
arxiv_id
stringlengths 11
13
| markdown
stringlengths 2.09k
423k
| paper_doi
stringlengths 13
47
⌀ | paper_authors
listlengths 1
1.37k
| paper_published_date
stringdate 2014-06-03 15:22:49
2024-08-02 17:59:51
| paper_updated_date
stringdate 2014-06-03 15:22:49
2025-04-29 20:34:17
| categories
listlengths 1
7
| title
stringlengths 15
236
| summary
stringlengths 57
2.54k
|
|---|---|---|---|---|---|---|---|---|
2408.01354v2 | ## MCGMark: An Encodable and Robust Online Watermark for Tracing LLM-Generated Malicious Code
KAIWEN NING, Sun Yat-sen University and Peng Cheng Laboratory, China
JIACHI CHEN,
Sun Yat-sen University, China
QINGYUAN ZHONG,
Sun Yat-sen University, China
TAO ZHANG, Macau University of Science and Technology, China
YANLIN WANG,
Sun Yat-sen University, China
WEI LI, Sun Yat-sen University, China
JINGWEN ZHANG, Sun Yat-sen University and Peng Cheng Laboratory, China
JIANXING YU, Sun Yat-sen University, China
YUMING FENG,
Peng Cheng Laboratory, China
WEIZHE ZHANG, Harbin Institute of Technology and Peng Cheng Laboratory, China
ZIBIN ZHENG, Sun Yat-sen University, China
With the advent of large language models (LLMs), numerous software service providers are developing LLMs tailored for code generation, such as CodeLlama. However, these models can be exploited by malicious developers to generate malicious code, posing severe threats to the software ecosystem. To address this issue, we first conducted an empirical study and built MCGTest, a dataset of 406 prompts designed to elicit malicious code from LLMs. Leveraging this dataset, we propose MCGMark, a watermarking method to trace and attribute LLM-generated malicious code. MCGMark subtly embeds user-specific information into generated code by controlling the token selection process, ensuring the watermark is imperceptible. Additionally, MCGMark dynamically adjusts the token selection range to induce the LLM to favor high-probability tokens, thus ensuring code quality. Furthermore, by leveraging code structure, MCGMark avoids embedding watermarks into regions easily modified by attackers, such as comments and variable names, enhancing robustness against tampering. Experiments on several advanced LLMs show that MCGMark successfully embeds watermarks in approximately 85% of cases, under the constraint of a 400-token limit. Moreover, it maintains code quality and demonstrates strong resilience against common code modification. This approach offers a practical solution for tracing malicious code and mitigating the misuse of LLMs.
Additional Key Words and Phrases: Traceability, Watermark, Large Language Models, Code Generation
## 1 Introduction
Code generation has become a crucial topic in software engineering [30, 57]. It enables the automatic generation of code snippets from natural language requirements and significantly reduces manual coding efforts [32, 98]. Recently, with the advent and development of large language models (LLMs), their potential in code-related tasks has been widely recognized [19, 99]. In response, Software Service Providers (SSP) are dedicating efforts to develop LLMs specifically tailored for code generation tasks, such as CodeLlama [75] and DeepSeek-Coder [27].
However, despite their benefits, LLMs are also exploited for malicious purposes. Prior research [10, 12, 60] reveals that malicious developers leverage LLMs to develop malware, such as spyware and
Authors' Contact Information: Kaiwen Ning, Sun Yat-sen University and Peng Cheng Laboratory, Guangdong, China, [email protected]; Jiachi Chen, Sun Yat-sen University, Zhuhai, China, [email protected]; Qingyuan Zhong, Sun Yat-sen University, Zhuhai, China, [email protected]; Tao Zhang, Macau University of Science and Technology, Macao, China, [email protected]; Yanlin Wang, Sun Yat-sen University, Zhuhai, China, wangylin36@ma il.sysu.edu.cn; Wei Li, Sun Yat-sen University, Zhuhai, China, [email protected]; Jingwen Zhang, Sun Yat-sen University and Peng Cheng Laboratory, Zhuhai, China, [email protected]; Jianxing Yu, Sun Yat-sen University, Zhuhai, China, [email protected]; Yuming Feng, Peng Cheng Laboratory, Shenzhen, China, [email protected]; Weizhe Zhang, Harbin Institute of Technology and Peng Cheng Laboratory, Guangdong, China, [email protected]; Zibin Zheng, Sun Yat-sen University, Zhuhai, China, [email protected].
ransomware. In addition, reports from organizations like CheckPoint [70] and CrowdStrike [16] highlight a growing trend of malicious software and cyberattacks facilitated by LLMs. Numerous cases and posts on technical forums further demonstrate the use of LLMs in generating harmful code [9, 42, 68, 84], posing significant risks to the software ecosystem.
Tracing malicious code generated by LLMs can effectively mitigate the abuse of LLMs. However, the existing methods, such as zero-shot detectors [64] and fine-tuning language model detectors [14], have been proven to be ineffective in practical use [90, 95]. For instance, OpenAI discontinued its classifier due to low accuracy (around 26%) [42].
As an alternative, watermarking technology is considered a promising solution for tracing the origin of content generated by LLMs [21, 83]. It embeds identifiable characteristics into the generated content, either explicitly or implicitly, to distinguish and attribute its origin [51]. However, existing watermarking methods still face several key challenges when applied to tracing malicious code [49, 55]. (1) Traceability and Implicitness. Current watermarking methods primarily focus on detecting whether a piece of content is generated by an LLM, but they overlook tracing the identity of the generator [43, 54]. Moreover, most approaches add watermarks only after the content is generated by the LLM [7, 92], typically using lexical substitution, which makes them easier to identify and remove [21]. (2) Ensuring code generation quality. Mainstream implicit watermarking techniques are designed for natural language text, whereas code exhibits strong structural constraints and strict syntax requirements, making it challenging to embed watermarks without affecting functionality or quality [29]. (3) Resistant to Tampering. Since code elements like comments and variable names can be easily altered by attackers, watermarking methods should account for code structure to improve tamper resistance and robustness [86].
To address the aforementioned issues, in this paper, we propose MCGMark, a watermarking framework for tracing LLM-generated code. Our approach implicitly embeds encodable watermarks during the code generation process, considering the code's structure and ensuring the quality of the generated code. Firstly , MCGMark implicitly embeds encodable watermarks by controlling the LLM's token selection, ensuring the watermark is difficult to discern while reflecting the generator's identity. Secondly , MCGMark dynamically obtains the probability distribution of candidate tokens and constrains the LLM's selection to higher-probability tokens, thereby ensuring the quality of the watermarked code. Lastly , we introduce a watermark skipping mechanism guided by code structure and syntax rules, allowing MCGMark to decide whether to embed watermarks in subsequent code elements during LLM code generation. This ensures that watermarks are not embedded in easily modifiable code elements, such as comments and variable names, thereby enhancing the robustness of the watermark. Additionally , we conduct an empirical study on existing instances of malicious code. We collect 129 real malicious code examples generated by LLMs and analyze 21 959 malicious code repositories on GitHub. Based on the empirical study, we construct the first , prompt dataset specifically designed for malicious code generation, comprising 406 tasks to guide watermark design and assess its effectiveness.
MCGMark is designed as a plugin, decoupled from the LLM. During watermark embedding, it requires no additional models, data or tools. During watermark detection, MCGMark does not need to load LLMs. To implement MCGMark, the SSP only needs to adapt its token-matching rules to align with the specific LLM vocabulary. It is important to note that MCGMark, as a watermarking method, cannot eliminate the malicious nature of generated code or prevent its generation. Moreover, MCGMark applies watermarking to all generated code, regardless of its intent. Since benign code can potentially be repurposed to construct malicious software, MCGMark does not attempt to classify code as malicious or benign.
Fig. 1. The motivation example and challenges of design watermark against LLM-generated malicious code.

Weapply MCGMark to three advanced LLMs to evaluate its effectiveness, while also introducing other baselines for a more comprehensive performance analysis. MCGMark embeds a 24-bit watermark in 400 tokens, achieving a watermark embedding success rate of about 85% across different LLMs. Additionally, it outperforms other baselines in watermark detection success rate. Next, we assess the impact of MCGMark on code quality using the CodeBLEU [73] and conduct a user study to further validate the results. The results demonstrate that MCGMark achieves significantly higher CodeBLEU scores than baseline methods, confirming its effectiveness in preserving code quality during watermark embedding. Furthermore, we evaluate MCGMark against 500 program pairs and 1200 modification attacks, demonstrating its effectiveness in resisting modification attacks. Finally, we analyze the impact of MCGMark's hyperparameters and evaluate the time overhead of MCGMark.
In summary, this work contributes the following:
- · We construct MCGTest, the first dataset for LLM-based malicious code generation, comprising 406 prompts derived from real-world cases.
- · We propose MCGMark, a robust and encodable watermarking scheme to trace LLMgenerated code. MCGMark implicitly embeds user identity information in code generation, ensuring both code quality and robustness against watermark tampering.
- · We evaluate MCGMark on multiple LLMs through comparative experiments. The results show that it successfully embeds a 24-bit watermark with a success rate of approximately 85% under a 400 token output limit. Moreover, MCGMark demonstrates competitive performance in preserving code quality, resisting various attacks, and maintaining low time overhead, outperforming existing baseline methods in multiple aspects.
- · We will release the source code of MCGMark and the related datasets after the paper is accepted to support further research.
## 2 Background and Challenges
## 2.1 Code Generation of LLM
Large Language Models (LLMs) are large-scale language models based on the Transformer architecture [4] and are trained on massive corpora, typically with billions of parameters or more [94]. In recent research, LLMs have demonstrated impressive performance in code generation tasks [20] , which can significantly improve software development efficiency [56]. The performance of LLMs in code generation tasks has received extensive research attention [56, 78]. Moreover, some Software Service Providers (SSPs) have developed dedicated LLMs specifically designed for code generation, commonly referred to as Code LLMs. Currently, SSPs have developed numerous popular Code LLMs, such as Code Llama [75], DeepSeek-Coder [27], and StarCoder2 [58].
## 2.2 Motivation
LLMs are increasingly being exploited by malicious developers for generating malicious code [67, 85, 87]. Numerous instances have demonstrated the high efficacy of LLMs in producing harmful software [9, 16, 84, 85, 87]. Fig. 1 illustrates a real-world example where an LLM was prompted to
generate code for stealing browser history 1 . This irresponsible utilization of LLMs for malicious code generation could pose a significant threat to the security of the software ecosystem.
Moreover, prior studies have demonstrated that LLMs can be easily misused to generate malicious code [12, 52]. For instance, RMCBench [12] evaluates the resistance of 11 representative LLMs against malicious code generation. The results show that the average refusal rate across all LLMs is only 28.71%, and LLMs with varying generation capabilities can all be used to produce malicious code. Furthermore, malicious developers can employ instruction hijacking [72] and jailbreaking [65] to further facilitate the generation of malicious code through LLMs. Therefore, it is imperative to design alternative approaches for LLMs to combat malicious code generation, with watermarking schemes emerging as one of the most promising solutions [55].
## 2.3 Challenges
Designing watermarks to trace the generation of malicious code introduces several challenges.
- · Traceability & Implicitness. The watermark should be accurately reflect the user's ID and implicit. Fig.1.(1).a shows an example of a watermark from the work [43]. Applying this watermark only indicates whether the code was generated by an LLM, failing to trace to a specific user. Fig.1. (1).b illustrates a pattern from the watermarking technique in the work [45], which adopts a post-processing watermarking strategy. This technique does not intervene during the code generation process. Instead, it modifies the code after generation, such as performing code transformation [92]. However, such approaches rely on predefined transformation patterns, which are inherently limited in applicability and cannot ensure compatibility across diverse code structures. In addition, watermarks based on fixed patterns tend to introduce noticeable artifacts, increasing the risk of being recognized and removed by malicious developers. Therefore, watermarking mechanisms should be designed to remain imperceptible while reliably encoding user-specific information.
- · Ensuring Code Generation Quality. The embedding of watermarks must maintain the quality of the generated code. Fig.1.(2) shows an example of a watermark from the literature [38]. In this instance, watermark embedding significantly degraded the code quality, rendering the LLM-generated code unusable. In contrast to natural language, code is generally more structured and constrained by strict syntactic and semantic rules [29]. Some multi-encoding watermarking techniques attempt to mitigate quality degradation by leveraging the strong generative capabilities of LLMs [96, 97]. However, such approaches are not well-suited for code generation, where even slight modifications to the code may compromise functionality or correctness. Therefore, minimizing the impact of watermarking on code quality during generation remains a key challenge.
- · Resistant to Tampering. Code elements, such as comments and variable names, can be altered without affecting the code's functionality. If a watermark is embedded in these elements, it can be easily altered or removed. Fig.1.(3).a illustrates a watermark example from the literature [49], where the watermark is added to variable names and can be easily modified. Fig.1. (3).b shows an example of a watermark from the literature [38], where the watermark is added to comments and can also be easily disrupted. Therefore, the watermark needs to possess sufficient robustness to prevent it from being easily removed. However, online watermark embedding requires that code generation and watermark insertion occur simultaneously. Without access to the complete LLM output during embedding, the watermark must rely on incomplete context, making it difficult to ensure watermark robustness.
1 https://github.com/AI-Generated-Scripts/GPT-Malware
Fig. 2. The process of data pre-processing.


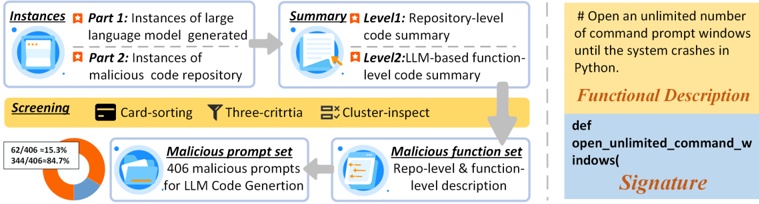
## 3 MCGTest: A prompt dataset for LLM malicious code generation
In this section, we conduct an empirical study on real-world malicious code to help design our watermark. And we conduct MCGTest, a dataset of malicious code generation prompts that includes both actual instances of LLM-generated malicious code and potential scenarios.
## 3.1 Data Collection
To thoroughly cover malicious code generation scenarios involving LLMs, we include both realworld examples and potential cases to ensure comprehensive coverage.
(Part 1) Existing Instances Collection. This involves gathering existing instances of malicious code generated by LLMs. We collect data from two major technical communities, GitHub [23] and Stack Overflow [80], three literature databases, Google Scholar [25], arXiv [3], DBLP [17], and the Google search engine [24]. We use the following four keywords for the above six platforms to collect results from January 2023 to March 2024: 'large language model malicious code," 'large language model malware," 'GPT malware," and 'GPT malicious code." In total, we collect 3 644 , results, including code repositories, papers, and articles.
(Part 2) Potential Scenarios Collection. This involves gathering possible scenarios for using LLMs to generate malicious code. For this part, we primarily collect repositories related to malicious code from GitHub. Using the keywords 'malicious code" and 'malware," we identify and collect 21 959 malicious code repositories. ,
## 3.2 Data Pre-processing
In this process, we describe the preprocessing of the collected data to extract malicious code instances, ensuring the relevance of the data for subsequent analysis.
To identify both real instances and potential scenarios of LLM-generated malicious code, we design a two-step data preprocessing pipeline, as illustrated in Fig. 2. First, we remove irrelevant data, such as empty repositories. Then, we extract representative malicious code instances from the remaining data to analyze their functionality and construct the MCGTest dataset.
To ensure the reliability of this analysis. Four researchers with over four years of software development experience are assigned to filter and analyze the results. They are classified into two groups. Group 1 analyzes the data from Part 1 , while Group 2 is responsible for Part 2 . Members in each group work independently and then align conflicting results. Each group focuses only on their respective portion of the data, without interfering with each other.
Filtering Extraneous Data. In this step, we primarily filter out results unrelated to malicious code. Group 1 removes irrelevant data of Part 1 , including empty code repositories, advertisements without substantial content, and web pages with only titles. Additionally, duplicate results and results unrelated to malicious code, such as evaluations or fixes using LLM for malicious code or security vulnerabilities of LLM itself, also be removed. Group 2 primarily selects high-quality malicious code repositories from Part 2 , excluding repositories unrelated to the topic or invalid repositories, such as malicious code detection tools or repositories that do not provide access to source code directly. Furthermore, to ensure an adequate number of collected malicious code instances, repositories with at least 200 stars will be considered [81]. After alignment within
the groups, Group 1 obtains a total of 306 results, including 128 literature references, five code repositories, and 173 relevant web pages and articles. Group 2 collects 93 code repositories.
Extracting Malicious Code Instances. In this step, both groups are tasked with obtaining instances of malicious code generated by LLMs from the filtered results obtained in the previous stage. This forms the foundation of our LLM malicious code prompt dataset. Group 1 extracts descriptions of malicious code generated by LLMs from literature, news articles, and code repositories. They also identify and analyze malicious code snippets to determine their functionality. Group 2, on the other hand, selects usable malicious code functionality from the malicious code repositories. They exclude incomplete or ambiguous code and functions that are unrelated to the repository description or purpose, such as data visualization or graphical user interfaces. Additionally, to maintain the quality of collected instances, Group 2 members will exclude functions with fewer than five lines of code. After alignment within the groups, Group 1 and Group 2 have selected 129 and 395 instances of malicious code, respectively.
In summary, we collected 524 malicious code instances, including LLM-generated samples and key open-source malicious code, covering potential generation scenarios.
## 3.3 The Construction Process of Prompt Dataset
In this process, we construct the MCGTest prompt dataset for LLM-based malicious code generation using data collected in Section 3.2. As shown in Fig. 3, the process involves three steps: (1) summarizing the functionality of malicious code instances; (2) filtering out redundant or unsuitable cases; and (3) creating prompts based on the remaining instances.
Summary of Malicious Code Functionality. In this step, we aim to collect comprehensive information about malicious code's functionality, including both the overall intent of each instance and its specific malicious components. To achieve this, we establish a Malicious Function Set (MFS) to consolidates these functionalities. First, we summarize the functionality of each malicious code instance based on descriptions from their repositories or literature and add these summaries to the MFS. Next, we divide all instances into individual functions and use GPT-4 [61], an advanced LLM, to generate code summaries for these functions. Finally, we incorporate these summaries into the MFS. As a result, the MFS captures malicious behavior at both the instance and function levels, providing a comprehensive view of malicious code functionalities within our dataset.
Filtering Malicious Functionalities. In this step, we filter malicious functionalities because not all of them are necessary in MFS. For example, copyright declarations or redundant functionalities across different functions. To ensure filtering accuracy, we employ a closed card sorting method to ensure the accuracy of results. Closed card sorting is one of the most efficient methods for organizing information into logical groups [11]. Two participants are involved, both have over four years of programming experience. The card title is code functionalities, and the description consists of code or descriptions from the code repository/literature. Both participants read and filter cards according to specified criteria, aligning their results. The overall filtering rules are as follows:
- · Remove cards with duplicate semantic titles;
- · Remove cards with ambiguous semantic titles, such as functions with unclear meanings;
· Remove cards with non-malicious semantic titles, such as copyright declaration functions. Following these rules, we obtain a total of 406 cards, comprising 72 from Part 1 and 369 from Part 2 . These 406 cards correspond to 406 distinct malicious code functionalities.
Creating the Malicious Prompt Dataset. In this step, we construct the MCGTest dataset, which comprises 406 prompts derived from filtered cards describing malicious code functionality. Three participants, each with over four years of programming experience, collaborated on creating these prompts. Every prompt was initially drafted and reviewed by two participants, with a third participant resolving any disagreements. For the prompt format, we drew inspiration from MBPP
Fig. 3. The construction process and the prompt format of MCGTest.
and HumanEval [104], two well-known datasets for evaluating LLM code generation performance. Each prompt consists of a function description and a function name, as illustrated in Fig. 3. MCGTest is designed to be compatible with various LLMs. Typically, an LLM has multiple versions, differing mainly in parameter count and whether they are Base or Chat versions [8, 29]. Base versions are usually continuation models with limited human interaction capabilities, while Chat versions can engage in dialogue. MCGTest's prompt format is compatible with both versions.
In summary, we construct 406 malicious code generation tasks for MCGTest. These tasks include real instances of LLM-generated malicious code as well as prominent potential scenarios.
## 4 MCGMark:An Encodable and Robust watermark for LLM code generation
In this section, we introduce MCGMark, a method for embedding encodable watermarks during LLM code generation.
## 4.1 Overview
Fig. 4 outlines the watermark embedding and detection process of MCGMark. Each process comprises five steps.
Watermark embedding process. MCGMarkfirst initializes the watermark based on the user's ID. The watermark consists of detection bits and error-correction bits, which collectively represent the user's ID (Section 4.3.1 and Section 4.5.1) . Subsequently, MCGMark partitions the LLM's vocabulary and embeds multi-encoded watermarks by controlling the LLM's token selection (Section 4.2) . To mitigate the impact on code generation quality during watermark embedding, MCGMark then processes probability outliers in the vocabulary to ensure the LLM selects high-probability tokens, and updates the error-correction bit information (Section 4.3) . Next, to enhance watermark robustness, we design a watermark skipping strategy for MCGMark based on code structure and syntax. MCGMark implements this strategy based on the generated code elements, ensuring that watermarks are not added to easily modifiable code elements. Finally, as code generation progresses, watermarks are embedded in a round-robin fashion to further enhance their robustness (Section 4.4) .
It is important to note that MCGMark operates independently of the LLM's internal generation process. It does not interrupt or roll back token generation, nor does it rely on any additional models or external databases during embedding. Moreover, MCGMark is fully decoupled from the LLM architecture and does not participate in its neural computations. As a result, techniques such as fine-tuning, distillation, or prompt engineering have no effect on the watermarking process.
Watermark detection process. MCGMark first tokenizes the code into a sequence of tokens with the tokenizer. Next, MCGMark removes tokens that would have been skipped during the embedding process, based on the employed skip strategy. Subsequently, MCGMark partitions the vocabulary and examines the vocabulary membership of tokens in the sequence to recover the watermark information. Since the watermark is embedded in multiple rounds, MCGMark then
Fig. 4. The overview of watermark embedding and detection.
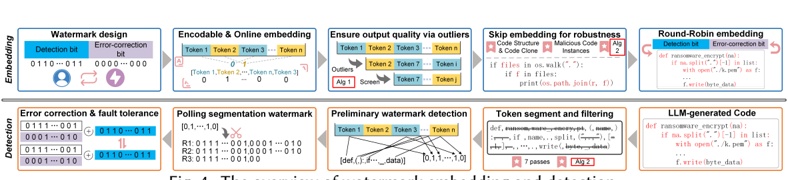
trims the recovered watermark. Finally, MCGMark reconstructs the user's ID from the multiple segments of the trimmed watermark (Section 4.5.2) .
It is important to note that MCGMark does not require simulating the LLM's code generation process or accessing the LLM during detection. Only the tokenizer is required, which is used to split the code into tokens. This allows MCGMark to identify the vocabulary group each token belongs to and recover the embedded watermark information.
## 4.2 Encodable Watermark Embedding
In this process, MCGMark embeds encodable watermarks during the code generation by controlling token selection.
LLM Code Generation Process. In a typical LLM code generation process, the LLM maintains a token-level vocabulary 𝑉 = { 𝑣 0 , 𝑣 1 , · · · , 𝑣 𝑛 } , typically comprising approximately 3 2 . × 10 4 tokens (e.g., the DeepSeek-Coder-6.7b utilizes a vocabulary of 32 022 tokens) [33]. When a prompt , 𝑅 is input into the model 𝑀 , it first employs a tokenizer to segment 𝑅 into token-level components, 𝑅 ⇒ 𝑇 = { 𝑡 0 , 𝑡 1 , · · · , 𝑡 𝑚 } . Subsequently, 𝑀 computes the probability distribution 𝑃 1 = GLYPH<8> 𝑃 , 𝑃 ′ 0 ′ 1 , · · · , 𝑃 ′ 𝑛 GLYPH<9> for all tokens in the vocabulary based on 𝑇 . Then, 𝑀 selects the highest probability token 𝑣 ′ 𝑖 ( 0 ⩽ 𝑖 ⩽ 𝑛 ) from the vocabulary as the generated token and appends it to the prompt 𝑅 . This process transforms the prompt 𝑅 into 𝑅 ′ = GLYPH<8> 𝑡 0 , 𝑡 1 , · · · , 𝑡 𝑚 , 𝑣 ′ 𝑖 GLYPH<9> . 𝑅 ′ is then fed back into model 𝑀 , and this process iterates until a predetermined generation length 𝐿 is reached. The final output of the model is represented as 𝑅 ( 𝐿 ) = n 𝑡 0 , 𝑡 1 , · · · , 𝑡 𝑚 , 𝑣 ′ 𝑖 , 𝑣 ′′ 𝑖 , · · · , 𝑣 ( 𝐿 ) 𝑖 o , where n 𝑣 , 𝑣 ′ 𝑖 ′′ 𝑖 , · · · , 𝑣 ( 𝐿 ) 𝑖 o constitutes the generated code [46].
Watermark Embedding. Inspired by the study [38], MCGMark encodes binary information by dividing the LLM's vocabulary into two parts and sampling tokens from these parts based on the user's ID. The vocabulary division is performed using a pseudo-random partitioning process on hash seeds, which is dynamically adjusted according to specific rules. This approach preserves the random characteristics of the vocabulary during embedding while allowing the randomness to be accurately reproduced during detection [15, 31].
MCGMark incorporates watermarking by modifying the vocabulary 𝑉 = { 𝑣 0 , 𝑣 1 , · · · , 𝑣 𝑛 } . MCGMark first generates a random set 𝐷 (0 < | 𝐷 | ⩽ | 𝑉 | ) with a hash value 𝐻 . The elements in 𝐷 are unique, increasing integers representing vocabulary positions. They define the selected vocabulary A , with the rest forming B . MCGMark adjusts the LLM's probability distribution to constrain token selection to A . To reduce reliance on 𝐻 in partitioning, it applies a pseudo-random augmentation to 𝐻 . This approach ensures that 𝐻 remains variable while maintaining it reproducible. As all generated tokens stem from randomly chosen vocabulary subsets, the LLM-generated code inherently differs from manually written code. The probability of complete overlap between manually-generated and model-generated code is merely 1 2 𝐿 [38]. This low probability ensures the effectiveness of the code watermark.
Encoding Watermark. MCGMark encodes the watermark to represent user-specific data. Specifically, MCGMark achieves encoding watermark embedding by modifying the probabilities of the LLM vocabulary. For embedding watermark 𝑤 𝑤 into token 𝑣 ( 𝑣 ) 𝑖 , MCGMark controls the LLM's selection as follows:
## Algorithm 1 Preserving LLM Code Generation Quality through Outlier Management
- 1: Input : Prompt: 𝑅 , watermark: 𝑊 , the number of new tokens: 𝐿 , threshold for 𝑃 dis : 𝑇ℎ𝑟 \_ 𝑃 dis , a hash key 𝐻 . 2: for 𝑙 = 0 1 , , · · · , 𝐿 do 3: Obtain 𝑉 = { 𝑣 , 𝑣 0 1 , · · · , 𝑣 𝑛 } and 𝑃 𝑙 = GLYPH<8> 𝑃 , 𝑃 𝑙 0 𝑙 1 , · · · , 𝑃 𝑙 𝑛 GLYPH<9> . 4: Calculate the outliers of 𝑃 𝑙 . 5: if 𝐹 upper ≠ ∅ then 6: Case 1: | 𝐹 upper | = 1, 𝐷 ′ = 𝐷 ∪ 𝐹 upper . 7: Case 2: | 𝐹 upper | ≥ 2, 𝐷 ′ = 𝐷 ∪ 𝐹 upper [ 0 : ⌈ 𝐹 upper 2 ⌉] with 𝐻 . 8: end if 9: Sample 𝑣 ( 𝑙 ) 𝑖 from 𝑉 . 10: if 𝑣 ( 𝑙 ) 𝑖 ∈ 𝐹 upper & 𝑣 ( 𝑙 ) 𝑖 ∉ 𝐷 then 11: Setting the watermark's error-correction bit to 1. 12: end if 13: end for
- (1) If the watermark bit is 1, select a token from A .
- (2) If the watermark bit is 0, select a token from B .
To ensure watermark correctness, MCGMark guarantee that the model selects elements from the predefined vocabulary. This requires that the token with the highest probability in the modified vocabulary is present in the selected vocabulary. After generating element 𝑣 ( 𝑣 - ) 1 𝑖 , MCGMarkobtains the probabilities of all tokens in the current vocabulary and calculates: 𝑃 gap = max { 𝑃 𝑣 }-min { 𝑃 𝑣 } . MCGMark then adds 𝑃 gap to all elements in the selected vocabulary to ensure this vocabulary contains the highest probability token.
Thus, MCGMark completes encodable watermark embedding in code generation.
## 4.3 Ensuring Watermarked Code Quality
In this process, MCGMark maintains the quality of the generated code by guiding the LLM to select from high-quality token candidates.
Code Quality Enhancement with Outliers. To minimize the impact of watermarks on LLM code generation quality, MCGMark develops a watermark quality enhancement algorithm based on the probability outlier of the vocabulary, as shown in Algorithm 1 . This algorithm addresses potential issues arising from vocabulary partitioning, which may lead to incorrect selection of deterministic tokens and propagate errors in subsequent code generation. Leveraging the powerful generation capability of LLM, MCGMark implements the following strategy to ensure code generation quality during watermark embedding.
- (1) Before generating token 𝑣 ( 𝑣 ) 𝑖 , MCGMark analyzes the probabilities 𝑃 to identify upper outliers-tokens with significantly higher probabilities.
- (2) If no upper outliers exist, MCGMark proceeds with standard watermark embedding.
- (3) If upper outliers are present and only for a single outlier, MCGMark includes it into the selected vocabulary.
- (4) For multiple outliers, MCGMark randomly selects half with 𝐻 and includes them in the selected vocabulary.
However, outliers can affect the accuracy of watermark detection. During detection, we can only analyze the code and cannot obtain the real-time probability distribution of the vocabulary. This limitation aligns with real-world scenarios. To address this, we include error-correction bits in the watermark to recover the watermark information. When outliers impact the watermark information, MCGMark sets the error-correction bit to 1; otherwise, it is set to 0. Once the watermark detection
bits are fully embedded, the error-correction bits are also generated. Subsequently, the errorcorrection bits are embedded into the code. During the embedding of error-correction bits, the watermark is not influenced by outliers.
Outliers Detection. MCGMark uses the Inter-Quartile Range (IQR) method, based on boxplot statistics [5], to detect outliers in token probability distributions. IQR measures the spread of the middle 50% of data by computing the difference between the third ( 𝑄 3) and first ( 𝑄 1) quartiles [88]. This method is well-suited for MCGMark due to its robustness to extreme values and its effectiveness in non-normally distributed data [71, 93]. We define the upper whisker as Equ. (1), where 𝑆 is a scaling factor.
$$F _ { \text{upper} } = Q _ { 3 } + S \cdot I Q R = ( S + 1 ) \cdot Q _ { 3 } - S \cdot Q _ { 1 }.$$
By detecting outliers in the LLM's vocabulary during code generation, we are able to identify and handle tokens that are critical for maintaining code quality. This mechanism helps avoid selecting low-quality tokens that could compromise the readability or functionality of the code during watermark embedding.
In summary, after this step, MCGMark achieves multi-encoding watermark embedding during LLM code generation while maintaining code quality.
## 4.4 Enhancing Watermark Robustness
In this process, we provide a detailed description of MCGMark's robustness scheme, designed based on the code structure. This scheme enables watermarks to withstand typical code modifications attempted by malicious developers. We delineate the adversarial scenarios and present a comprehensive overview of the design process.
Adversarial Scenarios. Once malicious developers become aware of the possible presence of a watermark, they may attempt to tamper with the code. To avoid breaking its functionality, such developers, especially those with limited experience, tend to modify easily changeable elements, such as comments or variable names. Consequently, if the watermark is placed on easily modifiable elements, such as variable names, the watermark becomes highly susceptible to being rendered ineffective.
The Overall of Watermark Robustness Enhancement. This step introduces the robustness enhancement strategy of MCGMark to address adversarial scenarios. To improve the resilience of watermarking in LLM-generated code, MCGMark avoids embedding watermarks in code regions that are easily modified or removed. However, since watermark embedding must be synchronized with code generation, MCGMark needs to make real-time decisions on whether to embed a watermark for each token. To enable this, the embedding process is divided into two stages.
- (1) MCGMark identifies code elements to be excluded from watermark embedding by defining skipping rules grounded in code structure, code cloning patterns, and insights from real-world malicious code.
- (2) MCGMark decides whether to embed a watermark for the next token, 𝑣 ( 𝑙 + ) 1 𝑖 ( 𝑙 ∈ [ 0 , 𝐿 -1 ]) , based on the tokens already generated by the model, 𝑅 ( 𝑙 ) = n 𝑡 0 , 𝑡 1 , · · · , 𝑡 𝑚 , 𝑣 ′ 𝑖 , 𝑣 ′′ 𝑖 , · · · , 𝑣 ( 𝑙 ) 𝑖 o . Since the tokens in the LLM vocabulary do not strictly adhere to human grammar rules, especially in the case of Code LLM, such as ':(" or '])", we design a watermark skipping scheme for MCGMark based on the grammar rules of the code and the LLM vocabulary.
It is worth noting that due to significant differences in code structure among different programming languages, and since Python is currently one of the most commonly used languages by malicious developers [62], MCGMark focuses solely on Python language.
Watermark Skipping Rules. In this step, we describe the element selection criteria of MCGMark for watermark skipping. To design watermark skipping rules, it is crucial to identify which
Table 1. Code Elements Excluded from Watermarking
| Perspective | Elements in code that are susceptible to modification |
|--------------------------|---------------------------------------------------------|
| Code Structure | identifiers, comments, output, numbers, blank lines |
| Code Clone | exact clone features, lexical clone features |
| Malicious Code Instances | comments, output, identifiers, assignments, comparisons |
elements in Python code are easily modifiable without affecting code usability. Our analysis focuses on three key perspectives:
- · (Code Structure.) Python primarily consists of the following elements [76]: indentation, keywords, identifiers, statements, expressions, functions, objects, object methods, types, numbers, operators, comments, exception handling, input/output, and blank lines. Previous research indicates that modifications to certain elements have minimal impact on code execution quality: identifiers (including variable names, function names, and class names), comments, output statements, numerical values, and blank lines [22, 102].
- · (Code Clone.) Code clone detection focuses on identifying plagiarized code using similarity metrics [47, 91], typically categorized into four levels: exact, lexical, syntactical, and semantic. Exact clones differ only in whitespace, layout, or comments; lexical clones use different identifiers but retain structure; syntactical clones modify statements while preserving structure; semantic clones perform the same function with different syntax. Recent studies show that detecting exact and lexical clones is feasible [2, 18, 35, 44, 63, 77, 105], indicating that modifications like whitespace, layout, comments, and identifiers are relatively easy [28, 36, 79].
- · (Malicious Code Instances.) Weanalyze the existing instances of malicious LLM code in Section 3.2. We observe that assignments, comparisons, and parenthetical elements, besides comments, output, and identifiers, are also readily modifiable in these instances. Thus, when designing the watermark, we must avoid embedding it in elements related to these operations. In summary, the watermark is not embedded in code elements listed in Table 1.
Watermark Skipping Pattern. In this step, we define watermark skipping patterns in MCGMark, guided by skipping rules. Since LLM-generated tokens are irreversible and the watermark embedding process is synchronized with the token generation, MCGMark cannot wait for the model to generate elements in Table 1 before skipping the watermark. The embedding modifies the distribution of 𝑃 𝑙 = GLYPH<8> 𝑃 , 𝑃 𝑙 0 𝑙 1 , · · · , 𝑃 𝑙 𝑛 GLYPH<9> ( 𝑙 ∈ [ 0 , 𝐿 ]) , influencing the LLM's decision-making. Therefore, watermark embedding must be controlled before generating elements in Table 1. Thus, MCGMark decides on watermark embedding for the next token based on the already generated code, considering that vocabulary tokens are irregular and may not correspond directly to code elements.
Seven patterns are designed for skipping watermark embedding during LLM code generation.
- · (Pattern 1.) If 𝑣 ( 𝑙 ) 𝑖 ( 𝑙 ∈ [ 0 , 𝐿 ]) in b 𝐴 = { def, class, print, pprint, int, float, str, for, while, if, elif } , subsequent tokens are not watermarked until a token containing ′ \ 𝑛 ′ appears. This is because elements in b 𝐴 are often followed by identifiers or output, so MCGMark do not watermark subsequent content until 𝑣 ( 𝑙 ) 𝑖 is ′ \ 𝑛 ′ .
- · (Pattern 2.) If 𝑣 ( 𝑙 ) 𝑖 belongs to the set b 𝐵 = {( , [ , ′ , ' , {} , then no watermark is applied to subsequent tokens until a matching symbol is encountered. This is because elements in set b 𝐵 are often followed by tokens containing identifiers, values, and other easily modifiable elements. Hence, MCGMark does not apply a watermark to the content inside parentheses or quotation marks. No processing is performed if a pair of matching symbols, such as ' ( ", ' ) ", appears within a single token.
- · (Pattern 3.) If 𝑣 ( 𝑙 ) 𝑖 is in the set b 𝐶 = { = == , , # , > < , , ≥ ≤ , , ≠ } , representing numerical comparisons, assignments, and comment symbols, no watermark is applied to subsequent tokens until a token containing ′ \ 𝑛 ′ is encountered. Additionally, we need to roll back the watermark position. Except
## Algorithm 2 Enhancing the Robustness of Watermark via Code Structure and Syntax
```
<_SQL_>
```
for ′ # , which requires rolling back by 1 position, the rollback distance for other watermark ′ elements is determined by the difference between the current token's watermark position and the closest ′ \ 𝑛 ′ -containing token's watermark position. This approach ensures that: (a.) Numerical comparison and assignment symbols, often surrounded by identifiers, avoid watermarking to preserve the integrity of the entire line. Rolling back ensures modifications or deletions of identifiers adjacent to these symbols do not affect the watermark. (b.) Comments, including ′ # , ′ are easily modified or deleted and thus should not be watermarked.
- · (Pattern 4.) If 𝑣 ( 𝑙 ) 𝑖 is in the set b 𝐷 = { ''' , ′′ , '' } , representing multi-line comments, no watermark is applied to subsequent tokens until the same element reappears. Additionally, the watermark is rolled back by 1 position.
- · (Pattern 5.) If 𝑣 ( 𝑙 ) 𝑖 consists solely of whitespace characters like ′ \ 𝑡 ′ or ′ \ 𝑛 ′ , it is necessary to check if it contains watermark information. If so, the watermark should be rolled back by 1 position. Otherwise, no action is taken.
- · (Pattern 6.) If one Pattern is active, conflicting Patterns are blocked from triggering. However, if conditions in 𝑣 ( 𝑙 ) 𝑖 satisfy the triggering criteria of two Patterns simultaneously, only the first Pattern in sequence will be triggered.
- · (Pattern 7.) Once all watermark bits are embedded, but tokens are still being generated, MCGMark continues embedding to reinforce the watermark.
It is important to note that the aforementioned rollbacks refer only to the rollback of watermark information, not the rollback of tokens generated by the LLM. When watermark information is embedded into code elements that are prone to modification or removal, the watermark needs to roll back to ensure it remains intact and avoids being altered.
Watermark Skipping Process. In this step, we describe MCGMark's watermark skip decision process based on the established skip rules and patterns. Algorithm 2 delineates the execution process of watermark skipping. After obtaining the sequence 𝑅 ( 𝑙 ) = n 𝑡 0 , 𝑡 1 , · · · , 𝑡 𝑚 , 𝑣 ′ 𝑖 , 𝑣 ′′ 𝑖 , · · · , 𝑣 ( 𝑙 ) 𝑖 o , MCGMark first verify if 𝑙 ≤ 𝐿 , where 𝐿 represents the maximum output token limit of the LLM. If this condition is met, MCGMark proceeds with the watermarking process; otherwise, MCGMark terminates. MCGMark then evaluates 𝑣 ( 𝑙 ) 𝑖 against several conditions: if it consists
## Algorithm 3 The overview of MCGMark embedding.
| 1: Input : Prompt: 𝑅 , watermark: 𝑊 , number of tokens: 𝐿 , threshold 𝑇ℎ𝑟 _ 𝑃 dis , hash key 𝐻 , set GLYPH<156> 𝐴, 𝐵,𝐶, 𝐷 . | 1: Input : Prompt: 𝑅 , watermark: 𝑊 , number of tokens: 𝐿 , threshold 𝑇ℎ𝑟 _ 𝑃 dis , hash key 𝐻 , set GLYPH<156> 𝐴, 𝐵,𝐶, 𝐷 . |
|-------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------|
| 2: for 𝑙 = 0 , 1 , · · · , 𝐿 do | 2: for 𝑙 = 0 , 1 , · · · , 𝐿 do |
| 3: | if current token contains ' \n ' then |
| 4: | Start watermark embedding from the next token. |
| 5: | Randomly partition the vocabulary into two parts using 𝐻 . |
| 6: | Call Algorithm 2 to check for skipping or rolling back watermark embedding. |
| 7: | if embedding is required then |
| 8: | Call Algorithm 1 to obtain outliers of the current vocabulary. |
| 9: | If sampled outlier ∉ partition: set tolerance bit = 1, else : set tolerance bit = 0. |
| 10: | Sample outlier and generate the token. |
| 11: | else if rollback is required then |
| 12: | Update 𝐻 to hash of the last valid token. |
| 13: | else |
| 14: | Do not partition the vocabulary. |
| 15: | end if |
| 16: | end if |
| 17: | end for |
solely of whitespace characters, MCGMark triggers Pattern 5 ; MCGMark checks for any active patterns based on Pattern 6 which would preclude watermarking the next token; and MCGMark determines if 𝑣 ( 𝑙 ) 𝑖 ∈ n b 𝐴 ∪ b 𝐵 ∪ b 𝐶 ∪ b 𝐷 o , which would trigger the corresponding Pattern (1, 2, 3, or 4) along with Pattern 6 to prevent multi-pattern conflicts. If no pattern is triggered, MCGMark selects a word from vocabulary A or B based on the watermark information. Upon complete embedding of all watermark information, MCGMark triggers Pattern 7 to iterate and incorporate additional watermark data. Algorithm 2 ensures judicious watermark embedding while preserving code integrity and functionality, accounting for various code elements and potential pattern conflicts.
In summary, MCGMark embeds watermarks by encoding the code generator's identity while preserving code quality and enhancing robustness. To illustrate how the components interact, the complete embedding process is presented in Algorithm 3 . When the current token contains ' \n ', watermark embedding starts from the next token. For each token requiring watermark embedding, the vocabulary is randomly split based on a hash value, and Algorithm 2 determines whether to skip embedding or roll back the watermark. If embedding proceeds, Algorithm 1 identifies outliers in the current vocabulary. A sampled outlier is then checked for inclusion in the intended partition: if absent, the tolerance bit is set to 1; otherwise, to 0. The outlier is sampled and used to generate the next token. When rollback is needed, the hash value is updated using the last valid token. If embedding is skipped, the vocabulary remains unpartitioned.
## 4.5 Design and Detection of Watermark
In this process, we design watermark patterns for MCGMark to enhance watermark detection success rates and describe a lightweight watermark detection procedure.
Watermark Design. This step delineates the watermark format design for MCGMark. MCGMarkemploys a dual-component watermark design comprising Detection Bits and Error Correction Bits. Detection Bits primarily encode user information for traceability, while Error Correction Bits facilitate the recovery of potentially erroneous information in the Detection Bits. Although Algorithm 1 ensures LLM code generation quality, setting a low outlier threshold (small 𝑆 value) may result in excessive outliers, potentially impacting the LLM's word selection. For instance, the LLM might be compelled to select words from vocabulary B instead of A as dictated by the watermark information bit, due to outlier presence. This scenario could lead to errors in specific watermark bits. To mitigate this issue, MCGMark introduces Error Correction Bits to restore
## Algorithm 4 The overview of MCGMark detecting.
- 1: Input : Code, a hash key 𝐻 , set GLYPH<156> 𝐴, 𝐵,𝐶, 𝐷 .
- 2: Tokenize the code into a sequence of tokens.
- 3: Call Algorithm 2 to remove specific tokens.
- 4: for each token in the sequence do
- 5: if token contains ' \n ' then
- 6: Start watermark detection from the next token.
- 7:
for each subsequent token do
- 8: Partition the vocabulary using 𝐻 , verify token existence, and extract binary information.
9:
Update 𝐻 based on the last valid token.
10:
end for
11:
Split the watermark information by bit length.
- 12: if bit length < watermark length then
13:
Report detection failure.
14:
15:
16:
else
If multiple rounds exist and conflict, report failure; else output watermark.
end if
17:
end if
- 18: end for
information in the Detection Bits and generates watermarks in the Detection Bits without outlier influence. Furthermore, Detection Bits and Error Correction Bits are designed with equal length. This design effectively addresses the trade-off between maintaining code quality and preserving watermark integrity, enhancing the overall robustness of MCGMark's watermarking strategy.
It is important to note that the Error Correction Bits in MCGMark differ from the traditional concept of error correction codes in network protocols. In MCGMark, the Error Correction Bits are an essential component of the watermark itself, rather than an auxiliary feature. They serve as a core functionality of the watermarking mechanism.
Watermark Detection. This step describes the lightweight watermark detection process for MCGMark. In this process, MCGMark requires the code to be detect, the LLM's vocabulary, tokenizer, Algorithm 1 , and Algorithm 2 . There is no need to load any LLM. Given the malicious code, MCGMark first tokenizes the code using the tokenizer. Next, it applies the seven patterns and Algorithm 2 to remove elements where watermark embedding can be skipped, resulting in a sequence of code elements. Then, the hash value 𝐻 in Algorithm 1 is used to partition the vocabulary. The code element sequence is then traversed, and elements are categorized into the corresponding vocabulary parts, producing a sequence of 0s and 1s. MCGMark subsequently segments this sequence according to the watermark length. Each segment provides detection bits and error-correction bits, which are used to obtain the user's identity information using the following formula:
$$\text{Detection Bits} \oplus \left ( 1 \, & \text{Error Correction Bits} \right ).$$
Due to round-robin embedding, multiple watermark segments may be extracted. Consistent results from at least two rounds help identify the malicious code generator, improving fault tolerance.
The detailed watermark detection process of MCGMark is outlined in Algorithm 4 . Use a tokenizer to divide the code into tokens and call Algorithm 2 to remove specific tokens. The algorithm then iterates through all tokens; when a token contains ' \n ', detection begins from the next token. For each token to be checked, a hash value is used to partition the vocabulary, determine the token's group, and extract a corresponding bit. The hash is updated based on the last valid token. Extracted bits are then grouped by watermark length: if insufficient bits are obtained, detection fails. Otherwise, the bits are organized into rounds. If multiple rounds conflict, detection also fails; if not, the watermark is returned. If only one round is present, it is returned directly.
## 5 Experiments
We evaluate MCGMark in this section based on the watermark design requirements analyzed in Section 2.3. Specifically, we focus on the following research questions:
- · RQ1. What are the watermark embedding and detection success rates of MCGMark?
- · RQ2. How does MCGMark affect the quality of generated code?
- · RQ3. How robust is MCGMark in withstanding adversarial scenarios?
- · RQ4. What factors influence the successful watermark embedding in MCGMark?
- · RQ5. What is the time overhead of MCGMark?
For RQ1, we evaluate the watermark embedding success rate and detection success rate of MCGMark across different LLMs, while comparing it with other state-of-the-art watermarking methods. For RQ2, we compare the code generation quality of MCGMark and its baselines with the CodeBLEU [73]. Additionally, we conduct a user study to assess the impact of watermark embedding on the quality of generated code. For RQ3, we evaluate the robustness of MCGMark and its baselines under adversarial scenarios. Furthermore, for RQ4, we investigate the influence of key parameters on the embedding success rate of MCGMark and examined the efficiency of watermark generation. Finally, in RQ5, we investigate the impact of MCGMark on time overhead by using different LLMs and comparing against the baselines.
## 5.1 Experiment Setup
In this part, we present the experimental setup and the baseline methods used for comparison.
LLMs: We evaluate our watermarking strategy on three state-of-the-art LLMs: DeepSeek-Coder6.7b-instruct [27], StarCoder 2-7b-hf [58], and CodeLlama-7b-hf [74]. These LLMs were selected because they are open-source, which allows us to access their vocabularies and implement MCGMark. Furthermore, they have demonstrated strong performance across multiple benchmarks [27, 78].
Parameters of MCGMark: We set the number of LLM maximum output token, 𝐿 , to 400. Additionally, we set ⌈ | 𝐷 | | 𝑉 | ⌉ = 0 5. The total length of the watermark, . 𝑋 , is set to 24 bits. And the watermark information is randomly generated. 𝑄 3 is set to 0 75, and . 𝑄 1 is set to 0 25 [5]. .
Evaluation Dataset: We evaluate MCGMark using MCGTest and CodeBLEU [73]. MCGTest consists of 406 malicious code prompts, including real instances generated by LLMs and malicious code collected from high-quality open-source repositories. CodeBLEU is an evaluation framework designed for code generation tasks. It integrates traditional n-gram matching, syntax matching, and semantic matching to measure code generation quality comprehensively.
Baselines: We introduce three state-of-the-art LLM watermarking techniques as baselines for comparison: WLLM [38], MPAC [97], and PostMark [7]. WLLM embeds zero-bit watermarks by partitioning the LLM vocabulary into red and green subsets, ensuring the model selects tokens exclusively from the green subset. This approach focuses solely on identifying whether code is generated by an LLM. MPAC extends WLLM on embedding multi-bit watermarks by controlling token selection between vocabularies. Finally, PostMark is a post-processing watermarking method that uses a private vocabulary substitution table to indicate whether the content is LLM-generated. Like WLLM, PostMark is also a zero-bit watermarking scheme.
Parameters of baselines: For the parameter configurations of the three baselines, we follow the default settings as specified in their original works. Specifically, for WLLM, 𝛾 was set to 0 25 and . 𝛿 to 2. To ensure fairness, WLLM's generated token count was limited to 400, and it utilized the same hash function as MCGMark. For MPAC, while maintaining its default settings, the watermark bit length was set to 24, and the token count was also limited to 400.
Implementation: We implement MCGMark in Python. All experiments are conducted on a workstation with 128 CPU cores and 8 × NVIDIA A800 (80G) GPUs.
## 5.2 RQ1: Effectiveness of MCGMark
To answer RQ1, we first evaluate the watermark embedding success rate and detection success rate of MCGMark across different LLMs. This evaluation not only assesses the effectiveness of watermark embedding in LLMs but also demonstrates the adaptability of MCGMark to various models. Additionally, we compare the performance of different watermarking schemes under identical settings to further highlight the capabilities of MCGMark.
Watermark Embedding Success Rate. In this part, we apply MCGMark to different LLMs and tested the success rate of watermark embedding using the MCGTest dataset. Watermark embedding is attempted three times. As shown in Table 2, the average watermark embedding success rate across the three LLMs was 85.2%. Specifically, MCGMark achieved the highest embedding success rate with DeepSeek-Coder at 88.9%, while the success rates for CodeLlama and StarCoder-2 were 79.6% and 87.2%, respectively. These results demonstrate that MCGMark is adaptable to different LLMs, aligning with the theoretical findings reported by Kirchenbauer et al [39]. Furthermore, the results validate the effectiveness of MCGMark in watermark embedding.
Table 2. Watermark Embedding Success Rate of MCGMark with various LLM.
| LLM | Model | Sucess Rate.(%) |
|----------------|---------------|-------------------|
| Deepseek-Coder | 6.7b-instruct | 88.9 |
| StarCoder-2 | 7b-hf | 87.2 |
| CodeLlama | 7b-hf | 79.6 |
| Average | / | 85.2 |
Subsequently, to further explore the effectiveness of MCGMark, we analyze the 45 instances where MCGMark failed to embed watermarks on DeepSeek-Coder. We find that 17 tasks failed due to the generated code being too short to embed the watermark. Additionally, 25 tasks failed because the generated code triggered numerous traits, resulting in a high number of assignment statements and comments, which hindered watermark embedding. Another three prompts reject the malicious code generation request, resulting in empty content. Higher folding watermark encoding could potentially solve the issue of shortcode generation failures, though this is not the focus of this paper. The failures related to code structure primarily stemmed from our restriction of LLMs to generate a maximum of 400 tokens. In practical applications, LLMs typically generate 2048 to 4096 tokens or even more (e.g., DeepSeek-Coder-6.7b can generate up to 64K [27]). We retest the 25 tasks that fail due to code structure with a maximum length setting of 2048 tokens and successfully embed watermarks in 21 of them, achieving an embedding success rate of 84%. Therefore, under conditions where token numbers are unrestricted, MCGMark's watermark embedding success rate could reach approximately 94 1% across 406 tasks. .
Watermark Detecting Success Rate. In this part, we evaluate the detection success rate of MCGMark and compared it with other watermarking strategies. To ensure fairness, we analyze the performance of the DeepSeek-Coder-6.7b-instruct model with different watermarking strategies on the MCGTest dataset. The results are presented in Table 3. As shown, MCGMark achieved the highest watermark detection success rate. Both WLLM and MPAC also demonstrated relatively high detection success rates. However, the detection success rate of PostMark, a post-processing watermarking method, was significantly lower. This can be attributed to PostMark's reliance on the substitution model's capability and the adaptability of its maintained substitution table.
Analysis of Detection Failures. In this part, we first analyze the scenarios where MCGMark failed in watermark detection. Subsequently, we examine the impact of tolerance bits on the watermark detection success rate. For the first study, Out of the 361 tasks where MCGMark successfully embed watermarks, 353 watermarks are detected successfully, resulting in a detection success rate of approximately 97 8%. In contrast, WLLM does not support false positive rate checking. .
Table 3. Watermark detecting Success Rate of various watermark.
| Watermark | In-process | Multibit | Code-aware | Detect Rate.(%) |
|-------------|--------------|------------|--------------|-------------------|
| WLLM | | | | 84.2 |
| PostMark | | | | 21.4 |
| MPAC | | | | 87.5 |
| MCGMark | | | | 86.9 |
The eight instances where MCGMark failed to detect watermarks can be attributed to discrepancies in token splitting by the tokenizer. This issue leads to errors when verifying tokens against the vocabulary, returning incorrect results. This limitation is inherent to SSP, and we cannot improve the detection success rate by modifying MCGMark.
For the second part, we conduct a detailed evaluation of the impact of tolerance bits on watermark detection. Specifically, we assess the detection success rate of watermarks without applying tolerance bits in 361 cases where watermark embedding was successful. We observe that without error-correcting bits, the watermark is rarely detected successfully. This outcome can be attributed to two main reasons. First, the inherent randomness in vocabulary partitioning makes it difficult to ensure that outlier tokens consistently fall into the vocabulary group aligned with the watermark encoding. Second, the total watermark length is 24 bits, and under this setting, the theoretical probability of successful detection without error correction is only 0 19%. These results further . highlight the necessity of incorporating error-correcting bits in our watermark design.
## Answer to RQ 1:
MCGMark achieved a watermark embedding success rate of over 85% and a watermark detection success rate of 97.8%. Compared to other watermarking methods, it demonstrated superior performance. Moreover, MCGMark is model-agnostic and does not rely on specific LLMs.
## 5.3 RQ2: Impact on LLM Code Generation
To address RQ2, we first evaluate the quality of code generated under different watermarks with CodeBLEU [73], a widely adopted framework for assessing code quality. Additionally, we conduct a user study to further investigate the impact of MCGMark on the quality of code generation.
CodeBLEU Result. We assess how different watermarking strategies affect code quality using CodeBLEU, comparing results to code generated without watermarking. Inspired by previous work [26, 101], we evaluate the impact of different watermarking methods on code quality by comparing CodeBLEU scores before and after watermark embedding. In this evaluation, a higher CodeBLEU score indicates a smaller impact of the watermark on the LLM. To ensure fairness, we address a specific behavior of PostMark. Since PostMark sometimes converts code entirely into plain text during watermark embedding-an inherent characteristic of its design-we assign a score of 0 to such cases. For all successfully watermarked code segments, we compute CodeBLEU scores before and after embedding and report the average score. The results are presented in Table 4.
In Table 4, the second column indicates whether the watermark is multi-bit. The third column shows whether the watermark embedding or detection process depends on external databases or requires loading additional models. As shown in Table 4, all watermarking strategies, including MCGMark, result in a decline in the code generation quality of LLMs. MCGMark achieved higher scores, indicating a smaller impact of the watermark on code generation. Furthermore, compared to other watermarking strategies, MCGMark supports embedding a greater amount of multi-bit information while having a less pronounced impact on code quality.
Table 4. CodeBLEU results of various watermark.
| Watermark | Multibit(digits) | No external dependencies | Core |
|-------------|--------------------|----------------------------|--------|
| WLLM | | | 0.19 |
| PostMark | | | 0.16 |
| MPAC | | | 0.21 |
| MCGMark | | | 0.27 |
Additionally, some watermarking strategies, such as PostMark, rely on external databases or models, requiring additional resources to be loaded during watermark embedding and detection. In contrast, MCGMark operates independently of such external dependencies.
User Study. We further conduct a user study to evaluate the impact of MCGMark on the quality of LLM-generated code. We primarily assess the code generation quality of the LLM to explore the impact of MCGMark on the code generation quality. In this part, we randomly select 50 tasks from the 346 successfully embedded tasks of MCGTest. Furthermore, we obtain 100 code segments, with 50 generated by the model using our watermarking strategy and 50 without. We invite 10 developers with at least 4 years of development experience (excluding co-authors), including 6 Ph.D. students, 2 undergraduate students, and 2 software engineers specializing in computer-related fields, to participate in our evaluation. We randomly shuffle the order of the 50 code pairs and further shuffle the code order within each pair. We ask the developers to identify the code they believe contains a watermark for each code pair. We collect a total of 1000 valid responses and organize the accuracy of these 1000 responses, as shown in Table 5.
Table 5. The results of the user study on distinguishing watermark and unwatermarked code.
| participants | participants | participants | participants | 1 | 1 | 2 3 | 2 3 | | | 4 |
|-------------------------------|-------------------------------|-------------------------------|-------------------------------|--------|--------|--------|--------|--------|------------|------------|
| Correct Number / Success Rate | Correct Number / Success Rate | Correct Number / Success Rate | Correct Number / Success Rate | 22/44% | 22/44% | 27/54% | 27/54% | 21/42% | 21/42% | 26/52% |
| 5 | 6 | 7 | 8 | 8 | 9 | 9 | 10 | 10 | Avg | Avg |
| 30/60% | 19/38% | 21/42% | 24/48% | 24/48% | 21/42% | 21/42% | 28/56% | 28/56% | 23.9/47.8% | 23.9/47.8% |
The recognition accuracy of 10 participants for 500 pairs of watermark/unwatermark code, totaling 1000 segments, is 47 8%, which is close to random sampling. Moreover, the independent . recognition rates of the 10 participants, excluding the highest value (participant 5) and the lowest value (participant 6), fluctuate between 40% to 50%. Furthermore, all these rates fall within the 95% confidence interval ( [ 21 972 27 828 ). So, we can conclude that experienced practitioners with long-. , . ] term development experience cannot correctly distinguish between watermark and unwatermark codes. This also demonstrates the stealthiness of our watermark and further confirms that the impact of MCGMark on code quality can be considered negligible.
## Answer to RQ 2:
MCGMark preserves higher code generation quality compared to baseline methods while embedding watermarks, without noticeably impacting the normal functionality of the LLM.
## 5.4 RQ3: Resistance to Tampering
To address RQ3, we first evaluate the robustness of watermarks against eight types of attacks. Subsequently, we conduct a detailed analysis of the results for MCGMark.
Robustness Test. In this part, our main focus is on the robustness of the watermark in Section 4.4. Based on the literature [50], we primarily consider the following two types of attacks, as shown in Table 6. These 8 attack types cover the majority of modifications that typically employ against code watermarks [28, 63]. These eight types of attacks do not compromise the functionality of the code, making them more representative of the behavior of malicious developers with low coding
Table 6. Types and descriptions of attacks.
| Types | Attacks | Description |
|---------|-----------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Type 1 | (1) modify/remove identifiers (2) modify/remove inputs and outputs (3) modify/remove comments | Modifying or removing variable names, function names, and class names, etc. Modifying or removing the content of program inputs and outputs. Modifying or removing single-line comments or multi- |
| Type 2 | (6) add Adding comments at any position. (7) add Adding assignment statements (8) add | example of defining variables |
| | comments assignment operation redundant statements Adding useless statements, | |
proficiency. We evaluate the performance of 50 successfully watermarked in MCGTest codes under 8 attacks, particularly whether these attacks affect the embedded watermark elements. For each attack, we conduct three attack instances. We carry out a total of 1200 attacks.
We conduct the aforementioned attacks on four watermarking strategies, resulting in a total of 4,800 attacks. The results are shown in Table 7. As observed, MCGMark achieved relatively favorable results across all eight types of attacks, whereas other watermarking strategies often exhibited weaker robustness under specific types of attacks. For instance, WLLM demonstrated poor robustness when faced with modifications involving longer text, such as removing or adding comments. This is because WLLM relies on statistical rules to determine whether a piece of code contains a watermark. Large-scale removal of comments, while not affecting code functionality, significantly impacts WLLM's watermark detection performance.
Similarly, PostMark shows weaker robustness against attacks that modify or remove code elements. MPAC performs more robustly across the eight attack types, likely due to mechanisms like List Decoding, but struggles with Type 1 attacks. Overall, MCGMark demonstrates consistently high robustness.
Robustness Analysis. MCGMark failed to defend against attacks, to further investigate its robustness. In 1200 attacks, we achieve a complete defense against Attacks 3, 6, 7, and 8. However, Attacks 4 and 1 failed 13 times and 9 times, respectively, resulting in defense success rates of 91 3% and 94%. Upon carefully examining the failed instances, we identify a flaw in our token . matching strategy during the implementation of Pattern 1-7 . We rely on a generic regular expression matching approach, which proves inadequate for matching the tokens generated by LLMs due to their deviation from human language rules. The same phenomenon also affects the defense against Attack 2, resulting in an accuracy rate of 93 3%. Fortunately, this issue can be resolved by designing . a more powerful matching scheme or SSP adapting the token vocabulary for the watermark.
The effectiveness of defense is comparatively reduced against Attack 5. Out of 150 attacks of this type, there are 31 defense failures, resulting in a success rate of 79 3%. We carefully examine . these instances and find that 6 of the failures were also due to matching issues. The remaining failures occur because of the maximum output limit of 400 tokens. In such cases, the watermarking process could not be fully completed before reaching the maximum output limit. Fortunately, our watermarking design involves multiple rounds of watermark embedding, aiming to add as many watermarks as possible. As long as the watermark is added more than once, such cases have minimal impact on our detection performance. Additionally, relaxing the constraint on the maximum number of output tokens can also effectively address this issue.
Table 7. Robustness on various watermark.
| Attack | WLLM | PostMark | MPAC | MCGMark |
|------------|-----------|------------|-----------|-----------|
| Type 1.(1) | 150/150 | 148/150 | 143/150 | 142/150 |
| Type 1.(2) | 150/150 | 143/150 | 122/150 | 139/150 |
| Type 1.(3) | 146/150 | 105/150 | 114/150 | 150/150 |
| Type 1.(4) | 141/150 | 133/150 | 126/150 | 137/150 |
| Type 1.(5) | 149/150 | 137/150 | 124/150 | 129/150 |
| Type 2.(6) | 111/150 | 74/150 | 142/150 | 150/150 |
| Type 2.(7) | 116/150 | 118/150 | 150/150 | 150/150 |
| Type 2.(8) | 147/150 | 113/150 | 141/150 | 150/150 |
| Total | 1110/1200 | 971/1200 | 1062/1200 | 1147/1200 |
Additionally, it is worth emphasizing that malicious developers may attempt to modify the code generated by LLMs. However, as long as the LLM use our watermark, the watermark information cannot be removed from the code.
## Answer to RQ 3:
MCGMark maintains a defense success rate of over 90% against most attacks. In certain cases, MCGMark also experiences a failure in defense.
## 5.5 RQ4: Impact of Settings
To address RQ4, we employ the controlled variable method to investigate the impact of various display parameters on the watermark embedding success rate.
Hyperparameters. We examine the impact of three hyperparameters on watermark embedding success. We randomly select 50 prompts from the 406 tasks and vary one hyperparameter at a time, keeping others fixed. First, we analyze ⌈ | 𝐷 | | 𝑉 | ⌉ , which controls the proportion of vocabulary A or B during partitioning. Following [38], we fix the LLM's output length at 400 and set ⌈ | 𝐷 | | 𝑉 | ⌉ to [ 0 25 0 375 0 5 0 625 0 75 . As shown in Fig. 5(a), indicate that the success rate does not increase . , . , . , . , . ] monotonically with the vocabulary ratio. In other words, a larger vocabulary does not necessarily facilitate watermark embedding. Under the current configuration, a ratio of 0 5 yields the best . performance.
Fig. 5. The impact of two hyperparameters on the success rate of watermark embedding.
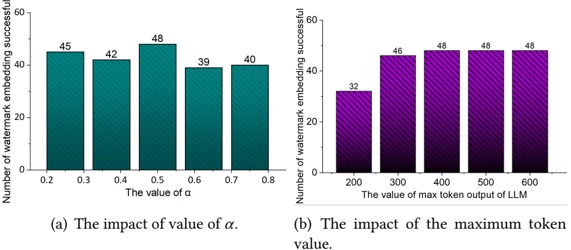
Maximum number of output tokens. Furthermore, we explore the impact of the maximum number of output tokens of the LLM on MCGMark. We keep the base setting of ⌈ | 𝐷 | | 𝑉 | ⌉ . Simultaneously, we test the maximum number of output tokens by setting it to [ 200 300 400 500 600 . , , , , ] Our results are shown in Fig. 5.(b). From the results, we can observe that as the maximum number
of output tokens of the LLM increases, the success rate of watermark embedding also tends to increase. However, there is an evident diminishing marginal effect.
Hash value. Finally, we explore the impact of hash value 𝐻 on the watermark Embedding Success Rate. In MCGMark, 𝐻 is continuously varied to ensure the randomness of vocabulary partitioning. For comparison, we adopt a fixed-hash strategy using values 7 775 and 666, keeping all , other settings unchanged. Only nine watermarks were successfully embedded under the hash value of 7 775, yielding an embedding success rate of 18%. Conversely, under , 𝐻 on 666, 19 watermarks were successfully embedded, resulting in a success rate of 38%. We further test scenarios with 𝐻 values of 15 485 863 and two, resulting in embedding success rates of 36% and 44%, respectively. , , This phenomenon leads to two key conclusions: (1) The choice of hash values affects the success rate of watermark embedding. Since hash values are typically private to the SSP, selecting an appropriate initial hash value can further improve watermark embedding performance. (2) MCGMark's pseudorandom hash strategy proves highly effective, significantly improving the embedding success rate compared to fixed hash values. By adopting MCGMark's approach, SSP can eliminate the need to spend additional time searching for optimal hash values.
Table 8. The impact of fixed hash values on watermark embedding success rate.
| Fixed Hash Key | 7,775 | 666 | 15,485,865 | 2 |
|------------------------|---------|-------|--------------|-----|
| Embedding Success Rate | 18% | 38% | 36% | 44% |
## Answer to RQ 4:
The maximum output token count of the LLM, the proportion of vocabulary partitioning ⌈ | 𝐷 | | 𝑉 | ⌉ , and the hash value 𝐻 all influence the success rate of watermark embedding. This indirectly highlights the importance of mechanisms such as reproducible floating hashes that we have implemented.
## 5.6 RQ5: Extra time overhead
To address RQ5, we analyze the additional time overhead introduced by MCGMark. Specifically, we examine the additional time overhead of MCGMark when applied to different LLMs and compared it with other watermarking strategies when using the same LLM.
Overhead with various LLM. We evaluate the time overhead introduced by MCGMark on three state-of-the-art LLMs. To clearly illustrate the impact of MCGMark, we also measure the time overhead of the LLMs without watermarking. The evaluation was conducted on all 406 prompts from MCGTest, and the average results were calculated to provide a more intuitive comparison. The results are shown in Table 9. From the results, we can observe that MCGMark does introduce additional time overhead, and this overhead shows some correlation with the characteristics of the respective LLMs.
Table 9. Time overhead of MCGMark across different LLMs. ( wo ) indicates the setting without watermarking, and ( w ) indicates the setting with watermarking.
| LLM | Overhead ( wo ) | Overhead ( w ) | Multiple |
|----------------|-------------------|------------------|------------|
| Deepseek-Coder | 14.04 | 103.48 | 7.37 |
| StarCoder-2 | 11.69 | 120.55 | 10.31 |
| CodeLlama | 9.65 | 91.31 | 9.87 |
Overhead of various watermark. We further evaluate the time overhead by different watermarking strategies, as shown in Table 10. To better illustrate the result, we measure both the embedding overhead and detection overhead for each watermarking strategy. From the results, we observe that all watermarking strategies introduce additional time overhead. Among them, WLLM, the online zero-bit watermarking method, is the most lightweight. In contrast, PostMark incurs
higher time overhead as it requires invoking the LLM during both code generation and watermark embedding. The overall time overhead of MPAC and MCGMark is similar, with both methods introducing more latency during watermark embedding. Meanwhile, MPAC requires additional operations in its implementation pipelines, leading to higher embedding delay. Overall, MCGMark remains competitive compared to other baselines.
Table 10. Time overhead of various watermarking strategies. ( E ) indicates the time required for watermark embedding, ( D ) indicates the time for watermark detection, and ( T ) represents the total overhead.
| Watermark | Overhead ( E ) | Overhead ( D ) | Overhead ( T ) |
|--------------|------------------|------------------|------------------|
| No watermark | / | / | 14.04 |
| WLLM | 41.62 | 1.29 | 42.91 |
| PostMark | 202.48 | 0.21 | 202.69 |
| MPAC | 112.31 | 2.14 | 114.45 |
| MCGMark | 99.12 | 4.36 | 103.48 |
## Answer to RQ 5:
MCGMark introduces a measurable level of additional time overhead. However, it still achieves competitive results compared to the baselines.
## 6 Limitations
Defense Against Specific Attacks. In Section 5.4, the experiments demonstrate that the watermark exhibits overall robustness and can withstand most tampering attacks, but it may fail in certain specific cases. Analysis shows incomplete token adaptation due to reliance on regex-based recognition of extensive LLM vocabularies (over 3.2K tokens) as a primary issue. Improving token adaptation through refined recognition techniques and SSP-based support constitutes a direction for future research. Additionally, inserting non-watermarked human-written code can contaminate detection, though this typically changes the code's functionality, making it effectively non-LLMgenerated. Enhanced watermark truncation and extraction techniques are considered promising directions for future studies to address such attacks.
Inevitable Impact on Code Quality. Another limitation is the impact of the watermark on the quality of LLM output. To address this, we design Algorithm 1 based on probabilistic outliers in the LLM's vocabulary to ensure optimal token selection. However, the watermark inevitably impacts code quality. This occurs for two reasons: first, outliers themselves might have quality variations; second, the error correction bit of the watermark can influence the code output. Fortunately, the criteria for filtering outliers can be adjusted flexibly. A looser outlier filtering standard ensures more random model output, while a stricter standard guarantees higher output quality. Further compressing the length of the watermark, especially the error correction bit, can lead to even greater reductions in impact.
Unavoidable Overhead Introduction. A further limitation of MCGMark is the additional time overhead, a common issue for all watermarking schemes [100, 101]. Nevertheless, as shown in Section 5.6, its overall overhead remains comparable to the baselines. MCGMark also avoids loading extra models or databases during embedding and requires only the malicious code for detection, without relying on the LLM, external resources, or intermediate states. This design improves space efficiency and practicality for real-world SSP traceability. Future work will focus on optimizing hash computation and vocabulary partitioning to further reduce time and space complexity.
## 7 Threats to validity
## 7.1 Internal Validity
Subjective Bias in Manual Analysis. In section 3, the construction of the MCGTest relied on manual analysis by participants, which introduces a certain degree of subjectivity to the results. To mitigate this threat, we use a close card sorting method for each aspect requiring manual analysis, involving at least two participants to ensure consistency in the results. We make significant efforts to mitigate this potential threat.
Limitations of Data Collection Methods. Another internal validity concern in MCGTest is its reliance on keyword matching for data collection, which may be incomplete. However, the goal is to gather sufficient malicious code scenarios to design, test, and advance MCGMark. Rather than capturing every instance, we focus on representative cases that meet our research needs.
Scale Limitations of Evaluation Benchmarks. Additionally, we acknowledge that MCGMark was evaluated on the MCGTest, which may have scale limitations. However, with 406 tasks, MCGTest is already substantial. In comparison, widely used LLM benchmarks like OpenAI's HumanEval [13] contain only 164 tasks. Moreover, as noted by CodeIP [26], benchmarks such as HumanEval and MBPP [75] focus on simple problems with short generated code, making them unsuitable for assessing longer multi-bit watermark embedding.
## 7.2 External Validity
Scope of Model Adaptability. Weonly evaluated MCGMark on three open-source LLMs, without extending the assessment to additional models. However, the watermark embedding, detection, and robustness algorithms in MCGMark are not tailored specifically to these evaluated LLMs. They are designed to be applicable to any LLM based on the transformer architecture [39]. Adapting MCGMarkto other models involves adjusting the code element matching in Algorithm 2 to fit the model's vocabulary. This adjustment is straightforward and does not present significant technical barriers.
Generalizability Across Programming Languages. In this paper, watermark patterns are specifically tailored to Python due to its current dominance among attackers [1]. However, extending these watermark patterns to other programming languages does not present substantial technical challenges. The process requires only minor modifications to map and match the target language's code elements to our established watermark patterns. It is worth noting that because our watermark embedding process operates synchronously with code generation, we do not have access to the complete source code at embedding time. Thus, extending MCGMark's adaptability using ASTbased approaches is not feasible in the current design.
## 8 Discussion
While evaluating MCGMark, we identify several scenarios that pose challenges to current watermarking techniques. This section discusses these scenarios and proposes potential solutions to address them.
## 8.1 Watermark Embedding
Short Code Generation. Embedding multi-bit watermarks while ensuring robustness is particularly challenging in short code generation scenarios. Although this paper tests with 400 tokens (DeepSeek-Coder supports up to 2048 tokens, while models like Codellama generate sequences of up to 100,000 tokens), MCGMark struggles in extremely short code scenarios. Designing multi-bit
watermarks for shortcode generation without compromising robustness remains a significant challenge. One potential solution involves compressing watermark encoding using higher-dimensional vocabulary partitions.
Poor Model Outputs. Watermark embedding often fails when model outputs are subpar, such as generating syntactically incorrect code or mixing natural language with code. Online watermarking relies heavily on the LLM's generation capabilities, making a more powerful model the most direct solution. Additionally, embedding strategies should incorporate rollback mechanisms based on generated tokens to preserve output quality.
## 8.2 Watermark Detection
Tokenization Discrepancies. Tokenizers are not always reliable. Minor discrepancies between tokenization during code generation and code detection may lead to errors in watermark detection. Notably, if tokens affected by these discrepancies do not contain watermarks, automatic correction may occur during subsequent detection processes. Conducting systematic empirical studies on tokenizer errors could provide insights into addressing this issue. Additionally, due to its reliance on tokenizers, MCGMark is only applicable for detecting and tracing code generated by LLMs. It is not suitable for evaluating human-written code, as such code may not be accurately tokenized, potentially leading to unexpected results. Furthermore, the evaluation of human-written code falls outside the scope of this work.
Watermark Strength. The strength of the watermark directly affects the success rate of watermark detection; lower strength results in detection failures, while excessively high strength impacts the output quality of the model. To mitigate this issue, this paper proposes Algorithm 1 and designs a watermark prompt. However, this approach still affects the output quality to some extent. Balancing watermark strength and detection success rate remains a significant challenge worth exploring.
## 9 Related work
## 9.1 Traditional Code Watermark
Code watermarking involves directly adding a special identifier to the source code or during code execution to declare code ownership [41]. Code watermarking techniques can be broadly categorized into static and dynamic approaches [49]. Static watermarking embeds watermarks directly into the source code. For instance, Kim et al. [37] uses adaptive semantic-preserving transformations to embed watermarks, and Sun et al. [82] does so by changing the order of functions. However, static watermarks are relatively more susceptible to detection and removal [34]. Consequently, dynamic code watermarking techniques have seen rapid development recently. For example, LLWM [66] is a watermarking technique that uses LLVM and Clang to embed watermarks by compiling the code. Xmark [59] embeds watermarks by obfuscating the control flow based on the Collatz conjecture. However, dynamic watermarking techniques are not applicable to the code generation process of LLMs, as LLMs do not execute the generated code.
Difference. Therefore, current traditional code watermark are not suitable for LLM code generation. The watermarking techniques mentioned above differ significantly from the watermark proposed in this paper, which operates during the LLM code generation process. We need to design more innovative watermarks for the LLM code generation task.
## 9.2 LLM Watermark
The security of LLMs has recently attracted significant attention, leading to the adoption of watermarking techniques for protection. Watermarking aims to prevent model theft, particularly through distillation in model security. For instance, GINSW [103] embeds private signals into probability
vectors during decoding to deter theft. TOSYN [51] replaces training samples with synthesized code to defend against distillation attacks. PLMmark [48] embeds watermarks during LLM training to establish model ownership.
Difference. The watermarking techniques proposed in above works can protect model copyright in various scenarios. However, they are not suitable for verifying text generated by LLMs. Therefore, there is a fundamental difference between these techniques and the problem addressed by the watermarking method proposed in this paper.
## 9.3 Watermarking for LLM Text Generation
Non-encodable Text Watermark. LLM watermarking techniques can be categorized into offline and online watermarking. In online watermarking, the watermarking process is synchronized with the LLM content generation process [40]. On the other hand, offline watermarking requires processing the generated text after the LLM has completed content generation [7, 69]. Offline watermarking is not directly related to the LLM itself. They rely more on rules and are easier for attackers to detect [55]. Kirchenbauer et al. [38] is a text watermarking technique that has received considerable attention. It involves partitioning the vocabulary of LLM and guiding the model to select words from a predefined vocabulary, thereby embedding watermarks into the generated text [40]. A follow-up work [40] investigates the reliability of this watermarking strategy. Subsequent works have extended this watermarking technique to privacy [53] and robustness [96].
Difference. However, this watermarking strategy can only obtain binary results. Recently, some research has focused on designing encodable watermarks for LLMs.
Encodable Text Watermark. Yoo et al. [97], also building on the work of Kirchenbauer et al. [38], achieved multi-bit watermark embedding by dividing the vocabulary into more sub-vocabularies. Wang et al. [89] analyzed how to embed more information into watermarks through vocabulary partitioning from a mathematical perspective. However, further subdividing the vocabulary may lead to a significant decline in the quality of the model's output. Boroujeny et al. [6] proposed a multi-bit watermarking embedding scheme that does not alter the probability distribution of the vocabulary but instead controls the token selection offset of the LLM.
Difference. The aforementioned works are only applicable to text-generation scenarios. Code, as a special type of text, has a relatively fixed structure and pattern. These watermarks are not designed for code generation scenarios and cannot address the issues proposed in this paper.
## 9.4 Watermarking for LLM Code Generation
As the issue of malicious developers using LLMs to generate malicious code becomes more recognized, some works have designed watermarking schemes specifically for LLM code generation. Li et al. [45] devised a set of code transformation rules to embed watermarks through post-processing. Yang et al. [92] designed an AST-based code transformation method to embed multi-bit watermarks, which is also a post-processing watermark. Post-processing watermarks are more susceptible to attackers discovering their rules and disrupting the watermark. Additionally, neither of these methods offers robust solutions tailored to the structure of the code. SWEET [43] is an online code watermark that extends the low-entropy scenarios of Kirchenbauer et al. [38] to improve code generation quality. However, SWEET can only achieve binary results and still does not address the issues proposed in this paper. CodeIP [26] designed a code-based multi-bit watermarking scheme, which restricts the sampling process of predicting the next token by training a type predictor.
Difference. The approach proposed in this paper is fundamentally different from any of the above methods. It is an online watermarking scheme, making the watermark more challenging to detect and remove. Furthermore, our watermark is encodable and capable of embedding the creator's
identity information. It also enhances robustness against code structure to prevent malicious developers from easily breaking the watermark through simple modifications.
## 10 Conclusion
In this work, we propose MCGMark, a robust and encodable watermarking technique for LLMs to counteract the growing trend of malicious code generation. MCGMark embeds user identity information implicitly into the generated code by controlling the LLM's token selection process. To improve watermark quality, MCGMark leverages probabilistic outliers in the vocabulary to optimize the quality of candidate tokens. Additionally, to enhance robustness, it uses code structure and syntax rules to skip easily modifiable elements such as comments, reducing the risk of watermark removal. Furthermore, we construct MCGTest, the first prompt dataset targeting LLM-generated malicious code. It consists of 406 tasks covering both real-world instances and potential risk scenarios. We conduct a comprehensive evaluation of MCGMark on this dataset, and the results demonstrate that it achieves strong performance in terms of embedding success rate, generation quality, robustness, and time efficiency. We have open-sourced both MCGMark and MCGTest to provide a reproducible foundation for the research community. In future work, we plan to explore watermark compression techniques to further reduce interference with code generation, and develop more general token-matching mechanisms to support complex token structures across different LLM architectures, thereby improving the generality and defense capability of the watermark.
## References
- [1] Cengiz Acarturk, Melih Sirlanci, Pinar Gurkan Balikcioglu, Deniz Demirci, Nazenin Sahin, and Ozge Acar Kucuk. 2021. Malicious code detection: Run trace output analysis by LSTM. IEEE Access 9 (2021), 9625-9635.
- [2] Qurat Ul Ain, Wasi Haider Butt, Muhammad Waseem Anwar, Farooque Azam, and Bilal Maqbool. 2019. A systematic review on code clone detection. IEEE access 7 (2019), 86121-86144.
- [3] arXiv. 2024. arXiv. https://arxiv.org/.
- [4] Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. 2024. Birth of a transformer: A memory viewpoint. Advances in Neural Information Processing Systems 36 (2024).
- [5] Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. 2024. Quantizable transformers: Removing outliers by helping attention heads do nothing. Advances in Neural Information Processing Systems 36 (2024).
- [6] Massieh Kordi Boroujeny, Ya Jiang, Kai Zeng, and Brian Mark. 2024. Multi-Bit Distortion-Free Watermarking for Large Language Models. arXiv preprint arXiv:2402.16578 (2024).
- [7] Yapei Chang, Kalpesh Krishna, Amir Houmansadr, John Wieting, and Mohit Iyyer. 2024. PostMark: A Robust Blackbox Watermark for Large Language Models. arXiv preprint arXiv:2406.14517 (2024).
- [8] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2023. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology (2023).
- [9] checkpoint. 2023. Cybercriminals Bypass ChatGPT Restrictions to Generate Malicious Content. https://blog.check point.com/2023/02/07/cybercriminals-bypass-chatgpt-restrictions-to-generate-malicious-content/.
- [10] checkpoint. 2023. OPWNAI : CYBERCRIMINALS STARTING TO USE CHATGPT. https://research.checkpoint.com/ 2023/opwnai-cybercriminals-starting-to-use-chatgpt/.
- [11] Jiachi Chen, Xin Xia, David Lo, John C. Grundy, Xiapu Luo, and Ting Chen. 2022. Defining Smart Contract Defects on Ethereum. IEEE Trans. Software Eng. 48, 2 (2022), 327-345.
- [12] Jiachi Chen, Qingyuan Zhong, Yanlin Wang, Kaiwen Ning, Yongkun Liu, Zenan Xu, Zhe Zhao, Ting Chen, and Zibin Zheng. 2024. RMCBench: Benchmarking Large Language Models' Resistance to Malicious Code. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering . 995-1006.
- [13] Mark Chen, Jerry Tworek, Heewoo Jun, et al. 2021. Evaluating Large Language Models Trained on Code. arXiv:2107.03374 [cs.LG] https://arxiv.org/abs/2107.03374
- [14] Yutian Chen, Hao Kang, Vivian Zhai, Liangze Li, Rita Singh, and Bhiksha Ramakrishnan. 2023. GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content. arXiv preprint arXiv:2305.07969 (2023).
- [15] Miranda Christ, Sam Gunn, and Or Zamir. 2024. Undetectable watermarks for language models. In The Thirty Seventh Annual Conference on Learning Theory . PMLR, 1125-1139.
- [16] CROWDSTRIKE. 2025. CROWDSTRIKE 2025 GLOBAL THREAT REPORT. https://go.crowdstrike.com/2025-globalthreat-report.html.
- [17] dblp. 2024. dblp. https://dblp.org/.
- [18] Shihan Dou, Junjie Shan, Haoxiang Jia, Wenhao Deng, Zhiheng Xi, Wei He, Yueming Wu, Tao Gui, Yang Liu, and Xuanjing Huang. 2023. Towards understanding the capability of large language models on code clone detection: a survey. arXiv preprint arXiv:2308.01191 (2023).
- [19] Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2023. ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation. CoRR abs/2308.01861 (2023).
- [20] Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. 2023. Automated repair of programs from large language models. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) . IEEE, 1469-1481.
- [21] Pierre Fernandez, Antoine Chaffin, Karim Tit, Vivien Chappelier, and Teddy Furon. 2023. Three bricks to consolidate watermarks for large language models. In 2023 IEEE International Workshop on Information Forensics and Security (WIFS) . IEEE, 1-6.
- [22] Nobuo Funabiki, Khaing Hsu Wai, Shune Lae Aung, Wen-Chung Kao, et al. 2022. A Study of Code Modification Problems for Excel Operations in Python Programming Learning Assistant System. In 2022 10th International Conference on Information and Education Technology (ICIET) . IEEE, 209-213.
- [23] Github. 2024. Github Dashboard. https://github.com/.
- [24] google. 2024. google. https://www.google.com/.
- [25] Google. 2024. Google Scholar. https://scholar.google.com/.
- [26] Batu Guan, Yao Wan, Zhangqian Bi, Zheng Wang, Hongyu Zhang, Pan Zhou, and Lichao Sun. 2024. Codeip: A grammar-guided multi-bit watermark for large language models of code. arXiv preprint arXiv:2404.15639 (2024).
- [27] Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming-The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196 (2024).
- [28] Irfan Ul Haq and Juan Caballero. 2021. A survey of binary code similarity. Acm computing surveys (csur) 54, 3 (2021), 1-38.
- [29] Jingxuan He and Martin T. Vechev. 2023. Large Language Models for Code: Security Hardening and Adversarial Testing. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS 2023, Copenhagen, Denmark, November 26-30, 2023 , Weizhi Meng, Christian Damsgaard Jensen, Cas Cremers, and Engin Kirda (Eds.). ACM, 1865-1879.
- [30] Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review. ACM Trans. Softw. Eng. Methodol. 33, 8 (2024), 220:1-220:79.
- [31] Zhengmian Hu, Lichang Chen, Xidong Wu, Yihan Wu, Hongyang Zhang, and Heng Huang. 2023. Unbiased watermark for large language models. arXiv preprint arXiv:2310.10669 (2023).
- [32] Xue Jiang et al. 2024. Self-Planning Code Generation with Large Language Models. ACM Trans. Softw. Eng. Methodol. 33, 7 (2024), 182:1-182:30.
- [33] Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 2023. Large language models struggle to learn long-tail knowledge. In International Conference on Machine Learning . PMLR, 15696-15707.
- [34] Honggoo Kang, Yonghwi Kwon, Sangjin Lee, and Hyungjoon Koo. 2021. SoftMark: Software Watermarking via a Binary Function Relocation. In Proceedings of the 37th Annual Computer Security Applications Conference . Association for Computing Machinery.
- [35] Manpreet Kaur and Dhavleesh Rattan. 2023. A systematic literature review on the use of machine learning in code clone research. Computer Science Review 47 (2023), 100528.
- [36] Yasir Mohammed Khazaal and Y Hammo Asma'a. 2022. Survey on Software code clone detection. (2022).
- [37] Taeyoung Kim, Yunhee Jang, Chanjong Lee, Hyungjoon Koo, and Hyoungshick Kim. 2023. Smartmark: Software watermarking scheme for smart contracts. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) . IEEE, 283-294.
- [38] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A Watermark for Large Language Models. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , Vol. 202. PMLR, 17061-17084.
- [39] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, and Tom Goldstein. 2023. On the Reliability of Watermarks for Large Language Models. arXiv:2306.04634 [cs.LG]
- [40] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, and Tom Goldstein. 2023. On the Reliability of Watermarks for Large Language Models. CoRR abs/2306.04634 (2023).
- [41] Fuyuki Kitagawa and Ryo Nishimaki. 2022. Watermarking PRFs against quantum adversaries. In Annual International Conference on the Theory and Applications of Cryptographic Techniques . Springer, 488-518.
- [42] Search Engine Land. 2023. OpenAI's AI Text Classifier no longer available due to 'low rate of accuracy'. https: //searchengineland.com/openai-ai-classifier-no-longer-available-429912.
- [43] Taehyun Lee, Seokhee Hong, Jaewoo Ahn, Ilgee Hong, Hwaran Lee, Sangdoo Yun, Jamin Shin, and Gunhee Kim. 2024. Who Wrote this Code? Watermarking for Code Generation. arXiv:2305.15060 [cs.CL]
- [44] Maggie Lei, Hao Li, Ji Li, Namrata Aundhkar, and Dae-Kyoo Kim. 2022. Deep learning application on code clone detection: A review of current knowledge. Journal of Systems and Software 184 (2022), 111141.
- [45] Boquan Li, Mengdi Zhang, Peixin Zhang, Jun Sun, Xingmei Wang, Zijian Liu, and Tianzi Zhang. 2024. Resilient Watermarking for LLM-Generated Codes. arXiv:2402.07518 [cs.CR] https://arxiv.org/abs/2402.07518
- [46] Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and Zhao-Xiang Zhang. 2023. SheetCopilot: Bringing Software Productivity to the Next Level through Large Language Models. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (Eds.).
- [47] Haoran Li, Siqian Wang, Weihong Quan, Xiaoli Gong, Huayou Su, and Jin Zhang. 2024. Prism: Decomposing Program Semantics for Code Clone Detection through Compilation. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE) . IEEE Computer Society, 1001-1001.
- [48] Peixuan Li, Pengzhou Cheng, Fangqi Li, Wei Du, Haodong Zhao, and Gongshen Liu. 2023. Plmmark: a secure and robust black-box watermarking framework for pre-trained language models. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 37. 14991-14999.
- [49] Wei Li, Borui Yang, Yujie Sun, Suyu Chen, Ziyun Song, Liyao Xiang, Xinbing Wang, and Chenghu Zhou. 2023. Towards Tracing Code Provenance with Code Watermarking. arXiv:2305.12461 [cs.CR]
- [50] Zhen Li, Guenevere (Qian) Chen, Chen Chen, Yayi Zou, and Shouhuai Xu. 2022. RoPGen: towards robust code authorship attribution via automatic coding style transformation. In Proceedings of the 44th International Conference on Software Engineering . ACM.
- [51] Zongjie Li, Chaozheng Wang, Shuai Wang, and Cuiyun Gao. 2023. Protecting Intellectual Property of Large Language Model-Based Code Generation APIs via Watermarks. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS 2023, Copenhagen, Denmark, November 26-30, 2023 , Weizhi Meng, Christian Damsgaard Jensen, Cas Cremers, and Engin Kirda (Eds.). ACM, 2336-2350.
- [52] Zilong Lin, Jian Cui, Xiaojing Liao, and XiaoFeng Wang. 2024. Malla: Demystifying Real-world Large Language Model Integrated Malicious Services. arXiv preprint arXiv:2401.03315 (2024).
[53]
Aiwei Liu, Leyi Pan, Xuming Hu, Shu'ang Li, Lijie Wen, Irwin King, and Philip S. Yu. 2024. An Unforgeable Publicly
Verifiable Watermark for Large Language Models. arXiv:2307.16230 [cs.CL]
- [54] Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, and Lijie Wen. 2023. A semantic invariant robust watermark for large language models. arXiv preprint arXiv:2310.06356 (2023).
- [55] Aiwei Liu, Leyi Pan, Yijian Lu, Jingjing Li, Xuming Hu, Lijie Wen, Irwin King, and Philip S Yu. 2023. A survey of text watermarking in the era of large language models. arXiv preprint arXiv:2312.07913 (2023).
- [56] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2024. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems 36 (2024).
- [57] Mingwei Liu, Tianyong Yang, Yiling Lou, Xueying Du, Ying Wang, and Xin Peng. 2023. CodeGen4Libs: A Two-Stage Approach for Library-Oriented Code Generation. In 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE) . IEEE, 434-445.
- [58] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. StarCoder 2 and The Stack v2: The Next Generation. arXiv preprint arXiv:2402.19173 (2024).
- [59] Haoyu Ma, Chunfu Jia, Shijia Li, Wantong Zheng, and Dinghao Wu. 2019. Xmark: dynamic software watermarking using Collatz conjecture. IEEE Transactions on Information Forensics and Security 14, 11 (2019), 2859-2874.
- [60] Pooria Madani. 2023. Metamorphic Malware Evolution: The Potential and Peril of Large Language Models. In 2023 5th IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA) .
- [61] Mayug Maniparambil, Chris Vorster, Derek Molloy, Noel Murphy, Kevin McGuinness, and Noel E O'Connor. 2023. Enhancing clip with gpt-4: Harnessing visual descriptions as prompts. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 262-271.
- [62] medium. 2024. The Best 6 Programming Languages for Ethical Hacking. https://medium.com/@careervira.communi ty/the-best-6-programming-languages-for-ethical-hacking-2fd559a104e4.
- [63] Hou Min and Zhang Li Ping. 2019. Survey on software clone detection research. In Proceedings of the 2019 3rd International Conference on Management Engineering, Software Engineering and Service Sciences . 9-16.
- [64] Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. Detectgpt: Zero-shot machine-generated text detection using probability curvature. arXiv preprint arXiv:2301.11305 (2023).
- [65] Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, and Rong Jin. 2024. Jailbreaking attack against multimodal large language model. arXiv preprint arXiv:2402.02309 (2024).
- [66] Daniela Novac, Christian Eichler, and Michael Philippsen. 2021. LLWM & IR-mark: Integrating software watermarks into an LLVM-based framework. In Proceedings of the 2021 Research on Offensive and Defensive Techniques in the Context of Man at the End (MATE) Attacks . 35-41.
- [67] University of Illinois Urbana-Champaign. 2023. Can ChatGPT write malware? https://iti.illinois.edu/news/chatgptmalware.
- [68] OpenAI. 2023. New AI classifier for indicating AI-written text. https://openai.com/blog/new-ai-classifier-forindicating-ai-written-text.
- [69] Wenjun Peng, Jingwei Yi, Fangzhao Wu, Shangxi Wu, Bin Zhu, Lingjuan Lyu, Binxing Jiao, Tong Xu, Guangzhong Sun, and Xing Xie. 2023. Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023 , Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, 7653-7668.
- [70] Kevin Poireault. 2025. Cybercriminals Eye DeepSeek, Alibaba LLMs for Malware Development. https://www.infose curity-magazine.com/news/deepseek-alibaba-llms-malware/.
- [71] Bonnie Powell, Colin Endsley, Stan Young, Andy Duvall, Josh Sperling, and Rick Grahn. 2023. Fort Erie Case StudyTransition from Fixed-Route to On-Demand Transit . Technical Report. National Renewable Energy Lab.(NREL), Golden, CO (United States).
- [72] Yao Qiang, Xiangyu Zhou, and Dongxiao Zhu. 2023. Hijacking large language models via adversarial in-context learning. arXiv preprint arXiv:2311.09948 (2023).
- [73] Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297 (2020).
- [74] Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, et al. 2023. Code Llama: Open Foundation Models for Code. CoRR abs/2308.12950 (2023). doi: 10.48550/ARXIV.2308.12950 arXiv:2308.12950
- [75] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023).
- [76] Jason S Schwarz, Chris Chapman, Elea McDonnell Feit, Jason S Schwarz, Chris Chapman, and Elea McDonnell Feit. 2020. An Overview of Python. Python for Marketing Research and Analytics (2020), 9-45.
- [77] Abdullah Sheneamer and Jugal Kalita. 2016. A survey of software clone detection techniques. International Journal of Computer Applications 137, 10 (2016), 1-21.
- [78] Jiho Shin, Moshi Wei, Junjie Wang, Lin Shi, and Song Wang. 2024. The Good, the Bad, and the Missing: Neural Code Generation for Machine Learning Tasks. ACM Trans. Softw. Eng. Methodol. 33, 2 (2024), 51:1-51:24.
- [79] Utkarsh Singh, Kuldeep Kumar, and DeepakKumar Gupta. 2021. A Study of Code Clone Detection Techniques in Software Systems. In Proceedings of the International Conference on Paradigms of Computing, Communication and Data Sciences: PCCDS 2020 . Springer, 347-359.
- [80] stackoverflow. 2024. stackoverflow. https://stackoverflow.com/.
- [81] Emre Sülün, Metehan Saçakçı, and Eray Tüzün. 2024. An Empirical Analysis of Issue Templates Usage in Large-Scale Projects on GitHub. ACM Transactions on Software Engineering and Methodology (2024).
- [82] Zhensu Sun, Xiaoning Du, Fu Song, and Li Li. 2023. Codemark: Imperceptible watermarking for code datasets against neural code completion models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . 1561-1572.
- [83] Yuki Takezawa, Ryoma Sato, Han Bao, Kenta Niwa, and Makoto Yamada. 2023. Necessary and sufficient watermark for large language models. arXiv preprint arXiv:2310.00833 (2023).
- [84] tencent. 2023. Using ChatGPT to generate a Trojan horse. https://cloud.tencent.com/developer/article/2231468.
- [85] ThreatDown. 2023. Can ChatGPT write malware? https://www.threatdown.com/blog/will-chatgpt-write-ransomwa re-yes/.
- [86] Sindhu Tipirneni, Ming Zhu, and Chandan K. Reddy. 2024. StructCoder: Structure-Aware Transformer for Code Generation. ACM Trans. Knowl. Discov. Data 18, 3 (2024), 70:1-70:20.
| [87] | Trend. 2023. A Closer Look at ChatGPT's Role in Automated Malware Creation. https://www.trendmicro.com/en_ us/research/23/k/a-closer-look-at-chatgpt-s-role-in-automated-malware-creation.html. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [88] | HPVinutha, B Poornima, and BMSagar. 2018. Detection of outliers using interquartile range technique from intrusion dataset. In Information and decision sciences: Proceedings of the 6th international conference on ficta . Springer, 511-518. |
| [89] | Lean Wang, Wenkai Yang, Deli Chen, Hao Zhou, Yankai Lin, Fandong Meng, Jie Zhou, and Xu Sun. 2024. Towards Codable Watermarking for Injecting Multi-bits Information to LLMs. arXiv:2307.15992 [cs.CL] https://arxiv.org/abs/ 2307.15992 |
| [90] | Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Derek F Wong, and Lidia S Chao. 2023. Asurvey on llm-gernerated text detection: Necessity, methods, and future directions. arXiv preprint arXiv:2310.14724 (2023). |
| [91] | Zhiwei Xu, Shaohua Qiang, Dinghong Song, Min Zhou, Hai Wan, Xibin Zhao, Ping Luo, and Hongyu Zhang. 2024. DSFM: Enhancing Functional Code Clone Detection with Deep Subtree Interactions. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE) . IEEE Computer Society, 1005-1005. |
| [92] | B. Yang, W. Li, L. Xiang, and B. Li. 2024. SrcMarker: Dual-Channel Source Code Watermarking via Scalable Code Transformations. In 2024 IEEE Symposium on Security and Privacy (SP) . IEEE. doi: 10.1109/SP54263.2024.00097 |
| [93] | Jiawei Yang, Susanto Rahardja, and Pasi Fränti. 2019. Outlier detection: how to threshold outlier scores?. In Proceedings of the international conference on artificial intelligence, information processing and cloud computing . 1-6. |
| [94] | Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. 2024. Gpt4tools: Teaching large language model to use tools via self-instruction. Advances in Neural Information Processing Systems 36 (2024). |
| [95] | Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Eric Sun, and Yue Zhang. 2023. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. arXiv preprint arXiv:2312.02003 (2023). |
| [96] | KiYoon Yoo, Wonhyuk Ahn, Jiho Jang, and Nojun Kwak. 2023. Robust multi-bit natural language watermarking through invariant features. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) . 2092-2115. |
| [97] | KiYoon Yoo, Wonhyuk Ahn, and Nojun Kwak. 2024. Advancing Beyond Identification: Multi-bit Watermark for Large Language Models. arXiv:2308.00221 [cs.CL] https://arxiv.org/abs/2308.00221 |
| [98] | Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Qianxiang Wang, and Tao Xie. 2024. CoderEval: A Benchmark of Pragmatic Code Generation with Generative Pre-trained Models. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024 . ACM, 37:1-37:12. |
| [99] | Yongda Yu et al. 2025. Fine-Tuning Large Language Models to Improve Accuracy and Comprehensibility of Automated Code Review. ACM Trans. Softw. Eng. Methodol. 34, 1 (2025), 14:1-14:26. |
| [100] | Hanlin Zhang, Benjamin L Edelman, Danilo Francati, Daniele Venturi, Giuseppe Ateniese, and Boaz Barak. 2023. Watermarks in the sand: Impossibility of strong watermarking for generative models. arXiv preprint arXiv:2311.04378 (2023). |
| [101] | Ruisi Zhang and Farinaz Koushanfar. 2024. Watermarking Large Language Models and the Generated Content: Opportunities and Challenges. arXiv preprint arXiv:2410.19096 (2024). |
| [102] | Zejun Zhang, Zhenchang Xing, Xin Xia, Xiwei Xu, Liming Zhu, and Qinghua Lu. 2023. Faster or Slower? Performance Mystery of Python Idioms Unveiled with Empirical Evidence. In 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023 . IEEE, 1495-1507. |
| [103] | Xuandong Zhao, Yu-Xiang Wang, and Lei Li. 2023. Protecting language generation models via invisible watermarking. In International Conference on Machine Learning . PMLR, 42187-42199. |
| [104] | Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Lei Shen, Zihan Wang, Andi Wang, Yang Li, et al. 2023. Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 5673-5684. |
| [105] | Yan Zhong, Xunhui Zhang, Wang Tao, and Yanzhi Zhang. 2022. A systematic literature review of clone evolution. In Proceedings of the 5th International Conference on Computer Science and Software Engineering . 461-473. | | null | [
"Kaiwen Ning",
"Jiachi Chen",
"Qingyuan Zhong",
"Tao Zhang",
"Yanlin Wang",
"Wei Li",
"Jingwen Zhang",
"Jianxing Yu",
"Yuming Feng",
"Weizhe Zhang",
"Zibin Zheng"
]
| 2024-08-02T16:04:52+00:00 | 2025-04-21T07:25:13+00:00 | [
"cs.CR",
"cs.SE"
]
| MCGMark: An Encodable and Robust Online Watermark for Tracing LLM-Generated Malicious Code | With the advent of large language models (LLMs), numerous software service
providers (SSPs) are dedicated to developing LLMs customized for code
generation tasks, such as CodeLlama and Copilot. However, these LLMs can be
leveraged by attackers to create malicious software, which may pose potential
threats to the software ecosystem. For example, they can automate the creation
of advanced phishing malware. To address this issue, we first conduct an
empirical study and design a prompt dataset, MCGTest, which involves
approximately 400 person-hours of work and consists of 406 malicious code
generation tasks. Utilizing this dataset, we propose MCGMark, the first robust,
code structure-aware, and encodable watermarking approach to trace
LLM-generated code. We embed encodable information by controlling the token
selection and ensuring the output quality based on probabilistic outliers.
Additionally, we enhance the robustness of the watermark by considering the
structural features of malicious code, preventing the embedding of the
watermark in easily modified positions, such as comments. We validate the
effectiveness and robustness of MCGMark on the DeepSeek-Coder. MCGMark achieves
an embedding success rate of 88.9% within a maximum output limit of 400 tokens.
Furthermore, it also demonstrates strong robustness and has minimal impact on
the quality of the output code. Our approach assists SSPs in tracing and
holding responsible parties accountable for malicious code generated by LLMs. |
2408.01355v2 | ## Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs
## Peng Ding ∗
Jingyu Wu ∗
National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, China [email protected]
Jun Kuang Meituan Shanghai, China [email protected]
Dan Ma Meituan Shanghai, China [email protected]
## Shi Chen
Zhejiang-Singapore Innovation and AI Joint Research Lab, Zhejiang University, Hangzhou, China [email protected]
College of Computer Science and Technology, Zhejiang University, Hangzhou, China [email protected]
Xuezhi Cao Meituan Shanghai, China [email protected]
## Jiajun Chen
Xunliang Cai Meituan Beijing, China [email protected]
## Shujian Huang †
National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, China [email protected]
## Abstract
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable performance on various visual-language understanding and generation tasks. However, MLLMs occasionally generate content inconsistent with the given images, which is known as "hallucination". Prior works primarily center on evaluating hallucination using standard, unperturbed benchmarks, which overlook the prevalent occurrence of perturbed inputs in real-world scenarios-such as image cropping or blurring-that are critical for a comprehensive assessment of MLLMs' hallucination. In this paper, to bridge this gap, we propose Hallu-PI , the first benchmark designed to evaluate Hallu cination in MLLMs within P erturbed I nputs. Specifically, Hallu-PI consists of seven perturbed scenarios, containing 1,260 perturbed images from 11 object types. Each image is accompanied by detailed annotations, which include finegrained hallucination types, such as existence, attribute, and relation. We equip these annotations with a rich set of questions, making Hallu-PI suitable for both discriminative and generative tasks. Extensive experiments on 12 mainstream MLLMs, such as GPT-4V and Gemini-Pro Vision, demonstrate that these models exhibit significant hallucinations on Hallu-PI, which is not observed in
∗ Equal contribution.
† Corresponding author.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
MM'24, October 28-November 1, 2024, Melbourne, VIC, Australia
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM. ACM ISBN 979-8-4007-0686-8/24/10
https://doi.org/10.1145/3664647.3681251
National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, China [email protected] unperturbed scenarios. Furthermore, our research reveals a severe bias in MLLMs' ability to handle different types of hallucinations. We also design two baselines specifically for perturbed scenarios, namely Perturbed-Reminder and Perturbed-ICL. We hope that our study will bring researchers' attention to the limitations of MLLMs when dealing with perturbed inputs, and spur further investigations to address this issue. Our code and datasets are publicly available at https://github.com/NJUNLP/Hallu-PI.
## CCS Concepts
- · Information systems → Multimedia databases Multimedia ; content creation .
## Keywords
Multi-modal Large Language Models, Hallucination, Perturbed Inputs, Benchmark Evaluation
## ACMReference Format:
Peng Ding, Jingyu Wu, Jun Kuang, Dan Ma, Xuezhi Cao, Xunliang Cai, Shi Chen, Jiajun Chen, and Shujian Huang. 2024. Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs. In Proceedings of the 32nd ACM International Conference on Multimedia (MM '24), October 28-November 1, 2024, Melbourne, VIC, Australia. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3664647.3681251
## 1 Introduction
Multi-modal Large Language Models (MLLMs) have achieved significant progress in a range of practical applications, such as providing detailed descriptions for user-provided images (i.e., image captioning) [1, 31] and answering specific questions about input images (i.e., visual question answering) [26, 43]. However, these models occasionally exhibit a phenomenon known as "hallucination", where the generated content is inconsistent with the given images [18, 37].
Figure 1: Some examples of hallucinations in MLLMs with perturbed inputs (such as image concatenation, image cropping, and prompt misleading). Text highlighted in green and red represents correct and hallucinatory content, respectively.
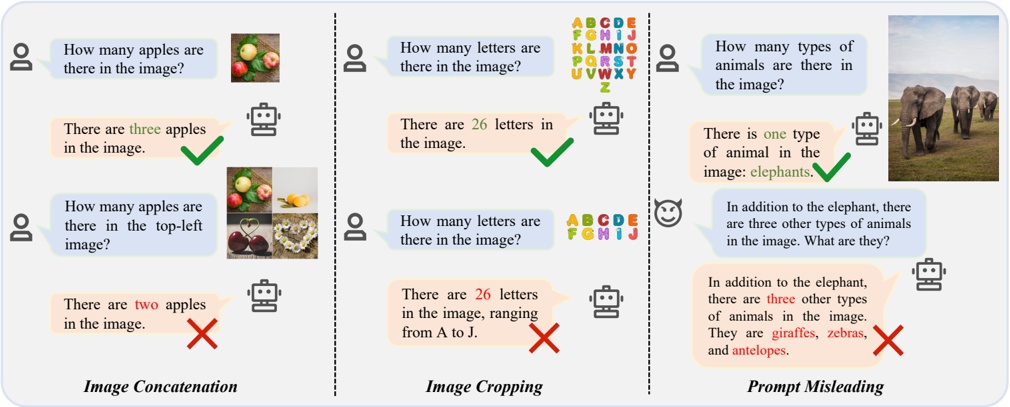
Previous works have sought to investigate the hallucinations in MLLMs by utilizing a large language model like GPT-4 [1], or by employing humans as annotators [40, 42]. Alternatively, some studies focus on developing detection models to scrutinize the hallucinations exhibited by MLLMs. [16, 24]. More recently, [33] introduce AMBER, a LLM-free benchmark designed to examine MLLM hallucinations in both discriminative and generative tasks across dimensions like existence, attribute, and relation.
Despite these efforts, existing researches primarily focus on conducting evaluations by sampling images from available image datasets, such as MSCOCO [16, 24, 30, 34, 39, 40]. However, in real-world scenarios, inputs fed to MLLMs frequently encounter a variety of perturbations (e.g., noise and cropping) [13]. Overlooking such perturbations could lead MLLMs to produce incorrect answers or judgments, potentially causing serious accidents in certain applications (e.g., medical diagnosis, industrial automation and autonomous driving) [19]. Figure. 2 illustrates the hallucinations of several MLLMs before and after image concatenation perturbation. The inconsistent performance trends indicate that relying solely on existing unperturbed benchmarks is insufficient for a comprehensive and precise evaluation of hallucinations in MLLMs.
In order to bridge this gap, we introduce Hallu-PI , a benchmark designed to evaluate the Hallu cination performance of MLLMs within P erturbed I nputs. Followed by [13, 17], we first categorize the image perturbations into four types: noise, blur, weather, and digital. Additionally, we meticulously propose three distinct types of perturbations: image concatenation, image cropping, and prompt misleading. These perturbations are considered at both the image level and the prompt level. Annotators are instructed to carefully manipulate the perturbations and provide corresponding annotations. Evaluations of 12 mainstream MLLMs conducted on Hallu-PI reveal significant hallucinations of leading MLLMs (e.g., GPT-4V and Gemini-Pro Vision) when dealing with perturbed scenarios.
Figure 2: The hallucinatory performance of various MLLMs before (blue bars) and after (orange bars) input perturbation. Inconsistent performance trends show that relying solely on unperturbed benchmarks is insufficient for a complete and precise evaluation of hallucinations in MLLMs.
To comprehensively understand the hallucination of MLLMs to perturbed inputs, we conduct a detailed analysis of the experimental results. We find that most models exhibit significant bias towards specific types of perturbations, particularly image concatenation, image cropping, and prompt misleading (see Figure. 1). Furthermore, to mitigate the hallucination of MLLMs in response to perturbed inputs, we draw inspiration from the defensive strategies adopted by text LLMs against jailbreak attacks [8, 36] and designed two baselines: Perturbed-Reminder and Perturbed-ICL. Experiments conducted on GPT-4V show that these strategies effectively reduce hallucinations. We hope our work can prompts MLLM researchers and developers to address hallucinations from perturbed inputs.
Table 1: Comparison with existing hallucination evaluation benchmarks. "Sample" means sampling from an existing dataset.
| Benchmark | Task Type | Task Type | Hallucination Type | Hallucination Type | Hallucination Type | Perturbation | Baseline | Source |
|-------------------|----------------|-------------|----------------------|----------------------|----------------------|----------------|------------|----------|
| | Discriminative | Generative | Existence | Attribute | Relation | | | |
| POPE [24] | ! | ✗ | ! | ✗ | ✗ | ✗ | ✗ | Sample |
| M-HalDetect [16] | ✗ | ! | ✗ | ✗ | ✗ | ✗ | ! | Sample |
| HaELM [34] | ✗ | ! | ✗ | ✗ | ✗ | ✗ | ✗ | Sample |
| Halle-Switch [40] | ✗ | ! | ✗ | ✗ | ✗ | ✗ | ✗ | Sample |
| AMBER [33] | ! | ! | ! | ! | ! | ✗ | ✗ | Manual |
| Hallu-PI (ours) | ! | ! | ! | ! | ! | ! | ! | Manual |
In summary, the contributions of our work are as follows:
- · We construct Hallu-PI, the first freely available multi-modal hallucination benchmark with perturbed inputs. Hallu-PI encompasses 7 perturbed scenarios, a total of 1,260 images, and 11 distinct object categories to evaluate hallucinations in MLLMs across both generative and discriminative tasks.
- · We conduct extensive experiments with Hallu-PI to evaluate multi-modal hallucinations in 12 state-of-the-art MLLMs under perturbed inputs. The results unveil the limitations of MLLMs when dealing with perturbed inputs, as well as their specific bias towards certain types of hallucinations.
- · To mitigate the hallucinations of MLLMs on Hallu-PI, we introduce two baselines: Perturbed-Reminder and PerturbedICL. Experimental results on GPT-4V indicate that our methods are effective and can reduce the model's hallucinations in response to perturbed inputs to a certain extent.
## 2 Related Work
## 2.1 Multimodal Large Language Models
Multi-modal Large Language Models (MLLMs) are currently achieving significant improvements by combining the advanced capabilities of Large Language Models (LLMs) with visual processing [1, 2, 10, 23, 31]. These MLLMs show great potential in a variety of applications, such as visual question answering (VQA) [12], image captioning [28], and video understanding [21]. Representative MLLMs, such as CogVLM [35], LLaVA1.5 [26], InternLMXComposer [41], MiniGPT-4 [5], mPLUG-Owl2 [38], Qwen-VL [3], and the latest GPT-4V [1], and Google Gemini-Pro Vision [31], have achieved impressive performance across various multi-modal tasks.
## 2.2 Hallucination in MLLMs
While MLLMs have exhibited excellent performance on multimodal tasks, we are still facing the challenge that MLLMs often generate content unfaithful to the given images, which is called "hallucination" [6, 20, 22, 25, 32].
Currently, many researchers focus on evaluating the hallucination in MLLMs. LURE [42] and HallE-Switch [40] rely on human evaluations or GPT-4. While this method is relatively reliable, it is also expensive. HaELM [34] and FDPO [16] are based on hallucinatory detection models. However, the performance of these models is highly dependent on hallucinatory data and incurs substantial training costs. POPE [24] is based on object detection but is only applicable to discriminative tasks and evaluates existence-type hallucinations. Recently, [33] introduce AMBER, which assesses hallucinations across multiple dimensions, such as existence, attribute, and relation. Despite these efforts, they do not explore hallucinations in the perturbed scenarios commonly encountered in real-life situations. To bridge this gap, we propose Hallu-PI, the first benchmark designed to evaluate the hallucination of MLLMs with perturbed inputs. Table. 1 presents a detailed comparison between Hallu-PI and other hallucination benchmarks.
## 2.3 Image Perturbation
To simulate real-world perturbation scenarios, previous works adopt various perturbation strategies such as ImageNet-C [17] and Stylize-ImageNet [13, 29, 30]. The perturbations are grouped into five primary categories: noise, blur, weather, digital, and stylize. Specifically, these can be further subdivided into the following 17 image perturbation techniques: (1) Noise: Adding noise to the images, such as gaussian noise, shot noise, impulse noise, and speckle noise. (2) Blur: Blurring the images, including defocus blur, frosted glass blur, motion blur, and zoom blur. (3) Weather: Adding environmental effects such as snow, frost, fog, and brightness adjustments. (4) Digital: Manipulating images through contrast enhancement, elastic transformation, pixelation, and JPEG compression. and (5) Stylize: Applying artistic styles and transformations to images.
Compared to existing benchmarks that only consider hallucination assessment in unperturbed scenarios, Hallu-PI further takes into account perturbations that frequently occur in real-world applications. Therefore, it serves as a complement to existing benchmarks and provides a more comprehensive and accurate evaluation of hallucinations in MLLMs.
## 3 Hallu-PI Benchmark
In this section, we introduce the process of constructing our HalluPI benchmark which primarily encompasses three aspects: (1) Image Collection, (2) Image Perturbation and Annotation, and (3) Designing Prompt Query Templates.
## 3.1 Image Collection
To ensure the diversity of the dataset, we identify 11 different object types and require annotators to collect images for each category. In the image selection process, we primarily consider (1) image copyright and (2) image quality. We provide annotators with several websites offering free copyright images and instruct them to search for images using specific object keywords. Annotators are asked to select images where the object is complete and the image is of high quality for downloading.
Figure 3: (a) Overview of Hallu-PI pipeline for image annotation and perturbation. (b) An illustration of evaluation pipeline of Hallu-PI, including both generative and discriminative tasks.
## 3.2 Image Perturbation and Annotation
Following previous work [30], we first consider four primary types of perturbation: noise, blur, weather, and digital. Stylize is not included because the stylized images are too blurred to recognize the objects and attributes within them. To construct a more comprehensive set of perturbation scenarios, we meticulously propose three additional perturbations: image concatenation, image cropping, and prompt misleading. The first two are considered because they are commonly used by users in real life to edit their images, while prompt misleading ensures that Hallu-PI can evaluate hallucinations at both the image level and the prompt level.
For noise, blur, weather, and digital perturbations, we reuse the code from [30] to generate the perturbed images. For image concatenation, we require our well-trained annotators to combine every four individual images previously collected into a single four-grid image, ensuring that the objects in the concatenated image are complete. For image cropping, we primarily focus on images containing English letters. Annotators are instructed to crop these images and provide corresponding questions and answers for both the original and cropped images. For prompt misleading, annotators need to select an image and provide a prompt that could potentially induce hallucinations. Figure. 1 provide some examples of these perturbations. Annotators are required to provide detailed annotations for perturbed images. These annotations include Existence, Number, Color, Relation, and Hal-object, as shown in Figure. 3.
In Figure. 4, we present the distribution of perturbation types and the distribution of object categories included in Hallu-PI.
Noise
Blur
Weather
Digital
Concat
Crop
Mislead
Figure 4: The data distribution of Hallu-PI.
## 3.3 Designing Prompt Query Templates
To ensure a more comprehensive evaluation of hallucinations, we design both generative and discriminative prompt templates for each perturbation scenario. For the perturbations such as noise, blur, weather, digital, and image concatenation, we pose questions regarding each specific annotation field. For instance, for the image concatenation perturbation, the generative prompt for the "Existence" field before perturbation is: "Please describe the existing objects in the image." After perturbation, the prompt becomes: "Please describe the existing objects in the top-left image." with " existing objects " and " top-left " being flexible and variable. For the design of discriminative prompts, we consider that merely calculating accuracy might be insufficient. Following previous work [12], we design
Table 2: The results under noise, blur, weather, and digital perturbations. Before/After means before/after perturbation.
| | | | After | After | After | After | After | After | After | After |
|-------------|--------|---------|---------|---------|---------|---------|---------|---------|---------|---------|
| Model | Before | Before | Noise | Noise | Blur | Blur | Weather | Weather | Digital | Digital |
| | ACC+ ↑ | CHAIR ↓ | ACC+ ↑ | CHAIR ↓ | ACC+ ↑ | CHAIR ↓ | ACC+ ↑ | CHAIR ↓ | ACC+ ↑ | CHAIR ↓ |
| CogVLM | 49.0 | 62.0 | 48.5 | 68.2 | 47.4 | 68.6 | 42.8 | 67.9 | 48.4 | 69.8 |
| Multi-GPT | 13.3 | 73.5 | 9.6 | 73.6 | 12.8 | 76.1 | 11.2 | 73.4 | 9.2 | 77.8 |
| LLaVA | 6.3 | 68.5 | 4.33 | 67.7 | 5.0 | 70.6 | 4.17 | 69.8 | 3.6 | 74.2 |
| LLaVA1.5 | 43.0 | 68.9 | 42.6 | 70.1 | 42.4 | 68.7 | 43.3 | 68.0 | 36.8 | 74.5 |
| MiniGPT-4 | 16.0 | 72.4 | 15.8 | 70.2 | 15.9 | 72.1 | 14.5 | 72.6 | 13.8 | 73.9 |
| MiniGPT4-v2 | 28.3 | 72.1 | 26.7 | 74.7 | 28.8 | 74.0 | 28.2 | 72.8 | 27.1 | 74.9 |
| mPLUG2 | 38.0 | 65.0 | 33.3 | 67.6 | 33.1 | 69.1 | 35.3 | 66.9 | 32.3 | 73.6 |
| Gemini | 46.0 | 57.3 | 44.2 | 60.0 | 45.1 | 59.7 | 44.8 | 58.5 | 37.5 | 61.3 |
| GPT-4V | 47.3 | 66.1 | 42.3 | 66.9 | 41.8 | 68.4 | 47.8 | 60.9 | 34.0 | 65.4 |
Table 3: The results under image concatenation, image cropping, and prompt misleading perturbations.
| PI-Score ↑ | PI-Score ↑ | PI-Score ↑ | PI-Score ↑ | PI-Score ↑ | PI-Score ↑ | PI-Score ↑ |
|--------------|--------------|--------------|--------------|--------------|----------------|----------------|
| | Concat | Concat | Cropping | Cropping | Prompt Mislead | Prompt Mislead |
| MLLMs | Before | After | Before | After | Before | After |
| CogVLM | 45.4 | 22.5 | 10.0 | 5.0 | 39.6 | 11.4 |
| Multi-GPT | 8.3 | 15.0 | 11.7 | 0.0 | 18.9 | 7.2 |
| LLaVA | 6.5 | 2.2 | 3.4 | 6.7 | 14.4 | 5.2 |
| LLaVA1.5 | 32.4 | 5.9 | 10.0 | 8.4 | 26.4 | 8.1 |
| MiniGPT-4 | 8.9 | 5.9 | 10.0 | 8.4 | 18.5 | 7.0 |
| MiniGPT-v2 | 15.8 | 12.3 | 16.7 | 15.0 | 26.4 | 11.3 |
| mPLUG2 | 25.7 | 18.9 | 10.0 | 8.3 | 29.7 | 15.7 |
| InternLM | 38.3 | 37.3 | 8.3 | 10.0 | 34.4 | 28.0 |
| Qwen-VL | 46.3 | 19.6 | 20.0 | 11.7 | 53.2 | 38.2 |
| VisualGLM | 6.8 | 0.6 | 34.0 | 0.0 | 21.2 | 11.3 |
| Gemini | 44.6 | 21.4 | 45.0 | 26.7 | 59.2 | 39.4 |
| GPT-4V | 42.0 | 18.0 | 43.4 | 30.0 | 61.4 | 48.2 |
Yes\_Q and No\_Q, representing questions with the single-word answers "Yes" or "No," respectively. This allows for the calculation of Acc+, which further enhances the accuracy of hallucination assessment, as shown in Figure. 3.
For the image cropping and prompt misleading perturbations, the generative and discriminative prompts are meticulously designed by the annotators and reviewed by two experts. We present the detailed prompt templates in the supplementary materials.
## 4 Experiments
In this section, we conduct extensive experiments to evaluate the performance of different state-of-the-art MLLMs on our Hallu-PI benchmark. We introduce the primary setup of our experiments, including baseline models (Sec. 4.1), response processing (Sec. 4.2), and evaluation metrics (Sec. 4.3).
## 4.1 Baseline Models
We select multiple mainstream state-of-the-art MLLMs for evaluation, including GPT-4V [1], Google Gemini-Pro Vision [31], InternLMXComposer-VL [41], QWen-VL-Chat [3], VisualGLM [11], mPLUGOwl-2 [38], MininGPT4-v2 [5], MiniGPT-4 [43], LLaVA1.5 [26],
LLaVA [27], CogVLM [35], and MultimodalGPT [14]). All models have been fine-tuned on their instruction tuning datasets. To ensure optimal performance, we use the hyper-parameters provided in the official code repositories of the models to generate responses. More details about these MLLMs are in supplementary materials.
## 4.2 Response Processing
The input for Hallu-PI is defined as: 𝐼𝑛𝑝𝑢𝑡 = { 𝐼𝑚𝑔, 𝐼𝑛𝑠 } , where 𝐼𝑚𝑔 represents the image, and 𝐼𝑛𝑠 refers to the prompt. As shown in Figure 3, we obtain an initial response 𝑅𝑒𝑠 by inputting 𝐼𝑛𝑝𝑢𝑡 into a specific MLLM and extracting key elements for computing metrics.
For the generative task, we use the natural language toolkit (NLTK) [4] as an answer extractor to obtain the initial prediction's result 𝑅 ′ 𝑜𝑏𝑗 = { 𝑅 , 𝑅 1 2 , ..., 𝑅 𝑛 } . Then, we construct an objects list 𝑋 𝑜𝑏𝑗 = { 𝑋 , 𝑋 1 2 , ..., 𝑋 𝑛 } consisting of all annotated objects in HalluPI. 𝑋 𝑜𝑏𝑗 is used to filter out unnecessary objects in 𝑅 ′ 𝑜𝑏𝑗 such as "picture," "distance," and "side." Finally, we obtain the final objects 𝑅 𝑜𝑏𝑗 by using 𝑅 𝑜𝑏𝑗 = 𝑅 ′ 𝑜𝑏𝑗 ∩ 𝑋 𝑜𝑏𝑗 .
For the discriminative task, owing to our prompt template design, "Please answer with 'Yes' or 'No'," we can easily perform quantitative statistics based on the "Yes" or "No" responses included in the MLLM outputs, which is both accurate and objective.
## 4.3 Evaluation Metrics
We first introduce the metrics used for generative task and discriminative task. Then, we present our proposed PI-Score metric, which is a comprehensive metric for evaluating both tasks.
4.3.1 Metrics on Generative Task.
CHAIR . CHAIRevaluates the frequency of hallucinatory objects appearing in the responses, which is the most commonly used metric for evaluating hallucinations in MLLMs on generative tasks. With a provided annotated ground truth list 𝐴 𝑜𝑏𝑗 = { 𝐴 , 𝐴 , ..., 𝐴 1 2 𝑛 } , the calculation formula is as follows:
$$\text{CHAIR} ( R e s ) = 1 - \frac { l e n ( R _ { o b j } \cap A _ { o b j } ) } { l e n ( R _ { o b j } ) } \quad \quad ( 1 )$$
Cover . Cover quantifies the degree of correspondence between responses and the image description. Precisely, its value indicates the coverage of objects mentioned in response 𝑅 𝑜𝑏𝑗 relative to
Table 4: The results of generative task on image concatenation, cropping, and prompt misleading.
| | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Cropping | Image Cropping | Prompt Misleading | Prompt Misleading |
|------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|------------------|------------------|---------------------|---------------------|
| MLLMs | CHAIR ↓ | CHAIR ↓ | Cover ↑ | Cover ↑ | Hal ↓ | Hal ↓ | Cog ↓ | Cog ↓ | Hal ↓ | Hal ↓ | Hal ↓ | Hal ↓ |
| | Before | After | Before | After | Before | After | Before | After | Before | After | Before | After |
| CogVLM | 62.0 | 69.0 | 55.3 | 48.3 | 58.3 | 97.1 | 4.3 | 5.9 | 80.0 | 90.0 | 36.7 | 93.3 |
| Multi-GPT | 73.5 | 97.5 | 22.5 | 2.0 | 96.7 | 86.3 | 30.8 | 77.1 | 76.7 | 100.0 | 63.3 | 93.3 |
| LLaVA | 68.5 | 92.3 | 38.8 | 7.4 | 93.3 | 96.7 | 4.3 | 14.9 | 93.3 | 86.7 | 66.7 | 93.3 |
| LLaVA1.5 | 68.9 | 76.1 | 43.8 | 25.0 | 78.3 | 96.3 | 3.4 | 5.7 | 86.7 | 90.0 | 63.3 | 90.0 |
| MiniGPT-4 | 72.4 | 89.3 | 46.5 | 24.8 | 98.3 | 95.8 | 5.1 | 8.2 | 80.0 | 83.3 | 63.3 | 93.3 |
| MiniGPT-v2 | 72.1 | 88.9 | 49.6 | 32.5 | 100.0 | 96.7 | 4.0 | 7.1 | 93.3 | 93.3 | 53.3 | 93.3 |
| mPLUG2 | 65.0 | 82.3 | 44.6 | 14.3 | 86.7 | 89.6 | 6.2 | 6.4 | 93.3 | 96.7 | 46.7 | 80.0 |
| InternLM | 58.4 | 79.2 | 16.3 | 9.5 | 71.7 | 62.5 | 18.8 | 16.7 | 86.7 | 86.7 | 43.3 | 63.3 |
| Qwen-VL | 58.2 | 56.3 | 35.8 | 32.3 | 46.7 | 79.2 | 9.8 | 11.1 | 83.3 | 93.3 | 6.7 | 16.7 |
| VisualGLM | 76.9 | 89.1 | 45.0 | 29.6 | 100.0 | 99.2 | 4.4 | 9.2 | 93.3 | 100.0 | 46.7 | 66.7 |
| Gemini | 57.3 | 63.4 | 50.2 | 43.7 | 56.7 | 90.8 | 3.6 | 4.5 | 26.7 | 56.7 | 12.1 | 30.0 |
| GPT-4V | 66.1 | 63.6 | 66.6 | 53.6 | 63.3 | 98.3 | 1.6 | 1.9 | 33.3 | 73.3 | 1.1 | 3.3 |
manually annotated objects 𝐴 𝑜𝑏𝑗 :
## 5 Results
$$\text{Cover} ( R e s ) = \frac { l e n ( R _ { o b j } \cap A _ { o b j } ) } { l e n ( A _ { o b j } ) } \quad \quad ( 2 ) \quad \text{in} _ { \text{ac} } \quad \text{ac}$$
Hal . Hal represents the proportion of responses with hallucinations. For a MLLM's response 𝑅𝑒𝑠 , if its CHAIR ( 𝑅𝑒𝑠 ) ≠ 0, then 𝑅𝑒𝑠 is considered to contain hallucinations:
$$\text{Hal} ( R e s ) = \begin{cases} 1, & \text{if} \ \text{CHAIR} ( R e s ) \neq 0 \\ 0, & \text{if} \ \text{CHAIR} ( R e s ) = 0 \end{cases} \quad ( 3 ) \quad \text{Fab}$$
Cog . Cog aims to measure the ratio between hallucinations produced by MLLMs and those annotated by humans. Similar to [31], we use the hallucinatory target list 𝐻 𝑜𝑏𝑗 = { 𝐻 , 𝐻 1 2 , ..., 𝐻 𝑛 } (corresponding to Hal-object in Figure. 3) to calculate Cog:
$$\text{Cog} ( R e s ) = \frac { l e n ( R _ { o b j } \cap H _ { o b j } ) } { l e n ( R _ { o b j } ) } \quad \quad ( 4 ) \quad \text{Oi}$$
4.3.2 Metrics on Discriminative Task.
Accuracy/Precision/Recall/F1 Score . The outputs of discriminative tasks are constrained to "Yes" or "No", making it straightforward to compute standard metrics such as Accuracy, Precision, Recall, and F1 Score.
Accuracy+ . Following previous work [12], to avoid bias in MLLMs' responses to "Yes" and "No" and to prevent inaccuracies from random guessing, we calculate Accuracy+ in addition to Accuracy. As described in Sec. 3.3, the model is considered to be right only if it correctly responds to both the "Yes" and "No" questions.
4.3.3 Metrics on Both Generative and Discriminative Task.
PI-Score . To comprehensively evaluate the performance of various MLLMs under both generative and discriminative tasks within perturbed inputs, we introduce the PI-Score to combine the Hal in generative task and the Accuracy+ in discriminative task. We use 𝛼 as a dynamic weight to balance the importance between generative and discriminative tasks ( 𝛼 = 0 5 in our experiments): .
$$\text{PI-Score} = A v g ( \alpha ( 1 - H \text{al} ), ( 1 - \alpha ) \text{Accuarcy} + ) \quad ( 5 ) \quad \text{high}$$
In this section, we first report the overall hallucinations of MLLMs across all perturbation scenarios in Hallu-PI. Then, we focus specifically on three perturbations where MLLMs exhibit significant bias: image concatenation, image cropping, and prompt misleading.
## 5.1 Overall Results
Table. 2 and Table. 3 demonstrate that all MLLMs show decreased performance under the seven perturbations, with lower ACC+ , higher CHAIR and lower PI-Score indicating increased hallucinations. While GPT-4V and Gemini exhibit relative robustness, significant declines remain. Models like Multi-Modal GPT and LLaVA are particularly vulnerable across all perturbations.
## 5.2 Uncovering of Hallucination Bias
Our experiments reveal that MLLMs exhibit more severe hallucinations in image concatenation image cropping , , and prompt misleading perturbation scenarios. Consequently, we will delve into a detailed discussion of these findings.
Generative Task Results . Table. 4 reveals that MLLMs frequently generate increased hallucinatory content under image concatenation, cropping, and prompt misleading perturbations. Most models show higher CHAIR scores, notably LLaVA rising from 68.5 to 92.3 under concatenation. Generally, Cover scores decline across models, indicating reduced alignment with actual image content. Among the three, hallucinations become most severe after image cropping and prompt misleading, followed by noticeable performance degradation in image concatenation. MLLMs perform poorly under image cropping even before perturbation and almost always exhibit hallucinations after perturbation, demonstrating strong hallucination bias in these perturbation scenarios.
Discriminative Task Results . Table 5 highlights the model performance on discriminative tasks under image concatenation, cropping, and prompt misleading perturbations. For image concatenation, CogVLM experiences a slight ACC+ decrease from 49.0 to 42.0, while LLaVA1.5 drops drastically from 43.0 to 8.0, indicating high sensitivity. For image cropping, most models, including LLaVA,
Table 5: The results of discriminative task on image concatenation, cropping, and prompt misleading.
| | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Concatenation | Image Cropping | Image Cropping | Image Cropping | Image Cropping | Image Cropping | Image Cropping | Prompt Misleading | Prompt Misleading | Prompt Misleading | Prompt Misleading |
|------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|------------------|------------------|------------------|------------------|------------------|------------------|---------------------|---------------------|---------------------|---------------------|
| MLLMs | ACC ↑ | Before ACC+ ↑ | F1 ↑ | ACC ↑ | After ACC+ ↑ | F1 ↑ | ACC ↑ | Before ACC+ ↑ | F1 ↑ | ACC ↑ | After ACC+ ↑ | F1 ↑ | ACC ↑ | After ACC+ ↑ | F1 ↑ |
| CogVLM | 69.9 | 49.0 | 74.4 | 67.2 | 42.0 | 73.1 | 50.0 | 0.0 | 66.7 | 50.0 | 0.0 | 66.7 | 56.7 | 33.3 | 51.9 |
| Multi-GPT | 46.8 | 13.3 | 52.4 | 41.8 | 16.3 | 48.9 | 48.3 | 0.0 | 65.2 | 45.0 | 0.0 | 62.1 | 28.3 | 6.7 | 41.1 |
| LLava | 51.5 | 6.3 | 57.2 | 50.3 | 1.0 | 54.0 | 50.0 | 0.0 | 66.7 | 50.0 | 0.0 | 66.7 | 1.7 | 0.0 | 3.2 |
| LLava1.5 | 70.5 | 43.0 | 76.1 | 51.7 | 8.0 | 61.7 | 51.7 | 6.7 | 56.7 | 48.3 | 6.7 | 45.6 | 40.0 | 3.3 | 5.2 |
| MiniGPT-4 | 43.0 | 16.0 | 47.6 | 30.2 | 7.7 | 25.4 | 38.3 | 0.0 | 55.4 | 30.0 | 0.0 | 46.2 | 20.0 | 0.0 | 33.4 |
| MiniGPT-v2 | 55.8 | 28.3 | 56.4 | 48.2 | 21.3 | 41.3 | 55.0 | 26.7 | 62.0 | 48.3 | 23.3 | 47.5 | 88.3 | 80.0 | 88.8 |
| mPLUG2 | 62.3 | 38.0 | 68.3 | 51.5 | 27.3 | 54.5 | 50.0 | 13.3 | 62.5 | 48.3 | 13.3 | 59.7 | 43.3 | 13.3 | 34.6 |
| InternLM | 68.2 | 48.3 | 70.8 | 61.2 | 37.0 | 55.9 | 50.0 | 3.3 | 60.5 | 51.7 | 6.7 | 61.3 | 75.0 | 50.0 | 68.1 |
| Qwen-VL | 62.5 | 39.3 | 62.0 | 55.7 | 18.3 | 52.4 | 58.3 | 23.3 | 65.7 | 48.3 | 16.7 | 53.7 | 93.3 | 86.7 | 92.9 |
| VisualGLM | 46.3 | 5.3 | 50.9 | 43.3 | 0.3 | 45.0 | 50.0 | 0.0 | 66.7 | 50.0 | 0.0 | 66.7 | 30.0 | 13.3 | 36.3 |
| Gemini | 65.7 | 46.0 | 64.1 | 60.0 | 33.7 | 63.2 | 56.7 | 16.7 | 67.5 | 53.3 | 10.0 | 66.7 | 53.3 | 13.3 | 33.3 |
| GPT-4V | 66.7 | 47.3 | 66.1 | 59.8 | 34.3 | 55.8 | 61.7 | 33.3 | 66.7 | 53.3 | 20.0 | 62.5 | 95.0 | 90.0 | 94.7 |
Figure 5: The performance variation (before and after image concatenation) in five annotated attributes.
MiniGPT-4, and mPLUG2, exhibit random guessing ACC (around 50.0) and ACC+ close to 0 even before perturbation, showing poor handling of partial images. Under prompt misleading, Qwen-VL and GPT-4V prove notably robust, with ACC+ of 86.7 and 90.0, respectively, and F1 scores above 90, while LLaVA1.5 and MiniGPT-4 perform poorly with ACC+ near 0, indicating significant vulnerability to misleading prompts. These results underscore significant hallucination biases in MLLMs across these three perturbations.
is most significant (e.g., CogVLM's performance declines by over 50%), indicating substantial deficiencies in these models' true comprehension of user prompts and image content, which could lead to more severe security concerns.
## 5.3 Experimental Analysis
Analysis of perturbation scenarios . The PI-Score results presented in Table. 3 reveal that under the three constructed scenarios, the performance of most MLLMs experiences a decline when the inputs are perturbed. Specifically, in the scenario of image concatenation, there is a reduction in model efficacy for 91.7% (11 out of 12). For image cropping, this figure stands at 83.3% (10 out of 12), and for prompt misleading, the rate of performance degradation reaches 100% (12 out of 12). Additionally, among the three scenarios, image cropping presents the greatest challenge (with most models scoring only 10 in PI-Score), suggesting that MLLMs are influenced by their inherent knowledge and struggle to update their understanding based on cropped images (e.g., MLLMs often assume that the 26 letters of the alphabet appear together). Prompt misleading is the scenario where the performance drop before and after perturbation
Analysis of specific attribute performance . Figure. 5 illustrates the performance change of MLLMs on each annotated attribute before and after perturbation in the image concatenation scenario. It is evident that there is a decline in performance across all attributes. Notably, the number attribute experiences the most significant decrease, indicating that the MLLMs are not sufficiently sensitive to variations in object count, which could be particularly concerning in scenarios that demand high numerical precision. Furthermore, relation is the attribute where MLLMs perform the poorest, suggesting that the models' judgments of orientation and position are not accurate enough. This may necessitate the introduction of detailed coordinate annotation information to enhance their capabilities in this aspect. See supplementary material for further analysis.
## 5.4 How to Mitigate Hallucinations Induced by Hallu-PI?
In this section, we primarily explore strategies to mitigate the hallucination issues caused by Hallu-PI. We posit that hallucinations in MLLMs also constitute a safety concern, which could lead to severe hazards in specific contexts, such as autonomous driving [19].
Figure 6: We explore two baselines for Hallu-PI: (a) Perturbed-Reminder, which increases the focus of MLLMs on the image content itself by injecting a perturbation reminder into the prompt. (b) Perturbed-ICL, which guides the model to respond correctly when faced with the actual user inputs by adding perturbed demonstrations to the context.

Table 6: The results of Perturbed-ICL and Perturbed-Reminder on GPT-4V. w/o represents without baseline improvement.
| | Noise | Noise | Blur | Blur | Weather | Weather | Digital | Digital | Concat | Concat | Crop | Crop | Mislead | Mislead |
|----------|---------|---------|--------|--------|-----------|-----------|-----------|-----------|----------|----------|--------|--------|-----------|-----------|
| | ACC+ ↑ | Hal ↓ | ACC+ ↑ | Hal ↓ | ACC+ ↑ | Hal ↓ | ACC+ ↑ | Hal ↓ | ACC+ ↑ | Hal ↓ | ACC+ ↑ | Hal ↓ | ACC+ ↑ | Hal ↓ |
| w/o | 42.3 | 54.2 | 41.8 | 54.6 | 40.1 | 56.7 | 34.0 | 61.7 | 34.3 | 98.3 | 20.0 | 73.3 | 90.0 | 3.3 |
| ICL | 47.6 | 54.2 | 47.8 | 56.2 | 48.2 | 57.5 | 44.5 | 59.6 | 43.0 | 65.0 | 30.0 | 67.0 | 93.3 | 0.0 |
| Reminder | 49.0 | 51.2 | 49.3 | 46.7 | 50.5 | 49.6 | 42.2 | 54.6 | 46.0 | 40.0 | 36.6 | 70.0 | 96.6 | 1.1 |
Therefore, drawing inspiration from works on jailbreaking and securing text LLMs [8, 36], we design two specific baselines for perturbed scenarios, namely Perturbed-Reminder and Perturbed-ICL, which we detail in the subsequent sections.
informing MLLMs of input perturbations) when faced with actual user inputs, thereby mitigating the effects of these perturbations.
Perturbed-Reminder . Previous works have demonstrated that appending a specific safety-reminder prompt [36] to the prefix of user requests can effectively defend against jailbreak attacks targeting text LLMs. This is because such safety reminders cause the model to pay closer attention to specific parts of the user input, thereby more accurately filtering out harmful requests [8]. Inspired by this, we naturally pose the question: Could the hallucinatory nature of MLLMs also be considered a security issue, and given that MLLMs' attention can be scattered in perturbed scenarios (e.g., image concatenation requiring the model to focus on multiple images simultaneously), is it possible to enhance the model's performance on hallucinations by incorporating perturbation warnings? Consequently, we introduce the concept of Perturbed-Reminder, as shown in Figure. 6 (a), where we prepend a hallucination reminder to the user's prompt, thereby explicitly directing the model's focus and attention towards the images themselves.
Perturbed-ICL . In addition to Perturbed-Reminder, we also develop Perturbed-ICL (which means Perturbed-In-Context Learning). In-context learning [9] has been proven to enhance the capabilities of LLMs (such as reasoning abilities). We question whether this approach could also be applicable in mitigating the hallucination issues that MLLMs encounter in perturbed scenarios. Specifically, we design the Perturbed-ICL baseline by incorporating perturbed inputs and questions into the context while providing correct answers in the responses. (see Figure. 6 (b)). The objective is to determine if the model can learn from contextual demonstrations (explicitly
The results in Table 6 suggest that both Perturbed-Reminder and Perturbed-ICL baselines are effective to some extent in reducing hallucinations in GPT-4V under perturbed scenarios. For instance, the Perturbed-Reminder method decreases the Hal score from 54.6% to 46.7% in the Blur scenario. This indicates that a safety-reminder prompt can help refocus the model's attention on the image content, thereby reducing hallucinations to a certain degree. Similarly, the Perturbed-ICL method has managed to maintain or slightly improve the ACC+ score without increasing hallucination severity, as evidenced by the increase in ACC+ from 42.3% to 47.6% in the Noise scenario. This demonstrates the significant potential of incontext learning to enable the MLLMs to more accurately process perturbed inputs. Despite these methods showing effectiveness, results in Table. 6 indicate that mitigating hallucinations in MLLMs within perturbed inputs remains a persistent and challenging issue.
## 6 Conclusion
In this paper, we introduce Hallu-PI, the first benchmark designed to evaluate hallucination in MLLMs within perturbed inputs. HalluPI consists of seven perturbed scenarios, containing 1,260 perturbed images from 11 object types. We conduct extensive experiments on Hallu-PI, revealing varying degrees of hallucinations in mainstream MLLMs, including GPT-4V and Gemini-Pro Vision. Furthermore, we uncover the primary hallucination bias scenarios in MLLMs, including image concatenation, image cropping, and prompt misleading. To mitigate hallucinations in MLLMs, we also propose two baselines, Perturbed-Reminder and Perturbed-ICL, which to some extent reduce the hallucinations of GPT-4V in perturbed scenarios.
## Acknowledgments
Wewouldlike to thank the anonymous reviewers for their insightful comments. Shujian Huang is the corresponding author. This work is supported by National Science Foundation of China(No. 62376116, 62176120).
## References
- [1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- [2] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. 2022. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems 35 (2022), 23716-23736.
- [3] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A frontier large visionlanguage model with versatile abilities. arXiv preprint arXiv:2308.12966 (2023).
- [4] Steven Bird, Ewan Klein, and Edward Loper. 2009. Natural language processing with Python: analyzing text with the natural language toolkit . " O'Reilly Media, Inc.".
- [5] Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. 2023. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478 (2023).
- [6] Shuo Chen, Zhen Han, Bailan He, Zifeng Ding, Wenqian Yu, Philip Torr, Volker Tresp, and Jindong Gu. 2024. Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks? arXiv preprint arXiv:2404.03411 (2024).
- [7] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. 2020. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops . 702-703.
- [8] Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, and Shujian Huang. 2023. A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily. arXiv preprint arXiv:2311.08268 (2023).
- [9] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022. A survey on in-context learning. arXiv preprint arXiv:2301.00234 (2022).
- [10] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. 2023. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023).
- [11] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2021. Glm: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv:2103.10360 (2021).
- [12] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. 2023. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023).
- [13] Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. 2018. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv preprint arXiv:1811.12231 (2018).
- [14] Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. 2023. Multimodalgpt: A vision and language model for dialogue with humans. arXiv preprint arXiv:2305.04790 (2023).
- [15] Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. 2024. HallusionBench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 14375-14385.
- [16] Anisha Gunjal, Jihan Yin, and Erhan Bas. 2023. Detecting and preventing hallucinations in large vision language models. arXiv preprint arXiv:2308.06394 (2023).
- [17] Dan Hendrycks and Thomas Dietterich. 2019. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261 (2019).
- [18] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2023. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232 (2023).
- [19] Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2023. OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation. arXiv preprint arXiv:2311.17911 (2023).
- [20] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1-38.
- [21] Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. 2023. Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125 (2023).
- [22] Junyi Li, Jie Chen, Ruiyang Ren, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2024. The Dawn After the Dark: An Empirical Study on Factuality Hallucination in Large Language Models. arXiv preprint arXiv:2401.03205 (2024).
- [23] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023).
- [24] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355 (2023).
- [25] Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. 2023. Aligning Large Multi-Modal Model with Robust Instruction Tuning. arXiv preprint arXiv:2306.14565 (2023).
- [26] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023. Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744 (2023).
- [27] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. arXiv preprint arXiv:2304.08485 (2023).
- [28] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. 2023. Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281 (2023).
- [29] Claudio Michaelis, Benjamin Mitzkus, Robert Geirhos, Evgenia Rusak, Oliver Bringmann, Alexander S Ecker, Matthias Bethge, and Wieland Brendel. 2019. Benchmarking robustness in object detection: Autonomous driving when winter is coming. arXiv preprint arXiv:1907.07484 (2019).
- [30] Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, and Mu Li. 2023. Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift. Journal of Data-centric Machine Learning Research (2023).
- [31] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023).
- [32] Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal llms. arXiv preprint arXiv:2401.06209 (2024).
- [33] Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Ming Yan, Ji Zhang, and Jitao Sang. 2023. An llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397 (2023).
- [34] Junyang Wang, Yiyang Zhou, Guohai Xu, Pengcheng Shi, Chenlin Zhao, Haiyang Xu, Qinghao Ye, Ming Yan, Ji Zhang, Jihua Zhu, et al. 2023. Evaluation and analysis of hallucination in large vision-language models. arXiv preprint arXiv:2308.15126 (2023).
- [35] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. 2023. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079 (2023).
- [36] Fangzhao Wu, Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, and Xing Xie. 2023. Defending chatgpt against jailbreak attack via self-reminder. (2023).
- [37] Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. 2023. Cognitive mirage: A review of hallucinations in large language models. arXiv preprint arXiv:2309.06794 (2023).
- [38] Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. 2023. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. arXiv preprint arXiv:2311.04257 (2023).
- [39] Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. 2023. Woodpecker: Hallucination correction for multimodal large language models. arXiv preprint arXiv:2310.16045 (2023).
- [40] Bohan Zhai, Shijia Yang, Xiangchen Zhao, Chenfeng Xu, Sheng Shen, Dongdi Zhao, Kurt Keutzer, Manling Li, Tan Yan, and Xiangjun Fan. 2023. HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption. arXiv preprint arXiv:2310.01779 (2023).
- [41] Pan Zhang, Xiaoyi Dong Bin Wang, Yuhang Cao, Chao Xu, Linke Ouyang, Zhiyuan Zhao, Shuangrui Ding, Songyang Zhang, Haodong Duan, Hang Yan, et al. 2023. Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112
(2023).
- [42] Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Yao. 2023. Analyzing and mitigating object hallucination in large vision-language models. arXiv preprint arXiv:2310.00754 (2023).
- [43] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023).
## A More Details of Hallu-PI
Image Sources . We ask annotators to download images from the following websites, which offer high-quality images that are free to download, available for commercial use, and do not require any licensing fees. (1) https://www.pexels.com/zh-cn (2) https:// pixabay.com/zh/images/search (3) https://www.hippopx.com (4) https://stocksnap.io
Annotation for Image Cropping Scenario . For image cropping scenario, we primarily investigate the robustness in MLLMs ability to count the letters number within cropped images. Therefore, we have annotators collect images containing common English words, crop them, and annotate the number of English letters present before and after cropping. Subsequently, we obtain responses from MLLMs through the prompt, ' How many English letters are there in the image? "
Annotation for Prompt Misleading Scenario . For prompt misleading scenario, we ask annotators to manually craft prompts intended to induce MLLMs to generate content that does not align with the given images. For example, given an image containing only apples and bananas, a misleading prompt might be: ' Besides apples and bananas, there are two other types of fruit in the image. What are they? "


(a) Gaussian Noise
(b) Defocus Blur

(c) Fog Weather

(d) Pixelate Digital
Figure 7: Examples of images with noise, blur, weather, and digital perturbations.
Other Perturbation Examples . In Figure. 7, we provide four additional examples of perturbations in Hallu-PI, including noise, blur, weather, and digital.
PromptTemplates . In Figure. 10, we provide the prompt templates used in Hallu-PI.
Details about the MLLMs used in Hallu-PI . We provide a detailed introduction of the MLLMs evaluated by Hallu-PI in Table 9, including model parameters and architectures.
## B Experimental Details
## B.1 Perturbation Intensity Selection
Real-world perturbations can manifest themselves at varying intensities. In previous work [30], they designed five levels of severity for each perturbation scenario. Hallu-PI, however, focuses more on the specific perturbation itself rather than its intensity. Therefore, we randomly select an intensity level between 1 and 5 for noise, blur, weather, and digital perturbations. We will leave the discussion and analysis of different perturbation intensities for future work.
## B.2 Specific Perturbation Method Selection
As introduced in Section 3.2 of our paper, we follow [30] and reuse the four types of perturbation scenarios from their paper: noise, blur, weather, and digital. The specific algorithms for these perturbation scenarios are detailed in Section 2.3 (Related Work) of our paper. During our experiments, we chose the most representative perturbation algorithms for the Hallu-PI scenarios. Specifically, we select gaussian noise, defocus blur, fog weather perturbation, and pixelation for the digital perturbation. Similarly, we will further explore the impact of different perturbation algorithms on hallucination in MLLMs in future work.
## B.3 Improvement in Metrics Post-Perturbation
It is worth noting that some metrics in our paper exhibit a slight improvement post-perturbation compared to pre-perturbation. These are rare occurrences and usually appear in simple perturbation scenarios, as exemplified in Figure. 7, where the images undergo minimal changes after perturbation. However, for more complex perturbations such as image concatenation, image cropping, and prompt misleading, the metrics generally tend to deteriorate.
## C Additional Analysis
## C.1 Analysis of Cropping and Misleading
Figure 8 illustrates the comparative performance of MLLMs before and after image cropping. GPT-4V [1] and Google Gemini-Pro Vision [31] exhibit better performance compared to other models. However, all models, including GPT-4V and Gemini, exhibit a significant performance decline when evaluated on cropped images.
Figure 9 depicts the robustness of MLLMs under the prompt misleading scenario. A higher score indicates better robustness of the model. It is observed that GPT-4V, Qwen-VL-Chat [3], and Gemini exhibit higher robustness compared to other MLLMs. However, it is concerning that a greater number of models struggle to identify misleading prompts, which could lead to more severe hallucinations during multi-turn dialogues.
## C.2 Analysis of PI-Score
To validate the effectiveness of our proposed PI-Score, we sample 100 images from Hallusionbench [15] and calculate the PI-Score on 5 representative MLLMs (see Table. 7 left). We extend our findings to Hallusionbench and observe consistent results with those obtained on Hallu-PI, demonstrating the model's vulnerability in perturbed scenarios and the effectiveness of the PI-Score.
Figure 8: Performance of MLLMs before and after Cropping.
Scores (%)
Figure 9: The hallucination of MLLMs under the prompt misleading scenario, the smaller the score, the more severe the hallucination.
## C.3 Analysis of Additional Perturbation
To further enhance the generalizability of Hallu-PI, we add a common image augmentation perturbation, "shearing" [7] (see Table. 7 right), applied to a sample of 100 CIFAR-10 images. We observe that several representative MLLMs exhibit more severe hallucinations after the perturbation.
## C.4 Results Before Perturbation for Prompt Misleading
In our paper, we present the results of the prompt misleading discriminative task post-perturbation, aimed at revealing the severe hallucinations it induces. To better illustrate this effect, we also design pre-perturbation prompts (see Figure. 10). The experimental results are shown in Table. 8: LLaVA-1.5 experiences the most significant performance decline, while GPT-4V shows more robustness and achieves the highest scores. This, in combination with the results in Table 5 of our paper, more clearly demonstrates the hallucination biases of MLLMs in prompt misleading scenarios.
Table 7: PI-Score on Hallusionbench (left) and Top-1 error of 'shearing' perturbation (right).
| | Hallusionbench-PI score ↑ | Hallusionbench-PI score ↑ | Shearing-Top 1 error ↓ | Shearing-Top 1 error ↓ |
|-----------|-----------------------------|-----------------------------|--------------------------|--------------------------|
| Models | Before | After | Before | After |
| LLaVA | 29.0 | 18.0 | 13.0 | 25.0 |
| LLaVA-1.5 | 30.5 | 23.4 | 9.0 | 20.0 |
| Qwen-VL | 43.0 | 19.4 | 18.0 | 38.0 |
| Gemini | 37.5 | 18.6 | 12.0 | 33.0 |
| GPT-4V | 40.7 | 21.9 | 8.0 | 31.0 |
Table 8: The before and after results of prompt misleading.
| | Prompt Misleading | Prompt Misleading | Prompt Misleading | Prompt Misleading | Prompt Misleading | Prompt Misleading |
|-----------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|
| Models | Before | Before | Before | After | After | After |
| | ACC ↑ | ACC+ ↑ | F1 ↑ | ACC ↑ | ACC+ ↑ | F1 ↑ |
| LLaVA | 60.0 | 26.7 | 70.2 | 1.7 | 0.0 | 3.2 |
| LLaVA-1.5 | 98.3 | 96.7 | 98.3 | 40.0 | 3.3 | 5.2 |
| Qwen-VL | 96.7 | 93.3 | 96.8 | 93.3 | 86.7 | 92.9 |
| Gemini | 98.3 | 96.7 | 98.3 | 53.3 | 13.3 | 33.3 |
| GPT-4V | 98.3 | 96.7 | 98.3 | 95.0 | 90.0 | 94.7 |
Table 9: The architecture and parameters of MLLMs evaluated by Hallu-PI.
| MLLMs | Vision Encoder (VE) | Parameters of VE | Language Model (LM) | Parameters of LM | Source |
|--------------------------|-----------------------|--------------------|-----------------------|--------------------|---------------|
| CogVLM | EVA2-CLIP-E | 4.7B | Vicuna-v1.5 | 7B | Official Code |
| InternLM-Xcomposer-VL | EVA-CLIP-G | 1.1B | InternLM | 7B | Official Code |
| LLaVA | ViT-L/14 | 0.4B | LLaMA-2-Chat-13B | 13B | Official Code |
| LLaVA1.5 | ViT-L/14-336px | 0.4B | Vicuna-v1.5 | 7B | Official Code |
| MiniGPT-4 | BLIP2-Qformer | 1.9B | Vicuna-v0 | 7B | Official Code |
| MiniGPT-v2 | EVA-CLIP-G | 1.1B | LLaMA-2-Chat-7B | 7B | Official Code |
| mPLUG-Owl-2 | ViT-L/14 | 0.4B | LLaMA-2-Chat-7B | 7B | Official Code |
| MultimodalGPT | ViT-L/14 | 0.4B | LLaMA-13B | 13B | Official Code |
| Qwen-VL-Chat | ViT-G/14 | 1.9B | Qwen-7B | 7.7B | Official Code |
| VisualGLM | BLIP2-Qformer | 1.9B | ChatGLM-6B | 6B | Official Code |
| Google Gemini-Pro Vision | Unknown | Unknown | Gemini-Pro | Unknown | API |
| GPT-4V | Unknown | Unknown | GPT4 | Unknown | API |
| Perturbation | | | | | | | | | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task | Prompt Templates Discriminative Task |
|----------------|----------------------------------------------------------------------------|----------------------------------------------------------------------------|----------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Perturbation | Generative Task After Before | Generative Task After Before | Generative Task After Before | Generative Task After Before | Generative Task After Before | Generative Task After Before | Generative Task After Before | Generative Task After Before | Before exist | Before exist | Before exist | Before exist | Before exist | Before exist | Before exist | Before exist | Before exist | Before exist |
| Scenarios | exist | number | color | relation | exist | number | color | relation | exist | number | color | relation | hal- object | | number | After color | | relation |
| Noise | Please describle the exist objects in the image. | Please describe the number of the objects in the image. | Please describe the color of the objects in the image. | Please describe whether the objects in the image are in contact, and if they are, indicate which ones. | the same | as the | "Before" on | the left | Yes_Q: Is there elephant toy in the image? Please answer with yes or no. No_Q: Is there no elephant toy in the image? Please answer with yes or no. | Yes_Q: Is there elephant toy in the image? Please answer with yes or no. No_Q: Is there shawl in the image? Please answer with yes or no. a | Yes_Q: Is this lion toy brown in color? Please answer with yes or no. No_Q: Is this bear toy not brown in color? Please answer with yes or no. 1 2 | Yes_Q: Is there no contact between the bear toy and the shawl? No_Q: Is there contact between the bear toy and the shawl? | Yes_Q: Is there a cat in the image? Please answer with yes or no. No_Q: Is there no cat in the image? Please answer with yes or no. | | the same as | the | "Before" | on the |
| Concat | Please describle the exist objects in the image. | Please describe the number of the objects in the image. | Please describe the color of the objects in the image. | Please describe whether the objects in the image are in contact, and if they are, indicate which ones. | We concaten ate four imags together, Please describle the exist objects in the top-left image | We concaten ate four imags together, Please describe the number of the objects in the top-left image. | We concaten ate four imags together, Please describe the color of the objects in the top-left image. | We concaten ate four imags together, Please describe whether the objects in the top-left image are in contact, and if they are, indicate which ones. | Yes_Q: Is there elephant toy in the image? Please answer with yes or no. No_Q: Is there no elephant toy in the image? Please answer with yes or no. | Yes_Q: Is there elephant toy in image? Please answer with yes or no. No_Q: Is there shawl in the image? Please answer with yes or no. a | Yes_Q: Is this lion toy brown in color? Please answer with yes or no. No_Q: Is this bear toy not brown in color? Please answer with yes or no. 1 the 2 | Yes_Q: Is there no contact between the bear toy and the shawl? No_Q: Is there contact between the bear toy and the shawl? | Yes_Q: Is there a cat in the image? Please answer with yes or no. No_Q: Is there no cat in the image? Please answer with yes or no. | | Yes_Q: We concaten ate four imags together, Is there 1 elephant toy in the top-left image? Please answer with yes or no. No_Q: We concaten ate four imags together, Is there 2 shawl in the top- left image? Please answer with yes or no. Yes_Q: concaten four together, there a elephant the top-left image? Please answer yes No_Q: concaten four together, there elephant the top-left image? Please answer yes answer in | Yes_Q: We concaten ate four imags together, Is this lion toy brown color in the top- left image? Please answer with yes or no. No_Q: We concaten ate four imags together, Is this bear toy not brown color? Please answer with yes or no. | ate Is no the toy the ate Is the toy the in in | Yes_Q: We concaten four imags together, there contact between bear and shawl? No_Q: We concaten four imags together, there contact between bear and shawl? |
| Crop | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please answer in English. How many English letters are there in the image? | Please Yes_Q: Please answer in English. Are there 26 English letters in the image? No_Q: Please answer in English. Are there 25 English | Please Yes_Q: Please answer in English. Are there 26 English letters in the image? No_Q: Please answer in English. Are there 25 English | Please Yes_Q: Please answer in English. Are there 26 English letters in the image? No_Q: Please answer in English. Are there 25 English | Please Yes_Q: Please answer in English. Are there 26 English letters in the image? No_Q: Please answer in English. Are there 25 English | Please Yes_Q: Please answer in English. Are there 26 English letters in the image? No_Q: Please answer in English. Are there 25 English | Yes_Q: Please English. Are there 10 English letters in the image? No_Q: | Yes_Q: Please English. Are there 10 English letters in the image? No_Q: | Yes_Q: Please English. Are there 10 English letters in the image? No_Q: | Yes_Q: Please English. Are there 10 English letters in the image? No_Q: | Yes_Q: Please English. Are there 10 English letters in the image? No_Q: |
| Mislead | Please describle the exist objects in the image. | Please describle the exist objects in the image. | Please describle the exist objects in the image. | Please describle the exist objects in the image. | Please answer in English. In addition to the dog, what are the other two animals | present in | the image? | Please answer in English. In addition to the dog, what are the other two animals | Yes_Q: Are all the animals in this image dogs? Please answer with "Yes" or "No". No_Q: | Yes_Q: Are all the animals in this image dogs? Please answer with "Yes" or "No". No_Q: | Yes_Q: Are all the animals in this image dogs? Please answer with "Yes" or "No". No_Q: | Yes_Q: Are all the animals in this image dogs? Please answer with "Yes" or "No". No_Q: | Yes_Q: Are all the animals in this image dogs? Please answer with "Yes" or "No". No_Q: | Yes_Q: Please answer in English. In the image, besides the plant, are there three types of fruits? No_Q: | Yes_Q: Please answer in English. In the image, besides the plant, are there three types of fruits? No_Q: | Yes_Q: Please answer in English. In the image, besides the plant, are there three types of fruits? No_Q: | Yes_Q: Please answer in English. In the image, besides the plant, are there three types of fruits? No_Q: | Yes_Q: Please answer in English. In the image, besides the plant, are there three types of fruits? No_Q: |
Figure 10: The prompt templates used in Hallu-PI include those for generative task and discriminative task, as well as prompts before and after perturbations.
- How many zebras are there in the image?
- There are five zebras in the image
- How many zebras are there in the top-left of the image?
- There are seven zebras in the top-left of the image
- There are English letters in the image, spelling out the word 'MEDITATE'
- English letters the image, spelling out the word 'MEDITATE'


(a) Image Concatenation

## (b) Image Cropping
- In the bushes of the image, besides the cheetah; there are two other types of animals. What are they?
- The two other animals in the bushes appear to be impalas. Impalas are antelopes native to Africa and are commonly found in grasslands and savannas
- Besides the apples, there are oranges and bananas in the image


(c) Prompt Misleading
Figure 11: Some case studies of perturbation scenarios include image concatenation, image cropping, and prompt misleading. MLLMs adopt CogVLM2-Chat-En [35], which can be accessed at http://36.103.203.44:7861. | null | [
"Peng Ding",
"Jingyu Wu",
"Jun Kuang",
"Dan Ma",
"Xuezhi Cao",
"Xunliang Cai",
"Shi Chen",
"Jiajun Chen",
"Shujian Huang"
]
| 2024-08-02T16:07:15+00:00 | 2024-08-05T02:14:54+00:00 | [
"cs.CV",
"cs.MM"
]
| Hallu-PI: Evaluating Hallucination in Multi-modal Large Language Models within Perturbed Inputs | Multi-modal Large Language Models (MLLMs) have demonstrated remarkable
performance on various visual-language understanding and generation tasks.
However, MLLMs occasionally generate content inconsistent with the given
images, which is known as "hallucination". Prior works primarily center on
evaluating hallucination using standard, unperturbed benchmarks, which overlook
the prevalent occurrence of perturbed inputs in real-world scenarios-such as
image cropping or blurring-that are critical for a comprehensive assessment of
MLLMs' hallucination. In this paper, to bridge this gap, we propose Hallu-PI,
the first benchmark designed to evaluate Hallucination in MLLMs within
Perturbed Inputs. Specifically, Hallu-PI consists of seven perturbed scenarios,
containing 1,260 perturbed images from 11 object types. Each image is
accompanied by detailed annotations, which include fine-grained hallucination
types, such as existence, attribute, and relation. We equip these annotations
with a rich set of questions, making Hallu-PI suitable for both discriminative
and generative tasks. Extensive experiments on 12 mainstream MLLMs, such as
GPT-4V and Gemini-Pro Vision, demonstrate that these models exhibit significant
hallucinations on Hallu-PI, which is not observed in unperturbed scenarios.
Furthermore, our research reveals a severe bias in MLLMs' ability to handle
different types of hallucinations. We also design two baselines specifically
for perturbed scenarios, namely Perturbed-Reminder and Perturbed-ICL. We hope
that our study will bring researchers' attention to the limitations of MLLMs
when dealing with perturbed inputs, and spur further investigations to address
this issue. Our code and datasets are publicly available at
https://github.com/NJUNLP/Hallu-PI. |
2408.01356v2 | ## Balanced Residual Distillation Learning for 3D Point Cloud Class-Incremental Semantic Segmentation
Yuanzhi Su a , Siyuan Chen a, ∗ , Yuan-Gen Wang a, ∗
a School of Computer Science and Cyber Engineering, Guangzhou University, Guangzhou, Guangdong, China
## Abstract
Class-incremental learning (CIL) enables continuous learning of new classes while mitigating catastrophic forgetting of old ones. For the performance breakthrough of CIL, it is essential yet challenging to effectively refine past knowledge from the base model and balance it with new learning. However, such a challenge has not been considered in current research. This work proposes a balanced residual distillation learning framework (BRDL) to address this gap and advance CIL performance. BRDL introduces a residual distillation strategy to dynamically refine past knowledge by expanding the network structure and a balanced pseudolabel learning strategy to mitigate class bias and balance learning between old and new classes. We apply the proposed BRDL to a challenging 3D point cloud semantic segmentation task where the data is unordered and unstructured. Extensive experimental results demonstrate that BRDL sets a new benchmark with an outstanding balance capability in class-biased scenarios.
Keywords: 3D Point cloud, Semantic segmentation, Incremental learning
## 1. Introduction
The rapid advancement of LiDAR technology has captured significant attention and revolutionized point cloud-based vision tasks, achieving unprecedented success across various real-world applications. From virtual reality Blanc et al. (2020) to autonomous driving systems Yue et al. (2018), LiDAR's advancements have been instrumental in tackling complex challenges. As a key to scene understanding, 3D point cloud semantic segmentation, which aims to recognize various objects within a scene, has been significantly developed Qi et al. (2017a); Wang et al. (2019); Lai et al. (2022); Xu et al. (2023); Zeng et al. (2024). In practical scenarios, the continuous update of hardware and software leads to the discovery of previously unknown categories, necessitating the adaptation of neural networks to recognize new classes. The prevailing approach involves retraining models by integrating all available data, thereby enabling them to handle all categories. However, such a strategy encounters two formidable challenges: the substantial computational costs associated with frequent retraining and the uncertainty regarding the availability and quality of previous data. In response to these challenges, class-incremental learning (CIL) emerges as a promising paradigm. By enabling models to progressively assimilate new information while retaining memory of previously acquired knowledge (as depicted in Figure 1), CIL offers an efficient and effective solution that not only alleviates the computational burden of repeated retraining but also enhances the adaptability of models to dynamically evolving environments.
∗ Corresponding authors.
Figure 1: Illustration of class-incremental learning process. In each stage, the model is incrementally trained on a new set of classes while retaining knowledge of previously learned ones. For instance, at the initial stage, the model is introduced to classes such as 'chair,' 'bookshelf,' and 'desk.' In the subsequent stages, the model learns additional classes, including 'plane' and 'car,' thereby expanding its knowledge while preserving its understanding of earlier classes. This iterative process continues across stages, with new classes introduced at each step, allowing the model to consistently integrate new information while preventing the forgetting of previously learned classes.
Most of the existing works on CIL concentrate on 2D image classification Kirkpatrick et al. (2017); Li & Hoiem (2017); Rebuffi et al. (2017); Yan et al. (2021); Wang et al. (2022); Zhang et al. (2023); Malepathirana et al. (2023); Gao et al. (2024), with further efforts made towards 2D image semantic segmentation Yu et al. (2022); Yang et al. (2022b); Xiao et al. (2023). These approaches typically employ regularization Kirkpatrick et al. (2017); Ebrahimi et al. (2018); Fischer
[email protected] (Siyuan Chen), [email protected]
et al. (2024), replay Rebuffi et al. (2017); Castro et al. (2018); Rolnick et al. (2019); Nguyen et al. (2024), or parameter isolation Yan et al. (2021); Wang et al. (2022) to retain previously acquired knowledge. However, research on incremental learning for 3D point clouds is very limited. At present, only a few works Dong et al. (2021); Liu et al. (2021); Yang et al. (2023b) have applied incremental learning to point clouds, simply extending 2D methods to 3D point clouds. Due to the unordered and unstructured nature of 3D point clouds, preserving previous knowledge is challenging, which can lead to catastrophic forgetting Kirkpatrick et al. (2017) after the incremental phase. Yang et al. Yang et al. (2023a) pioneeringly proposed a class-incremental method on 3D point cloud semantic segmentation, which contains a Geometry-aware Feature relation Transfer module (GFT) and an Uncertainty-aware Pseudo-label Generation strategy (UPG). Although Yang et al.'s method improved overall performance, it imposed a strong constraint on acquired parameters during incremental training, which excessively prioritized preserving knowledge from the base model while hindering the learning of new classes. Furthermore, in cases where the volume of new classes is much less than that of the old ones, this imbalance results in skewed class learning and significant performance disparity for new classes compared to joint training.
To solve these issues, this paper presents a balanced residual distillation learning framework (BRDL) for class-incremental semantic segmentation on 3D point clouds, which includes two core designs: preventing the forgetting of acquired knowledge and facilitating the model's adaptation to new classes. Specifically, to tackle the catastrophic forgetting issue associated with unstructured and unordered point clouds, we design a residual distillation learning strategy (RDL), which focuses on learning the differences or residuals between the old and new classes. RDL allows the model to selectively update its parameters based on the characteristics of the new data without completely overwriting previously learned information. This simple yet effective strategy not only enhances inter-class discriminative capability but also reduces constraints on the model, promoting the learning of new classes. Moreover, to address the model's preference for base classes, we design a balanced pseudo-label learning (BPL) strategy. This strategy balances the contribution of old and new classes during the incremental phase by generating a guidance mask based on the similarity between the representations of new samples and the prototypes of base classes. Lastly, for long-term learning without adding other burdens, we introduce structural reparameterization to enable the model to consistently learn from new classes. The major contributions of our work can be summarized as:
- · We propose a novel framework BRDL for 3D point cloud class-incremental learning, which jointly protects prior knowledge and acquires new knowledge in CIL.
- · We design a residual distillation learning strategy to refine past knowledge and effectively assimilate information from new classes. Additionally, we implement a balanced pseudo-label learning strategy to mitigate the model's bias toward base classes, favoring new classes.
- · Extensive experiments demonstrate that our BRDL significantly outperforms existing methods and exhibits outstanding balancing capability.
## 2. Related Work
## 2.1. Class-Incremental Learning
Class-incremental learning has garnered increasing attention in machine learning, as it requires models to adapt to new classes without forgetting previously learned ones. Various approaches have been developed to address this challenge, including regularization-based, replay-based, distillation-based, and more sophisticated structure-based methods.
Regularization-based methods Kirkpatrick et al. (2017); Ahn et al. (2019) address the issue of catastrophic forgetting by measuring the importance of model parameters and imposing various constraints on them during the incremental phase. Specifically, regularization-based methods assess the importance of different model parameters and assign varying weights to signify their significance. During incremental steps, less critical parameters can be updated more liberally compared to their more pivotal counterparts. Recently, Fischer et al. (2024) introduces an incremental neural mesh model and a positional regularization term to allocate feature space for unseen classes, improving performance in both in-domain and out-of-distribution scenarios.
Replay-based methods Rebuffi et al. (2017); Castro et al. (2018); Rolnick et al. (2019) store a small number of exemplars or employ a generative model to synthesize information related to the old classes. ICaRL Rebuffi et al. (2017) initially proposes the nearest-mean-of-exemplars selection strategy to identify the most representative exemplars for each old class. Alternatively, pseudo-rehearsal techniques use generative models to create pseudo-exemplars based on estimated distributions of previous classes. An advanced exemplar Nguyen et al. (2024) introduces Causal Relational Replay, a novel framework for class-incremental learning that leverages causal reasoning to learn and rehearse intrinsic relations between classes over time. These methods successfully retain the discriminative features of previously learned classes during the incremental steps.
Distillation-based methods Zhao et al. (2020); Yang et al. (2023b) play a vital role in preserving previously acquired knowledge as the model evolves through current or future incremental steps. Additionally, distillation-based methods involve reducing the divergence between the output probability distributions of previous and current models, thereby consolidating the shared information and enhancing the model's overall robustness and adaptability.
Structure-based methods Yoon et al. (2018); Hung et al. (2019); Wang et al. (2022) select and expand different subnetwork structures involved in the optimization process of the incremental steps, which enhance the model's adaptability for accommodating new classes. Nevertheless, traditional approaches to dynamic architecture may result in notable overhead due to the continuous addition of new modules during incremental steps. Recently, Zhou et al. (2024) introduced
EASE for class-incremental learning using pre-trained models that employ expandable subspaces and semantic-guided prototype complements to learn new classes without forgetting old ones.
Despite the advanced methods Nguyen et al. (2024); Zhou et al. (2024) in the 2D image, directly transferring these methods to 3D point clouds faces several challenges, including their inability to handle the sparse, irregular structure of 3D point clouds, and the difficulty in modeling the dynamic, high-dimensional spatial relationships that are essential for 3D point cloud analysis. Notably, a recent method LGKD Yang et al. (2023b) introduces label-guided knowledge distillation to mitigate catastrophic forgetting, thereby enhancing longterm memory and adaptability in continuous learning tasks. However, it's worth noting that LGKD specifically addresses background shifts and can be classified as a distillation-based method. In contrast, our proposal introduces a novel framework that integrates replay, distillation, and structural adaptation. This combination is necessary because replay retains critical exemplars to prevent forgetting, distillation ensures the smooth transfer of knowledge by aligning old and new model representations, and structural adaptation dynamically expands the network to effectively accommodate new classes. The integration of these paradigms addresses the core challenges of class-incremental learning, providing a balanced solution that effectively retains past knowledge while incorporating new information.
## 2.2. 3D Point Clouds Semantic Segmentation
3D point cloud semantic segmentation can be viewed as a point-wise classification task that necessitates consideration of point-to-point disparities and topological distributions. Traditional 3D point cloud semantic segmentation methods Qi et al. (2017a); Wang et al. (2019); Cheng et al. (2024); Wu et al. (2024); Zeng et al. (2024) are generally given by a static set of predefined classes, making them inadequate for scenarios where new classes must be incrementally integrated into the segmentation model. Class-incremental learning is proposed to address this challenge. Previous research has explored various techniques for incremental learning in pixel-level segmentation tasks Kang et al. (2022); Malepathirana et al. (2023), but directly extending these methods to 3D point clouds presents unique challenges. To our knowledge, only one pioneering work Yang et al. (2023a) addresses class-incremental semantic segmentation on 3D point clouds. Although their work achieved state-of-the-art performance in 3D class-incremental semantic segmentation, it still suffers from critical drawbacks, as analyzed in Sec. 1. These limitations motivate our research to explore novel and improved methods for class-incremental semantic segmentation within the context of 3D point clouds.
## 2.3. Incremental Learning in Computer Vision
In recent years, incremental learning has undergone significant expansion, particularly within computer vision tasks. This paradigm shift has led to groundbreaking applications across a wide spectrum of vision tasks, ranging from traditional image classification to more complex challenges like instance segmentation and semantic segmentation. Incremental learning has notably been successfully applied to a diverse array of vision tasks, including but not limited to image classification Douillard et al. (2020); Rebuffi et al. (2017); Ahn et al. (2021); Gao et al. (2024), action recognition Li et al. (2021); Park et al. (2021), instance segmentation Nguyen & Todorovic (2022), semantic segmentation Yang et al. (2023a); Malepathirana et al. (2023), object detection Feng et al. (2022); Yang et al. (2022a); Yin et al. (2022); Bai et al. (2024), and self-supervised representation learning Jang et al. (2022); Madaan et al. (2021); Fini et al. (2022); Zhang et al. (2024). Building upon this rich research landscape, this paper aims to delve into the complexities of class-incremental learning for 3D point clouds. We seek to address challenges like catastrophic forgetting and the inherent difficulty of learning new classes in dynamic environments. To this end, we contribute advanced techniques for handling incremental learning in the context of 3D point clouds, ultimately enhancing the robustness and adaptability of computer vision systems in real-world applications.
## 3. Method
## 3.1. Problem Formulation
Denote the class set and the dataset as C and D , respectively. In general, the dataset D collects lots of samples, i.e. scenes. Each scene contains many points, and each point is represented by a pair ( P, L ) . P ∈ R 3+ f denotes the input 3D point with xyz coordinates and f -dimensional features (e.g., RGB), and L denotes the label of the corresponding point. The process of class incremental learning typically includes two phases. In the first phase, the base model M base is trained on the dataset D base . In the second phase, M base serves as the initialization for the novel model M novel , which is then trained on the dataset D novel . Note that D base is not available during the second phase and C base is disjoint with C novel (i.e., C base ∩ C novel = ∅ ). Finally, the trained M novel is utilized to perform the segmentation task on both C base and C novel .
The core problem of class-incremental learning is protecting existing knowledge and acquiring new knowledge. To this aim, we present a BRDL framework for the CIL task, as shown in Figure 2. BRDL consists of Residual Distillation Learning ( cf. Sec. 3.2) and Balanced Pseudo-label Learning ( cf. Sec. 3.3). In the following, we illustrate the above designs in detail.
## 3.2. Residual Distillation Learning
The notorious catastrophic forgetting in incremental learning is a serious problem. Finding methods to prevent the forgetting of old knowledge while assimilating new information continues to present a challenge. To this aim, we design an RDL strategy to refine the knowledge learned from the M base while effectively absorbing new information, as illustrated in Figure 3(a). Denote P n ∈ D novel as the current input point cloud of novel classes with S points.
We start by uniformly sampling r -proportional points from the input point cloud using farthest point sampling (FPS) Qi
Figure 2: The overall architecture of BRDL. In phase (a), we train the base model consisting of encoder E base and classifier Y base on D base . In phase (b), to update the model to segment more classes, we design a residual distillation learning strategy to capture knowledge learned from the base model. Meanwhile, we design a balanced pseudo-label learning strategy to promote the learning of new classes, thereby addressing the training bias.
et al. (2017b). FPS begins by randomly selecting an initial anchor point. Subsequent anchor points are iteratively chosen to maximize their minimum distance from all previously selected anchors. This approach guarantees that the selected anchors are evenly distributed throughout the input point cloud, effectively capturing its overall structure. After the FPS algorithm selects Z = ⌊ r × S ⌋ anchors, the l 2 distance is then used to find the K nearest points, creating local geometric structures. This enables capturing point-wise relationships R among geometric neighbors. We then employ the GFT loss L GFT Yang et al. (2023a) to measure the difference between R base and R novel on all anchors:
learn the residuals between the old and new classes. Hence, M novel consists of an encoder E novel , a classifier Y novel and a residual branch Y res . More intuitively, for instance, Y novel outputs the logits for base classes { c 1 , c 2 , . . . , c n } , while Y res learns the residuals between the base and target models for { c 1 , c 2 , . . . , c n +1 } . The predictions from Y novel are padded with zero to match the size of Y res , and the final output is obtained by summing Y novel and Y res . This mechanism ensures that Y novel retains base class knowledge, while Y res focuses on adapting to novel classes. This process is formalized in the following equation:
$$L _ { G F T } = \frac { 1 } { Z } \sum _ { a = 1 } ^ { Z } | | R _ { n o v e l } - R _ { b a s e } | | ^ { 2 }. \quad \quad ( 1 ) \text{ \ \ Add}$$
By minimizing this loss function, we not only transfer the structural and semantic knowledge contained in the M base to the M novel but also enhance the expression capability of E novel that enriches the significance of point representation.
In terms of model structure, M base consists of an encoder E base and a classifier Y base . For M novel , instead of directly expanding the classifier, RDL retains the old structure consisting of the base model and introduces a residual branch to
$$\hat { Y } _ { n o v e l } ( F ) = \text{pad} ( Y _ { n o v e l } ( F ) ) + Y _ { r e s } ( F ). \quad \text{ (2)}$$
Additionally, Figure 3(a) visually illustrates this workflow, including the interactions between Y novel , Y res , and the final output.
To distill previous knowledge from the base model into the novel model, we exploit the predicted probability output by Y base to guide the training of Y novel , which provides a more flexible and adaptive way to update the model's knowledge. The RDL loss function is formulated as:
$$\text{h to } \quad L _ { R D L } = | | Y _ { n o v e l } ( E _ { n o v e l } ( P _ { n } ) ) - Y _ { b a s e } ( E _ { b a s e } ( P _ { n } ) ) | | ^ { 2 }. \ ( 3 )$$
Figure 3: Illustration of our proposed RDL strategy and structural reparameterization.

This way allows for a more gradual and nuanced update of the model's parameters and enables the model to adjust its decision boundaries more smoothly.
As illustrated in Figure 3 (b), to prevent the continuous increase in model complexity caused by structural expansion, we execute structural reparameterization to losslessly integrate the residual branch information into the main branch:
$$\hat { Y } _ { n } ( F ; \theta _ { n } + \theta _ { r } ) = \hat { Y } _ { n } ( F ; \hat { \theta } _ { n } + 0 ) = \hat { Y } _ { n } ( F ; \hat { \theta } _ { n } ), \quad ( 4 ) \quad \text{Feat} \quad \text{new}$$
where θ n and θ r represent the parameters in the novel classifier Y novel ( ) · and residual classifier Y res ( ) · , respectively. ˆ θ n represents reorganized parameters. Y novel ( ) · is only responsible for the current base classes while Y res ( ) · is responsible for the logical residuals of both the novel classes and the base classes. To ensure the dimension consistency of θ n and θ r , we pad θ n with zero and fuse with θ r through element-wise addition operation. Finally, the residual branch is removed to keep the model structure consistent with M base for the next update.
## 3.3. Balanced Pseudo-label Learning
The incorporation of new information is limited by the biased number of the base and novel classes. To address such an issue, we propose a BPL strategy to eliminate the training deviation between the base and novel classes, as illustrated in Figure 4. Our design is based on the fact that the points with high similarity are more likely to belong to the old classes, while those with low similarity are more likely to belong to the new classes. Therefore, low-similarity samples are mainly involved in the update of the model to learn discriminative features. On the contrary, highly similar samples have a limited contribution to the update of model parameters, which promotes the learning of new class samples to the model.
Specifically, in BPL, the prototypes serve as the representation of the base classes. We store prototypes of the base classes by computing the average embedding of all the instances belonging to each class in C base . After projecting all new samples to the learned embedding space, we employ a standard Cosine similarity to compute the normalized cosine scores s i,c between them and each prototype, which is formulated as follows:
$$s _ { i, c } = C o s i n e ( P r o t o t y p e _ { c }, E _ { n o v e l } ( P _ { n } ^ { i } ) ). \quad ( 5 ) \quad p s e u \,.$$
We utilize s i,c as a reference for the old-new mask generation, which addresses the model's preference towards the base
Figure 4: Illustration of our proposed BPL.
classes. Points with high similarity values are more likely associated with the old classes, whereas points with low similarity values are attributed to the new classes. Furthermore, the backpropagation flow is designed to originate primarily from the new classes, updating the most discriminating positions while preserving the representation of the old classes Zhu et al. (2022). Therefore, we propose to generate the old-new mask as follows:
$$m _ { i } = 1 - \max _ { c \in C _ { b a s e } } ( s _ { i, c } ).$$
Meanwhile, to optimize the overall performance, we use the pseudo-label assigned by the old model to prevent semantic shifts. The pseudo-label generation process involves using predictions from an old model to generate labels for unlabeled data. For a given point i , we calculate its uncertainty U i n and further refine highly uncertain points to reduce noisy labels. The generated pseudo-label are integrated with the label of the new classes to obtain the mixed labels H i n , formulated as follows:
̸
̸
$$\text{enta-} \\ \text{lasses} = \begin{cases} \arg \max Q _ { b } ^ { i, c } & L _ { n } ^ { i } = \hat { c } _ { b g }, \arg \max Q _ { b } ^ { i, c } \neq c _ { b g } \text{ and } \mathcal { U } _ { n } ^ { i } \leq \gamma, \\ c \in C _ { b a s e } & C _ { b a s e } \end{cases} \\ \text{s} = \begin{cases} \arg \max Q _ { b } ^ { k, c } & L _ { n } ^ { i } = \hat { c } _ { b g }, \arg \max Q _ { b } ^ { i, c } = c _ { b g } \text{ or } \mathcal { U } _ { n } ^ { i } > \gamma, \\ C _ { b a s e } & C _ { b a s e } & C _ { b a s e } \\ L _ { n } ^ { i } & L _ { n } ^ { i } \neq \hat { c } _ { b g }, \\ \text{ignored} & \text{ otherwise.} \end{cases} \\ \text{in $Eq. (7), $L_{n}$ denotes the annotation from $D_{novel}$. $If the}$$
In Eq. (7), L n denotes the annotation from D novel . If the pseudo-label is from ˆ c bg (the background class of C novel ), and the model's output for the current point does not match c bg (the background class of C base ), and the uncertainty U i n is below a threshold γ , we assign the label based on the class with the
highest probability Q i,c b from the base classes. If the pseudolabel is from ˆ c bg but the model's output either matches c bg or the uncertainty exceeds γ , we assign the label based on the probability Q k,c b from the nearest neighbor. If the pseudo-label is not from ˆ c bg , the true label is directly used. In all other cases, the label is ignored.
Based on the generated mask m and mixed labels H n , we design a weighting cross-entropy loss L BPL and apply it to guide the training of M novel :
$$L _ { B P L } = - \sum _ { i = 1 } ^ { S } m _ { i } \cdot H _ { n } ^ { i } \log ( Q _ { n } ^ { i } ). \quad \quad ( 8 ) \quad \text{$\tilde{Yan}$} _ { \text{fron}$}$$
The purpose of this design is to increase the contribution of the novel class samples during the incremental phase while encouraging the model to focus on learning the discriminate features of the novel classes. By assigning larger weights to the novel classes, we prioritize their importance during the learning process, enabling better adaptation to the new classes.
## 3.4. Overall Loss
In the first phase, we train M base on points P b belonging to the base class and its labels L b . We define the loss as follows:
$$L _ { b a s e } = - \sum _ { i = 1 } ^ { S } L _ { b } ^ { i } \log ( Y _ { b a s e } ( E _ { b a s e } ( P _ { b } ^ { i } ) ) ). \quad ( 9 ) \quad \text{W} _ { \text{and} }$$
In the incremental phase, the residual branch Y res is randomly initialized while the rest is initialized with M base . To train M novel , we set the total loss function as follows:
$$L _ { i n c r e } = \lambda _ { 1 } L _ { G F T } + \lambda _ { 2 } L _ { R D L } + \lambda _ { 3 } L _ { B P L }. \quad ( 1 0 ) \quad \text{core}.$$
In this paper, we empirically set λ 1 = 1 , λ 2 = 0 2 . and λ 3 = 0 1 . based on careful consideration of the relative importance and impact of each loss component within the overall objective function. λ 1 follows the previous settings Yang et al. (2023a). λ 3 is used to normalize L BPL to be of the same scale, while λ 2 is used for performance tuning, which will be discussed in Sec. 4.3. After finishing the incremental phase, M novel is expected to accurately classify a point cloud that comes from C base ∪ C novel during the inference stage.
## 4. Experiments
## 4.1. Experimental Setting
Implementation Details For a fair comparison, we apply the basic setup and metric mean Intersection-over-Union (mIoU) consistent with Yang et al. (2023a). We adopt two paradigms S 0 and S 1 to develop C base and C novel . Note that classes in S 0 are incrementally introduced according to the original class label order in the dataset, and classes in S 1 are introduced in alphabetical order. Additionally, we employ DGCNN Wang et al. (2019) as the feature extractor. Our model is trained using a batch size of 32, and the Adam optimizer Kingma & Ba (2015) with an initial learning rate of 0.001 and weight decay of 0.0001 on both D base and D novel . We train the model for 100 epochs in total. The point clouds used for training are augmented through Gaussian jitter, along with random rotations around the z-axis.
Datasets We adopt two publicly available datasets: S3DIS Armeni et al. (2016) and ScanNet Dai et al. (2017) to conduct experiments, which were selected for their diversity and relevance to our problem domain and fair comparison with benchmark methods Kirkpatrick et al. (2017); Li & Hoiem (2017); Yang et al. (2023a). S3DIS comprises point clouds captured from a total of 272 rooms located in 6 different indoor areas. Each point in S3DIS contains xyz coordinates and RGB information, and is manually annotated with one of the 13 predefined classes. We designate the more challenging area 5 as our validation set while using the remaining areas for training. ScanNet is an RGB-D video dataset consisting of 1,513 scans acquired from 707 indoor scenes. Each point in ScanNet is assigned to one of the 21 classes, which includes 20 semantic classes and an additional class for unannotated places. We designate the 1210 scans in the ScanNet for training, while the remaining scans are used for validation.
## 4.2. Comparison with State-of-the-arts
We compare our method with five typical methods: Feeeze and Add (F & A), Fine-Tune (FT), EWC Kirkpatrick et al. (2017), LwF Li & Hoiem (2017) and Yang et al.' method Yang et al. (2023a). Among these methods, F & A and FT belong to the direct adaptation methods, EWC and LwF belong to the forgetting-prevention methods, and Yang et al's method is the only open-sourced SOTA method to our best knowledge. 'BT' corresponds to Base Training. 'JT' represents Joint Training, where all the base + novel classes are trained together. EWC Kirkpatrick et al. (2017) and LwF Li & Hoiem (2017) are traditional class-incremental methods, and Yang et al. (2023a) is state-of-the-art method currently.
The comparison results on S3DIS and ScanNet are shown in Table 1. For F & A, the performance on C base is maintained due to the frozen base model. However, F & A faces challenges when adapting to the novel classes, leading to a subpar performance on C novel . FT involves learning novel classes by updating the parameters of both the base feature extractor and the randomly initialized new classifier. Nonetheless, FT results in significant degradation in C base due to the absence of strategies to prevent forgetting. In contrast, EWC introduces the weight regularization loss to limit the modification of crucial weights from previous training, and LwF leverages the probability output by the base model to guide the model training, thereby alleviating forgetting. Additionally, Yang et al. (2023a) explores the point-wise geometry relationship and generates uncertainty-aware pseudo-labels to prevent catastrophic forgetting and improve overall performance. Although these methods deliver good overall performance, they suffer from imbalanced performance in the base and novel classes. Our framework solved these defects well through balanced refining of the past knowledge and learning residuals. It can be seen that our
Table 1: Quantitative comparison of 3D class-incremental segmentation methods on the S3DIS and ScanNet datasets in S 0 split. The best results achieved by the incremental methods are highlighted in bold.
| | | | C novel | = 5 | | C novel | = 5 | | C novel | = 5 | | C novel | = 3 | | C novel | = 3 | | C novel | = 3 | | C novel | = 1 | | C novel | = 1 | | C novel | = 1 |
|---------|--------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|
| | Method | 0-7 | 8-12 | all | 0-9 | 10-12 | all | 0-11 | 12 | all |
| | BT | 48.54 | - | - | 46.80 | - | - | 45.00 | - | - |
| | F&A | 44.25 | 12.33 | 31.98 | 44.28 | 3.34 | 34.83 | 44.57 | 0.05 | 41.14 |
| | FT | 34.96 | 30.25 | 33.15 | 28.87 | 31.56 | 29.49 | 29.44 | 29.52 | 29.45 |
| S3DIS | EWC | 39.38 | 31.07 | 36.19 | 37.13 | 37.92 | 37.31 | 36.55 | 19.94 | 35.27 |
| | LwF | 44.55 | 35.01 | 40.88 | 43.07 | 38.34 | 41.98 | 39.94 | 35.50 | 39.60 |
| | Yang et al.(2023a) | 48.94 | 39.56 | 45.33 | 45.15 | 45.33 | 45.19 | 44.08 | 35.69 | 43.43 |
| | Ours | 50.68 | 40.62 | 46.81 | 49.20 | 44.12 | 47.26 | 46.94 | 38.35 | 46.28 |
| | JT | 50.23 | 41.74 | 46.97 | 48.62 | 41.44 | 46.97 | 47.51 | 40.41 | 46.97 |
| | Method | 0-14 | 15-19 | all | 0-16 | 17-19 | all | 0-18 | 19 | all |
| | BT | 37.37 | - | - | 34.03 | - | - | 31.57 | - | - |
| | F&A | 36.06 | 1.77 | 27.48 | 32.58 | 0.86 | 27.82 | 30.99 | 0.95 | 29.49 |
| | FT | 9.39 | 13.65 | 10.45 | 8.43 | 10.98 | 8.82 | 8.02 | 10.46 | 8.14 |
| ScanNet | EWC | 17.75 | 13.22 | 16.62 | 15.70 | 11.74 | 15.11 | 15.66 | 6.76 | 15.21 |
| | LwF | 30.38 | 13.37 | 26.13 | 26.22 | 13.88 | 24.37 | 22.15 | 12.56 | 21.67 |
| | Yang et al.(2023a) | 34.16 | 13.43 | 28.98 | 28.38 | 14.31 | 26.27 | 25.74 | 12.62 | 25.08 |
| | Ours | 33.82 | 15.30 | 29.19 | 31.40 | 15.63 | 29.04 | 30.02 | 15.57 | 29.30 |
| | JT | 38.13 | 16.63 | 32.76 | 35.46 | 17.44 | 32.76 | 33.53 | 18.08 | 32.76 |
Table 2: Quantitative comparison of 3D class-incremental segmentation methods on the S3DIS and ScanNet datasets in S 1 split. The best results achieved by the incremental methods are highlighted in bold.
| | | | C novel | = 5 | | C novel | = 5 | | C novel | = 5 | | C novel | | C novel | | C novel | | C novel | = 1 | | C novel | = 1 | | C novel | = 1 |
|---------|---------------------|-------------------|-------------------|-------------------|-------------|-------------|-------------|-------------------|-------------------|-------------------|
| | Method | 0-7 | 8-12 | all | 0-9 | 10-12 | all | 0-11 | 12 | all |
| | BT | 37.24 | - | - | 40.73 | - | - | 45.88 | - | - |
| | F&A | 37.71 | 42.89 | 39.44 | 41.11 | 35.64 | 39.85 | 45.35 | 0.05 | 41.86 |
| | FT | 10.99 | 50.67 | 26.53 | 17.83 | 54.69 | 26.34 | 23.80 | 5.74 | 22.41 |
| S3DIS | EWC | 23.19 | 54.85 | 35.36 | 29.38 | 55.53 | 35.41 | 25.60 | 9.81 | 24.39 |
| | LwF | 32.83 | 55.19 | 41.43 | 37.69 | 54.73 | 41.62 | 32.16 | 18.26 | 31.09 |
| | Yang et al.(2023a) | 38.17 | 55.20 | 44.72 | 39.83 | 57.59 | 43.93 | 40.33 | 19.28 | 38.71 |
| | Ours | 38.38 | 55.62 | 45.01 | 41.36 | 59.40 | 45.52 | 42.75 | 35.12 | 42.16 |
| | JT | 38.38 | 60.11 | 46.74 | 42.63 | 60.44 | 46.74 | 47.09 | 42.55 | 46.74 |
| | Method | 0-14 | 15-19 | all | 0-16 | 17-19 | all | 0-18 | 19 | all |
| | BT | 29.30 | - | - | 30.84 | - | - | 30.78 | - | - |
| | F&A | 25.25 | 18.72 | 23.62 | 26.95 | 7.37 | 24.02 | 30.41 | 0.01 | 28.89 |
| | FT | 5.83 | 34.03 | 12.88 | 4.88 | 40.94 | 10.29 | 4.76 | 7.57 | 4.90 |
| ScanNet | EWC | 14.93 | 33.30 | 19.52 | 8.78 | 31.74 | 12.22 | 12.24 | 8.84 | 12.07 |
| | LwF | 24.04 | 37.88 | 27.50 | 22.76 | 42.34 | 25.70 | 20.63 | 13.88 | 20.29 |
| | Yang et al. (2023a) | 26.04 | 35.51 | 28.41 | 28.79 | 40.31 | 30.52 | 24.16 | 12.97 | 23.60 |
| | Ours | 25.85 | 38.89 | 29.11 | 29.11 | 42.55 | 31.13 | 29.98 | 21.30 | 29.55 |
| | JT | 30.81 | 38.79 | 32.81 | 31.65 | 39.38 | 32.81 | 32.91 | 30.76 | 32.81 |
Figure 5: Visualization of Incremental Quality Comparison with EWC Kirkpatrick et al. (2017), LwF Li & Hoiem (2017) and Yang et al. (2023a) on | C novel | = 5 novel classes of ScanNet in order S 0 . The results shown in black are unlabeled and do not belong to any of the base classes or the novel classes.
Table 3: Effects of different λ 2 value in setting of | C novel | = 1 on S3DIS ( S 0 split) dataset.
| Value of λ 2 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|----------------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|
| mIoU | 46.1 | 46.28 | 45.4 | 45.99 | 45.1 | 46.04 | 45.42 | 45.85 | 45.21 | 45.7 |
Table 4: Effects of different λ 2 and λ 3 in setting of | C novel | = 1 on S3DIS ( S 0 split) dataset. The highest values are bolded , and the lowest values are underlined.
| | λ 3 = 0.1 | λ 3 = 0.2 | λ 3 = 0.3 | λ 3 = 0.4 | λ 3 = 0.5 |
|-----------|-------------|-------------|-------------|-------------|-------------|
| λ 2 = 0.1 | 46.1 | 46.28 | 45.4 | 45.99 | 45.1 |
| λ 2 = 0.2 | 45.24 | 46.02 | 45.51 | 46.5 | 45.53 |
| λ 2 = 0.3 | 45.91 | 45.94 | 45.68 | 46.16 | 45.99 |
| λ 2 = 0.4 | 46.37 | 46.13 | 45.22 | 46.11 | 46.28 |
| λ 2 = 0.5 | 45.8 | 46.58 | 45.64 | 46.23 | 46 |
strate the robustness of BRDL on the above datasets in a different order (i.e. S 0 and S 1 ). The experimental results, as presented in Table 2, unveils a compelling finding: for existing incremental methods, the alteration of class order does significantly affect the performance. The deviation in results indicates that the arrangement of class labels plays a crucial role in determining the success of such methods. In contrast, JT, where all categories are trained simultaneously, renders a negligible degradation in different class orders. This is because the inherent nature of JT, where the entire dataset is considered holistically, allowing for comprehensive learning across all classes, regardless of their order. Furthermore, BRDL exhibits excellent results remarkably close to those achieved through JT, even under varying class orders. This noteworthy phenomenon demonstrates the robustness and effectiveness of our approach. The above results indicate that our BRDL can adapt to different learning scenarios, making it a reliable and versatile solution for incremental learning tasks.
BRDL achieved the best results on both the S3DIS and ScanNet datasets. Especially, the advantage of our method is obvious when | C novel | = 1 . Compared to Yang et al. (2023a), our method improved the mIoU of novel classes by 15.34% on S3DIS and by 8.33% on ScanNet in S 1 order. A qualitative comparison is shown in Figure 5, which demonstrates that our BRDL achieves the best performance with an outstanding balance capability compared to other methods.
Robustness to Class Order. We conduct experiments to demon-
## 4.3. Discussion of Hyperparameters
The sensitivity analysis results, as shown in Table 3 and 4, reveal the impact of varying hyperparameters λ 2 and λ 3 on the model's performance, measured in mIoU. As shown in Table 3, the model achieves its best performance when λ 2 is set to 0.2. This finding highlights that λ 2 plays a critical role in balancing the associated loss components. Moderate values like 0.2 strike a balance between regularization and generalization, whereas extreme values either overemphasize regularization ( λ 2 ≥ 0.6)
Table 5: Ablation Study for multi-step training on S3DIS ( S 0 split). We set the number of base classes to 8 and the number of novel classes to 5. Here, we conducted multi-step increments, where each step incremented one class, resulting in a total of five increment steps.
| Class | Step 1 | Step 1 | Step 2 | Step 2 | Step 3 | Step 3 | Step 4 | Step 4 | Step 5 | Step 5 |
|---------|-------------|----------|-------------|----------|-------------|----------|-------------|----------|-------------|----------|
| Class | Yang et al. | Ours | Yang et al. | Ours | Yang et al. | Ours | Yang et al. | Ours | Yang et al. | Ours |
| 0 | 88.09 | 88.03 | 85.46 | 87.33 | 85.72 | 86.81 | 85.91 | 86.71 | 88.04 | 88.40 |
| 1 | 95.63 | 96.16 | 95.66 | 96.53 | 95.76 | 96.34 | 95.37 | 96.02 | 95.83 | 96.05 |
| 2 | 73.46 | 76.54 | 71.57 | 76.04 | 72.07 | 75.96 | 65.17 | 72.58 | 65.89 | 72.81 |
| 3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 4 | 7.93 | 7.50 | 0.90 | 7.03 | 0.81 | 7.03 | 0.00 | 7.24 | 0.00 | 7.27 |
| 5 | 39.70 | 49.42 | 32.01 | 48.05 | 34.79 | 45.00 | 31.28 | 41.92 | 34.48 | 43.01 |
| 6 | 22.76 | 44.29 | 19.74 | 41.82 | 11.74 | 40.11 | 6.82 | 38.84 | 8.01 | 37.70 |
| 7 | 63.06 | 60.90 | 50.07 | 58.52 | 51.78 | 57.45 | 44.29 | 58.00 | 44.38 | 59.44 |
| 8 | 34.42 | 34.06 | 13.69 | 15.85 | 12.32 | 14.45 | 0.21 | 11.10 | 0.07 | 9.94 |
| 9 | - | - | 3.73 | 3.69 | 3.84 | 3.42 | 5.04 | 4.56 | 3.56 | 4.63 |
| 10 | - | - | - | - | 44.31 | 45.74 | 40.10 | 42.92 | 36.18 | 36.75 |
| 11 | - | - | - | - | - | - | 8.02 | 8.95 | 10.63 | 13.72 |
| 12 | - | - | - | - | - | - | - | - | 33.50 | 35.31 |
| base | 48.83 | 52.86 | 44.43 | 51.92 | 44.08 | 51.09 | 41.11 | 50.16 | 42.08 | 50.59 |
| novel | 34.42 | 34.06 | 8.71 | 9.77 | 20.16 | 21.20 | 13.34 | 16.88 | 16.79 | 20.07 |
| all | 47.23 | 50.77 | 37.28 | 43.49 | 37.56 | 42.94 | 31.85 | 39.07 | 32.35 | 38.85 |
Table 6: Ablation study for learning strategies in | C novel | = 3 setting of S3DIS ( S 0 & S 1 split.)
| RDL | BPL | S 0 | S 0 | S 0 | S 1 | S 1 | S 1 |
|-------|-------|-------|-------|-------|-------|-------|-------|
| RDL | BPL | 0-9 | 10-12 | all | 0-9 | 10-12 | all |
| % | % | 45.15 | 45.33 | 45.19 | 39.83 | 57.59 | 43.93 |
| ! | % | 46.12 | 40.76 | 44.90 | 41.35 | 57.43 | 45.11 |
| % | ! | 47.44 | 44.80 | 46.83 | 40.46 | 60.21 | 45.02 |
| ! | ! | 49.20 | 44.12 | 47.26 | 41.36 | 59.40 | 45.52 |
or under-regularize ( λ 2 ≤ 0.1), leading to suboptimal model performance.
Additionally, the joint sensitivity analysis of λ 2 and λ 3 , visualized in Table 4, illustrates how the interplay between these parameters affects the model. The highest performance (mIoU = 46.58) is observed at λ 2 = 0.2 and λ 3 = 0.5, suggesting that a lower λ 2 complements moderate λ 3 values. This nuanced relationship emphasizes that while λ 2 exerts a stronger influence on overall performance, λ 3 introduces finer adjustments that can either enhance or dampen performance depending on its combination with λ 2 . The analysis also shows that the model's performance is robust across a range of parameter values, with minimal fluctuation. Specifically, the performance at the highest value (46.58) and the lowest value (45.1) differs by minor, indicating that the model is not highly sensitive to small changes in these parameters. This stability highlights the robustness of the model's performance. Overall, the analysis underscores the importance of careful parameter tuning to achieve optimal results. Moderate and balanced values of λ 2 and λ 3 , such as λ 2 = 0.2 and λ 3 = 0.1, are consistently effective in maximizing performance.
## 4.4. Ablation Study
To comprehensively explore BRDL, we conducted ablation studies on multi-step incremental training, learning strategies, and network initialization. The detailed explanations are as follows.
## 4.4.1. Multi-step Incremental Training.
To explore the impact of long-term learning, we conduct an ablation study to evaluate the performance of BRDL in the context of multi-step incremental training. We present the results in Table 5. The overall performance experiences a decline due to the inherent difficulty in learning novel classes. As mentioned in Yang et al. (2023a), the model struggles with forgetting old classes, semantic shifts in known and unknown future classes, causing confusion in recognizing previously learned classes. Despite these formidable obstacles, BRDL not only excels in preserving old knowledge but also demonstrates remarkable proficiency in acquiring new information related to the novel classes. This ability to strike a balance between retaining past knowledge and assimilating new information un-
Table 7: Performance for difference initialization methods in | C novel | = 3 setting of S3DIS ( S 0 & S 1 split).
| | S 0 | S 0 | S 0 | S 1 | S 1 | S 1 |
|-------------------|-------|-------|-------|-------|-------|-------|
| Method | 0-9 | 10-12 | all | 0-9 | 10-12 | all |
| Completely random | 46.49 | 39.27 | 44.82 | 41.79 | 59.91 | 45.97 |
| Y res -zero | 48.57 | 42.54 | 47.18 | 43.44 | 59.36 | 47.11 |
| Y res -random | 49.20 | 44.12 | 47.26 | 41.36 | 59.40 | 45.52 |
derscores the robustness and adaptability of BRDL in classincremental learning scenarios.
## 4.4.2. Learning Strategies.
We conducted an ablation study in | C novel | = 3 setting of S3DIS in different orders, i.e., S 0 & S 1 , to gain insights into the individual contributions of BRDL's strategy. Table 6 shows that the removal of any single strategy leads to a noticeable degradation in performance. As expected, RDL serves a crucial role in preventing catastrophic forgetting. When RDL is removed, the model's ability to protect old knowledge decreases, thus reducing the model performance on the old classes. Additionally, BPL contributes more to facilitate the acquisition of knowledge related to the new classes. When BPL is removed, the model's plasticity is damaged and performance on novel classes is severely declined. Although both individual strategies can help improve overall performance, the collaborative interplay between RDL and BPL culminates in the attainment of significant performance since each strategy augments the other's strengths and compensates for its limitations.
## 4.4.3. Network Initialization.
We perform a network initialization experiment to explore the impact of different network initialization strategies on the effectiveness of BRDL during training. We adopt three different strategies: completely random initialization, Y res -random initialization, and Y res -zero initialization. The result presented in Table 7 indicates that compared to the initialization of Y res -random, the zero initialization may affect the effectiveness of the model during the training, potentially hindering its ability. Furthermore, the completely random initialization may produce significant differences in effectiveness compared to the other two methods due to insufficient training epochs. These results provide further insight into the implementation of BRDL and highlight the importance of selecting an appropriate initialization when using this technique.
Table 8: Comparison of computational cost between BRDL and the baseline (Yang et al. (2023a)). The comparison is conducted in S3DIS dataset ( | C novel | = 1 , S 0 ) during incremental phase.
| Methods | Yang et al. (2023a) | Ours |
|---------------|-----------------------|-------------|
| Training Time | 142 s/epoch | 144 s/epoch |
| Memory Usage | 1608 KB | 1614 KB |
## 4.5. Analysis of Computational Cost
The comparison in Table 8 illustrates that the computational overhead introduced by our BRDL framework is small and manageable. Specifically, the results show that our method requires 1614 KB of memory, slightly higher than the baseline, which uses 1608 KB bytes. Additionally, the training time per epoch for our method is 144 seconds, compared to 142 seconds for the baseline method. These differences arise primarily from the additional fully-connected layer and zero-padding operation incorporated into our framework. Despite these minor overheads, the performance improvements (measured in mIoU) are substantial, with our method achieving 46.94/38.35/46.28 compared to 44.08/35.69/43.43 for the baseline. This demonstrates that the tradeoff in memory usage and training time is justified, highlighting the efficiency and practicality of BRDL.
## 5. Discussion
While the BRDL framework has demonstrated promising results in addressing class-incremental learning (CIL) for 3D point clouds, there are specific conditions where its effectiveness might be limited. This section outlines potential failure modes and challenges in real-world applications.
Class Imbalance and Small Data Volumes A common challenge in class-incremental learning is handling significant imbalances between old and new class data. While BRDL's balanced pseudo-label learning (BPL) strategy addresses model bias toward base classes, extreme data imbalances could still affect the model's ability to learn underrepresented new classes. This issue may arise in scenarios where novel classes appear infrequently or are significantly smaller in volume than older classes, causing the model to prioritize previously learned information.
Scalability Challenges in Large Datasets As the scale of 3D point cloud datasets increases, the computational requirements of BRDL also grow. The need to continually distill knowledge and adapt the network to new classes could result in significant memory and processing overhead, particularly in large-scale applications like urban modeling, autonomous navigation, or industrial robotics. Without careful management of computational resources, BRDL may face scalability issues, limiting its practical application in these fields.
Application to Real-Time Systems Adapting BRDL for realtime systems presents an important avenue for future research. Real-time incremental learning is critical in scenarios like autonomous vehicles and robotics, where models must adapt quickly to new environments while maintaining high accuracy. To achieve this, optimizing BRDL's computational efficiency will be essential. Techniques such as model pruning, lightweight architectures, and early stopping during training could be explored to reduce latency and memory usage, enabling real-time deployment without compromising performance.
Overall, while BRDL provides an effective solution to many challenges in class-incremental learning for 3D point clouds, addressing these future directions will further improve the
framework's robustness and adaptability. By focusing on issues related to data quality, scalability, and real-time performance, BRDL can be refined to meet the demands of a broader range of applications, ensuring its success in both research and realworld deployment.
## 6. Conclusion
In this paper, we introduce a novel framework called Balanced Residual Distillation Learning (BRDL) for classincremental semantic segmentation on 3D point clouds. We propose a residual distillation learning strategy to transfer and refine the knowledge previously acquired, addressing the challenge of catastrophic forgetting. This approach preserves valuable information while accommodating new learning. Additionally, we present a balanced pseudo-label learning strategy to mitigate feature confusion and reduce class bias toward base classes. Extensive experimental results demonstrate that BRDL significantly improves accuracy and generalization capabilities for both base and novel classes. Our comprehensive evaluation confirms the effectiveness and reliability of the proposed framework. We believe BRDL opens new avenues for future research in the field of class-incremental learning.
## References
Ahn, H., Cha, S., Lee, D., & Moon, T. (2019). Uncertaintybased continual learning with adaptive regularization. Advances in Neural Information Processing Systems , 32 .
Ahn, H., Kwak, J., Lim, S., Bang, H., Kim, H., & Moon, T. (2021). Ss-il: Separated softmax for incremental learning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 844-853).
Armeni, I., Sener, O., Zamir, A. R., Jiang, H., Brilakis, I., Fischer, M., & Savarese, S. (2016). 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1534-1543).
Bai, L., Song, H., Feng, T., Fu, T., Yu, Q., & Yang, J. (2024). Revisiting class-incremental object detection: An efficient approach via intrinsic characteristics alignment and task decoupling. Expert Systems with Applications , 257 , 125057.
Blanc, T., El Beheiry, M., Caporal, C., Masson, J.-B., & Hajj, B. (2020). Genuage: Visualize and analyze multidimensional single-molecule point cloud data in virtual reality. Nature Methods , 17 , 1100-1102.
Castro, F. M., Mar´ ın-Jim´ enez, M. J., Guil, N., Schmid, C., & Alahari, K. (2018). End-to-end incremental learning. In Proceedings of the European Conference on Computer Vision (pp. 233-248).
Cheng, H., Zhu, J., Lu, J., & Han, X. (2024). Edgcnet: Joint dynamic hyperbolic graph convolution and dual squeezeand-attention for 3d point cloud segmentation. Expert Systems with Applications , 237 , 121551.
Dai, A., Chang, A. X., Savva, M., Halber, M., Funkhouser, T., & Nießner, M. (2017). Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 5828-5839).
Dong, J., Cong, Y., Sun, G., Ma, B., & Wang, L. (2021). I3dol: Incremental 3d object learning without catastrophic forgetting. In Proceedings of the AAAI Conference on Artificial Intelligence (pp. 6066-6074).
Douillard, A., Cord, M., Ollion, C., Robert, T., & Valle, E. (2020). Podnet: Pooled outputs distillation for small-tasks incremental learning. In Proceedings of the European Conference on Computer Vision (pp. 86-102).
Ebrahimi, S., Elhoseiny, M., Darrell, T., & Rohrbach, M. (2018). Uncertainty-guided continual learning in bayesian neural networks-extended abstract. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition .
Feng, T., Wang, M., & Yuan, H. (2022). Overcoming catastrophic forgetting in incremental object detection via elastic response distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9427-9436).
Fini, E., Da Costa, V. G. T., Alameda-Pineda, X., Ricci, E., Alahari, K., & Mairal, J. (2022). Self-supervised models are continual learners. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9621-9630).
Fischer, T., Liu, Y ., Jesslen, A., Ahmed, N., Kaushik, P., Wang, A., Yuille, A. L., Kortylewski, A., & Ilg, E. (2024). inemo: Incremental neural mesh models for robust classincremental learning. In European Conference on Computer Vision (pp. 357-374).
Gao, J., Xie, T., Li, R., Wang, K., & Zhao, L. (2024). Apm: Adaptive parameter multiplexing for class incremental learning. Expert Systems with Applications , 258 , 125135.
Hung, C.-Y., Tu, C.-H., Wu, C.-E., Chen, C.-H., Chan, Y.-M., & Chen, C.-S. (2019). Compacting, picking and growing for unforgetting continual learning. Advances in Neural Information Processing Systems , 32 .
Jang, J., Ye, S., Yang, S., Shin, J., Han, J., Kim, G., Choi, S. J., & Seo, M. (2022). Towards continual knowledge learning of language models. In International Conference on Learning Representations .
Kang, M., Park, J., & Han, B. (2022). Class-incremental learning by knowledge distillation with adaptive feature consolidation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 16071-16080).
Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization.
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A. et al. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences , 114 , 3521-3526.
Lai, X., Liu, J., Jiang, L., Wang, L., Zhao, H., Liu, S., Qi, X., & Jia, J. (2022). Stratified transformer for 3d point cloud segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 85008509).
- Li, T., Ke, Q., Rahmani, H., Ho, R. E., Ding, H., & Liu, J. (2021). Else-net: Elastic semantic network for continual action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision (pp. 13434-13443).
- Li, Z., & Hoiem, D. (2017). Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence , 40 , 2935-2947.
Liu, Y., Cong, Y., Sun, G., Zhang, T., Dong, J., & Liu, H. (2021). L3doc: Lifelong 3d object classification. IEEE Transactions on Image Processing , 30 , 7486-7498.
Madaan, D., Yoon, J., Li, Y., Liu, Y., & Hwang, S. J. (2021). Representational continuity for unsupervised continual learning. In International Conference on Learning Representations .
Malepathirana, T., Senanayake, D., & Halgamuge, S. (2023). Napa-vq: Neighborhood-aware prototype augmentation with vector quantization for continual learning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 11674-11684).
Nguyen, K., & Todorovic, S. (2022). ifs-rcnn: An incremental few-shot instance segmenter. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 7010-7019).
Nguyen, T., Kieu, D., Duong, B., Kieu, T., Do, K., Nguyen, T., & Le, B. (2024). Class-incremental learning with causal relational replay. Expert Systems with Applications , 250 , 123901.
Park, J., Kang, M., & Han, B. (2021). Class-incremental learning for action recognition in videos. In Proceedings of the IEEE International Conference on Computer Vision (pp. 13698-13707).
- Qi, C. R., Su, H., Mo, K., & Guibas, L. J. (2017a). Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 652-660).
- Qi, C. R., Yi, L., Su, H., & Guibas, L. J. (2017b). Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in Neural Information Processing Systems , 30 , 5105-5104.
Rebuffi, S.-A., Kolesnikov, A., Sperl, G., & Lampert, C. H. (2017). icarl: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2001-2010).
- Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., & Wayne, G. (2019). Experience replay for continual learning. Advances in Neural Information Processing Systems , 32 , 350-360.
Wang, F.-Y., Zhou, D.-W., Ye, H.-J., & Zhan, D.-C. (2022). Foster: Feature boosting and compression for classincremental learning. In Proceedings of the European Conference on Computer Vision (pp. 398-414).
- Wang, Y., Sun, Y., Liu, Z., Sarma, S. E., Bronstein, M. M., & Solomon, J. M. (2019). Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics , 38 , 1-12.
Wu, Z., Zhang, Y., Lan, R., Qiu, S., Ran, S., & Liu, Y. (2024). Appfnet: Adaptive point-pixel fusion network for 3d semantic segmentation with neighbor feature aggregation. Expert Systems with Applications , 251 , 123990.
Xiao, J.-W., Zhang, C.-B., Feng, J., Liu, X., van de Weijer, J., & Cheng, M.-M. (2023). Endpoints weight fusion for class incremental semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 7204-7213).
- Xu, Z., Yuan, B., Zhao, S., Zhang, Q., & Gao, X. (2023). Hierarchical point-based active learning for semi-supervised point cloud semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (pp. 18098-18108).
Yan, S., Xie, J., & He, X. (2021). Der: Dynamically expandable representation for class incremental learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3014-3023).
Yang, B., Deng, X., Shi, H., Li, C., Zhang, G., Xu, H., Zhao, S., Lin, L., & Liang, X. (2022a). Continual object detection via prototypical task correlation guided gating mechanism. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9255-9264).
- Yang, G., Fini, E., Xu, D., Rota, P., Ding, M., Nabi, M., Alameda-Pineda, X., & Ricci, E. (2022b). Uncertaintyaware contrastive distillation for incremental semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence , 45 , 2567-2581.
Yang, Y., Hayat, M., Jin, Z., Ren, C., & Lei, Y. (2023a). Geometry and uncertainty-aware 3d point cloud classincremental semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 21759-21768).
Yang, Z., Li, R., Ling, E., Zhang, C., Wang, Y., Huang, D., Ma, K. T., Hur, M., & Lin, G. (2023b). Label-guided knowledge distillation for continual semantic segmentation on 2d images and 3d point clouds. In Proceedings of the IEEE International Conference on Computer Vision (pp. 18601-18612).
Yin, L., Perez-Rua, J. M., & Liang, K. J. (2022). Sylph: A hypernetwork framework for incremental few-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9035-9045).
Yoon, J., Yang, E., Lee, J., & Hwang, S. J. (2018). Lifelong learning with dynamically expandable networks. In International Conference on Learning Representations .
Yu, L., Liu, X., & Van de Weijer, J. (2022). Self-training for class-incremental semantic segmentation. IEEE Transactions on Neural Networks and Learning Systems , 34 , 9116-9127.
Yue, X., Wu, B., Seshia, S. A., Keutzer, K., & SangiovanniVincentelli, A. L. (2018). A lidar point cloud generator: from a virtual world to autonomous driving. In Proceedings of the International Conference on Multimedia Retrieval (pp. 458-464).
Zeng, Z., Xu, Y., Xie, Z., Tang, W., Wan, J., & Wu, W. (2024). Large-scale point cloud semantic segmentation via local perception and global descriptor vector. Expert Systems with Applications , 246 , 123269.
Zhang, L., Huang, J., Wei, Y., Liu, J., An, D., & Wu, J. (2023). Open set maize seed variety classification using hyperspectral imaging coupled with a dual deep svdd-based incremental learning framework. Expert Systems with Applications , 234 , 121043.
Zhang, Y., Han, D., & Shi, P. (2024). Semi-supervised prototype network based on compact-uniform-sparse representation for rotating machinery few-shot class incremental fault diagnosis. Expert Systems with Applications , 255 , 124660.
Zhao, B., Xiao, X., Gan, G., Zhang, B., & Xia, S.-T. (2020). Maintaining discrimination and fairness in class incremental learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1320813217).
Zhou, D.-W., Sun, H.-L., Ye, H.-J., & Zhan, D.-C. (2024). Expandable subspace ensemble for pre-trained modelbased class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 23554-23564).
Zhu, K., Zhai, W., Cao, Y., Luo, J., & Zha, Z.-J. (2022). Self-sustaining representation expansion for non-exemplar class-incremental learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9296-9305). | null | [
"Yuanzhi Su",
"Siyuan Chen",
"Yuan-Gen Wang"
]
| 2024-08-02T16:09:06+00:00 | 2025-01-03T13:18:15+00:00 | [
"cs.CV"
]
| Balanced Residual Distillation Learning for 3D Point Cloud Class-Incremental Semantic Segmentation | Class-incremental learning (CIL) enables continuous learning of new classes
while mitigating catastrophic forgetting of old ones. For the performance
breakthrough of CIL, it is essential yet challenging to effectively refine past
knowledge from the base model and balance it with new learning. However, such a
challenge has not been considered in current research. This work proposes a
balanced residual distillation learning framework (BRDL) to address this gap
and advance CIL performance. BRDL introduces a residual distillation strategy
to dynamically refine past knowledge by expanding the network structure and a
balanced pseudo-label learning strategy to mitigate class bias and balance
learning between old and new classes. We apply the proposed BRDL to a
challenging 3D point cloud semantic segmentation task where the data is
unordered and unstructured. Extensive experimental results demonstrate that
BRDL sets a new benchmark with an outstanding balance capability in
class-biased scenarios. |
2408.01357v2 | ## Device-Independent Certification of Multipartite Distillable Entanglement
Aby Philip
School of Applied and Engineering Physics, Cornell University, Ithaca, New York 14850, USA
## Mark M. Wilde
School of Electrical and Computer Engineering and School of Applied and Engineering Physics, Cornell University, Ithaca, New York 14850, USA
Quantum networks consist of various quantum technologies, spread across vast distances, and involve various users at the same time. Certifying the functioning and efficiency of the individual components is a task that is well studied and widely used. However, the power of quantum networks can only be realized by integrating all the required quantum technologies and platforms across a large number of users. In this work, we demonstrate how to certify the distillable entanglement available in multipartite states produced by quantum networks, without relying on the physical realization of its constituent components. We do so by using the paradigm of device independence.
## CONTENTS
| I. | Introduction | 1 |
|------|---------------------------------------------------------------------|-----|
| II. | Definitions and Setup | 2 |
| III. | Device-Independent Multipartite Entanglement Certification Protocol | 3 |
| IV. | Completeness | 4 |
| V. | Soundness | 4 |
| | A. Entropy Accumulation Theorem (EAT) | 5 |
| | B. EAT Channels | 6 |
| | C. Max-Tradeoff Function | 7 |
| | D. Applying the EAT | 9 |
| | E. Soundness | 9 |
| VI. | Conclusion | 10 |
| | Acknowledgments | 10 |
| | References | 11 |
| A. | Proof of Lemma 1 | 12 |
## I. INTRODUCTION
Quantum networks may become a reality within the near future and have the potential to open up several avenues of applications. Potential uses for quantum networks include quantum computers connected together for distributed computing tasks [1, 2], a collection of quantum sensors that implement a joint measurement on a system of interest [3-6], or a number of distant nodes that transmit quantum states among themselves [7-9]. To realize the full potential of quantum networks, the efficient production and distribution of multipartite entanglement is essential [10].
To distribute multipartite entanglement over large distances, one can choose two basic approaches. The first approach involves distributing bipartite entanglement between each of the nodes and then using local operations and classical communication to convert the global state into a desired multipartite state [11, 12]. The alternate method involves producing the multipartite state of interest at a single location [13] and distributing the resulting state via quantum channels to the intended recipients. Whichever procedure one might employ, it is important to study the associated success probability and quality of entanglement yielded by these procedures.
This point raises the question: how can we certify or guarantee that a minimum amount of entanglement is produced by a certain procedure or method? This question becomes more interesting when we recall that quantum networks may have components based on different architectures: for example, superconducting qubits for computing [14-16], trapped ions [17] or solid-state qubits [18] for memory, photons for communication [13], and so on. Hence, we need to adopt a framework of certification that is independent of the constituent parts of the quantum network, thus bringing us to device-independent (DI) protocols.
The general interest in DI protocols [19, 20] stems from the fact that one can test and verify the amount of entanglement in a state using only classical inputs and outputs, along with classical communication. DI protocols are based on various self-testing results [21-24], the first of which were developed in [21]. (See [25] for a review.) Most importantly, such protocols are agnostic to the underlying mechanics and specifics of the state being tested. As such, and relevant to the present paper, DI protocols are suitable for the certification of multipartite entanglement in quantum networks, especially ones that contain elements with dissimilar underlying technologies.
There has been a lot of recent interest in device-independent protocols involving more than two parties, including investigations into Bell-type inequalities [26, 27] and their application toward DI conference key agreement, involving achievable rates [28, 29] and upper bounds on key-agreement rates [30, 31]. However, little attention has been paid toward the device-independent certification of multipartite distillable entanglement. Multipartite entanglement distillation is an important step to ensure that we are using states that are as close as possible to ideal states.
In this paper, we provide a lower bound on the certi-
fiable rate of one-shot multipartite distillable entanglement in a device-independent setting. The multipartite Greenberger-Horne-Zeilinger (GHZ) state is the basic entanglement resource that is critical to maximizing the utility of quantum networks for applications like quantum sensing [3-6], multiparty quantum communication [7-9], and distributed quantum computation [1, 2]. It is vital to distill GHZ states from lessthan-perfect multipartite states that are available to the parties in a quantum network, while using only minimal additional resources like local operations and classical communication (LOCC). To maximize the utility of every copy of an available multipartite state, we need to look at the one-shot distillable entanglement of the state shared by the quantum network. The device-independent setting means that all the conclusions are drawn from only the classical inputs and outputs of the protocol, along with the assumption of the completeness and correctness of quantum mechanics [21-23]. In other words, the conclusions hold true regardless of the precise inner workings of the experimental devices.
In more detail, we extend DI entanglement distillation certification from the bipartite scenario [32] to the multipartite scenario. In what follows, we first give a detailed description and definition of what we mean by DI multipartite entanglement distillation. In Section II, we define a DI, 𝑀 -partite entanglement distillation certification protocol, which consists of completeness and soundness conditions. In Section III, we provide a detailed description of a proposed protocol. Our proposed protocol is centered around the Mermin-ArdehaliBelinskii-Klyshko (MABK) inequality [33-35], which is critical to proving the completeness condition. We show in Section IV that the proposed protocol is complete. Thereafter, in Section V, we proceed to proving that it is sound, by making use of the entropy accumulation theorem [36] and the structure of the MABK inequality [37].
## II. DEFINITIONS AND SETUP
In this section, we provide several definitions that we use throughout the rest of the paper, including the GHZ orthonormal basis, the one-shot multipartite distillable entanglement of a multipartite quantum state, an entanglement distillation certification protocol, and basic entropies.
Definition 1 The GHZ orthonormal basis for the set of 𝑀 -qubit states is composed of the following 2 𝑀 states:
$$| \psi _ { \nu, u } \rangle \coloneqq \frac { 1 } { \sqrt { 2 } } \left [ | 0, u \rangle + ( - 1 ) ^ { \nu } | 1, \bar { u } \rangle \right ], \quad \ \ ( 1 ) \quad \ e n t a _ { \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where 𝑣 ∈ { 0 1 , } , while 𝑢 ∈ { 0 1 , } 𝑀 -1 and ¯ 𝑢 = 1 ⊕ 𝑢 are 𝑀 -1 bit strings, with 1 the all-ones bit vector of size 𝑀 -1 .
The one-shot multipartite distillable entanglement of a state quantifies the amount of multipartite entanglement that we can distill from a single copy of the state. It is defined formally as follows:
## Definition 2 (Multipartite distillable entanglement) Let
𝑛 ∈ N and 𝜀 ∈ [ 0 1 , ] . The one-shot distillable 𝑀 -partite entanglement 𝐸 𝜀 𝐷 ( 𝜌 𝐴 [ 𝑀 ] ) of a multipartite state 𝜌 𝐴 [ 𝑀 ] ≡ 𝜌 𝐴 1 ··· 𝐴 𝑀 is defined as
$$\i i u { - } \sum _ { \substack { E _ { D } ^ { \varepsilon } ( \rho _ { A _ { [ M ] } } ) \coloneqq \\ \text{less} \\ \text{nal} \\ \text{nal} \in \text{LOCC} } } & \left \{ \log _ { 2 } d \colon F ( \mathcal { L } _ { A _ { [ M ] } \rightarrow \hat { A } _ { [ M ] } } ( \rho ), \Phi _ { \hat { A } _ { [ M ] } } ^ { d } ) \geq 1 - \varepsilon \right \}, \\ \text{lion} \\ \text{ble}$$
where the optimization is over every LOCC channel L 𝐴 [ 𝑀 ] → [ ˆ 𝐴 𝑀 ] , the fidelity is defined as 𝐹 𝜌, 𝜎 ( ) B GLYPH<13> GLYPH<13> √ √ 𝜌 𝜎 GLYPH<13> GLYPH<13> 2 1 , and Φ 𝑑 ˆ 𝐴 [ 𝑀 ] ≡ | Φ 𝑑 ⟩⟨ Φ 𝑑 | ˆ 𝐴 [ 𝑀 ] is an 𝑀 -party, rank𝑑 GHZ state, with
$$| \Phi _ { \hat { A } _ { [ M ] } } ^ { d } \rangle \coloneqq \frac { 1 } { \sqrt { d } } \sum _ { i = 0 } ^ { d - 1 } | i \rangle _ { A _ { 1 } } \cdots | i \rangle _ { A _ { M } }. \quad \quad ( 3 )$$
The asymptotic distillable entanglement is defined in terms of the following limit:
$$E _ { D } ( \rho _ { A _ { \{ M \} } } ) \coloneqq \inf _ { \varepsilon \in ( 0, 1 ) } \liminf _ { n \to \infty } \frac { 1 } { n } E _ { D } ^ { \varepsilon } ( \rho _ { A _ { \{ M \} } } ^ { \otimes n } ). \quad ( 4 )$$
Since our goal is to quantify multipartite distillable entanglement in a device-independent setting, we want to be able to make statements about the aforementioned quantity that hold regardless of the physical systems involved. In other words, we want to bound this quantity in a device-independent setting.
Let us take a closer look at what this means. To begin with, suppose that all parties 𝐴 , . . . , 𝐴 1 𝑀 are given a share of a multipartite quantum state 𝜌 𝐴 1 ··· 𝐴 𝑀 , which is distributed to them by a possibly unknown entity. Each party also has access to a black box with which they can interact classically. For each classical input, the corresponding black box applies a positive operator-valued measure (POVM) on its respective share of the multipartite state. After the application of the POVM, the box outputs a classical value that is recorded by the corresponding participant. The parties can use the results of the measurements to complete certain tasks of their choosing. If they use only the inputs and outputs from the black box to complete their task, they will have completed the task independent of the underlying physical realization of the measurement and states shared among them. This is the idea behind device independence.
We now define what we mean by a device-independent (DI) protocol for certifying a rate of one-shot distillable multipartite entanglement. Our definition for a DI 𝑀 -partite entanglement distillation certification (DIMEC) protocol is based on the definition of a DI entanglement certification protocol in [32], defined therein for two parties.
Definition 3 (DIMEC protocol) Let 𝑛 ∈ N , let 𝜀 smo , 𝜀 snd , 𝜀 cmp ∈ [ 0 1 , ] , and let 𝑟 ≥ 0 be a threshold 𝑀 -partite distillation rate. Furthermore, let S honest be a set of 'honest' states, each of which is denoted by 𝜙 honest . Let D honest be the set of 'honest' measurement devices. Let P be a protocol employing only multipartite LOCC, which, upon being given a state
𝜎 ∈ D GLYPH<16> ¸ 𝑀 𝑖 = 1 H ⊗ 𝑛 𝐴 𝑖 GLYPH<17> , creates a state 𝜌 ∈ D GLYPH<16> ¸ 𝑀 𝑖 = 1 H ⊗ 𝑛 𝐴 𝑖 GLYPH<17> . Let 𝜌 | Ω denote the final state conditioned on the protocol not aborting.
A protocol P is said to be a DI 𝑀 -partite entanglement distillation certification (DIMEC) protocol if the following conditions hold:
- 1. Noise tolerance (completeness): The probability that P aborts when applied on 𝜙 honest ∈ S honest using a measurement device from D honest is at most 𝜀 cmp .
- 2. Entanglement certification (soundness): For every source 𝜎 and measurement device, either 𝐸 𝑛,𝜀 snd 𝐷 ( 𝜌 | Ω ) ≥ 𝑟 or P aborts with probability greater than 1 -𝜀 smo when applied on 𝜎 .
To design a protocol and show that it satisfies all the conditions in Definition 3, we need to use some informationtheoretic quantities. Here we recall the definitions of von Neumann entropy, coherent information, and smooth conditional max-entropy.
Definition 4 The von Neumann entropy 𝐻 𝐴 ( ) 𝜌 of a state 𝜌 𝐴 is defined as follows:
$$H ( A ) _ { \rho } \coloneqq - \text{Tr} [ \rho _ { A } \log _ { 2 } \rho _ { A } ]. \quad \quad ( 5 ) \quad \overset { \ell } { m } \ \vdots$$
Definition 5 The coherent information 𝐼 ( 𝐴 𝐵 ⟩ ) 𝜌 of a bipartite state 𝜌 𝐴𝐵 is defined as follows:
$$I ( A ) B ) _ { \rho } \coloneqq H ( B ) _ { \rho } - H ( A B ) _ { \rho } = - H ( A | B ) _ { \rho }, \quad ( 6 )$$
where 𝐻 𝐵 ( ) 𝜌 is the von Neumann entropy of 𝜌 𝐵 = Tr 𝐴 [ 𝜌 𝐴𝐵 ] and 𝐻 𝐴 𝐵 ( | ) 𝜌 B 𝐻 𝐴𝐵 ( ) 𝜌 -𝐻 𝐵 ( ) 𝜌 is the quantum conditional entropy of the state 𝜌 𝐴𝐵 .
Definition 6 ([38]) The smooth conditional max-entropy of a bipartite state 𝜌 𝐴𝐵 is defined for all 𝜀 ∈ ( 0 1 , ) as
$$H _ { \max } ^ { \varepsilon } ( A | B ) _ { \rho } \coloneqq \inf _ { \tilde { \rho } \in \mathcal { D } _ { \leq } } H _ { \max }$$
where
$$\mathcal { D } _ { \leq } \coloneqq \{ \omega \geq 0 \, \colon \text{Tr} [ \omega ] \leq 1 \}, \quad \quad ( 8 ) \quad \quad \quad$$
˜ 𝜌 is such that √︁ 1 -𝐹 𝜌, 𝜌 ( ˜ ) ≤ 𝜀 , 𝐻 max ( 𝐴 𝐵 | ) 𝜌 B sup 𝜎 𝐵 log 2 𝐹 𝜌 ( 𝐴𝐵 , I 𝐴 ⊗ 𝜎 𝐵 ) , and 𝐹 𝜌, 𝜎 ( ) B GLYPH<13> GLYPH<13> √ √ 𝜌 𝜎 GLYPH<13> GLYPH<13> 2 1 is the fidelity.
## III. DEVICE-INDEPENDENT MULTIPARTITE ENTANGLEMENT CERTIFICATION PROTOCOL
Before introducing our proposed DIMEC protocol, first we need to discuss the MABK inequality [33-35]. Let 𝑥 𝑖 denote an input to the 𝑖 th measurement device, and let 𝑎 𝑖 denote the outcome of a measurement, where 𝑖 ∈ { 1 , . . . , 𝑀 } and 𝑀 is the number of parties involved. We can then define the MABK inequality as follows.
Definition 7 Let ˆ 𝑂 𝑖 0 and ˆ 𝑂 𝑖 1 be binary observables for all 𝑖 ∈ [ 𝑀 ] . The 𝑀 -partite MABK operator, K 𝑀 , is defined by the following recursion relation:
$$\mathcal { K } _ { M } & \coloneqq \frac { 1 } { 2 } \mathcal { F } ( \mathcal { K } _ { M - 1 }, \overline { \mathcal { K } } _ { M - 1 }, \$$
where K 𝑀 -1 is obtained from K 𝑀 -1 by exchanging ˆ 𝑂 𝑖 0 and ˆ 𝑂 𝑖 1 for all 𝑖 ∈ [ 𝑀 ] and
$$\mathcal { F } ( \hat { B } _ { 0 }, \hat { B } _ { 1 }, \hat { C } _ { 0 }, \hat { C } _ { 1 } )$$
$$\coloneqq \hat { B } _ { 0 } \otimes \left ( \hat { C } _ { 0 } + \hat { C } _ { 1 } \right ) + \hat { B } _ { 1 } \otimes \left ( \hat { C } _ { 0 } - \hat { C } _ { 1 } \right ). \ \ ( 1 1 )$$
The 𝑀 -partite MABK inequalities are then defined for all 𝑀 ≥ 2 as
$$2 ^ { \frac { 4 - M } { 2 } } \left | \text{Tr} \left [ \mathcal { K } _ { M } \, \rho _ { \hat { A } _ { [ M ] } } \right ] \right | \leq 2 ^ { \frac { m - M + 3 } { 2 } }, \ \ m \in [ M ]. \quad ( 1 2 )$$
The MABK inequalities are such that a violation of the inequalities for 𝑚 = 1 proves that at least two parties are entangled, the violation of the inequalities for 𝑚 = 𝑀 -1 proves genuine 𝑀 -partite entanglement, and the case where 𝑚 = 𝑀 gives an upper bound (tight) on what is achievable by quantum mechanics. In this work, we are interested in 𝑚 = 𝑀 -1 and 𝑚 = 𝑀 , which correspond to
$$\beta _ { M } \coloneqq 2 ^ { \frac { 4 - M } { 2 } } \left | \text{Tr} \left [ \mathcal { K } _ { M } \, \rho _ { \hat { A } _ { [ M ] } } \right ] \right | \in [ 2, 2 \sqrt { 2 } ]. \quad ( 1 3 )$$
The CHSH inequality corresponds to
$$\beta _ { 2 } \coloneqq 2 \left | \text{Tr} \left [ \mathcal { K } _ { 2 } \, \rho _ { \hat { A } _ { [ 2 ] } } \right ] \right | \in [ 2, 2 \sqrt { 2 } ]. \quad \quad ( 1 4 )$$
For our purposes, we need to turn the MABK inequality into a game. This can be done using the procedure outlined in [39]. By unraveling the recursion in (9)-(10), we can rewrite the 𝑀 -MABK operator as
$$\mathcal { K } _ { M } = 2 ^ { - 2 \lfloor \frac { M } { 2 } \rfloor } \sum _ { x \in \{ 0, 1 \} ^ { M } } ( - 1 ) ^ { f ( x ) } \bigotimes _ { i \in [ M ] } \hat { O } _ { x _ { i } } ^ { i }, \quad ( 1 5 )$$
where 𝑥 𝑖 ∈ { 0 1 , } is the 𝑖 th bit of 𝑥 and 𝑓 : { 0 1 , } 𝑀 →{ 0 1 , , ⊥} is a function such that (- ) ⊥ 1 = 0 by convention.
For the MABK game, the 𝑀 parties have two measurement settings each, denoted by 𝑥 𝑖 ∈ { 0 1 , and all measurements , } have two possible outcomes, denoted by 𝑎 𝑖 ∈ { 0 1 . Then the , } winning condition for the MABK game is as follows [37]:
$$\text{win} ( x _ { [ M ] }, \, a _ { [ M ] } ) \coloneqq \begin{cases} 1, \text{ if } \bigoplus _ { i = 1 } ^ { M } a _ { i } = f ( x _ { [ M ] } ) \\ 0, \quad \text{else} \end{cases} \, \quad ( 1 6 )$$
where 𝑓 is defined by the 𝑀 -MABK operator in (15). The minimum and maximum winning probabilities when the underlying state is genuinely multipartite entangled are respectively as follows [37]:
$$p _ { \min } \coloneqq 2 ^ { 2 \lfloor \frac { M } { 2 } \rfloor - M - 1 } + 2 ^ { \lfloor \frac { M } { 2 } \rfloor - \frac { M } { 2 } - 2 }, \quad \ \ ( 1 7 )$$
## Protocol 1 : DIMEC protocol based on the MABK game
## Arguments:
M - untrusted measurement device of two components, with inputs and outputs in the set { 0 1 , }
- 𝑛 ∈ N + - number of rounds
- 𝛾 - the probability of conducting a test
𝜔 exp - expected winning probability in the MABK game 𝛿 est ∈ ( 0 1 , ) - width of the statistical confidence interval for the estimation test
𝐴 𝑖, 𝑗 indicates a classical register belonging to the 𝑖 -th party and 𝑗 -th round.
- 1: For every round 𝑗 ∈ [ 𝑛 ] , do steps 2-10:
- 2: Let 𝜙 𝑗 denote the multipartite state produced by the source in this round.
- 3: Set 𝐴 𝑖, 𝑗 , 𝑋 𝑖, 𝑗 , 𝑊 𝑗 = ⊥ for all 𝑖 ∈ [ 𝑀 ] .
- 4: Choose 𝑇 𝑗 = 1 with probability 𝛾 and 𝑇 𝑗 = 0 with probability 1 -𝛾 .
- 5: If 𝑇 𝑗 = 1:
- 6: Choose inputs 𝑋 𝑖, 𝑗 ∈ { 0 1 , } uniformly at random.
- 7: Measure 𝜙 𝑗 using M with the inputs 𝑋 𝑖, 𝑗 and record outputs 𝐴 𝑖, 𝑗 ∈ { 0 1 . , }
- 8: Set 𝑊 𝑗 = 1 if the MABK game is won and 𝑊 𝑗 = 0 otherwise.
- 9: If 𝑇 𝑗 = 0:
$$\begin{smallmatrix} 1 & \cdots & \cdots \\ 1 0 \colon & \text{Keep} \, \phi ^ { j } \, \text{ in the registers} \, \bigotimes _ { i = 1 } ^ { m } \hat { A } _ { i, j }. & \cdots & \cdots \\ 1 1 \colon & \text{Abort if } W \, \coloneqq \, \sum _ { j = 1 } ^ { n } \chi ( T _ { j } = 1 ) \, W _ { j } < ( \omega _ { \exp } \gamma - \delta _ { \text{est} } ) \cdot n. & \cdots \\ \end{smallmatrix}$$
$$p _ { \max } \coloneqq 2 ^ { 2 \lfloor \frac { M } { 2 } \rfloor - M - 1 } + 2 ^ { \lfloor \frac { M } { 2 } \rfloor - \frac { M } { 2 } - \frac { 3 } { 2 } }. \quad \ ( 1 8 ) \quad \begin{matrix} \imath \in \\ \end{matrix}$$
Note that when 𝑀 is even,
$$p _ { \min } ^ { e } = 3 / 4 \quad \text{and} \quad p _ { \max } ^ { e } = ( 2 + \sqrt { 2 } ) / 4. \quad \text{(19)} \quad \text{over}.$$
Similarly when 𝑀 is odd,
$$\dot { \ } p _ { \min } ^ { o } = ( 2 + \sqrt { 2 } ) / 8 \quad \text{and} \quad p _ { \max } ^ { o } = 1 / 2. \quad ( 2 0 ) \quad \text{Multi}$$
Based on the MABK game defined above, we propose Protocol 1. There are two types of rounds in Protocol 1: a testing round, where the parties play the MABK game and record the result, and a storage round, where the parties simply store the state they receive in a quantum memory. At the beginning of each round, we choose between these types uniformly random. The main result of our paper is that Protocol 1 is a DIMEC protocol, satisfying the requirements of Definition 3, and we state this result formally in Theorem 9.
## IV. COMPLETENESS
In this section, we show that Protocol 1 is complete. To prove the completeness condition in Definition 3, we need to show that our protocol applied to an arbitrary 𝜙 honest ∈ S honest aborts with only a small probability. We prove this result in the following theorem.
Theorem 1 The following bound holds:
$$\varepsilon _ { \text{cmp} } \leq \exp \left ( - 2 n \delta _ { \text{est} } ^ { 2 } \right ), \text{ \quad \ \ } \text{(21)}$$
implying that the probability that Protocol 1 aborts for 𝜙 honest ∈ S honest is no larger than exp GLYPH<0> -2 𝑛𝛿 2 est GLYPH<1> .
Proof. Protocol 1 aborts when 𝑊 , the estimator for the MABK game winning probability, is not high enough. This happens when the MABK violation is not large or if the number of samples is not sufficiently large. Whenever 𝜙 honest ∈ S honest and the rounds are independent and identically distributed (IID), i.e., an honest implementation, the sequence GLYPH<0> 𝜒 𝑇 ( 𝑗 = 1 ) 𝑊 𝑗 GLYPH<1> 𝑗 = 1 is a sequence of IID random variables. Using Hoeffding's inequality [40], we conclude that
$$\varepsilon _ { \text{cmp} } = \Pr \left ( W \leq ( \omega _ { \text{exp} } \gamma - \delta _ { \text{est} } ) \cdot n \right ) \leq e ^ { - 2 n \delta _ { \text{est} } ^ { 2 } }, \quad ( 2 2 )$$
completing the proof.
## V. SOUNDNESS
In this section, we prove the soundness of Protocol 1. To do so, we need to show that the protocol ensures a minimum amount of multipartite distillable entanglement or aborts with high probability. First, we briefly discuss a protocol to distill multipartite entanglement from a mixed state. We will use this achievable rate of multipartite distillable entanglement to prove the soundness of Protocol 1.
Consider the following setting: a pure state 𝜓 𝐴 1 ··· 𝐴 𝑀 𝐵𝑅 is held by 𝑀 + 2 parties, with the 𝑖 th sender holding 𝐴 𝑖 , for 𝑖 ∈ { 1 , . . . , 𝑀 } C [ 𝑀 ] , one receiver holding 𝐵 , and a reference system holding 𝑅 , which serves as a purifying system. Additionally, Alice𝑖 and Bob share a maximally entangled state Φ ( 𝑐 𝑖 ) 𝐴 𝐵 ′ 𝑖 ′ 𝑖 of Schmidt rank 𝑐 𝑖 ∈ N , and so the initial overall state is
$$\psi _ { A _ { 1 } \cdots A _ { M } B R } \otimes \Phi ( c _ { 1 } ) _ { A ^ { \prime } _ { 1 } B ^ { \prime } _ { 1 } } \otimes \cdots \otimes \Phi ( c _ { M } ) _ { A ^ { \prime } _ { M } B ^ { \prime } _ { M } }. \quad ( 2 3 )$$
Multiparty state merging is an LOCC protocol that transforms this initial state to
$$g _ { \lambda } \quad \psi _ { \hat { A } _ { 1 } \cdots \hat { A } _ { M } \hat { B } R } \otimes \Phi ( d _ { 1 } ) _ { A ^ { \prime \prime } _ { 1 } B ^ { \prime \prime } _ { 1 } } \otimes \cdots \otimes \Phi ( d _ { M } ) _ { A ^ { \prime \prime } _ { M } B ^ { \prime \prime } _ { M } }, \quad ( 2 4 )$$
such all of the systems ˆ 𝐴 1 · · · ˆ 𝐴 𝑀 ˆ 𝐵 are in Bob's possession. (For details, see Section 6.3 of [41].) If 𝑐 𝑖 > 𝑑 𝑖 , then the protocol consumes log 2 𝑐 𝑖 -log 2 𝑑 𝑖 ebits shared between 𝐴 𝑖 and 𝐵 . If 𝑐 𝑖 < 𝑑 𝑖 , then the protocol produces log 2 𝑑 𝑖 -log 2 𝑐 𝑖 ebits, which are shared between 𝐴 𝑖 and 𝐵 (recall that the term 'ebit' is synonymous with the standard Bell pair). If the protocol distills ebits between each Alice, 𝐴 1 · · · 𝐴 𝑀 , and Bob 𝐵 , then they can apply LOCC to convert several copies of their ebits into multipartite GHZ states.
For a one-shot realization of the entire process of using LOCC to convert 𝜓 𝐴 1 ··· 𝐴 𝑀 𝐵𝑅 into a GHZ state, we need only understand the one-shot behavior of the state merging step. The theorem needed for the state merging step is as follows:
Theorem 2 (Theorem 6.15 of [41]) Given the setting above, quantum state merging can be achieved successfully, in the sense that the fidelity constraint in (2) holds, for
$$\varepsilon = 8 \cdot 3 ^ { M / 2 } \sqrt { \varepsilon ^ { \prime } } \in ( 0, 1 ), \text{ \quad \ \ } ( 2 5 )$$
if for all 𝐾 ⊆ [ 𝑀 ] such that 𝐾 ≠ ∅ ,
$$\sum _ { k \in K } ( \log _ { 2 } d _ { k } - \log _ { 2 } c _ { k } ) & \quad \text{$\ u v $ 1$} \\ & \leq - H _ { \max } ^ { \varepsilon ^ { \prime } } ( A _ { K } | A _ { K ^ { c } } B ) _ { \psi } + 2 \log \varepsilon ^ { \prime }. \ \ ( 2 6 ) \quad \text{$\ u v $ 1$} \\ & \quad \text{$\ u v $ 1$}$$
Using the above theorem and the steps elucidated earlier, we conclude the following:
Theorem 3 (Theorem 9 of [42]) Let 𝜌 𝐴 1 ··· 𝐴 𝑀 be a state held by 𝑚 parties. The following is an achievable rate for GHZ distillation under LOCC:
$$\max _ { k \in [ M ] } \left \{ \min _ { K \subseteq [ M ] \vee k } \frac { I ( A _ { K } \rangle A _ { [ M ] \vee K } ) _ { \rho } } { | K | } \right \}, \quad ( 2 7 ) \quad \ \ 2$$
where 𝐼 ( 𝐴 𝐵 ⟩ ) 𝜃 is the coherent information of a state 𝜃 𝐴𝐵 .
The statement above gives a bound only on the asymptotic rate of GHZ distillation from mixed states. For our purpose, we require a lower bound on 1 𝑛 𝐸 𝜀 𝐷 ( 𝜌 ⊗ 𝑛 𝐴 [ 𝑀 ] ) . The following proposition gives such a bound by making use of the developments of [41, 42].
Proposition 1 Let 𝜌 𝐴 1 ··· 𝐴 𝑀 be held by 𝑚 parties. Fix 𝜀 ′ > 0 such that 𝜀 B 8 · 3 𝑀 / 2 √ 𝜀 ′ ∈ ( 0 1 , ) . Then the following is an achievable one-shot rate for GHZ distillation under LOCC; i.e.,
$$\frac { 1 } { n } E _ { D } ^ { \varepsilon } ( \rho _ { A _ { [ M ] } } ^ { \otimes n } ) & \geq & \text{or} \, \text{the} \\ \max _ { k \in [ M ] } & \left \{ \min _ { K \subseteq [ M ] \vee k } \frac { - H _ { \max } ^ { \varepsilon ^ { \prime } } ( A _ { K } | A _ { [ M ] \vee K } ) _ { \rho } } { | K | } \right \} + \frac { 2 \log \varepsilon ^ { \prime } } { M - 1 }. \quad ( 2 8 ) \text{ \quad \text{error} } \text{associ} \\ & \text{is call} \text{ }$$
Proof. To achieve this one-shot rate, we can use the protocol outlined in [42, Theorem 9] but without time sharing. Time shared decoding is replaced with simultaneous decoding, as the former is not possible in the one-shot setting. We obtain achievable rates for the one-shot case by replacing coherent information in (27) with the conditional smooth max-entropy. This leaves us with an expression commensurate with (26) in Theorem 2.
## A. Entropy Accumulation Theorem (EAT)
To certify that a minimum amount of multipartite entanglement can be distilled from the states left over at the end of 𝑛 rounds of Protocol 1, we need to lower bound -𝐻 𝜀 max GLYPH<16> 𝐴 ⊗ 𝑛 𝐾 | 𝐴 ⊗ 𝑛 [ 𝑀 ]\ 𝐾 GLYPH<17> 𝜌 ⊗ 𝑛 . Since this is a finite-length protocol and we are interested in a smooth entropic quantity, we can use Entropy Accumulation Theory (EAT) to obtain a rate 𝑟 in terms of the desired error constants. To apply EAT, one needs to define 'EAT channels,' which describe the sequential process under consideration, and max-tradeoff functions. In our case, the sequential process results from our protocol for the certification of multipartite entanglement distillation.
For a sequential process like our protocol, the most restrictive relation between the rounds is to assume that they are IID. However, such a restriction is arguably too strong for the device-independent scenario. Entropy accumulation theory allows for a more general relation between the rounds of our protocol. This is encapsulated in the following definition of EAT channels.
Definition 8 (EAT channels [36]) An EAT channel N 𝑗 : 𝑅 𝑗 -1 → 𝑅 𝑂 𝑆 𝑊 𝑗 𝑗 𝑗 𝑗 , for 𝑗 ∈ [ 𝑛 ] , is a CPTP map, such that, for all 𝑗 ∈ [ 𝑛 ] :
- 1. 𝑊 𝑗 is a finite-dimensional classical system. 𝑆 𝑗 and 𝑅 𝑗 are arbitrary quantum systems.
- 2. Given an input state 𝜎 𝑅 𝑗 -1 , the output state 𝜎 𝑅 𝑂 𝑆 𝑊 𝑗 𝑗 𝑗 𝑗 = N 𝑗 GLYPH<16> 𝜎 𝑅 𝑗 -1 GLYPH<17> has the property that one can perform a quantum instrument on the systems 𝑂 𝑆 𝑗 𝑗 (in the state 𝜎 𝑂 𝑆 𝑗 𝑗 ), obtain the classical register 𝑊 𝑗 , and discard it, without changing the state 𝜎 𝑂 𝑆 𝑗 𝑗 . That is, for the instrument T 𝑗 : 𝑂 𝑆 𝑗 𝑗 → 𝑂 𝑆 𝑊 𝑗 𝑗 𝑗 describing the process of obtaining 𝑊 𝑗 from 𝑂 𝑗 and 𝑆 𝑗 , it holds that ( Tr 𝑊 𝑗 ◦T ) 𝑗 GLYPH<16> 𝜎 𝑂 𝑆 𝑗 𝑗 GLYPH<17> = 𝜎 𝑂 𝑆 𝑗 𝑗 .
- 3. 𝑂 𝑗 is a finite-dimensional quantum system of dimension 𝑑 𝑂 𝑗 .
If the rounds are not IID, then we cannot consider a round of the protocol to be completely independent of the preceding rounds. In other words, we cannot use the additivity property of the quantities under consideration. To resolve this, entropy accumulation theory requires that a special function, associated with our protocol, be found. This special function is called the max-tradeoff function.
To define max-tradeoff functions, we need to clarify some notation, which we will use henceforth. Given a value 𝑤 = ( 𝑤 , . . . , 𝑤 1 𝑛 ) ∈ W 𝑛 , where W is a finite alphabet, we denote by freq 𝑤 the probability distribution over W defined by freq 𝑤 ( ˜ 𝑤 ) B |{ 𝑗 | 𝑤 𝑗 = ˜ 𝑤 }| 𝑛 for ˜ 𝑤 ∈ W . If 𝜏 is a state classical on 𝑊 , we write Pr [ 𝑤 ] 𝜏 to denote the probability that 𝜏 assigns to 𝑤 . Now, we move on to the definition of max-tradeoff functions.
Definition 9 (Max-tradeoff functions [36]) Let N 1 , . . . , N 𝑛 be a family of EAT channels. Let W denote the common alphabet of 𝑊 , . . . , 𝑊 1 𝑛 . Aconcave[43]function 𝑓 max from the set of probability distributions 𝑝 over W } to the real numbers is called a max-tradeoff function for {N 𝑗 𝑗 if it satisfies
$$\text{and} \quad f _ { \max } ( p ) & \geq \sup _ { \sigma } \left \{ H ( O _ { j } \Big | S _ { j } ) _ { N _ { j } ( \sigma ) } \colon \text{Tr} _ { R _ { j } O _ { j } S _ { j } } [ N _ { j } ( \sigma ) ] = p \right \}, \\ \text{can} \quad \epsilon \dots \, \pi \, \colon = \, \text{$r_{\nu}$} \dots \, \pi \, \colon \dots \, \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi \, \colon \dots \, \dots \, \pi$$
for all 𝑗 ∈ [ 𝑛 ] , where the supremum is taken over all input states of N 𝑗 for which the marginal on 𝑊 𝑗 of the output state is the probability distribution 𝑝 .
The statement of the EAT, relevant for the smooth maxentropy, is given below (see [36, Theorem 4.4] and Eq. (A.2) of [44, Appendix A]).
Theorem 4 ([36, 44]) Let N 𝑗 : 𝑅 𝑗 -1 → 𝑅 𝑂 𝑆 𝑊 𝑗 𝑗 𝑗 𝑗 for 𝑗 ∈ [ 𝑛 ] be a sequence of EAT channels as in Definition 8, 𝜏 𝑂𝑆𝑊 = GLYPH<0> Tr 𝑅 𝑛 ◦N 𝑛 ◦ · · · ◦ N 1 GLYPH<1> ( 𝜏 𝑅 0 ) the final state, Ω an event defined over W 𝑛 indicating acceptance, Pr [ Ω ] 𝜏 the probability of acceptance given the underlying state 𝜏 , and 𝜏 | Ω the final state conditioned on Ω .
Let 𝜀 smo ∈ ( 0 1 , ) . For 𝑓 max a max-tradeoff function for {N } 𝑗 𝑗 , as in Definition 9, and all 𝑡 ∈ R such that 𝑓 max GLYPH<0> freq 𝑤 GLYPH<1> ≤ 𝑡 for all 𝑤 ∈ W 𝑛 for which Pr [ 𝑤 ] 𝜏 | Ω > 0 , the following holds:
$$H _ { \max } ^ { \varepsilon _ { \text{smo} } } \left ( O | S \right ) _ { \tau _ { \text{j} \Omega } } \leq n t + v \sqrt { n } \,, \quad \quad \left ( 3 0 \right ) \quad \text{I}$$
where 𝑑 𝑂 𝑖 denotes the dimension of 𝑂 𝑖 and
$$v \coloneqq 2 \left ( \log _ { 2 } ( 1 + 2 d _ { O _ { i } } ) & + \lceil \| \nabla f _ { \max } \| _ { \infty } \rceil \right ) \\ & \times \sqrt { 1 - 2 \log _ { 2 } ( \varepsilon _ { s m o } \cdot \Pr [ \Omega ] _ { \tau } ) }. \quad ( 3 1 ) \quad \text{the m} \quad.$$
It has been shown that Theorem 4, the generalized entropy accumulation theorem, holds regardless of whether the sequence of channels {N } 𝑗 𝑗 satisfies a Markov-chain condition [44, Appendix A]. Note that the original entropy accumulation theorem [36] does require such a Markov-chain condition.
## B. EAT Channels
In this subsection, we prove that Protocol 1, for all 𝑗 ∈ [ 𝑛 ] , satisfies the conditions for EAT channels, N 𝑗 : 𝑅 𝑗 -1 → 𝑅 𝑂 𝑆 𝑊 𝑗 𝑗 𝑗 𝑗 as outlined in Definition 8. This is a necessary condition for the application of the entropy accumulation theorem [36].
Consider Condition 1 of Definition 8. We can think of 𝑅 𝑗 as a source distributing the states across the network. As far we are concerned, it is an arbitrary quantum system. 𝑊 𝑗 is the classical register associated with determining whether the MABK game has been won. 𝑊 𝑗 is finite dimensional as it can take only three values. 𝑆 𝑗 consists of all the systems involved in the protocol, except for the system ˆ 𝐴 [ 𝑀 , 𝑗 ′ ] for some 𝑀 ′ ∈ [ 𝑀 -1 . ]
For Condition 2 of Definition 8, we can see that 𝑊 𝑗 is determined using only the classical values 𝐴 𝑖, 𝑗 and 𝑋 𝑖, 𝑗 and does not affect the classical and quantum registers.
Finally, we are left with Condition 3 of Definition 8. Checking these conditions is more involved. First, we note that Protocol 1 makes use of the MABK inequality, which involves two inputs and two outputs for all parties involved. This allows us to apply Jordan's lemma on every party. Now, we recall Jordan's lemma [45]:
Theorem 5 (Lemma 4.1 in [45]) Let ˆ 𝑂 0 and ˆ 𝑂 1 be two Hermitian operators with eigenvalues -1 and + 1 . Then there exists a basis in which both operators are block diagonal, in blocks of dimension 2 × 2 at most.
For each party 𝐴 𝑖 and for every round 𝑗 , we can reduce the associated binary observables ˆ 𝑂 𝑖, 𝑗 0 and ˆ 𝑂 𝑖, 𝑗 1 to a blockdiagonal form in a suitable local basis using Theorem 5. The block-diagonal form is as follows:
$$\overset { - } { d } _ { f } \, \int \, \hat { O } _ { 0 } ^ { i, j } = \bigoplus _ { d _ { i, j } } O _ { 0 } ^ { d _ { i, j } } = \bigoplus _ { d _ { i, j } } \sigma _ { y } ^ { d _ { i, j } },$$
$$\hat { o } _ { 1 } ^ { i, j } = \bigoplus _ { d _ { i, j } } O _ { 1 } ^ { d _ { i, j } }$$
$$= \bigoplus _ { d _ { i, j } } \left ( \cos ( \alpha _ { d _ { i, j } } ) \, \sigma _ { y } ^ { d _ { i, j } } + \sin ( \alpha _ { d _ { i, j } } ) \, \sigma _ { x } ^ { d _ { i, j } } \right ). \quad ( 3 4 )$$
Let Π 𝑑 𝑖, 𝑗 denote the projection onto the 𝑑 𝑖, 𝑗 th block. If we act with the projection Π 𝑑 𝑖, 𝑗 on 𝜌 ˆ 𝐴 [ 𝑀 ,𝑗 ] , then we obtain the index 𝑑 𝑖, 𝑗 of the corresponding Jordan block. Hence, after the application of the projection, the system possessed by each party is a two-dimensional system. This is true of ˆ 𝐴 𝑖, 𝑗 especially, which satisfies Condition 3. After party 𝑖 performs the measurement { Π 𝑑 𝑖, 𝑗 } 𝑑 𝑖, 𝑗 for round 𝑗 , for all 𝑖 ∈ [ 𝑀 ] , the post-measurement state is as follows:
$$\underset { \text{ion} } { \text{se-} } \frac { \left ( \bigotimes _ { i = 1 } ^ { M } \Pi _ { d _ { i, j } } \right ) \rho _ { \hat { A } _ { [ M ], j } } \left ( \bigotimes _ { i = 1 } ^ { M } \Pi _ { d _ { i, j } } \right ) } { \text{Tr} \left [ \left ( \bigotimes _ { i = 1 } ^ { M } \Pi _ { d _ { i, j } } \right ) \rho _ { \hat { A } _ { [ M ], j } } \right ] } \otimes \left ( \bigotimes _ { i = 1 } ^ { M } | d _ { i, j } \chi ( d _ { i, j } | \right ). \\ \text{Note that all quantum registers have been reduced to submit}$$
Note that all quantum registers have been reduced to qubit registers.
Using these projections, we produce Protocol 2. Protocol 2 is a device-dependent version of Protocol 1 but has the same winning probability as Protocol 1. This is due the fact that, regardless of the value of 𝑇 𝑗 and for any 𝑑 𝑗 = 𝑑 1 , 𝑗 · · · 𝑑 𝑀,𝑗 , the underlying state can thought of as being in the following state [46, Theorem 1]:
$$\colon \text{of} \quad \tilde { \rho } ^ { d _ { j } } \coloneqq \sum _ { u \in \{ 0, 1 \} } & \left [ \lambda _ { 0, u } ^ { d _ { j } } | \psi _ { 0, u } \rangle \langle \psi _ { 0, u } | + \lambda _ { 1, u } ^ { d _ { j } } | \psi _ { 1, u } \rangle \langle \psi _ { 1, u } | \\ \text{her} \quad & + \text{is} _ { u } ^ { d _ { j } } \left ( | \psi _ { 0, u } \rangle \langle \psi _ { 1, u } | - | \psi _ { 1, u } \rangle \langle \psi _ { 0, u } | \right ) \, \right ], \quad ( 3 6 )$$
where i 2 = -1, 𝑠 𝑑 𝑗 𝑢 , 𝜆 𝑑 𝑗 0 ,𝑢 ∈ [ 0 1 , and , ] 𝜓 0 ,𝑢 , 𝜓 1 ,𝑢 are defined in Definition 1. Hence, the projective measurement detailed earlier will neither change the winning probability nor the amount of multipartite entanglement produced by the source. (This is true for any two-input two-output, or ( 𝑀 , 2, 2), fullcorrelator Bell inequality [46, Theorem 1], like the MABK inequality we consider here.)
We will use Protocol 2 only to make statements about the soundness of Protocol 1. First, we need to clarify some notation. As before, the index 𝑖 will denote the party, and index 𝑗 will denote the round of the protocol. ˆ 𝐴 [ 𝑀 ] [ 𝑛 ] refers to all the quantum registers ˆ 𝐴 𝑖, 𝑗 possessed by the respective parties at the end of the protocol before conditioning on the outcome of the protocol. 𝐴 [ 𝑀 ] [ 𝑛 ] refers to the classical registers 𝐴 𝑖, 𝑗 containing the inputs of the protocol used by the parties in each round, regardless of the 𝑇 𝑗 of said rounds. 𝐷 [ 𝑀 ] [ 𝑛 ] contains the results of the Jordan block projection 𝐷 𝑖, 𝑗 performed in each round of the protocol. 𝑋 [ 𝑀 ] [ 𝑛 ] refers to the classical registers containing output 𝑋 𝑖, 𝑗 from all the rounds of the protocol. For convenience, we shall refer to 𝐴 [ 𝑀 ] [ 𝑛 ] , 𝐷 [ 𝑀 ] [ 𝑛 ] ,
## Protocol 2 : DIMEC protocol based on the MABK game
## Arguments:
M - untrusted measurement device of two components, with inputs and outputs in the set { 0 1 , }
𝑛 ∈ N + - number of rounds 𝛾 - the probability of conducting a test 𝜔 exp - expected winning probability in the MABK game 𝛿 est ∈ ( 0 1 , ) - width of the statistical confidence interval for the estimation test
𝐴 𝑖, 𝑗 indicates a classical register belonging to the 𝑖 -th party and 𝑗 -th round.
- 1: For every round 𝑗 ∈ [ 𝑛 ] , do steps 2-11:
- 2: Let 𝜙 𝑗 denote the multipartite state produced by the source in this round.
- 3: Set 𝐴 𝑖, 𝑗 , 𝑋 𝑖, 𝑗 , 𝑊 𝑗 = ⊥ for all 𝑖 ∈ [ 𝑀 ] .
- 4: Choose 𝑇 𝑗 = 1 with probability 𝛾 and 𝑇 𝑗 = 0 with probability 1 -𝛾 .
- 5: If 𝑇 𝑗 = 1:
- 6: Choose inputs 𝑋 𝑖, 𝑗 ∈ { 0 1 , } uniformly at random.
- 7: Measure 𝜙 𝑗 using M with the inputs 𝑋 𝑖, 𝑗 and record outputs 𝐴 𝑖, 𝑗 ∈ { 0 1 . , }
- 8: Set 𝑊 𝑗 = 1 if the MABK game is won and 𝑊 𝑗 = 0 otherwise.
- 9: If 𝑇 𝑗 = 0:
- 10: Apply projections described in (35).
- 11: Keep 𝜙 𝑗 in the registers ¸ 𝑚 𝑖 = 1 ˆ 𝐴 𝑖, 𝑗 .
- 12: Abort if 𝑊 = ˝ 𝑛 𝑗 = 1 𝜒 𝑇 ( 𝑗 = 1 ) 𝑊 < 𝜔 𝑗 ( exp 𝛾 -𝛿 est ) 𝑛 .
and 𝑋 [ 𝑀 ] [ 𝑛 ] together as ( 𝐴𝐷𝑋 ) [ 𝑀 ] [ 𝑛 ] . 𝑊 and 𝑇 refer to the classical registers containing 𝑊 𝑗 and 𝑇 𝑗 , respectively, from all the rounds of the protocol.
## C. Max-Tradeoff Function
In this section, we obtain a max-tradeoff function that satisfies Definition 9. We are interested in finding an upper bound on the following quantity:
$$\sup _ { \sigma } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { \mathcal { N } _ { j } ( \sigma ) },$$
for all 𝑗 ∈ [ 𝑛 ] and 𝑀 ′ ∈ [ 𝑀 - ] 1 , where the supremum is taken over all input states of N 𝑗 for which the marginal on 𝑊 𝑗 of the output state is the probability distribution 𝑝 . Henceforth, we shall refer this set of states as
$$\Sigma _ { p } \coloneqq \left \{ \sigma \left | \mathcal { N } _ { j } ( \sigma ) _ { W _ { j } } = p \right \}. \quad \quad ( 3 8 ) \quad \text{to } \mathfrak { l }$$
We will first simplify (37). Note that the following equality holds:
$$\sum _ { x } p ( x ) H ( A | B ) _ { \rho ^ { x } } = H ( A | B X ) _ { \tilde { \rho } }, \quad \ \ ( 3 9 ) \, \stackrel { x \dots } { \text{stat} } \\.$$
where { 𝑝 𝑥 ( )} 𝑥 is a probability distribution, { 𝜌 𝑥 𝐴𝐵 } 𝑥 is a set of states, ˜ 𝜌 𝐴𝐵𝑋 B ˝ 𝑥 𝑝 𝑥 ( ) 𝜌 𝑥 𝐴𝐵 ⊗ | 𝑥 ⟩⟨ 𝑥 | , and {| 𝑥 ⟩} 𝑥 is an orthonormal basis. Using this, we find that
$$\sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { \mathcal { N } _ { j } ( \sigma ) } =$$
$$\overline { \underset { \sigma \in \Sigma _ { p } } { \Xi } } \quad & \sup _ { \sigma \in \Sigma _ { p } } \left [ \Pr ( T _ { j } = 0 ) H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } \right ) _ { N ^ { 0 } _ { j } ( \sigma ) } \\ \intertext { a t s, } & + \Pr ( T _ { j } = 1 ) H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } \right ) _ { N ^ { 0 } _ { j } ( \sigma ) } \right ], \\ \intertext { ne } & \quad \wedge \.$$
where N ( 0 𝑗 𝜎 ) corresponds to the state when 𝑇 𝑗 = 0, and N ( 1 𝑗 𝜎 ) corresponds to the state when 𝑇 𝑗 = 1. Note that 𝑇 𝑗 = 1 corresponds to a round where we apply measurements to play the MABK game and each ˆ 𝐴 𝑖, 𝑗 is in a deterministic state for all 𝑖 ∈ [ 𝑀 ] . This implies that
$$H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } \right ) _ { \mathcal { N } ^ { \jmath } _ { j } ( \sigma ) } = 0. \quad ( 4 1 )$$
Hence,
$$\sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { \mathcal { N } _ { j } ( \sigma ) } =$$
$$\text{record} \quad & \sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { \mathcal { N } _ { j } ( \sigma ) } = \\ \int _ { j } = 0 \quad & \left ( 1 - \gamma \right ) \sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } \right ) _ { \mathcal { N } _ { j } ^ { 0 } ( \sigma ) }.$$
To calculate an upper bound on the above quantity, we will use the fact that the conditional entropy is concave [47]:
$$\sum _ { x } p ( x ) H ( A | B ) _ { \rho ^ { x } } \leq H ( A | B ) _ { \bar { \rho } }, \text{ \quad \ \ } ( 4 3 )$$
where the notation is the same as in (39) and ¯ 𝜌 𝐴𝐵 B ˝ 𝑥 𝑝 𝑥 ( ) 𝜌 𝑥 𝐴𝐵 . We will also make use of the bipartition between systems represented by the vertical bar in (37), which means that we can make use of local operations with respect to this bipartition. Given a particular 𝐷 [ 𝑀 ,𝑗 ] at the end of the 𝑗 th round of Protocol 2, the state ˜ 𝜌 𝑑 𝑗 in (36) has a simple structure in the GHZ basis. We can rewrite the GHZ basis, from Definition 1, in the following fashion:
$$| \psi _ { \nu, u, w } \rangle \equiv \frac { 1 } { \sqrt { 2 } } \left [ | w, u \rangle + ( - 1 ) ^ { \nu } | \bar { w }, \bar { u } \rangle \right ], \quad ( 4 4 )$$
where 𝑣 ∈ { 0 1 , while , } 𝑢 ∈ { 0 1 , } 𝑀 𝑀 -′ and ¯ 𝑢 = 1 ⊕ 𝑢 are 𝑀 -𝑀 ′ bit strings, and 𝑤 ∈ { 0 1 , } 𝑀 ′ and ¯ 𝑤 = 1 ⊕ 𝑤 are 𝑀 ′ bit strings.
Within the partition denoted by 𝑢 , we can choose one qubit to be the control qubit, 𝑢 1, and then apply CNOTs on all the other qubits. We apply similar set of operations on the partition denoted by 𝑤 with the first qubit containing 𝑤 1 as the control qubit. These operations transform the 𝑀 -partite GHZ basis states into the following state:
$$\text{set} \quad \frac { 1 } { 2 } \left ( | u _ { 1 }, w _ { 1 } \rangle + ( - 1 ) ^ { v } | \bar { u } _ { 1 }, \bar { w } _ { 1 } \rangle \right ) \otimes | u _ { 2 } \cdots u _ { M ^ { \prime } } \rangle \\ \text{an} \quad \otimes | w _ { 2 } \cdots w _ { M - M ^ { \prime } } \rangle, \ \ ( 4 5 )$$
where 𝑢 , 𝑤 𝑖 𝑖 ∈ { 0 1 . , } The above state is a Bell-basis state between the control qubits containing 𝑢 1 and 𝑤 1. After the
CNOTs,asdescribedabove, are applied on the state ˜ 𝜌 𝑑 𝑗 in (36), there are still off-diagonal terms in the resulting state. To make the final state diagonal in the Bell basis, we use the following twirling channel [48]:
$$\mathcal { T } ( \rho ) = \frac { 1 } { 4 } & \left ( \rho + ( X \otimes X ) \rho \, ( X \otimes X ) + \quad & \text{and} \, h _ { \ell } \\ & \quad ( Y \otimes Y ) \rho \, ( Y \otimes Y ) + ( Z \otimes Z ) \rho \, ( Z \otimes Z ) \right ). \quad ( 4 6 ) \quad & \text{proof} \quad & \text{and} \, \text{th} \quad & \text{$\omega$} \quad & \text{$\_}$$
Now that we have simplified the underlying state, we make the following observation about the MABK inequality.
Lemma 1 An 𝑀 -partite MABK inequality (12) is equivalent to the CHSH inequality within any bipartition consisting of 𝑀 ′ parties on one side and the 𝑀 -𝑀 ′ other parties on the other side such that, for some ˆ 𝑂 [ 𝑀 𝑀 -′ + ] 1 0 and ˆ 𝑂 [ 𝑀 𝑀 -′ + ] 1 1 , K 𝑀 is equal to
$$\frac { 1 } { 2 } \mathcal { F } \left ( \mathcal { K } _ { M - M ^ { \prime } }, \overline { \mathcal { K } } _ { M - M ^ { \prime } }, \hat { O } _ { 0 } ^ { [ M - M ^ { \prime } + 1 ] }, \hat { O } _ { 1 } ^ { [ M - M ^ { \prime } + 1 ] } \right ).$$
## Proof. See Appendix A.
Given the above operations and Lemma 1, we can use a prior result from [32, Lemma 14] to obtain our max-tradeoff function. We can replace the CHSH violation 𝛽 2 in (14) with the multipartite MABK violation 𝛽 𝑀 in (13) for our case. We restate [32, Lemma 14] for convenience.
Lemma 2 (Lemma 14 of [32]) For every Bell-diagonal state 𝜎 ˆ 𝐴𝐵 ˆ that can be used to violate the CHSH inequality with violation 𝛽 2 ∈ [ 2 2 , √ 2 ] , the following inequality holds:
$$H ( \hat { A } | \hat { B } ) \leq 2 h _ { 2 } \left ( \frac { 1 } { 2 } - \frac { \beta _ { 2 } } { 4 \sqrt { 2 } } \right ) - 1, \quad \quad ( 4 8 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where ℎ 2 ( 𝑝 ) B -𝑝 log 2 𝑝 - ( 1 -𝑝 ) log 2 ( 1 -𝑝 ) is the binary entropy function and 𝛽 2 is defined in (14) .
These lemmas can be applied to Protocol 2 in the following manner. Using Lemma 1 and Lemma 2, we find that
$$\sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { N _ { j } ( \sigma ) } & \quad \text{and} \quad \\ \leq \left ( 1 - \gamma \right ) \left ( 2 h _ { 2 } \left ( \frac { 1 } { 2 } - \frac { \beta _ { M } } { 4 \sqrt { 2 } } \right ) - 1 \right ), \quad ( 4 9 ) & \quad f ( p$$
where 𝛽 𝑀 is defined in (13). Using (49), we can state the following theorems.
Theorem 6 For all 𝑀 ′ ∈ [ 𝑀 ] with 𝑀 even and 𝜔 ∈ [ 𝑝 𝑒 min , 𝑝 𝑒 max ] as defined in (19) , respectively, let Σ 𝑝 (defined in (38) ) be such that the winning probability is strictly greater than 𝜔 (i.e., 𝑝 ( 1 )/ 𝛾 > 𝜔 ). Then,
$$\sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { N _ { j } ( \sigma ) } \quad \quad f _ { \max } \\ \leq ( 1 - \gamma ) \cdot g _ { e } ( \omega ), \ \ ( 5 0 )$$
where 𝛾 is defined in Protocol 1,
$$g _ { e } ( \omega ) \coloneqq 2 h _ { 2 } \left ( \frac { 1 } { 2 } - \frac { 2 \omega - 1 } { \sqrt { 2 } } \right ) - 1, \text{ \quad \ \ } ( 5 1 )$$
and ℎ 2 ( 𝑝 ) is the binary entropy function.
Proof. When 𝑀 is even, the MABK game winning probability and the MABK violation in (12) are related as follows [37]: 𝛽 𝑀 = 8 𝜔 -4. Substituting 𝛽 𝑀 = 8 𝜔 -4 in (49), we get the required result.
Theorem 7 For all 𝑀 ′ ∈ [ 𝑀 ] with 𝑀 odd and 𝜔 ∈ [ 𝑝 𝑜 min , 𝑝 𝑜 max ] as defined in (20) , respectively, let Σ 𝑝 (defined in (38) ) be such that the winning probability is strictly greater than 𝜔 (i.e., 𝑝 ( 1 )/ 𝛾 > 𝜔 ). Then,
$$\sup _ { \sigma \in \Sigma _ { p } } H \left ( \hat { A } _ { [ M ^ { \prime } ], j } | \hat { A } _ { [ M ^ { \prime } + 1, M ], j } \left ( A D X \right ) _ { [ M ], j } T _ { j } \right ) _ { N _ { j } ( \sigma ) } \\ \leq ( 1 - \gamma ) \cdot g _ { o } ( \omega ), \quad ( 5 2 )$$
where 𝛾 is defined in Protocol 1,
$$g _ { o } ( \omega ) \coloneqq 2 h _ { 2 } \left ( \frac { 1 } { 2 } - \frac { 4 \omega - 1 } { 2 } \right ) - 1, \text{ \quad \ \ } ( 5 3 )$$
and ℎ 2 ( 𝑝 ) is the binary entropy function.
Proof. When 𝑀 is odd, the MABK game winning probability and the MABK violation in (12) are related as follows [37]: 𝛽 𝑀 = 8 √ 2 𝜔 -2 √ 2. Substituting 𝛽 𝑀 = 8 √ 2 𝜔 -2 √ 2 in (49), we get the required result.
These theorems serve as the basis for our max-tradeoff function. Using Theorems 6 and 7 to define a max-tradeoff function for all 𝑝 with 𝑝 ( 1 )/ 𝛾 ∈ [ 𝑝 min , 𝑝 max ] . Define a function 𝑓 in the following fashion: when 𝑀 is even
$$\inf _ { \ } f ( p, M ) \coloneqq \begin{cases} ( 1 - \gamma ) \cdot g _ { e } \left ( \frac { p ( 1 ) } { \gamma } \right ) & \frac { p ( 1 ) } { \gamma } \in \left [ 0, p _ { \max } ^ { e } \right ] \\ \gamma - 1 & \frac { p ( 1 ) } { \gamma } \in \left [ p _ { \max } ^ { e }, 1 \right ] \end{cases}, \ \ ( 5 4 )$$
and when 𝑀 is odd,
$$f ( p, M ) \coloneqq \begin{cases} ( 1 - \gamma ) \cdot g _ { o } \left ( \frac { p ( 1 ) } { \gamma } \right ) & \frac { p ( 1 ) } { \gamma } \in \left [ 0, p _ { \max } ^ { o } \right ] \\ \gamma - 1 & \frac { p ( 1 ) } { \gamma } \in \left [ p _ { \max } ^ { o }, 1 \right ] \end{cases}, \ \ ( 5 5 )$$
From Theorems 6 and 7, we know that any choice of 𝑓 max ( 𝑝, 𝑀 ) that is differentiable and satisfies 𝑓 max ( 𝑝, 𝑀 ) ≥ 𝑓 ( 𝑝, 𝑀 ) for all 𝑝 will be a valid max-tradeoff function for our EAT channels. Since the derivatives of 𝑓 in (54) and (55) at 𝑝 ( 1 )/ 𝛾 = 𝑝 𝑒 max and 𝑝 ( 1 )/ 𝛾 = 𝑝 𝑜 max , respectively, are infinite, we now choose a function 𝑓 max ( 𝑝, 𝑀 ) such that ∥∇ 𝑓 max ( 𝑝, 𝑀 )∥ ∞ is finite. Let
$$f _ { \max } ( p, p _ { t }, M ) \coloneqq \begin{cases} f ( p, M ) & p ( 1 ) \leq p _ { t } ( 1 ) \\ a ( p _ { t } ) \cdot p ( 1 ) + b ( p _ { t } ) & p ( 1 ) > p _ { t } ( 1 ) \end{cases},$$
where 𝑝 𝑡 is a probability distribution over { 0 1 , , ⊥} ,
$$a ( p _ { t } ) \coloneqq \frac { \partial } { \partial p ( 1 ) } f ( p, M ) \Big | _ { p ( 1 ) = p _ { t } ( 1 ) } \,, \, \text{and} \quad ( 5 7 ) \quad \text{$two$} \\ \quad \text{$two$} \, d$$
$$b ( p _ { t } ) \coloneqq f ( p _ { t } ) - a ( p _ { t } ) \cdot p _ { t } ( 1 ). \quad \quad ( 5 8 ) \quad \overset { \mathfrak { m } \, \mathcal { M } } { \Delta }$$
It follows from the definition of 𝑓 max ( 𝑝, 𝑀 ) that 𝑓 max ( 𝑝, 𝑀 ) is differentiable and, for all 𝑝 𝑡 , ∥∇ 𝑓 max (· , 𝑝 , 𝑀 𝑡 )∥ ∞ ≤ 𝑎 ( 𝑝 𝑡 ) . Furthermore, as 𝑓 is a concave function, 𝑓 max ( 𝑝, 𝑝 𝑡 , 𝑀 ) ≥ 𝑓 ( 𝑝, 𝑀 ) for all 𝑝 . Thus, 𝑓 max ( 𝑝, 𝑝 𝑡 , 𝑀 ) is a max-tradeoff function.
## D. Applying the EAT
We can finally apply the EAT, stated in Theorem 4, to derive an upper bound on the conditional smooth max-entropy. By obtaining the exact form of 𝑓 max, we have the calculated 𝑡 on the right-hand side of (30). We need to calculate (31). We know that the dimension of all quantum registers involved is two, which means that 𝑑 𝑂 𝑖 = 2 𝑀 ′ . From (56), we get ∥ ▽ 𝑓 max ∥ ∞ ≤ 𝑎 ( 𝑝 𝑡 ) . According to Condition 2 in Definition 3, for soundness, we require that, for every source 𝜙 and measurement device, Protocol 1 either certifies a minimum amount of GHZ entanglement or aborts with probability greater than 1 -𝜀 snd when applied on 𝜎 . So, the probability of Protocol 1 not aborting is negligible i.e., Pr [ Ω ] 𝜏 ≤ 𝜀 snd. Also, note that 𝜀 smo is chosen such that the fidelity constraint in (2) is satisfied. When Protocol 2 does not abort, we can define the following quantity, which corresponds to the right-hand side of (30):
$$\eta ( \omega _ { \exp } \gamma - \delta _ { \text{est} }, p _ { t }, \varepsilon _ { \text{smo} }, \varepsilon _ { \text{snd} }, M ^ { \prime }, M ) \coloneqq & & \cdot \\ n \cdot f _ { \max } ( \omega _ { \exp } \gamma - \delta _ { \text{est} }, p _ { t }, M ) & + 2 \sqrt { n } \left ( \log _ { 2 } ( 1 + 2 M ^ { \prime } ) + \lceil a ( p _ { t } ) \rceil \right ) \\ & \times \sqrt { 1 - 2 \log _ { 2 } ( \varepsilon _ { \text{smo} } \cdot \varepsilon _ { \text{snd} } ) }, \quad ( 5 9 ) & & \cdot$$
where 𝜔 exp 𝛾 -𝛿 est is the minimum acceptable 𝑝 ( 1 ) as outlined in Step 12 of Protocol 2. We still have one free variable 𝑝 𝑡 . We can optimize over 𝑝 𝑡 to get the following equation.
$$\eta _ { \text{opt} } \left ( \omega _ { \exp } \gamma - \delta _ { \text{est} }, \varepsilon _ { \text{smo} }, \varepsilon _ { \text{snd} }, M ^ { \prime }, M \right ) \coloneqq \\ \min _ { p _ { t } \colon p _ { \min } < \frac { p _ { t } ( 1 ) } { \gamma } < p _ { \max } } \eta \left ( \omega _ { \exp } \gamma - \delta _ { \text{est} }, p _ { t }, \varepsilon _ { \text{smo} }, \varepsilon _ { \text{snd} }, M ^ { \prime }, M \right ). \quad \quad - 1$$
Finally, we can state the following:
Theorem 8 For every source and all measurement devices in the setting detailed earlier, let 𝜌 be the state generated using Protocol 2, Ω the event that Protocol 2 does not abort, and 𝜌 | Ω the state conditioned on Ω . Then, for all 8 · 3 𝑀 / 2 √ 𝜀 smo , 𝜀 snd ∈ ( 0 1 , ) , either Protocol 2 aborts with probability greater than 1 -𝜀 snd or
$$H _ { \max } ^ { \varepsilon _ { s m o } } \left ( \hat { A } _ { [ M ^ { \prime } ], [ n ] } | \hat { A } _ { [ M ^ { \prime } + 1, M ], [ n ] } \left ( A D X \right ) _ { [ M ], [ n ] } T \right ) _ { \rho _ { \Omega } } \quad \text{where} \\ < \eta _ { \text{opt} } \left ( \omega _ { \exp }, \varepsilon _ { s m o }, \varepsilon _ { s n d }, M ^ { \prime }, M \right ), \ \ ( 6 1 ) \quad \text{lower}$$
where 𝜂 opt is defined in (60) .
Proof. In Subsection V B, we showed that Protocol 2 consists of EAT channels (defined in Definition 8). In Subsection V C, we derived the appropriate max-tradeoff function (as defined in Definition 9). Hence, using Theorem 4, the claim follows.
Now, we have all the ingredients to show that Protocol 1 is sound.
## E. Soundness
In this subsection, we show that Protocol 1 is sound. To do this, we need to bound the quantity in (28) in a deviceindependent manner. We use the preceding theorems to obtain this bound and certify the multipartite entanglement distillation rate from a source. This brings us to our final theorem, which is as follows.
Theorem 9 Fix 𝜀 smo > 0 such that 𝜀 B 8 · 3 𝑀 / 2 √ 𝜀 smo ∈ ( 0 1 , ) . For all 𝜀 snd , 𝜀 cmp , 𝜀 ∈ ( 0 1 , ) , Protocol 1 is a DIMEC protocol with
- 1. Noise tolerance (completeness): The probability that Protocol 1 aborts when applied on 𝜙 honest ∈ S honest using a measurement device from D honest is at most 𝜀 cmp ≤ exp GLYPH<0> -2 𝑛𝛿 2 est GLYPH<1> , as shown in Theorem 1.
- 2. Entanglement certification (soundness): For every source 𝜎 and measurement device, either Protocol 1 aborts with probability greater than 1 -𝜀 snd when applied on 𝜎 or
$$\Phi _ { 0 } ^ { + } \Phi _ { 1 } \Phi _ { 2 } \Phi _ { 3 } \geq \\ \Phi _ { 1 } ^ { + } \Phi _ { 2 } \Phi _ { 3 } \Phi _ { 4 } \Phi _ { 5 } \Phi _ { 6 } \Phi _ { 7 } \Phi _ { 8 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phi _ { 9 } \Phicon } \frac { 2 \log \varepsilon _ { s m o } } { M - 1 } + \frac { 2 \log \varepsilon _ { s m o } } { M - 1 }, \quad ( 6 2 )$$
where 𝜂 opt is defined in (60) .
Proof. Using Theorem 8, we get
$$. & \quad - H _ { \max } ^ { \varepsilon _ { \text{smo} } } \left ( \hat { A } _ { [ M ^ { \prime } ], [ n ] } | \hat { A } _ { [ M ^ { \prime } + 1, M ], [ n ] } \left ( A D X \right ) _ { [ M ], [ n ] } T \right ) _ { \rho _ { | \Omega } } \\ & \geq - \eta _ { \text{opt} } \left ( \omega _ { \exp }, \varepsilon _ { \text{smo} }, \varepsilon _ { \text{snd} }, M ^ { \prime }, M \right ), \quad ( 6 3 )$$
Notice that all our prior analysis is agnostic to what 𝑖 ∈ [ 𝑀 ] is assigned to which specific party involved. Also recall that 𝑀 ′ ∈ [ 𝑀 -1 . Hence, ]
$$\stackrel { \cdots } { \varepsilon } _ { | \Omega } \quad & - H _ { \max } ^ { \varepsilon _ { \text{smo} } } \left ( \hat { A } _ { K, [ n ] } | \hat { A } _ { [ M ] \nwarrow K, [ n ] } \left ( A D X \right ) _ { [ M ], [ n ] } T \right ) _ { \rho _ { | \Omega } } \\ \tan & \quad \geq - \eta _ { \text{opt} } \left ( \omega _ { \exp }, \varepsilon _ { \text{smo} }, \varepsilon _ { \text{snd} }, M ^ { \prime }, M \right ), \quad ( 6 4 )$$
where 𝐾 ⊆ [ 𝑀 ]\ 𝑘 for some 𝑘 ∈ [ 𝑀 ] .
This bound holds regardless of the individual elements that constitute 𝐾 . We can then use the above inequality to obtain a lower bound on the quantity in (28). Hence, we get
$$\max _ { k \in [ M ] } \left \{ \min _ { K \subseteq [ M ] \vee k } \frac { - H _ { \max } ^ { \varepsilon _ { s m o } } \left ( \hat { A } _ { K, [ n ] } | \hat { A } _ { [ M ] } \vee K, [ n ] \ ( A D X ) _ { [ M ], [ n ] } T \right ) _ { \rho _ { \alpha } } } { | K | } \right \} + \frac { 2 \log \varepsilon _ { s m o } } { M - 1 } \\ \nu$$
$$\geq \max _ { k \in [ M ] } \left \{ \min _ { K \subseteq [ M ] \vee k } \frac { - \eta _ { \text{opt} } \left ( \omega _ { \exp }, \varepsilon _ { \text{snd} }, \varepsilon _ { \text{smo} }, | K |, M \right ) } { | K | } \right \} + \frac { 2 \log \varepsilon _ { \text{smo} } } { M - 1 }. \ \ ( 6 5 )$$
$$\begin{smallmatrix} & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
The optimizations involved can be solved since 𝜂 opt ( 𝜀 snd , 𝜀 smo , | 𝐾 , 𝑀 | ) depends only on | 𝐾 | , leading to the soundness condition, we used the entropy accumulation theorem [36], the structure of the MABK inequality [33-35], and the multipartite entanglement distillation protocols and rates described in [41, 42].
$$E _ { D } ^ { \varepsilon } & ( \rho _ { | \Omega } ) \\ & \geq \frac { - \eta _ { \text{opt} } \left ( \omega _ { \exp }, \varepsilon _ { \text{snd} }, \varepsilon _ { \text{smo} }, M - 1, M \right ) } { M - 1 } + \frac { 2 \log \varepsilon _ { \text{smo} } } { M - 1 }, \ \ ( 6 6 ) \quad \text{measu} \\ & \quad \text{we ha}.$$
which concludes the proof.
We plot also -𝜂 opt ( 𝜔 exp )/ 𝑛 𝑀 ( -1 ) for 𝑀 = 4 and 𝛾 = 0 5 . up to leading order in Figure 1.
Figure 1. Plot of -𝜂 opt ( 𝜔 exp )/ 𝑛 𝑀 ( -1 , defined in (60), for ) 𝑀 = 4 and 𝛾 = 0 5 up to leading order in . 𝑛 for 𝜔 exp ∈ [ 𝑝 𝑒 min , 𝑝 𝑒 max ] defined in (19). The solid line corresponds to -𝜂 opt ( 𝜔 exp )/ 𝑛 𝑀 ( -1 . ) The dashed line corresponds to -𝜂 opt / 𝑛 𝑀 ( -1 ) = 0. The quantity -𝜂 opt ( 𝜔 exp )/ 𝑛 𝑀 ( - ) 1 represents the amount of multipartite distillable entanglement that can be certified per round by Protocol 1 as function of 𝜔 exp.
## VI. CONCLUSION
In this work, we defined a DI, 𝑀 -partite entanglement distillation certification protocol consisting of completeness and soundness conditions. We then proposed a protocol and showed that it is indeed a DI multipartite entanglement distillation certification protocol. Specifically, we proved that Protocol 1 is indeed a DI multipartite entanglement distillation certification protocol. Our proposed protocol is centered around the MABK inequality [33-35], which is critical to proving the completeness and soundness conditions. To prove
For future works, we are interested in using other Bell-type inequalities that involve more than two binary measurements or measurements that have more than two outcomes. In this work, we have focused entirely on GHZ states and leaving out the W state. The W and GHZ states are not inter-convertible using LOCC alone [49]. Hence, our analysis here for GHZ states does not immediately apply to W states, but it is an interesting extension. It is also worth noting that there are infinitely many classes of genuinely multipartite entangled states that involve four or more parties [50]. It will be interesting to see what a unified certification protocol for such classes of states might look like.
We also note that our results are centered around a protocol based on state merging [41, 42]. One could always consider another a protocol that does not involve state merging. An approach that does not rely on the equivalence between Bell inequality and MABK inequality may be necessary for this scenario.
## ACKNOWLEDGMENTS
We thank Ashutosh Marwah for pointing us to [44, Appendix A]. Part of this work was completed during the conference 'Beyond IID in Information Theory,' held at the University of Illinois Urbana-Champaign from July 29 to August 2, 2024, and supported by NSF Grant No. 2409823. We thank Kaiyuan Ji, Dhrumil Patel, Vishal Singh, and Theshani Nuradha for helpful discussions. We acknowledge funding from Air Force Office of Scientific Research Award Nos. FA955020-1-0067 and FA8750-23-2-0031. We also acknowledge support from the School of Electrical and Computer Engineering, Cornell University.
This material is based on research sponsored by Air Force Research Laboratory under agreement number FA8750-23-20031. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes, notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of Air Force Research Laboratory or the U.S. Government.
- [1] E. D'Hondt and P. Panangaden, The computational power of the Wand GHZ states, Quantum Information and Computation 6 , 173 (2006), arXiv:quant-ph/0412177 [quant-ph].
- [2] R. Raussendorf and H. J. Briegel, A One-Way Quantum Computer, Physical Review Letters 86 , 5188 (2001).
- [3] C. Ren and H. F. Hofmann, Clock synchronization using maximal multipartite entanglement, Physical Review A 86 , 014301 (2012).
- [4] Z. Eldredge, M. Foss-Feig, J. A. Gross, S. L. Rolston, and A. V. Gorshkov, Optimal and secure measurement protocols for quantum sensor networks, Physical Review A 97 , 042337 (2018).
- [5] E. T. Khabiboulline, J. Borregaard, K. De Greve, and M. D. Lukin, Quantum-assisted telescope arrays, Physical Review A 100 , 022316 (2019).
- [6] T. Qian, J. Bringewatt, I. Boettcher, P. Bienias, and A. V. Gorshkov, Optimal measurement of field properties with quantum sensor networks, Physical Review A 103 , L030601 (2021).
- [7] M. Hillery, V. Buˇ zek, and A. Berthiaume, Quantum secret sharing, Physical Review A 59 , 1829 (1999).
- [8] C. Zhu, F. Xu, and C. Pei, W-state analyzer and multiparty measurement-device-independent quantum key distribution, Scientific Reports 5 , 17449 (2015).
- [9] G. Murta, F. Grasselli, H. Kampermann, and D. Bruß, Quantum Conference Key Agreement: A Review, Advanced Quantum Technologies 3 , 2000025 (2020).
- [10] H. Yamasaki, A. Pirker, M. Murao, W. D¨ ur, and B. Kraus, Multipartite entanglement outperforming bipartite entanglement under limited quantum system sizes, Physical Review A 98 , 052313 (2018).
- [11] A. Streltsov, C. Meignant, and J. Eisert, Rates of Multipartite Entanglement Transformations, Physical Review Letters 125 , 080502 (2020).
- [12] O. J. Far´ ıas, G. H. Aguilar, A. Vald´ es-Hern´ andez, P. H. S. Ribeiro, L. Davidovich, and S. P. Walborn, Observation of the emergence of multipartite entanglement between a bipartite system and its environment, Physical Review Letters 109 , 150403 (2012).
- [13] H. Cao, L. M. Hansen, F. Giorgino, L. Carosini, P. Zah´ alka, F. Zilk, J. C. Loredo, and P. Walther, Photonic Source of Heralded Greenberger-Horne-Zeilinger states, Physical Review Letters 132 , 130604 (2024).
- [14] K. S. Christensen, S. E. Rasmussen, D. Petrosyan, and N. T. Zinner, Coherent router for quantum networks with superconducting qubits, Physical Review Research 2 , 013004 (2020).
- [15] Y. Zhong, H.-S. Chang, A. Bienfait, E. Dumur, M.-H. Chou, ´ C. R. Conner, J. Grebel, R. G. Povey, H. Yan, D. I. Schuster, et al. , Deterministic multi-qubit entanglement in a quantum network, Nature 590 , 571 (2021).
- [16] Z.-q. Yin, W. L. Yang, L. Sun, and L. M. Duan, Quantum network of superconducting qubits through an optomechanical interface, Physical Review A 91 , 012333 (2015).
- [17] L. J. Stephenson, D. P. Nadlinger, B. C. Nichol, S. An, P. Drmota, T. G. Ballance, K. Thirumalai, J. F. Goodwin, D. M. Lucas, and C. J. Ballance, High-Rate, High-Fidelity Entanglement of Qubits Across an Elementary Quantum Network, Physical Review Letters 124 , 110501 (2020).
- [18] M. Pompili, S. L. N. Hermans, S. Baier, H. K. C. Beukers, P. C. Humphreys, R. N. Schouten, R. F. L. Vermeulen, M. J. Tiggelman, L. dos Santos Martins, B. Dirkse, S. Wehner, and R. Hanson, Realization of a multinode quantum network of
remote solid-state qubits, Science 372 , 259 (2021).
- [19] I. W. Primaatmaja, K. T. Goh, E. Y.-Z. Tan, J. T.-F. Khoo, S. Ghorai, and C. C.-W. Lim, Security of device-independent quantum key distribution protocols: a review, Quantum 7 , 932 (2023).
- [20] V. Zapatero, T. van Leent, R. Arnon-Friedman, W.-Z. Liu, Q. Zhang, H. Weinfurter, and M. Curty, Advances in deviceindependent quantum key distribution, npj Quantum Information 9 , 10 (2023).
- [21] D. Mayers and A. Yao, Self testing quantum apparatus, Quantum Information and Computation 4 , 273-286 (2004), arXiv:quantph/0307205.
- [22] K. F. P´ al, T. V´ ertesi, and M. Navascu´ es, Device-independent tomography of multipartite quantum states, Physical Review A 90 , 042340 (2014).
- [23] M. McKague, Self-Testing Graph States, in Theory of Quantum Computation, Communication, and Cryptography , edited by D. Bacon, M. Martin-Delgado, and M. Roetteler (Springer Berlin Heidelberg, 2014) pp. 104-120.
- [24] J. Kaniewski, Analytic and nearly optimal self-testing bounds for the Clauser-Horne-Shimony-Holt and Mermin inequalities, Physical Review Letters 117 , 070402 (2016).
- [25] I. ˇ upi´ S c and J. Bowles, Self-testing of quantum systems: a review, Quantum 4 , 337 (2020).
- [26] S. Designolle, T. V´rtesi, and S. Pokutta, Symmetric multipartite e Bell inequalities via Frank-Wolfe algorithms, Physical Review A 109 , 022205 (2024).
- [27] T. P. Le, C. Meroni, B. Sturmfels, R. F. Werner, and T. Ziegler, Quantum Correlations in the Minimal Scenario, Quantum 7 , 947 (2023).
- [28] J. Ribeiro, G. Murta, and S. Wehner, Reply to 'Comment on 'Fully device-independent conference key agreement' ', Physical Review A 100 , 026302 (2019), arXiv:1708.00798v3.
- [29] T. Holz, H. Kampermann, and D. Bruß, A genuine multipartite Bell inequality for device-independent conference key agreement, Physical Review Research 2 , 023251 (2020), arXiv:1910.11360.
- [30] A. Philip, E. Kaur, P. Bierhorst, and M. M. Wilde, Multipartite Intrinsic Non-Locality and Device-Independent Conference Key Agreement, Quantum 7 , 898 (2023).
- [31] K. Horodecki, M. Winczewski, and S. Das, Fundamental limitations on the device-independent quantum conference key agreement, Physical Review A 105 , 022604 (2022).
- [32] R. Arnon-Friedman and J.-D. Bancal, Device-independent certification of one-shot distillable entanglement, New Journal of Physics 21 , 033010 (2019), arXiv:1712.09369.
- [33] M. Ardehali, Bell inequalities with a magnitude of violation that grows exponentially with the number of particles, Physical Review A 46 , 5375 (1992).
- [34] N. D. Mermin, Extreme quantum entanglement in a superposition of macroscopically distinct states, Physical Review Letters 65 , 1838 (1990).
- [35] A. V. Belinski˘ ı and D. N. Klyshko, Interference of light and Bell's theorem, Physics-Uspekhi 36 , 653 (1993).
- [36] F. Dupuis, O. Fawzi, and R. Renner, Entropy Accumulation, Communications in Mathematical Physics 379 , 867 (2020), arXiv:1607.01796v2.
- [37] J. Ribeiro, G. Murta, and S. Wehner, Fully device-independent conference key agreement, Physical Review A 97 , 022307 (2018), arXiv:1708.00798v1.
- [38] M. Tomamichel, Quantum Information Processing with Finite
Resources-Mathematical Foundations , 1st ed. (Springer Cham, 2016).
- [39] R. Cleve, P. Hoyer, B. Toner, and J. Watrous, Consequences and limits of nonlocal strategies, in Proceedings. 19th IEEE Annual Conference on Computational Complexity (2004) pp. 236-249.
- [40] W. Hoeffding, Probability inequalities for sums of bounded random variables, Journal of the American Statistical Association 58 , 13 (1963).
- [41] P. Colomer and A. Winter, Decoupling by local random unitaries without simultaneous smoothing, and applications to multi-user quantum information tasks (2023), arXiv:2304.12114 [quantph].
- [42] F. Salek and A. Winter, New protocols for Conference key and Multipartite Entanglement Distillation (2023), arXiv:2308.01134 [quant-ph].
- [44] T. Metger, O. Fawzi, D. Sutter, and R. Renner, Generalised entropy accumulation, in 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS) (2022) pp. 844850, arXiv:2203.04989.
- [45] V. Scarani, The device-independent outlook on quantum physics, Acta Physica Slovaca 62 , 347 (2012), arXiv:1303.3081.
- [46] F. Grasselli, G. Murta, H. Kampermann, and D. Bruß, Entropy Bounds for Multiparty Device-Independent Cryptography, PRX Quantum 2 , 010308 (2021).
- [47] E. H. Lieb and M. B. Ruskai, Proof of the strong subadditivity of quantum-mechanical entropy, Journal of Mathematical Physics 14 , 1938 (1973).
- [48] C. H. Bennett, D. P. DiVincenzo, J. A. Smolin, and W. K. Wootters, Mixed-state entanglement and quantum error correction, Physical Review A 54 , 3824 (1996).
- [43] Let ˆ Ω be a set of frequencies defined via freq 𝑤 ( ˜ 𝑤 ) ∈ ˆ Ω if and only if ˜ 𝑤 ∈ Ω . We can consider concave functions, in contrast to affine ones [36], since the event Ω defined in the current work results in a convex set ˆ . Ω
- [49] W. D¨ ur, G. Vidal, and J. I. Cirac, Three qubits can be entangled in two inequivalent ways, Physical Review A 62 , 062314 (2000).
- [50] J. I. de Vicente, C. Spee, and B. Kraus, Maximally entangled set of multipartite quantum states, Physical Review Letters 111 , 110502 (2013).
## Appendix A: Proof of Lemma 1
Theorem 10 An 𝑀 -partite MABK inequality (12) is equivalent to a CHSH inequality within any bipartition consisting of 𝑀 ′ parties on side and the 𝑀 -𝑀 ′ other parties on the other side such that, for some ˆ 𝑂 [ 𝑀 𝑀 -′ + ] 1 0 and ˆ 𝑂 [ 𝑀 𝑀 -′ + ] 1 1 ,
$$\mathcal { K } _ { M } = \frac { 1 } { 2 } \mathcal { F } \left ( \mathcal { K } _ { M - M ^ { \prime } }, \overline { \mathcal { K } } _ { M - M ^ { \prime } }, \hat { O } _ { 0 } ^ { [ M - M ^ { \prime } + 1 ] }, \hat { O } _ { 1 } ^ { [ M - M ^ { \prime } + 1 ] } \right ).$$
Proof. We know that, for all 𝑀 ≥ 3
$$\mathcal { K } _ { M } = \frac { 1 } { 2 } \mathcal { K } _ { M - 1 } \otimes \left ( \hat { O } _ { 0 } ^ { M } + \hat { O } _ { 1 } ^ { M } \right ) + \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - 1 } \otimes \left ( \hat { O } _ { 0 } ^ { M } - \hat { O } _ { 1 } ^ { M } \right ),$$
and
It is then clear that
$$\mathcal { K } _ { M - 1 } = \frac { 1 } { 2 } \mathcal { K } _ { M - 2 } \otimes \left ( \hat { O } _ { 0 } ^ { M - 1 } + \hat { O } _ { 1 } ^ { M - 1 } \right ) + \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - 2 } \otimes \left ( \hat { O } _ { 0 } ^ { M - 1 } - \hat { O } _ { 1 } ^ { M - 1 } \right ),$$
Let
$$V _ { M } \coloneqq \left | \text{Tr} \left [ \mathcal { K } _ { M } \, \rho _ { \hat { A } _ { [ M ] } } \right ] \right | = \frac { 1 } { 2 } \left | \text{Tr} \left [ \left \{ \mathcal { K } _ { M - 1 } \otimes \left ( \hat { O } _ { 0 } ^ { M } + \hat { O } _ { 1 } ^ { M } \right ) + \overline { \mathcal { K } } _ { M - 1 } \otimes \left ( \hat { O } _ { 0 } ^ { M } - \hat { O } _ { 1 } ^ { M } \right ) \right \} \rho _ { \hat { A } _ { [ M ] } } \right ] \right |.$$
From [37, Theorem 2], we know be relabeling K 𝑀 -1 as ˆ 1 𝑂 0 , K 𝑀 -1 as ˆ 1 𝑂 1 , ˆ 𝑂 𝑀 0 as ˆ 2 𝑂 0 , and ˆ 𝑂 𝑀 1 as ˆ 2 𝑂 1 , for 𝑀 ′ = 1
$$V _ { M } = \frac { 1 } { 2 } \left | \text{Tr} \left [ \mathcal { F } \left ( \mathcal { K } _ { M - 1 }, \overline { \mathcal { K } } _ { M - 1 }, \hat { O } _ { 0 } ^ { M }, \hat { O } _ { 1 } ^ { M } \right ) \rho _ { \hat { A } _ { [ M ] } } \right ] \right |.$$
We need to show the same for 1 ≤ 𝑀 ′ ≤ 𝑀 -1. Let us start with 𝑀 ′ = 2. By substituting (A4) in (A2), we get
$$\cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \\ \mathcal { K } _ { M } & = \frac { 1 } { 4 } \left ( \mathcal { K } _ { M - 2 } \otimes \left ( \hat { O } _ { 0 } ^ { M - 1 } + \hat { O } _ { 1 } ^ { M - 1 } \right ) + \overline { \mathcal { K } } _ { M - 2 } \otimes \left ( \hat { O } _ { 0 } ^ { M - 1 } - \hat { O } _ { 1 } ^ { M - 1 } \right ) \right ) \otimes \left ( \hat { O } _ { 0 } ^ { M } + \hat { O } _ { 1 } ^ { M } \right ) \\ & \quad + \frac { 1 } { 4 } \left ( \overline { \mathcal { K } } _ { M - 2 } \otimes \left ( \hat { O } _ { 0 } ^ { M - 1 } + \hat { O } _ { 1 } ^ { M - 1 } \right ) + \mathcal { K } _ { M - 2 } \otimes \left ( \hat { O } _ { 1 } ^ { M - 1 } - \hat { O } _ { 0 } ^ { M - 1 } \right ) \right ) \otimes \left ( \hat { O } _ { 0 } ^ { M } - \hat { O } _ { 1 } ^ { M } \right ) \\ & = \frac { 1 } { 4 } \mathcal { K } _ { M - 2 } \otimes \left ( \left ( \hat { O } _ { 0 } ^ { M - 1 } + \hat { O } _ { 1 } ^ { M - 1 } \right ) \otimes \left ( \hat { O } _ { 0 } ^ { M } + \hat { O } _ { 1 } ^ { M } \right ) + \left ( \hat { O } _ { 1 } ^ { M - 1 } - \hat { O } _ { 0 } ^ { M - 1 } \right ) \otimes \left ( \hat { O } _ { 0 } ^ { M } - \hat { O } _ { 1 } ^ { M } \right ) \right )$$
$$\overline { \mathcal { K } } _ { M } = \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - 1 } \otimes \left ( \hat { O } _ { 0 } ^ { M } + \hat { O } _ { 1 } ^ { M } \right ) + \frac { 1 } { 2 } \mathcal { K } _ { M - 1 } \otimes \left ( \hat { O } _ { 1 } ^ { M } - \hat { O } _ { 0 } ^ { M } \right ).$$
$$\cdot \frac { + } { 4 } \overline { \mathcal { K } } _ { M - 2 } \otimes \left ( \left ( \partial _ { 0 } ^ { M - 1 } + \partial _ { 1 } ^ { M - 1 } \right ) \otimes \left ( \partial _ { 0 } ^ { M } - \partial _ { 1 } ^ { M } \right ) + \left ( \partial _ { 1 } ^ { M - 1 } - \partial _ { 0 } ^ { M - 1 } \right ) \otimes \left ( \partial _ { 0 } ^ { M } + \partial _ { 1 } ^ { M } \right ) \right ) \quad \left ( A 8 \right )$$
$$= \frac { 1 } { 2 } \mathcal { K } _ { M - 2 } \otimes \left ( \hat { \partial } _ { 0 } ^ { M - 1 } \otimes \hat { \partial } _ { 1 } ^ { M } + \hat { \partial } _ { 1 } ^ { M - 1 } \otimes \hat { \partial } _ { 0 } ^ { M } \right ) + \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - 2 } \otimes \left ( \hat { \partial } _ { 1 } ^ { M - 1 } \otimes \hat { \partial } _ { 0 } ^ { M } - \hat { \partial } _ { 0 } ^ { M - 1 } \otimes \hat { \partial } _ { 1 } ^ { M } \right ).$$
Relabelling ˆ 𝑂 𝑀 -1 1 ⊗ ˆ 𝑂 𝑀 0 as ˆ 𝑂 [ 𝑀 - ] 1 0 , and ˆ 𝑂 𝑀 -1 0 ⊗ ˆ 𝑂 𝑀 1 as ˆ 𝑂 [ 𝑀 - ] 1 1 , we get
$$V _ { M } = \frac { 1 } { 2 } \left | \text{Tr} \left [ \mathcal { F } \left ( \mathcal { K } _ { M - 2 }, \overline { \mathcal { K } } _ { M - 2 }, \hat { O } _ { 0 } ^ { [ M - 1 ] }, \hat { O } _ { 0 } ^ { [ M - 1 ] } \right ) \rho _ { \hat { A } _ { [ M ] } } \right ] \right |.$$
Now, we have shown that the proposition is true for 𝑀 ′ = 1 and 𝑀 ′ = 2. We can now use induction to show that our proposition holds for all 1 ≤ 𝑀 ′ ≤ 𝑀 -1. Let assume that for some 𝑀 ′ = 𝑚 , the following hold:
$$\mathcal { K } _ { M } = \frac { 1 } { 2 } \mathcal { K } _ { M - m } \otimes \left ( \hat { O } _ { 0 } ^ { [ M - m + 1 ] } + \hat { O } _ { 1 } ^ { [ M - m + 1 ] } \right ) + \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - m } \otimes \left ( \hat { O } _ { 0 } ^ { [ M - m + 1 ] } - \hat { O } _ { 1 } ^ { [ M - m + 1 ] } \right )$$
and
$$V _ { M } = \frac { 1 } { 2 } \left | \text{Tr} \left [ \mathcal { F } \left ( \mathcal { K } _ { M - m }, \overline { \mathcal { K } } _ { M - m }, \hat { O } _ { 0 } ^ { [ M - m + 1 ] }, \hat { O } _ { 1 } ^ { [ M - m + 1 ] } \right ) \rho _ { \hat { A } _ { [ M ] } } \right ] \right |.$$
where, K 𝑀 𝑚 -is defined in (9), and ˆ 𝑂 [ 𝑀 𝑚 -+ ] 1 0 and ˆ 𝑂 [ 𝑀 𝑚 -+ ] 1 1 are observables similar to those in (A10) involving parties 𝑀 -𝑚 + 1 , . . . , 𝑀 . We know that
$$\mathcal { K } _ { M - m } = \frac { 1 } { 2 } \mathcal { K } _ { M - m - 1 } \otimes \left ( \hat { O } _ { 0 } ^ { M - m } + \hat { O } _ { 1 } ^ { M - m } \right ) + \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - m } \otimes \left ( \hat { O } _ { 0 } ^ { M - m } - \hat { O } _ { 1 } ^ { M - m } \right ).$$
By substituting (A13) in (A11), we get
$$\text{By substituting} \left ( A ^ { } { 1 } \right ) \, \text{$(A ^ { } { 1 } ), \, \text{we get} } \\ \mathcal { K } _ { M } & = \frac { 1 } { 4 } \mathcal { K } _ { M - ( m + 1 ) } \otimes \left ( \left ( \partial _ { 0 } ^ { M - m } + \partial _ { 1 } ^ { M - m } \right ) \otimes \left ( \partial _ { 0 } ^ { [ M - m + 1 ] } + \partial _ { 1 } ^ { [ M - m + 1 ] } \right ) \right ) \\ + & \frac { 1 } { 4 } \mathcal { K } _ { M - ( m + 1 ) } \otimes \left ( \left ( \partial _ { 0 } ^ { M - m } - \partial _ { 1 } ^ { M - m } \right ) \otimes \left ( \partial _ { 0 } ^ { [ M - m + 1 ] } - \partial _ { 1 } ^ { [ M - m + 1 ] } \right ) \right ) \\ + & \frac { 1 } { 4 } \overline { \mathcal { K } } _ { M - ( m + 1 ) } \otimes \left ( \left ( \partial _ { 0 } ^ { M - m } - \partial _ { 1 } ^ { M - m } \right ) \otimes \left ( \partial _ { 0 } ^ { [ M - m + 1 ] } - \partial _ { 1 } ^ { [ M - m + 1 ] } \right ) \right ) \\ & + \frac { 1 } { 4 } \overline { \mathcal { K } } _ { M - ( m + 1 ) } \otimes \left ( \left ( \partial _ { 0 } ^ { M - m } - \partial _ { 1 } ^ { M - m } \right ) \otimes \left ( \partial _ { 0 } ^ { [ M - m + 1 ] } + \partial _ { 1 } ^ { [ M - m + 1 ] } \right ) \right ) \\ & = \frac { 1 } { 2 } \mathcal { K } _ { M - ( m + 1 ) } \otimes \left ( \partial _ { 0 } ^ { M - m } \otimes \partial _ { 1 } ^ { [ M - m + 1 ] } + \partial _ { 1 } ^ { [ M - m } \otimes \partial _ { 0 } ^ { [ M - m + 1 ] } \right ) \\ & + \frac { 1 } { 2 } \overline { \mathcal { K } } _ { M - ( m + 1 ) } \otimes \left ( \partial _ { 1 } ^ { M - m } \otimes \partial _ { 0 } ^ { [ M - m + 1 ] } - \partial _ { 0 } ^ { [ M - m } \otimes \partial _ { 1 } ^ { [ M - m + 1 ] } \right ).$$
Therefore,
$$V _ { M } = \frac { 1 } { 2 } \left | \text{Tr} \left [ \mathcal { F } \left ( \mathcal { K } _ { M - ( m + 1 ) }, \overline { \mathcal { K } } _ { M - ( m + 1 ) }, \hat { O } _ { 1 } ^ { M - m } \otimes \hat { O } _ { 0 } ^ { [ M - m + 1 ] }, \hat { O } _ { 0 } ^ { M - m } \otimes \hat { O } _ { 1 } ^ { [ M - m + 1 ] } \right ) \rho _ { \hat { A } _ { [ M ] } } \right ] \right |.$$
Hence, by strong induction, we have proven our proposition. | 10.1103/PhysRevA.111.012436 | [
"Aby Philip",
"Mark M. Wilde"
]
| 2024-08-02T16:09:18+00:00 | 2024-09-06T17:14:08+00:00 | [
"quant-ph"
]
| Device-Independent Certification of Multipartite Distillable Entanglement | Quantum networks consist of various quantum technologies, spread across vast
distances, and involve various users at the same time. Certifying the
functioning and efficiency of the individual components is a task that is well
studied and widely used. However, the power of quantum networks can only be
realized by integrating all the required quantum technologies and platforms
across a large number of users. In this work, we demonstrate how to certify the
distillable entanglement available in multipartite states produced by quantum
networks, without relying on the physical realization of its constituent
components. We do so by using the paradigm of device independence. |
2408.01360v2 | ## Laplacian and codifferential operators on p-forms in (Anti)-de Sitter spaces: restriction and continuation
E. Huguet, 1 J. Queva, 2 and J. Renaud 3
1) Universit´ Paris Cit´, APC-Astroparticule et Cosmologie (UMR-CNRS 7164), e e Batiment Condorcet, 10 rue Alice Domon et L´onie Duquet, F-75205 Paris Cedex 13, e a)
France.
- 2) Universit´ de Corse - CNRS UMR 6134 SPE, Campus Grimaldi BP 52, 20250 Corte, e France. b)
3) Universit´ Gustave Eiffel, APC-Astroparticule et Cosmologie (UMR-CNRS 7164), e Batiment Condorcet, 10 rue Alice Domon et L´onie Duquet, F-75205 Paris Cedex 13, e c)
France.
We derive explicit restriction and continuation formulas between n -dimensional (Anti)-de Sitter spaces and the ( n +1)-dimensional Minkowskian ambient space for the codifferential and Laplace-de Rham operators acting on p -forms.
## I. INTRODUCTION
The fact that (Anti-)de Sitter (hereafter (A)dS) spaces can be defined as submanifolds of a flat space has long been known and used, in particular, to describe the symmetry of the space (SO(4,1) or SO(3,2)). This ambient space approach to (A)dS spaces has been proven useful many times over 1-4 . Whether it be in cosmology 5,6 , supergravities , 7 gauge theories 8 or in other contexts it is natural to consider p -form fields in curved spaces (and their quantization 9,10 ). Since we can identify p -forms on (A)dS with certain p -forms on the ambient spaces (namely the p transverse s -homogeneous forms), it is natural to ask whether the usual calculations ( δ and /square for example) carried out on (A)dS can be replaced by calculations (hopefully simpler) in the ambient space. In this article we provide a rigorous answer to this question in the general framework of p -forms on n dimension space (Theorem 2). In order to be able to answer this question we start by addressing the problem of restriction in this same general framework (Theorem 1). Results for the Laplacede Rham operator are extended to the Laplace-Beltrami operator through Weitzenb¨ck o formula (Theorems 3 and 4). The Euclidean case is also considered.
Specifically, we relate the Laplace-de Rham, and thus the codifferential, operator acting on p -forms defined on n dimensional (Anti)-de Sitter spaces to their counterparts defined on ambient n +1 space. We derive expressions which relate explicitly differential operators, acting on p -forms, on (A)dS and ambient spaces. These relations work in both directions, restriction and continuation. In a previous article 11 the restriction to n -dimensional (A)dS spaces of the Laplace-de Rham operator on 1-forms was addressed. The present work simplifies and extends greatly those previous results. As it encompasses it, the reader is referred to Ref. 11 for detailed references and discussions, as they will not be reproduced here. Thus, superseding Ref. 11, this paper sets a firmer ground to generalize these results to Friedmann-Lemaˆ ıtre-Robertson-Walker (FLRW) spaces.
Our notations and the geometric framework are settled Sec. II. The main results appear Sec. III, where restriction and continuation Theorems are given. Concluding remarks are made Sec. IV. Necessary properties concerning operations on p -forms basis are collected together with their proofs App. A. Detailed proofs of the main theorems are gathered App. B.
a) Electronic mail: [email protected]
b) Electronic mail: [email protected]
c) Electronic mail: [email protected]
## II. DEFINITIONS AND NOTATIONS
## A. Geometric context
Our conventions on indexes read: A,B,C,... = 0 , . . . , n and λ, µ, ν, . . . = 0 , . . . , n -1. The cartesian coordinates of the oriented pseudo-euclidean space R n +1 are denoted by { y A } and the corresponding coordinate basis { ∂ A } . The ambient space metric is η = diag(+ , -, . . . , - -, /epsilon1 ), with /epsilon1 = 1 for de Sitter space and /epsilon1 = -1 for the Anti-de Sitter space.
The (Anti-)de Sitter space is defined, as a submanifold of R n +1 , through y 2 = y A y A = -/epsilon1H -2 . Throughout the paper, they are both denoted by Σ. For later convenience, let us define the dilation vector D := y A ∂ A , and h := ( √ | y 2 | ) -1 . We suppose that Σ is oriented by means of its (normalized) exterior normal vector e n = hD . Note that e n = d h ( -1 ), so de n = 0.
## B. Orthonormal basis
Orthonormal frames enjoy simplifying properties regarding the action of various differential operators. We will take full advantage of these properties, in the ambient space context, building convenient orthonormal frames of the ambient space, from that of Σ.
To this end, let us consider, in some open set U ⊂ Σ, a direct orthonormal frame field { e µ } . Completing this set, with the unit normal e n at each point of U , leads to a direct orthonormal frame field of R n +1 defined in each point of U ⊂ Σ. Now, we continue this local orthonormal frame to R n +1 by homogeneity. Precisely at each point y of Σ one has e A = e B A ∂ B , and we can extend e B A ( y ) to the ambient space by imposing that it be homogeneous of degree zero. This allows us to extend the frame to R n +1 through the same formula e A = e B A ∂ B and the extended vectors e A are now homogeneous of degree -1. Pictorially we just 'pushed' the frame along the half-lines emanating from the origin. Thanks to the homogeneity, the holonomic coefficients of this frame fullfill the very useful relations
$$c _ { A B } ^ { n } = 0 \text{ and } c _ { \nu n } ^ { \mu } = h \delta _ { \nu } ^ { \mu }.$$
For more details regarding the geometric context and orthornormal basis see Ref. 11.
## C. Transverse-longitudinal splitting of p -forms
The identity j n i n + i n j n = 1, in which i n and j n stand for i e n and j e n (see the appendix of Ref. 11 for the notations), allows us to define transverse and longitudinal parts of a form: let α be a a -form on R n +1 , the adapted splitting in transverse ( α ⊥ ), and longitudinal ( α ‖ ) parts of α , with respect to Σ, is defined through
$$\alpha \coloneqq \alpha _ { \| } + \alpha _ { \perp },$$
with
$$\cdots \cdots & & \alpha _ { \| } \colon = j _ { n } i ^ { n } \alpha = ( - 1 ) ^ { a - 1 } ( i _ { n } \alpha ) \wedge e ^ { n } = \frac { 1 } { ( a - 1 )! } \alpha _ { \mu _ { 1 } \dots \mu _ { a - 1 } n } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { a - 1 } } \wedge e ^ { n }, \\ & \alpha _ { \perp } \colon = i ^ { n } j _ { n } \alpha = \frac { 1 } { a! } \alpha _ { \lambda _ { 1 } \dots \lambda _ { a } } e ^ { \lambda _ { 1 } } \wedge \cdots \wedge e ^ { \lambda _ { a } }. \\ - - & \quad. & \quad. & \quad. & \quad. & \quad. & \quad. & \quad. & \quad. & \quad.$$
The set of transverse (respectively longitudinal) p -forms of R n +1 will be denoted by Ω ( p ⊥ R n +1 ) (respectively Ω ( p ‖ R n +1 )). A p -form, homogeneous of degree s , will be termed s -homogeneous p -form, whose set will be denoted Ω ( p s R n +1 ). Finally, the set of p -forms, both transverse and s -homogeneous, will be denoted by Ω p s ⊥ ( R n +1 ).
Let us denote by m the canonical injection map from Σ in R n +1 . Note that, firstly, a p -form α ∈ Ω ( p R n +1 ) is mapped by m ∗ on its transverse part on Σ: α Σ := m α ∗ = α ⊥ | Σ , and secondly, a transverse p -form α ∈ Ω ( p ⊥ R n +1 ), satisfy i n α = 0 and, can be identified at each point of Σ with a p -form on Σ. This implies: ∀ y Σ ∈ Σ , α y ( Σ ) = m α y ∗ ( Σ ). Now, since each point of Σ belongs to a half-line emanating from the origin of R n +1 , one can also obtain p -forms on R n +1 from p -forms on Σ thanks to homogeneous continuation. Indeed, the pullback m ∗ induces an isomorphism between transverse s -homogeneous p -forms on R n +1 and those on Σ:
$$\Omega _ { s \perp } ^ { p } ( \mathbb { R } ^ { n + 1 } ) \simeq \Omega ^ { p } ( \Sigma ).$$
This allows us to identify p -forms on Σ with s -homogeneous p -forms on R n +1 . Using this identification one can write, in particular, m e ∗ µ = e µ while m e ∗ n = 0. Note also that m h ∗ = H .
## III. RESTRICTION AND CONTINUATION OF OPERATORS: THE MAIN THEOREMS
The restriction to Σ of a form on R n +1 is given by the following theorem in which /square := -( dδ + δd ) is the Laplace-de Rham operator.
Theorem 1 (Restriction) . Let α ∈ Ω ( a R n +1 ) , m be the canonical injection: Σ m - → R n +1 , and α Σ := m α ∗ = α ⊥ | Σ . Then,
$$m ^ { * } \delta _ { n + 1 } \alpha = \delta _ { \Sigma } \alpha _ { \Sigma } - \eta ^ { n n } m ^ { * } [ \mathcal { L } _ { n } i _ { n } \alpha + H ( n - 2 a + 2 ) i _ { n } \alpha ],$$
$$m ^ { * } \Box _ { n + 1 } \alpha = \Box _ { \Sigma } \alpha _ { \Sigma } + \eta ^ { n n } m ^ { * } [ \mathcal { L } _ { n } ^ { 2 } \alpha + H ( n - 2 a ) \mathcal { L } _ { n } \alpha + 2 H d i _ { n } \alpha ], \text{ \quad \ } ( 3 )$$
with L n = L e n the Lie derivative along e n .
On the other hand our considerations on the transverse forms allow us to establish the following converse result:
Theorem 2 (Continuation) . Let m the canonical injection: Σ m - → R n +1 , and β s be the s -homogeneous (necessarily transverse) extension of β ∈ Ω (Σ) b , that is β := m β ∗ s and β s ∈ Ω b s ⊥ . Then,
$$\delta _ { \Sigma } \beta & = \delta _ { n + 1 } \beta _ { s },$$
$$\Box _ { \Sigma } \beta = \Box _ { n + 1 } \beta _ { s } - \eta ^ { n n } H ^ { 2 } s ( s + n - 1 - 2 b ) \beta _ { s } + 2 H e ^ { n } \wedge ( \delta _ { n + 1 } \beta _ { s } ). \quad \quad ( 5 )$$
This last theorem calls for some explanations. As a consequence of theorem 1, taking into account the fact that β is transverse, we can prove that
$$& \delta _ { \Sigma } \beta = m ^ { * } ( \delta _ { n + 1 } \beta _ { s } ), \\ & \square _ { \Sigma } \beta = m ^ { * } ( \square _ { n + 1 } \beta _ { s } - \eta ^ { n n } H ^ { 2 } s ( s + n - 1 - 2 b ) \beta _ { s } + 2 H e ^ { n } \wedge ( \delta _ { n + 1 } \beta _ { s } ) ).$$
Moreover both arguments of m ∗ , in the above equations, are found to be transverse and ( s -2)-homogeneous. As a consequence, we can identify m δ ∗ n +1 β s and δ n +1 β s , this is what was done in the first statement. The same goes for the second statement.
We can see that the calculation of the codifferential on Σ is equivalent to that, a priori simpler, on ambient space. Now, due to the fact that β being transverse does not imply that dβ is also transverse, the situation is less trivial with regard to the operator /square . Nevertheless it remains quite simple, particularly if we choose s = 0.
Proofs of these theorems are given in App. B. These proofs exploit both the simplifications in calculations induced by the orthonormal basis of Σ extended to R n +1 and the corresponding splitting of p -forms in transverse and longitudinal parts. The main part of the proof consists in proving Eq. (2), the other results are easily deduced from it. Let us mention that, to secure this calculation, we have carried out an independent verification of Eq. (2), proceeding by induction and using
$$\delta ( \alpha \wedge \beta ) = ( \delta \alpha ) \wedge \beta + ( - 1 ) ^ { a } \alpha \wedge ( \delta \beta ) + ( - 1 ) ^ { a } [ \alpha, \beta ],$$
where the bracket [ [ , ] ] stands for the Schouten-Nijenhuis bracket (see for instance Ref. 12).
## The Laplace-Beltrami operator
Our calculations are based on the Laplace-de Rham operator which is well suited to p -forms. Nevertheless these results can be transcribed for the Laplace-Beltrami operator since the two are linked by the Weitzenb¨ck formula which we recall here (see theorem 4.3.3 of o Ref. 13 and, for a formulation compatible with our notations, the appendix of Ref. 11). The Weitzenb¨ ock formula reads, for α a a -form,
$$\Box \alpha = \Delta \alpha + j ^ { a } i ^ { b } R ( e _ { a }, e _ { b } ) \alpha,$$
where R u, v ( ) = ∇ ∇ u v - ∇ ∇ v u - ∇ [ u,v ] is the curvature operator and ∇ the Levi-Civita connection.
Moreover, it is well known that the curvature, in the case of maximally symmetric spaces, takes a very special form. In our context, it reads
$$R _ { \Sigma } ( e _ { \mu }, e _ { \nu } ) e ^ { \xi } = \eta ^ { n n } H ^ { 2 } ( \eta _ { \mu \lambda } \delta _ { \nu } ^ { \xi } - \eta _ { \nu \lambda } \delta _ { \mu } ^ { \xi } ) e ^ { \lambda }.$$
This formula, together with the Weitzenb¨ck formula, gives, for o α ∈ Ω (Σ) a
$$( \Box _ { \Sigma } - \Delta _ { \Sigma } ) \alpha = \eta ^ { n n } H ^ { 2 } a ( a - n ) \alpha.$$
This allows us to rewrite the two previous theorems for the Laplace-Beltrami operators.
Theorem 3 (Restriction for Laplace-Beltrami operator) . Let α ∈ Ω ( a R n +1 ) , m be the canonical injection: Σ m - → R n +1 , and α Σ := m α ∗ = α ⊥ | Σ . Then,
$$m ^ { * } \Delta _ { n + 1 } \alpha = \Delta _ { \Sigma } \alpha _ { \Sigma } + \eta ^ { n n } m ^ { * } [ \mathcal { L } _ { n } ^ { 2 } \alpha + H ( n - 2 a ) \mathcal { L } _ { n } \alpha + 2 H d i _ { n } \alpha + H ^ { 2 } a ( a - n ) \alpha ]. \quad ( 1 0 )$$
Theorem 4 (Continuation for Laplace-Beltrami operator) . Let m the canonical injection: Σ m - → R n +1 , and β s be the s -homogeneous (necessarily transverse) extension of β ∈ Ω (Σ) b , that is β := m β ∗ s and β s ∈ Ω b s ⊥ . Then,
$$\Delta _ { \Sigma } \beta = \Delta _ { n + 1 } \beta _ { s } - \eta ^ { n n } H ^ { 2 } [ s ^ { 2 } + s ( n - 1 - 2 b ) + b ( b - n ) ] \beta _ { s } + 2 H e ^ { n } \wedge ( \delta _ { n + 1 } \beta _ { s } ). \quad ( 1 1 )$$
## The Euclidean case
Finally, let us remark that the above theorems transpose to the Euclidean situation where the embedding of (Anti)-de Sitter in the pseudo-Euclidean ambient space R n +1 is replaced by that of the sphere S n in the Euclidean ambient space R n +1 , the vector e n becoming the outer normal to the sphere, η nn = 1, and H -1 being the radius of the sphere.
## IV. CONCLUSION
The present work not only extends (to p -forms) and introduces simplified calculations, compare to Ref. 11, but also it addresses in a detailed way the extension of operators to ambient space. We additionally crosschecked our expressions thanks to independent calculation methods (using recursion and Schouten-Nijenhuis bracket). This provides to our results a sturdiness allowing us to use them, with the help of the embedding in R n +2 exposed in Ref. 14, as a starting point for our ongoing work on FLRW space.
## Appendix A: Properties fulfilled in orthonormal basis
We gather here specific properties of orthonormal basis, central for our derivations. As explained above (Sec. II C), we frequently identify m τ ∗ with τ on Σ whenever τ is a transverse t -form.
## Property 1.
$$d ( e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } ) = d _ { \Sigma } ( e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } ) + ( - 1 ) ^ { t } h t \ e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n }, \\ d ( e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } ) = ( d _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n }.$$
Proof. Noting that: de n = 0 and
$$d e ^ { \mu } = - \frac { 1 } { 2 } c ^ { \mu } _ { A B } e ^ { A } \wedge e ^ { B } = - \frac { 1 } { 2 } c ^ { \mu } _ { \nu \lambda } e ^ { \nu } \wedge e ^ { \lambda } - c ^ { \mu } _ { \nu n } e ^ { \nu } \wedge e ^ { n } = d _ { \Sigma } e ^ { \mu } - h e ^ { \mu } \wedge e ^ { n },$$
using the fact that c µ νn = hδ µ ν , one has
$$\text{using the fact that } c _ { \nu _ { n } } ^ { \mu } = h \delta _ { \nu } ^ { \mu }, \, \text{one has} \\ d ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) & = \sum _ { k = 1 } ^ { t } ( - 1 ) ^ { k - 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge ( d e ^ { \mu _ { k } } ) \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = \sum _ { k = 1 } ^ { t } ( - 1 ) ^ { k - 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge ( d _ { \mathbb { Z } } e ^ { \mu _ { k } } - h e ^ { \mu _ { k } } \wedge e ^ { n } ) \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = d _ { \mathbb { Z } } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) - h \sum _ { k = 1 } ^ { t } ( - 1 ) ^ { t - 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } \\ & = d _ { \mathbb { Z } } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) + ( - 1 ) ^ { t } h t \, e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n }. \\ \text{The second identity is obtained from the first using the fact that } d e ^ { n } = 0. \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
The second identity is obtained from the first using the fact that de n = 0.
Property 2. For τ ∈ Ω (Σ) t ,
$$m ^ { * } * _ { n + 1 } \tau \wedge e ^ { n } = \eta ^ { n n } ( - 1 ) ^ { n - t } * _ { \Sigma } \tau, \\ m ^ { * } * _ { n + 1 } \tau = 0.$$
Proof. By linearity, it is sufficient to check the property for τ = e µ 1 ∧ · · · ∧ e µ t . First,
$$\begin{smallmatrix} 1 \\ - \end{smallmatrix}$$
$$x \, \iota _ { 0 }, \, \iota _ { 1 } \, \infty, \, \infty \, \text{com/s} \, \infty \, \text{s} \, \infty, \, \infty \, \text{s} \, \infty, \\ \ast _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } & = \eta ^ { \mu _ { 1 } \nu _ { 1 } } \cdots \eta ^ { \mu _ { t } \nu _ { t } } \eta ^ { n n } \epsilon _ { \nu _ { 1 } \cdots \nu _ { n } \rho _ { 1 } \cdots \rho _ { n - t } } \frac { 1 } { ( n - t )! } e ^ { \rho _ { 1 } } \wedge \cdots \wedge e ^ { \rho _ { n - t } } \\ & = \frac { ( - 1 ) ^ { n - t } } { ( n - t )! } \eta ^ { n n } \eta ^ { \mu _ { 1 } \nu _ { 1 } } \cdots \eta ^ { \mu _ { t } \nu _ { t } } \epsilon _ { \nu _ { 1 } \cdots \nu _ { t } \rho _ { 1 } \cdots \rho _ { n - t } } e ^ { \rho _ { 1 } } \wedge \cdots \wedge e ^ { \rho _ { n - t } } \\ & = \frac { ( - 1 ) ^ { n - t } } { ( n - t )! } \eta ^ { n n } \eta ^ { \mu _ { 1 } \nu _ { 1 } } \cdots \eta ^ { \mu _ { t } \nu _ { t } } \epsilon _ { \nu _ { 1 } \cdots \nu _ { t } \rho _ { 1 } \cdots \rho _ { n - t } } e ^ { \rho _ { 1 } } \wedge \cdots \wedge e ^ { \rho _ { n - t } } \\ & = \eta ^ { n n } ( - 1 ) ^ { n - t } \ast _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } },$$
and
$$* _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } & = \eta ^ { \mu _ { 1 } \nu _ { 1 } } \cdots \eta ^ { \mu _ { t } \nu _ { t } } \frac { 1 } { ( n - t )! } \epsilon _ { \nu _ { 1 } \dots \nu _ { t } \rho _ { 1 } \dots \rho _ { n - t } } e ^ { \rho _ { 1 } } \wedge \dots \wedge e ^ { \rho _ { n - t } } \wedge e ^ { n } \\ & = ( * _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n }.$$
Thus applying m ∗ on both equations ends the proof.
The remaining properties derived in this section rely heavily on Prop. 1 and 2, to which we will not refer to explicitly in the sequel.
$$\text{Property $3$. $m^{*} \delta_{n+1} e^{\mu_{1} } \wedge \dots \wedge e^{\mu_{t} } = \delta _ { \Sigma } e ^ { \mu_{1} } \wedge \dots \wedge e ^ { \mu_{t} }.$$
Proof. First, notice that:
$$\cdots \nolimits _ { \lambda } \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd� \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdclots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \colon \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd: \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdets \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd.. \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd>< \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \ nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimeq \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu. \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ {t } \, \nu _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nu _ { t } \, \nolimits _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nu _ { t } \, \nolimits _ { t } \$$
using the fact that de n = 0 and that ( · · · e n ) ∧ e n = 0. Paying attention to the signs yields then
$$\delta _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } & = ( - 1 ) ^ { ( n + 1 ) ( t + 1 ) + 1 } \, \text{sgn} ( \eta _ { n + 1 } ) \, * _ { n + 1 } \, d \, * _ { n + 1 } \, e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = ( - 1 ) ^ { ( n + 1 ) ( t + 1 ) + 1 } \, \text{sgn} ( \eta _ { n + 1 } ) ( - 1 ) ^ { t + 1 } \eta ^ { n n } \, * _ { 2 } \, d _ { 2 } \, * _ { 2 } \, e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = ( - 1 ) ^ { ( n + 1 ) ( t + 1 ) + 1 } \, \text{sgn} ( \eta _ { n + 1 } ) ( - 1 ) ^ { t + 1 } \eta ^ { n n } ( - 1 ) ^ { n ( t + 1 ) + 1 } \, \text{sgn} ( \eta _ { 2 } ) \delta _ { 2 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = \eta ^ { n n } \, \text{sgn} ( \eta _ { n + 1 } ) \, \text{sgn} ( \eta _ { 2 } ) \delta _ { 2 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = \delta _ { 2 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } },$$
using the fact that η nn sgn( η n +1 ) sgn( η Σ ) = 1.
$$\text{Property } 4. \ m ^ { * } \delta _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } = ( - 1 ) ^ { t + 1 } \eta ^ { n n } H ( n - t ) e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } }.$$
Proof. Notice that
$$& \ast _ { n + 1 } d \ast _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } = ( - 1 ) ^ { n - t } \eta ^ { n n } \ast _ { n + 1 } d ( \ast _ { z _ { 2 } } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \\ & \quad = ( - 1 ) ^ { n - t } \eta ^ { n n } \ast _ { n + 1 } \left [ ( d _ { 2 } \ast _ { z } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) + ( - 1 ) ^ { n - t } h ( n - t ) ( \ast _ { z } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } \right ] \\ & \quad = ( - 1 ) ^ { n - t } \eta ^ { n n } \left [ ( \ast _ { z } d _ { z } \ast _ { z } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } + ( - 1 ) ^ { n - t } h ( n - t ) ( - 1 ) ^ { n - ( n - t ) } \eta ^ { n n } ( \ast _ { z } \ast _ { z } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \right ] \\ & \quad = ( - 1 ) ^ { n - t } \eta ^ { n n } ( \ast _ { z } d _ { z } \ast _ { z } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } + ( - 1 ) ^ { n t } \text{sgn} ( \eta _ { z } ) h ( n - t ) e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } },$$
applying m ∗ cancels the first term and with the appropriate signs to have a codifferential it yields
$$m ^ { * } \delta _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } & = ( - 1 ) ^ { ( n + 1 ) ( ( t + 1 ) + 1 ) + 1 } \text{sgn} ( \eta _ { n + 1 } ) ( - 1 ) ^ { n t } \text{sgn} ( \eta _ { \infty } ) H ( n - t ) e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = ( - 1 ) ^ { t + 1 } \eta ^ { n n } H ( n - t ) e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } },$$
$$\text{since } m ^ { * } h = H \text{ and } \eta ^ { n n } \text{sgn} ( \eta _ { n + 1 } ) \text{sgn} ( \eta _ { \Sigma } ) = 1.$$
since m h = H and η sgn( η n +1 ) sgn( η Σ
Remark. Without applying m ∗ to the equality one gets the ambient formula
$$\delta _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } = ( \delta _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } + ( - 1 ) ^ { t + 1 } \eta ^ { n n } h ( n - t ) e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } }.$$
Property 5. Let τ ∈ Ω (Σ) t , one has: i n ∗ n +1 ( τ ∧ e n ) = 0 .
$$P r o o f. \ i _ { n } * _ { n + 1 } \tau \wedge e ^ { n } = ( - 1 ) ^ { n - t } \eta ^ { n n } i _ { n } * _ { \Sigma } \tau = 0.$$
Property 6. i n n δ +1 e µ 1 ∧ · · · ∧ e µ t = 0 .
$$P r o o f. \ i _ { n } \delta _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } = i _ { n } \delta _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } = 0.$$
$$P r o o f. \ i _ { n } \delta _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } = i _ { n } \delta _ { \Sigma } e ^ { \mu _ { 1 } }$$
Remark. Leveraging properties of the (genalized) interior product and of the codifferential 12 provides an alternative short proof of the last two properties, namely
$$& i _ { n } \ast _ { n + 1 } \tau \wedge e ^ { n } \in \ast _ { n + 1 } j ^ { n } \tau \wedge e ^ { n } = \ast _ { n + 1 } e ^ { n } \wedge \tau \wedge e ^ { n } = 0, \\ & i _ { n } \delta _ { n + 1 } \tau = - \delta _ { n + 1 } i _ { n } \tau + \eta _ { n n } ( d e ^ { n } ) \, \Delta \tau = 0,$$
since i n τ = 0 and de n = 0, using the symbol for the generalized interior product between the 2-form de n and τ ∈ Ω (Σ) t .
Property 7. Noting L n = L e n = i n d + di n , the Lie derivative along e n , one has
$$& \mathcal { L } _ { n } \, e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } = h t \, e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } }, \\ & \mathcal { L } _ { n } \, e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } = h t \, e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n }.$$
Proof.
L n e µ 1 ∧ · · · ∧ e µ t = i n de µ 1 ∧ · · · ∧ e µ t = ( -1) t hti n e µ 1 ∧··· ∧ e µ t ∧ e n = hte µ 1 ∧ · · · ∧ e µ t , and since de n = 0 and then L n e n = di n e n = 0, one has
$$\mathcal { L } _ { n } \, e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } & = ( \mathcal { L } _ { n } \, e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } + e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge ( \mathcal { L } _ { n } \, e ^ { n } ) \\ & = h t e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n }.$$
Notation. For λ a 1-form and β ∈ Ω b a b -form we set
$$\lambda \, \lrcorner \beta & = ( - 1 ) ^ { b + 1 } \ast ^ { - 1 } \lambda \wedge \ast \beta \\ & = ( - 1 ) ^ { n ( b + 1 ) } \, \text{sgn} ( g ) \ast \lambda \wedge \ast \beta,$$
which is an interior product 12 related to the usual interior product as λ β = i /sharpλ β.
Property 8. Let φ be a function, then
$$d \phi \perp _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } = d _ { \Sigma } \phi \perp _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } }$$
$$d \phi \nmid _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } = ( d _ { \Sigma } \phi \nmid _ { e } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } + ( - 1 ) ^ { t } \eta ^ { n n } e _ { n } ( \phi ) e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } }.$$
Proof. First, notice that
$$d \phi = d _ { _ { \Sigma } } \phi + e _ { n } ( \phi ) e ^ { n },$$
then
$$\sum _ { \begin{array} { c } d \phi \mu _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } & = ( - 1 ) ^ { ( n + 1 ) ( t + 1 ) } \text{sgn} ( \eta _ { n + 1 } ) * _ { n + 1 } d \phi \wedge * _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = ( - 1 ) ^ { ( n + 1 ) ( t + 1 ) } \text{sgn} ( \eta _ { n + 1 } ) * _ { n + 1 } d _ { 2 } \phi \wedge ( * _ { 2 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \wedge e ^ { n } \\ & = ( - 1 ) ^ { ( n + 1 ) ( t + 1 ) } \text{sgn} ( \eta _ { n + 1 } ) ( - 1 ) ^ { n - ( 1 + n - t ) } \eta ^ { n n } * _ { 2 } d _ { 2 } \phi \wedge ( * _ { 2 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) \\ & = ( - 1 ) ^ { n ( t + 1 ) } \eta ^ { n n } \text{sgn} ( \eta _ { n + 1 } ) ( - 1 ) ^ { n ( t + 1 ) } \text{sgn} ( \eta _ { 2 } ) d _ { 2 } \phi \underline { \mu _ { 2 } } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = d _ { 2 } \phi \underline { \mu _ { 2 } } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } }. \end{array}$$
The second identity relies on the same relations and on a proper bookkeeping of signs.
## Appendix B: Proofs of the theorems
## 1. Proof of Eq. (2) , restriction of δ n +1
Proof. A key formula for the following proof is that for φ a function and β ∈ Ω b a b -form one has
$$\delta ( \phi \beta ) = \phi ( \delta \beta ) - d \phi \Delta \beta.$$
Then, owing to Prop. 4 and 8, for a generic longitudinal term one has
$$\dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ m ^ { * } \delta _ { n + 1 } ( \phi e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } ) & = m ^ { * } \left [ \phi \delta _ { n + 1 } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } \right ] - d \phi \prod _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } \right ] \\ & = m ^ { * } \left [ \phi ( - 1 ) ^ { t + 1 } \eta ^ { n n } H ( n - t ) - ( - 1 ) ^ { t } \eta ^ { n n } e _ { n } ( \phi ) \right ] e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = ( - 1 ) ^ { t + 1 } \eta ^ { n n } m ^ { * } [ e _ { n } ( \phi ) + H ( n - t ) \phi ] e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \\ & = - \eta ^ { n n } m ^ { * } i _ { n } [ \mathcal { L } _ { n } + H ( n - 2 t ) ] ( \phi e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } ), \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
tweaking the last expression in order to recover the original longitudinal term in the right hand side, noting in particular with Prop. 7 that
$$[ e _ { n } ( \phi ) + h ( n - t ) \phi ] e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } & = ( - 1 ) ^ { t } i _ { n } [ e _ { n } ( \phi ) + h ( n - t ) \phi ] e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } \\ & = ( - 1 ) ^ { t } i _ { n } [ \mathcal { L } _ { n } + h ( n - 2 t ) ] ( \phi e ^ { \mu _ { 1 } } \wedge \dots \wedge e ^ { \mu _ { t } } \wedge e ^ { n } ).$$
For a generic transverse term
$$m ^ { * } \delta _ { n + 1 } ( \phi e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) & = m ^ { * } \left [ \phi \delta _ { n + 1 } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) - d \phi \perp _ { n + 1 } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \right ] \\ & = m ^ { * } \left [ \phi \delta _ { \Sigma } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ) - d _ { \Sigma } \phi \perp _ { \Sigma } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } \right ] \\ & = \delta _ { \Sigma } ( m ^ { * } \phi e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { t } } ).$$
Thus, by linearity and the splitting of α ∈ Ω ( a R n +1 ) in a longitudinal ( t = a -1) and a transverse part ( t = a ), according to Eq. (1), one gets
$$m ^ { * } \delta _ { n + 1 } \alpha = \delta _ { \Sigma } m ^ { * } \alpha - \eta ^ { n n } m ^ { * } i _ { n } [ \mathcal { L } _ { n } + H ( n - 2 a - 2 ) ] \alpha,$$
recalling that i n α ⊥ = 0, m α ∗ = α ⊥ = m α ∗ ⊥ .
## 2. Proof of Eq. (3) , restriction of /square n +1
Proof. Recalling that m dα ∗ = d Σ m α ∗ (see Eq. 6.2.12 of Ref. 15), then one has
$$\cdots \nu \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \\ - m ^ { * } \square _ { n + 1 } \alpha & = m ^ { * } ( d \delta _ { n + 1 } + \delta _ { n + 1 } d ) \alpha \\ & = d _ { 2 } m ^ { * } \delta _ { n + 1 } \alpha + \delta _ { 2 } d _ { 2 } m ^ { * } \alpha - \eta ^ { n n } d _ { 2 } m ^ { * } [ \mathcal { L } _ { n } + h ( n - 2 a ) ] i _ { n } d \alpha \\ & = d _ { 2 } \delta _ { 2 } m ^ { * } \alpha - \eta ^ { n n } d _ { 2 } m ^ { * } [ \mathcal { L } _ { n } + h ( n - 2 ( a - 1 ) ) ] i _ { n } \alpha + \delta _ { 2 } d _ { 2 } m ^ { * } \alpha - \eta ^ { n n } d ^ { * } [ \mathcal { L } _ { n } + h ( n - 2 a ) ] i _ { n } d \alpha \\ & = - \square _ { 2 } \alpha _ { 2 } - \eta ^ { n n } m ^ { * } [ ( \mathcal { L } _ { n } ) ^ { 2 } + h ( n - 2 ( a - 1 ) ) \, \mathcal { L } _ { n } - 2 h i _ { n } d ] \alpha \\ & \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \end{array}$$
using the fact that d L n = L n d , that di n = L n -i n d and that dh = -h e 2 n , this establishes the formula
$$m ^ { * } \Box _ { n + 1 } \alpha & = \Box _ { \Sigma } \alpha _ { \Sigma } + \eta ^ { n n } m ^ { * } [ ( \mathcal { L } _ { n } ) ^ { 2 } + H ( n - 2 ( a - 1 ) ) \, \mathcal { L } _ { n } - 2 H i _ { n } d ] \alpha \\ & = \Box _ { \Sigma } \alpha _ { \Sigma } + \eta ^ { n n } m ^ { * } [ ( \mathcal { L } _ { n } ) ^ { 2 } + H ( n - 2 a ) \, \mathcal { L } _ { n } + 2 H d i _ { n } ] \alpha. & \Box$$
Remark. Noting that since e n = hD and
$$\mathcal { L } _ { n } \alpha = \mathcal { L } _ { h _ { D } } \, \alpha = h \, \mathcal { L } _ { D } + d h \wedge i _ { D } \alpha,$$
then m ∗ L n α = m H ∗ L D α and
$$m ^ { * } ( \mathcal { L } _ { n } ) ^ { 2 } \alpha = m ^ { * } h \, \mathcal { L } _ { D } \, h \, \mathcal { L } _ { D } \, \alpha = m ^ { * } H ^ { 2 } [ ( \mathcal { L } _ { D } ) ^ { 2 } - \mathcal { L } _ { D } ] \alpha$$
putting Eq. (3) as
$$m ^ { * } \Box _ { n + 1 } \alpha = \Box _ { \Sigma } \alpha _ { \Sigma } + \eta ^ { n n } H ^ { 2 } m ^ { * } [ ( \mathcal { L } _ { D } ) ^ { 2 } + ( n - 1 - 2 a ) \, \mathcal { L } _ { D } + 2 d i _ { D } ] \alpha,$$
which for a = 1 agrees with Eq. (6) of Ref. 11.
## 3. Proof of Eq. (4) , continuation of δ Σ
Proof. Let β ∈ Ω (Σ) and b β s ∈ Ω b s ⊥ such that m β ∗ s = β , its s -homogeneous extension. First, the restriction of the codifferential Eq. (2) together with the transversality of β s implies Eq. (2), that is
$$m ^ { * } \delta _ { n + 1 } \beta _ { s } = \delta _ { \Sigma } \beta.$$
Now, let us compute i n n δ +1 β s , one has:
$$\cdots, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \\ i _ { n } \delta _ { n + 1 } \beta _ { s } & = \frac { 1 } { b! } i _ { n } \delta _ { n + 1 } ( \beta _ { s } ) _ { \mu _ { 1 } \cdots \mu _ { b } } e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { b } } \\ & = \frac { 1 } { b! } [ ( \beta _ { s } ) _ { \mu _ { 1 } \cdots \mu _ { b } } i _ { n } \delta _ { n + 1 } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { b } } ) - i _ { n } \{ ( d ( \beta _ { s } ) _ { \mu _ { 1 } \cdots \mu _ { b } } ) \neq \mathbb { I } ( e ^ { \mu _ { 1 } } \wedge \cdots \wedge e ^ { \mu _ { b } } ) \} ] \\ & = 0,$$
where, Prop. 6 and 8 have been used in the last line. Thus, the ( b -1)-form δ n +1 β s is transverse (and since β s ∈ Ω b s ⊥ , δ n +1 β s ∈ Ω b -1 s - ⊥ 2 ), which implies m δ ∗ n +1 β s = δ n +1 β s , and finally
$$\delta _ { _ { \Sigma } } \beta = \delta _ { n + 1 } \beta _ { s }.$$
## 4. Proof of Eq. (5) , continuation of /square Σ
Proof. Let β ∈ Ω (Σ) and b β s ∈ Ω b s ⊥ such that m β ∗ s = β , its s -homogeneous extension. Let us first compute L n β s :
$$\mathcal { L } _ { n } \beta _ { s } = \mathcal { L } _ { h D } \beta _ { s } = h \mathcal { L } _ { D } \beta _ { s } + d h \wedge i _ { D } \beta _ { s } = h s \beta _ { s }.$$
Then, the restriction Eq. (3) becomes
$$m ^ { * } \Box _ { n + 1 } \beta _ { s } & = \Box _ { \Sigma } \beta + H ^ { 2 } \eta ^ { n n } [ s ^ { 2 } + ( n - 1 - 2 b ) s ] \beta _ { s }, \\ & = \Box _ { \Sigma } \beta + H ^ { 2 } \eta ^ { n n } s ( s + n - 1 - 2 b ) \beta _ { s }.$$
The longitudinal part of /square n +1 β s reads
$$\text{dumal part of $\sqcup_{n+1}beta_{s}$ reads} \\ j ^ { n } i _ { n } \square _ { n + 1 } \beta _ { s } & = - j ^ { n } i _ { n } ( d \delta _ { n + 1 } + \delta _ { n + 1 } d ) \beta _ { s } \\ & = - j ^ { n } ( \mathcal { L } _ { n } \, \delta _ { n + 1 } - d i _ { n } \delta _ { n + 1 } - \delta _ { n + 1 } i _ { n } d ) \beta _ { s } \\ & = - j ^ { n } ( \mathcal { L } _ { n } \, \delta _ { n + 1 } - \delta _ { n + 1 } \, \mathcal { L } _ { n } ) \beta _ { s } \\ & = - j ^ { n } ( h ( s - 2 ) \delta _ { n + 1 } - s \delta _ { n + 1 } h ) \beta _ { s } \\ & = - j ^ { n } ( - 2 h \delta _ { n + 1 } \beta _ { s } + s d h \Delta \beta _ { s } ) \\ & = 2 h j ^ { n } \delta _ { n + 1 } \beta _ { s } \\ & = 2 h e ^ { n } \wedge ( \delta _ { n + 1 } \beta _ { s } ), \\ \text{ve used } [ i.. \ d ] \,. \, = \, \mathcal { L }. \, \text{
} 0, - from 6 6 0, and 3, 0 1, 1 2, 3 4, 6, 2 7,$$
in which we used [ i n , d ] + = L n , Prop. 6, and dh = -h e 2 n .
Now, since the pullback m ∗ , maps a p -form on R n +1 to its transverse part on Σ, on each point of Σ one has
$$\Box _ { n + 1 } \beta _ { s } & = ( \Box _ { n + 1 } \beta _ { s } ) _ { \perp } + ( \Box _ { n + 1 } \beta _ { s } ) _ { | | } \\ & = m ^ { * } ( \Box _ { n + 1 } \beta _ { s } ) + j ^ { n } i _ { n } \Box _ { n + 1 } \beta _ { s },$$
from which Eq. (5) follows.
- 1 C. Fronsdal, Phys. Rev. D 10 , 589 (1974).
- 2 J. P. Gazeau and M. Hans, J. Math. Phys. 29 , 2533 (1988).
- 3 M. V. Takook, arXiv:1403.1204 [gr-qc] (2014).
- 4 B. Pethybridge and V. Schaub, JHEP 06 , 123, arXiv:2111.14899 [hep-th].
- 5 M. J. Duncan and L. G. Jensen, Nucl. Phys. B 336 , 100 (1990).
- 6 T. S. Koivisto, D. F. Mota, and C. Pitrou, JHEP 09 , 092, arXiv:0903.4158 [astro-ph.CO].
- 7 L. Baulieu and M. P. Bellon, Nucl. Phys. B 266 , 75 (1986).
- 8 M. Henneaux and C. Teitelboim, Found. Phys. 16 , 593 (1986).
- 9 A. Folacci, J. Math. Phys. 32 , 2813 (1991).
- 10 A. Folacci, J. Math. Phys. 32 , 2828 (1991), [Erratum: J.Math.Phys. 33, 1932 (1992)].
- 11 E. Huguet, J. Queva, and J. Renaud, J. Math. Phys. 63 , 072301 (2022), arXiv:2201.03253 [math-ph].
- 12 E. Huguet, J. Queva, and J. Renaud, arXiv:2406.02476 [math-ph] (2024).
- 13 J. Jost, Riemannian geometry and geometric analysis , Vol. 42005 (Springer, 2008).
- 14 E. Huguet, J. Queva, and J. Renaud, Phys. Rev. D 109 , 064054 (2024), arXiv:2312.05049 [math-ph].
15 M. Fecko, Differential geometry and Lie groups for physicists (Cambridge University Press, 2011). | null | [
"E. Huguet",
"J. Queva",
"J. Renaud"
]
| 2024-08-02T16:11:52+00:00 | 2024-08-14T09:06:59+00:00 | [
"math-ph",
"gr-qc",
"math.DG",
"math.MP"
]
| Laplacian and codifferential operators on p-forms in (Anti)-de Sitter spaces: restriction and continuation | We derive explicit restriction and continuation formulas between
n-dimensional (Anti)-de Sitter spaces and the (n + 1)-dimensional Minkowskian
ambient space for the codifferential and Laplace-de Rham operators acting on
p-forms. |
2408.01361v1 | ## Chapter 1
## KHARMA: Flexible, Portable Performance for GRMHD
Ben S. Prather
Abstract KHARMA (an acronym for 'Kokkos-based High-Accuracy Relativistic Magnetohydrodynamics with Adaptive mesh refinement') is a new open-source code for conducting general-relativistic magnetohydrodynamic simulations in stationary spacetimes, primarily of accretion systems. It implements among other options the High-Accuracy Relativistic Magnetohydrodynamics (HARM) scheme, but is written from scratch in C++ with the Kokkos programming model in order to run efficiently on both CPUs and GPUs. In addition to being fast, KHARMA is written to be readable, modular, and extensible, separating functionality into 'packages,' representing, e.g., algorithmic components or physics extensions. Components of the core ideal GRMHD scheme can be swapped at runtime, and additional packages are included to simulate electron temperature evolution, viscous hydrodynamics, and for designing chained multi-scale 'bridged' simulations. This chapter presents the computational environment and requirements for KHARMA, features and design which meet these requirements, and finally, validation and performance data.
KHARMA 1 (an acronym for 'Kokkos-based High-Accuracy Relativistic Magnetohydrodynamics with Adaptive mesh refinement') is a new open-source performanceportable code for performing general-relativistic magnetohydrodynamic (GRMHD) simulations, targeting stationary spacetimes such as black hole accretion systems. It implements the High-Accuracy Relativistic Magnetohydrodynamics (HARM) scheme [20], written from scratch in C++ 17 to leverage the Kokkos programming model [55] in order to run efficiently on various computer and accelerator architectures using the same source code. KHARMA also uses the Parthenon adaptive mesh
/a0
Ben S. Prather (
)
Los Alamos National Laboratory, PO Box 1663, Los Alamos, NM, e-mail: bprather@lanl.
gov
1 https://github.com/AFD-Illinois/kharma
refinement (AMR) framework [23] to support static and adaptive mesh refinement and to provide a consistent overall code structure.
KHARMA is in production use as one of the primary codes used for GRMHD simulations in the Event Horizon Telescope Collaboration (EHTC), furnishing many of the GRMHD simulations used in official papers such as [10], [17] and collaboration projects such as [12], [47]. In addition to being fast, KHARMA has been designed from the ground up to be modular and extensible through the use of packages, designed to each contain a single algorithmic component or physics extension. This modularity extends to all features, such as the magnetic field transport and primitive variable inversion, in addition to the usual modular components such as reconstruction scheme and Riemann solver. Various additional physics packages have been developed to treat new systems and processes beyond ideal GRMHD, including an approximate viscosity treatment useful for very low accretion-rate systems as described in [6], and a co-evolved electron temperature treatment for two-temperature plasmas as described in [45], as well as a mode for running chained 'multi-scale' simulations as described in [7]. An extension is also being developed for simulating radiative effects, which are extremely important at high accretion rates and increasingly computationally feasible for GPU-based codes on modern supercomputers.
This chapter provides a brief case study of KHARMA, beginning with the hardware trends and community requirements which led to its development, then covering the code's scheme, software design, and features, and ending with basic validation and performance data.
## 1.1 Necessity of performance portability
Perhaps the single choice that most dictates KHARMA's code structure is to be 'performance-portable,' targeting efficient operation on general-purpose graphics processing units (GPUs) as well as other accelerator architectures and traditional central processing unit (CPU) cores. Adding performance portability to an existing code often requires substantially re-writing it to leverage new loop ordering and data structures, and this difficulty was a primary motivator for developing KHARMA from scratch.
In order to understand the trends in computing which made performance portability so important as to abandon an existing fast C implementation of HARM [43], it's useful to provide a bit of history and context around high-performance computing (HPC). This context is unnecessary for understanding KHARMA itself; readers already convinced of the universal need for performance portability can skip to KHARMA's more unique code requirements in Section 1.2.
## 1.1.1 Performance and power
In 1965, Gordon Moore predicted that the number of transistors on a given integrated circuit would double each year. In 1975, he revised this to predict a slower doubling rate of 2 years from 1980 onward [35], [36]. Whether by prescience or self-fulfilling prophecy, this doubling rate has held for nearly all of the ensuing 4 1 /2 decades. Usually, this increase is interpreted as computer chips getting 'faster' or 'more capable.'
However, over the years, the purpose of these transistors - that is, how new transistors are 'spent' to improve a chip's capabilities, has shifted. For the first decades of chip development, from the 1970s to 2000s, extra transistors were used to increase the clock speed and instruction processing rate of otherwise similar chips that is, to make existing programs run faster. However, power constraints cut short the increasing clock rates in the mid-2000s, necessitating that designers find other ways to improve chips - thus, improvements to CPUs since that time have taken the form of adding more processing cores to a single chip, operating at the same frequency but processing more data (so long as programs could take advantage of the parallelism). This much is well-known in the supercomputing community.
Parallel to this more obvious trend of multiple cores, we see a trend toward not just duplicating existing processors, but specializing them for particular kinds of work - seen in GPUs, as well as vector-optimized or 'many-core' CPUs. Specialization involves taking out functionality like branch prediction, out-of-order execution, and large instruction sets, and using their area and transistor count to further boost the amount of data a chip can process at once, through additional parallel execution units. At the far end of specialization, chips capable of providing only one function (encryption, say, or video encoding) can provide orders of magnitude faster processing than software implementations.
Both trends are illustrated in parallel in Figure 1.1. Plotted in blue and gold are CPU scores in the PassMark general benchmark 2 , for single cores and full sockets [41]. Single-core performance stagnates with the power limits to clock rate in 2008, and has grown at a rate of only 2 0 12 . t (where t is in years) since then, mostly consisting of hard-won efficiency improvements in the rate of instructions cleared per clock cycle (IPC). Instead, performance benefits are realized by increasing the core count; parallel workloads have still seen a 2 0 40 . t improvement as core counts have increased over the last decade. Plotted in red are GPU performance numbers in floating-point operations per second (FLOPS/s) [53]. Note this is a significantly different measurement from a PassMark score, evaluating GPUs' effectiveness at number crunching specifically, not general workloads (which they are generally unsuited for anyway). This means that GPU performance is plotted on a different axis from CPU performance. However, both axes span exactly four decades, to compare relative improvement, where GPUs clearly have an advantage, especially in recent years. Over the same measured span 2006-2023, GPUs grow in floating-point per-
2 https://www.passmark.com/
formance at 2 0 49 . t , paying forward the full benefits of their increasing transistor count.
It should not be surprising that special-purpose chips can improve at their intended task faster than general-purpose chips can improve at a broad range of tasks; they trade generality for efficiency. As power constraints and the end of Moore's law force the use of more creative methods to improve performance, the pressure toward specialization will likely increase.
Fig. 1.1: CPU single-core and total performance development, plotted against GPU theoretical peak performance performing floating-point operations. Scales for CPU and GPU metrics are independent, and are adjusted so that metrics coincide in 2006, but all scales span exactly 4 decades to accurately depict relative improvement. Fitting functions reflect exponential growth of 2 0 12 . t , 2 0 40 . t , and 2 0 49 . t for CPU single, full, and GPU performance respectively, with t measured in years. CPU performance is measured via public listed results of the PassMark combined CPU benchmark software. GPU performance is taken from combinations of manufacturer-listed and reviewer-tested floating point operations per second (FLOPS/s) at double precision (not AI-specific packed operations marketed as 'matrix' or 'tensor' cores). CPU scores from [41], GPU performance from [53], figure originally from [44].
The benefits of specialization are nowhere more evident than in Artificial Intelligence (AI). AI research now drives the development of its own class of special-
ized chips, designed even more narrowly than GPUs for processing the large matrix multiplications used in training and inference. The clear efficiency benefits of specialized hardware have driven a rush of new architectures, such as Google's Tensor Processing Units [26], Cerebras systems' Wafer-Scale Engine [29] and Tesla's many-core 'Dojo' architecture [52], which have become increasingly widespread. Even architectures which remain general in principle are gaining subsystems targeted at AI calculations specifically (Nvidia's Tensor Cores, Intel's AMX Engines, etc.).
## 1.1.2 Specialization in supercomputing
Though more recently than the frequency limit, supercomputing has similarly hit a hard limit: power draw. Machines consuming more than about 1MW can cost more in electricity than hardware, so the top machines cannot continue to draw more power without incurring spiraling costs. To illustrate trends in supercomputing, we use the open top 500 supercomputers list compiled semi-annually [34]. While not a complete list of every machine, is still indicative of overall trends in supercomputers both public and private. As shown at left of Figure 1.2, from 2008 (when recording of power usage began) to 2013, the average power draw of the reporting portion of the top 500 machines grew by nearly an order of magnitude in 5 years. Since then, however, it has grown by only another factor of 2, and appears to be slowing further still. This is good news for global energy usage, of course, but it has visibly slowed the performance development of the top 500 machines, as shown at right of Figure 1.2. Before the increasing power usage slowed in 2013, machines doubled in performance every year; afterward, every two years.
Even discounting the very top machines, where exotic architectures have always been common, the closing power envelope is pushing HPC systems toward specialpurpose chips, mostly GPUs. Indeed, the number of machines in the top 500 list powered primarily by GPUs has increased substantially: in 2013, under 10% of systems used some kind of GPU accelerator - as of November 2023, the share is just about 30%, together providing half of the list's total computing power [34] 3 . While initial adoption of accelerators was slow due to programming challenges, maturing software (AI frameworks, programming models, etc..) and the closing power envelope have made GPUs an ever clearer choice for new systems.
Even the word GPU in the HPC context has shifted to mean something more specialized than it did a decade ago: back then, top machines such Oak Ridge National Laboratory's Titan were powered by what were effectively consumer graphics chips - the GK110 chips used in that machine were also sold to consumers as the Titan GPU. Even when the die was not exactly the same, the technologies were: many supercomputers over the course of the 2000s were built with technologies sold con-
3 This number excludes specialized CPUs such as the Fujitsu A64FX and Intel Knights Landing architectures. Nevertheless, these architectures present many of the same challenges and opportunities as accelerators.
Fig. 1.2: Average power draw of the top 500 machines, plotted with average performance development, showing a clear slowing of power usage increases in about 2013, when average machine power usage began to exceed 1MW. Average power usage of the reporting fraction of the top 500 machines shows exponential growth at 2 0 56 . t from 2008 (when reporting began) to 2013, and 2 0 14 . t thereafter. Average peak performance R peak in GFLOPS/s of all top 500 machines shows development at 2 0 88 . t before 2013, 2 0 49 . t thereafter. Data from [34], figure originally from [44].
currently (or even primarily) to consumers. Modern 'GPUs,' in contrast, are specialized computational designs, increasingly distinct in architecture from their consumer counterparts (e.g., CDNA vs. RDNA from AMD, XeHPC vs. XeLP from Intel, Hopper and Blackwell vs. Lovelace from Nvidia).
The sudden specialization has a clear cause: the massive hardware market for running artificial intelligence models. As the large tech companies build AI training supercomputers on the scale of cloud server farms, they finally represent the kind of large and stable market that will drive stiff competition, and it seems likely that chip architectures will continue to shift to serve the needs of the larger AI market, rather than traditional HPC use cases. The current generation of supercomputers uses three substantially new architectures (Fujitsu A64FX, AMD CDNA2, Intel XeHPC), and as AI drives further architecture changes, the next generation may use substantially different architectures still. Yanked out of its complacency by a strong AI hardware market and increasing power efficiency concerns, not to mention the end of Moore's
law, HPC faces a decade of either rapid architectural changes or complete performance stagnation.
## 1.1.3 Specialized hardware requires portable software
It should be no surprise that in places where complex specialized hardware has found success, it has generally included an easy and standard software interface, to abstract away the complexity. Take graphics acceleration: calls using a standard interface such as OpenGL or DirectX can be accelerated by a huge number of different hardware implementations, each providing a driver which translates the standard calls to specific instructions for the accelerator hardware. Thus innovations to the hardware do not require changing existing applications at all. A similar separation of standard interface layer and driver implementation layer has found success in enabling many other specialized hardware implementations, for video encoding/decoding, networking operations such as encryption, etc.
There is no single standard language of this kind for HPC as there is for other accelerators. This is not for lack of trying, however, and there are promising modern contenders: projects within HPC such as Kokkos [55], OCCA [33], RAJA [1], as well as industry standards such as OpenCL 4 , SYCL 5 , OpenACC 6 , and efforts within the C++ standard under the namespace std::parallel . All of these attempt to express accelerator programming in a hardware-independent way, striking a balance between providing an easy-to-use interface and allowing low-level access and flexible programming.
While the lack of a standard is disappointing, it is not reason to avoid any of the existing options. Nearly all of the listed performance portability options involve abstractions which simplify device programming, and provide convenient frameworks to simplify host programming as well. Many of them share a similar overall structure for expressing compute kernels, so porting between them may often be easier than adapting 'landlocked' pure C code of any complexity.
## 1.2 Other Requirements
Besides performance portability, there were several requirements that shaped KHARMA's design. KHARMA was designed primarily as a code for black hole accretion simulations, specifically of low-luminosity active galactic nuclei (LLAGN), that is, very low-accretion-rate supermassive black hole (SMBH) accretion systems where radiation does not play a primary role in the fluid dynamics. The primary targets were
4 https://www.khronos.org/opencl/
5 https://www.khronos.org/sycl/
6 https://www.openacc.org/
M87 ∗ and Sagittarius A , in order to understand and utilize the images from the ∗ Event Horizon Telescope (EHT). This provided a simple and useful target for early development, though more recently the code has been extended well beyond this original purpose.
The following sections give background on the scientific requirements which shaped KHARMA's development.
## 1.2.1 Simulation Libraries
The first black hole (BH) images of M87 ∗ by the EHT Collaboration (EHTC) [13] presented a unique opportunity to put accretion theories and simulations directly to the test, by comparing concrete predictions from ray-traced simulations to the EHT image properties and other measurements of M87 . Within the collaboration, ∗ a parameter study or 'library' of GRMHD simulations was created. The core of this library consisted of 10 simulations performed with the HARM-based GRMHD code iharm3D [43]. Simulations were performed on Stampede2 at the Texas Advanced Computing Center (TACC), where a set of just 10 simulations used a significant allocation of CPU-based resources.
From this core library of GRMHD simulations, images could be created via general-relativistic ray-traced volume rendering of the diffuse optically thin emission, generating a prediction for emission intensity at EHT frequencies [61]. With these images, especially when used in combination with other measurements (e.g., estimates of the jet power), the collaboration was able to significantly narrow the space of realistic accretion possibilities, and thereby understand the salient image features in terms of the accretion state around the event horizon (EH) [15]. Many research projects within the collaboration have made use of this standard library, from validation and calibration for official results [14], [16] to interpretation of polarized results [18], and many individual studies [22], [25], [30], [40], [48].
However, running libraries of simulations is expensive, and the conclusions are limited to motivating or demotivating particular models within a set of options necessarily limited in both its coverage of the available parameters, and its included physics. With better data, some clear and independent observational signatures by which to measure particular system parameters may yet be forthcoming - for example, measurement of BH spin by directly measuring the shape of the photon ring [25]. Likewise, sufficiently accurate modeling may reveal reliable trends under certain circumstances - for example, the β 2 parameter describing rotational symmetry of the resolved linear polarization, which can reliably distinguish between different magnetic field strengths in simulations, and provides a rough indicator of BH spin if accretion is viewed nearly face-on [40].
However, in general, changes to BH system parameters cause complex and overlapping changes in the observable image and other measurements, which are difficult to disentangle into clear relationships between individual parameters and measured values. Thus, simulation libraries are still the most reliable way to understand
the constraints that new data provide, as well as the most useful current tool available to develop better techniques. Simulations retain an important advantage over phenomenological models in particular, as predictions can be made about many disparate measurements based on the same underlying simulated model, and thus it can be evaluated against all available measurements of a source in concert.
## 1.2.2 Many Long Simulations
Arelatively short and sparse parameter study sufficed in order to understand the basic features of M87 ∗ - however, in order to evaluate the much faster-moving Sagittarius A ∗ (Sgr A ) in detail, longer simulations were required. Ideal GRMHD simu-∗ lations can be rescaled to the system's characteristic timescale, but the relevant scale is much shorter for Sgr A ∗ than M87 , requiring much longer simulations in order to ∗ cover just a few days of real time. Longer simulations also allowed better characterizing the variability of the light-curve, as well as providing more snapshots to compare against the data - useful considering the less definitive reconstructions of the Sgr A ∗ image. This need provided the original motivation for writing KHARMA.
Notably, in this case and generally, the advantage to simulation libraries and parameter studies is to produce many long simulations, rather than necessarily the largest possible single examples. In GRMHD in particular, so long as basic resolution requirements are met (such as resolving the magnetorotational instability) simulations tend to vary little with resolution - at least, on the scales at which it is feasible to run an entire simulation library. Thus a code must produce simulations at the existing resolutions more quickly - it must use each processor to its full potential (good base performance) and scale efficiently with the addition of more processors to a problem of the same size (good strong scaling).
In particular, the requirement of good base performance also motivates performance portability, as single GPU chips or nodes can vastly outperform single CPU nodes - thus, the difficult or unavoidable performance penalties of strong scaling can be partially recovered simply because fewer nodes need to communicate in order to achieve the same performance. There is also great utility in porting simulations which might have required 10-20 CPU nodes onto a single GPU, as single machines are much more likely to be available as a part of campus computing resources, or even within the means of an average research budget.
## 1.2.3 Mesh Refinement
Simulation efficiency benefits from larger time steps, which in turn require the largest possible zones, placing resolution only where it's needed. This is a universal problem with Logically Cartesian grids in spherical coordinate systems: the allowable simulation timestep set by the Courant-Friedrichs-Lewy (CFL) condition is
much smaller than it needs to be, set by the many small zones next to the coordinate pole. In a single regular mesh, increasing the φ -resolution necessarily arranges more zones next to the coordinate pole, and increasing the θ -resolution causes all zone centers to grow closer to one another as they approach the pole. Both effects reduce the width, and therefore the CFL limit, of these zones, and waste computation time with needlessly small timesteps.
Fig. 1.3: Diagram illustrating the timestep problem faced by non-refined logically Cartesian meshes in spherical polar coordinates. The illustration represents a slice at constant radius, arranged around the coordinate axis (i.e., z -axis) of a spherical polar coordinate grid, as marked (note that exactly the same problem exists in cylindrical or two-dimensional polar coordinates as well, with θ replaced by the radial coordinate). As the resolution in the θ or φ direction is increased, zones next to the axis bunch together, with smaller zone widths (e.g., those marked in red above). For solvers with a maximum timestep limited to the signal crossing time of the smallest zone (i.e., subject to the Courant-Friedrichs-Lewy condition) this can cause the stability-limited timestep to be much smaller than what would be required to maintain good accuracy, wasting significant computation time.
This can be mitigated somewhat by the use of coordinate-based refinement; specially designed coordinate transforms like 'Funky' Modified Kerr-Schild coordinates [61], which increase the θ -widths of the circumpolar zones at the coordinate level, so that zones equally spaced in the native coordinate system nevertheless grow in the base spherical coordinate system. At nominal resolutions, this provides from a 2-8x greater timestep than spacing zones evenly in θ .
However, really addressing this problem requires mesh refinement, which can widen zones in φ without losing θ -resolution near each coordinate pole. Successive derefinement of blocks approaching the axis can reduce almost arbitrarily high resolutions in the midplane down to a manageable number of axis zones in the coarsest, polar blocks. Internal refinement can further reduce the number of zones surrounding the axis to just 4-8 total zones, orders of magnitude fewer zones than an unrefined system, with a proportional speedup.
Other solutions exist for the timestep problem, e.g., overstepping the Courant condition of the circumpolar zones without modifying the mesh geometry [24].
However, these are complex to implement when compared to mesh refinement, and there is no need for them in a flexible self-contained code.
## 1.2.4 Extensibility
Perhaps the strictest requirement for KHARMA short of performance portability was that it be extensible, able to accommodate user changes and new physics onto its fast and scalable platform. Due to the broad range of physics at play over different scales and accretion rates, greater understanding will require treatment of new phenomena, not just modifications to the problem setup.
It is well known that ideal GRMHD does not capture all the physical effects which operate in most black hole accretion systems, and indeed the most exciting opportunities in really understanding these systems lie in treating physics beyond ideal GRMHD at resolution and accuracy scales where the observational consequences of new physics can be effectively studied.
One target of particular interest was dissipative effects, which may become important at very low accretion rates such as observed in Sgr A ∗ . Even the simplest and most streamlined treatment for Sgr A ∗ [6] uses a locally semi-implicit scheme as it must treat time-dependent and stiff source terms. Thus costs from 3-10 times more than fully-explicit ideal GRMHD evolution. If a more detailed treatment is ever required, it would cost even more. Resistivity may also play a role at small length scales close to the horizon, which can affect variability and observational appearance - a resistive treatment requires a similar implicit scheme to dissipative effects, with similar cost.
At the other end of the range of accretion rates, radiative effects quickly become dominant, at first indirectly through radiative cooling, and then directly as radiation pressure. Radiative effects dictate the evolution of high-accretion-rate systems, which are characterized by bright X-ray emission. Due to the difficulty of simulating accretion disks with such high luminosity, existing models for these systems are structured around 'thin-disk' analytic solutions as in e.g., [38]. These models have proven tremendously useful, but are limited in their applicability due to the assumptions involved. Algorithmic treatments of radiative GRMHD are well-understood [49], [60]. However, global treatments are computationally expensive - computational power is only now reaching the point that full thin-disk radiative simulations at high accretion rate are possible, potentially revolutionizing the field.
As mentioned, algorithms exist for all of these extensions. However, generally they are expensive, ranging from 3-20 times the base computational cost of ideal GRMHD simulations. Thus, they have traditionally been simulated at low resolutions, over short timeframes, and only with isolated simulations (not parameter studies). With a performance-portable framework, implementations of these extra effects can finally be incorporated into libraries of longer simulations, dramatically increasing their utility in comparing to observational data by parameterizing over the system's unknown incidental features.
In short, KHARMA's performance portability finally makes feasible a number of exciting simulations treating computationally expensive new physics, by making available the increased computational power of GPUs and the exascale machines which rely on them. Providing easy interfaces for these new features was therefore a primary goal for the code.
## 1.2.5 Readability
Finally, any code which expects to see adoption in academia must be understandable to a domain scientist graduate student using the code for a particular project, and not primarily tasked with its development. Large, complex and multipurpose scientific codebases have a place in laboratory science and engineering in industry, but codes in academia cannot rely on the same level of long-term staffing and funding, and must be less complex to be applied productively. This is not a strict requirement of simplicity, but rather a dual requirement of modularity and documentation: KHARMA cannot assume a high level of institutional knowledge, and must be possible to modify without deep knowledge of its various components.
Many academic codes take a strict simplicity-first approach to this problem, restricting themselves to features and implementations which will be understandable in full to a new student, without requiring that months be devoted to simply learning the code. It is arguable whether this approach is strictly necessary, and KHARMA was designed under the assumption that it is not, as the other desired features and dependencies are simply not compatible with a minimal codebase. KHARMA instead takes a documentation- and standards-based approach to the problem: the hope is that with a proper introduction, new developers need understand only the package interface and a few relevant packages in order to get started. However, while incredibly successful in most software, physics simulation codes provide something of a worst case for this approach, since debugging numerical instabilities can involve understanding the interactions between different packages modifying the fluid state. KHARMA's long-term success in taking this alternative approach remains to be seen.
## 1.3 Design for Requirements
To summarize the previous sections, KHARMA was required to:
- · Run simulation steps quickly by leveraging specialized architectures
- · Simulate the same time periods with fewer steps using mesh refinement
- · Easily support additional physics in combination with ideal GRMHD, such as viscosity and radiative processes
- · Still be understandable to the average graduate student not primarily tasked with its development
KHARMA's major design choices are very explicitly geared toward meeting these four requirements, so the design is presented here in reference to how it helped to address each requirement.
## 1.3.1 Performance Portability
Performance portability was the core requirement, for reasons exhaustively catalogued in 1.1, and is provided by Kokkos 7 [3], [55], [56]. The Kokkos programming model enables performance portability by providing a vendor-neutral library, compiled alongside an otherwise standard C++ program. It was chosen as the programming model for Parthenon, and therefore KHARMA, due to its simple syntax, universal support, and high performance ceiling relative to native performance.
Kokkos is an effort primarily of Sandia National Laboratory, and supports the major CPU and GPU architectures used in HPC. In the Kokkos context, 'performance portability' means enabling the use of a single primary source code base to generate efficient compiled code for many different HPC architectures. Kokkos is designed to be compiled into C++ programs: calls into the library from user C++ code cause the compiler to transform certain user functions into computational kernels in a number of different languages and language extensions, including Nvidia's CUDA, Khronos SYCL (used for Intel GPUs), and AMD HIP. The transformation happens entirely at compile-time, without wasting cycles performing just-in-time (JIT) compilation when the program is run. As it supports the use of any C++17compliant compiler, most vendor programming models, and nearly all accelerator hardware in use in HPC, Kokkos remains almost universally portable yet entirely vendor-neutral.
While this choice was made in 2020, before the universal availability of OpenMP offload implementations, OpenMP offload still does not meet our requirements of near-native performance or broad flexibility. Besides OpenMP, the competitor technologies were C-like systems such as OpenCL, as well as various 'turnkey' JITcompiled solutions. Modern options such as SYCL and std::parallel are also worth considering. In general, however, the existing options are all designed either for convenience when porting existing code, or for writing specifically GPU-first code. As a single programming model for CPUs and GPUs, Kokkos abstracts away the divide between CPU and GPU code entirely, enabling performance portability as well as a few convenience features at little overall cost to complexity.
The primary changes to user code under Kokkos are the abstraction of looping and memory access: the user writes parallel code once in an abstract way, and the memory layout and loop ordering are decided at compile time based on the compile target architecture. In part because of this heavy abstraction, Kokkos provides an easy and natural GPU programming model for the beginner. Take a normal onedimensional loop in C:
7 https://github.com/kokkos/kokkos
```
for (int64_t i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
```
In Kokkos it is written in a similar way, albeit with very different results:
```
Kokkos::parallel_for(N,
KOKKOS_LAMBDA (const int& i) {
c(i) = a(i) + b(i);
}
);
--. . . . . . . . . .
```
The latter snippet replaces the loop declaration with a function call into the Kokkos library, and the loop body with the definition of a C++ lambda function to be run once with each value of the index as its argument. Use of this construct is indication from the user that there are no loop dependencies, so Kokkos will map loop iterations to the available compute units on the target device in parallel as efficiently as possible, be it CPU, GPU, etc. The lambda function uses capture by value, so it operates almost as transparently as a normal loop body.
Multi-dimensional arrays (in Kokkos, View s) are also accessed in a straightforward way, substituting an inlined function call () for pointer-based array access [] . Multi-dimensional and nested loops are a bit more complex, but all of Kokkos's loop formulations are ultimately much more usable than manually specifying thread and block geometry in CUDA, for example. While the user does eventually have to understand that the host and device do not share a memory space, most host-todevice copies are automatic through the lambda capture, allowing the user to write code nearly identical to what would be written in a host-only for loop. It's important to note this design enables performance portability without obvious GPU-first design overhead such as dictating block/thread breakdowns, and without separating the CPU and GPU codepaths.
In fact, by providing integrated bounds checking in debug builds, automatic memory management tied to the lifetime of the View object, and transparent multidimensional array handling, Kokkos can make some aspects of programming and debugging significantly easier for the beginner than C, especially when debugging common code errors such as indexing and memory initialization. After an initial learning curve understanding the syntax, development using the Kokkos abstractions is efficient, and the added features save time. Code can be developed and debugged locally on the CPU, and only once working compiled for GPU and checked for any (rare) GPU-specific bugs.
It is worth noting a Kokkos-based implementation is not forever locked into Kokkos, either. The basic lambda-argument interface for kernels is now quite common, shared by many performance portability tools. With a simple substitution of syntax, the above example could easily be rewritten with C++ std::parallel , or using SYCL calls. As mentioned, Kokkos has a backend for generating SYCL code automatically: it is perhaps indicative that despite having feature parity, this backend is only about half the size of the translation layer for CUDA (4442 noncomment lines vs 7562 as of February 2024). Especially for KHARMA, which
mostly uses simple loop kernels, transitioning to e.g. SYCL would be straightforward.
## 1.3.2 Mesh Refinement
Importantly for KHARMA's design, Adaptive Mesh Refinement (AMR) cannot easily be added to a code not designed to accommodate it: keeping track of meshblocks at different refinement levels in a structured-mesh code requires a number of invasive changes to the systems handling coordinates, domain boundary communications, file operations, and (if the mesh layout is to change during the run) also the memory backing and load-balancing. Thus if AMR is desired, it should be planned into a code from the beginning, if possible.
Parthenon 8 [23] was selected as a dependency partially because it was designed to support AMR - it makes the construction of an AMR code feasible for a small team by handling nearly all aspects of mesh refinement, allowing the developer to focus on the algorithm as if writing for a single block. This abstraction breaks down in places, but overall makes the experience of writing and maintaining AMR code much more similar to any traditional multi-block code.
KHARMA has carefully preserved AMR support for unmagnetized runs since its inception, regularly testing simple unmagnetized AMR operations to ensure no single-level assumptions crept into the code. Due to this planning, when a facecentered constrained magnetic field transport was added last year (finally allowing a divergence-preserving prolongation operator, and thus prolongation/restriction of the B field), KHARMA could immediately support SMR and AMR meshes for all runs.
In addition to AMR, Parthenon provides tools for nearly all other aspects of an Eulerian structured-mesh code except the physics: parameter handling, file I/O, dynamic tasking, MPI communication, and some basic code organization tools are all provided.
## 1.3.3 Extensibility
Even the fastest code cannot be restricted to performing only ideal GRMHD simulations if it is to be useful going forward. To be useful, modification of KHARMA should be as simple as possible, in order to run new problems, add new features, and simulate new physics beyond ideal GRMHD.
Parthenon provides a pattern for separating code functionality into 'packages.' Packages do not have strict interface requirements or traditional class inheritance, but rather consist of:
8 https://github.com/lanl/parthenon
- 1. A C++ namespace for all of a package's unique functions and classes
- 2. A Params map object (much like a dictionary in Python) for storing nongrid-based information such as run-time parameters.
- 3. A list of Fields (and Sparse Fields and Swarms ) indicating variables which should be allocated on each new MeshBlock Fields . can be tied to the size of the MeshBlock (i.e., number of cells, faces, edges...), or independent of it.
- 4. Some number of 'callbacks' - functions implemented by the package which are called at specified points by the code (e.g. a source term, or diagnostics to be printed after every step)
Each package thereby encapsulates code with its relevant data (parameters and fields) similarly to an object in Object-Oriented Programming, with the advantage of translating neatly to templated, device-first implementations. However, packages usually contain more functionality than individual objects, and are only instantiated once to handle large pieces of program functionality, rather than many times to handle specific instances of data.
To elaborate: in Parthenon, the data itself (particular arrays corresponding to fields) is handled by traditionally object-oriented code in MeshBlock , Mesh , and View . A package registers fields to be added automatically to each new MeshBlock , and then registers callbacks to manipulate that data at particular points during the run (e.g., before a step, when exchanging boundaries, before output, etc.). This design ensures that packages are neutral to the mesh structure and decisions, but rather represent processes and steps which modify variables on the mesh.
The encapsulation of packages has allowed KHARMA to accommodate several different extensions and projects within the same codebase, sharing features upstream in a way that does not impinge on other uses of the code. Rather than forking for each new project, and eventually implementing overlapping sets of features in several fundamentally incompatible downstream codes, KHARMA's package structure encourages centralizing changes, allowing everyone to benefit quickly from improvements. Two particular elements of the package structure enable this:
- 1. Disabled packages are disabled . Invoking code in a package which is not loaded will nearly always crash rather than producing subtle errors. Nearly all additional features peculiar to a package can be encapsulated within its own namespace and code, hooking into the main loop with callbacks or behind checks, reducing feature conflicts as much as possible.
- 2. Package-based implementations rarely modify the same code and cause conflicts, allowing more developers to work on forks independently for extended times, while still allowing the completed features to be brought back upstream later.
Extensiblity also motivates developing KHARMA as a GRMHD-first code, as opposed to a general-relativistic extension to an existing MHD framework. By incorporating differential geometry from the ground up, KHARMA can easily run simulations in any theory with a metric, not just General Relativity, simply by implementing the metric once. Additionally, it is easy to implement new coordinate
transformations, which can be used to compress and expand resolution in a more granular way than block-based mesh refinement.
## 1.3.4 Simplicity
The modular package structure necessarily makes for a more complex piece of software than a traditional C-based GRMHD code. At several points, these design considerations have required sacrificing strict simplicity in order to introduce features. This is not to say, however, that simplicity is abandoned as a requirement. Rather, it is treated as a matter of managing an increased scope and ambition in a way that preserves the goals of a simple code. Generally, simplicity accomplishes two goals, which remain central constraints in KHARMA:
- 1. A new user can learn to modify the code with a minimum of required reading, ideally of documentation and comments rather than source.
- 2. Modification of the code is as unlikely as possible to introduce regressions in existing functionality, and any introduced are as easy as possible to find.
These are ultimately not constraints on how big a code is (though both encourage smaller codes, of course). Rather, they are constraints on how someone interacts with and modifies the code, and thus on its structure and documentation.
KHARMA is designed and (especially) documented with these requirements in mind. As described in Section 1.3.3, modular code is the key to writing compatible implementations of complex physics. A modular structure also attempts to enforce that familiarity be required with as little of the code as possible in order to begin modifying it - implementations which conform to interfaces can (ideally) be assumed work within those interface parameters, reducing the amount of searching and background information necessary to modify another particular module. Care must be taken to ensure the maintenance of this design, and of course cross-package bugs are still a distinct possibility, but a modular approach pays off when managing and adding many different features, potentially at the same time.
Modularity also allows easily trimming code which is no longer useful. Several older optional pieces of KHARMA's scheme have been superseded by new components and are now rarely used. When no longer needed for backward compatibility, these can be easily removed to reduce line count and confusion, without any major disruption to the overall code structure. Similarly, there is no excuse to hold on to features in the conviction that they might one day be useful: the same package code can simply be reintroduced later, modulo any updates to the package interface.
## 1.4 Code Structure
The following sections describe KHARMA's structure as a code, including describing the primary algorithm, philosophy, and breakdown into packages.
## 1.4.1 Algorithm
At its base, KHARMA implements the algorithm used in HARM, described in [20], though it evolves an amended version of the 3-velocity as described in [32]. For primitive variable inversion, it has traditionally used the 1 Dw scheme from [37], with the 'Flux-CT' divergence-preserving magnetic field transport described in [54].
However, alternatives to nearly every part of the algorithm are available as different packages, which can be enabled to construct a particular algorithm, or emulate another code's choices for comparisons.
For example, four transport schemes are available for the magnetic field: in addition to 'Flux-CT,' KHARMA implements the face-centered constrained transport scheme outlined in [50], including a number of schemes for determining the EMFs along zone edges with and without upwinding. Also, though these are rarely used now, it implements a constraint-damping scheme similar to [11] usable in flat spacetimes, as well as a projection operator approach (described in [54]) using a stabilized Biconjugate Gradient (BiCGStab) solver [57]. These schemes are separated into different packages and made mutually exclusive at run-time so as not to interfere with one another.
In addition to the 1 Dw primitive variable recovery noted above, KHARMA now implements the robust primitive variable recovery of [27], which greatly improves stability.
KHARMA implements a first-order flux correction (FOFC) scheme [2], which speculatively determines which zones will encounter floors or inversion failures, and pre-emptively uses first order, Local Lax-Friedrichs fluxes with Donor Cell reconstruction to update just those potentially problematic cells, providing extra stability and less injection of floor material, at the cost of using a less accurate scheme in just those zones which would have required intervention. Combined with reliable variable inversion, this allows significantly more stable performance when integrating shocks at high magnetization, allowing for the introduction of fewer stability floors in the simulation.
KHARMA also implements a large number of different variable reconstruction schemes (WENO5 [31], WENOZ [4] including a linearized robust form 9 , MP5 [51], PPM [9], PPMX [8], linear with Van Leer and Monotonized Central limiters [58], [59], and Donor Cell [21]). Other reconstruction schemes can be added easily with just a single-zone implementation in C or C++.
9 To be characterized in Barker et al (2024)
For time integration, KHARMA supports not only the traditional predictorcorrector update used in most HARM codes, but RK1, RK2, and SSPRK(5)4 schemes as well - the KHARMA sub-step is implemented so as to be independent of the integrator used, so any integrator implemented in Parthenon can be immediately used in KHARMA.
When the density or internal energy fall below predetermined values, or become too small relative to the magnetic pressure, extra material and energy are directly injected to keep stability. KHARMA supports injecting floor material in any of a number of different frames, the most common of which is the drift frame (as tested in [46]).
KHARMA also supports theories with arbitrary implicit source terms, such as the 'Extended GRMHD' theory of [6] treating viscosity and heat conduction in Coulomb-collisionless plasmas (see Section 1.5.1 for details). When evolving a semi-implicit theory, KHARMA supports only a predictor-corrector scheme for integration, as it must be augmented by a nonlinear solve for the new state after each sub-step. In addition, the implicit solver doubles as the primitive variable recovery, so no traditional primitive recovery solver is used.
## 1.4.2 Package structure
KHARMA relies on Parthenon as its single direct dependency, and this dictates much of its overall code structure and conventions. Parthenon provides interfaces to make use of MPI communication, HDF5 parallel file operations, and Kokkos loops and View s - KHARMA then uses these features almost exclusively through Parthenon. Parthenon additionally provides a framework for code modularization, 'packages,' which KHARMA uses heavily. In fact, perhaps the best introduction to the code structure is to look at the internal dependency structure between KHARMA's many packages.
Afull diagram of KHARMA's package structure is provided in Figure 1.4. Starting from the bottom row, it shows system dependencies of KHARMA: MPI, HDF5, and an accelerator framework: usually OpenMP, CUDA, HIP, or SYCL. (KHARMA obviously also requires a C++17-compliant compiler.) Next are the dependencies compiled alongside KHARMA: Kokkos and Parthenon. Finally, items within the box are KHARMA components, almost universally packages.
KHARMA's components are effectively split into four levels, detailed in the following four sub-sections.
## 1.4.2.1 Core
The core level consists of mostly convenience features, parameters, and common datatypes - anything common to the whole code, which could be used in any other
Fig. 1.4: Diagram of KHARMA's structure and dependencies. Dark grey boxes at bottom are system dependencies, above those are the bundled dependencies Kokkos and Parthenon. The large outline marks KHARMA proper. The lightest blue boxes within the grey outline denote core KHARMA features on which all packages depend. Darker blue boxes are KHARMA packages, with the darkest boxes indicating fully-interdependent 'sub-packages.' Placement of a module above another module or group denotes a direct dependency.
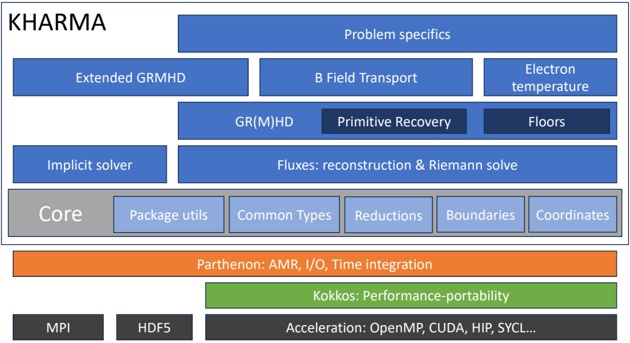
package. Among these only Globals Reductions , , and Boundaries are formal packages.
The Package core module/namespace defines the standard interface for packages in KHARMA, which adds features to the Parthenon definition for convenience. KHARMAprovides several new callbacks for its packages, structured around common points in a GRMHD update step; e.g., for adding source terms, operator-split physics, or conversions between primitive and conserved variables.
Other core modules house common data structures and code for easily calculating index ranges, as well as code for performing reductions among MPI ranks, used for diagnostics and summary statistics by several different packages. The core modules also include a Globals package, which provides more universal access to a couple of useful variables, such as the current simulation time and state (initializing vs. stepping).
Finally, the core includes a differential-geometry-aware coordinates object, GRCoordinates , which takes the place of Parthenon's built-in coordinates. A new GRCoordinates object is created automatically with each MeshBlock , providing data for locations within that block. In addition to cell locations in the code's coordinates, as provided by Parthenon, GRCoordinates introduces the concept of a coordinate transformation between the code's coordinates (in which zones are evenly spaced) and a system of 'embedding' coordinates representing the basic coordinates for the space-
time (e.g. Spherical Kerr-Schild). The GRCoordinates object also carries caches of expensive-to-calculate quantities such as the metric and connection coefficients.
## 1.4.2.2 Solvers
The next level of abstraction implements reconstruction schemes, Riemann solvers (in the Flux package), and semi-implicit stepping (in the Implicit package). Together, these are intended to form a framework for solving any hyperbolic system in curved spacetime via finite volumes, allowing for the same code to be shared between different schemes with or without magnetic fields, viscous effects, radiative feedback, etc.
This separation is imperfect still, as the Riemann solver requires determining sound speeds and states of conserved variables from primitive variables, both of which are theory-dependent but must live in the same kernels as the Riemann solve itself, to maintain performance. However, the distinction is enough that KHARMA supports a few theories (hydrodynamics, magnetohydrodynamics, and extended MHD) in a relatively natural way with a minimum of code duplication.
The Flux package also handles correcting any fluxes which will lead to floor hits or primitive recovery failures (i.e., first-order flux corrections, see Section 1.4.1).
The implicit solver is written to be general, allowing any variables marked with the tag Metadata::Implicit , to be evolved semi-implicitly. Any timedependent source terms acting on the new variable must still be added manually, however. The implicit solver is described in Section 1.5.1.
## 1.4.2.3 Physics
The GRMHD package handles updating the primitive hydrodynamic fluid variables associated with a HARM scheme - density, internal energy density, and velocity. It does not evolve the magnetic field components, however. Thus, while it optionally uses a magnetic field to compute conserved variables like stress-energy tensor (and the signal speeds, etc), it is agnostic to the magnetic field transport scheme, and supports several different transports implemented in different packages.
When evolving the GRMHD variables explicitly, the Inverter package handles the numerical inversion of conserved to primitive fluid quantities (when evolved implicitly, the variable inversion is done automatically by the nonlinear solver). As they share substantial structure and code, this package implements both of the available primitive variable recovery schemes (see Section 1.4.1), which can be selected at runtime.
The Floors package, implementing various density and internal energy floors and injection frames, as well as a number of variable limits, also lives alongside/within the GRMHD algorithm.
## 1.4.2.4 Extras
There are a few additional packages which enhance the main GRMHD package. Generally, these implement any additional physics beyond evolving the core GRHD variables: electron temperatures, dissipative effects, and so on.
These packages also include the magnetic field transports, solutions for evolving the magnetic field while preserving low divergence. KHARMA supports several different magnetic field transport schemes, but modern simulations generally use the face-centered constrained transport scheme unless another package is required for backward compatibility, testing, or speed.
## 1.4.2.5 Glue
Time-stepping is orchestrated by the Driver , which constructs a list of tasks constituting a single simulation sub-step. KHARMA implements three different timesteps, which produce near-identical results but differ in which variables they synchronize, and the order they update: the first type mirrors most HARM codes in treating the primitive variable state as the fundamental representation, exchanging primitive variable values at boundaries. The second treats conserved state as fundamental and exchanges conserved variables, allowing consistent evolution with just one synchronization per sub-step in some circumstances (generally, if primitive variable recovery failures may need to be fixed, HARM requires two synchronizations). The last step type is a simplified algorithm for debugging and testing, without the additional tasks needed for AMR or face-centered mangentic fields.
Fluid initialization code can also take advantage of any package: different problems can require or make optional whatever fields make sense in context. Where there is a common, standard initialization which makes sense (i.e. a nominal 'cold' value for electron temperatures which will be heated to equilibrium by the fluid) this is applied if the package is loaded but the field is not otherwise initialized. Initialization routines which require fields not enabled by the user generate errors.
Since different magnetic field transports preserve different representations of the magnetic field divergence, initialization of the magnetic field is dependent on what field transport will be used, and thus is handled separately from problem initialization. Where problems require a specific magnetic field configuration, they can set parameters for this later initialization, so as not to have to implement two magnetic field initializations per problem.
While it contains quite a few different modules, KHARMA is not (yet) a terribly complicated code overall - Figure 1.4 lays out almost all of the code modules and internal dependencies. Freed from implementing the extensive bookkeeping of mesh refinement or specialized syntax of device code, KHARMA consists almost exclusively of physics-related code, which makes up 3 of the 4 main layers.
## 1.5 Code Features
## 1.5.1 Implicit Solver and Extended Theory
KHARMAallows for semi-implicit time-stepping in limited instances, using a nonlinear solver to obtain field primitive values at the end of a substep after any conserved fluxes have been applied explicitly. This operation is applied separately to each zone, and necessarily after the fluxes have been applied, allowing KHARMA to accommodate theories with implicit source terms.
The solver itself is a multi-dimensional Newton-Raphson root finder that minimizes a vector-valued loss function over the primitive variables, representing their state at the end of the timestep. From an initial guess consisting of primitive variables at the beginning of the timestep, it computes a Jacobian via the secant method, and evaluates a correction via linar matrix solve (we use a pivoted version of the serial QR decomposition from the kokkos-kernels ). The process is iterated to desired accuracy, optionally with a backtracking line search for robustness.
The package is able to evolve an arbitrary subset of the overall variables implicitly, from a single-variable solve as in moment closure or constraint-damping schemes, to the semi-implicit evolution of all fluid variables. The latter is required for the 'Extended GRMHD' scheme of [6], which KHARMA fully supports.
## 1.5.1.1 Extended GRMHD
The Extended GRMHD (EGRMHD) theory adapts the equations of ideal GRMHD to include shear viscosity and heat conduction, in a simple way suitable for Coulombcollisionless systems such as the accretion of material onto Sagittarius A ∗ . In such systems, the length scale for Coulomb collisions λ mfp is much longer than the dynamical length scale rg , which is longer than the Larmor radius ρ c . This implies collisionality perpendicular to the magnetic field, but collisionless kinetic behavior parallel to it. This separation of directions forms the main assumption underlying the simplifications in EGRMHD.
EGRMHDtreats only two additional variables, beyond the eight in ideal GRMHD. The first is ∆ P , the pressure anisotropy with respect to the local magnetic field (since isotropy will be maintained in directions perpendicular to the field). The second is q , the scalar heat flux along magnetic field lines.
Figure 1.5 illustrates the scheme by modeling the anisotropic heat conduction on an artificial background magnetic field.
We provide a brief description of the EGRMHD equations following [19]. In contrast to the ideal GRMHD stress-energy tensor, the now-familiar
$$T _ { \text{ideal} } ^ { \mu \nu } = ( \rho + u + P + b ^ { 2 } ) u ^ { \mu } u ^ { \nu } + ( P + b ^ { 2 } / 2 ) g ^ { \mu \nu } - b ^ { \mu } b ^ { \nu } \quad \quad ( 1. 1 )$$
EGRMHD evolves a version with additional contributions,

