 2232,
'token_str': ' massive',
'sequence': 'The Milky Way is a massive galaxy.'},
{'score': 0.06434620916843414,
'token': 650,
'token_str': ' small',
'sequence': 'The Milky Way is a small galaxy.'}]
Tokenize the text and return the `input_ids` as PyTorch tensors. You'll also need to specify the position of the `` token:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="pt")
>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
Pass your inputs to the model and return the `logits` of the masked token:
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
Then return the three masked tokens with the highest probability and print them out:
>>> top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
>>> for token in top_3_tokens:
print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
Tokenize the text and return the `input_ids` as TensorFlow tensors. You'll also need to specify the position of the `` token:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="tf")
>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
Pass your inputs to the model and return the `logits` of the masked token:
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
Then return the three masked tokens with the highest probability and print them out:
>>> top_3_tokens = tf.math.top_k(mask_token_logits, 3).indices.numpy()
>>> for token in top_3_tokens:
print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
|
tasks/zero_shot_image_classification.md
|
# Zero-shot image classification
[[open-in-colab]]
Zero-shot image classification is a task that involves classifying images into different categories using a model that was
not explicitly trained on data containing labeled examples from those specific categories.
Traditionally, image classification requires training a model on a specific set of labeled images, and this model learns to
"map" certain image features to labels. When there's a need to use such model for a classification task that introduces a
new set of labels, fine-tuning is required to "recalibrate" the model.
In contrast, zero-shot or open vocabulary image classification models are typically multi-modal models that have been trained on a large
dataset of images and associated descriptions. These models learn aligned vision-language representations that can be used for many downstream tasks including zero-shot image classification.
This is a more flexible approach to image classification that allows models to generalize to new and unseen categories
without the need for additional training data and enables users to query images with free-form text descriptions of their target objects .
In this guide you'll learn how to:
* create a zero-shot image classification pipeline
* run zero-shot image classification inference by hand
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q transformers
## Zero-shot image classification pipeline
The simplest way to try out inference with a model supporting zero-shot image classification is to use the corresponding [`pipeline`].
Instantiate a pipeline from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads):
thon
>>> from transformers import pipeline
>>> checkpoint = "openai/clip-vit-large-patch14"
>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
Next, choose an image you'd like to classify.
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
Pass the image and the candidate object labels to the pipeline. Here we pass the image directly; other suitable options
include a local path to an image or an image url.
The candidate labels can be simple words like in this example, or more descriptive.
>>> predictions = detector(image, candidate_labels=["fox", "bear", "seagull", "owl"])
>>> predictions
[{'score': 0.9996670484542847, 'label': 'owl'},
{'score': 0.000199399160919711, 'label': 'seagull'},
{'score': 7.392891711788252e-05, 'label': 'fox'},
{'score': 5.96074532950297e-05, 'label': 'bear'}]
## Zero-shot image classification by hand
Now that you've seen how to use the zero-shot image classification pipeline, let's take a look how you can run zero-shot
image classification manually.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads).
Here we'll use the same checkpoint as before:
>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
Let's take a different image to switch things up.
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
Use the processor to prepare the inputs for the model. The processor combines an image processor that prepares the
image for the model by resizing and normalizing it, and a tokenizer that takes care of the text inputs.
>>> candidate_labels = ["tree", "car", "bike", "cat"]
>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
Pass the inputs through the model, and post-process the results:
>>> import torch
>>> with torch.no_grad():
outputs = model(**inputs)
>>> logits = outputs.logits_per_image[0]
>>> probs = logits.softmax(dim=-1).numpy()
>>> scores = probs.tolist()
>>> result = [
{"score": score, "label": candidate_label}
for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
]
>>> result
[{'score': 0.998572, 'label': 'car'},
{'score': 0.0010570387, 'label': 'bike'},
{'score': 0.0003393686, 'label': 'tree'},
{'score': 3.1572064e-05, 'label': 'cat'}]
```
|
tasks/translation.md
|
# Translation
[[open-in-colab]]
Translation converts a sequence of text from one language to another. It is one of several tasks you can formulate as a sequence-to-sequence problem, a powerful framework for returning some output from an input, like translation or summarization. Translation systems are commonly used for translation between different language texts, but it can also be used for speech or some combination in between like text-to-speech or speech-to-text.
This guide will show you how to:
1. Finetune [T5](https://huggingface.co/t5-small) on the English-French subset of the [OPUS Books](https://huggingface.co/datasets/opus_books) dataset to translate English text to French.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[BART](../model_doc/bart), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [Encoder decoder](../model_doc/encoder-decoder), [FairSeq Machine-Translation](../model_doc/fsmt), [GPTSAN-japanese](../model_doc/gptsan-japanese), [LED](../model_doc/led), [LongT5](../model_doc/longt5), [M2M100](../model_doc/m2m_100), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [NLLB](../model_doc/nllb), [NLLB-MOE](../model_doc/nllb-moe), [Pegasus](../model_doc/pegasus), [PEGASUS-X](../model_doc/pegasus_x), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [SeamlessM4T](../model_doc/seamless_m4t), [SwitchTransformers](../model_doc/switch_transformers), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM-ProphetNet](../model_doc/xlm-prophetnet)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate sacrebleu
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load OPUS Books dataset
Start by loading the English-French subset of the [OPUS Books](https://huggingface.co/datasets/opus_books) dataset from the 🤗 Datasets library:
>>> from datasets import load_dataset
>>> books = load_dataset("opus_books", "en-fr")
Split the dataset into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> books = books["train"].train_test_split(test_size=0.2)
Then take a look at an example:
>>> books["train"][0]
{'id': '90560',
'translation': {'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
'fr': 'Mais ce plateau élevé ne mesurait que quelques toises, et bientôt nous fûmes rentrés dans notre élément.'}}
`translation`: an English and French translation of the text.
## Preprocess
The next step is to load a T5 tokenizer to process the English-French language pairs:
>>> from transformers import AutoTokenizer
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
The preprocessing function you want to create needs to:
1. Prefix the input with a prompt so T5 knows this is a translation task. Some models capable of multiple NLP tasks require prompting for specific tasks.
2. Tokenize the input (English) and target (French) separately because you can't tokenize French text with a tokenizer pretrained on an English vocabulary.
3. Truncate sequences to be no longer than the maximum length set by the `max_length` parameter.
>>> source_lang = "en"
>>> target_lang = "fr"
>>> prefix = "translate English to French: "
>>> def preprocess_function(examples):
inputs = [prefix + example[source_lang] for example in examples["translation"]]
targets = [example[target_lang] for example in examples["translation"]]
model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
return model_inputs
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
>>> tokenized_books = books.map(preprocess_function, batched=True)
Now create a batch of examples using [`DataCollatorForSeq2Seq`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [SacreBLEU](https://huggingface.co/spaces/evaluate-metric/sacrebleu) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> metric = evaluate.load("sacrebleu")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the SacreBLEU score:
>>> import numpy as np
>>> def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
>>> def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load T5 with [`AutoModelForSeq2SeqLM`]:
>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
At this point, only three steps remain:
1. Define your training hyperparameters in [`Seq2SeqTrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the SacreBLEU metric and save the training checkpoint.
2. Pass the training arguments to [`Seq2SeqTrainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = Seq2SeqTrainingArguments(
output_dir="my_awesome_opus_books_model",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=2,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
>>> trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_books["train"],
eval_dataset=tokenized_books["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
>>> trainer.train()
`
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
Then you can load T5 with [`TFAutoModelForSeq2SeqLM`]:
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
tokenized_books["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_test_set = model.prepare_tf_dataset(
tokenized_books["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
The last two things to setup before you start training is to compute the SacreBLEU metric from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
output_dir="my_awesome_opus_books_model",
tokenizer=tokenizer,
)
Then bundle your callbacks together:
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for translation, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text you'd like to translate to another language. For T5, you need to prefix your input depending on the task you're working on. For translation from English to French, you should prefix your input as shown below:
>>> text = "translate English to French: Legumes share resources with nitrogen-fixing bacteria."
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for translation with your model, and pass your text to it:
>>> from transformers import pipeline
>>> translator = pipeline("translation", model="my_awesome_opus_books_model")
>>> translator(text)
[{'translation_text': 'Legumes partagent des ressources avec des bactéries azotantes.'}]
You can also manually replicate the results of the `pipeline` if you'd like:
Tokenize the text and return the `input_ids` as PyTorch tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
Use the [`~transformers.generation_utils.GenerationMixin.generate`] method to create the translation. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text Generation](../main_classes/text_generation) API.
>>> from transformers import AutoModelForSeq2SeqLM
>>> model = AutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
Decode the generated token ids back into text:
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Les lignées partagent des ressources avec des bactéries enfixant l'azote.'
Tokenize the text and return the `input_ids` as TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
>>> inputs = tokenizer(text, return_tensors="tf").input_ids
Use the [`~transformers.generation_tf_utils.TFGenerationMixin.generate`] method to create the translation. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text Generation](../main_classes/text_generation) API.
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
Decode the generated token ids back into text:
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Les lugumes partagent les ressources avec des bactéries fixatrices d'azote.'
|
tasks/summarization.md
|
# Summarization
[[open-in-colab]]
Summarization creates a shorter version of a document or an article that captures all the important information. Along with translation, it is another example of a task that can be formulated as a sequence-to-sequence task. Summarization can be:
- Extractive: extract the most relevant information from a document.
- Abstractive: generate new text that captures the most relevant information.
This guide will show you how to:
1. Finetune [T5](https://huggingface.co/t5-small) on the California state bill subset of the [BillSum](https://huggingface.co/datasets/billsum) dataset for abstractive summarization.
2. Use your finetuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[BART](../model_doc/bart), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [Encoder decoder](../model_doc/encoder-decoder), [FairSeq Machine-Translation](../model_doc/fsmt), [GPTSAN-japanese](../model_doc/gptsan-japanese), [LED](../model_doc/led), [LongT5](../model_doc/longt5), [M2M100](../model_doc/m2m_100), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [NLLB](../model_doc/nllb), [NLLB-MOE](../model_doc/nllb-moe), [Pegasus](../model_doc/pegasus), [PEGASUS-X](../model_doc/pegasus_x), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [SeamlessM4T](../model_doc/seamless_m4t), [SwitchTransformers](../model_doc/switch_transformers), [T5](../model_doc/t5), [UMT5](../model_doc/umt5), [XLM-ProphetNet](../model_doc/xlm-prophetnet)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate rouge_score
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load BillSum dataset
Start by loading the smaller California state bill subset of the BillSum dataset from the 🤗 Datasets library:
>>> from datasets import load_dataset
>>> billsum = load_dataset("billsum", split="ca_test")
Split the dataset into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> billsum = billsum.train_test_split(test_size=0.2)
Then take a look at an example:
>>> billsum["train"][0]
{'summary': 'Existing law authorizes state agencies to enter into contracts for the acquisition of goods or services upon approval by the Department of General Services. Existing law sets forth various requirements and prohibitions for those contracts, including, but not limited to, a prohibition on entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between spouses and domestic partners or same-sex and different-sex couples in the provision of benefits. Existing law provides that a contract entered into in violation of those requirements and prohibitions is void and authorizes the state or any person acting on behalf of the state to bring a civil action seeking a determination that a contract is in violation and therefore void. Under existing law, a willful violation of those requirements and prohibitions is a misdemeanor.\nThis bill would also prohibit a state agency from entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between employees on the basis of gender identity in the provision of benefits, as specified. By expanding the scope of a crime, this bill would impose a state-mandated local program.\nThe California Constitution requires the state to reimburse local agencies and school districts for certain costs mandated by the state. Statutory provisions establish procedures for making that reimbursement.\nThis bill would provide that no reimbursement is required by this act for a specified reason.',
'text': 'The people of the State of California do enact as follows:\n\n\nSECTION 1.\nSection 10295.35 is added to the Public Contract Code, to read:\n10295.35.\n(a) (1) Notwithstanding any other law, a state agency shall not enter into any contract for the acquisition of goods or services in the amount of one hundred thousand dollars ($100,000) or more with a contractor that, in the provision of benefits, discriminates between employees on the basis of an employee’s or dependent’s actual or perceived gender identity, including, but not limited to, the employee’s or dependent’s identification as transgender.\n(2) For purposes of this section, “contract” includes contracts with a cumulative amount of one hundred thousand dollars ($100,000) or more per contractor in each fiscal year.\n(3) For purposes of this section, an employee health plan is discriminatory if the plan is not consistent with Section 1365.5 of the Health and Safety Code and Section 10140 of the Insurance Code.\n(4) The requirements of this section shall apply only to those portions of a contractor’s operations that occur under any of the following conditions:\n(A) Within the state.\n(B) On real property outside the state if the property is owned by the state or if the state has a right to occupy the property, and if the contractor’s presence at that location is connected to a contract with the state.\n(C) Elsewhere in the United States where work related to a state contract is being performed.\n(b) Contractors shall treat as confidential, to the maximum extent allowed by law or by the requirement of the contractor’s insurance provider, any request by an employee or applicant for employment benefits or any documentation of eligibility for benefits submitted by an employee or applicant for employment.\n(c) After taking all reasonable measures to find a contractor that complies with this section, as determined by the state agency, the requirements of this section may be waived under any of the following circumstances:\n(1) There is only one prospective contractor willing to enter into a specific contract with the state agency.\n(2) The contract is necessary to respond to an emergency, as determined by the state agency, that endangers the public health, welfare, or safety, or the contract is necessary for the provision of essential services, and no entity that complies with the requirements of this section capable of responding to the emergency is immediately available.\n(3) The requirements of this section violate, or are inconsistent with, the terms or conditions of a grant, subvention, or agreement, if the agency has made a good faith attempt to change the terms or conditions of any grant, subvention, or agreement to authorize application of this section.\n(4) The contractor is providing wholesale or bulk water, power, or natural gas, the conveyance or transmission of the same, or ancillary services, as required for ensuring reliable services in accordance with good utility practice, if the purchase of the same cannot practically be accomplished through the standard competitive bidding procedures and the contractor is not providing direct retail services to end users.\n(d) (1) A contractor shall not be deemed to discriminate in the provision of benefits if the contractor, in providing the benefits, pays the actual costs incurred in obtaining the benefit.\n(2) If a contractor is unable to provide a certain benefit, despite taking reasonable measures to do so, the contractor shall not be deemed to discriminate in the provision of benefits.\n(e) (1) Every contract subject to this chapter shall contain a statement by which the contractor certifies that the contractor is in compliance with this section.\n(2) The department or other contracting agency shall enforce this section pursuant to its existing enforcement powers.\n(3) (A) If a contractor falsely certifies that it is in compliance with this section, the contract with that contractor shall be subject to Article 9 (commencing with Section 10420), unless, within a time period specified by the department or other contracting agency, the contractor provides to the department or agency proof that it has complied, or is in the process of complying, with this section.\n(B) The application of the remedies or penalties contained in Article 9 (commencing with Section 10420) to a contract subject to this chapter shall not preclude the application of any existing remedies otherwise available to the department or other contracting agency under its existing enforcement powers.\n(f) Nothing in this section is intended to regulate the contracting practices of any local jurisdiction.\n(g) This section shall be construed so as not to conflict with applicable federal laws, rules, or regulations. In the event that a court or agency of competent jurisdiction holds that federal law, rule, or regulation invalidates any clause, sentence, paragraph, or section of this code or the application thereof to any person or circumstances, it is the intent of the state that the court or agency sever that clause, sentence, paragraph, or section so that the remainder of this section shall remain in effect.\nSEC. 2.\nSection 10295.35 of the Public Contract Code shall not be construed to create any new enforcement authority or responsibility in the Department of General Services or any other contracting agency.\nSEC. 3.\nNo reimbursement is required by this act pursuant to Section 6 of Article XIII\u2009B of the California Constitution because the only costs that may be incurred by a local agency or school district will be incurred because this act creates a new crime or infraction, eliminates a crime or infraction, or changes the penalty for a crime or infraction, within the meaning of Section 17556 of the Government Code, or changes the definition of a crime within the meaning of Section 6 of Article XIII\u2009B of the California Constitution.',
'title': 'An act to add Section 10295.35 to the Public Contract Code, relating to public contracts.'}
There are two fields that you'll want to use:
- `text`: the text of the bill which'll be the input to the model.