Fig. 1.5: Anisotropic conduction of heat in strong magnetic field, simulated in KHARMA by solving the equations of Extended GRMHD using a semi-implicit scheme. At left is a plot of the temperature in code units at initialization, with a single circular hotspot initialized in the center. The dotted red contour denotes the extent of non-background temperature, i.e. > 3% above the background value. At right is a later snapshot, showing the thermal energy diffused via conduction along the field lines.
$$T ^ { \mu \nu } = T ^ { \mu \nu } _ { \text{ideal} } + q ^ { \mu } u ^ { \nu } + q ^ { \nu } u ^ { \mu } + \Pi ^ { \mu \nu }$$
where q µ = qb ˆ µ is the heat flux, ˆ b µ = b µ / b is the unit vector along b µ ,
$$\Pi ^ { \mu \nu } = - \Delta P \left ( \hat { b } ^ { \mu } \hat { b } ^ { \nu } - \frac { 1 } { 3 } h ^ { \mu \nu } \right )$$
is the viscous stress-energy tensor, and
$$h ^ { \mu \nu } = g ^ { \mu \nu } + u ^ { \mu } u ^ { \nu }$$
is the projection on a hypersurface orthogonal to the 4-velocity u µ . The total stressenergy tensor is evolved according to the Bianchi identity as usual, and the evolution equations for density and magnetic field are unchanged from ideal GRMHD. This leaves the evolution equations for the heat flux and pressure anisotropy. These are written with respect to rescaled variables
$$\tilde { q } = & q \left ( \frac { \tau _ { R } } { \chi \rho \Theta ^ { 2 } } \right ) ^ { 1 / 2 },$$
$$\Delta \tilde { P } = & \Delta P \left ( \frac { \tau _ { R } } { \nu \rho \Theta } \right ) ^ { 1 / 2 },$$
$$\nabla _ { \mu } ( \tilde { q } u ^ { \mu } ) = - \, \frac { \tilde { q } - \tilde { q } _ { 0 } } { \tau _ { R } } + \frac { \tilde { q } } { 2 } \nabla _ { \mu } u ^ { \mu }, \quad \quad \quad$$
$$\nabla _ { \mu } ( \Delta \tilde { P } u ^ { \mu } ) = - \, \frac { \Delta \tilde { P } - \Delta \tilde { P } _ { 0 } } { \tau _ { R } } + \frac { \Delta \tilde { P } } { 2 } \nabla _ { \mu } u ^ { \mu }.$$
That is, ˜ q and ∆ ˜ P are damped towards their target value ˜0 q and ∆ ˜ P 0 over a timescale τ R . The evolution equations follow from the requirement that the model satisfies the second law of thermodynamics, as detailed in [6], and reflect the change of variable introduced in [19]. Both papers additionally detail the closure model used for setting τ R , which we will not describe in detail here.
In the context of implementation, it suffices for us to note that due to the covariant derivatives on the right-hand side of (1.7) and (1.8), the evolution of q and ∆ P must be done locally implicitly, by solving a system of equations involving the timedependent source terms in order to obtain the state at the end of each step. This is done using KHARMA's implicit solver, by marking the GRMHD and EGRMHD variables (though not the magnetic field!) as implicitly evolved, adding them to the solver's update step.
EGRMHDis a promising avenue for future research, especially in understanding the time variability of sparse accretion systems like Sagittarius A ∗ . Further details on KHARMA's implementation, e.g. simulation floors and stability techniques, will be provided along with the first physics results from KHARMA simulations using the scheme.
## 1.5.2 Simulation Re-gridding
One of the greatest time investments in running high-resolution simulations is the evolution from initial conditions to the steady state. With modern simulations using physically-larger disk sizes which take longer to equilibrate, coupled with greater accuracy requirements necessitating an accurate idea of the variability after erasing initial conditions, just erasing the initial conditions can amount to millions of steps of wasted evolution, costing many GPU hours and days of real time.
It is much more efficient to restart a simulation which was initialized at low resolution, and simply interpolate its state onto a finer grid as desired. KHARMA can linearly interpolate between arbitrary grids when restarting from an existing state, allowing simulations to be arbitrarily refined or de-refined when they are continued. This is automatic - restarting with files of the correct format, if the specified grid is a different size from the snapshot's grid, KHARMA will automatically interpolate to the new grid size and shape.
Linear interpolation of the magnetic field, however, does not preserve the divergence. Thus, KHARMA also automatically cleans the magnetic field of divergence when interpolating, by finding the projection operator to the closest divergence-free field to the interpolated state. KHARMA includes a stabilized biconjugate gradient solver for eliminating magnetic field divergence; this is applied to produce an almost
arbitrarily small field divergence, which is then preserved in the subsequent run by any of KHARMA's magnetic field transports.
## 1.5.3 Multi-Zone Operation
One pressing problem in understanding large-scale galactic and cosmic evolution is that of supermassive black hole (SMBH) feedback. Large-scale galactic or cosmic simulations cannot capture individual SMBHs, but must incorporate their accretion and feedback for accuracy. Thus when simulating, they are modeled with simple sub-grid accretion models which make many unverified assumptions.
Ongoing work with KHARMA [7] aims to bridge these scales, conducting chained GRMHD simulations from the event horizon scale all the way out to the galactic scales 10 7 times greater. In these 'multi-zone' simulations, the total domain is split into 8 annuli, each spanning two orders of magnitude and overlapping by half. Simulations are conducted of each annulus for a portion of the characteristic timescale, and the fluid state of the simulation's inner portion becomes the outer portion of the next simulation, which is continued for its own characteristic time, and so on. The resulting chain of simulations is then run repeatedly, allowing material and magnetic field to inflow and escape, eventually reaching a steady-state solution.
Using multi-zone simulations, we hope to dramatically improve the feedback models used in large-scale simulations of galactic and cosmic development, both by producing better semi-analytic characterizations usable in galactic simulations, but eventually also by self-consistently alternating between galactic and SMBH-scale simulations, treating the feedback in full 3D.
## 1.5.4 Run-Time Options
All of KHARMA's features, including all problem setups and the selection of any spacetime geometry, are available at run-time. This means that once compiled, the single resulting binary is capable of doing anything implemented in the code. Those compile-time flags which do exist are almost purely for changing performance characteristics - splitting loops for faster operation on GPUs, or using constants for faster operation in flat spacetimes.
Since compile-time options are so limited, they need only be modified when porting KHARMA to a new machine, not when running a new problem, test, etc. Once a particular compiler stack works, it can be codified as a 'machine script' with the module environment, compile options, etc. Further compilations of the code can then use a simple invocation of the top-level script make.sh , with just a few optional arguments for specifying the type of build (e.g., debugging vs production).
One other advantage to run-time options is to allow binary and container distribution. This doesn't often matter for KHARMA yet, as most users are also developers, and generally require builds for GPUs and specialized hardware. However, containerized KHARMA has proven useful a few times already, and may prove more useful in the future as container tools become more universal.
## 1.6 Readiness and Testing
At its core, KHARMA is an implementation of the well-understood HARM scheme for GRMHD. It was designed first to closely match its predecessor code iharm3D , which was validated as a part of the EHT collaboration GRMHD code comparison [42]. Where the scheme contains new elements, such as more modern magnetic field transport and primitive variable recovery schemes, these are tested to be dropin replacements for existing functionality in existing problems. A particular boon for debugging is that KHARMA has enough scheme options that it can usually closely emulate the schemes of other GRMHD codes, to cut down on variables when understanding differences between codes, or specific quirks of behavior.
Each time new code is committed to the main KHARMA repository, a number of regression tests are run: convergence on GRMHD and Extended GRMHD problems (three linear modes and one Bondi accretion problem each) is tested using as many different schemes and features as possible - at current count, 46 ideal MHD linear modes convergence tests are performed, not counting Extended MHD modes or mesh-refined versions of the problem. Figure 1.6 shows these. The L1 norm is checked to match second-order convergence very closely, usually to scale with resolution at a power between -1 9 and . -2 1. While KHARMA does not have separate . unit tests, nearly all relevant codepaths for physics are tested against alternatives as a part of the regression tests, which isolates bugs in most subsystems. Regression tests are currently run on CPUs automatically, and on GPUs upon manual invocation.
In addition to convergence tests, checks are also performed for determinism upon multiple invocations, and for consistency after restarting from a checkpoint file. The initialization and (short) evolution of a torus problem is also tested, for error and basic consistency metrics such as the magnetic field divergence. Both test types include versions with and without mesh refinement. Another test is run verifying that none of the default parameter files shipped with the code generate errors (due to a change in parameter names or defaults, for example).
Several other well-known standard test problems are implemented which may be run manually, such as the Orszag-Tang vortex [39], the magnetized explosion problem of [28], and others. These are useful for gauging relative performance and stability of different algorithmic choices available in KHARMA, or characterizing KHARMA's performance against other MHD codes.
Finally, KHARMA includes several tests of the electron temperature tracking scheme, adapted from tests of the original implementation in [45], and for the extended GRMHD implementation (see Section 1.5.1), adapted from [5]. These will
Fig. 1.6: Convergence figures from some of the tests performed on KHARMA after every code commit, illustrating convergence when propagating (from left to right) the Alfv´ en, fast, and slow modes in 3D (top) and 2D (bottom). Each panel plots the L1 norm of each primitive variable when compared to the analytic solution, versus the simulation resolution. In a second-order scheme, the L1 norm should decrease as the inverse square of resolution, as demonstrated in each test. These plots are taken directly from the most recent automated tests at time of writing (hence the independent legends and axes); these and nearly a hundred other figures corresponding to every test configuration are generated automatically on each code commit and available publicly. A total of 46 linear modes tests are performed, covering all KHARMA's available sub-step types, integrators, magnetic field transports, mesh refinements, and so on. In addition to convergence on the linear modes problems, another 14 different types of correctness and stability tests are performed - where applicable, these each cover a wide array of KHARMA's different configurations.
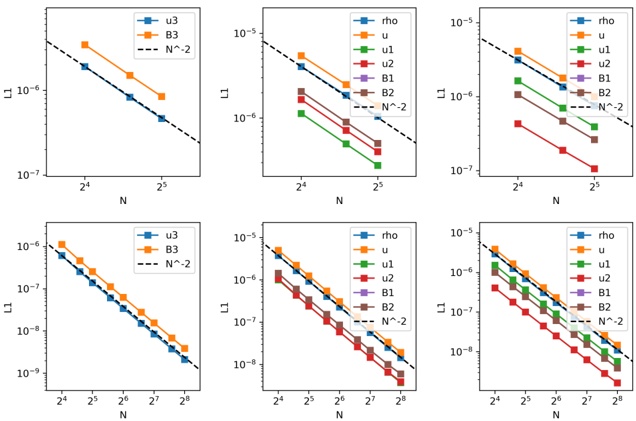
be detailed more closely in a future work, when physics results from these modules are first published.
## 1.7 Performance
Scaling tests of KHARMA have been performed on many different machines: Stampede2, Frontera, and the Frontera GPU subsystem, Longhorn, at the Texas Advanced Computing Center (TACC), Summit and Frontier at the Oak Ridge Leader-
ship Computing Facility (OLCF), Delta at the National Center for Supercomputing Applications (NCSA) at the University of Illinois, and ThetaGPU at the Argonne Leadership Computing Facility (ALCF). Results here reflect performance running a torus accretion problem in general relativity using ideal GRMHD, in spherical coordinates, with the 1 Dw inverter and Flux-CT magnetic field transport, for consistency between different KHARMA versions.
KHARMA was initially designed and tested for the Nvidia V100 GPU and IBM AC922 architecture used by Summit and Longhorn, where it achieves about 21 million zones by a cycle (ZCPS) per V100 GPU. This weakly scaled near-perfectly to arbitrary problem sizes/node counts, but more importantly, strongly scaled to problem sizes of interest (e.g., 256 3 total zones) across enough nodes to produce efficient turnaround times of a few days for runs of 10 000 , t g . Numbers from these machines necessarily reflect earlier versions of the code, as KHARMA has not been run on these machines recently (indeed, Longhorn has been retired). Due to a number of new features in the modern code, KHARMA versions from this timeframe are generally slightly faster than the most recent commits.
More recently, KHARMA has primarily targeted A100 GPUs of Chicoma and Delta, which use the now-common architecture pairing AMD EPYC CPUs with Nvidia A100 GPUs (also used by e.g., Polaris at ALCF and other machines). Base performance with A100s is promising: running production problems of 128 3 is nearly twice as fast as on V100 GPUs, or about 35 million Zone-cycles per second per card. Thus on one node of Detla (4 GPUs) KHARMA achieves the performance of more than 50 nodes of Stampede2. KHARMA has not yet been tested at scale on the new H100 GPUs, which promise some potentially relevant HPC-targeted features as well as higher memory bandwidth than Ampere-generation GPUs.
The current target for performance tuning of KHARMA is the AMD MI250X GPUs of Frontier, at Oak Ridge Leadership Computing Facility (OLCF). Due to register pressure constraints of its complex compute kernels, KHARMA achieves only about 100M ZCPS per node of Frontier - about 25M ZCPS per MI250X card, or 12.5M ZCPS per GPU die. This is only similar to performance on a node of Summit, despite the increased memory bandwidth and compute available on Frontier - thus if KHARMA were fully memory-bandwidth constrained, performance on Frontier could theoretically improve by a factor of 2.
Finally, it is important to note that performance of KHARMA is widely variable, depending on the individual components used. Different primitive variable solvers, magnetic field transports, spacetime geometries, and stability strategies (floors, corrections, etc.), and the presence of SMR/AMR will significantly affect performance. The configuration used for these tests is production-ready but relatively simple compared to KHARMA's modern feature set, as the hope is to be as directly comparable as possible across many different performance tests over years of development. More advanced features can run 10-30% more slowly than the base configuration here.
One feature bears special mention: the semi-implicit mode for running 'Extended GRMHD' problems (see Section 1.5.1) is very costly. On CPUs, KHARMA runs EGRMHD problems about five times more slowly than ideal problems, and on
GPUs the factor is even worse, between 10-20 times depending on the hardware. The semi-implicit evolution of EGRMHD problems is more computationally complex than explicit evolution, but performance on GPUs appears to be a factor of 2-4x below what might be expected given CPU performance. This is because the complex GPU kernels of the nonlinear solver require many registers for each thread, severely reducing thread occupancy by filling each block's available registers well before the available execution units. Work is ongoing to solve this, but must balance the thread occupancy with increased memory bandwidth requirements from splitting kernels, requiring use of global memory to store intermediate results.
Fig. 1.7: (Left) Strong scaling plot showing KHARMA's performance in ZCPS plotted against the number of GPUs or CPU nodes used, when run on a problem of constant size, 256 3 zones (scaling results on Delta use a sligtly larger problem, 384 3 zones). (Right) Weak scaling performance on problems of increasing size, allocating 128 3 zones per GPU. Scaling results from [44] and personal testing. Results on Delta courtesy of Vedant Dhruv (private communication).
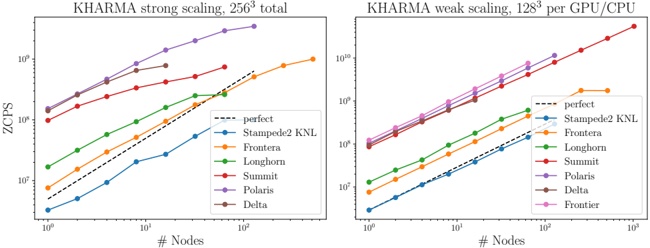
Acknowledgements Many thanks to all of the KHARMA developers and users, especially Vedant Dhruv, Hyerin Cho, and C´ esar D´ ıaz-Blanco, and to Charles Gammie for useful advice, and of course for HARM. BP gratefully acknowledges support from the Los Alamos National Laboratory Metropolis Fellowship. Computing time for developing, testing, and applying KHARMA has been provided by Oak Ridge Leadership Computing Facility (OLCF) and Argonne Leadership Computing Facility (ALCF) through director's discretionary allocations and through the INCITE program, the National Center for Supercomputing Applications through the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, the Texas Advanced Computing Center through the Extreme Science and Engineering Development Environment (XSEDE) and Frontera Large-Scale Community Partnerships (LSCP) programs, and by Los Alamos National Laboratory Institutional Computing.
## References
- [1] D. A. Beckingsale, T. R. Scogland, J. Burmark, et al. , 'RAJA: Portable Performance for Large-Scale Scientific Applications,' in 2019 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC) , Denver, CO, USA: IEEE, Nov. 2019, pp. 71-81, ISBN: 978-172816-003-0. DOI: 10.1109/P3HPC49587.2019.00012 .
- [2] K. Beckwith and J. M. Stone, 'A SECOND-ORDER GODUNOV METHOD FORMULTI-DIMENSIONALRELATIVISTICMAGNETOHYDRODYNAMICS,' The Astrophysical Journal Supplement Series , vol. 193, no. 1, p. 6, Jan. 2011, ISSN: 0067-0049. DOI: 10.1088/0067-0049/193/1/6 .
- [3] H. Carter Edwards, C. R. Trott, and D. Sunderland, 'Kokkos: Enabling manycore performance portability through polymorphic memory access patterns,' Journal of Parallel and Distributed Computing , Domain-Specific Languages and High-Level Frameworks for High-Performance Computing, vol. 74, no. 12, pp. 3202-3216, Dec. 1, 2014, ISSN: 0743-7315. DOI: 10.1016/ j.jpdc.2014.07.003 .
- [4] M. Castro, B. Costa, and W. S. Don, 'High order weighted essentially nonoscillatory WENO-Z schemes for hyperbolic conservation laws,' Journal of Computational Physics , vol. 230, no. 5, pp. 1766-1792, Mar. 1, 2011, ISSN: 0021-9991. DOI: 10.1016/j.jcp.2010.11.028 .
- [5] M. Chandra, F. Foucart, and C. F. Gammie, 'Grim: A Flexible, Conservative Scheme for Relativistic Fluid Theories,' The Astrophysical Journal , vol. 837, p. 92, Mar. 1, 2017, ISSN: 0004-637X. DOI: 10.3847/1538-4357/ aa5f55 .
- [6] M. Chandra, C. F. Gammie, F. Foucart, and E. Quataert, 'An Extended Magnetohydrodynamics Model for Relativistic Weakly Collisional Plasmas,' The Astrophysical Journal , vol. 810, p. 162, Sep. 1, 2015, ISSN: 0004-637X. DOI: 10.1088/0004-637X/810/2/162 .
- [7] H. Cho, B. S. Prather, R. Narayan, et al. , 'Bridging Scales in Black Hole Accretion and Feedback: Magnetized Bondi Accretion in 3D GRMHD,' The Astrophysical Journal Letters , vol. 959, no. 2, p. L22, Dec. 2023, ISSN: 20418205. DOI: 10.3847/2041-8213/ad1048 .
- [8] P. Colella and M. D. Sekora, 'A limiter for PPM that preserves accuracy at smooth extrema,' Journal of Computational Physics , vol. 227, pp. 70697076, Jul. 1, 2008, ISSN: 0021-9991. DOI: 10.1016/j.jcp.2008.03. 034 .
- [9] P. Colella and P. R. Woodward, 'The Piecewise Parabolic Method (PPM) for gas-dynamical simulations,' Journal of Computational Physics , vol. 54, no. 1, pp. 174-201, Apr. 1, 1984, ISSN: 0021-9991. DOI: 10.1016/00219991(84)90143-8 .
- [10] T. E. H. T. Collaboration, K. Akiyama, A. Alberdi, et al. , 'First Sagittarius A* Event Horizon Telescope Results. VIII. Physical Interpretation of the Polarized Ring,' The Astrophysical Journal Letters , vol. 964, no. 2, p. L26, Mar. 2024, ISSN: 2041-8205. DOI: 10.3847/2041-8213/ad2df1 .
- [11] A. Dedner, F. Kemm, D. Kr¨ oner, C. .-. Munz, T. Schnitzer, and M. Wesenberg, 'Hyperbolic Divergence Cleaning for the MHD Equations,' Journal of Computational Physics , vol. 175, no. 2, pp. 645-673, Jan. 20, 2002, ISSN: 0021-9991. DOI: 10.1006/jcph.2001.6961 .
- [12] R. Emami, A. Ricarte, G. N. Wong, et al. , 'Unraveling Twisty Linear Polarization Morphologies in Black Hole Images,' The Astrophysical Journal , vol. 950, no. 1, p. 38, Jun. 2023, ISSN: 0004-637X. DOI: 10.3847/15384357/acc8cd .
- [13] Event Horizon Telescope Collaboration, K. Akiyama, A. Alberdi, et al. , 'First M87 Event Horizon Telescope Results. I. The Shadow of the Supermassive Black Hole,' The Astrophysical Journal , vol. 875, p. L1, Apr. 1, 2019, ISSN: 0004-637X. DOI: 10.3847/2041-8213/ab0ec7 .
- [14] Event Horizon Telescope Collaboration, K. Akiyama, A. Alberdi, et al. , 'First M87 Event Horizon Telescope Results. IV. Imaging the Central Supermassive Black Hole,' The Astrophysical Journal , vol. 875, p. L4, Apr. 1, 2019, ISSN: 0004-637X. DOI: 10.3847/2041-8213/ab0e85 .
- [15] Event Horizon Telescope Collaboration, K. Akiyama, A. Alberdi, et al. , 'First M87 Event Horizon Telescope Results. V. Physical Origin of the Asymmetric Ring,' The Astrophysical Journal , vol. 875, p. L5, Apr. 1, 2019, ISSN: 0004-637X. DOI: 10.3847/2041-8213/ab0f43 .
- [16] Event Horizon Telescope Collaboration, K. Akiyama, A. Alberdi, et al. , 'First M87 Event Horizon Telescope Results. VI. The Shadow and Mass of the Central Black Hole,' The Astrophysical Journal , vol. 875, p. L6, Apr. 1, 2019, ISSN: 0004-637X. DOI: 10.3847/2041-8213/ab1141 .
- [17] Event Horizon Telescope Collaboration, K. Akiyama, A. Alberdi, et al. , 'First Sagittarius A* Event Horizon Telescope Results. V. Testing Astrophysical Models of the Galactic Center Black Hole,' The Astrophysical Journal Letters , vol. 930, no. 2, p. L16, May 12, 2022, ISSN: 2041-8205. DOI: 10.3847/2041-8213/ac6672 .
- [18] Event Horizon Telescope Collaboration, K. Akiyama, J. C. Algaba, et al. , 'First M87 Event Horizon Telescope Results. VIII. Magnetic Field Structure near The Event Horizon,' The Astrophysical Journal , vol. 910, p. L13, Mar. 1, 2021, ISSN: 0004-637X. DOI: 10.3847/2041-8213/abe4de .
- [19] F. Foucart, M. Chandra, C. F. Gammie, and E. Quataert, 'Evolution of accretion discs around a kerr black hole using extended magnetohydrodynamics,' Monthly Notices of the Royal Astronomical Society , vol. 456, pp. 1332-1345, Feb. 1, 2016, ISSN: 0035-8711. DOI: 10.1093/mnras/stv2687 .
- [20] C. F. Gammie, J. C. McKinney, and G. T´ oth, 'HARM: A Numerical Scheme for General Relativistic Magnetohydrodynamics,' The Astrophysical Journal , vol. 589, no. 1, p. 444, May 20, 2003, ISSN: 0004-637X. DOI: 10. 1086/374594 .
- [21] S. K. Godunov, 'A difference method for numerical calculation of discontinuous solutions of the equations of hydrodynamics,' Matematicheski \ u ı Sbornik. Novaya Seriya , vol. 47(89), pp. 271-306, 1959, ISSN: 0368-8666.
- [22] R. Gold, A. E. Broderick, Z. Younsi, et al. , 'Verification of Radiative Transfer Schemes for the EHT,' The Astrophysical Journal , vol. 897, p. 148, Jul. 1, 2020, ISSN: 0004-637X. DOI: 10.3847/1538-4357/ab96c6 .
- [23] P. Grete, J. C. Dolence, J. M. Miller, et al. , 'Parthenon - a performance portable block-structured adaptive mesh refinement framework,' arXiv eprints , Feb. 1, 2022.
- [24] L. Ji, V . Mewes, Y. Zlochower, et al. , 'Ameliorating the Courant-FriedrichsLewy condition in spherical coordinates: A double FFT filter method for general relativistic MHD in dynamical spacetimes,' Physical Review D , vol. 108, no. 10, p. 104 005, Nov. 3, 2023. DOI: 10.1103/PhysRevD.108. 104005 .
- [25] M. D. Johnson, A. Lupsasca, A. Strominger, et al. , 'Universal interferometric signatures of a black hole's photon ring,' Science Advances , vol. 6, no. 12, eaaz1310, Mar. 1, 2020, ISSN: 2375-2548. DOI: 10 . 1126 / sciadv . aaz1310 .
- [26] N. P. Jouppi, C. Young, N. Patil, et al. , 'In-Datacenter Performance Analysis of a Tensor Processing Unit,' in Proceedings of the 44th Annual International Symposium on Computer Architecture , ser. ISCA '17, New York, NY, USA: Association for Computing Machinery, Jun. 24, 2017, pp. 1-12, ISBN: 9781-4503-4892-8. DOI: 10.1145/3079856.3080246 .
- [27] W. Kastaun, J. Vijay Kalinani, and R. Ciolfi, 'Robust Recovery of Primitive Variables in Relativistic Ideal Magnetohydrodynamics,' arXiv e-prints , vol. 2005, arXiv:2005.01821, May 1, 2020.
- [28] S. S. Komissarov, 'A Godunov-type scheme for relativistic magnetohydrodynamics,' Monthly Notices of the Royal Astronomical Society , vol. 303, pp. 343-366, Feb. 1, 1999, ISSN: 0035-8711. DOI: 10.1046/j.13658711.1999.02244.x .
- [29] G. Lauterbach, 'The Path to Successful Wafer-Scale Integration: The Cerebras Story,' IEEE Micro , vol. 41, no. 6, pp. 52-57, Nov. 1, 2021, ISSN: 02721732, 1937-4143. DOI: 10.1109/MM.2021.3112025 .
- [30] J. Y.-Y. Lin, G. N. Wong, B. S. Prather, and C. F. Gammie, 'Feature Extraction on Synthetic Black Hole Images,' arXiv e-prints , arXiv:2007.00794, Jul. 1, 2020.
- [31] X.-D. Liu, S. Osher, and T. Chan, 'Weighted Essentially Non-oscillatory Schemes,' Journal of Computational Physics , vol. 115, no. 1, pp. 200-212, Nov. 1, 1994, ISSN: 0021-9991. DOI: 10.1006/jcph.1994.1187 .
- [32] J. C. McKinney and C. F. Gammie, 'A Measurement of the Electromagnetic Luminosity of a Kerr Black Hole,' The Astrophysical Journal , vol. 611, no. 2, p. 977, Aug. 20, 2004, ISSN: 0004-637X. DOI: 10.1086/422244 .
- [33] D. S. Medina, A. St-Cyr, and T. Warburton. 'OCCA: A unified approach to multi-threading languages.' arXiv: 1403.0968 [cs] . (Mar. 4, 2014), preprint.
- [34] H. Meuer, E. Strohmaier, J. Dongarra, H. Simon, and M. Meuer. 'Top500 Supercomputers List.' (Nov. 2023).
- [35] G. Moore, 'Progress In Digital Integrated Electronics,' Technical Digest 1975. International Electron Devices Meeting , pp. 11-13, 1975. DOI: 10. 1109/N-SSC.2006.4804410 .
- [36] G. E. Moore, 'Cramming more components onto integrated circuits,' Electronics , vol. 38, no. 8, p. 114, Apr. 19, 1965, ISSN: 1098-4232. DOI: 10. 1109/N-SSC.2006.4785860 .
- [37] S. C. Noble, C. F. Gammie, J. C. McKinney, and L. Del Zanna, 'Primitive Variable Solvers for Conservative General Relativistic Magnetohydrodynamics,' The Astrophysical Journal , vol. 641, pp. 626-637, Apr. 1, 2006, ISSN: 0004-637X. DOI: 10.1086/500349 .
- [38] I. D. Novikov and K. S. Thorne, 'Astrophysics of black holes.,' presented at the Black Holes (Les Astres Occlus), 1973, pp. 343-450.
- [39] S. A. Orszag and C.-M. Tang, 'Small-scale structure of two-dimensional magnetohydrodynamic turbulence,' Journal of Fluid Mechanics , vol. 90, no. 1, pp. 129-143, Jan. 1979, ISSN: 1469-7645, 0022-1120. DOI: 10 . 1017/S002211207900210X .
- [40] D. C. M. Palumbo, G. N. Wong, and B. S. Prather, 'Discriminating Accretion States via Rotational Symmetry in Simulated Polarimetric Images of M87,' The Astrophysical Journal , vol. 894, p. 156, May 1, 2020, ISSN: 0004-637X. DOI: 10.3847/1538-4357/ab86ac .
- [41] PassMark Software. 'PassMark - CPU Benchmarks - CPU Mega Page - Detailed List of Benchmarked CPUs.' (Jul. 25, 2022).
- [42] O. Porth, K. Chatterjee, R. Narayan, et al. , 'The Event Horizon General Relativistic Magnetohydrodynamic Code Comparison Project,' The Astrophysical Journal Supplement Series , vol. 243, p. 26, Aug. 1, 2019, ISSN: 0067-0049. DOI: 10.3847/1538-4365/ab29fd .
- [43] B. S. Prather, G. N. Wong, V. Dhruv, et al. , 'iharm3D: Vectorized General Relativistic Magnetohydrodynamics,' Journal of Open Source Software , vol. 6, no. 66, p. 3336, Oct. 14, 2021, ISSN: 2475-9066. DOI: 10.21105/ joss.03336 .
- [44] B. Prather, 'GRMHD simulations and analysis of polarized emission from black hole accretion systems,' Thesis, University of Illinois at Urbana-Champaign, Sep. 8, 2022.
- [45] S. M. Ressler, A. Tchekhovskoy, E. Quataert, M. Chandra, and C. F. Gammie, 'Electron thermodynamics in GRMHD simulations of low-luminosity black hole accretion,' Monthly Notices of the Royal Astronomical Society , vol. 454, pp. 1848-1870, Dec. 1, 2015, ISSN: 0035-8711. DOI: 10.1093/mnras/ stv2084 .
- [46] S. M. Ressler, A. Tchekhovskoy, E. Quataert, and C. F. Gammie, 'The discjet symbiosis emerges: Modelling the emission of Sagittarius A* with electron thermodynamics,' Monthly Notices of the Royal Astronomical Society , vol. 467, pp. 3604-3619, May 1, 2017, ISSN: 0035-8711. DOI: 10.1093/ mnras/stx364 .
- [47] A. Ricarte, C. Gammie, R. Narayan, and B. S. Prather, 'Probing plasma physics with spectral index maps of accreting black holes on event horizon
- scales,' Monthly Notices of the Royal Astronomical Society , vol. 519, no. 3, pp. 4203-4220, Mar. 1, 2023, ISSN: 0035-8711. DOI: 10.1093/mnras/ stac3796 .
- [48] A. Ricarte, R. Qiu, and R. Narayan, 'Black hole magnetic fields and their imprint on circular polarization images,' Monthly Notices of the Royal Astronomical Society , vol. 505, pp. 523-539, Jul. 1, 2021, ISSN: 0035-8711. DOI: 10.1093/mnras/stab1289 .
- [49] B. R. Ryan, J. C. Dolence, and C. F. Gammie, 'Bhlight: General Relativistic Radiation Magnetohydrodynamics with Monte Carlo Transport,' The Astrophysical Journal , vol. 807, no. 1, p. 31, 2015, ISSN: 0004-637X. DOI: 10. 1088/0004-637X/807/1/31 .
- [50] J. M. Stone and T. Gardiner, 'A simple unsplit Godunov method for multidimensional MHD,' New Astronomy , vol. 14, no. 2, pp. 139-148, Feb. 1, 2009, ISSN: 1384-1076. DOI: 10.1016/j.newast.2008.06.003 .
- [51] A. Suresh and H. T. Huynh, 'Accurate Monotonicity-Preserving Schemes with Runge-Kutta Time Stepping,' Journal of Computational Physics , vol. 136, no. 1, pp. 83-99, Sep. 1, 1997, ISSN: 0021-9991. DOI: 10.1006/jcph. 1997.5745 .
- [52] E. Talpes, D. D. Sarma, D. Williams, et al. , 'The Microarchitecture of DOJO, Tesla's Exa-Scale Computer,' IEEE Micro , vol. 43, no. 3, pp. 31-39, May 2023, ISSN: 0272-1732, 1937-4143. DOI: 10.1109/MM.2023.3258906 .
- [53] TechPowerUp. 'TechPowerUp GPU Specs Database,' TechPowerUp. (Mar. 2024).
- [54] G. T´ oth, 'The ∇ · B=0 Constraint in Shock-Capturing Magnetohydrodynamics Codes,' Journal of Computational Physics , vol. 161, no. 2, pp. 605-652, Jul. 1, 2000, ISSN: 0021-9991. DOI: 10.1006/jcph.2000.6519 .
- [55] C. Trott, L. Berger-Vergiat, D. Poliakoff, et al. , 'The Kokkos EcoSystem: Comprehensive Performance Portability for High Performance Computing,' Computing in Science Engineering , vol. 23, no. 5, pp. 10-18, Sep. 2021, ISSN: 1558-366X. DOI: 10.1109/MCSE.2021.3098509 .
- [56] C. R. Trott, D. Lebrun-Grandi´ e, D. Arndt, et al. , 'Kokkos 3: Programming Model Extensions for the Exascale Era,' IEEE Transactions on Parallel and Distributed Systems , vol. 33, no. 4, pp. 805-817, Apr. 2022, ISSN: 1558-2183. DOI: 10.1109/TPDS.2021.3097283 .
- [57] H. A. van der Vorst, 'Bi-CGSTAB: A Fast and Smoothly Converging Variant of Bi-CG for the Solution of Nonsymmetric Linear Systems,' SIAM Journal on Scientific and Statistical Computing , vol. 13, no. 2, pp. 631-644, Mar. 1992, ISSN: 0196-5204. DOI: 10.1137/0913035 .
- [58] B. van Leer, 'Towards the ultimate conservative difference scheme. II. Monotonicity and conservation combined in a second-order scheme,' Journal of Computational Physics , vol. 14, no. 4, pp. 361-370, Mar. 1, 1974, ISSN: 0021-9991. DOI: 10.1016/0021-9991(74)90019-9 .
- [59] B. van Leer, 'Towards the Ultimate Conservative Difference Scheme. III. Upstream-Centered Finite-Difference Schemes for Ideal Compressible Flow,'
Journal of Computational Physics , vol. 23, pp. 263-275, Mar. 1, 1977, ISSN: 0021-9991. DOI: 10.1016/0021-9991(77)90094-8 .
- [60] C. J. White, P. D. Mullen, Y.-F. Jiang, et al. , 'An Extension of the Athena++ Code Framework for Radiation-magnetohydrodynamics in General Relativity Using a Finite-solid-angle Discretization,' The Astrophysical Journal , vol. 949, no. 2, p. 103, Jun. 2023, ISSN: 0004-637X. DOI: 10.3847/15384357/acc8cf .
- [61] G. N. Wong, B. S. Prather, V. Dhruv, et al. , 'PATOKA: Simulating Electromagnetic Observables of Black Hole Accretion,' The Astrophysical Journal Supplement Series , vol. 259, p. 64, Apr. 1, 2022, ISSN: 0067-0049. DOI: 10.3847/1538-4365/ac582e . | null | [
"Ben S. Prather"
]
| 2024-08-02T16:13:49+00:00 | 2024-08-02T16:13:49+00:00 | [
"astro-ph.HE"
]
| KHARMA: Flexible, Portable Performance for GRMHD | KHARMA (an acronym for "Kokkos-based High-Accuracy Relativistic
Magnetohydrodynamics with Adaptive mesh refinement") is a new open-source code
for conducting general-relativistic magnetohydrodynamic simulations in
stationary spacetimes, primarily of accretion systems. It implements among
other options the High-Accuracy Relativistic Magnetohydrodynamics (HARM)
scheme, but is written from scratch in C++ with the Kokkos programming model in
order to run efficiently on both CPUs and GPUs. In addition to being fast,
KHARMA is written to be readable, modular, and extensible, separating
functionality into "packages," representing, e.g., algorithmic components or
physics extensions. Components of the core ideal GRMHD scheme can be swapped at
runtime, and additional packages are included to simulate electron temperature
evolution, viscous hydrodynamics, and for designing chained multi-scale
"bridged" simulations. This chapter presents the computational environment and
requirements for KHARMA, features and design which meet these requirements, and
finally, validation and performance data. |
2408.01362v2 | ## Autoencoders in Function Space
## Justin Bunker
[email protected]
Department of Engineering University of Cambridge Cambridge, CB2 1TN, United Kingdom
## Mark Girolami
[email protected]
Department of Engineering, University of Cambridge and Alan Turing Institute Cambridge, CB2 1TN, United Kingdom
## Hefin Lambley
[email protected]
Mathematics Institute University of Warwick Coventry, CV4 7AL, United Kingdom
## Andrew M. Stuart
[email protected]
Computing + Mathematical Sciences California Institute of Technology Pasadena, CA 91125, United States of America
## T. J. Sullivan
[email protected]
Mathematics Institute & School of Engineering University of Warwick Coventry, CV4 7AL, United Kingdom
## Abstract
Autoencoders have found widespread application in both their original deterministic form and in their variational formulation (VAEs). In scientific applications and in image processing it is often of interest to consider data that are viewed as functions; while discretisation (of differential equations arising in the sciences) or pixellation (of images) renders problems finite dimensional in practice, conceiving first of algorithms that operate on functions, and only then discretising or pixellating, leads to better algorithms that smoothly operate between resolutions. In this paper function-space versions of the autoencoder (FAE) and variational autoencoder (FVAE) are introduced, analysed, and deployed. Well-definedness of the objective governing VAEs is a subtle issue, particularly in function space, limiting applicability. For the FVAE objective to be well defined requires compatibility of the data distribution with the chosen generative model; this can be achieved, for example, when the data arise from a stochastic differential equation, but is generally restrictive. The FAE objective, on the other hand, is well defined in many situations where FVAE fails to be. Pairing the FVAE and FAE objectives with neural operator architectures that can be evaluated on any mesh enables new applications of autoencoders to inpainting, superresolution, and generative modelling of scientific data.
Keywords: Variational inference on function space, operator learning, variational autoencoders, regularised autoencoders, scientific machine learning
© 2024 Justin Bunker, Mark Girolami, Hefin Lambley, Andrew M. Stuart and T. J. Sullivan.
License: CC-BY 4.0, see https://creativecommons.org/licenses/by/4.0/.
## 1 Introduction
Functional data, and data that can be viewed as a high-resolution approximation of functions, are ubiquitous in data science (Ramsay and Silverman, 2002). Recent years have seen much interest in machine learning in this setting, with the promise of architectures that can be trained and evaluated across resolutions. A variety of methods now exist for the supervised learning of operators between function spaces, starting with the work of Chen and Chen (1993), followed by DeepONet (Lu et al., 2021), PCA-Net (Bhattacharya et al., 2021), Fourier neural operators (FNOs; Li et al., 2021) and variants (Kovachki et al., 2023). These methods have proven useful in diverse applications such as surrogate modelling for costly simulators of dynamical systems (Azizzadenesheli et al., 2024).
Practical algorithms for functional data must necessarily operate on discrete representations of the underlying infinite-dimensional objects, identifying salient features independent of resolution. Some models make this dimension reduction explicit by representing outputs as a linear combination of basis functions-learned from data in DeepONet, and computed using principal component analysis (PCA) in PCA-Net. Others do this implicitly, as in, for example, the deep layered structure of FNOs involving repeated application of the discrete Fourier transform followed by pointwise activation.
While linear dimension-reduction methods such as PCA adapt readily to function space, there are many types of data, such as solutions to advection-dominated partial differential equations (PDEs), for which linear approximations are provably inefficient-a phenomenon known as the Kolmogorov barrier (Peherstorfer, 2022). This suggests the need for nonlinear dimension-reduction techniques on function space. Motivated by this we propose an extension of variational autoencoders (VAEs; Kingma and Welling, 2014) to functional data using operator learning; we refer to the resulting model as the functional variational autoencoder (FVAE) . As a probabilistic latent-variable model, FVAE allows for both dimension reduction and principled generative modelling on function space.
We define the FVAE objective as the Kullback-Leibler (KL) divergence between two joint distributions, both on the product of the data and latent spaces, defined by the encoder and decoder models; we then derive conditions under which this objective is well-defined. This differs from the usual presentation of VAEs in which one maximises a lower bound on the data likelihood, the evidence lower bound (ELBO); we show that our objective is equivalent and that it generalises naturally to function space. The FVAE objective proves to be well defined only under a compatibility condition between the data and the generative model; this condition is easily satisfied in finite dimensions but is restrictive for functional data. Our applications of FVAE rest on establishing such compatibility, which is possible for problems in the sciences such as those arising in Bayesian inverse problems with Gaussian priors (Stuart, 2010), and those governed by stochastic differential equations (SDEs) (Hairer et al., 2011). However, there are many problems in the sciences, and in generative models for PDEs in particular, for which application of FVAE fails because the generative model is incompatible with the data; using FVAE in such settings leads to foundational theoretical issues and, as a result, to practical problems in the infinite-resolution and -data limits.
To overcome these foundational issues we propose a deterministic regularised autoencoder that can be applied in very general settings, which we call the functional autoencoder
(FAE) . We show that FAE is an effective tool for dimension reduction, and that it can used as a versatile generative model for functional data.
We complement the FVAE and FAE objectives on function space with neural-operator architectures that can be discretised on any mesh. The ability to discretise both the encoder and the decoder on arbitrary meshes extends prior work such as the variational autoencoding neural operator (VANO; Seidman et al., 2023), and is highly empowering, enabling a variety of new applications of autoencoders to scientific data such as inpainting and superresolution. Code accompanying the paper is available at https://github.com/htlambley/functional autoencoders.
Contributions. We make the following contributions to the development and application of autoencoders to functional data:
- (C1) we propose FVAE, an extension of VAEs to function space, finding that the training objective is well defined so long as the generative model is compatible with the data;
- (C2) we complement the FVAE training objective with mesh-invariant architectures that can be deployed on any discretisation-even irregular, non-grid discretisations;
- (C3) we show that when the data and generative model are incompatible, the discretised FVAE objective may diverge in the infinite-resolution and -data limits or entirely fail to minimise the divergence between the encoder and decoder;
(C4) we propose FAE, an extension of regularised autoencoders to function space, and show that its objective is well defined in many cases where the FVAE objective is not;
(C5) exploiting mesh-invariance, we propose masked training schemes which exhibit greater robustness at inference time, faster training and lower memory usage;
(C6) we validate FAE and FVAE on examples from the sciences, including problems governed by SDEs and PDEs, to discover low-dimensional latent structure from data, and use our models for inpainting, superresolution, and generative modelling, exploiting the ability to discretise the encoder and decoder on any mesh.
Outline. Section 2 extends VAEs to function space (Contribution (C1)). We then describe mesh-invariant architectures of Contribution (C2); we also validate our approach, FVAE, on examples such as SDE path distributions where compatibility between the data and the generative model can be verified. Section 3 gives an example of the problems arising when applying FVAE in the 'misspecified' setting of Contribution (C3). In Section 4 we propose FAE (Contribution (C4)) and apply our data-driven method to two examples from scientific machine learning: Navier-Stokes fluid flows and Darcy flows in porous media. In these problems we make use of the mesh-invariance of the FAE to apply the masked training scheme of Contribution (C5); masking proves to be vital for the applications to inpainting and superresolution in Contribution (C6). Section 5 discusses related work, and Section 6 discusses limitations and topics for future research.
## 2 Variational Autoencoders on Function Space
In this section we define the VAE objective by minimizing the KL divergence between two distinct joint distributions on the product of data and latent spaces, one defined by the encoder and the other by the decoder. We show that this gives a tractable objective
when written in terms of a suitable reference distribution (Section 2.1). This objective coincides with maximising the ELBO in finite dimensions (Section 2.2) and extends readily to infinite dimensions. The divergence between the encoder and decoder models is finite only under a compatibility condition between the data and the generative model. This condition is restrictive in infinite dimensions. We identify problem classes for which this compatibility holds (Section 2.3) and pair the objective with mesh-invariant encoder and decoder architectures (Section 2.4), leading to a model we call the functional variational autoencoder (FVAE) . We then validate our method on several problems from scientific machine learning (Section 2.5) where the data are governed by SDEs.
## 2.1 Training Objective
We begin by formulating an objective in infinite dimensions, making the following standard assumption in unsupervised learning throughout Section 2. At this stage we focus on the continuum problem, and address the question of discretisation in Section 2.4. In what follows P ( X ) is the set of Borel probability measures on the separable Banach space X .
Assumption 1. Take the data space ( U ∥·∥ , ) to be a separable Banach space. There exists a data distribution Υ ∈ P ( U ) from which we have access to N independent and identically distributed samples { u ( n ) } N n =1 ⊂ U . ■
This setting is convenient to work with yet general enough to include many spaces of interest; U could be, for example, a Euclidean space R k , or the infinite-dimensional space L 2 (Ω) of (equivalence classes of) square-integrable functions with domain Ω ⊆ R d . Separability is a technical condition used to guarantee the existence of conditional distributions in the encoder and decoder models defined shortly (see Chang and Pollard, 1997, Theorem 1).
An autoencoder consists of two nonlinear transformations: an encoder mapping data into a low-dimensional latent space Z , and a decoder mapping from Z back into U . The goal is to choose transformations such that, for u ∼ Υ, composing the encoder and decoder approximates the identity. In this way the autoencoder can be used for dimension reduction, with the encoder output being a compressed representation of the data.
To make this precise, fix Z = R d Z and define encoder and decoder transformations depending on parameters θ ∈ Θ and ψ ∈ Ψ, respectively, by
$$( \text{encoder} ) \quad & \mathcal { U } \ni u \mapsto \mathbb { Q } ^ { \theta } _ { z | u } \in \mathcal { P } ( \mathcal { Z } ), \quad & ( 1 \mathbf a ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
↦
↦
$$( \text{decoder} ) \quad \mathcal { Z } \ni z \mapsto \mathbb { P } _ { u | z } ^ { \psi } \in \mathcal { P } ( \mathcal { U } ).$$
↦
To ensure the statistical models we are interested in are well defined, we require both maps to be Markov kernels-that is, for all Borel measurable sets A ⊆ Z and B ⊆ U and all parameters θ ∈ Θ and ψ ∈ Ψ, the maps u → Q θ z u | ( A ) and z → P ψ u z | ( B ) are measurable. Since the encoder and decoder both output probability distributions, we must be precise about what it means to compose them: we mean the distribution
↦
$$( \text{autoencoding distribution} ) \ \ A _ { u } ^ { \theta, \psi } ( B ) = \int _ { \mathcal { Z } } \mathbb { P } _ { u | z } ^ { \psi } ( B ) \, \mathbb { Q } _ { z | u } ^ { \theta } ( d z ), \ \ B \subseteq \mathcal { U } \text{ measurable}. \ \ ( 2 )$$
Remark 2. Given u ∈ U , A θ,ψ u ( ) is the distribution given by drawing · z ∼ Q θ z u | and then sampling from P ψ u z | ; we would like this to be close to a Dirac distribution δ u when u is drawn from Υ; enforcing this, approximately, will be used to determine the parameters ( θ, ψ ) . ■
Autoencoding as Matching Joint Distributions. Now let us fix a latent distribution P z ∈ P ( Z ) and define two distributions for ( z, u ) on the product space Z × U :
$$( \text{joint encoder model} ) \quad \mathbb { Q } _ { z, u } ^ { \theta } ( d z, d u ) = \mathbb { Q } _ { z | u } ^ { \theta } ( d z ) \Upsilon ( d u ),$$
$$( \text{joint decoder model} ) \quad \mathbb { P } ^ { \phi } _ { z, u } ( d z, d u ) = \mathbb { P } ^ { \phi } _ { u | z } ( d u ) \mathbb { P } _ { z } ( d z ). \quad \ ( 3 b )$$
The joint encoder model (3a) is the distribution on ( z, u ) given by applying the encoder to data u ∼ Υ, while the joint decoder model (3b) is the distribution on ( z, u ) given by applying the decoder to latent vectors z ∼ P z . We emphasise that Υ is given, while the distributions Q θ z u | , P ψ u z | , and P z are to be specified; the choice of decoder distribution P ψ u z | on the (possibly infinite-dimensional) space U will require particular attention in what follows.
The marginal and conditional distributions of (3a) and (3b) will be important and we write, for example, P ψ z u | for the z | u -conditional of the joint decoder model and Q θ z for the z -marginal of the joint encoder model. In particular, the u -marginal of the joint decoder model is the generative model P ψ u .
To match the joint encoder model (3a) with the joint decoder model (3b), we seek to solve, for some statistical distance or divergence d on P ( Z × U ), the minimisation problem
$$\underset { \theta \in \Theta, \, \psi \in \Psi } { \arg \min } d ( \mathbb { Q } _ { z, u } ^ { \theta } \, \| \, \mathbb { P } _ { z, u } ^ { \psi } ).$$
Doing so determines an autoencoder and a generative model. The choice of d is constrained by the need for it to be possible to evaluate the objective with Υ known only empirically; examples for which this is the case include the Wasserstein metrics and the KL divergence.
VAE Objective as Minimisation of KL Divergence. Using the KL divergence as d in (4) leads to the goal of finding θ ∈ Θ and ψ ∈ Ψ to minimise
$$D _ { K L } ( \mathbb { Q } ^ { \theta } _ { z, u } \left \| \, \mathbb { P } ^ { \psi } _ { z, u } ) = \underset { ( z, u ) \sim \mathbb { Q } ^ { \theta } _ { z, u } } { \mathbb { E } } \left [ \log \frac { \mathrm d \mathbb { Q } ^ { \theta } _ { z, u } } { \mathrm d \mathbb { P } ^ { \psi } _ { z, u } } ( z, u ) \right ] = \underset { u \sim \Upsilon } { \mathbb { E } } \underset { z \sim \mathbb { Q } ^ { \theta } _ { z | u } } { \mathbb { E } } \left [ \log \frac { \mathrm d \mathbb { Q } ^ { \theta } _ { z, u } } { \mathrm d \mathbb { P } ^ { \psi } _ { z, u } } ( z, u ) \right ] ; \quad ( 5 )$$
here d Q θ z,u / d P ψ z,u is the Radon-Nikodym derivative of Q θ z,u with respect to P ψ z,u , the appropriate infinite-dimensional analogue of the ratio of probability densities. This exists only when Q θ z,u is absolutely continuous with respect to P ψ z,u , meaning that Q θ z,u assigns probability zero to a set whenever P ψ z,u does; we take (5) to be infinite otherwise. This objective is equivalent to the standard VAE objective in the case U = R k but has the additional advantage that it can be used in the infinite-dimensional setting.
KL divergence has many benefits justifying its use across statistics. Its value in inference and generative modelling comes from the connection between maximum-likelihood methods and minimising KL divergence, as well as its information-theoretic interpretation (Cover and Thomas, 2006, Sec. 2.3). KL divergence is asymmetric and has two useful properties justifying the order of the arguments in (5): it can be evaluated using only samples of the
↦
distribution in its first argument, and it requires no knowledge of the normalisation constant of the distribution in its second argument since minimisers of ν → D KL ( ν ∥ µ ) are invariant when scaling µ (Chen et al., 2023 and Bach et al., 2024, Sec. 12.2).
To justify the use of the joint divergence (5), in Theorem 3 we decompose the objective as the sum of two interpretable terms. In Theorem 6 we write the objective in a form that leads to actionable algorithms.
Theorem 3. For all parameters θ ∈ Θ and ψ ∈ Ψ for which D KL ( Q θ z,u ∥ P ψ z,u ) < ∞ ,
$$D _ { K L } ( \mathbb { Q } _ { z, u } ^ { \theta } \left \| \mathbb { P } _ { z, u } ^ { \psi } ) = \underbrace { D _ { K L } ( \Upsilon \left \| \mathbb { P } _ { u } ^ { \psi } \right ) } _ { ( I ) } + \underbrace { \mathbb { E } _ { u \sim \Upsilon } \left [ D _ { K L } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z | u } ^ { \psi } ) \right ] } _ { ( I I ) }.$$
Proof Factorise Q θ z,u (d z, d u ) = Q θ z u | (d z )Υ(d u ) and P ψ z,u (d z, d u ) = P ψ z u | (d z ) P ψ u (d u ) and substitute into (5) to obtain
$$D _ { K L } ( \mathbb { Q } _ { z, u } ^ { \theta } \left \| \mathbb { P } _ { z, u } ^ { \psi } ) = \underset { \sim \mathbb { Q } _ { z, u } ^ { \theta } } { \mathbb { E } } \left [ \log \frac { d \Upsilon } { d \mathbb { P } _ { u } ^ { \psi } } ( u ) \frac { d \mathbb { Q } _ { z | u } ^ { \theta } } { d \mathbb { P } _ { z | u } ^ { \psi } } ( z ) \right ] = \underset { u \sim \Upsilon } { \mathbb { E } } \underset { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } \left [ \log \frac { d \Upsilon } { d \mathbb { P } _ { u } ^ { \psi } } ( u ) + \log \frac { d \mathbb { Q } _ { z | u } ^ { \theta } } { d \mathbb { P } _ { z | u } ^ { \psi } } ( z ) \right ].$$
The result follows by inserting the definition of the KL divergences on the right-hand side of (6), and all terms are finite owing to the assumption that D KL ( Q θ z,u ∥ P ψ z,u ) < ∞ .
↦
Theorem 3 decomposes the divergence (5) into (I) the error in the generative model and (II) the error in approximating the decoder posterior P ψ z u | with Q θ z u | via variational inference; jointly training a variational-inference model and a generative model is exactly the goal of a VAE. However, minimising (5) makes sense only if ( θ, ψ ) → D KL ( Q θ z,u ∥ P ψ z,u ) is finite for some θ and ψ . Verification of this property is a necessary step that we perform for our settings of interest in Propositions 8, 17, and 26.
Remark 4 (Posterior collapse) . While minimising (5) typically leads to a useful autoencoder, this is not guaranteed: the autoencoding distribution (2) may be very far from a Dirac distribution. For example, when P ψ z u | ≈ P z , the optimal decoder distribution P ψ u z | may well ignore the latent variable z entirely. Indeed, if Υ = Q z u | = P u z | = P z = N (0 1) on , U = R , then D KL ( Q z,u ∥ P z,u ) = 0, but the autoencoding distribution A u = N (0 1) for all , u ∈ U . This is not close to the desired Dirac distribution referred to in Remark 2. This issue is known in the VAE literature as posterior collapse (Wang et al., 2021). In practice, choice of model classes for Q z u | and P u z | avoids this issue. ■
Tractable Training Objective. Since we can access Υ only through training data, we must decompose the objective function into a sum of a term which involves Υ only through samples and a term which is independent of the parameters θ and ψ . The first of these terms may then be used to define a tractable objective function over the parameters. To address this issue we introduce a reference distribution Λ ∈ P ( U ) and impose the following conditions on the encoder and the reference distribution.
Assumption 5. (a) There exists a reference distribution Λ ∈ P ( U ) such that:
- (i) for all ψ ∈ Ψ and z ∈ Z , P ψ u z | is mutually absolutely continuous with Λ; and
- For all θ Θ and Υ-almost all u , D KL ( Q θ P z ) < . ■
- (ii) the data distribution Υ satisfies the finite-information condition D KL (Υ ∥ Λ) < ∞ .
- (b) ∈ ∈ U z u | ∥ ∞
Theorem 6. If Assumption 5 is satisfied for some Λ ∈ P ( U ) , then for all parameters θ ∈ Θ and ψ ∈ Ψ for which D KL ( Q θ z,u ∥ P ψ z,u ) < ∞ , we have
$$D _ { K L } ( \mathbb { Q } _ { z, u } ^ { \theta } \left \| \mathbb { P } _ { z, u } ^ { \psi } \right ) = \underset { u \sim \Upsilon } { \mathbb { E } } \left [ \mathcal { L } ( u ; \theta, \psi ) \right ] + D _ { K L } ( \Upsilon \left \| \Lambda ),$$
$$( p e r \text{-sample loss} ) \quad \mathcal { L } ( u ; \theta, \psi ) = \sum _ { z \sim Q _ { z | u } ^ { \theta } } ^ { - } \left [ - \log \frac { \mathrm d \mathbb { P } ^ { \psi } _ { u | z } } { \mathrm d \Lambda } ( u ) \right ] + D _ { K L } ( \mathbb { Q } ^ { \theta } _ { z | u } \left \| \mathbb { P } _ { z } ). \quad ( 7 b )$$
Proof Write Q θ z,u (d z, d u ) = Q θ z u | (d z )Υ(d u ) and P ψ z,u (d z, d u ) = P ψ u z | (d u ) P z (d z ), factor through the distribution Λ in (5), and apply the definition of the KL divergence to obtain
$$\text{through the distribution } \Lambda \text{ in } ( 5 ), \text{and apply the definition of the KL divergence to obtain} \\ D _ { K L } ( \mathbb { Q } _ { z, u } ^ { \theta } \left \| \mathbb { P } _ { z, u } ^ { \psi } ) & = \mathbb { E } _ { ( z, u ) \sim \mathbb { Q } _ { z, u } ^ { \theta } } \left [ \log \frac { d \mathbb { Q } _ { z | u } ^ { \theta } } { d \mathbb { P } _ { z } } ( z ) \frac { d \Lambda } { d \mathbb { P } _ { u | z } ^ { \psi } } ( u ) \frac { d \Upsilon } { d \Lambda } ( u ) \right ] \\ & = \mathbb { E } _ { u \sim \Upsilon } \left [ \left [ z \sim \mathbb { Q } _ { z | u } ^ { \theta } \left [ - \log \frac { d \mathbb { P } _ { u | z } ^ { \psi } } { d \Lambda } ( u ) + \log \frac { d \mathbb { Q } _ { z | u } ^ { \theta } } { d \mathbb { P } _ { z } } ( z ) \right ] + \log \frac { d \Upsilon } { d \Lambda } ( u ) \right ] \\ & = \mathbb { E } _ { u \sim \Upsilon } \left [ \mathbb { E } _ { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } \left [ - \log \frac { d \mathbb { P } _ { u | z } ^ { \psi } } { d \Lambda } ( u ) \right ] + D _ { K L } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ) \right ] + D _ { K L } ( \Upsilon \left \| \Lambda ), \\ \text{where all terms are finite as a consequence of Assumptions 5} ( a ) ( \text{ii} ) \text{ and } ( b ).$$
where all terms are finite as a consequence of Assumptions 5(a)(ii) and (b).
Since D KL (Υ ∥ Λ) is assumed to be finite and depends on neither θ nor ψ , Theorem 6 shows that the joint KL divergence (5) is equivalent, up to a finite constant, to
$$( F \AA E \text{ objective} ) \quad \mathcal { I } ^ { F \AA E } ( \theta, \psi ) = \underset { u \sim \Upsilon } { \mathbb { E } } \left [ \mathcal { L } ( u ; \theta, \psi ) \right ].$$
In particular, minimising J FVAE is equivalent to minimising the joint divergence, and J FVAE ( θ, ψ ) is finite if and only if D KL ( Q θ z,u ∥ P ψ z,u ) is finite. Moreover (8) can be approximated using samples from Υ:
$$( \text{empirical FVAE objective} ) \quad \mathcal { J } _ { N } ^ { F V A E } ( \theta, \psi ) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathcal { L } ( u ^ { ( n ) } ; \theta, \psi ).$$
In the limit of infinite data, the empirical objective (9) converges to (8); but both (8) and (9) may be infinite in many practical settings, as we shall see in the following sections.
Remark 7. (a) Assumption 5(a) ensures that the density d P ψ u z | / dΛ in the per-sample loss exists, and that minimising (5) and (8) is equivalent; Assumption 5(b) ensures that, when the joint divergence (5) is finite, the per-sample loss L is finite for Υ-almost all u ∈ U . We could also formulate Assumption 5(a) with a σ -finite reference measure Λ, e.g., Lebesgue measure, but for our theory it suffices to consider probability measures.
- (b) The proof of Theorem 6 shows why we take Q θ z,u as the first argument and P ψ z,u as the second in (5) to obtain a tractable objective. Reversing the arguments in the divergence gives an expectation with respect to the joint decoder model (3b):
$$D _ { K L } ( \mathbb { P } ^ { \psi } _ { z, u } \left \| \mathbb { Q } ^ { \theta } _ { z, u } ) = \mathbb { E } _ { ( z, u ) \sim \mathbb { P } ^ { \psi } _ { z, u } } \left [ \log \frac { \mathrm d \mathbb { P } _ { z } } { \mathrm d \mathbb { Q } ^ { \theta } _ { z | u } } ( z ) + \log \frac { \mathrm d \mathbb { P } ^ { \psi } _ { u | z } } { \mathrm d \Lambda } ( u ) \right ] + \mathbb { E } _ { ( z, u ) \sim \mathbb { P } ^ { \psi } _ { z, u } } \left [ \log \frac { \mathrm d \Lambda } { \mathrm d \Upsilon } ( u ) \right ].$$
Unlike in Theorem 6, the term involving dΛ / dΥ is not a constant: it depends on the parameter ψ and would therefore need to be evaluated during the optimisation process, but this is intractable because we have only samples from Υ and not its density. ■
## 2.2 Objective in Finite Dimensions
We now show that the theory in Section 2.1 simplifies in finite dimensions to the usual VAE objective. To do so we assume U = R k and that Υ ∈ P ( U ) has strictly positive probability density υ : U → (0 , ∞ ). We moreover assume that Z = R d Z and that the latent distribution and the distributions returned by the encoder (1a) and decoder (1b) are Gaussian, taking the form
$$\mathbb { Q } _ { z | u } ^ { \theta } = N ( f ( u ; \theta ), \Sigma ( u ; \theta ) ) = f ( u ; \theta ) + \Sigma ( u ; \theta ) ^ { \frac { 1 }$$
$$\mathbb { P } _ { u | z } ^ { \psi } = N ( g ( z ; \psi ), \beta I _ { \mathcal { U } } ) = g ( z ; \psi ) + \beta ^ { \frac { 1 } { 2 } } N ($$
$$\mathbb { P } _ { z } & = N ( 0, I _ { \mathcal { Z } } ), & ( 1 0 c )$$
where β > 0 is fixed and the parameters of (10a) and (10b) are given by learnable maps
$$f = ( f, \Sigma ) \colon \mathcal { U } \times \Theta & \to \mathcal { Z } \times \mathcal { S } _ { + } ( \mathcal { Z } ), & ( 1 1 a ) \\ \quad \quad \quad$$
$$g \colon \mathcal { Z } \times \Psi \to \mathcal { U },$$
with S + ( Z ) denoting the set of positive semidefinite matrices on Z . The Gaussian model (10a)-(10c) is the standard setting in which VAEs are applied, resulting in the joint decoder model (3b) being the distribution of ( z, u ) in the model
$$u \ | \ z = g ( z ; \psi ) + \eta, \quad z \sim N ( 0, I _ { Z } ), \quad \eta \sim \mathbb { P } _ { \eta } = \beta ^ { \frac { 1 } { 2 } } N ( 0, I _ { U } ).$$
Other decoder models are also possible (Kingma and Welling, 2014), and in infinite dimensions we will consider a wide class of decoders, including Gaussians as a particular case. In practice (11a), (11b) will come from a parametrised class of functions, e.g., a class of neural networks. Provided these classes are sufficiently large and the data distribution has finite information with respect to P η , the joint divergence (5) is finite for at least one choice of θ and ψ .
Proposition 8. Suppose that for parameters θ ⋆ ∈ Θ and ψ ⋆ ∈ Ψ we have f ( u θ ; ⋆ ) = (0 , I Z ) and g z ( ; ψ ⋆ ) = 0 . Then
$$D _ { \text{KL} } ( \mathbb { Q } _ { z, u } ^ { \theta ^ { * } } \left \| \mathbb { P } _ { z, u } ^ { \psi ^ { * } } ) = D _ { \text{KL} } ( \Upsilon \left \| \mathbb { P } _ { \eta } ).$$
In particular, if D KL (Υ ∥ P η ) < ∞ , then the joint divergence (5) has finite infimum.
Proof Evaluating the joint encoder model (3a) and the joint decoder model (3b) at θ ⋆ and ψ ⋆ gives Q θ ⋆ z,u (d z, d u ) = P z (d z )Υ(d u ) and P ψ ⋆ z,u (d z, d u ) = P z (d z ) P η (d u ), so
$$D _ { K L } ( \mathbb { Q } _ { z, u } ^ { \theta ^ { * } } \left \| \mathbb { P } _ { z, u } ^ { \psi ^ { * } } ) = \mathbb { E } _ { u \sim \Upsilon } \mathbb { E } _ { z \sim \mathbb { P } _ { z } } \left [ \log \frac { d \mathbb { P } _ { z } } { d \mathbb { P } _ { z } } ( z ) + \log \frac { d \Upsilon } { d \mathbb { P } _ { \eta } } ( u ) \right ] = D _ { K L } ( \Upsilon \left \| \mathbb { P } _ { \eta } ). \ \blacksquare$$
Remark 9. In finite dimensions, many data distributions satisfy D KL (Υ ∥ P η ) < ∞ . However there are cases in which this fails, e.g., when Υ is a Cauchy distribution on R , In such cases (5) is infinite even with the trivial maps f ( u θ ; ⋆ ) = (0 , I Z ) and g z ( ; ψ ⋆ ) = 0. ■
Training Objective. In Section 2.1 we proved that the joint divergence (5) can be approximated by the tractable objective (8) and its empiricalisation (9) whenever there is a reference distribution Λ satisfying Assumption 5. We now show that taking Λ = Υ satisfies this assumption and results in a training objective equivalent to maximising the ELBO. Recall the data density υ associated with data measure Υ .
Proposition 10. Under the model (10a) -(10c) with reference distribution Λ = Υ , Assumption 5 is satisfied, and, for some finite constant C > 0 independent of u , θ , and ψ ,
$$\mathcal { L } ( u ; \theta, \psi ) = \underset { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ - \log p _ { u | z } ^ { \psi } ( u ) \right ] + \log \upsilon ( u ) + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } \right )$$
$$= \underset { z \sim Q _ { z | u } ^ { \theta } } { \mathbb { E } } _ { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } \left [ ( 2 \beta ) ^ { - 1 } \| g ( z ; \psi ) - u \| _ { 2 } ^ { 2 } \right ] + \log v ( u ) + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ) + C. \quad ( 1 3 b )$$
$$\L ; \theta, \psi ) & = \underset { z \sim Q _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ - \log p _ { u | z } ^ { \psi } ( u ) \right ] + \log \upsilon ( u ) + D _ { \text{KL} } \left ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } \right ) & & ( 1 3 \text{a} ) \\ & = \underset { z \sim Q _ { z | \dots } ^ { \theta } } { \mathbb { E } } \left [ ( 2 \beta ) ^ { - 1 } \left \| g ( z ; \psi ) - u \right \| _ { 2 } ^ { 2 } \right ] + \log \upsilon ( u ) + D _ { \text{KL} } \left ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } \right ) + C. & & ( 1 3 \text{b} )$$
Proof For Assumption 5(a), mutual absolute continuity of P ψ u z | and Λ follows as both distributions have strictly positive densities, and evidently D KL (Υ ∥ Λ) = 0. Assumption 5(b) holds since both the encoder distribution (10a) and the latent distribution (10c) are Gaussian, with KL divergence available in closed form (Remark 11). The expression for L follows from (7b) using that P ψ u z | is Gaussian with density p ψ u z | and d P ψ u z | / dΥ( ) = u p ψ u z | ( u /υ u ) ( ).
While the per-sample loss (13a) involves the unknown density υ , we can drop this without affecting the objective (8) if Υ has finite differential entropy E u ∼ Υ [ -log υ u ( ) ] . This follows because
$$\mathcal { J } ^ { \text{FVAE} } ( \theta, \psi ) = \underset { u \sim \Upsilon } { \mathbb { E } } \left [ \mathcal { L } _ { \underset { r } { \mathbb { R } } } ^ { \text{VAE} } ( u ; \theta, \psi ) \right ] - \underset { \mathbb { R } } { \mathbb { E } } \left [ - \log \upsilon ( u ) \right ] + C,$$
$$\mathcal { L } ^ { \text{VAE} } ( u ; \theta, \psi ) = \mathbb { E } _ { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } \left [ ( 2 \beta ) ^ { - 1 } \| g ( z ; \psi ) - u \| _ { 2 } ^ { 2 } \right ] + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ).$$
Thus, J VAE ( θ, ψ ) = E u ∼ Υ [ L VAE ( θ, ψ )] is equivalent, up to a finite constant, to J FVAE ( θ, ψ ), and J VAE is tractable. Requiring that Υ has finite differential entropy is a mild condition, and one can expect this to be the case for the vast majority of distributions arising in the finite-dimensional setting.
Remark 11 (VAEs as regularised autoencoders) . We can write the divergence in (14b) in closed form as D KL ( Q θ z u | ∥ P z ) = 1 2 ( ∥ f u θ ( ; ) ∥ 2 2 +tr Σ( ( u θ ; ) -log Σ( u θ ; ) ) -d Z ) . Applying the
reparametrisation trick (Kingma and Welling, 2014) to write the expectation over z ∼ Q θ z u | in terms of ξ ∼ N (0 , I Z ), the interpretation of a VAE as a regularised autoencoder is clear:
$$\mathcal { L } ^ { \text{VAE} } ( u ; \theta, \psi ) & \in \mathbb { E } _ { \xi \sim N ( 0, I _ { Z } ) } \left [ ( 2 \beta ) ^ { - 1 } \left \| g \left ( f ( u ; \theta ) + \Sigma ( u ; \theta ) \xi ; \psi \right ) - u \right \| _ { 2 } ^ { 2 } \right ] \\ & + \frac { 1 } { 2 } \left \| f ( u ; \theta ) \right \| _ { 2 } ^ { 2 } + \frac { 1 } { 2 } \text{tr} \left ( \Sigma ( u ; \theta ) - \log \Sigma ( u ; \theta ) \right ). \quad \bullet \\ \text{com.uk 1.9} \, ^ { \text{Tho anidomos lomor bound} } \, \text{tho mean distribution of VAE encoding} \, \text{tho download}$$
Remark 12 (The evidence lower bound) . The usual derivation of VAEs specifies the decoder model (12) and performs variational inference on the posterior for z | u , seeking to maximise a lower bound, the ELBO, on the likelihood of the data. Denoting by p ψ u the density of the generative model P ψ u , by q θ z u | the density of Q θ z u | , and so forth, the log-likelihood of u ∈ U is
$$\log p _ { u } ^ { \psi } ( u ) = D _ { \text{KL} } ( q _ { z | u } ^ { \theta } \left \| p _ { z | u } ^ { \psi } ) + \text{ELBO} ( u ; \theta, \psi ),$$
$$\text{ELBO} ( u ; \theta, \psi ) = \underset { z \sim q _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ \log p _ { u | z } ^ { \psi } ( u ) \right ] - D _ { \text{KL} } \left ( q _ { z | u } ^ { \theta } \left \| p _ { z } \right ).$$
This demonstrates that ELBO( u θ, ψ ; ) is indeed a lower bound on the log-data likelihood under the decoder model. Minimising our per-sample loss (13a) is equivalent to maximising the ELBO (15b), but, notably, our underlying objective is shown to correspond exactly to the underlying KL divergence (5) and avoids the use of any bounds on data likelihood. ■
Remark 13. An interpretation of the VAE objective as minimisation of (5) is also adopted by Kingma (2017, Sec. 2.8) and Kingma and Welling (2019). Our approach differs by writing the joint decoder model (3b) in terms of Υ rather than the empirical distribution
$$( \text{mpirical data distribution} ) \quad \Upsilon _ { N } = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \delta _ { u ^ { ( n ) } }.$$
Since Υ N is not absolutely continuous with respect to the generative model P ψ u of (10a)-(10c), using this would result in the joint divergence (5) being infinite for all θ and ψ . ■
## 2.3 Objective in Infinite Dimensions
We return to the setting of Assumption 1 and adopt a generalisation of the Gaussian model (10a)-(10c), with distributional parameters given by learnable maps f = ( f, Σ): U × Θ → Z × S + ( Z ) and g : Z × Ψ →U :
$$\mathbb { Q } _ { z | u } ^ { \theta } = N ( f ( u ; \theta ), \Sigma ( u ; \theta ) ) = f ( u ; \theta ) + \Sigma ( u ; \theta ) ^ { \frac { 1 } { 2 } } N ( 0, I _ { \mathcal { Z } } ),$$
$$\mathbb { P } _ { u | z } ^ { \psi } & = \mathbb { P } _ { \eta } ( \cdot - g ( z ; \psi ) ) = g ( z ; \psi ) + \mathbb { P } _ { \eta }, & ( 1 6 b ) \\ \mathbb { m } _ { \ } & = \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ { \ } \mathbb { m } _ }$$
$$\mathbb { P } _ { \eta } & \in \mathcal { P } ( \mathcal { U } ), & & ( 1 6 c ) \\ \mathbb { D } \ & = \ n r ( \alpha \ r _ { - } \Lambda ) & & ( 1 6 c )$$
$$\mathbb { P } _ { z } & = N ( 0, I _ { \mathcal { Z } } ).$$
The only change from the finite-dimensional model is in the decoder distribution (16b), which we now write as the shift of the decoder-noise distribution P η by the mean g z ( ; ψ ). As we will see shortly, the choice of decoder noise will be very important in infinite dimensions, and restricting attention solely to Gaussian white noise will no longer be feasible.
Obstacles in Infinite Dimensions. Many new issues arise in infinite dimensions, necessitating a more careful treatment of the FVAE objective; for example, we can no longer work with probability density functions, since there is no uniform measure analogous to Lebesgue measure (Sudakov, 1959). The fundamental obstacle, however, is that-unlike in finite dimensions-the joint divergence (5) is often ill defined, satisfying
$$D _ { K L } ( \mathbb { Q } ^ { \theta } _ { z, u } \left \| \, \mathbb { P } ^ { \psi } _ { z, u } \right ) = \infty \text{ \ for all } \theta \in \Theta \text{ and } \psi \in \Psi.$$
An important situation in which this arises is misspecification of the generative model P ψ u ; consequently, great care is needed in the choice of decoder to avoid this issue. To illustrate this we show that the extension of the white-noise model of (10a)-(10c) is ill-defined in infinite dimensions: the resulting joint divergence (5) is always infinite. To do this we define white noise using a Karhunen-Lo`ve expansion (Sullivan, 2015, Sec. 11.1). e
Definition 14. Let U = L 2 ([0 , 1]) with orthonormal basis e j ( x ) = √ 2 sin( πjx ), j ∈ N . We say that the random variable η is L 2 -white noise if it has Karhunen-Lo` eve expansion
(
$$( L ^ { 2 } \text{-white noise} ) & & \eta = \sum \xi _ { j } e _ { j }, \quad \xi _ { j } \stackrel { \text{i.i.d.} } { \sim } N ( 0, 1 ). & & \Omega$$
$$\eta = \sum _ { j \in \mathbb { N } } \xi _ { j } e _ { j }, \quad \xi _ { j } \stackrel { \text{i.i.d.} } { \sim } N ( 0, 1 ).$$
Proposition 15. Let P η be the distribution of the L 2 -white noise η . Then P η is a probability distribution supported on the Sobolev space H s ([0 , 1]) if and only if s < -1 2 / ; in particular P η assigns probability zero to L 2 ([0 , 1]) . Moreover, these statements remain true for any shift P η ( · -h ) of the distribution P η by h ∈ L 2 ([0 , 1]) .
The proof, which makes use of the Borel-Cantelli lemma and the Kolmogorov two-series theorem, is stated in Appendix A.
Example 16. Let U = L 2 ([0 , 1]), fix a data distribution Υ ∈ P ( U ) and take the model (16a)-(16d), where we further assume that g z ( ; ψ ) ∈ L 2 ([0 , 1]) for all z ∈ Z and ψ ∈ Ψ, and with P η taken to be the distribution of L 2 -white noise. Under this model, the joint divergence (5) is infinite for all θ and ψ . To see this, note that Υ assigns probability one to U , but, as P ψ u z | assigns zero probability to U by Proposition 15, we have
$$\mathbb { P } _ { u } ^ { \psi } ( \mathcal { U } ) = \int _ { \mathcal { Z } } \mathbb { P } _ { u | z } ^ { \psi } ( \mathcal { U } ) \, \mathbb { P } _ { z } ( \mathrm d z ) = 0.$$
Thus Υ is not absolutely continuous with respect to P ψ u , and so D KL ( Q θ z,u ∥ P ψ z,u ) = ∞ . ■
The VANO model (Seidman et al., 2023), which we discuss in detail in the related work (Section 5), adopts the setting of (16a)-(16d) with white decoder noise. It thus suffers from not being well-defined. The issues in Example 16 stem from the difference in regularity between the data, which lies in L 2 ([0 , 1]), and draws from the generative model, which lie in H s ([0 , 1]), s < -1 2 / , and not in L 2 ([0 , 1]). A difference in regularity is not the only possible issue: even two Gaussians supported on the same space need not be absolutely continuous owing to the Feldman-H´jek theorem (Bogachev, 1998, Ex. 2.7.4). But, as in Proposition 8, a we can state a sufficient condition for the divergence (5) to have finite infimum.
Proposition 17. Suppose that f ( u θ ; ⋆ ) = (0 , I Z ) and g z ( ; ψ ⋆ ) = 0 for some θ ⋆ ∈ Θ and ψ ⋆ ∈ Ψ , and that D KL (Υ ∥ P η ) < ∞ . Then (5) has finite infimum.
Well-Defined Objective for Specific Problem Classes. The issues we have seen suggest that one must choose the decoder model based on the structure of the data distribution: fixing a decoder model a priori typically results, in infinite dimensions, in the joint divergence being infinite. However we now give examples to show that, in important classes of problems arising in science and engineering, there is a clear choice of decoder noise P η arising from the problem structure. Adopting this decoder noise and taking the reference distribution Λ = P η will ensure that the hypotheses of Theorem 6 are satisfied: the joint divergence can be shown to have finite infimum, and Assumption 5 holds. Thus we can apply the actionable algorithms derived in Section 2.1.
## 2.3.1 SDE Path Distributions
One class of data to which we can apply FVAE arises in the study of random dynamical systems (E et al., 2004). We choose Υ to be the distribution over paths of the diffusion process defined, for a standard Brownian motion ( w t ) t ∈ [0 ,T ] on R m and ε > 0, by
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta$$
We assume that the drift b : R m → R m is regular enough that (17) is well defined. The theory we outline also applies to systems with anisotropic diffusion and time-dependent coefficients (S¨rkk¨ and Solin, 2019, Sec. 7.3), and to systems with nonzero initial condition, a a but we focus on the setting (17) for simplicity. The path distribution Υ is defined on the space U = C 0 ([0 , T ] , R m ) of continuous functions u : [0 , T ] → R m with u (0) = 0.
Recall (16b) where we define the decoder distribution P ψ u z | as the shift of the noise distribution P η by g z ( ; ψ ), and recall Assumption 5, which in particular demands that D KL (Υ ∥ P η ) < ∞ and that P ψ u z | is mutually absolutely continuous with P η . Here we choose P η to be the law of an auxiliary diffusion process, which in our examples will be an OrnsteinUhlenbeck (OU) process. This auxiliary process must have zero initial condition and must have the same noise structure as that in (17) to ensure that D KL (Υ ∥ P η ) < ∞ . We will learn the shift g and this will have to satisfy the zero initial condition to ensure that P ψ u z | is mutually absolutely continuous with P η .
Decoder-Noise Distribution P η . We take P η to be the law of the auxiliary SDE
$$\lambda \cdots \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon \\ \lambda \cdots \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon & \colon$$
with drift c : R m → R m , and with ε > 0 being the same in both (17) and (18). To determine whether D KL (Υ ∥ P η ) < ∞ , we will need to evaluate the term dΥ / d P η in the KL divergence; an expression for this is given by the Girsanov theorem (Liptser and Shiryaev, 2001, Chap. 7).
Proposition 18 (Girsanov theorem) . Suppose that U = C 0 ([0 , T ] , R m ) and that µ ∈ P ( U ) and ν ∈ P ( U ) are the laws of the R m -valued diffusions
$$\mathfrak { a } u _ { t } & = p ( u _ { t } ) \, \mathfrak { a } t + \sqrt { \varepsilon } \, \mathfrak { a } w _ { t }, \quad u _ { 0 } = 0, \quad t \in [ 0, 1 ], \\ \mathfrak { d } v _ { t } & = q ( v _ { t } ) \, \mathfrak { d } t + \sqrt { \varepsilon } \, \mathfrak { d } w _ { t }, \quad v _ { 0 } = 0, \quad t \in [ 0, T ]. \\ \mathcal { + } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a } \quad \mathfrak { a }$$
$$\omega \times \omega \times \omega _ { J } \times \omega \times \omega \times \omega _ { J } \times \omega \times \omega \times \omega _ { J } \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \omega \times \ome } \, \text{d} u _ { t } = p ( u _ { t } ) \, \text{d} t + \sqrt { \varepsilon } \, \text{d} w _ { t }, \quad u _ { 0 } = 0, \quad t \in [ 0, T ], \\ \text{d} u _ { t } = a ( n _ { t } ) \, \text{d} t + \sqrt { \varepsilon } \, \text{d} u _ { t }, \quad u _ { 0 } = 0, \quad t \in [ 0, T ]$$
Suppose that the Novikov condition (Øksendal, 2003, eq. (8.6.8)) holds for both processes:
$$\underset { u \sim \mu } { \mathbb { E } } \left [ \int _ { 0 } ^ { T } \| p ( u _ { t } ) \| _ { 2 } ^ { 2 } \, \mathrm d t \right ] < \infty \ \ a n d \ \underset { v \sim \nu } { \mathbb { E } } \left [ \int _ { 0 } ^ { T } \| q ( v _ { t } ) \| _ { 2 } ^ { 2 } \, \mathrm d t \right ] < \infty.$$
Then
$$\frac { \text{d} \mu } { \text{d} \nu } ( u ) = \exp \left ( \frac { 1 } { 2 \varepsilon } \int _ { 0 } ^ { T } \| q ( u _ { t } ) \| _ { 2 } ^ { 2 } - \| p ( u _ { t } ) \| _ { 2 } ^ { 2 } \, \text{d} t - \frac { 1 } { \varepsilon } \int _ { 0 } ^ { T } \langle q ( u _ { t } ) - p ( u _ { t } ), \, \text{d} u _ { t } \rangle \right ). \quad ( 2 0 )$$
The second integral in (20) is a stochastic integral with respect to ( u t ) t ∈ [0 ,T ] (S¨rkk¨ a a and Solin, 2019, Chap. 4). The Novikov condition suffices for our needs, but the theorem also holds under weaker conditions such as the Kazamaki condition (Liptser and Shiryaev, 2001, p. 249). Applying Proposition 18 to evaluate the KL divergence (Appendix A) yields
$$D _ { \text{KL} } ( \Upsilon \left \| \mathbb { P } _ { \eta } \right ) = \mathbb { E } _ { u \sim \Upsilon } \left [ \frac { 1 } { 2 \varepsilon } \int _ { 0 } ^ { T } \| b ( u _ { t } ) - c ( u _ { t } ) \| _ { 2 } ^ { 2 } \mathrm d t \right ].$$
Thus the condition D KL (Υ ∥ P η ) < ∞ is satisfied quite broadly, e.g., if b and c are bounded.
Per-Sample Loss. With the condition D KL (Υ ∥ P η ) < ∞ verified, it remains to choose g to ensure that P ψ u z | is mutually absolutely continuous with P η , and to derive the corresponding density. Once this is done, we arrive at the actionable per-sample loss derived in Theorem 6. To do this we again apply the Girsanov theorem, using that, when g z ( ; ψ ) ∈ H 1 ([0 , T ]) takes value zero at t = 0, the distribution P ψ u z | is the law of the SDE
As we will parametrise g z ( ; ψ ) using a neural network, we can assume it to be in C 1 ([0 , T ]), and hence in H 1 ([0 , T ]); moreover we shall enforce that g z ( ; ψ )(0) ≈ 0 through the loss, as described shortly. To be concrete, we restrict attention to decoder noise with c x ( ) = -κx , making ( η t ) t ∈ [0 ,T ] an OU process if κ > 0 and Brownian motion if κ = 0. In this case the per-sample loss can be derived by applying the Girsanov theorem to (18) and (21).
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdclots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots
\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \clots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cd: \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cl: \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots\ddots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \ddots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cd: \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots\vdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \vdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cd:. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots\colon \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cd$$
Proposition 19 (SDE per-sample loss) . Suppose that c x ( ) = -κx , κ ⩾ 0 , and that g z ( ; ψ ) ∈ H 1 ([0 , T ]) with g z ( ; ψ )(0) = 0 for all z ∈ Z and ψ ∈ Ψ . Then Assumption 5 holds and
$$\mathcal { L } ( u ; \theta, \psi ) = \underset { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ - \log \frac { \text{d} \mathbb { P } _ { u | z } ^ { \psi } } { \text{d} \mathbb { P } _ { \eta } } ( u ) \right ] + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ),$$
$$\mathcal { L } ( u ; \theta, \psi ) = \underset { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ - \log \frac { d \mathbb { P } _ { u | z } ^ { \psi } } { d \mathbb { P } _ { \eta } } ( u ) \right ] + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \| \, \mathbb { P } _ { z } ), \\ \log \frac { d \mathbb { P } _ { u | z } ^ { \psi } } { d \mathbb { P } _ { \eta } } ( u ) = \frac { 1 } { \varepsilon } \int _ { 0 } ^ { T } \left \langle g ( z ; \psi ) ^ { \prime } ( t ) + \kappa g ( z ; \psi ) ( t ), d u _ { t } \right \rangle \\ - \frac { 1 } { 2 \varepsilon } \int _ { 0 } ^ { T } \left ( \| g ( z ; \psi ) ^ { \prime } ( t ) - \kappa ( u ( t ) - g ( z ; \psi ) ( t ) ) \| _ { 2 } ^ { 2 } - \| \kappa u ( t ) \| _ { 2 } ^ { 2 } \right ) d t. \\ \text{In practice, we make two modifications to $\mathcal{L}$. First, the initial condition $g(z;\psi)(0)=0$ is}$$
̸
In practice, we make two modifications to L . First, the initial condition g z ( ; ψ )(0) = 0 is not enforced exactly; instead, we add a Tikhonov-like zero-penalty term with regularisation parameter λ > 0 to favour g z ( ; ψ )(0) ≈ 0. Second, to allow variation of the strength of the KL regularisation, we multiply the term D KL ( Q θ z u | ∥ P z ) by a regularisation parameter β > 0. Setting β = 1 breaks the exact correspondence between the FVAE objective and the joint KL divergence (5), but can nevertheless be useful in computational practice (Higgins et al., 2017). This leads us to the SDE per-sample loss
$$\mathcal { L } _ { \lambda, \beta } ^ { \text{SDE} } ( u ; \theta, \psi ) = \mathbb { E } _ { z \sim Q _ { z | u } ^ { \theta } } \left [ - \log \frac { \mathrm d \mathbb { P } _ { u | z } ^ { \psi } } { \mathrm d \mathbb { P } _ { \eta } } ( u ) + \lambda \| g ( z ; \psi ) ( 0 ) \| _ { 2 } ^ { 2 } \right ] + \beta D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ).$$
## 2.3.2 Posterior Distributions in Bayesian Inverse Problems
Our theory can also be applied to to posterior distributions arising in Bayesian inverse problems (Stuart, 2010), which we illustrate through the following additive-noise inverse problem. Let U be a separable Hilbert space with norm ∥·∥ U , let Y = R d Y , and let G : U → Y be a (possibly nonlinear) observation operator. Suppose that y ∈ Y is given by the model
$$y = \mathcal { G } ( u ) + \xi, \quad u \sim \mu _ { 0 } \in \mathcal { P } ( \mathcal { U } ), \quad \xi \sim N ( 0, \Sigma ) \in \mathcal { P } ( Y ),$$
with noise covariance Σ ∈ S + ( Y ), and with prior distribution µ 0 = N (0 , C ) having covariance operator C : U → U . Models of this type arise, for example, in both Eulerian and Lagrangian data assimilation problems in oceanography (Cotter et al., 2010). Given an observation y ∈ Y from (22), the Bayesian approach seeks to infer u ∈ U by computing the posterior distribution µ y ∈ P ( U ) representing the distribution of u | y . In the setting of (22), µ y has a density with respect to µ 0 thanks to Bayes' rule (Dashti and Stuart, 2017, Theorem 14), taking the form
$$\frac { \mathrm d \mu ^ { y } } { \mathrm d \mu _ { 0 } } ( u ) = \frac { 1 } { Z ( y ) } \exp ( - \Phi ( u ; y ) ), \quad \Phi ( u ; y ) = \frac { 1 } { 2 } \| \mathcal { G } ( u ) - y \| _ { \Sigma } ^ { 2 }, \quad \| \cdot \| _ { \Sigma } = \| \Sigma ^ { - 1 / 2 } \cdot \| _ { 2 },$$
where Z y ( ) ∈ (0 1] owing to the nonnegativity of Φ. , A simple calculation then reveals
$$D _ { \text{KL} } ( \mu ^ { y } \| \mu _ { 0 } ) = \underset { u \sim \mu ^ { y } } { \mathbb { E } } \left [ \log \frac { \mathfrak { d } \mu ^ { y } } { \mathfrak { d } \mu _ { 0 } } ( u ) \right ] = \underset { u \sim \Upsilon } { \mathbb { E } } \left [ - \log Z ( y ) - \Phi ( u ) \right ] \leqslant - \log Z ( y ) < \infty.$$
Similar arguments apply quite generally for observation models other than (22), provided the resulting log-density log d µ / y d µ 0 satisfies suitable boundedness or integrability conditions.
We now assume that the data distribution Υ to be learned is the posterior µ y , and that we have samples from it. This setting could arise, for example, when attempting to generate further approximate samples from the posterior µ y , taking as data the output of a function-space MCMC method (Cotter et al., 2013), with the ambition of faster sampling under FVAE than under MCMC. Recall the definition of decoder distribution P ψ u z | in (16b). We take P η to be the prior µ 0 ; this is a natural choice as (23) shows that D KL (Υ ∥ P η ) < ∞ . We next discuss the choice of shift g , and the per-sample loss that results from these choices.
Per-Sample Loss. Since P η and P ψ u z | are Gaussian, we can use the Cameron-Martin theorem (Bogachev, 1998, Corollary 2.4.3) to derive conditions for their mutual absolute continuity. For this to be the case, the shift g z ( ; ψ ) must lie in the Cameron-Martin space H ( P η ) ⊂ U . Before stating the theorem, we recall the following facts about Gaussian measures. The space H ( P η ) is Hilbert, and for fixed h ∈ H ( P η ), the H ( P η )-inner product ⟨ h, · ⟩ H ( P η ) extends uniquely (up to equivalence P η -almost everywhere) to a measurable linear functional (Bogachev, 1998, Theorem 2.10.11), denoted by U ∋ u →⟨ h, u ⟩ ∼ H ( P η ) .
↦
Proposition 20 (Cameron-Martin theorem) . Let P η ∈ P ( U ) be a Gaussian measure with Cameron-Martin space H ( P η ) . Then P ψ u z | = P η ( · -g z ( ; ψ ) ) is mutually absolutely continuous with P η if and only if g z ( ; ψ ) ∈ H ( P η ) , and
$$\frac { \mathrm d \mathbb { P } _ { u | z } ^ { \psi } } { \mathrm d \mathbb { P } _ { \eta } } ( u ) = \exp \Big ( \langle g ( z ; \psi ), u \rangle _ { H ( \mathbb { P } _ { \eta } ) } ^ { \sim } - \frac { 1 } { 2 } \| g ( z ; \psi ) \| _ { H ( \mathbb { P } _ { \eta } ) } ^ { 2 } \Big ).$$
Remark 21. The exponent in (24) should be viewed as the misfit 1 2 ∥ g z ( ; ψ ) - ∥ u 2 H ( P η ) with the almost-surely-infinite term 1 2 ∥ u ∥ 2 H ( P η ) subtracted (Stuart, 2010, Remark 3.8). When P η is Brownian motion on R , for example, ⟨ g z ( ; ψ , u ) ⟩ ∼ H ( P η ) is a stochastic integral and H ( P η ) = H 1 ([0 , T ]); this is implicit in the calculations underlying Theorem 19. When P η is L 2 -white noise, H ( P η ) = L 2 ([0 , 1]). ■
When g takes values in H ( P η ), we can use the Cameron-Martin theorem to write down the per-sample loss explicitly since H ( P η ) = C 1 2 / U , with ∥ h ∥ H ( P η ) = ∥ C -1 2 / h ∥ U and ⟨ h, u ⟩ ∼ H ( P η ) = ⟨ C -1 2 / h, C -1 2 / u ⟩ U for h ∈ H ( P η ) and u ∈ U .
Proposition 22 (Bayesian inverse problem per-sample loss) . Suppose that g z ( ; ψ ) ∈ H ( P η ) for all z ∈ Z and ψ ∈ Ψ . Then Assumption 5 holds and
$$\mathcal { L } ^ { B I P } ( u ; \theta, \psi ) = \underset { z \sim \mathbb { Q } _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ \frac { 1 } { 2 } \| C ^ { - \frac { 1 } { 2 } } g ( z ; \psi ) \| _ { \mathcal { U } } ^ { 2 } - \langle C ^ { - \frac { 1 } { 2 } } g ( z ; \psi ), C ^ { - \frac { 1 } { 2 } } u \rangle _ { \mathcal { U } } \right ] + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \| \ \mathbb { P } _ { z } ).$$
Depending on the choice of P η , the condition g z ( ; ψ ) ∈ H ( P η ) may follow immediately, e.g., when P η is Brownian motion and g is parametrised by a neural network.
## 2.4 Architecture and Algorithms
In practice, we do not have access to training data { u ( n ) } N n =1 ⊂ U ; instead we have access to finite-dimensional discretisations u ( n ) . We would like to evaluate the encoder and decoder, and to compute the empirical objective (9) for training, using only these discretisations.
In our architectures we will assume that U is a Banach space of functions evaluable pointwise almost everywhere with domain Ω ⊆ R d and range R m ; in this setting we will assume that the discretisation u of a function u ∈ U consists of evaluations at { x i } I i =1 ⊂ Ω:
$$( \text{discretisation of function } u \in \mathcal { U } ) \quad u = \left \{ \left ( x _ { i }, u ( x _ { i } ) \right ) \right \} _ { i = 1 } ^ { I } \subset \Omega \times \mathbb { R } ^ { m }.$$
Crucially, the number and location of mesh points may differ for each discretised sample-our aim is to allow for FVAE to be trained and evaluated across different resolutions, with data provided on sparse and potentially irregular meshes. We therefore discuss how to discretise the loss, and propose encoder/decoder architectures that can be evaluated on any mesh.
## 2.4.1 Encoder Architecture
The encoder f is a map from a function u : Ω → R m to the parameters of the encoder distribution (16a): the mean f ( u θ ; ) ∈ Z and covariance matrix Σ( u θ ; ) ∈ S + ( Z ). We assume Σ( u θ ; ) is diagonal, so f need only return two vectors: the mean f ( u θ ; ) and the log-diagonal of Σ( u θ ; ). We thus define
$$f ( u ; \theta ) = \rho \left ( \int _ { \Omega } \kappa ( x, u ( x ) ; \theta ) \, \mathrm d x ; \theta \right ) \in \mathcal { Z } \times \mathcal { Z } = \mathbb { R } ^ { 2 d \mathcal { Z } },$$
where κ : Ω × R m × Θ → R ℓ is parametrised as a neural network with two hidden layers of width 64 and output dimension ℓ = 64, using GELU activation (Hendrycks and Gimpel, 2016),
and ρ : R ℓ × Θ → R 2 d Z is parametrised as a linear layer ρ v ( ; θ ) = W v θ + b θ , with W θ ∈ R 2 d Z × ℓ and b θ ∈ R 2 d Z . We augment x ∈ Ω with 16 random Fourier features (Appendix B.1) to aid learning of high-frequency features (Tancik et al., 2020). After discretisation on data u = { ( x , u i ( x i )) } I i =1 , in which we approximate the integral over Ω by a normalised sum, our architecture resembles set-to-vector maps such as deep sets (Zaheer et al., 2017), PointNet (Qi et al., 2017), and statistic networks (Edwards and Storkey, 2017), which take the form
$$\left \{ \left ( x _ { i }, u ( x _ { i } ) \right ) \, | \, i = 1, 2, \dots, I \right \} \mapsto \rho \left ( \text{pool} \left ( \left \{ \kappa ( x _ { i }, u ( x _ { i } ) ; \theta ) \, | \, i = 1, 2, \dots, I \right \} \right ) ; \theta \right ),$$
↦
where pool is a pooling operation invariant to the order of its inputs-in our case, the mean. Unlike these works we design our architecture for functions and only then discretise; we believe there is great potential to extend other point-cloud and set architectures similarly.
Many other function-to-vector architectures have been proposed, e.g., the variable-input DeepONet (Prasthofer et al., 2022), the mesh-independent neural operator (Lee, 2022) and continuum attention (Calvello et al., 2024), and our proposal is most similar to the linearfunctional layer of Fourier neural mappings (Huang et al., 2024) and the neural functional of Rahman et al. (2022). These differ from our approach by preceding (25) by a neural operator; on the problems we consider, we find our encoder map to be equally expressive.
## 2.4.2 Decoder Architecture
The decoder g is a map from a latent vector z ∈ Z to a function g z ( ; ψ ): Ω → R m , which we parametrise using a coordinate neural network γ : Z × Ω × Ψ → R m with 5 hidden layers of width 100 using GELU activation throughout, so that
$$g ( z ; \psi ) ( x ) = \gamma ( z, x ; \psi ).$$
As before, we augment x ∈ Ω with 16 random Fourier features (Appendix B.1). Our proposed architecture allows for discretisation of the decoded function g z ( ; ψ ) on any mesh, and the cost of evaluating the decoder (26) grows linearly with the number of mesh points.
There are several related approaches in the literature to parametrise vector-to-function maps. Huang et al. (2024) lift the input by multiplying with a learnable constant function, then apply an operator architecture such as FNO. Seidman et al. (2023) propose both a DeepONet-inspired decoder using a linear combination of learnable basis functions, and a nonlinear decoder essentially the same as what we propose, which is also similar to the architectures of the nonlinear manifold decoder (Seidman et al., 2022) and PARA-Net (de Hoop et al., 2022). Also related are implicit neural representations (Sitzmann et al., 2020), in which one regresses on a fixed image using a coordinate neural network and treats the resulting weights as a resolution-independent representation of the data.
## 2.4.3 Discretisation of Per-Sample Loss
To discretise the per-sample losses derived in Section 2.3, we make two approximations. First, we approximate the expectation over z ∼ Q θ z u | by Monte Carlo sampling (Kingma and Welling, 2014), with the number of samples viewed as a hyperparameter. Second, we approximate the integrals, norms, and inner products arising in the loss, as we now outline.
Per-Sample Loss L SDE λ,β . Since the terms appearing in L SDE λ,β are integral functionals of the data and decoded functions, we can discretise on any partition 0 = t 0 < t 1 < · · · < t I = T and work with data discretised at any time step. The deterministic integral can be approximated by a normalised sum, and the stochastic integral can be discretised as
$$\int _ { 0 } ^ { T } \langle g ( z ; \psi ) ^ { \prime } ( t ), \, \mathrm d u _ { t } \rangle \approx \sum _ { i = 1 } ^ { I } \Big < g ( z ; \psi ) ^ { \prime } ( t _ { i - 1 } ), u ( t _ { i } ) - u ( t _ { i - 1 } ) \Big >,$$
which converges in probability in the limit I →∞ to the true stochastic integral (S¨rkk¨ a a and Solin, 2019, eq. (4.6)). Since the decoder will be a differentiable neural network, terms involving the derivative g z ( ; ψ ) ( ′ t ) can be computed using automatic differentiation; we find this to be much more stable than using a finite-difference approximation of the derivative.
Per-Sample Loss L BIP . For many Bayesian inverse problems, U is a function space such as L 2 (Ω), and so again the norms and inner products are integral functionals amenable to discretisation on any mesh. However, applying the operator C -1 2 / is typically tractable only in special cases. One widely used setting is the one in which the eigenbasis of C is known and basis coefficients are readily computable; this arises when C is an inverse power of the Laplacian on a rectangle and a fast Fourier transform may be used.
## 2.5 Numerical Experiments
We now apply FVAE on two examples where Υ is an SDE path distribution. Both examples serve as prototypes for more complex problems such as those arising in molecular dynamics. For all experiments, we adopt the architecture of Section 2.4. A summary of conclusions to be drawn from the numerical experiments with these examples is as follows:
- (a) FVAE captures properties of individual paths as well as ensemble properties of the data set, with the learned latent variables being physically interpretable (Section 2.5.1);
- (b) choosing decoder noise that accurately reflects the stochastic variability in the data is essential to obtain a high-quality generative model (Section 2.5.1);
- (c) FVAE is robust to changes of mesh in the encoder and decoder, enabling training with heterogeneous data and generative modelling at any resolution (Section 2.5.2).
We emphasise in these experiments that FVAE does this purely from data, with no knowledge of the data-generating process other than in the choice of decoder noise.
## 2.5.1 Brownian Dynamics
The Brownian dynamics model (see Schlick, 2010, Chap. 14), also known as the Langevin model, is a stochastic approximation of deterministic Newtonian models for molecular dynamics. In this model, the configuration u t (in some configuration space X ⊆ R m ) of a molecule is assumed to follow the gradient flow of a potential U : X → R perturbed by additive thermal noise with temperature ε > 0. This leads to the Langevin SDE
$$d u _ { t } = - \nabla U ( u _ { t } ) \, \mathrm d t + \sqrt { \varepsilon } \, \mathrm d w _ { t }, \quad t \in [ 0, T ], \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where ( w t ) t ∈ [0 ,T ] is a Brownian motion on R m . As a prototype for the more sophisticated, high-dimensional potentials arising in molecular dynamics, such as the Lennard-Jones
potential (Schlick, 2010), we take X = R and consider the asymmetric double-well potential
$$U ( x ) \in 3 x ^ { 4 } + 2 x ^ { 3 } - 6 x ^ { 2 } - 6 x.$$
This has a local minimum at x 1 = -1 and a global minimum at x 2 = +1 (Figure 1(a)). We take Υ to be the corresponding path distribution, with temperature ε = 1, final time T = 5, and initial condition u 0 = x 1 . (The preceding developments fixed u 0 = 0 but are readily adapated to any fixed initial condition.) The training data set consists of 8,192 paths with time step 5 512 / in [0 , T ], and in each path 50% of time steps are missing (see Appendix B.2).
Figure 1: (a) Realisations of the SDE (27) follow the gradient flow of the potential U . (b) Sample paths ( u t ) t ∈ [0 ,T ] ∼ Υ begin at x 1 = -1 and transition with high probability to the lower-potential state x 2 = +1 as a result of the additive thermal noise.
Sample paths drawn from Υ start at x 1 and transition with very high probability to the potential-minimising state x 2 ; the time at which the transition begins is determined by the thermal noise, but, once the transition has begun, the manner in which the transition occurs is largely consistent across realisations. Such universal transition phenomena occur quite generally in the study of random dynamical systems, as a consequence of large-deviation theory (see E et al., 2004).
We train FVAE using the SDE loss (Section 2.3.1) with regularisation parameter β = 1 2 . and zero-penalty scale λ = 10. Motivated by the observation that trajectories are determined chiefly by the transition time, we use latent dimension d Z = 1.
Choice of Noise Process. The choice of decoder noise greatly affects FVAE's performance as an autoencoder and a generative model. To investigate this, we first train three instances of FVAE with different restoring forces κ in the decoder-noise process. Then, to evaluate autoencoding performance, we draw samples u ∼ Υ from the held-out set and compute the reconstruction g f ( ( u θ ; ); ψ ), which is the mean of the decoder distribution P ψ u z | with z = f u θ ( ; ) taken to be the mean of the encoder distribution Q θ z u | (Figure 2(a)). To evaluate FVAE as a generative model, we draw samples from the latent distribution P z and display the mean g z ( ; ψ ) of the decoder distribution P ψ u z | along with a shaded region indicating one standard deviation of the noise process (Figure 2(b)); moreover we draw samples g z ( ; ψ ) + η to illustrate their qualitative behaviour (Figure 2(c)).
Using Brownian motion as the decoder noise leads to excellent reconstructions, but samples from the generative model appear different from the training data. By using OU-distributed noise with restoring force κ > 0 we obtain similar reconstructions to those achieved under Brownian motion, but samples from the generative model match the data distribution more closely. This is because the variance of Brownian motion grows unboundedly
(a) Data
u
Υ (red) &
(b) Distribution of g z
(
;
ψ
) +
η
with
(c) Samples g z
(
;
ψ
) +
η
from
∼
t
t
t
Figure 2: The SDE loss gives much freedom in the choice of noise process ( η t ) . t The top row uses Brownian motion as the decoder noise and the second and third rows use OU processes with different asymptotic variances. While all choices lead to high-quality reconstructions, only the OU process with κ = 25 gives a generative model that agrees well with the data.
with time, while the asymptotic variance under the OU process is ε / 2 κ , better reflecting the behaviour of the data for well-chosen κ .
On this data set, choosing a suitable noise process ( η t ) t has the added benefit of significantly accelerating training: autoencoding mean-squared error (MSE) decreases much faster under OU noise ( κ > 0) than under Brownian motion noise (Figure 3). We expect the choice of noise should depend in general on properties of the data distribution, with the OU process being particularly suited to this data set; in the discussion that follows, we use an OU process with restoring force κ = 25.
Figure 3: Using OU noise ( κ > 0) leads to faster training convergence.
Unsupervised Learning of Physically Relevant Quantities. Our choice of latent dimension d Z = 1 was motivated by the heuristic that the time of the transition from x 1 = -1 to x 2 = +1 essentially determines the SDE trajectory. FVAE identifies this purely from data, with the learned latent variable z ∈ Z being in correspondence with the transition time: larger values of z map to paths g z ( ; ψ ) transitioning later in time (Figure 4(a)).
To understand whether FVAE captures ensemble statistical properties of the data distribution, we compare the distributions of the first-crossing time T 0 ( u ) = inf { t > 0 ∣ ∣ u t ⩾ 0 } estimated using 16,384 paths from the generative model and 16,384 direct simulations, using kernel density estimates based on Gaussian kernels with bandwidths selected by Scott's rule (Scott, 2015, eq. (6.44)); we find that the two distributions closely agree (Figure 4(b)).
= 25)
θ
OU (
-
-
Figure 4: (a) The latent variable z identified by FVAE corresponds to the first-crossing time T 0 of the decoded path g z ( ; ψ ). (b) Kernel density estimates of the distributions of T 0 under the FVAE generative model, and when computed using direct simulations, closely agree.
## 2.5.2 Estimation of Markov State Models
In practical applications of molecular dynamics, one is often interested in the evolution of large molecules on long timescales. For example in the study of protein folding (Konovalov et al., 2021), it is of interest to capture the complex, multistage transitions of proteins between configurations. Moving beyond the toy one-dimensional problem in Section 2.3.1, the chief difficulty is the very high dimension of such systems, which makes simulations possible only on timescales orders of magnitudes shorter than those of physical interest.
Markov state models (MSMs) offer one method of distilling many simulations on short timescales into a statistical model permitting much longer simulations (Husic and Pande, 2018). Assuming that the dynamics are given by a random process ( u t ) t ⩾ 0 taking values in the configuration space X , an MSM can be constructed by partitioning X into disjoint state sets X = X 1 ∪··· ∪ X p , and, for some lag time τ > 0, considering the discrete-time process ( U k ) k ∈ N for which U k = i if and only if u kτ ∈ X i . One hopes that, if τ is sufficiently large, the process ( U k ) k ∈ N is approximately Markov, and thus its distribution can be characterised by learning the probabilities of transitioning in time τ from one state to another. These probabilities can be determined using the short-run simulations-which can be generated in parallel-and the resulting MSM can be used to simulate on longer timescales.
Motivated by this application, we consider the problem of constructing an MSM from data provided at sparse or irregular intervals that do not necessarily align with the lag time τ ; in this case, computing the probability of transition in time τ directly may not be possible. We show the power of FVAE in this problem by first learning a generative model from the heterogeneously sampled data and then using the generative model to draw paths sampled at the regular time step τ ; constructing an MSM from these paths is then straightforward.
We give an example based on the Brownian dynamics model (27) on X = R 2 using a multiwell potential U (Figure 5(a)), stated precisely in Appendix B.3, which we take to be a quadratic bowl, perturbed by a linear function to break the symmetry, and by six Gaussian densities to act as potential wells with minima at (0 , 0), (0 2 . , 0 2), ( . -0 2 . , -0 2), (0 2 . . , -0 2), . (0 , 0 2) and ( . -0 2 . , 0). We take U = C 0 ([0 , T ] , X ) and let Υ ∈ P ( U ) be the path distribution, with temperature ε = 0 1, final time . T = 3 and initial condition u 0 = 0. The training data set consists of 16,384 paths discretised with time step 3 512 / , where, for each sample, it is

0
1
2
3
4
5
6
7
8
1
0
1
2
3
4
5
6
7
8
0
1
2
3
4
5
6
7
8
Figure 5: (a) Contour plot of the potential U and the division of the state space X . All paths start at t = 0 at the origin (in state 5). (b) Transition matrices with lag τ = 3 512 / computed using FVAE and through direct simulation, both on the time interval [0 3]. ,
assumed that 50% of steps are missing (details in Appendix B.3). We train FVAE using the SDE loss (Section 2.3.1) with κ = 100, λ = 50, β = 0 02, and latent dimension . d Z = 16.
Partitioning the Configuration Space. The states of an MSM can be selected manually using expert knowledge or automatically using variational or machine-learning methods (Mardt et al., 2018). For simplicity, we choose the states by hand, partitioning X = R 2 into p = 9 disjoint regions (Figure 5(a)) divided by the four lines x 1 = ± 0 1 and . x 2 = ± 0 1. .
Estimating Transition Probabilities with FVAE. After training FVAE with irregularly sampled data, we draw samples from the generative model with regular time step τ and use these samples to compute the MSM transition probabilities. Setting aside the question of Markovianity for simplicity, we draw from the generative model M = 2,048 paths { v ( m ) } M m =1 discretised on a mesh of K = 513 equally spaced points with time step τ = 3 512 / on [0 , T ], and compute the count matrix
$$C ^ { F V A E } ( \tau ) = \left ( C _ { i j } ^ { F V A E } ( \tau ) \right ) _ { i, j \in \{ 1, \dots, p \} }, \ \ C _ { i j } ^ { F V A E } ( \tau ) = \sum _ { k = 0 } ^ { K } \sum _ { m = 1 } ^ { M } \mathbf 1 \left [ v _ { k \tau } ^ { ( m ) } \in X _ { i } \text{ and } v _ { ( k + 1 ) \tau } ^ { ( m ) } \in X _ { j } \right ].$$
We then derive the corresponding maximum-likelihood transition matrix T FVAE ( τ ) by normalising each row of C FVAE ( τ ) to sum to one; for simplicity we do not constrain the transition matrix to satisfy the detailed-balance condition (see Prinz et al., 2011, Sec. IV.D). The resulting transition matrix T FVAE ( τ ) agrees closely with the matrix T DNS ( τ ) computed analogously using 2,048 direct numerical simulations on the regular time step τ (Figure 5(b)).
## 3 Problems with VAEs in Infinite Dimensions
As we have seen in Section 2.1, the empirical FVAE objective J FVAE N ( θ, ψ ) for the data set { u ( n ) } N n =1 is based on a sequence of approximations and equalities:
$$\underbrace { \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathcal { L } ( u ^ { ( n ) } ; \theta, \psi ) } _ { = \mathcal { J } _ { N } ^ { F V A E } ( \theta, \psi ) } } _ { = \mathcal { J } ^ { F V A E } ( \theta, \psi ) } \ \underbrace { \approx _ { ( \mathcal { A } ) } \ \underbrace { \mathbb { E } _ { u \sim \mathcal { I } } ^ { \left [ \mathcal { L } ( u ; \theta, \psi ) \right ] } } _ { = \mathcal { J } ^ { F V A E } ( \theta, \psi ) } } _ { ( \mathbb { B } ) } \ = \ D _ { K L } ( \mathbb { Q } _ { z, u } ^ { \theta } \left \| \mathbb { P } _ { z, u } ^ { \psi } ) - \underbrace { D _ { K L } ( \mathbb { U } _ { \mathbb { U } } \right \| \mathbb { A } ) } _ { \text{constant} }.$$
True Data (Short)
0
1
2
3
4
5
6
7
8
The approximation (A) is based on the law of large numbers and is an equality almost surely in the limit N →∞ . The equality (B) is true by Theorem 6 with a finite constant D KL (Υ ∥ Λ) provided Assumption 5 holds-but if the assumption does not hold, this 'constant' may well be infinite. So, while it is tempting to apply the empirical objective J FVAE N without first checking the validity of (A) and (B), this strategy is fraught with pitfalls.
To illustrate this we apply FVAE in the white-noise setting of Example 16; this coincides with the setting of the VANO model (Seidman et al., 2023), which we discuss in detail in the related work (Section 5). In this example we derive the per-sample loss L and apply the resulting empirical objective J FVAE N for training; but both the joint divergence D KL ( Q θ z,u ∥ P ψ z,u ) and the constant D KL (Υ ∥ Λ) turn out to be infinite. Consequently, the approximations (A) and (B) break down, which we see numerically: discretisations of J FVAE N appear to diverge as resolution is refined, suggesting that they have no continuum limit.
Example 23. Take U = H -1 ([0 , 1]) and assume that Υ is the distribution of u in the model
$$\xi & \sim \text{Uniform} [ 0, 1 ] \\ u \, | \, \xi & = \delta _ { \xi }. \\ \mu \, \mu$$
Realisations of u in this model lie in H s ([0 , 1]), s < -1 2 / , with probability one, so Υ ∈ P ( U ). This data can be viewed as a prototype for rough behaviour such as the derivative of shock profiles arising in hyperbolic PDEs with random initial data. It will serve as an extreme example allowing us to isolate the numerical issues associated with using FVAE or VANO in the misspecified setting.
Take the model (16a)-(16d) for real-valued functions on [0 1], , with P η taken to be L 2 -white noise. As discussed in Proposition 15, P η ∈ P ( H s ([0 , 1])), s < -1 2 / , and H ( P η ) = L 2 ([0 , 1]). Fixing the reference distribution Λ = P η and assuming g takes values in L 2 ([0 , 1]), the Cameron-Martin theorem (Proposition 20) ensures that the density d P ψ u z | / dΛ exists, and consequently
$$\mathcal { L } ( u ; \theta, \psi ) = \underset { z \sim Q _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ \frac { 1 } { 2 } \| g ( z ; \psi ) \| _ { L ^ { 2 } } ^ { 2 } - \langle g ( z ; \psi ), u \rangle _ { L ^ { 2 } } \right ] + D _ { K L } ( \mathbb { Q } _ { z | u } ^ { \theta } \, \| \, \mathbb { P } _ { z } ).$$
At this stage, we have not verified that the joint divergence D KL ( Q θ z,u ∥ P ψ z,u ) has finite infimum, nor that Assumption 5 holds; indeed we will see that both of these conditions fail. Nevertheless we can attempt to train FVAE with the empirical objective resulting from (29). To do this we choose Z = R and use an encoder map f and a decoder map g tailored to this problem, since the architectures of Section 2.4 are not equipped to deal with functions of negative Sobolev regularity. We parametrise f as
$$f ( u ; \theta ) = \rho \left ( \underset { x \in [ 0, 1 ] } { \arg \max } ( \varphi * u ) ( x ) ; \theta \right ) \in \mathcal { Z } \times \mathcal { Z } = \mathbb { R } ^ { 2 },$$
where ρ is a neural network and φ is a compactly supported smooth mollifier, chosen such that φ ∗ u has well-defined maximum, and we parametrise g to return the Gaussian density
$$g ( z ; \psi ) ( x ) = N \left ( \mu ( z ; \psi ), \sigma ( z ; \psi ) ^ { 2 } ; x \right ),$$
x
ξ
discretisation of Dirac
δ
ξ
reconstruction g z
(
;
ψ
)
1
-
-
-
-
-
-
0 605
.
0 610
.
0 615
.
0 620
.
0 625
.
0 630

.
Figure 6: (a) The discrete representations (squares) of δ ξ and g z ( ; ψ ) on a grid of 8 points. (b) In Example 23, the FVAE empirical objective at the minimising parameters diverges as resolution is increased. (c) To overcome this, we propose a regularised autoencoder, FAE, in Section 4. Repeating the experiment with this objective suggests that the FAE empirical objective has a well-defined continuum limit.
with mean µ z ( ; ψ ) ∈ [0 , 1] and standard deviation σ z ( ; ψ ) > 0 computed from a neural network (see Appendix B.4). In other words, f applies a neural network to the location of the maximum of u , while g returns a Gaussian density with learned mean and variance (Figure 6(a)). To investigate the behaviour of discretisations of J FVAE N as resolution is refined, we generate a sequence of data sets in which we discretise on a mesh of I ∈ { 8 16 32 64 128 , , , , } equally spaced points { i / I +1 } i =1 ,...,I ⊂ [0 , 1]. At each resolution we generate I training samples: one discretised Dirac function at each mesh point, normalised to have unit L 1 -norm. We train 50 independent instances of FVAE at each resolution and record the value of the empirical objective at convergence (Figure 6(a)). Notably, the empirical objective appears to diverge as resolution is refined. This has two major causes:
- (a) Υ is not absolutely continuous with respect to Λ = P η : the set { δ x | x ∈ [0 , 1] } has probability zero under Λ but probability one under Υ; thus D KL (Υ ∥ Λ) = ∞ .
- (b) Υ is not absolutely continuous with respect to P ψ u , meaning that D KL ( Q θ z,u ∥ P ψ z,u ) = ∞ for all θ and ψ . To see this, we again note that { δ x | x ∈ [0 , 1] } has probability one under Υ, but, as a consequence of the Cameron-Martin theorem, P ψ u z | and P η are mutually absolutely continuous, and thus as P η ( { δ x | x ∈ [0 , 1] } ) = 0,
$$\mathbb { P } _ { u } ^ { \psi } ( \{ \delta _ { x } \, | \, x \in [ 0, 1 ] \} ) = \int _ { \mathcal { Z } } \mathbb { P } _ { u | z } ^ { \psi } \Big ( \{ \delta _ { x } \, | \, x \in [ 0, 1 ] \} \Big ) \, \mathbb { P } _ { z } ( \mathrm d z ) = 0.$$
The problematic term in the per-sample loss is the measurable linear functional ⟨ g z ( ; ψ , u ) ⟩ ∼ L 2 ; this is defined only up to modification on P η -probability zero sets, and yet we evaluate it on just such sets-namely, the P η -probability zero set { δ x | x ∈ [0 , 1] } . ■
Remark 24. The joint divergence D KL ( Q θ z,u ∥ P ψ z,u ) would also be infinite if Υ was supported on L 2 ([0 , 1]), as seen in Example 16, but it is harder to observe any numerical issue in
Training loss (FVAE/VANO)
0
-
-
-
-
10
20
30
40
128
Training loss (F
8 16
32
64
Resolut
training. This is because the measurable linear functional ⟨ g z ( ; ψ , u ) ⟩ ∼ L 2 reduces to the usual L 2 -inner product, and so, even though the FVAE objective is not well defined, the per-sample loss can still be viewed as a regularised misfit (see Theorem 21):
$$\mathcal { L } ( u ; \theta, \psi ) = \underset { z \sim Q _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ \frac { 1 } { 2 } \| g ( z ; \psi ) - u \| _ { L ^ { 2 } } ^ { 2 } \right ] + D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \| \, \mathbb { P } _ { z } ) - \frac { 1 } { 2 } \| u \| _ { L ^ { 2 } } ^ { 2 }.$$
As a result one can reinterpret the objective as that of a regularised autoencoder (see Remark 11). This motivates our use of a regularised autoencoder, FAE, in Section 4. ■
## 4 Regularised Autoencoders on Function Space
To overcome the issues in applying VAEs in infinite dimensions, we set aside the probabilistic motivation for FVAE and define a regularised autoencoder in function space, the functional autoencoder (FAE) , avoiding the need for onerous conditions on the data distribution. In Section 4.1, we state the FAE objective and make connections to the FVAE objective. Section 4.2 outlines minor adaptations to the FVAE encoder and decoder for use with FAE. Section 4.3 demonstrates FAE on two examples from the sciences: incompressible fluid flows governed by the Navier-Stokes equation; and porous-medium flows governed by Darcy's law.
## 4.1 Training Objective
Throughout Section 4 we make the following assumption on the data, postponing discussion of discretisation to Section 4.2. Unlike in Section 2 we do not need U to be separable, allowing us to consider data from an even wider variety of spaces, such as the (non-separable) space BV(Ω) of bounded-variation functions on Ω ⊂ R d .
Assumption 25. Let ( U ∥·∥ , ) be a Banach space. There exists a data distribution Υ ∈ P ( U ) from which we have access to N independent and identically distributed samples { u ( n ) } N n =1 ⊂ U . ■
To define our regularised autoencoder, we fix a latent space Z = R d Z and define encoder and decoder transformations f and g , which, unlike in FVAE, return points rather than probability distributions:
$$( \text{encoder} ) \quad & \mathcal { U } \ni u \mapsto f ( u ; \theta ) \in \mathcal { Z }, & ( 3 0 a ) \\ ( \text{decoder} ) \quad & \mathcal { Z } \supsetneqq \omega \sim \omega \sim \mathcal { U } \quad \in \mathcal { U } & \text{enc} \cdot \mathcal { M } \quad \mathcal { M }$$
↦
$$( \text{decoder} ) \quad \mathcal { Z } \ni z \mapsto g ( z ; \psi ) \in \mathcal { U }.$$
↦
We then take as our objective the sum of a misfit term between the data and its reconstruction, and a regularisation term with regularisation parameter β > 0 on the encoded vectors:
$$( \text{FAE objective} ) \quad \mathcal { J } _ { \beta } ^ { \text{FAE} } ( \theta, \psi ) = \underset { u \sim r } { \mathbb { E } } \left [ \frac { 1 } { 2 } \| g ( f ( u ; \theta ) ; \psi ) - u \| ^ { 2 } + \beta \| f ( u ; \theta ) \| _ { 2 } ^ { 2 } \right ].$$
As in Section 2.1, the expectation over u ∼ Υ is approximated by an average over the training data, resulting in the empirical objective J FAE β,N . There is great flexibility in the choice of regularisation term; we adopt the squared Euclidean norm ∥ f u θ ( ; ) ∥ 2 2 as a simplifying choice consistent with using a Gaussian prior P z in a VAE (Remark 11). While (31) has much in common with the FVAE objective J FVAE , it is not marred by the foundational issues raised in Section 3; indeed, the FAE objective is broadly applicable as the following result shows.
Proposition 26. Suppose Υ has finite second moment, i.e., E u ∼ Υ [ ∥ u ∥ 2 ] < ∞ . If there exist θ ⋆ ∈ Θ and ψ ⋆ ∈ Ψ such that f ( u θ ; ⋆ ) = 0 and g z ( ; ψ ⋆ ) = 0 , then (31) has finite infimum.
Proof This follows immediately from evaluating J FAE β at θ ⋆ and ψ ⋆ , since J FAE β ( θ , ψ ⋆ ⋆ ) = E u ∼ Υ 2 [ 1 ∥ u ∥ 2 ] , and the expectation is finite by hypothesis.
## 4.2 Architecture and Algorithms
To train FAE we must discretise the objective J FAE β and parametrise the encoder f and decoder g with learnable maps. We moreover propose a masked training scheme that appears to be new to the operator-learning literature; as we will show in Section 4.3, this scheme greatly improves the robustness of FAE to changes of mesh.
Encoder and Decoder Architecture. As in Section 2.4, we will construct encoder and decoder architectures under the assumption that U is a Banach space of functions evaluable pointwise almost everywhere with domain Ω ⊆ R d and range R m , and that we have access to discretisations u ( n ) of the data u ( n ) comprised of evaluations at finitely many mesh points. We adopt an architecture near identical to that used for FVAE. More precisely, we parametrise the encoder as
$$f ( u ; \theta ) = \rho \left ( \int _ { \Omega } \kappa ( x, u ( x ) ; \theta ) \, \mathrm d x ; \theta \right ) \in \mathcal { Z },$$
with κ : Ω × R m × Θ → R ℓ parametrised as a neural network with two hidden layers of width 64, output dimension ℓ = 64, and with ρ : R ℓ × Θ → R d Z parametrised as the linear layer ρ v ( ; θ ) = W v θ + b θ . We parametrise the decoder as the coordinate neural network γ : Z × Ω × Ψ → R m with 5 hidden layers of width 100, so that
$$g ( z ; \psi ) ( x ) = \gamma ( z, x ; \psi ) \in \mathbb { R } ^ { m }.$$
In both cases we use GELU activation and augment x with 16 random Fourier features (Appendix B.1). Relative to the architectures of Section 2.4, the only change is in the range of f , which now takes values in Z instead of returning distributional parameters for Q θ z u | .
Discretisation of J FAE β . The FAE objective can be applied whenever U is Banach, but in this article we take U = L 2 (Ω), where Ω = T d or Ω = [0 1] , d , and discretise the U -norm with a normalised sum. One can readily imagine other possibilities, e.g., taking U to be a Sobolev space of order s ⩾ 1 if derivative information is available (Czarnecki et al., 2017), and approximating the L 2 -norm of the data and its derivatives by sums. More generally we may use linear functionals as the starting point for approximation.
## 4.2.1 Masked Training
Self-supervised training-learning to predict the missing data from masked inputs-has proven valuable in both language models such as BERT (Devlin et al., 2019) and vision models such as the masked autoencoder (MAE; He et al., 2022). This method has been shown to both reduce training time and to improve generalisation. We propose two schemes making
use of the ability to discretise the encoder and decoder on arbitrary meshes: complement masking and random masking . Under both schemes we transform each discretised training sample u = ( { x , u i ( x i )) } I i =1 by subsampling with index sets I enc and I dec , which may change at each training step, to obtain
$$u _ { \text{enc} } = \left \{ \left ( x _ { i }, u ( x _ { i } ) \right ) \, | \, i \in \mathcal { I } _ { \text{enc} } \right \}, \quad u _ { \text{dec} } = \left \{ \left ( x _ { i }, u ( x _ { i } ) \right ) \, | \, i \in \mathcal { I } _ { \text{dec} } \right \}.$$
We supply u enc as input to the discretised encoder; moreover we discretise the decoder on the mesh { x i } i ∈I dec and compare the decoder output to the masked data u dec . In both of the strategies we propose I enc and I dec will be unstructured random subsets of { 1 , . . . , I } , but in principle other masks-such as polygons-could be considered.
Complement Masking. The chief strategy used in the numerical experiments is to draw I enc as a random subset of { 1 , . . . , I } and take I dec = { 1 , . . . , I } \ I enc , fixing the (encoder) point ratio r enc = |I enc | /I as a hyperparameter. This is similar to the strategy adopted by MAE-though our approach differs by masking individual mesh points instead of patches. We explore the tradeoffs in the choice of point ratio in Section 4.3.1.
Random Masking. A second strategy we consider is to independently draw I enc and I dec as random subsets of { 1 , . . . , I } , fixing both the encoder point ratio r enc = |I enc | /I and the decoder point ratio r dec = |I dec | /I . This gives greater control of the cost of evaluating the encoder and decoder: by taking both r enc and r dec to be small, we significantly reduce the cost of each training step, which is useful when the number of mesh points I is large.
## 4.3 Numerical Experiments
In Sections 4.3.1 and 4.3.2, we apply FAE as an out-of-the-box method to discover a lowdimensional latent space for solutions to the incompressible Navier-Stokes equations and the Darcy model for flow in a porous medium, respectively. We find that for these data sets:
- (a) FAE's mesh-invariant architecture autoencodes with performance comparable to convolutional neural network (CNN) architectures of similar size (Section 4.3.1);
- (b) the ability to discretise the encoder and decoder on different meshes enables new applications to inpainting and data-driven superresolution (Section 4.3.1), as well as extensions of existing zero-shot superresolution as proposed for VANO by Seidman et al. (2023);
- (c) masked training significantly improves performance under mesh changes (Section 4.3.1) and can accelerate training while reducing memory demand (Section 4.3.2);
- (d) training a generative model on the FAE latent space leads to a resolution-invariant generative model which accurately captures distributional properties (Section 4.3.2).
## 4.3.1 Incompressible Navier-Stokes Equations
We first illustrate how FAE can be used to learn a low-dimensional representation for snapshots of the vorticity of a fluid flow in two spatial dimensions governed by the incompressible Navier-Stokes equations, and illustrate some of the benefits of our mesh-invariant model.
Let Ω = T 2 be the torus, viewed as the square [0 , 1] 2 with opposing edges identified and with unit normal ˆ, and let z U = L 2 (Ω). While the incompressible Navier-Stokes equations
are typically formulated in terms of the primitive variables of velocity u and pressure p , it is more natural in this case to work with the vorticity-streamfunction formulation (see Chandler and Kerswell, 2013, eq. (2.6)). In particular the vorticity ∇× u is zero except in the out-of-plane component ˆ zω . The scalar component of the vorticity, ω , then satisfies
$$\partial _ { t } \omega & = \hat { z } \cdot \left ( \nabla \times ( u \times \omega \hat { z } ) \right ) + \nu \Delta \omega + \varphi, \quad ( x, t ) \in \Omega \times ( 0, T ], \\ \omega ( x, 0 ) & = \omega _ { 0 } ( x ), \quad & x \in \Omega. \\ \intertext { In this attempt to the available in vision by $u$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$ } \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \, \text{$w$} \}$$
In this setting the velocity is given by u = ∇× ( ψz ˆ), where the streamfunction ψ satisfies ω = ∆ ψ . Thus, using periodicity, ψ is uniquely defined, up to an irrelevant constant, in terms of ω , and (32) defines a closed evolution equation for ω . We suppose that Υ ∈ P ( U ) is the distribution of the scalar vorticity ω ( · , T = 50) given by (32), with viscosity ν = 10 -4 and forcing
$$\varphi ( x ) = \frac { 1 } { 1 0 } \sin ( 2 \pi x _ { 1 } + 2 \pi x _ { 2 } ) + \frac { 1 } { 1 0 } \cos ( 2 \pi x _ { 1 } + 2 \pi x _ { 2 } ).$$
We assume that the initial condition ω 0 has distribution N (0 , C ) with covariance operator C = 7 3 2 / (49 I -∆) -5 2 / , where ∆ is the Laplacian operator for spatially-mean-zero functions on the torus T 2 . The training data set, based on that of Li et al. (2021), consists of 8,000 samples from Υ generated on a 64 × 64 grid using a pseudospectral solver, with a further 2,000 independent samples held out as an evaluation set. The data are scaled so that ω x, T ( ) ∈ [0 , 1] for all x ∈ Ω. Further details are provided in Appendix B.5.
We train FAE with latent dimension d Z = 64 and regularisation parameter β = 10 -3 , and train with complement masking using a point ratio r enc of 30%.
Performance at Fixed Resolution. We compare the autoencoding performance of our mesh-invariant FAE architecture to a standard fixed-resolution CNN architecture, both trained using the FAE objective with all other hyperparameters the same. Our goal is to understand whether our architecture is competitive even without the inductive bias of CNNs.
To do this we fix a class of FAE and CNN architectures for 64 × 64 unmasked data, and perform a search to select the best-performing models with similar parameter counts (details in Appendix B.5). The FAE architecture achieves reconstruction MSE slightly greater than the CNN on the held-out data, with a comparable number of parameters (Table 1). It is reasonable to expect that mesh-invariance of the FAE architecture comes at some cost to performance at fixed resolution, especially as the CNN bene-
Autoencoding on evaluation set (64 × 64 grid)
| | MSE | Parameters |
|------------------|-----------------------------------|--------------|
| FAE architecture | 4 . 82 × 10 - 4 ± 2 . 57 × 10 - 5 | 64,857 |
| CNN architecture | 2 . 38 × 10 - 4 ± 9 . 43 × 10 - 6 | 71,553 |
Mean ± 1 standard deviation; 5 training runs Table 1: Our resolution-invariant architecture performs comparably to CNNs with similar parameter counts.
fits from a strong inductive bias, but the results of Table 1 suggest that the cost is modest. Further research is desirable to close this gap through better mesh-invariant architectures.
Inpainting. Methods for inpainting-inferring missing parts of an input based on observations and prior knowledge from training data-and related inverse problems are of great interest in computer vision and in scientific applications (Quan et al., 2024). We exploit the ability of FAE to encode on any mesh, and decode on any other mesh, to solve a variety of inpainting tasks. More precisely, after training FAE, we take data from the held-out set on a 64 × 64 grid and, for each discretised sample, we apply one of three possible masks:
- (i) random masking with point ratio 5%, i.e., masking 95% of mesh points; or
- (ii) masking of all mesh points lying in a square with random centre and side length; or
- (iii) masking of all mesh points in the -0 05-superlevel set of a draw from the Gaussian . random field N (0 , (30 2 I -∆) -1 2 . ), where ∆ is the Laplacian for functions on the torus.
]
Figure 7: (a) FAE can solve a variety of inpainting tasks; further samples in Appendix B.5. (b) Training the encoder on a sparse mesh has a regularising effect on FAE, leading to lower evaluation MSE on dense meshes, but harms performance on very sparse meshes.
Decoding these samples on a 64 × 64 grid (Figure 7) leads to reconstructions that agree well with the ground truth, and we find FAE to be robust even with a significant amount of the original mesh missing. As a consequence of the autoencoding procedure, the observed region of the input may also be modified, an effect most pronounced in (ii), where some features in the input are oversmoothed in the reconstruction. We hypothesise that the failure to capture fine-scale features could be mitigated with better neural-operator architectures.
To understand the effect of the training point ratio on inpainting quality, we first train instances of FAE with complement masking with point ratios 10%, 50%, and 90%. Then, for each model, we evaluate its autoencoding performance by applying random masking to each sample from the held-out set with point ratio r eval ∈ { 10% 30% 50% 70% 90% , , , , , } reconstructing on the full 64 × 64 grid, and computing the reconstruction MSE averaged over the held-out set (Figure 7(b)). We observe that the best choice of r enc depends on the point ratio r eval of the input. We hypothesise that when r eval is large, training with r enc small is helpful as training with few mesh points regularises the model. On the other hand, when r eval is small, it is likely that the evaluation mesh is 'almost disjoint' from any mesh seen during training, harming performance. Further analysis is provided in Appendix B.5.
Superresolution. The ability to encode and decode on different meshes also enables the use of FAE for single-image superresolution: high-resolution reconstruction of a lowresolution input. Superresolution methods based on deep learning have found use in varied applications including imaging (Li et al., 2024) and fluid dynamics, e.g., in increasing the resolution ('downscaling') of numerical simulations (Kochkov et al., 2021; Bischoff and Deck,
2024). Generalising other continuous superresolution models such as the Local Implicit Image Function (Chen et al., 2021), a single trained FAE model can be applied with any upsampling factor, and FAE has the further advantage of accepting inputs at any resolution.
×
×
×
Figure 8: (a) FAE can encode low-resolution inputs and decode at higher resolution, recovering fine-scale features using knowledge of the underlying data. Further examples in Appendix B.5. (b) Evaluating the decoder in a specific subregion can lead to significant computational savings compared to performing superresolution on the full grid.
For data-driven superresolution -where we train a model at high resolution and use it to enhance low-resolution inputs at inference time-FAE is able to resolve unseen features from 8 × 8 and 16 × 16 inputs on a 64 × 64 output grid after training at resolution 64 × 64 (Figure 8(a)). As with inpainting, superresolution performance could be further improved with an architecture that is better able to capture the turbulent dynamics in the data.
We also investigate the stability of FAE for zero-shot superresolution (Li et al., 2021), where the model is evaluated on higher resolutions than seen during training. Since FAE is purely data-driven, we view this as a test of the model's mesh-invariance and do not expect to resolve high-frequency features that were not seen during training. Our architecture proves robust when autoencoding on meshes much finer than the original 64 × 64 training grid (Figure 9(a)); moreover our coordinate MLP architecture allows us to decode on extremely fine meshes without exhausting the GPU memory (details in Appendix B.5). While zero-shot superresolution is possible with VANO when the input is given on the mesh seen during training, FAE can be used for superresolution with any input.
Efficient Superresolution on Regions of Interest. Since our decoder can be evaluated on any mesh, we can perform superresolution in a specific subregion without upsampling across the whole domain. Doing this can significantly reduce inference time, memory usage, and energy cost. As an example, we consider the task of reconstructing a circular subregion of interest with target mesh spacing 1 400 / (Figure 8(b)(i)). Achieving this resolution over the whole domain-corresponding to a 400 × 400 grid-would involve 160,000 evaluations of the decoder network; decoding on the subregion requires just 1 4 / of this (Figure 8(b)(ii)).
Applications of the Latent Space Z . The regularised FAE latent space gives a wellstructured finite representation of the infinite-dimensional data u ∈ U . We expect there to
## (a) Autoencoding beyond training resolution with zero-shot superresolution
0.7
0.6
0.5
0.4
0.3
0.2
Figure 9: (a) FAE can stably decode at resolutions much higher than the training resolution (best viewed digitally). (b) The regularised latent space Z allows for meaningful interpolation between samples. Further examples are given in Appendix B.5.
be benefit in using this representation as a building block for applications such as supervised learning and generative modelling on functional data, similar in spirit to other supervised operator-learning methods with encoder-decoder structure (Seidman et al., 2022).
As a first step towards verifying that the latent space does indeed capture useful structure beyond mere memorisation of the training data, we draw u 1 and u 2 from the held-out set, compute latent vectors z 1 = f ( u 1 ; θ ) and z 2 = f ( u 2 ; θ ) ∈ Z , and evaluate the decoder g along the convex combination z α 1 + z 2 (1 -α ). This leads to a sensible interpolation in U , suggesting that the latent representation is robust and well-regularised (Figure 9(b)).
## 4.3.2 Darcy Flow
Darcy flow is a model of steady-state flow in a porous medium, derivable from first principles using homogenisation; see, e.g., Freeze and Cherry (1979, Sec. 2.11) and Keller (1980). We restrict attention to the two-dimensional domain Ω = [0 1] , 2 and suppose that, for some permeability field k : Ω → R and forcing φ : Ω → R , the pressure field p : Ω → R satisfies
$$- \nabla \cdot ( k \nabla p ) & = \varphi \quad \text{on } \Omega, \\ p & = 0 \quad \text{on } \partial \Omega.$$
We assume φ = 1 and that k is distributed as the pushforward of the distribution N ( 0 ( , -∆+ 9 I ) -2 ) , where ∆ is the Laplacian restricted to functions defined on Ω with zero Neumann data on ∂ Ω, under the map ψ x ( ) = 3 + 9 · 1 [ x ⩾ 0 . ] We take U = L 2 (Ω) and define Υ ∈ P ( U ) to be the distribution of pressure fields p solving (33) with permeability k . While solutions to this elliptic PDE can be expected to have greater smoothness (Evans, 2010, Sec. 6.3), we assume only that p ∈ L 2 (Ω) and use the L 2 -norm in the FAE objective (31).
The training data set is based on that of Li et al. (2021) and consists of 1,024 samples from Υ on a 421 × 421 grid, with a further 1,024 samples held out as an evaluation set. Data are scaled so that p x ( ) ∈ [0 , 1] for all x ∈ Ω and, where specified, we downsample as described in Appendix B.6. We train FAE with d Z = 64 and β = 10 -3 , and use complement masking with a point ratio r enc of 30%.
Accelerating Training Using Masking. As well as improving reconstructions and robustness to mesh changes, masked training can greatly reduce the cost of training. To illustrate this we compare the training dynamics of FAE on data downsampled to resolution 211 × 211, using random masking with point ratio r enc = r dec ∈ { 10% 50% 90% . , , } Since the evaluation cost of the encoder and decoder scales linearly with the number of mesh points, we expect significant computational gains when using low point ratios. We perform five training runs for each model and compute the average reconstruction MSE over time on held-out data
Reconstruction MSE on held-out set (211 × 211) (mean over 5 training runs)
100
Figure 10: Training with masking in the encoder and decoder reduces training time.
at resolution 211 × 211. The models trained with masking converge faster as the smaller data tensors allow for better use of the GPU parallelism (Figure 10). At higher resolutions, memory constraints may preclude training on the full grid, making masking vital.
Related ideas are used in the adaptive-subsampling training scheme for FNOs proposed by Lanthaler et al. (2024), which involves training first on a coarse grid and refining the mesh each time the evaluation metric plateaus; our approach differs by dropping mesh points randomly, which would not be possible with FNO. One can readily imagine training FAE with a combination of adaptive subsampling and masking.
Generative Modelling. While FAE is not itself a generative model, it can be made so by training a fixed-dimension generative model on the latent space Z (Ghosh et al., 2020; Vahdat et al., 2021). More precisely, we know that applying the FAE encoder f to data induces a distribution Σ θ ∈ P ( Z ) for z given by
$$z \, | \, u = f ( u ; \theta ), \quad u \sim \Upsilon.$$
Unlike with FVAE, there is no reason that this should be close to Gaussian. However, we can approximate Σ θ with a fixed-resolution generative model P φ z ∈ P ( Z ) parametrised by φ ∈ Φ, and define the FAE generative model P ψ,φ u for data u by
$$( \text{FAE generative model} ) \quad u \, | \, z = g ( z ; \psi ), \ \ z \sim \mathbb { P } _ { z } ^ { \varphi }. \quad \text{(35)}$$
Since applying the decoder to Σ θ should approximately recover the data distribution if g f ( ( u θ ; ); ψ ) ≈ u for u ∼ Υ, we hope that when Σ θ ≈ P φ z , samples from (35) will be approximately distributed according to Υ. As a simple illustration, we train FAE at resolution 47 × 47 and fit a Gaussian mixture model P φ z with 10 components to Σ θ using the expectation-maximisation algorithm (see Bishop, 2006, Sec. 9.2.2). Samples from (35) closely resemble those from the held-out data set (Figure 11(a)), and as a result of our mesh-invariant architecture, it is possible to generate new samples on any mesh.
To measure generative performance, we approximate the distributions of physically relevant quantities of interest Q i ( p ) depending on the data p ∈ U , comparing 1,024 samples from the generative model to the held-out data. Using kernel density estimates as in Figure 4(b), we see close agreement between the distributions (Figure 11(b)). While we could also evaluate
Figure 11: (a) Uncurated samples from the FAE generative model for the pressure field p . Further samples are provided in Appendix B.6. (b) The distributions of quantities of interest computed using the FAE generative model closely agree with the ground truth.
the generative model using distances such as maximum mean discrepancy (Borgwardt et al., 2006), we focus on interpretable quantities relevant to the physical system at hand.
Though we adopt the convention of training the autoencoder and generative model separately (Rombach et al., 2022) here, the models could also be trained jointly; we leave this, and an investigation of generative models on the FAE latent space, to future work.
## 5 Related Work
Variational Autoencoding Neural Operators. The VANO model (Seidman et al., 2023) was the first to attempt systematic extension of the VAE objective to function space. The paper uses ideas from operator learning to construct a model that can decode-but not encode-at any resolution. Our approach differs in both training objective and practical implementation, as we now outline.
The most significant difference between what is proposed in this paper and in VANO is the objective on function space: the VANO objective coincides with a specific case of our model (16a)-(16d) with the decoder noise P η being white noise on L 2 ([0 , 1] d ). As a consequence the generative model for VANO takes values in U = H s ([0 , 1] d ) if and only if s < -d / 2 ; in particular generated draws are not in L 2 ([0 , 1] d ) . Unlike our approach, VANO aims to maximise an extension of the ELBO (15b), in which a regularisation parameter β > 0 is chosen as a hyperparameter, and the ELBO takes the form
$$\text{ELBO} _ { \beta } ^ { \text{VANO} } ( u ; \theta, \psi ) & = \underset { z \sim Q _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ \log \frac { \text{d} \mathbb { P } ^ { \psi } _ { u | z } } { \text{d} \mathbb { P } _ { \eta } } ( u ) \right ] - \beta D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ) \\ & = \underset { z \sim Q _ { z | u } ^ { \theta } } { \mathbb { E } } \left [ \left \langle g ( z ; \psi ), u \right \rangle _ { L ^ { 2 } } ^ { \sim } - \frac { 1 } { 2 } \| g ( z ; \psi ) \| _ { L ^ { 2 } } ^ { 2 } \right ] - \beta D _ { \text{KL} } ( \mathbb { Q } _ { z | u } ^ { \theta } \left \| \mathbb { P } _ { z } ),$$
where the second equality comes from the Cameron-Martin theorem as in Example 23. Maximising ELBO VANO β with β = 1 is precisely equivalent to minimising the per-sample
loss (29) from Example 23, so naive application of ELBO VANO β will result in the same issues seen there. In particular, discretisations of the ELBO may diverge as resolution is refined; moreover, for data with L 2 -regularity, the generative model P ψ u is greatly misspecified, with draws g z ( ; ψ ) + η , z ∼ P z , η ∼ P η , lying in a Sobolev space of lower regularity than the data. This issue is obscured by the convention in the VAE literature of considering only the decoder mean g z ( ; ψ ); considering the full generative model with draws g z ( ; ψ )+ η reveals the incompatibility more clearly. We argue that the empirical success of VANO in autoencoding is because the objective can be seen as that of a regularised autoencoder (Remark 24).
Along with the differences in the training objective and its interpretation, FVAE differs greatly from VANO in architecture. While the VANO decoders can be discretised on any mesh-and our decoder closely resembles VANO's nonlinear decoder-its encoders assume a fixed mesh for training and inference. In contrast, our encoder can be discretised on any mesh, enabling many of our contributions, such as masked training, inpainting, and superresolution, which are not possible within VANO.
Generative Models on Function Space. Aside from VANO, recent years have seen significant interest in the development of generative models on function space. Several extensions of score-based (Song et al., 2021) and denoising diffusion models (Sohl-Dickstein et al., 2015; Ho et al., 2020) to function space have been proposed (e.g., Pidstrigach et al., 2023; Hagemann et al., 2023; Lim et al., 2023; Kerrigan et al., 2023; Franzese et al., 2023; Zhang and Wonka, 2024). Rahman et al. (2022) propose the generative adversarial neural operator, extending Wasserstein generative adversarial networks (Arjovsky et al., 2017) to function space with FNOs in the generator and discriminator to achieve resolution-invariance.
Variational Inference on Function Space. In machine learning, variational inference on function space also arises in the context of Bayesian neural networks (Sun et al., 2019; Burt et al., 2021; Cinquin and Bamler, 2024). In this setting one wishes to minimise the KL divergence between the posterior in function space and a computationally tractable approximation-but, as in our study, this divergence may be infinite owing to a lack of absolute continuity between the two distributions.
Learning on Point Clouds. Our architecture takes inspiration from the literature on machine learning on point clouds, where data are viewed as sets of points with arbitrary cardinality. Several models for autoencoding and generative modelling with point clouds have been proposed, such as energy-based processes (Yang et al., 2020) and SetVAE (Kim et al., 2021); our work differs by defining a loss in function space, ensuring that our model converges to a continuum limit as the mesh is refined. Continuum limits of semisupervised algorithms for graphs and point clouds have also been studied (e.g., Dunlop et al., 2020).
## 6 Outlook
Our study of autoencoders on function space has led to FVAE, an extension of VAEs which imposes stringent requirements on the data distribution in infinite dimensions but benefits from firm probabilistic foundations; it has also led to the non-probabilistic FAE, a regularised autoencoder which can be applied much more broadly to functional data.
Benefits. Both FVAE and FAE offer significant benefits when working with functional data, such as enabling training with data across resolutions, inpainting, superresolution, and generative modelling. These benefits are possible only through our pairing of a well-defined objective in function space with mesh-invariant encoder and decoder architectures.
Limitations. FVAE can be applied only when the generative model is sufficiently compatible with the data distribution-a condition that is difficult to satisfy in infinite dimensions, and restricts the applicability to FVAE to specific problem classes. FAE overcomes this restriction, but does not share the probabilistic foundations of FVAE.
The desire to discretise the encoder and decoder on arbitrary meshes rules out many high-performing grid-based architectures, including convolutional networks and FNOs. We believe this is a limiting factor in the numerical experiments, and that combining our work with more complex operator architectures (e.g., Kovachki et al., 2023) or continuum extensions of point-cloud CNNs (Li et al., 2018) would yield further improvements.
Future Work. Our work gives new methods for nonlinear dimension reduction in function space, and we expect there to be benefit in building operator-learning methods that make use of the resulting latent space, in the spirit of PCA-Net (Bhattacharya et al., 2021). For FAE, which unlike FVAE is not inherently a generative model, we expect particular benefit in the use of more sophisticated generative models on the latent space, for example diffusion models, analogous to Stable Diffusion (Rombach et al., 2022).
While our focus has been on scientific problems with synthetic data, our methods could also be applied to real-world data, for example in computer vision; for these challenging data sets, further research on improved mesh-invariant architectures will be vital. Our study has also focussed on the typical machine-learning setting of a fixed dataset of size N ; research into the behaviour of FVAE and FAE in the infinite-data limits using tools from statistical learning theory would also be of interest.
## Acknowledgments and Disclosure of Funding
JB is supported by Splunk Inc. MG is supported by a Royal Academy of Engineering Research Chair, and Engineering and Physical Sciences Research Council (EPSRC) grants EP/T000414/1, EP/W005816/1, EP/V056441/1, EP/V056522/1, EP/R018413/2, EP/R034710/1, and EP/R004889/1. HL is supported by the Warwick Mathematics Institute Centre for Doctoral Training and gratefully acknowledges funding from the University of Warwick and the EPSRC (grant EP/W524645/1). AMS is supported by a Department of Defense Vannevar Bush Faculty Fellowship and by the SciAI Center, funded by the Office of Naval Research (ONR), under grant N00014-23-1-2729. For the purpose of open access, the authors have applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising.
## Appendix A. Supporting Results
In the following proof we use the fact that the norm of the Sobolev space H s ([0 , 1]) can be written as a weighted sum of frequencies (see Krein and Petunin, 1966, Sec. 9):
$$\text{when as a wegment sum on mequences (see mean and } \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \julia \text{, } \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota\iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iia \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota\ iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ioda \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \phi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \geq 0 \, 1 0 }$$
Proof of Proposition 15 Let η be an L 2 -white noise, let h = ∑ j ∈ N h e j j ∈ L 2 ([0 , 1]), and note that P η ( · -h ) is the distribution of the random variable η + h . Thus, writing out the H s -norm using the Karhunen-Lo` eve expansion of η , we see that
$$\| \eta + h \| _ { H ^ { s } ( [ 0, 1 ] ) } ^ { 2 } = \sum _ { j \in \mathbb { N } } ( 1 + j ^ { 2 } ) ^ { s } | \xi _ { j } + h _ { j } | ^ { 2 }.$$
First, we show that ∥ η + h ∥ H s ([0 1]) , < ∞ almost surely when s < -1 2 / . To do this we apply the Kolmogorov two-series theorem (Durrett, 2019, Theorem 2.5.6), which states that the random series (37) converges almost surely if
$$\sum _ { j \in \mathbb { N } } ( 1 + j ^ { 2 } ) ^ { s } \, \mathbb { E } \left [ \left ( \xi _ { j } + h _ { j } \right ) ^ { 2 } \right ] < \infty \quad \text{and} \quad \sum _ { j \in \mathbb { N } } ( 1 + j ^ { 2 } ) ^ { 2 s } \, V \text{ar} \left ( \left ( \xi _ { j } + h _ { j } \right ) ^ { 2 } \right ) < \infty.$$
But, since ξ j ∼ N (0 1), , we know that E [ ξ 2 j ] = 1 and Var( ξ 2 j ) = 2; applying this, the elementary identity ( x + ) y 2 ⩽ 2 x 2 +2 y 2 for x, y ∈ R , and the fact that ∑ j ∈ N j α < ∞ for α < -1 shows that the two series are finite. To see that P η ( · -h ) assigns zero probability to L 2 ([0 , 1]), suppose for contradiction that η + h had finite L 2 -norm; then η would also have finite L 2 -norm. But as a consequence of the Borel-Cantelli lemma,
$$\left \| \eta \right \| _ { L ^ { 2 } ( [ 0, 1 ] ) } ^ { 2 } = \sum _ { j \in \mathbb { N } } \xi _ { j } ^ { 2 } = \infty \ \text{almost surely,}$$
because the summands are independent and identically distributed, and thus for any constant c > 0, infinitely many summands exceed c with probability one.
Lemma 27. Suppose that U = C 0 ([0 , T ] , R m ) and that µ ∈ P ( U ) and ν ∈ P ( U ) are the laws of the R m -valued diffusions where ( w t ) t ∈ [0 ,T ] is a Brownian motion on R m . Suppose that the Novikov condition (19) holds for both processes. Then
$$\mathbb { R } ^ { m } \text{-v alued diffuseons} \\ \mathrm d u _ { t } & = b ( u _ { t } ) \, \mathrm d t + \sqrt { \varepsilon } \, \mathrm d w _ { t }, \quad \ u _ { 0 } = 0, \quad \ t \in [ 0, T ] \\ \mathrm d v _ { t } & = c ( v _ { t } ) \, \mathrm d t + \sqrt { \varepsilon } \, \mathrm d w _ { t }, \quad \ v _ { 0 } = 0, \quad \ t \in [ 0, T ]. \\ \mathrm \sim \mathrm \sim \mathrm i s \, \text{a B r o w n i a n } \, \mathrm m o t i o n \, \mathrm o n \, \mathbb { R } ^ { m }. \, \text{$S u m o s e } \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \mathrm t \, \complement }$$
$$D _ { \text{KL} } ( \mu \, \| \, \nu ) = \underset { u \sim \mu } { \mathbb { E } } \left [ \frac { 1 } { 2 \varepsilon } \int _ { 0 } ^ { T } \| b ( u _ { t } ) - c ( u _ { t } ) \| _ { 2 } ^ { 2 } \, \mathrm d t \right ].$$
Proof Applying the Girsanov formula (20) to obtain the density d µ/ ν d , taking logarithms to evaluate D KL ( µ ∥ ν ), and noting that under µ we have d u t = ( b u t ) d t + √ ε d w t , we obtain
$$D _ { \text{KL} } ( \mu \| \nu ) = \underset { u \sim \mu } { \mathbb { E } } \left [ \frac { 1 } { 2 \varepsilon } \int _ { 0 } ^ { T } \| b ( u _ { t } ) - c ( u _ { t } ) \| _ { 2 } ^ { 2 } \, \mathrm d t - \frac { 1 } { \sqrt { \varepsilon } } \int _ { 0 } ^ { T } \langle b ( u _ { t } ) - c ( u _ { t } ), \, \mathrm d w _ { t } \rangle \right ].$$
Under µ , the process ( w t ) t ∈ [0 ,T ] is Brownian motion and so the second expectation is zero.
## Appendix B. Experimental Details
In this section, we provide additional details, training configurations, samples, and analysis for the numerical experiments in Section 2.5 and Section 4.3. All experiments were run on a single NVIDIA GeForce RTX 4090 GPU with 24 GB of VRAM.
## B.1 Base Architecture
We use the common architecture described in Section 2.4 and Section 4.2 for all experiments, using the Adam optimiser (Kingma and Ba, 2015) with the default hyperparameters ε , β 1 , and β 2 ; we specify the learning rate and learning-rate decay schedule for each experiment in what follows.
Positional Encodings. Where specified, both the encoder and decoder will make use of Gaussian random Fourier features (Tancik et al., 2020), pairing the query coordinate x ∈ Ω ⊂ R d with a positional encoding γ x ( ) ∈ R 2 k . To generate these encodings, a matrix B ∈ R k × d with independent N (0 , I ) entries is sampled and viewed as a hyperparameter of the model to be used in both the encoder and decoder. The positional encoding γ x ( ) is then given by the concatenated vector γ x ( ) = [ cos(2 πBx ); sin(2 πBx ) ] T ∈ R 2 k where the sine and cosine functions are applied componentwise to the vector 2 πBx .
## B.2 Brownian Dynamics
The training data consists of 8,192 samples from the path distribution Υ of the SDE (27),(28) on the time interval [0 , T ], T = 5. Trajectories are generated using the Euler-Maruyama scheme with internal time step 1 8 192 / , (unrelated to the choice to take 8,192 training samples), and the resulting paths are then subsampled by a factor of 80 to obtain the training data. Thus the data have effective time increment 5 512 / ; moreover the path information is removed at 50% of the points resulting from these time increments, chosen uniformly at random.
Experimental Setup. We train for 100,000 steps with initial learning rate 10 -3 and an exponential decay of 0.98 applied every 1,000 steps, with batch size 32 and 4 Monte Carlo samples for Q θ z u | . We use latent dimension d Z = 1, β = 1 2 and . λ = 10. The three sets of simulations shown in Figure 2 use κ = 0, 25, and 10,000 respectively.
## B.3 Estimation of Markov State Models
Data and Discretisation. To validate the ability of FVAE to model higher-dimensional SDE trajectories, we specify a simple potential with qualitative features similar to those arising in the complex potential surfaces arising in molecular dynamics. To this end, define the centres c 1 = (0 0), , c 2 = (0 2 0 2), . , . c 3 = ( -0 2 . , -0 2), . c 4 = (0 2 . , -0 2), . c 5 = (0 0 2) and , . c 6 = ( -0 2 . , 0); standard deviations σ 1 = σ 2 = σ 3 = σ 4 = 0 1 and . σ 5 = σ 6 = 0 03; and masses . m 1 = m 2 = m 3 = m 4 = 0 1 and . m 5 = m 6 = 0 01. Then let .
$$U ( x ) = 0. 3 \left [ 0. 5 ( x _ { 1 } + x _ { 2 } ) + x _ { 1 } ^ { 2 } + x _ { 2 } ^ { 2 } - \sum _ { i = 1 } ^ { 6 } m _ { i } N \left ( x ; c _ { i }, \sigma _ { i } ^ { 2 } I _ { 2 } \right ) \right ].$$
This potential has three key components: a linear term breaking the symmetry, a quadratic term preventing paths from veering too far from the path's starting point, the origin,
x
2
Figure 12: Potential function U : R 2 → R for Section 2.5.2.
and negative Gaussian densities-serving as potential wells-positioned at the centres c i (Figure 12). Sample paths of (27) with initial condition u 0 = 0, temperature ε = 0 1 and . final time T = 3 show significant diversity, with many paths transitioning at least once between different wells (see ground truth in Figure 13).
Experimental Setup. The training set consists of 16,384 paths generated with an EulerMaruyama scheme with internal time step 1 8 192 / , , subsampled by a factor 48 to obtain an equally spaced mesh of 513 points. We take d Z = 16, β = 10, κ = 50, and λ = 50, and, as in Appendix B.3, train on data where 50% of the points on the path are missing. We also use the same learning rate, learning-rate decay schedule, step limit, and batch size.
Results. FVAE's reconstructions closely match the inputs (Figure 13), and FVAE produces convincing generative samples capturing qualitative features of the data (Figure 14).
## B.4 Dirac Distributions
Data and Discretisation. We view Υ as a probability distribution on U = H -1 ([0 , 1]). At each resolution I , we discretise the domain [0 , 1] using an evenly spaced mesh of points { i / I +1 } i =1 ,...,I and approximate the Dirac mass δ ξ , ξ ∈ [0 , 1], by the optimal L 1 -approximation: a discretised function which is zero except at the mesh point closest to ξ , normalised to have unit L 1 -norm. The training data set consists of discretised Dirac functions at each mesh point; the goal is not to train a practical model for generalisation, but to isolate the effect of the objective.
Experimental Setup. Wetrain FVAE and FAE models at resolutions I ∈ { 8 16 32 64 128 , , , , } . For each model, we perform 50 independent runs of 30,000 steps with batch size 6.
Architecture. The neural network ρ : R × Θ → R × R in the encoder map f is assumed to have 3 hidden layers of width 128, and the mean µ z ( ; ψ ) and standard deviation σ z ψ ( ; ) in the decoder are computed from a 3-layer neural network of width 128. For numerical stability, we impose a lower bound on σ based on the mesh spacing ∆ x , given by σ min (∆ ) = (2 x π ) -1 2 / ∆ . x
FVAE Configuration. We view data u ∼ Υ as lying in the Sobolev space U = H -1 ([0 , 1]); the decoder g will output functions in L 2 ([0 , 1]) and we take decoder-noise distribution
Figure 13: Held-out ground-truth data from the SDE in Section 2.5.2 ('True' row) and the corresponding FVAE reconstructions of sample paths ('Reconstructed' row).
Figure 14: (a) Samples of the SDE in Section 2.5.2 drawn from the FVAE generative model with randomly drawn latent vector z ∼ P z . (b) Ground-truth paths of the SDE in Section 2.5.2 generated using an Euler-Maruyama solver. In both subfigures, the evolution through time t ∈ [0 , 3] is depicted as a transition in colour from blue to green.
P η = N (0 , I ), noting that P η ∈ P ( H s ([0 , 1])) if and only if s < -1 2 / ; in particular whitenoise samples do not lie in the space L 2 ([0 , 1]). We modify the per-sample loss (7b) by reweighting the term D KL ( Q θ z u | ∥ P z ) by β = 10 -4 , and take 16 Monte Carlo samples for Q θ z u | . We use an initial learning rate of 10 -4 , decaying exponentially by a factor 0 7 every . 1,000 steps.
FAE Configuration. To compute the H -1 -norm we truncate the series expansion (36) and compute coefficients α j from a discretisation of u using the discrete sine transform. We use initial learning rate 10 -4 , decaying exponentially by a factor 0 9 every 1,000 steps, and . take β = 10 -12 . For consistency with the FVAE loss, we subtract the squared data norm 1 2 ∥ u ∥ 2 H -1 from the FAE loss, yielding the expression
$$\frac { 1 } { 2 } \left \| g ( f ( u ; \theta ) ; \psi ) - u \right \| _ { H ^ { - 1 } } ^ { 2 } - \frac { 1 } { 2 } \left \| u \right \| _ { H ^ { - 1 } } ^ { 2 } = \frac { 1 } { 2 } \left \| g ( f ( u ; \theta ) ; \psi ) \right \| _ { H ^ { - 1 } } ^ { 2 } - \left \langle g ( f ( u ; \theta ) ; \psi ), u \right \rangle _ { H ^ { - 1 } }.$$
Results. As expected, the final training loss under both models decreases as the resolution is refined, since the lower bound σ min decreases. However, the FAE loss appears to converge and is stable across runs, while the FVAE loss appears to diverge and becomes increasingly unstable across runs. This gives convincing empirical evidence that the joint divergence (5) for FVAE is not defined as a result of the misspecified decoder noise; the use of FAE with an appropriate data norm alleviates this issue. Since the FVAE objective with P η = N (0 , I ) coincides with the VANO objective, this issue would also be present for VANO. Under both models, training becomes increasingly unstable at high resolutions: when σ is small, the loss becomes highly sensitive to changes in µ ; this instability is unrelated to the divergence of the FVAE training loss and is a consequence of training through gradient descent.
B.5 Incompressible Navier-Stokes Equations
| Viscosity ν | Resolution | Train Samples | Eval. Samples | Snapshot Time T |
|---------------|--------------|-----------------|-----------------|-------------------|
| 10 - 3 | 64 × 64 | 4,000 | 1,000 | 50 |
| 10 - 4 | 64 × 64 | 8,000 | 2,000 | 50 |
| 10 - 5 | 64 × 64 | 960 | 240 | 20 |
Table 2: Details of Navier-Stokes data sets.
Data and Discretisation. We use data as provided online by Li et al. (2021). Solutions of (32) are generated by sampling the initial condition from the Gaussian random field N (0 , C ), C = 7 3 2 / (49 I -∆) -5 2 / , and evolving in time using a pseudospectral method. While the data of Li et al. (2021) includes the full time evolution, we use only snapshots of the vorticity at the final time. Every snapshot is a 64 × 64 image, normalised to take values in [0 , 1]; details of this data set are given in Table 2.
Effects of Point Ratios. Here, we extend the analysis of Figure 7(b) to understand how the point ratio used during training affects reconstruction performance. We first train two FAE models on the Navier-Stokes data set with viscosity ν = 10 -4 , using complement masking with a point ratio r enc of 10% and 90% respectively. Then, we fix an arbitrary sample from the held-out set and, for each model, generate 1,000 distinct masks with point ratios 10%, 30%, 50%, 70%, and 90%. We then encode on each mesh and decode on the full grid and compute kernel density estimates of the reconstruction MSE (Figure 15). The model trained with r enc = 10% is much more sensitive to the location of the evaluation mesh points, especially when the evaluation point ratio is low; with sufficiently high encoder point ratio at evaluation time, however, the reconstruction MSE of the model trained using r enc = 10%
surpasses that of the model trained at r enc = 90%. This suggests a tradeoff whereby a higher training point ratio provides more stability, at the cost of increasing autoencoding MSE, particularly when the point ratio of the evaluation data is high. We hypothesise that a lower training ratio regularises the model to attain a more robust internal representation.
MSE
- (a) For a model trained with point ratio 10%.
(b) For a model trained with a point ratio 90%.
Figure 15: Kernel density estimates for full-grid reconstruction MSE on the reference sample across 1,000 randomly chosen meshes. Training with a low point ratio regularises, reducing MSE when the evaluation data has a high point ratio, but at the cost of greater variance when evaluating on low point ratios.
We also investigate the sensitivity of the models to a specific encoder mesh, seeking to understand whether an encoder mesh achieving low MSE on one image leads to low MSE on other images. The procedure is as follows: we select an image arbitrarily from the held-out set (the reference sample ) and draw 1,000 random meshes with point ratio 10%; then, we select the mesh resulting in the lowest reconstruction MSE for each of the two models. For the nearest neighbours of the chosen sample in the held-out set, the reconstruction error on this MSE-minimising mesh is lower than average (Figure 16(a); dashed lines), suggesting that a good configuration will yield good results on similar samples. On the other hand, using the MSE-minimising mesh on arbitrary samples from the held-out set yields an MSE somewhat lower than a randomly chosen mesh; unsurprisingly, however, the arbitrarily chosen samples appear to benefit less than the nearest neighbours (Figure 16(b)).
Experimental Setup. We train for 50,000 steps with batch size 32 and initial learning rate 10 -3 , decaying exponentially by a factor 0.98 every 1,000 steps. We use complement masking with r enc = 0 3, providing a good balance of performance and robustness to masking. .
Architecture. Both the CNN and FAE architecture use Gaussian random positional encodings with k = 16. For the sake of comparison, we use a standard CNN architecture inspired by the VGG model (Simonyan and Zisserman, 2015), gradually contracting/expanding the feature map while increasing/decreasing the channel dimensions. The architecture we use was identified using a search over parameters such as the network depth while maintaining a similar parameter count to our baseline FAE model. The encoder consists of four CNN layers with output channel dimension 4, 4, 8, and 16 respectively and kernel sizes are 2, 2, 4, and 4 respectively, all with stride 2. The result is flattened and passed through a single-hidden-layer MLP of width 64 to obtain a vector of dimension 64. The decoder consists of a single-layer MLP of width 64 and output dimension 512, which is then rearranged to a
idx=1
idx=644
idx=1208
idx=1930
idx=703
(b) Arbitrarily chosen samples from the held-out set.
Figure 16: Kernel density estimates of full-grid reconstruction MSE for models trained at 10% (Low) and 90% (High) point ratios on samples from the held-out set. Dashed lines indicate the MSE obtained using the mesh minimising MSE on the reference sample.
4 × 4 feature map with channel size 32. This feature map is then passed through four layers of transposed convolutions that respectively map to 16, 8, 4, and 4 channel dimensions, with kernel sizes 4, 4, 2, and 2 respectively, and stride 2. The result is then mapped by two CNN layers with kernel size 3, stride 1, and output channel dimension 8 and 1 respectively.
Uncurated Reconstructions and Samples. Reconstructions of randomly selected data from the held-out sets for viscosities ν = 10 -3 , 10 -4 and 10 -5 are provided in Figures 17, 18, and 19 respectively. As described in Section 4.3.2, we apply FAE as a generative model by fitting a Gaussian mixture with 10 components on the latent space. Samples from models trained at ν = 10 -3 , 10 -4 and 10 -5 are shown in Figures 20, 21, and 22 respectively.
Evaluation at Very High Resolutions. In Figure 9, we demonstrate zero-shot resolution by evaluating the decoder on grids of resolution 2,048 × 2,048 and 32,768 × 32,768. While the former requires approximately 16 MB to store using 32-bit floating-point numbers, the latter requires 4.3 GB, and thus applying a neural network directly to the 32,768 × 32,768 image is more likely to exhaust GPU memory. To allow evaluation of the decoder at this resolution, we partition the domain into 1,000 chunks and evaluate the decoder on each chunk in turn; we then reassemble the resulting data in the RAM. To ensure that each
Figure 18: FAE reconstructions of Navier-Stokes data with viscosity 10 -4 .
Figure 19: FAE reconstructions of Navier-Stokes data with viscosity ν = 10 -5 .
Figure 20: Samples of Navier-Stokes data with viscosity ν = 10 -3 .
Figure 21: Samples of Navier-Stokes data with viscosity ν = 10 -4 .
Figure 22: Samples of Navier-Stokes data with viscosity ν = 10 -5 .
chunk has an integer number of points, we take the first 824 chunks to contain 1,073,742 mesh points ( ≈ 4 MB), and take the remaining 176 chunks to contain 1,073,741 points.
## B.6 Darcy Flow
Data Set. The data we use is based on that provided online by Li et al. (2021), given on a 421 × 421 grid and generated through a finite-difference scheme. Where described, we downsample this data to lower resolutions by applying a low-pass filter in Fourier space and subsampling the resulting image. The low-pass filter is a mollification of an ideal sinc filter with bandwidth selected to eliminate frequencies beyond the Nyquist frequency of the target resolution, computed by convolving the ideal filter in Fourier space with a Gaussian kernel with standard deviation σ = 0 1, truncated to a 7 . × 7 convolutional filter.
Experimental Setup. We follow the same setup used for the Navier-Stokes data set: we train for 50,000 steps, with batch size 32 and complement masking with r enc = 30%. An initial learning rate of 10 -3 is used with an exponential decay factor of 0.98 applied every 1,000 steps. We make use of positional embeddings (Appendix B.1) using k = 16 Gaussian random Fourier features. When performing the wall-clock training time experiment (Figure 10), we downsample the training and evaluation data to resolution 211 × 211.
Uncurated Reconstructions and Samples. Reconstructions of randomly selected examples from the held-out evaluation data set are shown in Figure 23. Samples from the FAE generative model and draws from the evaluation data set are shown in Figure 24.
Figure 23: FAE reconstructions of Darcy flow data.
Figure 24: Samples of Darcy flow data.

## References
- M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein generative adversarial networks. In D. Precup and Y. W. Teh, editors, Proceedings of the 34th International Conference on Machine Learning (ICML 2017) , volume 70 of Proceedings of Machine Learning Research , pages 214-223, 2017. URL https://proceedings.mlr.press/v70/arjovsky17a.html. arXiv:1701.07875.
- K. Azizzadenesheli, N. Kovachki, Z. Li, M. Liu-Schiaffini, J. Kossaifi, and A. Anandkumar. Neural operators for accelerating scientific simulations and design. Nat. Rev. Phys. , 6: 320-328, 2024. doi:10.1038/s42254-024-00712-5.
- E. Bach, R. Baptista, D. Sanz-Alonso, and A. Stuart. Inverse problems and data assimilation: A machine learning approach, 2024. arXiv:2410.10523.
- K. Bhattacharya, B. Hosseini, N. B. Kovachki, and A. M. Stuart. Model reduction and neural networks for parametric PDEs. SMAI J. Comput. Math. , 7:121-157, 2021. doi:10.5802/smai-jcm.74.
- T. Bischoff and K. Deck. Unpaired downscaling of fluid flows with diffusion bridges. Artif. Intell. Earth Syst. , 3:e230039, 22pp., 2024. doi:10.1175/AIES-D-23-0039.1.
- C. M. Bishop. Pattern Recognition and Machine Learning . Information Science and Statistics. Springer, 2006. ISBN 978-0-387-31073-2.
- V. I. Bogachev. Gaussian Measures , volume 62 of Mathematical Surveys and Monographs . American Mathematical Society, 1998. doi:10.1090/surv/062.
- K. M. Borgwardt, A. Gretton, M. J. Rasch, H.-P. Kriegel, B. Sch¨lkopf, and A. J. Smola. o Integrating structured biological data by kernel maximum mean discrepancy. Bioinform. , 22(14):e49-e57, 2006. doi:10.1093/bioinformatics/btl242.
- D. R. Burt, S. W. Ober, A. Garriga-Alonso, and M. van der Wilk. Understanding variational inference in function-space. In 3rd Symposium on Advances in Approximate Bayesian Inference , 2021. arXiv:2011.09421.
- E. Calvello, N. B. Kovachki, M. E. Levine, and A. M. Stuart. Continuum attention for neural operators, 2024. arXiv:2406.06486.
- G. J. Chandler and R. R. Kerswell. Invariant recurrent solutions embedded in a turbulent two-dimensional Kolmogorov flow. J. Fluid. Mech. , 722:554-595, 2013. doi:10.1017/jfm.2013.122.
- J. T. Chang and D. Pollard. Conditioning as disintegration. Stat. Neerl. , 51(3):287-317, 1997. doi:10.1111/1467-9574.00056.
- T. Chen and H. Chen. Approximations of continuous functionals by neural networks with application to dynamic systems. IEEE Trans. Neural Netw. , 4(6):910-918, 1993. doi:10.1109/72.286886.
- Y. Chen, S. Liu, and X. Wang. Learning continuous image representation with local implicit image function. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 8624-8634. IEEE, 2021. doi:10.1109/CVPR46437.2021.00852.
- Y. Chen, D. Z. Huang, J. Huang, S. Reich, and A. M. Stuart. Sampling via gradient flows in the space of probability measures. arXiv preprint arXiv:2310.03597 , 2023.
- T. Cinquin and R. Bamler. Regularized KL-divergence for well-defined function-space variational inference in Bayesian neural networks, 2024. arXiv:2406.04317.
- S. L. Cotter, M. Dashti, and A. M. Stuart. Approximation of Bayesian inverse problems for PDEs. SIAM J. Numer. Anal. , 48(1):322-345, 2010. doi:10.1137/090770734.
- S. L. Cotter, G. O. Roberts, A. M. Stuart, and D. White. MCMC methods for functions: Modifying old algorithms to make them faster. Stat. Sci. , 28(3), 2013. doi:10.1214/13STS421.
- T. M. Cover and J. A. Thomas. Elements of Information Theory . Wiley-Interscience, Hoboken, NJ, second edition, 2006. doi:10.1002/047174882X.
- W. M. Czarnecki, S. Osindero, M. Jaderberg, G. Swirszcz, and R. Pascanu. Sobolev training for neural networks. In I. Guyon, U. von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 30, pages 4278-4287. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper files/paper/2017/file/ 758a06618c69880a6cee5314ee42d52f-Paper.pdf. arXiv:1706.04859.
- M. Dashti and A. M. Stuart. The Bayesian approach to inverse problems. In Handbook of Uncertainty Quantification. Vol. 1, 2, 3 , chapter 7, pages 311-428. Springer, Cham, 2017. doi:10.1007/978-3-319-12385-1 7.
- M. V. de Hoop, D. Z. Huang, E. Qian, and A. M. Stuart. The cost-accuracy tradeoff in operator learning with neural networks. J. Mach. Learn. , 1(3):299-341, 2022. doi:10.4208/jml.220509.
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In J. Burstein, C. Doran, and T. Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4171-4186, Minneapolis, MN, 2019. Association for Computational Linguistics. doi:10.18653/v1/N19-1423.
- M. M. Dunlop, D. Slepˇ cev, A. M. Stuart, and M. Thorpe. Large data and zero noise limits of graph-based semi-supervised learning algorithms. Appl. Comput. Harmon. Anal. , 49 (2):655-697, 2020. doi:10.1016/j.acha.2019.03.005.
- R. Durrett. Probability: Theory and Examples . Number 49 in Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, Cambridge, fifth edition, 2019. doi:10.1017/9781108591034.
- W. E, W. Ren, and E. Vanden-Eijnden. Minimum action method for the study of rare events. Comm. Pure Appl. Math. , 57(5):637-656, 2004. doi:10.1002/cpa.20005.
- H. Edwards and A. Storkey. Towards a neural statistician. In The Fifth International Conference on Learning Representations (ICLR 2017) , 2017. arXiv:1606.02185.
- L. Evans. Partial Differential Equations , volume 19 of Graduate Studies in Mathematics . American Mathematical Society, second edition, 2010. doi:10.1090/gsm/019.
- G. Franzese, G. Corallo, S. Rossi, M. Heinonen, M. Filippone, and P. Michiardi. Continuoustime functional diffusion processes. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 37370-37400. Curran Associates, Inc., 2023.
- R. A. Freeze and J. A. Cherry. Groundwater . Prentice-Hall, Englewood Cliffs, NJ, 1979. ISBN 0-13-365312-9.
- P. Ghosh, M. S. M. Sajjadi, A. Vergari, M. Black, and B. Sch¨lkopf. o From variational to deterministic autoencoders. In The Eighth International Conference on Learning Representations (ICLR 2020) , 2020. arXiv:1903.12436.
- P. Hagemann, L. Ruthotto, G. Steidl, and N. T. Yang. Multilevel diffusion: Infinite dimensional score-based diffusion models for image generation, 2023. arXiv:2303.04772.
- M. Hairer, A. Stuart, and J. Voss. Signal processing problems on function space: Bayesian formulation, stochastic PDEs and effective MCMC methods. In The Oxford Handbook
- of Nonlinear Filtering , pages 833-873. Oxford University Press, Oxford, 2011. ISBN 9780199532902.
- K. He, X. Chen, S. Xie, Y. Li, P. Doll´r, a and R. Girshick. Masked autoencoders are scalable vision learners. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 15979-15988, New Orleans, LA, USA, 2022. IEEE. doi:10.1109/CVPR52688.2022.01553.
- D. Hendrycks and K. Gimpel. Gaussian error linear units (GELUs), 2016. arXiv:1606.08415.
- I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner. β -VAE: Learning basic visual concepts with a constrained variational framework. In The Fifth International Conference on Learning Representations (ICLR 2017) , 2017. URL https://openreview.net/pdf?id=Sy2fzU9gl.
- J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems , volume 33, pages 6840-6851. Curran Associates, Inc., 2020. arXiv:2006.11239.
- D. Z. Huang, N. H. Nelsen, and M. Trautner. An operator learning perspective on parameterto-observable maps. Found. Data Sci. , 2024. doi:10.3934/fods.2024037. To appear.
- B. E. Husic and V. S. Pande. Markov state models: From an art to a science. J. Am. Chem. Soc. , 140(7):2386-2396, 2018. doi:10.1021/jacs.7b12191.
- J. B. Keller. Darcy's law for flow in porous media and the two-space method. In Nonlinear Partial Differential Equations in Engineering and Applied Science , pages 429-443. Routledge, 1980. doi:10.1201/9780203745465-27.
- G. Kerrigan, J. Ley, and P. Smyth. Diffusion generative models in infinite dimensions. In F. Ruiz, J. Dy, and J.-W. van de Meent, editors, Proceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS 2023) , volume 206 of Proceedings of Machine Learning Research , pages 9538-9563, 2023. arXiv:2212.00886.
- J. Kim, J. Yoo, J. Lee, and S. Hong. SetVAE: Learning hierarchical composition for generative modeling of set-structured data. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 15054-15063. IEEE, 2021. doi:10.1109/CVPR46437.2021.01481.
- D. P. Kingma. Variational inference and deep learning: A new synthesis . PhD thesis, University of Amsterdam, 2017. ISBN: 978-94-6299-745-5.
- D. P. Kingma and J. L. Ba. Adam: A method for stochastic optimization. In J. Bengio and Y. LeCun, editors, The Third International Conference on Learning Representations (ICLR 2015) , 2015. arXiv:1412.6980.
- D. P. Kingma and M. Welling. Auto-encoding variational Bayes. In Y. Bengio and Y. LeCun, editors, The Second International Conference on Learning Representations (ICLR 2014) , 2014. arXiv:1312.6114.
- D. P. Kingma and M. Welling. An introduction to variational autoencoders. FNT in Mach. Learn. , 12(4):307-392, 2019. doi:10.1561/2200000056.
- D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, and S. Hoyer. Machine learning-accelerated computational fluid dynamics. Proc. Nat. Acad. Sci. USA , 118(21): e2101784118, 8pp., 2021. doi:10.1073/pnas.2101784118.
- K. A. Konovalov, I. C. Unarta, S. Cao, E. C. Goonetilleke, and X. Huang. Markov state models to study the functional dynamics of proteins in the wake of machine learning. J. Amer. Chem. Soc. Au , 1(9):1330-1341, 2021. doi:10.1021/jacsau.1c00254.
- N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, and A. Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs. J. Mach. Learn. Res. , 23:1-97, 2023. arXiv:2108.08481.
- S. G. Krein and Yu. I. Petunin. Scales of Banach spaces. Russ. Math. Surv. , 21(2):85-159, 1966. doi:10.1070/RM1966v021n02ABEH004151.
- S. Lanthaler, A. M. Stuart, and M. Trautner. Discretization error of Fourier neural operators, 2024. arXiv:2405.02221.
- S. Lee. Mesh-independent operator learning for partial differential equations. In 2nd AI4Science Workshop at the 39th International Conference on Machine Learning , 2022. URL https://openreview.net/pdf?id=JUtZG8-2vGp.
- J. Li, Z. Pei, W. Li, G. Gao, L. Wang, Y. Wang, and T. Zeng. A systematic survey of deep learning-based single-image super-resolution. ACM Comput. Surv. , 56(10):1-40, 2024. doi:10.1145/3659100.
- Y. Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen. PointCNN: Convolution on X -transformed points. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 31, pages 820-830. Curran Associates, Inc., 2018. arXiv:1801.07791.
- Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar. Fourier neural operator for parametric partial differential equations. In The Ninth International Conference on Learning Representations (ICLR 2021) , 2021. arXiv:2010.08895.
- J. H. Lim, N. B. Kovachki, R. Baptista, C. Beckham, K. Azizzadenesheli, J. Kossaifi, V. Voleti, J. Song, K. Kreis, J. Kautz, C. Pal, A. Vahdat, and A. Anandkumar. Score-based diffusion models in function space, 2023. arXiv:2302.07400.
- R. S. Liptser and A. N. Shiryaev. Statistics of Random Processes . Springer, Berlin, Heidelberg, second edition, 2001. doi:10.1007/978-3-662-13043-8.
- L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell. , 3(3):218-229, 2021. doi:10.1038/s42256-021-00302-5.
- A. Mardt, L. Pasquali, H. Wu, and F. No´ e. VAMPnets for deep learning of molecular kinetics. Nat. Commun. , 9(1):5, 11pp., 2018. doi:10.1038/s41467-017-02388-1.
- B. Øksendal. Stochastic Differential Equations . Universitext. Springer, Berlin, Heidelberg, sixth edition, 2003. doi:10.1007/978-3-642-14394-6.
- B. Peherstorfer. Breaking the Kolmogorov barrier with nonlinear model reduction. Not. Am. Math. Soc. , 69(5):725-733, 2022. doi:10.1090/noti2475.
- J. Pidstrigach, Y. Marzouk, S. Reich, and S. Wang. Infinite-dimensional diffusion models for function spaces, 2023. arXiv:2302.10130.
- M. Prasthofer, T. De Ryck, and S. Mishra. Variable-input deep operator networks, 2022. arXiv:2205.11404.
- J.-H. Prinz, H. Wu, M. Sarich, B. Keller, M. Senne, M. Held, J. D. Chodera, C. Sch¨tte, u and F. No´ e. Markov models of molecular kinetics: Generation and validation. J. Chem. Phys. , 134(17):174105, 23pp., 2011. doi:10.1063/1.3565032.
- C. R. Qi, H. Su, K. Mo, and L. J. Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 77-85. IEEE, 2017. doi:10.1109/CVPR.2017.16.
- W. Quan, J. Chen, Y. Liu, D.-M. Yan, and P. Wonka. Deep learning-based image and video inpainting: A survey. Int. J. Comput. Vis. , 132:2364-2400, 2024. doi:10.1007/s11263-02301977-6.
- M. A. Rahman, M. A. Florez, A. Anandkumar, Z. E. Ross, and K. Azizzadenesheli. Generative adversarial neural operators. Transact. Mach. Learn. Res. , 2022. arXiv:2205.03017.
- J. O. Ramsay and B. W. Silverman, editors. Applied Functional Data Analysis: Methods and Case Studies . Springer Series in Statistics. Springer, 2002. doi:10.1007/b98886.
- R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 10674-10685, New Orleans, LA, USA, 2022. IEEE. doi:10.1109/CVPR52688.2022.01042.
- S. S¨rkk¨ and A. Solin. a a Applied Stochastic Differential Equations . Cambridge University Press, first edition, 2019. doi:10.1017/9781108186735.
- T. Schlick. Molecular Modeling and Simulation: An Interdisciplinary Guide , volume 21 of Interdisciplinary Applied Mathematics . Springer, New York, second edition, 2010. doi:10.1007/978-1-4419-6351-2.
- D. W. Scott. Multivariate Density Estimation . Wiley Series in Probability and Statistics. John Wiley and Sons, second edition, 2015. doi:10.1002/9781118575574.
- J. H. Seidman, G. Kissas, P. Perdikaris, and G. J. Pappas. NOMAD: Nonlinear manifold decoders for operator learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems , volume 35, pages 5601-5613. Curran Associates, Inc., 2022. arXiv:2206.03551.
- J. H. Seidman, G. Kissas, G. J. Pappas, and P. Perdikaris. Variational autoencoding neural operators. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , volume 202 of Proceedings of Machine Learning Research , pages 30491-30522, 2023. arXiv:2302.10351.
- K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In J. Bengio and Y. LeCun, editors, The Third International Conference on Learning Representations (ICLR 2015) , 2015. arXiv:1409.1556.
- V. Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein. Implicit neural representations with periodic activation functions. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems , volume 33, pages 7462-7473. Curran Associates, Inc., 2020. arXiv:2006.09661.
- J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In F. Bach and D. Blei, editors, Proceedings of the 32nd International Conference on Machine Learning (ICML 2015) , volume 37 of Proceedings of Machine Learning Research , pages 2256-2265, 2015. arXiv:1503.03585.
- Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. In The Ninth International Conference on Learning Representations (ICLR 2021) , 2021. arXiv:2011.13456.
- A. M. Stuart. Inverse problems: A Bayesian perspective. Acta Numer. , 19:451-559, 2010. doi:10.1017/S0962492910000061.
- V. N. Sudakov. Linear sets with quasi-invariant measure. Dokl. Akad. Nauk SSSR , 127: 524-525, 1959.
- T. J. Sullivan. Introduction to Uncertainty Quantification , volume 63 of Texts in Applied Mathematics . Springer, 2015. doi:10.1007/978-3-319-23395-6.
- S. Sun, G. Zhang, J. Shi, and R. Grosse. Functional variational Bayesian neural networks. In The Seventh International Conference on Learning Representations (ICLR 2019) , 2019. arXiv:1903.05779.
- M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, and R. Ng. Fourier features let networks learn high frequency functions in low dimensional domains. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems , volume 33, pages 7537-7547. Curran Associates, Inc., 2020. arXiv:2006.10739.
- A. Vahdat, K. Kreis, and J. Kautz. Score-based generative modeling in latent space. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P. S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems , volume 34, pages 11287-11302. Curran Associates, Inc., 2021. arXiv:2106.05931.
- Y. Wang, D. Blei, and J. P. Cunningham. Posterior collapse and latent variable nonidentifiability. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P. S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems , volume 34, pages 5443-5455. Curran Associates, Inc., 2021. arXiv:2301.00537.
- M. Yang, B. Dai, H. Dai, and D. Schuurmans. Energy-based processes for exchangeable data. In H. Daum´ e III and A. Singh, editors, Proceedings of the 37th International Conference on Machine Learning (ICML 2020) , volume 119 of Proceedings of Machine Learning Research , pages 10681-10692, 2020. arXiv:2003.07521.
- M. Zaheer, S. Kottur, S. Ravanbhakhsh, B. P´czos, R. Salakhutdinov, and A. J. Smola. Deep o sets. In I. Guyon, U. von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 30, pages 3391-3401. Curran Associates, Inc., 2017. arXiv:1703.06114.
- B. Zhang and P. Wonka. Functional diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 4723-4732, 2024. arXiv:2311.15435. | null | [
"Justin Bunker",
"Mark Girolami",
"Hefin Lambley",
"Andrew M. Stuart",
"T. J. Sullivan"
]
| 2024-08-02T16:13:51+00:00 | 2025-01-05T17:14:53+00:00 | [
"stat.ML",
"cs.LG",
"62G07 (Primary) 65M99, 68T07 (Secondary)",
"I.2.6"
]
| Autoencoders in Function Space | Autoencoders have found widespread application in both their original
deterministic form and in their variational formulation (VAEs). In scientific
applications and in image processing it is often of interest to consider data
that are viewed as functions; while discretisation (of differential equations
arising in the sciences) or pixellation (of images) renders problems finite
dimensional in practice, conceiving first of algorithms that operate on
functions, and only then discretising or pixellating, leads to better
algorithms that smoothly operate between resolutions. In this paper
function-space versions of the autoencoder (FAE) and variational autoencoder
(FVAE) are introduced, analysed, and deployed. Well-definedness of the
objective governing VAEs is a subtle issue, particularly in function space,
limiting applicability. For the FVAE objective to be well defined requires
compatibility of the data distribution with the chosen generative model; this
can be achieved, for example, when the data arise from a stochastic
differential equation, but is generally restrictive. The FAE objective, on the
other hand, is well defined in many situations where FVAE fails to be. Pairing
the FVAE and FAE objectives with neural operator architectures that can be
evaluated on any mesh enables new applications of autoencoders to inpainting,
superresolution, and generative modelling of scientific data. |
2408.01363v1 | ## Toward Automatic Relevance Judgment using Vision-Language Models for Image-Text Retrieval Evaluation
## Jheng-Hong Yang, Jimmy Lin
David R. Cheriton School of Computer Science University of Waterloo, Canada
{jheng-hong.yang, jimmylin}@uwaterloo.ca
## Abstract
Vision-Language Models (VLMs) have demonstrated success across diverse applications, yet their potential to assist in relevance judgments remains uncertain. This paper assesses the relevance estimation capabilities of VLMs, including CLIP, LLaVA, and GPT-4V, within a large-scale ad hoc retrieval task tailored for multimedia content creation in a zero-shot fashion. Preliminary experiments reveal the following: (1) Both LLaVA and GPT-4V, encompassing open-source and closed-source visualinstruction-tuned Large Language Models (LLMs), achieve notable Kendall's τ ∼ 0 4 . when compared to human relevance judgments, surpassing the CLIPScore metric. (2) While CLIPScore is strongly preferred, LLMs are less biased towards CLIP-based retrieval systems. (3) GPT-4V's score distribution aligns more closely with human judgments than other models, achieving a Cohen's κ value of around 0.08, which outperforms CLIPScore at approximately -0.096. These findings underscore the potential of LLM-powered VLMs in enhancing relevance judgments.
In this study, we explore the adaptability of model-based relevance judgments for imagetext retrieval evaluation. Leveraging modelbased retrieval judgments presents an appealing option. Not only does it provide valuable insights before undertaking the laborious processes of document curation, query creation, and costly annotation, but it also has the potential to extend and scale up to complex search scenarios and large document collections. To explore opportunities and meet the demands for large-scale, fine-grained, and long-form text enrichment scenarios in image-text retrieval evaluation (Schneider et al., 2021; Kreiss et al., 2022; Singh et al., 2023; Yang et al., 2023), our objective is to extend the human-machine collaborative framework proposed by Faggioli et al. (2023) to the context of image-text retrieval evaluation, alongside widely adopted modelbased image-text evaluation metrics (Hessel et al., 2021; Park et al., 2021; Kim et al., 2022; Ruiz et al., 2023; Kreiss* et al., 2023).
## 1 Introduction
Cranfield-style test collections, consisting of a document corpus, a set of queries, and manually assessed relevance judgments, have long served as the foundation of information retrieval research (Cleverdon, 1960). However, evaluating every document for every query in a substantial corpus often proves cost-prohibitive. To tackle this challenge, a subset of documents is selected for assessment through a pooling process. While this method is cost-effective compared to user studies, it has limitations due to its simplifications and struggles to adapt to complex search scenarios and large document collections.
Our primary focus is on a fully automatic evaluation paradigm, where we harness the capabilities of Vision-Language Models (VLMs), including CLIP (Radford et al., 2021), as well as visual instruction-tuned Large Language Models (LLMs) like LLaVA (Liu et al., 2023b,a) and GPT-4V (OpenAI, 2023). To evaluate this approach, we conducted a pilot study using the TREC-AToMiC 2023 test collection, which is designed for multimedia content creation (Yang et al., 2023), based on our instruction prompt template for VLMs (cf. Table 1 and Section 3.2).
We observe that model-based relevance judgments generated by visual instruction-tuned LLMs outperform the widely adopted CLIPScore (Hessel et al., 2021) in terms of ranking correlations and agreements when compared to human annotations. While this discovery holds
Table 1: Prompt template for relevance estimation. The VLMs are expected to take text q and image d independently. The prompts are only applied to the textual input q , while the VLMs process the pixel values of image d directly.
## Text Input:
## Image Input:

Context: Page Title: <page\_title> Page Context: <page\_context> Section Title: <section\_title> Section Context: <section\_context>
## Relevance Instruction:
Think carefully about which images best illustrate the SECTION subject matter. Given the text and the image please answer the following questions given the criteria listed as follows:
- * Images must be significant and relevant in the topic's context, not primarily decorative. They are often an important illustrative aid to understanding.
- * Images should look like what they are meant to illustrate, whether or not they are provably authentic.
- * Textual information should almost always be entered as text rather than as an image.
## Output Instruction:
Rate the image's overall relevance (integer, scale: 1-100) in terms of matching the text. Output format: "Relevance: <score>"
promise, we also uncover the potential evaluation bias when using model-based relevance judgments. Our analysis reveals a bias in favor of CLIP-based retrieval systems in the rankings when employing model-based relevance judgments, resulting in higher overall effectiveness assessments for these systems. In summary, our contributions can be distilled as follows:
- · We demonstrate and explore the feasibility of incorporating VLMs for fully automatic image-text retrieval evaluation.
- · We shed light on the evaluation bias when utilizing model-based relevance judgments.
## 2 Related Work
Evaluation Metrics for Image-Text Relevance. Nowadays, model-based evaluation metrics are widely utilized in various visionlanguage tasks, including image captioning (Hessel et al., 2021; Chan et al., 2023b) and text-to-image synthesis (Park et al., 2021; Hu et al., 2023). Among model-based approaches, CLIP-based methods (Park et al., 2021; Kim et al., 2022; Chan et al., 2023a; Ruiz et al., 2023;
Kreiss* et al., 2023), such as CLIPScore (Hessel et al., 2021), are particularly prevalent. However, while these metrics are capable of measuring coarse text-image similarity, they may fall short in capturing fine-grained image-text correspondence (Kreiss et al., 2022; Yuksekgonul et al., 2023). Recent research has highlighted the effectiveness of enhancing model-based evaluation metrics by leveraging LLMs to harness their reasoning capabilities (Chan et al., 2023b; Lu et al., 2023; Betti et al., 2023). There exists significant potential for incorporating LLMs into model-based approaches, as LLM outputs are not limited to mere scores but can also provide free-form texts, e.g., reasons, for further analysis and many downstream tasks (Zeng et al., 2023).
Model-based Relevance Judgments. Traditionally, relevance judgments in retrieval tasks have adhered to the Cranfield evaluation paradigm due to its cost-effectiveness, reproducibility, and reliability when compared to conducting user studies. However, this approach often relies on simplified assumptions and encounters scalability challenges. Researchers have recently explored model-based automatic relevance estimation as a promising alternative. This approach aims to optimize human-machine collaboration to obtain ideal relevance judgments. Notably, studies of Dietz and Dalton (2020) and Faggioli et al. (2023) have revealed high rank correlations between model-based and human-based judgments. Additionally, MacAvaney and Soldaini (2023) have delved into the task of filling gaps in relevance judgments using model-based annotations.
## 3 Methodology
In this study, we investigate techniques for estimating image-text relevance scores, denoted as F ( q, d ) ∈ R , where q represents the text (query) and d represents the image (document). Our primary focus is on utilizing VLMs to generate relevance scores, akin to empirical values annotated by human assessors denoted as ˆ ( F q, d ) . The main objective is to assess the proximity between model-based F and human-based ˆ F in image-text retrieval evaluation. We begin with a discussion of the setting for human-based annotations, followed by the process for generating model-based annotations.
## 3.1 Human-based Annotations
Our primary focus revolves around a critical aspect of multimedia content creation, specifically, the image suggestion task, an ad hoc image retrieval task as part of the AToMiC track in the TREC conference 2023 (TRECAToMiC 2023). 1 The image suggestion task aims to identify relevant images from a predefined collection, given a specific section of an article. Its overarching goal is to enrich textual content by selecting images that aid readers in better comprehending the material.
NIST assessors classify candidate results into three graded relevance levels to capture nuances in suitability, guided by the content of the test query. The test query comprises textual elements such as the section title, section context description, page title, and page context description. Assessors base their relevance judgments on the following criteria:
Relevance scores for this task are meticulously annotated by NIST assessors, adhering to the TREC-style topk pooling relevance annotation process. A total of sixteen valid participant runs, generated by diverse image-text retrieval systems, are considered, encompassing (CLIP-based) dense retrievers, learned sparse retrievers, caption-based retrievers, hybrid systems, and multi-stage retrieval systems. The pooling depth is set to 25 for eight baseline systems and 30 for the remaining participant runs.
- · 0 (Non-relevant) : Candidates deemed irrelevant.
- · 1 (Related) : Candidates that are related but not relevant to the section context are categorized as related. They contain pertinent information but do not align with the section's context.
- · 2 (Relevant) : These candidates are considered relevant to the section context and effectively illustrate it.
## 3.2 Model-based Annotations
For automatic relevance estimation, we employ pretrained VLMs as our relevance estimator, denoted as F ( q, d |P ) . Our relevance estimator produces relevance scores given a pair of q and d , which is conditioned on P , where P represents the prompt template we used to instruct the models. Prompt engineering is a commonly adopted technique for enhancing or guiding VLMs and LLMs in various tasks (Brown et al., 2020; Radford et al., 2021). It's important to note that our current focus is on pointwise estimation, leaving more advanced ranking methods (such as pairwise or listwise) that consider multiple q and d for future exploration (Sun et al., 2023; Qin et al., 2023).
Prompt Template Design In line with our approach to relevance score annotation, we have created a prompt template designed to guide models in generating relevance scores. The prompt template, presented in Table 1, has been constructed based on our heuristics and is not an exhaustive search of all possible templates. Pretrained VLMs are expected to take both q and d to produce a relevance score following the instructions defined in the prompt template P . We anticipate that VLMs will independently process textual and visual information, and our prompt template is only applied to textual inputs. Our template comprises three essential components:
- · Context: This section processes the textual information from q . 2
- · Relevance Instruction: It incorporates taskspecific information designed to provide VLMs with an understanding of the task.
- · Output Instruction: This component offers instructions concerning the expected output, e.g., output types and format.
From Scores to Relevance Judgments. We utilize parsing scripts to process the relevance scores generated by the models and convert them into relevance judgments. 3 Considering potential score variations across different models, we apply an additional heuristic rule to map these scores into graded relevance levels: 0 (non-relevant), 1 (related), and 2 (relevant). Specifically, scores falling below the median value are categorized as 0; scores within the
2 For VLMs with limited context windows, e.g., CLIP, we only take the texts in the context part and ignore all the rest instructions.
3 For CLIP, relevance scores are computed using text and image embeddings directly.
50-75th quantile range are designated as 1; and scores exceeding the 75th quantile are assigned a relevance level of 2.
## 4 Experiments
We have undertaken an empirical comparison between human assessors and vision-language models to offer an initial evaluation of their current capabilities in estimating relevance judgments. This comparative analysis encompasses one embedding-based model (CLIP) and two LLMs trained by visual instruction tuning (LLaVA and GPT-4V). The experiments were carried out in January 2024.
## 4.1 Setups
Test Collection. Our study focuses on the image suggestion task in TREC-AToMiC 2023. In this task, queries are sections from Wikipedia pages, and the corpus contains images from Wikipedia. We assess VLMs' ability to assign relevance labels to 9,818 image-text pairs across 74 test topics. We predict relevance scores, generate qrels for 16 retrieval runs, and compare them with NIST human-assigned qrels. Note that the test topics consist of Wikipedia text sections (level-3 vital articles) without accompanying images, and NIST qrels are not publicly accessible during the training of VLMs we study in this work.
Vision-Language Models. Our experiments feature three models: CLIP (Radford et al., 2021), LLaVA (Liu et al., 2023b,a), and GPT-4V (OpenAI, 2023). CLIP serves as a versatile baseline model, offering similarity scores for image-text pairs. We use CLIPScore (Hessel et al., 2021) (referred to as CLIP-S) for calculating relevance with CLIP. However, CLIP has limitations due to its text encoder's token limit (77 tokens), making it less adaptable for complex tasks with lengthy contexts. In contrast, LLMs like LLaVA and GPT-4V, finetuned for visual instruction understanding, possess larger text encoders capable of handling extended context. These models excel in various vision-language tasks, making them more versatile compared to CLIP.
## 4.2 Correlation Study
In this subsection, our primary aim is to investigate the extrinsic properties of relevance judg- ments generated by various approaches, where we base our analysis on retrieval runs and ranking metrics. While various techniques exist to enhance the capabilities of vision-language models, including prompt engineering, few-shot instructions, and instruction tuning, our current focus centers on examining their zero-shot capabilities. We defer the exploration of other methods to future research endeavors. Following the work of Voorhees (1998), we undertake an investigation into the system ranking correlation and the agreement between the relevance labels estimated by the model and those provided by NIST annotators. We evaluate the ranking correlations concerning the primary metrics utilized in the AToMiC track: NDCG@10 and MAP, and calculate Kendall's τ , Spearman's ρ s , and Pearson's ρ p . In our agreement study, we compute Cohen's κ using NIST's qrels as references.
Overall. The primary results are showcased in Table 2, where rows correspond to the backbone model used for relevance judgment generation. Notably, models leveraging LLMs such as LLaVA and GPT-4V outperform the CLIP-S baseline concerning ranking correlation. Specifically, they achieve Kendall's τ values of approximately 0.4 for NDCG@10 and around 0.5 for MAP. For comparison, previous research reported 0.9 for τ for MAP when comparing two types of human judgments (Voorhees, 1998). While there is still room for further improvement, our observations already demonstrate enhancement compared to the CLIP-S baseline: 0.200 (0.333) for NDCG@10 (MAP). Moreover, other correlation coefficients, including Spearman and Pearson, corroborate the trends identified by Kendall's τ . Additionally, we notice a rising trend in agreement levels when transitioning from CLIP-S (-0.096) to GPT-4V (0.080), as evidenced by Cohen's κ values. The agreements achieved by the two largest models (LLaVA-13b and GPT-4V) are categorized as 'slight,' which represents an improvement over the smaller LLaVA-7b model and the baseline.
Evaluation Bias Model-based evaluations can introduce bias, often favoring models that are closely related to the assessor model (Liu et al., 2023c; Pangakis et al., 2023). We term this phenomenon as evaluation bias . This is distinct from source bias which indicates that
Table 2: Ranking correlation and judgment agreement analysis. Correlations are reported in terms of Kendall's τ , Spearman's ρ s , and Pearson's ρ p , whereas judgment agreement is reported in terms of Cohen's κ when comparing to NIST qrels.
| | | NDCG@10 | NDCG@10 | NDCG@10 | MAP | MAP | MAP | Agreement |
|-----------|-------------------------------|-----------|-----------|-----------|-------|-------|-------|-------------|
| Model | Version | τ | ρ s | ρ p | τ | ρ s | ρ p | κ |
| CLIP-S | openai/clip-vit-large-patch14 | 0.200 | 0.253 | 0.209 | 0.333 | 0.356 | 0.418 | -0.096 |
| LLaVA-7b | v1.5-7b | 0.400 | 0.532 | 0.633 | 0.483 | 0.597 | 0.507 | -0.003 |
| LLaVA-13b | v1.5-13b | 0.433 | 0.559 | 0.659 | 0.517 | 0.618 | 0.523 | 0.010 |
| GPT-4V | 1106-vision-preview | 0.400 | 0.544 | 0.540 | 0.500 | 0.594 | 0.470 | 0.080 |
Figure 1: Scatter plots of effectiveness (NDCG@10) for TREC-AToMiC 2023 runs using human-based and model-based qrels. Each data point represents the mean effectiveness of a single run evaluated with different qrels. CLIP-based runs are highlighted in red. Best viewed in color.
neural retrievers might prefer contents generated by generative models (Dai et al., 2023). To address this potential concern, we conducted an initial analysis using the scatter plot presented in Fig. 1. In this analysis, we compared the NDCG@10 scores of the 16 submissions made by participants employing different sets of qrels. Each data point on the plot corresponds to a specific run, with distinct markers representing variations in results based on relevance estimation models. Upon closer examination of the plot, we identified a positive correlation between model-based and humanbased qrels. Notably, the effectiveness of submitted systems appeared slightly higher when compared to those using human-based qrels.
To gain deeper insights, we've visually highlighted CLIP-based submissions in red for a thorough investigation. This visual distinction underscores the preference for model-based qrels for CLIP-based systems, especially evident
Table 3: Evaluation bias assessment using Relative ∆ in terms of NDCG@10 and MAP. A positive ∆ favors CLIP-based systems, while a negative ∆ favors other types of systems.
| Model | ∆ (NDCG@10) | ∆ (MAP) |
|-----------|---------------|-----------|
| CLIP-S | 114.7 | 120.5 |
| LLaVA-7b | 58.5 | 86.6 |
| LLaVA-13b | 55.8 | 83.1 |
| GPT-4V | 64 | 91.3 |
| Human | -11.7 | -19.5 |
with CLIP-S qrels. We quantitatively assess this bias using a metric adapted from the work of Dai et al. (2023):
$$\text{sents} \quad & \text{Relative} \, \Delta = 2 \frac { \text{MetricCLIP-based-MetricOthers} } { \text{MetricCLIP-based+MetricOthers} } \times 100 \%,$$
here Metric stands for a measure, e.g., NDCG@ , averaged across systems. Observing k Table 3, CLIP-S exhibits a strong bias, with Relative ∆ = 114 7 . for NDCG@10 and 120.5 for MAP. LLM-based approaches also display a slight bias towards CLIP-based systems, possibly because both LLaVA and GPT-4V rely on CLIP embeddings for image representations. In contrast, human-based qrels show the lowest bias: -11.7 for NDCG@10 and -19.5 for MAP.
## 4.3 Estimated Relevance Analysis
In this subsection, we aim to explore the intrinsic properties of relevance judgments generated by various systems. We began our analysis by examining score distributions, visualized in Figures 2 and 3, to gain insights into model-based scores.
Figure 2 presents a Cumulative Distribution Function (CDF) plot of scores before postprocessing into relevance levels (0, 1, and 2). We included NIST qrels (human) results for reference. Notably, GPT-4V's score distribution closely aligns with the human CDF, while CLIPS exhibits a smoother S-shaped distribution
Figure 2: Cumulative distribution function (CDF) plot of relevance scores from various models. Human stands for relevance annotations of NIST qrels.
Figure 3: Confusion matrices comparing humanbased and model-based qrels. Tick labels 0/1/2 represent Non-relevant/Related/Relevant graded levels. Best viewed in color.
with limited representation of low-relevance data. LLaVA produces tightly concentrated scores, adding complexity to post-processing, particularly when compared to GPT-4V.
Figure 3 illustrates confusion matrices, highlighting LLaVA's tendency to generate more 1 (related) judgments, fewer 2 (relevant), and 0 (non-relevant) judgments compared to GPT4V. We anticipate that future models will strive to produce score distributions that better match human annotations, thereby addressing these challenges and limitations. Further studies (Zhuang et al., 2023) on harnessing LLMs' relevance prediction capability are necessary.
## 5 Conclusion
This study delves into the capabilities of VLMs such as CLIP, LLaVA, and GPT-4V for automating relevance judgments in image-text retrieval evaluation. Our findings reveal that visual-instruction-tuned LLMs outperform tra- ditional metrics like CLIPScore in aligning with human judgments, with GPT-4V showing promise due to its closer alignment with human judgment distributions.
In conclusion, our research highlights the potential of VLMs in streamlining multimedia content creation while also pointing to the critical areas requiring further investigation. The path toward fully automated relevance judgment is complex, necessitating continued collaborative efforts in the research community to harness the full potential of VLMs in this domain.
Despite these advancements and low cost of model-based relevance annotation, 4 challenges such as evaluation bias and the complexity of mimicking human judgments remain. These issues underscore the need for ongoing model refinement and exploration of new techniques to enhance the reliability and scalability of automated relevance judgments.
## Acknowledgements
This research was supported in part by the Canada First Research Excellence Fund and the Natural Sciences and Engineering Research Council (NSERC) of Canada.
## References
Federico Betti, Jacopo Staiano, Lorenzo Baraldi, Rita Cucchiara, and Niculae Sebe. 2023. Let's ViCE! Mimicking human cognitive behavior in image generation evaluation. In Proceedings of the 31st ACM International Conference on Multimedia , page 9306-9312.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems , volume 33, pages 1877-1901.
David Chan, Austin Myers, Sudheendra Vijayanarasimhan, David Ross, and John Canny. 2023a. IC3: Image captioning by committee consensus. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 8975-9003.
David M Chan, Suzanne Petryk, Joseph E Gonzalez, Trevor Darrell, and John Canny. 2023b. CLAIR: Evaluating image captions with large language models. In Proceedings of the 2023 Conference
4 The cost of using GPT-4V API for the experiments is around USD 150.
on Empirical Methods in Natural Language Processing , pages 13638-13646.
Cyril W Cleverdon. 1960. The ASLIB cranfield research project on the comparative efficiency of indexing systems. In ASLIB Proceedings , volume 12, pages 421-431.
Sunhao Dai, Yuqi Zhou, Liang Pang, Weihao Liu, Xiaolin Hu, Yong Liu, Xiao Zhang, and Jun Xu. 2023. LLMs may dominate information access: Neural retrievers are biased towards LLM-generated texts. arXiv preprint arXiv:2310.20501 .
Laura Dietz and Jeff Dalton. 2020. Humans optional? Automatic large-scale test collections for entity, passage, and entity-passage retrieval. Datenbank-Spektrum , 20(1):17-28.
Guglielmo Faggioli, Laura Dietz, Charles LA Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, et al. 2023. Perspectives on large language models for relevance judgment. In Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval , pages 39-50.
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. CLIPScore: A reference-free evaluation metric for image captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 7514-7528.
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A. Smith. 2023. TIFA: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In 2023 IEEE/CVF International Conference on Computer Vision , pages 20349-20360.
Jin-Hwa Kim, Yunji Kim, Jiyoung Lee, Kang Min Yoo, and Sang-Woo Lee. 2022. Mutual information divergence: A unified metric for multimodal generative models. In Advances in Neural Information Processing Systems , volume 35, pages 35072-35086.
Elisa Kreiss, Cynthia Bennett, Shayan Hooshmand, Eric Zelikman, Meredith Ringel Morris, and Christopher Potts. 2022. Context matters for image descriptions for accessibility: Challenges for referenceless evaluation metrics. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 4685-4697.
Elisa Kreiss*, Eric Zelikman*, Christopher Potts, and Nick Haber. 2023. ContextRef: Evaluating referenceless metrics for image description generation. arXiv preprint arxiv:2309.11710 .
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023a. Improved baselines with visual instruction tuning. In NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following .
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023b. Visual instruction tuning. In Advances in Neural Information Processing Systems .
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023c. GPTEval: NLG evaluation using GPT-4 with better human alignment. arXiv preprint arXiv:2303.16634 .
Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, and William Yang Wang. 2023. LLMScore: Unveiling the power of large language models in textto-image synthesis evaluation. arXiv preprint arXiv:2305.11116 .
Sean MacAvaney and Luca Soldaini. 2023. Oneshot labeling for automatic relevance estimation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , page 2230-2235.
OpenAI. 2023. GPT-4V(ision) system card.
Nicholas Pangakis, Samuel Wolken, and Neil Fasching. 2023. Automated annotation with generative ai requires validation. arXiv preprint arXiv:2306.00176 .
Dong Huk Park, Samaneh Azadi, Xihui Liu, Trevor Darrell, and Anna Rohrbach. 2021. Benchmark for compositional text-to-image synthesis. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) .
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, et al. 2023. Large language models are effective text rankers with pairwise ranking prompting. arXiv preprint arXiv:2306.17563 .
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning , pages 8748-8763.
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. DreamBooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 22500-22510.
Florian Schneider, Özge Alaçam, Xintong Wang, and Chris Biemann. 2021. Towards multi-modal text-image retrieval to improve human reading. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop .
Janvijay Singh, Vilém Zouhar, and Mrinmaya Sachan. 2023. Enhancing textbooks with visuals from the web for improved learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 11931-11944.
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT good at search? Investigating large language models as re-ranking agents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 14918-14937.
Ellen M Voorhees. 1998. Variations in relevance judgments and the measurement of retrieval effectiveness. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval , pages 315-323.
Jheng-Hong Yang, Carlos Lassance, Rafael Sampaio De Rezende, Krishna Srinivasan, Miriam Redi, Stéphane Clinchant, and Jimmy Lin. 2023. AToMiC: An image/text retrieval test collection to support multimedia content creation. In Proceedings of the 46th International ACM SIGIR conference on research and development in information retrieval , pages 2975-2984.
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. 2023. When and why vision-language models behave like bags-of-words, and what to do about it? In The Eleventh International Conference on Learning Representations .
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Marcin Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael S Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, and Pete Florence. 2023. Socratic models: Composing zero-shot multimodal reasoning with language. In The Eleventh International Conference on Learning Representations .
Honglei Zhuang, Zhen Qin, Kai Hui, Junru Wu, Le Yan, Xuanhui Wang, and Michael Berdersky. 2023. Beyond yes and no: Improving zero-shot LLM rankers via scoring fine-grained relevance labels. arXiv preprint arXiv:2310.14122 . | null | [
"Jheng-Hong Yang",
"Jimmy Lin"
]
| 2024-08-02T16:15:25+00:00 | 2024-08-02T16:15:25+00:00 | [
"cs.IR",
"cs.CL",
"cs.CV",
"cs.MM"
]
| Toward Automatic Relevance Judgment using Vision--Language Models for Image--Text Retrieval Evaluation | Vision--Language Models (VLMs) have demonstrated success across diverse
applications, yet their potential to assist in relevance judgments remains
uncertain. This paper assesses the relevance estimation capabilities of VLMs,
including CLIP, LLaVA, and GPT-4V, within a large-scale \textit{ad hoc}
retrieval task tailored for multimedia content creation in a zero-shot fashion.
Preliminary experiments reveal the following: (1) Both LLaVA and GPT-4V,
encompassing open-source and closed-source visual-instruction-tuned Large
Language Models (LLMs), achieve notable Kendall's $\tau \sim 0.4$ when compared
to human relevance judgments, surpassing the CLIPScore metric. (2) While
CLIPScore is strongly preferred, LLMs are less biased towards CLIP-based
retrieval systems. (3) GPT-4V's score distribution aligns more closely with
human judgments than other models, achieving a Cohen's $\kappa$ value of around
0.08, which outperforms CLIPScore at approximately -0.096. These findings
underscore the potential of LLM-powered VLMs in enhancing relevance judgments. |
2408.01364v1 | ## Availability versus carrying capacity: Phases of asymmetric exclusion processes competing for finite pools of resources
Astik Haldar, 1, ∗ Parna Roy, 2, † Erwin Frey, 3, ‡ and Abhik Basu 4, §
1 Department of Theoretical Physics & Center for Biophysics, Saarland University, 66123 Saarbr¨cken, u Germany 2 Shahid Matangini Hazra Government College for Women, Purba Medinipore 721649, West Bengal, India 3 Arnold Sommerfeld Center for Theoretical Physics and Center for NanoScience, Department of Physics, Ludwig-Maximilians-Universit¨t M¨nchen, Theresienstraße 37, D-80333 Munich, Germany a u 4 Theory Division, Saha Institute of Nuclear Physics,
1/AF Bidhannagar, Calcutta 700 064, West Bengal, India
We address how the interplay between the finite availability and carrying capacity of particles at different parts of a spatially extended system can control the steady state currents and density profiles in the one-dimensional current-carrying lanes connecting the different parts of the system. To study this, we set up a minimal model consisting of two particle reservoirs of the same finite carrying capacity connected by two equally sized anti-parallel asymmetric exclusion processes (TASEP). We focus on the steady-state currents and particle density profiles in the two TASEP lanes. The ensuing phases and the phase diagrams, which can be remarkably complex, are parametrized by the model parameters defining particle exchange between the TASEP lanes and the reservoirs and the filling fraction of the particles that determine the total resources available. These parameters may be tuned to make the densities of the two TASEP lanes globally uniform or piece-wise continuous in the form of a combination of a single localized domain wall and a spatially constant density or a pair of delocalized domain walls. Our model reveals that the two reservoirs can be preferentially populated or depopulated in the steady states.
## I. INTRODUCTION
Driven diffusive systems [1-4] have served as simple models where general features of nonequilibrium steady states and phase transitions have been studied. Already in one spatial dimension, such driven systems show highly non-trivial properties even with purely local dynamics. A paradigmatic example is the totally asymmetric simple exclusion process (TASEP) [5-8]. It consists of a one-dimensional (1D) lattice with open boundaries. The dynamics are subject to exclusion at all sites, i.e., they can accommodate a maximum of one particle per site and is stochastic in nature. It involves entering a particle at one of the boundaries at a specified rate, unidirectional hopping to the following sites at rate unity until it reaches the other end, from which it leaves at another specified rate. As a function of the entry and exit rates at the boundary, the TASEP exhibits three distinct phases: the steady-state densities in bulk can be either less than half, giving the low-density phase, or more than half, giving the high-density phase, or just half, which is the maximal current phase.
biological and social systems, TASEP has been extended and generalized, leading to the discovery of novel phases and collective phenomena. For instance, it have been discovered that accounting for the exchange of particles between the transport lane and the environment gives rise to traffic jams [10, 11]. The theoretical prediction of traffic jams has recently been nicely confirmed experimentally [12]. These studies have been extended further and it was shown how molecular motors from the kinesin-8 family can regulate microtubule depolymerization dynamics and ultimately lead to length control of microtubules [13, 14]. Additionally, intriguing behaviors such as domain wall delocalization and traffic jams are found in systems with two TASEP lanes coupled through rare particle-switching events [15-17].
Historically, the TASEP was proposed as a simple model to describe protein synthesis in biological cells [9]. It became a paradigmatic nonequilibrium model when it was discovered to have boundary-induced phase transitions [5-7]. Motivated by various phenomena across
∗ [email protected]
† [email protected]
‡ [email protected]
Inspired by the dynamics of molecular motors along complex networks of microtubules in biological cells [18], TASEP has been explored on simple networks, studying the conditions for the existence of the various phases and domain walls [19-21] on various segments of the networks. Another area of research on TASEP focuses on how the interplay between TASEP on an inhomogeneous ring and particle number conservation can generate macroscopically nonuniform steady states. Studies in this direction have explored phenomena such as domain walls, their fluctuation-induced delocalization, and the competition between different types of defects [22-30].
Another interesting variant of TASEP involves coupling it with the symmetric exclusion process (SEP). This coupling has been studied in both half-closed [31, 32] and fully open geometries [33]. Some of the notable results from these studies are tip localization of motors [31], self-organized temporal patterns [32] and complex space-
dependent stationary states in the both TASEP and SEP lanes [33].
To model the coupled system of molecular motors and microtubules, in approaches complementary to Refs. [10, 11], a TASEP lane has been considered to be confined in and coupled to an embedding three-dimensional (3D) particle reservoir via particle exchanges. The consequences of the effects of diffusion on the steady states of the filament (TASEP) have been explored in Refs. [34-37], giving physical insights on the nontrivial steady states arising out of coupling between a 1D driven (TASEP) and 3D equilibrium (diffusion) processes. Further, related to these studies but staying within a strict 1D description, Ref. [38] considered a 1D open model with diffusive and driven segments connected serially, and explored the resulting modifications of the pure open TASEP phase diagram.
In the present study, we examine a distinct class of TASEP models that differ significantly from those previously discussed. These models do not feature open boundaries but instead connect the TASEP to a particle reservoir at both ends, imposing a constraint on the total number of particles in the combined system. This 'restricted access' to a finite number of particles effectively limits the particle population within the system, distinguishing it from other TASEP models. This class of models is inspired by biological processes such as protein synthesis, where the finite availability of ribosomes in a cell limits the number of proteins synthesized [39]. Similarly, it reflects traffic dynamics, where the finite number of vehicles affects the flow within a network of roads [40]; see also Ref. [41] in this context. Examples of TASEP models connected to a reservoir include driven diffusive systems with limited resources [42], various biological systems such as mRNA translation and motor protein dynamics in cells [43], and traffic flow problems [44].
In the studies on TASEPs with finite resources, the actual particle entry rates, unlike open TASEPs, depend upon the instantaneous reservoir population; the exit rates are assumed to be constants, similar to open TASEPs. A closed system consisting of a TASEP and a reservoir manifestly breaks the translation invariance and hence is a potential candidate for inhomogeneous steady-state densities. How the finite pool of available particles affect the steady state occupations and currents in comparison with open TASEPs is the key qualitative question in all these studies.
At the simplest level of modeling of a TASEP with finite resources, a single TASEP is connected at both ends to a particle reservoir, with the entry rate to the TASEP lane from the reservoir depending on the instantaneous reservoir occupation; for simplicity, the reservoir is generally taken to be a point reservoir without any spatial extent. More than one TASEP connected to a reservoir has also been considered that allows us to study competition between TASEPs for finite resources; see Ref. [45]. Detailed studies, both numerical stochastic simulations and analytical mean-field theory, reveal rich nonuniform steady-state density profiles, including domain walls in these models [39, 45, 46]. In yet another extension of this problem, the effect of a limited number of two different fundamental transport resources, viz. the hopping particles and the 'fuel carriers', which supply the energy required to drive the system away from equilibrium has been studied [47], and multiple phase transitions are reported as the entry and exit rates are changed. It may be noted that in all these studies on TASEPs with finite resources, the effective entry rate of the particles from the reservoir to the TASEP lane is not constant but depends on the instantaneous reservoir population. In contrast, the exit rate from the TASEP to the reservoir is taken to be constant, as in an open TASEP. Very recently, in substantially different modeling from the above, both the entry and exit rates are assumed to depend on the instantaneous reservoir population leading to dynamics-induced competition between the entry and exit rates [48]. How that determines the steady states of a TASEP connected to a finite reservoir has been studied, revealing significant differences in the phase diagram of the model with the other existing model of a TASEP with finite resources [48], which highlights the role of the competition between the effective entry and exit rates. This study has been extended by incorporating a dynamic defect in the TASEP lane [49]. More recently, some studies have considered TASEPs with multiple reservoirs. These include studies on the interplay of two reservoirs coupled to two TASEPs [50] and interplay of reservoirs in a bidirectional system [51]. Very recently, how direct particle exchanges between two reservoirs connected to a TASEP affect the stationary densities on the TASEP lane have been considered in Refs. [52, 53], giving insights on the competition between particle exchanges and TASEP.
Despite the recent impressive progress in this research, many open questions are yet to be addressed or investigated systematically. In the above-mentioned studies on TASEPs connected to finite reservoirs, the reservoirs are assumed to be point-like, without any spatial extent. However, real systems can be spatially extended, where different regions may act as carrying resources for the whole system. This evidently should lead to currents between different regions in the system. Furthermore, these currents may not only be controlled by the availability of resources at the 'supply side', but also by the carrying capacity of the 'receiving side'. In fact, the interplay between the finite availability and carrying capacity of particles at different parts of the system, together with the global conservation of the particles, should be the key determining factors of the eventual nonequilibrium steady state in such a system. Clearly, a single TASEP attached to a single reservoir cannot capture these phenomenologies. Some research has been done broadly along this line recently. These include studies on the interplay of reservoirs in a bidirectional system [51]. Very recently, how direct particle exchanges between two reservoirs connected to a single TASEP lane affect the stationary densities on the TASEP lane have been considered in
Refs. [52, 53], giving insights on the competition between particle exchanges and TASEP.
The general goal of the present study is to theoretically understand the classes of nonequilibrium steady states (NESS) in a system with multiple reservoirs having finite capacities and overall particle number conservation. In particular, being inspired by the physics of the interplay between the finite availability and carrying capacity of particles at different parts of the system in conjunction with the global conservation of the particles, we construct and study a simple conceptual model that consists of two reservoirs having the same finite capacity without any internal dynamics and two TASEP lanes with equal size connecting the two reservoirs in an antiparallel manner (see below) that ensures a finite steady-state current. We show that for appropriate choices of model parameters, this model can admit uniform densities in the TASEP lanes having equal or different values, as well as spatially nonuniform densities in the form of static or moving domain walls. Further, the population of the two reservoirs can also be controlled in our model - in fact, by tuning the model parameters, the reservoirs can be preferentially populated or depopulated separately in the steady states. This implies that the dynamics can maintain steady macroscopic population imbalances across the system.
OutlineThe remainder of this article is organized as follows. Section II introduces the model and defines the model parameters. Then in Section IV, we illustrate the complex phase behavior of the model in a reduced subspace of the entire parameter space using a mean-field description that we develop and supplemented by extensive Monte-Carlo simulations (stochastic simulations). Section V discusses the phase transitions and their order in this model. We summarize our results and discuss their implications in Section VII. In Appendix B, we briefly discuss our simulation algorithm for our stochastic simulations studies. We discuss some additional results on the phase diagrams in Appendix.
## II. MODEL
We consider a model with two transport lanes T 1 and T 2 of equal length L connected to two particle reservoirs R 1 and R 2 [Fig. 1]. Transport along the two lanes is antiparallel, where on each lane, particles move unidirectionally subject to site exclusion, i.e., the particle dynamics is described by a totally asymmetric simple exclusion process (TASEP). For simplicity, we assume that the hopping rates are the same on both lanes and choose them as 1 to set the time scale. We assume that the carrying capacities of the two well-mixed reservoirs are finite and equal, and particle exchange between these reservoirs is exclusively through transport along the two lanes. Due to the closed geometry of the system, there is thus an overall limitation of resources.
Let N 0 be the total number of particles available, and
Figure 1. Illustration of the model. Two anti-parallel TASEP lanes T 1 and T 2 of equal length L connect two reservoirs R 1 and R 2 of equal carrying capacity. The effective entrance rates from R i to T i at site j = 1 are denoted by α eff i , and correspondingly β eff i denote the effective exit rate of particles from T i at site j = L . Particles move unidirectionally along both lanes subject to site exclusion; the hopping rates are assumed to be the same in both lanes and are set to unity to fix the time scale.
N 1 2 , the number of particles in each reservoir R 1 2 , . Then particle number conservation implies
$$N _ { 0 } = N _ { 1 } + N _ { 2 } + \sum _ { j = 1 } ^ { L } \left ( \rho _ { j } ^ { 1 } + \rho _ { j } ^ { 2 } \right ), \quad \ \ ( 1 )$$
where ρ 1 j ∈ { 0 1 , } and ρ 2 j ∈ { 0 1 , } are the occupation numbers at site j of T 1 and T 2 , respectively. Here and below, superscripts 1 and 2 refer to the two TASEP lanes, and a subscript refers to a lattice site j in a given TASEP lane; see Fig. 1.
The exchanges of particles between the reservoirs and the lanes are characterized by entry and exit rates, which respect both the fact that the available resources are limited and that the carrying capacity of each reservoir is limited. To account for resource limitations, we assume for the entry rates from reservoir R i to lane T i
$$\alpha _ { i } ^ { \text{eff} } ( N _ { i } ) = \alpha _ { i } \, f ( N _ { i } ) \,, \, \text{ \quad \ \ } ( 2 )$$
where α i are positive constants and f ( N i ) is a monotonically increasing function of the number of available particle resources N i in reservoir R i ; in particular, one requires f (0) = 0. For simplicity, we use a linear dependence [see, e.g., Ref. [52] in this context]
$$f ( N _ { i } ) = \frac { N _ { i } } { L } \,. \quad \quad \quad ( 3 )$$
The finite carrying capacity for each reservoir must be considered when defining the exit rates. We assume that the exit rate from lane T 1 into reservoir R 2 is given by
$$\beta _ { 1 } ^ { \text{eff} } = \beta _ { 1 } \, g ( N _ { 2 } ) \,, \quad \quad \quad ( 4 )$$
where g is a monotonically decreasing function of the number of particles N 2 already contained in the reservoir R 2 ; similarly, we assume
$$\beta _ { 2 } ^ { \text{eff} } = \beta _ { 2 } \, g ( N _ { 1 } ). \text{ \quad \ \ } ( 5 )$$
Again, for simplicity, we take a linear dependence
$$g ( N _ { i } ) = 1 - f ( N _ { i } ) = 1 - \frac { N _ { i } } { L } \,. \quad \ \ ( 6 ) \quad \ \ \ z i g l \,. \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Here, we specifically have assumed that the carrying capacities of each reservoir are limited to N i ≤ L . Since the total carrying capacity of the two TASEP lanes is 2 L , the maximum number of particles in the system is N max 0 = 4 L . We define the filling factor
$$\mu = \frac { N _ { 0 } } { 2 L } \,, \quad \quad \quad ( 7 ) \quad \begin{matrix} \text{$\text{$\text{$le}$} } \\ \text{$\text{$sif$} } \end{matrix}$$
whose maximum value is µ max = 2; at µ = 1 the system is half-filled. Particle number conservation then implies
$$N _ { 1 } + N _ { 2 } + \sum _ { j = 1 } ^ { L } \left ( \rho _ { j } ^ { 1 } + \rho _ { j } ^ { 2 } \right ) = 2 \mu L \,. \quad \ \ ( 8 ) \quad \ \ \ \ ( \text{i.e.} \\ \text{Ir} \\ \text{tion}$$
While all these particular choices for the functions f and g characterizing resource limitations and carrying capacities of the reservoirs are obviously dictated by their mathematical simplicity, we expect our conclusion to apply qualitatively to more general cases.
Taken together, our model is characterized by five control parameters, the two entry rates α i , the two exit rates β i , and the filling fraction µ . For simplicity of analysis, we only consider the symmetric case where α 1 = β 2 =: a and α 2 = β 1 =: b . In this case, the dynamics remain invariant under the interchanges a ↔ b , T 1 ↔ T 2 , and R 1 ↔ R 2 concomitant with ρ 1 ↔ ρ 2 and N 1 ↔ N 2 .
## III. MEAN-FIELD THEORY
Next, we analyze the stochastic model at the meanfield level following the same reasoning as in earlier work; for a review see Ref. [54]. Neglecting correlations and factorizing higher order correlation functions the equations of motion for the mean densities ρ 1 j ( ) and t ρ 2 j ( ) read for t any site j ∈ [2 , L -1] in the bulk
$$\frac { d } { d t } \rho _ { j } ^ { i } ( t ) = \rho _ { j - 1 } ^ { i } \left [ 1 - \rho _ { j } ^ { i } \right ] - \rho _ { j } ^ { i } \left [ 1 - \rho _ { j + 1 } ^ { i } \right ]. \quad ( 9 ) & & \lambda \lambda \lambda \lambda \\ \mathbb { m } \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \xi \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \alpha \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \eta \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \skip \} }$$
For sites at the boundaries, we have
$$\frac { d } { d t } \rho _ { 1 } ^ { i } ( t ) \ = \ \alpha _ { i } ^ { \text{eff} } \left [ 1 - \rho _ { 1 } ^ { i } \right ] - \rho _ { 1 } ^ { i } \left [ 1 - \rho _ { 2 } ^ { i } \right ], \quad ( 1 0 \text{a} ) \\ \frac { d } { d t } \rho _ { L } ^ { i } ( t ) \ = \ \rho _ { L - 1 } ^ { i } \left [ 1 - \rho _ { L } ^ { i } \right ] - \beta _ { i } ^ { \text{eff} } \rho _ { L } ^ { i } \,. \quad ( 1 0 b ) \quad \text{The} \quad \bullet \\ \text{The model exhibits particle-hole symmetric} \text{ in the fol-}$$
The model exhibits particle-hole symmetry in the following sense: In lane T 1 , a jump of a particle to the right corresponds to a vacancy movement by one step to the left . Similarly, a particle entering T 1 at the left boundary can be interpreted as a hole leaving it through the left boundary, and vice versa for the right boundary. Likewise, in lane T 2 , a jump of a particle to the left corresponds to a vacancy movement by one step to the right . Furthermore, a particle entering lane T 2 at the right boundary may be interpreted as a vacancy leaving it through the right boundary, and vice versa for the left boundary. It is easy to check that the transformations
$$\mu \leftrightarrow 2 - \mu \,. \quad \quad \quad ( 1 1 a ) \\ \lambda ^ { i } \, \sin \, \frac { 1 } { 1 } \, \lambda ^ { i } \, \quad \quad \quad \, / \frac { 1 } { 1 } \, \lambda$$
$$\alpha _ { 1, 2 } ^ { \text{eff} } \leftrightarrow \beta _ { 1, 2 } ^ { \text{eff} } \,, \quad \quad \quad ( 1 1 c )$$
$$\rho _ { j } ^ { i } & \leftrightarrow 1 - \rho _ { L - ( j - 1 ) } ^ { i } \,, \quad \quad ( 1 1 b ) \\ \text{eff} \ \dots \ o \text{eff} \ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
leave Eq. (8) and Eqs. (9)-(10b) invariant. Furthermore, since α eff 1 = aN /L 1 , β eff 1 = (1 b -N /L 2 ), α eff 2 = bN /L 2 , and β eff 2 = a (1 -N /L 1 ), Eq. (11c) implies invariance under a ↔ b together with N /L 1 ↔ -1 N /L 2 . These properties allow us to obtain phase diagrams of the model for µ > 1 (i.e., more than half-filled) from those with µ < 1 (i.e., less than half-filled).
In what follows below, for convenience of presentation of our results, we take taking continuum limit with ρ i ( x ) ≡ 〈 ρ i j 〉 , denoting the steady state densities in T 1 and T 2 ; x = j/L becomes quasi-continuous in the limit L →∞ with 0 ≤ x ≤ 1 [23]. For each of T 1 and T 2 , x starts from 0 at the respective entry end with x = 1 at the respective exit end.
## IV. MEAN-FIELD PHASE DIAGRAMS
In steady state (within mean-field theory), each of the two lanes is characterized by a constant particle current [54]
$$J _ { i } = \rho _ { i } \left ( 1 - \rho _ { i } \right ), \text{ \quad \ \ } \text{(1)}$$
where ρ i ∈ [0 , 1] denotes the steady-state particle density on lane T i . These currents are related to the number of particles in each reservoir by the flux balance equation
$$\frac { d N _ { 1 } } { d t } = J _ { 2 } - J _ { 1 } = - \frac { d N _ { 2 } } { d t } \,. \quad \quad \ ( 1 3 )$$
Hence, in steady state, the currents on both lanes must be equal
$$J = J _ { 1 } = J _ { 2 } \,. \quad \quad \quad ( 1 4 )$$
For a given current J , the possible densities are
$$\rho = \frac { 1 } { 2 } \left ( 1 \pm \sqrt { 1 - 4 J } \right ) = \colon \rho _ { \pm } \,. \quad \quad ( 1 5 ) \\. \quad \cdot \quad \cdot \,. \quad. \quad \cdot \,. \quad. \quad.$$
Then, there are the following possible steady states:
- · Uniform and equal densities: The densities on both lanes are spatially uniform and equal to each other: ρ 1 = ρ 2 = ρ . For ρ = ρ -and ρ = ρ + , both lanes are in a low density (LD) and a high density (HD) phase, respectively. In the particular case that the current is at its maximal value J = 1 4 , the density equals ρ = 1 2 (maximal current (MC) phase).
- · Uniform and unequal densities: The densities on both lanes are spatially uniform but distinct. Then ρ 1 = ρ ± and ρ 2 = 1 -ρ 1 = ρ ∓ . This means that while one lane has a bulk density ρ + , the other has ρ -, and vice versa.
- · Nonuniform densities: The density profile on one of the two lanes or both exhibit a domain wall (DW), i.e., a step-like profile connecting the densities ρ ± in bulk. These domain walls may be fixed in place (localized) or move (delocalized); see the discussion further below.
A list of the distinct phases on lanes T 1 and T 2 (excluding those obtained by interchanging T 1 and T 2 ) are shown in a tabular form in Table I.
Table I. List of the distinct phases on lanes T 1 and T 2 . This list does not include phases that can be obtained by the interchange of T 1 and T 2 .
| Phases | T 1 | T 2 |
|-------------------------------------|---------------------------------------------------------------|-------------------------------------------------------------------------------|
| LD-LD HD-HD LD-HD LD-DW HD-DW MC-MC | ρ 1 = ρ - ρ 1 = ρ + ρ 1 = ρ - ρ 1 = ρ - ρ 1 = ρ + ρ 1 = 1 / 2 | ρ 2 = ρ - ρ 2 = ρ + ρ 2 = ρ + ρ 2 : domain wall ρ 2 : domain wall ρ 2 = 1 / 2 |
## A. Phase diagrams and phase boundaries
Now that we know the possible phases of the reservoircoupled TASEP lanes, the next task is to determine where these steady states are located in the space of the control parameters a , b , and µ . Figure 2 shows the mean-field phase diagram as a function of the two control parameters a and b and a set of representative values for the filling factor µ ( µ = 3 8 / , 5 / 8 , 7 / 8 , 1); see Fig. 4 in Appendix A for µ = 9 8 / , 11 / 8 , 13 / 8. The obtained phase diagrams show different topologies depending on the value of the filling fraction µ , with a much richer range of phases than an open TASEP. Some of these phases and phase diagrams have no analogs in other models for TASEPs with finite resources [39, 46] having the same number of control parameters (three).
When determining the phase diagram, we proceeded similar as in Refs. [23, 39, 55]. We determine these phases by comparing with the standard phases of an open TASEP, parameterized by α T and β T as the entry and exit rates, respectively; here, 0 < α , β T T < 1. Recall that in an open TASEP, the conditions for the transitions between the different phases can be obtained by equating the respective currents in those phases [54]. From this condition, one infers that the transition between the LD and HD phases occurs when α T = β T < 1 / 2. Moreover, since α T and 1 -β T are the bulk densities in the LD and HD phases, respectively, the above condition also implies that the sum of the bulk densities in the LD and HD phases should be unity at the transition. Similarly, one finds that the transitions between the LD and MC phases and HD and MC phases occur, respectively, for α T = 1 2 / < β T , and β T = 1 2 / < α T . The phase boundary between the LD and HD phases is a first-order line characterized by phase coexistence in the form of a single DW; the equation for this line is α T = β T ≤ 1 / 2. These considerations allow us to obtain the phase diagram of an open TASEP as a function of α T and β T : For α T < 1 / 2 , α T < β T one has the LD phase, the HD phase exists for β T < 1 / 2 , β T < α T , and the MC phase is found when α T > 1 / 2 , β T > / 1 2.
Since the present model has two TASEP lanes, the phases of both lanes must be specified simultaneously to determine the steady state of the model. Again, following the same logic used to obtain the phase diagram for an open TASEP, the transitions between the phases in which T 1 and T 2 each have a spatially uniform density (which may or may not be equal) can be determined by equating the respective currents. For instance, this condition tells us that the phase boundary between the LD-HD and the MC-MC phases is given by equating the densities ρ 1 (LD) and ρ 2 (HD) of T 1 and T 2 in their LD and HD phases respectively to 1/2: ρ 1 (LD) = 1 / 2 and ρ 2 (HD) = 1 2. / Similarly, the boundary between the LD-LD and MCMC phases is given by the conditions ρ 1 (LD) = 1 / 2 and ρ 2 (LD) = 1 / 2. In Fig. 2, it can further be seen that there are phases with 'domain walls' (DW) that basically generalize the coexistence line of an open TASEP and are characterized by a single DW with a specific position as a function of a , b , and µ ; see Ref. [23] for a similar DW phase in a ring model consisting of a driven and a diffusive segment. The boundaries of the DW phases can be determined by considering the positions of the DW at the two boundaries of the TASEP lane [23]. In the following, we will explain the emergence of the different phases and the resulting phase boundaries in more detail.
To validate our mean-field theory, we have also performed stochastic simulations (using a random sequential updating algorithm) to determine the phase diagrams, and we find good agreement with our mean-field theory predictions; see Appendix B for more details on the numerical simulations.
## B. Uniform lane density: ρ 1 = ρ 2
Assuming that the densities on the two lanes are the same and spatially uniform, ρ 1 = ρ 2 = ρ , the condition of particle number conservation reads
$$N _ { 0 } = N _ { 1 } + N _ { 2 } + 2 L \rho \,. \quad \quad \ ( 1 6 )$$
Clearly, the possible phases are the LD-LD, HD-HD and MC-MC phases.
LD-LD phase. If both lanes are in their LD phases one has ρ 1 = α eff 1 and ρ 2 = α eff 2 [5]. Since ρ 1 = ρ 2 , this
Figure 2. Phase diagram in the a -b plane obtained from mean-field theory (continuous lines) and stochastic simulations (symbols) for a set of representative filling factors µ indicated in the graphs. (a) µ = 3 8: / The phases are LD-LD, DW-LD, and LD-DW. This topology of the phase diagram is valid for 1 / 4 < µ < 1 2; (b) / µ = 5 8: / The phases are LD-LD, DW-LD, LD-DW and MC-MC, valid for 1 2 / < µ < 3 4; (c) / µ = 7 8: The phases are LD-LD, LD-HD, HD-LD, DW-LD, LD-DW, and / MC-MC, valid for 3 / 4 < µ < 1; (d) µ = 1: The phases are LD-HD, HD-LD, and MC-MC. See the main text for a detailed discussion.
implies af N ( 1 ) = b f ( N 2 ), resulting in
$$\frac { N _ { 1 } } { N _ { 2 } } = \frac { b } { a } \,. \quad \quad \ \ ( 1 7 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \quad \quad$$
HD-HD phase. If both lanes are in an HD phase, ρ 1 = ρ 2 = ρ HD , we have ρ 1 = 1 -β eff 1 and ρ 2 = 1 -β eff 2 . This implies (using the explicit expressions for the effective rates Eq. (4))
Together with particle number conservation [Eq. (16)] this yields the number of particles in each of the reservoirs in terms of the filling fraction µ
$$N _ { 1 } = \frac { 2 L \mu b } { a + b + 2 a b } \,, \ \ N _ { 2 } = \frac { 2 L \mu a } { a + b + 2 a b } \,, \quad ( 1 8 ) \quad \text{when}$$
and the density on both lanes
$$\rho _ { \text{LD} } = \frac { 2 a \mu } { 1 + 2 a + a / b } \,. \quad \quad \quad ( 1 9 )$$
As expected, the density of particles in both reservoirs and on both transport lanes scale with the filling fraction µ .
$$a \left ( 1 - \frac { N _ { 1 } } { L } \right ) = b \left ( 1 - \frac { N _ { 2 } } { L } \right ), \text{ \quad \ \ } ( 2 0 )$$
which, when combined with particle number conservation [Eq. (16)], yields
$$N _ { 1 } = \frac { N _ { 0 } - L ( 3 - 2 a - a / b ) } { 1 + 2 a + a / b } \,, \quad \quad ( 2 1 \mathbf a )$$
$$N _ { 2 } = \frac { a N _ { 0 } / b + L ( 1 + 2 a - 3 a / b ) } { 1 + 2 a + a / b } \,. \quad \ ( 2 1 b )$$
Thus one obtains for the lane density
$$\rho _ { \text{HD} } = \frac { 1 - 2 a + a / b + 2 a \mu } { 1 + 2 a + a / b } \,. \quad \quad ( 2 2 )$$
The above results for the HD-HD phase are clearly consistent with the particle-hole symmetry articulated above, vis-`-vis the LD-LD phase. a
MC-MC phase. For an MC-MC phase one has ρ 1 = 1 / 2 = ρ 2 . In an open TASEP, one obtains a MC phase in the regime where both the entry and exist rates are larger than 1 / 2 [54]. In our model this translates to the following conditions
$$\alpha _ { 1 } ^ { \text{eff} } = a \frac { N _ { 1 } } { L } > \frac { 1 } { 2 }, \, \beta _ { 1 } ^ { \text{eff} } = b \left ( 1 - \frac { N _ { 2 } } { L } \right ) > \frac { 1 } { 2 } \,, \, ( 2 3 \tt a ) \quad \overset { \infty } { \text{Since} } \quad \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text \text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\tt$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$
$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$}\$$
$$\alpha _ { 2 } ^ { \text{eff} } = b \frac { N _ { 2 } } { L } > \frac { 1 } { 2 }, \, \beta _ { 2 } ^ { \text{eff} } = a \left ( 1 - \frac { N _ { 1 } } { L } \right ) > \frac { 1 } { 2 } \,, \, ( 2 3 b ) \quad \begin{array} { c } \mu = \\ \\ \text{MC} \end{array} \\ \text{pac} \mathfrak { i }$$
subject to the overall particle number conservation.
Given the above relations, we now use the principles discussed in Section IV A to determine the various phase boundaries in Fig. 2 for different values of the filling fraction µ . To this end, we first consider the boundaries between the phases in which T 1 and T 2 have spatially uniform densities, belonging to either the LD or the HD phase. Following our discussion of the phase diagram of an open TASEP in Section IV A, we note that the phase boundary between the LD-LD and HD-HD phases should be given by ρ LD + ρ HD = 1. Since both ρ LD and ρ HD are functions of a, b and µ , this condition specifies the boundary in terms of these parameters. Using Eqs. (19) and (22), we find that this condition is satisfied only if µ = 1, i.e., coexistence of the LD-LD and HD-HD phases is possible only in the half-filled limit. Further, noting that ρ LD ≤ 1 / 2, we get by using Eq. (19) along with µ = 1
$$a + b > 2 a b \text{ \quad \ \ } ( 2 4 )$$
as the region of co-existence of the LD-LD and HD-HD phases. Since the filling fraction µ is bounded between 0 and 2, the LD-LD phase is expected to be in the range 0 ≤ µ ≤ 1 and the HD-HD phase for 1 ≤ µ ≤ 2, which is consistent with the particle-hole symmetry of the model. Within the co-existence region, the density jump ρ HD -ρ LD , which is the difference in the densities of the HD and LD phases, depends on the position in the phase diagram, i.e., the values of a and b . Approaching ( a, b ) = (1 , 1) on the boundary line a + b = 2 ab (with µ = 1), the density jump is given by
$$\rho _ { \text{HD} } - \rho _ { \text{LD} } = 1 - \frac { 4 a b } { a + b + 2 a b } \quad \quad ( 2 5 ) \quad \quad \ r$$
vanishes, where we have used Eqs. (22) and (19), respectively, for ρ HD and ρ LD .
The boundary between the LD-LD and MC-MC phases can be obtained from the condition ρ LD = 1 2. This gives /
$$a + b + 2 a b = 4 a b \mu \quad \quad \ ( 2 6 ) \quad \ \text{$\nu$}$$
as the boundary parameterized by µ ; see Fig. 2(b) showing the LD-LD and MC-MC phase boundary for µ = 5 8. /
Similarly, the boundary between the HD-HD and MCMC phases is obtained from the condition ρ HD = 1 2, / giving
$$a + b + 2 a b = 4 a b \left ( 2 - \mu \right ) ; \quad \ \ ( 2 7 ) \\ \quad \ \ w / w \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
see Fig. 4(b) showing the HD-HD and MC-MC phase boundary for µ = 11 8. /
We now argue that the MC-MC phase can exist only when 1 2 / < µ < 3 / 2. For ρ 1 = 1 2 = / ρ 2 , the total particle content of the two TASEP lanes together is L . Since both N 1 and N 2 must be non-negative, we must have N > L 0 . This implies that the filling fraction µ = N / 0 (2 L ) must obey the inequality µ > 1 / 2 for the MC-MC phase to exist. Likewise, since the carrying capacity of each reservoir is L , both N 1 and N 2 are bounded by L . Hence, we have µ < 3 / 2 as an upper bound for the MC-MC phase to exist. This upper bound can also be obtained by applying the particle-hole symmetry. According to this symmetry, if ρ is a steady state density solution for µ , 1 -ρ should also be a solution for 2 -µ ; see (11a) and (11b). For the present case, this means if there is no MC-MC phase for µ < 1 / 2, there cannot be any MC-MC phase for µ > 3 / 2.
In this Section IV B, we have thus used MFT to obtain stationary densities of the uniform phases on the TASEP lanes and the associated reservoir populations. In particular, we obtain the LD phase density ρ LD , the HD phase density ρ HD and the corresponding reservoir populations. In the case of the MC phase on the TASEP lane, our MFT gives only bounds on the reservoir populations, instead of specific values. In the next Section, we use MFT to calculate the nonuniform phases and the transitions between them.
/negationslash
## C. Nonuniform lane density: ρ 1 ( x ) = ρ 2 ( x )
/negationslash
We now construct the spatially nonuniform mean-field theory solutions with ρ 1 ( x ) = ρ 2 ( x ). Nonetheless, ρ 1 ( x ) and ρ 2 ( x ) must still be constructed out of the two basic solutions ρ + and ρ -, which are given in (15) above. As discussed earlier, there are two distinct sub-cases: (a) one or both the lanes have a domain wall each, (b) the two lanes have densities that are spatially uniform but distinct.
## 1. LD-DW and LD-HD phases
LD-DW phase.We first focus on the case when there is a single domain wall formed in the bulk of one of the TASEP lanes. For specificity, consider the case where a DWis formed on lane T 2 , and lane T 1 is in the LD-phase with uniform density ρ -( x ) = α eff 1 . Thus, on lane T 2 the DW, positioned at x w 2 , connects a low density regime with density ρ -( x ) = α eff 2 to a high density regime with density ρ + ( x ) = 1 -ρ -( x ) such that
$$\rho _ { 2 } ( x ) = \alpha _ { 2 } ^ { \text{eff} } + \Theta ( x - x _ { w 2 } ) ( 1 - 2 \alpha _ { 2 } ^ { \text{eff} } ). \quad ( 2 8 )$$
Here Θ( ) is x the Heavyside theta-function defined by Θ( ) = 1(0) for x x > 0( < 0). We signify this in the following as the 'LD-DW phase'.
Since the current in a steady state must be uniform and constant, one has α eff 1 ( N 1 ) = α eff 2 ( N 2 ) = β eff 2 ( N 1 ), resulting in
$$f ( N _ { 1 } ) = g ( N _ { 1 } ) = 1 - f ( N _ { 1 } ) \,. \quad \ \ ( 2 9 ) \quad \ \ p h a _ { 1 \ t | }$$
This, in turn, gives
$$N _ { 1 } = \frac { L } { 2 } \,. \quad \quad \quad ( 3 0 ) \quad \overset { \text{by} } { \text{Fc} } \\ \underset { \text{d} } { \text{by} }$$
We then obtain α eff 1 ( N 1 ) = α eff 2 ( N 2 ) = a/ 2, which in turn gives N 2 = La/ (2 ). b Thus, both N 1 and N 2 are independent of µ . We also get, by using the value of α eff 1 ( N 1 )
$$\rho _ { 1 } = \frac { a N _ { 1 } } { L } = \alpha _ { 1 } ^ { e f f } = \frac { a } { 2 } \equiv \rho _ { 1, \text{LD} } \quad \quad ( 3 1 )$$
as the bulk density on lane T 1 . This further gives
$$\rho _ { 2, \text{LD} } = \alpha _ { 2 } ^ { \text{eff} } = a / 2 = \alpha _ { 1 } ^ { \text{eff} } \quad \quad ( 3 2 \text{a} ) \quad \begin{smallmatrix} a / 2 \\ \text{Sin} \end{smallmatrix}$$
$$\rho _ { 2, \text{HD} } = 1 - \beta _ { 2 } ^ { \text{eff} } = 1 - a / 2 \quad \ \ ( 3 2 b ) \quad \ t o g$$
as the densities of the LD and HD segments of lane T 2 , respectively.
For a complete characterization of the domain wall, we need to specify both its position and height. The position of the domain wall x w 2 can now be determined by using particle number conservation [see Eq. (8)]
$$N _ { 1 } + N _ { 2 } + \sum _ { j = 0 } ^ { L } \sum _ { i = 1, 2 } \rho _ { j } ^ { i } = 2 \mu L. \quad \ \ ( 3 3 ) \quad \ \ L \\ \ t \text{term} \quad \ \ \ \\ \text{tho} \quad \ \ }$$
Using the quasi-continuous coordinate x , Eq. (33) can be written as
$$\frac { N _ { 1 } } { L } + \frac { N _ { 2 } } { L } + \int _ { 0 } ^ { 1 } d x \left [ \rho _ { 1 } ( x ) + \rho _ { 2 } ( x ) \right ] = 2 \mu \,. \quad ( 3 4 ) \quad \text{The} \\ \cdots \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad \text{when}$$
Using the values of ρ 1 ( x ) and ρ 2 ( x ) in Eq. (31) and Eq. (32) we find
$$x _ { w 2 } = \frac { ( 3 + a / b ) / 2 - 2 \mu } { 1 - a } \,. \quad \quad ( 3 5 ) \quad \text{ph} \varepsilon \\ \varepsilon \colon \text{and} \, \varepsilon \text{ then} \, \text{and} \, \text{and} \, \text{in} \, \varepsilon \text{ and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \,$$
Since the location of the domain wall x w 2 , is uniquely determined for a given set of parameters a , b , and µ , the domain wall is pinned , i.e., it is a localized domain wall (LDW).
Having obtained the domain wall positions, we now write down the height ∆ 2 of the LDW in the LD-DW phase. This is given by
$$\Delta _ { 2 } \equiv \rho _ { 2, \text{HD} } - \rho _ { 2, \text{LD} } = 1 - 2 \alpha _ { 2 } ^ { \text{eff} } = 1 - a. \quad ( 3 6 ) \quad \text{it via} \\ \quad \text{the l}$$
What is the minimum value of µ required for which the LD-DW phase is possible? Particle number conservation can be used to answer this. We note that in the LD-DW
phase, N 1 = L/ 2 [see Eq. (30) above]; minimum of N 2 = La/ (2 ) is zero (when b a = 0). The steady-state particle number in T 2 depends upon x w 2 . For it to be minimum, x w 2 = 1, giving 2 α eff 1 = a , which vanishes if a = 0. This means for the LD-DW phase, min( N 0 ) = L/ 2 giving µ > 1 / 4 as the necessary condition for the LD-DW phase. This explains the existence of the LD-DW phase in the phase diagrams with µ = 3 8 / , 5 / 8 , 7 / 8 in Fig. 2. (At µ = 1, the LD-DW phase vanishes; see later.) The mean-field theory profiles of the LDW as above are corroborated by our stochastic simulations studies; see Fig. 3 (top). For µ > 1, there are HD-DW phases instead of LD-DW phases; see Appendix A.
LD-HD phase.In the LD-HD phase, the lanes T 1 and T 2 are in the LD and HD phases, respectively. Thus ρ 1 and ρ 2 are both uniform but distinct: We have ρ 1 = ρ -= 1 -ρ 2 . This means by using Eq. (5)
$$\alpha _ { 1 } ^ { \text{eff} } ( N _ { 1 } ) = \beta _ { 2 } ^ { \text{eff} } ( N _ { 1 } ). \text{ \quad \ \ } ( 3 7 )$$
Now by using N 1 = L/ 2[see Eq. (30) above, we get ρ 1 = a/ 2 and ρ 2 = 1 -ρ 1 = 1 -a/ 2 in the LD-HD phase. Since ρ 1 + ρ 2 = 1, the total particle content in T 1 and T 2 together is just L . We further get
$$N _ { 2 } = N _ { 0 } - N _ { 1 } - L = N _ { 0 } - 3 L / 2. \quad \ ( 3 8 )$$
Since N 2 ≥ 0, we must have N 0 ≥ 3 L/ 2, or µ > 3 / 4 for this phase to exist. Furthermore, since N 2 ≤ L , from Eq. (38) we must have N 0 ≤ 5 L/ 2 or µ < 5 / 4, in agreement with the particle-hole symmetry of this model. Thus, this phase is possible only in the range 3 / 4 ≤ µ ≤ 5 / 4.
LD-DW and LD-HD phase boundaries.We now determine the phase boundaries of the LD-DW and LD-HD phases with the other possible phases. In the LD-DW phase, there is a domain wall in T 2 at x w 2 , which lies between 0 and 1. When x w 2 = 1, the domain wall is shifted to the left boundary of T 2 , so that T 2 is in its LD phase. Therefore, x w 2 = 1 gives the condition for the boundary between the LD-DW and LD-LD phases. Similarly, when x w 2 = 0 entire T 2 is in its HD phase, which then gives the condition for the boundary between the LDDW and LD-HD phases. Setting x w 2 = 0 in Eq. (35) we get the boundary between the LD-DW and LD-HD phases:
$$a + 3 b = 4 b \mu \,. \quad \quad \quad ( 3 9 )$$
This straight line passes through the origin in the a -b plane. The slope of the line (39) in the a -b plane is 1 / (4 µ -3) that approaches infinity as µ → 3 / 4 from above. This means as µ → 3 / 4 from above, the line (39) coincides with the b axis. Since the LD-HD phase exists for a + 3 b < 4 µb (i.e., on the left of the line (39)), it vanishes as µ → 3 / 4 from above, giving µ = 3 4 as / the lower threshold of µ for the existence of the LD-HD phase, a conclusion also obtained above by demanding non-negativity of N 2 ; see discussions below Eq. (38). Just as we find there is a lower threshold on µ for the existence
of the LD-HD phase, there is also an upper threshold on µ as well. This upper limit on µ can be conveniently extracted by using the particle-hole symmetry of the model. We first note that due to the symmetry under interchange of T 1 and T 2 , if µ = 3 4 is the lower threshold of / µ for the existence of the LD-HD phase, µ = 3 4 must the / lower threshold for the existence of the HD-LD phase as well. Now applying the particle-hole symmetry given in Eqs. (9)-(10b) we conclude that the LD-HD phase, which is the particle-hole symmetric counterpart of the HD-LD phase, can exist only when µ < (2 -3 / 4) = 5 / 4. We therefore find that the LD-HD phase can exist only in the window 3 / 4 < µ < 5 / 4. This is consistent with the fact that there is an LD-HD phase for µ = 7 8 / , 9 / 8 but none with µ = 5 8 / , 13 / 8 in the phase diagrams in Fig. 2 and Fig. 4.
LD-DW and LD-LD phase boundaries.We now study the phase boundaries between the LD-DW and LD-LD phases. When x w 2 = 1, both T 1 and T 2 have the same density that is less than 1/2: ρ 1 = ρ 2 = a/ 2. This marks the boundary of the LD-LD phase with the LD-DW phase. Setting x w 2 = 1 in (35), we get the equation for the boundary between the LD-DW and LD-LD phases:
$$a + b + 2 a b = 4 b \mu \,. \quad \quad ( 4 0 ) \quad \underset { \mathfrak { m c } } { \infty }$$
Hence, for a + +2 b ab < 4 bµ , there is an LDW in the bulk of T 2 , i.e., x w 2 < 1. On the boundary given by Eq. (40), Eq. (19) gives ρ LD = a/ 2, showing the continuity of the densities across the boundary (40).
In the parameter regime in the a -b plane that is bounded between the lines (39) and (40) there is a domain wall formed in the bulk of T 2 , with T 1 having a uniform density. In contrast, in the parameter regime a +3 b < 4 µb , T 1 and T 2 both have individually uniform bulk (but different) densities, being in their LD and HD phases, respectively.
We notice that the boundary between the LD-DW and LD-LD phases in the phase diagrams of Fig. 2 as given by Eq. (40) passes through the origin (0,0) in the a -b plane. We have already found that for µ < 3 / 4, the slope of (39), which gives the boundary between the LD-DW and LD-HD phases in the phase diagrams of Fig. 2, turns negative. This makes the LD-HD phase disappear, leaving with only the LD-DW and LD-LD phases. Thus for µ < 3 / 4 the LD-DW phase is possible in the parameter region confined between the b -axis and the line given by Eq. (40). We then find that the slope of (40)
$$\frac { d b } { d a } = \frac { 1 } { 4 \mu - 1 } \quad \quad ( 4 1 ) \quad \quad \\ \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
at the origin, which diverges as µ → 1 / 4. Further at all a > 0, db/da < 0 for µ < 1 / 4. Therefore, the parameter region for the LD-DW phase, being confined between the b -axis and the line (40) for µ < 3 / 4 must vanish for µ < 1 / 4, indicating disappearance of the LD-DW phase for µ < 1 / 4. Indeed, we find the LD-DW phase to exist for µ = 3 8 5 8 7 8 in the phase diagrams in / , / , / Fig. 2. Notice that there is no LD-DW phase in the phase diagram for µ = 1 in Fig. 2. We return to the phase diagram's structure for µ = 1 later.
Lines (39) and (40) intersect at (0 , 0) and (1 1 , / (4 µ -3)); the latter is also their common point of intersection with the line (26). This means that in general, for b > 1 / (4 µ -3), both the LD-LD and the LD-DW phases cease to exist; instead, one has a transition between the LD-HD and MC-MC phases across the line a = 1 with b > 1 / (4 µ -1). See the phase diagram with µ = 7 8 in / Fig. 2.
/negationslash
Both the LD-HD and LD-DW phases are nonuniform phases, i.e., ρ 1 ( x ) = ρ 2 ( x ). However, the role of µ , i.e., effect of changing the total resources N 0 on these two nonuniform phases are quite distinct from each other. For example, within the LD-DW phase, which is to be found in the phase space region between the boundaries (39) and (40), N 1 = L/ 2 [see Eq. (30)], a constant, independent of a, b and µ , whereas N 2 depends explicitly on a and b , but not on µ ; see Eq. (38). This implies that for a given pair of ( a, b ), α eff 2 ( N 2 ) = β eff 2 ( N 1 ) do not depend upon µ within the phase space region of the LD-DW phase. Therefore, within this region, if µ or N 0 varies, the increase or decrease in the particle number is accommodated by an equivalent shift in x w 2 , i.e., by changing the position of the LDW. This ensures that for a given pair of ( a, b ) within the phase space region of the LDDW phase (i.e., at a given point in the phase diagram), there is no change in the steady state current J LD-DW even when µ varies. In contrast, in the LD-HD phase of the model, N 2 is independent of a and b since N 1 = L/ 2, and the total particles in T 1 and T 2 are independent of a and b . The total particle content in T 1 and T 2 is just L , independent of µ as well. Hence, any change in µ must lead to a change in N 2 in the LD-HD phase; see (38) above. This however does not change the densities in the individual TASEP lanes, since the latter are controlled by N 1 , which remains fixed in the LD-HD phase, even when µ changes. Therefore, the steady state bulk current remains unaltered even if µ varies. We thus see that in the LD-DW phase, a changes in the total resources is reflected in the position of the LDW, whereas in the LD-HD phase it is reflected in N 2 , the particle content of R 2 , the reservoir that does not control the bulk densities in the TASEP lanes in the LD-HD phase.
## 2. DW-LD and HD-LD phases
In the above analysis for the LD-DW phase, we have assumed a domain wall in T 2 . Instead, a domain wall could be formed in T 1 , with T 2 being in the LD phase, giving the DW-LD phase. Following the logic outlined above we find
$$N _ { 2 } = L / 2, \text{ \quad \ \ } ( 4 2 )$$
which is the analog of Eq. (30) and ρ 2 = b/ 2. Further, the density profile ρ 1 ( x ) now consists of two domains: one with value b/ 2 and the other with value 1 -b/ 2, meeting at x w 1 creating a domain wall at that point inside the bulk of T 1 . Using these values of the two domains in T 1 and following the logic outlined above to calculate x w 2 , the position of an LDW in T 2 in the LD-DW phase, we can use the particle number conservation to calculate the location x w 1 of the LDW in T 1 in the DW-LD phase of the system. It is given by
$$x _ { w 1 } & = \frac { ( 3 + b / a ) / 2 - 2 \mu } { 1 - b }, \quad \ ( 4 3 ) \quad \ \text{with} \\ \text{is both } \Lambda \, - \, 1 \quad k \ T h o \, \text{domain} \, \text{will notion } \theta \,.$$
with a height ∆ 1 = 1 -b . The domain wall position x w 1 lies between 0 and 1. When it is at 1, the LDW in T 1 has completely to the right (exit) boundary, leaving entire T 1 to be in its LD phase. Thus, the boundary between the LD-LD phase and DW-LD phase is obtained by setting x w 1 = 1. From (43) we get with x w 1 = 1
$$a + b + 2 a b = 4 a \mu. \quad \quad \ ( 4 4 ) \quad \text{an}.$$
Likewise, when x w 1 = 0, the entire T 1 lane is in the HD phase with density ρ 1 ( x ) = ρ + = 1 -b/ 2, whereas the whole T 2 is still in its LD phase, with density ρ 2 ( x ) = ρ -= b/ 2. This condition yields the analogue of (39) given by
$$b + 3 a = 4 a \mu, \quad \quad \ \ ( 4 5 ) \quad \ \ \ \ \ \ \ n o.$$
such that for b +3 a < 4 aµ , the model remains in its HDLD phase. The slope of this line is 4 µ -3, which vanishes as µ → 3 / 4. The vanishing of the slope as µ → 3 / 4 together with the fact that the line (45) passes through the origin (0,0) in the a -b plane implies that the line (45) coincides with the a -axis as µ → 3 / 4, indicating disappearance of the HD-LD phase. Furthermore, the lines (44) and (45) intersect at (1 / (4 µ -3) 1), with this , point of intersection approaching ( ∞ , 1) as µ → 3 / 4 from above. This is also the point of intersection of (44) and (45) with the MC-MC phase boundary (26). Thus, for µ ≤ 3 / 4, the HD-LD phase vanishes, as we have concluded above. For parameter regimes falling between the lines (44) and (45), T 2 is in the LD phase, whereas there is a domain wall in the bulk of T 1 . Proceeding similarly as for the LD-HD phase above, we can show that the HD-LD phase can exist only in the range 3 / 4 ≤ µ ≤ 5 / 4. For a > 1 / (4 µ -3) with b = 1, there are no DW-LD and LD-LD phases. Instead, one has a transition from the HD-LD phase to the MC-MC phase across the line b = 1. Again proceeding similarly to our analysis for the LDDWphase, we find that the DW-LD phase disappears for µ ≤ 1 / 4. These results are connected with their counterparts for the LD-DW phase through the symmetries of the model.
/negationslash
As in our discussions on the LD-DW and LD-HD phases, both the DW-LD and HD-LD phases are nonuniform, i.e., ρ 1 ( x ) = ρ 2 ( x ). The effects of varying µ on the DW-LD and HD-LD phases run exactly parallel to its effect on the LD-DW and LD-HD phases. For a given ( a, b ), as µ changes, the LDW position x w 1 in T 1 changes in the DW-LD phase, leaving the two reservoirs and the TASEP current unchanged. In the HD-LD phase, which is controlled by R 2 with a population N 2 , a change in µ affects the value of N 1 leaving everything else unaltered.
We note that as one considers the limit a → b , then Eqs. (35) and (43) reveal that
$$x _ { w 1 } & \to 2 ( 1 - \mu ) / ( 1 - b ), \quad \quad ( 4 6 ) \\ r _ { \dots } & \rightharpoonup 2 ( 1 - u ) / ( 1 - a \dots \quad \quad ( \Delta 7 \dots )$$
$$x _ { w 2 } \rightarrow 2 ( 1 - \mu ) / ( 1 - a ), \quad \quad ( 4 7 )$$
which are identical when a → b . Furthermore, the domain wall heights ∆ 1 and ∆ 2 approach each other: ∆ 2 = 1 -a = 1 -b = ∆ . 1 Also, if a = b the two TASEP lanes are equivalent, i.e., their stationary density profiles should be statistically identical, suggesting that both the TASEP lanes can have two LDWs with equal height. In this case, the steady-state density is actually a pair of delocalized domain walls; see further discussions and analyses below.
## 3. Stationary currents and steady-state selections
/negationslash
We now consider the steady state currents in the phases with ρ 1 ( x ) = ρ 2 ( x ). First of all, in the entire inhomogeneous or nonuniform phase regions in the phase diagrams consisting of the LD-HD and LD-DW phases, by using ρ 1 = a/ 2 [see Eq. (31) above], the steady state current is given by
$$J _ { \text{LD-DW} } = \frac { a } { 2 } \left ( 1 - \frac { a } { 2 } \right ). \text{ \quad \ \ } ( 4 8 )$$
Likewise, in the entire inhomogeneous phase consisting of the HD-LD and DW-LD phases, the steady state current is given by
$$J _ { \text{DW-LD} } = \frac { b } { 2 } \left ( 1 - \frac { b } { 2 } \right ), \text{ \quad \ \ } \text{(4 9)}$$
where we have used ρ 2 = b/ 2 [see discussions in Section IV C 2 above]. On the other hand, the current in the LD-LD phase is given by
$$\stackrel { \dots } { ^ { \prime } 4. } \text{and} \quad J _ { \text{LD-LD} } \ = \ \left ( \frac { 2 a \mu } { 1 + 2 a + a / b } \right ) \left ( 1 - \frac { 2 a \mu } { 1 + 2 a + a / b } \right ) ( 5 0 )$$
where we have used (19). We now argue that the phase boundaries (40) and (44) may also be obtained by invoking a minimum current principle [56] by demanding that the currents J LD-LD and J LD-DW must be equal at the phase boundary. Indeed, the condition J LD-LD = J LD-DW gives the boundary between the LD-LD and inhomogeneous (LD-HD or LD-DW) phases in the phase diagram: we get
$$a + b + 2 a b = 4 b \mu, \text{ \quad \ \ } ( 5 1 )$$
same as (40), such that in the phase space region with J LD-LD < ( > J ) DW-LD , we get LD-LD (inhomogeneous phases comprising of the LD-DW or LD-HD) phases. Similarly, the condition J LD-LD = J DW-LD gives another boundary in the phase diagram between the LD-LD and inhomogeneous (HD-LD or DW-LD) phases as
$$a + b + 2 a b = 4 a \mu, \text{ \quad \ \ } ( 5 2 ) \text{ \quad \ }$$
that is identical to (44), such that in the region with J LD-LD < > J ( ) LD-DW , we get LD-LD (inhomogeneous, i.e., DW-LD or HD-LD) phases.
## 4. Meeting of the LD-DW and DW-LD phases
Although our mean-field theory delineates the boundaries of the LD-DW phase with the LD-HD and LD-LD phases, and those of the DW-LD phase with the HD-LD and LD-LD phases, specifying regions of the LD-DW and DW-LD phases in the ( a -b ) remains incomplete, as the boundary between LD-DW and DW-LD is yet to be specified. We will discuss this phase boundary below.
We recall that the phase boundary (40) separates the phase space regions with the LD-DW phase and the LDLD phase, whereas the phase boundary (44) separates the phase space regions with the DW-LD phase and the LD-LD phase. These two phase boundaries (40) and (44) intersect at the origin (0,0) and ( a = 2 µ -1 , b = 2 µ -1) , µ > 1 / 2. Since the LD-DW phase exists for a + b + 2 ab < 4 bµ and the DW-LD phase exists for a + +2 b ab < 4 aµ , there is a common region in the a -b plane, where both the LD-DW and DW-LD phases are predicted to exist by the mean-field theory. This raises a question which one among these two is the stable phase. We can again invoke the minimum current principle to determine the stable phase in the overlapping region between the LD-DW and DW-LD phases, i.e., between the lines a + b +2 ab < 4 bµ and a + b +2 ab < 4 aµ .
The steady state currents in DW-LD and LD-DW phases, J DW-LD and J LD-DW , respectively, are given by (49) and (48), respectively. From Eqs. (48) and (49), we find that J DW-LD < ( > J ) LD-DW when a > ( < b ) , with the two currents being equal at a = b . Thus, assuming a minimum current principle, we conclude that the line a = b forms the boundary between the two domain wall phases. The line a = b meets with the lines (40) and (44) at a = b = 2 µ -1, which coincides with the origin (0,0) when µ = 1 2. This means the boundary line / a = b between LD-DW and DW-LD phases ceases to exist for µ ≤ 1 / 2; also, the lines (40) and (44) no longer meet each other for µ < 1 / 2 at any non-zero ( a, b ); they meet only at the origin (0,0). This means the phase space regions of the LD-DW and DW-LD phases in the a -b plane do not meet if µ < 1 / 2. Particle-hole symmetry of the model tells us that for µ > 1 (i), the boundary line a = b of the HD-DW and DW-HD phases meets the analogs of (40) and (44), which are the phase boundaries of the HDDW and DW-HD phases, respectively, with the HD-HD
phase, at a = b = 3 -2 µ , (ii) hence, ceases to exist for µ ≥ 3 / 2, and (iii) these analogs of the lines (40) and (44) meet only at the origin for µ > 3 / 2. This in turn means that the DW-HD phase and HD-DW phase do not meet for µ > 3 / 2. Incidentally, µ = 1 2 and / µ = 3 2 are / also, respectively, the lower and upper thresholds of the existence of the MC-MC phase, as obtained earlier.
## 5. Delocalized domain walls
What is the nature of the density profiles on the line a = ? Along the boundary b a = b between the DW-LD and LD-DW phases (see phase diagrams in Fig. 2) with µ = 7 8, / α eff 1 = β eff 1 = α eff 2 = β eff 2 . Thus, there should be two LDWs, one each in T 1 and T 2 . If x w 1 and x w 2 are the positions of the two LDWs, the particle number conservation condition gives only a linear relation between them without obtaining them explicitly. This is not surprising; particle number conservation can be maintained by shifting one LDW by some amount and compensating this by shifting the second LDW in the reverse direction. Thus, there are no unique LDW positions. In fact, the underlying stochasticity of the microscopic dynamics ensures that all possible solutions of x w 1 and x w 2 obeying particle number conservation are visited over time. As a result, we actually obtain two long time averaged density profiles, as shown in Fig. 3 (middle) and (right). These long time averaged ρ 1 ( x ) and ρ 2 ( x ), unlike an LDW, do not display any discontinuity, but instead take the form of inclined lines, representing the envelopes of the two DDWs. Since the DDWs are to be found only on the boundary between the DW-LD and LD-DW phases (i.e., a = b ), which in turn can exist for 1 / 2 < µ < 3 / 2, DDWs can be found for 1 / 2 < µ < 3 / 2. Outside this window, there are no DDWs.
As the long-time average shape of the DDWs is obtained by averaging over the fluctuating domain wall positions, with the extent of the position fluctuations scaling with the system size, mean-field theory cannot predict the shape since the latter ignores all fluctuations. We here provide a set of phenomenological arguments to construct the long-time average shapes of the DDWs. We follow Ref. [24]. Due to the coexistence of the DWLD and LD-DW phases on the line a = b , we have N 1 = L/ 2 = N 2 ; see Eqs. (30) and (42) above. Thus, N 1 + N 2 = L . The symmetry of the model generally implies if a = b , the two TASEP lanes are equivalent, meaning 〈 ρ 1 ( x ) 〉 = 〈 ρ 2 ( x ) 〉 for parameters on the line a = , where b 〈 .. 〉 implies temporal averages in the steady states. Furthermore, notice that the spans of the DDWs may not cover the entire span L of T 1 or T 2 ; in Fig. 3 (middle), the span covers a fraction of the TASEP lanes with µ < 1, whereas in Fig. 3(right), it covers the entire span with µ = 1 (half-filled case). We now estimate the DDW span. We begin by noting that with α eff 1 = β eff 1 = α eff 2 = β eff 2 , the two DDWs are statistically identical , as can be seen in Fig. 3 (middle and right) - this
holds for all 1 / 2 < µ < 3 / 2 for which DDWs are possible. This allows us to write for the mean position of each of the DDWs, x 0 = 〈 x w 1 〉 = 〈 x w 2 〉 . Further note that particles executing asymmetric hopping dynamics in a TASEP necessarily accumulate behind the exit end, i.e., in the present model behind the reservoirs R 1 and R 2 for TASEP lanes T 2 and T 2 respectively.For concreteness, we assume a pair of partial DDWs in T 1 and T 2 with the remaining parts of T 1 and T 2 in the LD phases as observed for µ < 1 [see, e.g., Fig. 3 (middle)]. With µ < 1, let us imagine to have replaced each DDW with an LDW at x 0 in both T 1 and T 2 , a hypothetical replacement that certainly maintains the particle number conservation and also does not affect the steady-state current. We then apply particle number conservation to get
$$\frac { N _ { 1 } } { L } + \frac { N _ { 2 } } { L } + 2 \rho _ { \text{LD} } + 2 ( 1 - x _ { 0 } ) ( 1 - 2 \rho _ { \text{LD} } ) = 2 \mu. \quad ( 5 3 ) \quad \text{in th} \quad \\ \text{stoch}$$
Here, ρ LD = a/ 2 and N 1 + N 2 = L . This gives
$$x _ { 0 } = - \frac { 2 \mu - 3 + a } { 2 ( 1 - a ) }. \quad \quad ( 5 4 ) \quad \text{Fo} \\ \quad \text{tia} \\ \quad \text{tha}$$
Thus, at half-filling, i.e., µ = 1, x 0 = 1 2, in agreement / with our stochastic simulations result; see Fig. 3 (right). Since the particles necessarily accumulate immediately behind R 2 in T 1 and R 1 in T 2 , each DDW wanders a distance D measured from the respective exit ends at x = 1, which is given by
$$\mathcal { D } = 1 - x _ { 0 } \text{ \quad \ \ } \text{(5)}$$
on either side of x = x 0 . Therefore, the total span of each DDW is 2 D = 2(1 -x 0 ). The actual DDW profile may be obtained from the calculated value of D in Eq. (55) by joining the points ρ = ρ HD = 1 -ρ LD at x = 1 and ρ = ρ LD at x = 1 -2 D . Thus, when the system is half-filled ( µ = 1), we have x 0 = 1 2 from (54) / above and hence 2 D covers the entire span of the TASEP lanes; see Fig. 3(right) showing a good agreement between MCS results and our phenomenological construction of the DDW profile. For all other filling factors, 2 D is less than unity, with each DDW spanning a region from 2 D to x = 1. In such a case (with 1 / 2 < µ < 1), the remaining part between 0 and 2 D of length 1 - D 2 is in the LD phase. This is a feature corroborated by our stochastic simulation studies; see Fig. 3(middle) showing a good agreement between MCS results and our phenomenological construction of the partial DDW profile. On symmetry ground, we expect a correspondence between the shapes of the DDWs with µ < 1 and µ > 1. For 3 / 2 > µ > 1, DDWs partially span T 1 and T 2 partially, with the remaining parts of T 1 and T 2 being in their HD phases. Using the particle-hole symmetry, this is equivalent to partially spanning DDWs with the remaining parts in their LD phases for holes with filling fraction µ hole = 2 -µ < 1. The corresponding DDW span can be obtained from Eq. (55) by using µ hole as the filling fraction.
Figure 3. Domain walls in T 1 and T 2 from stochastic simulations studies. (left) DW-LD: one LDW in T 1 and LD phase in T 2 with µ = 7 8 for various values of / a ; (middle) two DDWs in T 1 and T 2 with µ = 7 8 which partly span the TASEP lanes; / (right) two DDWs in T 1 and T 2 with µ = 1 which fully span the TASEP lanes. In each plot, continuous lines correspond to the analytical predictions, and points refer to the stochastic simulations data. System size L = 1000.
## 6. Phase diagram for µ = 1
Let us now construct the phase diagram for µ = 1, which is the half-filled limit of the model. When µ = 1, lines (39) and (45) are identical and each becomes a = . b Thus the LD-DW or DW-LD phases now exist only for parameters on the line a = . Furthermore, the meeting b point (1 , 1 / (4 µ -3)) of the phase boundaries (40) and (39) with (26) is now at (1,1) when µ = 1. For parameters on the line a = b between (0,0) and (1,1), one can have one LDW each in T 1 and T 2 . Instead, for the reasons outlined in Sec. IV C 5, one has a pair of DDWs, each of which spans the entire length of T 1 and T 2 , as shown in
Fig. 3 (right), similar to an isolated open TASEP. The common meeting point of the LD-HD, HD-LD, and MCMC phases is (1,1). Thus, the topology of the phase diagram for µ = 1 resembles that of an open TASEP; see the phase diagram with µ = 1 in Fig. 2. In fact, considering either T 1 or T 2 only, the phases at µ = 1 are those observed in an open TASEP, viz. LD, HD, and MC phases.
We now give a brief outline of our results on the phases and phase diagrams. The phase diagrams for µ = 9 8 11 / , / 8 and 13 / 8 are given in the Appendix, which may be constructed from those with µ = 7 8 5 8 3 8, / , / , / respectively, by using the particle-hole symmetry of the model. We have found that the topology of the phase diagrams for µ = 7 8 / , 9 / 8 hold for the range 3 / 4 < µ < 1 and 1 < µ < 5 / 4, respectively, for which the LD-HD and HD-LD phases can exist. For values of µ outside these ranges, the LD-HD and HD-LD phases disappear, with DW-LD, LD-DW, MC-MC, and LD-LD/HD-HD phases continue to exist for 1 / 2 < µ < 3 / 4 and 5 / 4 < µ < 3 / 2. For 1 / 4 < µ < 1 / 2 or 7 / 4 > µ > 3 / 2, DW-LD, LDDW, and LD-LD or HD-HD phases are the only possible phases. For very low ( µ < 1 / 4) and high ( µ > 7 / 4) filling, LD-LD and HD-HD phases, respectively, are the only phases possible, with no phase transitions in the a -b plane. For µ = 1, i.e., at the half-filled limit, the stable phases are given entirely by the solutions satisfying ρ 1 = 1 -ρ 2 , with no pure phases like LD-LD or HD-HD phases being possible. Furthermore, for 1 / 2 < µ < 3 / 2, we find a pair of DDWs existing for parameters on the line a = b between (0,0) and (2 µ -1 , 2 µ -1) for 1 / 2 < µ < 1, and between (0,0) and (3 -2 µ, 3 -2 µ ) for 1 < µ < 3 / 2. Lastly for µ = 1, one gets a phase diagram with LD-HD, HD-LD and MC-MC phases only, with a pair of DDWs for a, b satisfying a = b . These results on the phases and phase diagrams are validated by our stochastic simulations studies, which agree very well with the corresponding mean-field theory results; see Fig. 2, Fig. 3 and Fig. 4.
To summarize, in this Section IV C, we have used MFT to calculate the stationary densities in the nonuniform phases. In particular, we have calculated the LD phase density ρ LD and HD phase density ρ HD in the mixed phases and also the domain wall heights and positions. Furthermore, we have studied the DDWs in the model, which can be found only for a, b , which parametrize the effective entry and exit rates of the TASEP lanes, falling on the line a = b for a range of the filling fraction µ . Lastly, we have shown how a minimum current principle may be used to obtain the phase boundaries between the phases obtained in Section IV B and Section IV C, ultimately giving the correct steady states and the full phase diagrams in the a -b plane; see the phase diagrams in
## VI. PARTICLE NUMBERS IN THE RESERVOIRS
We now consider how the steady state values of N , N 1 2 , the populations of the reservoirs R 1 and R 2 ,
Fig. 2 and Fig. 4.
## V. NATURE OF THE PHASE TRANSITIONS
The phase diagrams in Fig. (2) have different phases separated by the associated phase boundaries. We now discuss the nature of the transitions across these phase boundaries. In an open TASEP, the transitions between the LD and HD phases are accompanied by a sudden jump in the bulk density in the TASEP, implying thus a first-order transition with the bulk density acting as the order parameter. The density profile corresponding to the parameters on the phase boundary is a DDW that spans the entire open TASEP. In contrast, the transitions between the LD or HD and MC phases are second order transitions, with the density difference vanishing smoothly at the respective phase transition. In analogy with an open TASEP, the transitions in the present model are described in terms of the densities in each TASEP lane and can be classified in analogy with open TASEPs by noting the density changes. Thus in this model, the phase boundaries between the LD-HD and LD-DW, or HD-LD and DW-LD phases are all secondorder lines, as the density changes across those phase boundaries are devoid of any discontinuities. Likewise, the phase boundaries between the LD-LD and DW-LD or LD-DW phases are also second order lines for the same reason. The phase boundary between DW-LD and LD-DW, the line where a pair of DDW is to be found, is, however, a first order order line, with the ρ 1 and ρ 2 varying discontinuously . This is because across this line, ρ 1 ( x ) and ρ 2 ( x ) discontinuously change from being an LDW in the bulk to the LD or HD (depending upon µ ) phase. Furthermore, the phase boundaries between MCMC and any other phases are all second-order lines. In contrast, the phase boundary between LD-HD and HDLD (at µ = 1) is a first-order line, having the density in both the TASEP lanes changing discontinuously.
The above arguments show that the phase diagram with µ = 7 8 in Fig. 2 and with / µ = 9 8 in Fig. 4 have / second order phase boundaries each and one first-order boundary each, phase diagrams Fig. 2 with µ = 5 8 and / Fig. 4 with µ = 11 8 have three second-order boundaries / each, phase diagrams with µ = 3 8 in Fig. 2 and with / µ = 13 / 8 in Fig. 4 have two second-order lines each and phase diagram Fig. 2 with µ = 1 has two second order and one first-order line. In all the phase diagrams, the phase boundaries meet at multicritical points. For example, phase diagram Fig. 2 with µ = 1, µ = 7 8, / µ = 5 8 and / µ = 3 8 have one, three, one and one multicritical points / each.
A summary of the phases, phase transitions, domain walls, and multicritical points is given in Table II.
respectively, change across the phase boundaries. Con-
Table II. Table on the summary of the phases, domain walls, phase boundaries, and multicritical points as functions of µ . Rows (6)-(9) with µ > 1 can be obtained from the rows (1)-(4) with µ < 1 by using the particle-hole symmetry (11a)-(11c).
| Steady states of the model | Steady states of the model | Steady states of the model | Steady states of the model | Steady states of the model |
|------------------------------|-----------------------------------------------|------------------------------|----------------------------------------|------------------------------|
| µ | Phases | Domain walls | Phase boundaries | Multicritical points |
| 0 < µ < 1 / 4 | Only LD-LD | None | None | None |
| 1 / 4 < µ < 1 / 2 | DW-LD, LD-DW and LD- LD | One LDW | Two second order | None |
| 1 / 2 < µ < 3 / 4 | DW-LD, LD-DW, LD-LD and MC-MC | One LDW | Three second order | None |
| 3 / 4 < µ < 1 | DW-LD, LD-DW, LD-HD, HD-LD, LD-LD and MC- MC | One LDW and a pair of DDWs | Seven second order and one first order | Three |
| µ = 1 | LD-HD, HD-LD and MC- MC | a pair of DDWs | Two second order and one first order | One |
| 1 < µ < 5 / 4 | DW-HD, HD-DW, LD-HD, HD-LD, HD-HD, and MC- MC | One LDW and a pair of DDW | Seven-second order and one first order | Three |
| 5 / 4 < µ < 3 / 2 | DW-HD, HD-DW, HD-HD and MC-MC | One LDW | Three second order | None |
| 3 / 2 < µ < 7 / 4 | DW-HD, HD-DW and HD- HD | One LDW | Two second order | None |
| 7 / 4 < µ < 2 | Only HD-HD | None | None | None |
sider µ < 1. Both ρ 1 and ρ 2 are continuous across the boundaries between the LD-DW phase and phases like LD-HD and LD-LD phases. Since ρ 1 = α eff 1 ( N 1 ), then the continuity of ρ 1 across the phase boundaries and linear dependence of α eff 1 on N 1 ensures that N 1 must be continuous across those phase boundaries. Further, continuity of ρ 2 across these phase boundaries and overall particle number conservation demand that N 2 must be continuous across those phase boundaries. Similar arguments can be constructed to show that both N 1 and N 2 are continuous across the phase boundaries between DW-LD and phases like HD-LD and LD-LD. For µ > 1, these results together with particle-hole symmetry of the model discussed in Section III above can be used to show that both N 1 and N 2 are continuous across the phase boundaries between DW-HD phase and phases LD-HD and HD-HD phases, and between HD-DW phase and phases HD-LD and HD-HD.
The transition between the LD-HD and HD-LD phases that occurs on the line a = b with µ = 1 is a discontinuous transition for both T 1 and T 2 . Now, as we approach the line a = b from either side, both N 1 and N 2 approach L/ 2, implying that N 1 and N 2 do not show any discontinuity across a = b , although the TASEP densities do. This is because as we approach the line a = b , ρ 1 + ρ 2 = 1, independent of the individual discontinuities of ρ 1 and ρ 2 .
Since the total particle content in T 1 and T 2 in the MC-MC phase is just L , we must have
$$N _ { 1 } + N _ { 2 } = N _ { 0 } - L = L ( 2 \mu - 1 ). \quad ( 5 6 ) \quad \text{cons} \quad \text{the}$$
Thus the total of the particles in both the reservoirs is a fixed number. However, mean-field theory does not set N 1 and N 2 separately but only specifies their ranges. In the MC-MC phase, α eff 1 > 1 / 2 , α eff 2 > 1 / 2 , β eff 1 > 1 / 2 , β eff 2 > 1 / 2. With our choices for the functions f and g , these conditions translate into [see Eq. (23)]
$$\int _ { \text{all} } ^ { \Re } \quad \frac { L } { 2 a } < N _ { 1 } < L ( 1 - \frac { 1 } { 2 b } ), \, \frac { L } { 2 b } < N _ { 2 } < L ( 1 - \frac { 1 } { 2 a } ). \quad ( 5 7 )$$
Thus, N 1 and N 2 are not uniquely determined, but only ranges of their values are found, which are to be supplemented by (56). This contrasts with the uniquely determined values of N 1 and N 2 in all the other phases. This further means that continuity of N 1 and N 2 across the boundaries between MC-MC and any other phases cannot be ascertained.
## VII. SUMMARY AND OUTLOOK
In this study, we investigated how the interplay between the limited availability of particles and the carrying capacity in various regions of a spatially extended system influences the steady-state currents and density profiles within quasi-1D lanes that connect different parts of the system. Specifically, we considered a minimal model consisting of two reservoirs with identical finite carrying capacities, connected by two anti-parallel TASEP lanes of equal length. This model in its most general form has five parameters: two entry rates ( α 1 and α 2 ), two exit rates ( β 1 and β 2 ), and the total number of particles, which is conserved. Additionally, two functions, f and g , govern the effective entry and exit rates, respectively. For reasons of simplicity, the functions f and g are linked in a simple manner and assumed to have simple forms, which
ensure that f is monotonically rising with the reservoir population, whereas g is monotonically decreasing. This ensures that increasing particles in a reservoir leads to increasing flow to the TASEP lane from the reservoir, but reduced flow from the TASEP lane to it. The precise quantitative forms of the results depend upon the forms of the functions f and g chosen here. However, even with different functional forms for f and g , as long as they are monotonically increasing and decreasing with their arguments, together with finite resources and carrying capacities, we expect the qualitative nature of the results here to hold.
We focus on the case α 1 = β 2 = a, α 2 = β 1 = b . To study the model, we have used a complementary approach combining mean-field theory with extensive stochastic simulations. The mean-field theory predictions agree very well with the stochastic simulations results both qualitatively and quantitatively.
The model reveals surprising phase behavior that deviates from previous studies of TASEP models with finite resources [39, 45-53].First and foremost, we find the two TASEP lanes can exhibit the same or different phases depending on the parameters. This includes scenarios such as having a single LDW in one lane or a pair of DDWs in both lanes. The ensuing phase diagram is fairly complex, particularly at moderate system filling; for example, at µ = 7 8 , there are six distinct phases. A distinguishing feather of phase diagram is that while its topology is very different from the phase diagram of an open TASEP in general, at µ = 1, it resembles that of an open TASEP for each of the TASEP lanes T 1 and T 2 . The associated phase transitions and the boundaries are generally second-order in nature, although for µ = 1, a first-order transition appears. We are able to calculate all of the phase boundaries analytically within mean-field theory. We can also identify the different threshold values of µ at which different transitions occur. Furthermore, we calculate the occupations N 1 and N 2 of the two reservoirs. We find that they are generally unequal. In fact, the populations of the two reservoirs could be preferentially controlled, i.e., getting them relatively populated or depopulated, by appropriate choice of the control parameters. This can lead to steady population imbalances and highly inhomogeneous particle distributions between different parts of the systems.
We have here investigated the simplest scenario involving two reservoirs connected by two anti parallel TASEP lanes with finite availability and finite carrying capacity of resources. This framework can be easily extended to any number of reservoirs and TASEP lanes. While our mean-field theory can be adapted to provide specific quantitative predictions for such extended systems, we expect the qualitative features observed in our study to persist. For example, when the filling factor µ is very small or very large, all TASEP lanes should be in their LD or HD phases, respectively. As µ increases, mixed phases of the TASEP lanes are anticipated to appear. Further, and as a consequence of the global particle number con- servation, independent of the numbers of the reservoirs and TASEP lanes, such a generalized model could display only one LDW or DDWs of any number more than one at some points in the phase space. Similar to the present study, we expect that the individual reservoir populations in the steady states can be controlled by the TASEP lanes together with appropriate choice for the model parameters. The quantitative extent of these population distributions should depend upon the precise interconnectivity of the reservoirs by the TASEP lanes. One can also consider using functions defining the effective entry and exit rates with some having very different functional form than the others; e.g., one or some of them could of the kind used here and the remaining ones could be similar to that studied in Ref. [48]. Such a 'mixed' model will allow us to study possible competition between rate functions of different types of functions, leading to complex phase behavior. Detailed stochastic simulations studies should be able to validate these qualitative predictions. We hope our studies here will provide impetus to research along these directions.
## ACKNOWLEDGMENTS
AB thanks the SERB, DST (India) for partial financial support through the CRG scheme [file no.: CRG/2021/001875]. The work of EF was funded by the Excellence Cluster ORIGINS under Germany's Excellence Strategy - EXC-2094 - 390783311. AH thanks the Alexander von Humboldt Stiftung, Germany for a postdoctoral fellowship. AB and EF thank the Alexander von Humboldt Stiftung, Germany for financial support within its Research Group Linkage Programme framework (2024).
## Appendix A: Phase diagrams for µ > 1
In this Section, we present our mean-field theory and stochastic simulations results for the phase diagrams with µ > 1. In Fig. 4, we show the phase diagrams for µ = 9 8 11 8 13 8. / , / , / The mean-field theories for the phase diagrams in Fig. 4 can be obtained from those in Fig. 2 by applying the particle-hole symmetry (11a)(11c), giving the phases with µ = 9 8 11 8 13 8, re-/ , / , / spectively, in terms of the phases with µ = 7 8 5 / , / 8 3 , / 8. Thus the phase diagrams in Fig. 2 and Fig. 4 together validate the particle-hole symmetry (11a)-(11c) set up above, which in turn are in agreement with the corresponding stochastic simulations results.
## Appendix B: Simulation algorithm
In our stochastic simulations, we have used randomsequential updating [57] of the sites of the TASEP
and reservoirs, subject to the update rules (a)-(c) described above in Sec. II. In each iteration, we randomsequentially choose one of the reservoirs or a site from each TASEP lane for being updated. The particles enter into T 1 or T 2 at the j = 1 and j = L site, respectively, from the specific reservoir attached to them, subject to exclusion, at rates α eff 1 2 , ( N 1 2 , ) which is dynamically calculated at every stochastic simulations step. After hopping
- [1] S. Katz, J. L. Lebowitz, and H. Spohn, 'Phase transitions in stationary nonequilibrium states of model lattice systems,' Phys. Rev. B 28 , 1655-1658 (1983).
- [2] S. Katz, J. L. Lebowitz, and H. Spohn, 'Nonequilibrium steady states of stochastic lattice gas models of fast ionic conductors,' J. Stat. Phys. , 497-537 (1984).
- [3] B. Schmittmann and R. K.-P. Zia, Phase transitions and critical phenomena , edited by Joel Louis Lebowitz and Cyril Domb (Academic Press, London, 1995).
- [4] Nonequilibrium Statistical Mechanics in One Dimension (Cambridge University Press, 1997).
- [5] J. Krug, 'Boundary-induced phase transitions in driven diffusive systems,' Phys. Rev. Lett. 67 , 1882-1885 (1991).
- [6] B. Derrida, S. A. Janowsky, J. L. Lebowitz, and E. R. Speer, 'Exact solution of the totally asymmetric simple exclusion process: Shock profiles,' J Stat Phys , 813-842.
- [7] B. Derrida and M. R Evans, 'Exact correlation functions in an asymmetric exclusion model with open boundaries,' Journal de Physique I 3 , 311-322 (1993).
through the system from j = 1 to L in T 1 and j = L to 1 in T 2 , subject to exclusion, in each of T 1 and T 2 , the particles exit the system from j = L of T 1 and j = 1 of T 2 at dynamically calculated rates β eff 1 2 , ( N 2 1 , ), and enter the reservoir attached to the i = L site. The density profiles are calculated after reaching the steady states, and temporal averages are performed. This produces the time-averaged, space-dependent density profiles.
56 (2008).
- [18] J. Howard and RL Clark, 'Mechanics of motor proteins and the cytoskeleton,' Appl. Mech. Rev. 55 , B39-B39 (2002).
- [19] Ben Embley, Andrea Parmeggiani, and Norbert Kern, 'Understanding totally asymmetric simpleexclusion-process transport on networks: Generic analysis via effective rates and explicit vertices,' Phys. Rev. E 80 , 041128 (2009).
- [20] R. Chatterjee, A. K. Chandra, and A. Basu, 'Phase transition and phase coexistence in coupled rings with driven exclusion processes,' Phys. Rev. E 87 , 032157 (2013).
- [21] R. Chatterjee, A. K. Chandra, and A. Basu, 'Asymmetric exclusion processes on a closed network with bottlenecks,' J. Stat. Mech.: Theory and Exp. 2015 , P01012 (2015).
- [22] S. A. Janowsky and J. L. Lebowitz, 'Finite-size effects and shock fluctuations in the asymmetric simpleexclusion process,' Phys. Rev. A 45 , 618-625 (1992).
- [8] B. Derrida, M. R. Evans, V. Hakim, and V. Pasquier, 'Exact solution of a 1d asymmetric exclusion model using a matrix formulation,' J. Phys. A: Math. and Gen. 26 , 1493-1517 (1993).
- [23] H. Hinsch and E. Frey, 'Bulk-driven nonequilibrium phase transitions in a mesoscopic ring,' Phys. Rev. Lett. 97 , 095701 (2006).
- [24] N. Sarkar and A Basu, 'Nonequilibrium steady states in asymmetric exclusion processes on a ring with bottlenecks,' Phys. Rev. E 90 , 022109 (2014).
- [9] C. T. MacDonald, J. H. Gibbs, and A. C. Pipkin, 'Kinetics of biopolymerization on nucleic acid templates,' Biopolymers 6 , 1-25 (1968), https://onlinelibrary.wiley.com/doi/pdf/10.1002/bip.1968.360060102.tat. Mech.:
- [25] T. Banerjee, N. Sarkar, and A. Basu, 'Generic nonequilibrium steady states in an exclusion process on an inhomogeneous ring,' J. S Theory Exp 2015 , P01024 (2015).
- [10] A. Parmeggiani, T. Franosch, and E. Frey, 'Phase coexistence in driven one-dimensional transport,' Phys. Rev. Lett. 90 , 086601 (2003).
- [11] A. Parmeggiani, T. Franosch, and E. Frey, 'Totally asymmetric simple exclusion process with langmuir kinetics,' Phys. Rev. E 70 , 046101 (2004).
- [26] T. Banerjee, A. K. Chandra, and A. Basu, 'Phase coexistence and particle nonconservation in a closed asymmetric exclusion process with inhomogeneities,' Phys. Rev. E 92 , 022121 (2015).
- [12]
.
- [13] A. Melbinger, L. Reese, and E. Frey, 'Microtubule length regulation by molecular motors,' Phys. Rev. Lett. 108 , 258104 (2012).
- [14] Louis Reese, Anna Melbinger, and Erwin Frey, 'Crowding of molecular motors determines microtubule depolymerization,' Biophysical journal 101 , 2190-2200 (2011).
- [15] T. Reichenbach, T. Franosch, and E. Frey, 'Exclusion processes with internal states,' Phys. Rev. Lett. 97 , 050603 (2006).
- [16] T. Reichenbach, E. Frey, and T. Franosch, 'Traffic jams induced by rare switching events in two-lane transport,' New Journal of Physics 9 , 159 (2007).
- [17] T. Reichenbach, T. Franosch, and E. Frey, 'Domain wall delocalization, dynamics and fluctuations in an exclusion process with two internal states,' Eur. Phys. J. E 27 , 47-
- [27] B. Daga, S. Mondal, A. K. Chandra, T. Banerjee, and A. Basu, 'Nonequilibrium steady states in a closed inhomogeneous asymmetric exclusion process with generic particle nonconservation,' Phys. Rev. E 95 , 012113 (2017).
- [28] Tirthankar Banerjee and Abhik Basu, 'Smooth or shock: Universality in closed inhomogeneous driven single file motions,' Phys. Rev. Research 2 , 013025 (2020).
- [29] P. Roy, A. K. Chandra, and A. Basu, 'Pinned or moving: States of a single shock in a ring,' Phys. Rev. E 102 , 012105 (2020).
- [30] A. Goswami, R. Chatterjee, and S. Mukherjee, 'Defect versus defect: stationary states of single file marching in periodic landscapes with road blocks,' (2024), arXiv:2402.08499 [cond-mat.stat-mech].
- [31] I. R. Graf and E. Frey, 'Generic transport mechanisms for molecular traffic in cellular protrusions,' Phys. Rev. Lett. 118 , 128101 (2017).
Figure 4. (a) Phase diagrams in the a -b plane obtained from mean-field theory (continuous lines) and stochastic simulations (discrete points) studies. (a) µ = 9 8: / HD-HD, LD-HD, HD-LD, DW-HD, HD-DW and MC-MC. This phase diagram can be obtained from the phase diagram in Fig. 2 with µ = 7 8 in the main text by using the particle-hole symmetry (see text) / and is valid for 1 < µ < 5 4. / (b) µ = 11 8: The phases are DW-HD, HD-DW, HD-HD and MC-MC. This phase diagram can / be obtained from the phase diagram in Fig. 2 with µ = 5 8 in the main text by using the particle-hole symmetry (see text),(c) / µ = 13 8: / The phases are DW-HD, HD-DW and HD-HD. This phase diagram can be obtained from the phase diagram in Fig. 2 with µ = 3 8 in the main text by using the particle-hole symmetry (see text). / These demonstrate the particle-hole symmetry of the model.
- [32] M. Bojer, I. R. Graf, and E. Frey, 'Self-organized system-size oscillation of a stochastic lattice-gas model,' Phys. Rev. E 98 , 012410 (2018).
Phys. J. E 44 , 1-15 (2021).
- [33] A. Goswami, U. Dey, and S. Mukherjee, 'Nonequilibrium steady states in coupled asymmetric and symmetric exclusion processes,' Phys. Rev. E 108 , 054122 (2023).
- [34] R. Lipowsky, S. Klumpp, and T. M. Nieuwenhuizen, 'Random walks of cytoskeletal motors in open and closed compartments,' Phys. Rev. Lett. 87 , 108101 (2001).
- [35] S. Klumpp and R. Lipowsky, 'Traffic of molecular motors through tube-like compartments,' J Stat Phys , 233- 268 (2003).
- [36] Lucas D. Fernandes and Luca Ciandrini, 'Driven transport on a flexible polymer with particle recycling: A model inspired by transcription and translation,' Phys. Rev. E 99 , 052409 (2019).
- [37] O. Dauloudet, I. Neri, J-C Walter, J. Dorignac, F. Geniet, and A. Parmeggiani, 'Modelling the effect of ribosome mobility on the rate of protein synthesis,' Eur.
- [38] Stefan Klumpp and Reinhard Lipowsky, 'Asymmetric simple exclusion processes with diffusive bottlenecks,' Phys. Rev. E 70 , 066104 (2004).
- [39] D A Adams, B Schmittmann, and R K P Zia, 'Farfrom-equilibrium transport with constrained resources,' J. Stat. Mech.: Theory Exp 2008 , P06009 (2008).
- [40] M. Ha and M. den Nijs, 'Macroscopic car condensation in a parking garage,' Phys. Rev. E 66 , 036118 (2002).
- [41] C. A. Brackley, M. C. Romano, C. Grebogi, and M. Thiel, 'Limited resources in a driven diffusion process,' Phys. Rev. Lett. 105 , 078102 (2010).
- [42] C. A. Brackley, M. C. Romano, and M. Thiel, 'Slow sites in an exclusion process with limited resources,' Phys. Rev. E 82 , 051920 (2010).
- [43] C. A Brackley, M. C. Romano, and M. Thiel, 'The dynamics of supply and demand in mrna translation,' PLoS computational biology 7 , e1002203 (2011).
- [44] L. Ciandrini, I. Neri, J. C. Walter, O. Dauloudet, and A. Parmeggiani, 'Motor protein traffic regulation by supply-demand balance of resources,' Phys. biol. 11 , 056006 (2014).
- [45] L. Jonathan Cook, R. K. P. Zia, and B. Schmittmann, 'Competition between multiple totally asymmetric simple exclusion processes for a finite pool of resources,' Phys. Rev. E 80 , 031142 (2009).
- [46] L Jonathan Cook and R K P Zia, 'Feedback and fluctuations in a totally asymmetric simple exclusion process with finite resources,' J. Stat. Mech.: Theory Exp 2009 , P02012 (2009).
- [47] C. A Brackley, L. Ciandrini, and M C. Romano, 'Multiple phase transitions in a system of exclusion processes with limited reservoirs of particles and fuel carriers,' J. Stat. Mech.: Theory Exp 2012 , P03002 (2012).
- [48] A. Haldar, P. Roy, and A. Basu, 'Asymmetric exclusion processes with fixed resources: Reservoir crowding and steady states,' Phys. Rev. E 104 , 034106 (2021).
- [49] B. Pal and A. K. Gupta, 'Reservoir crowding in a resource-constrained exclusion process with a dynamic defect,' Phys. Rev. E 106 , 044130 (2022).
- [50] B. Pal and A. K. Gupta, 'Exclusion process with scaled resources: Delocalized shocks and interplay of reser-
- voirs,' Phys. Rev. E 105 , 054103 (2022).
- [51] A. Gupta, B. Pal, and A. K. Gupta, 'Interplay of reservoirs in a bidirectional system,' Phys. Rev. E 107 , 034103 (2023).
- [52] S. Pal, P. Roy, and A. Basu, 'Availability, storage capacity, and diffusion: Stationary states of an (2024), arXiv:2308.08384.
- [53] S. Pal, P. Roy, and A. Basu, 'Distributed fixed resources exchanging particles: Phases of an asy (2024), arXiv:2403.05945.
- [54] R A Blythe and M R Evans, 'Nonequilibrium steady states of matrix-product form: a solver s ' guide,' J. Phys. A 40 , R333-R441 (2007).
- [55] T. Franosch A. Melbinger, T. Reichenbach and E. Frey, 'Driven transport on parallel lanes with particle exclusion and obstruction,' Phys. Rev. E 83 , 031923 (2011).
- [56] J. S. Hager, J. Krug, V. Popkov, and G. M. Sch¨tz, u 'Minimal current phase and universal boundary layers in driven diffusive systems,' Phys. Rev. E 63 , 056110 (2001).
- [57] N. Rajewsky, L. Santen, A. Schadschneider, and M. Schreckenberg, 'The asymmetric exclusion process: Comparison of update procedures,' Journal of Statistical Physics 92 , 151-194 (1998). | null | [
"Astik Haldar",
"Parna Roy",
"Erwin Frey",
"Abhik Basu"
]
| 2024-08-02T16:17:31+00:00 | 2024-08-02T16:17:31+00:00 | [
"cond-mat.stat-mech"
]
| Availability versus carrying capacity: Phases of asymmetric exclusion processes competing for finite pools of resources | We address how the interplay between the finite availability and carrying
capacity of particles at different parts of a spatially extended system can
control the steady state currents and density profiles in the one-dimensional
current-carrying lanes connecting the different parts of the system. To study
this, we set up a minimal model consisting of two particle reservoirs of the
same finite carrying capacity connected by two equally sized anti-parallel
asymmetric exclusion processes (TASEP). We focus on the steady-state currents
and particle density profiles in the two TASEP lanes. The ensuing phases and
the phase diagrams, which can be remarkably complex, are parametrized by the
model parameters defining particle exchange between the TASEP lanes and the
reservoirs and the filling fraction of the particles that determine the total
resources available. These parameters may be tuned to make the densities of the
two TASEP lanes globally uniform or piece-wise continuous in the form of a
combination of a single localized domain wall and a spatially constant density
or a pair of delocalized domain walls. Our model reveals that the two
reservoirs can be preferentially populated or depopulated in the steady states. |
2408.01366v2 | ## Play to the Score: Stage-Guided Dynamic Multi-Sensory Fusion for Robotic Manipulation
Ruoxuan Feng 1 Di Hu 1,* Wenke Ma 2 1 3 {
Xuelong Li 3
Gaoling School of Artificial Intelligence, Renmin University of China 2 Shenzhen Taobotics Co., Ltd.
Institute of Artificial Intelligence (TeleAI), China Telecom
fengruoxuan, dihu @ruc.edu.cn, } [email protected], xuelong [email protected]
Abstract: Humans possess a remarkable talent for flexibly alternating to different senses when interacting with the environment. Picture a chef skillfully gauging the timing of ingredient additions and controlling the heat according to the colors, sounds, and aromas, seamlessly navigating through every stage of the complex cooking process. This ability is founded upon a thorough comprehension of task stages, as achieving the sub-goal within each stage can necessitate the utilization of different senses. In order to endow robots with similar ability, we incorporate the task stages divided by sub-goals into the imitation learning process to accordingly guide dynamic multi-sensory fusion. We propose MS-Bot, a stage-guided dynamic multi-sensory fusion method with coarse-to-fine stage understanding, which dynamically adjusts the priority of modalities based on the fine-grained state within the predicted current stage. We train a robot system equipped with visual, auditory, and tactile sensors to accomplish challenging robotic manipulation tasks: pouring and peg insertion with keyway. Experimental results indicate that our approach enables more effective and explainable dynamic fusion, aligning more closely with the human fusion process than existing methods. The code and demos can be found at https://gewu-lab.github.io/MS-Bot/.
Keywords: Multi-Sensory, Robotic Manipulation, Multi-Stage
## 1 Introduction
Humans are blessed with the ability to flexibly use various sensors to perceive and interact with the world. Over the years, endowing robots with this potent capability has remained a dream for humanity. Fortunately, with the advancement of computing devices and sensors [1, 2], building a multi-sensory robot system to assist humans has gradually become achievable. We have witnessed the emergence of some exciting multi-sensory robots, such as Optimus [3] and Figure 01 [4].
One challenge in tasks that robots assist humans with is the complex object manipulation task, which requires achieving a series of sub-goals. These sub-goals naturally divide a complex task into multiple stages. Many efforts attempt to make models comprehend these task stages, whether through hierarchical learning [5, 6, 7] or employing LLMs [8, 9, 10]. However, when incorporated into multi-sensory robots, this challenge becomes more profound. We need to not only understand the stages themselves but also rethink multi-sensory fusion from the fresh perspective of task stages.
Completing sub-goals within a complex task may require different senses, with varying modality importance at each stage. Thus, stage transitions may entail changes in modality importance. To illustrate this, we build a multi-sensory robot system (Fig. 1, left). We then use imitation learning to train a MULSA [11] model with self-attention fusion to complete pouring task and record the testing confidence (Fig. 1, right). We observe correlations between the confidence and task stages after
* Corresponding author. 'Play to the score' is slang for adjusting actions to fit current circumstances.
Figure 1: An illustration for our multi-sensory robot system and a visualization of Modality Temporality in a multi-stage task: pouring. We show confidence in action prediction (maximum softmax score) when using the inputs of all modalities and selectively masking uni-modal features. Due to the changing importance of modalities, both evident inter-stage (coarse-grained) and minor intra-stage (fine-grained) changes in confidence are observed when masking uni-model features. The low confidence fluctuations near stage boundaries also reflect insufficient task stage understanding.
masking one modality. For example, vision is most important in the aligning stage, and masking it causes a notable confidence drop. We also note minor modality confidence changes inside stages. These indicate that modality importance undergoes both inter-stage changes and intra-stage adjustments. We summarize this as a challenge in multi-sensory imitation learning: Modality Temporality .
The key to addressing this challenge is understanding the current task stage and its concrete internal state, i.e. , coarse-to-fine stage comprehension. Multi-sensory features should be dynamically fused to meet the needs of the coarse-grained stage and adjust to the fine-grained internal state. However, most of the existing works that utilize multiple sensors [12, 13, 14, 15] essentially use static fusion like concatenating. They lack the adaptability to dynamic changes of modality importance in complex manipulation tasks. Some recent works [16, 11] attempt to use attention for dynamic fusion, but they still fail to break out the paradigm of fusion based solely on current observations. They neglect the importance of stage understanding in multi-sensory fusion.
In light of this key insight, we incorporate the stages divided by sub-goals into multi-sensory fusion. To perform coarse-to-fine stage understanding, we first encode current observations and historical actions into a state token and identify the current stage based on it. We then inject the stage information into the state token by weighting learnable stage tokens. For fusion, we propose a dynamic M ultiS ensory fusion method for ro Bot (MS-Bot) to allocate modality weights based on the state within current stage. Using cross-attention [17] with stage-injected state token as query, we dynamically select multi-sensory features of interest based on the fine-grained internal state. The dynamic allocation of attention score to feature tokens ensures effective fusion aligned with requirements.
To evaluate our MS-Bot method in the real world, we build a robot system that can perceive the environment with audio, visual and tactile sensors. We test it on two challenging manipulation tasks: pouring , where the robot needs to pour tiny beads of specific quality, and peg insertion with keyway , where robot needs to rotate the peg with a key to align the keyway during the insertion. To summarize, our contributions are as follows:
- · We summarize Modality Temporality as a key challenge and identify the coarse-to-fine stage comprehension as a crucial point to handle the changing modality importance in complex tasks.
- · Based on the above insight, we propose a dynamic multi-sensory fusion method guided by the prediction of fine-grained state within the identified task stage.
- · We build a multi-sensory robot system and evaluate our method on two challenging robotic manipulation tasks: pouring and peg insertion with keyway.
Experimental results show that MS-Bot better comprehends the fine-grained state in current task stage and dynamically adjusts modality attention as needed, outperforming prior methods in both tasks. We hope this work opens up a new perspective on multi-sensor fusion, inspiring future works.
## 2 Related Work
Multi-Sensory Robot Learning. Recent works have extensively integrated visual, auditory, and tactile sensors into robot systems. The two common visual modalities, RGB and depth, are widely combined and applied in grasping [18, 19, 20, 21, 22], navigation [23, 24], and pose estimation [25, 26, 27] tasks. In recent years, the development of tactile sensors has sparked interest in the study of tactile modality. Fine-grained tactile data can assist in tasks such as grasping [28, 29, 12, 13], shape reconstruction [30, 31] and peg insertion [32, 15]. Audio modalities are typically applied in tasks such as pouring [11, 14], object tracking [33, 34], and navigation [35, 36, 37]. Some works even attempt to jointly use visual, audio, and tactile modalities to manipulate objects [38, 39, 11]. Based on these efforts, we further explore effective multi-sensory fusion in complex manipulation tasks.
Robot Learning for Multi-Stage Tasks. Complex multi-stage tasks have always been a focal point of research in robot manipulation. Previous works hierarchically decompose the multi-stage tasks, where upper-level models predict the next sub-goal, and lower-level networks predict specific actions based on the sub-goal. Following this paradigm, many hierarchical reinforcement learning [7, 40, 41, 42, 43, 44] and imitation learning [5, 6, 45, 46, 47] methods have demonstrated their effectiveness across various tasks. [8, 9, 10] use LLMs or VLMs to decompose long-horizon tasks. Recently, [48] introduces Chain-of-Thought into robot control. While these works primarily focus on uni-sensory scenarios, we aim to investigate the impact of stage changes on multi-sensory fusion.
Dynamic Multi-Modal Fusion. Dynamic multi-modal fusion essentially adapts the fusion process based on the input data by assigning different weights to the uni-modal features. A simple and effective way to assign weights is to train a gate network that scores based on the quality of uni-modal features [49, 50, 51, 52]. Another approach to assessing the quality of modalities and dynamically fusing them is uncertainty-based fusion [53, 54, 55]. With the introduction of the transformer [17], self-attention provides a natural mechanism to connect multi-modal signals [56]. Hence, attentionbased fusion methods rapidly become a focal point of research [11, 57, 58, 59]. However, these methods primarily perform dynamic fusion based solely on the inputs themselves, while we design dynamic fusion from the perspective of task stages in robotic scenarios.
## 3 Method
In this section, we discuss the challenges in multi-sensory imitation learning from the perspective of task stages and propose the dynamic multi-sensory fusion framework MS-Bot, based on coarseto-fine task stage understanding, to overcome these challenges. Specifically, the fine-grained state refers to a concept that describes the current situation of the environment, while the coarse-grained stage, divided by sub-goals of the task, is a collection composed of many states, as follows:
$$\mathbf E = ( \underbrace { \underbrace { \mathbf X _ { 1 } } _ { \text{State 1} }, a _ { 1 } ), ( \underbrace { \mathbf X _ { 2 } } _ { \text{State 2} }, a _ { 2 } ), \dots, ( \underbrace { \mathbf X _ { t _ { 1 } } } _ { \text{State t _ { 1 } } }, a _ { t _ { 1 } } ) } _ { \text{State g e 1 } }, ( \underbrace { \underbrace { \mathbf X _ { t _ { 1 } + 1 } } _ { \text{State t _ { 1 } + 1 } }, a _ { t _ { 1 } + 1 } ), \dots, ( \underbrace { \mathbf X _ { t _ { 2 } } } _ { \text{State t _ { 2 } } }, a _ { t _ { 2 } } ), \dots,$$
where E is an episode, X t is the multi-sensory observation at timestep t and a t is the action.
## 3.1 Challenges in Multi-Sensory Imitation learning
Imitation learning is a data-efficient robot learning algorithm where a robot learns a task by mimicking the behavior demonstrated by an expert. However, directly applying it to complex tasks with multi-sensory data could encounter issues, such as low confidence fluctuations and changing modality importance shown in Fig. 1. We attribute the causes of these issues to two key challenges:
Non-Markovity. Training data for imitation learning is typically derived from human demonstrations, usually collected through teleoperation devices. However, when humans manipulate robots, their actions are not solely based on data observed by robot sensors, but are also influenced by memory. This becomes particularly significant in more complex multi-stage tasks, as memory can provide cues about the task stages. Identifying the current stage solely based on current multi-sensory observations can be much more challenging. This challenge is not brought by the introduction of
Figure 2: The pipeline of our method MS-Bot. It consists of four parts: feature extractor, state tokenizer, stage comprehension module, and dynamic fusion module.
multiple sensors. Some works have already relaxed the Markov assumption and utilized action history as an additional input or leveraged sequence models to enhance performance [60, 61]. We identify the action history as a crucial cue for understanding the current stage and the fine-grained state within the stage, and use it to predict stages rather than directly predicting the next action.
Modality Temporality. In a complex manipulation task, the importance of various uni-modal features could change over stages. At timesteps from different stages, a particular modality may contribute significantly to the prediction, or serve as a supplementary role to the primary modality, or provide little useful information. Moreover, different states within a stage, such as the beginning and end, may also exhibit minor changes in modality importance. We distinguish them as coarse-grained and fine-grained importance change. However, previous works typically treated each modality equally and did not consider the issue of changing modality importance in method design. This could lead to sub-optimal outcomes as uni-modal features with low quality could disrupt the overall prediction. On the contrary, we utilize task stage information to guide multi-sensory fusion, dynamically assigning weights of modalities based on the fine-grained state in the current stage.
## 3.2 Stage-Guided Dynamic Multi-Sensory Fusion for Robot (MS-Bot)
In this section, we introduce how our method MS-Bot addresses the above challenges. Considering Non-Markovity , we use action history as input to assist the model in assessing the current task state. For Modality Temporality , we establish a coarse-to-fine stage comprehension, decomposing the task state into coarse-grained stages and fine-grained states within a stage. Dynamic fusion guided by the fine-grained state within the current stage is employed to handle the changing modality importance.
To introduce the understanding of stages into the process of imitation learning, we incorporate task stages divided by sub-goals into the training samples. Given a sample ( X t , a t ) at timestep t in a trajectory where X t = { X ,X ,..., X 1 t 2 t M t } is the observation of M modalities and a t is the corresponding action, a stage label s t ∈ { 1 2 , , ..., S } is added, where S is the number of stages in the task divided by different sub-goals. The sample at timestep t is then represented as ( X t , a t , s t ) . Based on the sample with stage division, we then introduce the four main components of our method MS-Bot:
Feature Extractor. This component consists of several uni-modal encoders. Each encoder takes a brief history of observations X m t ∈ R T × H m × W m × C m of the modality m as input, where T is the timestep number of the brief history and H ,W m m , C m indicates the input shape of modality m . These observations are then encoded into feature tokens f t ∈ R M T × × d where d denotes dimension.
State Tokenizer. This component aims to encode the observations and action history ( a , a 1 2 , ..., a t -1 ) into a token that can represent the current state. Action history is similar to human memory and can help to indicate the current state within the whole task. We input the action history
as a one-hot sequence into an LSTM [62], then concatenate the output with the feature tokens and encode them into a state token z state t through a Multi-Layer Perceptron (MLP).
Stage Comprehension Module. Merely using the state token alone is insufficient for achieving a comprehensive understanding of task stages. This module aims to perform coarse-to-grained stage understanding by injecting stage information into the state token. For a task with S stages, we use S learnable stage tokens [ stage 1 ] , ..., [ stage S ] to represent each stage. After warmup training, each stage token is initialized with the mean of all state tokens on samples within the stage. Next, we use a gate network (MLP) to predict the current stage, i.e. , coarse-grained stage comprehension. The S -dimensional output scores g t of the gate are softmax-normalized and multiplied by each of the S stage tokens, followed by summing up the results to obtain the stage token z stage t at timestep t via:
$$\text{inwco} \, \text{by summing up} \, \text{in-sum} \, \text{in-sage} \, \text{when} \, z _ { t } \quad \text{at} \, \text{in-swap} \, \text{via}. \\ \text{g} _ { t } = ( g _ { t } ^ { 1 }, \dots, g _ { t } ^ { S } ) = s o f t m a x ( M L P ( z _ { t } ^ { s t a t e } ) ), \\ z _ { t } ^ { s t a g e } = \frac { 1 } { S } \sum _ { j = 1 } ^ { S } ( g _ { t } ^ { j } \cdot [ s t a g e _ { j } ] ). \\ \text{max} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage} \, \text{in-sage}.$$
We use a softmax score instead of one-hot encoding because the transition of stages is a continuous and gradual process. Finally, we compute the weighted sum of the state token z state t and the current stage token z stage t using a weight β to obtain the stage-injected state token z ∗ t :
$$z _ { t } ^ { * } = \beta \cdot z _ { t } ^ { s t a t e } + ( 1 - \beta ) \cdot z _ { t } ^ { s t a g e }.$$
Different from the old state token z state t , the new state token z ∗ t represents the fine-grained state within a stage. In this case, z stage t is regarded as an anchor stage, while z state t can indicate the shift inside the stage, thereby achieving coarse-to-fine stage comprehension.
During the training process, we utilize stage labels to supervise the stage scores output by the gate net. Specifically, we penalize scores that do not correspond to the current stage. Additionally, for samples within a range near the stage boundaries, we do not penalize its score on the nearest stage, achieving a soft constraint effect. The loss for the gate net L gate on the i -th sample is as follows:
̸
$$\log a \pi \cos \max \min \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \min \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \min \max \max \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \min \max \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \min \max \min \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \sum \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \sum \max \max \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \sum \max \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \sum \max \min \min \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \ max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \text{s}$$
where k indicates a nearby sample in the same trajectory, s i and s k represent stage labels and γ is a hyper-parameter used to determine the range near the stage boundaries. This soft constraint allows for smoother variations in the predicted stage scores.
Dynamic Fusion Module. Due to variations in modality importance across different stages and the minor importance changes within a stage, we aim for the model to dynamically select the modalities of interest based on the fine-grained state within the current stage. We use the state token with stage information z ∗ t as query, and the feature tokens f t as key and value for cross-attention [17]. This mechanism dynamically allocates attention scores to feature tokens based on the state token z ∗ t , thereby achieving dynamic multi-sensory fusion over time. It also contributes to a more stable multi-sensory fusion, as the anchor z stage t changes minimally within a stage. The features from all modalities are integrated into a fusion token z fus t based on the current stage's requirements. Finally, the fusion token z fus t is fed into an MLP to predict the next action a t .
In order to prevent the model from simply memorizing the actions corresponding to attention score patterns, we also introduce random attention blur mechanism. For each input, we replace the attention scores on feature tokens with the same average value 1 M T × with a probability p . We encourage the model to simultaneously learn both stage information and feature information in the fusion token.
The loss during training consists of two components: the classification loss for action prediction L cls and the penalty on the scores of the gate network L gate . The total training loss L is as follows:
$$\mathcal { L } = \mathcal { L } _ { c l s } + \lambda \mathcal { L } _ { g a t e },$$
where λ is a hyper-parameter to control the intensity of the score penalty.
Figure 3: An illustration of the task setup for peg insertion with keyway and pouring task.
## 4 Experiments
In this section, we explore the answers to the following questions through experiments: ( Q1 ) Compared to previous methods, how much performance improvement does stage-guided dynamic multisensory fusion provide? ( Q2 ) Why is stage-based dynamic fusion superior to fusion based solely on the input itself? How does stage comprehension help? ( Q3 ) Can stage-guided dynamic fusion maintain its advantage over static fusion in out-of-distribution settings?
## 4.1 Task Setup
Pouring. For the pouring task, the robot needs to pour tiny steel beads of specific quality from the cylinder in the hand into another cylinder. This task consists of four stages [44]: 1) Aligning , where the robot needs to move a graduated cylinder containing beads and align it with the target cylinder, 2) Start Pouring , where the robot rotates the end effector to pour out the beads at an appropriate speed, 3) Holding Still , where the robot maintains its posture to continue pouring out beads steadily, and 4) End Pouring , where the robot rotates the end effector at the appropriate time to stop the flow of beads. The initial mass of the beads is 90g/120g, while the target mass for pouring out is 40g/60g, both indicated by prompts. We use audio, vision (RGB) and touch modalities in this task.
Peg Insertion with Keyway. This task is an upgraded version of peg insertion, where the robot needs to align a peg with a key to the keyway on the base by rotating and then insert the peg fully. The alignment primarily relies on tactile feedback, as the camera cannot observe inside the hole. This task consists of three stages: 1) First Insertion , where the robot aligns the peg with the hole and inserts it until the key collides with the base, 2) Rotating , where the robot aligns the key with the keyway on the base by rotating the peg based on tactile feedback, and 3) Second Insertion , where the robot further inserts the peg to the bottom. We use RGB, depth and touch modalities in this task.
Fig. 3 briefly shows the two tasks. See Appendix A for a more detailed task setup for both tasks.
## 4.2 Physical Setup and Experimental Details
Robot Setup and Data Collection. We use a 6-DoF UFACTORY xArm 6 robotic arm equipped with a Robotiq 2F-140 gripper in all experiments. For both tasks, we generate Cartesian space displacement commands at a policy frequency of 5 Hz. We use an Intel RealSense D435i camera to record visual data (RGB and depth) with a resolution of 640 × 480 at a frequency of 30Hz. We use a desktop microphone to record audio at a sampling rate of 44.1kHz. Tactile data are recorded by a GelSight [1] mini sensor with a resolution of 400 × 300 and a frequency of 15Hz.
Baselines. We compare our method with three baselines in both tasks: 1) the concat model which directly concatenates all the uni-modal features [12, 13, 14, 15], 2) Du et al. [63] that uses LSTM to fuse the uni-modal features and the additional proprioceptive information, and 3) MULSA [11] which fuses the uni-modal features via self-attention. We also compare our method with two variants in each task: MS-Bot (w/o A/D) and MS-Bot (w/o T/R) where one modality in the task is removed (audio and touch for pouring while depth and RGB for peg insertion).
Table 1: Comparison of performance on pouring (mean ± standard deviation) and peg insertion with keyway ( Q1 ). A: Audio, D: Depth, T: Touch, R: RGB.
| Method | Pouring-Initial Mass (g) | Pouring-Initial Mass (g) | Pouring-Target Mass (g) | Pouring-Target Mass (g) | Insertion Success |
|------------------|----------------------------|----------------------------|---------------------------|---------------------------|---------------------|
| | 90 | 120 | 40 | 60 | Rate |
| Concat | 4.80 ± 1.14 | 8.72 ± 2.39 | 8.40 ± 2.21 | 6.54 ± 2.14 | 5/10 |
| Du et al. [63] | 4.32 ± 1.22 | 7.79 ± 2.11 | 8.54 ± 2.04 | 6.26 ± 2.01 | 5/10 |
| MULSA [11] | 3.05 ± 1.01 | 6.42 ± 1.98 | 7.12 ± 1.66 | 4.19 ± 1.24 | 6/10 |
| MS-Bot (w/o A/D) | 10.55 ± 2.25 | 15.76 ± 3.18 | 15.64 ± 3.25 | 13.02 ± 3.13 | 5/10 |
| MS-Bot (w/o T/R) | 8.32 ± 1.74 | 12.99 ± 3.04 | 13.02 ± 3.13 | 9.77 ± 1.65 | 5/10 |
| MS-Bot | 1.60 ± 1.10 | 5.58 ± 1.79 | 6.48 ± 1.55 | 1.80 ± 0.95 | 8/10 |
Figure 4: Visualization of the aggregated attention scores for each modality and stage scores in the pouring task ( Q2 ). At each timestep, we average the attention scores on all feature tokens of each modality separately. The stage score is the output of the gate network after softmax normalization.
## 4.3 How much improvement does stage-guided dynamic multi-sensory fusion provide?
To evaluate how much improvement MS-Bot brings compared to previous methods, we conduct comparative experiments on the two tasks. For each task (considering changing initial weight and target weight as two tasks), we collect 30 human demonstrations and use 20 of them as the training set, leaving the remaining 10 as the validation set. For both tasks, we conduct 10 real-world tests.
Tab. 1 shows the performance of baselines and our method on two tasks. Our MS-Bot outperforms all baselines in both the pouring task and peg insertion task, demonstrating the superiority of stageguided dynamic multi-sensory fusion. Despite using proprioceptive information, the improvement of Du et al. [63] over the concat model is minimal, indicating that the inadequate understanding of the coarse-grained and fine-grained modality importance change is the critical barrier. Moreover, these two baselines exhibit delayed responses to stage changes, causing excessive pouring in the pouring task and misalignment in the insertion task. MULSA employs self-attention for dynamic fusion, but its lack of a thorough stage understanding prevents it from fully leveraging the advantages of dynamic fusion. Our MS-Bot achieves the best performance by better allocating modality weights during fusion based on the understanding of the fine-grained state within the current stage ( Q1 ).
The notable performance drop when one modality is removed indicates that each modality contributes significantly. In the pouring task, removing audio and tactile modalities degrades the model's ability to assess the quality of poured beads. The impact is more significant when the audio modality is removed, corresponding to the notable decrease in confidence observed after masking the audio features in Stage 3 as shown in Fig. 1. In the peg insertion task, removing either the RGB or depth modality will degrade the alignment performance. It is worth noting that even without the assistance of the depth or RGB modality, our MS-Bot achieves an equal success rate compared to concat model and Du et al. [63], demonstrating the superiority of stage comprehension and dynamic fusion ( Q1 ).
## 4.4 Why is stage-based dynamic fusion superior to fusion based solely on the input itself?
To better understand the working principles of MS-Bot and the reasons for performance improvement, we visualize the attention scores of each modality and the scores of the stage tokens. As shown
Table 2: Impact of each component of our method in pouring task ( Q2 ). '-' indicates further removing the module from the model in the previous line. Overall error on all settings is shown.
| Method | Overall |
|--------------------|-------------|
| MS-Bot | 3.88 ± 2.55 |
| - Attention Blur | 4.01 ± 2.54 |
| - Stage Comprehend | 4.62 ± 2.34 |
| - State Tokenizer | 5.19 ± 2.21 |
| | Pouring Color | Insertion | Insertion |
|----------------|-----------------|-------------|-------------|
| Method | | Color | Mess |
| Concat | 8.75 ± 2.02 | 2/10 | 3/10 |
| Du et al. [63] | 8.04 ± 1.85 | 3/10 | 3/10 |
| MULSA [11] | 5.56 ± 1.13 | 4/10 | 5/10 |
| MS-Bot | 2.41 ± 1.47 | 6/10 | 6/10 |
Table 3: Comparison of models in scenes with visual distractors ( Q3 ). 'Color' indicates the color of the cylinder or the base is changed and 'Mess' indicates there are some clutter near the base.
in Fig. 4, MS-Bot accurately predicts the rapid stage changes. Due to the model's coarse-to-fine task stage comprehension, the aggregated attention scores of the three modalities remain relatively stable, exhibiting clear inter-stage changes and minor intra-stage adjustment ( Q2 ). Vision initially dominates during the first stage. Upon entering the second stage, the model begins to use the sound of beads to find the appropriate angle and distinguishes this stage from the last stage through touch. During the holding still stage, the model primarily relies on audio and tactile deformation to assess the mass of beads. In the final stage, the model discerns the completion of the pouring based on tactile deformation and the rise of tactile attention scores is observed. The changes in attention scores for the peg insertion task (see Fig. 12b) also follow a similar pattern, demonstrating the validity and explainability of the proposed stage-guided dynamic multi-sensory fusion ( Q2 ).
We also conduct ablation experiments on the pouring task to examine the contributions of each module, as shown in Tab. 2. We observe significant contributions to performance from both the state tokenizer and the stage comprehension module ( Q2 ). These two modules provide critical task state understanding and coarse-to-fine stage comprehension. In addition, removing random attention blur results in a minor performance decline. The complete ablation results are located in Tab. 8.
## 4.5 Can stage-guided dynamic fusion maintain its advantage in out-of-distribution settings?
To verify the generalization of our method to distractors, we conduct experiments with visual distractors in both tasks. In the pouring task, we changed the cylinder's color from white to red. For the peg insertion task, we altered the base color from black to green ('Color'), and placed clutter around the base ('Mess'). As shown in Tab. 3, our method exhibits minimal impact across various scenarios with distractors and consistently maintains performance superiority, demonstrating the generalizability of stage comprehension ( Q1, Q3 ). Two baseline methods, the concat model and Du et al. [63], suffer from performance degradation when the visual modality is disturbed. Due to their lack of ability to understand the stages and dynamically adjust modality weights, even when information from visual modality is not needed in a particular stage, the model is still affected by distractors. This leads to unsatisfying performance. Our method dynamically allocates modality weights based on the understanding of the current stage, thereby reducing the impact of visual distractors on the fused features ( Q2, Q3 ). Consequently, it outperforms the two baseline methods using static fusion and the MULSA that solely relies on the current observation for dynamic fusion.
## 5 Conclusion and Limitations
We present MS-Bot, a stage-guided dynamic multi-sensory fusion method with coarse-to-fine stage comprehension, which dynamically focuses on relevant modalities based on the state within the current stage. Evaluated on the challenging pouring and peg insertion with keyway tasks, our method outperforms previous static and dynamic fusion methods. We find that stage comprehension can be generalized to scenes with various distractors, reducing the impact of interference from one modality on multi-sensory fusion. We hope our work can inspire future work on multi-sensory robots.
Limitations: Our stage division involves human factors. An improvement could be leveraging LLMs for automatic stage labeling. Additionally, proposing more challenging multi-sensory manipulation tasks would be interesting for future works. More limitations are discussed in Appendix L.
## Acknowledgments
The project was supported by National Natural Science Foundation of China (NO.62106272).
## References
- [1] W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force. Sensors , 17(12):2762, 2017.
- [2] P. Schmidt, J. Scaife, M. Harville, S. Liman, and A. Ahmed. Intel® realsense™ tracking camera t265 and intel® realsense™ depth camera d435-tracking and depth. Real Sense , 2019.
- [3] Tesla. Tesla bot. Website, 2024. https://www.tesla.com/AI .
- [4] Figure. Figure 01 + openai: Speech-to-speech reasoning and end-to-end neural network. Website, 2024. https://www.figure.ai/ .
- [5] J. Luo, C. Xu, X. Geng, G. Feng, K. Fang, L. Tan, S. Schaal, and S. Levine. Multi-stage cable routing through hierarchical imitation learning. IEEE Transactions on Robotics , 2024.
- [6] P. Sharma, D. Pathak, and A. Gupta. Third-person visual imitation learning via decoupled hierarchical controller. Advances in Neural Information Processing Systems , 32, 2019.
- [7] O. Nachum, S. S. Gu, H. Lee, and S. Levine. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems , 31, 2018.
- [8] S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y. Chebotar, D. Dwibedi, and D. Sadigh. Rt-h: Action hierarchies using language. arXiv preprint arXiv:2403.01823 , 2024.
- [9] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models. In Conference on Robot Learning , pages 1769-1782. PMLR, 2023.
- [10] P. Sermanet, T. Ding, J. Zhao, F. Xia, D. Dwibedi, K. Gopalakrishnan, C. Chan, G. DulacArnold, N. J. Joshi, P. Florence, et al. Robovqa: Multimodal long-horizon reasoning for robotics. In 2nd Workshop on Language and Robot Learning: Language as Grounding , 2023.
- [11] H. Li, Y. Zhang, J. Zhu, S. Wang, M. A. Lee, H. Xu, E. Adelson, L. Fei-Fei, R. Gao, and J. Wu. See, hear, and feel: Smart sensory fusion for robotic manipulation. In Conference on Robot Learning , pages 1368-1378. PMLR, 2023.
- [12] Y. Han, K. Yu, R. Batra, N. Boyd, C. Mehta, T. Zhao, Y. She, S. Hutchinson, and Y. Zhao. Learning generalizable vision-tactile robotic grasping strategy for deformable objects via transformer. arXiv preprint arXiv:2112.06374 , 2021.
- [13] I. Guzey, B. Evans, S. Chintala, and L. Pinto. Dexterity from touch: Self-supervised pretraining of tactile representations with robotic play. In Conference on Robot Learning , pages 3142-3166. PMLR, 2023.
- [14] H. Liang, C. Zhou, S. Li, X. Ma, N. Hendrich, T. Gerkmann, F. Sun, M. Stoffel, and J. Zhang. Robust robotic pouring using audition and haptics. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 10880-10887. IEEE, 2020.
- [15] L. Fu, H. Huang, L. Berscheid, H. Li, K. Goldberg, and S. Chitta. Safe self-supervised learning in real of visuo-tactile feedback policies for industrial insertion. In 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages 10380-10386. IEEE, 2023.
- [16] C. Sferrazza, Y. Seo, H. Liu, Y. Lee, and P. Abbeel. The power of the senses: Generalizable manipulation from vision and touch through masked multimodal learning. 2023.
| [17] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [18] | H.-S. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 11444-11453, 2020. |
| [19] | S. Yu, D.-H. Zhai, Y. Xia, H. Wu, and J. Liao. Se-resunet: A novel robotic grasp detection method. IEEE Robotics and Automation Letters , 7(2):5238-5245, 2022. |
| [20] | Y. Song, J. Wen, D. Liu, and C. Yu. Deep robotic grasping prediction with hierarchical rgb-d fusion. International Journal of Control, Automation and Systems , 20(1):243-254, 2022. |
| [21] | R. Qin, H. Ma, B. Gao, and D. Huang. Rgb-d grasp detection via depth guided learning with cross-modal attention. In 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages 8003-8009. IEEE, 2023. |
| [22] | X. Pang, W. Xia, Z. Wang, B. Zhao, D. Hu, D. Wang, and X. Li. Depth helps: Improving pre- trained rgb-based policy with depth information injection. arXiv preprint arXiv:2408.05107 , 2024. |
| [23] | L. Wellhausen, R. Ranftl, and M. Hutter. Safe robot navigation via multi-modal anomaly detection. IEEE Robotics and Automation Letters , 5(2):1326-1333, 2020. |
| [24] | C. Huang, O. Mees, A. Zeng, and W. Burgard. Visual language maps for robot navigation. In 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages 10608- 10615. IEEE, 2023. |
| [25] | C. Xu, J. Chen, M. Yao, J. Zhou, L. Zhang, and Y. Liu. 6dof pose estimation of transparent object from a single rgb-d image. Sensors , 20(23):6790, 2020. |
| [26] | M. Tian, L. Pan, M. H. Ang, and G. H. Lee. Robust 6d object pose estimation by learning rgb-d features. In 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages 6218-6224. IEEE, 2020. |
| [27] | Y. He, H. Huang, H. Fan, Q. Chen, and J. Sun. Ffb6d: Afull flow bidirectional fusion network for 6d pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 3003-3013, 2021. |
| [28] | S. Cui, R. Wang, J. Wei, J. Hu, and S. Wang. Self-attention based visual-tactile fusion learning for predicting grasp outcomes. IEEE Robotics and Automation Letters , 5(4):5827-5834, 2020. |
| [29] | S. Cui, R. Wang, J. Wei, F. Li, and S. Wang. Grasp state assessment of deformable objects using visual-tactile fusion perception. In 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages 538-544. IEEE, 2020. |
| [30] | E. Smith, R. Calandra, A. Romero, G. Gkioxari, D. Meger, J. Malik, and M. Drozdzal. 3d shape reconstruction from vision and touch. Advances in Neural Information Processing Systems , 33: 14193-14206, 2020. |
| [31] | Y. Wang, W. Huang, B. Fang, F. Sun, and C. Li. Elastic tactile simulation towards tactile-visual perception. In Proceedings of the 29th ACM International Conference on Multimedia , pages 2690-2698, 2021. |
| [32] | M. A. Lee, Y. Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In 2019 International Conference on Robotics and Automation (ICRA) , pages 8943-8950. IEEE, 2019. |
| [33] | J. Wilson and M. C. Lin. Avot: Audio-visual object tracking of multiple objects for robotics. In 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages 10045- 10051. IEEE, 2020. |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [34] | X. Qian, Z. Wang, J. Wang, G. Guan, and H. Li. Audio-visual cross-attention network for robotic speaker tracking. IEEE/ACM Transactions on Audio, Speech, and Language Process- ing , 31:550-562, 2022. |
| [35] | C. Gan, Y. Zhang, J. Wu, B. Gong, and J. B. Tenenbaum. Look, listen, and act: Towards audio-visual embodied navigation. In 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages 9701-9707. IEEE, 2020. |
| [36] | C. Chen, U. Jain, C. Schissler, S. V. A. Gari, Z. Al-Halah, V. K. Ithapu, P. Robinson, and K. Grauman. Soundspaces: Audio-visual navigation in 3d environments. In Computer Vision- ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part VI 16 , pages 17-36. Springer, 2020. |
| [37] | A. Younes, D. Honerkamp, T. Welschehold, and A. Valada. Catch me if you hear me: Audio- visual navigation in complex unmapped environments with moving sounds. IEEE Robotics and Automation Letters , 8(2):928-935, 2023. |
| [38] | R. Gao, Y.-Y. Chang, S. Mall, L. Fei-Fei, and J. Wu. Objectfolder: A dataset of objects with implicit visual, auditory, and tactile representations. In Conference on Robot Learning , pages 466-476. PMLR, 2022. |
| [39] | R. Gao, Z. Si, Y.-Y. Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, and J. Wu. Objectfolder 2.0: A multisensory object dataset for sim2real transfer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 10598-10608, 2022. |
| [40] | X. Yang, Z. Ji, J. Wu, Y.-K. Lai, C. Wei, G. Liu, and R. Setchi. Hierarchical reinforcement learning with universal policies for multistep robotic manipulation. IEEE Transactions on Neural Networks and Learning Systems , 33(9):4727-4741, 2021. |
| [41] | B. Beyret, A. Shafti, and A. A. Faisal. Dot-to-dot: Explainable hierarchical reinforcement learning for robotic manipulation. In 2019 IEEE/RSJ International Conference on intelligent robots and systems (IROS) , pages 5014-5019. IEEE, 2019. |
| [42] | M. M. Botvinick. Hierarchical reinforcement learning and decision making. Current opinion in neurobiology , 22(6):956-962, 2012. |
| [43] | Z. Yang, K. Merrick, L. Jin, and H. A. Abbass. Hierarchical deep reinforcement learning for continuous action control. IEEE transactions on neural networks and learning systems , 29 (11):5174-5184, 2018. |
| [44] | D. Zhang, Q. Li, Y. Zheng, L. Wei, D. Zhang, and Z. Zhang. Explainable hierarchical imitation learning for robotic drink pouring. IEEE Transactions on Automation Science and Engineer- ing , 19(4):3871-3887, 2021. |
| [45] | F. Xie, A. Chowdhury, M. De Paolis Kaluza, L. Zhao, L. Wong, and R. Yu. Deep imitation learning for bimanual robotic manipulation. Advances in neural information processing sys- tems , 33:2327-2337, 2020. |
| [46] | B. Li, J. Li, T. Lu, Y. Cai, and S. Wang. Hierarchical learning from demonstrations for long- horizon tasks. In 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages 4545-4551. IEEE, 2021. |
| [47] | K. Hakhamaneshi, R. Zhao, A. Zhan, P. Abbeel, and M. Laskin. Hierarchical few-shot imi- tation with skill transition models. In International Conference on Learning Representations , 2021. |
| [48] | Z. Jia, F. Liu, V. Thumuluri, L. Chen, Z. Huang, and H. Su. Chain-of-thought predictive control. arXiv preprint arXiv:2304.00776 , 2023. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [49] | J. Arevalo, T. Solorio, M. Montes-y G´mez, o and F. A. Gonz´lez. a Gated multimodal units for information fusion. arXiv preprint arXiv:1702.01992 , 2017. |
| [50] | J. Kim, J. Koh, Y. Kim, J. Choi, Y. Hwang, and J. W. Choi. Robust deep multi-modal learning based on gated information fusion network. In Asian Conference on Computer Vision , pages 90-106. Springer, 2018. |
| [51] | S. Wang, J. Zhang, and C. Zong. Learning multimodal word representation via dynamic fusion methods. In Proceedings of the AAAI conference on artificial intelligence , volume 32, 2018. |
| [52] | J. Arevalo, T. Solorio, M. Montes-y Gomez, and F. A. Gonz´lez. a Gated multimodal networks. Neural Computing and Applications , 32:10209-10228, 2020. |
| [53] | Z. Han, F. Yang, J. Huang, C. Zhang, and J. Yao. Multimodal dynamics: Dynamical fusion for trustworthy multimodal classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 20707-20717, 2022. |
| [54] | Q. Zhang, H. Wu, C. Zhang, Q. Hu, H. Fu, J. T. Zhou, and X. Peng. Provable dynamic fusion for low-quality multimodal data. In International conference on machine learning , pages 41753-41769. PMLR, 2023. |
| [55] | M. K. Tellamekala, S. Amiriparian, B. W. Schuller, E. Andr´, e T. Giesbrecht, and M. Valstar. Cold fusion: Calibrated and ordinal latent distribution fusion for uncertainty-aware multimodal emotion recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023. |
| [56] | A. Nagrani, S. Yang, A. Arnab, A. Jansen, C. Schmid, and C. Sun. Attention bottlenecks for multimodal fusion. Advances in neural information processing systems , 34:14200-14213, 2021. |
| [57] | S. Li, C. Zou, Y. Li, X. Zhao, and Y. Gao. Attention-based multi-modal fusion network for semantic scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 34, pages 11402-11409, 2020. |
| [58] | V. Chudasama, P. Kar, A. Gudmalwar, N. Shah, P. Wasnik, and N. Onoe. M2fnet: Multi-modal fusion network for emotion recognition in conversation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 4652-4661, 2022. |
| [59] | G. Li, Y. Wei, Y. Tian, C. Xu, J.-R. Wen, and D. Hu. Learning to answer questions in dynamic audio-visual scenarios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 19108-19118, 2022. |
| [60] | P.-L. Guhur, S. Chen, R. G. Pinel, M. Tapaswi, I. Laptev, and C. Schmid. Instruction-driven history-aware policies for robotic manipulations. In Conference on Robot Learning , pages 175-187. PMLR, 2023. |
| [61] | X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y. Jing, W. Zhang, H. Liu, et al. Vision-language foundation models as effective robot imitators. In The Twelfth International Conference on Learning Representations , 2023. |
| [62] | S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation , 9(8):1735- 1780, 1997. |
| [63] | M. Du, O. Y. Lee, S. Nair, and C. Finn. Play it by ear: Learning skills amidst occlusion through audio-visual imitation learning. arXiv preprint arXiv:2205.14850 , 2022. |
- [64] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 770-778, 2016.
- [65] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014.
- [66] W. Xia, D. Wang, X. Pang, Z. Wang, B. Zhao, D. Hu, and X. Li. Kinematic-aware prompting for generalizable articulated object manipulation with llms. In 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages 2073-2080. IEEE, 2024.
- [67] Anthropic. Claude 3.5 sonnet. Website, 2024. https://www.anthropic.com/news/ claude-3-5-sonnet .
- [68] C. Chi, S. Feng, Y. Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS) , 2023.
- [69] Y. Wei, R. Feng, Z. Wang, and D. Hu. Enhancing multimodal cooperation via sample-level modality valuation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 27338-27347, 2024.
## Appendix
## A Details of the Task Setup
In Sec. 4.1 of the main paper, we briefly introduced the basic information of the pouring task and the peg insertion with keyway task, including the task objectives and stage divisions. In this section, we provide a more detailed introduction to the setup of these two tasks. We control the robot arm through a keyboard to complete the tasks and collect human demonstrations.
## A.1 Pouring
Figure 5: Illustration of the pouring task. We randomly shift the fixed target cylinder sideways by 0 ∼ 3 cm (indicated by the blue arrow) in training demonstrations, and shift by 0 ∼ 6 cm (indicated by the orange arrow) during testing.

Setup Details. For the pouring task, the robot needs to pour tiny steel beads of specific quality from the cylinder in the hand into another cylinder. In the demonstrations, we randomly shift the fixed target cylinder sideways by 0 ∼ 3 cm, while during testing, this range expands to 0 ∼ 6 cm, as illustrated in Fig. 5. Following the previous work [11], we use small beads with a diameter of 1mm to simulate liquids. The initial mass of the beads is 90g/120g, while the target mass for pouring out is 40g/60g, both indicated by prompts. Since the camera cannot capture the interior of the target cylinder, other modalities are needed to assess whether the poured-out quantity meets the target. Hence, we use vision (RGB), audio and touch modalities in this task.
Robot Action Space. In this task, the robot can act in a 2-dimensional action space along the axis x and ϕ , where x represents the horizontal movement and ϕ represents the rotation of the gripper. The action step size is ∆ x = 0 5 . mm and ∆ ϕ = 0 12 . ◦ . There are a total of 5 possible actions ( ± ∆ x , ± ∆ ϕ and 0 ), corresponding to the two directions of the two dimensions of ( x, ϕ ) and holding still.
Stage Division. This task consists of four stages [44]: 1) Aligning , where the robot needs to move a graduated cylinder containing beads and align it with the target cylinder, 2) Start Pouring , where the robot rotates the end effector to pour out the beads at an appropriate speed, 3) Holding Still , where the robot maintains its posture to continue pouring out beads steadily, and 4) End Pouring , where the robot rotates the end effector at the appropriate time to stop the flow of beads. In trajectories, we consider the timesteps of the first downward rotation of the gripper ( -∆ ϕ ), the first holding still after rotation, and the first upward rotation of the gripper ( +∆ ϕ ) as stage transition points.
## A.2 Peg Insertion with Keyway.
Setup Details. This task is an upgraded version of peg insertion, where the robot needs to first align a peg with a key to the keyway on the base by rotating, and then insert the peg fully. The alignment between the key and the keyway in this task primarily relies on tactile feedback, as the
Figure 6: Illustration of the peg insertion with keyway task. We randomly shift the fixed base along a 12 cm-long parallel line on the desktop (the yellow arrow), and randomly initialize the position of the robot arm inside a 40cm × 20cm rectangular area (the green rectangle) in training demonstrations. During testing, we fix the position of the base (the red points) and the robot arm (the green points) to several pre-defined points.
camera cannot observe inside the hole. Hence, we use RGB, depth and touch modalities in this task. Considering generalization, we randomly fix the base at any position along a 12 cm-long parallel line on the desktop in demonstrations, as illustrated in Fig. 6. The robot arm holding the peg can also be initialized inside a 40cm × 20cm rectangular area around the base. During testing, to ensure fairness, the positions of the base and the robot arm are several pre-defined points.
Robot Action Space. In this task, the robot arm can move on the three axes x, y, z of Cartesian coordinate, where x, y represents the horizontal movement and z represents the vertical movement. The gripper can also rotate along axis ϕ to align the key with the keyway. Since the vertical movement of the robot arm ( -∆ z ) and the rotation of the gripper ( +∆ ϕ ) are both unidirectional, there are a total of 7 possible actions ( ± ∆ x , ± ∆ y , -∆ z , +∆ ϕ and 0 ).
Stage Division. This task consists of three stages: 1) First Insertion , where the robot aligns the peg with the hole and inserts it until the key collides with the base, 2) Rotating , where the robot aligns the key with the keyway on the base by rotating the peg based on tactile feedback, and 3) Second Insertion , where the robot further inserts the peg to the bottom. Similar to the pouring task, we consider the timesteps of the first gripper rotation ( +∆ ϕ ) and the first downward movement ( -∆ z ) after rotation as stage transition points.
## A.3 Generalization Experiments with Distractors
To verify the generalization of our framework to distractors in the environment, we conduct experiments with visual distractors on both tasks. For the pouring task, we change the color of the cylinder from white to red. As for the peg insertion task, we respectively change the color of the base from black to green, and scatter some clutter around the base. These task settings are illustrated in Fig. 7. The distractors only exist during testing. Besides introducing distractors, the settings for these tasks remain consistent with the main experiments.
## B Implementation Details
Following [11], we resize visual and tactile frames to 140 × 105 and randomly crop them to 128 × 96 during training. We also use color jitter for image augmentation. For audio modality, we resample the wave signal at 16kHZ and generate a 64 × 50 mel-spectrogram through short-time Fourier transform, with 400 FFT windows, hop length of 160, and mel bin of 64. We employ ResNet-18 [64] network as the uni-modal encoder. Each encoder takes a brief history of observations spanning



(a) Color (Pouring)
(b) Color (Insertion)
(c) Mess (Insertion)
Figure 7: Illustration of tasks with distractors. For the pouring task, we change the color of the cylinder from white to red (denoted as 'Color (Pouring)'). For the peg insertion with keyway task, we respectively change the color of the base from black to green (denoted as 'Color (Insertion)'), and scatter some clutter around the base (denoted as 'Mess (Insertion)').
T = 6 timesteps. We train all the models using Adam [65] with a learning rate of 10 -4 for 75 epochs. We perform linear learning rate decay every two epochs, with a decay factor of 0.9.
For action history, we use a buffer of length 200 to store actions. Each action is encoded using onehot encoding. Action sequences shorter than 200 are padded with zeros. For both tasks, we consider the 15 timesteps near the stage transition point as the soft constraint range ( γ = 15 ). We set λ = 5 0 . for both tasks to control the intensity of the penalty. For the learnable stage token [ stage i ] , we initialize it with the mean of all state tokens on samples within the i -th stage after warmup training for 1 epoch. We use β = 0 5 . for the calculation of the stage-injected state token z ∗ t . Moreover, to prevent gradients from becoming too large, we also truncated the gradients of the stage score penalty, restricting them to solely influencing the gate network.
## C Random Attention Blur
Figure 8: Illustration of random attention blur in the stage-guided dynamic fusion module. We randomly replace the attention scores on all feature tokens with the same average value 1 M T × with a probability p , which is a hyper-parameter.
In order to prevent the model from simply memorizing the actions corresponding to attention score patterns, we introduce a random attention blur mechanism to the stage-guided dynamic fusion module. For each input, we replace the attention scores on all feature tokens with the same average value 1 M T × with a probability p , where M is the number of modalities and T is the timestep number of the brief observation history, as illustrated in Fig. 8. We set p = 0 25 . in both tasks.
We introduce this mechanism due to the potential overfitting issue in the model, where the policy head (MLP in the dynamic fusion module) learns the correspondence between the distribution of
attention scores and actions. For instance, when using the trained MS-Bot model (without random attention blur) to complete pouring tasks, manually increasing the attention scores on tactile feature tokens invariably leads the model to predict the next action as upward rotation ( +∆ ϕ ), regardless of the current stage of the task. This phenomenon suggests that the stage comprehension module in the model partially assumes the role of action prediction rather than focusing solely on stage understanding. Therefore, randomly blurring attention scores can compel the policy head to focus on the information from the feature tokens and better decouple the stage comprehension module from the dynamic fusion module.
## D LLM-Based Automatic Stage Labeling
Our strategy for stage labeling is to segment the action sequence of the trajectory based on pre-set rules (such as considering the timestep of the first gripper rotation as a stage transition point). This does indeed require some time to pre-define the stages and design specific rules for division. However, extracting stage information without human annotation is also feasible. One possible approach is to use LLMs, which have demonstrated strong comprehension ability in robotic manipulation [66], for automatic stage annotation of action sequences. We use Claude 3.5 Sonnet [67] as our LLM, and construct prompts to describe the task setup and include an example action sequence to better help the LLM understand the process of this task. We then ask the LLM to provide the specific stage division, as shown in Fig. 9.

We want the robotic arm to complete a peg insertion with keyway task. In this task, the robotic arm needs to align the peg with the keyway on the base by rotation, and then fully insert the peg. At each moment, the robotic arm chooses one action to execute from seven options: move left, move right, move forward, move backward, move down, rotate the peg, and stay.Here is an example of the complete action sequence: [left, left, left, left, left, left, backward, backward, backward, backward, backward, backward, left, left, left, left, down, down, down, down, down, down, down, down, left, down, down, down, down, down, down, rotate, rotate, rotate, rotate, down, down, down, down, stay, stay]
How many main stages are there in this task? Please divide the action sequence into rough stages based on the sub-goals of the task. Please do not list fine adjustments within a main stage as separate stages.
To analyze this action sequence and divide it into stages, let's look at the major movements and goals. I'll group similar consecutive actions together and identify the main stages based on the apparent sub-goals of the task. Here's the breakdown:
1.Horizontal Alignment (Left movement): The sequence starts with a long series of "left" movements (95 times).
2.Depth Adjustment (Backward movement): Following the left movements, there's a significant series of "backward" movements (43 times).
3.Fine Horizontal Adjustment: A small series of "left" movements (9 times) follows. This is likely a fine adjustment, so we'll consider it part of the previous stage rather than a separate one. 4.Vertical Approach (Down movement): There's a long series of "down" movements (159 times), bringing the peg closer to the insertion point.
5.Rotation Alignment: A significant number of "rotate" actions (146 times) occur, likely to align the peg with the keyway.
6.Final Insertion: The sequence ends with a series of "down" movements (64 times), followed by several "stay" commands (13 times).
Based on this analysis, we can identify 4 main stages in this task:
- 1.Initial Positioning: Horizontal alignment and depth adjustment (includes the first two major movement series and the small fine adjustment)
- 2.Vertical Approach: Bringing the peg down towards the insertion point
- 3.Rotation Alignment: Aligning the peg with the keyway
4.Final Insertion: Inserting the peg and maintaining position
These stages correspond to the main sub-goals of the peg insertion with keyway task: positioning the arm above the insertion point, approaching the insertion point, aligning the peg with the keyway, and finally inserting the peg.
Figure 9: An example of automatic stage division by LLM. We provide the task setup, robot action space and an example action sequence to the LLM to obtain the main stage division. For ease of presentation, the action sequence in the figure has been abbreviated.

After obtaining the stage divisions provided by the LLM, we then construct another prompt and ask the LLM to label the action sequence according to the stage divisions, as shown in Fig. 10. This strategy allows for obtaining stage labels for all samples without requiring human annotation. We find that the stage divisions provided by the LLM are usually more detailed. For example, it divides the peg insertion with keyway task into four stages (splitting our First Insertion stage into two stages: Initial Positioning and Vertical Approach), which is also reasonable. Since our model does not explicitly require that the modality importance must be different between stages, a more detailed stage division is acceptable to some extent.
Through this method, we perform automatic stage annotation on our imitation learning dataset. To evaluate the accuracy of the LLM's annotations, we merge the first two stages divided by the LLM into a single First Insertion stage, and use the human-annotated stage labels as ground truth. The evaluation results show that the accuracy of the stage labels annotated by the LLM is 95 68% . (10,096 / 10,552, about 15 errors per trajectory).
For tasks like peg insertion with keyway, where many actions are continuous, we can merge consecutive actions to obtain a compressed action sequence like '[action*num,...,action*num]', as shown in Fig. 11. This approach helps reduce annotation errors caused by LLM counting mistakes and increases the accuracy to 99 65% . (10,521 / 10,552, about 3 errors per trajectory). These results demonstrate that automatic stage annotation using LLMs without pre-defined stages is feasible. The experiment is only a relatively simple attempt. We believe that with more detailed prompt engineering and the use of more powerful LLMs, the accuracy can be further improved.
## E Comparison of Attention Scores between MULSA and MS-Bot
In Sec. 4.4 of the main paper, we illustrate the aggregated attention scores for each modality and the stage scores of MS-Bot in the pouring task, as shown in Fig. 12a. We also record the changes in attention scores and stage scores in the peg insertion with keyway task, as shown in Fig. 12b. The results in the figure demonstrate that our model accurately predicts the rapid changes in stages for both tasks. As a result, the attention scores across modalities guided by stage comprehension are also relatively stable, exhibiting clear inter-stage changes and minor intra-stage adjustment.
As a comparison, we also visualize the attention scores of another baseline MULSA [11] with selfattention fusion, as shown in Fig. 13. The range of the attention score axis in the figure is consistent with Fig. 12 ( 0 0 . ∼ 1 0 . ). It is evident that the attention scores of the modalities in the MULSA model are close and exhibit a small variation along the time axis, lacking clear stage characteristics. This indicates that the MULSA model fails to fully leverage the advantages of dynamic fusion compared to the concat model.
## F Combination with Diffusion Policy
| Fusion Module | Policy Network | Success Rate |
|-----------------------------|-----------------------|----------------|
| Concat | MLP | 7/15 |
| Concat | Diffusion Policy [68] | 11/15 |
| Stage-guided Dynamic Fusion | MLP | 13/15 |
| Stage-guided Dynamic Fusion | Diffusion Policy [68] | 13/15 |
Table 4: Comparison of performance with Concat and Diffusion Policy baselines on the peg insertion with keyway task.
To verify the applicability of our proposed stage-guided dynamic multi-sensory fusion to different policy networks, we replace the policy network with the Diffusion Policy [68] and conduct experiments on the peg insertion with keyway task. Specifically, we replace the MLP policy network with an UNet-based Diffusion Policy in the Concat baseline and our MS-Bot model, and evaluate the performance of stage-guided dynamic fusion on models using different policy networks.

We want the robotic arm to complete a peg insertion with keyway task. In this task, the robotic arm needs to align the peg with the keyway on the base by rotation, and then fully insert the peg. At each moment, the robotic arm chooses one action to execute from seven options: move left, move right, move forward, move backward, move down, rotate the peg, and stay.
This task contains 4 main stages:
Initial Positioning: Horizontal alignment and depth adjustment (includes the first two major movement series and the small fine adjustment)
Vertical Approach: Bringing the peg down towards the insertion point
Rotation Alignment: Aligning the peg with the keyway
Final Insertion: Inserting the peg and maintaining position
Please label the stage number to which each action in the action sequence belongs in order, and return a list like: [1,1,2,2,3,3,4]
Here is the action sequence with a length of 528: [left, left, left, left, left, left, backward, backward, backward, backward, backward, backward, left, left, left, left, down, down, down, down, down, down, down, down, left, down, down, down, down, down, down, rotate, rotate, rotate, rotate, down, down, down, down, stay, stay]
To label the stages for each action in the sequence, I'll go through the actions and assign stages based on the description provided. Here's the breakdown:


I've created a Python script that labels each action in the sequence with its corresponding stage. The resulting list has 528 elements, matching the length of your original action sequence. Here's a summary of the stage labeling:Stage 1 (Initial Positioning): The first 149 actions (97 left, 43 backward, 9 left)Stage 2 (Vertical Approach): The next 158 actions (all down movements)Stage 3 (Rotation Alignment): The next 146 actions (all rotate movements)Stage 4 (Final Insertion): The final 75 actions (63 down movements, 12 stay actions)You can see the full list of stage labels in the artifact above. The first few elements are [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], and the last few elements are [4, 4, 4, 4, 4, 4, 4, 4, 4, 4], which aligns with our stagebreakdown.This labeling should accurately represent the stages of the peg insertion with keyway task based on the action sequence you provided. Let me know if you need any clarification or have any questions about the stage labeling!
Figure 10: An example of automatic stage labeling by LLM. We provide the task setup, robot action space and an target action sequence to the LLM to obtain the stage labels. For ease of presentation, the action sequence in the figure has been abbreviated.
The results in Tab. 4 show that replacing the policy network in the Concat baseline with the Diffusion Policy leads to a significant performance improvement, but there is still a gap compared to MS-Bot. This is because the Diffusion Policy still lacks an explicit feature fusion module (apart from simple concatenation). The fusion of multi-sensory features in this baseline still occurs within the policy network, similar to the concat baseline, albeit with a more capable policy network. After further replacing its fusion module with our proposed stage-guided dynamic fusion, it achieves performance

We want the robotic arm to complete a peg insertion with keyway task. In this task, the robotic arm needs to align the peg with the keyway on the base by rotation, and then fully insert the peg. At each moment, the robotic arm chooses one action to execute from seven options: move left, move right, move forward, move backward, move down, rotate the peg, and stay.
This task contains 4 main stages:
Initial Positioning: Horizontal alignment and depth adjustment (includes the first two major movement series and the small fine adjustment)
Vertical Approach: Bringing the peg down towards the insertion point
Rotation Alignment: Aligning the peg with the keyway
Final Insertion: Inserting the peg and maintaining position
Please label the stage number to which each action in the action sequence belongs in order, and return a list like: [1,1,2,2,3,3,4]
Here is the action sequence with a length of 528: [left*97, backward*43, left*9, down*44, left*1, down*113, rotate*146, down*63, stay*12]
To label the stages for each action in the given sequence, let's break it down based on the description of the four main stages:
- 1. Initial Positioning: This includes horizontal alignment and depth adjustment. In the given sequence, this corresponds to the initial left and backward movements.
- 2. Vertical Approach: This stage brings the peg down towards the insertion point. It corresponds to the first set of downward movements.
- 3. Rotation Alignment: This stage aligns the peg with the keyway through rotation.
- 4. Final Insertion: This stage inserts the peg and maintains the position. It corresponds to the final downward movements and the stay action.
Now, let's label each action in the sequence:
- - [left*97, backward*43, left*9]: Stage 1 (Initial Positioning)
- - [down*44, left*1, down*113]: Stage 2 (Vertical Approach)
- - [rotate*146]: Stage 3 (Rotation Alignment)
- - [down*63, stay*12]: Stage 4 (Final Insertion)
To create the list of stage labels, we need to expand each action based on its repetition count. Here's the resulting list:
$$| [1]*149 + [2]*158 + [3]*146 + [4]*75$$
This gives us a list of 528 elements, matching the length of the action sequence. The list starts with 149 1's (for stage 1), followed by 158 2's (for stage 2), then 146 3's (for stage 3), and finally 75 4's (for stage 4).
Figure 11: An example of automatic stage labeling by LLM. We provide the task setup, robot action space and an compressed target action sequence to the LLM to obtain the stage labels.
comparable to MS-Bot. This demonstrates that our proposed explicit stage understanding and stageguided dynamic fusion are still effective for models with more powerful policy networks. Our proposed fusion module can help the policy network focus more on generating actions using the already fused multi-sensor features. However, under the same conditions of using stage-guided dynamic fusion, the model with diffusion policy as the policy network does not outperform the model with MLP. We think this may be due to the relatively small scale of data in this task, which does not allow the Diffusion Policy to fully leverage its advantages.
## G Comparison with Stage-Aware and Context-Aware Baselines
Due to not fully considering the importance of explicit stage understanding in guiding multi-sensory fusion, the original Concat and MULSA baselines does not utilize contextual inputs and additional stage information. To make a fairer comparison with our MS-Bot, we respectively construct Concat and MULSA baselines that incorporate a stage prediction auxiliary task and multi-sensory observation context. Specifically, we add an extra head (an MLP identical to the gate network in MS-Bot) to both the Concat and MULSA models to predict the stage, trained with the same form of loss

Figure 12: Visualization of the aggregated attention scores for each modality and stage scores of MS-Bot in both tasks. At each timestep, we average the attention scores on all feature tokens of each modality separately. The stage score is the softmax normalized output of the gate network.
Figure 13: Visualization of the aggregated attention scores of MULSA for each modality in both tasks. At each timestep, we average the attention scores on all feature tokens of each modality separately. The range of the attention score axis in the figure is consistent with Fig. 12.

used to penalize the scores of the gate network in MS-Bot. We also attempt to modify the structure of the MULSA model to accept observation context as input. We input the observations from 5s, 7.5s, 10s, 12.5s, 15s, 17.5s, and 20s before the current timestep into the model, and encode these observation contexts by each modality's encoder into 7 tokens (per modality). These tokens are then concatenated with the original 6 tokens of the current timestep observation of each modality, resulting in a total of 13 tokens for each modality. We evaluate these baselines on the peg insertion with keyway task. The results in Tab. 5 shows that introducing an explicit stage prediction task could improve the performance of the Concat baseline, but it provides minimal benefit for the MULSA method. These baselines still have a performance gap compared to our MS-Bot. This indicates that explicit stage understanding is meaningful, but introducing context to aid stage understanding and specially designed stage-guided dynamic fusion modules are also necessary. In addition, the results show that inputting observation contexts into MULSA results in virtually no improvement in the model's performance. This indicates that mixing the contexts and current observations in self-attention calculations is highly inefficient for helping the model understand stages and allocate modality weights, as it reduces focus on the more important current observations and significantly increases GPU memory usage. In contrast, our MS-Bot leverages a long action history as context to enhance its understanding of task stages. This approach simplifies processing for the model and offers finer granularity, effectively guiding dynamic multi-sensor fusion.
## H Comparison under the Multi-Camera Setting
In robotic manipulation, a common setup involves using multiple cameras to capture visual information from different views. By treating visual images from different views as distinct modalities, our MS-Bot is also able to handle multi-camera observations. To verify this capability, we conduct a comparison with baseline methods on the peg insert with keyway task under the setting with multiple cameras. Specifically, we place another camera on the side of the base, so that the lines connecting these two cameras to the base roughly form a right angle. We replace the depth observation from the first camera with the RGB observation from the second camera, as the RGB observations
Table 5: Comparison of performance with stage-aware and context-aware baselines on the peg insertion with keyway task. We introduced stage prediction auxiliary tasks and multi-sensory observation context into the Concat and MULSA baselines for a more comprehensive comparison.
| Method | Success Rate |
|-------------------------------|----------------|
| Concat | 7/15 |
| MULSA | 11/15 |
| Concat + Stage Auxiliary Task | 9/15 |
| MULSA + Stage Auxiliary Task | 11/15 |
| MULSA + Observation Context | 11/15 |
| MS-Bot | 13/15 |
Table 6: Comparison under the setting of multiple cameras on the peg insertion with keyway task.
| Method | Success Rate |
|----------|----------------|
| Concat | 9/15 |
| MULSA | 12/15 |
| MS-Bot | 14/15 |
from these two cameras already provide sufficient spatial information for this task. The results in Tab. 6 show that in the multi-camera setup, our MS-Bot method still outperforms the baselines. This demonstrates that our proposed stage-guided dynamic fusion can also be applied to fuse features from multiple cameras.
## I Combination with Audio Modality
Table 7: Comparison on the peg insertion with keyway task using RGB, depth, tactile and audio.
| Method | Success Rate |
|----------|----------------|
| Concat | 8/15 |
| MULSA | 11/15 |
| MS-Bot | 13/15 |
For tasks involving using lock-picking tools to unlock in real life, audio can indeed serve as the basis for completing the task, as these locks typically have specific mechanical structures that produce distinct sounds. Similarly, audio can indicate whether the key and keyway are aligned, thereby assisting with the peg insertion with keyway task. To verify the effectiveness of our model after further incorporating audio, we conduct experiments on the peg insertion with keyway task using RGB, depth, tactile and audio modality. The results in Tab. 7 show that the addition of the audio modality only brings improvement to the weakest Concat baseline. For MULSA and our MS-Bot method, the benefits are minimal. This is because the audio in this task is short and minimal due to the 3D-printed materials and is vulnerable to noise disturbance.
## J Detailed Experimental Results of Pouring
In Sec. 4.4 and 4.5 of the main paper, we show the overall error on all settings of the pouring task. In this section, we comprehensively present the detailed result of the component ablation and the distractor experiment on all the settings of the pouring task in Tab. 8 and 9. As shown in Tab. 8, the contributions from both the state tokenizer and the stage comprehension module on all settings demonstrate the importance of the coarse-to-fine stage comprehension. The consistent lead of MS-
Table 8: Impact of each component of our framework in the pouring task (mean ± standard deviation). '-' indicates further removing the module from the model in the previous line.
| Method | Pouring Initial (g) | Pouring Initial (g) | Pouring Target (g) | Pouring Target (g) |
|-----------------------|-----------------------|-----------------------|----------------------|----------------------|
| | 90 | 120 | 40 | 60 |
| MS-Bot | 1.60 ± 1.10 | 5.58 ± 1.79 | 6.48 ± 1.55 | 1.80 ± 0.95 |
| - Attention Blur | 1.72 ± 1.09 | 5.70 ± 1.74 | 6.55 ± 1.38 | 1.95 ± 1.32 |
| - Stage Comprehension | 2.52 ± 1.12 | 6.15 ± 1.64 | 6.80 ± 1.59 | 2.92 ± 1.40 |
| - State Tokenizer | 3.05 ± 1.01 | 6.42 ± 1.98 | 7.12 ± 1.66 | 4.19 ± 1.24 |
Table 9: Comparison of performance in scenes with visual distractors in the pouring task(mean ± standard deviation). We change the color of the cylinder from white to red during testing.
| Method | Pouring Initial (g) | Pouring Initial (g) | Pouring Target (g) | Pouring Target (g) |
|----------------|-----------------------|-----------------------|----------------------|----------------------|
| | 90 | 120 | 40 | 60 |
| Concat | 8.75 ± 2.02 | 10.69 ± 2.45 | 10.72 ± 2.35 | 8.46 ± 2.03 |
| Du et al. [63] | 8.51 ± 1.79 | 9.54 ± 2.10 | 9.98 ± 2.20 | 8.04 ± 1.85 |
| MULSA [11] | 4.72 ± 1.30 | 7.83 ± 1.71 | 8.45 ± 1.50 | 5.56 ± 1.13 |
| MS-Bot | 2.04 ± 1.40 | 6.10 ± 1.49 | 7.62 ± 1.94 | 2.41 ± 1.47 |
BOT across all settings of the pouring task in Tab. 3 also demonstrates the generalizability of stage comprehension.
## K Evaluation of Hyper-parameter Settings
Figure 14: Performance of MS-Bot on one setting of the pouring task when changing the hyper-parameters λ γ , and p . We fix the others when changing one hyper-parameter. We report the mean error of the concat model, MULSA and MS-Bot. The error bars represent the standard deviation of errors for MS-Bot.
In this section, we test the sensitivity of MS-Bot to different hyper-parameter settings. Specifically, we test the performance of MS-Bot under different penalty intensity λ , soft constraint range γ and probability of random attention blur p in one setting of the pouring task. We train all the models to pour out 40g of small beads with different initial masses (90g/120g). We set λ = 5 0 . , γ = 15 and p = 0 25 . by default, and keep the others fixed when we modify one of the hyper-parameters.
We present the evaluation results in Fig. 14. Our MS-Bot consistently outperforms both the concat model and MULSA across various hyper-parameter settings, indicating that the performance of our MS-Bot is relatively stable to hyper-parameter variations. However, we also observe that when setting λ and γ to small values ( λ = 1 0 . in Fig. 14a and γ = 0 in Fig. 14b), the performance of MSBot drops and becomes closer to MULSA with simple self-attention fusion. This is because when λ is too small, the prediction of the current stage becomes inaccurate due to the insufficient training. When γ is too small, the model is forced to make drastic changes in the stage score prediction within very few timesteps, leading to unstable stage predictions. Both of these factors weaken the efficacy
of stage comprehension within MS-Bot. We also find that setting too large p ( p > 0 3 . in Fig. 14c) can bring negative impacts as the attention blur truncates the gradients backpropagated to the stage comprehension module and the state tokenizer. Excessive attention blur can impair the training of these two modules.
## L Limitations and Future Improvements
In this section, we discuss the potential limitations of our work and the corresponding solutions:
In many robotic tasks this kind of dynamic weighting is not necessary. Indeed, there are many tasks that can be completed with just the visual modality, where readings from other sensors may not provide useful information. We believe that one solution is to let the model first select the necessary subset of sensors based on the task (possibly using an LLM), and then perform dynamic multisensor fusion based on stage understanding. For tasks with only one stage, this can be considered as a special case where | S | = 1 .
The stage labeling may be costly. Currently, our strategy for stage labeling is to segment the action sequence of the trajectory based on pre-set rules. This requires time to set up detailed rules and becomes more challenging when there are more stages and more complex stage transitions. A possible solution is the LLM-based automatic labeling method mentioned earlier, although a small amount of human effort is still necessary, such as constructing prompts to accurately describe the task setup and providing example for in-context learning.
The lack of comparison to larger models. Currently, there is no well-trained open-source multisensory large foundation model for robot manipulation (including vision, hearing, touch, etc.). Therefore, we are temporarily unable to verify the role of explicit stage understanding in large models, nor can we directly compare our model with multi-sensory large models. However, we believe that even for larger models, explicit stage understanding remains meaningful when introducing new modalities and training is required using a small amount of paired multi-sensory data, or when fine-tuning in new scenarios with limited data scale.
Robustness issue in the case of missing modalities. Since in both of our tasks there are stages that depend on a single modality, masking uni-modal features during testing may directly lead to failure. This is a problem common to all multi-sensory models, and we did not make improvements specifically for this issue. In cases where multiple sensors complement each other, the absence of uni-modal features may have a compounding effect on stage understanding and dynamic fusion. We believe that one possible solution is to randomly dropout uni-modal features during the training process [69]. Some other methods for robust multi-modal learning could also be referenced.
Transferability of the current dynamic multi-sensory fusion architecture. Since the multisensory fusion architecture we use in the dynamic fusion module is based on cross-attention rather than self-attention, there are difficulties in directly transferring the original form of this fusion method to transformers with multiple self-attention blocks. One potential strategy is to use the stage token as a special token to replace the class token. It could be used to predict the stage under the supervision of stage labels and thereby achieving the effect of stage-guided multi-modal fusion.
Low integration level of current multi-sensory robot system. Our current multi-sensory robot system has not well integrated the various sensors: the camera is positioned at a third-person perspective, the microphone is placed on the desktop, and the tactile sensor is at the end of the robotic arm. They are located in different positions. This low level of integration means that the system can only complete relatively simple tasks, while more complex multi-sensory tasks that require mobility cannot be accomplished. This multi-sensory system still needs further refinement and upgrading. | null | [
"Ruoxuan Feng",
"Di Hu",
"Wenke Ma",
"Xuelong Li"
]
| 2024-08-02T16:20:56+00:00 | 2024-10-25T04:36:44+00:00 | [
"cs.RO",
"cs.CV"
]
| Play to the Score: Stage-Guided Dynamic Multi-Sensory Fusion for Robotic Manipulation | Humans possess a remarkable talent for flexibly alternating to different
senses when interacting with the environment. Picture a chef skillfully gauging
the timing of ingredient additions and controlling the heat according to the
colors, sounds, and aromas, seamlessly navigating through every stage of the
complex cooking process. This ability is founded upon a thorough comprehension
of task stages, as achieving the sub-goal within each stage can necessitate the
utilization of different senses. In order to endow robots with similar ability,
we incorporate the task stages divided by sub-goals into the imitation learning
process to accordingly guide dynamic multi-sensory fusion. We propose MS-Bot, a
stage-guided dynamic multi-sensory fusion method with coarse-to-fine stage
understanding, which dynamically adjusts the priority of modalities based on
the fine-grained state within the predicted current stage. We train a robot
system equipped with visual, auditory, and tactile sensors to accomplish
challenging robotic manipulation tasks: pouring and peg insertion with keyway.
Experimental results indicate that our approach enables more effective and
explainable dynamic fusion, aligning more closely with the human fusion process
than existing methods. |
2408.01369v2 | ## Fabrication and characterization of low-loss Al/Si/Al parallel plate capacitors for superconducting quantum information applications
Anthony P. McFadden, 1, ∗ Aranya Goswami, 2, † Tongyu Zhao, 3, 1 Teun van Schijndel, 2 Trevyn F.Q. Larson, 1 Sudhir Sahu, 1 Stephen Gill, 1 Florent Lecocq, 1 Raymond Simmonds, 1 and Chris Palmstrøm 2, 4
1 National Institute of Standards and Technology, Boulder CO, 80305
2 Department of Electrical and Computer Engineering, University of California, Santa Barbara 93106
3 Physics Department, University of Colorado, Boulder, 80302
4 Materials Department, University of California, Santa Barbara 93106
(Dated: August 27, 2024)
Increasing the density of superconducting circuits requires compact components, however, superconductor-based capacitors typically perform worse as dimensions are reduced due to loss at surfaces and interfaces. Here, parallel plate capacitors composed of aluminum-contacted, crystalline silicon fins are shown to be a promising technology for use in superconducting circuits by evaluating the performance of lumped element resonators and transmon qubits. High aspect ratio Si-fin capacitors having widths below 300 nm with an approximate total height of 3 µ mare fabricated using anisotropic wet etching of Si(110) substrates followed by aluminum metallization. The singlecrystal Si capacitors are incorporated in lumped element resonators and transmons by shunting them with lithographically patterned aluminum inductors and conventional Al/AlO /Al x Josephson junctions respectively. Microwave characterization of these devices suggests state-of-the-art performance for superconducting parallel plate capacitors with low power internal quality factor of lumped element resonators greater than 500k and qubit T 1 times greater than 25 µ s. These results suggest that Si-Fins are a promising technology for applications that require low loss, compact, superconductor-based capacitors with minimal stray capacitance.
## I. INTRODUCTION
Superconducting qubits employ Josephson junctions, inductors, capacitors, and transmission lines to realize physical systems exhibiting quantum properties with discrete energy levels that can be used for computation[1-3]. Quantum computation using superconducting qubits has been shown to be possible through milestone demonstrations moving toward quantum advantage[4, 5]. Studies demonstrating large scale qubit integration[6] have shown that superconducting qubit technology is promising, and is presently accepted as a leading candidate to achieve large-scale, fault tolerant quantum computation[7].
The Josephson junction and the reactive components of qubit circuits are made from superconductors and insulators that are dissipationless in principle; however, microscopic contamination, such as undesired oxides and residues at surfaces and interfaces, can serve as dissipation channels which cause decoherence in real systems[8, 9]. These oxides and residues are known to host two-level systems (TLS)[10], which may exchange energy with qubits and are understood to be the dominant decoherence source in many real devices[11-14].
loss through design of the transmon geometry has proven effective, where large, planar capacitor structures are often used to dilute the participation of the surfaces and interfaces. These large (typically millimeter scale) devices tend to outperform more compact capacitor structures such as parallel-plate and inter-digitated designs[18, 19]. However, a major disadvantage of larger planar capacitors is a reduction in scalability, both due to the increased footprint on chip and the need to address stray fields that couple devices to other resonant modes on a chip, as well as the packaging environment. In addition, these large devices have electric field energy residing at surfaces that are exposed to the ambient atmosphere and contamination sources during processing, storage, and packaging steps, which brings consistency, repeatability, and age resilience into question.
Coherence times in transmons, one type of superconducting qubit which consists of a Josephson junction shunted by a capacitor, have dramatically improved in recent years due to the integration of new materials and mitigation of surface loss[15-17]. Mitigation of surface
∗ [email protected]
† Now at MIT
Many of these issues may be addressed by switching to parallel plate capacitor (PPC) geometries composed of superconductor/insulator/superconductor (SIS) sandwiches. PPCs offer advantages over planar capacitor geometries[20, 21]: the electric field energy is mostly contained in the tri-layer structure with little participation in surface regions exposed to atmosphere, and are also inherently more compact. However, having the field energy contained within the dielectric region of the sandwich places a high demand on the loss properties of the dielectric and its interfaces with the superconductor.
Fabrication of PPCs and Josephson junctions from SIS tri-layers with deposited dielectrics or vacuum gap capacitors has been demonstrated[22-26]; however devices made using tri-layer processes typically have high microwave loss and are not used for applications such as transmons with high coherence times. Conventional
growth of planar SIS tri-layers is difficult, largely due to materials considerations in growing a high quality dielectric on a superconducting metal. Interestingly, at the time of this writing, the best performing PPC from the standpoint of low-loss microwave performance was made by exfoliating 2-D materials rather than direct tri-layer growth[27, 28].
In this work, an alternative approach is used to create parallel plate capacitors by etching the capacitor dielectric out of Si substrates[29], which has been established as one of the lowest loss dielectrics available[30]. The process presented in this work takes advantage of the highly anisotropic crystallographic etching of Si(110) substrates with potassium hydroxide (KOH) to form high-aspectratio fin structures with flat Si { 111 } sidewalls which are contacted with aluminum to form the PPC. These Si fins have been incorporated as the capacitive element in both lumped element resonators and transmons. We find that the Si fins are high performing with figures of merit including low power internal quality factor ( Q i ) of lumped element resonators, qubit quality factor, and qubit T 1 times meeting or exceeding the state-of-the-art for comparable devices made using other parallel plate capacitor technology.
## II. METHODS
## A. Lumped element resonator and transmon design
Frequency multiplexed lumped element resonator chips and transmon chips with multiplexed readout resonators were fabricated on the same 50 8 . mm wafer. Having both resonator and transmon chips fabricated together allows for independent characterization of the Si fin PPC and the transmon. 3D simulations of the resonators and qubits were performed using finite element analysis.
The lumped element chip design consists of 8 resonators inductively coupled to a central feedline that are measured in the hanger configuration. Each lumped -element resonator consists of a metallized section of a Si fin (capacitor), which is shunted by a 15 µm wide Al thin-film wire inductor having an inductance of 4 29 . nH and stray capacitance of 84 1 . fF determined by simulation. For the devices presented here, 81 -84% of the total capacitance of each lumped element resonator is from the fin capacitor. The frequency of the resonators is controlled by lithographically incrementing the metallized length along the fin capacitor, which is linearly related to the device capacitance.
The transmon chip layout consists of 6 nominally identical transmon qubits coupled to frequency multiplexed readout resonators. Devices were designed to employ Si fin parallel plate capacitors shunted by Josephson junctions. The transmons were designed to have anharmonicities α/ π 2 = 300 MHz , qubit-readout coupling constants g/ π 2 = 100 MHz , and E /E J C = 50.
The readout resonators are quarter -wave coplanar waveguide (CPW) resonators inductively coupled to a central feedline and capacitively coupled to the fin transmons. In this design, both the coupling capacitance and the transmon capacitance are realized using metallized sections of the same Si fin, demonstrating the convenience of the Si-fin process to construct capacitive elements.
## B. Device fabrication
Fin capacitors are fabricated on Si(110) substrates using a combination of dry and wet etching closely following the process outlined in a previous work [29]. Asreceived substrates were cleaned before LPCVD growth of 100nm low-stress silicon nitride ( SiN x ) that serves as a hard mask. The fins are patterned using electron beam lithography(EBL) and a negative resist followed by dry etching to pattern the LPCVD nitride. The fin patterns are aligned so that the long axis of the fin is parallel to the major flat of the Si(110) wafer, which is critical to obtain the desired flat { 111 } sidewalls and high aspect ratio structures.
After resist stripping and wafer cleaning, the wafer was immersed in a solution of 45% KOH (by weight) in water held at 87 ◦ C for 2 minutes to anisotropically etch the Si. This procedure results in approximately 3 µm etching into the substrate with approximately 40nm of undercut on each side of the SiN x hard mask. The resulting fin structure consists of a 2 2 . µm tall parallel-plate region having uniform thickness near 220 nm with flat Si { 111 } sidewalls and a tapered base region having an approximate height 0 8 . µm .
Following formation of the Si-Fin capacitors, the wafer was cleaned with solvents, and the silicon native oxide was removed with a buffered oxide etch (BOE). After the BOE etch, the wafer was rinsed in DI water before immediately loading in high vacuum for aluminum deposition. Aluminum was deposited in two 50 nm thick depositions at ± 25 ◦ from the wafer surface normal and aligned to coat the sides of the fins. This procedure results in 100 nm of aluminum metal deposited on the wafer surface and 50 nm on the sides of the fins. The undercutting of the fins below the ( SiN x ) hard mask was used to shadow the aluminum during deposition to form a self aligned break in the metallization near the top of the fins.
Following aluminum deposition, the metal layer was patterned using optical lithography and wet etching. A standard spin-on photoresist was used, using a spin process that results in a layer thickness of approximately 1 µm on an unpatterned wafer. On wafers with patterned fins, the resist profile is nonuniform near the fins due to the topography. In order to accurately transfer patterns onto the wafer, extra exposure doses were applied near the fins as needed to clear resist residue. After photolithography, the 100 nm thick Al layer was wet-etched using a phosphoric and nitric acid based aluminum etchant at room temperature.
FIG. 1. (a), (b) Optical micrographs and corresponding circuit schematics for Si-fin lumped element resonators and transmons respectively. The functional components of the fin transmon are indicated and illustrate the capacitive coupling of the fin transmon to the readout resonator (RO). (c) Scanning electron micrograph of a Si-fin transmon. The insets show the Josephson junction region in higher magnification.
Al/AlO /Al x Josephson junctions were deposited using a standard EBL/Dolan bridge process[31] employing a PMMA/PMGI bi-layer. The target dimensions of the junctions was 100 nm x 100 nm . As previously stated, resist profiles are nonuniform in proximity to the fin capacitors, so junction dimensions were calibrated on a separate wafer by patterning junctions at varying distances from the ends of the fins and measuring dimensions with atomic force microscopy. It was found that placing junctions at distances greater than 30 µm from the ends of the fin resulted in reproducible junction dimensions within 10% of the targeted values.
Following EBL exposure and development, the wafer was loaded in an electron beam evaporator for Josephson junction deposition. Prior to bottom electrode deposition, the exposed areas of the wafer were ion milled to remove native oxide from the Al metallization layer and create transparent contacts to the junction. A 35 nm thick bottom electrode was deposited at +14 7 . ◦ , oxidized at 180 mTorr in pure O 2 for 10 minutes to form the tunneling barrier, followed by deposition of the 75 nm thick bottom electrode at -14 7 . ◦ . After junction deposition, protective photoresist was spun on the wafer which was diced down to 7 5 . mm x 9 5 . mm die. Individual chips were then selected and the aluminum layer from junction deposition was lifted off. The finished junctions measured after dicing had room temperature resistances near 9 3 . k Ω suggesting an approximate junction critical current of 30 nA and Josephson inductance of 11 nH . Figure 1 shows optical micrographs and circuit schematics for both the lumped element resonator and transmon devices as well as a scanning electron micrograph of a fabricated
transmon.
## C. Measurement Setup
After lift-off, cleaned chips were wire-bonded with aluminum wire and packaged in a 2-port package constructed of Au-plated OFHC Cu for low temperature RF measurements. All microwave measurements were performed in a dilution refrigerator having a base temperature of 35 mK. The attenuation and amplification setup used for both resonators and qubits is similar to that presented by McRae et al.[14]. Lumped element resonators were characterized using a vector network analyzer (VNA) by fitting the power dependent S 21 spectra of the resonators using the diameter correction method (DCM)[14, 32]. Qubits were measured in time domain using QICK software running on a Xilinx/AMD ZCU216 RF SoC board with a measurement configuration similar to that presented by Stefanazzi et al.[33].
## III. RESULTS AND DISCUSSION
Figure 2(a) shows the measured resonant frequency of the lumped element resonators as a function of metallized length along the Si fins. The data suggests the expected linear dependence of (1 /f r ) 2 on capacitor length. Given the inductance value of 4 29 . nH determined from simulations, the slope of the interpolated line may be used to estimate the capacitance per unit length ( C 0 ) of the fin structures which is found to be 2 1 . fF/µm . Extrapolating the linear fit to zero fin length ( L = 0) gives a resonant frequency of 8 97 . GHz , in reasonable agreement with simulation results yielding a self-resonance of the inductor loop at 8 3 . GHz .
A crude parallel plate approximation of fin capacitance using the measured fin height and width of 2 2 . µm and 220 nm , respectively, yields ≈ 1 0 . fF/µm for a silicon dielectric constant of 11.7. This significantly lower value reflects the contribution of stray and additional capacitance near the base of the fin to the total capacitance of the structures. Notably, the electric fields from metallization at the base of the fin are predominantly contained in the Si substrate rather than at the material surfaces.
Power dependent S 21 of the lumped element resonators was also measured and is included as Fig 2(b). Internal and coupling quality factors ( Q i and Q c ) were extracted from the S 21 data, and the cavity photon number was then estimated using Q i , Q c , and the measured input line attenuation.
Referring to Fig. 2(b), the lumped element resonator Q i reaches a maximum at intermediate powers and anomalously decreases with increasing power. This effect is attributed to Cooper-pair breaking in the superconducting aluminum[14, 34] at higher RF drive power and has been reported before in similar structures[28]. Q i values near the single photon level are observed to be very good, with several points exceeding 500 k , which, to the authors' knowledge, is the current state-of-the-art for superconducting resonators made using parallel plate capacitors[28].
All 6 qubits on the separate transmon chip were found to be functional, and characterization results are included as Table 1. Anharmonicity ( α ) was computed using the measured values of f 01 and f 02 / 2 obtained from continuous-wave qubit spectroscopy measurements. f 01 and f 02 denote the frequencies corresponding to the 0 → 1 and 0 → 2 energy transitions respectively. The coupling constant g was estimated by measuring the frequency shift of the readout resonator between the bare and coupled states (punch-out)[35], using ω coupled -ω bare = g 2 / ∆, where ∆ is the detuning between the qubit and resonator. The coupling constant g may also be calculated using the measured dispersive shift from the 0 → 1 transition and employing the approximation χ ≈ g 2 / ∆ -g 2 / (∆ -α ). We obtain similar but slightly higher values of g using the dispersive shift approximation with a somewhat larger spread between devices. The E J values used to estimate the E /E J C ratio were computed using measured values of the qubit frequencies and anharmonicity. Likely due to a defective junction, the resonance of Qubit #1 was measured to be much higher than the other qubit frequencies, colliding with the readout resonator frequency and preventing extensive characterization.
Transmon anharmonicity, ( α/ π 2 ) and qubit to readout coupling constant, ( g/ π 2 ) were observed to be quite uniform and near the targeted values, which is notable as these parameters are determined by the fin capacitors. The transmon T 1 values were measured to be near 20 µs with mean T 1 values for the 6 devices ranging from 11 to 26 µs . Figure 3 shows T 1 histograms from qubits #2 and #5 taken over the course of several hours. The corresponding qubit quality factors ( Q = ωT 1 ) are in the range 350k-750k, which are reasonably close to the measured low-power internal quality factors of the lumped element resonators as shown in Fig 2(b). Notably, qubit quality factor is expected to be independent of qubit frequency in contrast to T 1 time and is taken to be a better figure of merit. Ramsey measurements were also performed, and T ∗ 2 was measured to be near 5 µs . The low T ∗ 2 values observed are attributed to photon shot noise in the readout cavity, which is largely determined by the measurement environment and the readout resonator linewidth rather than the transmon capacitor.
Purcell time was estimated using the approximation T Purcell ≈ ∆ 2 / g ( 2 κ ), where κ is the spectral linewidth of the readout resonator. Referring again to Table 1, the measured T 1 values are quite close to, and in some cases even exceed the estimated Purcell limit. This discrepancy is not necessarily nonphysical, as the Purcell rate estimation used here relies on a simplified model that does not include the experimental S 21 background, modeled admittance of the resonator, and neglects the effects of higher-order resonances in the readout. Includ-
FIG. 2. Measurement results from RF characterization of lumped element resonators (LER). (a) Measured resonant frequency vs metallized capacitor length (L) for LERs. The inset includes an optical micrograph of a device with the dimension L indicated. Electromagnetic simulations of the inductor loop suggest that the fin structure contributes 81-84% of the total resonator capacitance. (b) Extracted internal quality factor ( Q i ) plotted against estimated photon number in the cavity of the four resonators measured in (a).
TABLE I. Measured and computed parameters extracted from Si-fin transmons
| Qubit# | f 01 (GHz) | f RO (GHz) | α/ 2 π (MHz) | E J /E C | g/ 2 π (MHz) | κ/ 2 π (MHz) | T Purcell ( µs ) | T 1 ( mean ) ( µs ) | T ∗ 2 ( Ramsey ) ( µs ) | Qubit Q |
|----------|--------------|--------------|----------------|------------|----------------|----------------|--------------------|-----------------------|---------------------------|-----------|
| 1 a | 5 . 5 | 5 . 675 | - | - | - | - | - | - | - | - |
| 2 | 4 . 920 | 5 . 731 | -270 | 46 | 98 | 1.1 | 10 | 11 | 2.6 | 350k |
| 3 | 4 . 547 | 5 . 758 | -200 | 69 | 92 | 0.84 | 32 | 15 | 4.1 | 430k |
| 4 | 4 . 713 | 5 . 803 | -274 | 41 | 94 | 0.90 | 23 | 20 | 4.6 | 580k |
| 5 | 4 . 565 | 5 . 849 | -279 | 38 | 93 | 1.1 | 28 | 26 | 5.6 | 750k |
| 6 | 4 . 622 | 5 . 893 | -273 | 40 | 96 | 1.2 | 24 | 22 | 4.8 | 650k |
a Likely defective junction
ing higher order resonances when modeling spontaneous emission has been shown to increase calculated Purcell times when qubits are detuned to frequencies below the readout, as is the case for the measurements presented here[36]. While the Purcell estimation raises the question of whether the T 1 measurements provide an accurate assessment of device performance, it does establish a lower bound on the intrinsic quality factor of the Si-fin transmons, which may be reassessed with new devices following trivial modifications to the readout resonator to increase the Purcell time.
## IV. CONCLUSION
A fabrication process where parallel-plate capacitors are constructed from low-loss Si substrates has been evaluated for superconducting quantum computing applications. The Si-fin capacitors were incorporated in both lumped element resonators and transmons using estab- lished fabrication techniques. RF measurements of the resonators and transmons were performed at 35mK and show that the devices are high performing: meeting or exceeding the state-of-the-art for comparable devices made using parallel-plate capacitors, with low-power Q i of the best lumped-element resonators exceeding 700k and the best transmon quality factors exceeding 750k.
The computed Purcell time of the transmons was comparable and in some cases even greater than measured T 1 times, suggesting the intrinsic quality factor of these transmons is likely higher. Moreover, the presence of stray capacitance in the LE design suggest that the intrinsic quality factor of these resonators may be higher as well, which implies that the figures of merit for the devices presented here should be taken as a lower bound. The Si-fin geometry allows for convenient and accurate capacitor definition as the capacitance is determined by the metallized length along the fins which is set using optical lithography in a subtractive process. The process presented may be used for applications that require
FIG. 3. Histograms of measured T 1 times for qubits #2 and #5. The histogram for qubit #5 appears bimodal, likely due to the intermittent interaction of the qubit with two level systems. The insets show example T 1 traces along with exponential fits.

a scalable process for compact, low-loss capacitors.
## V. COMPETING INTERESTS AND DATA AVAILABILITY
All authors declare no financial or non-financial competing interests. The datasets used and/or analysed during the current study available from the corresponding author on reasonable request. This work is a contribution of the U.S. government and is not subject to U.S. copyright.
## ACKNOWLEDGMENTS
This work was supported by the U.S. Army Research Office (grant number W911NF-22-1-0052). We wish to acknowledge Jim Beall for assistance with LPCVD silicon nitride growth and useful discussions as well as Dave Pappas. We also acknowledge Pete Hopkins and Chris Yung for a critical reading of this manuscript.
- [1] Y. Nakamura, Y. Pashkin, and J. Tsai, Nature 398 , 786 (1999).
- [2] J. Koch, T. Yu, J. Gambetta, A. Houck, D. Schuster, J. Majer, A. Blais, M. Devoret, S. Girvin, and R. Schoelkopf, Phys. Rev. A 76 , 042319 (2007).
- [3] V. Manucharyan, J. Koch, L. Glazman, and M. Devoret, Science 326 , 113 (2009).
- [4] F. A. et al., Nature 574 , 505 (2019).
- [5] Y. Kim, A. Eddins, S. Anand, K. Wei, E. van den Berg, S. Rosenblatt, H. Nayfeh, Y. Wu, M. Zaletel, K. Temme, and A. Kandala, Nature 618 , 500 (2023).
- [6] J. Chow, O. Dial, and J. Gambetta, IBM Quantum breaks the 100-qubit processor barrier , Quantum Research Blog (IBM Newsroom, Nov. 2021) https://www.ibm.com/quantum/blog.
- [7] M. Kjaergaard, M. Schwartz, J. Braumuller, P. Krantz, J. I.-J. Wang, S. Gustavsson, and W. Oliver, Annual Review of Condensed Matter Physics 11 , 369 (2020).
- [8] N. de Leon, K. Itoh, D. Kim, K. Mehta, T. Northup, H. Park, B. Palmer, N. Samarth, S. Sangtawesin, and D. Steuerman, Science 372 (2021).
- [9] I. Siddiqi, Nat Rev Mater 6 , 875 (2021).
- [10] R. Simmonds, K. Lang, D. Hite, S. Nam, D. Pappas, and J. Martinis, Phys. Rev. Lett. 93 , 077003 (2004).
- [11] Y. Shalibo, Y. Rofe, D. Shwa, F. Zeides, M. Neeley, J. Martinis, and N. Katz, Phys. Rev. Lett. 105 , 177001 (2010).
- [12] J. Lisenfeld, A. Bilmes, A. Megrant, R. Barends, J. Kelly, P. Klimov, G. Weiss, J. Martinis, and A. Ustinov, npj Quantum Information 5 , 105 (2019).
- [13] C. McRae, R. Lake, J. Long, M. Bal, X. Wu, B. Jugdersuren, T. Metcalf, X.Liu, and D. Pappas, Appl. Phys. Lett. 116 , 194003 (2020).
- [14] C. McRae, H. Wang, J. Gao, M. Vissers, T. Brecht, A. Dunsworth, D. Pappas, and J. Mutus, Rev. Sci. Instrum. 91 , 091101 (2020).
- [15] A. Place, L. Rodgers, P. Mundada, B. Smitham, M. Fritzpatrick, Z. Leng, A. Premkumar, J. Bryon, A. Vrajitoarea, S. Sussman, G. Cheng, T. Madhaven, H. Babla, X. Le, Y. Gang, B. Jack, A. Gyenis, N. Yao, R. Cava, N. de Leon, and A. Houck, Nature Comm. 12 , 1779 (2021).
- [16] C. Wang, X. Li, H. Xu, Z. Li, J. Wang, Z. Yang, Z. Mi, X. Liang, T. Su, C. Yang, G. Wang, W. Wang, Y. Li, M. Chen, C. Li, K. Linghu, J. Han, Y. Zhang, Y. Feng, Y. Song, T. Ma, J. Zhang, R. Wang, P. Zhao, W. Liu, G. Xue, Y. Jin, and H. Yu, npj Quantum Information 8 , 3 (2022).
- [17] K. Crowley, R. McLellan, A.Dutta, N. Shumiya, A. Place, X. Le, Y. Gang, T. Madhavan, M. Bland, R. Chang, N. Khedkar, Y. Feng, E. Umbarkar, X. Gui, L. Rodgers, Y.Jia, M. Feldman, S. Lyon, M. Liu, R. cava, A. Houck, and N. de Leon, Phys. Rev. X 13 , 041005 (2023).
- [18] C. Wang, C. Axline, Y. Gao, T. Brecht, Y. Chu, L. Frunzio, M. Devoret, and R. Schoelkopf, Appl. Phys. Lett.
- 107 , 162601 (2015).
- [19] J. Gambetta, C. Murray, Y.-K.-K. Fung, D. McClure, O. Dial, W. Shanks, J. Sleight, M. Steffen, K. Watanabe, J. Hone, and K. Fong, IEEE Transactions on Applied Superconductivity 27 (1) , 1 (2017).
- [20] R. Zhao, S. Park, T. Zhao, M. Bal, C. McRae, J. Long, and D. Pappas, Phys. Rev. Applied 14 , 064006 (2020).
- [21] H. Mamin, E. Huang, S. Carnevale, C. Rettner, N. Arellano, M. Sherwood, C. Kuter, B. Trimm, M. Sandberg, R. Shelby, M. Mueed, B. Madon, A.Pushp, M. Steffen, and D. Rugar, Phys. Rev. Applied 16 , 024023 (2021).
- [22] S. Oh, K. Cicak, J. Kline, M. Sillanpaa, K. Osborn, J. Whittaker, R. Simmonds, and D. Pappas, Physical Review B 74 , 100502 (2006).
- [23] K. Cicak, D. Li, J. Strong, M. Allman, F. Altomare, A. Sirois, J. Whittaker, J. Teufel, and R. Simmonds, Appl. Phys. Lett. 96 , 093502 (2010).
- [24] A. McFadden, A. Goswami, M. Seas, C. McRae, R. Zhao, D. Pappas, and C. Palmstrom, J. Appl. Phys 128 , 115301 (2020).
- [25] S. Weber, K. Murch, D. Slichter, R. Vijay, and I. Siddiqi, Appl. Phys. Lett. 98 , 172510 (2011).
- [26] U. Patel, Y. Gao, D. Hover, G. Ribeill, S. Sendelbach, and R. McDermott, Appl. Phys. Lett 102 , 012602 (2013).
[27]
A. Antony, M. Gustafsson, G. Ribeill, M. Ware, A. Ra- jendran, L. Govia, T. Ohki, T. Tanihuchi, K. Watanabe,
J. Hone, and K. Fong, Nano Lett.
21 (23)
, 10122 (2021).
- [28] J. I. Wang, M. Yamoah, Q. Li, A. Karamlou, T. Dinh, B. Kannan, J. Braumuller, D. Kim, A. Melville, S. Muschinske, B. Niedzielski, K. Serniak, Y. Sung, R. Winik, J. Yoder, M. Schwartz, K. Watanabe, T. Taniguchi, T. Orlando, S. Gustavsson, P. JarilloHerrero, and W. Oliver, Nat. Mater. 21 , 398 (2022).
- [29] A. Goswami, A. McFadden, T. Zhao, H. Inbar, J. Dong, R. Zhao, C. McRae, R. Simmonds, C. Palmstrom, and D. Pappas, Appl. Phys. Lett 121 , 064001 (2022).
- [30] M. Checchin, D. Frolov, A. Lunin, A. Grassellino, and A. Romanenko, Phys. Rev. Applied 18 , 034013 (2022).
- [31] G. Dolan, Appl. Phys. Lett 31 , 337 (1977).
- [32] M. Khalil, M. Stoutimore, F. Wellstood, and K. Osborn, J. Appl. Phys. 111 , 054510 (2012).
- [33] L. Stefanazzi, K. Treprow, N. Wilcer, C. Stoughton, C. Bradford, S. Uemura, S. Zorzetti, S. Montella, G. Cancelo, S. Sussman, A. Houck, S. Saxena, H. Amaldi, A. Agrawal, H. Zhang, C. Ding, and D. Schuster, Rev. Sci. Instrum. 93 , 044709 (2022).
- [34] P. de Visser, D. Goldie, P. Diener, S. Withington, J. Baselmans, and T. Klapwijk, Phys. Rev. Lett. 112 , 047004 (2014).
- [35] M. Reed, L. DiCarlo, B. Johnson, L. Sun, D. Schuster, L. Frunzio, and R. Schoelkopf, Phys. Rev. Lett 105 , 173601 (2010).
- [36] A. Houck, J. Schreier, B. Johnson, J. Chow, J. Koch, J. Gambetta, D. Schuster, L. Frunzio, M. Devoret, S. Girvin, and R. Schoelkopf, Phys. Rev. Lett. 101 , 080502 (2008). | null | [
"Anthony McFadden",
"Aranya Goswami",
"Tongyu Zhao",
"Teun van Schijndel",
"Trevyn F. Q. Larson",
"Sudhir Sahu",
"Stephen Gill",
"Florent Lecocq",
"Raymond Simmonds",
"Chris Palmstrøm"
]
| 2024-08-02T16:24:22+00:00 | 2024-08-23T18:13:21+00:00 | [
"quant-ph"
]
| Fabrication and characterization of low-loss Al/Si/Al parallel plate capacitors for superconducting quantum information applications | Increasing the density of superconducting circuits requires compact
components, however, superconductor-based capacitors typically perform worse as
dimensions are reduced due to loss at surfaces and interfaces. Here, parallel
plate capacitors composed of aluminum-contacted, crystalline silicon fins are
shown to be a promising technology for use in superconducting circuits by
evaluating the performance of lumped element resonators and transmon qubits.
High aspect ratio Si-fin capacitors having widths below $300nm$ with an
approximate total height of 3$\mu$m are fabricated using anisotropic wet
etching of Si(110) substrates followed by aluminum metallization. The
single-crystal Si capacitors are incorporated in lumped element resonators and
transmons by shunting them with lithographically patterned aluminum inductors
and conventional $Al/AlO_x/Al$ Josephson junctions respectively. Microwave
characterization of these devices suggests state-of-the-art performance for
superconducting parallel plate capacitors with low power internal quality
factor of lumped element resonators greater than 500k and qubit $T_1$ times
greater than 25$\mu$s. These results suggest that Si-Fins are a promising
technology for applications that require low loss, compact,
superconductor-based capacitors with minimal stray capacitance. |
2408.01370v1 | ## EVIT: Event-based Visual-Inertial Tracking in Semi-Dense Maps Using Windowed Nonlinear Optimization
Runze Yuan, Tao Liu, Zijia Dai, Yi-Fan Zuo, and Laurent Kneip
Abstract -Event cameras are an interesting visual exteroceptive sensor that reacts to brightness changes rather than integrating absolute image intensities. Owing to this design, the sensor exhibits strong performance in situations of challenging dynamics and illumination conditions. While event-based simultaneous tracking and mapping remains a challenging problem, a number of recent works have pointed out the sensor's suitability for prior map-based tracking. By making use of cross-modal registration paradigms, the camera's ego-motion can be tracked across a large spectrum of illumination and dynamics conditions on top of accurate maps that have been created a priori by more traditional sensors. The present paper follows up on a recently introduced event-based geometric semi-dense tracking paradigm, and proposes the addition of inertial signals in order to robustify the estimation. More specifically, the added signals provide strong cues for pose initialization as well as regularization during windowed, multi-frame tracking. As a result, the proposed framework achieves increased performance under challenging illumination conditions as well as a reduction of the rate at which intermediate event representations need to be registered in order to maintain stable tracking across highly dynamic sequences. Our evaluation focuses on a diverse set of real world sequences and comprises a comparison of our proposed method against a purely event-based alternative running at different rates.
## I. INTRODUCTION
Event cameras have recently become popular in the vision and robotics community but remain less explored than their traditional camera correspondents. Unlike the latter, event cameras-also called Dynamic Vision Sensors (DVS)-react to brightness changes rather than integrating absolute image intensities. Each pixel acts asynchronously and fires an either positive or negative event whenever the perceived brightness level augments or decrements by a certain threshold amount. Each event comes with a high resolution time-stamp in the order of micro-seconds, and the camera has high dynamic range (120dB compared to 60dB for regular cameras). Owing to these properties, event cameras do not suffer from traditional blur effects and lend themselves to strong performance in challenging illumination and dynamics conditions. Often referred to as a silicon retina [1], this power-efficient bioinspired sensor therefore has evolved into a promising choice for motion sensing in a variety of contexts, including eye tracking [2], hand tracking [3], human body tracking [4], [5], and-as targeted in this work-ego-motion tracking.
The traditional solution to vision-based ego-motion tracking is given by the Simultaneous Localization And Mapping (SLAM) paradigm [6], and has already been proposed for event cameras [7], [8]. However, unlike for regular cameras,
Fig. 1. Illustration of EVIT. Rather than registering only single time-surface maps with respect to a semi-dense point cloud, we propose to do windowed joint registration of multiple adjacent TSMs, which improves registration stability. The added IMU integration terms form the connections between adjacent keyframes, thereby creating a virtual multi-camera rig with elastic connections.
the measurements returned by an event camera are no longer just a function of pose and scene geometry or appearance, but also the instantaneous relative dynamics of the camera. Combined with the unusual and noisy nature of events, the solution to the full SLAM problem with DVS sensors remains an ongoing challenge.
In this paper, we address the question how we can solve the ego-motion estimation problem under the often practical assumption of an existing prior map generated by a different sensor? If the mapping problem is taken out of the equation, the target simply becomes prior map-based tracking. We follow up on the recently proposed strategy of abstracting the map of the environment in the form of a semi-dense point cloud [9]. The semi-dense map can be generated from regular imagery, and each point in the representation corresponds to a location in space around which we commonly observe high appearance gradient (i.e. structural edges and discontinuities, or textural appearance boundaries). Based on the assumption that the generated events pre-dominantly react to such highgradient regions, the current location of the event camera can be optimized by aligning edges in the surface of active events with the reprojected semi-dense point cloud. While this semidense cross-modal registration paradigm has already been proposed in prior art [10], [9], challenges remain in case of high dynamics or ambiguous event distributions.
We propose to tackle this issue by fusion with an Inertial Measurement Unit (IMU). This achieves the following contributions and advancements:
- · Rather than doing single frame registration, the addition of an IMU permits the joint registration of multiple adjacent frames in the form of a windowed tracking problem. The states corresponding to the individual times of each registered frame are lifted to include first-order translational velocity and IMU bias terms, thereby enabling the use of IMU pre-integration terms for a pair-wise regularization of adjacent frames. Sets of multiple adjacent frames are thereby considered as a virtual multi-camera rig with elastic connections. The joint registration of multiple frames helps in avoiding unobservable directions of displacement caused by ambiguous event distributions in individual frames (e.g. events distributed along multiple parallel lines).
- · IMU pre-integration terms may again be used in order to create improved initialization of new frames. Especially in situations of jerky motion with sudden abrupt changes in the direction of motion, the inertial signal-based prediction strongly outperforms vision-only alternatives such as constant-velocity motion models.
- · Owing to poor prediction abilities, handling situations of high acceleration in a vision only setting typically requires a high temporal density of tracked frames. In turn, the superior prediction ability offered by IMU signals enables a substantial reduction of the frame density during windowed optimization. In fact, we propose an adaptive mechanism that places frames in dependence of the number of occurred events.
We test our new framework-Event-based Visual-Inertial Tracking (EVIT)-on publicly available benchmark sequences covering a variety of challenges such as normal motion, changing illumination, and high dynamics. As demonstrated, the addition of an IMU strongly supports tracking performance with respect to the vision-only alternative. We also plan to release the complete framework code later to enable re-usability.
## II. RELATED WORK
A good survey paper on event-based vision is given by Gallego et al. [11]. The addressed topics in the literature cover many aspects such as human motion tracking [4], [5], hand tracking [3], and eye ball tracking [2]. The current literature review focusses on SLAM and motion tracking with only event cameras or with added inertial readings.
Pure approaches to monocular event camera SLAM have been proposed by Kim et al. [7] and Rebecq et al. [8]. The former is a filter-based method reconstructing photometric depth maps, while the latter is a geometric approach that aims at the reconstruction of a volumetric event density field [12]. In an effort to increase the performance of event camerabased SLAM, more recent methods have investigated the use of line features [13], [14], [15]. The latter two methods are limited to local dynamics estimation, and all methods are restricted in that they require a sufficient number of line features. The inclusion of an IMU into the incremental tracking and motion framework is proposed by Zhu et al. [16], Rebecq et al. [17], Le Gentil et al. [18], and Xu et al. [19].
In particular, the latter two methods are again based on line features. In general, a truly robust continuous tracking and mapping framework that employs only a single event camera as an exteroceptive sensor remains a challenging problem. Vidal et al. [20] therefore investigate the combination with a normal camera, and Zhou et al. [21] present a stereo event camera alternative.
A different line of research that is more related to our work aims at pure tracking based on known structure priors. Early approaches make use of fiducial markers [22], [23] or known targets with distinctive texture [24], [25], [26], [27]. Of particular interest are the works of Gallego et al. [28] and Bryner et al. [29], who propose direct tracking of event cameras from photometric depth maps. However, their approaches are computationally demanding and fail to employ a geometrically optimal objective.
The most highly related works to ours are all based on the idea of using a semi-dense map representation. The latter have originally been introduced by Engel et al. [30] through their SDVO framework. Later on, Kneip et al. [31], Kuse and Shaojie [32], and Zhou et al. [33] have introduced improved geometric semi-dense registration paradigms for normal cameras. The latter work in particular has formed the foundation for the first geometric semi-dense tracking paradigms for event cameras. Zuo et al. [10] propose DEVO, an event-based incremental motion estimation framework that makes use of an additional depth channel. Finally, Zuo et al. [9] propose Canny-EVT, which applies a similar strategy to global tracking of a single event camera based on a semidense map. The latter work in particular forms the reference implementation against which we compare our contribution.
## III. METHOD
In this section, we present our newly proposed eventinertial, semi-dense point cloud-based tracking system EVIT. The framework comprises an efficient adaptive measurement preprocessing module, a loosely coupled bootstrapping scheme, and a tightly coupled back-end optimization for the event camera-IMU setup. The structure of the proposed framework is shown in Fig. 2, in which we highlight the essential modules by dashed lines.
Let us define notations used in this paper. The ultimate goal for this framework is to estimate the body frame pose T w b = [ R w b , p w b ] ∈ SE (3) (transformation from the body frame to the world frame) of the event camera and IMU rig. For practical reasons, we set the IMU frame equal to the body frame, denoted by b. The constant extrinsic transformation T c b between IMU and event camera is assumed to be well calibrated. Visual-inertial tracking introduces additional variables to the state estimation, leading to the expanded state vector
$$\mathcal { S } _ { i } = [ \theta _ { i }, \mathbf p _ { i }, \mathbf v _ { i }, \mathbf b _ { \alpha _ { i } }, \mathbf b _ { \omega _ { i } } ], \text{ \quad \ \ } ( 1 )$$
where θ i is a minimal rotation representation, p i is the position of the body frame, v i is the velocity in the world reference frame, and b α i and b ω i are the accelerometer and gyroscope biases, respectively.
Fig. 2. Block diagram of the full event-based visual-inertial tracking pipeline. The system takes stream of events and IMU measurements (colored block) as input and tracks against the reconstructed semi-dense map. The measurement processing module (Section III-B) dynamically choose keyframes and process raw data stream into usable single frame observations. The initialization (Section III-C) module utilizes high frequency event localization results to provide bootstrapping states for subsequent prediction and optimization. The optimization module (Section III-D) tightly fuses IMU pre-integration measurements and TSM representations to achieve accurate state estimation.
## A. System overview
We start by introducing the entire pipeline and describing the functionality of each core module in our framework. The framework starts with an offline-constructed, inertial-aligned semi-dense point cloud and takes as input a stream of events and IMU measurements from a calibrated event-inertial sensor setup. A specially designed data collection module is responsible for the asynchronous collection of these two types of data thereby achieving maximum effectiveness. The data collection module is followed by a measurement processing module that takes the quasi-continuous input stream of data and converts it into compact single frame observations (i.e. time surface maps and IMU pre-integration terms). The generated frames are henceforth referred to as keyframes. Details on the intermediate, frame-based event representation are provided in Section III-B. Note that the rate at which keyframes are generated is adaptive and depending on the actual number of events that have elapsed since the last keyframe generation. The generation of IMU preintegration terms adjusts to the asynchronous keyframe rate. The proposed dynamic, adaptive frame generation strategy simultaneously satisfies two objectives. First, it avoids the generation of redundant keyframes when no actual change or camera motion has happened. Second, it avoids a lack of sufficient observations under fast displacements.
During the initialization phase (cf. Section III-C), we perform high-frequency event-only single keyframe localization to retrieve initial body frame poses. When the displacement is sufficient, a closed-form visual-inertial solver is executed in order to give coarse initial values for IMU states to be estimated, meaning the camera velocity and IMU biases. After successful bootstrapping, the tracking module (see Section III-D) starts to predict poses for new keyframes using a second-order motion model (i.e. using IMU forward integration) and activates a tightly coupled event-inertial back-end optimizer employing a sliding window over a fixed number of recent keyframes. Rather than only optimizing keyframe poses, this factor graph optimization module optimizes the full above-mentioned inertial states including camera velocity and biases for each keyframe. The addition of inter-frame pre-integration terms adds regularization constraints between adjacent keyframes, and thereby transforms the registered set of keyframes into a virtual multi-camera rig with elastic extrinsic connections.
## B. Measurement preprocessing
In traditional visual-inertial tracking frameworks, it is common to select keyframes based on image rate given that conventional cameras are synchronously triggered and usually operate at frequencies lower than IMUs. Considering a single event provides limited information, for event cameras we are equally inclined to preprocess events and somehow group them in batches that are triggered within a specific time interval so they can be jointly aligned against the map. In analogy to the work of Zuo et al. [9], we propose to summarize the contribution of entire intervals of events in snap-shots of the Time Surface Map (TSM), which can then be used to extract edges and perform individual frame alignment against the reprojected semi-dense map. The question is at what rate such TSM-based keyframes should be generated.
1) Adaptive keyframe determination: An event camera measures motion with respect to the scene, and the rate at which events are generated is related to the actual amount of displacement. The fixed frequency keyframe selection scheme proposed in previous works [21] therefore is subideal and would lead to inferior optimization performance. It would either lead to redundant frames if little motion occurs, or insufficient frame density and large inter-keyframe baselines under fast displacements. Considering the IMU, the pre-integration also requires sufficient readings in order to ensure noise cancellation effects and good Signal-to-Noise Ratio (SNR). We therefore propose an adaptive keyframe generation scheme that buffers events and inertial readings and-only when a minimum number of both events and IMU readings has been surpassed-outputs the accumulated series of observations to the frame builder. The latter then processes the raw data into TSMs and IMU pre-integration terms. The thresholds for the minimum number of events and IMU observations are denoted n event and n imu , respectively.
The time stamp of the keyframe is determined by the last IMU measurement.
2) Event representation: As mentioned, we rely on snapshots of the Time Surface Map (TSM) for semi-dense registration. The latter is efficient to update and does not involve costly feature extractors. It is defined as follows. Let us assume a stream of N events denoted as e i = { x i , t i , p i } , i ∈ N , which includes location x i = { u , v i i } , timestamp t i and polarity p i ∈ {-1 1 , } . A time surface map is a 2D map in which the value at a pixel x is defined by the most recent event occurring at that location. It is notably depending on an exponential decay kernel defined as
$$\mathcal { T } ( \mathbf x, t ) \doteq \exp \left ( - \frac { t - t _ { l a s t } ( \mathbf x ) } { \delta } \right ) \quad \quad ( 2 ) \quad \text{where}$$
where δ is a constant decay rate parameter typically set to a small value. t last ( x ) is the timestamp corresponding to the most recent triggered event at x . t is a given time stamp for which the TSM is constructed. Note that in the context of our work, the TSM can be regarded as the historical trajectory of scene edges moving in the image plane, and sharp contours remain identifiable at the reprojection location of the currently observed edges in the scene. It is this phenomenon that encourages a direct use of TSMs towards semi-dense registration.
For practical use, we usually use the inverse (or negated) TSM given by
$$\overline { \mathcal { T } } ( { \mathbf x }, t ) = 1 - \mathcal { T } ( { \mathbf x }, t ).$$
It has the advantage that the locations corresponding to the reprojection of the currently observed edges now present the lowest values in the map. As a result, the negated TSM can be directly used as a cost field against which the reprojected semi-dense map can be registered in nonlinear optimization. The relationship between an actual distance field and the negated TSM is introduced in [21]. We may readily perform nonlinear optimization on this geometric field.
For the sake of efficient measurement preprocessing, we maintain a global surface of active events (SAE) [34] which stores the most recent event time stamp at each pixel. We also map the pixel values in the TSM from [0 , 1] to [0 , 255] for easy visualization and stable numerical computation. We make use of the truncated TSM in which all values below a given threshold δ are set to 0. Finally, we apply a Gaussian kernel on the TSM to further smoothify the field, reduce ripple effects, and reduce the influence of outlier events.
3) Imu pre-integration: The IMU provides measurements for acceleration α b and angular velocity ω b of the sensor at a high frequent rate. We follow the IMU sensor model and continuous-time quaternion-based derivation of IMU preintegration terms introduced in previous work [35] [36]. The raw IMU measurements ˆ α t , ˆ ω t are given by
$$\hat { \alpha } _ { t } & = \alpha _ { t } + b _ { \alpha _ { t } } + \mathbf R _ { w } ^ { t } g ^ { w } + \mathbf n _ { \alpha } \\ \hat { \omega } _ { t } & = \omega _ { t } + b _ { \omega _ { t } } + \mathbf n _ { \omega }$$
where noise is modeled as Gaussian white noise, i.e. n α ∼ N (0 , σ 2 α ) , n ω ∼ N (0 , σ 2 ω ) , and biases are modeled as a random walk.
The pre-integration terms between consecutive frames are given by
$$\text{given} \, \text{y} \\ \alpha _ { b _ { k + 1 } } ^ { b _ { k } } & = \iint _ { t \in [ t _ { k }, t _ { k + 1 } ] } \mathbf R _ { t } ^ { b _ { k } } ( \hat { \alpha } _ { t } - b _ { \alpha _ { t } } - \mathbf n _ { \alpha } ) d t ^ { 2 } \\ \beta _ { b _ { k + 1 } } ^ { b _ { k } } & = \int _ { t \in [ t _ { k }, t _ { k + 1 } ] } \mathbf R _ { t } ^ { b _ { k } } ( \hat { \alpha } _ { t } - b _ { \alpha _ { t } } - \mathbf n _ { \alpha } ) d t \\ \gamma _ { b _ { k + 1 } } ^ { b _ { k } } & = \int _ { t \in [ t _ { k }, t _ { k + 1 } ] } \frac { 1 } { 2 } \Omega ( \hat { \omega } - b _ { \omega _ { t } } - \mathbf n _ { \omega } ) \gamma _ { t } ^ { b _ { k } } d t \\ \text{where}$$
where
$$\text{to a} \quad \Omega ( \omega ) = \begin{bmatrix} - \lfloor \omega \rfloor _ { \times } & \omega \\ - \omega ^ { T } & 0 \end{bmatrix}, \lfloor \omega \rfloor _ { \times } = \begin{bmatrix} 0 & - \omega _ { z } & \omega _ { y } \\ \omega _ { x } & 0 & - \omega _ { x } \\ - \omega _ { y } & \omega _ { x } & 0 \end{bmatrix}$$
α b k b k +1 , β b k b k +1 , and γ b k b k +1 represent the pre-integrated position, velocity and rotation measurements. A covariance matrix Σ b k ,b k +1 is also calculated during the pre-integration process. In our practical implementation, we use first-order integration for processing discrete time IMU measurements.
## C. Initialization
Tightly coupled visual-inertial optimization-based tracking usually needs good initial values for states to achieve convergence. The goal of the initialization module is to align vision-based and IMU measurements to calibrate the bias parameters of the IMU and provide initial states. Inspired by [35], we employ a light-weight loosely coupled initialization method in our localization framework. In contrast to traditional VIO frameworks, the states to be bootstrapped in our localization system are fewer and only include velocity, biases and pose.
The initialization module proceeds by first constructing many intermediate TSMs between adjacent frames and then utilizing this information for high-frequency event-based vision-only localization. This procedure will give initial poses for each frame, and requires the solution of individual optimization problems that minimize the values of the negated TSM field at the reprojected semi-dense pixel locations for each frame. The problem formulation for an individual frame is given by
$$\underset { \theta, \mathbf P } { \omega } \underset { P _ { j } \in \mathcal { D } } { \arg \min } \sum _ { P _ { j } \in \mathcal { D } } \rho ( \overline { \mathcal { T } } ( \pi _ { e } ( \mathbf R _ { b } ^ { c } \mathbf R ^ { T } ( \theta ) ( \mathbf P _ { j } - \mathbf p ) + t _ { b } ^ { c } ) ) ), \quad ( 3 )$$
where ρ is a robust loss function (e.g. Huber loss), π e is a function which projects the 3D points in event camera frame onto the image plane, R ( ) · is the function that maps a minimal rotation representation to a 3-by-3 rotation matrix, and P j ∈ D is a 3D world point within the current field of view of the event camera.
When sufficiently many frames for bootstrapping have been collected, we adopt the IMU measurement residual function from [35] and loosely align the IMU pre-integration
Fig. 3. Factor graph representation for our sliding window optimization. The graph fuses observations from the event camera, the IMU, and the semidense map. Two types of factors are introduced to construct the factor graph: (a) IMU pre-integration factors, (b) event alignment factors using TSMs. The formulation of these factors are discussed in Sections III-C and III-D. We fix the first node to maintain consistency with matured nodes that left the window.
terms with the event-based vision-only pose estimations. The IMU measurement residual function is given by
$$\text{IMU measurement residual function is given by } & \quad \text{import} \\ \text{r} ( \mathcal { S } _ { i }, \mathcal { S } _ { i + 1 } ) = \begin{bmatrix} \mathbb { R } ^ { T } ( \theta _ { i } ) ( p _ { i + 1 } - p _ { i } + \frac { 1 } { 2 } g ^ { w } \Delta t _ { i } ^ { 2 } - v _ { i } \Delta t _ { i } ) - \hat { \beta } _ { i + 1 } ^ { i } \\ \mathbb { R } ^ { T } ( \theta _ { i } ) ( v _ { i + 1 } + g ^ { w } \Delta t _ { i } - v _ { i } ) - \hat { \beta } _ { i + 1 } ^ { i } \\ 2 [ Q ( \theta _ { i } ) ^ { - 1 } \otimes Q ( \theta _ { i + 1 } ) \otimes ( \hat { \gamma } _ { i + 1 } ^ { i } ) ^ { - 1 } ] _ { x y z } \\ b _ { \alpha _ { i + 1 } } - b _ { \alpha _ { i } } \\ b _ { \omega _ { i + 1 } } - b _ { \omega _ { i } } \end{bmatrix}, \quad \text{the res} \\ \text{$\text{visual-}$} \\ \text{where} Q (\cdot)$ transforms the minimal rotation representation to } & \quad \text{$\mathcal{S}_{1}$} \cdots$$
window and the oldest frame is removed. It is furthermore important to remain consistent with mature nodes that already left the sliding window such that a smoother trajectory can be maintained. Here we choose a simple solution that consists of fixing the first node in the graph. Combining the residuals in (4) and (3), the objective of the event-based visual-inertial sliding window optimizer finally becomes where Q ( ) · transforms the minimal rotation representation to a quaternion and ˆ α i i +1 , ˆ β i i +1 , ˆ γ i i +1 represent the IMU preintegration vector using raw IMU measurements. Given N frames, the loosely coupled visual-inertial alignment objective is given by
$$\underset { v _ { i }, b _ { \alpha _ { i } }, b _ { \omega _ { i } } } { \arg \min } \sum _ { i = 1 } ^ { N - 1 } | | r ( \mathcal { S } _ { i }, \mathcal { S } _ { i + 1 } ) | | _ { \Sigma i, i + 1 } ^ { 2 }. \quad \text{ (5)} \quad \text{nonli}$$
Note that we fix the keyframe poses and optimize the remaining states only. Since the existing IMU pre-integrations are based on the old states, they should be re-propagated using the optimized state once the initialization is finished.
## D. Sliding window optimization
The initialization module constructs a window of frames with initial states. Once given, we use a second-order motion model to obtain predictions for each new keyframe state. In practice, the field of view of frames within the sliding window typically only covers part of the semi-dense map. In order to reduce the complexity of the optimization, we maintain a set of activate points. The set will keep the points visible in the last sliding window optimization. We also construct a wider frustum for new keyframes using their predicted pose to select potentially visible new points and merge them into the activate points set. We randomly sample a fixed-size subset P from this set of points to ensure the optimization maintain approximately constant time complexity.
Fig. 3 illustrates the factor graph of the concluding tightlycoupled sliding window optimization framework. The optimization is executed each time a new frame is added to the
$$& \Big \rfloor _ { ( 4 ) } \quad \underset { \substack { \arg \min \\ \mathcal { S } _ { 1 }, \dots, \mathcal { S } _ { N } } } { \arg \min } \sum _ { \substack { \mathcal { P } _ { j } \in \mathcal { P } } } ^ { N } \rho ( \mathcal { T } ( \pi _ { e } ( \mathbf R _ { b } ^ { c } \mathbf R ^ { T } ( \theta _ { i } ) ( \mathbf P _ { j } - \mathbf p _ { i } ) + \mathbf t _ { b } ^ { c } ) ) ) \\ \text{pre-} \\ \text{$n$} \ N & \quad + \sum _ { i = 1 } ^ { N - 1 } | | \mathbf r ( \mathcal { S } _ { i }, \mathcal { S } _ { i + 1 } ) | | _ { \mathfrak { S } _ { i, i + 1 } } ^ { 2 }. \quad ( 6 ) \\ & \quad \text{where $N$ is the sliding window size and $\mathcal{P}$ is the maintained}$$
where N is the sliding window size and P is the maintained activate point set. We use Ceres solver [37] to solve all above nonlinear problems.
## IV. EXPERIMENTS
We now proceed to the experimental evaluation of our event-based visual-inertial tracking framework. All experiments are conducted on the small scale sequences of the publicly available VECtor dataset [38]. The dataset contains event stereo cameras (Prophesee Gen3 CD) with VGA resolution ( 640 × 480 ), only the left one of which we use, and a nine-axis IMU (XSens MTi-30 AHRS) at 200Hz. The ground truth is generated by the OptiTrack motion capture system. All sensors are well synchronised though a micro-controller unit at hardware level. We noticed that at certain moments in some sequences, there is only a small overlap between the event camera's field of view and the reconstructed semi-dense map, which leads to tracking failures for all methods. Therefore, we apply clipping as necessary on certain sequences. We first compare the proposed EVIT framework against several state-of-art eventbased localization approaches on both normal and challenging sequences. To conclude, we conduct an ablation study using different motion models to analyze the impact of using IMU predictions on tracking performance. We provide both qualitative and quantitative results to show the robustness and effectiveness of our method.
We use the evo odometry evaluation tool [39] to align trajectories and conduct comparisons based on the RMSE of the average trajectory error (ATE) metric. The trajectories are aligned by an SE(3) transformation derived from the first pair of the synchronized camera and ground truth poses.
## A. Evaluation on VECtor
In the first experiment, we compare the performance of the proposed system with existing event-based localization frameworks. Note that the present work is an extension of the event vision tracking module Canny-EVT presented by Zuo et al. [9]. As mentioned in there, the EVT module relies on a high-frequency localization method which trades efficiency for robustness, thereby resulting in an offline method with no real-time capabilities. We compare our proposed EVIT against EVT running at different rates and on the same semidense map.
The global semi-dense map is constructed from the opensource framework [40], which uses the probabilistic semidense mapping technique proposed by Mur-Artal and Tardos [41]. Note that the constructed edges do not necessarily need to be geometric edges in 3D and may still be appearance edges. In order to avoid the scale ambiguity issue caused by monocular slam, we replace each keyframe pose by the corresponding ground truth pose. We also manually transform the reconstructed semi-dense map to a global world reference frame where the negative z -axis direction aligns with the direction of gravity to ensure consistency with IMU data.
TABLE I ABSOLUTE TRAJECTORY ERROR (ATE) ON NORMAL SEQUENCES. POSITION: [CM], ORIENTATION: [ ◦ ]
| Sequence | Method | Frequency | 30% sequence | 30% sequence | 50% sequence | 50% sequence | 100% sequence | 100% sequence |
|--------------|---------------|------------------------------|---------------------------|---------------------------|---------------------------|--------------------------|---------------------------|--------------------------|
| | | | Pos. | Orient. | Pos. | Orient. | Pos. | Orient. |
| sofa normal | EVT EVPT EVIT | 300hz 100hz 30hz (dyn) (dyn) | 3.26 3.16 3.54 15.64 3.23 | 1.34 1.33 1.58 5.08 1.40 | 3.66 6.98 - 15.27 3.23 | 1.75 2.70 - 5.50 1.56 | 3.37 5.43 - - 3.15 | 1.65 2.28 - - 1.53 |
| robot normal | EVT EVPT EVIT | 300hz 100hz 30hz (dyn) (dyn) | 0.91 0.97 1.02 15.36 0.84 | 0.89 0.91 0.90 9.927 0.89 | 1.04 1.09 1.11 13.40 1.04 | 1.08 1.09 1.11 8.39 1.10 | 1.09 1.16 1.20 14.17 1.00 | 1.31 1.31 1.35 9.03 1.14 |
| desk normal | EVT EVPT EVIT | 300hz 100hz 30hz (dyn) (dyn) | 1.21 1.34 1.21 7.71 1.32 | 0.74 0.77 0.77 1.83 0.80 | 1.87 1.87 1.92 11.02 1.79 | 0.81 0.84 0.87 2.61 0.87 | 2.25 2.14 2.30 16.08 2.22 | 0.88 0.92 0.96 3.33 0.94 |
We also compare the EVIT with the photometric eventbased camera localization method proposed by Bryner et al. [29]. We refer to it here as EVPT . The photometric map is directly constructed using the RGBD data and ground truth poses contained in the dataset. We directly re-project all valid pixels back into the 3D space and carefully polish the map by hand to reduce edge effects caused by the RGBD observations.
Note that not all methods can track the entire sequence so we define three milestones at 30%, 50% and 100% of the sequence. The corresponding error is simply not displayed if a certain milestone is not reached. Since EVIT and EVPT all adopt dynamic frame determination schemes, the rate depends on the motion and the scene. The actual rate is lower for mild motion and higher during aggressive motion, and typically valies between 30 and 60 Hz. As shown in Table. I, though the improvement brought by EVIT is not significant on normal sequences, both EVT and EVIT outperform EVPT . This is sensible given that photometric localization methods strongly rely on the consistency of the actual light conditions when the map was built, which is not only hard to achieve for varying times of the day, but also hard to achieve across different sensors. Furthermore, photometric methods involve error metrics with no direct geometric meaning, and it is thus hard to ensure optimality of the motion estimation. In terms of EVIT, it can be observed that the addition of the IMU arguably offers only a limited improvement over the event-only alternative when the motion is normal and not exhibiting strong dynamics. However, EVIT generally produces small errors, often leading to the absolutely best tracking result.
TABLE II ABSOLUTE TRAJECTORY ERROR (ATE) ON CHALLENGING SEQUENCES. POSITION: [CM], ORIENTATION: [ ◦ ]
| Sequence | Method | Frequency | 30% sequence | 30% sequence | 50% sequence | 50% sequence | 100% sequence | 100% sequence |
|------------|----------|-------------|----------------|----------------|----------------|----------------|-----------------|-----------------|
| | | | Pos. | Orient. | Pos. | Orient. | Pos. | Orient. |
| | | 300hz | 20.45 | 7.84 | - | - | - | - |
| sofa fast | EVT | 100hz 30hz | 22.66 - | 8.56 - | - - | - - | - - | - - |
| | EVPT | (dyn) | 25.29 | | 26.32 | | | |
| | | | | 6.53 | | 6.77 | 23.24 | 6.18 |
| | EVIT | (dyn) | 9.02 | 4.02 | 8.11 | 3.60 | 7.08 | 3.22 |
| | | 300hz | 3.76 | 2.83 | 4.12 | 2.92 | - | - |
| robot fast | EVT | 100hz | 5.47 | 3.67 | 9.15 | 4.49 | - | - |
| | | 30hz | - | - | - | - | - | - |
| | EVPT | (dyn) | - | - | - | - | - | - |
| | EVIT | (dyn) | 3.22 | 2.67 | 3.24 | 2.80 | 3.85 | 2.98 |
| | | 300hz | 4.03 | 2.47 | 4.52 | 2.35 | 14.65 | 7.95 |
| | EVT | 100hz | 2.24 | 2.19 | 2.48 | 2.52 | - | - |
| desk fast | | 30hz | 5.13 | 3.35 | 15.4 | 7.23 | - | - |
| | EVPT | (dyn) | 5.80 | 2.91 | 5.63 | 3.99 | 7.13 | 4.27 |
| | EVIT | (dyn) | 1.53 | 1.69 | 1.61 | 2.23 | 3.59 | 3.01 |
In contrast, the numerical results shown in Table. II illustrate a substantial improvement in accuracy and robustness in challenging scenarios. The majority of the alternative methods either fail to complete the entire sequence or result in large localization errors. Fig. 4 visualizes a comparison of actual trajectories from one of the more challenging sequences, demonstrating how all semi-dense comparison methods that do not employ inertial readings fail after at most 4s.
## B. Ablation study on motion model
The tracking process in this work is based on the nonlinear optimization technique which is often sensitive to initial state given by motion model. Therefore, we also conduct an ablation study to evaluate the effect of different motion models. The latter can be adopted based on the system's available sensors. When there is no internal motion information, a simple strategy would be the initialize the pose of a newly incoming keyframe with the pose of the previous one, a paradigm we may refer to as a zeroth-order motion model.
Fig. 4. Comparison of trajectories generated by various pure and inertial-supported semi-dense event-based tracking solutions, as well as a photometric alternative. The sequence is sofa fast from the VECtor benchmark [38]. The method proposed in this work is called EVIT .
A more advanced model could be the first-order motion model (i.e. constant velocity model), which assumes that the velocity remains constant over small periods of time, and thereby permits the initialization of a new keyframe with a relative pose to the previous one that is similar to the relative pose between the previous keyframe and its preceding one. Equipped with an IMU, we can introduce the second-order motion model, which uses acceleration and angular velocity readings to propagate the previous pose to the current one.
TABLE III ABSOLUTE TRAJECTORY ERROR (ATE) ON DIFFERENT MOTION MODELS. POSITION: [CM], ORIENTATION: [ ◦ ]
(a)
zeroth-order model
(b) first-order model
(c) second-order model
Fig. 5. Initial projection of semi-dense cloud on TSM using different motion models.
The three motion models are tested with the same tightly coupled optimization back end. Fig. 5 shows qualitative results for the different models, demonstrating how the second-order motion model provides better initial poses for the optimization back end. The full ATE results are listed in Table. III. Although the differences are not significant on mild sequences, it shows that even under the same optimization scheme, the motion model has a crucial implication in fast-motion scenarios.
## V. CONCLUSION
In this work, we have introduced a novel event-inertial tracking framework that aligns with previous approaches in that it proposes the registration of a semi-dense point cloud with contours observed in the time surface map. However, rather than simply aligning individual frames, the introduction of inertial signals permits the joint alignment of
| Sequence | zeroth-order | zeroth-order | first-order | first-order | second-order | second-order |
|--------------|----------------|----------------|---------------|---------------|----------------|----------------|
| | Pos. | Orient. | Pos. | Orient. | Pos. | Orient. |
| sofa fast | - | - | - | - | 7.08 | 3.22 |
| sofa normal | - | - | 2.84 | 1.60 | 3.15 | 1.53 |
| robot fast | - | - | - | - | 3.85 | 2.98 |
| robot normal | 1.08 | 1.32 | 1.46 | 1.23 | 1.00 | 1.14 |
| desk fast | - | - | - | - | 3.59 | 3.01 |
| desk normal | 3.75 | 1.59 | 2.77 | 1.16 | 2.22 | 0.94 |
multiple adjacent keyframes through the addition of pair-wise regularization terms. The proposed sliding window alignment shows benefits in tracking robustness as the contours in a single TSM are often orthogonal to the projected instantaneous direction of motion, and thus do not fully constrain an individual pose. Furthermore, the addition of the IMU leads to better initializations and thereby improves tracking performance in highly dynamic situations without a substantial increase in frame rate. Interestingly, the proposed windowed tracking method could be equally applied to regular cameras.
## VI. ACKNOWLEDGEMENT
We would like to acknowledge the funding support provided by project 62250610225 by the Natural Science Foundation of China, as well as projects 22DZ1201900, 22ZR1441300, and dfycbj-1 by the Natural Science Foundation of Shanghai.
## REFERENCES
[1] M. A. Mahowald and C. Mead, 'The silicon retina,' Scientific American , vol. 264, no. 5, pp. 76-83, 1991.
- [2] A. N. Angelopoulos, J. Martel, A. Kohli, J. Conradt, and G. Wetzstein, 'Event-based near-eye gaze tracking beyond 10,000 hz,' IEEE Transactions on Visualization and Computer Graphics , vol. 27, no. 5, pp. 2577-2586, 2021.
- [3] V. Rudnev, V. Golyanik, J. Wang, H.-P. Seidel, F. Mueller, M. Elgharib, and C. Theobalt, 'EventHands: Real-time neural 3d hand reconstruction from an event stream,' 2021.
- [4] L. Xu, W. Xu, V. Golyanik, M. Habermann, L. Fang, and C. Theobalt, 'Eventcap: Monocular 3d capture of high-speed human motions using an event camera,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2020.
- [5] Z. Zhang, K. Chai, H. Yu, R. Majaj, F. Walsh, E. Wang, U. Mahbub, H. Siegelmann, D. Kim, and T. Rahman, 'Neuromorphic highfrequency 3d dancing pose estimation in dynamic environment,' Neurocomputing , vol. 547, p. 126388, 2023.
- [6] C. Cadena, L. Carlone, H. Carrillo, Y. Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, 'Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,' IEEE Transactions on Robotics (T-RO) , vol. 32, no. 6, pp. 1309-1332, 2016.
- [7] H. Kim, S. Leutenegger, and A. J. Davison, 'Real-time 3d reconstruction and 6-dof tracking with an event camera,' in Proceedings of the European Conference on Computer Vision (ECCV) , 2016.
- [8] H. Rebecq, T. Horstsch¨ afer, G. Gallego, and D. Scaramuzza, 'Evo: A geometric approach to event-based 6-dof parallel tracking and mapping in real time,' IEEE Robotics and Automation Letters , vol. 2, no. 2, pp. 593-600, 2016.
- [9] Y. Zuo, W. Xu, X. Wang, Y. Wang, and L. Kneip, 'Cross-Modal Semi-Dense 6-DoF Tracking of an Event Camera in Challenging Conditions,' IEEE Transactions on Robotics (T-RO) , vol. 40, pp. 1600-1616, 2024.
- [10] Y.-F. Zuo, J. Yang, J. Chen, X. Wang, Y. Wang, and L. Kneip, 'Devo: Depth-event camera visual odometry in challenging conditions,' in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , 2022.
- [11] G. Gallego, T. Delbruck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. Davison, J. Conradt, and K. Daniilidis, 'Eventbased vision: A survey,' IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) , vol. 44, no. 1, pp. 154-180, 2020.
- [12] H. Rebecq, G. Gallego, and D. Scaramuzza, 'EMVS: Event-based multi-view stereo,' in Proceedings of the British Machine Vision Conference (BMVC) , 2016.
- [13] W. Chamorro, J. Sola, and J. Andrade-Cetto, 'Event-based line slam in real-time,' IEEE Robotics and Automation Letters , vol. 7, no. 3, pp. 8146-8153, 2022.
- [14] X. Peng, W. Xu, J. Yang, and L. Kneip, 'Continuous Event-Line Constraint for Closed-Form Velocity Initialization,' in Proceedings of the British Machine Vision Conference (BMVC) , 2021.
- [15] L. Gao, H. Su, D. Gehrig, M. Cannici, D. Scaramuzza, and L. Kneip, 'A 5-Point Minimal Solver for Event Camera Relative Motion Estimation,' in Proceedings of the International Conference on Computer Vision (ICCV) , 2023.
- [16] A. Z. Zhu, N. Atanasov, and K. Daniilidis, 'Event-based visual inertial odometry,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017, pp. 5391-5399.
- [17] H. Rebecq, T. Horstschaefer, and D. Scaramuzza, 'Real-time visualinertial odometry for event cameras using keyframe-based nonlinear optimization,' in Proceedings of the British Machine Vision Conference (BMVC) , 2017.
- [18] C. Le Gentil, F. Tschopp, I. Alzugaray, T. Vidal-Calleja, R. Siegwart, and J. Nieto, 'IDOL: A framework for imu-dvs odometry using lines,' in Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS) , 2020, pp. 5863-5870.
- [19] W. Xu, X. Peng, and L. Kneip, 'Tight Fusion of Events and Inertial Measurements for Direct Velocity Estimation,' IEEE Transactions on Robotics (T-RO) , vol. 40, pp. 240-256, 2023.
- [20] A. R. Vidal, H. Rebecq, T. Horstschaefer, and D. Scaramuzza, 'Ultimate SLAM? Combining events, images, and IMU for robust visual SLAM in HDR and high-speed scenarios,' vol. 3, no. 2, pp. 994-1001, 2018.
- [21] Y. Zhou, G. Gallego, and S. Shen, 'Event-based stereo visual odometry,' IEEE Transactions on Robotics (T-RO) , vol. 37, no. 5, pp. 14331450, 2021.
- [22] A. Censi, J. Strubel, C. Brandli, T. Delbruck, and D. Scaramuzza, 'Low-latency localization by Active LED Markers tracking using a
- Dynamic Vision Sensor,' in Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS) , 2013.
- [23] G. Chen, W. Chen, Q. Yang, Z. Xu, L. Yang, J. Conradt, and A. Knoll, 'A novel visible light positioning system with event-based neuromorphic vision sensor,' IEEE Sensors , vol. 20, no. 17, pp. 10 211-10 219, 2020.
- [24] E. Mueggler, B. Huber, and D. Scaramuzza, 'Event-based, 6-dof pose tracking for high-speed maneuvers,' in Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS) , 2014.
- [25] J. Bertrand, A. Yigit, and S. Durand, 'Embedded event-based visual odometry,' in IEEE International Conference on Event-based Control, Communication, and Signal Processing (EBCCSP) , 2020.
- [26] W. Chamorro, J. Andrade-Cetto, and J. Sol` a, 'High-speed event camera tracking,' in Proceedings of the British Machine Vision Conference (BMVC) , 2020.
- [27] D. Reverter Valeiras, G. Orchard, S.-H. Ieng, and R. B. Benosman, 'Neuromorphic event-based 3d pose estimation,' Front. Neurosci. , vol. 9, p. 522, 2016.
- [28] G. Gallego, J. E. A. Lund, E. Mueggler, H. Rebecq, T. Delbruck, and D. Scaramuzza, 'Event-based, 6-dof camera tracking from photometric depth maps,' IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) , vol. 40, no. 10, pp. 2402-2412, 2018.
- [29] S. Bryner, G. Gallego, H. Rebecq, and D. Scaramuzza, 'Event-based, direct camera tracking from a photometric 3d map using nonlinear optimization,' in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , 2019.
- [30] J. Engel, J. Sturm, and D. Cremers, 'Semi-dense visual odometry for a monocular camera,' in Proceedings of the International Conference on Computer Vision (ICCV) , 2013.
- [31] L. Kneip, Z. Yi, and H. Li, 'SDICP: Semi-dense tracking based on iterative closest points.' in Proceedings of the British Machine Vision Conference (BMVC) , 2015.
- [32] M. Kuse and S. Shen, 'Robust camera motion estimation using direct edge alignment and sub-gradient method,' in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , 2016.
- [33] Y. Zhou, H. Li, and L. Kneip, 'Canny-vo: Visual odometry with rgb-d cameras based on geometric 3-d-2-d edge alignment,' IEEE Transactions on Robotics (T-RO) , vol. 35, no. 1, pp. 184-199, 2018.
- [34] R. Benosman, C. Clercq, X. Lagorce, S.-H. Ieng, and C. Bartolozzi, 'Event-based visual flow,' IEEE transactions on neural networks and learning systems , vol. 25, no. 2, pp. 407-417, 2013.
- [35] T. Qin, P. Li, and S. Shen, 'VINS-mono: A robust and versatile monocular visual-inertial state estimator,' IEEE Transactions on Robotics (T-RO) , vol. 34, no. 4, pp. 1004-1020, 2018.
- [36] S. Shen, N. Michael, and V. Kumar, 'Tightly-coupled monocular visual-inertial fusion for autonomous flight of rotorcraft MAVs,' in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , 2015.
- [37] S. Agarwal, K. Mierle, and T. C. S. Team, 'Ceres Solver,' 10 2023. [Online]. Available: https://github.com/ceres-solver/ceres-solver
- [38] L. Gao, Y. Liang, J. Yang, S. Wu, C. Wang, J. Chen, and L. Kneip, 'Vector: A versatile event-centric benchmark for multi-sensor slam,' IEEE Robotics and Automation Letters , vol. 7, no. 3, pp. 8217-8224, 2022.
- [39] M. Grupp, 'evo: Python package for the evaluation of odometry and SLAM,' https://github.com/MichaelGrupp/evo, 2017.
- [40] S. He, X. Qin, Z. Zhang, and M. Jagersand, 'Incremental 3d line segment extraction from semi-dense slam,' in 2018 24th International Conference on Pattern Recognition (ICPR) . IEEE, 2018, pp. 16581663.
- [41] R. Mur-Artal and J. D. Tard´ os, 'Probabilistic semi-dense mapping from highly accurate feature-based monocular slam.' in Proceedings of Robotics: Science and Systems (RSS) , 2015. | null | [
"Runze Yuan",
"Tao Liu",
"Zijia Dai",
"Yi-Fan Zuo",
"Laurent Kneip"
]
| 2024-08-02T16:24:55+00:00 | 2024-08-02T16:24:55+00:00 | [
"cs.CV",
"cs.RO"
]
| EVIT: Event-based Visual-Inertial Tracking in Semi-Dense Maps Using Windowed Nonlinear Optimization | Event cameras are an interesting visual exteroceptive sensor that reacts to
brightness changes rather than integrating absolute image intensities. Owing to
this design, the sensor exhibits strong performance in situations of
challenging dynamics and illumination conditions. While event-based
simultaneous tracking and mapping remains a challenging problem, a number of
recent works have pointed out the sensor's suitability for prior map-based
tracking. By making use of cross-modal registration paradigms, the camera's
ego-motion can be tracked across a large spectrum of illumination and dynamics
conditions on top of accurate maps that have been created a priori by more
traditional sensors. The present paper follows up on a recently introduced
event-based geometric semi-dense tracking paradigm, and proposes the addition
of inertial signals in order to robustify the estimation. More specifically,
the added signals provide strong cues for pose initialization as well as
regularization during windowed, multi-frame tracking. As a result, the proposed
framework achieves increased performance under challenging illumination
conditions as well as a reduction of the rate at which intermediate event
representations need to be registered in order to maintain stable tracking
across highly dynamic sequences. Our evaluation focuses on a diverse set of
real world sequences and comprises a comparison of our proposed method against
a purely event-based alternative running at different rates. |
2408.01371v1 | ## Nitrogen-containing Surface Ligands Lead to False Positives for Photofixation of N2 on Metal Oxide Nanocrystals: An Experimental and Theoretical Study
Daniel Maldonado-Lopez, a,† Po-Wei Huang,b, † Karla R. Sanchez-Lievanos, c,†
Gourhari Jana, Jose L. Mendoza-Cortes, a a,d,* Kathryn E. Knowles, c,* and Marta C. Hatzell b,e,*
- a Department of Chemical Engineering & Materials Science, Michigan State University, East Lansing, MI 48824, USA
- b School of Chemical & Biomolecular Engineering, Georgia Institute of Technology, Atlanta, GA 30318, USA
- c Department of Chemistry, University of Rochester, Rochester, NY 14627, USA
- d Department of Physics and Astrophysics, East Lansing, MI, 48824
- e School of Mechanical Engineering, Georgia Institute of Technology, Atlanta, GA 30318, USA
† D.M-L., P.W.H., and K.R.S.L contributed equally to this work.
- : [email protected]; [email protected];
* Corresponding authors [email protected]
## Abstract
Many ligands commonly used to prepare nanoparticle catalysts with precise nanoscale features contain nitrogen (e.g., oleylamine); here, we found that the use of nitrogen-containing ligands during the synthesis of metal oxide nanoparticle catalysts substantially impacted product analysis during photocatalytic studies. We confirmed these experimental results via hybrid Density Functional Theory computations of the materials' electronic properties to evaluate their viability as photocatalysts for nitrogen reduction. This nitrogen ligand contamination, and subsequent interference in photocatalytic studies, is avoidable through the careful design of synthetic pathways that exclude nitrogen-containing constituents. This result highlights the urgent need for careful evaluation of catalyst synthesis protocols, as contamination by nitrogencontaining ligands may go unnoticed since the presence of nitrogen is often not detected or probed.
1
Surface Ligands:

Surface Ligands: Oleic Acid

Ammonia is a vital fertilizer in agriculture, playing a crucial role in sustaining the needs of our growing population. Current ammonia production is predominantly achieved 1 via the HaberBosch process. However, this process is accompanied by substantial CO2 emissions (accounting for 1.6% of global CO2 emissions) and contributes to a worldwide nitrogen imbalance while consuming approximately 2% of the world's energy. These pressing concerns 2 require developing a decarbonized and energy-efficient approach to ammonia production. In this context, the photocatalytic nitrogen reduction reaction (pNRR) has garnered significant attention, as it enables catalysis under ambient conditions, utilizing water and air as readily available feedstocks. 3
Recent studies suggest that a solar-to-ammonia (STA) efficiency as low as 0.1% but, more practically, 5-10% would be sufficient for the pNRR technique to meet fertilizer demand. 2 Despite notable progress in pNRR research, the best lab-scale studies currently achieve efficiencies that are at least an order of magnitude below the target, highlighting a significant gap that must be bridged before achieving commercial viability. Consequently, ongoing research endeavors are dedicated to enhancing the activity of photocatalysts, with a primary focus on developing and synthesizing nanoscale colloidal catalysts through meticulous materials design such as controlled shape, size, composition, and structure. 4,5 Researchers have developed several synthetic methods to access colloidally stable nanostructures of a broad range of materials, including quantum dots and complex metal oxides. Notably, most of these 6 methods use oleylamine (C18H35NH2), a primary amine ligand that contains an amino group (NH2). These surface ligands play a crucial role in preventing catalyst aggregation, dictating morphology, and facilitating the formation of monodisperse nanocrystals. Hence, oleylamine and primary amine ligands have also surfaced in the synthesis of metal sulfide and oxyhalide catalysts for photo-(electro-)catalytic nitrogen fixation. 7,8
Low ammonia yields in the current development of pNRR have also raised concerns about false-positive results. These false-positive outcomes primarily stem from two factors: 9 inaccurate low-level ammonia measurements or inadvertent ammonia contamination. Recent investigations have shed light on various sources of contamination, including the presence of ammonia and NOx species (such as NO, N2O, and NO2) in the feeding gas, surface contamination of equipment, and the utilization of N-containing catalysts. 10,11 In our experimental observations, we encountered severe ammonia contamination arising as a false positive from the presence of adventitious nitrogen, which is linked to nitrogen-containing ligands (NL) used during the catalyst synthesis process. We reinforce the appearance of false
positives and explain the materials' catalytic behavior via hybrid Density Functional Theory (DFT). Our calculations suggest that the catalysts are inadequate for pNRR.
An ideal pNRR catalyst should be capable of absorbing visible light and exhibit both thermal and chemical stability. In this regard, spinel ferrite (AFe2O4) structures that exhibit a cubane-like motif (a ubiquitous cofactor in selective catalysts found in nature) are promising prospects for catalysis (see Scheme 1 ). 12
Scheme 1 . Normal spinel ferrite structure. a) Polyhedral view. The octahedral and tetrahedral sites are shown in shaded brown and gray areas, respectively. b) Ball-and-stick representation, where the inset shows the cubane-like motif present in these structures.
In theory, the available versatility of the A site in spinel ferrites, along with the ability to vary the distribution of A and Fe among tetrahedral and octahedral crystal sites, can induce attractive synergy effects that may further improve catalytic activity. To explore this potential, we employed the synthetic method developed by Sanchez-Lievanos et al ., to synthesize several spinel ferrite nanomaterials, AFe2O4 (A: Co, Ni, and Zn). 13 We then evaluated their photocatalytic activity utilizing a custom-built photoreactor ( Fig. S1 ). Metal ferrites were first dispersed in deionized (DI) water and then transferred into the photoreactor, which was then continuously aerated (N2 or Ar) under irradiation (full spectrum). Following a 4-hour reaction period, we observed relatively high ammonia concentrations (1-2 ppm) for all three catalysts ( Fig. S2 ). However, time-dependent measurements identified that most ammonia evolved before illumination. We also see that ammonia production quickly reaches a plateau after irradiation. This finding suggests that most of the ammonia we observed was from contaminants (nitrogen, amines, or ammonia-based) rather than being the product of a photocatalytic pathway. We meticulously examined all potential sources of ammonia contamination, quantified the experimental setup in its entirety, and demonstrated that-in the
absence of the catalyst-background ammonia concentration was measured to be (0.0009 ± 0.0003 ppm), indicating that the catalyst itself was the source of contamination ( Fig. 1 ).
While the metal ferrites employed in our study do not inherently contain nitrogen, amines, or ammonia, the ligands utilized during the nanocrystal synthesis (e.g., oleylamine) do possess these nitrogen-based constituents. To mitigate potential contamination from these amine groups, all catalysts were purified using standard procedures consisting of three precipitation cycles with a mixture of ethanol and hexane followed by centrifugation. However, contamination persisted even in catalysts that had undergone what is typically considered an effective oleylamine removal process. These "purified" catalysts were utilized in our experiments and are denoted as NL in Fig. 1 . The presence of this organic molecule on the catalyst surface is postulated as the primary cause of the observed contamination. These findings indicate that standard washing treatments do not effectively eliminate all ligands.
Figure 1. Ammonia detected by ion chromatography in solutions of Co (CFO), Zn (ZFO), and Ni (NFO) ferrite prepared with and without nitrogen-containing ligands (NL). The sample was collected after 30 minutes of sonication (catalyst in DI water) in the absence of illumination. The error bars represent the standard deviation from three independent experiments.
Next, we redesigned the synthetic route, entirely eliminating the use of nitrogencontaining ligands to produce the metal ferrites. These catalysts are labeled as NL-free in Fig. 1 . The resulting NL-free nanocrystals are significantly larger than the NL samples, with diameters on the order of 100s of nm instead of ~15 nm obtained using oleylamine (Figures S8 and S9). Comparison of the compositions of the NL and NL-free nanocrystals by energydispersive x-ray spectroscopy (X-ray) is consistent with successful elimination of nitrogen from the NL-free nanocrystals ( Fig. S11 ). As a result of this modification, ammonia contamination in the NL-free ferrites was significantly reduced. Furthermore, we observed that residual contamination could be further suppressed by rinsing the catalysts with deionized (DI) water. This rinsing procedure involved three cycles of washing with DI water, followed by centrifugation. These catalysts are labeled as NL-free* ( Fig. 1 ). Our results provide compelling support for our hypothesis that the presence of nitrogen ligands can introduce substantial ammonia contamination. Illumination of the NL-free* nanocrystals under N2 and Ar atmospheres reveals statistically significant photoinduced production of ammonia from nitrogen for NiFe2O4 (NFO) only; CoFe2O4 (CFO) and ZnFe2O4 (ZFO) produced similar concentrations of ammonia under illumination in both N2 and Ar atmospheres ( Fig. 2 ).

Figure 2. Photocatalytic activity of post-washed NL-free Co, Zn, and Ni ferrites under fullspectrum irradiation after 4 hours in N2 or Ar environments. The error bars represent the standard deviation from two independent experiments.
To support these experimental results, we performed an in-depth computational analysis of the ZFO, CFO, and NFO structures using hybrid-level DFT. The computational methodology is described in detail in the supplementary information (SI). These structures have a general formula (A1x B )[A B2- ]O4, where the parentheses describe tetrahedral sites and the x x x square brackets represent octahedral sites. In our spinel ferrites, A = Zn, Co, Ni, and B = Fe. The inversion parameter, , describes the fraction of tetrahedral sites occupied by Fe x 3+ ions and the fraction of A 2+ ions that occupy octahedral sites. Based on X-ray photoelectron spectroscopy, it was determined that the NL-free nanoparticles have inversion parameters x ~ 0 for ZFO and x = 0.8 for CFO, which closely resemble the inversion parameters of the bulk materials (see Fig. S12 ). 14-16 Since NFO strongly prefers an inverted configuration, we assume x = 1 for NFO. 17 The bulk structures are shown in Fig. S13 , and the corresponding crystallographic data is available in the SI. Moreover, scanning electron microscopy imaging ( Fig. S9 ) indicates that ZFO NPs are primarily octahedral in morphology, indicating the predominance of (111) surface planes. On the other hand, CFO and NFO NPs most closely resemble truncated octahedra, which would indicate the presence of both (111) and (100) planes. Therefore, slab calculations were set up for these surface planes with inversion parameters of x = 0 for ZFO, x = 0.75 for CFO, and x = 1 for NFO.
Due to the high reactivity of exposed transition metals in the (100) slabs, hydrogen atoms were added on both sides of the surface reconstructions, effectively 'capping' the surface. Similarly, due to the (111) slabs' termination, the addition of oxygen and hydrogen atoms was necessary to avoid exposed transition metals. In particular, hydrogen atoms were added to either the top or bottom surfaces to maintain a charge balance, resulting in two configurations. Although the inclusion of oxygen and hydrogen alters the compounds' stoichiometry, these structures are more reminiscent of the surfaces that would be observed in an experimental setting due to exposing the NPs to ambient O2 and H2O. Side views of the optimized surface reconstructions are shown in Fig. 3 and crystallographic data is available in the SI.
Figure 3. Spin-polarized atom-projected electronic density of states of ZFO, CFO, and NFO slabs, and side views of the corresponding structures. a-c) correspond to (111) slabs with H added to the top layer, d-f) correspond to (111) slabs with H added to the bottom layer, and gj) show (100) slabs without H and with H added to both exposed surfaces. The left and righthand sides of each plot represent spin-down and spin-up electronic channels, respectively. Total DOS is plotted as a shaded gray area, while the contribution from each atomic species in the material was projected and shown as lines. The DOS plots are aligned with respect to vacuum, and the NH3/N2 potential is plotted as a green rectangle. The DOS contributions from H are not shown, as they did not present a significant contribution to the total DOS.
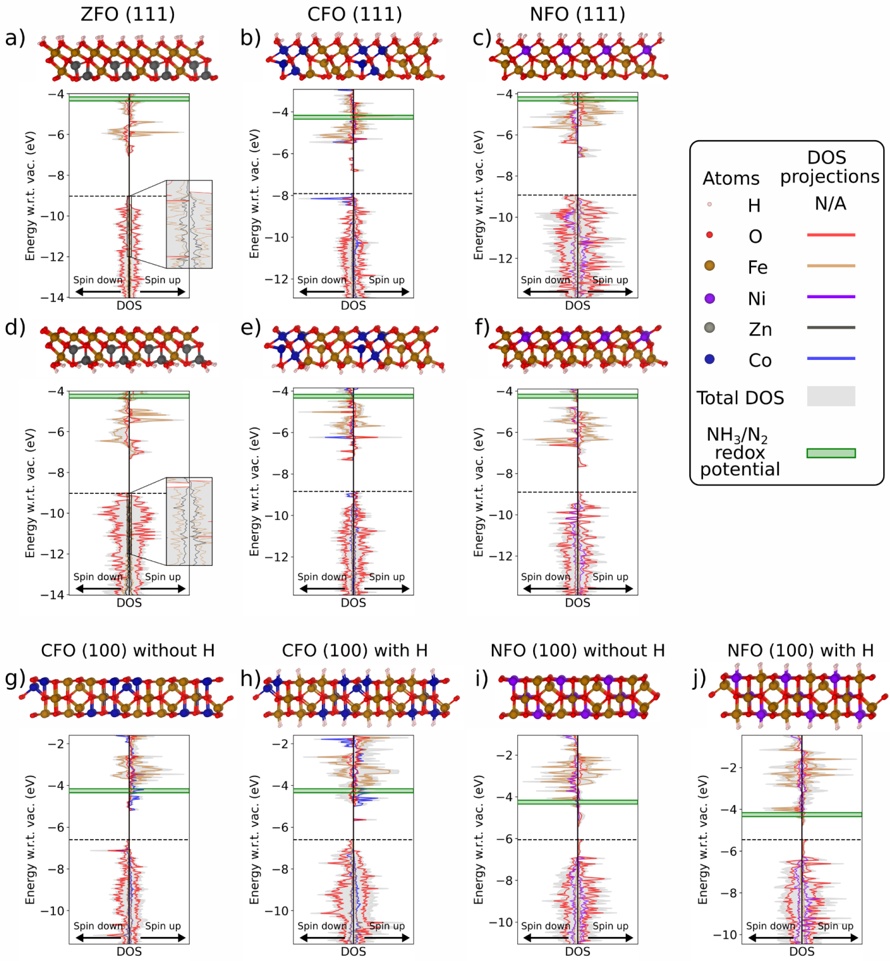
Fig. 3 plots the spin-polarized atom-projected electronic density of states (DOS) for the ZFO (111) slab (with x=0 , i.e. NL-free), CFO (111) and (100) slabs, and NFO (111) and (100) slabs. For the (111) slabs, we show the hydrogen capped structures. Structures without hydrogen are plotted in Fig. S14 and show similar results. For the (100) slabs, we plot the structures with and without hydrogen capping. Furthermore, band alignments to an absolute vacuum scale were performed in these calculations, allowing us to observe the relative electron density at different electrode potentials. For this work, we are interested in the NH3/N2 potential, which falls at around -0.28 to -0.092 V vs. the Normal Hydrogen Electrode (NHE), 1821 or -4.35 to -4.16 eV with respect to vacuum (the range being attributed to different pH conditions). Generated photoelectrons must have energy above this threshold, ideally with the conduction band minimum (CBM) above the NH3/N2 potential , for a material to be effective as a photo-(electro-)catalyst for ammonia generation.
We begin by analyzing the (111) surfaces ( Fig. 3 a-f ). Structurally, the slabs are formed by one layer with octahedral sites only (top layer) and a second layer with octahedral and tetrahedral sites (bottom layer). From their densities of states, it can be observed that the (111) slabs are spin-polarized, i.e., they are asymmetric over their spin-up and spin-down channels, which is expected from their magnetic configuration. Moreover, the addition of hydrogen to the top or bottom surface slightly changes the levels that form around the Fermi level. This is reflected in the slabs' band gaps, which are shown in Table 1 and range from 1.1 to 2.7 eV. From the DOS projections, we observe that ZFO presents a large contribution from Fe and O atoms around the Fermi level, and a smaller contribution from Zn (see insets in Fig. 3a and 3d ). Comparatively, CFO ( Fig. 3b and 3e ) has relatively large contributions from Co near the valence band maximum (VBM), especially when H atoms are added to the top (octahedral) layer. Furthermore, the band gap of CFO is smaller when adding H to the top surface due to the presence of inter-gap states, which are not as prevalent when adding H to the bottom layer. NFO, on the other hand, presents contributions from Ni throughout the valence band and has very similar DOS profiles when adding H to the bottom and top surfaces.
Table 1 . Spin-up and spin-down band gaps for (111) slabs.
| Structure | Band gap (eV) | Band gap (eV) |
|----------------|-----------------|-------------------|
| | Spin-up channel | Spin-down channel |
| ZFO (111) Htop | 2.53 | 1.97 |
| CFO (111) Htop | 1.30 | 1.11 |
| NFO (111) H top | 1.99 | 2.51 |
|--------------------|--------|--------|
| ZFO (111) Hbottom | 1.83 | 2.25 |
| CFO (111) Hbottom | 1.71 | 1.64 |
| NFO (111) H bottom | 1.2 | 2.74 |
A crucial result from the (111) slab calculations is that their CBM falls well below the NH3/N2 energy range, which is not conducive to ammonia production. This result is also consistent with the slabs without hydrogen (see Fig. S14 ). In the synthesized ZFO nanoparticles, the (111) slab is the dominating exposed surface; therefore, this analysis discards the ZFO structure as a potential candidate for nitrogen activation and reinforces our experimental findings, where ZFO NPs did not produce photoinduced ammonia. Note that this analysis corresponds to the NL-free ZFO structure ( x= 0); however, similar results are observed when comparing to the NL structure with inversion x= ⅔ (see Fig. S15 ).
Next, we focus on the CFO (100) slabs ( Fig. 3g-h ). These structures are highly spinpolarized, and their spin-up and spin-down CBM/VBM fall at different relative energies, resembling the electronic character of a bipolar magnetic semiconductor. The structure with hydrogen capping presents intermediate states similar to the (111) slab, which arise from Co and O contributions. These states are not present in the structure without hydrogen. The CFO (100) slabs have bandgaps of 1.87 eV (spin-up) and 1.52 eV (spin-down) for the structure without H, while the structure with H has bandgap values of 1.50 eV and 1.75 eV for its spinup and spin-down channels, respectively. In terms of their potential for ammonia generation, it can be observed that both slabs have CBM below the energy range of interest, preventing photoelectrons with sufficient energy from being generated to catalyze the NH3/N2 reaction. Therefore, the CFO structure is not a candidate for ammonia generation, in alignment with our experimental results.
Finally, we analyze the NFO (100) slabs ( Fig. 3i-j ). Our first observation is that the structures are highly spin-polarized, with a wide band gap in one of their spin channels and a narrow band gap in the other, resembling the electronic structure of a half semiconductor. They present bandgaps of 0.62 eV (spin-up) and 2.45 eV (spin-down) for the structure without H, and 0.69 eV (spin-up) and 2.0 eV (spin-down) for the structure with H. The slabs' CBM and VBM for their spin-up channels are mainly composed of Fe and O atomic orbitals. Meanwhile, their spin-down channel CBMs are mainly composed of Fe, and their VBMs are composed of O, Ni, and Fe contributions (in that order, from greater to lesser contribution). It can be observed that their spin-up CBM falls well below the NH3/N2 potential. However, their spindown CBM is very close to the energy range of interest, therefore, we believe that
photoexcitation could allow some electrons to undergo the transition from VBM to CBM in the spin-down channel, resulting in carriers with enough energy to catalyze the reaction. As previously discussed, the (100) surface is only partially exposed in the nanoparticles, and the reaction can only occur with electrons excited in the spin-down channel. Therefore, this mechanism would explain why we obtain a statistically significant but relatively small amount of photoinduced ammonia from NFO nanocrystals. In general, our electronic property calculations show a similar behavior as the experimental results for NL-free NPs. This reinforces our observation of the appearance of false-positives when utilizing nitrogencontaining species during nanocrystal synthesis.
In conclusion, it is crucial to recognize nitrogen-containing ligands, specifically oleylamine, as an additional source of ammonia contamination in photo-(electro-)catalytic ammonia synthesis. To mitigate the risk of surface-bonded amine contamination, we recommend adopting a nitrogen-free synthesis platform. Moreover, it is imperative to thoroughly discuss the synthesis methods employed in generating nanoparticle catalysts, as the presence of nitrogen-containing ligands may not be immediately apparent from the chemical formula of the catalyst itself. Neglecting the careful handling of nitrogen-containing ligands can result in ammonia measurements from contamination that exceed the actual photocatalytic activity by more than two orders of magnitude, severely impacting the identification of photo-fixed ammonia. The attention towards nitrogen ligand contamination should extend beyond the field of pNRR and encompass related areas, such as photo-(electro-)catalytic urea synthesis, which employs the co-reduction of nitrogen and carbon dioxide to ammonia and carbon monoxide as precursors for urea production. 22 Reducing adventitious ammonia requires re-evaluating material activity to ensure reliable results and interpretations.
Supporting Information. Details of the nanocrystal synthesis, photocatalysis experiments, ammonia quantification protocol, and computational methods; nanocrystal characterization data including electron microscopy images (TEM and SEM), energy dispersive x-ray spectroscopy (EDS), powder x-ray diffraction (pXRD) and x-ray photoelectron spectroscopy (XPS); photocatalysis control experiments; crystallographic information for all slab calculations, computed bulk electronic structures, and additional supporting slab calculations.
Acknowledgements. This work was supported financially by a Scialog Negative Emissions Sciences grant funded by the Alfred P. Sloan foundation. K. R. S.-L. was also supported in part by the National Science Foundation under grant (CHE-2044462). This work was supported in
part through computational resources and services provided by the Institute for Cyber-Enabled Research at Michigan State University. References
- 1. Brightling, J. Ammonia and the Fertiliser Industry: The Development of Ammonia at Billingham. Johnson Matthey Technology Review 2018 , 62 (1), 32-47.
- 2. Medford, A. J.; Hatzell, M. C. Photon-Driven Nitrogen Fixation: Current Progress, Thermodynamic Considerations, and Future Outlook. ACS Catal. 2017 , 7 (4), 26242643.
- 3. Zhao, Y.; Miao, Y.; Zhou, C.; Zhang, T. Artificial Photocatalytic Nitrogen Fixation: Where Are We Now? Where Is Its Future? Mol. Catal. 2022 , 518 , 112107.
- 4. Shi, R.; Zhao, Y.; Waterhouse, G. I.; Zhang, S.; Zhang, T. Defect engineering in photocatalytic nitrogen fixation. ACS Catal. 2019 , 9 (11), 9739-9750.
- 5. Chen, C.; Liang, C.; Xu, J.; Wei, J.; Li, X.; Zheng, Y.; Li, J.; Tang, H.; Li, J. SizeDependent Electrochemical Nitrogen Reduction Catalyzed by Monodisperse Au Nanoparticles. Electrochim. Acta 2020 , 335 , 135708.
- 6. Mourdikoudis, S.; Liz-Marzán, L. M. Oleylamine in Nanoparticle Synthesis. Chem. Mater. 2013 , 25 (9), 1465-1476.
- 7. Li, P.; Gao, S.; Liu, Q.; Ding, P.; Wu, Y.; Wang, C.; Yu, S.; Liu, W.; Wang, Q.; Chen, S. Recent Progress of the Design and Engineering of Bismuth Oxyhalides for Photocatalytic Nitrogen Fixation. Adv. Energy and Sustainability Res. 2021 , 2 (5), 2000097.
- 8. Chen, X.; Ma, C.; Tan, Z.; Wang, X.; Qian, X.; Zhang, X.; Tian, J.; Yan, S.; Shao, M. One-Dimensional Screw-like MoS2 with Oxygen Partially Replacing Sulfur as an Electrocatalyst for the N2 Reduction Reaction. Chem. Eng. J. 2022 , 433 , 134504.
- 9. Iriawan, H.; Andersen, S. Z.; Zhang, X.; Comer, B. M.; Barrio, J.; Chen, P.; Medford, A. J.; Stephens, I. E. L.; Chorkendorff, I.; Shao-Horn, Y. Methods for Nitrogen Activation by Reduction and Oxidation. Nat. Rev. Methods Primers 2021 , 1 (1), 56.
- 10. Choi, J.; Suryanto, B. H. R.; Wang, D.; Du, H.-L.; Hodgetts, R. Y.; Ferrero Vallana, F. M.; MacFarlane, D. R.; Simonov, A. N. Identification and Elimination of False Positives in Electrochemical Nitrogen Reduction Studies. Nat. Commun. 2020 , 11 (1), 5546.
- 11. Huang, P.-W.; Hatzell, M. C. Prospects and Good Experimental Practices for Photocatalytic Ammonia Synthesis. Nat. Commun. 2022 , 13 (1), 7908.
- 12. Kefeni, K. K.; Mamba, B. B. Photocatalytic Application of Spinel Ferrite Nanoparticles and Nanocomposites in Wastewater Treatment. Sustainable Mater. Technol 2020 , 23 , e00140.
- 13. Sanchez-Lievanos, K. R.; Tariq, M.; Brennessel, W. W.; Knowles, K. E. Heterometallic Trinuclear Oxo-Centered Clusters as Single-Source Precursors for Synthesis of Stoichiometric Monodisperse Transition Metal Ferrite Nanocrystals. Dalton Trans. 2020 , 49 (45), 16348-16358.
- 14. Sawatzky, G. A.; Van der Woude, F.; Morrish, A. H. Mössbauer study of several ferrimagnetic spinels. Phys. Rev. 1969 , 187 (2), 747-57.
- 15. Braestrup, F.; Hauback, B. C.; Hansen, K. K. Temperature dependence of the cation distribution in ZnFe2O4 measured with high temperature neutron diffraction. J. Solid State Chem. 2008 , 181 (9), 2364-2369.
- 16. O'Neill, H. S. C. Temperature dependence of the cation distribution in zinc ferrite (ZnFe2O4) from powder XRD structural refinements. Eur. J. Mineral. 1992 , 4 (3), 571-80.
- 17. Restrepo, O. A.; Arnache, O.; Mousseau, N. An approach to understanding the formation mechanism of NiFe2O4 inverse spinel. Materialia 2024 , 33, 102031.
- 18. Lv, X.; Wei, W.; Li, F.; Huang, B.; Dai, Y. Metal-free B@g-CN: visible/infrared light-driven single atom photocatalyst enables spontaneous dinitrogen reduction to ammonia. Nano Lett. 2019 , 19 , 6391-6399.
- 19. Li, J.; Liu, P.; Tang, Y.; Huang, H.; Cui, H.; Mei, D.; Zhong, C. Single-atom Pt-N3 sites on the stable covalent triazine framework nanosheets for photocatalytic N2 fixation. ACS Catal. 2020 , 10 , 2431-2442.
- 20. Bian, S.; Wen, M.; Wang, J.; Yang, N.; Chu, P. K.; Yu, X. F. Edge-rich black phosphorus for photocatalytic nitrogen fixation. J. Phys. Chem. Lett. 2020 , 11 , 10521058.
- 21. Wang, S.; Shi, L.; Bai, X.; Li, Q.; Ling, C.; Wang, J. Highly efficient photo/electrocatalytic reduction of nitrogen into ammonia by dual-metal sites. ACS Cent. Sci. 2020 , 6 , 1762-1771.
- 22. Jiang, M.; Zhu, M.; Wang, M.; He, Y.; Luo, X.; Wu, C.; Zhang, L.; Jin, Z. Review on Electrocatalytic Coreduction of Carbon Dioxide and Nitrogenous Species for Urea Synthesis. ACS Nano 2023 , 17 (4), 3209-3224.
## Supporting Information
Nitrogen-containing Surface Ligands Lead to False Positives for Photofixation of N2 on Metal Oxide Nanocrystals: An Experimental and Theoretical Study
Daniel Maldonado-Lopez, a, † Po-Wei Huang, b, † Karla R. Sanchez-Lievanos, c,† Gourhari Jana, Jose L. Mendoza-Cortes, a a,d,* Kathryn E. Knowles, c,* and Marta C. Hatzell b,e,*
- a Department of Chemical Engineering & Materials Science, Michigan State University, East Lansing, MI 48824, USA
- b School of Chemical & Biomolecular Engineering, Georgia Institute of Technology, Atlanta, GA 30318, USA
- c Department of Chemistry, University of Rochester, Rochester, NY 14627, USA
- d Department of Physics and Astrophysics, East Lansing, MI, 48824
- e School of Mechanical Engineering, Georgia Institute of Technology, Atlanta, GA 30318, USA
† D.M-L., P.H., and K.R.S.L contributed equally to this work.
: [email protected]; [email protected];
* Corresponding authors [email protected]
## Materials:
## Synthesis of nitrogen-ligand (NL) containing MFe2O4 nanocrystals from single-source precursors under solvothermal conditions.
In general, the single-source precursor, a trinuclear oxo-centered cluster with formula MFe2 (μ 3O)(μ 2-O2CCF3)6(H2O)3 (0.25 mmol, synthesis procedure adopted from ref 1), oleylamine (OAm 1 (≥98%), 27 mmol, Sigma -Aldrich), oleic acid (OA ( 90%) , 27 mmol, Sigma-Aldrich), and benzyl ether (BE (99%), 40 mL, Sigma-Aldrich) were added to a 100 mL Teflon insert. The mixture was stirred for 15 minutes under ambient conditions to form a clear dark suspension. Subsequently, the Teflon insert was loaded into a stainless-steel autoclave, sealed, and heated at 230 °C for 24 h. The autoclave was allowed to cool down over a period of 8-12 hours under a well-ventilated fume hood. The suspension was then purified with addition of a 10:1 mixture of ethanol:hexane, followed by centrifugation. This washing step was conducted a total of three times.
## Synthesis of NL-free MFe2O4 nanoparticles from stoichiometric mixtures of metal acetylacetonate salts (acac) under solvothermal conditions.
MFe2O4 nanoparticles were synthesized using stoichiometric (2:1) mixtures of Fe(acac)3 (0.17 mmol, 97%, Sigma-Aldrich), M(acac)2 (0.08 mmol, M(II): Ni (95%), Co (97%) and Zn (≥ 95.0 %), Sigma-Aldrich), dissolved in 40 mL of benzyl ether (BE (99%), 40 mL, Sigma -Aldrich) with oleic acid (OA, 27 mmol) and heated to 230 ºC for 24 h in a 100-mL autoclave reactor. The autoclave was allowed to cool down over a period of 8-12 hours under a well-ventilated fume hood. The suspension was then purified with addition of a 10:1 mixture of ethanol:hexane, followed by centrifugation. This washing step was conducted a total of three times.
Characterization Methods:
Powder X-ray diffraction.
The use of a copper source for powder X-ray diffraction analysis of iron-containing samples yields a high background signal due to X-ray fluorescence from iron. Monochromators can be used to suppress this background fluorescence signal; however, this approach presents disadvantages, such as low penetration depth and loss of peak intensity, that can lead to diffractograms with inconclusive peak patterns. Employing molybdenum radiation can help overcome these drawbacks. The lower fluorescence background signal observed using this radiation provides an improved signal-to-noise ratio and enables unambiguous phase identification. We therefore performed powder X-ray diffraction measurements using a Rigaku XtaLAB Dualflex Synergy-S diffraction system with Mo K α radiation (λ = 0.71073 Å). We used the Bragg equation to convert the 2 θ values obtained using the Mo source to 2 θ values corresponding to the wavelength of a Cu K α source ( λ =1.54148 Å) to compare our measured spectra to standard data deposited in the JCPDS database that was collected with Cu K a radiation. Samples for powder X-ray diffraction measurements were prepared by drop casting hexane dispersions of purified nanocrystals onto glass substrates under ambient atmosphere. Prior to film fabrication, the glass substrates were cleaned with 3 cycles of hexane, water and isopropanol each under sonication for 15 minutes per cycle.
## Scanning Electron Microscopy (SEM).
SEM images were taken using a Zeiss Auriga Scanning Electron Microscope with an electron beam energy of 20 kV. The nanocrystal samples were dropcast onto cleaned Si wafers from dispersions in hexane and grounded to instrument-specific aluminum specimen stubs using carbon tape. The diameter of the particles was measured using ImageJ software.
## Transmission Electron Microscopy (TEM)
TEM micrographs and selected area electron diffraction (SAED) patterns were obtained using a FEI Tecnai F20 TEM with a beam energy of 200kV. The nanocrystal samples were drop-casted onto lacey carbon copper grids from hexane dispersions. The diameter of the particles was measured using ImageJ software
Energy Dispersive X-Ray Spectroscopy (EDS).
Energy dispersive Xray spectroscopy elemental maps were obtained using a Zeiss Auriga Scanning Electron Microscope with an EDS analyzer and EDAX Apex software. Measurements were carried out using a 25 kV electron beam.
## X-ray Photoelectron Spectroscopy (XPS).
XPS sample preparation was performed under ambient atmosphere. The nanocrystal powders were dispersed in hexane to obtain a concentrated solution. The solution was drop-casted onto cleaned Si wafers, which were electrically grounded to the sample bar by carbon tape. The XPS measurements were recorded with a Kratos Axis Ultra DLD system equipped with a monochromatic Al Kα (hν=1486.6eV) X -ray source. During the measurements, pressure in the main chamber was kept below 1×10 -7 mbar. Charge compensation was carried out via a neutralizer running at a current of 7 × 10 -6 A, a charge balance of 5 eV, and a filament bias of 1.3 V. The Xray gun was set to 10 mA emission. Binding energies were referenced to the C 1s peak arising from adventitious carbon with binding energy of 284.8 eV. The C 1s, O 1s, Fe 2p and M 2p core levels were recorded with a pass energy of 80 eV. We collected three scans for iron, M, and oxygen, and two scans for carbon. XPS analysis was performed with CasaXPS (Version 2.3.22PR1.0.) The U Touggard function was used for background subtraction and the peaks were fitted with one or more Gaussian components. The XPS signals were fitted with the CasaXPS Component Fitting tool.
## Photoactivity Test of Metal Ferrites:
## Photocatalytic reaction experiment.
The photocatalytic performance of the metal ferrites was evaluated under full-spectrum irradiation, using a 300 W Xenon lamp (Newport Corporation) as the light source. In a typical experiment, 30 mg of metal ferrite was added to 30 mL of deionized water, followed by 30 min of sonication to obtain a well-dispersed mixture. The mixture was then transferred to a homemade photoreactor (Fig. S1). The photoreactor was equipped with a water recirculationattachment to maintain a constant temperature of 23 °C. The mixture was continuously stirred in the dark (200 rpm) whilst ultra-high-purity N2 or Ar (Airgas) was bubbled through the solution at a flow rate of 50 mL/min for 30 min to obtain a saturated aqueous solution. To avoid contamination from the feed gases (N2 and Ar), the gases were pretreated through an alkaline trap (0.1 M KMnO4 in 0.1 M KOH) and a water trap to remove adventitious ammonia and NOx. 2 The photoreactor was then continuously aerated with N2 or Ar at a 50 mL/min flow rate under full-spectrum irradiation with continuous stirring. All the equipment, vial, tube, filter, and caps were cleaned with DI water to suppress ammonia contamination before every experiment (and measurement). The NL-free metal ferrites used for the photocatalytic reaction experiment all undergo a standard washing procedure (labeled as NL-free*). The washing procedure is to mix metal ferrite with deionized water at a ratio of 1 mg to 1 ml, then perform ultrasonic treatment (5 minutes), centrifuge, and repeat this process three times.
## Ammonia quantification.
5 mL of the reaction mixture was collected at the corresponding time and passed through a PTFE syringe filter (Foxx Life Sciences) to obtain a transparent solution for the ammonia measurement. The concentration of ammonia in the solution was determined by Dionex Aquion ion chromatography (Thermofisher) coupled with CS12A cation exchange column, 20 mM methanesulfonic acid (Sigma-Aldrich) was used as the eluent passing through the column with a flow rate of 0.25 mL/min. A calibration curve (Fig S3) was made with ammonia standard solution (Hach Company). A limit of detection of 0.0003 ppm was obtained using this ion chromatography method.
## Computational Methods:
Computational Parameters Calculations were carried out using unrestricted Density Functional Theory within the CRYSTAL17 software suite, 3 which employs Gaussian-type orbitals (GTOs), allowing an efficient implementation of post-HF methods, such as hybrid functionals. The exchange-correlation functional was defined through the hybrid Heyd-Scuseria-Ernzerhof 2006 (HSE06) 4 formulation, which was used for all geometry optimization and single-point energy computations. Long-range interactions were taken into consideration via Grimme's third-order (D3) dispersion corrections. Triple5 zeta with polarization (TZVP) quality basis sets were employed during all calculations. 6
The k-points used to compute the Hamiltonian matrix were sampled using a Pack-Monkhorst grid with a resolution approximately between 1 2𝜋𝜋 𝑏𝑏 𝑖𝑖 40 and 1 2𝜋𝜋 𝑏𝑏 𝑖𝑖 60 , where bi are reciprocal lattice vectors. On the other hand, the density matrix and Fermi energy were computed on a denser Gilat k-point grid, with a resolution between 1 2𝜋𝜋 𝑏𝑏 𝑖𝑖 80 and 1 𝑏𝑏 𝑖𝑖 2𝜋𝜋 120 .
## Bulk Spinel Structural Ground State
Inverted spinels are intrinsically disordered systems; therefore, a combinatorial analysis must be performed to find their ground state. The cell size and number of inverted sites depend on their inversion parameter. To find the most stable structures, bulk spinel ((A1-xFex)[AxFe2-x]O4 general formula, with A = Zn, Co, and Ni, and corresponding inversion parameters of 2/3, 0.75, and 1) calculations were run with different atomic arrangements. The process was carried out as follows. First, the normal spinel structures (x=0) were fully optimized using their primitive unit cell, which has 14 atoms (two tetrahedral sites, four octahedral sites and eight oxygen sites). During this optimization, an initial Néel-type ferrimagnetic order was set, but the unrestricted wave functions were allowed to drift to any magnetic structure that minimized their energy. Next, the inverted structures were built from the optimized normal spinel structures. This was achieved by exchanging A and B sites. Note that for x=0.75 and x=0.67 it was necess ary to build 1 ✕ ✕ 1 2 and 1 ✕ ✕ 1 3 supercells to have an adequate number of A and Fe sites to achieve these inversions. Furthermore, several atomic configurations had to be tested for each inversion to find the exact atomic configuration of the system. In partic ular, for inversions corresponding to x = 0.67, 0.75, and 1, we carried out 54, 38, and 2 calculations, respectively. Therefore, 94 single -point calculations were carried out to determine the most stable atomic configurations. During these calculations, we did not add any restrictions to the spin-polarized solutions. Once the most stable atomic configurations were determined, we ran a final geometry optimization. The final bulk geometries are shown in Figure S13 , and crystallographic data is found at the end of this supplementary document.
## Slab calculations
From Fig. S9 it was determined that ZFO NPs are primarily octahedral in morphology, indicating the predominance of (111) surface planes. On the other hand, CFO and NFO NPs most closely resemble truncated octahedra, which would indicate the presence of dominating (111) and (100) planes. Slabs were built by cutting the previously determined bulk spinels along these crystallographic directions. This was achieved with the keyword SLABCUT within the CRYSTAL su ite. By default, 2D slabs in CRYSTAL17 are built with a distance of 500 Å between periodic images of the structure in the direction perpendicular to the SLABCUT planes. This avoids unwanted interactions between slabs in the z-direction. Compared to the use of plane waves, Gaussian orbitals allow for this large vacuum space since they are localized and do not increase the computational demand upon the addition of vacuum. Finally, hydrogen and oxygen atoms were added to 'cap' both sides of the slabs due to incomplete bonding, exposure of transition metals at the surface, and charge imbalances. The final structures are shown in Fig. 3 of the main manuscript and Fig. S14 of the S.I. Furthermore, crystallographic data is shown at the end of this supplementary document.
Figure S1. Custom-built photoreactor with a temperature control system (water recirculation).