- `summary`: a condensed version of `text` which'll be the model target.
## Preprocess
The next step is to load a T5 tokenizer to process `text` and `summary`:
>>> from transformers import AutoTokenizer
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
The preprocessing function you want to create needs to:
1. Prefix the input with a prompt so T5 knows this is a summarization task. Some models capable of multiple NLP tasks require prompting for specific tasks.
2. Use the keyword `text_target` argument when tokenizing labels.
3. Truncate sequences to be no longer than the maximum length set by the `max_length` parameter.
>>> prefix = "summarize: "
>>> def preprocess_function(examples):
inputs = [prefix + doc for doc in examples["text"]]
model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
labels = tokenizer(text_target=examples["summary"], max_length=128, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
>>> tokenized_billsum = billsum.map(preprocess_function, batched=True)
Now create a batch of examples using [`DataCollatorForSeq2Seq`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [ROUGE](https://huggingface.co/spaces/evaluate-metric/rouge) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> rouge = evaluate.load("rouge")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the ROUGE metric:
>>> import numpy as np
>>> def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
result = rouge.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load T5 with [`AutoModelForSeq2SeqLM`]:
>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
At this point, only three steps remain:
1. Define your training hyperparameters in [`Seq2SeqTrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the ROUGE metric and save the training checkpoint.
2. Pass the training arguments to [`Seq2SeqTrainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = Seq2SeqTrainingArguments(
output_dir="my_awesome_billsum_model",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=4,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
>>> trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_billsum["train"],
eval_dataset=tokenized_billsum["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
Then you can load T5 with [`TFAutoModelForSeq2SeqLM`]:
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
>>> tf_train_set = model.prepare_tf_dataset(
tokenized_billsum["train"],
shuffle=True,
batch_size=16,
collate_fn=data_collator,
)
>>> tf_test_set = model.prepare_tf_dataset(
tokenized_billsum["test"],
shuffle=False,
batch_size=16,
collate_fn=data_collator,
)
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
The last two things to setup before you start training is to compute the ROUGE score from the predictions, and provide a way to push your model to the Hub. Both are done by using [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [`~transformers.KerasMetricCallback`]:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
output_dir="my_awesome_billsum_model",
tokenizer=tokenizer,
)
Then bundle your callbacks together:
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callbacks to finetune the model:
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
For a more in-depth example of how to finetune a model for summarization, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text you'd like to summarize. For T5, you need to prefix your input depending on the task you're working on. For summarization you should prefix your input as shown below:
>>> text = "summarize: The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country. It'll lower the deficit and ask the ultra-wealthy and corporations to pay their fair share. And no one making under $400,000 per year will pay a penny more in taxes."
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for summarization with your model, and pass your text to it:
>>> from transformers import pipeline
>>> summarizer = pipeline("summarization", model="stevhliu/my_awesome_billsum_model")
>>> summarizer(text)
[{"summary_text": "The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country."}]
You can also manually replicate the results of the `pipeline` if you'd like:
Tokenize the text and return the `input_ids` as PyTorch tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_billsum_model")
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
Use the [`~transformers.generation_utils.GenerationMixin.generate`] method to create the summarization. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text Generation](../main_classes/text_generation) API.
>>> from transformers import AutoModelForSeq2SeqLM
>>> model = AutoModelForSeq2SeqLM.from_pretrained("stevhliu/my_awesome_billsum_model")
>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
Decode the generated token ids back into text:
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.'
Tokenize the text and return the `input_ids` as TensorFlow tensors:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_billsum_model")
>>> inputs = tokenizer(text, return_tensors="tf").input_ids
Use the [`~transformers.generation_tf_utils.TFGenerationMixin.generate`] method to create the summarization. For more details about the different text generation strategies and parameters for controlling generation, check out the [Text Generation](../main_classes/text_generation) API.
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("stevhliu/my_awesome_billsum_model")
>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
Decode the generated token ids back into text:
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.'
|
tasks/knowledge_distillation_for_image_classification.md
|
# Knowledge Distillation for Computer Vision
[[open-in-colab]]
Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student). To distill knowledge from one model to another, we take a pre-trained teacher model trained on a certain task (image classification for this case) and randomly initialize a student model to be trained on image classification. Next, we train the student model to minimize the difference between it's outputs and the teacher's outputs, thus making it mimic the behavior. It was first introduced in [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531). In this guide, we will do task-specific knowledge distillation. We will use the [beans dataset](https://huggingface.co/datasets/beans) for this.
This guide demonstrates how you can distill a [fine-tuned ViT model](https://huggingface.co/merve/vit-mobilenet-beans-224) (teacher model) to a [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (student model) using the [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) of 🤗 Transformers.
Let's install the libraries needed for distillation and evaluating the process.
```bash
pip install transformers datasets accelerate tensorboard evaluate --upgrade
In this example, we are using the `merve/beans-vit-224` model as teacher model. It's an image classification model, based on `google/vit-base-patch16-224-in21k` fine-tuned on beans dataset. We will distill this model to a randomly initialized MobileNetV2.
We will now load the dataset.
thon
from datasets import load_dataset
dataset = load_dataset("beans")
We can use an image processor from either of the models, as in this case they return the same output with same resolution. We will use the `map()` method of `dataset` to apply the preprocessing to every split of the dataset.
thon
from transformers import AutoImageProcessor
teacher_processor = AutoImageProcessor.from_pretrained("merve/beans-vit-224")
def process(examples):
processed_inputs = teacher_processor(examples["image"])
return processed_inputs
processed_datasets = dataset.map(process, batched=True)
Essentially, we want the student model (a randomly initialized MobileNet) to mimic the teacher model (fine-tuned vision transformer). To achieve this, we first get the logits output from the teacher and the student. Then, we divide each of them by the parameter `temperature` which controls the importance of each soft target. A parameter called `lambda` weighs the importance of the distillation loss. In this example, we will use `temperature=5` and `lambda=0.5`. We will use the Kullback-Leibler Divergence loss to compute the divergence between the student and teacher. Given two data P and Q, KL Divergence explains how much extra information we need to represent P using Q. If two are identical, their KL divergence is zero, as there's no other information needed to explain P from Q. Thus, in the context of knowledge distillation, KL divergence is useful.
thon
from transformers import TrainingArguments, Trainer
import torch
import torch.nn as nn
import torch.nn.functional as F
class ImageDistilTrainer(Trainer):
def __init__(self, *args, teacher_model=None, **kwargs):
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self.student = student_model
self.loss_function = nn.KLDivLoss(reduction="batchmean")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.teacher.to(device)
self.teacher.eval()
self.temperature = temperature
self.lambda_param = lambda_param
def compute_loss(self, student, inputs, return_outputs=False):
student_output = self.student(**inputs)
with torch.no_grad():
teacher_output = self.teacher(**inputs)
# Compute soft targets for teacher and student
soft_teacher = F.softmax(teacher_output.logits / self.temperature, dim=-1)
soft_student = F.log_softmax(student_output.logits / self.temperature, dim=-1)
# Compute the loss
distillation_loss = self.loss_function(soft_student, soft_teacher) * (self.temperature ** 2)
# Compute the true label loss
student_target_loss = student_output.loss
# Calculate final loss
loss = (1. - self.lambda_param) * student_target_loss + self.lambda_param * distillation_loss
return (loss, student_output) if return_outputs else loss
We will now login to Hugging Face Hub so we can push our model to the Hugging Face Hub through the `Trainer`.
thon
from huggingface_hub import notebook_login
notebook_login()
Let's set the `TrainingArguments`, the teacher model and the student model.
thon
from transformers import AutoModelForImageClassification, MobileNetV2Config, MobileNetV2ForImageClassification
training_args = TrainingArguments(
output_dir="my-awesome-model",
num_train_epochs=30,
fp16=True,
logging_dir=f"{repo_name}/logs",
logging_strategy="epoch",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
report_to="tensorboard",
push_to_hub=True,
hub_strategy="every_save",
hub_model_id=repo_name,
)
num_labels = len(processed_datasets["train"].features["labels"].names)
# initialize models
teacher_model = AutoModelForImageClassification.from_pretrained(
"merve/beans-vit-224",
num_labels=num_labels,
ignore_mismatched_sizes=True
)
# training MobileNetV2 from scratch
student_config = MobileNetV2Config()
student_config.num_labels = num_labels
student_model = MobileNetV2ForImageClassification(student_config)
We can use `compute_metrics` function to evaluate our model on the test set. This function will be used during the training process to compute the `accuracy` & `f1` of our model.
thon
import evaluate
import numpy as np
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
acc = accuracy.compute(references=labels, predictions=np.argmax(predictions, axis=1))
return {"accuracy": acc["accuracy"]}
Let's initialize the `Trainer` with the training arguments we defined. We will also initialize our data collator.
thon
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator()
trainer = ImageDistilTrainer(
student_model=student_model,
teacher_model=teacher_model,
training_args=training_args,
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
tokenizer=teacher_extractor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
)
We can now train our model.
thon
trainer.train()
We can evaluate the model on the test set.
thon
trainer.evaluate(processed_datasets["test"])
On test set, our model reaches 72 percent accuracy. To have a sanity check over efficiency of distillation, we also trained MobileNet on the beans dataset from scratch with the same hyperparameters and observed 63 percent accuracy on the test set. We invite the readers to try different pre-trained teacher models, student architectures, distillation parameters and report their findings. The training logs and checkpoints for distilled model can be found in [this repository](https://huggingface.co/merve/vit-mobilenet-beans-224), and MobileNetV2 trained from scratch can be found in this [repository](https://huggingface.co/merve/resnet-mobilenet-beans-5).
|
tasks/idefics.md
|
# Image tasks with IDEFICS
[[open-in-colab]]
While individual tasks can be tackled by fine-tuning specialized models, an alternative approach
that has recently emerged and gained popularity is to use large models for a diverse set of tasks without fine-tuning.
For instance, large language models can handle such NLP tasks as summarization, translation, classification, and more.
This approach is no longer limited to a single modality, such as text, and in this guide, we will illustrate how you can
solve image-text tasks with a large multimodal model called IDEFICS.
[IDEFICS](../model_doc/idefics) is an open-access vision and language model based on [Flamingo](https://huggingface.co/papers/2204.14198),
a state-of-the-art visual language model initially developed by DeepMind. The model accepts arbitrary sequences of image
and text inputs and generates coherent text as output. It can answer questions about images, describe visual content,
create stories grounded in multiple images, and so on. IDEFICS comes in two variants - [80 billion parameters](https://huggingface.co/HuggingFaceM4/idefics-80b)
and [9 billion parameters](https://huggingface.co/HuggingFaceM4/idefics-9b), both of which are available on the 🤗 Hub. For each variant, you can also find fine-tuned instructed
versions of the model adapted for conversational use cases.
This model is exceptionally versatile and can be used for a wide range of image and multimodal tasks. However,
being a large model means it requires significant computational resources and infrastructure. It is up to you to decide whether
this approach suits your use case better than fine-tuning specialized models for each individual task.
In this guide, you'll learn how to:
- [Load IDEFICS](#loading-the-model) and [load the quantized version of the model](#loading-the-quantized-version-of-the-model)
- Use IDEFICS for:
- [Image captioning](#image-captioning)
- [Prompted image captioning](#prompted-image-captioning)
- [Few-shot prompting](#few-shot-prompting)
- [Visual question answering](#visual-question-answering)
- [Image classificaiton](#image-classification)
- [Image-guided text generation](#image-guided-text-generation)
- [Run inference in batch mode](#running-inference-in-batch-mode)
- [Run IDEFICS instruct for conversational use](#idefics-instruct-for-conversational-use)
Before you begin, make sure you have all the necessary libraries installed.
```bash
pip install -q bitsandbytes sentencepiece accelerate transformers
To run the following examples with a non-quantized version of the model checkpoint you will need at least 20GB of GPU memory.
## Loading the model
Let's start by loading the model's 9 billion parameters checkpoint:
>>> checkpoint = "HuggingFaceM4/idefics-9b"
Just like for other Transformers models, you need to load a processor and the model itself from the checkpoint.
The IDEFICS processor wraps a [`LlamaTokenizer`] and IDEFICS image processor into a single processor to take care of
preparing text and image inputs for the model.
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16, device_map="auto")
Setting `device_map` to `"auto"` will automatically determine how to load and store the model weights in the most optimized
manner given existing devices.
### Quantized model
If high-memory GPU availability is an issue, you can load the quantized version of the model. To load the model and the
processor in 4bit precision, pass a `BitsAndBytesConfig` to the `from_pretrained` method and the model will be compressed
on the fly while loading.
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor, BitsAndBytesConfig
>>> quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> model = IdeficsForVisionText2Text.from_pretrained(
checkpoint,
quantization_config=quantization_config,
device_map="auto"
)
Now that you have the model loaded in one of the suggested ways, let's move on to exploring tasks that you can use IDEFICS for.
## Image captioning
Image captioning is the task of predicting a caption for a given image. A common application is to aid visually impaired
people navigate through different situations, for instance, explore image content online.
To illustrate the task, get an image to be captioned, e.g.:
Photo by [Hendo Wang](https://unsplash.com/@hendoo).
IDEFICS accepts text and image prompts. However, to caption an image, you do not have to provide a text prompt to the
model, only the preprocessed input image. Without a text prompt, the model will start generating text from the
BOS (beginning-of-sequence) token thus creating a caption.
As image input to the model, you can use either an image object (`PIL.Image`) or a url from which the image can be retrieved.
>>> prompt = [
"https://images.unsplash.com/photo-1583160247711-2191776b4b91?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3542&q=80",
]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
A puppy in a flower bed
It is a good idea to include the `bad_words_ids` in the call to `generate` to avoid errors arising when increasing
the `max_new_tokens`: the model will want to generate a new `` or `` token when there
is no image being generated by the model.
You can set it on-the-fly as in this guide, or store in the `GenerationConfig` as described in the [Text generation strategies](../generation_strategies) guide.
## Prompted image captioning
You can extend image captioning by providing a text prompt, which the model will continue given the image. Let's take
another image to illustrate:
Photo by [Denys Nevozhai](https://unsplash.com/@dnevozhai).
Textual and image prompts can be passed to the model's processor as a single list to create appropriate inputs.
>>> prompt = [
"https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
"This is an image of ",
]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
This is an image of the Eiffel Tower in Paris, France.
## Few-shot prompting
While IDEFICS demonstrates great zero-shot results, your task may require a certain format of the caption, or come with
other restrictions or requirements that increase task's complexity. Few-shot prompting can be used to enable in-context learning.
By providing examples in the prompt, you can steer the model to generate results that mimic the format of given examples.
Let's use the previous image of the Eiffel Tower as an example for the model and build a prompt that demonstrates to the model
that in addition to learning what the object in an image is, we would also like to get some interesting information about it.
Then, let's see, if we can get the same response format for an image of the Statue of Liberty:
Photo by [Juan Mayobre](https://unsplash.com/@jmayobres).
>>> prompt = ["User:",
"https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
"Describe this image.\nAssistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.\n",
"User:",
"https://images.unsplash.com/photo-1524099163253-32b7f0256868?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3387&q=80",
"Describe this image.\nAssistant:"
]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=30, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
User: Describe this image.
Assistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.
User: Describe this image.
Assistant: An image of the Statue of Liberty. Fun fact: the Statue of Liberty is 151 feet tall.
Notice that just from a single example (i.e., 1-shot) the model has learned how to perform the task. For more complex tasks,
feel free to experiment with a larger number of examples (e.g., 3-shot, 5-shot, etc.).
## Visual question answering
Visual Question Answering (VQA) is the task of answering open-ended questions based on an image. Similar to image
captioning it can be used in accessibility applications, but also in education (reasoning about visual materials), customer
service (questions about products based on images), and image retrieval.
Let's get a new image for this task:
Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
>>> prompt = [
"Instruction: Provide an answer to the question. Use the image to answer.\n",
"https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
"Question: Where are these people and what's the weather like? Answer:"
]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=20, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Provide an answer to the question. Use the image to answer.
Question: Where are these people and what's the weather like? Answer: They're in a park in New York City, and it's a beautiful day.
## Image classification
IDEFICS is capable of classifying images into different categories without being explicitly trained on data containing
labeled examples from those specific categories. Given a list of categories and using its image and text understanding
capabilities, the model can infer which category the image likely belongs to.
Say, we have this image of a vegetable stand:
Photo by [Peter Wendt](https://unsplash.com/@peterwendt).
We can instruct the model to classify the image into one of the categories that we have:
>>> categories = ['animals','vegetables', 'city landscape', 'cars', 'office']
>>> prompt = [f"Instruction: Classify the following image into a single category from the following list: {categories}.\n",
"https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
"Category: "
]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=6, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Classify the following image into a single category from the following list: ['animals', 'vegetables', 'city landscape', 'cars', 'office'].
Category: Vegetables
```
In the example above we instruct the model to classify the image into a single category, however, you can also prompt the model to do rank classification.
## Image-guided text generation
For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
useful to create descriptions of products, ads, descriptions of a scene, etc.
Let's prompt IDEFICS to write a story based on a simple image of a red door:
Photo by [Craig Tidball](https://unsplash.com/@devonshiremedia).
>>> prompt = ["Instruction: Use the image to write a story. \n",
"https://images.unsplash.com/photo-1517086822157-2b0358e7684a?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=2203&q=80",
"Story: \n"]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, num_beams=2, max_new_tokens=200, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Use the image to write a story.
Story:
Once upon a time, there was a little girl who lived in a house with a red door. She loved her red door. It was the prettiest door in the whole world.
One day, the little girl was playing in her yard when she noticed a man standing on her doorstep. He was wearing a long black coat and a top hat.
The little girl ran inside and told her mother about the man.
Her mother said, “Don’t worry, honey. He’s just a friendly ghost.”
The little girl wasn’t sure if she believed her mother, but she went outside anyway.
When she got to the door, the man was gone.
The next day, the little girl was playing in her yard again when she noticed the man standing on her doorstep.
He was wearing a long black coat and a top hat.
The little girl ran
Looks like IDEFICS noticed the pumpkin on the doorstep and went with a spooky Halloween story about a ghost.
For longer outputs like this, you will greatly benefit from tweaking the text generation strategy. This can help
you significantly improve the quality of the generated output. Check out [Text generation strategies](../generation_strategies)
to learn more.
## Running inference in batch mode
All of the earlier sections illustrated IDEFICS for a single example. In a very similar fashion, you can run inference
for a batch of examples by passing a list of prompts:
>>> prompts = [
[ "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
"This is an image of ",
],
[ "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
"This is an image of ",
],
[ "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
"This is an image of ",
],
]
>>> inputs = processor(prompts, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> for i,t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
0:
This is an image of the Eiffel Tower in Paris, France.
1:
This is an image of a couple on a picnic blanket.
2:
This is an image of a vegetable stand.
## IDEFICS instruct for conversational use
For conversational use cases, you can find fine-tuned instructed versions of the model on the 🤗 Hub:
`HuggingFaceM4/idefics-80b-instruct` and `HuggingFaceM4/idefics-9b-instruct`.
These checkpoints are the result of fine-tuning the respective base models on a mixture of supervised and instruction
fine-tuning datasets, which boosts the downstream performance while making the models more usable in conversational settings.
The use and prompting for the conversational use is very similar to using the base models:
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> checkpoint = "HuggingFaceM4/idefics-9b-instruct"
>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?",
"\nAssistant:",
],
]
>>> # --batched mode
>>> inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
>>> # --single sample mode
>>> # inputs = processor(prompts[0], return_tensors="pt").to(device)
>>> # Generation args
>>> exit_condition = processor.tokenizer("", add_special_tokens=False).input_ids
>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
|
tasks/image_classification.md
|
# Image classification
[[open-in-colab]]
Image classification assigns a label or class to an image. Unlike text or audio classification, the inputs are the
pixel values that comprise an image. There are many applications for image classification, such as detecting damage
after a natural disaster, monitoring crop health, or helping screen medical images for signs of disease.
This guide illustrates how to:
1. Fine-tune [ViT](model_doc/vit) on the [Food-101](https://huggingface.co/datasets/food101) dataset to classify a food item in an image.
2. Use your fine-tuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[BEiT](../model_doc/beit), [BiT](../model_doc/bit), [ConvNeXT](../model_doc/convnext), [ConvNeXTV2](../model_doc/convnextv2), [CvT](../model_doc/cvt), [Data2VecVision](../model_doc/data2vec-vision), [DeiT](../model_doc/deit), [DiNAT](../model_doc/dinat), [DINOv2](../model_doc/dinov2), [EfficientFormer](../model_doc/efficientformer), [EfficientNet](../model_doc/efficientnet), [FocalNet](../model_doc/focalnet), [ImageGPT](../model_doc/imagegpt), [LeViT](../model_doc/levit), [MobileNetV1](../model_doc/mobilenet_v1), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [NAT](../model_doc/nat), [Perceiver](../model_doc/perceiver), [PoolFormer](../model_doc/poolformer), [PVT](../model_doc/pvt), [RegNet](../model_doc/regnet), [ResNet](../model_doc/resnet), [SegFormer](../model_doc/segformer), [SwiftFormer](../model_doc/swiftformer), [Swin Transformer](../model_doc/swin), [Swin Transformer V2](../model_doc/swinv2), [VAN](../model_doc/van), [ViT](../model_doc/vit), [ViT Hybrid](../model_doc/vit_hybrid), [ViTMSN](../model_doc/vit_msn)
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
We encourage you to log in to your Hugging Face account to upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
## Load Food-101 dataset
Start by loading a smaller subset of the Food-101 dataset from the 🤗 Datasets library. This will give you a chance to
experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset
>>> food = load_dataset("food101", split="train[:5000]")
Split the dataset's `train` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
>>> food = food.train_test_split(test_size=0.2)
Then take a look at an example:
>>> food["train"][0]
{'image': ,
'label': 79}
Each example in the dataset has two fields:
- `image`: a PIL image of the food item
- `label`: the label class of the food item
To make it easier for the model to get the label name from the label id, create a dictionary that maps the label name
to an integer and vice versa:
>>> labels = food["train"].features["label"].names
>>> label2id, id2label = dict(), dict()
>>> for i, label in enumerate(labels):
label2id[label] = str(i)
id2label[str(i)] = label
Now you can convert the label id to a label name:
>>> id2label[str(79)]
'prime_rib'
## Preprocess
The next step is to load a ViT image processor to process the image into a tensor:
>>> from transformers import AutoImageProcessor
>>> checkpoint = "google/vit-base-patch16-224-in21k"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
Apply some image transformations to the images to make the model more robust against overfitting. Here you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module, but you can also use any image library you like.