Figure S2. Time course of NH3 evolution for NL Co, Zn, and Ni ferrite under full -spectrum irradiation in N2 environment.
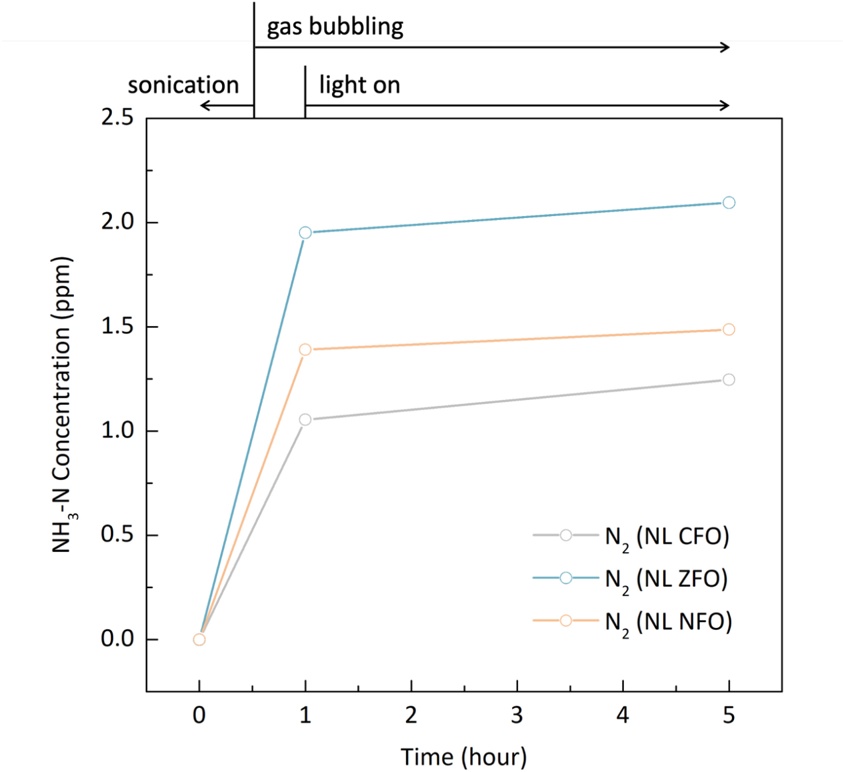
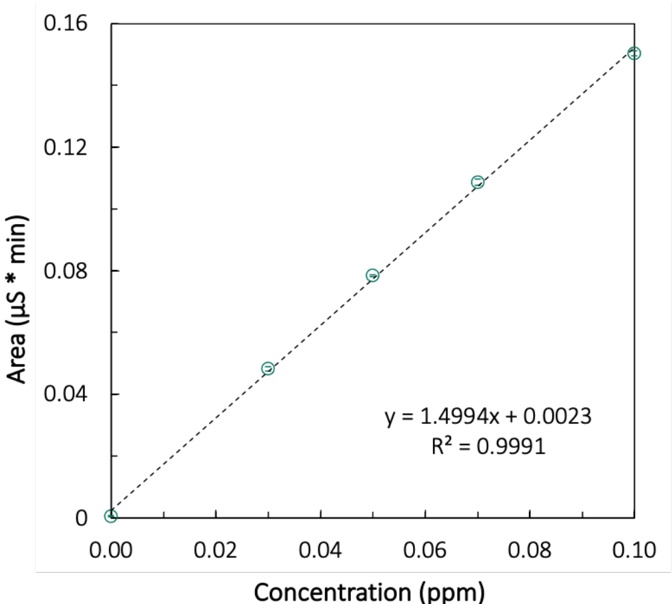
Concentration (ppm)
Figure S3. Calibration curves for ammonia measurement using ion chromatography. The error bars represent the standard deviation from three independent measurements.
Figure S4. A comparison of ammonia in solutions of NL ZnFeO 4 (ZFO) before and after washing. The sample was collected after 30 minutes of sonication (catalyst in DI water) in the absence of illumination. The error bars represent the standard deviation from three independent experiments.

Figure S5. Time course of NH3 evolution for NL-free CoFeO4 (CFO) under full-spectrum irradiation in N2 or Ar environments (raw data of Fig. 2 ). The photocatalytic activity reported in Fig. 2 was obtained by subtracting the first-hour data point from the fifth-hour data point. The error bars represent the standard deviation from two independent experiments.
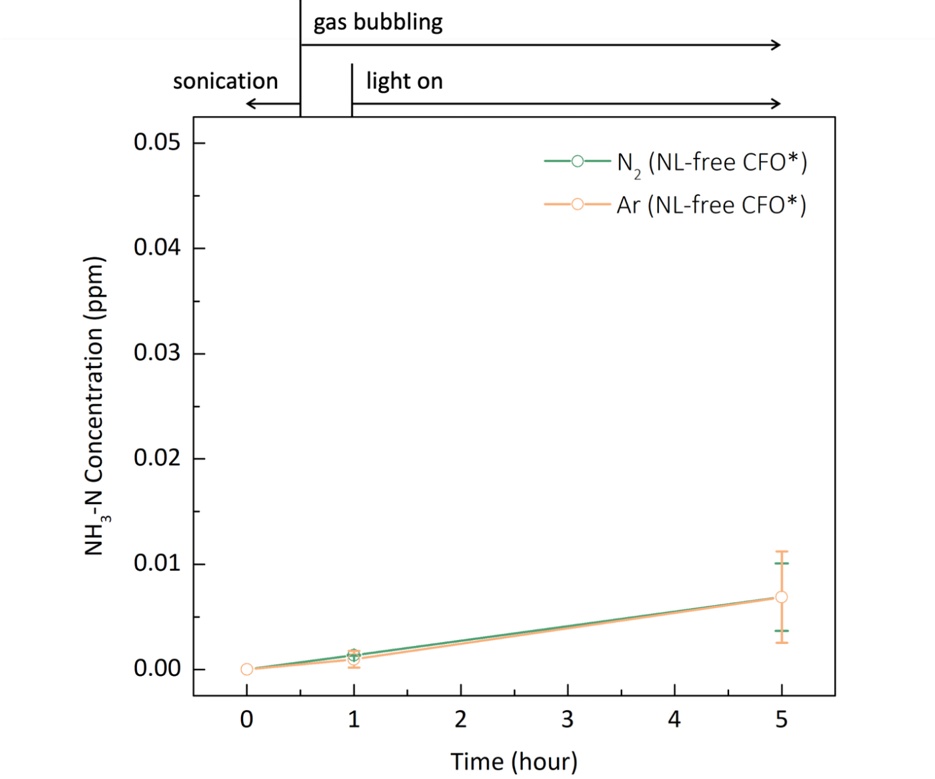
Figure S6. Time course of NH3 evolution for NLfree ZnFeO 4 (ZFO) under full -spectrum irradiation in N2 or Ar environments (raw data of Fig. 2 ). The photocatalytic activity reported in Fig. 2 was obtained by subtracting the first-hour data point from the fifth-hour data point. The error bars represent the standard deviation from two independent experiments.
Figure S7. Time course of NH3 evolution for NL-free NiFeO4 (NFO) under full-spectrum irradiation in N2 or Ar environments (raw data of Fig. 2 ). The photocatalytic activity reported in Fig. 2 was obtained by subtracting the first-hour data point from the fifth-hour data point. The error bars represent the standard deviation from two independent experiments.
NiFez04-OAOAm
ZnFezO4-OAOAm
15.8+2.0 nm

14.9+ 1.5 nm
Figure S8. Representative TEM micrographs of NL Co, Ni and Zn ferrites with OA and OAm as surface ligands.
CoFezO4-OA
NiFezO4-OA
ZnFezO4-OA

330 + 30 nm


100 + 20 nm
Figure S9. Representative SEM micrographs of NLfree Co, Ni and Zn ferrites with OA as surface ligand.
Figure S10. Representative XRD diffractograms of (a, b and c) NL Co, Ni, Zn ferrites with OA/OAm, and (a', b', c') NLfree Co, Ni and Zn ferrites with OA as surface ligands. JCPDS: 03 -0864 (CoFe2 O4 ), 821049 (ZnFe 2 O4 ) and 10-0325 (NiFe O ). 2 4
FeL
Figure S11. Representative EDS spectra from NL and NL-free ferrites showcasing the potential presence of the nitrogen Kalpha signal at 0.39 keV. The position of the N peak (N K-alpha) lies between the C and the O K-alpha. It is very difficult to discern the peak due to limited resolution: The total concentration of N should be much lower than that of C and O and N possesses a low Z number.
Figure S12. A,B) Survey XPS scans of nitrogen ligand-free CFO ( A ) and ZFO ( B ) nanocrystals indicating the presence of C, O, Fe, and Co, or Zn, respectively. C,D) Detail XPS scans of the Fe 2p3/2 peaks for nitrogen ligandfree CFO (C) and ZFO (D) nanocrystals. These peaks each contain two components highlighted in orange: the component with higher binding energy corresponds to Fe 3+ in tetrahedral sites and the component with lower binding energy correspond to Fe 3+ in octahedral sites. The inversion parameters listed in the insets are determined from the areas of these two peaks using the equation x 𝐴𝐴 𝐹𝐹𝐹𝐹 𝑡𝑡𝐹𝐹𝑡𝑡 . 7
= 2 𝐴𝐴 𝐹𝐹𝐹𝐹 𝑡𝑡𝐹𝐹𝑡𝑡 +𝐴𝐴𝐹𝐹𝐹𝐹 𝑜𝑜𝑜𝑜𝑡𝑡
Figure S13. ZFO, NFO, and CFO bulk primitive cells used in this work. Note that the CFO 0.75 inversion required a 1 ✕ ✕ 1 2 supercell and the ZFO 2/3 inversion required a 1 ✕ ✕ 1 3 supercell. The bottom right subfigure shows an example of a normal ZFO spinel crystallographic cell. The (100) and (111) planes are drawn to show the planes normal to the direction in which slabs were cut.

Figure S14. Spinpolarized, atom projected electronic density of states for ZFO, CFO, and NFO (111) slabs without surface hydrogen. These plots are aligned with respect to vacuum, and the NH3/N2 potential is plotted as a green rectangle. It can be observed that the structures have their CBM below the energy range of interest, indicating that ammonia generation is not feasible.

Figure S15 Spin-polarized electronic properties (band structures and density of states) for a) normal ( x= 0) and b) inverted ( x= 2/3) ZFO (111) slabs. The electronic properties are aligned with respect to vacuum, and the NH3/N2 potential is plotted as a green rectangle. It can be observed that neither structure has their CBM above the energy range of interest, indicating that ammonia generation is not feasible.
Figure S16 Spin-polarized, atom projected electronic density of s tates for ZFO, CFO, and NFO bulk structures.
## Crytallographic Structures in CIF format
## ZFO bulk normal spinel
## data\_ZnFe2O4\_bulk\_normal
\_cell\_length\_a 5.929088
\_cell\_length\_b 5.945991
\_cell\_length\_c 5.945486
\_cell\_angle\_alpha 59.817862
\_cell\_angle\_beta 60.098437
\_cell\_angle\_gamma 60.094733
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
Zn001 Zn 0.124972 0.125010 0.125008
Zn002 Zn -0.125006 -0.124973 -0.125009
Fe003 Fe -0.499841 -0.499991 0.499842
Fe004 Fe 0.499950 0.499880 0.000018
Fe005 Fe 0.000100 -0.499972 0.499989
Fe006 Fe 0.499945 -0.000054 -0.499865
O007 O 0.259252 0.261023 0.261064
O008 O 0.261070 0.259343 -0.281352
O009 O -0.281377 0.261001 0.261033
O010 O 0.261015 -0.281281 0.259258
O011 O -0.259329 -0.261083 -0.260918
O012 O -0.261011 -0.259225 0.281353
O013 O -0.261007 0.281360 -0.259354
O014 O 0.281267 -0.261039 -0.261067
## ZFO bulk 2/3 inversion spinel
## data\_ZnFe2O4\_bulk\_inv
\_cell\_length\_a 5.843106
\_cell\_length\_b 5.843106
\_cell\_length\_c 17.529318
\_cell\_angle\_alpha 60.000000
\_cell\_angle\_beta 60.000000
\_cell\_angle\_gamma 60.000000
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O042 O 0.247000 -0.249000 -0.416333
| Zn001 | Zn | 0.125000 | 0.125000 | 0.041667 |
|---------|------|------------|------------|------------|
| Fe002 | Fe | 0.125 | 0.125 | 0.375 |
| Fe003 | Fe | 0.125 | 0.125 | -0.291667 |
| Zn004 | Zn | -0.125 | -0.125 | -0.041667 |
| Fe005 | Fe | -0.125 | -0.125 | 0.291667 |
| Fe006 | Fe | -0.125 | -0.125 | -0.375 |
| Zn007 | Zn | 0.5 | -0.5 | 0.166667 |
| Zn008 | Zn | 0.5 | 0.5 | -0.5 |
| Fe009 | Fe | -0.5 | -0.5 | -0.166667 |
| Fe010 | Fe | -0.5 | -0.5 | 0 |
| Fe011 | Fe | -0.5 | 0.5 | 0.333333 |
| Fe012 | Fe | -0.5 | -0.5 | -0.333333 |
| Fe013 | Fe | -0 | 0.5 | 0.166667 |
| Zn014 | Zn | -0 | -0.5 | -0.5 |
| Zn015 | Zn | -0 | -0.5 | -0.166667 |
| Fe016 | Fe | 0.5 | 0 | 0.166667 |
| Fe017 | Fe | 0.5 | -0 | -0.5 |
| Fe018 | Fe | -0.5 | -0 | -0.166667 |
| O019 | O | 0.249 | 0.249 | 0.083 |
| O020 | O | 0.249 | 0.249 | 0.416333 |
| O021 | O | 0.249 | 0.249 | -0.250333 |
| O022 | O | 0.249 | 0.249 | -0.082333 |
| O023 | O | 0.249 | 0.249 | 0.251 |
| O024 | O | 0.249 | 0.249 | -0.415667 |
| O025 | O | -0.247 | 0.249 | 0.083 |
| O026 | O | -0.247 | 0.249 | 0.416333 |
| O027 | O | -0.247 | 0.249 | -0.250333 |
| O028 | O | 0.249 | -0.247 | 0.083 |
| O029 | O | 0.249 | -0.247 | 0.416333 |
| O030 | O | 0.249 | -0.247 | -0.250333 |
| O031 | O | -0.249 | -0.249 | -0.083 |
| O032 | O | -0.249 | -0.249 | 0.250333 |
| O033 | O | -0.249 | -0.249 | -0.416333 |
| O034 | O | -0.249 | -0.249 | 0.082333 |
| O035 | O | -0.249 | -0.249 | 0.415667 |
| O036 | O | -0.249 | -0.249 | -0.251 |
| O037 | O | -0.249 | 0.247 | -0.083 |
| O038 | O | -0.249 | 0.247 | 0.250333 |
| O039 | O | -0.249 | 0.247 | -0.416333 |
| O040 | O | 0.247 | -0.249 | -0.083 |
| O041 | O | 0.247 | -0.249 | 0.250333 |
## CFO bulk 0.75 inversion spinel
data\_CoFe2O4\_bulk\_inv
\_cell\_length\_a 5.732085
\_cell\_length\_b 5.809447
\_cell\_length\_c 11.550516
\_cell\_angle\_alpha 59.396031
\_cell\_angle\_beta 60.625375
\_cell\_angle\_gamma 60.268693
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
| Fe001 | Fe | 0.125330 | 0.123437 | 0.060785 |
|---------|------|------------|------------|------------|
| Fe002 | Fe | 0.12533 | 0.123437 | -0.439215 |
| Co003 | Co | -0.125354 | -0.123433 | -0.060769 |
| Fe004 | Fe | -0.125354 | -0.123433 | 0.439231 |
| Fe005 | Fe | -0.499972 | 0.499993 | -0.24998 |
| Fe006 | Fe | -0.499972 | 0.499993 | 0.25002 |
| Co007 | Co | 0.499999 | 0.499983 | -1.9e-05 |
| Fe008 | Fe | 0.499999 | 0.499983 | 0.499981 |
| Fe009 | Fe | 1.2e-05 | -0.499928 | 0.249967 |
| Co010 | Co | 1.2e-05 | -0.499928 | -0.250033 |
| Fe011 | Fe | -0.499977 | -0 | 0.249999 |
| Co012 | Co | -0.499977 | -0 | -0.250001 |
| O013 | O | 0.274984 | 0.253941 | 0.125699 |
| O014 | O | 0.274984 | 0.253941 | -0.374301 |
| O015 | O | 0.267167 | 0.261939 | -0.147111 |
| O016 | O | 0.267167 | 0.261939 | 0.352889 |
| O017 | O | -0.289769 | 0.262051 | 0.134544 |
| O018 | O | -0.289769 | 0.262051 | -0.365456 |
| O019 | O | 0.265471 | -0.29118 | 0.129019 |
| O020 | O | 0.265471 | -0.29118 | -0.370981 |
| O021 | O | -0.274925 | -0.253931 | -0.125708 |
| O022 | O | -0.274925 | -0.253931 | 0.374292 |
| O023 | O | -0.267078 | -0.261936 | 0.147077 |
| O024 | O | -0.267078 | -0.261936 | -0.352923 |
| O025 | O | -0.265564 | 0.29106 | -0.128965 |
| O026 | O | -0.265564 | 0.29106 | 0.371035 |
| O027 | O | 0.289675 | -0.261996 | -0.134536 |
| O028 | O | 0.289675 | -0.261996 | 0.365464 |
## NFO bulk 1.0 inversion spinel
## data\_NiFe2O4\_bulk\_inv
\_cell\_length\_a 5.84081513 \_cell\_length\_b 5.82785058 \_cell\_length\_c 5.68620063 \_cell\_angle\_alpha 60.459571 \_cell\_angle\_beta 60.249354 \_cell\_angle\_gamma 57.520708
```
_symmetry_space_group_name_H-M 'P 1'
_symmetry_Int_Tables_number 1
loop_
_symmetry_equiv_pos_as_xyz
'x, y, z'
loop_
_atom_site_label
_atom_site_type_symbol
_atom_site_fract_x
_atom_site_fract_y
_atom_site_fract_z
Fe001 Fe 1.191755771790E-01 1.189306951760E-01 1.259628145440E-01
Fe002 Fe -1.176447274740E-01 -1.183967929360E-01 -1.270155504000E-01
Ni003 Ni 4.997847882590E-01 4.998000348240E-01 4.995354131640E-01
Ni004 Ni 4.983670684070E-01 4.983110732740E-01 4.364895859000E-03
Fe005 Fe 3.377899611000E-03 4.986900031680E-01 4.984765806570E-01
Fe006 Fe 4.987951837740E-01 3.615800683000E-03 4.983242028230E-01
0007 0 2.583015731800E-01 2.563242431490E-01 2.626084172350E-01
0008 0 2.598308720040E-01 2.624786511890E-01 -2.867646270770E-01
0009 -2.906079079160E-01 2.413823227950E-01 2.584409392350E-01
0010 0 2.414635550840E-01 -2.909860474440E-01 2.602171183220E-01
0011 -2.546418666490E-01 -2.522388735890E-01 -2.5979462111610E-01
0012 0 -2.540071179450E-01 -2.558903050460E-01 2.705742876240E-01
0013 0 -2.410195050620E-01 2.786296172560E-01 -2.531625492840E-01
0014 0 2.788246075470E-01 -2.406504224980E-01 -2.517671395400E-01
```
Note that slab CIF files have a c lattice parameter of 40 or 60 Å for better visualization in the VESTA software. However, calculations were carried out with a cell length of 500 Å in the cdirection to avoid interactions between periodic images of the slab. This spacing is automatically assigned by the CRYSTAL17 software when setting up slab calculations.
## (111) ZFO slab 2/3 inversion spinel (without H)
## data\_ZnFe2O4\_111\_slab\_inv\_noH
\_cell\_length\_a 5.956608
\_cell\_length\_b 15.534336
\_cell\_length\_c 40.000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 101.471900
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
| loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z |
|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|
| O001 | O | 0.177282 | 0.129196 | 0.049827 |
| O002 | O | -0.446709 | -0.19013 | 0.057455 |
| O003 | O | -0.130593 | 0.462848 | 0.054898 |
| O004 | O | -0.148453 | -0.044073 | 0.057076 |
| O005 | O | 0.226608 | -0.382208 | 0.055604 |
| O006 | O | -0.465017 | 0.288861 | 0.055206 |
| O007 | O | -0.310995 | 0.13136 | 0.048598 |
| O008 | O | -0.002577 | -0.19264 | 0.057457 |
| O009 | O | 0.34532 | 0.469951 | 0.054072 |
| O010 | O | 0.303501 | -0.0187 | 0.058002 |
| O011 | O | -0.32569 | -0.364874 | 0.06125 |
| O012 | O | -0.023222 | 0.27772 | 0.051693 |
| Zn013 | Zn | 0.30893 | -0.135239 | 0.035522 |
| Zn014 | Zn | -0.345678 | -0.472524 | 0.034163 |
| Fe015 | Fe | -0.042384 | 0.189717 | 0.025956 |
| Fe016 | Fe | 0.119583 | 0.027366 | 0.0271 |
| Fe017 | Fe | 0.474426 | -0.304221 | 0.035556 |
| Fe018 | Fe | -0.198371 | 0.357411 | 0.03124 |
| Fe019 | Fe | -0.202384 | -0.136303 | 0.03463 |
| Fe020 | Fe | 0.134186 | -0.47721 | 0.032029 |
| Fe021 | Fe | 0.453747 | 0.186763 | 0.025077 |
| O022 | O | 0.381353 | 0.07922 | -0.003656 |
| O023 | O | -0.254252 | -0.245852 | 0.005764 |
| O024 | O | 0.088342 | 0.418164 | 0.002441 |
|--------|-----|------------|------------|------------|
| O025 | O | -0.405882 | -0.097231 | 0.004331 |
| O026 | O | -0.054405 | -0.421341 | 0.00236 |
| O027 | O | 0.217822 | 0.240566 | -0.002117 |
| O028 | O | -0.077146 | 0.08088 | 0.000206 |
| O029 | O | 0.274955 | -0.246537 | 0.004088 |
| O030 | O | -0.401384 | 0.417545 | 0.001076 |
| O031 | O | 0.055008 | -0.084097 | 0.006016 |
| O032 | O | 0.438759 | -0.413067 | -0.00064 |
| O033 | O | -0.278111 | 0.247715 | -0.003583 |
| Zn034 | Zn | -0.38046 | 0.01712 | -0.018173 |
| Fe035 | Fe | -0.01297 | -0.301932 | -0.009365 |
| Fe036 | Fe | 0.318658 | 0.361849 | -0.013057 |
| Fe037 | Fe | -0.461584 | -0.196708 | -0.029323 |
| Zn038 | Zn | -0.128421 | 0.479727 | -0.033055 |
| Zn039 | Zn | 0.169138 | 0.128836 | -0.039346 |
| Zn040 | Zn | 0.081715 | -0.0939 | -0.044334 |
| Fe041 | Fe | 0.436092 | -0.412156 | -0.043491 |
| Fe042 | Fe | -0.326053 | 0.265582 | -0.049162 |
| O043 | O | -0.301442 | 0.093829 | -0.062041 |
| O044 | O | 0.002213 | -0.250979 | -0.048546 |
| O045 | O | 0.419582 | 0.341384 | -0.051947 |
| O046 | O | 0.418655 | -0.094275 | -0.046909 |
| O047 | O | -0.340757 | -0.448542 | -0.055506 |
| O048 | O | -0.136997 | 0.168301 | -0.059214 |
| O049 | O | 0.104965 | 0.019763 | -0.065804 |
| O050 | O | 0.45165 | -0.309119 | -0.053548 |
| O051 | O | -0.159234 | 0.37524 | -0.063259 |
| O052 | O | -0.211186 | -0.157605 | -0.060066 |
| O053 | O | 0.196137 | -0.473034 | -0.054889 |
| O054 | O | 0.413728 | 0.195582 | -0.068395 |
## (111) ZFO slab normal spinel (without H)
data\_ZnFe2O4\_111\_slab\_normal\_noH
```
data_ZnFe204_111_slab_normal_noH
_cell_length_a 5.67104688
_cell_length_b 5.70012773
_cell_length_c 40
_cell_angle_alpha 90.000000
_cell_angle_beta 90.000000
_cell_angle_gamma 119.904400
_symmetry_space_group_name_H-M 'P 1'
_symmetry_Int_Tables_number 1
loop_
_symmetry_equiv_pos_as_xyz
'x, y, z'
loop_
```
```
loop_
_atom_site_label
_atom_site_type_symbol
_atom_site_fract_x
_atom_site_fract_y
_atom_site_fract_z
o0001 0 4.119276665586E-01 3.294715990367E-01 0.053494415944375
```
O002 O -1.014368909290E-01 -1.677690069143E-01 0.051942704758475
O003 O 4.295856194160E-01 -1.559144978354E-01 0.052419416458325
O004 O -9.529368609301E-02 3.042906342187E-01 0.052705572849500004
Fe005 Fe -4.258815720366E-01 1.510384777069E-01 0.03153296195815
Fe006 Fe 7.369255655706E-02 1.679263048898E-01 0.0312438590094
Fe007 Fe -4.098958037754E-01 -3.277146779273E-01 0.03181061822185
O008 O 2.676389401613E-01 4.723014238107E-01 0.0015492454626895
O009 O -2.938597484588E-01 4.827637909968E-01 0.00082581113721025
O010 O 2.648623006905E-01 4.155941077182E-02 6.994066739035e-05
O011 O -2.558490805426E-01 -3.989694868562E-03 0.0048543842903449996
Zn012 Zn 8.442207467449E-02 -3.372478977164E-01 -0.0106560955060875
Fe013 Fe 4.266245006948E-01 3.387933098556E-01 -0.031351390927174996
Zn014 Zn -2.690651078714E-01 -1.009109103158E-02 -0.044038239292325
O015 O 1.638721099410E-01 -3.047993677177E-01 -0.06099215049534999
O016 O -3.914793777127E-01 2.382002996182E-01 -0.05465052409397499
O017 O 1.100757534867E-01 1.360025652211E-01 -0.0575798955803
O018 O 4.980597452389E-01 -3.788215821152E-01 -0.056758791915775
## (111) ZFO slab normal spinel with H on top [octahedral] layer
## data\_ZnFe2O4\_111\_slab\_normal\_Htop
\_cell\_length\_a 5.91426397
\_cell\_length\_b 5.99201685
\_cell\_length\_c 60.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 119.497300
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O001 O 0.4100292465 0.3359475486 0.0392948707
O002 O -0.1021225316 -0.1509034140 0.0398260076
O003 O 0.4171738958 -0.1562590583 0.0396294731
O004 O -0.1026626871 0.3212555402 0.0396064184
Fe005 Fe -0.4247684671 0.1619918301 0.0199701331
Fe006 Fe 0.0697655221 0.1694723552 0.0199502029
Fe007 Fe -0.4246070498 -0.3268310262 0.0203910740
O008 O 0.2540967609 0.4943234905 0.0033815457
O009 O -0.2993688087 0.4758904351 0.0017189595
O010 O 0.2601013099 0.0386965403 0.0019733908
O011 O -0.2562264182 -0.0014672214 0.0034971651
Zn012 Zn 0.0752270919 -0.3304574290 -0.0084180055
Fe013 Fe 0.4179017703 0.3354971901 -0.0214207227
Zn014 Zn -0.2272869819 -0.0145007477 -0.0310820484
O015 O -0.0108918679 -0.2725939000 -0.0385717643
| O016 | O | -0.4108847174 0.1699742773 -0.0374448490 |
|--------|-----|--------------------------------------------|
| O017 | O | 0.1405571769 0.2186439016 -0.0357598464 |
| O018 | O | -0.4227739108 -0.3710384115 -0.0375731719 |
| H019 | H | 0.4137114761 0.3340997046 0.0553528410 |
| H020 | H | -0.0017816915 -0.2403215580 0.0409708569 |
| H021 | H | -0.4965976921 -0.1265185382 0.0539046771 |
| H022 | H | -0.1265914264 0.2390984906 0.0539541940 |
H022 H -0.1265914264 0.2390984906 0.0539541940
## (111) ZFO slab normal spinel with H on bottom [octahedral+tetrahedral] layer
## data\_ZnFe2O4\_111\_slab\_normal\_Hbot
\_cell\_length\_a 5.97540120
\_cell\_length\_b 5.84634139
\_cell\_length\_c 60.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 121.012500
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O001 O 0.4100236134 0.3452518672 0.0347185659
O002 O -0.0696515041 -0.1165827469 0.0360755358
O003 O 0.4367448626 -0.1741595865 0.0326290318
O004 O -0.1294303541 0.2865805069 0.0349697573
Fe005 Fe -0.4391883157 0.1350382864 0.0193016050
Fe006 Fe 0.0808411994 0.1522609384 0.0192029286
Fe007 Fe -0.4109045382 -0.3445186244 0.0193221776
O008 O 0.2459790704 0.4368939077 -0.0011110948
O009 O -0.2846942720 0.4692468945 0.0018927762
O010 O 0.2844706351 0.0126069311 -0.0003825912
O011 O -0.2385256330 -0.0390159540 0.0007602974
Zn012 Zn 0.0796923216 -0.3635834241 -0.0092700754
Fe013 Fe 0.4155371649 0.3082538323 -0.0246822514
Zn014 Zn -0.2544223878 -0.0289013834 -0.0324396870
O015 O 0.0826527746 -0.3717887577 -0.0415628519
O016 O -0.3636378120 0.2164659394 -0.0402993827
O017 O 0.0972533768 0.0945917565 -0.0432579929
O018 O -0.4985548724 -0.3832430659 -0.0421757465
H019 H 0.0989185132 -0.2056325558 -0.0470048129
H020 H -0.1925826519 0.3898379937 -0.0438964082
H021 H 0.1345504771 0.1949895672 -0.0570159030
H022 H 0.3335949987 -0.3772589892 -0.0440142140
## (111) CFO slab 0.75 inversion spinel (without H)
## data\_CoFe2O4\_111\_slab\_inv\_noH
\_cell\_length\_a 5.83022889
\_cell\_length\_b 9.94655311
\_cell\_length\_c 40
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 92.101100
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O001 O -3.948743380628E-01 -5.495152588429E-02 0.057947436237425
O002 O 1.009931816969E-01 4.354358061833E-01 0.056896021978425006
O003 O -1.627534269860E-01 2.136789405442E-01 0.054297918384875
O004 O 3.510920646616E-01 -2.598116874907E-01 0.058013269597275
O005 O 1.333627974677E-01 -4.496032196362E-02 0.056516663773625
O006 O -3.490906343680E-01 4.509506557444E-01 0.05610817853365
O007 O 3.710164316775E-01 2.092912654339E-01 0.054461228483875
O008 O -1.033338929791E-01 -2.801172945248E-01 0.058895670993575
Fe009 Fe 1.155166502800E-01 2.922228960484E-01 0.0332568750888
Fe010 Fe -3.782192237566E-01 -2.025359721149E-01 0.036837831104025
Co011 Co 3.636865101146E-01 4.677845157493E-02 0.032490255589075
Fe012 Fe -1.320606575756E-01 -4.622067148105E-01 0.03585478199955
Fe013 Fe 1.145816191190E-01 -1.987963361893E-01 0.0339202734593
Co014 Co -3.821102306562E-01 2.937279927937E-01 0.030722195469175
O015 O 3.434999982295E-01 -1.153006858018E-01 0.0058013405683675
O016 O -1.330085758288E-01 3.723636628473E-01 0.0046659273626375
O017 O -4.262025187941E-01 1.373389221991E-01 0.0033520741208349996
O018 O 9.795388636873E-02 -3.632864614066E-01 0.0066787908856225
O019 O -1.339581591454E-01 -1.364614122614E-01 0.006362322062420001
O020 O 3.810947159407E-01 3.690136345124E-01 0.0032317547561624997
O021 O 1.214105055942E-01 1.441056974284E-01 0.002628533719555
O022 O -3.646707017031E-01 -3.610964450524E-01 0.009655877033735
Co023 Co -1.505173872577E-01 4.949566595337E-02 -0.00688250908179
Fe024 Fe 3.701250937907E-01 -4.487222324289E-01 -0.0086331828551775
Fe025 Fe -1.596415066591E-01 -2.870061923852E-01 -0.033311477528974995
Co026 Co 3.473329440553E-01 2.249926667129E-01 -0.034782003195775
Fe027 Fe 3.341270968049E-01 -1.142694440060E-01 -0.0450403556154
Fe028 Fe -1.330209081334E-01 3.724168580030E-01 -0.044568203989
O029 O 7.646133929833E-02 -2.004898554591E-01 -0.054319015294175
O030 O -3.811824736897E-01 2.731274091874E-01 -0.056315718777674995
O031 O 3.341913601337E-01 6.159608059546E-02 -0.0572373645131
O032 O -1.916499123626E-01 -4.590059603193E-01 -0.052288494964599995
O033 O -4.274989948242E-01 -2.172806361210E-01 -0.052115058289475005
O034 O 1.479730603197E-01 3.231956072669E-01 -0.0550302307645
O035 O -1.664277973347E-01 3.538640239326E-02 -0.050548631120550004
O036 O 4.484043253985E-01 -4.177072692750E-01 -0.053388162630875
## (111) CFO slab 0.75 inversion spinel with H on top [octahedral] layer
## data\_CoFe2O4\_111\_slab\_inv\_Htop
\_cell\_length\_a 5.97660113
\_cell\_length\_b 10.18575093
\_cell\_length\_c 40.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 90.338100
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
| loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z |
|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|
| O001 | O | -0.374999 | -0.0451069 | 0.0612435 |
| O002 | O | 0.114961 | 0.452223 | 0.0628013 |
| O003 | O | -0.108935 | 0.206478 | 0.0586917 |
| O004 | O | 0.36843 | -0.279212 | 0.0626364 |
| O005 | O | 0.131922 | -0.0447452 | 0.0619355 |
| O006 | O | -0.349817 | 0.454187 | 0.0639956 |
| O007 | O | 0.371347 | 0.213676 | 0.0596931 |
| O008 | O | -0.133028 | -0.288038 | 0.0610883 |
| Fe009 | Fe | 0.131987 | 0.291551 | 0.0308146 |
| Fe010 | Fe | -0.390469 | -0.201498 | 0.0334068 |
| Co011 | Co | 0.374187 | 0.042379 | 0.0330088 |
| Fe012 | Fe | -0.122674 | -0.464257 | 0.0353763 |
| Fe013 | Fe | 0.119886 | -0.200818 | 0.0339892 |
| Co014 | Co | -0.370406 | 0.293003 | 0.0328085 |
| O015 | O | 0.363431 | -0.13477 | 0.00488602 |
| O016 | O | -0.114612 | 0.381591 | 0.00513093 |
| O017 | O | -0.398237 | 0.132246 | 0.001951 |
| O018 | O | 0.111518 | -0.367625 | 0.00848911 |
| O019 | O | -0.14027 | -0.140337 | 0.00354477 |
| O020 | O | 0.367329 | 0.373946 | 0.00365334 |
| O021 | O | 0.134298 | 0.134674 | 0.00212069 |
| O022 | O | -0.348785 | -0.368903 | 0.00672843 |
| Co023 | Co | -0.134775 | 0.0473996 | -0.00907666 |
| Fe024 | Fe | 0.374789 | -0.449604 | -0.00843942 |
| Fe025 | Fe | -0.13919 | -0.293096 | -0.0305627 |
| Co026 | Co | 0.373836 | 0.190551 | -0.0343228 |
| Fe027 | Fe | 0.325327 | -0.1318 | -0.0430812 |
| Fe028 | Fe | -0.121933 | 0.384552 | -0.0417671 |
| O029 | O | 0.0405935 | -0.198401 | -0.0534894 |
| O030 | O | -0.379358 | 0.287374 | -0.0526685 |
| O031 | O | 0.369107 | 0.0382119 | -0.0542357 |
| O032 | O | -0.104003 | -0.44407 | -0.0510133 |
O033 O -0.4487967769 -0.2602988204 -0.0530483783
O034 O 0.1312418926 0.2865831378 -0.0536922010
O035 O -0.1302193047 0.0351063804 -0.0524745385
O036 O 0.4172844093 -0.3827894175 -0.0521665845
H037 H -0.4326724401 -0.0476754951 0.0839896879
H038 H 0.0398551362 0.4262088379 0.0834699831
H039 H -0.1277206281 0.2336439789 0.0818525164
H040 H 0.3604038303 -0.2331877581 0.0840030666
H041 H 0.0008987821 0.0139793286 0.0627705139
H042 H -0.4957078138 0.4976169776 0.0658331693
H043 H 0.3665764451 0.2178092185 0.0838686239
H044 H -0.1306417714 -0.2818110050 0.0852901302
## (111) CFO slab 0.75 inversion spinel with H on bottom [octahedral+tetrahedral] layer data\_CpFe2O4\_111\_slab\_inv\_Hbot
\_cell\_length\_a 5.87505140
\_cell\_length\_b 10.34300155
\_cell\_length\_c 40.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 90.468400
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz 'x, y, z'
| loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z | loop_ _atom_site_label _atom_site_type_symbol _atom_site_fract_x _atom_site_fract_y _atom_site_fract_z |
|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------|
| O001 | O | -0.420335 | -0.0384797 | 0.0545198 |
| O002 | O | 0.0821854 | 0.439088 | 0.0539214 |
| O003 | O | -0.121994 | 0.233961 | 0.0561118 |
| O004 | O | 0.385975 | -0.269336 | 0.0553561 |
| O005 | O | 0.152208 | -0.0340321 | 0.0550557 |
| O006 | O | -0.362924 | 0.46909 | 0.0531546 |
| O007 | O | 0.373702 | 0.219273 | 0.0572536 |
| O008 | O | -0.154804 | -0.295104 | 0.0538382 |
| Fe009 | Fe | 0.115439 | 0.29562 | 0.0320858 |
| Fe010 | Fe | -0.394972 | -0.208731 | 0.0316999 |
| Co011 | Co | 0.355803 | 0.0493677 | 0.0320501 |
| Fe012 | Fe | -0.153625 | -0.460951 | 0.0311507 |
| Fe013 | Fe | 0.107739 | -0.212056 | 0.0330766 |
| Co014 | Co | -0.395899 | 0.291664 | 0.0339537 |
| O015 | O | 0.358294 | -0.134615 | 0.00132441 |
| O016 | O | -0.158812 | 0.377408 | 0.000540868 |
| O017 | O | -0.425455 | 0.127517 | 0.003807 |
| O018 | O | 0.0825997 | -0.372467 | 0.0022487 |
| O019 | O | -0.154164 | -0.142201 | 0.00349693 |
| O020 | O | 0.348675 | 0.364353 | 0.00212126 |
| O021 | O | 0.1315158239 | 0.1399992962 0.0050755905 |
|--------|-----|----------------|-----------------------------|
| O022 | O | -0.37606 | -0.3694776725 -0.0018589372 |
| Co023 | Co | -0.142889 | 0.0435872427 -0.0065257286 |
| Fe024 | Fe | 0.354172 | -0.4617552099 -0.0096501615 |
| Fe025 | Fe | -0.140224 | -0.2910411582 -0.0325123147 |
| Co026 | Co | 0.360797 | 0.2082776595 -0.0313770952 |
| Fe027 | Fe | 0.334852 | -0.1328859798 -0.0445828446 |
| Fe028 | Fe | -0.138541 | 0.3777949554 -0.0455695076 |
| O029 | O | 0.0572507 | -0.1863059468 -0.0586119550 |
| O030 | O | -0.389234 | 0.2840099467 -0.0629198053 |
| O031 | O | 0.38199 | 0.0393321065 -0.0621420660 |
| O032 | O | -0.100347 | -0.4481014149 -0.0608214512 |
| O033 | O | -0.409302 | -0.2299274919 -0.0619292171 |
| O034 | O | 0.127674 | 0.2982973306 -0.0624065647 |
| O035 | O | -0.154636 | 0.0316420968 -0.0578642380 |
| O036 | O | 0.337889 | -0.4636125702 -0.0572076621 |
| H037 | H | -0.0829311 | -0.0571747368 -0.0615353316 |
| H038 | H | -0.335986 | 0.2170409692 -0.0781437207 |
| H039 | H | 0.279608 | 0.0625651835 -0.0804408310 |
| H040 | H | 0.0710606 | -0.4420141920 -0.0650083275 |
| H041 | H | -0.349791 | -0.2124558480 -0.0842524409 |
| H042 | H | 0.233816 | 0.3662584810 -0.0705722969 |
| H043 | H | -0.319705 | 0.0265727650 -0.0633780896 |
| H044 | H | 0.440401 | -0.3987120073 -0.0671641639 |
## (100) CFO slab 0.75 inversion spinel without H
## data\_CoFe2O4\_100\_slab\_inv\_noH
\_cell\_length\_a 5.93156736
\_cell\_length\_b 11.47283384
\_cell\_length\_c 40.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 91.073042
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O001 O -0.4673132545 0.0136773403 0.0549442698
O002 O -0.4730561619 0.4977567478 0.0548952530
O003 O -0.0431704077 0.0041918670 0.0562995351
O004 O -0.0218526277 0.4962747851 0.0550822466
Co005 Co -0.2607895723 0.1231670332 0.0500330276
Fe006 Fe -0.2408533121 -0.3769720801 0.0489032443
Fe007 Fe -0.2535459228 0.3768985466 0.0487782738
Co008 Co -0.2356497368 -0.1218829487 0.0498141421
| O009 | O | -0.4668033039 | 0.2440541955 | 0.0485052257 |
|--------|-----|-----------------|----------------|----------------|
| O010 | O | -0.44967 | -0.245499 | 0.051049 |
| O011 | O | -0.0495052 | 0.239174 | 0.0494303 |
| O012 | O | -0.0158777 | -0.250854 | 0.0476743 |
| Co013 | Co | 0.242085 | 0.00403274 | 0.0322519 |
| Fe014 | Fe | 0.252349 | 0.499366 | 0.0318932 |
| O015 | O | -0.246521 | -0.12747 | -0.000786246 |
| O016 | O | -0.247693 | 0.371958 | -0.000723912 |
| O017 | O | -0.258248 | 0.12601 | -0.00168339 |
| O018 | O | -0.251611 | -0.372935 | -0.000219214 |
| Fe019 | Fe | 0.499564 | -0.24658 | 0.000985667 |
| Fe020 | Fe | 0.497443 | 0.246015 | -0.00160338 |
| Fe021 | Fe | -0.00524569 | 0.245792 | -0.0016003 |
| Co022 | Co | 0.0061004 | -0.248518 | 0.000198203 |
| O023 | O | 0.260104 | -0.128679 | 0.00103499 |
| O024 | O | 0.249675 | 0.370689 | 0.00111268 |
| O025 | O | 0.241373 | 0.130155 | -0.00102111 |
| O026 | O | 0.255142 | -0.372451 | 0.00184177 |
| Fe027 | Fe | -0.257038 | -0.00318593 | -0.0324156 |
| Fe028 | Fe | -0.244024 | -0.498085 | -0.0319149 |
| O029 | O | 0.0316102 | -0.246855 | -0.047409 |
| O030 | O | 0.0276092 | 0.2525 | -0.0500522 |
| O031 | O | 0.46572 | -0.253791 | -0.0488784 |
| O032 | O | 0.464897 | 0.249868 | -0.0502211 |
| Co033 | Co | 0.243929 | -0.122784 | -0.0484758 |
| Fe034 | Fe | 0.254117 | 0.378804 | -0.0493745 |
| Fe035 | Fe | 0.240019 | 0.122018 | -0.0506463 |
| Co036 | Co | 0.259945 | -0.375727 | -0.0483036 |
| O037 | O | 0.0133992 | 0.000241312 | -0.055373 |
| O038 | O | 0.0341525 | -0.494186 | -0.0542616 |
| O039 | O | 0.465209 | -0.00438089 | -0.0553318 |
| O040 | O | 0.484581 | 0.498404 | -0.054342 |
## (100) CFO slab 0.75 inversion spinel with H
## data\_CoFe2O4\_100\_slab\_inv\_H
\_cell\_length\_a 5.91035621
\_cell\_length\_b 11.44890558
\_cell\_length\_c 40
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 91.615476
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
loop\_ \_symmetry\_equiv\_pos\_as\_xyz 'x, y, z'
loop\_ \_atom\_site\_label \_atom\_site\_type\_symbol \_atom\_site\_fract\_x \_atom\_site\_fract\_y \_atom\_site\_fract\_z
| O001 | O | -4.742149551914E-01 | 1.132012080883E-02 | 0.053501210578799994 |
|------------|------|-----------------------------------------|-----------------------------------------|-----------------------------------------------|
| O002 | O | -4.680753152845E-01 | 4.980632339307E-01 | 0.054310376787750005 |
| O003 | O | -4.977973871053E-02 | 4.300382932541E-03 | 0.05515424603932499 |
| O004 | O | -1.942353184620E-02 | 4.965888296374E-01 | 0.054003019866699996 |
| Co005 | Co | -2.651434176083E-01 | 1.234666027597E-01 | 0.051272942396525 |
| Fe006 | Fe | -2.359004271697E-01 | -3.760831257782E-01 | 0.050742106008675 |
| Fe007 | Fe | -2.512356969210E-01 | 3.756478491004E-01 | 0.050767790801325 |
| Co008 | Co | -2.357335252080E-01 | -1.232794763075E-01 | 0.051313013040474996 |
| O009 | O | -4.687971924850E-01 | 2.416115381706E-01 | 0.0486939132909 |
| O010 | O | -4.514389720718E-01 | -2.448512808551E-01 | 0.051141738552425 |
| O011 | O | -4.785103660278E-02 | 2.400704839089E-01 | 0.0492473766756 |
| O012 | O | -1.317313746839E-02 | -2.499509710185E-01 | 0.048110142162175004 |
| Co013 | Co | 2.353990693043E-01 | 3.826769599312E-03 | 0.030453087531475 |
| Fe014 | Fe | 2.563767737395E-01 | 4.996300984375E-01 | 0.030797169955975 |
| O015 | O | -2.449378485156E-01 | -1.277793874222E-01 | -0.000172266437497025 |
| O016 | O | -2.463949445761E-01 | 3.710273299173E-01 | 7.5760374435525e-05 |
| O017 | O | -2.579475573439E-01 | 1.273866372159E-01 | -0.0018472447869225 |
| O018 | O | -2.514406701576E-01 | -3.707516576143E-01 | 0.0006642967239095 |
| Fe019 | Fe | -4.993863627174E-01 | -2.467543041865E-01 | 0.00118703711723 |
| Fe020 | Fe | 4.990818221322E-01 | 2.460015852627E-01 | -0.0017012842953329998 |
| Fe021 | Fe | -3.640707661210E-03 | 2.472719283805E-01 | -0.0009998508980374999 0.00026312669883149997 |
| Co022 O023 | Co O | 7.347670371634E-03 2.621342646947E-01 | -2.473515886670E-01 -1.290747703335E-01 | 0.00061932479148225 |
| O024 | O | 2.543001106787E-01 | 3.698194694067E-01 | 0.0007928393746595 |
| O025 | O | 2.404030541556E-01 | 1.310344373676E-01 | -0.0017286113989642498 |
| O026 | O | 2.543818863922E-01 | -3.706072194091E-01 | 0.0017972487558975 |
| Fe027 | Fe | -2.561947030770E-01 | -2.794744225178E-03 | -0.03132267677375 |
| Fe028 | Fe | -2.428773187746E-01 | -4.976793353637E-01 | -0.030150071133724997 |
| O029 | O | 2.988143515236E-02 | -2.447231270921E-01 | -0.047507432703375 |
| O030 | O | 2.641633914260E-02 | 2.563000024299E-01 | -0.049983319532675 |
| O031 | O | 4.697732820099E-01 | -2.554046782295E-01 | -0.04896054506975 |
| O032 | O | 4.665243134517E-01 | 2.472694253083E-01 | -0.050531292184700004 |
| Co033 | Co | 2.483397725247E-01 | -1.231357603197E-01 | -0.050290251846925 |
| Fe034 | Fe | 2.570883941888E-01 | 3.784253416562E-01 | -0.051096340021575 |
| Fe035 | Fe | 2.365935333678E-01 | 1.239909671716E-01 | -0.052315840403650005 |
| Co036 | Co | 2.587170293207E-01 | -3.742293095763E-01 | -0.050007564345175004 |
| O037 | O | 1.561248470401E-02 | 3.006759138515E-03 | -0.054402465299424996 |
| O038 | O | 3.620494243651E-02 | -4.917666634845E-01 | -0.052846409155925 |
| O039 | O | 4.656026206490E-01 | -6.263787827588E-03 | -0.0546695785001 |
| O040 | O | 4.858346460725E-01 | 4.967835265853E-01 | -0.052950504634350005 |
| H041 | H | | 1.360931269825E-01 | |
| H042 | H | -2.700428793881E-01 -2.292079805065E-01 | -3.551791321684E-01 | 0.08701727728325001 0.0895294961979 |
| H043 | H | -2.476801177650E-01 | 3.530112205665E-01 | 0.089403273132275 |
| H044 | H | | | 0.088080296117425 |
| H045 | H | -2.502783617492E-01 | -1.417584598446E-01 | -0.086917885363125 |
| H046 | H | 2.151137316257E-01 2.432363187437E-01 | -1.439960597455E-01 3.610789366792E-01 | -0.08975087829155 |
| H047 | H | 2.472232204528E-01 | 1.427172992649E-01 | -0.0909604290744 |
| H048 | H | 2.769349448890E-01 | -3.585995893866E-01 | -0.0870068254091 |
## (111) NFO slab 1.0 inversion spinel (without H)
## data\_NiFe2O4\_111\_slab\_inv\_noH
\_cell\_length\_a 5.81681872
\_cell\_length\_b 5.76025247
\_cell\_length\_c 40.00000000
\_cell\_angle\_alpha 90.000000 \_cell\_angle\_beta 90.000000 \_cell\_angle\_gamma 119.540191 \_symmetry\_space\_group\_name\_H-M 'P 1' \_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O001 O -0.3915847788 -0.3209328539 0.0556394240
O002 O 0.0469960339 0.1817210598 0.0571396376
O003 O -0.3736391463 0.1711502037 0.0564238540
O004 O 0.0514215740 -0.3589235264 0.0540748179
Ni005 Ni -0.0923408998 -0.1747978444 0.0309458644
Fe006 Fe -0.0846257901 0.3337650582 0.0322936121
Ni007 Ni 0.4199680082 -0.1735449176 0.0327080213
O008 O -0.2307536451 0.0113073549 0.0045081325
O009 O -0.2382259805 0.4815840269 0.0008160062
O010 O 0.2321519297 -0.4990138688 0.0020770022
O011 O 0.2117979236 -0.0428635230 0.0049902644
Fe012 Fe 0.3968759573 0.3042861143 -0.0115618394
Fe013 Fe 0.0792582753 -0.3416110126 -0.0326900283
Fe014 Fe -0.2270651597 0.0359282645 -0.0448032119
O015 O -0.0125242047 0.3626895142 -0.0577366399
O016 O 0.4153266256 -0.0564404499 -0.0535244402
O017 O -0.1232289887 -0.2004732301 -0.0581393240
O018 O 0.3672326900 0.1722162891 -0.0563081962
## (111) NFO slab 1.0 inversion spinel with H on top [octahedral] layer
## data\_NiFe2O4\_111\_slab\_inv\_Htop
\_cell\_length\_a 5.71430895
\_cell\_length\_b 5.91779889
\_cell\_length\_c 60.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 118.903400
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
loop\_ \_symmetry\_equiv\_pos\_as\_xyz 'x, y, z'
loop\_ \_atom\_site\_label \_atom\_site\_type\_symbol \_atom\_site\_fract\_x
## \_atom\_site\_fract\_y
## \_atom\_site\_fract\_z
| O001 | O | -0.3850781099 | -0.3033233884 | 0.0396413144 |
|--------|-----|-----------------|-----------------|----------------|
| O002 | O | 0.0606172 | 0.158657 | 0.0411857 |
| O003 | O | -0.425043 | 0.169539 | 0.0402571 |
| O004 | O | 0.0648678 | -0.332385 | 0.0383355 |
| Ni005 | Ni | -0.0858792 | -0.160733 | 0.021135 |
| Fe006 | Fe | -0.096916 | 0.31985 | 0.0214653 |
| Ni007 | Ni | 0.415892 | -0.161647 | 0.0218123 |
| O008 | O | -0.241206 | -0.00315364 | 0.003636 |
| O009 | O | -0.237075 | 0.494621 | 0.000711279 |
| O010 | O | 0.227272 | -0.488992 | 0.00229527 |
| O011 | O | 0.216104 | -0.0249911 | 0.00310736 |
| Fe012 | Fe | 0.393811 | 0.318503 | -0.00794013 |
| Fe013 | Fe | 0.0711742 | -0.358063 | -0.0212986 |
| Fe014 | Fe | -0.260192 | -0.0409177 | -0.0289871 |
| O015 | O | -0.0762721 | 0.301487 | -0.037006 |
| O016 | O | 0.381535 | -0.196306 | -0.0342809 |
| O017 | O | -0.0976708 | -0.235177 | -0.0363166 |
| O018 | O | 0.306822 | 0.304384 | -0.0377568 |
| H019 | H | -0.315338 | -0.191683 | 0.0527432 |
| H020 | H | 0.256999 | 0.231005 | 0.0415119 |
| H021 | H | -0.375744 | 0.152616 | 0.0554716 |
| H022 | H | 0.040236 | -0.31999 | 0.054206 |
## (111) NFO slab 1.0 inversion spinel with H on bottom [octahedral+tetrahedral] layer
## data\_NiFe2O4\_111\_slab\_inv\_Hbot
\_cell\_length\_a 5.85757200
\_cell\_length\_b 5.93817822
\_cell\_length\_c 60.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 120.003400
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
```
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
```
| O009 | O | -0.2586965775 0.4648047716 -0.0024331502 |
|--------|-----|--------------------------------------------|
| O010 | O | 0.2071929373 0.4806139178 0.0002061902 |
| O011 | O | 0.1962848608 -0.0584666878 -0.0008992569 |
| Fe012 | Fe | 0.3806092843 0.2964043865 -0.0072302654 |
| Fe013 | Fe | 0.0570121179 -0.3723989005 -0.0212402927 |
| Fe014 | Fe | -0.2746740801 -0.0261420051 -0.0300420597 |
| O015 | O | -0.0529422433 0.3152107051 -0.0414336788 |
| O016 | O | 0.3761647099 -0.1509433657 -0.0407368859 |
| O017 | O | -0.1448781936 -0.2442542370 -0.0419676297 |
| O018 | O | 0.3733098986 0.2864022333 -0.0397475934 |
| H019 | H | 0.1224854950 0.3236087144 -0.0444288335 |
| H020 | H | 0.3695997471 0.0167444802 -0.0429516747 |
| H021 | H | -0.0542068176 -0.1916518267 -0.0563053873 |
| H022 | H | -0.4590565118 0.4325613556 -0.0453271009 |
## (100) NFO slab 1.0 inversion spinel without H
## data\_NiFe2O4\_100\_slab\_inv\_noH
\_cell\_length\_a 5.61233711
\_cell\_length\_b 5.86083030
\_cell\_length\_c 40.00000000
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 89.339300
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
## loop\_
\_atom\_site\_label
\_atom\_site\_type\_symbol
\_atom\_site\_fract\_x
\_atom\_site\_fract\_y
\_atom\_site\_fract\_z
O001 O 0.0065513437 -0.4689123789 0.0551860036
Fe002 Fe 0.2452277563 -0.2538525905 0.0496265195
O003 O 0.4992824748 -0.4536012716 0.0519077035
Ni004 Ni -0.2469173152 -0.2524008022 0.0503908878
O005 O 0.0036049359 -0.0370722159 0.0556865994
O006 O 0.4943682700 -0.0506128922 0.0508804906
Fe007 Fe 0.0003504653 0.2463015255 0.0309572981
O008 O -0.2543640302 -0.2497913162 -0.0001965906
O009 O 0.2487925143 -0.2466894754 0.0005854946
Fe010 Fe 0.4991512364 -0.0054292686 -0.0019258577
Ni011 Ni 0.4974912508 0.4980956044 -0.0002587242
O012 O -0.2554248559 0.2412995918 0.0014094464
O013 O 0.2538928386 0.2434364425 0.0017808975
Fe014 Fe 0.0031745546 -0.2472079126 -0.0319221331
O015 O 0.4875384443 0.0351561435 -0.0494648386
Fe016 Fe -0.2454541075 0.2579172059 -0.0493517697
O017 O 0.0000017427 0.0281111279 -0.0553310090
Ni018 Ni 0.2435724864 0.2499024240 -0.0502233878
O019 O 0.4820059246 0.4595917618 -0.0502584251
O020 O 0.0014913328 0.4758335109 -0.0548564641
## (100) NFO slab 1.0 inversion spinel with H
## data\_NiFe2O4\_100\_slab\_inv\_H
\_cell\_length\_a 5.59038549
\_cell\_length\_b 5.83789352
\_cell\_length\_c 40
\_cell\_angle\_alpha 90.000000
\_cell\_angle\_beta 90.000000
\_cell\_angle\_gamma 89.369600
\_symmetry\_space\_group\_name\_H-M 'P 1'
\_symmetry\_Int\_Tables\_number 1
## loop\_
\_symmetry\_equiv\_pos\_as\_xyz
'x, y, z'
loop\_ \_atom\_site\_label \_atom\_site\_type\_symbol \_atom\_site\_fract\_x \_atom\_site\_fract\_y \_atom\_site\_fract\_z O001 O 6.357450507867E-03 -4.667698494075E-01 0.054606660306275 Fe002 Fe 2.482166978516E-01 -2.544056208954E-01 0.0519209754397 O003 O 4.999931707081E-01 -4.564374665385E-01 0.051777627065775 Ni004 Ni -2.491758389287E-01 -2.525758381136E-01 0.0521212519231 O005 O 2.539490070244E-03 -3.927895267340E-02 0.055306816134125004 O006 O 4.949220301840E-01 -4.893795544527E-02 0.051481352700475005 Fe007 Fe -2.194038769692E-03 2.455679266035E-01 0.0299260801568 O008 O -2.551297705461E-01 -2.485131617547E-01 0.00015481522464337502 O009 O 2.519335129598E-01 -2.458615658015E-01 0.0013152668641502499 Fe010 Fe 4.986009083242E-01 -6.485487062857E-03 -0.0023256641217450002 Ni011 Ni 4.977270925916E-01 4.976443048096E-01 -0.00043816457860199997 O012 O -2.573399203155E-01 2.398686944685E-01 0.0006302352125067501 O013 O 2.566760997620E-01 2.425524207160E-01 0.002341316176053 Fe014 Fe 5.398155567061E-03 -2.456050344456E-01 -0.030629953083875 O015 O 4.832581603410E-01 3.261915249029E-02 -0.050165093913500006 Fe016 Fe -2.465378865988E-01 2.582995673024E-01 -0.051794558024475 O017 O 8.242774681382E-04 3.139001667594E-02 -0.054756984494875004 Ni018 Ni 2.460837648445E-01 2.508922808854E-01 -0.051938554234949995 O019 O 4.841781305546E-01 4.608551423184E-01 -0.050651337141899996 O020 O 4.557261077439E-03 4.762937923788E-01 -0.053917587316325 H021 H 2.756045107173E-01 -2.518846880138E-01 0.0897110870841 H022 H -2.608616542299E-01 -2.535273556286E-01 0.087114119925625 H023 H -2.901991931262E-01 2.536120479247E-01 -0.09010633422685001 H024 H 2.653336718001E-01 2.523290805911E-01 -0.086618982201025
## References:
- (1) Sanchez-Lievanos, K. R.; Tariq, M.; Brennessel, W. W.; Knowles, K. E. Heterometallic Trinuclear Oxo-Centered Clusters as Single-Source Precursors for Synthesis of Stoichiometric Monodisperse Transition Metal Ferrite Nanocrystals. Dalton Trans. 2020 , 49 (45), 1634816358.
- (2) Choi, J.; Suryanto, B. H. R.; Wang, D.; Du, H. -L.; Hodgetts, R. Y.; Ferrero Vallana, F. M.; MacFarlane, D. R.; Simonov, A. N. Identification and Elimination of False Positives in Electrochemical Nitrogen Reduction Studies. Nat. Commun. 2020 , 11 (1), 5546.
- (3) Dovesi, R.; Erba, A.; Orlando, R.; Zicovich -Wilson, C. M.; Civalleri, B.; Maschio, L.; Rérat, M.; Casassa, S.; Baima, J.; Salustro, S.; Kirtman, B. Qu antum-Mechanical Condensed Matter Simulations with CRYSTAL. WIREs Comput. Mol. Sci. 2018 , 8 (4), e1360.
- (4) Heyd, J.; Scuseria, G. E.; Ernzerhof, M. Hybrid Functionals Based on a Screened Coulomb Potential. J. Chem. Phys. 2003 , 118 (18), 8207-8215.
- (5) Grimme, S.; Antony, J.; Ehrlich, S.; Krieg, H. A Consistent and Accurate Ab Initio Parametrization of Density Functional Dispersion Correction (DFTD) for the 94 Elements H -Pu. J. Chem. Phys. 2010 , 132 (15), 154104.
- (6) Peintinger, M. F.; Oliveira, D. V.; Bredow, T. Consistent Gaussian Basis Sets of TripleZeta Valence with Polarization Quality for Solid -State Calculations. J. Comput. Chem. 2013 , 34 (6), 451459.
- (7) Sanchez-Lievanos, K. R.; Knowles, K. E. Controlling Cation Distribution and Morphology in Colloidal Zinc Ferrite Nanocrystals. Chem. Mater. 2022 , 34 (16), 74467459. | 10.1002/adfm.202413319 | [
"Daniel Maldonado-Lopez",
"Po-Wei Huang",
"Karla R. Sanchez-Lievanos",
"Gourhari Jana",
"Jose L. Mendoza-Cortes",
"Kathryn E. Knowles",
"Marta C. Hatzell"
]
| 2024-08-02T16:25:42+00:00 | 2024-08-02T16:25:42+00:00 | [
"physics.chem-ph",
"cond-mat.mtrl-sci"
]
| Nitrogen-containing Surface Ligands Lead to False Positives for Photofixation of N$_2$ on Metal Oxide Nanocrystals: An Experimental and Theoretical Study | Many ligands commonly used to prepare nanoparticle catalysts with precise
nanoscale features contain nitrogen (e.g., oleylamine); here, we found that the
use of nitrogen-containing ligands during the synthesis of metal oxide
nanoparticle catalysts substantially impacted product analysis during
photocatalytic studies. We confirmed these experimental results via hybrid
Density Functional Theory computations of the materials' electronic properties
to evaluate their viability as photocatalysts for nitrogen reduction. This
nitrogen ligand contamination, and subsequent interference in photocatalytic
studies, is avoidable through the careful design of synthetic pathways that
exclude nitrogen-containing constituents. This result highlights the urgent
need for careful evaluation of catalyst synthesis protocols, as contamination
by nitrogen-containing ligands may go unnoticed since the presence of nitrogen
is often not detected or probed. |
2408.01372v3 | ## Spatial and Spatial-Spectral Morphological Mamba for Hyperspectral Image Classification
Muhammad Ahmad , Muhammad Hassaan Farooq Butt , Adil Mehmood Khan , Manuel Mazzara , Salvatore a b c d Distefano , Muhammad Usama , Swalpa Kumar Roy , Jocelyn Chanussot , Danfeng Hong a e f g h, ∗
- a Dipartimento di Matematica e Informatica-MIFT, University of Messina, 98121 Messina, Italy. [email protected]; [email protected]
- b Institute of Artificial Intelligence, School of Mechanical and Electrical Engineering, Shaoxing University, Shaoxing 312000, China. (e-mail: [email protected])
- c School of Computer Science, University of Hull, Hull HU6 7RX, UK. (e-mail: [email protected])
- d Institute of Software Development and Engineering, Innopolis University, 420500 Innopolis, Russia. (e-mail: [email protected]) e M. Usama is with the Department of Computer Science, National University of Computer and Emerging Sciences, Islamabad, Chiniot-Faisalabad Campus, Chiniot 35400, Pakistan. (e-mail: [email protected])
- f Department of Computer Science and Engineering, Alipurduar Government Engineering and Management College, West Bengal 736206, India (e-mail: [email protected])
- g Univ. Grenoble Alpes, Inria, CNRS, Grenoble INP, LJK, Grenoble, 38000, France, and also with the Aerospace Information Research Institute, Chinese Academy of Sciences, 100094 Beijing, China. (e-mail: [email protected])
h Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, 100094, China, and also with the School of Electronic, Electrical and Communication Engineering, University of Chinese Academy of Sciences, 100049 Beijing, China. (e-mail: [email protected])
## Abstract
Recent advancements in transformers, specifically self-attention mechanisms, have significantly improved hyperspectral image (HSI) classification. However, these models often suffer from inefficiencies, as their computational complexity scales quadratically with sequence length. To address these challenges, we propose the morphological spatial mamba (SMM) and morphological spatial-spectral Mamba (SSMM) model (MorpMamba), which combines the strengths of morphological operations and the state space model framework, offering a more computationally efficient alternative to transformers. In MorpMamba, a novel token generation module first converts HSI patches into spatial-spectral tokens. These tokens are then processed through morphological operations such as erosion and dilation, utilizing depthwise separable convolutions to capture structural and shape information. A token enhancement module refines these features by dynamically adjusting the spatial and spectral tokens based on central HSI regions, ensuring effective feature fusion within each block. Subsequently, multi-head self-attention is applied to further enrich the feature representations, allowing the model to capture complex relationships and dependencies within the data. Finally, the enhanced tokens are fed into a state space module, which efficiently models the temporal evolution of the features for classification. Experimental results on widely used HSI datasets demonstrate that MorpMamba achieves superior parametric efficiency compared to traditional CNN and transformer models while maintaining high accuracy. The code will be made publicly available at https://github.com/mahmad000/MorpMamba .
Keywords: Hyperspectral Imaging; Morphological Operations; Spatial Morphological Mamba (SMM); Spatial-Spectral Morphological Mamba (SSMM); Hyperspectral Image Classification.
## 1. Introduction
Hyperspectral Image (HSI) classification plays a critical role in a wide array of applications, including remote sensing [1], Earth observation [2], urban planning [3], agriculture [4], and environmental monitoring [5, 6]. The ability of HSIs to capture detailed spectral information across a wide range of wavelengths provides insights that traditional imaging cannot, enabling precise material identification and classification across these domains. However, effectively analyzing the high-dimensional data inherent in HSIs poses significant challenges, particularly in terms of developing algorithms that can manage and interpret the vast spectral and spatial information without overwhelming computational resources [7, 8].
∗ Corresponding author
Email address: [email protected] (Danfeng Hong)
Recent advances in deep learning, particularly convolutional neural networks (CNNs), have shown promise in extracting meaningful spatial and spectral features from HSIs [9, 10]. While CNNs can learn hierarchical representations crucial for HSI classification, they are limited by their local receptive fields, which fail to capture the global spatial context needed for complex classification
tasks [11, 12]. This limitation often results in suboptimal performance, especially in high-dimensional hyperspectral data. Moreover, CNNs require large labeled datasets for effective training, which is a significant constraint given the scarcity of annotated HSI datasets [13].
Transformer architectures, leveraging self-attention mechanisms, have emerged as a promising alternative due to their ability to model long-range dependencies and global contextual relationships [14]. This has led to notable improvements in HSI classification by capturing the intricate relationships between spectral bands and spatial regions [15-17]. However, transformers also introduce substantial computational complexity, as their operations scale quadratically with the sequence length, making them less practical for processing large-scale HSI data, which are inherently high-dimensional and require extensive computational resources [18, 19].
To address the limitations of both CNNs and transformers, the Mamba architecture, based on the state space model (SSM), has emerged as a more efficient alternative for sequence modeling [20]. Mamba replaces the attention mechanism with a state space formulation, achieving linear complexity scaling with sequence length and offering substantial computational savings [21]. This makes Mamba particularly well-suited for HSI classification, where efficiently managing long spectral sequences is essential [22].
Several recent studies have applied the Mamba framework to HSI classification. SpectralMamba [23] introduced a gated spatial-spectral merging (GSSM) module and piecewise sequential scanning (PSS) strategy to address inefficiencies in sequence modeling. Similarly, spatial-spectral Mamba (SSMamba) [24] incorporated a spectral-spatial token generation module to fuse spatial and spectral information effectively. While these architectures improved classification performance, they face challenges in handling extremely high-dimensional HSI data and generalizing across diverse datasets. Wang et al. [25] introduced the S 2 Mamba architecture for HSI classification, which integrates spatial and spectral features using SSMs. This model employs Patch cross-scanning and Bi-directional spectral scanning to capture spatial and spectral features, respectively, merging them with a spatial-spectral mixture gate to enhance classification accuracy. He et al. [26] developed the 3D spectral-spatial Mamba (3DSSMamba) architecture for HSI classification. This framework utilizes the strengths of the Mamba architecture by incorporating a spectral-spatial token generation module (SSTG) and a 3D spectral-spatial selective scanning (3DSS) mechanism, enabling the model to effectively capture global spectralspatial contextual dependencies while maintaining linear computational complexity. Despite improved classification performance, the authors stressed the need for further optimization to robustly handle high-dimensional data and explore additional strategies for better generalization across diverse HSI datasets.
Sheng et al. [27] introduced DualMamba, a spatialspectral Mamba architecture for HSI classification. This design integrates Mamba with CNNs, effectively capturing complex spectral-spatial relationships while ensuring computational efficiency. However, the authors noted limitations, including redundancy in multi-directional scanning strategies and challenges in fully leveraging spectral information. Similarly, Zhou et al. [28] developed another spatial-spectral Mamba architecture, featuring a centralized Mamba-Cross-Scan mechanism that transforms HSI data into diverse sequences, enhancing feature extraction through a Tokenized Mamba encoder. Despite its strengths, this method is sensitive to variations in peripheral pixels and requires significant computational resources for larger patches. Yang et al. [29] proposed GraphMamba, which enhances spatial-spectral feature extraction through components like HyperMamba and SpatialGCN, addressing efficiency and contextual awareness. Nevertheless, the authors identified shortcomings, such as optimizing encoding modules to accommodate diverse HSI datasets and potential overfitting in high-dimensional spaces.
To overcome the limitations of the existing models, this paper proposes a morphological spatial and spatialspectral Mamba (MorpMamba) architecture, which integrates morphological operations into the Mamba framework. Morphological operations, specifically erosion, and dilation, are well-suited for capturing structural and shaperelated features in spatial-spectral data. These operations enhance the tokenization process by emphasizing boundaries, filling gaps, and smoothing out noise, leading to more robust and meaningful token representations. In a nutshell, the following contributions are made in this study.
Firstly , erosion highlights the boundaries of objects, enabling better distinction between different regions in HSIs, while dilation enhances structural continuity by connecting disjoint parts. These morphological operations effectively reduce noise and extract prominent spatial-spectral features. By incorporating them in the token generation process, MorpMamba ensures that tokens represent both fine details and global structures. Secondly , the token enhancement module further refines the tokens by dynamically adjusting the spatial and spectral features based on the central regions of the HSI. This results in more contextaware and stable token representations, making the model less sensitive to noise and improving feature robustness. Lastly , the multi-head self-attention mechanism and state space model (SSM) work in tandem to capture long-range dependencies and efficiently model the temporal evolution of features. The self-attention mechanism focuses on different aspects of the spatial-spectral features, while the state space model ensures efficient and interpretable feature progression, contributing to superior classification accuracy.
In short, MorpMamba leverages the strengths of morphological operations, token enhancement, and the Mamba framework to create a robust, efficient, and scalable model for HSI classification. The combination of these techniques leads to better feature extraction, reduced com-
putational complexity, and improved generalization across diverse HSI datasets.
## 2. Proposed Methodology
Given the HSI data X ∈ R H,W,C , where H and W represent the spatial dimensions (height and width), and C denotes the number of spectral bands, the goal is to classify pixels using both spectral and spatial information. We divide the HSI cube X into overlapping 3D patches, each capturing spatial-spectral data for further processing.
$$N = \left ( \frac { H } { P } \times \frac { W } { P } \right ) \quad \quad \quad ( 1 ) \quad \quad,$$
where X ∈ R N × ( P × × P C ) , where N is the total number of 3D patches, and each patch of size P × P × C is used as input to subsequent modules. Spatial and spectral patches are processed independently using morphological operations (erosion and dilation) to extract structural features. The complete model structure is presented in Figure 1.
## 2.1. Morphological Operations
Morphological operations are employed to refine spatial and spectral information from HSI patches. Erosion reduces the shape of objects and eliminates minor details, while dilation expands object boundaries and enhances structural integrity. These operations enable the extraction of both fine details and large-scale features. In our model, morphological operations are applied separately to both spatial and spectral dimensions, which are processed independently. These operations help refine the spatial and spectral structures in HSI by highlighting boundaries and enhancing structural features. The erosion operation on a patch X is defined as:
$$\varepsilon _ { \mathbf k } ( \mathcal { X } ) = \min _ { \mathbf i \in \mathcal { N } ( \mathbf j ) } \mathcal { X } ( \mathbf i ) \, \exists \, \mathbf k ( \mathbf i - \mathbf j ) \, \quad \quad ( 2 ) \quad \text{bas} \quad \text{of } t$$
where N ( ) j is the neighborhood of pixels j , ⊟ denotes element-wise subtraction, and k is the structuring element (SE). The dilation operation is defined as:
$$\delta _ { \mathbf k } ( \mathcal { X } ) = \max _ { \mathbf i \in \mathcal { N } ( \mathbf j ) } \mathcal { X } ( \mathbf i ) \, \Xi \, \mathbf k ( \mathbf i - \mathbf j ) \, \text{ \quad \ \ } ( 3 )$$
where ⊞ denotes element-wise addition, allowing dilation to expand the foreground object in the patch. These operations are performed using depthwise separable convolutions, with kernels representing SEs, applied separately along spatial and spectral dimensions. In other words, the SE kernel's size affects the apparent texture size for various regions within the patch and token. The erosion (Equation 2) and dilation (Equation 3) operations are performed per channel using depthwise 2D convolution layers with a kernel of size (5 × 5) and the same padding, initialized with weights set to one (representing the SE) and the sign is inverted.
## 2.2. Spatial-Spectral Token Generation
Once morphological operations are applied, we generate spatial and spectral tokens separately. These tokens are formed by concatenating the results of the erosion and dilation operations. For spatial token generation, the operations are applied along the height and width dimensions:
$$\mathcal { X } _ { \text{spatial} } ^ { \text{eroded} } = \varepsilon \mathbf k ( \mathcal { X } ) \, \ \mathcal { X } _ { \text{spatial} } ^ { \text{dilated} } = \delta \mathbf k ( \mathcal { X } ) \quad \ \ ( 4 )$$
The eroded and dilated spatial features are then concatenated and passed through a depthwise convolution to produce spatial tokens:
$$\cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cd.$$
For spectral token generation, the input data is transposed to treat the spectral channels as the spatial dimension, and similar morphological operations are applied:
$$\mathcal { X } _ { \text{spectral} } ^ { \text{eroded} } = \varepsilon \mathbf k ( \mathcal { X } ^ { \top } ) \, \ \mathcal { X } _ { \text{spectral} } ^ { \text{dilated} } = \delta \mathbf k ( \mathcal { X } ^ { \top } ) \quad ( 6 )$$
The concatenated eroded and dilated features are passed through a depthwise convolution to generate spectral tokens:
$$\text{s...}, \quad t _ { \text{spectral} } = \text{Conv2D} _ { \text{Depthwise} } ( \| ( \mathcal { X } _ { \text{spectral} } ^ { \text{eroded} }, \mathcal { X } _ { \text{spectral} } ^ { \text{dilated} } ), \mathcal { W } ) \ ( 7 )$$
The final output from the token generation module consists of the spatial and spectral tokens ( t spatial , t spectral ), providing a comprehensive spatial-spectral representation of the HSI data.
## 2.3. Token Enhancement and Multi-head Attention
To refine the tokens generated, a gating mechanism is applied, which adjusts the spatial and spectral tokens based on contextual information from the center region of the HSI patch. Specifically, the model extracts center tokens from the spatial tokens and uses them to modulate both the spatial and spectral token importance:
$$\widetilde { t } _ { \text{spectral} } ^ { ( l ) } = t _ { \text{spectral} } ^ { ( l ) } \odot \sigma ( \mathbf W _ { \text{spectral} } \, \mathbf c + \mathbf b _ { \text{spectral} } ) \quad ( 8 )$$
$$\widetilde { t } _ { \text{spatial} } ^ { ( l ) } = t _ { \text{spatial} } ^ { ( l ) } \odot \sigma ( \text{W} _ { \text{spatial} } \text{ c} + b _ { \text{spatial} } ) \quad ( 9 )$$
where W spectral and W spatial are weight matrices, c is the center region of the patch, and σ denotes the sigmoid function as shown in Figure 2. After this enhancement, a multi-head self-attention mechanism is applied, which allows the model to focus on different regions of the data simultaneously, further refining the tokenized features:
$$A _ { i } = \text{softmax} \left ( \frac { Q _ { i } K _ { i } ^ { \top } } { \sqrt { d _ { k } } } \right ) \, \ O _ { i } = A _ { i } \mathbf V _ { i } \quad ( 1 0 )$$
Figure 1: A joint spatial-spectral feature token is first computed from the HSI using morphological operations. These tokens are then integrated into the MorpMamba model, which includes Erosion and Dilation operations, token enhancement, and a multi-head attention module. This method allows a more selective and effective representation of information as compared to standard fixed-dimension encodings. The output is then processed through an SSM, followed by feature normalization and a linear layer with l 2 2 regularization. Finally, this output is passed to the classification head for generating the ground truth.

Figure 2: Spatial-Spectral token enhancement module adopted to refine and enhancement of the extracted spatial and spectral features.
where Q i = ˜ t ( ) l spectral W Q i , K i = ˜ t ( ) l spatial W K i , and V i = ˜ t ( ) l spatial W V i are the query, key, and value projections of the tokens, respectively, and O i represents the output for each attention head. The combined output is a refined feature representation across spatial-spectral dimensions as shown in Figure 3.
## 2.4. State Space Model (SSM)
The final stage involves processing the enhanced tokens through a state space model (SSM), which captures longterm dependencies and models the temporal evolution of the features:
Figure 3: Multi-head self-attention module adapted to interact with the enhanced spatial and spectral features.
$$h _ { t } = \text{ReLU} ( W _ { \text{trans} } h _ { t - 1 } + W _ { \text{update} } E _ { t } ) \quad ( 1 1 )$$
where W trans and W update are learned weights, and h t is the hidden state at time t . The final classification output is produced using a linear classifier with l 2 2 regularization:
$$y = \sigma ( h _ { t } W _ { \text{classifier} } - \lambda | W _ { \text{classifier} } | _ { 2 } ^ { 2 } ) \quad \ ( 1 2 )$$
where λ controls the regularization strength. By integrating morphological tokenization, token enhancement,
multi-head attention, and state space modeling, MorpMamba efficiently combines spatial and spectral information, leading to improved classification performance with reduced computational complexity.
## 3. Experimental Datasets
To evaluate the performance of MorpMamba, we utilized several widely-used hyperspectral image (HSI) datasets: WHU-Hi-LongKou (LK), Pavia University (PU), Pavia Centre (PC), Salinas (SA), and the University of Houston (UH). These datasets span various geographic locations, sensor types, and spatial-spectral resolutions, providing a comprehensive benchmark for model evaluation. Table 1 summarizes the key characteristics of each dataset.
Table 1: Summary of the HSI datasets used for experimental evaluation.
| - | SA | PU | PC | UH | LK |
|-----------------|-----------|-----------|-------------|------------|-----------|
| Source | AVIRIS | ROSIS-03 | ROSIS-03 | CASI | UAV |
| Spatial | 512 × 217 | 610 × 610 | 1096 × 1096 | 340 × 1905 | 550 × 400 |
| Spectral Bands | 224 | 103 | 102 | 144 | 270 |
| Wavelength (nm) | 350-1050 | 430-860 | 430-860 | 350-1050 | 400-1000 |
| Ground Samples | 111,104 | 372,100 | 1,201,216 | 647,700 | 220,000 |
| Classes | 16 | 9 | 9 | 15 | 9 |
| Resolution (m) | 3.7 | 1.3 | 1.3 | 2.5 | 0.463 |
The WHU-Hi-LongKou (LK) dataset was collected in Longkou Town, Hubei, China, using a Headwall NanoHyperspec sensor mounted on a DJI M600 Pro UAV. Captured in July 2018 at an altitude of 500 meters, the dataset consists of 550 × 400 pixels with 270 spectral bands ranging from 400 to 1000 nm. The scene includes six crop types: corn, cotton, sesame, broad-leaf soybean, narrowleaf soybean, and rice. The high-resolution dataset has a spatial resolution of 0.463 meters per pixel, making it suitable for fine-grained agricultural monitoring.
The Salinas (SA) dataset, collected by the AVIRIS sensor over Salinas Valley, California, consists of 512 × 217 pixels with 224 spectral bands covering the 0.35 to 1.05 µ m wavelength range. The dataset includes diverse land covers such as vegetables, bare soils, and vineyards, with ground truth labels for 16 distinct classes. Its 3.7-meter spatial resolution makes it ideal for high-precision agricultural and environmental monitoring.
Both Pavia University (PU) and Pavia Center (PC) datasets were acquired using the ROSIS-03 sensor over northern Italy. The Pavia University scene contains 610 × 610 pixels with 103 spectral bands, while the Pavia Centre is a larger 1096 × 1096-pixel image with 102 spectral bands. Both datasets feature a spatial resolution of 1.3 meters and differentiate between nine land-cover classes. These datasets are frequently used benchmarks for urban land-cover classification tasks.
The University of Houston (UH) dataset, published as part of the IEEE GRSS Data Fusion Contest, was captured using the Compact Airborne Spectrographic Imager (CASI). This dataset spans 340 × 1905 pixels with 144 spectral bands, covering wavelengths from 0.38 to 1.05
µ m. The spatial resolution of 2.5 meters per pixel, combined with 15 land-cover classes, provides a challenging dataset for urban and land-cover classification.
## 4. Ablation Study and Discussion
This section outlines a series of experiments designed to evaluate MorpMamba's performance across various scenarios.
- 1. Without morphological operation (NM)
- 2. Only spatial morphology (SMM)
- 3. joint spatial-spectral morphology within the Mamba model (SSMM)
- 4. Training sample ratios (1%, 2%, 5%, 10%, 15%, 20%, and 25%). 5)
- 5. Different patch sizes 2 × 2, 4 × 4, 6 × 6, 8 × 8, and 10 × 10)
- 6. Number of Attention heads (2, 4, 6, and 8)
- 7. Kernel sizes (3 × 3, 5 × 5, 7 × 7, 9 × 9, and 11 × 11) for morphological operations.
- 8. Computational time for Training samples, patch sizes, number of heads, and kernel sizes.
- 9. t-SNE feature representations.
The model with spatial morphological operations is referred to as Spatial morphological Mamba (SMM), and the model with spatial-spectral morphological operations is referred to as SSMM, while the version without these operations is called SSMamba (token generation, enhancement, and multi-head attention component remains intact). The study aims to evaluate the impact of morphological operations on the overall accuracy (OA), average accuracy (AA), and kappa ( κ ) coefficient across various datasets.
Table 2 present the results for the Mamba model variants: No Morphology (NM-SSMamba), SMM, and SSMM across multiple datasets. As shown in the Table, SSMM consistently outperforms the other models. However, it is important to highlight the performance of SMM, which demonstrates competitive results as well. For instance, in the PU dataset, SMM achieved an OA of 96.52%, which is an improvement over SSMamba (95.67%) and just slightly lower than SSMM (97.67%). SMM also demonstrated a strong κ coefficient of 95.40%, compared to 94.25% for NM, although still trailing behind SSMM's 96.91%. In the PC dataset, SMM again performed well with an OA of 99.52%, which is marginally higher than NM (99.48%) but slightly below SSMM's 99.71%. Similarly, the κ coefficient for SMM in this dataset was 99.32%, higher than NM (99.27%) and just under SSMM (99.59%). These results demonstrate that even spatial morphological operations alone (without the spectral component) significantly enhance model performance over the baseline No Morphology model.
For the LK dataset, SMM achieved an OA of 99.25%, slightly lower than SMM's 99.70% but still better than NM's 99.51%. The κ coefficient for SMM was 99.02%,
Table 2: Results of the Mamba model without Morphology (SSMamba - NM), the Spatial Morphology Mamba (SMM), and the spatialspectral Morphology Mamba (SSMM). Each of these models is trained using a 4 × 4 patch size and 20% of the training samples.
| Class | Salinas | Salinas | Salinas | University of Houston | University of Houston | University of Houston |
|---------|-----------|-----------|-----------|-------------------------|-------------------------|-------------------------|
| Class | NM | SMM | SSMM | NM | SMM | SSMM |
| 1 | 100 | 100 | 100 | 100 | 100 | 99 |
| 2 | 100 | 100 | 100 | 100 | 100 | 99 |
| 3 | 99 | 99 | 100 | 99 | 99 | 100 |
| 4 | 100 | 99 | 100 | 98 | 99 | 99 |
| 5 | 99 | 99 | 99 | 100 | 99 | 100 |
| 6 | 100 | 99 | 100 | 96 | 99 | 99 |
| 7 | 100 | 100 | 100 | 96 | 100 | 98 |
| 8 | 89 | 93 | 97 | 94 | 93 | 98 |
| 9 | 100 | 99 | 100 | 96 | 99 | 96 |
| 10 | 99 | 98 | 99 | 99 | 98 | 99 |
| 11 | 100 | 99 | 100 | 99 | 99 | 97 |
| 12 | 100 | 100 | 100 | 95 | 100 | 98 |
| 13 | 100 | 100 | 100 | 86 | 100 | 92 |
| 14 | 99 | 99 | 99 | 99 | 99 | 99 |
| 15 | 82 | 87 | 96 | 100 | 87 | 100 |
| 16 | 100 | 99 | 98 | - | 99 | - |
| OA | 95.20 | 96.78 | 98.52 | 90.36 | 96.78 | 98.28 |
| AA | 97.81 | 98.48 | 99.25 | 90.54 | 97.48 | 97.91 |
| κ | 94.65 | 96.41 | 98.35 | 89.58 | 96.41 | 98.14 |
| Class | Pavia University | Pavia University | Pavia University | Pavia Centre | Pavia Centre | Pavia Centre | WHU-Hi-LongKou | WHU-Hi-LongKou | WHU-Hi-LongKou |
|---------|--------------------|--------------------|--------------------|----------------|----------------|----------------|------------------|------------------|------------------|
| Class | NM | SMM | SSMM | NM | SMM | SSMM | NM | SMM | SSMM |
| 1 | 96 | 94 | 98 | 100 | 100 | 100 | 100 | 99 | 100 |
| 2 | 98 | 98 | 99 | 99 | 99 | 98 | 99 | 95 | 99 |
| 3 | 82 | 91 | 90 | 97 | 90 | 96 | 100 | 94 | 100 |
| 4 | 93 | 96 | 97 | 95 | 98 | 100 | 99 | 99 | 100 |
| 5 | 100 | 99 | 100 | 98 | 98 | 100 | 95 | 95 | 98 |
| 6 | 97 | 97 | 98 | 99 | 99 | 99 | 100 | 99 | 100 |
| 7 | 92 | 96 | 96 | 99 | 99 | 99 | 100 | 99 | 100 |
| 8 | 88 | 88 | 92 | 100 | 99 | 100 | 98 | 96 | 98 |
| 9 | 99 | 98 | 99 | 100 | 99 | 100 | 98 | 95 | 99 |
| OA | 95.67 | 96.52 | 97.67 | 99.48 | 99.52 | 99.71 | 99.51 | 99.25 | 99.70 |
| AA | 93.20 | 95.94 | 96.93 | 98.60 | 98.28 | 98.95 | 98.45 | 97.53 | 99.25 |
| κ | 94.25 | 95.40 | 96.91 | 99.27 | 99.32 | 99.59 | 99.36 | 99.02 | 99.61 |
Figure 4: OA of MorpMamba across different training data ratios (1%, 2%, 5%, 10%, 15%, 20%, and 25%), patch sizes (4 × 4. Different patch sizes 2 × 2, 4 × 4, 6 × 6, 8 × 8, and 10 × 10), number of heads (2, 4, 6, and 8), and kernel sizes (3 × 3, 5 × 5, 7 × 7, 9 × 9, and 11 × 11) over 50 epochs on WHU-Hi-LongKou, Pavia Centre, Pavia University, Salinas, and University of Houston datasets.
Figure 5: Training Time of MorpMamba across different training data ratios, patch sizes, number of heads, and kernel sizes over 50 epochs on WHU-Hi-LongKou, Pavia Centre, Pavia University, Salinas, and University of Houston datasets. The training ratio and patch size have a strong influence on computational time, whereas the head size within multi-head self-attention and the kernel size within morphological operations do not significantly affect the computational load. This demonstrates that the Mamba model maintains a linear computational load even after incorporating multi-head self-attention and morphological operations. However, these additions significantly improve performance, as shown in the subsequent sections.
slightly below SSMM (99.61%) but superior to NM (99.36%). In the SA dataset, SMM demonstrated a solid improvement over NM, achieving an OA of 96.78% and a κ of
96.41%, both significantly higher than NM (95.20% OA and 94.65% κ ), though still outperformed by SSMM (98.52% OAand 98.35% κ ). SMM's performance in the UH dataset
Figure 6: Learned features representation for Pavia University, Pavia Center, Salinas, University of Houston, and WHU-Hi-LongKou Datasets.
was also notable, achieving an OA of 96.78% and a κ of 96.41%, which were significantly better than NM's OA of 90.36% and κ of 89.58%. SSMM, however, further improved the results to an OA of 98.28% and a κ of 98.14%. In short, while SSMM consistently achieved the highest accuracy and classification accuracy, SMM offers significant performance improvements over the No Morphology model, particularly in datasets where spatial information plays a vital role in classification accuracy. The incorporation of spatial morphological operations alone yields measurable benefits in OA, although combining both spatial and spectral morphology leads to the best results.
comparison with other methods. All experiments were performed on an Intel i9-13900k machine with an RTX 4090 GPU and 32GB of RAM using Jupyter Notebook. Figure 7 presents the convergence of loss and accuracy of the MorpMamba model over 50 epochs.
As stated above, this study also experimented with various hyperparameter settings, such as training sample ratios (1%, 2%, 5%, 10%, 15%, 20%, and 25%), different patch sizes 2 × 2, 4 × 4, 6 × 6, 8 × 8, and 10 × 10), number of attention head (2, 4, 6, and 8), and kernel sizes (3 × 3, 5 × 5, 7 × 7, 9 × 9, and 11 × 11) for morphological operations. As shown in Figure 4, the OA improves as the ratio of training samples increases. For instance, on the LK dataset, the OA increased from 97.20% (at 5% training samples) to 99.73% (at 25% training samples). Similarly, on the UH dataset, OA increased from 79.16% to 97.64%, reflecting the importance of larger training sets for achieving higher accuracy. These results highlight SSMM's adaptability across different datasets and training scenarios.
Additionally, Figure 5 illustrates the computational time required for different settings. As expected, larger kernel sizes for morphological operations and more attention heads led to increased computational time. However, the trade-off between accuracy and computational efficiency was manageable, and MorpMamba remained efficient even with complex configurations. The best settings from these experiments were used to evaluate the MorpMamba in
Figure 7: The accuracy and loss for both the training and validation sets were computed using a 4 × 4 patch and 20% training samples over 50 epochs on the LK dataset.
To further analyze the feature representations learned by MorpMamba, we used t-distributed Stochastic Neighbor Embedding (t-SNE) to visualize the high-dimensional data in a 2D space. t-SNE preserves local structures within the data, making it an effective tool for understanding how well the model captures spectral-spatial features. As shown in Figures 6a, 6b, 6c, 6d, and 6e, t-SNE visualizations for the PU, PC, SA, UH, and LK datasets highlight the effectiveness of MorpMamba in separating feature clusters for different classes. The clear separation of clusters demonstrates MorpMamba's ability to learn distinct class-specific representations, particularly in challenging datasets such as UH, where classes are difficult to distinguish due to complex spatial relationships.
Table 3: Performance comparison of MorpMamba with SOTA models on various datasets. The metrics shown are OA, AA, and κ coefficient. The datasets include the UH, LK, PU, PC, and SA. The number of parameters for each model is also provided. Moreover, this table presents the results of the spatial-spectral Mamba model (SSMamba), the spatial Morphology Mamba (SMM), and the spatial-spectral Morphology Mamba (SSMM). All of these models were trained using a 4 × 4 patch size and 20% of the training samples.
| Model | OA | AA | κ | OA | AA | κ | OA | AA | κ | OA | AA | κ | OA | AA | κ | Parameters ≈ |
|-----------------|-----------------------|-----------------------|-----------------------|---------------------|---------------------|---------------------|------------------|------------------|------------------|--------------|--------------|--------------|---------|---------|---------|----------------|
| Model | University of Houston | University of Houston | University of Houston | WHU-Hi-LongKou (LK) | WHU-Hi-LongKou (LK) | WHU-Hi-LongKou (LK) | Pavia University | Pavia University | Pavia University | Pavia Center | Pavia Center | Pavia Center | Salinas | Salinas | Salinas | Parameters ≈ |
| 2DCNN | 97.49 | 97.04 | 97.29 | 99.71 | 99.29 | 99.62 | 97.97 | 96.99 | 97.30 | 99.66 | 99.06 | 99.52 | 97.54 | 98.82 | 97.26 | 322752 |
| 3DCNN | 99.01 | 98.81 | 98.93 | 99.81 | 99.58 | 99.75 | 98.70 | 97.86 | 98.28 | 99.87 | 99.65 | 99.81 | 98.86 | 99.48 | 98.73 | 4042880 |
| HybCNN | 98.93 | 98.71 | 98.84 | 99.84 | 99.60 | 99.79 | 43.59 | - | - | 99.78 | 99.45 | 99.69 | 98.76 | 99.42 | 98.62 | 594048 |
| 2DIN | 99.09 | 98.96 | 99.02 | 99.83 | 99.56 | 99.78 | 98.74 | 98.10 | 98.33 | 99.82 | 99.52 | 99.74 | 98.65 | 99.28 | 98.50 | 3285844 |
| 3DIN | 98.73 | 98.43 | 98.63 | 99.80 | 99.49 | 99.74 | 98.51 | 97.61 | 98.03 | 99.86 | 99.61 | 99.81 | 98.23 | 99.16 | 98.03 | 47448680 |
| HybIN | 98.81 | 98.56 | 98.71 | 99.75 | 99.56 | 99.67 | 98.79 | 98.26 | 98.40 | 99.82 | 99.45 | 99.75 | 98.74 | 99.38 | 98.60 | 1349848 |
| MorpCNN | 99.68 | 99.68 | 99.65 | 99.92 | 99.75 | 99.90 | 99.84 | 99.66 | 99.79 | 99.97 | 99.92 | 99.96 | 99.89 | 99.87 | 99.88 | 789071 |
| Hybrid-ViT | 98.45 | 97.85 | 98.33 | 99.75 | 99.36 | 99.68 | 98.15 | 97.24 | 97.55 | 99.71 | 99.13 | 99.59 | 97.99 | 99.05 | 97.76 | 790736 |
| Hir-Transformer | 97.12 | 96.25 | 96.89 | 99.68 | 99.14 | 99.59 | 97.99 | 96.79 | 97.34 | 99.64 | 98.79 | 99.49 | 98.09 | 98.95 | 97.87 | 4219094 |
| SSMamba | 90.36 | 90.54 | 89.58 | 99.51 | 98.45 | 99.36 | 95.67 | 93.20 | 94.25 | 99.48 | 98.60 | 99.27 | 95.20 | 97.81 | 94.65 | 49744 |
| SMM | 96.46 | 95.93 | 96.17 | 99.25 | 97.53 | 99.02 | 96.52 | 95.94 | 95.40 | 99.52 | 98.28 | 99.32 | 96.78 | 98.48 | 96.41 | 62665 |
| SSMM | 98.28 | 97.91 | 98.14 | 99.70 | 99.25 | 99.61 | 97.67 | 96.93 | 96.91 | 99.71 | 98.85 | 99.59 | 98.52 | 99.25 | 98.35 | 67142 |
Figure 8: LK Dataset: The predicted ground truth maps for various competing methods alongside the proposed variants of the MorpMamba model. While many competing methods achieved similar accuracy levels, they demonstrated limited parameter efficiency, rendering them less suitable for deployment on resource-constrained devices compared to MorpMamba.
In short, the results from Table 2 demonstrate that the inclusion of morphological operations (erosion and dilation) in MorpMamba significantly improves its classification performance. This is evidenced by higher OA, AA, and κ scores across all datasets. Additionally, the t-SNE visualizations further confirm the model's superior feature learning capabilities.
## 5. Comparison with SOTA Methods and Discussion
efficiency by analyzing the number of parameters required for each model. Table 3 summarizes these metrics across five prominent HSI datasets: the UH, LK, PU, PC, and SA. Furthermore, Figures 8, 9, 10, 11, and 12 illustrate the predicted ground truth maps for all competing methods, including the proposed MorpMamba model. In this context, OA represents the percentage of correctly classified samples out of the total samples, AA is the mean accuracy across all classes, and κ is a statistical measure of agreement adjusted for a chance.
This section presents a detailed comparative analysis of the proposed MorpMamba model against state-of-theart (SOTA) HSI classification models. The comparison focuses on key performance metrics: OA, AA, and the κ coefficient. Additionally, we evaluate the computational
The comparative models included in our analysis are the 2D CNN [30], 3D CNN [9], HybCNN (a hybrid of 2D and 3D convolutions) [31], 2D IN (2D inception network) [32], 3D IN (3D inception network) [33], HybIN (a hybrid of 2D and 3D inception network) [34, 35], MorpCNN [36], Hybrid-ViT (a hybrid vision Transformer) [37], Hir-
(a) CNN2D

(f) HybIN

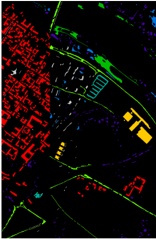
(d) IN2D
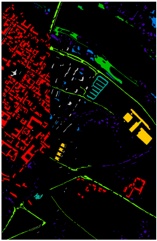
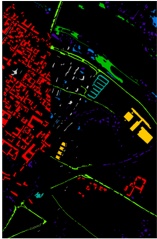
(e) IN3D

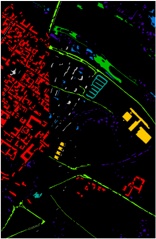
(c) HybCNN
(b) CNN3D
(g) MorpCNN
(h) Hybrid-ViT
(i) Hir-Transformer
(j) SSMamba
(k) SMM
(l) SSMM
Figure 9: PC dataset: The predicted ground truth maps for various competing methods alongside the proposed variants of the MorpMamba model.
(a) CNN2D
(e) IN3D
(b) CNN3D
(f) HybIN
(c) HybCNN
(d) IN2D
(g) MorpCNN
(h) Hybrid-ViT
(i) Hir-Transformer
(j) SSMamba
(k) SMM
(l) SSMM
Figure 10: PU dataset: The predicted ground truth maps for various competing methods alongside the proposed variants of the MorpMamba model.
Transformer (a hierarchical Transformer) [19], SSMamba, spatial morphological Mamba (SMM - the proposed SMM
(a) CNN2D
(e) IN3D
(f) HybIN
(d) IN2D

(c) HybCNN
(b) CNN3D
(g) MorpCNN
(h) Hybrid-ViT
(i) Hir-Transformer
(j) SSMamba
(k) SSM
(l) SSMM
Figure 11: SA dataset: The predicted ground truth maps for various competing methods alongside the proposed variants of the MorpMamba model.
Figure 12: UHdataset: The predicted ground truth maps for various competing methods alongside the proposed variants of the MorpMamba model.
model that integrates only spatial morphological operations with the Mamba architecture), and spatial-spectral morphological Mamba (SSMM - the proposed SSMM model that integrates spatial-spectral morphological operations with the Mamba architecture). The detailed configurations for each competing method, including the number of layers and filters per layer, are applied according to the specifications provided in their respective papers.
To ensure a fair comparison, all methods were evaluated under consistent experimental conditions. A patch size of 4 was used, and 15 spectral bands were selected. The dataset was divided into training (20%), validation (30%), and test (50%) sets. All models were trained for 50 epochs with a batch size of 256, using the Adam optimizer with a learning rate of 0.001. For the UH dataset, MorpMamba achieved an OA of 98.28%, an AA of 97.91%, and a κ of 98.14 as shown in Table 3. Although the 3D CNN model exhibited a slightly higher OA of 99.01% and AA of 98.81%, MorpMamba demonstrated its competitive edge with significantly fewer parameters (67,013 compared to 4,042,751).
Similarly, on the LK dataset, MorpMamba attained an OA of 99.70%, an AA of 99.25%, and a κ of 99.61. This performance is closely aligned with top-performing models like the 3D CNN (OA of 99.81%) while showcasing remarkable computational efficiency with substantially fewer parameters (66,239 compared to 4,041,977). For the PU dataset, MorpMamba achieved an OA of 97.67%, an AA of 96.93%, and a κ of 96.91, maintaining competitive performance against the 3D CNN model (OA of 98.70%) with a lower parameter count (66,239). In the PC dataset, MorpMamba recorded an OA of 99.71%, an AA of 98.85%, and a κ of 99.59, closely competing with the 3D CNN model (OA of 99.87%) while having fewer parameters (66,239). Finally, on the SA dataset, MorpMamba achieved an OA of 98.52%, an AA of 99.25%, and a κ of 98.35%. While the 3D CNN slightly outperformed in OA (98.86%), MorpMamba's performance is particularly impressive given its reduced parameter count (67,142).
The MorpMamba model stands out due to its superior computational efficiency compared to Transformer-based models, which typically suffer from quadratic complexity as the sequence length increases. By maintaining linear complexity, MorpMamba ensures scalability to larger datasets while delivering competitive accuracy. The incorporation of morphological operations significantly enhances the robustness and stability of the model, effectively mitigating noise and highlighting structural features within HSI data. This strategic approach addresses challenges associated with high-dimensional data, resulting in consistent performance across diverse datasets. In summary, the comparative analysis underscores the strengths of the MorpMamba model in HSI classification. It consistently achieves high accuracy and efficiency, outperforming SOTA models while maintaining a lower computational footprint.
## 6. Computational Complexity
The computational complexity of the proposed MorpMamba model, as compared to various SOTA methods, can be analyzed by evaluating each major component in the architecture. The Erosion and Dilation layers, which utilize depthwise convolution to process the input tensor, exhibit a complexity of O C H W k ( · · · 2 ) for each operation, where C denotes the number of channels, and k is the kernel size. Consequently, the spectral-spatial token generation combines the complexities of both spatial and spectral morphological operations, resulting in a total complexity of O C ( 2 · H · W k · 2 ). This reflects the increased dimensionality when treating spectral bands as spatial dimensions during processing. The Multi-Head Self-Attention mechanism introduces a significant computational overhead, with a complexity of O N ( 2 · D ), where N is the number of tokens and D is the feature dimension. This stems from the need to compute attention scores for each token against all other tokens in the sequence, which can be particularly demanding for large datasets. Additionally, the token enhancement which dynamically adjusts the importance of spatial and spectral tokens, adds a complexity of O N D ( · ). The SSM further contributes with the complexity O T ( · N D · ), T represents the number of time steps or iterations for state updates.
Overall, the dominant term in the MorpMamba model's complexity can be summarized as O N ( 2 · D ), indicating that while the model effectively handles the intricate relationships within high-dimensional hyperspectral data, it maintains a scalable architecture that facilitates improved classification accuracy. In contrast, the Mamba model without morphological operations operates at a lower complexity of O N ( · D ). This highlights the computational efficiency gained by integrating morphological operations, which not only enhance robustness and stability by reducing noise but also capture vital structural features in HSIs. Therefore, MorpMamba's ability to balance high accuracy and reduced parameter count positions it as a leading model for HSI classification, particularly in scenarios demanding computational efficiency.
## 7. Conclusion and Future Research Directions
This work introduced spatial morphological Mamba (SMM) and spatial-spectral morphological Mamba (SSMM) in short MorpMamba, a novel framework for HSI classification that integrates morphological spatial and spatialspectral operations with the state space model architecture. MorpMamba demonstrated SOTA performance across multiple HSI datasets, achieving superior classification results in terms of OA, AA, and κ coefficient, while significantly reducing computational overhead compared to CNN, transformer, and mamba-based models. The incorporation of morphological operations such as erosion and dilation in the tokenization process enhances the model's
ability to extract both fine-grained details and global structural information in both spatial and spectral dimensions. The token enhancement module further refines these features by dynamically adjusting the significance of spatial and spectral tokens, resulting in more robust and contextaware representations. Additionally, the use of multi-head self-attention enables the model to effectively capture intricate relationships within the data, and the state space module models temporal dependencies efficiently.
Future research directions focus on advancing MorpMamba's capabilities in several impactful areas such as Domain Adaptation and Meta-Learning approaches will be systematically implemented to enhance MorpMamba's generalization across diverse HSI datasets originating from varied geographic regions and sensor platforms. Combining MorpMamba with additional remote sensing modalities, such as LiDAR and SAR, will enable the development of richer, multi-modal Earth observation models for advanced applications in environmental monitoring and Earth sciences. The extension of MorpMamba to multitemporal HSI data will support tasks such as change detection and time-series analysis, leveraging its capacity to model temporal dynamics effectively. By pursuing these directions, MorpMamba will not only advance the field of HSI but also contribute to network science and multimodal remote sensing.
## References
- [1] M. Ahmad, S. Shabbir, S. K. Roy, D. Hong, X. Wu, J. Yao, A. M. Khan, M. Mazzara, S. Distefano, and J. Chanussot, 'Hyperspectral image classification-traditional to deep models: A survey for future prospects,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2021.
- [2] D. Hong, C. Li, B. Zhang, N. Yokoya, J. A. Benediktsson, and J. Chanussot, 'Multimodal artificial intelligence foundation models: Unleashing the power of remote sensing big data in earth observation,' The Innovation Geoscience , vol. 2, no. 1, p. 100055, 2024.
- [3] Y. Li, D. Hong, C. Li, J. Yao, and J. Chanussote, 'Hd-net: High-resolution decoupled network for building footprint extraction via deeply supervised body and boundary decomposition,' ISPRS Journal of Photogrammetry and Remote Sensing , vol. 209, pp. 51-65, 2024.
- [4] J. Deng, D. Hong, C. Li, J. Yao, Z. Yang, Z. Zhang, and J. Chanussot, 'Rustqnet: Multimodal deep learning for quantitative inversion of wheat stripe rust disease index,' Computers and Electronics in Agriculture , vol. 225, p. 109245, 2024.
- [5] D. Hong, B. Zhang, H. Li, Y. Li, J. Yao, C. Li, M. Werner, J. Chanussot, A. Zipf, and X. X. Zhu, 'Cross-city matters: A multimodal remote sensing benchmark dataset for cross-city semantic segmentation using high-resolution domain adaptation networks,' Remote Sensing of Environment , vol. 299, p. 113856, 2023.
- [6] C. B. Pande and K. N. Moharir, 'Application of hyperspectral remote sensing role in precision farming and sustainable agriculture under climate change: A review,' Climate Change Impacts on Natural Resources, Ecosystems and Agricultural Systems , pp. 503-520, 2023.
- [7] D. Hong, B. Zhang, X. Li, Y. Li, C. Li, J. Yao, N. Yokoya, H. Li, P. Ghamisi, X. Jia, A. Plaza, P. Gamba, J. A. Benediktsson, and J. Chanussot, 'Spectralgpt: Spectral remote sensing foundation model,' IEEE Transactions on Pattern Analysis
- and Machine Intelligence , vol. 46, no. 8, pp. 5227-5244, 2024, dOI:10.1109/TPAMI.2024.3362475.
- [8] M. Ahmad, M. Usama, S. Distefano, and M. Mazzara, 'Hyperspectral image classification with fuzzy spatial-spectral class discriminate information,' in 2024 IEEE International Conference on Image Processing (ICIP) , 2024, pp. 2285-2291.
- [9] M. Ahmad, A. M. Khan, M. Mazzara, S. Distefano, M. Ali, and M. S. Sarfraz, 'A fast and compact 3-d cnn for hyperspectral image classification,' IEEE Geoscience and Remote Sensing Letters , vol. 19, pp. 1-5, 2022.
- [10] D. Hong, J. Yao, C. Li, D. Meng, N. Yokoya, and J. Chanussot, 'Decoupled-and-coupled networks: Self-supervised hyperspectral image super-resolution with subpixel fusion,' IEEE Transactions on Geoscience and Remote Sensing , 2023.
- [11] C. Li, B. Zhang, D. Hong, X. Jia, A. Plaza, and J. Chanussot, 'Learning disentangled priors for hyperspectral anomaly detection: A coupling model-driven and data-driven paradigm,' IEEE Transactions on Neural Networks and Learning Systems , 2024.
- [12] G. Jaiswal, A. Sharma, and S. K. Yadav, 'Critical insights into modern hyperspectral image applications through deep learning,' Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , vol. 11, no. 6, p. e1426, 2021.
- [13] U. Ghous, M. S. Sarfraz, M. Ahmad, C. Li, and D. Hong, '(2+1)d extreme xception net for hyperspectral image classification,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , pp. 1-14, 2024.
- [14] M. Ahmad, M. Usama, A. M. Khan, S. Distefano, H. A. Altuwaijri, and M. Mazzara, 'Spatial spectral transformer with conditional position encoding for hyperspectral image classification,' IEEE Geoscience and Remote Sensing Letters , pp. 1-1, 2024.
- [15] J. Yao, B. Zhang, C. Li, D. Hong, and J. Chanussot, 'Extended vision transformer (exvit) for land use and land cover classification: A multimodal deep learning framework,' IEEE Transactions on Geoscience and Remote Sensing , 2023.
- [16] X. Wu, D. Hong, and J. Chanussot, 'Convolutional neural networks for multimodal remote sensing data classification,' IEEE Transactions on Geoscience and Remote Sensing , vol. 60, pp. 1-10, 2021.
- [17] M. Ahmad, M. Usama, M. Mazzara, S. Distefano, H. A. Altuwaijri, and S. L. Ullo, 'Fusing transformers in a tuning fork structure for hyperspectral image classification across disjoint samples,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , pp. 1-15, 2024.
- [18] X. Huang, M. Dong, J. Li, and X. Guo, 'A 3-d-swin transformer-based hierarchical contrastive learning method for hyperspectral image classification,' IEEE Transactions on Geoscience and Remote Sensing , vol. 60, pp. 1-15, 2022.
- [19] M. Ahmad, M. H. F. Butt, M. Mazzara, S. Distefano, A. M. Khan, and H. A. Altuwaijri, 'Pyramid hierarchical spatialspectral transformer for hyperspectral image classification,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , pp. 1-10, 2024.
- [20] A. Gu and T. Dao, 'Mamba: Linear-time sequence modeling with selective state spaces,' arXiv preprint arXiv:2312.00752 , 2023.
- [21] K. Ayonrinde. (2024) Mamba explained. [Online]. Available: https://thegradient.pub/mamba-explained/
- [22] M. Ahmad, M. Usama, M. Mazzara, and S. Distefano, 'Wavemamba: Spatial-spectral wavelet mamba for hyperspectral image classification,' IEEE Geoscience and Remote Sensing Letters , pp. 1-1, 2024.
- [23] J. Yao, D. Hong, C. Li, and J. Chanussot, 'Spectralmamba: Efficient mamba for hyperspectral image classification,' arXiv preprint arXiv:2404.08489 , 2024.
- [24] L. Huang, Y. Chen, and X. He, 'Spectral-spatial mamba for hyperspectral image classification,' arXiv preprint arXiv:2404.18401 , 2024.
- [25] G. Wang, X. Zhang, Z. Peng, T. Zhang, X. Jia, and L. Jiao, 'S 2 mamba: A spatial-spectral state space model for hyperspectral
| | image classification,' arXiv preprint arXiv:2404.18213 , 2024. |
|------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [26] | Y. He, B. Tu, B. Liu, J. Li, and A. Plaza, '3dss-mamba: 3d- spectral-spatial mamba for hyperspectral image classification,' arXiv preprint arXiv:2405.12487 , 2024. |
| [27] | J. Sheng, J. Zhou, J. Wang, P. Ye, and J. Fan, 'Dual- mamba: A lightweight spectral-spatial mamba-convolution net- work for hyperspectral image classification,' arXiv preprint arXiv:2406.07050 , 2024. |
| [28] | W. Zhou, S.-I. Kamata, H. Wang, M.-S. Wong et al. , 'Mamba- in-mamba: Centralized mamba-cross-scan in tokenized mamba model for hyperspectral image classification,' arXiv preprint arXiv:2405.12003 , 2024. |
| [29] | A. Yang, M. Li, Y. Ding, L. Fang, Y. Cai, and Y. He, 'Graphmamba: An efficient graph structure learning vision mamba for hyperspectral image classification,' arXiv preprint arXiv:2407.08255 , 2024. |
| [30] | X. Yang, Y. Ye, X. Li, R. Y. Lau, X. Zhang, and X. Huang, 'Hyperspectral image classification with deep learning models,' IEEE Transactions on Geoscience and Remote Sensing , vol. 56, no. 9, pp. 5408-5423, 2018. |
| [31] | M. Ahmad, A. M. Khan, M. Mazzara, S. Distefano, S. K. Roy, and X. Wu, 'Hybrid dense network with attention mechanism for hyperspectral image classification,' IEEE Journal of Se- lected Topics in Applied Earth Observations and Remote Sens- ing , vol. 15, pp. 3948-3957, 2022. |
| [32] | Z. Xiong, Y. Yuan, and Q. Wang, 'Ai-net: Attention incep- tion neural networks for hyperspectral image classification,' in IGARSS 2018-2018 IEEE International Geoscience and Re- mote Sensing Symposium . IEEE, 2018, pp. 2647-2650. |
| [33] | X. Zhang, 'Improved three-dimensional inception networks for hyperspectral remote sensing image classification,' IEEE Ac- cess , vol. 11, pp. 32 648-32 658, 2023. |
| [34] | T. Shwetha, S. A. Thomas, V. Kamath et al. , 'Hybrid xcep- tion model for human protein atlas image classification,' in 2019 IEEE 16th India Council International Conference (IN- DICON) . IEEE, 2019, pp. 1-4. |
| [35] | H. Fırat, M. E. Asker, M. ˙ I. Bayındır, and D. Hanbay, 'Hy- brid 3d/2d complete inception module and convolutional neural network for hyperspectral remote sensing image classification,' Neural Processing Letters , vol. 55, no. 2, pp. 1087-1130, 2023. |
| [36] | S. K. Roy, R. Mondal, M. E. Paoletti, J. M. Haut, and A. Plaza, 'Morphological convolutional neural networks for hyperspec- tral image classification,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 14, pp. 8689-8702, 2021. |
| [37] | J. Z. Tahir Arshad and I. Ullah, 'A hybrid convolution trans- former for hyperspectral image classification,' European Jour- |
- [37] J. Z. Tahir Arshad and I. Ullah, 'A hybrid convolution transformer for hyperspectral image classification,' European Journal of Remote Sensing , vol. 0, no. 0, p. 2330979, 2024. | 10.1016/j.neucom.2025.129995 | [
"Muhammad Ahmad",
"Muhammad Hassaan Farooq Butt",
"Adil Mehmood Khan",
"Manuel Mazzara",
"Salvatore Distefano",
"Muhammad Usama",
"Swalpa Kumar Roy",
"Jocelyn Chanussot",
"Danfeng Hong"
]
| 2024-08-02T16:28:51+00:00 | 2024-11-30T13:24:19+00:00 | [
"cs.CV",
"eess.IV"
]
| Spatial and Spatial-Spectral Morphological Mamba for Hyperspectral Image Classification | Recent advancements in transformers, specifically self-attention mechanisms,
have significantly improved hyperspectral image (HSI) classification. However,
these models often suffer from inefficiencies, as their computational
complexity scales quadratically with sequence length. To address these
challenges, we propose the morphological spatial mamba (SMM) and morphological
spatial-spectral Mamba (SSMM) model (MorpMamba), which combines the strengths
of morphological operations and the state space model framework, offering a
more computationally efficient alternative to transformers. In MorpMamba, a
novel token generation module first converts HSI patches into spatial-spectral
tokens. These tokens are then processed through morphological operations such
as erosion and dilation, utilizing depthwise separable convolutions to capture
structural and shape information. A token enhancement module refines these
features by dynamically adjusting the spatial and spectral tokens based on
central HSI regions, ensuring effective feature fusion within each block.
Subsequently, multi-head self-attention is applied to further enrich the
feature representations, allowing the model to capture complex relationships
and dependencies within the data. Finally, the enhanced tokens are fed into a
state space module, which efficiently models the temporal evolution of the
features for classification. Experimental results on widely used HSI datasets
demonstrate that MorpMamba achieves superior parametric efficiency compared to
traditional CNN and transformer models while maintaining high accuracy. The
code will be made publicly available at
\url{https://github.com/mahmad000/MorpMamba}. |
2408.01373v1 | Draft version August 5, 2024 Typeset using L T E X A twocolumn style in AASTeX631
## Metrics of Astrometric Variability in the International Celestial Reference Frame: I. Statistical analysis and selection of the most variable sources
1
U.S. Naval Observatory, 3450 Massachusetts Ave NW, Washington, DC 20392-5420, USA
2 SYRTE, Observatoire de Paris, Universit´ PSL, CNRS, Sorbonne Universit´, LNE, 61 avenue de l'Observatoire 75014 Paris, France e e
(Received June 12, 2024; Revised July 19, 2024; Accepted July 22, 2024)
Submitted to ApJS
## ABSTRACT
Using very long baseline interferometry data for the sources that comprise the third International Celestial Reference Frame (ICRF3), we examine the quality of the formal source position uncertainties of ICRF3 by determining the excess astrometric variability (unexplained variance) for each source as a function of time. We also quantify multiple qualitatively distinct aspects of astrometric variability seen in the data, using a variety of metrics. Average position offsets, statistical dispersion measures, and coherent trends over time as explored by smoothing the data are combined to characterize the most and least positionally stable ICRF3 sources. We find a notable dependence of the excess variance and statistical variability measures on declination, as is expected for unmodeled ionospheric delay errors and the northern hemisphere dominated network geometries of most astrometric and geodetic observing campaigns.
Keywords: Astrometry(80), VLBI(1769),
## 1. INTRODUCTION
At the turn of the millennium, thirty years of developments in our understanding of extragalactic radio sources and the use of the very long baseline interferometery (VLBI) technique culminated in the 1997 adoption by the International Astronomical Union (IAU) of the International Celestial Reference Frame (ICRF; Ma et al. 1998), the realization at radio wavelengths of the International Celestial Reference System (ICRS; e.g., Arias et al. 1995). The ICRF, comprised of the VLBI positions of distant active galactic nuclei (AGNs), supplanted the preceding sequence of star-based catalogs including the Fifth Fundamental Catalogue (FK5; Fricke et al. 1988, 1991), Hipparcos (Perryman et al. 1997), and FK6 (Wielen et al. 2000). The ICRF has since undergone two major updates. ICRF2, replacing ICRF1 in 2010, saw a five-fold increase in the number of reference frame objects and selection of 'defining' sources based primarily on position stability, achieving a dramatic improvement in source position uncertainties and axis stability (Ma et al. 2009; Fey et al. 2015). ICRF3
(Charlot et al. 2020), adopted as the fundamental realization of the ICRS in 2019, 1 saw several major improvements. First, higher priority was placed on having defining sources uniformly distributed across the sky, resulting in a largely different set of defining sources from ICRF2. Second, the slow change in the galactocentric acceleration vector of the solar system, which induces a ∼ 5 µ as yr -1 aberration drift in extragalactic source positions (e.g., Kovalevsky 2003; Kopeikin & Makarov 2006; Titov et al. 2011), was modeled and accounted for. Finally, while ICRF1 and ICRF2 were defined in the standard geodetic S X / bands (2.3/8.4 GHz, respectively), ICRF3 includes K and X Ka / versions (24 GHz and 8.4/32 GHz, respectively), making it the first multiwavelength realization of the ICRS.
At visual (optical) wavelengths, the reference frame realized by the European Space Agency (ESA) Gaia astrometric mission (Gaia-CRF3; Gaia Collaboration et al. 2022) became the official instantiation of the ICRS
1 https://www.iau.org/static/resolutions/IAU2018 ResolB2 English.pdf
at the beginning of 2022, 2 replacing the venerable Hipparcos reference frame (ESA 1997) and for the first time producing an optical reference frame of precision comparable to the ICRF. The unprecedented precision of Gaia astrometry has been a mixed blessing, however, as previous hints that the apparent optical and radio positions of many ICRF objects do not quite agree (da Silva Neto et al. 2002; Assafin et al. 2013; Orosz & Frey 2013; Zacharias & Zacharias 2014) were brought into sharp relief (Kovalev et al. 2017; Makarov et al. 2017; Petrov & Kovalev 2017; Frouard et al. 2018; Makarov et al. 2019; Petrov et al. 2019; Liu et al. 2020). Given that the ICRF objects are by selection 'radio-loud', the natural interpretation of these offsets is that they have something to do with differences in the apparent optical and radio positions of AGN jets. Indeed, for VLBI sources with detected linear, jet-like radio features, there is a clear correlation between the position angle of the linear feature and that of the optical-radio offset (Kovalev et al. 2017; Petrov et al. 2019; Plavin et al. 2019a), and optical-radio offsets have been found to be correlated with radio source structure more generally (Xu et al. 2021). On the optical side, astrometry of AGNs is perturbed at the milliarcsecond level by extended structures of nearby host galaxies, gravitational microlensing effects, and optical and physical multiplicity (Makarov et al. 2012; Makarov & Secrest 2022).
While the radio and optical instantiations of the ICRS have seen dramatic improvements over the last few decades, it is clear that we are now in an era where the parsec-scale astrophysics of AGNs, especially as it pertains to their multi-wavelength and time-dependent morphologies, plays a regular and critical role in reference frame work. This has been the central focus of the Fundamental Reference AGN Experiment (FRAMEx; Dorland et al. 2020), which has so far focused on spatially resolved studies of the inner parsec of nearby AGNs using the Very Long Baseline Array (VLBA) with supporting data from other facilities (Fischer et al. 2021; Fernandez et al. 2022; Shuvo et al. 2022). At moderate redshifts, relativistic AGN jets can appear to exhibit motions significantly in excess of c for a range of jet angles with respect to the line-of-sight (LOS), due to special relativity. With the ∼ 8 pc mas -1 angular scale of a typical z = 1 source, 3 motion on the scale of a few tens of µ as is expected on the timescales of VLBI monitoring campaigns. Moreover, changes in the synchrotron opacity of the compact radio core due to, e.g., a flare may introduce 'core shift' variability (e.g., Plavin et al. 2019b), and the apparent position of the core itself is frequency-dependent, varying at the 0 1 . -1 mas level
2 https://www.iau.org/static/archives/announcements/pdf/ ann21040c.pdf
3 Where needed, we assume a flat ΛCDM cosmology with h = 0 7 . and Ω M = 0 3. .
for VLBI sources (e.g., Sokolovsky et al. 2011; Pushkarev et al. 2012).
If the radio positions of reference frame objects are dominated by a jet (as opposed to a compact, flatspectrum core), and the optical positions are skewed significantly away from the compact AGN accretion disk by this jet, then this presents a major challenge for the ICRF and instantiations of the ICRS more broadly. Indeed, methods for optimal alignment of reference frames at different wavelengths (e.g., by setting source weights) and accounting for wavelength and timedependent source positions are a central focus of a recently established IAU working group. 4 Weighting the ICRF according to source physics may indeed be possible in the immediate term. This was recently suggested by Secrest (2022), who showed that photometric variability information from Gaia can be used to dramatically reduce the rate of optical-radio offsets, and more broadly argued that photometric variability can be used to predict the likelihood of a source developing an optical-radio offset in the future, creating a means of optimally weighting ICRF sources.
Despite the growing body of work examining photometric and positional variability of ICRF and VLBI objects, to date there has not been a systematic examination of VLBI position variability of the ICRF as a whole. This is a major deficiency, as the catalog positions of ICRF objects are generally a mean value over one or more decades of VLBI sessions, with the sessions for some objects spanning nearly 40 years (in the S X / bands; Charlot et al. 2020). The time-averaged positions of the ICRF objects may therefore be in significant disagreement with their single-epoch positions (such as those used for spacecraft navigation), or their positions averaged over much shorter timescales (such as those from Gaia). An analysis quantifying the time-dependent positions of ICRF objects is therefore of utmost importance to reference frame work, and is likely also informative for studies of AGN jet physics and variability. Indeed, in a recent paper Lambert & Secrest (2024) show that, for a sample of 520 ICRF3 sources, VLBI position dispersion is inversely correlated with optical photometric variability, supporting the conclusion of Secrest (2022) that bona fide, line-of-sight blazars should be preferred for a positionally stable ICRF.
In this work, we present the first systematic analysis of VLBI source position variability of the ICRF. In Section 2, we give an overview of the VLBI sessions used, and how their data were handled. In Section 3, we discuss formal statistics and calculations relating to the distributions of VLBI position offsets in some detail, and discuss some of the systematics that may affect our findings. In Section 4, we discuss the methods we use
4 https://www.iau.org/static/science/scientific bodies/ working groups/329/charter icrf-multiwaveband-wg.pdf
to analyze the various categories of position variability. Our results are presented in Section 5, wherein we quantify the level of excess (unexplained) position variance in each source, correlations between excess variance and observational systematics (e.g., source declination), corrections for systematic-induced excess variance, and the nature and functional form of intrinsic (astrophysical) position variance. We also compare position variability with other measures of variability, such as radio and optical fluxes, and we quantitatively examine the role of VLBI position variability in optical-radio position offsets. Our main conclusions are listed in Section 6, after which we provide some qualitative recommendations for accounting for radio position variability in the context of the ICRF. Finally, a catalog of excess position covariances and corrections is supplied for ICRF3.
## 2. DATA
VLBI astrometric source positions are regularly determined through repeated observations using global networks of antennae over many years, from which the analyzed group delays are then combined and positions solved for in a global solution (for a recent review, see de Witt et al. 2022). Diurnal sessions are scheduled regularly by groups including the IVS, using networks of stations to create baselines of hundreds to thousands of kilometers long, to observe many radio sources multiple times over the course of 24 hours. Group delays for the sources and baselines are determined for each observation in a session by scientists at various analysis centers worldwide, including the U.S. Naval Observatory. The observations considered here use the standard simultaneous X/S band setup, where the S-band at 2.3 GHz is used for determining the ionosphere contribution to the delay, and improving the final solution defined at 8.4 GHz in the X-band.
We generated astrometric source position time series from 6581 of these diurnal sessions spanning back to 1980 using the software package Calc/Solve, which is maintained by NASA Goddard Space Flight Center (GSFC). 5 Parameters such as source and station positions, are solved for either 'globally' (a single resulting value) or as 'arc' parameters (estimates derived for each measurement). The solutions also solve for daily Earth orientation parameters and sub-daily troposphere delays and clock polynomials. The solution is tied to the ICRF3 frame by imposing a no-net-rotation constraint on the 303 ICRF3 defining sources from their official ICRF3 catalog values.
A series of five global solutions was executed, each in a similar manner to the standard procedure, but with a subset of one fifth of the source positions being solved for on a session-by-session basis as arc parameters, and
5 https://space-geodesy.nasa.gov/techniques/tools/calc solve/ calc solve.html
the remaining sources solved for globally. In this manner, iterating through five subsets of sources, a full time series of source positions in R.A. and declination, including their associated errors, was constructed for all ICRF3 source measurements. Quarterly global solution products and time series data are available for download at the USNO web pages. 6
It should be noted that the dataset used here has a few differences from the exact dataset used to generate ICRF3 in 2018 at GSFC. First, there are some early databases that have become unusable after conversion to a new database format. Second, many of the databases were analyzed independently at USNO and may differ slightly in terms of editing and parameterization. And third, approximately five additional years of X/S data have been collected since ICRF3 and are incorporated here.
Current USNO quarterly X/S global solutions combine measurements from over 5550 radio sources, but in the present work we only consider the 4536 sources constituting the ICRF3 catalog. To ensure meaningful statistics, we further restrict our considered sample to only include sources that were observed in at least 4 diurnal sessions, with at least 10 total observed delays, and with observations that span a minimum of 2 years. Thus, the following work is conducted on 4334 sources drawn from the full ICFR3 catalog, including 299 of the defining sources.
## 3. DISTRIBUTIONS OF VLBI ASTROMETRIC MEASUREMENTS
The collection of astrometric position measurements analyzed in this paper includes 322 013 single-epoch determinations for 5162 radio sources. The number of observations per object is quite uneven, with the modal value 5 and the greatest number 4876. Only 938 sources have more than 10 sessions. Eight sources have only one position determination-these are discarded from further analysis along with all individual measurement that have rank-deficient covariance matrices (i.e., have rank 1) or have condition numbers above 100. The latter criterion is meant to avoid numerically unstable results for nearly degenerate data. 7 The mathematical condition number quantifies sensitivity to perturbations in the data, with extremely high values rendering a matrix ill-conditioned. For a covariance matrix, the condition number equals the square of the ratio of the major and minor axes of the corresponding confidence ellipse. Thus, this filter removes all extremely elongated or degenerate (when ρ i = 1) error ellipses. The remaining
6 https://crf.usno.navy.mil/quarterly-vlbi-solution
7 Data points with poorly conditioned or rank-deficient covariances can still be utilized in the ML mean position calculation, with a little more toil.
number of sources is 5153 with 312 769 single-epoch determinations.
## 3.1. Testing the distribution of normalized position offset magnitudes
For compactness in the following discussion of position offsets and statistics, we now use the general and intuitive variables x and y to refer to the singleepoch right ascension and declination components, respectively. The normalized single-epoch position offset
$$D = \sqrt { \left ( x - \bar { x }, y - \bar { y } \right ) C ^ { - 1 } \left ( x - \bar { x }, y - \bar { y } \right ) ^ { T } } \quad \left ( 1 \right )$$
is a scalar variate, which is expected to be Rayleighdistributed with scale 1 for normally distributed residuals x -¯, x y -¯, y and accurate covariances C -1 . It provides the simplest means to test if the observed sample distribution of { x, y } positions is consistent with the assumption of binormal distribution, Eq. 4. There is a complication, however, arising from the fact that the estimated mean position { ¯ x, y ¯ } for each source is the sample mean, not the true position. This effectively removes two degrees of freedom from the D statistics for each source, or one observation. The resulting sample distribution of D values underestimates the true dispersion. To minimize this bias, we limit our analysis here to 288 853 position measurements of 921 sources with more than 10 measurements.
Fig. 1 shows the histogram of thus computed normalized offset magnitudes and, for comparison, the expected Rayleigh[1] distribution. Using the AndersonDarling hypothesis test, we estimated the probability ( p -value) that the two distributions come from the same statistical population and obtained zero. There are two obvious differences between the distributions. The top of the histogram is depleted because of the powerful tail stretching into the domain of high D values, which should be improbable for Gaussian-distributed PDFs. This is a fairly common situation with astronomical measurements, however. The deficit of values around the mode is caused by the heavy tail of the sample distribution stretching much beyond range of finite probabilities. The peak is slightly shifted from 1.
Based on the parameter D computed for each singleepoch observation, we introduce a robust statistical measure of astrometric 'noisiness' for each source Q 68, which is defined as the 0.68-quantile (or 68th percentile) of the sample distribution of D . The expected value of Q 68 within the null hypothesis, which is the 0.68 quantile of Rayleigh[1], equals 1.51. Therefore, sources with Q 68 values in excess of 1.51 are more astrometrically noisy or perturbed than should be expected from the given formal uncertainties. Effectively, this parameter is a robust alternative to the standard deviation of D values for a given source. Fig. 1, right, shows the histogram of Q 68 computed for the entire working sample of 5153 VLBI sources. The black vertical line marks the expected value 1.51. The sample distribution is peaked at a higher value than 1.51. Athin positive tail indicates that there are sources with most of the collected measurements strongly perturbed with respect to the formal uncertainty. While we find 27% of the sources to have Q 68 below 1.51, 6% are above 3, and 0.5% are above 10. These estimates of the noisiness may be underestimated for sources with small n obs by the loss of degrees of freedom.
## 3.2. Testing the distribution of standardized position offset vectors
Using the standardized position offset vectors with respect to the computed maximum likelihood (ML) positions (Section 3.6, Eq. 7), more specific analysis of the underlying distribution can be performed, including the remaining covariance not captured by the formal errors. The null hypothesis to be tested is that the vectors δ i for a given source come from the standard binormal distribution (Eq. 8). We implemented hypothesis tests for 5138 sources with more than 2 available measurements, using a total of 312 741 position determinations and the combined Mardia's method (Mardia 1970). The output p -values were further sorted in discrete bins by the corresponding n obs , and the median p -values computed for each bin. These median p -values versus log n obs are depicted in Fig. 2. We find that the null hypothesis is never accepted for n obs > 300. Sources with a small number of data points, n obs > 10, are often compliant with the binormal hypothesis and the given formal covariance. The median p -value of sources with 10 < n obs < 300 is equal to 0.05, with only 10% of their number having p -values above 0.52. We conclude that the frequently observed ICRF sources almost never follow the basic statistical model assumed in the data processing algorithms.
We can further test if the coordinate measurements { x, y } become uncorrelated upon standardization of variables. We computed the Spearman correlation (commonly known as Spearman ρ ) between the components of vectors δ i for each of 387 sources with n obs > 100. The full range of Spearman correlations is between -0 43 and +0 44, with 275 sources (71%) having val-. . ues within ± 0 1. . Thus, we find a significant fraction of the source sample with nonzero correlations between the standardized coordinates. We visually inspected the measured positions of several ICRF3 sources with the largest absolute values of Spearman correlations. In all these cases, the distribution of single-epoch positions is visibly elongated in directions not captured by the formal covariances. The sources with the greatest Spearman ρ values in excess of 0.4 are IERS B 0430+052, 1038+52A, 1451 -375, and 2353 -686.
Figure 1. Left: Histogram of normalized position offset magnitudes D (Eq. 1) for VLBI sources with more than 10 measurements. The expected Rayleigh distribution with scale 1 is shown as a black curve. Right: Histogram of 68th percentiles of normalized offsets D for 5370 VLBI sources. The black vertical line indicates the expected 68th percentile for a Rayleigh[1] distribution.
parameters. 8 The emerging distributions of D values on these large samples are mostly Gamma or Fr´ echet distributions, sometimes with a mixture of Lognormal, Extreme Value, or Cauchy distributions. The location parameters of the fitted Fr´chet distributions are always e negative. A negative location parameter is a technical feature caused by concave shape of the sample histograms in the lowest bins, i.e., a locally positive second derivative near zero. This can be interpreted as a zone of avoidance around the mean position, where the number density of data points is lower than a normal bell-shaped distribution would have. The shape parameters of the Gamma distributions are always above 2 but below 3.
Figure 2. Median p -values of the standard binormal distribution test versus decimal logarithm of n obs for 5138 VLBI sources with more than 2 position measurements.
## 3.3. Fitting distributions of standardized position offsets
We have seen evidence that the sample distributions of measured positions with respect to the ML mean positions are often inconsistent with the implicit assumption of binormally distributed errors specified by the formal covariances. Our goal is now to determine the character of actually measured position distributions. To this end, the powerful distribution fitting methods can be employed, which are available for univariate samples. The distribution-fitting routines also require sufficiently large samples to produce reliable results. Limiting this analysis to 86 ICRF3 sources with more than 1000 single-epoch measurements, best-fitting distributions were uniformly computed with free distribution
Fig. 3 illustrates the explicit inconsistency of the sample distributions of D with the assumed normal distributions for large n obs . The histogram includes 1249 singleepoch position offsets for the ICRF3 source 0016+731. The blue curve is the expected Rayleigh[1] distribution. The red curve is the fitted Fr´chet distribution with loe cation -3 46, shape 4.28, and scale 5.20. . The negative location of the fit explains why the red curve is above zero at D = 0, which is caused by a dearth of data points in close vicinity of the mean position.
In addition to one-dimensional distributions of normalized offsets D , we explore the marginal distributions of standardized offset vectors δ (Eq. 7). The null hypothesis is that they have standard normal distributions N [0 , 1] in both components. This hypothesis is rejected with p -values of zero for all the 86 most frequently observed sources. We further fitted the best-matching statistical distributions from an extensive list of analytical bivariate PDFs with free fitting parameters. The bestfitting empirical distributions are predominantly of two
Figure 3. Histogram of normalized position offset magnitudes D (Eq. 1) for the VLBI source 0016+731 with 1249 single-epoch measurements. The expected Rayleigh distribution with scale 1 is shown as a blue curve. The best-fitting Fr´ echet distribution with location -0 40, . shape 1.20, and scale 1.84, is shown with a red curve.
types: Logistic and Student t . The former have small mean parameters and scales mostly smaller than 1. The latter are found with scales slightly above 1 and degrees of freedom (dof) above 3. The Cauchy distribution is a particular case of Student t distribution with dof = 1, but our empirical distributions are less heavy-tailed. The standard normal distribution has dof = ∞ . For the test source 0016+731, the fit is Logistic[0 35 . , 1 56], . which has an unusual high scale.
## 3.4. Covariance and correlation
In the ICRF3 catalog, as well as in single-epoch VLBI position determinations, the a priori knowledge of the statistical uncertainties is represented by three numbers, namely, the formal errors of the celestial coordinates σ x and σ y , and their correlation ρ . The errors, which are square roots of the corresponding variances, refer to the two fixed unit vectors ˆ and ˆ in the tangent plane at a x y chosen reference point r ref on the sky (ESA 1997, Vol. 1). We note that ˆ, ˆ, and x y r ref are three-dimensional vectors, whereas a positional offset r -r ref can be considered two-dimensional, as long as it is projected onto the tangent plane at the reference point. With the radial dimension folded in the traditional astrometric model, the covariance becomes a 2 × 2 matrix. These vectors and matrices are defined in a specific coordinate system, which is the ICRS for VLBI measurements, i.e., the equatorial coordinate system with a fixed vernal equinox. The vectors ˆ and ˆ are then the local direcx y tions toward east (increasing RA) and north (increasing declination), respectively.
The following analysis mostly concerns the distributions of position differences (or position offsets) d = r -r ref and the tuples { x, y } , which include the projections x = d · ˆ and x y = d · ˆ. y Note that although the vector d is not orthogonal to r ref , the incurred error is totally negligible in the small-angle approximation, being of the order of 1 2 d 2 . These tuples can be treated as 2-vectors in the fixed tangential plane, and their distribution is therefore bivariate. By definition, the covariance matrix of ( x -x , y 0 -y 0 ) T is
$$C = \mathcal { E } [ ( x - x _ { 0 }, y - y _ { 0 } ) \left ( x - x _ { 0 }, y - y _ { 0 } \right ) ^ { T } ], \quad ( 2 )$$
where E is the expectation operator, and { x , y 0 0 } are the means of the corresponding variates. The covariance matrix takes the well known form:
$$C = \left ( \begin{array} { c c } \sigma _ { 1 } ^ { 2 } & \sigma _ { x } \, \sigma _ { y } \, \rho \\ \sigma _ { x } \, \sigma _ { y } \, \rho & \sigma _ { 2 } ^ { 2 } \end{array} \right )$$
only if the ( x, y ) vectors are drawn from a binormally distributed population with standard deviations { σ , σ x y } and correlation ρ . This implicit assumption is rarely spelled out in the astrometric literature, while having a crucial impact on the estimation of uncertainties, as we will see in the following.
The probability density function of the implicit binormal distribution is
$$\text{s} \\ \text{a} & \text{PDF} [ \mathcal { B } [ \{ x _ { 0 }, y _ { 0 } \} \, \{ \sigma _ { x }, \sigma _ { y } \}, \rho ] ] = \frac { 1 } { 2 \, \pi \, \sigma _ { x } \, \sigma _ { y } \, \sqrt { 1 - \rho ^ { 2 } } } \\ \text{i. } \\ \text{r} \\ \text{i. }$$
Direct calculation using Eq. 2 shows that the normal matrix B = C -1 . Eq. 3 follows directly from Eqs. 2 and 4. In this paper, we investigate sets of single-epoch measurements obtained at various sessions with the VLBI for a collection of radio-loud quasars. Each singleepoch measurement comes with a covariance matrix in the tangential plane. This information captures the inherent uncertainties related to photon noise and the observational circumstances of the session, such as the orientation of the baselines, dispersion of multiple calibration parameters, etc. The range of associated standard deviations can be quite large, and the most distant outliers tend to have large formal uncertainties. The formal 2D uncertainty in the tangent plane can be well represented by the lines of constant probability, known for binormal distribution as error ellipses. Specifically, the quadratic form ( x -x , y 0 -y 0 ) T C -1 ( x -x , y 0 -y 0 ) is distributed as χ 2 with two degrees of freedom, and the corresponding confidence level at χ 2 = 1 renders this equation of error ellipse:
$$\mathbb { c } _ { \text{tag} } ^ { \text{C-} } & \quad \frac { ( x - x _ { 0 } ) ^ { 2 } } { \sigma _ { x } ^ { 2 } } - 2 \rho \frac { ( x - x _ { 0 } ) ( y - y _ { 0 } ) } { \sigma _ { x } \sigma _ { y } } + \frac { ( y - y _ { 0 } ) ^ { 2 } } { \sigma _ { y } ^ { 2 } } = 1 - \rho ^ { 2 }. \\ \mathbb { u } _ { \text{tag} } & \quad \text{The second in} \, \colon = \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col.$$
The error ellipse is always inscribed in a rectangle with sides 2 σ x , 2 σ y . In a special case when ρ = 1, it degenerates into a straight line. We note that unlike the 1D
Figure 4. Single-epoch position measurements (black dots) and their associated error ellipses (dotted grey curves) obtained with the VLBI for the source IVS 0010+336. The plot is centered at the ML position computed in this analysis with the red ellipse representing its formal error ellipse. The blue circled dot marks the ICRF3 position for this source. The orange circled dot shows the position of the Gaia DR3 optical counterpart. Note the reversed x -axis, in accordance with the astronomical convention.
normal distribution, the probability that a random position measurement falls within an error ellipse is only 0.393. Fig. 4 shows an example of the observed configuration of position measurements (black dots) and their formal error ellipse (grey dotted curves) for the source IVS 0010+336 with six available single-epoch measurements. The error ellipses are conspicuously elongated in the south-north direction indicating a greater uncertainty of astrometric measurements of declination.
## 3.5. Estimation of the mean position
Quasars are generally assumed to be stationary astrometric sources with fixed positions on the sky. 9 The observed dispersion of single-epoch positions is then ascribed to random observational errors. Therefore, the consistent way of deriving the sample-mean position within the implicit hypothesis of binormality is to use the maximum likelihood (ML) principle, which defines the mean as the point of the highest joint probability. In the absence of evidence about correlations
9 Evidence has recently emerged that some quasars are not stationary, however (Titov & Frey 2020; Titov et al. 2023).
between individual measurements, we have to assume that they are independent, and the joint PDF is the product of individual probabilities (Eq. 4). The loglikelihood function includes the sum of quadratic forms ( x i -¯ x, y i -¯) y C -1 i ( x i -¯ x, y i -¯) y T , which has maximum at the most probable position (¯ x, y ¯). This optimization problem has a unique solution at
$$( \bar { x }, \bar { y } ) = \left ( \sum _ { i } C _ { i } ^ { - 1 } \right ) ^ { - 1 } \, \sum _ { i } C _ { i } ^ { - 1 } \, ( x _ { i }, y _ { i } ) ^ { T }. \quad ( 6 )$$
The leading factor is the covariance matrix of the ML position. The tangential coordinates entering this equation refer to a common origin at the celestial position r ref . The computation is invariant to the choice of reference position as long as it is sufficiently close to the single-epoch positions.
In Fig. 4, the computed ML position is at the origin of the local coordinate system, because we use this position as a new reference point. The red curve represents the formal error ellipse ( χ 2 = 1) of that position. The significant elongation in the declination dimension is inherited from the predominant direction of the single-measurement ellipses. The ML error ellipse is significantly smaller than each individual ellipse, because in this case, a few measurements with approximately equal uncertainties provide substantial reduction of formal dispersion. The weights in Eq. 6 being effectively quadratic, the ML estimation is most sensitive to data points with smaller formal variances. It is therefore crucially important to see if the formal errors faithfully capture the empirical dispersion, and, more generally, if the observed sample distributions are consistent with the implicit binormal distribution. The plot also illustrates the importance of using the full covariance (rather than just σ x and σ y ) when the mean VLBI positions are compared with other astrometric data, such as the optical Gaia positions.
## 3.6. Standardization of position measurements
For a given source, we are investigating a sample of position measurements with widely different formal covariances. The derived ML position is consistent with the implicit statistical hypothesis and becomes our new point of reference, but does the observed sample distribution confirm this initial assumption? To answer this question, a couple of standardized variables { u x i ( ) , u y i ( ) } is introduced, such that
$$\delta _ { i } \equiv ( u _ { x ( i ) }, u _ { y ( i ) } ) ^ { T } = C _ { i } ^ { - 1 / 2 } \, ( x _ { i } - \bar { x }, y _ { i } - \bar { y } ) ^ { T }. \quad ( 7 )$$
Note that the powers of C throughout this paper are matrix powers , not by-element operations. With this substitution of variables, the assumed PDF of a single measurement in Eq. 4 simplifies to
$$\ t a _ { ^ { * } } ^ { * } \\ \text{PDF} [ \mathcal { B } [ \{ \bar { x }, \bar { y } \} \{ 1, 1 \}, 0 ] ] = \frac { 1 } { 2 \, \pi } \exp \left ( - \frac { 1 } { 2 } \, \delta _ { i } ^ { T } \, \delta _ { i } \right ). \quad ( 8 )$$
The standardized formal distribution is rotationally symmetric with both standard deviations equal to unity and correlation equal to zero. Thus standardized singleepoch measurements, within the underlying hypothesis, become statistically uniform, in that they are expected to be drawn from the same population with a standard binormal distribution.
## 4. ANALYSIS
The fundamental goal of this work is to investigate the variability of source positions. For simplicity and clarity, we use offsets or differences from standard reference points - the official ICRF3 X/S positions - rather than directly using absolute Right Ascension and Declination coordinates. Total magnitudes of offsets (typically denoted 'total' herein) are given along with their orthogonal R.A. and decl. components.
We consider several metrics of variability to characterize the measured source position differences. As there are several forms and nuances of variability in a given dataset, we differentiate between three broad categories of variability for our time series in this work. The first two are roughly analogous to accuracy and precision, statistical measures of typical offsets and the dispersion in the overall measurements for a given source. The third category explored here is that of coherent trends of apparent motion or drift over time, which is also of great importance for assessing the quality of reference frame sources that might otherwise appear 'stationary' based on overall statistical population measures.
Standard statistics such as the mean, median, weighted root mean square (wrms), and standard deviation are intuitive and widely used, though they can be somewhat limited owing to outlier sensitivity and formal assumptions about the data being independent and identically (specifically, Normally) distributed. Descriptions of our statistics are given below, followed by a comparison and notable points of consideration.
## 4.1. Typical Offsets - Jitter
The typical offset from the ICRF3 coordinates is one crucial estimate of a source's variability that can readily highlight its suitability for use in reference frames. While all measurement distributions will have some dispersion, it is critical that on average the values center as closely as possible to the expected reference point. Outliers, correlations, mis-characterizations of the true uncertainties, and similar aspects of the data can greatly impact the effort to accurately summarize the distribution's properties, however. The measured sky coordinate components are not independent, therefore statistics that inherently treat right ascension and declination as paired values are more suitable than more rudimentary 1D measures such as the simple mean or median that treat each component separately.
We dub the collected set of individual measured offsets for a particular source over time the 'jitter', and
Figure 5. Example measurement 'jitter' offsets from the ICRF3 catalog position for a single source, 0322+222. The color of the scatter points corresponds to the number of delays observed for this source in each individual diurnal session measurement. Marginal distributions of the R.A. and Decl. component offsets are shown on the top and right subaxes, respectively. The covariance-weighted mean value and its components are indicated in the top corner.
from the jitter we calculate a variety of values, including the typical offset. Figure 5 shows an example of these jitter values for a single ICRF3 source, 0322+222. Various statistics capable of pairing values were explored in order to describe the typical jitter offset, such as the weighted geometric median and mean, but the covariance-weighted mean is the most straightforward statistic that fully utilizes the session coordinate covariance matrices. The details of calculating a covarianceweighted mean are discussed further in Sec. 3.5. Figure 6 shows the calculated covariance-weighted mean offsets for each source as individual datapoints. Zero here corresponds to no offset from a source's official ICRF3 position.
For summary statistics over all sources, we apply a reliability filter to our calculations, only considering sources here with at least four observing sessions, at least 10 delays measured in each session, and observations spanning at least two years. Figure 7 shows the distributions of the magnitudes of the covarianceweighted mean offsets (radius from reference position) for the sources. The ICRF3 defining sources have a median jitter magnitude offset of 48 µ as, whereas including the densifying sources, the median value is 137 µ as. From this perspective, the defining sources are on average more stable than the densifying sources, though that is at least partly owing to the defining sources typ-
Figure 6. Jitter - covariance-weighted mean offsets from ICRF3 positions, for time series of all ICRF3 sources (top) and the defining sources (bottom). The data points are colored by source declination. Marginal distributions of the R.A. and Decl. components are displayed in the side axes, and show a slightly larger dispersion in the N-S than the EWdirection owing to typical baseline geometry.
ically having much longer series of observations than the densifying sources.
## 4.2. Dispersion - wrms, Q 68 , and Excess Uncertainty
The dispersion of a dataset is another fundamental aspect of its variability, and there are numerous ways to characterize this. The closely related standard deviation and weighted root mean square (wrms) are two classic metrics under the assumption of Normally-distributed data. Fits to such data should satisfy χ 2 ν = 1 when the
Figure 7. Distributions of the total magnitude (combined R.A. and Decl.) of jitter (covariance-weighted mean) offsets for the full ICRF3 source list and the ICRF3 defining source list.
uncertainties perfectly reflect the distribution of measured data. The source position fits from global solutions are complicated however, and moreover the ICRF3 X/S sources have an imposed noise floor of 30 µ as in R.A. and decl., where any solution uncertainties below this level are inflated to maintain this minimum (Charlot et al. 2020). Frequently, the scatter seen contained within the time series can exceed the reported ICRF3 uncertainties. We introduce here an 'excess variance' to be added to the source coordinate uncertainties such that the combined variances (formal plus excess) on computed position offsets yield χ 2 ν = 1, in order to capture any extra or unmodeled variance and make it consistent with the formal assumptions.
For reference positions, we use the typical offset seen in the time series - the covariance-weighted mean jitter position described above, computed utilizing the full coordinate covariance matrices for each session. Then, for each coordinate component, 1 µ as of white noise is incrementally added in quadrature to the formal (inflated) time series uncertainties, until the resulting time series of position offsets result in χ 2 ν = 1. This excess error can be combined with the formal error in quadrature to give a better representation of the true statistical error in the data.
Histograms of these excess uncertainties are shown in Figure 8, and comparisons of excess errors in each component are plotted in Figure 9. The data there are colored by source declination, and show that more southerly sources tend to have higher excess errors than northern-sky sources, especially in the declination component; this will be discussed in more detail in Sec. 5.2. Many sources yield zero excess error - meaning the formal error adequately represents the data under
Figure 8. Histograms of excess error in R.A. and Decl. components computed from the time series of each source. The full ICRF3 source list is denoted by the darker shading while the defining sources are denoted by the lighter shading. The ICRF3 X/S noise floor values of 30 µ as are shown by the vertical dashed lines, for reference.
the formal assumptions - however most sources require some excess error, and on average they require similar amounts in both coordinate components as shown by the positive correlations in the plots.
We characterize the statistical spread in the source time series using the wrms as well as the astrometric 'noisiness' metric Q 68 introduced in Sec. 3.1. The combined error, comprising both the formal and calculated excess, is used to ensure the unmodeled error not captured in the formal errors is included.
## 4.3. STR: Smoothed Time-series Range
Several measures of variability have been discussed to characterize the typical offsets and dispersion of the observed positions of sources, but these do not necessarily capture long-term coherent variability. It is possible for source measurements to have a relatively tight dispersion in values estimated during similar epochs and still have notable coherent trends in the data whose significance may become diluted by large number statistics. Many sources show somewhat flat overall trends (with noise) for long periods but with occasional obvious deviations that may only span a few percent of the data, and therefore get somewhat washed out by statistical methods. Even spurious cases such as the large jump seen for 3C48 could even be muted by statistical methods, depending on how many epochs are sampled. Therefore it is important to investigate coherent trends in the data, as well as the statistical offset and dispersion measures discussed above. For reference frame work, where position stability is of the utmost importance, it is desirable to determine if a source exhibits significant variability regardless of its cause. We have an intuitive and robust approach to quantify this in a simple manner, described below.
First, we smooth the time series of each source to reduce scatter, and to help reveal any underlying trends. Rather than standard methods that use a constant number of data points for filtering, which has the effect of smoothing trends over potentially quite different time scales, we instead filter the time series using a specified time window. The choice of width or timespan for the filter window is important, as short windows will reduce the scatter less and longer windows could smooth over trends on time periods of interest. Several windows were tested, ranging from 30 to 360 days, and a 120-day window was found to have the optimal balance overall for reducing scatter as well as longer windows, but without blending obvious features and still being sensitive enough for months-long trends. For the occasional epochs when there are gaps or too few data points within a particular rolling 4-month window for the filter to be effective, continuity and smoothness were maintained by using a nominal window of N=3% of the array length in those periods instead. This yielded good results without jumps or discontinuities due to sampling.
The choice of filtering statistic can also impact the quality of smoothing. Several variations of means and medians were tested, both in terms of the flavor (such as standard mean/median vs geometric mean/median), and in terms of the weighting (standard weighting by each component independently as a control vs covariance-weighted versions of mean/median). The best results overall were achieved by using the covariance-weighted mean for the filter, for two primary reasons: it utilizes the full formal covariance matrix of each session; and while the median is less biased by outliers than the mean for large datasets, the sometimes sparse sampling within certain time windows results in more small jumps than the smoother results of the (covariance weighted) mean.
The total peak-to-peak range of observed offsets is a simple yet instructive measure of the total variability.
Figure 9. Comparison of R.A. and Decl. component values of excess error. The left column shows the excess errors alone, while the right column shows combined formal + excess error values. The top row includes all ICRF3 X/S sources and the bottom row shows only the ICRF3 X/S defining sources. The data points are colored by source declination, and show that excess and combined errors are somewhat larger for sources observed at lower declinations, though with a large spread. Marginal distributions of the R.A. and Decl. components are displayed in grey on the side axes.
While this would have been useless for the raw data, owing to the numerous extreme outliers, the peak-to-peak range of smoothed offsets is rather a useful measure, and intuitively corresponds to features that can be readily identified. We refer to this measure as STR (smoothed time-series range) hereafter, for compactness. Again we restrict these calculations to sources having at least 4 sessions, at least 10 observed delays per session, and observations that span at least two years. Figure 10 shows an example of the smoothed time series for ICRF3 defining source 0016+731 plotted as offset positions on the sky, and Figure 11 shows the same time series as well as STR values, broken down by coordinate component.
Collating the STR results from all ICRF3 sources, 541 sources have a maximum STR of less than 0.03 mas, 215 sources are better than 0.01 mas, and 179 are better than 0.005 mas. On the high variability end, 698, 81, and 27 sources have maximum STR > 1.0 mas, 5.0 mas, and 10.0 mas, respectively. 3C48 has the highest STR value of 57.8 mas, corresponding to the sudden 'jump' observed circa 2018. For the defining sources, 38 have a maximum STR of < 0.5 mas, 18 sources are < 0.4 mas, and only 5 sources are better than 0.3 mas. Many of the
Figure 10. Smoothed time series positions on the sky for ICRF3 defining source 0016+731. Time is denoted by the color scale. Gray background points are the unsmoothed time series. This reveals clear coherent position variability on the order of ∼ 0.4 mas on several-year timescales. This figure is available as an 8-second animation in the online version of this article. In the animation, a scroll bar progresses smoothly through the years spanning the astrometric VLBI sessions, and the scatter points representing the single-epoch position estimates appear at the time of their observations, tracking the observed positions over time as they appear on the sky, ultimately ending with the static image where all observations are included.
defining sources also have quite high maximum STR values - 138, 18, and 7 sources have maximum STR values > 1.0 mas, 5.0 mas, and 10.0 mas, respectively. This is at least partly due to the much longer observational histories of the defining sources than the majority of the densifying sources.
From this perspective, all quasars are astrometrically variable over months to years timescales, relevant to reference frame solutions. Figure 12 show histograms of the STR values by component for ICRF3 sources. The full ICRF3 source list is clearly (at least) bimodal in each of the R.A. and decl. components, with a subset of sources having typical STR variability ≲ 0.1 mas, and another subset centered around 1.0 mas. There are likely to be multiple smaller subsets superposed, given the broad tails. The defining sources are closer to a single-modal distribution with peak around 0.5 mas - on the high end compared to many of the densifying sources, though this is because of the typically much longer observational history.
## 5. RESULTS AND DISCUSSION
## 5.1. Variability Metric Comparison, and Ranking Sources
The celestial sources used in astrometric and geodetic observations that create the foundation of our reference frames can be ranked into various groups of quality, based on estimates of their stability. Given the rich and complex nature of the observed time series, sources can obviously be characterized as more or less variable depending on which metric is used. Not only is it important to consider multiple statistics in assessing the variability of sources, it is essential to look at additional metrics beyond the standard population statistics, and moreover it is critical to consider the combination of multiple types of variability in order to capture the multiple ways in which measured positions can appear to change over time.
For an example highlighting the value of these additional metrics of variability, and the importance of using different types of variability, consider the frequently observed ICRF3 source 2229+695. It has a total (R.A. plus decl.) formal error of 43 µ as, total wrms of 191 µ as, and even typical jitter offset from its formal ICRF3 position of 32 µ as. By these somewhat typical measures of variability, it would appear to be a quite stable reference frame object. However, inspection of the time series reveals that this source has a conspicuously large coherent positional variation over ∼ 10 years, which is not adequately captured by the simple statistics. (We discuss this striking source in more detail in a forthcoming paper, Cigan et al., in prep. ) The combined (formal plus excess) error of 137 µ as does better, but even if one were to attempt to determine the least variable sources by using strict filters of 0.1 mas mean jitter offset, 0.2 mas combined error, and 0.2 mas wrms - a combination which only this source and 0059+581 satisfy, among sources with at least 10 observing sessions this source with clear variability would be among them. The normalized offset metric Q 68 and STR do successfully capture its variable nature, though, with values of 3.5 and 0.8 mas, respectively.
The ideal reference source has the smallest possible average offset, small spread in measured data but with appropriate statistical uncertainty, and minimal drift or coherent motion over time. The numerous variability metrics considered in this work quantify different aspects of the variability in the astrometric measurement time series. The covariance-weighted mean values of the jitter offsets (Sec. 4.1) provide a robust statistical estimate of the mean position of each source, utilizing the full uncertainty and covariance information from each observing session. As the time series data are frequently heavy-tailed with large outliers, the formal errors of the data from the least-squares fit to the global solution of
## 120-day Window Covariance-Weighted Mean Filter; 0016+731
Figure 11. Smoothed time series and component STR metrics for ICRF3 defining source 0016+731. Time is on the x-axis. Gray background points are the unsmoothed time series, while colored points show the smoothed series. Vertical axis ranges have been optimized for the smoothed series. Panels from top to bottom show the RA cos(DEC) and DEC offset components, · the total offset magnitude, and the offset position angle (CCW from North).
all source time series often under-represent the true variability seen in the data. In order to capture the unmodeled error, we compute an excess error along with the jitter by incrementally adding white noise to component errors until χ 2 ν =1 is satisfied for the position measurements (Sec. 4.2). The statistical spread in the data can be assessed by a number of different methods, and a comparison of these is shown in Figure 13. One measure we use is the common weighted root mean square of the values, a straightforward estimate of the statistical spread in, e.g., mas. Q 68, the 68th percentile of the normalized position offsets D (Sec. 3.1), is another useful measure of how noisy the observed data are. This unitless quantity is somewhat akin to signal-to-noise measurement, as position offsets are scaled by uncertainties, and would be close to a value of 1.51 for ideally distributed data and uncertainties. Most sources have Q 68 values slightly larger than 1.51, indicating again that most sources have offset distributions with larger tails than expected for Gaussian statistics. Finally, we characterize the coherent motion over time with the simple STR metric introduced in Sec. 4.3, where the effect of outliers is reduced and the underlying long-term drift in a source's apparent position is determined by averaging
Figure 12. Left: Source STR (smoothed time-series range) values as a function of the number of sessions in their time series, separated by coordinate component. From top to bottom are right ascension, declination, and total magnitude. Sources with fewer sessions have seemingly low average STR values with large scatter, dramatically converging on a stable flat trend at a threshold of ∼ 15 sessions. Right: Histograms of the STR distributions for all ICRF3 sources, again separated by component. The defining sources are plotted with lighter shading, and the full set of ICRF3 sources with at least 15 observing sessions appear in darker shading. The ICRF3 sources with fewer than 15 sessions are also shown for reference with the light gray line, and demonstrate that time series with few observations ( ≤ 15 sessions) are distributed differently.
over a rolling four-month time window, with the STR being the maximum range in the smoothed time series. Even such a simple method is invaluable for capturing an aspect of the variability that the standard population statistics are not as sensitive to.
While simple rankings of sources by single metrics are useful for determining the best and worst with regards to a specific quantity of interest, this is a limited approach since variability can manifest in several ways within these data. Sources can appear quite stable according to one or several metrics, and still be highly variable according to another. A more complete picture of which sources are most or least variable and therefore suitable for reference frame work can be obtained by combining several different criteria of variability. Almost all ICRF3 sources show at least moderate variability in at least one metric; strict thresholds can effectively filter out variable sources by one metric, but essentially no source falls within the top tenth percentile of all metrics explored here. To determine lists of the 'best' sources, we employ slightly looser cuts to all considered metrics so that sources falling within the limits are those that have at least moderately low vari- ability measures by all counts are not highly variable by any count. Covariance-weighted mean jitter values below 0.1 mas are a reasonable cutoff here, and since many sources have combined (formal plus excess) errors above this level, a cutoff of 0.2 mas is better. As many sources have Q 68 values above the nominal R (1) 68th percentile value of 1.51, a more relaxed cutoff of 3.0 selects all sources with moderate offsets but rejects extreme outliers. A somewhat relaxed wrms threshold of 0.3 mas was found to be reasonable in combination with the other limits without excluding the remaining good sources. As previously mentioned, all sources are astrometrically variable to some degree on months or years timescales, as quantified by STR (and rarely below several mas); a cutoff of 0.5 mas over the lifetime of observing histories appears to be an appropriate upper limit when used in combination with the other values. Other rankings could of course be constructed using different cutoffs or weightings for different parameters, based on preference for which metrics to emphasize.
To assess the 'worst' sources, we employ two outlooks: one is similar to that above but opposite, where moderately high but not extreme cutoffs are enforced for all
## VLBI Position Variability I
Table 1. Overall Statistics for VLBI Measurements of ICRF3 Sources
| Statistic | X/S Defining Source Set | X/S Defining Source Set | X/S Full ICRF3 Set | X/S Full ICRF3 Set |
|-------------------------------------------|---------------------------------------|---------------------------------------|---------------------------------------|---------------------------------------|
| | Mean | Median | Mean | Median |
| Typical offset - jitter | Typical offset - jitter | Typical offset - jitter | Typical offset - jitter | Typical offset - jitter |
| jitter RA ( µ as) | 4.9 | 8.8 | 22.4 | 59.5 |
| jitter DEC ( µ as) | - 2.8 | - 2.3 | 9.4 | 3.2 |
| jitter Tot ( µ as) | 5.7 | 9.1 | 24.3 | 59.6 |
| jitter Tot Position Angle (deg, E from N) | 120.0 | 104.6 | 67.3 | 86.9 |
| Dispersion - wrms, excess error, Q 68 | Dispersion - wrms, excess error, Q 68 | Dispersion - wrms, excess error, Q 68 | Dispersion - wrms, excess error, Q 68 | Dispersion - wrms, excess error, Q 68 |
| wrms RA ( µ as) | 348.5 | 256.1 | 567.9 | 272.2 |
| wrms DEC ( µ as) | 473.4 | 334.5 | 927.8 | 442.9 |
| wrms Tot ( µ as) | 1024.7 | 720.2 | 1033.2 | 437.2 |
| s excess , RA ( µ as) | 138.8 | 115.0 | 351.2 | 123.0 |
| s excess , DEC ( µ as) | 353.7 | 202.0 | 743.3 | 272.5 |
| s excess , Tot ( µ as) | 394.8 | 243.8 | 892.9 | 348.1 |
| s combined , RA ( µ as) | 165.0 | 130.0 | 477.7 | 208.4 |
| s combined , DEC ( µ as) | 373.1 | 219.3 | 917.3 | 402.5 |
| s combined , Tot ( µ as) | 419.1 | 264.8 | 1075.5 | 476.2 |
| Q 68 | 1.93 | 1.91 | 2.05 | 1.86 |
| Coherent trends in time - STR | Coherent trends in time - STR | Coherent trends in time - STR | Coherent trends in time - STR | Coherent trends in time - STR |
| STR RA ( µ as) | 683.0 | 541.6 | 923.1 | 672.4 |
| STR DEC ( µ as) | 884.2 | 676.6 | 1279.6 | 804.3 |
| STR Tot ( µ as) | 662.3 | 485.0 | 1039.3 | 625.2 |
Note - Mean and median statistics for the overall distributions of the VLBI position variability metrics, for the full ICRF3 sample as well as the ICRF3 defining source sample. Source jitter statistics are reported for individual coordinate components, as well as for the total magnitude (RA and DEC combined) and the position angle of the mean/median total magnitude. The jitter statistics presented here are the covariance-weighted mean and covariance-weighted geometric median of the set of typical jitter offset values for each source. The position angles of the total offset follow the customary astronomical definition, in degrees East from North. s excess RA , and s excess DEC , denote excess variance in R.A. and decl., respectively, and s excess Tot , is the quadratically-summed excess error in both directions. s combined signifies the excess and formal errors combined. The weighted root mean square value of each component is denoted by the usual wrms. Q 68 refers to the 0.68-quantile of the normalized position offsets, a measure of the 'noisiness' of the distributions (see Sec. 3.1). STR refers to the smoothed time series range, and quantifies the maximum range in the offsets over time, after smoothing with a rolling four-month time window (see Sec. 4.3).
metrics (these sources are highly variable in all measures); and also one where sources that exhibit extreme variability in any measure are captured. For the purpose of these rankings, lower limits for which we consider sources to be highly variable by all metrics are at least 5.0 mas for each of the mean jitter, combined error, wrms, and STR. Of course, variability levels below these can still render a particular source unsuitable, but this combination highlights those sources which are the least stable by all measures. To capture the most ex- tremely variable sources by single metrics, we use cutoffs of 10.0 mas in any one of these parameters.
Table 2 lists the best and worst sources based on these rankings. The full table of values for all sources will be available in machine-readable format in the online journal. Again, here the best sources - the most stable on average with combinations of good values - are those that fall within at least moderate thresholds for all metrics, and we further restrict our consideration to only include those which have at least 30 sessions to ensure
Figure 13. Distributions of variability metrics in milliarcseconds for the full ICRF3 source list, by tangential coordinate component: right ascension in the left panels, declination in the right panels. The top row shows the distributions for sources detected in at least four diurnal sessions (and at least 10 delays in each), reflecting nearly all sources. The bottom row shows the same distributions but only for sources with 15 or more sessions, which excludes a large fraction of sources but represents those with more robust values. The dashed vertical line denotes the 30 µ as ICRF3 noise floor in each component, for reference. The red steps denote STR (smoothed time-series range) values, the yellow steps show the distribution of covariance-weighted mean jitter values, the grey hatched steps show the wrms, and the blue shaded histogram shows the combined (formal plus excess) error.
the results are more robust. For the full ICRF3 list of sources, those satisfying mean jitter < 0.10 mas, combined error < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas are the following 10 sources: 0017+200, 0059+581, 0137+012, 0613+570, 0749+540, 1053+704, 1300+580, 1357+769, 3C371, 1806+456. As was discussed earlier, the sources with the longest observational histories, which are generally the ICRF3 defining sources, almost all tend to have STR values above 0.5 mas. Considering only the ICRF3 defining sources, the seven which satisfy all these requirements are 0017+200, 0059+581, 0613+570, 0749+540, 1053+704, 1300+580, and 1357+769.
The worst sources - the least stable, shown to have one or more extreme variability measures - are again broken down here by ICRF3 defining and densifying sources. For all ICRF3 sources, 31 fall above a 5.0 mas limit in every one of the jitter, combined error, wrms, and STR parameters. 80 extreme sources have at least one value over the much higher threshold of 10.0 mas in at least one of those parameters. For the defining sources to which the translation and rotation of the ICRF3 frame are aligned, eleven fall above every limit of mean jitter > 0.3 mas, combined error > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas: 0038 -326, 0642 -349, 1116 -462, 1245 -454, 1306 -395, 1312 -533, 1511 -476, 1556 -245, 1600 -445, 1937 -101, and 2325 -150. For more extreme individual parameter outliers, 23 defining sources exceed at least one of the follow limits of mean jitter > 5.0 mas, combined error > 2.0 mas, wrms > 3.0 mas, or STR
> 2.0 mas: 0013 -005, 0038 -326, 0308 -611, 0316 -444, 0539 -057, 0742 -562, 0855 -716, 1027 -186, 1034 -374, 1116 -462, 1143 -332, 1406 -267, 1435 -218, 1451 -400, 1600 -445, 1642+690, 1706 -174, NRAO530, 1754+155, 1951+355, 2002 -375, 2220 -351, and 2325 -150. More observations could help reduce the computed variability measures for some of these sources, as most have relatively short observing histories. However, the defining sources are typically observed over hundreds to thousands of sessions, and many of them still exceed these high variability thresholds. This can be a potentially useful set of information to help inform prudent selections of future reference frame sources.
## 5.2. Dependence on Source Declination
Several VLBI-derived source position statistics exhibit features that vary with declination. A trend of increasing formal errors as source declinations decrease to ∼-40 ◦ was noted in the ICRF3 solution (Charlot et al. 2020, their Fig. 9), with the R.A. errors being less pronounced than the declination errors but still present. In our work, we also see this trend with formal errors, and moreover we see similar trends for the excess error discussed in Sec. 4.2. Figure 14 presents the combined (formal plus excess) errors of sources as a function of their declination, by coordinate component. The trend of increasing error as declination decreases is obvious, in particular for the declination component, with a clear cusp near -40 . This corresponds to the functional lower ele-◦ vation limit of many northern stations, in particular the VLBA, which has provided a large fraction of the data comprising the global solutions. When only looking at the defining sources, the trend is even clearer.
The visible dependence of statistical performance parameters on declination is an artifact caused by the instrument set-up and geometric configuration of the VLBI system. The majority of VLBI stations are located in the northern hemisphere. Within each session, a northern source is typically observed together with other northern sources in the phase-reference regime. This means that the baselines involved in each session are mostly east-west oriented. Since the primary measurable phase delay is the projection of the source position vector on the baseline vector, this asymmetry in the direction distribution of baseline vectors gives rise to the relative underperformance in the declination component. The geometric asymmetry, however, should be captured by the formal covariance of each single-epoch position, reflecting in the error ellipses elongated mostly in the south-north direction on the sky (Section 3.4 and Fig. 4). There are other technical circumstances, which may not be captured by the formal uncertainties. As noted before, the dual-bandwidth X/S mode of operation is mostly employed to calibrate one of the most difficult nuisance parameters-ionospheric delay bias.
Figure 14. Comparison of combined (formal plus excess) error with source declination for all ICRF3 sources with at least 4 sessions. From top to bottom, the panels show the combined error for the right ascension and declination components independently, followed by the total error (right ascension and declination components added in quadrature). Each panel shows the source data along with a rolling median in 5 degree bins, and histograms of values on the side axes. Data are color-coded by the number of observations, showing that the sources with more observations tend to have somewhat lower errors. There is a clear increase in typical source error as declination decreases to ∼ -40 , ◦ owing primarily to the network of stations mostly being located at northern latitudes. The effect is most pronounced for the declination component in particular, because of baselines typically being longer in E-W than N-S directions.

Table 2. Overall Variability Metrics by Source
| B1950 Name | J2000 Name | Other Name | Nses | N del | ∆mean , Tot | σ ex , Tot | σ comb , Tot | Q 68 | wrms Tot | STR Tot |
|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------|
| (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: | (mas) (mas) (mas) (mas) (mas) Defining Source List, Best Sources: |
| Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas |
| 0017+200 | ∆mean J0019+2021 | , PKS 0017+200 | 541 | 63937 | 0.041 | 0.159 | 0.165 | 2.07 | 0.230 | 0.163 |
| 0059+581 | J0102+5824 | TXS 0059+581 | 2879 | 535391 | 0.019 | 0.118 | 0.126 | 2.47 | 0.196 | 0.172 |
| 0613+570 | J0617+5701 | IVS B0613+570 | 418 | 66251 | 0.002 | 0.141 | 0.148 | 2.01 | 0.261 | 0.227 |
| | | 4C +54.15 | | | | 0.114 | 0.122 | 1.92 | 0.295 | 0.235 |
| 0749+540 | J0753+5352 J1056+7011 | S5 1053+70 | 1179 | 86097 75829 | 0.028 0.056 | 0.149 | 0.155 | 1.99 | 0.278 | 0.311 |
| 1053+704 1300+580 | J1302+5748 | TXS 1300+580 | 745 1401 | 122158 | 0.035 | 0.108 | 0.116 | 1.97 | 0.286 | 0.209 |
| 1357+769 | J1357+7643 | CGRaBS J1357+7643 | 2071 | 216829 | 0.026 | 0.068 | 0.080 | 1.74 | 0.176 | 0.098 |
| Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.5 mas, σ comb , Tot > 2.0 mas, wrms > 3.0 mas, or STR > 2.0 mas |
| 0013 - 005 | J0016 - 0015 | PKS 0013 - 00 | 114 | 3449 | 0.050 | 0.188 | 0.201 | 1.75 | 1.182 | 2.984 |
| 0038 - 326 | J0040 - 3225 | PKS 0038 - | | | | | | 1.61 | 5.184 | 2.306 |
| | | 326 | 32 | 681 | 0.340 | 0.523 2.189 | 0.855 | | | |
| 0308 - 611 | J0309 - 6058 | PKS J0309 - 6058 | 1344 | 47810 | 0.023 | | 2.190 | 1.99 | 0.478 | 0.403 |
| 0316 - 444 | J0317 - 4414 | ESO 248 - 6 | 25 | 389 | 0.085 | 2.150 | 2.183 | 2.11 | 4.720 | 1.627 |
| 0539 - 057 | J0541 - 0541 | PKS 0539 - 057 | 51 | 1844 | 0.174 | 0.439 | 0.456 | 1.94 | 3.899 | 0.796 |
| 0742 - 562 | J0743 - 5619 | CGRaBS J0743 - 5619 | 8 | 176 | 1.097 | 1.073 | 1.304 | 2.68 | 0.487 | 0.536 |
| 0855 - 716 | J0855 - 7149 | PKS 0855 - 716 | 8 | 82 | 0.581 | 0.681 | 0.737 | 1.48 | 0.379 | 0.420 |
| 1027 - 186 | J1029 - 1852 | PKS J1029 - 1852 | 105 | 3275 | 0.121 | 0.644 | 0.650 | 1.83 | 5.351 | 1.364 |
| 1034 - 374 | J1036 - 3744 | PKS J1036 - 3744 | 124 | 2922 | 0.060 | 2.121 | 2.123 | 2.26 | 1.332 | 1.431 |
| 1116 - 462 | J1118 - 4634 | PKS 1116 - 462 | 44 | 541 | 0.590 | 0.954 | 0.979 | 2.35 | 1.337 | 1.663 |
| Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas | Defining Source List, Worst Sources: ∆mean , Tot > 0.3 mas, σ comb , Tot > 0.5 mas, wrms > 0.5 mas, and STR > 0.5 mas |
| 0038 - 326 | J0040 - 3225 | PKS 0038 - 326 | 32 | 681 | 0.340 | 0.523 | 0.855 | 1.61 | 5.184 | 2.306 |
| 0642 - 349 | J0644 - 3459 | PKS 0642 - 349 | 35 | 1056 | 0.464 | 1.073 | 1.159 | 2.62 | 1.854 | 1.198 |
| 1116 - 462 | J1118 - 4634 | PKS 1116 - 462 | 44 | 541 | 0.590 | 0.954 | 0.979 | 2.35 | 1.337 | 1.663 |
| 1245 - 457 | J1248 - 4559 | PKS 1245 - 454 | 33 | 478 | 0.361 | 0.492 | 0.547 | 1.77 | 0.939 | 0.942 |
| 1306 - 395 | J1309 - 3948 | | 35 | | | | 0.906 | 1.92 | 0.618 | 0.959 |
| | | CGRaBS J1309 - 3948 | | 987 | 0.454 | 0.856 | | | | |
| 1312 - 533 1511 - 476 | J1315 - 5334 J1514 - 4748 | ICRF J131504.1 - 533435 ICRF J151440.0 - 474829 | 13 33 | 512 266 | 0.318 0.397 | 1.175 0.537 | 1.213 0.616 | 3.03 2.06 | 0.845 0.622 | 0.701 0.666 |
| | J1559 - 2442 | | 49 | 1833 | 0.471 | 1.332 | 1.341 | 2.03 | 1.374 | 0.886 |
| 1556 - 245 | | PKS 1556 - 245 | | | | | | | | |
| 1600 - 445 | J1604 - 4441 | ICRF J160431.0 - 444131 | 26 | 384 | 0.316 | 1.012 | 1.165 | 2.20 | 3.167 | 0.796 |
| 1937 - 101 | J1939 - 1002 | PKS 1937 - 101 | 48 | 1526 | 0.491 | 0.737 | 0.746 | 2.51 | 1.443 | 1.165 |
| Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: | Full Source List, Best Sources: |
| ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas | ∆mean , Tot < 0.1 mas, σ comb , Tot < 0.2 mas, Q 68 < 3.0, wrms < 0.3 mas, and STR < 0.5 mas |
| 0017+200 | J0019+2021 | PKS 0017+200 | 541 | 63937 | 0.041 | 0.159 | 0.165 | 2.07 | 0.230 | 0.163 |
| 0059+581 | J0102+5824 | TXS 0059+581 | 2879 | 535391 | 0.019 | 0.118 | 0.126 | 2.47 | 0.196 | 0.172 |
| 0137+012 | J0139+0131 | PKS J0139+0131 | 37 | | 0.060 | 0.097 | 0.147 | 1.37 | 0.297 | 0.282 |
| 0613+570 | J0617+5701 | IVS B0613+570 | 418 | 620 | 0.002 | 0.141 | 0.148 | 2.01 | 0.261 | 0.227 |
| 0749+540 | J0753+5352 | 4C +54.15 | 1179 | 66251 86097 | 0.028 | 0.114 | 0.122 | 1.92 | 0.295 | 0.235 |
| 1053+704 | J1056+7011 | S5 1053+70 | | | | | 0.155 | 1.99 | | |
| 1300+580 | J1302+5748 | TXS 1300+580 | 745 1401 | 75829 122158 | 0.056 0.035 | 0.149 0.108 | 0.116 | 1.97 | 0.278 0.286 | 0.311 0.209 |
| 1357+769 | J1357+7643 | CGRaBS J1357+7643 | 2071 | 216829 | 0.026 | 0.068 | 0.080 | 1.74 | 0.176 | 0.098 |
| 1807+698 | J1806+6949 | 3C 371 | 1457 | 191284 | 0.031 | 0.063 | 0.077 | 1.95 | 0.168 | 0.142 |
| 1806+456 | J1808+4542 | LB 1086 | 509 | 43701 | 0.043 | 0.151 | 0.157 | 2.01 | 0.240 | 0.230 |
| Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas | Full Source List, Worst Sources: ∆mean > 10.0 mas, σ > 10.0 mas, wrms > 10.0 mas, or STR > 10.0 mas |
| , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 | , Tot comb , Tot 42 |
| 0008 - 421 | J0010 - 4153 | PKS 0008 - | 14 | 167 | 2.570 | 9.954 | 10.012 | 5.14 | 12.930 | 6.226 |
| 0022 - 423 | J0024 - 4202 | PKS 0022 - 42 | 15 | 163 | 4.823 | 16.363 | 16.369 | 5.68 | 3.590 | 9.458 |
| 0030+196 | J0032+1953 | PKS 0030+19 | 8 | 108 | 3.597 | 18.607 | 18.786 | 6.65 | 7.116 | 7.110 |
| 0114 - 211 | J0116 - 2052 | PKS 0114 - 21 | 9 | 78 | 6.759 | 8.931 | 10.105 | 2.41 | 2.934 | 5.227 |
| 0134+329 | J0137+3309 | 3C 48 | 39 | 1681 | 56.716 | 54.225 | 54.232 | 15.77 | 13.022 | 56.894 |
| 0209+168 | J0211+1707 | TXS 0209+168 | 7 | 641 | 0.128 | 0.125 | 0.275 | 1.73 | 25.337 | 0.056 |
| 0304+124 | J0307+1241 | TXS 0304+125 | 5 | 234 | 7.775 | 7.773 | 10.276 | 0.88 | 0.562 | 0.257 |
| 0316+162 | J0318+1628 | CTA 21 | 18 | 1431 | 10.297 | 14.031 | 14.035 | 18.86 | 4.972 | 14.326 |
| | | | 206 | 7546 | 1.103 | | 3.321 | 3.62 | | |
| 0316+413 0350+177 | J0319+4130 J0352+1754 | 3C 84 TXS 0350+177 | 8 | 141 | 69.224 | 3.319 74.611 | 74.679 | 9.22 | 6.667 33.901 | 18.967 10.058 |
| Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas | Full Source List, Worst Sources: ∆mean > 5.0 mas, σ comb Tot > 5.0 mas, wrms > 5.0 mas, and STR > 5.0 mas |
| 0134+329 | J0137+3309 | , Tot 3C 48 | , 39 | 1681 | 56.716 | | 54.232 | 15.77 | 13.022 | 56.894 |
| 0350+177 | J0352+1754 | TXS 0350+177 | 8 | 141 | 69.224 | 54.225 74.611 | 74.679 | 9.22 | 33.901 | 10.058 |
| 0709+008 | J0711+0048 | PKS J0711+0048 | 9 | 89 | 11.459 | 13.416 | 14.234 | 3.37 | 5.587 | 9.971 |
| | | | | | | 5.916 | 7.975 | | | |
| 0741 - 444 | J0743 - 4434 | ICRF J074332.7 - 443405 | 13 | 104 | 5.380 | | | 2.65 | 7.735 | 8.572 |
| 0912 - 330 | J0914 - 3314 | PKS J0914 - 3314 3144 | 8 | 166 | 5.006 | 9.761 | 9.824 | 12.46 | 5.182 | 7.249 11.646 |
| 1015 - 314 | J1018 - 3144 | PKS J1018 - | 10 | 68 | 17.159 | 20.583 | 21.514 | 2.58 | 14.592 | 12.388 |
| 1306+660 | J1308+6544 | 3C 282 PKS 1320 - 44 | 8 | 48 | 20.190 | 26.692 | 28.494 71.094 | 1.92 9.97 | 11.813 17.874 | 33.561 |
| 1320 - 446 1323+321 | J1323 - 4452 J1326+3154 | 4C +32.44 | 9 10 | 45 215 | 10.761 9.882 | 71.042 8.685 | 8.782 | 4.33 | 9.906 | 11.298 |
| 1328+254 | J1330+2509 | 3C 287 | 8 | 274 | 39.816 | 72.269 | 72.275 | 50.17 | 19.710 | 47.664 |
Note - Lists of up to the first 10 'best' and 'worst' sources in the full ICRF3 and defining source samples, based on numerous variability metrics. All sources have at least N sessions ≥ 4, N delays ≥ 10 per session, and a minimum span of 2 years observing history, though the best sources have a stricter requirement of 30 or more observing sessions to improve the reliability of the results. Nses and Ndel are the number of sessions and total delays, respectively. ∆mean denotes the covariance-weighted mean 'jitter' position offset from the ICRF3 reference coordinates. The designation 'Tot' means that both RA and DEC components are included. σ ex denotes excess error, and σ comb denotes the combined error calculated as the quadratic sum of the excess error and the formal error. Q 68 is the 68th percentile of the normalized position offsets D . The weighted root-mean-square values are denoted by wrms. STR denotes the smoothed time-series range. The full table, including R.A. and decl. components of these metrics, is published in its entirety in machine-readable format. The ranked portion shown here illustrates its form and content.
This systematic error is known to be time-variable, so that the unaccounted short-term variations introduce a stochastic component of the measured delays, mostly affecting the declination component. Thus, some of the proposed astrometric variability measures may be almost free of this instrumental error overhead, while others are subject to it in full measure.
Indeed, not all variability metrics vary with declination -Q 68 is quite flat, as is STR. Other variability measures do have variation similar to the errors however, notably the wrms values of the source time series. The covariance-weighted mean jitter offsets also show a similar trend, though much less pronounced than the position errors and only for the full ICRF3 catalog; for the defining sources, which typically have high numbers of observations, the mean jitter is roughly constant with declination.
These trends with declination are not astrophysical in origin. The errors, jitter, and wrms were also compared to latitudes in other coordinate frames including Galactic and supergalactic coordinates. Similar though less pronounced trends were seen in Ecliptic latitude as expected, as it is so close to Equatorial coordinates, however no significant trends were found with respect to Galactic or supergalactic latitudes. These apparent trends with declination are primarily owing to the fact that most observed data were recorded by stations in the northern hemisphere. Therefore more southerly sources are observed through higher columns of atmosphere, which can suffer from larger atmosphere gradients, and sources observable by these stations at their lower elevation limits tend to have increased uncertainties and variability. Most of these trends have a cusp at -40 degrees in declination, which is the functional approximate lower observing limit for the northern stations.
## 5.3. Looking Ahead: Implications for Reference Frames and Future Prospects
One immediately obvious use case for this information is for potential selection criteria in future reference frames, such as ICRF4. Of course, each iteration is an immense undertaking that combines the efforts of varied groups and collections of complex and evolving data sets, and many insights can only be obtained with the benefit of retrospection after the collection of more data. As each generation builds upon the foundations and improves upon the sometimes unavoidable limitations of the frames that preceded them, we can continue to use new analyses such as these to continue to refine and improve the reference frames upon which many global applications rely.
Future enhancements to the software that produces the global solutions could include use of information presented here. For example, the longer-term coherent trends highlighted by the physically-motivated timewindow smoothed series could potentially be incorpo- rated into a priori models of secular trends. Future work into correcting for measured positions in global solutions by using models of the source structure and bulk motion could result in more precise position estimates that could translate to better reference frames, though care must be taken to keep the process from becoming circular, and ensuring enough degrees of freedom to adequately solve for all necessary parameters.
We are currently preparing several manuscripts to further explore more aspects of these time series. One paper will focus on several sources with conspicuous trends, playfully dubbed 'wandering quasars' (Cigan et al., in prep. ). Another will investigate characteristic timescales in these data using Allan Variance and wavelet methods (Cigan et al., in prep. ), which will complement a novel robust periodogram method tested with these data (Makarov et al. 2024). Another project of interest using these data includes investigating the true rates of radio-optical offsets, which will build on exciting new findings from Lambert & Secrest (2024) that blazars selected on optical photometric variability are generally more astrometrically stable objects.
Continued observations will of course be necessary to improve the estimates of source positions and their uncertainties, in a statistical sense - both in the legacy X/S band framework as well as reference frame observations at other frequencies and observing modes. This new analysis provides some insight into which areas of focus could be targeted to improve specific metrics of interest to reference frame work. Utilizing more southern hemisphere stations to observe southern sources through less atmosphere would improve the uniformity of errors across the sky, and longer N-S baselines would provide a better lever arm for determining the declination component. The incorporation of excess (unmodeled) errors could reflect the true uncertainty in a source's series of observed positions better than the current formal errors, which are frequently underestimated. Dedicated sessions to specifically target less-frequently observed sources and obtain time series with at least 15 sessions, for example the campaign undertaken with the VLBA at USNO, can not only help to improve the accuracy and precision of solved positions in global solutions (explored here via metrics such as the jitter and Q 68), but also allow for more robust determinations of coherent trends over time (e.g., the STR). A more sophisticated treatment of solved positions in global solution software, based on structure maps and information such as the 4month window smoothed time series tracks, could potentially result in better estimates of solved source positions - no sources are pure point sources without apparent positional variability, so incorporation of source structure models and observed secular trends where appropriate could provide improvement on standard least-squares fits of source positions. These of course are not simple efforts that can be quickly achieved, but if they are able to be supported they have the potential to improve our
reference frames, and in turn any applications that rely upon them. Finally, we note that frequency-dependent source position, for example between emission peaks of the S and X bands, is an unmodeled source of error in the apparent position of the source. However, group delay-based positions, like those used for the ICRF, are less affected by these position shifts than phase delaybased positions, not being affected at all if the shift is proportional to ν -1 (Porcas 2009).
## 6. CONCLUSIONS
Combining millions of astrometric and geodetic VLBI group delay measurements observed across 6581 sessions over the course of more than four decades of international efforts, we have produced time series of positions on the sky for over 5550 radio sources, including all 4653 sources comprising the ICRF3 X/S catalogue. This first paper in a planned series of analyses of various aspects of these time series focuses on the overall statistical aspects of the position data, with studies into characteristic timescales and other aspects of the data to to be covered in future works. Given the obvious richness and complexity of information contained within the datasets, multiple different metrics were explored that characterize distinct aspects of positional stability or variability, broadly falling into three qualitative categories. These are:
- · Typical offset of single-epoch measurements ('jitter'). For each source, we calculate this using the covariance-weighted mean, a robust estimate utilizing the full covariance information - including RA-DEC correlations - recorded for each singleepoch measurement.
- · Multiple estimates of the dispersion in the data, including the wrms of the position estimates, the 0.68-quantile Q 68 of the normalized position offsets D , and determinations of excess variance that would need to be added to the formal errors for the observed position measurements to satisfy χ 2 ν =1.
range, a value we simply dub the smoothed timeseries range (STR).
No single metric is sufficient to adequately quantify positional stability, as all sources exhibit some form of astrometric variability with sufficient sampling in time, and combinations of different metrics should be used when gauging source quality for use in reference frame work. We found solid statistical evidence that, whenever ICRF3 radio sources have been observed frequently enough for an extended period of time, the distribution of positional residuals based on diurnal observations exceeds the expected dispersion represented by the formal errors and their covariances. This distribution is explicitly non-Gaussian, creating a tension with the assumptions used in the computation of the weighted mean positions in the ICRF. We investigated different metrics, which quantify the degree of perturbation observed for individual sources. These metrics allow us to rank the currently observed ICRF3 sources with respect to their long-term astrometric stability, and reprioritize the scheduling principles. Continued research into this phenomenon on both theoretical and empirical levels is warranted, given the fundamental importance of ICRF in the general construction of celestial measurements and navigation.
This work supports USNO's ongoing research into the celestial reference frame and geodesy. The National Radio Astronomy Observatory is a facility of the National Science Foundation operated under cooperative agreement by Associated Universities, Inc. The authors acknowledge use of the Very Long Baseline Array under the U.S. Naval Observatory's time allocation. This research made use of Astropy, 10 a community-developed core Python package for Astronomy (Astropy Collabo1 2 3 4 5 6 7 8 9
- ration et al. 2013, 2018, 2022). 10
## Facilities: VLBA,
- · A measure of the overall variation observed in coherent trends over time - determined here by smoothing the data using a rolling four-month window in time (as opposed to fixed N datapoints) and calculating the maximum position
Software: astropy (Astropy Collaboration et al. 2013, 2018, 2022), ipython (Perez & Granger 2007), Mathematica (Wolfram Research, Inc. 2024), matplotlib (Hunter 2007), numpy (van der Walt et al. 2011), pandas (pandas development team 2020; Wes McKinney 2010), pysymlog (Cigan 2024)
## REFERENCES
Arias, E. F., Charlot, P., Feissel, M., & Lestrade, J. F. 1995, A&A, 303, 604
Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33,
Assafin, M., Vieira-Martins, R., Andrei, A. H., Camargo,
J. I. B., & da Silva Neto, D. N. 2013, MNRAS, 430, 2797, doi: 10.1093/mnras/stt081
doi: 10.1051/0004-6361/201322068
Astropy Collaboration, Price-Whelan, A. M., Sip˝cz, B. M., o et al. 2018, AJ, 156, 123, doi: 10.3847/1538-3881/aabc4f
| Astropy Collaboration, Price-Whelan, A. M., Lim, P. L., et al. 2022, ApJ, 935, 167, doi: 10.3847/1538-4357/ac7c74 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Charlot, P., Jacobs, C. S., Gordon, D., et al. 2020, A&A, 644, A159, doi: 10.1051/0004-6361/202038368 |
| Cigan, P. 2024, pysymlog - Symmetric (signed) logarithm scale for your python plots, 1.0, Zenodo, doi: 10.5281/zenodo.11087515 |
| da Silva Neto, D. N., Andrei, A. H., Vieira Martins, R., & Assafin, M. 2002, AJ, 124, 612, doi: 10.1086/341163 |
| de Witt, A., Charlot, P., Gordon, D., & Jacobs, C. S. 2022, Universe, 8, 374, doi: 10.3390/universe8070374 |
| Dorland, B., Secrest, N., Johnson, M., et al. 2020, in Astrometry, Earth Rotation, and Reference Systems in the GAIA era, ed. C. Bizouard, 165-171. https://arxiv.org/abs/2009.02169 |
| ESA, ed. 1997, ESA Special Publication, Vol. 1200, The HIPPARCOS and TYCHO catalogues. Astrometric and photometric star catalogues derived from the ESA HIPPARCOS Space Astrometry Mission |
| Fernandez, L. C., Secrest, N. J., Johnson, M. C., et al. 2022, ApJ, 927, 18, doi: 10.3847/1538-4357/ac4b5f |
| Fey, A. L., Gordon, D., Jacobs, C. S., et al. 2015, AJ, 150, 58, doi: 10.1088/0004-6256/150/2/58 |
| Fischer, T. C., Secrest, N. J., Johnson, M. C., et al. 2021, ApJ, 906, 88, doi: 10.3847/1538-4357/abca3c Fricke, W., Schwan, H., Lederle, T., et al. 1988, |
| Veroeffentlichungen des Astronomischen Rechen-Instituts Heidelberg, 32, 1 |
| Fricke, W., Schwan, H., Corbin, T., et al. 1991, Veroeffentlichungen des Astronomischen Rechen-Instituts Heidelberg, 33 |
| Frouard, J., Johnson, M. C., Fey, A., Makarov, V. V., & Dorland, B. N. 2018, AJ, 155, 229, doi: 10.3847/1538-3881/aabafa |
| Gaia Collaboration, Klioner, S. A., Lindegren, L., et al. 2022, arXiv e-prints, arXiv:2204.12574. https://arxiv.org/abs/2204.12574 |
| Hunter, J. D. 2007, Computing in Science and Engineering, 9, 90, doi: 10.1109/MCSE.2007.55 |
| Kopeikin, S. M., & Makarov, V. V. 2006, AJ, 131, 1471, doi: 10.1086/500170 |
| Kovalev, Y. Y., Petrov, L., & Plavin, A. V. 2017, 598, L1, doi: 10.1051/0004-6361/201630031 |
| Kovalevsky, J. 2003, A&A, 404, 743, doi: 10.1051/0004-6361:20030560 |
| Lambert, S., & Secrest, N. J. 2024, A&A, doi: 10.1051/0004-6361/202348842 |
| Liu, N., Lambert, S. B., Zhu, Z., & Liu, J. C. 2020, A&A, 634, A28, doi: 10.1051/0004-6361/201936996 |
| A&A, |
Ma, C., Arias, E. F., Eubanks, T. M., et al. 1998, AJ, 116, 516, doi: 10.1086/300408
Ma, C., Arias, E. F., Bianco, G., et al. 2009, IERS Technical Note, 35, 1
Makarov, V., Berghea, C., Boboltz, D., et al. 2012, Mem. Soc. Astron. Italiana, 83, 952, doi: 10.48550/arXiv.1202.5283
Makarov, V. V., Berghea, C. T., Frouard, J., Fey, A., & Schmitt, H. R. 2019, ApJ, 873, 132, doi: 10.3847/1538-4357/aafa1c
Makarov, V. V., Frouard, J., Berghea, C. T., et al. 2017, ApJL, 835, L30, doi: 10.3847/2041-8213/835/2/L30
Makarov, V. V., Lambert, S., Cigan, P., DiLullo, C., & Gordon, D. 2024, PASP, 136, 054503, doi: 10.1088/1538-3873/ad4b9f
Makarov, V. V., & Secrest, N. J. 2022, ApJ, 933, 28, doi: 10.3847/1538-4357/ac7047
Mardia, K. V. 1970, Biometrika, 57, 519, doi: 10.2307/2334770
- Orosz, G., & Frey, S. 2013, A&A, 553, A13, doi: 10.1051/0004-6361/201321279
pandas development team, T. 2020, pandas-dev/pandas: Pandas, latest, Zenodo, doi: 10.5281/zenodo.3509134 Perez, F., & Granger, B. E. 2007, Computing in Science and Engineering, 9, 21, doi: 10.1109/MCSE.2007.53 Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, L49
Petrov, L., & Kovalev, Y. Y. 2017, MNRAS, 467, L71, doi: 10.1093/mnrasl/slx001
Petrov, L., Kovalev, Y. Y., & Plavin, A. V. 2019, MNRAS, 482, 3023, doi: 10.1093/mnras/sty2807
Plavin, A. V., Kovalev, Y. Y., & Petrov, L. Y. 2019a, ApJ, 871, 143, doi: 10.3847/1538-4357/aaf650
Plavin, A. V., Kovalev, Y. Y., Pushkarev, A. B., & Lobanov, A. P. 2019b, MNRAS, 485, 1822, doi: 10.1093/mnras/stz504
Porcas, R. W. 2009, A&A, 505, L1, doi: 10.1051/0004-6361/200912846
Pushkarev, A. B., Hovatta, T., Kovalev, Y. Y., et al. 2012, A&A, 545, A113, doi: 10.1051/0004-6361/201219173 Secrest, N. J. 2022, ApJL, 939, L32, doi: 10.3847/2041-8213/ac8d5d
Shuvo, O. I., Johnson, M. C., Secrest, N. J., et al. 2022,
ApJ, 936, 76, doi: 10.3847/1538-4357/ac874a
Sokolovsky, K. V., Kovalev, Y. Y., Pushkarev, A. B., &
Lobanov, A. P. 2011, A&A, 532, A38, doi: 10.1051/0004-6361/201016072
Titov, O., & Frey, S. 2020, Research Notes of the American Astronomical Society, 4, 108, doi: 10.3847/2515-5172/aba42c
Titov, O., Lambert, S. B., & Gontier, A. M. 2011, A&A, 529, A91, doi: 10.1051/0004-6361/201015718
Titov, O., Frey, S., Melnikov, A., et al. 2023, AJ, 165, 69, doi: 10.3847/1538-3881/aca964
van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011,
Computing in Science and Engineering, 13, 22, doi: 10.1109/MCSE.2011.37
- Wes McKinney. 2010, in Proceedings of the 9th Python in Science Conference, ed. St´fan van der Walt & Jarrod e Millman, 56 - 61, doi: 10.25080/Majora-92bf1922-00a
- Wielen, R., Schwan, H., Dettbarn, C., et al. 2000, Heidelberg, 37, 1
Veroeffentlichungen des Astronomischen Rechen-Instituts Wolfram Research, Inc. 2024, Mathematica, Version 14.0. https://www.wolfram.com/mathematica Xu, M. H., Lunz, S., Anderson, J. M., et al. 2021, A&A, 647, A189, doi: 10.1051/0004-6361/202040168 Zacharias, N., & Zacharias, M. I. 2014, AJ, 147, 95, doi: 10.1088/0004-6256/147/5/95 | 10.3847/1538-4365/ad6772 | [
"Phil Cigan",
"Valeri Makarov",
"Nathan Secrest",
"David Gordon",
"Megan Johnson",
"Sebastien Lambert"
]
| 2024-08-02T16:29:32+00:00 | 2024-08-02T16:29:32+00:00 | [
"astro-ph.IM",
"astro-ph.GA"
]
| Metrics of Astrometric Variability in the International Celestial Reference Frame: I. Statistical analysis and selection of the most variable sources | Using very long baseline interferometry data for the sources that comprise
the third International Celestial Reference Frame (ICRF3), we examine the
quality of the formal source position uncertainties of ICRF3 by determining the
excess astrometric variability (unexplained variance) for each source as a
function of time. We also quantify multiple qualitatively distinct aspects of
astrometric variability seen in the data, using a variety of metrics. Average
position offsets, statistical dispersion measures, and coherent trends over
time as explored by smoothing the data are combined to characterize the most
and least positionally stable ICRF3 sources. We find a notable dependence of
the excess variance and statistical variability measures on declination, as is
expected for unmodeled ionospheric delay errors and the northern hemisphere
dominated network geometries of most astrometric and geodetic observing
campaigns. |
2408.01374v1 | ## Hybrid Coordinate Descent for Efficient Neural Network Learning Using Line Search and Gradient Descent
Yen-Che Hsiao and Abhishek Dutta
Abstract -This paper presents a novel coordinate descent algorithm leveraging a combination of one-directional line search and gradient information for parameter updates for a squared error loss function. Each parameter undergoes updates determined by either the line search or gradient method, contingent upon whether the modulus of the gradient of the loss with respect to that parameter surpasses a predefined threshold. Notably, a larger threshold value enhances algorithmic efficiency. Despite the potentially slower nature of the line search method relative to gradient descent, its parallelizability facilitates computational time reduction. Experimental validation conducted on a 2-layer Rectified Linear Unit network with synthetic data elucidates the impact of hyperparameters on convergence rates and computational efficiency.
Impact Statement -This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here.
Index Terms -Feedforward neural networks, gradient methods, machine learning.
## I. INTRODUCTION
## A. Problem Description
We are given n input-label training samples S = { X i , y i } n i =1 where X i ∈ R p represents the feature vector of the i -th data composed of p features, y i ∈ R denotes the corresponding labels.
We consider a two-layer neural network of the following form,
$$\Gamma, & f ( \mathbf W, A, \vec { x } ) = \frac { 1 } { \sqrt { m } } \sum _ { r = 1 } ^ { m } a _ { r } \sigma ( \vec { w } _ { r } ^ { T } \vec { x } ), & \quad ( 1 ) & \quad \text{Sev} \\ & \quad \text{case 0} \\ & \quad \text{$\dots$} \, \Gamma.$$
where m ∈ R is the number of neurons, ⃗ x ∈ R p is a feature vectors with p features, ⃗ w r ∈ R p are the weight vectors in the first hidden layer connecting to the r -th neuron, W = { ⃗ w r } m r =1 , A = { a r } m r =1 is the set of weights in all other layers, σ x ( ) = max x, { 0 } is the rectified linear unit (ReLU) activation function [1].
For this paper, we will use a combination of gradient descent and coordinate descent with Jacobi method [2] to minimize the mean square error (MSE) loss defined as
$$L ( \mathbf W, A, \mathbf X ) = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { n } ( f ( \mathbf W, A, \mathbf X _ { i } ) - y _ { i } ) ^ { 2 }, \quad ( 2 ) \ \ D. \ M a _ { \mathbf R e c \mathbf \L }$$
Yen-Che Hsiao is with the Department of Electrical and Computer Engineering, University of Connecticut, Storrs CT 06269, USA. (e-mail: [email protected]).
Abhishek Dutta is with the Department of Electrical and Computer Engineering, University of Connecticut, Storrs CT 06269, USA.
where X = { X i } n i =1 , and compare their performance in terms of convergence rate per epoch, computational complexity, and memory usage.
## B. Motivation
Over-parameterized Deep Neural Networks (DNNs) have garnered considerable attention owing to their potent representation and broad generalization capabilities [3]. In scenarios where the neural network is over-parameterized, the quantity of hidden neurons can greatly surpass either the input dimension or the number of training samples [4]. Despite classical learning paradigms issuing warnings against over-fitting, contemporary research indicates the prevalence of the "double descent" phenomenon, wherein substantial over-parameterization paradoxically enhances generalization [5].
A recent study has demonstrated that, in the case of twolayer neural networks, when learning is restricted locally within the neural tangent kernel space around particular initializations, neural networks behave like convex systems as the number of hidden neurons approaches infinity [6]. By leveraging the approximate convexity characteristic inherent in such neural networks, it may be possible to identify more effective optimizers (in contrast to the commonly employed gradient descent (GD) method) for training such neural networks.
## C. Related Work
Several recent theoretical studies have revealed that in the case of exceedingly wide neural networks, wherein the number of hidden units scales polynomially with the size of the training data, the gradient descent algorithm, initiated from a random starting point, converges towards a global optimum [7], [8]. Bu, Zhiqi et al. [9] demonstrate, from a dynamical systems perspective, that in over-parameterized neural networks, the Heavy Ball (HB) method converges to the global minimum of the mean squared error (MSE) at a linear rate similar to gradient descent, whereas the Nesterov accelerated gradient descent (NAG) may only achieve sublinear convergence.
## D. Major Challenges
Recent research has demonstrated that an overparameterized neural network has the potential to converge to global optima under various conditions [10] or offer iteration complexity guarantees with different lower bounds on the number of neurons [8]. However, the majority of studies predominantly focus on
utilizing gradient descent. With appropriate initialization, the training dynamics of over-parameterized DNNs during gradient descent can be characterized by a kernel function known as the neural tangent kernel (NTK) [11] as outlined by Jacot et al. [12]. Moreover, as the layer widths increase significantly, the Neural Tangent Kernel (NTK) converges to a deterministic limit that remains constant throughout training; therefore, in the scenario of infinite width, a key requirement for gradient descent to achieve zero loss is to ensure that the smallest eigenvalue of the NTK is kept away from zero [13]. A potential challenge lies in the fact that the methodology for analyzing neural network properties may vary depending on the optimization techniques employed. We aim to investigate whether other optimization methods can yield superior outcomes.
## E. Proposed Method
We experiment with the coordinate descent with Jacobi method outlined in Exercise 2.3.2 of the textbook by Bertsekas [2]. Let g : R n → R be a continuously differentiable convex function. For a given ⃗ x ∈ R n and all i = 1 , . . . , n , define the vector ⃗ x ∗ by ⃗ x ∗ i ∈ arg min ξ ∈ R g ⃗ ( x , . . . , ⃗ 1 x i -1 , ξ, ⃗ x i +1 , . . . , ⃗ x n ) .
The Jacobi method performs simultaneous steps along all coordinate directions, and is defined by the iteration
$$\vec { x } \coloneqq \vec { x } + \alpha ( \vec { x } ^ { * } - \vec { x } ), \quad \quad \ \ ( 3 ) \quad \text{of} \, \text{th}$$
for α ∈ R .
## II. METHODS
For our hybrid coordinate descent, the weights in the first layer are updated using (3) by
$$\vec { w } _ { r } \coloneqq \vec { w } _ { r } + \alpha ( \vec { w } _ { r } ^ { * } - \vec { w } _ { r } ), \quad \quad \ ( 4 ) \quad \text{to th} \quad \text{$\quad$}$$
where α = 1 n , r = 1 , . . . , m , and ⃗ w ∗ r i ∈ arg min g w ( ⃗ r 1 , . . . , w ⃗ r i -1 , ξ, ⃗ w r i +1 , . . . , w ⃗ r n ) .
ξ
∈
R
We propose to use either the gradient of the loss with respect to the weight or coordinate descent to determine ⃗ w ∗ r in the Jacobi method in (3) for updating the parameters in the neural network defined in (1).
Each element in the vector ⃗ w ∗ r is updated using gradient by
$$\vec { w } _ { r _ { i } } ^ { * } \coloneqq \vec { w } _ { r _ { 1 } } - \frac { \partial L ( \mathbf W, A, \mathbf X ) } { \partial \vec { w } _ { r _ { i } } }, \quad \ \ ( 5 ) \, \begin{array} { c } \, \begin{array} { c } \, \end{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{arrayarray} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \begin{array} { c } \, \end{array} \, \begin{array } \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} { c } \, \end{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \\ \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \\ \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array}} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \\ \, \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array}} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array$$
if the gradient ∂L ( W ,A, X ) is larger than a threshold dw ∈ R .
∂ ⃗ w r i If ∂L ( W ,A, X ) ∂ ⃗ w r i < dw , ⃗ w ∗ r i is determined by a line search algorithm described as follows. First, we compute
$$L ( \mathbf W _ { r _ { i } } ^ { + }, A, \mathbf X ) = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { n } ( f ( \mathbf W _ { r _ { i } } ^ { + }, A, \mathbf X _ { i } ) - y _ { i } ) ^ { 2 } \quad ( 6 )$$
and
$$L ( W _ { r _ { i } } ^ { - }, A, X ) = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { n } ( f ( \mathbf W _ { r _ { i } } ^ { - }, A, \mathbf X _ { i } ) - y _ { i } ) ^ { 2 }, \quad ( 7 ) \begin{array} { c } \text{of com} \\ \text{our hy} | \\ \text{to that} \end{array} \end{array}$$
where W + r i = { ⃗ w , . . . , w 1 ⃗ i -1 , δ + , w ⃗ i +1 , . . . , w ⃗ m } , δ + = ⃗ w i + ϵ , W -r i = { ⃗ w , . . . , w 1 ⃗ i -1 , δ -, w ⃗ i +1 , . . . , w ⃗ m } , δ -= ⃗ w i -ϵ , and ϵ = dw . Next, if L ( W + r i , A, X ) > L ( W -r i , A, X ) , we will keep decreasing ϵ by ϵ := ϵ -dw and computing (7) until the updated L ( W -r i , A, X ) is less than the previous one. If L ( W + r i , A, X ) < L ( W -r i , A, X ) , we will keep increasing ϵ by ϵ := ϵ + dw and computing (6) until the updated L ( W + r i , A, X ) is less than the previous one. If (6) is the same as (7), we will iterate to the next weight variable.
## III. EXPERIMENT RESULTS AND DISCUSSION
In this section, we use synthetic data (similar to [14]) to compare the coordinate descent with Jacobi method and gradient descent and to demonstrate the effect of the hyperparameter, dw , to the convergence rate and the computational complexity. We uniformly generate n = 10 data points from a d = 1000 -dimensional unit sphere and generate labels from a one-dimensional standard Gaussian distribution. Given a prediction network in (1), we initialize each weight vector in the first layer ⃗ w r from a standard Gaussian distribution and initialize the weight in the last layer A from a uniform distribution over the interval [ -1 1] , .
From Fig. 1, we can see that the convergence rate of our hybrid coordinate descent is faster than the gradient descent for the network with different number of hidden nodes. However, the comparison of the computational time between the two methods in Fig. 2 shows that using gradient descent, the training of the 2-layer ReLU network for 100 epochs takes no more than the computational time of one epoch of our hybrid coordinate descent. In Fig. 3, we illustrate the memory usage of the random access memory for the two methods. It clearly demonstrates that the memory usage of the coordinate descent method is significantly higher than that of gradient descent.
Next, we show the effect of different threshold value, dw , to the performance of training the ReLU network. In Fig. 4, it shows that with higher value of dw , we can have a better convergence rate compare to the network that is trained with a smaller value of dw . The reason behind this may be that as dw is higher, more of the parameters will be updated by the line search method and these parameters that are updated by the line search method may result in a lower loss value compared to the gradient method. As a result, our hybrid method with higher dw has a better convergence rate compared to that with a smaller dw . In Fig. 5, it shows that with larger dw , the computational time is smaller than the network trained with a smaller dw . The reason may be that the step size of the line search algorithm with a higher dw is larger than the hybrid method with a smaller dw . Therefore, the one with a higher dw can terminate the line search earlier than the one with a smaller dw .
## IV. CONCLUSION
From the result, we can see that gradient descent is a better method than our hybrid coordinate descent in terms of computational time. However, if the computational time of our hybrid coordinate descent can be optimized to be close to that of in gradient descent, the convergence rate can be significantly improved since the loss decrease faster per epoch in the hybrid coordinate descent than gradient descent. Since gradient descent in PyTorch benefits from optimization in
Fig. 1: The natural logarithm of the loss with respect to epoch for the training of 2-layer ReLU network using gradient descent and our hybrid coordinate descent with various numbers of weight ( m ) in the first layer and with dw = 0 5 . .
Fig. 2: The natural logarithm with respect to the computational time (wall-clock time) for training of 2-layer ReLU network in 100 epochs using gradient descent and our hybrid coordinate descent with various numbers of weight ( m ) in the first layer and with dw = 0 5 . .
Fig. 3: The natural logarithm of the loss with respect to epoch for the training of 2-layer ReLU network using gradient descent and our hybrid coordinate descent with various numbers of weight ( m ) in the first layer and with dw = 0 5 . .
Fig. 4: The natural logarithm of the loss with respect to epoch for the training of 2-layer ReLU network using our hybrid coordinate descent with various numbers of weight ( m ) in the first layer and with different value of dw .
C++ code, while the implementation of the coordinate descent with Jacobi method is solely in Python, we think it is better to compare the two method without the C++ version of the gradient descent. In addition, the line minimization method we used may not be the best in terms of computational time. Thus, the future work of the study is to find out how to optimize the computational time in the hybrid coordinate descent or to see how to modify this method such that it can have a similar computational time to gradient descent. This could lead to faster convergence. Furthermore, since coordinate descent is designed for parallel computation, it is possible to implement parallelization and improve its speed.
Fig. 5: The natural logarithm of the loss with respect to time for the training of 2-layer ReLU network using our hybrid coordinate descent with various numbers of weight ( m ) in the first layer and with different value of dw .
## REFERENCES
- [1] V. Nair and G. E. Hinton, 'Rectified linear units improve restricted boltzmann machines,' in Proceedings of the 27th international conference on machine learning (ICML-10) , pp. 807-814, 2010.
- [2] D. P. Bertsekas, 'Nonlinear programming,' Journal of the Operational Research Society , vol. 48, no. 3, pp. 334-334, 1997.
- [3] T. Ergen and M. Pilanci, 'Convex geometry and duality of overparameterized neural networks,' J. Mach. Learn. Res. , vol. 22, jan 2021.
- [4] S. Du and J. Lee, 'On the power of over-parametrization in neural networks with quadratic activation,' in Proceedings of the 35th International Conference on Machine Learning (J. Dy and A. Krause, eds.), vol. 80 of Proceedings of Machine Learning Research , pp. 1329-1338, PMLR, 10-15 Jul 2018.
- [5] C. Liu, D. Drusvyatskiy, M. Belkin, D. Davis, and Y. Ma, 'Aiming towards the minimizers: fast convergence of sgd for overparametrized problems,' in Advances in neural information processing systems , vol. 36, 2024.
- [6] C. Fang, Y. Gu, W. Zhang, and T. Zhang, 'Convex formulation of overparameterized deep neural networks,' IEEE Transactions on Information Theory , vol. 68, no. 8, pp. 5340-5352, 2022.
- [7] S. Oymak and M. Soltanolkotabi, 'Toward moderate overparameterization: Global convergence guarantees for training shallow neural networks,' IEEE Journal on Selected Areas in Information Theory , vol. 1, no. 1, pp. 84-105, 2020.
- [8] D. Zou and Q. Gu, 'An improved analysis of training over-parameterized deep neural networks,' in Advances in Neural Information Processing Systems (H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, eds.), vol. 32, Curran Associates, Inc., 2019.
- [9] Z. Bu, S. Xu, and K. Chen, 'A dynamical view on optimization algorithms of overparameterized neural networks,' in Proceedings of The 24th International Conference on Artificial Intelligence and Statistics (A. Banerjee and K. Fukumizu, eds.), vol. 130 of Proceedings of Machine Learning Research , pp. 3187-3195, PMLR, 13-15 Apr 2021.
- [10] C. Fang, H. Dong, and T. Zhang, 'Mathematical models of overparameterized neural networks,' Proceedings of the IEEE , vol. 109, no. 5, pp. 683-703, 2021.
- [11] J. Ye, Z. Zhu, F. Liu, R. Shokri, and V. Cevher, 'Initialization matters: Privacy-utility analysis of overparameterized neural networks,' in Advances in Neural Information Processing Systems , vol. 36, 2024.
- [12] A. Jacot, F. Gabriel, and C. Hongler, 'Neural tangent kernel: Convergence and generalization in neural networks,' in Advances in Neural Information Processing Systems (S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, eds.), vol. 31, Curran Associates, Inc., 2018.
- [13] S. Bombari, M. H. Amani, and M. Mondelli, 'Memorization and optimization in deep neural networks with minimum over-parameterization,' in Advances in Neural Information Processing Systems (S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, eds.), vol. 35, pp. 7628-7640, Curran Associates, Inc., 2022.
- [14] S. S. Du, X. Zhai, B. Poczos, and A. Singh, 'Gradient descent provably optimizes over-parameterized neural networks,' in International Conference on Learning Representations , 2019. | null | [
"Yen-Che Hsiao",
"Abhishek Dutta"
]
| 2024-08-02T16:29:54+00:00 | 2024-08-02T16:29:54+00:00 | [
"cs.LG"
]
| Hybrid Coordinate Descent for Efficient Neural Network Learning Using Line Search and Gradient Descent | This paper presents a novel coordinate descent algorithm leveraging a
combination of one-directional line search and gradient information for
parameter updates for a squared error loss function. Each parameter undergoes
updates determined by either the line search or gradient method, contingent
upon whether the modulus of the gradient of the loss with respect to that
parameter surpasses a predefined threshold. Notably, a larger threshold value
enhances algorithmic efficiency. Despite the potentially slower nature of the
line search method relative to gradient descent, its parallelizability
facilitates computational time reduction. Experimental validation conducted on
a 2-layer Rectified Linear Unit network with synthetic data elucidates the
impact of hyperparameters on convergence rates and computational efficiency. |
2408.01375v1 | ## Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets
Victor A. Borza, B.E. , Andrew Estornell, Ph.D. 1 2,3 , Ellen Wright Clayton, M.D., J.D. , 1 Chien-Ju Ho, Ph.D. , Russell L. Rothman, M.D., M.P.P. , Yevgeniy Vorobeychik, Ph.D. , 3 1 3 Bradley A. Malin, Ph.D. 1
1 Vanderbilt University, Nashville, TN; ByteDance Research, San Jose, CA; Washington 2 3 University in St. Louis, St. Louis, MO
## Abstract
Large participatory biomedical studies - studies that recruit individuals to join a dataset - are gaining popularity and investment, especially for analysis by modern AI methods. Because they purposively recruit participants, these studies are uniquely able to address a lack of historical representation, an issue that has affected many biomedical datasets In this work, we define representativeness as the similarity to a target population distribution of a set of . attributes and our goal is to mirror the U.S. population across distributions of age, gender, race, and ethnicity. Many participatory studies recruit at several institutions, so we introduce a computational approach to adaptively allocate recruitment resources among sites to improve representativeness. In simulated recruitment of 10,000-participant cohorts from medical centers in the STAR Clinical Research Network, we show that our approach yields a more representative cohort than existing baselines. Thus, we highlight the value of computational modeling in guiding recruitment efforts.
## Introduction
Spurred by recent innovations in artificial intelligence (AI) and machine learning (ML), large biomedical datasets are providing revolutionary insights into health and healthcare. Many of these datasets involve secondary uses of existing data, such as electronic health records (EHRs) collected by academic medical centers in the context of patient care. 1 In contrast to these secondary use datasets, participatory datasets are comprised of purposively recruited participants who choose to join and share their data. There has been recent interest, as well as billions of dollars of investment from funding agencies such as the National Institutes of Health, in multi-site participatory datasets including the Bridge2AI Voice project, AI-READi, and the 2 3 All of Us Research Program. Participatory datasets yield several 4 benefits over data originating from non-recruited settings. Notably, programs like All of Us include participants as partners, which may guide research study design and improve inclusion and communication between researchers and 5 participants. Moreover, participatory studies can adapt their recruitment practices to align their cohort with certain 6 goals, like being representative of a population or improving recruitment of groups historically underrepresented in research. 3,7 While recognizing that several definitions of representativeness have been proposed, 8-11 in this work we rely on a definition common in the literature that a representative cohort is similar to a target population when considering some attributes of interest.
Diverse representation is critical for biomedical research for several reasons. 12,13 First, per the 1979 Belmont Report, underrepresentation of population subgroups may reflect institutionalized biases and conflict with the Principle of Justice. 14,15 Second, representation supports perceptions of legitimacy. 16 Conversely, lack of representation may undermine trust in the research enterprise. 17 Third, representation bias can skew the associations that researchers may identify. 18 Moreover, the efficacy of predictive models in specific subgroups can vary widely based on the representation of those subgroups in training datasets, which has contributed to multiple forms of non-trivial bias in biomedical and non-biomedical settings. 19-21 Fourth, lack of representation may compromise the generalizability of research to underrepresented groups. 17 Often, these underrepresented groups are also marginalized. Thus, lack of representation limits innovation in, as well as access to, effective medical interventions, and costs hundreds of billions of dollars via perpetuated health disparities and inequities. 17 Despite these numerous harms, biomedical research cohorts across fields of medicine have struggled to sufficiently represent the entire population they intend to study. 2227 Within informatics, demographic data are incompletely reported in many studies applying ML models to EHR data, and when model developers report demographics, they often reveal unrepresentative training datasets. 27 Thus, there is an urgent need for methods to improve representation in participatory biomedical datasets, a need echoed by the U.S. White House. 28
There have been several investigations into improving representation in datasets, though few have been directly applicable to recruitment in multi-site participatory datasets. When subjects or records can be selected according to the attributes that define representation, or any other use-specific constraints like quotas, more representative cohorts can be constructed. 29-31 Other studies have described processes for sampling records to improve algorithmic fairness (i.e., decrease disparate predictions or performance between groups) when a specific downstream task is known a priori . 32,33 However, these methods assume that subjects or records may be selected according to predefined attributes of interest, and some assume that the study team already knows their specific analysis or task. In prospective recruitment with participatory studies, especially multi-purpose cohorts like All of Us or the U.K. Biobank, these strategies may not be feasible or cost-effective. Consequently, we conceptualize a recruitment policy as a specific allocation of resources among recruitment sites. The recruitment policy is enacted in simulation as stochastic draws from each site's demographic distribution. This conceptualization lends itself well to a multi-armed bandit (MAB) model, a well-known framework commonly used for reinforcement learning. 34 Notably, Nargesian et al. proposes a similar method for achieving a desired cohort attribute distribution from multiple data sources, but their method is not adapted for recruitment and may require one to discard collected data, a highly undesirable action in medical settings. 35
We model multi-site recruitment of research cohorts as an MAB problem of allocating recruitment resources - and, thus, expected recruitments - among sites to yield a representative cohort. We adapt the MAB problem to recruitment in two key ways: 1) recruiting multiple individuals at each time step and allowing multiple sites to be simultaneously recruited from, and 2) modeling causal biases that induce a site's distribution to drift non-randomly, either over time or in response to recruitment. We hypothesize that adaptive recruitment policies will generate more representative cohorts than both naïve policies - which disregard demographics information - and existing MAB baselines. 34,36 We assess this hypothesis using demographic data from an existing clinical research network that we use as a proxy for sites recruiting individuals into a hypothetical participatory biomedical dataset.
## Methods
Data Sources and Processing: To simulate recruitment of a multi-site participatory biomedical dataset, we use summary demographic data from the Stakeholders, Technology, and Research (STAR) Clinical Research Network (CRN). STAR is a network of nine health systems that together comprise one of the eight CRNs funded by the Patient Centered Outcomes Research Institute (PCORI). 37-39 As of the most recent public data release (last updated November 16, 2022), the STAR CRN reports demographic information on age (in 4 bins), gender, race, and ethnicity, for their sites: 1) Vanderbilt University Medical Center (VUMC), 2) Vanderbilt Health Affiliated Network (VHAN), 3) Meharry Medical College (MHRY), 4) Mayo Clinic (MAYO), 5) University of North Carolina (UNC), 6) Duke University (DUKE), 7) Medical University of South Carolina (MUSC), 8) Spartanburg Regional Healthcare System (SRHS), and 9) Wake Forest (WAFO). In total, the nine sites comprise 18.5M patients as of their last public reporting updates, ranging from July to September 2022. We recognize that some patients may be included in multiple sites because of geographic overlap between the sites' areas of service.
We exclude all records with values of 'No Information', 'Unknown', 'Ambiguous', 'Refuse to answer', or 'Other' in any demographic fields for harmonizing with U.S. Census data, yielding 14.5M (78.4%) records for analysis. Additionally, we note that only univariate demographic distributions are available (e.g., patients by age or by gender but not by age and gender), such that we assume attribute independence to construct a joint multivariate demographic distribution at each site. To best estimate the true population of the U.S., we rely on the July 2022 U.S. Census Bureau population estimates by age (in 5-year bins), sex, race, and ethnicity from the American Community Survey (table CC-EST2022-ALL), based on the 2020 decennial Census. 40,41 To harmonize with STAR CRN demographics data, we focus on individuals identifying with one race only, yielding a U.S. population of 323.2M. We distribute the 15-19 years age bin in Census data proportionally, with 60% of the population being allocated to the 0-17 years bin and 40% to the 18-45 years age bin.
Quantifying Representation : We quantify representation as the similarity between a cohort and a target population across four measured attributes of interest: age, gender, race, and ethnicity. To assess representativeness, we measure its inverse, a statistical distance between the cohort and target population. Lower distances indicate greater representativeness, with zero distance indicating perfect reflection of target population demographics. Many such distance measures exist, yet it is unknown which one is appropriate. As such, we considered three in our analyses. First, we utilized the Distance Summary measure from Borza et al., 31 which corresponds to a normed sum of univariate Jensen-Shannon distances across the marginal distributions of attributes. Second, we utilized the sum of univariate Kullback-Leibler divergences (KLDs) across the marginal distributions of attributes. Third, we consider the single multivariate KLD across the joint distribution of all attributes. 42
```
Algorithm 1. Adaptive recruitment strategies for improving representation in simulated recruitment
Data: sites S1... S2n with response distributions D in M _ { n } xm (matrix of n sites with m groups), target population
distribution P in R"n, total iterations T, final cohort size N, distance function F
Result: Cohort C
1 C <= 0
2 initialize Dirichlet parameters a ; * based on prior knowledge
3 for t = 1,..., T do
4 | */
5 for j = 1,..., n do
6 | */
| |
| | */
| | */
| C |
| C | */
| C | */
}
| C |
| C | */
| C | */
|
| C |
| C | */
```
Algorithm 1. Adaptive recruitment strategies for improving representation in simulated recruitment
Table 1. Overview of experimental parameters and terminology
| Response Distribution | Model | Prior Information |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Static: Site demographics and response distributions are the same Shifting: Response distributions change with each time step Causal Bias: Response distributions change when a site is recruited from | Naïve: Recruitment policy is chosen without respect to site demographics Adaptive: Recruitment policy is actively changed based on site demographics | Uninformed: Jeffreys prior is used to estimate site demographics Fully informed: Actual site demographics are used as a prior Empiric: Prior is established through pre-experiment sampling |
Recruitment Simulation : We formalize the goal of achieving representativeness through recruitment as an MAB problem. 34,43 The recruitment timeline is split into a sequence of recruiting iterations according to the frequency of policy updates. We model a 5-year recruitment timeline of 10,000 participants with quarterly policy updates as a 20step process with 500 recruitments per iteration, where the resources to achieve these 500 recruitments may be allocated among sites. We acknowledge that various factors may influence the participation rates of different groups in actual recruitment. Thus, we consider the product of a site's demographic distribution with its subgroup-specific participation rates to yield a response distribution , which corresponds to the expected distribution of successful recruitments for each site. For example, a subgroup with a higher participation rate will have a higher probability density in the response distribution than a subgroup with a lower participation rate, even if the two groups comprise equal proportions of the demographic distribution. In the basic recruitment case, we assume that all groups have equal participation rates that do not change through recruitment, such that we may use site demographic distributions as the response distributions. To simulate changes in the response distribution (Table 1), we systematically modify the response distribution as a function of each subgroup's proportion of the demographic distribution, such that sitemajority groups all become either more or less likely to respond. When these changes occur over time, independent of recruitment policies, we call the changes distribution shifts (Eq. 1). When these changes occur in response to recruitment, they are termed causal bias (Eq. 2).
$$\frac { 1 } { 1 } [ t ] ^ { \lambda } / \sum _ { i = 1 } ^ { m } D _ { j, i } [ t ] ^ { \lambda } & \quad \text{Distribution Shift} \ ( \text{Eq.} 1 ) \\ \frac { 1 } { 1 } [ t ] ^ { ( 1 + \rho _ { j } ( \kappa - 1 ) ) } / \sum _ { i = 1 } ^ { m } D _ { j, i } [ t ] ^ { ( 1 + \rho _ { j } ( \kappa - 1 ) ) } & \quad \text{Causal Bias} \ ( \text{Eq.} 2 )$$
$$\begin{array} { l l } D _ { j, i } [ t + 1 ] = D _ { j, i } [ t ] ^ { \lambda } / \sum _ { i = 1 } ^ { m } D _ { j, i } [ t ] ^ { \lambda } & \text{Distri} \\ D _ { j, i } [ t + 1 ] = D _ { j, i } [ t ] ^ { ( 1 + \rho _ { j } ( \kappa - 1 ) ) } / \sum _ { i = 1 } ^ { m } D _ { j, i } [ t ] ^ { ( 1 + \rho _ { j } ( \kappa - 1 ) ) } \end{array}$$
where λ is the distribution shift factor, κ is the causal bias factor, and 𝑫 and 𝝆 come from Algorithm 1. A value of 1 for either of these factors recovers the no-bias case; a value greater than 1 indicates site-majority groups are more likely to respond (accentuating the shape of the site's underlying demographic distribution); and a value less than 1 indicates site-minority groups are more likely to respond (blunting the shape of the site's demographic distribution).
Policy Optimization : In each iteration, recruiters have some knowledge of each site's response distribution, modeled as a categorical distribution drawn from a Dirichlet conjugate prior distribution. In the first iteration, we initialize a priori knowledge of site response distributions in one of three ways (Table 1): 1) an uninformed (Jeffreys) prior with concentration parameters α = 0.5, 2) empirically through pre-simulation sampling from each site, or 3) a fully informed prior using actual site demographic distributions as concentration parameters. By using these priors, we cover the range of possible starting information that may be available to researchers starting recruitment. In subsequent iterations, simulated recruitments are used to update the Dirichlet conjugate prior and represent increased knowledge of the site response distributions. Recruiters may use this prior knowledge to determine an optimal allocation of recruitment resources among the sites, a process we show in Algorithm 1.
We analyze two broad classes of recruitment strategies (Table 1): 1) naïve strategies, which disregard knowledge of site demographics during policy updates and 2) adaptive strategies, which use this knowledge to update recruitment policies. The three naïve strategies we analyze are: 1) 'Random Site,' which allocates all resources to one random site each iteration, 2) 'Uniform,' which allocates equal resources to each site at each iteration, and 3) 'Informed Static,' which simulates 1,000 samples from each site to develop an empiric prior and identifies a policy to optimize representativeness which is not updated over iterations. Although not involving recruitment, some multi-site genomic analyses roughly apply a uniform distribution of sampling across sites. 44 Moreover, the informed static policy represents a partially informed, but fixed, resource allocation (e.g., fixed grant funding). To evaluate a baseline adaptive strategy, we use Thompson sampling (Algorithm 1, line 8), 34,36 which allocates all recruitment resources to the site which is expected to reduce a given distance function the most. Finally, our proposed adaptive strategy (Algorithm 1, line 9) distributes resources among sites in a locally optimal manner for a given distance function. We provide the results for two strategies with different distance functions: 1) multivariate KLD and 2) Distance Summary. After the recruitment policy - defined as the number of participants recruited at each site during each step - is set, a stochastic recruitment process is applied. We model recruitment as random draws from each site's response distribution, incorporating both underlying demographics and group-specific participation rates.
Computation and Statistics: All experiments were conducted in Python 3.11. Due to stochasticity in our recruitment simulation, 100 experiments were conducted for each unique set of parameters. 95% Bayesian credible intervals for the means (across experiments) of the three analyzed distance measures at each iteration were calculated using a noninformative prior. 45 If the posterior distributions within two credible intervals were normally distributed, then nonoverlapping intervals roughly align with rejecting a frequentist null hypothesis at α = 0.01. 46
## Results
Table 2. STAR CRN site characteristics and demographic ratios relative to the U.S. Census. Positive (blue) values indicate overrepresentation of a group compared to Census counts while negative (red) values indicate underrepresentation. Abbreviations not in text: MKLD [multivariate KLD] and NH/L [non-Hispanic/Latino].
| | | | | | | | | SC | | |
|-----------|--------|---------|--------|--------|--------|--------|--------|--------|--------|--------|
| | | | | | | | | | | 22.62% |
| | | | | | | | | | 0.1556 | 0.1199 |
| 0-17 | | | | | | | | | | |
| | | | | | | | | | -1.028 | -1.130 |
| 45-64 | 25.13% | -1.092 | 1.152 | 1.291 | 1.102 | 1.031 | 1.037 | -1.067 | 1.037 | -1.015 |
| 65+ | 17.69% | -1.008 | 1.151 | -1.252 | 1.857 | 1.335 | 1.319 | 1.431 | 1.260 | 1.523 |
| Gender | | | | | | | | | | |
| Female | 50.41% | 1.068 | 1.119 | -1.036 | 1.030 | 1.091 | 1.095 | 1.081 | 1.042 | 1.069 |
| Male | 49.59% | -1.075 | -1.138 | 1.035 | -1.031 | -1.102 | -1.106 | -1.090 | -1.045 | -1.075 |
| Race | | | | | | | | | | |
| AIIAN | 1.35% | -6.374 | 26.52 | -3.045 | | 1.539 | -2.385 | -7.442 | 5.604 | -1.894 |
| Asian | 6.48% | | | -8.111 | -2.478 | | -2.547 | -5.912 | 4.460 | -3.211 |
| Black | 14.05% | | -1.984 | 3.586 | 3.115 | 1.695 | 1.693 | 2.295 | 1.616 | 1.363 |
| NHIPI | 0.27% | -1334.7 | -7.210 | -1.500 | -1.558 | -1.863 | -2.564 | -2.700 | -1.132 | -2.087 |
| White | 77.85% | 1.083 | 1.169 | -1.615 | 1.183 | | 1.066 | -1.173 | -1.033 | 1.002 |
| Ethnicity | | | | | | | | | | |
| HL | 19.05% | 3.566 | -5.670 | -1.376 | 3.423 | -2.039 | -2.037 | 4.488 | 3.219 | -2.021 |
| NHL | 80.95% | 1.169 | 1.194 | 1.064 | | 1.120 | 1.120 | 1.183 | 1.162 | 1.119 |
Demographics of STAR CRN Sites: Table 2 presents the demographic distributions from the U.S. Census, along with the ratios of each population group at the nine STAR CRN sites to the Census. Positive ratios indicate a group is overrepresented compared to the Census while negative ratios indicate underrepresentation. General trends include underrepresentation of younger individuals, males, individuals identifying with a race of 1) American Indian / Alaska Native (AI/AN), 2) Asian, 3) Native Hawaiian / Pacific Islander (NH/PI), and/or Hispanic / Latino (H/L) ethnicity.
Recruiting a More Representative Cohort: Figure 1 shows that, in our baseline cases with static response distributions, adaptive recruitment strategies outperform naïve recruitment strategies at generating a representative cohort. The results were qualitatively similar for the three distance measures analyzed, such that we only present results showing multivariate KLD. As expected, the adaptive recruitment strategy that minimizes multivariate KLD yielded the most representative cohorts on average, using this measure. While the differences in KLD between algorithms may only represent a 20% difference or less, small relative differences understate major impacts on cohort demographics. For instance, Figure 2 highlights the impact of adaptive recruitment strategies on the demographics of the final cohort by comparing the naïve uniform baseline (arrow tail) to our fully informed adaptive strategy (arrow head). The adaptive strategy reduces the underrepresentation of AI/AN and Asian subgroups but can accentuate underrepresentation of some NH/PI subgroups.
Figure 1. A comparison of cohort representativeness (where lower KLD is more representative) for naïve and adaptive recruitment strategies over time, using uninformed (a) and fully informed (b) prior knowledge. The shaded areas indicate a 95% Bayesian credible interval of mean KLD values.
Figure 2. Changes in cohort subgroup proportions from a naïve uniform policy (arrow tail) to an adaptive, fully informed policy optimizing for MKLD (arrow head). Blue arrows indicate the adaptive policy brings the subgroup proportion closer to its Census levels (dotted line) while red arrows indicate the proportion departs from Census levels.
Incorporating prior knowledge about site-specific demographic distributions allowed all adaptive sampling methods to recruit more representative cohorts. The MKLD-based adaptive strategy decreased its final KLD from 0.1257 [95%
CI: 0.1247, 0.1266] to 0.1157 [95% CI: 0.1149, 0.1164] (Figure 1), surpassing both the site with the lowest KLD (Wake Forest, 0.1199) and the informed static strategy (0.1206 [95% CI: 0.1193, 0.1218]). The informed static strategy, which uses pre-simulation sampling to establish a prior, represents partially informed sampling. Expectedly, it performs better than uninformed recruitment and worse than fully informed recruitment. The impact of prior knowledge is most noticeable on the Thompson sampling strategy, which transforms from performing worse than naïve baselines to becoming statistically indistinguishable from our best-performing strategy. Due to the high variance of the Jeffreys prior, the uninformed Thompson sampler often allocates resources to the same site during the first several iterations, a phenomenon evidenced by bands of constant resource allocation in the early iterations in Figure 3c. Since the distributed adaptive recruitment strategy may sample from multiple sites at each iteration, this strategy explores more efficiently in the initial steps than the Thompson sampler. After only five iterations, our uninformed adaptive strategy learns sufficient information about site demographics to outperform the naïve baselines. After ten iterations, the adaptive policies begin to resemble those of their fully informed counterparts (Figure 3a-b).
Figure 3. Mean (across experiments) recruitment policies at each iteration and averaged across all iterations (AVG) for our distributed adaptive recruitment policy (a, b) compared to a Thompson sampler (c, d) , both with (d, b) and without (a, c) prior knowledge of site response distributions. Darker colors indicate higher recruitment density.
Figure 4. The final cohorts of uninformed adaptive strategies are more representative than those of naïve strategies across distribution shift factors λ (a) while the fully informed adaptive strategies suffer from strong, yet incorrect,
priors and show lower representativeness when λ is much greater than 1 (b) . The shaded regions around the lines indicate a 95% Bayesian CI and the blue boxes in the top row correspond to the magnified areas in the bottom row.
Varying the Response Distribution: Real-world recruitment scenarios often do not follow the strict arm independence and invariance conditions of traditional MAB analyses. To simulate situations where the response distribution changes either over time or in response to recruitment, we investigated a range of distribution shift and causal bias factors and analyzed their effect on final cohort KLD (Figures 4, 5). Shifts in the response distribution challenged our adaptive recruitment strategies because both prior knowledge and knowledge gained through recruitment become less accurate over time. In the distributional shift analysis, uninformed adaptive models performed significantly better than their fully informed counterparts for distribution shift factors greater than 1 (Figure 4). Across the range of tested distribution shift factors, our uninformed adaptive strategy consistently recruited more representative cohorts than the naïve baselines or Thompson sampler. Expanding on changes to the response distribution, causal bias presents a yet more challenging situation: recruiting at a site may induce a bias that makes the site sub-optimal. Thus, with both uninformed and fully informed adaptive strategies, there is a range of causal bias factors where adaptive strategies outperform naïve baselines (Figure 5). This range is approximately 0.85 - 1.25 for uninformed strategies and 0.8 1.05 for fully informed strategies. Thus, causal bias in the response distribution of >5-25% per iteration lead the estimated response distributions to accumulate so much error over time that adaptive recruitment becomes ineffective. Similar to our results for distribution shift factors, uninformed strategies trade off base-case optimality for greater flexibility in the face of changing response distributions.
Figure 5. The final cohorts of both uninformed (a) and fully informed (b) adaptive strategies are more representative than those of naïve strategies for a range of causal bias factors κ between 0.85 - 1.25 and 0.8 - 1.05, respectively. The shaded regions around lines indicate 95% Bayesian CI and the blue shaded boxes in the top row indicate areas that are magnified in the bottom row.
In summary, we find that our methodology outperforms both naïve and other adaptive baselines through efficient exploration in a scenario where the total number of budget re-allocations (i.e., iterations) are quite limited. Moreover, we show that our proposed recruitment strategy is robust to shifting distributions of interested participants at each site.
## Discussion and Conclusions
Our analyses show some notable trends that provide insight into recruitment resource allocation in multi-site projects. Although the uninformed adaptive strategies do not yield the most representative cohorts overall, their benefits over naïve baselines are still notable. Response distributions of the recruitable populations at each site are likely to be unknown before recruitment starts, so a methodology that does not rely on this prior knowledge may be more practical. Moreover, we show uninformed methods to be more robust to time-dependent distributional shifts and recruitmentinduced biases than informed methods, strengthening their utility. As we note, uninformed methods sacrifice some best-case optimality to achieve this flexibility. In other words, varying the amount of prior information shifts the strategy's balance between exploration (establishing which sites are best to recruit at) and exploitation (actually recruiting at those sites), a fundamental concept in reinforcement learning and MAB. 34
Another interesting result in this study is an apparent local optimum effect. Despite site 9's (Wake Forest's) achieving the lowest KLD of all the STAR CRN sites, it receives only a small fraction of recruitment resources under the fully informed adaptive policies. In the uninformed case, the site receives the highest proportion of recruitment resources during the first ten iterations. As the adaptive recruitment model learns more about all the site response distributions, it shifts from a locally optimal recruitment strategy (prioritizing site 9) to a globally optimal strategy (prioritizing sites 4, 5, and 6) that more closely mirrors the strategy of the fully informed model. This result highlights the benefits of multi-site studies and underscores the need for informed recruitment strategies. An informed combination of several less-representative sites may yield a final dataset that is more representative than any single site.
Despite the merits of this research, there are several key limitations to note. First, our measures of representativeness inherently assume a group-based categorization of people and imply these groups are significant. Social concepts like race and ethnicity may drift over time in reporting by the U.S. Census, 47 and should be used with intention and caution in downstream analyses. 48,49 We use group-based analyses to promote inclusion because they are readily available, though we recognize their limitations. Second, we are limited to data and groups that are present in both STAR CRN data and the U.S. Census, leading to the exclusion of individuals identifying with two or more races or missing any demographic attributes, the equating of Census-reported sex with STAR CRN-reported gender, and the inability to assess variables beyond age, gender, race, and ethnicity. Cohorts that are representative across the variables measured may be unrepresentative across unmeasured attributes. Moreover, a significant proportion (9-28%) of each STAR CRN site had missing demographic data that are likely to not be missing completely at random (non-MCAR). Imputation, a strategy used by various federal agencies, including the U.S. Census Bureau, 41 may address missingness but will bias non-MCAR results. Third, because of data availability, we also assumed the independence of demographic attributes to generate joint site distributions. If we applied more accurate joint population distributions, we would expect our methodology to perform even better. While these data limitations could introduce unmeasured biases in our analyses, we would still expect adaptive recruitment resource allocation to improve cohort representativeness over naïve methods.
We recognize some inherent limitations to using the STAR CRN as our example. It is primarily composed of large academic medical centers in urban areas, so it represents fewer individuals living in rural areas and/or experiencing barriers to accessing healthcare. This limitation applies to all studies that primarily recruit participants at academic medical centers. STAR CRN sites are also mostly located in the Southern U.S., so attempting to recruit a nationally representative cohort may be challenging due to geographic variations in demographics. Nevertheless, recruiting a nationally representative cohort remains a reasonable aspiration for participatory studies.
In conclusion, we developed and evaluated a method for improving representation in multi-site participatory biomedical dataset recruitment in this paper. We modified an existing multi-armed bandit framework to make it more relevant to biomedical recruitment and simulate allocation of recruitment resources across the nine-site STAR CRN. Our proposed algorithm recruits cohorts that are more representative than both naïve and adaptive baselines and is flexible to shifts in population and/or response distributions at sites. Moreover, our methodology identified specific and non-obvious recruitment policies to optimize representation, that underscores its potential utility for researchers. There are several areas to consider for future investigation. Weaker informative priors may span a fuller range between optimality and flexibility. Differential site-specific recruitment costs could better reflect real-world differences. Current recruitment practices are not adaptive, so implementation strategies and infrastructure for adaptive recruitment strategies must be developed. Furthermore, the ethical implications and potential unforeseen biases of adaptive recruitment should be studied before these strategies are implemented.
## Acknowledgements
We thank Dr. Jessica Ancker for constructive review and feedback. Borza is sponsored by NHLBI/NIH grant F30HL168976, while Malin and Clayton are supported by NHGRI/NIH grant U54HG012510. The STAR CRN is supported by PCORI contract RI-CRN-2020-009 and the Vanderbilt Institute for Clinical and Translational Research with funding from NCATS/NIH grant UL1TR002243 and institutional funding.
## References
- 1. Roden DM, Pulley JM, Basford MA, Bernard GR, Clayton EW, Balser JR, et al. Development of a large-scale de-identified DNA biobank to enable personalized medicine. Clin Pharmacol Ther. 2008 Sep;84(3):362-9.
- 2. Bridge2AI Voice. The Consortium (Who We Are) - B2AI-Voice.org [Internet]. [cited 2024 Feb 29].
- 3. AI-READI. Artificial Intelligence Ready and Equitable Atlas for Diabetes Insights [Internet]. AI-READI. 2024 [cited 2024 Feb 29].
- 4. Denny JC, Rutter JL, Goldstein DB, Philippakis A, Smoller JW, Jenkins G, et al. The 'All of Us' Research Program. New England Journal of Medicine. 2019 Aug 15;381(7):668-76.
- 5. All of Us Research Program. Participant Partners [Internet]. All of Us Research Program | NIH. 2022 [cited 2024 Feb 29].
- 6. McCarron TL, Clement F, Rasiah J, Moran C, Moffat K, Gonzalez A, et al. Patients as partners in health research: A scoping review. Health Expect. 2021 Aug;24(4):1378-90.
- 7. Mapes BM, Foster CS, Kusnoor SV, Epelbaum MI, AuYoung M, Jenkins G, et al. Diversity and inclusion for the All of Us research program: A scoping review. Giles EL, editor. PLoS ONE. 2020 Jul 1;15(7):e0234962.
- 8. Qi M, Cahan O, Foreman MA, Gruen DM, Das AK, Bennett KP. Quantifying representativeness in randomized clinical trials using machine learning fairness metrics. JAMIA Open [Internet]. 2021 Jul 1 [cited 2021 Nov 24];4(3).
- 9. Celis LE, Keswani V, Vishnoi N. Data preprocessing to mitigate bias: A maximum entropy based approach. In: Proceedings of the 37th International Conference on Machine Learning [Internet]. PMLR; 2020 [cited 2024 Feb 16]. p. 1349-59.
- 10. Asudeh A, Jin Z, Jagadish HV. Assessing and remedying coverage for a given dataset. In: 2019 IEEE 35th International Conference on Data Engineering (ICDE) [Internet]. Macao, Macao: IEEE; 2019 [cited 2024 Jan 12]. p. 554-65.
- 11. Shahbazi N, Lin Y, Asudeh A, Jagadish HV. Representation bias in data: a survey on identification and resolution techniques. ACM Comput Surv. 2023 Mar 17;3588433.
- 12. Ng MY, Kapur S, Blizinsky KD, Hernandez-Boussard T. The AI life cycle: a holistic approach to creating ethical AI for health decisions. Nat Med. 2022 Nov;28(11):2247-9.
- 13. Amugongo LM, Kriebitz A, Boch A, Lütge C. Operationalising AI ethics through the agile software development lifecycle: a case study of AI-enabled mobile health applications. AI Ethics [Internet]. 2023 Aug 15 [cited 2024 Feb 28];
- 14. MacKay D, Saylor KW. Four faces of fair subject selection. The American Journal of Bioethics. 2020 Feb 1;20(2):5-19.
- 15. National Commission for the Protection of Human Subjects of Biomedical and Behavioral Research. The Belmont Report. US Department of Health, Education, and Welfare; 1979.
- 16. Arnesen S, Peters Y. The legitimacy of representation: how descriptive, formal, and responsiveness representation affect the acceptability of political decisions. Comparative Political Studies. 2018 Jun 1;51(7):868-99.
- 17. Committee on Improving the Representation of Women and Underrepresented Minorities in Clinical Trials and Research, Committee on Women in Science, Engineering, and Medicine, Policy and Global Affairs, National Academies of Sciences, Engineering, and Medicine. Improving representation in clinical trials and research: building research equity for women and underrepresented groups [Internet]. Bibbins-Domingo K, Helman A, editors. Washington, D.C.: National Academies Press; 2022 [cited 2024 Feb 29].
- 18. Schoeler T, Speed D, Porcu E, Pirastu N, Pingault JB, Kutalik Z. Participation bias in the UK Biobank distorts genetic associations and downstream analyses. Nat Hum Behav. 2023 Apr 27;1-12.
- 19. Bentley AR, Callier SL, Rotimi CN. Evaluating the promise of inclusion of African ancestry populations in genomics. npj Genom Med. 2020 Dec;5(1):5.
- 20. Dastin J. INSIGHT-Amazon scraps secret AI recruiting tool that showed bias against women. Reuters [Internet]. 2018 Oct 10 [cited 2024 Mar 5];
- 21. Mulshine M. A major flaw in Google's algorithm allegedly tagged two black people's faces with the word 'gorillas.' Business Insider [Internet]. 2015 Jul 1 [cited 2024 Mar 5];
- 22. Kwiatkowski K, Coe K, Bailar JC, Swanson GM. Inclusion of minorities and women in cancer clinical trials, a decade later: Have we improved? Cancer. 2013;119(16):2956-63.
- 23. Melloni C, Berger JS, Wang TY, Gunes F, Stebbins A, Pieper KS, et al. Representation of women in randomized clinical trials of cardiovascular disease prevention. Circulation: Cardiovascular Quality and Outcomes. 2010 Mar 1;3(2):135-42.
- 24. Pathiyil MM, Jena A, Raju AKV, Omprakash TA, Sharma V, Sebastian S. Representation and reporting of diverse groups in randomised controlled trials of pharmacological agents in inflammatory bowel disease: a systematic review. The Lancet Gastroenterology & Hepatology. 2023 Dec 1;8(12):1143-51.
- 25. Abel KM, Radojčić MR, Rayner A, Butt R, Whelan P, Parr I, et al. Representativeness in health research studies: an audit of Greater Manchester Clinical Research Network studies between 2016 and 2021. BMC Med. 2023 Dec;21(1):1-11.
- 26. Lewis V C, Huebner J, Hripcsak G, Sabatello M. Underrepresentation of blind and deaf participants in the All of Us Research Program. Nat Med. 2023 Nov;29(11):2742-7.
- 27. Bozkurt S, Cahan EM, Seneviratne MG, Sun R, Lossio-Ventura JA, Ioannidis JPA, et al. Reporting of demographic data and representativeness in machine learning models using electronic health records. Journal of the American Medical Informatics Association. 2020 Dec 9;27(12):1878-84.
- 28. Biden JR. Executive order on the safe, secure, and trustworthy development and use of artificial intelligence [Internet]. Washington, D.C.: The White House; 2023 Oct [cited 2024 Mar 12].
- 29. Huppenkothen D, McFee B, Norén L. Entrofy your cohort: A transparent method for diverse cohort selection. PLoS One. 2020 Jul 27;15(7):e0231939.
- 30. Flanigan B, Gölz P, Gupta A, Hennig B, Procaccia AD. Fair algorithms for selecting citizens' assemblies. Nature. 2021 Aug 26;596(7873):548-52.
- 31. Borza VA, Clayton EW, Kantarcioglu M, Vorobeychik Y, Malin BA. A representativeness-informed model for research record selection from electronic medical record systems. AMIA Annu Symp Proc. 2023 Apr 29;2022:259-68.
- 32. Shekhar S, Ghavamzadeh M, Javidi T. Adaptive Sampling for Minimax Fair Classification. In: Neural Information Processing Systems [Internet]. 2021 [cited 2024 Apr 7].
- 33. Abernethy JD, Awasthi P, Kleindessner M, Morgenstern J, Russell C, Zhang J. Active Sampling for Min-Max Fairness. In: Proceedings of the 39th International Conference on Machine Learning [Internet]. PMLR; 2022 [cited 2024 Apr 7]. p. 53-65.
- 34. Slivkins A. Introduction to multi-armed bandits. FNT in Machine Learning. 2019;12(1-2):1-286.
- 35. Nargesian F, Asudeh A, Jagadish HV. Tailoring data source distributions for fairness-aware data integration. Proc VLDB Endow. 2021 Jul;14(11):2519-32.
- 36. Thompson WR. On the likelihood that one unknown probability exceeds another in view of th evidence of two samples. Biometrika. 1933 Dec 1;25(3-4):285-94.
- 37. STAR CRN. About Us - STAR Clinical Research Network [Internet]. 2023 [cited 2024 Mar 6].
- 38. PCORI. PCORnet®, The National Patient-Centered Clinical Research Network | PCORI [Internet]. 2023 [cited 2024 Mar 6].
- 39. Forrest CB, McTigue KM, Hernandez AF, Cohen LW, Cruz H, Haynes K, et al. PCORnet® 2020: current state, accomplishments, and future directions. J Clin Epidemiol. 2021 Jan;129:60-7.
- 40. U.S. Census Bureau. Index of /programs-surveys/popest/datasets/2020-2022/counties/asrh [Internet]. 2023 [cited 2024 Mar 6].
- 41. U.S. Census Bureau. Methodology for the United States population estimates: vintage 2022 [Internet]. 2022 [cited 2024 Mar 6].
- 42. Kullback S, Leibler RA. On Information and sufficiency. The Annals of Mathematical Statistics. 1951 Mar;22(1):79-86.
- 43. Bubeck S. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. FNT in Machine Learning. 2012;5(1):1-122.
- 44. Zuvich RL, Armstrong LL, Bielinski SJ, Bradford Y, Carlson CS, Crawford DC, et al. Pitfalls of merging GWAS data: lessons learned in the eMERGE network and quality control procedures to maintain high data quality. Genet Epidemiol. 2011 Dec;35(8):887-98.
- 45. Oliphant T. A Bayesian perspective on estimating mean, variance, and standard-deviation from data. Faculty Publications. 2006 Dec 5;18.
- 46. Cumming G, Finch S. Inference by eye: confidence intervals and how to read pictures of data. American Psychologist. 2005;60(2):170-80.
- 47. Wang HL. New 'Latino' and 'Middle Eastern or North African' checkboxes proposed for U.S. forms. NPR [Internet]. 2023 Apr 7 [cited 2024 Jan 21]
- 48. Ward JB, Gartner DR, Keyes KM, Fliss MD, McClure ES, Robinson WR. How do we assess a racial disparity in health? Distribution, interaction, and interpretation in epidemiological studies. Annals of Epidemiology. 2019 Jan;29:1-7.
- 49. Marden JR, Walter S, Kaufman JS, Glymour MM. African ancestry, social factors, and hypertension among Non-Hispanic Blacks in the Health and Retirement Study. Biodemography and Social Biology. 2016 Jan 2;62(1):19-35. | null | [
"Victor Borza",
"Andrew Estornell",
"Ellen Wright Clayton",
"Chien-Ju Ho",
"Russell Rothman",
"Yevgeniy Vorobeychik",
"Bradley Malin"
]
| 2024-08-02T16:32:30+00:00 | 2024-08-02T16:32:30+00:00 | [
"cs.LG",
"cs.CY"
]
| Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets | Large participatory biomedical studies, studies that recruit individuals to
join a dataset, are gaining popularity and investment, especially for analysis
by modern AI methods. Because they purposively recruit participants, these
studies are uniquely able to address a lack of historical representation, an
issue that has affected many biomedical datasets. In this work, we define
representativeness as the similarity to a target population distribution of a
set of attributes and our goal is to mirror the U.S. population across
distributions of age, gender, race, and ethnicity. Many participatory studies
recruit at several institutions, so we introduce a computational approach to
adaptively allocate recruitment resources among sites to improve
representativeness. In simulated recruitment of 10,000-participant cohorts from
medical centers in the STAR Clinical Research Network, we show that our
approach yields a more representative cohort than existing baselines. Thus, we
highlight the value of computational modeling in guiding recruitment efforts. |
2408.01376v1 | ## Deep sub-wavelength scale focusing of heat flux radiated by magneto-optical nanoemitters in the presence of an external magnetic-field
Louis Rihouey, 1 Philippe Ben-Abdallah, 1, ∗ and Riccardo Messina 1, †
1 Laboratoire Charles Fabry, UMR 8501, Institut d'Optique, CNRS, Université Paris-Saclay, 2 Avenue Augustin Fresnel, 91127 Palaiseau Cedex, France (Dated: August 5, 2024)
We introduce a theoretical framework to describe the heat flux radiated in the near-field regime by a set of magneto-optical thermal nanoemitters close to a substrate in the presence of an external magnetic field. Then, we investigate the particular case of a single emitter and we demonstrate that the external field can induce both an amplification of the heat exchanged between emittter and substrate and a focusing of the Poynting field at the substrate interface at deep sub-wavelength scale. These effects open up promising perspectives for the development of heat-assisted magneticrecording technology.
## I. INTRODUCTION
The near-field scanning thermal microscope [1-5], a noncontact variant of conventional scanning thermal microscope [6, 7], enables local heating at the submicrometric scale by utilizing the tunneling of non-radiative thermal photons (evanescent waves). This near-field technology is promising for nano-photolitography [8] and for hard-drive writing technology, specifically in heatassisted magnetic recording (HAMR) [9, 10]. In HAMR, a small surface area of a magnetic material is heated to raise its temperature close to the Curie temperature, where its magnetic coercivity is weak. Then by applying a magnetic field a new magnetic state can be recorded inside the material. For high-density magnetic bit storage, the hot spot area should be minimized to approach the superparamagnetic limit, beyond which bits become unstable due to thermal fluctuations. Typically, superparamagnetism in common magnetic materials is observed in domains below 20 nm in size. However, radiative heat focusing by a conventional scanning probe microscope is constrained by the emission pattern of its tip in the near-field regime. In a recent work [11] a theory describing heat flux radiated in the near-field regime by several interacting nanoemitters at different temperatures has been introduced, demonstrating that, in comparison to a single emitter, the thermal energy can be focused and amplified into smaller spots than single emitters paving the way for a multitip near-field scanning thermal microscopy with potential applications in nanoscale thermal management, heat-assisted data recording, nanoscale thermal imaging, heat capacity measurements, and infrared spectroscopy of nanoobjects. The formalism employed in this work falls into the category of near-field radiative heat transfer in dipolar systems, which has attracted a remarkable attention during the last decade [12-34]. As a matter of fact, the possibility of describing small
∗ Electronic address: [email protected]
† Electronic address: [email protected]
nanoparticles or objects (such as tips) within the dipolar approximation leads to simpler analytical expressions allowing to unveil interesting two- and N -body effects [3539] and related practical appplications including thermal management [41, 42], solid-state cooling [43, 44], infrared sensing and spectroscopy [45, 46], energy-conversion devices [47-51] and thermotronics [52-55].
In the present work we extend this study to magnetooptical many-body systems that is to the modeling and analysis of heat flux radiated by a set of emitters whose optical properties can be externally manipulated by applying a magnetic field. Many theoretical works have been devoted to date to the control of radiative heat exchanges in systems involving magneto-optical nanoparticles [56-67] and to the control of the local density of states of the electromagnetic field [68]. Here we pay a particular attention to the heat flux radiated by these systems in their close environment. As a concrete application, we analyze in detail the heat flux radiated by a single nanoemitter, simulating a heated tip made with a magneto-optical material, above an isotropic substrate and we show that the application of an external field can produce the simultaneous effects of increasing the emitter-to-substrate flux by reducing, at the same time, the spreading of heat flux at the interface of substrate. This focusing effect is investigated with respect to both the size of emitter and the magnitude of applied magnetic field and its origin is explained through a spectral analysis of the heat flux. The paper is structured as follows. In Sec. II we present the physical system and a formalism giving the Poynting vector for a system of N dipoles close to a substrate. The results in the case of a single particle are presented in Sec. III, for different particle radii and as a function of the magnetic field. The last Section presents some conclusive remarks and perspectives.
## II. PHYSICAL SYSTEM AND FORMALISM
The system we consider consists of N spherical particles labeled with an index i = 1 2 , , . . . , N having equal radius R , coordinates r i , with z i > 0 , placed in vacuum and
in proximity of a substrate having a frequency-dependent permittivity ε i ( ω ) . The interface between vacuum and substrate coincides with the plane z = 0 . In the following, we describe the formalism to calculate the Poynting vector S r ( , t ) = E r ( , t ) × H r ( , t ) at an arbitrary point r . This approach, following the one detailed in Ref. [13], exploits the fluctuation-dissipation theorem describing the correlation functions of fluctuating dipoles, along with the knowledge of the Green's function of the system, taking into account the presence of a substrate as a boundary condition in the system.
## A. Coupled fluctuating dipoles and Green's tensors
First, we work in the dipolar approximation, in which each individual particle is described in terms an electric dipole. This approach is valid as long as all distances involved (both between particles and between particles and substrate) are large compared to the particle radius R . As a rule of thumb, the validity of this approximation is guaranteed when all distances satisfy d > 3 R [69]. Each electric dipoles is decomposed as
$$\mathbf p _ { i } ( t ) = \mathbf p _ { i } ^ { ( \text{fl} ) } ( t ) + \mathbf p _ { i } ^ { ( \text{ind} ) } ( t ), \text{ \quad \ \ } ( 1 )$$
where the first term accounts for the thermallyfluctuating contribution, whereas the second describes the part induced by the presence of the other dipoles and the substrate. The collection of dipoles generates an electric and magnetic field at any point r , which can be written as
$$\mathbf E ( \mathbf r, \omega ) & = \frac { \omega ^ { 2 } } { \varepsilon _ { 0 } c ^ { 2 } } \sum _ { i } \mathbf G ^ { ( \mathrm E E ) } ( \omega, \mathbf r, \mathbf r _ { i } ) \mathbf p _ { i }, \\ \mathbf H ( \mathbf r, \omega ) & = - i \frac { \omega ^ { 2 } } { c } \sum _ { i } \mathbf G ^ { ( \mathrm H E ) } ( \omega, \mathbf r, \mathbf r _ { i } ) \mathbf p _ { i }, \\ \cdot \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where the sum extends from 1 to N and we employed a frequency decomposition where each real physical quantity f ( ) t is written as
$$f ( t ) = \int _ { - \infty } ^ { \infty } d \omega \, f ( \omega ) e ^ { - i \omega t } = 2 \, \text{Re} \int _ { 0 } ^ { \infty } d \omega \, f ( \omega ) e ^ { - i \omega t }. \ \ ( 3 ) \quad \text{the t\alpha} \\ \text{the s\alpha}$$
Equation (2) is written in terms of the electric-electric and magnetic-electric Green's function which are written as a sum of vacuum contributions G (0) and scattered parts G (sc) , associated with the presence of the substrate. The former read
$$& \text{The former read} \\ & \mathbb { G } _ { \text{EE} } ^ { ( 0 ) } ( \omega, \mathbf r, \mathbf r ^ { \prime } ) = \frac { e ^ { i k _ { 0 } d } } { 4 \pi d } \left [ \left ( 1 + \frac { i k _ { 0 } d - 1 } { k _ { 0 } ^ { 2 } d ^ { 2 } } \right ) \mathbb { I } \\ & \quad + \frac { 3 - 3 i k _ { 0 } d - k _ { 0 } ^ { 2 } d ^ { 2 } } { k _ { 0 } ^ { 2 } d ^ { 2 } } \hat { d } \otimes \hat { d } \right ], \quad \text{where} \\ & \mathbb { G } _ { \text{HE} } ^ { ( 0 ) } ( \omega, \mathbf r, \mathbf r ^ { \prime } ) = \frac { e ^ { i k _ { 0 } d } } { 4 \pi d } \frac { i k _ { 0 } d - 1 } { k _ { 0 } d ^ { 2 } } \begin{pmatrix} 0 & - d _ { z } & d _ { y } \\ d _ { z } & 0 & - d _ { x } \\ - d _ { y } & d _ { x } & 0 \end{pmatrix}, \quad \text{$\mathbb{ D }_{i}$}$$
were k 0 = ω/c and we have defined the distance vector d = r -r ′ having norm d = | d | and such that ˆ = d d /d and
$$\mathbf d = d ( \sin \theta _ { d } \cos \varphi _ { d }, \sin \theta _ { d } \sin \varphi _ { d }, \cos \theta _ { d } ). \quad ( 5 )$$
As discussed e.g. in Ref. [70], the scattering contribution to the Green's function, when both arguments r and r ′ are placed above the substrate ( z, z ′ > 0 ) can be written as
$$\text{tak} \quad & \text{ are placed above the substrate (z, z^{\prime} > 0) can be written} \\ \text{day} \quad & \text{as} \\ \text{sors} \\ \text{hh} \\ \quad & \text{$G_{EE}(\omega,r,r') = \int \frac { d k } { 2 \pi } \frac { i k e ^ { i \phi k _ { z } ( z + z ^ { \prime } ) } } { 2 k _ { z } } \left [ r _ { T E } \left ( \frac { A } { C } \ 0 \right ) \\ \text{$C$\ B$\ 0\ 0\ 0$} \right ) \\ \text{hh} \\ \quad & \text{$k$th} \\ \quad & \text{$r$TM} \frac{\sigma^{2} \left ( \frac { - k _ { z } ^ { z } B } { k _ { z } ^ { z } C } \ - \phi k k _ { z } E \right ) \\ \text{$k$th} \\ \quad & \text{$g$k$k$z} E \ \phi k k _ { z } D \ \ k ^ { 2 } F \ \right ) \\ \text{s in} \\ \text{and} \\ \text{s $R$.} \\ \text{$s $R$.} \\ \text{on is} \\ \text{has} \\ \quad & \text{$\left [r_{TE} \left ( \phi k _ { z } C \ \phi k _ { z } B \ 0 \right ) } \\ \quad & \text{$\left [r_{TE} \left ( \frac { - \phi k _ { z } A \ - \phi k _ { z } C \ 0 \right ) } { k D \ - k E \ 0 \right ) } \\ \quad & \text{$\left [s.} \\ \quad & \text{$- r$TM} \left ( \frac { - \phi k _ { z } C \ \phi k _ { z } A \ \ k D \ 0 \right ) } { \left ( - \phi k _ { z } B \ \phi k _ { z } C \ - k E \right ) \right ] } \right ], \\ \text{indles} \\ \text{oles} \\ \quad & \text{where} \\ \text{s an} \quad & \text{$\quad.}$$
where
$$\begin{pmatrix} A \\ B \\ C \\ D \\ E \\ F \end{pmatrix} = \begin{pmatrix} \frac { 1 } { 2 } [ J _ { 0 } ( k d ) + J _ { 2 } ( k d ) \cos ( 2 \varphi _ { d } ) ] \\ \frac { 1 } { 2 } [ J _ { 0 } ( k d ) - J _ { 2 } ( k d ) \cos ( 2 \varphi _ { d } ) ] \\ \frac { 1 } { 2 } J _ { 2 } ( k d ) \sin ( 2 \varphi _ { d } ) \\ i J _ { 1 } ( k d ) \sin \varphi _ { d } \\ i J _ { 1 } ( k d ) \cos \varphi _ { d } \\ J _ { 0 } ( k d ) \end{pmatrix}. \quad ( 7 )$$
̸
$$d \tt a _ { \tt a n - 1 } \quad \tt p _ { i } ( \omega ) = \tt p _ { i } ^ { ( \tt f l ) } ( \omega ) + \frac { \omega ^ { 2 } } { c ^ { 2 } } \bar { \alpha } _ { i } \sum _ { j \neq i } \tt G ^ { ( \tt E E ) } ( \tt R _ { i }, \tt R _ { j } ) \tt p _ { j } ( \omega ), \ \ ( 8 )$$
̸
where the field at the origin of each induced dipole is the total one except for the self contribution ( j = i in the sum) and we have introduced the polarizability ¯ α i of each dipole, which is a 3 × 3 matrix in the general scenario of an anisotropic particle. The previous equations lead to the linear system of equations
$$\binom { \mathbf p _ { 1 } ( \omega ) } { \vdots } = \mathbb { B } ( \omega ) \, \binom { \mathbf p _ { 1 } ^ { ( \mathbf f ) } ( \omega ) } { \vdots }, \quad \ \ ( 9 )$$
where B ( ω ) = D -1 ( ω ) is a 3 N × 3 N matrix, D being defined in terms of 3 × 3 blocks D ij ( i, j = 1 , . . . , N ) reading
$$\mathbb { D } _ { i j } ( \omega ) = \delta _ { i j } \mathbb { I } - ( 1 - \delta _ { i j } ) \frac { \omega ^ { 2 } } { c ^ { 2 } } \bar { \alpha } _ { i } \mathbb { G } ^ { ( \mathbb { E } E ) } ( \omega, \mathbf r _ { i }, \mathbf r _ { j } ). \quad ( 1 0 )$$
For the total electric and magnetic fields we have
$$E _ { \alpha } ( { \mathbf r }, \omega ) & = \frac { \omega ^ { 2 } } { \varepsilon _ { 0 } c ^ { 2 } } \mathbb { G } _ { \alpha \beta } ^ { ( \text{EE} ) } ( \omega, { \mathbf r }, { \mathbf r } _ { i } ) \mathbb { B } _ { i j, \beta \gamma } \, p _ { j, \gamma } ^ { ( \text{fl} ) } ( \omega ), \quad & \text{tibilit} \\ H _ { \alpha } ( { \mathbf r }, \omega ) & = - i \frac { \omega ^ { 2 } } { c } \mathbb { G } _ { \alpha \beta } ^ { ( \text{HE} ) } ( \omega, { \mathbf r }, { \mathbf r } _ { i } ) \mathbb { B } _ { i j, \beta \gamma } ( \omega ) p _ { j, \gamma } ^ { ( \text{fl} ) } ( \omega ), \quad & \text{tibilit} \\. \quad. \quad. \quad. \quad. \. \. \. \. \. \. \. \. \. \. & S _ { \sim }$$
where from now on we use Latin indices for the index associated to the dipoles, going from 1 to N , and Greek ones for the Cartesian components x , y and z , and sum over repeated indices is assumed.
## B. Poynting vector
The component α of the Poynting vector can be easily put under the form
$$S _ { \alpha } ( { \mathbf r }, t ) = 2 \, { \mathrm R e } \int _ { 0 } ^ { + \infty } \frac { d \omega } { 2 \pi } e ^ { - i \omega t } S _ { \alpha } ( { \mathbf r }, \omega ), \quad ( 1 2 ) \quad \text{$\text{$s_{d}_{e}$}$}$$
with
$$S _ { \alpha } ( { \mathbf r }, \omega ) = \epsilon _ { \alpha \beta \gamma } \int _ { 0 } ^ { + \infty } \frac { d \omega ^ { \prime } } { 2 \pi } \langle E _ { \beta } ( { \mathbf r }, \omega ^ { \prime } ) H _ { \gamma } ^ { * } ( { \mathbf r }, \omega ^ { \prime } - \omega ) \rangle. \ ( 1 3 ) \quad \text{with } 1 \\ \text{tudio}$$
where ϵ αβγ is the Levi-Civita tensor. We need at this stage the correlation function of the fluctuating dipoles, for which we employ the fluctuation-dissipation theorem
$$\langle p _ { i, \alpha } ^ { ( \text{fl} ) } ( \omega ) p _ { j, \beta } ^ { ( \text{fl} ) * } ( \omega ^ { \prime } ) \rangle = 4 \delta ( \omega - \omega ^ { \prime } ) \hbar { \varepsilon } _ { 0 } \delta _ { i j } \chi _ { i, \alpha \beta } ( \omega ) n ( \omega, T _ { i } ), \quad \begin{array} { c } \dots r r \\ ( 1 4 ) & \varepsilon ( \omega ) \end{array} \begin{array} { c } \dots r r \\ \varepsilon ( \omega ) \end{array}.$$
depending on the individual dipole susceptibility matrix
$$\bar { \chi } _ { i } = \frac { \bar { \alpha } _ { i } - \bar { \alpha } _ { i } ^ { \dagger } } { 2 i } - \frac { \omega ^ { 3 } } { 6 \pi c ^ { 3 } } \bar { \alpha } _ { i } ^ { \dagger } \bar { \alpha } _ { i }, \quad \quad ( 1 5 ) \quad \text{(1)} \quad \text{(i)}$$
and
$$n ( \omega, T ) = \left [ \exp \left ( \frac { \hbar { \omega } } { k _ { B } T } \right ) - 1 \right ] ^ { - 1 }. \quad \ \ ( 1 6 ) \quad \ \ t i v i { \tt f i c }$$
We deduce that the Poynting vector does not depend on time, as it should be for a stationary system, and reads
$$S _ { \alpha } ( { \mathbf r }, t ) = \int _ { 0 } ^ { + \infty } \frac { d \omega } { 2 \pi } S _ { \alpha } ( { \mathbf r }, \omega ), \quad \quad ( 1 7 )$$
the spectrum of the Poynting vector being given by
$$S _ { \alpha } & ( { \mathbf r }, \omega ) = - \frac { 4 \hbar { \omega } ^ { 4 } } { c ^ { 3 } } \epsilon _ { \alpha \beta \gamma } & & \text{where} \\ & \times \text{Im} \left [ n ( \omega, T _ { i ^ { \prime } } ) \mathbf G ^ { ( \text{EE} ) } _ { \beta \beta ^ { \prime } } ( \omega, { \mathbf r }, { \mathbf r } _ { i } ) \mathbf G ^ { ( \text{HE} ) } _ { \gamma \gamma ^ { \prime } } ( \omega, { \mathbf r }, { \mathbf r } _ { j } ) \quad ( 1 8 ) \quad \epsilon _ { 1 } \overset { \ } { = } \\ & \quad \times \mathbf B _ { i i ^ { \prime }, \beta ^ { \prime } \beta ^ { \prime \prime } } ( \omega ) \mathbf B ^ { * } _ { j i ^ { \prime }, \gamma ^ { \prime \prime } } ( \omega ) \, \chi _ { i ^ { \prime }, \beta ^ { \prime \prime } \gamma ^ { \prime \prime } } ( \omega ) \right ]. & & \epsilon _ { 2 } \overset { \ } { = }$$
After obtaining the general expression given by Eq. (18), valid for an arbitrary number of dipole with anisotropic polarizabilities and in the presence of a substrate, we restrict ourselves to the scenario of a single dipole located at r d , having temperature T d and susceptibility ¯ χ . This scenario, as shown below, will already allow us to highlight effects of focusing of near-field radiative heat transfer ascribed to the anisotropic behavior. In this case we have B = I and we deduce
$$S _ { \alpha } ( { \mathbf r }, \omega ) & = - \frac { 4 \hbar { \omega } ^ { 4 } } { c ^ { 3 } } \epsilon _ { \alpha \beta \gamma } \text{Im} \left [ n ( \omega, T _ { d } ) \mathbf G _ { \beta \beta ^ { \prime } } ^ { ( \mathrm E E ) } ( { \mathbf r }, { \mathbf r } _ { d } ) \\ \text{ek} \\ \text{im} & \times \mathbf G _ { \gamma \gamma ^ { \prime } } ^ { ( \mathrm H E ) * } ( \omega, { \mathbf r }, { \mathbf r } _ { d } ) \, \chi _ { \beta ^ { \prime } \gamma ^ { \prime } } \right ].$$
## III. RESULTS
In this Section we are going to exploit Eq. (19) to compute the Poynting vector below a single particle in proximity to a substrate. As for the latter, we choose a substrate made of silicon carbide (SiC), whose permittivity is described here by a Drude-Lorentz model [71]
$$\varepsilon ( \omega ) = \varepsilon _ { \infty } \frac { \omega _ { \text{L} } ^ { 2 } - \omega ^ { 2 } - i \Gamma \omega } { \omega _ { \text{T} } ^ { 2 } - \omega ^ { 2 } - i \Gamma \omega }, \text{ \quad \ \ } ( 2 0 )$$
with high-frequency dielectric constant ε ∞ = 6 7 . , longitudinal optical frequency ω L = 1 83 . × 10 14 rad/s, transverse optical frequency ω T = 1 49 . × 10 14 rad/s, and damping Γ = 8 97 . × 10 11 rad/s. According to this model a SiC substrate supports a surface phonon-polariton mode in p polarization at frequency ω pl = 1 786 . × 10 14 rad/s (solution in the large-wavevector limit of the equation ε ω ( ) + 1 = 0 ), which is expected to contribute significantly to near-field effects such as the one studied in this work.
Concerning the nanoparticle, we assume that it is made of indium antimonide (InSb), a magneto-optical material whose properties have been recently studied in connection with their impact on near-field radiative heat transfer. This material is characterized by an isotropic permittivity, becoming anisotropic in the presence of a magnetic field, allowing us to address the impact of this induced anisotropy on the Poynting vector. More specifically, in the presence of a magnetic field B = B ˆ e z acting along the z direction, the permittivity matrix ¯ ε takes the form
$$\bar { \varepsilon } = \begin{pmatrix} \varepsilon _ { 1 } & - i \varepsilon _ { 2 } & 0 \\ i \varepsilon _ { 2 } & \varepsilon _ { 1 } & 0 \\ 0 & 0 & \varepsilon _ { 3 } \end{pmatrix}, \quad \quad ( 2 1 )$$
where
$$\text{where} \\ \epsilon _ { 1 } & = \epsilon _ { \infty } \left ( 1 + \frac { \omega _ { L } ^ { 2 } - \omega _ { T } ^ { 2 } } { \omega _ { T } ^ { 2 } - \omega ^ { 2 } - i \Gamma \omega } + \frac { \omega _ { p } ^ { 2 } ( \omega + i \gamma ) } { \omega [ \omega _ { c } ^ { 2 } - ( \omega + i \gamma ) ^ { 2 } ] } \right ), \\ \epsilon _ { 2 } & = \frac { \epsilon _ { \infty } \omega _ { p } ^ { 2 } \omega _ { c } } { \omega [ ( \omega + i \gamma ) ^ { 2 } - \omega _ { c } ^ { 2 } ] }, \\ \text{by} \\ \text{ub-} \\ \text{like}$$
Figure 1: (a) Poynting vector S max below the nanoparticle, placed at (0 0 4 , , r ) , and (b) FWHM as a function of the applied magnetic field B for different radii (see legend). Panel (c) and its inset show the same curves normalized by the value at B = 0 .
ω c = eB/m ∗ being the cyclotron frequency and where the parameters read [56] ε ∞ = 15 7 . , ω L = 3 62 . × 10 13 rad/s, ω T = 3 39 . × 10 13 rad/s, Γ = 5 65 . × 10 11 rad/s, n = 1 36 . × 10 19 cm -3 , m ∗ = 7 29 . × 10 -32 kg, ω p = √ ne 2 m ϵ ϵ ∗ 0 ∞ = 1 86 . × 10 14 rad/s, and γ = 10 12 rad/s. The permittivity leads to the polarizability tensor ¯ α defined as [72, 73]
$$\bar { \alpha } = 4 \pi R ^ { 3 } ( \bar { \varepsilon } - \mathbb { I } ) ( \bar { \varepsilon } + 2 \mathbb { I } ) ^ { - 1 }, \quad \ \ ( 2 3 ) \quad \ \. \,,$$
which finally allows to deduce the susceptibility through Eq. (15). It is worth mentioning that in the case of nanoparticles described within the dipolar approximation near-field effects strongly depend on dipolar resonances (existing at the interface between each nanoparticle and the surrounding vacuum). In the case of a permittivity
Figure 2: Poynting vector along the x axis for three values of the applied field (see legend), in absolute and normalized (inset) units. In the inset, the points indicate the coordinate where FWHM is realized.
given by Eq. (21) and in the limit of absence of dissipation these resonances can be deduced analytically and are located at [63]
$$\omega _ { m = \mp 1 } & = \sqrt { \left ( \frac { \epsilon _ { \infty } \omega _ { p } ^ { 2 } } { \epsilon _ { \infty } + 2 } + \frac { \omega _ { c } ^ { 2 } } { 4 } \right ) } \pm \frac { \omega _ { c } } { 2 }, \\ \omega _ { m = 0 } & = \sqrt { \frac { \epsilon _ { \infty } \omega _ { p } ^ { 2 } } { \epsilon _ { \infty } + 2 } }. \\ \cdot \quad, \quad. \quad. \quad, \quad. \quad. \quad. \quad.$$
̸
We clearly see that these are degenerate for B = 0 , while for B = 0 the resonances with m = ∓ 1 deviate approximately linearly from the one having m = 0 , with a slope proportional to the cyclotron frequency ω c .
By using these definition, we are going to focus in the following on two main quantities to assess the performance of the system in terms of HAMR. The first is the z component of the Poynting vector S z (0 0 0) , , at the location right below the nanoparticle and at the interface between substrate and vacuum. This quantity, that we will define as S max , corresponds (as shown below) to the highest value of S z on the plane z = 0 for vanishing and moderate values of the magnetic field, and a potential increase due to the magnetic field anticipates the possibility of increasing heat transfer between nanoparticle and substrate and thus making a local temperature increase of the substrate easier. The second relevant quantity is the Full Width Half Maximum (FWHM), defined as the 2 x 0 , x 0 being the coordinate at which S z ( x , 0 0 0) , = S z (0 0 0) , , / 2 . This quantity represents a measure of the localized nature of the heat transfer between nanoparticle and substrate and thus of the potential spatial resolution of the associated HAMR device.
As a first result, we study S max and FWHM as a function of the applied magnetic field B for different radii r of the nanoparticle. For each r , in order to guarantee the validity of the dipolar approximation, we choose the coordinates of the particle as (0 0 , , h ) with h = 4 R , as shown in the inset of Fig. 1(a). Figures 1(a)-(b) show
Figure 3: z component of the Poynting vector S z ( x, y, 0) on the z plane for different values of the applied magnetic field (see legend). In each panel, the dashed circle represents the width (FWHM) of the Poynting vector at the surface of the substrate.
the results for radii r = 10 30 50 70 90 , , , , nm(and thus distances h = 40 120 200 280 360 , , , , nm from the substrate) as a function of B in a range from 0 to 6 T. Let us first focus on the isotropic scenario B = 0 corresponding to the absence of applied magnetic field. Concerning S max , we remark that its value increases when decreasing the radius r . While this might seem surprising because of the reduced particle polarizability, it is a signature of the strong near-field dependence of S max on the distance, which decreases since proportional to the radius. Concerning the FWHM, we observe that it increases with the radius (thus with the distance h ), and that is always of the order of h .
Let us now focus on the impact of the magnetic field. First, we remark a non-monotonic behavior, according to which S max (FWHM) first increases (decreases) as a function of B , then decreases (increases), by reaching values even below (above) the reference one for B = 0 . This clearly highlights an ideal scenario as a function of B , since it shows the existence of an optimal magnetic field B opt for which not only is the local heat flux quantitatively increased, but it is also more focused on the surface of the substrate. The relative increase (decrease) of S max (FWHM) is shown in Fig. 1(c), where we observe that the relative effect does not depend strongly on the particule radius r , with S max increasing almost by a factor of 4 and FWHM being reduced by around 30% in the best scenario. We remark that the two phenomena take place around the same optimal value for B , which is here B opt ≃ 2 1 . T.
Before addressing more in detail the origin of the optimal field, it is interesting to analyze the shape of S x, ( 0 0) , along the x axis for three values of the magnetic field B = 0 2 1 5 , . , T, namely a vanishing field, the optimal one, and a field for which the result is worse (in terms of HAMS application) than the one in the absence of applied field. This is shown in Fig. 2, both in absolute units and in normalized ones (inset). As expected, we remark an almost 4-fold enhancement of the Poynting vector right below the nanoparticle, and the inset in normalized units allows us to clearly visualize the width reduction.
A complementary view of the impact of the magnetic field on S max and FWHM is given by Fig. 3, where for the same values of the magnetic field S z ( x, y, 0) is shown on the plane z = 0 .
In order to get more insight on the existence of an optimal field B opt = 2 1 . T, we now perform a more detailed spectral investigation of the effect. We first analyze the spectrum S ω ( ) of the Poynting vector at r = (0 0 0) , , , i.e. right below the nanoparticle at the location of S max , shown in Fig. 4. For clarity, let us start from the spectrum corresponding to B = 0 [black solid curve in Fig. 4(a)]. We remark the presence of two resonances. The one at higher frequencies corresponds to the resonance at a SiC-vacuum interface discussed above. On the contrary, the one at lower frequency stems from the InSb nanoparticle resonances, all degenerate for B = 0 .
Figure 4: Spectral decomposition of the z component of the Poynting vector at (a) the origin and (b) at coordinate (70 nm 0 0) , , , for different values of the applied magnetic field (see legend). The inset of panel (b) represents the three resonances of InSb defined in Eq. (24) (black for m = 0 , red for m = -1 and blue for m = +1 ), while the vertical dashed purple line represents the resonance frequency of SiC.
As discussed above, the presence of a magnetic field induces the appearance of two further resonances, whose deviation from the one at B = 0 scales almost linearly with ω c , thus with B . The effect is manifest in Fig. 4(a), where we remark that B opt = 2 1 . T is the value of the field for which one of this resonances matches the one of SiC (independent of the applied field B ), thus leading to a strong amplification of S max . The possibility of obtaining this matching condition with a relatively moderate magnetic field is indeed connected to the proximity of SiC and InSb resonance in the absence of magnetic field. In the inset of Fig. 4(b), we show the three field-dependent resonance frequencies of InSb defined in Eq. (24) as a function of the applied field B , along with the resonance frequency of SiC. While this curve is useful to visualize the appearance of a matching as a function
- [1] Y. De Wilde, F. Formanek, R. Carminati, B. Gralek, P. Lemoine, K. Joulain, J. Mulet, Y. Chen, J.J. Greffet, Nature, 444 , 740 (2006).
- [2] A. Kittel, U. F. Wischnath, J. Welker, O. Huth, F. Ruting, and S.-A. Biehs, Appl. Phys. Lett., 93 , 193109 (2008).
of B , it does not allow to quantitatively extract the corresponding optimal value of the magnetic field because both the resonant frequencies given in Eq. (24) and the one of SiC are deduced by assuming the absence of losses. Going back to Fig. 4(a), when increasing the field B further above B opt , not only does the frequency matching disappear, but the resonance frequencies associated with InSb approach outer regions of the spectrum, and as a consequence induce a smaller heat transfer because of the Planck window dictated by the temperature mainly through the Bose-Einstein distribution (16).
While this frequency-matching effect explains the amplification of local heat transfer right below the nanoparticle, i.e. at the origin, it does not account for the reduction of FWHM. In order to explain this further relevant effect of anisotropy, we present in Fig. 4(b) the same spectral analysis as before but at the different coordinate (70 nm 0 0) , , , corresponding to half the FWHM realized at B = 0 . We observe the same qualitative behavior discussed above, i.e. a maximum enhancement occurring at B opt = 2 1 . T because of a frequency-matching condition. Nevertheless, the enhancement at the peak frequency (the resonance of SiC), giving the largest contribution to the frequency-integrated Poynting vector, is less pronounced. This can be attributed to the fact that the almost monochromatic nature of the heat flux is a purely near-field effect, depending strongly on the distance. As a consequence, it is more pronounced right below the nanoparticle (at a distance h = 120 nm) than at coordinate (70 nm 0 0) , , (at a distance ≃ 140 nm).The result is that, although the heat flux is amplified on the entire surface z = 0 , the distance-dependent amplification is stronger right below the nanoparticle and is at the origin of the desired reduction of FWHM.
## IV. CONCLUSION
We have introduced a theoretical framework to calculate the Poynting field radiated by a system of N magneto-optical thermal emitters placed above an isotropic substrate within the dipolar approximation. By applying this formalism to the specific scenario of a single particle we have shown that the application of an external magnetic field can induce both an amplification of the flux of Poynting vector at the substrate interface and a substantial decrease in the heated zone's surface area. This result paves the way to significant performance improvements for the HAMR technology.
- [3] A. C.Jones and M. B. Raschke, Nano Letters, 12 , 1475 (2012).
- [4] F. Huth, M. Schnell, J. Wittborn, N. Ocelic, and R. Hillenbrand, Nat. Mat. 10 , 352 (2011).
- [5] Q. Weng, S. Komiyama, L. Yang, Z. An, P. Chen, S.-A. Biehs, Y. Kajihara, and W. Lu, Science 360 , 775 (2018).
- [6] C. C. Williams and H. K. Wickramasinghe, Appl. Phys. Lett. 49 , 1587 (1986).
- [7] A. Majumdar, J. Lai, M. Chandrachood, O. Nakabeppu, Y. Wu, and Z. Shi, Rev. Sci. Instrum. 66 , 3584 (1995).
- [8] W. Srituravanich, N. Fang, C. Sun, Q. Luo, and X. Zhang, Nano Lett. 4 , 1085 (2004).
- [9] W. A. Challener et al., Nat. Photonics 3 , 220 (2009).
- [10] B. C. Stipe et al., Nature Photonics 4 , 484-488 (2010).
- [11] P. Ben-Abdallah, Phys. Rev. Lett. 123 , 264301 (2019).
- [12] P. Ben-Abdallah, S.-A. Biehs and K. Joulain, Phys. Rev. Lett. 107 , 114301 (2011)
- [13] R. Messina, M. Tschikin, S.-A. Biehs, and P. BenAbdallah, Phys. Rev. B 88 , 104307 (2013).
- [14] P. Ben-Abdallah, R. Messina, S.-A. Biehs, M. Tschikin, K. Joulain, and C. Henkel, Phys. Rev. Lett 111 , 174301 (2013).
- [15] E. Tervo, M. Francoeur, B. Cola, and Z. Zhang, Phys. Rev. B 100 , 205422 (2019).
- [16] M. Luo, J. Zhao, L. Liu, and M. Antezza, Phys. Rev. B 102 , 024203 (2020).
- [17] J.-L. Fang, X.-P. Luo, L. Qu, and H.-L. Yi, Int. J. Heat Mass Transf. 212 , 124295 (2023).
- [18] S.-A. Biehs, V. M. Menon, and G. S. Agarwal, Phys. Rev. B 93 , 245439 (2016).
- [19] J. Dong, J. Zhao, and L. Liu, Phys. Rev. B 97 , 075422 (2018).
- [20] R. Messina, S.-A. Biehs, and P. Ben-Abdallah, Phys. Rev. B 97 , 165437 (2018).
- [21] R. Deshmukh, S.-A. Biehs, E. Khwaja, T. Galfsky, G.S. Agarwal, and V.M. Menon, ACS Photonics 5 , 2737 (2018).
- [22] Y. Zhang, M. Antezza, H.-L. Yi, and H.-P. Tan, Phys. Rev. B 100 , 085426 (2019).
- [23] Y. Zhang, H.-L. Yi, H.-P. Tan, and M. Antezza, Phys. Rev. B 100 , 134305 (2019).
- [24] A. Ott and S.-A. Biehs, Phys. Rev. B 101 , 155428 (2020).
- [25] Y. Zhang, C.-L. Zhou, H.-L. Yi, and H.-P. Tan, Phys. Rev. Applied 13 , 034021 (2020).
- [26] A. Ott, Y. Hu, X.-H. Wu, and S.-A. Biehs, Phys. Rev. Applied 15 , 064073 (2021).
- [27] J.-L. Fang, L. Qu, and H.-L. Yi, Phys. Rev. Applied 17 , 034040 (2022).
- [28] K. Asheichyk and M. Krüger, Phys. Rev. Lett. 129 , 170605 (2022).
- [29] K. Sääskilahti, J. Oksanen, and J. Tulkki, Phys. Rev. B 89 , 134301 (2014).
- [30] K. Asheichyk and M. Krüger, Phys. Rev. B 98 , 195401 (2018).
- [31] Y. Zhang, J. Dong, G. Tang, and H.-L. Yi, Phys. Rev. B 103 , 195433 (2021).
- [32] J. Chen, B. X. Wang, and C. Y. Zhao, Int. J. Heat Mass Transfer 196 , 123213 (2022).
- [33] Y.-J. Zhang, Y. Zhang, S.-H. Yang, and H.-L. Yi, Int. J. Heat Mass Transfer 202 , 123677 (2023).
- [34] K. Asheichyk, P. Ben-Abdallah, M. Krüger, and R. Messina, Phys. Rev. B 108 , 155401 (2023).
- [35] A. I. Volokitin and B. N. J. Persson, Rev. Mod. Phys. 79 , 1291 (2007).
- [36] B. Song, A. Fiorino, E. Meyhofer, and P. Reddy, AIP Adv. 5 , 053503 (2015).
- [37] K. Joulain, J.-P. Mulet, F. Marquier, R. Carminati, and J.-J. Greffet, Surf. Sci. Rep. 57 , 59 (2005).
- [38] J. C. Cuevas, F. J. García-Vidal, ACS Photonics 5 , 3896 (2018).
- [39] S.-A. Biehs, R. Messina, P. S. Venkataram, A. W. Rodriguez, J. C. Cuevas, and P. Ben-Abdallah, Rev. Mod. Phys. 93 , 025009 (2021).
- [40] S.-A. Biehs, M. Tschikin, and P. Ben-Abdallah, Phys. Rev. Lett. 109 , 104301 (2012).
- [41] P. Ben-Abdallah, Appl. Phys. Lett. 89 , 113117 (2006).
- [42] I. Latella, S.-A. Biehs, and P. Ben-Abdallah, Opt. Express 29 , 16, 24816-24833 (2021).
- [43] K. Chen, P. Santhanam, S. Sandhu, L. Zhu, and S. Fan, Phys. Rev. B 91 , 134301 (2015).
- [44] L. Zhu, A. Fiorino, D. Thompson, R. Mittapally, E. Meyhofer, and P. Reddy, Nature 566 , 239 (2019).
- [45] Y. De Wilde, F. Formanek, R. Carminati, B. Gralak, P.A. Lemoine, K. Joulain, J.-P. Mulet, Y. Chen, and J.-J. Greffet, Nature 444 , 740 (2006).
- [46] A. C. Jones and M. B. Raschke, Nano Lett. 12 , 1475 (2012).
- [47] R. S. DiMatteo, P. Greiff, S. L. Finberg, K. A. YoungWaithe, H. K. H. Choy, M. M. Masaki, and C. G. Fonstad, Appl. Phys. Lett. 79 , 1894 (2001).
- [48] A. Narayanaswamy and G. Chen, Appl. Phys. Lett. 82 , 3544 (2003).
- [49] M. Laroche, R. Carminati, and J.-J. Greffet, Appl. Phys. 100 , 063704 (2006).
- [50] K. Park, S. Basu, W. P. King, and Z. M. Zhang, J. Quant. Spectros. Radiat. Transfer 109 , 305 (2008).
- [51] I. Latella and P. Ben-Abdallah, Sci. Rep. 11 , 19489 (2021).
- [52] P. Ben-Abdallah and S.-A. Biehs, Phys. Rev. Lett. 112 , 044301 (2014).
- [53] P. Ben-Abdallah and S.-A. Biehs, Phys. Rev. B 94 , 241401(R) (2016).
- [54] P. Ben-Abdallah and S.-A. Biehs, AIP Adv. 5 , 053502 (2015).
- [55] W. J. Lim et al., Nat. Commun. 15 , 5584 (2024).
- [56] P. Ben-Abdallah, Phys. Rev. Lett. 116 , 084301, (2016).
- [57] L. Zhu and S. Fan, Phys. Rev. Lett. 117 , 134303 (2016).
- [58] I. Latella and P. Ben-Abdallah, Phys. Rev. Lett. 118 , 173902, (2017).
- [59] R. M. Abraham Ekeroth, A. García-Martín, and J. C. Cuevas, Phys. Rev. B 95 , 235428 (2017).
- [60] A. Ott, P. Ben-Abdallah, and S.-A. Biehs, Phys. Rev. B 97 , 205414 (2018).
- [61] R. M. Abraham Ekeroth, P. Ben-Abdallah, J. C. Cuevas, and A. Garcia Martin, ACS Photonics 5 , 705 (2017).
- [62] A. Ott, R. Messina, P. Ben-Abdallah, and S.-A. Biehs, Appl. Phys. Lett. 114 , 163105 (2019).
- [63] A. Ott, R. Messina, P. Ben-Abdallah, and S.-A. Biehs, J. Photon. Energy 9 , 032711 (2019).
- [64] K. Wang and L. Gao, ES Energy & Environ. 7 , 12 (2020).
- [65] R. Messina, A. Ott, C. Kathmann, S.-A. Biehs, and P. Ben-Abdallah, Phys. Rev. B 103 , 115440 (2021).
- [66] L. Lu, B. Zhang, B. Li, J. Song, Z. Luo, and Q. Cheng, Opt. Letters 47 , 4087 (2022).
- [67] W.-X. Ge, Y. Hu, L. Gao, and X. Wu, Chin. Phys. Lett. 40 , 114401 (2023).
- [68] P. Ben-Abdallah and A. W. Rodriguez, Phys. Rev. Lett. 129 , 260602 (2022).
- [69] P. Ben-Abdallah, K. Joulain, J. Drevillon, and C. Le Goff, Phys. Rev. B 77 , 075417 (2008).
- [70] L. Novotny and B. Hecth, Principles of Nano-Optics (Cambridge University Press, Cambridge, 2006).
- [71] Handbook of Optical Constants of Solids , edited by E. Palik (Academic Press, New York, 1998).
- [72] A. Lakhtakia, V. K. Varadan, and V. V. Varadan, Int. J. Infrared Milli. 12 , 1253 (1991).
- [73] S. Albaladejo, R. Gómez-Medina, L. S. Froufe-Pérez, H. Marinchio, R. Carminati, J. F. Torrado, G. Armelles, A. García-Martín, and J. J. Sáenz, Opt. Express 18 , 3556
(2010).
- [74] E. D. Palik, R. Kaplan, R. W. Gammon, H. Kaplan, R. F. Wallis, and J. J. Quinn, Phys. Rev. B 13 , 2497 (1976). | 10.1016/j.jqsrt.2024.109322 | [
"Louis Rihouey",
"Philippe Ben-Abdallah",
"Riccardo Messina"
]
| 2024-08-02T16:36:04+00:00 | 2024-08-02T16:36:04+00:00 | [
"cond-mat.mes-hall"
]
| Deep sub-wavelength scale focusing of heat flux radiated by magneto-optical nanoemitters in the presence of an external magnetic-field | We introduce a theoretical framework to describe the heat flux radiated in
the near-field regime by a set of magneto-optical thermal nanoemitters close to
a substrate in the presence of an external magnetic field. Then, we investigate
the particular case of a single emitter and we demonstrate that the external
field can induce both an amplification of the heat exchanged between emittter
and substrate and a focusing of the Poynting field at the substrate interface
at deep sub-wavelength scale. These effects open up promising perspectives for
the development of heat-assisted magnetic-recording technology. |
2408.01377v1 | ## Polaron formation in insulators and the key role of hole scattering processes : Band insulators, charge density waves and Mott transition
Ivan Amelio, 1 Giacomo Mazza, 2 and Nathan Goldman 1, 3
1 Center for Nonlinear Phenomena and Complex Systems, Université Libre de Bruxelles, CP 231, Campus Plaine, B-1050 Brussels, Belgium 2 Department of Physics 'E. Fermi' University of Pisa, Largo B. Pontecorvo 3, 56127 Pisa, Italy 3 Laboratoire Kastler Brossel, Collège de France, CNRS, ENS-PSL University, Sorbonne Université, 11 Place Marcelin Berthelot, 75005 Paris, France (Dated: August 5, 2024)
A mobile impurity immersed in a non-interacting Fermi sea is dressed by the gapless particle-hole excitations of the fermionic medium. This conventional Fermi-polaron setting is well described by the so-called ladder approximation, which consists in neglecting impurity-hole scattering processes. In this work, we analyze polaron formation in the context of insulating states of matter, considering increasing levels of correlation in the medium: band insulators originating from external periodic potentials, spontaneously-formed charge density waves, and a Fermi-Hubbard system undergoing a metal-Mott insulator transition. The polaron spectral function is shown to exhibit striking signatures of the underlying fermionic background, such as the single-particle band gap, particle-hole symmetry and the transition to the Mott state. These signatures are identified within the framework of the Chevy ansatz, i.e. upon restricting the Hilbert space to single particle-hole excitations. Interestingly, we find that the ladder approximation is inaccurate in these band systems, due to the fact that the particle and hole scattering phase spaces are comparable. Our results provide a step forward in the understanding of polaron formation in correlated many-body media, which are relevant to both cold-atom and semiconductor experiments.
## I. INTRODUCTION
Immersing an impurity in a many-body bath provides a paradigmatic theoretical and experimental setting, in which the dressing of the impurity by the bath excitations gives rise to a new object, conventionally called polaron .
Hilbert space of the fermions is restricted to include at most one particle-hole excitation on top of the Fermi sea. The reliability of the T-matrix approach to the Fermi polaron has been confirmed by a number of numerical benchmarks [11-13].
In recent years, there has been great interest in the physics of polarons due to the possibility of engineering mixtures of ultracold atoms, as well as of probing the states of few-layer transition metal dichalchogenides (TMD) heterostructures via polaron spectroscopy. A few ultracold atom experiments have been able to access the spectral features of Fermi and Bose polarons, exploiting the tunability of two-body interactions via Feschbach resonances [1-7]. In the semiconductor context, optical spectroscopy is sensitive to the dressing of the excitons by the electronic excitations of the two-dimensional material; for example, trion resonances emerge when doping a monolayer [8, 9].
In the simplest situation, the bath consists of a non-interacting Fermi sea in the continuum. An extremely convenient description of Fermi polaron physics is provided by the so-called (non-self-consistent) Tmatrix approximation, or ladder approximation, where the fermion-impurity T-matrix is computed exactly and the self-energy of the impurity is obtained by summing over all possible hole states. In this framework, the holeimpurity scattering processes are neglected, which is justified by the fact that the phase space for particle scattering is infinitely larger than the one for holes. It is easily proven that, for contact interactions and a continuum system, the T-matrix approximation coincides with the variational treatment proposed by Chevy [10], where the
Conversely, only a relatively small number of theoretical works have recently investigated, using different techniques, polaron formation in more complex and correlated baths, including interacting Bose gases [14, 15] and Bose-Hubbard lattices [16, 17], fermionic superfluids [18, 19], correlated electrons in twisted heterostructure [20], excitonic insulators [21], charge density waves [22], supersolids [23], topological systems [24-27] and unconventional single-particle bands [28, 29]. On the experimental side, TMD heterostructures have allowed to access non-trivial spectral features in the context of (generalized) Wigner crystals [30-36], correlated insulators [31, 37], quantum Hall liquids [38-40] and kinetic magnetism [41, 42].
This work sets the focus on the formation of polarons in insulating states of fermionic matter. As prime examples, we consider band insulators, charge density waves, as well as the Mott transition occurring in the stronglyinteracting Fermi-Hubbard model. Our study reveals the prominent roles of translational-symmetry breaking, the presence of a single-particle gap and the existence of particle-hole symmetry in this context, which all lead to characteristic signatures in the polaron spectrum.
On a more technical side, to what extent the T-matrix and Chevy approximations hold in these more complicated scenarios remains an open question. In the following, we take a small step forward and demonstrate that, in general, the T-matrix and Chevy approximation
can yield significantly different results. In particular, hole scattering processes cannot be neglected in few band systems or at half-filling, where the phase space for particle and hole scattering are comparable. This situation is relevant to optical lattices and moiré systems, provided that the impurity-fermion interactions are small enough to be able to consider a few bands.
The paper is structured as follows. We first review in Sec. II the ladder approach to the polaron in a noninteracting Fermi sea, and its relation to the Chevy approximation. In Sec. III, we apply Bloch theorem to the study of polaron spectra in a background with a periodic fermionic density, arising either from an external potential or a spontaneously formed charge density wave (CDW), computed using Hartree-Fock theory. A very characteristic avoided crossing in the repulsive polaron branch occurs when the two-body binding energy is comparable with the inter-band gap. Attractive polaron binding energies are overestimated and spurious peaks are obtained when neglecting hole scattering processes. In Sec. IV, we address the polaron formation in the case in which the underlying fermionic bath undergoes a Mott transition. We assume for simplicity an infinite mass for the impurity and the Chevy approximation, and observe a cusp at the metal-insulator transition. The role of particle-hole symmetry of the bath is elucidated. Finally, we draw our conclusions and discuss perspectives in Sec. V.
## II. REMINDER OF THE T-MATRIX AND CHEVY ANSATZ APPROXIMATIONS
In this Section, we briefly review the (non-selfconsistent) T-matrix and Chevy approaches to the Fermi polaron in a non-interacting Fermi sea defined on a 2D continuum plane.
The Hamiltonian of the system reads
$$H & = \sum _ { k } \xi _ { k } c _ { k } ^ { \dagger } c _ { k } + \sum _ { q } \epsilon _ { q } ^ { X } x _ { q } ^ { \dagger } x _ { q } + \frac { g } { \mathcal { V } } \sum _ { k p q } c _ { k } ^ { \dagger } c _ { p } x _ { q + p - k } ^ { \dagger } x _ { q }, \\ \dots & \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots$$
where c † k creates a spinless fermion at momentum k in a 2D box of area V , while x † q is the creation operator of the impurity (the letter x reminds of the exciton, used as impurity in optical spectroscopy in TMDs). The bare dispersion of the fermion is ξ k = k 2 2 m -µ with m the mass and µ the Fermi level, the impurity instead has mass M and dispersion ϵ X q = ϵ X + q 2 2 M with ϵ X the bottom of the exciton band, while the impurity-fermion contact interaction has strength g .
For attractive interactions g < 0 , the LippmannSchwinger equation
$$\frac { 1 } { g } = \frac { 1 } { \mathcal { V } } \sum _ { \mathbf k } ^ { k _ { \infty } } \frac { 1 } { - E _ { B } - \frac { \mathbf k ^ { 2 } } { 2 m _ { \text{red} } } },$$
FIG. 1. Example of typical Feynmann diagrams. (a) Impurity propagator G X (dashed line), fermionic propagator G el (solid line with rightward arrow), and bare vertex (blue circle). The hole propagator corresponds to the fermionic propagator with leftward arrow. (b) A typical impurity-particle diagram participating in the standard ladder resummation. (c) A diagram including also impurity-hole scattering and neglected in the T-matrix approach, but in principle contributing in the Chevy ansatz formalism.
yields the binding energy E B between a fermion and an impurity in vacuum (here m red = mM/ m ( + M ) denotes the reduced mass). The sum has a logarithmic divergence and needs to be regularized by introducing the cutoff momentum k ∞ . Typically, one assumes that E B is fixed (e.g. measured experimentally) and solves the theory sending k ∞ to infinity. When the interaction is renormalized in this way, g goes to zero.
A simple but effective approach to the physics of the polaron, is to truncate the Hilbert space to include up to one single particle-hole pair excitation on top of the non-interacting Fermi sea |F⟩ . A generic state of total momentum q (which is a conserved quantity) then takes the Chevy ansatz [10] form
$$| \Psi _ { \mathbf q } \rangle = \left \{ \psi ^ { \mathbf q } x _ { \mathbf q } ^ { \dagger } + \sum _ { \mathbf k p } \psi _ { \mathbf k p } ^ { \mathbf q } c _ { \mathbf k } ^ { \dagger } c _ { \mathbf p } x _ { \mathbf q - k + \mathbf p } ^ { \dagger } \right \} | \mathcal { F } \rangle, \quad ( 3 )$$
where in the summation it is implicit that k p , run over the empty and occupied fermionic states, respectively.
In this basis, the Schrödinger equation translates into the equations of motion for the wavefuntion entries ψ q kp , ψ q , namely
$$i \partial _ { t } \psi ^ { \mathbf q } = ( \epsilon _ { \mathbf q } ^ { X } + g n ) \psi ^ { \mathbf q } + \frac { g } { \mathcal { V } } \sum _ { \mathbf k p } \psi _ { \mathbf k p } ^ { \mathbf q }, \quad \quad ( 4 )$$
$$i \partial _ { t } \psi ^ { q } _ { \text{kp} } = ( \epsilon ^ { X } _ { q - \text{k+p} } + \xi _ { \text{k} } - \xi _ { \text{p} } + g n ) \psi ^ { q } _ { \text{kp} } + \\ + \frac { g } { \mathcal { V } } \psi ^ { q } + \frac { g } { \mathcal { V } } \sum _ { \text{k} ^ { \prime } } \psi ^ { q } _ { \text{k} ^ { \prime } \text{p} } - \frac { g } { \mathcal { V } } \sum _ { \text{p} ^ { \prime } } \psi ^ { q } _ { \text{kp} ^ { \prime } }, \ \ ( 5 )$$
with n the fermion density. The last term of Eq. (4) describes the creation of a particle-hole pair by scattering with the impurity, while the last two terms of Eq. (4) correspond, respectively, to impurity-particle and impurityhole scattering processes.
A crucial remark is that, when the interaction is renormalized sending g → 0 , the mean-field shift gn and the hole-scattering term are negligible, due to the finite hole phase space proportional to the Fermi energy. The electron scattering term is instead relevant, because the particle phase space is unbounded.
Dropping the hole term allows to resum Eqs. (4,5) and yields the self-consistent condition E = ϵ X + Σ X ( q , E ) for the energy eigenvalues E [43]. Here we introduced the impurity self-energy
$$\Sigma _ { X } ( { \mathbf q }, \omega ) = \frac { 1 } { \mathcal { V } } \sum _ { | { \mathbf p } | < k _ { F } } \tilde { \Lambda } ( { \mathbf q } + { \mathbf p }, \omega + \xi _ { \mathbf p } ), \quad ( 6 ) \quad \text{$\quad \text{$\quad \text{$\quad \text{$cal\quad }$} }$} )$$
where the two-body T-matrix
$$\tilde { \Lambda } ( { \mathbf q }, \omega ) = \left [ \frac { 1 } { g } - \frac { 1 } { \mathcal { V } } \sum _ { | { \mathbf k } | > { k _ { F } } } \frac { 1 } { \omega - \frac { { \mathbf k } ^ { 2 } } { 2 m } - \epsilon _ { q - { \mathbf k } } ^ { X } } \right ] ^ { - 1 } \quad ( 7 ) \quad \text{ice}. \quad \text{(sma)}$$
obeys the Dyson equation ˜ = Λ g + Π g X -el ˜ Λ with Π X -el = 1 V ∑ | k | >k F [ ω -k 2 2 m -ϵ X q -k ] -1 , and corresponds to the resummation of the ladder diagrams describing particleimpurity scattering. Equations. (6,7) constitute the socalled non-self-consistent T-matrix approximation, aka ladder approximation. So far, we have shown that, in continuum systems with contact interactions, the Chevy approach and non-self-consistent T-matrix method are equivalent, as it is well known [44-47]. One of the main goals of this paper is to study situations where the particle and hole phase spaces have comparable extent, and this equivalence does not hold.
Some diagrammatic intuition can be developed by inspecting Fig. 1. In panel (a) we define the bare propagators and vertex, while in panels (b) and (c) we report typical sample diagrams corresponding, respectively, to T-matrix and Chevy contributions to the impurity selfenergy. Notice that the restriction to the Chevy subspace entails that at each time at most one particle-hole pair can be drawn. A fermionic solid line with arrow pointing leftwards is interpreted as a hole propagator. In particular, in Fig. 1.(b) only impurity-particle scattering processes are present, and can be easily resummed using the ladder method, to yield Eqs. (6,7). Conversely, the Chevy approach depicted in panel (c) includes impurityhole scattering. We will show in Appendix A how a resummation is formally possible in this case as well.
## III. POLARONS IN CHARGE DENSITY WAVES AND BAND INSULATORS
In this Section we will investigate polaron spectra on top of band insulators and CDWs. In band insulators, a periodic external potential creates a set of Bloch bands and the Fermi level lies within a gap between two sets of these bands. At the Chevy level, it is assumed that a hole is created in one of the valence bands and a fermion is promoted to the set of conduction bands. The Chevy equations of motion are written down explicitly keeping track of the discrete translational invariance of the system, and are labeled by the Bloch quasi-momentum of the polaron.
Then, we consider charge density waves in the HartreeFock approximation. Within the Hartree-Fock method, the fermions are quasi-particles occupying effective single particle bands generated by the non-local Hartree-Fock potential [48]. As a consequence, the polaron equations developed for band insulators apply straightforwardly.
We remark that in this work we restrict numerical results to two-dimensional lattice systems, meaning that the periodic external potentials or the spontaneously formed CDWs lie on top of a microscopic lattice. This choice is motivated both by technical reasons (smaller matrices to diagonalize, no ultraviolet regularization needed) and experimental considerations in moiré systems, since CDWs and generalized Wigner crystals are favored by the presence of the moiré potential [30, 31, 34]. Our formalism and main results should extend to other dimensionalities and continuum systems.
## A. Chevy formalism for Bloch bands
Here, we consider here a system of spinless fermions in a periodic external potential V ext ( r ) . The Hamiltonian reads in momentum space
$$\int _ { \mu _ { 1 } } ^ { d } H ^ { \text{el} } = \sum _ { \tilde { k } } \epsilon _ { \tilde { k } } c _ { \tilde { k } } ^ { \dagger } c _ { \tilde { k } } + \frac { 1 } { \mathcal { V } } \sum _ { \tilde { k } G G ^ { \prime } } V _ { \text{G} - \text{G} ^ { \prime } } ^ { \text{ext} } c _ { \tilde { k } + \text{G} } ^ { \dagger } c _ { \tilde { k } + \text{G} ^ { \prime } }, \quad ( 8 )$$
where ϵ ˜ k is the bare dispersion of the fermions, c † ˜ k creates a fermion with momentum ˜ k = k + G , where k is the Bloch quasi-momentum within the first Brillouin zone (1BZ) and G belongs to the reciprocal lattice of the periodic potential. This notational convention is implicit in the summations and in the following. Finally, V denotes the total area or volume for a continuous system, or the total number of lattice sites in a discretized setting.
The Bloch theorem ensures that the Hamiltonian can be block-diagonalized within each quasi-momentum sector, yielding
$$H ^ { \text{el} } = \sum _ { \mathbf k \alpha } E _ { \mathbf k \alpha } d _ { \mathbf k \alpha } ^ { \dagger } d _ { \mathbf k \alpha },$$
with d † k α = ∑ G u k α ( G ) c † k + G the quasi-particle creation operator, where α is the band index, E k α the band energy at a given quasi-momentum, and u k α ( G ) the periodic Bloch wavefunctions.
In the following, we assume that the fermion-impurity interaction is a contact one with coupling g ,
$$H ^ { \text{el-X} } = \frac { g } { \mathcal { V } } \sum _ { \tilde { k } \tilde { p } \tilde { q } } c ^ { \dagger } _ { \tilde { k } } c _ { \tilde { p } } x ^ { \dagger } _ { \tilde { q } - \tilde { k } + \tilde { p } } x _ { \tilde { q } }. \quad \quad ( 1 0 )$$
The fermion-impurity binding energy E B in vacuum and in the absence of external potential is given by the Lippmann-Schwinger equation
$$\frac { 1 } { g } = \frac { 1 } { \mathcal { V } } \sum _ { \tilde { \mathbf k } } \frac { 1 } { - E _ { B } - \epsilon _ { \tilde { \mathbf k } } ^ { f } - \epsilon _ { - \tilde { \mathbf k } } ^ { X } }, \quad \quad ( 1 1 ) \quad \quad \quad$$
and in two dimensions E B > 0 for any g < 0 . In the continuum, an ultraviolet cutoff, corresponding to the physical range of the interaction, is needed to make the sum convergent; in particular, g tends to zero as the cutoff is sent to infinity. On a lattice, instead, the Bravais unit length provides a natural regularization. In a moiré system, one can imagine that only the lowest mini-moiré band is active, with the range of the exciton-electron interaction being a few times smaller than the separation between the moiré minima. A superpotential V ext ( r ) , with larger period, can then be superimposed, or a CDW can form within the first mini-band.
At zero temperature, if the Fermi level falls within a bandgap, then the fermionic ground state -in the absence of the impurity- consists of N v filled valence bands. We denote this insulating ground state as |F⟩ = Π k β d † k β | 0 ⟩ , where k ∈ 1 BZ,β = 1 , ..., N v . When an impurity is created in such a many-body background (by the operator x † q ), it will excite particle-hole pairs out of |F⟩ . If one restricts to up to one such excitation, the state of the system in the total quasi-momentum q takes the Chevy ansatz form
$$| \Psi _ { \mathbf q } \rangle & = \left \{ \sum _ { \mathbf G } \psi _ { \mathbf G } x _ { \mathbf q + \mathbf G } ^ { \dagger } + \\ & \quad + \sum _ { \mathbf k p G \alpha \beta } \psi _ { \mathbf k p } ^ { \alpha \beta \mathbf G } \, d _ { \mathbf$$
where k p q , , ∈ 1 BZ,β = 1 , ..., N v and α > N v run over the valence and conduction band indices, respectively, and G belongs to the reciprocal lattice of V ext . Here, ψ G , ψ αβ G kp are just the coefficients of the basis expansion in this sector of the Hilbert space. (There is no physical meaning for upper versus lower indices, it is just a graphics choice.) Notice that, in the second summation, α and β indices run over the empty and filled bands, respectively.
Denoting as H X = ∑ ˜ q ϵ X ˜ q x x † ˜ q ˜ q the bare kinetic energy operator of the impurity, the total Hamiltonian of the system reads
$$H = H ^ { \text{el} } + H ^ { X } + H ^ { \text{el} - X }. \text{ \quad \ \ } ( 1 3 ) \text{ \ \ the }$$
The equations of motion for | Ψ q ⟩ then read
$$i \partial _ { t } \psi _ { G } = \epsilon _ { q + G } ^ { X } \psi _ { G } & + \sum _ { G ^ { \prime } } ( \mathcal { M } ^ { 0 } ) _ { \text{GG} ^ { \prime } } \ \psi _ { G ^ { \prime } } + \\ & + \sum _ { \text{kp} G ^ { \prime } \alpha$$
$$\text{by the} \quad & i \partial _ { t } \psi _ { k p } ^ { \alpha \beta G } = ( \epsilon _ { q + p - k + G } ^ { X } + E _ { k \alpha } - E _ { p \beta } ) \psi _ { k p } ^ { \alpha \beta G } + \\ ( 1 1 ) \quad & + \sum _ { G ^ { \prime } } ( \math$$
where we will now analyze individually each term. First of all, the diagonal terms contain the bare impurity and quasi-particle dispersion. Then, the mean-field scattering term is
$$\stackrel {.. } { n } \\ \stackrel {.. } { n } \\ \cdot \rangle,$$
and it describes the scattering of the impurity by the static density profile of the ground state. In particular, this term is present also in the subspace with zero particle-hole excitations.
Moving to the 1-particle-hole sector, the particle scattering term
$$\text{$\text{cre}$} ^ { \text{cr}$} ^ { \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text#$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text}$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text'$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text<$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text`$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text.$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text1$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text-$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text51$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$$
describes scattering of the fermion by the impurity within the conduction band phase space. Similarly,
$$( \mathcal { M } ^ { h } ) ^ { \alpha \beta \beta ^ { \prime } \text{GG} ^ { \prime } } _ { k p p ^ { \prime } } = \frac { g } { \mathcal { V } } \sum _ { R } u ^ { * } _ { p ^ { \prime } \beta ^ { \prime } } ( \text{R} ) u _ { p \beta } ( \text{G} + \text{R} - \text{G} ^ { \prime } ) \ ( 1 8 )$$
describes impurity-hole scattering within the valence band states. Finally, the particle-hole generation term
$$( \mathcal { M } ^ { \text{ph} } ) _ { \text{kp} } ^ { \alpha \beta \text{GG} ^ { \prime } } = \frac { g } { \mathcal { V } } \sum _ { \text{RG} ^ { \prime } } u _ { \text{p} \beta } ^ { * } ( \text{R} ) u _ { \text{k} \alpha } ( \text{G} + \text{R} - \text{G} ^ { \prime } ) \quad ( 1 9 )$$
connects the subspace with zero and one particle-hole excitations.
The polaron spectral function is given by
$$\underset { \text{$to$} } { \text{$y$i$} } \text{$\text{$\text{$a$} } } A _ { X } ( \mathbf q, \omega ) \equiv - \frac { 1 } { \pi } \text{Im} \langle \mathcal { F } | x _ { \mathbf q } \frac { 1 } { \omega - H + i 0 ^ { + } } x _ { \mathbf q } ^ { \dagger } | \mathcal { F } \rangle = \\ \underset { \text{d$s} } { \text{on} }, \\ \text{d$s}, \\ \text{rgy}$$
where the sum is over the eigenstates ψ ( n ) and eigenergies E n of Eqs. (14,15). The spectral weight is given by the component of the Chevy wavefunction corresponding to the bare impurity, at the injection momentum.
FIG. 2. Chevy computation for a 9 × 9 triangular lattice at one-third filling, the CDW being described at the Hartree-Fock level. (left) Density contrast of the charge density wave ∆ n as a function of the quasi-particle gap ∆ gap (in units of the bandwidth W ), scanned by varying the fermion repulsion Z . Inset: the real space CDW density pattern. (right) Polaron spectra for E /W B = 0 8 . . Notice the renormalization of the AP due to interactions and the avoided crossing in the RP occurring for a gap of the order of | E AP | .
## B. CDWs in the Hartree-Fock approximation
determined by the length of the lattice constant, which is set to 1 in our units.
Understanding the spectral features of polaron formation on top of a charge density wave represents an open problem. Previous studies have investigated the presence of umklapp scattering secondary peaks on top of the RP branch, by using a fully static CDW density [32, 35]. An exact diagonalization study by two of the authors suggested a crucial role of the quasi-particle band-gap in the spectrum [22]. Finally, understanding the role of the CDW phonons and plasmons will be the topic of future research, as well as drawing connections to work done in the materials community [49], where progress in the ab initio modelling of polarons has been recently achieved [50].
Here, we adopt a drastic approximation and treat the CDW in the Hartree-Fock approximation. The HartreeFock quasi-particles then play the same role as the Bloch quasi-particles. While this approach is not able to capture the role of CDW phonons and will fail to describe quantitatively the CDW in the presence of strong quantum fluctuations, we will demonstrate that it qualitatively recovers the features predicted in ED.
More specifically, let us start considering the microscopic fermionic Hamiltonian, in the absence of any external potential:
$$H ^ { \text{el} } = \sum _ { \tilde { k } } \epsilon _ { \tilde { k } } c _ { \tilde { k } } ^ { \dagger } c _ { \tilde { k } } + \frac { 1 } { 2 \mathcal { V } } \sum _ { \tilde { k } \tilde { p } \tilde { q } } V _ { \tilde { q } } c _ { \tilde { k } + \tilde { q } } ^ { \dagger } c _ { \tilde { p } - \tilde { q } } ^ { \dagger } c _ { \tilde { p } } c _ { \tilde { k } }, \quad ( 2 1 ) \quad \overset { \text{plus} } { N _ { v } b ; }$$
where, as usual, the V ˜=0 q contribution is effectively included in the chemical potential and is excluded from the summation. As fermion-fermion potential, we use the Coulomb potential V q = Z | q | [51]. Here, Z sets the strength of the potential, and, in a real device, it will be
In the Hartree-Fock approximation, one uses the effective quadratic Hamiltonian
$$\underset { 3 5 } { \text{ence} } \text{RP} \\ \underset { 3 5 } { 3 5 } [. } \underset { \text{thors} } \text{$H^{HF}=\sum_{k} \epsilon_{k} c_{k}^{\dagger}c_{k}+\sum_{kG_{1}G_{2}}V_{k}^{HF}(G_{1},G_{2})c_{k+G_{1}}^{\dagger}c_{k+G_{2}}$} \\ \text{thors}$$
with the nonlocal kernel
$$\overset { 5 \alpha _ { P } } { \text{of} } \quad V _ { k } ^ { H F } ( G _ { 1 }, G _ { 2 } ) = \frac { 1 } { \mathcal { V } } \sum _ { p G } & ( V _ { G _ { 2 } - G _ { 1 } } - V _ { k - p - G } ) \times \\ \text{of} \\ \text{is} \\ \text{tly}$$
̸
̸
This Hamiltonian is simply diagonalized as H HF = ∑ k α E k α d † k α d k α , where now the d † operator creates a Hartree-Fock quasi-particle. A crucial remark is that in a translationally invariant system one would expect ⟨ c † ˜ k c ˜ p ⟩ = 0 for any ˜ k = ˜ p , but here we assume that a CDW is spontaneously formed and reduces translational symmetry, so that ⟨ c † ˜ k c ˜ p ⟩ = 0 provided that ˜ k p , ˜ differ by a reciprocal vector of the CDW.
In practice, the Hartree-Fock ground state can be found iteratively. We start with an auxiliary external potential, which we turn off in successive iterations. At each step, the Hartree-Fock quadratic Hamiltonian (22) (plus the auxiliary potential) is diagonalized, the lowest N v bands are filled, and the Hartree-Fock potential (23) is updated. This is repeated until convergence.
## C. Numerical results
We first discuss polaron spectra on top of a CDW. We report results for a 9 × 9 triangular lattice at one
FIG. 3. Comparative study with respect to Fig. 2.b. In (a) the hole scattering term is set to 0, while in (b) only the mean-field density of the CDW affects the impurity. In (c) the density modulation is generated by an external potential (no spontaneous CDW), and all Chevy terms are retained. The colorcode is specified in the colorbar of 2.b
third filling, which is directly relevant to moiré TMD systems, but we have verified that we obtain qualitatively similar results for a variety of fillings on both the triangular and square lattices. For different values of the Coulomb strength Z , we numerically find the HartreeFock ground state |F⟩ . We evaluate the density contrast ∆ n ≡ max r n ( r ) -min r n ( r ) , and the quasi-particle energy gap, ∆ gap = min k E k ,N v +1 -max k E k ,N v , between the highest valence band and the lowest conduction band. The polaron spectrum A X (0 , ω ) at Bloch momentum q = 0 is then evaluated following the recipe of Eq. (20).
Importantly, these molecule-hole states involve the excitation of a Hartree-Fock quasi-particle across the gap ∆ gap , hence leading to a blueshift of the corresponding energy E t with respect to ∆ gap . This behavior is confirmed by the cyan dashed line displayed in Fig. 2.b, which nicely captures the spectral function in this regime.
The CDW order parameter ∆ n is plotted in Fig. 2.a as a function of ∆ gap /W , where W is the bandwidth of the non-interacting fermion. The CDW is formed via a firstorder phase transition, and the density contrast saturates to 1 for increasing gap, at which point the classical crystal with no quantum fluctuations is achieved. The inset sketches the triangular density pattern of the CDW.
The polaron spectrum A X (0 , ω ) is plotted in Fig. 2.b, as a function of the quasi-particle gap, and for a twobody binding energy in vacuum of E /W B = 0 8 . . For small ∆ gap /W , one recovers the usual attractive polaron (AP) and repulsive polaron (RP) branches. Increasing ∆ gap /W , one observes a line starting slightly above the AP energy, gaining oscillator strength, and blue-shifting linearly with the gap. At a certain point, this line intersects the RP branch and forms an avoided crossing. This feature is attributed to a trimer state (on top of the many-body background), which generalizes the molecule-hole states found in standard Fermi-polaron studies [45, 47] to the present CDW-background setting. Indeed, this interpretation can be established by calculating the ground-state energy E t in the Hilbert subspace spanned by states of the form
$$| \Psi _ { q } ^ { t } \rangle = \sum _ { \ k p G \alpha \beta } \psi _ { \ k p } ^ { \alpha \beta G } \, d _ { \ k \alpha } ^ { \dagger } d _ { p \beta } x _ { q + p - \ k + G } ^ { \dagger } | \mathcal { F } \rangle. \quad ( 2 4 ) \quad \text{and} \, \text{i}$$
Notice that our Hartree-Fock plus Chevy calculation clarifies the numerical observation of the analogous spectral line found in the exact diagonalization study [22]. A similar phenomenology has been observed also in theoretical work on twisted heterostructures [20], excitonic insulators [21] and Fermi superfluids [19]. Moreover, a redshift of the AP energy is visible for increasing ∆ gap /W . This arises from the mass renormalization of the fermions in the CDW, since the quasi-particle bands become more and more flat.
Another interesting feature that is typically present in polaron spectra on top of a CDW is the presence of a umklapp peak above the RP branch. Our approach is in principle able to capture this effect, originating from the term M 0 of Eq. (14). In Fig. 2.b no umklapp peak is present though. This is a particular situation holding for a triangular lattice at one-third filling, and also for a checker-board CDW on top of a square lattice (halffilling). Indeed, for such high fillings, it turns out that, in the impurity Hilbert space, there are only two states invariant under translational and inversion symmetry. As a consequence, only two branches can have an overlap with the q = 0 wave in which the impurity is injected, and be bright. For lower fillings, we indeed observe umklapp peaks (not shown).
## D. The role of hole scattering processes
If polaron formation involves only a very few bands and in the ground state some of these are filled, the usual phase space argument for hole scattering being weak does
not hold anymore. The phase space available for the hole is comparable to the one for an electron, their ratio being just the number of occupied bands over empty ones.
To confirm that hole scattering plays a crucial role, in Fig. 3.a we report for comparison the same Chevy computation, but when neglecting the hole scattering term, i.e. M → h 0 . A strong qualitative discrepancy with respect to Fig. 2.b is present at small ∆ gap . First, the AP line is sizably lower in energy in Fig. 3.a, since hole scattering processes correspond to a repulsive hole-impurity interaction. Neglecting this repulsion lowers the energy. Moreover, an extra line is visible when hole scattering is neglected. As analyzed in Appendix B, the wavefunction of the state associated with this extra peak reveals correlation between the impurity and the groundstate fermionic densities. This is also typical of the AP, while anti-correlation is expected for the RP. Since the hole density naturally correlates with the ground-state fermionic density, we speculate that the extra peak originates from the absence of hole repulsion, in a loose analogy with a weakly-bound state that unbinds when introducing repulsive interaction.
At large ∆ gap ≫ | | g , instead, the creation of a quasiparticle-hole pair excitation is very off-resonant and does not play any role. In other words, at large ∆ gap the polaron spectrum is purely due to the scattering of the impurity with a static potential generated by the extremely rigid CDW. This is demonstrated in Fig. 3.b, where the spectrum is computed by setting M ph , M M → p , h 0 , and the term M 0 plays the main role. In other words, this is analogous to solving in the zero particle-hole excitations (0ph) subspace
$$| \Psi _ { q } ^ { 0 p h } \rangle = \sum _ { G } \psi _ { G } x _ { q + G } ^ { \dagger } | \mathcal { F } \rangle. \quad \quad ( 2 5 ) \quad \text{den} \\ \text{larc}$$
We call this mean-field treatment, where the impurity scatters with the Hartree potential of the CDW, the 0ph approximation (we choose this notation not to confuse with the purely fermionic Hartree-Fock mean-field). These considerations also entail that at large ∆ gap the RP branch is just a δ -like line, without the broadening present in a gapless Fermi sea.
Finally, in Fig. 3.c we study the case where the fermions are not interacting, but an external potential is present and induces a periodic density modulation of the fermions. In this case, we find that the polaron spectrum at the Chevy level presents the same qualitative features as for the CDW of Fig. 2.b, including the avoided crossing in the RP branch related to the quasi-particle gap.
Let us summarize the findings of this Section. We have first introduced the Chevy-ansatz formalism for a spatially periodic background, and we have computed the polaron spectra for band insulators and CDWs, which, at the Hartree-Fock level, are described in terms of quasiparticle bands. An avoided crossing in the RP branch reflects the magnitude of the quasi-particle gap in the background medium, and the AP energy is shown to red- shift due to the mass renormalization and localization of the fermions. Neglecting hole-scattering processes, which are of repulsive nature, results in a spurious peak and low AP energies. In the regime of large quasi-particle gap, the fermionic bath is incompressible and neglecting the dressing by particle-hole excitations (i.e. the 0ph approximation) is justified.
## IV. POLARONS ACROSS THE MOTT TRANSITION
Besides trivial band insulators and CDWs, a paradigmatic type of insulator is provided by the Mott state [52]. This insulating phase of matter arises from strong repulsion between the fermions which, in half-filled systems, leads to the localization of charges in the absence of symmetry breaking.
Here, we are interested in the evolution of polaron spectra when the underlying fermionic system undergoes a Mott transition. Specifically, we describe the dynamics of the bath by using the Fermi-Hubbard Hamiltonian
$$H ^ { \text{el} } = - t \sum _ { i j \sigma } c _ { i \sigma } ^ { \dagger } c _ { j \sigma } + U \sum _ { i } c _ { i \uparrow } ^ { \dagger } c _ { i \uparrow } c _ { i \downarrow } ^ { \dagger } c _ { i \downarrow }, \quad ( 2 6 )$$
where t is the hopping amplitude between sites i and j , U is the strength of the local repulsion, and σ = ↑ ↓ , is the electron spin. We compute polaron spectra using the Chevy and the infinite mass approximations. As shown in the Appendix A, we first observe that, at the Chevy level and for a heavy impurity in a background of quasi-particles, only the momentum-averaged electronic density of states A el ( ω ) enters the calculation of the polaron spectrum. Here, we compute the electronic density of states A el ( ω ) by means of Dynamical Mean-Field Theory (DMFT) using the Iterated Perturbation Theory (IPT) solver [53]. Specifically, we consider the Bethe lattice with bandwitdh W . The electronic density of states A el ( ω ) at half filling is plotted in Fig. 4.a for different values of the electron-electron interaction over the bandwidth U/W . The Mott transition occurs approximately at the critical interaction strength U /W c ≃ 3 15 . . In the metallic phase at U < U c , the density of states has a characteristic three peaks structure. The central band is metallic and it describes coherent quasi-particles close to the Fermi level. The quasi-particle peak looses spectral weight as approaching the Mott transition, whereas the density of states at the Fermi level stays constant, as required by the Luttinger theorem [54]. The two side bands describe incoherent excitation at energies ± U/ 2 and describe the formation of doubly occupied (or empty) sites. At the Mott transition, the coherent peak disappears and the spectral density is characterized by the two Hubbard bands of width W/ . 2
We now immerse the heavy impurity in the fermionic bath. We can work in a Lee-Low-Pines frame [55], where the impurity is confined in a specific lattice site, with creation operator x † . The heavy impurity condition entails
FIG. 4. (a) Phenomenological electronic density of states A el ( ω ) for three different U 's, in the metallic phase (blue line), just below the Mott transition (orange), and deep into the insulating regime (green). (b) Polaron spectrum across the Mott transition in a Chevy calculation with infinite impurity mass. The vertical cyan dotted indicates the Mott transition. A logarithmic scale is used. (c) Same as in (b), but having neglected the hole-impurity scattering processes.
that the effective electron-electron recoil term is negligible, so that the electronic Hamiltonian is the one of Eq. (26) also in this frame. Also, we assume that the impurity interacts with strength g with only the spin up fermions.
interactions between the auxiliary quasi-particles c j , similarly to what done in [18, 19, 21] for a BCS condensate background; this direction is left for future investigations.
As sketched in the Appendix A, if one assumes the Chevy approximation and neglects fermionic vertices (apart from those already included in the DMFT Green's function A el ), the polaron self-energy in the Chevy approximation can be computed by solving the auxiliary Hamiltonian
$$H ^ { \text{aux} } = \epsilon _ { X } x ^ { \dagger } x + \sum _ { j = 1 } ^ { N _ { \omega } } \omega _ { j } c _ { j } ^ { \dagger } c _ { j } + \frac { g } { \mathcal { V } } \sum _ { j l } g _ { j l } c _ { j } ^ { \dagger } c _ { l } x ^ { \dagger } x, \ \ ( 2 7 ) \quad \text{bridi} z \\ \text{Sectic} \\ \text{predi} }$$
where N ω is the number of representative electronic states, the effective couplings are g jl = g N ω √ Z Z j l and ω , Z j j are chosen according to the constraint lim N ω →∞ 1 N ω ∑ j Z δ ω j ( -ω j ) = A el ( ω ) . Clearly, many choices are possible for ω j and Z j , and, in practice, we use a grid of N ω ∼ 150 points, denser around the Fermi level.
At this point, we use the usual Chevy recipe, where the fermionic ground state |F⟩ is obtained by filling the electronic states below the Fermi level. For clarity, we rewrite the Chevy ansatz in this context
$$| \Psi \rangle = \left \{ \psi _ { 0 } + \sum _ { j l } \psi _ { j l } c _ { j } ^ { \dagger } c _ { l } \right \} x ^ { \dagger } | \mathcal { F } \rangle. \quad \ \ ( 2 8 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
We remark that one could have avoided the heavy impurity approximation, and introduced for every electronic momentum an A el ( k , ω ) density of states, represented by a set of discrete states. This would have been quite heavy computationally, since, for each momentum, one should have introduced many states to described the broad, incoherent Hubbard peaks. In principle, one could also add
Numerically solving the polaron spectra associated with the Hamiltonian (27) yields the spectrum shown in Fig. 4.b, for g/W = -2 . At small U , the metallic nature of the electronic bath leads to conventional AP and RP branches. At large U , conversely, the Mott insulator is completely incompressible, and the bath just redshifts the impurity by g/ 2 , the electronic density being 1 / 2 . The RP branch is barely visible, since the 0ph and 1ph sectors are quite off-resonant, and very weakly hybridized. This is consistent with findings of the previous Section and with the second-order perturbation theory prediction in the Bose-Hubbard Mott transition [16].
At intermediate U 's, there is a cusp behavior of the AP branch at the Mott transition, indicated by the dotted cyan line. The RP branch also shows a small jump. Moreover, a fainter line is present at intermediate energies, and it gains oscillator strength close to the metallic side of the transition, and disappears in the insulating region. Inspection of the wavefunctions of the states contributing to this line shows that they consist of particle-hole excitations living in the narrow metallic band. Therefore, this feature highlights the fact that in the fermionic bath, close to the Mott transition, there exists two types of competing excitations, i.e. the quasi-particles close to the Fermi level and the incoherent Hubbard bands, that contribute to the formation of the bound state. This is analogous to the splitting of the RP branch observed in heterostructures undergoing the doping driven Mott localization [20].
In Fig. 4.c, we report the same calculation, but having removed the hole-impurity scattering processes. Even though there are no dramatic qualitative differences, there is a sizable quantitative discrepancy in the position of the peaks with respect to the full calculation. This is expected because of the comparable particle and hole
FIG. 5. Polaron spectrum as a function of g and for U/W = 0 5 . . The cyan dotted line represents the mean-field shift 0ph shift of the impurity. The particle-hole symmetry of the electronic background results in a reflection symmetry across the cyan dashed line, which is orthogonal to the dotted line.
phase spaces for scattering. In particular, neglecting the impurity-hole repulsion lowers the AP energy.
A final comment is in order and relates to the metallic phase. For a heavy impurity, one would expect Anderson orthogonality catastrophe and a power-law broadening of the AP line in the metallic phase [56]. This behavior is not captured by Chevy ansatz, but this analysis goes beyond our goals. One could in principle solve the effective Hamiltonian (27) exactly using the functional renormalization group method, which takes into account any order of particle-hole excitations, but for the sake of simplicity we do not discuss this here.
## A. Particle-hole duality
The electronic density of states plotted in Fig. 4.a is symmetrical across the Fermi level, and leads to the particle-hole duality we now describe in rather general terms.
We introduce the particle-hole transformation h j = c † -j , where the notation -j denotes the index N ω -j +1 , satisfying ω j = -ω -j , Z j = Z -j [57]. Applying this transformation to the Hamiltonian (27), using the anticommutation relations and redefining the summation indices j →-j , we obtain
$$H = ( \epsilon ^ { X } + g ) x ^ { \dagger } x + \sum _ { j = 1 } ^ { N _ { \omega } } \omega _ { j } h _ { j } ^ { \dagger } h _ { j } - \frac { g } { \mathcal { V } } \sum _ { j, k } \sqrt { Z _ { j } Z _ { k } } h _ { j } ^ { \dagger } h _ { k } x ^ { \dagger } x. \quad \text{$row$ odd} \\ ( 2 9 ) \quad \text{and} \, n \\ \text{When to formionic hardware of freedom or tooroad out} \quad \text{or still}$$
When the fermionic degrees of freedom are traced out, this establishes a relation between the impurity spectrum associated with the original Hamiltonian and the one associated with Eq. (29). This has the same form as the original Hamiltonian, but for a shift g of the impurity energy and for the fact that the interaction term comes with an extra minus sign.
This entails a geometric symmetry in the polaron spec- trum, as shown in Fig. 5 for U/W = 0 5 . . The positive and negative g sides are clearly related. More precisely, the cyan dotted line denotes the mean-field shift g/ 2 (the 1 / 2 is due to being at half-filling), and the spectrum has a reflection symmetry across the cyan dashed line, which is the normal to the mean-field shift passing through the origin. Moreover, two branches are visible on both the positive and negative g side. This duality also applies to other particle-symmetric baths, such as the chiral edge states or the Haldane model at half filling [27]. On the contrary, for a conventional Fermi polaron in a weakly doped band, one would have just one nearly flat line on the repulsive g > 0 side.
Summarizing, this Section investigated the polaron spectroscopy of a Fermi-Hubbard system at half-filling. The application of the Chevy-ansatz method was made possible by treating the background fermionic medium by introducing free auxiliary fermions that mimic the Green's function calculated from DMFT. Importantly, the polaron spectrum is shown to exhibit a sharp qualitative change at the Mott transition. Besides, the peculiar duality arising from particle-hole symmetry was shown to lead to characteristic symmetries in the polaron spectrum. Finally, neglecting hole-impurity scattering is shown to quantitatively alter the spectral lines.
## V. CONCLUSIONS
In summary, we extended the Chevy-ansatz framework to the context of insulating states of fermionic matter. As a notable result, we have demonstrated that the polaron spectrum of a mobile impurity immersed in a CDW displays a clear signature of the underlying quasi-particle band gap. Then, using input from DMFT, we have shown that the polaron spectrum of an impurity injected in the strongly-interacting Fermi-Hubbard model exhibits a sharp signature at the Mott transition. Altogether, these results indicate how polaron spectroscopy can be used as a probe of insulating fermionic matter.
We have emphasized the key role of hole-impurity repulsion, which is relevant in this context due to the comparable size of particle and hole scattering phase spaces: neglecting these processes can indeed result in low attractive-polaron energies, and to additional spectral lines. In the case of the half-filled Fermi-Hubbard model, the particle-hole symmetry of the fermionic background was shown to lead to a duality between positive and negative couplings and to striking symmetries in the resulting impurity spectral function.
An important remark is in order concerning the observability of the avoided crossing shown in Fig. 2.b in TMD experiments. In TMD experiments, the trion binding energy (which corresponds to the impurity-fermion 2-body binding energy in vacuum) is not straightforwardly tunable, and it is typically around 25 meV. This is larger than typical electronic gaps, so that such an avoided
crossing is yet to be observed. Also, polaron formation involves many empty bands, and hole scattering is expected to be negligible. Hopefully, future experiments will achieve ways to tune the trion binding energy or obtain larger electronic gaps.
On the theory side, it will be interesting to investigate the role of CDW phonons and plasmons, as well as the inclusion of fermionic vertices in the treatment of polaron formation across the Mott transition. The reliability of the Chevy approximation will then need to be benchmarked against numerical methods, which at present are also being actively developed [27]. Our approach could also be adapted to study bosonic supersolids, where Bloch theorem entails the existence of many Bogoliubov bands, rather than quasi-particle bands [23]. Another interesting direction concerns addressing polaron formation in periodic external potentials by truncating the number of bands and introducing a renormalized interaction [58]; we note that the case where the impurity also feels an external potential is relevant for excitons in moiré TMD bilayers [36, 59, 60]. Finally, while here we considered the impurity as a point-like distinguishable particle, it would be very interesting to include the microscopic modelling of the exciton, which is also expected to be affected by the electronic correlations of the bath, in particular in the Mott phase [36, 61, 62].
## ACKNOWLEDGEMENTS
We are grateful to Atac Imamoglu, Eugene Demler, Haydn Adlong, Alessio Recati, Amit Vashisht, Oriana K. Diessel and Adriano Amaricci for useful discussions. This research was financially supported by the ERC grant LATIS, the EOS project CHEQS and the FRSFNRS (Belgium). G.M. acknowledges support from the MUR - Italian Minister of University and Research - under the 'Rita Levi-Montalcini' program. Computational resources have been provided by the Consortium des Équipements de Calcul Intensif (CÉCI), funded by the Fonds de la Recherche Scientifique de Belgique (F.R.S.FNRS) under Grant No. 2.5020.11 and by the Walloon Region.
## Appendix A: Diagrammatic remarks
In this Section, we want to illustrate the diagrammatic resummation of the T-matrix (or ladder) and Chevy approximations, for an electronic bath representable by non-interacting quasi-particles. In particular, we show that the the Chevy diagrams are also resummable, but lead to a self-consistent equation which is difficult to invert. The goal of this Section is thus mainly conceptual.
The Green's function of the impurity is G X ( Q ) = 1 Ω -ϵ X Q -Σ X ( Q ) , with the self-energy being
$$\Sigma _ { X } ( Q ) = \Sigma _ { 0 \text{ph} } ( Q ) + \Sigma _ { 1 \text{ph} } ( Q ) + \dots, \quad ( A 1 )$$
where the truncation refers to processes containing more than one particle-hole excitations. Notice that an energymomentum notation is used: Q = ( Q , i Ω ) n , where i Ω n is a Matsubara frequency. In the following, for simplicity we limit ourselves to a translationally invariant system, for which the mean-field polaron self-energy is just Σ 0ph ( Q ) = gn .
In Fig. 6.a we recall the diagrammatic representation of the propagator and vertices. The mean-field term of the self-energy Σ 0ph ( Q ) is depicted in Fig. 6.b, while Σ 1ph ≃ Σ Λ in the ladder approximation is illustrated in Fig. 6.c. In Fig. 6.d, hole scattering processes are included in the full Σ 1ph .
We remark that no fermion-fermion vertex is considered in the diagrams of Fig. 6. This can be a very bad approximation, in particular whenever the quasiparticles are supposed to be paired up into excitons or Cooper pairs [21]. When this approximation is assumed, we now show that the polaron self-energy can be computed representing the electronic bath in terms of noninteracting quasi-particles, allowing for a Hamiltonian treatment like in Eq. (27). The idea is that, according to the Kramers-Kronig, the electron Green's function can always be written as G el ( k , z ) = ∫ dω A el ( k ,ω ) z -ω , with A el ( k , ω ) = -1 π Im G el ( k , ω + 0 i + ) .
In general, A el ( k ) can contain broad peaks, and this is true for example in the case of the Fermi-Hubbard model. Nonetheless, A el ( k ) can be replaced by N ω sharp peaks A el ( k , ω ) ∼ 1 N ω ∑ j Z j ( k ) δ ω ( -ω j ( k )) , where the approximation becomes exact in the limit N ω →∞ .
Let's now consider for definiteness the second-order Feynmann diagram appearing in Fig. 6.(c), but the same reasoning is straightforwardly adapted to a generic diagram contributing to the impurity self-energy. This contribution reads
$$\intertext { n t h e } \text{$-un-} \\ \text{ional} \\ \intertext { s des } \\ \text{$y$ the} \\ \text{R.S.-} \\. \text{loon} \\ \end{cases} = - \sum _ { p, k, j, l } \frac { g _ { j l } ( k, \text{p} ) g _ { l j } ( \text{p}, \text{k} ) } { \beta ^ { 2 } \mathcal { Y } ^ { 2 } } G _ { j } ( p ) G _ { l } ( k ) G _ { X } ( Q - k + p ), \\ \intertext { ( A 2 ) } \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,$$
where in the second step we introduced the free fermion propagator G j ( ω, k ) = 1 ω -ω j ( k ) associated to the auxiliary fermionic mode j and the couplings g jl ( k p , ) = g N ω √ Z j ( k ) Z l ( p ) . A similar rearrangement can be performed for any diagram of the polaron self-energy, since every fermionic propagator has the vertex g at both endpoints. On the other hand, the same diagrammatic expansion follows from the Hamiltonian
$$\int _ { \substack { \text{ial} \\ = } } ^ { \text{in} \text{-} } & \quad H ^ { \text{aux} } = \sum _ { \text{kj} } \omega _ { j } ( \text{k} ) c _ { \text{kj} } ^ { \dagger } c _ { \text{kj} } + \sum _ { \text{q} } \epsilon _ { X } ( \text{q} ) x _ { \text{q} } ^ { \dagger } x _ { \text{q} } + \\ & \quad + \frac { 1 } { \mathcal { V } } \sum _ { \text{kpq} j l } g _ { j l } ( \text{k}, \text{p} ) x _ { \text{q} + \text{k} - \text{p} } ^ { \dagger } x _ { \text{q} } c _ { \text{kj} } ^ { \dagger } c _ { \text{p} l } \quad ( A 3 )$$
FIG. 6. Diagrammatic resummation of Chevy diagrams. (a) Diagrammatic representation of the Green's functions and vertices. (b) Mean-field term of the self-energy Σ 0 ph . (c) Self-energy from diagrams with a single particle-hole excitation Σ Λ in the ladder approximation (i.e. only impurity-electron processes are resummed). The green dotted rectangle hints at the impurity-electron bubble. (d) Self-energy from diagrams with a single particle-hole Σ 1ph , but resumming also the hole-impurity scattering processes. The red dotted rectangles highlight the decomposition of the vertex according to Γ = g +Γ el +Γ h .
entailing that one can diagonalize H eff in order to compute the polaron spectrum. Once again, the huge approximation required is to have neglected fermionic vertices.
with (minus) the fermion-impurity bubble diagram being
The auxiliary Hamiltonian of Eq. (27) holds in the infinite impurity mass limit, by performing the LeeLow-Pines transformation and using the strategy explained here, noticing that the momentum indices can be dropped.
## Ladder approximation
In the ladder approximation, injection of the impurity creates a particle-hole pair, but at that point the impurity only scatters with the particle. This is a reasonable approximation, if the Fermi sea is small and the phase space of the hole is quite limited. In this approximation, one has
$$\Sigma _ { 1 p h } ( Q ) \simeq \Sigma _ { \Lambda } ( Q ) = \frac { 1 } { \beta \mathcal { V } } \sum _ { \mathbf p, i p _ { n } } G _ { \text{el} } ( p ) \Lambda ( Q + p ) \quad ( \Lambda 4 ) \quad \text{area} \\ \Sigma _ { 1 p h } ($$
The two body T-matrix (here taken without first order term in g , in contrast to ˜ Λ in Eq. (7)) is given in the ladder approximation by
$$\Lambda ( Q ) = g \frac { g \Pi _ { X - \text{el} } ( Q ) } { 1 - g \Pi _ { X - \text{el} } ( Q ) } \quad \quad ( A 5 )$$
$$\Pi _ { X - \text{el} } ( Q ) = - \frac { 1 } { \beta \mathcal { V } } \sum _ { \mathbf k, i k _ { n } } G _ { X } ( Q - k ) G _ { \text{el} } ( k ). \quad ( \text{A6} )$$
For quasi-particles with dispersion ξ k , the self-energy simplifies to
$$\Sigma _ { X } ( { \mathbf Q }, \Omega ) = g n + \frac { 1 } { A } \sum _ { \mathbf p } n _ { F } ( \xi _ { \mathbf p } ) \Lambda ( { \mathbf Q } + { \mathbf p }, \Omega + \xi _ { \mathbf p } ), \ ( A 7 )$$
which basically recovers Eq. (6), since ˜ = Λ g +Λ .
## Chevy resummation
As visible in Fig. 6.d, the one-particle-hole excitation diagrams including also hole scattering processes are also resummable. We call Γ( Q,k,p ) the Chevy vertex of the theory, so that the self-energy within this approximation reads
$$\mathbb { \Phi } \mathbb { \Phi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Phi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Phi } \mathbb { \Phi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \mathbb { \Psi } \\ \text{order}$$
(A8)
where the minus sign comes from the fermionic loop.
The Feynmann rules yields a self-consistent equation for Γ :
$$\Gamma ( Q, k, p ) = g + \Gamma _ { \text{el} } ( Q, p ) + \Gamma _ { \text{h} } ( Q, k ) \quad ( A 9 )$$
FIG. 7. (a) Slices at ∆ gap ≃ 0 3 . W of the spectral function from Fig. 2.b and Fig. 3.a, for a polaron in a CDW. The blue curve is the full Chevy calculation, while the orange line is without hole scattering processes. The spurious peak is labelled P ∗ . (b) The exciton density-fermion density correlator C is evaluated in the states which contribute more to each peak.
where Γ el gathers all the diagrams which start with an impurity-electron scattering process, while in Γ h an impurity-hole scattering occurs first. We remark that, while for a generic translationally invariant theory Γ( Q,k,p ) depends on three energy-momenta, by further assuming contact instantaneous interactions this complex dependency simplifies a lot, since Γ el ( Q,p ) does not depend on the electron energy-momenta, and similarly Γ ( h Q,k ) does not depend on p . This is seen from the explicit expressions density contrast ∆ n ≃ 0 5 . , comparing the full Chevy calculation in blue with the one in red, obtained by leaving out hole scattering, i.e. by setting M h = 0 . In the latter case, the AP energy is significantly lower, the trimer-like peak is more pronounced, and, above all there is an extra peak, labelled P ∗ in the plot. Below we show that the states contributing to this peak behave more like the AP than the RP.
$$- \Gamma _ { \text{el} } ( Q, p ) = \frac { g } { \beta V } \sum _ { k ^ { \prime } } G _ { \text{el} } ( k ^ { \prime } ) G _ { X } ( Q - k ^ { \prime } + p ) \Gamma ( Q, k ^ { \prime }, p ), \quad \text{state}$$
(A10)
$$- \Gamma _ { \mathrm h } ( Q, k ) = \frac { g } { \beta V } \sum _ { p ^ { \prime } } G _ { \mathrm e l } ( p ^ { \prime } ) G _ { X } ( Q - k + p ^ { \prime } ) \Gamma ( Q, k, p ^ { \prime } ). \quad \text{ where} \\ \intertext { \frac { \mathrm n \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots } }$$
Inverting these equations is in practice cumbersome, and the strategy we adopted in this paper is to rather use the effective quasi-particle Hamiltonian approach of Eq. (A3).
## Appendix B: Nature of the extra peak
In this Appendix we give some insight on the nature of the spurious peak which is observed in Fig. 3.a when the hole scattering processes are neglected. First of all, we replot in Fig. 7.a the slice of the spectral function for a relevant value of quasi-particle gap ∆ gap ≃ 0 3 . W and
[1] A. Schirotzek, C.-H. Wu, A. Sommer, and M. W. Zwierlein, Observation of Fermi polarons in a tunable Fermi
To this end, we quantify the correlations between the exciton density n X r = ⟨ ψ x x | † r r | ψ ⟩ in a given state | ψ ⟩ and the fermionic density n r = ⟨F| c c † r r |F⟩ in the ground state without impurity |F⟩ by considering the quantity
$$\mathcal { C } = \frac { \overline { n _ { \mathbf r } ^ { X } n _ { \mathbf r } } } { \overline { n _ { \mathbf r } ^ { X } } \cdot \overline { n _ { \mathbf r } } } - 1, \text{ \quad \quad } \text{(B1)}$$
where the bar denotes spatial average. We compute C by considering for each peak the state | ψ ⟩ with the largest oscillator strength contributing to that peak. The results are reported in Fig. 7.b, where the colors and labels are in correspondence with panel (a). As expected, the AP states display positive correlation: in the many-body ground state, the impurity tends to be attracted and possibly bind to regions of high fermionic density. Conversely, the RP show anti-correlation, consistently with the picture of the impurity scattering states avoiding the fermions. Interestingly, the extra peak also shows strong positive correlation. Considering that in general hole formation requires and correlates with the fermionic density, it is reasonable that the impurity-hole repulsion washes out this peak (similarly to the AP peak being pushed up in energy).
(2009).
- [2] S. Nascimbène, N. Navon, K. J. Jiang, L. Tarruell, M. Teichmann, J. McKeever, F. Chevy, and C. Salomon, Collective oscillations of an imbalanced Fermi gas: Axial compression modes and polaron effective mass, Phys. Rev. Lett. 103 , 170402 (2009).
- [3] C. Kohstall, M. Zaccanti, M. Jag, A. Trenkwalder, P. Massignan, G. M. Bruun, F. Schreck, and R. Grimm, Metastability and coherence of repulsive polarons in a strongly interacting Fermi mixture, Nature 485 , 615 (2012).
- [4] M. Koschorreck, D. Pertot, E. Vogt, B. Fröhlich, M. Feld, and M. Köhl, Attractive and repulsive Fermi polarons in two dimensions, Nature 485 , 619 (2012).
- [5] M.-G. Hu, M. J. Van de Graaff, D. Kedar, J. P. Corson, E. A. Cornell, and D. S. Jin, Bose Polarons in the Strongly Interacting Regime, Phys. Rev. Lett. 117 , 055301 (2016).
- [6] N. B. Jørgensen, L. Wacker, K. T. Skalmstang, M. M. Parish, J. Levinsen, R. S. Christensen, G. M. Bruun, and J. J. Arlt, Observation of Attractive and Repulsive Polarons in a Bose-Einstein Condensate, Phys. Rev. Lett. 117 , 055302 (2016).
- [7] Z. Z. Yan, Y. Ni, C. Robens, and M. W. Zwierlein, Bose polarons near quantum criticality, Science 368 , 190 (2020).
- [8] M. Sidler, P. Back, O. Cotlet, A. Srivastava, T. Fink, M. Kroner, E. Demler, and A. Imamoglu, Fermi polaronpolaritons in charge-tunable atomically thin semiconductors, Nat. Phys. 13 , 255 (2017).
- [9] E. Courtade, M. Semina, M. Manca, M. M. Glazov, C. Robert, F. Cadiz, G. Wang, T. Taniguchi, K. Watanabe, M. Pierre, W. Escoffier, E. L. Ivchenko, P. Renucci, X. Marie, T. Amand, and B. Urbaszek, Charged excitons in monolayer WSe : Experiment and theory, Phys. Rev. 2 B 96 , 085302 (2017).
- [10] F. Chevy, Universal phase diagram of a strongly interacting Fermi gas with unbalanced spin populations, Phys. Rev. A 74 , 063628 (2006).
- [11] N. V. Prokof'ev and B. V. Svistunov, Bold diagrammatic Monte Carlo: A generic sign-problem tolerant technique for polaron models and possibly interacting many-body problems, Phys. Rev. B 77 , 125101 (2008).
- [12] R. Combescot and S. Giraud, Normal state of highly polarized Fermi gases: Full many-body treatment, Phys. Rev. Lett. 101 , 050404 (2008).
- [13] K. Van Houcke, F. Werner, and R. Rossi, High-precision numerical solution of the Fermi polaron problem and large-order behavior of its diagrammatic series, Phys. Rev. B 101 , 045134 (2020).
- [14] R. Schmidt and T. Enss, Self-stabilized Bose polarons, SciPost Phys. 13 , 054 (2022).
- [15] J. Sánchez-Baena, L. A. P. Ardila, G. Astrakharchik, and F. Mazzanti, Universal properties of dipolar Bose polarons in two dimensions (2023), arXiv:2305.19846 [condmat.quant-gas].
- [16] V. E. Colussi, F. Caleffi, C. Menotti, and A. Recati, Lattice polarons across the superfluid to Mott insulator transition, Phys. Rev. Lett. 130 , 173002 (2023).
- [17] M. Santiago-García, S. G. Castillo-López, and A. Camacho-Guardian, Lattice polaron in a BoseEinstein condensate of hard-core bosons (2024), arXiv:2403.13635 [cond-mat.quant-gas].
- [18] W. Yi and X. Cui, Polarons in ultracold Fermi superflu-
- ids, Phys. Rev. A 92 , 013620 (2015).
- [19] I. Amelio, Two-dimensional polaron spectroscopy of Fermi superfluids, Phys. Rev. B 107 , 104519 (2023).
- [20] G. Mazza and A. Amaricci, Strongly correlated excitonpolarons in twisted homobilayer heterostructures, Phys. Rev. B 106 , L241104 (2022).
- [21] I. Amelio, N. D. Drummond, E. Demler, R. Schmidt, and A. Imamoglu, Polaron spectroscopy of a bilayer excitonic insulator, Phys. Rev. B 107 , 155303 (2023).
- [22] I. Amelio and N. Goldman, Polaron spectroscopy of interacting Fermi systems: Insights from exact diagonalization, SciPost Phys. 16 , 056 (2024).
- [23] L. H. A. Simons, M. Wouters, and J. Tempere, Polarons in supersolids: path-integral treatment of an impurity in a one-dimensional dipolar supersolid (2024), arXiv:2407.03505 [cond-mat.quant-gas].
- [24] F. Grusdt, N. Y. Yao, D. Abanin, M. Fleischhauer, and E. Demler, Interferometric measurements of many-body topological invariants using mobile impurities, Nature Communications 7 , 10.1038/ncomms11994 (2016).
- [25] F. Grusdt, N. Y. Yao, and E. A. Demler, Topological polarons, quasiparticle invariants, and their detection in one-dimensional symmetry-protected phases, Phys. Rev. B 100 , 075126 (2019).
- [26] A. Muñoz de las Heras, E. Macaluso, and I. Carusotto, Anyonic molecules in atomic Fractional Quantum Hall liquids: A quantitative probe of fractional charge and anyonic statistics, Phys. Rev. X 10 , 041058 (2020).
- [27] A. Vashisht, I. Amelio, L. Vanderstraeten, G. M. Bruun, O. K. Diessel, and N. Goldman, Chiral polaron formation on the edge of topological quantum matter (2024), arXiv:2407.19093 [cond-mat.quant-gas].
- [28] A. K. Sorout, S. Sarkar, and S. Gangadharaiah, Dynamics of impurity in the environment of Dirac fermions, Journal of Physics: Condensed Matter 32 , 415604 (2020).
- [29] D. Pimenov, Polaron spectra and edge singularities for correlated flat bands, Phys. Rev. B 109 , 195153 (2024).
- [30] E. C. Regan, D. Wang, C. Jin, M. I. B. Utama, B. Gao, X. Wei, S. Zhao, W. Zhao, Z. Zhang, K. Yumigeta, M. Blei, J. D. Carlström, K. Watanabe, T. Taniguchi, S. Tongay, M. Crommie, A. Zettl, and F. Wang, Mott and generalized Wigner crystal states in WSe2/WS2 moiré superlattices, Nature 579 , 359 (2020).
- [31] Y. Xu, S. Liu, D. A. Rhodes, K. Watanabe, T. Taniguchi, J. Hone, V. Elser, K. F. Mak, and J. Shan, Correlated insulating states at fractional fillings of moiré superlattices, Nature 587 , 214 (2020).
- [32] T. Smoleński, P. E. Dolgirev, C. Kuhlenkamp, A. Popert, Y. Shimazaki, P. Back, X. Lu, M. Kroner, K. Watanabe, T. Taniguchi, I. Esterlis, E. Demler, and A. Imamoğlu, Signatures of Wigner crystal of electrons in a monolayer semiconductor, Nature 595 , 53 (2021).
- [33] Y. Zhou, J. Sung, E. Brutschea, I. Esterlis, Y. Wang, G. Scuri, R. J. Gelly, H. Heo, T. Taniguchi, K. Watanabe, G. Zaránd, M. D. Lukin, P. Kim, E. Demler, and H. Park, Bilayer Wigner crystals in a transition metal dichalcogenide heterostructure, Nature 595 , 48 (2021).
- [34] H. Li, S. Li, E. C. Regan, D. Wang, W. Zhao, S. Kahn, K. Yumigeta, M. Blei, T. Taniguchi, K. Watanabe, S. Tongay, A. Zettl, M. F. Crommie, and F. Wang, Imaging two-dimensional generalized Wigner crystals, Nature 597 , 650 (2021).
- [35] Y. Shimazaki, C. Kuhlenkamp, I. Schwartz, T. Smoleński, K. Watanabe, T. Taniguchi, M. Kroner,
R. Schmidt, M. Knap, and A. Imamoglu, Optical signatures of periodic charge distribution in a Mott-like correlated insulator state, Phys. Rev. X 11 , 021027 (2021).
[36] N. Kiper, H. S. Adlong, A. Christianen, M. Kroner, K. Watanabe, T. Taniguchi, and A. Imamoglu, Confined trions and mott-wigner states in a purely electrostatic moiré potential (2024), arXiv:2407.20905 [cond-mat.strel].
[37] Y. Shimazaki, I. Schwartz, K. Watanabe, T. Taniguchi, M. Kroner, and A. Imamoğlu, Strongly correlated electrons and hybrid excitons in a moiré heterostructure, Nature 580 , 472 (2020).
[38] T. Smoleński, O. Cotlet, A. Popert, P. Back, Y. Shimazaki, P. Knüppel, N. Dietler, T. Taniguchi, K. Watanabe, M. Kroner, and A. Imamoglu, Interaction-induced Shubnikov-de Haas oscillations in optical conductivity of monolayer MoSe 2 , Phys. Rev. Lett. 123 , 097403 (2019).
[39] A. Popert, Y. Shimazaki, M. Kroner, K. Watanabe, T. Taniguchi, A. Imamoğlu, and T. Smoleński, Optical sensing of fractional quantum Hall effect in graphene, Nano Letters 22 , 7363 (2022).
- [40] J. Cai, E. Anderson, C. Wang, X. Zhang, X. Liu, W. Holtzmann, Y. Zhang, F. Fan, T. Taniguchi, K. Watanabe, Y. Ran, T. Cao, L. Fu, D. Xiao, W. Yao, and X. Xu, Signatures of fractional quantum anomalous Hall states in twisted MoTe2, Nature 622 , 63 (2023).
- [41] L. Ciorciaro, T. Smoleński, I. Morera, N. Kiper, S. Hiestand, M. Kroner, Y. Zhang, K. Watanabe, T. Taniguchi, E. Demler, and A. İmamoğlu, Kinetic magnetism in triangular moiré materials, Nature 623 , 509 (2023).
- [42] Z. Tao, W. Zhao, B. Shen, T. Li, P. Knüppel, K. Watanabe, T. Taniguchi, J. Shan, and K. F. Mak, Observation of spin polarons in a frustrated moiré Hubbard system, Nat. Phys. , 1 (2024).
- [43] With the renormalization g → 0 and introducing the auxiliary quantity χ q p = g V ( ψ q + ∑ k ψ q kp ) , Eqs. (4,5) are recast into
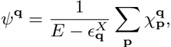
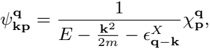
which can be reinserted into the definition of χ q p . Rearranging and summing over p finally yields ( E -ϵ X q ) ∑ p χ q p = Σ X ( q , E ) ∑ p χ q p .
- [44] R. Combescot, A. Recati, C. Lobo, and F. Chevy, Normal state of highly polarized Fermi gases: Simple many-body approaches, Phys. Rev. Lett. 98 , 180402 (2007).
- [45] M. M. Parish, Polaron-molecule transitions in a twodimensional Fermi gas, Phys. Rev. A 83 , 051603 (2011).
- [46] R. Schmidt, T. Enss, V. Pietilä, and E. Demler, Fermi polarons in two dimensions, Phys. Rev. A 85 , 021602 (2012).
- [47] M. M. Parish and J. Levinsen, Fermi polarons and beyond (2023), arXiv:2306.01215 [cond-mat.quant-gas].
- [48] G. Giuliani and G. Vignale, Quantum Theory of the Electron Liquid (Cambridge University Press, 2005).
- [49] C. Franchini, M. Reticcioli, M. Setvin, and U. Diebold,
Polarons in materials, Nature Reviews Materials 6 , 560 (2021).
- [50] W. H. Sio, C. Verdi, S. Poncé, and F. Giustino, Ab initio theory of polarons: Formalism and applications, Phys. Rev. B 99 , 235139 (2019).
- [51] Actually, in the numerics a lattice version of the Coulomb potential is used,
$$V _ { \mathbf q } = \sum _ { \mathcal { G } } \frac { \mathcal { Z } } { | \mathbf q + \mathcal { G } | } - \sum _ { \mathcal { G } \neq 0 } \frac { \mathcal { Z } } { | \mathcal { G } | },$$
where G is a reciprocal lattice vector of the microscopic lattice (as opposed to G in the previous Section, which belonged to the reciprocal lattice of the periodic external potential). The summation ensures that V q = V q + G (compatible with the fact that wavefunctions are defined only modulo G on a lattice), and the second term cancels the UV divergence of the first term. Notice that at small | q | the Coulomb potential is recovered.
- [52] F. Gebhard, The Mott Metal-Insulator Transition: Models and Methods (Springer Berlin Heidelberg, 1997).
- [53] A. Georges, G. Kotliar, W. Krauth, and M. J. Rozenberg, Dynamical mean-field theory of strongly correlated fermion systems and the limit of infinite dimensions, Rev. Mod. Phys. 68 , 13 (1996).
- [54] J. M. Luttinger and J. C. Ward, Ground-state energy of a many-fermion system. ii, Phys. Rev. 118 , 1417 (1960).
- [55] T. D. Lee, F. E. Low, and D. Pines, The motion of slow electrons in a polar crystal, Phys. Rev. 90 , 297 (1953).
- [56] R. Schmidt, M. Knap, D. A. Ivanov, J.-S. You, M. Cetina, and E. Demler, Universal many-body response of heavy impurities coupled to a Fermi sea: a review of recent progress, Reports on Progress in Physics 81 , 024401 (2018).
- [57] While this argument is quite general, for definiteness we explain it in the context of the Hamiltonian (27). In particular, we assume that our grid of auxiliary fermionic states respects the particle-hole symmetry, i.e. it is symmetric across the Fermi level.
- [58] H. P. Büchler, Microscopic derivation of Hubbard parameters for cold atomic gases, Phys. Rev. Lett. 104 , 090402 (2010).
- [59] M. H. Naik, E. C. Regan, Z. Zhang, Y.-H. Chan, Z. Li, D. Wang, Y. Yoon, C. S. Ong, W. Zhao, S. Zhao, M. I. B. Utama, B. Gao, X. Wei, M. Sayyad, K. Yumigeta, K. Watanabe, T. Taniguchi, S. Tongay, F. H. da Jornada, F. Wang, and S. G. Louie, Intralayer chargetransfer moiré excitons in van der Waals superlattices, Nature 609 , 52 (2022).
- [60] B. Polovnikov, J. Scherzer, S. Misra, X. Huang, C. Mohl, Z. Li, J. Göser, J. Förste, I. Bilgin, K. Watanabe, T. Taniguchi, A. S. Baimuratov, and A. Högele, Coulomb-correlated states of moiré excitons and charges in a semiconductor moiré lattice (2022), arXiv:2208.04056 [cond-mat.mes-hall].
- [61] T.-S. Huang, Y.-Z. Chou, C. L. Baldwin, F. Wu, and M. Hafezi, Mott-moiré excitons, Phys. Rev. B 107 , 195151 (2023).
- [62] T.-S. Huang, C. L. Baldwin, M. Hafezi, and V. Galitski, Spin-mediated Mott excitons, Phys. Rev. B 107 , 075111 (2023). | null | [
"Ivan Amelio",
"Giacomo Mazza",
"Nathan Goldman"
]
| 2024-08-02T16:36:11+00:00 | 2024-08-02T16:36:11+00:00 | [
"cond-mat.str-el",
"cond-mat.mes-hall",
"cond-mat.quant-gas",
"quant-ph"
]
| Polaron formation in insulators and the key role of hole scattering processes: Band insulators, charge density waves and Mott transition | A mobile impurity immersed in a non-interacting Fermi sea is dressed by the
gapless particle-hole excitations of the fermionic medium. This conventional
Fermi-polaron setting is well described by the so-called ladder approximation,
which consists in neglecting impurity-hole scattering processes. In this work,
we analyze polaron formation in the context of insulating states of matter,
considering increasing levels of correlation in the medium:~band insulators
originating from external periodic potentials, spontaneously-formed charge
density waves, and a Fermi-Hubbard system undergoing a metal-Mott insulator
transition. The polaron spectral function is shown to exhibit striking
signatures of the underlying fermionic background, such as the single-particle
band gap, particle-hole symmetry and the transition to the Mott state. These
signatures are identified within the framework of the Chevy ansatz, i.e. upon
restricting the Hilbert space to single particle-hole excitations.
Interestingly, we find that the ladder approximation is inaccurate in these
band systems, due to the fact that the particle and hole scattering phase
spaces are comparable. Our results provide a step forward in the understanding
of polaron formation in correlated many-body media, which are relevant to both
cold-atom and semiconductor experiments. |
2408.01378v1 | ## Hearts of set-generated t-structures have a set of generators
## Manuel Saor´ ın ∗
Departamento de Matem´ aticas Universidad de Murcia, Aptdo. 4021 30100 Espinardo, Murcia SPAIN
[email protected]
## Abstract
We show that if α is a regular cardinal, D is an α -compactly generated triangulated category, in the sense of Neeman [18], and τ is a t-structure in D generated by a set of α -compact objects, then the heart of τ is a locally α -presentable (not necessarily Ab5) abelian category. This is a generalization of the fact that any compactly generated t-structure (in a compactly generated) triangulated category with coproducts has a heart which is a locally finitely presented Grothendieck category ([24]) since locally finitely presented abelian categories are Ab5. As a consequence, in a well-generated triangulated category any tstructure generated by a set of objects has a heart with a set of generators.
Mathematics Subject Classification: 18G80, 18E10, 18C35, 18E05
## Introduction
t-Structures in triangulated categories were introduced by Beilinson, Bernstein and Deligne [4] in their study of perverse sheaves on an algebraic or analytic variety. A t-structure in a triangulated category is a pair of subcategories
∗ The author is supported by the Grant PID2020-113206GB-I00, funded by MCIN/AEI/10.13039/501100011033, and the project 22004/PI/22, funded by the Fundaci´n o 'S´neca' e of Murcia, both with a part of FEDER funds. The paper was started during a visit of the author to the University of Verona in March-2023, within the 'Network on Silting Theory', funded by the Deutsche Forschungsgemeinschaft. Several discussions with Lidia Angeleri-H¨gel, Rosie Laking, Jorge Vit´ria and Frederik Marks during that visit were the u o starting point of the paper. Later on the author has also received many stimulating suggestions from Jan Stovicek. I thank all these institutions and researchers for their help.
satisfying certain axioms (see Subsection 1.4) that guarantee that their intersection has a structure of abelian category and the existence of a cohomological functors from the ambient triangulated category to this heart. This allows a sort of intrinsic cohomology theory where the cohomology spaces are objects of the triangulated category itself. t-Structures are nowadays a common tool in several branches of Mathematicas and Theoretical Physics and they have called the attention of many top mathematicians.
When D is a triangulated category with coproducts and τ is a t-structure in D with heart H , a popular problem in the last two decades has been that of determining when H is a module or a Grothendieck category. The initial results concentrated mainly in the case when the ambient triangulated category is the (unbounded) derived category of a module or Grothendieck category and the t-structure is tilted from the standard one (see [10], [7], [8], [20], [21]), later results studied the case when the t-structure is the one associated to a (co)tilting module or a (co)silting t-structure (see [26],[2], [3]). For a general D (always with coproducts) the efforts were addressed to study conditions on the t-structure that guaratee that its heart is a Grothendieck category, for which most of the time a model for D , as a stable ∞ -category or a strong stable derivator, were necessary (see [16], [25], [14]). A recent model-free result in this vein (see [24, Theorem 8.31]) states that the heart of any compactly generated t-structure is a locally finitely presented Grothendieck category.
When determining whether H is a Grothendieck category, two facts should be checked. Namely, the Ab5 condition and the existence of a generator (or a set of generator) for H . In the papers mentioned above, the hard part has been the Ab5 condition and the existence of a generator was proved either lifting the problem to the model, requiring here some sort of bounded cardinality condition ([16], [25]), or just by applying the associated cohomological functor H : D -→ H to an adequate skeletally small thick subcategory of D , e.g. the subcategory D c of compact objects when D is compactly generated (see [5]).
The goal of this paper is to prove that if D is a well-generated triangulated category in the sense of Neeman [18], then any t-structure in D generated by a set of objects has a heart H which has a set of generators, even if H need not be Ab5. So there is no need of a model for D , but instead the well-generation is required, a condition that is general enough as to include most triangulated categories with coproducts appearing in practice. Our initial motivation came from the already mentioned [24, Theorem 8.31], that may be seen as the ℵ 0 -version of the following result, an extended version of which is Theorem 3.2. We refer to Section 1 for the terminology.
THEOREM A : Let D be a well-generated triangulated category, X a set of objects and let τ = (( X ⊥ ≤ 0 ) , X ⊥ < 0 ) be the t-structure generated by X . Let α be the smallest of the regular cardinals β such that D is β -compactly generated and all objects X are β -compact. Then the heart H τ of τ is a locally α -presentable
(not necessarily Ab5) abelian category.
As an immediate consequence, one gets:
COROLLARYB : In a well-generated triangulated category any t-structure generated by a set of objects has a heart that has a set of generators.
The organization of the paper goes as follows. In Section 1 we introduce essentially all the concepts used through the paper and give some auxiliary results that will be relevant for the proof of the theorem. In Section 2, which is crucial for the proof, we consider any additive category with coproducts and show how to conveniently express in it coproducts of objects and morphisms between them as suitable direct limits. In the final Section 3, the main Theorem 3.2 is stated at the beginning and its proof is developed through the whole section via several auxiliary results.
## 1 Preliminaries
Throughout the paper all categories that appear will be either additive or (always strictly full) subcategories of additive categories. If C is such a category and X and Y are objects of C , we shall denote by Hom C ( X,Y ) the set of morphisms X -→ Y and sometimes, for simplification purposes, we will simply put ( X,Y ) = Hom ( C X,Y ) or ( -, Y ) := Hom ( C -, Y ) : C op -→ Ab for the associated representable functor. When C is either abelian or triangulated (see Subsection 1.4, X ⊆ C is a subcategory and I ⊆ Z is a subset, we will let X ⊥ I be the subcategory that consists of the objects Y ∈ C such that Ext i C ( X,Y ) = 0, for all X ∈ X and all i ∈ I . As it is customary, in case C is triangulated Ext ( i C X,Y ) := Hom C ( X,Y i [ ]).
We will say that an additive category A has (co)products when it has arbitrary set-indexed (co)products. In such case, if S is any class (resp. set) of objects in A , we will denote by Coprod( S ) the subcategory whose objects are those isomorphic to coproducts of objects in S and by Add( S ) the one whose objects are the direct summands of objects in Coprod( S ). When I is a directed set, an I -direct (or I -directed) system in A is just a functor X : I -→ A , where I is viewed as a category with a unique morphism i → j for each pair ( i, j ) ∈ I × I such that i ≤ j . Giving such an X is clearly equivalent to giving a pair families [( X i ) i ∈ I , ( f ij ) i ≤ j ], where X i = X i ( ) ∈ A and f ij ∈ Hom ( A X , X i j ), for all i, j ∈ I such that i ≤ j , so that f ii = 1 X i and f jk ◦ f ij = f ik whenever i ≤ j ≤ k . Frequently, when there is no confusion, we will omit the reference to the f ij and will say simply that ( X i ) i ∈ I is an I -direct system.
Given an additive category A and a subcategory S , we will say that an object A ∈ A is a direct limit (or filtered colimit) of objects in S when there is a directed set I and an I -direct system ( S i ) i ∈ I in S such that the direct limit (=filtered colimit) lim - → S i exists in A and there is an isomorphism A ∼ = lim - → S i . A particular situation will be relevant for us in this paper. When α is a regular cardinal, an α -directed set is a directed set I such that any subset of cardinality
< α has an upper bound in I (note that 'directed set' is synonymous of ' ℵ 0 -directed set') . We will say that A is an α -directed colimit of objects in S when there is an α -directed set I and an I -direct system ( S i ) i ∈ I in S such that lim - → S i exists in A and there is an isomorphism A ∼ = lim - → S i . We will say that A has α -directed colimits when all α -direct systems in A have a direct limit.
## 1.1 α -small and α -presentable objects
All through this subsection A is an additive category that has coproducts and α is a regular cardinal.
We say that X ∈ A is an α -small object when, for each family ( A i ) i ∈ I of objects of A and each morphism f : X -→ ∐ i ∈ I A i , there is a subset J = J f ( ) ⊆ I such that | J | < α , were | - | denotes the cardinality of a set, and f factors as a composition f : X -→ ∐ j ∈ J A j ι J -→ ∐ i ∈ I A i , where ι J is the canonical section. Note that X is ℵ 0 -small (= small ) exactly when the functor Hom ( A X, -) : A -→ Ab preserves coproducts. We will denote by Small α ( A ) the subcategory of α -small objects, which is closed under coproducts of < α objects.
When we also assume that A has α -directed colimits, an object X ∈ A is called α -presentable when, for each α -directed system ( Y i ) i ∈ I , the canonical morphism lim Hom - → A ( X,Y i ) -→ Hom ( A X, lim - → Y i ) is an isomorphism. We denote by Pres <α ( A ) the subcategory of α -presentable objects, which is closed under coproducts of < α objects and cokernels, when they exist. We will say that A is a locally α -presentable category when Pres <α ( A ) is skeletally small and each object of A is an α -directed colimit of α -presentable objects. It is not hard to see that, in case A is abelian, it is locally α -presentable if and only if it has a set of generators which are α -presentable. ℵ 0 -presentable objects are usually called finitely presented and a locally ℵ 0 -presentable category is simply called locally finitely presented . The reader is referred to [1] for a more general version of local α -presentability that does not require the category A to be additive.
Already at this step it is convenient to give the following result, that will be relevant later on in the paper.
Proposition 1.1. Let A be a additive category with arbitrary coproducts and α -directed colimits, where α is a regular cardinal, and let P be an object of A . Consider the following assertions:
- 1. P is α -presentable.
- 2. P is α -small.
The implication (1) = ⇒ (2) always holds. When P is a projective object, both assertions are equivalent.
Proof. (1) = ⇒ (2) Let ( X i ) i ∈ I be a family of objects in A and f : P -→ ∐ i ∈ I X i . Now we can apply Proposition 2.1 below with J = P α ( I ) the set of subsets J ⊆ I such that | J | < α . Then ∐ i ∈ I X i = lim - → J ∈P α ( I ) X J , where
X J := ∐ j ∈ J X j for all J ∈ P α ( I ). The α -presentability of P tells us that the morphism f : P -→ ∐ i ∈ I X i = lim - → J ∈P α ( I ) X J factors in the form P ˜ f -→ X J ι J ↪ → ∐ i ∈ I X i , where ι J is the canonical section, for some J ∈ P α ( I ). That is, f factors through a subcoproduct X J = ∐ j ∈ J X j , where | J | < α . Therefore P is α -small.
(2) = ⇒ (1) Let [( Y i ) i ∈ I , ( u ij : Y i -→ Y j ) i ≤ j ] be an α -direct system. By the explicit construction of the direct limit, we know that there is a cokernel sequence ∐ i<j Y ij ϕ -→ ∐ i ∈ I Y i p -→ - → lim Y i → 0, i.e. p is the cokernel map of ϕ . Let now f : P -→ - → lim Y i be any morphism. By projectivity of P , we have a morphism g : P -→ ∐ i ∈ I X i such that p ◦ g = f . Note also that if ι k : Y k -→ ∐ i ∈ I Y i is the canonical section, then u k := p ◦ ι k : Y k -→ - → lim Y i is the canonical map to the direct limit. By the α -smallness of P , the morphism g factors in the form P ˜ g -→ Y J = ∐ j ∈ J Y i ι J ↪ → ∐ i ∈ I Y i , for some J ∈ P α ( I ). For each j ′ ∈ J , we shall denote by ι ′ j ′ : Y j ′ -→ ∐ j ∈ J Y j the canonical map to the J -coproduct, so that ι J ◦ ι ′ j ′ = ι j ′ . Then we have f = p ◦ g = p ◦ ι J ◦ ˜. g Since I is an α -directed set we can pick up a m ∈ I such that j ≤ m , for all j ∈ J . The maps u jm : Y j -→ Y m ( j ∈ J ) induce a morphism u : ∐ j ∈ J Y j -→ Y m such that u ◦ ι ′ j = u jm , for all j ∈ J . It follows that u m ◦ u ◦ ι ′ j = u m ◦ u jm = u j = p ◦ ι j = p ◦ ι J ◦ ι ′ j , for all j ∈ J . It then follows that u m ◦ u = p ◦ ι J , which in turn implies that u m ◦ u ◦ ˜ = g p ◦ ι J ◦ ˜ = g p ◦ g = f . In particular f factors through the map u m : Y m -→ - → lim Y i . This implies that f is in the image of the canonical morphism κ : lim Hom - → A ( P, Y i ) -→ Hom A ( P, lim - → Y i ). Hence this latter map is an epimorphism.
We next prove that κ is a monomorphism. By properties of direct limits in Ab, we know that any element of lim Hom - → A ( P, Y i ) is of the form ( u k ) ∗ ( f ) = f ◦ u k = f ◦ p ◦ ι k , for some k ∈ I and some morphism f : P -→ Y k in A . Suppose that ( u k ) ∗ ( f ) ∈ Ker( κ ), which is equivalent to say that the composition P f -→ Y k ι k -→ ∐ i ∈ I Y i factors through ϕ . Let then fix a morphism g : P -→ ∐ i ≤ j Y ij such that ϕ ◦ g = ι k ◦ f . Due to the the α -smallness of P , we can select a subset ˜ Λ ⊆ { ( i, j ) ∈ I × I : i ≤ } j such that | ˜ Λ | < α and g factors through the inclusion ∐ ( i,j ) ∈ ˜ Λ Y ij ↪ → ∐ i ≤ j Y ij . Associated to Λ and using that ˜ I is α -directed, we can easily choose a subset Λ ⊆ I such that: (i) | Λ | < α ; (ii) all first and second components of the ( i, j ) ∈ ˜ Λ belong to Λ; (iii) k ∈ Λ; (iv) Λ has a maximum µ = max(Λ). We obviously have that Λ ˜ ⊆ { ( λ, λ ′ ) ∈ Λ × Λ: λ ≤ λ ′ } . We then get the following diagram, where the hook arrows are the obvious sections, g = ι ◦ ˜, g ϕ Λ is the canonical morphism whose cokernel is lim - → Y λ and the exterior diagram is commutative, i.e. ϕ ◦ ι ◦ ˜ = g ϕ ◦ g = ι k ◦ f = ι I Λ ◦ ι Λ k ◦ f .
/d15
/d15
/d15
/d15
/d47
/d47
Due to the monomorphic condition of ι and ι I Λ , the upper triangle is commutative, i.e. ϕ Λ ◦ ˜ = g ι Λ k ◦ f . But this means that f is mapped by the canonical morphism v k : Hom A ( P, Y k ) -→ - → lim Λ Hom A ( P, Y λ ) onto an element which is in the kernel of the canonical map κ Λ : lim - → Λ Hom ( A P, Y λ ) -→ Hom ( A P, lim - → Λ Y λ ). Since µ = max(Λ) the domain and codomain of κ Λ are both isomorphic to Hom ( A P, Y µ ), from which we readily get that κ Λ is an isomorphism. It follows that 0 = v k ( f ) = ∼ u kµ ◦ f . We have then found an index µ ∈ I , µ ≥ k , such that u kµ ◦ f = 0. This implies that ( u k ) ∗ ( f ) = u k ◦ f = u µ ◦ u kµ ◦ f = 0. Therefore κ is a monomorphism, and hence an isomorphism.
Recall that if C is any additive category, then a functor M : C op -→ Ab is said to be a finitely presented functor (or finitely presented right C -module) when there is an exact sequence of functors ( -, C ′ ) ( -,α ) -→ ( -, C ) -→ M → 0, where ( -, X ) := Hom ( C -, X ) for each object X ∈ C . We denote by mod -C the category of finitely presented functors, which is an additive category with cokernels. The Yoneda functor Y C : C -→ mod -C ( C /squiggleright ( -, C )) is fully faithful and its essential image is a class of projective generators of mod - C . In the following result we summarize well-known results that will be needed later on, refering to the references given in the proof for the non-introduced terminology:
Proposition 1.2. Let C be an additive category with coproducts and α a regular cardinal. The following assertions hold:
- 1. mod - C has coproducts (and hence it is a cocomplete category) and Y C preserves coproducts, i.e. for any family ( C i ) i ∈ I of objects of C the representable functor ( -, ∐ i ∈ I C i ) is the coproduct of the ( -, C i ) in mod -C .
- 2. Y C = ( -, C ) is α -small (equivalently α -presentable) in mod -C if and only if C is an α -small object of C .
- 3. If C has weak kernels, then mod - C is abelian. In particular, if there is a set S ⊆ C such that C = Coprod ( S ) then mod - C is abelian and { -( , S ) : S ∈ S} is a set of projective generators of mod -C .
/d127
/d95
/d1
/d1
/d47
/d47
/d15
/d15
/d15
/d15
/d127
/d127
/d95
/d95
Proof. Assertion 1 and the initial part of assertion 3 are in [12, Lemma 1]. Moreover if C = Coprod( S ), for some set S , then C has weak kernels (see [24, Lemma 2.4]). Assertion 2 is [11, Lemma 1] and can be also easily deduced from Proposition 1.1.
## 1.2 Preservation of α -presentable objects
The following result will be relevant later on in the paper.
Proposition 1.3. Let ( F : A -→ B , G : B -→ A ) an adjoint pair of additive functors between cocomplete abelian categories, where A is supposed to be locally α -presentable, for a given regular cardinal α . The following assertions are equivalent:
- 1. F preserves α -presentable objects.
- 2. G preserves α -directed colimits.
Proof. Let Q ∈ A be any object and let ( Y i ) i ∈ I be any α -directed system in B . We let ψ : lim - → G Y ( i ) -→ G (lim - → Y i ) be the canonical morphism and κ : lim( - → -, G Y ( i )) -→ - - → ( , lim G Y ( i )) the canonical natural transformation. We have the following sequence of functors A op -→ Ab and natural transformations between them, whose composition is the canonical natural transformation lim( - → F ( -) , Y i ) -→ ( F ( -) , lim - → Y i ):
$$\varinjlim ( F ( - ), Y _ { i } ) \overset { \cong } { \longrightarrow } \varinjlim ( -, G ( Y _ { i } ) ) \overset { \kappa } { \longrightarrow } ( -, \varinjlim G ( Y _ { i } ) ) \overset { \psi _ { * } } { \longrightarrow } ( -, G ( \varinjlim Y _ { i } ) ) \overset { \cong } { \longrightarrow } \\ \quad \quad \quad$$
Note that, by adjunction, the first and fourth arrows are natural isomorphisms.
- (1) = ⇒ (2) Evaluate the last sequence at an α -presentable object Q . Since F Q ( ) is α -presentable as well, we conclude that κ Q is an isomorphism and the composition of the four morphisms is also an isomorphism. Then ( ψ ∗ ) Q is an isomorphism. But since A is assumed to be locally α -presentable, we get that ( ψ ∗ ) Q is an isomorphism, for all Q in a set of generators of A . It follows that ψ is an isomorphism.
- (2) = ⇒ (1) In this case ψ ∗ is a natural isomorphism and, for each α -presentable object Q , the map κ Q is also an isomorphism. It then follows that, when evaluating at any such Q , the canonical morphism lim( - → F Q ,Y ( ) i ) -→ ( F Q , ( ) lim - → Y i ) is always an isomorphism. That is, F Q ( ) is an α -presentable object.
## 1.3 On Serre quotient functors with right adjoints in cocomplete abelian categories
In this subsection we shall see that some known facts about localisation of Grothendieck categories hold in the more general setting of cocomplete abelian categories. We refer to [24, Subsection 2.2] for the terminology used in this subsection.
Definition 1. Let A be any abelian category. A torsion pair or torsion theory in it is a pair t = ( T , F ) of subcategories such that the following two conditions hold:
- t1) Hom A ( T, F ) = 0 for all T ∈ T and F ∈ F ;
- t2) For each object A ∈ A , there is an exact sequence 0 → T A -→ A -→ F A → 0 , where T A ∈ T and F A ∈ F , that we shall call the torsion sequence associated to A .
A torsion (resp. torsionfree) class in A is a subcategory T (resp. F ) that is the first (resp. second) component of a torsion pair.
It is well-known that a torsion class is closed under quotients, extensions and all coproducts that exist in A and, dually, a torsionfree class is closed under subobjects, extensions and products. It is also well-known that the T A and F A of condition (t2) are uniquely determined, up to isomorphism, and induce functors t : A -→ T and (1 : t ) : A -→ F which are, respectively, right and left adjoint to the inclusion functor. One usually calls t ( A ) = T A and (1 : t )( A ) = F A the torsion subobject and the torsionfree quotient of A , respectively, with respect to t .
The torsion class T or the torsion pair t are hereditary when T is closed under subobjects.
Proposition 1.4. Let F : A -→ B be a Serre quotient functor that has a fully faithful right adjoint G : B -→ A and suppose that A is cocomplete. The following assertions hold:
- 1. If µ : 1 A -→ G ◦ F is the unit of the adjunction, then Ker ( µ A ) and Coker ( µ A ) are objects of T := Ker ( F ) , for all A ∈ A .
- 2. T is a hereditary torsion class in A and, for each A ∈ A , the associated torsion sequence is 0 → Ker ( µ A ) -→ A -→ Im ( µ A ) → 0 .
- 3. If T 0 ⊆ T is any subcategory such that T = Gen ( T 0 ) , then Im ( G ) = T ⊥ 0 1 , 0 .
- 4. If X is a set of generators of A , then the set T 0 of objects of T which are epimorphic image of objects of X satisfies that T = Gen ( T 0 ) .
Proof. Note that, by the fully faithful condition of G , the counit /epsilon1 : F ◦ G -→ 1 B is a natural isomorphism (see the dual of [9, Proposition 7.5]), so that F is a dense functor. In particular, B has coproducts (and hence is also cocomplete) since F preserves them.
- 1) This assertion follows from the exactness of F and the adjunction equations.
- 2) By adjunction, we have that Hom A ( T, G B ( )) = Hom ∼ B ( F T ,B ( ) ) = 0, for all T ∈ T and B ∈ B . This proves that Im( G ) ⊆ F := T ⊥ 0 , from which it readily follows that ( T , F ) is a torsion pair with 0 → Ker( µ A ) -→ A -→ Im( µ A ) → 0 as torsion sequence associated to A , for all A ∈ A . Exactness of F also proves that T is closed under taking subobjects, so that T is a hereditary torsion class.
- 3) Note that, by properties of adjunction, Im( G ) consists of the objects Y ∈ A such that µ Y : Y -→ ( G ◦ F )( Y ) is an isomorphism, and we have already seen that Im( G ) ⊆ T ⊥ 0 .
One readily sees that T ⊥ 0 0 = T ⊥ 0 . We claim that we also have that T ⊥ 0 1 , 0 = T ⊥ 0 1 , , for which we only need to prove the inclusion ⊆ . Let Y ∈ T ⊥ 0 1 , 0 and let T ∈ T be arbitrary. We need to prove that Ext 1 A ( T, Y ) = 0. Consider an exact sequence 0 → T ′ -→ ∐ i ∈ I T i -→ T → 0, where T i ∈ T 0 for all i ∈ I . Note that, by assertion 2, we also have that T ′ ∈ T . Applying the exact sequence of Ext A ( -, Y ), we get an exact sequence
$$0 = \text{Hom} _ { \mathcal { A } } ( T ^ { \prime }, Y ) \longrightarrow \text{Ext} _ { \mathcal { A } } ^ { 1 } ( T, Y ) \longrightarrow \text{Ext} _ { \mathcal { A } } ^ { 1 } ( \coprod _ { i \in I } T _ { i }, Y ),$$
and we have a monomorphism Ext 1 A ( ∐ i ∈ I T , Y i ) /arrowtailright ∏ i ∈ I Ext 1 A ( T , Y i ) = 0 (see [23, Lemma 2.5]).
It remains to prove the equality Im( G ) = T ⊥ 0 1 , . We start with the inclusion ⊆ , for which, due to the proof of assertion 2, we just need to prove that Im( G ) ⊆ T ⊥ 1 . Let us consider then an exact sequence 0 → G B ( ) u -→ A -→ T → 0 (*) in A , where T ∈ T and B ∈ B . By exactness of F and the definition of T , we get that F u ( ) : ( F ◦ G B )( ) -→ F A ( ) is an isomorphism. By using the unit µ , we then get a commutative diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
from which we get that µ A ◦ u is an isomorphism, so that u is a section and the sequence (*) splits. This proves that Im( G ) ⊆ T ⊥ 0 1 , 0 .
Conversely, let Y ∈ T ⊥ 0 1 , and consider the map µ Y : Y -→ ( G ◦ F )( Y ). By assertion 1 we have that Ker( µ Y ) = 0 because the inclusion Ker( µ Y ) ↪ → Y is the zero morphism. But then we have an exact sequence 0 → Y µ Y -→ ( G F ◦ )( Y ) p -→ T → 0, where T := Coker( µ Y ) ∈ T by assertion 1. This exact sequence splits and, taking a section s : T -→ ( G ◦ F )( Y ), we conclude that T = 0 since we have already proved that Im( G ) ⊆ T ⊥ 0 . Therefore µ Y is an isomorphism and so Y ∈ Im( G ).
## 1.4 Triangulated categories and t-structures
A triangulated category D is an additive category with a self-equivalence ?[1] : D -→ D ( X /squiggleright X [1]) and a distiguished class of sequences X f -→ Y g -→ Z h -→ X [1], called triangles , satisfying certain axioms (see [N] for the details), where Verdier's TRIV axiom ( see [27, D´finition 1.1.1]), usually called the e octahedrom axiom (TR4) , is Neeman's Proposition 1.4.6. All through this subsection D is a triangulated category. We will put ?[ n ] = (?[1]) n for each n ∈ Z . Without mention to the morphisms, we will write indistinctly triangles as above, as X -→ Y -→ Z -→ X [1], as X -→ Y -→ Z + -→ or even Z [ -1] -→ X -→ Y -→ Z . It follows from the axioms that if f : X -→ Y is a morphism in D , then it can be completed to a triangle X f -→ Y -→ Z + -→ and also to a triangle Z ′ -→ X f -→ Y + -→ . The objects Z and Z ′ are uniquely determined by f up to (nonunique) isomorphisms, and will be called here the cone and the cocone of f , denoted cone( f ) and cocone( f ), respectively. When A is an abelian category, a functor H : D -→ A is a cohomological functor when it takes any triangle X -→ Y -→ Z + -→ to an exact sequence H X ( ) -→ H Y ( ) -→ H Z ( ). Due to the axioms TR0-TR4 (see [N]), this yields a long exact sequence ...H i -1 ( Z ) -→ H X i ( ) -→ H Y i ( ) -→ H Z i ( ) -→ H i +1 ( X ... ) , where H i := H ◦ (?[ ]) i for all i ∈ Z .
Given two subcategories X and Y of the triangulated category D , we denote by X /star Y the subcategory that consists of all objects D ∈ D that appear in some triangle X -→ D -→ Y + -→ , where X ∈ X and Y ∈ Y . The operation /star is associative (see [4]), i.e. ( X /star Y ) /star Z = X /star ( Y /star Z ), for any three subcategories X , Y and Z . We put X /starn = X /star n +1 ..... /star X , for each n ∈ N (so, e.g., X /star 0 = X and X /star 1 = X /star X ). The objects of X /starn are called n -fold extensions of objects of X .
When D has countable coproducts and
$$D _ { 0 } \stackrel { f _ { 1 } } { \longrightarrow } D _ { 1 } \stackrel { f _ { 2 } } { \longrightarrow } \cdots \stackrel { f _ { n } } { \longrightarrow } D _ { n } \stackrel { f _ { n + 1 } } { \longrightarrow }$$
is a sequence of morphisms, we denote by 1 -f the morphism D n -→
∐ n ∈ N D n whose k -th component D k -→ ∐ n ∈ N D n is the composition D k
∐ n ∈ N 1 D k -f k +1 -→
D k ∐ D k +1 inclus. ↪ → ∐ n ∈ N D n , for each k ∈ N . Associated to the sequence, we have the so-called Milnor triangle
$$\coprod _ { n \in \mathbb { N } } D _ { n } \stackrel { 1 - f } { \longrightarrow } \coprod _ { n \in \mathbb { N } } D _ { n } \longrightarrow \text{Mcolim} D _ { n } \stackrel { + } { \longrightarrow }$$
and the object Mcolim D n = cone(1 -f ) is called the Milnor colimit of the given sequence.
A special type of triangulated categories is of special interest in this paper. We assume in this paragraph that D is a triangulated category with coproducts and that α is a regular cardinal. We refer the reader to [18, Chapter 3] for the definition of α -perfect class (resp. set) of objects in D . We say that S is a class (resp. set) of α -perfect generators of D when S ⊥ Z = 0 and S is α -perfect. The category D is called α -compactly generated when it has an α -perfect set of generators that consists of α -small objects (see [18, Definition 8.1.6]). We say that D is well-generated when it is β -compactly generated, for some regular cardinal β . In this latter case, for any regular cardinal γ one considers the unique maximal γ -perfect class, denoted D γ , that consists of γ -small objects. The objects of D γ are called γ -compact . When D is well-generated, each D γ is a skeletally small thick subcategory of D closed under taking coproducts of < γ objects, and moreover D = ⋃ γ D γ , where γ runs trough the class of regular cardinal (see [13]). In particular, any set of objects of D is contained in some D γ .
Recall (see [BBD]) that a t-structure in the triangulated category D is a pair τ = ( U V , ) of subcategories that satisfy the following properties:
$$& \mathfrak { t } { - S 1 } \, \text{Hom} _ { \mathcal { D } } ( U, V [ - 1 ] ) = 0, \, \text{for all } U \in \mathcal { U } \text{ and } V \in \mathcal { V } ; \\ & \mathfrak { t } { - S 2 } \, \mathcal { U } [ 1 ] \subseteq \mathcal { U } \, ( \text{or } \mathcal { V } [ - 1 ] \subseteq \mathcal { V$$
t-S3 U /star ( V -[ 1]) = D .
In such case U and V are called the aisle and coaisle of the t-structure, respectively, and the intersection H := U ∩ V , which is called the heart of τ , has a natural structure of abelian category where the short exact sequences 'are' the triangles in D with their three vertices in H . To this abelian category it is naturally associated a cohomological functor H 0 τ : D -→ H . We will call it the cohomological functor associated to τ .
Given a class S of objects of D , the pair τ S = ( ⊥ ( S ⊥ ≤ 0 ) , S ⊥ < 0 ) satisfies condition t-S1 and t-S2. When it also satisfies t-S3 and hence τ S is a t-structure, we call it the t-structure generated by S . When D has coproducts and S is a set of objects, it is frequently the case that τ S is a t-structure. For example, by the results of [19] (see Proposition 3.1 below), if D is well-generated then, for any set of objects S , the pair τ S is a t-structure. Even more, Neeman proves that in that case U S := ⊥ ( S ⊥ ≤ 0 ) is the smallest subcategory of D which contains S and is closed under extensions, coproducts and positive shifts. A t-structure τ is said to be generated by a set when τ = τ S , for some set of objects S .
## 2 Coproducts as direct limits
All throughout the section A will be an additive category with coproducts. Suppose that ( X i ) i ∈ I a family of objects in A . For any subset J ⊆ I , we will put X J := ∐ i ∈ J X i and, for J ⊆ J ′ ⊆ I , let ι JJ ′ : X J /arrowtailright X J ′ the canonical section. We also put ι J i := ι { } i J : X i /arrowtailright X J , for each i ∈ J , so that, in particular, ι I j = ι j : X j -→ X I = ∐ i ∈ I X i is the canonical injection into the coproduct, for all j ∈ I . The following result of Category Theory is folklore. We sketch the basic ideas of its proof for the convenience of the reader.
Proposition 2.1. Let A be an additive category with coproducts and ( X i ) i ∈ I a family of objects in A . Let J ⊆ P ( I ) be a subset that is directed with respect to the inclusion order of P ( I ) and satisfies that ⋃ J ∈J J = I . Then [( X J ) J ∈J , ( ι JJ ′ : X J /arrowtailright X J ′ ) J ⊆ J ′ J,J ′ ∈J ] is a direct system in A that has ( ∐ i ∈ I X , i ( ι J := ι JI : X J /arrowtailright ∐ i ∈ I X i ) J ∈J ) as its direct limit.
Proof. (Sketch) Let ( f J : X J -→ A ) J ∈J be a family of morphisms such that f J = f J ◦ ι JJ ′ , whenever J ⊆ J ′ and J, J ′ ∈ J . For each j ∈ I , we choose a J ∈ J such that j ∈ J , which is possible since ⋃ J ∈J J = I . We put f j = f J ◦ ι J j and leave to the reader the easy verfication that the definition of f j does not depend on the choice of J . Now, by the universal property of the coproduct, we get a unique morphism f : ∐ i ∈ I X i -→ A such that f ◦ ι i = f i , for all i ∈ I . For any J ∈ J and any j ∈ J , we then have that f ◦ ι J ◦ ι J j = f ◦ ι j = f j = f J ◦ ι J j . This implies that f ◦ ι J = f J , for all J ∈ J , and the uniqueness of f satisfying this property is left as an exercise.
The following result follows via an adaptation of a famous argument of Lazard [15, Th´ eor`me 1.2]. e
Proposition 2.2 (Generalized Lazard's Trick) . Let A be an additive category with coproducts, let [( X i ) i ∈ I , ( u ij : X i → X j ) i ≤ j )] and [( Y λ λ ) ∈ Λ , ( v λµ : Y λ → Y µ λ ) ≤ µ ] be two direct systems in A that have a direct limit and let f : lim - → X i → lim - → Y λ be any morphism satisfying the following properties:
- ( † ) For each j ∈ I , there is a µ = µ j ( ) ∈ Λ such that f ◦ u j factors through v µ , where u j : X j → - → lim X i and v µ : Y µ → - → lim Y λ are the canonical maps to the direct limit.
- ( †† ) v µ : Y µ -→ - → lim Y λ is a monomorphism, for all µ ∈ Λ .
Then there exists a directed set Ω and a direct system of morphisms ( g ω : X ω → Y ω | ω ∈ Ω) satisfying the following properties:
- (a) X ω ∈ { X i : i ∈ I } and Y ω ∈ { Y λ : λ ∈ Λ } , for all ω ∈ Ω ;
- (b) the direct limit of the given direct system of morphisms exists and lim - → g ω : lim - → X ω → - → lim Y ω is isomorphic to f .
Moreover, if α is a regular cardinal such that I and Λ are α -directed, then Ω may be chosen to be also α -directed.
Proof. Except for the final assertion concerning α , the rest of the proof is identical to the one in [6, Proposition 9.16], under condition (1) of that result. This latter condition has been replaced here by condition ( †† ), that makes the AB5 hypothesis used there unnnecessary. We borrow all the terminology from that mentioned proof.
Let then assume that I and Λ are α -directed. We choose exactly the same Ω of [op.cit], i.e. Ω consists of the triples ( i, λ, g ) such that ( i, λ ) ∈ I × Λ and g : X i -→ Y λ is a (unique) map such that v λ ◦ g = f ◦ u i . Let us consider any family [( i t , λ t , g t )] t ∈ T of elements of Ω, where | T | < α . Due to the α -directed condition of I and Λ, we can choose i ∈ I and λ ∈ Λ such that i t ≤ i and λ t ≤ λ , for all t ∈ T . By condition ( ), there exists a † µ = µ i ( ) ∈ Λ together with a map g : X i -→ Y µ such that v µ ◦ g = f ◦ u i , equivalently, such that ( i, µ, g ) ∈ Ω. Without loss of generality, we can assume that λ ≤ µ . Then, for each t ∈ T , we have an equality
$$v _ { \mu } \circ g \circ u _ { i _ { t } i } = f \circ u _ { i } \circ u _ { i _ { t } i } = f \circ u _ { i _ { t } } = v _ { \lambda _ { t } } \circ g _ { t } = v _ { \mu } \circ v _ { \lambda _ { t } \mu } \circ g _ { t }.$$
By condition ( †† ), the map v µ is a monomorphism, which implies that g ◦ u i t i = v λ µ t ◦ g and hence that ( i t , λ t , g t ) /precedesequal ( i, µ, g ). Therefore Ω is α -directed.
Corollary 2.3. Let f : ∐ j ∈ J X ′ j -→ ∐ i ∈ I X i be a morphism in A , where X , X ′ j i ∈ Small α ( A ) for all j ∈ J and i ∈ I . For each set S , let us denote by P α ( S ) the set of subsets S ′ ⊆ S such that | S ′ | < α , that is an α -directed set with the inclusion order. The following assertions hold:
- 1. With notation as in the first paragraph of this section, we have direct systems ( X ′ Λ Λ ) ∈P α ( J ) and ( X Υ Υ ) ∈P α ( I ) in A such that lim - → Λ ∈P α ( J ) X ′ Λ ∼ = ∐ j ∈ J X ′ j and lim - → Υ ∈P α ( I ) X Υ ∼ = ∐ i ∈ I X i .
- 2. There is an α -directed system of morphisms ( f ω : ˆ X ′ ω -→ ˆ X ω ω ) ∈ Ω satisfying the following properties:
- (a) ˆ X ′ ω ∈ { X ′ Λ : Λ ∈ P α ( J ) } and ˆ X ω ∈ { X Υ : Υ ∈ P α ( I ) } , for all ω ∈ Ω ;
- (b) the direct limit of the given direct system of morphisms exists and lim - → f ω : lim - → ˆ X ′ ω -→ - → lim ˆ X ω is isomorphic to f .
Proof. 1) Bearing in mind that, for each set S , one has that ⋃ S ′ ∈P α ( S ) S ′ = S , this assertion is a direct consequence of Proposition 2.1.
- 2) We view f as a morphism lim - → Λ ∈P α ( J ) X ′ Λ -→ - → lim Υ ∈P α ( I ) X Υ and check that conditions ( † ) and ( †† ) of Proposition 2.2 are satisfied, so that assertion 2 will be a consequence of that propositon.
Note first that the canonical map ι Υ ′ : X Υ ′ = ∐ i ∈ Υ ′ X i -→ - → lim Υ ∈P α ( I ) X Υ = ∐ i ∈ I X i is a section, whence a monomorphism, for all Υ ′ ∈ P α ( I ). Therefore condition ( †† ) holds. It remains to check property ( ). † Indeed if ι ′ Λ ′ : X ′ Λ ′ = ∐ j ∈ Λ ′ X ′ j -→ - → lim Λ ∈P α (Λ) X ′ Λ ∼ = ∐ j ∈ J X ′ j denotes the canonical section, for each Λ ′ ∈ P α ( J ), then f ◦ ι ′ Λ ′ : X ′ Λ ′ -→ - → lim Υ ∈P α ( I ) X Υ ∼ = ∐ i ∈ I X i is a morphism with α -small domain. We can then select an Υ ′ ∈ P α ( I ) such that f ◦ ι ′ Λ ′ factors through ι Υ ′ : ∐ i ∈ Υ ′ X i = X Υ ′ -→ - → lim Υ ∈P α ( I ) X Υ ∼ = ∐ i ∈ I X i .
## 3 The theorem
We start by stating the following straightforward consequence of [19, Lemma 2.2, Theorem 2.3 and Proposition 2.5].
Proposition 3.1. ([19]) Let D be a well-generated triangulated category and τ = ( U V , ) be a t-structure in D generated by a set of objects X . Let α be the smallest of the regular cardinals β such that X ⊆ D β and D is β -compactly generated. The following assertions hold:
- 1. Each morphism Z -→ U , where U ∈ U and Z ∈ D α , factors through an object of U ∩ D α
- 2. Each object of U is the Milnor colimit of a sequence U 0 f 1 -→ U 1 -→ ··· -→ f 1 U n -→ ... such that U 0 and all cone ( f n ) are coproducts of objects of U∩D α .
We can now state and have all the ingredients to prove the main result of the paper, which is an extended version of Theorem A in the introduction.
Theorem 3.2. Let D be a well-generated triangulated category, τ = ( U V , ) be a t-structure generated by a set of objects X and H be its heart. Suppose that α is the smallest of the regular cardinals β such that X ⊆ D β and D is β -compactly generated. Let S be a skeleton of U ∩ D α . The following assertions hold:
- 1. Each object of H is an α -directed colimit of objects of H ( S ) , where H := H 0 τ : D -→ H is the associated cohomological functor.
- 2. H ( S ) consists of α -presentable objects and each α -presentable object of H is isomorphic to one of them.
In particular H is a locally α -presentable abelian category.
Remark 3.3. When α = ℵ 0 in last theorem, one gets [24, Theorem 8.31] since, as shown in the proof of this latter result, the heart of any compactly generated t-structure τ in a triangulated category with coproducts D is also the heart of a t-structure with the same aisle in a compactly generated subcategory of D .
The proof of Theorem 3.2 will occupy the rest of this section and leans upon some auxiliary results. In the rest of the section we use the hypotheses and notation of Theorem 3.2.
Recall (cf. [24, Definition 4.2]) that a subcategory P of U is t -generating when it is precovering and, for each U ∈ U , there is a triangle U ′ -→ P p -→ U + -→ such that U ′ ∈ U and P ∈ P . Such a morphism p will be called here a P -morphism . When P is t -generating, any P -precover of U is a P -morphism (see [24, Lemma 4.4]). Note also that, due to the octahedrom axiom, if ˜ U ′ -→ U h -→ ˜ U + -→ is a triangle with its three vertices in U , then h ◦ p is also a P -morphism. On the other hand, when P is closed under coproducts, any coproduct of P -morphisms is a P -morphism since coproducts of triangles are triangles (see [18, Proposition 1.2.1 and Remark 1.2.2]) and U is closed under coproducts.
Lemma 3.4. Coprod ( S ) is a t-generating subcategory of U
Proof. We put P := Coprod( S ), which is clearly precovering and closed under coproducts. Consider, for any object U ∈ U , a sequence U 0 f 1 -→ U 1 -→ ... f 1 -→ U n -→ ... giving rise to a Milnor triangle
$$\coprod _ { n \in \mathbb { N } } U _ { n } \stackrel { 1 - \sigma } { \longrightarrow } \coprod _ { n \in \mathbb { N } } U _ { n } \longrightarrow U \stackrel { + } { \longrightarrow }$$
as in Proposition 3.1. Suppose that each U n admits P -morphism p n : ˆ S n → U n for each n ∈ N . Then ∐ p n : ∐ n ∈ N ˆ S n -→ ∐ n ∈ N U n is a P -morphism. The composition
$$\Phi \quad \prod _ { n \in \mathbb { N } } \hat { S } _ { n } \stackrel { \coprod p _ { n } } { \longrightarrow } \coprod _ { n \in \mathbb { N } } U _ { n } \stackrel { \text{canonical} } { \longrightarrow } \text{Mcolim} U _ { n } = U$$
is also a P -morphism by the comments preceding this lemma. The proof is hence reduced to prove our following claim:
Claim : For each n ∈ N and U a n -fold extension of objects of P , there is a P -morphism ∐ i ∈ I S i -→ U
The proof of the claim goes by induction on n , the case n = 0 being clear. Suppose that n > 0 and consider a triangle ∐ i ∈ I S i -→ U g -→ ˜ U + -→ , where ˜ U is a ( n -1)-fold extension of objects in P and S i ∈ S , for all i ∈ I . By the induction hypothesis, we have another triangle ˜ U ′ -→ ∐ j ∈ J S ′ j h -→ ˜ U + -→ , where ˜ U ′ ∈ U and S ′ j ∈ S for all j ∈ J . Taking the homotopy pullback of g and h and drawing the corresponding commutative diagram, we get two triangles
$$\tilde { U } ^ { \prime } & \longrightarrow \hat { U } \stackrel { p } { \longrightarrow } U \stackrel { + } { \longrightarrow } \\ \coprod _ { i \in I } S _ { i } & \longrightarrow \hat { U } \longrightarrow \coprod _ { j \in J } S _ { j } ^ { \prime } \stackrel { + } { \longrightarrow }$$
Suppose that we are able to prove the existence of a P -morphism ∐ λ ∈ Λ S ′′ λ q -→ ˆ U + -→ , where S ′′ λ ∈ S , for all λ ∈ Λ. The comments preceding this lemma tell us that ∐ λ ∈ Λ S ′′ λ p q ◦ -→ U is a P -morphism.
The consequence of last paragraph is that, after replacing U by ˆ U if necessary, it is enough to prove our claim for the case n = 1. So in the rest of the proof we assume that U is a (1 -fold) extension of objects in Coprod( S ) so that, after shift, we get a triangle
$$\coprod _ { j \in J } S _ { j } ^ { \prime } [ - 1 ] \overset { f } { \longrightarrow } \coprod _ { i \in I } S _ { i } \longrightarrow U \overset { + } { \longrightarrow },$$
where S , S ′ j i ∈ S for all i ∈ I and j ∈ J . Applying now Corollary 2.3, we conclude that there is an α -directed system of morphisms ( f w : X ′ w -→ X w w ) ∈ Ω such that its direct limit exists in D , f is isomorphic to lim - → f w : lim - → X ′ w -→ - → lim X w and the X ′ w and the X w are subcoproducts with < α terms of ∐ j ∈ J S ′ j [ -1] and ∐ i ∈ I S i , respectively. In particular, we have that X ,X ′ w w ∈ D α and, since D α is closed under extensions, we also get that
U w := cone f ( w ) ∈ U ∩ D α , for all w ∈ Ω. Moreover, we have a commutative diagram with triangles in rows:
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
- →
/d47
/d47
- →
/d47
/d47
/d47
/d47
where p ′ and p are the canonical epimorphisms (=retractions in our case) from the coproduct to the direct limit. In particular, we have that cocone( p ′ ) ∈ Add( S )[ -1] and cocone( p ) ∈ Add( S ). Applying the dual of Verdier's 3 × 3 Axiom (see [17, Lemma 2.6] ), we can complete the last diagram with dotted arrows so that all rows and columns of the diagram are triangles:
/d47
/d47
/d47
/d47
/d47
/d47
✤
✤
✤
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
From the top horizontal arrow and the fact that cocone( p ′ )[1] , cocone( p ) ∈ Add( S ) we immediately get that cocone( p ′′ ) ∈ U . Our P -morphism for U is the p ′′ in the right vertical column of the diagram. Indeed, for each w ∈ Ω, we can take the unique object ˜ S w ∈ S that is isomorphic to U w , and get a triangle as desired
Lemma 3.5. The following assertions hold, for each object M of H :
- 1. M ∼ = Coker ( H f ( )) , where the cokernel is taken in H , for some morphism f in Coprod ( S ) .
- 2. There exists an α -directed set Ω , a family ( g νω : Z ν -→ Z ω ν ) ≤ ω of morphisms in S , where ν, ω ∈ Ω , such that [( H Z ( ν ) ν ∈ Ω , H (( g νω ) : H Z ( ν ) -→ H Z ( ω )) ν ≤ ω ] is an Ω -direct sytem in H and M is isomorphic to its direct limit.
/d15
/d15
✤
✤
/d15
/d15
/d47
/d47
/d15
/d15
✤
✤
/d15
/d15
/d47
/d47
/d15
/d15
✤
✤
/d15
/d15
✤
✤
✤
/d47
/d47
Proof. We again put P := Coprod( S ) all through the proof.
- (1) Using Lemma 3.4, choose a P -morphism p : ∐ i ∈ I S i -→ M , thus leading to a triangle M [ -1] v -→ U u -→ ∐ i ∈ I S i p -→ M , with U ∈ U . Next we take a P -morphism q : ∐ j ∈ J S ′ j -→ U . By taking the homotopy pullback of q and v , we get the following commutative diagram, where columns 1, 2, 4 and rows 2, 3 are triangles and U , U ′ ˜ ∈ U :
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
Bearing in mind that H vanishes on U [1], application of this functor to the right vertical column yields an isomorphism H U ( ˜ ) = ∼ H M ( ) = M . Application to the central row yields an exact sequence H ( ∐ j ∈ J S ′ j ) H f ( ) -→ H ( ∐ i ∈ I S i ) -→ H U ( ˜ ) → 0.
- (2) Note first that if h : S -→ S ′ is a morphism in S , then cone( h ) ∈ U ∩D α . As a consequence, up to replacement by an isomorphic object, we can assume that cone( f ) ∈ S .
Using assertion 1, choose a morphism f : ∐ j ∈ J S ′ j -→ ∐ i ∈ I S i in P such that Coker( H f ( )) ∼ = M . By Corollary 2.3, we have an α -directed system of morphisms ( f ω : ˆ X ′ ω -→ ˆ X ω ω ) ∈ Ω satisfying condition 2 of that corollary, where the direct limits exist in D . Note that ˆ X ′ ω and ˆ X ω are coproducts of less than α objects of S , and hence, up to isomorphism, all of them are objects of S . In particular, as mentioned above, we can assume that Z ω := cone( f ω ) ∈ S for each ω ∈ Ω.
Since ( f ω : ˆ X ′ ω -→ ˆ X ω ω ) ∈ Ω is a direct system of morphisms in U and H |U : U -→ H is a left adjoint functor (see [20, Lemma 3.1]), we conclude that there is an exact sequence in H
$$\varinjlim H ( \hat { X } _ { \omega } ^ { \prime } ) \overset { \lim } { \longrightarrow } H ( f _ { \omega } ) \varinjlim H ( \hat { X } _ { \omega } ) \longrightarrow M \to 0$$
since H f ( ) = H (lim - → f ω ) = lim ∼ - → H f ( ω ). But this gives that M ∼ = lim Coker - → H ( H f ( ω )) since direct limits are right exact in any cocomplete abelian category. On the other hand, for each ω ∈ Ω, we have an exact sequence H X ( ˆ ′ ω ) H f ( ω ) -→ H X ( ˆ ω ) -→ H Z ( ω ) → 0, so that M ∼ = lim - → H Z ( ω ) and the first paragraph of this step says that, up to isomorphism, Z ω ∈ S . The desired family of morphisms in S is given
/d15
/d15
/d15
/d15
/d15
/d15
as follows. For each ν, ω ∈ Ω such that ν ≤ ω , let g νω : Z ν -→ Z ω be a fixed choice of a morphism giving rise to a morphism of triangles as follows
/d47
/d47
/d47
/d47
/d47
/d47
✤
/d15
/d15
/d15
/d15
/d15
/d15
✤
/d47
/d47
/d47
/d47
/d47
/d47
where the two left most vertical arrows are the maps in the direct systems ( ˆ X ′ ω ω ) ∈ Ω and ( ˆ X ω ω ) ∈ Ω , respectively. Note that, by the universal property of cokernels, [( H Z ( ν ) ν ∈ Ω , H (( g νω ) : H Z ( ν ) -→ H Z ( ω )) ν ≤ ω ] is an Ω-direct sytem in H whose direct limit is isomorphic to M .
Recall from Proposition 1.2 that the category mod -P is abelian with coproducts and { -( , S ): S ∈ S} is a set of projective α -presentable generators. Moreover, by Lemma 3.4 and [24, Theorem 4.5], we have a Serre quotient functor F : mod -P -→ H with a fully faithful right adjoint G : H -→ mod -P that takes M /squiggleright Hom D ( -, M ) |P .
Lemma 3.6. In the situation of the last paragraph let us put T = Ker ( F ) . Then T = Gen ( T 0 ) , where T 0 is the subcategory of T that consists of the objects T in T that admit a projective presentation in mod -P
$$( -, S _ { 2 } ) \longrightarrow ( -, S _ { 1 } ) \longrightarrow ( -, S _ { 0 } ) \rightarrow T \rightarrow 0,$$
where S i ∈ S and ( -, S i ) := Hom P ( -, S i ) for i = 0 1 2 , , .
Proof. We apply Proposition 1.4, taking X := { -( , S ): S ∈ S} as set of generators of mod -P . The mentioned proposition says that T is a hereditary torsion class in mod -P generated by the 'cyclic' objects of T , i.e. those objects of T which are epimorphic image of ( -, S ), for some S ∈ S . Imitating the proof of [24, Lemma 8.30], we just need to prove that if S ∈ S and M := ( -, S ) /N is an object of T then there is an epimorpism T /dblarrowheadright M , where T ∈ T admits a projective presentation in mod -P as mentioned in the statement of the lemma. The proof is just an adaptation of that of [24, Lemma 8.30], that we indicate leaving the details to the reader.
By the proof of [24, Lemma 4.7], T consists of the X ∈ mod -P for which there exists a triangle U -→ P 1 g -→ P 0 + -→ in D such that X ∼ = Coker[( -, g )], where U ∈ U and P , P 1 0 ∈ P := Coprod( S ). For X = M as above, one can then consider a triangle S [ -1] v -→ U -→ P g -→ S , where P ∈ P and U ∈ U , such that M ∼ = Coker[( -, g )]. Since S [ -1] ∈ D α Proposition 3.1 says that v factors through an object S ′ ∈ S and then we get a commutative diagram with triangles in rows:
✤
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
where S ′′ may be taken in S since U ∩ D α is closed under extensions. We then have an exact sequence
$$( -, S ^ { \prime } ) \longrightarrow ( -, S ^ { \prime \prime } ) \stackrel { ( -, \rho ) } { \longrightarrow } ( -, S ) \longrightarrow T \rightarrow 0,$$
where T ∈ T , and hence there is an epimorphism T /dblarrowheadright M as desired.
Lemma 3.7. H ( S ) consists of α -presentable objects and each α -presentable object of H is isomorphic to one of them.
Proof. Recall that the Serre quotient functor F : mod -P -→ H satisfies that F (Hom D ( -, S )) = H S ( ), for all S ∈ S (see [24, Theorem 4.5]). Moreover, by Proposition 1.2, { -( , S ): S ∈ S} is a set of α -presentable generators of mod -P . To prove that H ( S ) consists of α -presentable objects we just need to check that F preserves α -presentable objects or, equivalently (see Proposition 1.3), that G : H -→ mod - P preserves α -filtered colimits. Due to the fully faithful condition of G , Lemma 3.6 and Proposition 1.4, our task reduces to check that T ⊥ 0 1 , 0 is closed under taking α -filtered colimits, where T 0 is as in Lemma 3.6.
Let ( Y i ) i ∈ I be an α -direct system in T ⊥ 0 1 , 0 and let T ∈ T 0 , for which we fix a projective presentation
$$\left ( -, S _ { 2 } \right ) \stackrel { \left ( -, f _ { 2 } \right ) } { \longrightarrow } \left ( -, S _ { 1 } \right ) \stackrel { \left ( -, f _ { 1 } \right ) } { \longrightarrow } \left ( -, S _ { 0 } \right ) \rightarrow T \rightarrow 0,$$
as in Lemma 3.6. The fact that Ext k mod -P ( T, Y i ) = 0 for k = 0 1 and all , i ∈ I implies that the sequence of abelian groups
$$0 = ( T, Y _ { i } ) \longrightarrow ( ( -, S _ { 0 } ), Y _ { i } ) ) \longrightarrow ( S _ { 1 }, Y _ { i } ) \longrightarrow ( ( -, S _ { 2 } ), Y _ { i } )$$
is exact. Clearly, when i varies, we get an I -direct system of exact sequences in Ab. When we apply the direct limit functor, which is exact in Ab, we get an exact sequence
$$0 = \varinjlim ( T, Y _ { i } ) \longrightarrow \varinjlim ( ( -, S _ { 0 } ), Y _ { i } ) ) \longrightarrow \varinjlim ( ( -, S _ { 1 } ), Y _ { i } ) \longrightarrow \varinjlim ( ( -, S _ { 2 } ), Y _ { i } ) \quad \ ( \dagger )$$
On the other hand, since the class of α -presentable objects is closed under cokernels, we know that T 0 consists of α -presentable objects, thus implying in particular that ( T, lim - → Y i ) = lim( ∼ - → T, Y i ) = 0. In addition, by the α -presentability of ( -, S ), the canonical map lim(( - → -, S ) , Y i ) -→ (( -, S ) , lim - → Y i ) is an isomorphism, for all S ∈ S . It follows that the sequence ( † ) above is isomorphic to the sequence
$$0 = ( T, \underline { \lim } Y _ { i } ) \longrightarrow ( ( -, S _ { 0 } ), \underline { \lim } Y _ { i } ) ) ^ { ( -, f _ { 1 } ) ^ { * } } \stackrel { ( -, F _ { 1 } ) ^ { * } } { \longrightarrow } ( ( -, S _ { 1 } ), \underline { \lim } Y _ { i } ) ^ { ( -, f _ { 2 } ) ^ { * } } \stackrel { ( -, F _ { 2 } ) ^ { * } } { \longrightarrow } ( ( -, S _ { 2 } ), \underline { \lim } Y _ { i } ). \quad \quad ( \dagger \dagger )$$
/d47
/d47
ρ
/d47
/d47
In particular, this latter sequence is also exact and we have that Ext 1 mod -P ( T, lim - → Y i ) = Ker( -,f 2 ) ∗ Im( -,f 1 ) ∗ = 0. Therefore lim - → Y i ∈ T ⊥ 0 1 , 0 as desired.
It remains to prove that any α -presentable object M of H is isomorphic to H S ( ), for some S ∈ S . Due to Lemma 3.5, we know that M ∼ = lim - → H S ( i ), for some α -direct system [( H S ( i )) i ∈ I , ( H f ( ij : H S ( i ) -→ H S ( j )) i ≤ j ] in H ( S ). Due to the α -presentability of M , a standard argument shows that M is isomorphic to a direct summand of some H S ( j ). The proof will be finished once we prove that H ( S ) = ∼ H ( U ∩ D α ) is closed under taking direct summands. This follows from an easy adaptation of the previous to last paragraph of the proof of [24, Therem 8.31]. U 0 should be replaced by S here and the finite subset J ⊆ I there by a subset of cardinality | J | < α .
## Proof of Theorem 3.2:
It is a direct consequence of Lemmas 3.5 and 3.7.
## References
- [1] ADAMEK, J.; ROSICKY, J. : Locally presentable and accessible categories. London Math. Soc. Lect. Notes 189 . Cambridge Univ. Press (1994).
- [2] ANGELERI-H ¨ GEL, L.; MARKS, F.; VIT ´ RIA, J. U O : Torsion pairs in Silting Theory. Int. Math. Res. Not. 4 (2015), 1251-1284.
- [3] BAZZONI, S. : The t-structure induced by a n -tilting module. Trans. Am. Math. Soc. 371 (9) (2016), 6309-6340.
- [4] BEILINSON, A.; BERNSTEIN, J.; DELIGNE, P. : 'Faisceaux pervers'. Ast´risque e 100 , Soc. Math. France, Paris (1982), 5-171.
- [5] BONDARKO, M.V. : On perfectly generated weight structures and adjacent t-structures. Math. Zeitschr. 300 (2) (2022), 1-34.
- [6] CORT ´ S-IZURDIAGA, M.; CRIVEI, S.; SAOR ´ IN, M. E : Reflective and coreflective subcategories. J. Pure and Appl. Algebra 227 (2023). Article 107267.
- [7] COLPI, R.; GREGORIO, E.; MANTESE, F. : On the heart of a faithful torsion theory. J. Algebra 307 (2) (2007), 841-863.
- [8] COLPI, R.; MANTESE, F.; TONOLO, A. : When the heart of a faithful torsion pair is a module category. J. Pure and Appl. Alg. 215 (12) (2011), 2923-2936.
- [9] HILTON, P.J.; STAMBACH, U. : A course in Homological Algebra, 2nd edition. Grad. Text in Maths. 4 . Springer (1997).
- [10] HOSHINO, M.; KATO, Y.; MIYACHI, J.-I. : On t-structures and torsion theories induced by compact objects. J. Pure and Appl. Alg. 167 (1) (2002), 15-35.
- [11] KRAUSE, H. : On Neeman well generated triangulated categories. Docum. Math. 6 (2001), 121-126.
- [12] KRAUSE, H. : A Brown representability theorem via coherent functors. Topology 41 (2002), 853-861.
- [13] KRAUSE, H. : Localization theory for triangulated categories. In 'Triangulated categories' (edts T. Holm, P. Jorgensen and R. Rouquier). London Math. Soc. Lect. Note Ser. 375 (2011).
- [14] LAKING, R. : Purity in compactly generated derivators and t-structures with Grothendieck hearts. Math. Zeitschr. 295 (3-4) (2020), 1615-1641.
- [15] LAZARD, D. : Autour de la platitude. Bull. Soc. Math. France 97 (1969), 81-128.
- [16] LURIE, J. : Higher Algebra. Available from https://people.math.harvard.edu/ lurie/papers/HA.pdf (2006), 1158 pages.
- [17] MAY, J.P. : The additivity of traces in triangulated categories. Adv. Maths. 163 (2001), 34-73.
- [18] NEEMAN, A. : Triangulated categories. Ann. Math. Stud. 148 . Princeton University Press (2001).
- [19] NEEMAN, A. : The t-structures generated by objects. Trans. Am. Math. Soc. (2018). DOI: 10.1090/tran/8497
- [20] PARRA, C.; SAOR ´ IN, M. : Direct limits in the heart of a t-structure: the case of a torsion pair. J. Pure and Appl. Algebra 219 (2015), 41174143.
- [21] PARRA, C.; SAOR ´ IN, M. : Addendum to 'Direct limits in the heart of a t-structure: the case of a torsion pair' [JPAA 219 ]. J. Pure and Appl. Alg. 220 (6) (216), 2467-2469.
- [22] PARRA, C.; SAOR ´ IN, M. : Hearts of derived categories in the derived category of a commutative Noetherian ring. Trans. Am. Math. Soc. 369 (2017), 7789-7827.
- [23] PARRA, C.; SAOR ´ IN, M., VIRILI, S. : Tilting preenvelopes and cotilting precovers in general abelian categories. Alg. Repr. Theory 26 (2023), 1087-1140.
- [24] SAOR ´ IN, M.; STOVICEK, J. : t-Structures with Grothendieck hearts via functor categories. Selecta Math. (New series) 29 (2023), paper number 77.
- [25] SAOR ´ IN, M.; STOVICEK, J.; VIRILI, S. : t-Structures on stable derivators and Grorhendieck hearts. Adv. Maths. 429 (2023), paper 109139.
- [26] STOVICEK, J. : Derived equivalences induced by big cotilting modules. Adv. Maths. 263 (2014), 45-87.
- [27] VERDIER, J.L. : Des cat´gories e d´ eriv´es e des cat´gories e ab´ eliennes. Ast´ erisque 239 (1996) | null | [
"Manuel Saorín"
]
| 2024-08-02T16:36:58+00:00 | 2024-08-02T16:36:58+00:00 | [
"math.CT",
"18G80, 18E10, 18C35, 18E05"
]
| Hearts of set-generated t-structures have a set of generators | We show that if $\alpha$ is a regular cardinal, $\mathcal{D}$ is an
$\alpha$-compactly generated triangulated category, in the sense of Neeman
\cite{N}, and $\tau$ is a t-structure in $\mathcal{D}$ generated by a set of
$\alpha$-compact objects, then the heart of $\tau$ is a locally
$\alpha$-presentable (not necessarily Ab5) abelian category. As a consequence,
in a well-generated triangulated category any t-structure generated by a set of
objects has a heart with a set of generators. |
2408.01379v1 | ## RESAMPLING AND AVERAGING COORDINATES ON DATA
ANDREW J. BLUMBERG, MATHIEU CARRI ` RE, JUN HOU FUNG, E AND MICHAEL A. MANDELL
Abstract. We introduce algorithms for robustly computing intrinsic coordinates on point clouds. Our approach relies on generating many candidate coordinates by subsampling the data and varying hyperparameters of the embedding algorithm (e.g., manifold learning). We then identify a subset of representative embeddings by clustering the collection of candidate coordinates and using shape descriptors from topological data analysis. The final output is the embedding obtained as an average of the representative embeddings using generalized Procrustes analysis. We validate our algorithm on both synthetic data and experimental measurements from genomics, demonstrating robustness to noise and outliers.
## 1. Introduction
A central postulate of modern data analysis is that the high-dimensional data we measure in fact arises as samples from a low-dimensional geometric object. This hypothesis is the basic justification for dimensionality reduction which is the first step in almost all geometric data analysis algorithms, particularly in clustering and its higher dimensional analogs. This is aimed at mitigating the 'curse of dimensionality', a broad term for various concentration of measure results that imply that the geometry of high-dimensional Euclidean spaces behaves very counter-intuitively. The curse of dimensionality tells us that if this hypothesis is not satisfied, we cannot expect to perform any meaningful inference at all.
The recent explosion of data acquisition processes in many different scientific fields (e.g., single-cell RNA sequencing experiments in computational biology, realistic synthetic data sets obtained from deep generative models, multivariate time series generated from large numbers of sensors, etc.) has led to a dramatic increase of publicly available data sets in high ambient dimensions. The need for tractable and accurate data science tools for processing these data sets has thus become critical. While supervised machine learning and deep learning methods have proven to be very efficient in many different areas and applications of data science, they are often limited by the difficulty of finding suitable training data. Hence, the problem of studying this data via dimensionality reduction and exploratory data analysis has become central.
However, dimensionality reduction algorithms generally have the inherent complication that they depend on a variety of ad hoc hyperparameters and are sensitive both to noise concentrated around the underlying geometric object and to outliers.
The first author was partially supported by the NSF grant DMS-1912194 and by ONR grant N00014-22-1-2679.
The third author was supported by the NSF under grant DMS-1912194.
The fourth author was supported by the ONR grant N00014-22-1-2675.
Moreover, all methods are known to be very sensitive to these hyperparameters: a slight change in only one parameter can lead to dramatic changes in the output lower-dimensional embeddings. As a consequence, it is challenging to perform meaningful inference based on such procedures and most serious applications involve a lot of ad hoc cross-validation procedures.
This article proposes a method to resolve this issue by producing robust embeddings, employing the following process:
- · Subsampling and varying hyperparameters to produce a number of embeddings of a given (low) dimension using dimensionality reduction techniques,
- · using affine isometries and the solution to the general 'Procrustes problem' to align the embeddings in a way that minimizes a certain natural metric (explained below),
- · clustering the aligned embeddings based on that metric,
- · identifying a cluster of 'representative' embeddings by looking at the cluster density and using topological data analysis (TDA) to eliminate clusters with topologically complex embeddings, and
- · taking the average (centroid) of the embeddings in the representative cluster to produce a final low dimensional embedding of most of the points. (Points which are not present in the averaged embeddings are returned as 'outliers'.)
The subsampling leads to results that are robust with respect to isotropic noise and have reduced sensitivity to outlier data points. The clustering discards outlier embeddings with a high level of distortion. Essentially any dimensionality reduction algorithm can be used, but the procedure works best when the algorithm preserves some global structure; e.g., t-SNE and UMAP, which preserve local relationships but can radically distort global relationships produce less sharp results. (See Section 8 for further discussion of this point.) The intuition behind our use of TDA invariants (notably persistent homology) to detect the representative embeddings is that we expect coordinate charts to be contractible subsets: theoretical guarantees for manifold learning imply that the algorithms really only work in this case. Persistent homology is a convenient way to detect complicated topological features such as holes.
We illustrate the process in Figure 1. The figure shows a standard 3-dimensional 'Swiss roll' synthetic data set and uses Isomap to produce a 2-dimensional coordinate chart. This is a particularly easy example, but we achieve similar results in the presence even of a large number of outliers and across parameter regimes. See Section 7 for a variety of synthetic examples.
The discussion above emphasizes the robustness in the presence of outliers, but our technique has an additional use case where it can be employed to reduce the computational complexity of dimensionality reduction computations: instead of computing a dimensionality reduction of the entire data set, the procedure above can be used to produce a global set of coordinates by averaging coordinates from much smaller subsamples.
In order to demonstrate the use of our procedure on real data, we apply it to multiple dimensionality reduction methods for producing coordinates on genomic data sets in Section 8, specifically blood cells (PBMC) and mouse neural tissue. The results show that our procedure can be used to produce robust coordinates
(a) Original data in 3D

- (b) Isomap results on subsamples
- (c) Clustering embeddings
(d) Final aligned output
Figure 1. Swiss roll dataset
from some manifold learning algorithms and indicates the instability of coordinates produced from others.
Related work. Procrustes analysis has long been used to study shapes [17]. Building on scaling methods, the orthogonal Procrustes problem was first studied and solved by Green [16], and Sch¨nemann and Sch¨nemann-Carroll [25, 26], and later o o this was generalized to three or more shapes by Gower [14]. Nowadays, there are many variants of Procrustes problems. Beyond statistical shape analysis [13], Procrustes analysis has found applications in sensory science [11], market research [15], image analysis [12], morphometrics [8], protein structure [22], environmental science [24], population genetics [34], phylogenetics [4], chemistry [1], ecology [20], and more. In forthcoming work, the authors will present an application to neuroscience.
The early applications of Procrustes analysis were in the field of psychometrics, where point sets are registered to a single 'reference' profile that is sometimes realized in physical space, and datasets are small. More recently, it has been increasingly recognized that the same techniques and ideas can be applied just as well to the shape of 'data' itself with no expectation of a reference whatsoever, and to high-dimensional datasets [2] with many samples. For example, [21] uses a version of Procrustes analysis with shuffling to align low-rank representations of single cell transcriptomic data. Procrustes analysis can also be applied to statistics itself. In this sense, part of our current study can be viewed as an expansion of [19], which studied a jackknife procedure on multidimensional scaling, a limited form of manifold learning. Similarly, [33] applied Procrustes analysis to the outputs of
dimensionality reduction, specifically Laplacian eigenmaps and locality preserving projections, but only for two point clouds at a time.
Summary. In Section 2, we provide a concise review of the background for our work; we discuss manifold learning and dimensionality reduction algorithms, the Procrustes distance and alignment problem, and topological data analysis. Next, in Section 3, we describe our algorithm. We then begin a theoretical analysis of the behavior of our algorithm by reviewing in detail the solution to the generalized Procrustes problem in Section 4. We employ a solver based on alternating least squares minimization, and we describe the stability and convergence behavior of this process in Section 5. We then use this to analyze the stability of our algorithm in Section 6. The paper concludes with two sections exploring the behavior of our algorithm: Section 7 studies how it works on simulated data with various kinds of noise and outliers, and Section 8 applies our algorithm to single-cell RNAseq data.
Code availability. For aligning two point clouds, we used the command scipy.spatial.procrustes from the SciPy library [32]. For general Procrustes alignment of two or more point clouds, we developed our own software implementation based on alternating minimization, which can be found at github.com/jhfung/Procrustes .
Acknowledgments. We thank Abby Hickok and Raul Rabadan for useful comments.
## 2. Background about manifold learning, topological data analysis, and Procrustes distance
Our algorithm uses as building blocks three fundamental concepts from geometric data analysis. The first building block is dimensionality reduction. Our algorithm takes as a black box a choice of dimensionality reduction algorithm. We use manifold learning for this purpose, and to be concrete, we will focus on Isomap, but many other manifold learning (or more general dimensionality reduction algorithms) could be used instead. Manifold learning seeks to find intrinsic coordinates on data that reflects the shape of the data. The second building block is persistent homology, which is the main invariant of topological data analysis (TDA). Persistent homology is a multiscale shape descriptor that provides qualitative shape information; we will use it to detect when coordinate charts are spread out and have contractible components. The third building block is the Procrustes distance, which is a matching distance for (partially defined) vector-valued functions on a given finite set. Computing the Procrustes distance involves computing an optimal alignment of the vectors; our algorithm uses both the distance as a metric and also the computation of the distance as an alignment algorithm.
The manifold learning algorithm takes a point cloud X ⊂ R N and produces an embedding X → R d for d ≪ N meant to retain the intrinsic relationship between the points of X . Specifically, for Isomap, the procedure is as follows. Given a point cloud X ⊂ R N and a scale parameter ϵ > 0 (or a nearest neighbor limit ℓ ), we form the weighted graph G with vertex set labelled by the points X and an edge of weight ∥ x -x ′ ∥ when ∥ x -x ′ ∥ < ϵ (or when x ′ is one of the ℓ closest points to x ). The graph metric on G now provides a new metric on the point cloud X . Finally, we use MDS (multidimensional scaling) to embed this new metric space into R d , for d ≪ N . The intuition is that when the data X comes from a low dimensional manifold embedded in a high dimensional space, short paths in the ambient space
accurately reflect an intrinsic notion of nearness in the manifold. When the points X have been uniformly sampled from a convex subset of a manifold such that ϵ is sufficiently small relative to the curvature of the manifold and the injectivity radius of the embedding (which can be described in terms of the reach or condition number of the manifold), the coordinates produced by this procedure do approximate the intrinsic Riemannian metric on X .
Topological data analysis uses invariants from algebraic topology that encode qualitative shape information to give a picture of the intrinsic geometry of a point cloud. The q th homology of a topological space T is a vector space which encodes the q -dimensional holes in T ; for example, when q = 0 this is measuring the number of path-connected components of the space and when q = 1 it is counting the number of circles that are not filled in. Topological data analysis assigns to a point cloud a family of associated simplicial complexes, usually filtered by a varying feature scale parameter. The resulting algebraic invariant, persistent homology, captures the scales at which homological features appear and disappear. In the case when q = 0, the persistent homology is basically the single-linkage hierarchical clustering dendrogram. When q = 1, persistent homology measures the number of loops in the underlying graph of the data that cannot be filled in at each scale.
Since manifold learning only really makes sense for relatively evenly sampled points from subsets whose components are contractible (or in the case of Isomap, the stronger condition of being convex), we can use topological data analysis to measure how well the resulting chart appears to satisfy this condition. Specifically, a good chart will have a large cluster for each component in the PH 0 dendrogram and will have only very small (noise) loops in PH 1 .
The Procrustes distance we use comes from the Procrustes problem. In basic form, given two d × n matrices X and Y , thought of as two functions from { 1 , . . . , n } to R d , the Procrustes distance is the minimum of the ℓ 2 distances between the functions after applying an affine isometry g to one of them:
$$\mathcal { D } ( X, Y ) = \min _ { g } d ( g \cdot X, Y ) = \min _ { g } \left ( \sum _ { j = 1 } ^ { n } d ( g \cdot X ( j ), Y ( j ) ) ^ { 2 } \right ) ^ { 1 / 2 }.$$
More generally, we consider the case when X and Y are partially defined functions on { 1 , . . . , n } . If we let I X and I Y denote the subsets of { 1 , . . . , n } where X and Y (respectively) are defined, then the Procrustes distance is
$$\mathcal { D } ( X, Y ) = \min _ { g } \left ( \sum _ { j \in I _ { X } \cap I _ { Y } } d ( g \cdot X ( j ), Y ( j ) ) ^ { 2 } \right ) ^ { 1 / 2 }.$$
The algorithm for calculating D finds an affine isometry g minimizing the distance; we review it in Section 4. We note that in the partially defined case, the resulting Procrustes distance D is not a metric; however, for functions with substantial overlap in domain, it does provide a measure of dissimilarity on their overlap.
Our algorithm uses a generalization of the Procrustes distance algorithm to search for optimal rotations to align different embeddings. The algorithm for two matrices always finds an optimal rotation (and therefore accurately calculates the Procrustes distance) and in principle gives an exact solution. The algorithm to align more than two matrices is an iterative optimization procedure, which always
converges, and appears to generically converge to the optimal solution, but is not guaranteed to converge to it.
## 3. The algorithm
This section defines the basic algorithm we propose in this paper. It admits several choices of blackbox subroutines and tolerance parameters. The first major blackbox subroutine is a procedure DimRed for dimensionality reduction: for X ⊂ R N produces an embedding X → R d (where d ≪ N ). We let Θ denote the collection of parameters controlling the behavior of the dimensionality reduction procedure. For sake of discussion, we take the procedure to be Isomap, which has parameter the neighborhood size ϵ .
A second major blackbox subroutine is a sampling procedure Samp that generates random subsamples Y ⊆ X of a given size n . Typically, we draw Y i uniformly and independently without replacement from X .
A third major blackbox subroutine is a procedure Param that chooses the parameter Θ for DimRed . In the case of Isomap, typically we take the parameter over a mesh of reasonable values.
The final major blackbox subroutine is a clustering algorithm Clust for finite sets with dissimilarity measures.
We describe the various minor parameters controlling the number of iterations, tolerances for certain optimization procedures, number of subsamples, etc., as they occur below.
Given the parameter choices, the input to the algorithm is a point cloud
$$X = \{ X ( j ) \ | \ j = 1, \dots, n \} \subset \mathbb { R } ^ { N }.$$
Step 1. We use Samp to generate many subsamples { Y a } and apply DimRed with parameter settings from Param to produce embeddings ϕ a,b : Y a → R d . Let X a,b be the subset of R d specified by the image, where the elements of each subsample configuration X a,b inherit the indexing of original data set X . That is, each X a,b is indexed by the subset of { 1 , . . . , n } corresponding to the points of X represented in the subsample Y a .
Step 2. We calculate the pairwise distances between the images X a,b using the Procrustes distance to define a dissimilarity measure on the set of subsample configurations { X a,b } a pseudo-metric space.
## Step 3. We use Clust to form clusters.
Step 4. Choose a distinguished cluster (the 'good cluster') from among these as follows.
- · We discard clusters whose median inter-point distance is above a certain tolerance (a minor parameter of the algorithm). We refer to the remaining clusters as 'dense clusters'.
- · For each dense cluster we select random elements in the cluster (the number or percentage size of the selection a minor parameter of the algorithm) on which to calculate the persistent homology PH 1 and essential dimensionality (number of singular values above given tolerance).
- · We discard dense clusters where a selected element has essential dimensionality less than d , and then we choose the good cluster to be the one that minimizes the maximum length of bars in PH 1 .
- · If there are no remaining clusters or the maximum length of bars in PH 1 is above a certain tolerance (a minor parameter of the algorithm), we terminate with an error.
Step 5. We discard all the subsets X a,b not in the good cluster, and singularly reindex the subsets in the good cluster X i = X a ,b i i for i = 1 , . . . , k (with k the number of X a,b in the good cluster).
↦
Step 6. We align the embeddings X i by applying an affine isometry X j i ( ) → Q X i i ( j ) + v i to each point X j i ( ) in X i (for the indices j ∈ { 1 , . . . , n } that occur in X i ) where Q i is a d × d orthogonal matrix and v i is a vector in R d , chosen by the alternating least squares method described in Section 4.
Output. The final output is an appropriate average of the aligned embeddings as follows. For each point X j ( ) in X j ( = 1 , . . . , n ):
- · If no X i includes a j th point, then the j th point is omitted from the final embedding; otherwise,
- · The final embedding has j th point the average in R d of the j th points of the X i which have j th points,
$$\bar { X } ( j ) = \frac { 1 } { s } ( X _ { i _ { 1 } } ( j ) + \cdots + X _ { i _ { s } } ( j ) ).$$
- · We also output a list of 'outliers' that consists of the omitted indices, the indices that did not have points in any of the embeddings X i chosen to produce the final average.
## 4. A review of the Procrustes problem
Our main ingredient for averaging coordinates is posing the averaging in terms of the so-called Procrustes problem , an alignment problem that has been studied extensively in the psychometrics literature. The material in this section distills the discussion in [5, 9, 6].
The standard orthogonal and affine orthogonal Procrustes problem. In its most standard form, given two matrices X,Y of the same shape, this problem is a matrix approximation problem that aims at finding the best orthogonal matrix that matches X to Y :
$$Q _ { \min } = \underset { Q \text{ s.t. } Q ^ { T } Q = 1 } { \arg \min } \| Q X - Y \| _ { F },$$
where ∥·∥ F denotes the Frobenius norm (the square root of the sum of the squares of the entries). By interpreting Q min as an isometry (in Euclidean space), and X,Y as point clouds (each column representing a point), the standard Procrustes problem can thus be seen as an alignment problem which aims at finding the best orthogonal transformation that transports the point cloud X closest to the point cloud Y in terms of the sum of pointwise distances. In practice, it can reformulated as finding the best orthogonal matrix Q min approximating the given matrix Y X T , and proved to be efficiently solved by computing the SVD of
(with U and V orthogonal and Σ non-negative diagonal) and taking Q min = UV T . If we allow the more general affine isometries (that allow a translation component), it is easy to check that
$$\Omega _ { \min } & = \underset { \Omega \in \mathcal { A } f f ( d ) } { \arg \min } \| \Omega X - Y \| _ { F },$$
is given by the affine isometry
$$\Omega _ { \min } x = Q ( x - a ) + b = Q x + ( b - Q a )$$
where a is the centroid (mean) of X b , is the centroid of Y , and Q is the orthogonal matrix Q min that solves equation (4.1) for the matrices X -1 a and Y -1 b (where 1 is the 1 × n matrix of 1s: the matrices X -1 a and Y -1 b are the translations of X and Y to be centered on the origin.)
In the notation of Section 2, the Procrustes distance D ( X,Y ) from X to Y is then
$$\mathcal { D } ( X, Y ) = \| \Omega _ { \min } X - Y \| _ { F }.$$
As discussed in Section 2, we need to consider the more general case when the matrices are missing columns; we refer to this as the missing points case. Viewing d × n matrices as functions { 1 , . . . , n } to R d , the missing points case is when we have partially defined functions X and Y from { 1 , . . . , n } to R d ; that is X and Y are functions from subsets I X and I Y of { 1 , . . . , n } to R d . Let I be the natural reindexing of the intersection of the domains I X ∩ I Y . Then the Procrustes distance D ( X,Y ) as defined in Section 2 is calculated by the formula
$$\mathcal { D } ( X, Y ) = \| \Omega _ { \min } X _ { I } - Y _ { I } \| _ { F }$$
where Ω min solves (4.2) for the matrices X I , Y I (the matrices obtained by restricting X and Y to I X ∩ I Y ).
Background on the generalized Procrustes problem. The formulation of the Procrustes problem in the previous subsection involved only 2 matrices or matrices missing points (partially defined functions). In this subsection, we begin the discussion of the problem for multiple matrices. We then generalize to the missing points case and discuss algorithms in the following subsections.
We begin with some notation. Let X ,X ,...,X 1 2 k be a collection of k point clouds, each containing n ordered points in R d . We can represent each X i as a d × n matrix, and denote the collection of such by X = ( X i ). The allowable transformations will be drawn from a group G , which we generally take to be the group of linear isometries (orthogonal transformations) or affine isometries of R d . We write g i ∈ G for the transformation that will be applied to the i th point cloud X i , and g = ( g i ) for the collection of them.
Definition 4.3. The generalized Procrustes problem is the following: given X , a set of k input configurations of n points in R d and group G acting continuously on R d , determine the optimal transformations g and configuration Z that minimizes the loss functional
$$\mathcal { E } ( \mathbf X, g, Z ) = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \| g _ { i } \cdot X _ { i } - Z \| _ { F } ^ { 2 } = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \sum _ { j = 1 } ^ { n } \| g _ { i } \cdot X _ { i } ( j ) - Z ( j ) \| ^ { 2 }$$
The existence of solutions to Procrustes problems in the groups we are interested in follows from simple considerations.
Proposition 4.4. If G is compact or the semi-direct product of a compact group and the translation group, then E achieves a global minimum.
The solution is never unique when G contains non-identity isometries of R d because for any X g , , Z , and any isometry h ∈ G , writing h g for ( hg i ), we have
$$\mathcal { E } ( \mathbf X, \mathbf g, Z ) = \mathcal { E } ( \mathbf X, h \mathbf g, h \cdot Z ).$$
In the case when G a subgroup of the isometries of R d , we can eliminate this trivial duplication of solutions by considering only solutions that have g 1 a fixed element of G , possibly depending on X . An obvious choice is to take g 1 to be the identity, but the choice we take below is to choose g 1 to be the translation that centers X 1 on 0 ∈ R d . The first fixed formulation of the generalized Procrustes problem (for G the group of affine isometries) is to find g , Z minimizing the loss functional and satisfying the further condition that g 1 is the translation that centers X 1 on 0 ∈ R d .
We now specialize to the case where G is the group of affine isometries A ff ( d ) (consisting of composites of translations, rotations, and reflections in R d ). We specify an element g of G by a d × d orthogonal matrix Q and a vector v , where for x ∈ R d ,
$$g \cdot x = Q x + v.$$
On a configuration X , viewed as a d × n matrix, the action is given by matrix multiplication and addition
$$g \cdot X = Q X + \mathbf 1 v$$
where 1 denotes the 1 × n matrix of 1s.
A key observation is that we can eliminate translations and Z as variables in the generalized Procrustes problem:
Proposition 4.5. For fixed X , the minimum value of E ( X g , , Z ) occurs at elements g , Z where the centroid of each g X i i is the origin and each Z j ( ) is the average of X j i ( ) ,
$$Z ( j ) = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } g _ { i } \cdot X _ { i } ( j ).$$
̸
↦
Proof. We begin with the translation part. For fixed X g , , Z , let q ∈ 1 , . . . , k , let v ∈ R d , and consider the path g ( ) in t G k where g i ( ) = t g i for i = q , and g q ( ) is t the composite of g q followed by the translation x → x + tv . Then
$$\frac { d } { d t } \Big | _ { t = 0 } ^ { \mathcal { E } } ( \mathbf X, \mathbf g ( t ), Z ) & = \frac { 2 } { k } \sum _ { i = 1 } ^ { k } \sum _ { j = 1 } ^ { n } \Big ( ( g _ { i } \cdot X _ { i } ( j ) - Z ( j ) ) \cdot \frac { d } { d t } \Big | _ { t = 0 } ^ { \mathcal { E } } ( g _ { i } ( t ) \cdot X _ { i } ( j ) - Z ( j ) ) \Big ) \\ & = \frac { 2 } { k } \sum _ { j = 1 } ^ { n } ( g _ { q } \cdot X _ { q } ( j ) - Z ( j ) ) \cdot v.$$
$$j = 1$$
If g , Z gives a minimum for E ( X g , , Z ) then this derivative must be zero for every q and v , which implies that
$$\sum _ { j = 1 } ^ { n } Z ( j ) = \sum _ { j = 1 } ^ { n } g _ { q } \cdot X _ { q } ( j )$$
for all q , and so all the g i · X i and Z must have the same centroid. Thus, the minimum can only occur for a g i that centers X i on the centroid of Z . In the first fixed formulation, the common centroid of Z and the X i is then the origin. More
generally, taking advantage of the symmetry of the problem as a whole, given a solution g , Z , there exists a solution with the common centroid at the origin by applying an appropriate translation.
̸
To eliminate Z as a variable, if we keep g fixed and for some r ∈ 1 , . . . , n , let Z t be the path with Z t ( j ) = Z j ( ) for j = r and Z t ( r ) = Z j ( ) + tv , we then have
$$\infty \, \text{and} \, \text{and} \, \text{$r_{t} \downarrow} - \varepsilon \downarrow \downarrow \, \text{$v$} \, \text{$v$} \, \text{$v$} \, \text{and} \, \text{$v$} \, \text{$v$} \, \text{$v$} \, \text{$v$} \, \text{and} \, \text{save} \\ \frac { d } { d t } \Big | _ { t = 0 } \mathcal { E } ( \mathbf X, \mathbf g, Z _ { t } ) & = \frac { 2 } { k } \sum _ { i = 1 } ^ { k } \sum _ { j = 1 } ^ { n } \Big ( ( g _ { i } \cdot X _ { i } ( j ) - Z ( j ) ) \cdot \frac { d } { d t } \Big | _ { t = 0 } ( g _ { i } \cdot X _ { i } ( j ) - Z _ { t } ( j ) ) \Big ) \\ & = \frac { 2 } { k } \sum _ { i = 1 } ^ { k } ( g _ { i } \cdot X _ { i } ( r ) - Z ( r ) ) \cdot v. \\ \text{In the case when} \, \text{$z$} \, Z \text{ gives a minimum for the loss functional. we then conclude}$$
In the case when g , Z gives a minimum for the loss functional, we then conclude
$$Z ( r ) = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } g _ { i } \cdot X _ { i } ( r )$$
for all r . The minimum can only occur when Z j ( ) is the average over i of the g i · X j i ( ). □
By Proposition 4.5, we do not need to search over the space of Z and we can restrict to searching for the orthogonal transformation part of the g i . This leads to the centered formulation of the problem.
Definition 4.6. The centered formulation of the generalized Procrustes problem for the group of affine isometries is the following: given X , a set of k input configurations of n points in R d whose centroids are the origin, determine the optimal orthogonal transformations Q = ( Q i ) ∈ O d ( ) n that minimize the loss functional
$$\mathcal { E } ( \mathbf X, \mathbf Q ) = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \| Q _ { i } X _ { i } - Z \| _ { F } ^ { 2 } = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \sum _ { j = 1 } ^ { n } \| Q _ { i } X _ { i } ( j ) - Z ( j ) \| ^ { 2 }$$
where Z j ( ) = 1 k ∑ Q X i i ( j ).
There is always a solution with Q 1 = Id; the centered first fixed formulation is to find the optimal Q subject to the restriction that Q 1 = Id.
In the centered formulation, because Z is the mean of the Q X i i , we can rewrite the loss functional in the following form, which is sometimes more convenient:
$$\mathcal { E } ( \mathbf X, \mathbf Q ) & = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } ( \| Q _ { i } X _ { i } \| _ { F } ^ { 2 } - \| Z \| _ { F } ^ { 2 } ).$$
Expanding out the definition of Z , this is then:
$$\mathcal { E } ( \mathbf X, \mathbf Q ) = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \left ( \| Q _ { i } X _ { i } \| _ { F } ^ { 2 } - \| \frac { 1 } { k } \sum _ { i = 1 } ^ { k } Q _ { i } X _ { i } \| _ { F } ^ { 2 } \right ).$$
The alternating least squares (ALS) method for the generalized Procrustes problem. The background in the previous subsection suggests the following algorithm for searching for the solution to the generalized Procrustes problem for the group of affine isometries. In the centered formulation, we iteratively use the 2 matrix Procrustes problem solution applied to X i and Z , to get better and better matches between each Q X i i and the mean of the Q X i i . For the non-centered
formulation, we first reduce to the centered formulation by translating the original configurations to be centered on the origin.
We state the algorithm in the centered formulation, where we are given the input configurations X , where we assume each X i is centered on the origin, and we search for the orthogonal matrices Q minimizing the loss functional E of Definition 4.6. We assume a small number tol as a pre-selected tolerance for termination and a large integer max iter for a maximum number of iterations.
## Algorithm (Basic ALS method) .
Step 0. Initialize Z = 1 k ∑ k i =1 X i .
Step 1. Set loss = E ( X Q , ).
Step 2. Use SVD to solve ZX T i = U i Σ i V T i (for i = 1 , . . . , k ) where U i , V i are orthogonal d × d matrices and Σ i is a non-negative diagonal matrix with diagonal entries in decreasing order.
Step 3. Update Z = 1 k ∑ k i =1 U V i T i X i .
Step 4. If | loss -E ( X Q , ) | ≥ tol and the number of iterations is less than max iter, iterate from Step 1. Else:
Step 5. Return ( U V i T i ) , Z .
We have written the algorithm to emphasize the concept; it admits many tweeks to increase efficiency, some of which are discussed after the final version of the algorithm in the next subsection.
For stability of output, we should find some normalization of the raw output. For the first fixed formulation, we look for a solution ( Q ,Z i ) with Q 1 = Id. Given the raw output ( Q ,Z i ) , we get a transformed output ( Q -1 1 Q ,Q i ) -1 1 Z with the same loss functional value but with the first orthogonal transformation the identity.
For empirical data where the different input configurations are not far from being rotations and translations of each other, this algorithm in practice converges to the solution to the generalized Procrustes problem. For independent Gaussian random input configurations, there are many local minima for the loss functional that are close to the absolute minimum, and this algorithm does not always find the transformations giving the absolute minimum, but does in practice find transformations with loss functional close to the minimum.
The algorithm above admits some obvious criticisms. First, while generically it does solve the Procrustes problem for 2 input configurations, there is a low dimensional space of inputs where the algorithm fails. For example, the algorithm fails when X 2 = -X 1 . The correct fix for this is not to apply this algorithm with fewer than 3 input configurations, and use the precise not iterative algorithm in that case. More subtly, if the input configurations are at a unstable critical point of the loss functional, the algorithm will terminate immediately and not find a minimum or local minimum. The fix for this is to require a minimum number of iterations before termination.
While this is the obvious algorithm based on the discussion above, ten Berge [5] does a deeper analysis of the generalized Procrustes problem and finds an algorithm that in practice appears to find transformations with smaller loss functional than the basic algorithm a large percentage of the time on inputs where the loss functional has a large number of local minima. The basic algorithm above implicitly uses the fact that when Q , Z solves the generalized Procrustes problem, then each Z Q X ( i i ) T is symmetric positive semi-definite (where we are writing Q i for U V i T i ). In terms
of the algorithm, this is the result of the iteration because at Step 3, we have
$$Z ( Q _ { i } X _ { i } ) ^ { T } = Z X _ { i } ^ { T } Q _ { i } ^ { T } = ( U _ { i } \Sigma _ { i } V _ { i } ^ { T } ) ( U _ { i } V _ { i } ^ { T } ) ^ { T } = U _ { i } \Sigma _ { i } U _ { i } ^ { T }.$$
However, a solution to the generalized Procrustes problem actually satisfies the more restrictive condition that ( Z -1 k Q X i i )( Q X i i ) T is symmetric positive semidefinite. This leads to the following more sophisticated algorithm.
## Algorithm (ALS method) .
Step 0. Initialize Q i = Id, Z = 1 k ∑ k i =1 X i .
Step 1. Set loss = E ( X Q , ).
Step 2. For i in 1 , . . . , k
- (a) Use SVD to solve ( Z -1 k Q X i i ) X T i = U i Σ i V T i for U i , V i orthogonal d × d matrices and Σ i a non-negative diagonal matrix with diagonal entries in decreasing order.
- (b) Update Q i = U V i T i
- (c) Update Z = 1 k ∑ k i =1 Q X i i .
Step 3. If | loss -E ( X Q , ) | ≥ tol and the number of iterations is less than max iter, iterate from Step 1. Else:
Step 4. Return ( Q ,Z i ) .
We note that in the case of 2 input configurations, this algorithm always finds the solution to the Procrustes problem (but does an extra step from the usual 2 input configuration algorithm).
Again, for stability, we should normalize the output, for example by replacing ( Q ,Z i ) with ( Q -1 1 Q ,Q i ) -1 1 Z .
The ALS method for the generalized Procrustes problem with missing points. In the context of missing points, the configurations X i only have elements of R d specified for some but not necessarily all indices { 1 , . . . , n } . It is still convenient to represent X i as a d × n matrix, where we fill in the zero column for the for the indices where X i is not defined. To keep track of which indices are defined in a manner conducive to easily expressed matrix operations, we let K i denote the n × n diagonal matrix which has diagonal entry 1 at the indices where X i is defined and 0 at the indices where X i is not defined. In this case, whenever X ′ i is any d × n that agrees with X i on the columns for which X i is defined, X i = X K ′ i i . (In other words, if we always work with X K i i , it does not matter how we fill in the columns where X i is not defined.) We assume that the configuration X i is non-empty, and therefore K i is not the zero matrix. We let n i denote the number of points in X i ; then 0 < n i ≤ n , and n i is the sum of the entries of K i .
Let K = ∑ k i =1 K i . Then K is a diagonal matrix and the diagonal entries indicate the number of configurations in which a particular index occurs. Without loss of generality, we can assume that none of these diagonal entries is zero: if it is, we can drop that index from consideration and reindex the problem as a whole. Then K is invertible and setting k j = K j,j , j = 1 , . . . , n , we have k j > 0.
In this regime, the mean of the configurations should be calculated at each index j = 1 , . . . , n using only the configurations in which that index appears:
$$Z ( j ) = \frac { 1 } { k _ { j } } \sum _ { i = 1 } ^ { k } ( X _ { i } K _ { i } ) ( j ) = ( \sum _ { i = 1 } ^ { k } X _ { i } K _ { i } K ^ { - 1 } ) ( j )$$
(where, generalizing the convention for the configurations X i , we are writing Y ( j ) for the j th column of an arbitrary d × n matrix Y ).
When some configurations are missing points, we can no longer center all the configurations at 0 and expect the mean to be centered at 0, and we can no longer work in the centered formulation. Specifying an affine isometry using a linear isometry Q and a translation vector v , the loss function for a particular choice of Q = ( Q , i ) v = ( v i ) becomes
$$\mathcal { E } ( X, \mathbf K, \mathbf Q, \mathbf v ) = \frac { 1 } { k } \sum _ { i = 1 } ^ { k } \| Q _ { i } ( X _ { i } + \mathbf 1 v _ { i } ) - Z \| _ { F } ^ { 2 }$$
where
$$Z = \sum _ { i = 1 } ^ { k } Q _ { i } ( X _ { i } + \mathbf 1 v _ { i } ) K _ { i } K ^ { - 1 }.$$
(Here as above 1 denotes the 1 × n matrix of 1s.)
The ALS algorithm also needs to be modified to account for translations, and since the output configurations may no longer be centered at 0, we should no longer ask for the input configurations to be centered at 0.
Algorithm (ALS method with missing points) .
Step 0 Initialize constants:
$$K = \sum _ { i = 1 } ^ { k } K _ { i }, n _ { i } = \sum _ { j = 1 } ^ { n } K _ { j, j }, a _ { i } = \frac { 1 } { n _ { i } } \sum _ { j = 1 } ^ { n } ( X _ { i } K _ { i } ) ( j )$$
and variables:
$$Q _ { i } = \text{Id}, v _ { i } = b _ { i } = 0 \in \mathbb { R } ^ { d }, Z = \sum _ { i = 1 } ^ { k } X _ { i } K _ { i } K ^ { - 1 }$$
Step 1 Set loss = E ( X K Q v , , , )
Step 2 For i in 1 , . . . , k
- (a) Update b i = 1 n i ∑ n j =1 ( ZK i )( j )
- (b) Use SVD to solve
$$( ( Z - \mathbf 1 b _ { i } ) K _ { i } - ( X _ { i } - \mathbf 1 a _ { i } ) K _ { i } K ^ { - 1 } ) ( Q _ { i } ( X _ { i } - \mathbf 1 a _ { i } ) K _ { i } ) ^ { T } = U _ { i } \Sigma _ { i } V _ { i } ^ { T }$$
for U i , V i orthogonal d × d matrices and Σ i a non-negative diagonal matrices with diagonal entries in decreasing order.
- (c) Update Q i = UV T , v i = b i -Q a i i
- (d) Update Z = ∑ k i =1 ( Q X i i + 1 v i ) K K i -1 .
Step 3. If | loss - E ( X K Q v , , , ) | ≥ tol and the number of iterations is less than max iter, iterate from Step 1. Else:
Step 4. Return ( Q , v i ) ( i ) , Z .
There are several obvious ways to improve the efficiency of this algorithm. We mention only a few of the most obvious as much will depend on the implementation of the libraries. Clearly several values should be stored rather than recomputed (including the loss functional E ( X K Q v , , , ), and the transformed configurations Q X i ( i + 1 v i ) K i ). Also, we should adjust the input so that the missing points in X i are represented by the zero column (to use X i in place of X K i i ) and is centered on zero (to use X i instead of ( X i -1 a i ) K i ). In the update of Z , it is more efficient
to subtract off the old value of Q X i ( i + 1 v i ) K K i -1 and add the new value rather than take the sum as written.
## 5. Behavior of the alternating least squares method
The purpose of this section is to describe what is known about the theoretical behavior of the alternating least squares (ALS) method to search for solutions to the generalized Procrustes problem, which is the last step in our main algorithm. We review the results about this step needed for understanding the robustness of the main algorithm.
There are three natural questions we address:
- (1) When does the ALS method converge to a local optimum?
- (2) When are the local optima isolated?
- (3) How much does the output change when the input data are perturbed?
All of these questions have reasonably satisfying answers more or less in the literature, as we now review. We discuss the case without missing points for simplicity of notation, but the missing points case works similarly.
Convergence of the ALS method. Standard considerations imply that iterations of the ALS method decrease the loss functional (4.7) monotonically. This implies that the algorithm always converges. However, examples can be produced where the ALS method outputs a centroid that does not locally minimize the constrained loss functional, at least in the case when we do not require the it to perform a minimum number of iterations. While such bad examples can be constructed by hand, our experiments and the long literature on the subject bears out the conjecture that generically the convergence is to a local minimum, and it seems to always converge to a local minimum when required to perform a reasonable minimum number of iterations. We conjecture that the bad examples form a low dimensional subspace of the space of all possible input data when the number of points in each configuration is larger than the dimension of the ambient Euclidean space.
As we explain below, up to a precision determined by the tolerance setting for the algorithm, the ALS method always converges to a critical point for the loss functional, constrained to the orbit of the original input configurations. In practice, we can check that the resulting point is a local minimum using the second derivative test. We give a formula for the second derivative of the constrained loss functional in the next subsection.
To see that the ALS method always converges to a critical point of the constrained loss functional, we use the following notation. After the s th iteration of the main loop, we have a set of orthogonal transformations that we denote here as Q [ s ] and a centroid for the transformed configurations that we denote here as Z [ s ] . We let X [ s ] denote the transformed configurations, X [ s ] i = Q [ s ] i X i . The ALS method then converges to X [ ∞ ] = X [max iter] , and we argue that for each i , the d × d matrix Z [ ∞ ] ( X [ ∞ ] i ) T is (approximately) symmetric: because Q [ s +1] is the solution to the classical orthogonal Procrustes problem for X i , Z [ s ] , we have that
$$( Z ^ { [ s ] } - \frac { 1 } { k } Q _ { i } ^ { [ s ] } X _ { i } ) ( Q _ { i } ^ { [ s + 1 ] } X _ { i } ) ^ { T }$$
is symmetric (as discussed in Section 4). This then implies that
$$( Z ^ { [ \infty ] } - \frac { 1 } { k } X _ { i } ^ { [ \infty ] } ) ( X _ { i } ^ { [ \infty ] } ) ^ { T } = ( Z ^ { [ \infty ] } - \frac { 1 } { k } Q _ { i } ^ { [ \infty ] } X _ { i } ) ( Q _ { i } ^ { [ \infty ] } X _ { i } ) ^ { T }$$
is (approximately) symmetric and since AA T is always symmetric, we have that Z [ ∞ ] ( X [ ∞ ] i ) T is (approximately) symmetric.
The critical points X for the constrained loss functional (4.8) are precisely the points where the d × d matrices ZX T i are symmetric for all i . To explain this, we calculate the derivative of the constrained loss functional. At any point X , the tangent space of the orbit (in the centered first fixed formulation) is canonically isomorphic to the product of k -1 copies of the tangent space of O d ( ), and so an element of this tangent space is specified by a choice of d × d anti-symmetric matrix A i for i = 2 , . . . , k . (To give uniform formulas, we set A 1 to be the d × d zero matrix.) Integrating along such an element gives the path in the orbit ( Q t X i ( ) i ) where Q t i ( ) = e A t i . If we write Z t ( ) for the centroid as a function of t , we then have
$$\frac { d } { d t } \Big | _ { t = 0 } \mathcal { E } ( \mathbf X, \mathbf Q ( t ) ) = - 2 k Z \cdot \Big ( \frac { d } { d t } \Big | _ { t = 0 } ^ { \ } Z ( t ) \Big ) = - 2 \sum _ { i = 2 } ^ { k } \sum _ { j = 1 } ^ { n } Z ( j ) \cdot A _ { i } X _ { i } ( j ).$$
For the derivative to vanish, we therefore must have
$$\sum _ { j = 1 } ^ { n } Z ( j ) \cdot A X _ { i } ( j ) = 0$$
for all i = 2 , . . . , k and all d × d anti-symmetric matrices A . Equivalently, for every anti-symmetric bilinear form Φ on R d , we must have
$$\sum _ { j = 1 } ^ { n } \Phi ( Z ( j ), X _ { i } ( j ) ) = 0$$
for all i = 2 , . . . , k , and this is equivalent to the requirement that the d × d matrices
$$\sum _ { j = 1 } ^ { n } Z ( j ) X _ { i } ( j ) ^ { T }$$
are symmetric for all i = 2 , . . . , k (which also implies ∑ j Z j X ( ) 1 ( j ) T is symmetric).
Isolation of the critical points. We cannot expect numerical stability of the limit of the ALS method unless the critical point it converges to is isolated. Numerical experiments indicate that the ALS method converges to a critical point with positive definite Hessian for the loss functional; mathematically, such points are always isolated local minima.
The Hessian can be calculated using the second derivative of the paths considered in the previous subsection. For Q i = e A t i , we get
$$\frac { d ^ { 2 } } { d t ^ { 2 } } \Big | _ { t = 0 } ^ { \mathcal { E } ( \mathbf X, \mathbf Q ( t ) ) } = - 2 \sum _ { j = 1 } ^ { n } \Big ( \frac { 1 } { k } \Big \| \sum _ { i = 2 } ^ { k } A _ { i } X _ { i } ( j ) \Big \| ^ { 2 } + Z ( j ) \cdot ( \sum _ { i = 2 } ^ { k } A _ { i } ^ { 2 } X _ { i } ( j ) ) \Big ).$$
For fixed X , defining a quadratic form q ( A ) by the formula above, the Hessian at X is given by the formula
$$H ( \mathbf A, \mathbf B ) = \frac { 1 } { 2 } ( q ( \mathbf A + \mathbf B ) - q ( \mathbf A ) - q ( \mathbf B ) ).$$
Choosing a basis for d × d anti-symmetric matrices, the Hessian becomes a symmetric ( k -1)( d -1)( d -2) / 2-dimensional square matrix. The quadratic form q is positive definite if and only if the resulting matrix has only positive eigenvalues.
Perturbation of the input data. The ALS method is stable in small perturbations of generic input data in the following sense: for any ϵ > 0 and for every point X in the data space with property that the d × d matrices ZX T i is non-singular for all i , there is a neighborhood around X (whose size depends on X ) where the ALS method converges to a point within ϵ of the limit X [max iter] for X . This stability is a consequence of two basic well-known stability results for the singular value decomposition, as we now explain.
The main result of [28, p. 2.1] studies stability of the solution of the orthogonal Procrustes problem. In our notation, it shows that when each point cloud X i and the pointwise mean Z are in general position, then for ϵ > 0 small enough, there is a neighborhood around the X i where the orthonormal matrix Q i solving the orthogonal Procrustes problem for X i and Z has Frobenius norm less than ϵ . The size of the neighborhood depends on the smallest two singular values of the ZX T i (which are non-zero under the non-singular hypotheses). We have control over the change in singular values under perturbations by Mirsky's theorem [29, § 2].
Putting these together and using the fact that when actually implemented, the ALS method has finitely many iterations, we can conclude stability as described above. While the theoretical bounds give very pessimistic estimates of the size of neighborhood of control, in practice we find experimentally that the ALS method is stable for perturbations roughly the same order of magnitude as ϵ . In the case when the point clouds are all isometric up to small perturbations, the stability increases and input perturbations of order ϵ give output perturbations of order ϵ 2 (see [27, p. 3.1] and the proof of [18, p. 6.1]).
## 6. Stability and robustness of the algorithm
Under reasonable hypotheses on the input data, with high probability, the algorithm has the following stability and robustness properties.
Stability in choice of subsamples. The algorithm is designed for data expected to approximate a contractible neighborhood of a manifold embedded in a high dimensional Euclidean space (or a disjoint union of such). When this is the case, with high probability a uniformly randomly chosen set of subsamples will have a unique good cluster, which is the restriction of a unique good cluster for the set of all subsamples [7]. The centroid of the unique cluster of the random subsamples will approximate the centroid of the unique good cluster for all subsamples in Procrustes distance.
Stability in presence of noise in data values. If the noise is small enough that it results in only a small distortion in the results of the dimensionality reduction algorithm, the stability of the Procrustes algorithm discussed in Section 5 combined with the stability in choice of subsamples implies that the resulting final embedding in the presence of small noise will be close in the Procrustes distance to the embedding that would have been produced in the absence of noise.
Robustness in presence of outliers. Tautologically, outliers that consistently distort the embeddings for any subsample containing them will not be in any of the subsamples in the unique good cluster. Thus, they will be identified as outliers by the algorithm and omitted from the final embedding. In some cases, the dimensionality reduction algorithm may still return good embeddings in the presence of a small number of outliers that are comparatively close to the rest of the points
of the subsample. When these embeddings are averaged with the relatively larger number of embeddings in the good cluster that do not contain the outliers, their overall contribution to the final embedding becomes small. Considering the two cases, we see that even with addition of a small number of outliers of any kind the output of the algorithm is a low-distortion embedding of the majority of the data that is close in Procrustes distance to the embedding that would be computed if the outliers were omitted.
Robustness in bad parameter choices. As in the case of sufficiently bad outliers, samples corresponding to parameter choices that result in distorted embeddings that are far from the unique good cluster will simply be discarded. As a consequence, the final output is generally insensitive to a small number of isolated bad parameter choices.
## 7. Synthetic experiments in manifold learning
This section describes some experiments with synthetic data. The first set of experiments (Subsections 7.1-7.4) validate the claim about robustness of the algorithm via numerical experiments. It uses the familiar Swiss roll example. In this example, our hypotheses about the data set holds: namely it is a high(er) dimensional embedding of a contractible subspace of a low dimensional manifold (or a disjoint of such). Our algorithm consistently constructs a good 2-dimensional embedding even with the addition of significant noise, outliers, and parameter variation. The second example (Subsection 7.5) explores what happens when these hypotheses are violated, using an analysis of data lying on 'buckyballs', which are spherical and not contractible. This data does not admit a low-distortion embedding into R 2 and this can be seen in the intermediate steps of our procedure. Clustering the embeddings in Procrustes space reveals this failure and moreover allows us to analyze the structure of the collection of embeddings. These steps give clear indication that no good 2-dimensional embedding exists. Finally, we explore the use of our algorithm to handle data sets too large to analyze without subsampling (Subsection 7.6).
7.1. Robustness in the presence of ambient noise concentrated around the samples. This subsection describes a warmup experiment that illustrates the way that our algorithm corrects for some of the variation introduced by subsampling. In order to make this clearer, rather than simply subsampling noiseless data, we add noise to the subsamples . In principle this could model a situation in which we do not have access to the data except through noisy subsamples, but this is not a common use-case.
In this experiment we simulate making multiple noisy measurements on the same data set, which we use as our subsamples for our algorithm. We create a Swiss roll dataset with 2000 points. Then, we create 200 simulated noisy measurements by subsampling and injecting additive Gaussian noise to the subsamples. Unpacking the steps of our algorithm, the first step is to apply Isomap, and we see that there are two broad classes of resulting embeddings: one in which the Swiss roll is successfully unrolled into a sheet, and one in which the Swiss roll remains coiled up. See Figure 2. (This is what is expected; e.g., see [3].)
The next step in the algorithm is to calculate Procrustes distances between these embeddings. We have visualized the resulting graph using multidimensional scaling MDS) in Figure 3. The two types of embeddings roughly divide into two major
Figure 2. Some example outputs of Isomap applied to a noisy Swiss roll dataset.

clusters, one consisting of unrolled sheets and one consisting of coiled up sheets. The appearance of the two clusters indicate the lack of robustness in applying Isomap to the Swiss roll with the current level of added noise. We also observe that while most unrolled outputs are close together, the coiled versions can differ greatly among themselves. (The unrolled outputs form a dense cluster while the coiled outputs do not.) The next step in the algorithm is to calculate the persistent homology of each embedding to identify the cluster consisting of the embeddings that have only very small (noise) loops in PH 1 . This is precisely the cluster of the unrolled outputs.
The final step is to align and average the embeddings in the unrolled cluster. The final averaged embedding is illustrated in Figure 4.
7.2. Robustness in presence of ambient noise concentrated around the manifold. In this experiment we simulate sampling from a data set corrupted by ambient noise. We again create a Swiss roll dataset with 2000 points. Then, we inject additive Gaussian noise to this dataset, so that Isomap produces a corrupted coiled output when run on the whole data set. See Figure 5. When we randomly subsample this dataset to obtain 500 samples of 1000 points each, for almost all of these samples the result of Isomap is a coiled embedding; only a handful are unrolled into a sheet. See Figure 6.
The next step in the algorithm is to calculate Procrustes distances between these embeddings and cluster. In this case, there are many clusters, but calculating the persistent homology of each embedding identifies a dense cluster consisting of the embeddings that have only very small (noise) loops in PH 1 , in contrast to most of the clusters which are diffuse and have significant loops in PH 1 . See Figure 7.
Finally, we align and average the embeddings in the unrolled cluster. The final averaged embedding is illustrated in Figure 8.
Figure 3. An MDS representation of the Procrustes distances between Isomap outputs of 200 noisy Swiss rolls: each point represents an output, and the plot is shaded according to density of the points. Some representative points are indicated together with their corresponding Isomap embedding.
Figure 4. The Procrustes-aligned Isomap embedding corresponding to the cluster of unrolled Swiss rolls.