Crop a random part of the image, resize it, and normalize it with the image mean and standard deviation:
>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
>>> normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
>>> size = (
image_processor.size["shortest_edge"]
if "shortest_edge" in image_processor.size
else (image_processor.size["height"], image_processor.size["width"])
)
>>> _transforms = Compose([RandomResizedCrop(size), ToTensor(), normalize])
Then create a preprocessing function to apply the transforms and return the `pixel_values` - the inputs to the model - of the image:
>>> def transforms(examples):
examples["pixel_values"] = [_transforms(img.convert("RGB")) for img in examples["image"]]
del examples["image"]
return examples
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.with_transform`] method. The transforms are applied on the fly when you load an element of the dataset:
>>> food = food.with_transform(transforms)
Now create a batch of examples using [`DefaultDataCollator`]. Unlike other data collators in 🤗 Transformers, the `DefaultDataCollator` does not apply additional preprocessing such as padding.
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
To avoid overfitting and to make the model more robust, add some data augmentation to the training part of the dataset.
Here we use Keras preprocessing layers to define the transformations for the training data (includes data augmentation),
and transformations for the validation data (only center cropping, resizing and normalizing). You can use `tf.image`or
any other library you prefer.
>>> from tensorflow import keras
>>> from tensorflow.keras import layers
>>> size = (image_processor.size["height"], image_processor.size["width"])
>>> train_data_augmentation = keras.Sequential(
[
layers.RandomCrop(size[0], size[1]),
layers.Rescaling(scale=1.0 / 127.5, offset=-1),
layers.RandomFlip("horizontal"),
layers.RandomRotation(factor=0.02),
layers.RandomZoom(height_factor=0.2, width_factor=0.2),
],
name="train_data_augmentation",
)
>>> val_data_augmentation = keras.Sequential(
[
layers.CenterCrop(size[0], size[1]),
layers.Rescaling(scale=1.0 / 127.5, offset=-1),
],
name="val_data_augmentation",
)
Next, create functions to apply appropriate transformations to a batch of images, instead of one image at a time.
>>> import numpy as np
>>> import tensorflow as tf
>>> from PIL import Image
>>> def convert_to_tf_tensor(image: Image):
np_image = np.array(image)
tf_image = tf.convert_to_tensor(np_image)
# `expand_dims()` is used to add a batch dimension since
# the TF augmentation layers operates on batched inputs.
return tf.expand_dims(tf_image, 0)
>>> def preprocess_train(example_batch):
"""Apply train_transforms across a batch."""
images = [
train_data_augmentation(convert_to_tf_tensor(image.convert("RGB"))) for image in example_batch["image"]
]
example_batch["pixel_values"] = [tf.transpose(tf.squeeze(image)) for image in images]
return example_batch
def preprocess_val(example_batch):
"""Apply val_transforms across a batch."""
images = [
val_data_augmentation(convert_to_tf_tensor(image.convert("RGB"))) for image in example_batch["image"]
]
example_batch["pixel_values"] = [tf.transpose(tf.squeeze(image)) for image in images]
return example_batch
Use 🤗 Datasets [`~datasets.Dataset.set_transform`] to apply the transformations on the fly:
food["train"].set_transform(preprocess_train)
food["test"].set_transform(preprocess_val)
As a final preprocessing step, create a batch of examples using `DefaultDataCollator`. Unlike other data collators in 🤗 Transformers, the
`DefaultDataCollator` does not apply additional preprocessing, such as padding.
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load an
evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load
the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
>>> import numpy as np
>>> def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy.compute(predictions=predictions, references=labels)
Your `compute_metrics` function is ready to go now, and you'll return to it when you set up your training.
## Train
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
You're ready to start training your model now! Load ViT with [`AutoModelForImageClassification`]. Specify the number of labels along with the number of expected labels, and the label mappings:
>>> from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
>>> model = AutoModelForImageClassification.from_pretrained(
checkpoint,
num_labels=len(labels),
id2label=id2label,
label2id=label2id,
)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. It is important you don't remove unused columns because that'll drop the `image` column. Without the `image` column, you can't create `pixel_values`. Set `remove_unused_columns=False` to prevent this behavior! The only other required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
>>> training_args = TrainingArguments(
output_dir="my_awesome_food_model",
remove_unused_columns=False,
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
per_device_eval_batch_size=16,
num_train_epochs=3,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
)
>>> trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=food["train"],
eval_dataset=food["test"],
tokenizer=image_processor,
compute_metrics=compute_metrics,
)
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
>>> trainer.push_to_hub()
If you are unfamiliar with fine-tuning a model with Keras, check out the [basic tutorial](./training#train-a-tensorflow-model-with-keras) first!
To fine-tune a model in TensorFlow, follow these steps:
1. Define the training hyperparameters, and set up an optimizer and a learning rate schedule.
2. Instantiate a pre-trained model.
3. Convert a 🤗 Dataset to a `tf.data.Dataset`.
4. Compile your model.
5. Add callbacks and use the `fit()` method to run the training.
6. Upload your model to 🤗 Hub to share with the community.
Start by defining the hyperparameters, optimizer and learning rate schedule:
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_epochs = 5
>>> num_train_steps = len(food["train"]) * num_epochs
>>> learning_rate = 3e-5
>>> weight_decay_rate = 0.01
>>> optimizer, lr_schedule = create_optimizer(
init_lr=learning_rate,
num_train_steps=num_train_steps,
weight_decay_rate=weight_decay_rate,
num_warmup_steps=0,
)
Then, load ViT with [`TFAutoModelForImageClassification`] along with the label mappings:
>>> from transformers import TFAutoModelForImageClassification
>>> model = TFAutoModelForImageClassification.from_pretrained(
checkpoint,
id2label=id2label,
label2id=label2id,
)
Convert your datasets to the `tf.data.Dataset` format using the [`~datasets.Dataset.to_tf_dataset`] and your `data_collator`:
>>> # converting our train dataset to tf.data.Dataset
>>> tf_train_dataset = food["train"].to_tf_dataset(
columns="pixel_values", label_cols="label", shuffle=True, batch_size=batch_size, collate_fn=data_collator
)
>>> # converting our test dataset to tf.data.Dataset
>>> tf_eval_dataset = food["test"].to_tf_dataset(
columns="pixel_values", label_cols="label", shuffle=True, batch_size=batch_size, collate_fn=data_collator
)
Configure the model for training with `compile()`:
>>> from tensorflow.keras.losses import SparseCategoricalCrossentropy
>>> loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
>>> model.compile(optimizer=optimizer, loss=loss)
To compute the accuracy from the predictions and push your model to the 🤗 Hub, use [Keras callbacks](../main_classes/keras_callbacks).
Pass your `compute_metrics` function to [KerasMetricCallback](../main_classes/keras_callbacks#transformers.KerasMetricCallback),
and use the [PushToHubCallback](../main_classes/keras_callbacks#transformers.PushToHubCallback) to upload the model:
>>> from transformers.keras_callbacks import KerasMetricCallback, PushToHubCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_eval_dataset)
>>> push_to_hub_callback = PushToHubCallback(
output_dir="food_classifier",
tokenizer=image_processor,
save_strategy="no",
)
>>> callbacks = [metric_callback, push_to_hub_callback]
Finally, you are ready to train your model! Call `fit()` with your training and validation datasets, the number of epochs,
and your callbacks to fine-tune the model:
>>> model.fit(tf_train_dataset, validation_data=tf_eval_dataset, epochs=num_epochs, callbacks=callbacks)
Epoch 1/5
250/250 [==============================] - 313s 1s/step - loss: 2.5623 - val_loss: 1.4161 - accuracy: 0.9290
Epoch 2/5
250/250 [==============================] - 265s 1s/step - loss: 0.9181 - val_loss: 0.6808 - accuracy: 0.9690
Epoch 3/5
250/250 [==============================] - 252s 1s/step - loss: 0.3910 - val_loss: 0.4303 - accuracy: 0.9820
Epoch 4/5
250/250 [==============================] - 251s 1s/step - loss: 0.2028 - val_loss: 0.3191 - accuracy: 0.9900
Epoch 5/5
250/250 [==============================] - 238s 949ms/step - loss: 0.1232 - val_loss: 0.3259 - accuracy: 0.9890
Congratulations! You have fine-tuned your model and shared it on the 🤗 Hub. You can now use it for inference!
For a more in-depth example of how to finetune a model for image classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
## Inference
Great, now that you've fine-tuned a model, you can use it for inference!
Load an image you'd like to run inference on:
>>> ds = load_dataset("food101", split="validation[:10]")
>>> image = ds["image"][0]
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for image classification with your model, and pass your image to it:
>>> from transformers import pipeline
>>> classifier = pipeline("image-classification", model="my_awesome_food_model")
>>> classifier(image)
[{'score': 0.31856709718704224, 'label': 'beignets'},
{'score': 0.015232225880026817, 'label': 'bruschetta'},
{'score': 0.01519392803311348, 'label': 'chicken_wings'},
{'score': 0.013022331520915031, 'label': 'pork_chop'},
{'score': 0.012728818692266941, 'label': 'prime_rib'}]
You can also manually replicate the results of the `pipeline` if you'd like:
Load an image processor to preprocess the image and return the `input` as PyTorch tensors:
>>> from transformers import AutoImageProcessor
>>> import torch
>>> image_processor = AutoImageProcessor.from_pretrained("my_awesome_food_model")
>>> inputs = image_processor(image, return_tensors="pt")
Pass your inputs to the model and return the logits:
>>> from transformers import AutoModelForImageClassification
>>> model = AutoModelForImageClassification.from_pretrained("my_awesome_food_model")
>>> with torch.no_grad():
logits = model(**inputs).logits
Get the predicted label with the highest probability, and use the model's `id2label` mapping to convert it to a label:
>>> predicted_label = logits.argmax(-1).item()
>>> model.config.id2label[predicted_label]
'beignets'
Load an image processor to preprocess the image and return the `input` as TensorFlow tensors:
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("MariaK/food_classifier")
>>> inputs = image_processor(image, return_tensors="tf")
Pass your inputs to the model and return the logits:
>>> from transformers import TFAutoModelForImageClassification
>>> model = TFAutoModelForImageClassification.from_pretrained("MariaK/food_classifier")
>>> logits = model(**inputs).logits
Get the predicted label with the highest probability, and use the model's `id2label` mapping to convert it to a label:
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
>>> model.config.id2label[predicted_class_id]
'beignets'
|
tasks/visual_question_answering.md
|
# Visual Question Answering
[[open-in-colab]]
Visual Question Answering (VQA) is the task of answering open-ended questions based on an image.
The input to models supporting this task is typically a combination of an image and a question, and the output is an
answer expressed in natural language.
Some noteworthy use case examples for VQA include:
* Accessibility applications for visually impaired individuals.
* Education: posing questions about visual materials presented in lectures or textbooks. VQA can also be utilized in interactive museum exhibits or historical sites.
* Customer service and e-commerce: VQA can enhance user experience by letting users ask questions about products.
* Image retrieval: VQA models can be used to retrieve images with specific characteristics. For example, the user can ask "Is there a dog?" to find all images with dogs from a set of images.
In this guide you'll learn how to:
- Fine-tune a classification VQA model, specifically [ViLT](../model_doc/vilt), on the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa).
- Use your fine-tuned ViLT for inference.
- Run zero-shot VQA inference with a generative model, like BLIP-2.
## Fine-tuning ViLT
ViLT model incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for
Vision-and-Language Pre-training (VLP). This model can be used for several downstream tasks. For the VQA task, a classifier
head is placed on top (a linear layer on top of the final hidden state of the `[CLS]` token) and randomly initialized.
Visual Question Answering is thus treated as a **classification problem**.
More recent models, such as BLIP, BLIP-2, and InstructBLIP, treat VQA as a generative task. Later in this guide we
illustrate how to use them for zero-shot VQA inference.
Before you begin, make sure you have all the necessary libraries installed.
```bash
pip install -q transformers datasets
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the 🤗 Hub.
When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
Let's define the model checkpoint as a global variable.
>>> model_checkpoint = "dandelin/vilt-b32-mlm"
## Load the data
For illustration purposes, in this guide we use a very small sample of the annotated visual question answering `Graphcore/vqa` dataset.
You can find the full dataset on [🤗 Hub](https://huggingface.co/datasets/Graphcore/vqa).
As an alternative to the [`Graphcore/vqa` dataset](https://huggingface.co/datasets/Graphcore/vqa), you can download the
same data manually from the official [VQA dataset page](https://visualqa.org/download.html). If you prefer to follow the
tutorial with your custom data, check out how to [Create an image dataset](https://huggingface.co/docs/datasets/image_dataset#loading-script)
guide in the 🤗 Datasets documentation.