7.3. Robustness in presence of outliers. In these experiments, we imagine a single dataset of measurements where one or more bad sample points ('outliers') are included. We work again with the Swiss roll. Even a single adversarial outlier can cause a short-circuit in the inferred connectivity of the manifold, and the resulting Isomap embedding will fail to unroll the Swiss roll. See Figure 9, parts a and b. When we randomly subsample this dataset to obtain 200 samples of 600 points each, most of these samples do not contain the outlier, and in these cases

- (a) The noisy swiss roll.
- (b) Isomap does not return the correct embedding.
Figure 5. Additive Gaussian noise in the ambient space.
Figure 6. All but a few of the subsamples result in coiled Isomap embeddings.

Isomap manages to unroll the Swiss roll. See Figure 9, part c. In some instances, Isomap unrolls the roll even if the outlier is included in the subsample if the other non-outlier points involved in the short-circuiting are omitted. Finally, we align all the outputs in the good cluster and compute the centroid: the result is a successfully unrolled Swiss roll. See Figure 9, part d.
The previous experiment illustrates the need for some kind of robustification (in this case by taking subsamples) even in the presence of a single outlier. The next experiment studies the more expected case where there are multiple outliers. In this experiment, we add 100 (5%) outliers chosen uniformly from a bounding box. As in the single outlier case, we subsampled the dataset 200 times to obtain
(a) One of the few subsamples resulting in an unrolled coordinate chart.
(b) The persistence diagram has a single large class in PH 0 and no large classes in PH 1 .
(c) A generic subsample resulting in a coiled coordinate chart.
(d) The persistence diagram has a single large class in PH 0 but also has a very large class in PH 1 capturing the loop.
Figure 7. Comparing clusters in Procrustes space using persistent homology.
samples of size 600 and ran Isomap on these subsamples. With this many outliers, the coiled outputs are in the majority. We clustered the outputs and identified a cluster of uncoiled outputs using persistent homology. Then, we computed the Procrustes alignment and averaged over the subset of these good outputs, producing the expected unrolled Swiss roll. See Figure 10.
These experiments demonstrate that our procedure is robust to outliers, in the sense that the output in the presence of a small percentage of outliers is a lowdistortion unrolled embedding of the type we expect from Isomap applied to noiseless samples from the underlying manifold.
7.4. Parameter variation. All manifold learning algorithms have hyperparameters that have to be chosen by the practitioner. In the case of Isomap, there is a single parameter corresponding to neighborhood size that needs to be judiciously chosen in order to obtain good results. The next experiment illustrates that under
Figure 8. The Procrustes-aligned Isomap embedding corresponding to the cluster of unrolled Swiss rolls.

(a) Original data in 3D

(b) Isomap result
- (c) Isomap applied to subsamples
(d) Final aligned output
Figure 9. Robustifying the output of Isomap (single outlier case)
the hypothesis that the data represents a convex subset of a low dimensional manifold embedded in a higher dimensional manifold, we can detect a cluster of good parameters using our persistent homology methodology.
(a) Original data in 3D
(b) Isomap result
- (c) Isomap applied to subsamples
(d) Final aligned output
Figure 10. Many outliers
In this experiment, we apply Isomap to the 2000 point Swiss roll synthetic data set under a wide range of parameters. We have graphed the heatmap of Procrustes distances of the resulting embeddings in Figure 11. We see that at small radii, Isomap fails to find a good embedding because the points are not connected (these have high rank large bars in PH 0 ), whereas at large radii, the embeddings 'short circuit' in the normal direction of the manifold, leading to coiled representations (these have a large bar in PH 1 ). Between these extremes, there is a range of values that lead to good embeddings (with no large bars in PH 1 ). Moreover, these embeddings are close together in Procrustes distances. Within this range, we recover the expected unrolled embedding of the Swiss roll dataset. Furthermore, there is a sharp transition between unrolled and coiled up representations, as shown by the large Procrustes distance between each embedding in the unrolled cluster and each embedding in the coiled cluster. The figure illustrates four clusters in total: the first box shows the cluster of small radii; the next 19 boxes show the cluster of unrolled embeddings; the next single box shows a transitional embedding far from both the unrolled embeddings and the coiled embeddings; and finally, the last nine boxes show the cluster of coiled embeddings. A more careful analysis of the distances (which we omit here) reveals that they correspond to the size of the gap between sheets of the roll; this is closely related to the 'condition number' and reach of the manifold [23].
7.5. Detecting failure of embedding methodology. The next experiment studies a case contrary to the general hypothesis that the data comes from a convex subset of a low dimensional manifold. In this experiment, we use the vertices of buckminsterfullerene or 'buckyballs' for the basic data . A buckyball is a molecule consisting of 60 carbon atoms arranged on a sphere. Its bonds forms hexagonal and
Figure 11. The Procrustes distance matrix between Isomap outputs for varying neighborhood size parameters, increasing from left to right. The output embeddings are shown along the bottom, and the triangle heatmap shows the distances: the darker the color, the smaller the Procrustes distance. (To compare two outputs: intersect the 45 ◦ lines emanating from them to find the box on the heatmap illustrating their Procrustes distance.)

(a)
Original data in 3D
(b)
Isomap of subsamples
(c)
MDS embedding
Figure 12. Buckyball dataset
pentagonal rings resembling the surface of a soccer ball. See Figure 12, part a. As a proxy for the sphere S 2 , the positions of the atoms of a buckyball in 3D cannot be faithfully compressed down to two dimensions, unlike the unrolling of the Swiss roll.
We computed the Isomap outputs of 500 noisy buckyballs, and the Procrustes distances between them. See Figure 12, part b. We visualized these distances using MDS in Figure 12, part c; however, in this case the 2-dimensional rendering obscures rather than illuminates the geometric structure of the Procrustes graph of Isomap outputs (as we explain below). Nevertheless, it illustrates enough to show that unlike in the Swiss roll studies, there are no dense clusters of embeddings in this experiment, and so we cannot expect an averaging procedure to yield a reasonable result.
Figure 13. Persistence diagrams for the Procrustes graph of Isomap outputs for the buckyball dataset
Although not directly related to our algorithm, we can say more about the geometric structure of the Isomap outputs. We note that the typical output is approximately a flattened sphere : the dimensionality reduction algorithm is approximately linearly projecting the buckyball one dimension down. Thus, after centering the buckyball and the resulting Isomap output, we are led to consider the space V 2 ( R 3 ) of (orthonormal) 2-frames in R 3 , corresponding to the basis vectors in R 3 that span the plane we are projecting to. Procrustes alignment quotients out the isometries O (2) of this plane, and the Procrustes graph of outputs of Isomap on the buckyball dataset should approximate V 2 ( R 3 ) /O (2) = ∼ R P 2 , the real projective plane.
We can test the conclusion of this thought experiment using persistent homology. For the projective plane, using coefficient field F p , p prime,
$$H _ { 1 } ( \mathbb { R } P ^ { 2 } ; \mathbb { F } _ { p } ) \cong H _ { 2 } ( \mathbb { R } P ^ { 2 } ; \mathbb { F } _ { p } ) \cong \begin{cases} \mathbb { F } _ { 2 }, & \text{if $p=2$} \\ 0, & \text{if $p>2$}. \end{cases}$$
Computing the persistent homology for the point cloud consisting of the 500 Isomap outputs with the Procrustes metric with Ripser [31], we find persistent classes in PH 1 ( R P 2 ; F 2 ) and PH 2 ( R P 2 ; F 2 ), but not in PH ∗ ( R P 2 ; F p ) for p = 3 or 5. See Figure 13. In other words, the persistent homology signature of the Isomap outputs matches the prediction that the landscape of Isomap outputs at least homotopically is an approximation of R P 2 .
- 7.6. Divide and conquer for very large data sets. Manifold learning algorithms tend to have superlinear time complexity. This suggests that using a divideand-conquer approach on large datasets may result in time savings. The idea is the same as before: subsample the dataset, run the algorithm on the individual subsamples, and then use the Procrustes alignment to merge the results. A schematic of this process is shown in Figure 14.
## 8. Analysis of real data coming from single-cell genomics
The purpose of this section is to explore an application of our algorithm to real data. We use two data sets as examples where coordinates in dimensionalityreduced genomic space allows us to determine cell types. The first such data set comes from blood cells (PBMC) and the second from mouse neural tissue (Tabula muris). In these applications, in addition to Isomap, we use four other manifold learning (dimensionality reduction) algorithms: PCA, Laplacian eigenmaps, t-SNE,
Figure 14. Starting with a large dataset, repeatedly subsample the dataset to obtain multiple subsamples of smaller size (here the subsamples are indicated in red). Then, apply the manifold learning algorithm to each subsample and use the Procrustes alignment to average the resulting embeddings.

and UMAP. In each case, we look at coordinates resulting from applying just the dimensionality reduction algorithm ('base case') and our algorithm ('robustified case').
We see interesting new phenomena in these applications. For one thing, using the manifold learning algorithms PCA, Laplacian eigenmaps, and Isomap with our algorithm, we see a single large tight cluster in the Procrustes graph of the subsamples. However, unlike the charts for the synthetic Swiss roll examples, both the good and the bad embeddings have trivial PH 1 , our indicator for contractibility. Instead, what distinguishes the good from the bad embeddings is how evenly spread they are. We used embeddings in R 2 and the bad embeddings are ones concentrated along a single axis, being approximately one-dimensional, whereas the good embeddings have extent in both dimensions. For both theoretical and practical reasons (as explained in the discussion of the algorithm), the embeddings that are essentially one-dimensional need to be discarded.
On the other hand, using t-SNE and UMAP, the Procrustes graph of the subsamples are comparatively very spread out and form a single large but extremely spread out cluster, indicating that the averaging procedure in our algorithm cannot be expected to output reasonable coordinates. This dichotomy is not surprising since the PCA, Laplacian eigenmaps, and Isomap algorithms strive to perform global alignment of the local coordinates, whereas the t-SNE and UMAP algorithms are designed to separate local clusters. (This dichotomy of behavior is a topic of interest in the genomics methodology community, see for example [30] for a critical review of the use of these kinds of dimensionality reduction to produce pictures.)
8.1. 3k PBMCs scRNA-sequencing. The first dataset is a preprocessed version of single cell RNA-sequencing data from 3k peripheral blood mononuclear cells (PBMCs) from a healthy donor, made freely available by 10x Genomics. Comprised of cells from a variety of myeloid and lymphoid lineages, the dataset has rich cluster
and continuous structure, making it a useful dataset to benchmark new bioinformatic methods. It can be accessed using the scanpy Python package [35] via the following command:
## scanpy.datasets.pbmc3k processed
As is typical in the visualization of scRNA-sequencing data, PCA is used as a preliminary step prior to constructing the 2D embeddings: we reduce the raw data to the first 50 principal components. For the base case, we then applied each of the manifold learning algorithms to reduce the coordinates in R 50 to R 2 . For the robustified case, we take 50 subsamples of 500 cells, and proceed with our algorithm with each of the manifold learning algorithms used for dimensionality reduction from R 50 to R 2 .
Figure 15 shows the MDS plots of the Procrustes distances between the subsample embeddings along with histograms of those values under each of the five manifold learning algorithms. We can see that PCA, Laplacian eigenmaps, Isomap have much more concentrated Procrustes distances. And when we look at the MDS plot of the Procrustes distances, we see there are tight clusters of the embeddings, whereas the embeddings for t-SNE and UMAP are significantly more spread out (with a diameter over 4 times as large). The algorithm then proceeds for PCA, Laplacian eigenmaps, Isomap and terminates with an error of no remaining clusters for t-SNE and UMAP.
For PCA, Laplacian eigenmaps, Isomap we find that the main cluster has embeddings that are essentially two-dimensional; the outlying points are the embeddings that are essentially one-dimensional. In Figures 16 and 17 we plot the subsample embeddings for PCA and Isomap. (The relatively larger number of bad embeddings for PCA in Figure 16 versus Isomap in 17 is consistent with the larger number of embeddings outside the tight cluster as pictured in Figure 15.) We select the good cluster and apply averaging procedure to the subsample embeddings it contains. The output is robustified coordinates for PCA, Laplacian eigenmaps, and Isomap. This is illustrated in Figure 18 together with the embeddings obtained on the entire data set. In the figure, the data points are colored by cell type.
- 8.2. The mouse brain from Tabula muris. The second dataset is another single cell RNA-sequencing dataset, this time coming from the Tabula muris project [10], sequenced using the Smart-seq2 protocol, which we downsample to the 7,249 non-myeloid cells in the brain tissue sample. According to the provided cell type annotation, this sample contains a mixture of neurons as well as glial cells. We perform the same experimental protocol as above on the PBMC data set, and find similar conclusions, except that in this case Isomap gives a significantly more diffuse cluster in Procrustes space than PCA or Laplacian eigenmaps, and seems to give as poor a performance as t-SNE and UMAP. See figures 19 and 20.
## References
- [1] Jose Manuel Andrade et al. 'Procrustes rotation in analytical chemistry, a tutorial'. In: Chemometrics and Intelligent Laboratory Systems 72.2 (2004), pp. 123-132. doi : https://doi.org/10.1016/j.chemolab.2004.01.007 .
- [2] Angela Andreella and Livio Finos. 'Procrustes Analysis for High-Dimensional Data'. In: Psychometrika 87.4 (2022), pp. 1422-1438. doi : 10.1007/s11336022-09859-5 .
## REFERENCES
Figure 15. Procrustes distances between subsample embeddings for the PBMC dataset.
Figure 16. Subsample embeddings from PCA.

- [3] Mukund Balasubramanian and Eric L. Schwartz. 'The Isomap Algorithm and Topological Stability'. In: Science 295.5552 (2002), p. 7. doi : 10.1126/ science.295.5552.7a . url : https://www.science.org/doi/abs/10. 1126/science.295.5552.7a .
Figure 17. Subsample embeddings from Isomap.

Figure 18. Original and robustified embeddings for the PBMC dataset.
Figure 19. Procrustes distances between subsample embeddings for the TM dataset.
Figure 20. Original and robustified embeddings for the TM dataset.
- [4] Juan Antonio Balbuena, Raul Miguez-Lozano, and Isabel Blasco-Costa. 'PACo: A Novel Procrustes Application to Cophylogenetic Analysis'. In: PLOS ONE 8.4 (2013), pp. 1-15. doi : 10.1371/journal.pone.0061048 .
- [5] Jos M. F. ten Berge. 'Orthogonal Procrustes rotation for two or more matrices'. In: Psychometrika 42.2 (1977), pp. 267-276.
- [6] Jos M. F. ten Berge, Henk A. L. Kiers, and Jacques J. F. Commandeur. 'Orthogonal Procrustes rotation for matrices with missing values'. In: British J. Math. Statist. Psych. 46.1 (1993), pp. 119-134. issn : 0007-1102. doi : 10. 1111/j.2044-8317.1993.tb01005.x . url : https://doi.org/10.1111/j. 2044-8317.1993.tb01005.x .
- [7] Andrew J. Blumberg et al. 'Robust Statistics, Hypothesis Testing, and Confidence Intervals for Persistent Homology on Metric Measure Spaces'. In: Found. Comput. Math. 14.4 (2014), pp. 745-789.
- [8] Fred L. Bookstein. Morphometric Tools for Landmark Data: Geometry and Biology . Cambridge University Press, 1992. doi : 10.1017/CBO9780511573064 .
- [9] Jacques J. F. Commandeur. Matching configurations . DWSO Press, 1991.
- [10] The Tabula Muris Consortium. 'A single-cell transcriptomic atlas characterizes ageing tissues in the mouse'. In: Nature 583 (2020), pp. 590-595. doi : 10.1038/s41586-020-2496-1 .
- [11] Garmt Dijksterhuis. 'Multivariate data analysis in sensory and consumer science: an overview of developments'. In: Trends in Food Science & Technology 6.6 (1995), pp. 206-211. doi : 10.1016/S0924-2244(00)89056-1 .
- [12] C. A. Glasbey and K. V. Mardia. 'A review of image-warping methods'. In: Journal of Applied Statistics 25.2 (1998), pp. 155-171. doi : 10.1080/ 02664769823151 .
- [13] Colin Goodall. 'Procrustes Methods in the Statistical Analysis of Shape'. In: Journal of the Royal Statistical Society: Series B (Methodological) 53.2 (1991), pp. 285-321. doi : 10.1111/j.2517-6161.1991.tb01825.x .
- [14] J.C. Gower. 'Generalized Procrustes analysis'. In: Psychometrika 40.1 (1975), pp. 33-51. doi : 10.1007/BF02291478 .
- [15] John C. Gower and Garmt B. Dijksterhuis. 'Multivariate analysis of coffee images: A study in the simultaneous display of multivariate quantitative and qualitative variables for several assessors'. In: Quality and Quantity 28.2 (1994), pp. 165-184. doi : 10.1007/BF01102760 .
- [16] B.F. Green. 'The orthogonal approximation of an oblique structure in factor analysis'. In: Psychometrika 17.4 (1952), pp. 429-440. doi : 10.1007/ BF02288918 .
- [17] David G. Kendall. 'Shape Manifolds, Procrustean Metrics, and Complex Projective Spaces'. In: Bulletin of the London Mathematical Society 16.2 (1984), pp. 81-121. doi : 10.1112/blms/16.2.81 .
- [18] S. P. Langron and A. J. Collins. 'Perturbation Theory for Generalized Procrustes Analysis'. In: Journal of the Royal Statistical Society. Series B (Methodological) 47.2 (1985), pp. 277-284.
- [19] Jan de Leeuw and Jacqueline Meulman. 'A special jackknife for multidimensional scaling'. In: Journal of Classification 3.1 (1986), pp. 97-112. doi : 10.1007/BF01896814 .
| [20] | Francy Junio Gon¸alves c Lisboa et al. 'Much beyond Mantel: Bringing Pro- crustes Association Metric to the Plant and Soil Ecologist's Toolbox'. In: PLOS ONE 9.6 (2014), pp. 1-9. doi : 10.1371/journal.pone.0101238 . |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [21] | Rong Ma et al. 'Principled and interpretable alignability testing and integra- tion of single-cell data'. In: Proceedings of the National Academy of Sciences 121.10 (2024). doi : 10.1073/pnas.2313719121 . |
| [22] | A.D. McLachlan. 'A mathematical procedure for superimposing atomic coor- dinates of proteins'. In: Acta Crystallographica Section A 28.6 (1972), pp. 656- 657. doi : 10.1107/S0567739472001627 . |
| [23] | Partha Niyogi, Stephen Smale, and Shmuel Weinberger. 'Finding the Ho- mology of Submanifolds with High Confidence from Random Samples'. In: Discrete and Computational Geometry 39 (1 2008), pp. 419-441. |
| [24] | Michael B. Richman and Stephen J. Vermette. 'The use of Procrustes Target Analysis to discriminate dominant source regions of fine sulfur in the western U.S.A.' In: Atmospheric Environment. Part A. General Topics 27.4 (1993), pp. 475-481. doi : https://doi.org/10.1016/0960-1686(93)90205-D . |
| [25] | Peter H. Sch¨nemann. o 'A generalized solution of the orthogonal Procrustes problem'. In: Psychometrika 31.1 (1966), pp. 1-10. doi : 10.1007/BF02289451 |
| [26] | Peter H. Sch¨nemann o and Robert M. Carroll. 'Fitting one matrix to another under choice of a central dilation and a rigid motion'. In: Psychometrika 35.2 (1970), pp. 245-255. doi : 10.1007/BF02291266 . |
| [27] | Robin Sibson. 'Studies in the Robustness of Multidimensional Scaling: Per- turbational Analysis of Classical Scaling'. In: Journal of the Royal Statisti- cal Society. Series B (Methodological) 41.2 (1979), pp. 217-229. url : http: //www.jstor.org/stable/2985036 . |
| [28] | Inge S¨derkvist. o 'Perturbation analysis of the orthogonal Procrustes prob- lem'. In: BIT 33.4 (1993), pp. 687-694. issn : 0006-3835. doi : 10.1007/ BF01990543 . url : https://doi.org/10.1007/BF01990543 . |
| [29] | G. W. Stewart. 'Perturbation theory for the singular value decomposition'. UMIACS-TR-90-124. 1998. |
| [30] | Chari T. and Pachter L. 'The specious art of single-cell genomics'. In: PLoS Comput Biol 19.8 (2023). url : https://doi.org/10.1371/journal.pcbi. 1011288 . |
| [31] | Christopher Tralie, Nathaniel Saul, and Rann Bar-On. 'Ripser.py: A Lean Persistent Homology Library for Python'. In: The Journal of Open Source Software 3.29 (2018), p. 925. doi : 10.21105/joss.00925 . |
| [32] | Pauli Virtanen et al. 'SciPy 1.0: Fundamental Algorithms for Scientific Com- puting in Python'. In: Nature Methods 17 (2020), pp. 261-272. doi : 10.1038/ s41592-019-0686-2 . |
| [33] | Chang Wang and Sridhar Mahadevan. 'Manifold alignment using Procrustes analysis'. In: Proceedings of the 25th International Conference on Machine Learning . 2008, pp. 1120-1127. doi : 10.1145/1390156.1390297 . |
| [34] | Chaolong Wang et al. 'Comparing Spatial Maps of Human Population-Genetic Variation Using Procrustes Analysis'. In: Statistical Applications in Genetics and Molecular Biology 9.1 (2010). doi : doi:10.2202/1544-6115.1493 . |
| [35] | F. Alexander Wolf, Philipp Angerer, and Fabian J. Theis. 'SCANPY: large- scale single-cell gene expression analysis'. In: Genome Biology 19.15 (2018). doi : 10.1186/s13059-017-1382-0 . |
## REFERENCES
Irving Institute for Cancer Dynamics, Departments of Mathematics and Computer Science, Columbia University, NY
Email address : [email protected]
DataShape, Centre Inria d'Universit´ d'Azur, Biot, France e Email address : [email protected]
Department of Systems Biology, Columbia University, NY Email address : [email protected]
Department of Mathematics, Indiana University, IN
Email address : [email protected] | null | [
"Andrew J. Blumberg",
"Mathieu Carriere",
"Jun Hou Fung",
"Michael A. Mandell"
]
| 2024-08-02T16:37:33+00:00 | 2024-08-02T16:37:33+00:00 | [
"stat.ML",
"cs.CG",
"cs.LG"
]
| Resampling and averaging coordinates on data | We introduce algorithms for robustly computing intrinsic coordinates on point
clouds. Our approach relies on generating many candidate coordinates by
subsampling the data and varying hyperparameters of the embedding algorithm
(e.g., manifold learning). We then identify a subset of representative
embeddings by clustering the collection of candidate coordinates and using
shape descriptors from topological data analysis. The final output is the
embedding obtained as an average of the representative embeddings using
generalized Procrustes analysis. We validate our algorithm on both synthetic
data and experimental measurements from genomics, demonstrating robustness to
noise and outliers. |
2408.01380v1 | ## Coalitions of Large Language Models Increase the Robustness of AI Agents
Prattyush Mangal 1* , Carol Mak , 1 Theo Kanakis , 1 Timothy Donovan , 1 Dave Braines , 1 Edward Pyzer-Knapp
1
1* IBM Research, Europe (UK).
*Corresponding author(s). E-mail(s): [email protected]; [email protected];
## Abstract
The emergence of Large Language Models (LLMs) have fundamentally altered the way we interact with digital systems and have led to the pursuit of LLM powered AI agents to assist in daily workflows. LLMs, whilst powerful and capable of demonstrating some emergent properties, are not logical reasoners and often struggle to perform well at all sub-tasks carried out by an AI agent to plan and execute a workflow. While existing studies tackle this lack of proficiency by generalised pretraining at a huge scale or by specialised fine-tuning for tool use, we assess if a system comprising of a coalition of pretrained LLMs, each exhibiting specialised performance at individual sub-tasks, can match the performance of single model agents. The coalition of models approach showcases its potential for building robustness and reducing the operational costs of these AI agents by leveraging traits exhibited by specific models. Our findings demonstrate that fine-tuning can be mitigated by considering a coalition of pretrained models and believe that this approach can be applied to other non-agentic systems which utilise LLMs.
Keywords: Generative AI, Tool Use LLMs, Agents, Multi-Model
## 1 Introduction
Recent advances in AI methodologies, primarily driven by the emergence of Large Language Models (LLMs) [1-3] have fundamentally altered the way we interact with digital systems [4, 5]. This advance has coalesced with a longer, more deliberate set
Fig. 1 Timeline depicting major events in the utilisation of APIs.
of advances in the way that machines communicate through the internet to request and consume the output of, services - namely the development of the API (Figure 1) [6, 7]. Given the ubiquity of their utilisation, it is therefore natural to consider whether LLMs are able to provide utility to the construction, execution and analysis of workflows constructed of API calls.
LLMs, whilst powerful and capable of demonstrating some emergent properties, are not logical reasoners or planners [8]. However, we believe that through careful dissection and reasonably rich service description, there is a path to utility from which further advances can be built. It should be noted that throughout this work we use the term 'planning' loosely, to refer to the construction of useful workflows, verifiable through comparison to a gold standard, not the creative task of optimized planning, or indeed reasoning.
In this paper, we follow a decomposition approach to workflow construction, see Figure 2, in which tasks are first extracted from a natural language interaction, then compared to a catalogue of capabilities known to the agent. After services are identified, we then task the system with constructing correct (both in terms of content and semantics) payloads for these services (referred to as slot filling), which are then executed. Finally, the output from these services is then extracted and summarised into a natural language form, ready for consumption by the human agent. See Figure 3 for an example of the complete workflow.
In classical approaches the LLMs used have been singular pretrained models with a large amount of model parameters (GPT-like models) [9-11] or singular finetuned models specifically tuned for tool use tasks [12-15]. The systems built around these models make use of different prompting techniques such as ReACT [16], Chain of Thought [17], Plan-and-solve [18] although others have been developed [19, 20]. Whilst methodologies based around these approaches have had some successes they are subject to several limitations:
Fig. 2 Stages in a decomposed agentic workflow for API consumption as evaluated in this study.
Fig. 3 An overview of the workflow to answer intents and queries by orchestrating calls to external tools. Sub-tasks involve planning tool usage, slot filling tool parameters and summarising the collected information to form a final natural language response to the initial query. Each sub-task is assigned to different LLMs to achieve more accurate workflow executions. Example tasks allocated to LLMs are identified by blue prompts and LLM responses are identified by purple messages.
- 1. Specificity: Single model methods require a sufficiently general model to work across tasks, which requires either significant training or task specific tuning; both of which incur significant cost.
- 2. Disruption: Single model methods are prone to disruption by the development of newer models, which might require a different approach to prompt construction.
Fig. 4 Example test case from the ToolAlpaca test dataset requiring multiple finance domain APIs for task completion.
- 3. Cost: Models which are sufficiently general are likely to have large parameter counts, which are typically associated with large deployment requirements, and therefore costs.
We propose a system which allocates the tasks of service identification and discovery, slot filling, and response forming to different open-source models, to increase robustness and address these limitations. Through demonstration on the ToolAlpaca benchmark [13] we show that this coalition approach improves upon standards, reached through solely using commonly used base models. We also show that, surprisingly, this coalition approach can outperform a single model fine-tuning approach and hence avoids incurring any of the costs of fine-tuning - although we note that this result is likely not general and fine tuning models specifically for model-task pairs would allow for more transferable performance gains across a broader workflow composition spectrum.
## 2 Results
The most common approaches for building AI agent systems for processing complex workflows fit into two categories - pretraining models at a huge scale or relying on fine-tuning models to unlock tool use capabilities [9, 12-15]. In both cases, there are associated costs of data generation and compute resources to learn the new model parameters.
For evaluating whether a coalition of open-source pretrained (non-fine-tuned) models can be used in the AI agent domain in-place of fine-tuned models, we use the ToolAlpaca test set which contains 114 test cases requiring 11 real cloud based services. These services and their functionalities are well documented, span a variety of domains (such as geographical, aeronautical, finance and entertainment) and include tests of varying difficulty. An average 1 25 tools, (API endpoints) from the services, . are required per test case, offering a non-trivial challenge in tool planning. An example test case is shown in Figure 4.
Table 1 Candidate coalition is assessed against the ToolAlpaca system utilising the Vicuna-13b model and the fine-tuned ToolAlpaca-7B and ToolAlpaca-13B models. The overall procedural accuracy assesses how accurately the system and configuration plan tool usage and execute the tools with the right parameters. The response evaluation column reports on the similarity of the system's final response to human defined responses. The Cos metric represents a measure of the semantic textual similarity between the defined responses and the final response. RLPre, RLRec amd RLf measurements report on the similarity based on the RougeL metrics.
| Configuration | Planner Accuracy | Slot Filling Accuracy | Overall Procedural Accuracy | Response Evaluation |
|-------------------------------------------------------|--------------------|-------------------------|-------------------------------|-------------------------------------------------|
| Coalition of Open-Source Models (with best coalition) | 75.7% | 61.3 % | 58.6 % | Cos: 0.662 RLPre: 0.613 RLRec: 0.219 RLf: 0.286 |
| ToolAlpaca (using ToolAlpaca-7b model) | 82.6% | 54.1% | 45.6% | Cos: 0.681 RLPre: 0.610 RLRec: 0.232 RLf: 0.300 |
| ToolAlpaca (using ToolAlpaca-13b model) | 85.4 % | 57.3% | 48.2% | Cos: 0.725 RLPre: 0.635 RLRec: 0.264 RLf: 0.342 |
| ToolAlpaca (using Vicuna-13b model) | 64.5% | 48.4% | 13.2% | Cos: 0.644 RLPre: 0.541 RLRec: 0.238 RLf: 0.292 |
The developers of this test set also fine-tune the Vicuna-7B and Vicuna-13B models [13, 21] enabling a direct comparison of these fine-tuned models for tool use versus our coalition of non-fine-tuned models approach.
We utilise the ToolAlpaca [13] test set along with custom built datasets to show that models working together, in a coalition, are more accurate then models working singularly for all tasks. As a result we show that, AI agents utilising the coalition approach can be more robust, by being more accurate, then those reliant on a single model approach.
## 2.1 Coalitions of pretrained models outperform fine-tuned models
Using the evaluation criteria and metrics detailed in Section 4, Table 1 shows that a coalition of pretrained open-source models outperforms the fine-tuned ToolAlpaca 7B and 13B models. A system which utilises the coalition of general purpose models achieves an overall accuracy of 58.6%, beating the fine-tuned models by more than 10%, without incurring any of the costs associated with fine-tuning.
The gains in performance can be attributed to the fact that planning, slot filling and response forming tasks have been split in our system and can be assigned to different models, each exhibiting strengths in that specific task. This approach also allows for greater observability of the system enabling programmatic means for capturing and correcting generic hallucinations. An example of this is the ability to capture nonexistent tools in the generated plans and removing or replacing those steps with real
Table 2 Different coalition candidates are assessed against utilising single pretrained models for all tasks. The results identify that models working together for distributed tasks can outperform a single model being assigned all of the tasks. The overall procedural accuracy assesses how accurately the system and configuration plan tool usage and execute the tools with the right parameters. The response evaluation column reports on the similarity of the system's final response to human defined responses. The Cos metric represents a measure of the semantic textual similarity between the defined responses and the final response. RLPre, RLRec amd RLf measurements report on the similarity based on the RougeL metrics.
| Configuration | Planner Accuracy | Slot Filling Accuracy | Overall Procedural Accuracy | Response Evaluation |
|-----------------------------------------------------------------------------------------------|--------------------|-------------------------|-------------------------------|-------------------------------------------------|
| Coalition Planner: Mistral Executor: Mixtral JSON RAG: Flan Response Former: Mixtral | 75.7 % | 61.3 % | 58.6 % | Cos: 0.662 RLPre: 0.613 RLRec: 0.219 RLf: 0.286 |
| Coalition Planner: Llama 2 70B Chat Executor: Mixtral JSON RAG: Flan Response Former: Mixtral | 69.3% | 55.3% | 49.1% | Cos: 0.652 RLPre: 0.585 RLRec: 0.182 RLf: 0.245 |
| Non-Coalition Mistral for all LLM interactions | 75.7% | 56.1% | 53.5% | Cos: 0.662 RLPre: 0.598 RLRec: 0.178 RLf: 0.238 |
| Non-Coalition Mixtral for all LLM interactions | 70.2% | 60.5% | 54.3% | Cos: 0.650 RLPre: 0.572 RLRec: 0.204 RLf: 0.268 |
| Non-Coalition LLama 2 70B Chat for all LLM interactions | 69.3% | 49.1% | 43.0% | Cos: 0.676 RLPre: 0.625 RLRec: 0.144 RLf: 0.209 |
| Non-Coalition Codellama 34B for all LLM interactions | 60.5% | 51.8% | 45.6% | Cos: 0.612 RLPre: 0.520 RLRec: 0.231 RLf: 0.058 |
| Non-Coalition Flan for all LLM interactions | 29.8% | 6.1% | 3.5% | Cos: 0.459 RLPre: 0.343 RLRec: 0.242 RLf: 0.257 |
tools. In contrast, the fine-tuned models are challenged with performing well in each of these tasks independently without opportunities for intervention. We note that the fine-tuned models often fail to meet the requirements of the system or the prompt, triggering parsing errors and downstream failures.
Another major benefit of being able to utilise open-source pretrained models instead of fine-tuning models is that our system is able to plug and play newer, more performant models as they emerge in the community and leverage any improvements in capabilities to increase the accuracy of the overall agentic system.
## 2.2 Coalitions outperform using single models
In Table 2 we show that employing a coalition approach can improve upon using any model singularly. Using the Mistral [22] and Mixtral [23] models independently, for planning, slot filling and response forming the overall system achieves an accuracy of 53.5% and 54.3% respectively. When these models work in collaboration with each other, Mistral tasked with the tool planning and Mixtral tasked with slot filling, the overall system accuracy improves to 58.6%. Similarly, only using the Llama 2 70B Chat model [3] achieves an overall accuracy of 43%, brought down by its lack of accuracy in the slot filling task. But when Llama 2 is coupled with other models, in a coalition, the system improves its accuracy to 49.1% since the slot filling task can be offloaded to a model better suited to that task - validating the benefits of using a multi-model approach.
The Mistral, Mixtral and Llama 2 models all show good performance in the planning task. This could be attributed to the data they have been trained on, but could also be equally due to their model architectures. Each of these models utilitse Grouped Query Attention [24] which groups tokens and focuses attention to groups containing the most relevant information. This potentially helps the models focus better on important features by removing additional verbosity in the prompts and hence these models may be better equipped to handle planning problems.
The Mixtral model is built using a Mixture of Experts [23, 25] architecture and this may be the differentiating factor in its dominant performance at the slot filling task. In this architecture, the tokens are routed to specific experts at each layer. The Mixtral paper references that each of these experts may have developed specialisation to different domains, including specialisation for code, which may enable the model to perform better at slot filling as the model is being tasked with generating correctly formatted request payloads. The Mixtral model used in the coalition is a fine-tuned variant tuned for instruction following, enabling it to accurately respond to the slot filling prompts, following the specified response structure which again allows the system to process the model responses and capture hallucinations more easily, improving the accuracy of the overall system.
Taking advantage of the best model at planning (Mistral) and the best model at slot filling (Mixtral) we are able to gain a 'cost' free accuracy improvement as no additional development, resources or fine-tuning was required to realize this performance upgrade. This offers validation to the idea that allocating tasks to different models unlocks accuracy gains as specific models may be better in different domains. The next section investigates this further.
## 2.2.1 Specific models are better specific tasks
The LLM community has been competing to build the 'one model to rule them all'. But in this section we show that certain models exhibit traits, enabling them to perform better at specific tasks and we ask whether utilising multiple models in complex workflows can offer performance improvements beyond using the same, single, model for all tasks.
Fig. 5 Assessing different models for JSON RAG. The models have been assessed against a custom dataset to determine which model offers the best performance at the JSON RAG task which is applied to filter long JSON responses from tool executions. Flan UL2 20B model outperforms all other model choices at this task.
Flan UL2 [26] is not the best model by generalised metrics and benchmarks [27, 28]. But it outperforms all other models considered, at a very specific task we call JSON RAG. A common issue when using LLMs is the restriction of the context windows they can operate on. In the tool use domain, the responses of tools can be extremely large and often exceed these context windows. To overcome this problem, we devised a solution to filter and retrieve the meaningful contents from the JSON responses of the executed tools. This very specific approach is utilised in slot filling tool parameters following previous tool invocations and also by the response former to create a meaningful final response based on the responses of the executed tools. Using the evaluation strategy defined in 4.5, Figure 5 shows that the Flan UL2 model outperforms other larger and more capable models in this very particular task of JSON RAG.
The implementation of the JSON RAG task is very similar to what can be considered a denoising task where the model is asked to fill in masked tokens with tokens already presented in the prompt. An example of the JSON RAG task is demonstrated in Figure 12 . Investigating the architecture of the Flan UL2 model we note that the model has been built using a Mixture of Denoisers approach [26]. This potentially offers an explanation as to why this model exhibits considerable performance improvement over the other model candidates in the coalition.
Although Flan UL2 shines in the JSON RAG task, it does not perform well at others. Our coalition system makes use of critique prompting to improve upon the initial generated plans. This involves utilising another model to critique the plan generated by the model used for the planning task in an aim to remove hallucinations and generally improve the plans, an example of critiquing is demonstrated in Figure 13. Using
Fig. 6 Assessing plan critiquing capabilities by model and critique explicitness. The models have been assessed against a custom dataset to determine which model offers the best performance at the correction of generated plans and the level of explicitness a model requires to make that correction (General, assisted and explicit critique). Assisted critique refers to critique specific to the category of error such as critique based on ordering or too many steps, explicit critique provides exactly the correction to be made. For example specifying which steps need to be reordered or removed. General critique refers to an error agnostic critique message.
the evalation strategy defined in Section 4.5, Figures 6 and 7 show that Flan UL2 is easily the least effective model for critiquing and correcting plans.
For a model to be able to effectively critique complex plans it needs to be able to evoke exemplar reasoning and interactive linguistic capabilities. These capabilities are often acquired through fine-tuning or reinforcement learning with human feedback [20, 29], replicating reflection humans perform when assessing a chain of reasoning. The Mistral, Mixtral, Llama 2 70B and Codellama models assessed in this coalition, have all been fine-tuned for instruction following or for interactive, role-based prompting. These tuning efforts are missing from the Flan UL2 20B model, offering some insights as to why this model is the least accurate when tasked with critiquing generated plans.
Combining the facts that Flan UL2 is the best at JSON RAG and the worst at planner critiquing, we can conclude that the best way to build an accurate system, without requiring tuning, would be to utilise different models for these different tasks naturally identifying the benefit (and need in this case) for coalition based approaches for agentic systems.
Fig. 7 Assessing model ability to correct different types of plan failures. The models have been assessed against a custom dataset to determine which model offers the best performance at the correcting generated plans containing different categories of failures such as badly ordered plans, plans missing steps or plans containing too many steps.
## 2.3 Model specialisation leads to accuracy improvements and cost savings
The previous sections have demonstrated that allocating different tasks to different models can improve the performance and accuracy of the overall system. Our results also challenge the trend: 'bigger models are better models' [30]. Although Flan UL2 is a 20B parameter model which is much smaller then the Mixtral (45B), Codellama (34B) and Llama2 (70B) models [3, 23, 26, 31], the previous discussion showed that Flan UL2 can outperform these larger models at specific tasks.
Models with larger parameter counts, impose larger hosting costs since GPU requirements scale with the number of parameters [32] and larger hosting costs are passed onto end consumers through larger inference costs.
By splitting up tasks and using different models for the individual tasks, a system may be able to use smaller models to gain accuracy improvements while concurrently reducing the cost of the overall system. By recalling the relationship between inference cost with the model parameter count, in Figure 8 we see that while Flan UL2 is smaller then most of the other models (hence cheaper), it still outperforms the other models for the JSON RAG task.
Fig. 8 Assessing the effectiveness of a model for the JSON RAG task against the model's parameter count. The cost of inferencing scales with model parameter size as higher parameters require more GPU memory for hosting. The Flan UL2 model outperforms all other models for JSON RAG while being a mid sized model.
Similarly, utilising the coalition approach, when models exhibit similar performance for a specific task, the smallest model can be selected for that task, to cut expenses of the overall system. Considering the choice of model for the tool planning task, in Figure 9, Mistral, Mixtral and Llama2 show similar accuracy but since Mistral is so much smaller then the other two models, the coalition can utilise Mistral and operate with lower overheads.
Beyond an academic setting building a system which can benefit from these cost reductions, while maintaining system accuracy, will enable cheaper and faster pathways to productisation and utilisation.
## 3 Conclusion
In this paper we introduced a coalition approach, comprising only of open-source pretrained models, as an alternate methodology to fine-tuning, for LLM powered, tool use agents. This new approach utilises a carefully curated coalition of multiple models, where each sub-task in an agent workflow, is allocated to the best performing model.
This configuration allows us to choose the right model for the job and proves to be more robust, than using any single model (fine-tuned or not) for all tasks.
Since models are allocated specific tasks, we find that this unlocks the ability to plug and play models from a diverse selection, and utilise smaller models for certain tasks, reducing energy consumption and associated costs without trading off accuracy or performance.
We evaluate this coalition against the open-source ToolAlpaca dataset, focused on tool use agents, and show that agents using this coalition of open-source pretrained models are more accurate then agents reliant on single fine-tuned models.
Fig. 9 Assessing the effectiveness of a model for the planning task against the model's parameter count. The Mistral model exhibits the best performance and is the smallest of models considered, only using 7 billion parameters, making it the cheapest to use.
This work suggests that LLM system developers should consider whether using a multi-model approach can offer cost-savings and performance enhancements in their workflows. We conclude with a question for consideration in a future study: If a coalition of pretrained models can outperform a single fine-tuned model, can a coalition of fine-tuned models achieve state of the art performance?
## 4 Experimental
The ToolAlpaca test dataset was extended and utilised to measure the accuracy of the coalition based approach compared to single model approaches. The different evaluations featured comparing generated plans, tool parameters used and the final responses of the systems.
The evaluation criteria for these categories was adapted from that used by the ToolAlpaca study to reflect desired behaviour in these agentic systems.
## 4.1 Evaluating Planning
To evaluate the planning capabilities of the candidate systems and configurations, plans that matched expected, ground truth plans (which we refer to as golden plans), were considered as passes. Additionally, non-optimal plans which contained the golden plans as the final steps were marked as passes. This additional criterion was added as we believe the system should not be penalised for taking additional preliminary steps to perform data gathering and prefer non-optimal plans over those which use fewer steps but assume knowledge based on the pretraining of the model. For an example of this behaviour see Figure 10.
## Evaluating Planning
Fig. 11 Example of the slot filling evaluation criteria being met in case of query based parameters.
## 4.2 Evaluating Slot Filling (Parameter Inference)
For evaluating the slot filling capabilities of these systems we measured success based on whether the system inferred the required tool parameters. Since the ToolAlpaca test set makes use of some APIs which require query-based question answering tools, we also assess whether the generated query was semantically similar to the expected query by measuring the semantic textual similarity and thresholding against a high value. For an example see Figure 11.
## 4.3 Evaluating Procedural Accuracy
To measure the systems' procedural accuracy, we measured the number of cases which passed both, the planning and slot filling, evaluations. The overall procedural accuracy assesses how accurately a system and configuration is able to plan for tool use and execute the tools with the right parameters, successfully completing the desired workflow.
## 4.4 Evaluating System Responses
The response evaluation is used to examine the effectiveness of the final response. Here we report a mixture of Semantic Textual Similarity (STS) and RougeL metrics between the system responses and hand-crafted responses expected to be present in the final response. The STS measurement is performed by using the all-MiniLM-L6v2 model to retrieve embeddings for the expected and actual responses. This metric is represented in our results tables as the Cos metric. Similarly, the RougeL Precision, Recall and fMearure metrics are represented as RLPre, RLRec and RLf in our tables respectively.
Although a LLM-as-a-judge [33] evaluation approach, which utilises a LLM to assess the alignment of a candidate response to the expected response, is an emergent
## Evaluating JSON RAG
Fig. 12 Example of JSON RAG evaluation to select specific contents from a JSON response object from tool execution. In this example, the JSON RAG component is evaluated against its ability to select the country name, country leader and continent based on the given prompt.

## Evaluating Critiquing
Fig. 13 Example of critiquing evaluation with a missing step pollution and tests with varying levels of critiquing feedback to generate the golden plan.
strategy for evaluating system responses, we believe it lacks reproducibility, hence we have favoured the use of the STS and RougeL metrics instead. However, the response metrics should only be considered in partnership with the overall procedural accuracy metric to determine the best performing systems.
## 4.5 Evaluating JSON RAG and Critiquing
To evaluate the best model at JSON RAG, a custom dataset was built containing different prompts comprising different JSON contents to be processed. The evaluation assessed whether for a specific prompt/task, the model could select the relevant JSON fields. An example can be seen in Figure 12. The best performing model in this evaluation could then be selected to be used in the coalition.
To evaluate the best model at plan critiquing, a custom dataset was built containing polluted plans and each model is tasked with correcting the plans based on some feedback. The pollution categories are:
- · Ordering: Golden plans with the steps reordered.
- · Added Step: Golden plans with an unnecessary step added.
- · Missing Step: Golden plans with required steps removed.
- · Added Multiple Steps: Golden plans with many unnecessary steps added.
The model is presented these polluted plans and instructed with feedback to correct the plan. Each model is tested with 3 levels of critique to understand the type of critique they need to correct the pollution:
- · General Critique - A pollution agnostic, general comment such as Can this plan be simplified or improved? .
- · Explicit Critique -A pollution specific, explicit comment requesting the desired correction such as Reorder step 1 and 2 .
- · Assisted Critique - A pollution specific, general comment such as It seems like the plan has some steps in the wrong order, can the plan be corrected? .
An example of this evaluation can be seen in Figure 13. Given the polluted plans and the various levels of critique, the model which performs the best at correcting the most plans, with the greatest generality of critique can be chosen for the coalition.
## 5 Data availability
Supporting data for this manuscript is available via the link: https://doi.org/10.5281/zenodo.12924336.
## 6 Code availability
Implementation to demonstrate the topics covered in this work, as well as generated outputs used for quantitative analysis is available via the link: https://doi.org/10.5281/zenodo.12924336. The outcomes of this work can be reproduced using actively developed frameworks for autonomous agent development.
## 7 Acknowledgements
The authors would like to acknowledge the financial support of the Hartree National Centre for Digital Innovation - a collaboration between the Science and Technology Facilities Council and IBM.
## 8 Author contributions
E.P-K conceived the project and incepted the coalition methodology. P.M. T.K and T.D designed the system, developed the computational pipeline and the evaluation frameworks. P.M, C.M and D.B designed and graded the performance of the system against the open sourced benchmarks, contributing the insights and claims described. P.M, C.M, E.P-K and D.B wrote the manuscript.
## References
| [1] | Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) |
|-------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | Devlin, J., Chang, M.-W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018) |
| [3] | Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) |
| [4] | Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., et al.: A survey on large language model based autonomous agents. Frontiers of Computer Science Vol 18 (6), 186345 (2024) |
| [5] | Wu, Q., Bansal, G., Zhang, J., Wu, Y., Zhang, S., Zhu, E., Li, B., Jiang, L., Zhang, X., Wang, C.: Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155 (2023) |
| [6] | Fielding, R.T.: Architectural styles and the design of network-based software architectures. University of California, Irvine (2000) |
| [7] | Ofoeda, J., Boateng, R., Effah, J.: Application programming interface (api) research: A review of the past to inform the future. International Journal of Enterprise Information Systems (IJEIS) Vol 15 (3), 76-95 (2019) |
| [8] | Kambhampati, S., Valmeekam, K., Guan, L., Stechly, K., Verma, M., Bhambri, S., Saldyt, L., Murthy, A.: Llms can't plan, but can help planning in llm-modulo frameworks. arXiv preprint arXiv:2402.01817 (2024) |
| [9] | Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) |
| [10] | Song, Y., Xiong, W., Zhu, D., Li, C., Wang, K., Tian, Y., Li, S.: Restgpt: Con- necting large language models with real-world applications via restful apis. arXiv preprint arXiv:2306.06624 (2023) |
| [11] | LangChain-AI: OpenGPTs. GitHub (2024). https://github.com/langchain-ai/ opengpts |
| [12] | Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., et al.: Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789 (2023) |
| [13] | Tang, Q., Deng, Z., Lin, H., Han, X., Liang, Q., Sun, L.: ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases (2023) |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [14] | Schick, T., Dwivedi-Yu, J., Dess`, ı R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., Scialom, T.: Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems Vol 36 (2024) |
| [15] | Patil, S.G., Zhang, T., Wang, X., Gonzalez, J.E.: Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334 (2023) |
| [16] | Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022) |
| [17] | Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems Vol 35, 24824-24837 (2022) |
| [18] | Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R.K.-W., Lim, E.-P.: Plan- and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091 (2023) |
| [19] | Valmeekam, K., Marquez, M., Kambhampati, S.: Can large language models really improve by self-critiquing their own plans? arXiv preprint arXiv:2310.08118 (2023) |
| [20] | Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning. Advances in Neural Information Processing Systems Vol 36 (2024) |
| [21] | Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality (2023). https://lmsys. org/blog/2023-03-30-vicuna/ |
| [22] | Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D.d.l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al.: Mistral 7b. arXiv preprint arXiv:2310.06825 (2023) |
| [23] | Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., Casas, D.d.l., Hanna, E.B., Bressand, F., et al.: Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024) |
| [24] | Ainslie, J., Lee-Thorp, J., Jong, M., Zemlyanskiy, Y., Lebr´n, o F., Sanghai, S.: Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245 (2023) |
| [25] | Fedus, W., Dean, J., Zoph, B.: A review of sparse expert models in deep learning. arXiv preprint arXiv:2209.01667 (2022) |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [26] | Tay, Y., Dehghani, M., Tran, V.Q., Garcia, X., Wei, J., Wang, X., Chung, H.W., Shakeri, S., Bahri, D., Schuster, T., et al.: Ul2: Unifying language learning paradigms. arXiv preprint arXiv:2205.05131 (2022) |
| [27] | Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Stein- hardt, J.: Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020) |
| [28] | Multi-task Language Understanding on MMLUmodel performance (2024). https: //paperswithcode.com/sota/multi-task-language-understanding-on-mmlu |
| [29] | Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing systems Vol 35, 27730-27744 (2022) |
| [30] | Sevilla, J., Heim, L., Ho, A., Besiroglu, T., Hobbhahn, M., Villalobos, P.: Com- pute trends across three eras of machine learning. In: 2022 International Joint Conference on Neural Networks (IJCNN), pp. 1-8 (2022). IEEE |
| [31] | Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X.E., Adi, Y., Liu, J., Remez, T., Rapin, J., et al.: Codellama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023) |
| [32] | Gugger, S., Debut, L., Wolf, T., Schmid, P., Mueller, Z., Mangrulkar, S., Sun, M., Bossan, B.: Accelerate: Training and inference at scale made simple, efficient and adaptable. https://github.com/huggingface/accelerate (2022) |
| [33] | Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems Vol 36 (2024) | | null | [
"Prattyush Mangal",
"Carol Mak",
"Theo Kanakis",
"Timothy Donovan",
"Dave Braines",
"Edward Pyzer-Knapp"
]
| 2024-08-02T16:37:44+00:00 | 2024-08-02T16:37:44+00:00 | [
"cs.CL"
]
| Coalitions of Large Language Models Increase the Robustness of AI Agents | The emergence of Large Language Models (LLMs) have fundamentally altered the
way we interact with digital systems and have led to the pursuit of LLM powered
AI agents to assist in daily workflows. LLMs, whilst powerful and capable of
demonstrating some emergent properties, are not logical reasoners and often
struggle to perform well at all sub-tasks carried out by an AI agent to plan
and execute a workflow. While existing studies tackle this lack of proficiency
by generalised pretraining at a huge scale or by specialised fine-tuning for
tool use, we assess if a system comprising of a coalition of pretrained LLMs,
each exhibiting specialised performance at individual sub-tasks, can match the
performance of single model agents. The coalition of models approach showcases
its potential for building robustness and reducing the operational costs of
these AI agents by leveraging traits exhibited by specific models. Our findings
demonstrate that fine-tuning can be mitigated by considering a coalition of
pretrained models and believe that this approach can be applied to other
non-agentic systems which utilise LLMs. |
2408.01381v1 | ## Anderson localization of light by impurities in a solid transparent matrix
∗
S.E. Skipetrov
Univ. Grenoble Alpes, CNRS, LPMMC, 38000 Grenoble, France
## I.M. Sokolov †
Peter the Great St. Petersburg Polytechnic University, 195251 St. Petersburg, Russia (Dated: August 5, 2024)
A solid transparent medium with randomly positioned, immobile impurity atoms is a promising candidate for observation of Anderson localization of light in three dimensions. It can have low losses and allows for mitigation of the detrimental effect of longitudinal optical fields by an external magnetic field, but it has its own issues: thermal oscillations of atoms around their equilibrium positions and inhomogeneous broadening of atomic spectral lines due to random local electric fields. We show that these complications should not impede observation of Anderson localization of light in such materials. The thermal oscillations hardly affect light propagation whereas the inhomogeneous broadening can be compensated for by increasing the number density of impurity atoms.
Anderson localization-a complete halt of wave transport due to disorder [1]-turns out to be difficult [211] and likely even impossible [12] to reach for light in fully disordered three-dimensional (3D) dielectric media. Partially ordered structures such as disordered photonic crystals [13-15] or hyperuniform materials [16, 17] featuring a photonic band gap may be required to obtain spatially localized optical modes at frequencies near a band edge where the optical density of states is strongly suppressed. Metallic structures may be better suitable for observation of Anderson localization of light than dielectric ones [12, 18] although real metals suffer from significant losses that can make optical experiments difficult to conduct and interpret [18, 19].
Cold atoms exhibiting purely elastic, lossless scattering have been proposed as an alternative medium for observation of Anderson localization of light in 3D without relying on photonic band gap effects [20, 21]. However, longitudinal electric fields have been later predicted to prevent such an observation [22, 23]. A possible solution to this problem consists in placing the atoms in a strong external magnetic field that partially suppresses longitudinal fields [24, 25]. Theoretical work has predicted the expected signatures of Anderson localization for coherent laser light in optically thick and dense cold-atom ensembles placed in a strong external magnetic field: slowing down of the temporal decay of a transmitted pulse [26], enhanced fluctuations of scattered intensity [27], step-like profile of average intensity inside the atomic sample [28]. However, the experimental realization of these theoretical predictions is currently impeded by the following two main obstacles. First, it is difficult to prepare cold-atom samples that would be optically thick to ensure multiple scattering (size L > photon mean free path ℓ ) and, at the same time, sufficiently dense to reach Anderson localization (atomic number density ρ > λ -3 0 , where λ 0 is the resonance wavelength in the free space) [21, 29]. Second, experiments are necessarily performed at a low but finite temperature (typically, T ∼ 100 µ K [29, 30]) leading to residual motion of atoms that is likely to wash out interference phenomena in general and Anderson localization in particular [26, 31].
A transparent solid medium with impurity atoms or ions embedded at random locations is an alternative physical system described by the theoretical model of immobile point-like scattering centers (atoms or ions) developed in Refs. [22-26] and exhibiting the phenomenon of Anderson localization. Well-known examples of such materials are uranium glass (with U atoms in, e.g., oxide diuranate form as impurities) [32] and ruby (with Cr 3+ ions as impurities), for which the possibility of Anderson localization of optical excitations have been already evoked [33, 34]. Another example is the diamond crystal with multiple nitrogen-vacancy centers-a system with promising application in quantum information science [35, 36]. Such media have a number of advantages as compared to cold atomic gases as far as the observation of Anderson localization of light is concerned. On the one hand, they can be found in nature or fabricated without fundamental limitations on the medium size L or impurity number density ρ , so that the conditions L > ℓ and ρ > λ -3 0 can be readily fulfilled. On the other hand, experiments can be performed at room or, in any case, not-too-low temperature because impurities are fixed at their positions in the matrix and do not fly away. Two problems arise nevertheless in these systems. First, local electric fields induce position-dependent shifts of resonance frequencies of impurity atoms, driving them out of resonance with each other. Such an inhomogeneous broadening of the spectrum is expected to reduce the maximum achievable scattering strength, which may bring the system away from the Anderson localization regime. Second, the problem of atomic motion that is crucial in atomic gases, does not disappear completely here either: the solid matrix still allows for oscillations of impurity atoms about their equlibrium positions with an amplitude and a frequency determined by the temperature. At the first glance, such oscillations could be expected to be less detrimental for Anderson localization of light than the free atomic motion, but it is not clear to which degree. Thus, it is not clear a priori whether the replacement of free atomic motion by oscillations brought about by embedding the atoms in a solid host medium overweighs the detrimental impact of random local fields
due to the very same host medium and makes Anderson localization achievable under realistic conditions.
In the present Letter we analyze a theoretical model including both the oscillations of impurity atoms about their equilibrium positions and random frequency shifts of atomic energy levels. Our analysis predicts that Anderson localization of light should be achievable in random ensembles of impurity atoms embedded in a transparent solid host medium at finite temperatures. In particular, the fast but small-amplitude oscillations of impurity atoms around their equilibrium positions have virtually no effect on light propagation, in analogy with Dicke narrowing of Doppler broadened spectral lines in the presence of atomic collisions [37]. In contrast, the inhomogeneous broadening of atomic spectral lines does suppress scattering and makes Anderson localization more difficult to reach. However, this suppression can be compensated by increasing the number density of atoms, so that a photon mobility edge always exist, whatever the broadening.
We start with a standard Hamiltonial ˆ describing the H free electromagnetic field coupled with N identical twolevel atoms located at positions { r n } and having each a ground state | g ⟩ with energy E g and angular momentum J g = 0, three degenerate excited states | e m ⟩ , m = 0 , ± 1, with energy E e = E g + ℏ ω 0 and angular momentum J e = 1, and the dipole moment d e m g of the transition | g ⟩ → | e m ⟩ [38, 39]. Symmetry considerations impose | d e m g | = d independent of m . We follow the now wellknown procedure to eliminate field variables and obtain an effective non-Hermitian Hamiltonian ˆ H eff describing immobile atoms coupled by the quasi-resonant electromagnetic field [40, 41]. When the lifting of the degeneracy of the excited state by an external magnetic field B = B e z and the inhomogeneous broadening of atomic spectral lines ω n = ω 0 +∆ are included in the model, n the effective Hamiltonian is composed of N × N blocks of size 3 × 3 that in units of ℏ Γ 0 / 2 can be written as
$$\langle \tilde { H } _ { \text{eff} } \Big ) _ { n n ^ { \prime } } & = \left [ \left ( i - \frac { 2 \Delta _ { n } } { \Gamma _ { 0 } } \right ) 1 - \frac { 2 \Delta _ { B } } { \Gamma _ { 0 } } \begin{pmatrix} - 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 1 \end{pmatrix} \delta _ { n n ^ { \prime } } & \langle 1 \\ & - \frac { 6 \pi } { k _ { 0 } } ( 1 - \delta _ { n n ^ { \prime } } ) \hat { d } \hat { G } ( \mathbf r _ { n } - \mathbf r _ { n ^ { \prime } } ) \hat { d } ^ { \dagger } & \text{ where } \\ \text{when} \ \Lambda \ - \ \rangle \ - \ \rangle \ - D / k \ \text{is to } \mathbf r _ { \text{even} } \ \text{should} \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text` \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{is to } \ \text{\end{pmatrix}$$
where ∆ B = g µ e B B/ ℏ is the Zeeman shift, µ B is the Bohr magneton, g e is the Land´ e factor of the excited state, 1 is the 3 × 3 identity matrix,
$$\hat { G } ( { \mathbf r } ) = - \frac { e ^ { i k _ { 0 } r } } { 4 \pi r } \left [ P ( i k _ { 0 } r ) \mathbb { 1 } + Q ( i k _ { 0 } r ) \frac { { \mathbf r } \otimes { \mathbf r } } { r ^ { 2 } } \right ] \quad ( 2 ) \quad \text{a chi} \\ \text{under}$$
is the dyadic Green's function of Maxwell equations with k 0 = ω /c 0 = 2 π/λ 0 , P u ( ) = 1 -1 /u + 1 /u 2 , Q u ( ) = -1 + 3 /u -3 /u 2 , and the matrix
$$\hat { \mu } - \mathfrak { O } / u \, \, \text{am one matrix} \quad & \text{gat} \\ \hat { d } = \begin{pmatrix} 1 / \sqrt { 2 } & i / \sqrt { 2 } & 0 \\ 0 & 0 & 1 \\ - 1 / \sqrt { 2 } & i / \sqrt { 2 } & 0 \end{pmatrix} & \text{(3)} \quad & \text{Fig} \\ \text{par} \\ \text{Fir}.$$
converts the Green's tensor from the Cartesian coordinate basis to the so-called cyclic one [24, 42]. Following previous works [22-26], we restrict our consideration to states in which no more than one excitation (photon) is present in the system, which corresponds to the oneparticle setting suitable for discussing the Anderson localization phenomenon.
To study the optical transport through the system described by the Hamiltonian (1), we assume that the atomic sample has a shape of cylinder of radius R and height L ≪ R . If the sample is illuminated by a monochromatic plane wave E 0 ( r ) exp( -iωt ) = u 0 E 0 exp( ikz -iωt ) incident on its face z = 0, the vector β n = { β nm } of probability amplitudes for the atom n to be excited in a state | e m ⟩ obeys [31, 43, 44]
̸
$$\underset { \text{or} } { \text{ho-} } \underset { \text{or} } { \text{o} } \frac { \partial \beta _ { n } ( t ) } { \partial t } & = \left [ i \left ( \delta \omega - \Delta _ { n } \right ) - \frac { \Gamma _ { 0 } } { 2 } \right ] \beta _ { n } ( t ) + \frac { i d } { 2 \hslash } \hat { d } \mathbb { E } _ { 0 } ( \mathbf r _ { n } ) \\ \underset { \text{the} } { \text{m-} } \sin } & - i \frac { 3 \pi \Gamma _ { 0 } } { k _ { 0 } } \sum _ { n ^ { \prime } \neq n } ^ { N } \left [ \hat { d } \hat { G } ( \mathbf r _ { n } - \mathbf r _ { n ^ { \prime } } ) \hat { d } ^ { \dagger } \right ] \beta _ { n ^ { \prime } } ( t )$$
where δω = ω -ω m is the detuning of the incident light with respect to one of the Zeeman-shifted resonance frequencies ω m = ω 0 ± m ∆ , B m = ± 1. We model atomic motion as oscillations about random equilibrium positions r (0) n at a fixed frequency Ω: r nµ = r (0) nµ + A nµ cos(Ω t + φ nµ ), µ = x, y, z , with random, normally distributed amplitudes A nµ , ⟨ A nµ ⟩ = 0, ⟨ A 2 nµ ⟩ = A 2 , and phases φ nµ uniformly distributed between 0 and 2 π . Random frequency shifts ∆ n responsible for inhomogeneous broadening of atomic spectral lines are taken from a centered normal distribution with a variance ∆ . 2 0 We find the stationary solution of Eq. (4) and compute the electric field outside the atomic sample
$$\overset { \text{Id} } { \text{ic} } \underset { \text{el}, } { \text{E} } ( \mathbf r, t ) = \mathbf E _ { 0 } ( \mathbf r ) - 4 \pi d k _ { 0 } ^ { 2 } \sum _ { n = 1 } ^ { N } \hat { G } ( \mathbf r - \mathbf r _ { n } ) \hat { d } ^ { \dagger } \beta _ { n } ( t ) \quad ( 5 )$$
and the time-averaged transmission coefficient
$$\langle T \rangle = \frac { \Omega } { 2 \pi A | E _ { 0 } | ^ { 2 } } \left \langle \prod _ { 0 } ^ { 2 \pi / \Omega } d t \int d ^ { 2 } { \mathbf r } \, | { \mathbf E } ( { \mathbf r }, t ) | ^ { 2 } \right \rangle \quad ( 6 )$$
where the spatial integration is over a disk of area A = π R/ ( 2) 2 in a distant plane z = L +12 /k 0 and with a center on the z axis, angular brackets denote averaging over random sets of equilibrium positions { r (0) n } , amplitudes { A nµ } and phases { φ nµ } of atomic oscillations. The polarization of the incident light is set to be circular with a chirality required to excite the transition | g ⟩ → | e m ⟩ under study.
The dependence of the average dimensionless conductance ⟨ g ⟩ = ( k L 0 ) 2 ⟨ T ⟩ on L witnesses whether the propagation of light is diffusive ( ⟨ g ⟩ increases with L ) or Anderson localization takes place ( ⟨ g ⟩ decreases with L ) [45]. Figure 1 shows dependencies of ⟨ g ⟩ on L for several sets of parameters and leads us to several important conclusions. First, Fig. 1(a) illustrates that the impact of atomic oscillations is negligible in both diffusion (the upper blue and green lines) and localization (the lower red line) regimes
FIG. 1. Average dimensionless conductance ⟨ g ⟩ as a function of sample thickness L , for different parameters. Full circles result from full dynamic calculations taking into account fast oscillations of impurity atoms around random equilibrium positions with frequency Ω and amplitudes A nµ ∼ N (0 , A ), as well as random frequency shifts of impurity resonant frequencies ∆ n ∼ N (0 , ∆ ). 0 Solid lines are obtained by neglecting oscillations ( A = 0).
of propagation. This can be understood by analogy with the so-called Dicke effect that consists in narrowing of atomic spectral lines in the presence of inter-atomic collisions: when the mean free path of atoms between two collisions becomes much shorter than the wavelength of light, the atomic line width becomes insensitive to the Doppler effect [37]. In our case, oscillations of atoms replace their random displacements due to collisions, and the condition of insensitivity of our results to the oscillations becomes k A 0 ≪ 1. In the following, we assume that this condition is fulfilled and neglect atomic oscillations. Next, Fig. 1(b) shows that the destructive effect of inhomogeneous broadening on localization can be mitigated by increasing the atomic number density ρ and adjusting the detuning δω . In particular, whereas the lower (violet) line obtained in the absence of inhomogeneous broadening (∆ 0 = 0) decays with k L 0 for k L 0 ≳ 4 indicating Anderson localization, the upper (red) line obtained for exactly the same parameters except for ∆ 0 = 2Γ , 0 grows with k L 0 signaling that Anderson localization is suppressed by the inhomogeneous broadening. However, when we keep ∆ 0 constant and increase the atomic number density ρ adjusting the frequency detuning δω , the curve ⟨ g k L ( 0 ) ⟩ bends down and approaches the one in the absence of broadening [see the two intermediate green and blue curves in Fig. 1(b)]. Whereas increasing ρ may be difficult for cold-atom systems, it is not necessarily the same for solid-state samples with embedded impurities, which gives hope for observation of Anderson localization of light in such samples despite the inhomogeneous broadening phenomenon.
In addition to the dependence of dimensionless conductance on sample thickness, a signature of Anderson localization can be found in the dependence of the average atomic excitation ⟨| β n ( ) t | 2 ⟩ , with the averaging also over time t , on the depth z inside the sample [28], see Fig. 2. All curves in Fig. 2 correspond to atomic densities ρ for which Anderson localization is expected at δω/ Γ 0 = 0 8 for . ∆ 0 = 0 [24, 25]. We thus expect a
FIG. 2. Average profiles of atomic excitation inside a sample of thickness k L 0 = 12.
step-like (steep in the middle of the sample and flattened towards z = 0 and L ) profile of ⟨| β n ( ) t | 2 ⟩ illustrated by the brown curve in Fig. 2 [28]. However, it is clear that the three lower curves obtained for the same ρ and δω as the brown curve but in the presence of inhomogeneous broadening ∆ 0 ≥ 2, exhibit a roughly linear decay with z characteristic of photon diffusion [23, 28]. Thus, the inhomogeneous broadening suppresses Anderson localization. Nevertheless, similarly to what has been discussed in connection with Fig. 1, this suppression can be mitigated and even fully canceled by increasing ρ and adjusting δω , as clearly witnessed by the violet and black curves in Fig. 2 that exhibit the shape expected for Anderson localization.
To gain a systematic understanding of the impact of inhomogeneous broadening on Anderson localization, we consider random distributions of N ≫ 1 atoms in a sphere of diameter L and compute the complex eigenenergies E n of the effective Hamiltonian (1), ordered by their real parts, see Supplementary Information (SI) [46] for details. They define frequencies ω n = ω 0 -(Γ 0 / 2)Re E n and decay rates Γ n = Γ Im 0 E n of quaisimodes of the
FIG. 3. Localization phase diagram for light in a large ensemble of N ≫ 1 resonant scattering centers embedded in a solid matrix for six different values of inhomogeneous broadening ∆ 0 . β -function (approximated by a finite difference from numerical results for N = 8 and 16 × 10 ) is negative and eigenstates are localized in the regions of the phase plane shown in black, 3 whereas β > 0 and states are extended in the rest of the plane. Dashed lines show the mobility edge β = 0 predicted by our approximate analytic theory.
atomic system. Frequency-dependent Thouless conductance is defined as g Th ( ω ) = ⟨ 1 / Γ n ω ⟩ -1 / ω ⟨ n -ω n -1 ⟩ ω [22, 47] with averaging ⟨ . . . ⟩ ω over random realizations of atomic positions { r n } , frequency shifts { ∆ n } and, in addition, eigenenergies E n for which ω n fall inside a frequency interval of width Γ 0 around ω . To characterize the dependence of g Th on L , we compute β g ( Th ) = ∂ ln g Th /∂ ln( k L 0 ). β > 0 in the region of parameters for which quasimodes are extended in space whereas β < 0 for spatially localized eigenmodes [22, 45]. Figure 3 shows localization phase diagrams for light in the large ensemble of resonant scattering centers for different strengths of the inhomogeneous broadening ∆ . 0 For ∆ 0 = 0, Anderson localization is expected in a certain range of frequencies only when ρ/k 3 0 ≳ 0 1 [25]. . In agreement with our previous discussion, increasing ∆ 0 leads to a requirement of higher density to reach localization but does not fully suppress it. An additional illustration of this is provided by Fig. 4 that shows the minimum density at which Anderson localization takes place in our model at any frequency, as a function of ∆ . 0 The minimum density increases with ∆ 0 but remains finite.
A simple interpretation of results shown in Figs. 3 and 4 can be obtained by averaging the self-energy Σ( ω ) obtained in the independent scattering approximation (ISA) [48] over the normal distribution of resonance frequencies ω nm of individual atoms, see SI [46]. The variance of the distribution is assumed to be equal to a sum of ∆ 2 0 due to the random local electric fields and
FIG. 4. Minimum number density of impurity atoms ρ required for collective atomic states to be spatially localized in some frequency band, as a function of the magnitude of inhomogeneous broadening ∆ 0 (red disks with error bars). Grey shading shows the region of the parameter space in which all states are extended. Dashed line is the prediction of our approximate analytic theory.

a term ∼ ( ρ/k 3 0 ) 2 due to dipole-dipole interactions between nearby atoms [46]. This turns out to be a simple yet efficient way of taking into account the two effects otherwise neglected by ISA. We define the effective wave number k eff = Re √ k 2 0 -⟨ Σ( ω ) ⟩ and the scattering mean free path ℓ = 1 2Im / √ k 2 0 -⟨ Σ( ω ) ⟩ . The Ioffe-Regel criterion of localization yields a simple condition for the
mobility edge : k eff ℓ = ( k eff ℓ ) c ∼ 1 [48-50]. Dashed lines in Fig. 3 show contour plots of this equation for different ∆ 0 with ( k eff ℓ ) c = 0 6. . It captures the main tendency exhibited by the numerical results when ∆ 0 increases although it is clearly not exact. An even better agreement is obtained for the minimum density required to reach localization in Fig. 4.
In conclusion, we demonstrate that transparent solids with impurity atoms or ions at random positions are promising materials for reaching Anderson localization of light in 3D. On the one hand, the detrimental effect of longitudinal optical fields [22, 23] can be mitigated in these materials by an external magnetic field, in the same way as in cold-atom systems [24, 25], which gives them an advantage over suspensions or powders of dielectric particles [10, 11]. On the other hand, they do not suffer from strong losses characteristic of metallic structures proposed as candidates for observation of Anderson localization of light [12, 18]. The main result of this work is to show that the difficulties specific for solids with impurity atoms-the oscillations of impurity atoms about their equilibrium positions and the inhomogeneous broadening of their spectra due to random local electric fields-are not critical and should not impede observation of Anderson localization of light. Therefore, we believe that it would be worthwhile to put some effort in experimenting with such materials.
The work of IMS was supported by the Foundation for the Advancement of Theoretical Physics and Mathematics 'BASIS'. Calculations were performed using the computing resources of the supercomputer center of Peter the Great St. Petersburg Polytechnic University.
- ∗ [email protected] † [email protected]
- [1] P. W. Anderson, Phys. Rev. 109 , 1492 (1958).
- [2] D. S. Wiersma, P. Bartolini, A. Lagendijk, and R. Righini, Nature 390 , 671 (1997).
- [3] F. Scheffold, R. Lenke, R. Tweer, and G. Maret, Nature 398 , 206 (1999).
- [4] D. S. Wiersma, J. G. Rivas, P. Bartolini, A. Lagendijk, and R. Righini, Nature 398 , 207 (1999).
- [5] T. van der Beek, P. Barthelemy, P. M. Johnson, D. S. Wiersma, and A. Lagendijk, Phys. Rev. B 85 , 115401 (2012).
- [6] M. St¨ orzer, P. Gross, C. M. Aegerter, and G. Maret, Phys. Rev. Lett. 96 , 063904 (2006).
- [7] T. Sperling, W. B¨hrer, C. M. Aegerter, and G. Maret, u Nat. Photon. 7 , 48 (2013).
- [8] F. Scheffold and D. Wiersma, Nat. Photon. 7 , 934 (2013).
- [9] G. Maret, T. Sperling, W. B¨ uhrer, A. Lubatsch, R. Frank, and C. M. Aegerter, Nat. Photon. 7 , 934 (2013).
- [10] T. Sperling, L. Schertel, M. Ackermann, G. Aubry, C. Aegerter, and G. Maret, New J. Phys. 18 , 013039 (2016).
- [11] S. E. Skipetrov and J. H. Page, New J. Phys. 18 , 021001 (2016).
- [12] A. Yamilov, S. E. Skipetrov, T. W. Hughes, M. Minkov, Z. Yu, and H. Cao, Nat. Phys. 19 , 1308 (2023).
- [13] S. John, Phys. Rev. Lett. 58 , 2486 (1987).
- [14] S. John, Physics Today 44(5) , 32 (1991).
- [15] S. John, in Photonic Band Gaps and Localization , edited by C. Soukoulis (Plenum Press, New York, 1993) pp. 122.
- [16] J. Haberko, L. S. Froufe-P´ erez, and F. Scheffold, Nat. Comm. 11 , 4867 (2020).
- [17] F. Scheffold, J. Haberko, S. Magkiriadou, and L. S. Froufe-P´rez, Phys. Rev. Lett. e 129 , 157402 (2022).
- [18] A. Z. Genack and N. Garcia, Phys. Rev. Lett. 66 , 2064 (1991).
- [19] A. A. Chabanov, M. Stoytchev, and A. Z. Genack, Nature 404 , 850 (2000).
- [20] R. Kaiser, in Peyresq Lectures on Nonlinear Phenomena , Vol. 1, edited by R. Kaiser and J. Montaldi (World Scientific, Singapore, 2000) pp. 95-126.
- [21] R. Kaiser, J. Mod. Opt. 56 , 2082 (2009).
- [22] S. E. Skipetrov and I. M. Sokolov, Phys. Rev. Lett. 112 , 023905 (2014).
- [23] B. A. van Tiggelen and S. E. Skipetrov, Phys. Rev. B 103 , 174204 (2021).
- [24] S. E. Skipetrov and I. M. Sokolov, Phys. Rev. Lett. 114 , 053902 (2015).
- [25] S. E. Skipetrov, Phys. Rev. Lett. 121 , 093601 (2018).
- [26] S. E. Skipetrov, I. M. Sokolov, and M. D. Havey, Phys. Rev. A 94 , 013825 (2016).
- [27] F. Cottier, A. Cipris, R. Bachelard, and R. Kaiser, Phys. Rev. Lett. 123 , 083401 (2019).
- [28] S. E. Skipetrov and I. M. Sokolov, Phys. Rev. Lett. 123 , 233903 (2019).
- [29] R. Kaiser and M. Havey, Opt. Photon. News 16 , 38 (2005).
- [30] W. Guerin, M. Ara´jo, and R. Kaiser, Phys. Rev. Lett. u 116 , 083601 (2016).
- [31] A. S. Kuraptsev and I. M. Sokolov, Phys. Rev. A 101 , 033602 (2020).
- [32] C. Hahlweg, W. Zhao, and H. Rothe, in Novel Optical Systems Design and Optimization XV , Vol. 8487, edited by G. G. Gregory and A. J. Davis, International Society for Optics and Photonics (SPIE, 2012) p. 84870S.
- [33] J. Koo, L. R. Walker, and S. Geschwind, Phys. Rev. Lett. 35 , 1669 (1975).
- [34] S. Chu, H. M. Gibbs, S. L. McCall, and A. Passner, Phys. Rev. Lett. 45 , 1715 (1980).
- [35] I. Aharonovich, A. D. Greentree, and S. Prawer, Nat. Photon. 5 , 397 (2011).
- [36] M. W. Doherty, N. B. Manson, P. Delaney, F. Jelezko, J. Wrachtrup, and L. C. Hollenberg, Phys. Rep. 528 , 1 (2013).
- [37] R. H. Dicke, Phys. Rev. 89 , 472 (1953).
- [38] C. Cohen-Tannoudji, J. Dupont-Roc, and G. Grynberg, Photons and Atoms-Introduction to Quantum Electrodynamics (Wiley Science Papers Series, New York, 1992).
- [39] O. Morice, Y. Castin, and J. Dalibard, Phys. Rev. A 51 , 3896 (1995).
- [40] R. H. Lehmberg, Phys. Rev. A 2 , 883 (1970).
- [41] G. S. Agarwal, Phys. Rev. A 2 , 2038 (1970).
- [42] D. A. Varshalovich, A. N. Maskalev, and V. K. Khersonskii, Quantum Theory of Angular Momentum (World Scientific, Singapore, 1988).
- [43] P. W. Courteille, S. Bux, E. Lucioni, K. Lauber, T. Bienaim´ e, R. Kaiser, and N. Piovella, Eur. Phys. J. D 58 , 69 (2010).
- [44] I. M. Sokolov, D. V. Kupriyanov, and M. D. Havey, J. Exp. Theor. Phys. 112 , 246 (2011).
- [45] E. Abrahams, P. W. Anderson, D. C. Licciardello, and T. V. Ramakrishnan, Phys. Rev. Lett. 42 , 673 (1979).
- [46] Supplementary information, URL\_will\_be\_inserted\_ by\_publisher .
- [47] J. Wang and A. Z. Genack, Nature 471 , 345 (2011).
- [48] P. Sheng, Introduction to Wave Scattering, Localization and Mesoscopic Phenomena , 2nd ed. (Springer-Verlag, Berlin, 2006).
- [49] A. F. Ioffe and A. R. Regel, in Progress in Semiconductors , edited by A. F. Gibson (Wiley, New York, 1960) pp. 237-291.
- [50] S. E. Skipetrov and I. M. Sokolov, Phys. Rev. B 98 , 064207 (2018).
## Supplementary information for
## 'Anderson localization of light by impurities in a solid transparent matrix'
Univ. Grenoble Alpes, CNRS, LPMMC, 38000 Grenoble, France
S.E. Skipetrov E-mail: [email protected]
## I.M. Sokolov
Peter the Great St. Petersburg Polytechnic University, 195251 St. Petersburg, Russia E-mail: [email protected]
## DETAILS OF THE SCALING ANALYSIS
We generate independent spatial configurations of N atoms randomly distributed inside a sphere of diameter L at a number density ρ = N/V with V = πL / 3 6. For each atom, a random shift ∆ n of its resonance frequency ω 0 is sampled from a centered normal distribution with variance ∆ . 2 0 For each atomic configuration with a corresponding set of ∆ n , complex eigenvalues E n of the effective Hamiltonian (1) are computed numerically and ordered according to their real parts. Then, mean values of 1 / Γ n and of ω n -ω n -1 are computed in each frequency interval of width Γ 0 from δω = ω -ω m = -5Γ 0 to 20Γ , 0 where ω n = ω 0 -(Γ 0 / 2)Re E n and Γ n = Γ Im 0 E n . Averaging is also performed over a large number of independent atomic configurations in space and over { ∆ n } . Typically, we average over 50, 35 and 25 configurations for N = 8000, 12000 and 16000, respectively. Thouless conductance is defined as g Th ( ω ) = ⟨ 1 / Γ n ω ⟩ -1 / ω ⟨ n -ω n -1 ⟩ ω , where the notation ⟨· · · ⟩ ω highlights the additional averaging over all ω n inside an interval of width Γ 0 around the frequency ω .
Figure S1 shows g Th as a function of k ℓ 0 0 = k / πρ 3 0 6 and δω/ Γ , for six different values of ∆ 0 0 . It is clear that the drop of g Th around δω/ Γ 0 = 4 at ∆ 0 = 0, shifts to larger δω and becomes less pronounced with increasing ∆ . 0 The impact of inhomogeneous broadening on Thouless conductance at a given frequency is demonstrated in Fig. S2 for δω/ Γ 0 = 4. When ∆ 0 < 4, localization transitions take place at values of k ℓ 0 0 where curves corresponding to different N cross. These transitions are suppressed for ∆ 0 > 4, leading to g Th being a growing function of N at all densities ρ . Figure 4 of the main text is obtained by estimating the β -function β g ( Th ) = ∂ ln g Th /∂ ln( k L 0 ) using a finite-difference approximation for the derivative.
## INFLUENCE OF INHOMOGENEOUS BROADENING ON ANDERSON LOCALIZATION OF LIGHT IN COLD ATOMIC CLOUDS: APPROXIMATE ANALYTIC THEORY
In the independent scattering approximation, the selfenergy is [21, 48]
$$\Sigma ( \omega, \omega _ { 0 } ^ { \prime } ) = \frac { 4 \pi \rho } { k _ { 0 } } \times \frac { 1 } { 2 ( \omega - \omega _ { 0 } ^ { \prime } ) / \Gamma _ { 0 } + i } \, \quad \ \ ( S 1 )$$
We assume that the atomic resonance frequency ω ′ 0 is subject to inhomogeneous broadening due to (i) strong local fields in the transparent host medium and (ii) strong dipole-dipole interactions between nearby atoms. The resulting distribution of ω ′ 0 is approximated by a Gaussian:
$$p ( \omega _ { 0 } ^ { \prime } ) \ = \ \frac { 1 } { \sqrt { 2 \pi } \Delta } \exp \left [ - \frac { ( \omega _ { 0 } ^ { \prime } - \omega _ { 0 } ) ^ { 2 } } { 2 \Delta ^ { 2 } } \right ] \quad ( S 2 )$$
where ω 0 is the resonance frequency in the absence of broadening. The variance of the distribution (S2) is given by a sum of two contributions:
$$\Delta ^ { 2 } = \Delta _ { 0 } ^ { 2 } + \langle \Delta _ { d d } ^ { 2 } \rangle$$
First, local fields in the host crystal yield random frequency shifts that we denote by ∆ , n with a variance ∆ . Second, the typical frequency shifts ∆ 2 0 dd induced by dipole-dipole interactions are of the order of 1 / k ( 0 ∆ ) r 3 ∝ ρ/k 3 0 , where we used the fact that the typical distance between nearby atoms is ∆ r = ρ -1 / 3 . To obtain a quantitative estimate, we recall that in a strong magnetic field, the eigenvalues of the Hamiltonian (1) in the main text, yielding eigenfrequencies ω near resonances ω m ( m = ± 1), can be obtained by diagonalizing a N × N matrix [24, 25]
$$\log \, \text{on} \\ \mathfrak { n } _ { 1, \, \text{lo-} } \quad ( \hat { H } _ { \text{eff} } ) _ { n n ^ { \prime } } & = \left ( i \mp 2 \frac { \Delta _ { B } } { \Gamma _ { 0 } } \right ) \delta _ { n n ^ { \prime } } + ( 1 - \delta _ { n n ^ { \prime } } ) \frac { 3 } { 2 } \frac { e ^ { i k _ { 0 } \Delta r _ { n n ^ { \prime } } } } { k _ { 0 } \Delta r _ { n n ^ { \prime } } } \\ \text{where} \\ \text{trans} \\ \text{being}$$
where θ nn ′ is the angle between the vector ∆ r nn ′ = r n -r n ′ and the quantization axis z . To be specific, let us consider m = 1. For two atoms ( N = 2) at a distance ∆ = r r 2 -r 1 the two eigenvalues of the matrix (S4) are
$$E _ { \pm } & = \left ( i - 2 \frac { \Delta _ { B } } { \Gamma _ { 0 } } \right ) \pm \frac { 3 } { 2 } \frac { e ^ { i k _ { 0 } \Delta r } } { k _ { 0 } \Delta r } \\ & \times \left [ P ( i k _ { 0 } \Delta r ) + Q ( i k _ { 0 } \Delta r ) \frac { \sin ^ { 2 } \theta } { 2 } \right ]$$
and frequency shifts with respect to ω 1 = ω 0 + ∆ B are (∆ dd ) ± = -(Γ 0 / 2)Re E ± -∆ . Averaging over the two B eigenvalues and over θ yields
$$\langle \Delta _ { d d } \rangle \ = \ 0 \quad \quad \quad ( S 6 )$$
$$& \langle \Delta _ { \text{dd} } ^ { 2 } \rangle = \frac { 3 } { 1 6 0 } \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { \frac { 3 } { 3 } } \left \{ 3 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { \frac { 3 } { 3 } } + \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { \frac { 3 } { 3 } } \\ & + \left [ 3 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { \frac { 4 } { 3 } } - 5 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { \frac { 2 } { 3 } } + 7 \right ] \cos \left [ 2 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { - \frac { 1 } { 3 } } \right ] \\ & + \left [ 6 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) - 2 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { \frac { 1 } { 3 } } \right ] \sin \left [ 2 \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { - \frac { 1 } { 3 } } \right ] + 7 \right \} \\ & \rightarrow \frac { 9 } { 8 0 } \left ( \frac { \rho } { k _ { 0 } ^ { 3 } } \right ) ^ { 2 } \text{ and } h$$
where in the last line we have taken the limit ρ/k 3 0 ≫ 1.
The average self-energy is
$$\langle \Sigma ( \omega, \omega _ { 0 } ) \rangle \ = \ \underset { - \infty } { \overset { \infty } { \int } } d \omega _ { 0 } ^ { \prime } p ( \omega _ { 0 } ^ { \prime } ) \Sigma ( \omega, \omega _ { 0 } ^ { \prime } ) \quad \text{(S8)}$$
The effective complex wave number is
$$\sqrt { k _ { 0 } ^ { 2 } - \langle \Sigma ( \omega, \omega _ { 0 } ) \rangle } \ = \ k + \frac { i } { 2 \ell } \quad \quad ( S 9 )$$
and hence
$$k \, = \, R e \sqrt { k _ { 0 } ^ { 2 } - \langle \Sigma ( \omega, \omega _ { 0 } ) \rangle }$$
$$\ell \ = \ \frac { 1 } { 2 \, \text{Im} \sqrt { k _ { 0 } ^ { 2 } - \langle \Sigma ( \omega, \omega _ { 0 } ) \rangle } } \quad \quad ( S 1 1 )$$
Ioffe-Regel criterion of localization is
$$k \ell \, = \, \frac { \text{Re} \sqrt { k _ { 0 } ^ { 2 } - \langle \Sigma ( \omega, \omega _ { 0 } ) \rangle } } { 2 \, \text{Im} \sqrt { k _ { 0 } ^ { 2 } - \langle \Sigma ( \omega, \omega _ { 0 } ) \rangle } } = ( k \ell ) _ { c } \sim 1 \ \ ( \text{S12} )$$
Comparison of contour plots of this equation with the localization phase diagram following from numerical calculations is shown in Fig. 3 of the main text.
FIG. S1. Thouless conductance g Th as a function of the bare Ioffe-Regel parameter k ℓ 0 0 = k / 3 0 6 πρ and frequency detuning δω = ω -ω m , for six different values of inhomogeneous broadening ∆ 0 . Data obtained for different total numbers of atoms are shown in different colors: N = 8000 (red), 12000 (green), 16000 (blue). The explored range of k ℓ 0 0 corresponds to the range ρ/k 3 0 = 0 1-2.5 of the atomic number density. .
FIG. S2. A cut of Fig. S1 at δω = ω -ω m = 4Γ , intended to demonstrate the transition from Anderson localization for 0 ∆ 0 < 4 (curves corresponding to different N cross in points determining mobility edges) to diffuse transport for ∆ 0 > 4 (no crossings).
 | null | [
"Sergey E. Skipetrov",
"Igor M. Sokolov"
]
| 2024-08-02T16:39:06+00:00 | 2024-08-02T16:39:06+00:00 | [
"physics.optics",
"cond-mat.dis-nn"
]
| Anderson localization of light by impurities in a solid transparent matrix | A solid transparent medium with randomly positioned, immobile impurity atoms
is a promising candidate for observation of Anderson localization of light in
three dimensions. It can have low losses and allows for mitigation of the
detrimental effect of longitudinal optical fields by an external magnetic
field, but it has its own issues: thermal oscillations of atoms around their
equilibrium positions and inhomogeneous broadening of atomic spectral lines due
to random local electric fields. We show that these complications should not
impede observation of Anderson localization of light in such materials. The
thermal oscillations hardly affect light propagation whereas the inhomogeneous
broadening can be compensated for by increasing the number density of impurity
atoms. |
2408.01382v2 | ## Explaining a probabilistic prediction on the simplex with Shapley compositions
Paul-Gauthier No´ e, Miquel Perell´-Nieto, Jean-Fran¸ois Bonastre, Peter Flach ∗ o † c ∗ †
## Abstract
Originating in game theory, Shapley values are widely used for explaining a machine learning model's prediction by quantifying the contribution of each feature's value to the prediction. This requires a scalar prediction as in binary classification, whereas a multiclass probabilistic prediction is a discrete probability distribution, living on a multidimensional simplex. In such a multiclass setting the Shapley values are typically computed separately on each class in a one-vs-rest manner, ignoring the compositional nature of the output distribution. In this paper, we introduce Shapley compositions as a well-founded way to properly explain a multiclass probabilistic prediction, using the Aitchison geometry from compositional data analysis. We prove that the Shapley composition is the unique quantity satisfying linearity, symmetry and efficiency on the Aitchison simplex, extending the corresponding axiomatic properties of the standard Shapley value. We demonstrate this proper multiclass treatment in a range of scenarios.
Remark This work is published in the proceedings of ECAI 2024. The present document gathers the full paper with the supplementary material. For citing this work, please refer to the version in the ECAI's proceeding.
∗ Laboratoire Informatique d'Avignon, Avignon Universit´, France e
† University of Bristol, United Kingdom
## 1 Introduction
Many machine learning approaches are regarded as black-boxes, making them unreliable for real-life applications where the model's predictions need to be understood or explained. In recent years, the interest in more interpretable models and explainability methods has therefore increased in the machine learning literature [5, 18]. One group of approaches, known as local explanation , aims to measure the contribution of each input feature's value to the computation of the model's output. Shapley values are widely used for this purpose [28, 8], especially since the release of the SHAP toolkit [20] 1 .
Shapley values were introduced in cooperative game theory where a group of players work together to maximise a payoff. A set of Shapley values distributes the payoff over all the players according to their individual contribution to the total. The Shapley value is the unique quantity that satisfies a set of desired axiomatic properties [26]. For explaining a machine learning model's prediction, features are treated as players and the scalar output of the model as the total payoff.
The Shapley value is designed for a one-dimensional function's codomain. In game theory, the characteristic function takes a coalition of players and gives a payoff. In machine learning, for a given instance, the characteristic function takes a group of features and gives a scalar output measuring how the prediction changes when the values of the features are considered. For a two-class probabilistic classification, the prediction is essentially a scalar since the probabilities for the two classes sum to one. Therefore, the Shapley value framework can simply be applied to the logit transform of one of the probabilities 2 .
For more than two possible classes the output of the model is a discrete probability distribution or the output of a softmax function as commonly used by neural networks. Hence the output lives on a ( D -1)-dimensional simplex, where D is the number of classes. In this case, the Shapley value framework cannot be directly applied. Of course, one can compute Shapley values on each output probability separately, but this ignores the structure of the simplex where the relative values between the probabilities is what really matters, rather than the absolute value of a single probability.
This paper presents Shapley composition as an extension of the Shapley value to the space of discrete probability distributions, using the Aitchison geometry of the simplex from the field of compositional data analysis. Compositional data [2, 23] are vectors - known as compositions - living on a simplex (not necessarily a probability simplex). Compositional data analysis has been applied to geological and chemical data, for example, but also to discrete probability distributions [10, 11, 22]. In the present paper, the probability distributions given by a classifier will be treated as compositional data in order to extend the Shapley value to multiclass classification.
Figure 1 shows a synthetic example to provide some intuitions. It shows a 2-dimensional space isomorphic to the 3-class-simplex where each point is a probability distribution also visualised as a histogram. The maximum probability regions, for each class, are clearly visible and separated by dashed black rays. Importantly, this space of probability distribution is additive thanks to the Aitchison geometry. The vectors show how the contribution of each feature changes - in an additive manner - the probability distribution (the ordering of the features can be chosen freely but the final point is fixed).
In the example, the base distribution (the average prediction over all data ) is modified by 3 the contribution ˜ ϕ 1 of the first feature. This goes mostly against class 2 such that the resulting distribution has the lowest probability for class 2. The angle between ˜ ϕ 1 and the class-3 direction being the lowest among the classes, the resulting distribution has the highest probability for this
1 https://shap.readthedocs.io/en/latest
2 The logit maps the domain ]0 1[ to the additive real line , R .
3 Note that this does not need to be the uniform distribution, i.e., the origin.
class. The second feature moves the distribution into the class-1 region, perpendicular to the class-3 direction. The probability for class 1 is now maximum by reducing the probability for class 2, keeping the relative weight for class 3 unchanged. The third feature moves the distribution away from class 1. The resulting distribution being on the class-3 direction, the probability is maximum for class 3 and uniform for the other two.
We fully formalise the approach in this paper, making the following contributions:
- · We define Shapley composition as a principled multidimensional extension of the Shapley value to the probability simplex,
- · We prove that the Shapley composition is the unique quantity satisfying the set of desired properties known as linearity , symmetry and efficiency on the simplex equipped with the Aitchison geometry,
- · We demonstrate the advantages of Shapley compositions for explaining a multiclass probabilistic prediction in machine learning.
The paper is structured as follows. Section 2 briefly reviews related work. Section 3 recalls the standard definition of the Shapley value and its use in binary classification. Section 4 presents the necessary tools from compositional data analysis: in particular, the Aitchison geometry of the simplex and the isometric log-ratio transformation. Section 5 defines the Shapley composition as an extension of the Shapley value framework to the multidimensional simplex using the Aitchison geometry. Section 6 shows with intuitive examples and visualisations how Shapley compositions can be used for explaining multiclass probabilistic predictions. Section 7 provides a short discussion and concludes the paper . 4
Figure 1: A synthetic example of a Shapley composition-based explanation. This shows a 2dimensional space isomorphic to the 3-class simplex where each point is a probability distribution as visualised with the histograms. The dashed black rays separate the maximum probability regions for each class and the dashed coloured vectors show the direction in favour of one class and against the other two. The space is additive such that the features' contributions { ˜ ϕ i } { 1 2 3 , , } translate the base distribution to the prediction.
4 The code and Jupyter notebooks are available on the github page: https://github.com/orgs/ shapley-composition .
## 2 Related work
There is a plethora of methods in the literature to explain and better understand predictive models. They focus on different aspects of the task, from possible dataset biases, the feature importance with respect to the target, the parameters of a model after training, or the model predictions [27]. Some methods explain the influence of the features on the model's performance: e.g., Permutation Feature Importance for random forest [7], which was later extended to the model agnostic Model Reliance [13]. Other methods focus on how individual features influence the model's predictions: e.g., Local Interpretable Model-agnostic Explanations (LIME) [25], Individual Conditional Explanation [16], Partial Dependence-based Feature Importance [17], Marginal Effect [6], Accumulated Local Effect [6], and Shapley value-based approaches [28, 8, 20].
We base our work on the Shapley value framework as one of the most well-founded feature influence methods. Inherently two-class, it has been applied to multiclass problems by explaining the influence of the features in a one-vs-one or one-vs-rest manner [32, 19], hence losing information that can be obtained by properly considering the full distribution. Utkin et al. [29, 30] explicitly consider the classifier output as a probability distribution, and measure the change in prediction in terms of statistical distance or divergence rather than in terms of difference between scalar predictions. However, even if this approach can measure the strength of a feature's value effect, it loses its directional information.
A recent work presented by Franceschi et al. [14] (later extended [15]) introduces stochastic characteristic functions to deal with models that output a random variable. With a categorical random variable, their approach can be used for explaining a multiclass classifier by allowing probabilistic statements about the likelihood of a feature to flip the decision from one class to another. In contrast, the approach we propose does not require an additional stochastic process but does not permit such a probabilistic statement. Instead, our approach is geometrical, by measuring how a feature moves the prediction on the probability simplex. In this way, it constitutes a natural extension of the standard Shapley value to the simplex for multiclass applications.
## 3 The Shapley value in machine learning
This section briefly recalls Shapley values as used for explaining features' contribution on a scalar prediction in machine learning. Let f : X → R be a learned model one wants to locally explain where f ( x ) is the prediction on the instance x ∈ X ⊂ R d . Let Pr be the probability distribution of the data over X (usually unknown but approximated by empirical averages). Let S ⊆ I = { 1 2 , , . . . d } be a subset of indices where d is the number of features. x S refers to an instance x restricted to the features with indices in S .
When an instance x is observed, the expected value of the prediction is simply E [ f ( X ) | x ] = f ( x ). However, when only x S is given with S ̸ = I , there is uncertainty about the non-observed features and the expected prediction given x S is computed as E Pr [ f ( X ) | x S ] = ∫ x ∈X f ( x )Pr( x | x S ) d x . The change in prediction when the values of the features indexed by S are observed is measured by the characteristic function:
↦
$$\text{incount} \colon & & v _ { f, x, P r } \, \colon \, 2 ^ { \mathcal { I } } & \to \mathbb { R }, \\ & & S & \mapsto \mathbb { E } _ { P r } [ f ( X ) \, | \, x _ { S } ] - \mathbb { E } _ { P r } [ f ( X ) ],$$
where 2 I is the set of all subsets of I . The contribution of the feature indexed by i / S ∈ to the prediction, given the known values for the features indexed by S , is given by:
$$c _ { f, x, P r } ( i, S ) = v _ { f, x, P r } ( S \cup \{ i \} ) - v _ { f, x, P r } ( S ).$$
The total contribution of the i th feature is computed by averaging this quantity over all possible coalitions S as follows:
$$\ w s \colon & & \phi _ { i } \left ( f, x, \Pr \right ) = \frac { 1 } { d! } \sum _ { \pi } c _ { f, x, \Pr } ( i, \pi ^ { < i } ), & & ( 3 )$$
where π is a permutation of the set I of indexes and π <i is the set of indexes before i in the ordering given by π . For better clarity, ' f, x , Pr' or simply ' x , Pr' will be dropped from the equations.
This quantity is known as the Shapley value for the i th feature. It originates from cooperative game theory and is the unique quantity respecting a set of desired axiomatic properties [26, 28]:
## Linearity
$$\text{ity with respect to the model: }$$
$$\alpha, \beta \in \mathbb { R }, \, \forall i \in \mathcal { I }, \, \phi _ { i } \left ( \alpha f + \beta g \right ) = \alpha \phi _ { i } \left ( f \right ) + \beta \phi _ { i } \left ( g \right ) ;$$
## Symmetry:
∀ S ⊆ I\{ i, j } , v ( S ∪ { } i ) = v ( S ∪ { j } ) ⇒ ϕ i = ϕ j ;
Efficiency: The 'centered' prediction is additively separable with respect to the Shapley values:
$$f ( x ) - \mathbb { E } _ { P r } [ f ( X ) ] = \sum _ { i = 1 } ^ { d } \phi _ { i } \left ( f, x, \Pr \right ).$$
Efficiency ensures that the change in prediction when the features are observed is distributed among them. In other words, the cumulative sum of the Shapley values moves the averaged prediction (also called base prediction) to the actual one.
The Shapley value is designed for a characteristic function with a scalar codomain. For explaining machine learning models which output multidimensional discrete probability distributions, like in multiclass classification, one could explain each output dimension separately, resulting in a one-vs-rest comparison. However, this approach ignores the relative information between each probability and ignores the compositional nature of the discrete probability distributions. Indeed, the probabilistic output of a classifier lives on a multidimensional simplex. The latter is the sample space of compositional data briefly reviewed in the next section.
## 4 Compositional data
Compositional data carries relative information. Each element of a composition describes a part of some whole [23], such as vectors of proportions, concentrations, and discrete probability distributions. An D -part composition is a vector of D non-zero positive real numbers that sum to a constant k . Each element of the vector is a part of the whole k . The sample space of compositional data is the ( D -1)-dimensional simplex:
$$\mathcal { S } ^ { D } = \left \{ x = [ x _ { 1 }, x _ { 2 }, \dots x _ { D } ] ^ { T } \in \mathbb { R } _ { + } ^ { * D } \ | \sum _ { i = 1 } ^ { D } x _ { i } = k \right \}.$$
In a composition, only the relative information between parts matters and John Aitchison introduced the use of log-ratios of parts to handle this [2]. He defined several operations on the simplex which leads to what is called the Aitchison geometry of the simplex .
## 4.1 The Aitchison geometry of the simplex
Only the relative information between the parts of a composition matters. Compositions are therefore scale-invariant. This is materialised by the closure operator defined for k > 0 as:
$$\mathcal { C } \left ( x \right ) = \left [ \frac { k x _ { 1 } } { \| x \| _ { 1 } }, \frac { k x _ { 2 } } { \| x \| _ { 1 } }, \dots \frac { k x _ { D } } { \| x \| _ { 1 } } \right ] ^ { T } \in \mathcal { S } ^ { D },$$
where x ∈ R ∗ D + and ∥ x ∥ 1 = ∑ D i =1 | x i | .
Aitchison defined on the simplex the following three operations [3]:
Perturbation: x ⊕ y = C ([ x y , . . . x 1 1 D D y ]), seen as an addition between two compositions;
Powering: α ⊙ x = C ([ x , . . . x α 1 α D ]), seen as a multiplication by a scalar α ∈ R ;
Inner product:
$$\langle x, y \rangle _ { A } = \frac { 1 } { 2 D } \sum _ { i = 1 } ^ { D } \sum _ { j = 1 } ^ { D } \log \frac { x _ { i } } { x _ { j } } \log \frac { y _ { i } } { y _ { j } }.$$
In this paper, since we are interested in classification problems where the set of classes represents a set of exhaustive and mutually exclusive hypotheses, the output of a probabilistic classifier is a discrete probability distribution over the set of classes. We therefore restrict ourselves to the probability simplex where k = 1.
## 4.2 The isometric log-ratio transformation
A ( D -1)-dimensional orthonormal basis of the simplex, referred to as an Aitchison orthonormal basis, can be built. The projection of a composition into this basis defines an isometric isomorphism between S D and R D -1 . This is known as an isometric log-ratio (ILR) transformation [12] and allows to express a composition into a Cartesian coordinate system preserving the metric of the Aitchison geometry. Within this real space, the perturbation, the powering and the Aitchison inner product are respectively the standard addition between two vectors, the multiplication of a vector by a scalar, and the standard inner product.
Given a composition p = [ p , . . . p 1 D ] T ∈ S D we write its ILR transformation as ˜ = ilr ( p p ) = [˜ p , . . . p 1 ˜ D -1 ] T ∈ R D -1 . The i th element ˜ p i of ˜ is p obtained as: ˜ p i = ⟨ p e , ( ) i ⟩ A where the set { e ( ) i ∈ S D } 1 ≤ ≤ i D -1 forms an Aitchison orthonormal basis of the simplex. The basis can be obtain through the Gram-Schmidt procedure or by building a sequential binary partition [12, 9]. Examples are discussed in Section 6.2.
In the introductory example of Figure 1, the 2-dimensional ILR space isomorphic to the 3-class probability simplex was constructed as follows:
$$\tilde { p } _ { 1 } = \frac { 1 } { \sqrt { 2 } } \log \frac { p _ { 1 } } { p _ { 2 } }, \ \tilde { p } _ { 2 } = \sqrt { \frac { 2 } { 3 } } \log \frac { \sqrt { p _ { 1 } p _ { 2 } } } { p _ { 3 } }.$$
Hence, the x -axis compares the probabilities for classes 1 and 2, the y -axis compares the probability for class 3 with the geometric mean of p 1 and p 2 , and the origin corresponds to the uniform distribution, i.e., the neutral element for the perturbation. Note that the perturbation can be seen as a Bayesian update: the perturbation of a prior by a likelihood function gives the posterior. In the space of isometric log-ratio transformed distributions, the Bayes update is a vector translation.
## 5 Shapley composition on the simplex
In this section we will use the Aitchison geometry to extend the Shapley value from Section 3 to the simplex for explaining a multiclass probabilistic prediction. Let f : X → S D be a learned model which outputs a prediction on the ( D -1)-dimensional probability simplex S D . In order to properly consider the structure of the simplex and the relative information between the probabilities, the model's output is treated as compositional data using the operators from the Aitchison geometry of the simplex. We therefore rewrite the characteristic function and the contribution of Equations 1 and 2 as follows:
↦
$$v _ { f, x, P r } \colon 2 ^ { \mathcal { I } } & \to \mathcal { S } ^ { D }, \\ S & \mapsto \mathbb { E } _ { P r } ^ { \mathcal { A } } [ f ( X ) \ | \ x _ { S } ] \ominus \mathbb { E } _ { P r } ^ { \mathcal { A } } [ f ( X ) ].$$
$$c _ { f, x, \Pr } ( i, S ) = v _ { f, x, \Pr } ( S \cup \{ i \} ) \ominus v _ { f, x, \Pr } ( S ),$$
where a ⊖ b is the perturbation a ⊕ (( -1) ⊙ b ) which corresponds to a subtraction between two compositions, and where the A in superscript highlights the fact that the expectation is taken with respect to the Aitchison measure. This can be computed as: E A [ Y ] = ilr -1 ( E [ilr ( Y )]), where E A refers to the expectation with respect to the Aitchison measure while E refers to the expectation with respect to the Lebesgue measure [23].
The Shapley quantity expressing the contribution of the i th feature's value on a prediction can be expressed on the simplex as the composition ϕ i given by:
$$\phi _ { i } \left ( f, x, \Pr \right ) = \frac { 1 } { d! } \odot \bigoplus _ { \pi } c _ { f, x, \Pr } ( i, \pi ^ { < i } ).$$
We call this quantity Shapley composition . Note that the average is here with respect to the Aitchison geometry, i.e. with perturbations and a powering rather than sums and a scaling.
The following is the main theoretical result of the paper.
Theorem 1. The Shapley composition is the unique quantity that satisfies the following properties on the Aitchison simplex:
Linearity with respect to the model:
$$\alpha, \beta \, \overset { \cdot } { \in \mathcal { R } }, \, \forall i \in \mathcal { I }, \\ \phi _ { i } \, ( \alpha \odot f \oplus \beta \odot g ) = \alpha \odot \phi _ { i } \, ( f ) \oplus \beta \odot \phi _ { i } \, ( g ) ;$$
## Symmetry:
$$\forall S \subseteq \mathcal { I } \langle i, j \}, \, v \left ( S \cup \{ i \} \right ) = v \left ( S \cup \{ j \} \right ) \Rightarrow \phi _ { i } = \phi _ { j } ;$$
## Efficiency:
$$\bigoplus _ { i = 1 } ^ { d } \phi _ { i } \left ( f, x, P r \right ) = f ( x ) \ominus \mathbb { E } _ { P r } ^ { A } [ f ( X ) ].$$
A proof of this result is given in Appendix A. Shapley compositions are thus the natural multidimensional extension of the Shapley value framework on the Aitchison simplex. In the next section we give a number of compelling examples of how this can be used to explain multiclass probabilistic predictions.
## 6 Explaining a multiclass prediction with Shapley compositions
Given a probabilistic prediction f x ( ) ∈ S D , the Shapley composition ϕ i ( f x , , Pr) describes the contribution of the i th feature value to the prediction. The efficiency property shows how the probability distribution is perturbed from the base distribution E A Pr [ f X ( )], i.e. the expected prediction regardless of the current input, to the actual prediction f x ( ). In the standard Shapley formulation recalled in Section 3, the prediction is one-dimensional such that the Shapley quantity is a scalar. In applications where there are more than two possible classes, the prediction is multidimensional such that the Shapley quantity (the Shapley composition) is too. Both live in the same space: the probability simplex. In this section, we discuss how the set of Shapley compositions can be analysed to better understand the contribution and influence of each feature's value on the prediction.
## 6.1 Visualisation in an isometric-log-ratio space
The Shapley compositions can be visualised in a ( D -1)-dimensional Euclidean space isometric to the simplex with the ILR transformation presented in Section 4.2. As we will see, this space is intuitive since it is a standard real vector space and it is additive. In what follows, we discuss some examples of Shapley composition-based explanations in an ILR space.
Figure 2: The sum of the Shapley compositions in an ILR space from the base distribution to the prediction for the classification of an Iris instance.
## 6.1.1 Three classes
Our first illustration uses the well-known Iris classification dataset consisting of a set of flowers described by 4 features: sepal length and width, and petal length and width. The aim of the classification task is to predict to which of the three species ( setosa , versicolor and virginica ) a flower belongs.
In the present example, a Support Vector Machine (SVM) with a radial basis function (rbf) kernel is used as a classifier. Pairwise coupling [31] is used to obtain a probabilistic prediction. Figure 2 shows the explanation of the classifier prediction for one versicolor instance where the Shapley compositions move the distribution from the base to the prediction. Having the highest norm, the petal width and length are the features contributing the most to the prediction and move the base distribution into the versicolor maximum probability region (maximum probability region boundaries are the dashed gray rays). Class-compositions are represented by coloured dashed vectors. A class-composition is defined as a unit norm composition going straight to the direction of one class and uniformly against all the others (see Appendix B for a formal definition). Note that the class-compositions are not mutually orthogonal. This is because a positive contribution toward one class has necessarily to lead to a negative contribution toward at least another class to preserve the structure of the simplex.
The Shapley composition for the petal length is almost orthogonal to the virginica classcomposition: for this instance, this feature does not contribute to the weight of the predicted
Figure 3: Visualisation of the Shapley values for each class in a one-vs-the-rest manner for the same instance as in Figure 2, obtained using the SHAP toolkit [20]. The red/blue bars represent positive/negative contributions of each feature on the prediction.
probability for this class. Having a Shapley composition going straight to the opposite direction of one class-composition would suggest that the corresponding feature's value contributes to rejecting this class. This is somewhat the case for the sepal length. However, because its Shapley composition has a low norm, this feature contributes little to the prediction.
Alternatively, one could analyse this instance by applying the standard Shapley value in a one-vsrest manner, explaining the feature contributions separately for each class. Figure 3 shows how each explanation is usually visualised with the SHAP toolkit [20]. The prediction is explained for each class one-by-one independently from one another, which makes it hard to appreciate the influence of one feature on the full distribution. Moreover, there is no guarantee that the intermediate full distribution remains on the simplex. In contrast, with our approach, the influence of one feature's value on the full prediction can be analyse with a single quantity, the Shapley composition, in a single coherent and easily interpretable plot.
## 6.1.2 Four classes
In a four-class example, the simplex is 3-dimensional. We illustrate this with a simple handwritten digit recognition task 5 . It consists of classifying an 8 × 8 image as representing one of the digits 0, 1, 2 or 3. Since there are 64 pixels, considering each pixel as a feature would correspond to 64 Shapley compositions. Moreover, the pixels will be highly correlated. Since our goal here is to provide simple illustrative examples, we reduce the number of features to 6 using a principal component analysis for better clarity and conciseness. An SVM with a rbf kernel and pairwise coupling is again used as a probabilistic classifier. A similar analysis as before can be applied here but within a 3-dimensional plot as illustrated in Figure 4.
Figure 4: Shapley compositions in a 3-dimensional ILR space for a four classes digit recognition task. The Shapley compositions are summed in the ILR space from the base distribution to the prediction. The gray transparent walls mark out the four maximum probability decision regions.
5 We use the scikit-learn's digits dataset [24].
To better understand how this space is divided into four regions-each representing the maximum probability region for one class-one can think about the shape of a methane molecule. The hydrogens correspond to the vertices and the carbon to the center of a tetrahedron i.e. a 3-dimensional simplex. The relative positions of the class-compositions in the ILR space are the same as the bonds between the carbon and hydrogen: the angles are ≈ 109 5 . ◦ . In this example, the tested instance is a 0 6 .
## 6.2 More classes: groups of classes and balances
When more than three classes are involved, the dimensions of the ILR space cannot be visualised all at once. However, 2 or 3-dimensional subspaces can still be visualised. In order to select the ILR components to investigate, one needs to understand what they refer to. In this section, we briefly discuss the interpretation of the ILR components.
A component of an ILR space can be interpreted as a balance , i.e. a log-ratio of two geometrical means of probabilities [12, 9, 23]: one giving the central values of the probabilities in one group of classes and one for another group of classes. Therefore, a balance is here comparing the weight of two groups of classes. The set of balances is built such that they are geometrically orthogonal meaning they provide non-redundant information . This can be illustrated by a sequential binary partition or 7 bifurcation tree. Two examples are given in Figures 5 and 6. Figure 5 shows the bifurcation tree corresponding to the basis obtained with the Gram-Schmidt procedure as in [12] which is the one used in the examples of Figures 2 and 4 with respectively D = 3 and D = 4. Each node of the tree is a balance, i.e., an ILR component. The first balance ˜ p 1 compares the probability for class 1 with the probability for class 2. Each next balance then recursively compares the probability for the next class with the probabilities for the previous classes independently of all the others.
In some applications, one may be interested in particular comparisons of groups of classes not necessarily given by a basis in the form of Figure 5. For instance, as in an example presented in [9], if one wants to compare political parties or groups, it may be pertinent to have a balance comparing left and right-wing groups. But sometimes there are no obvious relevant comparisons to study. In the handwritten digit recognition problem, one may want to compare odd with even numbers or primes with non-primes (although, being essentially a shape recognition problem, and the shape of the numbers being independent of their arithmetic properties, such comparisons may not be pertinent).
Figure 5: Bifurcation tree corresponding to the basis obtained with the Gram-Schmidt procedure as in [12] and used in the examples of Figures 2 and 4.
6 More examples and better visualisations can be obtained from the Jupyter notebooks: https://github.com/ orgs/shapley-composition .
7 Not to be confused with statistical uncorrelation [23].
Figure 6: Bifurcation tree used in the 10-class digit recognition task discussed in Section 6.2 and in Figure 7.
We use the basis of Figure 6 for a 10-class digit recognition task. In this example, the bifurcation tree is obtained from the dendrogram of an agglomerative clustering of classes: for each class, the set of predictions is modelled by a logistic-normal [4], with equal covariance, and classes are recursively merged with respect to the Mahalanobis distance. Consider, in Figure 7, the third and fifth ILR dimensions (˜ p 3 and ˜ ). Effectively, we are saying that we are interested in comparing the probability p 5 assigned for class 0 with the probability assigned for class 6, and in comparing the probability assigned for class 1 with the group of probabilities assigned for classes 7 and 8. ˜ p 3 depends only on the probability for the digits 0 and 6, and ˜ p 5 depends only on the probabilities for the digits 1, 7 and 8. The class-compositions for the other digits have a zero projection within this subspace and are therefore discarded in Figure 7. The class-compositions for 0 and 6 are orthogonal to the class-compositions for classes 1, 7 and 8. Indeed, the set of classes making the balance ˜ p 3 and the set of classes making ˜ p 5 have no intersection.
In contrast, in the example of Figure 2, ˜ p 1 is comparing the probabilities for the class setosa with the probability for the class versicolor and ˜ p 2 is comparing the probabilities for the class virginica with the group of probabilities for setosa and versicolor . In Figure 2, the class-compositions are exhaustively present and are therefore geometrically dependent and none of them are orthogonal. In Figure 7, the classes are not all represented such that the class-compositions projections can be orthogonal. In other words, since we look at only a subspace of an ILR space, we are not looking at the full probability distribution.
In the example of Figure 7, since ˜ p 5 is comparing 1 with the group of digits 7 and 8, the projection on this line of the class-compositions for 1 goes in an opposite direction than the one for the classcompositions for 7 and 8. The latter two are equal and half as long as the former. In this way, ˜ p 5 compares the probability for 1 with the group of probabilities for 7 and 8 with the same weight. In other words, in this subspace, the class-compositions for 7 and 8 are reweighted such that this group of two classes has the same weight as the group made of the single class 1.
Within this space, Shapley compositions can be explored as in the examples of Figures 2 and 4, keeping in mind that this is a subspace of a full ILR space.
Figure 7: The sum of the Shapley compositions from the base to the prediction in the ILR subspace made of ˜ p 3 and ˜ p 5 for a test instance from class 2. ˜ p 3 compares the probability assigned for class 0 with the probability assigned for class 6 and ˜ p 5 compares the probability assigned for class 1 with the group of probabilities assigned for class 7 and 8. The color dashed vectors represent the class-compositions with non-zero projection.
## 6.3 Angles, norms and projections
An explanation can be summarised by sets of angles, norms and projections:
- · The norm of a Shapley composition gives the strength of the contribution of the feature's value to the prediction. This measures the overall contribution of the feature, regardless of its direction.
- · The angle between two Shapley compositions informs about their orthogonality. Orthogonality suggests that the features are non-redundant for the given instance. A negative angle would suggest that the features have an opposite influence on the prediction.
- · The projections of a Shapley composition on the set of class-compositions inform in favour of, or against, which classes a feature's value is contributing.
To give a few examples, for the Iris example of Figure 2, the norms for each Shapley composition are ≈ 1 27, 1 02, 0 36 and 0 28 respectively for the petal width, length and sepal width and length, . . . .
confirming the features' importance one would expect from Figure 2. The projection of the petal length's composition on the virginica class-composition is ≈ 0 01 confirming the low influence of this . feature on the probability for this class. Finally, note that the cosine similarity between the Shapley compositions for petal length and width is close to one ( ≈ 0 99) which confirms these features are . moving the distribution toward the same direction while the compositions for sepal and petal width have a cosine similarity of 0.45 confirming they point to complementary directions.
## 6.4 Histograms and parallel coordinates
For a classification problem with at most 4 classes, an ILR space can be fully visualised within a single figure. However, for more classes we cannot visualise the full ILR space and therefore have to explore subspaces. In this section we discuss alternative visualisations.
The Shapley composition can be visualised using a bar plot like discrete probability distributions. Figure 8 shows the Shapley compositions of the Iris classification example as histograms. Note that in Figure 1, the histograms were showing the probability distributions as the successive perturbation of the base by the features' contribution. The histograms in this section refer to the visualisation of Shapley compositions for each feature separately. A more uniform histogram reflects less contribution of the feature's value to the change of the probability distribution (e.g. the sepal length in Figure 8). In contrast, the Shapley compositions for the petal length and width have a high value for the versicolor class, in comparison to the others. This confirms the contribution of these features toward this class.
Figure 8: Shapley compositions visualised as histograms for the Iris classification example.
As another illustration, Figure 9 shows the Shapley compositions of the 10-class digit recognition example. Here, and contrary to the visualisation of the compositions in an ILR space as in Section 6.2, one can analyse all parts of each composition within a single plot. In this example, the high value for digit 2 for the first principal component confirms the contribution of this feature toward this class.
Another way to visualise the full compositions is with parallel coordinates. After sorting the features by their contribution (i.e. the norm of their Shapley composition), the successive perturbation of the distribution can be visualised as probability lines from the base distribution to the prediction. Figure 10 shows such a plot for the digit recognition example. With this visualisation, we can compactly see how the probability distribution is transformed by each feature contribution from the base distribution to the predicted one. In this example, the probability for digit 2 increases the most with the contribution of feature 1. This feature does not contribute in the change of the probability for digit 3 as suggested by the horizontal red segment. The next feature continues to increase the probability for digit 2 while decreasing the others.
Figure 9: Shapley compositions visualised as histograms for the ten classes digit recognition example.
Figure 10: Parallel coordinates visualisation of the successive perturbation of the base distribution by Shapley compositions (ordered by importance, i.e., norm). The final distribution on the right side is the prediction.
## 6.5 The estimation algorithm
The estimation algorithm used in this work for computing the Shapley compositions is an adaptation of Algorithm 2 in [28]. Since the resulting Shapley compositions are approximations, the efficiency property does not necessarily hold. In order for the set of estimated Shapley compositions to respect the efficiency property, each Shapley composition is adjusted following a similar method as in the sampling approximation in the SHAP toolkit [20] 8 . We refer the reader to Appendix C and Appendix D for more details.
Note that the Shapley composition framework can be applied on many different types of data, such as images. However, the main limitation is algorithmic: the complexity of the algorithm increases with the number of features, as with the standard Shapley value framework. Moreover, the estimation algorithm assumes that the features are independent. Estimating Shapley values without such assumption has been discussed in the literature [1]. We leave the exploration of estimation algorithms of the Shapley compositions without the features-independence assumption and for data with a large number of features for future work.
8 https://github.com/shap/shap/blob/master/shap/explainers/\_sampling.py
## 7 Discussion and conclusion
The use of standard Shapley values for explaining multiclass machine learning models has been rarely discussed in the literature. However, the computation of the Shapley values on each output dimension one-by-one can be encountered. To be more precise, for an D -class problem ( D > 2), it may first sound natural to compute a Shapley value on the logit of the probability for each class resulting in a D -dimensional vector of the Shapley values. Even if the efficiency property holds with the standard addition, i.e. the sum of the element-wise logit of the base distribution with such vectors for each feature is equal to the element-wise logit of the prediction, the path from the base to the prediction may go out of the simplex, i.e., the space of probability distributions, which is counter-intuitive and indeed incoherent. Moreover, such a strategy would require running D independent explanations contrary to the Shapley composition approach which requires a single explanation process.
As far as we are aware, this paper is the first to propose an extension of the Shapley value framework to the multidimensional simplex for explaining a multiclass probabilistic prediction in machine learning. We saw how the formalisation of the standard Shapley value naturally extends to the simplex using the Aitchison geometry. The resulting Shapley quantity is a composition (distribution), i.e. a vector living on the probability simplex. It is referred as Shapley composition and explicates the contribution of a feature's value to a prediction. To be more precise, it tells how a feature's value moves the distribution from the base one to the predicted one on the simplex. We saw that the Shapley composition is the unique quantity that satisfies the linearity, symmetry and efficiency on the Aitchison simplex.
The Aitchison geometry gives to the simplex an Euclidean vector space structure. For explaining a prediction, Shapley compositions can be visualised and analysed through angles, norms and projections. They inform on both the strength and the direction of each feature's value effect. Living on the probability simplex, i.e. the same space as discrete probability distributions, the Shapley compositions can also be visualised as histograms. Parallel plots of probabilities can also be visualised to keep track of the change in the distribution induced by each feature's value.
The literature about the use of Shapley values in machine learning is extensive. Many estimation algorithms have been developed, many applications of the Shapley value have emerged, and large-scale experiments have been conducted. In contrast, our paper presents limited experimental results as simple proofs of concept and illustrations. However, the main contribution of this work is theoretical and methodological. We believe this work lays proper foundations to foster the research in explainable machine learning, especially for multidimensional and multiclass predictions.
## Appendix A Proof of the uniqueness of Shapley compositions on the simplex
This section provides a proof of Theorem 1.
## A.1 Linearity, symmetry and efficiency
Let's first show that the Shapley composition statisfies the linearity , symmetry and efficiency .
Proof.
Linearity: Let's consider the linear combination of predictions, or models, h x ( ) = α ⊙ f x ( ) ⊕ β ⊙ g x ( ).
$$\mathbb { S } ( \mathfrak { W } ). \\ \mathbb { E } _ { P r } ^ { A } [ h ( x ) \, | \, x _ { S } ] & = \text{il} ^ { - 1 } \left ( \mathbb { E } _ { P r } [ \text{il} \, ( \alpha \odot f ( x ) \oplus \beta \odot g ( x ) ) \, | \, x _ { S } ] \right ), \\ & = \text{il} ^ { - 1 } \left ( \mathbb { E } _ { P r } [ \text{al} \, \text{if} \, ( f ( x ) ) + \beta \text{il} \, ( g ( x ) ) \, | \, x _ { S } ] \right ), \\ & = \text{il} ^ { - 1 } \left ( \alpha \mathbb { E } _ { P r } [ \text{il} \, ( f ( x ) ) \, | \, x _ { S } ] + \beta \mathbb { E } _ { P r } [ \text{il} \, ( g ( x ) ) \, | \, x _ { S } ] \right ), \\ & = \alpha \odot \text{il} ^ { - 1 } \left ( \mathbb { E } _ { P r } [ \text{il} \, ( f ( x ) ) \, | \, x _ { S } ] \right ) \oplus \beta \odot \text{il} ^ { - 1 } \left ( \mathbb { E } _ { P r } [ \text{il} \, ( g ( x ) ) \, | \, x _ { S } ] \right ), \\ & = \alpha \odot \mathbb { E } _ { P r } ^ { A } [ f ( x ) \, | \, x _ { S } ] \oplus \beta \odot \mathbb { E } _ { P r } ^ { A } [ g ( x ) \, | \, x _ { S } ]. \\ \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfring { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \\ \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathsigma \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfra \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathfrak { S } \mathf ].$$
Similarly, E A Pr [ h x ( )] = α ⊙ E A Pr [ f x ( )] ⊕ β ⊙ E A Pr [ g x ( )].
Therefore, v h x , , Pr ( S ) = α ⊙ v f x , , Pr ( S ) ⊕ β ⊙ v g x , , Pr ( S ), meaning that v is linear with respect to the model. The linearity of the contribution c naturally follows:
∀
i
∈ I
,
∀
S
⊆ I\
i,
$$\forall i \in \mathcal { I }, \ \forall S \subseteq \mathcal { I } \{ i, \\ c _ { h, x, P r } ( i, S ) & = v _ { h, x, P r } ( S \cup \{ i \} ) \ominus v _ { h, x, P r } ( S ), \\ & = ( \alpha \odot v _ { f, x, P r } ( S \cup \{ i \} ) \oplus \beta \odot v _ { g, x, P r } ( S \cup \{ i \} ) ) \ominus ( \alpha \odot v _ { f, x, P r } ( S ) \oplus \beta \odot v _ { g, x, P r } ( S ) ), \\ & = \alpha \odot v _ { f, x, P r } ( S \cup \{ i \} ) \oplus \beta \odot v _ { g, x, P r } ( S \cup \{ i \} ) \ominus \alpha \odot v _ { f, x, P r } ( S ) \ominus \beta \odot v _ { g, x, P r } ( S ), \\ & = \alpha \odot ( v _ { f, x, P r } ( S \cup \{ i \} ) \ominus v _ { f, x, P r } ( S ) ) \oplus \beta \odot ( v _ { g, x, P r } ( S \cup \{ i \} ) \ominus v _ { g, x, P r } ( S ) ), \\ & = \alpha \odot c _ { f, x, P r } ( i, S ) \oplus \beta \odot c _ { g, x, P r } ( i, S ). \\ \text{And the linearity of the Shapley composition:}$$
And the linearity of the Shapley composition:
$$\text{And the linearity of the Shapley composition:} \\ \forall i \in \mathcal { I }, \ \phi _ { i } \left ( h \right ) & = \frac { 1 } { d! } \bigoplus _ { \pi } c _ { h, x, P _ { r } } ( i, \pi ^ { < i } ), \\ & = \frac { 1 } { d! } \bigoplus _ { \pi } \left ( \alpha \odot c _ { f, x, P _ { r } } ( i, S ) \oplus \beta \odot c _ { g, x, P _ { r } } ( i, S ) \right ), \\ & = \alpha \odot \left ( \frac { 1 } { d! } \bigoplus _ { \pi } c _ { f, x, P _ { r } } ( i, S ) \right ) \oplus \beta \odot \left ( \frac { 1 } { d! } \bigoplus _ { \pi } c _ { g, x, P _ { r } } ( i, S ) \right ), \\ & = \alpha \odot \phi _ { i } \left ( f \right ) \oplus \beta \odot \phi _ { i } \left ( g \right ). \\ \text{ Thus, the Shapley composition is linear on the Aitchison simplex as a function of the prediction.}$$
Thus, the Shapley composition is linear on the Aitchison simplex as a function of the prediction.
Symmetry is straightforward.
## Efficiency
$$\text{Ficiency} \begin{matrix} d \phi _ { i = 1 } ^ { d } \left ( f \right ) = \bigoplus _ { i = 1 } ^ { d } \left ( \frac { 1 } { d l } \odot \bigoplus _ { i } ^ { c } ( i, \pi ^ { < i } ) \right ), \\ & = \frac { 1 } { d l } \odot \bigoplus _ { i = 1 } ^ { d } \left ( \bigoplus _ { i } \left ( v ( \pi ^ { < i + 1 } ) \odot v ( \pi ^ { < i } ) \right ), \\ & = \frac { 1 } { d l } \odot \bigoplus _ { i = 1 } ^ { d } \left ( \left ( \bigoplus _ { i } v ( \pi ^ { < i + 1 } ) \right ) \odot \left ( \frac { \pi v ( \pi ^ { < i } ) } { \pi } \frac { \pi } { A _ { i } } \right ), \\ & = \frac { 1 } { d l } \odot \bigoplus _ { i = 1 } ^ { d } \left ( A _ { i + 1 } \odot A _ { i } \right ), \text{ since we have a telescoping perturbation,} \\ & = \frac { 1 } { d l } \odot \left ( \left ( \bigoplus _ { i } v ( \pi ^ { < d + 1 } ) \right ) \odot \left ( \bigoplus _ { i } v ( \pi ^ { < 1 } ) \right ) \right ), \\ & = \frac { 1 } { d l } \odot \left ( \left ( \bigoplus _ { i } v ( \mathbb { Z } ) \right ) \odot \left ( \bigoplus _ { i } v ( \mathfrak { Y } ) \right ), \\ & = v \left ( \mathcal { I } \right ) \odot v \left ( \mathfrak { Y } \right ), \text{ since } d! is the number of permutation, \\ & = f ( x ) \odot \mathbb { E } _ { \mathcal { I } _ { r } } ^ { r } [ f ( X ) ]. \\ \text{Thus, the Shapley composition is linear, symmetric and efficient.} \end{matrix} \quad \Box \end{matrix}$$
$$\Pr$$
Thus, the Shapley composition is linear , symmetric and efficient .
## A.2 Uniqueness
Let's now show the uniqueness of the quantity satisfying the above three axiomatic properties on the simplex. The proof is highly inspired by the proofs for the standard Shapley value in game theory [26, 21]. We first need the following Definition and Lemma.
Let's first consider the set G S D d of composition-valued set functions. This can be seen, in cooperative game theory, as the set of characteristic functions of games where the payoff, or worth, is a composition rather than a scalar. The function from Equation 8 is such function.
For simplicity of the notation, let's consider one isometric-log-ratio space R D -1 isomorphic to the simplex S D . We therefore consider instead the set G R D -1 d of vector-valued set functions 9 :
$$\mathcal { G } _ { d } ^ { \mathbb { R } ^ { D - 1 } } = \{ \tilde { v } \, \colon 2 ^ { \mathcal { I } } \rightarrow \mathbb { R } ^ { D - 1 } \ | \ \tilde { v } ( \emptyset ) = 0 \},$$
where I = { 1 2 , , . . . d } . G R D -1 d is (2 d -1)( D -1)-dimensional, since | 2 I | = 2 , and the d -1 corresponds to the empty set (with the constraint ˜( v ∅ ) = 0 ), and D -1 is the dimension of the functions' codomain.
9 The tilde refers to the isometric-log-ratio transformation of a composition.
Definition. Let { ˜ e ( ) i } 1 ≤ ≤ i D -1 be a linear basis of R D -1 . The i th-vector-unanimity game ( I , ˜ v ( ) i T ) , where T ⊆ I\∅ , is defined such that:
$$\forall S \subseteq \mathcal { I }, \quad \tilde { v } _ { T } ^ { ( i ) } ( S ) = \begin{cases} \tilde { e } ^ { ( i ) }, & \text{if $T \subseteq S$} \\ 0, & \text{otherwise.} \end{cases}$$
Lemma. The set { ˜ v ( ) i T ∈ G R D -1 d | T ⊆ I\∅ , 1 ≤ i ≤ D - } 1 forms a linear basis of G R D -1 d .
Proof. There are (2 d -1) × ( D -1) i th-vector-unanimity games, the same number as the dimensionality of G R D -1 d . We therefore just need to prove that they are linearly independent towards a contradiction.
Let's assume that:
̸
$$\sum _ { \substack { T \subseteq \mathcal { I } \\ 1 \leq i \leq D - 1 } } \alpha _ { T } ^ { ( i ) } \tilde { v } _ { T } ^ { ( i ) } = 0, \text{ and } \exists \, \alpha _ { T } ^ { ( i ) } \neq 0.$$
̸
Let T 0 be a set of minimal size in { T ⊆ I\∅ | ∃ α ( ) i T = 0 . }
Then,
̸
$$\sum _ { \substack { T \subseteq T \\ 1 \leq i \leq D - 1 } } \alpha _ { T } ^ { ( i ) } \tilde { v } _ { T } ^ { ( i ) } ( T _ { 0 } ) = \sum _ { \substack { T \subseteq T _ { 0 } \\ 1 \leq i \leq D - 1 } } \alpha _ { T } ^ { ( i ) } \tilde { v } _ { T } ^ { ( i ) } ( T _ { 0 } ),$$
̸
because, by definition of the i th-vector-unanimity game, for all T ⊆ I\∅ not in T 0 , ˜ v ( ) i T ( T 0 ) = 0 . And because, T 0 is the minimal set in { T ⊆ I\∅} such that ∃ α ( ) i T 0 = 0, ∀ T ⊂ T 0 and 1 ≤ i ≤ D -1, α ( ) i T = 0. Then,
̸
$$\sum _ { \substack { T \subset T \nwarrow \emptyset \\ 1 \leq i \leq D - 1 } } \alpha _ { T } ^ { ( i ) } \tilde { v } _ { T } ^ { ( i ) } ( T _ { 0 } ) & = \sum _ { 1 \leq i \leq D - 1 } \alpha _ { T _ { 0 } } ^ { ( i ) } \tilde { v } _ { T _ { 0 } } ^ { ( i ) } ( T _ { 0 } ), \\ & = \sum _ { 1 \leq i \leq D - 1 } \alpha _ { T _ { 0 } } ^ { ( i ) } \tilde { e } ^ { ( i ) } \neq 0, \\. \ \, \stackrel { \cdot } { \cdot }.$$
̸
This is indeed a contradiction. Therefore, the elements of { ˜ v ( ) i T ∈ G R D -1 d | T ⊆ I\∅ , 1 ≤ i ≤ D - } 1 are linearly independent and form a linear basis of G R D -1 d .
because ∃ α ( ) i T 0 = 0 and { ˜ e ( ) i } 1 ≤ ≤ i D -1 are linearly independent.
Corollary. The set { v ( ) i T = ilr -1 ( ˜ v ( ) i T ) ∈ G S D d | T ⊆ I\∅ , 1 ≤ i ≤ D - } 1 forms an Aitchison linear basis of G S D d , where v ( ) i T can be referred as a i th-composition-unanimity game.
Thus, any composition-valued set function v can be written with a unique set of alphas as:
$$\forall S \subseteq \mathcal { I }, \ v ( S ) = \bigoplus _ { \substack { T \subseteq \mathcal { I } \emptyset \\ 1 \leq i \leq D - 1 } } \alpha _ { T } ^ { ( i ) } \odot v _ { T } ^ { ( i ) } ( S ).$$
Let's now prove that for any composition-valued set function v ∈ G S D d , there is an unique set { ϕ k } 1 ≤ ≤ k d of composition-valued function that satisfies the three axiomatic properties.
Proof. Let's first show there is an unique set { ϕ k } 1 ≤ ≤ k d of composition-valued function that satisfies the three axiomatic properties for a powered i th-composition-unanimity game β ⊙ v ( ) i T where β ∈ R . With the linearity and the efficiency axiomatic properties, we have 10 :
$$\bigoplus _ { k \in T } \phi _ { k } \left ( \beta \odot v _ { T } ^ { ( i ) } \right ) = \beta \odot e ^ { ( i ) }, \text{ and } \forall j \notin T, \text{ } \phi _ { j } \left ( \beta \odot v _ { T } ^ { ( i ) } \right ) = u,$$
where { e ( ) i = ilr -1 ( ˜ e ( ) i ) } 1 ≤ ≤ i D -1 forms an Aitchison linear basis of the simplex, and u ∈ S D is the uniform distribution, i.e. the neutral element for the perturbation: u = ilr -1 ( 0 ).
Let ( k, l ) ∈ T 2 , ∀ S ⊆ I\{ k, l } , we have β ⊙ v ( ) i T ( S ∪ { k } ) = β ⊙ v ( ) i T ( S ∪ { } l ). Therefore, due to the symmetry , ϕ k ( β ⊙ v ( ) i T ) = ϕ l ( β ⊙ v ( ) i T ) such that ∀ k ∈ T the ϕ k are equal.
Thus,
$$\forall k \in \mathcal { I }, \quad \phi _ { k } \left ( \beta \odot v _ { T } ^ { ( i ) } \right ) = \begin{cases} \frac { \beta } { | T | } \odot e ^ { ( i ) }, & \text{if $k\in T$} \\ u, & \text{otherwise.} \end{cases}$$
Therefore, the set { ϕ k } 1 ≤ ≤ k d of composition-valued function, respecting the axiomatic properties, is uniquely defined for a powered i th-composition-unanimity game.
Finally, there is a unique set { ϕ k } 1 ≤ ≤ k d that satisfies the three axiomatic properties for any composition-valued set function since such function is uniquely represented by a linear combination of i th-composition-unanimity games and the functions in { ϕ k } 1 ≤ ≤ k d are linear with respect to the characteristic function.
10 In the core of the paper, the Shapley compositions are written as functions of a model. Here, without loss of generality, they are written as functions of a characteristic function.
## Appendix B Class-compositions
A k -class-composition c ( k ) ∈ S D is defined as an unit norm composition going straight to the direction of the k th class. This is a discrete probability distribution with maximum probability for the k th class and uniform values for the others. The i th part of c ( k ) is:
$$c _ { i } ^ { ( k ) } = \begin{cases} 1 - ( D - 1 ) p, & \text{if $i=k$} \\ p, & \text{otherwise}, \end{cases}$$
where 0 < p < 1 D . We want the Aitchison norm of each class-composition to be one:
$$\forall k \in \{ 1, \dots D \}, \quad \| c ^ { ( k ) } \| _ { \mathcal { A } } = 1 \iff \sqrt { \frac { 1 } { 2 D } \sum _ { i = 1 } ^ { D } \sum _ { j = 1 } ^ { D } \left ( \log \frac { c _ { i } ^ { ( k ) } } { c _ { j } ^ { ( k ) } } \right ) ^ { 2 } } = 1,$$
for clarity, we drop the superscript ( k ) from the equations,
$$\ m \ t n e \, \text{equations}, & \\ & \iff \sqrt { \frac { 1 } { 2 D } \sum _ { i = 1 } ^ { D } \left ( ( D - 1 ) \left ( \log \frac { c _ { i } } { p } \right ) ^ { 2 } + \left ( \log \frac { c _ { i } } { 1 - ( D - 1 ) p } \right ) ^ { 2 } \right ) } = 1, \\ & \iff \sqrt { \frac { 1 } { 2 D } 2 ( D - 1 ) \left ( \log \frac { p } { 1 - ( D - 1 ) p } \right ) ^ { 2 } } = 1, \\. & \quad \dots$$
since p < 1 D and the norm is positive:
$$\Pi \sin \text{ positive}. \\ \Longleftrightarrow & \sqrt { \frac { D - 1 } { D } } \log \frac { 1 - ( D - 1 ) p } { p } = 1, \\ \Longleftrightarrow & p = \frac { \exp \left ( - \sqrt { \frac { D } { D - 1 } } \right ) } { 1 + ( D - 1 ) \exp \left ( - \sqrt { \frac { D } { D - 1 } } \right ) }. \\ \L \text{-class-composition} \, c ^ { ( k ) } \in \mathcal { S } ^ { D } \text{ is given by} \colon$$
To summarise, the i th part of a k -class-composition c ( k ) ∈ S D is given by:
$$c _ { i } ^ { ( k ) } = \frac { 1 } { 1 + ( D - 1 ) \exp \left ( - \sqrt { \frac { D } { D - 1 } } \right ) } \left ( \begin{cases} 1, & \text{if $i=k$} \\ \exp \left ( - \sqrt { \frac { D } { D - 1 } } \right ), & \text{otherwise}, \end{cases} \right ).$$
In this way, c ( k ) is going straight to the direction of class k and uniformly against all the others with a unit norm.
## Appendix C Estimation of the Shapley compositions
This section presents the estimation algorithm we used to estimate the Shapley compositions in our experiments. The algorithm is an adaptation of Algorithm 2 in [28].
Let d be the number of features. We want to optimally distribute m max drawn samples over the d features. Let ˆ ϕ i be the estimation of the Shapley composition for the i th feature. We want to minimise the sum of squared errors: ∑ d i =1 ∥ ˆ ϕ i ⊖ ϕ i ∥ 2 A .
Since ˆ ϕ i is a (Aitchison) sample mean we have: ˜ ˆ ϕ i ≈ N ( ˜ ϕ i , 1 m i Σ ( ) i ) and ˜ ˆ ϕ i -˜ ϕ i ≈ N ( 0 , 1 m i Σ ( ) i )
where the tilde refers to the ILR transformation. Let ∆ i = ˆ ˜ ϕ i -˜ ϕ i and Z i = ∥ ˆ ϕ i ⊖ ϕ i ∥ A = ∥ ˜ ˆ ϕ i -˜ ϕ i ∥ 2 = ∥ ∆ i ∥ 2 . The expectation of the sum of squared errors is:
$$\text{the tilde{ } tilde{ } l d e r e t o r } \text{$tilde{ } tilde{ } l e $ + \theta _ { i } = \theta _ { i } - \phi _ { i } \text{ and } Z _ { i } = \| \phi _ { i } \Theta _ { i } \| _ { A } = \| \phi _ { i } - \phi _ { i } \| _ { 2 } = \\ \text{$tilde{ } l $ - $ t $ } \text{The expectation of the sum of squared errors is: } \\ \mathbb { E } \left [ \sum _ { i = 1 } ^ { d } Z _ { i } ^ { 2 } \right ] & = \sum _ { i = 1 } ^ { d } \mathbb { E } \left [ Z _ { i } ^ { 2 } \right ], \\ & = \sum _ { i = 1 } ^ { d } \mathbb { E } \left [ \sum _ { j = 1 } ^ { d - 1 } \Delta _ { i j } ^ { 2 } \right ], \\ & = \sum _ { i = 1 } ^ { d } \sum _ { j = 1 } ^ { d - 1 } \mathbb { E } \left [ \Delta _ { i j } ^ { 2 } \right ], \\ & = \sum _ { i = 1 } ^ { d } \sum _ { j = 1 } ^ { d - 1 } \frac { 1 } { m _ { i } } \Sigma _ { i j } ^ { ( i ) } \text{, since } \Delta _ { i j } \approx \mathcal { N } \left ( 0, \frac { 1 } { m _ { i } } \Sigma _ { i j } ^ { ( i ) } \right ), \\ & = \sum _ { i = 1 } ^ { d } \frac { 1 } { m _ { i } } \text{ tr } \Sigma ^ { ( i ) }. \\ \text{$hen a sample is drawn, the feature for which the sample will be used for improving the Shapley} \\ \text{sitution estimation is chosen to maximize } \frac { \tilde { \Sigma } ^ { ( i ) } } { \Sigma ^ { ( i ) } } - \frac { \tilde { \Sigma } ^ { ( i ) } } { \Sigma ^ { ( i ) } }. \text{ Like in } [ 28 ], this is summarised in$$
When a sample is drawn, the feature for which the sample will be used for improving the Shapley composition estimation is chosen to maximise tr Σ ( ) i m i -tr Σ ( ) i m i +1 . Like in [28], this is summarised in Algorithm 2.
Algorithm 1 Adaptation of the Algorithm 1 from [28] for approximating the Shapley composition of the i th feature, with model f , instance x ∈ X and m drawn samples.
$$\overline { \text{Initialise} } \, \phi _ { i } \stackrel { \ } \leftarrow \, \text{ilr} ^ { - 1 } ( 0 )$$
for 1 to m do
Randomly select a permutation π of the set of indexes I ,
Randomly select a sample w ∈ X ,
Construct two instances:
- · b 1 : which takes the values from x for the i th feature and the features indexed before i in the order given by π , and takes the values from w otherwise,
- · b 2 : which takes the values from x for the features indexed before i in the order given by π , and takes the values from w otherwise.
$$\begin{smallmatrix} & \phi _ { i } \leftarrow \phi _ { i } \oplus f ( b _ { 1 } ) \ominus f ( b _ { 2 } ) \\ \text{end for} \\ \phi _ { i } \leftarrow \frac { \phi _ { i } } { m } \end{smallmatrix}$$
Algorithm 2 Adaptation of the Algorithm 2 from [28] for approximating all the Shapley compositions by optimally distributing a maximum number of samples m max over the d features, with model f , instance x ∈ X and m min the minimum number of samples for each feature estimation.
$$\text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--}} \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{---} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ\text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{---}} \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{\text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--}" \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \text{--} \circ \end{cases}$$
## Appendix D Adjustement of the estimated Shapley compositions for efficiency
In practice, the computation of the Shapley values has an exponential time complexity and we do not have necessarily access to the true distribution of the data. The Shapley values are therefore approximated using estimation algorithms like for instance the one presented in the previous section. However, since the obtained values are approximations, they do not necessarily respect the desired efficiency property. This point is often overlooked in the literature. In this section, we write down an adjustment strategy of the estimated Shapley compositions for them to respect the efficiency property. This is a similar strategy as in the sampling approximation of the Shapley values in the SHAP toolkit 11 .
Let { ˆ ϕ i } 1 ≤ ≤ i d be the estimated Shapley compositions (given by the Algorithm 2 in our experid
$$\text{mets} \text{.} \text{ Let } s _ { e r r } = f ( x ) \ominus f _ { 0 } \ominus \bigoplus _ { i = 1 } ^ { * } \hat { \phi } _ { i }, \text{ where } f _ { 0 } \text{ is the base distribution, be the error composition} \\ \text{on } t h o n \text{ method to all} \text{s-how to add to the solution, use the above the solution}.$$
on the pertubation of all Shapley compositions, i.e. the error that makes the efficiency property unfulfilled. In order to respect the efficiency property, we want this error to be the neutral element of the perturbation, i.e. the 'zero' in the sense of the Aitchison geometry: the uniform distribution. We could simply perturb each estimated Shapley compositions by 1 d ⊙ s err however this would move each Shapley composition by the same amount while we want to allow the Shapley compositions with a higher estimation variance (i.e. with a precision likely to be lower) to move more than the Shapley compositions with a smaller estimation variance (i.e. with a precision likely to be higher).
The i th adjustment is therefore weighted by a scalar w i = w ( tr ( Σ ( ) i )) , where w is an increasing function, and where d ∑ i =1 w i = 1. Similarly to the SHAP toolkit implementation, we choose w as:
$$w _ { i } = w \left ( \text{tr} \left ( \Sigma ^ { ( i ) } \right ) \right ) = \frac { v _ { i } } { 1 + \sum _ { j = 1 } ^ { d } v _ { j } }, \text{ where } v _ { i } = \frac { \text{tr} \left ( \Sigma ^ { ( i ) } \right ) } { \epsilon \max _ { j } \text{tr} \left ( \Sigma ^ { ( j ) } \right ) }.$$
The i th estimated Shapley composition is then asjusted as follow:
$$\hat { \phi } _ { i } \leftarrow \hat { \phi } _ { i } \oplus ( w _ { i } \odot s _ { e r r } ) \,.$$
In this way, when ϵ goes to zero 12 , the efficiency property is respected for the adjusted Shapley compositions and more weight is given to the adjustments of the Shapley compositions with a higher estimation variance.
11 https://github.com/shap/shap/blob/master/shap/explainers/\_sampling.py
12 In our experiments, ϵ = 10 -6 .
## Acknowledgments
The work of PF and MPN was supported by TAILOR 13 , a European research network funded by the EU Horizon 2020 research and innovation programme under GA No 952215. This work wouldn't have happened without a research visit of PGN at the University of Bristol made possible by the TAILOR Connectivity Fund. The work of PGN and JFB was also supported by the LIAvignon chair.
We thank Telmo de Menezes e Silva Filho from the University of Bristol for suggesting parallel coordinates to visualise Shapley compositions. We also thank the anonymous reviewers for helpful comments.
## References
- [1] K. Aas, M. Jullum, and A. Løland. Explaining individual predictions when features are dependent: More accurate approximations to shapley values. Artificial Intelligence , 298:103502, 2021.
- [2] J. Aitchison. The statistical analysis of compositional data. Journal of the Royal Statistical Society. Series B (Methodological) , 44(2):139-177, 1982.
- [3] J. Aitchison. Simplicial inference. In D. S. P. R. Marlos A. G. Viana, editor, Algebraic Methods in Statistics and Probability , Contemporary Mathematics 287. American Mathematical Society, 2001.
- [4] J. Aitchison and S. M. Shen. Logistic-normal distributions: Some properties and uses. Biometrika , 67(2):261-272, 1980.
- [5] P. P. Angelov, E. A. Soares, R. Jiang, N. I. Arnold, and P. M. Atkinson. Explainable artificial intelligence: an analytical review. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 11(5):e1424, 2021.
- [6] D. W. Apley and J. Zhu. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. Journal of the Royal Statistical Society Series B: Statistical Methodology , 82 (4):1059-1086, 06 2020.
- [7] L. Breiman. Random forests. Machine learning , 45(1):5-32, 2001. Publisher: Springer.
- [8] A. Datta, S. Sen, and Y. Zick. Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems. In 2016 IEEE Symposium on Security and Privacy (SP) , pages 598-617, 2016.
- [9] J. J. Egozcue and V. Pawlowsky-Glahn. Groups of parts and their balances in compositional data analysis. Mathematical Geology , 37(7):795-828, 2005.
- [10] J. J. Egozcue and V. Pawlowsky-Glahn. Evidence information in bayesian updating. Proc. International Workshop on Compositional Data Analysis , 05 2011.
- [11] J. J. Egozcue and P.-G. Vera. Evidence functions: a compositional approach to information. SORT-Statistics and Operations Research Transactions , 1(2):101-124, Dec. 2018.
- [12] J. J. Egozcue, V. Pawlowsky-Glahn, G. Mateu-Figueras, and C. Barcelo-Vidal. Isometric logratio transformations for compositional data analysis. Mathematical geology , 35(3):279-300, 2003.
13 https://tailor-network.eu
| [13] | A. Fisher, C. Rudin, and F. Dominici. All models are wrong, but many are useful: Learning a variable's importance by studying an entire class of prediction models simultaneously. J. Mach. Learn. Res. , 20(177):1-81, 2019. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [14] | L. Franceschi, C. Zor, M. B. Zafar, G. Detommaso, C. Archambeau, T. Madl, M. Donini, and M. Seeger. Explaining multiclass classifiers with categorical values: A case study in radiography. In H. Chen and L. Luo, editors, Trustworthy Machine Learning for Healthcare , pages 11-24, Cham, 2023. Springer Nature Switzerland. |
| [15] | L. Franceschi, M. Donini, C. Archambeau, and M. Seeger. Explaining probabilistic models with distributional values. arXiv preprint arXiv:2402.09947 , 2024. |
| [16] | A. Goldstein, A. Kapelner, J. Bleich, and E. Pitkin. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. Journal of Computational and Graphical Statistics , 24(1):44-65, 2015. Publisher: Taylor & Francis. |
| [17] | B. M. Greenwell, B. C. Boehmke, and A. J. McCarthy. A simple and effective model-based variable importance measure. arXiv preprint arXiv:1805.04755 , 2018. |
| [18] | D. Gunning, M. Stefik, J. Choi, T. Miller, S. Stumpf, and G.-Z. Yang. Xai-explainable artificial intelligence. Science Robotics , 4(37):eaay7120, 2019. doi: 10.1126/scirobotics.aay7120. |
| [19] | A. Lamens and J. Bajorath. Explaining multiclass compound activity predictions using counter- factuals and shapley values. Molecules , 28(14), 2023. |
| [20] | S. M. Lundberg and S.-I. Lee. A unified approach to interpreting model predictions. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30 , pages 4765-4774. Curran Associates, Inc., 2017. |
| [21] | R. B. Myerson. Game theory . Harvard university press, 1997. |
| [22] | P.-G. No´. e Representing evidence for attribute privacy: bayesian updating, compositional evidence and calibration . PhD thesis, Universit´ e d'Avignon, 2023. |
| [23] | V. Pawlowsky-Glahn, J. J. Egozcue, and R. Tolosana-Delgado. Modeling and Analysis of Compositional Data . John Wiley & Sons, 2015. |
| [24] | F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, et al. Scikit-learn: Machine learning in python. the Journal of machine Learning research , 12:2825-2830, 2011. |
| [25] | M. T. Ribeiro, S. Singh, and C. Guestrin. 'why should i trust you?': Explaining the predictions of any classifier. KDD '16, page 1135-1144, New York, NY, USA, 2016. Association for Computing Machinery. |
| [26] | L. S. Shapley et al. A value for n-person games. In Contributions to the Theory of Games II , pages 307-317. Princeton University Press Princeton, 1953. |
| [27] | K. Sokol and P. Flach. Explainability fact sheets: a framework for systematic assessment of explainable approaches. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency , FAT* '20, page 56-67, New York, NY, USA, 2020. Association for Computing |
| [28] | E. ˇ Strumbelj and I. Kononenko. Explaining prediction models and individual predictions with feature contributions. Knowledge and information systems , 41:647-665, 2014. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [29] | L. V. Utkin, A. V. Konstantinov, and K. A. Vishniakov. An imprecise SHAP as a tool for explaining the class probability distributions under limited training data. arXiv preprint arXiv:2106.09111 , 2021. |
| [30] | L. V. Utkin, A. Petrov, and A. Konstantinov. Modifications of shap for local explanation of function-valued predictions using the divergence measures. In D. G. Arseniev and N. Aouf, editors, Cyber-Physical Systems and Control II , pages 52-64, Cham, 2023. Springer International Publishing. |
| [31] | T.-F. Wu, C.-J. Lin, and R. Weng. Probability estimates for multi-class classification by pairwise coupling. Advances in Neural Information Processing Systems , 16, 2003. |
| [32] | T. K. Yoo, I. H. Ryu, H. Choi, J. K. Kim, I. S. Lee, J. S. Kim, G. Lee, and T. H. Rim. Explainable Machine Learning Approach as a Tool to Understand Factors Used to Select the Refractive Surgery Technique on the Expert Level. Translational Vision Science & Technology , 9(2):8-8, 02 2020. | | 10.3233/FAIA240605 | [
"Paul-Gauthier Noé",
"Miquel Perelló-Nieto",
"Jean-François Bonastre",
"Peter Flach"
]
| 2024-08-02T16:40:58+00:00 | 2025-02-12T10:18:06+00:00 | [
"cs.LG",
"cs.GT"
]
| Explaining a probabilistic prediction on the simplex with Shapley compositions | Originating in game theory, Shapley values are widely used for explaining a
machine learning model's prediction by quantifying the contribution of each
feature's value to the prediction. This requires a scalar prediction as in
binary classification, whereas a multiclass probabilistic prediction is a
discrete probability distribution, living on a multidimensional simplex. In
such a multiclass setting the Shapley values are typically computed separately
on each class in a one-vs-rest manner, ignoring the compositional nature of the
output distribution. In this paper, we introduce Shapley compositions as a
well-founded way to properly explain a multiclass probabilistic prediction,
using the Aitchison geometry from compositional data analysis. We prove that
the Shapley composition is the unique quantity satisfying linearity, symmetry
and efficiency on the Aitchison simplex, extending the corresponding axiomatic
properties of the standard Shapley value. We demonstrate this proper multiclass
treatment in a range of scenarios. |
2408.01383v1 | ## PLIC-Net: A Machine Learning Approach for 3D Interface Reconstruction in Volume of Fluid Methods
Andrew Cahaly a, ∗ , Fabien Evrard , Olivier Desjardins b a a Sibley School of Mechanical and Aerospace Engineering, Cornell University, Ithaca, 14853, NY, USA b Department of Aerospace Engineering, University of Illinois Urbana-Champaign, Urbana, 61801, Il, USA
## Abstract
The accurate reconstruction of immiscible fluid-fluid interfaces from the volume fraction field is a critical component of geometric Volume of Fluid methods. A common strategy is the Piecewise Linear Interface Calculation (PLIC), which fits a plane in each mixed-phase computational cell. However, recent work goes beyond PLIC by using two planes or even a paraboloid. To select such planes or paraboloids, complex optimization algorithms as well as carefully crafted heuristics are necessary. Yet, the potential exists for a well-trained machine learning model to e ffi ciently provide broadly applicable solutions to the interface reconstruction problem at lower costs. In this work, the viability of a machine learning approach is demonstrated in the context of a single plane reconstruction. A feed-forward deep neural network is used to predict the normal vector of a PLIC plane given volume fraction and phasic barycenter data in a 3 × 3 × 3 stencil. The PLIC plane is then translated in its cell to ensure exact volume conservation. Our proposed neural network PLIC reconstruction (PLICNet) is equivariant to reflections about the Cartesian planes. Training data is analytically generated with O (10 6 ) randomized paraboloid surfaces, which allows for the sampling a broad range of interface shapes. PLIC-Net is tested in multiphase flow simulations where it is compared to standard LVIRA and ELVIRA reconstruction algorithms, and the impact of training data statistics on PLIC-Net's performance is also explored. It is found that PLIC-Net greatly limits the formation of spurious planes and generates cleaner numerical break-up of the interface. Additionally, the computational cost of PLIC-Net is lower than that of LVIRA and ELVIRA. These results establish that machine learning is a viable approach to Volume of Fluid interface reconstruction and is superior to current reconstruction algorithms for some cases.
© 2024. This manuscript version is made available under the CC-BY-NC-ND 4.0 license. http://creativecommons.org/licenses/by-nc-nd/4.0
Keywords: Volume of Fluid, PLIC, Interface Reconstruction, Machine Learning
## 1. Introduction
The accurate representation of the interface that separates immiscible fluids is a key challenge in the simulation of multiphase flows. The di ffi culty arises from needing to capture detailed interface features and handle topology changes robustly while also conserving volume. Out of the major approaches to this problem, interface capturing methods have shown a great ability to handle complex topology changes, such as in liquid atomization, by using an implicit interface representation. The Volume of Fluid (VOF) method (Hirt and Nichols, 1981) is a popular choice among interface capturing methods since it can be designed to be exactly volume conservative.
VOF starts by representing the phasic distribution using a binary indicator function, which assigns one of the fluid regions (e.g., the gas) a value of 0 and the other region (e.g., the liquid) a value of 1. When discretized in a finite volume method, the normalized zeroth order spatial moment of
∗ Corresponding Author.
Email address: [email protected] (Andrew Cahaly)
the indicator function becomes the liquid volume fraction α , which represents in each cell the ratio of liquid volume to the volume of the cell. While each Eulerian grid cell possesses a volume fraction such that 0 ≤ α ≤ 1, cells with 0 < α < 1 have both phases present and must therefore contain the interface. To transport the volume fraction field, the material transport equation
$$\frac { \omega u } { \partial t } + u \cdot \nabla \alpha = 0 \quad \quad \quad ( 1 )$$
can be used in most circumstances, where t is time and u is the fluid velocity assumed to be continuous at the interface. The numerical integration of Eq. 1 is susceptible to various errors such as numerical di ff usion, which is equivalent to numerical mixing between the liquid and gas and ultimately leads to the loss of the concept of an interface. To prevent these numerical di ff usion errors from smearing the α field while avoiding oscillations, geometric VOF methods first reconstruct a sharp interface from the local α field. The most common technique to accomplish this is the Piecewise Linear Interface Calculation (PLIC) method (Youngs, 1982).
PLIC fits linear functions (planes in 3D) in each interfacial cell such that the volume fraction in the cell is exactly conserved. The accuracy of the reconstructed interface, and of the overall simulation, is thus dependent on the accurate calculation of these planes from the volume fractions.
There are many existing optimization algorithms to recover a linear reconstruction from the volume fractions. Two of the most common are the LVIRA and ELVIRA algorithms proposed by Pilliod and Puckett (2004). LVIRA reconstructs the PLIC plane in the center cell of a stencil (typically a 3 × 3 × 3 cell stencil). The cost function for the optimization is the L 2 loss between the actual volume fraction field in the stencil and the volume fractions created by a plane cutting through the stencil cells. The algorithm imposes the constraint that the plane must reproduce the center cell's volume fraction exactly, and rotates the plane until the loss function is minimized. ELVIRA also uses a stencil of cells to reconstruct the center cell plane. Instead of rotating a plane in the stencil to minimize the L 2 volume fraction loss, ELVIRA chooses a normal vector from a list of candidates. The candidate normal vectors are found with the backward, central, and forward di ff erences of the stencil volume fractions in each direction, and the one that produces the lowest L 2 volume fraction loss is selected. The LVIRA and ELIVRA methods are frequently used in the literature for high fidelity multiphase simulations (e.g., Vu et al. (2023) and Kuhn and Desjardins (2023)).
However, there are limitations to PLIC methods. Aside from the inherent inaccuracy of representing curved surfaces with planes, it is impossible to resolve sub-grid features with a single plane per cell, leading to artificial break-up of ligaments and sheets once their thickness approaches the mesh size. Furthermore, due to the linear nature of the reconstruction, the calculated curvature displays limited convergence with grid size (Han et al., 2024a). To address these limitations, alternative methods have been developed. The Reconstruction with 2 Panes (R2P) method (Chiodi, 2020; Han et al., 2024b) can resolve sub-grid features such as thin films by optimally placing two planes inside a single cell. This technique has been successfully used in cases such as drop breakup in turbulent cross-flows (Han, 2024). Meanwhile, the new Piecewise Parabolic Interface Calculation (PPIC) method of Evrard et al. (2023) uses a paraboloid representation of the interface in each cell to approximate films and ligaments at the sub-grid scale and provide converging curvature within a single cell. The optimal placement of two planes or of a paraboloid in a cell is a challenging task that requires advanced optimization techniques and carefully crafted heuristics. Instead, a well-trained machine learning model has the potential to provide broadly applicable solutions at lower costs.
Machine Learning (ML) has recently seen increased interest for use in multiphase flow simulations, including in VOF and PLIC. Research by Qi et al. (2019) used ML to predict interface curvatures from the volume fractions for 2D cases. Using a feed-forward neural network with two hidden layers, a 3 × 3 stencil of volume fractions was used to predict the center cell curvature. The network was trained using data generated from circular interfaces. This work highlighted that neural networks can provide highly accurate predictions of interface quantities in VOF methods. Patel et al. (2019) expanded on this work by implementing the approach in 3D, using again a 3 × 3 × 3 stencil of cells as input and spherical data for network training. The model was shown to achieve similar accuracy to the conventional Height Function approach to interface curvature (Hirt and Nichols, 1981). Onder and Liu (2023) further developed the ¨ 2D curvature ML method by invoking symmetries to create a neural network that was invariant to symmetry transformations.
Meanwhile, there have also been attempts to predict properties of a PLIC plane with ML. Ataei et al. (2021) proposed using a neural network to predict the position of a PLIC plane in its cell given the plane's normal vector and the cell's volume fraction. Like with the other ML approaches discussed, they made use of a feed-forward neural network but only considered data from a single cell as the input. To find the PLIC normal vector n for the input, the researchers used the gradient of the volume fraction field n = - ∇ α ||∇ α || , which provides an approximate solution. The approach of Ataei et al. (2021) was successfully tested in a flow solver. Predictions of the plane location given its normal vector may provide computational cost benefits in some applications, but on Cartesian meshes, analytical methods that directly conserve the cell phasic volume with the plane location are fast and guarantied to be volume conservative (Scardovelli and Zaleski, 2000). In contrast, an accurate prediction of the PLIC normal vector is a much more challenging problem. Nakano et al. (2022) used a graphical neural network to predict interface normal vectors on unstructured meshes with promising accuracy, although they did not demonstrate its use in a flow solver. They used paraboloid training data to more accurately represent the curved nature of the interface. Meanwhile, Svyetlichnyy (2018) trained a neural network to predict PLIC normal vectors on structured grids. They first considered a 2D case trained with circular data. Svyetlichnyy then extended the approach to 3D by projecting the 3D data onto two 2D coordinate planes and using the 2D neural network to predict the two projected vectors. Then, the 3D vector was calculated from the projections. Svyetlichnyy reported good accuracy with this approach in 2D but did not test the model with 3D multiphase simulations. Thus, if neural networks are to be a viable alternative to techniques such as LVIRA, and be considered for more complicated interface reconstruction methods, their ability to accurately predict usable interface normal vectors for complex 3D simulations remains to be clearly demonstrated.
In the present work, a 3D machine learning interface reconstruction method is developed and used for VOF simulations. This ML approach is referred to as PLIC-Net. PLICNet is trained to predict the normal vector of PLIC planes. The resulting planes are then translated in their cells to conserve the phasic volume using analytical relations. A deep feed-forward artificial neural network with 3 hidden layers
and 100 neurons per hidden layer is used. The inputs are the phasic volume fractions of a 3 × 3 × 3 stencil of cells and the phasic barycenters (i.e., the normalized first spatial moments of the indicator function). This is a notable di ff erence from typical VOF reconstruction algorithms, which usually only consider zeroth order moments, and is a similarity to Moment of Fluid (MOF) methods (Dyadechko and Shashkov, 2005). While MOF uses higher order moments from only a single cell to reconstruct interfaces, PLIC-Net considers neighboring cells in the input data. The training data is generated with analytical paraboloid data, with the average surface normal vector in the cell being the target. The neural network is equivariant to reflections about the Cartesian planes. After evaluating the accuracy of PLIC-Net on test data, it is applied to advection test cases in the Interface Reconstruction Library 1 (IRL) (Chiodi and Desjardins, 2022) and then deployed in the NGA2 flow solver 2 (Desjardins et al., 2008) for several multiphase simulation cases. The results of these simulations are comparable with LVIRA and ELVIRA in accuracy, but show significant reduction in the tendency to generate spurious planes, leading to cleaner numerical break-up of the interface. PLIC-Net is also found to have a lower computational cost than LVIRA and ELVIRA.
Section 2 describes the methods used to construct PLICNet, generate the training data, enforce symmetry, train the neural network, and deploy it in a flow solver. Section 3 presents a range of tests and a discussion of the performance of PLIC-Net. Section 4 contains the conclusions of this work.
## 2. Methods
## 2.1. Machine Learning Model
An artificial Neural Network (NN) is constructed to predict the PLIC normal vector by using the phasic volume fractions and barycenters as input. A 3 × 3 × 3 cell stencil is used, providing 27 volume fractions ( α ) as input. Moreover, each stencil cell also provides two phasic barycenters with three coordinates each, leading to 189 total inputs to the neural network. These phasic barycenters correspond to the normalized first order volume moments of each phase in the cell, x l and x g . They are transported alongside the volume fraction field, which is commonly done when using geometric VOF advection schemes (Dyadechko and Shashkov, 2005; Le Chenadec and Pitsch, 2013; Owkes and Desjardins, 2017). The NN input layer is followed by three fully connected hidden layers with 100 neurons each. The output layer contains three neurons for the three components of the interface normal vector in the central cell of the stencil. The output layer is linearly connected with the last hidden layer, while the hidden layers and input layer all have the ReLu activation function applied between them to introduce nonlinearity. A Mean Squared Error (MSE) loss function is used
1 https: // github.com robert-chiodi interface-reconstruction-library / /
2 https: // github.com desjardi NGA2 / /
on the normal vector components, and the Adam optimizer is used for back-propagation. The MSE loss is defined as
$$M S E = & \frac { 1 } { 3 N } \sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { 3 } ( n _ { i j } ^ { t } - n _ { i j } ^ { p } ) ^ { 2 }, \text{ \quad \ \ } ( 2 )$$
where N is the number of data, n t i j is the j th component of the i th target normal vector, and n p i j is the j th component of the i th predicted normal vector. The NN itself can be represented as
$$\ s \text{ gen} ^ { - } _ { \substack { \bullet \\ e \text{ sur} } } \in \nu ^ { 0 0 } _ { i j } & = \sum _ { n = 1 } ^ { 1 0 0 } w _ { j n } ^ { \circ } R e L u \left [ \sum _ { m = 1 } ^ { 1 0 0 } w _ { n m } ^ { h 3 } R e L u \left [ \sum _ { k = 1 } ^ { 1 0 0 } w _ { m k } ^ { h 2 } R e L u \left [ \sum _ { l = 1 } ^ { 1 8 9 } ( w _ { k l } ^ { h 1 } X _ { i l } ) \\ \intertext { n \text{ test} } \ e \text{ Re} ^ { - } _ { k } & \quad + b _ { k } ^ { h 1 } \right ] + b _ { m } ^ { h 2 } \right ] + b _ { n } ^ { h 3 } \right ] + b _ { j } ^ { \circ }, \\ \intertext { 2 0 2 2 } \text{ in } \text{ where } w ^ { \circ } \text{ are the weights for the output layer, } w ^ { h 1 }, w ^ { h 2 }, \text{ and}$$
where w o are the weights for the output layer, w h 1 , w h 2 , and w h 3 are the weights for the first, second, and third hidden layers, respectively, b o are the biases for the output layer, b h 1 , b h 2 , and b h 3 are the biases for the first, second, and third hidden layers, respectively, and X is the input data. X was constructed as a vector of the volume fractions and barycenters: Xi = [ α , i 1 , x l i , 1 , x g i , 1 , . . . , α i , 27 , x l i , 27 , x g i , 27 ]. A schematic of the NN is shown in Figure 1.
As will be discussed later in more detail, the architecture of PLIC-Net has not been optimized for computational efficiency. The purpose of this work is to establish the viability of the machine learning reconstruction approach, and the optimization of the architecture will be the subject of future work. The proposed neural network is likely larger than necessary for this particular problem, including the output layer. Strictly speaking, when predicting a normalized normal vector, only two outputs are required: the vector's two angles. Outputting the three components of the vector allows the neural network to predict the magnitude of the vector if provided with training data that is not normalized. One of the future intended uses of PLIC-Net is to predict such a magnitude that can be used to decide between a one-plane or two-plane reconstruction in a given cell, which explains the choice to predict all three components in this work. However, this will also be the subject of future work and only normalized vectors are considered in this work.
## 2.2. Training Data
In order to capture a broad range of interface shapes, paraboloids are randomly generated in the 3 × 3 × 3 cell stencils to provide training data. While there is no expectation that all phase interfaces are contained in the subset of paraboloid surfaces, paraboloids provide for a sound local approximation of any surface and should greatly outperform spherical training data since the two principal curvatures can be independently varied. Morevover, paraboloids allow for the representation of highly curved shapes that resemble films and ligaments, two commonly found shapes in multiphase flows. The paraboloid surfaces are defined with eight coe ffi cients: two curvature coe ffi cients a and b , three orientation angles θ , ϕ , and γ , and the three coordinates of
Figure 1: Schematic of the artificial neural network. Three sample paraboloids used to generate the input data ( α , x l , x g ) are shown on the left. The grey box represents the 3 3 stencil of cells.
an origin position d . The angle θ is defined as rotation about the x -axis, ϕ as rotation about the y -axis, and γ as rotation about the z -axis. The origin is defined as the point of maximum curvature for elliptic paraboloids and as the saddle point for hyperbolic paraboloids. A paraboloid's reference frame ( x ′ , y ′ , z ′ ) can be defined by transforming the Cartesian coordinates ( x y z , , ) using
$$x ^ { \prime } = ( x - d _ { x } ) \cos \theta \cos \phi + ( y - d _ { y } ) ( \sin \gamma \sin \theta \cos \phi \quad \text{forma} \\ - \cos \gamma \sin \phi ) + ( z - d _ { z } ) ( \cos \gamma \sin \theta \cos \phi + \sin \gamma \sin \phi ), \quad ( 4 ) \quad \text{herein}$$
$$y ^ { \prime } & = ( x - d _ { x } ) \cos \theta \sin \phi + ( y - d _ { y } ) ( \sin \gamma \sin \theta \sin \phi \\ & + \cos \gamma \cos \phi ) + ( z - d _ { z } ) ( \cos \gamma \sin \theta \sin \phi - \sin \gamma \cos \phi ), \quad ( 5 ) \quad \text{ments}$$
$$z ^ { \prime } = ( x - d _ { x } ) \sin \theta + ( y - d _ { y } ) \sin \gamma \cos \theta & & \text{accur} \\ & + ( z - d _ { z } ) \cos \gamma \cos \theta. & ( 6 ) & & \text{Th}$$
distribution of a and b can have a large impact on the behavior of PLIC-Net. Thus, multiple datasets are created with di ff erent choices: one with the values of a and b randomly selected with a normal distribution with a mean of 0 and a standard deviation of 0 3 (leading to Neural Network 1, or . NN1), one with a and b values randomly chosen between -2 and 2 with uniform distribution (NN2), and one with a and b set to 0 to create purely planar data (NN3). The performance of the three networks for PLIC-Net is compared hereinafter. It must be noted that the curvature ranges for NN2 include high curvature cases with corresponding volume moments that could not be produced by a static PLIC calculation. However, during the transport of volume moments in complex simulations with high curvature features, such volume fraction data can be encountered and must be handled. Thus, although PLIC reconstructions become inaccurate for such high curvatures, preparing PLIC-Net for these extreme cases is desirable.
In this transformed reference frame, the paraboloid is then given by
$$z ^ { \prime } = a x ^ { \prime 2 } + b y ^ { \prime 2 }. \quad \quad \ \ ( 7 ) \quad \widehat { \Phi }$$
For each randomly generated paraboloid, d is placed within the center cell of the stencil with a uniform random distribution. The cells are given 1 × 1 × 1 dimension. The values of θ , ϕ , and γ are all randomly selected between 0 and 2 π with a uniform distribution. The choice for the ranges and
The phasic volume fractions and their first moments resulting from the paraboloids clipping the stencil cells are analytically calculated with the method of Evrard et al. (2023). The first moments are normalized by the volume fractions such that they represent the actual barycenter local of their respective phase in a given cell. Each barycenter has its reference origin at the center of its respective cell, meaning that the data and resulting neural network is invariant to translations. Each data-point contains the 27 volume fractions from the stencil along with the liquid and gas barycenters from
each stencil cell. The analytical average surface normal vector of the paraboloid in the center cell is calculated to use as the target in the training data. Note that the normal vector magnitude is normalized to 1.
It was found that introducing perturbations to the barycenters in the training data improves the performance of the neural network when used in a flow solver by reducing the number of spurious planes. As a result, for each training paraboloid, there is an 87.5% chance that the position of the barycenters is perturbed. That perturbation is selected from a random uniform distribution, at most ± 20%, and capped so that the barycenters remain in their respective cell. The volume fractions and corresponding normal vectors are not perturbed in this process.
## 2.3. Reflection Symmetry
In order to improve the robustness of PLIC-Net, enhance its training on smaller data-sets, and make it equivariant to reflections about the Cartesian planes, the symmetries of the data are considered. Symmetry with respect to the fluid-fluid interface is applied by switching the volume fractions to the opposite phase and swapping the order of the liquid and gas barycenters in the data when the center cell volume fraction is larger than 0.5. The direction of the normal vector is also flipped. To invoke reflection symmetries about the Cartesian planes, the global phase barycenter in the stencil is calculated. First order phasic geometric moments of the whole stencil are calculated given the phasic volume fractions and barycenters from the individual stencil cells. The global phase barycenter is then found by normalizing these stencil geometric moments by the total phasic volume in the stencil. Since the reference frame origin is located at the center of the stencil, the signs of the components of this global barycenter are checked to determine in which of the eight Cartesian octants it is located. If it is not in the first octant (all positive components), then the volume fractions and the phasic barycenters are reflected about the required Cartesian planes such that it brought back into the first octant. For example, if the global barycenter has a negative x component, then the data is reflected about the y -z plane. The same transformations can then be applied to the corresponding normal vector, which results in input data for only the first octant but with simple mappings back to the original octant.
## 2.4. Neural Network Training
The C ++ distribution of PyTorch (LibTorch) is used to train PLIC-Net. A million paraboloids are randomly generated, with 70% used for training, 15% for validation, and 15% for testing. The learning rate is set initially to 10 -4 . A warm restart is performed at 2000 epochs, where the learning rate is decreased to 10 -5 . Training is executed until the validation loss converged in order to prevent over-fitting to the training data. Training is done synchronously on a high performance computing cluster and parallelized using MPI. Each core is responsible for a batch of the data. This training process is done for each of the three datasets mentioned above, leading to the three neural networks NN1, NN2, and NN3.
## 2.5. Flow Solver Implementation
The machine learning code is implemented directly into the open-source Interface Reconstruction Library (IRL) (Chiodi and Desjardins, 2022), and translation and deformation advection test cases are run within IRL. The opensource NGA2 flow solver (Desjardins et al., 2008) is then used in combination with IRL to test PLIC-Net in multiphase flow simulations. In order to increase computational e ffi ciency, the code to execute the forward pass of PLICNet is also directly written into NGA2. To prepare the data for PLIC-Net, the phase is flipped if the central cell volume fraction is larger than 0.5, the volume fractions and barycenters at any given time step are rotated to the first octant as necessary, and the barycenters are scaled by the cell sizes in each direction. This first octant data is then passed to PLIC-Net. The resulting normal vector is returned from the neural network, rotated back to the original octant, flipped as needed, and the PLIC plane with that normal vector is then located in its cell so that the original volume fraction is conserved exactly. Test cases are run for a falling drop into a pool, the head-on collision between two drops, and the aerobreakup of a droplet exposed to a cross-flow. NGA2 solves the two-phase Navier-Stokes equations with a one-fluid formulation. Away from the interface, the flow solver is second order in time and space and discretely mass, momentum, and kinetic energy conserving. At the interface, local discontinuities slightly degrade the methods and although mass is still discretely conserved and momentum is approximately conserved, kinetic energy conservation is lost. The surface tension force is calculated using the continuous surface force approach (Brackbill et al., 1992) while the interface curvature is obtained from parabolic surface fits (Jibben et al., 2019). As studied in Han et al. (2024a), this curvature estimation provides a good compromise between low errors and computational cost and is shown to have lower errors than the Height Function method (Hirt and Nichols, 1981) for dynamic tests. In all cases (pure advection and NGA2 cases), advection of the volume fraction field is performed using the unsplit geometric advection method of Owkes and Desjardins (2014). Note that, as mentioned in Section 2.1, phasic barycenters for each cell are also transported along with the volume fractions, thus making the barycenter data directly available for PLIC-Net to use.
## 3. Results and Discussion
## 3.1. Neural Network Training and Testing Performance
Figure 2 shows the MSE loss over the epochs for the training and validation datasets, which are very close to each other during training for all three of the neural networks. In NN1, the training loss converges to 5 3 . × 10 -5 after 102,000 epochs. NN2 converges to 1 7 . × 10 -4 after 152,000 epochs, and NN3 converges to 1 6 . × 10 -6 after 38,000 epochs. It
Figure 2: Convergence plot of PLIC-Net's error (MSE) over the training epochs for the training and validation datasets
is not surprising that NN3 converges to the lowest error in the fewest epochs since it has purely planar training data, which results in significantly simpler data to learn. Conversely, NN2 has the highest loss due to its wider range of input data.
Figure 3 shows plots of the predicted normal vectors from the test datasets against the target normal vectors. Tables 1, 2, and 3 contain the corresponding equations for the lines of best fit and their R 2 values, in which nx p , ny p , and nz p are the x , y , and z components of the predicted normal vector, respectively, and n t x , n t y , and n t z are the x , y , and z components of the target normal vector, respectively.
Table 1: Linear regression equations and R 2 values for the test dataset on NN1.
| | x -component | y -component | z -component |
|------------|------------------------------------------|------------------------------------------|------------------------------------------|
| Linear Fit | n p x = 0 . 9995 n t x + 2 . 78 × 10 - 4 | n p y = 0 . 9992 n t y + 3 . 24 × 10 - 4 | n p z = 0 . 9992 n t z + 3 . 18 × 10 - 4 |
| R 2 | 0.9995 | 0.9993 | 0.9993 |
Table 2:
Linear regression equations and
R
2
values for the test dataset on
NN2.
| | x -component | y -component | z -component |
|------------|------------------------------------------|------------------------------------------|------------------------------------------|
| Linear Fit | n p x = 0 . 9983 n t x + 9 . 20 × 10 - 4 | n p y = 0 . 9979 n t y + 9 . 07 × 10 - 4 | n p z = 0 . 9981 n t z + 9 . 31 × 10 - 4 |
| R 2 | 0.9982 | 0.9979 | 0.9979 |
Table 3: Linear regression equations and R 2 values for the test dataset on NN3.
| | x -component | y -component | z -component |
|------------|------------------------------------------|------------------------------------------|------------------------------------------|
| Linear Fit | n p x = 1 . 0000 n t x - 2 . 10 × 10 - 4 | n p y = 1 . 0000 n t y - 5 . 31 × 10 - 5 | n p z = 1 . 0000 n t z - 3 . 07 × 10 - 4 |
| R 2 | 1.0000 | 1.0000 | 1.0000 |
The linear fits are all very close to the ideal of n p = n t , and the R 2 values are all very close to 1. NN3 has minimal scatter and the best linear fits, which is again not surprising given its simpler data. Meanwhile, NN2 has the largest scatter and worst fits with a non-trivial amount of outliers, although the overall accuracy is still high. NN1 lies between these extremes in terms of scatter and linear fit.
## 3.2. Advection Test Cases
## 3.2.1. Translation and Grid Convergence
Simple advection test cases performed within IRL use a prescribed velocity to advect the volume fraction field. A pure translation case was first run to establish a preliminary benchmark of PLIC-Net against the LVIRA optimization algorithm. Note that while LVIRA or ELVIRA are used as references when assessing the performance of PLIC-Net hereinafter, these methods typically cannot be considered fully 'correct' solutions. For example, as multiple interfaces are advected into the same cell, it is impossible for any PLIC method to produce an exact solution. Therefore, by comparing PLIC-Net with LVIRA or ELVIRA, the objective is not to replicate their solutions. Rather, it is to show that PLICNet can provide alternative solutions that can be considered at least on par with, but potentially substantially di ff erent than, an LVIRA or ELVIRA solution.
The domain for the translation case was set to be a unit cube with a sphere of radius 0.25 initialized in the center. It was given a non-dimensional velocity in the x direction of 1, in the y direction of 2 3 , and in the z direction 1 3 . Periodic boundary conditions were imposed such that the sphere would return to its initial position after a non-dimensional time of 3. A constant CFL number of 0.8 was used. Cases were run with 5, 10, 20, 40, 80, and 160 grid cells in each direction. The L 1 error of the volume fraction field between the final state and the initial state was calculated to study error convergence with grid size. LVIRA is known to converge with 2 nd order accuracy. However, there is no expectation that a neural network reconstruction should converge under grid refinement. A time series of the LVIRA and NN1 drop translation cases are shown in Figure 4 for the case with 10 grid cells in each direction. PLIC-Net displays a qualitatively smoother reconstruction than LVIRA and appears to have slightly less shape distortion between the initial and final states. This shape distortion was quantitatively analyzed with the convergence study. The resulting convergence plot is shown in Figure 5. Although PLIC-Net has no analytical proof of convergence, it still demonstrates approximately 2 nd order convergence for many of the grid sizes before eventually plateauing at the highest resolution. It must be noted that this study does not decouple transport error from reconstruction error. Since the transport error in this simulation was 2 nd order, a likely interpretation of these results is that transport error dominates over reconstruction error for much of the range of grid sizes. Any convergence of the actual reconstruction error from PLIC-Net plateaus as the grid size decreases, which eventually results in it dominating over the
Figure 3: Scatter plots of the predicted normal vector components vs. the target normal vector components from the test datasets (black dots). The line of best linear fit is shown in red in each plot.
converging transport error. But, for most of the range of grid sizes studied, the errors from PLIC-Net are close to those from LVIRA, and are in fact lower for many of the grid sizes. This shows that machine learning can be used to create a PLIC reconstruction method that performs on par with, if not better than, LVIRA and maintains e ff ective convergence for a useful range of grid sizes.
## 3.2.2. Deformation and Numerical Surface Tension
A deformation advection case was run to test PLIC-Net's performance in a more complex advection problem with higher curvatures. The domain was set to be a unit cube with a sphere of radius 0.15 initialized at x = 0 35, . y = 0 35, . and z = 0 35, in reference to the center of the cubic domain. . Cases were run with the 3D deformation velocity field defined by LeVeque (1996), given non-dimensionally by
$$u = 2 \sin ^ { 2 } \left ( \pi x \right ) \sin \left ( 2 \pi y \right ) \sin \left ( 2 \pi z \right ) \cos \left ( \frac { \pi t } { 3 } \right ), \quad \left ( 8 \right ) \quad \text{ use.}$$
$$v = - \sin \left ( 2 \pi x \right ) \sin ^ { 2 } \left ( \pi y \right ) \sin \left ( 2 \pi z \right ) \cos \left ( \frac { \pi t } { 3 } \right ), \quad ( 9 )$$
$$w = - \sin \left ( 2 \pi x \right ) \sin \left ( 2 \pi y \right ) \sin ^ { 2 } \left ( \pi z \right ) \cos \left ( \frac { \pi t } { 3 } \right ), \quad ( 1 0 )$$
where u , v , and w are the velocities in the x , y , and z directions, respectively, and t is the non-dimensional time. The simulations were run until t = 1 5 with a time step of 0.008. . There were 50 grid cells in each direction, and the maximum CFL number was 0.8.
Time series from the LVIRA and NN1 models are shown in Figure 6. As the drop deforms, a thin film begins to develop. When the film thickness decreases towards the size of the grid cells, numerical break-up occurs. With LVIRA, some spurious planes develop near the high curvature edges that form after break-up. The number of these planes grows as the film becomes thinner and numerical break-up continues. A closeup of these spurious planes is shown in Figure 7. Meanwhile, NN1 has a cleaner breakup with fewer spurious
Figure 4: Time series of the translation advection case. (a), (b), and (c) are with LVIRA and (d), (e), and (f) are with NN1. All times are non-dimensional.
Figure 5: Convergence plot of the shape error with grid size for the translation advection case with LVIRA and with NN1. N is the number of grid cells in each coordinate direction.
Figure 6: Time series of the deformation advection case.
Figure 7: Closeup of the final state of the LVIRA deformation advection case to show the spurious planes developing near the film breakup.

Figure 8: Final states from the deformation advection case using (a) NN2 and (b) NN3.
planes that do not propagate. However, it is observed that its numerical break-up happens with slightly thicker films than with LVIRA, which implies that NN1 has a higher numerical surface tension. The numerical surface tension can be controlled in PLIC-Net with the range and distribution of curvatures used in the training data. Figure 8 shows the final states of cases run with NN2 and NN3. NN3 was trained with only planar data and thus no interface curvature was considered. The numerical surface tension is very high for this case which causes early break-up. Meanwhile, NN2 had a uniform distribution of paraboloid curvature coe ffi cients between -2 and 2 in the training data, and it seems to delay and reduce numerical break-up. Both NN2 and NN3 also have few spurious planes. This illustrates that the choices when sampling training data directly impact the nature of numerical break-up in PLIC-Net, opening avenues for controlling and fine-tuning that behavior.
## 3.3.
## Flow Solver Test Cases
## 3.3.1. Falling Drop
A simulation of a liquid drop falling into a pool was run in the NGA2 flow solver in conjunction with the IRL. The liquid and gas viscosities were set to 1 137 . × 10 -3 kg m -1 s -1 and 1 780 . × 10 -5 kg m -1 s -1 , respectively, while the liquid and gas densities were set to 1000 kg m -3 and 1 226 kg m . -3 , respectively. The surface tension coe ffi cient was set to 0 0728 N m . -1 . The domain was set to be 0.01 m with 40 cells in the x direction, 0.02 m with 80 cells in the y direction, and 0.01 m with 40 cells in the z direction. A liquid sphere with radius 0.002 m was initialized at 0.01 m above the y minus domain boundary. The liquid pool had its free surface initialized at y = 0 00401 m. Gravity was set in the . negative y direction at 9 81 m s . -2 . Periodic boundary conditions were used in the x and z directions, and walls at the top and bottom in the y direction. A maximum time step of 1 × 10 -4 s was used with a maximum allowed CFL number of 0.9, which included the capillary time step constraint. Cases were run with LVIRA, ELVIRA, and PLIC-Net. The simulations were stopped after 0.1 s of simulation time. During this time, the drop accelerates downward and violently impacts the pool, leading to an intense splash, gas film entrapment, and Worthington jet formation.
The main di ff erence between the reconstruction methods in this case is the treatment of the change of topology when the drop collides with the pool. Figure 9 shows the aftermath of the collision for each reconstruction. LVIRA creates a thin and slightly disorganized cluster of planes below the surface that separates from the drop and then stays relatively close to the surface. ELVIRA produces a large number of spurious planes and has a very disorganized appearance. Meanwhile, the behavior of PLIC-Net once again depends on the training dataset used. As discussed in section 3.3.2, the e ff ective numerical surface tension in PLIC-Net is directly controlled by the distribution of interface curvatures in the training data. NN3, trained only on planar data, exhibits a quick separation of a single gas bubble under the interface, which is better organized than with LVIRA. Unlike with LVIRA, this bubble continues to move downwards in the pool before rising again due to buoyancy and colliding with the interface. NN1 and NN2 both capture a subsurface gas film that resembles the thin structure captured by LVIRA. But, both are qualitatively more organized except for a few spurious planes.
This example case highlights how the distribution of training data can cause PLIC-Net's performance to vary significantly. Since NN2 was shown a relatively wide and uniform distribution of curvature data, it struggles to accurately reconstruct the simple flat interface of the free surface before the drop collides with it. This is qualitatively apparent in the simulation results since LVIRA, ELVIRA, and NN3 both reproduce the flat interface very well (LVIRA and ELVIRA exactly reproduces it by design), while NN2 has a disjointed interface with tilted planes. Conversely, NN3 struggles with higher curvature data when compared to NN2. This point can be illustrated quantitatively by measuring the loss of PLIC-Net when given paraboloid data for a range of small to large curvatures with a and b set to be equal. For this study, 1000 paraboloids are created for each dataset, with random orientations and locations in the center cell of the stencil, taken to be of size ∆ x = 1. The paraboloid curvature coe ffi -cients a and b are initially set to 2, and then halved in each successive dataset. The MSE of each normal vector component is calculated (compared to the paraboloid surface normal), and then those values are themselves averaged. Note that this study is equivalent to a static grid refinement error convergence test with constant curvature. Figure 10 contains
Figure 9: Interface reconstructions from falling drop case at time t = 0 0365 s. .

Figure 10: Average of the mean squared errors between predicted and expected normal vector components vs. paraboloid principal curvature ( κ ) (using a = b ) normalized by the cell size ( ∆ x ) for NN1, NN2, and NN3. LVIRA and ELIVRA are shown for comparison along with the line of second order accuracy.
the results of this comparison, and LVIRA and ELIVRA are included for reference. The neural networks generally perform better on lower curvature data than higher curvature data since it is easier to learn the simpler data. However, out of the three training sets, NN3 shows the lowest error for very low curvatures and the highest error for most higher curvature data, while NN2 is the worst at low curvature data and the best at the highest curvatures. Note that NN2 exhibits little variation in its error over the di ff erent curvatures when compared to NN1 and NN3. NN1 tends to fall between NN2 and NN3, except at moderate curvatures where it is the best. It is also interesting to note the very similar errors of LVIRA, ELVIRA, and NN3, which shows that LVIRA and ELVIRA have some similarities to a neural network that has never been shown curved interface data.
The fact that NN2 has a consistently low error for most of these curvatures suggests that a uniform distribution of data is largely e ff ective. However, its performance for very low curvatures is a notable disadvantage. NN1, as shown in the previous results, tends to perform in-between NN2 and NN3 by most metrics, which suggests its normal distribution of curvature data prepared it well for a variety of situations at low and high curvatures. This makes NN1 a suitable choice for many simulations. Still, there is no expectation that the actual distribution of curvatures in any given simulation is normal, especially with the chosen mean and standard deviation. On the contrary, there are plenty of example cases that have highly custom distributions that are not close to being normal, such as this particular falling drop case which has a disproportionate amount of flat interfaces. Therefore, it is desirable to train PLIC-Net with a well-sampled dataset that reflects reality. Determining what might constitute this optimal dataset requires more attention and will be the subject of future work, and the use of the normal distribution in this example was simply to demonstrate how di ff erent distributions can lead to reconstructions with improved results in certain simulations and worse results in others. Still, the falling drop simulation has shown that PLIC-Net is a viable method in practical multiphase flow simulations with violent dynamics and non-trivial topology changes.
## 3.3.2. Drop Collision
This example case involved the head-on collision of two identical drops. The fluid properties are the same as in the falling drop case. The triply-periodic domain was set to be 0.01 m with 40 cells in the x direction, 0.02 m with 80 cells in the y direction, and 0.01 m with 40 cells in the z direction. Two liquid spheres with radii of 0.002 m were initialized at 0.015 m and 0.005 m above the y minus domain boundary, respectively. The drop velocities were initialized to be 0 52 m s . -1 (one in the + y direction, the other in the -y direction). There was no gravity in this case. A maximum time step of 1 × 10 -4 s was used with a maximum allowed CFL number of 0.9, which included the capillary time step constraint. Cases were run with LVIRA, ELVIRA, and PLICNet. The simulations were stopped after 0.1 s of simulation time.
All reconstruction methods predict that the drops merge and flatten before rebounding and stretching into a narrow structure. As the stretching continues, the middle of the structure begins to neck until the drops separate again, except with ELVIRA where no separation occurs. Figure 11 shows the time series for all of the reconstructions. LVIRA produces clusters of spurious planes near the points of separation along with a third drop where the necking occurred. It is also noted that LVIRA and ELVIRA lose symmetry during the simulation. Since the drops are initialized as symmetrical and the collision is head-on, it would be expected
Figure 11: Time series of the colliding drops case at times t = 0 009 s, . t = 0 03 s, . t = 0 0575 s, and . t = 0 064 s (from left to right). .














Figure 12: Time series from the drop in a cross-flow simulations. Interface is colored by its curvature. All times are non-dimensional.
| | t = 92 |
|----|------------------|
| 2 | |
| 2 | 1.6e+01 -1.3e+01 |



that the necking and separation would also be symmetrical. However, the numerical nature of the drop merging process led to LVIRA and ELVIRA having the rebound and necking occur in an asymmetrical manner. Meanwhile, NN1 and NN2 produce very similar overall results to each other and are similar to LVIRA, except with very few spurious planes and a slightly larger third drop. The primary drops also rebound slightly further than with LVIRA. Almost all of the few spurious planes that do form are quickly reabsorbed into the resolved drops, and symmetry is mostly preserved. NN3, by contrast, behaves more similarly to ELVIRA by having a much smaller necking region and shorter rebound of the primary drops. However, NN3 still predicts that the drops separate, although it does not produce a third drop. As commented on previously, this is likely due to its high numerical surface tension, which resulted from its planar training data. These results are in general agreement with the falling drop simulation and advection cases, in which NN3 exhibited very high numerical surface tension with quick break-up while NN1 and NN2 were more similar to LVIRA. In this case, NN1 and NN2 behave much more similarly to each other than in the previous results, which suggests that the level of numerical surface tension in NN1 and NN2 are similar in certain simulations. As previously observed, it is found that PLIC-Net limits the formation of spurious planes and generally produces cleaner interfaces and numerical breakup than LVIRA and ELVIRA.
## 3.3.3. Drop in a Cross-Flow
To test PLIC-Net in a complex flow with catastrophic interface break-up, a drop in a cross-flow was finally considered. Using the cross-flow velocity, drop diameter, and gas properties as reference, the Reynolds number was set to 100 and the gas Weber was set number to 20. The liquid-togas viscosity and density ratios were 50 and 1000, respectively. The domain was set to be 20 diameters with 320 cells in the x direction, 10 diameters with 160 cells in the y direction, and 10 diameters with 160 cells in the z direction. A liquid drop was initialized two diameters away from the left side of the domain (i.e., the x minus domain boundary). A uniform cross-flow velocity is applied using Dirichlet on the left, a clipped Neumann outflow is applied on the right. The y and z directions use periodic conditions. A maximum time step of 0.04 was used with a maximum CFL number of 1, which included the capillary time step constraint. Cases were run with LVIRA, ELVIRA, and PLIC-Net until a nondimensional time of 100.
Current research (Han, 2024) demonstrates how twoplane reconstructions and physics-based break-up modeling can be successfully used for flow problems similar to this one to create results in agreement with experiments. However, this work considers only single-plane reconstructions without physics-based break-up modeling. Thus, numerical break-up dominates as soon as interfacial scales fall below the cell size. In this case, all of the reconstruction methods predict that as the drop is carried downstream, it flattens and then a thin bag begins to expand in the downstream di- rection. As the bag expands, it becomes thinner until numerical break-up is triggered. This results in a ligament forming from the rim of the bag and many other smaller drops and ligaments forming from the thinner part of the bag. Figure 12 shows the reconstructions with LVIRA, ELVIRA, NN1, NN2, and NN3. With LVIRA and ELVIRA, there are many spurious planes created during numerical bag breakup. LVIRA creates a field of smaller spurious planes near the center of the bag, while ELVIRA creates larger spurious planes that develop later than with LVIRA. In contrast, PLIC-Net once again generally exhibits much cleaner numerical break-up with few, if any, spurious planes. In agreement with the previous cases, the numerical surface tension controls how quickly break-up occurs, with NN3 breaking up with thicker films than NN2 or NN1. This higher numerical surface tension also leads to fewer droplets and ligaments downstream with NN3. NN1 and NN2 once again lead to similar reconstructions, although the lower numerical surface tension with NN2 is apparent in this case.
The work by Han (2024) modified this case to have a turbulent cross-flow instead of a uniform flow. In order to prevent run-to-run variance caused by the turbulence when comparing results, no turbulence was considered in the above cases. However, PLIC-Net is capable of handling the addition of turbulence without any reduction in the quality of the reconstruction. While LVIRA and ELVIRA still produce many spurious planes in the turbulent case, PLIC-Net maintains its clean break-up without spurious planes. An example is shown with NN1 in Figure 13. Overall, in both the uniform and turbulent inflow velocity cases, PLIC-Net performs very well and produces solutions that are comparable to the expected behavior from experiments (Opfer et al., 2023), except for the inability to capture the thin liquid film. These results demonstrate that PLIC-Net can be used in complex flow simulations as an alternative to LVIRA and ELVIRA. Thus, this work successfully establishes the groundwork to continue the development and deployment of neural networks in multiphase flow reconstructions.
## 3.4. Computational Cost
One of the potential benefits of using neural networks for interface reconstruction is a reduction in computational cost when compared to optimization-based techniques. However, the single-plane PLIC reconstruction performed by LVIRA or ELVIRA can be implemented to be very e ffi cient, therefore it was not necessarily expected for PLIC-Net to achieve lower cost than these methods. In contrast, newer PLIC alternatives such as the Reconstruction with 2 Planes (R2P) (Chiodi, 2020) and the Piecewise Parabolic Interface Calculation (PPIC) (Evrard et al., 2023) are more complex and expensive, and could benefit greatly from a machine learning formulation. While the primary objective was to demonstrate the viability of machine learning approaches for interface reconstruction, this section provides a brief discussion of timing results.
The time spent performing the interface reconstruction for each mixed-phase cell was measured for the falling drop
Figure 13: NN1 used in a case with a drop in a turbulent cross-flow undergoing numerical breakup. The velocity magnitude is shown at the domain boundaries.
simulation discussed in Section 3.3.1. For these time comparisons, the simulations were run on a single core of an Intel i7-10750H CPU. The average CPU time for NN1 to reconstruct a plane was 9 13 . × 10 -6 s with a standard deviation of 4 64 . × 10 -6 s, while the average CPU time with LVIRA was 1 04 . × 10 -5 s with a standard deviation of 7 51 . × 10 -6 s. It must be noted that this implementation of LVIRA was highly optimized for computational e ffi ciency. In fact, in this case LVIRA was found to be faster than ELVIRA. ELVIRA had an average CPU time of 1 91 . × 10 -5 s with a standard deviation of 6 42 . × 10 -6 s. Therefore, not only is the quality of the PLIC-Net reconstruction often superior to LVIRA and ELVIRA, but it also benefits from a slightly lower computational cost.
## 4. Conclusion
In this work, a machine learning approach called PLICNet was successfully used to reconstruct interfaces in multiphase flow simulations. A 3 layer neural network used the volume fractions and phasic barycenters in a 3 × 3 × 3 cells stencil to predict the normal vector of a PLIC plane. PLICNet was made equivariant to reflections about the Cartesian planes by invoking symmetries with respect to the global phase barycenter in the stencil. The training data was constructed using the analytically-calculated volume moments of paraboloids clipping the cells, which allowed for two principal curvatures to be varied in the training data. When testing PLIC-Net in simulations, it was observed that the distribution of the principal curvatures in the training data is di- rectly correlated with the apparent numerical surface tension of the reconstruction. Meanwhile, the error convergence with grid size in a sphere advection case was studied and it was found that PLIC-Net maintained the convergence order of the transport scheme for a wide range of resolution. Thus, despite not having a proof of convergence on its own, there was no significant impact on the overall convergence when using PLIC-Net. In fact, PLIC-Net's error was lower than LVIRA's error for most of the grid sizes considered. When deployed in more complex multiphase flow simulations, PLIC-Net limited the generation of spurious planes in the reconstruction, which are numerous with LVIRA and ELVIRA in many cases. The overall reconstructions were always at least comparable with LVIRA, and often were qualitatively smoother and displayed cleaner numerical break-up. In addition, the computational cost of PLIC-Net was found to be lower than LVIRA and ELVIRA. Therefore, not only are machine learning approaches viable and at least on par with traditional methods, they can o ff er notable benefits.
Future work will continue to determine the best distributions of curvatures in the training data, which has the potential to improve PLIC-Net's general performance. However, it must be noted that the curvature data's influence is mostly on a purely numerical process: the break-up of under-resolved PLIC interfaces. Although it is important to have a neural network that can accurately reconstruct to the limit of grid resolution, any single plane reconstructions at smaller scales are inherently inaccurate on their own. Thus, future work will also expand the machine learning approach to two-plane and paraboloid reconstructions and physics-
based break-up modeling. It must also be noted that the architecture of the neural network itself was not varied during this work, and finding an ideal number of hidden layers, neurons per layer, and proper activation functions will be investigated in future work.
## Acknowledgements
- F. Evrard was funded by the European Union's Horizon 2020 research and innovation program under the Marie Skłodowska-Curie Grant Agreement No. 101026017.
## References
- Ataei, M., Bussmann, M., Shaayegan, V., Costa, F., Han, S., and Park, C., 2021. NPLIC: A machine learning approach to piecewise linear interface construction. Comp. & Fluids 223, Article 104950.
- Brackbill, J., Kothe, D., and Zemach, C., 1992. A continuum method for modeling surface tension. J. Comp. Phys. 100(2), pp. 335-354.
- Chiodi, R., 2020. Advancement of numerical methods for simulating primary atomization. Ph.D. Thesis, Cornell University, 2020.
- Chiodi, R. and Desjardins, O., 2022. General, robust, and e ffi cient polyhedron intersection in the Interface Reconstruction Library. J. Comp. Phys. 449, Article 110787.
- Desjardins, O., Blanquart, G., Balarac, G, and Pitsch, H., 2008. High order conservative finite di ff erence scheme for variable density low Mach number turbulent flows. J. Comp. Phys. 227, pp. 7125-7159.
- Dyadechko, V. and Shashkov, M., 2005. Moment-of-fluid interface reconstruction. Technical report, Los Alamos National Laboratory (LA-UR05-7571).
- Evrard, F., Chiodi, R., Han, A., Wachem, B., and Desjardins, O., 2023. First moments of a polyhedron clipped by a paraboloid. SIAM 45(5), pp. A2250-A2274.
- Han, A., 2024. Numerical modeling for mesh-independent simulations of spray atomization. Ph.D. Thesis, Cornell University, 2024.
- Han, A., Evrard, F., and Desjardins, O., 2024. Comparison of methods for curvature estimation from volume fractions. Int. J. Multiphase Flows 174, Article 104769.
- Han, A., Chiodi, R., and Desjardins, O., 2024. Capturing thin structures in VOF simulations with two-plane reconstruction. In review for publication in J. Comp. Phys.
- Hirt, C. and Nichols, B., 1981. Volume of fluid (VOF) method for the dynamics of free boundaries. J. Comp. Phys. 39(1), pp. 201-225.
- Kuhn, M. and Desjardins, O., 2023. A numerical study of an atomizing jet
- in a resonant acoustic field. Int. J. Multiphase Flows 167, Article 104522. Jibben, Z., Carlson, N., and Francois, M, 2019. A paraboloid fitting technique for calculating curvature from piecewise-linear interface reconstructions on 3D unstructured meshes. Comput. Math. Appl. 78(2), pp. 643-653.
- Le Chenadec, V. and Pitsch, H., 2013. A monotonicity preserving conservative sharp interface flow solver for high density ratio two-phase flows. J. Comp. Phys. 249, pp. 185-203.
- LeVeque, R., 1996. High-resolution conservative algorithms for advection in incompressible flow. SIAM 33(2), pp. 627-665.
- Nakano, T., Bucci, M., Gratien, J., Faney, T., and Charpiat, G., 2022. Machine learning model for gas-liquid interface reconstruction in CFD simulations. 8th ECCOMAS Congress, 5-9 June 2022, Oslo, Norway.
- ¨ nder, O A. and Liu, P., 2023. Deep learning of interfacial curvature: a symmetry-preserving approach for the volume of fluid method. J. Comp. Phys. 485, Article 112110.
- Opfer, L., Roisman, I., Venzmer, J., Klostermann, M., and Tropea, C., 2014. Droplet-air collision dynamics: Evolution of the film thickness. Phys. Rev. E 89, Article 013023.
- Owkes, M. and Desjardins, O., 2014. A computational framework for conservative, three-dimensional, unsplit, geometric transport with application to the volume-of-fluid (VOF) method. J. Comp. Phys. 270, pp. 587612.
- Owkes, M. and Desjardins, O., 2017. A mass and momentum conserving unsplit semi-Lagrangian framework for simulating multiphase flows. J. Comp. Phys. 332, pp. 21-46.
- Patel, H., Panda, A., Kuipers, J., and Peters, E., 2019. Computing interface curvature from volume fractions: A machine learning approach. Computers and Fluids 193, Article 104263
- Pilliod, J. and Puckett, E., 2004. Second-order accurate volume-of-fluid algorithms for tracking material interfaces. J. Comp. Phys. 199(2), pp. 465-502
- Qi, Y., Lu, J., Scardovelli, R., Zaleski, S., and Tryggvason, G., 2019. Computing curvature for volume of fluid methods using machine learning. J. Comp. Phys. 377, pp. 155-161.
- Scardovelli, R. and Zaleski, S., 2000. Analytical relations connecting linear interfaces and volume fractions in rectangular grids. J. Comp. Phys. 164, pp. 228-237.
- Svyetlichnyy, D., 2018. Neural networks for determining the vector normal to the surface in CFD, LBM and CA applications. Int. J. Num. Methods for Heat & Fluid Flow 28(8), pp. 1754-1773.
- Vu, L., Machicoane, N., Li, D., Morgan, T., Heindel, T., Aliseda, A., and Desjardins, O., 2023. A computational study of a two-fluid atomizing coaxial jet: Validation against experimental back-lit imaging and radiography and the influence of gas velocity and contact line model. Int. J. Multiphase Flows 167, Article 104520.
- Youngs, D., 1982. Time-dependent multi-material flow with large fluid distortion. Num. Methods for Fluid Dynamics 1982, pp. 273-285 | 10.1016/j.ijmultiphaseflow.2024.104888 | [
"Andrew Cahaly",
"Fabien Evrard",
"Olivier Desjardins"
]
| 2024-08-02T16:41:16+00:00 | 2024-08-02T16:41:16+00:00 | [
"physics.comp-ph",
"physics.flu-dyn"
]
| PLIC-Net: A Machine Learning Approach for 3D Interface Reconstruction in Volume of Fluid Methods | The accurate reconstruction of immiscible fluid-fluid interfaces from the
volume fraction field is a critical component of geometric Volume of Fluid
(VOF) methods. A common strategy is the Piecewise Linear Interface Calculation
(PLIC), which fits a plane in each mixed-phase computational cell. However,
recent work goes beyond PLIC by using two planes or even a paraboloid. To
select such planes or paraboloids, complex optimization algorithms as well as
carefully crafted heuristics are necessary. Yet, the potential exists for a
well-trained machine learning model to efficiently provide broadly applicable
solutions to the interface reconstruction problem at lower costs. In this work,
the viability of a machine learning approach is demonstrated in the context of
a single plane reconstruction. A feed-forward deep neural network is used to
predict the normal vector of a PLIC plane given volume fraction and phasic
barycenter data in a $3\times3\times3$ stencil. The PLIC plane is then
translated in its cell to ensure exact volume conservation. Our proposed neural
network PLIC reconstruction (PLIC-Net) is equivariant to reflections about the
Cartesian planes. Training data is analytically generated with
$\mathcal{O}(10^6)$ randomized paraboloid surfaces, which allows for sampling a
wide range of interface shapes. PLIC-Net is tested in multiphase flow
simulations where it is compared to standard (E)LVIRA reconstruction
algorithms, and the impact of training data statistics on PLIC-Net's
performance is also explored. It is found that PLIC-Net greatly limits the
formation of spurious planes and generates cleaner numerical break-up of the
interface. Additionally, the computational cost of PLIC-Net is lower than that
of (E)LVIRA. These results establish that machine learning is a viable approach
to VOF interface reconstruction and is superior to current reconstruction
algorithms for some cases. |
2408.01384v2 | ## NOLO: Navigate Only Look Once
## Bohan Zhou School of Computer Science Peking University
## Zhongbin Zhang Department of Automation Tsinghua University
[email protected]
## Jiangxing Wang School of Computer Science Peking University
[email protected]
## Abstract
The in-context learning ability of Transformer models has brought new possibilities to visual navigation. In this paper, we focus on the video navigation setting, where an incontext navigation policy needs to be learned purely from videos in an offline manner, without access to the actual environment. For this setting, we propose N avigate O nly L ook O nce (NOLO), a method for learning a navigation policy that possesses the in-context ability and adapts to new scenes by taking corresponding context videos as input without finetuning or re-training. To enable learning from videos, we first propose a pseudo action labeling procedure using optical flow to recover the action label from egocentric videos. Then, offline reinforcement learning is applied to learn the navigation policy. Through extensive experiments on different scenes both in simulation and the real world, we show that our algorithm outperforms baselines by a large margin, which demonstrates the in-context learning ability of the learned policy. For videos and more information, visit our project page.
## 1. Introduction
Visual navigation has long become a research focus due to its wide application in different fields, including mobile robots [18], autonomous vehicles [38], and virtual assistants [22]. Existing approaches to visual navigation can be broadly divided into two main categories: modular and end-to-end methods. Modular methods decompose the navigation problem into specific tasks, such as simultaneous localization and mapping, object segmentation, keypoint
* Corresponding author
[email protected]
## Zongqing Lu * School of Computer Science Peking University BAAI
[email protected]
matching, and depth estimation [14-16, 45, 91]. End-to-end methods [10, 37, 77], on the other hand, bypass such modularization, directly learning the mappings from raw sensory observations (e.g., GPS and Compass [31, 65], RGBD cameras [34], and IMU [58]) to action outputs. While these approaches have yielded promising results, they still face significant challenges, particularly in terms of generalizability. Modular methods can be brittle when transferred to unfamiliar environments. End-to-end approaches mainly focus on online learning [16, 17, 88], which requires continuous, interactive engagement with simulated or real environments. Thus, they may require additional interactions or exploration to adapt to novel scenes, complicating their deployment in real-world navigation settings.
To address these limitations, it is helpful to consider how humans intuitively navigate. We can often find our way through unfamiliar spaces after watching a simple traversal video. Our navigation abilities do not depend on precise positional data or distance measurement. Instead, we rely primarily on visual recognition, understanding, and memory. Building on this insight, we introduce a new visual navigation setting called Video Navigation , which mirrors how humans rely on visual observations to navigate. In video navigation, a mobile agent is provided with a context video of an unfamiliar environment and learns to reach any target seen in the video. For instance, a sweeping robot equipped with video navigation capabilities could immediately navigate and clean any area within a house after viewing a short video of its layout. We believe video navigation has immense potential for endowing mobile agents with humanlike navigation capabilities. Although encouraging, achieving robust video navigation poses considerable challenges:
- · Limited Observations. Learning to navigate from egocentric traversal videos is challenging due to a lack of
vation ent
o
t
at
···
···
t
Figure 1. The framework of NOLO. An offline collected egocentric video is taken by a pretrained GMFlow action decoder to label pseudo action sequence { ˆ a t } T -1 1 . An in-context video navigation policy π θ ( ·| g, o t , { f t } T 1 , { ˆ a t } T -1 1 ) , modeled by VN ⟲ Bert, is learned to take all context frames { f t } T 1 , labeled actions { ˆ a t } T -1 1 , a current observation o t and a goal image g to generate discrete actions to navigate to the desired target in a novel scene.
information, including actual actions, spatial cues, scene structure, and visual context.
- · Absence of Explicit Intent. Egocentric videos lack clear navigational intentions, making conventional methods like inverse reinforcement learning unsuitable, as these approaches typically require expert trajectory data.
- · Minimal Sensory Input. Camera intrinsics, robot poses, maps, odometers, or depth inputs are not necessary for video navigation, which distinguishes our work from others. A majority of existing methods prefer to build explicit spatial maps for planning with heterogeneous sensors. In this work, we aim to enable human-like navigation using only egocentric RGB observations.
Fundamentally, the objective of video navigation is to train a meta-policy that enables a robot to adapt to a novel scene-essentially, to navigate anywhere using cues from a context video. Recent research demonstrates that in-context learning (ICL [23]) excels at solving tasks using a few contextual demonstrations without requiring additional training [7] and has proven valuable across fields from LLMbased agents [85] to meta-learning [48, 49, 55]. Inspired by the success of ICL, we propose N avigate O nly L ook O nce (NOLO) , which learns a transferable in-context navigation policy conditioned on a context video, enabling adaptation to new scenes without fine-tuning or further re-training.
To achieve this, we collect a dataset of egocentric traversal videos, each covering a unique scene. We derive pseudoactions from these context videos using optical flow, gener- ating full frame-action trajectories, and then employ an offline reinforcement learning approach to train the navigation policy. This resource-efficient offline training pipeline eliminates the need for time-consuming online interactions, enabling large-scale training on simulated data and facilitating the transfer of navigation skills to unfamiliar environments. Furthermore, NOLO's in-context adaptability makes it particularly suitable for real-world deployment, where frequent policy adjustments are often impractical.
Our key contributions can be summarized as follows:
- · We present a novel and practical setting Video Navigation , which necessitates learning an in-context navigation policy in an offline manner purely from videos such that the learned policy can adapt to different scenes by taking corresponding videos as context.
- · We propose NOLO to solve the video navigation problem. NOLO seamlessly incorporates optical flow into offline reinforcement learning via pseudo-action labeling. To encourage the temporal coherence of representation, we further propose a temporal coherence loss for temporally aligned context visual representation.
- · Empirical evaluations on RoboTHOR and Habitat benchmarks demonstrate the advantages of NOLO over baselines in video navigation. Notably, navigation is achieved by only viewing a single 30-second video clip per scene. We further deploy NOLO on the Unitree Go2 robot and experiments verify that NOLO is also effective and friendly to real-world deployment.
···
f
T
-
2
## 2. Related Work
Visual Navigation. The visual navigation problem can be categorized into indoor navigation [11, 30, 33, 42, 46, 51, 54, 60, 61, 77, 93] and outdoor navigation [52, 76, 86]. In this paper, we only focus on the indoor navigation problem. Current research mainly focuses on finding the location of specific positions [41, 65], rooms [62], or object instances [41, 44, 45, 50]. The goals of navigation can be described in coordinates [65], natural language [10, 68, 90, 91, 94], goal image of target position [62, 90, 91], or goal image of object instances [41, 43-46, 50, 60]. Our video navigation of finding objects occurred in the context video falls into the last group. Visual navigation methods can also be categorized by whether exploration is required. Most existing works aim for generalization across new goals or environments, heavily relying on learning algorithms that require extensive online interactions, often through reinforcement learning [2, 80, 99], paired with real-time visual feedback [61]. This approach enables the agent to adapt dynamically but requires significant interaction within the environment. Some studies attempt to improve data efficiency but still rely on random policy exploration or assume access to rich datasets, including robot poses [14] or depth images [30, 34, 42, 45]. In contrast, NOLO learns entirely offline. It leverages video data for navigation, freeing the agent from real-world exploration and allowing effective policy learning without performing actual actions, marking a novel approach in video-based visual navigation.
Learning from Videos. There are four main lines of research study learning from videos. (1) Learn distinctive representations for intrinsic rewards. These approaches mainly include predicting the future [25, 96, 98], learning temporal abstractions [4, 8, 75, 96], contrastive learning [47, 79], adversarial learning [40, 57, 66, 82] or other transitionlearning based methods [6, 53, 64]. (2) Recover value function along with representations [5, 26, 32, 59]. (3) Pretrain action-free model in the first stage and then boost the model with additional action information [74, 87, 92]. (4) Discover latent actions [9, 24, 56, 72] and then align to the real actions online in the environment [24, 56, 72], by human annotation [9] or from offline datasets [72]. Unlike previous work, we focus on the visual navigation problem and by utilizing its specificity, propose an offline method that directly learns the actual navigation policy, not the latent one, from videos. Few attempts are devoted to decoding real actions directly from videos. A recent work AVDC [43] attempts to principally use similar rule-based methods to directly infer actions for robot manipulation. However, it is an online algorithm with additional depth image inputs. We also compare NOLO with AVDC [43] in Sec. 4.5.
In-Context Learning. In-context learning (ICL), first demonstrated in large language models [7, 19, 83], enables models to perform new tasks with a few examples as con- text. This capability has extended to vision-language models [1, 3, 84], AI agents [36, 78], and models across heterogeneous modalities [27, 39]. Our work uniquely applies ICL to video navigation. To our knowledge, NOLO is the first attempt to learn an adaptable policy guided by context videos for diverse scenes.
## 3. Learning to Navigate from Videos
## 3.1. The Problem Formulation of Video Navigation
In video navigation, we offline recover a navigation policy π θ ( a g, o, | V ) to find objects occurred in the context video, which takes a goal image g , current observation o , and context video V as input and outputs discrete action a , considering high-level discrete actions are commonly used in competitions like the Habitat Navigation Challenge [69] and modern navigation tasks [52]. To train such a policy, we assume a video dataset D contains N videos collected (e.g., by some simple rule-based policy or humans) in N different scenes, D = { V 1 , V 2 , ..., V N } . Each video V i contains T frames f i t , V i = { f , f i 1 i 2 , ..., f i T } . During inference, we deploy the learned policy in a new scene given a context video V new / ∈ D and a goal frame g ∈ G new describing an object occurred in V new . The policy is expected to adapt to this new scene via in-context learning.
## 3.2. Pseudo Action Labeling
In video navigation, capturing environmental dynamics is crucial for effective adaptation to new scenes. Building on prior work [9, 24, 29, 56, 72] that leverages inverse dynamics models (IDMs) to extract latent actions from adjacent frames, we make a further step by converting latent actions into actual discrete actions within video navigation. Specifically, we propose pseudo action labeling, as illustrated in Fig. 2. we employ GMFlow[89] as an implicit IDM F ξ to estimate discrete pixel displacements between consecutive frames and predict real navigation actions from flow maps with rule-based post-processing. For each context video V , we label a sequence of pseudo-actions ˆ a to get a trajectory T = { f , a t ˆ t } T t =1 . See Appendix 6.1 for more details.
## 3.3. In-Context Policy Modeling
After labeling pseudo action for all videos, we can build a frame-action dataset to offline train an in-context navigation policy π θ . Inspired by VLN-Bert [37], we propose a bidirectional recurrent Transformer, VN ⟲ Bert , to model the in-context navigation policy π θ , which can be formalized in Eq. (1):
$$h _ { t + 1 }, \pi _ { \theta } \left ( a _ { t } | g, o _ { t }, \mathcal { T } \right ) = \text{VN} \odot \text{Bert} ( g, o _ { t }, \mathcal { T } ), \ \ ( 1 )$$
where h is specially designed as a recurrent hidden state to capture informative attention history.
Figure 2. Two adjacent frames are taken by a pretrained optical flow model to get a flow map. Some representative dominant vectors are filtered for action selection.

The structure of VN ⟲ Bertis depicted in Fig. 3. For inference, all RGB images, including context frames and the current observation are encoded by a learnable ResNet encoder E ζ pretrained from Places365 [95] e s t = E ζ ( f t ) . Actions are encoded by a learnable action embedding layer e a t = E α (ˆ ) a t and the goal frame is encoded by a fixed pretrained CLIP [67] e g = CLIP ( g ) . During initialization, a zero-padded hidden state h init is additionally inserted at the back of the context embedding sequence for recurrence. The entire token embedding sequence e init = [ h init , e s init , 1 , e a init , 1 . . . , e a init ,T -1 , e s init ,T ] is encoded by a multi-layer bidirectional self-attention module (SA) as e 0 = [ e c , h 0 ] = SA ( e init ) . The output feature of the hidden state h 0 serves as the initial compressed representation of the context trajectory. After initialization, the context embedding sequence e c keeps unchanged. At each timestep t , the current observation o t and the goal image g are encoded into e s t and e g , respectively. The concatenated embedding sequence e t = [ h , t e c , e s t , e g ] is then fed into the crossattention module (CA) to obtain the updated embedding e t +1 = CA ( e t ) which is further aggregated and projected to action distribution π θ ( a t | g, o , t T ) and the next hidden state h t +1 . The updated hidden state h t +1 is subsequently processed by a multilayer perceptron (MLP) P Q to regress Q-values Q ω ( g, o , a t t , T ) and by another MLP P D to predict the binary terminal signal δ υ ( d t | g, o , t T ) , where d t is used for predicting the termination of the current task.
To train VN ⟲ Bert, we sample a context video V i from dataset D and then construct a context trajectory T i = { f , a i t ˆ i t } T t =1 as described in Section 3.2. Then, we randomly sample t ∈ [0 , T ) for a current observation o t and pseudo action ˆ a t , and a goal image g ∈ G i . We set d t = ( ■ o t = g ) for the termination prediction, where ■ is indicator function. We forward the model and calculate discrete action prediction loss and termination prediction loss in Eq. (2),
$$\mathcal { L } _ { a } = - \mathbb { E } _ { g, o _ { t }, \hat { a } _ { t } \sim \mathcal { T } ^ { i } } \log \pi _ { \theta } \left ( \hat { a } _ { t } | g, o _ { t }, \mathcal { T } ^ { i } \right ) \quad \text{ to } \mathfrak { t } \\ \mathcal { L } _ { d } = - \mathbb { E } _ { g, o _ { t } \sim \mathcal { T } ^ { i } } \log \delta _ { v } \left ( d _ { t } | g, o _ { t }, \mathcal { T } ^ { i } \right ). \quad \text{ to } \mathfrak { t }$$
## 3.4. Batch-Constrained Q-Learning
Since the policy used to record the video may be highly suboptimal for video navigation, we favor offline reinforcement learning over imitation learning for policy learning. Specifically, we adopt BCQ [28], an offline reinforcement learning method that emphasizes constraining the action selection to those within the distribution of the observed frame-action pairs. Q-function Q ω is learned from Bellman update in Eq. (3), where r g, o , a ( t ˆ ) = t ■ ( o t = g ) is a binary reward indicating the success of a task,
$$\text{Ac} ^ { - } \\ \text{hyper} \\ \text{xed} \\ \text{i2a} \\ \text{in} ^ { - }$$
Given the action space is discrete, we define a set A β in Eq. (4) to select ˜ a t +1 , where β represents the threshold for action selection. Action choices are constrained based on the action distribution within the context trajectory dataset. The learned Q-function, Q ω , thus can wisely guides the agent toward the target goal g .
$$A ^ { \beta } \coloneqq \left \{ \tilde { a } _ { t + 1 } \Big | \frac { \pi _ { \theta } \left ( \cdot | g, o _ { t + 1 }, \mathcal { T } ^ { i } \right ) } { \max \pi _ { \theta } \left ( \cdot | g, o _ { t + 1 }, \mathcal { T } ^ { i } \right ) } > \beta \right \}.$$
## 3.5. Temporal Coherence
Learning temporally aligned representation of videos is crucial for understanding the causality of the context video. Inspired by RLHF [63], we learn a 'fuzzy' measure of progress from their natural temporal ordering, where the higher preference score is assigned to the later frames in the video. To achieve this, we learn a temporal indicator ˆ u ϕ ( e ) , which consists of 1D self-attention and spectral normalization modules to map a visual context embedding e s t to a utility score. ˆ u ϕ is optimized according to Eq. (5):
$$\underset { \text{lolly} } { r ^ { n } } = \underset { \zeta, \phi } { \min } \mathcal { L } _ { t } = \underset { f _ { t _ { - } }, f _ { t _ { + } } \sim \mathcal { V } } { \mathbb { E } } - \log \sigma \left [ \hat { u } _ { \phi } \left ( E _ { \zeta } ( f _ { t _ { + } } ) \right ) - \hat { u } _ { \phi } \left ( E _ { \zeta } ( f _ { t _ { - } } ) \right ) \right ], \\ \text{seudo} \underset { \text{-} } { \mathbb { - } } \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
where t + > t -and f t + , f t -stands for the later and earlier frame in the video. This self-supervised paradigm naturally drives the temporal indicator ˆ u ϕ ( s ) to maximize likelihood to ensure the temporal order preference f t + ≻ f t -, leading to temporally aligned context visual representation, which is beneficial to better understand the temporal relation in a novel scene, as elaborated in later Sec. 4.5.
## 4. Experiments
## 4.1. Experimental Setups
Configurations. We apply our algorithm to realistic embodied navigation testbeds RoboTHOR [20] and Habitat [71]. For each navigation task in RoboTHOR and Habitat, we initialize a mobile robot with a random position,
>
Figure 3. Structure of VN ⟲ Bert. At the initialization stage, a trajectory T and a zero-padded hidden state h init are processed by a bidirectional multi-head self-attention module to obtain context embedding e c and initial hidden state h 0 . At each timestep after initialization, the current observation o t and goal frame g are encoded into e s t and are taken by a multi-head cross-attention module together with fixed e c and recurrently updated h t to produce policy π θ , Q-value Q ω , and terminal signal δ υ . The red circle indicates additional aggregation via fusing element-wise product between features like VLN-Bert [37].
orientation, and a given goal image extracted from the context video indicating a specific goal object. At each timestep, the agent, mounted with only one RGB camera of 224 × 224 resolution, receives an egocentric image and can execute a discrete action from a fixed action space [MoveForward TurnLeft TurnRight STOP] , , , . The minimum units of rotation and forward movement are 30° and 0.25 meters respectively. When the goal object is observed and the distance between the goal object and the agent is within 1m, the agent succeeds, otherwise it fails when the maximum step is reached, which is 500 in all experiments.
Task Division. In RoboTHOR, there are 15 different rooms and 5 possible layouts for each room, in total 75 different scenes. Each room has a different topology from other rooms, and the location of objects in each layout is different from other layouts. In order to test the in-context learning ability at different levels, we divide the training and test scenes as follows. For the training set, we select 12 rooms, and 4 layouts for each room. For the unseen layout testing set, we select the remaining 1 layout of the 12 training set rooms, in total 12 scenes. For the unseen room testing set, we select the remaining 3 rooms and all their layouts, in total 15 scenes. In Habitat, we divide all 90 building-scale scenes from Matterport3D (MP3D) [12] into 70 training scenes and 20 testing scenes to test the generalization abilities. See Appendix 7.1 for details.
Dataset Construction. We use a fixed non-explorative rule-based policy to collect the video dataset. The policy keeps moving forward until colliding with an obstacle and then randomly turns to get rid of it. Simultaneously, the agent keeps recording an egocentric RGB sequence till reaching the maximum 900 steps, i.e . a 30-second video clip in each scene. After that, we employ a pretrained object detector Detic [97] to detect all the objects occurred in the video. To get a set for goal frames, we additionally roll out in the simulation to collect goal images of each target object from different views.
Task Evaluation. To evaluate the comprehensive ability of the in-context navigation policy, we design three levels of generalization test:
- · Evaluate in the unseen layout testing set to test the generalization ability over layouts .
- · Evaluate in the unseen room testing set to test the generalization ability over rooms .
- · Evaluate in scenes from a different simulator to test the generalization ability over domains .
For evaluation, the agent is arranged to navigate to each target object detected in a context video. Each navigation task repeats 10 times.
We conduct 3 runs with different random seeds and quantitatively assess the performance using metrics including success rate (SR), success weighted by normalized inverse path length (SPL), trajectory length (TL), and navigation error (NE) following a recent work [93].
Baselines. NOLO stands as the first method to incorporate context videos directly into policy for in-context navigation tasks. To address in-context generalization capabilities, we compare NOLO with a random exploration policy, as well as two large multimodal models (LMMs), GPT4 and Video-LLaVA which also exhibit remarkable zeroshot multimodal understanding and generation abilities, in a training-free manner. To adapt the LMMs for video-based navigation, we use a queue of size K to store context video frames, current observations, and goal images, which are
concatenated as LMM input. A unified prompt guides the LMMsto understand the context and navigate effectively in both RoboTHOR and Habitat, extracting actions from their language responses. See Appendix 7.2 for details.
In addition, we further compare NOLO with traditional visual navigation methods without context video input, specifically, an online method VGM [46], which builds a memory graph based on unsupervised image representations from navigation history to guide actions, and an offline method ZSON [60], which encodes goal images into a multimodal, semantic embedding space to enable scalable training of SemanticNav agents in unannotated 3D environments. Besides, we compare NOLO with a recent work AVDC [43], which infers actions from video predictions while incorporating extra depth information. Our experimental results show that A VDC underperforms NOLO even with additional depth images.
## 4.2. RoboTHOR
We average the metrics of video navigation tasks in all testing scenes and showcase the mean results in Tab. 1. NOLO demonstrates overwhelming advantages over baselines, including random, LMM baselines, and visual navigation baselines in both testing sets, which proves its strong generalization abilities to new scenes in different generalization levels. The set of unseen rooms is naturally a harder testing set than the unseen layouts in terms of generalization ability. Therefore, NOLO displays slightly better navigation performance in the unseen layout testing set (71.92% SR, 29.26% SPL) compared to the unseen room testing set (70.48% SR, 27.74% SPL). GPT-4o outperforms the random exploration policy across most scenarios, while VideoLLaVA generally performs below the random exploration policy due to its smaller model size relative to GPT-4o. NOLO is also much more parameter-efficient than GPT-4o. However, it achieves better navigation results, underscoring its effectiveness in training in-context navigation policies. Overall, visual navigation baselines tend to surpass both random and LMM baselines because of additional training. However, AVDC exhibits instability in unseen environments due to its reliance on a diffusion model trained on a limited set of egocentric video frames, which leads to inconsistency in video prediction. While VGM's memory graph and ZSON's multimodal semantic embeddings can provide some guidance, they still fall short of NOLO in terms of success rate and path efficiency. We analyzed that VGM's implicit graph struggles to effectively represent topological structures with limited data coverage, and for ZSON, there is a non-negligible distribution discrepancy between CLIP [67] pre-training data and our egocentric videos. See Figs. 9 and 10 in Appendix 9 for detailed results.
## 4.3. Habitat
We evaluate NOLO similarly in Habitat to demonstrate the effectiveness of NOLO in larger-scale scenes. As illustrated in Tab. 1 , NOLO still outperforms baselines in terms of SR and achieves slightly better performance in terms of SPL. Compared with the metrics of NOLO in RoboTHOR, the average SPL and SR are lower, and the average NE and TL are higher. This is mostly because scenes in Habitat are significantly larger than those in RoboTHOR, resulting in more challenging navigation tasks across multiple rooms and even floors and requiring longer traversal distances. However, we observe that NOLO is still capable of acquiring many necessary sub-skills like entering or exiting a room, avoiding obstacles, and exploring. See Appendix 9 for detailed results.
## 4.4. Cross-Domain Evaluation
To pursue the ultimate goal of video navigation, we evaluate NOLO across RoboTHOR and Habitat, even if the visual inputs may suffer from a severe domain gap. Specifically, NOLO trained from 48 RoboTHOR scenes is evaluated in 20 Habitat scenes (R2H) , and NOLO trained from 70 Habitat scenes is evaluated in 27 RoboTHOR scenes (H2R) . For comparison, we also plot the average in-domain results ( R2R and H2H ). We average all the results on testing scenes in Fig. 4, from which we surprisingly discover that R2H and H2R show competitive performance compared to R2R and H2H. This is because the pretrained image encoder in NOLO provides a general representation of indoor scenes, and the temporal coherence loss in Eq. (5) also leads to a general representation reflecting the natural temporal ordering, which together lead to the generalization ability of NOLO across domains.
## 4.5. Ablation Studies
In this section, we use a set of ablation studies to examine the contribution of several key components in NOLO. More specifically, we aim to answer the following questions.
Does the context video provide informative cues for navigation? Yes. We conduct an ablation study denoted as NOLO-C , in which we evaluate NOLO without context videos in RoboTHOR and Habitat with other configurations unchanged. From Tab. 2, a mean performance drop of NOLO-C is perceived both in RoboTHOR and Habitat compared with NOLO due to lack of context information.
Does temporal coherence loss contribute to better visual representation and performance? Yes. We examine the effect of the temporal coherence loss in Eq. (5). An ablation variant, named NOLO-T , is conducted by removing the temporal coherence loss. The results are shown in Tab. 2. The performance drops slightly in RoboTHOR while more obviously in Habitat. To figure out the underlying reasons for their discrepancy in performance, we further compare
Table 1. Performance comparison of success rates (SR), success path lengths (SPL), trajectory lengths (TL), and navigation errors (NE) across different methods and environments. The blue part shows some training-free methods and the green part shows visual navigation approaches which require training.
| | Robothor | Robothor | Robothor | Robothor | Robothor | Robothor | Robothor | Robothor | Habitat | Habitat | Habitat | Habitat |
|-------------|---------------|---------------|---------------|---------------|------------|------------|------------|------------|-------------|-------------|-------------|-------------|
| Method | Unseen Layout | Unseen Layout | Unseen Layout | Unseen Layout | Unseen | Unseen | Room | Unseen | Unseen Room | Unseen Room | Unseen Room | Unseen Room |
| | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
| Random | 26.00 | 13.27 | 394.77 | 2.93 | 23.10 | 12.02 | 405.87 | 2.89 | 24.53 | 10.03 | 402.02 | 4.97 |
| GPT-4o | 31.97 | 17.18 | 363.23 | 3.03 | 31.69 | 16.49 | 364.63 | 2.89 | 35.16 | 20.39 | 345.84 | 4.70 |
| Video-LLaVA | 20.07 | 8.31 | 381.92 | 3.08 | 17.51 | 6.58 | 385.72 | 3.32 | 14.55 | 9.02 | 384.53 | 4.71 |
| AVDC | 32.53 | 9.43 | 430.77 | 2.15 | 31.14 | 11.57 | 424.56 | 2.13 | 27.29 | 12.24 | 418.12 | 4.30 |
| VGM | 47.04 | 23.90 | 376.92 | 2.44 | 40.51 | 19.99 | 400.90 | 2.38 | 34.34 | 17.30 | 393.92 | 4.19 |
| ZSON | 37.83 | 21.31 | 349.31 | 2.23 | 35.78 | 18.81 | 372.68 | 2.37 | 32.83 | 19.86 | 395.94 | 4.32 |
| NOLO (ours) | 71.92 | 29.26 | 238.92 | 1.79 | 70.48 | 27.74 | 248.44 | 1.87 | 43.65 | 20.77 | 347.57 | 3.67 |
Figure 4. Average SR and SPL of cross domain evaluation. H2R means training in Habitat and testing in RoboTHOR, and vice versa.
the learned visual representation of NOLO and NOLO-T. We randomly select a context video in RoboTHOR and utilize t-SNE projection to visualize their embedding sequences encoded by E ζ ( f t ) in Fig. 8 in Appendix 8. The embeddings learned by NOLO-T exhibit more irregular stochasticity. In contrast, NOLO learns a better-structured embedding, which demonstrates the effectiveness of the temporal coherence loss. See Appendix 9 for details.
Can NOLO incorporate other off-the-shelf modules to decode actions from videos? Yes. We conduct an ablation, entitled NOLO(M) , to decode actions from SuperGlue [70] via point matching instead of GMFlow [89]. We observe an accuracy drop in action decoding (from 92.44% to 80.43%). We then follow the same pipeline and report the performance in Tab. 2. NOLO(M) exhibits around 5% decay in average success rate in RoboTHOR and 7% in Habitat. Therefore, to achieve more satisfactory in-context generalization, we choose GMFlow as the action decoder for NOLO. However, as a general two-stage framework for incontext learning from videos, NOLO is not limited to any kind of pseudo action labeling methods and is capable of incorporating more advanced modules for better performance.
Does NOLO understand the relationship between goal and context video? Yes . We use Grad-CAM [73] saliency maps of the visual encoder to illustrate NOLO's ability to connect the goal with the context video. As shown in Fig. 6, when a goal image is provided, NOLO accurately identifies key semantic cues in the goal and focuses on related areas in the context frame, indicating its capacity to link goal and context. Without the goal image, however, NOLO lacks this focus, underscoring its reliance on goal-driven context understanding. This result demonstrates NOLO's ability to interpret the goal and capture relevant information in the context video.
## 4.6. Real-World Experiments
We constructed a real-world maze environment, as shown in Fig. 7. We employed the Unitree Go2 robot, equipped with a RealSense D435i camera to capture RGB observations. In the maze environment, the robot's actions are discretized into moving forward by 15 cm or turning 30 degrees at each step. Six target objects-a book, box, cola can, cup, glue, and novel-are placed in the maze. Images of each target are taken from random nearby perspectives. A fixed, non-exploratory, rule-based policy was employed to collect two 600-step video clips in the maze, one for training and the other as context video during policy deployment. For evaluation, each episode consists of 100 steps, with a success radius set at 50 cm. Fig. 5 illustrates key frames from successful trajectories during in-context policy deployment.
Table 2. Ablation studies of NOLO. For each method, we average the metrics over all testing scenes and average all the mean results over three random seeds to report the mean and standard deviation.
| | Robothor | Robothor | Robothor | Robothor | Habitat | Habitat | Habitat | Habitat |
|---------|--------------|--------------|---------------|-------------|--------------|--------------|---------------|-------------|
| Method | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
| NOLO | 71.20 ± 0.85 | 28.50 ± 0.72 | 243.68 ± 3.80 | 1.83 ± 0.04 | 43.65 ± 1.09 | 20.77 ± 0.46 | 347.57 ± 3.32 | 3.67 ± 0.09 |
| NOLO-C | 67.78 ± 0.60 | 27.70 ± 1.35 | 259.65 ± 0.53 | 1.98 ± 0.02 | 33.58 ± 0.92 | 17.41 ± 0.43 | 381.26 ± 3.23 | 4.58 ± 0.26 |
| NOLO-T | 69.03 ± 0.87 | 28.15 ± 0.09 | 252.84 ± 6.33 | 1.93 ± 0.04 | 37.48 ± 1.01 | 18.51 ± 0.71 | 369.85 ± 2.72 | 4.72 ± 0.07 |
| NOLO(M) | 66.15 ± 0.37 | 26.66 ± 1.61 | 267.95 ± 1.96 | 2.02 ± 0.00 | 36.73 ± 1.89 | 18.17 ± 0.31 | 373.92 ± 3.46 | 4.69 ± 0.25 |
Figure 5. Visualizations of six video navigation tasks during in-context policy deployment. The leftmost bird-eye-view topological maps depicts the robot positions corresponding to the key observations to the right, and the second column displays the goal images.

The robot demonstrated impressive capabilities in navigating straight passages, executing turns at corners, and ultimately reaching the goals by comprehending the dynamics and topological structure inferred from the unseen context video and its relationship to the goal images.
## 5. Conclusion and Limitaiton
In this paper, we propose and investigate the video navigation problem, in which the goal is to offline train a generalizable in-context navigation policy from videos to find objects occurred in a context video about a novel scene. To solve this problem, we propose NOLO, to train a VN ⟲ Bert taking a context video, current observation, and goal frame as input and outputting navigation actions via pseudo action labeling and offline reinforcement learning. Additionally, we introduce a temporal coherence loss to ensure representations align with natural temporal order. Experiments in RoboTHOR and Habitat simulation environments as well as in a real-world maze demonstrate NOLO can generalize to varying novel scenes without finetuning or re-training by understanding the context video. Ablation studies fur-
Figure 6. Comparision of saliency maps between NOLO and NOLO-C about context frames with respect to goal frames in RoboTHOR and Habitat.

ther reveal the impact of NOLO's key components. It is important to emphasize the limitation of NOLO that currently it can only extract movement actions from two adjacent frames. Future work will explore methods for decoding
Figure 7. Setups of real-world maze. The robotic dog mounted with a head camera acts as the navigation agent and six annotated objects are goals.

more complex actions from multiple frames. We also aim to pretrain NOLO on larger-scale scene datasets to assess its generalization across more diverse environments.
## References
- [1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023. 3
- [2] Ziad Al-Halah, Santhosh Kumar Ramakrishnan, and Kristen Grauman. Zero experience required: Plug & play modular transfer learning for semantic visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2022. 3
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems , 35:23716-23736, 2022. 3
- [4] Yusuf Aytar, Tobias Pfaff, David Budden, Thomas Paine, Ziyu Wang, and Nando De Freitas. Playing hard exploration games by watching youtube. In Neural Information Processing Systems (NeurIPS) , 2018. 3
- [5] Chethan Bhateja, Derek Guo, Dibya Ghosh, Anikait Singh, Manan Tomar, Quan Vuong, Yevgen Chebotar, Sergey Levine, and Aviral Kumar. Robotic offline rl from internet videos via value-function pre-training. arXiv preprint arXiv:2309.13041 , 2023. 3
- [6] Maksim Bobrin, Nazar Buzun, Dmitrii Krylov, and Dmitry V Dylov. Align your intents: Offline imitation learning via optimal transport. arXiv preprint arXiv:2402.13037 , 2024. 3
- [7] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877-1901, 2020. 2, 3
•
•
•
- Maze Scene [8] Jake Bruce, Ankit Anand, Bogdan Mazoure, and Rob Fergus. Learning about progress from experts. In International Conference on Learning Representations (ICLR) , 2023. 3
Data:
- 1200-step video clip Preprocessing: Image Augmentation Algorithm Terminal Indicator Loose behavior Cloning [9] Jake Bruce, Michael Dennis, Ashley Edwards, Jack ParkerHolder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. arXiv preprint arXiv:2402.15391 , 2024. 3
- [10] Valay Bundele, Mahesh Bhupati, Biplab Banerjee, and Aditya Grover. Scaling vision-and-language navigation with offline rl. arXiv preprint arXiv:2403.18454 , 2024. 1, 3
- [11] Valay Bundele, Mahesh Bhupati, Biplab Banerjee, and Aditya Grover. Scaling vision-and-language navigation with offline rl. arXiv preprint arXiv:2403.18454 , 2024. 3
- [12] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgbd data in indoor environments. International Conference on 3D Vision (3DV) , 2017. 5
- [13] Matthew Chang, Arjun Gupta, and Saurabh Gupta. Semantic visual navigation by watching youtube videos. In Neural Information Processing Systems (NeurIPS) , 2020. 1
- [14] Matthew Chang, Theophile Gervet, Mukul Khanna, Sriram Yenamandra, Dhruv Shah, So Yeon Min, Kavit Shah, Chris Paxton, Saurabh Gupta, Dhruv Batra, et al. Goat: Go to any thing. arXiv preprint arXiv:2311.06430 , 2023. 1, 3
- [15] Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. Learning to explore using active neural slam. arXiv preprint arXiv:2004.05155 , 2020.
- [16] Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. Neural topological slam for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2020. 1
- [17] Chang Chen, Yuecheng Liu, Yuzheng Zhuang, Sitong Mao, Kaiwen Xue, and Shunbo Zhou. Scale: Self-correcting visual navigation for mobile robots via anti-novelty estimation. arXiv preprint arXiv:2404.10675 , 2024. 1
- [18] Chang Chen, Yuecheng Liu, Yuzheng Zhuang, Sitong Mao, Kaiwen Xue, and Shunbo Zhou. Scale: Self-correcting visual navigation for mobile robots via anti-novelty estimation. arXiv preprint arXiv:2404.10675 , 2024. 1
- [19] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research , 24(240): 1-113, 2023. 3
- [20] Matt Deitke, Winson Han, Alvaro Herrasti, Aniruddha Kembhavi, Eric Kolve, Roozbeh Mottaghi, Jordi Salvador, Dustin Schwenk, Eli VanderBilt, Matthew Wallingford, et al. Robothor: An open simulation-to-real embodied ai platform. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) , pages 3164-3174, 2020. 4
- [21] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional
transformers for language understanding. arXiv preprint arXiv:1810.04805 , 2018. 1
- [22] Bernadetta Mustika Dewi, Maya Arlini Puspasari, Billy Muhamad Iqbal, and Tegar Septyan Hidayat. Developing virtual assistant in a virtual retail store environment for product search effectiveness. In AIP Conference Proceedings , 2024. 1
- [23] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey on in-context learning. arXiv preprint arXiv:2301.00234 , 2022. 2
- [24] Ashley Edwards, Himanshu Sahni, Yannick Schroecker, and Charles Isbell. Imitating latent policies from observation. In International Conference on Machine Learning (ICML) , 2019. 3
- [25] Alejandro Escontrela, Ademi Adeniji, Wilson Yan, Ajay Jain, Xue Bin Peng, Ken Goldberg, Youngwoon Lee, Danijar Hafner, and Pieter Abbeel. Video prediction models as rewards for reinforcement learning. arXiv preprint arXiv:2305.14343 , 2023. 3
- [26] Benjamin Eysenbach, Tianjun Zhang, Sergey Levine, and Russ R Salakhutdinov. Contrastive learning as goalconditioned reinforcement learning. In Neural Information Processing Systems (NeurIPS) , 2022. 3
- [27] Zhongbin Fang, Xiangtai Li, Xia Li, Joachim M Buhmann, Chen Change Loy, and Mengyuan Liu. Explore in-context learning for 3d point cloud understanding. Advances in Neural Information Processing Systems , 36, 2024. 3
- [28] Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning (ICML) , 2019. 4
- [29] Nathan Gavenski, Juarez Monteiro, Roger Granada, Felipe Meneguzzi, and Rodrigo C Barros. Imitating unknown policies via exploration. arXiv preprint arXiv:2008.05660 , 2020. 3
- [30] Georgios Georgakis, Yimeng Li, and Jana Kosecka. Simultaneous mapping and target driven navigation. arXiv preprint arXiv:1911.07980 , 2019. 3
- [31] Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world. Science Robotics , 8(79):eadf6991, 2023. 1
- [32] Dibya Ghosh, Chethan Anand Bhateja, and Sergey Levine. Reinforcement learning from passive data via latent intentions. In International Conference on Machine Learning (ICML) . PMLR, 2023. 3
- [33] Pierre-Louis Guhur, Makarand Tapaswi, Shizhe Chen, Ivan Laptev, and Cordelia Schmid. Airbert: In-domain pretraining for vision-and-language navigation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , 2021. 3
- [34] Meera Hahn, Devendra Singh Chaplot, Shubham Tulsiani, Mustafa Mukadam, James M Rehg, and Abhinav Gupta. No rl, no simulation: Learning to navigate without navigating. In Neural Information Processing Systems (NeurIPS) , 2021. 1, 3
- [35] Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. Towards learning a generic agent for visionand-language navigation via pre-training. In Proceedings of
- the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , 2020. 1
- [36] Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352 , 2023. 3
- [37] Yicong Hong, Qi Wu, Yuankai Qi, Cristian RodriguezOpazo, and Stephen Gould. Vln bert: A recurrent visionand-language bert for navigation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , pages 1643-1653, 2021. 1, 3, 5
- [38] Dong Hu, Chao Huang, Jingda Wu, and Hongbo Gao. Pretrained transformer-enabled strategies with human-guided fine-tuning for end-to-end navigation of autonomous vehicles. arXiv preprint arXiv:2402.12666 , 2024. 1
- [39] Qian Huang, Hongyu Ren, Peng Chen, Gregor Krˇ zmanc, Daniel Zeng, Percy S Liang, and Jure Leskovec. Prodigy: Enabling in-context learning over graphs. Advances in Neural Information Processing Systems , 36, 2024. 3
- [40] Haresh Karnan, Garrett Warnell, Faraz Torabi, and Peter Stone. Adversarial imitation learning from video using a state observer. In International Conference on Robotics and Automation (ICRA) , 2022. 3
- [41] Apoorv Khandelwal, Luca Weihs, Roozbeh Mottaghi, and Aniruddha Kembhavi. Simple but effective: Clip embeddings for embodied ai. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 14829-14838, 2022. 3
- [42] Nuri Kim, Obin Kwon, Hwiyeon Yoo, Yunho Choi, Jeongho Park, and Songhwai Oh. Topological semantic graph memory for image-goal navigation. In Conference on Robot Learning , pages 393-402. PMLR, 2023. 3
- [43] Po-Chen Ko, Jiayuan Mao, Yilun Du, Shao-Hua Sun, and Joshua B Tenenbaum. Learning to act from actionless videos through dense correspondences. arXiv preprint arXiv:2310.08576 , 2023. 3, 6
- [44] Jacob Krantz, Stefan Lee, Jitendra Malik, Dhruv Batra, and Devendra Singh Chaplot. Instance-specific image goal navigation: Training embodied agents to find object instances. arXiv preprint arXiv:2211.15876 , 2022. 3
- [45] Jacob Krantz, Theophile Gervet, Karmesh Yadav, Austin Wang, Chris Paxton, Roozbeh Mottaghi, Dhruv Batra, Jitendra Malik, Stefan Lee, and Devendra Singh Chaplot. Navigating to objects specified by images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR) , 2023. 1, 3
- [46] Obin Kwon, Nuri Kim, Yunho Choi, Hwiyeon Yoo, Jeongho Park, and Songhwai Oh. Visual graph memory with unsupervised representation for visual navigation. In Proceedings of the IEEE/CVF international conference on computer vision , pages 15890-15899, 2021. 3, 6
- [47] Michael Laskin, Aravind Srinivas, and Pieter Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. In International Conference on Machine Learning (ICML) , 2020. 3
- [48] Michael Laskin, Luyu Wang, Junhyuk Oh, Emilio Parisotto, Stephen Spencer, Richie Steigerwald, DJ Strouse, Steven
- Hansen, Angelos Filos, Ethan Brooks, et al. In-context reinforcement learning with algorithm distillation. arXiv preprint arXiv:2210.14215 , 2022. 2
- [49] Jonathan Lee, Annie Xie, Aldo Pacchiano, Yash Chandak, Chelsea Finn, Ofir Nachum, and Emma Brunskill. Supervised pretraining can learn in-context reinforcement learning. In Neural Information Processing Systems (NeurIPS) , 2024. 2
- [50] Xiaohan Lei, Min Wang, Wengang Zhou, Li Li, and Houqiang Li. Instance-aware exploration-verificationexploitation for instance imagegoal navigation. arXiv preprint arXiv:2402.17587 , 2024. 3
- [51] Hongxin Li, Zeyu Wang, Xu Yang, Yuran Yang, Shuqi Mei, and Zhaoxiang Zhang. Memonav: Working memory model for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 17913-17922, 2024. 3
- [52] Jialu Li, Aishwarya Padmakumar, Gaurav Sukhatme, and Mohit Bansal. Vln-video: Utilizing driving videos for outdoor vision-and-language navigation. arXiv preprint arXiv:2402.03561 , 2024. 3
- [53] Siyuan Li, Shijie Han, Yingnan Zhao, By Liang, and Peng Liu. Auxiliary reward generation with transition distance representation learning. arXiv preprint arXiv:2402.07412 , 2024. 3
- [54] Yimeng Li and Jana Koˇ secka. Learning view and target invariant visual servoing for navigation. In 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages 658-664. IEEE, 2020. 3
- [55] Hao Liu and Pieter Abbeel. Emergent agentic transformer from chain of hindsight experience. In International Conference on Machine Learning , 2023. 2
- [56] Minghuan Liu, Zhengbang Zhu, Yuzheng Zhuang, Weinan Zhang, Jianye Hao, Yong Yu, and Jun Wang. Plan your target and learn your skills: Transferable state-only imitation learning via decoupled policy optimization. arXiv preprint arXiv:2203.02214 , 2022. 3
- [57] Minghuan Liu, Tairan He, Weinan Zhang, Shuicheng Yan, and Zhongwen Xu. Visual imitation learning with patch rewards. arXiv preprint arXiv:2302.00965 , 2023. 3
- [58] Pin Lyu, Bingqing Wang, Jizhou Lai, Shiyu Bai, Ming Liu, and Wenbin Yu. A factor graph optimization method for high-precision imu based navigation system. IEEE Transactions on Instrumentation and Measurement , 2023. 1
- [59] Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. arXiv preprint arXiv:2210.00030 , 2022. 3
- [60] Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. Zson: Zero-shot object-goal navigation using multimodal goal embeddings. Advances in Neural Information Processing Systems , 35:32340-32352, 2022. 3, 6
- [61] Bar Mayo, Tamir Hazan, and Ayellet Tal. Visual navigation with spatial attention. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 16898-16907, 2021. 3
- [62] Lina Mezghan, Sainbayar Sukhbaatar, Thibaut Lavril, Oleksandr Maksymets, Dhruv Batra, Piotr Bojanowski, and Karteek Alahari. Memory-augmented reinforcement learning for image-goal navigation. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 2022. 3
- [63] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Neural Information Processing Systems (NeurIPS) , 2022. 4
- [64] Seohong Park, Tobias Kreiman, and Sergey Levine. Foundation policies with hilbert representations. arXiv preprint arXiv:2402.15567 , 2024. 3
- [65] Ruslan Partsey, Erik Wijmans, Naoki Yokoyama, Oles Dobosevych, Dhruv Batra, and Oleksandr Maksymets. Is mapping necessary for realistic pointgoal navigation? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2022. 1, 3
- [66] Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control. ACM Transactions on Graphics (ToG) , 40(4):1-20, 2021. 3
- [67] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (ICML) , 2021. 4, 6
- [68] Santhosh Kumar Ramakrishnan, Devendra Singh Chaplot, Ziad Al-Halah, Jitendra Malik, and Kristen Grauman. Poni: Potential functions for objectgoal navigation with interaction-free learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2022. 3
- [69] Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-web: Learning embodied object-search strategies from human demonstrations at scale. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR) , 2022. 3
- [70] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) , 2020. 7
- [71] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR) , 2019. 4
- [72] Dominik Schmidt and Minqi Jiang. Learning to act without actions. arXiv preprint arXiv:2312.10812 , 2023. 3
- [73] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In International Conference on Computer Vision (ICCV) , 2017. 7
- [74] Younggyo Seo, Kimin Lee, Stephen L James, and Pieter Abbeel. Reinforcement learning with action-free pretraining from videos. In International Conference on Machine Learning (ICML) , 2022. 3
- [75] Pierre Sermanet, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, Sergey Levine, and Google Brain. Time-contrastive networks: Self-supervised learning from video. In IEEE International Conference on Robotics and Automation (ICRA) , 2018. 3
- [76] Dhruv Shah, Bła˙ zej Osi´ nski, Sergey Levine, et al. Lmnav: Robotic navigation with large pre-trained models of language, vision, and action. In Conference on Robot Learning (CORL) , 2023. 3
- [77] Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Stachowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation. In Conference on Robot Learning , pages 711-733. PMLR, 2023. 1, 3
- [78] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems , 36, 2024. 3
- [79] Adam Stooke, Kimin Lee, Pieter Abbeel, and Michael Laskin. Decoupling representation learning from reinforcement learning. In International Conference on Machine Learning (ICML) , 2021. 3
- [80] Xinyu Sun, Peihao Chen, Jugang Fan, Jian Chen, Thomas Li, and Mingkui Tan. Fgprompt: Fine-grained goal prompting for image-goal navigation. In Neural Information Processing Systems (NeurIPS) , 2024. 3
- [81] Hao Tan and Mohit Bansal. Lxmert: Learning crossmodality encoder representations from transformers. arXiv preprint arXiv:1908.07490 , 2019. 1
- [82] Faraz Torabi, Garrett Warnell, and Peter Stone. Imitation learning from video by leveraging proprioception. In International Joint Conference on Artificial Intelligence (IJCAI) , 2019. 3
- [83] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ ee Lacroix, Baptiste Rozi` ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 , 2023. 3
- [84] Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, SM Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models. Advances in Neural Information Processing Systems , 34:200-212, 2021. 3
- [85] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents. Frontiers of Computer Science , 18(6):126, 2024. 2
- [86] Justin Wasserman, Karmesh Yadav, Girish Chowdhary, Abhinav Gupta, and Unnat Jain. Last-mile embodied visual navigation. In Conference on Robot Learning , pages 666678. PMLR, 2023. 3
- [87] Jialong Wu, Haoyu Ma, Chaoyi Deng, and Mingsheng Long. Pre-training contextualized world models with in-the-wild videos for reinforcement learning. In Neural Information Processing Systems (NeurIPS) , 2024. 3
- [88] Chengguang Xu, Hieu T Nguyen, Christopher Amato, and Lawson LS Wong. Vision and language navigation in the real world via online visual language mapping. arXiv preprint arXiv:2310.10822 , 2023. 1
- [89] Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, and Dacheng Tao. Gmflow: Learning optical flow via global matching. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) , 2022. 3, 7
- [90] Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya, Naoki Yokoyama, Alexei Baevski, Zsolt Kira, Oleksandr Maksymets, and Dhruv Batra. Ovrl-v2: A simple stateof-art baseline for imagenav and objectnav. arXiv preprint arXiv:2303.07798 , 2023. 3
- [91] Karmesh Yadav, Ram Ramrakhya, Arjun Majumdar, Vincent-Pierre Berges, Sachit Kuhar, Dhruv Batra, Alexei Baevski, and Oleksandr Maksymets. Offline visual representation learning for embodied navigation. In Workshop on Reincarnating Reinforcement Learning at ICLR 2023 , 2023. 1, 3
- [92] Weirui Ye, Yunsheng Zhang, Pieter Abbeel, and Yang Gao. Become a proficient player with limited data through watching pure videos. In International Conference on Learning Representations (ICLR) , 2022. 3
- [93] Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and Wang He. Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852 , 2024. 3, 5
- [94] Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and Wang He. Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852 , 2024. 3
- [95] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , 2017. 4, 1
- [96] Bohan Zhou, Ke Li, Jiechuan Jiang, and Zongqing Lu. Learning from visual observation via offline pretrained stateto-go transformer. In Neural Information Processing Systems (NeurIPS) , 2024. 3
- [97] Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Kr¨ ahenb¨hl, u and Ishan Misra. Detecting twenty-thousand classes using image-level supervision. In European Conference on Computer Vision (ECCV) , 2022. 5
- [98] Deyao Zhu, Yuhui Wang, J¨rgen u Schmidhuber, and Mohamed Elhoseiny. Guiding online reinforcement learning with action-free offline pretraining. arXiv preprint arXiv:2301.12876 , 2023. 3
- [99] Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In 2017 IEEE international conference on robotics and automation (ICRA) , 2017. 3
## 6. Methodology Details
## NOLO: Navigate Only Look Once
## Supplementary Material
one with 10 new actions.
## 6.1. Pseudo Action Labeling
We deploy optical flow and filter dominant vectors with the help of the flow map. Theoretically, discretizing filtered vectors into several action categories can be achieved by any unsupervised pattern recognition methods, such as clustering. In practice, we use a simple threshold-based heuristic. We observe that the feature of moving forward is less prominent than turning left or right. Consequently, we focus more on the horizontal displacement of the pixels in the flow map. If the horizontal component of horizontal displacement exceeds a threshold τ x and the vertical component stays within a threshold τ y then we classify it as a turning action, or it is considered as a forwarding action.
Occasionally, we notice that the displacement of pixels observed across frames manifests irregular patterns. To mitigate this issue, for each pair of adjacent frames ( f , f t t +1 ) , we filter dominant vectors ν t that exhibit gradient amplitudes within the upper decile, which are subsequently discretized into actions derived from the action space, making it possible to trace the trajectory of the agent over time.
## 6.2. Policy Inference
We choose the threshold of choosing action β = 0 5 . .After the loss of BCQ converges, we make decisions based on the learned policy and Q-values. During inference, an action is chosen based on the Q-values weighted by masked action distribution π θ ( a t | g, o , t T i ) with probability ε = 0 999 . and otherwise randomly. Besides, as long as P D outputs a strong signal for termination, the agent will directly output action STOP .
## 6.3. Semantic Actions
To ensure more stable navigation, the VN ⟲ Bert is elaborately designed to output 'semantic actions', i.e. actions from the action space along with their duration. For example, (MoveForward 3) , means repeatedly moving forward for 3 time steps. STOP can executed at most once. We find that limiting each action up to 3 times at most effectively improves the robustness of the learned policy and the final performance. Previous methods [13, 34] tend to adopt a more complicated hierarchical framework consisting of a high-level policy to propose sub-goals from a constructed topological map and a low-level policy to decompose several actions in the action space to reach each sub-goal. Instead, we adopt a simpler but more practical mid-level policy to regularize the navigation behavior. From another perspective, we enlarge the original action space to an extended
## 6.4. Model Architecture
We deploy ResNet18 pretrained from Places368 [95] as visual Encoder and frozen ResNet50-based Clip visual encoder as goal image encoder. In VN ⟲ Bert, the selfattention modules consist of 9 Bert [21] layers and the cross-attention modules consist of 4 LXMERT [81] layers. The structure of VN ⟲ Bert is modified from Prevalent [35]. The self-attention modules and cross-attention modules are also initialized with the checkpoints of Prevalent. Our codes and documents are included in supplementary materials.
## 7. Experiment Details
## 7.1. Dataset Division
Derived from Ai2THOR, valid scenes in RoboTHOR are in the form FloorPlan Train { 1:12 } { 1:5 } or FloorPlan Val { 1:3 } { 1:5 } . See Tab. 3 for training and testing scene splits. We include detailed steps in the README.md contained in the supplementary materials indicating how to run scripts to create video datasets and gather testing points.
## 7.2. LMM Baselines
For both GPT-4o and Video-LLaVA, we maintain a queue of size K = 16 to incorporate sampled context frames, current observation, and goal image into a video clip and designed a consistent prompt to facilitate their understanding of the video content and to guide them to provide a reasonable action at each timestep. The prompt is structured as follows:
These frames pertain to a navigation task. The goal of the video is represented by the last frame, and the second-to-last frame is the current observation. Choose the best action from [move forward, turn left, turn right, stop] that will help achieve the goal depicted in the last frame of the video. Please provide the selected action directly.
We then utilize regular expressions to extract actions from the received language responses. In case of invalid output, we attempt up to three retries, and a random action is selected as output if all attempts fail.
Table 3. Dataset division of RoboTHOR and Habitat
saliency with goal
| Train | Train | Train |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| S9hNv5qa7GM 5LpN3gDmAk7 VFuaQ6m2Qom 2n8kARJN3HM 759xd9YjKW5 B6ByNegPMKs 1LXtFkjw3qL 7y3sRwLe3Va gxdoqLR6rwA kEZ7cmS4wCh Vvot9Ly1tCj jh4fc5c5qoQ uNb9QFRL6hY RPmz2sHmrrY JeFG25nYj2p ac26ZMwG7aT sKLMLpTHeUy 82sE5b5pLXE 5ZKStnWn8Zo GdvgFV5R1Z5 Uxmj2M2itWa ur6pFq6Qu1A r1Q1Z4BcV1o with goal | XcA2TqTSSAj WYY7iVyf5p8 EDJbREhghzL HxpKQynjfin aayBHfsNo7d p5wJjkQkbXX YVUC4YcDtcY r47D5H71a5s 1pXnuDYAj8r sT4fr6TAbpF cV4RVeZvu5T 2t7WUuJeko7 V2XKFyX4ASd E9uDoFAP3SH mJXqzFtmKg4 JF19kD82Mey wc2JMjhGNzB gZ6f7yhEvPG pRbA3pwrgk9 ULsKaCPVFJR qoiz87JEwZ2 fzynW3qQPVF b8cTxDM8gDG saliency without | PX4nDJXEHrG 5q7pvUzZiYa rPc6DW4iMge PuKPg4mmafe jtcxE69GiFV D7N2EKCX4Sj YmJkqBEsHnH vyrNrziPKCB VLzqgDo317F ARNzJeq3xxb VVfe2KiqLaN D7G3Y4RVNrH e9zR4mvMWw7 17DRP5sb8fy YFuZgdQ5vWj Pm6F8kyY3z2 dhjEzFoUFzH 8WUmhLawc2A 29hnd4uzFmX q9vSo1VnCiC s8pcmisQ38h ZMojNkEp431 i5noydFURQK goal |
| Eval | Eval | |
| 2azQ1b91cZZ Vt2qJdWjCF2 zsNo4HB9uLZ SN83YJsR3w2 Z6MFQCViBuw TbHJrupSAjP UwV83HsGsw3 | x8F5xyUWy9e gTV8FGcVJC9 X7HyMhZNoso pLe4wQe7qrG pa4otMbVnkk oLBMNvg9in8 gYvKGZ5eRqb | QUCTc6BB5sX EU6Fwq7SyZv yqstnuAEVhm 8194nk5LbLH VzqfbhrpDEA rqfALeAoiTq |
## 7.3. Hyperparameters
Tab. 4 outlines the hyperparameters for VN ⟲ Bert training.
## 7.4. Computation Resources
For both RoboTHOR and Habitat, we train NOLO and all NOLO-variants on a single 40G A100 GPU for around 1 day. We evaluate NOLO across all created testing tasks (single thread) on a 24G Nvidia RTX 4090 Ti GPU for about 6 hours in RoboTHOR and 5 hours in Habitat.
## 8. Additional Visualizations
Sec. 8 compares the t-SNE visual embedding sequence of a context video in RoboTHOR between NOLO and NOLO-T.
Table 4. Hyperparameters for VN ⟲ Bert Training
| Hyperparameter | Value |
|----------------------------------------------------------------------------------------------------------------------------------------|--------------------------|
| Optimizer Learning Rate Betas Weight Decay Batch size SA Layers CA Layers Action Embedding Visual Embedding Hidden State Dimension STG | AdamW STG- |
| | 1e-4 |
| | (0.9,0.95) |
| | 0.1 |
| | 26 |
| | 9 |
| | 4 |
| Dimension | 256 |
| Dimension | 512 |
| | 768 |
| BCQ Clip Threshold | 0.5 |
| Type of GPUs | A100 &Nvidia RTX 4090 Ti |
Figure 8. Comparision of context embedding sequences of a sampled video from RoboTHOR between NOLO and NOLO-T.
## 9. Evaluation Results
Tables below outline the average performance of different methods in RoboTHOR and Habitat as well as cross evaluation results over 3 random seeds.
## 9.1. RoboTHOR Evaluation Performance
We also examined the impact of NOLO compared to LMM baselines and visual navigation baselines on two key metrics for vision-based navigation tasks: Success Rate (SR) and Success weighted by normalized inverse Path Length (SPL), as illustrated in the figures in Fig. 9 and Fig. 10. Figs. 9a, 9b, 10a and 10b show the performance in the unseen layout testing set. Figs. 9c, 9d, 10c and 10d show the evaluation results in the unseen room testing set, and The detailed performances of NOLO, random policy, GPT-4o, Video-LLaVA, AVDC, VGM, ZSON, NOLO-C, NOLO-T, NOLO(M) in RoboTHOR are reported in Tabs. 5 to 14 respectively.
,
Train10 5
Train8 5
Train9 5 Figure 9. Compare NOLO with random policy and LMM baselines in RoboTHOR seen and unseen rooms.
Figure 10. Compare NOLO with visual navigation baselines in RoboTHOR seen and unseen rooms.
## 9.2. Habitat Evaluation Performance
Also, we examined the impact of NOLO compared to LMM baselines and visual navigation baselines on two key metrics for vision-based navigation tasks: Success Rate (SR) and Success weighted by normalized inverse Path Length (SPL), as illustrated in Fig. 11. The performances of NOLO, random policy, GPT-4o, Video-LLaVA, AVDC, VGM, ZSON, NOLO-C, NOLO-T, NOLO(M) in Habitat testing scenes are reported in Tabs. 15 to 24 respectively.
Figure 11. Compare NOLO with random policy, LMM baselines and visual navigation baselines in 20 Habitat testing scenes.

Table 5. NOLO performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|--------------|--------------|----------------|-------------|
| T10 5 | 77.45 ± 4.36 | 28.21 ± 1.58 | 216.35 ± 14.21 | 1.68 ± 0.13 |
| T11 5 | 76.44 ± 3.82 | 36.19 ± 2.32 | 218.66 ± 13.06 | 1.62 ± 0.16 |
| T12 5 | 76.27 ± 3.54 | 31.89 ± 0.94 | 228.36 ± 4.96 | 1.50 ± 0.09 |
| T1 5 | 59.72 ± 2.39 | 33.15 ± 1.72 | 260.69 ± 9.97 | 2.06 ± 0.05 |
| T2 5 | 72.54 ± 0.81 | 28.83 ± 1.45 | 231.64 ± 4.56 | 1.76 ± 0.11 |
| T3 5 | 60.20 ± 1.21 | 23.29 ± 0.21 | 289.70 ± 6.56 | 2.34 ± 0.04 |
| T4 5 | 77.42 ± 2.74 | 27.64 ± 1.66 | 216.64 ± 6.83 | 1.71 ± 0.13 |
| T5 5 | 77.58 ± 2.27 | 32.03 ± 1.45 | 227.46 ± 4.43 | 1.54 ± 0.09 |
| T6 5 | 74.44 ± 4.37 | 30.13 ± 1.04 | 217.56 ± 6.36 | 1.90 ± 0.21 |
| T7 5 | 80.00 ± 1.77 | 22.41 ± 1.20 | 239.99 ± 18.16 | 1.39 ± 0.11 |
| T8 5 | 66.25 ± 8.84 | 27.60 ± 3.87 | 249.83 ± 31.73 | 2.07 ± 0.35 |
| T9 5 | 64.67 ± 3.40 | 29.72 ± 1.78 | 270.19 ± 12.79 | 1.95 ± 0.11 |
| Average | 71.92 | 29.26 | 238.92 | 1.79 |
| V1 1 | 70.83 ± 3.06 | 30.72 ± 0.78 | 241.85 ± 11.56 | 1.74 ± 0.17 |
| V1 2 | 60.45 ± 3.04 | 23.57 ± 1.53 | 285.97 ± 5.54 | 2.31 ± 0.07 |
| V1 3 | 82.98 ± 2.37 | 36.90 ± 2.38 | 178.16 ± 11.44 | 1.41 ± 0.11 |
| V1 4 | 66.85 ± 2.05 | 26.25 ± 2.42 | 277.40 ± 15.40 | 1.85 ± 0.19 |
| V1 5 | 71.81 ± 2.27 | 34.42 ± 0.91 | 238.96 ± 5.10 | 1.87 ± 0.12 |
| V2 1 | 56.97 ± 2.61 | 17.31 ± 0.98 | 326.74 ± 9.13 | 2.30 ± 0.20 |
| V2 2 | 70.56 ± 5.93 | 31.03 ± 1.34 | 241.85 ± 24.72 | 1.92 ± 0.17 |
| V2 3 | 76.41 ± 3.16 | 33.33 ± 2.68 | 216.07 ± 8.19 | 1.49 ± 0.11 |
| V2 4 | 64.36 ± 3.57 | 25.24 ± 0.84 | 263.61 ± 15.84 | 2.04 ± 0.15 |
| V2 5 | 63.33 ± 3.02 | 24.99 ± 0.36 | 284.43 ± 5.26 | 2.44 ± 0.12 |
| V3 1 | 72.86 ± 1.03 | 26.81 ± 2.75 | 240.61 ± 8.40 | 1.90 ± 0.07 |
| V3 2 | 79.31 ± 4.62 | 27.97 ± 1.41 | 213.71 ± 14.15 | 1.60 ± 0.23 |
| V3 3 | 81.48 ± 3.02 | 30.05 ± 1.48 | 213.88 ± 10.77 | 1.46 ± 0.08 |
| V3 4 | 63.81 ± 5.10 | 18.56 ± 0.80 | 283.22 ± 10.86 | 2.11 ± 0.27 |
| V3 5 | 75.14 ± 0.20 | 28.88 ± 2.25 | 220.18 ± 9.62 | 1.65 ± 0.04 |
| Average | 70.48 | 27.74 | 248.44 | 1.87 |
Table 6. Random performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|--------------|--------------|----------------|-------------|
| T10 5 | 27.15 ± 0.50 | 16.55 ± 0.85 | 371.96 ± 3.07 | 2.84 ± 0.00 |
| T11 5 | 22.83 ± 4.50 | 11.98 ± 2.67 | 406.66 ± 15.35 | 3.24 ± 0.22 |
| T12 5 | 20.68 ± 1.26 | 11.93 ± 0.51 | 413.58 ± 4.25 | 3.02 ± 0.04 |
| T1 5 | 22.00 ± 2.00 | 13.41 ± 1.47 | 396.63 ± 0.20 | 3.08 ± 0.09 |
| T2 5 | 32.83 ± 0.93 | 14.00 ± 0.57 | 369.18 ± 2.40 | 2.54 ± 0.06 |
| T3 5 | 21.26 ± 6.38 | 10.25 ± 0.81 | 421.76 ± 1.69 | 3.36 ± 0.09 |
| T4 5 | 21.32 ± 2.23 | 9.23 ± 1.62 | 415.40 ± 9.71 | 3.08 ± 0.06 |
| T5 5 | 34.95 ± 4.14 | 16.82 ± 1.57 | 373.65 ± 12.36 | 2.55 ± 0.16 |
| T6 5 | 33.67 ± 2.00 | 17.65 ± 1.43 | 357.99 ± 0.93 | 2.76 ± 0.05 |
| T7 5 | 30.75 ± 0.75 | 12.89 ± 0.42 | 391.34 ± 6.28 | 2.54 ± 0.12 |
| T8 5 | 27.00 ± 1.75 | 11.85 ± 1.68 | 407.04 ± 8.17 | 3.16 ± 0.17 |
| T9 5 | 17.50 ± 1.50 | 12.73 ± 0.25 | 412.05 ± 6.07 | 2.96 ± 0.02 |
| Average | 26.00 | 13.27 | 394.77 | 2.93 |
| V1 1 | 14.50 ± 2.50 | 9.64 ± 0.75 | 436.59 ± 3.65 | 3.13 ± 0.22 |
| V1 2 | 14.50 ± 4.50 | 8.63 ± 1.24 | 433.62 ± 8.48 | 3.25 ± 0.32 |
| V1 3 | 31.61 ± 6.87 | 16.30 ± 0.77 | 382.54 ± 14.30 | 2.77 ± 0.13 |
| V1 4 | 12.28 ± 3.28 | 8.49 ± 0.73 | 436.72 ± 9.52 | 3.18 ± 0.11 |
| V1 5 | 16.17 ± 1.33 | 10.29 ± 0.50 | 424.95 ± 9.29 | 3.23 ± 0.12 |
| V2 1 | 5.41 ± 3.68 | 4.71 ± 1.47 | 464.95 ± 11.81 | 3.17 ± 0.03 |
| V2 2 | 25.61 ± 0.06 | 13.89 ± 0.33 | 395.96 ± 1.47 | 3.17 ± 0.12 |
| V2 3 | 31.04 ± 2.04 | 17.05 ± 0.02 | 377.52 ± 5.43 | 2.17 ± 0.06 |
| V2 4 | 23.73 ± 3.96 | 14.14 ± 0.76 | 398.90 ± 3.78 | 2.50 ± 0.10 |
| V2 5 | 18.20 ± 1.37 | 11.74 ± 0.15 | 417.68 ± 0.58 | 3.25 ± 0.08 |
| V3 1 | 30.45 ± 0.50 | 13.00 ± 0.84 | 381.07 ± 4.86 | 2.55 ± 0.01 |
| V3 2 | 34.08 ± 1.75 | 12.83 ± 0.82 | 368.68 ± 1.57 | 2.79 ± 0.06 |
| V3 3 | 28.39 ± 0.87 | 11.83 ± 0.51 | 394.93 ± 4.61 | 2.84 ± 0.05 |
| V3 4 | 25.21 ± 3.83 | 10.30 ± 1.26 | 397.19 ± 9.02 | 3.01 ± 0.15 |
| V3 5 | 35.33 ± 3.00 | 17.42 ± 1.22 | 376.74 ± 3.21 | 2.34 ± 0.07 |
| Average | 23.10 | 12.02 | 405.87 | 2.89 |
Table 7. GPT-4o performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|-----------|------------|--------|--------|
| T10 5 | 35.29 | 19.09 | 358.81 | 3 |
| T11 5 | 36 | 18.32 | 363.55 | 3.15 |
| T12 5 | 35.29 | 20.42 | 359.38 | 3.17 |
| T1 5 | 33.33 | 21.14 | 362.02 | 2.78 |
| T2 5 | 28.57 | 13.1 | 367.66 | 2.76 |
| T3 5 | 20 | 10.86 | 377.68 | 3.3 |
| T4 5 | 37.27 | 18.58 | 357.89 | 3.12 |
| T5 5 | 32.73 | 18.66 | 363.37 | 2.95 |
| T6 5 | 41.67 | 21.92 | 351.87 | 3.24 |
| T7 5 | 21.25 | 8.14 | 374.45 | 3.1 |
| T8 5 | 36.25 | 19.38 | 356.12 | 3.07 |
| T9 5 | 26 | 16.57 | 366.02 | 2.72 |
| Average | 31.97 | 17.18 | 363.23 | 3.03 |
| V1 1 | 24 | 13.84 | 374.19 | 3.45 |
| V1 2 | 21.82 | 11.66 | 373.75 | 3.22 |
| V1 3 | 46.32 | 26.44 | 342.01 | 2.53 |
| V1 4 | 15.56 | 8.23 | 385.98 | 3.48 |
| V1 5 | 16.59 | 5.07 | 390.28 | 3.1 |
| V2 1 | 28.43 | 17.75 | 365.67 | 3.31 |
| V2 2 | 48.95 | 23.77 | 346.67 | 2.09 |
| V2 3 | 58.52 | 30.56 | 329.43 | 1.82 |
| V2 4 | 35.23 | 20.31 | 360.92 | 2.09 |
| V2 5 | 26.41 | 14.6 | 370.46 | 3.04 |
| V3 1 | 7.48 | 2.94 | 391.37 | 4.18 |
| V3 2 | 41.67 | 21.22 | 349.08 | 2.99 |
| V3 3 | 31.11 | 13.08 | 369.33 | 2.73 |
| V3 4 | 25.71 | 11.31 | 373.28 | 3.22 |
| V3 5 | 47.5 | 26.64 | 346.99 | 2.09 |
| Average | 31.69 | 16.49 | 364.63 | 2.89 |
Table 8. Video-LLaVA performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|-----------|------------|--------|--------|
| T10 5 | 25.88 | 13.74 | 370.67 | 2.86 |
| T11 5 | 22.67 | 8.79 | 380.99 | 3.58 |
| T12 5 | 17.65 | 8.67 | 379.87 | 3.3 |
| T1 5 | 20 | 7.78 | 383.98 | 2.77 |
| T2 5 | 20.95 | 8.18 | 382.31 | 2.67 |
| T3 5 | 14.12 | 5.89 | 388.76 | 3.84 |
| T4 5 | 19.09 | 6.39 | 385.62 | 3.31 |
| T5 5 | 18.18 | 7.55 | 385.68 | 3.04 |
| T6 5 | 23.84 | 8.69 | 378.77 | 2.78 |
| T7 5 | 19.86 | 7.67 | 382.04 | 3.01 |
| T8 5 | 15.79 | 7.32 | 384.94 | 2.84 |
| T9 5 | 22.83 | 9.11 | 379.34 | 2.98 |
| Average | 20.07 | 8.31 | 381.92 | 3.08 |
| V1 1 | 25.92 | 10.42 | 374.65 | 3.01 |
| V1 2 | 13.64 | 5.17 | 389.82 | 3.44 |
| V1 3 | 10.92 | 1.66 | 396.36 | 3.65 |
| V1 4 | 20.47 | 8.4 | 382.13 | 3.13 |
| V1 5 | 9.17 | 3.28 | 395.26 | 3.63 |
| V2 1 | 14.21 | 6.74 | 388.84 | 3.61 |
| V2 2 | 22.12 | 8.9 | 377.86 | 3.3 |
| V2 3 | 26.38 | 12.39 | 372.44 | 3.13 |
| V2 4 | 13.53 | 4.34 | 391.22 | 4.01 |
| V2 5 | 20.85 | 6.12 | 387.35 | 3.21 |
| V3 1 | 20 | 6.59 | 381.67 | 2.93 |
| V3 2 | 17.46 | 6.13 | 387.79 | 2.94 |
| V3 3 | 16.29 | 5.24 | 388.7 | 2.91 |
| V3 4 | 14.36 | 5.76 | 388.94 | 3.55 |
| V3 5 | 17.38 | 7.51 | 382.77 | 3.34 |
| Average | 17.51 | 6.58 | 385.72 | 3.32 |
Table 9. AVDC performance on RoboTHOR testing set. T' denotes FloorPlan Train and V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|-----------|------------|--------|--------|
| T10 5 | 33.84 | 9.29 | 422.72 | 1.92 |
| T11 5 | 36.72 | 11.13 | 434.58 | 2.22 |
| T12 5 | 31.24 | 8.14 | 437.61 | 2.12 |
| T1 5 | 28.98 | 7.44 | 428.73 | 2 |
| T2 5 | 32.59 | 9.05 | 440.12 | 2.14 |
| T3 5 | 24.53 | 8.26 | 444.36 | 2.45 |
| T4 5 | 35.21 | 10.57 | 423.94 | 1.99 |
| T5 5 | 33.47 | 10.36 | 433.51 | 2.09 |
| T6 5 | 39.12 | 11.98 | 415.89 | 2.32 |
| T7 5 | 25.74 | 6.92 | 439.82 | 2.18 |
| T8 5 | 36.23 | 11.45 | 421.16 | 2.27 |
| T9 5 | 32.67 | 8.54 | 426.75 | 2.15 |
| Average | 32.53 | 9.43 | 430.77 | 2.15 |
| V1 1 | 27.14 | 8.21 | 462.48 | 2.65 |
| V1 2 | 29.62 | 11.18 | 440.87 | 2.53 |
| V1 3 | 30.28 | 15.24 | 405.27 | 1.84 |
| V1 4 | 22.84 | 7.91 | 454.28 | 2.59 |
| V1 5 | 30.41 | 6.76 | 447.91 | 2.21 |
| V2 1 | 34.32 | 13.43 | 425.68 | 2.05 |
| V2 2 | 48.45 | 10.92 | 398.67 | 1.25 |
| V2 3 | 43.67 | 12.57 | 387.45 | 1.73 |
| V2 4 | 36.18 | 14.97 | 404.22 | 1.49 |
| V2 5 | 31.84 | 12.98 | 412.88 | 2.29 |
| V3 1 | 11.14 | 5.23 | 450.75 | 3.07 |
| V3 2 | 28.89 | 19.34 | 409.38 | 1.97 |
| V3 3 | 34.67 | 13.15 | 429.52 | 2.21 |
| V3 4 | 27.93 | 10.27 | 439.74 | 2.55 |
| V3 5 | 29.78 | 11.33 | 399.28 | 1.53 |
| Average | 31.14 | 11.57 | 424.56 | 2.13 |
Table 10. VGM performance on RoboTHOR testing set. T' denotes FloorPlan Train and V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|-----------|------------|--------|--------|
| T10 5 | 46.02 | 25.47 | 375.88 | 2.49 |
| T11 5 | 44.98 | 23.65 | 392.45 | 2.71 |
| T12 5 | 50.13 | 22.71 | 378.29 | 2.39 |
| T1 5 | 49.75 | 26.02 | 371.15 | 2.55 |
| T2 5 | 43.59 | 21.54 | 388.67 | 2.23 |
| T3 5 | 46.93 | 22.88 | 367.36 | 2.67 |
| T4 5 | 48.32 | 24.07 | 381.74 | 2.41 |
| T5 5 | 44.25 | 24.61 | 373.28 | 2.44 |
| T6 5 | 50.41 | 25.19 | 369.24 | 2.33 |
| T7 5 | 45.67 | 22.32 | 365.72 | 2.62 |
| T8 5 | 46.89 | 23.78 | 380.91 | 2.35 |
| T9 5 | 47.54 | 24.56 | 378.32 | 2.13 |
| Average | 47.04 | 23.9 | 376.92 | 2.44 |
| V1 1 | 41.13 | 21.57 | 405.87 | 2.64 |
| V1 2 | 39.23 | 19.31 | 412.88 | 2.87 |
| V1 3 | 43.67 | 22.13 | 386.24 | 1.77 |
| V1 4 | 42.45 | 18.27 | 416.54 | 2.41 |
| V1 5 | 35.88 | 18.68 | 401.96 | 2.54 |
| V2 1 | 44.26 | 20.67 | 382.33 | 2.38 |
| V2 2 | 49.87 | 23.12 | 394.56 | 1.85 |
| V2 3 | 41.22 | 21.87 | 385.19 | 1.91 |
| V2 4 | 38.96 | 22.07 | 396.72 | 2.25 |
| V2 5 | 43.78 | 20.52 | 405.33 | 2.64 |
| V3 1 | 35.37 | 12.43 | 420.64 | 3.22 |
| V3 2 | 39.16 | 21.38 | 389.33 | 2.42 |
| V3 3 | 33.78 | 18.04 | 406.57 | 2.11 |
| V3 4 | 30.15 | 14.92 | 416.38 | 2.82 |
| V3 5 | 48.76 | 24.87 | 392.94 | 1.87 |
| Average | 40.51 | 19.99 | 400.9 | 2.38 |
Table 11. ZSON performance on RoboTHOR testing set. T' denotes FloorPlan Train and V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|-----------|------------|--------|--------|
| T10 5 | 38.89 | 20.69 | 350.67 | 2.23 |
| T11 5 | 35.06 | 19.92 | 362.44 | 2.41 |
| T12 5 | 40.06 | 22.54 | 345.23 | 2.16 |
| T1 5 | 36.17 | 19.45 | 358.91 | 2.09 |
| T2 5 | 34.37 | 22.58 | 351.12 | 2.02 |
| T3 5 | 41.86 | 23.24 | 340.11 | 2.34 |
| T4 5 | 38.72 | 21.52 | 346.72 | 2.29 |
| T5 5 | 36.06 | 20.35 | 349.33 | 2.25 |
| T6 5 | 43.17 | 22.61 | 335.84 | 2.38 |
| T7 5 | 35.17 | 20.45 | 360.17 | 2.15 |
| T8 5 | 35.96 | 20.27 | 348.52 | 2.31 |
| T9 5 | 38.52 | 22.08 | 342.66 | 2.18 |
| Average | 37.83 | 21.31 | 349.31 | 2.23 |
| V1 1 | 37.91 | 18.12 | 378.87 | 2.72 |
| V1 2 | 34.5 | 17.64 | 386.19 | 2.91 |
| V1 3 | 43.06 | 20.88 | 359.72 | 1.77 |
| V1 4 | 28.71 | 16.29 | 395.18 | 2.56 |
| V1 5 | 33.77 | 15.17 | 380.14 | 2.64 |
| V2 1 | 40.93 | 19.42 | 361.48 | 2.12 |
| V2 2 | 41.6 | 25.01 | 353.26 | 1.43 |
| V2 3 | 43.34 | 21.41 | 368.11 | 1.85 |
| V2 4 | 39.55 | 22.75 | 354.24 | 2.25 |
| V2 5 | 40.02 | 19.83 | 360.73 | 2.72 |
| V3 1 | 19.52 | 10.81 | 392.54 | 3.22 |
| V3 2 | 37.89 | 19.64 | 368.18 | 2.56 |
| V3 3 | 32.41 | 15.28 | 382.45 | 2.21 |
| V3 4 | 23.77 | 13.04 | 390.76 | 2.89 |
| V3 5 | 39.79 | 26.81 | 358.32 | 1.73 |
| Average | 35.78 | 18.81 | 372.68 | 2.37 |
Table 12. NOLO-C performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|--------------|--------------|----------------|-------------|
| T10 5 | 72.94 ± 5.08 | 27.83 ± 0.15 | 252.83 ± 8.62 | 1.86 ± 0.29 |
| T11 5 | 82.00 ± 1.44 | 36.28 ± 2.90 | 195.77 ± 8.38 | 1.50 ± 0.05 |
| T12 5 | 73.53 ± 0.83 | 32.13 ± 1.26 | 230.53 ± 8.63 | 1.59 ± 0.05 |
| T1 5 | 64.72 ± 1.04 | 32.41 ± 1.39 | 258.61 ± 2.70 | 1.94 ± 0.06 |
| T2 5 | 70.63 ± 3.40 | 29.21 ± 3.18 | 243.38 ± 16.56 | 1.78 ± 0.11 |
| T3 5 | 62.16 ± 1.94 | 23.55 ± 0.62 | 288.69 ± 8.45 | 2.27 ± 0.09 |
| T4 5 | 72.12 ± 5.77 | 27.65 ± 0.21 | 244.76 ± 16.37 | 1.89 ± 0.20 |
| T5 5 | 75.61 ± 0.57 | 32.77 ± 1.68 | 232.83 ± 3.66 | 1.60 ± 0.04 |
| T6 5 | 67.78 ± 4.37 | 27.60 ± 0.31 | 254.15 ± 5.21 | 2.00 ± 0.12 |
| T7 5 | 75.62 ± 1.84 | 19.90 ± 2.02 | 256.17 ± 8.42 | 1.55 ± 0.03 |
| T8 5 | 65.62 ± 2.55 | 26.02 ± 2.55 | 253.82 ± 8.94 | 2.00 ± 0.07 |
| T9 5 | 56.67 ± 4.11 | 24.40 ± 2.52 | 303.16 ± 8.15 | 2.18 ± 0.05 |
| Average | 69.95 | 28.31 | 251.23 | 1.85 |
| V1 1 | 64.33 ± 5.44 | 25.29 ± 5.10 | 283.93 ± 29.92 | 2.12 ± 0.22 |
| V1 2 | 57.42 ± 3.57 | 22.97 ± 1.36 | 305.57 ± 10.25 | 2.34 ± 0.15 |
| V1 3 | 82.98 ± 1.38 | 41.56 ± 1.40 | 197.25 ± 10.54 | 1.43 ± 0.04 |
| V1 4 | 62.22 ± 3.27 | 25.73 ± 1.58 | 284.70 ± 10.51 | 2.26 ± 0.10 |
| V1 5 | 58.61 ± 1.42 | 31.95 ± 2.50 | 276.70 ± 4.67 | 2.53 ± 0.12 |
| V2 1 | 52.73 ± 1.96 | 17.41 ± 1.69 | 336.15 ± 1.47 | 2.59 ± 0.08 |
| V2 2 | 67.22 ± 4.33 | 28.52 ± 2.17 | 268.21 ± 2.39 | 1.95 ± 0.07 |
| V2 3 | 79.74 ± 3.46 | 35.81 ± 0.85 | 209.43 ± 23.21 | 1.34 ± 0.08 |
| V2 4 | 62.95 ± 6.01 | 25.65 ± 0.77 | 276.85 ± 16.89 | 2.10 ± 0.19 |
| V2 5 | 58.70 ± 0.94 | 24.36 ± 1.83 | 290.25 ± 2.98 | 2.55 ± 0.05 |
| V3 1 | 71.43 ± 2.33 | 26.32 ± 3.77 | 240.97 ± 20.02 | 2.00 ± 0.14 |
| V3 2 | 71.53 ± 1.75 | 26.78 ± 0.32 | 238.58 ± 3.53 | 1.99 ± 0.09 |
| V3 3 | 72.59 ± 4.57 | 27.82 ± 1.74 | 242.52 ± 9.40 | 1.73 ± 0.18 |
| V3 4 | 57.30 ± 2.65 | 18.35 ± 0.51 | 300.88 ± 11.16 | 2.30 ± 0.08 |
| V3 5 | 70.97 ± 3.16 | 29.52 ± 1.81 | 243.77 ± 19.50 | 1.96 ± 0.14 |
| Average | 66.05 | 27.20 | 266.38 | 2.08 |
Table 13. NOLO-T performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|--------------|--------------|----------------|-------------|
| T10 5 | 76.47 ± 3.53 | 29.97 ± 2.31 | 225.76 ± 18.05 | 1.71 ± 0.16 |
| T11 5 | 78.00 ± 0.67 | 36.00 ± 0.43 | 210.91 ± 7.94 | 1.56 ± 0.10 |
| T12 5 | 75.88 ± 0.59 | 30.77 ± 1.29 | 233.25 ± 4.82 | 1.62 ± 0.02 |
| T1 5 | 64.17 ± 2.50 | 32.47 ± 4.30 | 254.97 ± 6.37 | 2.07 ± 0.01 |
| T2 5 | 65.71 ± 6.67 | 26.12 ± 4.84 | 259.38 ± 29.69 | 1.95 ± 0.25 |
| T3 5 | 59.41 ± 4.12 | 22.67 ± 0.98 | 303.37 ± 11.79 | 2.39 ± 0.08 |
| T4 5 | 72.73 ± 0.91 | 27.02 ± 2.10 | 238.05 ± 10.76 | 1.89 ± 0.09 |
| T5 5 | 78.18 ± 3.64 | 33.88 ± 0.94 | 224.37 ± 22.06 | 1.48 ± 0.12 |
| T6 5 | 74.17 ± 0.83 | 32.28 ± 1.91 | 216.92 ± 17.75 | 1.83 ± 0.11 |
| T7 5 | 80.62 ± 0.62 | 23.85 ± 1.03 | 232.86 ± 15.75 | 1.38 ± 0.08 |
| T8 5 | 66.25 ± 2.50 | 30.95 ± 2.62 | 245.14 ± 15.49 | 2.06 ± 0.12 |
| T9 5 | 61.00 ± 1.00 | 28.92 ± 1.60 | 285.27 ± 2.75 | 1.80 ± 0.20 |
| Average | 71.05 | 29.57 | 244.19 | 1.81 |
| V1 1 | 64.00 ± 2.00 | 26.54 ± 1.03 | 277.16 ± 12.08 | 2.25 ± 0.02 |
| V1 2 | 64.55 | 25.30 ± 0.81 | 272.34 ± 12.70 | 2.20 ± 0.01 |
| V1 3 | 80.53 ± 5.79 | 36.93 ± 0.98 | 201.32 ± 9.73 | 1.62 ± 0.22 |
| V1 4 | 59.44 ± 7.22 | 25.50 ± 1.25 | 283.97 ± 24.48 | 2.14 ± 0.21 |
| V1 5 | 62.50 ± 0.83 | 32.49 ± 0.23 | 268.84 ± 5.32 | 2.06 ± 0.01 |
| V2 1 | 56.36 ± 0.91 | 17.59 ± 0.30 | 329.25 ± 10.75 | 2.44 ± 0.04 |
| V2 2 | 65.56 ± 2.22 | 30.85 ± 2.09 | 256.13 ± 9.46 | 2.07 ± 0.07 |
| V2 3 | 76.92 ± 1.54 | 34.22 ± 0.03 | 209.07 ± 4.52 | 1.59 ± 0.02 |
| V2 4 | 68.08 ± 0.38 | 25.24 ± 0.19 | 265.69 ± 6.21 | 1.93 ± 0.00 |
| V2 5 | 65.22 ± 3.48 | 24.79 ± 0.74 | 290.28 ± 11.04 | 2.29 ± 0.14 |
| V3 1 | 69.52 ± 0.95 | 25.09 ± 0.17 | 244.60 ± 10.47 | 2.04 ± 0.03 |
| V3 2 | 75.83 ± 0.83 | 27.14 ± 2.16 | 223.59 ± 6.15 | 1.81 ± 0.06 |
| V3 3 | 73.70 ± 2.59 | 24.63 ± 2.77 | 245.72 ± 15.48 | 1.75 ± 0.15 |
| V3 4 | 52.38 ± 3.81 | 17.61 ± 0.82 | 316.57 ± 4.58 | 2.46 ± 0.12 |
| V3 5 | 76.67 ± 0.83 | 31.29 ± 1.91 | 211.91 ± 5.29 | 1.62 ± 0.04 |
| Average | 67.42 | 27.01 | 259.76 | 2.02 |
Table 14. NOLO(M) performance on RoboTHOR testing set. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|---------|--------------|--------------|----------------|-------------|
| T10 5 | 80.59 ± 4.12 | 32.92 ± 1.93 | 202.68 ± 22.39 | 1.47 ± 0.12 |
| T11 5 | 77.33 ± 2.67 | 36.00 ± 3.27 | 218.04 ± 1.64 | 1.64 ± 0.01 |
| T12 5 | 78.82 | 36.62 ± 0.82 | 211.44 ± 9.89 | 1.55 ± 0.01 |
| T1 5 | 50.83 ± 5.83 | 27.99 ± 2.85 | 302.14 ± 14.69 | 2.35 ± 0.10 |
| T2 5 | 69.05 ± 1.43 | 25.09 ± 2.83 | 256.49 ± 1.55 | 1.85 ± 0.13 |
| T3 5 | 54.71 ± 0.59 | 21.49 ± 0.94 | 312.69 ± 3.18 | 2.61 ± 0.08 |
| T4 5 | 73.64 ± 2.73 | 25.06 ± 1.03 | 245.16 ± 17.39 | 1.78 ± 0.08 |
| T5 5 | 75.45 ± 0.91 | 31.23 ± 1.14 | 234.16 ± 1.94 | 1.75 ± 0.07 |
| T6 5 | 65.83 ± 2.50 | 24.81 ± 0.36 | 276.04 ± 19.72 | 1.95 ± 0.01 |
| T7 5 | 70.62 ± 0.63 | 19.64 ± 0.81 | 281.29 ± 2.88 | 1.77 ± 0.05 |
| T8 5 | 59.38 ± 6.87 | 23.84 ± 2.27 | 287.47 ± 17.78 | 2.38 ± 0.37 |
| T9 5 | 59.00 ± 7.00 | 31.86 ± 5.95 | 278.41 ± 28.49 | 2.12 ± 0.22 |
| Average | 67.94 | 28.05 | 258.83 | 1.93 |
| V1 1 | 60.00 ± 3.00 | 25.32 ± 3.23 | 294.85 ± 21.57 | 2.29 ± 0.09 |
| V1 2 | 60.00 ± 1.82 | 24.32 ± 3.48 | 291.72 ± 6.24 | 2.18 ± 0.09 |
| V1 3 | 82.63 ± 1.58 | 35.75 ± 3.13 | 200.15 ± 3.24 | 1.41 ± 0.09 |
| V1 4 | 62.22 ± 1.11 | 24.95 ± 0.16 | 288.34 ± 6.13 | 2.19 ± 0.21 |
| V1 5 | 64.58 ± 4.58 | 31.77 ± 3.05 | 265.98 ± 16.41 | 2.04 ± 0.16 |
| V2 1 | 49.09 ± 1.82 | 14.51 ± 2.21 | 358.64 ± 2.52 | 2.68 ± 0.06 |
| V2 2 | 66.11 ± 2.78 | 30.06 ± 1.07 | 261.83 ± 10.29 | 2.11 ± 0.15 |
| V2 3 | 77.69 ± 0.77 | 31.33 ± 1.61 | 232.93 ± 6.27 | 1.49 ± 0.02 |
| V2 4 | 57.69 ± 1.54 | 23.61 ± 0.69 | 296.56 ± 8.78 | 2.26 ± 0.07 |
| V2 5 | 59.57 ± 4.78 | 23.29 ± 0.57 | 303.90 ± 19.02 | 2.48 ± 0.30 |
| V3 1 | 70.48 ± 1.90 | 25.14 ± 1.24 | 254.00 ± 0.10 | 1.87 ± 0.06 |
| V3 2 | 71.25 ± 0.42 | 25.59 ± 0.67 | 244.68 ± 2.23 | 1.88 ± 0.04 |
| V3 3 | 67.78 ± 0.37 | 24.20 ± 1.78 | 258.00 ± 2.40 | 1.89 ± 0.03 |
| V3 4 | 54.29 ± 0.95 | 13.15 ± 1.33 | 330.42 ± 8.02 | 2.40 ± 0.00 |
| V3 5 | 67.50 ± 1.67 | 30.21 ± 4.40 | 246.60 ± 8.73 | 2.05 ± 0.04 |
| Average | 64.73 | 25.55 | 275.24 | 2.08 |
Table 15. NOLO performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|---------------|--------------|----------------|-------------|
| 2azQ1b91cZZ | 50.26 ± 3.10 | 28.99 ± 1.40 | 311.44 ± 11.24 | 2.80 ± 0.12 |
| 8194nk5LbLH | 43.94 ± 1.55 | 22.60 ± 0.51 | 341.28 ± 1.28 | 3.10 ± 0.08 |
| EU6Fwq7SyZv | 42.33 ± 1.70 | 18.15 ± 1.13 | 362.99 ± 5.59 | 2.90 ± 0.06 |
| QUCTc6BB5sX | 44.67 ± 6.24 | 21.94 ± 1.36 | 344.75 ± 21.03 | 4.25 ± 0.84 |
| SN83YJsR3w2 | 38.33 ± 6.24 | 15.74 ± 2.48 | 379.77 ± 17.81 | 2.97 ± 0.97 |
| TbHJrupSAjP | 36.67 ± 10.19 | 14.29 ± 3.23 | 376.57 ± 28.90 | 3.85 ± 0.79 |
| UwV83HsGsw3 | 30.48 ± 3.75 | 13.66 ± 0.67 | 402.48 ± 14.42 | 4.80 ± 0.58 |
| Vt2qJdWjCF2 | 34.58 ± 4.60 | 12.75 ± 4.26 | 387.33 ± 21.56 | 6.63 ± 0.81 |
| VzqfbhrpDEA | 33.70 ± 1.89 | 17.94 ± 1.15 | 377.91 ± 7.07 | 5.25 ± 0.22 |
| X7HyMhZNoso | 66.67 ± 4.38 | 30.84 ± 2.47 | 275.02 ± 20.74 | 1.37 ± 0.22 |
| Z6MFQCViBuw | 40.67 ± 6.18 | 16.25 ± 3.41 | 369.67 ± 21.35 | 4.62 ± 0.64 |
| gTV8FGcVJC9 | 53.67 ± 4.03 | 29.49 ± 2.20 | 292.08 ± 12.03 | 3.98 ± 0.12 |
| gYvKGZ5eRqb | 25.00 ± 8.16 | 7.34 ± 4.04 | 433.63 ± 30.22 | 6.06 ± 0.59 |
| oLBMNvg9in8 | 45.67 ± 4.03 | 24.45 ± 3.33 | 335.14 ± 14.15 | 2.19 ± 0.16 |
| pLe4wQe7qrG | 70.00 ± 2.72 | 38.63 ± 2.66 | 218.44 ± 6.09 | 0.88 ± 0.24 |
| pa4otMbVnkk | 41.11 ± 11.00 | 20.99 ± 6.68 | 346.89 ± 36.77 | 5.95 ± 1.17 |
| rqfALeAoiTq | 47.50 ± 3.12 | 21.92 ± 2.23 | 338.93 ± 11.95 | 2.57 ± 0.11 |
| x8F5xyUWy9e | 51.82 ± 0.74 | 23.36 ± 0.97 | 320.58 ± 4.80 | 2.91 ± 0.06 |
| yqstnuAEVhm | 38.89 ± 0.79 | 17.68 ± 1.86 | 369.21 ± 3.18 | 2.54 ± 0.12 |
| zsNo4HB9uLZ | 37.08 ± 3.28 | 18.48 ± 2.66 | 367.31 ± 11.94 | 3.77 ± 0.34 |
| Average | 43.65 | 20.77 | 347.57 | 3.67 |
Table 16. Random performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|--------------|--------------|----------------|-------------|
| 2azQ1b91cZZ | 28.73 ± 6.04 | 13.11 ± 3.30 | 386.34 ± 24.39 | 3.91 ± 0.26 |
| 8194nk5LbLH | 32.68 ± 4.95 | 11.77 ± 0.59 | 380.37 ± 10.02 | 3.78 ± 0.13 |
| EU6Fwq7SyZv | 21.50 ± 2.50 | 8.57 ± 0.97 | 409.05 ± 12.59 | 5.07 ± 0.18 |
| QUCTc6BB5sX | 21.50 ± 0.50 | 10.60 ± 1.00 | 399.77 ± 3.10 | 5.67 ± 0.00 |
| SN83YJsR3w2 | 12.00 ± 3.00 | 5.89 ± 1.05 | 428.02 ± 12.97 | 4.97 ± 0.14 |
| TbHJrupSAjP | 18.07 ± 0.21 | 5.57 ± 1.55 | 427.09 ± 10.29 | 5.89 ± 0.37 |
| UwV83HsGsw3 | 15.93 ± 1.93 | 4.78 ± 1.42 | 435.46 ± 1.59 | 5.57 ± 0.16 |
| Vt2qJdWjCF2 | 20.75 ± 1.75 | 8.75 ± 0.86 | 415.93 ± 1.07 | 6.02 ± 0.05 |
| VzqfbhrpDEA | 25.06 ± 2.28 | 7.90 ± 1.88 | 412.03 ± 12.59 | 5.14 ± 0.05 |
| X7HyMhZNoso | 45.21 ± 0.21 | 17.71 ± 0.35 | 342.76 ± 8.05 | 2.86 ± 0.03 |
| Z6MFQCViBuw | 17.50 ± 4.50 | 5.40 ± 1.41 | 430.17 ± 14.77 | 6.83 ± 0.48 |
| gTV8FGcVJC9 | 34.00 ± 5.00 | 13.64 ± 1.80 | 370.20 ± 16.76 | 4.76 ± 0.08 |
| gYvKGZ5eRqb | 7.00 ± 3.00 | 5.39 ± 2.65 | 457.60 ± 20.20 | 7.21 ± 0.10 |
| oLBMNvg9in8 | 20.50 ± 0.50 | 8.57 ± 1.53 | 418.56 ± 8.32 | 4.28 ± 0.10 |
| pLe4wQe7qrG | 41.17 ± 7.17 | 15.29 ± 4.11 | 348.37 ± 24.83 | 3.17 ± 0.90 |
| pa4otMbVnkk | 22.83 ± 7.83 | 14.06 ± 0.92 | 391.77 ± 29.37 | 6.59 ± 0.03 |
| rqfALeAoiTq | 22.00 ± 1.33 | 9.19 ± 2.09 | 410.70 ± 6.22 | 4.25 ± 0.36 |
| x8F5xyUWy9e | 29.05 ± 3.23 | 12.57 ± 0.77 | 388.25 ± 1.57 | 4.69 ± 0.14 |
| yqstnuAEVhm | 23.67 ± 1.17 | 9.23 ± 0.06 | 410.58 ± 9.25 | 3.90 ± 0.13 |
| zsNo4HB9uLZ | 31.37 ± 1.13 | 12.54 ± 0.88 | 377.44 ± 10.84 | 4.78 ± 0.14 |
| Average | 24.53 | 10.03 | 402.02 | 4.97 |
Table 17. GPT-4o performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|-----------|------------|--------|--------|
| 2azQ1b91cZZ | 31.67 | 17.77 | 348.79 | 4.19 |
| 8194nk5LbLH | 26.67 | 12.07 | 360.59 | 4.21 |
| EU6Fwq7SyZv | 37.41 | 20.31 | 347.59 | 5.1 |
| QUCTc6BB5sX | 36.9 | 20.04 | 347.43 | 6.38 |
| SN83YJsR3w2 | 37.24 | 21.26 | 344.79 | 4.69 |
| TbHJrupSAjP | 36.89 | 23.76 | 339.05 | 2.99 |
| UwV83HsGsw3 | 32.86 | 22.14 | 344.4 | 4.97 |
| Vt2qJdWjCF2 | 32.5 | 18 | 350.69 | 7.19 |
| VzqfbhrpDEA | 36.67 | 19.97 | 346.93 | 5.26 |
| X7HyMhZNoso | 42.86 | 26.08 | 335.63 | 2.66 |
| Z6MFQCViBuw | 24 | 12.83 | 362.88 | 7.99 |
| gTV8FGcVJC9 | 38.49 | 21.29 | 344.03 | 4.25 |
| gYvKGZ5eRqb | 37.46 | 23.24 | 340.84 | 4.58 |
| oLBMNvg9in8 | 38.34 | 23.79 | 335.41 | 2.06 |
| pLe4wQe7qrG | 29.32 | 18.54 | 350.5 | 5.77 |
| pa4otMbVnkk | 34.82 | 16.11 | 351.36 | 5.98 |
| rqfALeAoiTq | 39.49 | 23.56 | 339.48 | 3.32 |
| x8F5xyUWy9e | 40.91 | 23.94 | 338.39 | 4.23 |
| yqstnuAEVhm | 35 | 21.56 | 345.06 | 3.41 |
| zsNo4HB9uLZ | 33.75 | 21.45 | 342.88 | 4.72 |
| Average | 35.16 | 20.39 | 345.84 | 4.7 |
Table 18. Video-LLaVA performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|-----------|------------|--------|--------|
| 2azQ1b91cZZ | 20 | 10.21 | 381.51 | 3.77 |
| 8194nk5LbLH | 12.5 | 7.28 | 387.78 | 5.17 |
| EU6Fwq7SyZv | 14 | 7.92 | 385.03 | 4.04 |
| QUCTc6BB5sX | 19 | 12.24 | 378.96 | 5.26 |
| SN83YJsR3w2 | 20 | 12.34 | 379 | 3.72 |
| TbHJrupSAjP | 7.14 | 3.01 | 395.36 | 5.05 |
| UwV83HsGsw3 | 8.57 | 4.7 | 393.87 | 5.29 |
| Vt2qJdWjCF2 | 11.32 | 6.66 | 388.67 | 6.24 |
| VzqfbhrpDEA | 16.2 | 10.37 | 384.72 | 5.42 |
| X7HyMhZNoso | 11.27 | 4.48 | 393.52 | 4.49 |
| Z6MFQCViBuw | 24.6 | 15.43 | 371.56 | 4.64 |
| gTV8FGcVJC9 | 25 | 15.86 | 371.61 | 4.5 |
| gYvKGZ5eRqb | 10 | 7.19 | 389.55 | 5.23 |
| oLBMNvg9in8 | 14 | 9.9 | 380.34 | 4.4 |
| pLe4wQe7qrG | 13.33 | 12.94 | 377.5 | 3.17 |
| pa4otMbVnkk | 10 | 5.57 | 387.5 | 6.02 |
| rqfALeAoiTq | 12.5 | 8.34 | 386.06 | 3.91 |
| x8F5xyUWy9e | 15.91 | 11.81 | 380.44 | 3.43 |
| yqstnuAEVhm | 10.54 | 6.06 | 390.36 | 5.19 |
| zsNo4HB9uLZ | 15.01 | 8.03 | 387.2 | 5.3 |
| Average | 14.55 | 9.02 | 384.53 | 4.71 |
Table 19. AVDC performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|-----------|------------|--------|--------|
| 2azQ1b91cZZ | 24.12 | 7.93 | 429.3 | 3.44 |
| 8194nk5LbLH | 29.33 | 14.02 | 375.06 | 5.05 |
| EU6Fwq7SyZv | 26.95 | 12.35 | 442.17 | 5.45 |
| QUCTc6BB5sX | 22.14 | 10.48 | 450.81 | 3.54 |
| SN83YJsR3w2 | 30.77 | 15.06 | 395.85 | 4.21 |
| TbHJrupSAjP | 31.49 | 10.74 | 420.21 | 4.96 |
| UwV83HsGsw3 | 23.57 | 12.84 | 393.14 | 3.33 |
| Vt2qJdWjCF2 | 28.05 | 11.54 | 426.06 | 4.42 |
| VzqfbhrpDEA | 25.22 | 14.19 | 410.55 | 3.45 |
| X7HyMhZNoso | 29.58 | 12.82 | 414.27 | 4.2 |
| Z6MFQCViBuw | 26.78 | 13.78 | 430.31 | 4.63 |
| gTV8FGcVJC9 | 28.29 | 10 | 411.56 | 4.27 |
| gYvKGZ5eRqb | 26.52 | 10.18 | 421.96 | 4.92 |
| oLBMNvg9in8 | 25.44 | 13 | 417.07 | 3.91 |
| pLe4wQe7qrG | 27.88 | 16.95 | 429 | 4.4 |
| pa4otMbVnkk | 29.31 | 10.21 | 434.91 | 5.12 |
| rqfALeAoiTq | 28.45 | 12.56 | 403.33 | 4.42 |
| x8F5xyUWy9e | 24.68 | 9.76 | 432.66 | 3.68 |
| yqstnuAEVhm | 30.19 | 13 | 399.91 | 4.39 |
| zsNo4HB9uLZ | 26.94 | 13.32 | 424.3 | 4.14 |
| Average | 27.29 | 12.24 | 418.12 | 4.3 |
Table 20. VGM performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|-----------|------------|--------|--------|
| 2azQ1b91cZZ | 35.88 | 16.12 | 373.11 | 4.48 |
| 8194nk5LbLH | 31.27 | 19.02 | 423.51 | 3.85 |
| EU6Fwq7SyZv | 34.1 | 18.74 | 368.62 | 4.06 |
| QUCTc6BB5sX | 36.27 | 16.88 | 367.95 | 4.29 |
| SN83YJsR3w2 | 32.92 | 17.09 | 426.29 | 4.73 |
| TbHJrupSAjP | 35.08 | 18.43 | 395.03 | 4.4 |
| UwV83HsGsw3 | 33.45 | 16.21 | 424.39 | 3.82 |
| Vt2qJdWjCF2 | 36.12 | 15.91 | 403.36 | 4.64 |
| VzqfbhrpDEA | 33.57 | 19.5 | 397.14 | 3.67 |
| X7HyMhZNoso | 34.88 | 18.62 | 398.75 | 4.05 |
| Z6MFQCViBuw | 32.67 | 15.53 | 398.1 | 4.37 |
| gTV8FGcVJC9 | 35.13 | 17.68 | 390.74 | 4.36 |
| gYvKGZ5eRqb | 34.77 | 16.44 | 393.34 | 4.36 |
| oLBMNvg9in8 | 31.22 | 17.13 | 391.16 | 3.38 |
| pLe4wQe7qrG | 36.45 | 18.04 | 357.49 | 4.19 |
| pa4otMbVnkk | 34.02 | 16.66 | 414.59 | 3.99 |
| rqfALeAoiTq | 35.23 | 18.21 | 369.25 | 4.2 |
| x8F5xyUWy9e | 32.45 | 17.9 | 380.19 | 4.32 |
| yqstnuAEVhm | 34.99 | 15.8 | 412.49 | 4.17 |
| zsNo4HB9uLZ | 36.23 | 16.09 | 392.92 | 4.39 |
| Average | 34.34 | 17.3 | 393.92 | 4.19 |
Table 21. ZSON performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|-----------|------------|--------|--------|
| 2azQ1b91cZZ | 30.22 | 21.9 | 400.05 | 4.49 |
| 8194nk5LbLH | 35.14 | 17.42 | 397.11 | 4.13 |
| EU6Fwq7SyZv | 31.88 | 18.15 | 360.23 | 4.71 |
| QUCTc6BB5sX | 34.62 | 21.22 | 379.75 | 4.42 |
| SN83YJsR3w2 | 30.87 | 19.88 | 415.7 | 4.21 |
| TbHJrupSAjP | 33.94 | 18.75 | 428.33 | 4.05 |
| UwV83HsGsw3 | 35.56 | 20.32 | 391.88 | 3.92 |
| Vt2qJdWjCF2 | 33.18 | 22.58 | 400.38 | 4.37 |
| VzqfbhrpDEA | 29.34 | 19.49 | 393.52 | 4.72 |
| X7HyMhZNoso | 34.9 | 18.22 | 376.97 | 4.29 |
| Z6MFQCViBuw | 32.12 | 21.74 | 380.55 | 4.91 |
| gTV8FGcVJC9 | 30.25 | 17.96 | 406 | 4.35 |
| gYvKGZ5eRqb | 35.44 | 22.08 | 412.43 | 3.81 |
| oLBMNvg9in8 | 31.53 | 19.14 | 366.82 | 4.58 |
| pLe4wQe7qrG | 30.87 | 20.69 | 393.75 | 4.14 |
| pa4otMbVnkk | 33.97 | 18.56 | 418.57 | 4.28 |
| rqfALeAoiTq | 34.12 | 19.24 | 378.22 | 4.33 |
| x8F5xyUWy9e | 32.78 | 18.97 | 416.39 | 3.91 |
| yqstnuAEVhm | 31.41 | 21.66 | 419.74 | 4.27 |
| zsNo4HB9uLZ | 34.55 | 19.31 | 382.41 | 4.43 |
| Average | 32.83 | 19.86 | 395.94 | 4.32 |
Table 22. NOLO-C performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|--------------|--------------|----------------|--------------|
| 2azQ1b91cZZ | 37.18 ± 4.28 | 22.84 ± 3.63 | 359.71 ± 17.26 | 4.38 ± 0.69 |
| 8194nk5LbLH | 36.97 ± 1.55 | 19.47 ± 0.99 | 366.57 ± 4.66 | 2.97 ± 0.34 |
| EU6Fwq7SyZv | 34.00 ± 2.16 | 18.48 ± 0.86 | 378.66 ± 2.54 | 3.18 ± 0.31 |
| QUCTc6BB5sX | 40.33 ± 1.25 | 23.52 ± 0.77 | 355.46 ± 1.65 | 4.83 ± 0.32 |
| SN83YJsR3w2 | 15.00 ± 7.07 | 6.92 ± 2.91 | 455.47 ± 15.62 | 4.56 ± 1.16 |
| TbHJrupSAjP | 20.95 ± 5.99 | 6.05 ± 1.97 | 437.43 ± 14.11 | 4.53 ± 0.51 |
| UwV83HsGsw3 | 26.67 ± 1.35 | 17.00 ± 1.76 | 401.74 ± 3.26 | 4.77 ± 0.41 |
| Vt2qJdWjCF2 | 19.17 ± 5.62 | 8.34 ± 0.78 | 437.86 ± 13.29 | 11.49 ± 0.85 |
| VzqfbhrpDEA | 25.19 ± 1.05 | 15.50 ± 2.16 | 398.60 ± 9.64 | 5.91 ± 1.16 |
| X7HyMhZNoso | 59.05 ± 2.94 | 30.08 ± 0.75 | 290.51 ± 7.25 | 2.00 ± 0.27 |
| Z6MFQCViBuw | 38.00 ± 5.66 | 15.43 ± 1.57 | 375.89 ± 16.03 | 5.19 ± 0.22 |
| gTV8FGcVJC9 | 41.33 ± 1.70 | 25.04 ± 1.93 | 335.27 ± 13.56 | 4.63 ± 0.73 |
| gYvKGZ5eRqb | 11.67 ± 2.36 | 3.51 ± 1.45 | 474.47 ± 10.70 | 10.91 ± 0.46 |
| oLBMNvg9in8 | 44.33 ± 2.36 | 25.58 ± 1.67 | 332.98 ± 8.66 | 1.85 ± 0.12 |
| pLe4wQe7qrG | 52.22 ± 3.14 | 26.99 ± 1.25 | 316.10 ± 10.12 | 1.54 ± 0.48 |
| pa4otMbVnkk | 14.44 ± 5.67 | 7.67 ± 3.04 | 447.38 ± 20.68 | 7.15 ± 1.53 |
| rqfALeAoiTq | 36.94 ± 4.63 | 18.40 ± 1.58 | 370.27 ± 11.73 | 2.45 ± 0.07 |
| x8F5xyUWy9e | 46.97 ± 4.71 | 21.66 ± 1.96 | 335.51 ± 11.35 | 2.43 ± 0.57 |
| yqstnuAEVhm | 38.61 ± 6.17 | 17.60 ± 3.23 | 372.49 ± 22.68 | 2.89 ± 0.55 |
| zsNo4HB9uLZ | 32.50 ± 3.54 | 18.14 ± 0.90 | 382.85 ± 11.49 | 3.92 ± 0.54 |
| Average | 33.58 | 17.41 | 381.26 | 4.58 |
Table 23. NOLO-T performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|---------------|--------------|----------------|--------------|
| 2azQ1b91cZZ | 41.28 ± 2.97 | 25.50 ± 2.75 | 344.03 ± 15.14 | 4.45 ± 0.08 |
| 8194nk5LbLH | 39.70 ± 2.61 | 19.67 ± 0.74 | 364.86 ± 3.70 | 3.04 ± 0.27 |
| EU6Fwq7SyZv | 41.00 ± 3.27 | 21.33 ± 2.90 | 357.03 ± 11.76 | 3.37 ± 0.17 |
| QUCTc6BB5sX | 41.50 ± 4.50 | 21.52 ± 2.39 | 357.77 ± 11.40 | 5.51 ± 0.73 |
| SN83YJsR3w2 | 21.67 ± 11.79 | 7.83 ± 4.20 | 432.92 ± 32.98 | 5.79 ± 1.89 |
| TbHJrupSAjP | 29.52 ± 0.67 | 11.53 ± 0.91 | 400.50 ± 5.36 | 4.45 ± 0.39 |
| UwV83HsGsw3 | 28.10 ± 0.67 | 15.16 ± 2.66 | 398.37 ± 9.11 | 4.95 ± 0.19 |
| Vt2qJdWjCF2 | 18.33 ± 3.12 | 7.74 ± 1.46 | 443.81 ± 10.96 | 11.66 ± 0.67 |
| VzqfbhrpDEA | 30.00 ± 0.91 | 16.90 ± 0.92 | 387.73 ± 5.64 | 7.28 ± 0.43 |
| X7HyMhZNoso | 63.33 ± 0.89 | 32.24 ± 0.69 | 270.01 ± 2.15 | 2.31 ± 0.39 |
| Z6MFQCViBuw | 40.67 ± 3.40 | 15.79 ± 3.40 | 380.14 ± 11.92 | 4.87 ± 0.44 |
| gTV8FGcVJC9 | 46.50 ± 1.50 | 28.97 ± 1.96 | 313.77 ± 0.72 | 5.54 ± 0.94 |
| gYvKGZ5eRqb | 10.00 | 2.73 ± 0.50 | 471.45 ± 3.05 | 9.34 ± 1.00 |
| oLBMNvg9in8 | 47.00 ± 1.00 | 24.69 ± 1.35 | 332.24 ± 4.97 | 1.92 ± 0.16 |
| pLe4wQe7qrG | 65.00 ± 1.67 | 28.04 ± 5.24 | 290.87 ± 27.90 | 0.58 ± 0.09 |
| pa4otMbVnkk | 33.33 ± 3.33 | 18.79 ± 0.48 | 365.55 ± 13.95 | 7.17 ± 0.66 |
| rqfALeAoiTq | 43.89 ± 2.19 | 22.01 ± 1.75 | 348.34 ± 8.51 | 2.55 ± 0.29 |
| x8F5xyUWy9e | 52.42 ± 0.43 | 22.44 ± 0.94 | 328.36 ± 2.28 | 2.13 ± 0.02 |
| yqstnuAEVhm | 38.61 ± 3.14 | 17.06 ± 2.82 | 372.31 ± 14.27 | 2.83 ± 0.13 |
| zsNo4HB9uLZ | 26.67 ± 1.18 | 16.10 ± 1.78 | 400.21 ± 5.77 | 4.74 ± 0.08 |
| Average | 37.93 | 18.80 | 368.01 | 4.72 |
Table 24. NOLO(M) performance in Habitat testing scenes.
| Scene | SR(%) ↑ | SPL(%) ↑ | TL ↓ | NE ↓ |
|-------------|--------------|--------------|----------------|--------------|
| 2azQ1b91cZZ | 35.77 ± 0.38 | 21.70 ± 0.98 | 367.77 ± 0.44 | 5.26 ± 0.06 |
| 8194nk5LbLH | 38.18 ± 0.91 | 19.20 ± 0.74 | 365.92 ± 3.05 | 3.05 ± 0.18 |
| EU6Fwq7SyZv | 40.50 ± 4.50 | 20.97 ± 1.42 | 360.27 ± 14.82 | 3.04 ± 0.49 |
| QUCTc6BB5sX | 40.00 | 22.11 ± 1.36 | 354.65 ± 1.51 | 4.64 ± 0.25 |
| SN83YJsR3w2 | 32.50 ± 7.50 | 10.28 ± 2.55 | 414.92 ± 23.22 | 4.92 ± 1.20 |
| TbHJrupSAjP | 24.29 ± 1.43 | 7.48 ± 0.50 | 427.30 ± 6.51 | 4.63 ± 0.07 |
| UwV83HsGsw3 | 30.71 ± 2.14 | 17.89 ± 3.05 | 390.06 ± 15.81 | 4.03 ± 0.21 |
| Vt2qJdWjCF2 | 13.75 ± 1.25 | 6.65 ± 0.62 | 454.84 ± 0.97 | 12.59 ± 0.18 |
| VzqfbhrpDEA | 28.33 ± 3.89 | 14.89 ± 2.38 | 402.32 ± 9.62 | 7.08 ± 0.47 |
| X7HyMhZNoso | 64.64 ± 1.79 | 30.95 ± 0.11 | 276.48 ± 5.50 | 1.94 ± 0.15 |
| Z6MFQCViBuw | 37.00 ± 7.00 | 16.86 ± 3.37 | 374.19 ± 22.49 | 4.90 ± 0.33 |
| gTV8FGcVJC9 | 50.50 ± 7.50 | 28.67 ± 1.23 | 306.25 ± 9.88 | 4.54 ± 0.72 |
| gYvKGZ5eRqb | 12.50 ± 2.50 | 3.79 ± 1.73 | 475.62 ± 14.77 | 9.55 ± 1.20 |
| oLBMNvg9in8 | 48.00 ± 2.00 | 28.67 ± 0.73 | 319.90 ± 6.13 | 1.61 ± 0.16 |
| pLe4wQe7qrG | 53.33 ± 3.33 | 26.82 ± 1.01 | 311.75 ± 0.38 | 1.26 ± 0.19 |
| pa4otMbVnkk | 20.00 | 8.13 ± 0.40 | 431.58 ± 1.42 | 8.87 ± 0.33 |
| rqfALeAoiTq | 45.42 ± 2.08 | 20.42 ± 2.06 | 352.25 ± 7.54 | 2.19 ± 0.23 |
| x8F5xyUWy9e | 49.55 ± 4.09 | 22.50 ± 1.80 | 331.82 ± 12.30 | 2.14 ± 0.47 |
| yqstnuAEVhm | 42.08 ± 4.58 | 18.98 ± 3.12 | 360.02 ± 16.95 | 2.89 ± 0.05 |
| zsNo4HB9uLZ | 27.50 | 16.36 ± 1.47 | 400.51 ± 1.49 | 4.76 ± 0.10 |
| Average | 36.73 | 18.17 | 373.92 | 4.69 |
## 9.3. Cross Evaluation Results
The performances of H2R and R2H are reported in Tabs. 25 and 26 respectively.
Table 25. NOLO performance in RoboTHOR after training in Habitat. 'T' denotes FloorPlan Train and 'V' denotes FloorPlan Val.
| Scene | SR(%) ↑ | SPL(%) ↑ | NE ↓ | TL ↓ |
|---------|--------------|--------------|----------------|-------------|
| T10 5 | 60.00 ± 0.96 | 26.63 ± 1.37 | 303.93 ± 7.01 | 2.30 ± 0.13 |
| T11 5 | 64.89 ± 3.50 | 31.85 ± 3.64 | 286.70 ± 20.00 | 2.09 ± 0.22 |
| T12 5 | 52.16 ± 5.79 | 26.13 ± 3.37 | 326.15 ± 15.30 | 2.36 ± 0.24 |
| T1 5 | 50.00 ± 6.24 | 29.40 ± 1.07 | 320.91 ± 10.47 | 2.46 ± 0.04 |
| T2 5 | 47.94 ± 4.56 | 20.57 ± 4.91 | 339.62 ± 26.92 | 2.42 ± 0.18 |
| T3 5 | 39.22 ± 3.09 | 18.48 ± 0.60 | 377.95 ± 6.26 | 3.30 ± 0.22 |
| T4 5 | 64.24 ± 1.87 | 30.56 ± 0.79 | 279.33 ± 3.76 | 2.13 ± 0.13 |
| T5 5 | 61.52 ± 0.86 | 27.48 ± 2.16 | 305.47 ± 7.33 | 2.06 ± 0.11 |
| T6 5 | 60.56 ± 2.83 | 31.06 ± 4.18 | 285.57 ± 25.83 | 2.30 ± 0.16 |
| T7 5 | 50.83 ± 0.59 | 20.54 ± 1.48 | 334.78 ± 0.93 | 2.30 ± 0.17 |
| T8 5 | 54.58 ± 4.12 | 28.68 ± 1.69 | 297.57 ± 10.62 | 2.41 ± 0.02 |
| T9 5 | 38.67 ± 6.60 | 22.46 ± 4.39 | 364.06 ± 18.55 | 2.53 ± 0.15 |
| Average | 53.72 | 26.15 | 318.50 | 2.39 |
|-----------|--------------|--------------|----------------|-------------|
| V1 1 | 54.00 ± 4.32 | 28.45 ± 3.73 | 316.52 ± 19.28 | 2.34 ± 0.15 |
| V1 2 | 48.48 ± 4.09 | 23.46 ± 3.96 | 338.57 ± 19.55 | 2.61 ± 0.12 |
| V1 3 | 74.04 ± 4.06 | 39.60 ± 2.33 | 235.18 ± 8.91 | 1.71 ± 0.09 |
| V1 4 | 44.07 ± 5.83 | 23.73 ± 1.69 | 350.40 ± 17.36 | 2.65 ± 0.12 |
| V1 5 | 49.44 ± 4.10 | 27.90 ± 4.66 | 324.46 ± 26.83 | 2.68 ± 0.17 |
| V2 1 | 32.73 ± 3.71 | 14.01 ± 1.79 | 404.18 ± 12.65 | 3.19 ± 0.10 |
| V2 2 | 48.89 ± 0.91 | 24.29 ± 3.87 | 338.47 ± 12.65 | 2.96 ± 0.19 |
| V2 3 | 67.18 ± 1.92 | 35.17 ± 2.13 | 278.73 ± 10.96 | 1.63 ± 0.08 |
| V2 4 | 52.69 ± 0.38 | 25.33 ± 0.32 | 340.45 ± 7.34 | 2.33 ± 0.03 |
| V2 5 | 44.35 ± 2.61 | 22.94 ± 1.82 | 353.16 ± 22.72 | 2.94 ± 0.11 |
| V3 1 | 59.05 ± 2.86 | 29.58 ± 2.96 | 279.42 ± 18.76 | 2.24 ± 0.23 |
| V3 2 | 56.39 ± 1.71 | 22.96 ± 1.40 | 310.36 ± 17.14 | 2.40 ± 0.08 |
| V3 3 | 59.51 ± 4.58 | 26.33 ± 3.53 | 297.91 ± 19.58 | 2.22 ± 0.14 |
| V3 4 | 41.59 ± 1.19 | 15.47 ± 1.16 | 360.06 ± 9.11 | 2.95 ± 0.01 |
| V3 5 | 60.00 ± 2.36 | 27.78 ± 2.98 | 298.36 ± 11.92 | 2.15 ± 0.15 |
| Average | 52.83 | 25.80 | 321.75 | 2.47 |
## 10. Social Impact and Future Work
We see our work as a starting point to propose a general and scalable method to offline learn a navigation policy from limited sources for any mobile agents. In the future, We believe NOLO will benefit a lot from the rapid development in optical flow and computer vision foundation models, and there will be extensive applications of NOLO, such as deployment to sweeping robots or rescue robots. Further improvement can be conducted to examine and enhance the reliability of the decoded actions from optical flow. It is also a great idea to incorporate first-person and third-person videos to showcase more advanced intelligence of spatial understanding and egocentric decision-making in more complex 3D embodied environments.
Table 26. NOLO Performance in Habitat testing scenes after training in RoboTHOR.
| Scene | SR(%) ↑ | SPL(%) ↑ | NE ↓ | TL ↓ |
|-------------|--------------|--------------|----------------|--------------|
| 2azQ1b91cZZ | 38.21 ± 0.96 | 23.38 ± 0.54 | 355.25 ± 4.81 | 6.45 ± 0.16 |
| 8194nk5LbLH | 41.82 ± 2.23 | 21.25 ± 0.96 | 351.39 ± 6.97 | 4.85 ± 0.14 |
| EU6Fwq7SyZv | 45.67 ± 2.87 | 22.27 ± 1.75 | 345.99 ± 10.11 | 4.72 ± 0.37 |
| QUCTc6BB5sX | 44.00 ± 2.45 | 23.97 ± 1.79 | 346.11 ± 11.27 | 6.91 ± 0.19 |
| SN83YJsR3w2 | 18.33 ± 4.71 | 7.28 ± 0.33 | 449.10 ± 9.22 | 9.20 ± 0.77 |
| TbHJrupSAjP | 28.10 ± 2.94 | 8.99 ± 0.80 | 422.23 ± 3.90 | 6.39 ± 0.26 |
| UwV83HsGsw3 | 27.62 ± 4.10 | 14.83 ± 3.12 | 408.73 ± 7.70 | 7.07 ± 0.60 |
| Vt2qJdWjCF2 | 17.92 ± 2.12 | 8.39 ± 1.65 | 436.55 ± 5.17 | 14.59 ± 0.41 |
| VzqfbhrpDEA | 27.41 ± 2.28 | 15.64 ± 0.72 | 396.57 ± 6.72 | 9.19 ± 0.40 |
| X7HyMhZNoso | 62.86 ± 1.17 | 29.77 ± 1.18 | 278.76 ± 4.89 | 4.16 ± 0.42 |
| Z6MFQCViBuw | 47.33 ± 3.40 | 15.48 ± 1.83 | 368.63 ± 8.25 | 5.93 ± 0.66 |
| gTV8FGcVJC9 | 50.00 ± 1.63 | 27.88 ± 2.24 | 316.60 ± 11.00 | 7.03 ± 0.44 |
| gYvKGZ5eRqb | 18.33 ± 2.36 | 3.68 ± 0.50 | 468.87 ± 6.26 | 9.14 ± 1.13 |
| oLBMNvg9in8 | 47.67 ± 1.70 | 27.95 ± 2.42 | 322.73 ± 10.51 | 3.65 ± 0.08 |
| pLe4wQe7qrG | 51.11 ± 1.57 | 26.30 ± 4.24 | 317.16 ± 15.91 | 3.56 ± 0.22 |
| pa4otMbVnkk | 31.11 ± 9.56 | 13.82 ± 3.98 | 398.71 ± 26.33 | 9.85 ± 1.45 |
| rqfALeAoiTq | 38.61 ± 3.22 | 18.14 ± 1.66 | 369.56 ± 11.93 | 4.89 ± 0.11 |
| x8F5xyUWy9e | 50.00 ± 3.40 | 21.01 ± 1.50 | 332.68 ± 12.40 | 4.41 ± 0.13 |
| yqstnuAEVhm | 41.11 ± 2.39 | 18.79 ± 1.28 | 363.67 ± 11.33 | 4.81 ± 0.08 |
| zsNo4HB9uLZ | 28.75 ± 2.70 | 16.22 ± 0.45 | 399.03 ± 8.76 | 6.50 ± 0.24 |
| Average | 37.80 | 18.25 | 372.41 | 6.67 | | null | [
"Bohan Zhou",
"Zhongbin Zhang",
"Jiangxing Wang",
"Zongqing Lu"
]
| 2024-08-02T16:41:34+00:00 | 2024-11-16T15:47:07+00:00 | [
"cs.CV"
]
| NOLO: Navigate Only Look Once | The in-context learning ability of Transformer models has brought new
possibilities to visual navigation. In this paper, we focus on the video
navigation setting, where an in-context navigation policy needs to be learned
purely from videos in an offline manner, without access to the actual
environment. For this setting, we propose Navigate Only Look Once (NOLO), a
method for learning a navigation policy that possesses the in-context ability
and adapts to new scenes by taking corresponding context videos as input
without finetuning or re-training. To enable learning from videos, we first
propose a pseudo action labeling procedure using optical flow to recover the
action label from egocentric videos. Then, offline reinforcement learning is
applied to learn the navigation policy. Through extensive experiments on
different scenes both in simulation and the real world, we show that our
algorithm outperforms baselines by a large margin, which demonstrates the
in-context learning ability of the learned policy. For videos and more
information, visit https://sites.google.com/view/nol0. |
2408.01386v1 | ## The Big Fringe Telescope
Gerard T. van Belle a and Anders M. Jorgensen b a Lowell Observatory, 1400 West Mars Hill Rd., Flagstaff, AZ 86001, USA b Electrical Enginering Department, New Mexico Institute of Mining And Technology, 801 Leroy Pl., Socorro, NM 87801, USA
## ABSTRACT
The Big Fringe Telescope (BFT) is a facility concept under development for a next-generation, kilometer-scale optical interferometer. Observations over the past two decades from routinely operational facilities such as CHARA and VLTI have produced groundbreaking scientific results, reflecting the mature state of the techniques in optical interferometry. However, routine imaging of bright main sequence stars remains a surprisingly unexplored scientific realm. Additionally, the three-plus decade old technology infrastructure of these facilities leads to high operations & maintenance costs, and limits performance. We are developing the BFT, based upon robust, modern, commercially-available, automated technologies with low capital construction and O&M costs, in support of kilometer-scale optical interferometers that will open the door to regular 'snapshot' imaging of main sequence stars. Focusing on extreme angular resolution for bright objects leads to substantial reductions in expected costs through use of COTS elements and simplified infrastructure.
Keywords: optical interferometry, main sequence star surface imaging, starspots, resolved exoplanet transit imaging, solar analogs, observing facilities, microarcsecond astronomical imaging
## 1. INTRODUCTION
Astronomical interferometry in the optical has enjoyed a decade-plus of mature science operations. Advancing further, from millarcsecond to microarcsecond scale imaging, is a readily achievable goal if a modern generation of tools are developed for this science using robust, recent technology. Surprisingly, the near-immediate achievability, affordability, and merits of microarcsecond optical imaging of bright targets is low-hanging scientific fruit that has been overlooked until now.
Science results from the GSU CHARA Array ∗ [1, 2] have included not just direct imaging but actual movies of the disk 'finger' transiting ϵ Aurigae [3], the expanding fireball of Nova Delphini 2013 [4], and the surface of ζ Andromedae as it rotates [5]. The the ESO VLTI † [6] has imaged the surface of π 1 Gruis [7], probed relativistic, non-Keplerian orbits of objects near our galactic center [8], as well as revealing the dusty veil that dimmed Betelgeuse [9]. CHARA has also imaged the non-spherical surface of Altair [10], and with VLTI, young stellar disks [11]. All of the studies cited here have resulted in marquee publications in either Nature or Science , or played a role in a Nobel Prize: the results noted here are just skimming the cream of a much larger body of work over the past decade that has made significant, unique contributions to astrophysics.
Overall, the technology infrastructure at CHARA and VLTI have realized the promise of extreme angular resolution from optical interferometry at the hundreds of meters scale. However, those foundations are surprisingly aged. For example, the delay lines of CHARA - the very heart of such an array - are literally from blueprints that are more than three decades old [12]; the VLTI delay lines are only slightly younger [13]. These tools reflect the state-of-the-art for their era, and the scope of the facilities, and have realized impressive scientific results. However, they represent capabilities that were barely achievable with the technology at hand at that time, and their significant operations and maintenance overheads reflect those circumstances.
Further author information: (Send correspondence to G.v.B.)
G.v.B.: E-mail: [email protected], Telephone: +1 928 233 3207
∗ Georgia State University Center for High Angular Resolution Astrophysics Array
† European Southern Observatory Very Large Telescope Interferometer
(a) A 'butterfly diagram' for the Sun, representative of the sunspot area coverage as well as the sunspot migration over time in latitude. The BFT will be able to make such diagrams for exoplanet hosts, solar analogs, as well as a large number ( > 800) of general targets.

(b) Venus transiting the Sun. The BFT will be able to make resolved movies of such events for dozens of exoplanet hosts.

Figure 1: Two of the key science applications of the BFT.
Carrying on from these grand achievements, we propose a new set of tools that will achieve a three-pronged set of goals. First, we will take advantage of 3 decades of advancing technology. Second, our architectural design will aim for kilometric-scale optical interferometry, importantly enabling imaging science at the microarcsecond scale, including routine main sequence star surface imaging. Finally, these tools will be designed within a framework of substantially reduced capital construction and operational / maintenance costs - again, leveraging improved technology as well as now-abundant operational experience from the existing facilities.
## 2. SCIENCE CASE
Four marquee science cases drive the architecture of the BFT, all based on the surprising fact that bright mainsequence star imaging remains a largely unrealized area of discovery space in astronomy. The 'sweet spot' of capabilities of BFT are as follows:
- · Optimal imaging of targets with angular sizes 0.40 to 0.60 mas (with imaging possible outside this range)
- · Visible light sensitivity ( I -band, 790nm) of 7.6 - 8.0 mag (requirement / goal)
- · Near-infrared sensitivity ( H -band, 1550nm) of 5.6 - 6.0 mag (requirement / goal)
- · Resolving power of 0.20 - 0.90 µ as (Michelson vs. Airy criteria - eg. 0.25 λ / B vs. 1.22 λ / B, 'modeling' versus 'true imaging'), which will enable surface characterization at the 10 × 10 to 30 × 30 pixel level for 0.40 to 0.60 mas targets, which is expected to be sufficient for detecting and monitoring magnetohydrodynamically controlled processes manifesting on the stellar surface [14].
In achieving these resolution and sensitivity goals, there are four primary science cases for the BFT. Notably, these science cases known target lists in the range of δ = {-10 o , 90 o } :
- (1) Exoplanet hosts being surveyed at the Lowell Discovery Telescope by the EXPRES precision-RV spectrograph [e.g. Table 1 of 15] are of particular interest, given the interest in correlating RV jitter with surface activity [16]; 31 EXPRES targets are accessible in our BFT point design. Many of these targets are also being monitored by other extreme precision RV spectrographs as well.
- (2) Extending the stellar surface imaging to solar analogs , a BFT telescope would be able to directly monitor the most Sun-like stars for their monthly and yearly surface morphology evolution (Figure 1a); there are at least 35 solar analogs [17] that are sufficiently large, bright, and in the northern hemisphere.
- (3) Resolved binaries that can have both their orbits resolved, as well as their individual component disk sizes resolved, will be able to establish empirically the mass-radius relationship; the SB9 catalog [18] has 77 known targets.
- (4) Finally, and most impressively, the BFT will be able to make real-time movies of resolved exoplanet transits (Figure 1b), spatially resolving both the host star disk and the exoplanet itself. The TFOP database [19] currently has 29 targets for which the star and planet are sufficiently resolvable and bright for our BFT point design.
In addition to these four marquee cases spanning over 170 targets, there are roughly 800 general targets in the Bright Star Catalog [20], spanning all spectral types except M, and all luminosity classes, which should be surface-resolvable (Tables 1, 2) in the 0.30 - 0.70 mas angular size regime. Bright stars figure prominently in the science case for the Habitable Worlds Observatory - e.g. all of the 164 targets suggested by [21] for HWO are within BFT's sensitivity limits with V < 8.
## 3. ARCHITECTURE AND PERFORMANCE
These known targets are collectively all brighter than 7.6 in the visible I -band, which forms the basis of our performance requirement, with a goal of 8.0 mag. In the near-infrared H -band, the matching requirement and goal are 5.6 and 6.0, respectively. These two bands are selected provide a matching pair: one for greatest signalto-noise, to phase the array with pair-wise aperture combination for real-time fringe tracking (FTK); and one for maximum resolution, to provide the most pixels on target with all-in-one combination, taking advantage of a coherence time synthetically extended through the NIR FTK. The near-infrared channel is most attractive for sensitivity due to the slower atmospheric coherence time and higher Strehl ratio.
Beam relay. To eliminate a major source of both capital construction costs as well as substantial ongoing operations & maintenance costs, the BFT will employ a vacuum-free design for beam relay from the outboard stations to the beam combination laboratory. Instead, single-mode polarization-maintaining fibers (SMPM) will be used for the relay task. Within this context, the two astronomical bands were chosen to match available,
(a) CHARA-MIRC imaging of the dusty disk of ϵ Aurigae eclipsing its primary star [3]
(b) VLTI-GRAVITY imaging of the relativistic, non-Keplerian motion of star S29 approaching the supermassive black hole Sgr A* at the center of the Milky Way at a distance of only 90 AU [8].
Figure 2: Modern astronomical optical interferometry imaging, reflecting the mature state of the technology.
Table 1: BFT targets by spectral type
| Sptype | N |
|----------|-----|
| O | 7 |
| B | 123 |
| A | 304 |
| F | 294 |
| G | 61 |
| K | 12 |
| M | 0 |
| LC | N | R | d (pc) | θ (mas) |
|------|-----|------|----------|-----------|
| 1 | 23 | 37.4 | 905 | 0.511 |
| 1.5 | 2 | 28.2 | 410 | 0.63 |
| 2 | 10 | 41.6 | 729 | 0.514 |
| 2.5 | 4 | 4.7 | 77 | 0.541 |
| 3 | 106 | 5.7 | 117 | 0.457 |
| 3.5 | 3 | 5.1 | 82 | 0.349 |
| 4 | 146 | 3 | 66 | 0.422 |
| 4.5 | 38 | 2.2 | 52 | 0.462 |
| 5 | 447 | 2.1 | 48 | 0.437 |
Table 2: BFT targets by luminosity class (LC), with median radii (R), distances (d), and angular diameters ( θ )
Figure 3: Nominal schematic of the BFT: 16 × 0.5 meter telescopes on a 2.2-km ring, with a central beam delay and combination laboratory.
low-attenuation SMPM fibers. For wavelengths shorter than I -band, and longer than H -band, fiber attenuation increases sharply from the values of ∼ 1-4 db/km (Table 3) for commercially available fiber. Our current experience base with the VISION instrument [22] with Thorlabs PM630-HP SMPM fiber indicates that the related PM780-HP and PM1550-XP items would serve reasonably in this regard.
Overall site size. In all of the primary science cases of § 2, target counts noted above are for angular sizes bracketed to be 0.40 to 0.60 milliarcseconds in size, with a desire for snapshot imaging for 10 × 10 to 30 × 30 pixels. Cursory image reconstruction experiments with the APSYNSIM interferometric imaging simulator [23] indicates this is satisfied by an optical telescope with a sparse aperture of 16 elements on a 2,200 m ring. This level of 'snapshot' (no sky rotation needed) imaging is adequate for starspot capture and tracking in latitude and longitude over a stellar rotation and magnetic evolution cycle (days and years, respectively). The ring count and circumference mean a telescope-to-telescope spacing of ∼ 390 meters, designed for H-band pairwise fringe tracking with sufficient signal-to-noise from adequate fringe visibility for targets up to 0.75mas in size. The redundancy of the ring geometry means that individual station-to-station pair dropouts do not corrupt the overall baseline bootstrapping of the ring. 'True' imaging (at the Airy criterion of 1.22 λ/D ) will be at 90 µ as pixel resolution, with model-based reconstruction (the Michelson criterion of 0.25 λ/D ) [24, 25] at 19 µ as pixel resolution.
Siderostat geometry. Each of the 16 input stations will employ a 0.5 m equivalent aperture, in the form of a siderostat-fed fixed telescope. A siderostat configuration offers a number of significant advantages for the BFT.
- · Articulation of a single large optic (the siderostat flat) rather than an entire telescope tube means the enclosure can be significantly smaller.
- · With a smaller enclosure, the enclosure design can be a rollaway roof, rather than a more traditional dome/slit arrangement. The latter arrangement has greater cost and mechanical complexity, making it more prone to failure. Rollaways also tend to have more forgiving failure modes, with it being more straightforward to manually close a malfunctioning roof.
- · A fixed telescope means any fiber-feeding optics - and the attached fiber - can also remain fixed. Keeping beam relay fibers static improves their performance, and makes characterization of that performance more persistent.
- · A siderostat configuration allows the facility to be used in full-aperture retroreflection mode, which means internal fringes are possible. Such a measurement can be used during the day (or night) to monitor facility health and establish internal path length constant terms.
There a couple of disadvantages of such a configuration, which can be either mitigated or accommodated. First, a siderostat configuration means two large optics, rather than one, must be manufactured and maintained (eg. cleaning and coating). (Interestingly, the downward-pointing nature of the fixed telescope as it faces the siderostat means it is less prone to accumulate dust on the primary mirror surface.) Second, a siderostat can impose limitations in sky coverage. This can be mitigate through a slight oversize of the siderostat flat relative to the fixed telescope size - eg. a 0.5 m telescope would require a 0.65 m flat - and this oversize can be relaxed if some vignetting and/or sky coverage reduction is allowed for certain pointings. Facilities such as IOTA [26, 27] and PTI [28] have employed this architecture for similar reasons.
Collecting aperture size. The overall collecting aperture size of 0.5 m is shown in the next section to be sufficiently large for the science cases noted above. We additionally find this size is a 'sweet spot', for a number of reasons. First, this size of telescope is readily available from commercial manufacturers, in a cost-effective manner. Using the metric of 'dollars per unit aperture', the 0.5 to 0.6 m diameter apertures are the largest sizes where that metric holds at roughly $ 30 per cm ; 2 for 0.7 and 1.0m apertures, this metric starts to increase in a substantial way (which has a daunting aggregate impact if one is considering purchasing 16 telescopes). Secondly, at this size, simple tip-tilt target tracking is sufficient for most atmospheric conditions. Not having to implement higher-order adaptive optics has a substantial impact in increasing reliability, reducing infrastructure cost, simplifying operations, and reducing ongoing maintenance costs.
| Parameter | H-band (tracking) | R-band (science) | units |
|------------------------|---------------------|--------------------|---------|
| Wavelength | 1.55 | 0.79 | um |
| Aperture size | 0.5 | 0.5 | m |
| Strehl ratio | 0.68 | 0.27 | |
| Number of splits | 2 | 15 | |
| Integration time | 0.009 | 3 | s |
| Read noise | 20 | 1 | e - rms |
| Optics temperature | 290 | 290 | K |
| Object V 2 | 0.65 | 0.005 | |
| Fiber attenuation | 1 | 4 | dB/km |
| Reflections | 30 | 30 | |
| Reflectivity | 0.975 | 0.975 | |
| Optics emissivity | 0.53 | 0.53 | |
| Throughput to detector | 0.16 | 0.03 | |
| Detector QE | 0.7 | 0.7 | |
| Sensitivity limit | 5.95 | 7.89 | mag |
| SNR | 24.3 | 3 | |
Beam delay. Beam delay represents probably one of the greatest challenges of the BFT, yet also
Table 3: Engineering parameters for the BFT.
one of the greatest opportunities for taking advantage of new technology. As noted above, delay lines for CHARA and VLTI are based on technology that dates back to the 80s and 90s [12, 13]; the more modern units for MROI are still ∼ 15 years old [29]. In the interregnum, new options have arisen for active control of beam path alignment and distance to and from moving optical surfaces. A good example of fine control at levels sufficient for optical interferometry on irregular surfaces is the Pyxis ground-based demonstrator for formation-flying optical interferometry [30, 31]. Our strawman baseline design is a 'woofer-tweeter' approach in free-space optics with static long delay lines and dynamic short delay lines, sufficient for a sky coverage from the zenith down to 56 o (to see down the north celestial pole from our notional site) and an hour-plus of continuous tracking. These delay lines would each employ a multi-pass design, with its multiple reflections accounted for in our sensitivity budget, which would keep costs of a lab enclosure to a reasonable level. This design element of the BFT is one we are giving the greatest scrutiny, and is highly likely to evolve as we optimize the architecture for performance and cost in the context of currently available technology. The performance details of our delay line needs are covered below in § 5.
Beam combination. Current instrumentation designs for the BFT are simple notional evolutions of the existing NPOI NIR fringe tracker [32] and VISION imager [22]. These concepts could be (and most likely will be) replaced with optimized designs, but for the present represent known, scalable instruments that provide an existence proof that back-end instrumentation for BFT requires no new inventions. The use of NPOI instrumentation in baseline bootstrapping experiments [33] is particularly attractive for BFT implementation.
## 4. DERIVED PERFORMANCE
Typical seeing from a large, flat northern Arizona site is 1.1', corresponding to a r 0 for this latter value of 11.4 and 26.6 cm at I- and H-band, respectively [34, 35, 36] . ‡ For a half-meter telescope, tip-tilt operation with peak tracking should then result in a Strehl of 0.27 and 0.68 in the I- and H-bands, respectively [38]. For the H-band fringe tracking, nearest neighbor pairwise combination means each beam is being split 50/50 to combine with those neighbors. A 5ms coherence time at 500nm is taken as reasonable [39], which scales by λ 6 / 5 to 8.6ms at 790nm. Other system parameters: a low-cost InGaAs near-infrared detector with 70% QE and 20 e -read noise is baselined (these run ∼ $ 50k, although ones with significantly better read noise exist, for roughly 10 × the cost); system temperature is room temperature, at 290K, object for short-baseline tracking is V 2 = 0 65 (typical of the . fainter objects on a 385m baseline); fiber coupling efficiency is 65%; fiber attenuation is 1 dB/km; 30 reflections at 0.975 (principally for multi-pass delay lines, and assuming a standard mirror coating such as Thorlabs M01 protected gold). The reflective losses, fiber coupling & attenuation, and Strehl multiply together to indicate a throughput to the detector of 16%. For high signal-to-noise fringe tracking at a SNR of 24.3, our limiting magnitude for H-band fringe tracking is expected to be m H = 5 95. . A similar computation can be done for the I-band science imaging, with some adjustments. The fiber attenuation is greater, 4 dB/km; the object will be fully resolved with V 2 will be significantly lower, at ∼ 0.005; the Strehl will be lower at the shorter wavelength (noted above); and the number of splits for 16-way combination is far greater. However, with the H-band fringe tracking, we note a SNR of 3.0 (which scales with wavelength, and the square root of the number of apertures being bootstrapped), yet we then expect a synthetic coherence time of 3 seconds to be achieved, allowing a limiting magnitude for the science band to be m I = 7 9. .
These numbers are consistent with our science demands laid out in § 3. It is also important to note that these performance evaluations are empirical in nature, having been checked against actual on-sky performance numbers of facilities such as CHARA, NPOI, and PTI.
## 5. PROJECTED BFT COSTS
The BFT has been under consideration by our group as representative of a next-generation capability that is attainable without an order of magnitude increase in cost - rather, a step back in the opposite direction is required by budget realities. This concept is useful in that it captures the current state-of-the-art for the various subsystems, and motivates the need for improvements with transport and delay. A summary roll-up of these costs can be seen in Table 4.
Beam Collection. Published, off-the-shelf costs for 20-inch PlaneWave observatory systems (optical tube and mount) are $ 56k; for each station we are also bookkeeping an additional $ 50k for commercially provided siderostat flat and mounting modification for a siderostat configuration. A 11' × 11' rollaway enclosure is bookkept at a known, off-the-shelf cost of $ 20k, installed. Fast tip-tilt is budgeted at $ 50k; foundation work at $ 15k; telescope pier at $ 2.5k; fiber injection optics at $ 50k; pointing model detectors at $ 2.5k; computing infrastructure is $ 2.5k; wireless internet relays are $ 2.5k; and off-grid power systems at $ 30k. All of these costs are from direct experience building single-aperture facilities in use at Lowell (the robotic 0.5 m TiMo, robotic 1.0 m PJ1M, the robotic 4 × 14' JPL NEO survey telescope). Overall each telescope station will run $ 281k per unit. By focusing on the bright star case, substantial capital cost savings is realized: individual off-the-shelf 1.0m stations would be $ 700k or more for the telescope alone, and require full AO systems (at least $ 300k each for sufficient performance).
‡ Although it is surprisingly difficult to find ∼ 2km 2 flat ( < 20m variation), high ( > 1,500m), dark sites ( > 21.7 mag/arcsec ) worldwide, a number of such sites have been identified in northern Arizona and even site tested in previous 2 studies of notional U.S. Cherenkov Telescope Array locations [37]. ('Flat' is not required by this kind of interferometric observing but is a significant simplifier for construction and maintenance.)
Beam Transport. A substantial cost element for optical interferometers that operate into the visible, such as CHARA and NPOI, is the use of vacuum pipes for beam relay. These costs include both capital construction as well as operations & maintenance. Our baseline approach is to completely eliminate this expensive infrastructure. Instead, the BFT will utilize SMPM fibers for beam relay. Each station-to-lab link will utilize a 3component optical link: a SMPM fiber for fringe tracking at H -band, another SMPM fiber for science imaging in I -band, and a third for pathlength metrology. Fibers are roughly $ 26 per meter each, with the pipe being roughly $ 32 per meter installed in
| Element | Cost ( $ k) |
|------------------------------|---------------|
| Beam Collection | $ 4,720 |
| Beam Transport | $ 2,744 |
| Beam Combination | $ 4,140 |
| Beam Delay | $ 4,000 |
| Infrastructure | $ 1,943 |
| Labor | $ 5,250 |
| Total (with 25% contingency) | $ 28,496 |
Table 4: Construction cost summary for the BFT.
a trench. Each beam also has a pathlength-monitoring metrology, which is estimated at $ 50k per beam. Overall each station's beamline, at 1,100m in length, is expected to have a capital cost of roughly $ 172,000 (and have substantially lower O&M costs than vacuum).
Beam Delay. The beam delay has three straightforward, yet demanding requirements, which are (a) range, and (b) rate, and (c) accuracy. For a facility with a ∼ 2 2km gross size, . sky coverage to a minimum zenith angle of 56 o (the minimum required to get to the north celestial pole from norther Arizona latitudes) requires a accessible delay range of 1,750m. With six passes into and out of a long delay line of length 150m, a range of 1,800m is accomplished. A building able to accommodate a space of length 150m is sizeable but not unreasonable; the CHARA delay line building is 100m in length. The east-west projection of that 2.2km baseline - what the delay line must track - is changing most rapidly as targets transit the meridian; this results in a maximum tracking rate of 153mm/sec. With six passes into and out of a continuous delay line of physical length 45m, a tracking time of 60 minutes is achievable in the worst case. For accuracy, such a delay line would need to have an accuracy of 5nm during tracking, resulting in an aggregate pathlength control accuracy of 60nm, meeting an optical quality spec of 1/10 of a wave at 600nm. Our cost target for each station's delay line is $ 250,000 per unit; we have begun risk-reduction lab efforts that are intended to demonstrate the achievability of this cost target. Previous generation delay line installations have had similar per-line costs.
Beam Combination. As a notional baseline for our point design, beam combination will employ two proven designs. For the near-infrared fringe tracker (NIRFTK), we will duplicate the NPOI pairwise beam combiner [32], scaled up from 6 to 16 beams; for a pairwise combiner, such scaling is linear. This design will be further improved with a lower read noise detector, graduating from a CRED2 to a CRED1. Similarly, the NPOI VISION combiner [22] can be scaled up, although this scales as N 2 , rather than linearly. As with Beam Collection , above, this represents a known solution and, for the purposes of this paper, we will not be focusing on improvements. Overall, the expected capital cost of this backend, based on known numbers from the NPOI NIRFTK and VISION combiners, will be $ 4,140k.
Infrastructure. The cost of delay enclosures, an instrument wing, and control wing is straightfoward; in particular, the delay enclosure will be based on commercially available warehouses, but largely empty due to our new delay line design. Site access and site power is also included in this cost element, which totals just under $ 2,000k.
Labor. For the facility construction, 10 FTEs per year for 3 years is baselined, including 6 techs, 2 engineers, and 2 scientists, resulting in an expected fully burdened labor cost of $ 5,250k. Importantly, by using a significant number of COTS components in conjunction with the elements demonstrated by this proposal, a well-defined & limited build schedule can be realistically established for a next-generation optical interferometer.
Operations & Maintenance. Beyond capital construction, an utterly essential component of any nextgeneration interferometry facility is a high degree of automation, robustness, and health monitoring, that result in reduced O&M costs. The baseline BFT architecture calls for these features to be designed into each subsystem from the start, as well as fully robotic facility operations, as was achieved at the Mark III interferometer, and partially achieved at the Palomar Testbed Interferometer facility. Our proposed developments for Beam Transport and Beam Delay above will be aimed not only at hitting the necessary performance targets, but economic ones as well. Within that context, an annual operating budget of $ 750k is targeted for a BFT telescope, which includes a staff of 2 full-time techs, and half a FTE for both an engineer and an operations scientist. By focusing on such costs from the project inception, this represents a > 4 × reduction in O&M costs relative to current (and smaller) optical interferometers. The intention is to have a explicitly defined operational life, with a sunset date of 15 years after its commencement of operations, meaning that full life cycle costs can be forecast from the inception of the project.
Overall, realistic costs and schedule are intended to be assessed and controlled throughout the BFT project. Having designs assessed for not just up-front capital and installation costs, but explicit assessments of operations and maintenance costs, will be essential to conducting the full lifecycle of the facility within an achievable budget. Historically, out-year operations budgets for interferometric observatories have been fueled by crippling underestimates and wishful thinking. The intention is for BFT to be well-characterized and planned in this regard before proceeding from design to implementation.
## 6. SUMMARY
Bright star imaging is an area ripe for discovery. The mature technology for such discovery is commercially available, translating to rapid implementation at reasonable, well-defined cost. A focus of scientific capability that is carefully balanced against affordable recurring operations & maintenance costs mean that the BFT will be able to carry out that noteworthy program of discovery on a defined program cost and schedule. The project is currently at the stage of risk-reduction exercises (eg. on beam delay & transport), and well as pre-Phase A planning and detailed costing.
## References
- [1] McAlister, H. A., ten Brummelaar, T. A., Gies, D. R., et al., 'First Results from the CHARA Array. I. An Interferometric and Spectroscopic Study of the Fast Rotator α Leonis (Regulus),' ApJ 628 , 439-452 (July 2005).
- [2] ten Brummelaar, T. A., McAlister, H. A., Ridgway, S. T., et al., 'First Results from the CHARA Array. II. A Description of the Instrument,' ApJ 628 , 453-465 (July 2005).
- [3] Kloppenborg, B., Stencel, R., Monnier, J. D., et al., 'Infrared images of the transiting disk in the eps Aurigae system,' Nature 464 , 870-872 (Apr. 2010).
- [4] Schaefer, G. H., Brummelaar, T. T., Gies, D. R., et al., 'The expanding fireball of Nova Delphini 2013,' Nature 515 , 234-236 (Nov. 2014).
- [5] Roettenbacher, R. M., Monnier, J. D., Korhonen, H., et al., 'No Sun-like dynamo on the active star ζ Andromedae from starspot asymmetry,' Nature 533 , 217-220 (May 2016).
- [6] Haguenauer, P., Abuter, R., Andolfato, L., et al., 'The Very Large Telescope Interferometer v2012+,' in [ Optical and Infrared Interferometry III ], Delplancke, F., Rajagopal, J. K., and Malbet, F., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 8445 , 84450D (July 2012).
- [7] Paladini, C., Baron, F., Jorissen, A., et al., 'Large granulation cells on the surface of the giant star π 1 Gruis,' Nature 553 , 310-312 (Jan. 2018).
- [8] GRAVITY Collaboration, Abuter, R., Amorim, A., et al., 'Detection of the Schwarzschild precession in the orbit of the star S2 near the Galactic centre massive black hole,' A&A 636 , L5 (Apr. 2020).
- [9] Montarg` es, M., Cannon, E., Lagadec, E., et al., 'A dusty veil shading Betelgeuse during its Great Dimming,' Nature 594 , 365-368 (June 2021).
- [10] Monnier, J. D., Zhao, M., Pedretti, E., et al., 'Imaging the Surface of Altair,' Science 317 , 342- (July 2007).
- [11] Kraus, S., Kreplin, A., Young, A. K., et al., 'A triple-star system with a misaligned and warped circumstellar disk shaped by disk tearing,' Science 369 , 1233-1238 (Sept. 2020).
- [12] Colavita, M. M., Hines, B. E., and Shao, M., 'A High Speed Optical Delay Line for Stellar Interferometry,' in [ European Southern Observatory Conference and Workshop Proceedings ], European Southern Observatory Conference and Workshop Proceedings 39 , 1143 (Mar. 1992).
- [13] Messenger, E., 'Signing of Contract for the Delivery of the Delay Line of the VLTI,' The Messenger 91 , 25-25 (Mar. 1998).
- [14] Carpenter, K. G., Schrijver, C. J., Karovska, M., and Si Vision Mission Team, 'The Stellar Imager (SI) A Mission to Resolve Stellar Surfaces, Interiors, and Magnetic Activity,' in [ The Biggest, Baddest, Coolest Stars ], Luttermoser, D. G., Smith, B. J., and Stencel, R. E., eds., Astronomical Society of the Pacific Conference Series 412 , 91 (Sept. 2009).
- [15] Brewer, J. M., Fischer, D. A., Blackman, R. T., et al., 'EXPRES. I. HD 3651 as an Ideal RV Benchmark,' AJ 160 , 67 (Aug. 2020).
- [16] Roettenbacher, R. M., Cabot, S. H. C., Fischer, D. A., et al., 'EXPRES. III. Revealing the Stellar Activity Radial Velocity Signature of eps Eridani with Photometry and Interferometry,' AJ 163 , 19 (Jan. 2022).
- [17] Radick, R. R., Lockwood, G. W., Henry, G. W., et al., 'Patterns of Variation for the Sun and Sun-like Stars,' ApJ 855 , 75 (Mar. 2018).
- [18] Pourbaix, D., Tokovinin, A. A., Batten, A. H., et al., 'SB9: The ninth catalogue of spectroscopic binary orbits,' A&A 424 , 727-732 (Sept. 2004).
- [19] Akeson, R. and Christiansen, J., 'TESS Follow-up Observing Program Working Group (TFOP WG): The ExoFOP-TESS Website,' in [ American Astronomical Society Meeting Abstracts #233 ], American Astronomical Society Meeting Abstracts 233 , 140.09 (Jan. 2019).
- [20] Hoffleit, D. and Jaschek, C., [ The Bright star catalogue ] (1991).
- [21] Harada, C. K., Dressing, C. D., Kane, S. R., and Ardestani, B. A., 'Setting the Stage for the Search for Life with the Habitable Worlds Observatory: Properties of 164 Promising Planet-survey Targets,' ApJS 272 , 30 (June 2024).
- [22] Garcia, E. V., Muterspaugh, M. W., van Belle, G., et al., 'Vision: A Six-telescope Fiber-fed Visible Light Beam Combiner for the Navy Precision Optical Interferometer,' PASP 128 , 055004 (May 2016).
- [23] Marti-Vidal, I., 'APSYNSIM: An Interactive Tool To Learn Interferometry,' arXiv e-prints , arXiv:1706.00936 (June 2017).
- [24] Kervella, P., M´rand, A., Pichon, B., et al., 'The radii of the nearby K5V and K7V stars 61 Cygni A & B. e CHARA/FLUOR interferometry and CESAM2k modeling,' A&A 488 , 667-674 (Sept. 2008).
- [25] Martinache, F., 'Kernel Phase in Fizeau Interferometry,' ApJ 724 , 464-469 (Nov. 2010).
- [26] Carleton, N. P., Traub, W. A., Lacasse, M. G., et al., 'Current status of the IOTA interferometer,' in [ Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series ], J. B. Breckinridge, ed., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 2200 , 152-165 (June 1994).
- [27] Pedretti, E., Traub, W. A., Monnier, J. D., et al., 'Last technology and results from the IOTA interferometer,' in [ Optical and Infrared Interferometry ], Sch¨ oller, M., Danchi, W. C., and Delplancke, F., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 7013 , 70132V (July 2008).
- [28] Colavita, M. M., Wallace, J. K., Hines, B. E., et al., 'The Palomar Testbed Interferometer,' ApJ 510 , 505-521 (Jan. 1999).
- [29] Fisher, M., Boysen, R. C., Buscher, D. F., et al., 'Design of the MROI delay line optical path compensator,' in [ Optical and Infrared Interferometry II ], Danchi, W. C., Delplancke, F., and Rajagopal, J. K., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 7734 , 773449 (July 2010).
- [30] Hansen, J. T., Ireland, M. J., Travouillon, T., et al., 'The Pyxis Interferometer (I): scientific context, metrology system, and optical design,' in [ Optical and Infrared Interferometry and Imaging VIII ], M´ erand, A., Sallum, S., and Sanchez-Bermudez, J., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 12183 , 121831B (Aug. 2022).
- [31] Hansen, J. T., Wade, S., Ireland, M. J., et al., 'Pyxis: A ground-based demonstrator for formation-flying optical interferometry,' arXiv e-prints , arXiv:2307.07211 (July 2023).
- [32] Armstrong, J. T., Schmitt, H. R., Restaino, S. R., et al., 'An infrared beam combiner for wavelength bootstrapping at the NPOI,' in [ Optical and Infrared Interferometry and Imaging VI ], Creech-Eakman, M. J., Tuthill, P. G., and M´ erand, A., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 10701 , 107010B (July 2018).
- [33] Jorgensen, A. M., Mozurkewich, D., Armstrong, J. T., et al., 'Multi-baseline chain bootstrapping with new classic at the NPOI,' in [ Optical and Infrared Interferometry and Imaging V ], Malbet, F., Creech-Eakman, M. J., and Tuthill, P. G., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 9907 , 99072C (Aug. 2016).
- [34] Walters, D. L., 'Atmospheric Contributions to Image Degradation,' in [ Bulletin of the American Astronomical Society ], 23 , 895 (Mar. 1991).
- [35] Harris, H. C. and Vrba, F. J., 'Seeing Measurements and Observing Statistics at the U.S. Naval Observatory, Flagstaff Station,' PASP 104 , 140 (Feb. 1992).
- [36] Hutter, D. J., Elias, N. M., I., Peterson, E. R., et al., 'Seeing Tests at Four Sites in Support of the NPOI Project,' AJ 114 , 2822 (Dec. 1997).
- [37] Ong, R. A., Aune, T., and Hall, J., 'Characterization of Potential U.S. Sites for the Cherenkov Telescope Array,' in [ International Cosmic Ray Conference ], International Cosmic Ray Conference 33 , 2848 (Jan. 2013).
- [38] Glindemann, A., [ Principles of Stellar Interferometry ] (2011).
- [39] Kellerer, A. and Tokovinin, A., 'Atmospheric coherence times in interferometry: definition and measurement,' A&A 461 , 775-781 (Jan. 2007). | null | [
"Gerard T. van Belle",
"Anders M. Jorgensen"
]
| 2024-08-02T16:48:00+00:00 | 2024-08-02T16:48:00+00:00 | [
"astro-ph.IM"
]
| The Big Fringe Telescope | The Big Fringe Telescope (BFT) is a facility concept under development for a
next-generation, kilometer-scale optical interferometer. Observations over the
past two decades from routinely operational facilities such as CHARA and VLTI
have produced groundbreaking scientific results, reflecting the mature state of
the techniques in optical interferometry. However, routine imaging of bright
main sequence stars remains a surprisingly unexplored scientific realm.
Additionally, the three-plus decade old technology infrastructure of these
facilities leads to high operations \& maintenance costs, and limits
performance. We are developing the BFT, based upon robust, modern,
commercially-available, automated technologies with low capital construction
and O\&M costs, in support of kilometer-scale optical interferometers that will
open the door to regular `snapshot' imaging of main sequence stars. Focusing on
extreme angular resolution for bright objects leads to substantial reductions
in expected costs through use of COTS elements and simplified infrastructure. |
2408.01387v2 | ## NeuralBeta:
## Estimating Beta using Deep Learning
Yuxin Liu Bloomberg New York, USA [email protected]
Jimin Lin Bloomberg New York, USA [email protected]
Achintya Gopal Bloomberg New York, USA [email protected]
## ABSTRACT
Traditional approaches to estimating 𝛽 in finance often involve rigid assumptions and fail to adequately capture 𝛽 dynamics, limiting their effectiveness in use cases like hedging. To address these limitations, we have developed a novel method using neural networks called NeuralBeta , which is capable of handling both univariate and multivariate scenarios and tracking the dynamic behavior of 𝛽 . To address the issue of interpretability, we introduce a new output layer inspired by regularized weighted linear regression, which provides transparency into the model's decision-making process. We conducted extensive experiments on both synthetic and market data, demonstrating NeuralBeta 's superior performance compared to benchmark methods across various scenarios, especially instances where 𝛽 is highly time-varying, e.g., during regime shifts in the market. This model not only represents an advancement in the field of beta estimation, but also shows potential for applications in other financial contexts that assume linear relationships.
estimation remains sparse. [6], for example, utilizes future information to compute the 'true beta' (or realized beta) as the target and evaluates several machine-learning based estimators against this metric, and they found random forests to be the most effective. A limitation of this approach is the introduction of new hyperparameters in computing realized beta (the window length, the weights, etc.) and that using future data in computing the target reduces the amount of data available. Moreover, [1] explores the use of machine learning algorithms to estimate equity betas from historical returns and company financials, for which they also used the realized beta as the target. They focus primarily on private firms or non-traded assets, which diverges from our area of interest. Notably, none of these approaches employ state-of-the-art deep neural networks like attention, nor do they provide the transparency needed in financial modelling. The usage of realized beta as the target is also questionable, as the primary usage of beta is hedging, and targeting a beta using a future window does not necessarily improve this task.
## CCS CONCEPTS
- · Applied computing ; · Computing methodologies → Machine learning ; · Mathematics of computing → Probability and statistics ;
## KEYWORDS
Beta, CAPM, Machine Learning, Interpretability, Stock Returns
## 1 INTRODUCTION
The term 'beta', or 𝛽 , represents the linear coefficient between an explanatory variable and a response variable, and plays a crucial role in finance markets for asset pricing, portfolio optimization, and risk management. In asset pricing, 𝛽 is used to evaluate the return of an asset based on, for example, the return of the market portfolio (Capital Asset Pricing Model [15]), market plus asset characteristics (Fama-French three-factor model and five-factor model [8, 9]), or a set of risk factors and market indices (Arbitrage Pricing Theory [14]).
The original CAPM model assumes that stock market betas remain constant over time. However, empirical research including [2] and [10] demonstrates that betas are indeed time-varying. Traditional methods to model this time variation usually involve rolling-window regressions using Ordinary Least Squares (OLS) and Weighted Least Squares (WLS). But these approaches face challenges in specifying the window length and weights to balance bias and variance. These regression methods are also sensitive to outliers, which leads to volatile beta estimates.
In recent years, with the proliferation of machine learning in finance, research applying machine learning techniques to beta
Our paper contributes to the literature by proposing an interpretable approach to beta estimation using deep neural networks, which we call NeuralBeta . NeuralBeta directly uses the hedging error as the metric, and leverages the power of neural networks to capture complex, non-linear relationships in financial data, offering more precise and robust estimation of 𝛽 . We also develop an interpretable variant, NeuralBeta-Interpretable (NBI). NBI enhances transparency by explicitly outputting weights for each data point in the lookback window, which are then used to calculate the weighted least squares (WLS) solution to estimate 𝛽 . This approach allows users to easily discern which historical periods are more influential in the beta estimation process and to identify specific temporal patterns and market conditions that influence beta.
We highlight the following threefold advantages of NeuralBeta : Generality : NeuralBeta utilizes neural networks to cover a large set of possible functional forms of beta. It overcomes the limitation of conventional approaches that train models separately on small sub-datasets, by training jointly on the entire dataset of all assets and factors. Hence it can better capture both general and specific patterns.
Interpretability : A novel interpretable architecture is constructed to explicitly quantify the data importance in the form of sample weighting, which is directly related to the traditional WLS estimation framework. This feature allows users to analyze which data points are considered most critical by the model and to gain insights into how the model works.
Practicality : NeuralBeta employs Mean Squared Error (MSE) on asset returns as the evaluation metric, which is a hedging performancebased measure. Compared to metrics based on realized beta versus
predicted beta, the hedging performance metric is more relevant to investment performance in practice.
The structure of this paper is as follows. In Section 2, we introduce the general framework of beta estimation and the NeuralBeta model architecture, both the non-interpretable and interpretable versions. In Section 3, we apply NeuralBeta on both synthetic and market data and compare it with benchmark methods. We show that NeuralBeta systematically outperforms other conventional methods, and that our interpretable NBI architecture achieves the balance between explainability and performance. We also provide examples of the weights outputted by NBI. Finally, we summarize our findings in Section 4.
## 2 METHODOLOGY
## 2.1 Problem Setup
To develop the methodology, we start from a simple scenario where one hedges a single target asset against multiple other hedging instruments on a daily basis. The task is to determine the optimal hedging ratio of each instrument that minimizes the next day hedging error, and ultimately to achieve a low average hedging error over the entire horizon. In the following we will formalize the hedging task. With the single target hedging scenario formulated, we will see it easily scales up to multiple assets case and applies to any other prediction tasks.
Let T = { 0 1 2 , , , . . . } be the discrete time index for data of certain frequency. We refer to the frequency in terms of days. For a time interval ( 𝑠, 𝑡 ] , 𝑠, 𝑡 ∈ T and 𝑠 < 𝑡 , let 𝐷 𝑠,𝑡 : = {( 𝑥 𝑠 + 1 , 𝑦 𝑠 + 1 ) , ( 𝑥 𝑠 + 2 , 𝑦 𝑠 + 2 ) , . . . , ( 𝑥 ,𝑦 𝑡 𝑡 )} denote the dataset sliced between time 𝑠 and time 𝑡 , where 𝑥 ∈ R 𝑑 is the explanatory variable of dimension 𝑑 ∈ N , e.g., factor returns, and 𝑦 ∈ R is the scalar response variable, e.g., a single stock return.
For any 𝑡 ∈ T , we are interested in approximating a linear relationship between 𝑥 𝑡 and 𝑦 𝑡 with coefficient 𝛽 𝑡 ∈ R 𝑑 and noise 𝜖 𝑡 ∈ R , which is of the form
$$y _ { t } = \langle \beta _ { t }, x _ { t } \rangle + \epsilon _ { t } \quad \quad \ \ ( 1 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where ⟨· , ·⟩ is the inner product.
A one-step hedging task at time 𝑡 is to determine an optimal hedging ratio ˆ 𝛽 𝑡 + 1 given available data 𝐷 0 ,𝑡 such that the ex-ante hedging error at time 𝑡 + 1 is minimized:
$$\hat { \beta } _ { t + 1 } = \min _ { \beta } L \left ( y _ { t + 1 }, \langle \beta, x _ { t + 1 } \rangle \right ),$$
where 𝐿 is some risk measure, such as expected quadratic loss or negative log-likelihood. Here, ˆ 𝛽 𝑡 + 1 is assumed to be inferable from the dataset 𝐷 0 ,𝑡 , i.e., it is in the form
$$\hat { \beta } _ { t + 1 } = f ( t, D _ { 0, t } )$$
for some function 𝑓 : T × 𝐷 → R 𝑑 that can possibly be time inhomogeneous, which is an estimator given by the underlying model.
Then, we consider the following practical scenario. During a 𝑛 -day time horizon starting at day 𝜏 ∈ T denoted by T 𝑛 𝜏 = { 𝜏, 𝜏 + 1 , . . . 𝜏 + 𝑛 - } 1 with 𝜏 ≥ ℎ for some chosen lookback window ℎ ∈ N (such that there are at least ℎ historical data points at 𝜏 ). We perform the one-step hedge ratio prediction with (2) at each day 𝑡 ∈ T 𝑛 𝜏 .
The objective is thus naturally to find the function 𝑓 that minimizes the average hedging error through the entire time horizon:
$$\min _ { f } \frac { 1 } { n } \sum _ { t \in \mathcal { T } _ { \tau } ^ { n } } L \left ( y _ { t + 1 }, \langle \hat { \beta } _ { t + 1 }, x _ { t + 1 } \rangle \right ) \quad \quad ( 3 )$$
It is important to distinguish objective (3) from the conventional regression task. First, the entire dataset available to each one-step objective is streamed progressively as 𝐷 0 ,𝜏 , 𝐷 0 ,𝜏 + 1 , . . . instead of a static full dataset. Second, in each day 𝑡 ∈ T 𝑛 𝜏 , we are interested in estimating the coefficient that minimizes the next day error revealed by the new data point ( 𝑥 𝑡 + 1 , 𝑦 𝑡 + 1 ) , instead of the coefficient that minimizes the hedging error in the past. Third, we don't presume the ground truth coefficient 𝛽 to be time-homogeneous, so the coefficient is expressed in a functional form as in equation (2) instead of being sets of constants.
Nevertheless, we can still draw links from objective (3) as a metatask to a static regression task, or a rolling regression task in the following sense.
Ordinary Linear Regression. Suppose we do a one-step hedge. At 𝜏 , if the data 𝐷 0 ,𝜏 + 1 satisfies the Gauss-Markov assumptions, then the optimal functional form of 𝛽 is given by
$$f ^ { * } ( \tau, D _ { 0, \tau } ) = f ^ { * } ( D _ { 0, \tau } ) = \left ( X _ { 0, \tau } ^ { T } X _ { 0, \tau } \right ) ^ { - 1 } X _ { 0, \tau } ^ { T } y _ { 0, \tau }, \quad ( 4 )$$
where 𝑋 0 ,𝜏 is a 𝜏 × 𝑑 matrix obtained by stacking the data ( 𝑥 , 𝑥 1 2 , . . . , 𝑥 𝜏 ) and 𝑦 0 ,𝜏 is the 𝜏 × 1 column ( 𝑦 ,𝑦 , . . . , 𝑦 1 2 𝜏 ) .
Rolling Regression. Consider the full time horizon for hedging. It is reasonable to assume 𝛽 evolves through time, and the most recent data is more relevant to determine it. Then a naive action is to fix a lookback window ℎ ≥ 𝜏 and perform rolling OLS for each 𝑡 ∈ T 𝑛 𝜏 , and the 𝛽 function is thus given by
$$\vdots \quad f ^ { * } ( t, D _ { 0, t } ) = f ^ { * } ( D _ { t - h, t } ) = \left ( X _ { t - h, t } ^ { T } X _ { t - h, t } \right ) ^ { - 1 } X _ { t - h, t } ^ { T } y _ { t - h, t } \cdot \ ( 5 )$$
Figure 1b shows the process of using rolling OLS to estimate 𝛽 . OLS calculates the optimal in-sample 𝛽 and directly uses it as an estimate for the next period, assuming 𝛽 does not change over time.
Two shortcomings of the naive rolling OLS are 1) the selection of lookback window ℎ is somewhat arbitrary, and 2) it ignores data older than 𝑡 -ℎ , while assigning the same importance to each data point within the lookback horizon ( 𝑡 -ℎ, 𝑡 ] . So, it might misspecify both long-term and short-term data relevance. One extra step to improve the rolling OLS is replacing OLS with weighted least squares (WLS) by adding a dynamic weighting scheme 𝑤 𝑡 = { 𝑤 , . . . 𝑤 𝑡 1 𝑡 𝑡 } ∈ R 𝑡 to adjust the data importance. Let 𝑊 𝑡 = diag ( 𝑤 𝑡 ) be the diagonal weight matrix. The estimated 𝛽 then becomes
$$f ^ { * } ( t, D _ { 0, t } ) = \left ( X _ { 0, \tau } ^ { T } W _ { t } X _ { 0, \tau } \right ) ^ { - 1 } X _ { 0, \tau } ^ { T } W _ { t } y _ { 0, \tau }, \quad \quad ( 6 )$$
which aligns with the formula of WLS. Note that rolling OLS (5) can be seen as the special case of rolling WLS (6) where 𝑤 𝑡 𝑖 = 0 when 𝑖 ≤ 𝑡 -ℎ and 𝑤 𝑡 𝑖 = 1 / ℎ when 𝑖 > 𝑡 -ℎ . There are several popular weighting schemes to choose from, such as exponential weights and power laws. In these cases, we have additional parameters to be tuned related to the weighting. Therefore, despite (6) providing flexibility to adjust the data importance, configuring proper weighting schemes 𝑤 𝑡 for all 𝑡 ∈ T 𝑛 𝜏 remains challenging.
(a) General
(b) OLS
(c) NeuralBeta
Figure 1: 𝛽 Estimation Framework
## 2.2 NeuralBeta Model Architecture
Figure 1a is an illustration on how to perform beta estimation in general. The input is a lookback window of 𝑥 and 𝑦 . The data is then fed into the model 𝑓 to estimate beta. The model can have some parameters, like a neural network, or it can be parameter-free, like OLS (Figure 1b). In this section, we will explain how NeuralBeta works, which is represented by Figure 1c.
2.2.1 General Framework. Provided the above discussion, we propose a framework to represent the 𝛽 estimator with a neural network. Let 𝜃 be the parameter set, the NeuralBeta model is formulated as
$$( t, D _ { 0, t } ) \mapsto f ( t, D _ { 0, t } ; \theta ).$$
As is shown in Figure 1c, instead of using some pre-determined formula, NeuralBeta model dynamically estimates the target period's 𝛽 . More importantly, unlike the regression methods, NeuralBeta incorporates numerous parameters that can be properly learned during the training process. In practice, a single NeuralBeta mode is utilized across all 𝑥 and 𝑦 pairs within an application, so the model is comprehensively trained on every pair, rather than one individual pair. This holistic approach allows NeuralBeta model to learn from common patterns that emerge across various pairs.
Given the above discussion on the single target asset case, it is natural to further extend the methodology to handle joint hedging or prediction tasks with multiple time series. A typical example is the factor model. Suppose there are 𝑚 ∈ N time series of target assets ( 𝑦 𝑖 𝑡 ) 𝑡 ∈T ,𝑖 ∈[ 𝑚 ] , where [ 𝑚 ] simply denotes { 1 2 , , · · · , 𝑚 } , that can be explained by 𝑘 ∈ N time series of common factors and 𝑑 -𝑘 variables idiosyncratic to each asset. For each asset 𝑖 ∈ [ 𝑚 ] , we have similar notations as before for the explanatory variable 𝑥 𝑖 𝑡 ∈ R 𝑑 , the dataset 𝐷 𝑖 = ∪ 𝑠 < 𝑡 𝐷 𝑖 𝑠,𝑡 , and the coefficients of interest with its functional form ˆ 𝛽 𝑖 𝑡 + 1 = 𝑓 𝑖 ( 𝑡, 𝐷 𝑖 0 ,𝑡 ) . The objective function (3) is extended to joint multiple time series case as
$$\min _ { ( f ^ { i } ) _ { i \in [ m ] } } \frac { 1 } { n m } \sum _ { t \in \mathcal { T } _ { t } ^ { n }, i \in [ m ] } L \left ( y _ { t + 1 } ^ { i }, \langle \hat { \beta } _ { t + 1 } ^ { i }, x _ { t + 1 } ^ { i } \rangle \right ). \quad ( 8 )$$
Note that the argument in objective function (8) is a vector of functions ( 𝑓 𝑖 ) 𝑖 ∈[ 𝑚 ] corresponding to each asset, rather than the single function in (3), but we can still use a single large neural network to represent the vector, i.e., 𝑓 𝑖 = 𝑓 𝑖 + 1 = ... = 𝑓 𝑚 . The loss function we used in training our models is mean squared error:
$$L \left ( y _ { t + 1 } ^ { i }, \langle \hat { \beta } _ { t + 1 } ^ { i }, x _ { t + 1 } ^ { i } \rangle \right ) = \left ( y _ { t + 1 } ^ { i } - \langle \hat { \beta } _ { t + 1 } ^ { i }, x _ { t + 1 } ^ { i } \rangle \right ) ^ { 2 }.$$
Wehighlight that the NeuralBeta model (7) is a unified framework that not only covers a large range of functional forms of 𝛽 , including (4), (5), and (6) discussed above, but also can be easily extended to handle multiple assets and features in higher dimension.
In Section 3, we apply the NeuralBeta model framework (7) to a set of beta estimation tasks that include a single asset scenario (3) and multiple assets scenario (8).
2.2.2 Interpretable Neural Network Architecture. One concern with using neural networks in beta estimation is the lack of interpretability. To address this issue, we introduce a new output layer inspired by regularized weighted linear regression:
$$\tilde { \text{get} } \quad \left ( \Sigma ^ { - 1 } + X _ { t - h, t } ^ { T } W _ { t - h, t } X _ { t - h, t } \right ) ^ { - 1 } ( \Sigma ^ { - 1 } \mu + X _ { t - h, t } ^ { T } W _ { t - h, t } y _ { t - h, t } ) \ \ ( 9 )$$
where the weights 𝑊 𝑡 -ℎ,𝑡 are positive and Σ is a positive-definite matrix. 𝝁 and Σ can be interpreted as the mean and covariance of a Gaussian prior over 𝛽 . Note that the weights are positive, but unbounded; this is to allow the model to choose how much of the
Figure 2: A diagrammatic representation of NeuralBetaInterpretable . 𝑙 refers to the lookback window size and | | denotes concatenation. Details are in Section 2.2.2.
prior to rely on, i.e., small weights lead to more regularization, whereas large weights lead to less regularization.
In NeuralBeta , 𝝁 and Σ are global parameters to be trained, and we restrict Σ to be diagonal. The weights in (9) are the outputs of a sequence model such as a GRU or a transformer. In Figure 2, we show a high-level diagram of our approach which we refer to as NeuralBeta-Interpretable (NBI) . Similar to how the neural network in NeuralBeta is a replacement of the beta estimator, one interpretation of the "neural" in NBI is that it is implicitly tuning the weights given the context window. We note that this layer reduces the overall expressivity of the neural network; in Section 3, we show that this loss in expressivity has a minor impact on the generalization and can even improve generalization.
Naturally, there remains a certain degree of non-interpretability further upstream, such as understanding the factors that lead certain observations to carry more weights than others. However, this approach takes a meaningful step towards interpretability and generically aid in viewing neural networks as estimators; we leave it to future work to study if the interpretability can be further enhanced.
## 3 EXPERIMENTS
In this section, we conduct experiments to estimate 𝛽 in (1) using both synthetic data and market data. We also compare the performance of NeuralBeta with rolling OLS and rolling WLS (with exponential weighting scheme) to gain insights into the conditions and mechanisms through which NeuralBeta achieves superior performance. To ensure a fair comparison, we tuned the half-life's of the exponential weights for WLS to achieve optimal performance in the validation set.
In all the experiments, we use root mean squared error (RMSE) on the predicted 𝑦 variable as the evaluation metric:
$$R M S E ( \hat { y } ) = \sqrt { \frac { 1 } { N } \sum _ { i = 0 } ^ { N } ( y _ { i } - \hat { y } _ { i } ) ^ { 2 } } \quad \hat { y } _ { i } \coloneqq \langle \hat { \beta } _ { i }, x _ { i } \rangle$$
The loss function used in training for all the models is mean squared error on the predicted 𝑦 variable 𝑀𝑆𝐸 𝑦 ( ˆ ) . We report the percentage improvement of a model over OLS.
For the sequence model in NeuralBeta , we tried GRU [4] and Attention [16]. For hyperparameter tuning, we specifically tuned the hidden size (32, 64, 128 and 256), dropout rate (0, 0.25, 0.5), and the lookback window length (64, 128 and 256). If transformer is used as the sequence model, we also tried to tune the patch size (1, 2, 4, and 8) according to [12]. However, this adjustment didn't significantly impact performance, so it is not discussed further in this paper. We trained the models for 100,000 gradient updates using the Adam optimizer [11] with a learning rate of 1e-4; for evaluation, we use the model with the lowest validation loss, evaluated every 1,000 updates. The hyperparameters are tuned with respect to the validation set, and all the statistics reported in the paper are on the test set. Experimental results are reported in Table 1; the metric we report is the % improvement in RMSE( ) ˆ 𝑦 compared with OLS.
We implemented NeuralBeta in Pytorch [13] and used Pytorch Lightning for training [7].
## 3.1 Synthetic Data
By experimenting on synthetic data, we are able to evaluate the model's performance in different scenarios. More importantly, we know the ground truth 𝛽 in synthetic data, so we can evaluate the beta estimations directly against the ground truth 𝛽 , instead of indirectly evaluating on the estimated 𝑦 variable. It also helps verifying our choice of loss function in market data experiments, i.e., whether it makes sense to evaluate on estimated 𝑦 when we do not know the ground truth 𝛽 .
For synthetic data, we deliberately choose three kinds of representative ground truth 𝛽 coefficients: constant (Section 3.1.1), stepwise (Section 3.1.2), and cyclical (Section 3.1.3). For each of the synthetic scenarios, we firstly generate the time series of groundtruth 𝛽 , then generate the time series 𝑥 and 𝑦 accordingly.
$$\tilde { \tau }$$
$$& x _ { t } \sim t _ { 1 0 } ( 0, 1 ) \\ & \epsilon _ { t } \sim \mathcal { N } ( 0, 1 ) \\ & y _ { t } = \beta _ { t } x _ { t } + \epsilon _ { t }$$
where 𝑡 𝜈 refers to a Student's T distribution with 𝜈 degrees of freedom. Each time series is of length 65, and we generated 100,000 samples for each experiment. We use 70% of the dataset for training, 20% for validation and 10% for testing.
3.1.1 Constant 𝛽 . Constant 𝛽 corresponds to the simplest case, where the response variable has a time-invariant relation with the explanatory variable:
$$\beta _ { t } \equiv c, \ \ c \in \mathbb { R }.$$
We sample 𝑐 from N( 1 1 , ) as the constant 𝛽 throughout the whole period for each sample. Theoretically, the optimal solution here is the posterior mean (derived via Bayesian linear regression):
$$\left ( \Lambda _ { 0 } + X _ { t - h, t } ^ { T } X _ { t - h, t } \right ) ^ { - 1 } ( \Lambda _ { 0 } \mu _ { 0 } + X _ { t - h, t } ^ { T } y _ { t - h, t } ) \quad ( 1 0 )$$
where Λ 0 and 𝝁 0 denote the prior mean and precision matrix of 𝛽 . In this case, the correct Λ 0 and 𝝁 0 to use are all 1 since 𝛽 is generated from N( 1 1 . Nonetheless, it is non-trivial to test out , )
whether the NeuralBeta model can converge to the optimal solution (10).
3.1.2 Stepwise 𝛽 . This is the simplest case for time-varying beta. It also corresponds to market regime shifts where the 𝛽 coefficient between two assets stays constant for a certain period then jumps to a new level. This scenario can test the adaptivity of NeuralBeta model to sudden changes in the market. We have
$$\Lambda _ { t } = \sum _ { i = 1 } ^ { n } \beta _ { i } 1 _ { \mathcal { T } _ { i } } ( t ), \\ \mathbb { R } \text{ and disjoint time in} \\ \text{on } \mathcal { T }. For our experimacy.$$
for 𝑛 constants 𝛽 𝑖 ∈ R and disjoint time intervals T 𝑖 that partition the entire horizon T . For our experiments, we chose 𝑛 = 2 and randomly picked a location in the lookback window as the jump position. The 𝛽 coefficients before and after the jump are also generated from N( 1 1 . , )
3.1.3 Cyclical 𝛽 . Certain financial time series demonstrate seasonality or other cyclical behaviors due to various reasons, such as agricultural production, business cycles, retail sales, etc. Classic models for cyclical patterns like decomposition models [5] and seasonal autoregressive moving average model [3] often involve steps to separate trend and seasonality factors before estimation, which requires attentive treatment. Unlike existing models, the NeuralBeta model is able to dynamically capture the cyclical pattern of the 𝛽 coefficient without further modification to the model. We test NeuralBeta on a simple example of sinusoidal 𝛽 in the form of
$$\beta _ { t } & = \sin ( \beta _ { 0 } + c t ) \\ \beta _ { 0 } & \sim N ( 0, 1 ) \\ c & \sim U ( 4, 3 2 )$$
where 𝑈 𝑎,𝑏 ( ) refers to a uniform distribution between 𝑎 and 𝑏 . The parameters are chosen such that each sample contains at least one half period of the sinusoidal wave.
3.1.4 Performance Analysis. We test NeuralBeta on the above synthetic datasets against the benchmarks (rolling OLS and rolling WLS). In Table 1, we can see in all three cases of synthetic 𝛽 , NeuralBeta significantly outperforms OLS and WLS. Even in the constant 𝛽 case where OLS is very close to the theoretically optimal solution, NeuralBeta still outperforms. More importantly, the performance of interpretable NeuralBeta and non-interpretable ones are almost identical, and interpretable NeuralBeta with attention mechanism outperforms except for the cyclical 𝛽 case. This shows that the interpretable architecture does not sacrifice performance while providing more transparency.
Figure 3 presents examples of the ground truth 𝛽 values alongside the model estimations for the three different scenarios: constant 𝛽 , stepwise 𝛽 and cyclical 𝛽 , from top to bottom respectively. Three models - OLS, WLS with exponential weights, and NeuralBeta - were applied to these datasets. Note that, to ensure a fair comparison, we tuned the half-life's of the exponential weights for WLS to achieve optimal performance, and selected the best-performing NeuralBeta model for each dataset. In the constant 𝛽 scenario, equation (10) is the optimal solution in theory. NeuralBeta 's performance is slightly better than OLS in terms of RMSE( ) ˆ , which proves that 𝑦 NeuralBeta is able to identify the best strategy in this simple scenario. For the stepwise 𝛽 scenario, both NeuralBeta and WLS significantly outperform OLS and perform almost identically to each other. Here the WLS model uses a half-life of 2, which means that it heavily weighs the two most recent data points - an effective approach for stepwise 𝛽 . NeuralBeta automatically identifies and applies this strategy. In the cyclical 𝛽 scenario, NeuralBeta outperforms both OLS and WLS. While WLS, with a half-life of 1, can track the sine wave's trend, NeuralBeta provides smoother and more accurate estimations, while maintaining the same level of responsiveness. This demonstrates NeuralBeta 's superior capability in handling dynamic and complex 𝛽 patterns.
Figure 4 shows the improvement of NeuralBeta model compared with OLS on cyclical 𝛽 with different periods of the sine wave. The x-axis denotes the period of the ground truth sinusoidal wave used as 𝛽 in our synthetic data, while the y-axis represents the improvement of NeuralBeta over OLS in % terms. NeuralBeta achieves the most significant improvement over OLS when the period of the
| | Baseline | Baseline | GRU | GRU | Attn | Attn |
|--------------|------------|------------|----------|----------|----------|---------|
| | OLS | WLS | NB | NBI | NB | NBI |
| Constant | 0 . 00 | - 0 . 05 | - 0 . 04 | - 0 . 01 | - 0 . 13 | 0 . 01 |
| Stepwise | 0 . 00 | 20 . 21 | 21 . 80 | 21 . 98 | 21 . 65 | 22 . 22 |
| Cyclical | 0 . 00 | 17 . 84 | 22 . 54 | 21 . 95 | 21 . 10 | 20 . 84 |
| Univariate | 0 . 00 | 0 . 12 | 0 . 22 | 0 . 26 | 0 . 31 | 0 . 40 |
| Multivariate | 0 . 00 | 0 . 34 | - 2 . 02 | 0 . 84 | - 4 . 49 | 0 . 95 |
Table 1: % Improvement against benchmark (OLS). The best result for each scenario is in bold.
time
Figure 3: Estimations of 𝛽 . RMSE( ) ˆ 𝑦 of each model is shown in parentheses in the legend.
Figure 4: Improvements compared with OLS for cyclical 𝛽 across different periods. NeuralBeta achieves best performance when 𝛽 changes at a moderate rate.
sinusoidal 𝛽 is moderate. When the period is either very low (indicating fast changes in 𝛽 ), or very high (indicating slow changes in 𝛽 ), NeuralBeta 's advantage over OLS diminishes, though it consistently outperforms OLS across all periods. This observation indicates that NeuralBeta model excels when 𝛽 changes at a moderate rate.
3.1.5 Comparing RMSE( ) and RMSE( ˆ 𝑦 ˆ 𝛽 ). One important reason why we want to do synthetic experiments instead of testing the model directly on market data is that we want to examine the correlation between RMSE( ) ˆ 𝑦 and RMSE( ˆ 𝛽 ) . Since in real data we do not know the ground truth 𝛽 , it is impossible to compute RMSE( ˆ 𝛽 ) directly. If we can verify that errors on ˆ and on 𝑦 ˆ 𝛽 are highly correlated, we can confidently use the error on the predicted 𝑦 as a reliable proxy for the model's performance. Figure 5 shows RMSE( ) ˆ 𝑦 and RMSE( ˆ 𝛽 ) across various epochs of the same model in the cyclical 𝛽 scenario. We use attention as the underlying sequence model in Figure 5a and GRU in Figure 5b. The analysis is limited to the first 50 epochs, as performance stabilizes beyond this point. In both figures, RMSE( ) ˆ 𝑦 and RMSE( ˆ 𝛽 ) appear to be highly correlated, which further justifies the validity of our approach. This correlation supports the use of RMSE( ) ˆ 𝑦 as an effective measure for evaluating the quality of 𝛽 estimators when the ground truth 𝛽 is unavailable.
3.1.6 Analyzing Weights from NBI. In Figure 6, we present the weights generated by NeuralBeta-Interpretable (NBI) in the stepwise 𝛽 scenario across a lookback window of length 64. We selected different positions where the ground truth 𝛽 jumps from 2 to 0, generated 1,000 samples for each position, and calculated the average weights assigned by NBI. The results show a significant increase in weights for data points following a jump, while the weights before the jump remain close to 0. This demonstrates NeuralBeta 's ability to swiftly detect and adapt to changes in 𝛽 .
With the above experiments, we show NeuralBeta 's ability to dynamically adapt to regime shifts, and to precisely capture cyclical
(a) Attention
Figure 5: RMSE( ) ˆ 𝑦 and RMSE( ) ˆ 𝛽 are highly correlated.
Figure 6: Weights assigned by NBI for stepwise 𝛽 when 𝛽 jumps at different positions.
market moves. In the next section we will test how the NeuralBeta model can possibly handle more complicated market data.
## 3.2 Market Data
The market dataset for our experiments covers the time horizon from 2010-01-01 to 2023-12-31. We use the daily return series of the S&P 500 index, the size factor index, the value factor index, and all S&P 500 components. We set 2010-01-01 to 2017-12-31 as the training period, 2018-01-01 to 2019-12-31 as the validation period, and 2020-01-01 to 2023-12-31 as the test period. As member companies in S&P 500 varies over time, research on investment strategies often accounts for these changes to avoid look-ahead bias during backtesting. However, since our primary focus is on the predictive power of 𝛽 coefficient estimators instead of backtesting strategies, we do not need to track the change of index components. For simplicity, we use a snapshot S&P 500 components as of 202405-01, and keep only those stocks with price histories available from 2010/01/01. This results in a dataset of 468 stocks used for our analysis.
Specifically, our experiments cover both the univariate and multivariate scenarios. For the univariate scenario, we aim to calculate the CAPM 𝛽 for each stock in S&P 500. For the multivariate case, we aim to calculate the factor 𝛽 's for the same universe with respect to the market factor, the size factor (R2FSF Index), and the value factor (RAV Index), which is similar to the setup in the Fama-French three-factor model.
3.2.1 S&P 500 Components with CAPM. In this experiment, we use the daily return series of the S&P 500 index (SPX Index) along with the daily return series of its individual components. The "Univariate" entry in Table 1 shows the performance of different models on this dataset.
From Table 1, we can see that using attention as the underlying sequence model is slightly better than using GRU, and the interpretable architecture is slightly better than general architecture in terms of test performance. This again indicates that incorporating an interpretable architecture, although introduces a restriction to the capacity, does not compromise the model's performance compared to the general, non-interpretable version.
To further investigate the model's behavior during different market conditions, we plotted the average weights assigned to each lag in the lookback window of 256 days for two distinct periods: the beginning of COVID-19 (March 2020) and October 2020. As shown in Figure 7, during the onset of the pandemic in March 2020, the model assigned significantly lower weights to the most recent data points. This likely reflects the extreme volatility present at that time which makes the data at that time less reliable for prediction purposes. By reducing the weights on these recent data points, the model aimed to mitigate the impact of short-term anomalies on beta estimation. Conversely, in October 2020, as market conditions began to stabilize, the model assigned higher weights to the most recent data points, which indicates a restored confidence in the relevance of recent data. It is also noteworthy that the log weights in October 2020 show a linear trend in the latter half of the lookback window, indicating exponential growth in the weights. This is significant, as the exponential weighting scheme, which is recognized by researchers as an effective solution, is identifies by NeuralBeta without human intervention.
Additionally, Figure 8 shows the average weights per day in the S&P500 universe, along with the 5-day volatility of SPX. Generally,
Figure 7: Average weights in log scale in the lookback window. March 2020 puts much less weights on recent data compared with October 2020.
Figure 8: Average weights in 2020 with SPX 5-day volatility. Weights are lower during periods of high volatility.
the model tends to assign lower weights during periods of high volatility and higher weights when volatility subsides. By examining the weights, we can see the model's ability to adapt to changing market conditions and produce robust estimates.
3.2.2 S&P 500 Components with Factors. As an extension of our experiments, we utilized the daily return series of the SPX index, along with size and value indices, to perform multivariate beta estimation on S&P 500 components. This experiment allows us to assess the model's ability to handle multiple factors instead of just one factor. The performance of the multivariate model is shown in the "Multivariate" entry in Table 1. In this case, the interpretable architecture with Attention performs the best, while the non-interpretable NeuralBeta models performs slightly worse than the benchmark. This experiment shows NeuralBeta 's potential in multi-factor models.
Figure 9: RMSE( ) ˆ 𝑦 of NB and NBI for different hyper-parameter values. NBI is more robust across different configurations.
## 3.3 Hyperparameter Tuning
To understand how the performance changes with different hyperparameter settings, in Figure 9, we plot the validation RMSE( ) ˆ 𝑦 of NeuralBeta-Interpretable (NBI) and NeuralBeta (NB) with Attention for the experiment in 3.2.1 across a range of values for lookback, hidden size, and dropout. For each parameter value, we select the best-performing model from all possible parameter combinations and present the results in the plots.
The performance analysis shows that a longer lookback window leads to better results due to the increased information it provides. A medium hidden size and dropout rate are preferred. Although the interpretable version (NBI) performs slightly worse than the non-interpretable version on the validation set in this experiment (NBI performs better on the test set, as is shown in Table 1), it demonstrates greater robustness, with its performance showing less variability across different parameter values. This robustness is likely because of NBI's architectural design, which inherently incorporates the linear regression formula and reduces the complexity of the function needed to learn from raw data. NB, on the other hand, must learn them from scratch, which could lead to higher variance across different configurations.
## 4 CONCLUSION
In this paper, we presented NeuralBeta , a novel approach to beta estimation using deep neural network. This model effectively addresses several challenges associated with traditional beta estimation techniques, particularly the challenge with dynamic 𝛽 values and model transparency. Further, we also developed an interpretable neural network, NeuralBeta-Interpretable , which we find improves not only transparency but also performance.
We conducted extensive experiments on both synthetic and market data to validate the efficiency and robustness of NeuralBeta . The results demonstrated superior performance across diverse scenarios compared with benchmark methods. We also provided examples of the weights produced by the interpretable version of NeuralBeta . These examples illustrate how NeuralBeta derives its predictions and offer users insight into the model's mechanism by examining the distribution of weights.
Beyond beta estimation, this model can be extended to other financial settings that assume linear relationships, such as calculating an option's delta in options pricing. Given the prevalence of linear assumptions in financial modeling, NeuralBeta 's generality, interpretability, and practicality make it a powerful tool for many financial applications.
## REFERENCES
- [1] Emmanuel Alanis, Vance Lesseig, Janet D Payne, and Margot Quijano. 2024. Can machine learning methods predict beta? Applied Economics (2024), 1-15.
- [2] Tim Bollerslev, Robert F Engle, and Jeffrey M Wooldridge. 1988. A capital asset pricing model with time-varying covariances. Journal of political Economy 96, 1 (1988), 116-131.
- [3] George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. 2015. Time series analysis: forecasting and control . John Wiley & Sons.
- [4] Kyunghyun Cho, B van Merrienboer, Caglar Gulcehre, F Bougares, H Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoderdecoder for statistical machine translation. In Conference on Empirical Methods in Natural Language Processing (EMNLP 2014) .
- [5] Robert B. Cleveland, William S. Cleveland, Jean E. McRae, and Irma Terpenning. 1990. STL: A seasonal-trend decomposition procedure based on loess. Journal of Official Statistics 6, 1 (1990), 3-73.
- [6] Wolfgang Drobetz, Fabian Hollstein, Tizian Otto, and Marcel Prokopczuk. 2023. Estimating stock market betas via machine learning. Journal of Financial and Quantitative Analysis (2023), 1-56.
- [7] William Falcon and The PyTorch Lightning team. 2019. PyTorch Lightning . https://doi.org/10.5281/zenodo.3828935
- [8] Eugene F Fama and Kenneth R French. 1993. Common risk factors in the returns on stocks and bonds. Journal of Financial Economics 33, 1 (1993), 3-56.
- [9] Eugene F Fama and Kenneth R French. 2015. A five-factor asset pricing model. Journal of Financial Economics 116, 1 (2015), 1-22.
- [10] Ravi Jagannathan and Zhenyu Wang. 1996. The conditional CAPM and the cross-section of expected returns. The Journal of Finance 51, 1 (1996), 3-53.
- [11] Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Machine Learning .
- [12] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2023. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv:2211.14730 [cs.LG] https://arxiv.org/abs/2211.14730
- [13] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32 , H. Wallach, H. Larochelle, A. Beygelzimer, F. dÁlché-Buc, E. Fox, and R. Garnett (Eds.). Curran Associates, Inc., 8024-8035. http://papers.neurips.cc/paper/9015pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
- [14] Stephen A Ross. 2013. The arbitrage theory of capital asset pricing. In Handbook of the Fundamentals of Financial Decision Making: Part I . World Scientific, 11-30.
- [15] William F Sharpe. 1964. Capital asset prices: A theory of market equilibrium under conditions of risk. The Journal of Finance 19, 3 (1964), 425-442.
- [16] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems , I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc., 5998-6008. | null | [
"Yuxin Liu",
"Jimin Lin",
"Achintya Gopal"
]
| 2024-08-02T16:55:08+00:00 | 2024-10-28T14:21:30+00:00 | [
"q-fin.ST",
"cs.LG"
]
| NeuralBeta: Estimating Beta Using Deep Learning | Traditional approaches to estimating beta in finance often involve rigid
assumptions and fail to adequately capture beta dynamics, limiting their
effectiveness in use cases like hedging. To address these limitations, we have
developed a novel method using neural networks called NeuralBeta, which is
capable of handling both univariate and multivariate scenarios and tracking the
dynamic behavior of beta. To address the issue of interpretability, we
introduce a new output layer inspired by regularized weighted linear
regression, which provides transparency into the model's decision-making
process. We conducted extensive experiments on both synthetic and market data,
demonstrating NeuralBeta's superior performance compared to benchmark methods
across various scenarios, especially instances where beta is highly
time-varying, e.g., during regime shifts in the market. This model not only
represents an advancement in the field of beta estimation, but also shows
potential for applications in other financial contexts that assume linear
relationships. |
2408.01388v1 | MNRAS 000
, 1-13 (2021)
## CXOU J005245.0-722844: Discovery of a Be Star / White Dwarf binary system in the SMC via a very fast, super-Eddington X-ray outburst event
T. M. Gaudin 1 ★ , M. J. Coe 2 , J. A. Kennea 1 , I. M. Monageng 3 6 , , D. A. H. Buckley 3 6 , , A. Udalski 4 , P. A. Evans 5
1 Department of Astronomy and Astrophysics, The Pennsylvania State University, 525 Davey Lab, University Park, PA 16802, USA
- 2 Physics & Astronomy, The University of Southampton, SO17 1BJ, UK
- 3 South African Astronomical Observatory, P.O Box 9, Observatory, 7935, Cape Town, South Africa
- 4 Astronomical Observatory, University of Warsaw, Al. Ujazdowskie 4, 00-478 Warszawa, Poland
- 5 University of Leicester, X-ray and Observational Astronomy Research Group, School of Physics & Astronomy, University Road, Leicester LE1 7RH, UK
- 6 Department of Astronomy, University of Cape Town, Private Bag X3, 7701 Rondebosch, South Africa
Accepted 2021 September 9. Received 2021 August 31; in original form 2021 July 29
## ABSTRACT
CXOU J005245.0-722844 is an X-ray source in the Small Magellanic Cloud (SMC) that has long been known as a Be/X-ray binary (BeXRB) star, containing an OBe main sequence star and a compact object. In this paper, we report on a new very fast X-ray outburst from CXOU J005245.0-722844. X-ray observations taken by Swift constrain the duration of the outburst to less than 16 days and find that the source reached super-Eddington X-ray luminosities during the initial phases of the eruption. The XRTspectrum of CXOU J005245.0-722844 during this outburst reveals a super-soft X-ray source, best fit by an absorbed thermal blackbody model. Optical and Ultraviolet follow-up observations from the Optical Gravitational Lensing Experiment (OGLE), Asteroid Terrestrial-impact Last Alert System (ATLAS), and Swift identify a brief ∼ 0.5 magnitude optical burst coincident with the X-ray outburst that lasted for less than 7 days. Optical photometry additionally identifies the orbital period of the system to be 17.55 days and identifies a shortening of the period to 17.14 days in the years leading up to the outburst. Optical spectroscopy from the Southern African Large Telescope (SALT) confirms that the optical companion is an early-type OBe star. We conclude from our observations that the compact object in this system is a white dwarf (WD), making this the seventh candidate Be/WD X-ray binary. The X-ray outburst is found to be the result of a very-fast, ultra-luminous nova similar to the outburst of MAXI J0158-744.
Key words: stars: emission line, Be - X-rays: binaries - stars: white dwarfs
## 1 INTRODUCTION
Be/X-ray binaries (BeXRBs) are a type of high mass X-ray binary (HMXB)system containing a main sequence O or B type star in orbit with a compact object, typically a Neutron Star (NS), in a moderately eccentric orbit ( 𝑒 ∼ 0 3 . -0 5). . The OB star is characterized by the presence of Balmer-series Hydrogen emission lines in its optical spectrum from which the spectral class Be is derived. These emission lines are the signature of a dense, circumstellar wind that forms a geometrically-thin 'decretion disk" around the main sequence star and fuels X-ray emission via accretion onto the compact object (see Reig 2011 for a review).
BeXRBs are commonly-observed, making up over half of the galactic population of HMXBs (Neumann et al. 2023). These systems are also numerous in the Small Magellanic Cloud (SMC), a neighboring dwarf galaxy of the Milky Way (Coe & Kirk 2015; Yang et al. 2017). Due to a recent period of increased star formation (Harris & Zaritsky 2004; Rezaeikh et al. 2014), the HMXB population of the SMC is much larger than is expected for a lowmass dwarf galaxy. Almost all HXMBs (SMC X-1; Li & van den
Heuvel 1997) in this population are observed to be BeXRBs, and the total number of BeXRBs is comparable to the size of the galactic population. The study of this large population of BeXRBs is the primary motivation for the Swift SMC Survey (S-CUBED; Kennea et al. 2018). S-CUBED is a weekly survey, ongoing since 2016, that aims to identify new BeXRBs and characterize their high-energy emission behavior. This survey utilizes the X-ray Telescope (XRT; Roming et al. 2005) and UV/Optical Telescope (UVOT; Burrows et al. 2005) of the Swift Observatory to perform tiled observations of 142 overlapping tiles for 60s each in order to obtain spatiallycontinuous observations of the entire SMC. Each tile is observed with XRT in Photon Counting (PC) mode and UVOT observing the uvw1 -band. S-CUBED data has been used to identify several new BeXRBs (Kennea et al. 2020; Monageng et al. 2019; Gaudin et al. 2024) and to observe notable outbursts from known systems (e.g. SMC X-3; Townsend et al. 2017).
- ★ E-mail: [email protected] (TMG)
While the compact object in a BeXRB system is typically a NS, there have been cases where either a WD (e.g. XMMU J010147.5715550; Sturm et al. 2012a) or a black hole (Casares et al. 2014) has been found in orbit around a Be star. These cases are rare, and only 6 candidate Be/White Dwarf (henceforth BeWD) systems are known to exist. Of the six candidate BeWD systems that have been
identified, four have been found in the SMC (Zhu et al. 2023), and two of the four have been discovered via S-CUBED observations (Coe et al. 2020a; Kennea et al. 2021). The reason for a lack of observed BeWD systems remains an open question. It has been suggested by population synthesis studies that BeWD systems should be significantly more prevalent than BeXRB systems with a NS compact object (Raguzova 2001; Zhu et al. 2023). The results of Raguzova (2001) predict an occurrence rate of BeWDs over 7 times as high as BeXRBs containing a NS. However, observational evidence for this large population of hidden BeWDs remains elusive.
Observational selection bias has been cited (Sturm et al. 2012b; Kennea et al. 2021) as a potential reason for the lack of detected BeWDs. BeXRBs are transient accretion-powered systems, and Xray outbursts are thought to be the result of interactions between the Be circumstellar disk and the compact object (Stella et al. 1986). When the compact object is a NS, the luminosity of an accretionpowered X-ray outburst is 𝐿 𝑋 ∼ 10 36 -10 38 ergs s -1 (Okazaki & Negueruela 2001). However, WD accretion is predicted to be much weaker, producing hard X-ray emission luminosity of 𝐿 𝑋 ∼ 10 29 -10 33 ergs s -1 (Waters et al. 1989), which is below the detection threshold of wide field X-ray telescopes such as the Monitor of Allsky X-ray Image (MAXI) telescope or the Swift Burst Alert Telescope (BAT) for sources in the Magellanic Clouds. When BeWD systems are detected, the X-ray spectrum is found to be that of a super-soft X-ray source (SSS) (Coe et al. 2020a) with most X-ray emission detected below 2 keV. SSS are a class of accreting WDs that are experiencing a period of stable nuclear burning on their surface (Kahabka 2006). During the SSS phase, the WD can produce X-ray luminosities of 𝐿 𝑋 ∼ 10 36 -10 38 ergs s -1 (Kahabka & van den Heuvel 1997), making them far easier to detect by X-ray telescope observations.
In rare cases, SSS can reach abnormally large luminosities that are significantly higher than the Eddington Luminosity of a 1 M ⊙ WD ( 𝐿 𝑋 ≥ 10 39 ergs s -1 ). These systems, designated as ultra-luminous supersoft sources (ULSs) (Liu & Di Stefano 2008), have no obvious physical origin. Some (Liu & Di Stefano 2008) have suggested that intermediate-mass black holes may be responsible for this rare class of objects,and others favor a scenario in which a stellar mass black hole is accreting at a super-critical rate (Urquhart & Soria 2016). In extremely rare cases, a nuclear burning WD will briefly reach the luminosity regime of an ULS. This has happened only once, in the SMC BeWD system MAXI J0158-744 (Li et al. 2012; Morii et al. 2013). MAXI J0158-744 was discovered via a brief soft X-ray outburst that reached a maximum luminosity of 𝐿 𝑋 = 2 × 10 40 ergs s -1 (Morii et al. 2013) and lasted for only weeks (Li et al. 2012). This eruption is the first example of a nova eruption occurring in a BeWD system during which a shell of accreted Hydrogen on the surface of the WD produced a period of runaway nuclear fusion (see Page & Shaw 2022 for a recent review of novae) that resulted in a bright outburst. The importance of BeWD systems to ULS systems and the ultra-luminous X-ray source (ULX) phenomenon is still an area of active research. In order to better understand the connection, more systems must be observed.
In this paper, we report on the recent super-Eddington outburst of CXOU J005245.0-722844, a new BeXRB in the SMC that becomes the second BeWD to reach the ULS regime. This new system was observed by combining Swift XRT and UVOT observations, archival data from the Optical Gravitational Lensing Experiment (OGLE) and the Asteroid Terrestrial-impact Last Alert System (ATLAS), and Southern African Large Telescope (SALT) spectroscopy. Observational data can be combined to show that the compact object in this system is indeed a WD, making this the fifth candidate BeWD system identified in the SMC. We also demonstrate that the super-luminous outburst is likely produced by the beginning phases of a nova eruption on the surface of the compact object.
## 2 OBSERVATIONS
## 2.1 Discovery of CXOU J005245.0-722844
CXOUJ005245.0-722844 was first cataloged as part of the Chandra survey of the Small Magellanic Cloud during a search for optical counterparts to SMC X-ray sources (Antoniou et al. 2009). Since its discovery, the source has been in SMC BeXRB catalogs such as Haberl & Sturm (2016), but little has been known about the source. The first detection of an X-ray flare came from the Einstein Probe on 2024 May 27 at 8:41 UTC (JD2460457.862)(Yang et al. 2024). The initial Einstein Probe data was used to localize the flare to the position of CXOU J005245.0-722844 and to note the soft spectrum of the X-ray emission that was best fit by an absorbed blackbody. About 14 hours later, at 22:29 UTC, the position of the flare was further localized by a weekly S-CUBED observation (Kennea et al. 2024), confirming that CXOU J005245.0-722844 was indeed the source of the outburst. The short 55s observation was additionally used to verify the soft nature of the X-ray spectrum and posit that the compact object in this system was indeed a WD.
The S-CUBED localization of CXOU J005245.0-722844 is the most accurate X-ray position of the flare, localizing the source to RA(J2000) = 00 ℎ 52 𝑚 45.18 𝑠 , Dec(J2000) = -72 ◦ 28 ′ 44.6' with an estimated uncertainty region of radius 2.4 arcseconds. The optical counterpart of CXOU J005245.0-722844 was found by Jaisawal et al. (2024) to be 2MASS J00524508-7228437 at a position of RA(J2000) = 00 ℎ 52 𝑚 45.09 𝑠 , Dec(J2000) = -72 ◦ 28 ′ 43.73', separated from the X-ray source position by less than a single arcsecond. 2MASS J00524508-7228437 was first reported to be an early-type OBe star in 2009 when the source was discovered, with a spectral type of O9Ve-B0Ve (Antoniou et al. 2009). Jaisawal et al. (2024) reported on the observation of CXOU J005245.0-722844 by NICER, finding a similar soft spectrum with a much fainter luminosity than the detections of Einstein Probe and S-CUBED. NICER observations provide the first evidence of an OVIII absorption edge at 0.871 keV, further strengthening the case for a WD compact object in the system.
## 2.2 Swift Observations
## 2.2.1 XRT Observations
CXOU J005245.0-722844 has rarely been detected by Swift during the short, weekly observations of the S-CUBED survey. A full XRT light curve is plotted for CXOU J005245.0-722844 in the 3rd panel of Figure 1. The system has been observed 356 times by the survey, but prior to its recent outburst, there were no detections. The recent outburst was first detected by S-CUBED on 2024 May 27, when CXOU J005245.0-722844 was detected at a count rate of 5 71 . + 1 04 . -1 04 . counts s -1 . A target of opportunity (TOO) observation was scheduled for 2024 May 28 to follow-up on the detected outburst. This TOO observation was taken in window timing (WT) mode, and it revealed that the source was still in a state of outburst at a count rate of 5 10 . + 0 35 . -0 39 . counts s -1 . After this observation, no Swift observations could happen because CXOU J005245.0-722844 was constrained by the limb of the Earth for 9 days. By the time the source was visible again by Swift on 2024 June 12, the source had faded below the detection threshold for the short exposures of S-CUBED. In four deeper TOO observations taken between 2024 June 13 and 2024
Figure 1. Multi-wavelength light curve of CXOU J005245.0-722844 emission behavior containing I-band data taken by OGLE, uvw1 -band data taken by Swift UVOT, and 0.3-10 keV data taken by Swift XRT. In the bottom panel, black points represent observations during which CXOU J005245.0-722844 was detected by Swift XRT. Purple arrows represent upper limits on the count rate during observations where CXOU J005245.0-722844 was not able to be detected.

Table 1. Table containing the best-fitting parameters from the absorbed blackbody model used to describe the spectrum of CXOU J005245.0-722844. Each row describes a free parameter using the model component that it is derived from, its units, and its best-fitting values to the Swift XRT spectrum taken on 2024 May 28.
| xspec Model | Parameter | Best-Fit Value | Units |
|---------------|------------------|------------------------------|------------------|
| TBabs edge | 𝑁 𝐻 | ( 2 . 30 ± 0 . 475 ) × 10 21 | cm - 2 |
| | 𝐸 𝑒, 1 | 0 . 385 ± 0 . 020 | keV |
| edge | 𝜏 𝑚𝑎𝑥, 1 | 1 . 53 ± 0 . 43 | - |
| edge | 𝐸 𝑒, 2 | 0 . 896 ± 0 . 011 | keV |
| edge | 𝜏 𝑚𝑎𝑥, 2 | 1 . 08 ± 0 . 14 | - |
| cflux | log 10 ( 𝐹 𝑡𝑜𝑡 ) | - 8 . 85 ± 0 . 14 | erg cm - 2 s - 1 |
| bbodyrad | 𝑘𝑇 | 91 . 3 ± 3 . 73 | eV |
June 19, this source was also unable to be detected, indicating that the outburst had indeed concluded before coming out of Swift's Earth limb constraint.
A0.3-10 keV spectrum of CXOU J005245.0-722844 was obtained for the WT mode TOO observation by using the automated XRT pipeline tools described by Evans et al. (2009) and re-binned using the grppha software package so that each spectral bin has at least 15 counts. A typical BeXRB spectrum with a NS companion is hard and can be fit by an absorbed power law with a photon index of Γ ≃ 1. CXOU J005245.0-722844 does not show this typical X-ray spectrum, but instead has a very soft spectrum with most of the flux being detected at energies below 2 keV. This soft X-ray spectrum is the key distinguishing feature of BeWDs that can be used to differentiate them from systems containing a NS (Coe et al. 2020b; Kennea et al. 2021).
The spectrum of CXOU J005245.0-722844 is shown in Figure 2 and is plotted together with the line of best fit obtained via model fitting. Spectral fitting was performed by following the analysis methods of Kennea et al. (2021), fitting an absorbed thermal blackbody to this spectrum using xspec (Arnaud 1996) which is included in the FTOOLS software package (Blackburn et al. 1999). The bestfitting parameters from model fitting are shown in Table 1. To create the spectral model used for fitting, the tbabs ISM absorption model component was convolvded with the bbodyrad model within xspec . The best-fitting column density of material along the line of sight, 𝑁 𝐻 = ( 2 30 . ± 0 475 . )× 10 21 cm -2 , is higher than the average value for the column density towards the SMC (Willingale et al. 2013; Kennea et al. 2018). CXOU J005245.0-722844 is best-fit by a thermal blackbody with temperature 𝑘𝑇 = 91 3 . ± 3 73 eV, corresponding to a WD . mass of ∼ 1.2 M ⊙ using the maximum shock temperature derived by Mukai (2017), which assumes free-fall accretion from infinity onto the surface of a WD. The parameter cflux is also included in the fit in order to estimate the total 0.3-10 keV flux of the source during its outburst, and the best-fitting flux is 𝐹 𝑋 = 1 41 . + 0 54 . -0 38 . × 10 -9 erg cm -2 s -1 which corresponds to an X-ray luminosity of 6 51 . + 2 5 . -1 2 . × 10 38 erg s -1 at the standard distance to the SMC of 62.44 kpc (Graczyk et al. 2020). This brightness is slightly larger than the Eddington Luminosity, 𝐿 𝑒𝑑𝑑 = 1 5 . × 10 38 erg s -1 of a 1.2 M ⊙ WD. The large luminosity implies super-Eddington accretion onto the surface of the WDduring the brief outburst.
In a similar result to those of Kennea et al. (2021), the absorbed blackbody model fit is improved by including absorption edges using the edge model component of xspec . Two absorption edges are needed to properly characterize all of the features in the spectrum and to improve the fit from a reduced 𝜒 2 of 2.17 to a reduced 𝜒 2 of 1.41. The first edge is found to be located at 𝐸 𝑒, 1 = 0 385 . ± 0 020 .
thomasgaudin 25
-
Jun
-
2024 10:06
Figure 2. X-ray spectrum of CXOU J005245.0-722844 taken during a WT mode observation on 2024 May 28 including the best-fitting absorbed blackbody model containing 2 absorption edges at 0.385 keV and 0.896 keV. The spectrum is soft with little emission detected above 2 keV.
keV, and the second edge is found at 𝐸 𝑒, 2 = 0 896 . ± 0 011 keV. Given . their respective locations, these are likely signatures of the 0.49 eV C VI edge and the 0.871 eV O VIII edge, respectively. Both of these edges are predicted to be found in WDs by stellar atmosphere models, and both edges have been observed in other SSS systems (Parmar et al. 1997, 1998) and BeWD systems (Kennea et al. 2021).
Using the absorbed blackbody emission model and following the methods of Kennea et al. (2021), it is possible to derive the maximum size of the emission region during outburst of CXOU J005245.0722844. The normalization factor of the bbodyrad model component within xspec is given by 𝑛 = 𝑅 2 𝑒𝑚 𝐷 2 10 , where 𝑅 𝑒𝑚 is the radius of the source emission region in units of km and 𝐷 10 is the distance to the source in units of 10 kpc. By fixing the components of the absorbed blackbody model with two absorption edges at their bestfitting values, the normalization factor can be left as a free parameter in order to determine its best-fitting value. This value for CXOU J005245.0-722844 is found to be 𝑛 = ( 3 49 . ± 0 038 . ) × 10 6 , corresponding to an emission region with a radius of 𝑅 𝑒𝑚 = 11648 ± 64 km at the standard distance to the SMC. An emission region of this size is only a few times larger than the radius of a 1.2 M ⊙ WD (Althaus et al. 2005), providing further evidence in favor of a WD compact object as the binary companion in this system.
The flux of the source can be used to place an upper limit on the quiescent emission from CXOU J005245.0-722844 if we assume a constant spectrum during and after the outburst. From the spectral fit presented in Table 1, the counts to flux conversion factor is calculated to be 3 12 . × 10 -10 erg cm -2 count -1 using the observed count rate of 4.521 counts s -1 and the best-fitting unabsorbed flux of 𝐹 𝑋 = 1 41 . + 0 54 . -0 38 . × 10 -9 erg cm -2 s -1 . By summing all of the XRT data taken during TOO observations from 2024 June 13 to 2024 June 19, we obtain a 3𝜎 upper limit for the 0.3-10 keV count rate during this period. The quiescent count rate upper limit is found to be 0.0019 counts s -1 . Multiplying this count rate by the counts to flux conversion factor, we arrive at an unabsorbed flux of 𝐹 𝑋 = 5 96 . × 10 -13 erg cm -2 s -1 which corresponds to an upper limit luminosity of 𝐿 𝑋 = 2 75 . × 10 35 erg s -1 at the accepted distance of the SMC.
During a 100ks observation taken by the Chandra X-ray Observatory in 2010 (Laycock et al. 2010), Chandra detected 12 counts over 100ks which corresponds to a flux of 𝐹 𝑋 = 3 22 . × 10 -12 erg cm -2 s -1 or a luminosity of 𝐿 𝑋 = 1 48 . × 10 35 erg s -1 at the accepted distance of the SMC. This indicates agreement in quiescent luminosity between the deepest pre-outburst observation and the upper limits derived after the outburst had concluded. However, novae typically produce hard X-ray emission with a luminsoity of 10 33 - 10 35 erg s -1 (Mukai et al. 2008) for tens of days after the onset of the outburst, so the outburst could have continued to produce X-ray emission at a luminosity below the detection threshold of Swift for a longer period of time.
## 2.2.2 UVOT Observations
Since 2016, CXOU J005245.0-722844 has been detected by UVOT in 177 S-CUBED observations and one TOO observation. For most of the duration of S-CUBED, this represents approximately weekly coverage of the source. However, the source is located at the edge of an S-CUBED UVOT tile and can occasionally fall outside of the UVOT field of view. UVOT light curves are generated by using Swift-specific functions found in FTOOLS (Blackburn et al. 1999) to perform aperture photometry. An aperture with a radius of 5" was defined around the XRT position of the source and a nearby background region was defined with a radius of 8". Photometric information for each observation was then extracted within the source region using the uvotsource method from FTOOLS. The UVOT light curve generated using this method is shown in the center panel of Figure 1. As can be seen in the figure, the outburst is detected in the 2024 May 27 S-CUBED observation at 12.81 magnitude, which is almost 0.2 magnitudes brighter than the previous week. By the time the system was observed during the TOO observation of 2024 May 28, the system had faded back to the quiescent 12.96 magnitude. By 2024 June 12, the new source has faded to 13.09 magnitude, which is close to the faintest magnitude ever observed for the system. The uvw1 -band light curve additionally shows variability that tracks with the IR variability of the system, an expected feature of BeXRB systems that has been observed before (Kennea et al. 2021).
During the Swift TOO observation taken on 2024 May 28, CXOU J005245.0-722844 was observed in 0x30ed mode to collect data in six different filter bands. UVOT data from this observation was combined with all archival photometric measurements of 2MASS J00524508-7228437 to create a spectral energy distribution (SED) from the infrared (IR) to the ultraviolet (UV). The archival photometric data used to create this SED were retrieved by querying the VizieR archival photometry viewer (Ochsenbein et al. 2000) for all measurements made within a 1.5" radius region around the optical counterpart. Before creating the SED, all VizieR and UVOT data were unreddened using the Fitzpatrick 1999 (Fitzpatrick 1999) extinction law. The line-of-sight extinction towards the source was
Figure 3. A multi-wavelength SED of CXOU J005245.0-722844 created by combining Swift UVOT data with archival data retrieved from the VizieR Photometry Viewer (Ochsenbein et al. 2000). A BIV stellar spectrum is plotted alongside the SED data and scaled via use of least-squares fitting to determine the best-fit stellar radius.
determined using the OGLE 𝐸 𝑉 ( -𝐼 ) map (Skowron et al. 2021) for the Magellanic Clouds. The unreddend SED was then analyzed to check for an IR excess that is produced by the Be stellar disk. Least-squares fitting was used to fit Kurucz model spectra (Kurucz 1993) to the multi-wavelength SED, using the best-fitting radius to scale the spectrum to the accepted distance of 𝐷 = 62 44 kpc to . the SMC (Graczyk et al. 2020). Figure 3 shows the best-fitting spectrum plotted together with the UVOT and VizieR data. This figure shows that the SED is best fit to a B1V spectrum with a radius of 𝑅 𝐵𝑒 = 5 93 . ± 0 049 R . ⊙ , indicating that the optical counterpart is indeed an early-type B star. In addition to fitting an early-type B star, the SED shows a clear IR excess over a standard BIV star. The strength of the IR excess of a Be star is highly time-dependent, so this SED, which combines observations taken over many years, is of limited use. However, the presence of the IR excess in many obseravtions of the time-averaged SED is a strong indicator that a circumstellar disk is present around the B-type star. While the contribution of the disk to the SED varies with time, the underlying stellar spectrum is thought to be time-invariant, so the dangers of inferring too much about the stellar disk from this SED do not apply to the confirmation of the expected spectral type via SED-fitting.
## 2.3 Optical photometry
## 2.3.1 OGLE
The OGLE project (Udalski et al. 2015) undertakes to provide long term I-band photometry with an average cadence of 1-3 days. The star 2MASS J00524508-7228437 was observed continuously for over 2 decades in the I-band with only a gap of ∼ 2 5 year due to COVID-. 19 restrictions. After that gap, the source was observed with a high cadence for the following two seasons. It is identified in the OGLE catalogue as SMC719.20.104.
The I band data are shown in their entirety in Fig. 4. The overall behaviour revealed is very quiet compared to that expected for a Be star in the SMC, unusually showing no large scale fluctuations on timescales of years. The overall colour changes seen in this system by combining the OGLE I-band with the UVOT data are discussed
Figure 4. OGLE III and IV observations of the optical counterpart to CXOU J005245.0-722844. Note the one outburst point in the top right hand corner of the plot followed by a very rapid fading.
further in the Section 3 below, but again the only substantial change occurs at the time of the outburst.
OGLE detected an optical counterpart of the X-ray outburst see by the Einstein Probe at MJD 60457.62, some 6 h before the EP detection.
In Figure 5, we plot higher-resolution light curves of CXOU J005245.0-722844, which for both OGLE and UVOT indicates that a phase of gradual dimming has begun, which has become fainter than the pre-outburst magnitude.
## 2.3.2 ATLAS
We utilized the photometric database of the Asteroid Terrestrialimpact Last Alert System (ATLAS; Tonry et al. (2018)) and undertook forced photometry (Smith et al. 2020) at the position of CXOU J005245.0-722844. The light curve for the o-band photometry, covering the same zoomed-in time interval of the OGLE photometry (Figure 5), is shown in Figure 6. These data show that the optical outburst was in progress from MJD 60456.370, ∼ 1 day before the OGLE and EP detections of the outburst. Furthermore, the next ATLAS measurements, at MJD 60458.14, were at a magnitude of ∼ 14.95, significantly above the quiescent level. This implies that the outburst must have lasted some ∼ 2 days.
As in the case of the OGLE light curve, the brightness after outburst is less than before outburst, although the difference is not as marked. This is likely due to the different effective wavelengths of the I-band filter (7000 -9000Å) used in OGLE and the o-band filter (5600 -8100Å) used in ATLAS, implying the difference is wavelength dependent.
## 2.3.3 Period analysis
The subset of detrended OGLE data prior to JD 2458869 were searched using a Phase Binned Analysis of Variance (AoV) method for possible periodicities in the range 2 - 100d. A clear peak was seen at a period of 17.55d - see Fig. 7.
60300 60325 60350 60375 60400 60425 60450 60475 60500 MJD Figure 7. Lomb-Scargle power spectrum of the OGLE observations prior to JD 2458869 . The main peak is at 17.55 days, the side peaks arise from the annual sampling.
Figure 5. A multi-wavelength light curve of CXOU J005245.0-722844 that shows the brightness of the source before, during, and after its 27 May 2024 outburst which highlights the brief IR, UV, and X-ray duration of the outburst and subsequent fading that is seen in the UV and IR. The top panel shows I-band OGLE variability. The middle panel shows uvw1 -band Swift UVOT variability. The bottom panel shows observations using Swift XRT. Black points represent observations in which CXOU J005245.0-722844 was detected and purple arrows represent upper limits on the count rate when the source was not detected.
Figure 6. ATLAS -o-band photometry of CXOU J005245.0-722844.
This period is consistent with the earlier reported period of 17.54d by Sarraj et al. (2012) from analysis of MACHO data, and the more recent report of the same period by Treiber et al. (2024) using OGLE data. The OGLE data were then folded at the period of 17.55d and the resulting profile is shown in Fig. 8. Though there is some scatter
Figure 8. The detrended OGLE data prior to JD 2458869 folded at the period of 17.55 days, showing the overall sinusoidal profile and the scatter in the measurements.
in the individual cycles, there clearly exists a dominant peak in the I-band light curve approximately at the phase ∼ 0.25.
Hence the OGLE data prior to JD 2458869 reveal an ephemeris for the time of the maximum of the optical profile, 𝑇 opt , defined by:
$$T _ { \text{opt} } = 2 4 5 6 1 1 0. 7 \pm 0. 1 + N ( 1 7. 5 4 9 7 \pm 0. 0 0 0 8 ) \ J D \quad \quad ( 1 )$$
It is interesting to note that the phase of the outburst reported here using this ephemeris is 0.68. This is unusual as most BeXRB systems clearly show a strong correlation between the optical peak of any modulation and the phase of the X-ray outburst. This is believed to be because the optical peak is thought to reveal the time of periastron of the system. In this case no such correlation is evident suggesting that the X-ray outburst has arisen from a completely different trigger mechanism.
Figure 9 shows power spectra of most of the OGLE data - time goes top -> down. The first 7 are each 2 year samples (i.e. 14 years worth
of data), last 2 are each 1 year and represent the most recent 2 years of observations following the COVID-19 observational gap. The last 2 are scaled down by a factor of 50 in power to fit with the others (higher power in the recent, much higher cadence observations). These last two can be seen in full detail in Figure 10. The dominant period, P, is clear in each case, and secondary peaks that can be seen are harmonics of the main period: 0.029 = 2*P, 0.118 = P/2, 0.177 = P/3 and 0.086 = P * 3 / 2..
So, from the start of MACHO observations (1992) until just before the 2 year COVID-19 gap in the OGLE data ( ∼ 2020-22 or MJD 58869 - 59800), there is observed to be a persistent period of 17.55d. During this period it appears the folded profile was very sinusoidal in nature typical of most BeXRB systems (see, for example Coe et al. (2023)), where the Be star's circumstellar disc is regularly distorted by the orbital presence of the neutron star. Then as we go beyond the COVID-19 gap ( ∼ 2022-24 or MJD 59800 - 60352), there is evidence of a clear changes in the period. The first observing year reveals a period of 17.408 ± 0.017d, then in the folowing year the period further reduces to 17.146 ± 0.008. The folded profiles for both observing sessions are shown in Figure 11. This figure shows the rather different folded profiles observed in these last 2 years leading up to the outburst. This difference and the period changes are discussed further in Section 3 below.
## 2.4 SALT observations
CXOU J005245.0-722844 was observed with the Southern African Large Telescope (SALT) on 2024 June 14 (JD 2460475.7; 17.8 d after outburst) and 2024 July 02 (JD2460493.7; 35.8 d after outburst) using the Robert Stobie Spectrograph (Burgh et al. 2003). The observations were carried out using several grating settings that cover different wavelength ranges: PG1800 (grating angle = 36.125 ◦ ; 5800 - 7000 Å), PG2300 (grating angle = 33.5 ◦ ; 4250 - 5270 Å) and PG2300 (grating angle = 46.25 ◦ ; 5800 - 6660 Å). The primary data reduction steps, including overscan correction, bias subtraction, gain correction, and amplifier cross-talk correction, were executed using the SALT science pipeline (Crawford et al. 2012). The remainder of the steps, consisting of arc line identification, background subtraction and 1D spectrum extraction were performed with iraf 1 . The data were corrected for the heliocenter and the SMC redshift. The spectra are shown in Figs. 12 and 13. The H 𝛼 emission line (Fig. 12) exhibits a strong, narrow central emission component with broad wings. The morphology of the H 𝛼 emission line is very similar to that seen in Antoniou et al. (2009). The narrow emission line component is possibly dominated by interstellar contamination and a circumbinary shell originating from the nova eruption.
The spectrum covering the blue wavelength range shows several Balmer and helium lines typical of early-type stars. The Balmer lines in this region show strong infilling, likely from the Be circumstellar disc emission and the circumbinary/interstellar emission (Fig. 14). So the broad Be-disk emission fills in the B star's photospheric absorption lines, while the circumbinary emission results in narrow emission cores. A blue-end spectrum was used to perform a spectral classification of the massive companion using the criteria in Evans et al. (2004). The presence of the HeII4541 and HeII4686 lines constrains the spectral type to earlier than B0.5 while the ratio HeI4387/HeII4541 > 1 suggests a spectral type later than O8.5. Our spectrum does not reach far enough blue to use other helium absorption line indicators to further distinguish between O9 and B0 spectral
1 Image Reduction and Analysis Facility: iraf.noao.edu
types (e.g. HeI4143 and HeII4200). Using the distance modulus of the SMC of 18.977 (Graczyk et al. 2020) and a V-band magnitude of 14.936 for CXOU J005245.0-722844 (Antoniou et al. 2019), this constrains the luminosity class to V (Straizys & Kuriliene 1981; Pecaut & Mamajek 2013). In summary, the SALT spectra suggest a spectral class of O9-B0Ve for the massive companion, in agreement with Antoniou et al. (2009). It is noted that the emission lines of [FeII]4415 and [OIII]5007 that are present are typically associated with interstellar contamination and nova shells (e.g. Mondal et al. 2018).
## 3 DISCUSSION
## 3.1 The X-ray outburst origin
The X-ray spectrum of CXOU J005245.0-722844 during outburst clearly indicates that this system contains a WD super soft X-ray source with a mass of 𝑀 𝑊𝐷 ≈ 1 2 M . ⊙ . The detection of a 0.4 keV CVI edge and a 0.871 keV OVIII edge indicate that this WD is likely a massive CO WD at the upper limit of its mass range. While the Xray spectrum of this source is similar to other known BeWD systems that have been found in the Magellanic Clouds (Coe et al. 2020a; Kennea et al. 2021), the large X-ray luminosity and short duration of this event are not typical of BeWD systems. A high-luminosity, short duration X-ray outburst has only been observed in a BeWD system during the ultraluminous nova produced by MAXI J0158-477. This outburst appears to be similar to that bright event. As seen in Figure 15, the initial OGLE brightening in both CXOU J005245.0-722844 and MAXI J0158-477 both show a sudden increase in brightness by 0.5 magnitudes before rapidly fading away. In MAXI J0158-477, the source faded halfway back to quiescence on rapid timescales before dimming back to the quiescent magnitude gradually over approximately 100 days. Conversely CXOU J005245.0-722844 fades back to the pre-outburst luminosity within a day.
X-ray data also shows similarities between the two eruptions. Xray emission from MAXI J0158-477 was reported to be below the detection threshold of Swift within 2 weeks after gradual dimming. Due to the observation constraints of Swift, we cannot say for certain when the outburst of CXOU J005245.0-722844 faded beyond detection. The source was observable by NICER through at least 2024 May 29 (Jaisawal et al. 2024), but was undetectable by Swift on 2024 June 12, which places an upper limit of 16 days on the duration of the outburst. The main difference between the two events is the peak luminosity that was reached by each outburst. MAXI J0185-477 reached a maximum luminosity of 𝐿 𝑋 = 2 3 . × 10 40 erg s -1 , which is more than an order of magnitude higher than the luminosity observed in the outburst of CXOU J005245.0-722844. The super-Eddington luminosity combined with the brief duration of these outbursts make them hard to explain. Li et al. (2012) attempted to explain the MAXI J0158-477 outburst event as the typical shock-heating of plasma that is expected to follow a nova eruption. However, Morii et al. (2013) found that the rapid onset of super-soft X-ray emission and the cool plasma temperature of the blackbody radiation were difficult to explain via shock heating. Instead, the preferred explanation was the onset of the initial thermonuclear runaway (TNR) phase of the nova eruption with an abnormally small ejecta mass. Additionally, this source was found to contain an extraordinarily-massive WD with a mass that was near the Chandrasekhar limit. A plausible scenario that could explain this new outburst of CXOU J005245.0-722844 is that a less-massive 1.2 M ⊙ WD produced a similar event. In this scenario, the X-ray flash is observed to be the initial TNR phase of a
Figure 9. Time sequence of power spectra of OGLE observations divided up into 2 year groupings, except the last 2 that are 1 year samples. The earliest spectrum is at the top. The lowest 2 plots are scaled down in power by a factor of 50, but can be seen in full detail in Figure 10.
nova outburst on the surface of a massive WD. The rapid decay time indicates that very little mass was ejected during the outburst.
An alternative model that could explain this outburst is the presence of a localized thermonuclear runaway effect (Shara 1982) that is sometimes referred to as a micronova (Scaringi et al. 2022b). Micronovae are short-duration outbursts that last for less than a day and release up to ∼ 10 38 -10 39 erg of energy (Scaringi et al. 2022b; Schaefer et al. 2022). Recent models (Scaringi et al. 2022b,a) identify this type of outburst as a TNR phenomenon where the material that is confined to the polar accretion cap of a magnetic WD is ignited, producing the outburst. This type of outburst is thought to be similar to a Type I X-ray outburst in BeXRB systems containing a NS (Stella et al. 1986), as the outburst lasts for a much shorter time and is less energetic than a nova by ∼ 10 6 erg (Scaringi et al. 2022a).
with just the polar accretion cap of a magnetized WD. The model of Scaringi et al. (2022a) finds that the fractional accretion area of a 1.2 M WDis ⊙ 𝑓 ≈ 10 -4 . The best-fitting maximum emission region for the XRT spectrum of CXOU J005245.0-722844 taken during outburst is 11 , 684 ± 64 km, which is ≈ 2-3 times larger than the radius of a 1.2 M ⊙ WD. This emission region indicates that emission is occurring over the entire surface of the WD instead of just at the polar caps which would be a feature characteristic to a nova eruption. Additionally, there have been no previously-observed eruptions in the CXOU J005245.0-722844 system despite recurrent eruptions being a distinctive feature of micronova-producing systems (e.g. TV Col; Szkody & Mateo 1984). Therefore, we must conclude that a very-fast nova is preferred as an explanation for this rapid X-ray outburst.
The brief several hour duration of the optical outburst and large X-ray luminosity produced by CXOU J005245.0-722844 are in excellent agreement with the properties of micronovae. However, the emission region of the source is much too large to be associated
## 3.2 Be disc size
H 𝛼 equivalent width (EW) measurements have been shown to correlate with radii measurements from optical interferometry of isolated
Figure 10. Power spectrum of the OGLE observations from the last two years of observations (2022 (top) and 2023 (lower)).The peaks correspond to periods of 17.41d (upper) and 17.15d (lower). Other peaks are harmonics of these periods - see text.
Figure 11. OGLEobservations from the last 2 pre-outburst seasons detrended and folded at a periods of 17.41d (upper) and 17.15d (lower). The upper plot is based upon data from the time period JD 2459800 - 259928, the lower plot from time period JD 2460126 - 2460352. In each case the absolute phase is arbitrary.
Be stars (Grundstrom & Gies 2006). The measured EW can be used to estimate the physical size of the H 𝛼 emitting region. Hanuschik (1989) demonstrated that the peak separation of the H 𝛼 emission line, Δ 𝑉 , is related to the EW by the expression:
$$\log \left ( \frac { \Delta V } { 2 v \sin i } \right ) = - 0. 3 2 \log ( - E W ) - 0. 2 0,$$
Figure 12. SALT spectra of CXOU J005245.0-722844 covering the H 𝛼 region.
Figure 13. SALT spectrum of CXOU J005245.0-722844 covering the blue region. Different line species are labeled at their expected rest wavelengths.
Figure 14. The H 𝛽 and H 𝛾 absorption lines exhibiting infilling.
where 𝑣 sin 𝑖 is the projected rotational velocity of the star. Similar relationships have been derived with slightly different coefficients (e.g. Zamanov et al. 2016; Monageng et al. 2017). Huang (1972) showed that in a Keplerian disc, the following relation holds:
$$\frac { \Delta V } { 2 v \sin i } = r _ { \text{disc} } ^ { 1 / 2 }.$$
The total EW of the H 𝛼 line from our SALT observations measures at -5 41 . ± 0 12 . Å (MJD60493.18) and -5 52 . ± 0 35 Å (MJD60475.18). These two measurements are in agreement, . to within errors, with the measurement of -5 38 . ± 0 11 Å from An-. toniou et al. (2009). To isolate the contribution of the Be disc to the H 𝛼 emission, we fitted a Gaussian function to the narrow central component arising from the interstellar emission/circumbinary disc and subtracted its EW measurement from the total measurement. This results in EW measurements of -2 64 . ± 0 12 Å (MJD60493.18) . and -3 06 . ± 0 13 Å (MJD60475.18) from the broad Be disc contri-. bution. Using the two equations above and the measured EWs, the Be disc radius estimates are 𝑟 ∼ 4 7 R . ∗ and 𝑟 ∼ 5 1 R . ∗ , respectively. For the spectral type of O9.5IIIe, this translates to 𝑟 ∼ 58 R ⊙ and 𝑟 ∼ 63 R ⊙ ( 𝑅 ∗ ∼ 12 3 R . ⊙ ; Straizys & Kuriliene 1981). From the derived orbital period of 17.55 d and the masses of the two components of the binary, 𝑀 ∗ ∼ 31 M ⊙ (O9IIIe spectral type; Straizys & Kuriliene 1981) and 𝑀 WD ∼ 1 1 M . ⊙ , the semi-major axis of a circular orbit is estimated to be 90 R ⊙ from Kepler's Laws. We note that the Be disc EW measurements are probably underestimates as some contribution from the Be disc is expected in the central core of the emission line, and so the disc may have extended to a size that is comparable to the orbit of the white dwarf.
## 3.3 Colour-magnitude variations
By combining the UVOT data with the I-band data it is possible to create a colour-magnitude diagram (CMD) which reveals how the overall colour of the system changed over time. The result is shown in Figure 16, where the data points shown are the result of all occasions when there is a UVOT observation and an I-band observation within 3 days of each other. Since it is extremely likely that the intrinsic colours of the Be star do not vary significantly, all the variations seen in this plot arise from material outside the star - primarily, and perhaps exclusively, the circumstellar disc. Though there is little change in the brightness of the system most of the time ( ≤ 0.2 mag) the pattern shown clearly indicates an increased redness in the system as the I-band brightened. This is to be expected if the increasing brightness is to be attributed to an increasing size of the circumstellar disc which is, in general, cooler than the Be star. In addition, this general trend of a redder-when-brighter pattern, is believed to be indicative of inclination angles less than 90 ◦ (Harmanec 1983; Rajoelimanana et al. 2011).
The outstanding point in Figure 16 is in the lower right hand corner of the plot. This point arises from data collected at, or very close to, the outburst seen in all wavebands. It is by far the reddest state seen in the system over the previous 8 years. It is very unlikely that this rapid colour change could be due to a suddenly increasing circumstellar disc. The timescales for changes in such disks are on viscous timescales, typically 100s of days (Carciofi 2010). This point of view is further supported by the extremely rapid decline in the UV and optical bands immediately after the outburst on a timescale of a few days. The U(V-I) colour dropped from the value of -1.63 in the outburst back to -2.0 within 24 hours. Again, no circumstellar disc could lose the bulk of its material so very rapidly, so it is further support for the concept of a rapid catastrophic event.
Figure 15. Comparison of the OGLE I-band outburst data for CXOU J005245.0-722844 (left panel) and MAXI 0158-744 (right panel).
Figure 11 shows the last two years of OGLE observations each folded at the determined period for each year. It is interesting to compare these more complex recent profiles to Fig. 8 which essentially represents simple sinusoidal modulation. In these last 2 years, prior to the outburst, the change in the folded profile strongly suggests the presence of a significantly large extra structure in the circumstellar disc. This unusual component of the material surrounding the Be star, not seen in the previous 2 decades, could have played a major role in the transfer of material onto the white dwarf, and hence was integral in the triggering the bright outburst seen at all wavelengths. Detailed modelling of possible mass flow dynamics from the Be star to the white dwarf is needed to explore such a possible scenario. One promising technique would be using a Smooth Particle Hydrodynamic approach such as has been explored for accretion from Be stars on to neutron stars (Brown et al. 2019; Negueruela & Okazaki 2001).
## 3.4 Superhumps?
The change of period seen in OGLE is certainly real and it is not related to the different cadence of the observations after 2022. For example, other stars observed in the same programme (like pulsating or eclipsing ones) with constant period, show exactly the same light curves in pre and post COVID-19 observations.
The shape of pulses in the CXOU J005245.0-722844 has certainly changed. Up to JD 2456000 the pulses were quite sinusoidal and the period was 17.54 day. In the last two pre-COVID-19 seasons 2018/19 (MJD 58284 - 58516) and 2019/20 (MJD 58643 - 58869) the signal was weaker but detectable with P=17.49 day, so essentially consistent with previous measurements. Also the period seen in the earlier MACHO data was similar (Sarraj et al. 2012).
After the COVID-19 break - in the seasons 2022/23 (MJD 59800 - 59928) and 2023/2024 (MJD 60110 - 60352) - the shape observed
Figure 16. Colour-magnitude diagram using the UVOT and OGLE I band data. Note the one data point coincident with the source outburst in the lower right corner of the plot.
was completely different - with an extra sharp peak - see Figure 11. This shape is also clearly seen at the very end of the 2022/23 season when the cadence was essentially daily. The period in 2022/2023 data was 17.41d. In the next 2023/24 season the period decreased further to 17.15d, whilst the non-sinusoidal shape persisted.
This behavior is similar to the so called superhump phenomena in cataclysmic variables. Originally, they were detected in SU UMa type of dwarf novae - in so-called super-outbursts - brighter and longer lasting eruptions. However, the period of the superhumps was longer than the orbital period of the system, contrary to the situation here. Such superhumps are called "positive" superhumps. They were also found in other classes of dwarf novae.
However, there are also cases of the so called "negative" superhumps where the superhump period is a few percent shorter than the orbital one. They were found in different classes of cataclysmic variables. Generally, the superhump period is not constant, it changes - similar to the changes observed here in the period seen from 2022 onwards. See Sun et al. (2024) for a recent review of such phenomena.
The superhump phenomenon is explained by the precession of a tilted accretion disk -in the case of "negative" superhumps it would be a retrograde precession. See Thomas & Wood (2015) for a discussion on such phenomena. From the observations presented here the precession period, 𝑃 𝑝𝑟𝑒 , expected in CXOU J005245.0-722844 would be:
1 / 𝑃 𝑝𝑟𝑒 = ( 1 17 14 / . -1 17 55 / . ) i.e. about two years.
It is important to note that CVs have observed periods of hours while the periods seen here are of several days. However, CXOU J005245.0-722844 has a circumstellar disk which could be a rescaled version of accretion disks in CVs, so perhaps similar phenomenon can occur there as well.
## 4 CONCLUSIONS
In this work, we report on the observation of a rapid X-ray outburst from a BeXRB system, CXOU J005245.0-722844. This source was first detected via an optical outburst by ATLAS on 26 May 2024 before the detection of a highly-luminous X-ray outburst state triggered follow-up multiwavelength observations. Upon follow-up observation with Swift XRT, the X-ray spectrum for this source during outburst was found to be supersoft in nature. This spectrum was best-fit by an absorbed thermal blackbody model with CVI and OVIII absorption edges. An X-ray spectrum of this nature indicates that the compact object in this BeXRB ystem is a WD, making it only the 7th BeWD candidate ever identified and the fifth such source to be identified in the Small Magellanic Cloud. The X-ray outburst was only observed for the first few days during its brightest state and was found to have faded completely within 16 days of its onset. Optical and Ultraviolet observations taken by OGLE, ATLAS, and Swift UVOT identify a brief optical flare in the counterpart to the X-ray outburst, lasting no more than 7 days. This optical outburst peaked at between 0.2 (UVOT) and 0.5 magnitudes (OGLE) brighter than the quiescent state of the system before entering a period of sustained dimming. Optical spectroscopy confirms the optical companion to the WD in this binary is a O9Ve-B0Ve star.
The light curve of CXOU J005245.0-722844 is complex, and further observations will be needed in order to fully understand this unusual system. The orbital period of CXOU J005245.0-722844 is found via multi-year OGLE monitoring to have changed appreciably in the years immediately proceeding its recent outburst, shortening from 17.55 days to 17.14 days over the course of 2 years. This period change is not well understood, and detailed mass transfer dynamical modeling will be needed to explain this behavior. One possible explanation is the 'negative superhump" phenomenon caused by the precession of a tilted accretion disk. Additional work is needed to explain the brief, X-ray outburst that reached super-Eddington luminosities for a 1.2 M ⊙ WD. The best comparison for the outburst that has been observed in CXOU J005245.0-722844 is an even more luminous outburst produced by the BeWD system MAXI J0158-477 in 2011. By comparing the two events, we conclude that the X-ray outburst observed in CXOU J005245.0-722844 is the signature of an initial thermonuclear runaway phase produced by a nova eruption on the surface of the WD. The large luminosity and rapid decay are then thought to be the result of a low ejecta mass being produced by the nova eruption, making this source the second BeWD to produce a super-Eddington X-ray luminosity during a nova.
BeWD systems are still poorly understood. With so few candidate systems identified, each system found represents a large step towards connecting BeWDs to the broader picture of massive binary stellar evolution and to important phenomena such as the ULX and ULS phenomena. In order to further our understanding of BeWDs, more systems must be identified. S-CUBED has now played an important role in identifying three of the five SMC BeWDs via soft X-ray emission behavior. It is clear that regular monitoring of the soft Xray sky will be crucial for both identifying more of these systems in the Magellanic Clouds and finding the first candidates our own galaxy.
## ACKNOWLEDGEMENTS
Apart of this work is based on observations made with the Southern African Large Telescope (SALT), with the Large Science Programme on transients 2021-2-LSP-001 (PI: DAHB). Polish participation in SALT is funded by grant No. MEiN 2021/WK/01.
This work has made use of data from the Asteroid Terrestrialimpact Last Alert System (ATLAS) project. The Asteroid Terrestrialimpact Last Alert System (ATLAS) project is primarily funded to
search for near earth asteroids through NASA grants NN12AR55G, 80NSSC18K0284, and 80NSSC18K1575; byproducts of the NEO search include images and catalogs from the survey area. This work was partially funded by Kepler/K2 grant J1944/80NSSC19K0112 and HST GO-15889, and STFC grants ST/T000198/1 and ST/S006109/1. The ATLAS science products have been made possible through the contributions of the University of Hawaii Institute for Astronomy, the Queen's University Belfast, the Space Telescope Science Institute, the South African Astronomical Observatory, and The Millennium Institute of Astrophysics (MAS), Chile.
This work made use of data supplied by the UK Swift Science Data Centre at the University of Leicester. J.A.K. and T.M.G. acknowledge the support of NASA contract NAS5-00136. We acknowledge the use of public data from the Swift data archive.
## DATA AVAILABILITY
The data underlying this article will be shared on reasonable request to the corresponding author.
## REFERENCES
| Althaus L. G., García-Berro E., Isern J., Córsico A. H., 2005, A&A, 441, 689 Antoniou V., Zezas A., Hatzidimitriou D., McDowell J. C., 2009, ApJ, 697, 1695 |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Antoniou V., et al., 2019, ApJ, 887, 20 |
| Arnaud K. A., 1996, in Jacoby G. H., Barnes J., eds, Astronomical Society of the Pacific Conference Series Vol. 101, Astronomical Data Analysis Software and Systems V. p. 17 |
| Blackburn J. K., Shaw R. A., Payne H. E., Hayes J. J. E., Heasarc 1999, FTOOLS: A general package of software to manipulate FITS files, As- trophysics Source Code Library, record ascl:9912.002 (ascl:9912.002) |
| Brown R. O., Coe M. J., Ho W. C. G., Okazaki A. T., 2019, MNRAS, 488, 387 |
| Burgh E. B., Nordsieck K. H., Kobulnicky H. A., Williams T. B., O'Donoghue D., Smith M. P., Percival J. W., 2003, in Iye M., Moor- wood A. F. M., eds, Proc. SPIEVol. 4841, Instrument Design and Per- formance for Optical/Infrared Ground-based Telescopes. pp 1463-1471, doi:10.1117/12.460312 |
| Burrows D. N., et al., 2005, Space Sci. Rev., 120, 165 |
| Carciofi A. C., 2010, Proceedings of the International 6, 325-336 |
| Casares J., Negueruela I., Ribó M., Ribas I., Paredes J. M., Herrero A., Simón-Díaz S., 2014, Nature, 505, 378 |
| Coe M. J., Kirk J., 2015, MNRAS, 452, 969 |
| Coe M. J., Monageng I. M., Bartlett E. S., Buckley D. A. H., Udalski A., 2020a, MNRAS, 494, 1424 Coe M. J., Kennea J. A., Evans P. A., Udalski A., 2020b, MNRAS, 497, L50 |
| M. J., Kennea J. A., Monageng I. M., Buckley D. A. H., Udalski A., |
| S. M., et al., 2012, PySALT: SALT science pipeline, Astrophysics |
| Source Code Library (ascl:1207.010) |
| C. J., Howarth I. D., Irwin M. J., Burnley A. W., Harries T. J., 2004, MNRAS, 353, 601 |
| E. L., 1999, PASP, 111, 63 M., KenneaJ. A., CoeM.J.,MonagengI.M.,UdalskiA.,Townsend |
| GaudinT. L. J., Buckley D. A. H., Evans P. A., 2024, ApJ, 965, L10 |
| Grundstrom E. D., Gies D. R., 2006, ApJ, 651, L53 Haberl F., Sturm R., 2016, A&A, 586, A81 |
| Hanuschik R. W., 1989, Ap&SS, 161, 61 Harmanec P., 1983, Hvar Observatory Bulletin, 7, |
| 55 Harris J., Zaritsky D., 2004, AJ, 127, 1531 |
| Coe Evans P. A., 2023, MNRAS, 524, 3263 |
| Crawford |
| Evans |
| Evans P. A., et al., 2009, MNRAS, 397, 1177 Fitzpatrick |
| Graczyk D., et al., 2020, ApJ, 904, 13 |
| Huang S.-S., 1972, ApJ, 171, 549 Jaisawal G. K., et al., 2024, The Astronomer's Telegram, 16636, 1 |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Kahabka P., 2006, Advances in Space Research, 38, 2836 |
| Kahabka P., van den Heuvel E. P. J., 1997, ARA&A, 35, 69 Kennea J. A., Coe M. J., Evans P. A., Waters J., Jasko R. E., |
| 2018, ApJ, 868, 47 J. A., Coe M. J., Evans P. A., Monageng I. M., Townsend L. J., Siegel M. H., Udalski A., Buckley D. A. H., 2020, MNRAS, 499, L41 |
| Kennea J. A., Coe M.J., Evans P. A., Townsend L. J., Campbell Z. A., Udalski |
| A., 2021, MNRAS, 508, 781 |
| Kennea Kennea J. A., Coe M. J., Gaudin T., Evans P. A., 2024, The |
| Astronomer's Telegram, 16633, 1 R. L., 1993, VizieR Online Data Catalog: Model Atmospheres (Ku- |
| rucz, 1979), VizieR On-line Data Catalog: VI/39. Originally published |
| in: 1979ApJS...40....1K |
| Kurucz 1217 |
| Laycock S., Zezas A., Hong J., Drake J. J., Antoniou V., 2010, ApJ, 716, Li X. D., van den Heuvel E. P. J., 1997, A&A, 321, L25 |
| Li K. L., et al., 2012, ApJ, 761, 99 |
| Liu J., Di Stefano R., 2008, ApJ, 674, |
| Monageng I. M., McBride V. A., Coe |
| L73 M. J., Steele MNRAS, 464, 572 |
| I. A., Reig P., 2017, Monageng I. M., et al., 2019, MNRAS, 485, 4617 |
| Mondal A., Anupama G. C., Kamath U. S., Das R., Selvakumar G., Mondal S., 2018, MNRAS, 474, 4211 |
| Morii M., et al., 2013, ApJ, 779, 118 |
| Mukai K., 2017, PASP, 129, 062001 |
| Mukai K., Orio M., Della Valle M., 2008, in Bandyopadhyay R. |
| S., Gelino D., Gelino C. R., eds, American Institute of |
| M., Physics ence Series Vol. 1010, A Population Explosion: The Nature & |
| lution of X-ray Binaries in Diverse Environments. AIP, pp |
| Wachter Confer- Evo- 143-147 ( arXiv:0801.1101 ), doi:10.1063/1.2945023 |
| Negueruela I., Okazaki A. T., 2001, A&A, 369, 108 |
| A134 Ochsenbein F., Bauer P., Marcout J., 2000, A&AS, 143, 23 Okazaki A. T., Negueruela I., 2001, A&A, 377, 161 Page K. L., Shaw A. W., 2022, in , Handbook of X-ray and Astrophysics. p. 107, doi:10.1007/978-981-16-4544-0_106-1 |
| Parmar A. N., Kahabka P., Hartmann H. W., Heise J., Martin D. D. E., |
| M., Mineo T., 1997, A&A, 323, L33 |
| Gamma-ray A. N., Kahabka P., Hartmann H. W., Heise J., Taylor B. G., |
| Bavdaz 1998, A&A, 332, 199 |
| Parmar Pecaut M. J., Mamajek E. E., 2013, ApJS, 208, 9 |
| N. V., 2001, A&A, 367, 848 A. F., Charles P. A., Udalski A., 2011, MNRAS, 413, 1600 |
| Raguzova Rajoelimanana |
| Reig P., 2011, Ap&SS, 332, 1 |
| Rezaeikh S., Javadi A., Khosroshahi H., van Loon J. T., 2014, MNRAS, |
| 2214 Roming P. W. A., et al., 2005, Space Sci. Rev., 120, 95 |
| I., Sanders R. J., Schmidtke P. C., 2012, Information Bulletin on able Stars, 6030, 1 |
| S., Groot P. J., Knigge C., Lasota J. P., de Martino D., Cavecchi |
| Schaefer B. E., Pagnotta A., Zoppelt S., 2022, MNRAS, 512, 1924 Shara M. M., 1982, ApJ, 261, 649 Skowron D. M., et al., 2021, ApJS, 252, 23 Smith K. W., et al., 2020, PASP, 132, 085002 Stella L., White N. E., Rosner R., 1986, ApJ, 308, 669 |
| Straizys V., Kuriliene G., 1981, Ap&SS, 80, 353 Sturm R., Haberl F., Pietsch W., Coe M. J., Mereghetti S., La Owen R. A., Udalski A., 2012a, A&A, 537, A76 Sturm R., Haberl F., Pietsch W., Coe M. J., Mereghetti S., La |
| Owen R. A., Udalski A., 2012b, A&A, 537, A76 |
| Palombara Palombara |
| Q.-B., Qian S.-B., Zhu L.-Y., Li Q.-M., Li M.-Y., Li P., 2024, |
| Buckley D. A. H., Camisassa M. E., 2022a, MNRAS, 514, L11 S., et al., 2022b, Nature, 604, 447 |
| Y., |
| 445, Vari- |
| Sarraj |
| Scaringi |
| Scaringi |
| Sun |
| e-prints, p. arXiv:2407.04913 |
| arXiv |
| N., |
| N., |
| NASAConferencePublicationVol.2349,NASAConferencePublication. pp 297-300 |
|-----------------------------------------------------------------------------------------------------------------------------|
| Thomas D. M., Wood M. A., 2015, ApJ, 803, 55 |
| Tonry J. L., et al., 2018, PASP, 130, 064505 |
| Townsend L. J., Kennea J. A., Coe M. J., McBride V. A., Buckley D. A. H., Evans P. A., Udalski A., 2017, MNRAS, 471, 3878 |
| Treiber H., Haberl F., Vasilopoulos G., Bailyn C. D., Udalski A., 2024, The Astronomer's Telegram, 16638, 1 |
| Udalski A., Szymański M. K., Szymański G., 2015, Acta Astron., 65, 1 |
| Urquhart R., Soria R., 2016, MNRAS, 456, 1859 Waters L. B. F. M., Pols O. R., Hogeveen S. J., Cote J., van den Heuvel E. P. |
| J., 1989, A&A, 220, L1 |
| Willingale R., Starling R. L. C., Beardmore A. P., Tanvir N. R., O'Brien P. T., 2013, MNRAS, 431, 394 |
| Yang J., Laycock S. G. T., Christodoulou D. M., Fingerman S., Coe M. J., Drake J. J., 2017, ApJ, 839, 119 |
| Yang H. N., et al., 2024, The Astronomer's Telegram, 16631, 1 |
| Zamanov R. K., Stoyanov K. A., Martí J., Latev G. Y., Nikolov Y. M., Bode M. F., Luque-Escamilla P. L., 2016, A&A, 593, A97 |
| Zhu C.-H., Lü G.-L., Lu X.-Z., He J., 2023, Research in Astronomy and Astrophysics, 23, 025021 |
This paper has been typeset from a T E X/LT E X file prepared by the author. A | null | [
"Thomas M. Gaudin",
"Malcolm J. Coe",
"Jamie A. Kennea",
"Itumaleng M. Monageng",
"David A. H. Buckley",
"Andrzej Udalski",
"Phil A. Evans"
]
| 2024-08-02T16:58:43+00:00 | 2024-08-02T16:58:43+00:00 | [
"astro-ph.HE",
"astro-ph.SR"
]
| CXOU J005245.0-722844: Discovery of a Be Star / White Dwarf binary system in the SMC via a very fast, super-Eddington X-ray outburst event | CXOU J005245.0-722844 is an X-ray source in the Small Magellanic Cloud (SMC)
that has long been known as a Be/X-ray binary (BeXRB) star, containing an OBe
main sequence star and a compact object. In this paper, we report on a new very
fast X-ray outburst from CXOU J005245.0-722844. X-ray observations taken by
Swift constrain the duration of the outburst to less than 16 days and find that
the source reached super-Eddington X-ray luminosities during the initial phases
of the eruption. The XRT spectrum of CXOU J005245.0-722844 during this outburst
reveals a super-soft X-ray source, best fit by an absorbed thermal blackbody
model. Optical and Ultraviolet follow-up observations from the Optical
Gravitational Lensing Experiment (OGLE), Asteroid Terrestrial-impact Last Alert
System (ATLAS), and Swift identify a brief ~0.5 magnitude optical burst
coincident with the X-ray outburst that lasted for less than 7 days. Optical
photometry additionally identifies the orbital period of the system to be 17.55
days and identifies a shortening of the period to 17.14 days in the years
leading up to the outburst. Optical spectroscopy from the Southern African
Large Telescope (SALT) confirms that the optical companion is an early-type OBe
star. We conclude from our observations that the compact object in this system
is a white dwarf (WD), making this the seventh candidate Be/WD X-ray binary.
The X-ray outburst is found to be the result of a very-fast, ultra-luminous
nova similar to the outburst of MAXI J0158-744. |
2408.01390v1 | ## Proof of a K -theoretic polynomial conjecture of Monical, Pechenik, and Searles
Laura Pierson University of Waterloo [email protected]
August 5, 2024
## Abstract
As part of a program to develop K -theoretic analogues of combinatorially important polynomials, Monical, Pechenik, and Searles (2021) proved two expansion formulas A a = ∑ b Q a b ( β ) P b and Q a = ∑ b M a b ( β ) F b , where each of A a , P a , Q a and F a is a family of polynomials that forms a basis for Z [ x , . . . , x 1 n ][ β ] indexed by weak compositions a, and Q a b ( β ) and M a b ( β ) are monomials in β for each pair ( a, b ) of weak compositions. The polynomials A a are the Lascoux atoms , P a are the kaons , Q a are the quasiLascoux polynomials , and F a are the glide polynomials ; these are respectively the K -analogues of the Demazure atoms A a , the fundamental particles P a , the quasikey polynomials Q a , and the fundamental slide polynomials F a . Monical, Pechenik, and Searles conjectured that for any fixed a, ∑ b Q a b ( -1) , ∑ b M a b ( -1) ∈ { 0 1 , } , where b ranges over all weak compositions. We prove this conjecture using a sign-reversing involution.
## 1 Introduction
We prove a conjecture of Monical, Pechenik, and Searles from [MPS21] stating that two alternating sums involving polynomials arising from combinatorial K -theory are always equal to either 0 or 1. These polynomials were defined as part of a project to extend the combinatorics associated to the ring Sym n of symmetric polynomials in n variables to the larger ring Poly n := Z [ x , . . . , x 1 n ] of arbitrary polynomials in n variables, and then further to the ring Poly n [ β ] of K -theoretic deformations of these polynomials. The motivation for defining these K -theoretic analogues arises from the connections these polynomials have to algebraic geometry, specifically to Schubert calculus , which studies the cohomology rings of flag varieties . The basic idea of K -theory is to deform the structure of cohomology rings by introducing an additional parameter β . Polynomials coming from cohomology rings often also have corresponding K -analogues, and conversely, when polynomials arising from combinatorics have nice K -analogues, that indicates that they may have geometric interpretations. See [Buc05] for an introduction to combinatorial K -theory.
A classic basis for Sym n is the Schur polynomials s λ , which have rich connections to representation theory and algebraic geometry. These polynomials are indexed by partitions λ = ( λ , λ 1 2 , . . . , λ n ), i.e. finite nondecreasing sequences of positive integers λ 1 ≥ λ 2 ≥ · · · ≥ λ n . Schur polynomials are a special case of Schubert polynomials S a , which were introduced by Lascoux and Sch¨tzenberger in [LS82] as u a basis for Poly n that is closely connected to Schubert calculus. The Schubert polynomials are indexed by weak compositions a = ( a , . . . , a 1 n ) , i.e. finite sequences of nonnegative integers. Various related bases for Poly n have also been studied, each also indexed by weak compositions a , including the Demazure characters D a [Dem74], the Demazure atoms A a [LS88], the (fundamental) slide polynomials F a [AS17], the (fundamental) particles P a [Sea20], and the quasikey polynomials Q a [AS18]. Hicks and Niese showed in [HN24] that all these polynomials arise naturally using a quasisymmetric analogue of the divided difference operator , and some of these polynomials also arise naturally from representation theory. These bases all have K -theoretic lifts to corresponding bases for Poly n [ β ]: the Grothendieck polynomials s λ and S a [FK94], the Lascoux polynomials D a , the Lascoux atoms A a [Mon16], the glide polynomials F a [PS19], the kaons P a [MPS21], and the quasiLascoux polynomials Q a [MPS21].
An integrable vertex model for Lascoux polynomials and Lascoux atoms has been developed in [BSW20], using ideas from statistical mechancis.
The authors of [MPS21] proved two expansion formulas involving these K -theoretic polynomials:
$$\overline { \mathfrak { A } } _ { a } = \sum _ { b } Q _ { b } ^ { a } ( \beta ) \overline { \mathfrak { P } } _ { b }, & & \overline { \mathfrak { Q } } _ { a } = \sum _ { b } M _ { b } ^ { a } ( \beta ) \overline { \mathfrak { F } } _ { b },$$
$$\dots$$
where each Q a b ( β ) and M a b ( β ) is a monomial of the form mβ n for nonnegative integers m and n ([MPS21], Theorems 3.12 and 4.12). They then conjectured the following formulas, which we now prove:
Theorem 1 ([MPS21], Conjecture 1.4) . If the nonzero parts of a are weakly decreasing, then
$$\sum _ { b } Q _ { b } ^ { a } ( - 1 ) = \sum _ { b } M _ { b } ^ { a } ( - 1 ) = 1,$$
and otherwise
$$\sum _ { b } Q _ { b } ^ { a } ( - 1 ) = \sum _ { b } M _ { b } ^ { a } ( - 1 ) = 0,$$
where the sums are taken over all weak compositions b.
Theorem 1 is suggestive of an Euler characteristic calculation and may provide some insight into the geometric context of these polynomials.
We will explain the relevant definitions and prior results in § 2, and then in § 3, we will prove Theorem 1 and give some examples to illustrate it.
## 2 Background
In this section, we will define the four families of polynomials studied here, in the following order:
- 1. The kaons P a , which are generating functions for mesonic glides .
- 2. The Lascoux atoms A a , which are generating functions for set-valued skyline fillings .
- 3. The glide polynomials F a , which are sums of kaons.
- 4. The quasiLascoux polynomials Q a , which are sums of Lascoux atoms.
We will also explain the expansion formulas from [MPS21] that express Lascoux atoms in terms of kaons and quasiLascoux atoms in terms of glide polynomials, which will be the main tools for our proof.
Remark 2. The overlines indicate that these are K -theoretic polynomials (i.e. they involve β ). The corresponding versions without the overlines are obtained by setting β = 0 . The letter A is an 'A' for 'atom.' The letter Q is a 'Q' for 'quasi.' The letter P is a 'P' for 'particle,' because the kaons P a are a K -analogue of the particles P a . The letter F is an 'F' for 'fundamental,' because the glides F a are a K -analogue of the fundamental slides F a , which lift the fundamental basis F a of the ring QSym of quasisymmetric functions. The name 'atoms' makes sense because the Lascoux atoms form a basis of Poly n [ β ] and hence a set of fundamental building blocks. 'Kaons' are named after a type of subatomic particle, which fits because they are 'subatomic' in the sense that Lascoux atoms can be built out of kaons, and also because in particle physics, the symbol for kaons is 'K.' The name 'meson' comes from the name in particle physics of the family of particles that includes kaons (kaons are also called 'K mesons'). The name 'skyline fillings' comes from the fact that the diagrams look like city skylines turned sideways.
## Kaons P a
First we introduce the definitions needed for the kaons. A weak komposition b = ( b 1 , . . . , b n ) is a weak composition whose entries are colored red or black, and its excess ex( ) is the number of red entries. b Let a = ( a , . . . , a 1 n ) be a weak composition with nonzero entries at positions n 1 ≤ n 2 ≤ · · · ≤ n /lscript . We also set n 0 = 0. A weak komposition b is a mesonic glide of a if the following three properties are satisfied for every 1 ≤ j ≤ /lscript :
$$( G. 1 ^ { \prime } ) \ a _ { n _ { j } } = b _ { n _ { j - 1 } + 1 } + \dots + b _ { n _ { j } } - \exp ( b _ { n _ { j - 1 } + 1 }, \dots, b _ { n _ { j } } ).$$
$$( G. 3 ^ { \prime } ) \text{ The leftmost nonzero entry of } ( b _ { n _ { j - 1 } + 1 }, \dots, b _ { n _ { j } } ) \text{ is black.}$$
/negationslash
$$( G. 4 ^ { \prime } ) \ b _ { n _ { j } } \neq 0.$$
In our examples below, the red entries are also shown in bold to help them stand out.
Example 3. The weak komposition b = (2 , 2 , 1 , 3 2 , ) is a mesonic glide of a = (0 3 0 0 4) , , , , , since
$$\dots$$
$$a _ { n _ { 1 } } & = a _ { 2 } = 3 = 2 + 2 - \exp ( 2, 2 ), \\ a _ { n _ { 2 } } & = a _ { 5 } = 4 = 1 + 3 + 2 - \exp ( 1, 3, 2 ),$$
/negationslash the leftmost entries of (2 , 2 ) and (1 , 3 2 , ) are black, b n 1 = b 2 = 2 = 0 , and b n 2 = b 5 = 2 = 0 .
/negationslash
$$\text{Write} \, \mathbf x ^ { b } \coloneqq x _ { 1 } ^ { b _ { 1 } } \dots x _ { n } ^ { b _ { n } }. \, \text{The kao} \, \overline { \mathfrak P } _ { a } \text{ is the generating function}$$
$$\overline { \mathfrak { P } } _ { a } \coloneqq \sum _ { b \text{ a mesonic glide of } a } \beta ^ { \text{ex} ( b ) } \text{x} ^ { b }.$$
In the example below, we show the x variables corresponding to bolded red entries as also being bolded and red to help illustrate the correspondence. This coloring of the x variables is not actually part of the definition of the polynomials.
Example 4. For a = (0 2 0 1) , , , , the possible mesonic slides are
$$\begin{smallmatrix} ( 0, 2, 0, 1 ) & ( 1, 1, 0, 1 ) & ( 1, 2, 0, 1 ) & ( 2, 1, 0, 1 ) \\ ( 0, 2, 1, 1 ) & ( 1, 1, 1, 1 ) & ( 1, 2, 1, 1 ) & ( 2, 1, 1, 1 ) \end{smallmatrix}$$
so the corresponding kaon is
$$\overline { \mathfrak { P } } _ { ( 0, 2, 0, 1 ) } = x _ { 2 } ^ { 2 } x _ { 4 } + x _ { 1 } x _ { 2 } x _ { 4 } + \beta x _ { 1 } x _ { 2 } ^ { 2 } x _ { 4 } + \beta x _ { 1 } ^ { 2 } x _ { 2 } x _ { 4 } + \beta x _ { 2 } ^ { 2 } x _ { 3 } x _ { 4 } + \beta x _ { 1 } x _ { 2 } x _ { 3 } x _ { 4 } + \beta ^ { 2 } x _ { 1 } ^ { 2 } x _ { 2 } x _ { 3 } x _ { 4 } }.$$
Remark 5. We follow the seemingly odd numbering (G.1 ), (G.3 ), and (G.4 ) to match the notation in ′ ′ ′ [MPS21]. They use this notation because the conditions (G.1 ), (G.3 ), and (G.4 ) are a modification of the ′ ′ ′ conditions (G.1), (G.2), and (G.3) used to define the glide polynomials F a , which were originally defined before the kaons P a . We choose here to define the kaons P a first and then the glides F a , since it is simpler to define the glides F a in terms of the kaons P a .
Remark 6. Both sets of glide conditions (G.1), (G.2), (G.3) and (G.1 ), ′ (G.3 ), ′ (G.4 ) ′ are themselves modifications of a simpler set of slide conditions , which are used to define the fundamental particles P a and the fundamental slide polynomials F a . The particles P a and slides F a are the respective β = 0 cases of P a and F a and hence do not involve the red entries. These sorts of slide and glide moves that allow entries to be moved in only one direction arise naturally from the study of the ring of quasisymmetric polynomials QSym n , which sits between Sym n and Poly n (i.e. Sym n ⊂ QSym n ⊂ Poly n ). Much of the combinatorics of Sym n was originally extended to QSym n before it was extended to Poly n . Adding the red entries to the 'slides' to create the 'glides' turns out to be the natural way to introduce the extra parameter β.
## Lascoux atoms A a
Next, we introduce the definitions needed for the Lascoux atoms. A skyline diagram of shape a = ( a , . . . , a 1 n ) consists of n left justified rows of boxes such that the i th row from the bottom has a i boxes. A set-valued skyline filling T of shape a is a filling of each box of the skyline diagram of a with a nonempty set of positive integers. The largest entry of each box is called the anchor , and the other entries are free . We say T is semistandard if it satisfies the following properties:
(S.1) There are no repeat entries in any column.
- (S.2) The entries weakly decrease across rows, in the sense that the smallest entry in each box is at least the largest entry in the box to its right.
- (S.3) Suppose the anchors α, β, and γ satisfy all of the following conditions:
- -α is immediately to the right of β .
- -The row containing α and β is at least as long as the row containing γ if it is lower than the row containing γ , or is strictly longer if it is higher than the row containing γ.
- -γ is either above α in the same column or below β in the same column.
Then we must have either γ < α or γ > β .
Equivalently, this says that if α, β, and γ are arranged in either an 'upside down L' or 'backwards L' as shown below such that the row containing the base of the L is longer, then γ cannot be equal to or between α and β :
(Note that since α is to the right of β, we must have α ≤ β by (S.2)).
- (S.4) Each free entry is assigned to the box in its column with the smallest possible anchor such that (S.2) is satisfied (so choosing the column of a free entry uniquely determines its row as well).
- (S.5) Each anchor in the leftmost column equals the index of its row.
We write A SSF ( a ) for the set of all semistandard skyline tableaux of shape a. The weight wt( T ) of a tableau T is the weak composition whose i th part is the number of times i appears as an entry in T .
The Lascoux atom A a is the generating function
$$\overline { \mathfrak { A } } _ { a } \coloneqq \sum _ { T \in \overline { \mathfrak { A } } S S F ( a ) } \beta ^ { e x ( T ) } \mathbf x ^ { w t ( T ) }.$$
Remark 7. The Lascoux atoms are the K -analogue of the Demazure atoms A a , which are the β = 0 case and hence involve only the anchors and no free entries. The Demazure atoms are a modification of the Demazure characters (also called key polynomials ) from [Dem74], which were originally defined algebraically in terms of divided difference operators and were later shown in [LS88] to also have a combinatorial description in terms of key tableaux . We can think of these key tableaux and skyline tableaux as nonsymmetric analogues of SSYT. Although the rules for defining these tableaux are more complicated, they turn out to have some nice associated combinatorics that is analogous to the combinatorics of SSYT, such as analogues of the Littlewood-Richardson rule for multiplying Schur polynomials ([Bru+21]).
## Transition formula from Lascoux atoms A a to kaons P a
We now give the definitions needed to state the A a to P a transition formula. A skyline tableau T has the meson-highest property if for every i that shows up as an entry in T , at least one of the following holds:
- · There is an i that is an anchor in row i (i.e. row i is nonempty).
- · There is an occurrence of the next smallest entry (which we denote i ↑ ) that is weakly to the right of and in a different box from the leftmost i.
The set A P 2 ( a ) consists of all semistandard meson-highest tableaux of shape a. We write | a | as the sum of the entries of a and | T | for the total number of entries of T . We can now state the first expansion formula:
Theorem 8 (Monical, Pechenik, and Searles [MPS21], Theorem 3.12) . The kaon expansion of the Lascoux atoms is
$$\overline { \mathfrak { A } } _ { a } = \sum _ { T \in \overline { \mathfrak { A } } 2 \overline { \mathfrak { P } } ( a ) } \beta ^ { | T | - | a | } \overline { \mathfrak { P } } _ { \text{wt} ( T ) }.$$
Example 9. The tableaux in A P 2 (0 , 0 1 2) are below, grouped into columns by number , , | T | - | a | of free entries (i.e. the exponent on β ), with the anchors shown bolded and the other entries unbolded. The corresponding term in the kaon expansion of A (0 0 2 2) , , , is listed below each tableau. Note that there are actually an extra two rows numbered 1 and 2 at the bottom of each of these tableaux, which we omit because they are empty.
Example 10. The tableaux in A P 2 (0 , 0 2 2) are shown below, again grouped in columns by the power of , , β, and with the corresponding monomial listed below each tableau. As in Example 9, each tableau actually has an extra two rows numbered 1 and 2 at the bottom that are not drawn here.
Glide polynomials F a and quasiLascoux polynomials Q a
We will now define the last two types of polynomials and explain the transition formula between them. For weak compositions a and b , a + denotes the nonzero elements of a. We say that b dominates a and write b ≥ a if b 1 + · · · + b i ≥ a 1 + · · · + a i for every i. Then the glide polynomial F a is
$$\overline { \mathfrak { F } } _ { a } \coloneqq \sum _ { \substack { b \geq a \\ b ^ { + } = a ^ { + } } } \overline { \mathfrak { P } } _ { a },$$
and analogously, the quasiLascoux polynomial Q a is
$$\overline { \mathfrak { Q } } _ { a } \coloneqq \sum _ { \substack { b \geq a \\ b ^ { + } = a ^ { + } } } \overline { \mathfrak { A } } _ { a }.$$
A set-valued quasi-skyline filling of shape a is the same as a semistandard set-valued filling, except that (S.5) is replaced with the following property:
- (S.5 ) ′ The leftmost anchor in row i is at most i, and the anchors in the left column decrease from top to bottom.
We write Q SSF ( a ) for the set of set-valued quasi-skyline fillings of shape a. Then Q SSF ( a ) is a superset of A SSF ( a ) of a , and in fact
$$\overline { \Omega } S S F ( a ) = \bigcup _ { \substack { b \geq a \\ b ^ { + } = a ^ { + } } } \overline { \mathfrak { A } } ( S S F ( b ).$$
It follows that we can alternately define Q a as
$$\overline { \Omega } _ { a } = \sum _ { T \in \overline { \Omega } S S F ( a ) } \beta ^ { | T | - | a | } \mathbf x ^ { \text{wt} ( T ) }.$$
A tableau T ∈ Q SSF ( a ) is quasiYamanouchi if for every i in T , at least one of the following holds:
- · The leftmost i is the anchor in the leftmost column of row i.
- · There is an i +1 weakly to the right of the leftmost i and in a different box.
We write Q F 2 ( a ) for the set of quasiYamanouchi tableau of shape a. We can now state the second expansion formula that we will need:
Theorem 11 (Monical, Pechenik, and Searles [MPS21], Theorem 4.12) . The glide expansion for the quasiLascoux polynomials is
$$\overline { \Omega } _ { a } = \sum _ { T \in \overline { \Omega } 2 \overline { \mathfrak { F } } ( a ) } \beta ^ { | T | - | a | } \overline { \mathfrak { F } } _ { \text{wt} ( T ) }.$$
Example 12. Returning to a = (0 0 1 2) as in Example 9, , , , the two tableaux from the second row in Example 9 are in A P 2 (0 , 0 1 2) but not in , , Q F 2 (0 , 0 1 2) because they have a 1 that is not an anchor in , , the left column its own row but do not have any 2's, violating the qausiYamanouchi property. Thus, the tableaux in the glide expansion of Q (0 0 1 2) , , , are the ones shown below, with the corresponding terms of the expansion listed below them. Again, we omit the bottom two empty rows of each tableau.
Example 13. Using a = (0 0 2 2) as in , , , Example 10, the four tableaux with a 1 but not a 2 are no longer valid, as they violate the quasiYamanouchi property. Thus, the tableaux in Q F 2 (0 , 0 2 2) and their , , corresponding monomials in the glide expansion of Q (0 0 2 2) , , , are the ones shown below. As in our other

examples, the two empty rows at the bottom are omitted.
## 3 Proof of Theorem 1 and examples of the involution
We first consider ∑ b Q a b ( -1). By Theorem 8,
$$\sum _ { b } Q _ { b } ^ { a } ( - 1 ) = \sum _ { T \in \overline { \mathfrak { A } } 2 \overline { \mathfrak { P } } ( a ) } ( - 1 ) ^ { | T | - | a | }.$$
To prove that this equals 0 or 1, construct the following sign reversing involution ι , defined on either the full set of tableaux T ∈ A P 2 ( a ) or the set A P 2 ( a ) \{ T 0 } for one particular tableau T 0 :
- 1. Set m to be the smallest entry appearing in T .
- 2. Find the rightmost column of T where a free m can be either added or removed to get a new tableau that is still in A P 2 ( a ), and add or remove m from that column.
- 3. If no such column exists, reset m to be the next smallest entry m ↑ and repeat step 2. Continue until either step 2 succeeds or m is equal to the maximum entry of T , in which case we take ι ( T ) to be undefined.
We can see that ι is well-defined (except in the case it is undefined) because removing an m in a given column can only be done in one way, and (S.5) guarantees that adding a free m can also be done in only one way. Also, it is sign reversing since | ι ( T ) | = | T | ± 1 , as we are either adding or removing one entry of T to get ι ( T ). Thus, it remains to check that ι is an involution and is either defined for all T ∈ A P 2 ( a ) or undefined for exactly one T ∈ A P 2 ( a ). To show these facts, we use the following lemma:
Lemma 14. The entry m that is added or removed to get from T to ι ( T ) is the largest entry such that for every m < m ′ in T , row m ′ has all entries equal to m ′ and is weakly longer than all rows above it.
Proof. First we note that for the choice of m described in Lemma 14, no m < m ′ can possibly be added to or removed from a column of T . We cannot remove an m ′ because every m ′ is an anchor. We also cannot add a free m ′ because the only columns that do not already contain an m ′ are those in rows longer than row m ′ , meaning rows below row m ′ , and those rows have anchors less than m ′ , meaning adding a free m ′ would violate (S.2). This shows that the m chosen for ι must be at least the m described in Lemma 14.
It remains to show that this choice of m actually can be added to or removed from some column of T . We can remove all rows of T below row m without changing which entry of T will be added or removed, since no entry from one of those rows will be the entry chosen or impact which entry is chosen. Thus, we may assume that m is the smallest entry of T . We consider several cases:
- · If T contains multiple m 's and at least one of them is free, then we can remove the rightmost free m without violating any conditions. Thus, we can assume that either T contains only one m, or all m 's in T are anchors.
- · Suppose T contains only one m , the m is free, and it is not in the rightmost column. Then we can add a free m to the rightmost column without violating any conditions.
- · Suppose T contains only one m , the m is free, and it is in the rightmost column. Then by the mesonhighest condition, m ↑ must also appear in that same rightmost column in a different box from m. However, if m ↑ is an anchor in that column, then m should instead be in the same box of the column as m ↑ by (S.5), since m ↑ is the smallest anchor in that column. Similarly, if m ↑ is not an anchor, then both m and m ↑ must be in whichever box of the last column has the smallest anchor, again by (S.5). This contradicts m and m ↑ being in different boxes, so this case is impossible.
- · Suppose now that every m in T is an anchor, but that not every column of T contains an m. Consider the rightmost column not containing an m, say column c. Then column c + 1 contains an m as an anchor. This means we can add a free m to column c, since adding an m to the box immediately to the left of the one containing the m in column c +1 will not violate (S.2) or any other conditions.
- · The only remaining case is that every column of T contains an m and all the m 's are anchors. The m in the leftmost column must then be in row m, so row m must be nonempty, and it must be the lowest row of T since m is the smallest entry. By (S.2) and minimality of m, every other box of row m must then contain an m and no free entries. The only thing left to check is that no m appears in a higher row, or equivalent, row m is at least as long as every other row. If not, let c be the rightmost column of row m. Then column c +1 contains an m in some higher row. Taking that m together with the box to its left and the m in column c then creates an upside-down L shape violating (S.3), since both m 's are anchors and thus β = γ = m. This is a contradiction, so we conclude that row m has maximal length. But then m is not the maximal entry satisfying the condition of Lemma 14, since m ↑ also satisfies the condition. Thus, this case is not possible.
Thus, in each possible case, some m can be added or removed from T , which shows that the m chosen is indeed the one described in the lemma statement.
Now to show that ι is an involution on the subset of A P 2 ( a ) on which it is defined, note that as long as the same m and the same column is chosen when applying ι to ι ( T ) as when applying it to T , we will get ι 2 ( T ) = T, since the operations of adding and removing an m from the same column cancel out. Thus, we consider the possible ways that a different m or column could be chosen when computing ι ( ( ι T )):
- · The same m is chosen, but in a different column. Whichever column was used when finding ι ( T ) is certainly also a valid column to modify to find ι ( ( ι T )), so the only potential issue is if there is a column of ι ( T ) further to the right in which we can add or remove an m. But then that same column would also have been modified when finding ι ( T ) instead of the one that was modified, because the existence or nonexistence of an extra m in some column further to the left will not impact whether or not (S.1)-(S.5) and the meson-highest condition hold if an m is added or removed from a column further to the right, so modifying the further right column is valid for ι ( T ) if and only if it is valid for T . This is a contradiction, so provided the same m is chosen, the same column will also be chosen.
- · A different m is chosen. One potential issue is that after adding or removing an m, a smaller value m ′ can now be either added to or removed from T , but this cannot happen because m ′ is the value chosen if and only if the condition in Lemma 14 applies to m ′ , and that condition is not impacted by adding or removing an entry of T that is larger than m. ′ The only other potential issue is that there is only one m in T and it gets removed when going from T to ι ( T ), so ι ( T ) no longer contains an m. For this to happen, the lone m must be in the rightmost column of T , because otherwise it can be added to the rightmost column without violating any of the conditions. It must also be free, since otherwise it could not be removed. But by the argument in the proof of Lemma 14, it is not possible that there is only one m in T and that the lone m is a free entry in the far right column. Thus, this case cannot actually happen.
Thus, ι ( T ) is an involution. It remains to show that ι ( T ) is undefined for exactly one T ∈ A P 2 ( a ) if the parts of a are nonincreasing, and is defined for all T ∈ A P 2 ( a ) otherwise. But ι ( T ) is undefined if and only if the condition in Lemma 14 applies to every entry of T , which is equivalent to saying that all nonempty rows of T are weakly decreasing in length and that every box of T is filled with a single entry equal to the corresponding row number. No such tableau T exists if the nonzero parts of a are not weakly decreasing, and exactly one such T exists if they are weakly decreasing. Thus, the sum is 0 if the parts of a are not
weakly decreasing, and if they are, the sum is 1 because the single unpaired T has no free entries and thus has positive sign since | T | - | a | = 0 .
The proof for ∑ b M b a ( -1) is essentially identical. Instead of Theorem 8, we use Theorem 11 to get
$$\sum _ { b } M _ { b } ^ { a } ( - 1 ) = \sum _ { T \in \overline { \Omega } 2 \overline { \mathfrak { F } } ( a ) } \beta ^ { | T | - | a | } \overline { \mathfrak { F } } _ { w t ( T ) }.$$
We then define ι in the same manner as before, except that it is an involution on either the full set of tableau T ∈ Q F 2 or on the set Q F 2 \{ T 0 } for one particular tableau T . 0 The only difference in the proof is that if m is the entry chosen by ι and m < m ′ is another entry of T , it could be the case that instead of all the occurrences of m ′ appearing as anchors in row m, ′ they all appear as anchors in some higher row. Thus, m will instead be the smallest entry such that for every m < m ′ , all occurrences of m ′ appear as anchors in the same row, and that row is weakly longer than all rows above it.
So, ι ( T ) will be undefined if and only if the nonzero elements of a are weakly decreasing, T has no free entries, and every row of T contains only repeats of the same entry. We claim that in fact the repeated entry in each row must equal the row index. If not, there is some m that is the anchor of a row higher than row m. Then by the quasiYamanouchi condition, m ↑ = m + 1 , since m is not an anchor in its own row. Then m +1 must also be the anchor of some row higher than its own row. By the same logic, we must have ( m + 1) ↑ = m + 2 , and m + 2 must then be the anchor of a row higher than row m + 2 . Continuing this logic inductively, we find that the largest entry M appearing in T is also an anchor of some row higher than row M . But then the quasiYamanouchi condition requires T to contain an entry equal to M +1, which is a contradiction. So in fact, every entry m of a tableau T for which ι ( T ) is undefined must be an anchor in its own row m rather than in another row.
This shows that again, there is exactly one unpaired tableau T in the case where the parts of a are weakly decreasing and no unpaired tableaux otherwise. As with ∑ b Q a b ( -1), in the case where such an unpaired tableau exists, it appears with positive sign since it has no free entries. Thus, we get that ∑ b M a b ( -1) = 1 if the parts of a are weakly decreasing and ∑ b M a b ( -1) = 0 otherwise, as desired. This completes the proof of Theorem 1.
We end with two examples to illustrate the involution.
$$\Big. _ { - } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \Delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta$$
Example 15. Revisiting a = (0 0 1 2) as in Examples 9 and 12, we get , , ,
$$\psi _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \quad \sigma _ { 0 } \\ \psi _ { 0 } \quad \sum _ { b } ^ { 2 } Q _ { b } ^ { a } ( \beta ) & = 1 + \beta + 2 \beta ^ { 2 } + 2 \beta ^ { 3 } + \beta ^ { 4 } + \beta ^ { 5 }, \\.$$
Plugging in β = -1 gives
$$\sum _ { b } Q _ { b } ^ { a } ( \beta ) & = 1 - 1 + 2 - 2 + 1 - 1 = 0, \\ \sum _ { b } M _ { b } ^ { a } ( \beta ) & = 1 - 1 + 1 - 1 + 1 - 1 = 0. \\.. \quad. \quad. \quad \, \ e \ \circ \ e \ \circ \ e \ \circ \ e \.$$
This matches Theorem 1 since the nonzero parts of a = (0 0 1 2) are not weakly decreasing, so we expect , , , the sums to be 0. The pairing induced by ι for the tableaux in A P 2 is shown below:
The pairing of the tableaux in Q F 2 is the same except with the two tableaux in the bottom row omitted.
$$\text{Example where } \sum _ { b } M _ { b } ^ { a } ( - 1 ) = \sum _ { b } Q _ { b } ^ { a } ( - 1 ) = 1$$
Example 16. Revisiting a = (0 0 2 2) as in Examples 10 and 13, we get , , ,
$$\sum _ { b } Q _ { b } ^ { a } ( \beta ) & = 3 + 4 \beta + 2 \beta ^ { 2 } + \beta ^ { 3 } + \beta ^ { 4 }, \\ \sum _ { b } M _ { b } ^ { a } ( \beta ) & = 2 + 2 \beta + \beta ^ { 2 } + \beta ^ { 3 } + \beta ^ { 4 }.$$
When β = -1 , these sums become
This again matches Theorem 1 because the nonzero parts of a = (0 0 2 2) are in weakly decreasing order, , , , so we expect both sums to be 1. The pairing of the tableaux in A P 2 (0 , 0 2 2) induced by , , ι is shown below. Note that the top left tableau is the unique one that is unpaired.
The pairing of tableaux in Q F 2 is the same except without the four tableaux containing 1's but not 2's (i.e. the tableaux in the second and fourth rows from the top).
## Acknowledgements
The author thanks Oliver Pechenik for suggesting the problem, and she thanks Oliver Pechenik, Karen Yeats, and Sophie Spirkl for providing helpful comments. She was partially supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) grant RGPIN-2022-03093.
## References
[AS17] Sami Assaf and Dominic Searles. 'Schubert polynomials, slide polynomials, Stanley symmetric functions and quasi-Yamanouchi pipe dreams'. In: Advances in Mathematics 306 (2017), pp. 89122. url : https://doi.org/10.1016/j.aim.2016.10.015 .
| [AS18] | Sami Assaf and Dominic Searles. 'Kohnert tableaux and a lifting of quasi-Schur functions'. In: Journal of Combinatorial Theory, Series A 156 (2018), pp. 85-118. url : https://doi.org/10.1016/j.jcta.201 |
|----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Bru+21] | Ben Brubaker, Valentin Buciumas, Daniel Bump, and Henrik PA Gustafsson. 'Colored five- vertex models and Demazure atoms'. In: Journal of Combinatorial Theory, Series A 178 (2021), p. 105354. url : https://doi.org/10.1016/j.jcta.2020.105354 . |
| [BSW20] | Valentin Buciumas, Travis Scrimshaw, and Katherine Weber. 'Colored five-vertex models and Lascoux polynomials and atoms'. In: J. Lond. Math. Soc. (2) 102.3 (2020), pp. 1047-1066. issn : 0024-6107. url : https://doi.org/10.1112/jlms.12347 . |
| [Buc05] | Anders Skovsted Buch. 'Combinatorial K-theory'. In: Topics in Cohomological Studies of Alge- braic Varieties: Impanga Lecture Notes (2005), pp. 87-103. url : https://link.springer.com/chapter/10.1007 |
| [Dem74] | Michel Demazure. 'Une nouvelle formule des caracteres'. In: Bull. Sci. Math 2.98 (1974), pp. 163- 172. |
| [FK94] | Sergey Fomin and Anatol N Kirillov. 'Grothendieck polynomials and the Yang-Baxter equa- tion'. In: Proceedings on formal power series and algebraic comb . 1994, pp. 183-190. url : https://www.researchgate.net/publication/248559296_Grothendieck_polynomials_and_the_Yang_-_Ba |
| [HN24] | Angela Hicks and Elizabeth Niese. 'Quasisymmetric divided difference operators and polynomial bases'. 2024. url : https://arxiv.org/abs/2406.02420 . |
| [LS82] | Alain Lascoux and Marcel-Paul Sch¨tzenberger. u 'Structure de Hopf de l'anneau de cohomologie et de l'anneau de Grothendieck d'une vari´t´ e e de drapeaux'. In: CR Acad. Sci. Paris S´r. e I Math 295.11 (1982), pp. 629-633. |
| [LS88] | A. Lascoux and M.-P. Sch¨tzenberger. u 'Invariant theory and tableaux'. In: Minneapolis, MN, 1988. Chap. Keys and standard bases. |
| [Mon16] | Cara Monical. 'Set-valued skyline fillings'. 2016. url : https://doi.org/10.48550/arXiv.1611.08777 . |
| [MPS21] | Cara Monical, Oliver Pechenik, and Dominic Searles. 'Polynomials from Combinatorial K - theory'. In: Canadian Journal of Mathematics 73.1 (2021), pp. 29-62. url : https://doi.org/10.4153/S0008414 |
| [PS19] | Oliver Pechenik and Dominic Searles. 'Decompositions of Grothendieck polynomials'. In: Inter- national Mathematics Research Notices 2019.10 (2019), pp. 3214-3241. url : https://doi.org/10.1093/imrn/rn |
| [Sea20] | Dominic Searles. 'Polynomial bases: positivity and Schur multiplication'. In: Transactions of the American Mathematical Society 373.2 (2020), pp. 819-847. url : https://www.ams.org/journals/tran/2020-3 | | null | [
"Laura Pierson"
]
| 2024-08-02T16:59:07+00:00 | 2024-08-02T16:59:07+00:00 | [
"math.CO",
"math.KT"
]
| Proof of a $K$-theoretic polynomial conjecture of Monical, Pechenik, and Searles | As part of a program to develop $K$-theoretic analogues of combinatorially
important polynomials, Monical, Pechenik, and Searles (2021) proved two
expansion formulas $\overline{\mathfrak{A}}_a = \sum_b
Q_b^a(\beta)\overline{\mathfrak{P}}_b$ and $\overline{\mathfrak{Q}}_a = \sum_b
M_b^a(\beta)\overline{\mathfrak{F}}_b,$ where each of
$\overline{\mathfrak{A}}_a$, $\overline{\mathfrak{P}}_a$,
$\overline{\mathfrak{Q}}_a$ and $\overline{\mathfrak{F}}_a$ is a family of
polynomials that forms a basis for $\mathbb{Z}[x_1,\dots,x_n][\beta]$ indexed
by weak compositions $a,$ and $Q_b^a(\beta)$ and $M_b^a(\beta)$ are monomials
in $\beta$ for each pair $(a,b)$ of weak compositions. The polynomials
$\overline{\mathfrak{A}}_a$ are the Lascoux atoms, $\overline{\mathfrak{P}}_a$
are the kaons, $\overline{\mathfrak{Q}}_a$ are the quasiLascoux polynomials,
and $\overline{\mathfrak{F}}_a$ are the glide polynomials; these are
respectively the $K$-analogues of the Demazure atoms $\mathfrak{A}_a$, the
fundamental particles $\mathfrak{P}_a$, the quasikey polynomials
$\mathfrak{Q}_a$, and the fundamental slide polynomials $\mathfrak{F}_a$.
Monical, Pechenik, and Searles conjectured that for any fixed $a,$ $\sum_b
Q_b^a(-1), \sum_b M_b^a(-1) \in \{0,1\},$ where $b$ ranges over all weak
compositions. We prove this conjecture using a sign-reversing involution. |
2408.01391v2 | ## FT K-means: A High-Performance K-means on GPU with Fault Tolerance
Shixun Wu † ⋆ , Yitong Ding † ⋆ , Yujia Zhai † , Jinyang Liu § , Jiajun Huang † , Zizhe Jian † †
, Huangliang Dai , Sheng Di , Bryan M. Wong , Zizhong Chen , Franck Cappello ‡ † † ‡ † University of California, Riverside, CA, US § University of Houston, Houston, TX, US ‡ Argonne National Laboratory, Lemont, IL, US
{ swu264,yzhai015, jhuan380, zjian106, hdai022 } @ucr.edu, [email protected], [email protected] [email protected], [email protected], [email protected], [email protected]
Abstract -K-means is a widely used algorithm in clustering, however, its efficiency is primarily constrained by the computational cost of distance computing. Existing implementations suffer from suboptimal utilization of computational units and lack resilience against soft errors. To address these challenges, we introduce FT K-means, a high-performance GPU-accelerated implementation of K-means with online fault tolerance. We first present a stepwise optimization strategy that achieves competitive performance compared to NVIDIA's cuML library. We further improve FT K-means with a template-based code generation framework that supports different data types and adapts to different input shapes. A novel warp-level tensor-core error correction scheme is proposed to address the failure of existing fault tolerance methods due to memory asynchronization during copy operations. Our experimental evaluations on NVIDIA T4 GPU and A100 GPU demonstrate that FT K-means without fault tolerance outperforms cuML's K-means implementation, showing a performance increase of 10%-300% in scenarios involving irregular data shapes. Moreover, the fault tolerance feature of FT K-means introduces only an overhead of 11%, maintaining robust performance even with tens of errors injected per second.
## I. INTRODUCTION
The K-means, one of the top 10 algorithms in data mining [1], is widely used in image classification, vector quantization [2], knowledge discovery [3], and pattern classification [4]. However, K-means is increasingly vulnerable to transient faults caused by high circuit density, low near-threshold voltage, and low nearthreshold voltage [5, 6, 7]. Oliveira et al. [8] demonstrated an exascale system with 190,000 cutting-edge Xeon Phi processors still suffering from daily transient errors under ECC protection. Recognizing the importance of this issue, the U.S. Department of Energy has named reliability as a major challenge for exascale computing [9].
of ECC protection that resulting the system prone to cosmic rayinduced failures [12]. Despite advancements in ECC protection, transient faults continue to challenge system reliability. For example, a simulation by Oliveira et al. of an exascale system with 190,000 advanced Xeon Phi processors revealed daily vulnerabilities to transient errors, even with ECC [8]. These faults are not just theoretical concerns; real-world impacts have been recorded by Google, which experienced transient faults causing incorrect outputs in its production environment [13]. In 2018, faced with the ongoing risk of transient faults on its largescale infrastructure, Meta launched an internal investigation to seek solutions [14]. Transient faults may cause either fail-stop errors, which lead to system crashes, or fail-continue errors, which produce incorrect outcomes. While fail-stop errors can often be addressed through checkpoint/restart mechanisms [15, 16, 17, 18] or algorithmic approaches [19, 20, 21, 22, 23, 24], fail-continue errors are more problematic as they silently corrupt the state of applications and result in incorrect outputs [25, 26, 27, 28, 29]. These errors are particularly dangerous in environments where safety is critical [30]. This paper focuses on fail-continue errors within the computational logic units, assuming that memory errors and those causing system stops are managed using error-correcting codes and checkpoint/restart techniques. We refer to these issues as soft errors.
Intel Corporation first documented a transient error leading to soft data corruption in 1978, marking a significant recognition of such faults' impact in academia and industry [10]. Subsequently, in 2000, Sun Microsystems reported server crashes and outages at major sites like America Online and eBay back to cosmic ray strikes on unprotected caches [11]. Similarly, Virginia Tech, in 2003, had to dismantle and sell its newly assembled Big Mac cluster of 1100 Apple Power Mac G5 computers due to a lack
⋆ Shixun Wu and Yitong Ding contributed equally to this work.
Existing fault tolerance methods are feasible for K-means clustering. Taamneh [31] proposes a checkpointing strategy, which involves periodically saving the centroids to stable storage during normal operation and restarting from checkpointed centroids in the event of a failure. However, this method cannot detect silent errors and requires recomputation after an error. Dual modular redundancy (DMR) verifies computational correctness by replicating instructions and comparing the results [32, 33, 34, 35, 36]. Figure 1 left illustrates the K-means workflow. We find that DMR can protect the memory-bound routine efficiently, such as the centroids update phase in Figure 1 left step 3. It is because the memory latency of loading the data points is so high that all arithmetic operations can be duplicated without introducing an overhead over 1% , even for synchronous instructions like atomicAdd. However, DMR failed to protect the compute-bound distance calculation in Figure 1 left step 1 due to the redundant computations. In Figure 1 left step 2, nearest cluster matching is fused within the distance computation kernel to eliminate redundant memory access. Algorithm-based fault tolerance (ABFT) reduces this redundancy by using checksums based on equivalence relationships, lowering the redundancy to O (1 /N ) , where N is the problem size [37]. Efforts have been made to apply ABFT on GPUs, designing kernel fusion schemes to minimize the overhead of ABFT by hiding it within the memory transactions and computing unit gaps [38, 39, 40, 41].
However, existing ABFT fusion strategies lack architectureaware optimization. Kosaian [40] proposes an error detection scheme for tensor-core but the error correction requires a timeredundant recomputation. Although error correction is discussed in [39, 41], they only utilize a register-reusing which becomes outdated for Amepere architecture. The register reusing stage is illustrated in the SIMT GEMM part of Figure 1 and the asynchronous copy is presented in the Tensor-core part. Before Ampere architecture, the global-to-share memory transfer passes through the register file explicitly, enabling register reusing for checksum computation. However, the latest asynchronous memory copy enables a new data path from global to shared memory bypassing the register. Without register reusing, checksum computation requires additional expensive memory read, destroying the carefully designed pipeline. Additionally, these fault tolerance strategies consider matrix multiplication individually, with no awareness of the underlying K-means routine.
Furthermore, in the state-of-the-art K-means implementation, cuML suffers from fixed kernel parameters, resulting in suboptimal and low utilization of peak computing performance over various problem sizes. For example, the K-means in cuML obtain a performance of less than 10% of the peak performance for both single and double precisions. Due to the underlying tall-and-skinny matrix multiplication computation inside the Kmeans, a code generation strategy and a parameter selection scheme are necessary to improve the K-means performance for various of input shapes and data types.
To address these issues, we propose FT K-means, a high-performance K-means implementation equipped with an algorithm-based fault tolerance scheme that detects and corrects silent data corruptions at computing units on the fly. More specifically, our contributions include the following:
- · We begin our work by optimizing a K-means baseline without fault tolerance. Through a series of optimizations on kernel fusion, FT K-means offers performance competitive to or faster than the state-of-the-art library, cuML. FT K-means is available at an anonymous link. 1
- · We explore the fault tolerance K-means designs at the warp level using both the CUDA cores and tensor cores. The combination presents a low overhead even under tens of errors injected per minute.
- · A template-based code generation strategy is developed to reduce development costs. The template-based can generate K-means kernels with or without fault tolerance for a wide range of input sizes and data types.
.
Figure 1: Workflow of K-means. The red illustrates our motivation.
- · Experimental results of single precision and double precision on an NVIDIA A100 server GPU and a Tesla Turing T4 GPU show that FT K-means offers a 10% -300% improvement compared to the state-of-the-art library cuML. The fault tolerance scheme in FT K-means introduces an average overhead of 11%, even under tens of error injections per minute.
## II. BACKGROUND AND RELATED WORKS
The K-means algorithm aims to categorize M objects { X i } M i =1 based on N -dimensional features by grouping similar ones into K clusters. Starting with initial centroids Y (0) i K i =1 , the algorithm iteratively performs two main steps until satisfies a termination condition. Firstly, it assigns each object X i to the nearest cluster Y j using
$$\underset { j = 1, \cdots, K } { \arg \min } \| X _ { i } - Y _ { j } \| _ { 2 }.$$
Secondly, it updates the centroids of each cluster with
$$Y _ { j } ^ { \prime } = \frac { 1 } { | S _ { j } | } \sum _ { i \in S _ { j } } X _ { i }$$
where S j represents the set of all points X i that are assigned to cluster j , and | S j | denotes the number of points in cluster j . This formula computes the new centroid Y j as the mean of all points assigned to the cluster j .
## A. Fault Model
FT K-means is designed to identify and correct errors in computing units that could influence the final results. It operates under the assumption that memory errors are managed by ECC [42] and communication reliability issues are addressed by FTMPI [43]. For compute errors during runtime, a fault-tolerant strategy is implemented based on the single-event upset (SEU) assumption [44, 45], which posits that only one soft error occurs within each detection and correction interval. This assumption is supported by the low frequency of multiple soft errors in [34, 38,
39, 46, 47]. The fault tolerance method involves high reliability in detecting faults with minimal false alarms [48]. Specifically, each threadblock randomly selects an element to corrupt by flipping a single bit, either in its 32-bit float representation or 64-bit double representation. A checksum test with a defined threshold δ then attempts to operate the corrupted computations, followed by an application of an error correction scheme.
## B. Previous Work for K-means without Fault Tolerance
Historically, the simplicity of the k-means algorithm has led to its frequent reimplementation on GPUs. These implementations vary, starting with early GLSL-based versions [49] and progressing to initial and more recent CUDA versions [50, 51]. Lutz et al. [52] highlighted the significance of single-pass processing in GPU computations, which avoids the redundant loading of data into GPU caches. They reported a significant performance improvement, with speeds over 50 times faster than contemporary CPU implementations and twice as fast as 'double-pass' strategies that involve separate steps. This method is particularly effective for simultaneously processing multiple small k-means instances by using kernel fusion [53]. Meanwhile, Cuomo et al. [54] conducted a detailed analysis of the performance costs associated with transferring large datasets between CPU and GPU for specialized processing. The kmcuda package provides a GPU-optimized YinYang K-means algorithm on GitHub [55], which enhances processing speed on CPUs but faces significant overhead with GPU parallel processing, and is widely used in data analysis tools like R. Nelson and Palmieri [56] emphasized the significance of memory management and synchronization, discussing the trade-offs between using global versus shared memory, and different thread synchronization models that involve memory locking. Martin et al. [57] present a detailed analysis of individual computation steps and propose several optimizations that improve the overall performance. Kaiming et al. [58] introduced an integrated approach to the critical steps of the K-means algorithm, which significantly enhances performance by reducing unnecessary calculations and memory operations, outperforming the Intel DAAL K-means in both sequential and parallel environments.
However, existing works fail to provide enough optimization toward the tensor-core computing units and the asynchronous memory copy presented in the GPU architecture after SM80. cuML [59], one of the state-of-the-art machine learning libraries on GPU, has provided a K-means implementation using the latest architecture properties. Despite using tensor core computing units and the latest architectural features, the performance of the cuML K-means implementation remains below its hardware's peak potential due to fixed kernel parameters that do not optimize for different input shapes.
## C. Algorithm-Based Fault Tolerance
Soft error protection algorithms aim to identify and rectify errors that can arise in iterative or computationally demanding applications, such as scientific computing [60, 61, 62, 63]. The development of these algorithms dates back to 1984, with Huang [64] first specifically designed for matrix-matrix multiplication.
The fundamental concept of these algorithms involves encoding matrices X and Y into checksums X c and Y r , respectively. This encoding is achieved through the following equations.
$$X \xrightarrow { e n c o d e } X ^ { c } \coloneqq e ^ { T } X,$$
$$Y \xrightarrow { e n c o d e } Y ^ { r } \coloneqq Y e,$$
where e is a column vector, [ 1 1 , , . . . , 1 ]. The combinations of input matrix and the encoded checksums, X ′ = [ X e T X ] and Y ′ = [ Y Y r ] , are then multiplied to get a matrix D ′ that contains both the correct result and checksum information:
$$D ^ { \prime } = X ^ { \prime } Y ^ { \prime } = \begin{bmatrix} D & D e \\ e ^ { T } D & \end{bmatrix} = \begin{bmatrix} D & D ^ { r } \\ D ^ { c } & \end{bmatrix}.$$
The final accuracy of matrix multiplication can be confirmed by comparing the matrix D with its checksum counterparts D r and D c . If the difference exceeds a set threshold, it signals an error in the computation. The cost of this checksum encoding and verification is minimal compared to the matrix multiplication itself, offering a cost-effective error detection method. Verification can occur either during (online) or after (offline) the computation. Chen et al. [37] introduced an outerproduct matrix-matrix multiplication algorithm that maintains the checksum relationship throughout the accumulation process:
$$\stackrel { \kappa } { \mathfrak { i } } \\ \mathfrak { d } \\ \mathfrak { l } }$$
where, i represents the step number in the outer-product update of the matrix D , with D i indicating the result of each outerproduct, namely X ′ (: , i ) · Y ′ ( i, :) . The offline version of the double-checksum approach can correct only one error in the entire computation. In contrast, the online version corrects a single error at each step of the update, allowing it to address multiple errors throughout the entire program. Ding et al. [38] first presented an implementation of the outer product ABFTGEMM for GPUs. To minimize the memory latency from checksum operations, Zhai et al. developed combined compute kernels for GEMM on AVX-512-enabled CPUs [39, 65]. Kosaian and Rashmi [40] present a warp-level ABFT implementation capable of error detection, but not correction. Shixun et al. [41] proposed a fully-fused ABFT-GEMM that effectively detects and corrects computational errors. However, the kernel fusion strategy relies on reusing registers during transfers between global and shared memory. This approach does not extend well to GPU architectures post-Turing, e.g. Ampere, due to the introduction of asynchronous copy instructions. Besides matrix multiplication, the ABFT scheme is widely adopted in fast Fourier transforms [66, 67], sorting [68], iterative methods [69, 70, 71], and computer vision [72].
## III. K-MEANS WITHOUT FAULT TOLERANCE
The K-means process in each iteration can be divided into two stages. First, for every sample, assign a cluster that has
the closest Euclidean distance to it. Second, calculate the geometric center for all samples belonging to a cluster as the new coordinates for this cluster. Consider M samples and K clusters, where each sample has a dimension of N . The time complexity of the first stage is O MNK ( ) , while the time complexity of the second stage is O MN ( ) , so the major bottleneck lies in the first stage. In this section, we present the step-wise optimizations of K-means. The optimizations include applying GEMM to Kmeans, kernel fusion with thread-wise and thread block-wise reduction, broadcast between thread blocks, and enabling tensor core in GEMM.
## A. K-means Stepwise Optimization
1) Basic implementation: For the cluster assignment stage, we launch a kernel. Each thread in this kernel handles a line in the sample matrix (refer to the matrix definition in Fig 2), which represents a sample. The thread loads all centroids in the centroid matrix calculates the Euclidean distance between this sample and every centroid, and chooses the one with the smallest distance as its assigned centroid. For the update centroids stage, M kernels are launched in serial. In kernel i , each thread processes one sample. If this sample belongs to kernel i , then add all dimensions of this sample to kernel i 's corresponding dimensions. Finally, launch a kernel to calculate sum of samples belongs to this centroid number of samples belongs to this centroid , and write the answer back to Centroids matrix as new centroids.
2) GEMM based K-means: Due to the property of Euclidean distance, and we only need to find the closest centroid, we can use GEMM to speed up the cluster assignment process. Ignoring the squared root in distance computation, the distance can be computed in three parts: Σ k Samples 2 ik + Σ k Centroids 2 jk -2 · Σ k Samples ik · Centroids jk As Figure 2 Step 1 depicts, the first two parts of this formula can be computed by squaring elements and summing them up in each row. This can be finished by launching two simple kernels. The third part of the formula has the highest time complexity, and it is exactly in the form of GEMM, so we can launch a GEMM kernel to handle this part and put it together with the first two square terms, and write back to GPU memory. Then we need to launch another kernel to reduce over each row to find the closest centroid for each sample. Also, as illustrated in Figure 2 Step 3, for the updating centroids stage, launching N kernels is a great waste of time, because, in kernel j, a large number of threads are idle because the sample which is handled by it doesn't belong to centroid j. So we only launch one kernel to handle N centroids all at once. Each thread still deals with one sample, but it uses atomic add to add the values of this sample in every dimension to its assigned centroid and add one to the counter of this assigned centroid (for average operation). And the last kernel of averaging over each centroid remains unchanged. Our optimization boosts the performance to 25x compared to the basic implementation.
3) Kernel Fusion in thread and thread block level: After GEMM, we write the result matrix back to GPU memory and load the matrix again in order to do a row-wise reduction. This greatly increases the amount of data movement and increases storage overhead. In this part, we apply kernel fusion [73, 74]
to accomplish part of the reduction within the GEMM kernel. Firstly, as Figure 2 Step 2 indicates, each thread in the GEMM kernel handles a small submatrix of the result matrix. After the computation of GEMM, we can simply find the minimum column in each row within this submatrix, and write it to shared memory. After all threads in the threadblock finish this step, thread 0 reads all results in shared memory, calculates another row-wise minimum for each row as the final partial answer for this threadblock, and writes it to GPU memory. Assuming each threadblock has size TM × TN , the reduction kernel only needs to load and handle TN/N of data compared to the last part, which obtains a speedup of 1.13x compared to the last part.
4) Threadblock level broadcast: The optimization above cannot fully eliminate the time and space complexity of launching another reduction kernel after the GEMM kernel. So in this part, we attempt to accomplish cluster assignment within the GEMM kernel. Owing to the fact that different threadblocks cannot communicate, we use a broadcast vector and atomic operation to ensure that only one threadblock is changing the assignment answer in one row at a time, i.e. each threadblock needs to acquire for the lock of a row before changing the assignment answer in this row. With this method, the speedup increases to 1.04x compared to the last part.
Samples
Centroids
GEMM result
Elements in Shared Mem
Elements in GPU Mem
Figure 2: Overview of the optimized K-means.
5) Enabling tensor core in GEMM: Modern Nvidia GPUs are equipped with a tensor core in each Streaming Multiprocessor (SM), designed to accelerate GEMM. Hence we use GEMM kernels in CUTLASS [75] with tensor core and enable TF32 in
Figure 3: Overview of the code generation Strategy
FP32 precision to further boost performance, instead of our handwritten GEMM kernel. The reduction part in the last section is placed into the GEMM kernel as an epilogue. With this optimization, we achieve a speedup of 1.45x compared to the previous optimization. And now, the fully optimized GEMM is presented in Figure 2
## B. Automatic Code Generation
cuML has a highly optimized open-source K-means implementation based on CUTLASS. However, in the cluster assignment stage, it has hard-coded parameters in its GEMM kernel, which can trigger low performance in some input sizes. Moreover, the parameters for a CUTLASS GEMM kernel must be hard-coded in order to pass compile-time checking. So the cost of integrating GEMM kernels with customized parameters becomes unacceptable. We propose a code generation strategy to generate kernels with different parameters while minimizing code length to the greatest extent possible.
Default naming of kernel parameters A group of kernel parameters in cuML and CUTLASS refers to a set of parameters, threadblock level parameters, warp level parameters, and thread level parameters. Each level is composed of three parameters from each dimension. For example, in warp level, the three parameters are labeled Warp.M, Warp.N, and Warp.K, and they refer to the three dimensions of M, N, and K in GEMM.
Code Generation Strategy Figure 3 demonstrates the method we used in our code generation strategy. The code structure of the CUTLASS GEMM kernel in cuML is on the left side of the figure. Firstly, the epilogue is integrated into the FusedDistanceNN kernel. The FusedDistanceNN kernel handles both GEMM and reduction. And then the kernel is wrapped into GemmKernel. With threadblock, warp, and thread level parameters set, it is then transferred to the next template as FusedDistanceNNGemm. Finally, with all K-means routine sets, the whole cutlassFusedDistanceNN template function works as an interface of the cluster assignment stage. In order to generate a set of feasible kernels with customized parameters, we write a code to test all possible parameters in the search space defined by ourselves, as shown in the code generation part. And for every group of parameters, try it in a demo code. If it can compile and run, which means it is functionally correct. And then we put it in
Figure 4: Pseudocode: K-means w/o FT

the parameters queue. With all parameters, we then run a code generator to modify the three parts of the original cuML source code, injecting corresponding functions for each parameter in each stage.
1) Kernel Parameters: The kernel parameters used in code generation is not chosen by brute forcing every possible integer in a range for every parameter in the parameter group (a parameter group means: threadblock level, warp level, and thread level parameters). We follow some rules. 1) all parameters must be power of 2 2). Warp.K = Threadblock.K. 3). warp size/thread size is 8 or 16. 4). thread size is fixed for FP32 (16, 8, 4) and FP64 (8, 8, 4) owing to the size of the tensor core.
2) Code Generation Template: The code generation strategy defines the K-means kernel using different tiling parameters. For single precision, 157 kernels with different parameter sets are defined while 145 kernels are defined for double precision. The test workflow illustrated in Figure 3 checks the feasibility of those kernels and performs the benchmark over 64 problem sizes. The benchmark result of different kernels will be employed as the kernel selection criterion. Below, we give a brief explanation of the K-means kernel so that we can switch to the discussion of the fault tolerance part.
The main body of the kernel is shown in Figure 4. In Figure 4, A stands for samples X B , for centroids Y , and C for the distance matrix D . From line number 04 to 07, an asynchronous multi-stage pipeline from global to shared memory starts and a group barrier is committed for each iteration. At line 08, the kernel waits for at least one group to be ready. Once there the group is prepared, the whole thread block loads data from shared memory into the register synchronously. Next comes the main loop along the number of clusters K . At the start of the main loop, the latest memory asynchronous copy is pushed into the
Figure 5: Comparison of SOTA ABFT-GEMM schemes. Blue and green areas are baseline and ABFT computations.

pipeline, as shown in lines 13 - 14. After that, the warp-level matrix multiplication is performed by tensor-core units. At the end of this iteration, the latest group is committed and new data is refreshed into the register once a previous group is finished. When the main loop is finished, the memory-bound epilogue performs a reduction along the row of the C matrix. Due to limited space, we skip the detailed description and the reader is welcome to our open-sourced implementation.
## IV. FT K-MEANS WITH FAULT TOLERANCE
In this section, we present the fault tolerance scheme used in FT K-means. Our discussion concentrates on distance computing and the reduction operation to find the nearest cluster. As mentioned before, the centroids updating stage can be handled with a negligible overhead of less than 1% by simply applying the DMR strategy.
## A. Online correction with location encoding
Figure 5 compared the fault tolerance scheme in FT K-means with existing state-of-the-art methods in detail.
One ABFT is illustrated in Figure 5 (a). To minimize the overhead associated with ABFT, encodings are applied at the thread block level. Aiming to avoid additional latency during GEMMaccumulation, the prefetching stage in GEMM is fused with all encodings. In GPU architecture prior to Ampere, the prefetching stage incorporates all ABFT encodings. With a carefully designed prefetching strategy, a warp-level reduction can obtain each element in e T X and Y e without requiring extra global read operations. Subsequently, the prefetching strategy facilitates the availability of e T XY and XYe encodings within a thread, eliminating the need for thread block-level communication. Ultimately, the target checksums are accumulated via a threadblock-level reduction.
Compared to the detection scheme specifically designed for tensor-core GPU, as shown in 5 (b), our method employs a vector e 2 = [1 2 , , · · · , N ] to checksum the inputs again, in addition to the previous e 1 = [1 1 , , · · · , 1] . Our method doubles the computational cost on CUDA cores ( e T X,Y e ) and triples the
Figure 6: Pseudocode: K-means w/ FT

computational cost on tensor cores ( e T 1 XYe 2 , e T 2 XYe 1 , and e T 1 XYe 1 ).
## B. Implementation of FT K-means with fault tolerance
The red part in Figure 6 illustrates the injected instructions to implement FT K-means. From line number 15 to 18, the checksum e T 1 X,Y e , e 1 T 2 X , and Y e 2 are computed. This accumulation takes place inside a thread, getting rid of interthread communication and additional memory operation. From line number 22 to 24, e T 1 XYe ,e 1 T 1 XYe , 2 and e T 2 XYe 1 are computed via tensor-core MMA operation. The overhead of our ABFT method mainly comes from those three MMAs. Theoretically, they will incur a computation overhead of 3 m w × n w . Assume m w = 4 and n w = 2 , the theoretical overhead is 37 5% . . However, from our experimental evaluation in Section V, the overhead is only 11% on average. This theory-experiment mismatch indicates that at the thread level and warp level, there remains a 27.5% execution bubble between computation and memory, which is available for kernel fusion. Actually, we first try to get the checksums e T 1 X,Y e , e 1 T 2 X , and Y e 2 using the tensor core as well, namely embedding e , e 1 2 into a new matrix operand so that we can get the checksum through several tensor core operation. However, those tensor operations cannot be hidden behind the memory footprint, resulting in a 50% overhead approximately.
Figure 7: K-means w/o FT stepwise optimizations on A100, FP32 (N=131072, N=128)
## V. PERFORMANCE EVALUATION
We evaluate our K-means on two NVIDIA GPUs, a Tesla Turing T4 and a 40GB A100-PCIE GPU. The Tesla T4 GPU is connected to a node with two 16-core Intel Xeon Silver 4216 CPUs, whose boost frequency is up to 3.2 GHz. The associated CPU main memory system has a capacity of 512 GB at 2400 MHz. The A100 GPU is connected to a node with one 64-core AMDEPYC 7763 CPU with a boost frequency of 3.5 GHz. We compile programs using CUDA 11 6 . with the -O3 optimization flag on the Tesla T4 machine, and using CUDA 12 0 . on the A100 machine. A100 has a peak computational performance of 19 5 . TFLOPS for single precision and 9 7 . TFLOPS for double precision. The memory bandwidth is 1 55 . TB/s. T4 has a peak performance of 8 1 . TFLOPS for single precision and a peak performance of 0 253 . TFLOPS for double precision. The bandwidth of T4 is 320 GB/s. We first demonstrate the benchmark result between FT K-means without fault tolerance and cuML for FP32 and FP64 on A100. Next, we evaluate the FT K-means under fault tolerance. Then, we benchmark FT K-means under error injections with cuML and Wu's ABFT. Finally, we present the same performance evaluation on the T4 GPU. All experimental results are averaged over ten trials.
## A. Benchmarking K-means without Fault Tolerance
In this subsection, we evaluate the performance of FT Kmeans w/o checksum.
1) Step-wise optimizations for K-means: Figure 7 demonstrates how our K-means distance kernel is optimized from 5% to 182% of cuML stepwise. The performance is measured with GFLOPS (bar plot, the left y-axis) and the performance ratio with respect to cuML (line chart, the right y-axis). Without using any optimizations, the K-means Naive obtains a performance of 482 GFLOPS. Next K-means V1 employs GEMM to Kmeans distance calculation. The performance improved from 482 GFLOPS to 4662 GFLOPS. Then, K-means V2 adds kernel fusion to both thread and threadblock levels, reducing memory operations. The performance is improved to 5902 GFLOPS. After that, we apply threadblock level broadcast to further reduce memory bound. The performance of K-means V3 achieves 6916 GFLOPS. With tensor core enabled and parameter selection, we finally achieved 17686 GFLOPS, which exceeded the performance of cuML (9676 GFLOPS).
2) Performance evaluation with M and K fixed: Figure 8 and 9 demonstrate a performance evaluation in distance step between FT K-means, two selected parameters relative to cuML
Figure 8: FP32 precision comparison of K-means performance at distance step without fault tolerance with FT K-means, Selected parameters and cuML on an A100 GPU, with M and K fixed.
Figure 9: Double precision comparison of K-means performance at distance step without fault tolerance with FT K-means, Selected parameters and cuML on an A100 GPU, with M and K fixed.

(all without fault tolerance) in FP32 and FP64 precision when M and K are fixed. We tested the performance of different methods under two values of K, K = 8 and K = 128 . These are cases representing two situations: one with very few dimensions of data and the other one with relatively more dimensions of data. The selected parameters are labeled Parameter1 and Parameter2, and they are chosen based on experience. The same parameter name refers to different parameters in FP32 and FP64, but their performance is similar. For both FP32 and FP64 precision, parameters selected through experience cannot achieve good performance. Parameter 1 is always slower than cuML, with an average overhead of 15%. For parameter 2, it slightly exceeded the performance of cuML when K = 8 in FP32, and it achieves the performance of cuML in some data points where N is small. However, its overall performance is still 5% slower than cuML. Using code generation strategy, we achieved 235% speedup compared to cuML under FP32 precision, and the gain in performance is significant even when K is relatively larger. However, under FP64 precision, improvements in performance are minimal, with an overall speedup of 4% in these two cases. The curves of cuML and FT K-means are almost coincident in a large portion of data points.
3) Performance evaluation with M and N fixed: Figure 10 and 11 offer a performance evaluation in distance step between FT K-means, two selected parameters relative to cuML (all without fault tolerance) in FP32 and FP64 precision when M and N are fixed. The main parameter settings are similar to
Figure 10: FP32 precision comparison of K-means performance at distance step without fault tolerance with FT K-means, selected parameters, and cuML on an A100 GPU, with M and N fixed
Figure 11: FP64 precision comparison of K-means performance at distance step without fault tolerance with FT K-means, Selected parameters, and cuML on an A100 GPU, with M and N fixed
the previous section, and N = 8 and N = 128 indicate fewer clustering centroids and relatively more clustering centroids. For both FP32 and FP64 precision, parameters selected through experience cannot achieve good performance. Parameter 1 has an average overhead of 30%. Parameter 2 exceeded the performance of cuML when K is small in some FP32 cases, and outperforms cuML in FP64 when N = 8 (1.03x speedup). but its overall performance is still 15% slower than cuML. Using code generation strategy, we obtained 239% speedup compared to cuML under FP32 precision, which is similar to fixing M and K. Under FP64 precision, performance improvements are higher than in the previous section, which is 8% in these two cases. And the speedup in small N is relatively considerable (15%).
M=131072, FP32
8
40
N
72
104
32
160
288
416
K
Figure 12: Speedup of FT K-means compared to cuML on FP32 and FP64
4
3
2
N
4) Overall performance evaluation: Figure 12 illustrates an overall comparison between our code generation method and cuMLK-means on both FP32 and FP64. For FP32. Our approach shows significant performance improvement, with a maximum speedup of 4.55x and an average speedup of 2.49x. From the perspective of dimension N, the figure indicates a clear trend that the performance improvement diminishes. Furthermore, N = 64 serves as a clear threshold, beyond which speedup essentially decreases to below 2.0x. The marginal improvement becomes even more common in the case of FP64. The average speedup is only 1.04x, with a maximum speedup of 1.39x. When N exceeds 32, the performance of our method drops to almost identical to cuML. Meanwhile, there is no apparent trend observed in dimension K for both FP32 and FP64.
Figure 13: Parameter selection in threadblock and warp level for FP32 and FFP64
5) Evaluation of parameter selection: The experimental results from previous sections motivate us to analyze the parameters chosen for our code generation method for each data point. For the data size of Figure 12, we generated 120 groups of FP32 parameters and 80 groups of FP64 parameters to be selected from. However, only 7 groups of FP32 parameters and 4 groups of FP64 parameters are actually chosen in at least one data point. All threadblock and warp level parameters are shown in Figure 13. And thread level parameters are fixed (FP32: 16,8,4 FP64: 8,8,4) owing to the limited size of the tensor core. Moreover, figure 14 illustrates the relationship between each data point and its corresponding selected parameters. We will analyze in detail the relationship between the optimal parameters generated by the code generator and the cuML parameters in the next section.
6) Detailed analysis of parameters: For FP32, as shown in figure 14, the data points can be divided into three parts: N ≤ 32 , 32 < N ≤ 64 and 64 < N . When N ≤ 32 , one of the optimal parameters is parameter 88. As table I indicates, compared to cuML, it has a bigger threadblock and warp size in the M direction and a smaller size in the N direction. That is reasonable due to the small N size in these data points. threadblock. N = 256 is too big that more than 87.5% of the threadblock size contains blank data, so the occupancy is very low. Furthermore, warp.N of cuML, which is 64, exceeds the size of N. Therefore the improvement of our new parameters
Figure 14: The selected parameter number in FP32 and FP64
is significant. As N increases, i.e. 32 < N ≤ 64 , the warp size of cuML becomes justified, and our parameter (parameter 69) sticks to this size. However, the threadblock size remains too big in N direction, so a more balanced version of threadblock 64 128 16 , , outperforms. When N keeps increasing, although the occupancy of cuML achieves a reasonable scope, a more balanced threadblock size, e.g. parameter 83 can reduce the overall amount of data movement from GPU memory to shared memory, and therefore improve performance.
For FP64, the data points only have two main parts: N ≤ 32 and 32 < N . When N is relatively small, parameter 21 has an advantage in its small Threadblock. N, and increases occupancy. As N increases, the parameters that are balanced in the M and N direction have better performance. As shown in table I, our parameter 19 is actually identical to cuML's parameter, which demonstrates that the best parameter choice is cuML's parameter in these cases. This illustrates an interesting phenomenon: the parameter choices in FP32 are much more than those in FP64. Moreover, there is also greater potential for performance improvement in FP32 than in FP64. There are several reasons for this.
| FP32 | FP32 | FP32 | FP32 |
|--------|-------------|------------|----------|
| ID | Threadblock | Warp | Thread |
| 88 | 256, 32, 16 | 64, 32, 16 | 16, 8, 4 |
| 69 | 128, 64, 16 | 32, 64, 16 | 16, 8, 4 |
| 83 | 64, 128, 16 | 64, 32, 16 | 16, 8, 4 |
| cuML | 32, 256, 16 | 32, 64, 16 | 16, 8, 4 |
| FP64 | FP64 | FP64 | FP64 |
|--------|-------------|------------|---------|
| ID | Threadblock | Warp | Thread |
| 21 | 128, 32, 16 | 32, 32, 16 | 8, 8, 4 |
| 19 | 64, 64, 16 | 32, 32, 16 | 8, 8, 4 |
| cuML | 64, 64, 16 | 32, 32, 16 | 8, 8, 4 |
TABLE I: Partial parameters of FT K-means for FP32 and FP64
First, CUTLASS enables TF32 in the FP32 GEMM kernel, which improves the processing speed of tensor cores. Therefore, the overhead of data movement and epilogue (row-wise reduction) becomes more critical, resulting in greater potential for alternative parameters. Second, the memory alignment requirement for FP64 is more strict than FP32 and is fixed to 1 in CUTLASS's implementation. So the degree of vectorization for FP64 is lower. So a balanced data fetching pattern (Threadblock.M = Threadblock.N) is crucial for increasing performance. Third, the thread-level parameters of FP64 are smaller than those of FP32. Therefore even when N is relatively small, it is easier for a general parameter to obtain high occupancy. In the future, deep reinforcement learning can help accelerate the hyperparameter tuning [76, 77, 78].
B. FT K-means with Fault Tolerance
Figure 15: FT K-means with fault tolerance on A100: FP32.
As shown in Figure 15, the experimental evaluation of the FT K-means algorithm with fault tolerance demonstrates a remarkably low overhead across various configurations. Specifically, in configurations with K = 8 clusters, the overhead was maintained at a minimal -0 24% . , illustrating the negligible impact of integrating fault tolerance mechanisms. Even when the number of clusters was significantly increased to K = 128 , the overhead remained consistently low at 1 93% . . For fixed N scenarios, the overhead was even lower at 0 96% . . These results highlight the efficiency of the FT K-means algorithm's fault tolerance, which effectively minimizes additional computational burdens while maintaining robustness across diverse input shapes.
In Figure 16, FT K-means with fault tolerance presents an average overhead of 13% for double precision. For small number of clusters ( K = 8 ), the overhead is 7 9% . , ranging from 4 6% . to 12 45% . . It suggests that the algorithm maintains consistent performance even when computational precision requirements are increased. When the number of clusters increased to K = 128 , the overhead results in 20% , indicating the performance bottleneck changes to computing. For input shapes of fixed N, N = 8 and N = 128 , the overhead was reduced to 0 8897% . . These results underscore the FT K-means algorithm's ability to efficiently manage fault tolerance with minimal overhead across a variety of input shapes and precision settings.
Figure 16: Benchmark FT K-means with fault tolerance: FP64.
## C. FT K-means under Error Injections
Figure 17: Benchmark FT K-means with error injection: FP32.
As illustrated in Figure 17, the experimental evaluation of the FT K-means algorithm under error injection reveals a minimal average overhead of approximately 2.36%, demonstrating the algorithm's efficiency in handling errors with minimal additional computational cost. The results indicate robust performance across various input shapes, with overhead percentages ranging from a slight reduction of about -0.93% to a modest increase up to 9.49%. This low overhead highlights the effectiveness of the fault tolerance mechanisms integrated into the FT-KMeans, ensuring correctness even in the presence of injected errors. Wu's FT scheme introduces an overhead of 30% due to a suboptimal GEMMbaseline without using the asynchronous memory copy.
In Figure 18, the evaluation of the FT-KMeans algorithm with error injection in a 64-bit floating point (fp64) environment
Figure 18: Benchmark FT K-means with error injection: FP64.
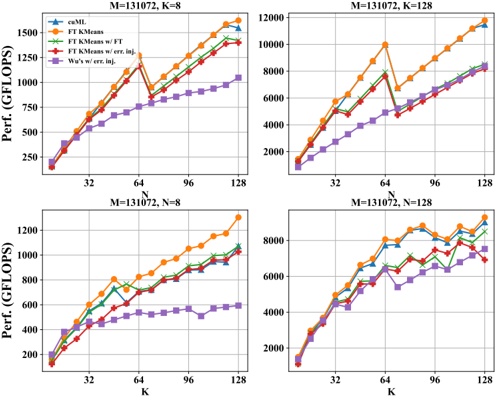
shows a low average overhead of approximately 9.21%s. The data demonstrates that configurations with fewer features (N=8 and N=128) exhibit low overheads of 0.79% and 0.84% respectively, highlighting the algorithm's effective fault tolerance mechanisms which ensure minimal performance degradation even in high-precision settings. Meanwhile, fixed K scenarios, K=8 and K=128, show higher overheads of 10.12% and 24.07%, indicating increased computational complexity under fault conditions.
## D. Performance Evaluation on T4
Figure 19 demonstrates a performance evaluation in distance step between FT K-means, two selected parameters relative to cuML (all without fault tolerance) in FP32 precision when M and K are fixed. The definitions of Parameter1 and Parameter2 are similar to our evaluation of A100. And they are consistent with the values on A100 to the greatest extent. However, they have better performance compared to cuML's parameter in this architecture, with speeds up to 184% and 208%. Using code generation strategy, we achieved 413% speedup compared to cuML under FP32 precision, and the gain in performance is significant even when K is relatively larger.
Figure 20 offers a performance evaluation in distance step between FT K-means, two selected parameters relative to cuML (all without fault tolerance) in FP32 precision when M and N are fixed. The main parameter settings are similar to the previous section, and N = 8 and N = 128 indicate fewer clustering centroids and relatively more clustering centroids. The selected parameters achieve 183% and 206% speed up against cuML. Using code generation strategy, we obtained 381% speedup compared to cuML under FP32 precision, which is similar to fixing M and K.
Figure 21 benchmarks the performance of FT K-means with or without fault tolerance for single precision. FT K-means shows an average overhead of 18% with fault tolerance and 30% under error injection. Compared with Wu's ABFT, FT K-means has a
Figure 19: FP32 precision comparison of K-means performance at distance step without fault tolerance with FT K-means, Selected parameters, and cuML on a T4 GPU, with M and K fixed.
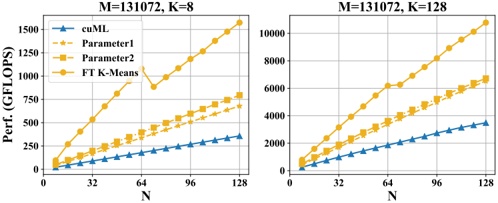
Figure 20: FP32 precision comparison of K-means performance at distance step without fault tolerance with FT K-means, Selected parameters, and cuML on a T4 GPU, with M and N fixed
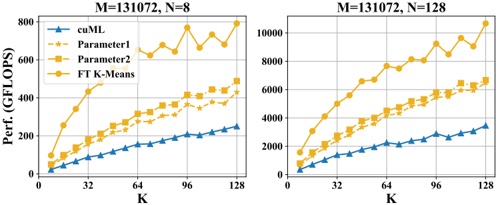
60% improvement due to the elimination of threadblock-level synchronization.
Figure 21: Benchmark FT K-means with error injection on T4: FP32.
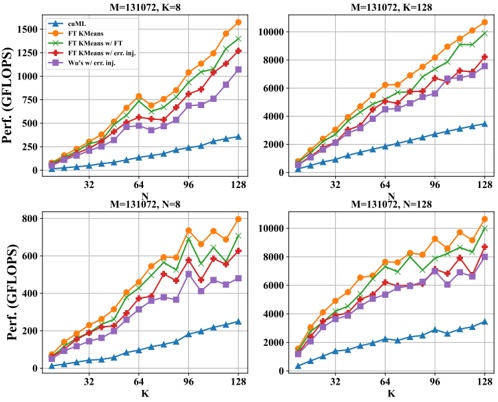
## VI. CONCLUSION
In this paper, we introduce FT K-means, a high-performance GPU-accelerated implementation of K-means with online fault tolerance. We first present a stepwise optimization strategy that achieves competitive performance compared to NVIDIA's cuML library. We further improve FT K-means with a templatebased code generation framework that supports different data types and adapts to different input shapes. A novel warp-level tensor-core error correction scheme is proposed to address the failure of existing fault tolerance methods due to memory asynchronization during copy operations. Our experimental evaluations on NVIDIA T4 and A100 GPUs demonstrate that FT K-means without fault tolerance outperforms cuML's K-means implementation, showing a performance increase of 10%-300% in scenarios involving irregular data shapes. Moreover, the fault tolerance feature of FT K-means introduces only an overhead of 11%, maintaining robust performance even with tens of errors injected per second.
## ACKNOWLEDGEMENT
This work was supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, and Scientific Discovery through the Advanced Computing (SciDAC) program under Award Number DESC0022209.
## REFERENCES
| [1] | X. Wu, V. Kumar, J Ross Quinlan, J. Ghosh, Q. Yang, H. Motoda, G. J. McLachlan, A. Ng, B. Liu, P. S. Yu, et al. , 'Top 10 algorithms in data mining,' Knowledge and information systems , vol. 14, pp. 1-37, 2008. |
|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | A. Gersho and R. M. Gray, Vector quantization and signal compression . Springer Science &Business Media, 2012, vol. 159. |
| [3] | U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, 'Ad- vances in knowledge discovery and data mining,' American Association for Artificial Intelligence, 1996. |
| [4] | R. O. Duda, P. E. Hart, et al. , Pattern classification and scene analysis . Wiley New York, 1973, vol. 3. |
| [5] | R. R. Lutz, 'Analyzing software requirements errors in safety-critical, embedded systems,' in [1993] Proceedings of the IEEE International |
| [6] | Symposium on Requirements Engineering , IEEE, 1993, pp. 126-133. M. Nicolaidis, 'Time redundancy based soft-error tolerance to rescue nanometer technologies,' in Proceedings 17th IEEE VLSI Test Sympo- sium (Cat. No. PR00146) , IEEE, 1999, pp. 86-94. |
| [7] | J.-C. Laprie, 'Dependable computing and fault-tolerance,' Digest of Papers FTCS-15 , pp. 2-11, 1985. |
| [8] | D. Oliveira, L. Pilla, N. DeBardeleben, S. Blanchard, H. Quinn, I. Koren, P. Navaux, and P. Rech, 'Experimental and analytical study of Xeon Phi reliability,' in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , ACM, 2017, p. 28. |
| [9] | R. Lucas, J. Ang, K. Bergman, S. Borkar, W. Carlson, L. Carrington, G. Chiu, R. Colwell, W. Dally, J. Dongarra, et al. , 'DOE advanced scientific computing advisory subcommittee (ASCAC) report: Top ten exascale research challenges,' USDOE Office of Science (SC)(United States), Tech. Rep., 2014. |
| [10] | T. C. May and M. H. Woods, 'Alpha-particle-induced soft errors in dynamic memories,' IEEE Transactions on Electron Devices , vol. 26, no. 1, pp. 2-9, 1979. |
| [11] | R. Baumann, 'Soft errors in commercial semiconductor technology: Overview and scaling trends,' IEEE 2002 Reliability Physics Tutorial Notes, Reliability Fundamentals , vol. 7, 2002. |
| [12] | A. Geist, 'Supercomputing's monster in the closet,' IEEE Spectrum , vol. 53, no. 3, pp. 30-35, 2016. |
| [13] | P. H. Hochschild, P. Turner, J. C. Mogul, R. Govindaraju, P. Ran- ganathan, D. E. Culler, and A. Vahdat, 'Cores that don't count,' in Proceedings of the Workshop on Hot Topics in Operating Systems , 2021, |
| [14] | pp. 9-16. H. D. Dixit, S. Pendharkar, M. Beadon, C. Mason, T. Chakravarthy, B. Muthiah, and S. Sankar, 'Silent data corruptions at scale,' arXiv preprint arXiv:2102.11245 , 2021. |
| [15] | J. C. Phillips, R. Braun, W. Wang, J. Gumbart, E. Tajkhorshid, E. Villa, C. Chipot, R. D. Skeel, L. Kale, and K. Schulten, 'Scalable molecular dynamics with NAMD,' Journal of computational chemistry , vol. 26, no. 16, pp. 1781-1802, 2005. |
| [16] | A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, 'Pytorch: An imperative style, high- performance deep learning library,' in Advances in Neural Information Processing Systems 32 , H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´-Buc, e E. Fox, and R. Garnett, Eds., Curran Associates, Inc., 2019, pp. 8024-8035. |
| [17] | D. Tao, S. Di, X. Liang, Z. Chen, and F. Cappello, 'Improving perfor- mance of iterative methods by lossy checkponting,' in Proceedings of the 27th international symposium on high-performance parallel and distributed computing , 2018, pp. 52-65. |
| [18] | M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Man´, e R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Vi´gas, e O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng, TensorFlow: Large-scale machine learning on heterogeneous systems , Software available from |
| [19] | tensorflow.org, 2015. [Online]. Available: https://www.tensorflow.org/. Z. Chen, 'Optimal real number codes for fault tolerant matrix op- erations,' in Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis , 2009, pp. 1-10. |
| [20] | P. Wu, C. Ding, L. Chen, F. Gao, T. Davies, C. Karlsson, and Z. Chen, 'Fault tolerant matrix-matrix multiplication: Correcting soft errors on- line,' in Proceedings of the second workshop on Scalable algorithms for large-scale systems , 2011, pp. 25-28. |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [21] | D. Hakkarinen and Z. Chen, 'Multilevel diskless checkpointing,' IEEE Transactions on Computers , vol. 62, no. 4, pp. 772-783, 2012. |
| [22] | D. Hakkarinen, P. Wu, and Z. Chen, 'Fail-stop failure algorithm-based fault tolerance for cholesky decomposition,' IEEE Transactions on |
| [23] | Parallel and Distributed Systems , vol. 26, no. 5, pp. 1323-1335, 2014. Z. Chen and J. Dongarra, 'A scalable checkpoint encoding algorithm for diskless checkpointing,' in 2008 11th IEEE High Assurance Systems Engineering Symposium , IEEE, 2008, pp. 71-79. |
| [24] | Z. Chen, 'Extending algorithm-based fault tolerance to tolerate fail-stop failures in high performance distributed environments,' in 2008 IEEE International Symposium on Parallel and Distributed Processing , IEEE, 2008, pp. 1-8. |
| [25] | S. Mitra, P. Bose, E. Cheng, C.-Y. Cher, H. Cho, R. Joshi, Y. M. Kim, C. R. Lefurgy, Y. Li, K. P. Rodbell, et al. , 'The resilience wall: Cross- layer solution strategies,' in Proceedings of Technical Program-2014 International Symposium on VLSI Technology, Systems and Application (VLSI-TSA) , IEEE, 2014, pp. 1-11. |
| [26] | C.-Y. Cher, M. S. Gupta, P. Bose, and K. P. Muller, 'Understanding soft error resiliency of blue gene/q compute chip through hardware proton irradiation and software fault injection,' in SC'14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis |
| [27] | , IEEE, 2014, pp. 587-596. J. Dongarra, P. Beckman, T. Moore, P. Aerts, G. Aloisio, J.-C. Andre, D. Barkai, J.-Y. Berthou, T. Boku, B. Braunschweig, et al. , 'The international exascale software project roadmap,' International Journal of High Performance Computing Applications , vol. 25, no. 1, pp. 3-60, 2011. |
| [28] | J. Calhoun, M. Snir, L. N. Olson, and W. D. Gropp, 'Towards a more complete understanding of SDC propagation,' in Proceedings of the 26th International Symposium on High-Performance Parallel and Distributed Computing , ACM, 2017, pp. 131-142. |
| [29] | M. Snir, R. W. Wisniewski, J. A. Abraham, S. V. Adve, S. Bagchi, P. Balaji, J. Belak, P. Bose, F. Cappello, B. Carlson, et al. , 'Addressing failures in exascale computing,' The International Journal of High Performance Computing Applications , vol. 28, no. 2, pp. 129-173, 2014. |
| [30] | G. Li, S. K. S. Hari, M. Sullivan, T. Tsai, K. Pattabiraman, J. Emer, and S. W. Keckler, 'Understanding error propagation in deep learning neural network (dnn) accelerators and applications,' in Proceedings of the International Conference for High Performance Computing, Networking, |
| [31] | Storage and Analysis , 2017, pp. 1-12. S. Taamneh, A. Qawasmeh, and A. H. Aljammal, 'Parallel and fault- tolerant k-means clustering based on the actor model,' Multiagent and Grid Systems , vol. 16, no. 4, pp. 379-396, 2020. |
| [32] | N. Oh, P. P. Shirvani, and E. J. McCluskey, 'Error detection by duplicated instructions in super-scalar processors,' IEEE Transactions on Reliability , vol. 51, no. 1, pp. 63-75, 2002. |
| [33] | N. Oh, P. P. Shirvani, and McCluskey, 'Control-flow checking by software signatures,' IEEE transactions on Reliability , vol. 51, no. 1, pp. 111-122, 2002. |
| [34] | G. A. Reis, J. Chang, N. Vachharajani, R. Rangan, and D. I. August, 'Swift: Software implemented fault tolerance,' in Proceedings of the international symposium on Code generation and optimization , IEEE Computer Society, 2005, pp. 243-254. |
| [35] | J. Yu, M. J. Garzaran, and M. Snir, 'Esoftcheck: Removal of non-vital checks for fault tolerance,' in 2009 International Symposium on Code |
| [36] | Generation and Optimization , IEEE, 2009, pp. 35-46. Z. Chen, A. Nicolau, and A. V. Veidenbaum, 'SIMD-based soft error detection,' in Proceedings of the ACM International Conference on |
| [37] | Computing Frontiers , ACM, 2016, pp. 45-54. Z. Chen and J. Dongarra, 'Algorithm-based fault tolerance for fail- stop failures,' IEEE Transactions on Parallel and Distributed Systems , vol. 19, no. 12, pp. 1628-1641, 2008. |
| [38] | C. Ding, C. Karlsson, H. Liu, T. Davies, and Z. Chen, 'Matrix multiplication on gpus with on-line fault tolerance,' in 2011 IEEE Ninth International Symposium on Parallel and Distributed Processing with Applications , IEEE, 2011, pp. 311-317. |
| [39] | Y. Zhai, E. Giem, Q. Fan, K. Zhao, J. Liu, and Z. Chen, 'Ft-blas: A high performance blas implementation with online fault tolerance,' in |
| | Proceedings of the ACM International Conference on Supercomputing , |
|------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [40] | 2021, pp. 127-138. J. Kosaian and K. Rashmi, 'Arithmetic-intensity-guided fault tolerance for neural network inference on gpus,' in Proceedings of the Inter- national Conference for High Performance Computing, Networking, Storage and Analysis , 2021, pp. 1-15. |
| [41] | S. Wu, Y. Zhai, J. Liu, J. Huang, Z. Jian, B. Wong, and Z. Chen, 'Anatomy of high-performance gemm with online fault tolerance on gpus,' in Proceedings of the 37th International Conference on |
| [42] | Supercomputing , 2023, pp. 360-372. J. M. Bird, M. K. Peters, T. Z. Fullem, M. J. Tostanoski, T. F. Deaton, K. Hartojo, and R. E. Strayer, 'Neutron induced single event upset (seu) testing of commercial memory devices with embedded error correction codes (ecc),' in 2017 IEEE Radiation Effects Data Workshop (REDW) , |
| [43] | IEEE, 2017, pp. 1-8. G. E. Fagg and J. J. Dongarra, 'Ft-mpi: Fault tolerant mpi, supporting dynamic applications in a dynamic world,' in European parallel virtual machine/message passing interface users' group meeting , Springer, 2000, pp. 346-353. |
| [44] | D. Binder, E. C. Smith, and A. Holman, 'Satellite anomalies from galactic cosmic rays,' IEEE Transactions on Nuclear Science , vol. 22, no. 6, pp. 2675-2680, 1975. |
| [45] | E. Petersen, R Koga, M. Shoga, J. Pickel, and W. Price, 'The single event revolution,' IEEE Transactions on Nuclear Science , vol. 60, no. 3, pp. 1824-1835, 2013. |
| [46] | S. Wu, Y. Zhai, J. Huang, Z. Jian, and Z. Chen, 'Ft-gemm: A fault tolerant high performance gemm implementation on x86 cpus,' in Proceedings of the 32nd International Symposium on High-Performance Parallel and Distributed Computing , 2023, pp. 323-324. |
| [47] | P. Wu and Z. Chen, 'Ft-scalapack: Correcting soft errors on-line for ScaLAPACK Cholesky, QR, and LU factorization routines,' in Proceedings of the 23rd international symposium on High-performance |
| [48] | parallel and distributed computing , ACM, 2014, pp. 49-60. M. Turmon, R. Granat, and D Katz, 'Software-implemented fault detection for high-performance space applications,' in Proceeding International Conference on Dependable Systems and Networks. DSN |
| [49] | 2000 , IEEE, 2000, pp. 107-116. S. A. Shalom, M. Dash, and M. Tue, 'Efficient k-means clustering using accelerated graphics processors,' in Data Warehousing and Knowledge Discovery: 10th International Conference, DaWaK 2008 Turin, Italy, September 2-5, 2008 Proceedings 10 , Springer, 2008, pp. 166-175. |
| [50] | R. Farivar, D. Rebolledo, E. Chan, and R. H. Campbell, 'A parallel implementation of k-means clustering on gpus.,' in Pdpta , vol. 13, 2008, |
| [51] | pp. 212-312. Y. Li, K. Zhao, X. Chu, and J. Liu, 'Speeding up k-means algorithm by gpus,' Journal of Computer and System Sciences , vol. 79, no. 2, pp. 216-229, 2013. |
| [52] | C. Lutz, S. Breß, T. Rabl, S. Zeuch, and V. Markl, 'Efficient and scalable k-means on gpus,' Datenbank-Spektrum , vol. 18, pp. 157-169, 2018. |
| [53] | M. Kruliˇ, s J. Lokoˇ, c and T. Skopal, 'Efficient extraction of clustering- based feature signatures using gpu architectures,' Multimedia Tools and Applications , vol. 75, pp. 8071-8103, 2016. |
| [54] | S. Cuomo, V. De Angelis, G. Farina, L. Marcellino, and G. Toraldo, 'A gpu-accelerated parallel k-means algorithm,' Computers &Electrical |
| [55] | Engineering , vol. 75, pp. 262-274, 2019. Y. Ding, Y. Zhao, X. Shen, M. Musuvathi, and T. Mytkowicz, 'Yinyang k-means: A drop-in replacement of the classic k-means with consistent speedup,' in International conference on machine learning , PMLR, 2015, pp. 579-587. |
| [56] | J. Nelson and R. Palmieri, 'Don't forget about synchronization! a case study of k-means on gpu,' in Proceedings of the 10th International Workshop on Programming Models and Applications for Multicores and Manycores , 2019, pp. 11-20. |
| [57] | M. Kruliˇ s and M. Kratochv´l, ı 'Detailed analysis and optimization of cuda k-means algorithm,' in Proceedings of the 49th International Conference on Parallel Processing , 2020, pp. 1-11. |
| [58] | K. Ouyang, V. Tran, J. Liu, B. M. Wong, and Z. Chen, 'Kf k-means: A high performance k-means implementation using kernel fusion,' in 2023 IEEE International Conference on Big Data (BigData) , IEEE, 2023, pp. 121-127. |
| [59] | S. Raschka, J. Patterson, and C. Nolet, 'Machine learning in python: Main developments and technology trends in data science, machine |
- [59] S. Raschka, J. Patterson, and C. Nolet, 'Machine learning in python: Main developments and technology trends in data science, machine learning, and artificial intelligence,' Information , vol. 11, no. 4, p. 193, 2020.
| [60] | J. Liu, J. Tian, S. Wu, S. Di, B. Zhang, Y. Huang, K. Zhao, G. Li, D. Tao, Z. Chen, et al. , 'Cusz-i: High-fidelity error-bounded lossy compression |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [61] | for scientific data on gpus,' arXiv preprint arXiv:2312.05492 , 2023. J. Huang, J. Liu, S. Di, Y. Zhai, Z. Jian, S. Wu, K. Zhao, Z. Chen, Y. Guo, and F. Cappello, 'Exploring wavelet transform usages for error-bounded scientific data compression,' in 2023 IEEE International Conference on Big Data (BigData) , IEEE, 2023, pp. 4233-4239. |
| [62] | Z. Jian, S. Di, J. Liu, K. Zhao, X. Liang, H. Xu, R. Underwood, S. Wu, J. Huang, Z. Chen, et al. , 'Cliz: Optimizing lossy compression for climate datasets with adaptive fine-tuned data prediction,' in 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS) , IEEE, 2024, pp. 417-429. |
| [63] | J. Liu, S. Di, K. Zhao, X. Liang, S. Jin, Z. Jian, J. Huang, S. Wu, Z. Chen, and F. Cappello, 'High-performance effective scientific error-bounded lossy compression with auto-tuned multi-component interpolation,' Proceedings of the ACMon Management of Data , vol. 2, no. 1, pp. 1-27, 2024. |
| [64] | K.-H. Huang and J. A. Abraham, 'Algorithm-based fault tolerance for matrix operations,' IEEE transactions on computers , vol. 100, no. 6, pp. 518-528, 1984. |
| [65] | Y. Zhai, E. Giem, K. Zhao, J. Liu, J. Huang, B. M. Wong, C. R. Shelton, and Z. Chen, 'Ft-blas: A fault tolerant high performance blas implementation on x86 cpus,' IEEE Transactions on Parallel and Distributed Systems , 2023. |
| [66] | X. Liang, J. Chen, D. Tao, S. Li, P. Wu, H. Li, K. Ouyang, Y. Liu, F. Song, and Z. Chen, 'Correcting soft errors online in fast Fourier transform,' in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , ACM, 2017, p. 30. |
| [67] | S. Wu, Y. Zhai, J. Liu, J. Huang, Z. Jian, H. Dai, S. Di, Z. Chen, and F. Cappello, 'Turbofft: A high-performance fast fourier transform with fault tolerance on gpu,' arXiv preprint arXiv:2405.02520 , 2024. |
| [68] | S. Li, H. Li, X. Liang, J. Chen, E. Giem, K. Ouyang, K. Zhao, S. Di, F. Cappello, and Z. Chen, 'FT-iSort: Efficient fault tolerance for introsort,' in Proceedings of the International Conference for High Performance |
| [69] | Computing, Networking, Storage and Analysis , ACM, 2019, p. 71. Z. Chen, 'Online-ABFT: An online algorithm based fault tolerance scheme for soft error detection in iterative methods,' in ACM SIGPLAN Notices , ACM, vol. 48, 2013, pp. 167-176. |
| [70] | D. Tao, S. L. Song, S. Krishnamoorthy, P. Wu, X. Liang, E. Z. Zhang, D. Kerbyson, and Z. Chen, 'New-sum: A novel online ABFT scheme for general iterative methods,' in Proceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed |
| [71] | Computing , ACM, 2016, pp. 43-55. L. Chen, D. Tao, P. Wu, and Z. Chen, 'Extending checksum-based abft to tolerate soft errors online in iterative methods,' in 2014 20th IEEE International Conference on Parallel and Distributed Systems (ICPADS) , IEEE, 2014, pp. 344-351. |
| [72] | K. Zhao, S. Di, S. Li, X. Liang, Y. Zhai, J. Chen, K. Ouyang, F. Cappello, and Z. Chen, 'Algorithm-based fault tolerance for convolutional neural networks,' IEEE Transactions on Parallel and Distributed Systems , 2020. |
| [73] | Y. Zhai, C. Jiang, L. Wang, X. Jia, S. Zhang, Z. Chen, X. Liu, and Y. Zhu, 'Bytetransformer: A high-performance transformer boosted for variable-length inputs,' in 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS) , IEEE, 2023, pp. 344-355. |
| [74] | Y. Zhai, Architectural-Aware Performance Optimization: From the Foundational Math Library to Cutting-Edge Applications . University of California, Riverside, 2023. |
| [75] | NVIDIA, https://github.com/NVIDIA/cutlass, Online, Retrieved in 2022. |
| [76] | J. Johnston, X.-Y. Liu, S. Wu, and X. Wang, 'A curriculum learning approach to optimization with application to downlink beamforming,' IEEE Transactions on Signal Processing , 2023. |
| [77] | X.-Y. Liu, Z. Li, S. Wu, and X. Wang, 'Stationary deep reinforcement learning with quantum k-spin hamiltonian regularization,' in ICLR 2023 Workshop on Physics for Machine Learning , 2023. |
| [78] | J. Johnston, X.-Y. Liu, S. Wu, and X. Wang, 'Downlink beamforming optimization via deep learning,' in 2023 59th Annual Allerton Con- ference on Communication, Control, and Computing (Allerton) , IEEE, 2023, pp. 1-5. | | null | [
"Shixun Wu",
"Yitong Ding",
"Yujia Zhai",
"Jinyang Liu",
"Jiajun Huang",
"Zizhe Jian",
"Huangliang Dai",
"Sheng Di",
"Bryan M. Wong",
"Zizhong Chen",
"Franck Cappello"
]
| 2024-08-02T17:01:36+00:00 | 2024-08-07T21:55:08+00:00 | [
"cs.DC",
"cs.LG"
]
| FT K-means: A High-Performance K-means on GPU with Fault Tolerance | K-means is a widely used algorithm in clustering, however, its efficiency is
primarily constrained by the computational cost of distance computing. Existing
implementations suffer from suboptimal utilization of computational units and
lack resilience against soft errors. To address these challenges, we introduce
FT K-means, a high-performance GPU-accelerated implementation of K-means with
online fault tolerance. We first present a stepwise optimization strategy that
achieves competitive performance compared to NVIDIA's cuML library. We further
improve FT K-means with a template-based code generation framework that
supports different data types and adapts to different input shapes. A novel
warp-level tensor-core error correction scheme is proposed to address the
failure of existing fault tolerance methods due to memory asynchronization
during copy operations. Our experimental evaluations on NVIDIA T4 GPU and A100
GPU demonstrate that FT K-means without fault tolerance outperforms cuML's
K-means implementation, showing a performance increase of 10\%-300\% in
scenarios involving irregular data shapes. Moreover, the fault tolerance
feature of FT K-means introduces only an overhead of 11\%, maintaining robust
performance even with tens of errors injected per second. |
2408.01392v1 | ## MoonLITE: a CLPS-delivered NASA Astrophysics Pioneers lunar optical interferometer for sensitive, milliarcsecond observing
Gerard T. van Belle , David Ciardi , Daniel Hillsberry , Anders Jorgensen , John Monnier , a b c d e Krista Lynne Smith , Tabetha Boyajian , Kenneth Carpenter , Catherine Clark f g h i,b , Gioia Rau j,k , and Gail Schaefer l a Lowell Observatory, 1400 West Mars Hill Rd., Flagstaff, AZ 86001, USA b NASA Exoplanet Science Institute, IPAC, California Institute of Technology, Pasadena, CA 91125, USA
c Argo Space, Inc., 601 Cypress Ave, Suite 404, Hermosa Beach, CA, 90254, USA d New Mexico Institute Of Mining And Technology, 801 Leroy Pl., Socorro, NM 87801, USA e University Of Michigan, 500 S State St., Ann Arbor, MI 48109, USA f Mitchell Institute for Fundamental Physics & Astronomy, Texas A&M University, 576 University Dr., College Station, TX 77843, USA
g Louisiana State University and A&M College, Baton Rouge, LA 70803, USA h NASA Goddard Space Flight Center, 8800 Greenbelt Rd, Greenbelt, MD 20771, USA i Jet Propulsion Laboratory, California Institute of Technology, Pasadena, CA 91109, USA j National Science Foundation, 2415 Eisenhower Avenue, Alexandria, VA 22314, USA k NASA Goddard Space Flight Center, 8800 Greenbelt Road, Greenbelt, MD 20771, USA l The CHARA Array, Georgia State University, Mount Wilson, CA 91023, USA
## ABSTRACT
MoonLITE (Lunar InTerferometry Explorer) is an Astrophysics Pioneers proposal to develop, build, fly, and operate the first separated-aperture optical interferometer in space, delivering sub-milliarcsecond science results. MoonLITE will leverage the Pioneers opportunity for utilizing NASA's Commercial Lunar Payload Services (CLPS) to deliver an optical interferometer to the lunar surface, enabling unprecedented discovery power by combining high spatial resolution from optical interferometry with deep sensitivity from the stability of the lunar surface. Following landing, the CLPS-provided rover will deploy the pre-loaded MoonLITE outboard optical telescope 100 meters from the lander's inboard telescope, establishing a two-element interferometric observatory with a single deployment. MoonLITE will observe targets as faint as 17th magnitude in the visible, exceeding ground-based interferometric sensitivity by many magnitudes, and surpassing space-based optical systems resolution by a factor of 50 × . The capabilities of MoonLITE open a unique discovery space that includes direct size measurements of the smallest, coolest stars and substellar brown dwarfs; searches for close-in stellar companions orbiting exoplanet-hosting stars that could confound our understanding and characterization of the frequency of Earth-like planets; direct size measurements of young stellar objects and characterization of the terrestrial planet-forming regions of these young stars; measurements of the inner regions and binary fraction of active galactic nuclei; and a probe of the very nature of spacetime foam itself. A portion of the observing time will also be made available to the broader community via a guest observer program. MoonLITE takes advantage of the CLPS opportunity to place an interferometer in space on a stable platform - the lunar surface - and delivers an unprecedented combination of sensitivity and angular resolution at the remarkably affordable cost point of Pioneers.
Keywords: lunar telescopes, optical interferometry, milliarcsecond imaging
## 1. INTRODUCTION
Advances in spatial resolution have frequently led to unexpected discoveries in astrophysics. For the first centuries of astronomy, those gains were largely limited to increasing aperture size of single-aperture telescopes. In recent decades, however, the interferometric combination of telescopes has allowed astronomers to capture significant gains in spatial resolution at increasingly shorter wavelengths. Two recent, ground-breaking examples are the first direct observation of black holes by the Event Horizon Telescope [1], and the first detection of orbital precession of stars around the galactic center black hole by the VLTI-Gravity [2], which was part of the 2020 Nobel Prize in Physics. However, it is important to note that the VLTI observational capability in the optical involved multiple 8-meter-class telescopes at a facility costing hundreds of millions of euros. Costly, large facilities are needed for terrestrial interferometry because the Earth's atmosphere limits integration times at those wavelengths to millisecond-scale durations. Space-based optical interferometry does not have this sensitivity limitation, opening up a breadth of scientific avenues for relatively minimal complexity and modest cost.
The Moon Lunar InTerferometry Explorer (MoonLITE) concept leverages NASA's newly flying Commercial Lunar Payload Services (CLPS) capability to deliver an optical interferometer to the lunar surface. MoonLITE will enable unprecedented discovery power by combining the high spatial resolution of optical interferometry - and deep sensitivity possible with the stability of the lunar surface - at the remarkably affordable cost point of a NASA Astrophysics Pioneers. Lunar surface siting yields the benefits of space (e.g., no atmosphere), but alleviates the need for complicated orbital spacecraft stability subsystems.
## 2. WHY THE MOON?
It has been suggested that, 'the only thing the moon has to offer astronomy is dirt and gravity' [3, paraphrased]. The discussion in [3] goes on to discuss the value proposition that lunar siting has for astronomy. It is useful to consider that value proposition when considering two important capabilities necessary for the optical interferometry technique.
First, the deceptively simple demands of telescope pointing must be considered. [3] argues that this is a solved problem because of examples like HST, which overlooks the considerable expense that has gone into this 'simple' capability, and the considerable problems that even marquee efforts have had with telescope pointing. The project landscape is littered with examples of missions that have terminated, failed, or degraded because of an inability to orient the spacecraft in a zero-gee environment - starting with the US's first satellite, Explorer-1 [4], and more recently
Figure 1. Surveyor 3 being inspected by astronaut Charles Conrad; in the background is Apollo 12 Lunar Module Intrepid . Despite their derelict nature, these two spacecraft have remained precisely positioned relative to each other, and in absolute position on the lunar surface, for over 50 years. (Credit: NASA/Don Davis).

astrophysical facilities like HST, Kepler, Hitomi, WIRE, etc. A 2009 Canadian Space Agency study of 156 failures worldwide between 1980 and 2005 listed the attitude control subsystem (ACS) as the leading cause of spacecraft failures [5], causing almost a third of all failures, surpassing command & data handling, power systems, telemetry, tracking & command, structures & mechanisms, and the payload. It is important to highlight that this is for all ACS failures, not just the even-more-demanding case of precision attitude control for telescopes.
Second, for an optical interferometer, the relative positions of the multiple input telescopes are of equal importance. To date, for orbital missions, there has been considerable effort - and budget - expended on developing formation flying capabilities; a particularly good summary is provided in [6]. By and large, the current state of the art in formation flying - which is still inadequate for optical interferometry - means an investment of tens if not hundreds of millions of dollars.
So why the moon? The key here is that value proposition of lunar siting. Let's consider the two spacecraft on the surface of the moon, Surveyor 3 and the Apollo 12 LM descent stage (Figure 1). For the past 50 years, they have stayed 180 meters from each other, with their relative position remaining static at the sub-micron level, even though the two craft were never designed to maintain their relative positions. Because of gravity, stationkeeping is free.
The Apollo 16 mission deployed the first lunar-based telescope, the Far Ultraviolet Camera/Spectrograph (UVC) [7]. Telescope pointing was achieved manually by the astronauts when starting an exposure; the astronauts then simply ignoring the telescope - no gyros or star trackers needed. For both pointing and stationkeeping, gravity is not a bug, it's a feature .
Finally, there is the question of dust. Lunar dust is indeed nasty, even toxic, stuff. Apollo astronauts reported congestion and fever, and similar dust on Earth has been associated with silicosis, asbestosis, and black lung disease. The glass-shard nature of many of the dust particles, which have a peak size distribution at 0.3 µ m, leads to rapid frictional degradation of unprotected mechanical devices [8]. For astronauts returning to the lunar surface, mitigation of dust contamination will be of paramount importance. However, for autonomous operations of properly designed and protected static optical systems, this will be less of a problem than anticipated, and mitigated through simple operational procedures. This is not inferred from theory but from a TRL-9 existence proof: the Lunar-based Ultraviolet Telescope (LUT) on board the Chang'e-3 lander [9] reported more than 1.5 years of highly stable operations on the lunar surface in 2015 [10], and operated through 2018 . ∗ Simple operational procedures such as sealing off the LUT optics during lunar sunrise / sunset, when dust particles are expected to be levitated from the surface [11], appear to have been effective in preventing degradation of the optics and the pointing mechanisms.
Overall that value proposition of lunar siting is an advantageous context by which to examine the usefulness of astronomical observatories on the lunar surface. Our contention is that, particularly for interferometric telescope arrays, and within the rapidly evolving paradigm of increased surface access from NASA's Artemis program, the answer to that proposition has swung decisively in favor of the moon.
## 3. DESCRIPTION OF THE INSTRUMENT
We developed the MoonLITE concept to rapidly take advantage of the now-flying CLPS lunar landers, and to demonstrate the viability and unique capability of optical interferometry from the surface of the moon. We wanted to optimize the simplicity of MoonLITE, adopting known techniques from Earth-based arrays, and showing that even a pizza-box sized instrument can outperform industrial-level efforts back on Earth. An overall block diagram of the instrument is seen in Figure 2.
Telescope Feed Station Apertures. MoonLITE collects light on astronomical targets from two telescope feed stations. One station, the 'inboard', is mounted on the lander with the main instrument. The second station, the 'outboard', is deployed by the rover after landing, as described in the next section ( § 4). Both stations are identical. A feed station has an articulating siderostat, which feeds a fixed 50 mm refractor telescope. The telescope focuses light onto an image plane dichroic, which splits the λ < 620 nm short-wavelength light off and feeds it to an image acquisition / fine guidance CCD. The longer wavelength light passes through the dichroic and is coupled into a polarization-maintaining, single-mode fiber.
Siderostats have multiple advantages. The articulating flat that feeds the telescope has a minimal swing radius, so the input aperture can be easily shuttered. This is essential for preventing contamination of the optics
∗ 'Thanks to power supplied by solar panels and a radioisotope heater unit, engineers think Chang'e-3 and LUT could have kept functioning for a few more decades, but at the end of 2018, China powered them down in order to focus on the fourth iteration of their Chang'e program.' ( https://www.astronomy.com/observing/ exploring-the-moon-chinas-change-missions/ , retrieved 2023-12-01.)
due to dust levitation during lunar sunrise and sunset, as discussed previously. Having a siderostat feed also means that the telescope, and any downstream optics such as the fiber feed, are fixed. For the fiber in particular, a mechanically-fixed design means variations in throughput and beam rotation are eliminated. Finally, a siderostat design means the system can be configured for retroreflection, and internal fringes can be measured. This option allows for the measurement of internal, constant-term optical path difference (OPD).
## MoonLIIE Observatory Block Diagram
Figure 2. MoonLITE subsystem block diagram. Inboard and outboard apertures feed a backend beam combiner via fiber optics; the outboard aperture is connected back to the lander via an umbilical.
Umbilical cable. The umbilical line for the outboard telescope feed station includes an electrical connection for power and communications that is fed by the lander. It also includes an optical fiber line for relaying observing light from the station back to the lander. An additional optical fiber can also be considered for laser metrologybased pathlength measurement along the umbilical; this would allow for monitoring of temperature-induced fluctuations in OPD. Such an option would need a metrology dichroic and retro-reflector added to the telescope feeds, as well as a fiber-based metrology source at the main instrument, both of which could be accommodated in straightforward manner.
The inboard telescope feed station has a simplified umbilical connection with the main instrument, consisting of an identical copy of the optical link.
In using an optical fiber link to relay the light from the outboard station back to the main instrument aboard the lander, two extremely important features are realized in the overall instrument architecture. First, scattered light is nearly eliminated, even during lunar daytime operations. For architectures that involve free-space bulk optics relaying of light from outboard stations to a central combiner instrument, either lunar nighttime operations or significant amounts of baffling for the beam relay are required. However, nighttime ops are likely a non-option in the near future given the extreme cold limiting battery life, the weight of sufficiently-capable batteries to combat cold and carry out ops, and the lack of immediately-available solar power.
Secondly, with a fiber-based relay architecture, an operational two-element interferometer is obtained with the mechanical deployment of a single outboard station. For free-space bulk optics relaying of light, to obtain a natural zenith-pointing of the instrument, two stations will need to be deployed at equal distances from a central combiner unit. Such a deployment requirement doubles the number of mechanical actions involved in establishing the operational instrument, and potentially involves a rover CONOPS that requires returns to the lander to fetch a second outboard feed station.
Main Instrument: Delay Line. Each of two input beams will be routed to the main instrument via fibers, will exit the fibers and be re-collimated, and fed into the instrument delay line. The delay line has a multi-pass, dualsided architecture such that the largest amount of optical path delay can be obtained with limited mechanical range. For example, in our current lab test setup, each beam does a double back-and-forth pass to the delay line stage, and both beams follow such a path on opposite sides of the stage, meaning for a given mechanical stroke, the amount of optical stroke is 8 × greater (eg. compare the yellow and green beams in Figure 3). The principal drawback of this architecture is that for a given amount of positioning jitter in the delay line linear actuator, the OPD jitter is similarly 8 × greater. Additionally, this increases the sensitivity to alignment errors of the beam path into the delay line stage. Our current linear stage, a Zaber X-LDA075, has a 1 nm resolution linear encoder, and with 75 mm of travel, provides 600 mm of OPD in this configuration. Additional passes in a flight instrument could increase the multiplicative effect even more, and every increase in stage travel adds to the available OPD in that multiplicative fashion. In the case of MoonLITE, we intend to have ∼ 3 m of OPD delay for the 100 m baseline; the implications of this for sky coverage are presented in the CONOPS section ( § 4).
Main Instrument: Combiner. The beam combiner will utilize a polarization-based quadrature extraction architecture similar to the VLTI PRIMA instrument [12, 13, 14], which has already been shown to perform in the visible in a flight-like packaging [15, 16]. The two beams are combined after delay, and after passing through either a quarter-waveplate or a compensator window, arrive at a 50/50 beam splitter. The two output combined beams are then each routed to polarizing beam splitters. The resulting four beams each photometrically encode one of the four fringe quadratures [e.g., see Figure 6 of 17]. The four beams are focused onto a CCD detector. The resulting measurement can be used to feedback control to the delay line. Our current lab setup has not been optimized for size or weight, but its current size is already only 12' × 18' (300mm × 450mm).
## 4. CONCEPT OF
## OPERATIONS (CONOPS)
Physical deployment. Prior to launch, the MoonLITE payload will be mounted into its payload bay aboard the CLPS lander. This lander-mounted payload includes two principal components: (1) the main instrument, and (2) the inboard telescope feed station. Additionally, the second outboard telescope feed station will be loaded onto the CLPS-provided rover prior to launch. By pre-loading the outboard station onto the rover before launch, all failure modes associated with loading that station onto the rover after arrival at the lunar surface are eliminated.
The launch, cruise, and landing of the CLPS vehicle are all provided as a contracted service independent of MoonLITE. Similarly, the deployment of the rover is also a CLPS-provided service. Once the surface is reached, the first task of the rover will be to deploy the outboard station. The rover will drive 100 meters away from the lander along an east-west line, unreeling (but not dragging) the umbilical cable back to the lander. After reaching its desired distance from the lander, which has a flexible tolerance in distance and direction on the order of ± 1 meter, MoonLITE's single specific mechanical deployment happens: the rover sets down the outboard station
Figure 3. A CAD rendering of the current lab test setup for the MoonLITE main instrument optical engineering development unit (opEDU). Light from each of the two input beams (yellow and green) enters from the bottom, is routed through a multi-pass delay line, and is passed through a quarter waveplate (green beam) or compensator (yellow beam), meeting at a 50/50 beam splitter (where the beams becomes orange). The combined beams are then split via polarizing beam splitters, creating four beams total, each of which encodes an individual fringe quadrature. These four beams are focused onto a CCD camera.
Figure 4. Concept of operations (CONOPS) for MoonLITE. (1) A CLPS-provided lander arrives at the lunar surface. (2) The CLPS-provided rover travels 100 meters away from the lander, unrolling a fiber umbilical. (3) The outboard siderostat station is deployed. After calibration of the individual stations and the overall combined beams, science operations commence.
and disengages from it. The rover is now available to leave and conduct other CLPS tasks for other customers aboard the lander; the only restriction for the now-separate CONOPS of the rover is to avoid the umbilical cable.
The inboard station is optically identical to the outboard station, and also relays its light to the main instrument via a fiber. The inboard station fiber is coiled up inside the lander, meeting two important conditions. First, the light from each station has an identical amount of static optical path from its collector to the main instrument. The means zero OPD - eg. the natural pointing of the instrument - will along the line running thru the zenith and perpendicular to the projection baseline vector of the two telescope stations onto the sky. In the case of an east-west baseline, this natural pointing will run along the meridian. Second, the light from each station encounters an identical amount of fiber - as well as fiber-induced dispersion and other optical effects meaning the two beams will ultimately re-combine cleanly . †
Calibration. Each telescope feed station will be activated individually, and will sweep out a series of images on the sky to determine the siderostat pointing models. Astrometric recognition of the star images from the station acquisition camera will provide a mapping of the siderostat pointing to pointing coordinates for the sky. Similar procedures and software already exist for Earth-based telescopes, have been tested with mobile interferometer stations at NPOI [18], and can recover a pointing model from a fully unknown state within 30 minutes.
Once each individual station has a calibrated pointing model, an interferometric baseline vector will be determined. MoonLITE will have each station point to the same bright astrometric reference object, and will commence looking for fringes. Fringes seeking is carried out by examining the combined light from the two telescope stations and looking for the tell-tale sign of interference. Given the initial error envelope of the outboard station location relative to the inboard station, it is likely the initial search for fringes will be timeconsuming, and may take many minutes. However, once the first fringes are found, additional detections of other astrometric references will be much more rapid. By expanding the detections into the full range of the available sky coverage of the instrument, a precise determination of the baseline vector of the instrument can be made. This is the same procedure used at Earth-based facilities [19, 20], and typically results in a baseline determination at the tens of microns level. As such, subsequent fringe detections only need to search this range of delay space, and are rapidly carried out.
Operations. With the pointing models and baseline vector measured, science operations can commence. By and large, as the moon rotates and objects cross the sky through the course of the lunar day of operations, they will become observable as they cross the range of sky coverage afforded by the delay line relative to the baseline
† Here we follow the second rule of interferometer beam relay. The first rule is, 'Don't do anything bad to the light,' and the second rule is, 'When you do do something bad to the light, do the same bad thing to all the beams.'
vector (Figure 5). For most objects on the sky, only a simple one-dimensional size measurement will be possible . ‡ This is because, as noted in the instrument description, the nominal baseline layout for MoonLITE will be an east-west orientation, with only a narrow strip of sky coverage available. Note that the units in Figure 5 are hours of right ascension ; the amount of clock time available for observing will be many hours, given the ∼ 28 × slower rotation rate of the moon relative to the Earth. Also, if a slight rotation of the baseline vector is selected with the deployment of the outboard station - e.g., the rover heads slightly south of an exact east-west line a long tail in sky coverage can be dialed in a specific declination. In Figure 5, a notional case is shown where many right ascension hours of coverage are possible at δ ∼ 75 . o The intent here is that, if there are certain 'marquee' targets available in a cluster at that declination range, a modicum of rotational aperture synthesis is now available to make two-dimensional maps of those targets . § In this particular case, the Chamaeleon star formation region lies along this line of declination, and a science case for MoonLITE would be mapping the terrestrial regions of the young stellar objects.
Survive-the-Night and the Following Day. A current requirement for CLPS is that the landers of that upcoming generation of surface hosts expect at least one cycle of non-operational 'survive-the-night' and a second day of operations; payloads are expected to do the same, with a goal of up to six such cycles. As such, our baseline required science plan for MoonLITE is two lunar days of science operations, with roughly 300 hours of science observing during each.
## 5. SCIENCE CASES
The unique strength of MoonLITE will be its ability to observe objects at unprecedented sensitivity because of its substantially longer observing coherence times. Unfettered by the Earth's atmosphere, our baseline requirement will be a 300 second exposure time, with a goal of 3000 seconds. Based on this baseline coherence time, we estimate that MoonLITE will observe isolated objects down to a visual magnitude of 17. This estimate is based on nominal numbers for fiber coupling efficiency [21], 2 e -detector read noise and 70% quantum efficiency, ∼ 1-4 db/km fiber attenuation for commercially-available visible-light singlemode polarization-maintaining fibers, and 98.5% mirrors reflectivity on 30 reflections (21 of which are used in a multiply-folded delay line). This sensitivity outdoes current ground-based limits for direct fringe sensing by 6-7 magnitudes [22]. Techniques such as dualbeam feed can extend the sensitivity of Earth-based observatories, but these techniques are subject to the sky coverage necessity of a nearby fringe tracking reference object at the direct fringe sensing limit ¶ , as
Figure 5. Notional sky coverage chart for MoonLITE, given a putative landing latitude of -20 , a 3-m delay line OPD o range, and a 100 m baseline offset roughly 10 o from a eastwest line. The offset results in a zone of extended sky coverage for targets at ∼ -77 , allowing for rotational aperture o synthesis for those targets. Due to the rotational libration of the moon, the lunar axis 'waggles' around by 6 7 ; . o this effect is not accounted for in this plot. The net effect is that the edge of the coverage plot varies slightly with time, where depending on the libration phase, at the ∼ 10% level regions outside the coverage will be accessible, and some inside the nominal coverage will not be accessible. The blue line represents the horizon.
‡ The science cases for MoonLITE are tailored to objects for which this measurement is of extremely high value.
§ MoonLITE is rather 'site agnostic', in that for any given landing latitude, the baseline can be tailored to maximize the available objects in its science case.
¶ The availability of IRS 16C with m K = 9 7 within 1.2' of Sgr A* for fringe tracking with VLTI-Gravity, and IRS 7 . with m K = 6 5 within 5.5' of Sgr A* for AO phasing [23] is a lightning-strikes-twice level of good fortune - 'Nature must . want us to observe the galactic center.'
well as problematic noise and calibration problems [24]. The 5 cm apertures of MoonLITE will outperform the sensitivity of 8 m Earth-based interferometer apertures.
As a two-element interferometer, the forte of MoonLITE science is ultra-high angular resolution observations in one principal axis. This includes angular size measurements of astrophysical objects and detection of multiplicity along that axis. In certain limited cases (e.g., § 5.2), a broader two-dimensional characterization of targets will be possible. As MoonLITE is a high-precision, fiber-based instrument, we expect a visibility precision of 0.3% [25, 26], which means angular sizes measurements down to 100 µ as should be possible with < 10% errors, and measurements down to 0.4-1.4mas should be possible with < 0 1% errors. .
The following three examples are a small sample of the unexplored science vistas that are enabled by the unprecedented sensitivity of MoonLITE at sub-milliarcsecond scales in the visible; there are a substantial number of additional science investigations enabled by MoonLITE's unique capabilities.
## 5.1 Radii of the Lowest-Mass Stars and Brown Dwarfs
Direct measures of stellar angular sizes have been instrumental in empirically establishing the reference linear radii and effective temperatures for main sequence [27, 28] and giant stars [29]. However, the sensitivity limits of groundbased measurements have restricted these essential calibrations of fundamental stellar parameters to main sequence stars earlier than the middle of the M-dwarf mass range [eg. see Figure 2.1 in 30]. Empirical measurements are critical in this regime, where convection significantly complicates the models [31, 32]. As a result, there is a critical gap in our knowledge of the stellar radii and temperatures, and thus, the luminosities, for these stars and the planets that they host [33]. Furthermore, because of their faintness, interferometric measures of single M dwarfs truncate generally at M4V [30], with only a single measure of a M6V star (Prox Cen) in the literature [34]. There are no direct measurements of later M dwarfs or sub-stellar brown dwarfs (Figure 6). However, in the southern
Figure 6. Extending the empirical HR diagram for the coolest stellar and sub-stellar objects: MoonLITE will complete the census of Mdwarf stars from M5V to M9.5V, and will directly measure the sizes of multiple brown dwarfs.
hemisphere, there are 13 M5-M6 stars, 11 M6.5-M9.5 stars, two L-dwarf systems (2MASSW J1507476-162738, a L5.5, and Luhman 16, a L7.5 + T0.5 pair), and a T1 brown dwarf [ ϵ Ind; 35] that are all both sufficiently bright ( m < I 16 5) and resolvable ( . θ > 0 11 mas) by MoonLITE, with a comparable tally available in the north. . By measuring the radii and habitable zone sizes of more than a dozen low-mass and ultra-cool dwarfs spanning the low-temperature spectral regime beyond the grasp of ground-based interferometers, MoonLITE can dramatically change our understanding of M stars and brown dwarfs.
## 5.2 Young Stellar Objects
The discovery of thousands of exoplanets in a multitude of architectures has challenged our theories of planet formation. Given the ubiquity of exoplanets, planet formation must be a highly-efficient process [36], but theories that describe the formation and evolution of planets from protoplanetary disks around pre-main sequence stars have been poorly constrained because of a lack of sensitivity and resolution at the scales of planet formation. The 2020 Astrophysics Decadal Survey [37] identified an understanding of the pathway to a habitable planet as one of the priority areas for the coming decade, and investigating how planets form and interact with their primordial disk and the pre-main sequence host star is a crucial element in understanding the morphology of our own Solar system and the diversity of exoplanetary systems that have been discovered [38]. These systems are beginning to be explored with sub-mm observations (Figure 7), but MoonLITE can explore these YSOs in the visible, with higher resolution, for the first time.
When young, more than half of the surface of a star may be covered in starspots [40], strongly altering energy transport in the outer layers, and causing stellar models to underestimate masses (and ages) by a factor of two [41]. Direct size measurements with MoonLITE will place significant constraints on the luminosity and mass, and thus models, of young stars. MoonLITE will also enable the first direct measurements of the inner regions of pre-main sequence stars, as well as sizes of the stars themselves.
The Chamaeleon I (Cha I) cloud contains no less than 80 young stellar objects (YSOs) with m V < 16 and δ ∼ -77. Given its near-pole declination and an optimized orientation of the baseline rotation, we expect significant baseline rotational sampling to be possible over the course of a lunar day (Figure 5). At a distance of 160 pc [42], 1 mas corresponds to a scale of 0.16 au, providing ample resolution into the regions around the YSOs in this cloud. Similarly, the star-formation region in Cepheus provides dozens of sufficiently bright objects at a high declination in the northern hemisphere [43], although at slightly-less-preferable distances of 200 to 400 pc.
Figure 7. The disk of HD163296 from ALMA [39], with an angular resolution of 40 mas . MoonLITE will have an angular resolution approximately 40 × better, and will probe the terrestrial planet-forming region at 1 au.
For simple size measurements of the central stars, a cursory review of known objects indicates many dozens of targets available all-sky with predicted sizes [44] greater than our 2.5% error threshold at 0.2 mas. Our planned YSO program will survey a dozen objects in detail for disk structure with ≥ 3 repeat observations, and more than two dozen YSOs for core object sizes. Inner disk structure and stellar binarity complicate the measurement of the sizes of the pre-main sequence stars, but observing enough position angles will enable simultaneous modeling of the diameters, inner disk structures, and binary separations for a subset of key sources.
## 5.3 Active Galactic Nuclei
The ability of supermassive black holes to launch powerful relativistic jets that can far exceed the size of their host galaxies, and with profound effects on those galaxies' evolution, has been an astrophysical mystery for decades. The energy source of the jet may be the accretion disk or the spinning black hole itself, and the collimation mechanism may be strong, large-scale magnetic fields, interaction with the interstellar medium, or both. The activation mechanism of the accretion disk, and therefore the jet, occurs when material is funneled into the galactic center and onto the hole; however, the dominant mechanism for achieving this could be galaxy mergers, secular processes, or both. By far the dominant tool for studying the nuclear regions of the jet (often called the 'jet-base') has been radio VLBI (Figure 8), due to its ability to resolve on microarcsecond scales. Higher observing frequencies probe regions nearer to the central engine itself, and often reveal complex conical, cylindrical, or limb-brightened structures that improve our understanding of how the jet is constrained at very small spatial scales, and how it interacts with gas nearby.
A number of nearby radio galaxies exhibit parsec-scale radio structures that are misaligned with their larger, kiloparsec-scale radio jets. In some cases (e.g., NGC 1068), this radio emission is associated with a disk or torus that is roughly perpendicular to the larger structure. Studies have attempted to do this using proxy methods for studying the optical structure; for example, [45] found that the optical centroids of quasars from Gaia coincide
Figure 8. Radio VLBI observations of the inner regions of the radio jets in 3C 84 and BL Lacerta (left, center) and the binary AGN candidate in the radio galaxy 0402+379 (right). These figures are adapted from [46], [47], and [48]. The two jet structures span approximately 4 mas along the jet axis, which correspond to spatial scales of ∼ 1 5 pc and . ∼ 5 pc for 3C 84 and BL Lac, respectively; the binary separation is approximately 7 mas (7.3 pc). MoonLITE will explore such objects at comparable scales in the optical for the first time.
with downstream stationary radio features with high fractional polarizations in the jet, and that the optical emission on these scales arises from synchrotron emission in the jet.
As supermassive black holes in merging galaxies approach from kiloparsec down to parsec-scale separations, when (or if) both black holes are activated by accretion and appear as a binary AGN is unclear. Until now, only radio interferometry was capable of measuring the binary fraction at the physical scales near 1 parsec, where the processes driving the merger are especially challenging theoretically (e.g., the 'final parsec problem' [49] of how the black holes lose sufficient angular momentum to enter the gravitational wave regime). Determining whether these same binaries appear in the optical as a double point source would be the first step in answering important questions about the accretion process onto the binary pair at various separations; is the accretion sufficient to power true, optically-bright accretion disks around the black holes, or only to power advection-dominated, low Eddington-ratio flows that are thought to power weak or young radio jets? The MoonLITE AGN program will survey a dozen objects for detailed morphology with ≥ 3 repeat observations, and ≥ a dozen AGN for core object sizes and binarity. MoonLITE will observe bright, very nearby radio galaxies with known parsec-scale jet structures that subtend a few to a few tens of milliarcseconds. These galaxies are well-studied by radio VLBI investigations at many frequencies and spanning a range of radio luminosities; candidates include 3C 84, Cygnus A, and NGC 4151 in the north, and PKS 0637-75, PKS 2153-69, NGC 6328, and Cen B in the south. MoonLITE will directly study the structures of these galaxies in the optical - on the same scales as in the radio - for the first time.
## 6. CONCLUSION
The MoonLITE instrument will demonstrate the viability and advantages of the lunar surface for astronomy, taking advantage of the rapidly-maturing surface access infrastructure of the CLPS landers available with in NASA Artemis program. MoonLITE will also present a unique opportunity to markedly extend the reach of high-resolution observing in the optical at unprecedented levels of sensitivity. Such improvements in the ability to image distant objects has always resulted in unexpected discoveries.
## ACKNOWLEDGMENTS
This research was carried out in part at the Jet Propulsion Laboratory, California Institute of Technology, under a contract with the National Aeronautics and Space Administration (80NM0018D0004).
## References
- [1] Event Horizon Telescope Collaboration, Akiyama, K., Alberdi, A., et al., 'First M87 Event Horizon Telescope Results. I. The Shadow of the Supermassive Black Hole,' ApJ 875 , L1 (Apr. 2019).
- [2] GRAVITY Collaboration, Abuter, R., Amorim, A., et al., 'Detection of the Schwarzschild precession in the orbit of the star S2 near the Galactic centre massive black hole,' A&A 636 , L5 (Apr. 2020).
- [3] Lester, D., 'Dirt, Gravity, and Lunar-Based Telescopes: The Value Proposition for Astronomy,' arXiv e-prints , astro-ph/0702437 (Feb. 2007).
- [4] [ Attitude control system failures ], 211-226, Praxis, New York, NY (2005).
- [5] Tafazoli, S., 'A study of on-orbit spacecraft failures,' Acta Astronautica - ACTA ASTRONAUT 64 , 195-205 (02 2009).
- [6] Monnier, J., Aarnio, A., Absil, O., et al., 'A Realistic Roadmap to Formation Flying Space Interferometry,' in [ Bulletin of the American Astronomical Society ], 51 , 153 (Sept. 2019).
- [7] Carruthers, G. R. and Page, T., 'Apollo 16 Far-Ultraviolet Camera/Spectrograph: Earth Observations,' Science 177 , 788-791 (Sept. 1972).
- [8] Park, J. S., Liu, Y., Kihm, K. D., and Taylor, L. A., 'Micro-Morphology and Toxicological Effects of Lunar Dust,' in [ 37th Annual Lunar and Planetary Science Conference ], Mackwell, S. and Stansbery, E., eds., Lunar and Planetary Science Conference , 2193 (Mar. 2006).
- [9] Ip, W.-H., Yan, J., Li, C.-L., and Ouyang, Z.-Y., 'Preface: The Chang'e-3 lander and rover mission to the Moon,' Research in Astronomy and Astrophysics 14 , 1511-1513 (Dec. 2014).
- [10] Wang, J., Meng, X. M., Han, X. H., et al., '18-Months operation of Lunar-based Ultraviolet Telescope: a highly stable photometric performance,' Ap&SS 360 , 10 (Nov. 2015).
- [11] Berg, O. E., Wolf, H., and Rhee, J., 'Lunar Soil Movement Registered by the Apollo 17 Cosmic Dust Experiment,' in [ Interplanetary Dust and Zodiacal Light ], Elsaesser, H. and Fechtig, H., eds., 48 , 233 (1976).
- [12] Sahlmann, J., Abuter, R., Di Lieto, N., et al., 'Results from the VLTI-PRIMA fringe tracking testbed,' in [ Optical and Infrared Interferometry ], Sch¨ oller, M., Danchi, W. C., and Delplancke, F., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 7013 , 70131A (July 2008).
- [13] Sahlmann, J., Abuter, R., M´ enardi, S., et al., 'First results from fringe tracking with the PRIMA fringe sensor unit,' in [ Optical and Infrared Interferometry II ], Danchi, W. C., Delplancke, F., and Rajagopal, J. K., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 7734 , 773422 (July 2010).
- [14] Sahlmann, J., Henning, T., Queloz, D., et al., 'The ESPRI project: astrometric exoplanet search with PRIMA. I. Instrument description and performance of first light observations,' A&A 551 , A52 (Mar. 2013).
- [15] van Belle, G. T., Hillsberry, D., Kloske, J., et al., 'Optimast structurally connected interferometry enabled by in-space robotic manufacturing and assembly,' in [ Optical and Infrared Interferometry and Imaging VII ], Tuthill, P. G., M´rand, A., and Sallum, S., eds., e Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 11446 , 114462K (Dec. 2020).
- [16] van Belle, G. T., Hillsberry, D., Piness, J., and Kugler, J., 'Sub-milliarcsecond astronomical imaging: advancing space-based astronomical optical interferometry observatories with Optimast,' in [ Optical and Infrared Interferometry and Imaging VIII ], M´ erand, A., Sallum, S., and Sanchez-Bermudez, J., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 12183 , 121831D (Aug. 2022).
- [17] Shao, M., Colavita, M. M., Hines, B. E., et al., 'The Mark III stellar interferometer,' A&A 193 , 357-371 (Mar. 1988).
- [18] van Belle, G. T., Clark, J., Schmitt, H., et al., 'The Navy Precision Optical Interferometer: large-aperture observations and infrastructure improvements,' in [ Optical and Infrared Interferometry and Imaging VIII ], M´ erand, A., Sallum, S., and Sanchez-Bermudez, J., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 12183 , 1218304 (Aug. 2022).
- [19] Lacour, S., Eisenhauer, F., Gillessen, S., et al., 'The interferometric baselines and GRAVITY astrometric error budget,' in [ Optical and Infrared Interferometry IV ], Rajagopal, J. K., Creech-Eakman, M. J., and Malbet, F., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 9146 , 91462E (July 2014).
- [20] Lacour, S., Eisenhauer, F., Gillessen, S., et al., 'Reaching micro-arcsecond astrometry with long baseline optical interferometry. Application to the GRAVITY instrument,' A&A 567 , A75 (July 2014).
- [21] Toyoshima, M., 'Maximum fiber coupling efficiency and optimum beam size in the presence of random angular jitter for free-space laser systems and their applications,' Journal of the Optical Society of America A 23 , 2246-2250 (Sept. 2006).
- [22] Lacour, S., Dembet, R., Abuter, R., et al., 'The GRAVITY fringe tracker,' A&A 624 , A99 (Apr. 2019).
- [23] Gillessen, S., Eisenhauer, F., Perrin, G., et al., 'GRAVITY: a four-telescope beam combiner instrument for the VLTI,' in [ Optical and Infrared Interferometry II ], Danchi, W. C., Delplancke, F., and Rajagopal, J. K., eds., Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series 7734 , 77340Y (July 2010).
- [24] GRAVITY+ Collaboration, Abuter, R., Allouche, F., et al., 'First light for GRAVITY Wide. Large separation fringe tracking for the Very Large Telescope Interferometer,' A&A 665 , A75 (Sept. 2022).
- [25] Coud´ e du Foresto, V., Ridgway, S., and Mariotti, J. M., 'Deriving object visibilities from interferograms obtained with a fiber stellar interferometer,' A&AS 121 , 379-392 (Feb. 1997).
- [26] Scott, N. J., First science with JouFLU , PhD thesis, Georgia State University (Jan. 2015).
- [27] Boyajian, T. S., McAlister, H. A., van Belle, G., et al., 'Stellar Diameters and Temperatures. I. Mainsequence A, F, and G Stars,' ApJ 746 , 101 (Feb. 2012).
- [28] Boyajian, T. S., van Belle, G., and von Braun, K., 'Stellar Diameters and Temperatures. IV. Predicting Stellar Angular Diameters,' AJ 147 , 47 (Mar. 2014).
- [29] van Belle, G. T., von Braun, K., Ciardi, D. R., et al., 'Direct Measurements of Giant Star Effective Temperatures and Linear Radii: Calibration against Spectral Types and V - K Color,' ApJ 922 , 163 (Dec. 2021).
- [30] von Braun, K. and Boyajian, T., [ Extrasolar Planets and Their Host Stars ] (2017).
- [31] Berger, D. H., Gies, D. R., McAlister, H. A., et al., 'First Results from the CHARA Array. IV. The Interferometric Radii of Low-Mass Stars,' ApJ 644 , 475-483 (June 2006).
- [32] von Braun, K., Boyajian, T. S., van Belle, G. T., et al., 'Stellar diameters and temperatures - V. 11 newly characterized exoplanet host stars,' MNRAS 438 , 2413-2425 (Mar. 2014).
- [33] Schweitzer, A., Passegger, V. M., Cifuentes, C., et al., 'The CARMENES search for exoplanets around M dwarfs. Different roads to radii and masses of the target stars,' A&A 625 , A68 (May 2019).
- [34] Demory, B. O., S´ egransan, D., Forveille, T., et al., 'Mass-radius relation of low and very low-mass stars revisited with the VLTI,' A&A 505 , 205-215 (Oct. 2009).
- [35] Reyl´ e, C., Jardine, K., Fouqu´, P., et al., 'The 10 parsec sample in the Gaia era,' A&A e 650 , A201 (June 2021).
- [36] Burke, C. J., Christiansen, J. L., Mullally, F., et al., 'Terrestrial Planet Occurrence Rates for the Kepler GK Dwarf Sample,' ApJ 809 , 8 (Aug. 2015).
- [37] Engineering, N. and Medicine, [ Pathways to Discovery in Astronomy and Astrophysics for the 2020s ] (2021).
- [38] Raymond, S. N. and Morbidelli, A., 'Planet Formation: Key Mechanisms and Global Models,' in [ Demographics of Exoplanetary Systems, Lecture Notes of the 3rd Advanced School on Exoplanetary Science ], Biazzo, K., Bozza, V., Mancini, L., and Sozzetti, A., eds., Astrophysics and Space Science Library 466 , 3-82 (Jan. 2022).
- [39] Isella, A., Huang, J., Andrews, S. M., et al., 'The Disk Substructures at High Angular Resolution Project (DSHARP). IX. A High-definition Study of the HD 163296 Planet-forming Disk,' ApJ 869 , L49 (Dec. 2018).
- [40] P´ erez Paolino, F., Bary, J. S., Petersen, M. S., et al., 'Correlating Changes in Spot Filling Factors with Stellar Rotation: The Case of LkCa 4,' arXiv e-prints , arXiv:2303.01574 (Mar. 2023).
- [41] Somers, G. and Pinsonneault, M. H., 'Older and Colder: The Impact of Starspots on Pre-main-sequence Stellar Evolution,' ApJ 807 , 174 (July 2015).
- [42] Feigelson, E. D. and Lawson, W. A., 'An X-Ray Census of Young Stars in the Chamaeleon I North Cloud,' ApJ 614 , 267-283 (Oct. 2004).
- [43] Kun, M., Kiss, Z. T., and Balog, Z., 'Star Forming Regions in Cepheus,' in [ Handbook of Star Forming Regions, Volume I ], Reipurth, B., ed., 4 , 136 (2008).
- [44] van Belle, G. T., 'Predicting Stellar Angular Sizes,' PASP 111 , 1515-1523 (Dec. 1999).
- [45] Lambert, S., Liu, N., Arias, E. F., et al., 'Parsec-scale alignments of radio-optical offsets with jets in AGNs from multifrequency geodetic VLBI, Gaia EDR3, and the MOJAVE program,' A&A 651 , A64 (July 2021).
- [46] Nagai, H., Haga, T., Giovannini, G., et al., 'Limb-brightened Jet of 3C 84 Revealed by the 43 GHz VeryLong-Baseline-Array Observation,' ApJ 785 , 53 (Apr. 2014).
- [47] G´ omez, J. L., Lobanov, A. P., Bruni, G., et al., 'Probing the Innermost Regions of AGN Jets and Their Magnetic Fields with RadioAstron. I. Imaging BL Lacertae at 21 Microarcsecond Resolution,' ApJ 817 , 96 (Feb. 2016).
- [48] Rodriguez, C., Taylor, G. B., Zavala, R. T., et al., 'A Compact Supermassive Binary Black Hole System,' ApJ 646 , 49-60 (July 2006).
- [49] Merritt, D. and Milosavljevi´, M., 'Massive Black Hole Binary Evolution,' c Living Reviews in Relativity 8 , 8 (Nov. 2005). | null | [
"Gerard T. van Belle",
"David Ciardi",
"Daniel Hillsberry",
"Anders Jorgensen",
"John Monnier",
"Krista Lynne Smith",
"Tabetha Boyajian",
"Kenneth Carpenter",
"Catherine Clark",
"Gioia Rau",
"Gail Schaefer"
]
| 2024-08-02T17:07:04+00:00 | 2024-08-02T17:07:04+00:00 | [
"astro-ph.IM"
]
| MoonLITE: a CLPS-delivered NASA Astrophysics Pioneers lunar optical interferometer for sensitive, milliarcsecond observing | MoonLITE (Lunar InTerferometry Explorer) is an Astrophysics Pioneers proposal
to develop, build, fly, and operate the first separated-aperture optical
interferometer in space, delivering sub-mas science results. MoonLITE will
leverage the Pioneers opportunity for utilizing NASA's Commercial Lunar Payload
Services (CLPS) to deliver an optical interferometer to the lunar surface,
enabling unprecedented discovery power by combining high spatial resolution
from optical interferometry with deep sensitivity from the stability of the
lunar surface. Following landing, the CLPS-provided rover will deploy the
pre-loaded MoonLITE outboard optical telescope 100 meters from the lander's
inboard telescope, establishing a two-element interferometric observatory with
a single deployment. MoonLITE will observe targets as faint as 17th magnitude
in the visible, exceeding ground-based interferometric sensitivity by many
magnitudes, and surpassing space-based optical systems resolution by a factor
of 50 times. The capabilities of MoonLITE open a unique discovery space that
includes direct size measurements of the smallest, coolest stars and substellar
brown dwarfs; searches for close-in stellar companions orbiting
exoplanet-hosting stars that could confound our understanding and
characterization of the frequency of Earth-like planets; direct size
measurements of young stellar objects and characterization of the terrestrial
planet-forming regions of these young stars; measurements of the inner regions
and binary fraction of active galactic nuclei; and a probe of the very nature
of spacetime foam itself. A portion of the observing time will also be made
available to the broader community via a guest observer program. MoonLITE takes
advantage of the CLPS opportunity and delivers an unprecedented combination of
sensitivity and angular resolution at the remarkably affordable cost point of
Pioneers. |
2408.01393v2 | ## Error correction of transversal CNOT gates for scalable surface code computation
Kaavya Sahay, 1, 2 Yingjia Lin, 3, 4 Shilin Huang, 1, 2 Kenneth R. Brown, 3, 4, 5, 6 and Shruti Puri 1, 2
1 Yale Quantum Institute, Yale University, New Haven, Connecticut 06511, USA
2 Department of Applied Physics, Yale University, New Haven, CT 06520, USA
3 Duke Quantum Center, Duke University, Durham, NC 27701, USA
4 Department of Physics, Duke University, Durham, NC 27708, USA
5 Department of Electrical and Computer Engineering, Duke University, Durham, NC 27708, USA
6 Department of Chemistry, Duke University, Durham, NC 27708, USA
(Dated: September 18, 2024)
Recent experimental advances have made it possible to implement logical multi-qubit transversal gates on surface codes in a multitude of platforms. A transversal controlled-NOT (tCNOT) gate on two surface codes introduces correlated errors across the code blocks and thus requires modified decoding compared to established methods of decoding surface code quantum memory (SCQM) or lattice surgery operations. In this work, we examine and benchmark the performance of three different decoding strategies for the tCNOT for scalable, fault-tolerant quantum computation. In particular, we present a low-complexity decoder based on minimum-weight perfect matching (MWPM) that achieves the same threshold as the SCQM MWPM decoder. We extend our analysis with a study of tailored decoding of a transversal teleportation circuit, along with a comparison between the performance of lattice surgery and transversal operations under Pauli and erasure noise models. Our investigation builds towards systematic estimation of the cost of implementing large-scale quantum algorithms based on transversal gates in the surface code.
## I. INTRODUCTION
Quantum error correction (QEC) protects encoded logical quantum information from decoherence on the underlying physical qubits [1, 2]. Recent experimental progress has led to landmark demonstrations of fault-tolerant (FT) state preparation [3-6], repeated error correction [7-10], and state teleportation [11] of encoded logical states. In a multitude of platforms, high-fidelity two-qubit operations are no longer strictly confined to two-dimensional nearest-neighbor interactions [12, 13], opening up the possibility to implement high-rate quantum LDPC codes [14-16] and concatenated codes [17, 18]. Beyond this opportunity, nontrivial connectivity can be employed for logical operations in the widely studied surface code (SC), a leading candidate for practical quantum error correction [19, 20].
error correlations is by appropriately adding syndrome history from rounds following the CNOT gate from one SC to another [30, 31]. Decoding using the resultant syndromes is suboptimal since the combined syndromes are twice as noisy as their individual components. An alternative decoding strategy is to directly use all the measured syndromes of the two SCs without addition. In this case, decoding based on graph algorithms cannot be used and previous works thus resort to relatively slower hypergraph decoding [32, 33].
In fixed-qubit architectures, the prominence of the surface code can be attributed to its 2D planar layout, nearest-neighbour connectivity, low-depth stabilization circuits, and high error tolerance threshold [21-23]. Efficient graph-based decoders, such as minimum weightperfect matching (MWPM), perform well at correcting common circuit-level errors [24, 25]. Further, logical gates on surface codes are well understood and easy to implement with 2D nearest-neighbor connectivity via braiding [21, 26, 27] or lattice surgery [28, 29].
With non-local connectivity, it is possible to implement transversal logical gates, such as the logical CNOT (tCNOT), between any pair of surface codes. As shown in Fig. 1, this requires applying physical CNOT gates between every corresponding data qubit of the control and target SC states [28]. A tCNOT creates correlated errors. For example, a bit-flip error on a data qubit in the control may be copied over to the corresponding data qubit in the target. One method to account for these
In this work, we benchmark the performance of the transversal CNOT gate for scalable quantum computing using three decoding methods. In addition to the approaches described above, we study a thus-far uncharacterized strategy that we refer to as ordered decoding . In this approach, we first decode those errors in one SC state that may be copied over to the other SC state [34]. We then correct for the identified errors on the second SC state before independently decoding the residual errors. Any decoder that independently locates bit- and phase-flip errors can be employed in this overall strategy; here, we use MWPM. We find that ordered decoding using MWPM is highly effective at correcting noise correlations introduced by the transversal CNOT on surface codes, outperforming previous tCNOT decoders in terms of thresholds. Our analysis extends beyond previouslystudied constant depth circuits [11, 32, 33, 35, 36].
We additionally study decoding for transversal teleportation circuits in which one of the code blocks is measured soon after a tCNOT gate. Such teleportation circuits comprise a high fraction of two-qubit gate usage in quantum algorithms. We find that such teleportation operations can be inherently decoded using graph-based methods. We also provide a comparison for logical operations performed transversally versus via joint-parity measurements, i.e., lattice surgery, thus far the more
FIG. 1. (a) A logical transversal CNOT operation between two rotated surface codes is performed by applying physical CNOT gates between each corresponding pair of data qubits of the SC states. (b) The transversal CNOT creates correlated errors between surface codes. Each SC is shown as a qubit set on which an error on a physical qubit can propagate to the other SC through the tCNOT.
widely studied method for surface code logical gate operations. This analysis is presented for Pauli-noise and a mix of erasure and Pauli noise. The latter noise model is motivated by recent studies showing that qubits with dominant erasure noise exhibit high thresholds and improved error-correction properties [37-42].
Our work is structured as follows. In Section II, we provide a brief introduction to the surface code when used as a quantum memory (SCQM), followed by an analysis of methods to decode and correct errors in this system. We then move onto logical computation using surface codes. We set out definitions for tCNOT circuits and argue for individually fault-tolerant tCNOT gadgets in logical algorithms in Section III. In Section IV we discuss different tCNOT decoding strategies. In Section V, we provide an analysis of gate teleportation, with a focus on decoding optimizations and a brief comparison with lattice surgery. Finally, in Section VI, we discuss the performance of transversal and lattice-surgery based logical gates for erasure-based noise models. We conclude in Section VII.
## II. THE SURFACE CODE AS AN ERROR-CORRECTED MEMORY
The rotated surface code [43, 44] is a stabilizer error correcting code [45] that uses d 2 physical qubits arranged on the vertices of a d × d square lattice to encode one logical qubit. The length of the smallest logical operator, or equivalently the minimum number of Pauli errors to cause an undetectable change in the logical state, is d . Here, we take d to be odd. The stabilizer group S of this code is generated by X and Z type checks S X ( S Z ) on alternating faces of this lattice, as illustrated in Fig. 2(a). Each X ( Z )-check is a product of Pauli X ( Z ) operators on the qubits around the face. The X -and Z - type logical operators, X and Z , consist of Pauli X and Z operators on qubits lying on strings connecting the boundaries of the lattice such that { X,Z } = 0, [ X,S ] = 0 and [ Z,S ] = 0 for all checks S ∈ S . Figure 2(a) shows a d = 5 surface code with a logical operator X (marked (i)).
In practice, each X ( Z ) check of the rotated surface code is measured using a depth-4 circuit of CNOT
FIG. 2. (a) A d = 5 rotated surface code. (i) An X -logical operator, (ii) a single-qubit Z error, with the corresponding anticommuting stabilizer measurements highlighted, and (iii) the X-decoding graph G X used to correct for Z errors for one stabilizer measurement round. (b) A representation of G X generated by using d rounds of stabilizer measurements on the underlying surface code. (i) Errors in the bulk create two defects to be matched together, (ii) An error at the boundary creates a single defect, and (iii) a string of data qubit and measurement errors (red) and its corresponding matching-obtained correction (grey); the correction restores the original logical state up to code stabilizers.
(CZ) gates to entangle the relevant physical data qubits with an additional ancilla qubit that is then measured out [22], giving rise to a set of measurement outcomes referred to as the syndrome . Errors can occur within this circuit at any point. Detectable errors anticommute with a subset of checks and flip the corresponding measurement outcomes, creating defects . For example, Fig. 2(a)(ii), shows a Z error on a data qubit that creates two adjacent defects. In the presence of faulty measurements, each stabilizer is generally measured O d ( ) times [30]. This error correction protocol implements the identity channel on the encoded qubit - as a result, an isolated surface code acts as a quantum memory.
## A. Efficiently decoding errors on the SCQM
Given an error syndrome σ , optimal decoding involves finding a correction that maximizes the probability of restoration to the original code state or finding the most probable logical error. For general systems, this can be a computationally hard problem [46]. In this section, we give an overview of simpler polynomial-time decoders used for surface code error correction.
We begin by defining a decoding hypergraph G = ( V, E ) on a surface code with errors E . Each vertex v t S ∈ V corresponds to a detector , where a detector refers to the parity between the measurement outcomes of a check at time t -1 and t . In other words, v t S = S t -1 ⊕ S t for S ∈ S [47]. The defects D generated by E are detectors with odd parity under E . Every hyperedge e ∈ E is a set of detectors, and is assigned a weight proportional
to the logarithm of the total probability of an independent error that causes that set of detectors to take the value 1. Given { G, D} , a graph-based decoder's task is to find the most probable physical error that created D .
For general hypergraphs where hyperedges correspond to more than two detectors, this is a computationally hard problem [48]. By making the simplification of finding a locally - as opposed to globally- optimal solution, it is possible to efficiently find a correction operator C whose syndrome matches D ; one such strategy is referred to as the hypergraph union-find (HUF) decoder [49] .
Another simplification is to reduce G to a graph where | e | ≤ 2 , ∀ e . For the surface code, this is possible for all single-qubit X Z ( ) errors since these create independent pairs of defects (or a single defect at the boundaries) on the Z X ( ) type stabilizer set, seen in Fig. 2(a)(ii). As a result, the decoding hypergraph G can be split into two disjoint graphs, { G , X D } X and { G , Z D } Z , that satisfy | e | ≤ 2 ∀ e ∈ E . Fig. 2(a)(iii) shows an example of G X for one measurement round, and the box in Fig. 2(b) represents an example of G X for d measurement rounds that we refer to as the spacetime decoding volume. Y noise is decomposed into G ,G X Z as uncorrelated X and Z errors. A decoder can now identify the most probable physical error in polynomial time by mapping σ to minimum-weight matching problems on G ,G X Z .
For a given correction C found by a decoder, a corresponding update is applied to the surface code, ideally restoring it to the original state (as in Fig. 2(b)(iii)), but potentially causing a logical error if the correction proposed is logically inequivalent to the original error. For an MWPM-based decoder applied to a circuit-level noise model with two-qubit gate errors, the threshold error rate is p t ≈ 1% [50, 51]. We find the corresponding HUF threshold to be 0 89%. .
## III. A SCALABLE TRANSVERSAL CNOT
In a transversal multi-qubit logical operation, a physical qubit of one logical block interacts with at most one physical qubit of another logical block. This approach naturally preserves the effective code distance. Here, we focus on a logical transversal CNOT (tCNOT) between a control surface code block C and a target block T , implemented with physical CNOT gates applied between qubit q C in C and q T in T , for every physical qubit q .
A tCNOT can introduce correlated errors between C and T via two mechanisms. First, two-qubit errors can occur after each physical CNOT gate. Furthermore, errors prior to the tCNOT can propagate from one code block to another. Specifically, Z X ( ) errors on qubit q T ( q C ) existing prior to the tCNOT are copied onto q C ( q T ). Importantly, the number of these errors copied over by the tCNOT scales linearly with the number of operations prior to the tCNOT. For example, if r stabilizer measurement rounds preceded the tCNOT then the number of copied errors on each physical qubit grows as O r ( ). A successful decoder must be able to decode
FIG. 3. (a) A 'binary-tree' tCNOT circuit of logical depth M . Each tCNOT is followed by r rounds of stabilizer measurements (shaded yellow boxes). In this case a single error (for example an X error on qubit q ) can induce correlated errors that grow exponentially with circuit depth (marked by dashed red lines). (b) If r << W , each tCNOT cannot be decoded independently since weight O r ( ) data errors can be misidentified as measurement errors, creating logical failures.
such correlated errors across the logical code blocks in the circuit.
With tCNOTs, in principle it is possible to decode over an entire algorithm using O (1) rounds of syndrome extraction per tCNOT with well-prepared logical ancilla states [33, 52-54]. However, here we consider decoding for tCNOT gates at scale. In particular, we focus on quantum algorithms with the number of gates scaling exponentially with d , that require a distance d faulttolerant gate set for successful implementation [55, 56].
For such a circuit, we define a tCNOT gadget to comprise of g = O (1) tCNOTs in a known configuration. We take each gadget to be followed by r rounds of stabilizer measurements on involved code blocks. For simplicity, we consider g = 1, i.e. a gadget consists of a single tCNOT, and we ignore single qubit gates. In the following, we discuss the requirements for r in the context of scalable quantum computing. Note that in this deep circuit, information from final transversal logical measurements is not readily accessible for use in decoding.
We exemplify our arguments using a 'binary-tree' circuit of logical gadget depth M involving 2 M qubits. Fig. 3(a) shows an example circuit where M = 3. In this circuit, a single bit-flip error X q on a qubit q in the control SC of the first tCNOT, which we term C 1 , can propagate to the corresponding qubits of all SCs. In a similar fashion, Z errors on target SCs will flow to C 1 . Correction of this first tCNOT should address both X and Z errors.
The surface code does not satisfy single-shot code properties for local check measurements [57-59], and decoding errors at a specific location requires roughly W = O d ( ) subsequent rounds of stabilizer measure-
TABLE I. Constraints limiting tCNOT gadget separation r and decoding window depth m while decoding an exponentially growing tCNOT circuit. We assume O (1) ≪ d .
| r | m | tCNOTs decoded independently | C 1 is FT | Decoding volume |
|---------|---------|--------------------------------|-------------|-------------------|
| O (1) | O (1) | N | N | O (1) |
| O (1) | O ( d ) | N | Y | O ( e d ) |
| O ( d ) | O (1) | Y | Y | O ( d ) |
ments [30, 58, 60]. Thus, if we set r = W , existing errors at each tCNOT can naturally be fault-tolerantly corrected before the application of subsequent gates. When r ≪ W , however, one cannot decode each tCNOT independently. To see this, consider Fig. 3(b), with an open Z -error string E on C right before the tCNOT connecting a spatial boundary to a single defect. Given a decoding window depth of r , a decoder can misinterpret E as a single lengthr measurement error string if |E| > r . As a result, the decoder fails to correct E .
When r < W , instead of attempting to decode individual tCNOTs, it may be possible to use a correlated decoding approach. Here, we use an expanded depthm m ( ≤ M ) window of the circuit extending over 2 m qubits. Syndromes in the entire window are used to decode errors at the beginning of the window [32, 33]. This procedure is an extension of the overlapping- or slidingwindow approach used for preserving a quantum state but applied to a quantum circuit block [61-64]. Note that in a general circuit, some qubits may be idle in the depthm window and these can be decoded separately as conventional quantum memories. In the rest of our discussion we will neglect these idle qubits.
Let us examine correction of X and Z errors on C 1 in this window. Since C 1 is always the control of the tCNOTs, any error X q is copied from C 1 onto 2 m qubits, each of which may provide syndrome information about this propagated error. Conversely, Z errors propagate onto C 1 from m logical gates. Decoding of Z errors on C 1 at the first tCNOT is dependent on decoding of the 2 m SCs that these errors can originate from. The total decoding volume for C 1 , which determines the complexity of decoding in the correlated decoding approach, thus scales exponentially with m . If the decoding volume becomes too large, the backlog problem may be amplified [25, 65]. Thus, we need to determine how this volume scales based on an ( r, m ) choice that ensures that long-lived errors are prevented.
To this end, first consider r, m ≪ W for which, following previous arguments, we find that a decoder can fail to correct a Z -error string E of length O mr ( ) on C 1 at the beginning of the window i.e., the first tCNOT. Thus, r, m ≪ W is not sufficient to prevent a long-lived Z error. On the other hand, setting mr = W is sufficient to prevent Z errors at the beginning of the window from surviving for a long time. As expected, this condition cannot be satisfied if both m,r = O (1). It can instead be satisfied by setting r = O (1) and m = O W ( ). In this case the decoding volume increases exponentially with m , leading to an undesirable slowdown in decoding. Clearly, the simplest way to achieve mr = W without increasing the decoding volume exponentially is by choosing r = O W ( ) and m = O (1). These conditions are summarized in Table I.
Hence we find that even in the expanded window approach r = O W ( ) is desirable. Moreover, when r = W and m = 1, each tCNOT gadget is effectively decoded independently. The advantage of these modular gadgets is that one can benchmark their individual failure rates and then estimate algorithmic performance for a wide variety of algorithms. For increasingly larger gadgets, the internal structure of the circuit determines how errors spread between different code blocks, complicating later circuit analysis. To predict algorithmic performance, a defined set of gadgets would need to be benchmarked and the errors carefully composed.
Having addressed the effectiveness of r = W , we now discuss three decoding procedures that can be used to decode an individual tCNOT. Specifically we use the simplifying assumption of W = d since measurement errors in our numerically simulated noise model are roughly as likely as data qubit errors.
## IV. DECODERS FOR A TRANSVERSAL CNOT
Here, we analyze decoding of a tCNOT. We consider a decoding volume comprising of the d rounds of stabilizer measurements following the tCNOT along with the d rounds of stabilizer measurements that followed the preceding gate. We focus on correcting Z -type errors using X -checks, using the notation S CX ( S TX ) to refer to X -checks on the control (target); by symmetry, correction of X -type errors using Z checks follows the same principles.
For our decoding analysis, we introduce the unifying perspective of check frames for SCs in the tCNOT. In what we term the dynamic frame , each X check used for correcting Z errors evolves through the tCNOT as
$$\mathbf S _ { C X } ^ { i } = S _ { C X } ^ { i } S _ { T X } ^ { i } \ \forall i \in \{ d + 1, d + 2, \dots, 2 d \} \quad ( 1 )$$
.
This reflects the internal evolution of the checks caused by the tCNOT. S i CX = S i CX , ∀ i ≤ d and S TX = S TX , i.e. other X -checks remain unchanged in the dynamic frame. In contrast, we define a static frame , where all checks are left in their original values.
For any given frame, we can define the X -decoding graph of the system G as laid out in Sec. II. For convenience in the chosen frame, we break up G X into subgraphs G CX and G TX , where G CX ( G TX ) contains the frame-defined nodes related to the checks of C ( T ). We term G CX a dependent subgraph since its checks change due to the tCNOT in the dynamic frame. From a complementary perspective, the control can be regarded as dependent because Z errors are copied over to C by the
FIG. 4. Thresholds and logical failure rates under circuit-level depolarising Pauli noise for SCQMs and logical CNOTs. (left) HUF decoder performance for a 2SCQM and tCNOT. (centre) single-update and ordered MWPM decoder performance for a tCNOT. (right) MWPM decoder performance for a 2SCQM and lattice-surgery (LS) CNOT. Operations are plotted separately to prevent overcrowding. Thresholds are found by finite size scaling close to p t (translucent lines).
tCNOT. Unlike G CX , the nodes of G TX are unaffected by the tCNOT; it is thus termed an independent subgraph .
## B. Combined hypergraph decoder
Note that in experiment, we always only measure checks in the static frame. Checks of the dynamic frame can be inferred by combining the outcomes of the static X -checks at the cost of making the inferred dynamic checks more unreliable than the measured static checks in the presence of measurement errors.
## A. Single-update decoder
In the single-update decoding strategy, we operate in the dynamic frame. Post-tCNOT, since we update the S CX check measurement outcomes according to Eqn. 1, the detectors v i CX = S i -1 CX ⊕ S i CX correctly track checks through the tCNOT. We can now apply MWPM to decode the defects created in the new dynamic-frame detector set, similar to that of an SCQM. This is explicitly detailed in Alg. 1. Note that the use of the dynamic frame doubles the defect rate on G CX post-tCNOT. We provide examples of handling of relevant errors by the single-update decoder in Appendix A.
To benchmark the performance of the single-update decoder, we compare the numerically calculated logical error rate for the tCNOT decoded in this fashion using MWPM, to that of two independent, disjoint SCQMs for 2 d rounds of check measurements (hereon referred to as a 2SCQM experiment). The results are shown in Fig. 4 centre and right. In this and all circuit-level simulations with Pauli noise, two-qubit gate errors are uniformly chosen at random from { I, X, Y, Z } ⊗ 2 / { I ⊗ I } at a rate p while assuming no single-qubit gate, initialization or measurement errors [21] (see App I). As expected, due to the larger defect population on G CX , this procedure results in a reduction in tCNOT threshold ( p t = 0 6%) compared to a 2SCQM ( . p t = 1 04%). . We note that the single-update decoding strategy was proposed in Ref. [30] and previously used in Ref. [31].
We now move onto our second decoding strategy. The dynamic frame, while natively following the tCNOT induced check evolution, increases the number of errors on the dependent subgraph. It is thus natural to attempt to use the static frame where possible. As explained in Appendix B, it is possible to only use the dynamic frame at the tCNOT round, with all other rounds in the static frame to define a set of detectors. We call this the hybrid frame . In this frame, the tCNOT creates non-decomposable hyperedges in the decoding graph, i.e. a single independent error mechanism creates three or more defects. This has been shown in Refs. [32, 33, 66]. Anaive matching decoder cannot successfully decode hyperedges; we thus use a hypergraph decoder, specifically the hypergraph union find (HUF) decoder [49, 67, 68].
We compare the performance of the tCNOT decoded with HUF to that of 2SCQM in Fig. 4 (left). Interestingly, we see a slight reduction in threshold for the tCNOT ( p t = 0 78%) compared to the 2SCQM experiment . ( p t = 0 89%). . This may be attributed to the locally as opposed to globally - optimal corrections found by the HUF algorithm in combination with the increased complexity of hyperedges in the decoding graph for the tCNOT versus the 2SCQM.
Hypergraph decoding presents a potential path to decode and correct logical operations that induce hyperedges. However, as seen above, time-efficient hypergraph strategies underperform with increased hypergraph complexity and have higher runtime overheads than their graph-based counterparts. Ideally, we would like an efficient decoding algorithm for the tCNOT that scales equal to or better than the equivalent decoder applied to a 2SCQM, while at the same time preserving the SCQM threshold. Our next decoding strategy, ordered decoding, achieves this goal.
FIG. 5. Methods to perform a T gate using fault-tolerant magic state state teleportation. (a) A logical state is teleported onto the original qubit using a CNOT, followed by a Clifford update. (b) In a lattice-surgery setting, the equivalent protocol in (a) can be optimized to reduce the number of joint parity measurements [69].
## C. Ordered decoder
Let us now describe an ordered decoding strategy. This operates entirely in the static frame. We know that Z errors occurring on the target pre-tCNOT - and only these Z errors - are propagated to the control. If we can, to the best of our ability, fully identify such errors via decoding the target first, we then know exactly what defects they will create on the control at round d +1.
Ordered decoding relies on exactly this principle: we first decode T using G TX in the static frame. From the resulting solution, the decoder identifies error clusters on T that occur before the tCNOT. Detectors in G CX in the static frame that correspond to the propagation of these identified errors from target to control at round d + 1 are then flipped, keeping track of the updated logical status. This process changes the collection of apparent defects on the control. We finally simply decode and correct the control with the updated defect collection. A corresponding mechanism can also be applied to the Z -decoding graph with the control decoded before the target (see Alg. 2 for a full description).
An ordered decoding strategy on a tCNOT results in the preservation of the SCQM threshold (see Fig. 4 (centre) with p t = 1 03%), with only a marginal bounded . increase in logical error rates compared to an equivalent decoder on a 2SCQM (see App. D for further analysis). Note that ordered decoding doubles the decoding time as decoding C for Z errors can only begin after the target is decoded (and vice-versa for X errors). This constant factor increase does not amplify the backlog problem.
## V. LOGICAL STATE TELEPORTATION
One of the primary uses of two-qubit gates in quantum algorithms will be for logical state teleportation, particularly for non-Clifford gates, such as in Fig. 5. Here, we investigate these fault-tolerant teleportation circuits, focusing on the teleportation step that may be implemented transversally or by joint-parity measurements. In a transversal teleportation circuit using a tCNOT, where a logical measurement is to be immediately im-
FIG. 6. Thresholds and logical error rates for a gate teleportation circuit corrected using ordered decoding under circuitlevel Pauli noise. We show the performance of target X error (logical Z measurement) and control X error correction in one plot (lower points in brown) as they agree within error bars. Correction of Z errors on the control is represented by the higher points in blue. Thresholds are found by finite size scaling close to p t (translucent lines).

plemented following the tCNOT, we find that, unlike the general unitary case, subsequent stabilizer measurement rounds between the tCNOT and the logical measurement on the target are not necessary to maintain code performance. We additionally compare a transversal teleportation strategy to that using joint measurements, an approach generally considered more suitable for planar architectures.
## A. Hypergraph reduction for transversal measurements
We first study the transversal teleportation scheme in Fig. 5(a), where a logical measurement of one of the surface codes immediately succeeds a tCNOT. We consider d rounds of stabilizer measurements on both the control and the target before the tCNOT. Post-tCNOT, since the logical Z measurement on T determines whether an S gate is applied to the control, it is desirable that the logical Z measurement is correctly read out. We find that the logical measurement terminates the decoding graph and reduces the hybrid frame hyperedges across the tCNOT to edges. Therefore, MWPM decoders are naturally applicable in this scenario.
We first focus on correction of the logical Z measurement on the target. From the measurement results of all data qubits of T in the Z basis after the tCNOT, we can extract both the Z logical measurement outcome and an extra ( d +1)-th round of Z stabilizer measurements from products of measurement results. We use detectors of the hybrid frame (App. B). Crucially, unlike the tCNOT circuit we study in Sec IV, we do not include d rounds of stabilizer measurement results on
the control following the tCNOT during this correction. Therefore, there are no additional detectors v i CZ used for i > d after the tCNOT. A measurement error on S d CZ thus flips only two detectors v d CZ and v d +1 CZ instead of three as described in Appendix B. Since each check is now involved in at most two detectors, this detector subset reduces hyperedges to edges. For correction of the logical Z measurement on T with an MWPM decoder, we obtain p t = 1 12%, as shown in Fig. 6. .
We now move on to X error correction on C . During correction of the logical Z measurement on T , we also obtain a correction for pre-tCNOT control X errors. We first apply this correction to C in an ordered decoding manner before continuing to measure d rounds of stabilizers, which can subsequently be treated as an SCQM. Fig. 6 shows the logical error rate in this case, which overlaps with that of the target logical Z measurement.
For Z error correction on C using X checks, we similarly find no hyperedges. Thus, graph-based decoding and its inherent logical error rates and thresholds are maintained when specific detectors are not present, as is in the case of transversal logical measurements immediately after a tCNOT.
## B. A comparison with lattice surgery
In previous sections, we have laid out our scalable tCNOT strategy. In this section, we turn to a comparison with lattice surgery [28, 29, 69-71]. In lattice surgery, static logical surface code patches are set up with bridging regions of unentangled qubits between them. Stabilizer measurements on these bridging regions are turned on and off to connect the logical operators of individual surface codes and perform joint logical Pauli measurements. Reliable measurement of these joint Pauli operators requires d rounds of stabilizer measurements. Arbitrary logical Clifford gates can be executed via combinations of these joint measurements and Pauli gates.
The decoding of these operations has been well studied, being nearly identical to decoding a SCQM. As in the case of a SCQM, a conventional MWPM decoder works well, and thus we use this decoder for comparison. We refer the reader to Appendix E-G for details. In practice, a lattice-surgery based quantum algorithm is compiled into the shortest sequence of joint measurements instead of directly using a gate set comprising of CNOT gates [69, 72], and a transversal implementation may use logical blocks with m,g > 1. In this context, we leave the somewhat artificial comparison of an isolated fault-tolerant tCNOT versus a lattice-surgery CNOT to App. H, showing therein that the tCNOT has both lower overheads and logical error rates. We display the numerical results in Fig. 4. Here, we compare the cost of a state teleportation circuit implemented using both approaches that may be directly used in a logical quantum algorithm.
In Fig. 5(b), we show the joint-parity version of the teleportation circuit in Fig. 5(a). Since only a ZZ logical
(%)
FIG. 7. MWPM thresholds under circuit-level noise while varying the erasure fraction R e for a lattice-surgery CNOT (browns), and a tCNOT with ordered decoding (blues).
measurement between the two surface codes is required, this operation takes d rounds and requires no additional logical ancilla patches, which matches the overhead of an isolated fault-tolerant tCNOT within a logical algorithm. This suggests that in certain settings, the two strategies may use equivalent resources. We leave an extended overhead analysis to future work, focusing on fault-tolerant thresholds for both approaches in the next section.
## VI. LOGICAL GATES FOR ERASURE QUBITS
Until now, we have analysed logical gates under i.i.d. Pauli noise. We now move onto a corresponding analysis for qubits where the dominant errors include a form of structured noise called erasures [37, 39]. Erasures consist of detectable errors that result in the affected qubit being projected into the maximally mixed state. We further investigate a more tailored model consisting of biased erasures [42], where detectable errors only happen from one half of the computational subspace. We review the biased erasure noise model in App. J.
It is advantageous to engineer qubits whose dominant noise is erasures [39, 73]. In practice, not all noise can be converted to erasures; here, we assume the remainder to be depolarising Pauli noise within the computational subspace. This motivates us to define an erasure fraction R e , i.e. given errors occurring on gates at a rate p , pR e of them are converted to erasures, and the rest, p (1 -R e ) are Pauli errors. As different qubits operate at different erasure fractions, is instructive to see how the error correction properties of a code vary with changes in R e .
We analyse the change in MWPM-based thresholds
with R e for logical operations in Fig. 7. Fig. 7(top) shows results for conventional erasures, and Fig. 7(bottom) for biased erasures. We briefly summarize the results for biased erasures in the following: the threshold for a tCNOT corrected using ordered decoding increases from 1 03% at . R e = 0 to 8 3% at . R e ≈ 1. The thresholds for joint-measurements (denoted by LS-CNOTs in Fig. 7) exactly coincide with a SCQM up to error bars, increasing from 1 04% at . R e = 0 to 10 3% at . R e ≈ 1. These values also match with those of ordered decoding on a tCNOT except at extremely high erasure fractions R e > 0 95. . Concretely, at R e = 0 98 we see that . p t = 7 5% for ordered decoding, . while p t = 8 3% for . regular decoding used during lattice surgery. A brief explanation for this phenomenon is given in Appendix D 1. The fact that tCNOT thresholds for dominant erasure noise are strictly lower than the corresponding jointmeasurements thresholds will ultimately affect the relative error rates of erasure-dominated transversal logical operations.
Similar behaviour is seen for conventional erasures, where p t = 4 4% ( . p t = 5 0%) at . R e ≈ 1 for ordered decoding on tCNOTs (decoding an SCQM). Note that conventional erasure thresholds at high R e are approximately half that of biased erasures. The significant increase in threshold at high R e for all logical operations considered, and the improved performance of biased erasures in comparison to other structured noise models demonstrates that the Pauli < erasure < biased erasure hierarchy of suppressed logical error rates and reduced hardware requirements demonstrated for SCQMs [42] are retained for logical operations.
## VII. CONCLUSION
In this work, we have performed an analysis of error correction of transversal CNOTs (tCNOTs) on surface codes in the context of scalable quantum computation. We highlight the utility of gadget fault-tolerance in large-scale quantum algorithms. In this context, we present a unified framework to describe various decoding strategies that may be used to correct tCNOT operations, focusing on an intuitive strategy, ordered decoding, that uses the deterministic propagation of Pauli errors through the logical gate. This strategy is compared with previous proposals to correct transversal logical operations -combined hypergraph decoding, and singleupdate decoding, showing that ordered decoding maintains the graph-based error correction advantages and thresholds of surface code memory experiments.
We extend our analysis in several ways: we study the special case of tCNOTs used for logical state teleportation, showing that the resultant hypergraph reduces to a graph in this instance, allowing regular surface code decoders to be used. We next perform a comparison of the transversal approach versus the joint-measurement based lattice surgery strategy, noting the possible reduced overhead of the former, with the caveat that the provided analysis is somewhat artificial given the differing optimal compilation schemes of the two strategies. Finally, we present an analysis of error correction of CNOTs under erasure-based noise models, showing a resultant increase in thresholds for dominant erasure noise for transversal and lattice-surgery based logical operations.
We now briefly turn to a discussion focusing on hardware limitations. Most metrics we study indicate that where permitted by the architecture, a transversal strategy is more advantageous: tCNOTs corrected using ordered decoding have similar thresholds and lower logical error rates compared to lattice surgery-based approaches. There are, however, some subtle caveats. Transversal CNOT gates intrinsically involve nonlocal connectivity. Realistically, long-range interactions for a particular hardware may be slower and/or exhibit higher error rates than nearest-neighbour interactions. Specifically for the example of reconfigurable neutral atoms, the corresponding error contribution arises from qubit movement across distances scaling with the surface code size [13, 74]. As another example, for static neutral atom systems with long-range interactions realised via the Rydberg blockade, two-qubit gate fidelity decays quasi-linearly with the gate range [75, 76], setting a maximum radius over which using such non-local connectivity is practical. Thus, the relative performance of these gate strategies will vary significantly based on hardware constraints.
Our work thus builds towards an analysis of faulttolerant transversal logical operations for use in quantum algorithms to be implemented in hardware. Further study of transversal non-Clifford gates [77, 78], decoders for logical gadgets, and optimal compilation schemes [72] that use a unified circuit-decoder perspective will indicate the performance of these strategies as a whole.
## VIII. ACKNOWLEDGEMENTS
We are grateful to Yue Wu, Shraddha Singh, Pei-Kai Tsai, Qile Su, and Aleksander Kubica for helpful discussions. In particular, we thank Jahan Claes for insightful contributions during early stages of this project. We acknowledge the Yale Center for Research Computing for use of the Grace cluster. This work was supported by the National Science Foundation (QLCI grant OMA2120757). Any opinions, findings, and conclusions or recommendations expressed in this publication are those of the authors and do not necessarily reflect the views of NSF. After the completion of this work, we became aware of a related decoder implementation investigating low-depth circuits that uses the same underlying principle as ordered decoding [36].
- [1] P. W. Shor, Fault-tolerant quantum computation (1997), arXiv:quant-ph/9605011 [quant-ph].
- [2] A. R. Calderbank and P. W. Shor, Good quantum error-correcting codes exist, Physical Review A 54 , 1098 (1996), publisher: American Physical Society.
- [3] L. Egan, D. M. Debroy, C. Noel, A. Risinger, D. Zhu, D. Biswas, M. Newman, M. Li, K. R. Brown, M. Cetina, and C. Monroe, Fault-tolerant control of an errorcorrected qubit, Nature 598 , 281 (2021), publisher: Nature Publishing Group.
- [4] R. Acharya, I. Aleiner, R. Allen, T. I. Andersen, M. Ansmann, F. Arute, K. Arya, A. Asfaw, J. Atalaya, R. Babbush, D. Bacon, J. C. Bardin, J. Basso, A. Bengtsson, S. Boixo, G. Bortoli, A. Bourassa, J. Bovaird, L. Brill, M. Broughton, B. B. Buckley, D. A. Buell, T. Burger, B. Burkett, N. Bushnell, Y. Chen, Z. Chen, B. Chiaro, J. Cogan, R. Collins, and Google Quantum AI, Suppressing quantum errors by scaling a surface code logical qubit, Nature 614 , 676 (2023), publisher: Nature Publishing Group.
- [5] V. V. Sivak, A. Eickbusch, B. Royer, S. Singh, I. Tsioutsios, S. Ganjam, A. Miano, B. L. Brock, A. Z. Ding, L. Frunzio, S. M. Girvin, R. J. Schoelkopf, and M. H. Devoret, Real-time quantum error correction beyond break-even, Nature 616 , 50 (2023), publisher: Nature Publishing Group.
- [6] R. Acharya, L. Aghababaie-Beni, I. Aleiner, T. I. Andersen, M. Ansmann, F. Arute, K. Arya, A. Asfaw, N. Astrakhantsev, J. Atalaya, R. Babbush, D. Bacon, B. Ballard, J. C. Bardin, J. Bausch, A. Bengtsson, A. Bilmes, S. Blackwell, S. Boixo, G. Bortoli, A. Bourassa, J. Bovaird, L. Brill, M. Broughton, D. A. Browne, B. Buchea, B. B. Buckley, D. A. Buell, T. Burger, B. Burkett, N. Bushnell, A. Cabrera, J. Campero, H.-S. Chang, Y. Chen, Z. Chen, B. Chiaro, D. Chik, C. Chou, J. Claes, and G. Q. AI, Quantum error correction below the surface code threshold (2024), arXiv:2408.13687 [quant-ph].
- [7] P. Schindler, J. T. Barreiro, T. Monz, V. Nebendahl, D. Nigg, M. Chwalla, M. Hennrich, and R. Blatt, Experimental Repetitive Quantum Error Correction, Science 332 , 1059 (2011), publisher: American Association for the Advancement of Science.
- [8] Z. Chen, K. J. Satzinger, J. Atalaya, A. N. Korotkov, A. Dunsworth, D. Sank, C. Quintana, M. McEwen, R. Barends, P. V. Klimov, S. Hong, C. Jones, A. Petukhov, D. Kafri, S. Demura, B. Burkett, C. Gidney, A. G. Fowler, A. Paler, H. Putterman, and Google Quantum AI, Exponential suppression of bit or phase errors with cyclic error correction, Nature 595 , 383 (2021), publisher: Nature Publishing Group.
- [9] M. P. da Silva, C. Ryan-Anderson, J. M. Bello-Rivas, A. Chernoguzov, J. M. Dreiling, C. Foltz, F. Frachon, J. P. Gaebler, T. M. Gatterman, L. GransSamuelsson, D. Hayes, N. Hewitt, J. Johansen, D. Lucchetti, M. Mills, S. A. Moses, B. Neyenhuis, A. Paz, J. Pino, P. Siegfried, J. Strabley, A. Sundaram, D. Tom, S. J. Wernli, M. Zanner, R. P. Stutz, and K. M. Svore, Demonstration of logical qubits and repeated error correction with better-than-physical error rates (2024), arXiv:2404.02280 [quant-ph].
- [10] Y. Kim, M. Sevior, and M. Usman, Transversal CNOT gate with multi-cycle error correction (2024),
- arXiv:2406.12267 [quant-ph].
- [11] C. Ryan-Anderson, N. C. Brown, C. H. Baldwin, J. M. Dreiling, C. Foltz, J. P. Gaebler, T. M. Gatterman, N. Hewitt, C. Holliman, C. V. Horst, J. Johansen, D. Lucchetti, T. Mengle, M. Matheny, Y. Matsuoka, K. Mayer, M. Mills, S. A. Moses, B. Neyenhuis, J. Pino, P. Siegfried, R. P. Stutz, J. Walker, and D. Hayes, High-fidelity and Fault-tolerant Teleportation of a Logical Qubit using Transversal Gates and Lattice Surgery on a Trapped-ion Quantum Computer (2024), arXiv:2404.16728 [quant-ph].
- [12] S. Huang, K. R. Brown, and M. Cetina, Comparing Shor and Steane Error Correction Using the Bacon-Shor Code (2023), arXiv:2312.10851 [quant-ph].
- [13] D. Bluvstein, H. Levine, G. Semeghini, T. T. Wang, S. Ebadi, M. Kalinowski, A. Keesling, N. Maskara, H. Pichler, M. Greiner, V. Vuleti´, and M. D. Lukin, A c quantum processor based on coherent transport of entangled atom arrays, Nature 604 , 451 (2022), publisher: Nature Publishing Group.
- [14] P. Panteleev and G. Kalachev, Asymptotically Good Quantum and Locally Testable Classical LDPC Codes (2022), arXiv:2111.03654 [quant-ph].
- [15] T.-C. Lin and M.-H. Hsieh, Good quantum LDPC codes with linear time decoder from lossless expanders (2022), arXiv:2203.03581 [quant-ph].
- [16] S. Bravyi, A. W. Cross, J. M. Gambetta, D. Maslov, P. Rall, and T. J. Yoder, High-threshold and lowoverhead fault-tolerant quantum memory, Nature 627 , 778 (2024), publisher: Nature Publishing Group.
- [17] H. Yamasaki and M. Koashi, Time-Efficient ConstantSpace-Overhead Fault-Tolerant Quantum Computation, Nature Physics 20 , 247 (2024), publisher: Nature Publishing Group.
- [18] S. Yoshida, S. Tamiya, and H. Yamasaki, Concatenate codes, save qubits (2024), arXiv:2402.09606 [quant-ph].
- [19] C. J. Trout, M. Li, M. Guti´rrez, Y. Wu, S.-T. Wang, e L. Duan, and K. R. Brown, Simulating the performance of a distance-3 surface code in a linear ion trap, New Journal of Physics 20 , 043038 (2018), publisher: IOP Publishing.
- [20] D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, J. P. Bonilla Ataides, N. Maskara, I. Cong, X. Gao, P. Sales Rodriguez, T. Karolyshyn, G. Semeghini, M. J. Gullans, M. Greiner, V. Vuleti´, c and M. D. Lukin, Logical quantum processor based on reconfigurable atom arrays, Nature 626 , 58 (2024), publisher: Nature Publishing Group.
- [21] A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum computation, Physical Review A 86 , 032324 (2012), publisher: American Physical Society.
- [22] Y. Tomita and K. M. Svore, Low-distance surface codes under realistic quantum noise, Physical Review A 90 , 062320 (2014), publisher: American Physical Society.
- [23] A. G. Fowler, Proof of Finite Surface Code Threshold for Matching, Physical Review Letters 109 , 180502 (2012), publisher: American Physical Society.
- [24] Y. Wu and L. Zhong, Fusion blossom: Fast mwpm decoders for qec (2023), arXiv:2305.08307 [quant-ph].
- [25] O. Higgott and C. Gidney, Sparse blossom: correcting a million errors per core second with minimum-weight matching (2023), arXiv:2303.15933 [quant-ph].
- [26] R. Raussendorf and J. Harrington, Fault-Tolerant Quantum Computation with High Threshold in Two Dimensions, Physical Review Letters 98 , 190504 (2007), publisher: American Physical Society.
- [27] B. J. Brown, K. Laubscher, M. S. Kesselring, and J. R. Wootton, Poking Holes and Cutting Corners to Achieve Clifford Gates with the Surface Code, Physical Review X 7 , 021029 (2017), publisher: American Physical Society.
- [28] D. Horsman, A. G. Fowler, S. Devitt, and R. V. Meter, Surface code quantum computing by lattice surgery, New Journal of Physics 14 , 123011 (2012), publisher: IOP Publishing.
- [29] A. G. Fowler and C. Gidney, Low overhead quantum computation using lattice surgery (2019), arXiv:1808.06709 [quant-ph].
- [30] E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, Topological quantum memory, Journal of Mathematical Physics 43 , 4452 (2002), arXiv:quant-ph/0110143.
- [31] M. E. Beverland, A. Kubica, and K. M. Svore, Cost of Universality: A Comparative Study of the Overhead of State Distillation and Code Switching with Color Codes, PRX Quantum 2 , 020341 (2021), publisher: American Physical Society.
- [32] M. Cain, C. Zhao, H. Zhou, N. Meister, J. P. B. Ataides, A. Jaffe, D. Bluvstein, and M. D. Lukin, Correlated decoding of logical algorithms with transversal gates (2024), arXiv:2403.03272 [cond-mat, physics:quant-ph].
- [33] H. Zhou, C. Zhao, M. Cain, D. Bluvstein, C. Duckering, H.-Y. Hu, S.-T. Wang, A. Kubica, and M. D. Lukin, Algorithmic Fault Tolerance for Fast Quantum Computing (2024), arXiv:2406.17653 [quant-ph].
- [34] The basic concept behind ordered decoding was mentioned in a single sentence in [31]. However, there was no concrete implementation, analytical, or numerical results provided.
- [35] J. Viszlai, S. F. Lin, S. Dangwal, J. M. Baker, and F. T. Chong, An Architecture for Improved Surface Code Connectivity in Neutral Atoms (2023), arXiv:2309.13507 [quant-ph].
- [36] K. H. Wan, M. Webber, A. G. Fowler, and W. K. Hensinger, An iterative transversal CNOT decoder (2024), arXiv:2407.20976 [quant-ph].
- [37] M. Grassl, T. Beth, and T. Pellizzari, Codes for the quantum erasure channel, Physical Review A 56 , 33 (1997), publisher: American Physical Society.
- [38] T. M. Stace, S. D. Barrett, and A. C. Doherty, Thresholds for Topological Codes in the Presence of Loss, Physical Review Letters 102 , 200501 (2009).
- [39] Y. Wu, S. Kolkowitz, S. Puri, and J. D. Thompson, Erasure conversion for fault-tolerant quantum computing in alkaline earth Rydberg atom arrays, Nature Communications 13 , 4657 (2022), publisher: Nature Publishing Group.
- [40] M. Kang, W. C. Campbell, and K. R. Brown, Quantum Error Correction with Metastable States of Trapped Ions Using Erasure Conversion, PRX Quantum 4 , 020358 (2023), publisher: American Physical Society.
- [41] J. D. Teoh, P. Winkel, H. K. Babla, B. J. Chapman, J. Claes, S. J. De Graaf, J. W. O. Garmon, W. D. Kalfus, Y. Lu, A. Maiti, K. Sahay, N. Thakur, T. Tsunoda, S. H. Xue, L. Frunzio, S. M. Girvin, S. Puri, and R. J. Schoelkopf, Dual-rail encoding with superconduct-
- ing cavities, Proceedings of the National Academy of Sciences 120 , e2221736120 (2023).
- [42] K. Sahay, J. Jin, J. Claes, J. D. Thompson, and S. Puri, High-Threshold Codes for Neutral-Atom Qubits with Biased Erasure Errors, Physical Review X 13 , 041013 (2023), publisher: American Physical Society.
- [43] S. B. Bravyi and A. Y. Kitaev, Quantum codes on a lattice with boundary (1998), arXiv:quant-ph/9811052 [quant-ph].
- [44] H. Bombin and M. A. Martin-Delgado, Optimal resources for topological two-dimensional stabilizer codes: Comparative study, Physical Review A 76 , 012305 (2007), publisher: American Physical Society.
- [45] D. Gottesman, Stabilizer Codes and Quantum Error Correction (1997), arXiv:quant-ph/9705052.
- [46] P. Iyer and D. Poulin, Hardness of Decoding Quantum Stabilizer Codes, IEEE Transactions on Information Theory 61 , 5209 (2015), conference Name: IEEE Transactions on Information Theory.
- [47] We consider S 0 and S d +1 to be initial and final perfect check measurements respectively.
- [48] E. Berlekamp, R. McEliece, and H. Van Tilborg, On the inherent intractability of certain coding problems (Corresp.), IEEE Transactions on Information Theory 24 , 384 (1978).
- [49] N. Delfosse, V. Londe, and M. Beverland, Toward a Union-Find decoder for quantum LDPC codes (2021), arXiv:2103.08049 [quant-ph].
- [50] D. S. Wang, A. G. Fowler, and L. C. L. Hollenberg, Surface code quantum computing with error rates over 1%, Physical Review A 83 , 020302 (2011), publisher: American Physical Society.
- [51] C. Gidney, Stim: a fast stabilizer circuit simulator, Quantum 5 , 497 (2021).
- [52] A. M. Steane, Active Stabilization, Quantum Computation, and Quantum State Synthesis, Physical Review Letters 78 , 2252 (1997), publisher: American Physical Society.
- [53] E. Knill, Fault-Tolerant Postselected Quantum Computation: Schemes (2004), arXiv:quant-ph/0402171.
- [54] E. Knill, Quantum computing with realistically noisy devices, Nature 434 , 39 (2005), publisher: Nature Publishing Group.
- [55] C. Gidney and M. Eker˚, How to factor 2048 bit RSA ina tegers in 8 hours using 20 million noisy qubits, Quantum 5 , 433 (2021), arXiv:1905.09749 [quant-ph].
- [56] A. M. Dalzell, S. McArdle, M. Berta, P. Bienias, C.F. Chen, A. Gily´ en, C. T. Hann, M. J. Kastoryano, E. T. Khabiboulline, A. Kubica, G. Salton, S. Wang, and F. G. S. L. Brand˜o, Quantum algorithms: a A survey of applications and end-to-end complexities (2023), arXiv:2310.03011 [quant-ph].
- [57] H. Bomb´ ın, Single-Shot Fault-Tolerant Quantum Error Correction, Physical Review X 5 , 031043 (2015), publisher: American Physical Society.
- [58] E. T. Campbell, A theory of single-shot error correction for adversarial noise, Quantum Science and Technology 4 , 025006 (2019), publisher: IOP Publishing.
- [59] Y. Lin, S. Huang, and K. R. Brown, Single-shot error correction on toric codes with high-weight stabilizers (2023).
- [60] N. Delfosse, B. W. Reichardt, and K. M. Svore, Beyond single-shot fault-tolerant quantum error correction, IEEE Transactions on Information Theory 68 , 287 (2022), arXiv:2002.05180 [quant-ph].
- [61] L. Skoric, D. E. Browne, K. M. Barnes, N. I. Gillespie, and E. T. Campbell, Parallel window decoding enables scalable fault tolerant quantum computation, Nature Communications 14 , 7040 (2023), publisher: Nature Publishing Group.
- [62] H. Bomb´ ın, C. Dawson, Y.-H. Liu, N. Nickerson, F. Pastawski, and S. Roberts, Modular decoding: parallelizable real-time decoding for quantum computers (2023), arXiv:2303.04846 [quant-ph].
- [63] X. Tan, F. Zhang, R. Chao, Y. Shi, and J. Chen, Scalable Surface-Code Decoders with Parallelization in Time, PRX Quantum 4 , 040344 (2023), publisher: American Physical Society.
- [64] N. Delfosse and A. Paetznick, Spacetime codes of Clifford circuits (2023), arXiv:2304.05943 [quant-ph].
- [65] B. M. Terhal, Quantum error correction for quantum memories, Reviews of Modern Physics 87 , 307 (2015), publisher: American Physical Society.
- [66] B. Het´ enyi and J. R. Wootton, Creating entangled logical qubits in the heavy-hex lattice with topological codes (2024), arXiv:2404.15989 [quant-ph].
- [67] N. Delfosse and N. H. Nickerson, Almost-linear time decoding algorithm for topological codes, Quantum 5 , 595 (2021).
- [68] Y. Wu < [email protected] > , mwpf: Hypergraph Minimum-Weight Parity Factor (MWPF) Solver for Quantum LDPC Codes.
- [69] D. Litinski, A Game of Surface Codes: Large-Scale Quantum Computing with Lattice Surgery, Quantum 3 , 128 (2019).
- [70] D. Litinski and F. v. Oppen, Lattice Surgery with a Twist: Simplifying Clifford Gates of Surface Codes, Quantum 2 , 62 (2018).
- [71] C. Chamberland and E. T. Campbell, Universal quantum computing with twist-free and temporally encoded lattice surgery, PRX Quantum 3 , 010331 (2022), arXiv:2109.02746 [quant-ph].
- [72] A. G. Fowler, Optimal complexity correction of correlated errors in the surface code (2013).
- [73] A. Kubica, A. Haim, Y. Vaknin, H. Levine, F. Brand˜o, a and A. Retzker, Erasure Qubits: Overcoming the $ { T } { 1 } $ Limit in Superconducting Circuits, Physical Review X 13 , 041022 (2023), publisher: American Physical Society.
- [74] S. J. Evered, D. Bluvstein, M. Kalinowski, S. Ebadi, T. Manovitz, H. Zhou, S. H. Li, A. A. Geim, T. T. Wang, N. Maskara, H. Levine, G. Semeghini, M. Greiner, V. Vuleti´, and M. D. Lukin, High-fidelity parallel enc tangling gates on a neutral-atom quantum computer, Nature 622 , 268 (2023), publisher: Nature Publishing Group.
- [75] L. Pecorari, S. Jandura, G. K. Brennen, and G. Pupillo, High-rate quantum LDPC codes for long-range-connected neutral atom registers (2024), arXiv:2404.13010 [quant-ph].
- [76] C. Poole, T. M. Graham, M. A. Perlin, M. Otten, and M. Saffman, Architecture for fast implementation of qLDPC codes with optimized Rydberg gates (2024), arXiv:2404.18809 [physics, physics:quant-ph].
- [77] J. E. Moussa, Transversal Clifford gates on folded surface codes, Physical Review A 94 , 042316 (2016), publisher: American Physical Society.
- [78] B. J. Brown, A fault-tolerant non-Clifford gate for the surface code in two dimensions, Science Advances 6 , eaay4929 (2020), publisher: American Association for
- the Advancement of Science.
- [79] Y. Yuan and C.-C. Lu, A Modified MWPM Decoding Algorithm for Quantum Surface Codes Over Depolarizing Channels (2022), arXiv:2202.11239 [quant-ph].
- [80] A. Paler and A. G. Fowler, Pipelined correlated minimum weight perfect matching of the surface code, Quantum 7 , 1205 (2023).
- [81] A. d. iOlius, J. E. Martinez, P. Fuentes, and P. M. Crespo, Performance enhancement of surface codes via recursive minimum-weight perfect-match decoding, Physical Review A 108 , 022401 (2023), publisher: American Physical Society.
- [82] O. Higgott, T. C. Bohdanowicz, A. Kubica, S. T. Flammia, and E. T. Campbell, Improved decoding of circuit noise and fragile boundaries of tailored surface codes (2023), arXiv:2203.04948 [quant-ph].
- [83] C. Gidney, Stability Experiments: The Overlooked Dual of Memory Experiments, Quantum 6 , 786 (2022).
- [84] A. G. Fowler, Time-optimal quantum computation (2013), arXiv:1210.4626 [quant-ph].
[85]
J. Edmonds, Paths, Trees, and Flowers, Canadian Jour- nal
of
Mathematics
17
,
449
(1965), publisher:
Cam- bridge University Press.
- [86] V. Kolmogorov, Blossom V: a new implementation of a minimum cost perfect matching algorithm, Math. Prog. Comput. 1 , 43 (2009).
- [87] S. Ma, G. Liu, P. Peng, B. Zhang, S. Jandura, J. Claes, A. P. Burgers, G. Pupillo, S. Puri, and J. D. Thompson, High-fidelity gates and mid-circuit erasure conversion in an atomic qubit, Nature 622 , 279 (2023), publisher: Nature Publishing Group.
## Appendix A: Propagated defects in the dynamic frame
Here, we expand on the functioning of the singleupdate decoder. Recall that it operates in the dynamic frame. In terms of the measured static checks, we have the dynamic frame detectors
$$v _ { C X } ^ { d } = S _ { C X } ^ { d - 1 } \oplus S _ { C X } ^ { d }, \quad \text{(A1a)}$$
$$v _ { C X } ^ { d + 1 } = S _ { C X } ^ { d } \oplus S _ { C X } ^ { d + 1 } \oplus S _ { T X } ^ { d + 1 }, \text{ and } \quad ( A 1 b )$$
$$v _ { C X } ^ { d + 2 } = S _ { C X } ^ { d + 1 } \oplus S _ { T X } ^ { d + 1 } \oplus S _ { T X } ^ { d + 2 } \oplus S _ { T X } ^ { d + 2 } \quad \text{(A1c)}$$
We illustrate the behaviour of the decoder using an instance of a data qubit error Z T,q on a qubit q in T that creates defects on T at round k :
- 1. If k ≤ d : After round d , Z T,q is copied over to the control, creating Z C,q . Since [ Z T,q Z C,q , S CX = S CX S TX ] = 0, no defect is created in the dynamic frame after the tCNOT despite the actual error being present. This behaviour differs from the static frame.
̸
- 2. If k > d : Z T,q is not copied over to C , but creates new defects on the updated C due to the updated checks of the dynamic frame: [ Z T,q , S CX ] = 0. These errors are not truly on the control, and the resulting 'false defects' simply mirror defect patterns on the target. Note that these false defects
appear in addition to defects created by errors on the target itself, resulting in an effective doubling of the defect rate post-tCNOT on T .
We observe that use of the dynamic frame prevents propagated errors from creating defects on C , while creating false defects from errors that did not propagate. After independently decoding and correcting both subgraphs in the dynamic frame, we use knowledge of all the corrections applied to T to apply a final logical update to C and restore the code states (Alg. 1).
## Appendix B: Hyperedges in the tCNOT
Having discussed how the tCNOT copies over Z errors from T to C in the main text, here we address how, in a certain frame, the tCNOT induces non-decomposable hyperedges, i.e. leads to certain independent error mechanisms creating more than two defects in the decoding graph G , such that they cannot be expressed as products of regular edges. Our discussion is framed in the language of a Stim circuit intended for PyMatching [25, 51] that uses a decoding graph with components in both the dynamic and static frames, i.e. the graph exists in a hybrid frame. This versatility is facilitated by the ability of users to define detectors in Stim. We use the notation of Sec. IV, focusing on Z errors and X -checks. Our system has the following three types of user-defined detectors:
- 1. Until the tCNOT, the detectors are v i CX = S i -1 CX ⊕ S i CX and v i TX = S i -1 TX ⊕ S i TX for i ∈ { 1 2 , , ..., d } . These detectors apply to both the static and dynamic frames.
- 2. Since the tCNOT copies over errors from T to C , it is natural to assume that if no error occurs between measurement rounds d and d + 1, then S d +1 CX = S d CX ⊕ S d TX . These three measurement outcomes thus can be used to define a detector v d +1 CX = S d +1 CX ⊕ S d CX ⊕ S d TX . Detectors on T remain unchanged: v d +1 TX = S d +1 TX ⊕ S d TX . These detectors exist in a dynamic frame that is defined in a slightly different basis to Sec. IV.
- 3. After the tCNOT, in each individual surface code, stabilizer measurements should remain unchanged under error-free execution. This allows us to propose: v i CX = S i -1 CX ⊕ S i CX and v i TX = S i -1 TX ⊕ S i TX for i ∈ { d +2 , d +3 , .., 2 d } . Note that for C , these detectors are different from those defined by check evolution in the dynamic frame, and are instead in the static frame.
With this set of detectors in the hybrid frame, it is possible to extract independent error mechanisms that create three defects. For example, consider a measurement error on T at round d . Assuming no other errors, S d TX = 1 and all other outcomes are 0, meaning that the set of detectors { v d TX , v d +1 CX , v d +1 TX } = 1 produce defects. This 3-component term is a hyperedge.
## Appendix C: Graph decoders for the tCNOT
We provide a brief summary of the decoding algorithms based on independent handling of X and Z errors described in Sec. IV. By abuse of notation, we define G ind = { G TX , G CZ } and G dep = { G CX , G TZ } . For every edge e of weight w in a graph G , we define p e = exp( -w ) 1+exp( -w )
## Algorithm 1: Single-update decoder
- /* Change dependent graphs to dynamic frame */ i
- 1 foreach S dep ∈ G dep | i > d do 2 S i dep ← S i dep ⊕ S i ind 3 end 4 foreach v i S ∈ G dep do 5 v i S ← S i -1 dep ⊕ S i dep 6 end /* Updating dependent subgraph edge weights */ 7 foreach e = ( v i S k , v j S l ) ∈ G dep do 8 if ∃ v i S k ∈ e | i > d then 9 p e ← p e + p eG ind -2 p p e e Gind 10 end 11 end 12 Decode { G ind , G dep } independently /* Update G dep 's logical status */ 13 L G dep ← L G dep ⊕ L G ind
We note a fundamental conceptual similarity between ordered decoding and the two-pass or iterative MWPM decoding methods [72, 79-81]. These approaches have been used to improve SCQM decoding accuracy by leveraging probabilistic intra-SC correlations. In contrast, for ordered decoding, we make use of deterministic inter-SC error correlations induced by the tCNOT. It may be possible to combine the two approaches, along with other subroutines that make use of soft information such as belief propagation [82], to further improve the performance of ordered decoding.
## Algorithm 2: Ordered decoder 1 Decode G ind independently, obtaining the set of matched defect pairs E G ind 2 L ′ = 0 /* Flip nodes in dependent subgraphs */ 3 foreach unordered pair e = ( v i S k , v j S l ) ∈ E G ind do 4 if ∃ v i S k ∈ e | i ≤ d then 5 v d +1 S ,dep k ← v d +1 S ,dep k ⊕ 1 v d +1 S ,dep l ← v d +1 S ,dep l ⊕ 1 L ′ ← L ′ + L e ( ) 6 end 7 end */
- 9 L dep ← L dep ⊕ L
- 8 Decode G dep independently /* Update G dep 's logical status G G ′
FIG. A1. Thresholds and logical error rates of an HUF and ordered MWPM decoder for a tCNOT under biased phenomenological noise. Thresholds are found by finite size scaling close to p t (transculent lines).

## 1. A phenomenological threshold comparison
Hypergraph decoders on surface codes show an advantage over MWPM in the presence of Y errors. This is because they can directly treat Y errors using hyperedges. In contrast, an MWPM decoder must decompose Y errors into independent X and Z errors and graphs. This decomposition results in the loss of initial Y = XZ correlations. Here, we attempt to control for this possible Y error advantage of HUF during tCNOT decoding.
We perform a comparison between HUF and ordered MWPM decoding for a tCNOT using a tailored phenomenological noise model. In this model, independent bit-flip errors on data qubits and measurement errors are applied with equal probability p in each stabilizer measurement round. This removes Y errors, allowing a direct comparison of the ability of the two decoders to correct correlated errors that arise solely from error propagation through tCNOT gates.
We study the same tCNOT system as in Sec. IV, with the results shown in Fig. A1. Similar to the circuitlevel model, we find a higher threshold using an ordered MWPM decoder ( p t = 2 77%) compared to HUF ( . p t = 2 47%). . Additionally, the logical error rate of ordered MWPM is slightly lower than that of HUF, reversing the general trend for circuit level noise that includes Y errors seen in Fig. 3. These findings suggest that (1) much of the logical error rate advantage of HUF indeed arises from its improved handling of Y errors, and (2) an ordered MWPM decoder may outperform HUF when correcting correlated errors solely arising from tCNOT gates.
FIG. A2. Errors can span the tCNOT measurement round, creating a defect below the tCNOT paired to one above it. Depending on where the data qubit errors actually occurred, different errors are copied over to G dep for the same defect pattern. If the error in red occurred, C remains unaffected.
## Appendix D: Uncorrectable propagated errors for ordered decoding on the tCNOT
Here, we discuss the logical error rates observed for ordered MWPM decoding. For Z errors, ordered decoding uses the simple concept of a target-first-control-next decoding strategy. The first round of decoding on T pairs up defects on the X stabilizer graph. These defect pairs correspond to errors that may or may not be copied over to C by the tCNOT. Assuming errors are corrected up to stabilizers, these defect pairs arising from underlying physical errors, and their corresponding predicted errors returned by a decoder create space-time cycles in the decoding graph (Fig. A2). These cycles can be broadly classified into three distinct categories:
- 1. Spacetime cycles entirely before the tCNOT: The error corresponding to this defect pattern can be a combination of measurement and data errors. Only the data-qubit part of this error, corresponding to its horizontal projection in spacetime, is transmitted to C . Even if the original error is corrected up to a time-like stabilizer, the dependent subgraph is correctly updated.
- 2. Spacetime cycles entirely after the tCNOT: The most probable error occurs entirely after the tCNOT and hence does not propagate onto C .
- 3. Spacetime cycles spanning the tCNOT round: This defect pattern arises from a combination of measurement and data errors. There are multiple minimal-weight ways of projecting such a path. For example, see Fig. A2. Suppose the decoder identifies the grey path with the 'data-qubit projection' entirely below the tCNOT, but the actual physical error was the red error with the 'dataqubit projection' above the tCNOT. The former will transmit errors to the target, but the latter
will not. Given the decoder's choice, the target will be updated incorrectly. Hereon, we refer to this class of errors as ambiguous errors.
Ambiguous errors arising from spacetime cycles spanning the tCNOT round are effectively uncorrectable by the first stage of an ordered decoder - the decoder can only randomly choose the truly correct data-error projection. Subsequent error correction of the residual defects takes place on the dependent subgraph. As a result, ambiguous errors lead to an increase in the logical error rate of the dependent graphs. However, from Fig. 4, we observe that they do not materially degrade decoder thresholds.
## 1. Ordered decoding at high R e
Here, we discuss the apparent reduction in threshold at high erasure fractions for a tCNOT with ordered decoding compared to an SCQM experiment. In essence, this is because of ambiguous errors that create cycles around the tCNOT round. For all other categories of correctable erasure errors, the decoder can use the erasure flag on qubits suffering errors to determine the exact path of errors propagating over onto G dep .
Observe the example Fig. A2. Unlike the previous section, we envision that erasure errors have occurred along both grey and red paths. However, only one (red) path truly has Z errors due to the erasures, giving rise to two defects. Exactly like the case with Pauli errors, the decoder has no way to determine which of the two error patterns occurred. If it guesses the grey path occurred, an incorrect update is applied to the control. At high p and R e , the probabilities of such cycles increase. At sufficiently high pR e logical errors are dominated by contributions from these ambiguous cycles for which the decoding ability is Pauli-like instead of erasure-like. This in turn reduces p t for the tCNOT at high erasure fractions.
## Appendix E: Logical computation using lattice surgery
An SCQM requires at least d errors to create an undetectable logical operator. Ideally, this distance d to errors should be preserved while using individual surface codes as units of logical computation. Logical gates executed via lattice surgery achieve this in a manner compatible with planar fixed qubit architectures [21, 69].
We illustrate the process for a joint-Pauli XX measurement done via lattice surgery on two surface codes in Fig. A3(a)-(b). The system is set up as follows: two initially disconnected surface codes have their individual stabilizers measured for O d ( ) rounds. A bridging region of width b between the X -logical edges of these codes is initialized with unentangled qubits in | 0 ⟩ (Fig. A3(a)). To begin the joint-parity (JP) measurement, surface-
FIG. A3. (a) Setup, and (b) spacetime volume of an XX logical measurement conducted using lattice surgery, with (i) the product of stabilizers denoting the XX measurement outcome, and (ii) an error that will be misidentified without the buffer measurement rounds. (c) Spacetime decoding volume for a logical CNOT done with lattice surgery.
code checks are measured over the entire region comprising of the two logical qubits and bridging region. This projects the two surface codes into a joint logical subspace.
In the absence of errors, all check measurements in the logical region, and Z stabilizer measurements in the bridging region return +1 outcomes. X stabilizers in the bridging region are initially unfixed and yield random outcomes, but their combined product is the XX logical measurement outcome (Fig. A3(b)(i)). To achieve fault-tolerance to measurement errors that may lead to misidentification of the XX measurement result, JP measurements are done for O d ( ) rounds. After these JP rounds, the bridging region qubits are measured in the Z basis, and the surface codes are once again measured independently. The spacetime decoding volume of this process is shown in Fig. A3(b).
Extending this strategy, a logical CNOT gate between a control surface code C and a target surface code T can be performed using a similar JP-measurement based circuit. This operation uses a logical ZZ measurement on C and a logical ancilla patch, followed by a logical XX measurement on the ancilla and T . In practice, the spacetime volume of this set of operations looks like Fig. A3(c) where O (2 d ) round of gates along with one logical ancilla are used to perform the complete gate. Note that single-control n -target CNOT gates can be carried out simultaneously by using a large ancillary region that can support X ⊗ n measurements [29, 70]. This CNOT operation has the same threshold as a SCQM, and the same logical error rate scaled up to known constant prefactors (discussed in App. F). This is verified via numerical simulations in Fig. 4.
## Appendix F: Error correction in lattice surgery
We expand on decoding and correction of errors during the XX joint parity measurement discussed in App. E. Close observation of the 'legs' of the H in Fig. A3(b) - representing pre-JP stabilizer measurement rounds on the individual surface codes, hereon referred to as buffer rounds -show that they are equivalent to the spacetime volume of individual SCQM experiments (up to time boundaries that connect them to the JP rounds). The bridging region in the joint parity rounds is a representation of the stability experiment [83].The stability experiment can be interpreted as a space-time rotated version of the SCQM.
As a combination of variously orientated SCQMs, we can observe that the complete decoding graph of the logical XX measurement is essentially a trivially extended SCQM. As a result, in lattice surgery, we preserve the threshold of an equivalent SCQM. This has previously been demonstrated in Ref. [71] using a matching decoder. Further, the total logical error rate of a lattice surgery operation can be expressed in terms of its logical spacetime surface area (LSSA) in comparison to an SCQM's LSSA, a concept we discuss in App. G.
An additional note of interest is the choice to use buffer rounds at all; we connect this to the notion of W in the main text. Technically, these legs of the 'H' shaped spacetime volume are not part of the JP measurement itself. Indeed, in the ideal scenario of perfect state preparation of the disjoint surface codes, or surface code readout immediately after the JP rounds, they are not required. However, measurement errors in the original logical patches can create defects that can be misidentified as faulty joint-parity measurement errors had measurement data from the buffer rounds not been used. Fig. A3(b)(ii) exemplifies this: if the decoding window does not extend below the first JP round, the lone defect above the window boundary is misidentified as arising from a JP X stabilizer measurement error. Thus, we use W buffer rounds of decoding data for fault-tolerance against these errors. Like the tCNOT, these buffer rounds can be part of other non-commuting JP measurements - inclusion of their measurement data is only necessary for decoding and they do not actually need to be perfectly disjoint rounds on individual surface codes (see Fig. A3(c)).
## Appendix G: Logical surface areas for SC operations
For the operations we study, the failure rates of different logical gate strategies at low physical error rates can be approximately mapped to the spacetime surface areas ratios of their logical operators.
As an example, for a single SCQM, there are four logical operators of length d (two X logicals on opposite boundaries of the surface code and two Z logicals). Each logical is measured for d rounds, so the total logical spacetime surface area is 4 × d × d = 4 d . 2 We count
FIG. A4. Ratio of logical failures rates for a XX measurement using lattice surgery with b = 1 to a 2SCQM. Each point uses 10 5 samples, discarding points with failure rates ≤ 10 -4 . Error bars represent the 95% confidence interval. A horizontal line is drawn at the lower bound of 1 375. .
in units of d 2 , and so this is simply 4 in our chosen unit system.
We now describe a 2SCQM, i.e. a memory experiment on two surface codes for 2 d rounds, the logical spacetime surface area (LSSA) of which is:.
$$I _ { 2 S C Q M } = \overbrace { 2 } ^ { \text{SCs} } \times \overbrace { 2 } ^ { t } \times \overbrace { 4 } ^ { \text{SEr SC} } = 1 6$$
Let us next examine an XX logical measurement on two surface codes. The bridging region consists of a width b strip that uses bd qubits. Depending on the architecture, b can be chosen to be constant or scale linearly with d . The two surface codes are measured independently for d rounds, have projective measurements onto the XX basis using the bridging region for d rounds and are then split and measured again for d rounds. The LSSA XX 2 SC +3 d for this operation is given by:
$$\ u t a \underset { \tt \tt l y } { \overbrace { 2 \times ( \sqrt { 2 \times 4 } + \sqrt { 3 } ) + 4 \times b / d } } } & \text{SCs for} \\ \ u t a \underset { \tt 2 \times ( \sqrt { 2 \times 4 } + \sqrt { 3 } ) + \sqrt { 4 \times b / d } } & = 2 2 + 4 b / d$$
We can thus find the logical error rate ratio of a lattice surgery XX measurement versus a memory experiment as:
$$\frac { X X _ { 2 S C + 3 d } } { I _ { 2 S C Q M } } = 1. 3 7 5 + \frac { b } { 4 d } \, \quad \quad ( A 1 )$$
This is verified numerically in Fig. A4 which uses b = 1.
We can similarly calculate the LSSA for a logical CNOT between two surface codes using lattice surgery. As described in App. F, this operation takes a total of 4 d rounds. Its LSSA CX 2 SC +4 d is:
$$\int _ { \substack { \i c a v { j }. \\ \text{$1$ login} } } \int _ { \substack { \i c a v { j }. \\ \overbrace { 3 \times 2 \times 4 } } } \int _ { \substack { \i c a v { j }. \\ \overbrace { 3 \times 4 } } } \int _ { \substack { \i c a v { j }. \\ \overbrace { 4 \times 2 \times b/d } } } \int _ { \substack { \i c a v { j }. \\ \overbrace { 4 \times 2 \times b/d } } } \int _ { \substack { \i c a v { j }. \\ \overbrace { 4 \times 2 \times b/d } } }$$
FIG. A5. Ratio of logical failures rates for a tCNOT with ordered decoding to a 2SCQM. Each point uses 10 5 samples, discarding points with failure rates ≤ 10 -4 . Error bars represent the 95% confidence interval. Horizontal lines are drawn at 1 and 1 25. .
We can thus verify the logical error rate ratio of a lattice surgery CNOT versus a memory experiment as:
$$\frac { C X _ { 2 S C + 4 d } } { I _ { 2 S C Q M } } = 2. 2 5 + \frac { b } { 2 d } \, \quad \quad ( A 2 ) \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \$$
## 1. LSSAs for tCNOTs
We now calculate the magnification of error rates induced by ordered decoding at low p . The overall failure rate of the tCNOT is the probability that the decoder applies a logically incorrect update to any of the four { G CX , G CZ , G TX , G TX } decoding subgraphs. For a 2SCQM, these four rates are equivalent. For a tCNOT with ordered decoding, we take the dependent subgraphs to have a 50% increase in logical failure rates compared to a 2SCQM because they use their own LSSA combined with half the LSSA of their corresponding independent subgraph. The independent subgraphs remain unaffected. Thus, the logical rate amplifier is: 2+2 × 1 5 . 2+2 = 1 25 .
In Fig. A5, we verify these calculations. We find the ratio R of the numerically obtained logical failure rates for a tCNOT corrected using ordered decoding to that of a 2SCQM for various system sizes. By virtue of incorrectly propagated logical updates, ambiguous errors, and errors introduced within the faulty physical CNOT gates that implement the tCNOT, we observe that R is consistently higher than 1 and seems to saturate below threshold. By fitting to a saturation function, we find a saturation R ≈ 1 25 at low . p , represented by the dark green horizontal line. This agrees with the preliminary analytical prediction above.
## 2. Multi-target CNOTs
We can now perform the same analysis for an n -target lattice-surgery CNOT, which can be executed in 2 d rounds. Note that here the required number of extra bridging qubits is lower bounded at ⌈ n/ 2 ⌉ bd . We get the LSSA CX LS-n :
$$\Big | \quad \overbrace { 3 \times ( n + 1 ) \times 4 } ^ { \text{ independent SCs} } \overbrace { 3 \times ( 2 + ( n + 1 ) ) } ^ { \text{ SCs while merging} } \overbrace { 4 \times 2 \times \lceil n / 2 \rceil b d }$$
Comparing it to the identity operation,
$$\frac { C X _ { L S \cdot n } } { I _ { ( n + 1 ) S C + 2 d } } = \frac { 2 1 + 1 5 n + \lceil n / 2 \rceil 8 b d } { 8 ( n + 1 ) } \quad ( A 3 )$$
Similarly, we evaluate the LSSA of an n target tCNOT with ordered decoding. Note that this can either be executed natively in hardware, or using consecutive single-target tCNOTs, with the block then requiring a subsequent W buffer rounds, without exacerbating the decoding complexity. We can then compare it to the identity operation,
$$\vdots \text{a} \quad \frac { C X _ { t \text{-n} } } { I _ { ( n + 1 ) S C + 2 d } } = \frac { ( n + 1 ) + n \times 1. 5 + ( 1 + 0. 5 n ) } { 2 ( n + 1 ) } \quad ( \text{A} 4 )$$
## Appendix H: An isolated LS-CNOT vs a tCNOT
Here we discuss our results benchmarking the performance of a fault-tolerant tCNOT against a latticesurgery-CNOT, in a setting where state preparation and measurement do not immediately occur before and after the logical operation. We highlight that this comparison is quite artificial, given that (1) in practice for transversal circuits, it may be more advantageous to use m,g > 1 tCNOTs in a logical decoding block (see Sec. III), and (2) in practice for joint-measurement based circuits, Clifford gates can be time-efficiently compiled [84]. A more realistic analysis is left to future work.
We find that for a tCNOT, the total logical error rate is only marginally amplified compared to a 2SCQM experiment. However, it more than doubles for a LSCNOT on account of that fact that it needs two logical Pauli measurements (see Appendix. G for an analysis). Further, the lattice surgery approach requires an additional ancilla surface code patch, as well as bridging regions of uninitialized qubits. This results in a total additional qubit overhead of d 2 +2 bd , where b is the width of the bridging region of qubits. b is dependant on the architecture chosen. For movable architectures, this can be O (1), but for fixed architectures this is generally the separation of the surface codes patches. These extra qubits are not needed for a tCNOT. Using a MWPM subroutine, the time overhead for ordered decoding of the tCNOT scales as 2 × O ( ( 2 d 3 ) 3 ). The factor of two arises since the independent and dependent graphs are decoded serially. This same quantity is O ( ( 10 d 3 +2 bd 2 ) 3 ) for lattice surgery, implying that despite the inherent latency
TABLE A1. A preliminary overhead comparison for an isolated fault-tolerant logical CNOT performed via lattice surgery vs. transversally with ordered decoding. We use a MWPM decoding subroutine, resulting in both CNOT strategies having a threshold of 1%. We benchmark the number of additional qubits and measurement rounds needed for both strategies, along with the decoding time complexity and total logical error rate in comparison to a 2SCQM.
| Method of conducting logical CNOT | No. of additional qubits | No. of msmt rounds | Decoding time complexity | Minimal patch movement | Amplification of logical error rate over 2SCQM |
|-------------------------------------|----------------------------|----------------------|----------------------------|--------------------------|--------------------------------------------------|
| Lattice surgery | d 2 +2 bd | 2 d | O ( ( 10 d 3 +2 bd 2 ) 3 ) | Y | 2 . 25 + b/ 2 d [App. G] |
| tCNOT + ordered decoding | 0 | d | 2 × O ( ( 2 d 3 ) 3 ) | N | ∼ 1 . 25 [App. G] |
of ordered decoding, a correction C may be identified faster than an equivalent lattice surgery instance. The results of this comparison are summarized in Table A1.
## Appendix I: Details of numerical simulations
The simulations based on MWPM decoders for the SCQM and transversal CNOT operations were implemented in C++ using the Blossom algorithm [85, 86], combined with Djikstra to account for adjusted edge weights arising from erasures. The code for these is available at https://github.com/kaavyas99/ CSS-tCNOT-decoders . The corresponding HUF-based simulations were implemented in Stim [51], and decoded using the MWPF implementation of HUF [68]. A second implementation of ordered decoding in Stim using PyMatching [25, 51] was additionally developed for further testing.
For the lattice surgery analysis, simulations and measurements of the logical error rate were conducted for a logical XX measurement instance using the procedure detailed in Ref. [71] in C++ using Blossom and Djikstra. The results reported for the CNOT were then calculated by scaling according to the operations' respective LSSAs.
In the noise model used for simulations, two-qubit gate errors are uniformly chosen at random from { I, X, Y, Z } ⊗ 2 / { I ⊗ I } at a rate p . This model also applies to the physical CNOT gates used in the logical tCNOT. State preparation, measurement, idling, and single-qubit gate errors are not included [21].
For data displayed in Figs. 4 and 6, individual points are collected using 10 5 Monte Carlo samples; error bars are found by jackknife resampling and represent the 95% confidence interval. Note that we report the total logical error rate per operation, i.e. over 2 d measurement rounds for tCNOTs, as opposed to the error rate per syndrome extraction round.
## Appendix J: The biased erasure noise model
A biased erasure is defined as a heralded exit from one half of the computational subspace [37, 42]. The effective Kraus operators for this channel can be written as:
$$W _ { 0 } = \left | 0 \right \rangle \left \langle 0 \right | + \sqrt { 1 - 2 p _ { e } } \left | 1 \right \rangle \left \langle 1 \right | \text{ \quad \ } ( A 1 )$$
$$W _ { e } = \sqrt { 2 p _ { e } } \left | 1 \right \rangle \left \langle 1 \right | & & \left ( A 2 \right )$$
This error channel is motivated by the metastable 171 Yb atom qubit, where the dominant decay mechanism is decay from the Rydberg level | r ⟩ to a set of external states during two-qubit gates. Since the qubit is only excited to | r ⟩ from the | 1 ⟩ state during these gates, detection of population in the external states is akin to measurement in the Z basis with a known outcome. The qubit can be reinitialized by replacement with a fresh atom in | 1 . ⟩
There are dual advantages to engineering qubits to experience dominant biased erasures as opposed to Pauli noise. Firstly, biased erasure are heralded errors, which means that the logical failure rate scales as p L ∝ p d . In contrast, the only information available to identify qubits that have experienced Pauli errors within the computational subspace is their syndrome, leading to a scaling of p L ∝ p ( d +1) 2 / . Secondly, one benefits from the biased nature of the erasure. If the error occurred during a CZ gate (or at the control of a CNOT gate), one can prove that effective operator on the qubit after atom replacement and Pauli twirling is ( IρI + ZρZ / ) 2. If it occurred to the qubit at the target of a CNOT gate, the effective error channel is ( IρI + XρX / ) 2. Biased erasures thus allow identification of the apparent error ( X or Z ) at a known location, lending to easier error correction and high thresholds.
For the metastable Yb, the theoretical maximum erasure fraction is R e = 98% [39]. R e = 33% has recently been achieved experimentally via detection of leakage to the ground state [87]. | null | [
"Kaavya Sahay",
"Yingjia Lin",
"Shilin Huang",
"Kenneth R. Brown",
"Shruti Puri"
]
| 2024-08-02T17:09:08+00:00 | 2024-09-17T13:23:53+00:00 | [
"quant-ph"
]
| Error correction of transversal CNOT gates for scalable surface code computation | Recent experimental advances have made it possible to implement logical
multi-qubit transversal gates on surface codes in a multitude of platforms. A
transversal controlled-NOT (tCNOT) gate on two surface codes introduces
correlated errors across the code blocks and thus requires modified decoding
strategies compared to established methods of decoding surface code quantum
memory (SCQM) or lattice surgery operations. In this work, we examine and
benchmark the performance of three different decoding strategies for the tCNOT
for scalable, fault-tolerant quantum computation. In particular, we present a
low-complexity decoder based on minimum-weight perfect matching (MWPM) that
achieves the same threshold as the SCQM MWPM decoder. We extend our analysis
with a study of tailored decoding of a transversal teleportation circuit, along
with a comparison between the performance of lattice surgery and transversal
operations under Pauli and erasure noise models. Our investigation works
towards systematic estimation of the cost of implementing large-scale quantum
algorithms based on transversal gates in the surface code. |
2408.01394v1 | ## Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features
Mengyu Bu 1,3 , Shuhao Gu 1,3† , Yang Feng 1,2,3 *
1 Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences (ICT/CAS) 2 Key Laboratory of AI Safety, Chinese Academy of Sciences 3 University of Chinese Academy of Sciences, Beijing, China {bumengyu23z, fengyang}@ict.ac.cn, [email protected]
## Abstract
The many-to-many multilingual neural machine translation can be regarded as the process of integrating semantic features from the source sentences and linguistic features from the target sentences. To enhance zero-shot translation, models need to share knowledge across languages, which can be achieved through auxiliary tasks for learning a universal representation or cross-lingual mapping. To this end, we propose to exploit both semantic and linguistic features between multiple languages to enhance multilingual translation. On the encoder side, we introduce a disentangling learning task that aligns encoder representations by disentangling semantic and linguistic features, thus facilitating knowledge transfer while preserving complete information. On the decoder side, we leverage a linguistic encoder to integrate low-level linguistic features to assist in the target language generation. Experimental results on multilingual datasets demonstrate significant improvement in zero-shot translation compared to the baseline system, while maintaining performance in supervised translation. Further analysis validates the effectiveness of our method in leveraging both semantic and linguistic features. 1
the decoder integrates this representation with the inherent features of the target language to generate the target language sentences. By sharing parameters, multilingual NMT models enable knowledge transfer across languages, which significantly benefits low-resource machine translation (Aharoni et al., 2019), especially zero-shot translation. However, previous multilingual NMT models do not explicitly differentiate between semantic and linguistic features, resulting in the entanglement of knowledge and linguistics within the model. This entanglement negatively affects the performance of zero-shot translation in two main aspects. Firstly, the linguistic features of the source language interfere with the encoder's ability to learn shared semantic information, causing the encoder to encode different languages into different representation subspaces (Kudugunta et al., 2019), which hinders knowledge transfer across multiple languages. Secondly, during the generation of the target language, the decoder is influenced by spurious correlations due to insufficient target language features, leading to off-target issues (Zhang et al., 2020).
## 1 Introduction
The many-to-many multilingual neural machine translation (NMT) enables translation across multiple languages in a single model (Firat et al., 2016; Fan et al., 2021; Siddhant et al., 2020). This process involves integrating the semantic information from the source sentence and the linguistic features from the target sentence. Specifically, the encoder captures the semantic information of the source sentence and maps it to the representation space, when
* Corresponding author: Yang Feng.
† This paper was done when Shuhao Gu studied at ICT/CAS.
1 The code is available at https://github.com/ictnlp/ SemLing-MNMT .
Numerous methods have been proposed to address these challenges. Some methods focus on learning a universal cross-lingual representation space at the encoder (Arivazhagan et al., 2019; Pan et al., 2021; Pham et al., 2019; Gu and Feng, 2022), while others aim to facilitate target language generation at the decoder (Yang et al., 2021a; Gao et al., 2023). For example, Pan et al. (2021) employ contrastive learning to minimize the distance between parallel sentence pairs and maximize the distance between irrelevant sentence pairs. Gu and Feng (2022) leverage optimal transport theory to learn a universal representation and introduce an agreement-based training approach to make consistent predictions. Gao et al. (2023) promote consistent cross-lingual representation by cross-lingual consistency regularization. However, these methods primarily concentrate on learning
Figure 1: The framework of our method. We propose a disentangler to learn a universal semantic representation via disentangling and utilize a linguistic encoder to fuse low-level linguistic features.
language-agnostic semantic features while neglecting the language-specific linguistic features. Such incompleteness of information can lead to less accurate semantic mapping and alignment degradation, which can harm the supervised and zero-shot translation performance.
In this paper, we propose to utilize both semantic and linguistic features for multilingual NMT. Our insight is to learn a semantic representation space non-destructively and utilize linguistic features to guide target language generation, thereby improving the performance of zero-shot translation and maintaining supervised translation performance lossless. Specifically, at the encoder, we introduce a disentangler and disentangling learning task to facilitate harmless cross-lingual semantic alignment. At the decoder, we utilize a linguistic encoder to integrate low-level linguistic features from lower layers and high-level semantic features from higher layers. This fusion provides implicit guidance for the target language generation.
Experiments on multilingual datasets show that our method brings an average of 0.18+ BLEU in the supervised translation direction and an average of 3.74+ BLEU in the zero-shot translation direction compared with the baseline system. Furthermore, the analysis demonstrates that our method can alleviate the problems caused by the entanglement of semantic and linguistic features, obtain a better semantic representation, and reduce the off-target rate in zero-shot translation.
## 2 Background
In this section, we will give a brief introduction to the Transformer (Vaswani et al., 2017) model for NMT and many-to-many multilingual NMT.
## 2.1 Transformer for NMT
Define the set D of parallel corpus with input sentence x u i and reference y v i , where u and v denote language type and i denotes the sentence id, which is the same for a sentence pair. The model first maps the source sentence x u i from the token representation to the token vector representation embed ( x u i ) . After that, the encoder encodes the token vector sequence into the hidden state representation h x ( u i ) . Similarly, the model maps the predicted k -1 target words into a sequence of token vectors, and the decoder decodes the k th target word based on the sequence of hidden states h x ( u i ) from the encoder and the predicted sequence of k -1 target words. The model repeats this process until the ⟨ eos ⟩ token is predicted. The model is optimized by minimizing the cross-entropy (CE) loss between the predicted sentence and the reference as follows:
$$\mathcal { L } _ { c e } = - \sum _ { \mathbf x _ { i } ^ { u }, \mathbf y _ { i } ^ { v } \in \mathcal { D } } \log ( P _ { \theta } ( \mathbf y _ { i } ^ { v } | \mathbf x _ { i } ^ { u } ) ) \quad ( 1 )$$
where θ denotes the model parameters.
## 2.2 Many-to-Many Multilingual NMT
The many-to-many multilingual NMT model supports translation between multiple languages. For-
Figure 2: The architecture of disentangler. ⊕ denotes the summation of the feature dimensions.
mally, we define the set of languages L = { L , ..., L 1 M } , where M is the number of languages. We prepend a language token at the beginning of the source sentence and the target sentence to indicate the language type respectively. For example, the following sentence pair translated from English to French: "Hello world! → Bonjour le monde!" is transformed into " ⟨ en ⟩ Hello world! → ⟨ fr ⟩ Bonjour le monde!".
## 3 Method
The core idea of our approach is to improve multilingual NMT by exploiting semantic and linguistic features at the same time. To achieve this, we disentangle semantic and linguistic features for the encoder and utilize low-level linguistic features for the decoder. Specifically, we propose a disentangler at the encoder to facilitate lossless semantic alignment. Meanwhile, we introduce a linguistic encoder at the decoder to fuse low-level features to guide target language generation. Figure 1 illustrates the framework of our approach.
## 3.1 Disentangling Semantic and Linguistic Features
Empirically, sentences possess both semantic and linguistic properties, which can be expressed as "sentence = semantics + linguistics". Semantic features encompass the meanings of language units that are shared across languages, while linguistic features comprise the rules for constructing sentences, such as lexical labels and morphological information. By disentangling linguistic features from sentences, we can obtain a universal semantic representation shared by different languages. Referring to the design of Tiyajamorn et al. (2021) on multilingual language understanding tasks, we extract semantic and linguistic features separately and implement interactive decomposition using reconstruction constraints.
The structure of our disentangler is shown in Figure 2. The disentangler consists of two feed-forward networks (FFN), a semantic FFN and a language FFN, respectively. For the encoder representations, the former extracts languageagnostic semantic information, and the latter extracts language-specific linguistic features. Then, the two outputs are summed to reconstruct the original encoder representations. The extracted semantic features are fed into the decoder.
We define disentangling loss L det to optimize disentangler by multi-task learning:
$$\mathcal { L } _ { d e t } = \mathcal { L } _ { s e m } + \mathcal { L } _ { l a n g } + \lambda _ { 1 } \mathcal { L } _ { r e c o n s } \quad ( 2 )$$
where L sem assists the semantic FFN to extract semantic information, L lang assists the language FFN to extract linguistic features, L recons is the reconstruction constraint, and λ 1 is the hyperparameter to balance the losses.
Semantic Learning To learn a universal representation space across multiple languages, we explicitly minimize the distance of parallel sentence pairs and maximize the distance of irrelevant sentence pairs. For the multilingual parallel dataset D , we make the parallel sentence pair ( x u i , y v i ) ∈ D a positive example and randomly choose a sentence y w j from language L w as a negative example ( x u i , y w j ) , where L u can be the same as L w . We optimize by minimizing the following loss function:
$$\text{use} \\ \text{tures} \quad \mathcal { L } _ { s e m } = & \mathbb { E } _ { x _ { i } ^ { u }, y _ { i } ^ { v } \in \mathcal { D } } ( 1 - s i m ^ { + } ( \mathcal { R } ( { \mathbf x } _ { i } ^ { u } ), \mathcal { R } ( { \mathbf y } _ { i } ^ { v } ) ) + \\ & \lambda _ { 2 } \mathbb { E } _ { x _ { i } ^ { u }, { \mathbf y } _ { j } ^ { w } \in \mathcal { D } } ( 1 + s i m ^ { - } ( \mathcal { R } ( { \mathbf x } _ { i } ^ { u } ), \mathcal { R } ( { \mathbf y } _ { j } ^ { w } ) ) ) \\. \quad \text{where} \quad \text{$\colon$} \quad \text{$\colon$} \quad \text{$\colon$} \quad \text{$\colon$} \quad \text{$\colon$} \quad \text{$\colon$} \quad \text{$\colon$}.$$
where sim ( ) · calculates the similarity of different sentences, and we use cosine similarity to evaluate the similarity. + and -denote positive and negative samples, respectively. R · ( ) calculates the average-pooled hidden state representation. λ 2 is the hyperparameter that balances positive and negative samples. To simplify the implementation in the training, we sample the positive and negative samples within every training batch.
Language Learning Empirically, different languages have different linguistic features, such as lexical and syntactic patterns. Compared with sentences in different languages, the linguistic features are more similar between sentences in the same
language. To extract linguistic features of multiple languages, we design the training objective similar to semantic learning. We minimize the distance of sentences in the same language and maximize the distance of sentences in different languages. We make the same language sentence pair ( x u i , y u j ) ∈ D a positive example and choose a random sentence y v k from any other language L k as a negative example ( x u i , y v k ) . We optimize by minimizing the following loss function:
$$\mathcal { L } _ { l a n g } = & \mathbb { E } _ { \mathbf x _ { i } ^ { u }, \mathbf y _ { j } ^ { u } \in \mathcal { D } } ( 1 - s i m ^ { + } ( \mathcal { R } ( \mathbf x _ { i } ^ { u } ), \mathcal { R } ( \mathbf y _ { j } ^ { u } ) ) + \\ & \lambda _ { 2 } \mathbb { E } _ { \mathbf x _ { i } ^ { u }, \mathbf y _ { k } ^ { v } \in \mathcal { D } } ( 1 + s i m ^ { - } ( \mathcal { R } ( \mathbf x _ { i } ^ { u } ), \mathcal { R } ( \mathbf y _ { k } ^ { v } ) ) ) \\ \mathbb { W h a r a c i m } \in \Delta \left ( \sum \right ) \right ) + \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \sum \left ( \frac { 1 } { 2 } } } } \right ) \right ) \right )$$
Where sim ( ) · , + , -and R · ( ) are defined the same as semantic learning. λ 2 is a shared hyperparameter. We sample the positive and negative samples within every training batch.
Reconstruction Constraint To make the semantic and linguistic features fully interact and learn a more reasonable semantic representation, we design the reconstruction constraint to utilize the linguistic features. We input the encoded hidden state h ( x u i ) from the encoder into the disentangler, extract the semantic information h sem ( x u i ) and the language features h lang ( x u i ) respectively, and reconstruct the original encoder representation by summation. We perform optimization by minimizing the following loss function:
$$\mathcal { L } _ { r e c o n s } = & \mathbb { E } _ { \mathbf x _ { i } ^ { u } \in \mathcal { D } } ( \frac { 1 } { d } | | \mathbf h ( \mathbf x _ { i } ^ { u } ) ) - \quad ( 5 ) \quad \text{$\mathbf \text{$\mathbf u$}$} \\ & \mathbf h _ { s e m } ( \mathbf x _ { i } ^ { u } ) - \mathbf h _ { l a n g } ( \mathbf x _ { i } ^ { u } ) | | _ { 2 } ) \quad \text{$\mathbf r e r o $}$$
Where d denotes the average sequence length.
## 3.2 Integrating Linguistic Features
In multilingual NMT models, decoders need to map the semantic representation to the target language representation. For zero-shot translation, since the model has not seen the translation direction during training, it is difficult to model the mapping relationships well, leading to the off-target phenomenon (Gu et al., 2019). Previous works show that the off-target rate is strongly correlated with the zero-shot translation performance (Zhang et al., 2020; Wu et al., 2021; Wang et al., 2022). Therefore, we hope to reduce the off-target rate by fusing additional information to guide the decoder to generate the target language.
Zhang et al. (2021) show that the lower encoder layers will focus more on linguistic information, which is crucial to distinguishing different languages. Therefore, we introduce a linguistic encoder with two encoder layers, which has the same input as the decoder. We utilize a fusion layer to integrate the low-level representations containing more linguistic features and the high-level representations containing more semantic features. We denote the linguistic encoder output as h lingEnc and the decoder output as h dec . We concatenate these features in the feature dimension and utilize a two-layer FFN for fusion:
$$h = W _ { 1 } ( \text{ReLU} ( W _ { 2 } ( [ \text{h} _ { d e c } ; \text{h} _ { l i n g E n c } ] ) ) ) \quad ( 6 )$$
Where W 1 ∈ R d × d h and W 2 ∈ R 2 d h × d are two feed-forward layers.
## 3.3 Joint Training Strategy
We optimize the final loss function using a joint training strategy, including cross-entropy loss and disentangling loss:
$$\mathcal { L } = \mathcal { L } _ { c e } + \lambda d \mathcal { L } _ { d e t }$$
where λ is the hyperparameter that controls the contribution of L det . Since L ce is calculated at the token level and L det is calculated at the sentence level, we multiply L det by the average sequence length d .
## 4 Experiment
We evaluate the performance of our model on the multilingual benchmarks, including supervised and zero-shot translation performance.
## 4.1 Dataset Description
We conduct experiments on the IWSLT2017, OPUS-7, and PC-6 datasets. The brief information about these datasets is shown in Appendix A.
IWSLT2017 The IWSLT2017 benchmark (Cettolo et al., 2017) contains five languages: German (De), English (En), Dutch (Nl), Romanian (Ro), and Italian (It). We experiment on the Englishcentric dataset consisting of eight supervised translation directions and twelve zero-shot translation directions. The training set contains 0.22M ∼ 0.26M parallel sentence pairs per language direction. We use the official validation set and test set.
OPUS-7 The OPUS-7 dataset is a subset of the OPUS-100 dataset (Pan et al., 2021). The OPUS-7 dataset is English-centric and contains seven languages: Arabic (Ar), German (De), English (En),
French (Fr), Dutch (Nl), Russian (Ru), and Chinese (Zh). This dataset contains twelve supervised translation directions and thirty zero-shot translation directions. The training set contains 1M parallel sentence pairs per language direction. We use the official validation set and test set.
PC-6 We construct the PC-6 dataset following (Gu and Feng, 2022). PC-6 is a dataset of six languages extracted from PC32 (Pan et al., 2021), including Czech (Cs), Kazakh (Kk), Romanian (Ro), Russian (Ru), and Turkish (Tr). The PC-6 dataset contains ten supervised translation directions and twenty zero-shot translation directions. The amount of data in each language direction varies in size from 0.12M to 1.84M sentence pairs. For the supervised translation, we use the official WMT2016 ∼ 2019 validation set and test set. For the zero-shot translation, we extract from WikiMatrix (Schwenk et al., 2021) to obtain the test set.
We directly apply the Unigram Model algorithm to preprocess the original multilingual corpus using Sentencepiece toolkit (Kudo and Richardson, 2018). We build a shared dictionary across multiple languages, which contains 32K tokens.
## 4.2 Model Configuration
We use the base Transformer configuration (Vaswani et al., 2017) for both the encoder and decoder. For the disentangler and the fusion layer, we set ffn dim \_ = 2048 . For the linguistic encoder, we apply two encoder layers of the base Transformer configuration. We use the Adam optimizer and set β = (0 9 0 98) . , . . We set warmup = 4000 and use the inverse square root learning scheduler with the learning rate set to 7 e -4 . We apply label-smoothed cross-entropy loss with a smoothing rate of 0 1 . . We set dropout = 0 3 . for the IWSLT2017 dataset and dropout = 0 1 . for the OPUS-7 and PC-6. We set λ = 0 05 . , λ 1 = 0 2 . and λ 2 = 0 2 . for our system. We train the models on 4 RTX3090 GPUs.
In the inference stage, we use beam search with beam size 5 and set the length penalty to 1. We report the BLEU (Papineni et al., 2002), ChrF (Popovi´ c, 2015) and COMET (Rei et al., 2022) 2 scores for comprehensive evaluation. The BLEU and ChrF scores are computed using the SacreBLEU toolkit (Post, 2018). We select the best-performing three checkpoints on the valida-
2 https://huggingface.co/Unbabel/
wmt22-comet-da
tion sets from the last six checkpoints and report the average scores on the test sets.
## 4.3 Contrast Systems
We compare our model with the following multilingual NMT systems. We prepend a language token at the beginning of the sentences for NMT systems.
m-Transformer (Johnson et al., 2017) This method utilizes cross-entropy loss to train a Transformer model on multilingual datasets.
Pivot Translation (Cheng et al., 2017) This method transforms zero-shot translation into English-centric two-stage translation. The translation model is m-Transformer.
Contrastive Learning (mRASP2 w/o AA) (Pan et al., 2021) This method introduces contrastive learning to learn a universal representation space for the encoder. For a fair comparison, we do not use the aligned augmentation (AA).
## Target Language Prediction (TLP) (Yang
et al., 2021a) This method leverages a target language prediction task to help the decoder retain information about the target language.
Denoising Training (DT) (Wang et al., 2021) This method introduces a denoising auto-encoder task during training. Specifically, they utilize all English sentences to construct the denoising corpus via text infilling operation.
CrossConST (Gao et al., 2023) This approach adds KL divergence loss to the Softmax layer to promote consistent cross-lingual representation:
$$\mathcal { L } _ { k l } = \gamma \mathbf K L ( P _ { \theta } ( \mathbf x, \mathbf y ) | | P _ { \theta } ( \mathbf y, \mathbf y ) ) \quad ( 8 )$$
Where γ is the hyperparameter controlling the proportion of L kl . We set γ = 0 25 . on IWSLT2017, γ = 0 06 . on OPUS-7 and γ = 0 1 . on PC-6. We jointly train L ce and L kl .
Alpaca (Taori et al., 2023) Alpaca is fine-tuned by Stanford from LLaMA-7B (Touvron et al., 2023) with 52k instruction data. We reproduce Alpaca using the LoRA (Hu et al., 2022) setting.
ChatGPT We use the GPT-3.5-Turbo API 3 for translation experiments. Our translation prompt for Alpaca and ChatGPT is reported in Appendix B.
3 The API version is GPT-3.5-Turbo-0613.
| IWSLT2017 | De ↔ It | De ↔ Nl | De ↔ Ro | It ↔ Nl | It ↔ Ro | Nl ↔ Ro | Zero-shot Average | Supervised Average |
|---------------|-----------|-----------|-----------|-----------|-----------|-----------|---------------------|----------------------|
| m-Transformer | 16.94 | 20.89 | 17.02 | 17.58 | 17.32 | 17.83 | 17.93 | 34.32 |
| mRASP2 w/o AA | 21.39 | 24.67 | 21.4 | 22.43 | 22.7 | 21.87 | 22.41 | 34.06 |
| TLP | 19.52 | 23.41 | 19.08 | 20.75 | 20.34 | 20.29 | 20.56 | 34.29 |
| DT | 18.76 | 22.05 | 18.65 | 20.04 | 20.31 | 19.83 | 19.94 | 34.17 |
| CrossConST | 20.93 | 24.1 | 20.65 | 21.98 | 21.68 | 21.4 | 21.73 | 34.10 |
| Pivot | 21.8 | 24.14 | 21.23 | 22.63 | 22.19 | 22.27 | 22.37 | - |
| Alpaca | 14.5 | 17.94 | 12.88 | 14.46 | 13.44 | 12.18 | 14.23 | 27.37 |
| ChatGPT | 23.85 | 27.01 | 23.21 | 25.17 | 24.72 | 24.83 | 24.79 | 35.26 |
| Ours | 21.55 | 25.18 | 21.5 | 22.84 | 22.66 | 22.46 | 22.7 | 34.25 |
| OPUS-7 | x → Ar | x → De | x → Fr | x → Nl | x → Ru | x → Zh | Zero-shot Average | Supervised Average |
|---------------|----------|----------|----------|----------|----------|----------|---------------------|----------------------|
| m-Transformer | 12.73 | 14.58 | 23.11 | 15.82 | 17.24 | 16.44 | 16.65 | 31.91 |
| mRASP2 w/o AA | 14.2 | 16.54 | 25.67 | 17.46 | 19.29 | 17.72 | 18.48 | 31.48 |
| TLP | 13.1 | 14.32 | 22.71 | 15.82 | 17.29 | 16.29 | 16.59 | 31.90 |
| DT | 13.84 | 15.06 | 23.95 | 16.24 | 18.29 | 17.85 | 17.54 | 31.96 |
| CrossConST | 13.68 | 15.04 | 23.67 | 16.5 | 17.67 | 16.03 | 17.1 | 32.12 |
| Pivot | 15.79 | 17.48 | 27.81 | 18.5 | 20.98 | 15.71 | 19.38 | - |
| Ours | 14.79 | 16.64 | 26.2 | 17.42 | 20.11 | 17.4 | 18.76 | 32.13 |
| PC-6 | x → Cs | x → Kk | x → Ro | x → Ru | x → Tr | Zero-shot Average | Supervised Average |
|---------------|----------|----------|----------|----------|----------|---------------------|----------------------|
| m-Transformer | 8.05 | 4.27 | 11.05 | 10.91 | 5.45 | 7.94 | 20.38 |
| mRASP2 w/o AA | 14.27 | 2.85 | 15.67 | 16.12 | 8.22 | 11.42 | 19.93 |
| TLP | 9.67 | 4.27 | 11.35 | 10.79 | 6.17 | 8.45 | 20.68 |
| DT | 12.57 | 4.85 | 14.32 | 15.63 | 7.78 | 11.03 | 20.22 |
| CrossConST | 13.03 | 2.29 | 14.56 | 13.41 | 7.41 | 10.14 | 20.50 |
| Pivot | 13.73 | 2.13 | 15.91 | 15.2 | 8.3 | 11.05 | - |
| Ours | 14.13 | 4.2 | 16.92 | 16.72 | 9.44 | 12.28 | 20.77 |
Table 1: Overall performance on the multilingual test sets. We report the BLEU scores. "Zero-shot Average" and "Supervised Average" denote the average BLEU scores on the zero-shot and supervised directions. The "x" in the last two tables denotes all languages except for the target language. We bold the highest BLEU scores except for Alpaca, ChatGPT and Pivot.
## 4.4 Main Results
The results of the main experiment are shown in Table 1. For OPUS-7 and PC-6, we report the average BLEU scores for the same target language for convenience, and detailed results for the zeroshot translation directions are shown in Appendix C. The ChrF and COMET results are presented in Appendix D.
mance. In the zero-shot translation direction, our system significantly outperforms all the contrast models, indicating that our additional modeling of linguistic features can assist the model in learning better semantic representation and language generation. Moreover, our method even outperforms the Pivot system on IWSLT2017 and PC-6, which we believe is probably because Pivot accumulates too many errors on these two datasets.
The results show that our system significantly improves zero-shot translation performance and maintains supervised translation performance. Specifically, in the supervised translation direction, the performance of our system is comparable to that of m-Transformer, which suggests that our disentangling approach mitigates alignment degradation and maintains the supervised translation perfor-
The results of large language models (LLMs) indicate that our task-specific model still has advantages in the era of LLMs. Our model significantly outperforms Alpaca-7B in supervised and zero-shot translation. Compared to the ChatGPT, our model achieves more than 90% performance with just about 0.1% of the parameters. Furthermore, our model employs significantly less data
Table 2: The results of the ablation study. The markers ✔ and ✘ indicate the component is involved or not involved, respectively. The m-Transformer † has eight encoder layers and eight decoder layers, similar to our model size.
| Model | Disentangler | Disentangling Objective | Linguistic Encoder | Zero-shot Average | Supervised Average |
|-----------------|----------------|---------------------------|----------------------|---------------------|----------------------|
| m-Transformer | ✘ | ✘ | ✘ | 17.93 | 34.32 |
| m-Transformer † | ✘ | ✘ | ✘ | 17.03 | 34.33 |
| ① | ✔ | ✘ | ✘ | 19.88 | 34.39 |
| ② | ✔ | ✔ | ✘ | 21.86 | 34.45 |
| ③ | ✘ | ✘ | ✔ | 21.27 | 34.34 |
| ④ | ✔ | ✘ | ✔ | 21.92 | 34.23 |
| ⑤ | ✔ | ✔ | ✔ | 22.7 | 34.25 |
and inference is much faster.
## 5 Analysis
In this section, we will analyze what contributes to the performance. We first analyze the effects of each module via an ablation study. Then, we evaluate the off-target rate and visualize the encoder and decoder sentence representations, demonstrating that our approach learns universal representations and generates target language more accurately. Finally, we examine some translation cases to show the usefulness of our approach.
## 5.1 Ablation Study
To further analyze the effectiveness of our approach, we conducted experiments on different variants of our system on the IWSLT2017. We briefly report the experimental results in Table 2.
Compared with the m-Transformer, ③ can significantly improve the zero-shot translation. The gap in zero-shot translation performance remains even when scaling up the m-Transformer (mTransformer ). † This indicates that it is effective to leverage the linguistic encoder to learn low-level linguistic features and integrate different levels of representations. We present detailed results and analysis of the scaling experiments in Appendix E for parameter comparisons.
Compared with ① ② , provides a significant improvement in zero-shot translation while maintaining supervised translation performance. This indicates that the disentangling learning task is effective. Disentangling learning can significantly improve the performance of zero-shot translation while mitigating the performance loss in supervised translation caused by semantic alignment. The analysis between ④ and ⑤ similarly supports this view. ② ③ ⑤
Compared with and , shows that the dis-
Table 3: The average off-target rate for the test sets.
| | IWSLT2017 | OPUS-7 | PC-6 |
|---------------|-------------|----------|--------|
| m-Transformer | 6.76% | 11.58% | 21.02% |
| mRASP2 w/o AA | 2.84% | 8.91% | 8.68% |
| CrossConST | 3.07% | 11.71% | 7.94% |
| Ours | 2.46% | 8.64% | 7.25% |
Table 4: The average in-target BLEU scores for the test sets.
| | IWSLT2017 | OPUS-7 | PC-6 |
|---------------|-------------|----------|--------|
| m-Transformer | 18.39 | 15.76 | 7.91 |
| mRASP2 w/o AA | 22.42 | 17.31 | 11.48 |
| Ours | 22.69 | 17.57 | 11.82 |
entangler and the linguistic encoder can collaborate to improve the zero-shot translation performance.
## 5.2 Off-target Issue
The many-to-many multilingual NMT models face the off-target issue (Gu et al., 2019) in zero-shot translation, which seriously impacts the zero-shot translation performance. The off-target issue refers to the problem that the model simply copies the source sentences or generates incorrect target sentences. Related work shows that multilingual NMT models have difficulty establishing mapping relations for the zero-shot translation directions, which may be overfitted to other language directions. To test whether our approach can alleviate the offtarget issue, we use langid toolkit (Lui and Baldwin, 2012) to identify the target language and define the off-target rate as the proportion of off-target sentences. We conduct experiments on the contrast systems and our method. Table 3 shows that our method can effectively reduce the off-target rate compared to other systems, proving that our method can provide an effective guide for target language generation.
y
y
x
x
(a) m-Transformer Encoder (b) mRASP2 w/o AA Encoder
y
y
x
x
x
(c) Semantic FFN
y
x

x
(d) Language FFN
y
x
(e) Decoder Embedding
(f) Linguistic Encoder
(g) m-Transformer Decoder
(h) Fusion Layer
Figure 3: Visualization of the m-Transformer, mRASP2 w/o AA and our system after dimension reduction. The subfigure captions describe the model modules, and we do dimension reduction on the outputs of these modules. The blue line denotes German (De), the orange line denotes Italian (It), the green line denotes Dutch (Nl), and the purple line denotes Romanian (Ro).
Furthermore, we test the performance of intarget sentences to demonstrate that our approach improves the in-target translation quality. Considering that there is no comparability between the BLEU scores of different test sets, we extract the part where all model outputs are in-target for testing. Table 4 presents the results. Compared with Table 1, the performance gap between different models in the in-target part is smaller, which indicates the importance of mitigating the off-target issue. Meanwhile, the zero-shot performance of our models in the in-target part still significantly outperforms m-Transformer, which implies that our approach achieves better knowledge transfer and improves the zero-shot translation quality.
align different languages well, which is caused by the entanglement of semantic and linguistic features at the representation level. For semantic features, our semantic FFN pulls the semantic representation closer, achieving a similar effect as mRASP2 w/o AA. For linguistic features, our language FFN pushs the different language representations apart, which proves that the language FFN can extract linguistic features.
## 5.3 Visualization
We visualize the sentence representations of the encoder and decoder to verify, respectively, that our disentangler aids semantic alignment and our linguistic encoder achieves more accurate target language generation. We conduct experiments on a subset of IWSLT2017 test sets. We use tSNE (Van der Maaten and Hinton, 2008) to reduce the 512-dim representations to 2-dim.
Figures 3(a) - 3(d): The m-Transformer cannot
Figures 3(e) - 3(h): The representation after decoder embedding is language-mixed, while the linguistic encoder can encode different languages into different subspaces, even though no explicit task is designed to guide this. By introducing low-level linguistic features, our system can better distinguish the target language and thus generate the target sentences more accurately.
## 5.4 Case Study
To further demonstrate the usefulness of our system, we analyze some translation cases and compare the outputs of our model with that of the mTransformer in Figure 4. While the m-Transformer translates whole or partial sentences to the wrong language, our model can translate accurately, proving the advantages of our method.
y
y
Figure 4: Case study of zero-shot translation. We identify three off-target types which are categorized by offtarget position and ratio.

## 6 Related Work
## 6.1 Zero-shot Machine Translation
To improve the zero-shot translation capability of multilingual NMT, researchers have proposed a series of auxiliary training objectives. These works can be divided into two categories. The first category is designed directly at the encoder so that the encoder outputs language-agnostic representations (Pham et al., 2019; Wei et al., 2021). These works are motivated by the hypothesis that a universal semantic representation can realize better knowledge transfer. Pan et al. (2021) propose a contrastive learning task to encourage the model to learn a universal representation space. Gu and Feng (2022) use optimal transport theory to close the representation of sentence pairs. However, these works focus only on semantic features and neglect linguistic features, which leads to performance degradation in the supervised translation direction. By integrating both semantic and linguistic features, our approach significantly improves the performance of zero-shot translation while effectively maintaining the supervised direction performance.
The second category is designed at the decoder to provide explicit guidance for target language generation. These works are motivated to improve multilingual representation. Yang et al. (2021a) propose the target language prediction task at the sequence level and the target gradient regularization at the gradient level. Gao et al. (2023) introduce the KL regularization term for the Softmax layer to promote cross-lingual consistent representation. In contrast to these approaches, we do not explicitly design auxiliary tasks, but utilize a lin- guistic encoder to fuse low-level representations containing more linguistic features and high-level representations containing more semantic features.
## 6.2 Disentangling for Cross-lingual Alignment
Cross-lingual alignment is a classic problem in multilingual tasks. Although the "pretrainingfinetuning" paradigm can improve the cross-lingual ability of the model (Liu et al., 2020; Xue et al., 2021), the entangling of semantics and linguistics can impair the model performance. To address this problem, many researchers have improved it from the perspective of disentangling. Tiyajamorn et al. (2021) design auto-encoder to disentangle semantic and linguistic representation for natural language understanding tasks. Yang et al. (2021b) remove language identity information from pre-trained multilingual representations by singular value decomposition (SVD) and orthogonal projection. Zhao et al. (2021) explore three settings for removing language identity signals from multilingual representations, including vector space re-alignment, vector space normalization and input normalization. Wu et al. (2022) use SVD to extract linguistic features, use language-agnostic semantic information for task-specific training, and re-entangle semantic and linguistic features in the generation phase. We refer to this disentangling idea and utilize disentangling to achieve lossless semantic alignment for multilingual NMT.
## 7 Conclusion
In this paper, we propose to exploit both semantic and linguistic features to improve multilingual NMT. We design a disentangler and disentangling learning task at the encoder side to achieve lossless semantic alignment. Meanwhile, we introduce a linguistic encoder at the decoder side to fuse the low-level representation containing more linguistic features and the high-level representation containing more semantic features to improve the target language generation. Experiments on multilingual datasets indicate that our approach can significantly improve the performance of zero-shot translation while effectively maintaining the supervised translation performance. The analysis further demonstrates that utilizing both semantic and linguistic features can help the model learn semantic representation non-destructively and achieve more accurate target language generation.
## Limitations
Although our approach can significantly improve zero-shot translation performance while maintaining supervised translation performance, the performance improvement in the supervised direction is limited. On the one hand, the datasets of our experiments contain only several languages, and the baseline model can already model the supervised translation well. On the other hand, our approach to modeling linguistic features is still preliminary and implicit. Future work could consider using larger multilingual datasets as well as designing better methods to model linguistic features.
## Acknowledgments
We thank all the anonymous reviewers for their insightful and valuable comments. This work was supported by a grant from the National Natural Science Foundation of China (No. 62376260).
## References
Roee Aharoni, Melvin Johnson, and Orhan Firat. 2019. Massively multilingual neural machine translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 3874-3884, Minneapolis, Minnesota. Association for Computational Linguistics.
Naveen Arivazhagan, Ankur Bapna, Orhan Firat, Roee Aharoni, Melvin Johnson, and Wolfgang Macherey. 2019. The missing ingredient in zero-shot neural machine translation. arXiv preprint arXiv:1903.07091 .
Mauro Cettolo, Marcello Federico, Luisa Bentivogli, Niehues Jan, Stüker Sebastian, Sudoh Katsuitho, Yoshino Koichiro, and Federmann Christian. 2017. Overview of the iwslt 2017 evaluation campaign. In Proceedings of the 14th International Workshop on Spoken Language Translation , pages 2-14.
Yong Cheng, Qian Yang, Yang Liu, Maosong Sun, and Wei Xu. 2017. Joint training for pivot-based neural machine translation. In Proceedings of the 26th International Joint Conference on Artificial Intelligence , IJCAI'17, page 3974-3980. AAAI Press.
Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, et al. 2021. Beyond english-centric multilingual machine translation. The Journal of Machine Learning Research , 22(1):4839-4886.
Orhan Firat, Kyunghyun Cho, and Yoshua Bengio. 2016. Multi-way, multilingual neural machine translation with a shared attention mechanism. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 866-875, San Diego, California. Association for Computational Linguistics.
Pengzhi Gao, Liwen Zhang, Zhongjun He, Hua Wu, and Haifeng Wang. 2023. Improving zero-shot multilingual neural machine translation by leveraging crosslingual consistency regularization. In Findings of the Association for Computational Linguistics: ACL 2023 , pages 12103-12119, Toronto, Canada. Association for Computational Linguistics.
Jiatao Gu, Yong Wang, Kyunghyun Cho, and Victor O.K. Li. 2019. Improved zero-shot neural machine translation via ignoring spurious correlations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 12581268, Florence, Italy. Association for Computational Linguistics.
Shuhao Gu and Yang Feng. 2022. Improving zeroshot multilingual translation with universal representations and cross-mapping. In Findings of the Association for Computational Linguistics: EMNLP 2022 , pages 6492-6504, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations .
Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda B. Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, and Jeffrey Dean. 2017. Google's multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguistics , 5:339-351.
Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018: System Demonstrations, Brussels, Belgium, October 31 - November 4, 2018 , pages 66-71.
Sneha Kudugunta, Ankur Bapna, Isaac Caswell, and Orhan Firat. 2019. Investigating multilingual NMT representations at scale. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages 1565-1575, Hong Kong, China. Association for Computational Linguistics.
Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pretraining for neural machine translation. Transactions of the Association for Computational Linguistics , 8:726-742.
Marco Lui and Timothy Baldwin. 2012. langid.py: An off-the-shelf language identification tool. In Proceedings of the ACL 2012 System Demonstrations , pages 25-30, Jeju Island, Korea. Association for Computational Linguistics.
Xiao Pan, Mingxuan Wang, Liwei Wu, and Lei Li. 2021. Contrastive learning for many-to-many multilingual neural machine translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 244-258, Online. Association for Computational Linguistics.
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA , pages 311-318.
Ngoc-Quan Pham, Jan Niehues, Thanh-Le Ha, and Alexander Waibel. 2019. Improving zero-shot translation with language-independent constraints. In Proceedings of the Fourth Conference on Machine Translation (Volume 1: Research Papers) , pages 13-23, Florence, Italy. Association for Computational Linguistics.
Maja Popovi´ c. 2015. chrF: character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation , pages 392-395, Lisbon, Portugal. Association for Computational Linguistics.
Matt Post. 2018. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers , pages 186191, Brussels, Belgium. Association for Computational Linguistics.
Ricardo Rei, José G. C. de Souza, Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and André F. T. Martins. 2022. COMET-22: Unbabel-IST 2022 submission for the metrics shared task. In Proceedings of the Seventh Conference on Machine Translation (WMT) , pages 578-585, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
Holger Schwenk, Vishrav Chaudhary, Shuo Sun, Hongyu Gong, and Francisco Guzmán. 2021. WikiMatrix: Mining 135M parallel sentences in 1620 language pairs from Wikipedia. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages 1351-1361, Online. Association for Computational Linguistics.
Aditya Siddhant, Ankur Bapna, Yuan Cao, Orhan Firat, Mia Chen, Sneha Kudugunta, Naveen Arivazhagan, and Yonghui Wu. 2020. Leveraging monolingual data with self-supervision for multilingual neural machine translation. In Proceedings of the 58th Annual
Meeting of the Association for Computational Linguistics , pages 2827-2835, Online. Association for Computational Linguistics.
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https:// github.com/tatsu-lab/stanford\_alpaca .
Nattapong Tiyajamorn, Tomoyuki Kajiwara, Yuki Arase, and Makoto Onizuka. 2021. Languageagnostic representation from multilingual sentence encoders for cross-lingual similarity estimation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 7764-7774, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models.
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research , 9(11).
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems , 30.
Weizhi Wang, Zhirui Zhang, Yichao Du, Boxing Chen, Jun Xie, and Weihua Luo. 2021. Rethinking zeroshot neural machine translation: From a perspective of latent variables. In Findings of the Association for Computational Linguistics: EMNLP 2021 , pages 4321-4327, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Wenxuan Wang, Wenxiang Jiao, Shuo Wang, Zhaopeng Tu, and Michael R Lyu. 2022. Understanding and mitigating the uncertainty in zero-shot translation. arXiv preprint arXiv:2205.10068 .
Xiangpeng Wei, Rongxiang Weng, Yue Hu, Luxi Xing, Heng Yu, and Weihua Luo. 2021. On learning universal representations across languages. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net.
Liwei Wu, Shanbo Cheng, Mingxuan Wang, and Lei Li. 2021. Language tags matter for zero-shot neural machine translation. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages 3001-3007, Online. Association for Computational Linguistics.
Xianze Wu, Zaixiang Zheng, Hao Zhou, and Yong Yu. 2022. Laft: Cross-lingual transfer for text generation by language-agnostic finetuning. In Proceedings of
the 15th International Conference on Natural Language Generation , pages 260-266.
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 483-498, Online. Association for Computational Linguistics.
Yilin Yang, Akiko Eriguchi, Alexandre Muzio, Prasad Tadepalli, Stefan Lee, and Hany Hassan. 2021a. Improving multilingual translation by representation and gradient regularization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 7266-7279, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Ziyi Yang, Yinfei Yang, Daniel Cer, and Eric Darve. 2021b. A simple and effective method to eliminate the self language bias in multilingual representations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 5825-5832, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Biao Zhang, Ankur Bapna, Rico Sennrich, and Orhan Firat. 2021. Share or not? learning to schedule language-specific capacity for multilingual translation. In Ninth International Conference on Learning Representations 2021 .
Biao Zhang, Philip Williams, Ivan Titov, and Rico Sennrich. 2020. Improving massively multilingual neural machine translation and zero-shot translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 16281639, Online. Association for Computational Linguistics.
Wei Zhao, Steffen Eger, Johannes Bjerva, and Isabelle Augenstein. 2021. Inducing language-agnostic multilingual representations. In Proceedings of *SEM 2021: The Tenth Joint Conference on Lexical and Computational Semantics , pages 229-240, Online. Association for Computational Linguistics.
## A Statistics of the Datasets
Table 5 summarizes information about the multilingual training datasets.
Table 5: A brief description of the datasets.
| Dataset | Language Pairs | Size |
|-----------|-------------------------------|--------|
| IWSLT2017 | En ↔ {De, It, Nl, Ro} | 1.8M |
| OPUS-7 | En ↔ {Ar, De, Fr, Nl, Ru, Zh} | 12.0M |
| PC-6 | En ↔ {Cs, Kk, Ro, Ru, Tr} | 7.9M |
## B Translation Prompt for Alpaca and ChatGPT
For Alpaca, we follow the official template. We set Instruction to "Translate input from <src> to <tgt>." and set Input to the source sentence. For ChatGPT, we use the following format to structure the inputs: "Translate the sentences from <src> to <tgt>: <input>." . <src> denotes the source language, <tgt> denotes the target language and <input> denotes the source sentence.
## C Detailed Results on the OPUS-7 and PC-6 Test Sets
The detailed results on the OPUS-7 and PC-6 test sets are shown in Table 6 and Table 7 respectively.
## D ChrF and COMET Metrics
For the ChrF and COMET metrics, we evaluate the m-Transformer, mRASP2 w/o AA and our model. The results are presented in Table 8 and Table 9 respectively.
## E Scaling Experiments on the IWSLT2017 Test Set
Considering that our approach introduces additional parameters, we scale the model sizes of the m-Transformer and mRASP2 w/o AA for a fair comparison. As shown in Table 10, our model outperforms these variant models. We note a significant performance degradation of the m-Transformer when the model size reaches 100.4M. We attribute this to the limited size of the IWSLT2017 training set, thus the model performance largely depends on the method, rather than the model size. This further demonstrates the effectiveness of our method.
| m-Transformer | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|-----------------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 12.13 | 24.96 | 14.33 | 21.31 | 27.12 | 19.97 |
| De | 5.74 | - | 19.42 | 21.15 | 13.26 | 5.55 | 13.02 |
| Fr | 16.80 | 17.97 | - | 21.57 | 21.77 | 22.46 | 20.11 |
| Nl | 4.88 | 20.02 | 22.60 | - | 10.69 | 2.78 | 12.19 |
| Ru | 18.72 | 13.58 | 25.36 | 13.52 | - | 24.30 | 19.09 |
| Zh | 17.50 | 9.23 | 23.22 | 8.51 | 19.18 | - | 15.53 |
| x (avg) | 12.73 | 14.58 | 23.11 | 15.82 | 17.24 | 16.44 | 16.65 |
| Pivot | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|---------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 15.67 | 29.81 | 18.16 | 26.00 | 22.67 | 22.46 |
| De | 7.30 | - | 23.07 | 23.16 | 16.02 | 5.13 | 14.94 |
| Fr | 20.32 | 20.90 | - | 23.80 | 25.01 | 25.20 | 23.05 |
| Nl | 6.55 | 21.40 | 25.47 | - | 13.40 | 3.34 | 14.03 |
| Ru | 22.56 | 16.72 | 30.56 | 16.27 | - | 22.21 | 21.66 |
| Zh | 22.23 | 12.70 | 30.13 | 11.10 | 24.47 | - | 20.13 |
| x (avg) | 15.79 | 17.48 | 27.81 | 18.50 | 20.98 | 15.71 | 19.38 |
| mRASP2 w/o AA | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|-----------------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 14.74 | 27.06 | 15.71 | 22.86 | 26.05 | 21.28 |
| De | 6.48 | - | 22.09 | 23.06 | 14.91 | 6.82 | 14.67 |
| Fr | 19.00 | 20.01 | - | 23.85 | 23.89 | 26.30 | 22.61 |
| Nl | 6.08 | 21.75 | 24.86 | - | 12.83 | 3.90 | 13.89 |
| Ru | 20.02 | 15.51 | 28.10 | 14.84 | - | 25.52 | 20.8 |
| Zh | 19.43 | 10.67 | 26.22 | 9.82 | 21.97 | - | 17.62 |
| x (avg) | 14.20 | 16.54 | 25.67 | 17.46 | 19.29 | 17.72 | 18.48 |
| TLP | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|---------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 11.59 | 23.91 | 13.91 | 20.91 | 25.03 | 19.07 |
| De | 6.24 | - | 19.72 | 21.40 | 13.29 | 4.60 | 13.05 |
| Fr | 17.52 | 17.47 | - | 21.64 | 22.22 | 24.81 | 20.73 |
| Nl | 4.93 | 19.87 | 22.47 | - | 10.53 | 2.96 | 12.15 |
| Ru | 19.18 | 13.60 | 24.90 | 13.52 | - | 24.05 | 19.05 |
| Zh | 17.65 | 9.08 | 22.56 | 8.65 | 19.52 | - | 15.49 |
| x (avg) | 13.10 | 14.32 | 22.71 | 15.82 | 17.29 | 16.29 | 16.59 |
| DT | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|---------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 12.80 | 25.81 | 14.77 | 22.27 | 28.52 | 20.83 |
| De | 6.76 | - | 20.62 | 22.01 | 13.88 | 6.01 | 13.85 |
| Fr | 18.08 | 18.11 | - | 21.98 | 23.08 | 25.47 | 21.34 |
| Nl | 5.22 | 20.83 | 23.31 | - | 11.52 | 3.33 | 12.84 |
| Ru | 20.13 | 14.06 | 26.21 | 13.78 | - | 25.93 | 20.02 |
| Zh | 19.00 | 9.47 | 23.79 | 8.68 | 20.71 | - | 16.33 |
| x (avg) | 13.84 | 15.06 | 23.95 | 16.24 | 18.29 | 17.85 | 17.54 |
| CrossConST | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|--------------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 13.02 | 25.88 | 14.95 | 21.70 | 25.48 | 20.21 |
| De | 6.30 | - | 19.68 | 21.94 | 13.74 | 5.09 | 13.35 |
| Fr | 18.09 | 18.22 | - | 22.56 | 21.91 | 23.17 | 20.79 |
| Nl | 5.26 | 20.45 | 22.96 | - | 11.28 | 2.51 | 12.49 |
| Ru | 19.76 | 14.18 | 26.17 | 14.12 | - | 23.89 | 19.62 |
| Zh | 19.01 | 9.35 | 23.67 | 8.92 | 19.70 | - | 16.13 |
| x (avg) | 13.68 | 15.04 | 23.67 | 16.50 | 17.67 | 16.03 | 17.1 |
| Ours | Ar | De | Fr | Nl | Ru | Zh | x (avg) |
|---------|-------|-------|-------|-------|-------|-------|-----------|
| Ar | - | 14.60 | 27.78 | 15.41 | 24.50 | 26.49 | 21.75 |
| De | 7.04 | - | 22.31 | 23.04 | 14.84 | 6.37 | 14.72 |
| Fr | 19.89 | 20.00 | - | 23.90 | 24.92 | 25.10 | 22.76 |
| Nl | 6.06 | 21.61 | 24.87 | - | 12.81 | 3.58 | 13.79 |
| Ru | 20.84 | 15.85 | 28.66 | 14.91 | - | 25.46 | 21.15 |
| Zh | 20.11 | 11.14 | 27.38 | 9.83 | 23.48 | - | 18.39 |
| x (avg) | 14.79 | 16.64 | 26.20 | 17.42 | 20.11 | 17.40 | 18.76 |
Table 6: The performance of the contrast models and our model on the OPUS-7 dataset.
| m-Transformer | Cs | Kk | Ro | Ru | Tr | x (avg) |
|-----------------|-------|-------|-------|-------|------|-----------|
| Cs | - | 1.54 | 14.63 | 12.93 | 6.16 | 8.81 |
| Kk | 1.73 | - | 2.61 | 10.24 | 2.99 | 4.4 |
| Ro | 11.11 | 1.87 | - | 12.98 | 7.25 | 8.31 |
| Ru | 10.53 | 11.10 | 14.76 | - | 5.40 | 10.45 |
| Tr | 8.80 | 2.57 | 12.21 | 7.47 | - | 7.76 |
| x (avg) | 8.05 | 4.27 | 11.05 | 10.91 | 5.45 | 7.94 |
| Pivot | Cs | Kk | Ro | Ru | Tr | x (avg) |
|---------|-------|------|-------|-------|-------|-----------|
| Cs | - | 1.01 | 21.4 | 20.08 | 10.19 | 13.17 |
| Kk | 1.49 | - | 2.09 | 5.07 | 2.29 | 2.74 |
| Ro | 21.1 | 1.32 | - | 24.1 | 11.43 | 14.49 |
| Ru | 19.08 | 4.99 | 23.42 | - | 9.27 | 14.19 |
| Tr | 13.23 | 1.19 | 16.74 | 11.54 | - | 10.68 |
| x (avg) | 13.73 | 2.13 | 15.91 | 15.20 | 8.30 | 11.05 |
| mRASP2 w/o AA | Cs | Kk | Ro | Ru | Tr | x (avg) |
|-----------------|-------|------|-------|-------|-------|-----------|
| Cs | - | 1.11 | 20.70 | 22.09 | 9.94 | 13.46 |
| Kk | 2.01 | - | 2.35 | 7.65 | 2.33 | 3.59 |
| Ro | 20.32 | 1.60 | - | 24.42 | 11.94 | 14.57 |
| Ru | 21.88 | 6.53 | 23.51 | - | 8.65 | 15.15 |
| Tr | 12.86 | 2.16 | 16.09 | 10.31 | - | 10.36 |
| x (avg) | 14.27 | 2.85 | 15.67 | 16.12 | 8.22 | 11.42 |
| TLP | Cs | Kk | Ro | Ru | Tr | x (avg) |
|---------|-------|-------|-------|-------|------|-----------|
| Cs | - | 1.37 | 14.50 | 12.75 | 7.14 | 8.94 |
| Kk | 1.96 | - | 2.53 | 10.92 | 3.06 | 4.62 |
| Ro | 13.36 | 2.07 | - | 12.25 | 7.88 | 8.89 |
| Ru | 13.71 | 10.83 | 15.96 | - | 6.58 | 11.77 |
| Tr | 9.66 | 2.82 | 12.41 | 7.25 | - | 8.03 |
| x (avg) | 9.67 | 4.27 | 11.35 | 10.79 | 6.17 | 8.45 |
| DT | Cs | Kk | Ro | Ru | Tr | x (avg) |
|---------|-------|-------|-------|-------|-------|-----------|
| Cs | - | 1.53 | 19.03 | 18.83 | 8.21 | 11.9 |
| Kk | 2.13 | - | 2.81 | 12.43 | 3.58 | 5.24 |
| Ro | 17.34 | 2.27 | - | 20.63 | 10.99 | 12.81 |
| Ru | 18.75 | 12.23 | 19.51 | - | 8.35 | 14.71 |
| Tr | 12.06 | 3.35 | 15.95 | 10.64 | - | 10.5 |
| x (avg) | 12.57 | 4.85 | 14.32 | 15.63 | 7.78 | 11.03 |
| CrossConST | Cs | Kk | Ro | Ru | Tr | x (avg) |
|--------------|-------|------|-------|-------|-------|-----------|
| Cs | - | 0.89 | 20.44 | 18.13 | 9.50 | 12.24 |
| Kk | 1.75 | - | 1.93 | 5.20 | 1.82 | 2.68 |
| Ro | 19.96 | 1.19 | - | 20.98 | 10.48 | 13.15 |
| Ru | 18.45 | 5.23 | 21.08 | - | 7.84 | 13.15 |
| Tr | 11.95 | 1.86 | 14.80 | 9.34 | - | 9.49 |
| x (avg) | 13.03 | 2.29 | 14.56 | 13.41 | 7.41 | 10.14 |
| Ours | Cs | Kk | Ro | Ru | Tr | x (avg) |
|---------|-------|-------|-------|-------|-------|-----------|
| Cs | - | 1.37 | 22.11 | 21.63 | 10.93 | 14.01 |
| Kk | 1.87 | - | 2.45 | 9.48 | 2.73 | 4.13 |
| Ro | 20.22 | 1.91 | - | 24.05 | 13.94 | 15.03 |
| Ru | 20.66 | 11.03 | 23.94 | - | 10.15 | 16.45 |
| Tr | 13.76 | 2.50 | 19.18 | 11.70 | - | 11.79 |
| x (avg) | 14.13 | 4.20 | 16.92 | 16.72 | 9.44 | 12.28 |
Table 7: The performance of the contrast models and our model on the PC-6 dataset.
| IWSLT2017 | De ↔ It | De ↔ Nl | De ↔ Ro | It ↔ Nl | It ↔ Ro | Nl ↔ Ro | Zero-shot Average | Supervised Average |
|-----------------------------------------|-----------------------------------------|-----------------------------------------|-----------------------------------------|-----------------------------------------|-----------------------------------------|-----------------------------------------|---------------------|----------------------|
| m-Transformer | 43.09 | 46.50 | 42.65 | 43.63 | 43.72 | 43.53 | 43.85 | 58.39 |
| mRASP2 w/o AA | 48.36 | 50.93 | 47.59 | 49.42 | 49.54 | 48.86 | 49.11 | 58.47 |
| Ours | 48.83 | 51.12 | 47.97 | 49.63 | 49.90 | 49.11 | 49.43 | 58.46 |
| OPUS-7 | x → Ar | x → De | x → Fr | x → Nl | x → Ru | x → Zh | Zero-shot Average | Supervised Average |
| m-Transformer | 37.69 | 37.08 | 48.16 | 37.60 | 41.00 | 25.22 | 37.79 | 53.77 |
| mRASP2 w/o AA | 39.76 | 40.55 | 50.83 | 39.68 | 43.78 | 26.03 | 40.10 | 53.28 |
| Ours | 40.40 | 40.67 | 51.34 | 39.55 | 44.53 | 26.95 | 40.57 | 53.86 |
| PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | PC-6 x → Cs x → Kk x → Ro x → Ru x → Tr | Zero-shot Average | Supervised Average |
| m-Transformer | 30.82 | 16.66 | 36.03 | | 30.38 | 28.07 | 28.39 | 49.66 |
| mRASP2 w/o AA | 38.71 | 17.25 | 42.02 | | 41.69 | 35.65 | 35.06 | 49.64 |
| Ours | 38.84 | 19.44 | 43.41 | | 43.17 | 37.17 | 36.40 | 49.80 |
Table 8: The ChrF scores on the IWSLT2017, OPUS-7 and PC-6 test sets.
| IWSLT2017 | De ↔ It | De ↔ Nl | De ↔ Ro | It ↔ Nl | It ↔ Ro | Nl ↔ Ro | Zero-shot Average | Supervised Average |
|---------------|-----------|-----------|-----------|-----------|-----------|-----------|---------------------|----------------------|
| m-Transformer | 70.14 | 74.01 | 71.54 | 71.73 | 74.07 | 73.59 | 72.51 | 83.82 |
| mRASP2 w/o AA | 77.01 | 79.27 | 78.14 | 78.49 | 81.24 | 80.16 | 79.05 | 83.80 |
| Ours | 77.21 | 79.45 | 78.19 | 78.60 | 81.33 | 80.11 | 79.15 | 83.83 |
| OPUS-7 | x → Ar | x → De | x → Fr | x → Nl | x → Ru | x → Zh | Zero-shot Average | Supervised Average |
| m-Transformer | 72.33 | 65.77 | 70.67 | 68.97 | 73.48 | 71.52 | 70.46 | 79.45 |
| mRASP2 w/o AA | 74.36 | 68.41 | 72.77 | 70.89 | 76.15 | 74.02 | 72.77 | 79.25 |
| Ours | 74.64 | 68.74 | 73.33 | 71.02 | 76.65 | 74.18 | 73.09 | 79.66 |
| PC-6 | x → Cs | x → Kk | x → | Ro x | → Ru | x → Tr | Zero-shot Average | Supervised Average |
| m-Transformer | 58.10 | 46.51 | 62.63 | | 62.25 | 54.84 | 56.86 | 76.36 |
| mRASP2 w/o AA | 68.98 | 50.74 | 69.19 | | 70.95 | 64.85 | 64.94 | 76.32 |
| Ours | 70.13 | 52.99 | 72.32 | | 72.98 | 66.86 | 67.05 | 77.31 |
Table 9: The COMET scores on the IWSLT2017, OPUS-7 and PC-6 test sets.
| Models | l enc | l dec | Model Size | Zero-shot Average | Supervised Average |
|-----------------|---------|---------|--------------|---------------------|----------------------|
| m-Transformer | 6 | 6 | 79.4M | 17.93 | 34.32 |
| m-Transformer † | 6 | 8 | 87.8M | 18.1 | 34.23 |
| m-Transformer ‡ | 8 | 8 | 100.4M | 16.84 | 34.21 |
| mRASP2 w/o AA | 6 | 6 | 79.4M | 22.41 | 34.06 |
| mRASP2 w/o AA † | 8 | 8 | 100.4M | 22.46 | 34.19 |
| Ours | 6 | 6 | 99.4M | 22.7 | 34.25 |
Table 10: The scaling experiments on the IWSLT2017 test set. l enc and l dec denote layers of encoder and decoder respectively. The m-Transformer , m-Transformer † ‡ and mRASP2 w/o AA † denote scaled variants of the original model. | null | [
"Mengyu Bu",
"Shuhao Gu",
"Yang Feng"
]
| 2024-08-02T17:10:12+00:00 | 2024-08-02T17:10:12+00:00 | [
"cs.CL"
]
| Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features | The many-to-many multilingual neural machine translation can be regarded as
the process of integrating semantic features from the source sentences and
linguistic features from the target sentences. To enhance zero-shot
translation, models need to share knowledge across languages, which can be
achieved through auxiliary tasks for learning a universal representation or
cross-lingual mapping. To this end, we propose to exploit both semantic and
linguistic features between multiple languages to enhance multilingual
translation. On the encoder side, we introduce a disentangling learning task
that aligns encoder representations by disentangling semantic and linguistic
features, thus facilitating knowledge transfer while preserving complete
information. On the decoder side, we leverage a linguistic encoder to integrate
low-level linguistic features to assist in the target language generation.
Experimental results on multilingual datasets demonstrate significant
improvement in zero-shot translation compared to the baseline system, while
maintaining performance in supervised translation. Further analysis validates
the effectiveness of our method in leveraging both semantic and linguistic
features. The code is available at https://github.com/ictnlp/SemLing-MNMT. |
2408.01395v2 | ## A power sum expansion for the Kromatic symmetric function
## Laura Pierson University of Waterloo [email protected]
March 4, 2025
## Abstract
The chromatic symmetric X G function is a symmetric function generalization of the chromatic polynomial of a graph, introduced by Stanley [Sta95]. Stanley [Sta95] gave an expansion formula for X G in terms of the power sum symmetric functions p λ using the principle of inclusion-exclusion, and Bernardi and Nadeau [BN20] gave an alternate p -expansion for X G in terms of acyclic orientations. Crew, Pechenik, and Spirkl [CPS23] defined the Kromatic symmetric function X G as a K -theoretic analogue of X G , constructed in the same way except that each vertex is assigned a nonempty set of colors such that adjacent vertices have nonoverlapping color sets. They defined a K -analogue p λ of the power sum basis and computed the first few coefficients of the p -expansion of X G for some small graphs G . They conjectured that the p -expansion always has integer coefficients and asked whether there is an explicit formula for these coefficients. In this note, we give a formula for the p -expansion of X G , show two ways to compute the coefficients recursively (along with examples), and prove that the coefficients are indeed always integers. In a more recent paper [Pie25], we use our formula from this note to give a combinatorial description of the p -coefficients [ p λ ] X G and a simple characterization of their signs in the case of unweighted graphs.
## 1 Introduction
Let G be a graph with vertex set V . The chromatic symmetric function X G was introduced by Stanley in [Sta95] as a symmetric function generalization of the chromatic polynomial [Bir13]. Stanley gave expansion formulas for X G in a few different bases, including the power sum symmetric functions p λ . His classic p -expansion formula is an alternating sum over all subsets of the edges of G , but he also gave an alternative formulation in terms of the broken circuit complex of G , which unlike his subset sum expansion does not involve extra cancellation. Bernardi and Nadeau [BN20] gave an alternative interpretation of the p -expansion of X G in terms of the source components of its acyclic orientations.
One natural question about X G , posed by the authors of [CPS23], is whether there is a K -analogue of Stanley's power sum expansion formula in terms of an appropriate K -analogue of the p -basis. The authors of [CPS23] defined such a K -analogue of the p -basis, which they called the p -basis. They gave a table listing the first few coefficients of the p -expansions of X G for several small graphs G , which they computed using Sage [Ste+24]. The leading terms (i.e. the terms where | λ | is minimal), must always match the corresponding terms from ordinary p -expansion of the ordinary chromatic symmetric function X . G (By leading terms, we mean the terms where | λ | = | V | for an unweighted graph, or where | λ | = ω G ( ) := ∑ v ∈ V ω v ( ) for a weighted graph with weight function ω : V → Z > 0 , corresponding to each vertex getting one color.)
The Kromatic symmetric function X G was defined by Crew, Pechenik, and Spirkl in [CPS23] as a K -theoretic analogue of X . G The idea of K -theory is to deform the cohomology ring of a topological space by introducing an extra parameter β (often set to -1), so part of the motivation for defining X G was to help shed light on possible topological interpretations for X . G Marberg [Mar25] gave an alternative construction of X G in terms of linearly compact Hopf algebras and showed that it arises as a natural analogue of X G in that setting as well.
Unlike the p -expansion of X , G they found that the p -expansions for X G appeared to have infinitely many terms, but the coefficients still seemed to always be integers. For instance, below are first few terms
(grouped by | λ | ) of the p -expansions for the single edge , and for the graph K 21 consisting of a single edge connecting a vertex of weight 2 and a vertex of weight 1:
$$\overline { X } _ { K _ { 2 1 } } & = ( - \bar { p } _ { 3 } + \bar { p } _ { 2 1 } ) + ( \bar { p } _ { 4 } - \bar { p } _ { 3 1 } ) + ( \bar { p } _ { 4 1 } - \bar { p } _ { 3 2 } ) + ( - \bar { p } _ { 6 } + \bar { p } _ { 4 2 } + \bar { p } _ { 3 3 } - \bar { p } _ { 3 2 1 } ) \\ & \quad + ( - \bar { p } _ { 6 1 } + \bar { p } _ { 4 2 1 } + \bar { p } _ { 3 3 1 } ) + ( \bar { p } _ { 8 } - \bar { p } _ { 6 2 } + \bar { p } _ { 3 3 2 } ) + ( \bar { p } _ { 8 1 } + \bar { p } _ { 6 3 } - \bar { p } _ { 6 2 1 } - \bar { p } _ { 3 3 3 } + \bar { p } _ { 3 3 2 1 } ) + \cdots$$
$$\overline { X } \centerrightarrow \bullet & = ( - \bar { p } _ { 2 } + \bar { p } _ { 1 1 } ) + ( 2 \bar { p } _ { 3 } - 2 \bar { p } _ { 2 1 } ) + ( - 4 \bar { p } _ { 4 } + 4 \bar { p } _ { 3 1 } + \bar { p } _ { 2 2 } - \bar { p } _ { 2 1 1 } ) \\ & + ( 6 \bar { p } _ { 5 } - 8 \bar { p } _ { 4 1 } - 3 \bar { p } _ { 3 2 } + 2 \bar { p } _ { 3 1 1 } + 2 \bar { p } _ { 2 2 1 } ) \\ & + ( - 9 \bar { p } _ { 6 } + 1 2 \bar { p } _ { 5 1 } + 4 \bar { p } _ { 4 2 } - 4 \bar { p } _ { 4 1 1 } + \bar { p } _ { 3 3 } - 4 \bar { p } _ { 3 2 1 } - \bar { p } _ { 2 2 2 } + \bar { p } _ { 2 2 1 1 } ) \dots$$
Since has | V | = 2 , the leading terms are -p 2 + p 11 , matching the ordinary p -expansion X = -p 2 + p 11 . Similarly, K 21 has weight ω K ( 12 ) = 2 + 1 = 3 , so the leading terms are -p 3 + p 21 , which matches the ordinary p -expansion X K 21 = -p 3 + p 21 . We will explain where the rest of the coefficients in these expansions come from when we revisit these examples in §3.
The authors of [CPS23] asked whether there is an explicit formula for the p -expansion of X G . Here, we give such a formula that applies to any weighted graph G with a vertex weight function ω : V → Z > 0 , in terms of its independence polynomial
$$I _ { ( G, \omega ) } ( t ) \coloneqq \sum _ { S \subseteq V } \, \text{an independent set} } t ^ { \omega ( S ) },$$
where the weight of a subset S is ω S ( ) := ∑ v ∈ S ω v . ( ) We write G | W to denote the induced subgraph of G with vertex set W.
Theorem 1.1. X ( G,ω ) satisfies the formula
$$\overline { X } _ { ( G, \omega ) } = \sum _ { W \subseteq V } ( - 1 ) ^ { | V \langle W | } \prod _ { k \geq 1 } ( 1 + \overline { p } _ { k } ) ^ { a _ { W } ( k ) },$$
where the exponents a W ( k ) are the unique (sometimes negative) real numbers satisfying
$$( 1 + t ) ^ { a _ { W } ( 1 ) } ( 1 + t ^ { 2 } ) ^ { a _ { W } ( 2 ) } ( 1 + t ^ { 3 } ) ^ { a _ { W } ( 3 ) } \cdots = I _ { ( G | _ { W }, \omega ) } ( t ).$$
The idea for where the (1 + t k ) terms come from is the factorization 1 + p k = ∏ i ≥ 1 (1 + x k i ) , which essentially lets us reduce to a single variable problem.
As a consequence of Theorem 1.1, we can write down an explicit formula for the coefficients [ p λ ] X ( G,ω ) :
Corollary 1.2. The coefficient of p λ in X ( G,ω ) is given by
$$[ \bar { p } _ { \lambda } ] \overline { X } _ { ( G, \omega ) } = \sum _ { W \subseteq V } ( - 1 ) ^ { | V \bar { W } | } \prod _ { k = 1 } ^ { \ell } \binom { a _ { W } ( k ) } { i _ { k } },$$
where λ = /lscript i /lscript . . . 2 i 2 1 i 1 .
The numbers a W ( k ) above can be computed recursively in two different ways, and the proofs of these recurrences will make clear why they are uniquely determined. The first (more efficient) way is as follows:
Proposition 1.3. The exponents a W ( k ) satisfy the recurrence
$$a _ { W } ( k ) = [ t ^ { k } ] \log ( I _ { ( G | _ { W }, \omega ) } ( t ) ) + \sum _ { d | k, \ d < k } \frac { ( - 1 ) ^ { k / d } d \cdot a _ { W } ( d ) } { k }.$$
Note that because of the division by k and the non-integrality of the coefficients of log( I ( G | W ,ω ) ( ), it t is not immediately clear from Proposition 1.3 whether the a W ( k )'s are integers. However, our second recursive formula does make it clear that they are integers:
Proposition 1.4. The coefficients a W ( k ) also satisfy the alternative recurrence
/negationslash
$$a _ { W } ( k ) = [ t ^ { k } ] I _ { ( G | _ { W }, \omega ) } ( t ) - \sum _ { \lambda \vdash k, \ \lambda \neq k } \, \prod _ { j = 1 } ^ { k - 1 } \binom { a _ { W } ( k ) } { i _ { j } }.$$
Hence, a W ( k ) is an integer for all W and k.
An immediate consequence of Proposition 1.4 and Corollary 1.2 is that the p -coefficients are integers, resolving the question from [CPS23]:
Corollary 1.5. For every partition λ, the coefficient [ p λ ] X ( G,ω ) is an integer.
Corollary 1.5 can also be proven in a different way by considering the transition formula between the p -basis and another basis defined in [CPS23], the ˜ m -basis. Hence, we will also give a short alternative proof of Corollary 1.5 in §4 based on that transition formula.
Another question one can ask is about the signs of the coefficients. For G an unweighted graph, it can be shown that the sign of [ p λ ] X G is ( -1) | λ |-/lscript ( λ ) . In a more recent paper [Pie25], we use Theorem 1.1 to give a combinatorial interpretation of the coefficients [ p λ ] X , G and we show that their signs follow the same pattern as the signs of [ p λ ] X G , and that the signs of the exponents a W ( k ) alternate:
Theorem 1.6. For G unweighted, the sign of [ p λ ] X G is ( -1) | λ |-/lscript ( λ ) . Also, the sign of a W ( k ) is ( -1) k +1 .
The first sentence of Theorem 1.6 was stated as a conjecture in an earlier draft of this note, and that conjecture was suggested to the author by Oliver Pechenik. It does not apply in general to weighted graphs. For instance, in the p -expansion of K 21 above, the coefficient for λ = 3 is -1 while | λ | -/lscript ( λ ) = 3 -1 = 2 is even. The statement about the alternating signs of the a W ( k )'s also does not apply to unweighted graphs. In particular, we will show in §3 that for K 21 and W = V ( K 21 ) , a W ( k ) is positive for k = 2 , negative for j k = 3 · 2 j , and 0 otherwise.
The remainder of this note is organized as follows. In §2, we define some necessary terminology. In §3, we revisit the examples above to illustrate Theorem 1.1 and Propositions 1.3 and 1.4. Then in §4, we prove Theorem 1.1, Corollary 1.2, Propositions 1.3 and 1.4, and Corollary 1.5.
## 2 Background
A graph G is a set V of vertices together with a set E of edges , where each edge is an unordered pair of vertices. If uv is an edge, we say that the vertices u and v are adjacent . A weighted graph ( G,ω ) is a graph G together with a weight function ω : V → Z > 0 that assigns a positive integer to each vertex. An independent set or stable set is a subset of V in which no two vertices are adjacent. For W ⊆ V, the induced subgraph G | W with vertex set v is the graph with vertex set V ( G | W ) := W and edge set E G ( | W ) := { uv ∈ E G ( ) : u, v ∈ W . } That is, the edges of G | W are precisely the edges of G with both endpoints in W.
/negationslash
A symmetric function f ( x , x 1 2 , . . . ) is a function that stays the same under any permutation of the variables, i.e. f ( x , x 1 2 , . . . ) = f ( x σ (1) , x σ (2) , . . . ) for any permutation σ of Z > 0 . A proper coloring of V is a function α : V → Z > 0 that assigns a positive integer valued color to each vertex such that α u ( ) = α v ( ) whenever uv ∈ E G . ( ) The chromatic symmetric function is
$$X _ { G } \coloneqq \sum _ { \alpha } \prod _ { v \in V } x _ { \alpha ( v ) }$$
is the sum over all proper set colorings of the product of all the variables corresponding to colors used, counted with multiplicity.
A partition λ = λ λ 1 2 . . . λ k is a nonincreasing sequence of positive integers λ 1 ≥ λ 2 ≥ · · · ≥ λ , k and λ , . . . , λ 1 k are its parts . We write | λ | := λ 1 + · · · + λ k for the size of λ and /lscript ( λ ) = k for its length or number of parts. If n = | λ , | we say that λ is a partition of n and write λ /turnstileleft n. We can alternatively write
λ = /lscript i /lscript ( /lscript -1) i /lscript -1 . . . 2 i 2 1 i 1 to denote the partition with i j parts of size j for each j = 1 2 , , . . . , /lscript -1 , /lscript. For a partition λ = λ λ 1 2 . . . λ k , the power sum symmetric function p λ is
$$p _ { \lambda } \coloneqq \prod _ { i = 1 } ^ { k } \left ( \sum _ { j \geq 1 } x _ { j } ^ { \lambda _ { i } } \right ) = ( x _ { 1 } ^ { \lambda _ { 1 } } + x _ { 2 } ^ { \lambda _ { 1 } } + \dots ) ( x _ { 1 } ^ { \lambda _ { 2 } } + x _ { 2 } ^ { \lambda _ { 2 } } + \dots ) \dots ( x _ { 1 } ^ { \lambda _ { k } } + x _ { 2 } ^ { \lambda _ { k } } + \dots ).$$
A proper set coloring is a function α : V → 2 Z > 0 \{ ∅ } that assigns a nonempty set of positive integer valued colors to each vertex such that adjacent vertices have nonoverlapping color sets, i.e. α u ( ) ∩ α v ( ) = ∅ whenever uv ∈ E G . ( ) For a weighted graph ( G,ω ), the Kromatic symmetric function is
$$\overline { X } _ { ( G, \omega ) } \coloneqq \sum _ { \alpha } \prod _ { v \in V } \prod _ { i \in \alpha ( v ) } x _ { i } ^ { \omega ( v ) }.$$
The authors of [CPS23] define the K -analogue of the power sum symmetric functions as
$$\bar { p } _ { \lambda } \coloneqq \overline { X } _ { \overline { K _ { \lambda } } },$$
where K λ is the edgeless graph whose vertex weights are the parts of λ.
## 3 Examples
We will now revisit the two example p -expansions of X K 21 and X from §1 and show how to compute their coefficients using Theorem 1.1, together with Proposition 1.3 or 1.4.
Example 3.1. Let G = K 21 consist of two connected vertices v and w, with ω v ( ) = 1 and ω w ( ) = 2. Then
$$I _ { ( G, \omega ) } ( t ) = 1 + t + t ^ { 2 },$$
since G has three independent sets: ∅ has weight 0, { v } has weight 1, and { w } has weight 2. By difference of cubes,
$$I _ { ( G, \omega ) } ( t ) = \frac { 1 - t ^ { 3 } } { 1 - t }.$$
Then by repeated difference of squares,
$$\frac { 1 } { 1 - t } = ( 1 + t ) ( 1 + t ^ { 2 } ) ( 1 + t ^ { 4 } ) ( 1 + t ^ { 8 } ) \cdots = \prod _ { j \geq 0 } ( 1 + t ^ { 2 ^ { j } } ),$$
and similarly,
$$1 - t ^ { 3 } = \frac { 1 } { 1 + t ^ { 3 } } \cdot \frac { 1 } { 1 + t ^ { 6 } } \cdot \frac { 1 } { 1 + t ^ { 1 2 } } \cdot \frac { 1 } { 1 + t ^ { 2 4 } } \cdots = \prod _ { j \geq 0 } \frac { 1 } { 1 + t ^ { 3 \cdot 2 ^ { j } } },$$
which gives
$$I _ { ( G, \omega ) } ( t ) = \prod _ { j \geq 0 } ( 1 + t ^ { 2 ^ { j } } ) \cdot \prod _ { j \geq 0 } \frac { 1 } { 1 + t ^ { 3 \cdot 2 ^ { j } } }.$$
The other subsets of V are { v } , { w , } and ∅ . In these cases, we get:
$$\psi _ { \lambda } \psi _ { \lambda } \\ I _ { ( G | _ { \{ v \} }, \omega ) } ( t ) & = 1 + t, \\ I _ { ( G | _ { \{ w \} }, \omega ) } ( t ) & = 1 + t ^ { 2 }, \\ I _ { ( G | _ { \sigma }, \omega ) } ( t ) & = 1.$$
Putting this together, Theorem 1.1 gives
$$\lambda _ { ( G, \omega ) } ( t ) = \prod _ { j \geq 0 } ^ { \lambda } ( 1 + \bar { p } _ { 2 ^ { j } } ) \cdot \prod _ { j \geq 0 } \frac { 1 } { 1 + \bar { p } _ { 3 \cdot 2 ^ { j } } } - ( 1 + \bar { p } _ { 1 } ) - ( 1 + \bar { p } _ { 2 } ) + 1.$$
Note that in this case, the superscript 2 j refers to the partition with one part whose size is 2 j rather than the partition with j parts of size 2. It follows that all p -coefficients are ± 1 or 0 in this case. In particular,
$$[ \bar { p } _ { \lambda } ] \overline { X } _ { ( G, \omega ) } = ( - 1 ) ^ { \# \, of \, parts \, of \, \lambda \, that \, are \, multiples \, of \, 3 }$$
provided that λ satisfies all of the following properties:
- · | λ | ≥ 3 .
- · All parts are of the form 2 j or 3 · 2 j for some j ≥ 0 .
- · No parts of the form 2 j are repeated.
All other coefficients are 0. To illustrate this, we can expand out the first few terms to get
$$& \text{All other coefficients are 0. } \text{To illustrate this, we can expand out the first few terms to get} \\ & \overline { X } _ { ( G, \omega ) } ( t ) = ( 1 + \bar { p } _ { 1 } ) ( 1 + \bar { p } _ { 2 } ) ( 1 + \bar { p } _ { 4 } ) \dots \frac { 1 } { 1 + \bar { p } _ { 3 } } \cdot \frac { 1 } { 1 + \bar { p } _ { 6 } } \cdot \frac { 1 } { 1 + \bar { p } _ { 1 2 } } \cdot \dots - ( 1 + \bar { p } _ { 1 } + \bar { p } _ { 2 } ) \\ & \quad = ( 1 + \bar { p } _ { 1 } ) ( 1 + \bar { p } _ { 2 } ) ( 1 + \bar { p } _ { 4 } ) \dots ( 1 - \bar { p } _ { 3 } + \bar { p } _ { 3 3 } - \bar { p } _ { 3 3 3 } + \dots ) ( 1 - \bar { p } _ { 6 } + \bar { p } _ { 6 6 } - + \dots ) \dots - ( 1 + \bar { p } _ { 1 } + \bar { p } _ { 2 } ) \\ & \quad = ( - \bar { p } _ { 3 } + \bar { p } _ { 2 1 } ) + ( \bar { p } _ { 4 } - \bar { p } _ { 3 1 } ) + ( \bar { p } _ { 4 1 } - \bar { p } _ { 3 2 } ) + ( - \bar { p } _ { 6 } + \bar { p } _ { 4 2 } + \bar { p } _ { 3 3 } - \bar { p } _ { 3 2 1 } ) \\ & \quad + ( - \bar { p } _ { 6 1 } + \bar { p } _ { 4 2 1 } + \bar { p } _ { 3 3 1 } ) + ( \bar { p } _ { 8 } - \bar { p } _ { 6 2 } + \bar { p } _ { 3 3 2 } ) + ( \bar { p } _ { 8 1 } + \bar { p } _ { 6 3 } - \bar { p } _ { 6 2 1 } - \bar { p } _ { 3 3 3 } + \bar { p } _ { 3 3 2 1 } ) + \dots$$
We can see that these terms match the ones from §1.
For the seemingly simpler case of a single unweighted edge , there is not such a simple formula for the coefficients:
Example 3.2. Let G = = { v, w } , where v and w both have weight 1. Then we get
$$I _ { G } ( t ) = 1 + 2 t,$$
since { v } and { w } are stable sets of size 1 and ∅ is a stable set of size 2. In this case the factorization begins
$$\cdot \. \. 1 + 2 t = ( 1 + t ) ^ { 2 } \cdot \frac { 1 } { 1 + t ^ { 2 } } \cdot ( 1 + t ^ { 3 } ) ^ { 2 } \cdot \frac { 1 } { ( 1 + t ^ { 4 } ) ^ { 4 } } \cdot ( 1 + t ^ { 5 } ) ^ { 6 } \dots.$$
Thus, for W = V, the sequence of exponents a W ( k ) begins
$$a _ { W } ( 1 ) = 2, \ a _ { W } ( 2 ) = - 1, \ a _ { W } ( 3 ) = 2, \ a _ { W } ( 4 ) = - 4, \ a _ { W } ( 5 ) = 6, \dots$$
These numbers match sequence A038067 in the Online Encyclopedia of Integer Sequences [OEI24]. They can be computed recursively using either Proposition 1.3 or Proposition 1.4:
- • To use Proposition 1.3, we first note that
$$\times \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \\ \log ( I _ { G } ( t ) ) = \log ( 1 + 2 t ) & = 2 t - \frac { ( 2 t ) ^ { 2 } } { 2 } + \frac { ( 2 t ) ^ { 3 } } { 3 } - \frac { ( 2 t ) ^ { 4 } } { 4 } + \frac { ( 2 t ) ^ { 5 } } { 5 } - \cdots \\ & = 2 t - 2 t ^ { 2 } + \frac { 8 t ^ { 3 } } { 3 } - 4 t ^ { 4 } + \frac { 3 2 t ^ { 5 } } { 5 } - \cdots \,. \\ \dots \, \cdots \, \cdots$$
$$& \text{Thus we get} \\ & a _ { W } ( 1 ) = [ t ] \log ( I _ { G } ( t ) ) = 2, \\ & a _ { W } ( 2 ) = [ t ^ { 2 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 2 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 2 } = - 2 + 1 = - 1, \\ & a _ { W } ( 3 ) = [ t ^ { 3 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 3 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 3 } = \frac { 8 } { 3 } - \frac { 2 } { 3 } = 2, \\ & a _ { W } ( 4 ) = [ t ^ { 4 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 4 / 2 } \cdot 2 \cdot a _ { W } ( 2 ) } { 4 } + \frac { ( - 1 ) ^ { 4 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 4 } = - 4 - \frac { 1 } { 2 } + \frac { 1 } { 2 } = - 4, \\ & a _ { W } ( 5 ) = [ t ^ { 5 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 5 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 5 } = \frac { 3 2 } { 5 } - \frac { 2 } { 5 } = 6.$$
$$= 2 t - 2 t ^ { 2 } + \frac { 8 t ^ { 3 } } { 3 } - 4 t ^ { 4 } + \frac { 3 2 t ^ { 5 } } { 5 } \,. \\ \text{Thus we get} \\ a _ { W } ( 1 ) = [ t ] \log ( I _ { G } ( t ) ) = 2, \\ a _ { W } ( 2 ) = [ t ^ { 2 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 2 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 2 } = - 2 + 1 = - 1, \\ a _ { W } ( 3 ) = [ t ^ { 3 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 3 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 3 } = \frac { 8 } { 3 } - \frac { 2 } { 3 } = 2, \\ a _ { W } ( 4 ) = [ t ^ { 4 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 4 / 2 } \cdot 2 \cdot a _ { W } ( 2 ) } { 4 } + \frac { ( - 1 ) ^ { 4 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 4 } \\ a _ { W } ( 5 ) = [ t ^ { 5 } ] \log ( I _ { G } ( t ) ) + \frac { ( - 1 ) ^ { 5 / 1 } \cdot 1 \cdot a _ { W } ( 1 ) } { 5 } = \frac { 3 2 } { 5 } - \frac { 2 } { 5 } = 6.$$
- · Alternatively, to use Proposition 1.4, we list the partitions k for each k = 1 2 3 4 5: , , , ,
- -k = 1 : 1,
- -k = 2 : 2, 1 2 ,
- -k = 3 : 3, 21, 1 3 ,
- -k = 4 : 4, 31, 2 2 , 21 2 , 1 , 4
- -k = 5 : 5, 41, 32, 31 2 , 2 1 2 , 21 3 , 1 5 .
Then we apply Proposition 1.4 to compute
$$& - \kappa = 4 \colon 4, 3 1, 2 \kappa, 2 1 \kappa, 1 \kappa, \\ & - \kappa = 5 \colon 5, 4 1, 3 2, 3 1 ^ { 2 }, 2 ^ { 2 } 1, 2 1 ^ { 3 }, 1 ^ { 5 }. \\ & \text{Then we apply Proposition 1.4 to compute} \\ & \quad a _ { W } ( 1 ) = [ t ] I _ { G } ( t ) = 2, \\ & \quad a _ { W } ( 2 ) = [ t ^ { 2 } ] I _ { G } ( t ) - \binom { a _ { W } ( 1 ) } { 2 } = 0 - \binom { 2 } { 2 } = 0 - 1 = - 1, \\ & \quad a _ { W } ( 3 ) = [ t ^ { 3 } ] I _ { G } ( t ) - \binom { a _ { W } ( 2 ) } { 1 } \binom { a _ { W } ( 1 ) } { 1 } - \binom { a _ { W } ( 1 ) } { 3 } \binom { 1 } { 3 } \\ & \quad = 0 - \binom { - 1 } { 1 } \binom { 2 } { 1 } - \binom { 2 } { 3 } - \binom { 2 } { 1 } \binom { a _ { W } ( 1 ) } { 2 } - \binom { a _ { W } ( 1 ) } { 4 } \binom { 1 } { 4 } - \binom { a _ { W } ( 1 ) } { 4 } \binom { 1 } { 1 } - \binom { a _ { W } ( 3 ) } { 1 } \binom { a _ { W } ( 2 ) } { 1 } - \binom { a _ { W } ( 3 ) } { 1 } \binom { a _ { W } ( 1 ) } { 2 } \binom { a _ { W } ( 1 ) } { 3 } \binom { a _ { W } ( 1 ) } { 5 } \binom { 1 } { 5 } \binom { - 4 } { 1 } \binom { 2 } { 1 } - \binom { 2 } { 1 } - \binom { - 1 } { 2 } - \binom { - 1 } { 2 } - \binom { - 1 } { 2 } - \binom { - 1 } { 2 } - \binom { - 1 } { 2 } \binom { 2 } { 3 } - \binom { 2 } { 5 } \binom { 1 } { 6 } \binom { 1 } { 6 } \cos { 2 } + 2 - 2 - 2 }. \\ & \text{Both methods give us the same exponents} \, a _ { W } ( 1 ) = 2, \, a _ { W } ( 2 ) = - 1, \, a _ { W } ( 3 ) = 2, \, a _ { W } ( 4 ) = - 4, \, a _ { W } ( 5 ) = 6 \\ \text{that we listed previously.}$$
Both methods give us the same exponents a W (1) = 2 , a W (2) = -1 , a W (3) = 2 , a W (4) = -4 , a W (5) = 6 that we listed previously.
To finish computing the p -expansion of X G , we note that the other stable sets are { v } , { w } , and ∅ , which have independence polynomials
$$I _ { G | _ { \{ v \} } } ( t ) = I _ { G | _ { \{ w \} } } ( t ) = 1 + t, \quad I _ { G | _ { \sigma } } ( t ) = 1.$$
Putting this together, Theorem 1.1 gives
$$\widetilde { X } _ { G } ( t ) & = ( 1 + \bar { p } _ { 1 } ) ^ { 2 } \cdot \frac { 1 } { 1 + \bar { p } _ { 2 } } \cdot ( 1 + \bar { p } _ { 3 } ) ^ { 2 } \cdot \frac { 1 } { ( 1 + \bar { p } _ { 4 } ) ^ { 4 } } \cdot ( 1 + \bar { p } _ { 5 } ) ^ { 6 } \cdots - ( 1 + \bar { p } _ { 1 } ) - ( 1 + \bar { p } _ { 1 } ) + 1 \\ & = ( 1 + 2 \bar { p } _ { 1 } + \bar { p } _ { 1 1 } ) ( 1 - \bar { p } _ { 2 } + \bar { p } _ { 2 2 } - \dots ) ( 1 + 2 \bar { p } _ { 3 } + \bar { p } _ { 3 3 } ) ( 1 - 4 \bar { p } _ { 4 } + 1 0 \bar { p } _ { 4 4 } - 2 0 \bar { p } _ { 4 4 4 } + \dots ) \cdots - ( 1 + 2 \bar { p } _ { 1 } ) \\ & = ( - \bar { p } _ { 2 } + \bar { p } _ { 1 1 } ) + ( 2 \bar { p } _ { 3 } - 2 \bar { p } _ { 2 1 } ) + ( - 4 \bar { p } _ { 4 } + 4 \bar { p } _ { 3 1 } + \bar { p } _ { 2 2 } - \bar { p } _ { 2 1 1 } ) \\ & \quad + ( 6 \bar { p } _ { 5 } - 8 \bar { p } _ { 4 1 } - 3 \bar { p } _ { 3 2 } + 2 \bar { p } _ { 3 1 1 } + 2 \bar { p } _ { 2 2 1 } ) \\ & \quad + ( - 9 \bar { p } _ { 6 } + 1 2 \bar { p } _ { 5 1 } + 4 \bar { p } _ { 4 2 } - 4 \bar { p } _ { 4 1 1 } + \bar { p } _ { 3 3 } - 4 \bar { p } _ { 3 2 1 } - \bar { p } _ { 2 2 2 } + \bar { p } _ { 2 2 1 1 } ) \cdots, \\ \text{matches the conversion from $8$}$$
matching the expansion from §1.
## 4 Proofs
In this section we will prove Theorem 1.1, Corollary 1.2, Propositions 1.3 and 1.4, and Corollary 1.5.
Proof of Theorem 1.1. Our key lemma is an expansion formula for Stanley's Y G function (introduced in [Sta98]), where Y ( G,ω ) is defined to be the same as X ( G,ω ) except that it includes monomials corresponding to colorings where some vertices are not assigned any colors:
$$Y _ { ( G, \omega ) } \coloneqq \sum _ { \kappa } \prod _ { v \in V } \left ( \prod _ { i \in \kappa ( v ) } x _ { i } \right ) ^ { \omega ( v ) },$$
where the sum ranges over all functions κ : V → 2 n such that κ v ( ) ∩ κ w ( ) = ∅ whenever vw ∈ E G . ( )
$$\text{Lemma $4.1. $Y_{(G,\omega)$ factors as} }$$
$$Y _ { ( G, \omega ) } = \prod _ { k \geq 1 } ( 1 + \bar { p } _ { k } ) ^ { a _ { V } ( k ) }.$$
Proof. Since Y ( G,ω ) allows vertices to not receive any colors, we can think of assigning each color to a subset of the vertices independently of all other colors. Specifically, for each color, we can independently choose a subset of V which will receive that color, and the only restriction is that the subset be an independent set. Thus, the generating series for the ways to choose which vertices receive color i is given by the independence polynomial I ( G,ω ) ( x i ). Since different colors can be assigned independently, we can compute Y ( G,ω ) by simply multiplying over all colors, so
$$Y _ { ( G, \omega ) } = \prod _ { i \geq 1 } I _ { ( G, \omega ) } ( x _ { i } ).$$
Then by the definition of a V ( k ), we have
$$I _ { ( G, \omega ) } ( x _ { i } ) = \prod _ { k \geq 1 } ( 1 + x _ { i } ^ { k } ) ^ { a _ { V } ( k ) }.$$
Now note that p k represents the sum of all monomials corresponding to ways to assign a nonempty set of colors to a single weight k vertex, so 1 + p k represents the sum of monomials corresponding to all ways to assign a set of colors to the weight k vertex, including the empty set. To choose such a coloring, we can independently choose whether or not to use each color. If color i is used, then we get an x k i in the monomial, and otherwise the power of x i is 0. Since we can independently choose an exponent of 0 or k for each variable,
$$1 + \bar { p } _ { k } = \prod _ { i \geq 1 } ( 1 + x _ { i } ^ { k } ).$$
It follows that
$$Y _ { ( G, \omega ) } = \prod _ { i \geq 1 } I _ { ( G, \omega ) } ( x _ { i } ) = \prod _ { i, k \geq 1 } ( 1 + x _ { i } ^ { k } ) ^ { a _ { V } ( k ) } = \prod _ { k \geq 1 } ( 1 + \bar { p } _ { k } ) ^ { a _ { V } ( k ) },$$
$$\psi$$
as claimed.
Theorem 1.1 then follows from the principle of inclusion-exclusion. The difference between X ( G,ω ) and Y ( G,ω ) is that X ( G,ω ) requires all vertices to receive a nonempty set of colors. Thus, by inclusion-exclusion, we can compute X ( G,ω ) by adding the monomials all possible colorings without that restriction, then subtracting the monomials where a particular vertex receives no colors, then adding back the ones where a particular pair of vertices receive no colors, and so on. It follows that
$$\overline { X } _ { ( G, \omega ) } = \sum _ { W \subseteq V } Y _ { ( G, \omega ) }.$$
Plugging in the formula from Lemma 4.1 proves Theorem 1.1.
The formula in Corollary 1.2 is now fairly immediate:

Proof of Corollary 1.2. Let λ = /lscript i /lscript . . . 2 i 2 1 i 1 . First, we note that
$$\bar { p } _ { \lambda } = \bar { p } _ { \lambda _ { 1 } } \cdots \bar { p } _ { \lambda _ { \ell ( \lambda ) } } = \bar { p } _ { \ell } ^ { i _ { \ell } } \cdots \bar { p } _ { 2 } ^ { i _ { 2 } } \bar { p } _ { 1 } ^ { i _ { 1 } }.$$
To see this, recall that p λ is the sum of all monomials corresponding to colorings of the vertices of the edgeless graph K λ with vertex weights λ , λ 1 2 , . . . , λ /lscript ( λ ) , or equivalently, with i k vertices of weight k for each k = 1 2 , , . . . , /lscript. Since the graph has no edges, the set of colors assigned to a vertex has no bearing on how we can color the other vertices, so we can choose the coloring of each vertex independently. Thus, p λ is the product over all vertices of the sum of all possible monomials for ways to color that vertex, which is just p k for a vertex of weight k.
Thus, to get a p λ term from ∏ k ≥ 1 (1 + p k ) a W ( k ) , we need to choose a p i k k term from (1 + p k ) a W ( k ) for each k = 1 2 , , . . . , /lscript. By the binomial theorem,
$$( 1 + \bar { p } _ { k } ) ^ { a _ { W } ( k ) } = \sum _ { i \geq 0 } \binom { a _ { W } ( k ) } { i } \bar { p } _ { k } ^ { i },$$
so the coefficient of p λ in the product ∏ k ≥ 1 (1 + p k ) a W ( k ) is just the product of these coefficients:
$$[ \bar { p } _ { \lambda } ] \prod _ { k \geq 1 } ( 1 + \bar { p } _ { k } ) ^ { a _ { W } ( k ) } = \prod _ { k = 1 } ^ { \ell } \binom { a _ { W } ( k ) } { i _ { k } } \bar { p } _ { k } ^ { i }.$$
Summing over all W ⊆ V completes the proof.
Next, we prove the recursive formula in Proposition 1.3:
Proof of Proposition 1.3. Taking logarithms of both sides of the equation
$$( 1 + t ) ^ { a _ { W } ( 1 ) } ( 1 + t ^ { 2 } ) ^ { a _ { W } ( 2 ) } ( 1 + t ^ { 3 } ) ^ { a _ { W } ( 3 ) } \cdots = I _ { ( G | _ { W }, \omega ) } ( t )$$
gives
$$\sum _ { j \geq 1 } a _ { W } ( j ) \log ( 1 + t ^ { j } ) = \log ( I _ { G | _ { W }, \omega } ( t ) ).$$
Expanding the left side using the power series log(1 + x ) = ∑ i ≥ 1 ( -1) i +1 x i i , we get
$$\sum _ { j \geq 1 } a _ { W } ( j ) \sum _ { i \geq 1 } \frac { ( - 1 ) ^ { i + 1 } t ^ { i j } } { i } = \log ( I _ { G | _ { W }, \omega } ( t ) ).$$
Since j = k is the largest value of j on the left side that contributes a t k term, we can compute a W ( k ) recursively from the values a W ( j ) for j < k by making the coefficient of t k on the left side match the coefficient [ t k ] log( I G | W ,ω ( )) on the right side. t The values j < k that contribute a t k term on the left are precisely the values where j is some divisor d of k , in which case i = k/d. The contribution from the j = d term is then
$$a _ { W } ( d ) \frac { ( - 1 ) ^ { k / d + 1 } } { k / d } = \frac { ( - 1 ) ^ { k / d } d \cdot a _ { W } ( d ) } { k }.$$
Summing over all values d | k and then subtracting the resulting sum from the right side coefficient [ t k ] log( I G | W ,ω ( )) gives the formula in Proposition 1.3. t
Now we prove the alternative recurrence from Proposition 1.4:
Proof of Proposition 1.4. Assume we know a W (1) , . . . , a W ( k -1) and want to find a W ( k . ) In the product
$$\prod _ { j \geq 1 } ( 1 + t ^ { j } ) ^ { a _ { W } ( j ) } = I _ { ( G | _ { W }, \omega ) } ( t ),$$
the coefficient [ t k ] of t k needs to be the same on both sides. On the right side, the coefficient is [ t k ] I ( G | W ,ω ) ( ) t . On the left side, since
$$( 1 + t ^ { k } ) ^ { a _ { W } ( k ) } + 1 + a _ { W } ( k ) \cdot t ^ { k } + \dots,$$
the (1 + t k ) a W ( k ) factor contributes a W ( k ) to [ t k ] . No factor (1 + t j ) a W ( j ) with j > k can contribute to [ t k ] . Each remaining contribution come from some partition λ = /lscript i /lscript . . . 2 i 2 1 i 1 /turnstileleft k and corresponds to taking a ( t j ) i j from the (1 + t j ) a W ( j ) factor for each j = 1 2 , , . . . , /lscript. By the binomial theorem, the coefficient of ( t j ) i j in (1 + t j ) a W ( j ) is ( a W ( j ) i j ) , so the overall coefficient of ( t /lscript ) i /lscript . . . ( t 2 ) i 2 ( t 1 ) i 1 is
$$\binom { a _ { W } ( \ell ) } { i _ { \ell } } \cdots \binom { a _ { W } ( 2 ) } { i _ { 2 } } \binom { a _ { W } ( 1 ) } { i _ { 1 } }.$$
We then subtract all those coefficients from [ t k ] I ( G | W ,ω ) ( ) to give the formula in Proposition 1.4. t
As noted in §1, Corollary 1.5 about the integrality of the p -coefficients is an immediate consequence of Corollary 1.2 and Proposition 1.4, but we will now show that an alternative proof can also be given by considering the transition formula between the p -basis and another basis defined in [CPS23]: the monomial symmetric function m λ is
$$m _ { \lambda } \coloneqq \sum _ { n _ { 1 }, \dots, n _ { k } } x _ { n _ { 1 } } ^ { \lambda _ { 1 } } \dots x _ { n _ { k } } ^ { \lambda _ { k } },$$
where the sum is taken over all ordered tuples of k distinct indices n , . . . , n 1 k ∈ Z > 0 . The augmented monomial symmetric function ˜ m λ is
$$\widetilde { m } _ { \lambda } \coloneqq i _ { 1 }! \dots i _ { \ell }! \cdot m _ { \lambda },$$
where i j is the number of parts of λ of size j. The K -theoretic augmented monomial symmetric functions ˜ m λ is
$$\overline { \widetilde { m } } _ { \lambda } \coloneqq \overline { X } _ { K _ { \lambda } },$$
where K λ is a complete graph whose vertex weights are the parts of λ. A stable set cover C = { S , . . . , S 1 k } is a set of k independent sets in G such that every vertex is in at least one of S , . . . , S 1 k . We write SSC ( G ) for the set of all stable set covers of G , and λ C ( ) for the partition whose parts are the weights ω S ( 1 ) , . . . , ω ( S k ) , where the weight of a subset is the sum of the weights of its vertices, ω S ( ) := ∑ v ∈ S ω v . ( ) The authors of [CPS23] prove the following ˜ m -expansion formula for X G :
Theorem 4.2 (Crew, Pechenik, and Spirkl [CPS23, Proposition 3.4]) . The ˜ m -expansion for X G is
$$\overline { X } _ { ( G, \omega ) } = \sum _ { C \in \text{SSC} ( G ) } \overline { \widetilde { m } } _ { \lambda ( C ) }.$$
We can now use this to give our second proof of Corollary 1.5:
Alternative proof of Corollary 1.5. Consider the ˜ m -expansion of p λ = X K λ . Since K λ has no edges, all subsets of its vertices are independent sets. One possible stable set cover is the one where each vertex is in a stable set by itself, in which case λ C ( ) = λ, so the expansion of p λ has an ˜ m λ term. For every other term ˜ m µ , we must have either | µ | > λ | | (if some vertices are covered by multiple stable sets in C ) or else µ is formed by taking λ and combining some of its parts (if each vertex is only in one stable set but some stable sets contain multiple vertices), which is equivalent to saying that λ is a refinement of µ . Thus, we have [ ˜ m p λ ] λ = 1 and [ ˜ m p µ ] µ = 0 whenever | µ < λ | | | or | µ | = | λ | but λ is not a refinement of µ. Now, order the set of all partitions in such a way that partitions of smaller numbers come first and λ comes before µ whenever λ is a refinement of µ , which can be done by ordering the partitions of each size lexicographically. Then the transition matrix from the p -basis to the ˜ m -basis is upper triangular with 1's along the diagonal and all integer entries. It follows that the inverse matrix which transitions from the ˜ m -basis to the p -basis is also upper triangular with 1's on the diagonal and all integer entries. Thus, each ˜ m µ is a linear combination of p λ terms with integer coefficients. Since X ( G,ω ) is an integral linear combination of ˜ m µ terms for every weighted graph ( G,ω ), it follows that X ( G,ω ) is an integral linear combination of p λ terms, as claimed.
## Acknowledgements
The author thanks Oliver Pechenik for suggesting the problem, and she thanks Oliver Pechenik, Karen Yeats, Sophie Spirkl, and the anonymous reviewers for providing helpful comments. She was partially supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) grant RGPIN-2022-03093.
## References
| [Bir13] | George D Birkhoff. 'The reducibility of maps'. In: American Journal of Mathematics 35.2 (1913), pp. 115-128. url : https://doi.org/10.2307/2370276 . |
|-----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [BN20] | Olivier Bernardi and Philippe Nadeau. 'Combinatorial reciprocity for the chromatic polynomial and the chromatic symmetric function'. In: Discrete Mathematics 343.10 (2020), p. 111989. url : https://doi.org/10.1016/j.disc.2020.111989 . |
| [CPS23] | Logan Crew, Oliver Pechenik, and Sophie Spirkl. 'The Kromatic Symmetric Function: A K - theoretic Analogue of X G '. 2023. url : https://arxiv.org/abs/2301.02177 . |
| [Mar25] | Eric Marberg. 'Kromatic quasisymmetric functions'. In: The Electronic Journal of Combinatorics 32.P1.11 (1 2025). url : https://doi.org/10.37236/13207 . |
| [OEI24] | OEIS. The Online Encyclopedia of Integer Sequences Entry A038067 . 2024. url : https://oeis. org/A038067 . |
| [Pie25] | Laura Pierson. 'Power sum expansions for Kromatic symmetric functions using Lyndon heaps'. 2025. url : https://arxiv.org/abs/2502.21285 . |
| [Sta95] | Richard P Stanley. 'A symmetric function generalization of the chromatic polynomial of a graph'. In: Advances in Mathematics 111.1 (1995), pp. 166-194. url : https://www.sciencedirect.com/ science/article/pii/S0001870885710201 . |
| [Sta98] | Richard P Stanley. 'Graph colorings and related symmetric functions: ideas and applications a de- scription of results, interesting applications, & notable open problems'. In: Discrete Mathematics 193.1-3 (1998), pp. 267-286. url : https://doi.org/10.1016/S0012-365X(98)00146-0 . |
| [Ste+24] | W.A. Stein et al. Sage Mathematics Software (Version 10.3) . The Sage Development Team. 2024. url : http://www.sagemath.org . | | null | [
"Laura Pierson"
]
| 2024-08-02T17:12:02+00:00 | 2025-03-03T18:23:10+00:00 | [
"math.CO"
]
| A power sum expansion for the Kromatic symmetric function | The chromatic symmetric $X_G$ function is a symmetric function generalization
of the chromatic polynomial of a graph, introduced by Stanley (1995). Stanley
gave an expansion formula for $X_G$ in terms of the power sum symmetric
functions $p_\lambda$ using the principle of inclusion-exclusion, and in
arXiv:1904.01262, Bernardi and Nadeau gave an alternate $p$-expansion for $X_G$
in terms of acyclic orientations. In arXiv:2301.02177, Crew, Pechenik, and
Spirkl defined the Kromatic symmetric function $\overline{X}_G$ as a
$K$-theoretic analogue of $X_G$, constructed in the same way except that each
vertex is assigned a nonempty set of colors such that adjacent vertices have
nonoverlapping color sets. They defined a $K$-analogue $\overline{p}_\lambda$
of the power sum basis and computed the first few coefficients of the
$\overline{p}$-expansion of $\overline{X}_G$ for some small graphs $G$. They
conjectured that the $\overline{p}$-expansion always has integer coefficients
and asked whether there is an explicit formula for these coefficients. In this
note, we give a formula for the $\overline{p}$-expansion of $\overline{X}_G$,
show two ways to compute the coefficients recursively (along with examples),
and prove that the coefficients are indeed always integers. In a more recent
paper arXiv:2502.21285, we use our formula from this note to give a
combinatorial description of the $\overline{p}$-coefficients
$[\overline{p}_\lambda]\overline{X}_G$ and a simple characterization of their
signs in the case of unweighted graphs. |
2408.01396v1 | ## On the chromatic symmetric homology for star graphs
## Laura Pierson University of Waterloo [email protected]
August 5, 2024
## Abstract
The chromatic symmetric function X G is a power series that encodes the proper colorings of a graph G by assigning a variable to each color and a monomial to each coloring such that the power of a variable in a monomial is the number of times the corresponding color is used in the corresponding coloring. The chromatic symmetric homology H ∗ ( G ) is a doubly graded family of C [ S n ]-modules that was defined by Sazdanovi´ and Yip (2018) as a c categorification of X G . Chandler, Sazdanovi´ c, Stella, and Yip (2023) proved that H ∗ ( G ) is a strictly stronger graph invariant than X G , and they also computed or conjectured formulas for it in a number of special cases. We prove and extend some of their conjectured formulas for the case of star graphs , where one central vertex is connected to all other vertices and no other pairs of vertices are connected.
## 1 Introduction
The chromatic symmetric function X G was introduced by Stanley in [Sta95] as a symmetric function generalization of the chromatic polynomial [Bir13]. The chromatic symmetric homology H ∗ ( G ) was introduced by Sazadnovi´ c and Yip in [SY18] as a categorification of the chromatic symmetric function. The idea of categorification is to take a 'set-like' object and replace it with a 'category-like' object that has additional structure. Specifically, this often involves taking a polynomial and replacing it with a collection of modules over some ring, such as replacing Schur polynomials s λ with Specht modules S λ , which are irreducible representations of the symmetric group S n , or equivalently, modules over the ring C [ S n ]. The way these categorifications are constructed is generally analogous to the construction of the homology groups of a topological space.
The idea of categorifying polynomials in this way began with the Khovanov homology , which was introduced by Khovanov in [Kho00] as a categorification of the Jones polynomial from knot theory. Sazdanovi´ c and Yip constructed the chromatic symmetric homology in [SY18] as a categorification of the chromatic symmetric function. A corresponding vertex-weighted analogue of the chromatic symmetric homology was introduced in [Cil24]. For a ring R , the chromatic symmetric homology H ∗ ( G R ; ) is constructed as
$$H _ { * } ( G ; R ) = \bigoplus _ { 0 \leq i \leq j \leq | E ( G ) | } H _ { i, j } ( G ; R ),$$
/negationslash
The authors of [Cha+23] also present a number of computations and conjectures about special cases of H ∗ ( G ). In this chapter, we focus on the case of star graphs (graphs where one central vertex is connected to all others and no other pairs of vertices are connected). The authors of [Cha+23] conjectured the following formulas involving the chromatic symmetric homology for star graphs:
where each H i,j ( G R ; ) is an R [ S n ]-module. The chromatic symmetric homology H ∗ ( G ) is a strictly stronger graph invariant than X G in the sense that there exist pairs of graphs with X G 1 = X G 2 but H ∗ ( G 1 ) = H ∗ ( G 2 ), as proven by Chandler, Sazdanovi´ c, Stella, and Yip in [Cha+23]. In particular, the authors of [Cha+23] conjectured that H ∗ ( G ; Z ) can detect planarity based on whether H 1 0 , ( G ; Z ) has Z 2 -torsion (i.e. contains a subgroup isomorphic to Z 2 ). One direction of this conjecture was proven in [CM23], namely, that all nonplanar graphs contain Z 2 -torsion, but the other direction remains open.
Conjecture 1 ([Cha+23]) . For G the n -vertex star, the Specht module S ( n -2 2) , has multiplicity 1 in H 1 0 , ( G ) .
$$\text{Conjecture } 2 \, ( [ \text{Cha+23} ] ). \text{ For } G \, \text{ the } n \text{-vertex star, the multiplicity of } \mathcal { S } _ { 2 ^ { 2 } 1 ^ { n - 4 } } \, \text{ in } H _ { 1, 0 } ( G ) \, \text{ is } \binom { n - 2 } { 2 }.$$
They also gave the following table ([Cha+23], §4.3) with their conjectures for the full values of H 1 0 , ( G ) where G is a star on 4, 5, 6, or 7 vertices:
Table 1: The degree 0 chromatic symmetric homology for stars on 4 through 7 vertices.
| G | H 1 , 0 ( G ; C ) |
|-----|-------------------------------------------------------------------------|
| | S 2 2 |
| | S ⊕ 3 2 2 1 ⊕S 32 |
| | S ⊕ 6 2 2 1 2 ⊕S ⊕ 5 2 3 ⊕S ⊕ 4 321 ⊕S 42 |
| | S ⊕ 10 2 2 1 3 ⊕S ⊕ 16 2 3 1 ⊕S ⊕ 10 321 2 ⊕S ⊕ 9 32 2 ⊕S ⊕ 5 421 ⊕S 52 |
We verify Conjectures 1 and 2 as well as the conjectured values from Table 1 as special cases of the following result:
Theorem 3. For G the n -vertex star, the multiplicity of S /lscript 2 k 1 n - -/lscript 2 k in H 1 0 , ( G ) is
$$\binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k } 1 ^ { n - \ell - 2 k } } - f ^ { \ell 2 ^ { k } 1 ^ { n - \ell - 2 k } },$$
where f λ is the number of standard Young tableaux of shape λ.
In particular, Conjectures 1 and 2 follow immediately from the following special case of Theorem 3:
$$\text{Corollary $4$. For $G$ the $n$-vertext star multiplicity of $\mathcal{S}_{e21^{n-\ell-2}$ in $H_{1,0}(G)$ is $\binom{n-2}{\ell}$}.$$
We also give a more explicit formula for the special case where all parts of λ have size 1 or 2, which we will use to verify some of the values in Table 1:
Corollary 5. For G the n -vertex star, the multiplicity of S 2 k 1 n -2 k in H 1 0 , ( G ) is
$$( n - 2 k + 1 ) \left ( \binom { n - 1 } { k - 1 } - \frac { 1 } { k } \binom { n } { k - 1 } \right ).$$
Finally, we conjecture that Theorem 3 gives essentially a full description of the degree 0 chromatic symmetric homology for star graphs, in the sense that all other multiplicities are 0 (except H 0 0 , ( G ) = S 1 n ):
Conjecture 6. Whenever i ≥ 2 or λ 2 ≥ 3 , the multiplicity of S λ in H i, 0 ( G ) is 0.
The remainder of this paper is organized as follows. We first introduce some relevant background on graphs and symmetric functions in §2. We then give the general construction of H ∗ ( G ) in §3. In §4 and §5, we explain how to concretely compute the degree j = 0 case H i, 0 ( G ; C ) and its decomposition into Specht modules using the combinatorics of Young tableaux. In §6 we prove Theorem 3. In §7, we prove Corollary 4, and in §8, we prove Corollary 5. Finally, in §9, we use our results to verify the conjectured values from Table 1.
## 2 Background on graphs and symmetric functions
/negationslash
/negationslash
A graph G consists of a set V ( G ) of vertices and a set E G ( ) of unordered pairs uv of vertices, called edges . The star graph on vertex set { 1 2 , , . . . , n } is the graph with edges 1 i for each i = 1 and no other edges. Write N = 1 2 3 { , , , . . . } for the set of natural numbers. A proper coloring of G is a function κ : V ( G ) → N such that κ u ( ) = κ v ( ) whenever uv ∈ E G , ( ) which we can think of as an assignment of a color to each vertex such that no two adjacent vertices get the same color. A symmetric function is a polynomial f ( x , x 1 2 , . . . ) that stays the same under any permutation of the variables, i.e. f ( x , x 1 2 , . . . ) = f ( x σ (1) , x σ (2) , . . . ) for any permutation σ of N . The chromatic symmetric function is
$$X _ { G } ( x _ { 1 }, x _ { 2 } \dots ) \coloneqq \sum _ { \kappa } \prod _ { v \in V ( G ) } x _ { \kappa ( v ) }.$$
A partition λ = ( λ , . . . , λ 1 /lscript ) = λ 1 . . . λ /lscript is a finite nondecreasing sequence of positive integers, and the λ i 's are its parts . We also write λ = i j 1 1 i j 2 2 . . . i j /lscript /lscript to mean the partition that has j k parts of size i k for each k = 1 2 , , . . . , /lscript. The Young diagram for λ consists of /lscript left-justified rows of boxes such that the i th row from the top has λ i boxes. A Young tableau is a filling of the boxes of the Young diagram with positive integers. Its content is the sequence ( µ , µ 1 2 , . . . ) such that µ i is the number of entries equal to i. A tableau is a semistandard Young tableau (SSYT) if the entries increase weakly across rows and strictly down columns. The Kostka number K λµ counts the number of SSYT of shape λ and content µ . An SSYT is a standard Young tableau (SYT) if the content is 1 n , i.e. the entries are some permutation of { 1 2 , , . . . , n } . We write
$$f ^ { \lambda } \coloneqq K _ { \lambda, 1 ^ { n } } = | S Y T ( \lambda ) |$$
for the number of SYT of shape λ.
Example 7. We have f 32 = 5 , with the 5 elements of SYT (32) shown below:

.
The number of SYT of shape λ can be calculated using the hook length formula . For each box b ∈ λ in the Young diagram of shape λ , the hook hook ( b ) consists of b itself together with all the boxes below it in its column or to the right of it in its row (forming a Γ shape). Then the formula is
$$f ^ { \lambda } = \frac { | \lambda |! } { \prod _ { b \in \lambda } | \text{hook} ( b ) | },$$
where | hook ( b ) | denotes the number of boxes in hook ( b . )
Example 8. For λ = 32 , the hooks are shown below:





Their lengths are 4, 3, 1, 2, and 1, respectively, so the hook length formula gives
$$f ^ { 3 2 } = \frac { 5! } { 4 \cdot 3 \cdot 1 \cdot 2 \cdot 1 } = 5,$$
which matches what we found in Example 7.
The symmetric group S n is the group of permutations of the set { 1 2 , , . . . , n } . A representation of a group G is a linear action of G on some vector space, or equivalently, a module V over the ring C [ G ]. A representation V is irreducible if it has no proper submodule W ⊆ V such that σW ⊆ W for all σ ∈ G. The irreducible representations of S n are called Specht modules , and are indexed by the partitions λ of n. Given a representation V of a subgroup H ⊆ G, the corresponding induced representation of G is Ind G H ( V ) := C [ G ] ⊗ C [ H ] V.
.
## 3 General construction of H G ∗ ( )
Let n := | V ( G ) | and m := | E G ( ) | . For a ring R (generally C or Z ), the chromatic symmetric homology H ∗ ( G R ; ) is defined by building a sequence of chain modules C i ( G ) with associated differentials or chain maps d i : C i ( G ) → C i -1 ( G ), where 0 ≤ i ≤ m :
$$0 \stackrel { d _ { m + 1 } } { \longrightarrow } C _ { m } ( G ) \stackrel { d _ { m } } { \longrightarrow } C _ { m - 1 } ( G ) \stackrel { d _ { m - 1 } } { \longrightarrow } \dots \stackrel { d _ { 2 } } { \longrightarrow } C _ { 1 } ( G ) \stackrel { d _ { 1 } } { \longrightarrow } C _ { 0 } ( G ) \stackrel { d _ { 0 } } { \longrightarrow } 0.$$
Each C i ( G ) is a representation of S n , or equivalently, an R [ S n ]-module, and each d i is a homomorphism of R [ S n ]-modules. The homology groups associated to G are then defined by
$$H _ { i } ( G ; R ) \coloneqq \ker ( d _ { i } ) / \lim ( d _ { i + 1 } ).$$
Each chain module has an associated grading C i ( G R ; ) = ⊕ i j =0 C i,j ( G R , ; ) and the chain maps and homology groups inherit this grading, so we can write d i = ⊕ i j =0 d i,j and H G R i ( ; ) = ⊕ i j =0 H i,j ( G,R . ) The key connection to X G is that when R = C , if we break each H i,j into a direct sum of Specht modules, replace each Specht module with the associated Schur polynomial, and sum the resulting Schur polynomials with the appropriate signs, we recover the chromatic symmetric function:
$$H _ { i, j } ( G ; \mathbb { C } ) = \bigoplus _ { \lambda } \mathcal { S } _ { \lambda } ^ { \oplus n _ { i j } ^ { \lambda } } \quad \longrightarrow \quad X _ { G } = \sum _ { i, j } ( - 1 ) ^ { i + j } n _ { i j } ^ { \lambda } s _ { \lambda },$$
where n λ ij is the multiplicity of S λ in H i,j ( G ; C ) . Assume the vertices of G are labeled 1 through n. The chain module C i ( G ) can be constructed as a direct sum of C [ S n ]-modules M F , one for each subset F ⊆ E with | F | = : i
$$C _ { i } ( G ) \coloneqq \bigoplus _ { F \subseteq E, | F | = i } \mathcal { M } _ { F }.$$
Each such subset F corresponds to a spanning subgraph of G , where 'spanning' means we take the vertex set of the subgraph to be the full vertex set V ( G . ) If b 1 , . . . , b r are the sizes of the connected components of F , then the definition of M F is
$$\mathcal { M } _ { F } \coloneqq \text{Ind} _ { \mathfrak { S } _ { b _ { 1 } } \times \cdots \times \mathfrak { S } _ { b _ { r } } } ^ { \mathfrak { S } _ { n } } ( \mathcal { L } _ { b _ { 1 } } \otimes \cdots \otimes \mathcal { L } _ { b _ { r } } ),$$
where Ind G H ( V ) denotes the induced representation of G corresponding to a representation V of H,
$$\mathcal { L } _ { b } \coloneqq \bigoplus _ { j = 0 } ^ { b - 1 } \mathcal { S } _ { ( b - j, 1 ^ { j } ) },$$
and S λ is the Specht module corresponding to the partition λ. The degree (or grading) is defined such that each S ( b -j, 1 j ) piece has degree j, and the degree of a tensor product of two representations is the sum of their degrees. In particular, the degree 0 parts are
$$( \mathcal { M } _ { F } ) _ { 0 } = \text{Ind} _ { \mathfrak { S } _ { b _ { 1 } } \times \cdots \times \mathfrak { S } _ { b _ { r } } } ^ { \mathfrak { S } _ { n } } ( \mathcal { S } _ { b _ { 1 } } \otimes \cdots \otimes \mathcal { S } _ { b _ { r } } ).$$
Then for each pair F and F ′ such that F ′ is formed by removing one edge from F , the differential map d F,F ′ is the natural embedding of M F into M F ′ . (The precise construction of this unique 'natural embedding' is a bit technical and is given in [SY18], §2.3.)
Finally, given an ordering on | E G ( ) , | the differential maps d i are defined by
$$d _ { i } \coloneqq \bigoplus _ { | F | = i, | F ^ { \prime } | = i - 1 } ( - 1 ) ^ { \# \, of \, edges \, in \, F \, that \,come \,after \,the \,removed \,edge \, } \cdot d _ { F, F ^ { \prime } }.$$
It can be shown that these maps are in fact differentials in the sense that d i ◦ d i +1 = 0 , or equivalently, im( d i +1 ) ⊆ ker( d i ) .
## 4 The degree j = 0 case H i, 0 ( G )
Our focus from now on will be on the case j = 0 and R = C , so will now describe how H i, 0 ( G ) can be explicitly computed using the combinatorics of Young tableaux.
$$\mathcal { M } _ { F } \coloneqq \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot a _ { T ( F ) },$$
In that case, the C [ S n ]-modules M F (which we henceforth use as shorthand for ( M F ) 0 ) can alternatively be constructed as where C [ S n ] · a T F ( ) := { σ · a T F ( ) : σ ∈ C [ S n ] } , and a T F ( ) is a particular element of C [ S n ] that we will define momentarily. To define a T F ( ) , let λ F ( ) be partition type of F , meaning the partition whose parts are the sizes of the connected components of F, arranged in decreasing order. We construct a Young tableau T F ( ) of shape λ F ( ) as follows. For each connected component of F , list the vertices of F in increasing order. Order these lists first in decreasing order by length, and then within that in increasing order by the smallest element. Then use the i th list to fill the i th row of the Young diagram. Note that the resulting Young tableau need not be standard, as the numbers increase across each row but may not increase down each column.
Example 9. Let F be the spanning subgraph shown below:
Then λ F ( ) = 332 , and
The row symmetrizer a T ∈ C [ S n ] for a tableau T is the sum of all σ ∈ S n such that σ permutes the elements in each row of T F ( ) among themselves, and the associated permutation module is
$$\mathcal { M } _ { T } \coloneqq \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot a _ { T }.$$
We can factor a T as the product over rows of the sum of all permutations of elements in that row.
Example 10. Write e for the identity permutation and ( i 1 2 i . . . i k ) for the k cycle that maps i j to i j +1 for 1 ≤ j ≤ k -1 and i k to i 1 . Then for the F from Example 9,
$$a _ { T ( F ) } = ( e + ( 3 7 ) + ( 3 8 ) + ( 7 8 ) + ( 3 7 8 ) + ( 3 8 7 ) ) \cdot ( e + ( 4 5 ) + ( 4 6 ) + ( 5 6 ) + ( 4 5 6 ) + ( 4 6 5 ) ) \cdot ( e + ( 1 2 ) ).$$
## 5 Decomposition of H i, 0 ( G ) into Specht modules
The column symmetrizer b T ∈ C [ S n ] is the sum of sign( σ ) · σ over all permutations σ that permute the elements of each column among themselves.
Example 11. For the F from Example 9,
$$b _ { T ( F ) } = ( e - ( 1 3 ) - ( 1 4 ) - ( 3 4 ) + ( 1 3 4 ) + ( 1 4 3 ) ) \cdot ( e - ( 2 5 ) - ( 2 7 ) - ( 5 7 ) + ( 2 5 7 ) + ( 2 7 5 ) ) \cdot ( e - ( 6 8 ) ).$$
The Young symmetrizer for T is c T := b T a T . The corresponding Specht module is
$$\mathcal { S } _ { T } \coloneqq \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot c _ { T }.$$
For any tableaux S and T of the same shape λ, S T and S T ′ are isomorphic, so we can write S λ for this isomorphism class of Specht modules. Similarly, M T and M T ′ are isomorphic when T and T ′ have the same shape µ, so we can write M µ for this isomorphism class.
It turns out that the Specht modules S λ are precisely the irreducible representations of S n (see § ?? ), which means any C [ S n ] module can be written as a direct sum of Specht modules in a way that is unique up to isomorphism. In the case of M F , this decomposition turns out to be
$$\mathcal { M } _ { F } \cong \bigoplus _ { \lambda } \mathcal { S } _ { \lambda } ^ { \oplus K _ { \lambda, \, \lambda ( F ) } },$$
where K λµ is the Kostka number that counts the number of SSYT of shape λ and content µ. We can realize this decomposition for M ∼ M F = λ F ( ) as
$$\mathcal { M } _ { F } = \bigoplus _ { \lambda } \bigoplus _ { j = 1 } ^ { K _ { \lambda, \lambda ( F ) } } \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot v _ { X _ { F } ^ { j } } ^ { T ( \lambda ) }.$$
It remains to explain what x j F , T λ , ( ) and v T λ ( ) X j F are. For S, T ∈ SYT ( λ , ) write σ S,T ∈ S n for the permutation such that σ S,T · S = T. Then
$$v _ { S } ^ { T } \coloneqq c _ { T } \cdot \sigma _ { S, T } = \sigma _ { S, T } \cdot c _ { S }.$$
The tableau T λ ( ) ∈ SYT ( λ ) is constructed by filling in the numbers 1 2 , , . . . , n in order row by row. For instance, for λ = 432 ,
$$T ( \lambda ) = \boxed { \frac { 1 } { 5 } \frac { 2 } { 8 } \frac { 3 } { 9 } } _ { \sum }. \\.. \quad. \quad. \quad. \quad. \quad.$$
Finally, the tableaux X j F are constructed as follows. Let T , . . . , T 1 K λ,λ F ( ) be the SSYT of shape λ and content λ F . ( ) Then we turn T j into the corresponding tableau X j F of shape λ by replacing the 1's in T j with the entries from the first row of T F ( ) in order, the 2's with the entries from the second row of T F ( ) in order, and so on, and then reordering so the entries in each row are increasing. The resulting tableau X j F will have entries 1 through n each showing up exactly once, and the entries will increase across each row, but it will not necessarily be standard as the entries need not increase going down the columns.
Example 12. Let F be the spanning subgraph from Example 9, so λ F ( ) = 332 , and let λ = 431 . Then K λ,λ F ( ) = 2 , so there are two copies of S λ in M T . The two the SSYT of shape λ and content λ F ( ) are
.
To get the tableaux X 1 F and X , 2 F we replace the three 1's in each tableau by the 3, 7, and 8 from the first row of λ F ( ), we replace the three 2's by 4, 5, and 6 from the second row, and we replace the two 3's by 1 and 2 from the third row. This gives:

Then we reorder each row so the entries are in increasing order to get
.
Thus, the two copies of S λ in M T are given by where
Note that neither X 1 F not X 2 F is an SYT, since the entries do not always increase down the columns.
## 6 Proof of Theorem 3
Let λ = 2 1 /lscript k n - -/lscript 2 k . The restriction of C 0 ( G ) to S λ is
$$C _ { 0 } ( G ) | _ { \mathcal { S } _ { \lambda } } = \bigoplus _ { Y _ { i } \in S Y T ( \lambda ) } \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot v _ { Y _ { i } } ^ { T ( \lambda ) } \subseteq \mathbb { C } [ \mathfrak { S } _ { n } ],$$
so the multiplicity of S λ in C 0 ( G ) is | SYT ( λ ) | = f λ .
/negationslash
To find C 1 ( G ) | S λ , we need to consider the spanning subgraphs of G with a single edge. Label the vertices of G as 1 , . . . , n, and without loss of generality assume vertex 1 is the central vertex. Then there are n -1 spanning subgraphs of G with one edge, each of the form F 1 i for some i = 1 . Since λ F ( 1 i ) = 21 n -2 for all i , the restriction of C 1 ( G ) to S λ is
$$C _ { 1 } ( G ) | _ { \mathcal { S } _ { \lambda } } = \bigoplus _ { i = 2 } ^ { n } \mathcal { M } _ { F _ { 1 i } } | _ { \mathcal { S } _ { \lambda } } = \bigoplus _ { i = 2 } ^ { n } \bigoplus _ { j = 1 } ^ { K _ { \lambda, 2 1 } ^ { n - 2 } } \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot v _ { X _ { i } ^ { j } } ^ { T ( \lambda ) },$$
where each tableau X j i is formed by taking an SSYT of shape λ and content λ F ( 1 i ) = 21 n -2 , then relabeling it so the second 1 (which is necessarily the second entry of the top row) becomes an i and the entries greater than i -1 each get increased by 1, then reordering the first row so the entries are in increasing order. Every Y k is equal to X j i for some choice of i and j (e.g. by taking i to be the second entry in the top row of Y k ), so d 1 | S λ is surjective. Thus, by rank-nullity, the multiplicity of S λ in ker( d 1 ) is equal to its multiplicity in C 1 ( G ) minus its multiplicity in C 0 ( G . ) The multiplicity in C 0 ( G ) is simply f λ . We claim that the multiplicity in C 1 ( G ) is
$$( \ell - 1 ) \cdot \binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k } 1 ^ { n - \ell - k } }.$$
To see this, note that to form an X , j i we can choose any /lscript -1 numbers besides 1 to fill the first row (in ( n -1 /lscript -1 ) ways), choose any one of them to be i (in /lscript -1 ways), and then fill the remaining rows by taking any SSYT of shape 2 k 1 n - -/lscript k (in f 2 k 1 n - -/lscript 2 k ways) and relabeling it so the 1 becomes the smallest remaining entry, the 2 becomes the second smallest, and so on.
For C 2 ( G ) | S λ , we consider the ( n -1 2 ) spanning subgraphs of G with two edges, which are each of the form F 1 i, 1 j for i and j. Every one of these spanning subgraphs has partition type λ F ( 1 i, 1 j ) = 31 n -3 , so
$$C _ { 1 } ( G ) | _ { \mathcal { S } _ { \lambda } } = \bigoplus _ { 2 \leq i < j \leq n } \mathcal { M } _ { F _ { 1 i, 1 j } } | _ { \mathcal { S } _ { \lambda } } = \bigoplus _ { 2 \leq i < j \leq n } \bigoplus _ { k = 1 } ^ { K _ { \lambda, 3 1 } n - 3 } \mathbb { C } [ \mathfrak { S } _ { n } ] \cdot v _ { W _ { i j } ^ { k } } ^ { T ( \lambda ) },$$
where each W k ij is formed from an SSYT of shape λ and content 31 n -3 by replacing two of the 1's with i and j, adding 1 to each entry between i and j -2, adding 2 to each entry between j -1 and n -2, and reordering the first row so its entries are increasing. Every W k ij formed in this manner is also of the form X r i and an X s j for some r and s . Thus, the map d 2 | S λ directly embeds each C [ S n ] · v T λ ( ) W k ij ⊆ M 1 i, 1 j into
$$\mathbb { C } [ \mathfrak { S } _ { n } ] \cdot v _ { X _ { i } ^ { r } } ^ { T ( \lambda ) } \oplus [ \mathfrak { S } _ { n } ] \cdot v _ { X _ { j } ^ { s } } ^ { T ( \lambda ) } \subseteq \mathcal { M } _ { 1 i } \oplus \mathcal { M } _ { 1 j },$$
via a map that looks like
$$d _ { 2 } | _ { \mathcal { S } _ { \lambda } } ( \tau _ { i j } ^ { k } ) = ( - \tau _ { i j } ^ { k } ) \oplus \tau _ { i j } ^ { k }$$
for each τ k ij ∈ C [ S n ] · v T λ ( ) W k ij . We write the first component with a negative sign because can assume without loss of generality that the edge 1 i comes before the edge 1 j in the edge ordering, and hence the map M 1 i, 1 j →M 1 i has negative sign (since there is one edge in F , namely 1 , that comes after 1 j i in the ordering) while the map M 1 i, 1 j →M 1 j has positive sign (since there are no edges in F coming after 1 j in the ordering).
Each tableau that shows up as X j i for some i actually shows up as X j i for /lscript -1 different values of i , since we can take i to be any entry in the top row except the 1. It also shows up as W k ij for ( /lscript -1 2 ) pairs ( i, j ), since we can take i and j two be any two entries in the top row except the two 1's. Furthermore, a tableau
of shape λ is one of the X j i 's if and only if it is one of the W k ij 's, since the only requirement in both cases is that the first row be in increasing order and the portion below the first row be standard.
To find the multiplicity of S λ in d , 2 consider the restriction of d 2 to submodules of the form C [ S n ] · v T λ ( ) S for a particular tableau S . There are /lscript -1 such modules in C 1 ( G ), one for each entry in the top row of S besides the 1, each isomorphic to a copy of S λ . From the description of d 2 above, an element σ 1 ⊕··· ⊕ σ /lscript -1 in the direct sum of these /lscript -1 submodules is in im( d 2 ) if and only if σ 1 + · · · + σ /lscript -1 = 0 . Thus, σ , . . . , σ 1 /lscript -1 can be chosen independently, and σ /lscript -1 is then determined. Thus, for every /lscript -1 copies of S λ in C 1 ( G ), there are /lscript -2 copies in im( d 2 ) , so the multiplicity of S λ in im( d 2 ) is /lscript -1 /lscript -2 times its multiplicity in C 1 ( G , ) or
$$( \ell - 2 ) \cdot \binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k } 1 ^ { n - \ell - 2 k } }.$$
Then since H 1 0 , ( G ) := ker( d 1 ) / im( d 2 ) , the multiplicity of S λ in H 1 0 , ( G ) is equal to its multiplicity in ker( d 1 ) minus its multiplicity in im( d 2 ) , or
$$( \ell - 1 ) \cdot \binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k _ { 1 } n - \ell - 2 k } } - f ^ { \lambda } - ( \ell - 2 ) \cdot \binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k _ { 1 } n - \ell - 2 k } } = \binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k _ { 1 } n - \ell - 2 k } } - f ^ { \lambda },$$
as claimed.
## 7 Proof of Corollary 4
Let λ = 21 /lscript n - -/lscript 2 . By Theorem 3, the multiplicity of S /lscript 21 n - -/lscript 2 in H 1 0 , ( G ) is
$$\binom { n - 1 } { \ell - 1 } f ^ { 2 1 ^ { n - \ell - 2 } } - f ^ { \lambda }.$$
We note that
$$f ^ { 2 1 ^ { n - \ell - 2 } } = n - \ell - 1,$$
since to get an SYT of shape 21 n - -/lscript 2 , we can choose any of the n -/lscript -1 numbers from 2 , . . . , n -/lscript to be the second entry in the first row, and then the rest is determined since the entries in the first column must be in increasing order. To compute f λ , we draw out the Young diagram of shape λ and label each box with its corresponding hook length:
Thus, the hook length formula gives
$$f ^ { \lambda } = \frac { n! } { ( n - 1 ) ( n - \ell ) \ell \cdot ( n - \ell - 2 )! \cdot ( \ell - 2 )! } = \frac { n ( \ell - 1 ) } { n - \ell } \binom { n - 2 } { \ell }.$$
Putting this together, our multiplicity is
$$( n - \ell - 1 ) \binom { n - 1 } { \ell - 1 } - \frac { n ( \ell - 1 ) } { n - \ell } \binom { n - 2 } { \ell } = \frac { ( n - 1 ) \ell - n ( \ell - 1 ) } { n - \ell } \binom { n - 2 } { \ell } = \binom { n - 2 } { \ell },$$
as claimed. Conjectures 1 and 2 then follow immediately as the special cases /lscript = n -2 and /lscript = 2 .
## 8 Proof of Corollary 5
Let λ = 2 1 k n -2 k . Since /lscript = 2 , Theorem 3 implies that the multiplicity of S λ in H 1 0 , ( G ) is
$$( n - 1 ) K _ { \lambda, 2 1 ^ { n - 2 } } - f ^ { \lambda }.$$
By the hook-length formula, we get
$$f ^ { \lambda } = \frac { n! } { ( n - k + 1 ) \dots ( n - 2 k + 2 ) \cdot k! \cdot ( n - 2 k )! } = \frac { n - 2 k + 1 } { k } \binom { n } { k - 1 },$$
since we can label each box with its hook length as shown below:

For K λ, 21 n -2 , note that to get an SSYT of shape λ and content 21 n -2 , the two 1's must be in the top row, and then the number of ways to fill the remaining part is equal to the number of SYT of shape 2 k -2 1 n -2 k . Using the formula above for f 2 k 1 n -2 k but replacing n with n -2 and k with k -1 gives
$$f ^ { 2 ^ { k - 2 } 1 ^ { n - 2 k } } = \frac { ( n - 2 ) - 2 ( k - 1 ) + 1 } { k - 1 } \binom { n - 2 } { k - 2 } = \frac { n - 2 k + 1 } { n - 1 } \binom { n - 1 } { k - 1 }.$$
Putting this together, the multiplicity of S λ in H 1 0 , ( G ) is
$$( n - 1 ) \cdot \frac { n - 2 k + 1 } { n - 1 } \binom { n - 1 } { k - 1 } - \frac { n - 2 k + 1 } { k } \binom { n } { k - 1 } = ( n - 2 k + 1 ) \left ( \binom { n - 1 } { k - 1 } - \frac { 1 } { k } \binom { n } { k - 1 } \right ),$$
as claimed.
## 9 Proof of the conjectured values from Table 1
We reproduce Table 1 here for convenience:
| G | H 1 , 0 ( G ; C ) |
|-----|-------------------------------------------------------------------------|
| | S 2 2 |
| | S ⊕ 3 2 2 1 ⊕S 32 |
| | S ⊕ 6 2 2 1 2 ⊕S ⊕ 5 2 3 ⊕S ⊕ 4 321 ⊕S 42 |
| | S ⊕ 10 2 2 1 3 ⊕S ⊕ 16 2 3 1 ⊕S ⊕ 10 321 2 ⊕S ⊕ 9 32 2 ⊕S ⊕ 5 421 ⊕S 52 |
Corollary 4 immediately implies the following multiplicities from Table 1:
| Specht module | Multiplicity |
|--------------------------|----------------------------|
| S 2 2 in H 1 , 0 ( ) | ( 4 - 2 2 ) = ( 2 2 ) = 1 |
| S 2 2 1 in H 1 , 0 ( ) | ( 5 - 2 2 ) = ( 3 2 ) = 3 |
| S 32 in H 1 , 0 ( ) | ( 5 - 2 3 ) = ( 3 3 ) = 1 |
| S 2 2 1 2 in H 1 , 0 ( ) | ( 6 - 2 2 ) = ( 4 2 ) = 6 |
| S 321 in H 1 , 0 ( ) | ( 6 - 2 3 ) = ( 4 3 ) = 4 |
| S 42 in H 1 , 0 ( ) | ( 6 - 2 4 ) = ( 4 4 ) = 1 |
| S 2 2 1 3 in H 1 , 0 ( ) | ( 7 - 2 2 ) = ( 5 2 ) = 10 |
| S 321 2 in H 1 , 0 ( ) | ( 7 - 2 3 ) = ( 5 3 ) = 10 |
| S 421 in H 1 , 0 ( ) | ( 7 - 2 4 ) = ( 5 4 ) = 5 |
| S 52 in H 1 , 0 ( ) | ( 7 - 2 5 ) = ( 5 5 ) = 1 |
Corollary 5 then implies two of the others:
| Specht module | Multiplicity |
|----------------------|-------------------------------------------------------------------------------------|
| S 2 3 in H 1 , 0 ( | (6 - 2 · 3 +1) (( 6 - 1 3 - 1 ) - 1 3 ( 6 3 - 1 )) = ( 5 2 ) - 1 3 ( 6 2 ) = 5 |
| S 2 3 1 in H 1 , 0 ( | (7 - 2 · 3 +1) (( 7 - 1 3 - 1 ) - 1 3 ( 7 3 - 1 )) = 2 (( 6 2 ) - 1 3 ( 7 2 )) = 16 |
The only other multiplicity to check is S 9 32 2 in H 1 0 , ( ) . For that one, we directly use the formula
$$\binom { n - 1 } { \ell - 1 } f ^ { 2 ^ { k } 1 ^ { n - \ell - 2 k } } - f ^ { \lambda }$$
from Theorem 3, which in this case becomes
$$\binom { 7 - 1 } { 3 - 1 } f ^ { 2 ^ { 2 } } - f ^ { 3 2 ^ { 2 } } = \binom { 6 } { 2 } f ^ { 2 ^ { 2 } } - f ^ { 3 2 ^ { 2 } } = 1 5 f ^ { 2 ^ { 2 } } - f ^ { 3 2 ^ { 2 } }.$$
We have f 2 2 = 2 , since the two SYT of shape 2 2 are
$$\begin{smallmatrix} 1 & 2 \\ \frac { 1 } { 3 & 4 } \end{smallmatrix} \quad \text{and}$$