Let's load the first 200 examples from the validation split and explore the dataset's features:
thon
>>> from datasets import load_dataset
>>> dataset = load_dataset("Graphcore/vqa", split="validation[:200]")
>>> dataset
Dataset({
features: ['question', 'question_type', 'question_id', 'image_id', 'answer_type', 'label'],
num_rows: 200
})
Let's take a look at an example to understand the dataset's features:
>>> dataset[0]
{'question': 'Where is he looking?',
'question_type': 'none of the above',
'question_id': 262148000,
'image_id': '/root/.cache/huggingface/datasets/downloads/extracted/ca733e0e000fb2d7a09fbcc94dbfe7b5a30750681d0e965f8e0a23b1c2f98c75/val2014/COCO_val2014_000000262148.jpg',
'answer_type': 'other',
'label': {'ids': ['at table', 'down', 'skateboard', 'table'],
'weights': [0.30000001192092896,
1.0,
0.30000001192092896,
0.30000001192092896]}}
The features relevant to the task include:
* `question`: the question to be answered from the image
* `image_id`: the path to the image the question refers to
* `label`: the annotations
We can remove the rest of the features as they won't be necessary:
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
As you can see, the `label` feature contains several answers to the same question (called `ids` here) collected by different human annotators.
This is because the answer to a question can be subjective. In this case, the question is "where is he looking?". Some people
annotated this with "down", others with "at table", another one with "skateboard", etc.
Take a look at the image and consider which answer would you give:
thon
>>> from PIL import Image
>>> image = Image.open(dataset[0]['image_id'])
>>> image
Due to the questions' and answers' ambiguity, datasets like this are treated as a multi-label classification problem (as
multiple answers are possibly valid). Moreover, rather than just creating a one-hot encoded vector, one creates a
soft encoding, based on the number of times a certain answer appeared in the annotations.
For instance, in the example above, because the answer "down" is selected way more often than other answers, it has a
score (called `weight` in the dataset) of 1.0, and the rest of the answers have scores < 1.0.
To later instantiate the model with an appropriate classification head, let's create two dictionaries: one that maps
the label name to an integer and vice versa:
>>> import itertools
>>> labels = [item['ids'] for item in dataset['label']]
>>> flattened_labels = list(itertools.chain(*labels))
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
>>> id2label = {idx: label for label, idx in label2id.items()}
Now that we have the mappings, we can replace the string answers with their ids, and flatten the dataset for a more convenient further preprocessing.
thon
>>> def replace_ids(inputs):
inputs["label"]["ids"] = [label2id[x] for x in inputs["label"]["ids"]]
return inputs
>>> dataset = dataset.map(replace_ids)
>>> flat_dataset = dataset.flatten()
>>> flat_dataset.features
{'question': Value(dtype='string', id=None),
'image_id': Value(dtype='string', id=None),
'label.ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None),
'label.weights': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None)}
## Preprocessing data
The next step is to load a ViLT processor to prepare the image and text data for the model.
[`ViltProcessor`] wraps a BERT tokenizer and ViLT image processor into a convenient single processor:
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
To preprocess the data we need to encode the images and questions using the [`ViltProcessor`]. The processor will use
the [`BertTokenizerFast`] to tokenize the text and create `input_ids`, `attention_mask` and `token_type_ids` for the text data.
As for images, the processor will leverage [`ViltImageProcessor`] to resize and normalize the image, and create `pixel_values` and `pixel_mask`.
All these preprocessing steps are done under the hood, we only need to call the `processor`. However, we still need to
prepare the target labels. In this representation, each element corresponds to a possible answer (label). For correct answers, the element holds
their respective score (weight), while the remaining elements are set to zero.
The following function applies the `processor` to the images and questions and formats the labels as described above:
>>> import torch
>>> def preprocess_data(examples):
image_paths = examples['image_id']
images = [Image.open(image_path) for image_path in image_paths]
texts = examples['question']
encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
for k, v in encoding.items():
encoding[k] = v.squeeze()
targets = []
for labels, scores in zip(examples['label.ids'], examples['label.weights']):
target = torch.zeros(len(id2label))
for label, score in zip(labels, scores):
target[label] = score
targets.append(target)
encoding["labels"] = targets
return encoding
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.map`] function. You can speed up `map` by
setting `batched=True` to process multiple elements of the dataset at once. At this point, feel free to remove the columns you don't need.
>>> processed_dataset = flat_dataset.map(preprocess_data, batched=True, remove_columns=['question','question_type', 'question_id', 'image_id', 'answer_type', 'label.ids', 'label.weights'])
>>> processed_dataset
Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'pixel_values', 'pixel_mask', 'labels'],
num_rows: 200
})
As a final step, create a batch of examples using [`DefaultDataCollator`]:
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
## Train the model
You’re ready to start training your model now! Load ViLT with [`ViltForQuestionAnswering`]. Specify the number of labels
along with the label mappings:
>>> from transformers import ViltForQuestionAnswering
>>> model = ViltForQuestionAnswering.from_pretrained(model_checkpoint, num_labels=len(id2label), id2label=id2label, label2id=label2id)
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]:
>>> from transformers import TrainingArguments
>>> repo_id = "MariaK/vilt_finetuned_200"
>>> training_args = TrainingArguments(
output_dir=repo_id,
per_device_train_batch_size=4,
num_train_epochs=20,
save_steps=200,
logging_steps=50,
learning_rate=5e-5,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=True,
)
2. Pass the training arguments to [`Trainer`] along with the model, dataset, processor, and data collator.
>>> from transformers import Trainer
>>> trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=processed_dataset,
tokenizer=processor,
)
3. Call [`~Trainer.train`] to finetune your model.
>>> trainer.train()
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method to share your final model on the 🤗 Hub:
>>> trainer.push_to_hub()
## Inference
Now that you have fine-tuned a ViLT model, and uploaded it to the 🤗 Hub, you can use it for inference. The simplest
way to try out your fine-tuned model for inference is to use it in a [`Pipeline`].
>>> from transformers import pipeline
>>> pipe = pipeline("visual-question-answering", model="MariaK/vilt_finetuned_200")
The model in this guide has only been trained on 200 examples, so don't expect a lot from it. Let's see if it at least
learned something from the data and take the first example from the dataset to illustrate inference:
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
>>> print(question)
>>> pipe(image, question, top_k=1)
"Where is he looking?"
[{'score': 0.5498199462890625, 'answer': 'down'}]
Even though not very confident, the model indeed has learned something. With more examples and longer training, you'll get far better results!
You can also manually replicate the results of the pipeline if you'd like:
1. Take an image and a question, prepare them for the model using the processor from your model.
2. Forward the result or preprocessing through the model.
3. From the logits, get the most likely answer's id, and find the actual answer in the `id2label`.
>>> processor = ViltProcessor.from_pretrained("MariaK/vilt_finetuned_200")
>>> image = Image.open(example['image_id'])
>>> question = example['question']
>>> # prepare inputs
>>> inputs = processor(image, question, return_tensors="pt")
>>> model = ViltForQuestionAnswering.from_pretrained("MariaK/vilt_finetuned_200")
>>> # forward pass
>>> with torch.no_grad():
outputs = model(**inputs)
>>> logits = outputs.logits
>>> idx = logits.argmax(-1).item()
>>> print("Predicted answer:", model.config.id2label[idx])
Predicted answer: down
## Zero-shot VQA
The previous model treated VQA as a classification task. Some recent models, such as BLIP, BLIP-2, and InstructBLIP approach
VQA as a generative task. Let's take [BLIP-2](../model_doc/blip-2) as an example. It introduced a new visual-language pre-training
paradigm in which any combination of pre-trained vision encoder and LLM can be used (learn more in the [BLIP-2 blog post](https://huggingface.co/blog/blip-2)).
This enables achieving state-of-the-art results on multiple visual-language tasks including visual question answering.
Let's illustrate how you can use this model for VQA. First, let's load the model. Here we'll explicitly send the model to a
GPU, if available, which we didn't need to do earlier when training, as [`Trainer`] handles this automatically:
>>> from transformers import AutoProcessor, Blip2ForConditionalGeneration
>>> import torch
>>> processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device)
The model takes image and text as input, so let's use the exact same image/question pair from the first example in the VQA dataset:
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
To use BLIP-2 for visual question answering task, the textual prompt has to follow a specific format: `Question: {} Answer:`.
>>> prompt = f"Question: {question} Answer:"
Now we need to preprocess the image/prompt with the model's processor, pass the processed input through the model, and decode the output:
>>> inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
"He is looking at the crowd"
As you can see, the model recognized the crowd, and the direction of the face (looking down), however, it seems to miss
the fact the crowd is behind the skater. Still, in cases where acquiring human-annotated datasets is not feasible, this
approach can quickly produce useful results.
|
tasks/image_captioning.md
|
# Image captioning
[[open-in-colab]]
Image captioning is the task of predicting a caption for a given image. Common real world applications of it include
aiding visually impaired people that can help them navigate through different situations. Therefore, image captioning
helps to improve content accessibility for people by describing images to them.
This guide will show you how to:
* Fine-tune an image captioning model.
* Use the fine-tuned model for inference.
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate -q
pip install jiwer -q
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
thon
from huggingface_hub import notebook_login
notebook_login()
## Load the Pokémon BLIP captions dataset
Use the 🤗 Dataset library to load a dataset that consists of {image-caption} pairs. To create your own image captioning dataset
in PyTorch, you can follow [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb).
thon
from datasets import load_dataset
ds = load_dataset("lambdalabs/pokemon-blip-captions")
ds
```bash
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 833
})
})
The dataset has two features, `image` and `text`.
Many image captioning datasets contain multiple captions per image. In those cases, a common strategy is to randomly sample a caption amongst the available ones during training.
Split the dataset’s train split into a train and test set with the [~datasets.Dataset.train_test_split] method:
thon
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
Let's visualize a couple of samples from the training set.
thon
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)
## Preprocess the dataset
Since the dataset has two modalities (image and text), the pre-processing pipeline will preprocess images and the captions.
To do so, load the processor class associated with the model you are about to fine-tune.
thon
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
thon
def transforms(example_batch):
images = [x for x in example_batch["image"]]
captions = [x for x in example_batch["text"]]
inputs = processor(images=images, text=captions, padding="max_length")
inputs.update({"labels": inputs["input_ids"]})
return inputs
train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
With the dataset ready, you can now set up the model for fine-tuning.
## Load a base model
Load the ["microsoft/git-base"](https://huggingface.co/microsoft/git-base) into a [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) object.
thon
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
## Evaluate
Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
thon
from evaluate import load
import torch
wer = load("wer")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score}
## Train!
Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
First, define the training arguments using [`TrainingArguments`].
thon
from transformers import TrainingArguments, Trainer
model_name = checkpoint.split("/")[1]
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=2,
save_total_limit=3,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
load_best_model_at_end=True,
)
Then pass them along with the datasets and the model to 🤗 Trainer.
thon
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
To start training, simply call [`~Trainer.train`] on the [`Trainer`] object.
thon
trainer.train()
You should see the training loss drop smoothly as training progresses.
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method so everyone can use your model:
thon
trainer.push_to_hub()
## Inference
Take a sample image from `test_ds` to test the model.
thon
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
image = Image.open(requests.get(url, stream=True).raw)
image
Prepare image for the model.
thon
device = "cuda" if torch.cuda.is_available() else "cpu"
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
Call [`generate`] and decode the predictions.
thon
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```bash
a drawing of a pink and blue pokemon
Looks like the fine-tuned model generated a pretty good caption!
|
tasks/document_question_answering.md
|
# Document Question Answering
[[open-in-colab]]
Document Question Answering, also referred to as Document Visual Question Answering, is a task that involves providing
answers to questions posed about document images. The input to models supporting this task is typically a combination of an image and
a question, and the output is an answer expressed in natural language. These models utilize multiple modalities, including
text, the positions of words (bounding boxes), and the image itself.
This guide illustrates how to:
- Fine-tune [LayoutLMv2](../model_doc/layoutlmv2) on the [DocVQA dataset](https://huggingface.co/datasets/nielsr/docvqa_1200_examples_donut).
- Use your fine-tuned model for inference.
The task illustrated in this tutorial is supported by the following model architectures:
[LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3)
LayoutLMv2 solves the document question-answering task by adding a question-answering head on top of the final hidden
states of the tokens, to predict the positions of the start and end tokens of the
answer. In other words, the problem is treated as extractive question answering: given the context, extract which piece
of information answers the question. The context comes from the output of an OCR engine, here it is Google's Tesseract.
Before you begin, make sure you have all the necessary libraries installed. LayoutLMv2 depends on detectron2, torchvision and tesseract.
```bash
pip install -q transformers datasets
```bash
pip install 'git+https://github.com/facebookresearch/detectron2.git'
pip install torchvision
```bash
sudo apt install tesseract-ocr
pip install -q pytesseract
Once you have installed all of the dependencies, restart your runtime.
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the 🤗 Hub.
When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()
Let's define some global variables.
>>> model_checkpoint = "microsoft/layoutlmv2-base-uncased"
>>> batch_size = 4
## Load the data
In this guide we use a small sample of preprocessed DocVQA that you can find on 🤗 Hub. If you'd like to use the full
DocVQA dataset, you can register and download it on [DocVQA homepage](https://rrc.cvc.uab.es/?ch=17). If you do so, to
proceed with this guide check out [how to load files into a 🤗 dataset](https://huggingface.co/docs/datasets/loading#local-and-remote-files).
>>> from datasets import load_dataset
>>> dataset = load_dataset("nielsr/docvqa_1200_examples")
>>> dataset
DatasetDict({
train: Dataset({
features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
num_rows: 1000
})
test: Dataset({
features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
num_rows: 200
})
})
As you can see, the dataset is split into train and test sets already. Take a look at a random example to familiarize
yourself with the features.
>>> dataset["train"].features
Here's what the individual fields represent:
* `id`: the example's id
* `image`: a PIL.Image.Image object containing the document image
* `query`: the question string - natural language asked question, in several languages
* `answers`: a list of correct answers provided by human annotators
* `words` and `bounding_boxes`: the results of OCR, which we will not use here
* `answer`: an answer matched by a different model which we will not use here
Let's leave only English questions, and drop the `answer` feature which appears to contain predictions by another model.
We'll also take the first of the answers from the set provided by the annotators. Alternatively, you can randomly sample it.
>>> updated_dataset = dataset.map(lambda example: {"question": example["query"]["en"]}, remove_columns=["query"])
>>> updated_dataset = updated_dataset.map(
lambda example: {"answer": example["answers"][0]}, remove_columns=["answer", "answers"]
)
Note that the LayoutLMv2 checkpoint that we use in this guide has been trained with `max_position_embeddings = 512` (you can
find this information in the [checkpoint's `config.json` file](https://huggingface.co/microsoft/layoutlmv2-base-uncased/blob/main/config.json#L18)).
We can truncate the examples but to avoid the situation where the answer might be at the end of a large document and end up truncated,
here we'll remove the few examples where the embedding is likely to end up longer than 512.
If most of the documents in your dataset are long, you can implement a sliding window strategy - check out [this notebook](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb) for details.
>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
At this point let's also remove the OCR features from this dataset. These are a result of OCR for fine-tuning a different
model. They would still require some processing if we wanted to use them, as they do not match the input requirements
of the model we use in this guide. Instead, we can use the [`LayoutLMv2Processor`] on the original data for both OCR and
tokenization. This way we'll get the inputs that match model's expected input. If you want to process images manually,
check out the [`LayoutLMv2` model documentation](../model_doc/layoutlmv2) to learn what input format the model expects.
>>> updated_dataset = updated_dataset.remove_columns("words")
>>> updated_dataset = updated_dataset.remove_columns("bounding_boxes")
Finally, the data exploration won't be complete if we don't peek at an image example.
>>> updated_dataset["train"][11]["image"]
## Preprocess the data
The Document Question Answering task is a multimodal task, and you need to make sure that the inputs from each modality
are preprocessed according to the model's expectations. Let's start by loading the [`LayoutLMv2Processor`], which internally combines an image processor that can handle image data and a tokenizer that can encode text data.
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
### Preprocessing document images
First, let's prepare the document images for the model with the help of the `image_processor` from the processor.
By default, image processor resizes the images to 224x224, makes sure they have the correct order of color channels,
applies OCR with tesseract to get words and normalized bounding boxes. In this tutorial, all of these defaults are exactly what we need.
Write a function that applies the default image processing to a batch of images and returns the results of OCR.
>>> image_processor = processor.image_processor
>>> def get_ocr_words_and_boxes(examples):
images = [image.convert("RGB") for image in examples["image"]]
encoded_inputs = image_processor(images)
examples["image"] = encoded_inputs.pixel_values
examples["words"] = encoded_inputs.words
examples["boxes"] = encoded_inputs.boxes
return examples
To apply this preprocessing to the entire dataset in a fast way, use [`~datasets.Dataset.map`].
>>> dataset_with_ocr = updated_dataset.map(get_ocr_words_and_boxes, batched=True, batch_size=2)
### Preprocessing text data
Once we have applied OCR to the images, we need to encode the text part of the dataset to prepare it for the model.
This involves converting the words and boxes that we got in the previous step to token-level `input_ids`, `attention_mask`,
`token_type_ids` and `bbox`. For preprocessing text, we'll need the `tokenizer` from the processor.
>>> tokenizer = processor.tokenizer
On top of the preprocessing mentioned above, we also need to add the labels for the model. For `xxxForQuestionAnswering` models
in 🤗 Transformers, the labels consist of the `start_positions` and `end_positions`, indicating which token is at the
start and which token is at the end of the answer.
Let's start with that. Define a helper function that can find a sublist (the answer split into words) in a larger list (the words list).
This function will take two lists as input, `words_list` and `answer_list`. It will then iterate over the `words_list` and check
if the current word in the `words_list` (words_list[i]) is equal to the first word of answer_list (answer_list[0]) and if
the sublist of `words_list` starting from the current word and of the same length as `answer_list` is equal `to answer_list`.
If this condition is true, it means that a match has been found, and the function will record the match, its starting index (idx),
and its ending index (idx + len(answer_list) - 1). If more than one match was found, the function will return only the first one.
If no match is found, the function returns (`None`, 0, and 0).
>>> def subfinder(words_list, answer_list):
matches = []
start_indices = []
end_indices = []
for idx, i in enumerate(range(len(words_list))):
if words_list[i] == answer_list[0] and words_list[i : i + len(answer_list)] == answer_list:
matches.append(answer_list)
start_indices.append(idx)
end_indices.append(idx + len(answer_list) - 1)
if matches:
return matches[0], start_indices[0], end_indices[0]
else:
return None, 0, 0
To illustrate how this function finds the position of the answer, let's use it on an example:
>>> example = dataset_with_ocr["train"][1]
>>> words = [word.lower() for word in example["words"]]
>>> match, word_idx_start, word_idx_end = subfinder(words, example["answer"].lower().split())
>>> print("Question: ", example["question"])
>>> print("Words:", words)
>>> print("Answer: ", example["answer"])
>>> print("start_index", word_idx_start)
>>> print("end_index", word_idx_end)
Question: Who is in cc in this letter?
Words: ['wie', 'baw', 'brown', '&', 'williamson', 'tobacco', 'corporation', 'research', '&', 'development', 'internal', 'correspondence', 'to:', 'r.', 'h.', 'honeycutt', 'ce:', 't.f.', 'riehl', 'from:', '.', 'c.j.', 'cook', 'date:', 'may', '8,', '1995', 'subject:', 'review', 'of', 'existing', 'brainstorming', 'ideas/483', 'the', 'major', 'function', 'of', 'the', 'product', 'innovation', 'graup', 'is', 'to', 'develop', 'marketable', 'nove!', 'products', 'that', 'would', 'be', 'profitable', 'to', 'manufacture', 'and', 'sell.', 'novel', 'is', 'defined', 'as:', 'of', 'a', 'new', 'kind,', 'or', 'different', 'from', 'anything', 'seen', 'or', 'known', 'before.', 'innovation', 'is', 'defined', 'as:', 'something', 'new', 'or', 'different', 'introduced;', 'act', 'of', 'innovating;', 'introduction', 'of', 'new', 'things', 'or', 'methods.', 'the', 'products', 'may', 'incorporate', 'the', 'latest', 'technologies,', 'materials', 'and', 'know-how', 'available', 'to', 'give', 'then', 'a', 'unique', 'taste', 'or', 'look.', 'the', 'first', 'task', 'of', 'the', 'product', 'innovation', 'group', 'was', 'to', 'assemble,', 'review', 'and', 'categorize', 'a', 'list', 'of', 'existing', 'brainstorming', 'ideas.', 'ideas', 'were', 'grouped', 'into', 'two', 'major', 'categories', 'labeled', 'appearance', 'and', 'taste/aroma.', 'these', 'categories', 'are', 'used', 'for', 'novel', 'products', 'that', 'may', 'differ', 'from', 'a', 'visual', 'and/or', 'taste/aroma', 'point', 'of', 'view', 'compared', 'to', 'canventional', 'cigarettes.', 'other', 'categories', 'include', 'a', 'combination', 'of', 'the', 'above,', 'filters,', 'packaging', 'and', 'brand', 'extensions.', 'appearance', 'this', 'category', 'is', 'used', 'for', 'novel', 'cigarette', 'constructions', 'that', 'yield', 'visually', 'different', 'products', 'with', 'minimal', 'changes', 'in', 'smoke', 'chemistry', 'two', 'cigarettes', 'in', 'cne.', 'emulti-plug', 'te', 'build', 'yaur', 'awn', 'cigarette.', 'eswitchable', 'menthol', 'or', 'non', 'menthol', 'cigarette.', '*cigarettes', 'with', 'interspaced', 'perforations', 'to', 'enable', 'smoker', 'to', 'separate', 'unburned', 'section', 'for', 'future', 'smoking.', '«short', 'cigarette,', 'tobacco', 'section', '30', 'mm.', '«extremely', 'fast', 'buming', 'cigarette.', '«novel', 'cigarette', 'constructions', 'that', 'permit', 'a', 'significant', 'reduction', 'iretobacco', 'weight', 'while', 'maintaining', 'smoking', 'mechanics', 'and', 'visual', 'characteristics.', 'higher', 'basis', 'weight', 'paper:', 'potential', 'reduction', 'in', 'tobacco', 'weight.', '«more', 'rigid', 'tobacco', 'column;', 'stiffing', 'agent', 'for', 'tobacco;', 'e.g.', 'starch', '*colored', 'tow', 'and', 'cigarette', 'papers;', 'seasonal', 'promotions,', 'e.g.', 'pastel', 'colored', 'cigarettes', 'for', 'easter', 'or', 'in', 'an', 'ebony', 'and', 'ivory', 'brand', 'containing', 'a', 'mixture', 'of', 'all', 'black', '(black', 'paper', 'and', 'tow)', 'and', 'ail', 'white', 'cigarettes.', '499150498']
Answer: T.F. Riehl
start_index 17
end_index 18
Once examples are encoded, however, they will look like this:
>>> encoding = tokenizer(example["question"], example["words"], example["boxes"])
>>> tokenizer.decode(encoding["input_ids"])
[CLS] who is in cc in this letter? [SEP] wie baw brown & williamson tobacco corporation research & development
We'll need to find the position of the answer in the encoded input.
* `token_type_ids` tells us which tokens are part of the question, and which ones are part of the document's words.
* `tokenizer.cls_token_id` will help find the special token at the beginning of the input.
* `word_ids` will help match the answer found in the original `words` to the same answer in the full encoded input and determine
the start/end position of the answer in the encoded input.
With that in mind, let's create a function to encode a batch of examples in the dataset:
>>> def encode_dataset(examples, max_length=512):
questions = examples["question"]
words = examples["words"]
boxes = examples["boxes"]
answers = examples["answer"]
# encode the batch of examples and initialize the start_positions and end_positions
encoding = tokenizer(questions, words, boxes, max_length=max_length, padding="max_length", truncation=True)
start_positions = []
end_positions = []
# loop through the examples in the batch
for i in range(len(questions)):
cls_index = encoding["input_ids"][i].index(tokenizer.cls_token_id)
# find the position of the answer in example's words
words_example = [word.lower() for word in words[i]]
answer = answers[i]
match, word_idx_start, word_idx_end = subfinder(words_example, answer.lower().split())
if match:
# if match is found, use `token_type_ids` to find where words start in the encoding
token_type_ids = encoding["token_type_ids"][i]
token_start_index = 0
while token_type_ids[token_start_index] != 1:
token_start_index += 1
token_end_index = len(encoding["input_ids"][i]) - 1
while token_type_ids[token_end_index] != 1:
token_end_index -= 1
word_ids = encoding.word_ids(i)[token_start_index : token_end_index + 1]
start_position = cls_index
end_position = cls_index
# loop over word_ids and increase `token_start_index` until it matches the answer position in words
# once it matches, save the `token_start_index` as the `start_position` of the answer in the encoding
for id in word_ids:
if id == word_idx_start:
start_position = token_start_index
else:
token_start_index += 1
# similarly loop over `word_ids` starting from the end to find the `end_position` of the answer
for id in word_ids[::-1]:
if id == word_idx_end:
end_position = token_end_index
else:
token_end_index -= 1
start_positions.append(start_position)
end_positions.append(end_position)
else:
start_positions.append(cls_index)
end_positions.append(cls_index)
encoding["image"] = examples["image"]
encoding["start_positions"] = start_positions
encoding["end_positions"] = end_positions
return encoding
Now that we have this preprocessing function, we can encode the entire dataset:
>>> encoded_train_dataset = dataset_with_ocr["train"].map(
encode_dataset, batched=True, batch_size=2, remove_columns=dataset_with_ocr["train"].column_names
)
>>> encoded_test_dataset = dataset_with_ocr["test"].map(
encode_dataset, batched=True, batch_size=2, remove_columns=dataset_with_ocr["test"].column_names
)
Let's check what the features of the encoded dataset look like:
>>> encoded_train_dataset.features
{'image': Sequence(feature=Sequence(feature=Sequence(feature=Value(dtype='uint8', id=None), length=-1, id=None), length=-1, id=None), length=-1, id=None),
'input_ids': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None),
'token_type_ids': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'bbox': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'start_positions': Value(dtype='int64', id=None),
'end_positions': Value(dtype='int64', id=None)}
## Evaluation
Evaluation for document question answering requires a significant amount of postprocessing. To avoid taking up too much
of your time, this guide skips the evaluation step. The [`Trainer`] still calculates the evaluation loss during training so
you're not completely in the dark about your model's performance. Extractive question answering is typically evaluated using F1/exact match.