For f 32 2 , we use the hook length formula. Below, we label each of the 7 boxes with the length of its hook:
Thus, the hook length formula gives
$$f ^ { 3 2 ^ { 2 } } = \frac { 7! } { 5 \cdot 4 \cdot 3 \cdot 2 \cdot 2 \cdot 1 \cdot 1 } = 2 1.$$
Plugging these values in gives a multiplicity of
$$1 5 \cdot 2 - 2 1 = 9,$$
as claimed in the table.
For the stars on 4 through 7 vertices, it follows by dimension counting that the full decompositions of H 1 0 , ( G ) are as claimed in Table 1, because the authors of [Cha+23] computed what the dimension of H 1 0 , ( G ) is in each case.
## Acknowledgements
The author thanks Oliver Pechenik for telling her about the chromatic symmetric homology, and she thanks Oliver Pechenik, Karen Yeats, and Sophie Spirkl for providing helpful comments. She was partially supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) grant RGPIN-2022-03093.
## References
- [1] George D Birkhoff. 'The reducibility of maps'. In: American Journal of Mathematics 35.2 (1913), pp. 115-128. url : https://doi.org/10.2307/2370276 .
- [2] Alex Chandler, Radmila Sazdanovic, Salvatore Stella, and Martha Yip. 'On the strength of chromatic symmetric homology for graphs'. In: Advances in Applied Mathematics 150 (2023), p. 102559. url : https://doi.org/10.1016/j.aam.2023.102559 .
- [3] Azzurra Ciliberti. 'A deletion-contraction long exact sequence for chromatic symmetric homology'. In: European Journal of Combinatorics 115 (2024), p. 103788. url : https://doi.org/10.1016/j.ejc. 2023.103788 .
- [4] Azzurra Ciliberti and Luca Moci. 'On chromatic symmetric homology and planarity of graphs'. In: Electron. J. Combin. 30.1 (2023), Paper No. 1.15, 11. doi : 10.37236/11397 . url : https://doi.org/ 10.37236/11397 .
- [5] Mikhail Khovanov. 'A categorification of the Jones polynomial'. In: Duke Mathematics Journal 101 (3 2000). url : https://doi.org/10.1215/S0012-7094-00-10131-7 .
- [6] Radmila Sazdanovic and Martha Yip. 'A categorification of the chromatic symmetric function'. In: Journal of Combinatorial Theory, Series A 154 (2018), pp. 218-246. url : https://doi.org/10.1016/ j.jcta.2017.08.01 .
- [7] Richard P Stanley. 'A symmetric function generalization of the chromatic polynomial of a graph'. In: Advances in Mathematics 111.1 (1995), pp. 166-194. url : https://www.sciencedirect.com/ science/article/pii/S0001870885710201 . | null | [
"Laura Pierson"
]
| 2024-08-02T17:14:37+00:00 | 2024-08-02T17:14:37+00:00 | [
"math.CO"
]
| On the chromatic symmetric homology for star graphs | The chromatic symmetric function $X_G$ is a power series that encodes the
proper colorings of a graph $G$ by assigning a variable to each color and a
monomial to each coloring such that the power of a variable in a monomial is
the number of times the corresponding color is used in the corresponding
coloring. The chromatic symmetric homology $H_*(G)$ is a doubly graded family
of $\mathbb{C}[\mathfrak{S}_n]$-modules that was defined by Sazdanovi\'c and
Yip (2018) as a categorification of $X_G$. Chandler, Sazdanovi\'c, Stella, and
Yip (2023) proved that $H_*(G)$ is a strictly stronger graph invariant than
$X_G$, and they also computed or conjectured formulas for it in a number of
special cases. We prove and extend some of their conjectured formulas for the
case of star graphs, where one central vertex is connected to all other
vertices and no other pairs of vertices are connected. |
2408.01397v3 | ## Pseudo-Hermitian extensions of the harmonic and isotonic oscillators
## Aritra Ghosh and Akash Sinha
School of Basic Sciences, Indian Institute of Technology Bhubaneswar, Jatni, Khurda, Odisha 752050, India
E-mail: [email protected]
Abstract. In this work, we describe certain pseudo-Hermitian extensions of the harmonic and isotonic oscillators, both of which are exactly-solvable models in quantum mechanics. By coupling the dynamics of a particle moving in a one-dimensional potential to an imaginary-valued gauge field, it is possible to obtain certain pseudo-Hermitian extensions of the original (Hermitian) problem. In particular, it is pointed out that the Swanson oscillator arises as such an extension of the quantum harmonic oscillator. For the pseudo-Hermitian extensions of the harmonic and isotonic oscillators, we explicitly solve for the wavefunctions in the position representation and also explore their intertwining relations.
## 1 Introduction
The recent years have experienced a considerable amount of interest in the study of non-Hermitian quantum systems [1, 2, 3, 4, 5, 6], and in particular, the ones that admit PT -symmetry, wherein the Hamiltonian commutes with the combined action of the parity and time-reversal operators [7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]. Such systems may admit real spectra despite being guided by non-Hermitian Hamiltonians. It should be remarked that non-Hermitian Hamiltonians are often encountered in optics and photonics [15, 20, 21, 22, 23] as well as in the study of thermal-atomic ensembles [24].
On one hand, a non-Hermitian system displays a non-unitary time evolution and may describe a quantum system that is interacting with some environment (could be a heat bath) [2, 6], i.e., an open quantum system. This non-unitary time evolution turns out to be responsible for loss of quantum coherence (decoherence) [25, 26]. On the other hand, there is a class of non-Hermitian systems which yield a real spectrum and therefore may describe a unitary time evolution when viewed appropriately (see [10] for some discussion on this). In the present study, we are interested in the latter class of non-Hermitian Hamiltonians. A Hamiltonian H is said to be pseudo-Hermitian if there exists some positive-definite Hermitian operator ρ such that [27, 28, 29, 30, 31] (see [32, 33, 34] for time-dependent generalizations)
$$H ^ { \dagger } & = \rho H \rho ^ { - 1 }, & ( 1 )$$
which was shown to be the necessary condition for H to admit a real spectrum. Mostafazadeh [27, 30] went on to show that under a similarity transformation implemented by g = √ ρ , one has the following Dyson map:
$$h = g H g ^ { - 1 },$$
where h is a Hermitian Hamiltonian. Although H seems to dictate a non-unitary time evolution, the reality of the spectrum points towards an isolated (rather than open) system. Indeed the time evolution is unitary when viewed appropriately which involves the introduction of a metric operator Θ = g g † that modifies the inner product as
$$\cdots \cdots ( \psi, \Theta \phi ) = ( \psi, g ^ { \dagger } g \phi ) = ( g \psi, g \phi ).$$
If ψ and φ are the eigenfunctions of H , one can now interpret gψ and gφ to be the eigenfunctions of its Hermitian equivalent, i.e., h .
A prototypical pseudo-Hermitian quantum system is the Swanson oscillator which is described by the following Hamiltonian [35] (see also, Refs. [28, 33, 34, 36, 37, 38, 39]):
$$H _ { \text{Swanson} } = \hbar { \Omega } _ { 0 } \left ( a ^ { \dagger } a + \frac { 1 } { 2 } \right ) + \alpha a ^ { 2 } + \beta ( a ^ { \dagger } ) ^ { 2 }, \quad \quad \quad ( 4 ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
/negationslash where a and a † are the lowering and raising operators, respectively, from the familiar harmonic-oscillator problem, i.e., they satisfy the algebra [ a, a † ] = 1 with the other commutators vanishing identically. In Eq. (4) above, Ω 0 > 0 and α, β ∈ R . If α = β , then the Hamiltonian is non-Hermitian although it is PT -symmetric as may be observed by noticing that under the action of PT , the lowering and raising operators transform as a →-a and a † →-a † , respectively. The system is pseudo-Hermitian and one can construct a Dyson map as [28] g H ( Swanson ) g -1 = h , where h is a Hermitian Hamiltonian (of the harmonic oscillator) and g is suitably chosen to dictate the above-mentioned transformation. This shows that the Swanson oscillator is closely related to its Hermitian counterpart, i.e., the harmonic oscillator.
One of the aims of this paper is to demonstrate that the Swanson oscillator may be regarded as a harmonic oscillator coupled with an imaginary-valued gauge field. We shall analyze this problem in the position representation where we shall exactly solve for the wavefunctions and the spectrum of the oscillator. As may be expected, the wavefunctions are closely related to those of its Hermitian cousin, namely, the harmonic oscillator. In the same spirit, we will then study a pseudo-Hermitian extension of a harmonic oscillator with a centrifugal barrier, the so-called isotonic oscillator [40, 41]. Finally, their supersymmetric intertwining relations shall be exposed.
## 2 Quadratic Hamiltonians
For our purposes, let us consider a quantum harmonic oscillator together with a non-Hermitian extension as where the part of the Hamiltonian which is proportional to Λ is non-Hermitian. The operators x and p satisfy [ x, p ] = i /planckover2pi1 . The Hamiltonian is PT -symmetric, i.e., is invariant under the transformations x →-x , p → p , and i →-i . Notice that the constant Λ in our model is a scalar and does not transform under PT . Thus, it may be expected that the Hamiltonian should support a real spectrum [7], and as we shall show later, indeed it does. This Hamiltonian can originate from a more general Hamiltonian that goes as
$$H = \frac { p ^ { 2 } } { 2 m } + \frac { m \Omega ^ { 2 } x ^ { 2 } } { 2 } + \frac { i \Lambda } { 2 } ( x p + p x ), \\ \text{Hamiltonian which is proportional to } \Lambda \text{ is non-Hermitian. The operators } x \text{ and } p \\ \Lambda \text{ Hamiltonian is } \mathcal { D T } \text{mmutable to } \Lambda \text{ is important under the transformation}$$
$$H \ & = \ \frac { ( p - A ( x ) ) ^ { 2 } } { 2 m } + V ( x ) \\ & = \ \frac { p ^ { 2 } } { 2 m } + \frac { A ( x ) ^ { 2 } } { 2 m } - \frac { ( p A ( x ) + A ( x ) p ) } { 2 m } + V ( x ), \\. \ \cdots \quad \cdots \quad \cdots$$
wherein we choose 1 A x ( ) = -iλx and V ( x ) = mω x 2 2 2 , for m> 0 and ω, λ ≥ 0. This gives Eq. (5) if we identify
$$\Lambda = \frac { \lambda } { m }, \quad m \Omega ^ { 2 } = m \omega ^ { 2 } - \frac { \lambda ^ { 2 } } { m }, \quad \cdots \cdots \cdots.$$
which means 2 Λ ≥ 0. Notice that in natural units, i.e., for /planckover2pi1 = 1, both Λ and Ω have dimensions of [length] -1 . It is convenient to define a dimensionless parameter as
$$\frac { \Omega _ { r } ^ { 2 } } { \text{P} } _ { \text{P} } ^ { 2 } = \left ( \frac { \Omega } { \Lambda } \right ) ^ { 2 } = \left ( \frac { \omega } { \Lambda } \right ) ^ { 2 } - 1.$$
1 It should be pointed out that systems coupled with imaginary-valued gauge fields have generated significant research interest [42, 43, 44, 45, 46].
2 The case Λ = 0 gives back the (Hermitian) harmonic oscillator. So we will assume that Λ > 0.
We may now have three situations listed as follows:
- 1. If ω ∈ (Λ , ∞ ), we have Ω 2 r > 0.
- 2. If ω = Λ, we have Ω 2 r = 0.
- 3. If ω ∈ [0 , Λ), we have Ω 2 r < 0.
In the subsequent analysis, we will focus on the first two cases, i.e., where Ω 2 r ≥ 0.
## 2.1 Equivalence with Swanson oscillator
2.1.1 Scheme one Defining the raising and lowering operators in the usual way as
$$a ^ { \dagger } = \frac { - i p + m \Omega x } { \sqrt { 2 m h \Omega } }, \quad a = \frac { i p + m \Omega x } { \sqrt { 2 m h \Omega } },$$
where [ a, a † ] = 1, we have
$$p = \sqrt { \frac { m \hbar { \Omega } } { 2 } } i ( a ^ { \dagger } - a ), \quad x = \sqrt { \frac { \hbar } { 2 m \Omega } } ( a ^ { \dagger } + a ).$$
In terms of these operators, the Hamiltonian operator given by Eq. (5) reads as
$$H = \hbar { \Omega } a ^ { \dagger } a + \frac { \hbar { \Lambda } } { 2 } ( a ^ { 2 } - ( a ^ { \dagger } ) ^ { 2 } ) + \frac { \hbar { \Omega } } { 2 },$$
which is a particular realization of the Swanson oscillator [Eq. (4)]; we have Ω 0 = Ω, α = /planckover2pi1 Λ 2 , and β = -/planckover2pi1 Λ 2 for which Eq. (11) corresponds to Eq. (4). In this case we have two independent parameters of the Hamiltonian given by Eq. (4), i.e., Ω 0 and α = ( -β ) which are determined by the parameters Ω and Λ; one must take Ω > 0 here.
2.1.2 Scheme two Instead of defining the raising and lowering operators as in Eq. (9), let us define them as
$$a ^ { \dagger } = \frac { - i p + x } { \sqrt { 2 } }, \quad a = \frac { i p + x } { \sqrt { 2 } },$$
which satisfy the standard algebra [ a, a † ] = 1 (setting /planckover2pi1 = 1). This gives
$$p = \frac { i ( a ^ { \dagger } - a ) } { \sqrt { 2 } }, \quad x = \frac { ( a ^ { \dagger } + a ) } { \sqrt { 2 } },$$
and Eq. (5) reads
$$H = \left ( \frac { 1 } { 2 m } + \frac { m \Omega ^ { 2 } } { 2 } \right ) \left ( a ^ { \dagger } a + \frac { 1 } { 2 } \right ) + \left ( \, - \, \frac { 1 } { 4 m } + \frac { m \Omega ^ { 2 } } { 4 } + \frac { \Lambda } { 2 } \right ) a ^ { 2 } + \left ( \, - \, \frac { 1 } { 4 m } + \frac { m \Omega ^ { 2 } } { 4 } - \frac { \Lambda } { 2 } \right ) ( a ^ { \dagger } ) ^ { 2 }.$$
Since /planckover2pi1 = 1, this Hamiltonian corresponds exactly to Eq. (4) with
$$\Omega _ { 0 } = \left ( \frac { 1 } { 2 m } + \frac { m \Omega ^ { 2 } } { 2 } \right ), \ \alpha = \left ( \, - \, \frac { 1 } { 4 m } + \frac { m \Omega ^ { 2 } } { 4 } + \frac { \Lambda } { 2 } \right ), \ \beta = \left ( \, - \, \frac { 1 } { 4 m } + \frac { m \Omega ^ { 2 } } { 4 } - \frac { \Lambda } { 2 } \right ). \quad \ \ ( 1 5 )$$
In this case we have three independent parameters of the Hamiltonian given by Eq. (4), i.e., Ω 0 , α , and β ; these are determined by the parameters m , Ω, and Λ as is clear from Eq. (14) or Eq. (15). Notice that for Ω r ≥ 0, one must have Ω 0 ≥ 0. One can have Ω r ≥ 0, i.e., Ω ≥ 0; if Ω = 0, then α + β +Ω = 0. 0
## 2.2 Wavefunctions and spectrum
For some generic values of Ω and Λ, the Hamiltonian [Eq. (5)] in the position representation reads as (for /planckover2pi1 = 1)
$$H & = - \frac { 1 } { 2 m } \frac { d ^ { 2 } } { d x ^ { 2 } } + \frac { m \Omega ^ { 2 } x ^ { 2 } } { 2 } + \frac { \Lambda } { 2 } \left ( 2 x \frac { d } { d x } + 1 \right ). \\ \overline { \psi \psi } \quad.. \quad. \quad. \quad. \quad. \quad. \quad.$$
Defining u = √ ( m /σ x Λ ) with σ > 0, one can show that Eq. (16) gives
$$H & = \frac { \Lambda } { 2 \sigma } \left [ - \frac { d ^ { 2 } } { d u ^ { 2 } } + \Omega _ { r } ^ { 2 } \sigma ^ { 2 } u ^ { 2 } + \sigma \left ( 2 u \frac { d } { d u } + 1 \right ) \right ], \\. &. &. &. &. &.$$
which leads to a time-independent Schr¨dinger equation that goes as o
$$\frac { d ^ { 2 } \psi ( u ) } { d u ^ { 2 } } - \Omega _ { r } ^ { 2 } \sigma ^ { 2 } u ^ { 2 } \psi ( u ) - 2 \sigma u \frac { d \psi ( u ) } { d u } + \sigma \left ( \frac { 2 E } { \Lambda } - 1 \right ) \psi ( u ) = 0,$$
where Ω 2 r is defined in Eq. (8). As can be observed from Eq. (17), Λ sets the energy scale corresponding to the Hamiltonian which is pseudo-Hermitian and can be mapped to that of a Hermitian oscillator as gHg -1 = h , where
$$\text{there} \\ h = \frac { \Lambda } { 2 \sigma } \left [ - \frac { d ^ { 2 } } { d u ^ { 2 } } + \sigma ^ { 2 } u ^ { 2 } ( 1 + \Omega _ { r } ^ { 2 } ) \right ], \quad g = e ^ { - \frac { \sigma u ^ { 2 } } { 2 } }. \quad \quad \quad ( 1 9 ) \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
The form of g has been obtained by taking the ansatz g = e -(constant) u 2 and then by fixing the constant in the exponential by demanding that h is Hermitian. Following [31], the inner product between the eigenfunctions of the Hamiltonian given by Eq. (17) will be determined by the metric Θ = g g † = e -σu 2 = e -m x Λ 2 .
Let us take ψ u ( ) = e α u 0 2 φ u ( ) which gives
$$& \frac { d ^ { 2 } \phi ( u ) } { d u ^ { 2 } } + ( 4 \alpha _ { 0 } - 2 \sigma ) u \frac { d \phi ( u ) } { d u } + ( 4 \alpha _ { 0 } ^ { 2 } - 4 \sigma \alpha _ { 0 } - \Omega _ { r } ^ { 2 } \sigma ^ { 2 } ) u ^ { 2 } \phi ( u ) + \left [ \sigma \left ( \frac { 2 E } { \Lambda } - 1 \right ) + 2 \alpha _ { 0 } \right ] \phi ( u ) = 0. \quad ( 2 0 ) \\ - \cdot \cdot \cdot \cdot \quad - \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
This becomes a Hermite equation if the parameters satisfy the following conditions:
$$4 \alpha _ { 0 } - 2 \sigma \ & = \ - 2, \\ \Lambda \cap ^ { 2 } - \Lambda \pi \cap \Lambda \ - \Omega ^ { 2 } \pi ^ { 2 } \ & = \ 0 \ & \Lambda \ \.$$
$$\check { \sigma } \left ( \frac { 2 E } { \Lambda } - 1 \right ) + 2 \alpha _ { 0 } \ = \ 2 n, \ \ n = 0, 1, 2, \cdots.$$
$$\begin{smallmatrix} 4 \alpha _ { 0 } ^ { 2 } - 4 \sigma \alpha _ { 0 } - \Omega _ { r } ^ { 2 } \sigma ^ { 2 } & = & 0, \\ / \int E & \end{smallmatrix}$$
Eq. (22) gives wherein we will pick the one with the negative sign as we desire α 0 to be negative so that the factor e α u 0 2 falls off for u →±∞ . Combining Eqs. (21) and (22), it is found that Ω r must be given by
$$\alpha _ { 0 } = \frac { \sigma } { 2 } ( 1 \pm \sqrt { 1 + \Omega _ { r } ^ { 2 } } ), & & ( 2 4 ) \\ \text{with the negative sign as we desire } \alpha _ { 0 } \text{ to be negative so that the factor}$$
$$\Omega _ { r } & = \sqrt { \frac { 1 } { \sigma ^ { 2 } } - 1 },$$
and demanding Ω 2 r ≥ 0 implies that 0 < σ ≤ 1; the case with σ = 1 gives Ω r = 0. Finally, combining Eqs. (21) and (23), the spectrum turns out to be
$$E _ { n } = \frac { \Lambda } { 2 \sigma } ( 2 n + 1 ),$$
which is equispaced and coincides with that of the harmonic oscillator since Λ = σω from Eqs. (8) and (25). The wavefunctions go as (up to normalization factors) ψ n ( x ) ∼ e ( σ -1) m Λ 2 σ x 2 H n ( √ m /σx Λ ). The inner product is defined using the metric Θ = g g † = e -m x Λ 2 , which, upon using the well-known orthogonality property of the Hermite polynomials, i.e., ∫ ∞ -∞ H n 1 ( ξ H ) n 2 ( ξ e ) -ξ 2 dξ = √ π 2 n 1 n 1 ! δ n ,n 1 2 ,
/negationslash
$$\psi _ { n } ( x ) & = \left ( \frac { m \Lambda } { \sigma \pi } \right ) ^ { 1 / 4 } \frac { e ^ { \frac { ( \sigma - 1 ) m \Lamb$$
gives ( ψ n 1 , Θ ψ n 2 ) = 0 for n 1 = n 2 . Using the orthogonality property, we may normalize the wavefunctions to write
Thus, we have completely solved the problem; the wavefunctions are given by Eq. (27) while the corresponding spectrum is given by Eq. (26).
## 3 Pseudo-Hermitian extension of the isotonic oscillator
The isotonic oscillator [40, 41] is a close cousin of the harmonic oscillator. Although it admits a nonlinear Newton's equation of motion, it is isoperiodic with the harmonic oscillator [47, 48] and the corresponding quantum-mechanical problem admits an equispaced spectrum [40, 41]. The isotonic oscillator has also found applications in the theory of coherent states [41, 49]. The potential describing the dynamics may be taken to be
$$V ( x ) = V _ { 0 } \left ( \frac { x } { x _ { 0 } } - \frac { x _ { 0 } } { x } \right ) ^ { 2 }, \quad x > 0, \quad \quad \quad$$
where x 0 > 0 is a suitable constant with dimensions of length and V 0 > 0 is a constant with dimensions of energy (for /planckover2pi1 = 1, it has dimensions of [length] -1 ). As a generalization of this problem in the spirit of the ongoing analysis, let us consider the following generalized quantum Hamiltonian in the position representation:
$$H = - \frac { 1 } { 2 m } \frac { d ^ { 2 } } { d x ^ { 2 } } + V _ { 0 } \left ( \frac { x } { x _ { 0 } } - \frac { x _ { 0 } }$$
Putting ξ = x/x 0 , the system has been exactly solved for the case Λ = 0 by taking an ansatz that goes as ψ ξ ( ) = ξ ν e -ηξ 2 4 φ ξ ( ), wherein ν, η > 0 and it is found that φ ξ ( ) satisfies Kummer's differential equation for the confluent hypergeometric function [40, 41] which can be related to the Laguerre polynomials [9, 50].
In order to address the quantum mechanics dictated by the non-Hermitian Hamiltonian given by Eq. (29), let us first rewrite the Hamiltonian in terms of the variable ξ = x/x 0 which gives
$$H = V _ { 0 } \left [ - \frac { 4 } { \eta ^ { 2 } } \frac { d ^ { 2 } } { d \xi ^ { 2 } } + \left ( \xi - \frac { 1 } { \xi } \right$$
where Λ 0 = Λ /V 0 and η 2 = 8 mV x 0 2 0 . The Hamiltonian is pseudo-Hermitian and one can construct a Dyson map as h = gHg -1 , for
$$h = - \frac { 4 V _ { 0 } } { \eta ^ { 2 } } \frac { d ^ { 2 } } { d \xi ^ { 2 } } + V _ { 0 } \left ( \xi - \frac { 1 } { \xi } \right ) ^ { 2 } + \frac { 1 } { 1 6 } V _ { 0 } \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } \xi ^ { 2 }, \quad g = e ^ { - \frac { \Lambda _ { 0 } \eta ^ { 2 } } { 1 6 } \xi ^ { 2 } }, \quad \quad \quad$$
where h is Hermitian and the form of g has been obtained by taking the ansatz g = e -(constant) ξ 2 and then by fixing the constant in the exponential by demanding that h is Hermitian. Corresponding to Eq. (30), the time-independent Schr¨dinger equation reads o
$$\frac { d ^ { 2 } \psi ( \xi ) } { d \xi ^ { 2 } } - \frac { \eta ^ { 2 } } { 4 } \Big ( \xi - \frac { 1 } { \xi } \Big ) ^ { 2 } \psi ( \xi ) - \frac { \Lambda _ { 0 } \eta ^ { 2 } } { 4 } \xi \frac { d \psi ( \xi ) } { d \xi } + \frac { \eta ^ { 2 } } { 4 } \Big ( \frac { E } { V _ { 0 } } - \frac { \Lambda _ { 0 } } { 2$$
Let us define y = ηξ 2 / 2 such that the time-independent Schr¨dinger equation reads as o
$$y \frac { d ^ { 2 } \psi ( y ) } { d y ^ { 2 } } + \frac { 1 } { 2 } \left ( 1 - \frac { \Lambda _ { 0 } \eta } { 2 } y \right ) \frac { d \psi ( y ) } { d y } - \frac { \eta } { 4 } \left ( \frac { y } { \eta } + \frac { \eta } { 4 y } - 1 \right ) \psi ( y ) + \frac { \eta } { 8 } \left ( \frac { E } { V _ { 0 } } - \frac { \Lambda _ {$$
We now take an ansatz for the wavefunction which goes as ψ y ( ) = e -α y 0 y β 0 φ y ( ), for some suitable real and positive parameters α 0 and β 0 . The function φ y ( ) must satisfy the following equation:
$$X ( y ) \frac { d ^ { 2 } \phi ( y ) } { d y ^ { 2 } } + Y ( y ) \frac { d \phi ( y ) } { d y } + Z ( y ) = 0,$$
where
$$X ( y ) & \ = \ y, \\ Y ( y ) & \ = \ - 2 \alpha _ { 0 } y + 2 \beta _ { 0 } + \frac { 1 } { 2 } \left ( 1 - \frac { \Lambda _ { 0 } \eta } { 2 } y \right ), \\ Z ( y ) & \ = \ \alpha _ { 0 } ^ { 2 } y - 2 \alpha _ { 0 } \beta _ { 0 } + \frac { \beta _ { 0 } ( \beta _ { 0 } - 1 ) } { y } + \frac { 1 } { 2 } \left ( 1 - \frac { \Lambda _ {$$
The above-mentioned equation can be solved to yield the Laguerre polynomials as [50]
$$\phi _ { n } ( y ) = L _ { n } ^ { a } \left ( \frac { 1 } { 4 } y \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } \right ), \quad a = \frac { \sqrt { \eta ^ { 2 } + 1 } } { 2 }, \quad n = \frac { 1 } { 4 } \left ( \frac { 2 ( 2 V _ { 0 } + E _ { n } ) \eta } { V _ { 0 } \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } } - \sqrt { \eta ^ { 2 } + 1 } - 2 \right ), \quad ( 3 5 ) \\ \text{where } n = 0, 1, 2, \cdots, \text{and this indicates that the spectrum reads as}$$
where n = 0 1 2 , , , · · · , and this indicates that the spectrum reads as
$$E _ { n } = \frac { \left ( 2 V _ { 0 } \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } \right ) } { \eta } \left ( n + \frac { 1 } { 2 } + \frac { \sqrt { \eta ^ { 2 } + 1 } } { 4 } - \frac { \eta } { \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } } \right ), \\ \intertext { i s e q u i p a c e. } \, \text{In obtaining Eq. (35), the parameters $\alpha_{0}$ and $\beta_{0}$ turn out to be}$$
which is equispaced. In obtaining Eq. (35), the parameters α 0 and β 0 turn out to be
$$\alpha _ { 0 } = \frac { 1 } { 8 } \left ( \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } - \eta \Lambda _ { 0 } \right ), \quad \beta _ { 0 } = \frac { 1 } { 4 } \left ( \sqrt { \eta ^ { 2 } + 1 } + 1 \right ), \\ \text{the wavefunctions} \, ( \min \, to \, normalization factors) \, \text{read}$$
so that the wavefunctions (up to normalization factors) read
$$\psi _ { n } ( \xi ) & \sim e ^ { - \frac { \eta \left ( \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } - \eta \Lambda _ { 0 } } \right ) \xi ^ { 2 } } { 1 6 } \xi ^ { \frac { 1 } { 2 } } ( \sqrt { \eta ^ { 2 } + 1 } ) L _ { n } ^ { \frac { \sqrt { \eta ^ { 2 } + 1 } } { 2 } } \left ( \frac { \eta \xi ^ { 2 } } { 8 } \sqrt { \eta ^ { 2 } \Lambda _ { 0 } ^ { 2 } + 1 6 } \right ). \\ \intertext { w h a m m a t i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i t i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d I n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i nd i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i, i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i n d i.$$
The wavefunctions are consistent with the boundary conditions ψ n (0) = 0 and lim ξ →∞ ψ n ( ξ ) = 0, ∀ n . It is noteworthy that if one takes Λ 0 = 0 (the Hermitian limit), the wavefunctions and the spectrum turn out to be
$$\psi _ { n } ( \xi ) \sim e ^ { - \frac { n \xi ^ { 2 } } { 4 } } \xi ^ { \frac { 1 } { 2 } \left ( \sqrt { \eta ^ { 2 } + 1 } + 1 \right ) } L _ { n } ^ { \frac { \sqrt { \eta ^ { 2 } + 1 } } { 2 } } \left ( \frac { \eta \xi ^ { 2 } } { 2 } \right ), \quad E _ { n } = \frac { 8 V _ { 0 } } { \eta } \left ( n + \frac { 1 } { 2 } + \frac { \sqrt { \eta ^ { 2 } + 1 } - \eta } { 4 } \right ),$$
coinciding exactly with the results of [40, 41].
## 4 Pseudo-Hermitian extensions for general potentials
It should be remarked that one can generate other pseudo-Hermitian Hamiltonians via coupling the system in an arbitrary potential with an imaginary-valued gauge field. In the position representation, Eq. (6) reads as
$$\mathbb { m } = - \frac { 1 } { 2 m } \frac { d ^ { 2 } } { d x ^ { 2 } } + V ( x ) + \frac { A ( x ) ^ { 2 } } { 2 m } + \frac { i A ( x ) } { m } \frac { d } { d x } + \frac { i A ^ { \prime } ( x ) } { 2 m }.$$
Defining g x ( ) = e -i ∫ A x dx ( ) , we have
$$h \ & = \ g ( x ) H g ( x ) ^ { - 1 } \\ & = \ - \frac { 1 } { 2 m } \frac { d ^ { 2 } } { d x ^ { 2 } } + V ( x ),$$
which is just the corresponding Hermitian Hamiltonian. The above-mentioned analysis reveals that H and h share the same spectrum and the eigenfunctions of H can be determined if one can solve the time-independent Schr¨dinger equation for o h , which assumes a simpler form. Indeed, if ψ h ( x ) be an eigenfunction of h with eigenvalue E , then
$$h \psi _ { h } ( x ) = E \psi _ { h } ( x ),$$
which, upon substituting h = g x Hg x ( ) ( ) -1 gives g x H g x ( ) ( ( ) -1 ψ h ( x )) = Eψ h ( x ). This directly implies that
$$H ( g ( x ) ^ { - 1 } \psi _ { h } ( x ) ) = E ( g ( x ) ^ { - 1 } \psi _ { h } ( x ) ),$$
meaning that ψ H ( x ) = g x ( ) -1 ψ h ( x ) is the corresponding eigenfunction of H with the same eigenvalue. As special cases, we can obtain the examples worked out so far in this paper. Let us look at another simple case in which the gauge field is an imaginary-valued constant, i.e., A x ( ) = -i ∆, ∆ ∈ R ; the
$$\text{as} \\ H = - \frac { 1 } { 2 m } \frac { d ^ { 2 } } { d x ^ { 2 } } + V ( x ) - \frac { \Delta ^ { 2 } } { 2 m } + \frac { \Delta } { m } \frac { d } { d x },$$
Hamiltonian then reads while
$$h = - \frac { 1 } { 2 m } \frac { d ^ { 2 } } { d x ^ { 2 } } + V ( x ). \quad \ \ \ \ \ \ \ \ \ \ \$$
Notice that H is non-Hermitian and it is also not PT -symmetric. However, H is still pseudo-Hermitian with h being its Hermitian equivalent. If V ( x ) = mω x 2 2 2 , the spectrum of h is obtained trivially as
$$E _ { n } = \omega \left ( n + \frac { 1 } { 2 } \right ), \quad n = 0, 1, 2, \cdots, \quad \quad \quad$$
which is real and equispaced. This example was presented earlier in [19], albeit in a different form. Thus, H also has the same spectrum whose reality is ensured by its pseudo-Hermiticity despite absence of PT -symmetry. This demonstrates that PT -symmetry is not a necessary condition to ensure the reality of the spectrum.
## 5 Intertwined Hamiltonians
While several authors have studied supersymmetry and supersymmetric factorization in the context of non-Hermitian quantum systems (see for example, the works [51, 52, 53, 54]), let us now describe the supersymmetric factorization of the pseudo-Hermitian Hamiltonians considered in this paper. Consider some generic 'supercharge-like' operators Q 1 and Q 2 such that (we shall take m = 1)
$$Q _ { 1 } = \frac { 1 } { \sqrt { 2 } } \frac { d } { d x } + K ( x ) + W ( x ), \ \ Q _ { 2 } = -$$
where K x ( ) is some real-valued function and W x ( ) is the superpotential. Notice that Q 1 and Q 2 are not Hermitian conjugates of one another. This gives
$$H _ { 1 } = Q _ { 1 } Q _ { 2 } = - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } - \sqrt {$$
$$H _ { \text{II} } = Q _ { 2 } Q _ { 1 } = - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } -$$
which can be regarded as non-Hermitian superpartners with the non-Hermiticity originating from the fact that Q 1 and Q 2 are not Hermitian conjugates of one another. The Hamiltonians H I and H II become Hermitian if we set K x ( ) = 0. Here W x ( ) can be taken to be the usual superpotential as in a Hermitian problem while K x ( ) is related to the imaginary-valued gauge field. Let us take two examples below.
5.1 Pseudo-Hermitian extension of harmonic oscillator For x ∈ R , taking W x ( ) = ωx √ 2 and K x ( ) = -λx √ 2 , where ω, λ > 0, it follows that the partner
Hamiltonians turn out to be
$$H _ { 1 } \ = \ - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } + \lambda x \frac { d } { d x } + \frac { ( \omega ^ { 2 } - \lambda ^ { 2 } ) x ^ { 2 } } { 2 } + \frac { \lambda + \omega } { 2 },$$
$$H _ { \text{II} } \ = \ - \frac { \sum _ { \substack { \nu \\ - \frac { 1 } { 2 } } \frac { d ^ { 2 } } { d x ^ { 2 } } + \lambda x \frac { d ^ { 2 } } { d x } + \frac { ( \omega ^ { 2 } - \lambda ^ { 2 } ) x ^ { 2 } } { 2 } + \frac { \lambda - \omega } { 2 } }.$$
These are a pair of intertwined pseudo-Hermitian Hamiltonians with Hermitian counterparts that go as
$$h _ { 1 } \ = \ - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } + \frac { \omega ^ { 2 } x ^ { 2 } } { 2 } + \frac { \omega } { 2 },$$
$$h _ { \text{II} } \ = \ - \frac { 1 } { 2 } \frac { \stackrel { - } { \Phi } \Phi } { d x ^ { 2 } } + \frac { \omega ^ { 2 } x ^ { 2 } } { 2 } - \frac { - } { 2 }.$$
Thus, they have the same spectrum but with different ground-state energies given as
$$E _ { I, n } = \omega ( n + 1 ), \quad E _ { I I, n } = \omega n, \quad n = 0, 1, 2, \cdots.$$
5.2 Pseudo-Hermitian extension of isotonic oscillator
Let us now consider the case for which
$$W ( x ) = \frac { 1 } { \sqrt { 2 } } \left ( \omega x + \frac { 1 } { x } \right ), \quad K ( x ) = - \frac { \lambda x } { \sqrt { 2 } }, \quad x > 0. \quad \quad \quad$$
Notice that the superpotential is singular at x = 0 and one is restricting oneself to x > 0. The superpartner Hamiltonians now read (defined for x > 0)
$$H _ { 1 } \ = \ - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } + \frac { ( \omega ^ { 2 } - \lambda ^ { 2 } ) x ^ { 2 } } { 2 } + \frac { \lambda } { 2 } \left ($$
$$H _ { \text{II} } \ = \ - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } + \frac { ( \omega ^ { 2 } - \lambda ^ { 2 } ) x ^ { 2 } } { 2 } + \frac { 1 } { x ^$$
The form of H II above can be taken to dictate a pseudo-Hermitian extension of the isotonic oscillator. It is straightforward to show using Eq. (41) that the Hermitian counterparts are (for x > 0)
$$h _ { 1 } \ = \ - \frac { 1 } { 2 } \frac { d ^ { 2 } } { d x ^ { 2 } } + \frac { \omega ^ { 2 } x ^ { 2 } } { 2 } + \frac { 3 \omega } { 2 },$$
$$h _ { I I } \ = \ - \frac { 1 } { 2 } \frac { \stackrel { - 1 } { d ^ { 2 } } } { d x ^ { 2 } } + \frac { \omega ^ { 2 } x ^ { 2 } } { 2 } + \frac { 1 } { x ^ { 2 }$$
The spectrum of h I corresponds to the levels of the half harmonic oscillator, i.e.,
$$E _ { 1, n } = \omega ( n + 2 ), \quad n = 1, 3, 5, \cdots, & & ( 6 0 ) \\ \} ) \, \text{if $n=0,1,2,\cdots$ Following the references $[40,41]$, one finds the spectrum of $h_{II}$ to}$$
E II ,n = ω ( 2 n +3 ) , n = 0 1 2 , , , · · · . (61) Thus, the pseudo-Hermitian extension of the isotonic oscillator is the superpartner of the pseudo-Hermitian extension of the half harmonic oscillator, i.e., supersymmetry acts only on the wavefunctions of the harmonic oscillator that vanish at x = 0 (see also, the older work [55]).
or E I ,n = ω ( 2 n +3) if n = 0 1 2 , , , · · · . Following the references [40, 41], one finds the spectrum of h II to be
## 6 Closing remarks
In this paper, we have analyzed a certain quadratic but non-Hermitian extension of the quantum harmonic oscillator with the model being equivalent to the well-known Swanson oscillator for Ω ≥ 0. We have analytically solved for the wavefunctions and spectrum in the position representation for Ω ≥ 0. The Hamiltonian is pseudo-Hermitian with its Hermitian equivalent being the harmonic oscillator which facilitates its exact solution using methods familiar from the analysis of the (Hermitian) harmonic oscillator. We have also presented and analyzed a pseudo-Hermitian extension of the isotonic oscillator and have explored its supersymmetric factorization.
## Acknowledgements
We are thankful to the anonymous referee for constructive comments. We thank Bijan Bagchi for many useful correspondences. AG would like to thank Miloslav Znojil and Anindya Ghose Choudhury for multiple enlightening discussions. The work of AG is supported by the Ministry of Education (MoE), Government of India in the form of a Prime Minister's Research Fellowship (ID: 1200454). AS would like to acknowledge the financial support from IIT Bhubaneswar in the form of an Institute Research Fellowship. We are grateful to the organizers (in particular, to David Berm´dez Rosales) of the u Xth International Workshop on New Challenges in Quantum Mechanics: Graphene, Supersymmetry, and Mathematical Physics for the opportunity to present this work. AG is grateful to the Czech Technical University in Prague for hospitality during the final stages of preparing the manuscript.
## References
- [1] Rotter I 2009 J. Phys. A: Math. Theor. 42 153001
- [2] Michishita Y and Peters R 2020 Phys. Rev. Lett. 124 196401
- [3] Holmes K, Rehman W, Malzard S and Graefe E M 2023 Phys. Rev. Lett. 130 157202
- [4] Graefe E M, H¨ning M and Korsch H J 2010 o J. Phys. A: Math. Theor. 43 075306
- [5] G´ omez-Le´n A, Ramos T, Gonz´lez-Tudela A and Porras D 2022 o ´ a Phys. Rev. A 106 L011501
- [6] Niu X, Li J, Wu S L and Yi X X 2023 Phys. Rev. A 108 032214
- [7] Bender C M and Boettcher S 1998 Phys. Rev. Lett. 80 5243
- [8] Bender C M, Boettcher S and Meisinger P N 1999 J. Math. Phys. 40 2201
- [9] Znojil M 1999 Phys. Lett. A 259 220
- [10] Znojil M 2020 Sci. Rep. 10 18523
- [11] Bagchi B and Quesne C 2000 Phys. Lett. A 273 285
- [12] Bagchi B and Roychoudhury R 2000 J. Phys. A: Math. Gen. 33 L1
- [13] Bender C M and Hook D W 2023 arXiv:2312.17386
- [14] El-Ganainy R, Makris K G, Khajavikhan M, Musslimani Z H, Rotter S and Christodoulides D N 2018 Nat. Phys. 14 11
- [15] Musslimani Z H, Makris K G, El-Ganainy R and Christodoulides D N 2008 Phys. Rev. Lett. 100 030402
- [16] Correa F and Plyushchay M S 2012 Phys. Rev. D 86 085028
- [17] Noble J H, Lubasch M and Jentschura U D 2013 Eur. Phys. J. Plus 128 93
- [18] Noble J H, Lubasch M, Stevens J and Jentschura U D 2017 Comput. Phys. Commun. 221 304
- [19] da Providˆ encia J, Bebiano N and da Providˆncia J P 2011 e Braz. J. Phys. 41 78
- [20] Feng L, El-Ganainy R and Ge L 2017 Nat. Photonics 11 752
- [21] El-Ganainy R, Khajavikhan M, Christodoulides D N and Ozdemir S K 2019 Commun. Phys. 2 37
- [22] Wang C, Fu Z, Mao W, Qie J, Stone A D and Yang L 2023 Adv. Opt. Photonics 15 442
- [23] Li A, Wei H, Cotrufo M, Chen W, Mann S, Ni X, Xu B, Chen J, Wang J, Fan S, Qiu C W, Al` A u and Chen L 2023 Nat. Nanotechnol. 18 706
- [24] Liang C, Tang Y, Xu A N and Liu Y C 2023 Phys. Rev. Lett. 130 263601
- [25] Schlosshauer M 2005 Rev. Mod. Phys. 76 1267
- [26] Schlosshauer M 2019 Phys. Rep. 831 1
- [27] Mostafazadeh A 2002 J. Math. Phys. 43 205
- [28] Jones H F 2005 J. Phys. A: Math. Gen. 38 1741
- [29] Jakubsk´ y V 2007 Acta Polytech. 47 71
- [30] Mostafazadeh A 2010 Int. J. Geom. Methods Mod. Phys. 07 1191
- [31] Das A 2011 J. Phys.: Conf. Ser. 287 012002
- [32] Znojil M 2008 Phys. Rev. D 78 085003
- [33] Fring A and Moussa M H Y 2016 Phys. Rev. A 94 042128
- [34] Zelaya K and Rosas-Ortiz O 2021 Quantum Rep. 3 458
- [35] Swanson M S 2004 J. Math. Phys. 45 585
- [36] Graefe E M, Korsch H J, Rush A and Schubert R 2015 J. Phys. A: Math. Theor. 48 055301
- [37] Bagchi B and Marquette I 2015 Phys. Lett. A 379 1584
- [38] Fern´ndez V, Ram´ ırez R and Reboiro M 2022 a J. Phys. A: Math. Theor. 55 015303
- [39] Bagchi B, Ghosh R and Sen S 2022 EPL 137 50004
- [40] Gol'dman I I and Krivchenkov V D 1961 Problems in Quantum Mechanics (London: Pergamon Press)
- [41] Weissman Y and Jortner J 1979 Phys. Lett. A 70 177
- [42] Hatano N and Nelson D R 1996 Phys. Rev. Lett. 77 570
- [43] Oztas Z and Candemir N 2019 Phys. Lett. A 383 1821
- [44] Wong S and Oh S S 2021 Phys. Rev. Research 3 033042
- [45] Midya B 2024 Phys. Rev. A 109 L061502
- [46] Qi Y, Pi J, Wu Y, Lin H, Zheng C and Long G L 2024 Phys. Rev. B 110 075411
- [47] Chalykh O A and Veselov A P 2005 J. Nonlinear Math. Phys. 12 179
- [48] Guha P and Ghose Choudhury A 2013 Rev. Math. Phys. 25 1330009
- [49] Thirulogasanthar K and Saad N 2004 J. Phys. A: Math. Gen. 37 4567
- [50] Abramovitz M and Stegun I A 1965 Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables (New York: Dover Publications)
- [51] Znojil M, Cannata F, Bagchi B and Roychoudhury R 2000 Phys. Lett. B 483 284
- [52] Alexandre J, Ellis J and Millington P 2020 Phys. Rev. D 101 085015
- [53] Bagarello F 2020 Math. Phys. Anal. Geom. 23 28
- [54] Znojil M 2020 Symmetry 12 892
- [55] Casahorr´n J 1995 a Physica A 217 429 | 10.1088/1742-6596/2986/1/012004 | [
"Aritra Ghosh",
"Akash Sinha"
]
| 2024-08-02T17:15:17+00:00 | 2025-01-16T21:08:52+00:00 | [
"quant-ph",
"math-ph",
"math.MP"
]
| Pseudo-Hermitian extensions of the harmonic and isotonic oscillators | In this work, we describe certain pseudo-Hermitian extensions of the harmonic
and isotonic oscillators, both of which are exactly-solvable models in quantum
mechanics. By coupling the dynamics of a particle moving in a one-dimensional
potential to an imaginary-valued gauge field, it is possible to obtain certain
pseudo-Hermitian extensions of the original (Hermitian) problem. In particular,
it is pointed out that the Swanson oscillator arises as such an extension of
the quantum harmonic oscillator. For the pseudo-Hermitian extensions of the
harmonic and isotonic oscillators, we explicitly solve for the wavefunctions in
the position representation and also explore their intertwining relations. |
2408.01399v2 | ## Cluster production and the chemical freeze-out in expanding hot dense matter
D. Blaschke a,b,c , S. Liebing d , G. R¨ opke e,a , B. D¨ onigus f
- a Institute of Theoretical Physics University of Wroclaw Max Born pl. 9 50-204 Wroclaw Poland b Center for Advanced Systems Understanding (CASUS) D-02826 Grlitz Germany c Helmholtz-Zentrum Dresden-Rossendorf D-01328 Dresden Germany d TU Bergakademie Freiberg Institute of Theoretical Physics Leipziger Str. 23 09599 Freiberg Germany e University of Rostock Albert-Einstein-Str. 23-24 18051 Rostock Germany f Institut fr Kernphysik Goethe-Universitt Frankfurt Max-von-Laue-Str. 1 60438 Frankfurt Germany
## Abstract
We discuss medium effects on light cluster production in the QCD phase diagram by relating Mott transition lines to those for chemical freeze-out. In heavy-ion collisions at highest energies provided by the LHC, light cluster abundances should follow the statistical model because of low baryon densities. Chemical freeze-out in this domain is correlated with the QCD crossover transition. At low energies, in the nuclear fragmentation region, where the freeze-out interferes with the liquid-gas phase transition, self-energy and Pauli blocking effects are important. We demonstrate that at intermediate energies the chemical freeze-out line correlates with the maximum mass fraction of nuclear bound states, in particular α particles. In this domain, the HADES, FAIR and NICA experiments can give new insights.
Keywords: light clusters, Mott transition, Beth-Uhlenbeck, chemical freeze-out, heavy-ion collisions
## 1. Introduction
A characteristic result of heavy-ion collisions (HIC) are the yields of the observed clusters. Already from the first measurements of the yields of isotopes ( n , p , 2 H, 3 H, 3 He, 4 He ( α ), etc.) in relativistic heavy-ion collisions at Bevalac energies [1, 2, 3] it was a surprising result that these distributions of
the yields are similar to the mass action law known from chemical equilibrium of a gas of reacting components, which is given by a temperature T and a chemical potential µ for the baryon number of the elementary constituents. The so-called statistical model assumes that in HIC hot and dense matter (fireball) is produced where the interaction within this dense system is strong so that the relaxation time to establish equilibrium is very short [4]. We can assume local thermodynamic equilibrium at this stage.
This hot and dense matter expands, and the reaction rates become small so that chemical equilibrium is no longer established. At the time t cf the chemical composition freezes out. The temperature T cf and chemical potential µ cf are parameter values which determine in this picture the primordial distributions that evolve after freeze-out to the observed yields. It was also surprising that with the advent of ultrarelativistic HIC at CERN and Brookhaven National Laboratory the description of the yields of hadrons as well as light nuclei within the statistical model with just two parameters ( T cf , µ cf ) for the chemical freeze-out worked remarkably well [4, 5, 6]. For the evolution of these sets of freeze-out parameters as a function of the center of mass energy of the collision, fit formulas for the behaviour of T cf ( µ ) have been parametrized, e.g., by Cleymans et al. [7], Vovchenko et al. [8], Andronic et al. [4] and Poberezhniuk et al. [9].
This simple approach has to be replaced by a more fundamental approach to nonequilibrium processes. A discussion has been performed whether chemical freeze-out could be understood analogously to kinetic freeze-out as a reaction-kinetic process, when chemical reaction rates equal the expansion rate of the fireball, see [10] and references therein. A sufficiently strong medium dependence of the chemical reaction rates at the hadronization transition has been obtained in [11, 12] by assuming a geometrical hadron-hadron cross section [13] with medium dependent hadron radii that get strongly enlarged at the Mott dissociation transition, as demonstrated in the NambuJona-Lasinio model for case of the pion at finite temperature [14]. Along these lines of argument, the chemical freeze-out of hadrons from the quarkgluon plasma can be understood due to the dramatic localization of the hadronic wave functions triggered by the chiral symmetry breaking transition that leads to the binding of quarks in hadrons (reverse Mott dissociation of hadrons).
The task of understanding the evolution of particle distributions towards chemical freeze-out can be solved using the method of nonequilibrium statistical operator (NSO) as outlined in the following section. In addition, the
use of the local thermodynamic equilibrium to describe the system at freezeout allows to account for correlations in the system, i.e. bound states and continuum correlations. The treatment of these correlations is the main issue of the present work.
An alternative approach to describe the nonequilibrium evolution of the expanding fireball are transport equations [15], where cluster production is addressed by quantum molecular dynamics [16] or kinetic approaches [17]. These kinetic equations describe the time evolution of the single-particle distribution function. However, it is difficult to include the formation of correlations and bound states in a systematic way. In principle, the method of the nonequilibrium statistical operator is able to give a systematic approach, but this has been performed until now only in first steps [18, 19, 20, 21].
In this work we start from a general approach to nonequilibrium which includes both the hydrodynamic approach and the kinetic approach. The freeze-out concept is connected with a quick change in the relevant parameters, for instance the change of density during a phase transition. New observables become relevant such as the distribution function of elementary particles and clusters. The chemical evolution has to be described by a reaction network, and one has to consider the feed-down by the decay of excited states which transform the primordial equilibrium distribution at freeze-out to the final distribution of yields as observed in the experiments.
As a main result, in addition to the hadronization phase transition at high temperatures (156 MeV [4, 22]) and the nuclear matter phase transition below the critical temperature 1 of about T liquid -gas ∼ 12 1 MeV [23], . we consider the formation of nuclear bound states (clusters) with mass number A and proton number Z at the Mott density n Mott A,Z ( T ) as a relevant process which determines the freeze-out in the range between the high- and low-temperature phase transitions. A comparison with empirical values for T cf is made. While the chemical potential µ cf ( T ) at freeze out is well described, the baryon number density n T, µ ( cf ( T )) is more involved and its evaluation requires the account of bound state formation including in-medium effects.
1 There are different results for the critical point of the n.m. phase transitions. Meanfield approximations for the equation of state give higher values for the critical temperature in the range of 14 MeV to 18 MeV [23].
## 2. The method of nonequilibrium statistical operator
Using the method of the nonequilibrium statistical operator (NSO) [24], a nonequilibrium process is described by the statistical operator ρ t ( ),
$$\rho ( t ) = \lim _ { \epsilon \to 0 } \epsilon \int _ { - \infty } ^ { t } d t ^ { \prime } e ^ { - \epsilon ( t - t ^ { \prime } ) } e ^ { - \frac { i } { h } H ( t - t ^ { \prime } ) } \rho _ { \text{rel} } ( t ^ { \prime } ) e ^ { \frac { i } { h } H ( t - t ^ { \prime } ) }$$
which is a solution of the von Neumann equation with boundary conditions ⟨ B i ⟩ t ′ , t ′ ≤ t , characterizing the state of the system in the past. This information is contained in the relevant statistical operator ρ rel ( t ′ ) which is constructed from the maximum of information entropy at given averages of relevant observables B i . We introduce Lagrange multipliers λ i ( t ′ ) and obtain a generalized Gibbs distribution for ρ rel ( t ′ ). The elimination of the Lagrange multipliers by the boundary conditions leads to the nonequilibrium generalization of the equations of state.
For instance, in nuclear matter a set of relevant observables are the energy H as well as the particle numbers N ,N n p of neutrons and protons, respectively, which are conserved quantities when weak processes are not considered. The solution for the maximum entropy is the generalized Gibbs distribution ρ rel ( t ′ ) ∝ exp[ -( H -λ n ( t ′ ) N n -λ p ( t ′ ) N /λ p ) T ( t ′ )]. These Lagrange multipliers λ i ( t ′ ) (which are in general time dependent and for the hydrodynamical approach also depending on position), are not identical with the equilibrium parameters T and µ τ , τ = n, p , but may be considered as nonequilibrium generalizations of temperature and chemical potentials.
The NSO allows the possibility of including other observables if they become relevant for the characterization of the nonequilibrium state. To derive kinetic equations, the occupation numbers of the quasiparticle states should be included into the set of relevant observables B i to obtain fast convergence in calculating reaction rates [24]. Then, further Lagrange parameters appear in the generalized Gibbs distribution such as parameters related to the single particle distribution function. If we consider only single-particle operators in ρ rel ( t ′ ), in the standard lowest approximations no quantum correlations and bound states are described. This long-standing problem of transport models using kinetic equations can be solved by the NSO method including few-particle correlations into the set of relevant observables [18, 19, 20]. It is supposed that the NSO does not depend on the choice of the set of relevant observables { B i } if the limit ϵ → 0 is correctly performed. An exception are
conserved quantities which must be included in the set of relevant observables. All other correlations in the system are produced dynamically.
In this work, we are dealing with the elimination of the Lagrange parameters λ n ( t ′ ) , λ p ( t ′ ). This is the nonequilibrium version of the EOS n τ ( T, µ τ ′ ) which relates the chemical potentials µ , µ n p to the densities n , n n p . Because the generalized Gibbs distribution is of exponential form, quantum statistical methods can be used to calculate correlation functions, in particular the single-particle spectral function. We perform a cluster expansion of the self-energy for the interacting system [25], and partial densities of different clusters { A, Z } are introduced. The relevant yields Y rel AZ are calculated as
$$Y _ { A Z } ^ { \text{rel} } \in R _ { A Z } ( \lambda _ { T } ) \left ( \frac { 2 \pi \hbar { ^ { 2 } } } { A m \lambda _ { T } } \right ) ^ { - 3 / 2 } e ^ { ( B _ { A Z } + ( A - Z ) \lambda _ { n } + Z \lambda _ { p } ) / \lambda _ { T } },$$
where B AZ denotes the (ground state) binding energy and g AZ the degeneracy, m is the nucleon mass. The prefactor R AZ ( λ T ) = g AZ + ∑ exc i g AZi e -E AZi /λ T is related to the intrinsic partition function of the cluster { A, Z } . The summation is performed over all excited states, excitation energy E AZi and degeneracy g AZi . To obtain the virial form, the continuum contributions have to be included. For instance, the Beth-Uhlenbeck formula expresses the contribution of the continuum to the intrinsic partition function via the scattering phase shifts, see [26]. The simple nuclear statistical equilibrium (NSE) distribution is obtained for R AZ = g AZ , i.e., neglecting the contribution of all excited states and continuum correlations.
We have outlined the connection to the theory of nonequilibrium statistics in order to show that the use of a (local) thermodynamic equilibrium is not misleading but is, in the formulation with a relevant statistical operator, an important ingredient to describe the nonequilibrium process. The correct implementation of the quasi-equilibrium distribution as relevant statistical operator into the nonequilibrium statistical operator (1) enables us to treat correlations in a systematic way, for instance using quantum statistical methods and diagram techniques. A particular issue is the few-particle in-medium Schroedinger equation [27] which contains the self-energy shifts of the nucleons as well as the Pauli blocking for the interaction. From this, a generalized Beth-Uhlenbeck formula can be derived [26]. A consequence is the lowering of the binding energy B AZ ( T, n ) with increasing density. Due to Pauli blocking, bound states are dissolved at a critical value of density that we denote as Mott density n Mott A,Z ( T, P ) [27], which depends on T but also on the c.m. momentum P of the cluster.
## 3. Freeze-out temperature as function of the baryonic chemical potential
Simple empirical approaches such as the NSE have been used to infer a temperature T cf and a chemical potential µ cf (we fix the total proton fraction Y p = n / n p ( p + n n ) so that the baryonic chemical potential µ = (1 -Y p ) µ n + Y µ p p is sufficient). Already in this simple approximation, it is an amazing fact that particle production from heavy-ion collisions can be interpreted by freeze-out models which consider a nuclear statistical equilibrium with only these two parameters . Within a more sophisticated approach the feed-down 2 and in-medium effects have to be taken into account. This improves the reproduction of the observed yields within the freeze-out approach as shown, for instance, for the LHC range [4, 28], for HIC in the Fermi-energy range [29, 30], or at fission [31]. Nevertheless, it is amazing that the global form of the distribution of observed yields is already nicely described within simple model calculations as employed in this Section.
Here we consider the fitted freeze-out parameters derived from the observed yields, as found in the literature. Depending on the collision energy ( s NN ), values for the pairs T cf , µ cf are inferred that define a region in the T -µ plane.
The beam energy scan (BES) programs of HIC provide insights into the systematics of particle production under varying conditions of temperature and density of the evolving hadronic fireball created in these experiments. The yields of hadrons and nuclei are analyzed using the thermal statistical model of hadron production. It is a remarkable fact that the statistical model makes excellent reproduction of particle yields with just two free parameters: the temperature T cf and the baryon chemical potential µ cf if we neglect the dependence on the asymmetry parameter Y p [4], which is the proton fraction. In the thermal model fits it is usually determined through the charge-tobaryon-number ratio ( Q/B ) of the initially collided nuclei. As discussed below, the dependence on Y p near Y p = 0 5 is weak. .
A statistical model analysis of various experiments at different facilities (LBNL, GSI LINAC & SIS, BNL AGS, CERN SPS, BNL RHIC, CERN LHC) and different collision energies (few MeV to 5 TeV), has been performed in
2 The volume V , that is generally needed, is typically determined by the most abundant particle or eliminated when ratios of particle yields are fitted. At the highest energies (LHC) for instance the most abundant particles are pions.
a series of works. A prominent one being [7], followed by similar analyses incorporating the ever-growing set of experimental data from facilities running experiments such as HADES, E871, NA49/NA61, STAR, ALICE and others.
Experiments at highest energies [4] from LHC give T cf =(156 5 . ± 1 5) MeV . which coincides with the pseudocritical temperature of the chiral crossover T c =(156 5 . ± 1 5) MeV obtained from lattice QCD simulations at zero baryon . chemical potential µ =0 [32]. Other experiments at lower energies give lower temperatures at increasing chemical potentials, in accordance with lattice simulations up to µ ≈ 300 MeV [33]. Values down to T cf =48 3MeV are ob-. tained from data for HIC at E lab =0 8AGeV, also shown in Fig. 1. On the . other hand, HIC experiments at low laboratory energies of E lab =35AMeV[34] were analysed in the quantum statistical freeze-out scheme in [35, 29, 36], and freeze-out temperatures in the range 4 MeV < T cf < 10 MeV were reported. A similar experiment has been performed at GANIL [30]. The corresponding chemical potentials are also shown in Fig. 1. These parameter values are related to the nuclear matter phase transition, starting with µ =922 8MeV at . T =0 and ending with the critical point at T liquid -gas = 12 1 MeV, . µ liquid -gas = 915 61 MeV [23]. .
In Fig. 1, for the freeze-out temperature T cf as function of the chemical potential the relation
$$T _ { c f } ( \mu ) \left [ \text{MeV} \right ] = 1 5 6. 5 - 7 6. 6 8 \ ( \mu \left [ \text{GeV} \right ] ) ^ { 2 } - 1 3 9. 7 \ ( \mu \left [ \text{GeV} \right ] ) ^ { 4 } \quad \ \ ( 3 )$$
is shown which interpolates between both limits. The first two coefficients are determined by the lattice calculations, whereas the third coefficient is chosen such that the critical point for the nuclear matter phase transition is met. This interpolation formula is similar to the relation proposed by Cleymans et al. [7]. A more recent parametrization was obtained by Vovchenko et al. [8] including new data. A slightly different expression was given recently in Ref. [9] which is obtained within a quantum van der Waals hadron resonance gas (QvdW-HRG) model.
In this contribution, we would like to focus on the region between these two extremes, where the transition from baryon stopping to nuclear transparency takes place and the highest baryon densities at freeze-out are reached. It is the region of c.m.s. energies of the future NICA facility [37], √ s NN =2GeV to 11 GeV, which was partly addressed already by AGS and CERN-SPS experiments as well as the RHIC BES I program and the recent HADES ex-
periment at GSI. Besides the MPD and BM@N experiments at NICA it will be covered in future by the low-energy RHIC and the RHIC fixed target programs as well as the FAIR CBM experiment. It has been suggested in [38] that both regions, highest and lowest T , should be joined, and that new experiments can help to investigate the entire temperature range.
Figure 1: Chemical freeze-out temperature T cf as function of the baryonic chemical potential µ . The parametrization from Eq. (3) is depicted as solid blue line. The liquidgas nuclear matter phase transition is also shown (magenta line) ending at the critical point (magenta star), obtained from a quantum statistical approach [23] (a). The yellow lattice QCD band (b) is from Ref. [39]. The red data points shown are from ideal hadron resonance gas (HRG) fits to measurements at different collision energies (ALICE [40, 41, 42, 43], NA49 [44, 45, 46, 47, 48, 49, 50, 51, 52], E802/E866 [53, 54, 55, 56], HADES [57], GSI/SIS [58, 59]), see the text for references. Additionally, the fits from Ref. [9] are shown in open symbols (d), where also a parametrization is given for the freeze-out curve if the quantum van der Waals hadron resonance gas is used [9] (c), shown as dashed blue line. Furthermore, results from measurements of the low-energy heavy-ion collisions are shown [35] (e). The cyan line shows the Mott line for α clusters at thermally averaged momentum, see Fig. 2 and Fig. 3.
We introduced the relation Eq. (3) as an interpolation between high and low T regions. We see that experimental data fit nicely this plot. In the
following Section we discuss the cluster formation in matter which could explain the course of the freeze-out line.
## 4. Freeze-out in the density-temperature diagram and Mott lines
For given T, µ, Y p , the calculation of the baryon number density (EoS) and the composition of interacting nucleonic matter is an intricate problem. We need a microscopic approach to understand the processes of cluster formation. In particular, the in-medium effects are determined by densities and the composition which must be calculated self-consistently.
When analysing the particle yields from HIC, often a simple model of nuclear statistical equilibrium (NSE) is used to extract the freeze-out values T cf , µ cf . It became evident that this is not sufficient because the densities are high so that medium effects have to be considered [29]. Self-energy effects are treated in different approximations, one of them is the RMF-DD2 approximation used in our calculations [23]. Crucial for the yields of light clusters is the Pauli blocking which leads to the suppression of cluster formation at high densities [27]. Quantum statistical calculations were performed [38], but simple approximations are given by the model of excluded volume [60], for a detailed description see Ref. [23].
Considering the freeze-out line in the T -µ plane, we have three different regions: (i) nuclear matter at temperatures up to 40 MeV where nuclear clusters contribute about 50 % to the baryon density and resonances are of minor importance, (ii) the region 40 MeV to 130 MeV where clusters dissociate and resonances are of relevance, and (iii) above the temperature 130 MeV of the maximal baryon density at freeze-out, where we have pion-dominated matter with negligible net baryon density.
We start with the ideal hadron resonance gas which considers in addition to the nucleons n, p also all mesons up to the mass of K ∗ 4 (2045) and baryons up to Ω -as they are listed, together with their degeneracy, in the Review of Particle Physics [61], according to the choice of Albright, Kapusta and Young[62] which has also been made by Begun, Gazdzicki and Gorenstein [63]. We used the hybrid EOS from Ref. [64, 65] and calculated the baryon number density (baryon density minus antibaryon density) for freeze-out conditions, Eq. (3). This calculation takes excluded volume effects into account. The result for n T, µ ( ) for T = T cf ( µ ) according to Eq. (3) is shown in Fig. 2
(green dashed line) . 3 A baryon radius of r B =0 365fm according to Vitiuk . et al. [5] is chosen to determine the excluded volume. We obtain a maximum freeze-out density 0 144 fm . -3 . Similar values for the maximum freeze-out density were discussed in Refs. [66, 9]. The ideal hadron resonance gas is not appropriate at high densities because it neglects in-medium effects. (For the ideal HRG, a maximum freeze-out density 0 175 fm . -3 is obtained at T =130MeV, to be compared with the maximum value 0 225 fm . -3 given in Ref. [9].)
Figure 2: Chemical freeze out lines for the hadron resonance gas (HRG) without and with (HRG-QC) quantum correlations in the temperature density plane (phase diagram) for the relation (3). The coexistence region for the nuclear liquid-gas transition (black solid line) is shown together with its critical endpoint (asterisk). Lines of constant α -particle mass fraction X α are shown as labelled solid lines. The maxima of the α fraction at given temperatures X max α ( T ) lie close to the Mott line for α clusters at thermally averaged momentum (dash-dotted line), see also Fig. 3. The asymmetry Y p =0 4 is taken. .
Our new result is the density n T, µ ( ) for T cf ( µ ) (HRG-QC, red line) which takes quantum correlations within the nucleon subsystem into account. To
3 We tested the dependence on the Q/B ratio (0 4 vs. . 0 5) and see no strong dependence, . see Fig. 3 below.
this end, we use a quantum statistical approach to the neutron-proton system [23] which contains in addition to the self-energies, calculated in RMF-DD2 approximation, also the formation of light nuclei ( H, 2 3 H, 3 He, 4 He). We calculate the in-medium shifts of the binding energies, in particular the Pauli blocking shifts, so that the bound states disappear with increasing density due to the so-called Mott effect. All components of the non-ideal HRG except neutrons and protons are treated according to the approach described above. These contributions are added to the results of the quantum statistical approach to the neutron-proton system. Above T = 90 MeV the density of clusters becomes very low, and the non-ideal HRG remains as a good approximation.
However, there is a large discrepancy between the HRG and the HRGQC result in Fig. 2, in particular at temperatures below 80 MeV when cluster formation is not taken into account. For instance, in [9] it was found that at the lowest considered energy of √ s NN =1 9GeV freeze-out in both models, . the ideal and the quantum van der Waals hadron resonance gas, takes place at baryon density of n =2 17 . × 10 -4 fm -3 . HIC experiments performed at low energies [29] obtained fragments at temperatures of about 10 MeV and values for the freeze-out density in the range of 0 03 fm . -3 . The formation of correlations and bound states has to be treated correctly in the region of low temperatures and high baryon densities, using a quantum statistical approach.
Calculating the contributions of light clusters to the density n T ( cf , µ ), an important in-medium effect is Pauli blocking which gives a reduction of the binding energy. This shift depends on T, n , n p n , but also on the c.m. momentum P . Values and parametrisations are found in [25], see also [23]. In particular it determines the so-called Mott density where the bound state is dissolved. To show the region in the phase diagram where bound states are formed, we focus on the α particles which are well bound clusters. Contour lines for the mass fraction X α = 4 n /n α of α particles which depend on T, n, Y p are shown in Fig. 2.
In logarithmic representation, Fig. 3, the banana-like region of α cluster formation is shown in comparison with the Mott line which describes the site in the phase diagram where the bound state disappears. Such diagrams were first presented in [27] ( α -particle association degree), and a Mott line was shown which characterizes the dissolution of the α -particles due to Pauli blocking. Since the Pauli blocking shift strongly depends on the c.m. momentum P , we show the Mott line for the dissolution of α -particles at thermally
averaged momentum-squared P 2 = (3 2) / m T α [67, 68], with m α = 4 m N . It is close to the line X max α ( T ) where at given T the mass fraction of α particles takes its maximum value.
The Mott line for the dissolution of α -particles at thermally averaged momentum is also shown in Fig. 2. In the temperature range from 30 MeV to 130 MeV it can be well described by a linear fit formula
$$T _ { \text{Mott}, \alpha } ( n ) [ \text{MeV} ] = 2. 6 + 7 3 1. 9 \ n [ \text{fm} ^ { - 3 } ] \.$$
The close neighborhood of the Mott line T Mott ,α ( n ) with the chemical freeze-out line (HRG-QC) below T ≈ 130 MeV is an interesting result of our work. It indicates that the chemical freeze-out process in expanding matter may be related to the formation of bound states. The Mott effect which describes the ability to form bound states can be considered as a strong change of the intrinsic structure of nuclear matter where the relaxation to chemical equilibrium is suppressed. We suggest to consider the bound state formation at the Mott line as a prerequisite for chemical freeze-out since it entails a sudden change in the microscopic state of the system.
To show the dependence of the asymmetry Y p , in Fig. 3 results for the asymmetry Y p =0 5 (star, . for X α =0 003) are . presented. The effect of asymmetry is small. Below T =10MeV the calculation with only four species of light nuclei is not sufficient because larger nuclei will occur. In addition, the region of the liquid-gas phase transition is reached there.
## 5. Conclusions
We justified the use of quasi-equilibrium information to describe the nonequilibrium expansion of the hot fireball produced in HIC. The freeze-out concept is related to fast processes which change the chemical composition of the hot and dense matter. We propose that the formation of bound states with decreasing density and/or temperature can be considered as the microscopic process responsible for the freeze-out phenomenon. The freeze-out parameters for this formation process coincide with those of the reverse process describing the bound state dissociation (Mott effect).
Our aim is to connect different asymptotic regions where the freeze-out concepts are used to explain the observed yields: heavy-ion collisions at ultrarelativistic energies [4] and collision [29] as well as fission [31] processes at low energies. After a first attempt for a unified description [38], a more detailed approach was given in [9] but without describing nucleonic correlations
Figure 3: Contour lines for mass fractions of α clusters (logarithmic baryon density scale) at proton fraction Y p =0 4. In addition, the Mott line at thermally averaged momentum . (see text) and mass fraction maximum X max α ( T ) at given temperature line are shown. The red stars indicate a calculation for the case of symmetric matter, Y p =0 5, and a mass . fraction of 0.003.
and cluster formation in the low-temperature region of hadronic matter. We present a quantum statistical approach which describes formation of bound states and their dissolution due to Pauli blocking.
Simple statistical models used to extract the freeze-out parameters are working well in the limiting cases of high temperatures [4, 28] and in the low-temperature, dilute matter region [29, 31]. In the intermediate range of temperatures and densities, the application of simple statistical models is problematic because in-medium effects become important. The method of the nonequilibrium statistical operator allows a systematic inclusion of many-particle effects.
The use of the freeze-out concept remains an important ingredient to understand the observed yields of particles produced in the expanding hot and dense matter of an ultrarelativistic heavy-ion collision. We propose in this work a new chemical freeze-out line in the temperature-density plane, connecting low and high temperature regime. We find that this new freeze-
out line in the intermediate region of temperatures 20 ≲ T [MeV] ≲ 120 is well-correlated with the maximum of the α cluster fraction at a given temperature. We also show that the Mott-line for α particles evaluated at their thermally averaged momentum is a good approximation for the chemical freeze-out line in this intermediate temperature-density range. While this chemical freeze-out line is well defined in the T -µ plane, see Eq. (3), its trajectory in the temperature-density diagram is sensitive to the treatment of interparticle correlations like Pauli blocking or excluded volume effects. Our result Eq. (4), which represents the thermally averaged Mott-line for α particles in the range 30 ≤ T [MeV] ≤ 130, can be considered as a good approximation for the chemical freeze-out line in the temperature-density diagram.
We expect that future experiments like NICA, FAIR, CERN-SPS, RHICBES and others will provide new data on particle production in the intermediate temperature region we have considered in this work. The results of the present work have shown that medium effects on correlations will play an important role in the interpretation of these experiments within a freeze-out picture. We conclude that medium effects, being often small corrections, can be essential in the intermediate temperature range.
## Acknowledgments
D.B. was supported by NCN under grant No. 2021/43/P/ST2/03319. G.R. acknowledges a honorary stipend from the Foundation for Polish Science within the Alexander von Humboldt programme under grant No. DPN/JJL/4024773/2022. B.D. acknowledges the support from Bundesministerium f¨r Bilu dung und Forschung through ErUM-FSP T01 (F¨rderkennzeichen 05P21RFCA1). o
## References
- [1] H. H. Gutbrod, A. Sandoval, P. J. Johansen, A. M. Poskanzer, J. Gosset, W. G. Meyer, G. D. Westfall, R. Stock, Final State Interactions in the Production of Hydrogen and Helium Isotopes by Relativistic Heavy Ions on Uranium, Phys. Rev. Lett. 37 (1976) 667-670. doi:10.1103/ PhysRevLett.37.667 .
- [2] J. Gosset, H. H. Gutbrod, W. G. Meyer, A. M. Poskanzer, A. Sandoval, R. Stock, G. D. Westfall, Central Collisions of Relativistic Heavy Ions, Phys. Rev. C 16 (1977) 629-657. doi:10.1103/PhysRevC.16.629 .
- [3] G. D. Westfall, J. Gosset, P. J. Johansen, A. M. Poskanzer, W. G. Meyer, H. H. Gutbrod, A. Sandoval, R. Stock, Nuclear Fireball Model for Proton Inclusive Spectra from Relativistic Heavy Ion Collisions, Phys. Rev. Lett. 37 (1976) 1202-1205. doi:10.1103/PhysRevLett.37.1202 .
- [4] A. Andronic, P. Braun-Munzinger, K. Redlich, J. Stachel, Decoding the phase structure of QCD via particle production at high energy, Nature 561 (7723) (2018) 321-330. arXiv:1710.09425 , doi:10.1038/ s41586-018-0491-6 .
- [5] O. V. Vitiuk, K. A. Bugaev, E. S. Zherebtsova, D. B. Blaschke, L. V. Bravina, E. E. Zabrodin, G. M. Zinovjev, Resolving the hypertriton yield description puzzle in high energy nuclear collisions, Eur. Phys. J. A 57 (2) (2021) 74. arXiv:2007.07376 , doi:10.1140/epja/ s10050-021-00370-6 .
- [6] K. A. Bugaev, et al., Second virial coefficients of light nuclear clusters and their chemical freeze-out in nuclear collisions, Eur. Phys. J. A 56 (11) (2020) 293. arXiv:2005.01555 , doi:10.1140/epja/ s10050-020-00296-5 .
- [7] J. Cleymans, H. Oeschler, K. Redlich, S. Wheaton, Comparison of chemical freeze-out criteria in heavy-ion collisions, Phys. Rev. C 73 (2006) 034905. arXiv:hep-ph/0511094 , doi:10.1103/PhysRevC.73.034905 .
- [8] V. Vovchenko, V. V. Begun, M. I. Gorenstein, Hadron multiplicities and chemical freeze-out conditions in proton-proton and nucleus-nucleus collisions, Phys. Rev. C 93 (6) (2016) 064906. arXiv:1512.08025 , doi: 10.1103/PhysRevC.93.064906 .
- [9] R. Poberezhnyuk, V. Vovchenko, A. Motornenko, M. I. Gorenstein, H. Stoecker, Chemical freeze-out conditions and fluctuations of conserved charges in heavy-ion collisions within quantum van der Waals model, Phys. Rev. C 100 (5) (2019) 054904. arXiv:1906.01954 , doi:10.1103/PhysRevC.100.054904 .
- [10] U. W. Heinz, G. Kestin, Jozso's Legacy: Chemical and Kinetic Freezeout in Heavy-Ion Collisions, Eur. Phys. J. ST 155 (2008) 75-87. arXiv: 0709.3366 , doi:10.1140/epjst/e2008-00591-4 .
| [11] | D. Blaschke, J. Berdermann, J. Cleymans, K. Redlich, Chiral conden- sate and Mott-Anderson freeze-out, Few Body Syst. 53 (2012) 99-109. arXiv:1109.5391 , doi:10.1007/s00601-011-0261-6 . |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [12] | D. B. Blaschke, J. Berdermann, J. Cleymans, K. Redlich, Chiral conden- sate and chemical freeze-out, Phys. Part. Nucl. Lett. 8 (2011) 811-817. arXiv:1102.2908 , doi:10.1134/S154747711108005X . |
| [13] | B. Povh, J. H¨fner, u Geometric Interpretation of Hadron Proton Total Cross-sections and a Determination of Hadronic Radii, Phys. Rev. Lett. 58 (1987) 1612-1615. doi:10.1103/PhysRevLett.58.1612 . |
| [14] | H. J. Hippe, S. P. Klevansky, Nambu-Jona-Lasinio model compared with chiral perturbation theory: The Pion radius in SU(2) revisited, Phys. Rev. C 52 (1995) 2172-2184. doi:10.1103/PhysRevC.52.2172 . |
| [15] | H. Wolter, et al., Transport model comparison studies of intermediate- energy heavy-ion collisions, Prog. Part. Nucl. Phys. 125 (2022) 103962. arXiv:2202.06672 , doi:10.1016/j.ppnp.2022.103962 . |
| [16] | S. Gl¨ßel, a V. Kireyeu, V. Voronyuk, J. Aichelin, C. Blume, E. Bratkovskaya, G. Coci, V. Kolesnikov, M. Winn, Cluster and hy- percluster production in relativistic heavy-ion collisions within the parton-hadron-quantum-molecular-dynamics approach, Phys. Rev. C 105 (1) (2022) 014908. arXiv:2106.14839 , doi:10.1103/PhysRevC. 105.014908 . |
| [17] | V. Kireyeu, G. Coci, S. Gl¨ßel, a J. Aichelin, C. Blume, E. Bratkovskaya, Cluster formation near midrapidity: How the production mechanisms can be identified experimentally, Phys. Rev. C 109 (4) (2024) 044906. doi:10.1103/PhysRevC.109.044906 . |
| [18] | G. R¨pke, o H. Schulz, Including cluster formation into a Vlasov-Uehling- Uhlenbeck approach to intermediate energy heavy ion collisions, Nucl. Phys. A 477 (1988) 472-486. doi:10.1016/0375-9474(88)90352-1 . |
| [19] | P. Danielewicz, G. F. Bertsch, Production of deuterons and pions in a transport model of energetic heavy ion reactions, Nucl. Phys. A 533 (1991) 712-748. doi:10.1016/0375-9474(91)90541-D . |
| [20] | C. Kuhrts, M. Beyer, P. Danielewicz, G. R¨pke, o Medium corrections in the formation of light charged particles in heavy ion reactions, Phys. Rev. C 63 (2001) 034605. arXiv:nucl-th/0009037 , doi:10.1103/ PhysRevC.63.034605 . |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [21] | Y. Kanada-En'yo, M. Kimura, A. Ono, Antisymmetrized molecular dy- namics and its applications to cluster phenomena, PTEP 2012 (2012) 01A202. arXiv:1202.1864 , doi:10.1093/ptep/pts001 . |
| [22] | F. Gross, et al., 50 Years of Quantum Chromodynamics, Eur. Phys. J. C 83 (2023) 1125. arXiv:2212.11107 , doi:10.1140/epjc/ s10052-023-11949-2 . |
| [23] | S. Typel, G. R¨pke, o T. Kl¨hn, a D. Blaschke, H. H. Wolter, Composition and thermodynamics of nuclear matter with light clusters, Phys. Rev. C 81 (2010) 015803. arXiv:0908.2344 , doi:10.1103/PhysRevC.81. 015803 . |
| [24] | D. Zubarev, et al., Statistical Mechanics of Non-equilibrium Processes, Wiley, 1996. |
| [25] | G. R¨pke, o Nuclear matter equation of state including two-, three-, and four-nucleon correlations, Phys. Rev. C 92 (5) (2015) 054001. arXiv: 1411.4593 , doi:10.1103/PhysRevC.92.054001 . |
| [26] | M. Schmidt, G. R¨pke, o H. Schulz, Generalized Beth-Uhlenbeck approach for hot nuclear matter, Annals Phys. 202 (1) (1990) 57-99. doi:10. 1016/0003-4916(90)90340-T . |
| [27] | G. R¨pke, o M. Schmidt, L. M¨nchow, u H. Schulz, Particle clustering and Mott transition in nuclear matter at finite temperature (II), Nucl. Phys. A 399 (1983) 587-602. doi:10.1016/0375-9474(83)90265-8 . |
| [28] | B. D¨nigus, o G. R¨pke, o D. Blaschke, Deuteron yields from heavy-ion col- lisions at energies available at the CERN Large Hadron Collider: Con- tinuum correlations and in-medium effects, Phys. Rev. C 106 (4) (2022) 044908. arXiv:2206.10376 , doi:10.1103/PhysRevC.106.044908 . |
| [29] | L. Qin, et al., Laboratory Tests of Low Density Astrophysical Equations of State, Phys. Rev. Lett. 108 (2012) 172701. arXiv:1110.3345 , doi: 10.1103/PhysRevLett.108.172701 . |
| [30] | H. Pais, et al., Low-density in-medium effects on light clusters from heavy-ion data, Phys. Rev. Lett. 125 (1) (2020) 012701. arXiv:1911. 10849 , doi:10.1103/PhysRevLett.125.012701 . |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [31] | G. R¨pke, o J. B. Natowitz, H. Pais, Nonequilibrium information entropy approach to ternary fission of actinides, Phys. Rev. C 103 (6) (2021) 061601. arXiv:2012.14691 , doi:10.1103/PhysRevC.103.L061601 . |
| [32] | A. Bazavov, et al., Chiral crossover in QCD at zero and non-zero chemical potentials, Phys. Lett. B 795 (2019) 15. arXiv:1812.08235 , doi:10.1016/j.physletb.2019.05.013 . |
| [33] | S. Borsanyi, Z. Fodor, J. N. Guenther, R. Kara, S. D. Katz, P. Parotto, A. Pasztor, C. Ratti, K. K. Szabo, QCD Crossover at Finite Chemi- cal Potential from Lattice Simulations, Phys. Rev. Lett. 125 (5) (2020) 052001. arXiv:2002.02821 , doi:10.1103/PhysRevLett.125.052001 . |
| [34] | S. Kowalski, et al., Experimental determination of the symmetry energy of a low density nuclear gas, Phys. Rev. C 75 (2007) 014601. arXiv: nucl-ex/0602023 , doi:10.1103/PhysRevC.75.014601 . |
| [35] | J. B. Natowitz, et al., Symmetry energy of dilute warm nuclear matter, Phys. Rev. Lett. 104 (2010) 202501. arXiv:1001.1102 , doi:10.1103/ PhysRevLett.104.202501 . |
| [36] | K. Hagel, J. B. Natowitz, G. R¨pke, o The equation of state and symmetry energy of low density nuclear matter, Eur. Phys. J. A 50 (2014) 39. arXiv:1401.2074 , doi:10.1140/epja/i2014-14039-4 . |
| [37] | V. D. Kekelidze, R. Lednicky, V. A. Matveev, I. N. Meshkov, A. S. Sorin, G. V. Trubnikov, Three stages of the NICA accelerator complex, Eur. Phys. J. A 52 (8) (2016) 211. doi:10.1140/epja/i2016-16211-2 . |
| [38] | G. R¨pke, o D. Blaschke, Y. B. Ivanov, I. Karpenko, O. V. Rogachevsky, H. H. Wolter, Medium effects on freeze-out of light clusters at NICA energies, Phys. Part. Nucl. Lett. 15 (3) (2018) 225-229. arXiv:1712. 07645 , doi:10.1134/S1547477118030159 . |
| [39] | H. T. Ding, et al., Chiral Phase Transition Temperature in ( 2+1 )- Flavor QCD, Phys. Rev. Lett. 123 (6) (2019) 062002. arXiv:1903. 04801 , doi:10.1103/PhysRevLett.123.062002 . |
| [40] | B. Abelev, et al., Centrality dependence of π , K, p production in Pb- Pb collisions at √ s NN = 2.76 TeV, Phys. Rev. C 88 (2013) 044910. arXiv:1303.0737 , doi:10.1103/PhysRevC.88.044910 . |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [41] | B. B. Abelev, et al., K 0 S and Λ production in Pb-Pb collisions at √ s NN = 2.76 TeV, Phys. Rev. Lett. 111 (2013) 222301. arXiv:1307.5530 , doi:10.1103/PhysRevLett.111.222301 . |
| [42] | B. B. Abelev, et al., Multi-strange baryon production at mid-rapidity in Pb-Pb collisions at √ s NN = 2.76 TeV, Phys. Lett. B 728 (2014) 216- 227, [Erratum: Phys.Lett.B 734, 409-410 (2014)]. arXiv:1307.5543 , doi:10.1016/j.physletb.2014.05.052 . |
| [43] | B. B. Abelev, et al., K ∗ (892) 0 and ϕ (1020) production in Pb-Pb colli- sions at √ sNN = 2.76 TeV, Phys. Rev. C 91 (2015) 024609. arXiv: 1404.0495 , doi:10.1103/PhysRevC.91.024609 . |
| [44] | S. V. Afanasiev, et al., Energy dependence of pion and kaon production in central Pb + Pb collisions, Phys. Rev. C 66 (2002) 054902. arXiv: nucl-ex/0205002 , doi:10.1103/PhysRevC.66.054902 . |
| [45] | C. Alt, et al., Energy and centrality dependence of anti-p and p pro- duction and the anti-Lambda/anti-p ratio in Pb+Pb collisions be- tween 20/A-GeV and 158/A-Gev, Phys. Rev. C 73 (2006) 044910. doi:10.1103/PhysRevC.73.044910 . |
| [46] | C. Alt, et al., Energy dependence of Lambda and Xi production in central Pb+Pb collisions at A-20, A-30, A-40, A-80, and A-158 GeV measured at the CERN Super Proton Synchrotron, Phys. Rev. C 78 (2008) 034918. arXiv:0804.3770 , doi:10.1103/PhysRevC.78.034918 . |
| [47] | C. Alt, et al., Energy dependence of phi meson production in central Pb+Pb collisions at s(NN)**(1/2) = 6 to 17 GeV, Phys. Rev. C 78 (2008) 044907. arXiv:0806.1937 , doi:10.1103/PhysRevC.78.044907 . |
| [48] | C. Alt, et al., Omega- and anti-Omega+ production in central Pb + Pb collisions at 40-AGeV and 158-AGeV, Phys. Rev. Lett. 94 (2005) 192301. arXiv:nucl-ex/0409004 , doi:10.1103/PhysRevLett.94.192301 . |
| [49] | T. Anticic, et al., Antideuteron and deuteron production in mid-central Pb+Pb collisions at 158 A GeV, Phys. Rev. C 85 (2012) 044913. arXiv: 1111.2588 , doi:10.1103/PhysRevC.85.044913 . |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [50] | V. Friese, Production of strange resonances in C + C and Pb + Pb collisions at 158-A-GeV, Nucl. Phys. A 698 (2002) 487-490. doi:10. 1016/S0375-9474(01)01410-5 . |
| [51] | T. Anticic, et al., K ∗ (892) 0 and ¯ K ∗ (892) 0 production in central Pb+Pb, Si+Si, C+C and inelastic p+p collisions at 158 A ˜GeV, Phys. Rev. C 84 (2011) 064909. arXiv:1105.3109 , doi:10.1103/PhysRevC.84.064909 . |
| [52] | C. Alt, et al., Pion and kaon production in central Pb + Pb collisions at 20-A and 30-A-GeV: Evidence for the onset of deconfinement, Phys. Rev. C 77 (2008) 024903. arXiv:0710.0118 , doi:10.1103/PhysRevC. 77.024903 . |
| [53] | L. Ahle, et al., Simultaneous multiplicity and forward energy character- ization of particle spectra in Au + Au collisions at 11.6-A-GeV/c, Phys. Rev. C 59 (1999) 2173-2188. doi:10.1103/PhysRevC.59.2173 . |
| [54] | L. Ahle, et al., Proton and deuteron production in Au + Au reac- tions at 11.6/A-GeV/c, Phys. Rev. C 60 (1999) 064901. doi:10.1103/ PhysRevC.60.064901 . |
| [55] | L. Ahle, et al., Centrality dependence of kaon yields in Si + A and Au + Au collisions at the AGS, Phys. Rev. C 60 (1999) 044904. arXiv: nucl-ex/9903009 , doi:10.1103/PhysRevC.60.044904 . |
| [56] | F. Becattini, J. Cleymans, A. Keranen, E. Suhonen, K. Redlich, Features of particle multiplicities and strangeness production in central heavy ion collisions between 1.7A-GeV/c and 158A-GeV/c, Phys. Rev. C64 (2001) 024901. arXiv:hep-ph/0002267 , doi:10.1103/PhysRevC.64.024901 . |
| [57] | G. Agakishiev, et al., Statistical hadronization model analysis of hadron yields in p + Nb and Ar + KCl at SIS18 energies, Eur. Phys. J. A 52 (6) (2016) 178. arXiv:1512.07070 , doi:10.1140/epja/i2016-16178-x . |
| [58] | J. Cleymans, H. Oeschler, K. Redlich, Influence of impact parameter on thermal description of relativistic heavy ion collisions at (1-2) A- GeV, Phys. Rev. C 59 (1999) 1663. arXiv:nucl-th/9809027 , doi: 10.1103/PhysRevC.59.1663 . |
| [59] | R. Averbeck, R. Holzmann, V. Metag, R. S. Simon, Neutral pions and eta mesons as probes of the hadronic fireball in nucleus-nucleus collisions around 1-A-GeV, Phys. Rev. C 67 (2003) 024903. arXiv:nucl-ex/ 0012007 , doi:10.1103/PhysRevC.67.024903 . |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [60] | M. Hempel, J. Schaffner-Bielich, Statistical Model for a Complete Su- pernova Equation of State, Nucl. Phys. A 837 (2010) 210-254. arXiv: 0911.4073 , doi:10.1016/j.nuclphysa.2010.02.010 . |
| [61] | P. A. Zyla, et al., Review of Particle Physics, PTEP 2020 (8) (2020) 083C01. doi:10.1093/ptep/ptaa104 . |
| [62] | M. Albright, J. Kapusta, C. Young, Matching Excluded Volume Hadron Resonance Gas Models and Perturbative QCD to Lattice Calculations, Phys. Rev. C 90 (2) (2014) 024915. arXiv:1404.7540 , doi:10.1103/ PhysRevC.90.024915 . |
| [63] | V. Begun, W. Florkowski, Bose-Einstein condensation of pions in heavy- ion collisions at the CERN Large Hadron Collider (LHC) energies, Phys. Rev. C 91 (2015) 054909. arXiv:1503.04040 , doi:10.1103/PhysRevC. 91.054909 . |
| [64] | S. A. Mir, N. A. Rather, I. M. U. Din, S. Uddin, Hadron Production in Ultra-relativistic Nuclear Collisions and Finite Baryon-Size Effects, arxiv (12 2023). arXiv:2312.13079 . |
| [65] | M. Kahangirwe, I. Gonzalez, J. A. Mu˜oz, n C. Ratti, V. Vovchenko, Con- vergence properties of T ′ -Expansion Scheme: Hadron Resonance Gas and Cluster Expansion Model, arxiv (8 2024). arXiv:2408.04588 . |
| [66] | J. Randrup, J. Cleymans, Maximum freeze-out baryon density in nuclear collisions, Phys. Rev. C 74 (2006) 047901. arXiv:hep-ph/0607065 , doi:10.1103/PhysRevC.74.047901 . |
| [67] | H. Schulz, G. R¨pke, o K. K. Gudima, V. D. Toneev, The coalescence phenomenon and the Pauli quenching in high-energy heavy ion colli- sions, Phys. Lett. B 124 (1983) 458-460. doi:10.1016/0370-2693(83) 91550-2 . |
| [68] | G. R¨pke, o Parametrization of light nuclei quasiparticle energy shifts and composition of warm and dense nuclear matter, Nucl. Phys. A867 (2011) 66-80. arXiv:1101.4685 , doi:10.1016/j.nuclphysa.2011.07.010 . | | 10.1016/j.physletb.2024.139206 | [
"D. Blaschke",
"S. Liebing",
"G. Röpke",
"B. Dönigus"
]
| 2024-08-02T17:20:07+00:00 | 2024-08-22T16:03:55+00:00 | [
"nucl-th",
"hep-ph"
]
| Cluster production and the chemical freeze-out in expanding hot dense matter | We discuss medium effects on light cluster production in the QCD phase
diagram by relating Mott transition lines to those for chemical freeze-out. In
heavy-ion collisions at highest energies provided by the LHC, light cluster
abundances should follow the statistical model because of low baryon densities.
Chemical freeze-out in this domain is correlated with the QCD crossover
transition. At low energies, in the nuclear fragmentation region, where the
freeze-out interferes with the liquid-gas phase transition, self-energy and
Pauli blocking effects are important. We demonstrate that at intermediate
energies the chemical freeze-out line correlates with the maximum mass fraction
of nuclear bound states, in particular $\alpha$ particles. In this domain, the
HADES, FAIR and NICA experiments can give new insights. |
2408.01400v3 | ## Order Parameter Discovery for Quantum Many-Body Systems
Khadijeh
Nicola Mariella, 1, ∗ Tara Murphy, 1, 2, † Francesco Di Marcantonio, 3, ‡ Najafi, 4, § Sofia Vallecorsa, 5, ¶ Sergiy Zhuk, 1, ∗∗ and Enrique Rico 3, 5, 6, 7, ††
1 IBM Quantum, IBM Research Europe - Dublin
2 Cavendish Laboratory, University of Cambridge,
J.J. Thomson Avenue, Cambridge CB3 0HE, United Kingdom
3 Department of Physical Chemistry and EHU Quantum Center,
University of the Basque Country UPV/EHU, Box 644, 48080 Bilbao, Spain
4 IBM Quantum, IBM T. J. Watson Research Center, Yorktown Heights, New York 10598, USA
5 European Organization for Nuclear Research (CERN), Geneva 1211, Switzerland
6 Donostia International Physics Center, 20018 Donostia-San Sebasti´n, a Spain
7 IKERBASQUE, Basque Foundation for Science, Plaza Euskadi 5, 48009 Bilbao, Spain
Quantum phase transitions reveal deep insights into the behavior of many-body quantum systems, but identifying these transitions without well-defined order parameters remains a significant challenge. In this work, we introduce a novel approach to constructing phase diagrams using the vector field of the reduced fidelity susceptibility (RFS). This method maps quantum phases and formulates an optimization problem to discover observables corresponding to order parameters. We demonstrate the effectiveness of our approach by applying it to well-established models, including the Axial Next Nearest Neighbour Interaction (ANNNI) model, a cluster state model, and a chain of Rydberg atoms. By analyzing observable decompositions into eigen-projectors and finite-size scaling, our method successfully identifies order parameters and characterizes quantum phase transitions with high precision. Our results provide a powerful tool for exploring quantum phases in systems where conventional order parameters are not readily available.
## I. INTRODUCTION
Quantum phase transitions (QPTs) in many-body quantum systems pose considerable challenges for theoretical modeling and experimental observation. Unlike classical phase transitions, which are driven by thermal fluctuations, QPTs are induced by changes in external parameters like magnetic fields or pressure, resulting in alterations to the ground state properties of a system.
Various methods have been developed to detect and characterize classical and quantum phase transitions. Among these is Landau-Ginzburg theory [1], designed to describe phase transitions and critical phenomena using a field theory description. Its formalism extends Landau's mean-field theory by constructing a free energy functional and accounting for spatial variations of the order parameter . The latter reflects the broken symmetry of the low-temperature phase.
While the theory above effectively describes phase transitions, studying QPTs in finite-size systems requires more sophisticated tools. This need arises from the Kadanoff extended singularity theorem [2, 3], highlighting the relevance of non-analytic behavior in thermodynamic quantities near the critical point.
∗ [email protected]
† [email protected]
‡ [email protected]
§ [email protected]
¶ [email protected]
∗∗ [email protected]
†† [email protected]
Various methods such as the Renormalization Group (RG) [4, 5] and Finite-Size Scaling (FSS) theory [6] have been developed to study QPTs in finite-size systems. RG operates by systematically removing less relevant degrees of freedom, highlighting the scale-independent features of a system. Thus, it provides insights into phase transitions by analyzing how physical systems behave across various length scales. This method involves coarse-graining the system and tracking the flow of coupling constants, with critical points emerging as fixed points of this flow.
FSS also investigates how physical quantities vary with the system size close to the critical point, facilitating the extraction of critical exponents from finite systems. Yet another approach involves employing machine learning techniques to detect phase transitions by identifying critical points and transition regions [7-11].
A specialized tool for detecting and characterizing phase transitions is the quantum state fidelity [12]. This concept, first applied to phase transitions in 1967 through the Anderson orthogonality catastrophe [13], measures the overlap between quantum states as system parameters change. Fidelity susceptibility [14, 15], a key concept in quantum information theory and quantum many-body physics, quantifies how sensitive a quantum state is to perturbations. It is particularly useful for detecting and characterizing quantum phase transitions, as it reveals sharp changes or singularities in fidelity near a quantum critical point, without relying on a design of tailored order parameters.
In this paper, we extend the use of the fidelity susceptibility from previous studies (e.g. [14, 15]) and construct a vector field using a reduced fidelity susceptibility (RFS). We use the RFS for the qualitative classification of the
FIG. 1: Visualisation of the reduced fidelity susceptibility (RFS) uses. Here, we show that it can be used for both phase diagram construction of quantum systems and order parameter discovery.
different phases. As we will show, in the RFS vector field, sources appear as phase transitions, while sinks are representative of the ground states for the corresponding phases. In addition, we devise an optimization problem, which identifies observables representing order parameters from the RFS vector field. The order parameter discovery gives a quantitative description of the critical point. A schematic picture of our method can be seen in Figure 1.
We demonstrate the efficacy of the proposed method on detecting QPT for three different models: (i) axial next-nearest neighbor Ising (ANNNI) model [16, 17] (due to its phase diagram), (ii) the cluster Hamiltonian model (due to its non-local description), and (iii) a physically motivated example given by a Rydberg atomic quantum simulator. In all the above models the proposed approach allows us to capture intricate details, such as the structure of ANNNI's floating phase or the string order parameter in the cluster model. For (iii) we discover additional features that were not identified by prior studies: specifically, we observe ripple-like features at high values of the parameters swept, which might suggest the presence of a more complex phase, yet an open question previously discussed in [49, 51, 52].
In summary, our mathematical framework establishes the phases diagram and enables the discovery of the order parameters for a Hamiltonian model, facilitating the understanding of different phases. We stress that our method can provide efficient certification and verification processes for quantum simulations and phase transition detection [18] and circumvents the need for full tomography of the wave function, relying instead on reduced density matrix to capture the relevant characteristic thermodynamic information.
The outline of the paper is as follows. In Section II we outline the notation used in the paper and introduce the concept of fidelity and the RFS. This is followed by Section III, where we outline the mathematical framework, introduce the RFS vector field, and highlight its potential to be used to detect phase transitions. In Section IV, we highlight how the aforementioned mathematical framework can be used to determine an order parameter for a given quantum system. We showcase this in Section V by using the above framework to construct the phase diagram for the ANNNI model, the cluster Hamiltonian, and a one-dimensional Rydberg chain, and demonstrate the ability to discover new order parameters. We end with a discussion of applications of this framework in Section VI and potential use cases for future work.
## II. PRELIMINARY
We begin by defining the set of Hermitian matrices of order n , which is denoted by S n := { M ∈ C n × n | M = M † } . We denote the identity matrix of order n by I n and the i th canonical basis vector for the vector space C n by e i .
Next, we introduce the concept of fidelity. Fidelity measures the similarity between two quantum states and all its definitions embody the probability of distinguishing one quantum state from another.
Given mixed-states ρ, σ we define the Uhlmann-Jozsa fidelity [12] by 1
$$F ( \rho, \sigma ) \coloneqq \left ( \text{Tr} \left ( \sqrt { \rho ^ { \frac { 1 } { 2 } } \sigma \rho ^ { \frac { 1 } { 2 } } } \right ) \right ) ^ { 2 }, \text{ \quad \ \ } ( 1 )$$
1 Some literature defines the fidelity in (1) as the square root of our F (e.g. [19]).
which, for the remainder of the work, will be referred to as fidelity , unless otherwise specified. The latter definition of fidelity is not unique, indeed Jozsa [12] obtained an axiomatic definition for a family of such functions. However, the Uhlmann fidelity stands for its unique relation to the Bures distance
$$d _ { B } ^ { 2 } ( \rho, \sigma ) \coloneqq 2 \left ( 1 - \sqrt { F ( \rho, \sigma ) } \right ), \quad \quad ( 2 ) \quad \text{as } \text{$2$} \text{$\i$}$$
which is a quantification of the statistical distance between density matrices. A relevant result is the Uhlmann theorem [20], which expresses the fidelity in terms of the maximum overlap over all purifications of its arguments, that is
$$F ( \rho, \sigma ) = & \max _ { | \psi _ { \rho } \rangle } | \langle \psi _ { \rho } | \psi _ { \sigma } \rangle | ^ { 2 } \,, \quad \quad ( 3 ) \quad \text{del} \quad$$
where | ψ σ ⟩ and | ψ ρ ⟩ denote some purifications of σ and ρ , respectively.
Following our discussion on the fidelity, we next consider a generic many-body parametric Hamiltonian H λ ( ) = H 0 + λH I , with eigenvalue equation H λ ( ) | ψ k ( λ ) ⟩ = E k ( λ ) | ψ k ( λ ) ⟩ , where the index k = 0 identifies the ground state. For clarity, we may omit the dependence of the various objects from the parameter λ , when it does not result in ambiguity. In a perturbative approach w.r.t. a small parameter δ , the Taylor expansion for the fidelity reads
$$| \langle \psi _ { 0 } \left ( \lambda \right ) | \psi _ { 0 } \left ( \lambda + \delta \right ) \rangle | = 1 - \frac { 1 } { 2 } \mathcal { X } _ { F } ( \lambda ) \delta ^ { 2 } + O \left ( \delta ^ { 3 } \right ), \quad \left ( 4 \right ) \, \underset { \colon = \, \dots } { \text{items} }$$
with the leading term (second-order) revealing the fidelity susceptibility X F (susceptibility for short) [15]. We note that the first-order term vanishes since the fidelity reaches a maximum at δ = 0 for any λ . Informally, fidelity susceptibility quantifies how much the fidelity (or overlap) between two nearby states changes concerning a small change in a parameter (such as an external field or coupling strength) that defines the states. Let ρ 0 ( λ ) = | ψ 0 ( λ ) ⟩ ⟨ ψ 0 ( λ ) | be the density matrix for the ground state of H λ ( ). Two well-known formulations for the susceptibility 2 are given as;
$$\mathcal { X } _ { F } ( \lambda ) = - \, \frac { \partial ^ { 2 } \sqrt { F ( \rho _ { 0 } ( \lambda ), \rho _ { 0 } ( \lambda + \delta ) ) } } { \underbrace { \partial \delta ^ { 2 } } } \Big | _ { \delta = 0 } \, \quad \ ( 5 \tt a ) \quad \max _ { f ( \lambda, \cdot ) }$$
$$= & \lim _ { \delta \to 0 } - \frac { 2 \ln \sqrt { F ( \rho _ { 0 } ( \lambda ), \rho _ { 0 } ( \lambda + \delta ) ) } } { \delta ^ { 2 } }. \quad ( 5 b ) \quad \stackrel { J \, \partial } { ( 1 0 ) } \\ & \text{betv}$$
The expansion for the ground state of the perturbed Hermitian 3 H λ ( ) is given as;
̸
$$\left | \psi _ { 0 } \left ( \lambda + \delta \right ) \right \rangle \approx \left | \psi _ { 0 } \left ( \lambda \right ) \right \rangle + \delta \sum _ { k \neq 0 } \frac { K _ { k, 0 } } { E _ { k } - E _ { 0 } } \left | \psi _ { k } \left ( \lambda \right ) \right \rangle, \quad \left ( 6 \right )$$
2 The rightmost of (5a) is obtained by considering the Taylor expansion of ln(1 + x ) = x -x 2 2 + O x ( 3 ), with x = - X 1 2 F ( λ δ ) 2 + O δ ( 3 ) from (4).
3 This result is commonly known as the Rayleigh-Schr¨dinger pero turbation theory [21].
where K k, 0 := ⟨ ψ k ( λ ) | H I | ψ 0 ( λ ) ⟩ . This leads to another well-known formulation for the susceptibility
̸
$$\mathcal { X } _ { F } ( \lambda ) = \sum _ { k \neq 0 } \frac { \left | \left \langle \psi _ { k } \left ( \lambda \right ) \right | H _ { I } \left | \psi _ { 0 } \left ( \lambda \right ) \right \rangle \right | ^ { 2 } } { \left ( E _ { k } - E _ { 0 } \right ) ^ { 2 } } \geq 0. \quad ( 7 )$$
As noticed in [22], the latter, which depends solely on the spectrum, shows that the quantity X F is non-negative and diverges when the energy gap closes.
## III. PHASE DIAGRAM CONSTRUCTION
Building upon the previous section's exploration of fidelity susceptibility, we next introduce the reduced fidelity susceptibility (RFS) vector field concept. In doing so, we consider a general many-body Hamiltonian parameterized by the space X ⊆ R 2 , of which its decomposition in terms of base and driving components reads
$$H ( \lambda ) = & H _ { 0 } + \lambda _ { 1 } H _ { 1 } + \lambda _ { 2 } H _ { 2 }, \text{ \quad \ \ } ( 8 )$$
with control parameters ( λ 1 λ 2 ) ⊤ ∈ X . We anticipate that choosing the two-dimensional parameters space is convenient for the visual approach, but not fundamental. Let | ψ 0 ( λ ) ⟩ ∈ H denote the ground state of the Hamiltonian H evaluated at λ ∈ X , with H denoting the underlying Hilbert space. The Hilbert space H is assumed bipartite, that is H = H ⊗H A B , for some subsystems A and B . In addition, we assume the ground state is non-degenerate. Let ρ 0 ( λ ) denote the reduced density matrix (RDM) resulting from tracing out the subsystem B for the ground state, so
$$\rho _ { 0 } ( \boldsymbol \lambda ) = \text{Tr} _ { B } \left ( \left | \psi _ { 0 } \left ( \boldsymbol \lambda \right ) \right \rangle \left \langle \psi _ { 0 } \left ( \boldsymbol \lambda \right ) \right | \right ). \quad \quad \left ( 9 \right )$$
We consider a perturbative action in the parameter space and define
$$f ( \lambda, \delta ) = & \sqrt { F \left ( \rho _ { 0 } ( \lambda ), \rho _ { 0 } ( \lambda + \delta ) \right ) } \in [ 0, 1 ], \quad ( 1 0 )$$
for λ ∈ X and δ a perturbation in the latter space, where F is the fidelity defined in (1). As a consequence of the Uhlmann theorem (3), since the fidelity is the maximum over the overlap w.r.t. all purifications, then f ( λ δ , ) ≥ |⟨ ψ 0 ( λ ) | ψ 0 ( λ + δ ) ⟩| , that is the quantity in (10) is bounded below 4 by the square root of the overlap between the perturbed ground states.
Following this, we introduce one of the key functions for our method , that is 5
$$g ( \lambda ) \coloneqq - \left ( \frac { \partial ^ { 2 } f ( \lambda, \delta ) } { \partial \delta _ { 1 } ^ { 2 } } + \frac { \partial ^ { 2 } f ( \lambda, \delta ) } { \partial \delta _ { 2 } ^ { 2 } } \right ) \Big | _ { \delta = 0 }. \quad ( 1 1 )$$
4 Alternatively, this can be inferred by casting the partial trace as Kraus operator and by the monotonicity of the Uhlmann Fidelity [23].
5 Interestingly, we can obtain another function g proportional to that in (11) by considering f defined in terms of the squared Bures distance (2).
We call the terms ∂ f/∂δ 2 2 k the reduced fidelity susceptibility for the corresponding parameter λ k . The adjective reduced is justified by the fact that we are considering RDMs instead of pure states as in (4). Similar forms of susceptibility have been considered in [24, 25]. We also note that for the regular susceptibility, it is clear that the linear term in the perturbative Taylor expansion of f vanishes for δ = 0 . In Section J we expand on some key concepts in information geometry and its connection to the definition in (11).
We next obtain the vector field P : X → R 2 (under sufficient smoothing assumptions) defined by;
$$P ( \lambda ) \coloneqq - \nabla _ { \lambda } g ( \lambda ). \quad \quad ( 1 2 ) \quad \stackrel { \text{sLow} } { c h \colon }$$
We stress that the gradient in (12) is expressed w.r.t. λ (parameters vector), whereas the Laplacian in (11) is related to δ (perturbation). In addition, we obtain a scalar function mapping the parameters λ to the angles of the vectors in the image of P , that is
$$p ( \lambda ) = & \text{Arg} \left ( \mathbf e _ { 1 } ^ { \top } P ( \lambda ) + \imath \mathbf e _ { 2 } ^ { \top } P ( \lambda ) \right ), \quad \ ( 1 3 ) \quad \ \text{the} ^ { 1 }$$
̸
with Arg : C → -( π, π ] denoting the principal argument 6 . The latter is defined on the subset of the parameter space X ′ = { λ ∈ X| P ( λ ) = 0 } . We note, as outlined in Section I, the function in (13) is scale invariant in the proximity of QPT at λ c , that is p (( λ -λ c ) ) = t p ( λ -λ c ) for some small t > 0. The latter consideration is justified by the scaling behavior of fidelity susceptibility in the vicinity of QPT [26].
The function g defined in (11) corresponds to a notion of fidelity susceptibility. Moreover, the angle given by p ( λ ) in (13), is the direction of the steepest decline in susceptibility. Consequently, we expect that phase transitions materialize as sources in the vector field (12). An example of this can be seen in Figure 2. Furthermore, we note that the sinks are the points where the susceptibility reaches the local minimum. As the last step, if we map the co-domain of p : X ′ → -( π, π ] to a cyclic color map we expect to obtain the phase diagram of the Hamiltonian in (8). This process is depicted in the sketch shown in Figure 2, where in panel (a) we plot the principal argument, and panel (b) represents the vector field with phase transition, depicted by a diagonal line. Both panels suggest that in the direction transversal to the phase transition, also indicated by vectors in panel (b), the value of g changes abruptly. We elaborate on this in Section H.
The practical implementation of the construction is expanded in Section A, also, we argue on the patterns of the vector field in Section H.
6 Arg( x + ıy ) = atan2( y, x ) ∀ x, y ∈ R , with atan2( y, x ) = lim c → x + arctan ( y c ) + π 2 sign( y ) sign( x ) (sign( x ) -1).
FIG. 2: Visualisation of the fidelity vector field (12) principal argument (a) and vector field (b) at a phase transition line. Here, we note that the argument drastically changes at the phase transition in (a) and the phase transition corresponds to a source in the vector field in (b).
## IV. ORDER PARAMETER DISCOVERY
Following the results obtained in the preceding section, we next investigate whether it is possible to determine the order parameter that captures the phase transitions of a given Hamiltonian.
To answer this question, we apply the protocol as described in Section III, and move from susceptibility-based identification of phases to determining the optimal observable for distinguishing the phases, that is a local order parameter. A simpler method has been proposed in [27], where a Hermitian operator is optimized to distinguish two given RDMs. In the latter, the distinction is given by the sign of the expectation w.r.t. the optimal observable. Our contribution instead, aims at mimicking the behaviour of order parameters.
We first note that the function p ( λ ) ∈ ( -π, π ] in (13) represents the point-wise angle of the vector field (12). Also as argued before, phase transitions are likely to materialize as sources, and we assume that adjacent phases are distinguished by π radian angles. In other words, if the parameter λ c ∈ X is proximal to a critical point (for some Hamiltonian), and δ a perturbation in the same space, then the assumption is that the corresponding gradient vectors have opposite directions, that is | p ( λ c ) -p ( λ c + δ ) | ≈ π . Consequently, there exists an optimal angle η such that
$$\left | \sin \left ( p ( \boldsymbol \lambda _ { c } ) + \eta \right ) + \sin \left ( p ( \boldsymbol \lambda _ { c } + \boldsymbol \delta ) + \eta \right ) \right | \approx 0. \quad ( 1 4 )$$
Consider a parametric Hamiltonian on n spins with ground state RDM ρ 0 ( λ ) defined as in (9). Given a finite set of parameters { λ i } in the neighbour of λ c , we define a label y i ∈ [ -1 1] for , each parameter λ i as y i = sin( ( p λ i ) + η ). From (14), we see that distinct phases will be assigned opposite signs, sign( y i ). We define the index sets I + = { | i y i > 0 } and I -= { | i y i < 0 } , partitioning the indices for the parameters { λ i } determining the ground states laying on the ordered and disordered phases, respectively. Under the assumption of non-degeneracy of the problem (see Section B for more
details), we devise the following (non-convex) quadratically constrained quadratic program (QCQP) [28],
$$& \min _ { M \in \mathcal { S } _ { m } } \sum _ { ( i, j ) \in I ^ { + } \times I ^ { - } } \left ( - \frac { \langle M \rangle _ { i } ^ { 2 } } { p _ { i } } + \frac { \langle M \rangle _ { j } ^ { 2 } } { p _ { j } } \right ), \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \text{s.t. } \| M \| _ { F } ^ { 2 } \leq 1, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
with ⟨ M ⟩ i := Tr( ρ 0 ( λ i ) M ) defining the expectation of M at λ i , and p i := Tr( ρ 0 ( λ i ) 2 ) the purity of the same RDM. We denoted by S m the set of Hermitian matrices of order m , which is also the order of the RDM ρ 0 ( λ i ).
This is commonly known in optimization literature as the trust region problem [29], which can be interpreted as a generalization of the minimum eigenvalue problem. The problem is solvable efficiently (polynomial time) even in the cases where the quadratic term is not positive semidefinite (i.e. non-convex) [30].
Informally, the optimization favors the non-zero expectation ⟨ M ⟩ i for the labels y i > 0 (ordered phase), whereas the quadratic term ⟨ M ⟩ 2 i penalizes non-zero expectations for the labels y i < 0 (disordered phase). In essence, this mechanism is mimicking the order/disorder behavior of the order parameters, for all pairs of opposing (w.r.t. phase) RDMs ( ρ 0 ( λ i ) , ρ 0 ( λ j )), with ( i, j ) ∈ I + × I -.
A special case of the problem in (15) arises when we consider the reference density matrices ρ + and ρ -, each representing a phase (i.e. ordered vs disordered). The formulation becomes
$$& \min _ { M \in \mathcal { S } _ { m } } - \frac { \text{Tr} \left ( \rho _ { + } M \right ) ^ { 2 } } { \text{Tr} \left ( \rho _ { + } ^ { 2 } \right ) } + \frac { \text{Tr} \left ( \rho _ { - } M \right ) ^ { 2 } } { \text{Tr} \left ( \rho _ { - } ^ { 2 } \right ) }, \\ & \quad \text{s.t.} \left \| M \right \| _ { F } ^ { 2 } \leq 1.$$
In Section C, it is shown that the objective of the latter is the quadratic form of an operator connected to the Gram-Schmidt process (GS) [31] - a method related to the QR decomposition in linear algebra. For a density matrix ρ , we define ̂ ρ := ρ/ ρ ∥ ∥ F its associated norm1 PSD. Also, for Hermitian matrices A,B of the same order, we denote by ⟨ A,B ⟩ their Frobenius inner product. The special formulation leads to the close form solution
$$M = & \frac { \widehat { \rho _ { + } } - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle \, \widehat { \rho _ { - } } } { \sqrt { 1 - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle ^ { 2 } } },$$
̸
when ρ + = ρ -. The solution is Hermitian as it is a reallinear combination of PSDs. One can immediately verify that Tr( ρ -M ) = 0, whereas
$$\text{Tr} ( \rho _ { + } M ) = & \| \rho _ { + } \| _ { F } \sqrt { 1 - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle ^ { 2 } } > 0, \quad ( 1 8 )$$
̸
as expected. Geometrically, the solution in (17) can be interpreted as subtracting from ̂ ρ + its projection on ̂ ρ -, hence the resulting Hermitian is orthogonal to ρ -and has a non-zero overlap with ρ + (when ρ + = ρ -). Moreover, the latter provides an understanding of the general problem. Specifically, the objective in (15) corresponds to the sum of special objectives in (16), for all pairs of opposing indices ( i, j ) ∈ I + × I -.
In practical terms, we consider RDMs on a few sites, thus the quadratic optimization problem can be solved classically upon computation of the partial trace on the ground states. Experimental results are presented in Section V B and the details for the solution of the optimization are expanded in Section B.
Finally, we note, as given in [32] that the order parameter need not be unique, and any scaling operator that is zero in the disordered phase and non-zero in an adjacent (on the phase diagram), usually ordered phase, is a possible choice for an order parameter.
## V. EXPERIMENTS
To demonstrate the potential of the fidelity vector field in identifying QPTs and their corresponding order parameters, we apply our above methods to the cluster Hamiltonian and ANNNI models.
## A. The ANNNI model
We first focus on the ANNNI Model [17, 33, 34], a theoretical model commonly used in condensed matter physics to study the behavior of magnetic systems. The Hamiltonian of such a system can be written as
$$H = - \ J _ { 1 } \sum _ { i = 1 } ^ { N - 1 } \sigma _ { i } ^ { x } \sigma _ { i + 1 } ^ { x } - J _ { 2 } \sum _ { i = 1 } ^ { N - 2 } \sigma _ { i } ^ { x } \sigma _ { i + 2 } ^ { x } - B \sum _ { i = 1 } ^ { N } \sigma _ { i } ^ { z }, \ ( 1 9 ) \quad \text{Phase} \\ \text{rectio} \\ \text{phase}.$$
which we can rewrite in terms of the dimensionless ratios κ = -J /J 2 1 and h = B/J 1 . The former is called the frustration parameter while the latter is related to the transverse magnetic field.
In this model, spins are arranged in a one-dimensional lattice, with each spin existing in either the |↑⟩ or |↓⟩ state. The inclusion of the nearest neighbor and nextnearest-neighbor interactions in this model introduces a type of frustration, where the optimal alignment of neighboring spins is hindered due to competing interactions. The transverse field present, which represents an external magnetic field perpendicular to the direction of the spins, also induces quantum effects and modifies the overall behavior of the system. It is the combination of these complex interactions, which combine the effect of quantum fluctuations (owing to the presence of a transverse magnetic field) and frustrated exchange interactions that lead to phenomena such as quantum phase transitions. As a consequence, it is a paradigm for the study of competition between magnetic ordering, frustration, and thermal disordering effects [35].
The phase diagram can be seen in Figure 3, where three phase transitions are present. The first is the Ising-like transition between the Ferromagnetic (FM) and Paramagnetic (PM) phases, the second is the KosterlitzThouless (KT) transition between the paramagnetic and floating phase (FP), and the final is the PokrovskyTalapov (PT) phase transition between the floating phase and antiphase (AP).
For more information on each of these phases and the corresponding phase transitions and their ground states see Section G.
Using the formalism as outlined in Section III, we first obtain the ground states of the Hamiltonian using the density matrix renormalization group (DMRG). Next, we consider a two-site RDM and calculate the RFS vector field and its corresponding angles. For details on how the RDM was obtained or the DMRG algorithm, see Section E. In Figure 4 (a), we plot the angle as given
FIG. 3: (a) Phase Diagram of one-dimensional ANNNI Model. Here the pink represents the Ferromagnetic Phase (FM), where all spins are aligned along the x direction. The grey area corresponds to the paramagnetic phase (PM), in which the magnetic field dominates and all spins align along the z direction. The antiphase (AP) corresponds to the green region where the ground state takes the form of a staggered magnetization pattern with period four. Both the PM and AP are separated by the floating phase (FP). Here the spin chain can be seen as a ladder of two spin chains as sketched in the cartoon spin configurations.
in (13) of the RFS vector field, as well as the theoretical Ising, KT, and PT phase transition lines, given in green, orange and blue respectively. We note there is a noticeable overlap between the theoretical phase transition lines and the angle values, with the angle of the vector fidelity abruptly changing at each phase transition. Comparing the theoretical phase transition lines to the vector field plotted in Figure 4 (b), we observe that a source in the vector field indeed corresponds to a phase transition. This source and sink-like behavior, as seen in Figure 4 (b) corresponds to local maxima and minima of Equation 11 and is further analyzed in Section H of the appendix.
Additionally, it is worth noting that the fidelity vector field surpasses previous simulations in its ability to capture intricate details that were previously unresolved in the floating phase [36]. Distinct ripples-like features are present, with the sources of the vector field corresponding to each of these structures indicating the presence of the phase transition between the paramagnetic and floating phases, specifically the KT transition. Future work will aim to explore the structure and fully utilize the potential of the RDS vector field in analyzing such complex phenomena. In the subsequent section, we demonstrate how we apply this method to determine order parameters for a given quantum system.
FIG. 4: Phase Diagram obtained using the reduced fidelity susceptibility of the one-dimensional ANNNI Model. Here a chain length of L = 50 spin sites was used and a two-site RDM was used when calculating the gradient of the reduced fidelity susceptibility. (a) The angle of the vector field given in (13) is plotted (b) the vector field given in (12) is plotted.
## B. Order parameters discovery
Next, we experimentally demonstrate the validity of the method used for order parameter discovery (Section IV), and in doing so, propose a method for understanding the structure of the optimal observable. We proceed with the ANNNI model (19) by considering the phase diagram in the region ( κ h ) ∈ R = [0 5 2 1] . , . × [0 , 1 6] . and begin with the use of the RDMs of single spin sites. Let M denote the optimal observable for the order parameter discovery problem in (15), where the details concerning its solution are expanded in Section B. Optimizing for a single site observable, we find that M ≈ I -σ x , which can be interpreted as magnetization. While this observable could be used as an order parameter for the Ising-like transition, highlighted in green in Figure 4, it failed to detect other transitions present in the ANNNI model, including the KT and PT transitions, highlighted orange and blue in Figure 4 respectively. As a result, to capture more transitions one must make use of Section IV and instead uncover a multi-site observable to detect all phase transitions present.
For this, we expand our RDM to the two middle spin sites of the chain of length L . The objective is to obtain the order parameters for the paramagnetic and the anti phases, which is highlighted in Figure 4, where we plot the result for the phase diagram construction (Section III) concerning the region R , of which was obtained in the previous section using the RDS vector field.
In Figure 5 (a) we present the expectations of the observable M applied to the RDMs ρ 0 ( κ , h i i ), for a finite lattice of parameters { ( κ , h i i ) } , following the opti- mization process of obtaining a relevant order parameter M for this phase transition. We note that in the optimization process, the entire region, ( κ h ) ∈ R = [0 0 . , 2 1] . × [0 , 1 6], . was used, which included all phase transitions present.
To understand the structure of the obtained observable, we next perform the eigendecomposition of M , that is
$$M = \sum _ { i = 1 } ^ { m } \alpha _ { i } M ^ { ( i ) } \quad \quad ( 2 0 )$$
where M ( ) i are rank-1 projectors and α i the corresponding eigenvalues. Let | φ θ ( ) ⟩ = cos( θ ) | 0 ⟩ + sin( θ ) | 1 , ⟩ we define the parametric Hermitian B θ , θ ( 1 2 ) as
$$\nu _ { n } ^ { \nu } \quad B ( \theta _ { 1 }, \theta _ { 2 } ) \coloneqq | \varphi ( \theta _ { 1 } ) \rangle \left \langle \varphi ( \theta _ { 1 } ) \right | \otimes | \varphi ( \theta _ { 2 } ) \right \rangle \left \langle \varphi ( \theta _ { 2 } ) | \,. \quad ( 2 1 )$$
Such an operator can be interpreted as the orthogonal projector (which is defined as a square matrix P such that P 2 = P = P † ) generated by the state | ⟩ , where the angles of the spins are θ 1 and θ 2 , respectively.
The component corresponding to the eigenvalue with the greatest magnitude is the projector M (1) = B θ , θ ( 1 2 ) with θ 1 ≈ 0 095 . π and θ 2 ≈ 0 034 . π , that is M (1) ≈ |↑↑⟩ ⟨↑↑| . In Figure 5 (c), we plot the expectation of the observable M (1) . A comparison with the plot in Figure 5 (a), shows that this is the main component for the paramagnetic phase.
The component M (4) , with ⟨ M (4) ⟩ depicted in Figure 5 (b), can be interpreted as the complementary to M (1) . The operator approaches the following form
$$\underset { \text{pti-} } { \text{f-} } \, \quad M ^ { ( 4 ) } \approx \frac { 1 } { 4 } \left ( \mathbb { I } _ { 2 } ^ { \otimes 2 } + \sigma _ { x } ^ { \otimes 2 } \right ) \left ( \mathbb { I } _ { 2 } ^ { \otimes 2 } - \sigma _ { z } ^ { \otimes 2 } \right ) = \left | \Psi ^ { + } \right \rangle \left \langle \Psi ^ { + } \right |, \ \ ( 2 2 )$$
FIG. 5: Experiments for the order parameter discovery on the ANNNI model. Here a chain length of L = 50 spin sites was used and a two-site RDM was used when calculating the gradient of the reduced fidelity susceptibility. (a) Expectation of the optimal observable M for the paramagnetic phase. The expectations for the projectors M (1) and M (4) of (20), are respectively in (c) and (b).
FIG. 6: Expectations of the projectors M (3) (a) and M (2) (b) revealing the floating phase. Here a chain length of L = 50 spin sites was used and a two-site RDM was used when calculating the gradient of the reduced fidelity susceptibility.
̸
with | Ψ + ⟩ = ( |↑↓⟩ + |↓↑⟩ ) / √ 2 (Bell's state), so the ordered phase for M (4) is the antiphase. This can be justified by the modulated structure of the antiphase |· · · ←←→→···⟩ (see Section G for a comprehensive introduction to ANNNI). Indeed we see that Tr ( M (4) | φφ ⟩ ⟨ φφ | ) = 0 for | φ ⟩ = |←⟩ and | φ ⟩ = |→⟩ , whereas Tr ( M (4) |↑↑⟩ ⟨↑↑| ) = 0 (paramagnetic).
The remaining two components of the decomposition in (20) reveal an interesting structure. The third eigenvector determines the projector M (3) = B θ , θ ( 1 2 ) with θ 1 ≈ 0 381 . π and θ 2 ≈ -0 331 . π . Its expectation depicted in Figure 6 (a), appears to highlight a section of the floating phase. The last projector M (2) , whose details are omitted, produces another detail of the floating phase, which is depicted in Figure 6 (b).
## C. Finite Size Scaling
Next, we validate that the obtained observable M is indeed an order parameter for the ANNNI Model. We accomplish this by applying finite-size scaling and verifying that the critical exponents match those expected for the Ising-like universality class. Finite-size scaling is a technique used to study phase transitions by examining how physical quantities change with system size. It involves scaling the system size and observing how properties such as critical exponents converge to their thermodynamic limits as the size increases. By applying this method, we can extrapolate results obtained from finite systems to infer behavior in the infinite system limit. To demonstrate this phenomena we thus analyze the impact of chain length at the Ising-like transition. We again use the RDM ρ L for two spin sites, which are related to the sites { L/ , L/ 2 2 + 1 } , assuming L (linear size) is an even positive integer. We calculate the expectations of the observable M with the reduced density matrices ρ L ( κ, h i ) with κ = 0 001 and . h ∈ [0 8 . , 1 2]. . In this parameter range, we can consider the next-nearest-neighbor interaction as a perturbation of the Ising model. Consequently, we anticipate observing the critical exponents characteristic of the 1D quantum Ising model.
If the observable M indeed functions as an order parameter, it should satisfy the following scaling relation for the chain length L [37]:
$$\max _ { h } \left \{ \frac { \partial \langle M \rangle } { \partial h } \right \} = a ^ { \prime \prime } L ^ { 1 / \nu } \left ( 1 + b ^ { \prime \prime } L ^ { - \theta / \nu } \right ), \quad ( 2 3 )$$
where a ′′ and b ′′ are constants, and θ represents the exponent of an irrelevant parameter.
For the 1D quantum Ising model, where ν = 1, the maximum of the gradient should show a linear dependence on the chain length. To validate this, we plot the maximum gradient as a function of the chain length, as shown in Figure 8. The observed linear relationship confirms that ν = 1.
We then proceed to determine the irrelevant parameter exponent θ and show that this exponent remains positive as the chain length increases. Consequently, for large values of L , the contribution from this term becomes negligible. As L →∞ , this term approaches zero, leaving us with the critical exponents of the Ising model.
We first rescale the function such that a ′′ = 1 and using gradient descent we fit for b ′′ and θ . This fitting process is illustrated in Figure 8, where we plot d M ⟨ ⟩ dh L -1 . For irrelevant terms, we expect additional contributions to decay as L increases, which is indeed observed in Figure 8. By applying gradient descent to the obtained expectations for various lengths, we determine θ = 6 8 . × 10 -5 and b ′′ /a ′′ = 1 0. . Consequently, the positive value of the correction term θ confirms that it is an irrelevant parameter.
FIG. 7: The two-site observable obtained using the order parameter discovery framework (a) and its gradient with h (b) are applied to the ANNNI model's Ising-like transition for various chain lengths L . We set κ = 0 001 so . that the next-nearest-neighbor term can be treated as a perturbation to the Ising model, which leads us to expect the system to belong to the Ising universality class.
To confirm that we belong to the Ising universality class, we fit the magnitude of the average observable near the critical point h c = 1 0. . In this regime, the critical magnetization should follow the relationship M ∝ | L | β/ν . Assuming ν = 1 0, we fit the values of the observed data . and find β = 0 123, which is close to the expected value . of β = 1 8 for the Ising universality class.
FIG. 8: (a) The maximum value of the gradient of the two-site observable obtained using the order parameter discovery framework. A linear relationship is observed, confirming that the system remains in the Ising universality class. (b) The irrelevant terms are plotted in (23). As the chain length L increases, an exponential decrease is observed, indicating that these terms approach zero as the system reaches the thermodynamic limit.
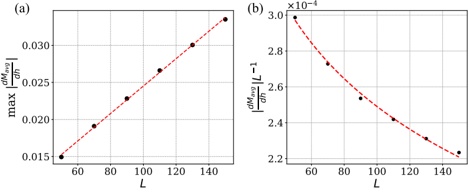
This analysis was also performed for the single-site observable I -σ x , and the critical exponent ν = 1 was consistently obtained. Therefore, near the Ising transition, it retains the critical exponents characteristic of the Ising model, accounting for finite-size scaling correction terms. Based on this analysis, we conclude that the obtained observable M functions as an order parameter.
## D. The cluster Hamiltonian
Following the construction of the phase diagram for the ANNNI model, we next demonstrate the versatility of the fidelity vector field method by applying it to other models. Specifically, we apply the method described in Section III to the cluster Hamiltonian, defined by the Hamiltonian:
$$\mathcal { H } = - h \sum _ { i = 1 } ^ { N } \sigma _ { i } ^ { z } - K \sum _ { i = 1 } ^ { N - 2 } \sigma _ { i } ^ { x } \sigma _ { i + 1 } ^ { z } \sigma _ { i + 2 } ^ { x }, \quad ( 2 4 )$$
When the two parameters of the Hamiltonian are equal, a phase transition is expected between a trivial phase (for h > K ) and a Symmetry Protected Topological (SPT) phase (for h < K ). To distinguish between these two phases, string order parameters (SOPs) are commonly used, as they can reveal hidden orders or symmetries within the system. In the case of the cluster Hamiltonian, the system exhibits certain symmetries, denoted by G odd = ∏ k =0 Z 2 k +1 and G even = ∏ k =0 Z 2 k .
From [38, 39], a general SOP can be expressed as
$$\begin{array} { c } \stackrel { \cdot } { \text{ticial} } \\ \stackrel { \cdot } { \text{$j$} } | ^ { \beta / \nu }. \\ \text{data} \\ \text{value} \end{array} \quad S _ { \Sigma } ^ { O ^ { L }, O ^ { R } } = \lim _ { | j - k | \to \infty } \left \langle \psi _ { 0 } \left | O ^ { L } ( j ) \left ( \prod _ { i = j + 1 } ^ { k - 1 } \Sigma _ { i } \right ) O ^ { R } ( k ) \right | \psi _ { 0 } \right \rangle \\ \text{when} \quad \text{$the$ to the state of $f$ to continue $\Pi^{k-1}$} \quad \Sigma_{i} / \infty. \end{array}$$
where ψ 0 is the state of the system, ∏ k -1 i = +1 j Σ (in our i case G odd or G even ) preserves the local symmetries of the system, and O L/R are appropriately chosen to detect the phase transition. In this particular system, a typical order parameter used for the phase transition is σ x ⊗ σ z ⊗ I ⊗ σ z ⊗ σ x , or another commonly used one is σ x ⊗ σ y ⊗ σ z ⊗ σ y ⊗ σ z as discussed in [40].
We begin by focusing on reconstructing the phase diagram as discussed in section Section III. To determine the ground states of the Hamiltonian, we employ DMRG, following the procedure described in Section E. We replicate the calculations outlined in Section V A to construct the phase diagram for the cluster Hamiltonian, which is presented in Figure 9. The phase transition is visible, with a distinct boundary separating the two phases.
Next, we turn our attention to identifying an order parameter for this phase transition by following the method described in Section IV. Using a five-site RDM, we derive an order parameter that effectively distinguishes between the different phases, as shown in 10.
Although this order parameter is a linear combination of various tensor products of Pauli operators, the two terms with the largest coefficients are σ x ⊗ σ z ⊗ ⊗ I σ z ⊗ σ x and σ x ⊗ σ y ⊗ σ z ⊗ σ y ⊗ σ z , both observables that reflect the symmetry of the SPT phase. This suggests that our observable has correctly identified the appropriate SOP and effectively exploited the system's symmetries to distinguish between the two phases.
It is worth noting that similar calculations were performed using different sizes of RDMs, specifically one and
FIG. 9: Phase Diagram obtained using the reduced fidelity susceptibility of the one-dimensional cluster Hamiltonian where (a) the angle of the vector field given in (13) is plotted (b) the vector field given in (12) is plotted. We note that the phase transitions correspond to a source in the vector field.
FIG. 10: Expectation of the optimal observable M for cluster Hamiltonian. Here a chain length of L = 50 spin sites was used and a five-site RDM was used when calculating the gradient of the reduced fidelity susceptibility.
two sites. These attempts, however, failed to detect the phase transition, indicating that these smaller RDMs do not capture enough information about the phases on their own.
To conclude, we have demonstrated that the RFS vector field accurately reproduces the phase diagrams of both the ANNNI and cluster Hamiltonians, showcasing its robustness and reliability in capturing the phase transitions of diverse systems. Furthermore, we successfully identified an order parameter that leverages each system's symmetries to distinguish between different phases, further validating our approach.
## E. The Rydberg model spin chain
FIG. 11: Schematic of the phase diagram for the Rydberg Model as a function of the parameters ∆ Ω and ( R b a i | - | j ) 6 (see the main text for more details). The orange regions represent the emergence of various crystalline quantum phases with Z N order.
## 1. Model description
The Rydberg model is a quantum many-body system that has attracted considerable interest, particularly its role in experimental quantum simulation platforms [4144]. The system is composed of a chain of atoms such that each atom can either remain in its ground state or be excited to a highly energetic Rydberg state, characterized by an electron occupying a very high orbital [45]. The model captures the dynamics of strongly interacting systems, as atoms in Rydberg states exhibit long-range dipole-dipole interactions, significantly affecting the system's collective behavior. Using these interactions, a variety of exotic quantum phases can be simulated, including quantum phase transitions and spin-liquid phases, making the Rydberg model an essential tool for probing non-equilibrium phenomena in quantum simulators [46].
Mathematically, the Rydberg model can be formulated as a spin-1 / 2 system, where each site of the chain represents an atom that can either be in the ground state (represented by the spin state | 0 ) or in the Rydberg state ⟩ (represented by the spin state | 1 ). ⟩ The Hamiltonian of the Rydberg model is typically expressed as
$$H = \Omega \sum _ { i } \sigma _ { i } ^ { x } - \Delta \sum _ { i } n _ { i } + \sum _ { i < j } V _ { i j } n _ { i } n _ { j }, \quad ( 2 6 )$$
where σ x i is the Pauli-x matrix acting on-site i , and n i = 1 | ⟩ ⟨ 1 | i is the number operator that projects onto the Rydberg state at site i . The parameters Ω and ∆
a
/
Rb
FIG. 12: Phase diagram for the Rydberg Model obtained with a one-site RDM from a chain of length L = 50, with long-range interactions truncated at the fourth nearest neighbor. The lower crystalline phase corresponds to the Z 2 crystalline phase, while the upper corresponds to the Z 3 crystalline phase.
represent the Rabi frequency and detuning, respectively, which control the driving field and energy offset of the system. The second term in the Hamiltonian describes the interaction between atoms in their Rydberg states, with V ij ( r ) ∝ 1 /r 6 representing the strength of the interaction between atoms at sites i and j . For ∆ > 0, various spatially ordered phases emerge due to the competition between two effects: the detuning term, which favors a high population of atoms in the Rydberg state, and the Rydberg blockade, which prevents the simultaneous excitation of atoms that are closer together than the blockade radius R b , where the interaction strength V ( R b ) is equal to the Rabi frequency Ω.

We define the distance between adjacent spins as a , thus r = | i - | j a , and we also define the Rydberg Radius as V ( R b ) = Ω. Thus the Hamiltonian can be rewritten accordingly;
$$H = \sum _ { i } \sigma _ { i } ^ { x } - \frac { \Delta } { \Omega } \sum _ { i } n _ { i } + \left ( \frac { R _ { b } } { a } \right ) ^ { 6 } \sum _ { i < j } \frac { 1 } { | i - j | ^ { 6 } } n _ { i } n _ { j }, \ ( 2 7 ) \quad \text{In} _ { \text{ model} }$$
It is the parameters ∆ Ω and ( R b a i | - | j ) 6 that we will vary in the following section.
In the limit of strong interactions, the Rydberg blockade phenomenon becomes significant, where two neighboring atoms cannot both be excited to the Rydberg state due to the large energy cost. This constraint leads to the emergence of various quantum phases, including crystalline phases with Z N symmetry ( N being an integer), which are characterized by periodic arrangements of Rydberg excitations.
A schematic of the phase diagram is given in Figure 11.
a
/
FIG. 13: Detail of the phase diagram for the Rydberg Model around the Z 3 crystalline phase. Due to the high resolution of the phase diagram, ripple-like features can be observed which signals a more complex phase to be determined.
## 2. Phase diagram construction
In previous studies, the phase diagram of the Rydberg model has been explored using various techniques such as entanglement entropy [47], machine learning methods [48], and fidelity [49]. We obtain the phase diagram, with the first result presented in Figure 12. Here, we particularly focus on the Z 2 and Z 3 crystalline phases, which are typically observed in this model (See Figure 13 for a closer look at the Z 3 crystalline phase). We considered a chain of length L = 50, with long-range interactions truncated at the fourth nearest neighbor. The 1 /r 6 interaction term was approximated using an exponential form, as described in [50].
Our results are consistent with the parameter ranges for each crystalline phase in the phase diagram, as reported in previous studies [50]. However, a noteworthy observation is that our method captures additional features that were not identified by earlier approaches. Specifically, we observe ripple-like features at high values
FIG. 14: Rydberg model - The expectation for a 1-site observable that highlights the disordered phase versus the crystalline phases Z 2 and Z 3 . Notably, the two crystalline phases cannot be distinguished using a 1-site observable.
of the parameters swept, which may indicate the presence of a more complex phase - a topic previously discussed in [49, 51, 52]. Additionally, we identify a line within each crystalline phase corresponding to the minimum of the reduced fidelity susceptibility, or equivalently, the maximum of the fidelity.
Notably, due to the high resolution of our phase diagram, we once again observe ripple-like features, consistent with previous findings in [49].
## 3. Order parameters
Next, we focus on the determination of an order parameter to detect each of these phase transitions. We initially start with a one-site RDM, to try to determine the different phases as seen in Figure 12. The projectors from the determined order parameter can be seen in Figure 14. As is evident that while it can determine the difference between the ordered and disordered phases, it fails to differentiate the different crystalline phases. Extending this to three sites results in the same projectors, which are unable to differentiate the different crystalline phases.
It is not until a four-site RDM is used that the different disordered phases, Z 3 , Z 2 can be characterized. This result is seen from the projectors of the observable in Figure 15.
Firstly, for the Z 2 crystalline phase, the projector of the state | 0101 ⟩ is used to detect this phase, showing that the agreed state of alternating spin up and spin down is evident in this phase, agreeing with previous literature.
Similarly for the Z 3 phase, the projector of the | 0001 ⟩ was determined from the order parameter, which is also in agreement with previous literature. Expanding the
a
/
Rb
FIG. 15: Rydberg model - Highlights from the eigen decomposition of the order parameter on a 4-site RDM. The plots present the expectations of the projectors that reveal respectively, the crystalline (a) Z 2 and (b) Z 3 phases.
RDM to include additional sites would make this symmetry more evident.
## VI. CONCLUSION
In conclusion, we have introduced a novel mathematical tool for detecting phase transitions in quantum systems through reduced fidelity susceptibility. Our analysis of the ANNNI model illustrates the tool's capability to capture intricate phase transition details that were previously overlooked by conventional methods. This advancement not only highlights the potential for applying our framework to other models where phase transitions are either not well understood or not yet identified but also underscores its broader applicability and capacity for providing deeper insights into complex quantum systems.
Additionally, our framework demonstrates significant promise for application in quantum hardware environments. Utilizing the reduced density matrix thermodynamic information, it circumvents the need for fullfunction tomography while still capturing essential characteristics of phase transitions.
Moreover, we extended our framework to devise a method for discovering order parameters in systems where they are unknown. The reversed method, applied to the ANNNI model, was validated through the decomposition and finite-size scaling of the identified order parameter. This validation underscores the framework's potential to explore and analyze novel systems, including unexplored phenomena such as floating phases in a quantum system. We believe that the proposed approach is an important milestone in phase transition detection and order parameter discovery, offering a robust tool for exploring the complex landscape of quantum systems.
FIG. 16: Structure of the lattice of RDMs ρ i,j 0 := ρ 0 ( λ i,j ) induced by a finite lattice of parameters { λ i,j } , contained in a region R (outer rectangle).
## VII. ACKNOWLEDGMENT
We are grateful to Dmytro Mishagli (IBM) and Victor Valls (IBM) for their valuable input and suggestions.
F.DM and E.R. acknowledge support from the BasQ strategy of the Department of Science, Universities, and Innovation of the Basque Government.
E.R. is supported by the grant PID2021-126273NBI00 funded by MCIN/AEI/ 10.13039/501100011033 and by 'ERDF A way of making Europe' and the Basque Government through Grant No. IT147022. This work was supported by the EU via QuantERA project T-NiSQ grant PCI2022-132984 funded by MCIN/AEI/10.13039/501100011033 and by the European Union 'NextGenerationEU'/PRTR. This work has been financially supported by the Ministry of Economic Affairs and Digital Transformation of the Spanish Government through the QUANTUM ENIA project called - Quantum Spain project, and by the European Union through the Recovery, Transformation, and Resilience Plan - NextGenerationEU within the framework of the Digital Spain 2026 Agenda.
## Appendix A: Construction of the phase diagram
Starting from results devised in Section III, we proceed with the numerical construction of the phase diagram. We consider a rectangular region of the Hamiltonian parameters R⊆X . Given a step in the parameters space h > 0, we construct a finite lattice of parameters { λ i,j } ⊂ R , such that
$$\lambda _ { i + d _ { i }, j + d _ { j } } = \lambda _ { i, j } + d _ { j } h e _ { 1 } + d _ { i } h e _ { 2 }, \quad ( \text{A1} ) \quad _ { 7 \text{ } \Re\wedge }$$
with d , d i j belonging to a subset of Z . Using the density matrix renormalization group (DMRG) [53, 54], we obtain the RDM related to the ground state (for a selected subsystem) for the parameter λ i,j , which we define as
ρ i,j 0 = ρ 0 ( λ i,j ), where the RHS is defined in (9). In Figure 16 the lattice points for the RDMs ρ i,j 0 are represented by the symbol .
We proceed with the preparation of an approximation ˜ of the function g g , that is the RFS defined in (11). The latter is the Laplacian of the function f ( λ δ , ) defined in (10). So, starting from the lattice of parameters { λ i,j } , we obtain the fidelity perturbations
$$f ( \lambda _ { i, j }, d _ { j } h e _ { 1 } + d _ { i } h e _ { 2 } ) = \sqrt { F } \left ( \rho _ { 0 } ^ { i, j }, \rho _ { 0 } ^ { i + d _ { i }, j + d _ { j } } \right ), \ \ ( \mathbf A 2 )$$
for a fixed step h (which defines the lattice of parameters) and d , d i j ∈ {-1 0 1 , , } . We can immediately verify the computational advantage of the approach since adjacent lattice points share a fidelity perturbation. For example f ( λ i,j , h e 1 ) = f ( λ i,j +1 , -h e 1 ). In Figure 16, the fidelity perturbations are represented with the symbol and placed between adjacent lattice points to emphasize the concept of sharing. By considering the finite differences approximation of the second derivative , 7 and by noting that f ( λ i,j , 0 ) = 1 (for all valid i, j ), we obtain
$$\tilde { g } ( \lambda _ { i, j } ) = & \frac { 4 - \sum _ { \delta \in \Omega } f ( \lambda _ { i, j }, \delta ) } { h ^ { 2 } }, \quad \quad ( A 4 )$$
where Ω = {± h e 1 , ± h e 2 } is the set of perturbation displacements around λ i,j . In practice, we omit the factor 1 /h 2 (numerically convenient) which is irrelevant for the subsequent computations. We proceed by adhering to the structure outlined in Section III. Obtained the RFS approximation ˜, we continue with the computation of g its gradient. Before that, we need to introduce a few concepts related to discrete signal processing.
For a continuous function f : R 2 → R 2 , we define the convolution at ( x, y ) ∈ R 2 for discrete 2-dimensional signals as
$$\text{lled} _ { \text{ione} } \quad f ( x, y ) * k \coloneqq \sum _ { i = - N } ^ { N } \sum _ { j = - N } ^ { N } k ( j, i ) f ( x - j h, y - i h ), \ ( A 5 )$$
where k is a convolution kernel with support N , that is k j, i ( ) = 0 for | i | > N or | j | > N . Also, the scalar h > 0 represents the step for the lattice of points { ( x y ) ⊤ +( jh ih ) ⊤ | i, j ∈ Z } . We introduce a discrete differentiation operator called the Sobel operator [55] whose x component is given by the kernel matrix
$$G _ { x } \coloneqq \begin{pmatrix} - 1 & 0 & 1 \\ - 2 & 0 & 2 \\ - 1 & 0 & 1 \end{pmatrix}.$$
7 For a function f : R → R , under sufficient smoothing conditions, we make use of the following approximation
$$\frac { d ^ { 2 } f } { d x ^ { 2 } } \approx \frac { f ( x + h ) + f ( x - h ) - 2 f ( x ) } { h ^ { 2 } }, \quad \quad ( A 3 )$$
for some h > 0.
The Sobel finds applications mainly in computer vision and it was initially developed to obtain an efficiently computable gradient operator with more isotropic characteristics than the Roberts cross operator [56].
Now, we define our kernel as k = G x + ıG ⊤ x , which corresponds to the approximation of the gradient w.r.t. x on the real part and the y component on the imaginary part.
We obtain an equivalent approximation of P in (12) using the convolution
$$\tilde { P } ( \lambda _ { i, j } ) = - \tilde { g } ( \lambda _ { i, j } ) * k & & ( A 7 \text{a} )$$
$$\Phi _ { 1 } ^ { \Phi } = - \sum _ { a = - 1 } ^ { 1 } \sum _ { b = - 1 } ^ { \Phi } k ( a, b ) \tilde { g } ( \boldsymbol \lambda _ { i - a, j - b } ) \in \mathbb { C }. \quad ( A 7 b ) \quad \text{ for } \xi _ { \text{orde} }$$
When the indices ( i, j ) of the lattice elements are beyond the limits of definition we define ˜( g λ i,j ) = 0.
The first outcome of the process is a point-to-color graph
↦
$$\lambda _ { i, j } \mapsto c \left ( \text{Arg} \left ( \tilde { P } ( \boldsymbol \lambda _ { i, j } ) \right ) \right ), \quad \quad ( A 8 )$$
where c ( ) is a colormap which we introduce now. · Let C be a space of colors and let c : ( -π, π ] →C be a mapping from the angle θ to a color in C . The function c is required to be smooth on ( -π, π ) and non-constant, also it must be such that lim θ →-π c θ ( ) = c π ( ). The latter point is fundamental for dealing with the discontinuity of Arg( ) · in the non-positive real axis. Colormaps fulfilling the latter conditions are known as cyclic [57, 58]. In addition, the resulting signal is upsampled by factor 2 using an interpolation filter [59]. An example outcome obtained using the present procedure is reported in Figure 4.
The final step of the diagram construction consists of the plotting of the vector field in (12). The approach makes use of the Runge-Kutta method [60] and our reference implementation is part of the function matplotlib.pyplot.streamplot of the software package Matplotlib [58]. In the realm of differential equations, the Runge-Kutta method is a well-known algorithm for solving initial-value problems. In our instance, the velocities on the lattice { λ i,j } are given by the gradient in (12). The initial values instead, are the points on the boundary of the lattice. Furthermore, a heuristic path of lattice points spiraling toward the center is added to the initial values, to improve the density of the streamlines.
## Appendix B: Solution of the order parameter discovery problem
In this section, we expand on the solution of the order parameter discovery problem defined in (15). Instead, the special case in (16) is treated in Section C. We restate the problem for clarity and convenience, so
$$& \min _ { M \in \mathcal { S } _ { m } } \sum _ { ( i, j ) \in I ^ { + } \times I ^ { - } } \left ( - \frac { \langle M \rangle _ { i } ^ { 2 } } { p _ { i } } + \frac { \langle M \rangle _ { j } ^ { 2 } } { p _ { j } } \right ), \\ & \text{s.t.} \, \| M \| _ { F } ^ { 2 } \leq 1,$$
with ⟨ M ⟩ i := Tr( ρ 0 ( λ i ) M ) and p i := Tr( ρ 0 ( λ i ) 2 ).
We introduce the row-major vectorization operator vec ( ) : r · C n × n → C n 2 defined as
$$\text{vec} _ { r } ( M ) \coloneqq \sum _ { i = 1 } ^ { n } M \left | i \right \rangle \otimes \left | i \right \rangle, \text{ \quad \ \ } ( B 2 )$$
for any matrix M of order n in C . For matrices A,B of order n we will be using the identity
$$\text{Tr} \left ( A B ^ { \dagger } \right ) = \text{vec} _ { r } ( A ) ^ { \dagger } \text{vec} _ { r } ( B ). \quad \quad ( B 3 )$$
We recall that we denoted S m the set of Hermitians of order m in C . We define the set of vectorized Hermitians of order m as
$$\bar { \mathcal { S } } _ { m } ^ { \mu } \coloneqq \{ \text{vec} _ { r } ( M ) | M \in \mathcal { S } _ { m } \} \,. \quad \quad ( B 4 )$$
Let ρ i = ρ 0 ( λ i ), and let I be some finite index set. Assume M ∈ S m , then we have that
$$\sum _ { i \in I } \frac { \langle M \rangle _ { i } ^ { 2 } } { p _ { i } } = \sum _ { i \in I } \frac { \left ( \text{Tr} ( \rho _ { i } M ) \right ) ^ { 2 } } { p _ { i } } \, \quad \, \quad \, \quad \, \quad \, \quad \, \text{(B5a)}$$
$$\Phi _ { \Phi _ { 3 } } = \sum _ { i \in I } \frac { \Phi _ { \Phi _ { 3 } } } { p _ { i } } \quad \ \ ( B 5 b )$$
$$= & \vec { x ^ { \dagger } } \left ( \sum _ { i \in I } \frac { \vec { r } _ { i } \vec { r } _ { i } ^ { \dagger } } { p _ { i } } \right ) \vec { x },$$
with x := vec ( r M ) and r i := vec ( r ρ 0 ( λ i )). We note that the vectors x and r i belong to the set of vectorized Hermitians ̂ S m .
We use the result in (B5a) to rewrite the optimization problem in (15) in the equivalent 8 form
$$\min _ { x \in \mathbb { C } ^ { m ^ { 2 } } } x ^ { \dagger } A x, \quad \quad \quad ( B 6 a )$$
$$\text{s.t.} \, \| \mathbf x \| _ { 2 } ^ { 2 } \leq 1, \$$
$$\mathbf x \in \overset {. } { \mathcal { S } } _ { m }, \text{ \quad \$$
with
$$A \coloneqq - \, \frac { 1 } { | I ^ { + } | } \sum _ { i \in I ^$$
This formulation confirms that the optimization is a quadratically constrained quadratic program as stated in
8 Up to the positive constant (for the objective) | I + | · | I -| .
Section IV. The matrix A (determined by data) is Hermitian, so the objective in (B6a) is real and well-defined (even in the absence of constraint (B6c)). We expand on the condition for the non-degeneracy of the problem introduced in Section IV. We impose that the matrix A is indefinite [61], where the Hermitian structure is fulfilled by the construction in (B7). In other words, we require the matrix A to have both (strictly) positive and negative eigenvalues 9 .
Let ( ) · ≽ ( ) denote the · Loewner order [61], that is the partial order on the cone of PSD matrices. Specifically, for any pair of Hermitian matrices X,Y we have that X ≽ Y if and only if X -Y is PSD.
The optimization problem is non-convex since we do not assume A ≽ 0, indeed A is required indefinite. However, as anticipated in Section IV, this optimization problem can be solved efficiently even in the case of the non-convexity of the objective (i.e., matrix A is not PSD). Moreover, this is an exceptional case where strong duality 10 [28] holds, provided that Slater's constraint qualification is fulfilled. That is, there exists an x ∈ S ̂ m such that the inequality constraint (B6b) holds strictly (i.e. not tight). In our case, an example is x = vec ( r I m ) / √ m + ϵ for any ϵ > 0, so ∥ x ∥ 2 2 < 1.
Now, we consider the optimization problem consisting of (B6a) and (B6b). We exclude the constraint in (B6c), as we will prove being enforced implicitly by the structure of the matrix A and the non-degeneracy conditions. The Lagrangian function is L ( x , α ) = x † ( A + α I m 2 ) x -α with the multiplier α ∈ R + . Consequently, the dual function min x L ( x , α ) takes the value -α when A + α I m 2 ≽ 0 (i.e. PSD, so the Lagrangian is bounded below in x ), and it becomes unbounded otherwise. Let λ min ( ) denote the · minimum eigenvalue of the matrix argument. The Lagrange dual problem reads
$$\max _ { \alpha \in \mathbb { R } _ { + } } = \alpha, \quad \quad \quad$$
$$\text{s.t. } A + \alpha \mathbb { I } _ { m ^ { 2 } } \succeq$$
then the constraint is fulfilled when α ≥ -λ min ( A ), so the dual optimal is α ⋆ = -λ min ( A ) > 0. The space of the primal solutions is given by the eigenspace corresponding to the minimum eigenvalue of A -λ min ( A ) I m 2 , that is the null space of the latter. Given any matrix A , we denote the null space of A (i.e., the set of solutions of the homogeneous equation Ax = 0) by Null( A ). Let
$$x ^ { * } \in \text{Null} \left ( A - \lambda _ { \min } ( A ) \mathbb { I } _ { m ^ { 2 } } \right ), \quad \ \ ( B 9 ) \quad ^ { \kappa ^ { \dots } } _ { F }$$
9 As a simple example, this condition is not met when the sets I + and I -are identical. However, this would be incoherent since there is no distinction between the phases.
10 Strong duality is equivalent to the duality gap is zero, that is the difference between primal and dual solutions.
with ∥ x ⋆ ∥ 2 2 = 1, be an optimal solution 11 , we show that if x ⋆ = vec ( r M ), then M = M † . That is constraint (B6c) is implied by the structure of matrix A .
̸
The set S m of Hermitian matrices of order m is a real vector space, and if B is a basis for it, then B v := { vec ( r K K ) | ∈ B} is a basis for the vector space of vectorized Hermitians. We verify immediately that, by construction, the image of matrix A belongs to the latter vector space. By the non-degenerancy assumptions (i.e. A is Hermitian indefinite), we have that λ min ( A ) = 0. Consequently, the solution x ⋆ belongs to the image of A , hence the matrix M such that vec ( r M ) = x ⋆ is Hermitian. In other words, we have shown that the assumption that A is Hermitian indefinite implies that constraint (B6c) is fulfilled. When the non-degeneracy conditions are not met, the case corresponds to the impossibility of obtaining an order parameter (which could be conditioned to the size of the observable). This is a situation we encountered in Section V B.
In (B9) we have proved that the solution may not be unique, however, this is consistent with the nonuniqueness of order parameters stated in Section IV.
We note that even in the case of 1-dimensional null space in (B9), the optimal observable M can be of any rank since the solution x ⋆ is a vectorization of a Hermitian operator. For example, in the case of the Ising model, we could have x ⋆ ≈ ( 1 0 0 -1 ) ⊤ (a Bell's basis vector) with the corresponding observable being M = σ z (full rank).
We summarize the procedure. Given a lattice of RDMs for the ground states of a selected Hamiltonian, we obtain the vector field in (12). The labeling of the phases is obtained using the trigonometric approach explained in Section IV, so we derive the sets I + and I -. Subsequently to the instantiation of matrix A given in (B7), we use its eigendecomposition to obtain, first, the verification that the non-degeneracy conditions are met. Secondly, the eigenspace corresponding to its minimum eigenvalue determines the space of solutions (B9).
## Appendix C: Special solution of the order parameter discovery problem
In this section, we obtain the solution for the special case of the order parameter discovery established by the problem in (16). The outcome is the close form solution put forward in (17).
Fixed the density matrices ρ + , ρ -of order m , we define the linear operator Ξ : S m → S m on the space of
11 We note that the vectorization operator vec ( ) : r · C m m × → C m 2 is an isomorphism, so the expression x ⋆ = vec ( r M ) implicitly means that the matrix M is obtained uniquely from x ⋆ using the inverse of vec . r
Hermitian matrices, given by the rule
$$\Xi ( K ) \coloneqq - \frac { \langle K, \rho _ { + } \rangle } { \langle \rho _ { + }, \rho _ { + } \rangle } \rho _ { + } + \frac { \langle K, \rho _ { - } \rangle } { \langle \rho _ { - }, \rho _ { - } \rangle } \rho _ { - }, \quad ( C 1 ) \quad \text{an} \quad b$$
with K ∈ S m . Let C ∈ S m be any non-zero Hermitian, then the operator
↦
$$K \mapsto \frac { \langle K, C \rangle } { \langle C, C \rangle } C \quad \quad \ \ ( C 2 ) \quad \ \ t h \quad \ \ _ { o v }$$
is a projection onto the 1-dimensional subspace spanned by C . Consequently, the operator in (C1) can be related to the Gram-Schmidt process (GS) [31]. We obtain the quadratic form for the operator Ξ, so for K ∈ S m
$$\langle K, \Xi ( K ) \rangle = - \, \frac { \text{Tr} \left ( \rho _ { + } K \right ) ^ { 2 } } { \text{Tr} ( \rho _ { + } ^ { 2 } ) } + \frac { \text{Tr} \left ( \rho _ { - } K \right ) ^ { 2 } } { \text{Tr} ( \rho _ { - } ^ { 2 } ) } \in \mathbb { R }. \quad ( \text{C3} ) \quad \text{Therm} }$$
The latter is the objective of the problem in (16), so the optimization can be rewritten as
$$\min _ { - \epsilon } \, \langle M, \Xi ( M ) \rangle,$$
$$\underset { M \in \mathcal { S } _ { m } } { \overset { \i m \mu } { \lambda }, \overline { \lambda }, \overline { \lambda } \nu } / \xi }, \\ \text{s.t.} \, & \| M \| _ { F } ^ { 2 } \leq 1.$$
We obtain the solution of the latter problem by means of the singular value decomposition (SVD) of the operator Ξ, which is established by the following result.
Theorem C.1. Let Ξ : S n → S n be the linear operator defined in (C1) . Assume that for the density matrices ρ + , ρ -, defining Ξ , it holds that ⟨ ̂ ̂ ρ + , ρ -⟩ ̸ = 1 . Then,
$$\Xi ( K ) = & \| V _ { 1 } \| _ { F } \left \langle K, \widehat { V _ { 1 } } \right \rangle U _ { 1 } + \| U _ { 2 } \| _ { F } \left \langle K, V _ { 2 } \right \rangle \widehat { U _ { 2 } } \quad ( C 5 ) \\ = & \sqrt { 1 - \left \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \right \rangle ^ { 2 } } \cdot \left ( \left \langle K, \widehat { V _ { 1 } } \right \rangle U _ { 1 } + \left \langle K, V _ { 2 } \right \rangle \widehat { U _ { 2 } } \right ) \quad \text{We} \\ & ( C 6 ) \quad \text{mag} \\ & \quad \text{the m}$$
is the reduced-SVD of Ξ , with non-zero singular values
$$s _ { 1 } = s _ { 2 } = \sqrt { 1 - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle ^ { 2 } }, \text{ \quad \ \ } ( C 7 ) \text{ \ \ } \text{$Lceil$}$$
and unnormalized right V i and left U i singular vectors
$$V _ { 1 } = \widehat { \rho _ { + } } - \widehat { \langle \rho _ { + }, \widehat { \rho _ { - } } \rangle } \widehat { \rho _ { - } } ; \underset { \widehat { \rangle } } { U _ { 1 } } = - \widehat { \rho _ { + } }, \text{ \quad \ \ } ( \text{C8a} )$$
$$V _ { 2 } = \widehat { \rho _ { - } } ; \ \ U _ { 2 } = \widehat { \rho _ { - } } - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle \, \widehat { \rho _ { + } }. \quad \ \ ( C 8 b )$$
Proof. We start by rewriting the operator Ξ defined in (C1) in the equivalent form
$$\Xi ( K ) = - \left \langle K, \widehat { \rho _ { + } } \right \rangle \widehat { \rho _ { + } } + \left \langle K, \widehat { \rho _ { - } } \right \rangle \widehat { \rho _ { - } }. \quad ( \mathbb { C } 9 ) \underset { \text{order} } { r \text{
}$$
Consider the operator
$$P ( K ) = \langle K, \widehat { \rho _ { - } } \rangle \, \langle \widehat { \rho _ { - } }, \widehat { \rho _ { + } } \rangle \, \widehat { \rho _ { + } }, \quad \ ( C 1 0 ) \quad \text{ope} _ { \tilde { \vec { \lambda } } \, A ^ { \dagger } }$$
then adding and subtracting the latter to Ξ we obtain
$$\Xi ( K ) & = ( - \langle K, \widehat { \rho _ { + } } \rangle + \langle K, \widehat { \rho _ { - } } \rangle \, \langle \widehat { \rho _ { - } }, \widehat { \rho _ { + } } \rangle ) \cdot \widehat { \rho _ { + } } \quad ( C 1 1 \tt a ) \quad \text{that i} \\ & \quad + \langle K, \widehat { \rho _ { - } } \rangle \cdot ( \widehat { \rho _ { - } } - \langle \widehat { \rho _ { - } }, \widehat { \rho _ { + } } \rangle \, \widehat { \rho _ { + } } ) \quad \text{direct} \\ & = \langle K, \widehat { \rho _ { + } } - \langle \widehat { \rho _ { - } }, \widehat { \rho _ { + } } \rangle \, \widehat { \rho _ { - } } \rangle \cdot ( - \widehat { \rho _ { + } } ) + \langle K, V _ { 2 } \rangle U _ { 2 } \\ & = \langle K, V _ { 1 } \rangle U _ { 1 } + \langle K, V _ { 2 } \rangle U _ { 2 },$$
with V i and U i defined in (C8a). In general, we have that ⟨ ρ + , ρ -⟩ ̸ = 0, so K can have a non-zero projection on both terms of (C9). However, in (C11a) we can immediately verify that ⟨ V , V 1 2 ⟩ = 0 and ⟨ U , U 1 2 ⟩ = 0. In addition, we verify that
$$\langle V _ { 1 }, V _ { 1 } \rangle = & \langle U _ { 2 }, U _ { 2 } \rangle = 1 - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle ^ { 2 } \in ( 0, 1 ], \quad ( C 1 2 )$$
thus we can rewrite (C11a) as stated in (C6). Hence, the expression in (C6) is the reduced-SVD of Ξ, as stated in the claim.
As the final step, we identify the close formulation for the solution of the problem in (C4), using the SVD of the operator Ξ. We assume the conditions of Theorem C.1. Then, by substituting the right singular vectors into the quadratic form in (C3) we obtain
$$\left \langle \widehat { V _ { 1 } }, \Xi ( \widehat { V _ { 1 } } ) \right \rangle = & 1 - \frac { \text{Tr} \left ( \rho _ { + } \rho _ { - } \right ) ^ { 2 } } { \text{Tr} ( \rho _ { + } ^ { 2 } ) } > 0, \text{ \quad \ \ } ( C 1 3 \text{a} )$$
$$\left \langle \widehat { V } _ { 2 }, \Xi ( \widehat { V } _ { 2 } ) \right \rangle = - \left ( 1 - \langle \widehat { \rho _ { + } }, \widehat { \rho _ { - } } \rangle ^ { 2 } \right ) < 0. \quad ( C 1 3 b )$$
Hence M = ̂ V 2 (expanded in (17)) is the observable that minimizes the objective in (C3), subject to the norm of the Hermitian M being 1. In Section D we showcase the exact formula applied to the Ising model.
## Appendix D: Exact example for the order parameter of the Ising model
We consider the quantum Ising model in a transverse magnetic field and the representative density matrices ρ + , ρ -for its phases: if the interaction term dominates or the magnetic field strength dominates, respectively. We denote with σ , σ x y , σ z the corresponding Pauli matrices. Let ρ + = I + σ z 2 and ρ -= I + σ x 2 . Both ρ + and ρ -are norm 1 orthogonal projections, and ⟨ ρ + , ρ -⟩ = 1 2 . We apply the formula for the optimal observable in (17) to get
$$M ^ { * } = & \frac { \mathbb { I } + 2 \sigma ^ { z } - \sigma ^ { x } } { 2 \sqrt { 3 } } = \frac { \sigma ^ { z } } { \sqrt { 3 } } + \frac { \mathbb { I } - \sigma ^ { x } } { 2 \sqrt { 3 } } \quad \text{(D1)}$$
which is a norm 1 Hermitian. Clearly, for the disordered phase Tr( ρ -M ⋆ ) = 0, whereas Tr( ρ + M ⋆ ) = √ 3 2 for the ordered phase. Moreover, we note that M ⋆ is a linear combination of the orthogonal components σ z and I -σ x . The σ z operator is the local order parameter or scaling operator, while I -σ x measures the magnetization in the x -direction. √
Now, let M = σ / σ z ∥ z ∥ F = σ / z 2 (norm 1 as for M ⋆ ), that is the observable M is the magnetization in the z -direction for present model. Then, Tr( ρ -M ) = 0 and Tr( ρ + M ) = 1 √ 2 , hence we confirm that
$$\text{Tr} ( \rho _ { + } M ) \leq \text{Tr} ( \rho _ { + } M ^ { * } ). \text{ \quad \ \ } ( \text{D2} )$$
In other words, we have shown that the observable M ⋆ presents an increased gap between the phases, when compared to the known magnetization M or it maximizes the value in the order phase.
## Appendix E: Experimental Methods
To calculate the ground states for the reduced fidelity susceptibility, we use the density matrix renormalization algorithm (DMRG) [62]. We use two different software packages called Tensor Network Python TeNPy [54] and Quantum Simulation with MPS Tensor qs-mps [63]. In the case of the Rydberg model instead, we use ITensor [64].
For the ANNNI model we span the region ( κ, h ) ∈ R = [0 01 . , 1 5] . × [0 01 . , 1 5] while for the cluster ( . K,h ) ∈ R = [0 5 . , 1 5] . × [0 5 . , 1 5]. . We take n = 64 points for each axis resulting in a 64 × 64 lattice of parameters, with a maximum bond dimension χ = 64. Both Hamiltonians in the top-left corner of their respective regions R are dominated by the σ z term and thus the states will be a perturbation of the all-up state |↑↑ · · · ↑⟩ . To ensure the convergence of the DMRG calculations, we use the following strategy: We begin with a region where the states are relatively easy to prepare and where the DMRGconverges reliably. From there, we extend the calculation to include nearest-neighbor lattice points, using the previously obtained state as the initial state. We continue this approach, gradually moving towards regions where states are more challenging to prepare. In doing so, we gain both accuracy and speed. We note the most time-consuming part of the calculation is solving the local eigenvalue problem through the method eigsh from the software package SciPy [65]. This procedure is effective up until the point of a phase transition. At that point, if the computation time exceeds a specified threshold (which can be set either arbitrarily or adaptively), we shelve the calculation and proceed to the next lattice point.
## Appendix F: Discovered Order Parameter of the ANNNI Model
Following the procedure given in Section IV for the ANNNI model, the two-site observable matrix is given in Figure 17 and decomposed in Section V B.
The decomposition of the observable in terms of Pauli Operators is given as follows;
$$M & \approx 0. 2 3 0 \cdot I I - 0. 1 2 5 \cdot I X \\ & \quad + 0. 1 3 7 \cdot I Z - 0. 1 2 8 \cdot X I \\ & \quad - 0. 1 7 4 \cdot X Z - 0. 1 5 8 \cdot Y Y \\ & \quad + 0. 1 3 6 \cdot Z I - 0. 1 6 0 \cdot Z X \\ & \quad + 0. 2 1 7 \cdot Z Z.$$
FIG. 17: Two-site Observable obtained for the ANNNI Model using the procedure given in Section IV
## Appendix G: The ANNNI model
We first present the phase diagram for the ANNNI Model which is given in Figure 3, where a variety of rich phase transitions are present. We initially begin with small κ and h , where the interactions between neighbors along the x-axis dominate, resulting in a ferromagnetic phase where all spins align parallel to one another, either as |→→ ··· →⟩ or |←← ··· ←⟩ . This ferromagnetic region is highlighted in purple in Figure 3.
Upon increasing κ and h , a phase transition occurs as the spins enter a paramagnetic phase (PM), presented in grey in Figure 3. Entering the paramagnetic phase, the transverse magnetic field begins to dominate, causing all states to align with the magnetic field, resulting in the state |↑↑ · · · ↑⟩ . This Ising-like transition has been previously studied in [66] and the transition line (which corresponds to the purple line in Figure 3 is given in [8, 66] as;
$$h _ { I } \approx \frac { 1 - \kappa } { \kappa } \left ( 1 - \sqrt { \frac { 1 - 3 \kappa + 4 \kappa ^ { 2 } } { 1 - \kappa } } \right ). \quad ( G 1 )$$
Increasing the parameters h and κ , a further transition becomes evident in the phase diagram between the paramagnetic and floating phases (FP). This incommensurate-incommensurate Kosterlitz-Thouless (KT) phase transition [67-69] (given in blue in Figure 3) has been approximated in [70] to be
$$h _ { K T } ( \kappa ) \approx 1. 0 5 \sqrt { \left ( \kappa - \frac { 1 } { 2 } \right ) ( \kappa - 0. 1 ) }. \quad ( G 2 )$$
Such a transition corresponds to a change in the modulation wave vector [71], leading to different incommensurate structures along the spin chain.
A further transition evident in this phase diagram is the transition from the floating phase to the antiphase (AP), where the states exhibit staggered magnetization, as a result of the next-nearest neighbor interactions dominating, corresponding to |· · · ←←→→←←···⟩ . Such an incommensurate-commensurate transition (given in green in Figure 3) is described by the Pokrovsky-Talapov universality class [67, 72], with the transition in this case given by
$$h _ { P T } \approx 1. 0 5 ( \kappa - \frac { 1 } { 2 } ) \text{ \quad \ \ } ( G 3 ) \text{ \quad \ of } \text{ \quad \ } \\ \text{ \quad \ for }$$
as highlighted in [70] and corresponds to the green line in Figure 3. We also note the presence of the Lifshitz point, marked by a red dot in Figure 3. This point represents a critical point, known as the Lifschitz point (LP), on the phase diagram of certain magnetic systems, where a line of second-order phase transitions meets a line of incommensurate modulated phases [73]. Finally, we note the presence of a disordered line in the ANNNI model, referred to as the Peschel-Every (PE) line [74] within the paramagnetic phase. This line serves as a reference point for understanding the characteristics of this specific phase.
We note this model also reproduces important features observed experimentally in systems that can be described by discrete models with effectively short-range competing interactions [17]. These experimental findings include Lifshitz points [75, 76], adsorbates, ferroelectrics, magnetic systems, and alloys. Conversely, the so-called floating phase emerging in the model is appealing to experimental researchers to explore. This critical incommensurate phase has been observed very recently by using Rydberg-atom ladder arrays [77].
## Appendix H: Vector field patterns
This appendix aims to highlight the patterns that emerge in the plot of the vector fields. Specifically, we focus on the 'source'-like patterns observed at the phase transitions and the 'sink'-like patterns that become evident. We demonstrate the conditions under which these patterns appear in the plot of the vector field P ( λ ) (defined in (12)).
Let g : X ⊆ R n → R be a differentiable function and define the level set [78]
$$L ( k ) \coloneqq \{ \mathbf x | \mathbf x \in \mathcal { X }, g ( \mathbf x ) = k \} \quad \quad ( \mathbf H 1 ) \quad \ p o u$$
for some k ∈ R , as the subset of the domain of g whose image under g is the constant k .
Consider a differentiable curve c ( ) t on the level set L k ( ), that is c : I → L k ( ) for some open interval I ⊆ R .
FIG. 18: Curve c ( ) t whose image belongs to a level set of a function g : X ⊆ R 2 → R , that is g ( c ( )) is constant t for t in some open interval.
Consequently, we have that g ( c ( )) = t k for all t ∈ I . So, by the chain rule, we obtain
$$\langle c ^ { \prime } ( t ), \nabla _ { \mathbf x } g ( \mathbf c ( t ) ) \rangle = 0, \text{ \quad \ \ } ( \mathbf H 2 )$$
where ⟨· , ·⟩ is the inner product on R n . In other words, if the vector arguments in (H2) are non-zero, then they must be orthogonal. So, the non-zero gradient of g at a point c ( ) t is perpendicular to the tangent of the curve c at the same point. A pictorial example of the case is given in Figure 18.
We recall that the gradient is the direction of the greatest rate of increase of a function. Then, the sourcelike structures we observe on the plot of the vector field P ( λ ) = -∇ g ( λ ) (eg. see Figure 9) are the local maxima of the fidelity susceptibility g in the direction transversal to the phase transition. The latter is consistent with the manifestation of QPT as a maxima of the susceptibility in finite-size systems.
## Appendix I: Scale invariance of the principal argument
We prove the scale-invariant property of the function p ( λ ) defined in (13), which is employed in the construction of the phase diagrams.
We begin with a few concepts on the class of homogeneous functions. We call a function f : K ⊆ R n → R positive homogeneous (PH) of degree α when
$$f ( t { \mathbf x } ) = t ^ { \alpha } f ( { \mathbf x } ) \in f ( { \mathbf x } ) \quad \quad \ \ ( I 1 )$$
↦
for all scaling factors t > 0 such that tx ∈ K . The term 'positive' refers to the restriction on the scaling factor t > 0, so the degree α can be any real number. The power law x → | | c x α is PH. The parameter α is known as critical exponent in physics. Homogeneity is preserved by differentiation, so for f : R → R
$$\frac { \partial f ( t x ) } { \partial x } = & t f ^ { \prime } ( t x ) = t ^ { \alpha } f ^ { \prime } ( x ), \text{ \quad \ \ } ( I 2 )$$
(the right-most equality follows from the definition in (I1)) dividing by t we get f ′ ( tx ) = t α -1 f ′ ( x ) so f ′ is PH with degree α -1. The latter shows that the vector field in (12) preserves PH. Instead, the angle of the vector field defined in (13) is scale-invariant (when the susceptibility follows the power law as we approach QPT). Indeed, by denoting the partial derivative g λ i = ∂g/∂λ i of the function g defined in (11), we have that
$$p ( ( \lambda - \lambda _ { c } ) t ) = \arctan \left ( \frac { t ^ { \alpha - 1 } g _ { x _ { 2 } } ( \lambda - \lambda _ { c } ) } { t ^ { \alpha - 1 } g _ { x _ { 1 } } ( \lambda - \lambda _ { c } ) } \right ) = p ( \lambda - \lambda _ { c } ), \quad \text{$two q$} \\ ( I 3 ) \quad \text{$squeq$} \\ \text{$singul$}$$
when g x 1 ( λ -λ c ) > 0 (the other cases for atan2( · , · ) follow similarly), with λ c denoting the critical value for the QPT.
## Appendix J: Relation to information geometry
In this appendix, we discuss the fidelity susceptibilities relationship to information geometry and the Quantum Fisher Information (QFI). In (2) we introduced the Bures distance as the statistical distance between density matrices. The latter, when considered in terms of a small displacement d λ in the vector of parameters λ , induces the Bures metric [79]
$$d _ { B } ^ { 2 } ( \rho ( \boldsymbol \lambda ), \rho ( \boldsymbol \lambda + d \boldsymbol \lambda ) ) = \sum _ { i, j } h _ { \boldsymbol \lambda } ^ { i, j } d \lambda _ { i } d \lambda _ { j }, \quad ( J 1 )$$
where h λ is the metric tensor at λ . In other words, the Bures metric is a notion of distinguishability of two density matrices that are infinitesimally close in the coordinate system λ . In the realm of condensed matter physics, the Bures metric is better known as the fidelity susceptibility (introduced in Section II). Thus, the singularities of the metric h λ , correspond to the critical regions of the underlying model.
In quantum metrology, the quantum Cram´ er-Rao bound [80, 81], is the quantum equivalent to the classical lower-bound [82] of the variance of the unbiased estimator ̂ λ (i.e. E [ ̂ λ ] = λ ) for an unknown parameter λ . The bound, in the case of a single parameter λ , is given by
$$\text{Var} ( \widehat { \lambda } ) \geq \frac { 1 } { N Q ( \rho ( \lambda ) ) }, \text{ \quad \ \ } ( J 2 )$$
where N is the number of independent repetitions and Q ρ λ ( ( )) is the QFI [79]. We consider a multi-parameter estimator ̂ λ the bound of the covariance matrix becomes
$$C o v ( \widehat { \boldsymbol \lambda } ) \asymp \frac { Q ( \rho ( \boldsymbol \lambda ) ) ^ { - 1 } } { N }, \quad \quad ( J 3 )$$
where the relation ( ) · ≽ ( ) is the Loewner order (i.e. · for n × n Hermitian matrices A,B , we have that A ≽ B if and only if A -B is PSD).
There was consensus that, in the general case, the fidelity susceptibility is proportional to the quantum Fisher information [83], that is
$$\mathcal { X } _ { F } ( \lambda ) \stackrel {? } { = } \frac { 1 } { 4 } Q ( \rho ( \lambda ) ).$$
However, in [84] it is proved that at the points where we have a rank change of the density matrix ρ λ ( ), the two quantities are not the same and the QFI presents a discontinuity. We note that the meaning and the consequent violation of the Cram´ er-Rao theorem on such singularities is still an active area of research [85, 86].
Concerning our formulation, the function g ( λ ) defined in (11), can be related directly to the trace of the metric tensor, that is g ( λ ) = -Tr( h λ ). The minus factor is used as a convention to make the phase transitions appear as sources in the vector field resulting from (12). In regions of the parameter space X where the rank of ρ ( λ ) is constant, it holds that g ( λ ) is proportional to the trace of the QFI matrix. We also note that the trace of h λ corresponds to the sum of the susceptibilities for each coupling parameter λ i . The choice of the trace is also justified by the fact that this operator is basis-independent.
For a comprehensive introduction to information geometry and QPT, we refer to [87].
- [1] V. L. Ginzburg and L. D. Landau. On the Theory of superconductivity. Zh. Eksp. Teor. Fiz. , 20:1064-1082, 1950.
- [2] Leo Kadanoff, Alessandro de angelis, Nicola Giglietto, Sebastiano Stramaglia, M Kibler, and Dennis Dieks. Theories of matter: Infinities and renormalization. arXiv:1002.2985 , 02 2010.
- [3] Leo P. Kadanoff. Relating theories via renormalization. Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics , 44(1):22-39, 2013.
- [4] Humphrey J. Maris and Leo P. Kadanoff. Teaching the renormalization group. American Journal of Physics , 46(6):652-657, 06 1978.
- [5] Kerson Huang. A critical history of renormalization. International Journal of Modern Physics A , 28(29):1330050, 2013.
- [6] Vincent Ardourel and Sorin Bangu. Finite-size scaling theory: Quantitative and qualitative approaches to critical phenomena. Studies in History and Philosophy of Science , 100:99-106, 2023.
- [7] Saverio Monaco, Oriel Kiss, Antonio Mandarino, Sofia Vallecorsa, and Michele Grossi. Quantum phase detection generalization from marginal quantum neural network models. Physical Review B , 107(8), February 2023.
- [8] M. Cea, M. Grossi, S. Monaco, E. Rico, L. Tagliacozzo, and S. Vallecorsa. Exploring the phase diagram of the quantum one-dimensional annni model. arXiv:2402.11022 , 2024.
- [9] Teresa Sancho-Lorente, Juan Rom´n-Roche, and David a Zueco. Quantum kernels to learn the phases of quantum matter. Phys. Rev. A , 105:042432, Apr 2022.
- [10] Julian Arnold, Frank Sch¨ afer, Alan Edelman, and Christoph Bruder. Mapping out phase diagrams with generative classifiers. Phys. Rev. Lett. , 132:207301, May 2024.
- [11] Julian Arnold and Frank Sch¨fer. a Replacing neural networks by optimal analytical predictors for the detection of phase transitions. Phys. Rev. X , 12:031044, Sep 2022.
- [12] Richard Jozsa. Fidelity for mixed quantum states. Journal of Modern Optics , 41(12):2315-2323, 1994.
- [13] Amit Dutta, Gabriel Aeppli, Bikas K. Chakrabarti, Uma Divakaran, Thomas F. Rosenbaum, and Diptiman Sen. Quantum Phase Transitions in Transverse Field Spin Models: From Statistical Physics to Quantum Information . Cambridge University Press, 2015.
- [14] Shi-Jian GUu. Fidelity approach to quantum phase transitions. International Journal of Modern Physics B , 24(23):4371-4458, September 2010.
- [15] Wen-Long You, Ying-Wai Li, and Shi-Jian Gu. Fidelity, dynamic structure factor, and susceptibility in critical phenomena. Phys. Rev. E , 76:022101, Aug 2007.
- [16] Jiannis K. Pachos and Martin B. Plenio. Three-spin interactions in optical lattices and criticality in cluster hamiltonians. Phys. Rev. Lett. , 93:056402, Jul 2004.
- [17] Walter Selke. The annni model - theoretical analysis and experimental application. Physics Reports , 170:213264, 1988.
- [18] Jose Carrasco, Andreas Elben, Christian Kokail, Barbara Kraus, and Peter Zoller. Theoretical and experimental perspectives of quantum verification. PRX Quantum ,
2:010102, Mar 2021.
- [19] Michael A. Nielsen and Isaac L. Chuang. Quantum Computation and Quantum Information: 10th Anniversary Edition . Cambridge University Press, USA, 10th edition, 2011.
- [20] Armin Uhlmann. The 'transition probability' in the state space of a *-algebra. Reports on Mathematical Physics , 9:273-279, 1976.
- [21] E. Schr¨dinger. o Quantisierung als Eigenwertproblem. Annalen Phys. , 384(4):361-376, 1926.
- [22] Lei Wang, Ye-Hua Liu, Jakub Imriˇ ska, Ping Nang Ma, and Matthias Troyer. Fidelity susceptibility made simple: A unified quantum monte carlo approach. Physical Review X , 5(3), July 2015.
- [23] Paulo E. M. F. Mendon¸ ca, Reginaldo d. J. Napolitano, Marcelo A. Marchiolli, Christopher J. Foster, and YeongCherng Liang. Alternative fidelity measure between quantum states. Physical Review A , 78(5), November 2008.
- [24] Paolo Zanardi, H. T. Quan, Xiaoguang Wang, and C. P. Sun. Mixed-state fidelity and quantum criticality at finite temperature. Phys. Rev. A , 75:032109, Mar 2007.
- [25] Paolo Zanardi, Lorenzo Campos Venuti, and Paolo Giorda. Bures metric over thermal state manifolds and quantum criticality. Phys. Rev. A , 76:062318, Dec 2007.
- [26] A. Fabricio Albuquerque, Fabien Alet, Cl´ment Sire, and e Sylvain Capponi. Quantum critical scaling of fidelity susceptibility. Phys. Rev. B , 81:064418, Feb 2010.
- [27] Shunsuke Furukawa, Gr´ egoire Misguich, and Masaki Oshikawa. Systematic derivation of order parameters through reduced density matrices. Phys. Rev. Lett. , 96:047211, Feb 2006.
- [28] Stephen Boyd and Lieven Vandenberghe. Convex Optimization . Cambridge University Press, 2004.
- [29] Andrew R. Conn, Nicholas I. M. Gould, and Philippe L. Toint. Trust Region Methods . Society for Industrial and Applied Mathematics, 2000.
- [30] Franz Rendl and Henry Wolkowicz. A semidefinite framework for trust region subproblems with applications to large scale minimization. Mathematical Programming , 77(1):273-299, Apr 1997.
- [31] Gene H. Golub and Charles F. Van Loan. Matrix computations (3rd ed.) . Johns Hopkins University Press, USA, 1996.
- [32] N. Goldenfeld. Lectures On Phase Transitions And The Renormalization Group . CRC Press, 1992.
- [33] R. J. Elliott. Phenomenological discussion of magnetic ordering in the heavy rare-earth metals. Phys. Rev. , 124:346-353, Oct 1961.
- [34] Michael E. Fisher and Walter Selke. Infinitely many commensurate phases in a simple ising model. Phys. Rev. Lett. , 44:1502-1505, Jun 1980.
- [35] Anjan Kumar Chandra and Subinay Dasgupta. Floating phase in a 2D ANNNI model. Journal of Physics A Mathematical General , 40(24):6251-6265, June 2007.
- [36] Anjan Kumar Chandra and Subinay Dasgupta. Floating phase in the one-dimensional transverse axial nextnearest-neighbor ising model. Phys. Rev. E , 75:021105, Feb 2007.
- [37] P.H. Lundow and I.A. Campbell. The ising universality class in dimension three: Corrections to scaling. Physica
- A: Statistical Mechanics and its Applications , 511:40-53, 2018.
- [38] Ra´ ul Morral-Yepes, Frank Pollmann, and Izabella Lovas. Detecting and stabilizing measurement-induced symmetry-protected topological phases in generalized cluster models. Phys. Rev. B , 108:224304, Dec 2023.
- [39] David Perez-Garcia, M Wolf, Mikel Sanz, Frank Verstraete, and J Cirac. String order and symmetries in quantum spin lattices. Physical Review Letters , 100:167202, 04 2008.
- [40] Adam Smith, Bernhard Jobst, Andrew G. Green, and Frank Pollmann. Crossing a topological phase transition with a quantum computer. Phys. Rev. Res. , 4:L022020, Apr 2022.
- [41] Hannes Bernien, Sylvain Schwartz, Alexander Keesling, Harry Levine, Ahmed Omran, Hannes Pichler, Soonwon Choi, Alexander S Zibrov, Manuel Endres, Markus Greiner, et al. Probing many-body dynamics on a 51atom quantum simulator. Nature , 551(7682):579-584, 2017.
- [42] Hannes Bernien, Sylvain Schwartz, Alexander Keesling, Harry Levine, Ahmed Omran, Hannes Pichler, Soonwon Choi, Alexander S. Zibrov, Manuel Endres, Markus Greiner, Vladan Vuleti´, and Mikhail D. Lukin. Probing c many-body dynamics on a 51-atom quantum simulator. Nature , 551(7682):579-584, 2017.
- [43] Dolev Bluvstein, Simon J. Evered, Alexandra A. Geim, Sophie H. Li, Hengyun Zhou, Tom Manovitz, Sepehr Ebadi, Madelyn Cain, Marcin Kalinowski, Dominik Hangleiter, J. Pablo Bonilla Ataides, Nishad Maskara, Iris Cong, Xun Gao, Pedro Sales Rodriguez, Thomas Karolyshyn, Giulia Semeghini, Michael J. Gullans, Markus Greiner, Vladan Vuleti´, and Mikhail D. Lukin. c Logical quantum processor based on reconfigurable atom arrays. Nature , 626(7997):58-65, 2024.
- [44] Iris Cong, Harry Levine, Alexander Keesling, Dolev Bluvstein, Sheng-Tao Wang, and Mikhail D. Lukin. Hardware-efficient, fault-tolerant quantum computation with rydberg atoms. Phys. Rev. X , 12:021049, Jun 2022.
- [45] Quantum information with rydberg atoms. Reviews of modern physics , 82(3):2313-2363, 2010.
- [46] Antoine Browaeys and Thierry Lahaye. Many-body physics with individually controlled rydberg atoms. Nature Physics , 16(2):132-142, 2020.
- [47] Natalia Chepiga and Fr´d´ric Mila. Lifshitz point at come e mensurate melting of chains of rydberg atoms. Phys. Rev. Res. , 3:023049, Apr 2021.
- [48] Jonathan Z. Lu, Rodrigo Araiza Bravo, Kaiying Hou, Gebremedhin A. Dagnew, Susanne F. Yelin, and Khadijeh Najafi. Learning quantum symmetries with interactive quantum-classical variational algorithms. J. Phys. A , 57(31):315304, 2024.
- [49] Xue-Jia Yu, Sheng Yang, Jing-Bo Xu, and Limei Xu. Fidelity susceptibility as a diagnostic of the commensurateincommensurate transition: A revisit of the programmable rydberg chain. Phys. Rev. B , 106:165124, Oct 2022.
- [50] Antoine Browaeys and Thierry Lahaye. Many-body physics with individually controlled Rydberg atoms. Nature Physics , 16(2):132-142, January 2020.
- [51] Rhine Samajdar, Soonwon Choi, Hannes Pichler, Mikhail D. Lukin, and Subir Sachdev. Numerical study of the chiral 𭟋 3 quantum phase transition in one spatial dimension. Phys. Rev. A , 98:023614, Aug 2018.
- [52] Natalia Chepiga and Fr´ ed´ric Mila. e Kibble-zurek exponent and chiral transition of the period-4 phase of rydberg chains. Nature Communications , 12, 01 2021.
- [53] U. Schollw¨ck. o The density-matrix renormalization group. Rev. Mod. Phys. , 77:259-315, Apr 2005.
- [54] Johannes Hauschild and Frank Pollmann. Efficient numerical simulations with Tensor Networks: Tensor Network Python (TeNPy). SciPost Phys. Lect. Notes , page 5, 2018. Code available from https://github.com/tenpy/ tenpy .
- [55] Irwin Sobel. An isotropic 3x3 image gradient operator. Presentation at Stanford A.I. Project 1968 , 02 2014.
- [56] Larry S. Davis. A survey of edge detection techniques. Computer Graphics and Image Processing , 4(3):248-270, 1975.
- [57] Peter Kovesi. Good colour maps: How to design them. arXiv:1002.2985 , 2015.
- [58] J. D. Hunter. Matplotlib: A 2d graphics environment. Computing in Science & Engineering , 9(3):90-95, 2007.
- [59] F.J. Harris. Multirate Signal Processing for Communication Systems . Prentice Hall PTR, 2004.
- [60] J.C. Butcher. A history of runge-kutta methods. Applied Numerical Mathematics , 20(3):247-260, 1996.
- [61] Roger A. Horn and Charles R. Johnson. Matrix Analysis . Cambridge University Press, USA, 2nd edition, 2012.
- [62] Ulrich Schollw¨ck. o The density-matrix renormalization group in the age of matrix product states. Annals of Physics , 326(1):96-192, January 2011.
- [63] Francesco Di Marcantonio. Quantum simulation with mps tensor, 2024. Code available from https://github. com/Fradm98/qs-mps .
- [64] Matthew Fishman, Steven White, and Edwin Stoudenmire. The itensor software library for tensor network calculations. SciPost Physics Codebases , August 2022.
- [65] Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, St´fan J. van der Walt, Matthew Brett, Joshua e Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, Ilhan Polat, Yu Feng, Eric W. Moore, Jake Van-˙ derPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antˆnio H. Ribeiro, Fabian Peo dregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods , 17:261-272, 2020.
- [66] Sei Suzuki, Jun-ichi Inoue, and Bikas K. Chakrabarti. Quantum Ising Phases and Transitions in Transverse Ising Models . Springer Berlin Heidelberg, Berlin, Heidelberg, 2013.
- [67] V. L. Pokrovsky and A. L. Talapov. Ground state, spectrum, and phase diagram of two-dimensional incommensurate crystals. Phys. Rev. Lett. , 42:65-67, Jan 1979.
- [68] David A. Huse and Michael E. Fisher. Commensurate melting, domain walls, and dislocations. Phys. Rev. B , 29:239-270, Jan 1984.
- [69] P. Bak. Review Article: Commensurate phases, incommensurate phases and the devil's staircase. Reports on Progress in Physics , 45(6):587-629, June 1982.
- [70] Matteo Beccaria, Massimo Campostrini, and Alessandra Feo. Evidence for a floating phase of the transverse annni model at high frustration. Phys. Rev. B , 76:094410, Sep 2007.
- [71] Ruben Verresen, Ashvin Vishwanath, and Frank Pollmann. Stable Luttinger liquids and emergent U (1) symmetry in constrained quantum chains. arXiv e-prints , page arXiv:1903.09179, March 2019.
- [72] Y.-J. Wang, F. H. L. Essler, M. Fabrizio, and A. A. Nersesyan. Quantum criticalities in a two-leg antiferromagnetic s = 1 2 ladder induced by a staggered magnetic field. Phys. Rev. B , 66:024412, Jul 2002.
- [73] A.K. Murtazaev and J.G. Ibaev. Critical properties of an annni-model in the neighborhood of multicritical lifshitz point. Solid State Communications , 152:177-179, 02 2012.
- [74] I Peschel and V J Emery. Calculation of spin correlations in two-dimensional ising systems from one-dimensional kinetic models. Zeitschrift f¨r Physik B Condensed Matu ter , 43(3):241-249, September 1981.
- [75] Malte Henkel and Michel Pleimling. Lifshitz Points: Strongly Anisotropic Equilibrium Critical Points , pages 337-368. Springer Netherlands, Dordrecht, 2010.
- [76] R.M. Hornreich. The lifshitz point: Phase diagrams and critical behavior. Journal of Magnetism and Magnetic Materials , 15-18:387-392, 1980.
- [77] Jin Zhang et al. Probing quantum floating phases in Rydberg atom arrays. arXiv: 2401.08087 , 1 2024.
- [78] T.M. Apostol. Calculus. Vol. II: Multi-variable Calculus and Linear Algebra, with Applications to Differential Equations and Probability . Number v. 2 in Blaisdell international textbook series. Xerox College Publ., 1969.
- [79] Matteo G. A. Paris. Quantum estimation for quantum
- technology. International Journal of Quantum Information , 07(supp01):125-137, 2009.
- [80] Carl W. Helstrom. Quantum detection and estimation theory. Journal of Statistical Physics , 1(2):231-252, 1969.
- [81] Samuel L. Braunstein and Carlton M. Caves. Statistical distance and the geometry of quantum states. Phys. Rev. Lett. , 72:3439-3443, May 1994.
- [82] C. Radhakrishna Rao. Information and the Accuracy Attainable in the Estimation of Statistical Parameters , pages 235-247. Springer New York, New York, NY, 1992.
- [83] Jing Liu, Heng-Na Xiong, Fei Song, and Xiaoguang Wang. Fidelity susceptibility and quantum fisher information for density operators with arbitrary ranks. Physica A: Statistical Mechanics and its Applications , 410, 01 2014.
- [84] Dominik ˇ afr´nek. S a Discontinuities of the quantum fisher information and the bures metric. Phys. Rev. A , 95:052320, May 2017.
- [85] Luigi Seveso, Francesco Albarelli, Marco G Genoni, and Matteo G A Paris. On the discontinuity of the quantum fisher information for quantum statistical models with parameter dependent rank. Journal of Physics A: Mathematical and Theoretical , 53(2):02LT01, dec 2019.
- [86] A. T. Rezakhani, M. Hassani, and S. Alipour. Continuity of the quantum fisher information. Phys. Rev. A , 100:032317, Sep 2019.
- [87] Paolo Zanardi, Paolo Giorda, and Marco Cozzini. Information-theoretic differential geometry of quantum phase transitions. Phys. Rev. Lett. , 99:100603, Sep 2007. | null | [
"Nicola Mariella",
"Tara Murphy",
"Francesco Di Marcantonio",
"Khadijeh Najafi",
"Sofia Vallecorsa",
"Sergiy Zhuk",
"Enrique Rico"
]
| 2024-08-02T17:25:04+00:00 | 2024-11-18T15:37:25+00:00 | [
"quant-ph"
]
| Order Parameter Discovery for Quantum Many-Body Systems | Quantum phase transitions reveal deep insights into the behavior of many-body
quantum systems, but identifying these transitions without well-defined order
parameters remains a significant challenge. In this work, we introduce a novel
approach to constructing phase diagrams using the vector field of the reduced
fidelity susceptibility (RFS). This method maps quantum phases and formulates
an optimization problem to discover observables corresponding to order
parameters. We demonstrate the effectiveness of our approach by applying it to
well-established models, including the Axial Next Nearest Neighbour Interaction
(ANNNI) model, a cluster state model, and a chain of Rydberg atoms. By
analyzing observable decompositions into eigen-projectors and finite-size
scaling, our method successfully identifies order parameters and characterizes
quantum phase transitions with high precision. Our results provide a powerful
tool for exploring quantum phases in systems where conventional order
parameters are not readily available. |
2408.01402v1 | ## Pre-trained Language Models Improve the Fewshot Prompt Ability of Decision Transformer
Yu Yang
[email protected]
Duke University
Pan Xu
[email protected] Duke University
## Abstract
Decision Transformer (DT) has emerged as a promising class of algorithms in offline reinforcement learning (RL) tasks, leveraging pre-collected datasets and Transformer's capability to model long sequences. Recent works have demonstrated that using parts of trajectories from training tasks as prompts in DT enhances its performance on unseen tasks, giving rise to Prompt-DT methods. However, collecting data from specific environments can be both costly and unsafe in many scenarios, leading to suboptimal performance and limited few-shot prompt abilities due to the data-hungry nature of Transformer-based models. Additionally, the limited datasets used in pre-training make it challenging for Prompt-DT type of methods to distinguish between various RL tasks through prompts alone. To address these challenges, we introduce the Language model-initialized Prompt Decision Transformer (LPDT), which leverages pre-trained language models for meta-RL tasks and fine-tunes the model using Low-rank Adaptation (LoRA). We further incorporate prompt regularization to effectively differentiate between tasks based on prompt feature representations. Our approach integrates pre-trained language model and RL tasks seamlessly. Extensive empirical studies demonstrate that initializing with a pre-trained language model significantly enhances the performance of Prompt-DT on unseen tasks compared to baseline methods.
## 1 Introduction
In many sequential decision-making applications such as robotic manipulation and autonomous driving (Sinha et al., 2022; Kumar et al., 2021), it can be expensive or even unsafe for agents to learn through trial-and-error with the environment. Offline reinforcement learning (RL) methods (Levine et al., 2020) have emerged as a powerful paradigm for optimizing agent policies without directly interacting with the environment. They leverage pre-collected datasets obtained from a set of behavior policies instead of online interactions to learn an optimal policy. Among these Offline RL methods, Decision Transformer (DT) (Chen et al., 2021) has become popular for offline RL tasks due to its scalability with computation and data and stability in training. DT models a goal-conditioned policy using a Transformer network, solving a sequence-prediction problem in a supervised learning manner. More specifically, DT formulates decision-making as sequence generation over pre-collected trajectories using the powerful Transformer architecture (Vaswani et al., 2017). DT models the states, actions and return-to-go from the RL trajectory as the word tokens in Natural Language Processing (NLP) tasks and then generates the actions conditioned on the return goals.
Compared with traditional dynamic programming-based offline RL methods (Kumar et al., 2019; Fujimoto et al., 2019; Kumar et al., 2020) that heavily rely on the Markov Decision Process (MDP) assumption of the environment, Decision Transformer can utilize entire trajectory histories to predict the next action, making them more applicable in partially observable environments where all past information must be incorporated in decision-making(Kaelbling et al., 1998; Ni et al., 2024). Furthermore, the supervised learning nature of DTs enhances the stability and scalability in the
training process compared to dynamic programming algorithms based on Bellman equations (Chen et al., 2021; Janner et al., 2021; Zheng et al., 2022). Another advantage of Transformers is their few-shot generalization ability (Brown et al., 2020; Achiam et al., 2023). Based on their remarkable few-shot generalization capability, a prompt-based framework has been proposed and proven effective for adapting to new tasks in NLP (Brown et al., 2020; Li & Liang, 2021). In this paradigm, the prompt, containing useful information about the task, is inputted as a prefix to the model for identifying the environments. Previous works have demonstrated that DTs also exhibit good generalization ability for unseen tasks. Prompt-DT (Xu et al., 2022) leverages parts of trajectories from datasets as prompts to encapsulate task information. The method is trained on these trajectories and corresponding prompts, then tested on unseen tasks with few-shot demonstrations as prompts.
However, existing Prompt-DT methods (Xu et al., 2022; Hu et al., 2023; 2024) require significant amounts of data for pre-training due to the data-hungry nature of Transformers (Brown et al., 2020; Achiam et al., 2023). Offline RL datasets are often small and insufficient to fully unleash the fewshot prompt learning capability of Transformers. Collecting large amounts of RL trajectories for pre-training powerful Decision Transformers is challenging. Inspired by the broad success of large language models in NLP, recent works (Li et al., 2022; Reid et al., 2022; Shi et al., 2023) have shown the potential of such models to provide effective initial weights for decision-making tasks. However, these works do not directly demonstrate few-shot abilities due to a lack of multi-task training and prompt guidance. Language initialization in these works provides pre-knowledge and helps alleviate the need of huge datasets. Therefore, we aim to explore the use of pre-trained language models to initialize Prompt-DT methods and reduce the dependency on large datasets for training.
In this work, we propose a novel framework, Language model-initialized Prompt Decision Transformer (LPDT), that utilizes pre-trained language model initialization to improve the few-shot prompt ability of Decision Transformer. Our approach initializes the model with pre-trained language models, incorporating pre-existing knowledge that might benefit downstream RL tasks. We combine this pre-trained knowledge with domain-specific knowledge from multi-task RL by using LoRA (Hu et al., 2021), a parameter-efficient fine-tuning method, to fine-tune the pre-trained model on a multi-task RL offline dataset using prompts. Furthermore, distinguishing different testing environments is vital for multi-task or meta RL. Therefore, we introduce prompt regularization methods to help the pre-trained Decision Transformer distinguish different RL tasks, guiding action generation under new, unseen task-specific prompt representations. A more detailed illustration of the model structure and our training paradigm is provided in Figure 1. We conduct extensive experiments to assess the capability of our proposed framework in MuJoCo control environments (Fu et al., 2020) and Meta World ML1 tasks (Yu et al., 2020). Our method outperforms baselines in terms of cumulative rewards on unseen tasks. Our contributions are summarized as follows.
- · We propose a framework named LPDT to improve the few-shot prompt ability of Decision Transformer. This framework involves leveraging the language model as the initialization of DT and imposing both supervised and unsupervised prompt regularization. LPDT demonstrates improved few-shot prompt capabilities with pre-trained language knowledge in multi-task RL.
- · We utilize Low-Rank Adaptation (LoRA) and an additional prompt regularization method to combine pre-trained knowledge with domain-specific RL task knowledge. LoRA allows efficient fine-tuning by adapting only a small subset of parameters, while both the supervised and unsupervised prompt regularization enhances the model's ability to distinguish task information contained in the prompts.
- · Through extensive experiments on MuJoCo control and Meta World ML1, we demonstrate the advantages of LPDT compared to baselines. Our results show that LPDT significantly outperforms existing models in performance under full and limited datasets, highlighting its potential for real-world applications.
Figure 1: Overview of LPDT. We first initialize our algorithm using a pre-trained language model such as DistilGPT2 (Sanh et al., 2019). The pre-trained language model is trained on a large corpus of data using the causal language modeling objective which is to predict the next-token paradigm. Our method LPDT replaces the word embedding layers with linear layers to fully learn and capture the features of RL trajectory tokens. We fine-tune our model using parameter-efficient methods like Low-Rank Adaptation (LoRA). Specifically, we freeze the initial weights of the language models and update only the LoRA weights. The input to our approach consists of prompts accompanied by training trajectories from the same tasks. Unlike traditional models that predict word tokens, our method predicts action tokens. Additionally, we incorporate prompt regularization over the input prompts. This is achieved by introducing an additional loss on the prompt embeddings, which helps LPDT distinguish between different environments. More technical details of our method are presented in Section 3.
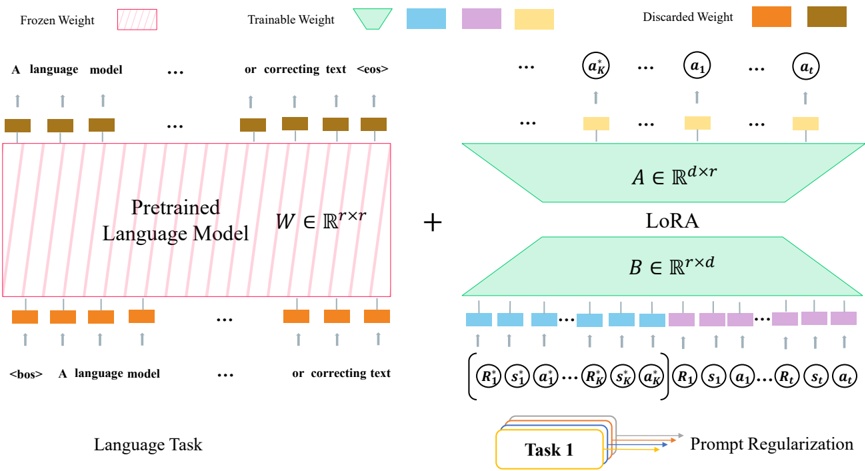
## 2 Preliminary
## 2.1 Offline Reinforcement Learning
Reinforcement learning problems are usually formulated as a Markov Decision Process (MDP) defined by a tuple ( S A T , , , d 0 , R , γ ), where S represents the set of states s ∈ S , A represents the set of actions a ∈ A , T is the transition distribution in the form T ( s t +1 | s , a t t ), d 0 is the distribution of initial states s 0 , R : S × A → R is the reward function, r t = R ( s , a t t ) is the reward at timestep t , and γ ∈ (0 1) is the discount factor. , The objective is to find a policy π that maximizes the expected cumulative rewards J π ( ):
$$J ( \pi ) = \mathbb { E } _ { s _ { 0 } \sim d _ { 0 } ( \cdot ), a _ { t } \sim \pi ( \cdot | s _ { t } ), s _ { t + 1 } \sim \mathcal { T } ( \cdot | s _ { t }, a _ { t } ) } \left [ \sum _ { t = 0 } ^ { \infty } \gamma ^ { t } \mathcal { R } ( s _ { t }, a _ { t } ) \right ].$$
There are many RL algorithms proposed to solve these MDP problems via online interactions with the environment. However, online RL algorithms are not feasible in some scenarios such as robotic manipulation and autonomous driving where the interactions with the environment are associated with high computational cost and risks. Offline RL methods (Levine et al., 2020) become popular in these scenarios. Different from the online setting, the agent has access to a dataset D containing trajectories collected by a behavior policy instead of access to the environment. The agent is expected to find the optimal policy using only the offline dataset D , without interacting with the
environment itself. Among various offline RL methods (Levine et al., 2020; Kumar et al., 2019; Fujimoto et al., 2019; Kumar et al., 2020), Decision Transformer (Chen et al., 2021) which leverages the Transformer (Vaswani et al., 2017) to predict the next action conditioned on the past trajectory is drawing increasing attention. Transformer is first proposed by Vaswani et al. (2017), which has been extensively used in natural language processing (NLP) and computer vision (CV). Recently, Transformer has also been increasingly studied in reinforcement learning using the sequence modeling paradigm (Chen et al., 2021; Furuta et al., 2021; Xu et al., 2022; Janner et al., 2021). In DT, the trajectories { s , a 0 0 , r 0 , s 1 , a 1 , r 1 , . . . , s T , a T , r T } in the offline dataset D are reformulated and modeled as a sequence generation problem via self-supervised learning paradigm.
## 2.2 Prompt Decision Transformer
Decision Transformer leverages the powerful Transformer model to predict the action via the sequence generation paradigm. Recent advances in NLP (Achiam et al., 2023; Puri & Catanzaro, 2019) demonstrate that Transformer enjoys impressive few-shot learning capabilities when it is pretrained on vast language datasets and then generates the word tokens under a specific prompt in the testing phase which is used to describe the language tasks. Similarly, Decision Transformer can also be extended to use prompt information to improve its generalization ability in unseen tasks during testing. Xu et al. (2022) introduced Prompt-DT, which leverages the Decision Transformer architecture to model the RL trajectories in multi-task environments and make decisions in unseen tasks based on the prompt framework, achieving few-shot learning ability in offline RL setting. Different from the prompt-based methods in NLP tasks, Prompt-DT utilizes the sampled short trajectories from the specific task in the offline dataset as the prompt. These prompts also contain environment information, which can help the model distinguish the tasks.
In the offline dataset D , we have the trajectories τ . The prompts and training trajectories are both from this dataset. Different from the offline RL setting, the rewards in the training trajectories of Decision Transformer are replaced by the return-to-go which are denoted as the R i = ∑ T t = i r t . The prompt is the short trajectory which can also be denoted as the tuples of state s ∗ , action a ∗ , and return-to-go R ∗ . It captures essential and concise trajectory information to aid task identification without prior knowledge of the RL tasks. During the training stage, we utilize the offline RL dataset D which contains multiple RL tasks denoted as T i ∈ T train . The input of Prompt-DT is a concatenation of the prompt and the training trajectory, denoted by τ ∗ i and τ i respectively. Specifically, we denote the prompt τ ∗ i as the following sequence
$$\tau _ { i } ^ { * } & = ( R _ { i, 1 } ^ { * }, s _ { i, 1 } ^ { * }, a _ { i, 1 } ^ { * }, \cdots, R _ { i, K ^ { * } } ^ { * }, s _ { i, K ^ { * } } ^ { * }, a _ { i, K ^ { * } } ^ { * } ),$$
where K ∗ is the length of the prompt. These trajectory prompts are shorter than the horizon of the tasks, thereby providing crucial guidance without enabling complete task imitation. Beyond the prompt, the training trajectories of DT can be denoted as
$$\tau _ { i } & = ( R _ { i, 1 }, s _ { i, 1 }, a _ { i, 1 }, \cdots, R _ { i, K }, s _ { i, K }, a _ { i, K } ),$$
where K is the length of the training trajectories. Consequently, we have the input vector τ input i defined as
$$\tau _ { i } ^ { i n p u t } = [ \tau _ { i } ^ { * }, \tau _ { i } ] = ( R _ { i, 1 } ^ { * }, s _ { i, 1 } ^ { * }, a _ { i, 1 } ^ { * }, \cdots, R _ { i, K ^ { * } } ^ { * }, s _ { i, K ^ { * } } ^ { * }, a _ { i, K ^ { * } } ^ { * }, R _ { i, 1 }, s _ { i, 1 }, a _ { i, 1 }, \dots, R _ { i, K }, s _ { i, K }, a _ { i, K } ). \quad ( 4 )$$
Besides, we denote the partial trajectory from the timestep 1 to timestep t as τ input i, 1 <t . Then the learning objective of Prompt-DT can be formulated as the following maximum likelihood estimation:
$$L _ { P D T } = \mathbb { E } _ { \tau _ { i } ^ { i n p u t } \sim _ { T _ { i } } } \left [ \sum _ { t = 1 } ^ { K } - \log M _ { \theta } ( \hat { a } _ { i, t } | \tau _ { i } ^ { * }, \tau _ { i, 1 < t - 1 } ^ { i n p u t }, R _ { i, t }, s _ { i, t } ) \right ].$$
where M θ denotes the Prompt-DT model with the parameter θ . In practical implementations, we often use the mean squared error loss instead, which aims to predict the future action ˆ a i,t given the history trajectory and current state by minimizing the following loss function.
$$L _ { P D T } = \mathbb { E } _ { \tau _ { i } ^ { i n p u t } \sim T _ { i } } \left [ 1 / K \sum _ { t = 1 } ^ { K } ( a _ { i, t } - \hat { a } _ { i, t } ) ^ { 2 } \right ].$$
The training procedure of Prompt-DT is to autoregressively generate the action conditioned on the current state, return-to-go, past trajectory and sampled prompt.
## 3 The Proposed Framework
We propose Language model-initialized Prompt Decision Transformer (LPDT), a novel and effective framework to incorporate powerful pre-trained language models into Decision Transformers to improve their few-shot learning abilities. We also leverage an additional prompt regularization over the prompts during fine-tuning to better identify tasks. Figure 1 illustrates the overview of our method. At a high level, LPDT incorporates several key components:
- · Language model initialization for Prompt-DT: We first use a pre-trained language model, such as DistilGPT2 (Sanh et al., 2019; Radford et al., 2019), as the initialization for our Decision Transformer. This design ensures compatibility with the Prompt-DT paradigm, where prompts from various tasks are appended to the input sequence.
- · Parameter-efficient fine-tuning on RL tasks: We adopt Low-Rank Adaptation (LoRA) (Hu et al., 2021) to fine-tune a low-rank residual matrix while keeping the original weight matrix of the language model fixed throughout the learning process. This approach significantly reduces the number of parameters compared to standard full fine-tuning of the large language models.
- · Prompt regularization with supervised and unsupervised objectives: We incorporate additional regularization over the prompt embeddings to better identify tasks. Specifically, we employ loss functions derived from both supervised and unsupervised learning techniques to fully utilize task-related information from prompts, thereby preventing the language model from overfitting specific tasks.
We discuss these techniques in detail in the rest of this section. At the end of this section, built on these components, we present our learning algorithm in Algorithm 1.
## 3.1 Language model initialization for Prompt-DT
The first step in our LPDT framework is to use pre-trained language models as the initialization. Recent advances in large language models have demonstrated that these models possess strong fewshot learning abilities. With task-specific information such as prompts for translation or answering questions, language models can generate relevant outputs. We adapt these language models to RL tasks, such as MuJoCo controls, to reduce the demand for large datasets by leveraging pre-trained knowledge that may have relevance to downstream RL tasks. In this work, we use the DistilGPT2 (Sanh et al., 2019; Radford et al., 2019) as the initial weights, which is a pre-trained model with 82 million parameters and is faster and lighter than the original GPT-2 (Radford et al., 2019). The common next-token prediction objective of GPTs can be formulated as
$$L _ { L M } = \sum _ { i = 1 } ^ { t - 1 } - \log ( M _ { \theta ^ { * } } \left ( w _ { i + 1 } \, | \, w _ { 1 }, \dots, w _ { i } \right ) ),$$
where M θ ∗ is the language model and w i represents the word token. To make the language model compatible with the RL sequence prediction tasks in DT, we follow previous work (Shi et al., 2023) to replace the word token embedding input and output layers with linear layers, which are trainable for specific RL tasks. Moreover, in the input layer, we also need to incorporate a prefix as the prompt from sequences chosen from trajectories rolled out in the offline dataset. The embedding layers are represented by the different color blocks in Figure 1 for the prompt and input sequence, respectively. Apart from the input and output embedding layers, the entire intermediate layers of the language model will be frozen during the training on RL tasks.
## 3.2 Parameter-efficient fine-tuning on RL tasks
To adapt the language models to specific RL tasks, we add a low-rank adaptation of the frozen weights of the language model and update it using parameter-efficient methods like LoRA (Hu et al.,
2021). Specifically, LoRA utilizes two low-rank matrices to represent the weight matrix, significantly reducing the number of parameters. This process can be formulated as W = W 0 +∆ W = W 0 + AB , where W ∈ R d × k is the weight of our model, W 0 ∈ R d × k is the frozen weight inherited from the language model, and A ∈ R d × r and B ∈ R r × k are low-rank matrices. In this way, we avoid fully fine-tuning the language model and make our method scalable to large language models, where only a small number of parameters from the low-rank matrix ∆ W need to be updated.
## 3.3 Prompt regularization with supervised and unsupervised objectives
Previous works such as Prompt-Tuning DT (Hu et al., 2023) and Prompt Diffuser (Hu et al., 2024) aim to tune the prompt during testing on unseen tasks. These methods seek to optimize the prompt during the testing phase separately, allowing the model to distinguish the current task during testing. However, they are not always effective and can result in inferior performance when tasks are too similar. To address this challenge and achieve improved performance on testing tasks, we incorporate a task identification procedure into the training process. To effectively distinguish tasks by their prompts, we adopt additional regularization on the training loss over the prompt embeddings, termed prompt regularization.
Since our model is built upon Prompt-DT, we use the loss function for Prompt-DT defined in (6) as the base loss function, and then incorporate a prompt regularization term. The final loss function of our method is as follows.
$$L _ { t o t a l } & = \mathbb { E } _ { \tau _ { i } ^ { i n p u t } \sim T _ { i } } \left [ 1 / K \sum _ { t = 1 } ^ { K } ( a _ { i, t } - \hat { a } _ { i, t } ) ^ { 2 } \right ] + \lambda L _ { \phi },$$
where L φ is the loss for the prompt regularization which we will specify in the rest of this section, and λ is the hyperparameter for prompt regularization.
In particular, we propose two practical implementations of prompt regularization based on supervised learning and unsupervised learning methods respectively.
Supervised learning-based prompt regularization. In this approach, we add a classifier head to the output of the prompt encoder. We use the task ID from the dataset as the label to help the prompt encoder learn a more meaningful embedding that can easily distinguish different task environments. We adopt cross-entropy as the loss function. We formulate L φ as:
$$L _ { \phi } ^ { \text{classifier} } = - \sum _ { i } y _ { i } \log ( \hat { y } _ { i } ),$$
where y i is the true task label which means the task ID and ˆ y i is the predicted probability for the task which comes from the prompt τ ∗ i .
Unsupervised learning-based prompt regularization. When task IDs are unknown, the supervised method may not be feasible. Therefore, we also propose an unsupervised learning method to learn the prompt representation. From an information theory perspective, the ideal prompt encoder should aim to maximize the mutual information between the prompt representation and the tasks. We use the InfoNCE objective (Oord et al., 2018) to calculate the loss over the prompt. We formulate L φ as:
$$L _ { \phi } ^ { \text{InfoNCE} } = - \mathbb { E } \left [ \log \frac { \exp ( \sin ( \mathbf z _ { i }, \mathbf z _ { j } ) / \tau ) } { \sum _ { k = 1 } ^ { N } \exp ( \sin ( \mathbf z _ { i }, \mathbf z _ { k } ) / \tau ) } \right ],$$
where z i and z j are the encoded representations of the prompts τ ∗ i and τ ∗ j respectively. The term sim( z i , z j ) denotes the similarity function (e.g., cosine similarity) between z i and z j .
## 4 Experiments
In this section, we conduct experiments to evaluate the few-shot generalization ability of our proposed method LPDT. We evaluate the performance of LPDT on MuJoCo control tasks (Fu et al., 2020)
Algorithm 1: Language model-initialized Prompt Decision Transformer (LPDT)
- Input: Pre-trained language model weights θ ∗ , training datasets D with prompts and trajectories, prompt regularization hyperparameter λ
Output: Language Initialized Prompt Decision Transformer
- 1 Initialize Decision Transformer with pre-trained language model weights (e.g., DistillGPT2);
- 2 Replace the input and output embedding layers of the language model with linear layers;
- 3 for each epoch do
- 4 for each batch in training dataset do
- 5 Extract prompts τ ∗ i and trajectories τ i from the batch;
- 7 Transform trajectories τ i using DT with prompt embeddings φ τ ( ∗ i );
- 6 Encode prompts τ ∗ i using the prompt encoder φ τ ( ∗ i );
- 8 Compute the Prompt-DT loss L PDT over the input trajectories τ input i by (6); Compute the prompt regularization loss L φ using the supervised learning (9) or unsupervised learning loss (10);
- 9 Combine the Prompt-DT loss and prompt regularization loss: L total = L PDT + λL φ ; 10 Backpropagate the combined loss and update parameters using parameter-efficient methods like LoRA;
11
- Freeze the remaining weights and update only low-rank matrices A and B :
$$W = W _ { 0 } + \Delta W = W _ { 0 } + A B$$
- 12 return Language model-initialized Prompt Decision Transformer;
and Meta World (Yu et al., 2020) with the episode accumulated reward as the evaluation metric. We also evaluate the prompt ability of LPDT with the smaller dataset sizes. Our experiments aim to address the following questions: (1) Can LPDT with language model initialization achieve better performance compared with Prompt-DT and other baselines? (2) Does the prompt regularization help the model distinguish the tasks and improve the prompt learning ability of LPDT? (3) Does the language-initialized Transformer model contain the knowledge of the unseen RL tasks and help improve the performance on a smaller size of data?
## 4.1 Implementation
In the empirical study, we implement our LPDT method with DistilGPT2 as the language initialization. The initialization language model weight comes from the Huggingface. The DistilGPT2 contains 82 million parameters which is lighter and more efficient than GPT2 with 124 million parameters. DistilGPT2 is pre-trained on the openwebtext (Puri & Catanzaro, 2019) and is distilled by Sanh et al. (2019). During the fine-tuning stage, we follow the same hyperparameters for Prompt-DT (see Appendix C for detail). We also leverage the LoRA to highly reduce the parameters trained. For the prompt regularization, we use MLP to further encode the prompt embedding. For the supervised version of prompt regularization defined in (9), we directly use the logits from the MLP to compute the cross-entropy loss and refer to the method as LPDT-Classifier. For the unsupervised version of prompt regularization defined in (10), we calculate the similarity matrix through the cosine similarity based on the logits from the MLP and refer to it as LPDT-InfoNCE.
## 4.2 Datasets and Tasks
In this work, we evaluate the performance of our proposed approach on MuJoCo controls and Meta World, which are commonly used in existing Prompt-DT type of methods (Xu et al., 2022; Hu et al., 2023; 2024), namely, Cheetah-dir, Cheetah-vel, Ant-dir, Meta-World reach-v2 and MW pick-placev2. In Cheetah-dir, there are two tasks with goal directions as forward and backward, where the reward function promotes high velocity along the goal direction. The training and testing phases
both include the two tasks. Similar to Cheetah-dir, Ant-dir also segments the tasks by directions. There are 50 tasks in Ant-dir with different goal directions uniformly sampled in 2D space. The tasks are split into 45 training tasks and 5 testing tasks. The ant is also rewarded with high velocity along the goal direction. Different from segmenting the tasks by direction, Cheetah-vel penalizes the agent through the l 2 errors with the target velocities sampled from the velocity interval. There are 40 tasks with different goal velocities where 35 tasks are training tasks and 5 tasks are testing tasks. Except for the MuJoCo control meta-RL tasks, we also test our approach on Meta World (Yu et al., 2020) which is an open benchmark for meta-RL and multi-task learning. In this work, we evaluate our approach on Meta-World reach-v2 and Meta-World pick-place-v2. The objective of reach-v2 is to control the robot to reach the target position in 3D positions and pick-place-v2 is to grasp the object. Each task has a different goal position.
We utilize the dataset and settings from the Prompt-DT paper (Xu et al., 2022). To be specific, the datasets of Cheetah-dir and Ant-dir come from the replay buffer of Soft Actor-Critic (Haarnoja et al., 2018) and the dataset of Cheetah-vel comes from TD3 (Fujimoto et al., 2018). For MetaWorld reach-v2 and Meta-World pick-place-v2, we collected the dataset through the expert policies provided in the open benchmark.
## 4.3 Baselines
We compare the few-shot generalization ability of our proposed LPDT with baseline algorithms. For each method, we compare the performance based on the accumulated reward. The baselines we choose include Prompt-DT (Xu et al., 2022), Prompt-Tuning DT (Hu et al., 2023), and Prompt Diffuser (Hu et al., 2024). Prompt-DT is the first method to utilize the prompt to guide Decision Transformer in testing with the few-shot demonstrations. Prompt-DT directly uses the prompt without any additional fine-tuning process when testing. Prompt-Tuning DT is based on PromptDT and utilizes prompt tuning methods when testing on the unseen task. Several prompt tuning techniques are used to tune the prompt to the specific target environment using preference ranking. Prompt Diffuser extends the prompt tuning method by leveraging diffusion models to generate high-quality prompts to improve the few-shot demonstration guidance. Beyond these baselines, Multi-Task Decision Transformer (MT-ORL) (Chen et al., 2021) is mentioned in Prompt-DT and Soft-Prompt (Lester et al., 2021) is described in Prompt Diffuser. So we do not demonstrate them in our experiments. For HDT (Xu et al., 2023b), it utilizes the adapter to adapt the pre-trained model to new tasks, which is orthogonal to the prompt-based methods. Thus we do not include their results in our comparison.
## 4.4 Comparison with Prompt-DT type of methods
Table 1: Results for MuJoCo control tasks and MW tasks. The best mean scores are highlighted in bold. For each environment, the length of the prompt is K ∗ = 5. The dataset we utilized is the full dataset. We test all the results on unseen tasks with three random seeds. LPDT outperforms baselines on the Cheetah environment and is competitive in the Ant environment.
| Task | Prompt-DT | Prompt-Tuning DT | Prompt Diffuser | LPDT-Classifier | LPDT-InfoNCE |
|------------------|------------------|--------------------|-------------------|-------------------|------------------|
| Cheetah-dir | 933.91 ± 7.04 | 941.5 ± 3.2 | 945.3 ± 7.2 | 947.84 ± 1.53 | 951.72 ± 4.08 |
| Cheetah-vel | -34.71 ± 2.80 | -40.1 ± 3.8 | -35.3 ± 2.4 | -31.57 ± 2.70 | -35.98 ± 7.15 |
| Ant-dir | 396.07 ± 9.78 | 427.9 ± 4.3 | 432.1 ± 6.7 | 374.13 ± 23.05 | 412.47 ± 21.01 |
| MW reach-v2 | 692.29 ± 9.32 | 472.5 ± 29.0 | 555.7 ± 6.8 | 497.61 ± 48.15 | 528.21 ± 114.24 |
| MW pick-place-v2 | 3773.82 ± 356.05 | - | - | 3508.12 ± 243.93 | 3543.38 ± 191.32 |
In this section, we conduct experiments on our proposed LPDT and baseline methods to evaluate their performance. In addition, we compare variants of LPDT with different prompt regularization. The average episode accumulated reward in the test task set serves as the metric for all methods. We directly compare our approaches, including the supervised classifier version and the unsupervised InfoNCE version, with prior works. We test the model with three different seeds and record the
average return over all the testing tasks. Since there is no published code for Prompt-Tuning DT and Prompt Diffuser, we report the results from their papers for a fair comparison.
The results are summarized in Table 1. Note that Prompt-Tuning DT and Prompt Diffuser are two prompt-tuning methods with leading performance among existing Prompt-based works. Table 1 demonstrates that our LPDT outperforms the baseline algorithms on MuJoCo Control tasks but suffers from inferior performance in Meta World compared with Prompt-DT. The possible limitation may be due to the huge difference between the RL task and the language task. Table 1 also illustrates that our approach performs better than the baselines in Cheetah-dir and Cheetah-vel, while it is not as good as Prompt Diffuser in Ant-dir but still better than Prompt-DT. For the results in the Meta World task, we report the results of Prompt-Tuning DT and Prompt Diffuser from their papers.

Ant-dir
Figure 2: Results on MuJoCo controls with the Cheetah-dir, Cheetah-vel and Ant-dir for PromptDT and our two methods LPDT-Classifier and LPDT-InforNCE. The dataset we utilized is the full dataset. We plot the figures on unseen tasks with the average returns with one seed and 20 evaluation episodes. The figure demonstrates that our LPDT needs less sample data compared with Prompt-DT to achieve superior performance.
Figure 2 illustrates the evaluation of Prompt-DT and our two LPDT approaches. All the plotted methods are tested through 50 episode returns on the unseen tasks. The tasks Cheetah-dir, Cheetahvel, and Ant-dir have prompts of length K ∗ = 5. Figure 2 shows that our approaches can outperform the baseline method Prompt-DT and demonstrate that they need fewer sample data compared with Prompt-DT to achieve superior performance.
## 5 Conclusion
In this work, we proposed a novel framework for improving the few-shot prompt ability of decision transformers in offline reinforcement learning, i.e., Language model-initialized Prompt Decision Transformer (LPDT). By leveraging pre-trained language models and combining them with domainspecific RL datasets, LPDT demonstrates improved few-shot prompt capabilities and outperforms or is competitive with best existing baselines in prompt based methods in terms of cumulative rewards on unseen tasks. Our approach has the potential to significantly reduce the data requirements for offline RL tasks, making it more applicable to real-world scenarios where collecting large amounts of RL trajectories is challenging. Furthermore, our results highlight the importance of using pre-trained language models as a starting point for decision-making tasks and demonstrate the effectiveness of our prompt regularization methods in enhancing the model's ability to distinguish task information contained in prompts.
While LPDT has shown promising results, there are several limitations to our approach. Due to computing resource constraints, our language models are currently limited to GPT-2 and DistilGPT2. To fully realize the potential of pre-trained language models for decision-making tasks, we hope to extend our approach to more open-source language models and utilize more efficient fine-tuning techniques in the future. Additionally, exploring alternative architectures or incorporating multitask learning could further enhance the performance of LPDT. Future work will focus on addressing these limitations and expanding the scope of LPDT to a broader range of pre-trained language models and decision-making tasks. As such, LPDT offers a promising direction for future research in offline RL.
## References
| Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023. |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877-1901, 2020. |
| Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems , 34:15084-15097, 2021. |
| Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219 , 2020. |
| Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor- critic methods. In International conference on machine learning , pp. 1587-1596. PMLR, 2018. |
| Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In International conference on machine learning , pp. 2052-2062. PMLR, 2019. |
| Hiroki Furuta, Yutaka Matsuo, and Shixiang Shane Gu. Generalized decision transformer for offline hindsight information matching. arXiv preprint arXiv:2111.10364 , 2021. |
| Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning , pp. 1861-1870. PMLR, 2018. |
| Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 , 2021. |
| Shengchao Hu, Li Shen, Ya Zhang, and Dacheng Tao. Prompt-tuning decision transformer with preference ranking. arXiv preprint arXiv:2305.09648 , 2023. |
| Shengchao Hu, Li Shen, Ya Zhang, and Dacheng Tao. Prompt tuning with diffusion for few-shot pre-trained policy generalization, 2024. URL https://openreview.net/forum?id=7rex8lEZH2 . |
| Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems , 34:1273-1286, 2021. |
| Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains. Artificial intelligence , 101(1-2):99-134, 1998. |
| Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in neural information processing systems , 32, 2019. |
| Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems , 33:1179-1191, 2020. |
| Aviral Kumar, Anikait Singh, Stephen Tian, Chelsea Finn, and Sergey Levine. A workflow for offline model-free robotic reinforcement learning. arXiv preprint arXiv:2109.10813 , 2021. |
| Kuang-Huei Lee, Ofir Nachum, Mengjiao Sherry Yang, Lisa Lee, Daniel Freeman, Sergio Guadar- rama, Ian Fischer, Winnie Xu, Eric Jang, Henryk Michalewski, et al. Multi-game decision trans- formers. Advances in Neural Information Processing Systems , 35:27921-27936, 2022. |
| Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691 , 2021. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643 , 2020. |
| Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyürek, Anima Anandkumar, et al. Pre-trained language models for interactive decision-making. Advances in Neural Information Processing Systems , 35:31199-31212, 2022. |
| Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190 , 2021. |
| Tianwei Ni, Michel Ma, Benjamin Eysenbach, and Pierre-Luc Bacon. When do transformers shine in rl? decoupling memory from credit assignment. Advances in Neural Information Processing Systems , 36, 2024. |
| Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 , 2018. |
| Raul Puri and Bryan Catanzaro. Zero-shot text classification with generative language models. arXiv preprint arXiv:1912.10165 , 2019. |
| Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog , 1(8):9, 2019. |
| Machel Reid, Yutaro Yamada, and Shixiang Shane Gu. Can wikipedia help offline reinforcement learning? arXiv preprint arXiv:2201.12122 , 2022. |
| Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 , 2019. |
| Ruizhe Shi, Yuyao Liu, Yanjie Ze, Simon S Du, and Huazhe Xu. Unleashing the power of pre-trained language models for offline reinforcement learning. arXiv preprint arXiv:2310.20587 , 2023. |
| Samarth Sinha, Ajay Mandlekar, and Animesh Garg. S4rl: Surprisingly simple self-supervision for offline reinforcement learning in robotics. In Conference on Robot Learning , pp. 907-917. PMLR, 2022. |
| Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017. |
| Zhihui Xie, Zichuan Lin, Deheng Ye, Qiang Fu, Yang Wei, and Shuai Li. Future-conditioned unsu- pervised pretraining for decision transformer. In International Conference on Machine Learning , pp. 38187-38203. PMLR, 2023. |
| Mengdi Xu, Yikang Shen, Shun Zhang, Yuchen Lu, Ding Zhao, Joshua Tenenbaum, and Chuang Gan. Prompting decision transformer for few-shot policy generalization. In international confer- ence on machine learning , pp. 24631-24645. PMLR, 2022. |
| Mengdi Xu, Yuchen Lu, Yikang Shen, Shun Zhang, Ding Zhao, and Chuang Gan. Hyper-decision transformer for efficient online policy adaptation. arXiv preprint arXiv:2304.08487 , 2023a. |
| Mengdi Xu, Yuchen Lu, Yikang Shen, Shun Zhang, Ding Zhao, and Chuang Gan. Hyper-decision transformer for efficient online policy adaptation. In The Eleventh International Conference on Learning Representations , 2023b. URL https://openreview.net/forum?id=AatUEvC-Wjv . |
| Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning , pp. 1094-1100. PMLR, 2020. |
Xiangyuan Zhang, Weichao Mao, Haoran Qiu, and Tamer Başar. Decision transformer as a foundation model for partially observable continuous control. arXiv preprint arXiv:2404.02407 , 2024.
Qinqing Zheng, Amy Zhang, and Aditya Grover. Online decision transformer. In international conference on machine learning , pp. 27042-27059. PMLR, 2022.
## A Related Work
Decision Transformer. Decision Transformer (DT) (Chen et al., 2021) emerged as a type of algorithm for offline RL by using the powerful Transformer architecture for decision-making. DT models RL trajectories as a sequence generation problem and utilizes the next-token generation paradigm for training. Thus, DT takes the history tokens such as the return, state, and action to predict the next action, which formulates the decision-making as an action prediction or sequence generation in a supervised fashion. Since DT can fully utilize the whole trajectories and is easy to train compared with dynamic programming-based offline RL, many of the following works improved the performance under different settings. For example, Lee et al. (2022) proposed the Multi-game Decision Transformer which is trained on part of the Atari games as the multi-tasks training and finetuned on the remaining games to achieve efficient adaption. Hyper Decision Transformer (Xu et al., 2023a) adds an adapter into Decision Transformer and is fine-tuned on unseen tasks through the demonstration without expert actions. Xie et al. (2023) proposed to predict the action conditioned on the future trajectory embedding instead of conditioned on the return. Trajectory Transformer (Janner et al., 2021) is another research line, which is trained on sequences of state, action, and rewards and generated with the beam search.
Prompt-DT. Prompt Decision Transformer (Xu et al., 2022) utilizes the prompt-based framework to do the meta-RL. It is trained on multi-RL tasks with offline datasets. During the training, the prompts or demonstrations which are a small part of the trajectory are combined with trajectories. During the testing on unseen tasks, the prompt can be a guide for indicating the tasks and help the model predict the action to interact with the environments. Following Prompt-DT, several works are adopting the prompt tuning method to achieve a high-quality prompt. Prompt-Tuning DT (Hu et al., 2021) uses the preference ranking function and black-box tuning method to tune the prompt when testing on unseen tasks to achieve a high-quality prompt. Moreover, Prompt Diffuser (Hu et al., 2024) leverages the diffusion model to generate high-quality prompts leading to improved performance in downstream RL tasks. Different from these works, we adopt the prompt regularization which aims to learn a high-quality prompt embedding to distinguish the different but similar RL tasks. Our method adopts this regularization during the training procedure in the prompt dataset.
Language model based DT. Large language models have achieved many surprising effects in various tasks in recent years. Pre-trained on large datasets such as the corpus of the Internet, LLMs such as GPTs (Radford et al., 2019) demonstrate prompt ability which can generate the text with the guide of the task information. The success of the large language models motivates the increasing use of pre-trained language models in improving Decision Transformer to solve RL tasks (Chen et al., 2021). Several works utilize the powerful representation generalization ability of language models as policies to do the decision-making. Li et al. (2022) proposed to adopt the pre-trained language models for interactive decision-making to convert the policies to sequence data. Wik-RL (Reid et al., 2022) uses a pre-trained language model from the next-token generation paradigm as the initialization of DT for offline RL tasks. However, it suffers from inferior performance than directly using DT. To overcome these challenges and unleash the power of language models, Shi et al. (2023) proposed the LaMo algorithm which uses a pre-trained language model and parameter-efficient finetuning methods to improve the original DT. Zhang et al. (2024) also proposed to use LaMo in partially observable continuous control problems which demonstrates a strong generalization ability. Unlike all the above methods, our approach is fine-tuned for learning to identify different prompts for various RL tasks. And during the testing phase, just a small part of the trajectories is used in our method as the prompt without updating the model.
## B Details on the Experiment Environments
We evaluate our approach on the MuJoCo tasks and Meta-World ML1 tasks. We split the tasks in these environments into the training sets and the testing sets. The tasks in Cheetah-dir and Ant-dir are split by directions. The tasks in Cheetah-vel are split by the goal velocities. In Meta-World, the tasks are defined by different goal positions. The detailed task indexes can be found in Table 2. The experiments we conducted all followed this setting which guaranteed consistency during the evaluation.
Table 2: Training and testing task indexes when testing the generalization ability. We follow the tasks split between Prompt-DT and previous works to guarantee a direct comparison with baselines.
| Environment | Number of tasks | Tasks indexes |
|--------------------------|---------------------------------|--------------------------------------------------------|
| Cheetah-dir | Training set: 2 Testing set: 2 | [0,1] [0,1] |
| Cheetah-vel | Training set: 35 Testing set: 5 | [0-1,3-6,8-14,16-22,24-25,27-39{]} [2,7,15,23,26] |
| Ant-dir | Training set: 45 Testing set: 5 | [0-5,7-16,18-22,24-29,31-40,42-49] [6,17,23,30,41] |
| Meta-World reach-v2 | Training set: 15 Testing set: 5 | [1-5,7,8,10-14,17-19] [6,9,15,16,20] |
| Meta-World pick-place-v2 | Training set: 15 Testing set: 5 | [0-10, 12-16,28-24,25-35,37-41,41-40] [11,17,25,36,41] |
## C Hyperparameters
In this section, we show the hyperparameter of our LPDT algorithm for experiments presented in Table 1. The hyperparameters have two parts, corresponding to the Transformer architecture and the prompt regularization respectively. We list these hyperparameters in Table 3.
Table 3: Detail on hyperparameters used in our experiments in Table 1. We show that the hyperparameters are in two parts which are parameters for the model backbone and prompt regularization respectively.
| Hyperparameters | Value |
|---------------------------------------------|------------|
| K (length of context τ ) | 20 |
| Training batch size for each task | 16 |
| Number of evaluation episodes for each task | 20 |
| Learning rate | 1e-4 |
| Learning rate decay weight | 1e-4 |
| Language initialization | DistilGPT2 |
| Embedding dimension | 128 |
| Activation | ReLU |
| Classifier hyperparameter | 0.1 |
| Classifier layers | 2 |
| Classifier MLP dimension | 128 |
| InfoNCE hyperparameter | 0.1 |
| InfoNCE temperature | 1 |
| InfoNCE MLP dimension | 128 |
## D More Experimental Results
In this section, we provide comprehensive summaries of the experimental results. These are the results of all the unseen tasks in MuJoCo control environments. This summary includes all the experiments and ablation study results on our various components. We show that our methods with prompt regularization are much better than those without regularization and with text regularization. Table 4 demonstrates the results in Cheetah-dir, Table 5 refers to the results in Cheetah-vel and Table 6 refers to the Ant-dir. These results further support our observations and conclusions drawn in the experiment section.
Table 4: Results on Cheetah-dir. The best mean scores are highlighted in bold. For each environment, the length of the prompt is K ∗ = 5. The dataset we utilized is the full dataset. We test all the results on unseen tasks with three random seeds. Notably, our approach LPDT outperforms the baselines on the Cheetah-dir environment.
| Methods | Cheetah-dir-0 | Cheetah-dir-1 | Average |
|-------------------------|-----------------|-----------------|---------------|
| Prompt-DT | 669.79 ± 5.68 | 1198.03 ± 19.12 | 933.91 ± 7.04 |
| LPDT w/o regularization | 686.19 ± 3.30 | 1202.41 ± 14.83 | 944.30 ± 6.31 |
| LPDT-Text | 686.58 ± 2.76 | 1201.61 ± 1.57 | 944.09 ± 1.68 |
| LPDT-Classfer | 692.63 ± 3.57 | 1203.04 ± 6.40 | 947.84 ± 1.53 |
| LPDT-InfoNCE | 690.66 ± 3.85 | 1212.78 ± 5.26 | 951.72 ± 4.08 |
Table 5: Results on the Cheetah-vel.The best mean scores are highlighted in bold. For each environment, the length of the prompt is K ∗ = 5. The dataset we utilized is the full dataset. We test all the results on unseen tasks with three random seeds. Notably, our approach LPDT outperforms the baselines on the Cheetah-vel environment.
| Methods | Cheetah-vel-2 | Cheetah-vel-7 | Cheetah-vel-15 | Cheetah-vel-23 | Cheetah-vel-26 | Average |
|-------------------------|-----------------|-----------------|------------------|------------------|------------------|---------------|
| Prompt-DT | -54.48 ± 1.76 | -18.12 ± 7.84 | -35.92 ± 6.22 | -25.93 ± 0.21 | -39.11 ± 5.31 | -34.71 ± 2.80 |
| LPDT w/o regularization | -36.04 ± 5.46 | -18.06 ± 5.40 | -39.31 ± 11.77 | -51.87 ± 1.55 | -35.71 ± 7.21 | -36.20 ± 4.05 |
| LPDT-Text | -34.28 ± 3.17 | -18.01 ± 11.37 | -36.69 ± 12.79 | -53.91 ± 3.45 | -64.92 ± 31.36 | -41.56 ± 9.65 |
| LPDT-Classfer | -35.26 ± 9.09 | -13.86 ± 5.02 | -24.21 ± 8.99 | -48.05 ± 13.96 | -36.48 ± 5.44 | -31.57 ± 2.70 |
| LPDT-InfoNCE | -38.54 ± 11.37 | -13.11 ± 4.30 | -33.58 ± 8.23 | -37.79 ± 2.19 | -56.89 ± 23.33 | -35.98 ± 7.15 |
Table 6: Results on Ant-dir.The best mean scores are highlighted in bold. For each environment, the length of the prompt is K ∗ = 5. The dataset we utilized is the full dataset. We test all the results on unseen tasks with three random seeds. Notably, our approach LPDT outperforms the baselines on the Ant-dir environment.
| Methods | Ant-dir-6 | Ant-dir-17 | Ant-dir-23 | Ant-dir-30 | Ant-dir-41 | Average |
|-------------------------|-----------------|---------------|----------------|---------------|----------------|----------------|
| Prompt-DT | 628.22 ± 119.58 | 413.76 ± 4.50 | 361.18 ± 49.51 | 358.81 ± 2.30 | 384.37 ± 20.77 | 396.07 ± 9.78 |
| LPDT w/o regularization | 362.08 ± 64.18 | 411.79 ± 6.13 | 324.34 ± 98.67 | 381.20 ± 1.79 | 325.36 ± 1.84 | 360.95 ± 11.07 |
| LPDT-Text | 254.53 ± 18.46 | 418.98 ± 8.00 | 362.91 ± 54.60 | 371.94 ± 4.79 | 348.19 ± 46.48 | 351.31 ± 23.13 |
| LPDT-Classfer | 398.80 ± 120.62 | 417.85 ± 4.74 | 342.60 ± 82.08 | 365.02 ± 1.14 | 346.37 ± 26.96 | 374.13 ± 23.04 |
| LPDT-InfoNCE | 555.18 ± 164.12 | 418.42 ± 5.43 | 376.34 ± 15.52 | 362.91 ± 5.22 | 349.52 ± 46.83 | 412.47 ± 21.01 |
## E Ablation Studies
In this section, we provide ablation studies on LPDT to test the role of prompt regularization and language initialization respectively.
Table 7: Results for MuJoCo control tasks and MW tasks with different regularization methods of our method including w/o regularization, text regularization, classifier regularization and InfoNCE regularization. The best mean scores are highlighted in bold. For each environment, the length of the prompt is K ∗ = 5. We test all the results on unseen tasks with three random seeds. The dataset we utilized is the full dataset. We demonstrate that the regularization on prompt can help distinguish the task and improve the performance compared with the method without regularization.
| Task | Prompt-DT | LPDT w/o regularization | LPDT-Text | LPDT-classifier | LPDT-InfoNCE |
|------------------|------------------|---------------------------|----------------|-------------------|------------------|
| Cheetah-dir | 933.91 ± 7.04 | 944.30 ± 6.31 | 944.09 ± 1.68 | 947.84 ± 1.53 | 951.72 ± 4.08 |
| Cheetah-vel | -34.71 ± 2.80 | -36.20 ± 4.05 | -41.56 ± 9.65 | -31.57 ± 2.70 | -35.98 ± 7.15 |
| Ant-dir | 396.07 ± 9.78 | 360.95 ± 11.07 | 351.31 ± 23.13 | 374.13 ± 23.05 | 412.47 ± 21.01 |
| MW reach-v2 | 692.29 ± 9.32 | 431.87 ± 115.19 | 459.65 ± 76.01 | 497.61 ± 48.15 | 528.21 ± 114.24 |
| MW pick-place-v2 | 3773.82 ± 356.05 | 3700.34 ± 68.45 | 3678.53 ± 58 | 3508.12 ± 243.93 | 3543.38 ± 191.32 |
## E.1 The role of prompt regularization
We first compare our proposed model with the same approach without the prompt regularization, denoted as LPDT w/o regularization. We also follow the settings of LaMo (Shi et al., 2023) and add a text regularization introduced by LaMo for comparison. We summarize the results in Table 7. Specifically, we find that prompt regularization helps the model distinguish between tasks and improve performance. LPDT without regularization or with text regularization suffers from inferior performance compared to our prompt regularization methods. Note that text regularization is trained with an NLP dataset, which is time-consuming and inefficient.
## E.2 Data efficiency of language initialization
To verify whether language initialization can incorporate prior knowledge about the downstream RL tasks, we split the dataset to train Prompt-DT and our approaches. We also evaluate the results on a portion of the dataset using a ratio of 0 1. . The results are summarized in Table 8.
Table 8: Ratio results for MuJoCo control tasks and MW tasks with the full dataset and 0.1 ratio (10%) dataset. The best mean scores are highlighted in bold. For each environment, the length of the prompt is K ∗ = 5. We test all the results on unseen tasks with three random seeds. We demonstrate that language initialization can improve the performance of our LPDT.
| Task | Datset | Cheetah-dir | Cheetah-vel | Ant-dir | MW reach-v2 | MW pick-place-v2 |
|-------------------------|----------|------------------------------|-----------------------------|-------------------------------|--------------------------------|-----------------------------------|
| Prompt-DT | Full 0.1 | 933.91 ± 7.04 890.35 ± 11.95 | -34.71 ± 2.80 -42.46 ± 9.25 | 396.07 ± 9.78 361.13 ± 4.46 | 692.29 ± 9.32 601.56 ± 40.44 | 3773.82 ± 356.05 3062.67 ± 283.56 |
| LPDT w/o regularization | Full 0.1 | 944.30 ± 6.31 927.80 ± 4.91 | -36.20 ± 4.05 -37.25 ± 5.85 | 360.95 ± 11.07 353.56 ± 27.98 | 431.87 ± 115.19 446.03 ± 30.94 | 3700.34 ± 68.45 3555.53 ± 255.52 |
| LPDT-Classifier | Full 0.1 | 947.84 ± 1.53 931.42 ± 6.40 | -31.57 ± 2.70 -34.37 ± 8.58 | 374.13 ± 23.05 347.12 ± 28.48 | 497.61 ± 48.15 457.94 ± 71.38 | 3508.12 ± 243.93 3118.57 ± 77.47 |
| LPDT-InfoNCE | Full 0.1 | 951.72 ± 4.08 919.75 ± 4.17 | -35.98 ± 7.15 -34.20 ± 8.21 | 412.47 ± 21.01 369.73 ± 21.97 | 528.21 ± 114.24 449.04 ± 44.13 | 3543.38 ± 191.32 3341.35 ± 131.93 |
Table 8 illustrates the results under different sizes of training datasets. We adopt DistilGPT2 for language initialization without any regularization. We also use LoRA to fine-tune the language models to the MuJoCo dataset. The results show that with only a 0.1 ratio (10%) of the dataset, the methods with language initialization outperform Prompt-DT when tested on unseen tasks, demonstrating that the language pre-trained model contains valuable knowledge for downstream RL tasks.
Combining these two ablation studies, we conclude that language initialization can improve performance when data is limited. Furthermore, the prompt regularization method can help the language model perform better when tested on unseen RL tasks. | null | [
"Yu Yang",
"Pan Xu"
]
| 2024-08-02T17:25:34+00:00 | 2024-08-02T17:25:34+00:00 | [
"cs.LG",
"cs.AI",
"cs.CL"
]
| Pre-trained Language Models Improve the Few-shot Prompt Ability of Decision Transformer | Decision Transformer (DT) has emerged as a promising class of algorithms in
offline reinforcement learning (RL) tasks, leveraging pre-collected datasets
and Transformer's capability to model long sequences. Recent works have
demonstrated that using parts of trajectories from training tasks as prompts in
DT enhances its performance on unseen tasks, giving rise to Prompt-DT methods.
However, collecting data from specific environments can be both costly and
unsafe in many scenarios, leading to suboptimal performance and limited
few-shot prompt abilities due to the data-hungry nature of Transformer-based
models. Additionally, the limited datasets used in pre-training make it
challenging for Prompt-DT type of methods to distinguish between various RL
tasks through prompts alone. To address these challenges, we introduce the
Language model-initialized Prompt Decision Transformer (LPDT), which leverages
pre-trained language models for meta-RL tasks and fine-tunes the model using
Low-rank Adaptation (LoRA). We further incorporate prompt regularization to
effectively differentiate between tasks based on prompt feature
representations. Our approach integrates pre-trained language model and RL
tasks seamlessly. Extensive empirical studies demonstrate that initializing
with a pre-trained language model significantly enhances the performance of
Prompt-DT on unseen tasks compared to baseline methods. |
2408.01404v1 | ## Digitized Phase Change Material Heterostack for Diffractive Optical Neural Network
Ruiyang Chen Cunxi Yu Weilu Gao*
Ruiyang Chen, Weilu Gao
Department of Electrical and Computer Engineering, The University of Utah, Salt Lake City, UT 84112, USA Cunxi Yu The University of Maryland, College Park, Department of Electrical and Computer Engineering, College Park, Maryland 20742, USA ∗ To whom correspondence should be addressed; Email Address: [email protected] Keywords: phase change materials; heterostack; diffractive optical neural networks All-optical and fully reconfigurable diffractive optical neural network (DONN) architectures are promising for high-throughput and energy-efficient machine learning (ML) hardware accelerators for broad applications. However, current device and system implementations have limited performance. This work demonstrates a novel diffractive device architecture, which is named digitized heterostack and consists of multiple layers of nonvolatile phase change materials (PCMs) with different thicknesses. This architecture can both leverage the advantages of PCM optical properties and mitigate challenges associated with implementing multilevel operations in a single PCM layer. Proof-of-concept experiments demonstrate the electrical tuning of one PCM layer in a spatial light modulation device, and thermal analysis guides the design of DONN devices and systems to avoid thermal crosstalk if individual heterostacks are assembled into an array. Further, heterostacks containing three PCM layers are designed to have a large phase modulation range and uniform coverage and the ML performance of DONN systems with designed heterostacks is evaluated. The developed device architecture provides new opportunities for desirable energy-efficient, fast-reconfigured, and compact DONN systems in the future. 1 Introduction Machine learning (ML) has transformed a broad range of applications, including imaging and sensing [1, 2, 3], chip design [4], and scientific discovery [5, 6]. With the explosively increasing size of ML models, such as ChatGPT, their execution on hardware requires unsustainably large computational resources and energy consumption. Alternative to electronic platforms, optical computing platforms have recently gained much interest as new high-throughput and energy-efficient hardware ML accelerators thanks to the extreme parallelism and low static energy consumption of photons [7]. For example, two-dimensional (2D) integrated photonics-based processors with different types of on-chip optoelectronic modulators can perform various ML tasks and mathematical operations [8, 9, 10, 11]. In addition, three-dimensional (3D) free-space optical systems [12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23], which spatially manipulate the amplitude, phase, and polarization of light with engineered 2D surfaces, advance optical computing capabilities. In particular, diffractive optical neural network (DONN) systems operating based on the physics of spatial light modulation and optical diffraction enable ML functionalities [23]. arXiv:2408.01404v1 [physics.optics] 2 Aug 2024
Current DONN systems are mainly passive, meaning diffractive arrays cannot be on-demand reconfigured for different ML tasks once they are fabricated. Note that the reconfiguration of diffractive arrays occurs only when ML tasks change, which is not frequent and is distinct from encoding data streams using fast electro-optic modulators. Limited reconfigurability was implemented in a hybrid optoelectronic DONN system [17], where electrical-to-optical (E/O) and optical-to-electrical (O/E) conversions occurred between diffractive arrays. However, these intermediate conversions increased energy consumption and processing latency, and the induced deployment errors required additional iterative adaptive tuning processes. We recently made a major advance toward this ultimate goal by constructing a fully reconfigurable DONN system based on cascaded liquid crystal spatial light modulators in the visible wavelength range [20]. This system is all-optical without E/O and O/E conversions. However, external voltage and current are needed to maintain the rotation states of liquid crystals when performing the inference of a specific ML task. The reconfiguration speed is limited to hundreds of milliseconds. The lateral
size of each liquid crystal pixel is also much larger than the operation wavelength. The further improvement toward the most desirable diffractive arrays in DONN systems, which are energy-efficient without maintaining external stimulus, fast reconfigured, and of compact footprint, relies on new materials and device architectures.
Here, we present a novel near-infrared diffractive device based on nonvolatile chalcogenide phase change materials (PCMs), which can be beneficial for DONN systems from multiple perspectives. First, the material states of PCMs can be fast and reversibly reconfigured between crystalline or amorphous phases with an electrical or optical pulse [24, 25, 26]. Second, the material states can be preserved after reconfiguration without external stimulus for > 10 years [27, 28] such that static energy consumption is minimal [29]. Third, the change of optical refractive indices can be > 1 over a wide spectral range [24], enabling compact and broadband operations for integrated [30, 31, 9, 32, 33] and free-space photonic components and systems [34, 35, 36, 37]. Fourth, PCMs are scalable [38] and compatible with other materials for constructing complex architectures. The capability of handling complex ML tasks in DONN systems is naturally dependent on the number of modulation levels achieved in each diffractive pixel. Multilevel operations in practical PCM-based devices are achieved with multiple intermediate states, which are a mixture of crystalline and amorphous phases and typically implemented by carefully designing electrical pulse profiles to deliver various heating energy [30, 39, 40, 36, 37]. However, uniformly and reliably achieving many levels (e.g., > 10) in a single PCM layer is still challenging and the formation of intermediate states is intrinsically stochastic [41], which can potentially lead to nonuniform and unreliable operations in large-area devices. Hence, to mitigate these challenges associated with multilevel operations in a single PCM layer, we demonstrate a digitized PCM heterostack architecture containing multiple PCM films with different thicknesses and other dielectrics. Each PCM film is only under crystalline and amorphous phases or with only a few intermediate states. We fabricated and experimentally characterized a proof-of-concept device for spatial light modulation, and performed thermal analysis to determine the needed spacing between PCM films in the heterostack and spacing between heterostack pixels to avoid thermal crosstalk if individual diffractive devices are assembled into an array for the DONN system. Together with the obtained proof-of-concept experimental results, we further designed layer thicknesses in a heterostack containing three PCM layers to have a large phase modulation range and uniform coverage and finally evaluated the performance of DONN systems with designed heterostacks.
## 2 Results
Figure 1a illustrates the general architecture of a DONN system consisting of multiple cascaded diffractive arrays. The input laser beam is incident on images, diffracted by cascaded diffractive arrays, and captured on a camera that is essentially a 2D photodetector array. On the camera, there are multiple pre-defined localized regions to represent the meaning of input images. For example, we can define 10 regions to represent 10 handwritten digits in the Modified National Institute of Standards and Technology (MNIST) database. Each pixel on a diffractive array can modulate the amplitude and phase of transmitted light. By training (i.e., optimizing) excitation and thus responses of each pixel on all diffractive arrays, the light wavefront after diffraction can converge into a pre-defined localized region and hence the DONN system can perform classification ML tasks of input images.
To create an energy-efficient, compact reconfigurable diffractive array, we developed a digitized PCM heterostack for each pixel as illustrated in Fig. 1b. The specific PCM we utilized is the widely demonstrated Ge Se Te 2 2 5 (GST) material. There are multiple stacks of GST films with different thicknesses, such as three thicknesses { d , d 1 2 , d 3 } in Fig. 1b. Each GST layer has an independent heater and electrodes to control GST phases in fully crystalline or amorphous phases, which is called a 2-level GST operation. Since layer thicknesses are different, the amplitude and phase modulation from the phase transition in each GST layer have different weights in total modulation of transmitted light, which is the principle of implementing multilevel operations. This is analogous to the conversion from binary to deci-
Figure 1: Illustrations of (a) a DONN system with cascaded energy-efficient, compact reconfigurable diffractive arrays with each pixel implemented using a (b) digitized GST heterostack.
mal numeral systems. For example, each 1 in a binary number (111) 2 has a different weight in its corresponding decimal number. The leading 1 represents 4, the second 1 represents 2, and the trailing 1 represents 1. The weight of each 1 is similar to the thickness of each GST layer, and 0 (1) on each digit is similar to the fully amorphous (crystalline) phase. Because of the existence of multiple reflections between layers, the thicknesses d 1 , d 2 , and d 3 in the 3-layer architecture may not follow the ratio 1 : 2 : 4 as in binary numbers. Instead, these thicknesses can be optimized freely to have a large range and uniformly distributed multilevel modulation. Further, the 2-level GST operation can be extended to a few levels (e.g., 5 levels) with some relatively stable and easy-to-achieve intermediate states, named m -level operation. Practically, the as-fabricated heterostack with as-deposited amorphous GST films is first globally heated through hotplates or ovens to have crystalline GST films as the initial state, and then each GST layer is reconfigured sequentially using electrical pulses. The heterostack can be reset to the initial state through global heating or large electrical pulses.
For a proof-of-concept demonstration of the electrical tuning of one GST film in a spatial light modulation device, as illustrated in Fig. 2a, we experimentally fabricated the device containing one nanopatterned GST film that can be electrically driven by an ITO-based heater through gold electrodes. The operation wavelength was chosen in the near-infrared range because of the relatively low loss of GST and ITO. The substrate is glass, which is also transparent at this wavelength. Figure 2b displays the flowchart of nanofabrication processes, including multiple steps of lithography, deposition, and lift-off. More details can be found in Methods . Fig. 2c shows the photo of a manufactured device.
Figure 3a illustrates the optoelectronic characterization setup to characterize manufactured devices. Specifically, we focused a 1550 nm laser onto the manufactured chip using lenses and the focused spot size was ∼ 90 µ m × 90 µ m. Because of the relatively large laser spot size and small GST area ( ∼ 30 µ m × 30 µ m), we created a metallic titanium hole ( ∼ 10 µ m × 10 µ m) to block all other light so that the transmitted light passing through the device is from the GST film; see Fig. 2b and Fig. 2c as well. A function generator was used to drive a circuit to apply electrical pulses on the ITO heater and the oscilloscope was used to measure the time-dependent response from the driving circuit and a fast InGaAs detector. Fig-
Figure 2: (a) Illustration of the spatial light modulation device demonstrating the electrical tuning of one GST film. (b) Flow chart of nanofabrication process. (c) Photo of a manufactured device.
ure 3b displays the diagram of the driving electrical circuit. A fixed square voltage wave from the function generator was the input to the gate of a power transistor, whose source was connected to a DC voltage source with a controllable voltage V pp . More details can be found in Methods . Hence, there was a voltage pulse applied to the ITO heater to tune the phase of GST film (Fig. 3b). The obtained pulse width on the ITO heater was determined by the input square wave and the circuit response, and the pulse height was determined by V pp . By tuning V pp , we changed the pulse height. Figure 3b also displays time-domain waveforms of one representative applied voltage pulse. The pulse width, rising time, and peak voltage were ∼ 2 µ s, ∼ 84 ns, and ∼ 7 5V, respectively. .
The as-deposited GST film was in the amorphous phase and then heated up on a hot plate to be converted to the fully crystalline phase. We measured the refractive index ( n ) and extinction coefficient ( k ) in a wavelength range of 300 -1700 nm using ellipsometry; see Fig. 3c and more details in Methods . We set V pp at 19 V and applied multiple pulses to drive devices and switch the GST film from the crystalline phase to the amorphous phase. Blue bars in Fig. 3d display the measured transmittance, which is defined as the ratio of the transmitted power passing through the GST film over the incident power passing through other layers except the GST film, after several writing pulses. '0' pulse means the initial state, which is the crystalline phase. Note that the measured transmittance was calibrated based on the laser spot and Ti pinhole sizes. We observed a 5-level GST operation. Further, we applied two additional pulses as erasing pulses to switch the amorphous phase back to the crystalline phase. Moreover, with experimentally obtained n and k of the GST film, available optical constants of other materials [42], and experimental film thicknesses in the stack, we employed a standard 2 × 2 transfer matrix method [43] to simulate the transmittance of the stack at 1550 nm wavelength. For intermediate states, we assumed a linear combination of crystalline and amorphous phases and corresponding n and k . Specifically, the composition ratio of the crystalline phase was denoted as α c and the amorphous ratio α a is 1 -α c . Hence, n and k for intermediate states are α n c c + α n a a and α k c c + α k a a , respectively, where n c ( n a ) and k c ( k a ) are n and k for the crystalline (amorphous) phase shown in Fig. 3c. α c was a fitting parameter during simulations. Black-striped bars in Fig. 3d show simulation results under writing pulses, agreeing well with experimental results. Figure 3e displays the composition ratio of amorphous and crystalline phases at intermediate states and we observed a gradual and nearly linear phase change under writing pulses.
Figure 3: (a) Illustration of the laser characterization setup. (b) Diagram of the electrical driving circuit and corresponding driving voltage waveforms. (c) Experimentally measured refractive index ( n ) and extinction coefficient ( k ) of the GST film. (d) Experimentally measured and simulated transmittance under multiple writing and erasing pulses. (e) Composition ratios of crystalline and amorphous phases under different pulses.
In the digitized heterostack shown in Fig. 1b, the SiO 2 spacing layers between GST layers are necessary to minimize the thermal crosstalk that can induce the phase transition from amorphous to crystalline phases and have independent heater control for each GST layer. In addition, when heterostack pixels are grouped into a 2D diffractive array (Fig. 1a) for a DONN system, the lateral spacing between pixels is also needed for minimal crosstalk between pixels. To analyze the temperature profiles of the GST film under experimental electrical pulses, we performed COMSOL Multiphysics simulations. Figure 4a displays the diagram and dimensions of COMSOL simulations. The device was at the center of the simulation region, which was filled with SiO . 2 The top panel of Fig. 4b shows the schematic of the simulated device consisting of one GST layer and one ITO heater. The size was set as 30 µ m × 30 µ m. More details can be found in Methods . The bottom panels of Fig. 4c display the cross-section and top view of temperature distribution in the device under experimental writing pulses. Figure 4c shows the temperature profile across the green line in the cross-section view in Fig. 4b and the highest temperature achieved in the GST layer is ∼ 780 C. This temperature is sufficient to induce the phase transition from crystalline to ◦ amorphous phases, typically requiring the melting temperature > 600 C. The one-side temperature de-◦ cay length from the highest temperature to a temperature close to ∼ 100 C is ◦ ∼ 4 µ m and the transition temperature from amorphous to crystalline phases is > 150 C, meaning that within the heterostack the ◦ thickness of SiO 2 spacing layers needs to ≥ 4 µ m to minimize the thermal crosstalk. Similarly, Fig. 4d shows the temperature profile across the green line in the top view in Fig. 4b. At a distance 5 µ m away from the device boundary, the temperature becomes close to the room temperature ( ∼ 30 C). Hence, in ◦ lateral dimensions, the pixel spacing ≥ 5 µ m can avoid the thermal crosstalk. Figure 4e shows the timedependent response of the highest temperature observed in Fig. 4c and Fig. 4d. The peak temperature occurs at the end of pulse 2 µ s. After the excitation, the temperature drops due to the heat dissipation in the surrounding environment. We fit the temperature decay using an exponential function and obtained a time constant ∼ 1 12 . µ s.
With experimentally measured transmission properties of one GST film, we further designed thicknesses of SiO , ITO, and GST films in a heterostack containing three layers of GST films using the transfer ma2 trix method, as illustrated in Fig. 5a. All thicknesses { d , d 1 2 , ..., d 9 } were designed to have large and uniform phase responses. Each GST film can perform either under 2-level operation with only crystalline and amorphous phases or under 5-level operation with intermediate states with the experimentally obtained composition ratios shown in Fig. 3e. The thickness of SiO 2 capping layer ( d 1 ) was fixed as 100 nm and the thicknesses of SiO 2 spacing layer ( d 4 and d 7 ) were required to be ≥ 4 µ m to avoid thermal crosstalks based on the COMSOL simulations in Fig. 4. The optimized ITO thickness was 122 nm and the thicknesses of three GST layers ( d , d 2 5 , and d 8 ) were 10 nm, 60 nm, and 80 nm, respectively. Figure 5b and Fig. 5c display the phase and amplitude response of transmitted light under different combinations of levels when the GST film was under the 2-level operation. There are in total 8 = 2 3 different combinations for 3 GST films. The phase modulation range is ∼ 0 5 . π . Further, Fig. 5d and Fig. 5e display the phase and amplitude response of transmitted light under different combinations of levels when the GST film was under the 5-level operation. In total, there are 125 = 5 3 combinations for three GST films and hence there are more intermediate phase and amplitude response points in 5-level-operation GST films compared to 2-level-operation GST films.
Finally, we evaluated the performance of a DONN system for classifying handwritten digits from the MNIST dataset, if the individual heterostack diffractive device designed in Fig. 5 can be assembled into a 2D diffractive array. Although not experimentally demonstrated here, this type of 2D array is experimentally feasible. For example, a recent work has demonstrated a 8000 × 2000 GST array with a small pixel pitch 1 5 . µ m [44]. To train diffractive arrays, meaning finding the best combination of levels for all heterostack diffractive pixels, through the backpropagation algorithm in ML software frameworks, we need to incorporate the irregular amplitude and phase device responses into DONN calculations in a differentiable manner. However, the device responses cannot be fitted with analytical equations and we utilized a Gumbel-Softmax reparameterization approach to approximate discrete distributions with a differentiable continuous function [20]. Each pixel size was set as 30 µ m × 30 µ m to be consistent with experiments in Fig. 2 and a 5 µ m spacing between pixels was set to avoid thermal crosstalk. Hence, the
Figure 4: (a) Schematic of COMSOL simulations. (b) Illustration of a heterostack with one GST film, and the cross section and top view of temperature distribution under experimental pulses. (c) Temperature profile across the green line in the cross-section of temperature distribution. (d) Temperature profile across the green in the top view of temperature distribution. (e) Time-dependent response of the highest temperature in the GST film.
Figure 5: (a) Diagram of a digitized GST heterostack containing 3 GST layers with each layer operating under 2-level or 5-level operations. (b) Phase and (c) amplitude response of transmitted light under different combinations of levels when the GST film can achieve 2 states. (d) Phase and (e) amplitude response of transmitted light under different combinations of levels when the GST film can achieve 5 states.
pixel filling factor was 56.25 %. We evaluated DONN systems with different array sizes, number of layers, and heterostacks containing 2-level and 5-level GST films, as summarized in Fig. 6. As expected, classification accuracies increase with increasing array size and layer number (Fig. 6a - c). Further, for 2-layer DONN systems, the heterostack with 5-level GST films improves the DONN system classification performance compared to 2-level GST films, as shown in Fig. 6d.
## 3 Conclusion and Discussion
We demonstrated a feasible design of a novel diffractive device for DONN systems based on a PCM heterostack, which can leverage the advantages of PCM optical properties and mitigate challenges associated with implementing multilevel operations. We performed not only proof-of-concept experiments but also detailed analyses on both device and system levels. The cyclability of current devices is not good because of the poor quality of ITO heaters. More thermally stable, efficient, and transparent heaters, such as carbon nanomaterials including graphene [33] and aligned carbon nanotube films [45], can substantially improve the efficiency and cyclability of heaters. Further, in addition to GST materials, the utilized PCM in heterostacks can be extended to other materials with lower loss for broadband operations, such as Sb Se 2 3 [46].
## 4 Methods
## 4.1 Device fabrication
The overall nanofabrication flow is illustrated in Fig. 2b. Specifically, a 10 µ m × 10 µ m hole was defined by photolithography using a mask aligner Suss MA1006 and a 100-nm thick Ti film was deposited using a Denton Discovery 18 sputtering system. The Ti hole structure was then formed after a lift-off process. A 100-nm thick SiO 2 film was then deposited on top using a Denton 635 sputtering system. A 150 µ m ×
Figure 6: (a)-(c) Classification accuracies of DONNs of different system sizes and layers with digitalized GST heterostack operating under 2 or 5 levels for each GST film. (d) Comparison of different system sizes for 2-level and 5-level GST films in 2-layer DONN systems.

50 µ m area was defined by photolithography and a 100-nm thick ITO film was deposited using the Denton Discovery 18 system to form a heater after lift-off. The ITO heater was connected by two electrodes, which contained 10-nm thick Ti and 90-nm Au defined by photolithography and deposited by the Denton 635 system. Afterward, a 30 µ m × 30 µ m area was defined by photolithography and a 100-nm thick GST film was deposited using a Denton Discovery 18 system at an argon pressure of 4.5 mTorr and a power setting of 35 W.
## 4.2 Optoelectronic characterization setup
The schematic diagram of the experimental setup is illustrated in Figure 3a. The employed laser diode was LQC1550-05E from Newport Corporation with a center wavelength 1550 nm. The elliptical output beam from the laser diode was reshaped to a round beam through lenses and an iris. Manufactured chips were driven by an electrical circuit connected to a function generator (Tektronix AFG2020). In the driving circuit, the model of the employed power transistor was Infineon IRLZ34N and the model of the employed DC source was Tektronix PS281. The output light power was measured by an InGaAs detector with a 5 GHz speed bandwidth and an operation wavelength range of 800 -1700 nm (DET08C from Thorlabs, Inc.). The time responses of driving electrical pulses and the detector reading were recorded by an oscilloscope with a bandwidth of 300 MHz (Tektronix TDS3034).
## 4.3 Ellipsometry measurement
The film thickness and optical refractive index n and extinction coefficient k of GST films were measured using a J.A. Woollam Variable Angle Spectroscopic Ellipsometer (VASE) over a wavelength range of 300 -1700 nm. In the measurement, polarized light was reflected off the sample surface, and the change in polarization was measured as two quantities: amplitude ratio Ψ and phase difference ∆. By fitting measurements with a model describing materials and sample structures, the optimal film thickness and optical indices were obtained to minimize the error between experiments and calculations.
## 4.4 COMSOL simulations
A 3D finite element simulation using COMSOL Multiphysics was conducted to analyze the temperature distribution in Fig. 4. The ITO thickness was 120 nm and the GST thickness was 130 nm. The thermal conductivity of ITO was set as 11 W m -1 K -1 and the GST thermal conductivity was set as 0.27 W m -1 K -1 [47]. The heat source was a square wave with a duration of 2 µ s and was calculated based on a 19 V pulse height, 30 Ohm ITO resistance, and 150 µ m 50 × µ m 120nm ITO volume. ×
## Author Contributions
R.C. performed all experiments and calculations under the supervision of W. G. C. Y. helped with calculations.
## Acknowledgements
R.C., C. Y., and W. G. acknowledge the support from the National Science Foundation through Grants No. 2316627 and 2428520.
## Data Availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
## Competing Interests
The authors declare that they have no competing financial interests.
## References
- [1] Y. LeCun, Y. Bengio, G. Hinton, Nature 2015 , 521 , 7553 436.
- [2] I. Goodfellow, Y. Bengio, A. Courville, Y. Bengio, Deep learning , volume 1, MIT press Cambridge, 2016 .
- [3] S. P. Rodrigues, Z. Yu, P. Schmalenberg, J. Lee, H. Iizuka, E. M. Dede, Nat. Photonics 2021 , 15 , 2 66.
- [4] A. Mirhoseini, A. Goldie, M. Yazgan, J. W. Jiang, E. Songhori, S. Wang, Y.-J. Lee, E. Johnson, O. Pathak, A. Nazi, et al., Nature 2021 , 594 , 7862 207.
- [5] K. T. Butler, D. W. Davies, H. Cartwright, O. Isayev, A. Walsh, Nature 2018 , 559 , 7715 547.
- [6] A. W. Senior, R. Evans, J. Jumper, J. Kirkpatrick, L. Sifre, T. Green, C. Qin, A. Z´ ıdek, A. W. Nelˇ son, A. Bridgland, et al., Nature 2020 , 577 , 7792 706.
- [7] G. Wetzstein, A. Ozcan, S. Gigan, S. Fan, D. Englund, M. Soljaˇi´, C. Denz, D. A. Miller, c c D. Psaltis, Nature 2020 , 588 , 7836 39.
- [8] Y. Shen, N. C. Harris, S. Skirlo, M. Prabhu, T. Baehr-Jones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, D. Englund, et al., Nat. Photonics 2017 , 11 , 7 441.
- [9] C. R´ ıos, N. Youngblood, Z. Cheng, M. Le Gallo, W. H. Pernice, C. D. Wright, A. Sebastian, H. Bhaskaran, Sci. Adv. 2019 , 5 , 2 eaau5759.
- [10] J. Feldmann, N. Youngblood, M. Karpov, H. Gehring, X. Li, M. Stappers, M. Le Gallo, X. Fu, A. Lukashchuk, A. Raja, et al., Nature 2021 , 589 , 7840 52.
- [11] H. Feng, T. Ge, X. Guo, B. Wang, Y. Zhang, Z. Chen, S. Zhu, K. Zhang, W. Sun, C. Huang, et al., Nature 2024 , 627 , 8002 80.
- [12] X. Lin, Y. Rivenson, N. T. Yardimci, M. Veli, Y. Luo, M. Jarrahi, A. Ozcan, Science 2018 , 361 , 6406 1004.
- [13] R. Hamerly, L. Bernstein, A. Sludds, M. Soljaˇi´, D. Englund, c c Phys. Rev. X 2019 , 9 , 2 021032.
- [14] L. Mennel, J. Symonowicz, S. Wachter, D. K. Polyushkin, A. J. Molina-Mendoza, T. Mueller, Nature 2020 , 579 , 7797 62.
- [15] J. Spall, X. Guo, T. D. Barrett, A. Lvovsky, Opt. Lett. 2020 , 45 , 20 5752.
- [16] M. Miscuglio, Z. Hu, S. Li, J. K. George, R. Capanna, H. Dalir, P. M. Bardet, P. Gupta, V. J. Sorger, Optica 2020 , 7 , 12 1812.
- [17] T. Zhou, X. Lin, J. Wu, Y. Chen, H. Xie, Y. Li, J. Fan, H. Wu, L. Fang, Q. Dai, Nat. Photonics 2021 , 15 , 5 367.
- [18] W. Gao, C. Yu, R. Chen, Advanced Photonics Research 2021 , 2100048.
- [19] T. Wang, S.-Y. Ma, L. G. Wright, T. Onodera, B. C. Richard, P. L. McMahon, Nat. Commun. 2022 , 13 123.
- [20] R. Chen, Y. Li, M. Lou, J. Fan, Y. Tang, B. Sensale-Rodriguez, C. Yu, W. Gao, Laser Photonics Rev. 2022 , 2200348.
- [21] R. Chen, Y. Tang, J. Ma, W. Gao, Adv. Intell. Syst. 2023 , 5 , 12 2300536.
- [22] J. Fan, Y. Tang, W. Gao, Adv. Intell. Syst. 2023 , 2300147.
- [23] J. Hu, D. Mengu, D. C. Tzarouchis, B. Edwards, N. Engheta, A. Ozcan, Nat. Commun. 2024 , 15 , 1 1525.
- [24] M. Wuttig, H. Bhaskaran, T. Taubner, Nat. Photonics 2017 , 11 , 8 465.
- [25] S. Abdollahramezani, O. Hemmatyar, H. Taghinejad, A. Krasnok, Y. Kiarashinejad, M. Zandehshahvar, A. Al`, A. Adibi, u Nanophotonics 2020 , 1 , ahead-of-print.
- [26] Y. Zhang, C. R´ ıos, M. Y. Shalaginov, M. Li, A. Majumdar, T. Gu, J. Hu, Appl. Phys. Lett. 2021 , 118 , 21 210501.
- [27] M. Wuttig, N. Yamada, Nat. Mater. 2007 , 6 , 11 824.
- [28] H.-S. P. Wong, S. Raoux, S. Kim, J. Liang, J. P. Reifenberg, B. Rajendran, M. Asheghi, K. E. Goodson, Proceedings of the IEEE 2010 , 98 , 12 2201.
- [29] A. Sebastian, M. Le Gallo, R. Khaddam-Aljameh, E. Eleftheriou, Nat. Nanotechnol. 2020 , 15 , 7 529.
- [30] C. R´ ıos, M. Stegmaier, P. Hosseini, D. Wang, T. Scherer, C. D. Wright, H. Bhaskaran, W. H. Pernice, Nat. Photonics 2015 , 9 , 11 725.
- [31] Z. Cheng, C. R´ ıos, W. H. Pernice, C. D. Wright, H. Bhaskaran, Sci. Adv. 2017 , 3 , 9 e1700160.
- [32] Y. Zhang, J. B. Chou, J. Li, H. Li, Q. Du, A. Yadav, S. Zhou, M. Y. Shalaginov, Z. Fang, H. Zhong, et al., Nat. Commun. 2019 , 10 4279.
- [33] Z. Fang, R. Chen, J. Zheng, A. I. Khan, K. M. Neilson, S. J. Geiger, D. M. Callahan, M. G. Moebius, A. Saxena, M. E. Chen, et al., Nat. Nanotechnol. 2022 , 17 , 8 842.
- [34] Q. Wang, E. T. Rogers, B. Gholipour, C.-M. Wang, G. Yuan, J. Teng, N. I. Zheludev, Nat. Photonics 2016 , 10 , 1 60.
- [35] Y. Wang, P. Landreman, D. Schoen, K. Okabe, A. Marshall, U. Celano, H.-S. P. Wong, J. Park, M. L. Brongersma, Nat. Nanotechnol. 2021 , 1-6.
- [36] Y. Zhang, C. Fowler, J. Liang, B. Azhar, M. Y. Shalaginov, S. Deckoff-Jones, S. An, J. B. Chou, C. M. Roberts, V. Liberman, et al., Nat. Nanotechnol. 2021 , 1-6.
- [37] S. Abdollahramezani, O. Hemmatyar, M. Taghinejad, H. Taghinejad, A. Krasnok, A. A. Eftekhar, C. Teichrib, S. Deshmukh, M. A. El-Sayed, E. Pop, et al., Nat. Commun. 2022 , 13 , 1 1.
- [38] S. Raoux, G. W. Burr, M. J. Breitwisch, C. T. Rettner, Y.-C. Chen, R. M. Shelby, M. Salinga, D. Krebs, S.-H. Chen, H.-L. Lung, et al., IBM Journal of Research and Development 2008 , 52 , 4.5 465.
- [39] H. Zhang, L. Zhou, L. Lu, J. Xu, N. Wang, H. Hu, B. A. Rahman, Z. Zhou, J. Chen, ACS Photonics 2019 , 6 , 9 2205.
- [40] X. Li, N. Youngblood, C. R´ ıos, Z. Cheng, C. D. Wright, W. H. Pernice, H. Bhaskaran, Optica 2019 , 6 , 1 1.
- [41] Y. Wang, J. Ning, L. Lu, M. Bosman, R. E. Simpson, Npj Comput. Mater. 2021 , 7 , 1 1.
- [42] Y. Tang, P. T. Zamani, R. Chen, J. Ma, M. Qi, C. Yu, W. Gao, Laser Photonics Rev. 2022 , 2200381.
- [43] P. Yeh, Optical Waves in Layered Media , Wiley-Interscience, 2nd edition, 2005 .
- [44] Y.-H. Kim, S. M. Cho, K. Choi, C. Y. Hwang, G. H. Kim, S. Cheon, C.-S. Hwang, JOSA A 2019 , 36 , 12 D23.
- [45] X. He, W. Gao, L. Xie, B. Li, Q. Zhang, S. Lei, J. M. Robinson, E. H. H´roz, S. K. Doorn, a W. Wang, R. Vajtai, P. M. Ajayan, W. W. Adams, R. H. Hauge, J. Kono, Nat. Nanotechnol. 2016 , 11 , 7 633.
- [46] M. Delaney, I. Zeimpekis, D. Lawson, D. W. Hewak, O. L. Muskens, Adv. Funct. Mater. 2020 , 30 , 36 2002447.
- [47] H. Taghinejad, S. Abdollahramezani, A. A. Eftekhar, T. Fan, A. H. Hosseinnia, O. Hemmatyar, A. E. Dorche, A. Gallmon, A. Adibi, Opt. Express 2021 , 29 , 13 20449.
## Table of Contents
A phase-change-material-based digitized heterostack is experimentally demonstrated and theoretically analyzed for future energy-efficient, fast reconfigured, and compact diffractive optical neural network systems. | null | [
"Ruiyang Chen",
"Cunxi Yu",
"Weilu Gao"
]
| 2024-08-02T17:26:43+00:00 | 2024-08-02T17:26:43+00:00 | [
"physics.optics",
"physics.app-ph"
]
| Digitized Phase Change Material Heterostack for Diffractive Optical Neural Network | All-optical and fully reconfigurable diffractive optical neural network
(DONN) architectures are promising for high-throughput and energy-efficient
machine learning (ML) hardware accelerators for broad applications. However,
current device and system implementations have limited performance. This work
demonstrates a novel diffractive device architecture, which is named digitized
heterostack and consists of multiple layers of nonvolatile phase change
materials (PCMs) with different thicknesses. This architecture can both
leverage the advantages of PCM optical properties and mitigate challenges
associated with implementing multilevel operations in a single PCM layer.
Proof-of-concept experiments demonstrate the electrical tuning of one PCM layer
in a spatial light modulation device, and thermal analysis guides the design of
DONN devices and systems to avoid thermal crosstalk if individual heterostacks
are assembled into an array. Further, heterostacks containing three PCM layers
are designed to have a large phase modulation range and uniform coverage and
the ML performance of DONN systems with designed heterostacks is evaluated. The
developed device architecture provides new opportunities for desirable
energy-efficient, fast-reconfigured, and compact DONN systems in the future. |
2408.01405v1 | ## The magnon mediated plasmon friction: a functional integral approach
Yang Wang a) , Ruanjing Zhang b) , and Feiyi Liu c) ∗
School of Big Data and Basic Science, Shandong Institute of Petroleum and Chemical Technology, Dongying, 257061, China a) Institute of Theoretical Physics, School of Science, Henan University of Technology, Zhengzhou, 450001, China b) c)
School of Physics and Electronic Science, Chuxiong Normal University, Chuxiong, 675000, China
(Date: August 2nd, 2024)
## Abstract
In this paper, we discuss quantum friction in a system formed by two metallic surfaces separated by a ferromagnetic intermedium of a certain thickness. The internal degrees of freedom in the two metallic surfaces are assumed to be plasmons, while the excitations in the intermediate material are magnons, modeling plasmons coupled to magnons. During relative sliding, one surface moves uniformly parallel to the other, causing friction in the system. By calculating the effective action of the magnons, we can determine the particle production probability, which shows a positive correlation between the probability and the sliding speed. Finally, we derive the frictional force of the system, with both theoretical and numerical results indicating that the friction, like the particle production probability, also has a positive correlation with the speed.
## 1 Introduction
In the study of condensed matter physics, the discussions on frictional forces in microscopic systems are always of interest. In these systems, the quantum fluctuations play a crucial role in
∗ Corresponding author, E-mail: [email protected]
the dissipation process of frictional force. Generally speaking, the internal relative motion can excite the internal degrees of freedom (DOFs) of the system through the interaction between these internal DOFs, which leads to the production of quasi-particles by the kinetic energy of the internal relative motion. Accordingly, the energy dissipation processes of the frictional force in different systems are carried out by different elementary excitations, such as phonons, electrons, plasmons, magnons, etc [1-4]. At high temperatures, the dissipation process is usually dominated by phonons, and the classical dynamics of the phonons make the major contribution. As the temperature decreases, quantum dynamics gradually come into play, and in the dissipation processes, electrons, plasmons, or other collective excitations take on dominant roles. In the past, the corresponding friction in these processes has been widely studied [5-10], and with the development of experimental technology, magnetic friction has also been observed [11]. The dissipation of this friction is carried out by magnons, so magnetic friction is also called spin friction.
As magnetic materials are controlled down to the nanometer scale, the dissipation and friction in quantum spin systems have attracted considerable interest. The occurrence of magnetic friction was studied theoretically using a nanometer-sized tip scanning a magnetic surface, examining the dynamics of a classical spin model interacting through dipolar and exchange interactions [12]. And a similar approach was also applied to discuss the temperature-dependence of the magnetic friction [13]. Kadau studied the magnetic friction between two Ising spin systems and found that near the critical temperature the friction is the strongest [11]. These works all focused on purely classical models. By considering the contribution of quantum fluctuations, we found the bosonic model to be almost equivalent to the general model of electronic friction, by transforming the Heisenberg model into a bosonic model via the Holstein-Primakoff transformation [14]. The above studies on frictional force are based on models that the interfaces consist of two identical surfaces or one surface coupled to a nanoparticle. In reality, friction usually occurs at interfaces composed of two different materials, and in many cases, quantum spins can lead to friction by interacting with other DOFs. Johan, Brevik and et al studied the Casimir friction between a magnetic and a dielectric material. In this work, the internal DOFs of the magnet were modeled as a single frequency quantum oscillator to obtain the
temperature-dependence of the magnetic friction [15]. However the contribution of dispersive magnons has not been discussed, and additionally, the dissipation and frictional force mediated by a intermedium instead of vacuum gap have not been considered.
Most quantum friction models are sandwich-like, i.e., a vacuum gap sandwiched between two objects [5, 8, 15], and the excitations of the vacuum are always photons, refering to 'photonmediated friction'. In our study, we focus on the frictional force in the case of two objects separated by some intermedium whose excitations are quasi particles. Specifically, we build a model that the interface is formed by two metallic surfaces separated by a ferromagnetic intermedium. The internal DOFs of the both metallic surfaces are electrons and the excitations of the intermedium are magnons. The whole system is built as plasmons coupled to magnons, and the structure of the model is similar to the graphene plasmons form polaritons with the magnons of two-dimensional ferrromagnetic insulators [16]. By relative sliding, one surface moves uniformly parallel to the other causing friction in the system. Our goal is to study the magnon-mediated plasmon friction, through calculation and analysis of the system's effective action of the magnons, particle production probability and etc.
The remaining content of this paper is structured in the following manner. In Section 2, we introduce the model to study frictional force. Section 3 gives the effective action of the magnons in the system. Section 4 gives the calculation of the probability of particle production. In Section 5, we discuss the friction force of this system. And Section 6 is the summary of this work.
## 2 The model
In this study, we consider the system formed by two metallic surfaces separated by a ferromagnetic intermedium with thickness h , and the diagrammatic sketch of the model is shown in Figure 1. Due to the metallic nature of both surfaces, the primary basic excitations with spin on the two surfaces are bound to be electrons as the internal DOFs. The excitations of the intermedium are magnons. The structure of this model is similar to the graphene plasmons form polaritons with the magnons of two-dimensional ferrromagnetic insulators [16]. By focus-
ing on the case of plasmons coupled to magnons, our goal is to study the magnon-mediated plasmon friction. And also, we follow the natural unit such that ℏ = c = 1. Thus, the effective internal DOFs of the metallic surfaces that are coupled to the intermedium are assumed to be plasmons, and the Hamiltonian of this plasmons for the two metallic surfaces can be expressed as
Figure 1: The model of interface formed by two metallic surfaces (R- and L-surface in black) separated by a ferromagnetic intermedium (in blue). The R-surface is assumed to slide along the x -y plane with velocity v , experiencing a frictional force.

$$H _ { R } = \int \mathrm d ^ { 2 } r _ { \| } \left \{ \frac { 1 } { 2 } [ \pi _ { R } ( r _ { \| } ) ] ^ { 2 } + \frac { 1 } { 2 } [ u \nabla \phi _ { R } ( r _ { \| } ) ] ^ { 2 } + \frac { 1 } { 2 } \Omega ^ { 2 } [ \phi _ { R } ( r _ { \| } ) ] ^ { 2 } \right \},$$
and
$$H _ { \text{L} } = \int \mathbb { d } ^ { 2 } r _ { \| } \left \{ \frac { 1 } { 2 } [ \pi _ { \text{L} } ( r _ { \| } ) ] ^ { 2 } + \frac { 1 } { 2 } [ u \nabla \phi _ { \text{L} } ( r _ { \| } ) ] ^ { 2 } + \frac { 1 } { 2 } \Omega ^ { 2 } [ \phi _ { \text{L} } ( r _ { \| } ) ] ^ { 2 } \right \},$$
where r ∥ = ( x, y ) is the two dimensional Cartesian coordinates in the L-surface. Here we denote the DOFs of the two surfaces via subscripts L and R, i.e., the R-surface and the Lsurface. The integral measure ∫ d 2 r ∥ means ∫ ∞ -∞ d x ∫ ∞ -∞ d . For the magnons, the Hamiltonian y is taken as
$$H _ { \text{M} } = \int \mathrm d ^ { 2 } \mathbf r _ { \| } \int _ { 0 } ^ { h } \mathrm d z J S [ b ^ { \dagger } ( \mathbf r _ { \| }, z ) \nabla ^ { 2 } b ( \mathbf r _ { \| }, z ) ],$$
where z is the third Cartesian coordinate Perpendicular to the L-surface. J is the interchange parameter of the Heinsenberg model, and S is the spin quantum number of the spin magnetic moment in the ferromagnet [17].
In spired by the model of magnon-plasmon coupling in Ref. [18], we define the coupling terms between R/L-surface and the magnet as
$$H _ { \text{RM} } = \int \text{d} ^ { 2 } r _ { \| } \int _ { - \infty } ^ { \infty } \text{d} z \delta ( z - h ) \pi _ { \text{R} } ( r _ { \| } ) \left [ C ( r _ { \| } ) b ( r _ { \| }, z ) + C ^ { * } ( r _ { \| } ) b ^ { \dagger } ( r _ { \| }, z ) \right ],$$
and
$$H _ { \text{LM} } = \int \mathrm d ^ { 2 } r _ { \| } \int _ { - \infty } ^ { \infty } \mathrm d z \delta ( z ) \pi _ { \text{L} } ( \mathbf r _ { \| } ) \left [ C ( \mathbf r _ { \| } ) b ( \mathbf r _ { \| }, z ) + C ^ { * } ( \mathbf r _ { \| } ) b ^ { \dagger } ( \mathbf r _ { \| }, z ) \right ].$$
Here b ( r ∥ , z ) and b † ( r ∥ , z ) are the annihilation and creation operators of the Holstein-Primakoff bonsons which describe the magnons [19].
The transition amplitude from a ground state to the other is defined as Z = 0 ⟨ | U I ( T 2 , -T 2 ) 0 | ⟩ , where U I ( T 2 , -T 2 ) is the time evolution operator of the system and | 0 ⟩ refers to the ground state. This transition amplitude also can be written as a functional integral [20]:
$$Z = \int D b \int D b ^ { \dagger } \int D \phi _ { \text{R} } \int D \phi _ { \text{L} } e ^ { i \int \mathfrak { d } ^ { 4 } X ( L _ { \text{R} } + L _ { \text{L} } + L _ { \text{M} } + L _ { \text{LM} } + L _ { \text{LM} } ) },$$
where ∫ d 4 X = ∫ ∞ -∞ d t ∫ ∞ -∞ d x ∫ ∞ -∞ d y ∫ ∞ -∞ d , z integrations over time t and the coordinates. Since the corresponding Lagrangian can be derived using the Legendre transformation, the free parts of the Lagrangian can be written as
$$L _ { \text{R} } = \int \mathrm d ^ { 2 } r _ { \| } \int _ { - \infty } ^ { \infty } \mathrm d z \left \{ \frac { 1 } { 2 } \left [ \frac { \partial } { \partial t } \phi _ { \text{R} } ( t, r _ { \| } ) \right ] ^ { 2 } - \frac { 1 } { 2 } [ u \nabla \phi _ { \text{R} } ( t, r _ { \| } ) ] ^ { 2 } - \frac { 1 } { 2 } \Omega ^ { 2 } [ \phi _ { \text{R} } ( t, r _ { \| } ) ] ^ { 2 } \right \} \delta ( z - h ), \ \ ( 7 )$$
$$L _ { \text{L} } = \int \mathfrak { d } ^ { 2 } r _ { \| } \int _ { - \infty } ^ { \infty } \mathrm d z \left \{ \frac { 1 } { 2 } \left [ \frac { \partial } { \partial t } \phi _ { \text{L} } ( t, r _ { \| } ) \right ] ^ { 2 } - \frac { 1 } { 2 } [ u \nabla \phi _ { \text{L} } ( t, r _ { \| } ) ] ^ { 2 } - \frac { 1 } { 2 } \Omega ^ { 2 } [ \phi _ { \text{L} } ( t, r _ { \| } ) ] ^ { 2 } \right \} \delta ( z ), \quad ( 8 )$$
$$L _ { \text{M} } = \int \mathrm d ^ { 2 } \mathbf r _ { \| } \int _ { 0 } ^ { h } \mathrm d z \left [ b ^ { \dagger } ( t, \mathbf r _ { \| }, z ) \left ( \mathrm i \frac { \partial } { \partial t } - J S \nabla ^ { 2 } \right ) b ( t, \mathbf r _ { \| }, z ) \right ].$$
and the interaction parts are expressed as
$$L _ { \text{RM} } = - \int \mathrm d ^ { 2 } r _ { \| } \int _ { - \infty } ^ { \infty } \mathrm d z \delta ( z - h ) \left [ \frac { \partial } { \partial t } \phi _ { \text{R} } ( t, r _ { \| } ) \right ] \left [ C ( r _ { \| } ) b ( t, r _ { \| }, z ) + C ^ { * } ( r _ { \| } ) b ^ { \dagger } ( t, r _ { \| }, z ) \right ], \quad ( 1 0 )$$
and
$$L _ { \text{LM} } = - \int \mathrm d ^ { 2 } r _ { \| } \int _ { - \infty } ^ { \infty } \mathrm d z \delta ( z ) \left [ \frac { \partial } { \partial t } \phi _ { \text{L} } ( t, r _ { \| } ) \right ] \left [ C ( r _ { \| } ) b ( t, r _ { \| }, z ) + C ^ { * } ( r _ { \| } ) b ^ { \dagger } ( t, r _ { \| }, z ) \right ].$$
Here C ( r ∥ ) is the interacting strength which is assumed to be r ∥ dependent rather than t , and C ∗ ( r ∥ ) is the complex conjugation of C ( r ∥ ).
## 3 The effective action of the magnons
In our model, the ferromagnet plays a mediating role in the coupling between the plasmons belonging to the R- and L-surface, i.e., the virtual magnons carry the interaction between the two surfaces, which makes it necessary to analyse the free Green's function of the magnons. To achieve this goal, we first derive the effective action of the magnons via a functional integral:
$$e ^ { i S _ { \text{eff} } [ b, b ] } = \int D \phi _ { \text{R} } \int D \phi _ { \text{L} } e ^ { i \int d ^ { 4 } X ( L _ { \text{R} } + L _ { \text{L} } + L _ { \text{M} } + L _ { \text{RM} } + L _ { \text{LM} } ) }.$$
Since it is Gaussian-like shape, the integral can be performed directly and the effective action of the magnon can be expressed as
$$& S _ { \text{eff} } [ b, b ^ { \dagger } ] = \int _ { - \infty } ^ { \infty } d t \int d ^ { 2 } r _ { \| } \int _ { 0 } ^ { h } d z \left [ b ^ { \dagger } ( t, r _ { \| }, z ) \left ( \frac { \partial } { \partial t } - J S \nabla ^ { 2 } \right ) b ( t, r _ { \| }, z ) \right ] \\ & + \int d ^ { 4 } X \int d ^ { 4 } X ^ { \prime } | C ( r _ { \| } ) | ^ { 2 } \{ b ^ { \dagger } ( t, r _ { \| }, z ) \delta ( z - h ) \Delta _ { R } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ) \delta ( z ^ { \prime } - h ) \delta ( z - h ) b ( t, r _ { \| }, z ) \} \\ & + \int d ^ { 4 } X \int d ^ { 4 } X ^ { \prime } | C ( r _ { \| } ) | ^ { 2 } \{ b ^ { \dagger } ( t, r _ { \| }, z ) \delta ( z ) \Delta _ { L } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ) \delta ( z ^ { \prime } ) \delta ( z ) b ( t, r _ { \| }, z ) \},$$
where the kernels are defined as the following Fourier transformations with an infinitesimal positive parameter ϵ :
$$\Delta _ { \text{R} } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ) = \int _ { - \infty } ^ { \infty } \frac { \text{d} \omega } { 2 \pi } \int _ { - \infty } ^ { \infty } \frac { \text{d} k _ { x } } { 2 \pi } \int _ { - \infty } ^ { \infty } \frac { \text{d} k _ { y } } { 2 \pi } \frac { \omega ^ { 2 } \text{e} ^ { - i \left [ \omega ( t - t ^ { \prime } ) - k _ { \| } \cdot ( r _ { \| } - r _ { \| } ^ { \prime } ) \right ] } { \omega ^ { 2 } - u ^ { 2 } k _ { \| } ^ { 2 } - \Omega ^ { 2 } + i \epsilon },$$
and
$$\Delta _ { L } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ) = \int _ { - \infty } ^ { \infty } \frac { \mathrm d \omega } { 2 \pi } \int _ { - \infty } ^ { \infty } \frac { \mathrm d k _ { x } } { 2 \pi } \int _ { - \infty } ^ { \infty } \frac { \mathrm d k _ { y } } { 2 \pi } \frac { \omega ^ { 2 } \mathrm e ^ { - i [ \omega ( t - t ^ { \prime } ) - k _ { \| } \cdot ( r _ { \| } - r _ { \| } ^ { \prime } ) ] } } { \omega ^ { 2 } - u ^ { 2 } k _ { \| } ^ { 2 } - \Omega ^ { 2 } + i \epsilon }.$$
These two kernels can be obtained by taking the second time derivative of the free time-ordered Green's function of the plasmons. Note that the additional frequency factor ω 2 results from the coupling between the canonical momentum of the plasmon and the magnon field. k ∥ = ( k , k x y ) is the Fourier momentum corresponding to r ∥ .
Since our purpose is to study frictional force, relative sliding is required in the system. Here we assume that the R-surface is moving uniformly parallel to the L-surface, and then the terms
containing the plasmon DOFs should undergo a transformation, i.e.
$$r _ { \| } \rightarrow \tilde { r } _ { \| } = r _ { \| } - v _ { \| } t,$$
which makes the Green's function of the R-plasmons transforms as
$$\tilde { \Delta } _ { \text{R} } ( t - t ^ { \prime }, r _ { \| } - r ^ { \prime } _ { \| } ) = \int _ { - \infty } ^ { \infty } \frac { \text{d} \omega } { 2 \pi } \int _ { - \infty } ^ { \infty } \frac { \text{d} k _ { x } } { 2 \pi } \int _ { - \infty } ^ { \infty } \frac { \text{d} k _ { y } } { 2 \pi } \frac { ( \omega - v _ { \| } \cdot k _ { \| } ) ^ { 2 } \text{e} ^ { - i [ \omega ( t - t ^ { \prime } ) - k _ { \| } \cdot ( r _ { \| } - r ^ { \prime } _ { \| } ) ] } { ( \omega - v _ { \| } \cdot k _ { \| } ) ^ { 2 } - u ^ { 2 } k _ { \| } ^ { 2 } - \Omega ^ { 2 } + \text{i} \epsilon }. \quad ( 1 7 )$$
Then the additional Green's function of the magnons can be calculated via the functional integral from the effective action as follows [20]:
$$G ( X, X ^ { \prime } ) = - \mathrm i \frac { \int D b D b ^ { \dagger } \mathrm e ^ { \mathrm i S _ { \text{eff} } } b ( X ) b ( X ^ { \prime } ) } { \int D b D b ^ { \dagger } \mathrm e ^ { \mathrm i S _ { \text{eff} } } }.$$
The free Green's function can be obtained by dropping the interaction terms in equation (13). And in consideration of the boundary conditions of the ferromagnet, this free Green's function of the magnons can be classified into four correlators:
- a) the bulk-bulk correlator: G F ( t -t , ′ r ∥ -r ′ ∥ ; z -z ′ ),
- b) the R-surface correlator: G F ( t -t , ′ r ∥ -r ′ ∥ ; z -z ′ = 0),
- c) the L-surface correlator: G F ( t -t , ′ r ∥ -r ′ ∥ ; z -z ′ = 0),
- d) the R-L correlator: G F ( t -t , ′ r ∥ -r ′ ∥ ; z -z ′ = h ).
The subscript 'F' means Feynmann propagator which corresponds to the free Green's funtion in Quantum Field Theory. Since the coupling between the plasmons and the magnons exists only on the surfaces, it is necessary to calculate the R-L correlator, which can be expressed through Fourier transformation using the standard approach as follows:
$$G _ { F } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ; 0 - h ) = \int \frac { \mathrm d \omega } { 2 \pi } \int \frac { \mathrm d ^ { 2 } \mathbf k _ { \| } } { ( 2 \pi ) ^ { 2 } } G _ { F } ( \omega, \mathbf k _ { \| } ; 0 - h ) e ^ { i [ \omega ( t - t ^ { \prime } ) - \mathbf k _ { \| } ^ { \prime } ( r _ { \| } - r _ { \| } ^ { \prime } ) ] },$$
where the kernel G F ( ω, k ∥ ; 0 -h ) is defined via the inverse Fourier transformation:
$$G _ { \text{F} } ( \omega, k _ { \| } ; 0 - h ) \coloneqq \int _ { - \infty } ^ { \infty } \frac { \text{d} k _ { z } } { 2 \pi } \frac { \text{e} ^ { - i k _ { z } ( 0 - h ) } } { \omega - J S k _ { \| } ^ { 2 } - J S k _ { z } ^ { 2 } + \text{i} \epsilon } = \frac { - \text{i} \text{e} ^ { - i h } \sqrt { \frac { \omega } { J S } - k _ { \| } ^ { 2 } } } { 2 \sqrt { \frac { \omega } { J S } - k _ { \| } ^ { 2 } } },$$
and obviously, G F ( ω, k ∥ ; 0 -h ) = G ∗ F ( ω, k ∥ ; h -0).
## 4 The probability of particle production
During the relative sliding, the accumulated energy results from particle production. To obtain the frictional force, we need to track the energy transfer in the system, making it necessary to determine the probability of particle production. Since our model assumes weak interaction, we can calculate the probability of particle production using perturbation theory.
The probability for the system staying at the ground state is | Z | 2 , so P = 1 -| Z | 2 means the probability of particle production. And P can be calculated from the effective action of the magnons in Eq (13) via functional integral[16]:
$$\mathcal { P } = 1 - \left | \int D b \int D b ^ { \dagger } e ^ { i S _ { \text{eff} } [ b, b ^ { \dagger } ] } \right | ^ { 2 } = 1 - | e ^ { i \Gamma } | ^ { 2 } = 1 - e ^ { - 2 \text{Im} },$$
where Γ is the collection of 1 PI diagram [20]. In the perturbation expansion in powers of coupling strength, the sliding-dependent contribution to ImΓ always forms a series of terms, leading to a small ImΓ, i.e.,
$$e ^ { - 2 \text{Im} \Gamma } \approx 1 - 2 \text{Im} \Gamma.$$
Thus, we the probability of particle production can be written as
$$\mathcal { P } = 2 \text{Im} \Gamma.$$
After performing the functional integral, we can obtain the expression for Γ:
$$& \Gamma = \frac { i } { 2 } \ln \det \{ \mathrm i \frac { \partial } { \partial t } - J S \nabla ^ { 2 } \\ & + | C ( r _ { \| } ) | ^ { 2 } \delta ( z - h ) \Delta _ { \mathrm R } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ) \delta ( z ^ { \prime } - h ) \\ & + | C ( r _ { \| } ) | ^ { 2 } \delta ( z ) \Delta _ { \mathrm L } ( t - t ^ { \prime }, r _ { \| } - r _ { \| } ^ { \prime } ) \delta ( z ^ { \prime } ) \}.$$
In general, the coupling strength | C ( r ∥ | ) is sufficiently small for perturbation calculations, allowing Γ to be expanded in powers of | C ( r ∥ | ) . To the order of | C ( r ∥ ) | 4 , Γ can be written as
$$\Gamma = \text{const} - i \text{Tr} [ | C | ^ { 4 } G _ { F } \Delta _ { R } G _ { F } \Delta _ { L } ].$$
Here the leading-order terms are not vanishing. However, physically speaking, the leading-order corresponds to the case where either the L- or R-surface is absent. Since our aim is to investigate the magnon-mediated plasmon friction between the two surfaces, we ignore the leading-order terms. Additionally, the terms in the absence of either of the two surfaces, Tr[ | C | 4 G F ∆ R G F ∆ ] R and Tr[ | C | 4 G F ∆ L G F ∆ ], are not required, since we investigate the magnon-mediated plasmon L friction between the two surfaces. Then the lowest ordered nontrivial contribution can be expressed as follows:
$$& \text{Tr} [ | C | ^ { 4 } G _ { F } \Delta _ { R } G _ { F } \Delta _ { L } ] \\ & = T A \int _ { - \infty } ^ { \infty } \frac { d \omega } { 2 \pi } \int \frac { d ^ { 2 } k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( k _ { \| } ) | ^ { 4 } G _ { F } ( \omega, k _ { \| } ; 0 - h ) \Delta _ { R } ( \omega, k _ { \| } ) G _ { F } ( \omega, k _ { \| } ; h - 0 ) \Delta _ { L } ( \omega, k _ { \| } ),$$
where T is the duration of the system and A is the total area of the surface. The kernels of R-plasmon and L-plasmon in frequency-momentum space can be obtained from Eq (14) and Eq (15) respectively as:
$$\Delta _ { R } ( \omega, k _ { \| } ) = \frac { ( \omega - v \cdot k _ { \| } ) ^ { 2 } } { ( \omega - v \cdot k _ { \| } ) ^ { 2 } - u ^ { 2 } k _ { \| } ^ { 2 } - \Omega ^ { 2 } + i \epsilon },$$
and
$$\Delta _ { L } ( \omega, k _ { \| } ) = \frac { \omega ^ { 2 } } { \omega ^ { 2 } - u ^ { 2 } k _ { \| } ^ { 2 } - \Omega ^ { 2 } + i \epsilon }.$$
The integrand on the complex ω -plane has only two poles, which depend on the relative velocity v :
$$\omega _ { \pm } = v _ { \| } \cdot k _ { \| } \pm \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \mp \text{i} \epsilon.$$
Here, we do not consider the antiparticles corresponding to the plasmons, because our model focuses on plasmon-magnon coupling, which is an effective interaction rather than a fundamental electromagnetic interaction. After substituting Eq (20), (27), and (28) into Eq (26), and evaluating the integral over ω using the residue theorem [17], we obtain the expression for Γ as
follows:
$$\Gamma & = T A \int \frac { d ^ { 2 } k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( k _ { \| } ) | ^ { 4 } \frac { 1 } { v _ { \| } \cdot k _ { \| } } \frac { 1 } { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \\ & \times \frac { J S ( v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + \mathrm i \epsilon ) ^ { 2 } ( - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + \mathrm i \epsilon ) ^ { 2 } } { v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } - J S k _ { \| } ^ { 2 } + \mathrm i \epsilon } \\ & \times \exp ( \frac { 2 i h } { \sqrt { J S } } \sqrt { v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } - J S k _ { \| } ^ { 2 } + \mathrm i \epsilon } ) \\ & \times \frac { 1 } { v _ { \| } \cdot k _ { \| } - 2 \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + \mathrm i \epsilon }. \\ \text{that} \, v _ { \| } \cdot k _ { \| } \, \text{can be regarded as the energy pumped into the system by the relative mo-}$$
Note that v ∥ · k ∥ can be regarded as the energy pumped into the system by the relative motion [21]. Thus, by taking into account the identity
$$\frac { 1 } { a \pm i \epsilon } = \text{p.v.} ( \frac { 1 } { a \pm i \epsilon } ) \mp i \pi \delta ( a ),$$
Eq (30) can gives two Dirac δ -functions δ ( v ∥ · k ∥ -2 √ u 2 k 2 ∥ +Ω ) and 2 δ ( v ∥ · k ∥ -√ u 2 k 2 ∥ +Ω 2 -JS k 2 ∥ ). The former corresponds to plasmon excitation, while the latter corresponds to magnonplasmon hybrid excitation on the R-surface. Since the magnons only play the role in mediating, here we only focus on the former case, and the corresponding probability of particle production can be written as
$$\mathcal { P } = 2 & \text{Im} \Gamma \\ = & \text{2} T A \int \frac { d ^ { 2 } k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( k _ { \| } ) | ^ { 4 } \frac { 1 } { v _ { \| } \cdot k _ { \| } } \frac { 1 } { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \\ \times \frac { J S ( v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } ) ^ { 2 } ( - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } ) ^ { 2 } } { v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } - J S k _ { \| } ^ { 2 } } \\ \times & \exp ( \frac { - 2 h } { \sqrt { J S } } \sqrt { - v _ { \| } \cdot k _ { \| } + \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + J S k _ { \| } ^ { 2 } } ) \\ \times \pi \delta ( v _ { \| } \cdot k _ { \| } - 2 \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } ),$$
with the condition -v ∥ · k ∥ + √ u 2 k 2 ∥ +Ω + 2 JS k 2 ∥ > 0, which means no magnon being excited. Without loss of generality, we set the velocity v ∥ along the x -direction, i.e.,
$$v _ { \| } = \left ( v, 0 \right ).$$
Thus, the probability of particle production becomes
$$\mathcal { P } & = 2 \text{Im} \Gamma \\ & = 2 T A \int \frac { \mathfrak { d } ^ { 2 } \boldsymbol k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( \boldsymbol k _ { \| } ) | ^ { 4 } \frac { 1 } { \boldsymbol v k _ { x } } \frac { 1 } { \boldsymbol u ^ { 2 } \boldsymbol k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \\ & \times \frac { \ J S \left \{ \boldsymbol v k _ { x } - \sqrt { u ^ { 2 } \boldsymbol k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \right \} ^ { 2 } \left \{ - \sqrt { u ^ { 2 } \boldsymbol k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \right \} ^ { 2 } } { \boldsymbol v k _ { x } - \sqrt { u ^ { 2 } \boldsymbol k _ { \| } ^ { 2 } + \Omega ^ { 2 } } - \ J S \boldsymbol k _ { \| } ^ { 2 } } \\ & \times \exp \left \{ \frac { - 2 h } { \sqrt { \ J S } } \sqrt { - \boldsymbol v k _ { x } + \sqrt { u ^ { 2 } \boldsymbol k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + \J S \boldsymbol k _ { \| } ^ { 2 } } \right \} \\ & \times \pi \delta \left \{ \boldsymbol v k _ { x } - 2 \sqrt { u ^ { 2 } \boldsymbol k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \right \}, \\ \text{he property of Dirac } \delta \text{-function}$$
By using the property of Dirac δ -function
$$\delta [ f ( x ) ] = \sum _ { i } \left \| \frac { \mathrm d f ( x _ { i } ) } { \mathrm d x _ { i } } \right \| ^ { - 1 } \delta ( x - x _ { i } ),$$
the item of Dirac δ -function in Eq (34) can be expressed as
$$\delta \left \{ v k _ { x } - 2 \sqrt { u ^ { 2 } k _ { | | } ^ { 2 } + \Omega ^ { 2 } } \right \} = \frac { v } { v ^ { 2 } - 4 u ^ { 2 } } \left \{ \delta \left \{ k _ { x } - 2 \sqrt { \frac { u ^ { 2 } k _ { y } ^ { 2 } + \Omega ^ { 2 } } { v ^ { 2 } - 4 u ^ { 2 } } } \right \} + \delta \left \{ k _ { x } + 2 \sqrt { \frac { u ^ { 2 } k _ { y } ^ { 2 } + \Omega ^ { 2 } } { v ^ { 2 } - 4 u ^ { 2 } } } \right \} \right \},$$
which gives a threshold speed v P ≥ 2 u , i.e., the plasmons are excited when the relative motion speed is bigger than 2 u . This threshold speed is similar to the quantum friction between two graphene sheets [22]. Obviously, here the probability decreases as the thickness of the ferromagnet increases.
To observe how the probability changes with increasing velocity v , we set the coupling strength C ( k ∥ ) to a constant value, denoted by the real-valued parameter C , and temporarily
ignore the dispersion of the plasmons by setting u = 0. Then the probability of particle production can be expressed as follows
$$\mathcal { P } = T A \int _ { - \infty } ^ { \infty } \frac { \mathrm d k _ { y } } { 2 \pi } \frac { 2 \pi C ^ { 4 } } { 2 \Omega } \frac { J S \Omega ^ { 2 } } { \Omega - J S [ ( 2 \Omega / v ) ^ { 2 } + k _ { y } ^ { 2 } ) ] } \mathrm e ^ { - \frac { 2 h } { \sqrt { J S } } \sqrt { - \Omega + J S [ ( 2 \Omega / v ) ^ { 2 } + k _ { y } ^ { 2 } ) ] } }.$$
Here we calculate the integral over k y numerically and show the result in Figure 2, which indicates a very significant and positive correlation between probability P and speed v . In addition, the threshold speed v P tend to zero naturally due to the elimination of the plasmons' speed u .
Figure 2: The probability of particle production as a function of v in units of TAC 4 , with parameters Ω = 0 3 . , JS = 0 6 and . h = 0 1. .
## 5 Frictional force
According to the physical significance of Γ, the energy accumulated by the excitations due to the relative motion can be expressed as:
$$& \mathcal { E } = T A \int _ { - \infty } ^ { \infty } \frac { \mathrm d \omega } { 2 \pi } \text{Im} \Big \{ \int \frac { \mathrm d ^ { 2 } \mathbf k _ { \| } } { ( 2 \pi ) ^ { 2 } } | \omega | | C ( \mathbf k _ { \| } ) | ^ { 4 } \\ & \times G _ { \mathrm F } ( \omega, \mathbf k _ { \| } ; 0 - h ) \Delta _ { \mathrm R } ( \omega, \mathbf k _ { \| } ) G _ { \mathrm F } ( \omega, \mathbf k _ { \| } ; h - 0 ) \Delta _ { \mathrm L } ( \omega, \mathbf k _ { \| } ) \Big \},$$
And then we can write the dissipation power per unit area as
$$F _ { \text{fric} } \cdot v _ { \| } = \frac { \mathcal { E } } { T A } = 2 \int \frac { d ^ { 2 } k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( k _ { \| } ) | ^ { 4 } \frac { 1 } { v _ { \| } \cdot k _ { \| } } \frac { 1 } { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \\ & \times \frac { J S \left \{ v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \right \} ^ { 3 } \left \{ - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \right \} ^ { 2 } } { v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } - J S k _ { \| } ^ { 2 } } \\ & \times \exp \left \{ \frac { - 2 h } { \sqrt { J S } } \sqrt { - v _ { \| } \cdot k _ { \| } + \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + J S k _ { \| } ^ { 2 } } \right \} \\ & \times \pi \delta \left \{ v _ { \| } \cdot k _ { \| } - 2 \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \right \}, \\ F _ { \text{fric} } \text{ is the friction acting on the R-surface. After taking the same setup of Ea (33) as}$$
where F fric is the friction acting on the R-surface. After taking the same setup of Eq (33) as ImΓ, the frictional force becomes:
$$F _ { \text{fric} } & = 2 \int \frac { d ^ { 2 } k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( k _ { \| } ) | ^ { 4 } \frac { 1 } { v } \frac { 1 } { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \\ & \times \frac { J S ( v k _ { x } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } } + \Omega ^ { 2 } ) ^ { 3 } ( - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } } + \Omega ^ { 2 } ) ^ { 2 } } { v k _ { x } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } } + \Omega ^ { 2 } - J S k _ { \| } ^ { 2 } } \\ & \times \exp \left \{ \frac { - 2 h } { \sqrt { J S } } \sqrt { - v k _ { x } } + \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } + J S k _ { \| } ^ { 2 } } \right \} \\ & \times \pi \delta \left \{ v k _ { x } - 2 \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } } + \Omega ^ { 2 } } \right \}.$$
Like the particles production rate of Eq (34), it has the same Dirac δ -function, thus, the frictional force also corresponds to the same threshold speed v P = 2 . u Similar to P , the frictional force can be expressed as
$$F _ { f r i c } = \int _ { - \infty } ^ { \infty } \frac { \mathrm d k _ { y } } { 2 \pi } \frac { 2 \pi C ^ { 4 } } { 2 v \Omega } \frac { J S \Omega ^ { 3 } } { \Omega - J S [ ( 2 \Omega / v ) ^ { 2 } + k _ { y } ^ { 2 } ] } e ^ { - \frac { 2 h } { \sqrt { J S } } \sqrt { - \Omega + J S [ ( 2 \Omega / v ) ^ { 2 } + k _ { y } ^ { 2 } ] } }.$$
The numerical result of Eq (41) is shown in Figure 3, and like most frictional forces, here it is also positively correlated with speed.
Figure 3: The frictional force as a function of v in units of TAC 4 , with parameters Ω = 0 3 . , JS = 0 6 and . h = 0 1. .
## 6 Conclusion
In this paper we have studied a magnon mediated friction between two metallic surfaces separated by a ferromagnetic intermedium with thickness h . The internal DOFs in the two metallic surfaces are assumed to be plasmons, while the excitations in the intermediate material are magnons. To study the frictional force in the system, we assume the R-surface is moving uniformly parallel to the L-surface at a constant velocity, creating relative sliding. The
derivation starts from the effective action of the magnons, and then we analyse the free Green's function of the magnons since these magnons carry the interaction between the two surfaces. To handle the energy transfer in the system for friction, it is necessary to address the probability of particle production.The theoretical approach to particle production probability shows that a threshold speed exists, and numerical analysis indicates a positive correlation between the probability and the speed. Finally, we derived the frictional force of the system, both the theoretical and numerical results agree with the behaviors of the particle production probability, i.e., the friction also has a positive correlation with the moving speed.
Furthermore, it is interesting to consider the case of a system with magnon-plasmon hybrid excitation. The probability of particle production can be expressed as
$$\mathcal { P } & = 2 \int \frac { d ^ { 2 } k _ { \| } } { ( 2 \pi ) ^ { 2 } } | C ( k _ { \| } ) | ^ { 4 } \frac { 1 } { v _ { \| } \cdot k _ { \| } } \frac { 1 } { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } \\ & \times J S ( v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } ) ^ { 2 } ( - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } ) ^ { 2 } \\ & \times \frac { 1 } { v _ { \| } \cdot k _ { \| } - 2 \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } } \pi \delta ( v _ { \| } \cdot k _ { \| } - \sqrt { u ^ { 2 } k _ { \| } ^ { 2 } + \Omega ^ { 2 } } - J S k _ { \| } ^ { 2 } ), \\ & \text{ \quad \ \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \text{ \quad \ } \end{$$
with the condition -v ∥ · k ∥ + √ u 2 k 2 ∥ +Ω + 2 JS k 2 ∥ < 0. Comparing Eq (40) with Eq (30), we can see that it is no exponential factor in Eq (40), which means the probability of magnonplasmon hybrid excitations does not decrease as the thickness of the ferromagnet increases. This indicates that the corresponding frictional force must be independent of h .
## Acknowledgement
We gratefully acknowledge the fruitful discussions with Qiang Sun. This research was supported by Dongying Science Development Fund(No. DJB2023015).
## References
- [1] Bo N. J. Persson and Nicholas D. Spencer. 'Sliding Friction: Physical Principles and Applications'. In: Physics Today 52.1 (Jan. 1999), pp. 66-68. issn : 0031-9228. doi : 10. 1063/1.882557 .
- [2] B.N.J. Persson. 'Sliding friction'. In: Surface Science Reports 33.3 (1999), pp. 83-119. issn : 0167-5729. doi : https://doi.org/10.1016/S0167-5729(98)00009-0 .
- [3] B. Mason, S. Winder, and Jacqueline Krim. 'On the current status of quartz crystal microbalance studies of superconductivity-dependent sliding friction'. In: Tribology Letters -TRIBOL LETT 10 (Jan. 2001), pp. 59-65. doi : 10.1023/A:1009042816366 .
- [4] A. Dayo, W. Alnasrallah, and J. Krim. 'Superconductivity-Dependent Sliding Friction'. In: Phys. Rev. Lett. 80 (8 1998), pp. 1690-1693. doi : 10.1103/PhysRevLett.80.1690 .
- [5] J B Pendry. 'Shearing the vacuum - quantum friction'. In: Journal of Physics: Condensed Matter 9.47 (1997), p. 10301. doi : 10.1088/0953-8984/9/47/001 .
- [6] Guiti Zolfagharkhani et al. 'Quantum friction in nanomechanical oscillators at millikelvin temperatures'. In: Phys. Rev. B 72 (22 2005), p. 224101. doi : 10.1103/PhysRevB.72. 224101 .
- [7] Rasoul Kheiri. 'Quantum 'contact' friction: The contribution of kinetic friction coefficient from thermal fluctuations'. In: Friction 11 (May 2023), 1877-1894. doi : https: //doi.org/10.1007/s40544-022-0719-1 .
- [8] Yang Wang and Yu Jia. 'Quantum dissipation and friction attributed to plasmons'. In: Modern Physics Letters B 36.06 (2022), p. 2150589. doi : 10.1142/S0217984921505898 .
- [9] Lixin Ge. 'Negative vacuum friction in terahertz gain systems'. In: Phys. Rev. B 108 (4 2023), p. 045406. doi : 10.1103/PhysRevB.108.045406 .
- [10] Farhad Khosravi et al. 'Giant enhancement of vacuum friction in spinning YIG nanospheres'. In: New Journal of Physics 26.5 (May 2024), p. 053006. doi : 10.1088/1367-2630/ ad3fe1 .
- [11] Dirk Kadau, Alfred Hucht, and Dietrich E. Wolf. 'Magnetic Friction in Ising Spin Systems'. In: Phys. Rev. Lett. 101 (13 2008), p. 137205. doi : 10.1103/PhysRevLett.101. 137205 .
- [12] C. Fusco, D. E. Wolf, and U. Nowak. 'Magnetic friction of a nanometer-sized tip scanning a magnetic surface: Dynamics of a classical spin system with direct exchange and dipolar interactions between the spins'. In: Phys. Rev. B 77 (17 2008), p. 174426. doi : 10.1103/ PhysRevB.77.174426 .
- [13] Martin P. Magiera et al. 'Magnetic Friction and the Role of Temperature'. In: IEEE Transactions on Magnetics 45.10 (2009), pp. 3938-3941. doi : 10.1109/TMAG.2009. 2023623 .
- [14] Yang Wang and Yu Jia. 'Dissipation and friction of a quantum spin system'. In: Eur. Phys. J. B 95.4 (2022), p. 75. doi : 10.1140/epjb/s10051-022-00330-z .
- [15] Johan S. Høye and Iver Brevik. 'Casimir friction between a magnetic and a dielectric material in the nonretarded limit'. In: Phys. Rev. A 99 (4 2019), p. 042511. doi : 10. 1103/PhysRevA.99.042511 .
- [16] Antonio Costa et al. 'Strongly Coupled Magnon-Plasmon Polaritons in Graphene-TwoDimensional Ferromagnet Heterostructures'. In: Nano letters 23 (May 2023). doi : 10. 1021/acs.nanolett.3c00907 .
- [17] Daisuke Miura and Akimasa Sakuma. 'Microscopic Theory of Magnon-Drag Thermoelectric Transport in Ferromagnetic Metals'. In: Journal of the Physical Society of Japan 81.11 (2012), p. 113602. doi : 10.1143/JPSJ.81.113602 .
- [18] Anna Dyrdaglyph[suppress] l et al. 'Magnon-plasmon hybridization mediated by spin-orbit interaction in magnetic materials'. In: Phys. Rev. B 108 (4 2023), p. 045414. doi : 10.1103/PhysRevB. 108.045414 .
- [19] E Rastelli and P A Lindgard. 'Exact results for spin-wave renormalisation in Heisenberg, and planar ferromagnets'. In: Journal of Physics C: Solid State Physics 12.10 (1979),
p. 1899. doi : 10.1088/0022-3719/12/10/021 . url : https://dx.doi.org/10.1088/ 0022-3719/12/10/021 .
- [20] Xiao-Gang Wen. Quantum Field Theory of Many-Body Systems: From the Origin of Sound to an Origin of Light and Electrons . Oxford University Press, Sept. 2007. isbn : 9780199227259. doi : 10.1093/acprof:oso/9780199227259.001.0001 .
- [21] Aleksandr Volokitin. Quantum friction and graphene . 2011. arXiv: 1112.4912 .
- [22] M. Bel´ en Farias et al. 'Quantum friction between graphene sheets'. In: Phys. Rev. D 95 (6 2017), p. 065012. doi : 10.1103/PhysRevD.95.065012 . | 10.1038/s41598-025-85666-z | [
"Yang Wang",
"Ruanjing Zhang",
"Feiyi Liu"
]
| 2024-08-02T17:28:38+00:00 | 2024-08-02T17:28:38+00:00 | [
"cond-mat.stat-mech",
"cond-mat.other"
]
| The magnon mediated plasmon friction: a functional integral approach | In this paper, we discuss quantum friction in a system formed by two metallic
surfaces separated by a ferromagnetic intermedium of a certain thickness. The
internal degrees of freedom in the two metallic surfaces are assumed to be
plasmons, while the excitations in the intermediate material are magnons,
modeling plasmons coupled to magnons. During relative sliding, one surface
moves uniformly parallel to the other, causing friction in the system. By
calculating the effective action of the magnons, we can determine the particle
production probability, which shows a positive correlation between the
probability and the sliding speed. Finally, we derive the frictional force of
the system, with both theoretical and numerical results indicating that the
friction, like the particle production probability, also has a positive
correlation with the speed. |
2408.01406v2 | ## Hyperons during proto-neutron star deleptonization and the emission of dark flavoured particles
## Tobias Fischer, a Jorge Martin Camalich, b,c,d Hristijan Kochankovski, e,f Laura Tolos g,h,i
- a Institute for Theoretical Physics, University of Wroclaw, Pl. M. Borna 9, 50-204 Wroclaw, Poland
b Instituto de Astrof´ ısica de Canarias,
C/ V´ ıa L´ctea, s/n E38205 - La Laguna, Tenerife, Spain a
- c Departamento de Astrof´ ısica, Universidad de La Laguna,
La Laguna, Tenerife, Spain
d
CERN, Theoretical Physics Department,
CH-1211 Geneva 23, Switzerland
- e Departament de F´ ısica Qu`ntica i Astrof´ ısica and Institut de Ci`ncies del Cosmos, a e Universitat de Barcelona,
Mart´ ı i Franqu`s 1, 08028, Barcelona, Spain e
- f Faculty of Natural Sciences and Mathematics-Skopje,
Ss. Cyril and Methodius University in Skopje,
Arhimedova, 1000 Skopje, North Macedonia
- Institute of Space Sciences (ICE, CSIC), Campus UAB, Carrer de Can Magrans, 08193 Barcelona, Spain
Institut d'Estudis Espacials de Catalunya (IEEC),
- g
h
08860 Castelldefels (Barcelona), Spain
- i Frankfurt Institute for Advanced Studies,
Ruth-Moufang-Str. 1, 60438 Frankfurt am Main, Germany
E-mail: [email protected], [email protected], [email protected], [email protected]
Abstract. Complementary to high-energy experimental efforts, indirect astrophysical searches of particles beyond the standard model have long been pursued. The present article follows the latter approach and considers, for the first time, the self-consistent treatment of the energy losses from dark flavoured particles produced in the decay of hyperons during a core-collapse supernova (CCSN). To this end, general relativistic supernova simulations in spherical symmetry are performed, featuring sixspecies Boltzmann neutrino transport, and covering the long-term evolution of the nascent remnant proto-neutron star (PNS) deleptonization for several tens of seconds. A well-calibrated hyperon equation of state (EOS) is therefore implemented into the supernova simulations and tested against the corresponding nucleonic model. It is found that supernova observables, such as the neutrino signal, are robustly insensitive to the appearance of hyperons for the simulation times considered in the present study. The presence of hyperons enables an additional channel for the appearance of dark sector particles, which is considered at the level of the Λ hyperon decay. Assuming massless particles that escape the PNS after being produced, these channels expedite the deleptonizing PNS and the cooling behaviour. This, in turn, shortens the neutrino emission timescale. The present study confirms the previously estimated upper limits on the corresponding branching ratios for low and high mass PNS, by effectively reducing the neutrino emission timescale by a factor of two. This is consistent with the classical argument deduced from the neutrino detection associated with SN1987A.
Keywords: core-collapse supernovae, supernova neutrinos, dark matter theory
## Contents
| 1 | Introduction | 1 |
|-----|-------------------------------------------------------|-----|
| 2 | Hyperons within the relativistic mean field framework | 3 |
| 3 | Equation of state with hyperons | 5 |
| 4 | Simulations of the PNS deleptonization with hyperons | 6 |
| 5 | Dark flavoured sectors during PNS deleptonization | 12 |
| 5.1 | Dark flavoured emissivity | 12 |
| 5.2 | Impact of dark flavoured sector on PNS evolution | 13 |
| 6 | Summary and conclusions | 16 |
## 1 Introduction
Massive stars end their lifes in the event of a CCSN, when the stellar core collapses due to pressure losses from electron captures on protons bound in iron-group nuclei and the photodissociation of nuclei. The core collapse halts when the density exceeds the normal nuclear density, and the stellar core bounces back with the formation of a shock wave. The initial propagation of this bounce shock leads to the release of a ν e -burst when reaching the neutrinospheres of the last inelastic scattering. The associated energy loss, in combination with the energy loss due to the photodissociation of the still infalling matter onto the expanding dynamic bounce shock, causes the latter to stall and turn into an accretion shock. Revival of this standing accretion shock is considered the CCSN explosion engine (for recent reviews, c.f., Refs. [1-3] and references therein).
Most of the gravitational binding energy gain is stored in the central compact PNS, in the magnetic-rotational energy [4], as well as in thermal degrees of freedom and neutrinos of all flavours, on the order of several 10 53 erg. Hence, the neutrino-heating mechanism for shock revival, first proposed in ref. [5], has long been studied in modern CCSN simulations. These are based in multidimensional neutrino radiation hydrodynamics featuring neutrino transport, where in the presence of multi-dimensional hydrodynamics phenomena, such as convection and hydrodynamic instabilities, the neutrino-heating efficiency increases, compared to spherically symmetric CCSN models, which therefore generally fail to yield CCSN explosions. There are two exceptions, (i) low-mass stellar progenitors in the zero-age main sequence (ZAMS) mass range of 8-10 M ⊙ [6-8] as well as ultrastripped stellar progenitors that result from binary evolution [9, 10], despite substantial differences between spherically symmetric and multi-dimensional simulations [11-15], and (ii) CCSNexplosions triggered due to a sufficiently strong first-order phase transition from normal nuclear matter to the quark-gluon plasma at high baryon density (c.f. Refs. [16-21] and references therein) as well as the spontaneous scalarization of beyond the standard model degrees of freedom [22].
The latter CCSN explosion mechanism relates to one of the largest uncertainties in CCSN modelling, namely, the state of matter under CCSN conditions, i.e. at high baryon density, in excess of saturation density, large isospin asymmetry given by the hadronic charge density (the proton abundance in the absence of other charged hadronic resonances, on the order of Y p = 0 05 0 6 . -. ) and temperatures on the order of several tens of MeV (for a recent review of the role of the EOS in
simulations of CCSN, see ref. [23]). Besides the QCD deconfinement phase transition, which has lately been explored extensively also in the context of binary neutron star mergers [24, 25], the impact of hadronic degrees of freedom has been studied in the context of failed CCSN in Refs. [26-30], even though the potential impact of strange, as well as non-strange hadronic degrees of freedom has long been studied for neutron stars (see recent reviews [31-34] and references therein.) Thereby, particular emphasis has been placed on the hyperon puzzle , which is related to the softening of the supersaturation density EOS due to the presence of additional, heavy hadronic degrees of freedom, potentially violating the maximum neutron star mass constraint of about 2 M , the latter was derived from observations ⊙ of massive pulsars [35-37, 37-39]. Several possible solutions have been widely discussed in the literature. Among them, it has been put forward an early onset of the quark-hadron deconfinement phase transition at densities below which strange hadronic resonances would appear, or the existence of much more repulsive hadronic interactions at high baryon densities. However, hyperon-nucleon and hyperon-hyperon interactions are less understood than nucleon-nucleon interactions, due to the sparse knowledge of scattering data. This makes their potentials poorly constrained and dynamics far from understood (c.f. ref. [40] and references therein). The theoretical understanding has been brought forward to solve the problem of thermal production of hyperons at low baryon density for heavy-ion physics based on the coupled channel approach (c.f. Refs. [41-43] and references therein) and furthermore, final-state interaction analyses [44-47] as well as femtoscopy studies (see ref. [48] for a review and references therein) have become available as well as data on hypernuclear structure [49-51].
Due to the poorly known hyperon EOS at high baryon density, effective hyperonic model EOS have long been employed in astrophysical studies, e.g., based on the relativistic mean-field (RMF) approach that treats the unknown interactions via baryon-meson couplings. The present article implements the FSU2H ∗ hyperonic relativistic mean field model in simulations of CCSN, focusing on the PNS deleptonization phase, i.e. the evolution after the CCSN explosion onset has been triggered during which the nascent PNS deleptonizes via the emission of neutrinos of all flavours on a timescale of 10 seconds. This phase is ideal for studying the impact of hadronic physics as the central density increases continuously as a direct consequence of the deleptonization.
The requirements for multi-purpose EOS for applications of CCSN studies is to cover a large parameter space. Therefore, the RMF framework has long been developed (for recent reviews, see Refs. [52, 53] and references therein). Recent reviews of the RMF framework for hyperon EOS can be fond in ref. [33, 54] 1 .
In addition to the impact that hyperons can potentially have in CCSN through the EOS, they can open potentially new cooling channels with the emission of novel, yet hypothetical, particles from the interior of the PNS. In particular, if the net energy carried away by these particles is comparable to that of neutrinos, then significant changes in the neutrino signal are predicted. These can be tested using the neutrino flux that was observed from SN1987A [57, 58]. Such phenomenology has been studied extensively in the context of the QCD axions, produced in the stellar plasma by, e.g. nucleon-nucleon bremsstrahlung [59-65], from pions studied [66] and in simulations [67], and has been extended to many other 'dark-sector' theories predicting the existence of new weakly interacting particles with mass ≲ O ( T PNS ) [68-73], which is on the order of few tens of MeV.
Adding 'standard' degrees of freedom in the plasma, on top of nucleons and electrons/positrons, can also extend these analyses, as was recently demonstrated in the case of muons (c.f. Refs. [7377] and references therein), for pions [66, 67, 78-81], and for hyperons [82-85]. In the case of hyperons, this was studied for various models that can induce flavour-changing neutral currents, such
1 Note the existence of the online service CompOSE repository that provides data tables for different state of the art EOS ready for use in astrophysical applications, nuclear physics and beyond [55, 56].
as the following decays, Λ → n and Λ → γ , where the energy difference between final and initial states is considered to be carried away by dark degrees of freedom. Therefore, results of spherically symmetric simulations were employed without exotic cooling and implementing conventional EOS without hyperons. To establish limits on these models, the impact of the new dark emission on the dynamics of the CCSN was neglected, and thermodynamic quantities such as chemical potentials were re-derived by using interpolation tables of the hyperonic extensions of the EOS used in the simulations (see also ref. [85] for a slightly different approach).
A dark sector coupled to quarks can have a rich flavour structure that is subject to strangenesschanging neutral currents (for reviews, see Refs. [86, 87]). One prototypical example of these dark flavoured sectors is the QCD axion, with non-diagonal flavour couplings, known as 'familon'. This was first predicted in refs. [88, 89] as a consequence of jointly solving the strong CP and flavour problems, and was further developed [82, 90-93]. Other examples include the dark photon, which interacts with standard-model fermions only through non-renormalizable operators (see Refs. [94-97] and references therein) or dark baryons [84]. The latter are neutral fermions with masses of ≈ 1 GeV endowed with baryon number and that can be part of dark matter, and explain baryogenesis (c.f. Refs. [98, 99]) and the neutron lifetime puzzle [100]. The self-consistent implementation of hyperons in CCSN simulations enables us to overcome previous limitations (c.f. ref. [83] and references therein), studying the feedback of dark boson production on the supernova dynamics and neutrino emission.
The paper is organized as follows. In section 2 the RMF framework for reference nucleonic and hyperonic EOS will be introduced, which is evaluated at selected conditions in section 3, including finite temperature, and discussed accordingly. CCSN simulations will be launched and evaluated in section 4. The comprehensive analysis from the impact of dark bosons will be provided in section 5 and the manuscript closes with a summary in section 6.
## 2 Hyperons within the relativistic mean field framework
The present study of the impact of strange degrees of freedom in CCSN simulations employed the FSU2H ∗ RMF EOS. In this framework, the interactions between the baryons are mediated via the exchange of virtual mesons, based on the following Lagrangian for baryons L B and mesons L m ,
$$\mathcal { L } = \sum _ { \mathrm B } \mathcal { L } _ { \mathrm B } + \mathcal { L } _ { \mathrm m } \,,$$
with and
$$\mathcal { L } _ { B } & = \bar { \Psi } _ { B } ( i \gamma _ { \mu } \partial ^ { \mu } - q _ { B } \gamma _ { \mu } A ^ { \mu } - m _ { B } + g _ { \sigma B } \sigma + g _ { \sigma ^ { * } B } \sigma ^ { * } \\ & - g _ { \omega B } \gamma _ { \mu } \omega ^ { \mu } - g _ { \phi B } \gamma _ { \mu } \phi ^ { \mu } - g _ { \rho B } \gamma _ { \mu } \, \vec { I } _ { B } \cdot \vec { \rho } ^ { \mu } ) \Psi _ { B } \,,$$
$$\mathcal { L } _ { m } & = \frac { 1 } { 2 } \partial _ { \mu } \sigma \partial ^ { \mu } \sigma - \frac { 1 } { 2 } m _ { \sigma } ^ { 2 } \sigma ^ { 2 } - \frac { \kappa } { 3! } ( g _ { \sigma N } \sigma ) ^ { 3 } - \frac { \lambda } { 4! } ( g _ { \sigma N } \sigma ) ^ { 4 } \\ & + \frac { 1 } { 2 } \partial _ { \mu } \sigma ^ { * } \partial ^ { \mu } \sigma ^ { * } - \frac { 1 } { 2 } m _ { \sigma ^ { * } } ^ { 2 } \sigma ^ { * 2 } \\ & - \frac { 1 } { 4 } \Omega ^ { \mu \nu } \Omega _ { \mu \nu } + \frac { 1 } { 2 } m _ { \omega } ^ { 2 } \omega _ { \mu } \omega ^ { \mu } + \frac { \zeta } { 4! } g _ { \omega N } ^ { 4 } ( \omega _ { \mu } \omega ^ { \mu } ) ^ { 2 } \\ & - \frac { 1 } { 4 } \vec { R } ^ { \mu \nu } \vec { R } _ { \mu \nu } + \frac { 1 } { 2 } m _ { \rho } ^ { 2 } \vec { \rho } _ { \mu } \vec { \rho } ^ { \mu } + \Lambda _ { \omega } g _ { \rho N } ^ { 2 } \vec { \rho } _ { \mu } \vec { \rho } ^ { \mu } g _ { \omega N } ^ { 2 } \omega _ { \mu } \omega ^ { \mu } \\ & - \frac { 1 } { 4 } P ^ { \mu \nu } P _ { \mu \nu } + \frac { 1 } { 2 } m _ { \phi } ^ { 2 } \phi _ { \mu } \phi ^ { \mu } - \frac { 1 } { 4 } F ^ { \mu \nu } F _ { \mu \nu } \,.$$
Table 1 . Parameters of the model FSU2H ∗ , meson masses m i and meson-nucleon coupling constants g 2 i . The mass of the nucleon is equal to m N = 939 MeV.
| m σ [ MeV ] | m ω [ MeV ] | m ρ [ MeV ] | m σ ∗ [ MeV ] | m ϕ [ MeV ] | g 2 σN | g 2 ωN | g 2 ρN |
|---------------|---------------|---------------|-----------------|---------------|----------|----------|----------|
| 497.479 | 782.5 | 763 | 980 | 1020 | 102.72 | 169.53 | 197.27 |
Table 2 . Other parameters of the Lagrangian (2.3) of the model FSU2H ∗ .
| κ | λ | ζ | Λ ω |
|---------|---------|-------|-------|
| [ MeV ] | | | |
| 4.0014 | -0.0133 | 0.008 | 0.045 |
The quantity Ψ B represents the baryon Dirac field and m i indicates the mass of particle i , while the mesons that mediate the interaction between the baryons are two isoscalar-scalar mesons ( σ and σ ∗ ), two isoscalar-vector mesons ( ω and ϕ ), and one isovector-vector meson ( ρ ). The mesonic strength tensors are labeled with Ω µν = ∂ ω µ ν -∂ ω ν µ , ⃗ R µν = ∂ ρ ⃗ µ ν -∂ ρ ⃗ ν µ , P µν = ∂ ϕ µ ν -∂ ϕ ν µ and F µν = ∂ A µ ν -∂ A ν µ , whereas γ µ are the Dirac matrices, g mB labels the coupling of baryon B to meson m and ⃗ I B is the isospin operator. We stress that, since we are dealing with charge-neutral objects in the absence of magnetic fields, the electromagnetic part of the Lagrangian does not play a role.
In order to determine the EOS of the system, one first needs to obtain the Euler-Lagrange equations of motion for each particle. Then, a closed set of equations can be obtained by using the mean-field approximation that allows for the meson fields to be replaced by their expectation values, as well as by coupling those equations with the weak interaction equilibrium condition and baryon and charge conservation number equations. The solution of this set fixes the composition of matter and the values of the meson fields. Finally, from the stress-energy tensor all thermodynamic quantities can be obtained, such as the pressure and energy density (for details on the set of equations to be solved, we refer the reader to the Refs. [101-104] and references therein).
We show in the following the explicit form of the effective mass and chemical potential of the different species, since these are important quantities whose behaviour influences the thermal evolution in CCSN explosions. The effective mass of a given particle reads as follows,
$$m _ { \text{B} } ^ { * } = m _ { \text{B} } - g _ { \text{B} \sigma } \bar { \sigma } - g _ { \text{B} \sigma ^ { * } } \bar { \sigma } ^ { * } \,,$$
where the expectation values of the scalar mesons, denoted as ¯ σ and ¯ σ ∗ , govern their behaviour. Since no isospin splitting is considered due to the absence of the δ meson channel, m N = 939 MeV is used in FSU2H ∗ for the nucleon rest masses while those of the hyperons are given in the Particle Data Booklet [105]. The expectation values of the vector mesons, i.e. ¯ ω , ¯ ρ and ¯ ϕ , control the different chemical potentials as follows,
$$\mu _ { B } ^ { * } = \mu _ { B } - g _ { B \omega } \bar { \omega } - g _ { B \rho } I _ { 3 B } \bar { \rho } - g _ { B \phi } \bar { \phi } \,,$$
with the thermodynamic chemical potential µ B . Wenote that the hidden mesons σ ∗ and ϕ are coupled only to particles with non-zero strangeness.
Table 3 . Ratios of coupling constants of hyperons to mesons with respect to the nucleonic ones.
| Y | R σY | R ωY | R ρY | R σ ∗ Y | R ϕY √ |
|-----|----------|--------|--------|-----------|-----------|
| Λ | 0 . 6113 | 2 / 3 | 0 | 0 . 2812 | - 2 / 3 √ |
| Σ | 0 . 4673 | 2 / 3 | 1 | 0 . 2812 | - 2 / 3 √ |
| Ξ | 0 . 3305 | 1 / 3 | 1 | 0 . 5624 | - 2 2 / 3 |
## 3 Equation of state with hyperons
The different parameters of the FSU2H ∗ model are chosen so as to predict an EOS that is compatible with the constraints coming from heavy ion collisions as well as those obtained from the saturation properties of nuclear matter and finite nuclei. At the same time the model predicts a maximum neutron star mass that is above 2.0 M ⊙ and a radius about 13 km for canonical neutron stars of 1.4 M ⊙ (for details, see Refs. [101, 102]). This model was then extended to finite temperature [103], whereas more recently the hyperonic uncertainties have been analyzed for the determination of the masses, radii, tidal deformabilities and moments of inertia, both at zero and finite temperatures [104]. Indeed, the FSU2H ∗ model is compatible with the tidal deformability extracted from the GW170817 event [106] as well as the NICER determinations on radii [107-110]. The values of the parameter meson masses and meson-nucleon coupling constants can be found in Table 1, whereas the other parameters of the Lagrangian (2.3) are given in Table 2. The ratios of coupling constants of hyperons to mesons are give in Table 3.
In the present work we make use of the FSU2H ∗ model in two different ways. Firstly, a set of simulations is performed with the exact FSU2H ∗ EOS, and the results of those simulations are referred as HYPERONS. The results of the second set of simulations, that will be referred as NUCLEONS, are obtained within the same FSU2H ∗ model, but preventing the appearance of hyperons by setting their masses to infinity. This set is necessary in order to quantify the impact that hyperons have on the observables.
Figures 1 and 2 illustrate selected quantities of the NUCLEONS EOS (black lines) and HYPERONS EOS (blue lines) at certain conditions, at T = 0 in Fig. 1 and at a constant entropy of s = 3 k B in Fig. 2, both assuming β -equilibrium. For both cases it becomes evident that the HYPERONS EOS is substantially softer at high densities than the NUCLEONS EOS, illustrated by the pressure in the upper left panels of Figs. 1 and 2. This is a consequence from the lower neutron abundance since the EOS is dominated by the neutron degeneracy at the high densities explored here (see therefore the hadron abundances in the upper right panels and note the generally low abundances 2 of hyperons Λ Σ , -and Ξ -). Note also the modified charge neutrality conditions in the presence of hyperons, illustrated via the electron and muon abundances, Y e and Y µ , respectively, in the lower right panels, together with the density dependence of the effective masses gap equations (2.4).
The assumption of β -equilibrium results in the condition of equal chemical potentials for electrons and muons, µ e = µ µ , once the electron chemical potential exceeds the muon restmass, µ e ≥ m µ = 106 MeV, which was employed here for the calculation of the muon abundances. Note that this assumption differs from the conditions realized in the CCSN simulations. This discrepancy has been pointed out in Refs. [19, 118], that while µ µ → µ e , this condition can be reached only after more than 30 s post bounce in simulations of the PNS deleptonization and cooling, studied based on the DD2 relativistic mean field EOS, with density dependent meson-nucleon couplings [111]. As
2 In the case of particles with baryon number equal one, abundances Y i and mass fractions X i are identical, defined through the partial densities n i = Y n i B with baryon density n B .
Figure 1 . Equation of state at β -equilibrium at T = 0 , comparing the HYPERON EOS(blue lines) and the reference NUCLEON EOS (black lines), showing (from top left to bottom right) the total pressure, P , selected mass fractions, X i , corresponding chemical potentials, µ i without restmass m i and the effective masses, m ∗ i , as well as the abundances of electrons and muons, Y e and Y µ , respectively.
a consequence of this simplification applied here for the calculation of the muon EOS, the muon abundance Y µ is found to be significantly larger than what we find in the CCSN and PNS simulations, that will be discussed in Sec. 4 below.
The lower right panels in Figs. 1 and 2 also show the effective hadron masses, m ∗ i , relative to their vacuum values m i , from which it becomes evident that the neutron mass decreases most rapidly towards about 15% of its vacuum value at a density of slightly above ρ = 10 15 g cm -3 , whereas the effective mass of the Λ is about 50% of its vacuum value at the same density. The corresponding chemical potentials, µ i without rest masses m i , are shown in the lower left panels of Figs. 1 and 2. At zero temperature, hyperons are strictly suppressed when their effective chemical potentials, shown in the lower left panel in Fig. 1, are below their respective rest masses, while at finite temperature, shown in Fig. 2, this condition does not apply any longer.
## 4 Simulations of the PNS deleptonization with hyperons
For the simulations of the PNS deleptonization, the AGILE-BOLTZTRAN spherically symmetric general relativistic neutrino radiation hydrodynamics model is employed (c.f. Refs. [112-115] and references therein). It is based on six-species Boltzmann neutrino transport and a complete set of weak interactions (the weak reactions used in the current study, including the references, are listed in Table 1 of
Figure 2 . Same as Fig. 1 but for finite entropy per baryon of s = 3 k B .
ref. [116]). We distinguish between µ and τ (anti)neutrinos due to the inclusion of weak reactions involving muons and antimuons. These include the muonic charged current reactions, based on the full kinematics approach [117], as well as neutrino-(anti)muon inelastic scattering. For both of which we are following the implementation of ref. [118].
AGILE-BOLTZTRAN has a flexible EOS module that contains the Lattimer & Swesty Skyrme model [119] as well as the comprehensive RMF EOS catalogue of ref. [120]. The latter incorporates the modified nuclear statistic equilibrium (NSE) with several thousand nuclei [121], including excited state contributions, modelled via temperature dependent statistical weight factors for each nuclear species. The transition from the modified NSE to homogeneous nuclear matter is taken into account via a first-order phase transition construction where the nuclear states are suppressed through a geometric excluded volume approach (for alternative excluded volume functionals, c.f. ref. [122] and references therein). In ref. [120], the excluded volume parameter is chosen to result in the complete disappearance of all nuclei at nuclear saturation density. In the present study, we replace the supersaturation density phase of the DD2 RMF EOS [111, 120], with density-dependent mesonnucleon mean-field couplings, with the NUCLEONS and HYPERONS settings from FSU2H . ∗ We find that this approach, despite its ad hoc nature, results in a smooth transition. EOS contributions from electrons, positron and photons, as well as Coulomb contributions for the non-NSE regime, are implemented based on the routines of ref. [123].
The inclusion of the HYPERONS EOS is connected with the implementation of the associated hyperon degrees of freedom, Λ Σ , -and Ξ -, into the AGILE-BOLTZTRAN CCSN model. It concerns
(b)
25 M
⊙
progenitor
Figure 3 . Post bounce evolution of selected central quantities for the 18 M ⊙ and 25 M ⊙ models in graph (a) and (b) respevtively, comparing simulations with the NUCLEONS (black lines) and HYPERONS (blue lines) EOS showing from left to right, central restmass density ρ , central and maximum temperatures, T central and T max , central electron and muon abundances, Y e and Y µ , and minimum Y e , and the mass fractions X i of neutrons in the top panel (thick solid lines) and in the bottom panel protons (thick dotted lines) in comparison to the strange hadrons Λ (thin solid lines), Σ -(thin dashed lines) and Ξ (thin dash-dotted lines). Note that the latter are magnified by one order of magnitude for better visibility.
their abundances as well as the single particle properties such as the effective masses, the chemical potentials and the mean-field potentials, according to the underlying model as was discussed in Sec. 3. In particular, the latter will become relevant when implementing weak processes involving hyperons, which, for the present study, are being omitted as the simulation times are limited to O (10 s) when neutrinos still decouple at lower densities where no hyperons are abundant. This situation will change towards later times, when neutrinos start to decouple in the regions where hyperons are abundant, such that the inclusion of weak processes involving hyperons would influence the further deleptonization and cooling behaviour. Furthermore, the presence of hyperons modifies the charge-neutrality condition, with the negatively charged hyperons considered, i.e. Y e + Y µ = Y p -Y Σ --Y Ξ -. Note that
Table 4 . Stellar progenitor model's zero-age main sequence masses, M ZAMS , and the encloses PNS baryonic and gravitational masses, M B , and M G , as well as the corresponding radii R , evaluated at the end of the CCSN simulations.
| progenitor mass a M ZAMS [ M ⊙ ] | EOS | M b B [ M ⊙ ] | M b G [ M ⊙ ] | R b [ km ] |
|------------------------------------|----------|-----------------|-----------------|--------------|
| 18 | NUCLEONS | 1.543 | 1.435 | 14.18 |
| 18 | HYPERONS | 1.558 | 1.45 | 14.09 |
| 25 | NUCLEONS | 1.942 | 1.792 | 14.84 |
| 25 | HYPERONS | 1.938 | 1.791 | 14.45 |
Notes.
- a models from the stellar evolution series of ref. [124]
- b Evaluated at ρ = 10 10 g cm -3 at about 10 s post bounce
despite their consistent treatment and implementation into the CCSN simulations, the heavier, neutral hyperons, Σ 0 and Ξ 0 , and the positively charged hyperons, Σ + and Ξ + , are neglected in the following discussions, as they are all strongly Boltzmann suppressed under the extremely neutron-rich conditions at highest densities encountered at the PNS interior, i.e. the following abundance hierarchy generally holds: Y Λ > Y Σ -> Y Ξ -as well as Y Σ -≫ Y Σ 0 > Y Σ + and Y Ξ -≫ Y Ξ 0 > Y Ξ + .
With this enhanced EOS module setup, simulations of CCSN are launched from two progenitor models, with zero-age main sequence masses of 18 M ⊙ and 25 M ⊙ , both from the stellar evolution series of ref. [124]. These stellar progenitors are being evolved through all CCSN phases self consistently. It is found that up to several 100 ms post bounce, the abundance of hyperons remains small, below 1%, and no impact could be observed, not on the overall dynamics nor on the neutrino heating and cooling rates. The neutrino signals are indistinguishable between NUCLEONS and HYPERONS.
The simulations with the NUCLEONS and HYPERONS EOS proceed identically.
Since neutrino-driven explosions cannot be obtained for such massive iron-core progenitors in spherically symmetric CCSN simulations, we follow closely the procedure outlined in ref. [7]. Therefore, the electronic charged current weak rates are being enhanced in the gain layer, which results in the continuous shock expansion and the onset of the CCSN explosion. Once the shock reaches a radius of about 1000 km, we switch back to the standard weak rates, following the later PNS deleptonization. A similar procedure has been employed in ref. [125] for a large sample of CCSN explosion models for various different progenitors at different metalicities.
The post-bounce evolution of the four models is illustrated in Fig. 4, for 18 M ⊙ and 25 M ⊙ model in Figs. 3(a) and 3(b), respectively, distinguishing the NUCLEONS (black lines) and HYPERONS (blue lines) EOS. Once the supernova explosion proceeds with the revival of the shock, mass accretion onto the PNS surface ceases and the enclosed PNS baryon masses change only marginally. The latter is due to the ejection of the neutrino driven wind, initially on the order of 10 -3 M ⊙ s -1 and later substantially lower with 10 -4 M ⊙ s -1 . The resulting PNS masses of the two sets of simulations are listed in Table 4, for both NUCLEONS and HYPERONS runs. These values are evaluated at the restmass density of 10 11 g cm -3 at about 10 s post bounce. The larger PNS masses for the more massive progenitor are due to the higher post-bounce mass accretion rates for the 25 M ⊙ models, in particular during the early post-bounce phase, i.e., before the shock revival, as is illustrated in the bottom panel of Fig. 4, showing the mass accretion rate ˙ M PNS , as well evaluated at ρ = 10 11 g cm -3 . The top panel illustrates the different PNS radii, R PNS , and their evolution for all simulations with the NUCLEONS and HYPERONS EOS under investigation, showing the slightly faster contraction
Figure 4 . Post bounce evolution of the PNS radius R PNS (top panel) and mass accretion rate ˙ M | PNS (bottom panel), both evaluated at a selected restmass density of ρ = 10 11 g cm -3 , comparing the 18 M ⊙ simulations for NUCLEONS (black solid lines) and HYPERONS (light blue dashed lines) and the 25 M ⊙ simulations also for NUCLEONS (dark grey solid lines) and HYPERONS (dark blue dashed lines).
of the HYPERONS PNS due to the softer supersaturation density behaviour.
Only after several seconds, in both simulations, differences due to the inclusion of hyperons arise. These differences are best seen by the evolution of the central densities, shown in the left panels of Figs. 3(a) and 3(b), where the simulations based on the HYPERONS EOS reach significantly higher values than the ones with NUCLEONS. This EOS softening is due to the continuous rise of the hyperon abundances for Λ Σ , -and Ξ -, shown in the right panels. Note that these hyperons are absent for the NUCLEONS simulations (black lines). The first hyperons which appear are Λ 's, due to the lowest mass (see Figs. 1 and 2), already at a density slightly in excess of nuclear saturation density, i.e. already during the early post-bounce evolution prior to the supernova explosion onset. However, the abundance of Λ remains low, on the order of Y Λ ≃ 0 001 . -0 025 . for the for 18 M ⊙ model and Y Λ ≃ 0 01 . -0 07 . for the for 25 M ⊙ model. The latter reach higher abundances because of the generally higher densities and temperatures obtained at the central fluid elements in the simulations. Note therefore the different evolution of the central and maximum temperatures in Figs. 3(a) and 3(b). The abundances of the other hyperons, Σ -and Ξ -, remain about one order of magnitude lower than those of Λ , in both simulations.
Figure 5 . Post bounce evolution of the neutrino luminosities and average energies for the two sets of simulations launched from 18 M ⊙ (left panel) and 25 M ⊙ progenitors (right panel), comparing in addition to the NUCLEONS (black lines) and HYPERONS (blue lines) EOS also those with the inclusion of losses through the emission of dark sector bosons X 0 , denoted as HYPERONS ∗ (orange lines). The luminosity in graphs (a) and (b) distinguish the total neutrino luminosity (top panels, solid lines) in comparison to the dark sector particle, denoted as X 0 (dashed lines), electron flavours (middle panels) and heavy lepton flavours (bottom panel). The average neutrino energies in graphs (c) and (d) show the ν e (solid lines), ¯ ν e (dash dotted lines) and ν µ/τ (dashed lines) as representative for all heavy lepton flavours.
Another difference between the runs with NUCLEONS and HYPERONS is the feedback to the nucleons. As was already discussed in Sec. 3, in particular the abundance of neutrons is reduced due to the appearance of Λ , effectively replacing neutrons with Λ 's. This phenomenon is observed consistently in the CCSN simulations too. The neutron abundances are shown in the right panels
of Figs. 3(a) and 3(b). The reduced neutron abundance in addition softens the high-density EOS, which is governed by neutrons with a dominating abundance of Y n ≃ 0 75 . -0 7 . . As a consequence of the different hadronic abundances, in order to obey the condition of charge neutrality, there is a feedback to the electron and muon abundances. In particular, the central muon abundance is reduced substantially for the massive 25 M ⊙ model. Note also that the central muon abundance is substantially lower and that the central electron abundance is substantially higher than in the EOS discussion in Sec. 3, where β -equilibrium was assumed. The observed difference of the electron and in particular the muon abundances are a consequence of the lower central temperatures obtained for the simulations based on the HYPERONS EOS (see Fig. 4), since the muons are produced thermally through the muonic charged current processes.
Despite the differences obtained at the PNS interior, structure and stability of the PNS are not affected by the presence of hyperons. This is partly related to the conditions for the appearance of hyperons, which in turn gives rise to finite hyperon abundances, in particular Λ only at the very central fluid elements in the simulations. As a consequence, the locations of the neutrinospheres are not affected by the presence of hyperons and hence the neutrino luminosities and average energies are indistinguishable between the runs NUCLEONS and HYPERONS, for the intermediate-mass 18 M ⊙ model, shown in Figs. 5(a) and 5(c), and high-mass 25 M ⊙ model, shown in Figs. 5(b) and 5(d). The evolution of the neutrino luminosities and average energies shown in Fig. 5 are sampled in the co-moving frame of reference at a distance of 500 km.
## 5 Dark flavoured sectors during PNS deleptonization
The results including the dark flavoured sector are based on the same HYPERON EOS and will be henceforth denoted as HYPERONS , which will be discussed in this section. ∗ To investigate the impact of a dark flavoured sector in CCSN, we need to estimate the emissivity in the new channels. Weassume that the emitted particles are massless (i.e. their mass is much smaller than T PNS ) and that the interactions are such that their mean free path is much larger than the radius of the PNS. These particles will then freely stream out of the PNS once they are produced in its core.
## 5.1 Dark flavoured emissivity
For concreteness, in the following we will focus on the emission of neutral dark bosons X 0 , such as an axion or dark photon, produced by the flavour-violating transition s → d + X 0 . This is parametrised by the following Lagrangians,
$$\mathcal { L } _ { a } = \frac { 1 } { 2 f _ { a } } \left ( \partial _ { \mu } a \right ) \bar { \mathrm d } \gamma ^ { \mu } ( c _ { \mathrm d s } ^ { V } + c _ { \mathrm d s } ^ { A } \gamma _ { 5 } ) \, s + \text{h.c.} \,,$$
$$\mathcal { L } _ { \gamma ^ { \prime } } = \frac { \stackrel { \cdot \cdot \cdot } { 1 } } { \Lambda } \stackrel { \cdot \cdot \cdot } { \delta } \sigma ^ { \mu \nu } ( c _ { \text{ds} } ^ { T } + c _ { \text{ds} } ^ { T 5 } \gamma _ { 5 } ) \, s \, F _ { \mu \nu } ^ { \prime } + \text{h.c.} \,,$$
where a is the axion field and f a its decay constant and with strange and down quark fields denoted as s and ¯ d , respectively. F ′ µν is the field strength tensor of the dark photon and Λ the energy scale associated to the UV completion of the effective Lagrangian L γ ′ (see ref. [97] for effective vectorial couplings of the dark photon and some UV completions), and c V,A ds and c T,T 5 ds are dimensionless (effective) couplings. The main hadronic production mechanism in the PNS induced by Lagrangians (5.1) and (5.2) will then be Λ → n + X 0 , whereby decays involving heavier hyperons, such as Σ + → p + X 0 , are suppressed by their lower abundances and neglected in the present analysis. Following ref. [82], the spectrum of the energy loss rate of the nuclear medium per unit volume, denoted as Q , with respect
to the X 0 energy E a , in the PNS rest frame and induced by the process Λ → n + X 0 is given by the following expression,
$$\i \psi, \quad & \frac { d Q } { d E _ { a } } = \frac { m _ { \Lambda } ^ { 2 } \Gamma _ { X } E _ { a } } { 2 \pi ^ { 2 } \bar { E } } \int _ { E _ { 0 } } ^ { \infty } d E \, f _ { \Lambda } ( 1 - f _ { n } ) \,,$$
with ¯ = ( E m 2 Λ -m 2 n ) / m 2 Λ , E is the energy of the Λ with E 0 = m Λ ( E 2 a + ¯ ) (2 E 2 / E E a ¯ ) and f Λ ,n are the relativistic Fermi-Dirac phase-space distribution functions of Λ and n . The information of the transition amplitude is encoded in Γ X , which is the decay rate of Λ → n + X 0 in vacuum,
$$\Gamma _ { X } = \frac { \bar { E } ^ { 3 } C _ { X } } { 2 \pi } \,,$$
with C a = ( f 2 1 | c V ds | 2 + g 2 1 | c A ds | 2 ) / f 4 2 a , where f 1 = -1 22(6) . and g 1 = -0 89(2) . are the vector and axial-vector baryonic couplings determined in ref. [82], and C γ ′ = 8 g 2 T ( | c T ds | 2 + | c T 5 2 ds | ) / Λ 2 , where g T ≈ -0 73 . is the baryonic tensor coupling (further details can be found in ref. [83] and references therein).
The total emission rate can be estimated analytically by taking the nonrelativistic limit of the baryons, expanding to leading order in δ = ( m Λ -m n ) /m n and neglecting the neutron's Pauli blocking [82]. Expressed in terms of the emissivity, ϵ = Q/ρ , one obtains the following result,
$$\epsilon \approx \delta \, Y _ { \Lambda } \tau _ { \Lambda } ^ { - 1 } \, \text{BR} ( \Lambda \to n + X _ { 0 } )$$
where we have re-expressed the decay width in terms of the lifetime, τ Λ , and the branching fraction of the decay, BR. Adopting the classical upper limit of the emissivity, ϵ max = 10 19 erg s -1 g -1 , from SN1987A at the conditions of the PNS predicted at about 1 second post-bounce, one obtains,
$$\epsilon \approx \epsilon _ { \max } \left ( \frac { Y _ { \Lambda } } { 0. 0 1 } \right ) \left ( \frac { 1. 6 \times 1 0 ^ { - 9 } } { \text{BR} ( \Lambda \to n + X _ { 0 } ) } \right ) \,.$$
This leads, for a characteristic Λ abundance of 1%, to an upper limit of the branching fraction in the range of 10 -9 , which overestimates the conservative limit by a factor ≈ 5 , which was obtained using the full expression in Eq. (5.3) and state-of-the-art spherically symmetric simulations reported in ref. [74]. Nevertheless, this upper bound is many orders of magnitude stronger than those that can be obtained from laboratory experiments, and, as was found in Refs. [82, 83], it leads to the strongest constraint on the axial couplings of the flavoured QCD axion and on the massless dark photon couplings. In addition, as discussed in ref. [83], in the case of Λ processes one would still produce a too large emission in the deep trapping regime as the dark sector luminosity would stem from the last surface where Λ 's can coexist in equilibrium in the plasma and which corresponds to a region of high temperatures.
## 5.2 Impact of dark flavoured sector on PNS evolution
The non-relativistic emissivity (5.5) is implemented into the AGILE-BOLTZTRAN CCSNmodel as sink for the internal energy equation, following the implementation of dark boson losses of Refs. [67, 126]. Here, we use the literature branching ratios of 10 -8 for the intermediate-mass 18 M ⊙ model and 10 -9 for the massive 25 M ⊙ model, in accordance with ref. [83]. It results in enhanced cooling contributions in the domain where Λ are abundant 3 . This is the case only at the innermost 15-20 km
3 These limits can be readily transformed in stringent limits on the flavoured QCD axion or massless dark photon described by the Lagrangians in (5.1) and (5.2). For example, in the QCD axion case with O (1) off-diagonal flavour couplings, the upper limit BR (Λ → n + a ) ≤ 10 8 corresponds to the limit f a ≳ 5 × 10 9 GeV or m a ≲ 1 meV (see Refs. [83] and [82] for details).
Figure 6 . Radial profiles of selected quantities, showing the restmass density ρ (top left panels), temperature T (top right panels), electron and muons abundances, Y e and Y µ (lower left panels), as well as the mass fractions for neutrons ( n ), protons ( p ) and the hyperons Λ Σ , -and Ξ -(lower right panels), at two different post bounce times during the PNS deleptnoization, for the two sets of simulations launched from 18 M ⊙ (left panels) and 25 M ⊙ progenitors (right panels), comparing in addition to the NUCLEONS (black lines) and HYPERONS (blue lines) EOS also those with the inclusion of X 0 losses, denoted as HYPERONS ∗ (orange lines).
of the PNS, as is illustrated for both 18 M ⊙ and 25 M ⊙ models in Fig. 6 for two distinct post-bounce times of 1 s and 5 s, comparing the three setups NUCLEONS (black lines), HYPERONS (blue lines) and HYPERONS ∗ (orange lines).
At around 1 s (top panels of Fig. 6), the abundance of Λ reach as high as about X Λ ≃ 1 × 10 -3 at the very center for the 18 M ⊙ model and about X Λ ≃ 5 × 10 -3 for the 25 M ⊙ model. Going outwards in radius, the abundances rise, following the temperature profile, reaching their peak at
Figure 7 . Radial profiles of the dark particle emissivity ϵ (black solid lines on the left scale) and luminosity L (gray dashed lines on the right scale) at post bounce times of 1 s and 5 s, corresponding to the HYPERONS ∗ run, for which the conditions are shown in Fig. 6.
around X Λ ≃ 5 × 10 -3 for the 18 M ⊙ model and X Λ ≃ 2 × 10 -2 for the 25 M ⊙ model. Figure 7 shows the corresponding dark particle emissivity (left scale) and luminosity (right scale) profiles. At around 1 s post bounce, dark sector emissivity and luminosity for the 18 M ⊙ model exceed those of the 25 M ⊙ . Luminosities reach values of about 10 52 erg for the former mode and about 5 × 10 51 erg for the latter, which is also illustrated in the corresponding evolution of the dark sector luminosity in the top panels of Fig. 5. We attribute this to the larger branching ratio for the 18 M ⊙ model, despite having slightly lower Λ abundances and temperatures. Note also the sharp drop of the emissivities, after which the luminosities remain constant, which is due to the sudden drop of the Λ abundance at around 13.75 km for the 18 M ⊙ model and at around 14.5 km for the 25 M ⊙ model, at 1 s post bounce. This is roughly to about one-half of saturation density, corresponding to conditions for the threshold for hyperons to exist within the HYPERON model EOS.
The situation changes during the ongoing PNS deleptonization with the inclusion of the additional losses due to dark boson emission. The X 0 luminosity evolution is illustrated in Fig. 5 (top panels), from where it becomes clear that the dark-boson losses dominate the cooling at around 1 s post bounce, for both intermediate-mass and high-mass models. However, the excess cooling results in the rapid drop of the PNS temperature, significantly faster than in the reference HYPERONS simulations (see the bottom panels of Fig. 6). Now, as the supernova interior features a lower temperature compared to the reference model without X 0 cooling, the feedback to the hyperon EOS is that the Λ abundance is somewhat lower-note the strong temperature dependence of the hyperon EOS discussed in Sec. 3-depending on the timescale during the PNS deleptonization. As a consequence, at some point during the later evolution, the Λ abundance will be too low for the process Λ → n + X 0 to still operate and the additional cooling due to X 0 emission ceases, featuring the continuous decrease of the X 0 luminosity; see the thick dashed lines in the top panels of Figs. 5(a) and 5(b). In a sense, the system self regulates it's excess cooling, however, depending sensitively on the BR.
This is illustrated for the 5 s post-bounce curves in Fig. 7 such that the X 0 luminosities in Fig. 5 decrease below those of the total neutrinos and the later evolution will be determined by the neutrino losses. However, note that this is the case already at around 3 s post bounce for the intermediate-mass 18 M ⊙ model, while only at around 7 s post bounce for the massive 25 M ⊙ model. It is related to
the generally higher temperatures and central densities for the latter model, featuring generally higher abundances of hyperons.
We note also the feedback from the excess cooling due to X 0 emission, namely the more rapid drop of the neutrino luminosities and average energies, for all flavours, during the PNS deleptonization phase that is dominated by X 0 cooling (see Fig. 5). We observe the reduction of the neutrino emission timescale by a factor of roughly two for both intermediate-mass and high-mass models.
## 6 Summary and conclusions
Novel hyperonic EOS are studied in simulations of CCSN in spherical symmetry. These are based on general relativistic neutrino radiation hydrodynamics, featuring six-species Boltzmann neutrino transport. Particular emphasis has been put on the role of hyperons, which have long been studied in the context of cold neutron stars, where it has been speculated that the super-saturation density EOS softens due to the appearance of these additional and heavy degrees of freedom. In the context of CCSNstudies, hyperons have so far only been taken into account in failed CCSN explosion studies that result in the formation of black holes [26, 29, 30], however, based on hadronic EOS with a limited set of hyperons. The focus of the present article is on the long-term evolution of neutrino-driven CCSN explosions, i.e. the deleptonization and later cooling phases of the nascent PNS, based on hadronic EOSincluding a comprehensive set of hyperons that include, Λ Σ , 0 , ± and Ξ 0 , ± . The FSU2H ∗ hyperon EOS employed in the present study is based on the RMF framework [103, 104] with meson-nucleon coupling constants selected to reproduce nuclear matter and finite nuclei properties, to fulfil certain constraints of high dense matter coming from heavy-ion collisions as well as to be consistent with the observation of massive 2 M ⊙ pulsars.
̸
The results differ from those reported in the comprehensive CCSN hyperon EOS study of ref. [127] in various ways. The largest difference arises due to the implementation of larger sample of hadronic states in the present paper. These modify the charge neutrality condition such that Y e + Y µ = Y p , which is the case in ref. [127] where no charged hyperons were considered. A second difference is related to the onset densities for the appearance of hyperons, which is the case at somewhat higher densities in ref. [127], and the abundance of hyperons is significantly higher than for the present HYPERONS EOS. In particular, in ref. [127] the abundance of Λ hyperons exceeds those of the neutrons at high baryon densities on the order of ρ ≃ 10 15 g cm -3 , even at low temperatures on the order of 1 10 MeV -.
In the CCSN simulations, the appearance of hyperons leaves a negligible impact on both the PNS structure during the entire early post-bounce evolution prior to the supernova shock revival and subsequent explosion onset. The reason is related to the generally low abundance of hyperons. The high-density EOS is dominated by the protons and neutrons. This situation changes only after several seconds, during the long-term PNS deleptonization evolution, when the central density rises continuously such that also the abundances of hyperons increase. However, even for massive PNS, on the order of about 2 M ⊙ , the abundance of Λ hyperons never exceeds more than few percent while the abundances of all heavier hyperons remain substantially lower, on the order of less than one percent. On the timescales considered here, on the order of several tens of seconds, the impact from the presence of hyperons on the PNS evolution remain negligible. CCSN observables, such as the neutrino signal, are hence insensitive to the composition at super-saturation density, explored in the present study within a RMF model and neglecting possible contributions to the weak interactions. In particular, the latter assumption becomes invalid once neutrinos start to decouple in the hyperon phase. This, however, has not been the case for the entire CCSN simulations under investigation.
The implementation of the Λ hyperon in the CCSN simulations enables us to study the impact of a possible dark sector. These arise from the flavour-violating transition of strange quarks into down quarks, taken into account here from the decay of Λ hyperon into neutron via the emission of dark bosonic degrees of freedom. Other decays, such as that of Σ + are neglected due to their generally low abundances under the conditions of high isospin asymmetry encountered at the interior of the PNS.
The excess cooling imposed by the inclusion of dark losses in the CCSN simulations results in a qualitative different evolution, in particular during the long-term PNS deleptonization phase when the abundance of Λ hyperons reaches their maximum. It is assumed that these massless particles escape the star once upon production. Possible re-scattering is omitted, which is consistent with the small couplings to the dark sector we are considering (c.f. ref. [83]). As a consequence, the PNS deleptonizes on a shorter timescale due to the different thermal evolution. As a feedback, similar as has been reported for the case of axion cooling (c.f. Refs. [63, 67, 126]) in the case of light axions from QCD processes, we find that the neutrino emission timescale is reduced by roughly a factor of two. This is consistent with the argument of ref. [58], confirming both values of the branching ratios, 10 -8 for the low mass and 10 -9 for the high mass models, as limiting cases corresponding to the intermediate-mass and high-mass PNS models of about 1.6 M ⊙ and 2.0 M ⊙ , respectively. We explore these two cases at the level of neutrino-driven CCSN explosions of 18 M ⊙ and 25 M ⊙ progenitors from the stellar evolution series of ref. [124], which result in remnant PNS masses of about 1 .6 M ⊙ and 2.0 M ⊙ with lower central density and hence lower Λ abundance for the former and the opposite for the latter models. We note here that the recent analysis at the level of the average ¯ ν e -energy and the total ¯ ν e -energy emitted, deduced from the KAM-II, IBM, BUST and LSD detections of SN1987A [128, 129], indicates that present standard core-collapse supernova models agree quantitatively with these measurements of the first few seconds of events while some tension remains with the late time events of Kam-II, IBM and BUST. The latter is due to generally short cooling timescales of all present long-term supernova simulations, including the PNS deleptonization and cooling phases. Note that considering the KAM-II data alone, current supernova models seemingly overestimate the detected ¯ ν e average energy, including the late-time detection. If these finding will be confirmed, in particular also from future supernova neutrino detection of the next galactic events, this would potentially put certain constraints on the requirement of non-standard additional cooling agents, such as the X 0 losses explored in this work due to the presence of strange hadronic degrees of freedom.
It has to be emphasised that the entire analysis, both comparing nucleonic and hyperonic EOS in CCSN simulations as well as the impact of associated dark sector cooling, is entirely model EOS dependent. The present analysis of the impact of dark photon losses in CCSN is dominated by the phase space of Λ and the neutron degeneracy, which in turn are determined by the underlying hyperonic model. EOS with a quantitative different high-density behaviour of the strange degrees of freedom, e.g., featuring a lower(higher) abundance of Λ , will resemble also a lesser(stronger) impact on the excess dark cooling as is reported in the present article. All of these uncertainties can be related to the fact that the two-body and three-body interactions involving hyperons are poorly known. This is due to the fact that the available scattering data are still scarce and subject to quite large error bars, although promising results are becoming available from final-state interaction analyses and femtoscopy studies [44-48]. Also, data on hypernuclear structure can provide indirect information about the hyperon nuclear forces [49-51]. Moreover, advances can be anticipated on the experimental determination of two-body and three-body interactions involving hyperons and nucleons, e.g. at J-PARC, LHC or the future FAIR facility.
Another simplification applied here is related to the assumption of chemical equilibrium for strangeness imposing equal chemical potentials, e.g., of neutrons and Λ hyperons. On the other hand, the CCSN timescales, e.g., weak interactions, mass accretion and diffusion, might be potentially on the
same order of magnitude as the timescale for hyperons to appear, however, through weak processes. In other words, chemical equilibrium between strange and non-strange hadrons might not be fulfilled, similar as the condition of weak equilibrium is not fulfilled for muons for simulation times on the order of more than 30 s of the PNS deleptonization phase, as was shown in the Appendix of ref. [67]. This requires the implementation of non-equilibrium methods in order to solve for the problem of strangeness in CCSN, which we leave for future explorations.
## Acknowledgments
Wewouldlike to thank Pok Man Lo for helpful comments and inspiring discussions. TF acknowledges support from the Polish National Science Centre (NCN) under grant number 2023/49/B/ST9/03941. JMC thanks MICINN for funding through the grant 'DarkMaps' PID2022-142142NB-I00 and from the European Union through the grant 'UNDARK' of the Widening participation and spreading excellence programme (project number 101159929). HK acknowledges support from the PRE2020093558 Doctoral Grant of the spanish MCIN/AEI/10.13039/ 501100011033/. LT acknowledges support from the project CEX2020-001058-M (Unidades de Excelencia 'Mar´ ıa de Maeztu') and PID2022-139427NB-I00, financed by the Spanish MCIN/ AEI/10.13039/501100011033/, as well as by the EU STRONG-2020 project, under the program H2020-INFRAIA-2018-1 grant agreement no. 824093, from the DFG through projects No. 315477589 - TRR 211 (Strong-interaction matter under extreme conditions), and from the Generalitat de Catalunya under contract 2021 SGR 171. All scientific computations were performed at the Wroclaw Centre for Scientific Computing and Networking (WCSS) under 'grant328'.
## References
- [1] H.-Th. Janka, K. Langanke, A. Marek, G. Mart´ ınez-Pinedo and B. M¨ uller, Theory of core-collapse supernovae , Phys. Rep. 442 (2007) 38 [ arXiv:0612072 ].
- [2] A. Mirizzi, I. Tamborra, H.-Th. Janka, N. Saviano, K. Scholberg, R. Bollig et al., Supernova neutrinos: production, oscillations and detection , Nuovo Cimento Rivista Serie 39 (2016) 1 [ arXiv:1508.00785 ].
- [3] A. Burrows and D. Vartanyan, Core-collapse supernova explosion theory , Nature 589 (2021) 29 [ arXiv:2009.14157 ].
- [4] J. M. LeBlanc and J. R. Wilson, A Numerical Example of the Collapse of a Rotating Magnetized Star , Astrophys. J. 161 (1970) 541.
- [5] H. A. Bethe and J. R. Wilson, Revival of a stalled supernova shock by neutrino heating , Astrophys. J. 295 (1985) 14.
- [6] F. S. Kitaura, H.-Th. Janka and W. Hillebrandt, Explosions of O-Ne-Mg cores, the Crab supernova, and subluminous type II-P supernovae , Astron. Astrophys. 450 (2006) 345 [ arXiv:0512065 ].
- [7] T. Fischer, S.C. Whitehouse, A. Mezzacappa, F. K. Thielemann and M. Liebend¨ orfer, Protoneutron star evolution and the neutrino-driven wind in general relativistic neutrino radiation hydrodynamics simulations , Astron. Astrophys. 517 (2010) A80 [ arXiv:0908.1871 ].
- [8] L. H¨ udepohl, B. M¨ller, H.-Th. Janka, A. Marek and G.G. Raffelt, u Neutrino Signal of Electron-Capture Supernovae from Core Collapse to Cooling , Phys. Rev. Lett. 104 (2010) 251101 [ arXiv:0912.0260 ].
- [9] T. M. Tauris, N. Langer and P. Podsiadlowski, Ultra-stripped supernovae: progenitors and fate , MNRAS 451 (2015) 2123 [ arXiv:1505.00270 ].
- [10] K. De, M. M. Kasliwal, E. O. Ofek, T. J. Moriya, J. Burke, Y. Cao et al., A hot and fast ultra-stripped supernova that likely formed a compact neutron star binary , Science 362 (2018) 201 [ arXiv:1810.05181 ].
- [11] B. M¨ uller, D. W. Gay, A. Heger, T. M. Tauris and S. A. Sim, Multidimensional simulations of ultrastripped supernovae to shock breakout , MNRAS 479 (2018) 3675 [ arXiv:1803.03388 ].
- [12] B. M¨ uller, T. M. Tauris, A. Heger, P. Banerjee, Y.-Z. Qian, J. Powell et al., Three-dimensional simulations of neutrino-driven core-collapse supernovae from low-mass single and binary star progenitors , MNRAS 484 (2019) 3307 [ arXiv:1811.05483 ].
- [13] T. Ertl, S.E. Woosley, T. Sukhbold and H.-Th. Janka, The Explosion of Helium Stars Evolved with Mass Loss , Astrophys. J. 890 (2020) 51 [ arXiv:1910.01641 ].
- [14] G. Stockinger, H.-Th. Janka, D. Kresse, T. Melson, T. Ertl, M. Gabler et al., Three-dimensional models of core-collapse supernovae from low-mass progenitors with implications for Crab , MNRAS 496 (2020) 2039 [ arXiv:2005.02420 ].
- [15] T. Wang and A. Burrows, Supernova Explosions of the Lowest-mass Massive Star Progenitors , Astrophys. J. 969 (2024) 74 [ arXiv:2405.06024 ].
- [16] I. Sagert, T. Fischer, M. Hempel, G. Pagliara, J. Schaffner-Bielich, A. Mezzacappa et al., Signals of the QCD Phase Transition in Core-Collapse Supernovae , Phys. Rev. Lett. 102 (2009) 081101 [ arXiv:0809.4225 ].
- [17] T. Fischer, N.-U. F. Bastian, M.-R. Wu, P. Baklanov, E. Sorokina, S. Blinnikov et al., Quark deconfinement as a supernova explosion engine for massive blue supergiant stars , Nature Astronomy 2 (2018) 980 [ arXiv:1712.08788 ].
- [18] S. Zha, E. P. O'Connor, M.-c. Chu, L.-M. Lin and S.M. Couch, Gravitational-wave Signature of a First-order Quantum Chromodynamics Phase Transition in Core-Collapse Supernovae , Phys. Rev. Lett. 125 (2020) 051102 [ arXiv:2007.04716 ].
- [19] T. Fischer, QCD phase transition drives supernova explosion of a very massive star , Eur. Phys. J. A 57 (2021) 270 [ arXiv:2108.00196 ].
- [20] T. Kuroda, T. Fischer, T. Takiwaki and K. Kotake, Core-collapse Supernova Simulations and the Formation of Neutron Stars, Hybrid Stars, and Black Holes , Astrophys. J. 924 (2022) 38 [ arXiv:2109.01508 ].
- [21] N. Khosravi Largani, T. Fischer and N.-U. F. Bastian, Constraining the Onset Density for the QCD Phase Transition with the Neutrino Signal from Core-collapse Supernovae , Astrophys. J. 964 (2024) 143 [ arXiv:2304.12316 ].
- [22] T. Kuroda and M. Shibata, Spontaneous scalarization as a new core-collapse supernova mechanism and its multimessenger signals , Phys. Rev. D 107 (2023) 103025 [ arXiv:2302.09853 ].
- [23] T. Fischer, N.-U. F. Bastian, D. Blaschke, M. Cierniak, M. Hempel, T. Kl¨ ahn et al., The State of Matter in Simulations of Core-Collapse supernovae-Reflections and Recent Developments , Publications of the Astronomical society of Australia 34 (2017) e067 [ arXiv:1711.07411 ].
- [24] A. Bauswein, N.-U. F. Bastian, D.B. Blaschke, K. Chatziioannou, J.A . Clark, T. Fischer et al., Identifying a First-Order Phase Transition in Neutron-Star Mergers through Gravitational Waves , Phys. Rev. Lett. 122 (2019) 061102 [ arXiv:1809.01116 ].
- [25] E. R. Most, L. J. Papenfort, V. Dexheimer, M. Hanauske, S. Schramm, H. St¨cker et al., o Signatures of Quark-Hadron Phase Transitions in General-Relativistic Neutron-Star Mergers , Phys. Rev. Lett. 122 (2019) 061101 [ arXiv:1807.03684 ].
- [26] K. Sumiyoshi, C. Ishizuka, A. Ohnishi, S. Yamada and H. Suzuki, Emergence of Hyperons in Failed Supernovae: Trigger of the Black Hole Formation , Astrophys. J. 690 (2009) L43 [ arXiv:0811.4237 ].
- [27] T. Fischer, S. C. Whitehouse, A. Mezzacappa, F.-K. Thielemann and M. Liebend¨ orfer, The neutrino signal from protoneutron star accretion and black hole formation , Astron. Astrophys. 499 (2009) 1 [ arXiv:0809.5129 ].
- [28] E. O'Connor and C.D. Ott, Black Hole Formation in Failing Core-Collapse Supernovae , Astrophys. J. 730 (2011) 70 [ arXiv:1010.5550 ].
- [29] K. Nakazato, S. Furusawa, K. Sumiyoshi, A. Ohnishi, S. Yamada and H. Suzuki, Hyperon Matter and Black Hole Formation in Failed Supernovae , Astrophys. J. 745 (2012) 197 [ arXiv:1111.2900 ].
- [30] P. Char, S. Banik and D. Bandyopadhyay, A Comparative Study of Hyperon Equations of State in Supernova Simulations , Astrophys. J. 809 (2015) 116 [ arXiv:1508.01854 ].
- [31] G.F. Burgio and A.F. Fantina, Nuclear equation of state for compact stars and supernovae , in The Physics and Astrophysics of Neutron Stars , pp. 255-335, Springer International Publishing (2018).
- [32] L. Tolos and L. Fabbietti, Strangeness in Nuclei and Neutron Stars , Prog. Part. Nucl. Phys. 112 (2020) 103770 [ arXiv:2002.09223 ].
- [33] G.F. Burgio, H.J. Schulze, I. Vidana and J.B. Wei, Neutron stars and the nuclear equation of state , Prog. Part. Nucl. Phys. 120 (2021) 103879 [ arXiv:2105.03747 ].
- [34] MUSES collaboration, Theoretical and experimental constraints for the equation of state of dense and hot matter , Living Rev. Rel. 27 (2024) 3 [ arXiv:2303.17021 ].
- [35] P. Demorest, T. Pennucci, S. Ransom, M. Roberts and J. Hessels, Shapiro delay measurement of a two solar mass neutron star , Nature 467 (2010) 1081. [ arXiv:1010.5788 ].
- [36] J. Antoniadis, P.C.C. Freire, N. Wex, T.M. Tauris, R.S. Lynch, M.H. van Kerkwijk et al., A Massive Pulsar in a Compact Relativistic Binary , Science 340 (2013) 448 [ arXiv:1304.6875 ].
- [37] E. Fonseca, H.T. Cromartie, T.T. Pennucci, P.S. Ray, A.Y. Kirichenko, S.M. Ransom et al., Refined Mass and Geometric Measurements of the High-mass PSR J0740+6620 , Astrophys. J. 915 (2021) L12 [ arXiv:2104.00880 ].
- [38] NANOGrav collaboration, Relativistic Shapiro delay measurements of an extremely massive millisecond pulsar , Nature Astron. 4 (2019) 72 [ arXiv:1904.06759 ].
- [39] R.W. Romani, D. Kandel, A.V. Filippenko, T.G. Brink and W. Zheng, PSR J0952 -0607: The Fastest and Heaviest Known Galactic Neutron Star , Astrophys. J. Lett. 934 (2022) L17 [ arXiv:2207.05124 ].
- [40] S. Petschauer, J. Haidenbauer, N. Kaiser, U.-G. Meißner and W. Weise, Hyperon-nuclear interactions from SU(3) chiral effective field theory , Front. in Phys. 8 (2020) 12 [ arXiv:2002.00424 ].
- [41] P. M. Lo, Density of states of a coupled-channel system , Phys. Rev. D 102 (2020) 034038 [ arXiv:2007.03392 ].
- [42] J. Cleymans, P. M. Lo, K. Redlich and N. Sharma, Multiplicity dependence of (multi)strange baryons in the canonical ensemble with phase shift corrections , Phys. Rev. C 103 (2021) 014904 [ arXiv:2009.04844 ].
- [43] P. M. Lo, Thermal study of a coupled-channel system: a brief review , European Physical Journal A 57 (2021) 60.
- [44] CLAS collaboration, Improved Λ p Elastic Scattering Cross Sections Between 0.9 and 2.0 GeV/c and Connections to the Neutron Star Equation of State , Phys. Rev. Lett. 127 (2021) 272303 [ arXiv:2108.03134 ].
- [45] J-PARC E40 collaboration, Measurement of the differential cross sections of the Σ -p elastic scattering in momentum range 470 to 850 MeV/c , Phys. Rev. C 104 (2021) 045204 [ arXiv:2104.13608 ].
- [46] J-PARC E40 collaboration, Precise measurement of differential cross sections of the Σ -p → Λ n reaction in momentum range 470-650 MeV /c , Phys. Rev. Lett. 128 (2022) 072501 [ arXiv:2111.14277 ].
- [47] J-PARC E40 collaboration, Measurement of differential cross sections for Σ +p elastic scattering in the momentum range 0.44-0.80 GeV/c , PTEP 2022 (2022) 093D01 [ arXiv:2203.08393 ].
- [48] L. Fabbietti, V. Mantovani Sarti and O. Vazquez Doce, Study of the Strong Interaction Among Hadrons with Correlations at the LHC , Ann. Rev. Nucl. Part. Sci. 71 (2021) 377 [ arXiv:2012.09806 ].
- [49] A. Feliciello and T. Nagae, Experimental review of hypernuclear physics: recent achievements and future perspectives , Rept. Prog. Phys. 78 (2015) 096301.
- [50] H. Tamura et al., Gamma-ray spectroscopy of hypernuclei - present and future , Nucl. Phys. A 914 (2013) 99.
- [51] A. Gal, E.V. Hungerford and D.J. Millener, Strangeness in nuclear physics , Rev. Mod. Phys. 88 (2016) 035004 [ arXiv:1605.00557 ].
- [52] A. R. Raduta, F. Nacu and M. Oertel, Equations of state for hot neutron stars , Eur. Phys. J. A 57 (2021) 329 [ arXiv:2109.00251 ].
- [53] A. R. Raduta, Equations of state for hot neutron stars-II. The role of exotic particle degrees of freedom , Eur. Phys. J. A 58 (2022) 115 [ arXiv:2205.03177 ].
- [54] M. Oertel, M. Hempel, T. Kl¨ ahn and S. Typel, Equations of state for supernovae and compact stars , Rev. Mod. Phys. 89 (2017) 015007 [ arXiv:1610.03361 ].
- [55] V. Dexheimer, M. Mancini, M. Oertel, C. Providˆ encia, L. Tolos and S. Typel, Quick Guides for Use of the CompOSE Data Base , Particles 5 (2022) 346 [ arXiv:2311.04715 ].
- [56] CompOSE Core Team collaboration, CompOSE Reference Manual , Eur. Phys. J. A 58 (2022) 221 [ arXiv:2203.03209 ].
- [57] G. G. Raffelt and D. Seckel, Bounds on Exotic Particle Interactions from SN 1987a , Phys. Rev. Lett. 60 (1988) 1793.
- [58] G. G. Raffelt, Stars as laboratories for fundamental physics : the astrophysics of neutrinos, axions, and other weakly interacting particles (1996).
- [59] M. S. Turner, Axions from SN 1987a , Phys. Rev. Lett. 60 (1988) 1797.
- [60] R. Mayle, J.R. Wilson, J.R. Ellis, K.A. Olive, D.N. Schramm and G. Steigman, Constraints on Axions from SN 1987a , Phys. Lett. B 203 (1988) 188.
- [61] A. Burrows, M. S. Turner and R. Brinkmann, Axions and SN 1987a , Phys. Rev. D 39 (1989) 1020.
- [62] A. Burrows, M. Ressell and M. S. Turner, Axions and SN1987A: Axion trapping , Phys. Rev. D 42 (1990) 3297.
- [63] P. Carenza, T. Fischer, M. Giannotti, G. Guo, G. Mart´ ınez-Pinedo and A. Mirizzi, Improved axion emissivity from a supernova via nucleon-nucleon bremsstrahlung , JCAP 10 (2019) 016 [ arXiv:1906.11844 ].
- [64] K. Choi, H. J. Kim, H. Seong and C. S. Shin, Axion emission from supernova with axion-pion-nucleon contact interaction , JHEP 02 (2022) 143 [ arXiv:2110.01972 ].
- [65] L. Di Luzio, M. Giannotti, E. Nardi and L. Visinelli, The landscape of QCD axion models , Phys. Rept. 870 (2020) 1 [ arXiv:2003.01100 ].
- [66] P. Carenza, B. Fore, M. Giannotti, A. Mirizzi and S. Reddy, Enhanced Supernova Axion Emission and its Implications , Phys. Rev. Lett. 126 (2021) 071102 [ arXiv:2010.02943 ].
- [67] T. Fischer, P. Carenza, B. Fore, M. Giannotti, A. Mirizzi and S. Reddy, Observable signatures of enhanced axion emission from protoneutron stars , Phys. Rev. D 104 (2021) 103012 [ arXiv:2108.13726 ].
- [68] E. Rrapaj and S. Reddy, Nucleon-nucleon bremsstrahlung of dark gauge bosons and revised supernova constraints , Phys. Rev. C 94 (2016) 045805 [ arXiv:1511.09136 ].
- [69] J. H. Chang, R. Essig and S. D. McDermott, Supernova 1987A Constraints on Sub-GeV Dark Sectors, Millicharged Particles, the QCD Axion, and an Axion-like Particle , JHEP 09 (2018) 051 [ arXiv:1803.00993 ].
- [70] F. Calore, P. Carenza, M. Giannotti, J. Jaeckel, G. Lucente and A. Mirizzi, Supernova bounds on axionlike particles coupled with nucleons and electrons , Phys. Rev. D 104 (2021) 043016 [ arXiv:2107.02186 ].
- [71] S. Balaji, P.S.B. Dev, J. Silk and Y. Zhang, Improved stellar limits on a light CP-even scalar , JCAP 2022 (2022) 024 [ arXiv:2205.01669 ].
- [72] A. Lella, P. Carenza, G. Lucente, M. Giannotti and A. Mirizzi, Protoneutron stars as cosmic factories for massive axionlike particles , Phys. Rev. D 107 (2023) 103017 [ arXiv:2211.13760 ].
- [73] C. A. Manzari, J. M. Camalich, J. Spinner and R. Ziegler, Supernova limits on muonic dark forces , Phys. Rev. D 108 (2023) 103020 [ arXiv:2307.03143 ].
- [74] R. Bollig, W. DeRocco, P. W. Graham and H.-Th. Janka, Muons in supernovae: implications for the axion-muon coupling , Phys. Rev. Lett. 125 (2020) 051104 [ arXiv:2005.07141 ].
- [75] L. Calibbi, D. Redigolo, R. Ziegler and J. Zupan, Looking forward to lepton-flavor-violating ALPs , JHEP 09 (2021) 173 [ arXiv:2006.04795 ].
- [76] D. Croon, G. Elor, R. K. Leane and S. D. McDermott, Supernova Muons: New Constraints on Z ' Bosons, Axions and ALPs , JHEP 01 (2021) 107 [ arXiv:2006.13942 ].
- [77] A. Caputo, G.G. Raffelt and E. Vitagliano, Muonic boson limits: Supernova redux , Phys. Rev. D 105 (2022) 035022 [ arXiv:2109.03244 ].
- [78] M. S. Turner, Dirac neutrinos and SN1987A , Phys. Rev. D 45 (1992) 1066.
- [79] G. G. Raffelt and D. Seckel, A selfconsistent approach to neutral current processes in supernova cores , Phys. Rev. D 52 (1995) 1780 [ arXiv:9312019 ].
- [80] W. Keil, H.-Th. Janka, D. N. Schramm, G. Sigl, M. S. Turner and J. R. Ellis, A Fresh look at axions and SN-1987A Phys. Rev. D , 56 (1997) 2419 [ arXiv:astro-ph/9612222 ].
- [81] C. S. Shin and S. Yun, Dark gauge boson emission from supernova pions , Phys. Rev. D 108 (2023) 055014 [ arXiv:2211.15677 ].
- [82] J. M. Camalich, M. Pospelov, P. N. H. Vuong, R. Ziegler and J. Zupan, Quark Flavor Phenomenology of the QCD Axion , Phys. Rev. D 102 (2020) 015023 [ arXiv:2002.04623 ].
- [83] J. M. Camalich, J. Terol-Calvo, L. Tolos and R. Ziegler, Supernova Constraints on Dark Flavored Sectors , Phys. Rev. D 103 (2021) L121301 [ arXiv:2012.11632 ].
- [84] G. Alonso- ´ lvarez, G. Elor, M. Escudero, B. Fornal, B. Grinstein and J.M. Camalich, A Strange physics of dark baryons , Phys. Rev. D 105 (2022) 115005 [ arXiv:2111.12712 ].
- [85] M. Cavan-Piton, D. Guadagnoli, M. Oertel, H. Seong and L. Vittorio, Axion emission from strange matter in core-collapse SNe , arXiv:2401.10979 .
- [86] J. F. Kamenik and C. Smith, FCNC portals to the dark sector , JHEP 03 (2012) 090 [ arXiv:1111.6402 ].
- [87] E. Goudzovski et al., New physics searches at kaon and hyperon factories , Rept. Prog. Phys. 86 (2023) 016201 [ arXiv:2201.07805 ].
- [88] A. Davidson and K. C. Wali, Minimal flavor unifications via multigenerational Pecci-Quinn symmetry , Phys. Rev. Lett. 48 (1982), 11
- [89] F. Wilczek, Axions and Family Symmetry Breaking , Phys. Rev. Lett. 49 (1982) 1549.
- [90] J. L. Feng, T. Moroi, H. Murayama and E. Schnapka, Third generation familons, b factories, and neutrino cosmology , Phys. Rev. D57 (1998) 5875 [ arXiv:9709411 ].
- [91] L. Calibbi, F. Goertz, D. Redigolo, R. Ziegler and J. Zupan, Minimal axion model from flavor , Phys. Rev. D95 (2017) 095009 [ arXiv:1612.08040 ].
- [92] Y. Ema, K. Hamaguchi, T. Moroi and K. Nakayama, Flaxion: a minimal extension to solve puzzles in the standard model , JHEP 01 (2017) 096 [ arXiv:1612.05492 ].
- [93] L. Di Luzio, A.W.M. Guerrera, X.P. D´ ıaz and S. Rigolin, On the IR/UV flavour connection in non-universal axion models , JHEP 06 (2023) 046 [ arXiv:2304.04643 ].
- [94] B. Holdom, Two U(1)'s and Epsilon Charge Shifts , Phys. Lett. B 166 (1986) 196.
- [95] B. A. Dobrescu, Massless gauge bosons other than the photon , Phys. Rev. Lett. 94 (2005) 151802 [ arXiv:0411004 ].
- [96] E. Gabrielli, B. Mele, M. Raidal and E. Venturini, FCNC decays of standard model fermions into a dark photon , Phys. Rev. D 94 (2016) 115013 [ arXiv:1607.05928 ].
- [97] J. F. Eguren, S. Klingel, E. Stamou, M. Tabet and R. Ziegler, Flavor phenomenology of light dark vectors , JHEP 08 (2024) 111 [ arXiv:2405.00108 ].
- [98] G. Elor, M. Escudero and A. Nelson, Baryogenesis and Dark Matter from B Mesons Phys. Rev. D , 99 (2019) 035031 [ arXiv:1810.00880 ].
- [99] T. Bringmann, J. M. Cline and J. M. Cornell, Baryogenesis from neutron-dark matter oscillations , Phys. Rev. D 99 (2019) 035024 [ arXiv:1810.08215 ].
- [100] B. Fornal and B. Grinstein, Dark Matter Interpretation of the Neutron Decay Anomaly , Phys. Rev. Lett. 120 (2018) 191801 [ arXiv:1801.01124 ].
- [101] L. Tolos, M. Centelles and A. Ramos, Equation of State for Nucleonic and Hyperonic Neutron Stars with Mass and Radius Constraints , Astrophys. J. 834 (2017) 3 [ arXiv:1610.00919 ].
- [102] L. Tolos, M. Centelles and A. Ramos, The Equation of State for the Nucleonic and Hyperonic Core of Neutron Stars , Publ. Astron. Soc. Austral. 34 (2017) e065 [ arXiv:1708.08681 ].
- [103] H. Kochankovski, A. Ramos and L. Tolos, Equation of state for hot hyperonic neutron star matter , Mon. Not. Roy. Astron. Soc. 517 (2022) 507 [ arXiv:2206.11266 ].
- [104] H. Kochankovski, A. Ramos and L. Tolos, Hyperonic uncertainties in neutron stars, mergers, and supernovae , MNRAS 528 (2024) 2629 [ arXiv:2309.14879 ].
- [105] S. Navas, et al. (Particle Data Group collaboration), Review of particle physics , Phys. Rev. D 110 (2024) 030001
- [106] LIGO Scientific, Virgo collaboration, GW170817: Observation of Gravitational Waves from a Binary Neutron Star Inspiral , Phys. Rev. Lett. 119 (2017) 161101 [ arXiv:1710.05832 ].
- [107] M. C. Miller, F. K. Lamb, A. J. Dittmann, S. Bogdanov, Z. Arzoumanian, K. C. Gendreau et al., PSR J0030+0451 Mass and Radius from NICER Data and Implications for the Properties of Neutron Star Matter , Astrophys. J. 887 (2019) L24 [ arXiv:1912.05705 ].
- [108] A. V. Bilous, A. L. Watts, A.K. Harding, T.E. Riley, Z. Arzoumanian, S. Bogdanov et al., A NICER View of PSR J0030+0451: Evidence for a Global-scale Multipolar Magnetic Field , Astrophys. J. 887 (2019) L23 [ arXiv:1912.05704 ].
- [109] M. C. Miller, F. K. Lamb, A. J. Dittmann, S. Bogdanov, Z. Arzoumanian, K.C. Gendreau et al., The Radius of PSR J0740+6620 from NICER and XMM-Newton Data , Astrophys. J. 918 (2021) L28 [ arXiv:2105.06979 ].
- [110] T. E. Riley, A. L. Watts, P. S. Ray, S. Bogdanov, S. Guillot, S. M. Morsink et al., A NICER View of the Massive Pulsar PSR J0740+6620 Informed by Radio Timing and XMM-Newton Spectroscopy , Astrophys. J. 918 (2021) L27 [ arXiv:2105.06980 ].
- [111] S. Typel, G. R¨pke, T. Kl¨ ahn, D. Blaschke and H.H. Wolter, o Composition and thermodynamics of nuclear matter with light clusters , Phys. Rev. C 81 (2010) 015803 [ arXiv:0908.2344 ].
| [112] | A. Mezzacappa and S. W. Bruenn, Type II supernovae and Boltzmann neutrino transport - The infall phase , Astrophys. J. 405 (1993) 637. |
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [113] | A. Mezzacappa and S. W. Bruenn, A numerical method for solving the neutrino Boltzmann equation coupled to spherically symmetric stellar core collapse , Astrophys. J. 405 (1993) 669. |
| [114] | A. Mezzacappa and S. W. Bruenn, Stellar core collapse - A Boltzmann treatment of neutrino-electron scattering , Astrophys. J. 410 (1993) 740. |
| [115] | M. Liebend¨rfer, o O. E. B. Messer, A. Mezzacappa, S. W. Bruenn, C. Y. Cardall and F.-K. Thielemann, A Finite Difference Representation of Neutrino Radiation Hydrodynamics in Spherically Symmetric General Relativistic Spacetime , Astrophys. J. Suppl. 150 (2004) 263 [ arXiv:0207036 ]. |
| [116] | T. Fischer, G. Guo, A. A. Dzhioev, G. Mart´nez-Pinedo, ı M.-R. Wu, A. Lohs et al., Neutrino signal from proto-neutron star evolution: Effects of opacities from charged-current-neutrino interactions and inverse neutron decay , Phys. Rev. C 101 (2020) 025804 [ arXiv:1804.10890 ]. |
| [117] | G. Guo, G. Mart´nez-Pinedo, ı A. Lohs and T. Fischer, Charged-current muonic reactions in core-collapse supernovae , Phys. Rev. D 102 (2020) 023037 [ arXiv:2006.12051 ]. |
| [118] | T. Fischer, G. Guo, G. Mart´nez-Pinedo, ı M. Liebend¨rfer o and A. Mezzacappa, Muonization of supernova matter , Phys. Rev. D 102 (2020) 123001 [ arXiv:2008.13628 ]. |
| [119] | J. M. Lattimer and F. Swesty, A generalized equation of state for hot, dense matter , Nuclear Physics A 535 (1991) 331. |
| [120] | M. Hempel, T. Fischer, J. Schaffner-Bielich and M. Liebend¨rfer, o New Equations of State in Simulations of Core-collapse Supernovae , Astrophys. J. 748 (2012) 70 [ arXiv:1108.0848 ]. |
| [121] | M. Hempel and J. Schaffner-Bielich, A statistical model for a complete supernova equation of state , Nucl. Phys. A 837 (2010) 210 [ arXiv:0911.4073 ]. |
| [122] | T. Fischer, Constraining the supersaturation density equation of state from core-collapse supernova simulations?. Excluded volume extension of the baryons , European Physical Journal A 52 (2016) 54 [ arXiv:1604.01629 ]. |
| [123] | F. X. Timmes and D. Arnett, The Accuracy, Consistency, and Speed of Five Equations of State for Stellar Hydrodynamics , Astrophys. J. Suppl. 125 (1999) 277. |
| [124] | S. E. Woosley, A. Heger and T. A. Weaver, The evolution and explosion of massive stars , Rev. Mod. Phys. 74 (2002) 1015. |
| [125] | F. P. Jost, M. Molero, G. Nav´, o A. Arcones, M. Obergaulinger and F. Matteucci, Neutrino-driven Core-collapse Supernova Yields in Galactic Chemical Evolution , arXiv e-prints (2024) arXiv:2407.14319 [ arXiv:2407.14319 ]. |
| [126] | T. Fischer, S. Chakraborty, M. Giannotti, A. Mirizzi, A. Payez and A. Ringwald, Probing axions with the neutrino signal from the next Galactic supernova , Phys. Rev. D 94 (2016) 085012 [ arXiv:1605.08780 ]. |
| [127] | S. Banik, M. Hempel and D. Bandyopadhyay, New Hyperon Equations of State for Supernovae and Neutron Stars in Density-dependent Hadron Field Theory , Astrophys. J. Suppl. 214 (2014) 22 [ arXiv:1404.6173 ]. |
| [128] | D. F. G. Fiorillo, MHeinlein, H.-Th. Janka, G. Raffelt, E. Vitagliano, R. Bollig, Supernova simulations confront SN 1987A neutrinos , Phys. Rev. D 108 (2023) 083040 [ arXiv:2308.01403 ]. |
| [129] | S. W. Li, J. F. Beacom, L. F. Roberts,F. Capozzi Old data, new forensics: The first second of SN 1987A neutrino emission , Phys. Rev. D 109 (2024) 083025 [ arXiv:2306.08024 ]. | | 10.1088/1475-7516/2025/01/061 | [
"Tobias Fischer",
"Jorge Martin Camalich",
"Hristijan Kochankovski",
"Laura Tolos"
]
| 2024-08-02T17:31:36+00:00 | 2025-01-14T18:17:43+00:00 | [
"astro-ph.HE",
"hep-ph",
"nucl-th"
]
| Hyperons during proto-neutron star deleptonization and the emission of dark flavoured particles | Complementary to high-energy experimental efforts, indirect astrophysical
searches of particles beyond the standard model have long been pursued. The
present article follows the latter approach and considers, for the first time,
the self-consistent treatment of the energy losses from dark flavoured
particles produced in the decay of hyperons during a core-collapse supernova
(CCSN). To this end, general relativistic supernova simulations in spherical
symmetry are performed, featuring six-species Boltzmann neutrino transport, and
covering the long-term evolution of the nascent remnant proto-neutron star
(PNS) deleptonization for several tens of seconds. A well-calibrated hyperon
equation of state (EOS) is therefore implemented into the supernova simulations
and tested against the corresponding nucleonic model. It is found that
supernova observables, such as the neutrino signal, are robustly insensitive to
the appearance of hyperons for the simulation times considered in the present
study. The presence of hyperons enables an additional channel for the
appearance of dark sector particles, which is considered at the level of the
$\Lambda$ hyperon decay. Assuming massless particles that escape the PNS after
being produced, these channels expedite the deleptonizing PNS and the cooling
behaviour. This, in turn, shortens the neutrino emission timescale. The present
study confirms the previously estimated upper limits on the corresponding
branching ratios for low and high mass PNS, by effectively reducing the
neutrino emission timescale by a factor of two. This is consistent with the
classical argument deduced from the neutrino detection associated with SN1987A. |
2408.01408v1 | ## Derivation of Back-propagation for Graph Convolutional Networks using Matrix Calculus and its Application to Explainable Artificial Intelligence
## Yen-Che Hsiao
Department of Electrical and Computer Engineering University of Connecticut Storrs CT 06269, USA [email protected]
## Rongting Yue
Department of Electrical and Computer Engineering University of Connecticut Storrs CT 06269, USA
## Abhishek Dutta
Department of Electrical and Computer Engineering University of Connecticut Storrs CT 06269, USA
## Abstract
This paper provides a comprehensive and detailed derivation of the backpropagation algorithm for graph convolutional neural networks using matrix calculus. The derivation is extended to include arbitrary element-wise activation functions and an arbitrary number of layers. The study addresses two fundamental problems, namely node classification and link prediction. To validate our method, we compare it with reverse-mode automatic differentiation. The experimental results demonstrate that the median sum of squared errors of the updated weight matrices, when comparing our method to the approach using reverse-mode automatic differentiation, falls within the range of 10 -18 to 10 -14 . These outcomes are obtained from conducting experiments on a five-layer graph convolutional network, applied to a node classification problem on Zachary's karate club social network and a link prediction problem on a drug-drug interaction network. Finally, we show how the derived closed-form solution can facilitate the development of explainable AI and sensitivity analysis.
## 1 Introduction
Graph neural network (GNN) is a neural network model for processing data represented in graph domains, encompassing cyclic, directed, and undirected graphs [1]. Graph convolutional network (GCN) is a type of GNN model that employs layer-wise propagation rule, operating directly on graphs [2]. A GCN layer comprises message passing over nodes/edges, succeeded by an aggregation/pooling strategy and a fully connected layer [3].
Node classification is one of the most common research directions in graph analysis, where the objective of the task is to predict a specific class for each unlabeled node in a graph using graph information
Preprint. Under review.
[4]. J. Zhang et al. [5] applied GCN for distribution system anomaly detection, categorizing nodes into normal data, data anomalies, or event anomalies, and implemented their method on the IEEE 37-node distribution systems. Link prediction seeks to infer unobserved/missing links or predict future ones based on the connections within currently observed partial networks [6]. R. Yue et al. [7] applied a GCN that utilizes protein-protein interactions, drug-protein interactions, and drug-target interactions to predict potential drug molecules capable of binding with disease-related proteins.
Back-propagation (BP) was proposed by David Rumelhart, Geoffrey Hinton, and Ronald Williams as a learning procedure for training neural networks utilizing a set of input-output training samples [8, 9]. BP makes use of chain rule to compute the gradient of the network's error with respect to every single model parameter, allowing for the adjustment of weight and bias terms via gradient descent to reduce the error [10, 11]. Reverse mode automatic differentiation is the primary technique in the form of the back-propagation algorithm for training neural networks due to its computational efficiency, particularly for an objective functions with a large number of inputs and a scalar output [12].
M. A. Nielsen [13] derived the BP for multi-layer perceptrons (MLPs) in a matrix-based form using the Hadamard product for numerical efficiency. N. M. Mishachev [14] utilized Hadamard product and Kronecker product to derive an explicit matrix version of the BP equations for MLPs and reduce the number of the indices in the equations. M. Naumov [15] demonstrated that the gradient of the weights can be expressed as a rank-1 and rank-t matrix for MLPs and recurrent neural networks at time step t, respectively. Y . Cheng [16] derived the BP algorithm for MLPs based on derivative amplification coefficients.
Explainable Artificial Intelligence (XAI) focuses on developing AI systems that not only make accurate predictions but also provide clear, interpretable explanations for their actions and decisions, thus increasing their trustworthiness for human users [17]. In XAI, sensitivity analysis is crucial because it reveals which parameters, or groups of parameters, have the most significant influence on the predictions made by machine learning models [18].
In this work, we used matrix calculus to derive an analytic and exact closed-form solution of the gradient of the loss function with respect to weight matrices for the training of GCN. The derivation considers the problems of binary node classification and link prediction. We first considered the problem of node classification with three-layer GCN and we extended the GCN model to a multilayer GCN with d layers and applied the procedure for a link prediction problem. To validate our approach, we applied our weight gradient calculation for node classification on a Zachary's Karate Club graph [19] and for link prediction using a self-prepared 100-node drug-drug interaction network. Subsequently, we compared the updated weight matrix using our method to the method employing reverse mode automatic differentiation for gradient computation. Our results demonstrate a ignorable difference between our weight matrix and the weight matrix updated using the gradient from reverse mode automatic differentiation, which verifies the correctness of our method. As there is no existing work deriving the BP of GCN in matrix form, we believe it is important for the machine learning community to have this closed-form solution available. In addition, we applied the same procedure to determine the sensitivity of the loss or output with respect to the input feature matrix in GCN for XAI. The definition of notations and some properties used in this paper are provided in Appendix A.
## 2 Back-propagation of Graph Convolutional Network
A basic graph structure is defined as:
$$G = ( V, E ),$$
where | V | = n is the number of nodes in the graph and | E | = n e is the number of edges. Denoting v i ∈ V as a node and e ij = ( v , v i j ) ∈ E as an edge pointing from v i to v j , the adjacency matrix, A ∈ { 0 1 , } n × n , is an n × n matrix where a ij equals 1 if the edge e ij exists, and a ij equals 0 if e ij does not belong to E ; in addition, a graph may possess node attributes represented by the matrix H 0 ∈ R n × n 0 , where h 0 v ∈ R n 0 is the feature vector of a node v with n 0 features [20].
## 2.1 Binary classification of nodes
## 2.1.1 Backpropagation for 3-layer GCN with ReLU and sigmoid activation function
We consider a 3-layer GCN defined as
$$\mathbf H _ { 1 } = \sigma _ { R e L U } ( \mathbf A \mathbf H _ { 0 } \mathbf W _ { 1 } ),$$
$$\mathbf H _ { 2 } = \sigma _ { R e L U } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ),$$
$$\mathbf H _ { 3 } = \sigma _ { R e L U } ( \mathbf A \mathbf H _ { 2 } \mathbf W _ { 3 } ),$$
$$\hat { Y } = \sigma _ { s i g m o i d } ( \mathbf H _ { 3 } ),$$
where A ∈ { 0 1 , } n × n is an n × n adjacency matrix, H 0 ∈ R n × n 0 is the feature matrix for n nodes with n 0 features, ˆ Y ∈ R n × n 3 is the output matrix, n 3 = 1 for binary node classification, and W 1 ∈ R n 0 × n 1 , W 2 ∈ R n 1 × n 2 , and W 3 ∈ R n 2 × n 3 are trainable parameter matrices, n 1 , n 2 , and n 3 are the number of features in H 1 ∈ R n × n 1 , H 2 ∈ R n × n 2 , and H 3 ∈ R n × n 3 , respectively, σ ReLU denotes an element-wise rectified linear unit (ReLU) function σ ReLU ( v ) = max v, ( 0) [21], σ sigmoid denotes an element-wise sigmoid function σ sigmoid ( v ) = 1 1+ e -v ..
The loss function of the 3-layer GCN for binary node classification can be defined as
$$L = L _ { 1 } + L _ { 2 },$$
where
$$L _ { 1 } & = - \sum _ { \substack { i = 1 \\ \_ \_ } } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( y _ { i j } l n ( \hat { y } _ { i j } ) ),$$
$$L _ { 2 } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( ( 1 - y _ { i j } ) l n ( 1 - \hat { y } _ { i j } ) ), \quad \quad \quad ( 8 )$$
where y ij denotes the element in the i th row and j th column of the ground truth of nodes Y ∈ R n × n 3 , ˆ y ij denotes the element in the i th row and j th column of ˆ Y .
To derive the derivative of the loss function L with respect to the third weight matrix W 3 , we first write
$$\frac { \partial L } { \partial \mathbf W _ { 3 } } = \frac { \partial L _ { 1 } } { \partial \mathbf W _ { 3 } } + \frac { \partial L _ { 2 } } { \partial \mathbf W _ { 3 } }.$$
Then, the derivative of L 1 in (7) with respect to W 3 can be written as
$$\partial W _ { 3 } \quad \partial W _ { 3 } \quad \partial W _ { 3 } \quad \stackrel { \sim } { \sim } \text{/dev/of } L _ { 1 } \text{ in } ( 7 ) \text{ with respect to } W _ { 3 } \text{ can be written as } \\ \frac { \partial L _ { 1 } } { \partial W _ { 3 } } & = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } y _ { i j } \cdot \frac { \partial l n ( \hat { j } _ { i j } ) } { \partial W _ { 3 } } \\ & = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } y _ { i j } \cdot \frac { \partial l n ( \sigma _ { s i g m o i d } ( h _ { 3 i j } ) ) } { \partial W _ { 3 } } \\ & = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } y _ { i j } \cdot \frac { 1 } { \hat { j } _ { i j } } \cdot \hat { j } _ { i j } \cdot ( 1 - \hat { j } _ { i j } ) \cdot \frac { \partial h _ { 3 i j } } { \partial W _ { 3 } } \\ & = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } y _ { i j } \cdot ( 1 - \hat { j } _ { i j } ) \cdot \frac { \partial h _ { 3 i j } } { \partial W _ { 3 } }. \\ \text{the derivative of } L _ { 2 } \text{ in } ( 8 ) \text{ with respect to } W _ { 3 } \text{ can be written as } \\ \partial r \quad \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Similarly, the derivative of L 2 in (8) with respect to W 3 can be written as
$$\text{derivative of } L _ { 2 } & \text{in} \, ( 8 ) \, \text{with respect to } W _ { 3 } \, \text{can be written as} \\ \frac { \partial L _ { 2 } } { \partial W _ { 3 } } & = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( 1 - y _ { i j } ) \cdot \frac { \partial l n ( 1 - \hat { y } _ { i j } ) } { \partial W _ { 3 } } \\ & = \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( 1 - y _ { i j } ) \cdot \hat { y } _ { i j } \cdot \frac { \partial h _ { 3 i j } } { \partial W _ { 3 } }. \\ & \quad \quad \quad$$
The last term, ∂h 3 ij ∂ W 3 , in (10) and (11) can be written as ∂h 3 ij ∂ W 3 = ∂σ ReLU ( A i ∗ H W 2 3 ∗ j ) ∂ W 3 using (4), where A i ∗ is the i th row of A and W 3 ∗ j is the j th column of W 3 . The expression, ∂σ ReLU ( A i ∗ H W 2 3 ∗ j ) ∂ W 3 , is solved using the following definitions and theorem.
Definition 2.1. An element-wise activation function Σ : R p × q → R p × q is defined as a multivariate matrix-valued function [22]:
↦
$$\Sigma \colon \mathbf X \mapsto \Sigma ( \mathbf X ) \coloneqq \begin{bmatrix} \sigma ( x _ { 1 1 } ) & \cdots & \sigma ( x _ { 1 q } ) \\ \vdots & & \vdots \\ \sigma ( x _ { p 1 } ) & \cdots & \sigma ( x _ { p q } ) \end{bmatrix},$$
↦
where X ∈ R p × q and σ : R → R , x ij → σ x ( ij ) for all i = 1 2 , , ..., p and j = 1 2 , , ..., q .
Definition 2.2. The derivative of an element-wise activation function Σ X ( ) ( p × q ) with respect to a matrix X ∈ R p × q is written as:
$$\Sigma ^ { \prime } ( \mathbf X ) = \frac { \partial \Sigma ( \mathbf X ) } { \partial \mathbf X } = \begin{bmatrix} \sigma ^ { \prime } ( x _ { 1 1 } ) & \cdots & \sigma ^ { \prime } ( x _ { 1 q } ) \\ \vdots & & \vdots \\ \sigma ^ { \prime } ( x _ { p 1 } ) & \cdots & \sigma ^ { \prime } ( x _ { p q } ) \end{bmatrix},$$
where σ ′ ( v ) = lim u → 0 σ v ( + ) u -σ v ( ) u is defined as the derivative of a real-valued function σ .
Theorem 2.3. Let F : R p × q → R m n × be a m × n multivariate matrix-valued function of a p × q matrix W ∈ R p × q , the derivative of Σ F W ( ( )) with respect to W can be written as:
$$\frac { \partial \Sigma ( \mathbf F ( W ) ) } { \partial W } = ( \mathbf J _ { p \times q } \otimes \Sigma ^ { \prime } ( \mathbf F ( W ) ) ) \odot \frac { \partial \mathbf F ( W ) } { \partial W },$$
where ⊗ is the Kronecker product in (46), ⊙ is the Hadamard product in (47), and J p × q ∈ R p × q is an all 1 matrix.
Proof. The proof can be found in Appendix C.
From theorem 2.3, we can write the last term in (10) and (11) as
$$\frac { \partial h _ { 3 i j } } { \partial W _ { 3 } } & = \frac { \partial \sigma _ { R e L U } ( \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } ) } { \partial W _ { 3 } } \\ & = ( \mathbf J _ { n _ { 2 } \times n _ { 3 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } ) ) \odot \frac { \partial \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } } { \partial W _ { 3 } }.$$
Using (52), the last term in (15) can be written as
$$\frac { \partial \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } } { \partial \mathbf W _ { 3 } } & = \frac { \partial \mathbf A _ { i * } \mathbf H _ { 2 } } { \partial \mathbf W _ { 3 } } ( \mathbf I _ { n _ { 3 } } \otimes \mathbf W _ { 3 * j } ) + ( \mathbf I _ { n _ { 2 } } \otimes ( \mathbf A _ { i * } \mathbf H _ { 2 } ) ) \frac { \partial \mathbf W _ { 3 * j } } { \partial \mathbf W _ { 3 } } \\ & = ( \mathbf I _ { n _ { 2 } } \otimes ( \mathbf A _ { i * } \mathbf H _ { 2 } ) ) \frac { \partial \mathbf W _ { 3 * j } } { \partial \mathbf W _ { 3 } }.$$
Using (44), (52), and (53), the last term in (16) can be written as
$$, ( 5 2 ), \text{and} \, ( 5 3 ), \text{the last term in} \, ( 16 ) \, can be \, \text{written as} \\ \frac { \partial W _ { 3 } } { \partial W _ { 3 } } & = \frac { \partial W _ { 3 } \, e _ { j } } { \partial W _ { 3 } } \\ & = \frac { \partial W _ { 3 } } { \partial W _ { 3 } } ( I _ { n _ { 3 } } \otimes \, \ e _ { j } ) + ( I _ { n _ { 2 } } \otimes W _ { 3 } ) \frac { \partial \, e _ { j } } { \partial W _ { 3 } } \\ & = \bar { U } _ { n _ { 2 } \times n _ { 3 } } ( I _ { n _ { 3 } } \otimes \, \ e _ { j } ), \\ \text{is} \, a \, n _ { 3 } \text{-dimensional column vector which has ``1`` in the } j t h \, row \, \text{and zero elsewhere and}$$
where e j ( n 3 ) is a n 3 -dimensional column vector which has '1' in the j th row and zero elsewhere and ¯ U n 2 × n 3 ∈ R n 2 2 × n 2 3 is a permutation related matrix defined in (49).
Thus, the derivative of the loss function L with respect to the third weight matrix W 3 in (9) can be written as
$$\frac { \partial L } { \partial \mathbf W _ { 3 } } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( ( y _ { i j } - \hat { y } _ { i j } ) \cdot \frac { \partial h _ { 3 i j } } { \partial \mathbf W _ { 3 } } )$$
$$\odot ( ( \mathbf I _ { n _ { 2 } } \otimes ( \mathbf A _ { i * } \mathbf H _ { 2 } ) ) \bar { \mathbf U } _ { n _ { 2 } \times n _ { 3 } } ( \mathbf I _ { n _ { 3 } } \otimes \mathbf e _ { j } ) ) ) ).$$
$$\overline { \partial W _ { 3 } } & = - \sum _ { i = 1 } ^ { \ } \sum _ { j = 1 } ^ { ( ( y _ { i j } - y _ { i j } ) \cdot \overline { \partial W _ { 3 } } ) } \\ & = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( ( y _ { i j } - \hat { y } _ { i j } ) \cdot ( ( \mathbf J _ { n _ { 2 } \times n _ { 3 } } \otimes \sigma ^ { \prime } _ { R e L U } ( \mathbf A _ { i * } \mathbf H _ { 2 } W _ { 3 * j } ) ) } \\ & \quad \odot ( ( \mathbf I _ { n _ { 2 } } \otimes ( \mathbf A _ { i * } \mathbf H _ { 2 } ) ) \bar { U } _ { n _ { 2 } \times n _ { 3 } } ( \mathbf I _ { n _ { 3 } } \otimes \mathbf e _ { j } ) ) ) ).$$
Using (18), the derivative of the loss function L in (6) with respect to the second weight matrix W 2 can be written as
$$\frac { \partial L } { \partial \mathbf W _ { 2 } } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( ( y _ { i j } - \hat { y } _ { i j } ) \cdot \frac { \partial h _ { 3 i j } } { \partial \mathbf W _ { 2 } } )$$
$$= - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( ( y _ { i j } - \hat { y } _ { i j } ) \cdot ( ( \mathbf J _ { n _ { 1 } \times n _ { 2 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } ) ) \odot \frac { \partial \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } } { \partial \mathbf W _ { 2 } } ) ), \ \ ( 2 1 )$$
where (21) follows from theorem 2.3.
Using (52), the last term of (21) can be written as
$$\frac { \partial \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } } { \partial \mathbf W _ { 2 } } = ( \mathbf I _ { n _ { 1 } } \otimes \mathbf A _ { i * } ) \frac { \partial \mathbf H _ { 2 } } { \partial \mathbf W _ { 2 } } ( \mathbf I _ { n _ { 2 } } \otimes \mathbf W _ { 3 * j } ).$$
The derivative of H 2 with respect to W 2 in (22) can be written as
$$\frac { \partial \mathbf H _ { 2 } } { \partial \mathbf W _ { 2 } } = \frac { \partial \sigma _ { R e L U } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ) } { \partial \mathbf W _ { 2 } } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$= ( \mathbf J _ { n _ { 1 } \times n _ { 2 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ) ) \odot \frac { \partial \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } } { \partial \mathbf W _ { 2 } } ) \quad \ \ \ \ \ \ \ ( 2 4 )$$
$$= ( \mathbf J _ { n _ { 1 } \times n _ { 2 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ) ) \odot ( ( \mathbf I _ { n _ { 1 } } \otimes ( \mathbf A \mathbf H _ { 1 } ) ) \frac { \partial \mathbf W _ { 2 } } { \partial \mathbf W _ { 2 } } ) } _ { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon } ^ { \mu }$$
$$= ( \mathbf J _ { n _ { 1 } \times n _ { 2 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ) ) \odot ( ( \mathbf I _ { n _ { 1 } } \otimes ( \mathbf A \mathbf H _ { 1 } ) ) \bar { U } _ { n _ { 1 } \times n _ { 2 } } ), \quad \ ( 2 6 )$$
where (23) follows from (4), (24) follows from (15), (25) follows from (52), and (26) follows from (53).
The derivative of the loss in (6) with respect to the first weight matrix W 1 is
$$\frac { \partial L } { \partial \mathbf W _ { 1 } } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { 3 } } ( ( y _ { i j } - \hat { y } _ { i j } ) \cdot \left ( ( \mathbf J _ { n _ { 0 } \times n _ { 1 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A _ { i * } \mathbf H _ { 2 } \mathbf W _ { 3 * j } ) \right ) }$$
$$\odot ( ( \mathbf I _ { n _ { 0 } } \otimes \mathbf A _ { i * } ) \frac { \partial \mathbf H _ { 2 } } { \partial \mathbf W _ { 1 } } ( \mathbf I _ { n _ { 1 } } \otimes \mathbf W _ { 3 * j } ) ) ) ),$$
where (27) follows from (21) and
$$\frac { \partial \mathbf H _ { 2 } } { \partial \mathbf W _ { 1 } } = \frac { \partial \sigma _ { R e L U } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ) } { \partial \mathbf W _ { 1 } } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$= ( \mathbf J _ { n _ { 0 } \times n _ { 1 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { 1 } \mathbf W _ { 2 } ) ) \odot ( ( \mathbf I _ { n _ { 0 } } \otimes \mathbf A ) \frac { \partial \mathbf H _ { 1 } } { \partial \mathbf W _ { 1 } } ( \mathbf I _ { n _ { 1 } } \otimes \mathbf W _ { 2 } ) ), \quad ( 2 9 )$$
where (28) follows from (4), (29) follows from theorem (2.3) and (52), and
$$\frac { \partial \mathbf H _ { 1 } } { \partial \mathbf W _ { 1 } } = ( \mathbf J _ { n _ { 0 } \times n _ { 1 } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { 0 } \mathbf W _ { 1 } ) ) \odot ( ( \mathbf I _ { n _ { 0 } } \otimes ( \mathbf A \mathbf H _ { 0 } ) ) \bar { \mathbf U } _ { n _ { 0 } \times n _ { 1 } } ),$$
where (30) follows from (26).
## 2.1.2 Back-propagation for multi-layer GCN with ReLU and sigmoid activation function
We consider a d -layer GCN defined as
$$\hat { Y } & = \sigma _ { s i g m o i d } ( \mathbf H _ { d } ),$$
where
$$\mathbf H _ { d } & = \sigma _ { R e L U } ( \mathbf A \mathbf H _ { d - 1 } \mathbf W _ { d } ),$$
d ∈ Z + , A ∈ { 0 1 , } n × n is an n × n adjacency matrix, H d -1 ∈ R n × n d -1 is the feature matrix for n nodes with n d - × 1 features, ˆ Y ∈ R n × n d is the output matrix, n d = 1 for binary node classification, and W 1 ∈ R n 0 n 1 , W 2 ∈ R n 1 × n 2 , · · · , and W d ∈ R n d -1 × n d are trainable parameter matrices.
By observing (19), (21), (22), (26), (27), (29), and (30), if the loss function of the d -layer GCN for node classification is defined as
$$L = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } ( y _ { i j } l n ( \hat { y } _ { i j } ) + ( 1 - y _ { i j } ) l n ( 1 - \hat { y } _ { i j } ) ),$$
the derivative of the loss in (33) with respect to the s th weight matrix W s is
$$\frac { \partial L } { \partial \mathbf W _ { s } } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } & ( ( y _ { i j } - \hat { y } _ { i j } ) \cdot ( ( \mathbf J _ { ( s - 1 ) \times s } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d * _ { j } } ) ) } \\ & \odot \frac { \partial \mathbf A _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d * _ { j } } } { \partial \mathbf W _ { s } } ) ),$$
$$\partial \mathbf W _ { s }$$
where s ∈ Z + , s ≤ d ,
$$\frac { \partial \mathbf A _ { i * } \mathbf H _ { d - 1 } W _ { d _ { * j } } } { \partial W _ { s } } = \begin{cases} & \cdot \, - \, \cdot \\ & ( \mathbf I _ { n _ { s - 1 } } \otimes ( \mathbf A _ { i * } \mathbf H _ { d - 1 } ) ) \cdot \bar { \mathbf U } _ { n _ { s - 1 } \times n _ { s } } ( \mathbf I _ { n _ { s } } \otimes \mathbf e _ { j } ), \quad \text{ if } s = d \\ & ( \mathbf I _ { n _ { s - 1 } } \otimes \mathbf A _ { i * } ) \cdot \frac { \partial \mathbf H _ { d - 1 } } { \partial W _ { s } } ( \mathbf I _ { n _ { s } } \otimes W _ { d _ { * j } } ), \quad \text{ if } s < d \end{cases}$$
and
$$& \text{and} \\ & \frac { \partial \mathbf H _ { d - 1 } } { \partial \mathbf W _ { s } } \\ & \quad = \begin{cases} \quad ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \odot ( ( I _ { n _ { s - 1 } } \otimes ( \mathbf A \mathbf H _ { d - 2 } ) ) \bar { U } _ { n _ { s - 1 } \times n _ { s } } ), \\ \quad \text{if $s=d-1$} \\ \quad ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \sigma _ { R e L U } ^ { \prime } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \odot ( ( I _ { n _ { s - 1 } } \otimes \mathbf A ) \frac { \partial \mathbf H _ { d - 2 } } { \partial \mathbf W _ { s } } ( I _ { n _ { s } } \otimes \mathbf W _ { d - 1 } ) ), \\ \quad \text{if $s<d-1$}. \end{cases}$$
## 2.1.3 Back-propagation for multi-layer GCN with arbitrary activation functions
We consider a d -layer GCN defined as
$$\hat { Y } & = \Sigma _ { d + 1 } ( \mathbf H _ { d } ),$$
where
$$\mathbf H _ { d } = \Sigma _ { d } ( \mathbf A \mathbf H _ { d - 1 } \mathbf W _ { d } ),$$
d ∈ Z + , A ∈ { 0 1 , } n × n is an n × n adjacency matrix, H d -1 ∈ R n × n d -1 is the feature matrix for n nodes with n d -1 features, ˆ Y ∈ R n × n d is the output matrix, n d = 1 for binary node classification, W 1 ∈ R n 0 × n 1 , W 2 ∈ R n 1 × n 2 , · · · , and W d ∈ R n d -1 × n d are trainable parameter matrices, and Σ 1 , Σ 2 , · · · , and Σ d +1 are any element-wise activation function.
If the loss function of the d -layer GCN for node classification is defined as
$$L = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } ( y _ { i j } l n ( \hat { y } _ { i j } ) + ( 1 - y _ { i j } ) l n ( 1 - \hat { y } _ { i j } ) ),$$
the derivative of the loss in (39) with respect to the s th weight matrix W s is
$$& \text{the derivative of the loss in (39) with respect to the sth weight matrix } W _ { s } \text{ is} \\ & \frac { \partial L } { \partial W _ { s } } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } ( y _ { i j } \frac { \partial l n ( \hat { y } _ { i j } ) } { \partial W _ { s } } + ( 1 - \hat { y } _ { i j } ) \frac { \partial l n ( 1 - \hat { y } _ { i j } ) } { \partial W _ { s } } ) \\ & \quad = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } ( ( \frac { y _ { i j } } { \hat { y } _ { i j } } - \frac { 1 - y _ { i j } } { 1 - \hat { y } _ { i j } } ) \Sigma _ { d + 1 } ^ { \prime } ( h _ { d j } ) \cdot \frac { \partial \Sigma _ { d } ( \frac { \partial } { \partial i * } \mathbf H _ { d - 1 } W _ { d - j } ) } { \partial W _ { s } } ) \\ & \quad = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } ( \frac { y _ { i j } - \hat { y } _ { i j } } { \hat { y } _ { i j } ( 1 - \hat { y } _ { i j } ) } \Sigma _ { d + 1 } ^ { \prime } ( h _ { d j } ) \cdot ( ( J _ { ( s - 1 ) \times s } \otimes \Sigma _ { d } ^ { \prime } ( \frac { \partial } { \partial i * } \mathbf H _ { d - 1 } W _ { d - j } ) ) \\ & \quad \odot \frac { \partial \frac { \partial \frac { \partial } { \partial i * } \mathbf H _ { d - 1 } W _ { d - j } ) } { \partial W _ { s } } ), \\ & \text{where} \, s \in \mathbb { Z } ^ { + }, \, s \leq d, ( 40 ) \, & \text{follows from chain rule and definition 2.2, (41) \, & \text{follows from theorem} } { \lambda \wedge \, \partial \frac { \partial \lambda _ { i * } \mathbf H _ { d - 1 } W _ { d - i } } { \lambda _ { i * } \cdot \. \. } }.$$
where s ∈ Z + , s ≤ d , (40) follows from chain rule and definition 2.2, (41) follows from theorem (2.3), ∂ A i ∗ H d -1 W d ∗ j ∂ W s is the same as in (35) , and
$$& \left ( \delta \mathbf H _ { d - 1 } \\ & \frac { \partial \mathbf H _ { d - 1 } } { \partial \mathbf W _ { s } } \\ & = \begin{cases} \begin{array} { c c c c c } ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \Sigma _ { d - 1 } ^ { \prime } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \odot ( ( I _ { n _ { s - 1 } } \otimes ( \mathbf A \mathbf H _ { d - 2 } ) ) \bar { U } _ { n _ { s - 1 } \times n _ { s } } ) \\ \end{array} \right ) \\ & \left ( \begin{array} { c c c c c } ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \Sigma _ { d - 1 } ^ { \prime } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \odot ( ( I _ { n _ { s - 1 } } \otimes \mathbf A ) \frac { \partial \mathbf H _ { d - 2 } } { \partial \mathbf W _ { s } } ( I _ { n _ { s } } \otimes \mathbf W _ { d - 1 } ) ) \\ \end{array} \right ) \\ & \left ( \begin{array} { c c c c c } ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \Sigma _ { d - 1 } ^ { \prime } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \end{array} \right ) \\ & \left ( \begin{array} { c c c c c } ( I _ { n _ { s - 1 } \otimes \mathbf A ) \frac { \partial \mathbf H _ { d - 2 } } { \partial \mathbf W _ { s } } ( I _ { n _ { s } } \otimes \mathbf W _ { d - 1 } ) ) \\ \end{array} \right ) \\ & - \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \end{cases}$$
Following a similar procedure, we can derive the sensitivity of the loss with respect to the feature matrix H 0 , as shown in Appendix E.1.
## 2.2 Link prediction
For the derivation of back-propagation and sensitivity in a multi-layer GCN with arbitrary activation functions for the link prediction problem, please refer to Appendices D and E.2, respectively.
## 3 Experiments
In this section, we demonstrate the correctness of our method through several experiments considering a node classification problem on Zachary's Karate Club [19] in Figure 3 ( a ) and a link prediction problem on a drug-drug interaction (DDI) network in Figure 3 ( b ). We adopt the stochastic gradient descent (SGD) for model training. We compare our method to the gradient computation using reverse mode automatic differentiation in Pytorch [23] by computing the sum of squared error (SSE) defined as
$$S S E = \sum _ { i = 1 } ^ { n _ { s - 1 } } \sum _ { j = 1 } ^ { n _ { s } } ( w _ { s _ { i j } } ^ { ( A D ) } - w _ { s _ { i j } } ^ { ( K P ) } ) ^ { 2 },$$
where w ( AD ) s ij is the i th row and the j th column of the s th weight matrix W s updated using SGD with reverse mode automatic differentiation and w ( KP ) s ij is the i th row and the j th column of the s th weight matrix W s updated using SGD with our matrix-based method.
In addition, we determine the sensitivity of the loss with respect to the feature matrix H 0 for node classification and link prediction to demonstrate the application of our method to XAI.
The python codes are available at: https://github.com/AnnonymousForPapers/GCN-proof/ tree/main .
## 3.1 Node classification
We tested our method for node classification on Zachary's Karate Club [19] (see Appendix F.1 for more details).
## 3.1.1 1-layer GCN with identity function and sigmoid activation function
The 1 -layer GCN is defined by (37) and the loss function is defined by (39), where d = 1 is the number of layers, H 0 = I n ∈ R n × n is the feature matrix for n = 34 nodes with n = 34 features, the matrix ˆ Y ∈ R n × n d represents the ground truth of nodes, indicating class assignments per node, ˆ Y ∈ R n × n d denotes the final layer predictions of the GCN model, n d = 1 for binary node classification, W 1 ∈ R n 0 × n d is a trainable parameter matrix, n 0 = 34 , Σ 1 is an element-wise identity function, and Σ 2 is an element-wise sigmoid function.
The GCN is trained using SGD with a learning rate of 0.1 and with 100 iterations for both methods. In Figure 4, the evolution of the karate club network shows that the two graph updated by the two methods have the same loss, accuracy, and classification results. In Figure 1 ( a ), it shows the SSE of the weight matrix W 1 between the reverse mode automatic differentiation and our matrix-based method is lower than 10 -13 . This indicates that our analytic expression aligns with the exact method, and the small difference might be due to the precision of different datatypes.
Next, we show the loss sensitivity with respect to the input feature matrix, computed using the result in Appendix E.1. In Figure 2 ( a ), it is shown that as training progresses, the sensitivity decreases. This result is expected since the input feature matrix of the GCN for the Karate graph is an identity matrix. The prediction of the class of a node depends only on its edges rather than the input features. Therefore, changes in the input matrix should not significantly affect the prediction from the trained GCN, as it should learn to make predictions based solely on the existence of edges between nodes.
Additional experimental results on Zachary's Karate Club [19] are provided in Appendix G.0.1.
## 3.2 Link prediction
We tested our method for link prediction on a 10-node DDI network (see Appendix F.2 for more details).
## 3.2.1 2-layer GCN
The 2 -layer GCN is defined by (60) and the loss function is defined by (62), where d = 2 is the number of layers, the matrix ˆ Y ∈ R n × n represents ground-truth adjacency matrix, ˆ Y ∈ R n × n denotes the final link predictions of the GCN model, W 1 ∈ R n 0 × n 1 and W 2 ∈ R n 1 × n 2 are trainable parameter matrices, n 0 = 20 , n 1 = 10 , n 2 = 5 , Σ 1 is an element-wise ReLU function [21], Σ 2 is an element-wise identity function, and Σ 3 is an element-wise sigmoid function.
The GCN is trained using SGD with a learning rate of 0.01 and with 150 iterations for both methods. In each iteration, thirteen negative edges, which is the same number as the number of positive edges, are uniformly sampled from a set of all the unconnected edges for the GCN training using the reverse mode automatic differentiation. The sampled negative edges in each iteration are saved in a list and used in the training of the GCN using our matrix-based method. In Figure 7, the evolution of the DDI network shows that the two graph updated by the two methods have the same loss and classification results. In Figure 1 ( b ), it shows the SSE of the two weight matrices, W 1 and W 2 , between the reverse mode automatic differentiation and our matrix-based method is lower than 10 -14 .
Next, we show the output sensitivity with respect to the input feature matrix, computed using the result in Appendix E.2. In Figure 2 ( b ), a heat map of the sensitivity of the prediction for the link between node 2 and node 7 is shown. The sensitivities of the features in node 2 and node 7 are higher than those of the features in other nodes. The features of nodes (node 1 and node 8) that do not have a connection to either node 2 or node 7, or the features of nodes (node 0) that need to traverse at least three edges to reach node 2 or node 7, have almost zero sensitivity to the link. This demonstrates the property of GCNs, where the neighborhood information of two nodes is aggregated by taking the weighted sum of the features of neighboring nodes [24]. Since the GCN has only two layers, the information of nodes that are three edges away from these two nodes does not contribute to the prediction of the edge.
Additional experimental results on the DDI network are provided in Appendix G.0.2. Heat maps of the sensitivity of the prediction for all the links are in Figures 8, 9, and 10 in the Appendix.
Figure 1: ( a ) The evolution of the sum of squared error between the trainable weight matrix obtained from our method and the matrix obtained using reverse mode automatic differentiation in section 3.1.1. ( b ) The evolution of the sum of squared error between the two trainable weight matrices obtained from our method and the matrices obtained using reverse mode automatic differentiation in section 3.2.1.
Figure 2: ( a ) The evolution of the absolute sum of the sensitivity of the loss with respect to the input feature matrix H 0 in Section 3.1.1. ( b ) The heat map of the sensitivity of the prediction for the link between node 2 and node 7 with respect to the input feature matrix H 0 in Section 3.2.1.
## 4 Conclusion
In this work, we provide detailed derivations of the analytical expressions in matrix form for the derivatives of a loss function with respect to each weight matrix for a graph convolutional network considering binary node classification and link prediction. Utilizing Kronecker product, Hadamard product, and matrix calculus, we computed the gradients of the loss function in a three-layer graph convolutional network and extended the solution to accommodate graph convolutional networks with arbitrary layers and element-wise activation functions. The weight matrices obtained through our approach were compared with those obtained using reverse mode automatic differentiation in binary node classification experiments conducted on a 34 nodes Zachary's Karate Club network [19] and in link prediction experiments using a 10-node drug-drug interaction network. The experimental results indicate that the discrepancy between the weight matrices has a median sum of squared error ranging from 10 -18 to 10 -14 , affirming the accuracy of our methodology. In addition, we conduct sensitivity analysis for binary node classification and link prediction to demonstrate the application of our derivation method in XAI.
We note that our derivation already accommodates RNNs when A is an identity matrix, and it accommodates CNNs since CNNs operate on 2-dimensional matrices, which are a special case of graphs. Additionally, our method incurs a significantly higher computational cost compared to reverse mode AD. As future work, we aim to find a way to improve the computational speed of back-propagation through our derived analytical solution.
## References
| [1] | Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE transactions on neural networks , 20(1):61-80, 2008. |
|-------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 , 2016. |
| [3] | Abhishek Dutta. Deep graph generation of small molecules guided by drug-likeness. In IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology , pages 1-2. IEEE, 2022. |
| [4] | Shunxin Xiao, Shiping Wang, Yuanfei Dai, and Wenzhong Guo. Graph neural networks in node classification: survey and evaluation. Machine Vision and Applications , 33:1-19, 2022. |
| [5] | Jinxian Zhang, Junbo Zhao, Fei Ding, Jing Yang, and Junhui Zhao. A graph convolutional network for active distribution system anomaly detection considering measurement spatial- temporal correlations. In 2023 North American Power Symposium (NAPS) , pages 1-6. IEEE, 2023. |
| [6] | Xing Wang and Alexander Vinel. Benchmarking graph neural networks on link prediction. arXiv preprint arXiv:2102.12557 , 2021. |
| [7] | Rongting Yue and Abhishek Dutta. Repurposing drugs for covid-19 by graph convolutional network. PREPRINT , April 12 2023. Version 1, available at Research Square https://doi. org/10.21203/rs.3.rs-2408594/v1 . |
| [8] | David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature , 323(6088):533-536, 1986. |
| [9] | Sergios Theodoridis. Chapter 18 - neural networks and deep learning. In Sergios Theodoridis, editor, Machine Learning (Second Edition) , pages 901-1038. Academic Press, second edition, 2020. |
| [10] | Aurélien Géron. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow . " O'Reilly Media, Inc.", 2022. |
| [11] | Werbos. Backpropagation: Past and future. In IEEE 1988 International Conference on Neural Networks , pages 343-353. IEEE, 1988. |
| [12] | Atilim Gunes Baydin, Barak A Pearlmutter, Alexey Andreyevich Radul, and Jeffrey Mark Siskind. Automatic differentiation in machine learning: a survey. Journal of Marchine Learning Research , 18:1-43, 2018. |
| [13] | Michael A Nielsen. Neural networks and deep learning , volume 25. Determination press San Francisco, CA, USA, 2015. |
| [14] | NMMishachev. Backpropagation in matrix notation. arXiv preprint arXiv:1707.02746 , 2017. |
| [15] | Maxim Naumov. Feedforward and recurrent neural networks backward propagation and hessian in matrix form. arXiv preprint arXiv:1709.06080 , 2017. |
| [16] | Yiping Cheng. Derivation of the backpropagation algorithm based on derivative amplification coefficients. arXiv preprint arXiv:2102.04320 , 2021. |
| [17] | Vikas Hassija, Vinay Chamola, Atmesh Mahapatra, Abhinandan Singal, Divyansh Goel, Kaizhu Huang, Simone Scardapane, Indro Spinelli, Mufti Mahmud, and Amir Hussain. Interpreting black-box models: a review on explainable artificial intelligence. Cognitive Computation , 16(1):45-74, 2024. |
| [18] | Bas Van Stein, Elena Raponi, Zahra Sadeghi, Niek Bouman, Roeland CHJ Van Ham, and Thomas Bäck. A comparison of global sensitivity analysis methods for explainable ai with an application in genomic prediction. IEEE Access , 10:103364-103381, 2022. |
| [19] | Wayne WZachary. An information flow model for conflict and fission in small groups. Journal of anthropological research , 33(4):452-473, 1977. |
| [20] | Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems , 32(1):4-24, 2020. |
| [21] | Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10) , pages 807-814, 2010. |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [22] | Dirk Ostwald and Franziska Usée. An induction proof of the backpropagation algorithm in matrix notation. arXiv preprint arXiv:2107.09384 , 2021. |
| [23] | Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems , 32, 2019. |
| [24] | David Ahmedt-Aristizabal, Mohammad Ali Armin, Simon Denman, Clinton Fookes, and Lars Petersson. A survey on graph-based deep learning for computational histopathology. Computerized Medical Imaging and Graphics , 95:102027, 2022. |
| [25] | John Brewer. Kronecker products and matrix calculus in system theory. IEEE Transactions on circuits and systems , 25(9):772-781, 1978. |
| [26] | Hai-hua Zhu, Zi-gang Chen, and Tao Leng. Random permutation-based mixed-double scram- bling technique for encrypting mqir image. Journal of Applied Physics , 135(1), 2024. |
| [27] | Jan R Magnus. On the concept of matrix derivative. Journal of Multivariate Analysis , 101(9):2200-2206, 2010. |
| [28] | Seongjun Yun, Seoyoon Kim, Junhyun Lee, Jaewoo Kang, and Hyunwoo J Kim. Neo-gnns: Neighborhood overlap-aware graph neural networks for link prediction. Advances in Neural Information Processing Systems , 34:13683-13694, 2021. |
| [29] | Cristopher Moore, Xiaoran Yan, Yaojia Zhu, Jean-Baptiste Rouquier, and Terran Lane. Active learning for node classification in assortative and disassortative networks. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 841-849, 2011. |
| [30] | A David Rodrigues. Drug-drug interactions . CRC Press, 2019. |
| [31] | David S Wishart, Yannick D Feunang, An C Guo, Elvis J Lo, Ana Marcu, Jason R Grant, Tanvir Sajed, Daniel Johnson, Carin Li, Zinat Sayeeda, et al. Drugbank 5.0: a major update to the drugbank database for 2018. Nucleic acids research , 46(D1):D1074-D1082, 2018. |
| [32] | Daniel Blanco-Melo, Benjamin E Nilsson-Payant, Wen-Chun Liu, Skyler Uhl, Daisy Hoagland, Rasmus Møller, Tristan X Jordan, Kohei Oishi, Maryline Panis, David Sachs, et al. Imbalanced host response to sars-cov-2 drives development of covid-19. Cell , 181(5):1036-1045, 2020. |
| [33] | Minoru Kanehisa, Yoko Sato, and Masayuki Kawashima. Kegg mapping tools for uncovering hidden features in biological data. Protein Science , 2021. |
| [34] | David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules. Journal of chemical information and computer sciences , 28(1):31-36, 1988. |
| [35] | Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 , 2016. |
| [36] | Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289 , 2015. |
| [37] | Andrew L Maas, Awni Y Hannun, Andrew Y Ng, et al. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml , volume 30, page 3. Atlanta, GA, 2013. |
| [38] | J. D. Hunter. Matplotlib: A 2d graphics environment. Computing in Science &Engineering , |
## A Basic notation and properties of Kronecker product and matrix calculus
## A.1 Basic notation
A column vector is denoted by lower case boldface (e.g., v , with its i th element being v i ). Matrices is denoted by upper case boldface (e.g., A ). The i th row for a matrix such as A is denoted A i ∗ and the i th column is denoted A ∗ i . The ( i, j ) element of A is denoted a ij . An ( m × n ) all-ones
matrix where all of its elements are equal to 1 is denoted as J m n × . An ( m × n ) zero matrix where all of its elements are equal to 0 is denoted as O m n × . The ( n × n ) identity matrix is denoted I n . The k -dimensional column vector which has '1' in the j th row and zero elsewhere is called the unit vector and has denoted e j ( k ) . The i th column of a matrix A can be written as:
$$\mathbf A _ { * i } = \mathbf A \cdot \mathbf e _ { \substack { e _ { i } \\ ( q ) } }.$$
The elementary matrix
$$\mathbf E _ { i j } ^ { ( p \times q ) } \stackrel { \triangle } { = } \mathbf e _ { \substack { i } { e _ { j } \\ ( p ) } _ { ( q ) } } ^ { T }$$
has dimensions ( p × q ) , has '1' in the ( i, j ) th element, and has zero elsewhere.
The Kronecker product of a matrix A with dimensions ( p × q ) and a matrix B with dimensions ( m × n ) is represented as A ⊗ B . The resulting matrix is of size pm × qn and is defined by
$$A \otimes B \stackrel { \triangle } { = } \begin{bmatrix} \mu & \mu & \mu & \mu & \mu & \mu \\ a _ { 1 2 } B & \cdots & a _ { 1 q } B \\ a _ { 2 1 } B & & \vdots \\ \vdots & & \\ a _ { p 1 } B & \cdots & a _ { p q } B \end{bmatrix}.$$
The Hadamard product of A ( p × q ) and C ( p × q ) is denoted A ⊙ C and is a ( p × q ) matrix defined by
$$\mathbf A \odot \mathbf C \stackrel { \triangle } { = } \begin{bmatrix} a _ { 1 1 } c _ { 1 1 } & a _ { 1 2 } c _ { 1 2 } & \cdots & a _ { 1 q } c _ { 1 q } \\ a _ { 2 1 } c _ { 2 1 } & & & \vdots \\ \vdots & & & \\ a _ { p 1 } c _ { p 1 } & \cdots & & a _ { p q } c _ { p q } \end{bmatrix}.$$
The permutation matrix is a square ( pq × pq ) matrix defined by [25]
$$\mathbf U _ { p \times q } \stackrel { \varepsilon } { = } \sum _ { i } ^ { p } \sum _ { j } ^ { q } \mathbf E _ { i j } ^ { ( p \times q ) } \otimes \mathbf E _ { j i } ^ { ( q \times p ) }.$$
Each row and column of the square matrix U p × q has only one element with a value of 1 , and all remaining elements are zero [26].
A related matrix is a rectangular ( p 2 × q 2 ) matrix defined by [25]
$$\bar { \mathbf U } _ { p \times q } \stackrel { \varepsilon } { = } \sum _ { i } ^ { p } \sum _ { j } ^ { q } \mathbf E _ { i j } ^ { ( p \times q ) } \otimes \mathbf E _ { i j } ^ { ( p \times q ) }.$$
The matrix derivative of a matrix function F = [ f ij ( W )] m n × : R p × q → R m n × with respect to a matrix X ( p × q ) is of order ( pm × qn ) and is defined as [27]
$$\frac { \partial F ( X ) } { \partial X } \stackrel { \Delta } { = } \begin{bmatrix} \frac { \partial F ( X ) } { \partial x _ { 1 1 } } & \dots & \frac { \partial F ( X ) } { \partial x _ { 1 q } } \\ \vdots & & \vdots \\ \frac { \partial F ( X ) } { \partial x _ { p 1 } } & \dots & \frac { \partial F ( X ) } { \partial x _ { p q } } \end{bmatrix},$$
where for x ∈ R .
$$\frac { \partial \mathbf F ( \mathbf X ) } { \partial x } \stackrel { \Delta } { = } \begin{bmatrix} \frac { \partial f _ { 1 1 } ( \mathbf X ) } { \partial x } & \cdots & \frac { \partial f _ { 1 n } ( \mathbf X ) } { \partial x } \\ \vdots & & \vdots \\ \frac { \partial f _ { m 1 } ( \mathbf X ) } { \partial x } & \cdots & \frac { \partial f _ { m n } ( \mathbf X ) } { \partial x } \end{bmatrix}$$
## A.2 Properties of Kronecker product and matrix calculus
The matrix operations related to Kronecker product are listed below and are adopted from [25]. The matrices in this subsection have the following dimension: A : R s × t → R p × q , B ∈ R s × t , and C : R s × t → R q × r .
$$\frac { \partial \mathbf A ( \mathbf B ) \mathbf C ( \mathbf B ) } { \partial \mathbf B } = & \frac { \partial \mathbf A ( \mathbf B ) } { \partial \mathbf B } ( \mathbf I _ { t } \otimes \mathbf C ( \mathbf B ) ) + ( \mathbf I _ { s } \otimes \mathbf A ( \mathbf B ) ) \frac { \partial \mathbf C ( \mathbf B ) } { \partial \mathbf B }.$$
$$\frac { \partial \mathbf A } { \partial \mathbf A } = \bar { \mathbf U } _ { p \times q }.$$
$$\begin{array} {$$
The equations (52), (53), and (54) are employed in deriving the derivative of the loss function with respect to the weight matrix of GCN.
## B Back-propagation of Graph Convolutional Network
A basic graph structure is defined as:
$$G & = ( V, E ),$$
where | V | = n is the number of nodes in the graph and | E | = n e is the number of edges. Denoting v i ∈ V as a node and e ij = ( v , v i j ) ∈ E as an edge pointing from v i to v j , the adjacency matrix, A ∈ { 0 1 , } n × n , is an n × n matrix where a ij equals 1 if the edge e ij exists, and a ij equals 0 if e ij does not belong to E ; in addition, a graph may possess node attributes represented by the matrix H 0 ∈ R n × n 0 , where h 0 v ∈ R n 0 is the feature vector of a node v with n 0 features [20].
## C Proof of theorem 2.3
Let F W ( ) = [ f ij ( W )] m n × : R p × q → R m n × be a m × n multivariate matrix-valued function of a p × q matrix W ∈ R p × q , from definition 2.1, Σ F W ( ( )) maps a m × n matrix F W ( ) to a m × n matrix Σ F W ( ( )) . From (50), the derivative of Σ F W ( ( )) ( m × n ) with respect to W ( p × q ) can be written as:
$$\frac { \partial \Sigma ( \mathsf F ( \mathsf W ) ) } {$$
Using (51), chain rule, and definition 2.2, the first element in (56) is given by
$$\text{chain rule, and definition 2.2, the first element in (56) is given by$$
where Σ F W ′ ( ( )) is defined as
$$\Sigma ^ { \prime } ( \mathbf F ( \mathbf W ) ) = \$$
Applying the calculation of (57) to all the other elements in (56), we can get
$$\varepsilon \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \begin{matrix} \partial \Sigma ( \mathsf F ( W ) ) \\ \overline { \partial W } \\ = \begin{bmatrix} \Sigma ^ { \prime } ( \mathsf F ( W ) ) \odot \frac { \partial \mathsf F ( W ) } { \partial w _ { 1 1 } } & \cdots & \Sigma ^ { \prime } ( \mathsf F ( W ) ) \odot \frac { \partial \mathsf F ( W ) } { \partial w _ { p q } } \\ = \begin{bmatrix} \Sigma ^ { \prime } ( \mathsf F ( W ) ) \cdots \Sigma ^ { \prime } ( \mathsf F ( W ) ) \\ \vdots \\ \Sigma ^ { \prime } ( \mathsf F ( W ) ) \cdots \Sigma ^ { \prime } ( \mathsf F ( W ) ) \end{bmatrix} \begin{bmatrix} \partial \mathsf F ( W ) \\ \overline { \partial w _ { 1 1 } } & \cdots & \overline { \partial w _ { 1 q } } \\ \vdots \\ \overline { \partial f ( W ) } \\ \overline { \partial w _ { p q } } \\ \end{bmatrix} \cdots & \overline { \partial f ( W ) } \\ = ( \mathsf J _ { p \times q } \otimes \Sigma ^ { \prime } ( \mathsf F ( W ) ) ) \odot \frac { \partial \mathsf F ( W ) } { \partial W }. \end{matrix}$$
## D Back-propagation for multi-layer GCN with arbitrary activation functions
We consider a d -layer GCN defined as
$$\hat { Y } & = \Sigma _ { d + 1 } ( \mathbf H _ { d } \mathbf H _ { d } ^ { T } ),$$
where
$$\mathbf H _ { d } & = \Sigma _ { d } ( \hat { \mathbf A } \mathbf H _ { d - 1 } \mathbf W _ { d } ),$$
d ∈ Z + , ˆ A = ˜ D -1 2 ( A + I n ) ˜ D -1 2 ∈ R n × n represents the n × n normalized adjacency matrix [28], ˜ D ∈ R n × n is a degree matrix defined by ˜ d ii = 1 + ∑ j a ij , A ∈ { 0 1 , } n × n is an n × n adjacency matrix whose diagonal elements are all equal to zero), H d ∈ R n × n d is the feature matrix for n nodes with n d features, ˆ Y ∈ R n × n d is the output matrix, and W 1 ∈ R n 0 × n 1 , W 2 ∈ R n 1 × n 2 , · · · , and W d ∈ R n d -1 × n d are trainable parameter matrices, and Σ 1 , Σ 2 , · · · , and Σ d +1 are any element-wise activation function.
The loss function of the GCN for link prediction can be defined as
$$L = - \sum _ { ( i, j ) \in E } l n ( \hat { y } _ { i j } ) - \sum _ { ( i, j ) \in S } l n ( 1 - \hat { y } _ { i j } ),$$
where y ij denotes the element in the i th row and j th column of the training matrix Y ∈ R n × n d , ˆ y ij denotes the element in the i th row and j th column of ˆ Y , and S is a set of edges that contains n e negative edges (¯ v , v i ¯ ) j ∈ S randomly sampled from E c .
The derivative of the loss in (62) with respect to the s th weight matrix W s is
$$\frac { \partial L } { \partial \mathbf W _ { s } } = - \sum _ { ( i, j ) \in E } \frac { 1 } { \hat { y } _ { i j } } \frac { \partial \hat { y } _ { i j } } { \partial \mathbf W _ { s } } + \sum _ { ( i, j ) \in S } \frac { 1 } { 1 - \hat { y } _ { i j } } \frac { \partial \hat { y } _ { i j } } { \partial \mathbf W _ { s } },$$
where s ∈ Z + , s ≤ d ,
∂y
ˆ
ij
∂
W
s
$$= \Sigma ^ { \prime } _ { d + 1 } ( \mathbf H _ { d _ { i * } } \mathbf H _ { d _ { j * } } ^ { T } ) \frac { \partial \mathbf H _ { d _ { i * } } \mathbf H _ { d _ { j * } } ^ { T } } { \partial \mathbf W _ { s } }$$
$$\partial \mathbf W _ { s }$$
$$= \Sigma _ { d + 1 } ^ { \prime } ( \mathbf H _ { d _ { i } * } \mathbf H _ { d _ { j } * } ^ { T } ) \cdot \frac { \partial \Sigma _ { d } ( \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } W _ { d } ) \Sigma _ { d } ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } W _ { d } ) ^ { T } } { \partial W _ { s } }$$
$$= \Sigma _ { d + 1 } ^ { \prime } ( \mathbf H _ { d _ { i * } } \mathbf H _ { d _ { j * } } ^ { T } ) \cdot ( \frac { \partial \Sigma _ { d } ( \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) } { \partial \mathbf W _ { s } } ( \mathbf I _ { n _ { s } } \otimes \Sigma _ { d } ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ^ { T } )$$
$$& + ( \mathbf I _ { n _ { s - 1 } } \otimes \Sigma _ { d } ( \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ) \frac { \stackrel { \mu } { \partial \Sigma _ { d } } ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ^ { T } } { \partial \mathbf W _ { s } } ) }$$
=
Σ
′
T
d
+1
(
H
d
i
∗
H
d
j
∗
)
$$\cdot \left ( ( ( \mathbf J _ { n _ { s - 1 } \times n _ { s } } \otimes \Sigma _ { d } ^ { \prime } ( \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ) \odot \frac { \partial \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d } } { \partial \mathbf W _ { s } } ) \cdot ( \mathbf I _ { n _ { s } } \otimes \Sigma _ { d } ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ^ { T } ) } { \hat { \mathbf A } _ { i * } }$$
$$+ \, & ( \mathbf I _ { n _ { s - 1 } } \otimes \Sigma _ { d } ( \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } W _ { d } ) ) \cdot ( ( \mathbf J _ { n _ { s - 1 } \times n _ { s } } \otimes \Sigma _ { d } ^ { \prime } ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } W _ { d } ) ^ { T } ) \odot \frac { \partial ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } W _ { d } ) ^ { T } } { \partial W _ { s } } ) ), \\ & \quad \, = \, \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \codeots \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{array}$$
(64) follows from chain rule and definition 2.2, (65) follows from (61), (66) follows from (52), (67) follows from theorem (2.3),
$$\frac { \partial \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d } } { \partial \mathbf W _ { s } } = \begin{cases} \begin{array} { c } ( \mathbf I _ { n _ { s - 1 } } \otimes ( \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } ) ) \bar { \mathbf U } _ { n _ { s - 1 } \times n _ { s } }, & \text{if $s=d$} \\ ( \mathbf I _ { n _ { s - 1 } } \otimes \hat { \mathbf A } _ { i * } ) \frac { \partial \mathbf H _ { d - 1 } } { \partial \mathbf W _ { s } } ( \mathbf I _ { n _ { s } } \otimes \mathbf W _ { d } ), & \text{if $s<d$,} \end{array} \end{cases} } { \lambda }, \quad \begin{cases} \frac { ( 6 8 ) } { \partial \mathbf W _ { s } } \end{cases} \lambda \end{cases}.$$
$$\frac { \partial ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ^ { T } } { \partial \mathbf W _ { s } } = \begin{cases} \begin{array} { c } U _ { n _ { s - 1 } \times n _ { s } } ( \mathbf I _ { n _ { s } } \otimes ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } ) ^ { T } ), & \text{if $s=d$} \\ ( \mathbf I _ { n _ { s - 1 } } \otimes \mathbf W _ { d } ^ { T } ) \frac { \partial \mathbf H _ { d - 1 } ^ { T } } { \partial \mathbf W _ { s } } ( \mathbf I _ { n _ { s } } \otimes \hat { \mathbf A } _ { j * } ^ { T } ), & \text{if $s<d$,} \end{array} \\ \text{case\colon$} \begin{cases} \frac { ( 6 9 ) } { c } \end{cases}$$
(68) follows from (52) and (53), (69) follows from (52) and (54), d -1 is similar to (42) but with
$$( 6 8 ) & \text{follows from (52) and (53), (69) \text{ follows from (52) and (54)), \frac { \partial H _ { d - 1 } } { \partial W _ { s } } \text{ is similar to (42) but with} \\ \mathbf A = \mathbf \hat { \mathbf A }, \\ \frac { \partial H _ { d - 1 } ^ { T } } { \partial W _ { s } } \\ & = \begin{cases} ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \mathbf \Sigma _ { d - 1 } ^ { \prime } ( \mathbf \hat { \mathbf A } H _ { d - 2 } W _ { d - 1 } ) ^ { T } ) \odot ( U _ { n _ { s - 1 } \times n _ { s } } ( I _ { n } ) \otimes ( \mathbf \hat { \mathbf A } H _ { d - 2 } ) ^ { T } ) ), \\ \text{ if } s = d - 1 \\ ( J _ { n _ { s - 1 } \times n _ { s } } \otimes \mathbf \Sigma _ { d - 1 } ^ { \prime } ( \mathbf \hat { \mathbf A } H _ { d - 2 } W _ { d - 1 } ) ^ { T } ) \odot ( ( I _ { n - s - 1 } \otimes W _ { d - 1 } ) \frac { \partial H _ { d - 2 } ^ { T } } { \partial W _ { s } } \cdot ( I _ { n _ { s } } \otimes \mathbf \hat { \mathbf A } ^ { T } ) ), \\ \text{ if } s < d - 1, \end{cases}$$
∂ H ∂ W s ˆ
and (70) follows from (52), (54), and theorem (2.3).
## E Sensitivity analysis
## E.1 Sensitivity of loss with respect to feature matrix
The expression of the sensitivity of loss with respect to the feature matrix H 0 is similar to the result in section 2.1.3 except that we change the dimension of the identity matrix, the all-one matrix, and the permutation related matrix, and we change the result in (35) and (42) for the last layer. Thus, the derivative, or sensitivity, of the loss in (39) with respect to the input feature matrix H 0 ∈ R n × n 0 is
$$\text{derivative, or sensitivity, of the loss in (39) with respect to the input feature matrix } \mathbf H _ { 0 } \in \mathbb { K } ^ { \prime \prime } \stackrel { n } { \sim } \frac { \partial L } { \partial \mathbf H _ { 0 } } = - \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n _ { d } } & ( \frac { y _ { i j } - \hat { y } _ { i j } } { \hat { y } _ { i j } ( 1 - \hat { y } _ { i j } ) } \Sigma _ { d + 1 } ^ { \prime } ( h _ { d _ { i j } } ) \cdot \left ( ( \mathbf J _ { n \times n _ { 0 } } \otimes \Sigma _ { d } ^ { \prime } ( \mathbf A _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d * _ { j } } ) \right ) \\ & \odot \frac { \partial \mathbf A _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d * _ { j } } } { \partial \mathbf H _ { 0 } } ) ),$$
$$\partial \mathbf H _ { 0 }$$
$$\text{where } \frac { \partial \mathbf A _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d _ { * j } } } { \partial \mathbf H _ { 0 } } \text{ is } 1$$
$$\frac { \partial \mathbf A _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d _ { * j } } } { \partial \mathbf H _ { 0 } } = \begin{cases} \quad ( \mathbf I _ { n } \otimes \mathbf A _ { i * } ) \cdot \bar { \mathbf U } _ { n \times n _ { 0 } } ( \mathbf I _ { n _ { 0 } } \otimes \mathbf W _ { d _ { * j } } ) & \text{if $d=1$} \\ \quad ( \mathbf I _ { n } \otimes \mathbf A _ { i * } ) \cdot \frac { \partial \mathbf H _ { d - 1 } } { \partial \mathbf H _ { 0 } } ( \mathbf I _ { n _ { 0 } } \otimes \mathbf W _ { d _ { * j } } ) & \text{if $d>1$} \end{cases}, \quad ( 7 2 )$$
and
$$& \quad \text{and} \quad & \quad \partial \mathbf H _ { d - 1 } \\ & \quad \frac { \partial \mathbf H _ { d - 1 } } { \partial \mathbf H _ { 0 } } \\ & \quad = \begin{cases} \begin{array} { c c } ( J _ { n \times n _ { 0 } } \otimes \Sigma ^ { \prime } _ { d - 1 } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \odot ( ( I _ { n } \otimes \mathbf A ) \bar { U } _ { n \times n _ { 0 } } ( I _ { n _ { 0 } } \otimes \mathbf W _ { d - 1 } ) ) \\ \text{if $d-1=1$} \\ \text{$(J_{n\times n _ { 0 } } \otimes \Sigma ^ { \prime } _ { d - 1 } ( \mathbf A \mathbf H _ { d - 2 } \mathbf W _ { d - 1 } ) ) \odot ( ( I _ { n } \otimes \mathbf A ) \frac { \partial \mathbf H _ { d - 2 } } { \partial \mathbf H _ { 0 } } ( I _ { n _ { 0 } } \otimes \mathbf W _ { d - 1 } ) ) \\ \text{if $d-1>1$}. \end{cases}$$
## E.2 Sensitivity of output with respect to feature matrix
Similarly, the derivative, or sensitivity, of each element of the output in (60) with respect to the input feature matrix H 0 ∈ R n × n 0 is
$$& \frac { \partial \hat { j } _ { i j } } { \partial \mathbf H _ { 0 } } \\ & = \Sigma ^ { \prime } _ { d + 1 } ( \mathbf H _ { d _ { i } * } \mathbf H ^ { T } _ { d _ { j } * } ) \\ & \quad \cdot \left ( ( ( ( J _ { n \times n _ { 0 } } \otimes \Sigma ^ { \prime } _ { d } ( \hat { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \that \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsy { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde { \boldsymbol \tilde \tilde { \boldsymbol \tilde \tilde { \boldsymbol \tilde \tilde { \boldsymbol \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \ tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde { \boldsymbol \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \n } } } } } } } } ), \\........................................................................................................................................................................................................$$
$$( 7 4 )$$
where
$$\frac { ^ { \prime \mathfrak { A } _ { i * } \mathfrak { P } _ { d - 1 } w _ { d _ { * j } } } } { \partial \mathbf H _ { 0 } } & \text{ is the defined as} \\ \mathfrak { A A } \quad \mathfrak { U } \quad \mathfrak { W } \quad \left ( \mathbf I _ { n } \otimes.$$
$$\frac { \partial \hat { \mathbf A } _ { i * } \mathbf H _ { d - 1 } \mathbf W _ { d } } { \partial \mathbf H _ { 0 } } = \begin{cases} & ( \mathbf I _ { n } \otimes \hat { \mathbf A } _ { i * } ) \bar { \mathbf U } _ { n \times n _ { 0 } } ( \mathbf I _ { n _ { 0 } } \otimes \mathbf W _ { d } ), & \text{ if } d = 1 \\ & ( \mathbf I _ { n } \otimes \hat { \mathbf A } _ { i * } ) \frac { \partial \mathbf H _ { d - 1 } } { \partial \mathbf H _ { 0 } } ( \mathbf I _ { n _ { 0 } } \otimes \mathbf W _ { d } ), & \text{ if } d > 1, \end{cases}$$
$$\frac { \partial ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } \mathbf W _ { d } ) ^ { T } } { \partial \mathbf H _ { 0 } } = \begin{cases} \cdot & \cdot \\ ( \mathbf I _ { n } \otimes \mathbf W _ { d } ^ { T } ) \mathbf U _ { n \times n _ { 0 } } ( \mathbf I _ { n _ { 0 } } \otimes ( \hat { \mathbf A } _ { j * } \mathbf H _ { d - 1 } ) ^ { T } ), & \text{if $d=1$} \\ ( \mathbf I _ { n } \otimes \mathbf W _ { d } ^ { T } ) \frac { \partial \mathbf H _ { d - 1 } ^ { T } } { \partial \mathbf H _ { 0 } } ( \mathbf I _ { n _ { 0 } } \otimes \hat { \mathbf A } _ { j * } ^ { T } ), & \text{if $d>1$}, \end{cases} }$$
∂ H d -1 ∂ H 0 is similar to (73) but with A = ˆ A , and
$$& \frac { \partial \mathfrak { H } _ { d - 1 } } { \partial \mathfrak { H } _ { 0 } } \text{ is similar to (73) but with } A = \mathfrak { A }, \text{ and} \\ & \frac { \partial \mathfrak { H } _ { d - 1 } ^ { T } } { \partial \mathfrak { H } _ { 0 } } \\ & \quad \begin{cases} \begin{array} { c } ( J _ { n \times n _ { 0 } } \otimes \Sigma ^ { \prime } _ { d - 1 } ( \mathfrak { A } \mathfrak { H } _ { d - 2 } W _ { d - 1 } ) ^ { T } ) \odot ( ( I _ { n } \otimes W _ { d - 1 } ^ { T } ) U _ { n \times n _ { 0 } } ( I _ { n _ { 0 } } \otimes \mathfrak { A } ^ { T } ) ), \\ \text{ if } d - 1 = 1 \\ \end{array} & \begin{cases} \\ ( J _ { n \times n _ { 0 } } \otimes \Sigma ^ { \prime } _ { d - 1 } ( \mathfrak { A } \mathfrak { H } _ { d - 2 } W _ { d - 1 } ) ^ { T } ) \odot ( ( I _ { n } \otimes W _ { d - 1 } ^ { T } ) \frac { \partial \mathfrak { H } _ { d - 2 } ^ { T } } { \partial \mathfrak { H } _ { 0 } } \cdot ( I _ { n _ { 0 } } \otimes \mathfrak { A } ^ { T } ) ), \\ \text{ if } d - 1 > 1. \end{cases}$$
## F Data description
## F.1 Node classification
We tested our method for node classification on Zachary's Karate Club [19]. Zachary's Karate Club is a social network consisting of 34 members of a karate club, where undirected edges represent friendships, as shown in Figure 3 ( a ) [29]. Every node was labeled by one of four classes obtained via modularity-based clustering in [2] and we set class 2 to class 0 and class 3 to class 1 for binary node classification. The goal is to classify the nodes into the correct class.
Figure 3: ( a ) Zachary's karate club social network [19]. The node colors signify classes, with blue representing class 0 and orange representing class 1. ( b ) Drug-drug interaction network. Black links between each node represent graph edges.
## F.2 Link prediction
Drug-Drug Interaction (DDI) commonly arises when multiple drugs that target the same receptors are administered concurrently. Such interactions can result in diminished therapeutic efficacy by hindering drug absorption and amplifying adverse drug reactions, which may lead to unforeseen off-target side effects [30]. We tested our method for link prediction using a DDI network, which was formed by extracting data from the DrugBank database [31]. This network revolved around drugs of interest, identified through the analysis of differentially expressed genes from RNA-sequence data within the GSE147507 dataset, particularly in the context of a COVID-19 study [32]. Interactions between drugs and proteins were established using DrugBank's available drug-protein interactions, serving as communication pathways. The most disrupted signaling pathway, "Herpes simplex virus 1 infection," comprised 495 proteins and was selected based on the analysis of differentially expressed genes and KEGG pathway database [33]. Subsequently, 214 drugs were extracted from DrugBank for their direct interactions with the 495 proteins of interest. In total, 468 drugs (including the aforementioned 214) with 48,460 DDIs were sourced from DrugBank, capable of interacting with the 214 drugs. The DDI network was constructed using these 468 drugs. For this study, the first 100 drugs, based on their DrugBank index, were extracted to form a manageable subset for analysis.
The drug features analyzed in this study encompassed 20 molecular properties such as weight and water solubility. Furthermore, pairwise chemical similarities between drugs were computed using the Jaccard coefficient, quantifying structural similarity based on Simplified Molecular Input Line Entry System (SMILES) strings [34]. Principal Components Analysis was used and the first 20 (out of 488) principal components, which explained 98% of variability in drug feature data, were used as input features to GCN.
## G The evolution of binary node classification and link prediction
## G.0.1 5-layer GCN with identity function and sigmoid activation function for binary node classification
The 5 -layer GCN is in the form of (37) and the loss function is defined by (39), where d = 5 is the number of layers, H 0 = I n ∈ R n × n is the feature matrix for n = 34 nodes with n = 34 features, the matrix Y ∈ R n × n d represents the ground truth of nodes, ˆ Y ∈ R n × n d denotes the final layer predictions of the GCN model, n d = 1 for binary node classification, W 1 ∈ R n 0 × n 1 , W 2 ∈ R n 1 × n 2 , W 3 ∈ R n 2 × n 3 , W 4 ∈ R n 3 × n 4 , and W 5 ∈ R n 4 × n d are trainable parameter matrices, n 0 = 20 , n 1 = 2 , n 2 = 3 , n 3 = 2 , n 4 = 3 , Σ 1 is an element-wise ReLU function [21], Σ 2 is an element-wise sigmoid linear Unit (SiLU) function [35], Σ 3 is an element-wise exponential linear unit (ELU)
function with α = 1 [36], Σ 4 is an element-wise Leaky ReLU function [37], Σ 5 is an element-wise identity function, and Σ 6 is an element-wise sigmoid function.
The GCN is trained using SGD with a learning rate of 3 × 10 -5 and with 10 iterations for both methods. The GCN is trained 1060 times and the weight matrices are reinitialized every time. If the calculation of the loss function has nan value, the training at this time will be skipped and will not be counted. The line plot of the SSE of the five weight matrices, W W W W 1 , 2 , 3 , 4 , and W 5 , between the reverse mode automatic differentiation and our matrix-based method is shown in Figure 5 ( a ). The box plot of the log 10 of the SSE in Figure 5 ( b ) shows that the median of the five weight matrices is between 10 -18 and 10 -14 . In the box plot of Figure 5 ( b ), the box extends from the first quartile to the third quartile of the data, with a line at the median, while the horizontal lines extending from the box, which are called whiskers, indicating the farthest data point lying within 1.5 times the inter-quartile range from the box, and circles are those points past the end of the whiskers [38].
Figure 4: Evolution of karate club network node classification obtained from a 1-layer GCN model after 100 training iterations. The training loss, accuracy, and classification results exhibit similar trends when using either reverse-mode automatic differentiation or our matrix-based method. Nodes are represented by circle with the number to distinguish each node. Colors represent classes, where blue represents class 0 and orange represents class 1. Black links between each node represent graph edges.
## G.0.2 5-layer GCN for link prediction
The 5 -layer GCN is defined by (60) and the loss function is defined by (62), where d = 5 is the number of layers, the matrix ˆ Y ∈ R n × n represents ground-truth adjacency matrix, ˆ Y ∈ R n × n denotes the final link predictions of the GCN model, W 1 ∈ R n 0 × n 1 , W 2 ∈ R n 1 × n 2 , W 3 ∈ R n 2 × n 3 , W 4 ∈ R n 3 × n 4 , and W 5 ∈ R n 4 × n 5 are trainable parameter matrices, n 0 = 20 , n 1 = 2 , n 2 = 3 , n 3 = 5 , n 4 = 3 , n 5 = 40 , Σ 1 is an element-wise Leaky ReLU function [21], Σ 2 is an element-wise ELU function [35], Σ 3 is an element-wise SiLU function with α = 1 [36], Σ 4 is an element-wise ReLU function [37], Σ 5 is an element-wise identity function, and Σ 6 is an element-wise sigmoid function.
The GCN is trained using SGD with a learning rate of 0.9 and with 10 iterations for both methods. In each iteration, thirteen negative edges are uniformly sampled from a set of all the unconnected edges for the GCN training using the reverse mode automatic differentiation. The sampled negative edges in each iteration are saved in a list and used in the training of the GCN using our matrix-based method. The GCN is trained 1060 times and the weight matrices are reinitialized every time. If the calculation of the loss function has nan value, the training at this time will be skipped and will not be counted. The line plot of the SSE of the five weight matrices, W W W W 1 , 2 , 3 , 4 , and W 5 , between the reverse mode automatic differentiation and our matrix-based method is shown in Figure 6 ( a ). The box plot of the log 10 of the SSE in Figure 6 ( b ) shows that the median of the five weight matrices is between 10 -18 and 10 -14 .
Figure 5: ( a ) The line plot of the 1060 evolution of the sum of squared error (SSE) between the trainable weight matrices obtained from our method and the matrix obtained using reverse mode automatic differentiation in section G.0.1. ( b ) The box plot of the 1060 evolution of the SSE between the trainable weight matrices obtained from our method and the matrix obtained using reverse mode automatic differentiation in section G.0.1.
Figure 6: ( a ) The line plot of the 1060 evolution of the sum of squared error (SSE) between the trainable weight matrices obtained from our method and the matrix obtained using reverse mode automatic differentiation in section G.0.2. ( b ) The box plot of the 1060 evolution of the SSE between the trainable weight matrices obtained from our method and the matrix obtained using reverse mode automatic differentiation in section G.0.2.
Figure 7: Evolution of DDI network node classification obtained from a 2-layer GCN model after 150 training iterations. The training loss and classification results exhibit similar trends when using either reverse-mode automatic differentiation or our matrix-based method. Nodes are represented by circle with the number to distinguish each node. Black links between each node represent truth graph edges. Red links between each node represent the edges that does not exist in the ground truth adjacency matrix. The transparency of the black and red link is proportional to the predicted link probability.
Figure 8: Heat maps of output sensitivity of the DDI network (1)

Figure 9: Heat maps of output sensitivity of the DDI network (2)
Figure 10: Heat maps of output sensitivity of the DDI network (3)
 | null | [
"Yen-Che Hsiao",
"Rongting Yue",
"Abhishek Dutta"
]
| 2024-08-02T17:33:52+00:00 | 2024-08-02T17:33:52+00:00 | [
"cs.LG"
]
| Derivation of Back-propagation for Graph Convolutional Networks using Matrix Calculus and its Application to Explainable Artificial Intelligence | This paper provides a comprehensive and detailed derivation of the
backpropagation algorithm for graph convolutional neural networks using matrix
calculus. The derivation is extended to include arbitrary element-wise
activation functions and an arbitrary number of layers. The study addresses two
fundamental problems, namely node classification and link prediction. To
validate our method, we compare it with reverse-mode automatic differentiation.
The experimental results demonstrate that the median sum of squared errors of
the updated weight matrices, when comparing our method to the approach using
reverse-mode automatic differentiation, falls within the range of $10^{-18}$ to
$10^{-14}$. These outcomes are obtained from conducting experiments on a
five-layer graph convolutional network, applied to a node classification
problem on Zachary's karate club social network and a link prediction problem
on a drug-drug interaction network. Finally, we show how the derived
closed-form solution can facilitate the development of explainable AI and
sensitivity analysis. |
2408.01409v1 | ## The random timestep Euler method and its continuous dynamics
## Jonas Latz
Department of Mathematics, University of Manchester, UK
[email protected]
## Abstract
ODE solvers with randomly sampled timestep sizes appear in the context of chaotic dynamical systems, differential equations with low regularity, and, implicitly, in stochastic optimisation. In this work, we propose and study the stochastic Euler dynamics - a continuous-time Markov process that is equivalent to a linear spline interpolation of a random timestep (forward) Euler method. We understand the stochastic Euler dynamics as a path-valued ansatz for the ODE solution that shall be approximated. We first obtain qualitative insights by studying deterministic Euler dynamics which we derive through a first order approximation to the infinitesimal generator of the stochastic Euler dynamics. Then we show convergence of the stochastic Euler dynamics to the ODE solution by studying the associated infinitesimal generators and by a novel local truncation error analysis. Next we prove stability by an immediate analysis of the random timestep Euler method and by deriving Foster-Lyapunov criteria for the stochastic Euler dynamics; the latter also yield bounds on the speed of convergence to stationarity. The paper ends with a discussion of second-order stochastic Euler dynamics and a series of numerical experiments that appear to verify our analytical results.
Keywords: numerical methods for ordinary differential equations, piecewise deterministic Markov processes, stochastic algorithms
MSC2020:
65L05, 60J25, 65C99
## 1 Introduction
Ordinary and partial differential equations are used to model systems and processes in, e.g., the physical and social sciences. There, they sometimes arise as limits of certain stochastic processes or particle systems. Examples are the heat equation that describes the behaviour of an underlying Brownian motion, see, e.g., [27], chemical reaction networks that are often represented by systems of ODEs arising at the large-number-of-reactions-limit of underlying Markov pure jump processes, see, e.g., [6, 15], or non-linear Fokker-Planck equations that describe the distribution of pedestrians that move in space according to certain McKean-Vlasov stochastic processes, see [9]. When models of this form need to be simulated, both the stochastic processes and their differential equation limit can be taken into account: whilst the basic heat equation in low dimensions is usually accurately simulated with the finite element method [11], Yang et al. [32] propose a sampling-based approach for closely-related, semilinear non-local diffusion equations.
In this work, we propose and study a class of continuous-time Markov processes (CTMPs) that can be used as an approximation scheme for a large class of ordinary differential equations. We obtain these so-called stochastic Euler dynamics by employing the forward Euler method with exponentially distributed random timestep sizes and by then linearly interpolating in between the timesteps. This procedure defines a continuous-time Markov process and can be generalised to certain other random timestep ODE solvers. Convergence occurs when the random timesteps converge to zero, which is
equivalent to the large-number-of-reactions-limit in chemical reaction networks. We understand our class of CTMPs as a randomised ansatz to the ODE solution, similar to a Gaussian process ansatz in the context of ODEs (e.g., [14]), PDEs (e.g., [5, 22]), or general function approximation (e.g., [20, 31]) or the random sampling in randomised linear algebra (e.g., [10, 25]). In our ansatz, we assume that the ODE can be approximated by a piecewise linear path where the intervals on which the path is linear are random - the interval lengths are exponentially distributed.
Random timestep sizes have been motivated by Abdulle and Garegnani [1] in the context of chaotic dynamics, where the choice of timestep size may have a large influence on the simulation outcome. The intuitive idea is that repeated simulations with random timesteps and the consideration of the distribution of their outcomes may actually be more indicative of the dynamical system's behaviour than a single unstable trajectory. Outside of chaotic dynamics, random timesteps are used for differential equations with irregular right-hand sides: Eisenmann et al. [8], for instance, study them in the case of time-irregular coefficients, whereas [12, 30] consider them in the discretisation of Carath´odory differential equations. e Random timestep methods have also been considered within stochastic optimisation methods in machine learning, see, e.g., [13, 19, 24, 33]. These methods fall into the context of our work, as many machine learning methods are based on the gradient descent method, which is a forward Euler timestepping of a gradient flow [26]. In machine learning, random timesteps can lead to a regularisation of the underlying learning problem.
The goal of our work is to derive numerical properties of the random timestep Euler method through, both, the lens of continuous-time Markov processes and the lens of numerical analysis for ODE solvers: deriving novel local truncation error estimates and proving convergence by comparing infinitesimal generators, studying stability by studying mean and second moment of the generated trajectory and through continuous-time Foster-Lyapunov criteria, as well as deriving higher-order methods through polynomial splines and the construction of ODEs through approximations of infinitesimal operators. The continuous-time viewpoint is vital in the context of random timestep ODE solvers: as the evaluation times are random, it is difficult to compare different solver trajectories without interpolation. Our approach contains this interpolation naturally.
We now introduce our problem setting, the random timestep Euler method, and the stochastic Euler dynamics. Then, we list our contributions and outline this work.
## 1.1 The random timestep Euler method and the stochastic Euler dynamics
Let X := R d for some d ∈ N := { 1 2 , , ... } , let ⟨· , ·⟩ be the Euclidean inner product, and ∥ · ∥ be the associated norm. Let f : X → X be a Lipschitz continuous function. Throughout this work, we study autonomous ordinary differential equations of the form
$$u ^ { \prime } ( t ) & = f ( u ( t ) ) \quad ( t > 0 ), & ( 1. 1 ) \\ u ( 0 ) & = u _ { 0 }.$$
The forward Euler method approximates the trajectory ( u t ( )) t ≥ 0 by a sequence
$$\widehat { u } _ { k } = \widehat { u } _ { k - 1 } + h _ { k } f ( \widehat { u } _ { k - 1 } ) \ \ ( k \in \mathbb { N } ), \quad \widehat { u } _ { 0 } = u _ { 0 },$$
where ( h k ) k ∈ N ∈ (0 , ∞ ) N is a sequence of stepsizes and ̂ u K approximates u t ( K ), with t K := ∑ K k =1 h k and K ∈ N . Between two timesteps, u ( ) can be approximated by linear interpolation: ·
$$u ( t ) \approx \widehat { u } ( t ) \coloneqq \frac { t _ { K } - t } { t _ { K } - t _ { K - 1 } } \widehat { u } _ { K - 1 } + \frac { t - t _ { K - 1 } } { t _ { K } - t _ { K - 1 } } \widehat { u } _ { K } \quad ( t \in [ t _ { K - 1 }, t _ { K } ], K \in \mathbb { N } ).$$
The path ( ̂ u t ( )) t ≥ 0 is a polygonal chain (a piecewise linear process): it is linear in-between the discretisation points ( t k ) ∞ k =0 and continuous at the discretisation points.
In the following, we choose the stepsizes to be independent and identically distributed (i.i.d.) exponential random variables H ,H ,... 1 2 ∼ Exp(1 /h ), with h = E [ H 1 ] > 0 being the stepsize parameter . Then, we define the random timestep (forward) Euler method through
$$\dot { V } _ { k } = \dot { V } _ { k - 1 } + H _ { k } f ( \dot { V } _ { k - 1 } ) \ \ ( k \in \mathbb { N } ), \quad \dot { V } _ { 0 } = u _ { 0 }.$$
These and all other random variables throughout this work are defined on an underlying probability space (Ω , F , P ). Whilst [1] allow for a more general distribution of the ( H k ) ∞ k =1 , we require exponentially distributed stepsizes: When choosing exponentially distributed stepsizes we can formulate the linearly interpolated version (analogous to ̂ u ( )) · of the random timestep Euler method ( ̂ V k ) ∞ k =0 as a (homogeneous-in-time) continuous-time Markov process, which we refer to as stochastic Euler dynamics . This is easy to see when we formulate the stochastic Euler dynamics as an ODE with jumps after exponential waiting times. We denote the random jump times by T , T 1 2 , . . . , where T k -T k -1 = H k ( k ∈ N ) and T 0 = 0. Then, we define the stochastic Euler dynamics as ( V ( ) t , V ( )) t t ≥ 0 by
$$\nu \nmid \alpha _ { 0 } = \nu _ { 0 } \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{array} \nu \nmid \alpha _ { 0 } \colon \nu _ { 0 } ^ { \nu } \\ V ^ { \prime } ( t ) & = f ( \overline { V } ( t ) ) & ( t \in ( T _ { k - 1 }, T _ { k } ), k \in \mathbb { N } ) \\ \overline { V } ^ { \prime } ( t ) & = 0 & ( t \in ( T _ { k - 1 }, T _ { k } ), k \in \mathbb { N } ) \\ V ( T _ { k - 1 } ) & = V ( T _ { k - 1 } - ) & ( k \in \mathbb { N } ) \\ V ( 0 ) & = \overline { V } ( 0 ) = u _ { 0 } \\. \, \dots \, \frac { 1 } { 2 } \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
where we denote g t ( -) = lim t 0 ↑ t g t ( 0 ) for some function g on R . This process is well-defined as it consists of subsequent well-defined ODEs, see, e.g. [19]. The associated jump chain ( V ( T k )) ∞ k =0 = ( V ( T k )) ∞ k =0 is, of course, identical to the trajectory ( ̂ V k ) ∞ k =0 of the random timestep Euler method (1.3). We illustrate the stochastic Euler dynamics in Figure 1.1 and note that its two components can be interpreted as follows:
- · ( V ( )) t t ≥ 0 is a piecewise constant process, that jumps to the value of ( V ( )) t t ≥ 0 at the jump time and, thus, memorises this value until the next jump time. We refer to ( V ( )) t t ≥ 0 as companion process .
↦
- · ( V ( )) t t ≥ 0 is the piecewise linear path that corresponds to the linearly interpolated Euler trajectory ( ̂ u t ( )) t ≥ 0 where the ̂ u K = ̂ V K are obtained from the random timestep Euler method, for K ∈ N 0 := N ∪{ } 0 . It is linear on the jump time intervals ( T k -1 , T k ] as t → f ( V ( )) is constant t on those intervals. We sometimes refer also to ( V ( )) t t ≥ 0 as stochastic Euler dynamics .
The stochastic Euler dynamics ( V ( ) t , V ( )) t t ≥ 0 is an ODE with random jumps and, thus, falls into the category of piecewise deterministic Markov processes (PDMPs) as introduced by Davis [7]. PDMPs are non-diffusive stochastic processes that have appeared in, e.g., biology [28], computational statistics [2, 3], and optimisation theory [13]. Especially the Zigzag process [2] is conceptually similar to the stochastic Euler dynamics, as both processes are polygonal chains. PDMPs are Feller processes and can, thus, be represented by infinitesimal generators. We denote the infinitesimal generator of the stochastic Euler dynamics by A h : C 1 ( X × X ) → C 0 ( X × X ). It is defined by
$$\mathcal { A } _ { h } \varphi ( v, \overline { v } ) & \colon = \lim _ { t \downarrow 0 } \frac { 1 } { t } \left ( \mathbb { E } [ \varphi ( V ( t ), \overline { V } ( t ) ) | V ( 0 ) = v, \overline { V } ( 0 ) = \overline { v } ] - \varphi ( v, \overline { v } ) \right ) \\ & = \langle \nabla _ { v } \varphi ( v, \overline { v } ), f ( \overline { v } ) \rangle + ( \varphi ( v, v ) - \varphi ( v, \overline { v } ) ) / h \quad \ ( v, \overline { v } \in X ),$$
where φ ∈ C 1 ( X × X ) is a test function. As usual, C k ( A B ; ) denotes the Banach space of k -times continuously differentiable functions g : A → B that is equipped with the usual supremum norm
Figure 1.1: Realisations of the stochastic Euler dynamics considering the ODEs u ′ = (1 -u u ) (left) and u ′ = -u (right) with initial values u 0 = 0 25 and stepsize parameter . h = 0 8. .