If you'd like to implement it yourself, check out the [Question Answering chapter](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing)
of the Hugging Face course for inspiration.
## Train
Congratulations! You've successfully navigated the toughest part of this guide and now you are ready to train your own model.
Training involves the following steps:
* Load the model with [`AutoModelForDocumentQuestionAnswering`] using the same checkpoint as in the preprocessing.
* Define your training hyperparameters in [`TrainingArguments`].
* Define a function to batch examples together, here the [`DefaultDataCollator`] will do just fine
* Pass the training arguments to [`Trainer`] along with the model, dataset, and data collator.
* Call [`~Trainer.train`] to finetune your model.
>>> from transformers import AutoModelForDocumentQuestionAnswering
>>> model = AutoModelForDocumentQuestionAnswering.from_pretrained(model_checkpoint)
In the [`TrainingArguments`] use `output_dir` to specify where to save your model, and configure hyperparameters as you see fit.
If you wish to share your model with the community, set `push_to_hub` to `True` (you must be signed in to Hugging Face to upload your model).
In this case the `output_dir` will also be the name of the repo where your model checkpoint will be pushed.
>>> from transformers import TrainingArguments
>>> # REPLACE THIS WITH YOUR REPO ID
>>> repo_id = "MariaK/layoutlmv2-base-uncased_finetuned_docvqa"
>>> training_args = TrainingArguments(
output_dir=repo_id,
per_device_train_batch_size=4,
num_train_epochs=20,
save_steps=200,
logging_steps=50,
evaluation_strategy="steps",
learning_rate=5e-5,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=True,
)
Define a simple data collator to batch examples together.
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
Finally, bring everything together, and call [`~Trainer.train`]:
>>> from transformers import Trainer
>>> trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=encoded_train_dataset,
eval_dataset=encoded_test_dataset,
tokenizer=processor,
)
>>> trainer.train()
To add the final model to 🤗 Hub, create a model card and call `push_to_hub`:
>>> trainer.create_model_card()
>>> trainer.push_to_hub()
## Inference
Now that you have finetuned a LayoutLMv2 model, and uploaded it to the 🤗 Hub, you can use it for inference. The simplest
way to try out your finetuned model for inference is to use it in a [`Pipeline`].
Let's take an example:
>>> example = dataset["test"][2]
>>> question = example["query"]["en"]
>>> image = example["image"]
>>> print(question)
>>> print(example["answers"])
'Who is ‘presiding’ TRRF GENERAL SESSION (PART 1)?'
['TRRF Vice President', 'lee a. waller']
Next, instantiate a pipeline for
document question answering with your model, and pass the image + question combination to it.
>>> from transformers import pipeline
>>> qa_pipeline = pipeline("document-question-answering", model="MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
>>> qa_pipeline(image, question)
[{'score': 0.9949808120727539,
'answer': 'Lee A. Waller',
'start': 55,
'end': 57}]
You can also manually replicate the results of the pipeline if you'd like:
1. Take an image and a question, prepare them for the model using the processor from your model.
2. Forward the result or preprocessing through the model.
3. The model returns `start_logits` and `end_logits`, which indicate which token is at the start of the answer and
which token is at the end of the answer. Both have shape (batch_size, sequence_length).
4. Take an argmax on the last dimension of both the `start_logits` and `end_logits` to get the predicted `start_idx` and `end_idx`.
5. Decode the answer with the tokenizer.
>>> import torch
>>> from transformers import AutoProcessor
>>> from transformers import AutoModelForDocumentQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
>>> model = AutoModelForDocumentQuestionAnswering.from_pretrained("MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
>>> with torch.no_grad():
encoding = processor(image.convert("RGB"), question, return_tensors="pt")
outputs = model(**encoding)
start_logits = outputs.start_logits
end_logits = outputs.end_logits
predicted_start_idx = start_logits.argmax(-1).item()
predicted_end_idx = end_logits.argmax(-1).item()
>>> processor.tokenizer.decode(encoding.input_ids.squeeze()[predicted_start_idx : predicted_end_idx + 1])
'lee a. waller'
```
|
internal/pipelines_utils.md
|
# Utilities for pipelines
This page lists all the utility functions the library provides for pipelines.
Most of those are only useful if you are studying the code of the models in the library.
## Argument handling
[[autodoc]] pipelines.ArgumentHandler
[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
## Data format
[[autodoc]] pipelines.PipelineDataFormat
[[autodoc]] pipelines.CsvPipelineDataFormat
[[autodoc]] pipelines.JsonPipelineDataFormat
[[autodoc]] pipelines.PipedPipelineDataFormat
## Utilities
[[autodoc]] pipelines.PipelineException
|
internal/time_series_utils.md
|
# Time Series Utilities
This page lists all the utility functions and classes that can be used for Time Series based models.
Most of those are only useful if you are studying the code of the time series models or you wish to add to the collection of distributional output classes.
## Distributional Output
[[autodoc]] time_series_utils.NormalOutput
[[autodoc]] time_series_utils.StudentTOutput
[[autodoc]] time_series_utils.NegativeBinomialOutput
|
internal/modeling_utils.md
|
# Custom Layers and Utilities
This page lists all the custom layers used by the library, as well as the utility functions it provides for modeling.
Most of those are only useful if you are studying the code of the models in the library.
## Pytorch custom modules
[[autodoc]] pytorch_utils.Conv1D
[[autodoc]] modeling_utils.PoolerStartLogits
- forward
[[autodoc]] modeling_utils.PoolerEndLogits
- forward
[[autodoc]] modeling_utils.PoolerAnswerClass
- forward
[[autodoc]] modeling_utils.SquadHeadOutput
[[autodoc]] modeling_utils.SQuADHead
- forward
[[autodoc]] modeling_utils.SequenceSummary
- forward
## PyTorch Helper Functions
[[autodoc]] pytorch_utils.apply_chunking_to_forward
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
[[autodoc]] pytorch_utils.prune_layer
[[autodoc]] pytorch_utils.prune_conv1d_layer
[[autodoc]] pytorch_utils.prune_linear_layer
## TensorFlow custom layers
[[autodoc]] modeling_tf_utils.TFConv1D
[[autodoc]] modeling_tf_utils.TFSequenceSummary
## TensorFlow loss functions
[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
## TensorFlow Helper Functions
[[autodoc]] modeling_tf_utils.get_initializer
[[autodoc]] modeling_tf_utils.keras_serializable
[[autodoc]] modeling_tf_utils.shape_list
|
internal/file_utils.md
|
# General Utilities
This page lists all of Transformers general utility functions that are found in the file `utils.py`.
Most of those are only useful if you are studying the general code in the library.
## Enums and namedtuples
[[autodoc]] utils.ExplicitEnum
[[autodoc]] utils.PaddingStrategy
[[autodoc]] utils.TensorType
## Special Decorators
[[autodoc]] utils.add_start_docstrings
[[autodoc]] utils.add_start_docstrings_to_model_forward
[[autodoc]] utils.add_end_docstrings
[[autodoc]] utils.add_code_sample_docstrings
[[autodoc]] utils.replace_return_docstrings
## Special Properties
[[autodoc]] utils.cached_property
## Other Utilities
[[autodoc]] utils._LazyModule
|
internal/tokenization_utils.md
|
# Utilities for Tokenizers
This page lists all the utility functions used by the tokenizers, mainly the class
[`~tokenization_utils_base.PreTrainedTokenizerBase`] that implements the common methods between
[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] and the mixin
[`~tokenization_utils_base.SpecialTokensMixin`].
Most of those are only useful if you are studying the code of the tokenizers in the library.
## PreTrainedTokenizerBase
[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
- __call__
- all
## SpecialTokensMixin
[[autodoc]] tokenization_utils_base.SpecialTokensMixin
## Enums and namedtuples
[[autodoc]] tokenization_utils_base.TruncationStrategy
[[autodoc]] tokenization_utils_base.CharSpan
[[autodoc]] tokenization_utils_base.TokenSpan
|
internal/audio_utils.md
|
# Utilities for `FeatureExtractors`
This page lists all the utility functions that can be used by the audio [`FeatureExtractor`] in order to compute special features from a raw audio using common algorithms such as *Short Time Fourier Transform* or *log mel spectrogram*.
Most of those are only useful if you are studying the code of the audio processors in the library.
## Audio Transformations
[[autodoc]] audio_utils.hertz_to_mel
[[autodoc]] audio_utils.mel_to_hertz
[[autodoc]] audio_utils.mel_filter_bank
[[autodoc]] audio_utils.optimal_fft_length
[[autodoc]] audio_utils.window_function
[[autodoc]] audio_utils.spectrogram
[[autodoc]] audio_utils.power_to_db
[[autodoc]] audio_utils.amplitude_to_db
|
internal/generation_utils.md
|
# Utilities for Generation
This page lists all the utility functions used by [`~generation.GenerationMixin.generate`],
[`~generation.GenerationMixin.greedy_search`],
[`~generation.GenerationMixin.contrastive_search`],
[`~generation.GenerationMixin.sample`],
[`~generation.GenerationMixin.beam_search`],
[`~generation.GenerationMixin.beam_sample`],
[`~generation.GenerationMixin.group_beam_search`], and
[`~generation.GenerationMixin.constrained_beam_search`].
Most of those are only useful if you are studying the code of the generate methods in the library.
## Generate Outputs
The output of [`~generation.GenerationMixin.generate`] is an instance of a subclass of
[`~utils.ModelOutput`]. This output is a data structure containing all the information returned
by [`~generation.GenerationMixin.generate`], but that can also be used as tuple or dictionary.
Here's an example:
thon
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
The `generation_output` object is a [`~generation.GreedySearchDecoderOnlyOutput`], as we can
see in the documentation of that class below, it means it has the following attributes:
- `sequences`: the generated sequences of tokens
- `scores` (optional): the prediction scores of the language modelling head, for each generation step
- `hidden_states` (optional): the hidden states of the model, for each generation step
- `attentions` (optional): the attention weights of the model, for each generation step
Here we have the `scores` since we passed along `output_scores=True`, but we don't have `hidden_states` and
`attentions` because we didn't pass `output_hidden_states=True` or `output_attentions=True`.
You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
will get `None`. Here for instance `generation_output.scores` are all the generated prediction scores of the
language modeling head, and `generation_output.attentions` is `None`.
When using our `generation_output` object as a tuple, it only keeps the attributes that don't have `None` values.
Here, for instance, it has two elements, `loss` then `logits`, so
thon
generation_output[:2]
will return the tuple `(generation_output.sequences, generation_output.scores)` for instance.
When using our `generation_output` object as a dictionary, it only keeps the attributes that don't have `None`
values. Here, for instance, it has two keys that are `sequences` and `scores`.
We document here all output types.
### PyTorch
[[autodoc]] generation.GreedySearchEncoderDecoderOutput
[[autodoc]] generation.GreedySearchDecoderOnlyOutput
[[autodoc]] generation.SampleEncoderDecoderOutput
[[autodoc]] generation.SampleDecoderOnlyOutput
[[autodoc]] generation.BeamSearchEncoderDecoderOutput
[[autodoc]] generation.BeamSearchDecoderOnlyOutput
[[autodoc]] generation.BeamSampleEncoderDecoderOutput
[[autodoc]] generation.BeamSampleDecoderOnlyOutput
[[autodoc]] generation.ContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.ContrastiveSearchDecoderOnlyOutput
### TensorFlow
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
[[autodoc]] generation.TFSampleEncoderDecoderOutput
[[autodoc]] generation.TFSampleDecoderOnlyOutput
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
### FLAX
[[autodoc]] generation.FlaxSampleOutput
[[autodoc]] generation.FlaxGreedySearchOutput
[[autodoc]] generation.FlaxBeamSearchOutput
## LogitsProcessor
A [`LogitsProcessor`] can be used to modify the prediction scores of a language model head for
generation.