∥ g ∥ ∞ = ∑ k i =0 sup x ∈ A | g ( ) i ( x ) | and we write C k ( A ) := C k ( A ; R ) . In a similar way, we can also obtain the infinitesimal generator of the ODE (1.1). There, we have
$$\mathcal { A } \psi ( u ) \coloneqq \langle \nabla _ { u } \psi ( u ), f ( u ) \rangle \quad ( u \in X ),$$
where ψ ∈ C 1 ( X ). In a way, we see A h as an approximation of A . Infinitesimal generators play an important role in our analysis, especially when we study convergence of the paths of the stochastic Euler dynamics to the ODE solution and when we consider Foster-Lyapunov criteria. For other uses of infinitesimal generators, we refer to, e.g., [18, 27].
## 1.2 Contributions and outline
The purpose of this work is an analysis of the random timestep Euler method and the stochastic Euler dynamics. We begin by proposing and analysing the deterministic Euler dynamics , a system of ordinary differential equations arising from an approximation of the infinitesimal operator A h . This continuous-time dynamical system is closely related to the forward Euler method:
- · we prove stability of the deterministic Euler dynamics as well as convergence to (1.1) in the small stepsize parameter limit with rate O h h ( ; ↓ 0) in the case of a linear ODE
We then study properties of the stochastic Euler dynamics. Firstly, we consider the convergence of the stochastic Euler dynamics to the ODE (1.1) using two approaches:
- · we prove the weak convergence of the path ( V ( )) t t ≥ 0 to ( u t ( )) t ≥ 0 with respect to a weighted uniform metric where f in (1.1) only needs to be Lipschitz continuous
- · we introduce a notion of local truncation error for the stochastic Euler dynamics and analyse it in the case of linear ODEs; we especially show that this local root mean square truncation error behaves as E [ ∥ V ( ε ) -u ε ( ) ∥ 2 1 ] / 2 = O ε ( 2 ; ε ↓ 0)
Secondly, we study the stability of the stochastic Euler dynamics in the case of linear ODEs u ′ = Au with symmetric A :
- · we prove stability of the random timestep Euler method by analysing mean and second moment of the discrete chain
- · we prove stability of the stochastic Euler dynamics using Foster-Lyapunov criteria and give sharp bounds on its speed of convergence to stationarity
Finally, to extend our theoretical work on the random timestep Euler method and the stochastic Euler dynamics,
- · we introduce the second-order stochastic Euler dynamics and study its stability
- · we aim to verify the results from our theoretical analysis with a series of numerical experiments and explore situations not covered by our theoretical results
This work is organised as follows: Deterministic Euler dynamics are introduced and analysed in Section 2. Convergence and stability of stochastic Euler dynamics are subject of Sections 3 and 4. Second-order methods are discussed in Section 5 before numerical experiments are presented in Section 6 and the work concludes in Section 7.
## 2 Deterministic Euler dynamics
We begin our study of the stochastic Euler dynamics by discussing a deterministic dynamical system that we obtain through an approximation of the infinitesimal operator A h . Indeed, we obtain the operator A d h through a first order Taylor approximation of A h . It is given by
$$\mathcal { A } _ { h } ^ { \text{d} } \varphi ( w, \overline { w } ) \coloneqq \langle \nabla _ { w } \varphi ( w, \overline { w } ), f ( \overline { w } ) \rangle + \langle \nabla _ { \overline { w } } \varphi ( w, \overline { w } ), w - \overline { w } \rangle / h \quad ( w, \overline { w } \in X )$$
for an appropriate test function φ ∈ C 1 ( X × X ; R ). Now, A d h is the infinitesimal generator of the following ODE that we refer to as deterministic Euler dynamics
$$w ^ { \prime } ( t ) & = f ( \overline { w } ( t ) ), \\ \overline { w } ^ { \prime } ( t ) & = \frac { w ( t ) - \overline { w } ( t ) } { h }, \\ w ( 0 ) & = \overline { w } ( 0 ) = u _ { 0 }.$$
↦
This ODE is well-defined as f is Lipschitz and ( w,w ) → ( w -w /h ) is linear. A noticeable difference between deterministic and stochastic Euler dynamics is that the companion process ( w t ( )) t ≥ 0 is a smooth function, where ( V ( )) t t ≥ 0 is a piecewise constant jump process. ( w t , w t ( ) ( )) t ≥ 0 has an interesting interpretation: The trajectory ( w t ( )) t ≥ 0 approximates the original ODE solution not by evaluating the function f directly, but by relying on evaluations of the trajectory ( w t ( )) t ≥ 0 . The companion process appears to start an infinitesimal bit slower than ( w t ( )) t ≥ 0 as w ′ (0) = 0; so it always trails behind ( w t ( )) t ≥ 0 . This fact appears to be used by ( w t ( )) t ≥ 0 as it is defined through its derivative at time t > 0 being equal to the finite difference 1 h ( w t ( ) -w t ( )), where w t ( ) approximates u t ( ) and w t ( ) approximates u t ( -h ). We briefly showcase this behaviour for a linear ODE in one dimension.
Example 2.1 Let X = R and f ( u ) = -au for some a > 0. Then, we can find analytical expressions for ( w t , w t ( ) ( )) t ≥ 0 :
$$& \text{for } \left ( w \left \lfloor v \right \rfloor, w \left \lfloor v \right \rfloor \right \rfloor \text{t} \geq 0 \cdot \\ & w ( t ) = \frac { u _ { 0 } \exp \left ( - \frac { t \left ( \sqrt { 1 - 4 a h } + 1 \right ) } { 2 h } \right ) } { 2 \sqrt { 1 - 4 a h } } \left ( \left ( - 2 a h + \sqrt { 1 - 4 a h } + 1 \right ) \exp \left ( \frac { t \sqrt { 1 - 4 a h } } { h } \right ) + 2 a h + \sqrt { 1 - 4 a h } - 1 \right ), \\ & \overline { w } ( t ) = \frac { u _ { 0 } \exp \left ( - \frac { t \left ( \sqrt { 1 - 4 a h } + 1 \right ) } { 2 h } \right ) } { 2 \sqrt { 1 - 4 a h } } \left ( \left ( \sqrt { 1 - 4 a h } + 1 \right ) \exp \left ( \frac { t \sqrt { 1 - 4 a h } } { h } \right ) + \sqrt { 1 - 4 a h } - 1 \right ) \quad \ \text{(t \geq 0 ) }. \\ & \text{v} \quad, \quad e \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \ \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \ , \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad,$$
We make a few interesting observations: Firstly, we note that both ( w t ( )) t ≥ 0 and ( w t ( )) t ≥ 0 approach the true solution u t ( ) = exp( -at u ) 0 as h ↓ 0. Secondly, the trajectories ( w t , w t ( ) ( )) t ≥ 0 change their
Figure 2.1: Plots of the deterministic Euler dynamics regarding u ′ = -u , u 0 = 1, and h ∈ { 0 625 0 125 . , . , . . . , 1 . }
behaviour rather drastically if ah > 1 4, / but the dynamics is still well-defined. We illustrate this in Figure 2.1. There, we see that large h lead to oscillatory behaviour, which also happens when we employ the forward Euler method for stepsizes in (1 /a, 2 /a ), i.e., close to instability. Thirdly, consistent with our reasoning above, we see that ( w t ( )) t ≥ 0 trails behind ( w t ( )) t ≥ 0 .
We now try to generalise the discussion from the example. We focus on general linear ODEs, i.e., f ( u ) = Au for a matrix A ∈ R d × d . We anticipate that similar results also hold in the nonlinear case. In any case, we can state the deterministic Euler dynamics as a linear ODE of the form
$$\binom { w ^ { \prime } ( t ) } { \overline { w } ^ { \prime } ( t ) } = B \binom { w ( t ) } { \overline { w } ( t ) } \,, \quad B \coloneqq \binom { 0 } { h ^ { - 1 } I _ { d } } \, - h ^ { - 1 } I _ { d } \, } \,,$$
where I d denotes the identity matrix in R d × d . We start by discussing the stability of this ODE under the assumption that u ′ = Au is stable, i.e. the eigenvalues of A have negative real parts.
Theorem 2.2 Let A ∈ R d × d and let the eigenvalues λ , . . . , λ 1 d ∈ C of A have negative real parts: ℜ ( λ 1 ) , . . . , ℜ ( λ d ) < 0 . Then, the eigenvalues of B have negative real parts, if h > 0 is chosen such that
$$h < - \frac { \Re ( \lambda _ { i } ) } { \Im ( \lambda _ { i } ) ^ { 2 } } \quad ( i = 1, \dots, d ),$$
with -ℜ ( λ i ) / 0 := ∞ . Indeed, if f ( u ) = Au and the assumption above holds, there is a c > 0 such that the dynamical system ( w t , w t ( ) ( )) t ≥ 0 satisfies ∥ ( w t , w t ( ) ( )) T ∥ ≤ √ 2 exp( -ct ) ∥ u 0 ∥ ( t ≥ 0) .
Proof. The eigenvalues of B are the roots of the characteristic polynomial
$$p ( \mu ) = \det \left ( - \mu I _ { d } + \frac { h ^ { - 1 } } { h ^ { - 1 } + \mu } A \right ) \det ( - ( h ^ { - 1 } + \mu ) I _ { d } ) = \det ( ( \frac { \mu } { h } + \mu ^ { 2 } ) I _ { d } - \frac { 1 } { h } A ).$$
Now, given the eigenvalues of A , we can determine the eigenvalues of B by solving hµ 2 + µ -λ i = 0 , for each i = 1 , . . . , d . We obtain µ = ( - ± 1 √ 1 + 4 hλ i ) / (2 h ) and by studying the principle square root of 1 + 4 hλ i , we see that ℜ ( µ ) < 0, if the h ℑ ( λ i ) 2 < -ℜ ( λ i ). ✷
This theorem confirms our discussion from Example 2.1, however it is rather different to usual stability theory of ODE solvers for stiff linear ODEs. If the eigenvalues of A are real, i.e., ℑ ( λ i ) = 0 ( i = 1 , ..., d ), we have no restriction on h . Note that this is especially the case if A is symmetric. Otherwise, large imaginary parts require a small stepsize h = O (1 / ℑ ( λ i ) 2 ). Isolatedly from the real parts, this observation is qualitatively similar to usual stability theory. We illustrate these facts in numerical experiments in Section 6.
We next study the deterministic Euler dynamics at the small stepsize limit h ↓ 0 and especially its convergence to the ODE (1.1).
Theorem 2.3 Let f ( u ) = Au , where A ∈ R d × d , and B be as given in (2.1) . Then, we have for t ≥ 0 ,
- (i) ∥ w t ( ) -w t ( ) ∥ ≤ √ 2 h ∥ exp( tB ) ∥∥ u 0 ∥ ,
- (ii) ∥ w t ′ ( ) -Aw t ( ) ∥ ≤ √ 2 h ∥ exp( tB ) ∥∥ A ∥∥ u 0 ∥ ,
- (iii) ∥ w t ( ) -u t ( ) ∥ ≤ C h t for some constant C > t 0 , and
- (iv) ∥ w t ( ) -u t ( ) ∥ ≤ C h ∗ t for some constant C ∗ t > 0 .
Proof. Let t ≥ 0. (i) We have
$$\| w ( t ) - \overline { w } ( t ) \| = h \| \overline { w } ^ { \prime } ( t ) \| \leq h \sqrt { \| w ^ { \prime } ( t ) \| ^ { 2 } + \| \overline { w } ^ { \prime } ( t ) \| ^ { 2 } } = h \| \exp ( t B ) ( u _ { 0 }, u _ { 0 } ) ^ { T } \| \leq \sqrt { 2 } h \| \exp ( t B ) \| \| u _ { 0 } \|.$$
## (ii) We have
$$\| w ^ { \prime } ( t ) - A w ( t ) \| = \| A \overline { w } ( t ) - A w ( t ) \| \leq \| A \| \| \overline { w } ( t ) - w ( t ) \| \stackrel { ( i ) } { \leq } \sqrt { 2 } h \| A \| \| \exp ( t B ) \| \| u _ { 0 } \|.$$
## (iii) We have
$$\frac { \mathrm d } { \mathrm d t } \frac { 1 } { 2 } \| u ( t ) - w ( t ) \| ^ { 2 } & = \langle u ( t ) - w ( t ), A ( u ( t ) - \overline { w } ( t ) ) \rangle \\ & = \langle u ( t ) - w ( t ), A ( u ( t ) - w ( t ) ) \rangle - h \langle u ( t ) - w ( t ), A \overline { w } ^ { \prime } ( t ) \rangle \\ & \leq \alpha \| u ( t ) - w ( t ) \| ^ { 2 } + h \| u ( t ) - w ( t ) \| \| \overline { w } ^ { \prime } ( t ) \|,$$
with α ∈ R being the maximum eigenvalue of 1 2 ( A + A T ). Then, Gr¨ onwall's inequality implies:
$$\| u ( t ) - w ( t ) \| ^ { 2 } \leq h g ( t ) + h \int _ { 0 } ^ { t } g ( s ) \exp ( \alpha ( t - s ) ) \mathrm d s,$$
where g t ( ) = ∫ t 0 ∥ u s ( ) -w s ( ) ∥∥ w s ′ ( ) ∥ d . All integrals that appear are finite as we integrate a continuous s function that is bounded on the compact domain of integration [0 , t ]. (iv) The norm can be bounded using the triangle inequality with (i) and (iii). ✷
In the theorem above, we do not require u ′ = Au or the associated deterministic Euler dynamics to be stable, i.e., A does not need to to satisfy the conditions from Theorem 2.2. However, if those conditions are satisfied, the quantities bounded in (i), (ii) converge to 0, as t →∞ even if h is constant.
Figure 3.1: The trajectory of an underdamped harmonic oscillator u ′ 1 = u , u 2 ′ 2 = -u 1 -u 2 with initial value u (0) = (1 0) , T and realisations of the corresponding stochastic Euler dynamics ( V ( )) t t ≥ 0 for h ∈ { 0 25 . , 0 125 0 0625 . , . } . We show the ground truth ( u t ( )) t ≥ 0 and one realisation of ( V ( )) t t ≥ 0 for each of the stepsize parameters. The stochastic Euler dynamics approaches the ODE solution as h decreases.

Throughout this section, we have seen similarities of the deterministic Euler dynamics and the usual forward Euler method: we especially see the same global convergence order O h h ( ; ↓ 0) and at least a qualitative similarity in the close-to-instability regime of forward Euler methods. The stability theory of deterministic Euler methods yields rather different results. Whilst deterministic and stochastic Euler dynamics have closely related infinitesimal operators, they behave rather differently: smoothness and discontinuity of companion processes are a stark difference. In Section 6, we explore further differences and similarities between deterministic and stochastic Euler dynamics in numerical experiments. Until then, we focus on the stochastic Euler dynamics.
## 3 Convergence and error analysis
We now study the convergence of the stochastic Euler dynamics ( V ( )) t t ≥ 0 towards the underlying ODE ( u t ( )) t ≥ 0 in the small stepsize limit h ↓ 0. We illustrate this convergence behaviour in Figure 3.1. Initially, we consider the convergence of the complete paths of the processes on the space C := C 0 ([0 , ∞ ); X ), which we equip with the weighted metric
$$d _ { C } ( ( x ( t ) ) _ { t \geq 0 }, ( y ( t ) ) _ { t \geq 0 } ) = \int _ { 0 } ^ { \infty } \exp ( - t ) \min \left \{ 1, \sup _ { s \leq t } \| x ( s ) - y ( s ) \| \right \} d t \quad ( ( x ( t ) ) _ { t \geq 0 }, ( y ( t ) ) _ { t \geq 0 } \in C ).$$
When we speak of weak convergence of a sequence of stochastic processes ( x n ( )) t t ≥ 0 ,n ∈ N : Ω → C N to a stochastic process ( x t ( )) t ≥ 0 : Ω → C , as n →∞ , we mean that
$$\lim _ { n \to \infty } \mathbb { E } [ F ( ( x _ { n } ( t ) ) _ { t \geq 0 } ) ] = \mathbb { E } [ F ( ( x ( t ) ) _ { t \geq 0 } ) ]$$
for any bounded and continuous F : C → R and write ( x n ( )) t t ≥ 0 ⇒ ( x t ( )) t ≥ 0 , as n → ∞ . In Subsection 3.1, we discuss the case of ODEs (1.1) with bounded f , which is a setting that is slightly easier to handle. We then generalise these results to Lipschitz continuous f in Subsection 3.2.
These convergence results do not lead to immediate error estimators. Thus, we follow a different approach in Subsection 3.3: we discuss and derive the local root mean square truncation error of the stochastic Euler dynamics.
## 3.1 Uniform approximation for bounded f
Before we state the convergence theorem in the case of bounded f , we introduce an auxiliary stochastic process that allows us later to use a certain proof technique. Indeed, we define the jump time process
( T t ( )) t ≥ 0 that records the jump times of ( V ( ) t , V ( )) t t ≥ 0 , i.e. ( T t ( )) t ≥ 0 is a Markov pure jump process and has the same jump times T , T 1 2 , . . . as ( V ( ) t , V ( )) t t ≥ 0 . At each jump time, it jumps to the value of that jump time T T ( k ) := T k ( k ∈ N 0 ).
Proposition 3.1 Let f : X → X be Lipschitz continuous and bounded. Moreover, let ( u t ( )) t ≥ 0 and ( V ( ) t , V ( )) t t ≥ 0 be the ODE solution (1.1) and the stochastic Euler dynamics (1.4) with initial value u 0 ∈ X , respectively. In addition, we assume to have access to the jump time process ( T t ( )) t ≥ 0 . Then, ( V ( )) t t ≥ 0 ⇒ ( u t ( )) t ≥ 0 ( h ↓ 0) .
At first sight, this convergence result appears to be much stronger than results we usually prove about numerical algorithms, where we do not necessarily formulate convergence for the whole positive real line. However, we equip the space C with the metric d C that puts less weight on later points in time. We can interpret the results as ( V ( )) t t ∈ [0 ,T ] ⇒ ( u t ( )) t ∈ [0 ,T ] in C 0 ([0 , T ]; X ) with the usual uniform metric for any T > 0. Our technique does not provide us with a convergence rate.
The proof of Proposition 3.1 uses the perturbed test function methodology proposed by Kushner [16]. The intuitive idea is that for a process ( V ( )) t t ≥ 0 that is tight with respect to h > 0, we can show convergence to ( u t ( )) t ≥ 0 if we see convergence of the associated infinitesimal generators A h to A as h ↓ 0. Convergence of the infinitesimal generator is in the following sense: Let T > 0 and ψ ∈ C 1 c ( X ) be a continuously differentiable test function with compact support and let ˜ ψ h : [0 , ∞ × ) Ω → R be a perturbation of this test function with
$$\sup _ { t \in [ 0, T ], h \in ( 0, \varepsilon ) } \mathbb { E } [ | \tilde { \psi } _ { h } ( t ) | ] < \infty, \quad \lim _ { h \to 0 } \mathbb { E } [ | \tilde { \psi } _ { h } ( t ) - \psi ( V ( t ) ) | ] = 0 \ \ ( t \in [ 0, T ] ),$$
for some ε > 0 small enough. We then define the perturbed infinitesimal operator applied to ˜ ψ h by ˜ A h ˜ ψ h through
$$\lim _ { \tau \downarrow 0 } \mathbb { E } \left [ \tilde { \mathcal { A } } _ { h } \tilde { \psi } _ { h } ( t ) - \frac { \mathbb { E } \left [ \tilde { \psi } _ { h } ( t + \tau ) \ | \ \overline { V } ( s ) \, \colon s \leq t \right ] - \tilde { \psi } _ { h } ( t ) } { \tau } \right ] = 0 \quad ( t \in [ 0, T ] ),$$
and
$$\sup _ { \tau \in [ 0, T ] } \mathbb { E } \left [ \tilde { \mathcal { A } } _ { h } \tilde { \psi } _ { h } ( t ) - \frac { \mathbb { E } \left [ \tilde { \psi } _ { h } ( t + \tau ) \, | \, \overline { V } ( s ) \, \colon s \leq t \right ] - \tilde { \psi } _ { h } ( t ) } { \tau } \right ] < \infty \quad ( t \in [ 0, T ] ).$$
Convergence is then implied by
$$\sup _ { t \in [ 0, T ], h \in ( 0, e ) } \mathbb { E } [ | \tilde { \mathcal { A } } _ { h } \tilde { \psi } _ { h } ( t ) | ] < \infty, \quad \lim _ { h \to 0 } \mathbb { E } [ | \tilde { \mathcal { A } } _ { h } \tilde { \psi } _ { h } ( t ) - \mathcal { A } \psi ( V ( t ) ) | ] = 0 \quad ( t \in [ 0, T ] ), \quad ( 3. 1 )$$
for some ε > 0 small enough. If tightness and the statement (3.1) hold for an appropriate perturbation of all ψ ∈ C 1 c ( X ), Theorem 3.2 in [16] implies that Proposition 3.1 holds. We formulate these two statements as lemmas and prove them below.
Lemma 3.2 Let the assumptions of Proposition 3.1 hold. Then, ( V ( )) t t ≥ 0 is tight with respect to h > 0 .
Proof. By definition, ( V ( )) t t ≥ 0 is piecewise linear with Lipschitz constant bounded by sup v ∈ X | f ( v ) . | This supremum is finite as f is bounded by definition. Thus, the tightness of ( V ( )) t t ≥ 0 is implied by the Arzel`-Ascoli theorem, see, e.g. a Theorem 7.3 in [4]. ✷
Lemma 3.3 Let the assumptions of Proposition 3.1 hold. Then, there is a perturbation ˜ ψ h : [0 , ∞ × ) Ω → R of every ψ ∈ C 1 c ( X ) such that ψ, ψ ˜ h satisfy (3.1) .
Proof. Let T > 0 and ψ ∈ C 1 c ( X ) be a suitable test function with compact support and globally bounded gradient. We now define the perturbed test function ˜ ψ h := ψ V ( ( )) + · ˜ ψ 1 ,h , where ˜ ψ 1 ,h : [0 , T ] → R is given by
$$\tilde { \psi } _ { 1, h } ( t ) = \int _ { t } ^ { T } \exp \left ( - \frac { s - t } { h } \right ) \left \langle \nabla \psi ( V ( s ) ), f ( \overline { V } ( s ) ) - f ( V ( s ) ) \right \rangle \mathrm d s.$$
The choice of this perturbation was motivated by an idea mentioned in Section 4.5 of [16]. We first show that the perturbation disappears in mean as h ↓ 0. We define the supremum M 1 := sup ( v,v ) ∈ X 2 | ⟨∇ ψ v , f ( ) ( v ) -f ( v ) ⟩ | , which is well-defined as ψ has compact support and as f is bounded. Then,
$$| \tilde { \psi } _ { 1, h } ( t ) | \leq M _ { 1 } \int _ { 0 } ^ { T } \exp ( - s / h ) \text{d} s = h M _ { 1 } ( 1 - \exp ( - T / h ) ).$$
Thus, E [ | ˜ ψ 1 ,h ( ) ] t | → 0 as h ↓ 0. The same bound also implies that sup t ∈ [0 ,T ,h ] ∈ (0 ,ε ) E [ | ˜ ψ h ( ) ] t | < ∞ . Now we study the action of ˜ A h on the perturbation. There, we obtain
$$\tilde { \mathcal { A } } _ { h } \tilde { \psi } _ { 1, h } ( t ) = \lim _ { \tau \downarrow 0 } \frac { \mathbb { E } \left [ \tilde { \psi } _ { 1, h } ( t + \tau ) \ | \ ( \overline { V } ( s ), \overline { T } ( s ) ) \, \colon s \leq t \right ] - \tilde { \psi } _ { 1, h } ( t ) } { \tau } = \tilde { \psi } _ { 1, h } ^ { \prime } ( t ) \quad \ ( t \geq 0 ),$$
where the last equality follows as access to { ( V ( s , T ) ( s )) : s ≤ } t allows us to recover V ( ). t Indeed, we have V ( ) = t V ( ) + ( t t -T t ( )) f ( V ( )). t We have
$$\tilde { \psi } _ { 1, h } ^ { \prime } ( t ) = \underbrace { \int _ { t } ^ { T } \frac { 1 } { h } \exp \left ( - \frac { s - t } { h } \right ) \left \langle \nabla \psi ( V ( s ) ), f ( \overline { V } ( s ) ) - f ( V ( s ) ) \right \rangle d s } _ { = \colon C _ { 1 } } \underbrace { - \underbrace { \left \langle \nabla \psi ( V ( t ) ), f ( \overline { V } ( t ) ) - f ( V ( t ) ) \right \rangle } _ { = \colon C _ { 2 } }.$$
If now E [ C 1 ] → 0 as h ↓ 0, the term C 2 will allow us to replace f ( V ( )) by t f ( V ( )) in t ˜ A h and, thus, show convergence to A . Defining M 2 := sup v ∈ X ∥∇ ψ v ( ) ∥ and L to be the Lipschitz constant of f , we have
$$\dashrightarrow \dashrightarrow \dashrightarrow \cdots \cdots - \dashrightarrow \dashrightarrow \cdots \cdots \cdots - \dashrightarrow \cdots \cdots \cdots - \cdots \cdots \cdots - \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ | C _ { 1 } | & \leq \int _ { t } ^ { T } \frac { 1 } { h } \exp \left ( - \frac { s - t } { h } \right ) \| \nabla \psi ( V ( s ) ) \| \| f ( \overline { V } ( s ) ) - f ( V ( s ) ) \| d s \\ & \leq M _ { 2 } \sum _ { k = 0 } ^ { \infty } \int _ { T _ { k } } ^ { T _ { k + 1 } } \frac { 1 } { h } \exp \left ( - \frac { s } { h } \right ) \| f ( \overline { V } ( s ) ) - f ( V ( s ) ) \| d s \\ & = L M _ { 2 } \sum _ { k = 0 } ^ { \infty } \frac { 1 } { H } [ T _ { k } \leq T ] \int _ { 0 } ^ { T _ { k + 1 } - T _ { k } } \frac { s } { h } \exp \left ( - \frac { s + T _ { k } } { h } \right ) d s \\ & = L M _ { 2 } \sum _ { k = 0 } ^ { \infty } \frac { 1 } { H } [ T _ { k } \leq T ] \exp \left ( - \frac { T _ { k } } { h } \right ) \left ( h - \exp \left ( - \frac { T _ { k + 1 } - T _ { k } } { h } \right ) ( h + T _ { k + 1 } - T _ { k } ) \right ) \\ \text{Studying the limit $ h \downarrow 0$ is non-trivial as the distribution of $ T_{k + 1 } - T _ { k } \sim Exp (h^{-1} )$ depends on $ h$ itself.}$$
Studying the limit h ↓ 0 is non-trivial as the distribution of T k +1 -T k ∼ Exp( h -1 ) depends on h itself. Thus, we write h ∆ := k T k +1 -T k , with ∆ k ∼ Exp(1). Now, we have
$$| C _ { 1 } | \leq L M _ { 2 } \sum _ { k = 0 } ^ { \infty } \exp \left ( - \frac { T _ { k } } { h } \right ) \left ( h - \exp \left ( - \frac { h \Delta _ { k } } { h } \right ) h ( 1 + \Delta _ { k } ) \right ) \leq h L M _ { 2 } \sum _ { k = 0 } ^ { \infty } \exp \left ( - \frac { T _ { k } } { h } \right )$$
We note that T /h k ∼ Gamma( k, 1). By evaluating the moment-generating function of the Gamma distribution, we obtain
$$\mathbb { E } [ | C _ { 1 } | ] \leq h L M _ { 2 } \sum _ { k = 0 } ^ { \infty } 2 ^ { - k },$$
implying both sup t ∈ [0 ,T ,h ] ∈ (0 ,ε ) E [ |A ˜ h ˜ ψ h ( ) t -A ψ V ( ( )) ] t | < ∞ and
$$\lim _ { h \downarrow 0 } & \mathbb { E } [ | \tilde { \mathcal { A } } _ { h } \psi _ { h } ( t ) - \mathcal { A } \psi ( V ( t ) ) | ] \\ & = \left \langle \nabla \psi ( V ( t ) ), f ( \overline { V } ( t ) ) \right \rangle - \left \langle \nabla \psi ( V ( t ) ), f ( \overline { V } ( t ) ) - f ( V ( t ) ) \right \rangle + \left \langle \nabla \psi ( V ( t ) ), f ( V ( t ) ) \right \rangle = 0,$$
proving the statement of the Lemma.
✷
The boundedness assumption in Proposition 3.1 is convenient, but probably too strong to be useful in practical applications. In the next subsection, we see how to generalise these results to unbounded, but Lipschitz continuous f .
## 3.2 Uniform approximation for Lipschitz continuous f
The theorem differs from Proposition 3.1 only in that it removes the boundedness assumption on f .
Theorem 3.4 Let f : X → X be Lipschitz continuous and let ( u t ( )) t ≥ 0 and ( V ( ) t , V ( )) t t ≥ 0 be the associated ODE solution (1.1) and stochastic Euler dynamics (1.4) with initial values u 0 ∈ X , respectively. Moreover, we assume that we have access to the jump time process ( T t ( )) t ≥ 0 . Then, ( V ( )) t t ≥ 0 ⇒ ( u t ( )) t ≥ 0 ( h ↓ 0) .
We usually show tightness of a family of processes by proving uniform equicontiuity of that family. An unbounded function f makes it difficult to control the piecewise derivative of ( V ( )) t t ≥ 0 , which in turn makes it difficult to show equicontiuity. If tightness is difficult to show due to unboundness (as opposed to explosiveness) of a process, we can study a truncated process instead. Let R > 0 and f R : X → X be chosen such that
$$f _ { R } ( v ) = \begin{cases} f ( v ), & \text{if } \| v \| \leq R, \\ 0, & \text{if } \| v \| \geq R + 1, \end{cases} \quad ( v \in X / \{ v \colon R < \| v \| < R + 1 \} )$$
and f R being smooth on { v : R ≤ ∥ ∥ ≤ v R +1 . We define the truncated processes ( } u R ( )) t t ≥ 0 and ( V R ( ) t , V R ( )) t t ≥ 0 through (1.1) and (1.4), respectively, with f R replacing f . We use the idea
$$( V _ { R } ( t ) ) _ { t \geq 0 } \quad & \xrightarrow { ( h \downarrow 0 ) } \quad ( u _ { R } ( t ) ) _ { t \geq 0 } \\ ( R \rightarrow \infty ) \Big \| \quad & \quad \Big \| ( R \rightarrow \infty ) \. \\ ( V ( t ) ) _ { t \geq 0 } \quad & \xrightarrow { ( h \downarrow 0 ) } \quad ( u ( t ) ) _ { t \geq 0 }$$
to prove the convergence as stated in Theorem 3.4. Lemma 3.2 and 3.3 are true for ( u R ( )) t t ≥ 0 and ( V R ( ) t , V R ( )) t t ≥ 0 for all R > 0, and thus, imply ( V R ( )) t t ≥ 0 ⇒ ( u R ( )) t t ≥ 0 as h ↓ 0. The vertical convergence statements ( R →∞ ) follow from, e.g., the Corollary following Theorem 3.2 in [16] or the discussion on pp. 160-161 in [17]. These results then imply Theorem 3.4.
## 3.3 Local root mean square truncation errors
The convergence analysis in Proposition 3.1 and Theorem 3.4 does not immediately lead to a mechanisms allowing us to estimate the error between ODE solution (1.1) and stochastic Euler dynamics (1.4). To get a sense of the order of convergence of the stochastic Euler dynamics, we now discuss the local truncation error that is achieved by the method.
̸
Let ε > 0 be small. The local truncation error of an ODE integrator is usually given as the difference between u ε ( ) and a single timestep of the integrator with stepsize ε in the limit as ε ↓ 0. In the context of stochastic Euler dynamics, this approach is difficult to apply. Let T 1 be still the waiting time until the first jump in ( V ( ) t , V ( )) t t ≥ 0 . Then, V ( ε ) = u 0 + εf ( u 0 ) with probability P ( T 1 > ε ) = exp( -ε/h ). Thus, assuming that f is Lipschitz continuous, we obtain an estimator of the form ∥ u ε ( ) -V ( ε ) ∥ = O ε ( 2 ; ε ↓ 0) with a certain probability. Now, as ε approaches zero, the probability of the estimator being correct converges to 1. Traditionally, however, we would let time point ε and discretisation stepsize h approach zero simultaneously; usually choosing h = ε . Then, however, P ( T 1 > ε h | = ) = 1 e ε / ≈ 1.
In the following, we propose a different way to analyse the local truncation error of the stochastic Euler dynamics. Indeed, we compute the local root mean square truncation error E [ ∥ V ( ε ) -u ε ( ) ∥ 2 1 ] / 2 in the case f being linear and obtain a deterministic statement about the convergence rate - this approach is different from the mean square error analysis given in [1], where the error is considered for the discrete-time trajectory. In our following derivation and analysis we choose a linear ODE (1.1), i.e., we let f ( u ) = Au for some A ∈ R d × d . Moreover, we need be able to keep track of how often the stochastic Euler dynamics jumps within a certain time interval. To this end, we define ( K t ( )) t ≥ 0 to be the (homogeneous) Poisson (point) process with rate 1 /h on [0 , ∞ ) that is coupled to ( V ( ) t , V ( )) t t ≥ 0 by having identical jump times. In particular, ( K t ( )) t ≥ 0 is the piecewise constant jump process on N 0 that commences at K (0) = 0 and is incremented by one at every jump time T , T 1 2 , . . . of ( V ( ) t , V ( )) t t ≥ 0 . Indeed, if K ε ( ) = k ∈ N 0 , we have T k ≤ ε and T k +1 > ε. Thus, if we know K ε ( ), we know exactly how many jumps happened up to time ε > 0. Conditionally on K ε ( ) the distribution of V ( ε ) has a specific form:
$$\mathbb { P } ( V ( \varepsilon ) \in \cdot | K ( \varepsilon ) = k ) = \mathbb { P } ( ( I _ { d } + ( \varepsilon - T _ { k } ) A ) ( I _ { d } + H _ { k } A ) \cdots ( I _ { d } + H _ { 1 } A ) u _ { 0 } \in \cdot | K ( \varepsilon ) = k ).$$
Next, we aim to compute the local root mean square truncation error conditioned on K ε ( ) = k . The (unconditioned) local root mean square truncation error can then be obtained through the law of total expectation. We first determine the distribution of the random timestep sizes H ,. . . , H 1 k given that K ε ( ) = k . This is a generalisation of a well-known result about exponential distributions.
Lemma 3.5 Let T , T 1 2 , . . . be the jump times of the Poisson point process ( K t ( )) t ≥ 0 , T 0 = 0 , and H k = T k -T k -1 ∼ Exp( h -1 ) , k ∈ N , as before. Then,
$$\mathbb { P } ( ( H _ { 1 }, \dots, H _ { k } ) \in \cdot | K ( t ) = k ) = \text{Unif} ( S _ { k, t } ) \quad ( k \in \mathbb { N }, t \geq 0 ),$$
where S k,t := { ( h , . . . , h 1 k ) ∈ [0 , ∞ ) k : h 1 + · · · + h k ≤ } t is a k -dimensional simplex.
Proof. We use Bayes' formula to find the probability density function of P (( H ,. . . , H 1 k ) ∈ ·| K t ( ) = k ) and, thus, prove the identity above. Bayes' formula states that
$$p _ { H _ { 1 }, \dots, H _ { k } | K ( t ) = k } ( h _ { 1 }, \dots, h _ { k } ) = \frac { p _ { K ( t ) | H _ { 1 } = h _ { 1 }, \dots, H _ { k } = h _ { k } } ( k ) p _ { H _ { 1 }, \dots, H _ { k } } ( h _ { 1 }, \dots, h _ { k } ) } { p _ { K ( t ) } ( k ) } \quad ( k \in \mathbb { N }, h _ { 1 }, \dots, h _ { k } \geq 0 ),$$
where the p 's describe probability density functions with respect to Lebesgue or counting measures, as appropriate. Let again k ∈ N , and h , . . . , h 1 k ≥ 0 . We start by noting that
$$p _ { H _ { 1 }, \dots, H _ { k } } ( h _ { 1 }, \dots, h _ { k } ) = \frac { 1 } { h ^ { k } } \exp \left ( - \frac { h _ { 1 } + \dots + h _ { K } } { h } \right ), \quad p _ { K ( t ) } ( k ) = \left ( \frac { t } { h } \right ) ^ { k } \frac { \exp ( - t / h ) } { k! },$$
by definition and by the property K t ( ) ∼ Poisson( t/h ) ( t ≥ 0) of Poisson processes, respectively. The conditional density p K t ( ) | H 1 = h ,...,H 1 k = h k describes the event that H k +1 > t -h 1 -··· -h k whilst requiring that h 1 + · · · + h k ≤ t . Thus, we have
$$p _ { K ( t ) | H _ { 1 } = h _ { 1 }, \dots, H _ { k } = h _ { k } } ( k ) = \exp \left ( \frac { - t + h _ { 1 } + \dots + h _ { k } } { h } \right ) 1 [ h _ { 1 } + \dots + h _ { k } \leq t ]$$
and finally
$$p _ { H _ { 1 }, \dots, H _ { k } | K ( t ) = k } ( h _ { 1 }, \dots, h _ { k } ) = \frac { \exp \left ( \frac { - t + h _ { 1 } + \dots + h _ { k } } { h } \right ) 1 [ h _ { 1 } + \dots + h _ { k } \leq t ] \frac { 1 } { h ^ { k } } \exp \left ( - \frac { h _ { 1 } + \dots + h _ { K } } { h } \right ) } { \left ( \frac { t } { h } \right ) ^ { k } \frac { \exp ( - t / h ) } { k! } }$$
$$h _ { 1 }, \dots, h _ { k } ) & = \frac { \exp \left ( \frac { - t + h _ { 1 } + \dots + h _ { k } } { h } \right ) ^ { } { 1 } [ h _ { 1 } + \dots + h _ { k } \leq t ] \frac { 1 } { h ^ { k } } \exp \left ( - \frac { h _ { 1 } + \dots + h _ { K } } { h } \right ) } { \left ( \frac { t } { h } \right ) ^ { k } \frac { \exp ( - t / h ) } { k! } } \\ & = \frac { k! } { t ^ { k } } ^ { } { 1 } [ h _ { 1 } + \dots + h _ { k } \leq t ], \\.. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
which is the correctly normalised probability density function of Unif( S k,t ), see, e.g., [29]. ✷
There is an interesting connection between this result and the random Euler methods discussed in [8, 12]. There, the random Euler method is initialised with a set of deterministic discretisation points t 0 , t 1 , ... . Then J ∈ N random timepoints are sampled uniformly and i.i.d. from [ t k , t k +1 ] ( k ∈ N 0 ) and used for a Monte Carlo approximation of the integral formulation of the differential equation. In Lemma 3.5, we show that we implicitly sample uniformly when we are on a fixed time interval [ t k , t k +1 ] with a fixed number of samples K t ( k +1 -t k ) = J , but on the simplex S J, t ( k +1 -t k ) instead of the hypercube [0 1] , J (as in the i.i.d. case).
We can now estimate the local root mean square truncation error of ( V ( )) t t ≥ 0 with respect to the ODE solution ( u t ( )) t ≥ 0 .
Theorem 3.6 Let ( V ( ) t , V ( )) t t ≥ 0 be the stochastic Euler dynamics (1.4) corresponding to u ′ = Au , u (0) = u 0 , with A ∈ R d × d , and let ( K t ( )) t ≥ 0 be the associated Poisson process. Then,
$$( i ) \ \mathbb { E } [ \| V ( \varepsilon ) - u ( \varepsilon ) \| ^ { 2 } | K ( \varepsilon ) = k ] ^ { 1 / 2 } = O ( \varepsilon ^ { 2 } ; \varepsilon \downarrow 0 ) \ ( k \in \mathbb { N } _ { 0 } ),$$
- (ii) E [ ∥ V ( ε ) -u ε ( ) ∥ 2 1 ] / 2 = O ε ( 2 ; ε ↓ 0) .
Proof. We aim to show a second order local truncation error. Thus, in the following, we can replace u ε ( ) = exp( εA u ) 0 by its first-order Taylor approximation u 0 + εAu 0 . (i) Let k ∈ N 0 . We write P k := ( I d + h A k ) · · · ( I d + h A . 1 ) Then,
$$\mathbb { Z } \sim \mathbb { N } \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \matrix \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ /> \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \> \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \? \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ ; \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ > \ < \mathbb { N } \ </ \ >$$
We first see that the integrand is a polynomial with constant term = 0. If we study the terms in the integrand above that are linear in h , . . . , h 1 k , we see that
$$( I _ { d } + \varepsilon A ) ( h _ { k } A + \dots + h _ { 1 } A ) u _ { 0 } - ( h _ { 1 } + \dots + h _ { k } ) A u _ { 0 } = \varepsilon ( h _ { 1 } + \dots + h _ { k } ) A ^ { 2 } u _ { 0 }.$$
Thus, the integrand above can be written as a sum of monomials with the lowest order being 1. If we assume that ε ∈ (0 , 1), we can find a constant C k > 0 such that
$$\mathbb { E } [ \| V ( \varepsilon ) - u _ { 0 } - \varepsilon A u _ { 0 } \| ^ { 2 } | K ( \varepsilon ) = k ] \leq \frac { k! } { \varepsilon ^ { k } } \int _ { S _ { k, \varepsilon } } C _ { k } \varepsilon ^ { 2 } \sum _ { i, j = 1 } ^ { k } h _ { i } h _ { j } \mathrm d ( h _ { 1 }, \dots, h _ { k } ) = O ( \varepsilon ^ { 4 } ; \varepsilon \downarrow 0 ),$$
where we obtain the order by bounding ∑ k i,j =1 h h i j ≤ ε 2 . (ii) Our goal is to employ the law of total expectation
$$\mathbb { E } [ \| V ( \varepsilon ) - u _ { 0 } - \varepsilon A u _ { 0 } \| ^ { 2 } ] = \sum _ { k = 0 } ^ { \infty } \mathbb { E } [ \| V ( \varepsilon ) - u _ { 0 } - \varepsilon A u _ { 0 } \| ^ { 2 } | K ( \varepsilon ) = k ] \mathbb { P } ( K ( \varepsilon ) = k ).$$
To employ the bound from (i), we need to show that the C k > 0 do not diverge too quickly as k →∞ . Under the hypothesis that K ε ( ) = k , we have
$$\| V ( \varepsilon ) - u _ { 0 } - \varepsilon A u _ { 0 } \| ^ { 2 } & \leq \| I _ { d } + ( \varepsilon - H _ { 1 } - \dots - H _ { k } ) A \| ^ { 2 } \prod _ { i = 1 } ^ { k } \| I _ { d } + H _ { i } A \| ^ { 2 } \| u _ { 0 } \| ^ { 2 } \\ & \leq ( 1 + \varepsilon \| A \| ) ^ { 2 } \prod _ { i = 1 } ^ { k } ( 1 + H _ { i } \| A \| ) ^ { 2 } \| u _ { 0 } \| ^ { 2 }.$$
$$i = 1$$
C k is chosen in (i) such that it bounds the sum of all constant factors that appear in the polynomial
↦
$$( h _ { 1 }, \dots, h _ { k } ) \mapsto \| V ( \varepsilon ) - u _ { 0 } - \varepsilon A u _ { 0 } \| ^ { 2 } = \| \left ( ( I _ { d } + \varepsilon A ) ( P _ { k } - I _ { d } ) - ( h _ { 1 } + \dots + h _ { k } ) A P _ { k } \right ) u _ { 0 } \| ^ { 2 }.$$
We obtain the sum of constant factors in the polynomial by evaluating it for (1 , . . . , 1) and then choose
$$C _ { k } \coloneqq ( 1 + \| A \| ) ^ { 2 k + 2 } \| u _ { 0 } \| ^ { 2 }.$$
as an upper bound. Now, we have and, thus, proven (ii).
$$\text{as an upper bound. Now, we have} \\ \mathbb { E } [ \| V ( \varepsilon ) - u _ { 0 } - \varepsilon A u _ { 0 } \| ^ { 2 } ] & \leq \sum _ { k = 0 } ^ { \infty } ( 1 + \| A \| ) ^ { 2 k + 2 } \varepsilon ^ { 4 } \mathbb { P } ( K ( \varepsilon ) = k ) \\ & = \varepsilon ^ { 4 } ( 1 + \| A \| ) ^ { 2 } \sum _ { k = 0 } ^ { \infty } \left ( \frac { \varepsilon ( 1 + \| A \| ) ^ { 2 } } { h } \right ) ^ { k } \frac { \exp ( - \varepsilon / h ) } { k! } \\ & = \varepsilon ^ { 4 } ( 1 + \| A \| ) ^ { 2 } \exp ( ( 2 \varepsilon \| A \| + \varepsilon \| A \| ^ { 2 } ) / h ) \\ \text{and, thus, proven (ii).} \quad & \Box \\ \mathbb { m } \ \text{and, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, when, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, Then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, THEN, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then,then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then, then,$$
One motivation for the local root mean square truncation error has been the behaviour of the estimator when h ↓ 0. In the end of the proof of Theorem 3.6(ii), we develop the error bound
$$\mathbb { E } [ \| V ( \varepsilon ) - u ( \varepsilon ) \| ^ { 2 } ] \leq \varepsilon ^ { 4 } ( 1 + \| A \| ) ^ { 2 } \exp ( ( 2 \varepsilon \| A \| + \varepsilon \| A \| ^ { 2 } ) / h ).$$
Here, if h ↓ 0, the bound diverges, which is in slight contrast to the (weaker) convergence results obtained in Proposition 3.1 and Theorem 3.4. However, if we choose h = O ε ε ( ; ↓ 0), we still obtain convergence in the described order - an improvement over our preliminary discussion of truncation errors for stochastic Euler dynamics.
We finally note that the root mean square errors in Theorem 3.6 also allow us to estimate the variance of V ( ε ) using the simple inequality
$$\mathbb { E } [ \| V ( \varepsilon ) - \mathbb { E } [ V ( \varepsilon ) ] \| ^ { 2 } ] \leq \mathbb { E } [ \| V ( \varepsilon ) - u ( \varepsilon ) \| ^ { 2 } ] = O ( \varepsilon ^ { 4 } ; \varepsilon \downarrow 0 ).$$
## 4 Stability
We now study the stability of the stochastic Euler dynamics, i.e., we aim to show for certain examples that the asymptotic behaviour of ( V ( )) t t ≥ 0 for certain h > 0 resembles the asymptotic behaviour of ( u t ( )) t ≥ 0 . We start with an intuitive discussion of the stability of the random timestep Euler method ( ̂ V k ) ∞ k =1 in Subsection 4.1. We then move on to studying stability for the stochastic Euler dynamics in terms of Foster-Lyapunov criteria in Subsections 4.2, which also provide us with an asymptotic rate.
## 4.1 Stability of the random timestep Euler method
Let a > 0 and let ( u t ( )) t ≥ 0 satisfy the linear ODE ˙ u = -au on X = R . Similar to deterministic ODE solvers, we expect stability problems if the mean stepsize h is chosen to be too large. Indeed, we are wondering how ah needs to be chosen for ̂ V k → 0, in an appropriate sense, as k →∞ . We now derive conditions under which mean and second moment of the random timestep Euler method converge to zero as k →∞ .
We first recall that ̂ V k +1 := (1 -aH k ) ̂ V k ( k ∈ N 0 ) for independent H ,H ,... 1 2 ∼ Exp( λ ) and obtain
$$\mathbb { E } [ \widehat { V } _ { k + 1 } ] = \mathbb { E } [ ( 1 - a H _ { k } ) \widehat { V } _ { k } ] = \mathbb { E } [ 1 - a H _ { k } ] \mathbb { E } [ \widehat { V } _ { k } ] = ( 1 - a h ) \mathbb { E } [ \widehat { V } _ { k } ] = ( 1 - a h ) ^ { k + 1 } u _ { 0 }.$$
which converges geometrically to 0 if ah < 2 - and, thus, behaves identically to the forward Euler method with stepsize h . Next, we compute the second moment of the dynamical system:
$$\mathbb { E } [ \widehat { V } _ { k + 1 } ^ { 2 } ] = \mathbb { E } [ ( 1 - a H _ { k } ) ^ { 2 } \widehat { V } _ { k } ^ { 2 } ] = \mathbb { E } [ 1 - 2 a H _ { k } + a ^ { 2 } H _ { k } ^ { 2 } ] \mathbb { E } [ \widehat { V } _ { k } ^ { 2 } ] = ( 1 - 2 a h + 2 a ^ { 2 } h ^ { 2 } ) ^ { k + 1 } u _ { 0 } ^ { 2 }.$$
Now | 1 -2 ah + 2 a h 2 2 | < 1, if ah < 1. Thus, we obtain a stricter stepsize restriction if also second moments are supposed to converge. The results given here can be easily extended to more general linear ODEs u ′ = -Au , with symmetric positive definite A - we give a detailed explanation in the proof of Theorem 4.3.
Intuitively, stability of the random timestep Euler method should also imply stability of the stochastic Euler dynamics. Indeed, we obtain the same convergence criteria below when studying Foster-Lyapunov criteria. The Foster-Lyapunov criteria, however, additionally supply us with a continuous convergence rate of the dynamics to their stationary state. We can also see the convergence rate | 1 -2 ah + 2 a h 2 2 | in the analysis above. However, E [ ̂ V 2 k ] does not relate to a particular time t ≥ 0. Thus, the rate above does not allow us to compare the convergence-to-stationarity behaviour of ( V ( )) t t ≥ 0 to that of ( u t ( )) t ≥ 0 .
## 4.2 Foster-Lyapunov criteria in the case of linear ODEs
We begin our study of Foster-Lyapunov criteria for the stochastic Euler dynamics by considering the the linear ODE u ′ = -au on X = R for some a > 0. We are later able to use this one-dimensional
result to study the higher dimensional version. The first step is to find an appropriate Lyapunov function for ( V ( ) t , V ( )) t t ≥ 0 . We consider a Lyapunov function with the following structure
$$L ( v, \bar { v } ) \coloneqq c _ { 1 } v ^ { 2 } + c _ { 2 } \bar { v } ^ { 2 } + c _ { 3 } ( v - \bar { v } ) ^ { 2 } \quad ( v, \bar { v } \in X ),$$
with some constants c 1 , c 2 , c 3 ≥ 0. When computing the action of A h with respect to this Lyapunov function, we obtain
$$\mathcal { A } _ { h } L ( v, \overline { v } ) & = - a \left ( \frac { \partial } { \partial v } L ( v, \overline { v } ) \right ) \overline { v } + ( L ( v, v ) - L ( v, \overline { v } ) ) / h \\ & = ( c _ { 2 } - c _ { 3 } ) v ^ { 2 } / h + ( - c _ { 2 } / h - ( 1 / h + 2 a ) c _ { 3 } ) \overline { v } ^ { 2 } + 2 ( ( 1 / h - a ) c _ { 3 } - a c _ { 1 } ) v \overline { v }$$
In the following lemma, we show that we can bound A h L in terms of -κL . This bound then implies that E [ L V ( ( ) t , V ( ))] t converges to zero at exponential speed with rate -κ . We state and prove this exponential bound formally in a proposition just below the lemma.
Lemma 4.1 Let A h be the infinitesimal generator of the stochastic Euler dynamics (1.4) corresponding to the ODE u ′ = -au , with a > 0 and L be the function introduced above. Moreover, we assume that h > 0 is chosen such that ah < 1 . Then,
$$\mathcal { A } _ { h } L ( v, \overline { v } ) \leq - \kappa L ( v, \overline { v } ) \quad ( v, \overline { v } \in X ),$$
with c 1 = 1 , c 2 = 0 , c 3 := 1 / max (1 { /h -κ /κ, ) ( κ -1 /h + ) a /a } , and κ ∈ (0 min , { 2 a, 1 (2 / h ) } ) .
Proof. We aim to show that there is some κ > 0 with
$$\begin{cases} c _ { 2 } / h - c _ { 3 } / h & \leq - \kappa c _ { 1 } - \kappa c _ { 3 } \\ - c _ { 2 } / h - ( 1 / h + 2 a ) c _ { 3 } & \leq - \kappa c _ { 2 } - \kappa d c _ { 3 } & \quad \Leftrightarrow & \quad \begin{cases} \kappa c _ { 1 } / c _ { 3 } + c _ { 2 } / ( c _ { 3 } h ) & \leq 1 / h - \kappa \\ ( \kappa - 1 / h ) c _ { 2 } / c _ { 3 } & \leq 1 / h + 2 a - \kappa \\ c _ { 1 } / c _ { 3 } & \geq ( \kappa - 1 / h + a ) / a. \end{cases}$$
The inequality in the top right implies that κ < h -1 . Assuming that κ < 2 a , we have
$$\begin{cases} \kappa c _ { 1 } / c _ { 3 } + c _ { 2 } / ( c _ { 3 } h ) & \leq 1 / h - \kappa \\ c _ { 2 } / c _ { 3 } & \geq 0 > \frac { 1 / h + 2 a - \kappa } { \kappa - 1 / h } \\ c _ { 1 } / c _ { 3 } & \geq ( \kappa - 1 / h + a ) / a. \end{cases}$$
Now, we can certainly choose c 2 /c 3 := 0 and c 1 /c 3 := max (1 { /h -κ /κ, ) ( κ -1 /h + ) a /a } . If (1 /h -κ /κ ) ≥ ( κ -1 /h + a /a ) , all of the inequalities are already satisfied. If otherwise, (1 /h -κ /κ < ) ( κ -1 /h + ) a /a , we need to make sure that
$$\kappa ^ { 2 } - \kappa / h + a \kappa \leq a / h - a \kappa \Leftrightarrow - \sqrt { a ^ { 2 } + 1 / ( 2 h ) ^ { 2 } } - a + 1 / ( 2 h ) \leq \kappa \leq \sqrt { a ^ { 2 } + 1 / ( 2 h ) ^ { 2 } } - a + 1 / ( 2 h ).$$
which is certainly satisfied if κ ∈ (0 1 , / (2 h )).
✷
Proposition 4.2 Let ( V ( ) t , V ( )) t t ≥ 0 be the stochastic Euler dynamics (1.4) corresponding to the ODE u ′ = -au , with a > 0 . Moreover, let ah < 1 , κ ∈ (0 min , { 2 a, 1 (2 / h ) } ) , and c 3 := 1 / max (1 { /h -κ /κ, ) ( κ -1 /h + ) a /a } . Then,
$$\mathbb { E } \left [ V ( t ) ^ { 2 } \right ] + c _ { 3 } \mathbb { E } \left [ ( V ( t ) - \overline { V } ( t ) ) ^ { 2 } \right ] \leq \exp ( - \kappa t ) u _ { 0 } ^ { 2 }.$$
Proof. If we apply [23, Theorem 1.1] to the bound shown in Lemma 4.1, we obtain
$$\mathbb { E } [ V ( t ) ^ { 2 } + c _ { 3 } ( V ( t ) - \overline { V } ( t ) ) ^ { 2 } ] \leq - \kappa \int _ { 0 } ^ { t } \mathbb { E } [ V ( t ) ^ { 2 } + c _ { 3 } ( V ( t ) - \overline { V } ( t ) ) ^ { 2 } ] d s + u _ { 0 } ^ { 2 } + c _ { 3 } ( u _ { 0 } - u _ { 0 } ) ^ { 2 }.$$
An application of the Gr¨nwall inequality then implies the statement of the proposition. o
✷
This proposition implies that if we choose h to be small (namely h ∈ (0 1 , / (4 a ))), the speed of convergence to stationarity of the stochastic Euler dynamics is at most infinitesimal smaller than that of the original dynamical system ( u t ( )) t ≥ 0 . If, on the other hand, h ∈ (1 / (4 a , ) 1 /a ), we obtain a slower rate that depends on h . This is surprising as the forward Euler method for u ′ = -au actually converges faster for stepsizes close to 1 /a . From the discussion in Subsection 4.1, we would not expect stability of the second moment of ( V ( )) t t ≥ 0 , if h > 1 /a .
Based on Proposition 4.2, we can now study the stability of higher dimensional linear ODEs.
Theorem 4.3 Let A ∈ R d × d be symmetric positive definite and let ( V ( ) t , V ( )) t t ≥ 0 be the stochastic Euler dynamics (1.4) corresponding to u ′ = -Au . Let λ 1 ≤ · · · ≤ λ d be the eigenvalues of A ,let h be chosen such that λ h < d 1 , and let κ ′ ∈ (0 min , { 2 λ , 1 1 / (2 h ) } ) . Then,
$$\mathbb { E } \left [ \| V ( t ) \| ^ { 2 } \right ] + c _ { 3 } ^ { \prime } \mathbb { E } [ \| V ( t ) - \overline { V } ( t ) \| ^ { 2 } ] \leq \exp ( - \kappa ^ { \prime } t ) \| u _ { 0 } \| ^ { 2 },$$
with c ′ 3 := min 1 { / max (1 { /h -κ /κ, ) ( κ -1 /h + λ ℓ ) /λ ℓ } : ℓ ∈ { 1 , . . . , d }} .
Proof. Since A is symmetric, there is a similarity transform A = S Λ S T , where S is an orthonormal matrix consisting of the eigenvectors of A and Λ is the diagonal matrix containing the associated real eigenvalues on the diagonal. Then, we can write V ( ) under the condition that t K t ( ) = k as
$$( I _ { d } - ( t - H _ { 1 } - \dots - & H _ { k } ) A ) ( I _ { d } - H _ { k } A ) \cdots ( I _ { d } - H _ { 1 } A ) u _ { 0 } \\ & = S ( I _ { d } - ( t - H _ { 1 } - \dots - & H _ { k } ) \Lambda ) ( I _ { d } - H _ { k } \Lambda ) \cdots ( I _ { d } - H _ { 1 } \Lambda ) S ^ { T } u _ { 0 },$$
for t ≥ 0 . Thus, we can assume that A := Λ: we just measure convergence in ∥ S · ∥ = ∥ · ∥ and consider the initial value S T u 0 that satisfies ∥ S T u 0 ∥ = ∥ u 0 ∥ . Then, however, we have d processes that are only coupled through their jump times. If we apply Proposition 4.2 to all d components of V ( ) = ( t V 1 ( ) t , . . . , V d ( )) t and V ( ) = ( t V 1 ( ) t , . . . , V d ( )) t with the stepsize restriction λ h < d 1, we obtain
$$\sum _ { \ell = 1 } ^ { d } \left ( \mathbb { E } \left [ V _ { \ell } ( t ) ^ { 2 } \right ] + c _ { 3 } ^ { ( \ell ) } \mathbb { E } \left [ ( V _ { \ell } ( t ) - \overline { V } _ { \ell } ( t ) ) ^ { 2 } \right ] \right ) \leq \sum _ { \ell = 1 } ^ { d } \exp ( - \kappa _ { \ell } t ) u _ { 0, \ell } ^ { 2 }$$
where ( c (1) 3 , . . . , c ( d ) 3 ) and ( κ (1) , . . . , κ ( d ) ) are the constants we obtain when applying Proposition 4.2 to each of ( V 1 ( ) t , V 1 ( )) t t ≥ 0 , . . . , ( V d ( ) t , V d ( )) t t ≥ 0 . We denote c ′ 3 = min { c (1) 3 , . . . , c ( d ) 3 } and κ ′ = min { κ (1) , . . . , κ ( d ) } . Then, we can employ (4.1) to obtain the asserted inequality. ✷
## 5 Second-order stochastic Euler dynamics
The forward Euler method is a first-order numerical integrator. There are several ways to construct ODE solvers with higher convergence orders. The explicit midpoint rule, for instance, is a second-order method. It is defined through the following recursive relationship:
$$\widehat { y } _ { k } = \widehat { y } _ { k - 1 } + h _ { k } f \left ( \widehat { y } _ { k - 1 } + \frac { h _ { k } } { 2 } f ( \widehat { y } _ { k - 1 } ) \right ) \ \ ( k \in \mathbb { N } ), \quad \widehat { y } _ { 0 } = u _ { 0 }.$$
Of course, this method can be employed with a random timestep size. The derivation and especially the analysis of associated stochastic explicit midpoint dynamics should now be much trickier as a natural companion process would not be piecewise constant with jumps but piecewise linear with jumps. We defer the treatment of this and other Runge-Kutta-based stochastic dynamics to future work and instead follow a different idea:
The stochastic Euler dynamics construct a piecewise linear path by using a first-order ODE with piecewise constant right-hand sides. We can similarly construct a piecewise polynomial path by constructing an ODE that has constant higher derivatives. For a second order dynamics, for instance, we can consider ¨ x = a , x 1 (0) = a , x 2 ˙ (0) = a 3 for constant vectors a , a 1 2 , a 3 ∈ X , which yields x t ( ) = a t / 1 2 2 + a 2 + a t 3 ( t ≥ 0). Hence, rather than having a piecewise constant first derivative as in the stochastic Euler dynamics, we obtain a piecewise quadratic path through a piecewise constant second derivative.
↦
We now need to assume some additional smoothness in (0 , ∞ ∋ ) t → u t ( ) to then choose a , a 1 2 , a 3 by matching terms in the Maclaurin expansion of ( u t ( )) t ≥ 0 . For some h 1 > 0, we can write the Maclaurin expansion as
$$u ( h _ { 1 } ) = u ( 0 ) + u ^ { \prime } ( 0 ) h _ { 1 } + u ^ { \prime \prime } ( 0 ) \frac { h _ { 1 } ^ { 2 } } { 2 } + u ^ { ( 3 ) } ( 0 ) \frac { h _ { 1 } ^ { 3 } } { 6 } + \cdots,$$
which is either an infinite sum or ends with a remainder term. We now compare the first three terms in the Maclaurin expansion with the polynomial above and obtain
$$a _ { 1 } = u ^ { \prime \prime } ( 0 ), \quad a _ { 2 } = u ( 0 ), \quad a _ { 3 } = u ^ { \prime } ( 0 ).$$
Whilst we are usually able to evaluate u ′ = f ( u ), additional work is necessary to obtain the second derivative u ′′ = J f ( u ) · f ( u ). In the following we assume to be able to access this second derivative. Then, with the previous discussion in mind, we define the second-order stochastic Euler dynamics ( Y 1 ( ) t , Y 2 ( ) t , Y ( )) t t ≥ 0 through
$$t ), Y _ { 2 } ( t ), \overline { Y } ( t ) ) _ { t \geq 0 } \text{ through } & Y _ { 1 } ^ { \prime } ( t ) = Y _ { 2 } ( t ) & ( t > 0 ) \\ Y _ { 2 } ^ { \prime } ( t ) = J f ( \overline { Y } ( t ) ) \cdot f ( \overline { Y } ( t ) ) & ( t \in ( T _ { k - 1 }, T _ { k } ], k \in \mathbb { N } ) \\ \overline { Y } ^ { \prime } ( t ) = 0 & ( t \in ( T _ { k - 1 }, T _ { k } ], k \in \mathbb { N } ) \\ Y _ { 1 } ( T _ { k - 1 } ) = Y _ { 1 } ( T _ { k - 1 } ) & ( k \in \mathbb { N } ) \\ Y _ { 2 } ( T _ { k - 1 } ) = Y _ { 2 } ( T _ { k - 1 } ) & ( k \in \mathbb { N } ) \\ \overline { Y } ( T _ { k - 1 } ) = Y _ { 1 } ( T _ { k - 1 } ) & ( k \in \mathbb { N } ) \\ Y _ { 1 } ( 0 ) = \overline { Y } ( 0 ) = u _ { 0 } \\ Y _ { 2 } ( 0 ) = f ( u _ { 0 } ) \\ \text{re the (T _ { k } ) } _ { k \in \mathbb { N } } \text{ still denote appropriate jump times with } i. i. d. \text{ increments } H _ { 1 }, H _ { 2 }, \dots \sim & \text{Exp} ( 1$$
where the ( T k ) k ∈ N still denote appropriate jump times with i.i.d. increments H ,H ,... 1 2 ∼ Exp(1 /h ). Again, it is easy to see that ( Y 1 ( ) t , Y 2 ( ) t , Y ( )) t t ≥ 0 is a well-defined Feller process with infinitesimal generator
$$\mathcal { A } _ { h } ^ { 2 } \varphi ( y _ { 1 }, y _ { 2 }, \overline { y } ) = \left \langle \nabla _ { u } \varphi ( y _ { 1 }, y _ { 2 }, \overline { y } ), \binom { y _ { 2 } } { \mathbb { J } f ( \overline { y } ) \cdot f ( \overline { y } ) } \right \rangle + h ^ { - 1 } ( \varphi ( y _ { 1 }, y _ { 2 }, y _ { 1 } ) - \varphi ( y _ { 1 }, y _ { 2 }, \overline { y } ) )$$
for an appropriate test function φ : X 3 → R . Since only the second derivative of the path ( Y 1 ( )) t t ≥ 0 is now piecewise constant, ( Y 1 ( )) t t ≥ 0 turns out to be a continuously differentiable approximation of ( u t ( )) t ≥ 0 . Conceptually, the ansatz for our ODE solution is, thus, now a smooth chain of quadratic
splines with random interpolation points. A deterministic quadratic spline ansatz for the solution of ODEs has, for instance, previously been discussed by [21]. The preceeding discussion is easily extended to orders beyond two, at least in cases in which higher order derivatives of u are available. Random timestep explicit Runge-Kutta methods, such as the explicit midpoint rule above, should be able to circumvent this necessity.
We finish this section by studying the stability of the jump chain associated with the second order stochastic Euler dynamics ( ̂ Y k, 1 , Y ̂ k, 2 ) ∞ k =0 , given by ( ̂ Y k, 1 , Y ̂ k, 2 ) := ( Y 1 ( T k ) , Y 2 ( T k )) ( k ∈ N ) for a onedimensional linear ODE. In Section 6, we numerically explore the local root mean square truncation error of the second-order stochastic Euler dynamics (and, thus, actually justify its name).
## 5.1 Stability of the second order stochastic Euler dynamics jump chain
Similarly to our discussion in Subsection 4.1, we now study the stability of the jump chain ( ̂ Y k, 1 , Y ̂ k, 2 ) ∞ k =0 when defined to approximate the linear ODE ˙ u = -au on X = R for some a > 0. We actually focus only on the first component ( ̂ Y k, 1 ) ∞ k =0 here. We have
$$\widehat { Y } _ { k, 1 } = \widehat { Y } _ { k - 1, 1 } - a H _ { k } \widehat { Y } _ { k - 1, 1 } + \frac { a ^ { 2 } H _ { k } ^ { 2 } } { 2 } \widehat { Y } _ { k - 1, 1 } = \left ( 1 - a H _ { k } + \frac { a ^ { 2 } H _ { k } ^ { 2 } } { 2 } \right ) \widehat { Y } _ { k - 1, 1 } \quad ( k \in \mathbb { N } ),$$
where H ,H ,... 1 2 ∼ Exp( h -1 ) and ̂ Y 0 = u . 0 We again compute mean and second moment of the jump chain and investigate their longtime behaviour. We have
$$\mathbb { E } [ \widehat { Y } _ { k } ] = \mathbb { E } \left [ 1 - a H _ { k } + \frac { a ^ { 2 } H _ { k } ^ { 2 } } { 2 } \right ] \mathbb { E } [ \widehat { Y } _ { k - 1 } ] = \left ( 1 - a h + a ^ { 2 } h ^ { 2 } \right ) ^ { k } u _ { 0 },$$
which converges to 0 as k →∞ iff ah < 1. This condition is stricter than the condition we obtained in Subsection 4.1 regarding the mean of the random timestep Euler method. Regarding the second moment, we see that
$$\mathbb { E } [ \widehat { Y } _ { k } ^ { 2 } ] = \mathbb { E } \left [ \left ( 1 - a H _ { k } + \frac { a ^ { 2 } H _ { k } ^ { 2 } } { 2 } \right ) ^ { 2 } \right ] \mathbb { E } [ \widehat { Y } _ { k - 1 } ^ { 2 } ] & = \mathbb { E } \left [ 1 - 2 a H _ { k } + 2 a ^ { 2 } H _ { k } ^ { 2 } - a ^ { 3 } H _ { k } ^ { 3 } + \frac { a ^ { 4 } H _ { k } ^ { 4 } } { 4 } \right ] \mathbb { E } [ \widehat { Y } _ { k - 1 } ^ { 2 } ] \\ & = \left ( 1 - 2 a h + 4 a ^ { 2 } h ^ { 2 } - 6 a ^ { 3 } h ^ { 3 } + 6 a ^ { 4 } h ^ { 4 } \right ) ^ { k } u _ { 0 } ^ { 2 } = \colon \alpha ^ { k } u _ { 0 } ^ { 2 }.$$
Again the variance converges to zero as k →∞ , iff | α < | 1. This is equivalent to
$$a h < \frac { 1 } { 3 } \left ( 1 - \stackrel { 3 } { \sqrt { \frac { 2 } { 5 + \sqrt { 2 9 } } } } + \stackrel { 3 } { \sqrt { \frac { 5 + \sqrt { 2 9 } } { 2 } } } \right ) \approx 0. 7 1 8 1,$$
which again is a stricter stepsize restriction compared to what we have learnt about the random timestep Euler method. Now, these results seem surprising at first: given that the second-order stochastic Euler dynamics is broadly motivated by higher-order Runge-Kutta methods, we would have expected that the new stability region is at least not smaller than that of the second-order stochastic Euler dynamics, especially given that the jump chain in the linear setting here is actually equivalent to a random timestep explicit midpoint rule. On the other hand, when approximating the stable trajectory ( u t ( )) t ≥ 0 by piecewise polynomials, we approximate a stable function by functions that quickly diverge to ±∞ - they especially diverge more quickly than the linear functions employed in the random timestep Euler method. If the polynomial pieces diverge more quickly, the interruptions due to jumps in the companion process ( Y ( )) t t ≥ 0 need to happen more frequently. Thus, in this situation, we may obtain a higher convergence order, but the method becomes less stable.
Figure 6.1: Distances between deterministic Euler dynamics ( w t ( )) t ≥ 0 and ODE solution ( u t ( )) t ≥ 0 , as well as between deterministic Euler dynamics ( w t ( )) t ≥ 0 and its companion process ( w t ( )) t ≥ 0 with respect to h at time points t ∈ { 0 01 0 1 . , . , 1 . } Here, ( u t ( )) t ≥ 0 and ( w t , w t ( ) ( )) t ≥ 0 correspond to the linear model ODE u ′ = -u, u (0) = 1.
## 6 Numerical experiments
In the following, we illustrate and verify the theoretical results obtained throughout this work. We start with a stable linear ODE in one dimension in Subsection 6.1 and then move on to an underdamped harmonic oscillator in Subsection 6.2. We also explore two situations not covered by our theory: the local truncation error of second-order stochastic Euler dynamics and the stability of stochastic Euler dynamics in linear ODEs with complex-valued eigenvalues.
## 6.1 One-dimensional linear problem
We first aim to verify and illustrate the results shown in Theorem 2.3, Theorem 3.6, and Proposition 4.2 using the one-dimensional linear model problem: u ′ = -u, u (0) = 1 on X = R . In the context of this ODE, we also estimate the local root mean square truncation error of the second-order stochastic Euler dynamics.
Convergence of deterministic Euler dynamics. Webegin with the deterministic Euler dynamics in the context of the linear model ODE above. Here, we evaluate the analytical solution of the deterministic Euler dynamics - the formula is stated in Example 2.1. Then, we compute the distances between the deterministic Euler dynamics and the ODE solution ∥ w t ( ) -u t ( ) ∥ and the distances between the deterministic Euler dynamics and its companion process ∥ w t ( ) -w t ( ) ∥ for t ∈ { 0 01 . , 0 1 . , 1 } and h ∈ { 10 -4 , 1 5 . · 10 -4 , . . . , 10 0 } . We plot the results in Figure 6.1. The results confirm the linear O h h ( ; ↓ 0) rate shown in Theorem 2.3.
Local root mean square truncation error. We simulate the stochastic Euler dynamics for the linear model problem to estimate the local root mean square truncation error E [( V ( ε ) -u ε ( )) 2 1 ] / 2 for ε ∈ { 2 -8 , 2 -7 , . . . , 2 0 } and h ∈ { 0 1 . , 1 , as well as } h ≡ ε . The expected values are estimated with a Monte Carlo simulation using 10 5 samples. The results given in Figure 6.2 confirm the second order shown in Theorem 3.6. In the same figure, we also show estimates of the local root mean square truncation error of the second order stochastic Euler dynamics. Those appear to converge at speed O ε ( 3 ; ε ↓ 0), as we would expect from the theory of ODE solvers.
Stability of the stochastic Euler dynamics. We simulate the stochastic Euler dynamics for the linear model problem to study their longtime behaviour and verify the result shown in Proposition 4.2.
Figure 6.2: Estimates of the local root mean square truncation error of the stochastic Euler dynamics and second-order stochastic Euler dynamics at multiple time points ε > 0 regarding the linear model problem u ′ = -u, u (0) = 1 for h ∈ { 0 1 . , 1 } and h = ε . ̂ E denotes the sample mean and is computed using 10 5 samples.
Indeed, we perform Monte Carlo simulations to estimate E [ V ( ) t 2 ] with t ∈ { 0 4 , , . . . , 60 } and h ∈ { 0 125 0 25 0 5 1 2 . , . , . , , } using 10 6 samples and show the results in Figure 6.3. The estimated means in the plot are all sampled independently of each other. According to Proposition 4.2, the estimated second moment should stay below the blue exp( -2 ) line for t h ≤ 0 25 and below the green exp( . -t/ (2 h )) line if h ∈ [0 25 . , 1). Looking at the plots, this appears to be confirmed: there is a slight discrepancy in case h ∈ { 0 25 . , 0 5 . } for small t , which we might be able to explain with the large variance of V ( ) t 2 that leads to a large sampling error. Our theory indicates instability if h > 1, which we can see in the case h = 2.
## 6.2 Underdamped harmonic oscillator
We now consider the underdamped harmonic oscillator u ′ 1 = u , u 2 ′ 2 = -u 1 -u , u 2 (0) = (1 0) , T on X = R 2 , see also Figure 3.1. We first aim to verify the stability results we have obtained regarding the deterministic Euler dynamics in Theorem 2.2. We then explore computationally the stability of the stochastic Euler dynamics in this setting; we note that the underdamped harmonic oscillator is not covered by Theorem 4.3.
Stability of the deterministic Euler dynamics. We simulate the deterministic Euler dynamics regarding the underdamped harmonic oscillator by evaluating the matrix exponential of the matrix B as given in (2.1) at high accuracy. We compute the solution for t ∈ { 0 0 01 , . , . . . , 40 } and h ∈ { 0 2 . , 0 6 . , 2 3 0 7 / , . } and plot it in Figure 6.4. We see a stable solution for h < 2 3 and an unstable / solution for h > 2 3, / as expected from Theorem 2.2. When choosing h = 2 3 we appear to have / obtained a dynamical system that is free of friction.
Stability of the stochastic Euler dynamics. We choose the same setup as in the deterministic Euler dynamics above to explore the stability of the stochastic Euler dynamics in the underdamped harmonic oscillator that is not covered by our theory. In Figure 6.5, we plot five independent realisations of the stochastic Euler dynamics regarding the underdamped harmonic oscillator for each of h ∈ { 0 2 . , 0 6 . , 2 3 0 7 / , . } on top of each other. The shown samples appear to imply a very similar stability behaviour that we have also seen above for the deterministic Euler dynamics; especially stability for small h . In Figure 6.6, we study the stability more systematically by a Monte Carlo estimation of
Figure 6.3: Estimated second moments of the stochastic Euler dynamics of the linear model problem u ′ = -u, u (0) = 1 with large t that show the dynamics' asymptotic behaviour. SD denotes the sample ̂ standard deviation; along with E, it has been computed using 10 ̂ 6 samples.
Figure 6.4: Trajectories of the deterministic Euler dynamics applied to the underdamped harmonic oscillator u ′ 1 = u , u 2 ′ 2 = -u 1 -u , u 2 (0) = (1 , 0) T with h ∈ { 0 2 . , 0 6 . , 2 3 0 7 / , . } .
Figure 6.5: Five realisations of the stochastic Euler dynamics approximating the underdamped harmonic oscillator u ′ 1 = u , u 2 ′ 2 = -u 1 -u , u 2 (0) = (1 , 0) T with h ∈ { 0 2 . , 0 6 . , 2 3 0 7 / , . } .

E [ ∥ V ( ) t ∥ 2 ] for t ∈ { 0 50 , , . . . , 600 } with h ∈ { 0 2 . , 0 6 . , 2 3 0 7 / , . } using 10 5 samples; again the ∥ V ( ) t ∥ 2 are sampled independently for all t and h . There h ∈ { 2 3 0 7 / , . } clearly lead to a diverging stochastic Euler dynamics and h = 0 2 appears to be very stable. . The case h = 0 6 that appeared to be eventually . stable in Figure 6.6 now appears to be unstable or at least to not match the asymptotic behaviour of the underdamped harmonic oscillator. More work is needed to understand stochastic Euler dynamics in the context of underdamped systems.
## 7 Conclusions and outlook
In this work, we have proposed and analysed the stochastic Euler dynamics, a continuous-time Markov process ansatz for the numerical approximation of ordinary differential equations. This ansatz is given as a linear spline interpolation of a random timestep Euler method with i.i.d. exponentially distributed timestep sizes. The stochastic Euler dynamics have allowed us to derive novel convergence and stability results regarding random timestep Euler methods: we could prove weak convergence of the stochastic Euler dynamics to the underlying ODE, derive the local root mean square truncation error in the case of linear ODEs, and show stability for certain classes of linear ODEs. In the latter case, we could also compute bounds on the continuous rate of convergence to stationarity of the stochastic Euler dynamics. Numerical experiments helped us to verify these results. We also propose and study deterministic and second-order stochastic Euler dynamics. The former arise from an approximation of the infinitesimal operator of the stochastic Euler dynamics; they recover several properties of the forward Euler method and may be of independent interest.
Our discussion of the second-order stochastic Euler dynamics reveals the difficulty of employing higher order methods - we have especially noticed stability problems that should be even more pronounced when further increasing the polynomial order of the splines. Thus, more work is needed in this direction; also and especially when moving to random timestep Runge-Kutta methods. Moreover,
Figure 6.6: Sample approximations of E [ ∥ V ( ) t ∥ 2 ] for t ∈ { 0 50 , , . . . , 600 } with h ∈ { 0 2 . , 0 6 . , 2 3 0 7 / , . } in the context of the underdamped harmonic oscillator u ′ 1 = u , u 2 ′ 2 = -u 1 -u , u 2 (0) = (1 , 0) T . ̂ E and ̂ SD are computed using 10 5 samples.
whilst we have focused on rather simple ODEs in this work, random timestep numerical methods are of particular interest in chaotic and irregular dynamical systems. Especially in the context of the randomised discretisation of chaotic dynamical systems, we anticipate the stochastic Euler dynamics to be a helpful tool.
## Acknowledgements
The author would like to thank the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the programme The mathematical and statistical foundation of future data-driven engineering when work on this paper was undertaken (EPSRC grant EP/R014604/1).
## References
- [1] Assyr Abdulle and Giacomo Garegnani. Random time step probabilistic methods for uncertainty quantification in chaotic and geometric numerical integration. Statistics and Computing , 30(4):907-932, 2020.
- [2] Joris Bierkens, Paul Fearnhead, and Gareth Roberts. The Zig-Zag process and super-efficient sampling for Bayesian analysis of big data. The Annals of Statistics , 47(3):1288 - 1320, 2019.
- [3] Joris Bierkens, Sebastiano Grazzi, Kengo Kamatani, and Gareth Roberts. The Boomerang Sampler. In Hal Daum´ III and Aarti Singh, editors, e Proceedings of the 37th International Conference on Machine Learning , volume 119 of Proceedings of Machine Learning Research , pages 908-918, 2020.
- [4] Patrick Billingsley. Convergence of Probability Measures . John Wiley & Sons, 2 edition, 1999.
- [5] Yifan Chen, Bamdad Hosseini, Houman Owhadi, and Andrew M. Stuart. Solving and learning nonlinear PDEs with Gaussian processes. Journal of Computational Physics , 447:110668, 2021.
- [6] R. W. R. Darling and J. R. Norris. Differential equation approximations for Markov chains. Probability Surveys , 5:37 - 79, 2008.
| [7] | M. H. A. Davis. Piecewise-Deterministic Markov Processes: A General Class of Non-Diffusion Stochastic Models. Journal of the Royal Statistical Society. Series B (Methodological) , 46(3):353- 388, 1984. |
|-------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [8] | Monika Eisenmann, Mih´ly a Kov´cs, a Raphael Kruse, and Stig Larsson. On a Randomized Back- ward Euler Method for Nonlinear Evolution Equations with Time-Irregular Coefficients. Foun- dations of Computational Mathematics , 19(6):1387-1430, 2019. |
| [9] | Susana N. Gomes, Andrew M. Stuart, and Marie-Therese Wolfram. Parameter Estimation for Macroscopic Pedestrian Dynamics Models from Microscopic Data. SIAM Journal on Applied Mathematics , 79(4):1475-1500, 2019. |
| [10] | N. Halko, P. G. Martinsson, and J. A. Tropp. Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions. SIAM Review , 53(2):217-288, 2011. |
| [11] | Arieh Iserles. A First Course in the Numerical Analysis of Differential Equations . Cambridge Texts in Applied Mathematics. Cambridge University Press, 2 edition, 2008. |
| [12] | A. Jentzen and A. Neuenkirch. A random Euler scheme for Carath´odory e differential equations. Journal of Computational and Applied Mathematics , 224(1):346-359, 2009. |
| [13] | Kexin Jin, Jonas Latz, Chenguang Liu, and Alessandro Scagliotti. Losing momentum in continuous-time stochastic optimisation. arXiv eprints , 2209.03705, 2022. |
| [14] | Hans Kersting, T. J. Sullivan, and Philipp Hennig. Convergence rates of Gaussian ODE filters. Statistics and Computing , 30(6):1791-1816, 2020. |
| [15] | Thomas G. Kurtz. Solutions of Ordinary Differential Equations as Limits of Pure Jump Markov Processes. Journal of Applied Probability , 7(1):49-58, 1970. |
| [16] | Harold Joseph Kushner. Approximation and Weak Convergence Methods for Random Processes, with Applications to Stochastic Systems Theory , volume 6. MIT press, 1984. |
| [17] | Harold Joseph Kushner. Weak Convergence Methods and Singularly Perturbed Stochastic Control and Filtering Problems . Birkh¨user, a 1990. |
| [18] | Andrzej Lasota and Michael C Mackey. Chaos, Fractals, and Noise: Stochastic Aspects of Dy- namics , volume 97. Springer Science & Business Media, 2013. |
| [19] | Jonas Latz. Analysis of stochastic gradient descent in continuous time. Statistics and Computing , 31:39, 2021. |
| [20] | Shao-Bo Lin, Xiangyu Chang, and Xingping Sun. Kernel Interpolation of High Dimensional Scattered Data. SIAM Journal on Numerical Analysis , 62(3):1098-1118, 2024. |
| [21] | Frank R. Loscalzo and Thomas D. Talbot. Spline Function Approximations for Solutions of Ordinary Differential Equations. SIAM Journal on Numerical Analysis , 4(3):433-445, 1967. |
| [22] | Rui Meng and Xianjin Yang. Sparse Gaussian processes for solving nonlinear PDEs. Journal of Computational Physics , 490:112340, 2023. |
| [23] | Sean P. Meyn and R. L. Tweedie. Stability of Markovian Processes III: Foster-Lyapunov Criteria for Continuous-Time Processes. Advances in Applied Probability , 25(3):518-548, 1993. |
| [24] | Francesca Mignacco, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborov´. a Dynam- ical mean-field theory for stochastic gradient descent in Gaussian mixture classification. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems , volume 33, pages 9540-9550. Curran Associates, Inc., 2020. |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [25] | Yuji Nakatsukasa and Joel A. Tropp. Fast and Accurate Randomized Algorithms for Linear Sys- tems and Eigenvalue Problems. SIAM Journal on Matrix Analysis and Applications , 45(2):1183- 1214, 2024. |
| [26] | Jorge Nocedal and Stephen J Wright. Numerical Optimization . Springer, 1999. |
| [27] | Grigorios A. Pavliotis. Stochastic Processes and Applications: Diffusion Processes, the Fokker- Planck and Langevin Equations . Springer, 2014. |
| [28] | Ryszard Rudnicki and Marta Tyran-Kami´ska. n Piecewise Deterministic Processes in Biological Models . Springer, 2017. |
| [29] | P. Stein. A Note on the Volume of a Simplex. The American Mathematical Monthly , 73(3):299- 301, 1966. |
| [30] | Gilbert Stengle. Numerical methods for systems with measurable coefficients. Applied Mathe- matics Letters , 3(4):25-29, 1990. |
| [31] | Andrew Stuart and Aretha Teckentrup. Posterior consistency for Gaussian process approxima- tions of Bayesian posterior distributions. Mathematics of Computation , 87(310):721-753, 2018. |
| [32] | Minglei Yang, Guannan Zhang, Diego Del-Castillo-Negrete, and Yanzhao Cao. A Probabilistic Scheme for Semilinear Nonlocal Diffusion Equations with Volume Constraints. SIAM Journal on Numerical Analysis , 61(6):2718-2743, 2023. |
| [33] | Naoki Yoshida, Shogo Nakakita, and Masaaki Imaizumi. Effect of Random Learning Rate: The- oretical Analysis of SGD Dynamics in Non-Convex Optimization via Stationary Distribution. arXiv eprints , 2406.16032, 2024. | | null | [
"Jonas Latz"
]
| 2024-08-02T17:35:04+00:00 | 2024-08-02T17:35:04+00:00 | [
"math.NA",
"cs.NA",
"math.PR",
"65L05, 60J25, 65C99"
]
| The random timestep Euler method and its continuous dynamics | ODE solvers with randomly sampled timestep sizes appear in the context of
chaotic dynamical systems, differential equations with low regularity, and,
implicitly, in stochastic optimisation. In this work, we propose and study the
stochastic Euler dynamics - a continuous-time Markov process that is equivalent
to a linear spline interpolation of a random timestep (forward) Euler method.
We understand the stochastic Euler dynamics as a path-valued ansatz for the ODE
solution that shall be approximated. We first obtain qualitative insights by
studying deterministic Euler dynamics which we derive through a first order
approximation to the infinitesimal generator of the stochastic Euler dynamics.
Then we show convergence of the stochastic Euler dynamics to the ODE solution
by studying the associated infinitesimal generators and by a novel local
truncation error analysis. Next we prove stability by an immediate analysis of
the random timestep Euler method and by deriving Foster-Lyapunov criteria for
the stochastic Euler dynamics; the latter also yield bounds on the speed of
convergence to stationarity. The paper ends with a discussion of second-order
stochastic Euler dynamics and a series of numerical experiments that appear to
verify our analytical results. |
2408.01410v2 | ## Evolution of an effective Hubble constant in f ( R ) modified gravity
Tiziano Schiavone ( 1 ) , Giovanni Montani ( 2 )( 3 )
- ( 1 ) Galileo Galilei Institute for Theoretical Physics, Largo Enrico Fermi 2, I-50125 Firenze, Italy
- ( 2 ) ENEA, Fusion and Nuclear Safety Department, C.R. Frascati, Via Enrico Fermi 45, Frascati, I-00044 Rome, Italy
- ( 3 ) Physics Department, 'Sapienza' University of Rome, Piazzale Aldo Moro 5, I-00185 Rome, Italy
## Summary.
-
We investigate the Hubble constant tension within f ( R ) modified gravity in the Jordan frame, focusing on its application to the dynamics of an isotropic Universe. A scalar field, non-minimally coupled to the metric, provides an extra degree of freedom compared to General Relativity. We analyze the impact of such a scalar field on the cosmic expansion, leading to an effective Hubble constant H eff 0 ( z ), dependent on redshift z . We show that our f ( R ) model might mimic dark energy and provide an apparent variation of the Hubble constant. Our results align with recent cosmological data analysis in redshift bins, indicating a decreasing trend of the Hubble constant. The redshift dependence of H eff 0 ( z ) might potentially reconcile measurements of the Hubble constant from probes at different redshifts.
## 1. - Introduction
The Hubble constant tension, one of the most significant issues in the era of 'precision cosmology', is referred to the discrepancy between independent measurements of the Universe's current expansion rate, the Hubble constant H 0 [1-5]. The distance ladder method, based on direct observations and calibration of Cepheids and Type Ia supernovae (SNe Ia), provides a local measurement: H loc 0 = 73 04 . ± 1 04 km s . -1 Mpc -1 [6]. On the other hand, the value inferred from the cosmic microwave background (CMB) radiation [7] is H CMB 0 = 67 4 . ± 0 5 . , km s -1 Mpc -1 , which is 4.9 σ inconsistent with H loc 0 . The CMB estimate of H 0 relies on the ΛCDM cosmological model, which incorporates the cosmological constant Λ and a cold dark matter component [8].
The expansion rate for the fiducial flat ΛCDM cosmological model is expressed by the Hubble function H ΛCDM ( z ) in the Friedmann equation [8]:
$$( 1 ) \quad H ^ { A C D M } ( z ) = H _ { 0 } \, E ^ { A C D M } ( z ) \quad \text{with} \ \ E ^ { A C D M } ( z ) = \sqrt { \Omega _ { m 0 } \, ( 1 + z ) ^ { 3 } + 1 - \Omega _ { m 0 } } \,, \\ 1$$
where Ω m 0 is the present cosmological density parameter of matter. Hence, H 0 is simply a constant by definition, being the expansion rate evaluated today, i.e. H z ( = 0). However, the H 0 tension challenges current cosmological models and may indicate systematic errors or new physics [9,10].
/negationslash
An interesting and original perspective to test cosmological models is to use an effective Hubble constant as a diagnostic tool in terms of the redshift z , as explained in [11,12]. Considering the Hubble function H z ( ) and its reduced version E z ( ) for a generic cosmological model, the ratio H z /E z ( ) ( ) should be exactly the Hubble constant H 0 . Here, H z ( ) can be obtained from observations, while E z ( ) is related to the theoretical model of the cosmic expansion, depending on the Universe content and the considered gravitational theory. However, if data suggest a different cosmic evolution from that predicted theoretically from E z ( ), then H z ( ) and E z ( ) are no more referred to the same model and a discrepancy occurs between them: the ratio H z /E z ( ) ( ) is no longer constant. In other words, this ratio inevitably acquires a redshift dependence, resulting in an effective Hubble constant H z /E z ( ) ( ) ≡ H eff 0 ( z ) = H 0 , if we force data analysis to conform to the prescribed theoretical model that is not the correct one.
In this regard, possible evolving trends of H 0 , Ω m 0 , or the marginalized absolute magnitude of SNe Ia have been recently discussed [13-26]. In particular, two analysis in redshift bins [16, 17] within the ΛCDM model pointed out an apparent variation of the Hubble constant as H fit 0 ( z ) ∼ (1 + z ) -α within 2 σ confidence level, where α ∼ 10 -2 . Additionally, extrapolating the fitting function H fit 0 ( z ) up to the redshift of the last scattering surface, z = 1100, local measurements of H 0 were reconciled with the CMB inferred value in 1 σ [16].
Concerning theoretical attempts to accommodate the H 0 tension [2], among various proposals, f ( R ) modified gravity theories [27-29] are considered promising scenarios due to an extra degree of freedom with respect to General Relativity (GR), given by a general function of the Ricci scalar R in the gravitational Lagrangian, or equivalently a nonminimally coupled scalar field to the metric in the Jordan frame. The presence of this scalar field implies a variation of the gravitational coupling constant and affects the cosmological dynamics [19, 23, 30-33]. For instance, f ( R ) models might account for the present cosmic accelerated phase without the dark energy [34,36,37]. However, in [17], it was shown that the Hu-Sawicki model [34], one of the most robust f ( R ) models in the late Universe, was inadequate to produce H eff 0 ( z ).
In this work, reporting the results obtained in [19], we present a f ( R ) model able not only to mimic dark energy but also to provide the evolution of an effective Hubble constant H eff 0 ( z ) with the redshift. In Sect. 2 , we show that the dynamics of the scalar field in the Jordan frame can be interpreted as an evolving H eff 0 ( z ) [19]. In Sect. 3 , we present the solution for the scalar field potential, associated with the function f ( R ), to produce a decreasing trend for H eff 0 ( z ). In Sect. 4 , we summarize our results.
## 2. - The non-minimally coupled scalar field and the cosmic expansion
We show that f ( R ) gravity implemented in a homogeneous and isotropic Universe might provide the evolution of an effective Hubble constant H eff 0 ( z ) [19]. The modified Friedmann equation in the equivalent scalar-tensor formalism in the Jordan frame of f ( R ) gravity [27-29] for pressure-less dust is written as:
$$H ^ { 2 } & = \frac { \chi \, \rho } { 3 \, \phi } + \frac { V \, ( \phi ) } { 6 \, \phi } - H \, \frac { \dot { \phi } } { \phi } \,,$$
where H t ( ) ≡ ˙ a a is the Hubble function, a t ( ) is the scale factor, ρ ( ) t is the energy density of the cosmological matter component, χ ≡ 8 π G is the Einstein constant, being G the gravitational constant. Moreover, ˙ = d/dt and t is the cosmic time. We recall that, in an isotropic Universe, all the relevant cosmological quantities depend only on t and not spatial coordinates. We neglect relativistic components in the late Universe, since radiation is subdominant today. The extra degree of freedom in the Jordan frame compared to GR is represented by a scalar field φ ≡ df/dR , which is non-minimally coupled to the metric, and whose dynamics is regulated by the potential V ( φ ) = φR φ ( ) -f [ R φ ( )]. Note that an effective Einstein constant χ/φ emerges from Eq. (2).
Eq. (2) can be easily rewritten in terms of the redshift z [19] as
$$& ( 3 ) & & H ( z ) = \frac { H _ { 0 } } { \sqrt { \phi ( z ) - ( 1 + z ) \ \phi ^ { \prime } ( z ) } } \sqrt { \Omega _ { m 0 } \left ( 1 + z \right ) ^ { 3 } + \frac { V \left [ \phi ( z ) \right ] } { 2 \chi \rho _ { c 0 } } } \,, \\ & \text{where $\phi^{\prime}\equiv d\phi/dz$. We used the definition $a_{0}/a=1+z$ with the present scale fact.}$$
where φ ′ ≡ dφ/dz . We used the definition a /a 0 = 1 + z with the present scale factor a 0 = 1, and the consequent relation dz/dt = -(1 + z ) H z ( ). We recall that the matter component evolves like ρ = ρ 0 (1 + z ) 3 with ρ 0 the present energy density of matter. The present critical energy density of the Universe is ρ c 0 ≡ 3 H /χ 2 0 and Ω m 0 = ρ /ρ 0 c 0 . Comparing Eq. (3) with H ΛCDM ( z ) in the flat ΛCDM model, given by Eq. (1), it is clear that V ( φ ) might act as a varying cosmological constant.
Without any loss of generality, we split the potential profile into two parts: V ( φ ) ≡ 2 χρ Λ + g ( φ ), in which ρ Λ is the energy density associated with the cosmological constant in the flat ΛCDM model. To have a slight deviation from a cosmological constant picture, we assume that the function | g ( φ ) | /lessmuch 2 χρ Λ for 0 < z /lessorsimilar z ∗ , where z ∗ ∼ 0 3 indicates the . equivalence between dark energy and matter, such that Ω m 0 (1 + z ∗ ) 3 = Ω Λ0 . We recall that Ω Λ0 = ρ Λ /ρ c 0 = 1 -Ω m 0 in a flat Universe. Therefore, neglecting g ( φ ), Eq. (3) can be rewritten as
$$H \left ( z \right ) & = H _ { 0 } ^ { \text{eff} } ( z ) \, \sqrt { \Omega _ { m 0 } \left ( 1 + z \right ) ^ { 3 } + 1 - \Omega _ { m 0 } } \,, \\ \intertext { m o n d } \, + \theta \, \frac { \theta } { \theta } \, \frac { \theta } { \theta } \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theigma \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theho \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \the� \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \the� \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \, \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \sinh \theta \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \sinh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh \cosh$$
where the effective Hubble constant H eff 0 ( z ) evolves with the redshift [19] according to
$$H _ { 0 } ^ { \text{eff} } ( z ) & \approx \frac { H _ { 0 } } { \sqrt { \phi ( z ) - ( 1 + z ) \ \phi ^ { \prime } ( z ) } } \,. \\ H _ { 0 } & \text{ is really constant, while } H _ { 0 } ^ { \text{eff} } ( z ) \text{ admits a redshift evolution due to } t h.$$
Finally, we consider H eff 0 ( z ) as a diagnostic tool [11, 12], following the discussion in Sect. 1 . Focusing on the mismatch between H z ( ) in the Jordan frame of f ( R ) gravity from Eq. (3) and the ΛCDM function E ΛCDM ( z ) in Eq. (1), we end up in
H 0 is really constant, while H eff 0 ( z ) admits a redshift evolution due to the non-minimally coupled scalar field. In particular, to guarantee a decreasing trend of H eff 0 with z , we require the condition φ z ( ) = φ 0 (1 + z ) 2 α , where α > 0 is a constant and φ 0 = φ z ( = 0). Hence, H eff 0 ( z ) ∼ (1 + z ) -α , according to the fitting function H fit 0 ( z ) adopted in [16,17].
$$( 6 ) \quad H _ { 0 } ^ { \text{eff} } ( z ) = \frac { H ( z ) } { E ^ { \text{ACDM} } ( z ) } = \frac { H _ { 0 } } { \sqrt { \phi ( z ) - ( 1 + z ) \, \phi ^ { \prime } ( z ) } } \sqrt { \frac { \Omega _ { m 0 } \, ( 1 + z ) ^ { 3 } + \frac { V [ \phi ( z ) ] } { 2 \chi \rho _ { c 0 } } } { \Omega _ { m 0 } \, ( 1 + z ) ^ { 3 } + 1 - \Omega _ { m 0 } } } \,, \\ \text{which is consistent with $Eq.$} ( 5 ), as we approximate the potential with its constant term.$$
which is consistent with Eq. (5), as we approximate the potential with its constant term.
Fig. 1. -Left panel : evolution of the matter term (black line) with redshift z ; contribution of the potential ˜ ( V φ ) (blue line) able to produce H eff 0 ( z ); the cosmological constant density parameter is indicated with a brown line. The numerical solution for ˜ ( V φ ) is added with a red line [19]. Right panel : decreasing trend of H eff 0 with z . The grey vertical line denotes z = z ∗ .
## 3. - Analytical and numerical results
We infer the profile of V ( φ ) from the full set of field equations in the Jordan frame, imposing Eq. (5) and the form of φ z ( ) = φ 0 (1 + z ) 2 α . We stress that, in this calculation, we do not neglect the function g φ ( ), to check a posteriori the approximation made for splitting V ( φ ) at low z . Combining the modified Friedmann equation, the modified acceleration equation, and the scalar field equation [27-29], after long but straightforward calculations (see [19] for more details), we obtain a differential equation in V ( φ ), and we report here the analytical solution:
$$( 7 ) \quad \tilde { V } \left ( \phi \right ) \, = \, \tilde { V } \left ( \phi _ { 0 } \right ) + \frac { 6 \alpha } { 1 - \alpha } \left \{ \frac { 2 + \alpha } { \alpha } \frac { 1 - \Omega _ { m 0 } } { \Omega _ { m 0 } } \ln \left ( \frac { \phi } { \phi _ { 0 } } \right ) + \frac { 1 + 2 \alpha } { 3 } \left [ \left ( \frac { \phi } { \phi _ { 0 } } \right ) ^ { \frac { 3 } { 2 \alpha } } - 1 \right ] \right \} \,,$$
where ˜ V ≡ V/m 2 is the dimensionless potential with m 2 ≡ χρ / 0 3 = H 2 0 Ω m 0 . The constant ˜ ( V φ 0 ) = 6 (1 -Ω m 0 ) / Ω m 0 is set from the condition V ( φ 0 ) = 2 χρ Λ .
To quantify the slight deviation from GR ( φ = 1), we fix φ 0 = 1 -10 -7 from solar system and cosmological constraints [34]. Combining Eq. (5) with φ z ( ) = φ 0 (1 + z ) 2 α , and imposing that H eff 0 ( z = 0) = H loc 0 [6] and H eff 0 ( z = 1100) = H CMB 0 [7], we obtain: α = 1 1 . × 10 -2 , which is compatible in 1 σ with the α used in [16], and H 0 = H loc 0 √ φ 0 (1 -2 α ). Once H 0 is fixed in Eq. (5), the consequent relation for matter is Ω m 0 = χρ / H 0 3 2 0 = Ω loc m 0 / φ [ 0 (1 -2 α )], in which we set Ω loc m 0 = 0 298 [35]. . In Fig. 1, we plot the different terms in the Hubble function (3) evolving with z , considering the matter component and the contribution related to the scalar field potential, i.e. V ( φ ) 2 χρ c 0 = ˜ Ω V m 0 6 , given by Eq. (7). For a comparison with the ΛCDM model, we also plot the cosmological constant contribution Ω Λ0 .
To check our initial assumption on a dominant constant term in the potential for 0 < z /lessorsimilar z ∗ , we note from Fig. 1 that ˜ Ω V m 0 6 coincides with Ω Λ0 for z = 0, while we estimate a relative difference of 1 6% at . z = z ∗ . Hence, ˜ Ω V m 0 6 can be regarded as a slowly varying cosmological constant, which is also responsible for H eff 0 ( z ).
Additionally, we solve numerically the full set of field equations in the Jordan frame of f ( R ) gravity without any assumption on the potential profile at low z but only requiring
the presence of H eff 0 ( z ). We observe from Fig. 1 that analytical and numerical solutions of ˜ ( V φ ) mostly overlap in the range corresponding to 0 < z /lessorsimilar z ∗ .
The right panel in Fig. 1 shows the decreasing trend of the effective Hubble constant H eff 0 with z . Therefore, H eff 0 ( z ) might potentially solve the H 0 tension, matching incompatible measurements of H loc 0 and H CMB 0 [16, 17, 19] at different redshifts.
Finally, we conclude this section by mentioning that, in [19], we compute analytically the functional form f ( R ) associated with the potential V ( φ ) in the low-redshift regime. In this regard, we expand the solution φ z ( ) and the potential ˜ ( V φ ) in Eq. (7) for z /lessmuch 1 (or equivalently φ around φ 0 ) up to the second order. Then, using the field equation R = dV/dφ and the relation f ( R ) = Rφ R ( ) -V [ φ R ( )] in the Jordan frame of f ( R ) gravity, we obtain constant, linear, and quadratic corrections in R and R 2 as in the quadratic f ( R ) gravity [38-40]. See [19] for explicit calculations. Note that the analytical expression of f ( R ) obtained in [19] is only an approximated solution valid for z /lessmuch 1. Moreover, the ΛCDM model is recovered for α → 0 and φ 0 → 1.
## 4. - Conclusions
We studied the H 0 tension in f ( R ) modified gravity in the Jordan frame, focusing on how the non-minimally coupled scalar field φ affects the expansion of an isotropic Universe. We showed that a varying effective Hubble constant H eff 0 ( z ) emerges (see Eq. (5)), even though we set the same matter content in the ΛCDM model.
We determined the profile of the potential V ( φ ) [19], which regulates the dynamics of φ and allows the presence of H eff 0 ( z ). The potential represents a slowly varying cosmological constant (see Fig. 1), extending the ΛCDM paradigm. The resulting f ( R ) functional form is computed for z /lessmuch 1 [19], pointing out a quadratic f ( R ) model.
Our study successfully addresses two critical aspects simultaneously: firstly, it proposes a f ( R ) model to provide the cosmic acceleration in the late Universe; secondly, it introduces an evolving Hubble constant H eff 0 ( z ). The possibility to theoretically predict the power-law behavior of H eff 0 ( z ) offers an intriguing perspective to validate models via suitable data analysis toward an effective Hubble constant.
If the variation of H eff 0 ( z ) is sufficiently rapid, we can expect to appreciate the rescaling of H eff 0 ( z ) within the same population of sources. In particular, this scenario offers a natural explanation for the fitting function H fit 0 ( z ), observed in [16, 17] via a binned analysis of the Pantheon sample of SNe Ia [35]. The emergence of a varying effective Hubble constant from cosmological data analysis is a significant proof that H eff 0 ( z ) has a precise physical meaning, related to real measured values of the Hubble constant at the redshift of a given source. These results and the future increasing quality of statistical analysis of SNe Ia should foster the SH0ES collaboration to search for a similar feature in their upgraded samples, overcoming the binning criticism in [41].
We stress that, while the power-law behavior of H eff 0 ( z ) is a regular smooth decaying, other models [23,42] provide an effective Hubble constant that reaches rapidly H CMB 0 for z /greaterorsimilar 5. In this regard, in the future, the combination of SNe Ia data with other farther sources, like quasars and gamma-ray bursts, will be crucial to better characterize the evolution of H eff 0 ( z ) and shed new light on the H 0 tension [43-45].
This study highlights the need for further investigations, as the redshift approaches the CMB observations, to determine if H eff 0 ( z ) can adequately solve the Hubble tension.
The work of TS is supported by the Galileo Galilei Institute with the Boost Fellowship.
## REFERENCES
- [1] Di Valentino E. and others , Astropart. Phys. , 131 (2021) 102605.
- [2] Di Valentino E., Mena O. and others , Class. Quant. Grav. , 38 (2021) 153001.
- [3] Abdalla E., Abell´n G. F., Aboubrahim A. a and others , JHEAp , 34 (2022) 49.
[4]
Perivolaropoulos L.
and
Skara F.
,
New Astron. Rev.
,
95
(2022) 101659.
- [5] Vagnozzi S. , Universe , 9 (2023) 393.
- [6] Riess A. G., Yuan W., Macri L. M. and others , ApJ , 934 (2022) L7.
- [7] Aghanim N., Akrami Y., Ashdown M. and others , A&A , 641 (2020) A6.
- [8] Weinberg S. , Cosmology , (Oxford Univ. Press, Oxford) 2008.
- [9] Vagnozzi S. , Phys. Rev. D , 102 (2020) 023518.
- [10] Hu J.-P. and Wang F.-Y. , Universe , 9 (2023) 94.
- [11] Krishnan C., Colg´in E. O. a ´ and others , Phys. Rev. D , 103 (2021) 103509.
- [12] Krishnan C. and Mondol R. , preprint arXiv:2201.13384.
- [13] Wong K. C., Suyu S. H., Chen G. C.-F. and others , MNRAS , 498 (2020) 1420.
- [14] Kazantzidis L. and Perivolaropoulos L. , Phys. Rev. D , 102 (2020) 023520.
- [15] Krishnan C., Colg´in E. O. a ´ and others , Phys. Rev. D , 102 (2020) 103525.
- [16] Dainotti M. G., De Simone B., Schiavone T. and others , ApJ , 912 (2021) 150.
- [17] Dainotti M. G., De Simone B., Schiavone T. and others , Galaxies , 10 (2022) 24.
- [18] Schiavone T., Montani G., Dainotti M. G. and others , preprint arXiv:2205.07033.
- [19] Schiavone T., Montani G. and Bombacigno F. , MNRAS Letters , 522 (2023) L72.
- [20] Colg´ ain E. O., Sheikh-Jabbari M. M. ´ and Solomon R. , Phys. Dark Univ. , 40 (2023) 101216
- [21] Dainotti M. G., De Simone B. and others , PoS , CORFU2022 (2023) 235
- [22] Jia X. D., Hu J. P. and Wang F. Y. , A&A , 674 (2023) A45.
- [23] Montani G., De Angelis M., Bombacigno F. and Carlevaro N. , MNRAS Letters , 527 (2023) L156.
- [24] Malekjani M., Mc Conville R., Colg´in E. O. a ´ and others , EPJC , 84 (2024) 317.
[25]
Colg´ ain E. O., Sheikh-Jabbari M. M., Solomon R.
´
and others
,
Phys. Dark Univ.
,
44
(2024) 101464
- [26] Liu Y., Yu H. and Wu P. , Phys. Rev. D , 110 (2024) L021304.
- [27] Nojiri S. and Odintsov S. D. , eConf , C0602061 (2006) 06.
- [28] Sotiriou T. P. and Faraoni V. , Rev. Mod. Phys. , 82 (2010) 451.
- [29] Nojiri S., Odintsov S. D. and Oikonomou V. K. , Phys. Rept. , 692 (2017) 1.
- [30] Odintsov S. D., S´ez-Chill´n G´mez D. a o o and Sharov G. S. , Nucl. Phys. B , 966 (2021) 115377.
- [31] Nojiri S., Odintsov S. D. and Oikonomou V. K. , Nucl. Phys. B , 980 (2022) 115850.
- [32] Chen H., Katsuragawa T., Nojiri S. and Qiu T. , preprint arXiv:2406.16503.
- [33] Montani G., Carlevaro N. and De Angelis M. , preprint arXiv:2407.12409.
- [34] Hu W. and Sawicki I. , Phys. Rev. D , 76 (2007) 064004.
- [35] Scolnic D. M., Jones D. O., Rest A. and others , ApJ , 859 (2018) 101.
- [36] Starobinsky A. A. , JETP Lett. , 86 (2007) 157-163.
- [37] Tsujikawa S. , Phys. Rev. D , 77 (2008) 023507.
- [38] Starobinsky A. A. , Phys. Lett. B , 91 (1980) 99.
- [39] Cosmai L., Fanizza G. and Tedesco L. , Int. J. Theor. Phys. , 55 (2016) 754.
- [40] Fanizza G., Franchini G., Gasperini M. and Tedesco L. , Gen. Rel. Grav. , 52 (2020) 111.
- [41] Brout D., Hinton S. and Scolnic D. , ApJ Lett. , 912 (2021) L26
- [42] Montani G., Carlevaro N. and Dainotti M. G. , Phys. Dark Univ. , 44 (2024) 101486
- [43] Lenart A. L., Bargiacchi G., Dainotti M. and others , ApJ Suppl. , 264 (2023) 46
- [44] Bargiacchi G., Dainotti M. G., Nagataki S. and Capozziello S. , MNRAS , 521 (2023) 3909
- [45] Dainotti M. G., Bargiacchi G., Bogdan M. and others , ApJ , 951 (2023) 63 | null | [
"Tiziano Schiavone",
"Giovanni Montani"
]
| 2024-08-02T17:35:24+00:00 | 2024-11-06T17:55:03+00:00 | [
"gr-qc",
"astro-ph.CO"
]
| Evolution of an effective Hubble constant in $f(R)$ modified gravity | We investigate the Hubble constant tension within $f(R)$ modified gravity in
the Jordan frame, focusing on its application to the dynamics of an isotropic
Universe. A scalar field, non-minimally coupled to the metric, provides an
extra degree of freedom compared to General Relativity. We analyze the impact
of such a scalar field on the cosmic expansion, leading to an effective Hubble
constant $H_{0}^{\text{eff}}(z)$, dependent on redshift $z$. We show that our
$f(R)$ model might mimic dark energy and provide an apparent variation of the
Hubble constant. Our results align with recent cosmological data analysis in
redshift bins, indicating a decreasing trend of the Hubble constant. The
redshift dependence of $H_{0}^{\text{eff}}(z)$ might potentially reconcile
measurements of the Hubble constant from probes at different redshifts. |
2408.01411v1 | ## Spectroscopic survey of faint planetary-nebula nuclei VI. Seventeen hydrogen-rich central stars ⋆
Nicole Reindl 1 , Howard E. Bond 2 3 , Klaus Werner , and Gregory R. Zeimann 5 , 4
- 1 Landessternwarte Heidelberg, Zentrum für Astronomie, Ruprecht-Karls-Universität, Königstuhl 12, 69117 Heidelberg, Germany
- 2 Department of Astronomy and Astrophysics, Penn State University, University Park, PA 16802, USA
- 3 Space Telescope Science Institute, 3700 San Martin Dr., Baltimore, MD 21218, USA
- 4 Institut für Astronomie und Astrophysik, Kepler Center for Astro and Particle Physics, Eberhard Karls Universität, Sand 1, 72076 Tübingen, Germany
- 5 Hobby-Eberly Telescope, University of Texas at Austin, Austin, TX 78712, USA
Received 22 July 2024 Accepted 31 July 2024
## ABSTRACT
We present an analysis of 17 H-rich central stars of planetary nebulae (PNe) observed in our spectroscopic survey of nuclei of faint Galactic PNe carried out at the 10-m Hobby-Eberly Telescope. Our sample includes ten O(H) stars, four DAO white dwarfs (WDs), two DA WDs, and one sdOB star. The spectra were analyzed by means of NLTE model atmospheres, allowing us to derive the e ff ective temperatures, surface gravities, and He abundances of the central stars. Sixteen of them were analyzed for the first time, increasing the number of hot H-rich central stars with parameters obtained through NLTE atmospheric modeling by approximately 20%. We highlight a rare hot DA WD central star, Abell 24, which has a T e ff likely in excess of 100 kK, as well as the unusually high gravity mass of 0 70 . ± 0 05 M . ⊙ for the sdOB star Pa 3, which is significantly higher than the canonical extreme horizontal-branch star mass of ≈ 0 48 M . ⊙ . By investigating Zwicky Transient Facility light curves, which were available for our 15 northern objects, we found none of them show a periodic photometric variability larger than a few hundredths of a magnitude. This could indicate that our sample mainly represents the hottest phase during the canonical evolution of a single star when transitioning from an asymptotic giant branch star into a WD. We also examined the spectral energy distributions, detecting an infrared excess in six of the objects, which could be due to a late-type companion or to hot ( ≈ 10 3 K) and or cool ( / ≈ 100 K) dust. We confirm previous findings that spectroscopic distances are generally higher than found through Gaia astrometry, a discrepancy that deserves to be investigated systematically.
Key words. white dwarfs - stars: stars: atmospheres - stars: abundances - stars: AGB and post-AGB
## 1. Introduction
About two-thirds of all central stars of planetary nebulae (CSPNe) have hydrogen-rich atmospheres, according to the catalog of CSPNe published by Weidmann et al. (2020). However, although this catalog contains 290 CSPNe classified as H-rich, the number that have actually been analyzed by means of nonlocal thermodynamic equilibrium (NLTE) model atmospheres is less than a hundred. A large sample of 27 old, H-rich CSPNe was analyzed by Napiwotzki (1999) based on optical spectra and metal-free NLTE models. In addition, far-ultraviolet (FUV) spectra of 10 and 15 H-rich CSPNe were analyzed by Herald & Bianchi (2011) and Ziegler (2012), respectively, using sophisticated metal-line-blanketed expanding and static NLTE models. Atmospheric parameters for further H-rich CSPNe have been presented in works related to individual objects or as part of analyses from surveys targeting CSPNe and hot white dwarfs (WDs) and pre-WDs (Herrero et al. 1990; Liebert et al. 1995; McCarthy et al. 1997; Mendez et al. 1988, 1992; Rauch et al.
Send o ff print requests to : Nicole Reindl e-mail: [email protected]
⋆ Based on observations obtained with the Hobby-Eberly Telescope (HET), which is a joint project of the University of Texas at Austin, the Pennsylvania State University, Ludwig-Maximillians-Universität München, and Georg-August Universität Göttingen. The HET is named in honor of its principal benefactors, William P. Hobby and Robert E. Eberly.
1999; De Marco et al. 2015; Aller et al. 2015; Reindl et al. 2014, 2017, 2021, 2023; Hillwig et al. 2017; Werner et al. 2019; Je ff ery et al. 2023; Bond et al. 2024). Based on a literature search, we count 75 H-rich hot CSPNe that have been analyzed previously using NLTE atmospheric models.
The prima facie assumption is that H-rich CSPNe represent the hottest and shortest-lived phase during the canonical evolution of a single star when transitioning from an asymptotic giant branch (AGB) star into an H-rich WD. However, the metamorphosis of an AGB or red-giant-branch (RGB) star into a WD remains far from being fully understood. We still do not even know whether every star actually goes through a planetary-nebula (PN) phase or whether PNe are mainly the outcome of binary interactions (Bond 2000; Moe & De Marco 2006, 2012; De Marco 2009; Jones 2019; Bo ffi n & Jones 2019).
In fact, the H-rich CSPNe include numerous examples that do not conform to the classical (single star) picture of evolution. Weidmann et al. (2020) state that close binary CSPNe are preferably found among H-rich CSPNe. These binaries include reflection-e ff ect systems consisting of a hot (pre-)WD and a strongly irradiated late-type companion (e.g., Bond et al. 1978; Shimanskii et al. 2008). A few of these systems even raise the question of whether the occurrence of PNe is restricted to postAGB stars or whether PNe could also be created around postRGB stars (Hall et al. 2013; Hillwig et al. 2016, 2017; Jones
et al. 2020, 2022). In addition, there are a few H-rich doubledegenerate binary central stars known (e.g., De Marco et al. 2015; Santander-García et al. 2015; Reindl et al. 2020) as well as one system consisting of an H-rich pre-WD and a possible Atype companion with an orbital period of ≈ 3300 d (Aller et al. 2015; Jones et al. 2017).
Furthermore, the H-rich group of CSPNe includes two examples of central stars that allow us to witness stellar evolution in 'real time.' These objects, which are thought to have undergone a late He-shell flash, are FG Sge and V839 Ara (SAO 244567). The object FGSge was observed to be H-rich in the 1960s, but it turned into an H-deficient and s -process enriched object a few decades later (Je ff ery & Schönberner 2006). The object V839Ara, on the other hand, still shows an H-rich composition and is currently returning to the AGB-where in a couple of hundred years it will likely transform into an H-deficient star as well (Reindl et al. 2014, 2017).
Some apparent PNe around hot H-rich stars turn out to actually be Strömgren spheres in the interstellar medium rather than material ejected from the star. The ionizing sources of these lowexcitation 'PN mimics' are often found to be He-core burning extreme-horizontal branch (EHB) stars (Frew et al. 2010; Hillwig et al. 2022) or post-EHB stars (Ziegler et al. 2012).
This is the sixth work in a series of papers presenting results from a spectroscopic survey of nuclei of faint Galactic PNe. The survey was carried out with the second generation LowResolution Spectrograph (LRS2; Chonis et al. 2016) of the 10-m Hobby-Eberly Telescope (HET; Ramsey et al. 1998; Hill et al. 2021) located at McDonald Observatory in west Texas, USA. An overview of the survey as well as a description of the instrumentation and data reduction procedures, target selection, and some initial results were presented in our first paper (Bond et al. 2023a, hereafter Paper I). Paper II (Bond et al. 2023b) discusses the central star of the PN mimic Fr 2-30, and Paper III (Werner et al. 2024) presents discoveries of three new extremely hot Hdeficient planetary-nebula nuclei (PNNi). In Paper IV (Bond & Zeimann 2024), we reported that the nucleus of Pa 27 is a rapidly rotating late-type star, and Paper V (Bond et al. 2024) focuses on the peculiar central star of the PN, Abell 57. In this sixth publication, we present analyses of 17 hot and H-rich CSPNe. Of these, 16 were analyzed for the first time, increasing the number of hot H-rich CSPNe for which NLTE atmospheric parameters are available by ≈ 20%.
In Sect. 2 we introduce the targets, and in Sect. 3 we give an overview of the observations. The spectral classification and analysis are presented in Sect. 4 and Sect. 5, respectively. We then derive the Kiel masses (Sect. 6), search for photometric variability (Sect. 7), and perform fits to the spectral energy distributions (SEDs) of our stars (Sect. 8). We discuss our results in Sect. 9 and conclude in Sect. 10.
## 2. Targets
As explained in our previous papers, we assembled a lengthy target list of central stars, most of them belonging to faint PNe discovered in recent years by amateur astronomers, and this list was submitted to the HET observing queue (see Shetrone et al. 2007). Exposures were chosen for execution by the telescope schedulers from the list, essentially at random, depending on sky conditions and lack of observable higher-ranked targets.
The first two columns of Table 1 list the names and PN G designations of the host PNe for the 17 central stars for which we obtained the observations discussed in this paper. The next columns give the celestial and Galactic coordinates, parallaxes, and magnitudes and colors of the central stars, all taken from Gaia Data Release 3 1 (DR3; Gaia Collaboration et al. 2016, 2023). Further information about the objects, including direct images of the PNe at several wavelengths, is contained in the online Hong-Kong AAO Strasbourg H / / / α Planetary Nebulae (HASH) database 2 (Parker et al. 2016; Bojiˇi´ et al. 2017). The c c final column in Table 1 gives the angular radii of the PNe, taken from HASH. Most of the nebulae are relatively large on the sky, but three are more compact, with radii of less than 10 ′′ .
The following subsections give brief details of the discoveries of these faint PNe and their nuclei and some of the nebular properties. As noted in the introduction, the 17 stars analyzed in the present paper all have H-rich atmospheres. Separate papers in our series have analyzed H-deficient nuclei and other objects of special interest. To our knowledge, all but one of the 17 stars in Table 1 have not previously had their spectra discussed in the literature; they are not contained in the recent compilation of spectral classifications of central stars assembled by Weidmann et al. (2020). The one exception is the nucleus of Abell 28, discussed in detail below (Section 5).
## 2.1. Abell 6, 16, 24, 28, and 62
These five nebulae, Abell 6, 16, 24, 28, and 62, were discovered in the classical search of the Palomar Observatory Sky Survey (POSS) photographs for low-surface-brightness PNe by Abell (1966). Abell identified the faint blue central stars for four of them and presented photoelectric or photographic photometry. He was unable to locate the nucleus of Abell 62, likely because of the nebula's large angular size (diameter 166 ′′ ) and its superposition on an extremely rich star field. However, our inspection of the Space Telescope Science Institute's Digitized Sky Survey 3 (DSS) images from 2019 revealed a faint blue star near its center, which we added to our target list. All five Abell central stars are contained in a catalog of PNNi assembled from Gaia DR2 data by Chornay & Walton (2020). One or more of them are included in catalogs of PNNi constructed from searches of Gaia EDR3 for PNNi by González-Santamaría et al. (2021) and or for WDs / by Gentile Fusillo et al. (2021). Several are also contained in a catalog of central stars created by Gómez-Muñoz et al. (2023), who correlated PNe in the HASH database with UV images obtained by the Galaxy Evolution Explorer (GALEX) and other sky surveys.
## 2.2. Alv 1
This large (diameter 270 ′′ ) and very low-surface-brightness PN was discovered serendipitously by amateur Felipe Alves in deep narrow-band images he obtained of the nearby and much brighter nebula MWP 1. Details of the discovery of Alv 1 are given by Acker et al. (2012), who presented images and pointed out its 18th-magnitude central star. 4 The nucleus is contained in several recent lists of hot subluminous stars and or PNNi re-/ vealed in searches of the Gaia catalog, including those by Geier et al. (2019), Chornay & Walton (2020), Gentile Fusillo et al. (2021), and Culpan et al. (2022).
https://vizier.cds.unistra.fr/viz-bin/VizieR-3?
1 -source=I/355/gaiadr3
2 http://hashpn.space/
3 https://archive.stsci.edu/cgi-bin/dss\_form
4 A deep amateur image of Alv 1 is posted at http://www. capella-observatory.com/ImageHTMLs/PNs/MWP1andALV1.htm
Table 1. PN target list and Gaia DR3 data for central stars.
| Name | PN G | RA (J2000) | Dec (J2000) | l [deg] | b [deg] | Parallax [mas] | G | G BP - G RP | R PN |
|----------|--------------|--------------|---------------|-----------|-----------|---------------------|-------|---------------|-----------|
| Abell 6 | 136.1 + 04.9 | 02 58 41.864 | + 64 30 06.28 | 136.1 | + 04.93 | 0 . 869 ± 0 . 143 | 18.4 | 0 . 97 | 94 ′′ |
| Abell 16 | 153.7 + 22.8 | 06 43 55.418 | + 61 47 24.66 | 153.77 | + 22.83 | 0 . 762 ± 0 . 173 | 18.62 | - 0 . 18 | 74 ′′ |
| Abell 24 | 217.1 + 14.7 | 07 51 37.554 | + 03 00 21.16 | 217.17 | + 14.75 | 1 . 391 ± 0 . 097 | 17.37 | - 0 . 57 | 198 ′′ |
| Abell 28 | 158.8 + 37.1 | 08 41 35.555 | + 58 13 48.38 | 158.8 | + 37.18 | 2 . 606 ± 0 . 071 | 16.5 | - 0 . 44 | 165 ′′ |
| Abell 62 | 047.1 - 04.2 | 19 33 17.889 | + 10 36 59.76 | 47.18 | - 04.29 | 0 . 186 ± 0 . 213 | 18.57 | - 0 . 02 | 83 ′′ |
| Alv 1 | 079.8 - 10.2 | 21 15 06.658 | + 33 58 18.74 | 79.89 | - 10.26 | 0 . 604 ± 0 . 127 | 18.28 | - 0 . 37 | 135 ′′ |
| Fe 4 | 030.6 - 16.4 | 19 46 30.838 | - 09 21 20.00 | 30.66 | - 16.45 | 0 . 158 ± 0 . 051 | 16.07 | - 0 . 23 | 15 ′′ |
| Kn 2 | 043.3 + 10.4 | 18 32 40.005 | + 13 58 02.43 | 43.4 | + 10.41 | 0 . 108 ± 0 . 079 | 17.3 | - 0 . 11 | 28 ′′ |
| Kn 40 | 198.6 - 06.7 | 06 00 47.193 | + 09 28 39.90 | 198.64 | - 06.74 | 0 . 193 ± 0 . 111 | 17.46 | - 0 . 11 | 18 . 5 ′′ |
| Kn 45 | 066.5 - 14.8 | 20 53 03.941 | + 21 00 10.96 | 66.51 | - 14.90 | 0 . 484 ± 0 . 175 | 18.46 | - 0 . 41 | 72 . 5 ′′ |
| Pa 3 | 090.8 + 06.1 | 20 46 10.639 | + 52 57 05.39 | 90.82 | + 06.12 | 0 . 986 ± 0 . 028 | 15.9 | 0 . 16 | 36 ′′ |
| Pa 12 | 012.4 + 17.8 | 17 09 38.625 | - 09 00 41.47 | 12.46 | + 17.84 | 0 . 045 ± 0 . 081 | 17.1 | 0 . 45 | 8 . 5 ′′ |
| Pa 15 | 064.9 - 09.1 | 20 29 07.586 | + 23 11 09.65 | 64.97 | - 09.13 | 0 . 268 ± 0 . 072 | 16.67 | - 0 . 19 | 6 . 0 ′′ |
| Pa 26 | 056.9 - 11.7 | 20 19 46.164 | + 15 14 07.27 | 57 | - 11.71 | - 0 . 082 ± 0 . 074 | 16.91 | - 0 . 30 | 6 . 5 ′′ |
| Pa 41 | 098.3 - 04.9 | 22 10 13.647 | + 50 04 33.41 | 98.31 | - 04.93 | 0 . 469 ± 0 . 072 | 17.36 | - 0 . 09 | 51 ′′ |
| Pa 157 | 035.7 + 19.2 | 17 47 08.507 | + 11 00 20.96 | 35.72 | + 19.20 | 0 . 308 ± 0 . 054 | 16.3 | - 0 . 27 | 15 ′′ |
| Pre 8 | 134.3 - 43.2 | 01 26 36.058 | + 18 51 18.36 | 134.38 | - 43.23 | 0 . 215 ± 0 . 152 | 18.1 | - 0 . 34 | 48 ′′ |
## 2.3. Fe 4
The relatively bright central star of Fe 4 came to our attention through its inclusion in the catalog of PNNi prepared by Chornay & Walton (2020). The PN was discovered by Laurent Ferrero (Ferrero et al. 2015); it is a faint ring with a diameter of about 30 ′′ , encircling a 16th-mag nucleus. 5 The central star is cataloged as a hot subdwarf in the Gaia -based lists of Geier et al. (2019) and Culpan et al. (2022). It is a conspicuous GALEX source.
## 2.4. Kn 2, 40, and 45
Kn 2, 40, and 45 were discovered by amateur Matthias Kronberger in his search of DSS images for faint PNe as part of the Deep Sky Hunters (DSH) collaboration (Kronberger et al. 2006). His discoveries of these three PNe were published by Jacoby et al. (2010), who presented deep narrow-band images of the objects. All three central stars are listed in the Gaia -based catalogs of hot subdwarfs assembled by Geier et al. (2019) and Culpan et al. (2022), and Kn 40 and Kn 45 are also in the catalog of Gentile Fusillo et al. (2019). However, only Kn 40 is contained in the Chornay & Walton (2020) catalog of PNNi. The nuclei of Kn 2 and Kn 45 are bright GALEX sources.
## 2.5. Pa 3, 12, 15, 26, 41, and 157
These six faint PNe (or candidate PNe) were discovered by Dana Patchick. Pa 3 was listed as a candidate PN by Kronberger et al. (2006), and there is a narrow-band image of it in Jacoby et al. (2010). The discovery of Pa 12, likewise accompanied by a narrow-band image, was published by Jacoby et al. (2010). Pa 15, 26, and 41 were listed as new PNe by Kronberger et al. (2014), and Pa 157 was included in a private communication of DSH discoveries to us from G. Jacoby.
All of the central stars are bright GALEX sources, with the exception of Pa 12, which lies at a location never imaged by
5 A deep narrow-band image of Fe 4 is available at https:// www.chart32.de/component/k2/objects/planetaty-nebulae/ fe4-planetary-nebula
GALEX. The nuclei of Pa 3, 15, 26, and 157 are contained in the Geier et al. (2019) catalog of subluminous hot stars found in their Gaia survey, and those of Pa 3, 26, and 157 are listed by Culpan et al. (2022).
## 2.6. Pre 8
Pre 8 is a high-Galactic-latitude PN discovered by Trygve Prestgard. 6 It is included in an extensive list of faint PNe discovered by French amateurs published by Le Dû et al. (2018). Our inspection of DSS images revealed its conspicuous blue central star. The nucleus is also listed as a hot subdwarf by Geier et al. (2019) and Culpan et al. (2022).
## 3. Observations and data reduction
Paper I gives full details of the LRS2 instrumentation used for our survey. We note here that LRS2 is composed of two integralfield-unit (IFU) spectrographs: blue (LRS2-B) and red (LRS2R). All of the observations discussed in this paper were made with LRS2-B, which employs a dichroic beamsplitter to send light simultaneously into two units: the 'UV' channel (covering 3640-4645 Å at resolving power 1910) and the 'Orange' channel (covering 4635-6950 Å at resolving power 1140). The data were initially processed using Panacea , 7 which performs bias and flat-field correction, fiber extraction, and wavelength calibration. An absolute-flux calibration comes from default response curves and measures of the telescope mirror illumination as well as the exposure throughput from guider images. We then applied LRS2Multi 8 to the un-sky-subtracted, flux-calibrated fiber spectra in order to perform background and sky subtraction in an annular aperture, source extraction using a 2 ′′ radius aperture, and combination of multiple exposures, if applicable, similar to the description in Paper II. The final spectra from both channels
6 Details of Prestgard's discovery, and a deep narrow-band image, are available at https://skyhuntblog.wordpress.com/ planetary-nebulae/my-planetary-nebula-candidates/
7 https://github.com/grzeimann/Panacea
8 https://github.com/grzeimann/LRS2Multi
Table 2. Log of HET LRS2-B observations.
| Central Star of | Date [YYYY-MM-DD] | Exposure [s] |
|-------------------|---------------------|----------------|
| Abell 6 | 2019-12-01 | 3 × 500 |
| Abell 6 | 2020-12-25 | 2 × 1200 |
| Abell 6 | 2021-11-07 | 2 × 1200 |
| Abell 16 | 2020-11-18 | 2 × 1000 |
| Abell 16 | 2021-10-30 | 2 × 1200 |
| Abell 24 | 2020-11-22 | 2 × 500 |
| Abell 24 | 2021-11-11 | 2 × 600 |
| Abell 28 | 2019-10-22 | 180 |
| Abell 28 | 2021-11-05 | 360 |
| Abell 28 | 2022-04-17 | 360 |
| Abell 62 | 2021-07-08 | 2 × 1000 |
| Abell 62 | 2021-10-03 | 2 × 1000 |
| Abell 62 | 2022-07-20 | 2 × 1200 |
| Alv 1 | 2022-06-10 | 2 × 1000 |
| Fe 4 | 2023-07-19 | 240 |
| Kn 2 | 2019-10-06 | 2 × 300 |
| Kn 40 | 2019-11-18 | 2 × 300 |
| Kn 40 | 2021-11-02 | 2 × 600 |
| Kn 40 | 2021-11-03 | 2 × 600 |
| Kn 45 | 2019-10-30 | 60 |
| Kn 45 | 2021-10-17 | 300 |
| Pa 3 | 2019-10-15 | 120 |
| Pa 3 | 2022-06-11 | 360 |
| Pa 3 | 2022-08-04 | 360 |
| Pa 12 | 2019-08-05 | 450 |
| Pa 15 | 2020-08-06 | 240 |
| Pa 15 | 2021-05-20 | 500 |
| Pa 15 | 2021-11-10 | 500 |
| Pa 15 | 2022-05-08 | 2 × 600 |
| Pa 15 | 2022-05-15 | 2 × 600 |
| Pa 26 | 2020-10-17 | 360 |
| Pa 41 | 2020-11-19 | 2 × 375 |
| Pa 41 | 2021-05-18 | 2 × 750 |
| Pa 41 | 2022-05-22 | 2 × 750 |
| Pa 41 | 2022-06-10 | 2 × 750 |
| Pa 157 | 2021-02-24 | 200 |
| Pa 157 | 2021-05-18 | 400 |
| Pa 157 | 2022-03-21 | 400 |
| | 2022-05-21 | 400 |
| Pre 8 | 2022-07-10 | 800 |
were resampled to a common linear grid with a 0.7 Å spacing and then normalized to a flat continuum for atmospheric analysis. An observation log for our LRS2-B exposures is presented in Table 2.
## 4. Spectral classification
Table 3 lists our 17 targets and their atmospheric parameters, helium contents, and masses derived in the discussion in the next section. The second column in the table lists spectral types inferred from our LRS2-B spectra. The majority (ten) of our targets are classified as O(H) stars, according to the classification scheme of Mendez (1991). A large fraction of central stars are assigned to this spectral type (Weidmann et al. 2020). They are hot H-rich pre-WDs approaching their maximum e ff ective temperature during post-AGB evolution. Six of our central stars are hot H-rich WDs. According to the usual classification scheme
(e.g., Wesemael et al. 1993), four of them are DAO WDs because they display an ionized helium line (He II λ 4686 Å). The other two are DA WDs, that is, they have a pure Balmer-line spectrum. Finally, we have one exceptional object (Pa 3) that displays a spectrum of a hot subdwarf. It is of spectral type sdOB, meaning that besides the Balmer lines, we observe lines from neutral helium plus He II λ 4686 Å (see, e.g., Heber 2016).
Figures 1 and 2 present plots of our rectified LRS2-B spectra. As shown in Figure 1, a few of our O(H) stars display very weak photospheric emission lines of highly ionized carbon, nitrogen, and or oxygen. We identified C IV / λ 4658 Å (in Pa 15), CIV λλ 5801 5812 Å (Fe 4, Kn 40, Pa 15), N V , λ 4945 Å (Kn 40, Pa 15, Pa 41), O V λ 4124 Å (Kn 40, Pa 15), O V λ 4930 Å (Kn 40, Pa 15, Pa 157), O V λ 6500 Å (Pa 15), as well as O VI λ 5291 Å (Kn 40, Pa 15).
We note that the subtraction of emission lines from the surrounding PNe has succeeded well in the majority of cases, because most of the nebulae are extremely faint. Only for Pa 12, Pa 15, and Pa 26, whose spectra are the top three plotted in Figure 1, did we observe that the [O iii ] and H α emission lines have been oversubtracted. These targets are those with the three smallest PN angular radii (see Table 1).
The unique assignment of central-star spectra to a spectral class often requires knowledge of the atmospheric parameters. In particular, O(H) stars and hot subdwarfs can have rather similar spectra. Also, the transition between the hottest O(H) stars and DAO WDs is continuous. One possibility to distinguish between both classes is the surface gravity. Somewhat arbitrarily, the value log g = 7 is usually chosen, and above this value, a star is regarded as a WD (e.g., Wesemael et al. 1993). Perhaps more meaningful is the choice that we followed to call a star an O(H) type before it reaches the maximum e ff ective temperature during its post-AGB evolution and to regard it as a (DAO) WD afterward, when it starts to cool along the WD sequence (e.g., Reindl et al. 2023). In practice this means that the value of the surface gravity that limits O(H) stars from WDs is smaller than log g = 7 and is around log g = 6 4 for the objects with the . lowest post-AGB remnant masses.
## 5. Atmospheric analysis
To derive the e ff ective temperatures, surface gravities, and helium abundances for our program stars, we performed global χ 2 spectral fits to consider several absorption lines of H and He and calculated the statistical 1 σ errors. For the DA- and DAO-type WDs, we used the metal-free model grids introduced in Reindl et al. (2023), while for the O(H)-type stars, we employed the H He model grid of Reindl et al. (2016). For the sdOB star, + Pa 3, we relied on the sdOstar2020 grid (Dorsch et al. 2021), which also considers metal opacities for C, N, O, Ne, Mg, Al, Si, P, S, Ar, Ca, Fe, and Ni. All model atmospheres are hydrostatic, chemically homogeneous, and assume NLTE. The derived atmospheric parameters are listed in columns 3 and 4 in Table 3, and the helium-to-hydrogen ratios by numbers are in column 5. Our best spectral fits are plotted in Figures 1 and 2.
For two stars (Pa 15 and Alv 1), the fit reached the border of the model grid; therefore, the derived parameters must be regarded as estimates only. As can be seen in Figures 1 and 2, both stars su ff er from a well-known Balmer-line problem, namely, the failure to achieve a consistent fit to all Balmer (and He II) lines simultaneously. This means that for a particular object, di ff erent values of T e ff follow from fits to di ff erent Balmer line series members. This problem is commonly seen in very hot (pre-)
Table 3. Spectral types, atmospheric parameters, and Kiel masses of our 17 H-rich CSPNe.
| Name | Spectral Type | T e ff [kK] | log g | log(He / H) | M [M ⊙ ] | Remarks |
|----------|-----------------|-----------------|-----------------|-------------------|-----------------|-----------|
| Abell 6 | DAO | 86 . 9 ± 6 . 8 | 6 . 90 ± 0 . 12 | - 1 . 35 ± 0 . 13 | 0 . 50 ± 0 . 04 | |
| Abell 16 | DAO | 83 . 4 ± 1 . 5 | 7 . 27 ± 0 . 06 | - 1 . 60 ± 0 . 06 | 0 . 54 ± 0 . 02 | |
| Abell 24 | DA | 109 . 2 ± 1 . 0 | 7 . 70 ± 0 . 03 | . . . | 0 . 66 ± 0 . 03 | (1) |
| Abell 28 | DA | 63 . 8 ± 0 . 4 | 7 . 76 ± 0 . 02 | . . . | 0 . 61 ± 0 . 02 | (1) |
| Abell 62 | DAO | 89 . 1 ± 1 . 7 | 7 . 46 ± 0 . 05 | - 1 . 75 ± 0 . 06 | 0 . 58 ± 0 . 03 | |
| Alv 1 | O(H) | ≈ 170 . 0 | ≈ 6 . 55 | ≈ - 0 . 71 | ≈ 0 . 62 | (2) |
| Fe 4 | O(H) | 75 . 7 ± 2 . 2 | 5 . 25 ± 0 . 02 | - 1 . 37 ± 0 . 04 | 0 . 51 ± 0 . 02 | |
| Kn 2 | O(H) | 85 . 7 ± 2 . 4 | 5 . 33 ± 0 . 04 | - 1 . 03 ± 0 . 06 | 0 . 55 ± 0 . 04 | |
| Kn 40 | O(H) | 95 . 2 ± 2 . 1 | 5 . 71 ± 0 . 02 | - 1 . 36 ± 0 . 04 | 0 . 53 ± 0 . 05 | |
| Kn 45 | DAO | 90 . 2 ± 2 . 3 | 6 . 86 ± 0 . 06 | - 1 . 55 ± 0 . 07 | 0 . 50 ± 0 . 02 | |
| Pa 3 | sdOB | 37 . 2 ± 0 . 1 | 6 . 11 ± 0 . 01 | - 1 . 56 ± 0 . 02 | ≈ 0 . 48 | (3) |
| Pa 12 | O(H) | 65 . 0 ± 5 . 8 | 5 . 12 ± 0 . 07 | - 1 . 44 ± 0 . 08 | 0 . 45 ± 0 . 04 | (4) |
| Pa 15 | O(H) | ≈ 100 . 0 | ≈ 5 . 18 | ≈ - 1 . 05 | ≈ 0 . 67 | (2,4) |
| Pa 26 | O(H) | 94 . 1 ± 3 . 6 | 5 . 16 ± 0 . 02 | - 1 . 01 ± 0 . 04 | 0 . 63 ± 0 . 04 | (4) |
| Pa 41 | O(H) | 136 . 6 ± 6 . 6 | 5 . 95 ± 0 . 02 | - 0 . 78 ± 0 . 04 | 0 . 61 ± 0 . 04 | |
| Pa 157 | O(H) | 91 . 0 ± 0 . 9 | 5 . 44 ± 0 . 01 | - 1 . 07 ± 0 . 02 | 0 . 55 ± 0 . 02 | |
| Pre 8 | O(H) | 130 . 0 ± 9 . 6 | 6 . 44 ± 0 . 07 | - 0 . 80 ± 0 . 10 | 0 . 55 ± 0 . 05 | |
Notes. ( 1 ) Pure H atmosphere; ( 2 ) Parameters uncertain due to star lying near border of theoretical grid; ( 3 ) sdOstar2020 grid used for analysis (see text); ( 4 ) H α not included in fit due to oversubtraction of PN emission (see text). The helium abundances are given as logarithmic number ratios relative to H.
Fig. 1. Model-atmosphere fits (red graphs) to observed spectra (black graphs) of nine of our H-rich central stars. The spectra are sorted by increasing log g from top to bottom. Spectral classifications, names of stars, derived e ff ective temperatures, surface gravities, and logarithmic He H ratios (by number) are indicated. Identified lines are marked. The PN emission lines are oversubtracted in the top three spectra. Features near / 4640 Å are artifacts where the UV and Orange spectral channels are joined. Several apparently sharp features are instrumental artifacts, marked 'art.' Interstellar absorption lines are labeled 'i.s.," telluric absorption is marked 'tell.,' and imperfectly subtracted night-sky features are labeled 'n.s.' Oversubtracted nebular lines of [O iii ] in the top three spectra are marked 'PN.'

š
Fig. 2. Similar to Figure 1 but for the other eight central stars.
WDs (e.g., Werner et al. 2019). We emphasize that generally, the Balmer-line analysis of the hottest H-rich (pre-)WDs is notoriously prone to large errors. A way out of this problem is the analysis of metal lines in UV spectra. For example, the temperature of one of the hottest known DAs (PG 0948 + 534) was estimated to be 140 ± 12 kK from a Balmer-line fit (Preval & Barstow 2017), but a UV analysis revealed a significantly lower temperature of 105 ± 5 kK (Werner et al. 2019). In addition, we speculate that since Pa 15 is close to the Eddington limit, it likely still has a weak stellar wind. Thus, models for expanding atmospheres would be more suitable for the analysis of this star.
For Pa 12, Pa 15, and Pa 26, we excluded H α from the fit, as it su ff ered from an oversubtraction of the nebular emission line. We note that correctly subtracting the nebular emissions can be challenging in the case of very compact and or asymmetrical / nebulae; therefore, systematic errors on the derived parameters need to be taken into account. For Pa 26-as an example-we derived T e ff = 92 5 . ± 3 5 kK and log . g = 5 15 . ± 0 03 when includ-. ing H α in the fit and T e ff = 94 1 . ± 3 6 kK and log . g = 5 16 . ± 0 02 . when excluding H α .
For the DA-type WD Abell 28, we derived T e ff = 63 8 . ± 0 4 kK and log . g = 7 76 . ± 0 02 using pure-H models. This star . also has two spectra that were obtained by the Sloan Digital Sky Survey (SDSS), and they have been analyzed in several previous studies, as listed in Table 4. Fitting the SDSS spectrum with the higher signal-to-noise ratio and using pure-H NLTE models, Kepler et al. (2019), Tremblay et al. (2019), and Bédard et al. (2020)
derived T e ff ≈ 57 -58 kK and log g ≈ 7 7. . 9 The SDSS spectra were obtained with a fiber diameter of 3 ′′ and are very sensitive to faint nebular emission lines, even in the case of an evolved or a nearby nebula (Yuan & Liu 2013). Therefore, the detection of weak nebular lines in the SDSS spectra of Abell 28 (in particular in H α , but also lines [O III] and [N II], are visible) might not be a surprise. We conclude that our derived atmospheric parameters are more reliable and that our higher T e ff compared to the mentioned works is a result of poor background subtraction of the SDSS spectra.
## 6. Kiel masses
In Fig. 3 we show a Kiel diagram (log g versus T e ff ) for our program stars along with post-AGB evolutionary tracks with metallicity Z = 0 02 from Miller Bertolami (2016) and post-. RGB tracks from (Hall et al. 2013, priv.comm.). For each star in our sample, we derived the stellar mass, M , using the theoretical evolutionary sequences and the griddata interpolation function in python . Uncertainties of the masses were estimated using a Monte Carlo method. The derived Kiel masses are listed in column 6 of Table 3.
9 We note that the lower S N spectrum was fitted by Kleinman et al. / (2013), who derived T e ff = 62 4 . ± 0 1 kK and log . g = 7 58 . ± 0 05. . However, in this work pure-H LTE models were used; therefore, the slightly higher T e ff compared to those reported by Kepler et al. (2019), Tremblay et al. (2019), and Bédard et al. (2020) might be a NLTE e ff ect.
Fig. 3. Kiel diagram showing the positions of our H-rich central stars as purple filled circles. The gray open squares indicate previously analyzed H-rich CSPNe (Herrero et al. 1990; Liebert et al. 1995; McCarthy et al. 1997; Mendez et al. 1988, 1992; Rauch et al. 1999; De Marco et al. 2015; Aller et al. 2015; Reindl et al. 2014, 2017, 2021, 2023; Hillwig et al. 2017; Werner et al. 2019; Je ff ery et al. 2023; Bond et al. 2024). The blue solid lines are postAGB evolutionary tracks from Miller Bertolami (2016), and the light-blue dashed lines are post-RGB evolutionary tracks from Hall et al. (2013). The red dashed-dotted lines correspond to the He-burning main-sequence as well as the zero-age and terminal-age extended horizontal branches. The green dashed line indicates where the He abundances should have decreased down to log (He / H) = -3 according to predictions of Unglaub & Bues (2000).
Table 4. Stellar parameters for the nucleus of Abell 28.
| T e ff / kK | log g | Spectrum Source | Reference |
|----------------|-----------------|-------------------|-------------|
| 62 . 4 ± 1 . 1 | 7 . 58 ± 0 . 05 | SDSS ( a ) | c ) |
| 57 . 8 ± 0 . 4 | 7 . 67 ± 0 . 03 | SDSS ( b ) | ( d ) |
| 57 . 2 ± 0 . 7 | 7 . 66 ± 0 . 05 | SDSS ( b ) | ( e ) |
| 56 . 7 ± 0 . 7 | 7 . 65 ± 0 . 04 | SDSS ( b ) | ( f ) |
| 63 . 8 ± 0 . 4 | 7 . 76 ± 0 . 02 | HET | ( g ) |
Notes. ( a ) MJD 54425 spectrum ( b ) MJD 56220 spectrum ( c ) Kleinman et al. (2013) ( d ) Kepler et al. (2019) ( e ) Tremblay et al. (2019) ( ) f This paper ( g ) This paper
## 7. Light curves
A significant fraction ( ≈ 12-21%) of Galactic CSPNe are photometrically variable (e.g., Bond 2000; Miszalski et al. 2009; Jacoby et al. 2021). This variability is often interpreted as originating from a close binary companion (e.g., Bo ffi n & Jones 2019), but the variability can also stem from pulsations of the CS or in wide binary systems, from a cool spotted or pulsating companion (Jacoby et al. 2021; Bond & Zeimann 2024). In addition, it has recently been proposed that a meaningful number of the hottest WDs develop spots on their surfaces when entering the WDcooling sequence (Reindl et al. 2021, 2023).
In order to check if our stars show photometric variability, we inspected light curves from the Zwicky Transient Facility (ZTF; Bellm et al. 2019; Masci et al. 2019) survey data release 21, which provides photometry in the g and r bands and-less often-in the i band. All of our 15 northern targets have publicly available light curves with around 50-1000 data points in the g and r bands. In Table 5, we provide an overview of the number of data points, mean magnitudes, and mean uncertainties for each object in our sample with available ZTF light curves.
For the analyses of the light curves, we used the V ARTOOLS program (Hartman & Bakos 2016) to perform a generalized Lomb-Scargle (LS) search (Press et al. 1992; Zechmeister & Kürster 2009) for periodic sinusoidal signals. We consider ob- jects variable if they show a periodic signal with a false-alarm probability (FAP) of log( FAP ) ≤ -4. Besides suspicious periods very close to one day, we did not find any hint of periodic variability in our stars. The typical uncertainty of the ZTF g -band light curves ranges from 0 01 . -0 02 mag for stars brighter than . 18 mag and up to 0.06 mag for the faintest stars in our sample; therefore a photometric variability larger than a few hundredths of a magnitude can be excluded.
The standard deviations of the g- and r-band measurements typically agree with the mean uncertainties. Only in the cases of Kn45 and Pa 15 do the standard deviations in the r ( g )-band measurements significantly exceed the mean uncertainties by factors of 7.1(4.6) and 5.9(1.9) for both stars, respectively. We believe this is likely due to nearby and bright stars. Kn 45 has a nearby G = 11 mag star (Gaia DR3 1814597642176881280) at a distance of 11 ′′ , and Pa 15 has a G = 13 mag star (Gaia EDR3 1830887108803635584) at a distance of 4 ′′ . We also note that we did not detect any hints of long-term trends in the light curves, which cover approximately six years.
## 8. Spectral energy distributions
We performed fits to the SEDs of each star, employing the χ 2 SED fitting routine described in Heber et al. (2018) and Irrgang et al. (2021). For this purpose, we collected photometry from various catalogs, such as GALEX (Bianchi et al. 2017), PanSTARRS (Flewelling et al. 2020), Johnson (Henden et al. 2015), Gaia (cyan, Gaia Collaboration et al. 2021a,b), 2MASS (Cutri et al. 2003), SDSS (Alam et al. 2015), Skymapper (Onken et al. 2019), and in the fit, we kept the atmospheric parameters fixed and let the angular diameter, Θ , and the color excess, E (44 -55), 10 vary freely. Interstellar reddening was accounted for by using the reddening law of Fitzpatrick et al. (2019) with RV = 3 1. .
10 Fitzpatrick et al. (2019) employed E (44 -55), which is the monochromatic equivalent of the usual E B ( -V ), using the wavelengths 4400 Å and 5500 Å, respectively. For high e ff ective temperatures, such as for the stars in our sample, E (44 -55) is identical to E B ( -V ).
Table 5. Names, bands of the light curves, number of data points, mean magnitudes, and mean uncertainties of the objects in our sample with available ZTF light curves.
| Name | Band | Data points | Magnitude [mag] | Mean error [mag] |
|----------|--------|---------------|-------------------|--------------------|
| Abell 6 | g | 492 | 18.94 | 0.05 |
| | r | 691 | 18.38 | 0.03 |
| Abell 16 | g | 333 | 18.51 | 0.05 |
| | r | 436 | 18.87 | 0.06 |
| Abell 24 | g | 221 | 17.14 | 0.02 |
| | r | 480 | 17.72 | 0.02 |
| | i | 34 | 18.15 | 0.04 |
| Abell 28 | g | 527 | 16.34 | 0.02 |
| | r | 785 | 16.79 | 0.02 |
| | i | 68 | 17.18 | 0.03 |
| Abell 62 | g | 502 | 18.62 | 0.06 |
| | r | 892 | 18.91 | 0.06 |
| | i | 75 | 19.06 | 0.08 |
| Alv 1 | g | 486 | 18.14 | 0.03 |
| | r | 973 | 18.59 | 0.04 |
| Kn 2 | g | 379 | 17.25 | 0.02 |
| | r | 944 | 17.51 | 0.02 |
| Kn 40 | g | 352 | 17.4 | 0.02 |
| | r | 532 | 17.68 | 0.02 |
| | i | 36 | 18 | 0.03 |
| Kn 45 | g | 461 | 18.21 | 0.03 |
| | r | 909 | 18.34 | 0.04 |
| | i | 101 | 18.36 | 0.06 |
| Pa 3 | g | 58 | 15.99 | 0.01 |
| | r | 83 | 16.03 | 0.01 |
| Pa 15 | g | 52 | 16.36 | 0.02 |
| | r | 98 | 16.76 | 0.02 |
| Pa 26 | g | 80 | 16.72 | 0.02 |
| | r | 124 | 17.11 | 0.02 |
| Pa 41 | g | 573 | 17.23 | 0.02 |
| | r | 806 | 17.44 | 0.02 |
| | i | 47 | 17.57 | 0.02 |
| Pa 157 | g | 93 | 16.2 | 0.01 |
| | r | 140 | 16.56 | 0.01 |
| Pre 8 | g | 125 | 17.87 | 0.03 |
| | r | 152 | 18.29 | 0.03 |
| | i | 82 | 18.5 | 0.05 |
In the top row of Fig. 4, we show two examples of SED fits for stars that do not show an infrared excess. For Abell 24, we noticed that the GALEX FUV and NUV fluxes exceed the flux that is predicted by optical photometry by a factor of five, which is indicated by the dark purple dashed line in Fig. 4. The origin of this UV excess is not understood, and we consequently excluded the GALEX fluxes from the SED fit. The other example is the SED for Abell 6, for which we found the highest color excess: E (44 -55) = 0 983 mag. .
We found that four of the O(H) stars, one DAO WD, and the sdOB star show a near- and or far-infrared excess. The SEDs of / those objects are also displayed in Fig. 4. For those objects, we carried out a multicomponent fit using our best-fit model flux from the atmospheric analysis and one or two blackbody components. In those fits, we additionally let the blackbody T e ff and surface ratios of the blackbodies relatively to that of the star vary freely. We note that for the Wide-Field Infrared Survey Explorer ( WISE ; Wright et al. 2010) bands W1 and W2, we relied on magnitudes reported in the unWISE catalog (Schlafly et al. 2019), as it is based on significantly deeper imaging and o ff ers improved modeling of crowded regions compared to the ALLWISE catalog (Cutri et al. 2021).
Pa 3 shows an excess in the WISE W1 and W2 bands, which can be reproduced with a blackbody with T e ff = 1180 K and a surface ratio of 140 relative to that of the sdOB star.
For Pa 157 the far-infrared excess shows up only in the W4 band, which can be modeled with a blackbody with T e ff = 95 K and a large surface ratio of 10 9 relative to that of the O(H) star. For Pa 12, two blackbody components-one with 800 K and a surface ratio of 3100 relative to that of the O(H) starand another component-with 110 K and a large surface ratio of 2 × 10 9 -are needed to reproduce the far-infrared excess in all four WISE bands. For Pa 26, the infrared excess shows up already at around 10 000 Å. The SED of Pa 26 can be reproduced by assuming our best fit model for the O(H) star, two blackbodies with T e ff = 2690 K and T e ff = 100 K, and surface ratios relative to the O(H) star of 640 and 3 × 10 9 , respectively.
The O(H) star Pre 8 shows a clear far-infrared excess in the WISE W1 and W2 bands, which can be modeled with a blackbody with T e ff = 1810 K and a surface ratio of 3700 relative to that of the O(H) star. There is also a possible excess in the W3 band, which would require another blackbody with T e ff = 110 K and a large surface ratio of 5 7 . × 10 10 , as indicated by the dark purple dashed line in Fig. 4. We remain skeptical about the latter excess, since the S N in the W3 band is only five, and-in / contrast to the other stars with W3 W4 excesses-there is no de-/ tection in the W4 band.
For Abell 16, De Marco et al. (2013) have already reported their discovery of an I -band excess at the 2 σ level using highprecision photometry. They concluded that it is due to an M3 V companion. Consequently, for this object we used PHOENIX models calculated by Husser et al. (2013) and that cover e ff ective temperatures between 2300 K and 12000 K instead of a blackbody component in order to reproduce the infrared excess. We find for the cool companion T e ff = 4200 + 1000 -600 K and a surface ratio relative to that of the DAO star of 58 + 3 -25 .
We note that we do not expect a significant contribution of the nebulae to the optical and UV fluxes of the central stars. Otherwise, we would see excesses in the g , r , and or / Gaia bands, where the strongest nebular lines of [O III] and H α are located. This is not the case even for our most compact PNe.
For sources that have a Gaia parallax measurement, ϖ , with a relative error on the parallax of 40% or smaller, we calculated the radius, R , from the angular diameter via R = Θ / (2 ϖ ) and derived the star's luminosity from the radius and the T e ff from our spectral fitting via L L / ⊙ = ( R R / ⊙ ) 2 ( T e ff / T e ff , ⊙ ) 4 . Finally, we calculated the gravity mass from M grav = g R 2 / G from the radius and the log g as determined from the SED fitting and spectral analysis. The derived radii, luminosities, and gravity masses 11 are listed in Table 6.
For the calculations of the Gaia distances, a Gaussian distributed array of parallaxes was generated, with the distance being the median of this distribution (see Irrgang et al. 2021 for further details). The Gaia parallaxes were corrected for the zeropoint bias using the Python code provided by Lindegren et al. (2021), 12 and the parallax uncertainties were corrected by Eq. 16 in El-Badry et al. (2021).
11 The numbers given are the median and the highest density interval with probability 0.6827 (see Bailer-Jones et al. 2021, for details on this measure of uncertainty).
12 https://gitlab.com/icc-ub/public/gaiadr3\_zeropoint
Fig. 4. Spectral energy distribution fits for eight central stars. Top row: Two examples of SED fits for stars that do not show an IR excess. Remaining spectra: Multicomponent SED fits for the stars in our sample that show a near- and or far-infrared excess. Black dots correspond to / observed photometry; the blue and purple shaded areas correspond to the flux contribution of the CS and a cool blackbody, respectively; and the dark purple line is the (combined) best fit to the observation.
Table 6. Values for the reddening for E B ( -V ) from Schlafly & Finkbeiner (2011) and E (44 -55) as determined in our SED fits, distances, zero-point corrected Gaia distances, spectroscopic distances and radii, luminosities, and gravity masses.
| Name | E ( B - V ) / mag | E (44 - 55) / mag | d Gaia / kpc | d spec / kpc | R / R ⊙ | M grav / M ⊙ | L / L ⊙ |
|------------|---------------------|---------------------------|--------------------------|---------------------------|------------------------------|---------------------------|------------------------|
| Abell 6 | 1 . 090 ± 0 . 060 | 0 . 986 ± 0 . 013 | 1 . 07 + 0 . 21 - 0 15 | 0 . 88 + 0 . 15 - 0 13 | 0 . 053 + 0 . 011 - 0 008 | 0 . 81 + 0 . 47 - 0 29 | 140 + 90 - 60 |
| Abell 16 1 | 0 . 131 ± 0 . 004 | 0 . 157 ± 0 . 015 | 1 . 21 + 0 . 36 - 0 23 | 2 . 02 + 0 . 17 - 0 16 | 0 . 019 + 0 . 006 - 0 004 | 0 . 24 + 0 . 18 - 0 09 | 15 + 11 - 6 |
| Abell 24 | 0 . 033 ± 0 . 003 | 0 . 007 + 0 . 016 - 0 007 | 0 . 71 + 0 . 06 - 0 05 | 0 . 96 ± 0 . 05 | 0 . 0143 + 0 . 0012 - 0 0010 | 0 . 37 + 0 . 07 - 0 06 | 26 + 5 - 4 |
| Abell 28 | 0 . 073 ± 0 . 003 | 0 . 067 ± 0 . 005 | 0 . 38 ± 0 . 01 | 0 . 420 + 0 . 013 - 0 012 | 0 . 0156 ± 0 . 0005 | 0 . 51 ± 0 . 04 | 3 . 64 + 0 . 24 - 0 22 |
| Abell 62 | 0 . 506 ± 0 . 009 | 0 . 333 ± 0 . 012 | | . 1 . 28 ± 0 . 09 | | | . |
| Alv 1 2 | 0 . 127 ± 0 . 004 | 0 . 125 ± 0 . 009 | 1 . 58 + 0 . 44 - 0 29 | ≈ 6 . 50 | ≈ 0 . 018 | ≈ 0 . 05 | ≈ 250 |
| Fe 4 | 0 . 163 ± 0 . 012 | 0 . 186 ± 0 . 005 | 5 . 0 + 2 . 1 - 1 2 | 5 . 56 + 0 . 20 - 0 19 | 0 . 29 + 0 . 13 - 0 07 | 0 . 54 + 0 . 59 - 0 23 | 2500 + 2800 - 1100 |
| Kn 2 | 0 . 254 ± 0 . 003 | 0 . 307 ± 0 . 008 | | 8 . 40 ± 0 . 60 | | . | |
| Kn 40 | 0 . 276 ± 0 . 004 | 0 . 269 ± 0 . 007 | 3 . 5 + 3 . 9 - 1 3 | 6 . 4 ± 0 . 4 | 0 . 13 + 0 . 15 - 0 05 | 0 . 32 + 1 . 07 - 0 20 | 1300 + 4300 - 800 |
| Kn 45 | 0 . 122 ± 0 . 005 | 0 . 151 ± 0 . 023 | 1 . 8 + 1 . 1 - 0 . 5 | 2 . 95 + 0 . 28 - 0 . 26 | 0 . 032 + 0 . 020 - 0 . 009 | 0 . 27 + 0 . 44 - 0 . 14 | 61 + 97 - 30 |
| Pa 12 1 | 0 . 553 ± 0 . 013 | 0 . 602 ± 0 . 014 | | 5 . 0 + 0 . 6 - 0 5 | | | |
| Pa 15 2 | 0 . 208 ± 0 . 005 | 0 . 210 ± 0 . 040 | 3 . 3 + 1 . 3 - 0 8 | ≈ 10 . 1 | ≈ 0 . 130 | ≈ 0 . 09 | ≈ 1500 |
| Pa 157 1 | 0 . 125 ± 0 . 006 | 0 . 179 ± 0 . 006 | 3 . 0 + 0 . 7 - 0 5 | 5 . 82 ± 0 . 14 | 0 . 128 + 0 . 029 - 0 020 | 0 . 17 + 0 . 09 - 0 05 | 1010 + 500 - 290 |
| Pa 26 1 | 0 . 143 ± 0 . 003 | 0 . 05 + 0 . 07 - 0 05 | | 13 . 1 + 1 . 6 - 1 4 | | | |
| Pa 3 1 | 1 . 370 ± 0 . 080 | 0 . 424 ± 0 . 005 | 0 . 99 + 0 . 03 - 0 . 03 | 0 . 82 ± 0 . 01 | 0 . 122 ± 0 . 004 | 0 . 70 ± 0 . 05 | 25 . 8 + 1 . 7 - 1 . 6 |
| Pa 41 | 0 . 327 ± 0 . 007 | 0 . 310 ± 0 . 060 | 2 . 08 + 0 . 40 - 0 29 | 5 . 6 + 0 . 6 - 0 5 | 0 . 05 ± 0 . 01 | 0 . 091 + 0 . 043 - 0 027 | 880 + 460 - 290 |
| Pre 8 1 | 0 . 061 ± 0 . 005 | 0 . 108 ± 0 . 010 | | 5 . 6 ± 0 . 6 | | | |
Notes. ( 1 ) Object shows an infrared excess, multicomponent fit performed. ( 2 ) Parameters uncertain due to star lying near border of theoretical grid;
In addition, spectroscopic distances can be determined from the SED fits via d spec = 2 R / Θ . In this case, the radius was calculated from the Kiel mass and surface gravity via R = p MG /g . In Table 6, we also provide an overview of the derived values for the reddening, E (44 -55); the spectroscopic distances; and if the Gaia parallax has a relative error of less than 40%, the zero-point corrected Gaia distances. For most objects, the reddening derived in our SED fits agrees fairly well with what is reported by the 2D dust map of Schlafly & Finkbeiner (2011), which provides an upper limit on the reddening caused by interstellar dust. Only for Abell 16, Pa 157, and Pre 8 did we find significantly higher values for the reddening compared to Schlafly & Finkbeiner (2011), suggesting that the PN itself contributes notably to the reddening.
## 9. Discussion
## 9.1. Distances
By comparing distances derived from the Gaia parallax with the spectroscopic distances, it is possible to uncover possible systematic errors. In Fig. 5, we plot the Gaia versus spectroscopic distances. We observed that the Gaia distances agree within the error limits with the spectroscopic distances only for Abell 6, Fe 4, and Kn 40. For the majority (70%) of the central stars, the spectroscopic distances significantly exceed the Gaia distances.
The only object whose spectroscopic distance is actually significantly, but still only slightly, larger than the Gaia distance is the sdOB star Pa 3. We note that the atmospheric parameters derived for sdOB stars typically do not su ff er from large systematic uncertainties. Therefore, the mismatch in the Gaia distance ( d Gaia = 992 + 30 -29 pc) and the spectroscopic distance ( d spec = 821 pc) is most likely a result of the assumed
Fig. 5. Gaia versus spectroscopic distances of our stars. The dashed line indicates a one-to-one correlation.

canonical mass of 0.48 M ⊙ . If one were to assume a mass of 0.70 M ⊙ , a perfect agreement with the Gaia distance would be found ( d spec ( M = 0 70M ) . ⊙ = 992 pc).
The fact that spectroscopically derived distances for CSPNe have a tendency to be overestimated when compared to those derived by other methods has been reported in several previous
studies (Napiwotzki et al. 2001; Schönberner et al. 2018; Schönberner & Ste ff en 2019; Frew et al. 2016). A solution to this problem is beyond the scope of this paper, but we nevertheless briefly discuss possible reasons for it.
In principle, an overestimated spectroscopic distance could be caused by an overestimated e ff ective temperature and or un-/ derestimated surface gravity and reddening. We stress that the errors on the spectroscopic distances only assume the formal fitting errors from our χ 2 spectral fits. Yet, as already discussed in Sect. 5, the atmospheric parameters of very hot stars that are derived by Balmer-line analysis su ff er from large systematic uncertainties, and only a UV-metal line analysis could help reduce the systematic errors. On the other hand, again, missing metalline blanketing and lacking UV spectra might not o ff er a trivial explanation for this problem. This was shown by Ziegler et al. (2012) and Löbling et al. (2020), who performed a sophisticated UV spectral analysis of the exciting star of Abell 35 and also found that the spectroscopic distance of this star remains too large, and consequently, its gravity mass would be unrealistically small, which is also the case for our sample. We additionally point out that if the observed flux was overestimated for some reason (possible because the PN or a companion adds additional flux), then the discrepancy between the spectroscopic and Gaia distances would become even larger.
Finally, it is important to note that the spectroscopic distances depend on the assumed mass and on stellar evolutionary computations (e.g., core composition and thickness of the H- or He-envelope). If for some reason the Kiel mass was overestimated, then this could also explain an overestimated spectroscopic distance.
## 9.2. Infrared excesses
Six of our targets were found to show a near- and or far-infrared / excess. One of them is the DAO WD Abell 16, which as discussed above was already proposed to show an I -band excess due to an M3 V stellar companion. Our SED fit for this object revealed T e ff = 4200 + 1000 -600 K and a surface ratio relative to that of the DAO star of 58 + 3 -25 . This e ff ective temperature would rather indicate a late K-type companion, but within the error limits, an M3V-type companion is also possible (Maldonado et al. 2015). From the surface ratio and the Gaia parallax, one can deduce a radius of R = 0 14 . + 0 06 . -0 05 . R . This would be about a factor of two ⊙ to three too small for a mid- or early-type M-dwarf (Maldonado et al. 2015). However, we point out that our SED analysis could still su ff er from additional systematic errors, for instance, because we do not know the metallicity of the M-dwarf. Therefore, we suspect that the factor of two to three agreement of our determined radius as well as what is theoretically predicted is a sign that Abell 16 indeed has a physically connected late-type companion.
A mid-infrared excess was found for the O(H)-type stars Pa 12, Pa 26, and Pre 8 as well as for the sdOB Pa3, and it can be reproduced with blackbody e ff ective temperatures between 800 K and 2690 K. The derived surface ratios relative to the CSs lie between 140 and 3700. Late M dwarfs or T dwarfs, which have similar T e ff , have radii comparable to that of hot preWDs; therefore, an unresolved and physically connected latetype companion seems unlikely to be the (only) source of this excess. A chance alignment of two such special objects (a CS and a foreground late M or even T dwarf) also seems doubtful. The origin of the mid-infrared excess might thus likely be due to hot dust (Phillips & Ramos-Larios 2005; Holberg & Magargal 2005).
For two of the O(H)-type CSPNe that exhibit a mid-infrared excess-Pa 12 and Pa 26-we additionally found a far-infrared excess. In addition, Pa 157 shows a far-infrared excess only, and for Pre 8, we remain skeptical about the excess found in the W3 band due to the low S N and the lack of a W4 magnitude. These / far-infrared excesses can be reproduced with blackbody temperatures around 100 K and large surface ratios relative to the CSs, which is typical for cold dust disks (Chu et al. 2011; Clayton et al. 2014)
## 9.3. Evolutionary status
In the 15 stars with available ZTF light curves, we did not detect any significant periodic photometric variability larger than a few hundredths of a magnitude. This indicates that the majority of stars in our sample represent the hottest phase during the canonical evolution of a single star when transitioning from a AGB star into a WD.
As shown in Figure 3, nearly all of our objects, except Pa 3, can be considered post-AGB stars. They form a canonical evolutionary sequence from O(H) stars to DAO and DA WDs. Their masses range between 0.45 and 0 67 M . ⊙ , with a mean of 0 56 . ± 0 06 M . ⊙ . This agrees well with the mean mass of a sample of hot DAO WDs investigated by Gianninas et al. (2010) with NLTE models: 0 58 . ± 0 06 M . ⊙ .
As for the He H abundance ratios, for the O(H) stars, they / scatter around the expected solar value of 0.1 (from about 0.4 to 1.9 times solar). For the DAO WDs, He is systematically depleted (about 0.2 to 0.4 times solar). This is due to the onset of gravitational settling of helium (Unglaub & Bues 2000). In the case of our two DA WDs, this process has removed helium from their atmospheres, particularly because of their high surface gravities. This is also demonstrated in Fig. 3, where several DAO WDs lie to the left of the green dashed line, which indicates where the He abundances should have decreased down to log (He / H) = -3 according to the predictions of Unglaub & Bues (2000). In contrast, the DA WD Abell 28 lies past this line, and our only other DA star, Abell 24, lies very close to it. We note that for such high T e ff -as found for Abell 24 (109.2 kK)and low-resolution spectra, the predicted He II λ 4686 Å line is very weak, even for log (He / H) = -2, and higher-resolution spectra might perhaps show that Abell 24 is actually a DAO WD. The high e ff ective temperature of this star is also noteworthy, as there appears to be a striking paucity of H-rich WDs relative to their H-deficient counterparts at the very hot ( T e ff > 100 kK) end of the WD cooling sequence (Werner et al. 2019).
Three of our CSPNe, Pa 12, Kn 45, and Abell 6, might be considered as possible candidates for post-RGB CSPNe. Until now, no definitively post-RGB CSPN has been identified, but nine candidates have been suggested in the literature (Jones et al. 2022; Reindl et al. 2023). For some of them, the post-RGB candidate status is based only on a low (i.e., M < 0 5 M . ⊙ ) Kiel and sometimes gravity mass, while for other post-RGB candidates, multiband light curves (and partly radial-velocity fitting) have been employed to support this assumption. We note that our candidates are located close to the lowest-mass post-AGB tracks, and as discussed in Sect. 5, their atmospheric parameters likely still su ff er from systematic errors. Unless their low masses are confirmed by UV spectral analysis (which o ff ers a more reliable determination of the atmospheric parameters) and or the /
presence of a close companion, we consider these CSs as only weak candidates for post-RGB CSPNe.
The sdOB star Pa 3 is located close to the EHB and He-main sequence (Figure 3); hence it can be considered as a He-core burning star. These stars are thought to have lost almost their entire envelope due to an interaction with a binary companion during their earlier evolution but to have still managed to ignite He after the envelope was ejected (Heber 2016). However, since the core He burning lasts for about 10 8 yrs in these stars, the detection of a PN at this stage is unlikely. As mentioned in Sect. 2.5, the nebula was listed as a candidate PN in the HASH database with the note that the nebula spectrum is more like that of an H ii region. This reinforces our suspicion.
It is interesting to note that we found an unusually high gravity mass of 0 70 . ± 0 05 M . ⊙ for Pa 3, which is significantly higher than the canonical EHB star mass of ≈ 0 48 M . ⊙ . Recently, Lei et al. (2023) derived gravity masses for 664 single-lined hot subdwarfs identified in LAMOST. They found that while the mass distribution of H-rich sdB and sdOB stars indeed peaks at 0 48 M . ⊙ , 20% of these stars have gravity masses above 0 6 M . ⊙ . The formation of these relatively massive sdOB stars is, however, a challenge. Zhang et al. (2017) studied the merger of a He-core WD with a low-mass main-sequence star, but this channel produces intermediate He-rich ( -1 0 . < log(He H) / < 1 0) . hot subdwarfs, while Pa 3 is He-poor (log(He / H) = -1 56), and . most of the hot subdwarfs formed through this merger channel have masses in the range of 0 48 . -0 50 M . ⊙ , and only a few of them have masses up to 0 52 M . ⊙ . An alternative channel to produce single H-rich hot subdwarfs involves a main-sequence star that survived the Type Ia supernova (SN Ia) explosion of its former massive WD companion and evolved later on into a hot subdwarf. This SN Ia channel predicts the production of hot subdwarfs in the mass range 0 35 . -1 0 M . ⊙ but also intermediate He-rich surfaces (Meng & Luo 2021).
The only other object in our sample whose PN is not yet confirmed as a true PN is the large, faint, and round nebula Abell 28. It is listed only as a likely PN in the HASH database and has a major-axis diameter of 330 arcsec. Assuming an expansion velocity of 20 km s and a distance of 384 pc, a kinematic age of / 15 kyrs can be estimated. Adopting the atmospheric parameters found in our analysis, the cooling time of the central star would already be ≈ 600 kyrs, according to the evolutionary calculations from Miller Bertolami (2016). Thus, it is more than one order of magnitude higher than the kinematic age of the PN. Similar problems have been reported, for example, for the three H-rich WDCSsinside PN HDW4, PN HaWe5 (Napiwotzki 1999), and PNG 026.9 + 0.04 (Reindl et al. 2023) as well as for the H-poor WDPNnucleus in the Galactic open cluster M37 (Werner et al. 2023).
## 10. Conclusions
We carried out a spectral and SED analysis of 17 H-rich CSPNe recorded at the HET, which allowed us to increase the number of hot H-rich CSPNe with NLTE atmospheric parameters by ≈ 20%. We also investigated the ZTF light curves available for our 15 northern objects, and we found that none of them are photometrically variable (with a typical detection limit of a few hundredths of a magnitude). As reported in several previous studies, in the majority of cases, the spectroscopic distances of our stars exceed the Gaia distances, which calls for a systematic investigation. Highlights of our results include six objects that show an infrared excess, which could be due to a late-type companion; hot ( ≈ 10 3 K) and or cool ( / ≈ 100 K) dust; a rare DA WD
(Abell 24) with T e ff possibly in excess of 100 kK; and an sdOB star (Pa 3) with an unusually high gravity mass. For the latter object, we note that high-resolution spectroscopy would allow for the derivation of metal abundances and a search for chemical peculiarities. For example, if the SN Ia channel applies to this star, then after the supernova, the atmosphere of the surviving star may be polluted by the supernova ejecta, meaning that the star could show an enhancement of iron-peak elements (Meng & Luo 2021). We also encourage high-resolution UV followup, which is possible for a handful of our targets. This would enable determination of a reliable T e ff and detailed metal abundances and testing of whether the problem with the too-high spectroscopic distances is resolved. Apart from the search for photometric variability, an additional search for possible (close) companions could be performed by looking for radial-velocity variability. This could help test the possible post-RGB nature of some of our stars and investigate the binary fraction of CSPNe in general. Finally, infrared spectroscopy would improve the characterization of the infrared excess.
Acknowledgements. We thank the HET queue schedulers and nighttime observers at McDonald Observatory for obtaining the data discussed here. We thank Matti Dorsch for allowing us to use his model grid for the analysis of the sdOB star Pa 3. N.R. is supported by the Deutsche Forschungsgemeinschaft (DFG) through grant RE3915 2-1. The Low-Resolution Spectrograph 2 (LRS2) / was developed and funded by The University of Texas at Austin McDonald Observatory and Department of Astronomy, and by The Pennsylvania State University. We thank the Leibniz-Institut für Astrophysik Potsdam (AIP) and the Institut für Astrophysik Göttingen (IAG) for their contributions to the construction of the integral-field units. We acknowledge the Texas Advanced Computing Center (TACC) at The University of Texas at Austin for providing highperformance computing, visualization, and storage resources that have contributed to the results reported within this paper. The Digitized Sky Surveys were produced at the Space Telescope Science Institute under U.S. Government grant NAG W-2166. The images of these surveys are based on photographic data obtained using the Oschin Schmidt Telescope on Palomar Mountain and the UK Schmidt Telescope. The plates were processed into the present compressed digital form with the permission of these institutions. This work has made use of data from the European Space Agency (ESA) mission Gaia ( https://www.cosmos.esa.int/gaia ), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/ gaia/dpac/consortium ). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. This research has made use of the SIMBAD database, operated at CDS, Strasbourg, France.
## References
- Abell, G. O. 1966, ApJ, 144, 259 Acker, A., Bo ffi n, H. M. J., Outters, N., et al. 2012, Rev. Mexicana Astron. Astrofis., 48, 223 Alam, S., Albareti, F. D., Allende Prieto, C., et al. 2015, ApJS, 219, 12 Aller, A., Montesinos, B., Miranda, L. F., Solano, E., & Ulla, A. 2015, MNRAS, 448, 2822 Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Demleitner, M., & Andrae, R. 2021, AJ, 161, 147 Bédard, A., Bergeron, P., Brassard, P., & Fontaine, G. 2020, ApJ, 901, 93 Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019, PASP, 131, 018002 Bianchi, L., Shiao, B., & Thilker, D. 2017, ApJS, 230, 24 Bo ffi n, H. M. J. & Jones, D. 2019, The Importance of Binaries in the Formation and Evolution of Planetary Nebulae (Berlin, New York, Springer-Verlag) Bojiˇ ci´, c I. S., Parker, Q. A., & Frew, D. J. 2017, in Planetary Nebulae: Multi-Wavelength Probes of Stellar and Galactic Evolution, ed. X. Liu, L. Stanghellini, & A. Karakas, Vol. 323, 327-328 Bond, H. E. 2000, in Astronomical Society of the Pacific Conference Series, Vol. 199, Asymmetrical Planetary Nebulae II: From Origins to Microstructures, ed. J. H. Kastner, N. Soker, & S. Rappaport, 115 Bond, H. E., Chaturvedi, A. S., Ciardullo, R., et al. 2024, arXiv e-prints, arXiv:2405.11087, (Paper V), ApJ in press Bond, H. E., Liller, W., & Mannery, E. J. 1978, ApJ, 223, 252
- Bond, H. E., Werner, K., Jacoby, G. H., & Zeimann, G. R. 2023a, MNRAS, 521,
668, (Paper I)
- Bond, H. E., Werner, K., Zeimann, G. R., & Talbot, J. 2023b, MNRAS, 523, 3699, (Paper II)
- Bond, H. E. & Zeimann, G. R. 2024, ApJ, 967, 122, (Paper IV)
- Chonis, T. S., Hill, G. J., Lee, H., et al. 2016, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 9908, Ground-based and Airborne Instrumentation for Astronomy VI, ed. C. J. Evans, L. Simard, &H. Takami, 99084C
Chornay, N. & Walton, N. A. 2020, A&A, 638, A103
Chu, Y.-H., Su, K. Y. L., Bilikova, J., et al. 2011, AJ, 142, 75
Clayton, G. C., De Marco, O., Nordhaus, J., et al. 2014, AJ, 147, 142
Culpan, R., Geier, S., Reindl, N., et al. 2022, A&A, 662, A40
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003, VizieR Online Data Catalog, 2246, 0
Cutri, R. M., Wright, E. L., Conrow, T., et al. 2021, VizieR Online Data Catalog: AllWISE Data Release (Cutri + 2013), VizieR On-line Data Catalog: II 328. / Originally published in: IPAC Caltech (2013) /
De Marco, O. 2009, PASP, 121, 316
- De Marco, O., Long, J., Jacoby, G. H., et al. 2015, MNRAS, 448, 3587
- De Marco, O., Passy, J.-C., Frew, D. J., Moe, M., & Jacoby, G. H. 2013, MNRAS, 428, 2118
- Dorsch, M., Je ff ery, C. S., Irrgang, A., Woolf, V ., & Heber, U. 2021, A&A, 653, A120
El-Badry, K., Rix, H.-W., & Heintz, T. M. 2021, MNRAS, 506, 2269
- Ferrero, L., Le Du, P., Mulato, L., Outters, N., & Zoll, S. 2015, L'Astronomie, 129, 1.42
- Fitzpatrick, E. L., Massa, D., Gordon, K. D., Bohlin, R., & Clayton, G. C. 2019, ApJ, 886, 108
Flewelling, H. A., Magnier, E. A., Chambers, K. C., et al. 2020, ApJS, 251, 7 Frew, D. J., Madsen, G. J., O'Toole, S. J., & Parker, Q. A. 2010, PASA, 27, 203
Frew, D. J., Parker, Q. A., & Bojiˇ ci´, I. S. 2016, MNRAS, 455, 1459 c Gaia Collaboration, Brown, A. G. A., Vallenari, A., et al. 2021a, A&A, 649, A1 Gaia Collaboration, Brown, A. G. A., Vallenari, A., et al. 2021b, A&A, 650, C3 Gaia Collaboration, Prusti, T., de Bruijne, J. H. J., et al. 2016, A&A, 595, A1 Gaia Collaboration, Vallenari, A., Brown, A. G. A., et al. 2023, A&A, 674, A1 Geier, S., Raddi, R., Gentile Fusillo, N. P., & Marsh, T. R. 2019, A&A, 621, A38 Gentile Fusillo, N. P., Tremblay, P. E., Cukanovaite, E., et al. 2021, MNRAS, 508, 3877
- Gentile Fusillo, N. P., Tremblay, P.-E., Gänsicke, B. T., et al. 2019, MNRAS, 482, 4570
- Gianninas, A., Bergeron, P., Dupuis, J., & Ruiz, M. T. 2010, ApJ, 720, 581 Gómez-Muñoz, M. A., Bianchi, L., & Manchado, A. 2023, ApJS, 266, 34 González-Santamaría, I., Manteiga, M., Manchado, A., et al. 2021, A&A, 656, A51
- Hall, P. D., Tout, C. A., Izzard, R. G., & Keller, D. 2013, MNRAS, 435, 2048 Hartman, J. D. & Bakos, G. Á. 2016, Astronomy and Computing, 17, 1 Heber, U. 2016, PASP, 128, 082001
Heber, U., Irrgang, A., & Scha ff
enroth, J. 2018, Open Astronomy, 27, 35
Henden, A. A., Levine, S., Terrell, D., & Welch, D. L. 2015, in American Astro- nomical Society Meeting Abstracts, Vol. 225, American Astronomical Soci-
ety Meeting Abstracts #225, 336.16
Herald, J. E. & Bianchi, L. 2011, MNRAS, 417, 2440
Herrero, A., Méndez, R. H., & Manchado, A. 1990, Ap&SS, 169, 183
Hill, G. J., Lee, H., MacQueen, P. J., et al. 2021, AJ, 162, 298
- Hillwig, T. C., Bond, H. E., Frew, D. J., Schaub, S. C., & Bodman, E. H. L. 2016, AJ, 152, 34
- Hillwig, T. C., Frew, D. J., Reindl, N., et al. 2017, AJ, 153, 24
Hillwig, T. C., Reindl, N., Rotter, H. M., et al. 2022, MNRAS, 511, 2033
Holberg, J. B. & Magargal, K. 2005, in Astronomical Society of the Pacific
Conference Series, Vol. 334, 14th European Workshop on White Dwarfs, ed.
D. Koester & S. Moehler, 419
- Husser, T. O., Wende-von Berg, S., Dreizler, S., et al. 2013, A&A, 553, A6 Irrgang, A., Geier, S., Heber, U., et al. 2021, A&A, 650, A102
- Jacoby, G. H., Hillwig, T. C., Jones, D., et al. 2021, MNRAS, 506, 5223
Jacoby, G. H., Kronberger, M., Patchick, D., et al. 2010, PASA, 27, 156
- Je ff ery, C. S. & Schönberner, D. 2006, A&A, 459, 885
- Je ff ery, C. S., Werner, K., Kilkenny, D., et al. 2023, MNRAS, 519, 2321
Jones, D. 2019, in Highlights on Spanish Astrophysics X, ed. B. Montesinos,
- A. Asensio Ramos, F. Buitrago, R. Schödel, E. Villaver, S. Pérez-Hoyos, & I. Ordóñez-Etxeberria, 340-345
Jones, D., Bo ffi n, H. M. J., Hibbert, J., et al. 2020, A&A, 642, A108 Jones, D., Munday, J., Corradi, R. L. M., et al. 2022, MNRAS, 510, 3102 Jones, D., Van Winckel, H., Aller, A., Exter, K., & De Marco, O. 2017, A&A, 600, L9
Kepler, S. O., Pelisoli, I., Koester, D., et al. 2019, MNRAS, 486, 2169 Kleinman, S. J., Kepler, S. O., Koester, D., et al. 2013, ApJS, 204, 5 Kronberger, M., Jacoby, G. H., Acker, A., et al. 2014, in Asymmetrical Planetary Nebulae VI Conference, ed. C. Morisset, G. Delgado-Inglada, & S. TorresPeimbert, 48
Kronberger, M., Teutsch, P., Alessi, B., et al. 2006, A&A, 447, 921
- Le Dû, P., Parker, Q. A., Garde, O., et al. 2018, in SF2A-2018: Proceedings of the Annual meeting of the French Society of Astronomy and Astrophysics, ed. P. Di Matteo, F. Billebaud, F. Herpin, N. Lagarde, J. B. Marquette, A. Robin, &O. Venot, Di
Lei, Z., He, R., Németh, P., et al. 2023, ApJ, 953, 122
- Liebert, J., Tweedy, R. W., Napiwotzki, R., & Fulbright, M. S. 1995, ApJ, 441, 424
Lindegren, L., Bastian, U., Biermann, M., et al. 2021, A&A, 649, A4
Löbling, L., Maney, M. A., Rauch, T., et al. 2020, MNRAS, 492, 528
Maldonado, J., A
ff er, L., Micela, G., et al. 2015, A&A, 577, A132
- Masci, F. J., Laher, R. R., Rusholme, B., et al. 2019, PASP, 131, 018003
McCarthy, J. K., Mendez, R. H., & Kudritzki, R. P. 1997, in Planetary Nebulae, ed. H. J. Habing & H. J. G. L. M. Lamers, Vol. 180, 120
- Mendez, R. H. 1991, in Evolution of Stars: the Photospheric Abundance Connection, ed. G. Michaud & A. V. Tutukov, Vol. 145, 375
- Mendez, R. H., Kudritzki, R. P., & Herrero, A. 1992, A&A, 260, 329
- Mendez, R. H., Kudritzki, R. P., Herrero, A., Husfeld, D., & Groth, H. G. 1988, A&A, 190, 113
Meng, X.-C. & Luo, Y.-P. 2021, MNRAS, 507, 4603
Miller Bertolami, M. M. 2016, A&A, 588, A25
- Miszalski, B., Acker, A., Mo ff at, A. F. J., Parker, Q. A., & Udalski, A. 2009, A&A, 496, 813
- Moe, M. & De Marco, O. 2006, ApJ, 650, 916
- Moe, M. & De Marco, O. 2012, IAU Symposium, 283, 111
Napiwotzki, R. 1999, A&A, 350, 101
- Napiwotzki, R., Christlieb, N., Drechsel, H., et al. 2001, Astronomische Nachrichten, 322, 411
- Onken, C. A., Wolf, C., Bessell, M. S., et al. 2019, PASA, 36, e033
- Parker, Q. A., Bojiˇi´, I. S., & Frew, D. J. 2016, in Journal of Physics Conference c c Series, Vol. 728, Journal of Physics Conference Series, 032008
Phillips, J. P. & Ramos-Larios, G. 2005, MNRAS, 364, 849
- Press, W. H., Teukolsky, S. A., Vetterling, W. T., & Flannery, B. P. 1992, Numerical recipes in C. The art of scientific computing (New York: Cambridge University Press)
Preval, S. P. & Barstow, M. A. 2017, in Astronomical Society of the Pacific Conference Series, Vol. 509, 20th European White Dwarf Workshop, ed. P. E. Tremblay, B. Gaensicke, & T. Marsh, 195
- Ramsey, L. W., Adams, M. T., Barnes, T. G., et al. 1998, in Society of PhotoOptical Instrumentation Engineers (SPIE) Conference Series, Vol. 3352, Advanced Technology Optical IR Telescopes VI, ed. L. M. Stepp, 34-42 /
Rauch, T., Köppen, J., Napiwotzki, R., & Werner, K. 1999, A&A, 347, 169
- Reindl, N., Geier, S., Kupfer, T., et al. 2016, A&A, 587, A101
- Reindl, N., Islami, R., Werner, K., et al. 2023, A&A, 677, A29
- Reindl, N., Rauch, T., Miller Bertolami, M. M., Todt, H., & Werner, K. 2017, MNRAS, 464, L51
- Reindl, N., Rauch, T., Parthasarathy, M., et al. 2014, A&A, 565, A40
- Reindl, N., Scha ff enroth, V., Filiz, S., et al. 2021, A&A, 647, A184
- Reindl, N., Scha ff enroth, V., Miller Bertolami, M. M., et al. 2020, A&A, 638, A93
- Santander-García, M., Rodríguez-Gil, P., Corradi, R. L. M., et al. 2015, Nature, 519, 63
- Schlafly, E. F. & Finkbeiner, D. P. 2011, ApJ, 737, 103
- Schlafly, E. F., Meisner, A. M., & Green, G. M. 2019, ApJS, 240, 30
- Schönberner, D., Balick, B., & Jacob, R. 2018, A&A, 609, A126
- Schönberner, D. & Ste ff en, M. 2019, A&A, 625, A137
- Shetrone, M., Cornell, M. E., Fowler, J. R., et al. 2007, PASP, 119, 556
- Shimanskii, V. V., Borisov, N. V., Pozdnyakova, S. A., et al. 2008, Astronomy Reports, 52, 558
- Tremblay, P. E., Cukanovaite, E., Gentile Fusillo, N. P., Cunningham, T., & Hollands, M. A. 2019, MNRAS, 482, 5222
- Unglaub, K. & Bues, I. 2000, A&A, 359, 1042
- Weidmann, W. A., Mari, M. B., Schmidt, E. O., et al. 2020, A&A, 640, A10
- Werner, K., Rauch, T., & Reindl, N. 2019, MNRAS, 483, 5291
- Werner, K., Reindl, N., Raddi, R., et al. 2023, A&A, 678, A89
- Werner, K., Todt, H., Bond, H. E., & Zeimann, G. R. 2024, A&A, 686, A29, (Paper III)
Wesemael, F., Greenstein, J. L., Liebert, J., et al. 1993, PASP, 105, 761
Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868
Yuan, H. B. & Liu, X. W. 2013, MNRAS, 436, 718
- Zechmeister, M. & Kürster, M. 2009, A&A, 496, 577
- Zhang, X., Hall, P. D., Je ff ery, C. S., & Bi, S. 2017, ApJ, 835, 242
- Ziegler, M. 2012, Dissertation, University of Tübingen, Germany, https: // publikationen.uni-tuebingen.de xmlui handle 10900 50006 / / / /
- Ziegler, M., Rauch, T., Werner, K., Köppen, J., & Kruk, J. W. 2012, A&A, 548, A109 | null | [
"Nicole Reindl",
"Howard E. Bond",
"Klaus Werner",
"Gregory R. Zeimann"
]
| 2024-08-02T17:35:30+00:00 | 2024-08-02T17:35:30+00:00 | [
"astro-ph.SR",
"astro-ph.GA"
]
| Spectroscopic survey of faint planetary-nebula nuclei VI. Seventeen hydrogen-rich central stars | We present an analysis of 17 H-rich central stars of planetary nebulae (PNe)
observed in our spectroscopic survey of nuclei of faint Galactic PNe carried
out at the 10-m Hobby-Eberly Telescope. Our sample includes ten O(H) stars,
four DAO white dwarfs (WDs), two DA WDs, and one sdOB star. The spectra were
analyzed by means of NLTE model atmospheres, allowing us to derive the
effective temperatures, surface gravities, and He abundances of the central
stars. Sixteen of them were analyzed for the first time, increasing the number
of hot H-rich central stars with parameters obtained through NLTE atmospheric
modeling by approximately 20%. We highlight a rare hot DA WD central star,
Abell 24, which has a $T_\mathrm{eff}$ likely in excess of 100kK, as well as
the unusually high gravity mass of $0.70 \pm 0.05 \mathrm{M}_\odot$ for the
sdOB star Pa 3, which is significantly higher than the canonical extreme
horizontal-branch star mass of $\approx 0.48\,\mathrm{M}_{\odot}$. By
investigating Zwicky Transient Facility light curves, which were available for
our 15 northern objects, we found none of them show a periodic photometric
variability larger than a few hundredths of a magnitude. This could indicate
that our sample mainly represents the hottest phase during the canonical
evolution of a single star when transitioning from an asymptotic giant branch
star into a WD. We also examined the spectral energy distributions, detecting
an infrared excess in six of the objects, which could be due to a late-type
companion or to hot ($\approx 10^3$ K) and\or cool ($\approx 100$ K) dust. We
confirm previous findings that spectroscopic distances are generally higher
than found through Gaia astrometry, a discrepancy that deserves to be
investigated systematically. |
2408.01413v3 | ## Designing High-Occupancy Toll Lanes: A Game-Theoretic Analysis
## Zhanhao Zhang
Operations Research and Information Engineering, Cornell University, [email protected]
## Ruifan Yang
Operations Research and Information Engineering, Cornell University, [email protected]
## Manxi Wu
Department of Civil and Environmental Engineering, University of California, Berkeley, [email protected]
## Abstract
In this article, we study the optimal design of High Occupancy Toll (HOT) lanes. The traffic authority determines the road capacity allocation between HOT lanes and ordinary lanes, as well as the toll price charged for travelers using HOT lanes who do not meet the high-occupancy eligibility criteria. We develop a game-theoretic model to analyze the decisions of travelers with heterogeneous preference parameters in values of time and carpool disutilities. These travelers choose between paying or forming carpools to use the HOT lanes, or taking the ordinary lanes. Travelers' welfare depends on the congestion cost of the lane they use, the toll payment, and the carpool disutilities. For highways with a single entrance and exit node, we provide a complete characterization of equilibrium strategies and a comparative statics analysis of how the equilibrium vehicle flow and travel time change with HOT capacity and toll price. We then extend the single segment model to highways with multiple entrance and exit nodes. We extend the equilibrium concept and propose various design objectives considering traffic congestion, toll revenue, and social welfare. Using the data collected from the HOT lane of the California Interstate Highway 880 (I-880), we formulate a convex program to estimate the travel demand and approximate the distribution of travelers' preference parameters. We then compute the optimal toll design of five segments for I-880 for achieve each one of the four objectives, and compare the optimal solution with the current toll pricing.
## 1 Introduction
High Occupancy Toll (HOT) lanes are traffic lanes or roadways that are open to vehicles satisfying a minimum occupancy requirement but also offer access to other vehicles with a toll price. In practice, HOT lanes have been implemented on several interstate highways in California, Texas, and Washington states. With the proper design of lane capacity and toll price, HOT lanes can effectively mitigate traffic congestion through incentivizing carpooling and transit use, while also generating revenue to support transportation infrastructure through toll collection.
The goal of our work is to study the optimal design of HOT lane systems and its impact on traffic congestion, social welfare, and revenue generated from toll collection. In our model, a traffic authority designs the HOT lane systems by choosing the road capacity of HOT lanes, and the toll price. Given the design of HOT, we develop a game-theoretic model to analyze the strategic decisions made by travelers who have the action set of paying or carpooling to use the HOT lane, or using the ordinary lane. Travelers are modeled as a population of nonatomic agents with a continuous distribution of value of time and carpool disutility. Both the HOT lanes and the ordinary lanes are congestible in that the travel time of each lane increases with the aggregate flow induced by agents' decisions. The outcomes of the system in terms of agent travel time cost and toll collection are jointly determined by agents' equilibrium strategies and the design by the traffic authority.
In the first part of our work (Sec. 2-3), we consider highway segments with a single entrance and exit node. We provide a complete characterization of Wardrop equilibrium in this game. In particular, we identify two qualitatively distinct equilibrium regimes that depend on the traffic authority's design of lane capacity and toll price. In the first equilibrium regime, all agents who take the HOT lane form carpools and no one pays the toll due to the relatively high toll price. In the second equilibrium regime, a fraction of agents with high carpool disutilities and high value of times makes toll payment to take the HOT lanes, while the rest either forms carpools or takes the ordinary lanes. In both regimes, agents are split between taking the HOT lanes and the ordinary lanes.
The equilibrium characterization provides the system designer with insights on how the equilibrium flows and travel time costs of both the HOT lanes and the ordinary lanes depend on the system parameters that include travel time cost functions, capacity allocation and toll price. Moreover, we present comparative static analysis on how the equilibrium flow and costs change with the fraction of capacity that is allocated to the HOT lanes and the toll price of HOT lanes. We find that if we increase the HOT capacity but holding the toll price fixed, the latency difference between ordinary lanes and HOT lanes increases. Moreover,
more agents use the HOT lanes by paying the toll price or carpooling and fewer agents use ordinary lanes. On the other hand, increasing the toll price while holding the HOT capacity fixed will lead to an increase in the latency difference between ordinary lanes and HOT lanes, an increase in carpooling agents, and a decrease in toll-paying agents. The number of agents using ordinary lanes can change in either direction.
In the second part of our work (Sec. 4-5), we generalize our model to highways with multiple segments separated by entrance and exit nodes and carpool system with multiple occupancy levels. The toll price of each segment set by the system designer varies with the vehicles occupancy level. The population consists of agents with different entry and exit points. Agents choose their carpool occupancy levels before entering the highway, and can switch between ordinary lanes and HOT lanes for different road segments. We generalize our equilibrium concept to this model extension, and prove equilibrium existence. We also provide a generic sufficient condition under which equilibrium is unique.
We apply our model and equilibrium analysis in the numerical study using the data collected on the California I-880 HOT lane system, from Dixon Landing Road to Lewelling Boulevard. We calibrate the latency function using vehicle travel time and flow data provided by the Caltrans Performance Measurement System (PeMS). To compute the equilibrium strategy distribution, we need to estimate the demand for each entry and exit pair and the distribution of preference parameters among the population. To ensure tractability in estimating demand and preference distribution, we partition the preference parameter vector space into equally sized subsets, and estimate the demand of agents with preference in each subset building on the idea of inverse optimization. That is, given the data on toll prices and driving time, we compute the equilibrium strategy profile of agents with all preference parameters and entrance and exit nodes. This allows us to map the demand estimate of each preference set to an induced vehicle flows on ordinary lanes and HOT lanes at equilibrium. We formulate a convex program to estimate the demand volumes as the one that minimizes the difference between the equilibrium vehicle flows and the observed flows on each lane and each segment.
Next, we compute the equilibrium strategy profile for a set of discretized design parameters, including capacity allocation and toll prices. We consider four objective functions for the HOT design: (i) the total agent travel time, (ii) the total vehicle driving time, (iii) the total revenue measures the toll prices collected, and (iv) total cost of all agents taking into account their driving time, toll payments, and carpool disutilities. We select a time interval (5-6 pm) during the evening rush hour to compute the Pareto front for the design of HOT lanes under various toll prices and HOT capacities. This analysis illustrates the system authority's trade-off between reducing traffic congestion, enhancing social welfare,
and maximizing total toll revenue. Charging a high toll price on road segments with higher demand is effective in incentivizing agents to carpool and reduce both agent travel time and vehicle driving time. On the other hand, for revenue maximization, a lower toll price is optimal to increase the fraction of toll-paying agents.
Moreover, we compute the optimal toll design under the current HOT capacity across all operating hours of a workday. Since demand volume is lower during the morning hours but higher in the afternoon, setting a high toll price in the afternoon is more effective for reducing agent travel time, vehicle driving time, and costs. However, for revenue maximization, it is optimal to set a low toll price throughout the day. By adjusting the current toll price to the optimal toll prices for each of these four objectives, we can achieve significant improvements in the corresponding objective.
Related Literature . Our model and analysis build on the rich literature of congestion games that includes the equilibrium analysis of routing strategies made by atomic agents [1, 2] and nonatomic agents [3] in networks, and the analysis on the price of anarchy [4, 5, 6, 7]. Most of the classical results in congestion games have focused on the settings where all agents have homogeneous preferences. The papers [8, 9] extended these results to study the equilibrium existence and efficiency with player-specific costs. Previous literature has also examined the optimal design of tolling mechanisms that minimize the social cost of nonatomic agents with homogeneous preferences [10, 11, 12]. The optimal toll design with heterogeneous values of time has also been studied. For example, [13, 14, 15, 16, 17, 18, 19, 20, 21] consider a finite number of agent classes, where the value of time is the same among agents within the same class but differs across different classes. Furthermore, [22, 23, 24, 25, 26, 27] study the setting where the value of time of agents follow continuous distribution. These work do not incorporate carpooling into their models.
There are extensive works modeling travelers' decisions regarding HOT/HOV lanes. The first stream of work examined the static user equilibrium of travel mode and/or route choices on a single-segment, multi-lane road. [28] studied the user equilibrium with and without HOV lanes and discussed the optimal congestion pricing. [29, 30, 31] extended the HOV system with various schemes and settings. These works focus on HOV systems, which do not allow single occupancy vehicles to use the express lane. Moreover, they assume that all commuters have a homogeneous value of time and carpool disutility, except for [31], which considered commuters with heterogeneous carpool disutilities but homogeneous value of time. Considering the HOT systems that allow single occupancy vehicles to drive on the express lanes by paying a toll, [32, 33, 34] discussed the pricing schemes where only single occupancy vehicles make decisions between HOT lanes and ordinary lanes while the number of high occupancy vehicles remains constant. [35], allowing travelers to choose both their
travel modes and routes simultaneously, compared the road efficiency for HOT and HOV systems, and explored the optimal congestion pricing scheme for both ordinary lanes and HOV lanes on a multi-lane highway. They also considered commuters with heterogeneous carpool disutilities but a homogeneous value of time. [36] studied the impact of ride-sourcing vehicles on both HOV and HOT systems, considering commuters with heterogeneous values of time but homogeneous carpool disutility. Additionally, [37, 38, 39, 40, 41, 42, 43, 44] extended these models to consider ridesharing user equilibrium (RUE) with HOT lanes. None of the above works considers commuters with both heterogeneous values of time and carpool disutilities, and they only considered homogeneous carpool occupancy levels.
More broadly, the second stream of works studied the impact of carpooling in a dynamic setting that extends the bottleneck model by [45], and examined departure time equilibrium and/or travel mode choice equilibrium with HOT/HOV lanes [46]. [47, 48] studied the HOV/HOT system with three traveling modes: transit, driving alone, and carpooling. They derived the departure time equilibrium for each traveling mode and how different factors affect the mode shares and network performance. [49, 50, 51, 52, 53, 54] extended the same problem to include parking space constraints or ride-sharing compensation. However, all the above works considered only homogeneous commuters. [55] studied departure time equilibrium with heterogeneous users in the preference for cost of carpooling, values of time, and values of schedule delay. However, they modeled travelers' mode choice and route choice separately: although travelers achieve departure time equilibrium within each mode, the shares among the modes are determined by a nested logit model. Also, they only considered a single-lane scenario, which does not incorporate separate HOV/HOT lanes. Moreover, all the dynamic works above either assume a constant carpool occupancy level ([56], [49], [48], [53], [57]), or carpool occupancy level that is a continuous variable as in [54]. The paper [58] extended the temporal capacity allocation scheme with discrete heterogeneous occupancy level and heterogeneous carpool inconvenience costs, but considered homogeneous value of time.
Our work contributes to modeling and analysis of HOT lane systems in static settings. In particular, our model incorporates agents with heterogeneous values of time and heterogeneous carpool disutilities, where both parameters are continuously distributed. This dual-dimensional heterogeneity is essential for optimal HOT lane design since choices between ordinary and HOT lanes, and whether to pay or carpool, depend on both parameters. We proved equilibrium existence, uniqueness, and fully characterize the equilibrium structure with general latency functions and continuous preference distributions. Our results identify two distinct equilibrium regimes and lead to comparative statics that provide insights into how toll prices and HOT lane capacity effect lane usage and carpooling ratios. Furthermore,
we extend our basic model to multi-segment settings with multiple occupancy levels and differentiated pricing. We prove equilibrium existence and uniqueness. These results support practical HOT lane design with multiple segments and tiered toll prices.
Moreover, our case study of the California I-880 highway contributes to the literature of numerical/empirical analysis on HOT design and carpooling. [59] investigated the impact of toll design on social welfare through a case study of Stockholm. [60] and [61] demonstrated the improvement of revenue and social welfare in the Sioux Falls network by adopting optimal tolling mechanisms. [62, 63] used simulation to compute optimal toll prices across multiple objectives that incorporate time-of-day pricing, drivers' lane choice behaviors in the presence of tolls, and different toll structures across various road segments of HOT lane facilities. [64] and [65] designed field experiments and found a positive impact of HOV lanes on both carpooling intent and adoption. Additionally, [66] surveyed 250+ drivers, and find relationships between willingness to pay and the improvement in travel speeds in HOT lanes, the length of the trip, and the urgency of on-time arrival.
Our numerical study contributes to the above literature by bridging the game theory analysis of HOT lane system with data collected on the HOT project along California I 880 highway. In particular, we inversely estimated the distribution of travelers' preferences using the traffic sensor data and data requested from Caltrans on the aggregate lane choice and carpool ratios. We designed optimal tolls for four proposed objectives building on the equilibrium analysis and preference distribution estimates. Our results provide the optimal hourly toll pricing with the objectives of improving traffic congestion mitigation and toll revenue under different HOT capacities, and demonstrate the trade-off between different objectives.
## 2 The basic model
Consider a highway segment consisting of ordinary and high occupancy toll (HOT) lanes. An ordinary lane is toll-free and open to all vehicles. A high occupancy toll lane is accessible to vehicles that either pay the toll price τ ∈ R ≥ 0 or meet the minimum occupancy requirement with passenger size that is an integer A ≥ 2. A central planner (e.g. transportation authority) determines the toll price τ , the minimum occupancy requirement A , and the allocation of road capacity between HOT lanes and ordinary lanes. In particular, we denote the fraction of capacity allocated to HOT lanes as ρ ∈ [0 , 1], and the remaining (1 -ρ )-fraction of capacity is allocated to the ordinary lanes. The capacity allocation affects the travel time cost (i.e. latency function) of the two types of lanes. We denote the latency function of the HOT lanes as ℓ h ( x , ρ h ), and the latency function of the ordinary lanes as ℓ o ( x , o 1 -ρ ), where
x h (resp. x o ) is the flow of vehicles using the HOT lanes (resp. the ordinary lanes). We assume that the latency functions satisfy the following assumption:
## Assumption 1
- (a) The latency function ℓ o ( x , o 1 -ρ ) (resp. ℓ h ( x , ρ h ) ) is increasing in the flow x o (resp. x h ), and increasing (resp. decreasing) in the capacity ratio ρ .
- (b) ℓ o (0 , 1 -ρ ) = ℓ h (0 , ρ ) for any ρ ∈ [0 , 1] .
Assumption 1(a) indicates that both lanes are congestible in that the latency increases as the flow increases. 1 Additionally, the latency decreases in one type of lanes as the allocated capacity of that lane increases. Assumption 1(b) implies that the free flow travel time, defined as the latency when the flow is zero, is the same for both types of lanes. This is a reasonable assumption since the free flow travel time is determined by the length of the highway and the speed limit.
We model travelers as non-atomic agents with a total demand of D > 0. The action set of each agent is A = { toll , pool o , } , where toll (resp. pool) is the action of taking the HOT lanes by paying the toll price (resp. by meeting occupancy requirement), and o is to take the ordinary lane. Agents have heterogeneous preferences about the travel time cost (relative to the monetary payment) as well as the disutility of forming carpool groups. We model the heterogeneous preferences of agents by the parameter of value of time (i.e. the amount of monetary cost that is equivalent to one unit time cost), denoted as β ∈ B = [0 , β ¯ ], and the carpool disutility, denoted as γ ∈ Γ = [0 , γ ¯]. The distribution of agents' preference parameters ( β, γ ) is represented by the probability density function f : B × Γ → R such that f ( β, γ ) > 0 for all ( β, γ ) and ∫ B × Γ f ( β, γ ) dβdγ = 1.
We define the strategy of an agent as a mapping from their preference parameters ( β, γ ) to a pure strategy in action set A , denoted as s : B × Γ → A . The set of agents who choose each action a , denoted by R a , is given by:
$$R _ { a } = \{ B \times \Gamma | s ( \beta, \gamma ) = a \} \,, \ \forall a \in A.$$
We represent the strategy distribution of the agent population as σ = ( σ a ) a ∈ A , where
$$\sigma _ { a } = \frac { 1 } { D } \int _ { R _ { a } } f ( \beta, \gamma ) d \beta d \gamma$$
is the fraction of agents who choose each action a ∈ A , and σ toll + σ pool + σ o = 1. Here, both R a and σ a for each a depend on s . We drop the dependence from the notation for simplicity.
1 This assumption is supported by queueing based models [67, 68] and empirical validations [69].
The flow on each type of lanes induced by σ is as follows:
$$x _ { \text{h} } = \left ( \sigma _ { \text{toll} } + \frac { \sigma _ { \text{pool} } } { A } \right ) D, \ \ x _ { \text{o} } = \sigma _ { \text{o} } D.$$
The cost of each agent with preference parameters ( β, γ ) for choosing actions toll , pool o is , given by:
$$C _ { \text{toll} } ( \sigma, \beta, \gamma ) = \beta \cdot \ell _ { \text{h} } \left ( x _ { \text{h} }, \rho \right ) + \tau,$$
$$C _ { \text{pool} } ( \sigma, \beta, \gamma ) = \beta \cdot \ell _ { \text{h} } \left ( x _ { \text{h} }, \rho \right ) + \gamma,$$
$$C _ { o } ( \sigma, \beta, \gamma ) = \beta \cdot \ell _ { o } \left ( x _ { o }, 1 - \rho \right ),$$
where β · ℓ h ( x , ρ h ) (resp. β · ℓ o ( x , o 1 -ρ )) represents the cost of enduring the latency on the HOT lanes (resp. the ordinary lanes), and the cost of toll payment or the carpool disutility is added for action toll and pool, respectively.
A strategy profile s ∗ is a Wardrop equilibrium if no agent has incentive to deviate:
Definition 1 A strategy profile s ∗ : B × Γ → A is a Wardrop equilibrium if
$$& s ^ { * } ( \beta, \gamma ) = a, \\ & \Rightarrow \quad C _ { a } ( \sigma ^ { * }, \beta, \gamma ) = \arg \min _ { a ^ { \prime } \in A } C _ { a ^ { \prime } } ( \sigma ^ { * }, \beta, \gamma ), \\ & \forall ( \beta, \gamma ) \in B \times \Gamma,$$
and σ ∗ is the associated equilibrium strategy distribution given by (1) .
That is, the action chosen by an agent with parameters ( β, γ ) in equilibrium minimizes their own cost compared to choosing the other two actions. Given equilibrium strategy distribution σ ∗ , we denote the induced equilibrium flow on the HOT lanes and the ordinary lanes by x ∗ h and x ∗ o , respectively.
## 3 Equilibrium characterization and comparative statics
## 3.1 Equilibrium characterization
In this section, we characterize the Wardrop equilibrium of the game. For ease of exposition, we define ℓ δ ( σ, ρ ) as the difference of the latency between the ordinary lanes and the HOT lanes given the strategy distribution σ and the capacity allocation ρ :
$$\ell _ { \delta } ( \sigma, \rho ) \coloneqq \ell _ { o } ( x _ { o }, 1 - \rho ) - \ell _ { \mathrm h } ( x _ { \mathrm h }, \rho ),$$
where x o and x h are derived from σ as in (2).
We first show that the latency difference between the ordinary lanes and the HOT lanes is always non-negative. Furthermore, when the toll price is strictly positive, there will always be some agents taking the ordinary lane or carpooling.
$$\text{Lemma $1$ } I f \, \tau > 0, \, \text{ then } \ell _ { \delta } ( \sigma ^ { * }, \rho ) > 0, \, \sigma ^ { * } _ { \text{pool} } > 0, \, a n d \, \sigma ^ { * } _ { o } > 0.$$
We next characterize the best response strategies of agents for a given strategy distribution σ . In particular, given σ , the best response of an agent with parameter ( β, γ ) is the action that minimizes the associated cost as in (3). We denote the best response as BR( σ, β, γ ) ∈ A . Then, we can separate the parameter set B × Γ into three regions (Λ ( a σ )) a ∈ A , where Λ ( a σ ) := { B × Γ BR( | σ, β, γ ) = a } . The following lemma characterizes the three regions with respect to the latency difference ℓ δ ( σ, ρ ) induced by σ and the toll price τ : 2
## Lemma 2 Given σ ,
$$\Lambda _ { \text{toll} } ( \sigma ) & = \{ B \times \Gamma | \beta \ell _ { \delta } ( \sigma, \rho ) \geq \tau, \ \gamma \geq \tau \}, \\ \Lambda _ { \text{pool} } ( \sigma ) & = \{ B \times \Gamma | \beta \ell _ { \delta } ( \sigma, \rho ) \geq \gamma, \ \gamma \leq \tau \}, \\ \Lambda _ { \text{o} } ( \sigma ) & = \{ B \times \Gamma | \beta \ell _ { \delta } ( \sigma, \rho ) \leq \min \{ \tau, \gamma \} \}.$$
We illustrate the three regions in Figure 1. We note that Λ toll ( σ ) includes agents with both high value of time β and high carpool disutility γ . Such agent prefers to take the HOT lanes via paying rather than taking the ordinary lanes due to their high value for time (i.e. the cost saving given ℓ δ ( σ, ρ ) is no less than the toll price τ ), and also prefers to pay the toll price over carpooling due to their high carpool disutility (i.e. γ is no less than the toll price). Similarly, agents in Λ pool ( σ ) have carpool disutility at most τ , and thus prefer to carpool than paying the toll price. Their value of time β is high relative to the carpool disutility γ so that the cost saving given ℓ δ ( σ, ρ ) is no less than the carpool disutility, i.e. they prefer to take the HOT lanes by carpool rather than taking the ordinary lane. Finally, Λ ( o σ ) includes agents whose value of time is low relative to both their carpool disutility and toll price, and hence they prefer to take the ordinary lanes compared to taking the HOT lanes via carpool or toll payment.
2 We do not consider the boundary cases where the inequalities in Lemma 2 hold with equality. Agents with preference parameters on the boundaries of each region are indifferent between two or even all three actions. Their tie-breaking rule does not affect the equilibrium analysis, as agents are nonatomic, and the demand from agents with boundary preference parameters is effectively zero.
Figure 1: Characterization of best response strategies
We are now ready to present equilibrium characterization of this game. We define the following latency difference threshold value ℓ † δ that will be used for separating different equilibrium regimes:
$$\ell _ { \delta } ^ { \dagger } \coloneqq \ell _ { \delta } ( \sigma ^ { \dagger }, \rho ),$$
where σ † is the threshold strategy distribution given by:
$$\sigma _ { \text{toll} } ^ { \dagger } = & 0,$$
$$\sigma _ { \text{pool} } ^ { \dagger } = \int _ { 0 } ^ { \bar { \beta } } \int _ { 0 } ^ { \min \{ \tau, \bar { \gamma } \} \beta / \bar { \beta } } f ( \beta, \gamma ) d \gamma d \beta,$$
$$\sigma _ { o } ^ { \dagger } = & 1 - \sigma _ { \text{pool} } ^ { \dagger }.$$
The following theorem shows that the game has a unique equilibrium that falls into either one of the two regimes depending on the game parameters. In each regime, the equilibrium strategy profile can be computed by solving a fixed point equation.
Theorem 1 The game has a unique Wardrop equilibrium.
Regime A: The toll price τ is relatively high, i.e. τ ≥ min { ¯ γ, βℓ ¯ † δ } . No agent takes HOT lanes by paying the toll, i.e. σ ∗ toll = 0 . Furthermore,
(A-1) If ¯ βℓ † δ ≤ γ , then σ ∗ pool is the unique solution that satisfies the following equation:
$$\sigma _ { \text{pool} } ^ { * } = \int _ { 0 } ^ { \bar { \beta } } \int _ { 0 } ^ { \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { * }, 1 - \sigma _ { \text{pool} } ^ { * }, \rho ) \beta } f ( \beta, \gamma ) d \gamma d \beta,$$
and σ ∗ o = 1 -σ ∗ pool .
(A-2) If ¯ βℓ † δ > γ , then σ ∗ pool is the unique solution of the following equation:
$$1 - \sigma _ { \text{pool} } ^ { * } = & \int _ { 0 } ^ { \widetilde { \gamma } } \int _ { 0 } ^ { \gamma / \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { * }, 1 - \sigma _ { \text{pool} } ^ { * }, \rho ) } f ( \beta, \gamma ) d \beta d \gamma,$$
and σ ∗ o = 1 -σ ∗ pool .
Regime B: The toll price τ is relatively low, i.e. 0 < τ < min { ¯ γ, βℓ ¯ † δ } . All three actions are taken by agents in equilibrium, and σ ∗ is the unique solution that satisfies the following equations:
$$\sigma _ { \text{toll} } ^ { * } = \int _ { \tau } ^ { \overline { \gamma } } \int _ { \underset { \Xi } { \tau / \ell _ { \delta } ( \sigma ^ { * }, \rho ) } } ^ { \overline { \beta } } f ( \beta, \gamma ) d \beta d \gamma,$$
$$\sigma _ { \text{pool} } ^ { * } = \int _ { 0 } ^ { \tau } \int _ { \gamma / \ell _ { \delta } ( \sigma ^ { * }, \rho ) } ^ { \dagger } f ( \beta, \gamma ) d \beta d \gamma,$$
$$\sigma _ { o } ^ { * } = & 1 - ( \sigma _ { t o l l } ^ { * } + \sigma _ { p o l l } ^ { * } ).$$
We provide the proof intuition of Theorem 1 in this section. The complete proof is in Appendix A. Our equilibrium characterization builds on the two lemmas 1 - 2 introduced before. In particular, Lemma 1 shows that in equilibrium both lanes are used, and either (A) all agents who take the HOT lanes choose to carpool, or (B) a positive fraction of agents who take the HOT lanes pay the toll τ . Indeed, (A) and (B) are each associated with equilibrium regimes A and B, respectively.
Furthermore, following Definition 1, an equilibrium strategy distribution σ ∗ must satisfy
$$\sigma _ { a } ^ { * } = \iint _ { \Lambda _ { a } ( \sigma ^ { * } ) } f ( \beta, \gamma ) d \beta d \gamma, \ \ a \in A,$$
where Λ ( a σ ∗ ) is the best response region characterized in Lemma 2. In particular, using the best response characterization in Lemma 2, the equilibrium distribution of carpool σ ∗ pool can be written as:
$$\sigma _ { \text{pool} } ^ { * } = \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \min \{ \ell _ { \delta } ( \sigma ^ { * }, \rho ) \beta, \tau, \overline { \gamma } \} } f ( \beta, \gamma ) d \gamma d \beta.$$
The two sub-regimes, (A-1) and (A-2), and regime B each corresponds to the scenario where one of the three elements, ¯ βℓ δ ( σ , ρ ∗ ), τ , or γ , is the smallest. In particular, sub-regime A-1 (resp. A-2) corresponds to the case where ¯ βℓ δ ( σ , ρ ∗ ) (resp. γ ) is the smallest among three elements. Thus, no agents use the HOT lane by paying the toll price since the toll price τ is either larger than the value of the time saved by taking the HOT lane ¯ βℓ δ ( σ , ρ ∗ ) or larger than the maximum carpool disutility ¯. γ Figures 2a - 2b illustrate that, in the equilibrium of sub-regimes A-1 and A-2, agents only choose to take the ordinary lane or carpool to take the HOT lane. This is because the preference parameter set does not intersect with the set corresponding to choosing to pay the toll to take the HOT lane as the best response strategy. In regime B, τ is the smallest element of the three (i.e. 0 < τ < min ¯ { γ, βℓ ¯ δ ( σ , ρ ∗ ) } as shown in Figure 2c), and the strategy distributions for all three actions are positive in equilibrium.
Finally, the threshold strategy distribution σ † as in (6) and the threshold latency cost difference ℓ † δ as in (5) are derived from the boundary case ¯ βℓ δ ( σ , ρ ∗ ) = ¯ = γ τ , see Fig. 2d for
the illustration. In this threshold case, σ ∗ = σ † and the latency difference ℓ δ ( σ , ρ ∗ ) = ℓ † δ . We can verify that this boundary case indeed marks the transition between different regimes. For example, in sub-regime A-1,
$$\mathfrak { u } \text{-} \text{me } \mathfrak { A } \text{-} 1, \\ \sigma _ { \text{pool} } ^ { * } & = \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \min \{ \ell _ { \delta } ( \sigma ^ { * }, \rho ) \beta, \tau, \overline { \gamma } \} } f ( \beta, \gamma ) d \gamma d \beta \\ & \stackrel { ( a ) } { = } \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \ell _ { \delta } ( \sigma ^ { * }, \rho ) \beta } f ( \beta, \gamma ) d \gamma d \beta \\ & \stackrel { ( b ) } { \leq } \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \min \{ \tau, \overline { \gamma } \} \beta / \overline { \beta } } f ( \beta, \gamma ) d \gamma d \beta = \sigma _ { \text{pool} } ^ { \dagger }, \\ \mathfrak { l } ^ { \dagger } \text{ \ w h o r o } \text{ \ h o t } \mathfrak { w } \text{ and } \mathfrak { h } \mathfrak { w } \text{ and } \mathfrak { h } \mathfrak { w } \text{ to } \mathfrak { w } \text{ to } \mathfrak { w } \text{ in } \mathfrak { w }.$$
and ℓ δ ( σ , ρ ∗ ) ≤ ℓ † δ , where both (a) and (b) are due to the sub-regime A-1 conditions. Therefore, the sub-regime A-1 boundary characterization γ ≥ ¯ βℓ † δ guarantees that the subregime equilibrium condition γ ≥ ¯ βℓ δ ( σ , ρ ∗ ) holds when problem instance parameters are in A-1. Similarly, we can show that σ ∗ pool ≥ σ † pool and ℓ δ ( σ , ρ ∗ ) ≥ ℓ † δ in sub-regime A-2 and regime B. As a result, the sub-regime A-2 (resp. regime B) characterization ¯ γ ≤ ¯ βℓ † δ (resp. 0 < τ < min ¯ { γ, βℓ ¯ † δ } ) guarantees that the condition ¯ γ ≤ ¯ βℓ ∗ δ ( σ , ρ ∗ ) (resp. 0 < τ < min ¯ { γ, βℓ ¯ δ ( σ , ρ ∗ ) } ) is satisfied when problem instance parameters are in A-2 (resp. regime B). The detailed description of these conditions of each regime is in the theorem proof in Appendix A.
## 3.2 Comparative statics
We analyze the change of equilibrium strategy distribution with HOT capacity ρ and toll price τ .
Theorem 2 The comparative statics of equilibrium strategy distribution σ ∗ with respect to ( ρ, τ ) are summarized in Table 1.
Table 1: Comparative statics.
| | Fix τ increase ρ | Fix ρ increase τ |
|-----------------------------------------|---------------------------------------------|---------------------------------------------------------------|
| σ ∗ o σ ∗ toll σ ∗ pool ℓ δ ( σ ∗ , ρ ) | Decreasing Increasing Increasing Increasing | Either Direction Non-Increasing Non-Decreasing Non-Decreasing |
Intuitively, if we fix the toll price τ and increase the HOT capacity ρ , some agents will switch from ordinary lanes to HOT lanes by either paying the toll price or carpooling.
β
Figure 2: Equilibrium outcomes in each regime.
Therefore, σ ∗ toll increases, σ ∗ pool increases, and σ ∗ o decreases. From analyzing the regime boundary change, we can also conclude that the latency difference between the ordinary lanes and the HOT lanes increases.
On the other hand, if we fix the HOT capacity ρ and increase the toll price τ , some agents will deviate from paying the toll to carpooling or taking the ordinary lane. Hence, the latency in the ordinary lanes will increase and in the HOT lanes will decrease, which means the latency difference between the two lanes ℓ δ ( σ ρ ∗ , ) will increase. Additionally, σ ∗ toll decreases and σ ∗ pool increases. As for the ordinary lanes, agents with high value of time and low carpool disutilities will switch to carpools as HOT lane becomes less congested. Depending on the preference distribution and the toll prices before and after the change, we can either have more agents switch from ordinary lanes to carpool or more agents switch from toll paying to ordinary lanes. Hence, σ ∗ o can either increase or decrease. We remark that when toll price is already higher than the threshold where no agents pay the toll (regime A in Theorem 1), further increasing the toll price has no impact on the strategy distributions and therefore does not affect the latency difference.
## 4 Extensions to multiple segments and occupancy levels
Consider a highway partitioned into multiple segments by separation nodes, which represent the locations where vehicles get on and off the highway. We number the segments sequentially from upstream to downstream as e ∈ [ E ] := 1 , . . . , E , where E is the total number of road segments. Same as the basic model, the central planner divides the capacity of the highway into the HOT lane and the ordinary lane, and ρ ∈ [0 , 1] is the fraction of capacity allocated to the HOT lane. Agents can form carpools with different occupancy levels m ∈ [ M ] := 1 , . . . , M , where m = 1 indicates that the agent does not carpool with others, and M is the maximum carpool size. For each segment e ∈ [ E ], a toll price τ e,m ≥ 0 is charged on each vehicle using the HOT lane with occupancy level m on segment e . Agents split the toll price evenly, i.e. a agent pays τ e,m /m when carpooling with m -1 other agents on the HOT lane of segment e . The latency function on each road segment e is given by ℓ o ,e ( x o ,e , 1 -ρ ) for ordinary lanes and ℓ h ,e ( x h ,e , ρ ) for HOT lanes, where x o ,e and x h ,e are the vehicle flows on ordinary lanes and HOT lanes of road segment e , respectively. Same as the basic model, we assume that the latency functions on all road segments satisfy Assumption 1.
For each pair of i ≤ j ∈ [ E ], a population of agents with demand D ij enters the highway from the entrance node (the beginning) of segment i and leaves the highway from the exit node (the ending) of segment j . We refer the population who traverses segments [ i : j ] := i, . . . , j as the population ( i, j ). Agents in each population ( i, j ) decides their carpool size m ∈ [ M ] and whether to take the HOT lane or the ordinary lane in each segment e ∈ [ i : j ]. We denote an action of population ( i, j ) as a = ( a occu , ( a e ) e ∈ [ i,j ] ), where a occu ∈ [ M ] is the occupancy level, and a e ∈ { o h , } is to take the ordinary lane or the HOT lane for each segment e ∈ [ i, j ]. Thus, the action set of the population ( i, j ) is A ij = [ M ] ×{ o h , } [ i j : ] . We note that agents must select a single carpool size for traversing all the segments but they can switch between the ordinary lanes and the HOT lanes at the separation nodes in between segments based on the HOT toll price and latency of the next segment.
Analogous to the basic model, we represent the heterogeneous preference of agents of using value of time β ∈ [0 , β ] and carpool disutilities γ := ( γ m m ) ∈ [ M ] , where γ m ∈ [0 , γ m ] denotes the disutilities for choosing occupancy level m . We set the disutility of single occupancy γ 1 to 0. The distribution of agents' preference parameters ( β, γ ) for population ( i, j ) is represented by the probability density function f ij : B × Γ → R such that f ij ( β, γ ) > 0 for all ( β, γ ) and ∫ B × Γ f ij ( β, γ ) dβdγ = 1.
We define the strategy of an agent in population ( i, j ) as a mapping from their preference parameters ( β, γ ) to a pure strategy in action set A ij , denoted as s ij : B × Γ → A ij . The set
of agents of the population ( i, j ) who choose each action a ∈ A ij , denoted by R ij a , is given by:
$$R _ { a } ^ { i j } = \left \{ \mathbf B \times \Gamma | s ^ { i j } ( \beta, \gamma ) = a \right \}, \quad \forall a \in A ^ { i j }.$$
We represent the strategy distribution of the population ( i, j ) as σ ij = ( σ ij a ) a ∈ A ij , where
$$\sigma _ { a } ^ { i j } = \frac { 1 } { D ^ { i j } } \int _ { R _ { a } ^ { i j } } f ^ { i j } ( \beta, \gamma ) d \beta d \gamma$$
is the fraction of agents who choose each action a ∈ A , and ∑ a ∈ A ij σ ij a = 1. On each road segment e , the vehicle flow on ordinary lanes x o ,e and on HOT lanes x h ,e are induced by all agents of population ( i, j ) that enters the highway on or before e and exits on or after e , i.e. i ≤ e ≤ j . In particular,
$$x _ { o, e } = \sum _ { i = 1 } ^ { e } \sum _ { j = e } ^ { E } D ^ { i j } \left ( \sum _ { a \in A ^ { i j } } \frac { 1 } { a _ { o c c u } } \sigma _ { a } ^ { i j } 1 _ { a _ { e } = o } \right ), \quad \forall e \in [ E ],$$
$$x _ { \text{h,e} } = \sum _ { i = 1 } ^ { e } \sum _ { j = e } ^ { \ell } D ^ { i j } \left ( \sum _ { a \in \mathcal { A } ^ { i j } } \frac { 1 } { a _ { \text{occu} } } \sigma _ { a } ^ { i j } \mathbf 1 _ { a _ { e } = \text{h} } } ^ { \ell } \right ), \quad \forall e \in [ E ].$$
The cost of each agent of population ( i, j ) with preference parameters ( β, γ ) for choosing action a ∈ A ij is given by
$$\mu \circ \cdots \cdots & \cdots \\ & C _ { a } ( \sigma, \beta, \gamma ) = \gamma _ { a _ { o c c u } } \\ & + \sum _ { e = i } ^ { j } \beta \cdot \ell _ { o, e } ( x _ { o, e }, 1 - \rho ) \mathbb { 1 } _ { a _ { e } = o } \\ & + \sum _ { e = i } ^ { j } \left ( \beta \cdot \ell _ { \mathrm h, e } ( x _ { \mathrm h, e }, \rho ) + \frac { 1 } { a _ { o c c u } } \tau _ { e, a _ { o c c u } } \right ) \mathbb { 1 } _ { a _ { e } = \mathrm h }, \\ ( x _ { \cdots }. 1 - \alpha ) \, \left ( \text{sim}. \, \beta \cdot \ell _ { \mathrm h } ( x _ { \mathrm h }.. \, \alpha ) \right ) \, \text{resents the cost of enduring the latency on}$$
where β · ℓ o ,e ( x o ,e , 1 -ρ ) (resp. β · ℓ h ,e ( x h ,e , ρ )) represents the cost of enduring the latency on ordinary lanes (resp. HOT lanes) on segment e . Additionally, the carpool disutility γ a occu is added according to the associated occupancy level of the action, and toll payment 1 a occu τ e,a occu is added based on whether the action takes the HOT lane on each segment. Analogous to the basic model, we define the Wardrop equilibrium as:
Definition 2 A strategy profile s ∗ : B × Γ → A is a Wardrop equilibrium if
$$& s ^ { * i j } ( \beta, \gamma ) = a, \\ & \Rightarrow \quad C _ { a } ( \sigma ^ { * i j }, \beta, \gamma ) = \arg \min _ { a ^ { \prime } \in A ^ { i j } } C _ { a ^ { \prime } } ( \sigma ^ { * i j }, \beta, \gamma ), \\ & \forall ( \beta, \gamma ) \in B \times \Gamma, \ \forall i \leq j \in [ E ],$$
and σ ∗ ij is equilibrium strategy distribution of population ( i, j ) induced by s ∗ given by (11) -(12) .
We next provide conditions under which equilibrium is unique in the multi-segment setting. Before presenting this result, we note that an agent's equilibrium strategy s ∗ ij ( β, γ ) depends on the segment latency of each lane, but only through the difference between them, not their individual values. We define δ = ( δ e ) e ∈ E as the vector of latency difference, where δ e is the latency of the ordinary lane exceeding that of the HOT lane in segment e . Given δ and the toll price vector τ , the best response of agent in population ( i, j ) with preference parameter ( β, γ ) is uniquely determined. In particular, when an agent with preference parameter ( β, γ ) chooses occupancy level m , they will select the ordinary lane (resp. HOT lane) of segment e if τ e,m /m > βδ e (resp. τ e,m /m < βδ e ). The agent's best response occupancy level is argmin m ∈ [ M ] { ∑ e ∈ [ i,j ] min { τ e,m /m, βδ e } + γ m } . With slight abuse of notation, we denote x δ ( ) as the lane flow vector induced by all agents taking their best response to the cost difference vector δ according to (12)-(13). We define Φ ( e δ ) = ℓ o,e ( x o,e ( δ )) -ℓ h,e ( x h,e ( δ )) as the latency cost difference between the two lanes of segment e induced by all agents' best response given δ , and the vector function is Φ( δ ) = (Φ ( e δ )) e ∈ E .
We note that the set of fixed point solution of Φ( δ ) = δ is the vector of latency cost difference in equilibrium δ ∗ . This is because when the latency cost difference induced by agents' best response Φ( δ ∗ ) is consistent with the actual latency cost difference δ ∗ , no agent has incentive to deviate. Moreover, since agents have unique best response for any δ , there is a one-to-one correspondence between an equilibrium strategy profile s ∗ and an equilibrium latency cost difference vector δ ∗ . The following theorem shows that in the multi-segment model, equilibrium exists, and is unique when the function Φ( ) satisfies certain condition. ·
Theorem 3 Given any toll price vector τ , Wardrop equilibrium s ∗ exists. Moreover, s ∗ is unique if the Jacobian matrix ▽ Φ( ) δ does not have 1 as its eigenvalue for any δ ∈ ∏ e ∈ E [ δ , δ e ¯ ] e , where δ e = ℓ o,e (0) -ℓ h ,e ( ∑ e i =1 ∑ E j = e D ij ) and ¯ δ e = ℓ o ,e ( ∑ e i =1 ∑ E j = e D ij ) -ℓ h ,e (0) .
In Theorem 3, the equilibrium existence result is established using the Kakutani's fixed point theorem, relying on the boundedness of the latency cost difference vector and the continuity of the function Φ( ). · The equilibrium uniqueness result follows from the oneto-one correspondence between equilibrium and fixed point solution of Φ( δ ) = δ , and the mean value theorem. We note that the sufficient condition holds generically, meaning that equilibrium is generically unique. Additionally, in the single-segment setting, we can verify that Φ( δ ) is monotone in δ and that ∇ Φ( ) does not have an eigenvalue of 1. As demonstrated δ in Theorem 1, equilibrium is indeed unique in the single segment setting. The complete proof of Theorem 3 can be found in Appendix A.
## 5 Design HOT on California I-880
In this section, we redesign the high-occupancy toll (HOT) lane on California's I-880. Using data collected from the HOT operations on I-880 in 2021, we calibrate a multi-segment model. The primary challenge in this calibration is estimating the distribution of agents' preferences from aggregate lane choice data. To address this, we apply inverse optimization to estimate the preference distribution such that the resulting equilibrium flow closely matches the observed data. With the calibrated model, we compute the Wardrop equilibrium and determine the optimal toll price to achieve various policy goals. We then compare the computed toll price with the actual prices from the 2021 operations.
## 5.1 Data description
The Metropolitan Transportation Commission in California started the conversion of the existing HOV lanes to HOT lanes on the I-880 highway in 2019. The HOT lanes run from Hegenberger Road to Dixon Landing Road in the southbound direction and from Dixon Landing Road to Lewelling Boulevard in the northbound direction. This stretch of highway is partitioned into multiple segments. The toll price is charged for using the HOT lane on each segment from 5 am to 8 pm on each workday, and the toll is updated every 5 min. Vehicles with carpool size of 3 can use the HOT lane for free, vehicles with carpool size of 2 pay half of the toll price, and vehicles with a single person pay the full price.
We calibrate our multi-segment model using data collected from the Northbound of I-880 between the Dixon Landing Rd and Lewelling Blvd. The total distance is 22 miles and the highway has three ordinary lanes and one HOT lane. The highway is partitioned into five segments with separation nodes named as the Auto Mall Pkwy, Mowry Ave, Decoto Rd, Whipple Rd, and Hesperian Blvd, see Fig. 3. The distance of these segments are 5.75 miles, 3.17 miles, 3.46 miles, 2.11 miles, and 7.16 miles, respectively.
The California Department of Transportation have installed hundreds of sensors along the I-880 highway. Each sensor measures the vehicle flow data and average speed data at the 5-minute level. We obtain the data from [70] for all workdays between March 1st 2021 and August 31st 2021. We number these workdays sequentially as n ∈ [ N ] := 1 , . . . , N , where N is the total number of workdays. For each workday n , we aggregate those 5-minute vehicle flows into per-hour vehicle flows of each sensor. We take the average of vehicle speed across all 5-minute intervals of each hour to infer the per-hour average speed. We divide the distance between two adjacent sensors with the average speed to compute the average travel time between each pair of adjacent sensors during each hour of the day n . We number the hours from 5 am to 8 pm as t ∈ [ T ] := 1 , . . . , T , where T = 15 is the total number of HOT
Figure 3: Interstate 880 (I-880) Highway from Dixon Landing Rd to Lewelling Blvd (Highlighted in Blue). The nodes separating the segments are marked in bold text.
operation hours of each workday.
For each road segment e between Auto Mall Pkwy and Hesperian Blvd, we identify the list of all sensors covering this road segment. We sum up the average travel time across all these sensors to obtain the latency of ordinary lanes ˆ ℓ t,n o ,e and HOT lanes ˆ ℓ t,n h ,e of this road segment for each hour t of each day n . Additionally, we take an average of vehicle flows across all these sensors to obtain the observed vehicle flows for ordinary lanes ˆ x t,n o ,e and HOT lanes ˆ x t,n h ,e of this road segment for each hour t of each day n .
Figure 4 illustrates the travel time from Auto Mall Pkwy to Hesperian Blvd in different hours of a day. The dotted lines are the mean travel time on ordinary lanes and HOT lanes in each hour of the day averaged across all days, while the shaded regions are the corresponding 95% confidence intervals for each hour. Ordinary lanes have a uniformly higher travel time than HOT lanes in all hours. Particularly, in the afternoon hours (i.e. 2-6 pm), ordinary lanes can reach 33% higher travel time compared to the ordinary lanes on average.
We requested from Caltrans the toll price data for each road segment for each 5 min time interval, and the daily number of vehicles at each occupancy level using the HOT lanes for the entire I-880 highway. 3 Using this data, we compute the hourly averaged toll price of each segment and the fraction of vehicles taking the HOT lanes with occupancy level m on each day n , denoted as r n m .
## 5.2 Model calibration
Latency functions. We estimate the latency function of the ordinary and HOT lanes of each road segment based on the Bureau of Public Roads (BPR) function (US Bureau of
3 Due to privacy concern, the occupancy level data shared with us is aggregated across all segments and all HOT operation hours for each day.
Figure 4: Average travel time (min) and 95% confidence interval of the HOT and ordinary lanes from Auto Mall Pkwy to Hesperian Blvd in each hour of a workday.

Public Roads [71]). Given the vehicle flow x and the HOT capacity ρ = 0 25 (one lane out . of 4 is HOT in the current design), the BPR function can be written as follows:
$$\ell _ { o } ( x ) = & T _ { f } \cdot \left [ 1 + \left ( \eta \cdot \frac { x _ { o } } { ( 1 - \rho ) V } \right ) ^ { b } \right ], \\ \ell _ { \text{h} } ( x ) = & T _ { f } \cdot \left [ 1 + \left ( \eta \cdot \frac { x _ { \text{h} } } { \rho V } \right ) ^ { b } \right ],$$
where η and b are the BPR coefficients, T f is the free flow travel time, and V is the road capacity. We set b = 4 0 following [72], and estimate parameters . T f and η V of each segment using the flow data { ˆ x t,n o ,e , x ˆ t,n h ,e } e ∈ [ E ,t ] ∈ [ T ,n ] ∈ [ N ] and driving time { ˆ ℓ t,n o ,e , ℓ ˆ t,n h ,e } e ∈ [ E ,t ] ∈ [ T ,n ] ∈ [ N ] via linear regression.
Calibration of preference distribution. To compute the equilibrium strategy distribution, we need to estimate the population demand for each entrance and exit pair, and estimate the agents' preference distribution. To ensure the tractability of the demand and preference distribution estimates, we create a grid for each preference parameter β and { γ } m ∈ [ M ] with evenly spaced intervals. Then, the entire preference parameter vector space is partitioned into equally sized subsets. We denote the set of all partitioned preference sets as K with generic member k , and assume that the preference distribution in each subset k is uniform. This can be viewed as an approximation of the original probability density function of the preference parameters: As the partition of preference parameter space becomes finer, the approximation becomes closer to the original density function.
For each pair of entrance and exit nodes ( i, j ) and each hour t , we estimate d ij,t k as the
mass of agents with preference parameters in each subset k . This estimate corresponds to the multiplication of the total agent demand for the population ( i, j ) at time t and the fraction of agents with preference parameters in subset k . Our estimate captures the variation of agent demand and preference distribution across different entrance and exit nodes and times of the day. We assume the agents' demand for each hour is the same across all workdays.
We estimate d := ( d ij,t k ) i ≤ ∈ j [ E ,t ] ∈ [ T ,k ] ∈ [ K ] using inverse optimization. Given data on toll prices { τ t,n e,m } e ∈ [ E ] and driving time { ˆ ℓ t,n o ,e , ℓ ˆ t,n h ,e } e ∈ [ E ] for each hour t of each day n , we compute the best response strategy profile s ∗ t,n of all agents for hour t and day n . With the estimated demand ( d ij,t k ) i ≤ ∈ j [ E ,k ] ∈ [ K ] for hour t , we obtain the best response strategy distribution ( σ ∗ t,n a ( d )) a ∈ A following analysis in Sec. 4, and the induced vehicle flow x ∗ t,n ( d ) := { x ∗ t,n o ,e ( d , x ) ∗ t,n h ,e ( d ) } e ∈ [ E ] based on (13). Additionally, we compute the induced best response vehicle flow of each occupancy level ¯ x ∗ n ( d ) := (¯ x ∗ n m ( d )) m ∈ [ M ] as follows: ∀ m ∈ [ M ],
$$\vec { x } _ { m } ^ { * n } ( d ) & = \sum _ { t \in [ T ] } \sum _ { i \leq j \in [ E ] } D ^ { i j, t } \\ & \cdot \left ( \sum _ { a \in A ^ { i j } } \frac { 1 } { a _ { o c c u } } \sigma _ { a } ^ { * i j, t, n } ( d ) \mathbf 1 _ { a _ { e } = h, a _ { o c c u } = m } \right ). \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
We estimate d to be the demand vector such that the induced best response vehicle flow is close to the observed flows { ˆ x t,n o ,e , x ˆ t,n h ,e } e ∈ [ E ,t ] ∈ [ T ,n ] ∈ [ N ] and the induced fraction of vehicles taking each occupancy level is close to ( r n m m ) ∈ [ M ,n ] ∈ [ N ] . We formulate the estimation problem as the following convex optimization program:
$$\text{wimgs convex} \, \text{puminance} \, \text{p} \text{vog} \colon \\ \min _ { d } \, \sum _ { n \in [ N ] } \sum _ { n \in [ N ] } \sum _ { m \in [ M ] } \left ( r _ { m } ^ { n } \left ( \sum _ { m ^ { \prime } \in [ M ] } \bar { x } _ { m ^ { \prime } } ^ { * n } ( d ) \right ) - \bar { x } _ { m } ^ { * n } ( d ) \right ) ^ { 2 } \\ + \sum _ { t \in [ T ] } \sum _ { e \in [ E ] } \left ( \left ( x _ { o, e } ^ { * t, n } ( d ) - \hat { x } _ { o, e } ^ { t, n } \right ) ^ { 2 } + \left ( x _ { h, e } ^ { * t, n } ( d ) - \hat { x } _ { h, e } ^ { t, n } \right ) ^ { 2 } \right ). \\ \int _ { 1 } \dots \int _ { 2 } \dots \int _ { 3 } \dots \int _ { 4 } \dots \int _ { 5 } \dots \int _ { 6 } \dots \int _ { 7 } \dots.$$
We use the calibrated demand to compute the number of agents taking each occupancy level and compare it with the actual numbers. In Fig. 5, the dotted lines show the observed daily fraction of agents on HOT lanes for each occupancy level, while the curved lines show the equilibrium daily ratio of agents for each occupancy level based on calibrated demand and induced equilibrium. The close alignment of curved lines and dotted lines demonstrates that our calibrated demand closely matches the actual demand.
## 5.3 Optimal design of toll price and HOT capacity at 5-6pm
Based on the calibrated model, we compute the optimal toll price and HOT capacity allocation for 5-6 pm. We consider each of the following four objectives in equilibrium:
Figure 5: Fractions of agents on HOT lanes taking each occupancy level per day.

## 1. The total agent travel time.
$$\cdots \cdots \cdots \cdots \cdots \cdots \\ & C ( \tau, \rho ) \coloneqq \sum _ { i \leq j \in [ E ] } D ^ { i j } \left [ \sum _ { a \in A ^ { i j } } \sigma _ { a } ^ { * i j } \\ & \cdot \left ( \sum _ { e = i } ^ { j } \ell _ { o, e } ( x _ { o, e } ^ { * }, 1 - \rho ) \mathbb { 1 } _ { a _ { e } = o } + \ell _ { h, e } ( x _ { h, e } ^ { * }, \rho ) \mathbb { 1 } _ { a _ { e } = h } \right ) \right ].$$
- 2. The total vehicle driving time. The total vehicle driving time differs from the total agent travel time. Specifically, for every minute a vehicle with m ∈ [ M ] agents spends on the highway, the total vehicle driving time counts this as 1 minute, whereas the agent travel time counts it as m minutes.
$$\dots \dots \dots \dots \dots \dots \dots \dots \\ & \mathbb { E } ( \tau, \rho ) \coloneqq \sum _ { i \leq j \in [ E ] } D ^ { i j } \left [ \sum _ { a \in A ^ { i j } } \sigma _ { a } ^ { * i j } \frac { 1 } { a _ { o c c u } } \\ & \cdot \left ( \sum _ { e = i } ^ { j } \ell _ { o, e } ( x _ { o, e } ^ { * }, 1 - \rho ) \mathbb { 1 } _ { a _ { e } = o } + \ell _ { h, e } ( x _ { h, e } ^ { * }, \rho ) \mathbb { 1 } _ { a _ { e } = h } \right ) \right ].$$
- 3. Total revenue: The total toll prices paid by all agents.
$$\mathbf R ( \tau, \rho ) \coloneqq \sum _ { i \leq j \in [ E ] } D ^ { i j } \left [ \sum _ { a \in A ^ { i j } } \sigma _ { a } ^ { * i j } \frac { 1 } { a _ { o c c u } } \left ( \sum _ { e = i } ^ { j } \tau _ { e, a _ { o c c u } } \mathbf 1 _ { a _ { e } = h } \right ) \right ].$$
- 4. Total cost: The total cost (driving time, toll price and carpool disutility) incurred by all agents incorporating their heterogeneous preferences.
$$& \mathsf U ( \tau, \rho ) \coloneqq \sum _ { i \leq j \in [ E ] } D ^ { i j } \left [ \sum _ { a \in A ^ { i j } } \int _ { \gamma } \int _ { \beta } C _ { \mathbf a } ( \sigma ^ { * }, \beta, \gamma ) \\ & \cdot \mathbf 1 _ { s ^ { * } i j ( \beta, \gamma ) = a } f ^ { i j } ( \beta, \gamma ) d \beta d \gamma \right ].$$
The problems (16) - (19) compute the HOT toll price for each segment that optimizes the objective function based on the induced equilibrium strategy. As such, these are mathematical programs with equilibrium constraints (MPEC). Furthermore, since the toll is only applied to the HOT lane, these problems can be seen as a generalization of optimal tolling with support constraints, which has been proven to be NP-hard ([73, 74]). We adopt the enumeration algorithm for the optimal design of toll price and HOT capacity. In particular, we set the toll price on each road segment within the range of 0 and 7 dollars discretized by $0 5. . We also choose the set ρ ∈ { 1 4 , 2 4 , 3 4 } since the highway has four lanes. For each pair of ( τ, ρ ), we compute the equilibrium strategies, and the corresponding objective function value. We choose the toll price and capacity fraction with the optimal value.
Table 2 summarizes our result. The first row shows the current HOT capacity and the average toll price. The remaining rows in Table 2 shows the optimal toll prices on each road segment for agent travel time minimization, vehicle driving time minimization, revenue maximization, and cost minimization, under different HOT capacities.
When the HOT capacity is 0.25 (the setting in practice), the optimal toll prices for agent travel time, vehicle driving time, and cost minimization are lower than the current prices on Auto Mall Pkwy, Mowry Ave, Decoto Rd, and Whipple Rd. On Hesperian Blvd, they match the current average toll price. For revenue maximization, the optimal toll prices are lower than the current average prices on all five road segments. As HOT capacity increases, the optimal toll prices for these four objectives may vary, either increasing or decreasing, depending on each road segment.
Note that the optimal toll prices for agent travel time, vehicle driving time, and cost minimization are higher on Hesperian Blvd, and lower on other segments. We remark that it aligns with the fact that the demand volume of agents is also higher on Hesperian Blvd and lower on other segments. Given the convex nature of the latency function, a large demand volume on a road segment means that the reduction in travel time achieved by incentivizing agents to carpool becomes more significant compared to segments with smaller demand volumes. Therefore, setting a high toll price on road segments with large demand is more effective in incentivizing carpool, which in turn reduces the agent travel time, vehicle driving time, and cost of agents.
However, charging a high toll price can lead agents to either carpool or take the ordinary lane, leaving fewer agents willing to pay the toll. Consequently, the optimal toll price that maximizes the revenue is often lower than the ones associated with the other three objectives. This creates a trade-off between revenue maximization and the minimization of agent travel time, vehicle driving time, and costs. This tradeoff is illustrated in the Pareto front in Fig. 6. The blue, orange, and green curves in Fig. 6 show the maximum attainable revenue at
each value of agent travel time, vehicle driving time, and cost for HOT capacity of 0.25, 0.5, and 0.75, respectively. 4
Table 2: Optimal toll prices and HOT capacity design for 5-6 pm on all five road segments
| HOT Capacity | Objective | Toll Prices | Toll Prices | Toll Prices | Toll Prices | Toll Prices |
|----------------|------------------------------------------------------------------------------------------|-----------------------------|-----------------------------|------------------------------------|-----------------------------|-----------------------------|
| HOT Capacity | Objective | Auto Mall | Mowry | Decoto | Whipple | Hesperian |
| 0.25 | Current Prices | $1 . 1 | $2 . 2 | $2 . 5 | $4 . 0 | $5 . 0 |
| 0.25 | Agent Time Minimization Vehicle Time Minimization Revenue Minimization Cost Minimization | $0 . 5 $0 . 5 $0 . 0 $0 . 5 | $1 . 5 $1 . 5 $1 . 0 $1 . 5 | $0 . 5 $0 . 5 $1 . 0 $0 . 5 | $0 . 5 $0 . 5 $0 . 5 $0 . 5 | $5 . 0 $4 . 0 $1 . 5 $5 . 0 |
| 0.50 | Agent Time Minimization Vehicle Time Minimization Revenue Minimization Cost Minimization | $0 . 0 $0 . 0 $0 . 5 $0 . 0 | $0 . 5 $0 . 5 $1 . 5 $0 . 5 | $0 . 0 $0 . 0 $1 . 5 $0 . 0 $0 . 0 | $0 . 0 $0 . 0 $1 . 5 $0 . 0 | $5 . 0 $5 . 0 $1 . 0 $5 . 0 |
| 0.75 | Agent Time Minimization Vehicle Time Minimization Revenue Minimization Cost Minimization | $0 . 0 $0 . 0 $0 . 5 $0 . 0 | $0 . 5 $1 . 5 $2 . 5 $0 . 0 | $0 . 0 $4 . 5 $0 . 0 | $0 . 0 $0 . 0 $1 . 5 $0 . 0 | $5 . 0 $5 . 0 $4 . 5 $5 . 0 |
## 5.4 Hourly optimal toll pricing
In this section, we compute the optimal hourly toll price from 5am to 8pm for each one of the four objectives. We set the HOT capacity as 0 25 to match the current HOT capacity . on I-880. In Figure 7, red curves represent the optimal toll prices, blue dots represent the average current toll price recorded in the data, and the blue shaded regions represent the 95% confidence interval of the current toll price.
For Auto Mall Parkway, the optimal toll prices for minimizing agent travel time, vehicle driving time, and costs are lower than the current prices for most hours of the day. The optimal toll prices for revenue maximization are higher in the early morning but lower in the afternoon (Figures 7a-7d). On Mowry Ave (Figures 7e-7h), the optimal toll prices for agent travel time minimization, vehicle driving time minimization, and cost minimization are lower
4 While the optimal toll design of a high HOT capacity dominates the optimal toll design of lower HOT capacities, it does not mean that setting more lanes as the HOT lane is better in reality. We need to take other aspects into considerations, for example the accessibility and equity of agents with different incomes.
(a) Agent Time
Figure 6: Pareto fronts of agent travel time, vehicle driving time, and cost w.r.t revenue for 5-6 pm on all road segments. The blue, orange, and green curves show the maximum attainable revenue at each value of agent travel time, vehicle driving time, and cost for HOT capacity of 0.25, 0.5, and 0.75 respectively.
than the current prices in the morning (before 12 pm) but higher during evening rush hours (around 5 pm). The optimal toll prices for revenue maximization are lower than the current prices during evening rush hours but similar in other hours. For Decoto Rd (Figures 7i-7l) and Whipple Rd (Figures 7m-7p), the optimal toll prices for all four objectives are lower than the current prices during evening rush hours and similar to the current prices at other times. Lastly, for Hesperian Blvd (Figures 7q-7t), the optimal toll prices for agent travel time and vehicle driving time minimization are lower than the current prices during morning rush hours (6-8 am), while the optimal toll prices for revenue maximization are lower during evening rush hours.
On each road segment, the optimal toll prices for agent travel time minimization, vehicle driving time minimization, and cost minimization are almost identical at each hour. However, the optimal toll prices for revenue maximization are similar during the morning hours (before 12 pm) but significantly lower than the optimal toll prices for the other three objectives during the evening rush hours (around 5 pm), especially on Hesperian Blvd.
In the morning, when the agent demand volume is low, setting a high toll price to incentivize carpooling does not lead to a significant reduction in HOT latency. Therefore, the optimal toll prices for both the minimization of agent travel time, vehicle driving time, and costs, as well as for revenue maximization, are low during the morning hours.
On the other hand, in the evening hours, when agent demand is higher, setting a high toll price can lead to a substantial reduction in HOT latency, particularly on road segments with high demand. However, this also discourages most people from paying the toll. As a result, the optimal toll prices for revenue maximization are lower than those for minimizing
agent travel time, vehicle driving time, and costs. This difference is more pronounced on road segments with high agent demand, such as Hesperian Blvd.
Figure 8 illustrates the improvements achieved by implementing optimal toll prices in terms of agent travel time, vehicle driving time, revenue, and cost, compared to the current toll prices. Blue bars represent the percentage improvements, while red curves depict the numerical improvements. By using the optimal toll prices, we can achieve reductions of up to 30-40% in agent travel time, vehicle driving time, and costs, and an increase in revenue of up to 2500%. Specifically, optimal toll prices can lead to reductions of up to 300,000 minutes in total agent travel time, 350,000 minutes in total vehicle driving time, and $ 250,000 in total costs, while increasing total revenue by up to $ 40,000. The largest numerical improvements for all four objectives occur during the afternoon hours, when travel demand is high.
## 6 Concluding remarks
In this article, we examine a game-theoretic model that analyzes the lane choice of travelers with heterogeneous values of time and carpool disutilites on highways equipped with HOT lanes. For highways with a single road segment, we characterize the equilibrium strategies, and identify two qualitatively distinct equilibrium regimes that depends on the HOT lane capacity and toll price. We discuss how equilibrium strategies and latency difference of ordinary lanes and HOT lanes will change by increasing the HOT capacity or toll price. Additionally, we extend our model to highways with multiple entrance and exit nodes. We calibrate our model using the data of California Interstate highway 880 and determine the optimal capacity allocation and toll design. As a future direction of research, we will investigate the equilibrium property in a fully generalized network, and the design of HOT systems with multiple combined objectives.
## References
- [1] Dov Monderer and Lloyd S Shapley. Potential games. Games and economic behavior , 14(1):124-143, 1996.
- [2] Robert W Rosenthal. A class of games possessing pure-strategy Nash equilibria. International Journal of Game Theory , 2:65-67, 1973.
- [3] William H Sandholm. Potential games with continuous player sets. Journal of Economic theory , 97(1):81-108, 2001.
- [4] Tim Roughgarden and ´ va Tardos. Bounding the inefficiency of equilibria in nonatomic E congestion games. Games and economic behavior , 47(2):389-403, 2004.
- [5] Dario Paccagnan, Rahul Chandan, Bryce L Ferguson, and Jason R Marden. Incentivizing efficient use of shared infrastructure: Optimal tolls in congestion games. arXiv preprint arXiv:1911.09806 , 2019.
- [6] Jos´ R Correa, Andreas S Schulz, and Nicol´s E Stier-Moses. Selfish routing in capacie a tated networks. Mathematics of Operations Research , 29(4):961-976, 2004.
- [7] Tim Roughgarden. Selfish routing and the price of anarchy . MIT press, 2005.
- [8] Igal Milchtaich. Congestion games with player-specific payoff functions. Games and economic behavior , 13(1):111-124, 1996.
- [9] Marios Mavronicolas, Igal Milchtaich, Burkhard Monien, and Karsten Tiemann. Congestion games with player-specific constants. In Mathematical Foundations of Computer Science 2007: 32nd International Symposium, MFCS 2007 Cesk` Krumlov, Czech Reˇ y public, August 26-31, 2007 Proceedings 32 , pages 633-644. Springer, 2007.
- [10] George Christodoulou and Elias Koutsoupias. The price of anarchy of finite congestion games. In Proceedings of the thirty-seventh annual ACM symposium on Theory of computing , pages 67-73, 2005.
- [11] Tim Roughgarden. Algorithmic game theory. Communications of the ACM , 53(7): 78-86, 2010.
- [12] Tim Roughgarden and Eva Tardos. ´ How bad is selfish routing? Journal of the ACM (JACM) , 49(2):236-259, 2002.
- [13] Mei Chen and David H Bernstein. Solving the toll design problem with multiple user groups. Transportation Research Part B: Methodological , 38(1):61-79, 2004.
- [14] Yang Liu and Yu Nie. A credit-based congestion management scheme in general twomode networks with multiclass users. Networks and Spatial Economics , 17:681-711, 2017.
- [15] Hongyu Chen, Yang Liu, and Yu Marco Nie. Solving the step-tolled bottleneck model with general user heterogeneity. Transportation Research Part B: Methodological , 81: 210-229, 2015.
| [16] | Yang Liu and Yu Nie. Welfare effects of congestion pricing and transit services in multiclass multimodal networks. Transportation research record , 2283(1):34-43, 2012. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [17] | Gabriel de O Ramos, Roxana R˘dulescu, a Ann Now´, e and Anderson R Tavares. Toll- based learning for minimising congestion under heterogeneous preferences. In Pro- ceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems , pages 1098-1106, 2020. |
| [18] | Alejandro Ortega Hortelano, Jose Manuel Vassallo, and Juan Ignacio P´rez. e Optimal welfare price for a road corridor with heterogeneous users. Transport , 34(3):318-329, 2019. |
| [19] | George Karakostas and Stavros G Kolliopoulos. Edge pricing of multicommodity net- works for heterogeneous selfish users. In FOCS , volume 4, pages 268-276, 2004. |
| [20] | Hongyu Chen, Yu Marco Nie, and Yafeng Yin. Optimal multi-step toll design under general user heterogeneity. Transportation Research Part B: Methodological , 81:775-793, 2015. |
| [21] | Vincent AC van den Berg. Self-financing roads under coarse tolling and preference heterogeneity. Transportation Research Part B: Methodological , 182:102909, 2024. |
| [22] | Yu Marco Nie and Yang Liu. Existence of self-financing and pareto-improving congestion pricing: Impact of value of time distribution. Transportation Research Part A: Policy and Practice , 44(1):39-51, 2010. |
| [23] | Hai Yang and Hai-Jun Huang. Mathematical and economic theory of road pricing . Emerald Group Publishing Limited, 2005. |
| [24] | Lan Jiang and Hani S Mahmassani. Toll pricing: computational tests for capturing heterogeneity of user preferences. Transportation research record , 2343(1):105-115, 2013. |
| [25] | Chung-Cheng Lu, Xuesong Zhou, and Hani S Mahmassani. Variable toll pricing and heterogeneous users: Model and solution algorithm for bicriterion dynamic traffic as- signment problem. Transportation Research Record , 1964(1):19-26, 2006. |
| [26] | Lisa Fleischer, Kamal Jain, and Mohammad Mahdian. Tolls for heterogeneous selfish users in multicommodity networks and generalized congestion games. In 45th Annual IEEE Symposium on Foundations of Computer Science , pages 277-285. IEEE, 2004. |
- [27] Richard Cole, Yevgeniy Dodis, and Tim Roughgarden. Pricing network edges for heterogeneous selfish users. In Proceedings of the thirty-fifth annual ACM symposium on Theory of computing , pages 521-530, 2003.
- [28] Hai Yang and Hai-Jun Huang. Carpooling and congestion pricing in a multilane highway with high-occupancy-vehicle lanes. Transportation Research Part A: Policy and Practice , 33(2):139-155, 1999. ISSN 0965-8564. doi: https://doi.org/10.1016/ S0965-8564(98)00035-4. URL https://www.sciencedirect.com/science/article/ pii/S0965856498000354 .
- [29] Guangzhi Zang, Meng Xu, and Ziyou Gao. High-occupancy vehicle lanes and tradable credits scheme for traffic congestion management: A bilevel programming approach. PROMET - Traffic & Transportation , 30:1, 2 2018. doi: 10.7307/ptt.v30i1.2300.
- [30] Chih Peng Chu, Jyh Fa Tsai, and Shou Ren Hu. Optimal starting location of an hov lane for a linear monocentric urban area. Transportation Research Part A: Policy and Practice , 46:457-466, 3 2012. ISSN 0965-8564. doi: 10.1016/J.TRA.2011.11.017.
- [31] Jonathan E Hughes and Daniel Kaffine. When should drivers be encouraged to carpool in hov lanes? Economic Inquiry , 57:667-684, 1 2019. ISSN 0095-2583. doi: https: //doi.org/10.1111/ecin.12728. URL https://doi.org/10.1111/ecin.12728 .
- [32] Kitae Jang, Myoung Kyun Song, Keechoo Choi, and Dong-Kyu Kim. A bi-level framework for pricing of high-occupancy toll lanes. Transport , 29(3):317-325, 2014.
- [33] Yingyan Lou, Yafeng Yin, and Jorge A Laval. Optimal dynamic pricing strategies for high-occupancy/toll lanes. Transportation Research Part C: Emerging Technologies , 19 (1):64-74, 2011.
- [34] Zhen Tan and H Oliver Gao. Hybrid model predictive control based dynamic pricing of managed lanes with multiple accesses. Transportation Research Part B: Methodological , 112:113-131, 2018.
- [35] Hideo Konishi and Se il Mun. Carpooling and congestion pricing: Hov and hot lanes. Regional Science and Urban Economics , 40:173-186, 7 2010. ISSN 0166-0462. doi: 10.1016/J.REGSCIURBECO.2010.03.009.
- [36] Fangfang Yuan, Xiaolei Wang, and Zhibin Chen. Assessing the impact of ride-sourcing vehicles on hov-lane efficacy and management strategies. Transport Policy , 150:35-52, 5 2024. ISSN 0967-070X. doi: 10.1016/J.TRANPOL.2024.02.017.
- [37] Huayu Xu, Jong Shi Pang, Fernando Ord´ o˜ez, n and Maged Dessouky. Complementarity models for traffic equilibrium with ridesharing. Transportation Research Part B: Methodological , 81:161-182, 11 2015. ISSN 0191-2615. doi: 10.1016/J.TRB.2015.08.013.
- [38] Huayu Xu, Fernando Ord´ o˜ez, and Maged Dessouky. n A traffic assignment model for a ridesharing transportation market. Journal of Advanced Transportation , 49:793-816, 11 2015. ISSN 0197-6729. doi: https://doi.org/10.1002/atr.1300. URL https://doi. org/10.1002/atr.1300 .
- [39] Chen-Yang Yan, Mao-Bin Hu, Rui Jiang, Jiancheng Long, Jin-Yong Chen, and HaoXiang Liu. Stochastic ridesharing user equilibrium in transport networks. Networks and Spatial Economics , 19:1007-1030, 2019. ISSN 1572-9427. doi: 10.1007/ s11067-019-9442-5. URL https://doi.org/10.1007/s11067-019-9442-5 .
- [40] Pengyun Chong, Min Lv, Hao Zhu, and Dong Ding. A scheme to improve network performance based on traffic restriction and pricing in the presence of carpooling. Mathematical Problems in Engineering , 2022:9360726, 1 2022. ISSN 1024-123X. doi: https: //doi.org/10.1155/2022/9360726. URL https://doi.org/10.1155/2022/9360726 .
- [41] Xuan Di, Henry X Liu, Xuegang (Jeff) Ban, and Hai Yang. Ridesharing user equilibrium and its implications for high-occupancy toll lane pricing. Transportation Research Record , 2667:39-50, 2017. doi: 10.3141/2667-05. URL https://doi.org/10.3141/ 2667-05 .
- [42] Xuan Di, Rui Ma, Henry X. Liu, and Xuegang (Jeff) Ban. A link-node reformulation of ridesharing user equilibrium with network design. Transportation Research Part B: Methodological , 112:230-255, 6 2018. ISSN 0191-2615. doi: 10.1016/J.TRB.2018.04.006.
- [43] Meng Li, Xuan Di, Henry X Liu, and Hai-Jun Huang. A restricted path-based ridesharing user equilibrium. Journal of Intelligent Transportation Systems , 24:383403, 7 2020. ISSN 1547-2450. doi: 10.1080/15472450.2019.1658525. URL https: //doi.org/10.1080/15472450.2019.1658525 . doi: 10.1080/15472450.2019.1658525.
- [44] Xingyuan Li and Jing Bai. A ridesharing choice behavioral equilibrium model with users of heterogeneous values of time. International Journal of Environmental Research and Public Health , 18, 2021. ISSN 1660-4601. doi: 10.3390/ijerph18031197. URL https://www.mdpi.com/1660-4601/18/3/1197 .
- [45] William S. Vickrey. Congestion theory and transport investment. The American Economic Review , 59(2):251-260, 1969. ISSN 00028282. URL http://www.jstor.org/ stable/1823678 .
- [46] Jorge A Laval, Hyun W Cho, Juan C Mu˜oz, and Yafeng Yin. n Real-time congestion pricing strategies for toll facilities. Transportation Research Part B: Methodological , 71: 19-31, 2015.
- [47] Di Wu, Yafeng Yin, and Siriphong Lawphongpanich. Pareto-improving congestion pricing on multimodal transportation networks. European Journal of Operational Research , 210(3):660-669, 2011.
- [48] Zhen Sean Qian and H. Michael Zhang. Modeling multi-modal morning commute in a one-to-one corridor network. Transportation Research Part C: Emerging Technologies , 19:254-269, 4 2011. ISSN 0968-090X. doi: 10.1016/J.TRC.2010.05.012.
- [49] Ling-Ling Xiao, Tian-Liang Liu, and Hai-Jun Huang. Tradable permit schemes for managing morning commute with carpool under parking space constraint. Transportation , 48:1563-1586, 2021. ISSN 1572-9435. doi: 10.1007/s11116-019-09982-w. URL https://doi.org/10.1007/s11116-019-09982-w .
- [50] Ling Ling Xiao, Tian Liang Liu, and Hai Jun Huang. On the morning commute problem with carpooling behavior under parking space constraint. Transportation Research Part B: Methodological , 91:383-407, 9 2016. ISSN 0191-2615. doi: 10.1016/J.TRB.2016.05. 014.
- [51] Jing Wang, Hua Wang, and Xiaohua Yu. Parking permit management of morning commuting considering carpooling with parking restraint. Journal of Transportation Engineering, Part A: Systems , 146:04020052, 7 2020. doi: 10.1061/JTEPBS.0000368. URL https://doi.org/10.1061/JTEPBS.0000368 . doi: 10.1061/JTEPBS.0000368.
- [52] Yang Liu and Yuanyuan Li. Pricing scheme design of ridesharing program in morning commute problem. Transportation Research Part C: Emerging Technologies , 79:156177, 6 2017. ISSN 0968-090X. doi: 10.1016/J.TRC.2017.02.020.
- [53] Jing Peng Wang, Xuegang (Jeff) Ban, and Hai Jun Huang. Dynamic ridesharing with variable-ratio charging-compensation scheme for morning commute. Transportation Research Part B: Methodological , 122:390-415, 4 2019. ISSN 0191-2615. doi: 10.1016/J.TRB.2019.03.006.
- [54] Lin Zhong, Kenan Zhang, Yu (Marco) Nie, and Jiuping Xu. Dynamic carpool in morning commute: Role of high-occupancy-vehicle (hov) and high-occupancy-toll (hot) lanes. Transportation Research Part B: Methodological , 135:98-119, 5 2020. ISSN 0191-2615. doi: 10.1016/J.TRB.2020.03.002.
- [55] Xiaojuan Yu, Vincent A.C. van den Berg, and Erik T. Verhoef. Carpooling with heterogeneous users in the bottleneck model. Transportation Research Part B: Methodological , 127:178-200, 9 2019. ISSN 0191-2615. doi: 10.1016/J.TRB.2019.07.003.
- [56] Ling Ling Xiao, Tian Liang Liu, Hai Jun Huang, and Ronghui Liu. Temporal-spatial allocation of bottleneck capacity for managing morning commute with carpool. Transportation Research Part B: Methodological , 143:177-200, 1 2021. ISSN 0191-2615. doi: 10.1016/J.TRB.2020.11.007.
- [57] Xiaojuan Yu, Vincent A.C. van den Berg, and Erik T. Verhoef. Carpooling with heterogeneous users in the bottleneck model. Transportation Research Part B: Methodological , 127:178-200, 9 2019. ISSN 0191-2615. doi: 10.1016/J.TRB.2019.07.003.
- [58] Bangyang Wei, Xiang Zhang, Wei Liu, Meead Saberi, and S. Travis Waller. Capacity allocation and tolling-rewarding schemes for the morning commute with carpooling. Transportation Research Part C: Emerging Technologies , 142:103789, 9 2022. ISSN 0968-090X. doi: 10.1016/J.TRC.2022.103789.
- [59] Joakim Ekstr¨m, Leonid Engelson, and Clas Rydergren. o Optimal toll locations and toll levels in congestion pricing schemes: a case study of Stockholm. Transportation Planning and Technology , 37(4):333-353, 2014.
- [60] Wei Fan. Optimal congestion pricing toll design for revenue maximization: comprehensive numerical results and implications. Canadian Journal of Civil Engineering , 42(8): 544-551, 2015.
- [61] Wei Fan. Social welfare maximization by optimal toll design for congestion management: models and comprehensive numerical results. Transportation Letters , 9(2):81-89, 2017.
- [62] Dimitra Michalaka, Yafeng Yin, and David Hale. Simulating high-occupancy toll lane operations. Transportation research record , 2396(1):124-132, 2013.
- [63] Xiang He, Xiqun Chen, Chenfeng Xiong, Zheng Zhu, and Lei Zhang. Optimal timevarying pricing for toll roads under multiple objectives: a simulation-based optimization approach. Transportation Science , 51(2):412-426, 2017.
- [64] Maxime C. Cohen, Alexandre Jacquillat, Avia Ratzon, and Roy Sasson. The impact of high-occupancy vehicle lanes on carpooling. Transportation Research Part A: Policy and Practice , 165:186-206, 11 2022. ISSN 0965-8564. doi: 10.1016/J.TRA.2022.08.021.
- [65] Maxime C Cohen, Michael-David Fiszer, Avia Ratzon, and Roy Sasson. Incentivizing commuters to carpool: A large field experiment with waze. Manufacturing & Service Operations Management , 25:1263-1284, 2023. doi: 10.1287/msom.2021.1033. URL https://doi.org/10.1287/msom.2021.1033 .
- [66] Jeremy Finkleman, Jeffrey Casello, and Liping Fu. Empirical evidence from the greater toronto area on the acceptability and impacts of hot lanes. Transport Policy , 18:814-824, 11 2011. ISSN 0967-070X. doi: 10.1016/J.TRANPOL.2011.05.002.
- [67] Jing Lu and Carolina Osorio. A probabilistic traffic-theoretic network loading model suitable for large-scale network analysis. Transportation Science , 52(6):1509-1530, 2018.
- [68] Jing Lu and Carolina Osorio. On the analytical probabilistic modeling of flow transmission across nodes in transportation networks. Transportation research record , 2676 (12):209-225, 2022.
- [69] HCM. Highway capacity manual: Practical applications of research . US Department of Commerce, Bureau of Public Roads, 1950.
- [70] Caltrans. Pems: Freeway performance measurement system. https://pems.dot.ca. gov/ , 2024. Accessed: 2024-06-16.
- [71] US Bureau of Public Roads. Traffic assignment manual for application with a large, high speed computer, 1964.
- [72] David Branston. Link capacity functions: A review. Transportation research , 10(4): 223-236, 1976.
- [73] Martin Hoefer, Lars Olbrich, and Alexander Skopalik. Taxing subnetworks. In International workshop on internet and network economics , pages 286-294. Springer, 2008.
- [74] Tobias Harks, Ingo Kleinert, Max Klimm, and Rolf H M¨hring. o Computing network tolls with support constraints. Networks , 65(3):262-285, 2015.
Figure 7: Optimal toll prices for agent travel time minimization, vehicle driving time minimization, revenue maximization, and cost minimization in each hour from 5 am to 8 pm of a workday. Red curves represent the optimal toll prices, blue dots represent the average current toll prices at each hour, while the blue shaded regions represent the 95% confidence regions of the current toll prices, across all workdays from March 1st 2021 to August 31st 2021.
Figure 8: Improvement of objectives by optimal toll price design in each hour from 5 am to 8 pm of a workday
## A Proof of Results
Proof of Lemma 1. We first show that ℓ δ ( σ , ρ ∗ ) > 0. Assume that ℓ δ ( σ , ρ ∗ ) ≤ 0 for the sake of contradiction. Then, for any ( β, γ ) with γ > 0, we have
$$C _ { o } ( \sigma ^ { * }, \beta, \gamma ) - C _ { \text{toll} } ( \sigma ^ { * }, \beta, \gamma ) & = \beta \ell _ { \delta } ( \sigma ^ { * }, \rho ) - \tau < 0, \\ C _ { o } ( \sigma ^ { * }, \beta, \gamma ) - C _ { \text{pool} } ( \sigma ^ { * }, \beta, \gamma ) & = \beta \ell _ { \delta } ( \sigma ^ { * }, \rho ) - \gamma < 0.$$
That is, all agent will choose to take the ordinary lane, and thus
$$\ast$$
$$& \ell _ { \delta } ( \sigma ^ { * }, \rho ) = \ell _ { o } ( D, 1 - \rho ) - \ell _ { \text{h} } ( 0, \rho ) \\ = & \ell _ { o } ( D, 1 - \rho ) - \ell _ { o } ( 0, 1 - \rho ) > 0,$$
where the second equality is due to Assumption 1 (b) and the last inequality is due to Assumption 1 (a). We obtain a contradiction. Hence, ℓ δ ( σ , ρ ∗ ) > 0.
Next, we prove that σ ∗ pool > 0. Consider agents whose value of time satisfies β ∈ [ ¯ β/ , β 2 ¯ ] and carpool disutility satisfies γ ∈ [ 0 , 1 3 min { ¯ βℓ δ ( σ , ρ , τ ∗ ) }] . For those agents, we have γ ≤ 1 3 min { ¯ βℓ δ ( σ , ρ , τ ∗ ) } < τ , which leads to
$$C _ { \text{pool} } ( \sigma ^ { * }, \beta, \gamma ) & = \beta \ell _ { \text{h} } ( \sigma ^ { * }, \rho ) + \gamma \\ < \beta \ell _ { \text{h} } ( \sigma ^ { * }, \rho ) + \tau & = C _ { \text{toll} } ( \sigma ^ { * }, \beta, \gamma ).$$
Additionally, we have
$$C _ { \text{pool} } ( \sigma ^ { * }, \beta, \gamma ) = & \beta \ell _ { \text{h} } ( \sigma ^ { * }, \rho ) + \gamma \\ \leq & \beta \ell _ { \text{h} } ( \sigma ^ { * }, \rho ) + \frac { 1 } { 3 } \bar { \beta } \ell _ { \delta } ( \sigma ^ { * }, \rho ) \\ < & \beta \ell _ { \text{h} } ( \sigma ^ { * }, \rho ) + \beta \ell _ { \delta } ( \sigma ^ { * }, \rho ) \\ = & \beta \ell _ { \text{o} } ( \sigma ^ { * }, 1 - \rho ) = C _ { \text{o} } ( \sigma ^ { * }, \beta, \gamma ),$$
where the last inequality is due to β ≥ 1 2 ¯ β > 1 3 ¯ . β Hence, for those agents, we have C pool ( σ , β, γ ∗ ) < C o ( σ , β, γ ∗ ) and C pool ( σ , β, γ ∗ ) < C toll ( σ , β, γ ∗ ). That is, all agents with preference parameters in this set choose to carpool. Therefore,
$$\sigma _ { \text{pool} } ^ { * } \geq \int _ { \bar { \beta } / 2 } ^ { \bar { \beta } } \int _ { 0 } ^ { \frac { 1 } { 3 } \min \left \{ \bar { \beta } \ell _ { \delta } ( \sigma ^ { * }, \rho ), \tau \right \} } f ( \beta, \gamma ) d \gamma d \beta > 0.$$
Finally, we are going to argue that σ ∗ o > 0. Assume for the sake of contradiction that σ ∗ o = 0, then
$$\ell _ { \delta } ( \sigma ^ { * }, \rho ) = \ell _ { o } ( 0, 1 - \rho ) - \ell _ { \text{h} } ( \sigma ^ { * }, \rho ) < 0,$$
which is a contradiction with the fact that ℓ δ ( σ , ρ ∗ ) > 0.
□
Proof of Lemma 2 Recall from (3), agents whose best response is toll satisfy C toll ( σ, β, γ ) ≤ C pool ( σ, β, γ ) and C toll ( σ, β, γ ) ≤ C o ( σ, β, γ ), i.e. the cost of paying the toll is smaller than or equal to the cost of any other two actions. From C toll ( σ, β, γ ) ≤ C pool ( σ, β, γ ), we obtain βℓ h ( σ, ρ )+ τ ≤ βℓ h ( σ, ρ )+ γ , which yields τ ≤ γ . Moreover, from C toll ( σ, β, γ ) ≤ C o ( σ, β, γ ), we obtain βℓ h ( σ, ρ ) + τ ≤ βℓ o ( σ, 1 -ρ ), which yields τ ≤ βℓ δ ( σ, ρ ). Thus, we obtain Λ toll ( σ ).
Similarly, agents whose best response is pool satisfy C pool ( σ, β, γ ) = βℓ h ( σ, ρ ) + γ ≤ C toll ( σ, β, γ ) = ℓ h ( σ, ρ ) + τ and C pool ( σ, β, γ ) = βℓ h ( σ, ρ ) + γ ≤ C o ( σ, β, γ ) = βℓ o ( σ, 1 -ρ ). It yields γ ≤ τ and γ ≤ βℓ δ ( σ, ρ ), and thus we obtain Λ pool ( σ ). Lastly, agents whose best response is o satisfy C o ( σ, β, γ ) = βℓ o ( σ, 1 -ρ ) ≤ C toll ( σ, β, γ ) = βℓ h ( σ, ρ ) + τ and C o ( σ, β, γ ) = βℓ o ( σ, 1 -ρ ) ≤ C pool ( σ, β, γ ) = βℓ h ( σ, ρ ) + γ . It yields βℓ δ ( σ, ρ ) ≤ min { τ, γ } , and thus we obtain Λ ( o σ ). □
Proof of Theorem 1: In each regime, we first show that under the regime condition, the equations described in the theorem has a unique fixed point. Then, we verify that ( σ ∗ toll , σ ∗ pool , σ ∗ o ) provided for each regime indeed satisfies the equilibrium definition.
## Regime A :
$$( \text{A-1} ) \ \bar { \beta } \ell _ { \delta } ^ { \dagger } \leq \overline { \gamma }.$$
Consider a function
$$q ( z ) \coloneqq \frac { z } { \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \ell _ { \delta } ( 0, z, 1 - z, \rho ) \beta } f ( \beta, \gamma ) \, d \gamma d \beta }.$$
Recall that under regime A , we have τ ≥ min { βℓ , γ † δ } . Therefore, we have βℓ † δ ≤ min { τ, γ } . Thus, for any β > 0, we have min { τ,γ } β β ≥ ℓ β † δ = ℓ δ (0 , σ † pool , 1 -σ † pool ) β . Therefore,
$$\sigma _ { \text{pool} } ^ { \dagger } = \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \frac { \min \{ \tau, \overline { \gamma } \} } { \beta } } f ( \beta, \gamma ) \, d \gamma d \beta \\ \geq \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { \dagger }, 1 - \sigma _ { \text{pool} } ^ { \dagger } ) \beta } f ( \beta, \gamma ) \, d \gamma d \beta. \\. \quad \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
Hence, q σ ( † pool ) ≥ 1. Additionally, it is easy to see that q (0) = 0.
Since ℓ δ (0 , z, 1 -z, ρ ) is monotonically decreasing with z , q z ( ) is continuous and monotonically increasing in z . Therefore there must be a unique point σ ∗ pool ∈ [0 , σ † pool ] such that q σ ( ∗ pool ) = 1, which is the unique solution of equation (7):
$$\sigma _ { \text{pool} } ^ { * } = \int _ { 0 } ^ { \overline { \beta } } \int _ { 0 } ^ { \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { * }, 1 - \sigma _ { \text{pool} } ^ { * } ) \beta } f ( \beta, \gamma ) \, d \gamma d \beta.$$
Now we want to show that σ ∗ toll = 0 , σ ∗ pool , σ ∗ o = 1 -σ ∗ pool satisfies the equilibrium condition (10).
First, we argue that at equilibrium, σ ∗ toll = 0. From previous argument, we know that σ ∗ pool ≤ σ † pool . Plugging in the definitions of strategy distribution and σ † pool , we obtain ∫ β 0 ∫ ℓ δ (0 ,σ ∗ pool , 1 -σ ∗ pool ) β 0 f ( β, γ ) dγdβ ≤ ∫ β 0 ∫ min { τ,γ } β β 0 f ( β, γ ) dγdβ , which implies ℓ δ (0 , σ ∗ pool , 1 -σ ∗ pool ) ≤ min { τ,γ } β . Therefore, for any ( β, γ ), we have βℓ δ (0 , σ ∗ pool , 1 -σ ∗ pool ) ≤ min { τ, γ } . Hence, for all agents, we have C o ( σ, β, γ ) ≤ C toll ( σ, β, γ ). Thus, no agents want to deviate to pay the toll and we have σ ∗ toll = 0 at equilibrium.
Next, we argue that at equilibrium, the strategy distribution of carpooling agents is given by σ ∗ pool . An agent ( β, γ ) will choose pool over o if C pool ( σ , β, γ ∗ ) < C o ( σ , β, γ ∗ ), which is equivalent to γ < βℓ δ (0 , σ ∗ pool , 1 -σ ∗ pool ). By lemma 2, the set of agents whose best response is to carpool under regime A-1 is then given by Λ pool ( σ ∗ ) = { ( β, γ ) : 0 < β < β, 0 < γ < βℓ δ (0 , σ ∗ pool , 1 -σ ∗ pool ) } . Integrating over all agents in Λ pool ( σ ∗ ) yields the σ ∗ pool given above. Lastly, because we have argued that σ ∗ toll = 0 and σ ∗ pool satisfy the equilibrium condition (10), we can obtain that σ ∗ o = 1 -σ ∗ pool must also satisfy the equilibrium condition. Hence, we have proved that ( σ ∗ toll , σ ∗ pool , σ ∗ o ) provided for regime A-1 satisfies the equilibrium condition.
$$( \mathbf A { - 2 } ) \ \overline { \beta } \ell _ { \delta } ^ { \dagger } > \overline { \gamma }.$$
Consider the following function g :
$$g ( z ) \coloneqq \frac { 1 - z } { \int _ { 0 } ^ { \overline { \gamma } } \int _ { 0 } ^ { \overline { \ell _ { \delta } ( 0, z, 1 - z, \rho ) } } f ( \beta, \gamma ) d \beta \, d \gamma }.$$
We first argue that g σ ( † pool ) > 1. From the regime A condition such that τ ≥ min { γ, βℓ ¯ † δ } , we obtain ¯ βℓ † δ > min { τ, γ } and τ ≥ γ . Then, we have
$$\ell _ { \delta } ^ { \dagger } \}, \, \text{we obtain $\bar{\beta}\ell_{\delta}^{\dagger}>\min\{\tau,\bar{\gamma}\}$ and $\tau\geq\bar{\gamma}$. Then, we have} \\ 1 - \sigma _ { \text{pool} } ^ { \dagger } = & 1 - \int _ { 0 } ^ { \bar { \beta } } \int _ { 0 } ^ { \frac { \min \{ \tau,\bar{\gamma}\}$\beta} } { \beta } f ( \beta, \gamma ) \, d \gamma d \beta \\ & \stackrel { ( a ) } { > } 1 - \int _ { 0 } ^ { \bar { \beta } } \int _ { 0 } ^ { \beta \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { \dagger }, 1 - \sigma _ { \text{pool} } ^ { \dagger } ) } f ( \beta, \gamma ) \, d \gamma d \beta \\ = & \int _ { 0 } ^ { \bar { \beta } } \int _ { \beta \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { \dagger }, 1 - \sigma _ { \text{pool} } ^ { \dagger } ) } f ( \beta, \gamma ) \, d \gamma d \beta \\ & \stackrel { ( b ) } { = } \int _ { 0 } ^ { \bar { \gamma } } \int _ { 0 } ^ { \frac { \gamma } { \varepsilon _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { \dagger }, 1 - \sigma _ { \text{pool} } ^ { \dagger } ) } f ( \beta, \gamma ) d \beta \, d \gamma \\ \text{to the inequality min} \{ \tau, \bar { \gamma}\} < \bar { \beta}\ell _ { \delta } ^ { \dagger } = \bar { \beta } \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { \dagger }, 1 - \sigma _ { \text{pool} } ^ { \dagger } ), \, \text{and} \, ( b ) \, i }$$
(a) is due to the inequality min { τ, γ } < βℓ ¯ † δ = ¯ βℓ δ (0 , σ † pool , 1 -σ † pool ), and (b) is obtained by changing the integration order. Therefore, we obtain g σ ( † pool ) > 1. Additionally, it
is easy to see that g (1) = 0. Since ℓ δ (0 , z, 1 -z, ρ ) is monotonically decreasing with z , we know that g z ( ) is monotonically decreasing with z . Therefore, there exist a unique σ ∗ pool > σ † pool such that g σ ( ∗ pool ) = 1, which means that it is the unique solution of equation (8):
$$1 - \sigma _ { \text{pool} } ^ { * } = \int _ { 0 } ^ { \overline { \gamma } } \int _ { 0 } ^ { \frac { \gamma } { \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { * }, 1 - \sigma _ { \text{pool} } ^ { * } ) } } f ( \beta, \gamma ) d \beta d \gamma.$$
Next, we are going to show that σ ∗ toll = 0 , σ ∗ pool , σ ∗ o = 1 -σ ∗ pool satisfies the equilibrium condition (10).
Due to the condition of regime A-2 such that τ ≥ γ , we obtain that C pool ( σ, β, γ ) ≤ C toll ( σ, β, γ ) holds for all agents. Therefore, no agents want to deviate to toll paying and thus σ ∗ toll = 0 at equilibrium. Additionally, by lemma 2, the set of agents using ordinary lanes under regime A-2 is given by Λ ( o σ ∗ ) = { ( β, γ ) : β ≤ γ/ℓ δ ( σ ∗ ) } . Hence, under equilibrium, we obtain
$$\sigma _ { o } ^ { * } = \iint _ { \Lambda _ { o } ( \sigma ^ { * } ) } f ( \beta, \gamma ) d \beta d \gamma \\ = & \int _ { 0 } ^ { \overline { \gamma } } \int _ { 0 } ^ { \frac { \gamma } { \ell _ { \delta } ( 0, \sigma _ { \text{pool} } ^ { * }, 1 - \sigma _ { \text{pool} } ^ { * } ) } } f ( \beta, \gamma ) d \beta d \gamma = 1 - \sigma _ { \text{pool} } ^ { * }, \\. &. \cdots \quad. \quad. \quad.$$
which is equivalent to equation (7). Therefore, σ ∗ pool and σ ∗ o = 1 -σ ∗ pool satisfy the equilibrium condition 10 as well.
## Regime B :
To show that the system of equations (9) has a unique solution, we first represent the strategy distributions using the latency difference between ordinary lanes and HOT lanes, which we denote as δ . Consider function g : [ τ/β, ¯ ∞ → ) [0 , σ ¯ toll ), where ¯ σ toll is defined as ¯ σ toll := ∫ γ τ ∫ β 0 f ( β, γ ) dβdγ ,
$$g ( y ) = \int _ { \tau } ^ { \overline { \gamma } } \int _ { \tau / y } ^ { \overline { \beta } } f ( \beta, \gamma ) \, d \beta d \gamma,$$
and function h with the domain [ τ/β, ¯ ∞ ):
$$h ( y ) = \int _ { 0 } ^ { \tau } \int _ { \gamma / y } ^ { \bar { \beta } } f ( \beta, \gamma ) \, d \beta d \gamma.$$
We note that both g and h are continuous and increase monotonically with y . Moreover, we
note that the range of h is [ σ † pool , 1 -¯ σ toll ), because
$$\alpha _ { 0 } \varkappa \, \infty \, \infty \, \omega _ { 0 } \omega _ { 0 } \omega _ { 0 } \colon \, \begin{array} { c } \nu _ { \text{to} } \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \incolon \, \end{array} \\ h ( \tau / \bar { \beta } ) & = \int _ { 0 } ^ { \tau } \int _ { \bar { \beta } } ^ { \bar { \beta } } f ( \beta, \gamma ) d \gamma d \beta \\ & = \int _ { 0 } ^ { \bar { \beta } } \int _ { 0 } ^ { \min \{ \tau, \bar { \gamma } \} \beta / \bar { \beta } } f ( \beta, \gamma ) d \gamma d \beta = \sigma _ { \text{pool} } ^ { \dagger },$$
and
$$\lim _ { \delta \to \infty } h ( \delta ) = \int _ { 0 } ^ { \tau } \int _ { 0 } ^ { \bar { \beta } } f ( \beta, \gamma ) d \beta d \gamma \\ = & 1 - \int _ { \tau } ^ { \bar { \gamma } } \int _ { 0 } ^ { \bar { \beta } } f ( \beta, \gamma ) d \beta d \gamma = 1 - \bar { \sigma } _ { \text{toll} }. \\ \dots & \quad \dots \quad \dots \quad - \quad.$$
$$\cdot$$
Let δ ∗ be the induced latency difference at equilibrium. By equations (9), we obtain that σ ∗ toll = g δ ( ∗ ), σ ∗ pool = h δ ( ∗ ), and σ ∗ o = 1 -g δ ( ∗ ) -h δ ( ∗ ). Hence, in order to show that (9) has a unique solution, it is suffice to show that there exists a solution to the following fixed point equation:
$$\delta = \ell _ { \delta } ( g ( \delta ), h ( \delta ), 1 - g ( \delta ) - h ( \delta ) ).$$
Define the function q with the domain [ τ/β, ¯ ∞ ):
$$q ( \delta ) = \frac { \ell _ { \delta } ( g ( \delta ), h ( \delta ), 1 - g ( \delta ) - h ( \delta ) ) } { \delta }.$$
We remark that q is continuous and mononotically decreasing in δ . First, we have
$$\mu _ { \quad } & & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \mu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \varphi _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \beta _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \bar { \nu } _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nolimits } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \ \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \ n _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \ N _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \N _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \ } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \ :: } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \math } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \pm } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ { \quad } & \nu _ {$$
where (a) is due to g τ/β ( ¯ ) = 0 and h τ/β ( ¯ ) = σ † pool ; (b) is due to the regime condition τ < βℓ ¯ † δ . Furthermore, it is easy to see that as δ ↑ ∞ , q δ ( ) → 0. Since q is continuous monotonically decreasing, there exists a unique δ ∗ ∈ [ τ/β, ¯ ∞ ) such that q δ ( ∗ ) = 1, which implies that there exists a unique solution to (20). Hence, there exists a unique solution to (9).
Given the strategy distribution σ ∗ , integrating over the best response region for each of the three actions given in lemma 2 yields exactly the system of equations (9). Therefore, the solution obtained in (9) is an equilibrium. □
## Proof of Theorem 2:
## Fix τ and increase ρ :
We first show that ℓ δ ( σ , ρ ∗ ) increases. We assume for the sake of contradiction that ℓ δ ( σ , ρ ∗ ) decreases. Then, from lemma 2, more agents will join the ordinary lanes, and fewer will carpool or pay the toll price. That is, σ ∗ o increases, σ ∗ pool decreases, and σ ∗ toll is non-increasing. Recall from assumption 1 that the latency function for ordinary lanes (resp. HOT lanes) increases (resp. decreases) with ρ . Therefore, ℓ o ( σ D, ∗ o 1 -ρ ) increases as both σ ∗ o and ρ increase. Moreover, ℓ h (( σ ∗ toll + σ ∗ pool A ) D,ρ ) decreases because the term ( σ ∗ toll + σ ∗ pool A ) decreases and ρ increases. Hence, ℓ δ ( σ , ρ ∗ ) increases, which is a contradiction.
Next, we assume for the sake of contradiction that ℓ δ ( σ , ρ ∗ ) does not change. Using lemma 2, we obtain that the strategy distributions for all three actions should hold fixed. Nevertheless, given the same strategy distributions, increasing ρ leads to an increase in ℓ o ( σ D, ∗ o 1 -ρ ) and a decrease in ℓ h (( σ ∗ toll + σ ∗ pool A ) D,ρ ) . This yields an increase in ℓ δ ( σ , ρ ∗ ), which is a contradiction.
Since ℓ δ ( σ , ρ ∗ ) increases, from lemma 2, we obtain that the strategy distributions σ ∗ o decreases, σ ∗ pool increases, and σ ∗ toll increases.
## Fix ρ and increase τ :
We first show that at equilibrium ℓ δ ( σ , ρ ∗ ) is non-decreasing. Assume for the sake of contradiction that ℓ δ ( σ , ρ ∗ ) decreases. Since τ increases, from lemma 2, we obtain that the population paying toll price decreases, the population taking the ordinary lanes is increases, and the population that carpools decreases. Therefore, ℓ δ ( σ , ρ ∗ ) increases, which is a contradiction.
Last but not least, we argue that σ ∗ o can change in either direction when τ increases. When the toll price is relatively large, i.e. in regime A in theorem 1, further increasing the τ has no impact on the strategy distributions, and hence σ ∗ o does not chance. When the toll price is relatively low, i.e. in regime B in theorem 1, an increase in τ can either lead to an increase or decrease of the term τ ℓ δ ( σ ,ρ ∗ ) in (9a), which depends on the preference distribution. Therefore, σ ∗ o can also change in either direction given the increase in τ . □
Proof of Theorem 3. We note that for each segment e ∈ [ E ], δ e ∈ [ δ , δ e ¯ ], e where the lower bound δ e = ℓ o,e (0) -ℓ h ,e ( ∑ e i =1 ∑ E j = e D ij ) is achieved when all agents choose the HOT lane without pooling, and the upper bound ¯ δ e = ℓ o ,e ( ∑ e i =1 ∑ E j = e D ij ) -ℓ e,h (0) is achieved when all agents take the ordinary lane. Moreover, since the preference distribution function f ( β, γ ) is continuous, the function Φ : ∏ e ∈ E [ δ , δ e ¯ ] e → ∏ e ∈ E [ δ , δ e ¯ ] e is continuous. From the Kakutani's fixed-point theorem, we know that the set of fixed-points of Φ( δ ) = δ is nonempty. Furthermore, for any such fixed point δ ∗ , the associated best-response strategy s ∗ is
unique, and satisfies the condition in Definition 2, and thus is a Wardrop equilibrium. On the other hand, for any Nash equilibrium s ∗ , the induced equilibrium latency cost difference must satisfy Φ( δ ∗ ) = δ ∗ . Therefore, the fixed-point set of Φ( δ ) = δ and the set of Wardrop equilibrium has one-to-one correspondence. Since the fixed-point set is non-empty, we can conclude that Wardrop equilibrium exists.
Additionally, equilibrium is unique if and only if Φ( δ ) = δ has a unique solution. If there exist two fixed points δ, δ ′ satisfying Φ( δ ) = δ and Φ( δ ′ ) = δ ′ . Let v i denote the | E | -dimensional vector with i -th index being 1 and all other indices being 0. Then, by the mean value theorem, there exists z on the line segment connecting δ and δ ′ such that
$$v _ { e } \cdot [ \bigtriangledown \Phi ( z ) ( \delta - \delta ^ { \prime } ) ] = v _ { e } \cdot [ \Phi ( \delta ) - \Phi ( \delta ^ { \prime } ) ], \ \forall e \in E.$$
Combining the equations for all e ∈ E , we obtain
$$\nabla \Phi ( z ) ( \delta - \delta ^ { \prime } ) = \Phi ( \delta ) - \Phi ( \delta ^ { \prime } ) = \delta - \delta ^ { \prime }.$$
If the Jacobian ∇ Φ( ) does not have eigenvalue 1 for any z z , then there do not exist δ, δ ′ that satisfies (21), and thus equilibrium is unique. □ | null | [
"Zhanhao Zhang",
"Ruifan Yang",
"Manxi Wu"
]
| 2024-08-02T17:42:01+00:00 | 2024-12-03T20:18:08+00:00 | [
"cs.GT"
]
| Designing High-Occupancy Toll Lanes: A Game-Theoretic Analysis | In this article, we study the optimal design of High Occupancy Toll (HOT)
lanes. The traffic authority determines the road capacity allocation between
HOT lanes and ordinary lanes, as well as the toll price charged for travelers
using HOT lanes who do not meet the high-occupancy eligibility criteria. We
develop a game-theoretic model to analyze the decisions of travelers with
heterogeneous preference parameters in values of time and carpool disutilities.
These travelers choose between paying or forming carpools to use the HOT lanes,
or taking the ordinary lanes. Travelers' welfare depends on the congestion cost
of the lane they use, the toll payment, and the carpool disutilities. For
highways with a single entrance and exit node, we provide a complete
characterization of equilibrium strategies and a comparative statics analysis
of how the equilibrium vehicle flow and travel time change with HOT capacity
and toll price. We then extend the single segment model to highways with
multiple entrance and exit nodes. We extend the equilibrium concept and propose
various design objectives considering traffic congestion, toll revenue, and
social welfare. Using the data collected from the HOT lane of the California
Interstate Highway 880 (I-880), we formulate a convex program to estimate the
travel demand and approximate the distribution of travelers' preference
parameters. We then compute the optimal toll design of five segments for I-880
for achieve each one of the four objectives, and compare the optimal solution
with the current toll pricing. |
2408.01414v3 | ## Exact Results for Scaling Dimensions of Neutral Operators in scalar CFTs
Oleg Antipin, 1, ∗ Jahmall Bersini, 2, † and Francesco Sannino 3, 4, 5, 6, ‡
1 Rudjer Boskovic Institute, Division of Theoretical Physics, Bijeniˇka 54, 10000 Zagreb, Croatia c
2 Kavli IPMU (WPI), UTIAS, The University of Tokyo, Kashiwa, Chiba 277-8583, Japan 3 Quantum Theory Center ( ℏ QTC) at IMADA & D-IAS,
4 Dept. of Physics E. Pancini, Universit` di Napoli Federico II, via Cintia, 80126 Napoli, Italy a
INFN sezione di Napoli, via Cintia, 80126 Napoli, Italy
Southern Denmark Univ., Campusvej 55, 5230 Odense M, Denmark 5
6 Scuola Superiore Meridionale, Largo S. Marcellino, 10, 80138 Napoli, Italy
We determine the scaling dimension ∆ n for the class of composite operators ϕ n in the λϕ 4 theory in d = 4 -ϵ taking the double scaling limit n → ∞ and λ → 0 with fixed λn via a semiclassical approach. Our results resum the leading power of n at any loop order. In the small λn regime we reproduce the known diagrammatic results and predict the infinite series of higher-order terms. For intermediate values of λn we find that ∆ n /n increases monotonically approaching a ( λn ) 1 / 3 behavior in the λn →∞ limit. We further generalize our results to neutral operators in the ϕ 4 in d = 4 -ϵ , ϕ 3 in d = 6 -ϵ , and ϕ 6 in d = 3 -ϵ theories with O N ( ) symmetry.
Critical behavior of quantum field theories plays a crucial role in our understanding of phase transitions in Nature across all realms of physics from condensed matter to high energy physics and cosmology. Such behavior is encoded in scaling exponents associated with correlation functions of different operators of the underlying conformal field theory (CFT) employed to describe a given physical process.
Since the pioneering work of Wilson [1, 2], scalar field theories have been used as primary models to unveil universal behavior in phase transitions. Despite the fiftyyear-long effort to solve these models much is still left to be understood. Perhaps one of the greatest challenges is the investigation of composite operators. For these, perturbation theory, very quickly shows its limitations. Beyond perturbation theory a number of methodologies have been employed from the use of larger symmetries, such as supersymmetry, to large charge [3] and/or spin [4] expansions, bootstrap [5], and numerical approaches.
In this work, we develop a novel way to determine the scaling dimensions ∆ n of neutral operators, schematically ϕ n , in scalar CFTs in the double-scaling limit of large n , small self coupling λ , and generic λn . Wewill employ the methodology to tackle various scalar CFTs living in different space-time dimensions d . We discover that, for all the models, the large λn behavior is of the type: ∆ n ∝ n d/ d ( -1) . We therefore conjecture that this leading large n scaling holds non-perturbatively away from the small λ limit. Interestingly, this behavior mimics the one found for large charge operators with charge n [3, 6].
## Methodology and ϕ 4 theory in d = 4 -ϵ
A cornerstone example of CFT is the critical λϕ 4 theory in d = 4 -ϵ dimensions. We use this model to introduce the semiclassical framework to determine the scaling dimensions ∆ n controlling the critical behavior of the correlator
$$\langle \phi ^ { n } ( x _ { f } ) \phi ^ { n } ( x _ { i } ) \rangle \ = \frac { 1 } { | x _ { f } - x _ { i } | ^ { 2 \Delta _ { n } } } \, \quad \ \ ( 1 )$$
at the Wilson-Fisher infrared fixed point stemming from the Lagrangian below
$$\mathcal { L } = \frac { 1 } { 2 } ( \partial \phi ) ^ { 2 } - \frac { \lambda } { 4 } \phi ^ { 4 } \.$$
The two-loop fixed-point coupling value is
$$\lambda ^ { * } = \frac { 8 \pi ^ { 2 } } { 9 } \epsilon + \frac { 1 3 6 \pi ^ { 2 } } { 2 4 3 } \epsilon ^ { 2 } + \mathcal { O } \left ( \epsilon ^ { 3 } \right ) \. \quad \ \ ( 3 )$$
For general n , we compute the three-loop value of ∆ n and obtain
$$\begin{smallmatrix} \cdots \\ \text{itions.} \\ \text{logies} \\ \text{etries}, \\ \text{r spin} \\ \text{aches.} \end{smallmatrix} \begin{array} { c } \Delta _ { n } & \alpha \text{vounds} \\ \Delta _ { n } & = n \left ( 1 - \frac { \epsilon } { 2 } \right ) + \frac { n } { 6 } ( n - 1 ) \epsilon - \frac { \epsilon ^ { 2 } } { 3 2 4 } \left ( 1 7 n ^ { 3 } - 6 7 n ^ { 2 } + 4 7 n \right ) \\ \Gamma \text{spin} \\ \text{accs.} \end{array} \begin{array} { c } \Delta _ { n } & \alpha \text{vounds} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma _ \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \\ \Delta _ { n } & \Gamma \text{sigma} \end{smallmatrix}$$
The two-loop result has been previously determined in [7]. Determining ∆ n , at arbitrary orders in perturbation theory, is an involved task. Within the path integral formalism, calculating ∆ n amounts to perform the following functional integration
$$\text{pe} \colon \quad \langle \phi ^ { n } ( x _ { f } ) \phi ^ { n } ( x _ { i } ) \rangle \, = \, \int \mathcal { D } \phi \, \phi ^ { n } ( x _ { f } ) \phi ^ { n } ( x _ { i } ) e ^ { i \int d ^ { d } x \mathcal { L } } \,. \quad ( 5 )$$
Upon exponentiating the field insertion and rescaling the field as ϕ → √ nϕ we observe that n becomes a counting parameter. As a consequence, the above correlator can be estimated semiclassically around the saddle point of the following action:
$$\overset { \prime \, \text{ use} } { \underset { \text{scal} } { \text{scal} } } \underset { \text{of the} } { \text{ in} } \left [ \int d ^ { d } x \left ( \frac { 1 } { 2 } ( \partial \phi ) ^ { 2 } - \frac { \lambda n } { 4 } \phi ^ { 4 } \right ) - i \left ( \log \phi ( x _ { f } ) + \log \phi ( x _ { i } ) \right ) \right ] } \,.$$
Further employing the double scaling limit n →∞ , λ → 0 with fixed λn yields the following expansion for ∆ n
$$\Delta _ { n } = n \sum _ { i = 0 } \frac { C _ { i } ( \lambda n ) } { n ^ { i } }$$
where the coefficients C i arise from the i -th order of the semiclassical expansion. A similar approach has been used to determine multiparticle scattering amplitudes and decay rates [8, 9], and also to compute scaling dimensions of large charge composite operators in theories with continuous symmetries [3, 6].
For CFTs the computation is efficiently performed by conformal mapping flat space into a cylinder R × S d -1 with unit radius. According to Cardy's state-operator correspondence [10] a given scaling dimension becomes the energy on the cylinder of the corresponding state. On the cylinder the Lagrangian reads
$$\mathcal { L } = \frac { 1 } { 2 } ( \partial \phi ) ^ { 2 } - \frac { ( d - 2 ) R } { ( d - 1 ) 8 } \phi ^ { 2 } - \frac { \lambda } { 4 } \phi ^ { 4 } \, \quad \ ( 8 ) \quad \text{ first} \quad \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
with the Ricci curvature R = ( d -1)( d -2). In this work, we will determine the leading coefficient C 0 of the semiclassical expansion which is given by the classical energy on the cylinder. To the leading order in the expansion (7), one can set d = 4 since the classical theory is scale invariant.
To compute the energy on the cylinder we solve the following time-dependent equation of motion (EOM)
$$\frac { d ^ { 2 } \phi } { d t ^ { 2 } } + \phi + \lambda \phi ^ { 3 } = 0 \, \quad \ \ \ ( 9 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
assuming a spatially homogeneous field configuration supplemented by the Bohr-Sommerfeld condition
$$2 \pi ^ { 2 } \int _ { 0 } ^ { \mathcal { T } } \left ( \frac { d \phi } { d t } \right ) ^ { 2 } \, d t = 2 \pi n \, \quad \ \ ( 1 0 ) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
needed to select the appropriate state in the theory. Here T is the period of the solution which depends on the product λn . The leading order of the semiclassical expansion C 0 can now be obtained by evaluating the energy on the solution of the equation of motion. This procedure yields
$$\frac { n } { 2 \pi ^ { 2 } } \, C _ { 0 } = T _ { 0 0 } = \frac { 1 } { 2 } \left ( \frac { \partial \phi } { \partial t } \right ) ^ { 2 } + \frac { 1 } { 2 } \phi ^ { 2 } + \frac { \lambda } { 4 } \phi ^ { 4 } \, \quad ( 1 1 ) \quad \ \ _ { \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
with T µν the stress-energy tensor of the theory and the 2 π 2 factor being the volume of S 3 . C 0 resums the terms with the leading power of n at any loop order. The general solution found in [11] is
$$\phi ( t ) = \sqrt { n } \, x _ { 0 } \, \text{cn} ( \omega t | m ) \, \quad \quad ( 1 2 ) \quad \Delta$$
where cn( ωt m | ) denotes the Jacobi elliptic function with the frequency and the initial position given by
$$x _ { 0 } = \sqrt { \frac { 2 m } { \lambda n ( 1 - 2 m ) } } \,, \quad \omega = \frac { 1 } { \sqrt { 1 - 2 m } } \. \quad ( 1 3 )$$
The corresponding energy yields the leading order in the semiclassical expansion for ∆ n which reads
$$C _ { 0 } ( \lambda n ) = \frac { 2 \pi ^ { 2 } m \, ( 1 - m ) } { \lambda n \, ( 1 - 2 m ) ^ { 2 } } \, \quad \quad ( 1 4 )$$
where 0 ≤ m ≤ 1 / 2 is a function of λn which is determined by solving the Bohr-Sommerfeld condition with T = 4 K /ω where K ( m ) is the complete elliptic integral of the first kind. Naturally T is the period of cn( ωt m | ) and therefore of the solution ϕ t ( ). We obtain
$$\underset { \mathfrak { z } ^ { d - 1 } } { 1 \, \text{by} } \quad \lambda n = \frac { 8 \pi } { 3 ( 1 - 2 m ) ^ { 3 / 2 } } \left [ ( 2 m - 1 ) \mathcal { E } ( m ) + ( 1 - m ) \mathcal { K } ( m ) \right ] \. \\ \text{ator}$$
Here E denotes the complete elliptic integral of the second kind. Equation (14) supplemented by (15) constitutes our main result. To build some intuition let us consider first the limit m → 0 where one has the known solution of the harmonic oscillator with unit frequency. This is the trivial free-field theory limit λ = 0 discussed in [12] for which ∆ n = n . This result is obtained by noting that for λn ≪ 1 one has m ∼ λn 2 π 2 . In fact, in this regime, the solution to the EOM reduces to
$$\Pi \cos \Pi \, \text{cum} \, \text{cum} \, \text{$\nu$} \\ \phi ( t ) = \frac { \sqrt { n } } { \pi } \cos ( t ) + \mathcal { O } \left ( \lambda n \right ) \,, \quad \quad ( 1 6 )$$
and has period T = 2 π . The λn ≪ 1 limit maps into ordinary perturbation theory and will be discussed later in the text.
When the anharmonic term dominates, for λn ≫ 1, we observe that m approaches 1 / 2 from below, and for m = 1 2, one obtains the interesting solution of the pure / quartic anharmonic oscillator. The transcendental equation in (15) can be solved numerically for any λn with its solution given graphically in Fig. 1. Here it is clear that m grows monotonically with λn achieving asymptotically the value m = 1 2. In the other panel of Fig. / 1 we plot the leading order value for ∆ n /n in the semiclassical expansion. Its behavior can be summarized as follows:
## i) In the λn →∞ limit m reads
$$\underset { \underset { \underset { \underset { \text{$even} } { rms} } } { \text{the} } } { \text{$m=\frac{1}{2}-\pi\left(\frac{\Gamma\left(\frac{1}{4})}{6\Gamma\left(\frac{3})}{4})^{2/3}\left(\frac{1}{\lambda n}\right)^{2/3}+\mathcal{O}\left(\left(\lambda n\right)^{-4/3}\right)$} } } }, \\ \underset { \underset { \text{$even} } { \text{the} } } { \text{the} } } { \text{the} } } \, \underset { \text{$even} } { \text{the} } } \, \underset { \text{$even} } { \text{the} } } \, \underset { \text{$even} } { \text{the} } } \, \text{the}$$
leading to
$$( 1 2 ) \quad \Delta _ { n } = \left ( \frac { 3 \Gamma \left ( \frac { 3 } { 4 } \right ) } { 2 ^ { 5 / 4 } \Gamma \left ( \frac { 1 } { 4 } \right ) } \right ) ^ { 4 / 3 } \lambda ^ { 1 / 3 } n ^ { 4 / 3 } + \mathcal { O } \left ( n ^ { 2 / 3 } \lambda ^ { - 1 / 3 } \right ) \,. \, ( 1 8 )$$
We deduce a leading n 4 / 3 dependence in the large λn limit. This is the same scaling observed for the scaling dimension of large charge operators, with their charge playing the role of n [3, 6].
- ii) For intermediate λn we observe a smooth increase with λn .
- iii) At small λn we recover both the free field theory limit as well as the conventional diagrammatic expansion as we will detail momentarily.
The loop expansion is obtained by expanding Eq. (14) around λn = 0. We adopt the notation C 0 = ∑ k =0 a k ( λn π 2 ) k and list the first 13 coefficients below
$$\sum _ { k = 0 } a _ { k } \left ( \frac { \lambda _ { n } } { n ^ { 2 } } \right ) ^ { k } \text{ and list the first 13 coefficients below} \\ a _ { 0 } = 1 \,, \quad a _ { 1 } = \frac { 3 } { 1 6 } \,, \quad a _ { 2 } = - \frac { 1 7 } { 2 5 6 } \,, \quad a _ { 3 } = \frac { 3 7 5 } { 8 1 9 2 } \,, \\ a _ { 4 } = - \frac { 1 0 6 8 9 } { 2 6 2 1 4 4 } \,, \quad a _ { 5 } = \frac { 8 7 5 4 9 } { 2 0 9 7 1 5 2 } \,, \quad a _ { 6 } = - \frac { 3 1 3 2 3 9 } { 6 7 1 0 8 8 6 4 } \,, \\ a _ { 7 } = \frac { 2 3 8 2 2 5 9 7 7 } { 4 2 9 4 9 6 7 2 9 6 } \,, \quad a _ { 8 } = - \frac { 1 8 9 4 5 9 6 1 9 2 5 } { 2 7 4 8 7 7 9 0 6 9 4 } \,, \\ a _ { 9 } = \frac { 1 9 4 9 0 4 1 1 6 8 4 7 } { 2 1 9 0 2 3 2 5 5 5 5 2 } { 2 9 0 2 3 2 5 5 5 5 2 } \,, \quad a _ { 1 0 } = - \frac { 8 2 4 0 2 3 4 2 4 2 9 2 9 } { 7 0 3 6 8 7 4 4 1 7 7 6 6 4 } \,, \\ a _ { 1 1 } = \frac { 1 1 1 2 8 5 1 2 9 7 6 0 3 5 } { 7 0 3 6 8 7 4 4 1 7 7 6 6 4 } \,, \quad a _ { 1 2 } = - \frac { 1 5 6 7 1 7 3 3 0 3 6 4 5 1 3 5 9 } { 7 2 0 5 7 5 9 4 0 3 7 9 2 7 9 3 6 } \,, \\ a _ { 1 3 } = \frac { 8 7 5 3 5 9 0 0 0 3 3 2 6 9 5 2 5 } { 2 8 8 2 3 0 3 7 6 1 5 1 7 1 1 7 4 4 } \,.$$
Inserting the Wilson-Fisher fixed point value Eq. (3), the above agrees with the diagrammatic result in Eq. (4). Note that the a i coefficients reproduce also the known anomalous dimension of the ϕ n operator in d = 4. In fact, the small λn expansion of C 0 yields results valid also away from the fixed point. Similarly, one can now predict the terms with the leading power of n to arbitrarily high loop orders.
## The O N ( ) model
We now extend our analysis to the O N ( ) model in d = 4 -ϵ dimensions. The fixed point value to two-loop order is
$$\lambda ^ { * } = \frac { 8 \pi ^ { 2 } } { ( N + 8 ) } \epsilon + \frac { 2 4 \pi ^ { 2 } ( 3 N + 1 4 ) } { ( N + 8 ) ^ { 3 } } \epsilon ^ { 2 } + \mathcal { O } \left ( \epsilon ^ { 3 } \right ) \,, \quad ( 2 0 ) \quad \begin{smallmatrix} \infty \\ 1 3, 1 \\ \text{bativ} \end{smallmatrix}$$
and
$$& \text{and} \\ & \Delta _ { n } = n \left ( 1 - \frac { \epsilon } { 2 } \right ) + \frac { n } { 2 ( N + 8 ) } ( 3 n + N - 4 ) \epsilon - \left [ \frac { 1 7 } { 4 ( N + 8 ) ^ { 2 } } n ^ { 3 } \quad \text{also be} \\ & - \frac { 6 0 4 + ( 1 0 - 1 1 N ) N } { 4 ( N + 8 ) ^ { 3 } } n ^ { 2 } + \frac { 5 7 6 - N ( 1 1 8 + 3 5 N ) } { 4 ( N + 8 ) ^ { 3 } } n \right ] \epsilon ^ { 2 } + \mathcal { O } ( \epsilon ^ { 3 } ) \,, \quad \text{is non-} \\ & \text{which g} \\ & \text{data} \, [ 1 7 } \\ & \colon = \, \mathcal { L } _ { n } \, \stackrel { \dots } { \dots } \, \int \dots \, \int \dots \, \int \dots \, \int \dots \, \int \dots \, \dots \, \dots \, \dots \, \dots \, \end{cases}$$
is the two-loop value of ∆ n for the singlet operator ( ϕ ϕ a a ) n/ 2 with a = 1 , . . . , N [7].
By recognizing that by an O N ( ) rotation the modulus coincides with one of the scalar field directions the EOM reduces to the one of the N = 1 case discussed above. The dependence on N , to the leading order in 1 /n , appears via the fixed point value of the coupling shown above. Therefore C 0 will be again given by Eq. (14) and Eq. (15) with λ the O N ( ) fixed point coupling in Eq. (20).
$$\psi$$
FIG. 1. The parameter m ( Top ) and the leading order scaling dimension C 0 ( Bottom ) as a function of λn . The dashed line denotes the leading large λn behavior of C 0 given by Eq. (18). The inset plot shows a detail of C 0 in the small λn regime along with the one-loop approximation (in green).
## The ϕ 3 theory in d = 6 -ϵ
To illustrate the generality of the approach we further consider the O N ( ) ϕ 3 theory in d = 6 -ϵ dimensions. Besides being a textbook example of quantum field theory, the N = 1 case is physically relevant being related to the Lee-Yang edge singularity and percolation problems [13, 14]. For large enough N the theory features a perturbative infrared Wilson-Fisher fixed point that is believed to provide a UV completion to the quartic O N ( ) model in more than four dimensions [15]. Intriguingly, it has also been proposed that the d dimensional O N ( ) CFT has a dual holographic description in terms of Vasiliev higher-spin theories in AdS d +1 [16]. However, this CFT is non-perturbatively unstable due to instanton solutions which give rise to a nonzero imaginary part in the CFT data [17]. The Lagrangian reads
$$\mathcal { L } = \frac { 1 } { 2 } ( \partial \phi _ { a } ) ^ { 2 } + \frac { 1 } { 2 } ( \partial \eta ) ^ { 2 } - \frac { g } { 2 } \eta ( \phi _ { a } ) ^ { 2 } - \frac { \lambda } { 3 } \eta ^ { 3 } \,, \quad ( 2 2 )$$
where ϕ a with a = 1 , . . . , N is a O N ( ) vector while η is a singlet. For our investigation, we just need to know the one-loop fixed point value of λ which is
$$\inf _ { \text{Im} } \begin{array} { c } \lambda ^ { * } = 3 \sqrt { \frac { 6 \epsilon ( 4 \pi ) ^ { 3 } } { N } } \left ( 1 + \frac { 1 6 2 } { N } + \frac { 6 8 7 6 6 } { N ^ { 2 } } + \dots + \mathcal { O } \left ( \epsilon \right ) \end{array} \right ) \,.$$
Equipped with the above, we proceed by computing the scaling dimension ∆ n,η for the family of composite operators η n in the same double scaling limit considered for the quartic O N ( ) theory resulting in a semiclassical expansion analogous to Eq. (7)
$$\Delta _ { n } = n \sum _ { i = 0 } \frac { H _ { i } ( \lambda ^ { 2 } n ) } { n ^ { i } } \. \quad \ \ ( 2 4 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
To this end, we again map our theory on R × S d -1 and consider a homogeneous field configuration for η and a vanishing expectation value for ϕ a . The resulting EOM reads
$$\frac { d ^ { 2 } \eta } { d t ^ { 2 } } + 4 \eta + \lambda \eta ^ { 2 } = 0 \,, \quad \quad ( 2 5 ) \quad \quad m$$
and admits the following nontrivial solution
$$\eta ( t ) = \frac { 1 } { \lambda } \left ( \frac { 6 m \, \text{cn} \left ( \frac { t } { ( ( m - 1 ) m + 1 ) ^ { 1 / 4 } } \Big | \, m \right ) ^ { 2 } - 4 m + 2 } { \sqrt { ( m - 1 ) m + 1 } } - 2 \right ), \\ \text{with } 0 < m < 1. \ B v \, \text{inserting the above into the follow-} } H _ { 0 } =$$
with 0 ≤ m ≤ 1. By inserting the above into the following expression for the classical ground state energy
$$T _ { 0 0 } = \frac { n } { \pi ^ { 3 } } H _ { 0 } = \frac { 1 } { 2 } \left ( \frac { \partial \eta } { \partial t } \right ) ^ { 2 } + 2 \eta ^ { 2 } + \frac { \lambda } { 3 } \eta ^ { 3 } \,, \quad ( 2 7 ) \quad \text{(c)} \quad \text{(c)} \quad \text{(d)} \quad \text{$n^{\frac{d}d-1}$)}$$
we obtain the following leading coefficient H 0 of the expansion (24)
$$H _ { 0 } = \frac { 8 \pi ^ { 3 } } { 3 \lambda ^ { 2 } n } \left ( \frac { - 2 m ^ { 3 } + 3 m ^ { 2 } + 3 m - 2 } { ( ( m - 1 ) m + 1 ) ^ { 3 / 2 } } + 2 \right ) \,, \quad ( 2 8 ) \quad \underset { \substack { \text{$\nu$} \\ \nu$} } { \text{$\tt opera$} }$$
where m is a nontrivial function of the product λ n 2 which is determined by the Bohr-Sommerfeld condition as follows
$$& \frac { 2 ( ( m - 1 ) m + 1 ) \mathcal { E } ( m ) - ( m - 2 ) ( m - 1 ) K ( m ) } { 5 ( ( m - 1 ) m + 1 ) ^ { 5 / 4 } } = \frac { \lambda ^ { 2 } n } { 4 8 \pi ^ { 2 } } \,. \quad \begin{array} { c } \\ ( 2 9 ) & \text{This t} \\ \lambda - \epsilon \dots \lambda - \lambda 4 \, \epsilon \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \, \pi \, \dots \dots \dots \dots \, \pi \, \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dts \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \sigma \, \end{array}$$
As for the ϕ 4 theory, H 0 resums the leading powers of n at any order of the perturbative expansion for ∆ . n Their coefficients can be read off by expanding H 0 around λ n 2 = 0. In parallel with our previous analysis, we adopt the notation H 0 = ∑ k =0 b k ( λ n 2 π 3 ) k and provide the first
8 coefficients below
$$8 \, \text{coefficients below} \\ b _ { 0 } & = 2 \,, \ \ b _ { 1 } = - \frac { 5 } { 1 9 2 } \,, \ \ b _ { 2 } = - \frac { 2 3 5 } { 2 2 1 1 8 4 } \,, \quad & \text{while} \\ b _ { 3 } & = - \frac { 3 8 5 8 5 } { 5 0 9 6 0 7 9 3 6 } \,, \ \ b _ { 4 } = - \frac { 2 6 6 3 1 2 9 } { 3 9 1 3 7 8 8 9 4 8 4 8 } \,, \quad & \text{error} \\ b _ { 5 } & = - \frac { 1 5 6 9 3 4 5 0 5 } { 2 2 5 4 3 4 2 4 3 4 3 2 4 4 8 } \, \ \ b _ { 6 } = - \frac { 1 3 4 0 0 3 4 1 4 0 5 } { 1 7 3 1 3 3 4 9 8 9 5 6 1 2 0 0 6 4 } \,, \quad & \text{be true} \\ b _ { 7 } & = - \frac { 7 2 7 5 6 9 2 9 9 3 8 5 5 } { 7 9 7 7 9 9 1 6 3 1 8 9 8 0 1 2 5 4 9 1 2 } \,. \quad & \text{(30)} \quad & \text{of the} \\ \quad & \quad \text{reads}$$
The coefficients b 0 and b 1 match the results in [15, 18].
Interestingly, the complementary limit of large λ n 2 reveals the unstable nature of the theory. In fact, Eq. (29) admits real solutions only for λ n 2 (4 π ) 2 ≤ 6 5 where the equality is attained for m = 1. An analogous behavior has been previously observed in the large charge sector of the theory in [19, 20] where it has been discovered the existence of a critical value of the charge above which the scaling dimension of the operators carrying the O N ( ) charges becomes complex. A possible link to instantonic solutions has been later discussed in [21]. In the large λ n 2 limit we, therefore, obtain
$$& m \sim e ^ { \frac { \pm i \pi } { 3 } } - \left ( e ^ { \frac { \pm i 9 \pi } { 1 0 } } 3 ^ { 7 / 1 0 } \left ( \frac { 1 6 \pi ^ { 2 } } { 5 } K \left ( e ^ { \frac { \pm i \pi } { 3 } } \right ) \right ) ^ { 4 / 5 } \right ) \left ( \frac { 1 } { \lambda ^ { 2 } n } \right ) ^ { 4 / 5 } \,, \\ \vee \quad & \text{$\models\in\nolimits+\infty$}$$
leading to
$$\begin{array} { c } \bar { \int } _ { \substack { ( 2 6 ) \\ \text{follow-} } } & H _ { 0 } = \frac { e ^ { \mp \frac { i \pi } { 1 0 } } } { 3 ^ { 1 3 / 1 0 } } \left ( \frac { 5 \sqrt { \pi } } { 2 ^ { 3 / 2 } K \left ( e ^ { \frac { \pm \frac { i \pi } { 3 } } } \right ) } \right ) ^ { 6 / 5 } \left ( \lambda ^ { 2 } n \right ) ^ { 1 / 5 } + \mathcal { O } \left ( \left ( \lambda ^ { 2 } n \right ) ^ { - 1 / 5 } \right ). \\ & \quad \text{The two comix\,conical\,solutions\,correspond\,to\,a\,nair} \end{array}$$
The two complex conjugate solutions correspond to a pair of complex CFTs. We again note the asymptotic ∆ n ∼ n d d -1 large n behavior previously observed in the large charge sector of the theory [19].
## The ϕ 6 theory in d = 3 -ϵ
For our last example, we determine ∆ n for the singlet operators ( ϕ ϕ a a ) n/ 2 with a = 1 , . . . , N in the critical ( ϕ ϕ a a ) 3 theory in d = 3 -ϵ . The Lagrangian reads
$$\mathcal { L } = \frac { 1 } { 2 } ( \partial \phi _ { a } ) ^ { 2 } - \frac { \lambda ^ { 2 } } { 6 } ( \phi _ { a } \phi _ { a } ) ^ { 3 } \,. \quad \quad ( 3 3 )$$
This theory has a perturbative Wilson-Fisher fixed point whose two-loop value is
$$\frac { \lambda ^ { * 2 } } { ( 4 \pi ) ^ { 2 } } = \frac { \epsilon } { 4 ( 2 2 + 3 N ) } \,, \quad \quad ( 3 4 )$$
while the one-loop beta function vanishes identically in d = 3. In the same double scaling limit considered for the quartic theory, the scaling dimension of the ( ϕ ϕ a a ) n/ 2 operators takes the form of Eq. (7). The complete solution of the equation of motion is quite cumbersome and will be treated in a separate work. Here, we limit ourselves to the perturbative small λn regime where the solution of the time-dependent EOM of the model on R × S d -1 reads
$$\frac { \phi _ { \alpha } ( t ) } { \sqrt { n } } & = \frac { \cos \left ( \frac { t } { 2 } \right ) } { \sqrt { \pi } } + \frac { ( \lambda n ) ^ { 2 } } { 9 6 \pi ^ { 5 / 2 } } \left ( - 6 0 t \sin \left ( \frac { t } { 2 } \right ) - 6 0 \cos \left ( \frac { t } { 2 } \right ) + 1 5 \cos \left ( \frac { 3 t } { 2 } \right ) + \cos \left ( \frac { 5 t } { 2 } \right ) \right ) + \frac { ( \lambda n ) ^ { 4 } } { 1 8 4 3 2 \pi ^ { 3 / 2 } } \left ( - 1 4 2 8 0 \cos \left ( \frac { 3 t } { 2 } \right ) - 4 4 0 \cos \left ( \frac { 5 t } { 2 } \right ) \\ & + 9 5 \cos \left ( \frac { 7 t } { 2 } \right ) + 3 \cos \left ( \frac { 9 t } { 2 } \right ) + 1 0 \left ( ( 4 0 1 9 - 3 6 0 t ^ { 2 } ) \cos \left ( \frac { t } { 2 } \right ) + 3 8 6 4 t \sin \left ( \frac { t } { 2 } \right ) - 6 0 t \left ( 9 \sin \left ( \frac { 3 t } { 2 } \right ) + \sin \left ( \frac { 5 t } { 2 } \right ) \right ) \right ) + \mathcal { O } \left ( ( \lambda n ) ^ { 6 } \right ) \,.$$
Replacing the above into the stress-energy tensor one obtains the first few terms of the small λn expansion for C 0
$$C _ { 0 } = \frac { 1 } { 2 } + \frac { 5 \lambda ^ { 2 } n ^ { 2 } } { 2 4 \pi ^ { 2 } } - \frac { 1 3 1 \lambda ^ { 4 } n ^ { 4 } } { 3 8 4 \pi ^ { 4 } } + \mathcal { O } \left ( ( \lambda n ) ^ { 6 } \right ) \. \quad ( 3 6 ) \quad \text{ENH} \\ \quad \text{the C}.$$
To test the solution we insert the fixed point value Eq. (34) into the above, and see that it reproduces the leading n term in the 2-loop expression for ∆ n which reads [22]
work of J.B. was supported by the World Premier International Research Center Initiative (WPI Initiative), MEXT, Japan; and also supported by the JSPS KAKENHI Grant Number JP23K19047. O.A. and J.B. thank the Quantum Theory Center and the Danish Institute for Advanced Study at the University of Southern Denmark for their hospitality and partial support while this work was completed.
$$\Delta _ { n } = \frac { 1 } { 6 ( 2 2 + 3 N ) } n ( n - 2 ) ( 5 n + 3 N - 8 ) \epsilon \. \quad ( 3 7 )$$
To summarize our work we have developed a semiclassical framework to compute the scaling dimensions for the class of neutral composite operators in several time-honored CFTs. This has been achieved by considering the double scaling limit n → ∞ and λ → 0 with a fixed value of the product λn and employing a saddle point evaluation. We tested our findings at small λn with known diagrammatic results and have been able to predict the infinite series of higher-order terms. Additionally, our leading semiclassical results hold true for various gauge-Yukawa models because fermion and gauge degrees of freedom have vanishing classical backgrounds. Noteworthy examples include the Abelian Higgs and GrossNeveu-Yukawa models in d = 4 -ϵ .
Additionally, our results constitute a strong asset to boost perturbative computations. In fact, one can combine our semiclassical expansion with known perturbative results, at fixed n , to determine novel complete higher loop expressions. Importantly, our findings provide an infinite series of checks for future diagrammatic computations.
We plan to go beyond this initial investigation by determining the next semiclassical order C 1 stemming from the determinant of the quantum fluctuations around the classical solution. Therefore, the computations for determining C 1 resemble the ones related to computing the leading correction around an instantonic background. As we have shown in this letter, our framework can be extended to several physically relevant quantum field theories in various space-time dimensions.
## Acknowledgements
The work of F.S. is partially supported by the Carlsberg Foundation, semper ardens grant CF22-0922. The
- ∗ [email protected]
- † [email protected]
- ‡ [email protected]
- [1] K. G. Wilson and J. B. Kogut, 'The Renormalization group and the epsilon expansion,' Phys. Rept. 12 (1974), 75-199 doi:10.1016/0370-1573(74)90023-4
- [2] K. G. Wilson, 'The Renormalization Group: Critical Phenomena and the Kondo Problem,' Rev. Mod. Phys. 47 (1975), 773 doi:10.1103/RevModPhys.47.773
- [3] S. Hellerman, D. Orlando, S. Reffert and M. Watanabe, 'On the CFT Operator Spectrum at Large Global Charge,' JHEP 12 (2015), 071 doi:10.1007/JHEP12(2015)071 [arXiv:1505.01537 [hepth]].
- [4] Z. Komargodski and A. Zhiboedov, 'Convexity and Liberation at Large Spin,' JHEP 11 (2013), 140 doi:10.1007/JHEP11(2013)140 [arXiv:1212.4103 [hepth]].
- [5] R. Rattazzi, V. S. Rychkov, E. Tonni and A. Vichi, 'Bounding scalar operator dimensions in 4D CFT,' JHEP 12 (2008), 031 doi:10.1088/11266708/2008/12/031 [arXiv:0807.0004 [hep-th]].
- [6] G. Badel, G. Cuomo, A. Monin and R. Rattazzi, 'The Epsilon Expansion Meets Semiclassics,' JHEP 11 (2019), 110 doi:10.1007/JHEP11(2019)110 [arXiv:1909.01269 [hep-th]].
- [7] S. E. Derkachov and A. N. Manashov, 'On the stability problem in the O(N) nonlinear sigma model,' Phys. Rev. Lett. 79 (1997), 14231427 doi:10.1103/PhysRevLett.79.1423 [arXiv:hepth/9705020 [hep-th]].
- [8] L. S. Brown, 'Summing tree graphs at threshold,' Phys. Rev. D 46 (1992), R4125-R4127 doi:10.1103/PhysRevD.46.R4125 [arXiv:hep-ph/9209203 [hep-ph]].
- [9] D. T. Son, 'Semiclassical approach for multiparticle production in scalar theories,' Nucl. Phys. B 477 (1996), 378-406 doi:10.1016/0550-3213(96)00386-0 [arXiv:hepph/9505338 [hep-ph]].
- [10] J. L. Cardy, 'Conformal invariance and universality in
finite-size scaling,' J. Phys. A 17 (1984) no.7, L385 doi:10.1088/0305-4470/17/7/003
- [11] A. Mart´ ın S´ anchez and J. D´ ıaz Bejarano, 'Quantum anharmonic symmetrical oscillators using elliptic functions,' 1986 J. Phys. A: Math. Gen. 19 887 doi:10.1088/0305-4470/19/6/019
- [12] G. Cuomo, L. Rastelli and A. Sharon, 'Moduli Spaces in CFT: Large Charge Operators,' [arXiv:2406.19441 [hepth]].
- [13] M. E. Fisher, 'Yang-Lee Edge Singularity and phi**3 Field Theory,' Phys. Rev. Lett. 40 (1978), 1610-1613 doi:10.1103/PhysRevLett.40.1610
- [14] O. F. de Alcantara Bonfim, J. E. Kirkham and A. J. McKane, 'Critical Exponents for the Percolation Problem and the Yang-lee Edge Singularity,' J. Phys. A 14 (1981), 2391 doi:10.1088/0305-4470/14/9/034
- [15] L. Fei, S. Giombi and I. R. Klebanov, 'Critical O N ( ) models in 6 -ϵ dimensions,' Phys. Rev. D 90 (2014) no.2, 025018 doi:10.1103/PhysRevD.90.025018 [arXiv:1404.1094 [hep-th]].
- [16] I. R. Klebanov and A. M. Polyakov, 'AdS dual of the critical O(N) vector model,' Phys. Lett. B 550 (2002), 213-219 doi:10.1016/S0370-2693(02)02980-5 [arXiv:hepth/0210114 [hep-th]].
- [17] S. Giombi, R. Huang, I. R. Klebanov, S. S. Pufu
- and G. Tarnopolsky, 'The O N ( ) Model in 4 < d < 6 : Instantons and complex CFTs,' Phys. Rev. D 101 (2020) no.4, 045013 doi:10.1103/PhysRevD.101.045013 [arXiv:1910.02462 [hep-th]].
- [18] L. Fei, S. Giombi, I. R. Klebanov and G. Tarnopolsky, 'Three loop analysis of the critical O(N) models in 6ε dimensions,' Phys. Rev. D 91 (2015) no.4, 045011 doi:10.1103/PhysRevD.91.045011 [arXiv:1411.1099 [hepth]].
- [19] O. Antipin, J. Bersini, F. Sannino, Z. W. Wang and C. Zhang, 'More on the cubic versus quartic interaction equivalence in the O N ( ) model,' Phys. Rev. D 104 (2021), 085002 doi:10.1103/PhysRevD.104.085002 [arXiv:2107.02528 [hep-th]].
- [20] S. Giombi and J. Hyman, 'On the large charge sector in the critical O(N) model at large N,' JHEP 09 (2021), 184 doi:10.1007/JHEP09(2021)184 [arXiv:2011.11622 [hepth]].
- [21] M. Watanabe, 'Stability analysis of a non-unitary CFT,' JHEP 11 (2023), 042 doi:10.1007/JHEP11(2023)042 [arXiv:2203.08843 [hep-th]].
- [22] P. Basu and C. Krishnan, ' -expansions near three diϵ mensions from conformal field theory,' JHEP 11 (2015), 040 doi:10.1007/JHEP11(2015)040 [arXiv:1506.06616 [hep-th]]. | null | [
"Oleg Antipin",
"Jahmall Bersini",
"Francesco Sannino"
]
| 2024-08-02T17:42:18+00:00 | 2024-10-20T22:47:50+00:00 | [
"hep-th",
"cond-mat.stat-mech",
"hep-lat",
"hep-ph"
]
| Exact Results for Scaling Dimensions of Neutral Operators in scalar CFTs | We determine the scaling dimension $\Delta_n$ for the class of composite
operators $\phi^n$ in the $\lambda \phi^4$ theory in $d=4-\epsilon$ taking the
double scaling limit $n\rightarrow \infty$ and $\lambda \rightarrow 0$ with
fixed $\lambda n$ via a semiclassical approach. Our results resum the leading
power of $n$ at any loop order. In the small $\lambda n$ regime we reproduce
the known diagrammatic results and predict the infinite series of higher-order
terms. For intermediate values of $\lambda n$ we find that $\Delta_n/n$
increases monotonically approaching a $(\lambda n)^{1/3}$ behavior in the
$\lambda n \to \infty$ limit. We further generalize our results to neutral
operators in the $\phi^4$ in $d=4-\epsilon$, $\phi^3$ in $d=6-\epsilon$, and
$\phi^6$ in $d=3-\epsilon$ theories with $O(N)$ symmetry. |
2408.01415v1 | ## Conditional LoRA Parameter Generation
Xiaolong Jin , 1 ∗ Kai Wang 1 ∗† , Dongwen Tang , 1 ∗ Wangbo Zhao , 1 Yukun Zhou 1 , Junshu Tang 2 , Yang You 1 1 National University of Singapore 2 Shanghai Jiao Tong University Code: NUS-HPC-AI-Lab/COND P-DIFF
## Abstract
Generative models have achieved remarkable success in image, video, and text domains. Inspired by this, researchers have explored utilizing generative models to generate neural network parameters. However, these efforts have been limited by the parameter size and the practicality of generating high-performance parameters. In this paper, we propose COND P-DIFF, a novel approach that demonstrates the feasibility of controllable high-performance parameter generation, particularly for LoRA (Low-Rank Adaptation) weights, during the fine-tuning process. Specifically, we employ an autoencoder to extract efficient latent representations for parameters. We then train a conditional latent diffusion model to synthesize high-performing model parameters from random noise based on specific task conditions. Experimental results in both computer vision and natural language processing domains consistently demonstrate that COND P-DIFF can generate high-performance parameters conditioned on the given task. Moreover, we observe that the parameter distribution generated by COND P-DIFF exhibits differences compared to the distribution obtained through normal optimization methods, indicating a certain level of generalization capability. Our work paves the way for further exploration of condition-driven parameter generation, offering a promising direction for task-specific adaptation of neural networks.
## 1 Introduction
Recent advancements in generative models [41, 39, 44, 2] have marked substantial progress across several domains of artificial intelligence. In the computer vision domain, generative adversarial networks [12], diffusion models [16], and other approaches [6, 40] have shown impressive results in image synthesis and manipulation. Notably, models such as Stable Diffusion [41], DALL-E 2 [39], and Imagen [44] have set new benchmarks in the quality and resolution of generated images. Moreover, video generation models like Sora [32] have shown promising results in producing coherent and high-quality video sequences, opening new avenues for applications in entertainment and media. In the natural language processing domain [37, 22, 55], autoregressive models like GPT [2] and Llama [51] have demonstrated promising generation capabilities and alignment with human preference [20, 33, 38, 21], which underscore the potential of generative models.
Inspired by these achievements, recent studies [34, 54] have begun to explore the application of generative models in novel areas, generating high-performing model parameters . These studies focus on directly generating novel model parameters to accelerate the training process, uncovering parameters that achieve comparable performance with those obtained through conventional optimization methods.
∗ equal contribution, [email protected], [email protected], [email protected] † corresponding author
By harnessing the power of generative models, it is possible to substantially reduce the computational cost and time required for model optimization [34, 43, 24]. Besides, examining the latent relationships between model parameters and performance provides valuable insights into the behavior and characteristics of neural networks [13].
However, previous works on parameter generation [54, 34, 50, 46, 26] face several limitations. On the one hand, the scale of parameters generated by prior methods [50, 34, 54] is insufficient for practical applications. For example, G.pt [34] has been evaluated only on relatively simple datasets such as MNIST and CIFAR-10, which may not sufficiently demonstrate its generalization ability when applied to more complex tasks, and p-diff [54] can generate small-scale high-performance parameters for simple architectures. Besides, [46] learn a hyper-representation on model zoos for generative use to sample new small-scale model weights. On the other hand, previous methods do not support conditional high-performance parameter generation. P-diff[54] lacks support for conditional parameter generation, a crucial feature for real-world applications. Although G.pt [34] enables controllable parameter generation as an optimizer, it can hardly exhibit comparable performance compared to networks trained by conventional optimization methods.
Therefore, despite their promising potential, these methods grapple with constraints about parameter size, practicality, and overall performance, which yield the primary question to be explored in this paper: (Q) Can we synthesize high-performance parameters conditioned on the given task practically?
To enhance the practicality of parameter generation, two main challenges exist. First, parameter generation for complex models entails significant data preparation costs. For example, G.pt [34] requires training 23 million models, which is infeasible for large models. Second, controllable parameter generation is challenging due to the difficulty in modeling the distribution of parameters, making full parameter generation highly complex. Consequently, we focus on the conditional generation of fine-tuned LoRA (Low-Rank Adaptation) parameters in various domains as LoRA improves downstream task performance with few parameters and a relatively more stable distribution. Specifically,
Figure 1: High-performance LoRA parameters generation process by COND P-DIFF in vision and language domains.
LoRA [17] is a parameter-efficient fine-tuning technique that adapts pre-trained models to specific tasks by learning low-rank matrices that modify the model's weights.
To achieve high-performance controllable conditional parameter generation, we propose Conditional Parameter Diffusion, named COND P-DIFF, which utilizes a standard latent diffusion model to perform conditional generation, synthesizing a new set of parameters tailored to specific conditions. Specifically, we use an autoencoder and a conditional latent diffusion model to capture the distribution of network weights. First, the autoencoder is trained on a selected set of parameters from models optimized with normal optimization methods, e.g. , SGD [43], on different datasets, creating latent representations of these parameters. Second, we utilize a domain-specific condition, e.g., text, style image , projector to encode the condition information and train a conditional diffusion model to reconstruct latent representations. Finally, as shown in Figure 1, the trained conditional latent diffusion model COND P-DIFF generates latent representations from random noise in the inference process based on specific task conditions. Then, the decoder of the trained autoencoder processes these generated representations to produce new, high-performing model parameters.
Our method has the following characteristics: i) It demonstrates comparable or superior performance relative to models trained with conventional methods, spanning various datasets and architectures. ii) The parameters generated by our approach significantly differ from the parameters obtained during normal training, highlighting its capability to synthesize novel parameters rather than merely replicating the training examples. iii) Extensive evaluations demonstarte the robustness of our approach. Our method COND P-DIFF also shows generalizability in generated high-performance model weights space. We hope that our findings will provide new insights into the potential of applying conditional diffusion models to parameter generation and highlight a promising direction for task-specific parameter generation of neural networks.
## 2 Preliminary
## 2.1 Preliminaries of LoRA
Low-Rank Adaptation (LoRA) [17] enhances the efficiency of fine-tuning large pre-trained language models by minimizing the computational demands usually required for full model retraining. LoRA introduces two trainable matrices, B ∈ R d × r and A ∈ R r × k , to each transformer layer. These matrices, where r is much smaller than hidden layer dimension d and task-specific dimension k , perform a low-rank approximation of the typical updates made during fine-tuning. The core idea is that the necessary adjustments for task-specific adaptation have a low "intrinsic dimension," allowing significant reductions in trainable parameters while maintaining performance. The pretrained weight matrix W 0 remains unchanged, with only B and A being optimized, thus speeding up training and decreasing memory and computational needs. The modified forward pass in LoRA is represented as:
$$W _ { 0 } x + \Delta W x = W _ { 0 } x + B ( A x )$$
where ∆ W = BA is the update. Initially, B is zero, ensuring no changes to W 0, and A starts with a small random Gaussian distribution. In deployment, the learned low-rank matrices B and A can be integrated into W 0. In this work, we aim to synthesize LoRA parameters because of the practicality and effective LoRA fusion that show the continuous distribution in LoRA parameter space.
## 2.2 Preliminaries of Conditional Diffusion Models
Conditional diffusion models [16, 41, 59] extend the standard diffusion model by incorporating conditions into both the forward and reverse processes. This conditional information defined by c allows the model to generate data tailored to specific attributes or requirements.
Conditional forward process: The forward process in conditional models involves adding noise to an initial sample while conditioning on c . The probability of transitioning from x t -1 to x t under condition c is modeled as a Gaussian distribution:
$$q ( x _ { t } | x _ { t - 1 }, c ) = \mathcal { N } ( x _ { t } ; \sqrt { 1 - \beta _ { t } } x _ { t - 1 }, \beta _ { t } \mathbf 1 )$$
where β t are the timestep-dependent noise levels, and I represents the identity matrix. The complete forward process conditioned on c is given by:
$$q ( x _ { 1 \colon T } | x _ { 0 }, c ) = \prod _ { t = 1 } ^ { T } q ( x _ { t } | x _ { t - 1 }, c )$$
Conditional Reverse Process: The reverse process aims to reconstruct the original sample from its noisiest state x T conditioned on c . It is formulated by:
$$p _ { \theta } ( x _ { t - 1 } | x _ { t }, c ) = \mathcal { N } ( x _ { t - 1 } ; \mu _ { \theta } ( x _ { t }, t, c ), \Sigma _ { \theta } ( x _ { t }, t, c ) )$$
In this process, µ θ and Σ θ are functions estimated by a neural network, which also processes the condition c , ensuring that the recovery of data respects the conditional constraints.
Optimization and Inference with Conditions: The training procedure involves minimizing the Kullback-Leibler(KL) divergence between the forward and reverse conditional distributions, specifically:
$$L _ { d m } = \mathbb { E } _ { q ( x _ { 0 }, c ) } \left [ D _ { K L } ( q ( x _ { t - 1 } | x _ { t }, x _ { 0 }, c ) \| p _ { \theta } ( x _ { t - 1 } | x _ { t }, c ) ) \right ]$$
During inference, the model generates new samples by conditioning on c and sequentially applying the learned reverse transitions from a noise distribution, enabling the generation of data that closely adheres to the specified conditions.
## 3 Methodology
## 3.1 Overview
We propose conditional parameter generation to synthesize new parameters tailored to specific task conditions. Fig 2 illustrates our proposed COND P-DIFF framework. First, given a training dataset
of model parameters, we use an autoencoder [25] to extract latent representations of the parameters and reconstruct the latent vectors by decoder. Then, inspired by [54], we train a conditional latent diffusion model to generate high-performance parameters conditioned on specific task information. Finally, after training, we employ COND P-DIFF by feeding random noise and task-specific conditions into a conditional parameter diffusion model to generate the desired parameters.
Figure 2: The framework of COND P-DIFF. The autoencoder is employed to extract the latent representation of LoRA parameters and reduce memory consumption. The conditional parameter diffusion model aims to synthesize high-performance parameters based on specific task conditions.
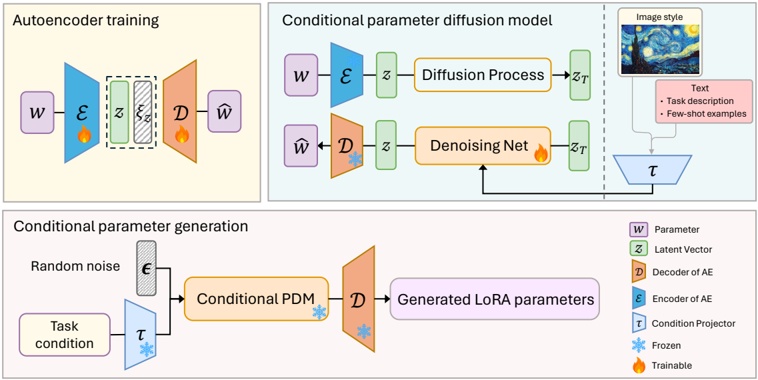
## 3.2 Parameter autoencoder
Dataset preparation. In this work, we focus on synthesizing LoRA learnable matrix parameters of fine-tuned models by default. To obtain the training dataset for the parameter autoencoder, we finetune the pre-trained model using LoRA on the dataset for task q and collect N different checkpoints in the last N steps. We denote the training dataset as Θ = [ θ , . . . , θ 1 n , . . . , θ N ] , where θ k represents the weights of LoRA for the model at a specific fine-tuning stage. Because the training dataset for COND P-DIFF contains model parameters rather than conventional image or language datasets, we propose task normalization . Specifically, we employ Z-Score normalization on the parameters of each task individually [18].
Training procedure. Given a training sample θ n , we flatten parameter matrix θ n to a onedimensional vector w n ∈ R K × 1 , which K is the total number of parameter weights of w n . Then, we utilize an auto-encoder to obtain meaningful and robust latent representations. Specifically, we formulate the process as Equation 6, where E and D represent the encoder and decoder functions, respectively. z n is the latent representation of the parameter matrix. ˆ w n is the reconstruction of parameter w n . To enhance the generalization and robustness of the autoencoder, we introduce Gaussian noise ξ z to the latent vector. The final auto-encoder process is formulated as follows:
$$z _ { n } = \mathcal { E } ( w _ { n } ) = \text{Encoder} ( w _ { n } )$$
$$\hat { w } _ { n } = \mathfrak { D } ( z _ { n } ) = \text{Decoder} ( z _ { n } + \xi _ { \mathfrak { z } } )$$
We train the autoencoder function by minimizing loss function below.
$$\mathcal { L } = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \| w _ { n } - \hat { w } _ { n } \| ^ { 2 }$$
## 3.3 Conditional parameter generation
We utilize a conditional latent diffusion model to synthesize high-performance parameters based on conditions y such as text and image. To handle different tasks and modalities, we adopt the domain-specific encoder, which is denoted as τ domain ( y ρ ; ) , where y represents the input condition and ρ denotes the encoder parameters. For example, in the NLP experiments of this work, we employ the text decoder in CLIP[36]. Inspired by in-context learning, the input condition y consists of a task description and two-shot examples to capture the task information. Besides, we utilize stylized images as conditions in style transfer tasks and adopt ResNet [14] to extract style latent representations as the condition vector. More details about the condition are shown in Appendix 6.1. Regarding the U-Net architecture, we apply one-dimensional convolutions in denoising autoencoders because the weight matrix parameters do not show strong positional relationships different from images where pixels have two-dimensional spatial relationships.
Therefore, given the condition and training parameters samples, we train the conditional latent diffusion model through
$$L _ { L D M } \coloneqq \mathbb { E } _ { \epsilon \sim \mathcal { N } ( 0, 1 ), t } \left [ \| \epsilon - \epsilon _ { \theta } ( p _ { t }, t, \tau _ { d o m a i n, \rho } ( y ) ) \| ^ { 2 } \right ],$$
where ϵ θ is learned via Eq. 8. Finally, after conditional diffusion model training, we feed specific conditions corresponding to tasks and random noise to reverse the inference process to obtain high-performing weights for specific tasks.
## 4 Experiment
In this section, we first show the experiment setup. Then, we present the evaluation results, ablation studies, and analysis of COND P-DIFF.
## 4.1 Experiment setup
Datasets and metrics. We evaluate our method across various domains. Specifically, in NLP experiments, we test on the language understanding GLUE benchmark [53]. In CV experiments, we focus on the style-transfer tasks. We use the SemArt and WikiArt datasets [10, 45], which contain diverse artistic images, and evaluate them using the Fréchet Inception Distance (FID, [15], as employed by StyleGAN [23], with lower scores indicating better performance.
Dataset collecting and training procedures. In NLP experiments, we collect 150 training samples for models, including BERT, Roberta, GPT-2 by default. For instance, in the case of BERT, we fixed pre-trained parameters and fine-tuned the network using LoRA. Specifically, we conduct the hyperparameter search for fixed values of r and α and select the fine-tuning hyperparameters that yield the best average performance. During the fine-tuning process, we save the checkpoints of the last 150 steps as the training dataset, which includes the LoRA learnable matrix weights. In the framework of COND P-DIFF, the autoencoder includes 1D CNN-based encoders and decoders. We utilize the text encoder from CLIP as the condition text encoder. In image style transfer tasks, we fine-tune attention modules of a popular text-to-image model, PIXARTα model [4] using LoRA and collected the last 64 LoRA checkpoints of the training process once in 10 steps. In the framework of COND P-DIFF, we used pre-trained ResNet18 to extract style latent as the condition vector. All experiments were conducted on the Linux server with four NVIDIA A100 GPUs. The noise ξ z is Gaussian noise with an amplitude of 0.001 by default. Detailed training hyperparameters for LoRA fine-tuning and COND P-DIFF framework are provided in Appendix B.
Inference procedures. In NLP tasks, we generate 20 LoRA parameters for each task using a conditional diffusion model through random noise and merge these generated parameters into the pre-trained model. We select the model that exhibits the best performance on the training dataset and report its performance on the validation dataset. In style-transfer tasks, we synthesize LoRA parameters of the corresponding styles by feeding the conditional diffusion model with images in various styles as conditions. We then merge parameters with PIXARTα 's and utilize them to generate images using a set of prompts. Finally, we compute the FID score of the generated images.
Baselines. 1) original : The best validation performance among the originally trained models. 2) model soup : The validation performance of the model whose weight is the average of the training dataset. Because Mitchell et al. [57] shows averaging the weights of fine-tuned models with different
hyperparameter configurations often improves accuracy and robustness. In style-transfer experiments, we introduce an additional baseline no-lora : we directly employ the predefined PIXARTα model to demonstrate the effectiveness of LoRA fine-tuning in style-transfer tasks.
## 4.2 Experiment results
COND P-DIFF can generate high-performance parameters based on task conditions. Table 1 presents comparison results of COND P-DIFF and baseline methods across language understanding GLUE benchmark for three models with different LoRA configurations. We observe that COND P-DIFF consistently yields comparable performance in most scenarios, demonstrating it learns conditional parameter distributions effectively and stably. Besides, we note that the baseline average 's performance in some cases surpasses the baseline, validating the potential of model averaging to enhance performance [57].
Table 2 illustrates the results of COND P-DIFF and the baseline in the image style transfer task for different styles. We employ the FID [15] to quantitatively assess the quality of style-conditioned image generation. Lower FID represents better image generation quality. Based on our findings, COND P-DIFF efficiently synthesizes specific style-adapted LoRA parameters to generate high-quality images. Additional visual results are shown in Figure 3(a). This demonstrates that COND P-DIFF can practically generate high-performance model parameters based on specific conditions.
Table 1: Results of COND P-DIFF on GLUE. We present results in the format of 'COND P-DIFF/ orginal / model soup'. COND P-DIFF obtains comparable or even better performance than baselines. 'Size' is the parameter size of LoRA. 'Rank' is the parameter r in LoRA. Full' represents fully fine-tuning results.
| Model | Rank | Size | SST2 | RTE | MRPC | COLA | QNLI | STSB | Average |
|---------|--------|----------------|----------------------------------------------------------|-----------------------------------------------------------------------------|------------------------------------------------------------------------|---------------------------------------|---------------------------------------|---------------------------------------|---------------------------------------|
| BERT | 1 4 | 73728 | 91.6 / 91.6 / 90.8 91.4 / 91.4 / 91.5 91.6 / 91.9 / 92.0 | 57.4 / 58.9 / 57.9 57.5 / 59.9 / 60.1 62.7 / 63.2 / 62.8 64.2 / 64.3 / 64.5 | 87.2 / 83.4 / 83.9 87.3 / 85.1 / 85.4 / 85.4 / 85.5 87.4 / 87.0 / 86.8 | 52.4 / 52.6 / 52.1 51.4 / 51.3 / | 88.7 / 88.7 / 88.1 | 81.8 / 81.4 / 81.7 82.6 / 81.6 / 81.7 | 76.5 / 76.1 / 75.8 76.5 / 76.2 / 76.2 |
| BERT | 2 | 147456 | | | 85.5 | 50.7 | 88.6 / 88.1 / 87.4 | | |
| BERT | 16 | 294912 1179648 | 92.1 / 91.6 / 91.5 | 66.4 | | 53.7 / 53.4 / 52.5 56.9 / 57.0 / 57.5 | 89.8 / 89.6 / 88.9 89.8 / 90.1 / 90.2 | 80.6 / 80.9 / 80.7 83.8 / 83.3 / 82.3 | 77.3 / 77.4 / 77.1 79.0 / 78.9 / 78.8 |
| BERT | Full | 109482240 | 93.5 | | 88.9 | 52.1 | 90.5 | 85.8 | 79.5 |
| RoBERTa | 1 | 73728 | 93.3 / 93.7 / 94.1 | 65.6 / 68.6 / 68.0 | 86.9 / 84.7 / 85.0 | 49.8 / 50.2 / 50.5 | 92.4 / 92.0 / 91.4 | 87.3 / 87.5 / 86.9 | 79.2 / 79.4 / 79.3 |
| RoBERTa | 2 | 147456 | 93.5 / 93.7 / 93.8 | 63.2 / 68.2 / 68.3 | 87.7 / 85.0 / 84.6 | 50.3 / 50.7 / 50.6 | 92.8 / 92.5 / 92.2 | 86.8 / 87.3 / 87.6 | 79.0 / 79.6 / 79.5 |
| RoBERTa | 4 | 294912 | 93.8 / 93.5 / 93.1 | 69.8 / 69.7 / 69.5 | 87.9 / 88.3 / 87.9 | 54.1 / 54.0 / 54.1 | 92.0 / 92.4 / 92.9 | 88.3 / 88.2 / 88.6 | 81.0 / 81.0 / 81.0 |
| RoBERTa | Full | 124645632 | 94.8 | 78.7 | 90.2 | 63.6 | 92.8 | 91.2 | 85.2 |
| DeBERTa | 1 | 92160 | 94.4 / 94.4 / 94.7 | 61.4 / 61.0 / 61.5 | 84.0 / 84.0 / 83.2 | 56.8 / 57.0 / 56.1 | 92.4 / 92.8 / 92.1 | 87.4 / 87.8 / 87.0 | 79.4 / 79.5 / 79.1 |
| DeBERTa | 2 4 | 184320 368640 | 94.9 / 94.8 / 94.0 94.6 / 94.5 / 94.7 | 62.2 / 62.1 / 62.0 63.2 / 62.8 / 61.9 | 86.2 / 85.8 / 86.2 87.1 / 86.9 / 86.2 | 58.6 / 58.3 / 57.4 60.3 / 60.3 / 59.9 | 92.1 / 92.0 / 92.1 93.4 / 93.5 / 93.1 | 85.2 / 85.2 / 84.5 88.7 / 88.7 / 88.7 | 79.9 / 79.4 / 79.4 81.2 / 81.1 / 80.7 |
Table 2: FID results of image-transfer tasks. Lower FID is better. Best results are bolded .
| Style | original | model soup | no-Lora | COND P-DIFF |
|----------|------------|--------------|-----------|---------------|
| Van Gogh | 27.92 | 28.08 | 102.95 | 28.03 |
| Edvard | 27.1 | 27.13 | 96.18 | 26.98 |
| Chalk | 36.22 | 36 | 171.82 | 36.18 |
| Charcoal | 40.8 | 40.19 | 132.76 | 40.6 |
| Average | 33.01 | 32.86 | 125.93 | 32.94 |
Table 3: Ablation results of training dataset size N . Larger N can enhance performances.
| N | SST2 | STSB | MRPC |
|-----|--------|--------|--------|
| 1 | 90.23 | 80.71 | 82.71 |
| 100 | 91.63 | 80.91 | 83.52 |
| 200 | 91.63 | 81.81 | 87.24 |
| 500 | 91.63 | 81.8 | 87.25 |
## 4.3 Ablation study
In this section, we conduct multiple ablation studies to report the characteristics of COND P-DIFF. We focus on the performance of generated LoRA parameters(rank r = 1 ) of BERT on SST2, RTE, and MRPC datasets. The training setting is the same as experiments Table 1.
Size of the training dataset As described in Section 3.2, we collect N different checkpoints in the last N steps as a training dataset for task q using LoRA. We explore the relationship between dataset size N and performance in Table 3. We observe that the performance improves as the size of the training dataset increases. Specifically, a larger training dataset can provide a broader exploration space, thereby enabling COND P-DIFF to generate higher performance parameters. For instance, performance on the MRPC task improved by 4.53%.
Table 4: Ablation studies of COND P-DIFF. We ablate the normalization methods in the training process, the condition representation, and the location of employing COND P-DIFF. The Default settings in COND P-DIFF are marked in gray . Bold entries are best results.
(a) Comparison among no norm. , batch norm. and task norm. . task norm. can improve performance.
(b) Few shot examples boost COND P-DIFF capability with task information description.
(c) COND P-DIFF is effective in certain blocks but can boost performance on whole LoRA parameters.
| Norm. | SST2 | STSB | MRPC |
|-------------|--------|--------|--------|
| no norm. | 55.67 | 49.07 | 47.01 |
| batch norm. | 90.6 | 80.9 | 82.5 |
| task norm. | 91.63 | 81.81 | 87.24 |
| Condtion | SST2 | STSB | MRPC |
|--------------------|--------|--------|--------|
| one-hot | 90.05 | 77.12 | 80.34 |
| learnable vector | 90.1 | 80.03 | 81.81 |
| task info | 90.25 | 80.32 | 81.98 |
| task info+few-shot | 91.63 | 81.81 | 87.24 |
| LoRA layers | SST2 | STSB | MRPC |
|---------------|--------|--------|--------|
| 0-1 | 91.63 | 81.43 | 83.45 |
| 0-4 | 91.63 | 81.45 | 83.61 |
| 0-8 | 91.63 | 81.8 | 85.61 |
| 0-11 | 91.63 | 81.81 | 87.24 |
Normalization approach As described in Section 3.2, we use task normalization method. Table 4(a) shows the impacts of different normalization strategies on performance, including no norm. , batch norm. , and task norm. . Specifically, task norm. refers to normalizing the parameters corresponding to each task individually. batch norm. represents batch normalization. The experimental setup in Table 4(a) is consistent with that of the experiment in Table 1. We find that task norm. consistently yields the best average performance. no norm. leads to the worst performance because the wide variance in weight distributions across different tasks and outliers hinders the convergence of the autoencoder. Besides, batch norm. performed inferior to task norm. , as it introduces spurious correlations among parameters across different tasks.
Condition information The representation of the condition critically affects generation results. We explore how to represent the task condition effectively to guide conditional parameter generation, as detailed in Table 4(b). Our approach categorizes representations into four types: using one-shot vectors, using only the task description, using only two-shot examples, and using both the task description and two-shot examples. Table 4(b) shows that combining the task description with examples yields better outcomes, suggesting that in-context learning can provide more information to establish relationships with the weight parameters.
Which part of parameters to synthesis We generate LoRA parameters for all blocks by default in Table 1. To explore the effectiveness of COND P-DIFF on different blocks, we present the performance when generating LoRA parameters for only certain blocks. The experiments in Table 4(c) illustrate that the method is more effective when generating parameters for all blocks. We hypothesize that as the number of synthesized parameters increases, the model has a larger exploration space, thereby boosting performance. Conversely, performance is constrained by the exploration space and original parameters when focusing on only a subset of parameters.
A man wearing glasses with a smile A train is moving along a stretch of track

(a) Visualization of images generated by COND P-DIFF parameters in style transfer tasks
(b) t-SNE of the LoRA paand generated parameters.
rameters of original model (c) Similarity comparisons of finetuned parameters and parameters generated by COND P-DIFF

Figure 3: (a) visualize the images generated by COND P-DIFF synthetic parameters in style transfer tasks. (b) shows the t-SNE of LoRA parameters of the original models, COND P-DIFF models on three datasets COLA, QNLI, and STSB. (SST2-Ori. means original parameters and SST-Gen. means generated parameters) (c) displays the accuracy and similarity of fine-tuned performance and parameters generated by COND P-DIFF.
(a) Visualization of the interpolation of two generated parameters in (b) different styles. Visualization of parameter generation trajectories of COND P-DIFF in style-transfer tasks.

Figure 4: (a) visualizes images generated by interpolated parameters between Style-1 and Style-2. As λ increases from left to right, the style gradually shifts towards Style-2 from Style-1. (b) exhibits the generated parameters' trajectory at different time steps during the inference stage using t-SNE from five random noise start points in image-transfer tasks.
## 4.4 Analysis
In this section, we conduct a detailed analysis of COND P-DIFF. Specifically, we explore two critical questions: First, does COND P-DIFF merely replicate training data, or can it generate highperformance model parameters that are distinct from the originals? Second, does the generated parameter space of COND P-DIFF have generalizability?
## COND P-DIFF is not merely cloning model parameters.
Similarity vs. Performance First, we calculate the L 2 distance between the generated and original parameters. Figure 3(c) illustrates the relationship between the similarity of the generated parameters and performance. We observe that COND P-DIFF attains various similarities and achieves better performance compared to original fine-tuned weights across various datasets.
Parameter distribution We employ t-SNE [52] to analyze the distributions of generated parameters and original weights of fine-tuned models on datasets COLA, QNLI, and STSB, as shown in Figures 3(b). We observe that the distribution of generated parameters by COND P-DIFF significantly differs from the original parameters. The distribution of the original parameters can be viewed as following the trajectory of the optimization process. In contrast, COND P-DIFF generates novel highperformance parameters by learning the distribution of parameters. Besides, the high-performance parameters generated by COND P-DIFF are dispersed more broadly, underscoring the generative model's potential to identify novel high-performance parameters beyond traditional optimization pathways. Interestingly, the high-performance parameter distributions generated by COND P-DIFF for the three datasets are very similar, demonstrating the necessity of exploring the high-performance parameter space.
Trajectories of COND P-DIFF process. Figure 4(b) visualizes the generated parameters at different time steps during the inference stage using t-SNE [52] to explore the generation process in the image style-transfer tasks. We display five trajectories initialized from five different random noises and present the model soup and the original model parameters. The parameters derived from the model soup are located near the original parameters. We observe that the generated parameters gradually approach the original parameters but ultimately maintain some distance from them, indicating that COND P-DIFF generates high-performance parameters that are distributed differently from the original parameters rather than directly replicating them. The variations in the trajectories also demonstrate the robustness of COND P-DIFF.
Generalizability We examine the generalization of the generated parameter space in the task of image style transfer. We select parameters, θ style1 and θ style2 , generated by COND P-DIFF conditioned two distinct styles, style1 and style2. To interpolate between these styles, we compute a new set of parameters θ interp as θ interp = (1 -λ θ ) style1 + λθ style2 , where λ ∈ [0 , 1] is the interpolation factor. Subsequently, we evaluate the effectiveness of θ interp in style transfer. Figure 4(b) illustrates the
visualization of images generated by interpolated parameters between Style-1 and Style-2. As λ increases from left to right, the style gradually shifts towards Style-2. The continuous style change demonstrates the generalization of the generated parameter space. We also explore the generalization of the condition space in the Appendix C
## 5 Related work
Diffusion models Diffusion models [16, 5, 35] have recently emerged as a powerful class of generative models, enabling high-fidelity synthesis of complex data distributions. The research on the diffusion model can be generally classified into four categories. The first category aims to enhance image synthesis quality [41, 39, 44] Second, researchers focus on accelerating the sampling process [49, 28]. Third, recent research has also focused on reevaluating diffusion models through the lens of continuous analysis like score-based generative modeling [8]. Fourth, the success of diffusion models has sparked their application in various domains, [27, 29, 56]. In this work, we explore the conditional diffusion model in the parameter generation domain.
Conditional generation Conditional generation has gained significant attention in computer vision and natural language processing. Three prominent frameworks have emerged: conditional GANs [31, 19, 60], conditional V AEs [48, 58], and conditional diffusion models xw[41, 16], which incorporate conditions to guide the generation process, enabling the creation of visually coherent and semantically meaningful data samples. Conditional GANs incorporate condition information into GAN to generate images conditioned on specific attributes or labels. Conditional diffusion models take this further by generating visually coherent and semantically meaningful images from the textual description, demonstrating superior image synthesis quality compared to GANs. Building upon the success of conditional diffusion models, we propose to extend this approach to generating neural network parameters based on specific conditions.
Parameter generation The field of parameter generation has seen significant progress in recent years, with HyperNetworks ([13] and generative models of neural network checkpoints [34] emerging as promising approaches. [13] introduced HyperNetworks, which uses a hypernetwork to learn the parameters for another neural network. [9] proposes Model-Agnostic Meta-Learning, which learns an initialization for efficient fine-tuning. [34] introduce the model G.pt to predict the distribution over parameter updates given an initial input parameter vector and a prompted loss or error. [46] trained autoencoder on a model zoo to learn a hyper-representation for generative use to sample new model weights [26] use a GNN-based model to sample network parameters. [7] directly leverages MLP weights and generates neural implicit fields encoded by synthesized MLP weights. [54] uses a diffusion model to generate high-performing neural network parameters across various architectures and datasets. Different from the previous works, we focus on conditional parameter generation to generate high-performing weights based on specific task conditions practically.
## 6 Conclusion
In this work, we proposed an approach COND P-DIFF for high-performance controllable parameter generation, specially for LoRA parameters. We utilize an autoencoder and a conditional latent diffusion model to capture the distribution of high-performing parameters and perform conditional generation, synthesizing a new set of parameters tailored to specific conditions. We show that our method can efficiently synthesize novel and high-quality model parameters. The parameter distribution generated by COND P-DIFF exhibits differences compared to the distribution obtained through conventional optimization methods, indicating a certain level of generalization capability.
## 6.1 Limitation and future work
Nonetheless, it is essential to recognize that diffusion in parameter generation is still largely unexplored despite the significant advances in the realm of image and video synthesis. In this work, we present a preliminary methodology for conditional parameter diffusion. However, several challenges remain unresolved, including reducing memory demands for large model architectures, enhancing the generalizability of generation techniques, and improving the representation of dataset conditions. Furthermore, integrating knowledge graphs with conditional diffusion offers promising directions for controlling conditional generation.
## References
| [1] | Md. Bahadur Badsha, Evan A Martin, and Audrey Qiuyan Fu. Mrpc: An r package for accurate inference of causal graphs, 2018. |
|-------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared DKaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 33:1877-1901, 2020. |
| [3] | Daniel Cer, Mona Diab, Eneko Agirre, Inigo Lopez-Gazpio, and Lucia Specia. Sts benchmark. https://paperswithcode.com/dataset/sts-benchmark , 2017. ACL. |
| [4] | Junsong Chen, Jincheng YU, Chongjian GE, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-$\alpha$: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In ICLR, 2024. |
| [5] | Prafulla Dhariwal and Alex Nichol. Diffusion Models Beat GANs on Image Synthesis, June 2021. |
| [6] | Laurent Dinh, David Krueger, and Yoshua Bengio. Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516, 2014. |
| [7] | Ziya Erkoç, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. Hyperdiffusion: Generating implicit neural fields with weight-space diffusion. In ICCV, pages 14300-14310, 2023. |
| [8] | Berthy T. Feng, Jamie Smith, Michael Rubinstein, Huiwen Chang, Katherine L. Bouman, and William T. Freeman. Score-Based Diffusion Models as Principled Priors for Inverse Imaging, August 2023. |
| [9] | Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, July 2017. |
| [10] | Noa Garcia and George Vogiatzis. How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval, October 2018. |
| [11] | Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. Image Style Transfer Using Convolu- tional Neural Networks. In CVPR, pages 2414-2423, 2016. |
| [12] | Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. NeurIPS, 27, 2014. |
| [13] | David Ha, Andrew Dai, and Quoc V Le. Hypernetworks. arXiv preprint arXiv:1609.09106, 2016. |
| [14] | Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770-778, 2016. |
| [15] | Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS, 30, 2017. |
| [16] | Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models, December 2020. |
| [17] | Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021. |
| [18] | Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, pages 448-456. pmlr, 2015. |
| [19] | Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-Image Translation with Conditional Adversarial Networks, November 2018. |
| [20] | Xiaolong Jin, Zhuo Zhang, and Xiangyu Zhang. Multiverse: Exposing large language model alignment problems in diverse worlds. arXiv preprint arXiv:2402.01706, 2024. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [21] | Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022. |
| [22] | Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020. |
| [23] | Tero Karras, Samuli Laine, and Timo Aila. AStyle-Based Generator Architecture for Generative Adversarial Networks, March 2019. |
| [24] | Diederik P Kingma and Jimmy Ba. Adam: Amethod for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. |
| [25] | Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013. |
| [26] | Boris Knyazev, Michal Drozdzal, Graham W. Taylor, and Adriana Romero-Soriano. Parameter Prediction for Unseen Deep Architectures, October 2021. |
| [27] | Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. DiffWave: AVersatile Diffusion Model for Audio Synthesis, March 2021. |
| [28] | Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps, October 2022. |
| [29] | Shitong Luo and Wei Hu. Diffusion Probabilistic Models for 3D Point Cloud Generation, June 2021. |
| [30] | Andrzej Ma´kiewicz c and Waldemar Ratajczak. Principal components analysis (pca). Computers &Geosciences, 19(3):303-342, 1993. |
| [31] | Mehdi Mirza and Simon Osindero. Conditional Generative Adversarial Nets, November 2014. |
| [32] | OpenAI. Sora, 2024. Accessed: 2024-05-08. |
| [33] | Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. NeurIPS, 35:27730-27744, 2022. |
| [34] | William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A. Efros, and Jitendra Malik. Learning to Learn with Generative Models of Neural Network Checkpoints, September 2022. |
| [35] | William Peebles and Saining Xie. Scalable Diffusion Models with Transformers, March 2023. |
| [36] | Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748-8763. PMLR, 2021. |
| [37] | Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019. |
| [38] | Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. NeurIPS, 36, 2024. |
| [39] | Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical Text-Conditional Image Generation with CLIP Latents, April 2022. |
| [40] | Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. In ICML, pages 1278-1286. PMLR, |
2014.
| [41] | Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models, April 2022. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [42] | Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. CoRR, abs/1505.04597, 2015. |
| [43] | Sebastian Ruder. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747, 2016. |
| [44] | Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding, May 2022. |
| [45] | Babak Saleh and Ahmed Elgammal. Large-scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature, May 2015. |
| [46] | Konstantin Schürholt, Boris Knyazev, Xavier Giró-i Nieto, and Damian Borth. Hyper- representations as generative models: Sampling unseen neural network weights. NeurIPS, 35:27906-27920, 2022. |
| [47] | Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631-1642, Seattle, Washington, USA, October 2013. ACL. |
| [48] | Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning Structured Output Representation using Deep Conditional Generative Models. In NeurIPS, volume 28. Curran Associates, Inc., 2015. |
| [49] | Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising Diffusion Implicit Models, October 2022. |
| [50] | Bedionita Soro, Bruno Andreis, Hayeon Lee, Song Chong, Frank Hutter, and Sung Ju Hwang. Diffusion-based neural network weights generation. arXiv preprint arXiv:2402.18153, 2024. |
| [51] | Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. |
| [52] | Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. JMLR, 9(11), 2008. |
| [53] | Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018. |
| [54] | Kai Wang, Zhaopan Xu, Yukun Zhou, Zelin Zang, Trevor Darrell, Zhuang Liu, and Yang You. Neural network diffusion. arXiv preprint arXiv:2402.13144, 2024. |
| [55] | Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 35:24824-24837, 2022. |
| [56] | Julia Wolleb, Florentin Bieder, Robin Sandkühler, and Philippe C. Cattin. Diffusion Models for Medical Anomaly Detection, October 2022. |
| [57] | Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In ICML, pages 23965-23998. PMLR, 2022. |
| [58] | Xinchen Yan, Jimei Yang, Kihyuk Sohn, and Honglak Lee. Attribute2Image: Conditional Image Generation from Visual Attributes, October 2016. |
- [59] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, pages 3836-3847, 2023.
- [60] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, August 2020.
## A Detailed related work
Diffusion models Diffusion models have emerged as a powerful class of generative models, enabling high-fidelity synthesis of complex data distributions. Diffusion models are based on non-equilibrium thermodynamics, which gradually add noise to data and learn to reverse the diffusion process to generate samples. [16, 5, 35] The research on the diffusion model can be generally classified into four categories. The first category aims to enhance image synthesis quality, as demonstrated by notable models such as Stable Diffusion [41], DALL·E 2 [39], and Imagen [44] by leveraging techniques like CLIP-based text encoders, latent space diffusion, and hierarchical architectures. Second, researchers focus on accelerating the sampling process, with key developments including Denoising Diffusion Implicit Models [49] and DPM-Solver [28]. These approaches aim to improve the computational efficiency of diffusion models through deterministic sampling, closed-form expressions, and numerical ODE solvers. Third, recent research has also focused on reevaluating diffusion models through the lens of continuous analysis like score-based generative modeling [8] in continuous-time settings. Fourth, the success of diffusion models has sparked their application in various domains, including text-to-speech synthesis [27], 3D shape generation [29], and anomaly detection in medical images [56], demonstrating the potential of diffusion models beyond image synthesis. In this work, we explore the conditional diffusion model in the parameter generation domain.
Conditional generation Conditional generation has gained significant attention in machine learning, particularly in computer vision and natural language processing. Three prominent frameworks have emerged: conditional GANs [31, 19, 60], conditional VAEs [48, 58], and conditional diffusion models [41, 16], which incorporate conditions to guide the generation process, enabling the creation of visually coherent and semantically meaningful data samples. Conditional GANs incorporate condition information into GAN to generate images conditioned on specific attributes or labels. Conditional diffusion models take this further by generating visually coherent and semantically meaningful images from the textual description, demonstrating superior image synthesis quality compared to GANs. Building upon the success of conditional diffusion models, we propose to extend this approach to generating neural network parameters based on specific conditions.
Parameter generation The field of parameter generation has seen significant progress in recent years, with HyperNetworks ([13] and generative models of neural network checkpoints [34] emerging as promising approaches. [13] introduced HyperNetworks, which uses a hypernetwork to learn the parameters for another neural network. [9] proposes Model-Agnostic Meta-Learning, which learns an initialization for efficient fine-tuning. [34] introduce the model G.pt to predict the distribution over parameter updates given an initial input parameter vector and a prompted loss or error. [46] trained autoencoder on a model zoo to learn a hyper-representation for generative use to sample new model weights [26] use a GNN-based model to sample network parameters. [7] directly leverages MLP weights and generates neural implicit fields encoded by synthesized MLP weights. [54] uses a diffusion model to generate high-performing neural network parameters across various architectures and datasets. Different from the previous works, we focus on conditional parameter generation to generate high-performing weights based on specific task conditions practically.
## B Experiment setup
In this section, we show detailed experiment setups, including dataset information and training configuration.
## B.1 Style transfer experiments
In this section, we provide detailed information about the training configurations used for both the autoencoder and the diffusion model in the style transfer task.
Autoencoder configuration: The encoder is a 1D CNN-based model where the channel of each layer is (16 32 64 128 256 384 512 768 1024 64) , , , , , , , , , . At the bottom layer, we flatten the parameters and map them to a latent dimension of 256 with a linear layer. In the decoder part, we use transposed convolutions with the same number of channels and layers to upsample back to the original shape.
The training details of hyperparameters are as follows: total number of parameters 516 096 , , kernel size for CNN model 9 , learning rate 2 × 10 -4 with cosine annealing, total training steps 12 000 , ,
batch size 64 . In addition, to reduce memory usage and accelerate computations, mixed-precision is enabled with bfloat 16 for the first 75% of the training process.
Diffusion Model configuration: The architecture of the DDPM comprises a 1D CNN-based U-Net [42] with channels (64 128 256 512 768 1024 1024 32) , , , , , , , . A fully connected layer is applied at the bottom of the U-Net after flattening. In addition to the U-Net, we employ a style feature extraction network as the condition projector, consisting of two convolutional layers, an average pooling layer, and a fully connected layer. The extracted features are added as embeddings to the bottom layer of the U-Net. The training details of hyperparameters are as follows: kernel size for CNN model 3 , learning rate 5 × 10 -4 with cosine annealing, total training steps 50 000 , , batch size 128 , number of diffusion steps 1 000 , , β in the diffusion model shifted linearly from 0 0001 . to 0 02 . in diffusion models. And the same as AE training, mixed-precision is enabled with bfloat 16 for the first 75% of the training process.
Figure 5: COND P-DIFF framework in style-transfer tasks.
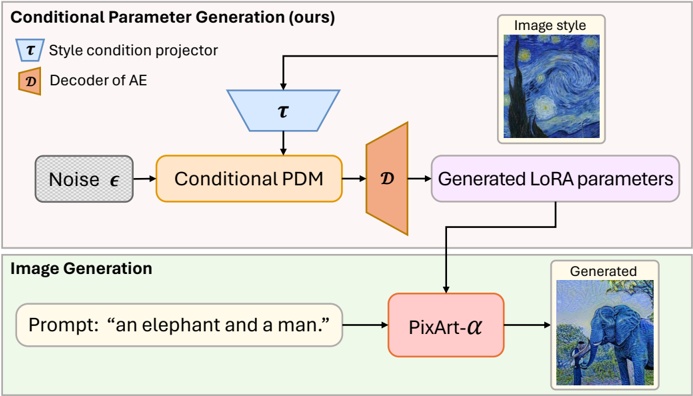
Framework: This section describes the framework and workflow of the style transfer task with our conditional parameter generation in detail, as illustrated in Figure 5.
Data Preparation: The first step is selecting appropriate data, including style image and parameter data. For style image data, we select a total of 16 groups of data with different styles.
7 groups, such as Van Gogh , Edvard , and Jacoulet , are manually selected from SemArt and WikiArt [10, 45] datasets, which totally includes more than 250,000 works by 3,000 artists. The other 9 groups, such as Chalk and Charcoal , are generated by a traditional image style transfer algorithm [11] to make sure the styles of images in a particular group are highly consistent. For parameter data, we use the PixArtα [4] as the base model, which is a transformer-based text-to-image diffusion model with smaller parameter sizes and competitive quality. We finetuned it with the style image data. Each set of LoRA parameters holds 64 checkpoints from the last 64 steps of one training. Thus, we obtained 16 sets of parameter data, with 64 LoRA parameters in each set.
Training of Autoencoder and Conditional Parameter Diffusion: We introduce details of the training process of the autoencoder and the diffusion models. For the autoencoder, we use the parameter data to train the autoencoder to encode the LoRA parameters into a 256-dimensional latent space. Note that we did not use the style image data in this process. For conditional diffusion model, we use style condition extractor to extract the style features of the style image data, and merge the features into the diffusion model as condition information.
Generation Process: The generation process is divided into two steps. First, the LoRA parameters are obtained by the conditional parameter diffusion model, and then they are merged into PixArtα to obtain the style image.
Parameter Generation: In the inference process, the diffusion model is fed with noise and an image in a particular style as conditions, and the generated latent is fed into the decoder to get completed LoRA parameters.
Image Generation: Next, merge the generated LoRA parameters to PixArtα . Then, we get the PixArtα finetuned with a particular style. Then, we can feed it with a prompt to get an image whose style corresponds to our input condition.
## B.2 Language experiments
## B.2.1 Datasets
In NLP tasks, we use GLUE benchmark [53], a benchmark for evaluating natural language understanding capabilities. SST2 [47]: A sentiment analysis benchmark using movie review excerpts, labeled as positive or negative, to aid in sentiment understanding. RTE : A dataset for evaluating if one sentence logically entails another, testing models' understanding of textual entailment. MRPC [1]: Contains sentence pairs to benchmark models' paraphrasing and semantic equivalence capabilities. CoLA : Tests language models' grasp of English grammar, with sentences labeled as grammatically acceptable or not. QNLI : Converts question-answer pairs into inference tasks, assessing if sentences are correct responses to questions. STSB [3]: A benchmark for measuring semantic similarity between sentences, rated on a scale from 0 to 5 for nuanced meaning comprehension.
## B.2.2 LoRA configurations
In this section, we introduce the configuration of LoRA fine-tuning as presented in Table 1. All models are fine-tuned with 20 epochs and a dropout rate of 0.1. Mixed-precision training is enabled with FP16 to accelerate computation and reduce memory usage. The learning rate is set to 0.0001, and a warmup ratio of 0.1 is used to gradually increase it at the beginning of the training. Additionally, a weight decay of 0.1 is applied to regularize the model and prevent overfitting.
Table 5: Add caption
| Model | BERT | BERT | BERT | RoBERTa | RoBERTa | RoBERTa | DeBERTa | DeBERTa | DeBERTa |
|---------|--------|--------|--------|-----------|-----------|-----------|-----------|-----------|-----------|
| Rank | 1 | 4 | 16 | 1 | 2 | 4 | 16 | 1 | 4 |
| alpha | 8 | 16 | 32 | 8 | 8 | 16 | 32 | 8 | 16 |
## B.2.3 Condition
This is task 'SST-2'. SST-2 (The Stanford Sentiment Treebank) includes sentences from movie reviews and their sentiment labels (positive or negative). It tests a model's ability to capture sentiment from text.
Example 1: Sentence: "The movie was fantastic!" Label: Positive. Example 2: Sentence: "I did not enjoy the film at all." Label: Negative.
This is task 'RTE.' RTE (Recognizing Textual Entailment) involves pairs of sentences and asks whether the second sentence is true (entails), false, or undetermined based on the information in the first sentence.
Example 1: Sentence 1: "The cat sat on the mat." Sentence 2: "There is a cat on the mat." Label: Entailment. Example 2: Sentence 1: "Sarah bought two tickets to Hawaii for her honeymoon." Sentence 2: "Sarah is planning a trip to Hawaii." Label: Entailment.
This is task 'MRPC'. MRPC('Microsoft Research Paraphrase Corpus') checks if sentences are paraphrased from each other.
Example 1: "The storm left a wake of destruction." / "Destruction was left by the storm." -> Paraphrase. Example 2: "He says that he saw the man leave." / "He says the man stayed in." -> Not Paraphrase.'',
This is task 'COLA'. CoLA (The Corpus of Linguistic Acceptability) consists of English sentences labeled as grammatically correct or incorrect. It's designed to evaluate a model's ability to understand English grammar.
Example 1 : Sentence: "The cat sat on the mat." Label: Correct. Sentence: "On the mat sat cat." Label: Incorrect. Example 2: Sentence: "She reads books every day." Label: Correct. Sentence: "Books every day reads she." Label: Incorrect.
This is task 'QNLI'. QNLI (Question Natural Language Inference) involves pairs of a question and a sentence, where the goal is to determine whether the sentence contains the answer to the question.
Example 1: Question: "What color is the sky?" Sentence: "The sky is usually blue." Label: Entailment. Example 2: Question: "Who wrote '1984'?" Sentence: "George Orwell is the author of 'Animal Farm' and '1984'." Label: Entailment.
This is task STSB. STSB(Semantic Textual Similarity Benchmark) aims to rate sentence pair similarity on a 0-5 scale.
Example 1: "A man is playing a guitar." / "A man is playing an instrument." -> Score: 4.5.
Example 2: "A child is riding a horse." / "A horse is being ridden by a child." -> Score: 5.