### PyTorch
[[autodoc]] AlternatingCodebooksLogitsProcessor
- __call__
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] EpsilonLogitsWarper
- __call__
[[autodoc]] EtaLogitsWarper
- __call__
[[autodoc]] ExponentialDecayLengthPenalty
- __call__
[[autodoc]] ForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] ForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] ForceTokensLogitsProcessor
- __call__
[[autodoc]] HammingDiversityLogitsProcessor
- __call__
[[autodoc]] InfNanRemoveLogitsProcessor
- __call__
[[autodoc]] LogitNormalization
- __call__
[[autodoc]] LogitsProcessor
- __call__
[[autodoc]] LogitsProcessorList
- __call__
[[autodoc]] LogitsWarper
- __call__
[[autodoc]] MinLengthLogitsProcessor
- __call__
[[autodoc]] MinNewTokensLengthLogitsProcessor
- __call__
[[autodoc]] NoBadWordsLogitsProcessor
- __call__
[[autodoc]] NoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] PrefixConstrainedLogitsProcessor
- __call__
[[autodoc]] RepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] SequenceBiasLogitsProcessor
- __call__
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] SuppressTokensLogitsProcessor
- __call__
[[autodoc]] TemperatureLogitsWarper
- __call__
[[autodoc]] TopKLogitsWarper
- __call__
[[autodoc]] TopPLogitsWarper
- __call__
[[autodoc]] TypicalLogitsWarper
- __call__
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] WhisperTimeStampLogitsProcessor
- __call__
### TensorFlow
[[autodoc]] TFForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForceTokensLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessorList
- __call__
[[autodoc]] TFLogitsWarper
- __call__
[[autodoc]] TFMinLengthLogitsProcessor
- __call__
[[autodoc]] TFNoBadWordsLogitsProcessor
- __call__
[[autodoc]] TFNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensLogitsProcessor
- __call__
[[autodoc]] TFTemperatureLogitsWarper
- __call__
[[autodoc]] TFTopKLogitsWarper
- __call__
[[autodoc]] TFTopPLogitsWarper
- __call__
### FLAX
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForceTokensLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessorList
- __call__
[[autodoc]] FlaxLogitsWarper
- __call__
[[autodoc]] FlaxMinLengthLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensLogitsProcessor
- __call__
[[autodoc]] FlaxTemperatureLogitsWarper
- __call__
[[autodoc]] FlaxTopKLogitsWarper
- __call__
[[autodoc]] FlaxTopPLogitsWarper
- __call__
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
- __call__
## StoppingCriteria
A [`StoppingCriteria`] can be used to change when to stop generation (other than EOS token). Please note that this is exclusivelly available to our PyTorch implementations.
[[autodoc]] StoppingCriteria
- __call__
[[autodoc]] StoppingCriteriaList
- __call__
[[autodoc]] MaxLengthCriteria
- __call__
[[autodoc]] MaxTimeCriteria
- __call__
## Constraints
A [`Constraint`] can be used to force the generation to include specific tokens or sequences in the output. Please note that this is exclusivelly available to our PyTorch implementations.
[[autodoc]] Constraint
[[autodoc]] PhrasalConstraint
[[autodoc]] DisjunctiveConstraint
[[autodoc]] ConstraintListState
## BeamSearch
[[autodoc]] BeamScorer
- process
- finalize
[[autodoc]] BeamSearchScorer
- process
- finalize
[[autodoc]] ConstrainedBeamSearchScorer
- process
- finalize
## Utilities
[[autodoc]] top_k_top_p_filtering
[[autodoc]] tf_top_k_top_p_filtering
## Streamers
[[autodoc]] TextStreamer
[[autodoc]] TextIteratorStreamer
|
internal/trainer_utils.md
|
# Utilities for Trainer
This page lists all the utility functions used by [`Trainer`].
Most of those are only useful if you are studying the code of the Trainer in the library.
## Utilities
[[autodoc]] EvalPrediction
[[autodoc]] IntervalStrategy
[[autodoc]] enable_full_determinism
[[autodoc]] set_seed
[[autodoc]] torch_distributed_zero_first
## Callbacks internals
[[autodoc]] trainer_callback.CallbackHandler
## Distributed Evaluation
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
## Distributed Evaluation
[[autodoc]] HfArgumentParser
## Debug Utilities
[[autodoc]] debug_utils.DebugUnderflowOverflow
|
internal/image_processing_utils.md
|
# Utilities for Image Processors
This page lists all the utility functions used by the image processors, mainly the functional
transformations used to process the images.
Most of those are only useful if you are studying the code of the image processors in the library.
## Image Transformations
[[autodoc]] image_transforms.center_crop
[[autodoc]] image_transforms.center_to_corners_format
[[autodoc]] image_transforms.corners_to_center_format
[[autodoc]] image_transforms.id_to_rgb
[[autodoc]] image_transforms.normalize
[[autodoc]] image_transforms.pad
[[autodoc]] image_transforms.rgb_to_id
[[autodoc]] image_transforms.rescale
[[autodoc]] image_transforms.resize
[[autodoc]] image_transforms.to_pil_image
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
|
model_doc/bert.md
|
# BERT
## Overview
The BERT model was proposed in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. It's a
bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence
prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
The abstract from the paper is the following:
*We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations
from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional
representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result,
the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models
for a wide range of tasks, such as question answering and language inference, without substantial task-specific
architecture modifications.*
*BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural
language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI
accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
## Usage tips
- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- BERT was trained with the masked language modeling (MLM) and next sentence prediction (NSP) objectives. It is
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation.
- Corrupts the inputs by using random masking, more precisely, during pretraining, a given percentage of tokens (usually 15%) is masked by:
* a special mask token with probability 0.8
* a random token different from the one masked with probability 0.1
* the same token with probability 0.1
- The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50% they are not related. The model has to predict if the sentences are consecutive or not.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A blog post on [BERT Text Classification in a different language](https://www.philschmid.de/bert-text-classification-in-a-different-language).
- A notebook for [Finetuning BERT (and friends) for multi-label text classification](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb).
- A notebook on how to [Finetune BERT for multi-label classification using PyTorch](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb). 🌎
- A notebook on how to [warm-start an EncoderDecoder model with BERT for summarization](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb).
- [`BertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
- A blog post on how to use [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf).
- A notebook for [Finetuning BERT for named-entity recognition](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) using only the first wordpiece of each word in the word label during tokenization. To propagate the label of the word to all wordpieces, see this [version](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) of the notebook instead.
- [`BertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
- [`BertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [`BertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`BertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
⚡️ **Inference**
- A blog post on how to [Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia](https://huggingface.co/blog/bert-inferentia-sagemaker).
- A blog post on how to [Accelerate BERT inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/bert-deepspeed-inference).
⚙️ **Pretraining**
- A blog post on [Pre-Training BERT with Hugging Face Transformers and Habana Gaudi](https://www.philschmid.de/pre-training-bert-habana).
🚀 **Deploy**
- A blog post on how to [Convert Transformers to ONNX with Hugging Face Optimum](https://www.philschmid.de/convert-transformers-to-onnx).
- A blog post on how to [Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS](https://www.philschmid.de/getting-started-habana-gaudi#conclusion).
- A blog post on [Autoscaling BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced).
- A blog post on [Serverless BERT with HuggingFace, AWS Lambda, and Docker](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker).
- A blog post on [Hugging Face Transformers BERT fine-tuning using Amazon SageMaker and Training Compiler](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler).
- A blog post on [Task-specific knowledge distillation for BERT using Transformers & Amazon SageMaker](https://www.philschmid.de/knowledge-distillation-bert-transformers).
## BertConfig
[[autodoc]] BertConfig
- all
## BertTokenizer
[[autodoc]] BertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
## BertModel
[[autodoc]] BertModel
- forward
## BertForPreTraining
[[autodoc]] BertForPreTraining
- forward
## BertLMHeadModel
[[autodoc]] BertLMHeadModel
- forward
## BertForMaskedLM
[[autodoc]] BertForMaskedLM
- forward
## BertForNextSentencePrediction
[[autodoc]] BertForNextSentencePrediction
- forward
## BertForSequenceClassification
[[autodoc]] BertForSequenceClassification
- forward
## BertForMultipleChoice
[[autodoc]] BertForMultipleChoice
- forward
## BertForTokenClassification
[[autodoc]] BertForTokenClassification
- forward
## BertForQuestionAnswering
[[autodoc]] BertForQuestionAnswering
- forward
## TFBertModel
[[autodoc]] TFBertModel
- call
## TFBertForPreTraining
[[autodoc]] TFBertForPreTraining
- call
## TFBertModelLMHeadModel
[[autodoc]] TFBertLMHeadModel
- call
## TFBertForMaskedLM
[[autodoc]] TFBertForMaskedLM
- call
## TFBertForNextSentencePrediction
[[autodoc]] TFBertForNextSentencePrediction
- call
## TFBertForSequenceClassification
[[autodoc]] TFBertForSequenceClassification
- call
## TFBertForMultipleChoice
[[autodoc]] TFBertForMultipleChoice
- call
## TFBertForTokenClassification
[[autodoc]] TFBertForTokenClassification
- call
## TFBertForQuestionAnswering
[[autodoc]] TFBertForQuestionAnswering
- call
## FlaxBertModel
[[autodoc]] FlaxBertModel
- __call__
## FlaxBertForPreTraining
[[autodoc]] FlaxBertForPreTraining
- __call__
## FlaxBertForCausalLM
[[autodoc]] FlaxBertForCausalLM
- __call__
## FlaxBertForMaskedLM
[[autodoc]] FlaxBertForMaskedLM
- __call__
## FlaxBertForNextSentencePrediction
[[autodoc]] FlaxBertForNextSentencePrediction
- __call__
## FlaxBertForSequenceClassification
[[autodoc]] FlaxBertForSequenceClassification
- __call__
## FlaxBertForMultipleChoice
[[autodoc]] FlaxBertForMultipleChoice
- __call__
## FlaxBertForTokenClassification
[[autodoc]] FlaxBertForTokenClassification
- __call__
## FlaxBertForQuestionAnswering
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
|
model_doc/squeezebert.md
|
# SqueezeBERT
## Overview
The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
instead of fully-connected layers for the Q, K, V and FFN layers.
The abstract from the paper is the following:
*Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets,
large computing systems, and better neural network models, natural language processing (NLP) technology has made
significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant
opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we
consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's
highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with
BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods
such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these
techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in
self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called
SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test
set. The SqueezeBERT code will be released.*
This model was contributed by [forresti](https://huggingface.co/forresti).
## Usage tips
- SqueezeBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
rather than the left.
- SqueezeBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
with a causal language modeling (CLM) objective are better in that regard.
- For best results when finetuning on sequence classification tasks, it is recommended to start with the
*squeezebert/squeezebert-mnli-headless* checkpoint.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## SqueezeBertConfig
[[autodoc]] SqueezeBertConfig
## SqueezeBertTokenizer
[[autodoc]] SqueezeBertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## SqueezeBertTokenizerFast
[[autodoc]] SqueezeBertTokenizerFast
## SqueezeBertModel
[[autodoc]] SqueezeBertModel
## SqueezeBertForMaskedLM
[[autodoc]] SqueezeBertForMaskedLM
## SqueezeBertForSequenceClassification
[[autodoc]] SqueezeBertForSequenceClassification
## SqueezeBertForMultipleChoice
[[autodoc]] SqueezeBertForMultipleChoice
## SqueezeBertForTokenClassification
[[autodoc]] SqueezeBertForTokenClassification
## SqueezeBertForQuestionAnswering
[[autodoc]] SqueezeBertForQuestionAnswering
|
model_doc/flaubert.md
|
# FlauBERT
## Overview
The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
*Language models have become a key step to achieve state-of-the art results in many different Natural Language
Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
contextualization at the sentence level. This has been widely demonstrated for English using contextualized
representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
community for further reproducible experiments in French NLP.*
This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
Tips:
- Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## FlaubertConfig
[[autodoc]] FlaubertConfig
## FlaubertTokenizer
[[autodoc]] FlaubertTokenizer
## FlaubertModel
[[autodoc]] FlaubertModel
- forward
## FlaubertWithLMHeadModel
[[autodoc]] FlaubertWithLMHeadModel
- forward
## FlaubertForSequenceClassification
[[autodoc]] FlaubertForSequenceClassification
- forward
## FlaubertForMultipleChoice
[[autodoc]] FlaubertForMultipleChoice
- forward
## FlaubertForTokenClassification
[[autodoc]] FlaubertForTokenClassification
- forward
## FlaubertForQuestionAnsweringSimple
[[autodoc]] FlaubertForQuestionAnsweringSimple
- forward
## FlaubertForQuestionAnswering
[[autodoc]] FlaubertForQuestionAnswering
- forward
## TFFlaubertModel
[[autodoc]] TFFlaubertModel
- call
## TFFlaubertWithLMHeadModel
[[autodoc]] TFFlaubertWithLMHeadModel
- call
## TFFlaubertForSequenceClassification
[[autodoc]] TFFlaubertForSequenceClassification
- call
## TFFlaubertForMultipleChoice
[[autodoc]] TFFlaubertForMultipleChoice
- call
## TFFlaubertForTokenClassification
[[autodoc]] TFFlaubertForTokenClassification
- call
## TFFlaubertForQuestionAnsweringSimple
[[autodoc]] TFFlaubertForQuestionAnsweringSimple
- call
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.