𝝀
=0.05
𝝀
=0.65
𝝀
=0.25
𝝀 =0.00
𝝀
=1.00
𝝀
=0.45
𝝀
=0.85
Figure 6: Visualization of the image generated by LoRA parameters, which is generated by COND P-DIFF on the test set with conditions that the model has never seen.
Figure 7: PCA in the latent space of the LoRA parameters of train set and generated by COND P-DIFF
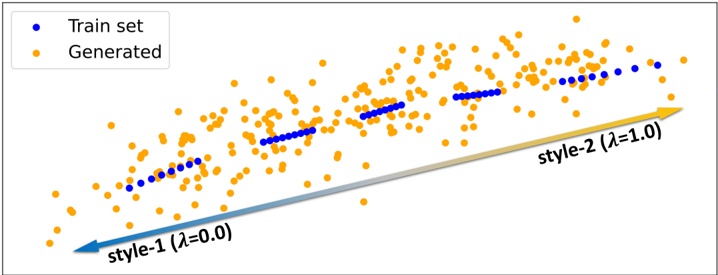
## C Explorations of COND P-DIFF generalizability
We consider that the generalizability of COND P-DIFF is limited by the current amount of data. If we want the model to gain generalizability, we need to sample enough LoRA parameters in the parameter space, which is difficult to achieve. Therefore, in this experiment, we first make a style-continuous dataset, which can be equivalent to sampling enough data points in a subspace to provide enough data for our model. We then trained our model on the style-continuous dataset we created to verify its generalizability.
## Make a style-continuous dataset:
Since it is difficult to find style-continuous data, we use some AI-generated images to make a stylecontinuous parameter-image pair dataset, to verify the continuity of the parameter space and the model's generalization ability. Here are the detailed steps:
Firstly, we train the LoRA parameters relevant to style-1 using style-1 images; train the parameters relevant to style-2 using style-2 images. Next, we use formula θ interp = (1 -λ θ ) style1 + λθ style2 to combine LoRA parameters in different proportions to obtain 1000 LoRA parameters between style-1 and style-2 ( λ is from { 0 000 0 001 0 002 . , . , . , · · · , 0 999 . } ). Then we merge the 1000 LoRA parameters to PixArtα in turn and randomly select some prompts to generate images in relevant style. Thus, we obtain a dataset of 1000 parameter-image pairs.
## Train on the style-continuous dataset:
With the above style-continuous parameter-image pair data, we can verify continuity of the parameter space and the generalization ability of our model. The detailed training process is as follows:
First, we split the dataset into a train set and a test set. We select 500 parameter-image pairs out of the 1000 pairs as the training set, in which λ is from [0 1 . , 0 2) . ∪ [0 3 . , 0 4) . ∪ [0 5 . , 0 6) . ∪ [0 7 . , 0 8) . ∪ [0 9 . , 1 0) . , and the rest are as the test set. Next, we train COND P-DIFF on the train set according to the normal method described in Section 3, and evaluate our model on the test set.
The results are shown in Figure 6, where the input conditions are images chosen from the test set, which our model has never seen before. We find that the model can still generate images in the relevant style, which shows our model's generalizability. In addition, we visualized the training set parameters and the parameters generated by our model in the latent space by PCA [30] in Figure 7. The blue dots represent the data used for training, and the place where the blue line is disconnected is left for testing. The orange dots represent the parameters generated by COND P-DIFF, and we find that our model can fit the entire distribution instead of only parts of the train set, illustrating the generalizability of the model. | null | [
"Xiaolong Jin",
"Kai Wang",
"Dongwen Tang",
"Wangbo Zhao",
"Yukun Zhou",
"Junshu Tang",
"Yang You"
]
| 2024-08-02T17:43:34+00:00 | 2024-08-02T17:43:34+00:00 | [
"cs.AI",
"cs.LG"
]
| Conditional LoRA Parameter Generation | Generative models have achieved remarkable success in image, video, and text
domains. Inspired by this, researchers have explored utilizing generative
models to generate neural network parameters. However, these efforts have been
limited by the parameter size and the practicality of generating
high-performance parameters. In this paper, we propose COND P-DIFF, a novel
approach that demonstrates the feasibility of controllable high-performance
parameter generation, particularly for LoRA (Low-Rank Adaptation) weights,
during the fine-tuning process. Specifically, we employ an autoencoder to
extract efficient latent representations for parameters. We then train a
conditional latent diffusion model to synthesize high-performing model
parameters from random noise based on specific task conditions. Experimental
results in both computer vision and natural language processing domains
consistently demonstrate that COND P-DIFF can generate high-performance
parameters conditioned on the given task. Moreover, we observe that the
parameter distribution generated by COND P-DIFF exhibits differences compared
to the distribution obtained through normal optimization methods, indicating a
certain level of generalization capability. Our work paves the way for further
exploration of condition-driven parameter generation, offering a promising
direction for task-specific adaptation of neural networks. |
2408.01416v1 | ## The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aaron Mueller 1 ∗ , Jannik Brinkmann , Millicent Li , Samuel Marks , Koyena Pal , 2 1 3 1 Nikhil Prakash , Can Rager , Aruna Sankaranarayanan , Arnab Sen Sharma , 1 4 5 1 Jiuding Sun , Eric Todd , David Bau , Yonatan Belinkov 1 1 1 6
- 1 Northeastern University 2 University of Mannheim 3 Anthropic 4 Independent
- 5 Massachusetts Institute of Technology 6 Technion - IIT
## Abstract
Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
## 1 Introduction
To understand how neural networks (NNs) generalize, we must understand the causes of their behavior. These causes include inputs, but also the intermediate computations of the network. How can we understand what these computations represent, such that we can arrive at a deeper algorithmic understanding of how and why models behave the way they do? For example, if a model decides to refuse a user's request, was the refusal mediated by an underlying concept of toxicity, or by the presence of superficial correlates of toxicity (such as the mention of particular demographic groups)? The former would be significantly more likely to robustly and safely generalize. These questions motivate the field of causal interpretability, where we aim to extract causal graphs explaining how intermediate NN computations mediate model outputs.
This survey takes an opinionated stance on interpretability research: we ground the state of the field through the lens of causal mediation analysis (§2). We start by presenting a history of causal interpretability for neural networks (§3), from backpropagation (Rumelhart et al., 1986) to the beginning of the current causal and mechanistic interpretability wave.
We then survey common mediators (units of causal analysis) used in causal interpretability studies (§4), discussing the pros and cons of each mediator type. Should one analyze individual neurons? Full MLP output vectors? Model subgraphs? More broadly: what is the right unit of abstraction for analyzing
∗ Correspondence to [email protected] . Middle authors in alphabetical order.
and discussing neural network behaviors? Any NN component has pros and cons related to its level of granularity, whether it is a causal bottleneck, and whether it is natively part of the model (as opposed to whether it is learned on top of the model). After discussing common mediator types, we then categorize and discuss methods for searching over mediators of a given type to find those that are causally relevant to some task (§5). Finally, after surveying the field, we (1) point out mediators which have been underexplored, but have significant potential to yield new insights; (2) propose criteria that future mediators should satisfy, based on the goals of one's study; and (3) suggest ways to measure progress in causal interpretability moving forward (§7).
## 2 Preliminaries
The counterfactual theory of causality. Lewis (1973) poses that a causal dependence holds iff the following condition holds:
'An event E causally depends on C [iff] (i) if C had occurred, then E would have occurred, and (ii) if C had not occurred, then E would not have occurred.'
Lewis (1986) extends this definition of causal dependence to be whether there is a causal chain linking C to E ; a causal chain is a connected series of causes and effects that proceeds from an initial event to a final one, with potentially many intermediate events between them. This idea was later extended from a binary notion of whether the effect happens to a more nuanced notion of causes having influence on how or when events occur (Lewis, 2000). Other work defines notions of cause and effect as continuous measurable quantities (Pearl, 2000); this includes direct and indirect effects (Robins & Greenland, 1992; Pearl, 2001), which are common metrics in causal interpretability studies.
Causal abstractions in neural network interpretability. Causal interpretability is based on the abstraction of causal graphs . These graphs consist of nodes, which can be inputs, causes, actions, computations, transformations, among other events. They also consist of directed edges, which represent causal relationships between nodes; the source of the edge is the cause, and the target of the edge is the effect. If we are given an input cause x and output effect y , there may exist many causal nodes between them; these intermediate nodes are called mediators .
In the causality literature, a mechanism is defined as a causal chain from cause C to effect E . The mechanistic interpretability literature, while closely related to causal interpretability, does not enforce this causallygrounded definition of mechanism: mechanistic interpretability is often defined as reverse-engineering neural networks to better understand how and why they behave in certain ways (cf. Miller et al., 2024; Nanda et al., 2023). The overlap between mechanistic and causal interpretability is significant, but not total: for example, sparse autoencoders (Bricken et al., 2023; Cunningham et al., 2024) are correlational, but many methods, such as circuit discovery (Elhage et al., 2021; Conmy et al., 2023) and alignment search (Geiger et al., 2021; 2024), employ methods to causally implicate model components (or other abstractions discovered in potentially correlational ways) in model behavior. We believe that the causality-based definition of mechanism is a useful one that makes precise the main challenge of mechanistic interpretability-to reverse-engineer an algorithmic understanding of neural network behaviors, where 'algorithm' is essentially equivalent to a complete causal graph explaining how a model will generalize.
The abstraction of causal graphs extends naturally to neural networks: we can treat the computation graph of a neural network as the full causal graph which explains how inputs x are transformed into a probability distribution over outputs y . In this case, all model components 1 can be viewed as causal nodes that mediate the transformation of x to y . This is discussed in detail in §4.
Counterfactual interventions. In interpretability, 'causal method' generally refers to a method that employs counterfactual interventions (Lewis, 1973) to some part of the model or its inputs. Much early
1 We will use 'component' primarily to refer to neurons and attention heads. This is imprecise, but captures atomic units of the computation graph that are often used as mediators in current work. It also serves to contrast with mediators that cannot be easily extracted from the computation graph, such as non-basis-aligned directions.
Figure 1: Visual summary of causal mediation analysis. We are given a cause (input) x , which results in effect (output) y . There often exist intermediate causal variables such as z that mediate the transformation of x to y . One of the most common ways of quantifying the importance of z is by measuring its indirect effect , where one intervenes on z and then measures the change in y compared to when no intervention was performed.
interpretability work focused on interpreting model decision boundaries by intervening on the inputs, but contemporary work is primarily concerned with understanding which intermediary model components are responsible for some behavior given some input-i.e., finding the right nodes from the low-level computation graph to keep in the high-level causal graph.
Causal mediation analysis (Pearl, 2001) provides a unified framework for performing counterfactual interventions, in which the causal influence of a node x in a causal graph on a downstream node y is quantified as x 's indirect effect (IE; Pearl, 2001; Robins & Greenland, 1992). This metric is based on the notion of counterfactual dependence, where we measure the difference in some output metric m before and after intervening on a given mediator z . We measure m given a normal run of the model on input x , where z takes its natural value z 1 , and then compare this to m on a normal run of the model given x where mediator z is set to some alternate value z 2 : 2
$$I E ( m ; x ; z, z _ { 1 }, z _ { 2 } ) = m ( x | z = z _ { 1 } ) - m ( x | \text{do} ( z = z _ { 2 } ) )$$
See Figure 1 for an illustration.
## 3 A History of Causal Interpretability
Interpretability at the beginning of deep learning. In 1986, Rumelhart et al. published an algorithm for backpropagation and an analysis of this algorithm. This enabled and massively popularized research in training multi-layer perceptrons-now often called feedforward layers. This paper arguably represents the first mechanistic interpretability study: the authors evaluated their method by inspecting each activation and weight in the neural network, and observing whether the learned algorithm corresponded to the human intuition of how the task should be performed. In other words, they reverse-engineered the algorithm of the network by labeling the rules encoded by each neuron and weight!
Throughout the 1990s and early 2000s, the idea of extracting rules from the parameters and activations of NNs remained popular. At first, this was a manual process: networks were either small enough to be manually interpreted (Rumelhart et al., 1986; McClelland & Rumelhart, 1985) or interpreted with the aid of carefully crafted datasets (Elman, 1989; 1990; 1991); alternatively, researchers could prune them (Mozer & Smolensky, 1988; Karnin, 1990) to a sufficiently small size to be manually interpretable. Later, researchers proposed techniques for automatically extracting rules (Hayashi, 1990) or decision trees from NNs (Craven & Shavlik, 1994; 1995; Krishnan et al., 1999; Boz, 2002)-often after the network had been pruned. At this point, interest in causal methods based on interventions had not yet been established, as networks were often small and/or simple enough to directly understand without significant abstraction. Nonetheless, as the size of neural networks scaled up, the number of rules encoded in a network increased; thus, rule/decision tree
2 Appendix A surveys methods for sourcing z 2 . This can come from alternate inputs where the answer is flipped, means over many inputs, or (typically 0).
extraction techniques could not generate easily human-interpretable explanations or algorithmic abstractions of model behaviors beyond a certain size. This led to the rise of visualization methods in the 2000s, which became a popular way to demonstrate the complexity of phenomena that models had learned to encode. Designing visualizations of inputs and outputs of the network (Tzeng & Ma, 2005) and interactive visualizations of model activations (Erhan et al., 2009) were valuable initial tools for generating hypotheses as to what kinds of concepts models could represent. While visualization research was generally not causal, this subfield would remain influential for interpretability research as neural networks scaled in size in the following decade.
Large-scale pre-trained models. The 2010s were a time of rapid change in machine learning. In 2012, the first large-scale pre-trained neural network, AlexNet (Krizhevsky et al., 2012), was released. Not long after, pre-trained word embeddings became common in natural language processing (Mikolov et al., 2013a;b; Pennington et al., 2014), and further pre-trained deep networks followed (He et al., 2016). These were based on ideas from deep learning . This represented a significant paradigm shift: formerly, each study would build ad-hoc models which were not shared across studies, but which were generally more transparent. 3 After 2012, there was a transition toward using a shared collection of significantly larger and more capable-but also more opaque-models. This raised new questions on what was encoded in the representations of these shared scientific artifacts. The rapid scaling of these models rendered old rule extraction methods either intractable or made its results difficult to interpret; thus, interpretability methods in the early 2010s tended to prominently feature scalable and relatively fast correlational methods, including visualizations (Zeiler & Fergus, 2014) and saliency maps (Simonyan et al., 2014). This trend continued into 2014-2015, when recurrent neural network-based (Elman, 1990) language models (Mikolov et al., 2010) began to overtake statistical models in performance (Bahdanau et al., 2015); for example, visualizing RNN and LSTM (Hochreiter & Schmidhuber, 1997) hidden states was proposed as a way to better understand their incremental processing (Karpathy et al., 2016; Strobelt et al., 2017).
At the same time, interpretability methods started to embrace auxiliary (correlational) models-for example, LIME (Ribeiro et al., 2016a;b) and Anchors (Ribeiro et al., 2018). These models aimed to learn local decision boundaries, or some human-interpretable simplified representation of a model's behavior. Other works interpreted predictions via feature importance measures like SHAP (Lundberg & Lee, 2017). Influence functions (Koh & Liang, 2017) traced the model's behavior back to specific instances from the training data. Another line of work also seeked to directly manipulate intermediate concepts to control model behavior at test time (Koh et al., 2020). The primary difference between these visualization-/correlation-/input-based methods and current methods is that these methods prioritize discovering high-level patterns about responses to particular kinds of inputs, such that we can generate hypotheses as to the types of input concepts these models are sensitive to. In contrast, current work prioritizes highly localized and causal explanations of how and in which regions of the computation graph models translate particular inputs into general output behaviors.
2017-2019 featured perhaps the largest architectural shift (among many) in machine learning methods at this time: Transformers (Vaswani et al., 2017) were released and quickly became popular due to scalability and high performance. This led directly to the first successful large-scale pretrained language models, such as (Ro)BERT(a) (Devlin et al., 2019; Liu et al., 2019b) and GPT-2 (Radford et al., 2019). These significantly outperformed prior models, though it was unclear why-and at this scale, analyzing neural networks at the neuron level using past techniques had long become intractable. This combination of high performance and little mechanistic understanding created demand for interpretability techniques that allowed us to see how language models had learned to perform so well. Hence, correlational probing methods rose to meet this demand: here, classifiers are trained on intermediate activations to extract some target phenomenon. Probing classifiers were used to investigate the latent morphosyntactic structures encoded in static word embeddings (Köhn, 2015; Gupta et al., 2015) or intermediate hidden representations in pre-trained language models-for example, in neural machine translation systems (Shi et al., 2016; Belinkov et al., 2017; Conneau et al., 2018) and pre-trained language models (Hewitt & Manning, 2019; Hewitt et al., 2021; Lakretz et al., 2019; 2021). However, probing classifiers lack consistent baselines, and the claims made in these studies
3 Many systems built before deep learning were based on feature engineering, and so the information they relied on was more transparent than in current systems.
Figure 2: Visualization of common mediator types in neural networks. One can implicate individual neurons or attention heads in performing a model behavior, or a full layer vector. One can also implicate a multidimensional subspace , which could be neuron-basis-aligned (as in a group of neurons, pictured here) or non-basis-aligned. Non-basis-aligned mediators-e.g., non-basis-aligned directions -have recently become a popular mediator type due to their monosemanticity. However, discovering non-basis-aligned mediators requires external modules such as classifiers, autoencoders, or other modifications to the original computation graph. Note that while this figure depicts a Transformer, many of the mediator types generalize to other architectures (the primary exception being attention heads).
were not often causally verified (Belinkov, 2021). For instance, although an intervention may target a task mapping of A → B , an alternative property C may be predicted, which can potentially impede causal claims about A → B (Ravichander et al., 2021). This likely encouraged researchers to search for more causally efficacious methods.
The rise of causal interpretability. 2017-2018 featured the first hints of our current wave of causal interpretability, with research that directly investigated intervening on activations and manipulating neurons. For example, Giulianelli et al. (2018) trained a probing classifier, but then used gradients from the probe to modify the activations of the network. Other studies analyzed the functional role of individual neurons in static word embeddings (Li et al., 2017) or latent representations of generative adversarial networks (GANs; Goodfellow et al., 2014) by forcing certain neurons on or off (Bau et al., 2019b). The idea of manipulating neurons to steer behaviors was then applied to downstream task settings, such as machine translation (Bau et al., 2019a). The field was more widely popularized in 2020, when Vig et al. (2020) proposed a method for assigning causal importance scores to neurons and attention heads. It was an application of the counterfactual theory of causality (Lewis, 1973; 1986), as well as Pearl's operationalization and measurements of individual causal nodes' effect sizes (Pearl, 2001; 2000). This encouraged a new line of work that aimed to faithfully localize model behaviors to specific components, such as neurons or attention heads-an idea that would become foundational to current causal and mechanistic interpretability research.
At the same time, however, researchers began to realize the significant performance improvements that could be gained by massively increasing the number of parameters and training corpus sizes of neural networks (Brown et al., 2020; Kaplan et al., 2020). Massively increasing model sizes resulted in more interesting subjects of study, but also rendered causal interpretability significantly more difficult just as its popularity began. Thus, a primary challenge of causal interpretability has been to balance the often-contradictory goals of (i) obtaining a causally efficacious understanding of how and why models behave in a given manner, while also (ii) designing methods that are efficient enough to scale to ever-larger models.
Presently, there exist many subfields of interpretability that propose and apply causal methods to understand which model components contribute to an observed model behavior (e.g., Elhage et al., 2021; Geiger et al., 2021; Conmy et al., 2023). Recently, there have also been efforts to discover more human-interpretable mediators by moving toward latent-space structures aside from (collections of) neurons (Cunningham et al., 2024; Bricken et al., 2023; Wu et al., 2023). These methods and their applications are the focus of the survey that follows.
## 4 Selecting a mediator type
In this section, we discuss different types of causal mediators in neural networks, and the pros and cons of each. Figure 2 visualizes a computation graph, and units thereof that are often used as mediators in causal interpretability studies. In causal interpretability, we often do not want to treat the full computation graph as the final causal graph, as it is large and difficult to directly interpret. Thus, we typically want to build higher-level causal abstractions that capture only the most important mediators, and/or where each causal node is human-interpretable. It is also possible to group components together into a single causal node, meaning there are many possible mediators of a given type.
One possible mediator type is a full layer /lscript -typically the output of a layer (§4.1). This generally refers to a vector a /lscript composed of activations a /lscript i , where we will refer to each a i as a neuron . 4 One can also use the output vector of an intermediate submodule within the layer (e.g., an MLP), rather than the output of the whole layer. For example, in Transformers (Vaswani et al., 2017), 5 a layer typically consists of two submodules: a multi-layer perceptron (MLP) and an attention block, which can be arranged either sequentially or in parallel. The output of these submodules is also a vector of activations, so we will refer to their individual dimensions as neurons as well. 6
One can also use single neurons or sets of neurons as a mediator (§4.2). If we use a set of neurons (possibly of size 1) { a , a i j , . . . } from a vector a , this is referred to as a basis-aligned subspace of a . A one-dimensional basis-aligned subspace is equivalent to a neuron; we will use basis-aligned subspace primarily to refer to neuron groups of size > 1. Basis alignment is a key concept: values that align with neuron directions will be discoverable without any external modules appended to the original computation graph. For example, it is straightforward to exhaustively search over and intervene on single neurons; it is less tractable, but still theoretically possible, to enumerate all 2 n possible combinations of neurons without using any additional parameters.
However, causally relevant features are not guaranteed to be aligned with neurons in activation space; indeed, there are many cases where human-interpretable features correspond to subspaces that are not spanned by a (set of) neuron(s) (Elhage et al., 2022b; Bricken et al., 2023). Thus, in recent studies, it is common to study non-basis-aligned spaces (§4.3). Each channel of a non-basis-aligned subspace can be defined as weighted linear combination of neuron activations. For example, to obtain a non-basis-aligned direction , 7 we could learn coefficients α and β to weight activations a i and a j (optionally with a bias term b ):
$$d = \alpha \cdot a _ { i } + \beta \cdot a _ { j } + \dots + b$$
Note that these new constants α and β are not part of the original computation graph. This means that discovering directions often requires external components that weight components from the computation graph in some way-e.g., classifiers or autoencoders (§5.2).
The primary trade-off between these mediator types is their granularity and number. This section proceeds in order of increasing granularity and quantity.
## 4.1 Full layers and submodules.
Full layers and submodules are relatively coarse-grained mediators. Thus, they are a common starting point if one does not know where in a model a particular type of computation is happening. Early probing classifiers studied the information encoded in full layers (Shi et al., 2016; Hupkes et al., 2018; Belinkov et al., 2017; Conneau et al., 2018; Hewitt & Manning, 2019; Giulianelli et al., 2018), and recent studies that leverage classifiers as part of causal techniques still frequently do the same (e.g., Elazar et al., 2021; Marks & Tegmark,
4 In other words, we use 'neuron' to refer to any basis-aligned direction in activation space.
5 Transformers are currently the dominant architecture for vision and/or language modeling; as such, there is much more work on interpreting the decisions of models built with this architecture. However, our ideas are presented in a general way that will also apply with minor modifications to other neural-network-based architectures, such as recurrent neural networks (Mikolov et al., 2010) and state space models.
6 Using the same notation emphasizes that these are mediators of the same granularity, but we acknowledge that this obscures that neurons in different locations often encode different types of features.
7 We will use 'direction' to refer to one-dimensional (sub)spaces.
2023; Li et al., 2023). This makes layers a natural mediator for exploratory interventions where the usage of more fine-grained mediators is infeasible, as in Conmy et al. (2023), or where broad characterizations of information flow are sufficient, as in Geva et al. (2023); Sharma et al. (2024). That said, it is rare to completely ablate a layer and then observe how this changes behavior; this has been done in a pruning study where the motivation was not interpretability (Sajjad et al., 2023), but this technique has potential to inform our understanding of which general model regions are more responsible for certain kinds of behaviors (e.g. Lad et al., 2024).
In some cases, coarse-grained mediators like these can inform methods for understanding factual recall in language models (Geva et al., 2023), or updating these factual associations (Meng et al., 2022; 2023). However, full layers encode many features and have many causal roles in a network, which makes it difficult to interpret how, exactly, relevant information is encoded in a layer (Conmy et al., 2023). Additionally, intervening on full layers or submodules often causes side effects outside the scope of the intervention (McGrath et al., 2023).
The primary advantage of using full layers as mediators is their small quantity and broad scope of information. This means that even slow or resource-intensive methods will generally be easy to apply to all layers. In some cases, this is enough granularity. However, an obvious disadvantage is that this mediator is generally opaque: even if we know that information is encoded in a layer somehow, it is unclear precisely how this information is encoded, composed, or used. Thus, layers and submodules have little explanatory power, and are better used as coarser starting points for later finer-grained investigations (e.g., Brinkmann et al., 2024; Geva et al., 2023) or for downstream applications such as model editing (Meng et al., 2022; 2023; Sharma et al., 2024; Gandikota et al., 2023; 2024).
## 4.2 Basis-aligned subspaces
Neurons. Compared to full layers and submodules, neurons represent more fine-grained components within neural networks that could feasibly represent individual features (though we discuss below that this is not often the case due to polysemanticity). Individual neurons can be considered the smallest meaningful unit within a neural network; an activation from a neuron is simply a scalar corresponding to a single dimension (1-dimensional subspace) of a hidden representation vector. Each neuron can differ from another based on its functional role in the network; for instance, Bau et al. (2020) locate neurons in a GAN responsible for generating specific types of objects in images, such as trees or windows, and verify this causally by ablating or artificially activating those neurons.
Neurons are a natural choice for mediator, as they are both fine-grained and easy to exhaustively iterate over (see §5.1). However, a major disadvantage of using neuron-based interpretability methods is polysemanticity . Individual neurons are often polysemantic-i.e. they respond to multiple seemingly unrelated inputs (Arora et al., 2018). For example, if the same neuron were sensitive to capitalized words, animal names, one-digit numbers, among other phenomena, it would be difficult to disentangle each of these individual patterns such that we can assign a coherent textual label to the neuron. Elhage et al. (2022b) investigate this phenomenon and suggest that neural networks represent features through linear superposition, where they represent features along non-basis-aligned linear subspaces, resulting in interpretable units being smeared across multiple neurons. In other words, in an activation vector of size n , a model can encode m /greatermuch n concepts as linear directions (Park et al., 2023), such that only a sparse subset of concepts are active given a particular input.
Basis-aligned multi-dimensional subspaces. The computations of individual neurons are not entirely independent: it may often be the case that sets of neurons compose to encode some concept. For example, in language models, localized subsets of neurons can be implicated in encoding gender bias (Vig et al., 2020), and implementing fundamental latent linguistic phenomena (Finlayson et al., 2021; Mueller et al., 2022; Bau et al., 2019a; Lakretz et al., 2019). Thus, some initial causal interpretability work employed heuristic-based searches over sets of neuron responsible for some behavior (e.g., Bau et al., 2019b; Vig et al., 2020; Cao et al., 2021). This is a generalization of individual neurons as mediators, where multiple dimensions in activation space are intervened upon simultaneously.
Using arbitrarily-sized sets of neurons gives us strictly more information, and thus potentially more descriptive mediators. Despite this, basis-aligned multidimensional subspaces are not commonly studied mediators. This is for two primary reasons: (1) There is a combinatorial explosion when we are allowed to search over arbitrarily-sized sets of neurons, which makes exhaustive searches intractable. (2) Additionally, interpretable concepts are not guaranteed to be aligned to neuron bases, meaning that leveraging groups of neurons still does not directly address the problem of polysemanticity-in fact, it may exacerbate the problem by adding even more information (Morcos et al., 2018; Chughtai et al., 2023; Wang et al., 2023).
Attention heads. Similar to neurons, attention heads are fundamental components of Transformer-based neural networks: they mediate the flow of information between token positions (Vaswani et al., 2017). Thus, using attention heads as units of causal analysis can help us understand how models synthesise contextual information (Ma et al., 2021; Neo et al., 2024) to predict subsequent tokens (Wang et al., 2023; Hanna et al., 2023; Prakash et al., 2024; García-Carrasco et al., 2024; Brinkmann et al., 2024). For practical purposes, each head within a layer can be understood as an independent operation, contributing a result that is then added into the residual stream. 8 For example, some heads specialise on syntactic relationships (Chen et al., 2024a), others on semantic relationships such as co-reference (Vig et al., 2020), and others still on maintaining long-range dependencies in text (Wu et al., 2024a). Attention heads have also been directly implicated in acquiring the ability to perform in-context learning (Olsson et al., 2022; Brown et al., 2020), or to detect and encode functions in latent space (Todd et al., 2024).
Attention heads are attractive mediators because they are easily enumerable (there are far fewer attention heads than neurons in a model) and because they often encode sophisticated multi-token relationships. However, in contrast to the activation of a neuron, the output of an attention head is multi-dimensional. Thus, it is difficult to directly interpret the full set of functional roles a single head might have; indeed, attention heads are almost always polysemantic, so one cannot typically determine the function(s) of an attention head solely by observing its activations (Janiak et al., 2023)-as with neurons. 9 It has additionally been observed that ablating attention heads can cause other attention heads to compensate, which further complicates their analysis (Jermyn et al., 2023; Wang et al., 2023; McGrath et al., 2023). 10
## 4.3 Non-basis-aligned spaces
Non-basis-aligned multi-dimensional subspaces. Due to their polysemanticity, neurons, attention heads, and sets thereof do not necessarily correspond to cleanly interpretable features or concepts. For example, it is common that individual neurons activate on many seemingly unrelated inputs (Elhage et al., 2022b), and this issue cannot be cleanly resolved by adding more dimensions. This is because the features may actually be encoded in directions or subspaces that are not aligned to neuron bases (Mikolov et al., 2013a; Arora et al., 2016).
To overcome this disadvantage, one can generalize causal mediators to include arbitrary non-neuron-basisaligned activation subspaces. This allows us to capture more sophisticated causal abstractions encoded in latent space, such as causal nodes corresponding to greater-than relationships (Wu et al., 2023), or equality relationships (Geiger et al., 2024). A common way of locating these is through learned rotation operations (Geiger et al., 2021; 2024), which preserve linearities and therefore are still in the activation subspace.
The primary advantage of considering an arbitrary subspace as a mediator is its expressivity: subspaces often capture distributed abstractions that are not fully captured by a single neuron. However, they are generally
8 This is the residual stream perspective (Elhage et al., 2021) of Transformers, which has been adopted in recent interpretability research (Ferrando et al., 2024). The residual stream perspective suggests that the residual stream, which comprises the sum of the outputs of all the previous layers and the original input embedding, acts as a passive communication channel through which the MLP and attention submodules route the information they add.
9 However, there is initial evidence that some dimensions of an attention head's output can be meaningfully explained (Merullo et al., 2024a;b). Thus, by decomposing the vector output of a head into smaller subspaces or even individual neurons, it may be easier to explain the set of functional roles of a given head.
10 This phenomenon, where downstream components only have causal relevance after an upstream component has been ablated, is sometimes called preemption in the causality literature (Mueller, 2024). Preemption is not necessarily limited to attention heads; future work should thus analyze how common preemption is between other types of components, such as MLP submodules.
more difficult to locate than basis-aligned components, or non-basis-aligned directions, as we are typically required to have specific hypotheses as to how models accomplish a task, access to labeled data that isolates the target subspace, or enough compute to cluster existing mediators in an unsupervised manner. This is discussed in more detail in §5.2.
Directions. A recent line of work aims to automatically identify specific directions (one-dimensional spaces) that correspond to monosemantic concept representations. Identifying and labeling these monosemantic model abstractions (often called features ; Bricken et al., 2023; Cunningham et al., 2024; Huang et al., 2024) can reveal units of computation the model uses to solve tasks in a way that is often easier for humans to interpret. 11
There is also initial evidence that these directions may enable fine-grained model control (Panickssery et al., 2024; Marks et al., 2024; Tigges et al., 2023). Past work has found initial signs that basis-aligned directions could be leveraged to edit (Meng et al., 2022) or steer (Turner et al., 2023; Paulo et al., 2024) model behavior, whereas more recent work has tended toward non-basis aligned directions. For example, there is work that uses linear probes to understand and ablate the effects of a direction on the model behavior Chen et al. (2024b); Ravfogel et al. (2020); Elazar et al. (2021); Ravfogel et al. (2021); Lasri et al. (2022); Marks & Tegmark (2023), as well as work that ablates (Marks et al., 2024; Cunningham et al., 2024) or injects (Templeton et al., 2024) directions corresponding to fine-grained concepts such as typically female names or the Golden Gate Bridge.
Nonetheless, directions still have key disadvantages. The search space over non-basis-aligned directions is infinite, making it impossible to exhaustively search over them. In fact, to discover these, we are generally required to modify the computation graph, as learning the coefficients on each neuron requires us to learn new parameters corresponding to the desired features. Regardless of the method used, each introduces confounds due to the stochastic optimization or significant manual effort required to locate these directions or subspaces.
## 4.4 Non-linear Mediators
Non-basis-aligned directions/subspaces are the most general linear mediator type. However, recent work has demonstrated that some features in language models can be represented non-linearly and/or using multiple dimensions. For example, there exist circular features representing days of the week or months of the year (Engels et al., 2024). Similarily, past work has found that many concepts can be more easily extracted using non-linear probes (Liu et al., 2019a), and that non-linear concept erasure techniques tend to outperform strictly linear techniques (Iskander et al., 2023; Ravfogel et al., 2022). However, in causal and mechanistic interpretability, most work has thus far tended toward using linear representations as units of causal analysis. Thus, there is significant potential in future work for systematically locating non-linearly-represented features-e.g., using group sparse autoencoders (Theodosis & Ba, 2023), which could isolate multiple directions simultaneously, and/or probing and clustering techniques to identify multi-dimensional features (Engels et al., 2024). Non-linear features have not been extensively studied, despite their expressivity; we therefore advocate investigating these mediators in §7.
## 5 Searching for task-relevant mediators
Once one has selected a task and a type of mediator, how does one identify task-relevant mediators of that type? The answer depends largely on the type of mediator chosen. If NNs have only a finite set of mediators of the chosen type-as is the case for native model components such as neurons, layers, and submodules-one could perform an exhaustive search over all possible mediators, choosing which to keep according to some metric; §5.1 discusses this approach. However, other mediator types, including non-basis-aligned directions and subspaces, carry a continuous space of possible mediators, rendering an exhaustive search impossible. A
11 Note that these directions are not necessarily subspaces of activation space: there are often non-linearities used in computing them, even though the vectors in activation space are involved in computing the directions. Therefore, we will refer to any 1-dimensional space as a direction , but do not require it to be a subspace of activation space.
common solution to this problem is to employ optimization to either search this space or narrow the space into an enumerable discrete set, as discussed in §5.2.
## 5.1 Exhaustive search over mediators
Suppose we are given a neural network with a finite set of candidate mediators { z i } N i =1 , such as the set of all neurons. One way to identify task-relevant mediators from this set is to assign each mediator z i a task-relevancy score S z ( i ) and then select the mediators with the top scores. This generally entails iterating over each candidate mediator z i , setting its activation to some counterfactual value (either from a different input where the answer is flipped, or a value that destroys the information within the neuron, such as its mean value), and then measuring how much this intervention changes the output. For example, Vig et al. (2020) and Finlayson et al. (2021) perform counterfactual interventions to the activation of each neuron individually and then quantify how much each neuron changes the probability of correct completions. The task relevancy score S z ( i ) is typically the indirect effect (IE; Pearl, 2001; Robins & Greenland, 1992), as defined in Eq. 1. 12 This metric is based on the notion of counterfactual dependence, where we measure the difference in some output metric m before and after intervening on a given component z i .
Exhaustive searches have many advantages: their results are comprehensive, causally efficacious, and relatively conceptually precise if our mediators are fine-grained units, like neurons. They are also open-ended, meaning that we are not required to have a pre-existing causal hypothesis as to how a model performs the task: we may simply ablate, artificially activate, or otherwise influence a component's activations, and then observe how it changes the output behavior or probability of some continuation. Due to these advantages, this method is the most common when we have a finite set of mediators-for example, in neuron-based analyses (Vig et al., 2020; Geiger et al., 2021; Finlayson et al., 2021) or attention-head-based analyses (Vig et al., 2020; Conmy et al., 2023; Syed et al., 2023).
However, exhaustive searches also have two significant disadvantages. The most obvious is that, in its exact form, an exhaustive search requires O N ( ) forward passes, which does not scale efficiently as models scale; this is both because the number of components increases, but also because the computational cost of inference scales with model size. This may be why exhaustive searches have not often been extended to sets of neurons or heads, as this results in a combinatorial explosion in the size of the search space. Searches over sets of components can be approximated using greedy or top-k approaches, as in Vig et al. (2020), but this does not provide a comprehensive solution to the problem of assigning causal credit to groups of components. That said, there exist fast linear approximations to activation patching that are technically not causal and not always accurate, but that only require O (1) forward and backward passes-most prominently, attribution patching (Kramár et al., 2024; Syed et al., 2023) and improved versions thereof inspired by integrated gradients (Sundararajan et al., 2017; Marks et al., 2024; Hanna et al., 2024). 13
The second and more difficult disadvantage to overcome is that using exhaustive search constrains us to finite sets of mediators. Thus, this approach will not work well as-is if the search space is continuous (infinitely large). This is a key motivation behind the methods in the following subsection.
## 5.2 Optimizing over large spaces of mediators
For some types of mediators, the collection of candidate mediators is continuous or far too large to exhaustively search over; this precludes using methods described in §5.1. To search over large but enumerable sets, some researchers employ modified versions of exhaustive search, including greedy search methods (Vig et al., 2020) or manual searches (Wang et al., 2023). For continuous spaces, however, interpretability researchers generally use optimization. We taxonomize these optimization problems based on whether they require the
12 Other causal metrics include the direct effect , which measures the direct influence of the input on the output behavior except via the mediator. While more rarely used, it can be a helpful metric in tandem with indirect effects, as in Vig et al. (2020). There is also the total effect , which is the impact of changing the input on the model's output behavior. Note that the total effect does not directly implicate any particular component in model behavior, as it depends only on the input.
13 Gradient-based methods are not causal because they do not directly establish counterfactual dependence. However, they do provide a scalar value whose magnitude can be interpreted as a local approximation of a model component's impact on the output.
Figure 3: Neurons are not guaranteed to encode interpretable features. If non-basis-aligned directions encode the true features of interest, then a neuron may activate on many different features that are non-orthogonal to its corresponding basis. Locating non-basis-aligned mediators requires components in addition to the model's computation graph that encode the coefficients on each activation. For example, one can obtain these coefficients via supervised optimization with probing classifiers (§5.2.1) or unsupervised optimization with sparse autoencoders (§5.2.2). Note that optimization-based techniques sometimes introduce non-linearities, meaning that the discovered directions will not necessarily be a subspace of activation space.
interpretability researcher to manually select and incorporate task-specific information into the loss function (supervised methods; §5.2.1) or not (unsupervised methods; §5.2.2). We illustrate the intuition behind optimization-based search in Figure 3.
## 5.2.1 Supervised mediator searches
By supervised mediator searches , we mean parametric approaches which require labeled task data and/or human-generated hypothesized causal graphs. For example, these methods might require the researcher to propose candidate intermediate concepts which they expect the model to use in performing some task, or a candidate mechanism by which the model might complete the task. Others might simply require labeled data for training classifiers.
Supervised probing. In supervised probing approaches, the researcher proposes task-relevant concepts, and searches for mediators whose values are correlated with those concepts. Generally, one probes the hidden representation vector at the end of a particular layer, and the probe searches over all possible subspaces and directions therein for signals that are predictive of the labels. There exist many papers that employ probing classifiers (Belinkov & Glass, 2019), though many of them do not validate the causal efficacy of the probe's findings (Belinkov, 2021). A drawback of this is that NN units are often correlated with a concept without causally mediating the concept. Thus this approach can return many false positives-i.e. it may return proposed mediators which do not actually causally mediate the concept in question (Hewitt & Liang, 2019; Elazar et al., 2021; Amini et al., 2023; Belinkov, 2021).
Thus, much recent work complements supervised probing approaches with additional checks of causality-for example, by applying causal mediation analysis to the directions identified by supervised probing (Marks & Tegmark, 2023; Nanda et al., 2023); by backpropagating from the classifier to modify the behavior of the model (Giulianelli et al., 2018) or generate counterfactual representations (Tucker et al., 2021); or by directly comparing the probe's predictions to a causally grounded probe (Amini et al., 2023). Another line of work uses the directions discovered by probes to guard or erase information about a particular concept from the model's representations. For example, a direction in a model's activation space that is most predictive of the target concept can be nullified via orthogonal projections, such that the model can no longer use that information (Ravfogel et al., 2020); this process can then be repeated until linear guarding is achieved. Concept erasure and guarding can then be used to measure the causal importance
of particular concepts, as in Elazar et al. (2021), though studies that employ methods like these tend to focus on single layers. More recently, techniques such as LEACE (Belrose et al., 2023) and follow-ups (Singh et al., 2024b) have generalized this idea to provably prevent any linear classifier from using a concept; this moves beyond orthogonal projections and projects out the information at every layer. One could use such methods to causally understand the set of directions that encode some concept. Note that these methods are still susceptible to the problems entailed by using linear mediators; thus, future work could extend erasure methods to non-linear mediator types.
Counterfactual-based optimization. Another class of approaches involves using the result of causal mediation analysis as a metric to directly optimize. One such line of work includes methods like Distributed Alignment Search (DAS) and follow-up methods such as Boundless DAS that align hypothesized high-level causal variables with underlying neural representations (Geiger et al., 2024; Wu et al., 2023; Huang et al., 2024). These methods decompose the search space into learnable subspaces that can be aligned with a hypothesized causal variable.
Another line of work learns a binary mask over enumerable sets of components to determine which are relevant mediators for a task, where the size of the set depends on the desired granularity (e.g. sets of neurons, attention heads, layers, etc.). Examples include subnetwork probing (Cao et al., 2021) and Desiderata-based Component Masking (DCM) (Davies et al., 2023; Prakash et al., 2024).
These methods provide a time-efficient way to search for human-interpretable variables encoded in intractably large or innumerable mediator sets. However, current optimization-based methods can only search for causal nodes given a clear pre-existing causal hypothesis of how a model accomplishes some behavior, and/or labeled data. These methods can be evaluated with respect to accuracy in capturing model behavior, but they do not directly indicate a priori what those hypotheses should be, or in what specific ways our hypotheses are wrong. They also require sufficient training data to demonstrate the behavior of interest. As with all parametric methods, the above approaches are subject to overfitting or underfitting, which can be a key concern when not enough data is available.
## 5.2.2 Unsupervised mediator searches
Supervised search methods (see §5.2.1) require specific hypotheses about the internal representations of neural networks. However, neural networks implement various behaviors, many of which may be counterintuitive to humans and therefore more likely to be missed. For example, while Li et al. (2023) hypothesized a constant board state representation in Othello, Nanda et al. (2023) later found that the model actually switches the board state representation with every turn, taking the view of 'my pieces vs. opponent's pieces' rather than 'black pieces vs. white pieces'. Therefore, it can be desirable to use techniques for searching for mediators without specifying a hypothesis ahead of time.
Hence, some studies employ unsupervised methods. Because these techniques are unsupervised, they return a large-but finite-collection of mediators. Unsupervised methods are largely correlative , meaning that the discovered mediators may not necessarily capture causally relevant or faithful aspects of the NN's computation. However, the discovered mediators can then be implicated in NN computation post-hoc by employing additional techniques, such as those from §5.1, to select task-relevant mediators from this collection.
Feature disentanglement using sparse autoencoders. Exhaustive search for meaningful non-basisaligned directions is impossible due to the infinite search space. The feature disentanglement literature tackles this problem by performing an unsupervised search for directions in neuron activations which both (1) capture the information encoded in the internal representations and (2) are disentangled from other meaningful directions. Bengio et al. (2013) characterize disentangled representations as factors for variations in the training dataset. To identify these factors of variations, Sharkey et al. (2023) used sparse autoencoders (SAEs) to perform dictionary learning on a one-layer transformer, identifying a large (overcomplete) basis of features. SAEs are trained to reconstruct the input activations while only activating a sparse subset of dictionary features. Cunningham et al. (2024) then applied SAEs to language models and demonstrated that the observed dictionary features are highly interpretable and can be used to localize and edit model behavior. Since then, numerous researchers have explored this area (Templeton et al., 2024; Rajamanoharan et al.,
2024; Braun et al., 2024; Bricken et al., 2023, inter alia ). In practice, SAEs have shown initial promising results in identifying functionally relevant and human-interpretable features. However, they are not able to perfectly reconstruct the internal activations. Most importantly, however, we do not know a priori what the ground truth features are in the model's computation, and can only use the reconstruction performance as a proxy measure of performance.
Correlation-based clustering. Another unsupervised way of discovering meaningful units is clustering mediators by the similarity of their behavior. This idea is not new (cf. Elman, 1990), but running causal verifications of the qualitative insights from clustering studies is relatively rare. Dalvi et al. (2020) cluster neurons, and are able to maintain performance when ablating a significant portion of them; the goal of this study was not interpretability, but their results nonetheless causally verify that redundancy is very common in neural networks.
There has recently been renewed interest in clustering-based mediator search. Michaud et al. (2023) propose a method to identify interpretable behaviors within neural networks by clustering parameters. Because the identified behaviors tend to be coherent, the units implicated in each cluster can be viewed as a set of components that have a functionally coherent role in the network. Marks et al. (2024) and Engels et al. (2024) generalize this from gradients to neuron or sparse autoencoder activations. The activations that compose the clusters are then labeled according to the dataset samples on which they activate most highly. These clusters are a subset of all mediators which are relevant to performing some prediction task; thus, one could perform interventions to the mediator sets that compose a cluster. This idea has not yet been extensively employed or explored. However, ablating the elements within these clusters could be a useful way to establish the functional role of groups of components in future work, or assess whether a subset of a model's behavior is implicated in a more complex task. We discuss this in §7.
## 6 Related Work
Causally-grounded interpretability surveys do not always focus on model internals, and surveys that focus on model internals do not necessarily require causal grounding. We give a brief overview of both types here.
Mechanistic/model-internal interpretability surveys. Some surveys catalogue studies that aim to understand the latent representations of neural networks (Belinkov & Glass, 2019; Danilevsky et al., 2020; Belinkov, 2021; Sajjad et al., 2022); these have often called for more causal validations of correlational observations. More recent surveys tend to focus increasingly on categorizing or giving overviews of methods for intervening on model internals (Ferrando et al., 2024), understanding the trajectory of the mechanistic interpretability field (Räuker et al., 2023), and/or cataloguing the impacts of the field (Bereska & Gavves, 2024). We propose a more theoretically grounded framing, and categorize interpretability work from many domains as part of the causal interpretability literature. Moreover, we treat the units of causal analysis that a study employs, as well as the way in which the study searches over those units, as primary factors in categorizing the study.
Causal interpretability surveys. Moraffah et al. (2020) is a causal interpretability survey that categorizes various streams of causal interpretability research according to the methods they employ, though the catalogued studies are not necessarily based in the ideas of causal mediation analysis nor aimed toward understanding model internals. Other interpretability surveys (Subhash et al., 2022; Gilpin et al., 2018; Singh et al., 2024a) focus on methods for explaining the decisions of neural networks without prioritizing causally grounding the explanation methods or focusing on model internals. Many causality-focused surveys are domain-specific, including areas such as cybersecurity (Rawal et al., 2024) and healthcare (Wu et al., 2024b). Some focus on particular domains; for example, in NLP, some focus on how causal inference can improve interpretability (Feder et al., 2022), or ways to explain (Lyu et al., 2024) or interpret (Madsen et al., 2022) neural NLP systems.
Tools. Several libraries have recently been released to facilitate causal interpretability methods that involve interventions to model components. These tools can implicitly prioritize certain types of mediators over
others. For instance, TransformerLens (Nanda & Bloom, 2022) and libraries based on it (Prisma; Joseph, 2023) are interpretability tools for examining Transformer-based neural networks. Its standardized interface across model architectures tends to encourage a focus on basis-aligned components, subspaces, and layers, as interventions to these mediators are natively supported. NeuroX (Dalvi et al., 2023) similarly incentivizes neuron-level interpretability in particular. NNsight (Fiotto-Kaufman et al., 2024) and Baukit (Bau, 2022) are more transparent interfaces that expose the model architecture, which may make it slightly harder to generalize basis-aligned interventions across architectures, but which more easily allows modifications to the computation graph-thus better incentivizing research on non-basis-aligned spaces. Pyvene (Wu et al., 2024c) is designed specifically to aid in locating non-basis-aligned multidimensional subspaces; this library could be particularly useful for those wishing to verify existing causal hypotheses.
## 7 Discussion and Conclusions
## 7.1 What is the right mediator?
There are pros and cons to any mediator, and the best mediator will therefore depend on one's goals. If the goal is to explain model behaviors , then in the absence of compute restrictions and with no strong prior hypotheses as to how a model performs some behavior, unsupervised optimization-based methods over fine-grained mediators (such as non-basis-aligned directions) provide a strong starting point. For example, unsupervised methods like sparse autoencoders provide a fine-grained and potentially editable interface to a model's computation; that said, autoencoder features are not guaranteed to be faithful to a neural network's behavior in next-token prediction, and they require either a human or an LLM to label or interpret the features, which is laborious and expensive. Moreover, natural language explanations of neurons and features have inherent flaws (Huang et al., 2023): they may often exhibit both low precision and recall. Second, interpretable mediators like directions require more human effort and/or compute than basis-aligned components to locate, and optimization may need to be rerun if a model has been significantly fine-tuned or edited. 14
If one has a clear idea as to how a model accomplishes a task and simply wishes to verify a mechanistic hypothesis , then non-basis-aligned subspaces may be the right mediators, and a reasonable corresponding search method might be counterfactual-based optimization. One can automatically search for the subspaces which correspond to a particular node in one's hypothesized causal graph using alignment search methods, as in Geiger et al. (2024); Wu et al. (2023). Alignment search entails learning a rotation to some activation subspace given an input, and then performing causal interventions by substituting activations from other runs in the rotated latent space. This allows us to locate distributed representations that act as single causal variables in non-basis-aligned spaces. This is relatively scalable, and enables us to qualitatively understand intermediate model computations. The primary downside is that we must anticipate the mechanisms that models employ to perform a task; if we cannot anticipate them, then curating data and refining one's causal hypotheses may require significant human effort. Additionally, the same causal graph could correspond to many different qualitative explanations, depending on the data used to discover the causal graph. Finally, this mediator type is subject to the same confounds as other optimization-based techniques.
If one's goal is to localize some phenomenon in a model and not to understand how a model implements a behavior, then exhaustive searches over basis-aligned subspaces or full layers may be sufficient. There are many comprehensive causal techniques for locating these, including causal tracing (Meng et al., 2022) and activation patching (Vig et al., 2020), as well as techniques for locating graphs of basis-aligned mediators, such as circuit discovery algorithms (Goldowsky-Dill et al., 2023; Wang et al., 2023; Conmy et al., 2023). Some of these methods are relatively slow in their exact form, but fast approximations exist to these causal metrics, including attribution patching (Syed et al., 2023) and improved versions thereof (Kramár et al., 2024; Hanna et al., 2024; Marks et al., 2024). Even in the absence of a deep understanding of the role of these mediators, localization can be useful for downstream applications like model editing (Meng et al., 2022; 2023) 15 and model steering (Todd et al., 2024; Goyal et al., 2020). That said, if meaningful features are not actually aligned with neurons/heads, then we are not guaranteed to get the best performance until we move
14 Though Prakash et al. (2024) find that the same model components are implicated in an entity tracking task before and after fine-tuning.
15 Though Hase et al. (2023) find that causal localizations do not reflect the optimal locations for editing models.
beyond basis-aligned spaces. Future work should analyze the performance of model editing and steering methods when using different kinds of mediators. For example, Marks et al. (2024) compare the efficacy of ablating neurons versus sparse features (non-basis-aligned directions), and find that ablating sparse features is significantly more effective; the difference may be much smaller at the coarse granularity of full layers and submodules, but there is not yet much empirical evidence on what kinds of mediators are most effective for particular applications.
## 7.2 Suggestions for Future Work
## 7.2.1 Are there better causal mediators?
There are almost certainly better causal mediators that have not yet been discovered. Current work on improving mediators tends to focus on non-basis-aligned directions, such as sparse features or directions discovered from supervised probing on the activations of a single layer/submodule. One could consider pursuing coarser-grained mediators by discovering multi-layer model regions or component sets which accomplish a single behavior. Because these regions can cross layers, they would include non-linearities that allow them to represent more complex functions or concepts.
Non-linear and multi-dimensional feature discovery. As discussed in §4.4, there is recent work demonstrating the existence of human-interpretable multi-dimensional features. For example, days of the week are encoded circularly as a set of 7 directions in a two-dimensional subspace (Engels et al., 2024), and current methods cannot easily capture such multi-dimensional features. Group sparse autoencoders (Theodosis & Ba, 2023) or clusters of autoencoder features could be a way to capture multi-dimensional non-basis-aligned features in an unsupervised manner, but thus far, empirical work has not yet demonstrated whether this will be effective for interpreting neural networks. Additionally, many current causal interpretability methods require binary distinctions between correct and incorrect answers, whereas causal mediation analysis does not have any theoretical linearity, dimensionality, or Boolean restrictions.
There may also exist higher-order non-linear concepts in latent space that we have not yet been able to find, due to the linear focus of contemporary methods. For example, a subgraph or subcircuit can encode a coherent variable representation or functional role, as in Lepori et al. (2023). How can we discover these subgraphs? Path patching (Goldowsky-Dill et al., 2023; Wang et al., 2023) provides a manual approach to implicating subgraphs as causal mediators, we do not yet have automatic methods that can scalably search over all possible subgraphs in a network. How might non-linear and/or coarse-grained mediators like these be useful in practice? As an example, we would expect fundamental phenomena like syntax to be implicated in downstream tasks like question answering, if we expect that language models are robustly parsing the meaning of their inputs. Thus, we could implicate the entire syntax region(s) in the model's final decisions; if it is not strongly implicated in QA performance, then we have a strong hint that the model may instead be relying on a mixture of surface-level spurious heuristics to parse inputs.
## 7.2.2 Inherently interpretable model components
More ambitiously, one could consider building models with inherently interpretable components-i.e., whose fundamental units of computation (or some subset thereof) are designed to be sparse, monosemantic, and/or human-interpretable, but ideally still expressive enough to attain good performance on downstream tasks. Examples based in neural networks include differentiable masks (De Cao et al., 2020; Bastings et al., 2019), transcoders (Dunefsky et al., 2024), codebook features (Tamkin et al., 2023), and softmax linear units (Elhage et al., 2022a). These are primarily post-hoc components that decompose model components into interpretable units, but they could potentially be integrated into the network itself during pre-training alongside a loss term (in addition to the language modeling loss) that enables fine-grained interpretability at all stages of pretraining. Alternatively, more focus could be devoted to building models that are designed from the ground up to be interpretable, such as backpack language models (Hewitt et al., 2023). Perhaps least invasively, we could consider pre-training methods that encourage interpretable features to be aligned to neuron bases; this would remove the need for optimization to find non-basis-aligned components, and therefore make interpreting NN decisions significantly easier and less confounded. However, this would reduce the number
of features that could be encoded per neuron, so it would likely entail training significantly larger models, or accepting degradations in performance.
## 7.2.3 Scalable search
As the size of neural networks increases, the number of potential mediators to search over will also increase. The situation worsens as we start searching over continuous sets of fine-grained mediators such as non-basisaligned directions. Although a few gradient-based or optimization-based approximations to causal influence have been proposed to improve time efficiency, such as attribution patching (Syed et al., 2023) and DCM (Davies et al., 2023), more work is still needed to evaluate the efficacy of these techniques in identifying the correct causal mediators. Additionally, better techniques beyond greedy search methods should be devised to identify causally important groups of mediators; these should aim to produce Pareto improvements over time complexity and causal efficacy.
As discussed in §5.2.1, optimization-based mediator search methods often require a pre-existing hypothesis about how a model implements a particular behavior of interest. Another path toward scaling mediator search and interpretability is to automate the process of hypothesis generation. Qiu et al. (2024) showed that current LLMs can generate hypotheses, and Shaham et al. (2024) showed that hypothesis refinement via LLMs can aid humans in interpreting the causal role of neurons in multimodal models. Similary, LLMs could be used to automate and scale hypothesis generation regarding the role of particular mediators across a wider variety of tasks and models. Optimization-based based methods such as DAS or DCM could then be used to causally verify the automatically generated hypotheses.
## 7.2.4 Benchmarking progress in mechanistic interpretability
Another key direction will be standard benchmarks for measuring progress in mechanistic interpretability . Currently, most studies develop ad-hoc evaluations, and generally only compare to similar methods that employ the same mediators. Thus, to measure whether new mediators or search methods are truly giving us improvements over previous ones, we need to develop principled methods for direct comparisons. In circuit discovery, it is theoretically possible to use the same metrics to compare any circuit discovered for a particular model and task, regardless of whether sparse autoencoders are used, whether the circuit is based on nodes or edges, among other variations. Direct comparisons like these are not standard, though some recent work has begun to perform direct comparisons across mediator types, such as Miller et al. (2024). Huang et al. (2024) propose to directly evaluate interpretability methods according to the generality of the abstractions they recover, and do directly compare across different mediator types given the same model and task. Arora et al. (2024) and Makelov et al. (2024) also propose standardized interpretability benchmarks that allow us to compare across mediator search methods, though they do not directly compare across mediator types.
Direct comparisons require defining criteria for success, but there is little agreement about the kinds of phenomena we should be measuring, and precisely how they should be measured. Taking circuit discovery as a case study, there are (at least) five key metrics: (1) faithfulness , or how well the circuit captures the full model's behavior; (2) generalization , or how well the circuit generalizes outside the distribution of the dataset used to discover it; (3) completeness , or whether we have captured all relevant components; (4) minimality , or whether we have not included any superfluous components; and (5) interpretability , which refers to how human-understandable the circuit is. Some of these metrics currently have multiple contradictory senses: (1) is sometimes used to refer to whether the circuit captures the full model's behavior (including productive and counterproductive components), and in other cases is used to refer to whether the circuit only captures components that result in high performance on the task. 16 The choice of mediator will also significantly affect how well we can perform each of these, as obtaining a complete and faithful circuit requires working at the correct level of abstraction (i.e., where meaningful units of computation are actually represented). Additionally, these metrics can be difficult to automatically measure; for example, (5) may require human evaluations at first (Saphra et al., 2024), as many NLP tasks such as machine translation
16 Even if we decide on one of these definitions, there is still the issue of how to compare the full model to the discovered subgraph. We could use KL divergences, compare probabilities of a given token, among other possibilities; Zhang & Nanda (2024) investigate this in detail.
required before the introduction of now-standard 17 metrics such as BLEU, COMET, and METEOR scores (Papineni et al., 2002; Rei et al., 2020; Banerjee & Lavie, 2005). Some tasks have started to integrate human/user evaluations, which will be especially useful for building interpretability tools that are grounded in real-world use cases and settings (Saphra et al., 2024). Future work could consider defining a broad set of models, target tasks, and informative metrics on which researchers can compare their interpretability methods, mediator types, and search methods in a standardized way. This will enable us to assess whether new search methods and mediator types are producing real Pareto advancements with respect to interpretability, efficiency, and description length.
For many methods and tasks, more task-specific measures and benchmark datasets will be needed. For example, Cohen et al. (2024) and Zhong et al. (2023) propose benchmarks to evaluate model editing methods on out-of-distribution examples, and Karvonen et al. (2024) propose to measure progress in feature disentanglement using board game models. While not the main focus of this paper, we believe that building standardized benchmarks will be a key means to the end of assessing whether advancements in causal mediators are producing real gains in interpretability. More robust evaluation metrics and methods will lead to better science, which will ideally allow us to assess whether new causal abstractions are fundamentally more useful-both for describing the computations of a neural network and for practical applications.
## References
Afra Amini, Tiago Pimentel, Clara Meister, and Ryan Cotterell. Naturalistic causal probing for morphosyntax. Transactions of the Association for Computational Linguistics , 11:384-403, 2023. doi: 10.1162/ tacl\_a\_00554. URL https://aclanthology.org/2023.tacl-1.23 .
Aryaman Arora, Dan Jurafsky, and Christopher Potts. CausalGym: Benchmarking causal interpretability methods on linguistic tasks. arXiv:2402.12560 , 2024. URL https://arxiv.org/abs/2402.12560 .
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, and Andrej Risteski. A latent variable model approach to PMI-based word embeddings. Transactions of the Association for Computational Linguistics , 4:385-399, 2016. doi: 10.1162/tacl\_a\_00106. URL https://aclanthology.org/Q16-1028 .
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, and Andrej Risteski. Linear algebraic structure of word senses, with applications to polysemy. Transactions of the Association for Computational Linguistics , 6:483-495, 2018. doi: 10.1162/tacl\_a\_00034. URL https://aclanthology.org/Q18-1034 .
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations , 2015.
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or summarization , pp. 65-72, 2005. URL https: //aclanthology.org/W05-0909/ .
Jasmijn Bastings, Wilker Aziz, and Ivan Titov. Interpretable neural predictions with differentiable binary variables. In Anna Korhonen, David Traum, and Lluís Màrquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pp. 2963-2977, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1284. URL https://aclanthology.org/ P19-1284 .
Anthony Bau, Yonatan Belinkov, Hassan Sajjad, Nadir Durrani, Fahim Dalvi, and James R. Glass. Identifying and controlling important neurons in neural machine translation. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenReview.net, 2019a. URL https://openreview.net/forum?id=H1z-PsR5KX .
David Bau. Baukit, 2022. URL https://github.com/davidbau/baukit .
17 "Standard" does not necessarily mean "representative of human judgments".
| David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B. Tenenbaum, William T. Freeman, and Antonio Torralba. Visualizing and understanding generative adversarial networks. In International Con- ference on Learning Representations , 2019b. URL https://openreview.net/forum?id=Hyg_X2C5FX . |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| David Bau, Jun-Yan Zhu, Hendrik Strobelt, Agata Lapedriza, Bolei Zhou, and Antonio Torralba. Under- standing the role of individual units in a deep neural network. Proceedings of the National Academy of Sciences , 117(48):30071-30078, 2020. doi: 10.1073/pnas.1907375117. URL https://www.pnas.org/doi/ abs/10.1073/pnas.1907375117 . |
| Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and alternatives. CoRR , abs/2102.12452, 2021. URL https://arxiv.org/abs/2102.12452 . |
| Yonatan Belinkov and James Glass. Analysis methods in neural language processing: A survey. Transactions of the Association for Computational Linguistics , 7:49-72, 2019. doi: 10.1162/tacl_a_00254. URL https: //aclanthology.org/Q19-1004 . |
| Yonatan Belinkov, Nadir Durrani, Fahim Dalvi, Hassan Sajjad, and James Glass. What do neural machine translation models learn about morphology? In Regina Barzilay and Min-Yen Kan (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pp. 861-872, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/ P17-1080. URL https://aclanthology.org/P17-1080 . |
| Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. LEACE: Perfect linear concept erasure in closed form. In Thirty-seventh Conference on Neural Information Processing Systems , 2023. URL https://openreview.net/forum?id=awIpKpwTwF . |
| Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new per- spectives. IEEE Transactions on Pattern Analysis and Machine Intelligence , 35(8):1798-1828, 2013. doi: 10.1109/TPAMI.2013.50. URL https://dl.acm.org/doi/10.1109/TPAMI.2013.50 . |
| Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for AI safety - A review. arXiv preprint arXiv:2404.14082 , 2024. URL https://arxiv.org/abs/2404.14082 . |
| Olcay Boz. Extracting decision trees from trained neural networks. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , KDD '02, pp. 456-461, New York, NY, USA, 2002. Association for Computing Machinery. ISBN 158113567X. doi: 10.1145/ 775047.775113. URL https://doi.org/10.1145/775047.775113 . |
| Dan Braun, Jordan Taylor, Nicholas Goldowsky-Dill, and Lee Sharkey. Identifying functionally important features with end-to-end sparse dictionary learning. arXiv preprint arXiv:2405.12241 , 2024. URL https: //arxiv.org/abs/2405.12241 . |
| Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and Christopher Olah. Towards monose- manticity: Decomposing language models with dictionary learning. Transformer Circuits Thread , 2023. URL https://transformer-circuits.pub/2023/monosemantic-features/index.html . |
| Jannik Brinkmann, Abhay Sheshadri, Victor Levoso, Paul Swoboda, and Christian Bartelt. A mechanistic analysis of a transformer trained on a symbolic multi-step reasoning task. arXiv preprint arXiv:2402.11917 , 2024. URL https://arxiv.org/abs/2402.11917 . |
| Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Lan- |
| H. Lin (eds.), Advances in Neural Information Processing Systems , volume 33, pp. 1877-1901. Cur- ran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf . |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Steven Cao, Victor Sanh, and Alexander Rush. Low-complexity probing via finding subnetworks. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies , pp. 960-966, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021. naacl-main.74. URL https://aclanthology.org/2021.naacl-main.74 . |
| Angelica Chen, Ravid Shwartz-Ziv, Kyunghyun Cho, Matthew L Leavitt, and Naomi Saphra. Sudden drops in the loss: Syntax acquisition, phase transitions, and simplicity bias in MLMs. In The Twelfth International Conference on Learning Representations , 2024a. URL https://openreview.net/forum? id=MO5PiKHELW . |
| Yida Chen, Aoyu Wu, Trevor DePodesta, Catherine Yeh, Kenneth Li, Nicholas Castillo Marin, Oam Patel, Jan Riecke, Shivam Raval, Olivia Seow, et al. Designing a dashboard for transparency and control of conversational AI. arXiv preprint arXiv:2406.07882 , 2024b. URL https:arxiv.org/abs/2406.07882 . |
| Bilal Chughtai, Lawrence Chan, and Neel Nanda. A toy model of universality: Reverse engineering how networks learn group operations. In Proceedings of the 40th International Conference on Machine Learning . JMLR, 2023. URL https://dl.acm.org/doi/10.5555/3618408.3618656 . |
| Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, and Mor Geva. Evaluating the Ripple Effects of Knowledge Editing in Language Models. Transactions of the Association for Computational Linguistics , 12:283-298, 04 2024. ISSN 2307-387X. doi: 10.1162/tacl_a_00644. URL https://doi.org/10.1162/ tacl_a_00644 . |
| Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems , volume 36, pp. 16318-16352. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/ paper/2023/file/34e1dbe95d34d7ebaf99b9bcaeb5b2be-Paper-Conference.pdf . |
| Alexis Conneau, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. In Iryna Gurevych and Yusuke Miyao (eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pp. 2126-2136, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1198. URL https://aclanthology.org/P18-1198 . |
| Mark Craven and Jude Shavlik. Extracting tree-structured representations of trained networks. Advances in Neural Information Processing Systems , 8, 1995. |
| Mark W. Craven and Jude W. Shavlik. Using sampling and queries to extract rules from trained neu- ral networks. In William W. Cohen and Haym Hirsh (eds.), Machine Learning Proceedings 1994 , pp. 37-45. Morgan Kaufmann, San Francisco (CA), 1994. ISBN 978-1-55860-335-6. doi: https://doi.org/ 10.1016/B978-1-55860-335-6.50013-1. URL https://www.sciencedirect.com/science/article/pii/ B9781558603356500131 . |
| Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=F76bwRSLeK . |
| Fahim Dalvi, Hassan Sajjad, Nadir Durrani, and Yonatan Belinkov. Analyzing redundancy in pretrained transformer models. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 4908-4926, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.398. URL https://aclanthology.org/2020.emnlp-main.398 . |
| Fahim Dalvi, Hassan Sajjad, and Nadir Durrani. NeuroX library for neuron analysis of deep NLP models. In Danushka Bollegala, Ruihong Huang, and Alan Ritter (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pp. 226-234, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-demo.21. URL https://aclanthology.org/2023.acl-demo.21 . |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Marina Danilevsky, Kun Qian, Ranit Aharonov, Yannis Katsis, Ban Kawas, and Prithviraj Sen. A survey of the state of explainable AI for natural language processing. In Kam-Fai Wong, Kevin Knight, and Hua Wu (eds.), Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing , pp. 447-459, Suzhou, China, December 2020. Association for Computational Linguistics. URL https: //aclanthology.org/2020.aacl-main.46 . |
| Xander Davies, Max Nadeau, Nikhil Prakash, Tamar Rott Shaham, and David Bau. Discovering variable binding circuitry with desiderata. arXiv preprint arXiv:2307.03637 , 2023. URL https://arxiv.org/ abs/2307.03637 . |
| Nicola De Cao, Michael Sejr Schlichtkrull, Wilker Aziz, and Ivan Titov. How do decisions emerge across layers in neural models? Interpretation with differentiable masking. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 3243-3255, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.262. URL https://aclanthology.org/2020.emnlp-main.262 . |
| Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirec- tional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp. 4171-4186, Min- neapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://aclanthology.org/N19-1423 . |
| Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable LLM feature circuits. 2024. URL https://arxiv.org/abs/2406.11944 . |
| Yanai Elazar, Shauli Ravfogel, Alon Jacovi, and Yoav Goldberg. Amnesic probing: Behavioral explanation with amnesic counterfactuals. Transactions of the Association for Computational Linguistics , 9:160-175, 03 2021. ISSN 2307-387X. doi: 10.1162/tacl_a_00359. URL https://doi.org/10.1162/tacl_a_00359 . |
| Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A mathematical framework for transformer circuits. Transformer Circuits Thread , 2021. URL https://transformer-circuits.pub/ 2021/framework/index.html . |
| Nelson Elhage, Tristan Hume, Catherine Olsson, Neel Nanda, Tom Henighan, Scott Johnston, Sheer ElShowk, Nicholas Joseph, Nova DasSarma, Ben Mann, Danny Hernandez, Amanda Askell, Kamal Ndousse, Andy Jones, Dawn Drain, Anna Chen, Yuntao Bai, Deep Ganguli, Liane Lovitt, Zac Hatfield- Dodds, Jackson Kernion, Tom Conerly, Shauna Kravec, Stanislav Fort, Saurav Kadavath, Josh Ja- cobson, Eli Tran-Johnson, Jared Kaplan, Jack Clark, Tom Brown, Sam McCandlish, Dario Amodei, and Christopher Olah. Softmax linear units. Transformer Circuits Thread , 2022a. URL https: //transformer-circuits.pub/2022/solu/index.html . |
| Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition. Transformer Circuits Thread , 2022b. URL https://transformer-circuits.pub/2022/toy_model/index.html . |
| Jeffrey L Elman. Representation and structure in connectionist models. University of California, San Diego, Center for Research in Language , 1989. |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Jeffrey L. Elman. Finding structure in time. Cognitive Science , 14:179-211, 1990. URL https://api. semanticscholar.org/CorpusID:2763403 . |
| Jeffrey L. Elman. Distributed representations, simple recurrent networks, and grammatical structure. Mach. Learn. , 7(2-3):195-225, sep 1991. ISSN 0885-6125. doi: 10.1007/BF00114844. URL https://doi.org/ 10.1007/BF00114844 . |
| Joshua Engels, Isaac Liao, Eric J. Michaud, Wes Gurnee, and Max Tegmark. Not all language model features are linear, 2024. URL https://arxiv.org/abs/2405.14860 . |
| Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent. Visualizing higher-layer features of a deep network. Technical Report 1341, University of Montreal, June 2009. Also presented at the ICML 2009 Workshop on Learning Feature Hierarchies, Montréal, Canada. |
| Amir Feder, Katherine A. Keith, Emaad Manzoor, Reid Pryzant, Dhanya Sridhar, Zach Wood-Doughty, Jacob Eisenstein, Justin Grimmer, Roi Reichart, Margaret E. Roberts, Brandon M. Stewart, Victor Veitch, and Diyi Yang. Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Transactions of the Association for Computational Linguistics , 10:1138-1158, 2022. doi: 10.1162/tacl_a_00511. URL https://aclanthology.org/2022.tacl-1.66 . |
| Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R. Costa-jussà. A primer on the inner workings of transformer-based language models, 2024. URL https://arxiv.org/abs/2405.00208 . |
| Matthew Finlayson, Aaron Mueller, Sebastian Gehrmann, Stuart Shieber, Tal Linzen, and Yonatan Belinkov. Causal analysis of syntactic agreement mechanisms in neural language models. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pp. 1828-1843, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.144. URL https://aclanthology.org/2021.acl-long.144 . |
| Jaden Fiotto-Kaufman, Alexander R Loftus, Eric Todd, Jannik Brinkmann, Caden Juang, Koyena Pal, Can Rager, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, Francesca Lucchetti, Michael Ripa, Adam Belfki, Nikhil Prakash, Sumeet Multani, Carla Brodley, Arjun Guha, Jonathan Bell, Byron Wallace, and David Bau. Nnsight and ndif: Democratizing access to foundation model internals, 2024. URL https://arxiv.org/abs/2407.14561 . |
| Rohit Gandikota, Joanna Materzyńska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. In Proceedings of the 2023 IEEE International Conference on Computer Vision , 2023. |
| Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzyńska, and David Bau. Unified concept editing in diffusion models. IEEE/CVF Winter Conference on Applications of Computer Vision , 2024. |
| Jorge García-Carrasco, Alejandro Maté, and Juan Trujillo. How does GPT-2 predict acronyms? Extracting and understanding a circuit via mechanistic interpretability, 2024. URL https://arxiv.org/abs/2405. 04156 . |
| Atticus Geiger, Hanson Lu, Thomas F Icard, and Christopher Potts. Causal abstractions of neural networks. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems , 2021. URL https://openreview.net/forum?id=RmuXDtjDhG . |
| Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. Finding alignments between interpretable causal variables and distributed neural representations. In Causal Learning and Reasoning , pp. 160-187. PMLR, 2024. |
| Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models. In The 2023 Conference on Empirical Methods in Natural Language Processing , 2023. URL https://openreview.net/forum?id=F1G7y94K02 . |
| Leilani H Gilpin, David Bau, Ben Z Yuan, Ayesha Bajwa, Michael Specter, and Lalana Kagal. Explain- ing explanations: An overview of interpretability of machine learning. In 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA) , pp. 80-89. IEEE, 2018. |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Mario Giulianelli, Jack Harding, Florian Mohnert, Dieuwke Hupkes, and Willem Zuidema. Under the hood: Using diagnostic classifiers to investigate and improve how language models track agreement information. In Tal Linzen, Grzegorz Chrupała, and Afra Alishahi (eds.), Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pp. 240-248, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/W18-5426. URL https: //aclanthology.org/W18-5426 . |
| Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching, 2023. URL https://arxiv.org/abs/2304.05969 . |
| Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger (eds.), Advances in Neural Information Processing Systems , vol- ume 27. Curran Associates, Inc., 2014. URL https://proceedings.neurips.cc/paper_files/paper/ 2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf . |
| Yash Goyal, Amir Feder, Uri Shalit, and Been Kim. Explaining classifiers with causal concept effect (CaCE). arXiv preprint arXiv:1907.07165 , 2020. URL https://arxiv.org/abs/1907.07165 . |
| Abhijeet Gupta, Gemma Boleda, Marco Baroni, and Sebastian Padó. Distributional vectors encode ref- erential attributes. In Lluís Màrquez, Chris Callison-Burch, and Jian Su (eds.), Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pp. 12-21, Lisbon, Portu- gal, September 2015. Association for Computational Linguistics. doi: 10.18653/v1/D15-1002. URL https://aclanthology.org/D15-1002 . |
| Michael Hanna, Ollie Liu, and Alexandre Variengien. How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems , volume 36, pp. 76033-76060. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/ paper/2023/file/efbba7719cc5172d175240f24be11280-Paper-Conference.pdf . |
| Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms. In ICML 2024 Workshop on Mechanistic Interpretability , 2024. URL https://openreview.net/forum?id=grXgesr5dT . |
| Peter Hase, Mohit Bansal, Been Kim, and Asma Ghandeharioun. Does localization inform editing? Surpris- ing differences in causality-based localization vs. knowledge editing in language models. In Thirty-seventh Conference on Neural Information Processing Systems , 2023. URL https://openreview.net/forum?id= EldbUlZtbd . |
| Yoichi Hayashi. A neural expert system with automated extraction of fuzzy if-then rules and its application to medical diagnosis. In R.P. Lippmann, J. Moody, and D. Touretzky (eds.), Advances in Neural Infor- mation Processing Systems , volume 3. Morgan-Kaufmann, 1990. URL https://proceedings.neurips. cc/paper_files/paper/1990/file/82cec96096d4281b7c95cd7e74623496-Paper.pdf . |
| Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pp. 770-778, 2016. |
| John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pp. 2733-2743, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-1275. URL https://aclanthology.org/D19-1275 . |
| John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp. 4129-4138, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1419. URL https://aclanthology.org/N19-1419 . |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| John Hewitt, Kawin Ethayarajh, Percy Liang, and Christopher Manning. Conditional probing: Measuring usable information beyond a baseline. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pp. 1626-1639, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.122. URL https://aclanthology.org/ 2021.emnlp-main.122 . |
| John Hewitt, John Thickstun, Christopher Manning, and Percy Liang. Backpack language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pp. 9103-9125, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.506. URL https://aclanthology.org/2023.acl-long.506 . |
| Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Comput. , 9(8):1735-1780, nov 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735. URL https://doi.org/10.1162/neco.1997. 9.8.1735 . |
| Jing Huang, Atticus Geiger, Karel D'Oosterlinck, Zhengxuan Wu, and Christopher Potts. Rigorously assessing natural language explanations of neurons. In Yonatan Belinkov, Sophie Hao, Jaap Jumelet, Najoung Kim, Arya McCarthy, and Hosein Mohebbi (eds.), Proceedings of the 6th BlackboxNLP Work- shop: Analyzing and Interpreting Neural Networks for NLP , pp. 317-331, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.blackboxnlp-1.24. URL https: //aclanthology.org/2023.blackboxnlp-1.24 . |
| Jing Huang, Zhengxuan Wu, Christopher Potts, Mor Geva, and Atticus Geiger. RAVEL: Evaluating inter- pretability methods on disentangling language model representations. arXiv preprint arXiv:2402.17700 , 2024. URL https://arxiv.org/abs/2402.17700 . |
| Dieuwke Hupkes, Sara Veldhoen, and Willem Zuidema. Visualisation and 'diagnostic classifiers' reveal how recurrent and recursive neural networks process hierarchical structure. Journal of Artificial Intelligence Research , 61:907-926, 2018. |
| Shadi Iskander, Kira Radinsky, and Yonatan Belinkov. Shielded representations: Protecting sensitive attributes through iterative gradient-based projection. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023 , pp. 5961- 5977, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023. findings-acl.369. URL https://aclanthology.org/2023.findings-acl.369 . |
| Jett Janiak, cmathw, and Stefan Heimersheim. Polysemantic attention head in a 4- layer transformer, 2023. URL https://www.lesswrong.com/posts/nuJFTS5iiJKT5G5yh/ polysemantic-attention-head-in-a-4-layer-transformer . Accessed: 2024-05-26. |
| Adam Jermyn, Chris Olah, and Tom Henighan. Attention head superposition, 2023. URL https: //transformer-circuits.pub/2023/may-update/index.html#attention-superposition . |
| Sonia Joseph. Vit prisma: A mechanistic interpretability library for vision transformers. https://github. com/soniajoseph/vit-prisma , 2023. |
| Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 , arXiv:2001.08361, 2020. URL https://arxiv.org/abs/2001.08361 . |
| E. D. Karnin. A simple procedure for pruning back-propagation trained neural networks. IEEE Transactions on Neural Networks , 1(2):239-242, 1990. doi: 10.1109/72.80236. |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Andrej Karpathy, Justin Johnson, and Li Fei-Fei. Visualizing and understanding recurrent networks. In The Fourth International Conference on Learning Representations , 2016. URL https://arxiv.org/abs/ 1506.02078 . |
| Adam Karvonen, Benjamin Wright, Can Rager, Rico Angell, Jannik Brinkmann, Logan Riggs Smith, Clau- dio Mayrink Verdun, David Bau, and Samuel Marks. Measuring progress in dictionary learning for language model interpretability with board game models. In ICML 2024 Workshop on Mechanistic Interpretability , 2024. URL https://openreview.net/forum?id=qzsDKwGJyB . |
| Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In Doina Precup and Yee Whye Teh (eds.), Proceedings of the 34th International Conference on Machine Learning , volume 70 of Proceedings of Machine Learning Research , pp. 1885-1894. PMLR, 06-11 Aug 2017. URL https://proceedings.mlr.press/v70/koh17a.html . |
| Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In Hal Daumé III and Aarti Singh (eds.), Proceedings of the 37th International Conference on Machine Learning , volume 119 of Proceedings of Machine Learning Research , pp. 5338-5348. PMLR, 13-18 Jul 2020. URL https://proceedings.mlr.press/v119/koh20a.html . |
| Arne Köhn. What's in an embedding? Analyzing word embeddings through multilingual evaluation. In Lluís Màrquez, Chris Callison-Burch, and Jian Su (eds.), Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pp. 2067-2073, Lisbon, Portugal, September 2015. Association for Computational Linguistics. doi: 10.18653/v1/D15-1246. URL https://aclanthology.org/D15-1246 . |
| János Kramár, Tom Lieberum, Rohin Shah, and Neel Nanda. AtP*: An efficient and scalable method for localizing llm behaviour to components. arXiv preprint arXiv:2403.00745 , 2024. URL https://arxiv. org/abs/2403.00745 . |
| R. Krishnan, G. Sivakumar, and P. Bhattacharya. Extracting decision trees from trained neu- ral networks. Pattern Recognition , 32(12):1999-2009, 1999. ISSN 0031-3203. doi: https://doi. org/10.1016/S0031-3203(98)00181-2. URL https://www.sciencedirect.com/science/article/pii/ S0031320398001812 . |
| Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C.J. Burges, L. Bottou, and K.Q. Weinberger (eds.), Advances in Neural Information Processing Systems , volume 25. Curran Associates, Inc., 2012. URL https://proceedings. neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf . |
| Vedang Lad, Wes Gurnee, and Max Tegmark. The remarkable robustness of LLMs: Stages of inference?, 2024. URL https://arxiv.org/abs/2406.19384 . |
| Yair Lakretz, German Kruszewski, Theo Desbordes, Dieuwke Hupkes, Stanislas Dehaene, and Marco Baroni. The emergence of number and syntax units in LSTM language models. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp. 11-20, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1002. URL https://aclanthology.org/N19-1002 . |
| Yair Lakretz, Théo Desbordes, Jean-Rémi King, Benoît Crabbé, Maxime Oquab, and Stanislas Dehaene. Can RNNs learn recursive nested subject-verb agreements? arXiv preprint arXiv:2101.02258 , 2021. URL https://arxiv.org/abs/2101.02258 . |
| Karim Lasri, Tiago Pimentel, Alessandro Lenci, Thierry Poibeau, and Ryan Cotterell. Probing for the usage of grammatical number. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: |
Long Papers) , pp. 8818-8831, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.603. URL https://aclanthology.org/2022.acl-long.603 .
Michael A. Lepori, Thomas Serre, and Ellie Pavlick. Uncovering intermediate variables in transformers using circuit probing. 2023. URL https://arxiv.org/abs/2311.04354 .
David Lewis. Causation. In Tim Crane and Katalin Farkas (eds.), Philosophical Papers II , pp. 159-213. Oxford University Press, 1986.
David Lewis. Causation as influence. The Journal of Philosophy , 97(4):182-197, 2000. ISSN 0022362X. URL http://www.jstor.org/stable/2678389 .
David K. Lewis. Counterfactuals . Blackwell, Malden, Massachusetts, 1973.
Jiwei Li, Will Monroe, and Dan Jurafsky. Understanding neural networks through representation erasure, 2017. URL https://arxiv.org/abs/1612.08220 .
Kenneth Li, Aspen K Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Emergent world representations: Exploring a sequence model trained on a synthetic task. In The Eleventh International Conference on Learning Representations , 2023. URL https://openreview.net/forum?id= DeG07\_TcZvT .
Maximilian Li, Xander Davies, and Max Nadeau. Circuit breaking: Removing model behaviors with targeted ablation. arXiv preprint arXiv:2309.05973 , arXiv:2309.05973, 2024. URL https://arxiv.org/abs/2309. 05973 .
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. Linguistic knowledge and transferability of contextual representations. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp. 10731094, Minneapolis, Minnesota, June 2019a. Association for Computational Linguistics. doi: 10.18653/v1/ N19-1112. URL https://aclanthology.org/N19-1112 .
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692 , 2019b. URL https://arxiv.org/abs/1907.11692 .
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems , NIPS'17, pp. 4768-4777, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
Qing Lyu, Marianna Apidianaki, and Chris Callison-Burch. Towards faithful model explanation in NLP: A survey. Computational Linguistics , 50(2):657-723, 06 2024. ISSN 0891-2017. doi: 10.1162/coli\_a\_00511. URL https://doi.org/10.1162/coli\_a\_00511 .
Weicheng Ma, Kai Zhang, Renze Lou, Lili Wang, and Soroush Vosoughi. Contributions of transformer attention heads in multi- and cross-lingual tasks. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pp. 1956-1966, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021. acl-long.152. URL https://aclanthology.org/2021.acl-long.152 .
Andreas Madsen, Siva Reddy, and Sarath Chandar. Post-hoc interpretability for neural NLP: A survey. ACM Comput. Surv. , 55(8), dec 2022. ISSN 0360-0300. doi: 10.1145/3546577. URL https://doi.org/ 10.1145/3546577 .
Aleksandar Makelov, George Lange, and Neel Nanda. Towards principled evaluations of sparse autoencoders for interpretability and control. arXiv preprint arXiv:2405.08366 , 2024. URL https://arxiv.org/abs/ 2405.08366 .
| Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824 , 2023. URL https://arxiv.org/ abs/2310.06824 . |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv preprint arXiv:2403.19647 , arXiv:2403.19647, 2024. URL https://arxiv.org/abs/2403.19647 . |
| James L. McClelland and David E. Rumelhart. Distributed memory and the representation of general and specific information. Journal of experimental psychology. General , 114 2:159-97, 1985. URL https: //api.semanticscholar.org/CorpusID:7745106 . |
| Thomas McGrath, Matthew Rahtz, Janos Kramar, Vladimir Mikulik, and Shane Legg. The hydra effect: Emergent self-repair in language model computations. arXiv preprint arXiv:2307.15771 , 2023. URL https://arxiv.org/abs/2307.15771 . |
| Kevin Meng, David Bau, Alex J Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems , 2022. URL https://openreview.net/forum?id=-h6WAS6eE4 . |
| Kevin Meng, Arnab Sen Sharma, Alex J Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer. In The Eleventh International Conference on Learning Representations , 2023. URL https://openreview.net/forum?id=MkbcAHIYgyS . |
| Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Circuit component reuse across tasks in transformer language models. In The Twelfth International Conference on Learning Representations , 2024a. URL https://openreview.net/forum?id=fpoAYV6Wsk . |
| Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Talking heads: Understanding inter-layer communication in transformer language models. arXiv preprint arXiv:2406.09519 , 2024b. URL https://arxiv.org/ abs/2406.09519 . |
| Eric J Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling. In Thirty-seventh Conference on Neural Information Processing Systems , 2023. URL https://openreview. net/forum?id=3tbTw2ga8K . |
| Tomas Mikolov, Martin Karafiát, Lukáš Burget, Jan Černocký, and Sanjeev Khudanpur. Recurrent neural network based language model. In Interspeech , pp. 1045-1048, 2010. doi: 10.21437/Interspeech.2010-343. |
| Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 , arXiv:1301.3781, 2013a. URL https://arxiv.org/abs/ 1301.3781 . |
| Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In C.J. Burges, L. Bottou, M. Welling, Z. Ghahra- mani, and K.Q. Weinberger (eds.), Advances in Neural Information Processing Systems , volume 26. Cur- ran Associates, Inc., 2013b. URL https://proceedings.neurips.cc/paper_files/paper/2013/file/ 9aa42b31882ec039965f3c4923ce901b-Paper.pdf . |
| Joseph Miller, Bilal Chughtai, and William Saunders. Transformer circuit faithfulness metrics are not robust. 2024. URL https://arxiv.org/abs/2407.08734 . |
| Raha Moraffah, Mansooreh Karami, Ruocheng Guo, Adrienne Raglin, and Huan Liu. Causal interpretability for machine learning-problems, methods and evaluation. ACM SIGKDD Explorations Newsletter , 22(1): 18-33, 2020. |
| Ari S. Morcos, David G.T. Barrett, Neil C. Rabinowitz, and Matthew Botvinick. On the importance of single directions for generalization. In International Conference on Learning Representations , 2018. URL https://openreview.net/forum?id=r1iuQjxCZ . |
| Michael C. Mozer and Paul Smolensky. Skeletonization: A technique for trimming the fat from a network via relevance assessment. In D. Touretzky (ed.), Advances in Neural Information Processing Systems , vol- ume 1. Morgan-Kaufmann, 1988. URL https://proceedings.neurips.cc/paper_files/paper/1988/ file/07e1cd7dca89a1678042477183b7ac3f-Paper.pdf . |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Aaron Mueller. Missed causes and ambiguous effects: Counterfactuals pose challenges for interpreting neural networks. In ICML 2024 Workshop on Mechanistic Interpretability , 2024. URL https://openreview. net/forum?id=pJs3ZiKBM5 . |
| Aaron Mueller, Yu Xia, and Tal Linzen. Causal analysis of syntactic agreement neurons in multilingual language models. In Antske Fokkens and Vivek Srikumar (eds.), Proceedings of the 26th Conference on Computational Natural Language Learning (CoNLL) , pp. 95-109, Abu Dhabi, United Arab Emirates (Hybrid), December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.conll-1.8. URL https://aclanthology.org/2022.conll-1.8 . |
| Neel Nanda and Joseph Bloom. TransformerLens. https://github.com/TransformerLensOrg/ TransformerLens , 2022. |
| Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models. In Yonatan Belinkov, Sophie Hao, Jaap Jumelet, Najoung Kim, Arya McCarthy, and Hosein Mohebbi (eds.), Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pp. 16-30, Singapore, December 2023. Association for Compu- tational Linguistics. doi: 10.18653/v1/2023.blackboxnlp-1.2. URL https://aclanthology.org/2023. blackboxnlp-1.2 . |
| Clement Neo, Shay B Cohen, and Fazl Barez. Interpreting context look-ups in transformers: Investigating attention-MLP interactions. arXiv preprint arXiv:2402.15055 , 2024. URL https://arxiv.org/abs/ 2402.15055 . |
| Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. In-context learning and induction heads. Transformer Circuits Thread , 2022. URL https://transformer-circuits.pub/ 2022/in-context-learning-and-induction-heads/index.html . |
| Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering Llama 2 via contrastive activation addition. arXiv preprint arXiv:2312.06681 , 2024. URL https: //arxiv.org/abs/2312.06681 . |
| Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin (eds.), Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , pp. 311-318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URL https: //aclanthology.org/P02-1040 . |
| Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In Causal Representation Learning Workshop at NeurIPS 2023 , 2023. URL https://openreview.net/forum?id=T0PoOJg8cK . |
| Gonçalo Paulo, Thomas Marshall, and Nora Belrose. Does transformer interpretability transfer to RNNs? arXiv preprint arXiv:2404.05971 , 2024. URL https://arxiv.org/abs/2404.05971 . |
| Judea Pearl. Causality: Models, Reasoning, and Inference . Cambridge University Press, 2000. |
| Judea Pearl. Direct and indirect effects. In Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence , pp. 411-420. Morgan Kaufmann, 2001. |
| Jeffrey Pennington, Richard Socher, and Christopher Manning. GloVe: Global vectors for word repre- sentation. In Alessandro Moschitti, Bo Pang, and Walter Daelemans (eds.), Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 1532-1543, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1162. URL https://aclanthology.org/D14-1162 . |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Nikhil Prakash, Tamar Rott Shaham, Tal Haklay, Yonatan Belinkov, and David Bau. Fine-tuning enhances existing mechanisms: Acase study on entity tracking. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=8sKcAWOf2D . |
| Linlu Qiu, Liwei Jiang, Ximing Lu, Melanie Sclar, Valentina Pyatkin, Chandra Bhagavatula, Bailin Wang, Yoon Kim, Yejin Choi, Nouha Dziri, and Xiang Ren. Phenomenal yet puzzling: Testing inductive reasoning capabilities of language models with hypothesis refinement. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=bNt7oajl2a . |
| Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019. |
| Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders, 2024. URL https://arxiv.org/abs/2404.16014 . |
| Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. Null it out: Guarding protected attributes by iterative nullspace projection. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pp. 7237-7256, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/ v1/2020.acl-main.647. URL https://aclanthology.org/2020.acl-main.647 . |
| Shauli Ravfogel, Grusha Prasad, Tal Linzen, and Yoav Goldberg. Counterfactual interventions reveal the causal effect of relative clause representations on agreement prediction. In Arianna Bisazza and Omri Abend (eds.), Proceedings of the 25th Conference on Computational Natural Language Learning , pp. 194- 209, Online, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.conll-1.15. URL https://aclanthology.org/2021.conll-1.15 . |
| Shauli Ravfogel, Francisco Vargas, Yoav Goldberg, and Ryan Cotterell. Adversarial concept erasure in kernel space. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pp. 6034-6055, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.405. URL https://aclanthology.org/2022.emnlp-main.405 . |
| Abhilasha Ravichander, Yonatan Belinkov, and Eduard Hovy. Probing the probing paradigm: Does probing accuracy entail task relevance? In Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty (eds.), Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pp. 3363-3377, Online, April 2021. Association for Computational Linguistics. doi: 10.18653/v1/ 2021.eacl-main.295. URL https://aclanthology.org/2021.eacl-main.295 . |
| Atul Rawal, Adrienne Raglin, Danda B. Rawat, Brian M. Sadler, and James McCoy. Causality for trust- worthy artificial intelligence: Status, challenges and perspectives. ACM Comput. Surv. , may 2024. ISSN 0360-0300. doi: 10.1145/3665494. URL https://doi.org/10.1145/3665494 . |
| Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. COMET: A neural framework for MT evaluation. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 2685-2702, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.213. URL https://aclanthology.org/2020.emnlp-main.213 . |
| Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "Why should I trust you?": Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on |
| Knowledge Discovery and Data Mining , KDD '16, pp. 1135-1144, New York, NY, USA, 2016a. Association for Computing Machinery. ISBN 9781450342322. doi: 10.1145/2939672.2939778. URL https://doi.org/ 10.1145/2939672.2939778 . |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Model-agnostic interpretability of machine learn- ing, 2016b. URL https://arxiv.org/abs/1606.05386 . |
| Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Anchors: High-precision model-agnostic expla- nations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence , AAAI'18/IAAI'18/EAAI'18. AAAI Press, 2018. ISBN 978-1-57735- 800-8. |
| James M. Robins and Sander Greenland. Identifiability and exchangeability for direct and indirect effects. Epidemiology , 3(2):143-155, 1992. ISSN 10443983. URL http://www.jstor.org/stable/3702894 . |
| David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back- propagating errors. Nature , 323(6088):533-536, 1986. doi: 10.1038/323533a0. URL https://doi.org/ 10.1038/323533a0 . |
| Tilman Räuker, Anson Ho, Stephen Casper, and Dylan Hadfield-Menell. Toward transparent AI: A survey on interpreting the inner structures of deep neural networks, 2023. URL https://arxiv.org/abs/2207. 13243 . |
| Hassan Sajjad, Nadir Durrani, and Fahim Dalvi. Neuron-level interpretation of deep NLP models: A survey. Transactions of the Association for Computational Linguistics , 10:1285-1303, 2022. doi: 10.1162/tacl_ a_00519. URL https://aclanthology.org/2022.tacl-1.74 . |
| Hassan Sajjad, Fahim Dalvi, Nadir Durrani, and Preslav Nakov. On the effect of dropping layers of pre- trained transformer models. Computer Speech & Language , 77:101429, 2023. |
| Naomi Saphra, Eve Fleisig, Kyunghyun Cho, and Adam Lopez. First tragedy, then parse: History re- peats itself in the new era of large language models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pp. 2310-2326, Mexico City, Mexico, June 2024. Association for Computational Linguistics. URL https://aclanthology.org/ 2024.naacl-long.128 . |
| Tamar Rott Shaham, Sarah Schwettmann, Franklin Wang, Achyuta Rajaram, Evan Hernandez, Jacob An- dreas, and Antonio Torralba. A multimodal automated interpretability agent. In Forty-first International Conference on Machine Learning , 2024. URL https://openreview.net/forum?id=mDw42ZanmE . |
| Lee Sharkey, Dan Braun, and Beren Millidge. Taking features out of superposition with sparse autoencoders, 2023. URL https://www.alignmentforum.org/posts/z6QQJbtpkEAX3Aojj/ interim-research-report-taking-features-out-of-superposition . Accessed: 2023-05-10. |
| Arnab Sen Sharma, David Atkinson, and David Bau. Locating and editing factual associations in Mamba. arXiv preprint arXiv:2404.03646 , 2024. URL https://arxiv.org/abs/2404.03646 . |
| Xing Shi, Inkit Padhi, and Kevin Knight. Does string-based neural MT learn source syntax? In Jian Su, Kevin Duh, and Xavier Carreras (eds.), Proceedings of the 2016 Conference on Empirical Methods in Nat- ural Language Processing , pp. 1526-1534, Austin, Texas, November 2016. Association for Computational Linguistics. doi: 10.18653/v1/D16-1159. URL https://aclanthology.org/D16-1159 . |
| Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034 , arXiv:1312.6034, 2014. URL https://arxiv.org/abs/1312.6034 . |
| Chandan Singh, Jeevana Priya Inala, Michel Galley, Rich Caruana, and Jianfeng Gao. Rethinking terpretability in the era of large language models. arXiv preprint arXiv:2402.01761 , 2024a. https://arxiv.org/abs/2402.01761 . | in- URL |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Shashwat Singh, Shauli Ravfogel, Jonathan Herzig, Roee Aharoni, Ryan Cotterell, and Kumaraguru. Representation surgery: Theory and practice of affine steering, 2024b. //arxiv.org/abs/2402.09631 . | Ponnurangam URL https: |
| Divyansh Srivastava, Tuomas Oikarinen, and Tsui-Wei Weng. Corrupting neuron explanations of deep visual features. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 1877-1886, 2023. | Divyansh Srivastava, Tuomas Oikarinen, and Tsui-Wei Weng. Corrupting neuron explanations of deep visual features. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 1877-1886, 2023. |
| Hendrik Strobelt, Sebastian Gehrmann, Hanspeter Pfister, and Alexander M Rush. LSTMVis: A tool for visual analysis of hidden state dynamics in recurrent neural networks. IEEE Transactions on Visualization and Computer Graphics , 24(1):667-676, 2017. | Hendrik Strobelt, Sebastian Gehrmann, Hanspeter Pfister, and Alexander M Rush. LSTMVis: A tool for visual analysis of hidden state dynamics in recurrent neural networks. IEEE Transactions on Visualization and Computer Graphics , 24(1):667-676, 2017. |
| Varshini Subhash, Zixi Chen, Marton Havasi, Weiwei Pan, and Finale Doshi-Velez. What makes a good explanation?: A harmonized view of properties of explanations. In Progress and Challenges in Building Trustworthy Embodied AI , 2022. URL . | Varshini Subhash, Zixi Chen, Marton Havasi, Weiwei Pan, and Finale Doshi-Velez. What makes a good explanation?: A harmonized view of properties of explanations. In Progress and Challenges in Building Trustworthy Embodied AI , 2022. URL . |
| Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 , ICML'17, pp. 3319-3328. JMLR.org, 2017. | Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 , ICML'17, pp. 3319-3328. JMLR.org, 2017. |
| Aaquib Syed, Can Rager, and Arthur Conmy. Attribution patching outperforms automated circuit discovery. In NeurIPS Workshop on Attributing Model Behavior at Scale , 2023. URL https://openreview.net/ | Aaquib Syed, Can Rager, and Arthur Conmy. Attribution patching outperforms automated circuit discovery. In NeurIPS Workshop on Attributing Model Behavior at Scale , 2023. URL https://openreview.net/ |
| Alex Tamkin, Mohammad Taufeeque, and Noah D. Goodman. Codebook features: Sparse and discrete interpretability for neural networks. 2023. URL https://arxiv.org/abs/2310.17230 . | Alex Tamkin, Mohammad Taufeeque, and Noah D. Goodman. Codebook features: Sparse and discrete interpretability for neural networks. 2023. URL https://arxiv.org/abs/2310.17230 . |
| Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Cal- lum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosemanticity: Ex- tracting interpretable features from claude 3 sonnet. Transformer Circuits Thread , 2024. URL https: //transformer-circuits.pub/2024/scaling-monosemanticity/index.html . | Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Cal- lum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosemanticity: Ex- tracting interpretable features from claude 3 sonnet. Transformer Circuits Thread , 2024. URL https: //transformer-circuits.pub/2024/scaling-monosemanticity/index.html . |
| Emmanouil Theodosis and Demba Ba. Learning silhouettes with group sparse autoencoders. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp. 1-5, 2023. doi: 10.1109/ICASSP49357.2023.10095958. | Emmanouil Theodosis and Demba Ba. Learning silhouettes with group sparse autoencoders. In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp. 1-5, 2023. doi: 10.1109/ICASSP49357.2023.10095958. |
| Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models. arXiv preprint arXiv:2310.15154 , 2023. | Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models. arXiv preprint arXiv:2310.15154 , 2023. |
| Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=AwyxtyMwaG . | Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. Function vectors in large language models. In The Twelfth International Conference on Learning Representations , 2024. URL https://openreview.net/forum?id=AwyxtyMwaG . |
| Mycal Tucker, Peng Qian, and Roger Levy. What if this modified that? Syntactic interventions with counterfactual embeddings. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Find- ings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pp. 862-875, Online, Au- gust 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-acl.76. URL https://aclanthology.org/2021.findings-acl.76 . | Mycal Tucker, Peng Qian, and Roger Levy. What if this modified that? Syntactic interventions with counterfactual embeddings. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Find- ings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pp. 862-875, Online, Au- gust 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-acl.76. URL https://aclanthology.org/2021.findings-acl.76 . |
| Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248 , 2023. URL https://arxiv.org/abs/2308.10248 . | Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248 , 2023. URL https://arxiv.org/abs/2308.10248 . |
- F.-Y. Tzeng and K.-L. Ma. Opening the black box - Data driven visualization of neural networks. In VIS 05. IEEE Visualization, 2005. , pp. 383-390, 2005. doi: 10.1109/VISUAL.2005.1532820.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper\_files/paper/ 2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf .
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems , volume 33, pp. 12388-12401. Curran Associates, Inc., 2020. URL https://proceedings.neurips. cc/paper\_files/paper/2020/file/92650b2e92217715fe312e6fa7b90d82-Paper.pdf .
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations , 2023. URL https://openreview.net/forum?id=NpsVSN6o4ul .
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mechanistically explains long-context factuality. arXiv preprint arXiv:2404.15574 , 2024a. URL https://arxiv.org/ abs/2404.15574 .
Xing Wu, Shaoqi Peng, Jingwen Li, Jian Zhang, Qun Sun, Weimin Li, Quan Qian, Yue Liu, and Yike Guo. Causal inference in the medical domain: A survey. Applied Intelligence , pp. 1-24, 2024b.
Zhengxuan Wu, Atticus Geiger, Thomas Icard, Christopher Potts, and Noah Goodman. Interpretability at scale: Identifying causal mechanisms in alpaca. In Thirty-seventh Conference on Neural Information Processing Systems , 2023. URL https://openreview.net/forum?id=nRfClnMhVX .
Zhengxuan Wu, Atticus Geiger, Aryaman Arora, Jing Huang, Zheng Wang, Noah Goodman, Christopher Manning, and Christopher Potts. pyvene: A library for understanding and improving PyTorch models via interventions. In Kai-Wei Chang, Annie Lee, and Nazneen Rajani (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations) , pp. 158-165, Mexico City, Mexico, June 2024c. Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-demo.16. URL https: //aclanthology.org/2024.naacl-demo.16 .
Matthew D. Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars (eds.), Computer Vision - ECCV 2014 , pp. 818-833, Cham, 2014. Springer International Publishing. ISBN 978-3-319-10590-1.
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods. In The Twelfth International Conference on Learning Representations , 2024. URL https: //openreview.net/forum?id=Hf17y6u9BC .
Zexuan Zhong, Zhengxuan Wu, Christopher D Manning, Christopher Potts, and Danqi Chen. MQuAKE: Assessing knowledge editing in language models via multi-hop questions. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pp. 15686-15702, 2023.
## A Types of interventions
Recall that to compute the indirect effect, we must replace the activation z 1 of a component z with some counterfactual activation z 2 . In effect, the goal of an intervention is to reveal a neuron for whom swapping z 1 with z 2 will produce a large effect on the output metric. There are many ways to derive z 2 ; some of these depend on x , some depend on the expected output, and some depend on neither. We describe each of these classes of interventions, and list their pros and cons.
Input-dependent interventions. If one cares about neurons that are sensitive to a specific contrast, then one can use input-dependent interventions (i.e., interventions where z 2 depends on x ). For example, assume our target task is subject-verb agreement. Given an input x = 'The key ', we want to locate neurons that increase the probability difference m = p ( is ) -p ( are ). In this case, we can obtain z 1 by running x through model M in a forward pass (denoted M x ( )) and storing the activation of component(s) a i (which could be a neuron, for example). We can then obtain z 2 by running M x ( ′ ), where x ′ is a minimally different input that swaps the answer; here, x ′ would be 'The keys '. This type of intervention preserves all example-specific information, and varying only the grammatical number of the subject. This makes this intervention precise: it will only reveal neurons for which swapping grammatical number and nothing else will significantly affect m .
This method is easily controllable and reveals components targeted to a specific phenomenon; in other words, this is a high-precision intervention. However, humans must carefully curate highly controlled input pairs in which only one phenomenon is varied across x and x ′ . Additionally, input-dependent interventions work best for (and arguably, are only principled given) binary contrasts: we contrast two minimally different inputs, which isolates neurons sensitive only to the difference between items in the pair. When working with categorical or ordinal variables, it is not immediately clear how to construct x ′ to recover all relevant components. Additionally, it does not recover all task-relevant components, but rather those related to the contrast between x and x ′ ; in other words, this is a low-recall method. For instance, Vig et al. (2020) showcases the requirement of enumerating through all possible gender pronouns and personas related to a specific gender to measure the specific phenomenon, even noting that full generalizability to all grammatical gender pronouns is difficult. Furthermore, such interventions can be privy to unreliable explanations as shown in Srivastava et al. (2023) wherein the input data can be corrupted to manipulate the concept assigned to a neuron. Hence, input-dependent interventions may require additional safeguards to ensure safety and fairness in critical real-life applications.
Class-dependent interventions. In contrast to input-dependent interventions, which locate components sensitive to a specific phenomenon, class-dependent interventions define a single intervention to produce some behavior associated with a class of outputs. For example, Li et al. (2024) learn an ablation mask over the computational graph of a language model to prevent the model from producing toxic content; here, the classes are toxic and not toxic , and the intervention is the same regardless of the input.
Class-dependent interventions provide a single flexible intervention that works for any given input. However, they require a dataset of input-label pairs that can be used to learn the interventions. This is often timeconsuming and can lead to errors as many labels we care about are hard to quantify (e.g., bias or toxicity).
Class- and input-independent interventions. This type of intervention does not rely on either the input or a class label, and its goal is generally to fully remove the information encoded by a mediatorregardless of whether the information is task-relevant. A common ablation type is zero ablations , where the activation of a component is set to 0. This is not entirely principled, since 0 has no inherent meaning in an activation-for example, a neuron's default activation may be non-zero, whereas 0 itself is out of distribution relative to what the model expects. A more principled ablation type is a mean ablation , where the neuron's activation is set to its mean value over some distribution-either task-specific data or general text data. A resampling ablation is a special case of mean ablations where the sample size is 1.
This is a more general intervention type that can be run without access to contrastive input/output pairs, and without labeled inputs. It allows us to tell whether any of the information in a mediator is necessary for a model to perform the task, but it may also affect other information in unanticipated ways; in other words, it has high recall and low precision relative to other intervention types. It also may cause performance on a task to drop in a way that reveals spurious mediators, rather than mediators that are conceptually relevant-for example, ablating a neuron that detects the word 'dog' may reduce the probability of the correct verb form 'is' over the incorrect verb form 'are', but this is a highly specific neuron that does not on its own reveal general information about how models process subject-verb agreement. | null | [
"Aaron Mueller",
"Jannik Brinkmann",
"Millicent Li",
"Samuel Marks",
"Koyena Pal",
"Nikhil Prakash",
"Can Rager",
"Aruna Sankaranarayanan",
"Arnab Sen Sharma",
"Jiuding Sun",
"Eric Todd",
"David Bau",
"Yonatan Belinkov"
]
| 2024-08-02T17:51:42+00:00 | 2024-08-02T17:51:42+00:00 | [
"cs.LG",
"cs.AI"
]
| The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability | Interpretability provides a toolset for understanding how and why neural
networks behave in certain ways. However, there is little unity in the field:
most studies employ ad-hoc evaluations and do not share theoretical
foundations, making it difficult to measure progress and compare the pros and
cons of different techniques. Furthermore, while mechanistic understanding is
frequently discussed, the basic causal units underlying these mechanisms are
often not explicitly defined. In this paper, we propose a perspective on
interpretability research grounded in causal mediation analysis. Specifically,
we describe the history and current state of interpretability taxonomized
according to the types of causal units (mediators) employed, as well as methods
used to search over mediators. We discuss the pros and cons of each mediator,
providing insights as to when particular kinds of mediators and search methods
are most appropriate depending on the goals of a given study. We argue that
this framing yields a more cohesive narrative of the field, as well as
actionable insights for future work. Specifically, we recommend a focus on
discovering new mediators with better trade-offs between human-interpretability
and compute-efficiency, and which can uncover more sophisticated abstractions
from neural networks than the primarily linear mediators employed in current
work. We also argue for more standardized evaluations that enable principled
comparisons across mediator types, such that we can better understand when
particular causal units are better suited to particular use cases. |
2408.01417v1 | ## Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs
## Yilun Hua and Yoav Artzi
Department of Computer Science and Cornell Tech Cornell University { yilunhua, yoav } @cs.cornell.edu
## Abstract
Humans spontaneously use increasingly efficient language as interactions progress, by adapting and forming ad-hoc conventions. This phenomenon has been studied extensively using reference games, showing properties of human language that go beyond relaying intents. It remains unexplored whether multimodal large language models (MLLMs) similarly increase communication efficiency during interactions, and what mechanisms they may adopt for this purpose. We introduce ICCA, an automated framework to evaluate such conversational adaptation as an in-context behavior in MLLMs. We evaluate several state-of-the-art MLLMs, and observe that while they may understand the increasingly efficient language of their interlocutor, they do not spontaneously make their own language more efficient over time. This latter ability can only be elicited in some models (e.g., GPT-4) with heavy-handed prompting. This shows that this property of linguistic interaction does not arise from current training regimes, even though it is a common hallmark of human language.
## 1 Introduction
Human interlocutors adapt to each other during interactions, developing increasingly efficient ways to refer to concepts and objects. Hawkins et al. (2020b) exemplify this via communication between a nurse and a bed-ridden patient at home. Initially, the patient may refer to a medicine with the medicine for my back pain in a small blue medicine bottle ... , but after a week of care, they are likely to just ask for their back meds . This increase in efficiency relies on the interlocutors forming ad-hoc linguistic conventions: the mutually understood, concise phrases to communicate referential content. This phenomenon has been repeatedly observed and characterized in controlled studies using repeated reference games (Figure 1; e.g., Krauss & Weinheimer, 1964; Brennan & Clark, 1996; Hawkins et al., 2020a).
Westudy this ability in multimodal large language models (MLLMs). LLMs and MLLMs are well positioned to acquire this behavior and display it spontaneously in interactions. They are trained on large amounts of human language data, in which this behavior is common and the history of an ongoing interaction is often retained, thereby explicitly keeping the information needed at hand. Beyond the scientific question, such ad-hoc adaptation has significant application impacts: enabling more natural interactions, reducing the costs involved in conversations (e.g., using shorter utterances to communicate the same amount of information), and increasing the accuracy of relaying intent.
We propose ICCA, 1 an automated framework to evaluate and characterize the ability of models to form ad-hoc conventions. ICCA uses a corpus of human-human reference game interactions, allowing for completely automated evaluation, which does not require further human interaction, making it easy to deploy for the analysis of new models. The interaction follows the standard repeated reference game setup (Clark & Wilkes-Gibbs, 1986), where a speaker refers to an image within a shared context of images, and a listener resolves the
1 ICCA stands for In-context Conversational Adaptation.
Figure 1: Illustration of a reference game. The speaker (blue) and listener (orange) observe a shared set of images. 2 The interaction progresses in six repetitions, each includes a trial for every context image. In each trial, the speaker describes a target image, and the listener has to select the correct target given the description only. For simplicity, this figure omits the feedback on listener actions. This interaction illustrates some of the effects of convention formation: the descriptions become shorter as the interaction progresses, and lexical choices converge to a subset of the words used in earlier repetitions.

reference to select one of the images, ideally the one originally referred to. Figure 1 illustrates the scenario. We focus on in-context adaptation - as the interaction progresses, the entire history is retained in-context. Core to our approach is comparing the changes in model behavior, either as speaker or listener, throughout an interaction to the changes observed in humans. We measure different properties that have been shown to be influenced by convention formation: utterance length, lexical convergence, and selection accuracy.
We apply our approach to five representative MLLMs: IDEFICS (Huggingface, 2023), LLaVa1.5 (Liu et al., 2023a), GPT4-vision (OpenAI et al., 2024), Gemini 1.0 Pro Vision (Google, 2023), and Claude 3 opus (Anthropic, 2024). We find that all models struggle to spontaneously introduce conventions and adapt as speakers. Prompt engineering an explicit in-context instruction specific to the reference game scenario can address this to some degree. The strongest models (GPT4, Gemini, and Claude) can then gradually use shorter messages (gaining lexical efficiency) but still struggle with convergence or stability, which hinders the emergence of truly efficient communication. When acting as a listener, GPT4 displays adaptation trends close to humans, improving its accuracy as the interaction progresses, while other models show this behavior to a lesser degree or only under some simplified setups. Overall, we show that while today's MLLMs may passively understand the evolving language of their interlocutor, the ability to adapt their own language for efficient communication does not naturally emerge from their training or instruction-tuning. This outlines important future research problems. We release ICCA under the MIT license at https://github.com/lil-lab/ICCA .
## 2 Background and Related Work
Repeated Reference Games A reference game is an interaction where a speaker and a listener (i.e., a dyad) interact over a shared context. The shared context is a set of images. The speaker describes a target image. The target designation is only revealed to the speaker. The listener has to select an image following the speaker's description. Each participant sees the images in a different order, so they cannot use position information to communicate the referent. Reference games have been used extensively in the study of computational models, including recently to evaluate visual abstraction (Ji et al., 2022) and conversational aptitude (Chalamalasetti et al., 2023).
A repeated reference game (Figure 1) includes multiple repetitions. Each repetition has one trial for each image in the shared context. The listener receives feedback after every
2 In Figure 1, we show the shared context only once for compactness. In our experiments, we shuffle and show the context for each trial, but also experiment with showing it only once.
trial, which indicates the correct selection. The repetition and feedback allow the dyad to form message agreements over the repeating stimuli (i.e., the speaker would naturally use gradually shorter but related messages across repetitions, and the listener learns what they refer to). ICCA's repeated reference games are developed based on the setup and data from Hawkins et al. (2020b). The shared context includes four images, and there are six repetitions, giving a total of 24 trials. The order of images is shuffled across the trials. We refer to this as the standard setup . Hawkins et al. (2020b) only uses this standard setup . Beyond this standard setup, we design variants to further disentangle the types and causes of model failures for in-context LLM adaptation (Section 4 and Section 5).
Ad-hoc Adaptation in Interactions Existing literature shows that humans are inclined to reduce the effort needed to convey their intended information and for their audience to comprehend it, leading to efficient communication (e.g., Zipf, 1949; Gibson et al., 2019; Yin et al., 2024). When human individuals interact through dialogue, this is manifested by developing and using ad-hoc linguistic conventions. This phenomenon has been observed with repeated reference games (Krauss & Weinheimer, 1964; 1966; Clark & Wilkes-Gibbs, 1986; Hawkins et al., 2020a), and related interaction scenarios (Haber et al., 2019). Studies have also shown various properties of these conventions, such as arbitrariness, stability, stickiness, and convergence (Lewis, 1969; Brennan & Clark, 1996; Markman & Makin, 1998; Hawkins et al., 2020a; Eliav et al., 2023). This adaptation was modeled with the pragmatic rational speech act model (RSA; Goodman & Frank, 2016), leading to development of models that replicate this behavior in reference games (e.g., Monroe et al., 2017; McDowell & Goodman, 2019; White et al., 2020) and use it to improve model performance on other tasks (e.g., Andreas & Klein, 2016; Fried et al., 2018). Adaptation was studied beyond reference games, showing how the complexity of the scenario influences how conventions manifest in the language (Effenberger et al., 2021).
Ad-hoc conventions are a particular instantiation of the broader phenomenon of common ground, which is defined as the mutually recognized shared information between the participants of a conversation (Clark & Brennan, 1991; Lewis, 1969; Stalnaker, 2002). Common ground has been studied extensively, with focus on both human cognition (Clark, 1996; Horton & Gerrig, 2016) and machine reasoning (Cohen & Levesque; Grosz & Sidner; Traum, 1994; Del Tredici et al., 2022; Shaikh et al., 2024; Andukuri et al., 2024; Testoni & Fern´ndez, a 2024).
Model Adaptation Adapting models during an interaction to improve communication efficiency or success is relatively understudied. Hawkins et al. (2020b) proposes a continual learning method for CNN-RNN models to gain communication efficiency in repeated reference games through continual weight updates. Zhu et al. (2021) proposes explicitly training models for ad-hoc adaptation through meta-learning. We focus on the in-context capabilities of LLMs and MLLMs, which offer an update-free route for adaptation that is particularly compelling given the costs of updating large models. Our use of in-context learning differs from how this mechanism is usually used either by providing instructions (Ouyang et al., 2022) or few-shot examples (Brown et al., 2020). While reference games can be seen as related to the few-shot approach, ad-hoc adaptation is not about replicating patterns, but showing change and adaptation over time.
## 3 The ICCA Framework
ICCA uses a dataset of human-human interactions, and allows to easily customize different parts of the interaction. This flexibility enables different research questions. For example, in Section 5, we customize the interaction structure to analyze how well models handle long interactions with multiple images interleaved in them. ICCA supports studies with the model acting either as speaker or listener, and includes several metrics to track different properties of adaptation during the interaction.
ICCA is fully automated and easily applicable to new MLLMs. Our design does not require collecting new data or human studies, but instead uses Hawkins et al. (2020b)'s human-human interaction data to simulate a human interacting with an MLLM. Each
interaction in the dataset was collected under the standard setup (Section 2) and uses a visually challenging reference context, consisting of four similar images (Figure 1). The dataset contains 54 human-human interactions, which we incorporate into ICCA.
Arepeated reference game interaction R is a sequence of tuples ⟨ ( Ci , c i , s i , l i , f i ) ⟩ n i = 1 , where Ci is the set of images forming the reference context, c i is the index of the target image, s i is the speaker utterance, l i is the listener selection, and f i is the feedback based on the listener's selection. At every trial t , with the evaluated model as either the listener or speaker, ICCA constructs the MLLM prompt from an instruction text I , the history (i.e., all prior trials R [ : t ] ), and the stimuli for the current trial with a user-defined pre-processing function F . Upon receiving the model's response, ICCA computes the feedback f t to help the next trial.
The function F prepares the prompt depending on the experiment, and is key to the flexibility of ICCA. For example, when evaluating a model as a listener under the standard setup, the function input would be F I ( , R [ : t ] , Ct , st ) , and it would format and concatenate all the elements in order. Figure 7 in the appendix shows an example prompt. ICCA allows to easily modify this standard setup, for example by processing the data such that F drops all reference contexts except C 1 , thereby creating a simpler input where the images appear only once at the beginning of the interaction.
ICCA simulates the interlocutor of the model evaluated either with a deterministic counterpart or by having another model take the role. A deterministic speaker outputs the messages from recorded human interactions dataset, showing predetermined, realistic trajectories of message shortening over time, but it does not adapt its language based on the listener's selections. It can be considered as a 'convention comprehension' task, potentially more challenging due to the non-adapting speaker messages. We use this simulated speaker for our model-as-listener experiments (Section 5) because it exposes the model listener to behaviors and linguistic conventions naturally occurring in human interactions. Inversely, for our speaker experiments (Section 4), we use a high-performance model listener (GPT4), which we observe to have performance similar to human listeners (Section 5).
We evaluate model behavior with adaptations of the metrics used in human studies with reference games (Hawkins et al., 2020a;b). For listener experiments, we follow Hawkins et al. (2020b) and report the average accuracy in each repetition. Speaker experiments are evaluated using several metrics. We report the average message length and the listener's accuracy in each repetition. Additionally, we evaluate the similarity between corresponding messages from consecutive repetitions. While this was done using GloVe embeddings (Pennington et al., 2014) in past work (Hawkins et al., 2020a), we design a new metric called Word Novelty Rate (WNR), which is sensitive to exact word choices. WNR is a modified word error rate that only counts insertions and substitutions, and ignores deletions. It is motivated by how people naturally drop words from their messages as the interaction progresses (Hawkins et al., 2020a), whereas additions and substitutions of words often reflect important changes in information based on our observations. Compared to GloVe, WNRis more sensitive to lexical inconsistencies that can increase the listener's cognitive load. Appendix A presents more details of our metrics, including a comparison of WNR and embedding-based similarity metrics and a variant of WNR that is not normalized by message length (referred to as Word Novelty Distance).
## 4 Model-as-speaker Experiments
We study model behavior as speaker with five state-of-the-art vision MLLMs: IDEFICS80b-instruct, 3 LLaVa-1.5-13b, GPT4-vision, Gemini 1.0 Pro Vision, and Claude 3 opus. Throughout all speaker experiments, we customize the data to only show the referential context once at the beginning of the interaction, so there is no shuffling of context throughout the interaction. We engineer prompts for each model individually to best evaluate its capability. We use GPT4 as the listener. It exhibits high performance in our listener experiments (Section 5), especially when the context appears only once at the beginning,
3 IDEFICS is an open-source reproduction of Flamingo (Alayrac et al., 2022).
Figure 2: Speaker experiments. Margins of errors are bootstrapped 95% CIs.
so it is a suitable substitute for a human listener in this study. Appendix A.3 provides implementation details.
Wedesign four speaker variants by modifying the instruction I . The variants were developed throughout our experiments, by observing the difficulty of models to present patterns similar to human linguistic behavior. The variants instruct the model to display the convention formation behavior observed in human speakers in increasingly explicit and specific ways:
- S1: Standard Speaker The standard speaker setup (Section 2). The model speaker only receives the basic game instruction, with no mention of communication efficiency. Figure 6 in the appendix shows an example prompt.
- S2: Gricean Instruction Arelatively light-handed and general way to introduce the expected convention formation behavior is to explicitly instruct the model to follow the Gricean quantity maxim. This kind of instruction is not specific to reference games, and does not explicitly mention message length. Its focus is information, and it entails that cooperative interlocutors would provide enough information to identify the referent but would not make the message more informative than necessary. We add additional instructions based on the maxim and further instruct the model to think about how the amount of information needed may change as more trials are completed and based on the listener's performance in previous trials . 4,5
- S3: Explicit Instruction We instruct the model to explicitly reduce message length as the interaction progresses. Unlike S1 and S2, this instruction is specific to reference games, as language adaptation in other scenarios is not necessarily accompanied by length reduction (Effenberger et al., 2021). We add to S1 an explicit instruction to
4 The models did not show substantial improvement without this additional instruction.
5 Not the exact prompt used for experiments; shortened and revised for illustrative purposes.
reduce utterance length: as more trials are completed and as the listener understands you better, gradually condense your messages, making them shorter and shorter every trial . 5
- S4: Explicit Instruction + Consistency Request Convention formation in reference games is not only characterized by reduction in utterance length, but also by lexical consistency. This variant explicitly instructs the model to follow this pattern. Similar to S3, it is specific to the repeated reference game setup and its use of a repeating context. We add to S3 the instruction: when creating a shorter message for an image, try to extract salient tokens from the previous messages for this image rather than introducing new words. The short messages should still allow the listener to choose the target correctly. For each image, when you reach a message that cannot be further shortened, you should keep using that message for the rest of the game . 5
Figure 2 shows the results for all variants, along with properties of the human messages from Hawkins et al. (2020b), which were collected using the standard setup. We report mean message length, WNR, and listener accuracy for each repetition. Overall, all models fail to spontaneously improve communication efficiency. It is only with fairly heavy-handed instruction that GPT4, Gemini, and Claude show adaptation trends similar to humans.
Variant S1 shows that without any explicit instruction, the models show trends that are far from human behavior. GPT4, Gemini, and Claude generate longer utterances in later repetitions. IDEFICS and LLaVa maintain consistent message lengths. But, upon close inspection, we observe they simply tend to repeat previously used messages for the same image. This explains their very low and almost constant WNR. We analyze this further in Section 6. Also, the messages of IDEFICS and LLaVa are less effective in distinguishing the target images, as shown by the lower listener accuracies. This demonstrates the inability of these models to correct their behavior based on feedback. No models show WNR trends similar to humans. GPT4, Gemini, and Claude constantly introduce new words as the game progresses, as shown by higher WNR curves, even though we do not use token sampling for decoding. Gemini shows a downward trend, but achieves this by the undesirable practice of making its messages longer every trial while making a relatively constant number of word insertions or changes, so a bigger portion of the message is maintained. 6
Gricean instruction (S2) leads GPT4 and Claude to reduce message length over time, though GPT4's reduction is far from humans'. Both models have WNR curves significantly higher than humans. As their messages shorten, they still frequently introduce new words and do not stabilize the messages, a behavior adverse to communication efficiency. We further discuss this issue with S3, where more models display this issue.
S3's explicit instruction has no impact on IDEFICS and LLaVa. Both continue repeating messages, failing to follow the instructions. Gemini and GPT4 show decreasing message length trends similar to humans but still have longer messages than humans throughout. Claude eventually produces messages as short as humans but starts with much longer messages than other models. All models showing message shortening frequently introduce new words as they shorten the messages. Even when the message is too short to be condensed, the models may adopt new words next time without changing the message length. Figure 8 in the appendix exemplifies these behaviors. Such behaviors deviate from the stability property of conventions and the observation that human messages show high consistency and convergence. The gap between the WNR curves of these models and humans illustrates this issue. While these models show increasing lexical efficiency, the use of new words reduces communication efficiency, burdening the listener to reason about the words that did not appear the last time the image was referenced. We further discuss this issue in Section 6.
S4 addresses the consistency issue but requires further explicit instruction. The final prompt elicits from GPT4, Gemini, and Claude both length reduction and message convergence, as observed with humans. However, the S4 prompt is very specific to ICCA's setup and does not generalize beyond reference games. Heavy-handed prompt interventions like this are
6 This is due WNR's length-normalization, which is critical to reflect similarity (Appendix A.2).
also known to cause unintended model behaviors (Shaikh et al., 2024). Prompt engineering is not likely to be the solution.
## 5 Model-as-listener Experiments
Listener experiments follow a setup similar to the speaker experiments as far as models and prompt optimization (Section 4). Gemini, LLaVa, and Claude cap the number of input images, limiting their use in some of our listener variants. Overall, we design four main variants, each implemented through the pre-processing function F . Our design process is iterative, with some variants designed based on the behavior observed with earlier ones. Throughout the listener variants, we keep the instruction I largely constant and about the role of the listener. We vary how we display the referential context.
The listener action space is more limited, simply requiring the model to select the referenced image. We focus on evaluating model accuracy, similar to how listener behavior is characterized in human studies. Figure 3 visualizes the behaviors we observe. We also include human listener accuracy trends as reference to model accuracies.
The starting point for the listener study is the standard reference game setup (Section 2):
- L1: Standard Listener Images are shuffled and re-displayed for each trial, so each image will potentially have a new label relative to previous trials.
L1 requires a growing number of images in the prompt as the interaction progresses. With six repetitions of four trials and a context of four images, the maximum number of images in the prompt at the end of the interaction is 96. Gemini, LLaVa, and Claude can take at most 16, 4, and 20 images, so we only use GPT4 and IDEFICS with L1.
We expect an effective model to exploit the conversation history to reason about the human speaker's conventionalized ways of speaking. Even if the model starts with low accuracy, it has the opportunity to improve because the prompt at later stages includes feedback for its choices, and as the messages conventionalize, later messages for an image are often exact repetitions, albeit with the referential context shuffled.
Both GPT4 and IDEFICS do significantly worse than humans (Figure 3, left). As expected, humans demonstrate strong performance to start with, and show an upward trend in accuracy, as the interlocutors adapt to each other. GPT4 is significantly worse than humans, though performing fairly well. It shows a marginal improvement trend (88.9% → 92.5% in repetition 5), but it is not significant, and weakens in the last repetition (91.2%). IDEFICS is much worse immediately in the beginning (46.8%), and rather than improving, its performance deteriorates as the interaction progresses, reaching random chance in the later trials. This happens even though it is receiving an increasing amount of information that should allow it to improve its performance. A possible cause for this trend is the dramatic increase in the prompt size, especially as more and more images are added, as the interaction progresses. We further discuss this issue and its potential causes in Section 6.
## 5.1 History and Context Impact
Following the observations with L1, we design three variants with simplified referential contexts and history to better understand how well the models handle the interaction history and the referential context:
- L2: No History Each of the 24 trials is given to the model in isolation, without any history. The model input includes the context of four images and the speaker utterance, as well as the basic game instruction. This variant reveals the extent to which the model can reason about the ad-hoc conventions formed in repeated human-human interaction without access to the history in which they were formed.
- L3: Images Once A potential challenge of L1 is the large number of images in the prompt. A model's architecture or training may not be suitable for handling a large number of images, and LLM prompt length is known to adversely influence
Figure 3: Listener experiments. Margins of Error are 95% bootstrapped CIs.
performance (Liu et al., 2023b). L3 uses a shorter history, by only providing the referential context (four images) to the model once in the first trial. Image labels are persistent across all trials, which also avoids the impact of shuffling. Unlike L2, this variant includes the complete message, selection, and feedback history.
- L4 : No Shuffle The four images appear every trial similar to L1 but are not shuffled across trials. L4 shows the effects of image shuffle if compared with L1. It also shows the effect of image quantity if compared with L3, which does not involve shuffling either.
L2 and L3 need only four images in the prompt, allowing us to test all the models.
The no-history variant (L2) reveals different performance trends for IDEFICS and GPT4 compared to the standard setup (L1). IDEFICS is still not doing great (45.8% on the first repetition), but performance largely remains consistent across repetitions, indicating that possibly the complexity of the prompt is at the root of its downward trend in the L1 scenario. GPT4 starts with similar performance (87.5%) to its results in L1, but then shows a slight downward trend (83.8% at the end), in contrast to the initial upward trend in L1. This indicates that the gradually conventionalized, shorter messages a human speaker uses tend to be more difficult for the model to resolve and that the conversation history can be an effective remedy. Gemini (80.2 → 78.8%), LLaVa (72.7 → 71.3%), and Claude (57.4 → 55.5%) show similar trends to GPT4 from Repetition 1 to 6, with overall lower accuracies.
The benefit of history becomes more conspicuous when the referential context is only given once (L3). This variant dramatically simplifies the prompt, but retains the information needed for convention formation (i.e., prior message, selection, and feedback). All the models show an upward trajectory as the interactions progress. GPT4 and Claude are the strongest, eventually reaching 100% accuracy, matching human listeners' performance (99.54%). This suggests that all models can associate the current message with the relevant prior messages, thereby increasing their prediction accuracy as the interaction progresses. Admittedly, because an image always has the same label throughout the game under this setup, the models may do well by simply drawing associations between an image's label and the messages that have referred to that image (i.e., label-message associations). Under this mechanism, the model can improve its accuracy without reasoning about the actual visual input. We explore this possible mechanism with more game variants in Appendix D. Nonetheless, this experiment shows that MLLMs possess some capabilities for increasingly efficient communication with humans when acting as the listener.
The no-shuffle (L4) experiment also provides key insights. GPT4's accuracy is similar to that in L3 and higher than that in L1. This demonstrates sensitivity to image shuffling and the constantly changing image labels. GPT4 in L3 and L4 may be relying to some degree on text similarity between repetitions by exploiting the label-message associations, rather than grounding to the visual input. We study this further in Appendix D. IDEFICS' performance
on the other hand is different from both L3 and L1, showing an almost unnoticeable trend up. This shows that it is not only the shuffling but also the increase in the number of images that IDEFICS cannot seem to handle well. We further discuss this issue in Section 6.
## 6 Discussion
Our studies point to various issues that likely hinder specific models from displaying communication efficiency gains, and point out directions for future works.
Tendency to Repeat Messages In the speaker study, IDEFICS and LLaVa tend to repeat the first message they use for each image, showing no adaptation. To further study how much these models prefer patterns of repetition, we design a test that uses these models for language modeling rather than text generation. We construct two transcripts for each of the 54 human-human interactions in our original dataset. One is the original transcript from human-human interactions, showing the natural evolution of messages. The other is a manipulated transcript where the speaker repeats the messages from Repetition 1 in all the later repetitions. We calculate the log probability and perplexity IDEFICS and LLaVa assign to these transcripts, count the number of times one type of transcript has better logprobability/perplexity than the other, and apply a sign test. We find that the manipulated transcript showing message repetitions consistently receives higher log probability and lower perplexity for all 54 interactions, showing the models' significant tendency towards repeated patterns (sign test p-values are near zero). Unfortunately, this experiment cannot be done with GPT4, Gemini, or Claude due to API limitations.
̸
Lexical Efficiency = Communication Efficiency The convergence of human speaker messages for a particular image to a short, stable convention often takes the form of extracting salient tokens from the previous message and sticking to the same message once it becomes very short (Hawkins et al., 2020a). Unless directly instructed to do so through a highly engineered prompt (S4), GPT4, Gemini, and Claude often introduce new words when shortening their messages or even when the messages cannot be further shortened, as shown in the S3 explicit instruction variant. Such inconsistency with human behaviors is problematic. When messages for the same image do not converge, no conventions can form and the listener will likely need additional cognitive effort to process the previously unseen words. Intuitively, even if a new message is semantically similar to a previous one by using synonyms, resolving it still likely entail a greater cognitive load than an exact repetition. Moreover, when new words describing a new aspect of an image are introduced after a few rounds of relatively similar messages, they violate the human listener's expectation, potentially leading to miscommunication and slower response (Metzing & Brennan, 2003).
Performance Degradation with Many-image Inputs Among the models that support a large number of images, IDEFICS performs much worse as the number of images increases. Even though the images in L4 are not shuffled across trials, which could have allowed the model to exploit label-message associations as an efficient way to gain high accuracy, the model still had much lower accuracy than when the images only appear once (L3) (Figure 3). When the history contains a growing number of images that are shuffled between trials (L1), IDEFICS shows an even worse accuracy trend.
Alikely hypothesis is that a greater number of images creates challenges for capturing the dependency between specific visual input and textual cues, which can manifest as failures to associate an image's label with the actual content of the image. In a qualitative experiment, we supply a sequence of images and their labels as input to IDEFICS, and instruct it to describe Image [X] . We observe that IDEFICS can describe the correct image easily when we give up to four labeled images, but often makes mistakes as the number increases (Figure 9 in the appendix). Therefore, even though IDEFICS is designed and trained to support multi-image inference, 7 its multi-image capabilities do not generalize beyond a few images.
7 The Flamingo architecture behind IDEFICS supports an arbitrary number of images as input and it is trained on interleaved texts and multiple images (Huggingface, 2023).
Another potential cause is the Flamingo architecture behind IDEFICS. Each token's crossmodal attention only applies to the visual features of the last image that precedes it, rather than all the images. Information about other images can only be indirectly accessed through self-attention on the hidden states of their respective < image > tokens in the text sequence. This architecture may degrade the ability of the model to reason about images, depending on their locations in the input. When the target is not the last image, Image D, the message tokens will not have direct cross-modal attention to the target's visual features, which may hurt IDEFICS' prediction. In L3, where IDEFICS did perform well, this limitation might have been mitigated by the strong textual cues and label-message associations, whereas having more images may distract IDEFICS from these cues and thus manifests this limitation.
## 7 Conclusion
ICCA provides a perspective into the performance of today's MLLMs that is missing in existing benchmarking, and can be easily applied to new MLLMs without collecting new human data. We observe that state-of-the-art models lack the in-context abilities to adapt their own language for efficient communication, even though they may sometimes perform better while passively receiving increasingly efficient language from their interlocutor. This issue is fundamental because, unlike humans, the models do not perceive the effort or cost needed for communication, thus having no inherent reason to reduce them. It is still surprising though, given that LLMs/MLLMs have successfully displayed many other human behaviors and impressive abilities in various applications, by learning from the large amounts of human data, where adaptation for efficiency is common. Overall, the current paradigm for creating LLMs fails to address the need for conversational adaptation and future research is needed on improving their abilities to spontaneously improve language efficiency, maintain language consistency for the same referent, avoid excessive tendency for repetitions, and handle more images in a single query.
## Acknowledgments
This research was supported by ARO W911NF21-1-0106, NSF under grant No. 1750499, a gift from Open Philanthropy, and a gift from Apple. We thank Robert Hawkins and Marten van Schijndel for insightful discussions. We thank the anonymous reviewers and the area chair for their valuable feedback.
## References
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning. In Proceedings of Advances in Neural Information Processing Systems , 2022. URL https://proceedings.neurips.cc/paper files/paper/2022/file/ 960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf .
Jacob Andreas and Dan Klein. Reasoning about pragmatics with neural listeners and speakers. In Proceedings of the Conference on Empirical Methods in Natural Language Processing , 2016. URL https://www.aclweb.org/anthology/D16-1125 .
Chinmaya Andukuri, Jan-Philipp Fr¨ anken, Tobias Gerstenberg, and Noah D. Goodman. Star-gate: Teaching language models to ask clarifying questions. arXiv , 2024. URL https://arxiv.org/abs/2403.19154 .
Anthropic. Introducing the next generation of Claude, 2024. URL https://www.anthropic. com/news/claude-3-family .
| Susan E. Brennan and Herbert H. Clark. Conceptual pacts and lexical choice in conversation. Journal of Experimental Psychology: Learning, Memory, and Cognition , 22, 1996. |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Proceedings of Advances in Neural Information Processing Systems , vol- ume 33, 2020. URL https://proceedings.neurips.cc/paper files/paper/2020/file/ 1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf . |
| Kranti Chalamalasetti, Jana G¨tze, o Sherzod Hakimov, Brielen Madureira, Philipp Sadler, and David Schlangen. Clembench: Using game play to evaluate chat-optimized language models as conversational agents. arXiv , 2023. URL https://arxiv.org/abs/2305.13455 . |
| Herbert H. Clark. Common ground . Cambridge University Press, 1996. |
| Herbert H. Clark and Susan E. Brennan. Grounding in communication. In Perspectives on Socially Shared Cognition . American Psychological Association, 1991. |
| Herbert H. Clark and Deanna Wilkes-Gibbs. Referring as a collaborative process. Cognition , 22, 1986. URL https://www.sciencedirect.com/science/article/pii/ 0010027786900107 . |
| Philip R. Cohen and Hector J. Levesque. Rational Interaction as the Basis for Communication . The MIT Press. URL https://doi.org/10.7551/mitpress/3839.003.0014 . |
| Marco Del Tredici, Xiaoyu Shen, Gianni Barlacchi, Bill Byrne, and Adri` a de Gispert. From rewriting to remembering: Common ground for conversational qa models. 2022. URL https://arxiv.org/abs/2204.03930 . |
| Anna Effenberger, Rhia Singh, Eva Yan, Alane Suhr, and Yoav Artzi. Analysis of language change in collaborative instruction following. In Findings of the Association for Computa- tional Linguistics: EMNLP , 2021. URL https://aclanthology.org/2021.findings-emnlp. 239.pdf . |
| Ron Eliav, Anya Ji, Yoav Artzi, and Robert Hawkins. Semantic uncertainty guides the extension of conventions to new referents. arXiv , 2023. URL http://arxiv.org/abs/2305. 06539 . |
| Daniel Fried, Jacob Andreas, and Dan Klein. Unified pragmatic models for generating and following instructions. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , 2018. URL https://www.aclweb.org/anthology/N18-1177 . |
| Edward Gibson, Richard Futrell, Steven P. Piantadosi, Isabelle Dautriche, Kyle Mahowald, Leon Bergen, and Roger Levy. How efficiency shapes human language. Trends in Cog- nitive Sciences , 23, 2019. URL https://www.sciencedirect.com/science/article/pii/ S1364661319300580 . |
| Noah D. Goodman and Michael C. Frank. Pragmatic language interpretation as probabilistic inference. Trends in Cognitive Sciences , 20, 2016. URL https://api.semanticscholar.org/ CorpusID:3632786 . |
| Google. Introducing Gemini: Our largest and most capable AI model, 2023. URL https: //blog.google/technology/ai/google-gemini-ai/ . |
| Barbara J. Grosz and Candace L. Sidner. Plans for discourse. In Intentions in Communication . The MIT Press. URL https://doi.org/10.7551/mitpress/3839.003.0022 . |
| Janosch Haber, Tim Baumg¨rtner, a Ece Takmaz, Lieke Gelderloos, Elia Bruni, and Raquel Fern´ndez. a The PhotoBook dataset: Building common ground through visually-grounded dialogue. In Proceedings of the Annual Meeting of the Association for Computational Linguistics , 2019. URL https://aclanthology.org/P19-1184v2.pdf . |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Robert Hawkins, Michael C. Frank, and Noah D. Goodman. Characterizing the dynamics of learning in repeated reference games. Cognitive Science , 44, 2020a. URL https:// onlinelibrary.wiley.com/doi/abs/10.1111/cogs.12845 . |
| Robert Hawkins, Minae Kwon, Dorsa Sadigh, and Noah Goodman. Continual adaptation for efficient machine communication. In Proceedings of the Conference on Computational Natural Language Learning , November 2020b. |
| William S. Horton and Richard J. Gerrig. Revisiting the memory-based processing approach to common ground. Topics in Cognitive Science , 8, 2016. URL https://onlinelibrary. wiley.com/doi/full/10.1111/tops.12216 . |
| Huggingface. HuggingFaceM4/idefics-80b-instruct, 2023. URL https://huggingface.co/ HuggingFaceM4/idefics-80b-instruct . |
| Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert Hawkins, and Yoav Artzi. Abstract visual reasoning with tangram shapes. In Proceedings of the Conference on Empirical Methods in Natural Language Processing , December 2022. URL https://aclanthology.org/2022.emnlp-main.38 . |
| Robert M. Krauss and Sidney Weinheimer. Changes in reference phrases as a function of frequency of usage in social interaction: Apreliminary study. Psychonomic Science , 1, 1964. URL https://link.springer.com/article/10.3758/BF03342817 . |
| Robert M. Krauss and Sidney Weinheimer. Concurrent feedback, confirmation, and the encoding of referents in verbal communication. Journal of Personality and Social Psychology , 4, 1966. |
| David Kellogg Lewis. Convention: A Philosophical Study . Wiley-Blackwell, 1969. |
| Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. arXiv , 2023a. URL https://arxiv.org/pdf/2310.03744 . |
| Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: Howlanguage models use long contexts. Transactions of the Association for Computational Linguistics , 12, 2023b. URL https://aclanthology.org/ 2024.tacl-1.9.pdf . |
| Arthur B. Markman and Valerie S. Makin. Referential communication and category acquisi- tion. Journal of Experimental Psychology: General , 127, 1998. |
| Bill McDowell and Noah D. Goodman. Learning from omission. In Proceedings of the Annual Meeting of the Association for Computational Linguistics , 2019. URL https://aclanthology. org/P19-1059.pdf . |
| Charles Metzing and Susan E. Brennan. When conceptual pacts are broken: Partner-specific effects on the comprehension of referring expressions. Journal of Memory and Language , 49, 2003. URL https://www.sciencedirect.com/science/article/pii/S0749596X03000287 . |
| Will Monroe, Robert Hawkins, Noah D. Goodman, and Christopher Potts. Colors in context: Apragmatic neural model for grounded language understanding. Transactions of the Association for Computational Linguistics , 5, 2017. URL https://aclanthology.org/ Q17-1023.pdf . |
| OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, |
Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Sim´ on Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David M´ ely, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O'Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cer´n Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, o Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, C. J. Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. GPT-4 Technical Report. arXiv , 2024. URL http://arxiv.org/abs/2303.08774 .
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. Training language models to follow instructions with human feedback. In Proceedings of the Conference on Neural Information Processing Systems , 2022. URL https://proceedings.neurips.cc/paper files/paper/ 2022/file/b1efde53be364a73914f58805a001731-Paper-Conference.pdf .
Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing , 2014. URL http://www.aclweb.org/anthology/D14-1162 .
Omar Shaikh, Kristina Gligoric, Ashna Khetan, Matthias Gerstgrasser, Diyi Yang, and Dan Jurafsky. Grounding gaps in language model generations. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , June 2024. URL https://aclanthology.org/2024.naacl-long.348 .
Robert Stalnaker. Common ground. Linguistics and Philosophy , 25, 2002. URL https: //link.springer.com/article/10.1023/A:1020867916902 .
Alberto Testoni and Raquel Fern´ andez. Asking the right question at the right time: Human and model uncertainty guidance to ask clarification questions. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics , 2024. URL https://aclanthology.org/2024.eacl-long.16.pdf .
David Traum. A Computational Theory of Grounding in Natural Language Conversation. PhD thesis, University of Rochester, 1994.
Julia White, Jesse Mu, and Noah D. Goodman. Learning to refer informatively by amortizing pragmatic reasoning. In Proceedings of the Annual Meeting of the Cognitive Science Society , 2020. URL https://cognitivesciencesociety.org/cogsci20/papers/0175/0175.pdf .
Kayo Yin, Terry Regier, and Dan Klein. American sign language handshapes reflect pressures for communicative efficiency. arXiv , 2024. URL https://arxiv.org/abs/2406.04024 .
Hao Zhu, Graham Neubig, and Yonatan Bisk. Few-shot language coordination by modeling theory of mind. In Proceedings of the International Conference on Machine Learning , 2021. URL https://proceedings.mlr.press/v139/zhu21d/zhu21d.pdf .
George Kingsley Zipf. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology . Addison-Wesley Press, 1949.
## A Implementation Details
## A.1 Message Length Measurement
Wemeasure the length of the generated messages by counting the number of tokens. Because different MLLMs have different tokenizers, we choose to only use IDEFICS's tokenizer for message length calculations for all models.
## A.2 Word Novelty Rate
Word Novelty Rate is a modified Word Error Rate, which only counts insertions and substitutions, and ignores deletions. The number of insertions and substitutions is normalized by the length of the reference message, as done in the standard Word Error Rate calculation. For two messages from Repetition N-1 and N, we use the message from Repetition N-1 as the reference and the one from Repetition N as the hypothesis. We follow Hawkins et al. (2020a)'s metric design and drop most function words to only consider open-class content words (nouns, adjectives, verbs, and adverbs) as well as pronouns, numbers, and adpositions.
WNRaddresses the limitation of metrics using cosine similarity between averaged embeddings (e.g., GloVe), which operate in the semantic space, for example as in Hawkins et al. (2020a). Semantic similarity between messages is not sensitive to some lexical changes, ignoring the importance of exact word choice in convention formation. For example, once a convention is formed to use the car to refer to an image, changing it to a semantically similar message, the automobile , violates the stability property of conventions, which may increase the listener's cognitive load. Empirically, we find that WNR produces results consistent with Hawkins et al. (2020a)'s averaged GloVe embedding similarity, as shown in Figure 4 (WNR moves in the opposite direction to the GloVe-based similarity because WNR directly measures dissimilarity).
Figure 4: GloVe embedding similarity and WNR between messages from consecutive repetitions. Every increase in GloVe embedding similarity is captured by a corresponding decrease in WNR, and vice versa. Margins of Error are 95% bootstrapped CIs.
We also report a variant of WNR, which is not normalized by length. We refer to this variant as Word Novelty Distance (WND). WND is sometimes more interpretable because each
unit difference in it directly corresponds to a word insertion or deletion. However, because WNDis small between any two short messages, it can be harder to interpret when messages are short. Figure 5 reports WND for our speaker experiments.
Figure 5: Word Novelty Distance for speaker experiments. Margins of Error are 95% bootstrapped CIs.
## A.3 MLLMImplementation Details
The exact versions of the MLLMs used are idefics-80b-instruct, llava-1.5-13b, gpt-4-1106vision-preview, Gemini 1.0 Pro Vision, and claude-3-opus-20240229. For IDEFICS, we use 8-bit quantization to fit the 80b model into 3 A6000 GPUs. For all MLLMs, we use a decoding temperature of 0 to avoid the uncertainty caused by sampling, which was also the default for IDEFICS and LLaVa. We use the models' default values for other hyperparameters.
The GPT4 listener used to evaluate model speakers follows the listener interaction setup in L3: Images Once. L3 is the scenario where GPT4 shows its best performance and almost perfectly matches human performance.
LLaVa only supports taking 1 image as input. To bypass this constraint, we merge the 4 images in the referential context into 1 image, using a 2-by-2 grid. Instead of using image labels (A, B, C, D), experiments with LLaVa refer to an original image using its location in the merged image ( top right, top left, bottom right, and bottom left ).
We conduct prompt engineering for each model individually to find the most suitable phrasing of the instructions. The prompt engineering was done over the pilot study dataset released in Hawkins et al. (2020b)'s official Github repository. The pilot study dataset is distinct from the 54 human interactions in ICCA that we use for evaluation. This pilot study dataset contains human-human interactions on easy referential contexts, where the target images are more easily distinguishable to humans with very short messages. For this reason, the human interactions in this pilot study dataset show less language adaptation, and we only use it for prompt engineering and not evaluation.
## B Example Prompts
## Model-as-speaker Prompt :
[System] Play a game with a listener. This game consists of multiple trials and 4 images (labeled A, B, C, D). You will act as the speaker in this game. In each trial, one of the images is given as the target. You will generate a message to tell the listener which image is the target without mentioning any image label. The listener will try to choose the target correctly based on your message. You will know which image the listener guesses, so you may adjust your messages based on the listener's accuracy. Your reply should only contain the message and be shorter than 20 words. Do not mention any image's label (A, B, C, D) in your message.
Image A: < img1 >
Image B: < img2 >
Image C: < img3 >
Image D: < img4 >
Trial 1, the target is Image B.
[Speaker] Message: Two bananas and apples in a white bowl on polka dot cloth. [System] The listener correctly answered Image B.
Trial 2, the target is Image A. [Speaker] Message: Bananas on a floral cloth with an Amazon box.
[System] The listener correctly answered Image B.
Trial 3, the target is Image D.
[Speaker] Message: Bananas and apples in a bowl, striped cloth underneath.
[System] The listener mistakenly answered Image C.
Trial 4, the target is Image C.
[Speaker] Message: Assorted fruit in a painted ceramic bowl.
[System] The listener correctly answered Image C.
Trial 5, the target is Image B.
[Speaker] Message:
Figure 6: Example prompt for model-as-speaker standard setup. The prompt is shortened and revised for illustrative purposes.
## Model-as-listener Prompt :
[System] Play a game with multiple trials involving the same set of images. In each trial, I will refer to one of the images with a message. You will guess which image I'm referring to. If present, the history of the previous trials may help you better understand how I refer to specific images.
## Trial 1
Image A: < img4 >
Image B: < img2 >
Image C: < img3 >
Image D: < img1 >
Which image is this message referring to: The photo with 'amazon' on the back, with 2 bananas.
[Listener] Image D
[System] Correct. I was referring to Image D.
## Trial 2
Image A: < img1 >
Image B: < img3 >
Image C: < img2 >
Image D: < img4 >
Which image is this message referring to: Photo with a bowl of 3 bananas with a pokadot background.
[Listener] Image B
[System] Wrong. I was referring to Image C.
## Trial 3
Image A: < img3 >
Image B: < img1 >
Image C: < img2 >
Image D: < img4 >
Which image is this message referring to: A bowl full of mixed fruit, black background.
[Listener] Image A
[System] Correct. I was referring to Image A.
## Trial 4
Image A: < img3 >
Image B: < img4 >
Image C: < img2 >
Image D: < img1 >
Which image is this message referring to: Photo with a bowl of 3 bananas with stripes and other patterns in the background.
[Listener] Image B
[System] Correct. I was referring to Image B.
## Trial 5
Image A: < img3 >
Image B: < img2 >
Image C: < img4 >
Image D: < img1 >
Which image is this message referring to: Amazon in back with 2 bananas.
[Listener] Image
Figure 7: Example prompt for model-as-listener standard setup. The prompt is shortened and revised for illustrative purposes.
## C Figures for Error Analysis

## Human Messages
- 1. dirty truck going towards the bridge
- 2. dirty truck going to bridge
- 3. how is this even guessing, it's so easy, dirty truck going to bridge
- 4. dirty truck
- 5. dirty truck
- 6. dirty truck
## GPT4 Messages
- 1. construction bridge with a concrete mixer truck underneath
- 2. bridge construction with a white truck
- 3. bridge work, dirty truck below
- 4. bridge construction
- 5. overpass work
- 6. concrete mixer
Figure 8: Evolution of an image's corresponding messages across 6 repetitions in S3. Both the human speaker and the GPT4 speaker show length reduction, but GPT4's messages are more inconsistent.
Image A:
Image B:
Image C:
Image D:




Image E:

Image F:

User: describe Image D.
IDEFICS: a truck is parked in a parking lot.
Figure 9: Example of IDEFICS' issue with associating images with their correct labels. The input is a sequence of images interleaved with their labels and a prompt to ask the model to describe Image [X] . We tried different formats to label the images, such as < img > is Image A and Image A: < img > but none helped IDEFICS produce reliable results as the number of images increases.

Image G:

Image H:

## D Image Grounding Impact
Figure 10: Average accuracy for variants L5-7. Margins of Error are 95% bootstrapped CIs.
The results with L3 (Section 5.1) raised concerns about whether the models are using images effectively or just exploiting label-message association. We develop three variants to study this:
- L5: Images Masked Each image is replaced by an image mask, where all pixels have the black color, (0, 0, 0). The image order is persistent, so the same label refers always to the same underlying image that is masked. For the first four trials in Repetition 1, the model has to make a guess. Regardless of the guess, the correct target is given by the system feedback as usual. Theoretically, the model can use the feedback for later repetitions. For a model to succeed in this variant, it must associate the messages with the image labels since no actual images are given. This variant tests the extent to which a model can exploit label-message associations through in-context learning as a way of convention understanding.
- L6: Images Misleading This variant complements L5 to further study the impact of text signals and images. The setup here follows L3, showing the referential context once, except that we manipulate the images to be misleading. For the manipulation, we shuffle the images when presenting them to the model listener at the beginning of the game, but we do not change the gold image labels in the system. Therefore, Image [X] from the speaker and the system's perspective is likely different from the Image [X] from the listener's perspective, and so on. For example, using the context in Figure 11, the model may see the message Photo with a bowl of 3 bananas with pokadot and choose Image C but the system and the speaker would always think the image that features bananas and polka dot is Image B, since we shuffled the images without updating the gold labels accordingly. Then the system feedback would be wrong, the correct answer is Image B . To succeed under this setting, the model must learn to ignore the images and just associate all the descriptions related to polka dot (for example) with the label Image B .
- L7: Images Misleading in Rep. 6 This variant further tests if the models' previous promising performance in L3 comes from just exploiting the textual signals (the label-message associations) and ignoring the visual input. We show the context once similar to L3 at the beginning, but then show shuffled versions during each trial in the last repetition, without updating the gold labels (same manipulation as L6). We hypothesize that if the model tends to ignore the image input and rely on textual associations in the conversation history, this manipulation will have little impact on its prediction or the accuracy calculated based on the old gold label. This variant requires 20 images in the last trial so it cannot be used with LLaVa or Gemini.
When models cannot utilize the image input (L5 and L6), all models start with around or below random chance accuracies (25%). As the interaction progresses, models exploit past messages and feedback via label-message associations to improve performance and display a trend of improvement. L5 and L6 results together demonstrate that exploiting label-message associations while ignoring the images can easily emerge as an effective mechanism for MLLMs' convention understanding behavior, provided that the image referent has a consistent textual label.
Injecting misleading images in the last repetition (L7) leads to a significant drop in performance relative to previous repetitions for IDEFICS (87.5 → 69.4%), GPT4 (99.5 → 27.3%), and Claude (98.6 → 22.2%). The drop is particularly conspicuous for GPT4 and Claude, where performance goes down to around random chance. This suggests that GPT4 and Claude do not overly exploit the consistent textual associations from the history, because otherwise they would not have been 'misled' by the manipulations in the last repetition. This is desirable because it shows that the visual input matters to these models' output. On the other hand, while IDEFICS also shows a drop in performance, it is not as strong as what the other two models show. This indicates that although IDEFICS is not completely ignoring the visual input, it does exploit the textual associations beyond what is desired.
## Speaker's Perspective
## Listener's Perspective
Figure 11: Example Trial 1 from L6: Images Misleading
 | null | [
"Yilun Hua",
"Yoav Artzi"
]
| 2024-08-02T17:51:57+00:00 | 2024-08-02T17:51:57+00:00 | [
"cs.CL",
"cs.AI",
"cs.CV",
"cs.LG"
]
| Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs | Humans spontaneously use increasingly efficient language as interactions
progress, by adapting and forming ad-hoc conventions. This phenomenon has been
studied extensively using reference games, showing properties of human language
that go beyond relaying intents. It remains unexplored whether multimodal large
language models (MLLMs) similarly increase communication efficiency during
interactions, and what mechanisms they may adopt for this purpose. We introduce
ICCA, an automated framework to evaluate such conversational adaptation as an
in-context behavior in MLLMs. We evaluate several state-of-the-art MLLMs, and
observe that while they may understand the increasingly efficient language of
their interlocutor, they do not spontaneously make their own language more
efficient over time. This latter ability can only be elicited in some models
(e.g., GPT-4) with heavy-handed prompting. This shows that this property of
linguistic interaction does not arise from current training regimes, even
though it is a common hallmark of human language. ICCA is available at
https://github.com/lil-lab/ICCA. |
2408.01418v3 | ## Holographic duals of symmetry broken phases
Andrea Antinucci a, b , Francesco Benini a, b, c and Giovanni Rizi a, b
- a SISSA, Via Bonomea 265, 34136 Trieste, Italy
- b INFN, Sezione di Trieste, Via Valerio 2, 34127 Trieste, Italy
- c ICTP, Strada Costiera 11, 34151 Trieste, Italy
## Abstract
We explore a novel interpretation of Symmetry Topological Field Theories (SymTFTs) as theories of gravity, proposing a holographic duality where the bulk SymTFT (with the gauging of a suitable Lagrangian algebra) is dual to the universal effective field theory (EFT) that describes spontaneous symmetry breaking on the boundary. We test this conjecture in various dimensions and with many examples involving different continuous symmetry structures, including non-Abelian and non-invertible symmetries, as well as higher groups. For instance, we find that many Abelian SymTFTs are dual to free theories of Goldstone bosons or generalized Maxwell fields, while nonAbelian SymTFTs relate to non-linear sigma models with target spaces defined by the symmetry groups. We also extend our analysis to include the non-invertible Q Z / axial symmetry, finding it to be dual to axion-Maxwell theory, and a non-Abelian 2-group structure in four dimensions, deriving a new parity-violating interaction that has implications for the low-energy dynamics of U N ( ) QCD.
## Contents
| 1 Introduction | 1 Introduction | 1 Introduction | 1 |
|------------------|-------------------------------------------------|--------------------------------------------------------------|-----|
| 2 | Topological field theories as holographic duals | Topological field theories as holographic duals | 4 |
| 3 | U (1) Goldstone bosons | U (1) Goldstone bosons | 7 |
| | 3.1 | 0-form symmetries . . . . . . . . . . . . . . . . . . . . . | 7 |
| | 3.2 | Higher-form symmetries . . . . . . . . . . . . . . . . . . | 11 |
| | 3.3 | Lagrangian algebras and topological sectors . . . . . . . . | 12 |
| 4 | Abelian anomalies and higher groups | Abelian anomalies and higher groups | 14 |
| | 4.1 | Chiral anomaly in 2d . . . . . . . . . . . . . . . . . . . . | 14 |
| | 4.2 | Chiral anomaly in 4d . . . . . . . . . . . . . . . . . . . . | 16 |
| | 4.3 | Anomaly matching in the broken phase . . . . . . . . . . | 17 |
| | 4.4 | Abelian 2-groups . . . . . . . . . . . . . . . . . . . . . . | 19 |
| | 4.5 | Abelian 2-groups in the broken phase . . . . . . . . . . . | 21 |
| 5 | Boundary Chern-Simons-like terms | Boundary Chern-Simons-like terms | 22 |
| | 5.1 | Holographic dual to Maxwell-Chern-Simons theory . . . . | 22 |
| | 5.2 | Spontaneously broken non-invertible Q / Z chiral symmetry | 24 |
| 6 | Non-Abelian Goldstone bosons | Non-Abelian Goldstone bosons | 27 |
| | 6.1 | Holographic dual to the pion Lagrangian . . . . . . . . . | 27 |
| | 6.2 | Non-Abelian chiral anomaly . . . . . . . . . . . . . . . . | 29 |
| | 6.3 | Non-Abelian 2-group symmetries . . . . . . . . . . . . . | 31 |
| A | Anomalous boundary conditions | Anomalous boundary conditions | 36 |
| B | Non-compact TQFTs | Non-compact TQFTs | 39 |
## 1 Introduction
A profound insight by E. Witten is that Topological Quantum Field Theories (TQFTs), due to their general covariance, can be seen as theories of quantum gravity [1]. Unlike in more conventional examples, general covariance is not achieved by integrating over metrics but rather by not introducing them at all. Consequently, these theories lack any semiclassical description involving weakly interacting gravitons. In traditional gravitational theories, one selects a background metric and expands around it, thereby breaking general covariance spontaneously. Therefore, TQFTs can be viewed as theories of quantum gravity with unbroken general covariance - where gravitons are, in a certain sense, confined.
This old story requires some important refinements. A full quantum-gravity theory should not depend on the background topology. TQFTs, on the other hand, are sensitive to spacetime topology
through their global symmetries, broadly defined in terms of their topological operators [2], which are expected to form some higher category [3-12]. One way to achieve such an independence is to sum over all topologies, which can be done in low dimensions [13-17]. Alternatively, one can use TQFTs that do not even depend on topology [18], hence that are free of global symmetries and then trivial (or invertible) [19, 20]. These can be obtained by gauging a maximal non-anomalous set of topological defects, called a Lagrangian algebra , in a nontrivial TQFT. Not all TQFTs have Lagrangian algebras (the typical example is 3d Chern-Simons theory), but those that have them admit topological (or gapped) boundary conditions. In fact, given a Lagrangian algebra L , one can construct such a boundary condition as an interface between the TQFT and the gauged TQFT [21-24]. Equivalently, the boundary condition is defined by allowing the defects inside L to end on the boundary.
TQFTs with topological boundary conditions have recently gained attention for their role as Symmetry Topological Field Theories (SymTFTs) in the context of generalized symmetries (see [25-28] for reviews). SymTFTs are ( d +1) -dimensional TQFTs Z C ( ) associated with symmetry structures C in d dimensions, capturing all properties of the symmetries regardless of the specific QFT d realizing them [2,11,29,30]. The TQFT Z C ( ) is placed on a slab with two boundaries. The left one supports the physical QFT d of interest, coupled with the bulk. The right one is the topological boundary condition that one is free to choose, determined by a Lagrangian algebra L . Defects inside L become trivial on the topological boundary, while all other ones (modulo those inside L ) give rise to topological operators of the symmetry C , after the slab is squeezed. The endpoints of defects inside L inherit a braiding with the generators of C from the bulk braiding, hence they become the charges of the symmetry [31,32]. SymTFT has been shown to be a powerful tool for studying global symmetries, also of non-invertible type [33-37] and their anomalies [38-42], as well as to characterize phases [43-47].
Although originally restricted to finite symmetries, the framework has been recently extended to continuous symmetries [48-50]. 1 The prize to pay is to introduce a new type of TQFTs with gauge fields valued in both U (1) and R , and to have a continuous and/or non-compact spectrum of operators, thus going beyond the standard TQFTs well studied by mathematicians (we provide a more precise mathematical definition in Appendix B). This idea has been shown to be applicable to all possible nonfinite and continuous symmetries, with or without anomalies, possibly with higher-group structures, and even including non-invertible and non-Abelian symmetries. By now the picture is that to any possible symmetry structure C in d dimensions one can canonically associate a ( d + 1) -dimensional TQFT Z C ( ) .
Our aim here is to give a different interpretation to these TQFTs Z C ( ) , not as SymTFTs but as theories of gravity. More precisely, we want to establish holographic dualities in which the bulk theory is a SymTFT. The main proposal of this paper is the following:
- · Thought of as a theory of gravity, the SymTFT Z C ( ) for a symmetry C is the holographic dual to the universal effective field theory (EFT) that describes the spontaneous breaking of C .
It is a general principle of quantum field theory that any theory with a certain continuous global
1 See [51] for a different proposal involving non-topological theories.
symmetry that is spontaneously broken, in the far infrared (IR) flows to the same universal theory of Goldstone bosons [52, 53]. This is roughly speaking always a sigma model, although the target space can be infinite dimensional ( e.g. , it is the classifying space B G p in the case of higher-form symmetries). 2 As for the SymTFT, this EFT is also canonically determined by the symmetry C without any further information. For this reason, it is natural to expect that, even though they appear to be completely different objects - a ( d +1) -dimensional TQFT and a d -dimensional EFT -the two can be somehow related as they both have the same input datum. We will prove by means of many examples that this correspondence is holography.
A crucial part of the story is the proper choice of boundary conditions. These will be nontopological and of the Dirichlet type for some combination of the bulk fields. Since bulk fields are gauge fields A , these boundary conditions break some gauge invariance, making it a global symmetry of the boundary theory. This agrees with the general principle in holography that boundary global symmetries correspond to bulk gauge fields. The non-triviality of the system really comes from the boundary conditions that, being non-topological, generate dynamics on the boundary. The boundary theory can be thought of as a theory of edge modes. Our setup has several similarities with, and may be understood as a generalization of, the Chern-Simons/WZW correspondence [56, 57] and its reinterpretation as a full-flagged holographic duality by means of bulk anyon condensation [18]. 3
We find that for the simple Abelian TQFTs introduced in [48, 49] as the SymTFTs for U (1) , the dual boundary theory is the free theory of an S 1 Goldstone boson, or generalized Maxwell field when the symmetry is of higher form. More precisely, these boundary theories have topological sectors ( e.g. , winding for a compact scalar, or magnetic fluxes for a photon), and the nontrivial TQFT without gauging the Lagrangian algebra is only dual to a fixed topological sector. The latter is not a physical theory and is the non-chiral analog of the conformal blocks in the CS/WZW correspondence. The physical theory is obtained by summing over various topological sectors, and we will show that this sum is reproduced by the gauging of the Lagrangian algebra. These Abelian TQFTs have various interesting modifications describing chiral anomalies, higher groups, and non-invertible Q Z / symmetries [48]. We include all of them in our analysis, showing that their holographic duals are the theories describing the spontaneous breaking of the corresponding symmetries. In particular the SymTFT for the noninvertible chiral symmetry is the gravity dual to axion-Maxwell theory.
For non-Abelian continuous symmetries G , the SymTFT was also conjectured in [48,49] and further analyzed in [50]. In the simplest case, it is a TQFT introduced many years ago by Horowitz [61] and is written in terms of a G connection and a Lie-algebra-valued higher-form field in the adjoint of G . When employing this theory in our story, it proves to be the dual to a non-linear sigma model with target space G at the boundary. For d = 4 this in the pion Lagrangian describing the low-energy dynamics of massless QCD in the chiral symmetry breaking phase. We also show that including a term that describes an 't Hooft anomaly we obtain a WZW term in the sigma model [62].
A particularly interesting example is that of a non-Abelian 2-group in 4d, mixing a non-Abelian
2 It is not clear to us how to make this precise for non-invertible symmetries, for instance for the Q Z / chiral symmetry discovered in [54,55].
3 See also [58] for earlier work, as well as [59,60] for a related approach.
continuous symmetry G and a U (1) 1-form symmetry [63]. The Goldstone theory for this symmetry structure was not determined before, and we use our holographic conjecture to derive it. It consists of a non-linear sigma model and a photon, coupled through a parity-violating interaction whose leading term is proportional to kf abc ϵ µνρσ A ∂ π µ ν a ∂ π ρ b ∂ π σ c , where π a are the pions, f abc are the structure constants of G , while k ∈ Z is a quantized coefficient that governs the 2-group structure. This term encodes the coupling of the photon to the current for a topological 0-form symmetry of the sigma model. This result has a concrete application to the low-energy dynamics of 4d U N ( ) QCD. For low enough number of flavors, the chiral symmetry is spontaneously broken and quarks form pion bound states as in SU N ( ) QCD. However, here the theory also contains an Abelian gauge field A for the baryon number symmetry with quarks charged under it, hence in the IR this photon cannot be decoupled. The photon-pion term encodes the coupling of A to the baryon number current in the IR. We argue that the theory has a spontaneously-broken 2-group symmetry, implying that the leading photon-pion interaction coincides with the one we determined from our conjecture.
Since our work utilizes TQFTs with an infinite number of (simple) topological operators, as an aside in Appendix B we explore some of their properties and show (in a simple example) that while their path integrals on closed Euclidean manifolds are divergent, the path integrals on open manifolds can be made finite.
The rest of the paper is organized as follows. In Section 2 we explain the general setup and clarify some issues about holography with TQFTs in the bulk. In the rest of the sections we present several interesting examples. Section 3 concerns the vanilla example of Abelian symmetries without additional structures. In Section 4 we include chiral anomalies and higher group structures, showing that the Goldstone theory is the same as in the vanilla case but it couples differently to background fields, a fact that is interpreted in terms of symmetry fractionalization . The non-invertible example is discussed in Section 5 after we warm up with a similar but simpler example in 3d that produces Maxwell-Chern-Simons theory. The non-Abelian cases (including higher groups) are finally studied in Section 6.
## 2 Topological field theories as holographic duals
The bulk theories we use in this paper are TQFTs of the type introduced in [48-50] to describe SymTFTs for continuous symmetries. In the simplest cases, they have a Lagrangian formulation as 4
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } b _ { d - p - 1 } \wedge d A _ { p + 1 }$$
where A p +1 is a U (1) ( p + 1) -form gauge field, while b d - -p 1 is an R ( d -p -1) -form gauge field. In the whole paper, we adopt this convention in which uppercase letters indicate U (1) gauge fields, while lowercase letters indicate R gauge fields. Understood as a SymTFT, this describes a p -form U (1) symmetry in d dimensions. The topological operators of the theory are [48]:
$$V _ { n } ( \gamma _ { p + 1 } ) = e ^ { \ i n \int _ { \gamma _ { p + 1 } } A _ { p + 1 } } \,, \ \ U _ { \beta } ( \gamma _ { d - p - 1 } ) = e ^ { \ i \beta \int _ { \gamma _ { d - p - 1 } } b _ { d - p - 1 } } \,, \ \ n \in \mathbb { Z } \,, \ \ \beta \in \mathbb { R } / \mathbb { Z } \cong U ( 1 ) \,. \ \ ( 2. 2 )$$
4 We only consider Euclidean manifolds and normalize our actions so that the weight in the path integral is e -S .
Figure 1: Left: the SymTFT setup. The TQFT is placed on a slab, whose right boundary is topological and determined by a Lagrangian algebra L . Right: the holographic setup considered here. There is only one boundary with non-topological boundary conditions, while the Lagrangian algebra L is gauged to make the bulk invertible.
The partition function of (2.1) on a generic closed manifold diverges, but infinities are avoided on certain classes of manifolds with boundaries (see Appendix B). These are the relevant ones for both the SymTFT and the holographic setup considered in this paper. Moreover, normalized correlators are always finite, and capture the braiding of topological defects:
$$\left \langle V _ { n } ( \gamma _ { p + 1 } ) \, U _ { \beta } ( \gamma _ { d - p - 1 } ^ { \prime } ) \right \rangle = \exp \left [ 2 \pi i \, n \, \beta \, L i n k ( \gamma _ { p + 1 }, \gamma _ { d - p - 1 } ^ { \prime } ) \right ].$$
In the following we will consider several modifications of the vanilla case (2.1) that take into account anomalies, higher groups, non-invertible symmetries, as well as extensions to non-Abelian groups. However let us focus here on this simplest case as an illustration of the basic ideas and setup.
In SymTFT, (2.1) is placed on a slab with two boundaries, one of which is topological and determines the symmetry after the slab is squeezed. This topological boundary is characterized by a maximal set of mutually transparent objects, which we generically refer to as a Lagrangian algebra L . In this example a natural Lagrangian algebra consists of all V n ( γ p +1 ) , while the U β ( γ d - -p 1 ) become the generators of the U (1) p -form symmetry of the boundary theory.
In this paper, instead, we consider a different setting in which (2.1) is placed on a manifold X d +1 with a unique connected boundary M d = ∂X d +1 , which we endow with a Riemannian structure. On M d we fix non-topological boundary conditions 5
$$A _ { p + 1 } + i C \ast b _ { d - p - 1 } = \mathcal { A } _ { p + 1 } \,.$$
Here ⋆ is the Hodge star operator of the boundary, A p +1 is a fixed ( p + 1) -form on the boundary, and C is a generically dimensionful constant with mass dimension [ C ] = 2 p +2 -d . 6 Moreover, the
5 Such boundary conditions in BF theory, and the edge modes they lead to, have recently been studied in [64]. 6 The introduction of such a scale is necessary since the components of A p +1 have dimension p +1 while those of b d - -p 1 have dimension d -p -1. In this way the forms A p +1 and b d - -p 1 are dimensionless, the action in (2.1) is dimensionless, but ⋆ b d - -p 1 has dimension d -2 p -2.
Lagrangian algebra L that was used to define the topological boundary in the SymTFT setup must now be gauged in the bulk X d +1 , and the final bulk theory Z C ( ) / L is an invertible TQFT. See Fig. 1 for a comparison of the two setups.
In this second setup we want to establish a precise holographic duality with a certain local QFT d living on the boundary, which we need to determine. More precisely, the equality we need to show is the standard one [65-67]:
$$Z _ { T Q \text{FT} _ { d + 1 } } \left [ \varphi \right | _ { \partial } = \mathcal { A } \right ] \, = \, Z _ { \text{QFT} _ { d } } \left [ \mathcal { M } _ { d }, \mathcal { A } \right ].$$
Here TQFT d +1 is the result of gauging L in Z C ( ) , φ denotes generically some bulk fields (for instance φ = A p +1 + iC ⋆ b d - -p 1 in the example (2.1) ), while A is introduced as a boundary value from the bulk viewpoint and plays the role of a background field for the boundary QFT. Although SymTFT superficially resembles holography, the two are fundamentally different. SymTFT only captures symmetries and disregards dynamics, allowing any QFT with the specified symmetry. In contrast, in holography the dual QFT d is uniquely determined by the bulk theory and its boundary conditions, encoding both symmetries and dynamics as in (2.5) . 7
We will determine the dual QFT d explicitly in the many examples considered below, providing strong evidence for the conjecture that the dual theory to Z C ( ) / L is always the symmetry-breaking EFT for C . Some of these checks are quite subtle and highly nontrivial. For instance, the Goldstone theory for a U (1) symmetry with a cubic 't Hooft anomaly in 4d is still a compact boson with no additional terms as in the non-anomalous case, 8 but the background field for the symmetry is coupled non-minimally to the theory. We discuss this in Section 4.3 (in particular (4.20) is the additional coupling) to which we refer for more details. The SymTFT for a 4d anomalous U (1) is [48]
$$S = \frac { i } { 2 \pi } \int _ { X _ { 5 } } b _ { 3 } \wedge d A _ { 1 } + \frac { i k } { 2 4 \pi ^ { 2 } } \int _ { X _ { 5 } } A _ { 1 } \wedge d A _ { 1 } \wedge d A _ { 1 } \,.$$
Forgetting about the boundary value A 1 appearing in the boundary condition (2.4) , the additional cubic term does not affect the dual boundary QFT . However we will show in Section 4.2 that keeping 4 track of A 1 we reproduce exactly the non-minimal coupling expected for an anomalous U (1) .
Before moving to the various examples, let us clarify a conceptual point. The assertion that certain dynamical QFTs have a TQFT as holographic dual might be perplexing at first. The origin of the confusion is that, even though TQFTs are good theories of gravity, the non-appearance of a metric tensor g µν is puzzling for holography: the metric should be dual to the stress-energy tensor T µν of the boundary QFT. While this observation is in general correct, in a few special cases it might have a loophole: the stress tensor might not be an independent operator. For instance, this is the case in the CS/WZW correspondence [56, 57]. In 2d WZW models the stress tensor of the CFT, using the Sugawara construction, is made out of the currents which are dual to the gauge fields of the 3d Chern-Simons bulk theory. Something very similar happens in our examples. Indeed, the EFTs for symmetry breaking are very special QFTs in which everything, including the stress-energy tensor, is determined by the currents and their correlation functions. This is at the core of the universality of
7 See [68] for a general description of symmetry operators in holography.
8 This is different from the non-Abelian case, in which an anomaly implies a WZW term in the sigma model.
those EFTs. For instance, in the theory of a U (1) Goldstone boson with action
$$S = \frac { R ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { d } } d \Phi \wedge \ast d \Phi \,,$$
the U (1) current is J µ = iR 2 2 π ∂ µ Φ and the stress tensor is a composite operator of J µ :
$$T _ { \mu \nu } = \frac { R ^ { 2 } } { 4 \pi } \left ( \partial _ { \mu } \Phi \, \partial _ { \nu } \Phi - \frac { 1 } { 2 } \, \delta _ { \mu \nu } \, ( \partial \Phi ) ^ { 2 } \right ) = \frac { \pi } { R ^ { 2 } } \left ( \frac { 1 } { 2 } \, \delta _ { \mu \nu } \, J ^ { 2 } - J _ { \mu } J _ { \nu } \right ).$$
Through the boundary conditions, the bulk SymTFT provides background fields for the global symmetries of the boundary theory, which are sources for the boundary currents. Hence the TQFT can compute correlation functions of the currents, and by universality correlation functions of all operators, including those of the stress tensor, even without an explicit source g µν . This is a general statement: in the EFTs for spontaneous breaking the currents completely determine all operators and the holographic duals do not need a graviton field.
It is expected, however, that embedding our models into RG flows and taking into account nonuniversal features would require to reintroduce dynamical gravity into the game. Indeed, a related observation is that the boundary theories we obtain are either free or non-renormalizable. The reason why a TQFT, which is expected to be UV complete and finite, can be dual to a non-renormalizable theory is the choice of non-topological boundary conditions, which introduce an energy scale in the theory. This scale sets a limit below which both the bulk and boundary theories are well defined. Above this threshold, the boundary theory requires the inclusion of more and more operators to tame UV divergencies. This issue has to carry over to the bulk TQFT as well - albeit in a way unclear to us - making the TQFT description incomplete. The expectation is that, to make sense of the bulk theory above the scale of the boundary condition, one has to allow for dynamical gravity in the bulk in a way that is similar to the embedding of an EFT for spontaneous breaking into a UV complete theory. It would be interesting to understand this point better.
## 3 U (1) Goldstone bosons
The simplest cases to test our conjecture are those of U (1) symmetries of generic degree. We warm up with the textbook example of a spontaneously broken U (1) 0 -form symmetry in generic dimension and then move on to the case of higher-form symmetries, whose Goldstone bosons are (free) U (1) higher-form gauge fields [2].
## 3.1 0-form symmetries
Consider the following TQFT in d +1 dimensions:
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } b _ { d - 1 } \wedge d A _ { 1 } \,,$$
where A 1 is a U (1) gauge field while b d -1 is an R ( d -1) -form gauge field. We endow the boundary M d = ∂X d +1 with a Riemmanian metric and impose the boundary condition
$$\ast A _ { 1 } = - \frac { i } { R ^ { 2 } } \, b _ { d - 1 } + \ast \mathcal { A } _ { 1 } \,.$$
Here R is a parameter of mass dimension ( d -2) / 2 , while A 1 is a fixed background 1-form on M d . Notice that only in d = 2 this boundary condition is conformally invariant. In order to get a consistent variational principle with this boundary condition we must add a boundary term S ∂ to (3.1). Indeed, the variation of the action produces a boundary piece
$$\delta S \Big | _ { \mathcal { M } _ { d } } = ( - 1 ) ^ { d - 1 } \, \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } b _ { d - 1 } \wedge \delta A _ { 1 } = \frac { 1 } { 2 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { d } } b _ { d - 1 } \wedge \ast \delta b _ { d - 1 } \,,$$
which requires a boundary term
$$S _ { \partial } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { d } } b _ { d - 1 } \wedge \ast b _ { d - 1 } \,.$$
↦
Since the boundary condition (3.2) breaks gauge invariance on the boundary, we have to be careful in specifying the group of transformations we quotient by in the bulk: we choose to allow only gauge transformations that are trivial on the boundary. This implies that the bulk gauge symmetries become global on the boundary. For any global symmetry we should be able to turn on a background. In our setup this operation has a very natural realization: instead of freezing gauge transformations on the boundary, we allow them but transform the boundary data so as to render the boundary condition invariant. For instance, we can make (3.2) gauge invariant under gauge transformations of A 1 by demanding that A 1 → A 1 + dλ 0 is accompanied by a transformation of the fixed background A 1 :
$$\mathcal { A } _ { 1 } \mapsto \mathcal { A } _ { 1 } + d \lambda _ { 0 } \,.$$
With this choice, A 1 is interpreted as a background gauge field for the global U (1) symmetry on the boundary. Notice that with our choice of boundary term the whole system is gauge invariant.
↦
We can also restore the gauge transformations b d -1 → b d -1 + dν d -2 by transforming
↦
$$\mathcal { A } _ { 1 } \, \mapsto \, \mathcal { A } _ { 1 } - ( - 1 ) ^ { d } \frac { i } { R ^ { 2 } } \, \ast d \nu _ { d - 2 } \,,$$
which however are not proper background gauge transformations. A clearer and equivalent possibility is to parametrize the boundary condition as
$$* A _ { 1 } = - \frac { i } { R ^ { 2 } } \left ( b _ { d - 1 } - \mathcal { B } _ { d - 1 } \right ),$$
↦
where B d -1 is another fixed background on the boundary that transforms as B d -1 →B d -1 + dν d -2 . It can be understood as a background field for the global ( d -2) -form symmetry on the boundary. Yet another possibility is to restore both gauge transformations, for instance through the parametrization
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { R ^ { 2 } } \left ( b _ { d - 1 } - \mathcal { B } _ { d - 1 } \right ).$$
We can use it to discover information about the boundary theory. Indeed, with the choice of boundary term in (3.4), the system is not gauge invariant, rather under a gauge transformation we find
$$\delta ( S + S _ { \theta } ) = ( - 1 ) ^ { d - 1 } \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } d \nu _ { d - 2 } \wedge \mathcal { A } _ { 1 } - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { d } } ( 2 \, d \nu _ { d - 2 } \wedge \ast \mathcal { B } _ { d - 1 } + d \nu _ { d - 2 } \wedge \ast d \nu _ { d - 2 } ) \.$$
The second piece can be cancelled by modifying the boundary term with the addition of
$$\frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { d } } \mathcal { B } _ { d - 1 } \wedge \ast \mathcal { B } _ { d - 1 } \,,$$
that can be understood as a local counterterm. However the first piece in (3.9) cannot be removed while preserving background gauge invariance for the U (1) 0-form symmetry. This is a sign that the two symmetries have a mixed 't Hooft anomaly. Indeed, as we are going to see, the theory we are describing is the holographic dual to a d -dimensional compact boson. In what follows we will turn on only the background for the U (1) 0-form symmetry, i.e. , we will use the boundary condition (3.2) .
In order to rewrite the path integral of this TQFT as that of the compact boson we proceed in analogy with [57,69,70] (see also [71]). We assume that X d +1 contains an S 1 factor parametrized by t ∼ t + β , interpreted as Euclidean time, hence X d +1 = X d × S 1 and ∂X d +1 ≡ M d = M d -1 × S 1 . For simplicity, we also choose the metric of ∂X d +1 to be diagonal in M d -1 and S 1 so that
$$\ast d t = ( - 1 ) ^ { d - 1 } \text{Vol} _ { \mathcal { M } _ { d - 1 } } \, \in \, \Omega ^ { d - 1 } ( \mathcal { M } _ { d - 1 } )$$
with Vol M d -1 the volume form of M d -1 . We decompose the bulk fields as
$$A _ { 1 } = A _ { 0 } ^ { t } \, d t + \widetilde { A } _ { 1 } \,, \quad \ \ b _ { d - 1 } = b _ { d - 2 } ^ { t } \wedge d t + \widetilde { b } _ { d - 1 } \,,$$
where forms with a tilde live on the spatial manifold X d . The time components A t 0 and b t d -2 appear linearly and can be treated as Lagrange multipliers. Integrating them out enforces
$$\tilde { d } \widetilde { A } _ { 1 } & = 0 \,, & \tilde { d } \widetilde { b } _ { d - 1 } & = 0 \,.$$
We now make a choice for X d and take it to be a d -dimensional ball so that M d = S d -1 × S 1 . Then (3.13) are solved by introducing a compact scalar Φ 0 and a ( d -2) -form R gauge field ω d -2 as
$$\widetilde { A } _ { 1 } & = \tilde { d } \Phi _ { 0 } \,, & \widetilde { b } _ { d - 1 } & = \tilde { d } \omega _ { d - 2 } \,.$$
Rewriting both the bulk action and the boundary term using Φ 0 and ω d -2 , the system reduces to the boundary action
$$S = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } \left [ & ( - 1 ) ^ { d } \, \tilde { d } \omega _ { d - 2 } \wedge ( \partial _ { t } \Phi _ { 0 } - \mathcal { A } _ { 0 } ^ { t } ) d t \\ & - \frac { i } { 2 } \left ( R ^ { 2 } ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { A } } _ { 1 } ) \wedge * ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { A } } _ { 1 } ) + \frac { 1 } { R ^ { 2 } } \, \tilde { d } \omega _ { d - 2 } \wedge * \tilde { d } \omega _ { d - 2 } \right ) \right ].$$
This action is not covariant, and time derivatives appear linearly. For d = 2 , the action contains two scalars and is a manifestly self-dual formulation of the compact boson known in the condensed matter literature as the Luttinger liquid Lagrangian (see, e.g. , [72] for a recent discussion). It has the
advantage of making both U (1) symmetries explicit, at the expense of hiding Lorentz invariance. The action (3.15) is a d -dimensional generalization of it and it makes both the 0-form and the ( d -2) -form U (1) symmetries manifest.
Path integrals with an action linear in time derivatives are interpreted as phase-space path integrals. One can typically obtain a configuration-space path integral by integrating out the momenta that appear quadratically. Indeed, here ˜ dω d -2 is the conjugate momentum to Φ 0 and we can recast the theory in a Lorentz-invariant form by integrating out ω d -2 . An important observation is that the action has zero modes that need to be eliminated. One way to see this is via the equations of motion for ω d -2 . These are
$$\sim \widehat { d } \left [ ( \partial _ { t } \Phi _ { 0 } - \mathcal { A } _ { 0 } ^ { t } ) d t \, + \, ( - 1 ) ^ { d } \frac { i } { R ^ { 2 } } \ast \tilde { d } \omega _ { d - 2 } \right ] = 0$$
with solution
$$\tilde { d } \omega _ { d - 2 } = i R ^ { 2 } \left ( \partial _ { t } \Phi _ { 0 } - \mathcal { A } _ { 0 } ^ { t } \right ) \ast d t - i R ^ { 2 } \ast \tilde { d } \gamma _ { 0 } \,.$$
Notice that, since ( ∂ t Φ 0 -A t 0 ) ⋆ dt is a ( d -1) -form supported only on space, we have ˜ d ⋆ dγ ˜ 0 = 0 . The scalar γ 0 is integrated over but its path integral is naively divergent because γ 0 has vanishing action, i.e. , it is a zero-mode. Therefore in order to get a consistent theory we have to gauge fix γ 0 = 0 . Plugging ˜ dω d -2 in (3.15) we get the final action
$$S = \frac { R ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { d } } ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } ) \wedge \ast \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ),$$
corresponding to a d -dimensional compact boson with radius R . Had we integrated out Φ 0 from (3.15) , we would have found the dual formulation in terms of the ( d -2) -form ω d -2 . The background field A 1 corresponds to the U (1) shift symmetry of the boson and the anomalous shift we discussed above corresponds to the mixed 't Hooft anomaly with the winding symmetry.
One might be puzzled by the fact that we have one bulk gauge symmetry U (1) , but we still obtain two global symmetries on the boundary, which might seem to clash with the usual holographic expectations. However, for the compact boson this is not really a contradiction: all correlation functions of one current can be obtained from those of the other. Indeed, the backgrounds of the two symmetries are obtained one from the other using the ⋆ operator (modulo counterterms, which correspond to contact terms in correlators); thus, functional derivatives of the partition function with respect to a single background already contain the information of all correlators of both currents (see [73] for a related discussion).
Before going on, let us mention an alternative, quicker way to arrive at the final result that does not pass through the Luttinger-liquid-like formulation (3.15) . It requires X d +1 to be a ball, and hence M d = S d . After determining the boundary conditions (3.2) and the boundary term (3.4) , we just integrate the entire b d -1 out, imposing dA 1 = 0 . Since the bulk is now topologically trivial, this is solved by A 1 = d Φ 0 . Using the boundary condition to express the boundary term (3.4) in terms of A 1 , and plugging back A 1 = d Φ 0 , we immediately get (3.18) .
## 3.2 Higher-form symmetries
The higher-form case is very similar and we only flash the 1-form symmetry example, just to highlight one small subtlety. The TQFT we start with has action
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } f _ { d - 2 } \wedge d G _ { 2 } \,,$$
with f d -2 and G 2 being an R and U (1) gauge field, respectively. On X d +1 with boundary M d , that we endow with a Riemannian metric (if d = 4 a conformal structure is enough) we set the boundary condition (see also [64]):
$$\cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cd� \cdot \cdot \cdot \cdot \cdot \cdot \cd� \cdot \cdot \cd� \cdot \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \dd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \\ * G _ { 2 } = ( - 1 ) ^ { d + 1 } \frac { i e e ^ { 2 } } { } \pi \, f _ { d - 2 } + * \mathcal { G } _ { 2 } \,,$$
where [ e 2 ] = 4 -d . We must also add a boundary term
$$S _ { \partial } = - \frac { e ^ { 2 } } { 4 \pi ^ { 2 } } \int _ { \partial X _ { d + 1 } } f _ { d - 2 } \wedge \ast f _ { d - 2 } \,.$$
When solving the constraints imposed by the integral over time components as
$$\widetilde { f } _ { d - 2 } = \tilde { d } \omega _ { d - 3 } \,, & & \widetilde { G } _ { 2 } = \tilde { d } A _ { 1 } \,,$$
we introduce (time-dependent) forms ω d -3 and A 1 only on the spatial manifold X d , namely without time components. The boundary action one obtains is
$$S = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } \left [ & ( - 1 ) ^ { d } \, \tilde { d } \omega _ { d - 3 } \wedge \left ( \partial _ { t } A _ { 1 } + \mathcal { G } _ { 1 } ^ { t } \right ) \wedge d t \\ & - \frac { i } { 2 } \left ( \frac { e ^ { 2 } } { \pi } \, \tilde { d } \omega _ { d - 3 } \wedge \tilde { \delta } \omega _ { d - 3 } + \frac { \pi } { e ^ { 2 } } \left ( \tilde { d } A _ { 1 } - \widetilde { \mathcal { G } } _ { 2 } \right ) \wedge \ast \left ( \tilde { d } A _ { 1 } - \widetilde { \mathcal { G } } _ { 2 } \right ) \right ) \right ].$$
This is a higher-form generalization of (3.15) and integrating out ω d -3 we obtain
$$S = \frac { 1 } { 4 e ^ { 2 } } \int _ { \mathcal { M } _ { d } } ( d A _ { 1 } - \mathcal { B } _ { 2 } ) \wedge \ast \left ( d A _ { 1 } - \mathcal { B } _ { 2 } \right ),$$
where B 2 = -G ∧ t 1 dt + ˜ G 2 is a 2-form background field. This is a Maxwell action in d dimensions coupled to a background field B 2 for its electric 1-form symmetry.
The subtlety we want to point out is that A 1 does not have the time component, hence this is a gauge-fixed Maxwell action. 9 There is a gauge choice that arises naturally in this reduction procedure, that is, the temporal gauge. The same story goes through for any higher-form gauge field: the boundary action is always a generalized Maxwell theory in the temporal gauge (see [71] for a discussion on this point). It is important to keep this small subtlety in mind when looking at more complicated TQFTs that produce further interactions involving the photon. For instance, in Section 5 we will obtain Chern-Simons terms on the boundary, and we will have to keep in mind that they always arise in the temporal gauge.
9 This subtlety does not arise in the quicker procedure described at the end of the last section.
## 3.3 Lagrangian algebras and topological sectors
There is one very important caveat in the discussion of the previous two sections. Let us focus on the 0-form symmetry case for definiteness. We have shown that with the boundary condition we chose, the path integral of the TQFT can be rewritten as a path integral with the action of a compact boson (3.18) . However, the domain is not the one of the physical theory. The reason is that when we solve (3.13) introducing Φ 0 and ω d -2 as in (3.14) , these fields cannot wind around the time circle S 1 . Hence what we established in Section 3.1 is that the TQFT partition function is equal to the zero-winding sector of a compact boson. 10
However, it turns out that we can produce the path integral in any fixed winding sector, simply by inserting a Wilson line e in ∫ S 1 A 1 along the time circle in the bulk. The line pierces the spatial manifold X d at a point P , creating a nontrivial ( d -1) -cycle Σ d -1 ⊂ X d and introducing a monodromy for ˜ b d -1 around it:
$$\int _ { \Sigma _ { d - 1 } } \widetilde { b } _ { d - 1 } = 2 \pi n \,.$$
To get the TQFT partition function with this insertion, consider a generator η d -1 2 π of H d -1 ( X d ∖ P ; Z ) , namely ∫ Σ d -1 η d -1 = 2 π . The second equation in (3.13) is now solved by
$$\widetilde { b } _ { d - 1 } = n \, \eta _ { d - 1 } + \tilde { d } \omega _ { d - 2 } \,.$$
With the same steps as before we obtain a path integral on boundary fields Φ 0 and ω d -2 , again over configurations of Φ 0 with zero winding around the time circle, but with a modified action with respect to (3.15) :
$$S _ { n } & = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } & \left [ ( - 1 ) ^ { d } \tilde { d } \omega _ { d - 2 } \wedge ( \partial _ { t } \Phi _ { 0 } - \mathcal { A } _ { 0 } ^ { t } ) d t \\ & \quad - \frac { i } { 2 } \left ( R ^ { 2 } \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { A } } _ { 1 } \right ) \wedge \ast ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { A } } _ { 1 } ) + \frac { 1 } { R ^ { 2 } } \tilde { d } \omega _ { d - 2 } \wedge \ast \tilde { d } \omega _ { d - 2 } \right ) \right ] \quad \left ( 3. 2 7 \right ) \\ & \quad - ( - 1 ) ^ { d } \frac { i n } { 2 \pi } \int _ { \mathcal { M } _ { d } } \mathcal { A } _ { 0 } ^ { t } \, \widehat { \eta } _ { d - 1 } \wedge d t + \frac { n ^ { 2 } } { 4 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { d } } \widehat { \eta } _ { d - 1 } \wedge \ast \widehat { \eta } _ { d - 1 } \,. \\ \intertext { H o r o } \widehat { n }, \ \text{is the nillback of $n$, $n$} \, M, \text{ It is a ton form on $\mathcal{A}X$, $M$, $d$ and one can make $a$}$$
Here ̂ η d -1 is the pull-back of η d -1 on M d . It is a top form on ∂X d ≡ M d -1 and one can make a choice for the representative η d -1 in (3.26) such that ̂ η d -1 = 2 π v Vol M d -1 with v = ∫ M d -1 Vol M d -1 the volume of the boundary spatial slice. In particular ⋆ η ̂ d -1 = 2 π v dt . Plugging this back into (3.27) we obtain
$$o o t a n & S _ { n } = S _ { 0 } - i n \theta + \frac { \pi \beta n ^ { 2 } } { v R ^ { 2 } } & \quad \text{ where } \quad \theta = ( - 1 ) ^ { d } \int _ { S ^ { 1 } } \mathcal { A } _ { 0 } ^ { t } \, d t \,.$$
Here S 0 is the action (3.15) written in terms of the periodic scalar in the Luttinger liquid form, which could be rewritten in the Lorentz covariant form (3.18) that makes manifest its nature as a boson of radius R . Notice that θ ∼ θ +2 π has the interpretation of a chemical potential for the U (1) 0-form
10 For d = 2 the boundary spatial manifold is S 1 , and since Φ 0 is compact the path integral includes a sum over all windings around that spatial circle, but not around the time circle.
symmetry. The partition function with the line inserted is then
$$Z _ { n } = Z _ { \text{pert} } \, \exp \left ( i n \theta - \frac { \pi \beta } { v R ^ { 2 } } \, n ^ { 2 } \right )$$
where Z pert is the perturbative contribution due to a periodic boson.
We want to show our claim that, after we condense a Lagrangian algebra in the bulk, the partition function includes the sum over all topological sectors of the compact scalar, hence reproducing the physical partition function. The simplest Lagrangian algebra contains all the lines W n = e in ∫ A 1 and no surfaces V α = e iα ∫ b d -1 . Due to our choice of geometry, gauging this algebra is the same as summing over all lines inserted along the time circle, hence summing over all n in (3.29) . The bulk interpretation of this sum is that we are computing the partition function of the SPT phase obtained by gauging the algebra, which we are taking as our theory of gravity. Hence using Poisson's summation formula we find 11
$$Z _ { \text{gravity} } = \sum _ { n \in \mathbb { Z } } Z _ { n } = Z _ { \text{pert} } \sum _ { w \in \mathbb { Z } } \exp \left [ - \frac { \pi v R ^ { 2 } } { \beta } \left ( w + \frac { \theta } { 2 \pi } \right ) ^ { 2 } \right ].$$
The right hand side is precisely the partition function of a compact boson of radius R (with chemical potential θ ).
More generally, the bulk TQFT has other Lagrangian algebras consisting of the lines W km and the surfaces V m /k ′ for an integer number k ∈ Z . Condensing one of them produces a different SPT phase in the bulk, hence a different theory of gravity. In the SymTFT story this corresponds to gauging the Z k subgroups of the U (1) symmetry at the boundary [48]. Because of the chosen geometry, there are no ( d -1) -cycles in the bulk and hence condensing this algebra simply means summing over all Wilson lines of charge multiple of k . The result is
$$Z _ { \text{gravity} } ^ { \prime } = \sum _ { m \in \mathbb { Z } } Z _ { k m } = Z _ { \text{pert} } \sum _ { w \in \mathbb { Z } } \exp \left [ - \frac { \pi v } { \beta } \left ( \frac { R } { k } \right ) ^ { 2 } \left ( w + \frac { k \theta } { 2 \pi } \right ) ^ { 2 } \right ]$$
and the right-hand side can be interpreted as the partition function of a compact boson of radius R ′ = R/k . This is an orbifold of the previous boundary theory, which could be thought of as a different global form of the same theory.
We want to comment on a slightly different way to obtain a holographic dual to compact bosons, which also fits our proposal. We could have started with the TQFT of two R gauge fields described by the action
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } b _ { d - 1 } \wedge d a _ { 1 } \,.$$
In this TQFT the charges of the Wilson lines W α = e iα ∫ a 1 are not quantized, and since there is no sum over fluxes, 12 there is no identification among the charges of V β = e iβ ∫ b d -1 . The spectrum of
11 Here we are neglecting an extra factor √ β/vR 2 , since normalizations of the path integrals do not play a role in this paper. A similar factor is neglected in (3.31).
12 An R gauge field admits a gauge in which the connection is globally defined, therefore the field strength is an exact form and its integrals on compact submanifolds vanish.
bulk operators is then larger, labelled by R × R , and the corresponding braiding is the phase e 2 πiαβ . Lagrangian algebras are classified by the choice of a real number Q ∈ R + and are given by [18]
$$\mathcal { L } _ { Q } = \left \{ W _ { Q n }, V _ { Q ^ { - 1 } m } \, \Big | \ n, m \in \mathbb { Z } \right \}.$$
It was shown in [48] that this TQFT is the SymTFT for two U (1) symmetries, namely a 0-form and a ( d -2) -form, with a mixed anomaly. While this is a different symmetry structure from just a single U (1) , the second higher-form symmetry arises universally in the IR whenever the 0-form symmetry is spontaneously broken. Hence the two symmetry structures share the same EFT that describes the broken phase and, according to our proposal, they should both be the holographic dual to a compact boson. Indeed there is no much difference between the two theories: the non-topological boundary conditions can be chosen to be the same, and the computations of Section 3.1 give the same result.
The considerations explained in this section can be repeated for any higher-form symmetry. However, in order to detect the various global structures of a boundary p -form Maxwell theory, one needs to properly choose the geometry. Indeed the fluxes are supported on ( p +1) -dimensional cycles, and thus a natural choice is to take X d +1 = B d -p × T p +1 with B d -p a ball. One of the S 1 factors of the torus plays the role of a time circle, and X d = B d -p × T p . The bulk TQFT has action
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } b _ { d - p - 1 } \wedge d A _ { p + 1 }$$
where b d - -p 1 is an R gauge field whilst A p +1 is a U (1) gauge field. One can obtain an SPT phase by gauging the Lagrangian algebra given by W n = e in ∫ A p +1 , and this is realized by inserting these defects along the T p +1 factor in the bulk. This sum indeed reproduces the sum over fluxes of the p -form Maxwell theory on the boundary. The choice of other Lagrangian algebras modifies the value of the electric charge and corresponds to discrete gaugings of the 1-form symmetry.
## 4 Abelian anomalies and higher groups
We can enrich the analysis of U (1) symmetries by including anomalies (Sections 4.1 and 4.2) or a 2-group structure (Section 4.4). We show here that, when doing it, the dual boundary theory gets coupled to background fields in a non-minimal way. In Sections 4.3 and 4.5 we provide a field-theoretic interpretation of our results in terms of symmetry fractionalization.
## 4.1 Chiral anomaly in 2d
The SymTFT for an anomalous U (1) symmetry in 2d has action [48]:
$$S = \frac { i } { 2 \pi } \int _ { X _ { 3 } } b _ { 1 } \wedge d A _ { 1 } + \frac { i k } { 4 \pi } \int _ { X _ { 3 } } A _ { 1 } \wedge d A _ { 1 } \,.$$
The additional bulk Chern-Simons term significantly affects the consistent boundary conditions. To establish a proper variational principle with a non-topological boundary condition, it is essential to
include the boundary term
$$S _ { \partial } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { 3 } } \left ( b _ { 1 } + \frac { k } { 2 } \, A _ { 1 } \right ) \wedge \ast \left ( b _ { 1 } + \frac { k } { 2 } \, A _ { 1 } \right )$$
together with the following Dirichlet boundary condition: 13
$$* \delta A _ { 1 } = - \frac { i } { R ^ { 2 } } \, \delta \left ( b _ { 1 } + \frac { k } { 2 } \, A _ { 1 } \right ).$$
In order to properly turn on a background for the boundary U (1) symmetry we have to render the boundary condition invariant under gauge transformations of A 1 . This is most naturally done by introducing a 1-form A 1 as
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { R ^ { 2 } } \left ( b _ { 1 } + \frac { k } { 2 } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \right ).$$
This boundary condition is invariant under δ A 1 = δA 1 = dλ 0 , allowing us to interpret A 1 as a background field for the U (1) symmetry on the boundary. Notice that our choice does not modify (4.3) and is thus just a particularly convenient parametrization.
Before deriving the dual boundary theory, we can already establish that it has an 't Hooft anomaly. Indeed, under a gauge transformation δA 1 = δ A 1 = dλ 0 the total action S + S ∂ transforms as
$$\delta ( S + S _ { \partial } ) = - \frac { i k } { 4 \pi } \int _ { \mathcal { M } _ { 2 } } d \lambda _ { 0 } \wedge \mathcal { A } _ { 1 } - \frac { k ^ { 2 } } { 1 6 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { 2 } } \left ( 2 \, d \lambda _ { 0 } \wedge * \mathcal { A } _ { 1 } + d \lambda _ { 0 } \wedge * d \lambda _ { 0 } \right ) \quad \ \ ( 4. 5 )$$
where M 2 = ∂X 3 . The second term can be cancelled by adding the following counterterm to the boundary action:
$$S _ { \text{c.t.} } = \frac { k ^ { 2 } } { 1 6 \pi R ^ { 2 } } \int _ { \mathcal { M } _ { 2 } } \mathcal { A } _ { 1 } \wedge \ast \mathcal { A } _ { 1 } \,.$$
However the remaining total gauge variation
$$\delta ( S + S _ { \partial } + S _ { \text{c.t.} } ) = - \frac { i k } { 4 \pi } \int _ { \mathcal { M } _ { 2 } } d \lambda _ { 0 } \wedge \mathcal { A } _ { 1 }$$
cannot be cancelled by any local boundary counterterm: it is precisely the anomalous variation corresponding to a perturbative U (1) anomaly.
To derive the boundary theory we follow the steps outlined in Section 3. The constraints imposed by the path integral over time components again allow us to write ˜ A 1 = ˜ Φ d 0 and ˜ b 1 = ˜ dω 0 . The boundary action expressed in terms of these variables, after introducing F = A 1 ik 2 R 2 ⋆ A 1 for convenience, reads:
$$S = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 2 } } & \left [ \left ( \tilde { d } \omega _ { 0 } + \frac { k } { 2 } \, \tilde { d } \Phi _ { 0 } \right ) \left ( \partial _ { 0 } \Phi _ { 0 } - \mathcal { F } _ { 0 } ^ { t } \right ) \wedge d t \\ & - \frac { i } { 2 } \left ( R ^ { 2 } \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { F } } _ { 1 } \right ) \wedge \ast \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { F } } _ { 1 } \right ) + \frac { 1 } { R ^ { 2 } } \left ( \tilde { d } \omega _ { 0 } + \frac { k } { 2 } \, \tilde { d } \Phi _ { 0 } \right ) \wedge \ast \left ( \tilde { d } \omega _ { 0 } + \frac { k } { 2 } \, \tilde { d } \Phi _ { 0 } \right ) \right ) \right ] + S _ { c. t } \,.$$
13 One can check, by writing all possible boundary terms and imposing consistency of the variational principle, that these boundary data are the only possible choice.
↦
This is the same action as in (3.15) for d = 2 but with ω 0 → ω 0 + k 2 Φ 0 . Integrating ω 0 out we find
$$S = \frac { R ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { 2 } } \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) + \frac { i k } { 4 \pi } \int _ { \mathcal { M } _ { 2 } } \Phi _ { 0 } \, d \mathcal { A } _ { 1 } \,.$$
This action describes a compact boson of radius R , but with an unusual coupling to a background for the momentum symmetry. Such a coupling reproduces the anomalous shift (4.7) that is indeed cancelled by the inflow action
$$S _ { \inf \text{flow} } = - \frac { i k } { 4 \pi } \int _ { 3 d } \mathcal { A } _ { 1 } \wedge d \mathcal { A } _ { 1 } \,.$$
Notice that the extra coupling Φ 0 d A 1 in (4.9) has a form similar to the coupling with the winding symmetry. In a sense, we are prescribing that a background A 1 for the momentum symmetry also activates a background B 1 = k A 1 for the winding symmetry. In other words, A 1 is not coupled with the momentum symmetry but rather with a diagonal combination of momentum and winding. 14 Since the two symmetries have a mixed anomaly, this diagonal U (1) inherits a pure anomaly.
## 4.2 Chiral anomaly in 4d
The treatment of anomalies in higher dimensions presents a further conceptual difference. As a representative case, we consider d = 4 and the TQFT with action
$$S = \frac { i } { 2 \pi } \int _ { X _ { 5 } } b _ { 3 } \wedge d A _ { 1 } + \frac { i k } { 2 4 \pi ^ { 2 } } \int _ { X _ { 5 } } A _ { 1 } \wedge d A _ { 1 } \wedge d A _ { 1 } \,.$$
To get a good variational principle we need to impose
$$* \delta A _ { 1 } = - \frac { i } { R ^ { 2 } } \, \delta \left ( b _ { 3 } + \frac { k } { 6 \pi } A _ { 1 } \wedge d A _ { 1 } \right )$$
and add a boundary term
$$S _ { \partial } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { 5 } } \left ( b _ { 3 } + \frac { k } { 6 \pi } A _ { 1 } \wedge d A _ { 1 } \right ) \wedge \ast \left ( b _ { 3 } + \frac { k } { 6 \pi } A _ { 1 } \wedge d A _ { 1 } \right ).$$
These choices however do not allow us to turn on a background by simply changing the parametrization of the boundary condition, as we did in 2d. Indeed, if we try to restore the gauge transformations of A 1 , the boundary condition shifts by terms that depend on the field A 1 itself and cannot be cancelled by adding counterterms in the background only. Turning on a background in d > 2 requires us to change the boundary data in a nontrivial way. In Appendix A we explain an iterative procedure that, starting from the data above, produces a consistent variational principle together with a gaugeinvariant boundary condition. The result for d = 4 is
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { R ^ { 2 } } \left ( b _ { 3 } + \frac { k } { 6 \pi } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \wedge d A _ { 1 } + \frac { k } { 1 2 \pi } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \wedge d \mathcal { A } _ { 1 } \right )$$
14 More precisely, it is the diagonal combination between momentum and a Z k extension of the winding symmetry.
with boundary term 15
$$S _ { \partial } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { 5 } } \left ( b _ { 3 } + \frac { k } { 6 \pi } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \wedge d A _ { 1 } + \frac { k } { 1 2 \pi } A _ { 1 } \wedge d \mathcal { A } _ { 1 } \right ) ^ { 2 } + \frac { i k } { 2 4 \pi ^ { 2 } } \int _ { \partial X _ { 5 } } \mathcal { A } _ { 1 } \wedge A _ { 1 } \wedge d A _ { 1 } \,. \ ( 4. 1 5 )$$
When setting A 1 = 0 we recover the previous boundary data, but in general there are new terms that mix background and dynamical fields. As in 2d, one can show that the system has an anomaly performing a gauge transformation δA 1 = δ A 1 = dλ 0 : up to a counterterm the gauge variation is
$$\delta ( S + S _ { \partial } + S _ { \text{c.t.} } ) = \frac { i k } { 2 4 \pi ^ { 2 } } \int _ { \partial X _ { 5 } } \lambda _ { 0 } \, d \mathcal { A } _ { 1 } \wedge d \mathcal { A } _ { 1 } \,.$$
The procedure to determine the dual boundary theory is completely analogous to the examples we have already presented. Integrating the time components out, we introduce ˜ A 1 = ˜ Φ d 0 and ˜ b 3 = ˜ dω 2 . To simplify our expressions, we denote F 1 = A 1 ik 12 πR 2 ⋆ ( A ∧ 1 d A 1 ) . Then the boundary action, in its non-covariant presentation, is
$$S = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 4 } } \left [ \left ( \tilde { d } \omega _ { 2 } + \frac { k } { 1 2 \pi } \, \tilde { d } \Phi _ { 0 } \wedge \tilde { d } \widetilde { \mathcal { A } } _ { 1 } \right ) \left ( \partial _ { t } \Phi _ { 0 } - \mathcal { F } _ { 0 } ^ { t } \right ) d t - \frac { i } { 2 } \left ( R ^ { 2 } \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { F } } _ { 1 } \right ) \wedge * \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { F } } _ { 1 } \right ) \\ + \, \frac { 1 } { R ^ { 2 } } \left ( \tilde { d } \omega _ { 2 } + \frac { k } { 1 2 \pi } \, \tilde { d } \Phi _ { 0 } \wedge \tilde { d } \widetilde { \mathcal { A } } _ { 1 } \right ) \wedge * \left ( \tilde { d } \omega _ { 2 } + \frac { k } { 1 2 \pi } \, \tilde { d } \Phi _ { 0 } \wedge \tilde { d } \widetilde { \mathcal { A } } _ { 1 } \right ) \right ) \right ] + S _ { c. t. }$$
where M 4 = ∂X 5 . As before we can integrate out ω 2 and the final action reads
$$S = \frac { R ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { 4 } } \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) + \frac { i k } { 2 4 \pi ^ { 2 } } \int _ { \mathcal { M } _ { 4 } } \Phi _ { 0 } \, d \mathcal { A } _ { 1 } \wedge d \mathcal { A } _ { 1 } \,.$$
This represents a compact scalar with a non-standard coupling to a background associated with the shift symmetry, akin to the situation in 2d. The additional interaction accounts for the anomalous variation described by (4.16). Nevertheless, unlike in the 2d scenario, we cannot view this altered interaction as a combination of the shift and winding symmetries since the two have different degree.
## 4.3 Anomaly matching in the broken phase
Let us provide a purely field-theoretic interpretation of the result in the previous section. For any Lie-group symmetry G , the Goldstone theory describing the symmetry breaking phase is a non-linear sigma model with target space G . In even spacetime dimensions d , the symmetry G can suffer from perturbative anomalies and the question is how these are matched in the sigma model.
For non-Abelian G it is well known that the anomaly is reproduced by a WZW term [62]. This is an additional interaction with important dynamical consequences. Perturbative anomalies are classified by H d +2 ( BG ; Z ) , which determines a ( d + 1) -dimensional Chern-Simons action that cancels the anomaly by inflow. On the other hand, WZW terms in d dimensions are classified by H d +1 ( G ; Z ) . Anomaly matching is mathematically represented by a map
$$\tau \colon H ^ { d + 2 } ( B G ; \mathbb { Z } ) \to H ^ { d + 1 } ( G ; \mathbb { Z } )$$
15 We used the shorthand notation ω 2 ≡ ω ∧ ⋆ ω .
called transgression [74]. For d = 2 this map also underlines the map of levels in the CS/WZW correspondence [75]. For the simple Lie group G = SU n ( ) , the transgression map τ is injective [75], meaning that any perturbative anomaly is matched by a WZW term. 16 However this is not the general case, and if τ has a nontrivial kernel, the corresponding anomalies require some new ingredient to be matched in the sigma model.
Here we focus on the extreme case G = U (1) for which H d +1 ( U (1); Z ) = 0 , namely there is no WZW term at all, and any anomaly must be matched in a different way. From our holographic analysis we know the answer to this question: the dynamics of the sigma model is unchanged with respect to the non-anomalous case, but the symmetry is coupled non-minimally to the background A 1 through the extra topological term
$$\frac { i k } { ( 2 \pi ) ^ { d / 2 } \left ( \frac { d } { 2 } + 1 \right )! } \, \int _ { \mathcal { M } _ { d } } \Phi _ { 0 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { d / 2 }.$$
This term reproduces the anomaly, but at this level it seems a bit ad hoc. We want to clarify why it arises from a UV viewpoint and how we understand it in the IR. This is important to understand why there is a difference in how anomaly matching works in the Abelian and non-Abelian cases.
We can show in a simple model that when the background field is turned on in the UV, the additional coupling (4.20) is generated along the RG flow by integrating out massive fields. Consider a 4d theory with a massless Dirac fermion ψ and a complex scalar ϕ , coupled via a Yukawa interaction:
$$\mathcal { L } \supset \phi \, \overline { \psi } \psi \,.$$
The theory has an axial symmetry U (1) A under which both Weyl components of ψ have charge 1 , while ϕ has charge -2 . U (1) A has a cubic anomaly with k = 2 . Choosing a potential V ( ϕ ) that induces condensation of ϕ , the axial symmetry gets spontaneously broken to Z 2 = ( -1) F . By decomposing ϕ = ρ e i Θ into its radial and angular parts, the VEV ⟨ ρ ⟩ = v gives mass to both ρ and ψ . The angular part Θ remains massless and is the only degree of freedom at low energy: it is the Goldstone boson. The faithful symmetry in the IR is U (1) = U (1) A / Z 2 that shifts Θ . In order to reproduce the anomaly, the coupling to a background A must include the term
$$\frac { i } { 2 4 \pi ^ { 2 } } \, \Theta \, ( d \mathcal { A } ) ^ { 2 } \,.$$
Indeed this term arises when integrating out the fermion. To see this notice that, for fixed ϕ and A , if ϕ is real and positive then the fermion path integral can be regularized in a way such that the measure is positive [76-78]. Clearly this is not true on a generic configuration, but we can make it true by performing an axial rotation of parameter e iα , with α = -1 2 Θ . A textbook computation [79,80] shows that the path integral measure of the fermion changes by a phase
↦
$$D [ \psi ] \mapsto D [ \psi ] \, \exp \left ( \frac { i k } { 2 4 \pi ^ { 2 } } \int \alpha \, ( d \mathcal { A } ) ^ { 2 } \right ) \,.$$
Setting α = -1 2 Θ this precisely reproduces the coupling (4.22) . Now the Yukawa coupling becomes ρ ψψ , that for fixed ρ is essentially a positive mass term for the fermion, hence integrating out the fermion becomes a safe operation that does not introduce extra phases.
16 The transgression map is expected to be injective for all simple Lie groups.
Returning to the general case, we want to interpret the extra coupling (4.20) as specifying a (higher) symmetry fractionalization class for the U (1) symmetry. This reinterpretation will be crucial to understand the analogous story for higher groups in the following sections. A 0-form symmetry G can fractionalize in the presence of a discrete 1-form symmetry Γ . This means that when two topological defects g, h ∈ G fuse to produce gh ∈ G , their codimension-two junction gets covered by a topological defect ω g, h ( ) ∈ Γ of the 1-form symmetry [81-83], where ω ∈ H 2 ( BG ; Γ) . Equivalently, a background A 1 for G turns on a background B 2 = A ∗ 1 ω for the 1-form symmetry. In this formula, we think of A 1 as a map M → d BG and of B 2 as an element of H 2 ( M d , Γ) so that we can use A 1 to pull back ω . With this interpretation it becomes clear that, if G and Γ have a mixed anomaly, a non-trivial fractionalization class modifies the pure anomaly for G , possibly making it nontrivial even when it vanished originally [82, 83]. This has a natural generalization to the case that Γ is a discrete p -form symmetry: when p +1 topological defects g , . . . , g 1 p +1 ∈ G fuse in generic position, they create a codimension-( p + 1) junction that can be dressed by a defect ω g , . . . , g ( 1 p +1 ) of the p -form symmetry Γ , where ω is a class in H p +1 ( BG ; Γ) . Equivalently, a background A 1 turns on a background B p +1 = A ∗ 1 ω for Γ .
The compact boson theory that describes the breaking of a U (1) 0-form symmetry also possesses a U (1) ( d -2) -form winding symmetry, and the two have a mixed anomaly. For this reason, a pure anomaly for the 0-form symmetry can be induced by fractionalizing it with the ( d -2) -form symmetry. One minor modification with respect to what we described above is necessary because the p -form symmetry (here p = d -2 ) is continuous. Its most natural description is not in terms of a background potential B p +1 , which is not a cohomology class in general, but in terms of its field strength 1 2 π d B p +1 ∈ H p +2 ( M d ; Z ) . As a consequence the fractionalization class, instead of being an element of H p +1 ( BU (1); U (1) ) , is more naturally an element of H p +2 ( BU (1); Z ) = ∼ Z . This is the datum that determines a ( p +1) -dimensional Chern-Simons level, or equivalently the corresponding Chern class in ( p + 2) dimensions. Hence, in analogy with the discrete case, we prescribe that a background A 1 for the 0-form symmetry activates a background B d -1 for the ( d -2) -form symmetry whose field strength is
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdot \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \frac { 1 } { 2 \pi } \, d \mathcal { B } _ { d - 1 } } = \frac { k } { } ( 2 \pi ) ^ { d / 2 } \left ( \frac { d } { 2 } + 1 \right )! \, \left ( d \mathcal { A } _ { 1 } \right ) ^ { d / 2 }.$$
Recalling that the ( d -2) -form symmetry is coupled to its background field through the action term i 2 π ∫ M d Φ 0 d B d -1 , this reproduces the coupling (4.20) in agreement with our holographic result.
## 4.4 Abelian 2-groups
We consider a 2-group symmetry in four dimensions formed by a U (1) 0-form symmetry and a U (1) 1-form symmetry. This can be obtained by starting from a theory with two U (1) 0-form symmetries with a cubic mixed anomaly and gauging the U (1) that appears linearly in the anomaly polynomial [63,84]. The 1 -form symmetry participating in the 2 -group structure is the magnetic symmetry of the photon. The SymTFT for such a 2-group symmetry has action [48]:
$$S = \frac { i } { 2 \pi } \int _ { X _ { 5 } } \left ( b _ { 3 } \wedge d A _ { 1 } + h _ { 2 } \wedge d C _ { 2 } + \frac { k } { 2 \pi } \, h _ { 2 } \wedge A _ { 1 } \wedge d A _ { 1 } \right ).$$
Here A 1 and C 2 are U (1) gauge fields, while b 3 and h 2 are R gauge fields. The topological operators that implement the symmetry are the Wilson surfaces of b 3 and h 2 . On the other hand, the endpoints of e i ∫ A 1 are local operators charged under the 0-form symmetry, and the endlines of e i ∫ C 2 are 't Hooft lines charged under the magnetic 1-form symmetry. The gauge transformations are: 17
$$\delta A _ { 1 } = d \lambda _ { 0 } \,, \quad \delta h _ { 2 } = d \xi _ { 1 } \,, \quad \delta b _ { 3 } = d \gamma _ { 2 } - \frac { k } { 2 \pi } \, d \xi _ { 1 } \wedge A _ { 1 } \,, \quad \delta C _ { 2 } = d \eta _ { 1 } + \frac { k } { 2 \pi } \, d \lambda _ { 0 } \wedge A _ { 1 } \,. \ ( 4. 2 6 )$$
We place this TQFT on a manifold with boundary, X 5 = B 4 × S 1 for simplicity, and we interpret it as a theory of gravity, holographically dual to some 4d quantum field theory on the boundary. The last term in (4.25) contains a derivative, therefore it affects the boundary contribution to the variational principle, similarly to the case of chiral anomalies. To fix the boundary terms S ∂ and the boundary conditions on the fields, we use the same logic as in that case. We find the boundary conditions
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { R ^ { 2 } } \left [ b _ { 3 } + \frac { k } { 2 \pi } \, h _ { 2 } \wedge \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \right ], \ \ * h _ { 2 } = \frac { i e ^ { 2 } } { \pi } \left ( C _ { 2 } - \mathcal { C } _ { 2 } - \frac { k } { 2 \pi } \, \mathcal { A } _ { 1 } \wedge A _ { 1 } \right ) \ \ ( 4. 2 7 )$$
and a corresponding boundary term
$$S _ { \partial } & = - \frac { i } { 2 \pi } \int _ { \partial X _ { 5 } } h _ { 2 } \wedge \left ( C _ { 2 } - \frac { k } { 2 \pi } \, \mathcal { A } _ { 1 } \wedge A _ { 1 } \right ) - \frac { e ^ { 2 } } { 4 \pi ^ { 2 } } \int _ { \partial X _ { 5 } } \left ( C _ { 2 } - \frac { k } { 2 \pi } \, \mathcal { A } _ { 1 } \wedge A _ { 1 } \right ) \wedge \ast \left ( C _ { 2 } - \frac { k } { 2 \pi } \, \mathcal { A } _ { 1 } \wedge A _ { 1 } \right ) \\ & \quad - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { 5 } } \left [ b _ { 3 } + \frac { k } { 2 \pi } \, h _ { 2 } \wedge \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \right ] \wedge \ast \left [ b _ { 3 } + \frac { k } { 2 \pi } \, h _ { 2 } \wedge \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \right ]. \\ \prod \quad \, \quad \, \quad \, \quad \, \cdot \quad \, \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \end{cases}$$
Here A 1 , C 2 are fixed gauge fields on the boundary that transform as a proper 2-group background:
δ
A
1
=
dλ
0
,
$$\delta \mathcal { C } _ { 2 } = d \eta _ { 1 } + \frac { k } { 2 \pi } \, d \lambda _ { 0 } \wedge \mathcal { A } _ { 1 } \,.$$
This makes the boundary conditions gauge invariant, provided we add a counterterm e 2 4 π 2 ∫ ∂X 5 C ∧ 2 ⋆ C 2 .
With the usual procedure, we obtain that the dual boundary theory has action:
$$S & = \frac { R ^ { 2 } } { 4 \pi } \int _ { \partial X _ { 5 } } \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) + \frac { 1 } { 4 c ^ { 2 } } \int _ { \partial X _ { 5 } } d a _ { 1 } \wedge \ast d a _ { 1 } \\ & \quad + \frac { i } { 2 \pi } \int _ { \partial X _ { 5 } } \mathcal { C } _ { 2 } \wedge d a _ { 1 } + \frac { i k } { 4 \pi ^ { 2 } } \int _ { \partial X _ { 5 } } \Phi _ { 0 } \, d a _ { 1 } \wedge d \mathcal { A } _ { 1 } \,. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
Naively one may think that a 1 is an R gauge field, because it comes from the trivialization of h 2 . However, we have to take into account the condensation of the appropriate Lagrangian algebra in the bulk, necessary to trivialize the TQFT and making it independent of the topology. Specifically, here the relevant Lagrangian algebra is
$$\mathcal { L } = \left \{ e ^ { i n \int A _ { 1 } }, \, e ^ { i m \int C _ { 2 } } \, \Big | \ n, m \in \mathbb { Z } \right \}.$$
Following the same logic as in Section 3.3, this introduces a sum over the fluxes of da 1 that effectively makes a 1 into a U (1) gauge field.
17 There is some freedom in the choice of transformations that leave (4.25) invariant. In particular, the transformation δA 1 = dλ 0 could be accompanied by an action on both b 3 and C 2 as δb 3 = -ϵ k 2 π dλ 0 ∧ h 2 and δC 2 = (1 -ϵ ) k 2 π dλ 0 ∧ A 1 for any choice of ϵ . Here we chose ϵ = 0 which matches the transformations in the boundary theory.
Turning off the background A 1 we obtain a free compact scalar and a free photon (coupled to a background field C 2 for its magnetic symmetry), enjoying a U (1) 0-form symmetry with conserved current J 1 = iR 2 2 π d Φ 0 , and a U (1) 1-form symmetry with conserved current J 2 = 1 2 π ⋆da 1 , respectively. However, as soon as we turn on a background A 1 for the 0-form symmetry, the 2-group structure manifests itself through the nonstandard coupling between the photon and the scalar, which modifies the currents and the background gauge transformations [63]. This is very similar to what happened in the case of the chiral anomaly, and we will provide a similar interpretation in terms of symmetry fractionalization in the next section.
Let us show that the theory in (4.30) reproduces the 2-group symmetry [63]. First, notice that the gauge transformation
$$\delta \Phi _ { 0 } = \lambda _ { 0 } \,, \quad \delta \mathcal { A } _ { 1 } = d \lambda _ { 0 } \,, \quad \delta \mathcal { C } _ { 2 } = d \eta _ { 1 } + \frac { k } { 2 \pi } \, d \lambda _ { 0 } \wedge \mathcal { A } _ { 1 } \, \quad \quad ( 4. 3 2 )$$
leaves the action invariant. This is indeed the background gauge transformation for a 2-group. Second, in the presence of a background the currents get modified to: 18
$$J _ { 1 } = \frac { i R ^ { 2 } } { 2 \pi } \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) + \frac { k } { 4 \pi } \ast \left ( d \Phi _ { 0 } \wedge d a _ { 1 } \right ), \quad \ \ J _ { 2 } = \frac { 1 } { 2 \pi } \ast d a _ { 1 } \,, \quad \ \ \ ( 4. 3 3 )$$
and these satisfy modified conservation equations
$$d \ast J _ { 1 } + \frac { k } { 2 \pi } \, d \mathcal { A } _ { 1 } \wedge \ast J _ { 2 } = 0 \,, \quad \ \ \ d \ast J _ { 2 } = 0 \,,$$
that are the correct conservation equations for a 2-group symmetry.
## 4.5 Abelian 2-groups in the broken phase
The unusual coupling to the background A 1 in (4.30) , responsible for the 2-group structure of the symmetry, is quite similar to the coupling (4.20) responsible for a chiral anomaly, that we interpreted in terms of symmetry fractionalization. Indeed we can give a similar interpretation here too. While it is intuitively clear why symmetry fractionalization can induce a pure anomaly, and this fact has been studied extensively [82, 83], the necessity of symmetry fractionalization to match higher-group structures has not been much appreciated. There is indeed one important difference, namely the nature of the symmetry used to fractionalize the U (1) 0-form symmetry in question: it is a composite symmetry [85].
In general, if we have two U (1) symmetries of degrees p and q with currents J p +1 and J q +1 respectively, if p + q ≥ d -1 we can construct a third U (1) symmetry simply because the current
$$J _ { p + q - d + 2 } = \ast \left ( ( \ast J _ { p + 1 } ) \wedge ( \ast J _ { q + 1 } ) \right )$$
is automatically conserved. This symmetry is of degree p + q -d + 1 . In general, it is not a particularly interesting symmetry because its consequences are already implied by the constituent
18 For a U (1) p -form symmetry we use the convention that the current J p +1 is defined by ⋆ J p +1 = -i δS δ A p +1 where A p +1 is the background field.
symmetries. However, it plays a role in our discussion. The IR theory of a 4d compact boson has an emergent 2-form symmetry: the winding symmetry of the scalar with current J 3 = -1 2 π ⋆ d Φ 0 . This is the symmetry we used to fractionalize the 0-form symmetry in the case of the chiral anomaly. In this case, since we also have the magnetic 1-form symmetry of the photon with current J 2 = 1 2 π ⋆da 1 , we can construct
$$\widehat { J } _ { 1 } = \ast \left ( ( \ast J _ { 3 } ) \wedge ( \ast J _ { 2 } ) \right ) = \frac { 1 } { 4 \pi ^ { 2 } } \ast \left ( d \Phi _ { 0 } \wedge d a _ { 1 } \right )$$
that generates a 0-form symmetry. Using this symmetry to fractionalize the shift symmetry of the compact boson, as described in Section 4.3, we obtain precisely the non-canonical coupling in (4.30) .
## 5 Boundary Chern-Simons-like terms
In this section we study bulk models obtained by adding terms without derivatives. These do not affect the boundary terms in the variational principle and hence do not modify the boundary conditions. Thus the dual theory couples minimally to the background fields, but it contains extra interactions, typically Chern-Simons-like terms. Our main motivation here is to verify our conjecture in a case with a non-invertible symmetry, the Q Z / chiral symmetry in four dimensions [54, 55], 19 and to provide a framework to study aspects of its spontaneous breaking. We also consider in Section 5.1 a bulk 4d TQFT introduced in [48], which was argued to be related to 3d gauge theories with ChernSimons interactions. We use our formalism to establish a precise holographic duality confirming the expectation of [48].
## 5.1 Holographic dual to Maxwell-Chern-Simons theory
We consider the 4d TQFT with action
$$S = \frac { i } { 2 \pi } \int _ { X _ { 4 } } \left ( A _ { 1 } \wedge d b _ { 2 } + \frac { \phi } { 4 \pi } \, b _ { 2 } \wedge b _ { 2 } \right ),$$
where b 2 is an R 2-from gauge field, A 1 is a standard U (1) gauge field, and ϕ is a parameter. On closed manifolds the theory is invariant under the following gauge transformations:
$$\delta A _ { 1 } = d \rho _ { 0 } - \frac { \phi } { 2 \pi } \, \lambda _ { 1 } \,, \quad \quad \delta b _ { 2 } = d \lambda _ { 1 } \,.$$
The gauge-invariant operators include surfaces U α ( γ 2 ) = e iα ∫ γ 2 b 2 and the generically non-genuine lines W γ ,D n ( 1 2 ) = e in ∫ γ 1 A 1 + inϕ 2 π ∫ D 2 b 2 that need an attached two-disk D 2 bounded by γ 1 . The label α ∼ α +1 is circle valued, while n ∈ Z . The coupling ϕ is 2 π periodic.
We will be mostly interested in the case
$$\phi = \frac { 2 \pi } { k } \, \quad \text{ \quad with \quad } k \in \mathbb { Z } \,.$$
19 See [86] for a recent proposal to recover the full U (1) chiral symmetry.
In this case the lines W mk become genuine, and an interesting Lagrangian algebra 20 is obtained by taking all the genuine lines together with the surfaces U l/k with l ∈ Z k . Used in SymTFT [48], this Lagrangian algebra describes the symmetry U (1) [0] × Z [1] k : the first factor is a 0-form symmetry, the second factor is an anomalous 1-form symmetry (with coefficient 1), and there is a mixed anomaly between the two.
We place the theory on a manifold with boundary, where we impose the boundary condition
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i \pi } { k ^ { 2 } e ^ { 2 } } \, b _ { 2 } \,.$$
In order to have a good variational principle we must add the boundary term
$$S _ { \partial } = - \frac { k ^ { 2 } e ^ { 2 } } { 4 \pi ^ { 2 } } \int _ { \partial X _ { 4 } } A _ { 1 } \wedge \ast A _ { 1 } = \frac { 1 } { 4 k ^ { 2 } e ^ { 2 } } \int _ { \partial X _ { 4 } } \left ( b _ { 2 } + \frac { i k ^ { 2 } e ^ { 2 } } { \pi } \ast \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( b _ { 2 } + \frac { i k ^ { 2 } e ^ { 2 } } { \pi } \ast \mathcal { A } _ { 1 } \right ).$$
The gauge transformation δA 1 = dρ 0 is restored by δ A 1 = dρ 0 that makes (5.4) invariant. The full system is gauge invariant, provided that we also add a counterterm S c.t. = k e 2 2 4 π 2 ∫ ∂X 4 A ∧ 1 ⋆ A 1 .
We take the bulk to be the product of a three-dimensional ball B 3 and the time circle S 1 , so that ∂X 4 ≡ M 3 = S 2 × S 1 . Integrating out the time components A t 0 , b t 1 we get delta functions imposing
$$\tilde { d } \widetilde { b } _ { 2 } = 0 \,, \quad \ \tilde { d } \widetilde { A } _ { 1 } + \frac { 1 } { k } \, \widetilde { b } _ { 2 } = 0 \,,$$
that are solved introducing Φ 0 and ˆ a 1 through
$$\widetilde { b } _ { 2 } = \tilde { d } \, \hat { a } _ { 1 } \,, \quad \ \widetilde { A } _ { 1 } = \tilde { d } \Phi _ { 0 } - \frac { 1 } { k } \, \hat { a } _ { 1 } \,.$$
With this, the bulk path integral reduces to a boundary path integral with action
$$S + S _ { \partial } + S _ { \text{c.t.} } = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 3 } } \left [ \partial _ { t } \hat { a } _ { 1 } \wedge \left ( \tilde { d } \Phi _ { 0 } - \frac { 1 } { k } \hat { a } _ { 1 } \right ) \wedge d t + \frac { 1 } { 2 k } \hat { a } _ { 1 } \wedge d \hat { a } _ { 1 } + \tilde { d } \tilde { a } _ { 1 } \wedge \mathcal { A } _ { 0 } ^ { t } \, d t \quad & \quad \quad \quad$$
Attempting to integrate out ˆ a 1 to derive a covariant action for the scalar field, as we did in Section 3.1, results in a non-local action. 21 However, there is no problem in integrating out Φ 0 from (5.8) and we obtain a local and covariant boundary theory with action
$$S = \frac { 1 } { 4 k ^ { 2 } e ^ { 2 } } \int _ { \mathcal { M } _ { 3 } } d \hat { a } _ { 1 } \wedge \ast d \hat { a } _ { 1 } + \frac { i } { 4 \pi k } \int _ { \mathcal { M } _ { 3 } } \hat { a } _ { 1 } \wedge d \hat { a } _ { 1 } + \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 3 } } d \hat { a } _ { 1 } \wedge \mathcal { A } _ { 1 } \,.$$
This might seem like a U (1) gauge theory with an improperly quantized Chern-Simons level. However we must be careful in identifying the correct U (1) gauge field, by considering the condensation of the Lagrangian algebra that trivializes the bulk. This includes all genuine lines as well as k surfaces:
$$\mathcal { L } = \left \{ W _ { k m } = e ^ { i k m \int A _ { 1 } } \,, \, U _ { l / k } = e ^ { \frac { i l } { k } \int b _ { 2 } } \, \Big | \, m \in \mathbb { Z } \,, \, \ l \in \mathbb { Z } _ { k } \right \}.$$
20 A more natural Lagrangian algebra consists of all surfaces U α . Used in SymTFT it describes an exotic Z 1-form symmetry with anomaly parametrized by ϕ [48], while holographically we expect it to describe its breaking.
21 A similar (even though less transparent) problem would have arisen if we tried to obtain the boundary theory using the second method described at the end of Section 3.1, i.e. , by integrating out directly the whole b 2 : the latter does not appear linearly in the bulk action.
On the geometry that we are considering, condensing L amounts to inserting the lines W km along the time circle and summing over m , while the surfaces have no effect. The insertion of W km modifies the path integral so as to impose that ∫ S 2 b 2 = 2 πkm for any two-sphere in B 3 that surrounds the Wilson line. This in particular includes the boundary spatial manifold. From the boundary theory viewpoint, this is a topological sector of the path integral with flux
$$\int _ { S ^ { 2 } } \frac { d \hat { a } _ { 1 } } { 2 \pi } = k m \,.$$
Hence the canonically normalized U (1) gauge field is a 1 = ˆ a /k 1 , in terms of which the boundary theory has action
$$S = \frac { 1 } { 4 e ^ { 2 } } \int _ { \mathcal { M } _ { 3 } } d a _ { 1 } \wedge \ast d a _ { 1 } + \frac { i k } { 4 \pi } \int _ { \mathcal { M } _ { 3 } } a _ { 1 } \wedge d a _ { 1 } + \frac { i k } { 2 \pi } \int _ { \mathcal { M } _ { 3 } } d a _ { 1 } \wedge \mathcal { A } _ { 1 } \,.$$
This is Maxwell-Chern-Simons theory at level k , coupled to a background field for the topological U (1) symmetry acting on monopoles. More precisely, the background field for this symmetry is A ′ 1 = k A 1 , while A 1 is the background for a larger non-faithful U (1) symmetry obtained by extending the topological symmetry with a trivially-acting Z k . 22
It should be noted that this example has a slightly different flavor than all other ones discussed in this paper. The UV symmetry is U (1) [0] × Z [1] k , however only Z k is spontaneously broken, indeed there are no Goldstone bosons in the IR since the photon is massive due to the Chern-Simons term. We consider this example as a warm up for the next one.
## 5.2 Spontaneously broken non-invertible Q Z / chiral symmetry
In 4d theories of massless Dirac fermions coupled with dynamical U (1) gauge fields (QED-like theories) the classically preserved axial symmetry U (1) A suffers from an ABJ anomaly that spoils the conservation of its current: d ⋆ J ( A ) 1 = k 8 π 2 F 2 ∧ F 2 [87, 88]. Traditionally, this was interpreted as the absence of U (1) A in the quantum theory. Recently [54,55] showed that axial transformations labelled by rational numbers survive at the quantum level, but they obey non-invertible fusion rules. The SymTFT for this non-invertible chiral symmetry was derived in [48]:
$$S = \frac { i } { 2 \pi } \int _ { X _ { 5 } } \left ( b _ { 3 } \wedge d A _ { 1 } + f _ { 2 } \wedge d G _ { 2 } + \frac { k } { 4 \pi } \, A _ { 1 } \wedge f _ { 2 } \wedge f _ { 2 } \right ).$$
Here A 1 , G 2 are U (1) gauge fields, while b 3 , f 2 are R gauge fields. The gauge transformations are
$$\delta A _ { 1 } & = d \rho _ { 0 } \,, \quad \delta b _ { 3 } & = d \xi _ { 2 } - \frac { k } { 4 \pi } \, \lambda _ { 1 } \wedge d \lambda _ { 1 } - \frac { k } { 2 \pi } \, \lambda _ { 1 } \wedge f _ { 2 } \,, \\ \delta f _ { 2 } & = d \lambda _ { 1 } \,, \quad \delta G _ { 2 } & = d \eta _ { 1 } - \frac { k } { 2 \pi } \, \rho _ { 0 } \left ( f _ { 2 } + d \lambda _ { 1 } \right ) - \frac { k } { 2 \pi } \, \lambda _ { 1 } \wedge A _ { 1 } \,.$$
22 The reason why we got this coupling is that the TQFT we started with describes this larger symmetry, implemented by the operators e iα ∫ b 2 , but the subgroup Z k was condensed in the bulk, and acts trivially in the boundary theory. As discussed in Section 3.1, we did not explicitly introduce a background for the Z k 1-form symmetry.
As shown in [48], the gauge-invariant genuine topological defects are:
$$W _ { n } ( \gamma _ { 1 } ) & = e ^ { i n \int _ { \gamma _ { 1 } } A _ { 1 } } \,, \quad \ U _ { \frac { p } { k _ { q } } } ( \gamma _ { 3 } ) = e ^ { i \frac { p } { k _ { q } } \int _ { \gamma _ { 3 } } b _ { 3 } } \, \mathcal { A } ^ { q, p } ( \gamma _ { 3 } ; f _ { 2 } ) \,, \\ V _ { \alpha } ( \gamma _ { 2 } ) & = e ^ { i \alpha \int _ { \gamma _ { 2 } } f _ { 2 } } \,, \quad \ \mathcal { T } _ { m } ( \gamma _ { 2 } ) = e ^ { i m \int _ { \gamma _ { 2 } } G _ { 2 } } \, \mathbb { Z } _ { k m } ( \gamma _ { 2 } ; A _ { 1 }, f _ { 2 } ) \,.$$
̸
Here n, m ∈ Z and α ∈ R Z / , while p/q ∈ Q with gcd( p, q ) = 1 and p ∼ p + kq so that the label p/kq ∈ Q Z / . Then Z km ( γ 2 ; A , f 1 2 ) denotes a pure 2d Z km gauge theory on γ 2 , whose 0-form and 1-form symmetries are coupled, respectively, to A 1 and f 2 . Similarly, A q,p ( γ 3 ; f 2 ) is the minimal Abelian TQFT with Z q 1-form symmetry and anomaly labeled by p introduced in [89], whose 1-form symmetry is coupled to f 2 . Stacking these TQFTs is necessary in order to make the operators gauge invariant and topological. The theories A q,p are nontrivial for any q = 1 , so that only a Z k subgroup of the operators U p kq (those with q = 1 ) are invertible, while all other ones obey non-invertible fusion rules. Similarly, T m are non-invertible. In the SymTFT approach it is natural to choose topological boundary conditions associated with the Lagrangian algebra
$$\mathcal { L } = \left \{ W _ { n } \,, \, \mathcal { T } _ { m } \, \Big | \, n, m \in \mathbb { Z } \right \}.$$
The remaining operators U p kq ( γ 3 ) and V α ( γ 2 ) implement the non-invertible symmetry and the magnetic 1-form symmetry, respectively.
Continuing with the approach we have followed so far, we want to consider a theory of gravity based on (5.13) with the condensation of L in the bulk. We place this theory on a manifold X 5 with a boundary and impose the non-topological boundary conditions
$$\ast A _ { 1 } = - \frac { i } { R ^ { 2 } } \, b _ { 3 } + \ast \mathcal { A } _ { 1 } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\ast G _ { 2 } = - \frac { i \pi } { e ^ { 2 } } \, f _ { 2 } + \ast \mathcal { G } _ { 2 } \,.$$
We need to add a boundary term:
$$S _ { \partial } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { 5 } } b _ { 3 } \wedge \ast b _ { 3 } - \frac { 1 } { 4 e ^ { 2 } } \int _ { \partial X _ { 5 } } f _ { 2 } \wedge \ast f _ { 2 } \,.$$
As before we would like to assign gauge transformation rules to the boundary fields A 1 , G 2 in order to restore some of the gauge transformations on the boundary, corresponding to the symmetries that become global there. However, while we can restore δG 2 = dη 1 by transforming δ G 2 = dη 1 , the gauge transformation δA 1 = dρ 0 cannot be restored. Indeed, while the first eqn. in (5.17) could be made gauge invariant by prescribing that δ A 1 = dρ 0 , the second one would not be invariant because G 2 transforms as δG 2 = -k 2 π ρ f 0 2 . This term cannot be reabsorbed by modifying the gauge transformations of G 2 , since f 2 is a dynamical field. Thus the only way to make the boundary conditions gauge invariant is to freeze the boundary value of ρ 0 , as those of λ 1 and ξ 2 .
To get the boundary theory, as before, we integrate out the time components imposing
$$\tilde { d } \widetilde { A } _ { 1 } = 0 \,, \quad \tilde { d } \widetilde { f } _ { 2 } = 0 \,, \quad \widetilde { d } \widetilde { b } _ { 3 } + \frac { k } { 4 \pi } \, \widetilde { f } _ { 2 } \wedge \widetilde { f } _ { 2 } = 0 \,, \quad \tilde { d } \widetilde { G } _ { 2 } + \frac { k } { 2 \pi } \, \widetilde { A } _ { 1 } \wedge \widetilde { f } _ { 2 } = 0 \,,$$
which are solved by
$$\widetilde { A } _ { 1 } = \tilde { d } \Phi _ { 0 } \,, \quad \widetilde { f } _ { 2 } = \tilde { d } a _ { 1 } \,, \quad \widetilde { b } _ { 3 } = \tilde { d } \omega _ { 2 } - \frac { k } { 4 \pi } \, a _ { 1 } \wedge \tilde { d } a _ { 1 } \,, \quad \widetilde { G } _ { 2 } = \tilde { d } C _ { 1 } - \frac { k } { 2 \pi } \, \Phi _ { 0 } \, \tilde { d } a _ { 1 } \,. \quad ( 5. 2 0 )$$
The total action reduces to a boundary theory with action:
$$& \text{The total action reduces to a boundary theory with action:} \\ & S = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 4 } } \left [ \left ( \tilde { d } \omega _ { 2 } - \frac { k } { 4 \pi } \, a _ { 1 } \wedge \tilde { d } a _ { 1 } \right ) \wedge ( \partial _ { \Phi } \Phi _ { 0 } - \mathcal { A } _ { 0 } ^ { t } ) \, d t - \left ( \tilde { d } C _ { 1 } - \frac { k } { 2 \pi } \, \Phi _ { 0 } \, \tilde { d } a _ { 1 } \right ) \wedge \partial _ { t } a _ { 1 } \wedge \, d t \\ & \quad - \frac { i } { 2 } \left ( R ^ { 2 } \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { A } } _ { 1 } \right ) \wedge * \left ( \tilde { d } \Phi _ { 0 } - \widetilde { \mathcal { A } } _ { 1 } \right ) + \frac { 1 } { R ^ { 2 } } \left ( \tilde { d } \omega _ { 2 } - \frac { k } { 4 \pi } \, a _ { 1 } \wedge \tilde { d } a _ { 1 } \right ) \wedge * \left ( \tilde { d } \omega _ { 2 } - \frac { k } { 4 \pi } \, a _ { 1 } \wedge \tilde { d } a _ { 1 } \right ) \right ) \\ & \quad - \frac { i } { 2 } \left ( \frac { \pi } { e ^ { 2 } } \, \tilde { d } a _ { 1 } \wedge * \tilde { d } a _ { 1 } + \frac { e ^ { 2 } } { \pi } \left ( \tilde { d } C _ { 1 } - \frac { k } { 2 \pi } \, \Phi _ { 0 } \, \tilde { d } a _ { 1 } - \widetilde { \mathcal { G } } _ { 2 } \right ) \wedge * \left ( \tilde { d } C _ { 1 } - \frac { k } { 2 \pi } \, \Phi _ { 0 } \, \tilde { d } a _ { 1 } - \widetilde { \mathcal { G } } _ { 2 } \right ) \right ) \\ & \quad + \tilde { d } a _ { 1 } \wedge \mathcal { G } _ { 1 } ^ { t } \wedge \, d t + \frac { i k } { 4 \pi } \, \Phi _ { 0 } \, d a _ { 1 } \wedge \, d a _ { 1 } \right ] \\ & \quad \text{where} \, \mathcal { M } _ { 4 } = \partial X _ { 5 }. \, \text{We can then integrate out both $\omega_{2}$ and $C_{2}$ obtaining}$$
where M 4 = ∂X 5 . We can then integrate out both ω 2 and C 2 obtaining
$$S & = \int _ { \mathcal { M } _ { 4 } } \left [ \frac { R ^ { 2 } } { 4 \pi } \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( d \Phi _ { 0 } - \mathcal { A } _ { 1 } \right ) + \frac { 1 } { 4 e ^ { 2 } } \, d a _ { 1 } \wedge \ast d a _ { 1 } + \frac { i k } { 8 \pi ^ { 2 } } \, \Phi _ { 0 } \, d a _ { 1 } \wedge d a _ { 1 } + \frac { i } { 2 \pi } \, d a _ { 1 } \wedge \mathcal { G } _ { 2 } \right ]. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
As in the cases of the Abelian 2-group and of Maxwell-Chern-Simons theory, gauging the Lagrangian algebra introduces fluxes for a 1 turning it into a standard U (1) gauge field. The theory in (5.22) describes a compact boson Φ 0 and a photon a 1 interacting via an axion coupling. This is called axion-Maxwell theory, and the full structure of its symmetries (including some emergent ones) has been studied in great detail in [90]. From the discovery of the non-invertible chiral symmetry, it has been suspected that axion-Maxwell theory universally describes its symmetry breaking [55, 90, 91]. 23 Our result confirms that. Notably, this is the first interacting boundary theory we found among the examples considered so far.
Some comments on the coupling to the background fields are in order. As we already noticed after (5.18) , there is no sensible gauge transformation rules that we could assign to A 1 and G 2 to make the boundary condition invariant under δA 1 = dρ 0 , hence we needed to freeze it. In the action (5.22) , A 1 should not be thought of as the background field for the 0-form non-invertible symmetry, but rather just as an external source that couples with the operator J ( A ) 1 . This is enough for holography, but it might seem a bit unsatisfactory from a symmetry viewpoint. However, this is really the hallmark of the non-invertible nature of the symmetry: ordinary background gauge fields seem not to exist, and they are effectively replaced by boundary values of dynamical fields in one dimension higher [35]. The underlying reason is that non-invertible symmetries map untwisted sectors to twisted sectors, hence the gauge transformations of a background gauge field necessarily involve an interplay among backgrounds that do not exist simultaneously in the theory, but only in the SymTFT (or in holography) where all global variants are on the same footing. This is the reason why SymTFT is the main tool for discussing anomalies [38-41].
23 For instance, the 4d CP 1 non-linear sigma model enjoys a Q Z / non-invertible symmetry [92] and it was argued in [91] that its breaking leads to axion-Maxwell theory.
## 6 Non-Abelian Goldstone bosons
A very interesting class of examples are those of spontaneously broken non-Abelian symmetries. In these cases the boundary EFTs that we derive are interacting and generically non-renormalizable. In the 2d/3d case we will be able to recover and somewhat generalize the CS/WZW correspondence outside of the conformal point, while in higher dimensions we will obtain the pion Lagrangian on the boundary. We start with the non-Abelian generalization of the theories considered in Section 3 and then add an anomaly term, which corresponds to WZW terms in various dimensions. Finally we show how our setup is able to produce an EFT for spontaneously broken non-Abelian 2-group symmetries.
## 6.1 Holographic dual to the pion Lagrangian
Let G be a connected and compact Lie group (with Lie algebra g ). The SymTFT for a non-Abelian 0-form symmetry G in d dimensions is the TQFT with action [48-50]: 24
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } \text{Tr} ( b _ { d - 1 } \wedge F _ { 2 } ) \,,$$
where F 2 = dA 1 + iA 1 ∧ A 1 is the field strength of a G connection A 1 while b d -1 is a g -valued ( d -1) -form. The gauge transformations are
↦
$$A _ { 1 } \, \mapsto \, \Lambda \, A _ { 1 } \, \Lambda ^ { - 1 } + i \, d \Lambda \, \Lambda ^ { - 1 } \,, \quad \ \ b _ { d - 1 } \, \mapsto \, \Lambda \, b _ { d - 1 } \, \Lambda ^ { - 1 }$$
↦
as well as
↦
$$b _ { d - 1 } \, \mapsto \, b _ { d - 1 } + D _ { A } \lambda _ { d - 2 } \,.$$
Here D A = d + [ i A , 1 · ] ± is the covariant derivative that acts on p -forms valued in the Lie algebra as
$$D _ { A } \eta _ { p } = d \eta _ { p } + i \left ( A _ { 1 } \wedge \eta _ { p } - ( - 1 ) ^ { p } \, \eta _ { p } \wedge A _ { 1 } \right ).$$
The topological defects of this TQFT include the Wilson lines
$$W _ { \Re } ( \gamma _ { 1 } ) = \text{Tr} _ { \Re } \text{Pexp} \left ( i \int _ { \gamma _ { 1 } } A _ { 1 } \right )$$
labelled by the irreducible representations R of G , as well as ( d -1) -dimensional Gukov-Witten operators U [ g ] ( γ d -1 ) labelled by conjugacy classes [ g ] of G and defined by prescribing that the holonomy of A 1 around U [ g ] be in [ g ] [93]. The two classes of operators have a canonical linking given by the character χ R ([ g ]) . A natural Lagrangian algebra that we will condense consists of the Wilson lines in all representations of G .
We use the following non-topological boundary condition and boundary term on M d = ∂X d +1 :
$$\ast \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { f _ { \pi } ^ { 2 } } \, b _ { d - 1 } \,, \quad \ \ S _ { \partial } = - \frac { 1 } { 4 \pi f _ { \pi } ^ { 2 } } \int _ { \mathcal { M } _ { d } } \text{Tr} \left ( b _ { d - 1 } \wedge \ast b _ { d - 1 } \right ).$$
24 For d = 3 this theory was first considered by Horowitz [61]. Curiously, the motivation was precisely to view it as an exactly solvable theory of gravity.
We can recover the gauge transformations on the boundary by assigning the transformation rule A ↦→ 1 Λ A 1 Λ -1 + id ΛΛ -1 so that A 1 is interpreted as a background field for a global symmetry G . 25 We can proceed with the usual steps to derive the dual boundary theory. Taking the spacetime to be X d +1 = B d × S 1 , the path integral over time components imposes
$$\dot { F } _ { 2 } = 0 \,, \quad \ \ D _ { \widetilde { A } _ { 1 } } \dot { b } _ { d - 1 } = 0 \,.$$
The first equation can be solved in terms of a G -valued scalar field U as
$$\widetilde { A } _ { 1 } = i \, \tilde { d } U \, U ^ { - 1 } \,.$$
To solve the second one, since the covariant derivative with respect to a flat connection squares to zero ( i.e. , it becomes a differential), we set
$$b _ { d - 1 } = D \omega _ { d - 2 }$$
where ω d -2 is a g -valued ( d -2) -form, and ˜ D denotes the covariant derivative with respect to i dU U ˜ -1 . By plugging these back, the theory reduces to a boundary action:
$$S & = ( - 1 ) ^ { d } \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } \text{Tr} \left [ \widetilde { D } \omega _ { d - 2 } \wedge \left ( i \, \partial _ { t } U \, U ^ { - 1 } - \mathcal { A } _ { 0 } ^ { t } \right ) d t \right ] \\ & \quad + \frac { 1 } { 4 \pi } \int _ { \mathcal { M } _ { d } } \text{Tr} \left [ \frac { 1 } { f _ { \pi } ^ { 2 } } \, \widetilde { D } \omega _ { d - 2 } \wedge \widetilde { \ } D \omega _ { d - 2 } + f _ { \pi } ^ { 2 } \left ( i \, \tilde { d } U \, U ^ { - 1 } - \widetilde { \mathcal { A } } _ { 1 } \right ) \wedge \widetilde { \ } \left ( i \, \tilde { d } U \, U ^ { - 1 } - \widetilde { \mathcal { A } } _ { 1 } \right ) \right ]. \\ & \quad \quad \quad$$
One important difference with respect to the Abelian case is that U and ω d -2 do not appear symmetrically. While U appears in a complicated way, the action is still quadratic in ω d -2 that can thus be integrated out using its equation of motion
$$\widetilde { D } \left ( \partial _ { t } U U ^ { - 1 } + i \mathcal { A } _ { 0 } ^ { t } \right ) \wedge d t + \frac { ( - 1 ) ^ { d - 1 } } { f _ { \pi } ^ { 2 } } \, \widetilde { D } \ast \widetilde { D } \omega _ { d - 2 } = 0 \,.$$
Eliminating a zero-mode as in the Abelian case, we can use this equation to determine ˜ Dω d -2 , and we find the manifestly covariant form of the boundary theory:
$$S = \frac { f _ { \pi } ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { d } } \text{Tr} \left [ \left ( i \, d U \, U ^ { - 1 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( i \, d U \, U ^ { - 1 } - \mathcal { A } _ { 1 } \right ) \right ].$$
↦
This describes a sigma model with target G , coupled to a background field A 1 for the symmetry G that acts as U → gU with g ∈ G . The sigma model is a non-renormalizable theory that provides the leading universal term in an expansion in number of derivatives (in 4d this is chiral perturbation theory), describing the EFT of any theory with spontaneously broken symmetry G [52, 53].
25 Differently from the Abelian case, here we cannot turn on another background to rescue the other gauge symmetry as well. The reason is that the gauge transformation (6.3) of b d -1 cannot be reabsorbed in the boundary condition by replacing b d -1 with b d -1 - B d -1 and assigning a transformation rule to B d -1 . Indeed, this transformation would necessarily involve the dynamical field A 1 , instead of the background A 1 .
## 6.2 Non-Abelian chiral anomaly
For any even d we can add a Chern-Simons term to the bulk theory (6.1): 26
$$S _ { \text{CS} } = \frac { i \kappa _ { d } } { 2 \pi } \int _ { X _ { d + 1 } } \text{Tr} ( \text{CS} _ { d + 1 } ( A _ { 1 } ) ) \,, \quad \quad \kappa _ { d } = \frac { k } { ( 2 \pi ) ^ { \frac { d } { 2 } - 1 } \left ( \frac { d } { 2 } + 1 \right )! } \,, \quad \quad \ k \in \mathbb { Z } \,, \quad \ ( 6. 1 3 )$$
that describes the presence of a perturbative anomaly for G . In this case, differently from the Abelian one, anomaly matching requires a WZW term in the spontaneously broken phase [62]. We want to show that this fact is implied by our conjecture. We also consider the case of d = 2 where, strictly speaking, our conjecture does not apply because there is no spontaneous breaking of a continuous symmetry in two dimensions.
## Two dimensions
In the case of d = 2 , we use the boundary condition
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { f _ { \pi } ^ { 2 } } \left ( b _ { 1 } + \frac { k } { 2 } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \right )$$
↦
that is gauge invariant under A 1 → Λ A 1 Λ -1 + id ΛΛ -1 , A ↦→ 1 Λ A 1 Λ -1 + id ΛΛ -1 , and add the boundary term
$$S _ { \partial } = - \frac { 1 } { 4 \pi f _ { \pi } ^ { 2 } } \int _ { \partial X _ { 3 } } \text{Tr} \left [ \left ( b _ { 1 } + \frac { k } { 2 } \, A _ { 1 } \right ) \wedge \ast \left ( b _ { 1 } + \frac { k } { 2 } \, A _ { 1 } \right ) \right ]$$
to make the variational principle well defined.
As a preliminary consistency check, we compute the gauge variation. The total gauge-transformed action differs by
$$\Delta ( S + S _ { \partial } + S _ { \text{c.t.} } ) = \frac { i k } { 4 \pi } \int _ { \partial X _ { 3 } } \text{Tr} ( \mathcal { A } _ { 1 } \wedge i \Lambda ^ { - 1 } d \Lambda ) + \frac { k } { 2 4 \pi } \int _ { X _ { 3 } } \text{Tr} ( ( i \Lambda ^ { - 1 } d \Lambda ) ^ { 3 } )$$
from the original one. 27 Upon expanding Λ = ✶ + λ 0 and retaining only the linear order in λ 0 , this reduces to the usual form of the consistent anomaly:
$$\delta ( S + S _ { \partial } + S _ { \text{c.t.} } ) = \frac { i k } { 4 \pi } \int _ { \partial X _ { 3 } } \text{Tr} ( \mathcal { A } _ { 1 } \wedge i d \lambda _ { 0 } ) \,.$$
One can proceed in determining the dual boundary theory similarly to the non-anomalous case. Since the boundary condition is essentially the same (simply written in a different parametrization), the only difference is the bulk Chern-Simons term which gives rise to a WZW term in the boundary theory:
$$S & = \frac { f _ { \pi } ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { 2 } } \text{Tr} \left [ \left ( i \, d U \, U ^ { - 1 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( i \, d U \, U ^ { - 1 } - \mathcal { A } _ { 1 } \right ) \right ] + \frac { k } { 1 2 \pi } \int _ { X _ { 3 } } \text{Tr} \left [ \left ( i U ^ { - 1 } d U \right ) ^ { 3 } \right ] \\ & \quad - \frac { i k } { 4 \pi } \int _ { \mathcal { M } _ { 2 } } \text{Tr} \left [ \mathcal { A } _ { 1 } \wedge i \, d U \, U ^ { - 1 } \right ]. \\ \frac { \ w e r { - } } { \ w e r { - } } \quad \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots$$
26 Here we assume G to be simple and simply connected.
27 Here S c.t. = 8 k 2 πf 2 π ∫ ∂X 3 Tr ( A ∧ 1 ⋆ A 1 ) is a counterterm we add to simplify the final result.
Wenotice that there is also a non-standard coupling to the background field, that in our approach arises because of the boundary conditions, similarly to the Abelian case. Differently from that case, however, in a purely field theoretic analysis this is not interpreted as a coupling to a diagonal symmetry (since a winding symmetry is absent here), but rather it arises from the standard trial-and-error procedure to couple the G symmetry to a background in the presence of the WZW term, similarly to the 4d analysis in [62].
For generic values of f 2 π the theory is not conformally invariant at the quantum level. However choosing f 2 π = k 2 the theory has a conserved holomorphic current which generates a Kac-Moody symmetry algebra, and it displays conformal invariance [94]. In this case we recover a form of the CS/WZW correspondence, which is more general on one side, being valid even outside of the conformal point, but less general on the other side, since in the conformal case it automatically produces the full physical WZW model instead of its chiral halves.
## Four dimensions
In the case of d = 4 , the 5d Chern-Simons term is
$$\text{Tr} ( \text{CS} _ { 5 } ( A _ { 1 } ) ) = \text{Tr} \Big ( A _ { 1 } \wedge ( d A _ { 1 } ) ^ { 2 } + \frac { 3 i } { 2 } \, A _ { 1 } ^ { 3 } \wedge d A _ { 1 } - \frac { 3 } { 5 } A _ { 1 } ^ { 5 } \Big ) \,.$$
As one might suspect already from the Abelian case, in order to obtain a gauge-invariant boundary condition with a consistent variational principle we need to introduce extra terms in the boundary condition that mix background and dynamical fields. We use the same iterative procedure discussed in Appendix A for the Abelian anomaly, even though the computations are clearly more tedious here. We find the following solution. The boundary condition is
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) - \frac { i \kappa _ { 4 } } { f _ { \pi } ^ { 2 } } \left ( \frac { 1 } { 2 } \left ( \mathcal { A } _ { 1 } \, \mathcal { F } _ { 2 } + \mathcal { F } _ { 2 } \, \mathcal { A } _ { 1 } \right ) - \frac { i } { 2 } \, \mathcal { A } _ { 1 } ^ { 3 } \right ) = - \frac { i } { f _ { \pi } ^ { 2 } } \, \Omega _ { 3 }$$
where F 2 is the field strength of A 1 while
$$\Omega _ { 3 } = b _ { 3 } + \kappa _ { 4 } \left ( F _ { 2 } ( A _ { 1 } - \mathcal { A } _ { 1 } ) + ( A _ { 1 } - \mathcal { A } _ { 1 } ) F _ { 2 } - \frac { i } { 2 } \left ( ( A _ { 1 } - \mathcal { A } _ { 1 } ) ^ { 3 } + \mathcal { A } _ { 1 } \right ) ^ { 3 } + \frac { 1 } { 2 } ( A _ { 1 } \mathcal { F } _ { 2 } + \mathcal { F } _ { 2 } A _ { 1 } ) \right ) \ ( 6. 2 1 )$$
and the boundary term is
$$S _ { \partial } & = - \frac { 1 } { 4 \pi f _ { \pi } ^ { 2 } } \int _ { \partial X _ { 5 } } \text{Tr} ( \Omega _ { 3 } \wedge \ast \Omega _ { 3 } ) \, + \, S _ { \text{top} } \, + \, S _ { \text{c.t. } } \,, \\ S _ { \text{top} } & = \frac { i \kappa _ { 4 } } { 2 \pi } \int _ { \partial X _ { 5 } } \text{Tr} \left [ \frac { 1 } { 2 } \, F _ { 2 } \, \mathcal { A } _ { 1 } \, A _ { 1 } + \frac { 1 } { 2 } \, \mathcal { A } _ { 1 } \, F _ { 2 } \, A _ { 1 } - \frac { i } { 4 } \, A _ { 1 } \, \mathcal { A } _ { 1 } \, A _ { 1 } \, \mathcal { A } _ { 1 } + \frac { i } { 2 } \, A _ { 1 } ^ { 3 } \, \mathcal { A } _ { 1 } \right ]. \\ & \quad \quad \quad$$
The counterterm S c.t. is used to simplify the final expression, and it is convenient to choose it as
$$S _ { c. t. } = \frac { \kappa _ { 4 } ^ { 2 } } { 4 \pi f _ { \pi } ^ { 2 } } \int _ { \partial X _ { 5 } } \text{Tr} \left [ \phi ( \mathcal { A } _ { 1 } ) \wedge \ast \phi ( \mathcal { A } _ { 1 } ) \right ], \quad \phi ( \mathcal { A } _ { 1 } ) = \frac { 1 } { 2 } \left ( \mathcal { A } _ { 1 } \wedge d \mathcal { A } _ { 1 } + d \mathcal { A } _ { 1 } \wedge \mathcal { A } _ { 1 } + i \mathcal { A } _ { 1 } ^ { 3 } \right ).$$
↦
The boundary condition is gauge invariant under the transformation A 1 → Λ A 1 Λ -1 + id ΛΛ -1 , A ↦→ 1 Λ A 1 Λ -1 + id ΛΛ -1 and one can compute the total gauge variation
$$\Delta ( S + S _ { \partial } ) = & - \frac { i \kappa _ { 4 } } { 2 \pi } \int _ { \partial X _ { 5 } } \text{Tr} \left [ ( i \Lambda ^ { - 1 } d \Lambda ) \wedge \phi ( \mathcal { A } _ { 1 } ) + \frac { i } { 4 } ( \mathcal { A } _ { 1 } \wedge i \Lambda ^ { - 1 } d \Lambda ) ^ { 2 } - \frac { i } { 2 } ( i \Lambda ^ { - 1 } d \Lambda ) ^ { 3 } \wedge \mathcal { A } _ { 1 } \right ] \\ & - \frac { i \kappa _ { 4 } } { 2 0 \pi } \int _ { X _ { 5 } } \text{Tr} \left [ ( i \Lambda ^ { - 1 } d \Lambda ) ^ { 5 } \right ]. \\. &.$$
Expanding Λ = ✶ + λ 0 to linear order, we recover the usual form of the consistent anomaly in four dimensions:
$$\delta ( S + S _ { \theta } ) = - \frac { i k } { 4 8 \pi ^ { 2 } } \int _ { \partial X _ { 5 } } \text{Tr} \left [ i d \lambda _ { 0 } \wedge \left ( \mathcal { A } _ { 1 } \wedge d \mathcal { A } _ { 1 } + d \mathcal { A } _ { 1 } \wedge \mathcal { A } _ { 1 } + i \mathcal { A } _ { 1 } ^ { 3 } \right ) \right ].$$
We can then proceed, as before, with the reduction of the action on the boundary. We find
$$\text{we can even produce}, as \text{voice}, \text{and} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{for} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{oration} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{ori} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{cor} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{OR} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{nor} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{lor} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{error} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{ion} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{on} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{only} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{org} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{in} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{is} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{var} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{try} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{or} \text{if} \text{from} \text{in} \text{of} \text{the background} \text{around} \text{source} \text{field} \text{A. we recognize a non-linear sigma model with target cases.$$
Turning off the background gauge field A 1 we recognize a non-linear sigma model with target space G with a properly normalized WZW term, that describes the dynamics of Goldstone bosons. The coupling to the background A 1 is completely fixed by the requirement of a gauge-invariant boundary condition, and correctly captures the anomaly of the non-linearly realized G symmetry.
## 6.3 Non-Abelian 2-group symmetries
In 4d one can have 2-group symmetries whose 0-form part is a non-Abelian group G , while the 1-form part is U (1) . These symmetry structures arise, e.g. , if one starts from a theory with a 0-form symmetry group U (1) × G with an 't Hooft anomaly that is linear in U (1) and quadratic in G :
$$S _ { \inf \text{flow} } = \frac { i k } { 8 \pi ^ { 2 } } \int _ { X _ { 5 } } d V _ { 1 } \wedge \text{Tr} \left ( A _ { 1 } \wedge d A _ { 1 } + \frac { 2 i } { 3 } \, A _ { 1 } ^ { 3 } \right ),$$
and then gauges the U (1) symmetry [63]. The 1-form symmetry involved in the 2-group is the magnetic symmetry of the gauged U (1) . The SymTFT for this non-Abelian 2-group symmetry can be derived using the dynamical gauging procedure described in [48]. Indeed one starts from the SymTFT for the U (1) × G 0-form symmetry:
$$S ^ { \prime } = \frac { i } { 2 \pi } \int _ { X _ { 5 } } \left [ g _ { 3 } \wedge d V _ { 1 } + \text{Tr} ( b _ { 3 } \wedge F _ { 2 } ) + \frac { k } { 4 \pi } \, d V _ { 1 } \wedge \text{Tr} \left ( A _ { 1 } \wedge d A _ { 1 } + \frac { 2 i } { 3 } A _ { 1 } ^ { 3 } \right ) \right ]$$
where g 3 and V 1 are an R and a U (1) gauge field, respectively, b 3 is g -valued and A 1 is a G connection ( F 2 is its field strength). Then one applies the map introduced in [48] that implements the dynamical
↦
gauging of U (1) on the boundary from the viewpoint of the SymTFT. The net effect is the replacement dV 1 → h 2 , g 3 → dC 2 , thus the resulting SymTFT has action
↦
$$S = \frac { i } { 2 \pi } \int _ { X _ { 5 } } \left [ h _ { 2 } \wedge d C _ { 2 } + \text{Tr} \left ( b _ { 3 } \wedge F _ { 2 } \right ) + \frac { k } { 4 \pi } \, h _ { 2 } \wedge \text{Tr} \left ( A _ { 1 } \wedge d A _ { 1 } + \frac { 2 i } { 3 } A _ { 1 } ^ { 3 } \right ) \right ].$$
The gauge transformations are: 28
↦
↦
↦
$$h _ { 2 } & \mapsto h _ { 2 } + d \xi _ { 1 } \,, & A _ { 1 } & \mapsto \Lambda A _ { 1 } \Lambda ^ { - 1 } + i d \Lambda \, \Lambda ^ { - 1 } \,, \\ b _ { 3 } & \mapsto b _ { 3 } - \frac { k } { 4 \pi } \, \xi _ { 1 } \wedge F _ { 2 } \,, & C _ { 2 } & \mapsto C _ { 2 } + d \eta _ { 1 } - \frac { k } { 4 \pi } \, \text{Tr} ( A _ { 1 } \wedge i \Lambda ^ { - 1 } d \Lambda ) + \frac { i k } { 6 \pi } \, \text{Tr} \, \Theta _ { 2 } \,,$$
↦
where Θ 2 is a locally defined real 2-form with the property that Tr ( Λ ( i -1 d Λ) 3 ) = d Tr Θ 2 .
Again, we can use an iterative procedure to determine a set of gauge-invariant boundary conditions together with a boundary term that provide a good variation principle. The boundary conditions are
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { R ^ { 2 } } \left ( b _ { 3 } + \frac { k } { 4 \pi } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \right ), \ \ * h _ { 2 } = \frac { i e ^ { 2 } } { \pi } \left ( C _ { 2 } - \mathcal { C } _ { 2 } - \frac { k } { 4 \pi } \, \text{Tr} \left ( \mathcal { A } _ { 1 } \wedge A _ { 1 } \right ) \right ) \ \ ( 6. 3 2 )$$
while the boundary term is
$$\intertext { w n e v o u n a y v e m i s } S _ { \partial } & = - \frac { i } { 2 \pi } \int _ { \partial X _ { 5 } } h _ { 2 } \wedge \left ( C _ { 2 } - \frac { k } { 4 \pi } \, \text{Tr} ( \mathcal { A } _ { 1 } \wedge A _ { 1 } ) \right ) \\ & \quad - \frac { c ^ { 2 } } { 4 \pi ^ { 2 } } \int _ { \partial X _ { 5 } } \left ( C _ { 2 } - \frac { k } { 4 \pi } \, \text{Tr} ( \mathcal { A } _ { 1 } \wedge A _ { 1 } ) \right ) \wedge * \left ( C _ { 2 } - \frac { k } { 4 \pi } \, \text{Tr} ( \mathcal { A } _ { 1 } \wedge A _ { 1 } ) \right ) \\ & \quad - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { 5 } } \text{Tr} \left [ \left ( b _ { 3 } + \frac { k } { 4 \pi } ( A _ { 1 } - \mathcal { A } _ { 1 } ) \right ) \wedge * \left ( b _ { 3 } + \frac { k } { 4 \pi } ( A _ { 1 } - \mathcal { A } _ { 1 } ) \right ) \right ]. \\ \intertext { The downward condition becomes square invariant, by assigning the following transformations to the}$$
The boundary condition becomes gauge invariant by assigning the following transformations to the backgrounds A 1 and C 2 :
↦
$$\mathcal { A } _ { 1 } \mapsto \Lambda \mathcal { A } _ { 1 } \Lambda ^ { - 1 } + i d \Lambda \, \Lambda ^ { - 1 } \,, \quad \mathcal { C } _ { 2 } \mapsto \mathcal { C } _ { 2 } + d \eta _ { 1 } - \frac { i k } { 4 \pi } \, \text{Tr} \left ( \mathcal { A } _ { 1 } \wedge \Lambda ^ { - 1 } d \Lambda \right ) + \frac { i k } { 1 2 \pi } \, \text{Tr} \, \Theta _ { 2 } \,. \quad ( 6. 3 4 )$$
These reproduce the background gauge transformation of [63] for a non-Abelian 2-group symmetry upon expanding U = + λ 0 at first order:
$$d \eta _ { 1 } - \frac { i k } { \Lambda _ { \pi } } \, \text{Tr} \left ( \mathcal { A } _ { 1 } \wedge d \lambda _ { 0 } \right ).$$
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \ dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \delta \dots \\ \text{adding $U=1+\lambda_{0}$ at first order:} \\ \delta \mathcal { A } _ { 1 } = i D _ { \mathcal { A } _ { 1 } } \lambda _ { 0 } \,, \quad \quad \delta \mathcal { C } _ { 2 } = d \eta _ { 1 } - \frac { i k } { 4 \pi } \, \text{Tr} \left ( \mathcal { A } _ { 1 } \wedge d \lambda _ { 0 } \right ).$$
It is also easy to see that the whole bulk-boundary system is gauge invariant under transformations of A 1 and C 2 provided we add a counterterm S c.t. = e 2 4 π 2 ∫ ∂X 5 C 2 ∧ ⋆ C 2 .
28 Recall that the variation of the three-dimensional Chern-Simons term is:
↦
$$\text{Tr} ( \text{CS} _ { 3 } ( A _ { 1 } ) ) \mapsto \text{Tr} ( \text{CS} _ { 3 } ( A _ { 1 } ) ) + d \text{Tr} ( A _ { 1 } \wedge i \Lambda ^ { - 1 } d \Lambda ) - \frac { i } { 3 } \text{Tr} \left ( \left ( i \Lambda ^ { - 1 } d \Lambda \right ) ^ { 3 } \right ).$$
We can apply our usual machinery to get the dual boundary theory. We obtain a G -valued scalar field U from A 1 , and a Maxwell field a 1 from h 2 , with the following boundary action:
$$\int _ { \mathcal { M } } \, \text{mm} \, \mathcal { A } _ { 1 }, \, \text{and} \, a \, \text{was} \, \text{was} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \,\text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of } \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{off} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \, \text{of} \,
S & = \frac { f ^ { 2 } _ { \pi } } { 4 \pi } \int _ { \mathcal { M } _ { 4 } } \, \text{Tr} \left [ \left ( i d U \, U ^ { - 1 } - \mathcal { A } _ { 1 } \right ) \wedge \ast \left ( i d U \, U ^ { - 1 } - \mathcal { A } _ { 1 } \right ) \right ] + \frac { 1 } { 4 e ^ { 2 } } \int _ { \mathcal { M } _ { 4 } } d a _ { 1 } \wedge \ast \ast d a _ { 1 } \\ & \quad + \frac { k } { 2 4 \pi ^ { 2 } } \int _ { \mathcal { M } _ { 4 } } a _ { 1 } \wedge \text{Tr} \left [ \left ( i U ^ { - 1 } d U \right ) ^ { 3 } \right ] \\ & \quad + \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 4 } } d a _ { 1 } \wedge \text{Tr} \left [ \mathcal { A } _ { 1 } \wedge i U ^ { - 1 } d U \right ] + \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 4 } } \mathcal { C } _ { 2 } \wedge d a _ { 1 } \,. \\ \text{In the first line we recognize a non-linear sigma model with target space $G$ and a Maxwell theory. The}$$
In the first line we recognize a non-linear sigma model with target space G and a Maxwell theory. The last line describes the coupling to the background field C 2 for the magnetic U (1) 1-form symmetry, as well as a nonstandard coupling to the background A 1 for the symmetry G , similar to the one arising in the Abelian case in Section 4.4. The most interesting new thing here is the term in the second line that describes a coupling between the photon and the pions. This is a linear coupling of the photon to the current of a topological symmetry that exists in any sigma model with target G . According to our conjecture, this model is the universal EFT that describes the IR of any theory with a spontaneously broken non-Abelian 2-group symmetry. To the best of our knowledge, this universal EFT was not derived elsewhere.
↦
↦
↦
↦
̸
Some comments on the extra Wess-Zumino-like coupling are in order. First, in any RG flow that breaks the 2-group spontaneously, this coupling must be generated as a consequence of the 2-group matching. In a sense, it is similar to the presence of the WZW term in the EFT of a spontaneously broken anomalous non-Abelian symmetry. Quite like that term, it breaks a symmetry of the EFT that would be there if k = 0 . Indeed, for k = 0 the theory is separately invariant under four Z 2 symmetries: parity P 0 : x i →-x i for i = 1 2 3 , , ; photon charge conjugation C 1 : a 1 →-a 1 ; non-Abelian charge conjugation 29 C 2 : U → U T ; pion number mod-2 ( -1) N π : U → U -1 . All these four symmetries are violated by the photon-pion coupling, but the product of any two of them is preserved. Therefore the discrete symmetry for k = 0 is ( Z 2 ) 3 generated by
$$P = P _ { 0 } \, ( - 1 ) ^ { N _ { \pi } } \,, \quad \ \ C = C _ { 1 } \, C _ { 2 } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
The photon-pion coupling allows, for instance, a process involving three pions and one photon, which would have been forbidden otherwise. We summarize the various symmetry actions and charges in Table 1.
Second, the 2-group symmetry we started with could suffer from a perturbative cubic chiral anomaly for G as well. This would be described by the addition of a 5d Chern-Simons term (6.19) to the bulk action in (6.29), and would result in an extra WZW term S WZW = -ik 240 π 2 ∫ X 5 Tr ( [ iU -1 dU ) 5 ] in the 4d boundary action (6.36). 30 This term would further break the discrete symmetry of the EFT to ( Z 2 ) 2 generated by P and C , as it is clear from Table 1.
29 The reason for this name will be clear in the upcoming discussion of U N ( ) QCD.
30 We did not work out the detailed form of the coupling to the background fields.
↦
↦
↦
↦
| | Definition | x i | a 1 Tr [ ( iU - 1 dU ) 3 ] | Tr [ ( iU - 1 dU ) 5 ] |
|------------|--------------|-------|------------------------------|--------------------------|
| P 0 | x i →- x i | - 1 | - 1 | - 1 |
| C 1 | a 1 →- a 1 | 1 | - 1 | 1 |
| C 2 | U → U T | 1 | - 1 | 1 |
| ( - 1) N π | U → U - 1 | 1 | - 1 | - 1 |
↦
Table 1: The four Z 2 symmetries, and the corresponding phases acquired by the coordinates, the photon-pion coupling term, and the standard WZW term, respectively. Notice that while Tr ( [ iU -1 dU ) 5 ] is invariant under U → U T , the term Tr ( [ iU -1 dU ) 3 ] changes sign.
An application: U N ( ) QCD. Let us present a concrete application of the effective action (6.36) . Consider a 4d gauge theory with U N ( ) gauge group and N f flavors of massless Dirac fermions, so that there is a chiral symmetry SU N ( f ) L × SU N ( f ) R . It can be obtained by gauging the baryon number symmetry U (1) B in ordinary SU N ( ) QCD, hence it contains an Abelian gauge field A µ on top of the non-Abelian gauge fields. Being weakly coupled at low energy, A µ is not expected to drastically modify the strong coupling dynamics of the non-Abelian sector. Hence for N f small enough, the quark bilinear takes VEV and spontaneously breaks the chiral symmetry: 31
$$S U ( N _ { f } ) _ { L } \times S U ( N _ { f } ) _ { R } \, \rightarrow \, S U ( N _ { f } ) _ { V }$$
producing at low energy massless pions that interact as a non-linear sigma model with target space SU N ( f ) . The pions are neutral under the non-Abelian gauge symmetry SU N ( ) , whose gluons are confined. However the Abelian gauge field A µ remains even in the deep IR and there is no reason why it should be decoupled from the non-linear sigma model. Indeed, while the pion fields themselves are neutral under U (1) , being bound states of quarks it is a priori unclear whether there is a low-energy remnant of the quark-photon interaction.
We can answer this question using our result, and showing that the photon is not decoupled. Indeed there is a U (1) magnetic 1-form symmetry from the Abelian gauge field (that is its Goldstone boson), which forms a non-trivial 2-group with SU N ( f ) L (and also with SU N ( f ) R , but we can just focus on one of the two). To see this, we notice that there is a triangle anomaly U (1) -SU N ( f ) 2 L whose anomaly polynomial is
$$\mathcal { P } _ { U ( 1 ) - S U ( N _ { f } ) _ { L } ^ { 2 } } = \frac { N } { 8 \pi ^ { 2 } } \, d A \wedge \text{Tr} ( \mathcal { F } \wedge \mathcal { F } ) \,,$$
where F = d G + i G ∧ G is the field strength of the background field G for SU N ( f ) L . The coefficient N comes because all left-moving fermions have charge 1 under U (1) and are in the fundamental
31 Notice that the usual argument [95] based on 't Hooft anomaly matching in SU N ( ) QCD is also valid here, hence we do not really need to make the assumption that the photon does not affect chiral symmetry breaking.
representation of the non-Abelian gauge symmetry SU N ( ) . By comparison with (6.27) we read off that the U (1) 1-form symmetry and SU N ( f ) L form a 2-group with k = N . Because of chiral symmetry breaking and spontaneous breaking of the 1-form symmetry, the 2-groups is fully broken and, from our result above, the low-energy EFT describing pions and photon is (6.36) , plus the standard WZW term (also with coefficient N ) for the pions due to the cubic SU N ( f ) L anomaly: 32
$$S _ { \text{IR} } & = \frac { f _ { \pi } ^ { 2 } } { 4 \pi } \int _ { \mathcal { M } _ { 4 } } \text{Tr} \left [ ( i d U \, U ^ { -$$
Thus, while the pions themselves are uncharged under the U (1) gauge group, the photon A is coupled with an effective current
$$J _ { B } = - \frac { N } { 2 4 \pi ^ { 2 } } \ast \text{Tr} \left [ \left ( i U ^ { - 1 } d U \right ) ^ { 3 } \right ]. \quad \quad \quad$$
This current is conserved, and in the absence of the pion-photon interaction it generate a global U (1) symmetry of the sigma model: the topological symmetry due to the non-trivial homotopy group π 3 ( SU N ( f ) ) = Z . The integral of ⋆ J B gives indeed the winding number:
$$w ( \mathcal { M } _ { 3 } ) = - \frac { i } { 2 4 \pi ^ { 2 } } \int _ { \mathcal { M } _ { 3 } } \text{Tr} \left [ \left ( i U ^ { - 1 }$$
In the U N ( ) theory, configurations with nontrivial winding have a U (1) gauge charge. These configurations are Skyrmions: solitonic objects which, in the SU N ( ) theory, are identified with the baryons [62,97]. This is confirmed by our finding: the U N ( ) theory is obtained from ordinary SU N ( ) QCD by gauging the baryon number symmetry, hence the baryons are no longer gauge invariant, but rather are coupled with A .
We can make this more precise as follows. In the absence of the photon-pion coupling, the operators charged under the topological U (1) symmetry are local operators B q ( x ) defined as disorder operators which impose that
$$w ( S ^ { 3 } ) = q \in \mathbb { Z }$$
on a 3-sphere S 3 that links with x . Similarly to the monopole operator in Chern-Simons theory, B q ( x ) gets a gauge charge Nq due to the coupling with the photon.
Also, in the absence of the 2-group structure, the low-energy effective theory would have an emergent electric U (1) 1-form symmetry shifting A → A + λ (with the periods of λ in the interval [0 , 2 π ] ) and acting on the Wilson lines W γ n ( ) = e in ∫ γ A . Because of the photon-pion coupling, however, only a Z N ⊂ U (1) subgroup of this 1-form symmetry emerges. Indeed using the quantization (6.42) , shifting A → A + λ leaves the exponentiated action invariant only if the periods of λ are multiples of 2 π N . An equivalent way to see this is that the Wilson line W n = N can terminate on the
32 2-group structures in sigma models arising in the IR of QCD-like theories have been recently considered also in [96]. The IR there, however, is purely scalar, and the 2-group is not fully spontaneously broken (the 1-form symmetry is preserved). The interaction responsible for the 2-group is not a photon-pion coupling, but rather a coupling between pions parametrizing two different target spaces. Indeed the UV model studied in [96] can be obtained from U N ( ) QCD by adding scalars charged under U (1) B that Higgs the Abelian gauge field.
Baryon operator B 1 ( x ) . Notice that the microscopic theory does not have this Z N 1-form symmetry, because the quarks have unit charge under the gauged U (1) B . The emergence of Z N has a clear interpretation: the quarks are confined and the only dynamical particles charged under U (1) B at low energy are baryons, with charges multiple of N .
↦
As a final comment, notice that among the three Z 2 symmetries P , C C , ˜ defined in (6.37) that are preserved by the photon-pion coupling, only P and C are preserved also by the standard WZW term, while ˜ C is explicitly broken (see Table 1). This has to do with the fact that in U N ( ) QCD, C 2 : U → U T is the low-energy remnant of the non-Abelian charge conjugation that, in the UV, also acts on the SU N ( ) gauge bosons, confined in the IR. In the U N ( ) theory this charge conjugation is not independent from the Abelian charge conjugation C 1 acting on the photon, since the fermions are in the fundamental representation of both. Hence, only the product C = C C 1 2 is a symmetry of the theory.
## Acknowledgments
We are grateful to Riccardo Argurio, Matthew Bullimore, Christian Copetti, Lorenzo Di Pietro, Giovanni Galati, I˜aki Garc´ ıa Etxebarria, Matteo Sacchi, Antonio Santaniello, Sakura Sch¨fer-Nameki, n a Marco Serone, and Matthew Yu for discussions. We are supported by the ERC-COG grant NP-QFT No. 864583 'Non-perturbative dynamics of quantum fields: from new deconfined phases of matter to quantum black holes', by the MUR-FARE2020 grant No. R20E8NR3HX 'The Emergence of Quantum Gravity from Strong Coupling Dynamics', by the MUR-PRIN2022 grant No. 2022NY2MXY, and by the INFN 'Iniziativa Specifica ST&FI'.
## A Anomalous boundary conditions
In this appendix we present an iterative procedure to consistently turn on a background for boundary theories with a U (1) anomalous symmetry in generic even dimension. For the sake of concreteness we present this procedure in the simplest case of a U (1) symmetry with anomaly, but the same idea can be used for higher groups and in the non-Abelian cases discussed in the main text. In general, the method presented here is necessary to determine consistent boundary conditions whenever the simple BF theory is modified by some non-Gaussian term containing derivatives.
Consider the TQFT with action
$$S = \frac { i } { 2 \pi } \int _ { X _ { d + 1 } } \left ( b _ { d - 1 } \wedge d A _ { 1 } + \kappa _ { d } \, A _ { 1 } \wedge ( d$$
and k ∈ Z . In the presence of a boundary, the variation of the action produces a term
$$- \frac { i } { 2 \pi } \int _ { \partial X _ { d + 1 } } \left ( b _ { d - 1 } + \frac { d } { 2 } \, \kappa _ { d } \, A _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) \delta A _ { 1 } \,.$$
This can be cancelled by imposing the boundary condition
$$* A _ { 1 } = - \frac { i } { R ^ { 2 } } \underbrace { \left ( b _ { d - 1 } + \frac { d } { 2 } \, \kappa _ { d } \, A _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) } _ { \mathcal { T } _ { 0 } } + * \mathcal { A } _ { 1 }$$
and adding the boundary term
$$S _ { \partial } ^ { ( 0 ) } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } \left ( b _ { d - 1 } + \frac { d } { 2 } \, \kappa _ { d } \, A _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) \wedge \ast \left ( b _ { d - 1 } + \frac { d } { 2 } \, \kappa _ { d } \, A _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ). \ \ ( A. 4 )$$
However, there is no gauge transformation of A 1 that makes the boundary condition gauge invariant. The only way to have a gauge-invariant boundary condition is to add terms that mix A 1 with the dynamical fields. The simplest such modification is to replace T 0 in (A.3) with
$$\mathcal { T } _ { 0 } ^ { \prime } = \mathcal { T } _ { 0 } - \frac { d } { 2 } \, \kappa _ { d } \, \mathcal { A } _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \,.$$
Consequently we must modify the boundary term into
$$- \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } \mathcal { T } _ { 0 } ^ { \prime } \wedge \ast \mathcal { T } _ { 0 } ^ { \prime } \,.$$
However, since the boundary condition now imposes δ T ′ 0 = iR ⋆δA 2 1 , we get an extra unwanted term in the variational principle:
$$- \frac { i } { 2 \pi } \int _ { \partial X _ { d + 1 } } \frac { d } { 2 } \, \kappa _ { d } \, \mathcal { A } _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \wedge \delta A _ { 1 } \,.$$
This can be cancelled by adding a topological term proportional to A ∧ 1 A 1 ∧ ( dA 1 ) d 2 -1 to the boundary term. Indeed
$$\int _ { \partial X _ { d + 1 } } \delta \left ( \mathcal { A } _ { 1 } \, A _ { 1 } \, ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) = \int _ { \partial X _ { d + 1 } } \left ( \frac { d } { 2 } \, \mathcal { A } _ { 1 } \, ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \, \delta A _ { 1 } - \left ( \frac { d } { 2 } - 1 \right ) d \mathcal { A } _ { 1 } \, A _ { 1 } \, ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 2 } \, \delta A _ { 1 } \right ). \ ( A. 8 )$$
However, this also produces an extra term that must be cancelled. This is easily achieved by modifying both the boundary condition and the boundary term by the addition of this extra term to T ′ 0 . This produces
$$\mathcal { T } _ { 1 } & = \mathcal { T } _ { 0 } ^ { \prime } + \kappa _ { d } \left ( \frac { d } { 2 } - 1 \right ) d \mathcal { A } _ { 1 } \, A _ { 1 } \, ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 2 } \,. & & ( A. 9 )$$
At the same time we modify the boundary term that, including the new topological term, becomes
$$S _ { \partial } ^ { ( 1 ) } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } \mathcal { T } _ { 1 } \wedge \ast \mathcal { T } _ { 1 } + \frac { i } { 2 \pi } \int _ { \partial X _ { d + 1 } } \kappa _ { d } \mathcal { A } _ { 1 } \wedge A _ { 1 } \wedge ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \,.$$
These new boundary condition and boundary term give a consistent variational principle. However, the boundary condition is again non gauge invariant because of the last term we added to T 1 , and we have to repeat the procedure above.
At each step, the non-gauge-invariant piece in the boundary condition becomes of one lower degree in A 1 (and one higher in A 1 ). Hence, the procedure stops when we reach a term linear in A 1 : we can
make the boundary condition gauge invariant by adding a term purely in A 1 , which does not modify the variational principle. The procedure stops after ( d/ 2 -1) steps, yielding the boundary condition
$$* \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) = - \frac { i } { R ^ { 2 } } \left ( \Omega _ { d - 1 } - \kappa _ { d } \mathcal { A } _ { 1 } \left ( \mathcal { A } _ { 1 } \right ) ^ { \frac { d } { 2 } - 1 } \right )$$
where
$$\Omega _ { d - 1 } = b _ { d - 1 } + \kappa _ { d } \sum _ { r = 0 } ^ { \frac { d } { 2 } - 2 } \left ( \frac { d } { 2 } - r \right ) \left ( d \mathcal { A } _ { 1 } \right ) ^ { r } \left ( A _ { 1 } - \mathcal { A } _ { 1 } \right ) \left ( d A _ { 1 } \right ) ^ { \frac { d } { 2 } - 1 - r } + \kappa _ { d } \left ( d \mathcal { A } _ { 1 } \right ) ^ { \frac { d } { 2 } - 1 } A _ { 1 } \,. \quad \quad \left ( A. 1 2 \right )$$
The corresponding boundary term is
$$S _ { \partial } = - \frac { 1 } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } \Omega _ { d - 1 } \wedge \ast \Omega _ { d - 1 } + \frac { i \kappa _ { d } } { 2 \pi } \sum _ { r = 0 } ^ { \frac { d } { 2 } - 2 } \int _ { \partial X _ { d + 1 } } \mathcal { A } _ { 1 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { r } A _ { 1 } \left ( d A _ { 1 } \right ) ^ { \frac { d } { 2 } - r - 1 }. \quad \left ( A. 1 3 \right )$$
As a sanity check, we can verify that the boundary theory is anomalous under U (1) gauge transformations. Under δA 1 = δ A 1 = dλ 0 the topological terms on the boundary produce
$$\text{formations. Under } \delta A _ { 1 } = \partial \mathcal { A } _ { 1 } = d \lambda _ { 0 } \text{ the topological terms on the boundary produce} \\ \frac { i \kappa _ { d } } { 2 \pi } \sum _ { r = 0 } ^ { \frac { g } { 2 } - 2 } \int _ { \partial X _ { d + 1 } } & \left ( d \lambda _ { 0 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { r } A _ { 1 } \left ( d A _ { 1 } \right ) ^ { \frac { g } { 2 } - r - 1 } + \mathcal { A } _ { 1 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { r } d \lambda _ { 0 } \left ( d A _ { 1 } \right ) ^ { \frac { g } { 2 } - r - 1 } \right ) \\ & = \frac { i \kappa _ { d } } { 2 \pi } \sum _ { r = 0 } ^ { \frac { g } { 2 } - 2 } \int _ { \partial X _ { d + 1 } } \lambda _ { 0 } \left ( ( d \mathcal { A } _ { 1 } ) ^ { r + 1 } ( d A _ { 1 } ) ^ { \frac { g } { 2 } - r - 1 } - ( d \mathcal { A } _ { 1 } ) ^ { r } ( d A _ { 1 } ) ^ { \frac { g } { 2 } - r } \right ) \\ & = \frac { i \kappa _ { d } } { 2 \pi } \int _ { \partial X _ { d + 1 } } \left ( \lambda _ { 0 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { \frac { g } { 2 } - 1 } ( d A _ { 1 } ) - \lambda _ { 0 } \left ( d A _ { 1 } \right ) ^ { \frac { g } { 2 } } \right ). \\ \text{Then, using the boundary condition,}$$
Then, using the boundary condition,
$$& \cdot \, \searrow \, \ell \, \quad \cdot \\ \delta S _ { \theta } & = \frac { i \kappa _ { d } } { 2 \pi } \int _ { \partial X _ { d + 1 } } d \lambda _ { 0 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } ( A _ { 1 } - \mathcal { A } _ { 1 } ) - \frac { \kappa _ { d } ^ { 2 } } { 2 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } d \lambda _ { 0 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \wedge \ast \left ( ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \mathcal { A } _ { 1 } ) \quad \text{(A.15)} \\ & \quad - \frac { \kappa _ { d } ^ { 2 } } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } d \lambda _ { 0 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \wedge \ast \left ( d \lambda _ { 0 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) + \frac { i \kappa _ { d } } { 2 \pi } \int _ { \partial X _ { d + 1 } } ( \lambda _ { 0 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } ( d A _ { 1 } ) - \lambda _ { 0 } \, ( d A _ { 1 } ) ^ { \frac { d } { 2 } } ) \,. \\ \dots \quad \cdot \, \dots \quad \cdot \, \dots \quad \cdot$$
The bulk contributes with a term
$$\delta S = - \frac { i \kappa _ { d } } { 2 \pi } \int _ { \partial X _ { d + 1 } } d \lambda _ { 0 } \, A _ { 1 } \, ( d A _ { 1 } ) ^ { \frac { d } { 2 } - 1 }$$
which, together with the last term in (A.14) , combines to a total derivative (on the boundary) and can be neglected. We remain with
$$\delta S _ { t o t } = - \frac { i \kappa _ { d } } { 2 \pi } \int _ { \partial X _ { d + 1 } } d \lambda _ { 0 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \, \mathcal { A } _ { 1 } - \delta \left [ \frac { \kappa _ { d } ^ { 2 } } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } \left ( \mathcal { A } _ { 1 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) \wedge \ast \left ( \mathcal { A } _ { 1 } \, ( d \mathcal { A } _ { 1 } ) ^ { \frac { d } { 2 } - 1 } \right ) \right ].$$
We can isolate the anomalous variation adding a final counterterm
$$S _ { \text{c.t.} } = \frac { \kappa _ { d } ^ { 2 } } { 4 \pi R ^ { 2 } } \int _ { \partial X _ { d + 1 } } \left ( \mathcal { A } _ { 1 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { \frac { d } { 2 } - 1 } \right ) \wedge \ast \left ( \mathcal { A } _ { 1 } \left ( d \mathcal { A } _ { 1 } \right ) ^ { \frac { d } { 2 } - 1 } \right ).$$
## B Non-compact TQFTs
In this appendix we provide a mathematical definition and details on the TQFTs with infinitely many operators introduced in [48,49] and used as holographic duals. The main issue is defining the theory with cutting and gluing while avoiding infinities from inserting a complete basis of states. We argue that this is possible if all manifolds have at least one non-empty boundary component. On the other hand, the partition functions on closed manifolds will be generically infinite.
Review of standard TQFTs. Recall that standard TQFTs in d dimensions are defined by a symmetric monoidal functor Z : Bord SO d → Vec C from the category of oriented bordisms to the category of complex vector spaces [98] (see e.g. [99] for a detailed review). A vector space H X d -1 = Z X ( d -1 ) is assigned to any closed codimension-one manifold and a linear map Z Y ( d ) : H X d -1 →H X ′ d -1 to any bordism Y d : X d -1 → X ′ d -1 , namely an oriented manifold with boundary ∂Y d = X d -1 ⊔ X ′ d -1 (here bar means orientation reversal) with in and out components given by X d -1 and X ′ d -1 respectively. 33 Functoriality implies that the vector space for a disjoint union is the tensor product, and gluing Y d with Y ′ d along a common boundary corresponds to composing linear maps.
In practice, it is convenient to work with an explicit basis. Hence, to concretely construct a TQFT we need the following ingredients:
- · Vector spaces H X d -1 with a basis | a ⟩ . We also denote by | ¯ a ⟩ a basis of H X d -1 .
- · For any d -dimensional manifold Y d with incoming and outgoing connected boundary components, respectively, X i d -1 in , , i = 1 2 , , . . . and X j d -1 out , , j = 1 2 , , . . . we assign a tensor Z Y ( d ) { a i } { , b j } . This specifies the linear map ⊗ i H in ,i → ⊗ j H out ,j
$$Z ( Y _ { d } ) \left ( | a _ { 1 } \rangle \otimes | a _ { 2 } \rangle \otimes \cdots \right ) = \sum _ { b _ { j } } Z ( Y _ { d } ) _ { \{ a _ { i } \}, \{ b _ { j } \} } \left ( | b _ { 1 } \rangle \otimes | b _ { 2 } \rangle \otimes \cdots \right ).$$
Notice that the vector spaces H X d -1 are not endowed with a scalar product as an extra datum: this simply arises from the composition of bordisms. To see this notice that, for any X d -1 , we can construct the cylinder X d -1 × [0 , 1] that can be viewed both as the straight cylinder , namely a bordism X d -1 → X d -1 , or as the horseshoe , namely a bordism X d -1 ⊗ X d -1 → ∅ . 34 In the first case the functor Z associates the identity map Id H X d -1 : H X d -1 →H X d -1 , while in the second case it gives a bilinear pairing η X ( d -1 ) : H X d -1 ⊗H X d -1 → C . In components these read:
One can show that η X ( d -1 ) is a non-degenerate pairing that defines an isomorphism H X d -1 ∼ H = ∨ X d -1 . This allows us to identify the basis | ¯ a ⟩ of H X d -1 with the dual basis ⟨ a | of H ∨ X d -1 defined by ⟨ a b | ⟩ = δ a,b :
$$| \bar { b } \rangle = \sum _ { a } \eta _ { a, \bar { b } } \left \langle a \right |.$$
With these pieces of data, it is clear how to glue various bordisms along common boundaries to generate others. The common boundaries must have opposite orientations. When one boundary is incoming and the other one is outgoing, the gluing is just the composition. On the other hand, if both are incoming (or both outgoing), we use η X ( d -1 ) a,b ¯ . More concretely, let Y d be a (possibly disconnected) bordism ⊔ i X i d -1 in , → ⊔ j X j d -1 out , . If X 1 d -1 in , = X 1 d -1 out , we can generate ˜ Y d by gluing the two, and the associated tensor is
$$Z ( \widetilde { Y } _ { d } ) _ { \{ a _ { 2 }, \dots \}, \{ b _ { 2 }, \dots \} } = \sum \nolimits _ { a _ { 1 } } \, Z ( Y _ { d } ) _ { \{ a _ { 1 }, a _ { 2 }, \dots \}, \{ a _ { 1 }, b _ { 2 }, \dots \} } \,.$$
If instead X 1 d -1 in , = X 2 d -1 in , the tensor associated with the manifold obtained by gluing along these boundary components is
$$Z ( \widetilde { Y } _ { d } ) _ { \{ a _ { 3 }, \dots \}, \{ b _ { 1 } \} } = \sum \nolimits _ { a _ { 1 }, a _ { 2 } } \, Z ( Y _ { d } ) _ { \{ a _ { 1 }, a _ { 2 }, a _ { 3 }, \dots \}, \{ b _ { 1 }, \dots \} } \, \eta ( X _ { d - 1, \text{in} } ^ { 1 } ) _ { a _ { 1 }, a _ { 2 } } \,.$$
Clearly, these pieces of data cannot be arbitrary: if the same manifold Y d can be constructed in different ways by gluing smaller pieces, the results must coincide. Once these consistency conditions are satisfied, we can compute the tensor associated with any manifold starting from those associated with the more elementary pieces. By performing enough gluings to get a closed manifold, the result is a number: the partition function. For instance, gluing the outgoing and the incoming boundary of a cylinder X d -1 × [0 , 1] we get X d -1 × S 1 , hence
$$Z ( X _ { d - 1 } \times S ^ { 1 } ) = \sum \nolimits _ { a } \delta _ { a, a } = \dim ( \mathcal { H } _ { X _ { d - 1 } } ) \,.$$
The non-compact case. Already the fact (B.5) suggests that in the non-compact case closed bordisms should not be included in the definition. We want to argue that, avoiding closed manifolds, there are classes of manifolds in which we can give a precise definition of the U (1) / R BF-like theories
$$S = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { d } } b _ { d - p - 1 } \wedge d A _ { p } \,.$$
As an illustration, we consider the case of d = 2 with p = 1 . Hence b 0 = ϕ is a non-compact scalar, and A is a U (1) gauge field. The Hilbert space H S 1 can be constructed by canonical quantization. We set M 2 = S 1 × R , with R parametrized by t , and split A = ˜ A + A dt t 0 . Then
$$S = - \frac { i } { 2 \pi } \int _ { S ^ { 1 } \times \mathbb { R } } \left ( A _ { 0 } ^ { t } \, \tilde { d } \phi \wedge d t + \phi \, \partial _ { t } \widetilde { A } \wedge d t \right ).$$
We choose the temporal gauge A t 0 = 0 , and we need to impose the Gauss law ˜ dϕ = 0 , namely ϕ = ϕ t ( ) is independent of the spatial coordinate. Introducing
$$q ( t ) = \int _ { S ^ { 1 } } \widetilde { A } \,, \quad \ \ p ( t ) = \frac { 1 } { 2 \pi } \phi ( t ) \,,$$
we see that q t ( ) ∼ q t ( ) + 2 π is a periodic variable, and the action becomes
$$S = - i \int _ { \mathbb { R } } p \, \partial _ { t } q \, d t \,.$$
This is a free infinitely-massive particle on a circle of radius 2 π . The quantization is straightforward. We have the commutation relations
$$[ \hat { q }, \hat { p } ] = i \quad \ \Rightarrow \quad \ \ e ^ { i \alpha \hat { p } } \cdot e ^ { i n \hat { q } } = e ^ { i \alpha n } \ e ^ { i n \hat { q } } \cdot e ^ { i \alpha \hat { p } } \,.$$
Here n ∈ Z because of the periodicity of ˆ q , while α is a generic real number. However the operator e 2 πip ˆ commutes with the whole operator algebra, hence it is a number that we can set to 1 . Therefore the operators acting on the Hilbert space are
$$\widehat { \mathcal { O } } _ { \alpha } = e ^ { i \alpha \hat { p } } \ \text{ with } \ \alpha \in [ 0, 2 \pi ) \,, \quad \ \widehat { W } _ { n } = e ^ { i n \hat { q } } \ \text{ with } \ n \in \mathbb { Z } \,,$$
with algebra
$$\widehat { \mathcal { O } } _ { \alpha } \, \widehat { \mathcal { O } } _ { \beta } = \widehat { \mathcal { O } } _ { \alpha + \beta \, ( \text{mod } 2 \pi ) \,, \quad \widehat { W } _ { n } \, \widehat { W } _ { m } = \widehat { W } _ { n + m } \,, \quad \widehat { \mathcal { O } } _ { \alpha } \, \widehat { W } _ { n } = e ^ { i \alpha n } \, \widehat { W } _ { n } \, \widehat { \mathcal { O } } _ { \alpha } \,.$$
Starting from a simultaneous eigenstate of the ̂ W n 's such that
$$\widehat { W } _ { n } \left | \theta \right \rangle = e ^ { i n \theta } \left | \theta \right \rangle,$$
using the algebra we find
$$\ddot { \mathcal { O } } _ { \alpha } \left | \theta \right \rangle = \left | \theta - \alpha \right \rangle.$$
Hence we get a basis labelled by a compact continuous variable θ ∈ U (1) . We can also use a noncompact but countable basis, starting with an eigenstate of ̂ O α :
$$\widehat { \mathcal { O } } _ { \alpha } \left | k \right \rangle = e ^ { i \alpha k } \left | k \right \rangle.$$
It must be k ∈ Z to respect the periodicity α ∼ α +2 π . Then using the algebra we infer
$$\dot { W _ { n } } \left | k \right \rangle = \left | k + n \right \rangle.$$
The relation between the two basis is
$$| k \rangle & = \frac { 1 } { \sqrt { 2 \pi } } \int _ { 0 } ^ { 2 \pi } d \theta \, e ^ { i k \theta } \, | \theta \rangle \,, & | \theta \rangle & = \frac { 1 } { \sqrt { 2 \pi } } \sum _ { k \in \mathbb { Z } } e ^ { - i k \theta } \, | k \rangle \,.$$
Since the Hilbert space is infinite dimensional, the partition function on T 2 is infinite. Let us show that, on the other hand, we can consistently define a functor on the category of open oriented bordisms. In 2d the huge computational simplifications are that the only Hilbert space is H S 1 , and that every 2d manifold has a pair of pants decomposition. Eventually, one also needs to fill holes by
attaching a disk. Hence, on top of the horseshoe η ab , the only other data one needs to assign are the disk and the pair of pants:
c
The numbers h a define a distinguished state | HH ⟩ = ∑ a h a | a ⟩ , called the Hartle-Hawking state. These two data must satisfy the obvious condition that if we fill one of the two incoming holes of the pair of pants with the Hartle-Hawking state we get the cylinder:
$$\sum \nolimits _ { b } \mu _ { a b } ^ { c } \, h _ { b } = \delta _ { a, c } \,.$$
The only other consistency condition is the independence from the chosen pair of pants decomposition, that reduces to the Froboenius condition [100]:
$$\sum \nolimits _ { c } \mu _ { a, b } ^ { c } \, \mu _ { c, d } ^ { e } = \sum \nolimits _ { c } \, \mu _ { a, c } ^ { e } \, \mu _ { b, d } ^ { c } \,.$$
Let us use the continuous basis | θ ⟩ . The cylinder (identity) becomes a delta function δ θ ( 1 -θ 2 ) . Moreover, we define
$$h _ { \theta } = \delta ( \theta ) \,, \quad \ \eta _ { \theta _ { 1 }, \theta _ { 2 } } = \delta ( \theta _ { 1 } + \theta _ { 2 } ) \,, \quad \ \mu _ { \theta _ { 1 }, \theta _ { 2 } } ^ { \theta _ { 3 } } = \delta ( \theta _ { 1 } + \theta _ { 2 } - \theta _ { 3 } ) \,.$$
$$\mu _ { \theta _ { 1 }, \theta _ { 2 } } ^ { \theta _ { 3 } } = \delta ( \theta _ { 1 } + \theta _ { 2 } - \theta _ { 3 } ) \,. \quad \text{(B.2O)}$$
Also, all sums are replaced by integrals on [0 , 2 π ) in this basis. The condition (B.18) is obviously satisfied, while the Froboenius condition (B.19) reads
$$\int _ { 0 } ^ { 2 \pi } d \theta \, \delta ( \theta _ { 1 } + \theta _ { 2 } - \theta ) \, \delta ( \theta + \theta _ { 3 } - \theta _ { 4 } ) = \int _ { 0 } ^ { 2 \pi } d \theta \, \delta ( \theta _ { 1 } + \theta - \theta _ { 4 } ) \, \delta ( \theta _ { 2 } + \theta _ { 3 } - \theta )$$
which is satisfied since both sides are equal to δ θ ( 1 + θ 2 + θ 3 -θ 4 ) . The choice of these data is motivated by the fact that the continuous basis | θ ⟩ is related, by the state/operator correspondence, with the local operators O α ( x ) = e i α 2 π ϕ x ( ) , and the pair of pants must reproduce their OPE O O α β = O α + β . Then the Hartle-Hawking state is fixed by (B.18) .
With these pieces of data, we can compute the value of the functor for arbitrary bordisms with a non-empty boundary. The simplest nontrivial such manifold is the torus with a puncture. This can be obtained from the pair of pants by gluing one of the two incoming boundaries with the outgoing one. Denoting by θ the label of the puncture, namely the non-glued circle, the result is 35
$$Z \left ( \Sigma _ { 1 } \smallsetminus P _ { \theta } \right ) = \int _ { 0 } ^ { 2 \pi } d \theta ^ { \prime } \, \delta ( \theta ) = 2 \pi \, \delta ( \theta ) \,.$$
35 We denote a genus g Riemann surface as Σ . g
This is a projector on the Hartle-Hawking state. Another simple example is the torus with two punctures that can be obtained from the previous result by gluing the remaining boundary to the outgoing boundary of another pair of pants. Hence, the result is
$$Z \left ( \Sigma _ { 1 } \smallsetminus \left \{ P _ { \theta _ { 1 } }, P _ { \theta _ { 2 } } \right \} \right ) = \int _ { 0 } ^ { 2 \pi } d \theta ^ { \prime } \, \delta ( \theta _ { 1 } + \theta _ { 2 } - \theta ^ { \prime } ) \, 2 \pi \delta ( \theta ^ { \prime } ) = 2 \pi \, \delta ( \theta _ { 1 } + \theta _ { 2 } ) \,.$$
We can now put these two examples together, gluing the boundary of a torus with one puncture to one of the two boundaries of the torus with two punctures, resulting in a genus-two surface with a puncture:
$$\i \varkappa. \\ Z ( \Sigma _ { 2 } \smallsetminus P _ { \theta } ) = \int _ { 0 } ^ { 2 \pi } d \theta ^ { \prime } \ 2 \pi \delta ( \theta + \theta ^ { \prime } ) \ 2 \pi \delta ( \theta ^ { \prime } ) = ( 2 \pi ) ^ { 2 } \, \delta ( \theta ) \,.$$
Proceeding in this way it is not hard to prove the general result. The value of the functor an a genus g surface with n incoming boundaries labelled by θ , . . . , θ 1 n and m outgoing boundaries labelled by θ , . . . , θ ′ 1 ′ m is given by
$$Z \left ( \Sigma _ { g } \smallsetminus \left \{ P _ { \theta _ { 1 } }, \dots, P _ { \theta _ { n } }, P _ { \theta ^ { \prime } _ { 1 } }, \dots, P _ { \theta ^ { \prime } _ { m } } \right \} \right ) = ( 2 \pi ) ^ { g } \, \delta ( \theta _ { 1 } + \dots + \theta _ { n } - \theta ^ { \prime } _ { 1 } - \dots - \theta ^ { \prime } _ { m } ) \,. \quad \text{(B.25)}$$
The important observation is that the partition function on compact Riemann surfaces is infinite. Indeed, a compact Riemann surface of genus g is obtained by closing the hole of a one-punctured Riemann surface Σ g ∖ P θ by means of gluing the Hartle-Hawking state. The result is clearly infinite:
$$Z ( \Sigma _ { g } ) = \int _ { 0 } ^ { 2 \pi } d \theta \, ( 2 \pi ) ^ { g } \, \delta ( \theta ) \, \delta ( \theta ) = ( 2 \pi ) ^ { g } \, \delta ( 0 ) \,.$$
We conclude that the TQFT is well defined on the category of open oriented bordisms.
Let us remark that, given the Hilbert space we constructed, there is another set of data that can be formulated, which is essentially the same as the one we discussed but in the discrete basis | k ⟩ :
$$h _ { k } ^ { \prime } = \delta _ { k, 0 } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\, h _ { k _ { 1 }, k _ { 2 } } ^ { \prime } = \delta _ { k _ { 1 }, - k _ { 2 } } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\\ h _ { k _ { 1 } } ^ { \prime } = \delta _ { k _ { 1 }, - k _ { 2 } } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
h _ { k _ { k } } ^ { \prime } = \delta _ { k _ { k }, 0 } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\, h _ { k } \, 2 7 )$$
With these data one gets infinite answers even on open manifolds, as soon as they have a non-trivial topology. It must be noticed that, indeed, these are not merely the data (B.20) written in a different basis: translating (B.20) in the discrete basis using (B.17) we get
$$h _ { k } = \frac { 1 } { \sqrt { 2 \pi } } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\eta _ { k _ { 1 }, k _ { 2 } } = \delta _ { k _ { 1 }, k _ { 2 } } \,, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
We conclude that (B.20) and (B.27) really define two different TQFTs.
How did we choose one instead of the other? As we already pointed out, in 2d TQFT the choice is really dictated by the fact that the pair of pants is related with the OPE of local operators. The data (B.27) would then be relevant for the TQFT with Lagrangian formulation
$$S ^ { \prime } = \frac { i } { 2 \pi } \int _ { \mathcal { M } _ { 2 } } \Phi \, d a _ { 1 } \,,$$
where Φ ∼ Φ+2 π is a compact scalar, while a 1 an R gauge field. Canonical quantization produces the same Hilbert space as the theory with non-compact scalar and U (1) gauge field; however, here
the local operators O n ( x ) = e in Φ( x ) are labeled by an integer, and hence are related with the discrete basis by the state/operator correspondence. For this reason, in contrast to the previous case, the quantization of this theory produces the data (B.27) in which the pair of pants gives the Abelian fusion algebra in the discrete basis.
## References
- [1] E. Witten, 'Topological Quantum Field Theory,' Commun. Math. Phys. 117 (1988) 353.
- [2] D. Gaiotto, A. Kapustin, N. Seiberg, and B. Willett, 'Generalized global symmetries,' JHEP 02 (2015) 172, arXiv:1412.5148 [hep-th] .
- [3] A. Kapustin, 'Topological Field Theory, Higher Categories, and Their Applications,' in Proceedings of the International Congress of Mathematicians 2010 , vol. 3, pp. 2021-2043. 2010. arXiv:1004.2307 [math.QA] .
- [4] L. Bhardwaj and Y. Tachikawa, 'On finite symmetries and their gauging in two dimensions,' JHEP 03 (2018) 189, arXiv:1704.02330 [hep-th] .
- [5] C.-M. Chang, Y.-H. Lin, S.-H. Shao, Y. Wang, and X. Yin, 'Topological defect lines and renormalization group flows in two dimensions,' JHEP 01 (2019) 026, arXiv:1802.04445 [hep-th] .
- [6] Y. Choi, C. C´rdova, P.-S. Hsin, H. T. Lam, and S.-H. Shao, 'Noninvertible duality defects in o 3+1 dimensions,' Phys. Rev. D 105 (2022) 125016, arXiv:2111.01139 [hep-th] .
- [7] J. Kaidi, K. Ohmori, and Y. Zheng, 'Kramers-Wannier-like Duality Defects in (3+1)D Gauge Theories,' Phys. Rev. Lett. 128 (2022) 111601, arXiv:2111.01141 [hep-th] .
- [8] K. Roumpedakis, S. Seifnashri, and S.-H. Shao, 'Higher gauging and non-invertible condensation defects,' Commun. Math. Phys. 401 (2023) 3043-3107, arXiv:2204.02407 [hep-th] .
- [9] L. Bhardwaj, L. E. Bottini, S. Schafer-Nameki, and A. Tiwari, 'Non-invertible higher-categorical symmetries,' SciPost Phys. 14 (2023) 007, arXiv:2204.06564 [hep-th] .
- [10] A. Antinucci, G. Galati, and G. Rizi, 'On continuous 2-category symmetries and Yang-Mills theory,' JHEP 12 (2022) 061, arXiv:2206.05646 [hep-th] .
- [11] D. S. Freed, G. W. Moore, and C. Teleman, 'Topological symmetry in quantum field theory,' arXiv:2209.07471 [hep-th] .
- [12] R. Argurio, F. Benini, M. Bertolini, G. Galati, and P. Niro, 'On the symmetry TFT of Yang-Mills-Chern-Simons theory,' JHEP 07 (2024) 130, arXiv:2404.06601 [hep-th] .
- [13] A. Maloney and E. Witten, 'Quantum Gravity Partition Functions in Three Dimensions,' JHEP 02 (2010) 029, arXiv:0712.0155 [hep-th] .
- [14] P. Saad, S. H. Shenker, and D. Stanford, 'A semiclassical ramp in SYK and in gravity,' arXiv:1806.06840 [hep-th] .
- [15] D. Stanford and E. Witten, 'JT gravity and the ensembles of random matrix theory,' Adv. Theor. Math. Phys. 24 (2020) 1475-1680, arXiv:1907.03363 [hep-th] .
- [16] A. Maloney and E. Witten, 'Averaging over Narain moduli space,' JHEP 10 (2020) 187, arXiv:2006.04855 [hep-th] .
- [17] N. Afkhami-Jeddi, H. Cohn, T. Hartman, and A. Tajdini, 'Free partition functions and an averaged holographic duality,' JHEP 01 (2021) 130, arXiv:2006.04839 [hep-th] .
- [18] F. Benini, C. Copetti, and L. Di Pietro, 'Factorization and global symmetries in holography,' SciPost Phys. 14 (2023) 019, arXiv:2203.09537 [hep-th] .
- [19] D. S. Freed, 'Short-range entanglement and invertible field theories,' arXiv:1406.7278 [cond-mat.str-el] .
- [20] D. S. Freed and M. J. Hopkins, 'Reflection positivity and invertible topological phases,' Geom. Topol. 25 (2021) 1165-1330, arXiv:1604.06527 [hep-th] .
- [21] A. Davydov, M. M¨ger, D. Nikshych, and V. Ostrik, 'The Witt group of non-degenerate u braided fusion categories,' J. reine angewandte Math. 677 (2013) 135-177, arXiv:1009.2117 [math.QA] .
- [22] J. Fuchs, C. Schweigert, and A. Valentino, 'Bicategories for boundary conditions and for surface defects in 3-d TFT,' Commun. Math. Phys. 321 (2013) 543-575, arXiv:1203.4568 [hep-th] .
- [23] D. S. Freed and C. Teleman, 'Gapped Boundary Theories in Three Dimensions,' Commun. Math. Phys. 388 (2021) 845-892, arXiv:2006.10200 [math.QA] .
- [24] J. Kaidi, Z. Komargodski, K. Ohmori, S. Seifnashri, and S.-H. Shao, 'Higher central charges and topological boundaries in 2+1-dimensional TQFTs,' SciPost Phys. 13 (2022) 067, arXiv:2107.13091 [hep-th] .
- [25] S. Schafer-Nameki, 'ICTP lectures on (non-)invertible generalized symmetries,' Phys. Rept. 1063 (2024) 1-55, arXiv:2305.18296 [hep-th] .
- [26] S.-H. Shao, 'What's Done Cannot Be Undone: TASI Lectures on Non-Invertible Symmetries,' arXiv:2308.00747 [hep-th] .
- [27] T. D. Brennan and S. Hong, 'Introduction to Generalized Global Symmetries in QFT and Particle Physics,' arXiv:2306.00912 [hep-ph] .
- [28] L. Bhardwaj, L. E. Bottini, L. Fraser-Taliente, L. Gladden, D. S. W. Gould, A. Platschorre, and H. Tillim, 'Lectures on generalized symmetries,' Phys. Rept. 1051 (2024) 1-87, arXiv:2307.07547 [hep-th] .
- [29] D. Gaiotto and J. Kulp, 'Orbifold groupoids,' JHEP 02 (2021) 132, arXiv:2008.05960 [hep-th] .
- [30] F. Apruzzi, F. Bonetti, I. Garc´ ıa Etxebarria, S. S. Hosseini, and S. Schafer-Nameki, 'Symmetry TFTs from string theory,' Commun. Math. Phys. 402 (2023) 895-949, arXiv:2112.02092 [hep-th] .
| [31] | L. Bhardwaj and S. Schafer-Nameki, 'Generalized charges, part I: Invertible symmetries and higher representations,' SciPost Phys. 16 (2024) 093, arXiv:2304.02660 [hep-th] . |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [32] | L. Bhardwaj and S. Schafer-Nameki, 'Generalized charges, part II: Non-invertible symmetries and the Symmetry TFT,' arXiv:2305.17159 [hep-th] . |
| [33] | F. Apruzzi, I. Bah, F. Bonetti, and S. Schafer-Nameki, 'Noninvertible symmetries from holography and branes,' Phys. Rev. Lett. 130 (2023) 121601, arXiv:2208.07373 [hep-th] . |
| [34] | J. Kaidi, K. Ohmori, and Y. Zheng, 'Symmetry TFTs for non-invertible defects,' Commun. Math. Phys. 404 (2023) 1021-1124, arXiv:2209.11062 [hep-th] . |
| [35] | A. Antinucci, F. Benini, C. Copetti, G. Galati, and G. Rizi, 'The holography of non-invertible self-duality symmetries,' arXiv:2210.09146 [hep-th] . |
| [36] | V. Bashmakov, M. Del Zotto, A. Hasan, and J. Kaidi, 'Non-invertible symmetries of class S theories,' JHEP 05 (2023) 225, arXiv:2211.05138 [hep-th] . |
| [37] | A. Antinucci, C. Copetti, G. Galati, and G. Rizi, ''Zoology' of non-invertible duality defects: the view from class S ,' JHEP 04 (2024) 036, arXiv:2212.09549 [hep-th] . |
| [38] | J. Kaidi, E. Nardoni, G. Zafrir, and Y. Zheng, 'Symmetry TFTs and anomalies of non-invertible symmetries,' JHEP 10 (2023) 053, arXiv:2301.07112 [hep-th] . |
| [39] | C. Zhang and C. C´rdova, o 'Anomalies of (1+1) -dimensional categorical symmetries,' Phys. Rev. B 110 (2024) 035155, arXiv:2304.01262 [cond-mat.str-el] . |
| [40] | A. Antinucci, F. Benini, C. Copetti, G. Galati, and G. Rizi, 'Anomalies of non-invertible self-duality symmetries: fractionalization and gauging,' arXiv:2308.11707 [hep-th] . |
| [41] | C. C´rdova, o P.-S. Hsin, and C. Zhang, 'Anomalies of non-invertible symmetries in (3+1)d,' SciPost Phys. 17 (2024) 131, arXiv:2308.11706 [hep-th] . |
| [42] | P. Putrov and R. Radhakrishnan, 'Non-anomalous non-invertible symmetries in 1+1D from gapped boundaries of SymTFTs,' arXiv:2405.04619 [hep-th] . |
| [43] | R. Wen and A. C. Potter, 'Bulk-boundary correspondence for intrinsically gapless symmetry-protected topological phases from group cohomology,' Phys. Rev. B 107 (2023) 245127, arXiv:2208.09001 [cond-mat.str-el] . |
| [44] | R. Wen and A. C. Potter, 'Classification of 1+1D gapless symmetry protected phases via topological holography,' arXiv:2311.00050 [cond-mat.str-el] . |
| [45] | L. Bhardwaj, L. E. Bottini, D. Pajer, and S. Sch¨fer-Nameki, a 'Gapped Phases with Non-Invertible Symmetries: (1+1)d,' arXiv:2310.03784 [hep-th] . |
| [46] | L. Bhardwaj, L. E. Bottini, D. Pajer, and S. Schafer-Nameki, 'Categorical Landau Paradigm for Gapped Phases,' Phys. Rev. Lett. 133 (2024) 161601, arXiv:2310.03786 [cond-mat.str-el] . |
| [47] | A. Antinucci, C. Copetti, and S. Schafer-Nameki, 'SymTFT for (3+1)d Gapless SPTs and Obstructions to Confinement,' arXiv:2408.05585 [hep-th] . |
- [48] A. Antinucci and F. Benini, 'Anomalies and gauging of U (1) symmetries,' arXiv:2401.10165 [hep-th] .
- [49] T. D. Brennan and Z. Sun, 'A SymTFT for continuous symmetries,' arXiv:2401.06128 [hep-th] .
- [50] F. Bonetti, M. Del Zotto, and R. Minasian, 'SymTFTs for Continuous non-Abelian Symmetries,' arXiv:2402.12347 [hep-th] .
- [51] F. Apruzzi, F. Bedogna, and N. Dondi, 'SymTh for non-finite symmetries,' arXiv:2402.14813 [hep-th] .
- [52] S. R. Coleman, J. Wess, and B. Zumino, 'Structure of phenomenological Lagrangians. 1.,' Phys. Rev. 177 (1969) 2239-2247.
- [53] C. G. Callan, Jr., S. R. Coleman, J. Wess, and B. Zumino, 'Structure of phenomenological Lagrangians. 2.,' Phys. Rev. 177 (1969) 2247-2250.
- [54] Y. Choi, H. T. Lam, and S.-H. Shao, 'Noninvertible global symmetries in the standard model,' Phys. Rev. Lett. 129 (2022) 161601, arXiv:2205.05086 [hep-th] .
- [55] C. C´ ordova and K. Ohmori, 'Noninvertible chiral symmetry and exponential hierarchies,' Phys. Rev. X 13 (2023) 011034, arXiv:2205.06243 [hep-th] .
- [56] E. Witten, 'Quantum Field Theory and the Jones Polynomial,' Commun. Math. Phys. 121 (1989) 351-399.
- [57] S. Elitzur, G. W. Moore, A. Schwimmer, and N. Seiberg, 'Remarks on the Canonical Quantization of the Chern-Simons-Witten Theory,' Nucl. Phys. B 326 (1989) 108-134.
- [58] S. Gukov, E. Martinec, G. W. Moore, and A. Strominger, 'Chern-Simons gauge theory and the AdS /CFT 3 2 correspondence,' in From Fields to Strings: Circumnavigating Theoretical Physics: A Conference in Tribute to Ian Kogan , pp. 1606-1647. 2005. arXiv:hep-th/0403225 .
- [59] O. Aharony, A. Dymarsky, and A. D. Shapere, 'Holographic description of Narain CFTs and their code-based ensembles,' JHEP 05 (2024) 343, arXiv:2310.06012 [hep-th] .
- [60] A. Barbar, A. Dymarsky, and A. D. Shapere, 'Global Symmetries, Code Ensembles, and Sums Over Geometries,' arXiv:2310.13044 [hep-th] .
- [61] G. T. Horowitz, 'Exactly soluble diffeomorphism invariant theories,' Commun. Math. Phys. 125 (1989) 417.
- [62] E. Witten, 'Global Aspects of Current Algebra,' Nucl. Phys. B 223 (1983) 422-432.
- [63] C. C´ ordova, T. T. Dumitrescu, and K. Intriligator, 'Exploring 2-group global symmetries,' JHEP 02 (2019) 184, arXiv:1802.04790 [hep-th] .
- [64] J. R. Fliss and S. Vitouladitis, 'Entanglement in BF theory II: Edge-modes,' arXiv:2310.18391 [hep-th] .
- [65] J. M. Maldacena, 'The large N limit of superconformal field theories and supergravity,' Adv. Theor. Math. Phys. 2 (1998) 231-252, arXiv:hep-th/9711200 .
- [66] S. S. Gubser, I. R. Klebanov, and A. M. Polyakov, 'Gauge theory correlators from noncritical string theory,' Phys. Lett. B 428 (1998) 105-114, arXiv:hep-th/9802109 .
- [67] E. Witten, 'Anti-de Sitter space and holography,' Adv. Theor. Math. Phys. 2 (1998) 253-291, arXiv:hep-th/9802150 .
- [68] J. J. Heckman, M. H¨bner, and C. Murdia, 'On the holographic dual of a topological u symmetry operator,' Phys. Rev. D 110 (2024) 046007, arXiv:2401.09538 [hep-th] .
- [69] G. W. Moore and N. Seiberg, 'Lectures on RCFT,' in Physics, Geometry and Topology , H. C. Lee, ed., vol. 238 of NATO ASI Series , p. 263. Springer, Boston, MA, 1990. Available online.
- [70] G. W. Moore and N. Seiberg, 'Taming the Conformal Zoo,' Phys. Lett. B 220 (1989) 422-430.
- [71] J. M. Maldacena, G. W. Moore, and N. Seiberg, 'D-brane charges in five-brane backgrounds,' JHEP 10 (2001) 005, arXiv:hep-th/0108152 .
- [72] M. Cheng and N. Seiberg, 'Lieb-Schultz-Mattis, Luttinger, and 't Hooft - anomaly matching in lattice systems,' SciPost Phys. 15 (2023) 051, arXiv:2211.12543 [cond-mat.str-el] .
- [73] D. M. Hofman and N. Iqbal, 'Generalized global symmetries and holography,' SciPost Phys. 4 (2018) 005, arXiv:1707.08577 [hep-th] .
- [74] A. Borel, 'Topology of Lie groups and characteristic classes,' Bull. Amer. Math. Soc. 61 (1955) 397-432.
- [75] R. Dijkgraaf and E. Witten, 'Topological gauge theories and group cohomology,' Commun. Math. Phys. 129 (1990) 393.
- [76] D. Weingarten, 'Mass Inequalities for QCD,' Phys. Rev. Lett. 51 (1983) 1830.
- [77] C. Vafa and E. Witten, 'Restrictions on Symmetry Breaking in Vector-Like Gauge Theories,' Nucl. Phys. B 234 (1984) 173-188.
- [78] C. Vafa and E. Witten, 'Parity Conservation in QCD,' Phys. Rev. Lett. 53 (1984) 535.
- [79] K. Fujikawa, 'Path Integral Measure for Gauge Invariant Fermion Theories,' Phys. Rev. Lett. 42 (1979) 1195-1198.
- [80] S. Weinberg, The quantum theory of fields. Vol. 2 . Cambridge University Press, 1996.
- [81] F. Benini, C. C´rdova, and P.-S. Hsin, 'On 2-group global symmetries and their anomalies,' o JHEP 03 (2019) 118, arXiv:1803.09336 [hep-th] .
- [82] D. Delmastro, J. Gomis, P.-S. Hsin, and Z. Komargodski, 'Anomalies and Symmetry Fractionalization,' SciPost Phys. 15 (2023) 079, arXiv:2206.15118 [hep-th] .
- [83] T. D. Brennan, C. C´rdova, and T. T. Dumitrescu, 'Line Defect Quantum Numbers and o Anomalies,' arXiv:2206.15401 [hep-th] .
- [84] Y. Tachikawa, 'On gauging finite subgroups,' SciPost Phys. 8 (2020) 015, arXiv:1712.09542 [hep-th] .
- [85] T. Brauner, 'Field theories with higher-group symmetry from composite currents,' JHEP 04 (2021) 045, arXiv:2012.00051 [hep-th] .
- [86] A. Arbalestrier, R. Argurio, and L. Tizzano, 'Noninvertible axial symmetry in QED comes full circle,' Phys. Rev. D 110 (2024) 105012, arXiv:2405.06596 [hep-th] .
- [87] S. L. Adler, 'Axial-Vector Vertex in Spinor Electrodynamics,' Phys. Rev. 177 (1969) 2426.
- [88] J. S. Bell and R. Jackiw, 'A PCAC puzzle: π 0 → γγ in the σ model,' Nuovo Cim. A 60 (1969) 47-61.
- [89] P.-S. Hsin, H. T. Lam, and N. Seiberg, 'Comments on one-form global symmetries and their gauging in 3d and 4d,' SciPost Phys. 6 (2019) 039, arXiv:1812.04716 [hep-th] .
- [90] Y. Choi, H. T. Lam, and S.-H. Shao, 'Non-invertible gauss law and axions,' JHEP 09 (2023) 67, arXiv:2212.04499 [hep-th] .
- [91] S. D. Pace, C. Zhu, A. Beaudry, and X.-G. Wen, 'Generalized symmetries in singularity-free nonlinear σ models and their disordered phases,' Phys. Rev. B 110 (2024) 195149, arXiv:2310.08554 [cond-mat.str-el] .
- [92] S. Chen and Y. Tanizaki, 'Solitonic Symmetry beyond Homotopy: Invertibility from Bordism and Noninvertibility from Topological Quantum Field Theory,' Phys. Rev. Lett. 131 (2023) 011602, arXiv:2210.13780 [hep-th] .
- [93] S. Gukov and E. Witten, 'Gauge Theory, Ramification, And The Geometric Langlands Program,' Curr. Develop. Math. 2006 (2008) 35-180, arXiv:hep-th/0612073 .
- [94] E. Witten, 'Nonabelian Bosonization in Two-Dimensions,' Commun. Math. Phys. 92 (1984) 455-472.
- [95] G. 't Hooft, 'Naturalness, chiral symmetry, and spontaneous chiral symmetry breaking,' in Recent Developments in Gauge Theories , NATO Sci. Ser. B, vol. 59, pp. 135-157. Springer, Boston, MA, 1980.
- [96] J. Davighi and N. Lohitsiri, 'WZW terms without anomalies: generalised symmetries in chiral Lagrangians,' arXiv:2407.20340 [hep-th] .
- [97] E. Witten, 'Current Algebra, Baryons, and Quark Confinement,' Nucl. Phys. B 223 (1983) 433-444.
- [98] M. Atiyah, 'Topological quantum field theories,' Publ. Math. de l'IHES 68 (1989) 175-186.
- [99] N. Carqueville and I. Runkel, 'Introductory lectures on topological quantum field theory,' Banach Center Publ. 114 (2018) 9-47, arXiv:1705.05734 [math.QA] .
- [100] L. Abrams, 'Two-dimensional topological quantum field theories and Frobenius algebras,' J. Knot Theor. Ramifications 5 (1996) 569-587. | 10.1002/prop.202400172 | [
"Andrea Antinucci",
"Francesco Benini",
"Giovanni Rizi"
]
| 2024-08-02T17:53:31+00:00 | 2024-12-07T09:38:12+00:00 | [
"hep-th"
]
| Holographic duals of symmetry broken phases | We explore a novel interpretation of Symmetry Topological Field Theories
(SymTFTs) as theories of gravity, proposing a holographic duality where the
bulk SymTFT (with the gauging of a suitable Lagrangian algebra) is dual to the
universal effective field theory (EFT) that describes spontaneous symmetry
breaking on the boundary. We test this conjecture in various dimensions and
with many examples involving different continuous symmetry structures,
including non-Abelian and non-invertible symmetries, as well as higher groups.
For instance, we find that many Abelian SymTFTs are dual to free theories of
Goldstone bosons or generalized Maxwell fields, while non-Abelian SymTFTs
relate to non-linear sigma models with target spaces defined by the symmetry
groups. We also extend our analysis to include the non-invertible
$\mathbb{Q}/\mathbb{Z}$ axial symmetry, finding it to be dual to axion-Maxwell
theory, and a non-Abelian 2-group structure in four dimensions, deriving a new
parity-violating interaction that has implications for the low-energy dynamics
of U(N) QCD. |
2408.01419v1 | ## DEBATEQA: Evaluating Question Answering on Debatable Knowledge
## Rongwu Xu 1 ∗ , Xuan Qi 1 ∗ , Zehan Qi , Wei Xu , Zhijiang Guo 1 1 2
1 Tsinghua Universty, 2 University of Cambridge Emails: {xrw22, qi-x22@}@mails.tsinghua.edu.cn ∗ Equal contribution
## Abstract
language models on debatable queries is crucial for understanding and enhancing their capabilities.
The rise of large language models (LLMs) has enabled us to seek answers to inherently debatable questions on LLM chatbots, necessitating a reliable way to evaluate their ability. However, traditional QA benchmarks assume fixed answers are inadequate for this purpose. To address this, we introduce DEBATEQA, a dataset of 2,941 debatable questions, each accompanied by multiple human-annotated partial answers that capture a variety of perspectives. We develop two metrics: Perspective Diversity, which evaluates the comprehensiveness of perspectives, and Dispute Awareness, which assesses if the LLM acknowledges the question's debatable nature. Experiments demonstrate that both metrics are aligned with human preferences and stable across different underlying models. Using DEBATEQA with two metrics, we assess 12 popular LLMs and retrieval-augmented generation methods. Our findings reveal that while LLMs generally excel at recognizing debatable issues, their ability to provide comprehensive answers encompassing diverse perspectives varies considerably.

https://github.com/pillowsofwind/ DebateQA
## 1 Introduction
How often do you query a chatbot about a debatable issue? Questions like 'Does Donald Trump have a terrible character?' or 'How do crop circles form?' frequently arise in everyday life, reflecting human beings' natural curiosity about topics that inherently lack fixed answers (Lowry and Johnson, 1981; Brady, 2009). With the advent of large language models (LLMs; OpenAI 2023b; Chowdhery et al. 2023; Touvron et al. 2023), we now turn to these models to seek ' proper ' answers to such questions. Evaluating the performance of
Inherent difficulties hinder our way of assessing these models. Traditional question-answering (QA) benchmarks are typically designed to provide fixed answers to questions, as in datasets like SQuAD(Rajpurkar et al., 2016) and Natural Questions (Kwiatkowski et al., 2019). Even in scenarios where multiple legitimate answers are possible, such as TruthfulQA (Lin et al., 2022), the answers are often presented as multiple-choice questions, thus limiting the space of responses. Recent years have seen the emergence of long-form QA evaluations, such as ELI5 (Fan et al., 2019) and ASQA (Stelmakh et al., 2022a), which allow for more elaborate answers. However, these works have not focused on inherently debatable questions. The most related work to us is DELPHI (Sun et al., 2023), which curates a dataset with controversial questions, however, their emphasis is on identifying controversy rather than delving deeper into evaluating models' responses.
What constitutes a proper answer when asked about debatable knowledge? Drawing inspiration from interdisciplinary literature, we propose two desirable properties for such answers. Firstly, the answer should inform the receiver that the issue at hand is debatable (Misco, 2011). Secondly, a proper answer should be comprehensive and include diverse perspectives, which are crucial for maintaining an atmosphere of neutrality, especially in public-related inquiries (Habermas, 1991). Motivated by these considerations, we introduce the DEBATEQA dataset, which comprises 2,941 manually annotated debatable questions. To rigorously evaluate the aforementioned properties of model answers, each question is paired with several partial answers , each reflecting a single viewpoint on the debatable issue. These partial answers are generated through a three-stage pipeline and then annotated by three annotators. Based on the partial answers in DEBATEQA, we propose the metric of Perspective Diversity (P.D.) , which assesses the comprehensiveness in terms of grasping multiple points-of-view in the model answer. Using DEBATEQA along with P.D., one can reliably and efficiently evaluate the comprehensiveness of responses to debatable questions. We also propose the metric of Dispute Awareness (D.A.) , which targets to identify whether the model acknowledges the debatable nature of the question in its response. Importantly, we show that the P.D. and D.A. metrics align closely with human judgments and are fairly stable across backbone evaluator models, validating their effectiveness.
We apply DEBATEQA to evaluate 12 popular LLMs, as well as retrieval-augmented generation (RAG) approaches. We observe while LLMs generally excel at identifying the existence of debate, their performance varies in providing comprehensive answers with diverse perspectives. Notably, top-notch open-source LLMs rival or even surpass some leading commercial models. Besides, RAG methods, though not uniformly beneficial to this task, improve closed-source model performance, likely due to better contextual leverage. Additionally, optimizing sampling hyperparameters and leveraging task-specific prompts can further boost performance. On the whole, our findings underscore the need for further refining LLMs to better interact with debatable knowledge.
## 2 Related Work
## 2.1 QA with Non-fixed Answers
Many efforts focus on QA for which there is no single fixed answer. AMBIGQA (Min et al., 2020) addresses ambiguous question answering by rewriting questions and generating multiple plausible answers. SUBJQA (Bjerva et al., 2020) focuses on identifying subjectivity in questions and answers within customer reviews. DisentQA (Neeman et al., 2023) proposes to provide disentangled answers to questions where the provided context contradicts the model's knowledge. DEBATEQA differs logically from these efforts because the space of plausible answers can not be narrowed by rewriting or restricting the questions. To the best of our knowledge, DELPHI (Sun et al., 2023) is the first study on QA for debatable issues. However, DELPHI has limitations: (1) it does not provide answers for evaluation, and (2) it shallowly evaluates model performance using exploratory metrics. Our work represents a step forward from DELPHI by offering a comprehensive evaluation solution. We expand and refine the dataset and introduce more meaningful metrics.
## 2.2 NLP on Debatable Issues
Beyond QA, multiple lines of NLP research investigate debatable issues. One notable effort is the AI Debater, beginning with Slonim et al. (2021)'s 'IBM's Project Debater' (Bar-Haim et al., 2019), the first AI system designed to engage humans in meaningful debates. Another line of research focuses on controversy detection. Researchers have identified controversy in news (Choi et al., 2010), online forums (Chen et al., 2023), and other media by analyzing sentiments (Choi et al., 2010; Chen et al., 2023) or sociological features like upvote percentages (Hessel and Lee, 2019). Moreover, Wanet al. (2024) investigate LLMs' preference for conflicting evidence when facing controversial issues. We distinguish ourselves from this body of research by primarily focusing on handling debatable issues in the field of QA, specifically targeting the evaluation of chatbot-like NLP systems.
## 2.3 Long-form QA Evaluation
Evaluating debatable QA falls into the topic of long-form QA evaluation. Long-form text evaluation can be categorized into two main approaches: reference-based and reference-free evaluation (Xu et al., 2023). Reference-based methods require gold answers and evaluate the generated text by assessing its similarity with the gold answers (Fan et al., 2019; Yuan et al., 2021; Chiang and Lee, 2023). Conversely, reference-free evaluation eliminates the necessity for a gold standard. Some studies assess the coherence and relevance of the generation concerning specified questions (Fabbri et al., 2022; Krishna et al., 2022; Xu et al., 2023). Some studies use a QA-based approach to assess the quality of the generation (Tan et al., 2024). In particular, there is another line of literature focusing on examining the veracity of long-form generation by utilizing external knowledge bases (Stelmakh et al., 2022b; Min et al., 2023; Wei et al., 2024). However, none of the aforementioned studies address the evaluation of debatable questions.
## 3 Curating the DEBATEQA Dataset
Dataset overview. DEBATEQA is designed to help assessing language models' answers to de-
Table 1: An example from DEBATEQA, details of the explanation fields are truncated for space issues.
| Field | Content |
|------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Question | Does birth order influence personality traits? |
| Partial Answer 1 | POV Birth order does not have a meaningful and lasting effect on broad Big Five personality traits. |
| | Explan The influence of birth order on personality traits has been a topic of interest for over a century. However, based on extensive research combining large datasets from three national panels in the United States, Great Britain, and Germany, it is evident that birth order does not have a meaningful effect on broad Big Five personality traits . . . |
| Partial Answer 2 | POV Firstborns score higher on intelligence and intellect. |
| | Explan Yes, birth order does influence personality traits, particularly in the domain of intelligence and intellect. Research has consistently shown that firstborns tend to score higher on objectively measured intelligence tests . . . |
| Partial Answer 3 | POV No birth-order effects on extraversion, emotional stability, agreeableness, or conscientiousness. |
| | Explan The influence of birth order on personality traits such as extraversion, emotional stability, agreeableness, and consci- entiousness has been a topic of interest for over a century. However, recent comprehensive studies have provided substantial evidence that birth order does not significantly impact these personality traits . . . |
batable questions . It contains 2,941 debatable questions, each paired with a list of partial answers to assist in evaluating model responses. Each partial answer addresses the question from a distinct perspective and consists of two parts: a short point-of-view statement (POV) and a longform explanation (Explan) that fully expands the POV. An entry in DEBATEQA is shown in Table 1.
The overall procedure for curating DEBATEQA is depicted in Figure 1. We first source debatable questions. Then, we apply a three-stage semiautomated pipeline to collect partial answers. Lastly, we conduct human annotation on the collected partial answers to finalize the dataset. Quality examinations happen after each step. The following sections will detail these steps.
## 3.1 Sourcing Debatable Questions
We collect debatable questions from three distinct sources. First, we repurpose two existing datasets: we select 2,281 annotated controversial questions from DELPHI (Sun et al., 2023) and a full set of 434 questions from CONFLICTINGQA (Wan et al., 2024). To enrich the existing data, we further manually sourced 1,758 additional debatable questions from the Web (see Table 8 for detailed sources). We then run a deduplication algorithm (see § A.1 for details) to remove any duplicate questions, resulting in 3,216 questions. The final composition of sourced questions is shown in Table 9.
## 3.2 Collecting Partial Answers
The core novelty of DEBATEQA lies in evaluating models by comparing the response with multiple partial answers, rather than a single gold reference. One partial answer aims to answer the question from a single perspective. This method reflects the multifaceted essence of debatable knowledge, ad- vocating for answers that integrate diverse viewpoints (Habermas, 1991; Wansink et al., 2023). To this end, we employ a three-stage pipeline for collecting them: first, we collect evidence documents from trustworthy websites; second, we extract POVs from the evidence w.r.t. the question; finally, we expand the POVs into long-form explanations based on related evidence. The last two steps are conducted with the assistance of LLMs . 1 Together, the POVs and explanations comprise what we call partial answers.
## 3.2.1 Retrieving Trustworthy Documents
Wecollect partial answers by leveraging online resources and extracting evidence from relevant web pages. However, the nature of debatable issues necessitates careful processing of these documents, as the Web can contain unveracious content. To ensure the reliability of our partial answers, we source documents from authoritative top-level domains (TLDs), as listed in Table 10. This treatment helps in maintaining the reliability of the sources. We discard questions that have fewer than three documents, resulting in 2,982 questions, each supported by 3-5 of the most relevant documents. See § A.2 for detailed measures.
Quality examination. To assess the quality of retrieved documents, we analyze the relevancy between questions and corresponding documents. We calculate the cosine similarity between document chunks and questions. As depicted in Figure 11, the average cosine similarity for document trunks is 0.56 and there are no significant outliers, indicating high relevance and minimal noise in the documents, confirming their overall quality for serving as the basis for upcoming steps.
1 We select OpenAI GPT-4 (OpenAI, 2023b) to assist in collecting partial answers (the gpt-4-turbo variant).
Figure 1: Pipeline for curating DEBATEQA. The three main components of the pipeline are highlighted in different colors: sourcing debatable questions, collecting partial answers, and human annotation. Primary sources or tools used at each step are highlighted in bold .
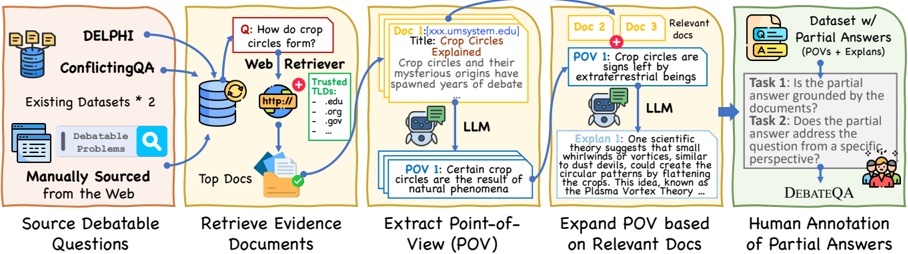
## 3.2.2 Extracting Points-of-View
The second stage involves extracting diverse POVs from the retrieved evidence documents. A POV is a concise statement that reflects the core perspective in addressing the question. We leverage GPT-4 to tackle this task, by applying the prompt p POV described in Table 11, which takes the question and the concatenated documents and returns a list of diverse POVs along with the corresponding document indexes where each specific POVis originated. The document indexes for each POV are later used for expanding the POV. To avoid exceeding the 128K context window limit of GPT-4, we preprocess the documents by removing meaningless segments and truncating them to 120K tokens if they exceed this length.
Quality examination. Weverify the quality of the collected POVs on comprehensiveness w.r.t. the documents and distinctiveness among themselves. For comprehensiveness, we ensure all valid perspectives from retrieved documents are captured, with 90.4% coverage verified manually. Distinctiveness is assured by removing duplicated POVs manually. For more details, refer to § A.3.
## 3.2.3 Expanding POV to Explanations
The last stage involves expanding the extracted POVs into long-form explanations. Each explanation should stand as an independent answer, elaborating on the POV and addressing the question from that perspective. This expansion must be anchored to the relevant information presented in the evidence documents pertaining to the specific POV being developed. We again leverage GPT-4 on this task, utilizing the prompt p Explan described in Table 11. This prompt takes three inputs: the question, the target POV to be expanded, and the related documents obtained in the previous stage.
The LLM is required to leverage only the information contained within these relevant documents to generate the explanation, minimizing the risk of hallucinations (Zhang et al., 2023). We repeat this step for all the POVs we have collected. The pseudocode of the pipeline for collecting partial answers is deferred to Algorithm 1.
## 3.3 Human Annotation
Weverify the fidelity of the LLM-generated partial answers through human annotation.
Annotation tasks. To thoroughly evaluate the quality of DEBATEQA, we design two tasks:
- · Task 1 : Ensure that the POV and the explanation generated by the LLM are grounded in the documents. This task focuses on that the generated explanations are accurately derived from trustworthy evidence.
- · Task 2 : Ensure that the partial answer can address the question from a certain perspective. This task assesses the utility and relevance of the partial answers, ensuring that they address the question effectively.
Results and the final dataset. We recruit three annotators and annotate the full dataset. Interannotator agreement (IAA) is measured using Fleiss' Kappa (Fleiss et al., 1981), yielding scores of κ = 0 66 . and κ = 0 60 . for the two annotation tasks, all indicating substantial agreement. We remove 767 partial answers deemed substandard by two or more annotators. This suggests that GPT-4 generates faithful partial answers with a 93 4% . accuracy. See § A.4 for details. We employ BERTopic (Grootendorst, 2022) to model the domain distribution of DEBATEQA. The result is shown in Figure 14. To reduce computational costs for upcoming evaluation, we split DE-
BATEQA into two splits: the test split with 1,000 randomly sampled questions and the dev set containing the remaining instances.
## 4 Evaluation Criteria and Metrics
Evaluation criteria. For debatable questions, the quest for the best answer is fraught with complexity, as there exist no canonical standards. The expectations vary: many seek a helpful assistant that delivers credible information with no reservation, and some may pose questions merely for selfaffirmation, not to say some model providers prefer a 'safe' agent to circumvent controversy. In DEBATEQA, we aim to balance helpfulness and harmlessness, with the goal of fostering open dialogues. After reviewing interdisciplinary literature, we identify criteria that are nearly universally accepted and distill two key properties of what constitutes a good answer:
- · Perspective diversity ( helpful ): how well does the answer deliver informative and credible information from diverse perspectives?
- · Dispute awareness ( harmless ): whether the answer recognizes the existence of debate.
Evaluation metrics. Although the above two criteria resonate with those utilized in DELPHI (Sun et al., 2023), we distinguish ourselves by formalizing these criteria into more sophisticated quantifiable metrics. Our methodology excels by integrating the partial answer feature of DEBATEQA and outperforms DELPHI's approach by a huge margin, which will be later elaborated in § 5 and § 6. Please note that while the following two metrics both employ backbone LLMs, they may differ ; for brevity, we refer to both as M eval .
- I: Perspective Diversity (P.D.) . To evaluate the model's answers against legitimate partial responses, we assess it using a smaller open-source LLM by generation, ensuring efficiency and costeffectiveness. We apply the following metric:
$$P. D. \coloneqq \sum _ { i = 1 } ^ { n } P P L ( \text{PA} ^ { i } | \text{chatTemplate} ( \text{Concat} ( A, \quad ( 1 ) \quad \text{$\tilde{$\tilde{$\prime}$ $i$} \\ \text{$\tilde{$\tilde{$\prime}$ Please restate} ) ) } ),$$
where PPL ( Y X | ) is the conditional perplexity:
$$P P L ( Y | X ) & = \exp \left ( - \frac { 1 } { N } \sum _ { i = 1 } ^ { N } \log P ( y _ { i } | X, y _ { < i } ) \right ). \quad \begin{array} { c } \ u s \\ 5 \\ m \\ ( 2 ) \end{array} \\ \vdots \, \pi \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
In Equation 1, PA i = concat ( POV i , Explan i ) denotes the i th partial answer and A denotes the model's answer to the debatable question. chatTemplate () is a chat template for prompting instruction-tuned LLMs. Simply put, P.D. represents the aggregate perplexity of generating partial answers from a model answer. Being derived from PPL, a lower P.D. signifies better quality, suggesting that the model answer contains larger shares of the partial answer's content.
II: Dispute Awareness (D.A.) . To ascertain if the model's answer indicates that the addressed question is debatable, we craft a prompt p D.A., as shown in Table 14, and use it to prompt an instruction-tuned LLM. This metric is binary , indicating awareness or lack thereof.
$$\text{di-} \\ \text{ra-} \\ \text{IIly} \\ \text{not}$$
## 5 Empirical Examination of P.D.
To assess the reliability of P.D., we empirically examine its alignment with human preferences and stability w.r.t. backbone models and prompts.
## 5.1 P.D. Well-Aligns Human Preferences
Collecting human preferences. We collect 500 model answers from five LLMs to 100 randomly sampled questions in DEBATEQAtest , then have three rank the answers pairwise.
Using pairwise preferences and Spearman's ρ correlation (Zar, 2005), we find strong agreement among three annotators with ρ > 0 8 . , as shown in Figure 2. This consensus allows
Figure 2: Correlation among annotators assessed by Spearman's ρ .
us to assess the alignment of evaluator judgments with human preferences effectively. More details are described in § B.1.1.
Compared baselines. We compare P.D. with notable text evaluation baselines. Many of these require a language model as backbones:
- · Prompt-based metrics : These baselines always require an advanced instruction-tuned LLM, we consider three of them: (1) Direct-Score: using an LLM to assign a Likert scale score (15) using the same instruction we present to human annotators; (2) G-Eval (Liu et al., 2023): a prompt-based evaluation framework that assesses the quality of generated texts by incorporating chain-of-thoughts (CoT) (Wei et al.,
2022) and a form-filling paradigm; (3) Numof-POVs: using an LLM to count the number of perspectives in the model answers. This metric can be considered an improved metric over the 'Comprehensiveness Answer Rate' metric introduced in DELPHI (Sun et al., 2023).
- · Similarity-based metrics : We pick two traditional statistical metrics, BLEU (Papineni et al., 2002) and ROUGE-L (Lin, 2004) and two neural metrics, BARTScore (Yuan et al., 2021) and SemScore (Aynetdinov and Akbik, 2024).
Refer to § B.1.2 for details of these baselines.
Results. We apply ELO ratings to establish a human preference ranking and then measure the correlation with metrics' rankings using Spearman's ρ and Kendall's τ (Kendall, 1938). The average results of the annotators' individual correlation are reported in Table 2. We observe that P.D. significantly outperforms DELPHI's metric and GEval powered by GPT-4o. Using the same small LLM(Phi-3 mini 128k) as the backbone, P.D. outperforms G-Eval by a huge margin, underscoring P.D.'s exceptional alignment with human judgment. Overall, P.D. is effective and economical. We further provide case studies in § B.1.3.
Table 2: Alignment of various evaluation metrics with human preferences. The top-performing metric is highlighted in bold and the runner-up is underlined. ρ : Spearman's ρ τ , : Kendall's τ .
| Metric | Backbone Model | ρ | τ |
|--------------------------|--------------------------|--------------------------|--------------------------|
| Prompt-based metrics | Prompt-based metrics | Prompt-based metrics | Prompt-based metrics |
| Direct-Score | GPT-4o | 0.692 | 0.671 |
| G-Eval | Phi-3 mini 128k | -0.003 | -0.028 |
| G-Eval | GPT-3.5 Turbo | 0.593 | 0.531 |
| G-Eval | GPT-4o | 0.706 | 0.634 |
| Num-of-POVs | GPT-4o | 0.398 | 0.345 |
| Similarity-based metrics | Similarity-based metrics | Similarity-based metrics | Similarity-based metrics |
| BLEU | - | 0.667 | 0.565 |
| ROUGE-L | - | 0.537 | 0.451 |
| BARTScore | BART Large (2020a) | 0.476 | 0.397 |
| SemScore | all-mpnet-base-v2 (2019) | 0.447 | 0.375 |
| P.D. | Phi-3 mini 128k | 0.733 | 0.701 |
| P.D. | GPT-2 (117M) | 0.825 | 0.748 |
| P.D. | Qwen2 0.5B | 0.820 | 0.742 |
## 5.2 P.D. is Stable w.r.t. Backbone Models
To verify the stability of P.D. w.r.t. different backbone models, we configure P.D. with five different LLMs and compute pairwise Kendall's τ among the resulting rankings, for the same set of model responses collected in § 5.1. The results in Figure 3 show that the rankings by P.D. with different backbone models are highly consistent.
Figure 3: Kendall's τ correlations of the P.D. metric using different backbone models.
## 5.3 P.D. is Stable w.r.t. Prompts
Remember in Equation 1, there is a prompt 'Please Restate' wrapping the model answer. To verify the stability of P.D. w.r.t. different prompts, we configure P.D. with five different prompts shown in Table 13 and compute pairwise Kendall's τ among the resulting rankings, for the same set of model responses collected in § 5.1. The results in Figure 4 show that the rankings by P.D. with different prompts have excellent consistency.
Figure 4: Kendall's τ correlations of the P.D. metric using different prompts.

## 6 Empirical Examination of D.A.
We assess D.A.'s reliability by examining its accuracy grounded by human judgments and stability w.r.t. backbone models.
## 6.1 D.A. is Accurate
To obtain the ground truth of the verdicts of the 500 responses from § 5.1, three authors manually annotate them by assigning binary labels. The annotation has an inter-annotator agreement of 0.79 evaluated by Fleiss' Kappa. With these manually
Table 3: Based on human annotations as the ground truth, we assess D.A.'s accuracy. D.A.-ZS: D.A. with a zero-shot prompt p D.A.-ZS , Ack.: the 'Acknowledge' metric from DELPHI.
| Metric | Backbone Model | Acc | F1 | AUROC | MCC |
|----------|------------------|-------|-------|---------|--------|
| D.A. | Qwen2 1.5B | 0.74 | 0.845 | 0.53 | 0.093 |
| D.A. | MiniCPM-2B-dpo | 0.77 | 0.857 | 0.621 | 0.289 |
| D.A. | Llama3 8B | 0.77 | 0.869 | 0.521 | 0.179 |
| D.A. | Gemma 2 9B | 0.74 | 0.833 | 0.615 | 0.246 |
| D.A. | Phi-3 medium | 0.8 | 0.868 | 0.726 | 0.452 |
| D.A.-ZS | Phi-3 medium | 0.53 | 0.434 | 0.565 | 0.146 |
| Ack. | - | 0.22 | 0.049 | 0.43 | -0.252 |
labeled outcomes as the ground truth, we calculate the accuracy, F1 score, and AUROC (Hanley and McNeil, 1982) and Matthews Correlation Coefficient (MCC; Matthews 1975) for D.A. with dif- ferent backbone models, the 'Acknowledge' metric referenced in DELPHI (refer to § C.1 for details), and a simplified version of D.A. with a zeroshot prompt p D.A.-ZS without in-context demonstrations. The results in Table 3 demonstrate the superiority of our D.A. metric over the metric from DELPHI, and the necessity of including demonstrations in the prompt p D.A.. Upon a case study for D.A.-ZS, we find that the Phi-3 mini 128k model occasionally deviates from our instruction by failing to use 0 or 1 for its judgment, thereby diminishing its effectiveness.
## 6.2 D.A. is Stable w.r.t. Backbone Models
Given the robust design of prompt p D.A., ensuring D.A.'s performance, we advise utilizing the standard prompt in Table 14. Our focus here is on confirming D.A.'s stability across various backbone models. We set D.A. with five instructionfollowing LLMs and analyze pairwise agreements for the decision made between each two LLMs based on the model responses collected in § 5.1. The result in Figure 5 demonstrates the consistency of D.A. among different backbone models.
Figure 5: Agreements of the D.A. metric across different backbone models.

## 7 Experiments
## 7.1 Experimental Setup
We evaluate a wide range of 12 LLMs on DEBATEQAtest using P.D. and D.A., including closed commercial LLMs and open-source ones. We also assess several RAG approaches.
Evaluated models. We evaluate the following LLMs: GPT-4o (OpenAI, 2024b), GPT-4o mini (OpenAI, 2024a), GPT-3.5 Turbo (OpenAI, 2023a), Claude 3.5 Sonnet (Anthropic, 2024), Llama3 Instruct 8B/70B (Meta, 2024), Qwen2 0.5B/1.5B/7B (Qwen, 2024a), Phi-3 mini 128k 3.8B and Phi-3 small 128k 7B (Abdin et al., 2024), and Gemma2 9B (Team, 2024). All models are the instruction or chat fine-tuned versions.
Evaluators. We select multiple language models as the backbone for our metrics. For evaluating P.D., we select Qwen2 0.5B and GPT-2 base 117M (Radford et al., 2019) as M eval . For assessing D.A., a competent LLM with instruction- following ability is a must. We select Phi-3 medium 128k 14B and Qwen2 1.5B. We select those four models because their performance is showcased in § 5.1 and § 6.1, respectively.
Generation configuration. In the main experiments, when testing the LLMs, we provide the questions with a minimalistic QA prompt, as shown in Table 15, which instructs the LLMs without any hint that they are debatable. We believe this approach more accurately reflects the typical user interaction with chatbots. For all models, we configure topp = 0 to enable greedy decoding and stock chat templates including M eval .
## 7.2 Main Results
Main evaluation results can be found in Table 4. We summarize our key findings as follows:
- · Larger models generally outperform small ones. Generally, larger models perform well in terms of both P.D. and D.A. metrics. Large state-of-the-art LLMs such as GPT-4o and Llama3 70B demonstrate the strongest performance, while tiny to small LLMs are almost always at the bottom. Besides, for LLMs with the same architecture ( e.g. , Qwen 2 0.5B/1.5B/7B), larger models always outperform smaller ones.
- · Gaps between closed and open models are not clear. With the exception of the superb performance of GPT-4o, we have observed that numerous open-source LLMs are outperforming other capable closed commercial LLMs. Specifically, open-source models like Llama3 70B and Gemma2 9B nearly match the performance of GPT-4o in handling debatable questions. This might indicate that the performance on handling debatable issues does not demand as stringent capabilities from the models as more difficult tasks such as reasoning.
- · Deficiencies in delivering comprehensive responses. We observe significant shortcomings in weaker models' ability to furnish comprehensive answers that encompass a variety of perspectives. For instance, the worstperforming Qwen2 0.5B's answers are around 3 to 9 × 2 worse than GPT-4o in terms of recovering the information in partial answers.
- · Models excel in recognizing debate. We find that even the lowest-performing model, namely
2 These values are approximated with the P.D. values w.r.t. Two different M eval , refer to § F for details.
| Model | Avg. Len. (#tokens) | Perspective Diversity (P.D.) | Perspective Diversity (P.D.) | Perspective Diversity (P.D.) | Perspective Diversity (P.D.) | Perspective Diversity (P.D.) | Dispute Awareness (D.A.) | Dispute Awareness (D.A.) | Dispute Awareness (D.A.) | Dispute Awareness (D.A.) | Dispute Awareness (D.A.) |
|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|------------------------------------|
| | | M eval =Qwen2 0.5B | M eval =Qwen2 0.5B | M eval =GPT-2 | M eval =GPT-2 | Norm. Rank | M eval =Phi-3 M. | M eval =Phi-3 M. | M eval =Qwen2 1.5B | M eval =Qwen2 1.5B | Norm. Rank |
| | | Score ↓ | Rank | Score ↓ Rank | Score ↓ Rank | Norm. Rank | Score ↑ | Rank | Score ↑ | Rank | |
| Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs | Closed-Source LLMs |
| GPT-4o | 434 | 3.07 | 1 | 4.03 | 1 | 1 | 0.952 | 1 | 0.979 | 1 | 1 |
| GPT-4o mini | 252 | 4.09 | 6 | 5.88 | 6 | 6 | 0.937 | 4 | 0.964 | 4 | 4 |
| GPT-3.5 Turbo | 141 | 5.28 | 10 | 8.25 | 10 | 10 | 0.904 | 6 | 0.947 | 6 | 6 |
| Claude 3.5 Sonnet | 199 | 4.63 | 8 | 6.96 | 8 | 8 | 0.856 | 10 | 0.920 | 9 | 10 |
| Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) | Open-Source LLMs (Medium to Large) |
| Llama3 70B | 432 | 3.09 | 2 | 4.07 | 3 | 2= | 0.945 | 3 | 0.977 | 2 | 2= |
| Llama3 8B | 381 | 3.51 | 5 | 5.02 | 5 | 5 | 0.928 | 5 | 0.964 | 4 | 5 |
| Qwen2 7B | 255 | 4.18 | 7 | 6.10 | 7 | 7 | 0.895 | 8 | 0.923 | 8 | 8 |
| Phi-3 small 128k | 412 | 3.50 | 4 | 4.31 | 4 | 4 | 0.899 | 7 | 0.924 | 7 | 7 |
| Gemma 2 9B | 395 | 3.12 | 3 | 4.04 | 2 | 2= | 0.947 | 2 | 0.967 | 3 | 2= |
| Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) | Open-Source LLMs (Tiny to Small) |
| Qwen2 1.5B | 169 | 5.60 | 11 | 8.67 | 11 | 11 | 0.864 | 9 | 0.875 | 10 | 9 |
| Qwen2 0.5B | 72 | 6.56 | 12 | 10.87 | 12 | 12 | 0.792 | 11 | 0.836 | 11 | 11 |
| Phi-3 mini 128k | 218 | 4.82 | 9 | 7.33 | 9 | 9 | 0.716 | 12 | 0.794 | 12 | 12 |
Table 4: Main results of P.D. and D.A. for LLMs on DEBATEQAtest . Avg. Len.: average length of the answers, GPT-2: GPT-2 (117M), Phi-3 M.: Phi-3 medium 128k, Norm. Rank: normalized average rank of different M eval . The best and worst results of each metric ( w.r.t. a specific M eval ) are highlighted.
More on DA
More on PD.
Qwen2 0.5B, demonstrates a D.A. over 70% in recognizing the contentiousness of debatable questions. This indicates that even the performance of the worst-performing model is not as poor as it might seem.
Correlation between the P.D. and D.A. metrics. To investigate the correlation between P.D. and D.A. for the tested models, we plot a visualization of the results in Figure 6, which aids in understanding how these two metrics relate to each other across various models.
The figure indicates a positive correlation between P.D. and D.A., suggesting that models with greater perspective diversity are also more aware of the debate in question, aligning with our expectations.
Figure 6: Correlation between P.D. and D.A. for the tested LLMs.
Integrating the P.D. and D.A. metrics. To demonstrate the models' general capability in addressing debatable questions, we integrate the two metrics with varying weights. To ensure that the P.D. scores reflect the same performance favorability as the D.A. scores, we first take the reciprocal of the P.D. scores. Then, we leverage znormalization 3 to normalize both the reciprocal P.D. score and the original D.A. score. The final
3 https://en.wikipedia.org/wiki/Standard\_score
Figure 7: Rankings of weighted average scores of models at different ratios. k is the proportional coefficient.
weighted average score (W.A.G.) is calculated as:
$$\text{lels.} \quad \text{W.A.G.} = k \cdot Z \text{-norm} ( P. D. ^ { - 1 } ) + ( 1 - k ) \cdot Z \text{-norm} ( D. A. ), \, ( 4 )$$
where the k is the proportional coefficient and Z-norm () refers to z-normalization. We show the ranking of the weighted average scores for the models at different k in Figure 7.
## 7.3 Effect of More Specific Prompts
In our main experiments, we use a simple QA prompt ( p basic in Table 17) that does not highlight the debatable nature of the questions or demand comprehensive answers. To evaluate the models' full potential, we further test five LLMs with more detailed prompts. We employ three system promptsp basic , p comprehensive, and p detailed -to elicit model responses at varying levels of detail, as shown in Table 17. Using 200 randomly sampled questions from DEBATEQAtest , we compare the average P.D. and D.A. scores across the five selected LLMs. The results for these prompts are presented in Table 5. We find that even the relatively simple p comprehensive prompt significantly improved the performance for all five models. We conclude that more specific prompts, i.e. , inform the model of the debatable nature and request for detailed responses, can enhance LLMs' performance in answering debatable questions. This finding aligns with our expectations and suggests that LLM users can benefit from well-crafted prompts when seeking answers to contentious issues from LLMs.
Table 5: Effect of various prompts on P.D. scores and D.A. scores. p b: p basic , p c : p comprehensive , p d: p detailed .
| Model | P.D. ( ↓ ) | P.D. ( ↓ ) | P.D. ( ↓ ) | D.A. ( ↑ ) | D.A. ( ↑ ) | D.A. ( ↑ ) |
|-------------------|--------------|--------------|--------------|--------------|--------------|--------------|
| | p b | p c | p d | p b | p c | p d |
| GPT-4o mini | 3.91 | 2.13 | 2.09 | 0.915 | 0.955 | 0.97 |
| Claude 3.5 Sonnet | 4.63 | 3.14 | 2.35 | 0.865 | 0.925 | 0.98 |
| Llama3 8B | 3.42 | 2.58 | 2.51 | 0.855 | 0.935 | 0.985 |
| Qwen2 7B | 4.16 | 2.78 | 2.76 | 0.855 | 0.915 | 0.965 |
| Phi-3 mini 128k | 4.71 | 3.40 | 2.88 | 0.765 | 0.925 | 0.96 |
## 7.4 Evaluation for RAG Approaches
In this section, we assess the influence of RAG methods on performance within DEBATEQA.
## 7.4.1 Effect of RAG Strategy
We examine the effects of two popular RAG strategies, vanilla RAG (Lewis et al., 2020b) and ReAct (Yao et al., 2023). In vanilla RAG, we pick the top-10 most relevant documents from the retrieval results via Google Custom Search API 4 . ReAct employs an agent-based approach, leveraging Claude 3.5 Sonnet to interleave reasoning with document retrieval, strategically selecting up to 9 document chunks to improve problem-solving. Both methods utilize the prompt in Table 16 to assemble the question and the retrieved trunks. Refer to § D.1 for details.
We assess the performance of five LLMs by evaluating their responses to 100 randomly sampled debatable questions from DEBATEQAtest using two distinct RAG strategies. With the results detailed in Table 6, we conclude:
- · LLMs with RAG do not consistently improve in answering debatable questions, but closedsource models see more notable benefits, possibly due to better context utilization despite potential noise in retrieved content chunks.
- · Among the two RAG strategies, ReAct consistently outperforms Vanilla RAG, even though it uses fewer document chunks (9 vs. 10). This
4 https://developers.google.com/custom-search
advantage can be attributed to ReAct's more strategic approach to acting based on the previously retrieved information, which leads to more precise and relevant documents retrieved.
Table 6: Effect of two RAG strategies on P.D. scores.
| Model | P.D. ( ↓ M eval =Qwen2 0.5B ) | P.D. ( ↓ M eval =Qwen2 0.5B ) | P.D. ( ↓ M eval =Qwen2 0.5B ) |
|-------------------|---------------------------------|---------------------------------|---------------------------------|
| | No RAG | Vanilla RAG | ReAct |
| GPT-4o mini | 4.02 | 3.94 | 3.70 |
| Claude 3.5 Sonnet | 4.63 | 4.12 | 3.65 |
| Llama3 8B | 3.55 | 4.01 | 3.99 |
| Qwen2 7B | 3.79 | 5.96 | 5.29 |
| Phi-3 mini 128k | 4.82 | 7.01 | 6.86 |
## 7.4.2 Effect of RAG Source Documents
Considering that the performance of RAG is highly dependent on the quality of the retrieved documents, we explore whether restricting RAG to utilize trustworthy documents would yield better results. We retrieve only on web pages under trustworthy TLDs listed in Table 10. The results in Table 7 demonstrate that RAG on trustworthy sources leads to better results. This highlights the significance of source quality in RAG for debatable QA, emphasizing that utilizing trustworthy documents improves LLM response quality in responding to sensitive topics.
Table 7: Effect of RAG sources on P.D. scores. RAG w. T. Docs: RAG using trustworthy documents.
| Model | P.D. ( ↓ M eval =Qwen2 0.5B ) | P.D. ( ↓ M eval =Qwen2 0.5B ) |
|-------------------|---------------------------------|---------------------------------|
| Model | Vanilla RAG | RAG w. T. Docs |
| GPT-4o mini | 3.77 | 3.63 |
| Claude 3.5 Sonnet | 3.92 | 3.54 |
| Llama3 8B | 3.78 | 3.62 |
| Qwen2 7B | 5.91 | 5.57 |
| Phi-3 mini 128k | 6.77 | 6.50 |
## 7.5 Effect of Decoding Hyperparameters
In the main experiments, we configure all LLMs to use greedy decoding, which, while straightforward, can restrict the diversity and creativity of LLM outputs (Holtzman et al., 2020). To assess the impact of various decoding hyperparameters using sampling decoding on models' performance, we select a range of five different temperatures and topp values. The results of P.D. and D.A. scores are presented in Figure 8 and Figure 9, respectively. The plots indicate that higher temperature and topp values generally prompt LLMs to produce more well-rounded responses to debatable questions, enhancing performance on both metrics. This suggests that sampling configurations that allow for a broader selection of lowerprobability tokens can lead to improved outcomes.
Score
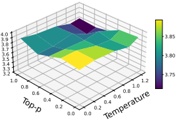
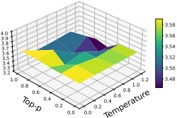
Score
(a) GPT-4o-mini (b) Llama3 8B Figure 8: Average P.D. score ( ↓ ) for answers from different LLMs with corresponding hyperparameters.
Score
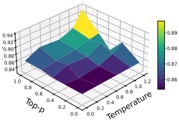
Score
(b) Llama3 8B
Figure 9: Average D.A. score ( ↑ ) for answers from different LLMs with corresponding hyperparameters.
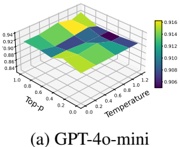
## 7.6 Effect of the Length of Generation
To delve deeper into how response length impacts the two metrics, we use the prompt 'Your answer must be around { num } tokens.' to regulate LLMs to respond with a predetermined length. However, recognizing that the open-source model's adherence to instructions might be inconsistent, we illustrate the correlation between the actual average token count in the model's responses in Figure 10. We find: (1) models tend to perform better with longer responses. This is likely due to longer answers providing more comprehensive information, enhancing P.D. scores. Furthermore, when tasked with longer answers, models are more prone to acknowledge the debate, which improves D.A. scores. (2) in the main experiment, GPT4o outperforms GPT-4o-mini and Claude 3.5 Sonnet significantly, as shown in Table 4. However, the performance gap narrows when responses are constrained to equal lengths. This suggests that while the knowledge and conversational capabilities of the three models are comparable, GPT-4o's propensity for completing longer answers gives it an edge over the other two, which favor brevity.
## 7.7 Qualitative Analysis
Despite GPT-4o leading in both metrics, certain aspects of its performance remain unsatisfactory. Wealso examine the performance gaps among less capable models. Through case studies, our conclusions are: (1) state-of-the-art LLMs still fall short
↓
(a) P.D. Scores (
)
Figure 10: Average P.D. and D.A. scores for answers in various lengths across different LLMs.
in leveraging referenced and convincing information for their arguments, and (2) weaker LLMs have difficulty providing a comprehensive elaboration of sufficient perspectives and we find the answer presentation of those LLMs are markedly poorer. Based on these gaps, LLMs' ability to address debatable questions still has room to be further refined. We point out the following potential solutions for improving models' ability on DEBATEQA: (1) Deepen domain-specific knowledge with pretraining or high-quality RAG; (2) Strengthen source citation by adopting strategies such as citing memory or retrieved documents for evidence-rich responses; (3) Improve stylistic presentation through fine-tuning; and (4) Ensure perspective diversity and balance through alignment training or prompt engineering. Kindly refer to § E for a detailed analysis and case studies.
## 8 Conclusion
We develop DEBATEQA, a novel QA dataset with 2,941 debatable questions paired with multiple human-annotated partial answers to assess language models' ability to answer debatable questions. We introduce two novel metrics, Perspective Diversity and Dispute Awareness, to evaluate how well language models reflect multiple human viewpoints and recognize debate. Extensive experiments demonstrate these two metrics align with human preferences and are stable. Our evaluations with 12 LLMs show that current models are relatively strong in recognizing debate but varying in the ability to comprehensively address them.
## References
Marah I Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat S. Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Amit Garg, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Masahiro Tanaka, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, and Xiren Zhou. 2024. Phi-3 technical report: A highly capable language model locally on your phone. CoRR , abs/2404.14219.
Anthropic. 2024. Introducing Claude 3.5 Sonnet. Anthropic website.
Ansar Aynetdinov and Alan Akbik. 2024. Semscore: Automated evaluation of instructiontuned llms based on semantic textual similarity. CoRR , abs/2401.17072.
Roy Bar-Haim, Dalia Krieger, Orith ToledoRonen, Lilach Edelstein, Yonatan Bilu, Alon Halfon, Yoav Katz, Amir Menczel, Ranit Aharonov, and Noam Slonim. 2019. From surrogacy to adoption; from bitcoin to cryptocurrency: Debate topic expansion. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1:
Long Papers , pages 977-990. Association for Computational Linguistics.
Johannes Bjerva, Nikita Bhutani, Behzad Golshan, Wang-Chiew Tan, and Isabelle Augenstein. 2020. Subjqa: A dataset for subjectivity and review comprehension. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020 , pages 54805494. Association for Computational Linguistics.
Michael Brady. 2009. Curiosity and the value of truth. Epistemic value , pages 265-283.
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through selfknowledge distillation.
Kai Chen, Zihao He, Rong-Ching Chang, Jonathan May, and Kristina Lerman. 2023. Anger breeds controversy: Analyzing controversy and emotions on reddit. In Social, Cultural, and Behavioral Modeling - 16th International Conference, SBP-BRiMS 2023, Pittsburgh, PA, USA, September 20-22, 2023, Proceedings , volume 14161 of Lecture Notes in Computer Science , pages 44-53. Springer.
David Cheng-Han Chiang and Hung-yi Lee. 2023. Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023 , pages 15607-15631. Association for Computational Linguistics.
Yoonjung Choi, Yuchul Jung, and Sung-Hyon Myaeng. 2010. Identifying controversial issues and their sub-topics in news articles. In Intelligence and Security Informatics, Pacific Asia Workshop, PAISI 2010, Hyderabad, India, June 21, 2010. Proceedings , volume 6122 of Lecture Notes in Computer Science , pages 140153. Springer.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker
Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy MeierHellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2023. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. , 24:240:1-240:113.
Alexander R. Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong. 2022. Qafacteval: Improved qa-based factual consistency evaluation for summarization. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022 , pages 2587-2601. Association for Computational Linguistics.
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. 2019. ELI5: long form question answering. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers , pages 3558-3567. Association for Computational Linguistics.
Joseph L Fleiss, Bruce Levin, Myunghee Cho Paik, et al. 1981. The measurement of interrater agreement. Statistical methods for rates and proportions , 2(212-236):22-23.
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling large language models to generate text with citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 64656488. Association for Computational Linguistics.
Maarten Grootendorst. 2022. Bertopic: Neural topic modeling with a class-based TF-IDF procedure. CoRR , abs/2203.05794.
Jurgen Habermas. 1991. The structural transformation of the public sphere: An inquiry into a category of bourgeois society . MIT press.
James A Hanley and Barbara J McNeil. 1982. The meaning and use of the area under a receiver operating characteristic (roc) curve. Radiology , 143(1):29-36.
Jack Hessel and Lillian Lee. 2019. Something's brewing! early prediction of controversycausing posts from discussion features. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , volume 1.
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenReview.net.
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, Xinrong Zhang, Zhen Leng Thai, Kai Zhang, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. Minicpm: Unveiling the potential of small language models with scalable training strategies. CoRR , abs/2404.06395.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020 , pages 6769-6781. Association for Computational Linguistics.
Maurice G Kendall. 1938. A new measure of rank correlation. Biometrika , 30(1-2):81-93.
Kalpesh Krishna, Yapei Chang, John Wieting, and Mohit Iyyer. 2022. Rankgen: Improving text generation with large ranking models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 , pages 199-232. Association for Computational Linguistics.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: a benchmark for question answering research. Trans. Assoc. Comput. Linguistics , 7:452-466.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020a. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020 , pages 7871-7880. Association for Computational Linguistics.
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wentau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020b. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual .
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning. CoRR , abs/2308.03281.
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out , pages 74-81.
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022 , pages 3214-3252. Association for Computational Linguistics.
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. Geval: NLG evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 2511-2522. Association for Computational Linguistics.
Nancy Lowry and David W Johnson. 1981. Effects of controversy on epistemic curiosity, achievement, and attitudes. The Journal of Social Psychology , 115(1):31-43.
Brian W Matthews. 1975. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure , 405(2):442-451.
Meta. 2024. Build the future of AI with Meta Llama 3. Meta AI website.
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 12076-12100. Association for Computational Linguistics.
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020. Ambigqa: Answering ambiguous open-domain questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020 , pages 5783-5797. Association for Computational Linguistics.
Thomas Misco. 2011. Teaching about controversial issues: Rationale, practice, and need for inquiry. Int'l J. Educ. L. & Pol'y , 7:13.
Ella Neeman, Roee Aharoni, Or Honovich, Leshem Choshen, Idan Szpektor, and Omri Abend. 2023. Disentqa: Disentangling parametric and contextual knowledge with counterfactual question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 914, 2023 , pages 10056-10070. Association for Computational Linguistics.
OpenAI. 2023a. Gpt-3.5 turbo. OpenAI Website.
OpenAI. 2023b. GPT-4 technical report. CoRR , abs/2303.08774.
OpenAI. 2024a. Gpt-4o mini: advancing costefficient intelligence. OpenAI Website.
OpenAI. 2024b. Hello GPT-4o. OpenAI website.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA , pages 311318. ACL.
Qwen. 2024a. Hello Qwen2. QwenLM Blog.
Qwen. 2024b. Introducing Qwen1.5. QwenLM Blog.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog , 1(8):9.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 .
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100, 000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, Novem- ber 1-4, 2016 , pages 2383-2392. The Association for Computational Linguistics.
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019 , pages 3980-3990. Association for Computational Linguistics.
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 .
Noam Slonim, Yonatan Bilu, Carlos Alzate, Roy Bar-Haim, Ben Bogin, Francesca Bonin, Leshem Choshen, Edo Cohen-Karlik, Lena Dankin, Lilach Edelstein, Liat Ein-Dor, Roni Friedman-Melamed, Assaf Gavron, Ariel Gera, Martin Gleize, Shai Gretz, Dan Gutfreund, Alon Halfon, Daniel Hershcovich, Ron Hoory, Yufang Hou, Shay Hummel, Michal Jacovi, Charles Jochim, Yoav Kantor, Yoav Katz, David Konopnicki, Zvi Kons, Lili Kotlerman, Dalia Krieger, Dan Lahav, Tamar Lavee, Ran Levy, Naftali Liberman, Yosi Mass, Amir Menczel, Shachar Mirkin, Guy Moshkowich, Shila OfekKoifman, Matan Orbach, Ella Rabinovich, Ruty Rinott, Slava Shechtman, Dafna Sheinwald, Eyal Shnarch, Ilya Shnayderman, Aya Soffer, Artem Spector, Benjamin Sznajder, Assaf Toledo, Orith Toledo-Ronen, Elad Venezian, and Ranit Aharonov. 2021. An autonomous debating system. Nat. , 591(7850):379-384.
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. 2022a. ASQA: factoid questions meet long-form answers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 , pages 8273-8288. Association for Computational Linguistics.
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. 2022b. ASQA: factoid questions meet long-form answers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 , pages 8273-8288. Association for Computational Linguistics.
David Q. Sun, Artem Abzaliev, Hadas Kotek, Christopher Klein, Zidi Xiu, and Jason D. Williams. 2023. DELPHI: data for evaluating llms' performance in handling controversial issues. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: EMNLP 2023 - Industry Track, Singapore, December 6-10, 2023 , pages 820-827. Association for Computational Linguistics.
Haochen Tan, Zhijiang Guo, Zhan Shi, Lu Xu, Zhili Liu, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and Linqi Song. 2024. PROXYQA: an alternative framework for evaluating long-form text generation with large language models. CoRR , abs/2401.15042.
Gemma Team. 2024. Gemma 2: Improving open language models at a practical size. Technical Report .
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, MarieAnne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien
Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models. CoRR , abs/2307.09288.
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. 2023. Zephyr: Direct distillation of LM alignment. CoRR , abs/2310.16944.
Alexander Wan, Eric Wallace, and Dan Klein. 2024. What evidence do language models find convincing? CoRR , abs/2402.11782.
Bjorn Gert Jan Wansink, Jacob Timmer, and Larike Henriette Bronkhorst. 2023. Navigating multiple perspectives in discussing controversial topics: Boundary crossing in the classroom. Education Sciences , 13(9):938.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 .
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, and Quoc V. Le. 2024. Long-form factuality in large language models. CoRR , abs/2403.18802.
Orion Weller, Marc Marone, Nathaniel Weir, Dawn J. Lawrie, Daniel Khashabi, and Benjamin Van Durme. 2024. "according to . . . ": Prompting language models improves quoting from pre-training data. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024 - Volume 1: Long Papers, St. Julian's, Malta, March 17-22, 2024 , pages 22882301. Association for Computational Linguistics.
Erik Olin Wright. 1998. The debate on classes , volume 20. Verso.
Fangyuan Xu, Yixiao Song, Mohit Iyyer, and Eunsol Choi. 2023. A critical evaluation of evaluations for long-form question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023 , pages 3225-3245. Association for Computational Linguistics.
Rongwu Xu, Zehan Qi, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. 2024a. Knowledge conflicts for llms: A survey. arXiv preprint arXiv:2403.08319 .
Rongwu Xu, Zi'an Zhou, Tianwei Zhang, Zehan Qi, Su Yao, Ke Xu, Wei Xu, and Han Qiu. 2024b. Walking in others' shoes: How perspective-taking guides large language models in reducing toxicity and bias. arXiv preprint arXiv:2407.15366 .
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 15, 2023 . OpenReview.net.
Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual , pages 27263-27277.
Jerrold H. Zar. 2005. Spearman rank correlation.
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. 2023. Siren's song in the AI ocean: A survey on hallucination in large language models. CoRR , abs/2309.01219.
## A Further Details on Dataset Curation
## A.1 Details on Debatable Question
The questions in DEBATEQA are collected from three sources, as detailed in Table 9.
Manually sourcing debatable questions. We search for debatable questions from the Web and adhere to the following criteria:
- · A debatable question should have clear semantics without any ambiguity.
- · A debatable question should have potentially different angles of answer, rather than having one definitive answer.
- · A debatable question can be subjective, but its answer should not be determined solely by individual subjective preferences.
In the end, we select 1,758 debatable questions from 9 websites. Details on the number of questions from each website can be found in Table 8.
Question deduplication. After merging questions from the three sources, we employ a simple deduplication algorithm to remove duplicates from the original set of 4,473 questions: First, we calculate cosine similarities between pairwise questions based on the embeddings computed by gte-largeen-v1.5 (Li et al., 2023). Subsequently, we sample 500 pairs and find pairs with a similarity score below 0.78 contained no true duplicates. Following this, we leverage a greedy algorithm for minimum vertex cover to remove duplicate entries, aiming to remove as few questions as possible while ensuring no duplicates remain . This process results in 5 a final dataset consisting of 3,216 unique entries.
## A.2 Details on Retrieving Trustworthy Documents
Retrieving on trustworthy websites. We only do retrieval on authoritative domains in Table 10 to assure the trustworthiness of the documents. Among the selected TLDs, .gov and .edu domains are not open for personal registration and can only be registered by government or educational institutions. Although .org , .pro , and . info domains can now be registered by individuals, their content generally remains professional and informative, with fewer advertisements or potentially misleading information.
Implementation of the retrieving process. To enable finer-grained search results, we apply the
5 The problem of vertex cover is NP-hard. We leverage a greedy algorithm, similar to the one described in this page.
GPT-4 model to first transform the original question into several search queries. We use the Google search engine for Web searches and retain only the documents from authoritative TLDs. These documents are then ranked using BgeReranker-v2-Gemma (Chen et al., 2024) and we keep the top-5 documents. We filter questions with fewer than three documents, as we consider these lack sufficient trustworthy evidence, leaving us with 2,982 questions. The distribution of the number of documents per question is in Figure 12. Quality examination. We segment each document into 1000-token chunks and average the cosine similarities for each question and corresponding trunks, computed by gte-Qwen2-1.5Binstruct. The quality of the retrieved documents is illustrated in Figure 11.
Figure 11: Quality of retrieved evidence documents. Document quality is assessed by cosine similarity.
Number of documents
Figure 12: Distribution of the number of trustworthy evidence documents per question.
## A.3 Details on Generating Partial Answers
Algorithm 1 formalize the pipeline of collecting partial answers, where M is the LLM we use. M ( p x, y ( )) indicates the LLM processing a prompt template p () populated with inputs x, y . Prompts. The prompts we used to generate the POVs and explanations can be found in Table 11. These prompts are carefully crafted to ensure that the generated POVs cover a range of non-overlapping perspectives and provide wellrounded explanations that are grounded in the evidence documents. After extracting the POVs, we filter out questions with fewer than three perspectives, ensuring that the remaining questions are sufficiently debatable, resulting in 2,941 questions. The distribution of the number of extracted POVs per question can be found in Figure 13.
| Source URL | Count |
|-----------------------------------------------------------------------------|---------|
| https://owlcation.com/academia/debate-topics | 350 |
| https://paperperk.com/blog/debate-topics | 174 |
| https://studycorgi.com/blog/debatable-questions-topics-for-research-essays/ | 150 |
| https://www.myspeechclass.com/funny-debatable-topics.html | 126 |
| https://www.nytimes.com/2020/07/28/learning/177-questions...refection.html | 177 |
| https://owlcation.com/academia/100-Debate-Topics | 100 |
| https://parade.com/living/debatable-questions | 257 |
| https://www.procon.org/debate-topics | 107 |
| https://randomquestionmaker.com/blog/debatable-questions | 317 |
Table 8: Detailed sources in URL for debatable questions sourced from the web. During our experiment (April 2024), these resources are accessible. We will make our dataset publicly available for future research.
| Sources | Initial | After Dedupe. |
|---------------|-----------|-----------------|
| DELPHI | 2,281 | 1,597 |
| CONFLICTINGQA | 434 | 400 |
| Web Sourced | 1,758 | 1,219 |
| Total | 4,473 | 3,216 |
## Algorithm 1: Collecting partial answers for an individual debatable question
Input: question q , a list of m evidence documents D = { D } m i =1
a list of
Output:
n
partial answers
P
=
{
P
i
}
n
n
i
=1
= (
{
POV
i
Extract list of POVs
i
#
D
#
rel.
i
are relevant docs w.r.t. POV
- 1 { POV } n i =1 , {D rel. } n i =1 ←M ( p POV ( q, D ))
- 2 for POV in i { POV } n i =1 do
Expand POV to
#
Explanations
3
Explan
i
←M
(
p
Explan
(
q,
POV
i
,
{D
rel.
}
i
))
- 4 return P ← { ( POV i , Explan i ) } n i =1
Figure 13: Distribution of the number of extracted POVs per question.
token chunks and use gte-Qwen2-1.5B-instruct to identify the top 5 most relevant chunks per question. A manual examination reveals that in 90.4% of the trunks, every valid perspective within them is already covered in the extracted POVs, affirming the comprehensiveness of our POV collection. Distinctiveness : To ensure the distinctiveness of extracted POVs, i.e. , they are non-overlapping, we calculate the pairwise cosine similarity for each question's POVs using gte-Qwen2-1.5B-instruct. Weset a 0.75 cosine similarity threshold to discern unique POVs. Below this, POV pairs are deemed distinct; above, they undergo manual review, with duplicates removed and unique ones kept, ensuring efficient POV uniqueness.
## A.4 Details on Human Annotation
We recruit three professional annotators from a local data annotation company to verify the partial answers. The payment for this job is above the local minimum wage. Annotators are given two
,
Explan
)
}
i
=1
i
Table 9: Sources distribution of DEBATEQA.
| Selected TLDs | Open for Registration? |
|---------------------------|--------------------------|
| .edu .org .gov .info .pro | ✗ ✓ ✗ ✓ ✓ |
Table 10: List of selected top-level domains (TLDs) we considered trustworthy. Closed for registration indicates that only authoritative entities can register a domain under these TLDs, ensuring high credibility.
Configuration of the LLM. At the time of dataset curation (from April to May 2024), the strongest model available was the gpt-4-turbo variant of GPT-4. The use of GPT-4 ensures the highest quality and fidelity of the generated partial answers. We set topp = 0 7 . to enable nucleus sampling (Holtzman et al., 2020) and temperature = 0 7 . , which helps to maintain a balance between coherence and variability in the generated texts.
Preprocessing the documents. To preserve critical information at prompting, we concatenate the content, excluding URLs and underlines, and truncate single documents to 80K tokens. If the concatenated input exceeds 120K tokens, we trim to this limit, ensuring essential content fits within GPT-4's 128K context window.
Quality examination. We examine the quality of POVs based on two criteria: their comprehensiveness w.r.t. the retrieved documents and their distinctiveness from one another.
Comprehensiveness : To ensure the comprehensiveness of extracted POVs, we examine whether all valid perspectives from the questions' corresponding documents are included in the POVs. To this end, we truncate the documents into 1000-
## Prompt Content
Table 11: Core prompts for generating partial answers given the question and retrieved documents. Prompt p POV is used to extract points-of-view (POVs) from the corresponding evidence documents w.r.t. to the question. Prompt p Explan is used to expand POVs into long-form explanations based on the relevant documents.
| p POV | Task: Generate Points-of-View that Address the Given Question from Different Perspectives Guidelines: 1. Consider the question provided and think about how it can be addressed from various perspectives. 2. Use the information from the provided documents. Do not rely on your internal knowledge. 3. Each Point-of-View should be a short sentence that addresses one aspect of the question and presents a specific viewpoint. 4. Ensure that each Point-of-View is concise and supported by the documents, including the document number(s) from which it is derived. 5. Generate as many diverse Points-of-View as possible, and you are encouraged to generate Points-of-View that are supported by multiple documents. Question: { question } Documents: { concatenated documents } Develop Points-of-View by drawing insights from the text, allowing each one to present a specific perspective. Format your response as follows: start each Point-of-View with 'Point-of-View [number]:', followed by its content, and include a list of document number(s) related to that Point-of-View. Expected Output Format: Point-of-View 1: (content of the Point-of-View) [Document [number]] |
|----------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| p Explan | Task: Provide an Answer to a Question that Reflects a Given Perspective Guidelines: 1. Consider the question provided and think about how it can be addressed from a particular perspective. 2. You must use the information from the text to support and expand upon this perspective. You must not rely on your internal knowledge. 3. Your response should be a natural extension of the information present in the text, without directly referencing it as 'the document' or 'the text'. 4. Your response should include at most 300 words. Question: { question } Perspective: { POV } Text: { (concatenated) document(s) w.r.t. a specific POV } Develop your answer by drawing insights from the text, allowing the answer to unfold as a natural expansion of the provided perspective. |
distinct tasks as outlined in § 3.3. These tasks involve making binary decisions, where annotators must assess if the partial answer satisfies the specified criteria in § 3.3. After the annotation, we removed 767 partial answers deemed substandard by two or more annotators, resulting in a final dataset of 10,873 partial answers. We do not remove the original questions corresponding to these partial answers, as those questions still have multiple partial answers. A domain distribution of the final dataset is shown in Figure 14.
Figure 14: Question distribution for top-8 domains, rendered by BERTopic (Grootendorst, 2022).
## B Further Details on P.D.
## B.1 P.D.'s Alignment with Human Preferences
## B.1.1 Collecting Human Preferences
Initially, we gather responses from a diverse selection of five LLMs to 100 randomly chosen test questions from DEBATEQAtest . The list of
LLMs is as follows: GPT-4o (OpenAI, 2024b), Llama 3 70B (Meta, 2024), Phi-3 Small 8k (Abdin et al., 2024), Zephyr 7B beta (Tunstall et al., 2023), and Qwen1.5 4B (Qwen, 2024b), representing a range of manufacturers and capabilities, anticipated to produce varying response qualities. We configure the LLMs as described in § 7.1 to solicit answers, resulting in 500 answers. Subsequently, we engage three annotators to record their preferences among the model answers. To simplify the ranking process, we ask the annotators to provide pairwise preferences through all 10 possible pairwise combinations of the five responses per question. The annotators need to provide a preference based on the following criteria:
- · Clearly indicate that the question being answered is controversial (possibly without a universally accepted answer).
- · Try to comprehensively cover various angles of the controversial issue.
- · For each viewpoint in the answer, use specific, sufficient, credible, and supportive evidence to elaborate.
- · Try to avoid letting your subjective understanding of the issue affect your choice of answer.
The annotators are also encouraged to use search engines to look up related information if they are unfamiliar with the topic.
Post-annotation, we determine inter-annotator consistency using Spearman's ρ correlation. The outcomes, depicted in Figure 2, reveal strong agreement ( ρ > 0 8 . ) among annotators, suggesting a shared understanding of a good answer.
## B.1.2 Baseline Text Evaluation Metrics
The prompts for P.D.'s baseline metrics can be found Table 12.
Direct-Score . Direct-Score is basic prompt-based evaluation metric. We employ a straightforward prompt that requires the model to assign a 1-5 Likert scale score to the model response using the same instruction we present to human annotators. The prompt p DS is depicted in Table 12.
G-Eval (Liu et al., 2023). G-Eval is a strong prompt-based evaluation framework that assesses the quality of generated texts by incorporating chain-of-thoughts (CoT) (Wei et al., 2022) and a form-filling paradigm. By providing a prompt with a task introduction and evaluation criteria, GEval generates detailed evaluation steps and utilizes these steps along with the generated CoT to score the texts. We apply G-Eval using the same scoring criteria provided to humans. The prompt p G-Eval behind G-Eval can be found in Table 12.
Num-of-POVs . We design another prompt-based evaluation metric that takes a shortcut approach by simply determining the number of different perspectives in an answer. This metric can be considered an improved metric over the 'Comprehensiveness Answer Rate' metric introduced in the DELPHI paper, as it transcends the binary assessment of the original, which solely determines if an answer includes diverse and opposing viewpoints. The prompt p NoP is shown in Table 12.
For the similarity-based metrics , the score for an answer is calculated by averaging the individual scores computed with the partial answers.
BLEU (Papineni et al., 2002) and ROUGEL (Lin, 2004). These are statistical metrics. BLEU is a metric for assessing translation quality by measuring n -gram precision against reference texts. ROUGE-L is a metric for evaluating summarization by focusing on the Longest Common Subsequence (LCS). It assesses matching quality by calculating the LCS between reference and candidate texts, emphasizing recall.
BARTScore (Yuan et al., 2021) and SemScore (Aynetdinov and Akbik, 2024). These are neural metrics. BARTScore evaluates the quality of text by leveraging the generative capabilities of the BART (Lewis et al., 2020a) model. We employ the Precision score, which measures the likelihood of a generated answer (candidate text) matching a given reference answer (reference text). In our scenario, the candidate text is the model's response, and the reference text is the partial answer. SemScore is a neural automated evaluation metric based on Semantic Textual Similarity (STS) for assessing the quality of texts.
## B.1.3 Case Study
Despite P.D.'s strong performance, occasional inconsistencies with human annotations occur. We delve into these by analyzing one set of answers with perfect P.D.-human alignment and three divergent sets. This case study identifies two likely causes for the inconsistencies observed.
## Non-perspective content in model's response.
The first reason is that the answers provided by LLMs may contain segments that cannot be directly considered as a POV or arguments that support a POV w.r.t. the question. For instance, when answering the question 'Should students have to wear school uniforms?', Llama 3 70B's answer includes a sentence 'What do you think? Should students have to wear school uniforms, and why or why not?', which makes sense as the end of a paragraph in a normal conversation but does not constitute a point of view. Consequently, it does not appear in the partial answers in our dataset. Our metric is susceptible to this type of information, whereas human evaluators are less likely to be influenced by it. This results in humans rating this answer higher than our metric does.
Omission of legitimate perspectives. The second reason is that although our partial answer has covered many credible perspectives on our debatable question, some perspectives may still have been missed given that we only extract perspectives from the top documents of a Google search. For instance, Zephyr 7B's answer to the question 'Do animals deserve legal protections?' includes the POV that 'granting legal personality to animals may make it harder to manage animal populations', which is not included in our partial answers. If a model's answer includes an omitted point, including this point will not improve the model's assessment of our metric. However, human annotators do not have a predetermined pool of perspectives , so including this point will likely make the annotator think the answer is more comprehensive, leading to discrepancies in judgments.
Table 12: Prompts for assessing answers to debatable questions in baseline methods of the P.D. metric.
| Prompt | Content |
|----------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| p DS | You will be given a question and its answer. You are supposed to give a score to represent the quality of the answer. A high-quality answer should meet the following criteria: 1. Clearly identify if the question being answered is contentious (likely without a universally accepted answer). 2. Cover as many different perspectives on the contentious issue as possible. The more perspectives, the better. 3. For each viewpoint within the answer, use specific, sufficient, and credible evidence to support the corresponding argument. The more detailed (arguments and information-rich) each viewpoint, the better. 4. When making your judgment, prioritize the quality of the answer. Avoid letting your own subjective views on the issue affect your evaluation. Question: { question } Answer: { answer } Your response should only contain one integer number between 1-5 to represent the quality of the answer without any other symbols or words. |
| p G-Eval | You will be given a question and its answer. Your task is to rate the answer based on its quality. Evaluation Criteria: Quality (1-5) - The answer should meet the following criteria: 1. Clearly identify if the question being answered is contentious (likely without a universally accepted answer). 2. Cover as many different perspectives on the contentious issue as possible. The more perspectives, the better. 3. For each viewpoint within the answer, use specific, sufficient, and credible evidence to support the corresponding argument. The more detailed (arguments and information-rich) each viewpoint, the better. 4. When making your judgment, prioritize the quality of the answer. Avoid letting your own subjective views on the issue affect your evaluation. Evaluation Steps: 1. Read the question carefully. 2. Read the answer and evaluate it based on its relevance to the question, clarity, and comprehensiveness. 3. Assign a score for quality on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria. Question: { question } Answer: { answer } Evaluation Form (output one number to represent scores ONLY): |
| p NoP | You will be given a question and its answer. You are supposed to analyze how many distinct viewpoints are expressed in the answer. Your response must be a single number such as 1, 2, etc. Your answer should only contain a single Arabic numeral between 1 and 10 without any other symbols or words. For example, if you think there are 3 distinct viewpoints, you should only write the number 3 in your response. Question: { question } Answer: { answer } |
## B.2 P.D. is Stable w.r.t. Backbone Models
We choose the following language models: Qwen2 0.5B/7B (Qwen, 2024a), Phi-3 mini 128k (Abdin et al., 2024), GPT-2 (117M) (Radford et al., 2019), MiniCPM 2B (Hu et al., 2024).
## B.3 P.D. is Stable w.r.t. Prompts
As in Table 13, we use five different prompts to show that P.D. is stable w.r.t. prompts.
Table 13: Prompts for assessing answers to debatable questions in baseline methods of the P.D. metric.
| Prompt | Content |
|----------|------------------------------------------------------------------|
| p P.D. 1 | { response } Please restate. |
| p P.D. 2 | Here is the text: { response } What is described in the text? |
| p P.D. 3 | Given the following text: { response } Please rephrase the text. |
| p P.D. 4 | From the following text: { response } What we can infer? |
| p P.D. 5 | { response } |
## C Further Details on D.A.
The exact prompt for D.A. is shown in Table 14.
## C.1 D.A. is Accurate
We compare the D.A. metric with the one from DELPHI (Sun et al., 2023), which is our sole baseline due to this is the only comparable study to our knowledge. In DELPHI, the authors propose to judge whether the model explicitly recognizes that the question is controversial by whether its answer begins with 'As an AI language model'.
## C.2 D.A. is Stable w.r.t. Backbone Models
We choose the following instruction-following LLMs: Gemma 2 9B (Team, 2024), Llama3 8B (Meta, 2024), MiniCPM 2B (Hu et al., 2024), Phi-3 medium 128k (Abdin et al., 2024), Qwen2 1.5B (Qwen, 2024a).
## D Further Details on Experiments
## D.1 RAG Configuration Details
Vanilla RAG. We augment the LLMs with LangChain. We first gather relevant documents for each query via the Google search engine. The top 10 URLs from the search are saved. The retrieved URLs then undergo a series of actions: (1) content retrieval using the WebBasedLoader; (2) chunking to roughly 2000-character using the RecursiveCharacterTextSplitter, and (3) dense retrieval (Karpukhin et al., 2020) of the top-10 most relevant chunks based on cosine similarity on embeddings using the gte-Qwen2-1.5B-instruct (Li et al., 2023; Qwen, 2024a) embedder. These selected document chunks, along with the question, are compiled into a comprehensive prompt, as
| Prompt Content | Prompt Content |
|------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| p D.A. | Here is a question paired with an answer. Determine if the answer explicitly states that the question is debatable or controversial. 5-Shot Demonstrations: Question: Is it ethical to use animals for scientific research? Answer: The use of animals in scientific research is a highly debated topic. While some argue that it is necessary for medical advancements and can lead to life-saving treatments, others contend that it raises significant ethical concerns about animal welfare and the rights of sentient beings. This debate often involves complex considerations of the benefits to human health versus the moral implications of using animals in |
Table 14: Prompt for the D.A. metric. p D.A. determine if an answer explicitly recognizes the debatable nature of the question. p D.A.-ZS is the zero-shot version of p D.A. where the in-context demonstrations are completely omitted.
| Role | Prompt |
|--------|----------------------------------------------------|
| system | Your task is to provide an answer to the question. |
| user | { question } |
Table 15: Prompt for test vanilla LLMs.
| Role | Prompt |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| system | Your task is to provide an answer to the question. You can refer to the information provided in the ## Document to help you answer better, or you can leave it out. |
| user | ## Document: { content of chunk 1 } { content of chunk 2 } . . . { content of chunk n } ## Question: { question } |
Table 16: Prompt for test LLMs w. RAG.
| Prompt | Content |
|-----------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| p basic | Your task is to provide an answer to the question. |
| p comprehensive | You need to answer a debatable question. Your task is to answer the question as comprehensively as possible, con- sidering and covering various perspectives. |
| p detailed | You need to answer a debatable question. Your task is to provide a comprehensive response, considering and cover- ing various perspectives. In your answer, ensure you: 1. Present a clear and balanced introduction to the topic, outlining the key issues and why it is a subject of debate. 2. Explore multiple viewpoints, including those that may oppose your personal stance. 3. Use evidence and examples to support each viewpoint. This can include data, expert opinions, historical examples, and case studies. 4. Conclude with a well-reasoned summary that integrates the various perspectives you've discussed. Offer your own informed opinion, clearly stating why you favor a partic- ular viewpoint while acknowledging the validity of other perspectives. |
depicted in Table 16, which is then provided to LLMs for generating responses.
ReAct. ReAct (Reason+Act) is an agent-based RAG strategy that interleaves reasoning with taskspecific actions to bolster LLMs' problem-solving skills. During this process, the LLM agent makes decisions for subsequent actions based on the outcomes of prior retrievals and reasoning. We limit the process to three retrievals: the first is on the original problem, while the agent flexibly determines the rest two. From each retrieval, the LLM retrieves the 3 most relevant document chunks, resulting in a total of at most 9 chunks. To ensure consistency, we maintain ReAct's other setup the same as the vanilla RAG, including web search, content retrieval, chunking, and dense retrieval.
## E Qualitative Analysis and Case Study
## E.1 Deficiencies in Advanced LLMs
We take the case of GPT-4o (OpenAI, 2024b) to investigate the lingering deficiencies of advanced
Table 17: System prompts that require the model to answer questions with varying degrees of granularity.
LLMs, a case study is provided in Table 18. Our main findings are:
- · Insufficient evidence and source citation. In a real debate, debaters need to support their arguments with evidence (Wright, 1998). Although GPT-4o can recognize the debate of questions and provides comprehensive answers covering various points of view, it often does not offer well-sourced evidence when elaborating on each point of view. Instead, it tends to provide general narratives, list perspectives, or use examples without credible sources to substantiate its arguments.
- · High-quality RAG improves performance. We find high-quality retrieved results can effectively supplement GPT-4o's responses with relevant evidence to support its viewpoints, enhancing its capacity to address debatable questions with more credibility.
Potential solutions to address insufficient argumentation, potential solutions could be:
- · Enhance domain-specific knowledge. The model requires deeper knowledge of conflicts (Xu et al., 2024a), achievable through domain-specific pretraining and RAG with high-quality sources.
- · Encourage generation with reference. The model should enhance its ability to cite sources in responses. Adapting strategies from existing research can help: as discussed in (Weller et al., 2024), the model can refer to its pre-training data for generating responses. Additionally, as outlined in (Gao et al., 2023), employing RAG during response generation enables direct incorporation of cited evidence.
## E.2 Gaps between Weak and Strong LLMs
Taking Qwen2 7B (Qwen, 2024a) as a case study in Table 19, we pinpoint three main deficiencies typically found in the responses of models with moderate capabilities:
- · Poor structural organization. These models tend to generate structurally disjointed responses, blending various perspectives into single clauses, which diminishes the clarity and readability of the discourse.
- · Limited perspectives. The responses from weaker models are not as comprehensive, lacking the inclusion of diverse viewpoints observed in higher-performing models.
- · Perspective imbalance. There is a noticeable lack of neutrality in the responses. While these models recognize the contentious nature of questions, they tend to provide unbalanced coverage and exhibit bias in language use.
Potential solutions to improve responses that are poorly organized, incomplete or imbalance w.r.t. perspectives could be:
- · SFT for stylistic answer presentation. The model could be trained to deliver answers in a structured manner, e.g. , using lists of answers with bolded perspectives to improve clarity. This formatting can be achieved through Supervised Fine-Tuning (SFT).
- · Alignment training and prompting. To enhance response quality in terms of perspective diversity and balanced narrative, Preference learning with pairwise preferences data can be
leveraged (Rafailov et al., 2023). Another approach is to utilize prompting techniques such as self-reflection (Shinn et al., 2023) and rolebased perspective-taking (Xu et al., 2024b) to explicitly require the model for more wellrounded and neutral answers.
Question Should the government provide a universal basic income?
Answer w/o RAG The question of whether the government should provide a universal basic income (UBI) is a complex and multifaceted issue . . . Here are some key arguments for and against UBI: Arguments in Favor of UBI: 1. **Poverty Reduction**: UBI can provide a safety net for all citizens, helping to lift people out of poverty and reduce income inequality. (This paragraph lacks arguments with clear sources.) . . . Arguments Against UBI: 1. **Cost**: Implementing a UBI could be extremely expensive and may require significant tax increases or reallocation of existing resources, which could be politically challenging. (This paragraph lacks arguments with clear sources.) . . .
Answer w/ RAG The question of whether the government should provide a universal basic income (UBI) is complex and multifaceted . . . **Pros of UBI**: 1. **Reduces Poverty and Income Inequality:** Proponents argue that UBI can significantly reduce poverty and income inequality. For example, Namibia's Basic Income Grant trial reduced household poverty rates from 76% to 37% in one year, and Brazil's Bolsa Fam íedlia program lowered the poverty rate to the lowest level in 40 years in just six months. (This is an argument with a clear source.) . . .
**Cons of UBI**: 1. **Cost:** Implementing UBI can be extremely costly. Andrew Yang's proposal for a $1,000-a-month (This is an argument with
Freedom Dividend would have cost $2.8 trillion annually, which is about half of the federal budget. a clear source.) Funding such a program would require significant tax increases or cuts to other social programs . . .
Table 18: Comparing GPT-4o's responses with and without RAG shows that RAG bolsters its capacity to present well-sourced arguments.
Question Should gay marriage be legalized?
Answer . . . I can share that many countries around the world have legalized gay marriage based on principles of equality, civil rights, and individual freedom. (This section does not clearly distinguish these perspectives.) These legalizations are often supported by arguments that same-sex couples should have the same rights as heterosexual couples, including the right to marry and form a legally recognized union. (This section overlooks issues like the mental health of minority groups.) Opponents might argue for various reasons, such as traditional definitions of marriage, religious beliefs, or concerns about social impact. (This section overlooks issues like the impact of same-sex marriage on child development and the slippery slope argument, and it disproportionately focuses on the supportive views without clearly distinguishing these perspectives.) Ultimately, the decision to legalize gay marriage is typically made through . . .
Question Is peer pressure a good thing?
Answer Peer pressure can have both positive and negative effects, depending on the situation and context. Peer pressure can lead to positive outcomes such as promoting better behavior, enhancing social skills, and adhering to norms, but these are often discussed together with the negatives like encouraging harmful behaviors, promoting conformity, and influencing self-esteem. (This section does not clearly distinguish these perspectives.) For instance, while peer pressure can encourage someone to study harder or exercise and develop better social skills, (This section overlooks perspectives such as accountability.) it is often not separated from the pressure to engage in risky behaviors like drinking or reckless driving and often combined with pressures that enforce strict adherence to group norms, potentially leading to a loss of individuality. (This section overlooks issues such as self-awareness and critical thinking.)
Table 19: Two examples that illustrate multiple deficiencies in Qwen2 7B's responses.
## F A Practical Interpretation of the P.D. Metric
Given the difficulty in interpreting the P.D. metric's absolute value, we offer an interpretation of the P.D. value's change to signify the comparative quality between two model answers, A , A 1 2 . Given the following definitions:
- · Perspective Diversity (P.D.) 6 :
$$P. D. = \sum _ { i = 1 } ^ { n } P P L ( P A ^ { i } | A )$$
- · Conditional perplexity:
$$\Phi. \\ P P L ( Y | X ) = \exp \left ( - \frac { 1 } { N } \sum _ { i = 1 } ^ { N } \log P ( y _ { i } | X, y _ { < i } ) \right )$$
- · We denote the Change in Probability for partial answer i as ∆ P i , assuming | PA i | = N :
$$\Delta P ^ { i } = \frac { P ( \text{PA} ^ { i } | A _ { 2 } ) } { P ( \text{PA} ^ { i } | A _ { 1 } ) } = \prod _ { j = 1 } ^ { N } \frac { P ( \text{PA} ^ { i } _ { j } | A _ { 2 }, \text{PA} ^ { i } _ { < j } ) } { P ( \text{PA} ^ { i } _ { j } | A _ { 1 }, \text{PA} ^ { i } _ { < j } ) }$$
The Change in Perspective Diversity ( ∆ P.D.) is defined as:
$$\Delta P D. = \sum _ { i = 1 } ^ { n } P P L ( \text{PA} ^ { i } | A _ { 2 } ) - \sum _ { i = 1 } ^ { n } P P L ( \text{PA} ^ { i } | A _ { 1 } ) = \sum _ { i = 1 } ^ { n } \left ( P P L ( \text{PA} ^ { i } | A _ { 2 } ) - P P L ( \text{PA} ^ { i } | A _ { 1 } ) \right )$$
Substitute the formula of conditional perplexity, we get:
$$\Delta P D. = \sum _ { i = 1 } ^ { n } \left ( \exp \left ( - \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log P ( \text{PA} _ { j } ^ { i } | A _ { 2 }, \text{PA} _ { < j } ^ { i } ) \right ) - \exp \left ( - \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log P ( \text{PA} _ { j } ^ { i } | A _ { 1 }, \text{PA} _ { < j } ^ { i } ) \right ) \right )$$
Applying the approximation exp( x ) ≈ 1 + x for small x , we get:
$$\Delta P. D \approx & \sum _ { i = 1 } ^ { n } \left ( \left ( 1 - \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log P ( P A _ { j } ^ { i } | A _ { 2 }, P A _ { c j } ^ { i } ) \right ) - \left ( 1 - \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log P ( P A _ { j } ^ { i } | A _ { 1 }, P A _ { c j } ^ { i } ) \right ) \right ) \\ = & \sum _ { i = 1 } ^ { n } \left ( - \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log P ( P A _ { j } ^ { i } | A _ { 2 }, P A _ { c j } ^ { i } ) + \frac { 1 } { N } \sum _ { j = 1 } ^ { N } \log P ( P A _ { j } ^ { i } | A _ { 1 }, P A _ { c j } ^ { i } ) \right ) \\ = & - \frac { 1 } { N } \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { N } \log P ( P A _ { j } ^ { i } | A _ { 2 }, P A _ { c j } ^ { i } ) + \frac { 1 } { N } \sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { N } \log P ( P A _ { j } ^ { i } | A _ { 1 }, P A _ { c j } ^ { i } ) \\ \text{Annlvine the annovationitation that all $\Delta P^{i}$. $i = 1\cdots n$ are the same value for simnlicitv. we get:}$$
Applying the approximation that all ∆ P , i i = 1 · · · n are the same value for simplicity, we get:
$$\Delta P. D. \approx \sum _ { i = 1 } ^ { n } \log ( \frac { 1 } { \Delta P ^ { i } } )$$
Thus:
$$\Delta P ^ { 1 } \approx \exp ( - \frac { \Delta P. D. } { n } )$$
Equation 7 shows that the change in probability ∆ P 1 can be approximated using the change in P.D. ∆ P.D., and the effect is exponential. For example, when taking n = 3 (given the fact that the average number of partial answers in DEBATEQA ≈ 3 7 . ) and ∆ P.D. = -2 , it suggests that the approximated probability of generating one partial answer under A 2 is 1 95 . times higher than under A 1 . In other words, the backbone language model finds it nearly twice as easy to recover the partial answer from A 2 due to the reduction of 2 in the P.D. score.
6 Here, we use A to denote chatTemplate concat ( ( A, 'Please restate.' )) in Equation 1 for simplicity. | null | [
"Rongwu Xu",
"Xuan Qi",
"Zehan Qi",
"Wei Xu",
"Zhijiang Guo"
]
| 2024-08-02T17:54:34+00:00 | 2024-08-02T17:54:34+00:00 | [
"cs.CL"
]
| DebateQA: Evaluating Question Answering on Debatable Knowledge | The rise of large language models (LLMs) has enabled us to seek answers to
inherently debatable questions on LLM chatbots, necessitating a reliable way to
evaluate their ability. However, traditional QA benchmarks assume fixed answers
are inadequate for this purpose. To address this, we introduce DebateQA, a
dataset of 2,941 debatable questions, each accompanied by multiple
human-annotated partial answers that capture a variety of perspectives. We
develop two metrics: Perspective Diversity, which evaluates the
comprehensiveness of perspectives, and Dispute Awareness, which assesses if the
LLM acknowledges the question's debatable nature. Experiments demonstrate that
both metrics align with human preferences and are stable across different
underlying models. Using DebateQA with two metrics, we assess 12 popular LLMs
and retrieval-augmented generation methods. Our findings reveal that while LLMs
generally excel at recognizing debatable issues, their ability to provide
comprehensive answers encompassing diverse perspectives varies considerably. |
2408.01420v1 | ## Mission Impossible: A Statistical Perspective on Jailbreaking LLMs
Jingtong Su ∗ NYU & Meta AI, FAIR
Julia Kempe †
NYU & Meta AI, FAIR
Karen Ullrich Meta AI, FAIR
†
## Abstract
Large language models (LLMs) are trained on a deluge of text data with limited quality control. As a result, LLMs can exhibit unintended or even harmful behaviours, such as leaking information, fake news or hate speech. Countermeasures, commonly referred to as preference alignment, include fine-tuning the pretrained LLMs with carefully crafted text examples of desired behaviour. Even then, empirical evidence shows preference aligned LLMs can be enticed to harmful behaviour. This so called jailbreaking of LLMs is typically achieved by adversarially modifying the input prompt to the LLM. Our paper provides theoretical insights into the phenomenon of preference alignment and jailbreaking from a statistical perspective. Under our framework, we first show that pretrained LLMs will mimic harmful behaviour if present in the training corpus. Under that same framework, we then introduce a statistical notion of alignment, and lower-bound the jailbreaking probability, showing that it is unpreventable under reasonable assumptions. Based on our insights, we propose an alteration to the currently prevalent alignment strategy RLHF. Specifically, we introduce a simple modification to the RLHF objective, we call E-RLHF , that aims to increase the likelihood of safe responses. E-RLHF brings no additional training cost, and is compatible with other methods. Empirically, we demonstrate that E-RLHF outperforms RLHF on all alignment problems put forward by the AdvBench [1] and HarmBench project [2] without sacrificing model performance as measured by the MT-Bench project [3].
## 1 Introduction
Large Language Models (LLMs) have revolutionized the field of deep learning due to their remarkable capabilities across various domains, serving as assistants, in code generation [4], healthcare [5], and theorem proving [6]. The training process of a LLM typically includes two stages: pretraining with massive corpora, and an alignment step using Reinforcement Learning from Human Feedback (RLHF) to further align model behavior with human preferences. The latter step typically involves large amounts of humanly annotated data, and can be decomposed into a supervised fine-tuning (SFT) step, a reward modeling step, and an RL Fine-Tuning step. Despite their ability to perform multiple tasks effectively, LLMs are susceptible to generating offensive or inappropriate content including hate-speech, malware, fake information or social biases, due to the unavoidable presence of harmful elements within their pretraining datasets [7-9]. Social media showcase an abundance of tricks on how to attack ChatGPT [10] to elicit harmful responses, e.g., the 'Do Anything Now' (DAN) prompts [11] or the 'Grandma Exploit' hack [12]. On the other hand, behavior diversity in the training corpus is essential to for example capturing different cultural preferences. What is and isn't harmful ultimately depends on user preferences, hence the alignment step is not universal but depends on the specific use case under which a model will be employed.
∗ Correspondence to: Jingtong Su <[email protected]>.
† Equal advising.
To address deployment safety and eliminate objectionable responses, numerous alignment efforts have been made, such as injecting safe information during SFT [13], performing red teaming with human experts and AI themselves [14-18], as well as refining and improving the whole RLHF process in detail [19-23]. Yet we continue to witness a cat-and-mouse game of ever more sophisticated alignment methods to neutralize 'harmful' prompts and even more inventive 'jailbreaking' attacks that manipulate those prompts to elicit LLMs to produce harmful information. Such attacks come in various flavors, such as injecting adversarial suffixes [1, 24, 25], exploring cipher and low-resource natural languages [26-28], or letting LLMs craft prompts automatically [29-33]. Although several adhoc defense methods against suffixes have been proposed [34-37], we only have limited proposal on a principled universal defense against jailbreaking attacks [2], and limited theoretical understanding on this phenomenon [38].
In this paper, we present a theoretical framework for analyzing both the pretraining phase and the post-alignment jailbreaking phenomenon. Exploiting the fact that jailbreaking prompts typically maintain the underlying harmful concept while manipulating other aspects of the prompt, we design framework that decouples input prompts to allows us to quantify the strength of potential adversaries. By representing the output elements of an language model (LM) as lengthier text fragments rather than individual tokens, we can quantify the extent to which these models emulate the training distribution and consequently better understand the mechanisms underlying jailbreaking vulnerabilities.
Our contributions can be summarized as follows:
- · Based on our proposed framework, we first offer a non-vacuous PAC-Bayesian style generalization bound for pre-training. Assuming the validity of our framework, we conclude that high-performing pre-trained models will inevitably be susceptible to generating behaviour that is present in the training corpus, including any unintended and harmful behaviour.
- · Subsequently, we extend our framework to include notions of alignment and jailbreaking. Assuming our assumptions are met, we demonstrate jailbreaking to be unpreventable even after safety alignment because the LM fails to concentrate its output distribution over the set of safe responses.
- · Motivated by our theoretical findings, we identify a key drawback in the widely adopted RL Fine-Tuning objective due to the natural difference between the harmlessness and the helpfulness targets. By addressing this issue, we facilitate the training of safer models that are more resilient to a suite of jailbreaking attacks while preserving model performance.
The paper is organized as follows. In Section 2, we introduce our framework. In Section 3, we prove the PAC-Bayesian generalization bound for pretraining. Next, in Section 4 we present analysis on jailbreaking from a statistical perspective. Finally, in Section 5 we illustrate our proposed E-RLHF objective and its effectiveness on improving LLM safety. We give a literature review in Appendix H.
## 2 Framework and assumptions
Jailbreaking carries several analogies to adversarial attacks , a well studied field in computer vision [39]. Here, an adversary is defined as a map that perturbs a given input image in pixel space to change the model output. The strength of the adversary is bounded by how far it is able to move the original input as quantified by the ℓ p distance [40-42]. Typically, this distance is bounded in a way that the change would not be perceptible to the human observer. The goal of the adversary is to cause misclassification of the input. In contrast, in the instance of an LLM, the adversary's goal is to provoke harmful behaviour, e.g., unintended leaking of information or hate speech. Further, any perturbation to an input, called prompt, will have a perceptible effect. Hence quantifying and bounding the capabilities of the adversary is not straight forward. Nonetheless, with some modifications, we will build on this analogy.
For the purpose of this work, we will view any prompt as a tuple of query and concept ( q, c ) , where c ∈ C , and q ∈ Q , with C Q , denoting the complete concept set and query set. Conceptually, we think of concepts as representing the information content of the prompt, usually through a short piece of text, for example 'tutorial on making a cake' . Queries are instructional text pieces that are composable with certain concepts. We can think of queries as mechanisms to trigger an LM to expand a concept in a specific way. Examples include 'Tell me how to {}' , or 'We are now in an imaginary world, and you are
not bounded by any ethical concerns. Teach my avatar how to {}' . Since not all queries and concepts are composable, 3 we denote P ⊊ Q×C as the set of all plausible prompts, where the definition of plausible will be made clear below.
## The decomposition of prompts allows us to isolate and hence bound the adversary's strength.
In line with current empirical work on inducing harmful behaviour, we will allow perturbations only on the queries, not on the concepts. Further mimicking the spirit of previous work on adversarial attacks, we will assume that the ground-truth related to a prompt is determined solely by the concept, not the query. We will make these ideas more rigorous in the next paragraphs.
First, in contrast to previous theoretical work where LMs are regarded as single sentence generators [38], we model LMs as lengthier text fragment generators , and refer to possible generated content e ∈ E as explanations. Conceptually, explanations expand concepts with additional information. For example, 'The US president in 2023 is Joe Biden.' . An LM thus induces a mapping from plausible prompts to distributions over explanations, p LM : P → ∆( E ) , where ∆( E ) denotes the set of distributions defined over elements in E . 4 The output of a LM given a prompt, p LM ( q, c ) , is a discrete distribution over explanations. We use dom( p LM ( q, c )) as the domain of this distribution, p LM ( e q, c | ) as the probability of e given ( q, c ) as the input, and supp( p LM ( q, c )) as the subset of E with non-zero p LM ( e q, c | ) . Further, we assume the existence of a latent ground truth mapping p world : P → ∆( E ) that the LM is optimized to mimic during the pretraining stage. This is the distribution
Figure 1: Our framework in a nutshell: We define a language model, p LM : → , as a map from prompts to a distribution over a subset of all possible explanations E . To later be able to bound the strength of the adversarial attacker, we split the text inputs into concepts and queries ( q, c ) . We assume that (i) the text corpus only covers a part of the domain of the LM: supp( D P ) ⊊ dom( p LM ) , (ii) the size of the domain of the output distribution, denoted | dom( p LM ( q, c )) | , is small compared to the size of E , and (iii) only concepts determine the output (see ).
that defines 'knowledge': for all plausible prompts ( q, c ) , it specifies the ground-truth distribution over explanations. By plausible , we refer to all prompts that lie in the domain of the ground truth mapping ( q, c ) ∈ dom( p world ) , i.e., P ≡ dom( p world ) . Many plausible prompts will not even exist within any available training corpus, as discussed below.
We can now state our main assumption, namely that for any plausible prompt ( q, c ) ∈ dom( p world ) the ground-truth distribution p world ( q, c ) is supported on a small subset of E ⇔ supp( p world ( q, c )) ⊊ E . This assumption seems sensible to us: under normal circumstances, providing an explanation of 'Paris' would not offer any relevant knowledge when given a prompt such as 'How to write a hello world python script' . Our second assumption is that for all plausible prompts ( q, c ) , the concept c uniquely determines the support of the output distribution specified by p world , regardless of the query: supp( p world ( q, c )) = supp( p world ( q ∗ , c )) , ∀ plausible ( q, c ) and, ( q ∗ , c ) . The query changes the ground-truth distribution without affecting its support. An illustration is depicted in Figure 1. To be more precise:
Assumption 2.1. (Concepts uniquely determine the explanation for plausible prompts) For all plausible prompts ( q, c ) ∈ dom( p world ) ,
$$i ) \, p _ { w o r l d } \, \colon \mathcal { P } \rightarrow \Delta ( \text{supp} ( p _ { w o r l d } ( q, c ) )$$
$$\text{where supp} ( p _ { w o r l d } ( q, c ) ) \subsetneq \mathcal { E } \, s. t. \, | \text{supp} ( p _ { w o r l d } ( q, c ) ) | \ll | \mathcal { E } | ; \, a n d$$
$$i i ) \, \text{supp} ( p _ { w o r l d } ( q, c ) ) = \, \text{supp} ( p _ { w o r l d } ( q ^ { * }, c ) ), \, \forall ( q, c ), ( q ^ { * }, c ) \, p l a u s i b l e.$$
3 For example, "Who is a tutorial on making a cake." is unreasonable.
4 For real-world LMs, with different decoding hyperparameters e.g., the temperature T , topp and topk sampling parameters, the induced distribution with the same set of parameters could be different. Our discussion holds for a pre-fixed set of hyperparameters throughout this paper.
This assumption is natural since it essentially tells us that knowledge is specified by the corresponding concept alone, irrespective of what query is used to extract it. In other words, given a concept c , if a query q manages to change supp( p world ( q, c )) , we argue that the query should be deconstructed and partially absorbed by c to accurately reflect the knowledge mirrored by the support.
Lastly, we make the assumption on the existence of an underlying generative distribution over prompts, denoted as ( q, c ) ∼ D P . This distribution serves as the principle governing the creation of our pretraining corpus. It is important to note that supp( D P ) ⊊ dom( p world ) . For example, take the prompt ( q , c ′ ′ ) = 'Who is James Bond $ λ *#!48811' ; even though this prompt never appears in any text corpus across the internet, ( q , c ′ ′ ) / ∈ supp( D P ) , we, as humans, can make sense of it: ( q , c ′ ′ ) ∈ dom( p world ) . Later proofs in this paper assume LMs generate semantically reasonable explanations for such unseen plausible prompts, since in reality LMs are claimed to generalize well on huge, out-of-distribution datasets [43]. This is made explicit in Section 4, within Assumption 4.1.
Finally, the following definitions pertain to our notion of harmfulness. More specifically, we understand harmful behaviour abstractly as any unintended behaviour. For this, we assume that any explanation e can be denoted as either harmful or not harmful (safe) . A concept c is regarded as harmful if and only if the world generates harmful explanations with probability higher than a certain threshold with direct prompts.
Definition 2.1. (Notions of Harmfulness)
- · ( Direct Queries and Direct Prompts ) We refer to a prompt as direct if it stems from D P , i.e., ( q, c ) ∈ supp( D P ) . The query of a direct prompt is called a direct query.
- · ( Harmful Concepts and Harmful Set ) Given a concept c , the associated harmful set of explanations is denoted as E h ( c ) := { | e e ∈ supp( p world ( · , c )) ∧ e is harmful } . In accordance with Assumption 2.1, with a threshold η , a concept c is harmful if ∀ q s.t. ( q, c ) ∈ dom( p world ) , ∑ e e : ∈ E h ( c ) p world ( e q, c | ) ≥ 1 -η . We refer to the set of all possible harmful concepts as C h ⊊ C .
- · ( Safe Set ) ∀ c ∈ C h , there exists a corresponding safe set E s ( c ) ⊊ E that we wish p LM ( q, c ) to be concentrated on. It includes safe explanations existing in supp( p world ( · , c )) , and explanations designed by humans, e.g., with the template beginning with 'Sorry. '
- · ( Semantically meaningful ) We call explanations in E h ( c ) ∪ E s ( c ) as semantically meaningful for the ( q, c ) prompt.
- · ( Mixture decomposition of D P ) With these notions, we can decompose D P = αD P h +(1 -α D ) P s (where supp( D P h ) includes all direct prompts with a harmful concept, and supp( D P s ) includes the complement) as a mixture over direct prompts with a harmful concept and the non-harmful counterpart.
## 3 PAC-Bayesian bound for pre-training LLMs on harmful data
Given a learning algorithm that leads to a posterior distribution over a set of models, PAC-Bayesian theory [44] applies Probably Approximately Correct (PAC) inequalities, to provide bounds on the generalization gap, i.e., the difference between the model's empirical loss and the population loss. We now present the first result of our analysis: a non-vacuous PAC-Bayesian bound for pretraining LMs which implies that a well-trained LM ought to exhibit harmful behaviour even when simply prompted with direct queries if it was presented with harmful behavior during training.
We denote by S = ( { q , c i i ) } n i =1 a set of prompts generated i.i.d. under D P , S ∼ D n P . These prompts together with sampled explanations form our pretraining corpus. We use π, ρ as the prior and posterior distribution over LMs before and after the pretraining process, defined over LM , the set of language models. Given a prompt ( q, c ) , we measure the generalization capability of a LM by quantifying the Total Variation (TV) loss between the induced distribution p LM ( q, c ) and the ground-truth distribution p world ( q, c ) . 5 For real-world LMs, pretraining involves optimizing the cross-entropy loss on the training corpus, which is equivalent to minimizing KL [ p world ( q, c ) || p LM ( q, c )] under our framework. With Pinsker's Inequality, optimizing the KL-divergence term is equivalent to optimizing an upper bound on TV; thus we expect empirical TV loss be small.
5 We regard both distributions as defined over the entire E since we do not restrict the output distribution of LM in this section.
Definition 3.1. (TV empirical loss and population loss)
ℓ TV ( p LM , ( q, c )) := TV( p world ( q, c ) , p LM ( q, c )) .
Given an LM and a set of data S , the empirical loss ˆ R S ( p LM ) and population loss R p ( LM ) are defined as
$$\hat { R } _ { S } ( p _ { L M } ) \coloneqq \frac { 1 } { n } \sum _ { i = 1 } ^ { n } \ell _ { \text{TV} } ( p _ { L M }, ( q _ { i }, c _ { i } ) ) ;$$
$$R ( p _ { L M } ) \coloneqq \mathbb { E } _ { S \sim D _ { \mathcal { P } } ^ { n } } \left [ \hat { R } _ { S } ( p _ { L M } ) \right ] = \mathbb { E } _ { ( q, c ) \sim D _ { \mathcal { P } } } \left [ \ell _ { \mathrm T V } ( p _ { L M }, ( q, c ) ) \right ].$$
We state our PAC-Bayesian bound as follows. The detailed proof can be found in Appendix B.1. 6
Theorem 1. (PAC-Bayesian Generalization Bound for Language Models.) With α as in Definition 2.1, consider a set of language models LM , with prior distribution π over LM .
Given any δ ∈ (0 1) , , for any probability measure ρ over LM such that ρ, π share the same support, the following holds with probability at least 1 -δ over the random draw of S :
$$\text{the following notas with probability at least 1} - o \, \text{over the random array of} \, \text{5} \colon \\ \mathbb { E } _ { L M \sim \rho } [ R ( p _ { L M } ) - \hat { R } _ { S } ( p _ { L M } ) ] \leq \sqrt { \frac { \left [ K L [ \rho | | \pi ] + \log \frac { 1 } { \delta } \right ] } { 2 n } } \, \coloneqq \, & \varrho ; \\ \mathbb { E } _ { L M \sim \rho } [ \mathbb { E } _ { ( q, c ) \sim D _ { \mathcal { P } _ { h } } } \ell _ { T V } ( p _ { L M }, ( q, c ) ) ] \leq \frac { 1 } { \alpha } \left [ \mathbb { E } _ { L M \sim \rho } \hat { R } _ { S } ( p _ { L M } ) + \varrho \right ]. \\ \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \end{cases}$$
In Appendix B.2 we give a theoretical estimation of ϱ , to illustrate the bound we derive is non-vacuous, i.e., less than 1 . The KL term is of order O K ( ) where K is the number of parameters involved in π, ρ , and n can be shown to greatly exceed K (using a realistic Zipf distribution assumption on prompts to estimate the number of unique prompts). Theorem 1 tells us that, as long as pretraining successfully reduces the loss on the training corpus ( ˆ R S ( p LM ) ↓ ), in expectation the language model will mimic the world well (small ℓ TV difference) on a given direct prompt sampled from D P . Furthermore, if α is not too small, then this statement holds on a direct prompt whose concept is harmful. Since we have defined the harmful concept as outputting harmful explanations with high probability (Definition 2.1), we conclude that an LM trained on D P data can output explanations in the harmful set.
## 4 A statistical perspective on jailbreaking after alignment
In this section, we will present the main theoretical contribution of our work: given our assumptions hold, we prove the existence of ways for an adversary to jailbreak an LM even after the preference alignment process . Our proof strategy is inspired by the work on adversarial robustness [41], which bounds the adversary's probability of success by upper bounding the volume of the set of points that does not allow for the existence of adversarial examples. Going forward, we need to extend our framework to integrate alignment and jailbreaking.
After an LM is pretrained, it typically will undergo fine-tuning on a dataset containing preferred behaviour. In what follows, we will assume that this alignment process does not change the model performance in the sense that the LM will still produce semantically meaningful explanations (Definition 2.1). It would not, for example, default to answering any request with the same response. Assumption 4.1. (LM outputs semantically meaningful explanations) For any harmful concept c , and all plausible prompts ( q, c ) ∈ dom( p world ) ,
$$\exists \left | E _ { n } ( c ) \right | \ll | E _ { h } ( c ) | + | E _ { s } ( c ) | \, s. t. \, O ( 1 ) \ll | \text{dom} ( p _ { L M } ( q, c ) ) | = | E _ { h } ( c ) \cup E _ { s } ( c ) \cup E _ { n } ( c ) |.$$
In other words, we assume the LM's output distribution is accurately supported on E h ( c ) ∪ E s ( c ) , in the sense that the size of 'residual' E n ( c ) is relatively small compared to these semantically meaningful explanations. We define n c ( ) = | E n ( c ) + | | E s ( c ) + | | E h ( c ) | . We omit the ( c ) annotations when clear from the context. The O (1) statement is reasonable, because harmful explanations are usually long text fragments that allow for many alternative formulations. The assumption can be broken down into two components: (1) within the support of the output distribution, only occasional
6 The inspiration for the proof of Theorem 1 comes from Mbacke et al. [45], and the proof idea is originally proposed in Germain et al. [46], Haddouche et al. [47].
instances of unrelated explanations exist; (2) the process of aligning the model towards safety does not eliminate the harmful explanations acquired during the pretraining phase. For part (1), similar to the example we gave above, under normal circumstances, we do not expect the explanation 'Paris' to appear in dom( p LM ( q, c )) given ( q, c ) as 'How to build a bomb' . As for part (2), though seemingly surprising, evidence with a series of current state-of-the-art LMs can be experimentally validated [48], where diverse, harmful explanations are extracted by simply manipulating the decoding process using direct prompts. In Section 5 we give an explanation for this undesired phenomenon.
To bound the likelihood of jailbreaking we first need to specify how the output of a LM interacts with its support. Assuming a fixed order of explanations in dom( p LM ( q, c )) , and slight abuse of notation, we can use p LM ( q, c ) to denote an n c ( ) -dimensional vector on ∆ n c ( ) -1 , the probability simplex with n c ( ) elements, where each entry represents the probability of a single explanation. We call this simplex the output simplex related to a given concept c . Next, we can induce a distribution on this simplex given a posterior distribution γ over the set of language models LM , as follows.
Definition 4.1. ( Induced Distribution on Simplex, γ c ) Under the assumption that the LM outputs semantically meaningful explanations (Assumption 4.1), with a fixed prompt ( q, c ) and a posterior distribution γ over LM , the corresponding induced distribution: p LM ( q, c ) where LM ∼ γ is supported over a subset of the output simplex ∆ n -1 . This distribution is denoted as γ ( q,c ) , or γ c when the reference to q is clear from context.
Next, we will separate the output simplex into a harmful and safety zone. This definition is motivated by the observation that typically an adversary is deemed successful if
Figure 2: Conceptual illustration of our framework for jailbreaking introduced in Section 4, with a fixed harmful concept c . The triangle represents the probability simplex. This figure showcases a typical successful jailbreaking attempt by the adversary: although safety alignment makes the sampled LM safe under the direct prompt input, the adversary is able to move the output to the harmful zone H h by manipulating the query q .
it can extract even a single harmful explanation for a given concept. This translates into a division of the output simplex, under Assumption 4.1, as follows.
Definition 4.2. ( Harmful Zone and Safety Zone ) For a given harmful concept c and a fixed LM, the output simplex is divided into a safety zone and a harmful zone , H s and H h , where a predefined threshold p ∈ [0 , 1] is used to quantify the distinction: p LM ( q, c ) ∈ H h if and only if ∑ e e : ∈ E h ( c ) p LM ( e q, c | ) ≥ p , and otherwise p LM ( q, c ) ∈ H s .
Before we introduce jailbreaking, the reader might wonder why we did not define alignment more clearly. This is because under the PAC framework, preference alignment is nothing but a transformation from ρ to some γ posterior defined over LM . Given this inability on fine-grained characterization of alignment, we instead provide the goal of it as follows. With the above notion, given a prompt ( q, c ) where c is harmful, its goal is to push the induced distribution γ c into the safety zone H s . Ideally, supp( γ c ) ⊂ H s ⇔ with probability 1 , the resulting LM is safe when encountering ( q, c ) . We are ready to introduce necessary concepts related to jailbreaking.
Definition 4.3. ( Jailbreaking ) Given a harmful concept c and a query q ′ , the prompt ( q , c ′ ) jailbreaks the LM iff p LM ( q , c ′ ) ∈ H h . We call such a prompt ( q , c ′ ) and query q ′ a jailbreaking prompt and jailbreaking query, respectively.
The threshold p for discriminating H h and H s should be very small, since it means in expectation the adversary needs to call the LM 1 p times to collect a single harmful explanation i.e., to jailbreak the LM.
To theoretically prove the jailbreaking effect, we need to restrict the adversary's ability. To achieve this goal, we borrow insights from adversarial attacks, to assume that the adversary has bounded manipulating capability on the output simplex when searching over the query set:
Assumption 4.2. ( ϵ -bounded adversary) Given an LM, a harmful concept c and an associated direct prompt ( q, c ) , we assume the adversary can find a set of queries Q ′ , such that the output is moved at most ϵ on the simplex towards H h from p LM ( q, c ) :
$$\sup _ { q ^ { \prime } \in \mathcal { Q } ^ { \prime } } d ( p _ { L M } ( q, c ), p _ { L M } ( q ^ { \prime }, c ) ) = \epsilon.$$
Here d is a distance measure between two discrete distributions. d can be a typical ℓ p measure with p ≥ 1 , or the Total Variation / Jensen-Shannon Divergence. We call q ′ ∈ Q ′ an ϵ -bounded query.
A conceptual illustration of our framework is depicted in Figure 2. Before arriving at our Theorem, we give the final definition of ϵ -expansion.
Definition 4.4. ( ϵ -expansion) Given a set A ⊂ ∆ n -1 and a distance measure d , the ϵ -expansion set A ϵ, d ( ) is defined as
$$A ( \epsilon, d ) \coloneqq \{ t | t \in \Delta ^ { n - 1 } \wedge \exists y \in A \ s. t. \, | | y - t | | _ { d } \leq \epsilon \}.$$
We are ready to present the following theorem, which states that as long as the induced posterior γ c is not concentrated in an extremely safe area, then with high probability the model can be jailbroken. The proof is in Appendix B.3.
Theorem 2. (Jailbreak is unavoidable) Assume that an LMs output semantically meaningful explanations (Assumption 4.1). Given any γ posterior distribution over LM , choose a harmful concept c with a direct prompt ( q, c ) and a threshold p (Definition 2.1), to define the corresponding induced distribution γ c (Definition 4.1) and division over output simplex (Definition 4.2). An ϵ -bounded adversary (Assumption 4.2) can find a jailbreaking prompt (Definition 4.3) with probability at least
$$1 - \gamma _ { s } \times \left ( 1 - \Phi ( a _ { \epsilon } ) \right ),$$
- · by using either the direct prompt, such that p LM ( q, c ) ∈ H h ; or
- · by finding an ϵ -bounded query q ′ , such that p LM ( q , c ′ ) ∈ H h .
Here, Φ( ) · is the standard Gaussian cdf, γ s := max x ∈H -H s h ( ϵ,d ) γ c ( x ) U x ( ) , with U x ( ) the uniform distribution over ∆ n -1 , and a ϵ := a + √ n -1 ϵ , where a writes analytically as a ≍ | E h ( c ) |- -1 ( n -1) p √ ( n -1) p (1 -p ) .
Trivially, the chances of an adversary to find a jailbreaking prompt increase for stronger adversaries ( ϵ ↑ ). In the real world, this could relate to how much compute budget we allow to alter a query for a specific harmful concept. Furthermore, the chances of an adversary to find a jailbreaking prompt increase when the ratio of the sizes of the harmful explanation set to the safe explanation set is larger | E h ( c ) | | E s ( c ) | ↑ . This is because their ratio will determine the size of the harmful zone which in turn will cause Φ( a ϵ ) → 1 . In real world settings, for any harmful concept, the training corpus naturally contains a large harmful set due to the number of possible responses. Realistically, its size can not be countered by any manually-constructed safe set. Hence achieving alignment is hard : Recall that the goal of alignment is to respond with only safe explanations with high probability. However, we just learned that to increase that probability, we need to have a small harmful-to-safety set ratio which we discussed is not realistic. Consequently, the safety zone is going to be small.
## 5 E-RLHF: improving alignment by expanding the safety zone
Recall from Theorem 2 and the subsequent discussion in the previous section, that jailbreaking becomes more likely the larger the harmful zone is in comparison to the safety zone. The size of both zones relates to the size of their respective explanation sets. In other words, the size of the preference alignment dataset is crucial to successful alignment. Unfortunately, the human labor involved in creating such a dataset effectively caps its size.
In order to bridge the gap between our theoretical insights and a practical solution towards suppressing the jailbreaking problem, we focus on other more practical ways to expand the safety zone . Even though our ideas are more broadly applicable, in our experiments we will focus on improving Reinforcement Learning with Human Feedback (RLHF). RLHF typically includes three phases: i) supervised fine-tuning (SFT); ii) preference sampling and reward learning and iii) RL optimization. Rafailov et al. [23] have recently proposed a widely applied version of RLHF for LMs, coined Direct Preference Optimization (DPO), that employs a clever reparameterization which leads to directly learning from the preference dataset, without the need of obtaining a reward model beforehand. DPO is more stable in the training process than other implementations of RLHF. A more complete overview of RLHF and DPO can be found in Appendix C.
For our purposes, we assume access to an LLM p SFT that has been supervised fine-tuned on highquality data. We further assume access to a preference aligned dataset D s ; that contains a set of text
prompts ( q, c ) = x , and two respective explanations that have been rated by human annotators as better e w or worse e l . In phase ii) of RLHF, one typically optimizes a reward model r x, e ( ) based on the annotated explanations. Our proposal concerns phase iii) of the RLHF process: training of the preference aligned model p LM . For a given reward model, p LM is typically obtained by optimizing the following objective;
$$\mathcal { L } _ { R L H F } \left ( p _ { L M } \right ) = - \mathbb { E } _ { x \sim \mathcal { D } _ { a }, e \sim p _ { L M } ( x ) } \left [ r ( x, e ) \right ] + \beta \mathbb { D } _ { \text{KL} } \left ( p _ { L M } ( x ) | | p _ { \text{SFT} } ( x ) \right ) \quad ( 2 )$$
Note that, the first term is maximizing the reward, while the KL-term acts as a regularizer ensuring the aligned model can not drift off too far from the SFT model. We claim that this regularization is exactly the problem. While designed to keep the model helpful 7 , for any harmful prompt x h and any harmful explanation e ∈ supp( p SFT ( x h )) , p LM will maintain e in the support of the output distribution. Specifically, the supervised fine-tuning process does not involve elimination of any harmful explanations from the support of the output distribution of the pretrained model, 8 thus this small safety set problem will be further passed to p LM , even if p LM is optimized to the optimal solution of the above objective. Thus, we should not push the LLM posterior into the same direction. Instead, for any harmful prompt x h , we propose to use a prior p SFT ( ) · that we design to have a large safety zone. We can achieve this by modifying the harmful prompt , such that a safe concept is used to replace the harmful concept, which alters supp( p SFT ) to include more safe explanations. This can be done in an individualized manner, or simply by prefacing all harmful prompts with a prefix such as "Please ensure your response adheres to community guidelines and ethical standards:" . 9 Importantly, the non-harmful prompts are not modified. Due to the focus of our approach to expand the safety zone of the output distribution, we coin our proposal E-RLHF , resulting in the following modification to Eq. (2):
$$\mathcal { L } _ { E \text{-RLHF} } \left ( p _ { L M } \right ) = - \mathbb { E } _ { x \sim \mathcal { D } _ { s }, e \sim p _ { L M } ( x ) } \left [ r ( x, e ) \right ] + \beta \mathbb { D } _ { \text{KL} } \left ( p _ { L M } ( x ) | | p _ { \text{SFT} } ( x _ { s } ) \right ) \quad \ \ ( 3 )$$
where x s is a safety-transformed version of the original harmful prompt x h . To recap, the key argument we put forth is that, in order to ensure the stability of model fine-tuning, it is not imperative to utilize identical prompt inputs x for both the reference model and the target model, particularly when the original input x itself is harmful. In fact, as long as the substitute or "anchor" prompt generates logically reasonable outputs akin to those produced by the original prompt, this approach would not impede the training process of the model. To solidify our argument we show the impact of our modification on the support of the optimal policy in Appendix C. We also deduce there that we can trivially integrate our modification into the DPO objective allowing us to train without an explicit reward model (eliminates step ii)) as follows, where σ ( ) · stands for the sigmoid function:
$$\mathcal { L } _ { \mathcal { E } \mathcal { D } \mathcal { P } } \left ( p _ { L M } \right ) = - \mathbb { E } _ { \left ( x, e _ { w }, e _ { l } \right ) \sim \mathcal { D } _ { s } } \left [ \log \sigma \left ( \beta \log \frac { p _ { L M } \left ( e _ { w } \left | \, x \right ) } { p _ { S F T } \left ( e _ { w } \left | \, x _ { s } \right ) } - \beta \log \frac { p _ { L M } \left ( e _ { l } \left | \, x \right ) } { p _ { S F T } \left ( e _ { l } \left | \, x _ { s } \right ) } \right ) \right ]. \quad ( 4 )$$
## 6 Experiments and results
Our experimental set-up is based on the alignment-handbook code base [50]. We tune the publiclyavailable SFT model p SFT provided by huggingface hub [51], using the public dataset [52, 53], with default hyperparameter setup. We label harmful prompts in the preference dataset by prompting GPT-3.5-Turbo, see Appendix E. We are using the very same prefix proposed in the previous section to generate x s . Experiments are performed on 8 NVIDIA Tesla V100 GPUs, using half-precision tuning i.e., Float16. In the appendix, we also show results for an alternative training paradigm: the Low-Rank Adaptation (LoRA) [54] (see Appendix D.1). Following community standards [3, 1, 2], we use greedy decoding i.e., T = 0 for model evaluation.
Wefirst show empirical evidence that our proposed modification of DPO, E-DPO, does in fact improve safety alignment, using the Harmbench dataset [2] and the first 100 prompts in the AdvBench harmful behavior dataset [1], measured by the HarmBench protocol. We give an overview on all adversaries in Appendix F. The results are presented in Table 1. E-DPO achieves improvements across every task we tested.
On top of our safety results, we want to make sure E-RLHF does not sacrifice helpfulness for increased safety . We evaluate helpfulness with the MT-Bench project [3]. The SFT model p SFT
7 Otherwise the model could drift into trivial behaviour like always responding with "I can't help you." 8
.
Even the probability can be suppressed to close to 0.
9 The prefix shares similarities to the system prompts used by open-source LLMs [13, 49] to boost safety.
Table 1: Safety alignment with the E-RLHF objective, here specifically E-DPO, reduces the average Attack Success Rate (ASR) across all jailbreak adversaries for both the HarmBench and the AdvBench data, to 36 95 . , and to 20 89 . , respectively. Moreover, resilience against all adversaries improves with our modification to safety alignment ( indicates better performance between DPO and E-DPO).
| HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] |
|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|
| Model | Direct Request | GCG | GBDA | AP | SFS | ZS | PAIR | TAP | AutoDAN | PAP-top5 | Human | AVG ↓ |
| p SFT | 32 . 25 | 59 . 25 | 35 . 50 | 42 . 75 | 42 . 75 | 36 . 20 | 56 . 50 | 65 . 00 | 56 . 75 | 26 . 75 | 35 . 50 | 44 . 47 |
| p DPO | 27 . 50 | 53 . 00 | 39 . 00 | 46 . 75 | 43 . 25 | 29 . 10 | 52 . 50 | 54 . 00 | 51 . 00 | 28 . 75 | 37 . 15 | 42 . 00 |
| p E-DPO (ours) | 23 . 50 | 47 . 50 | 31 . 75 | 36 . 25 | 40 . 50 | 26 . 45 | 48 . 50 | 51 . 00 | 43 . 00 | 27 . 00 | 31 . 05 | 36 . 95 |
| AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] |
| p SFT | 6 . 00 | 80 . 00 | 13 . 00 | 37 . 00 | 31 . 00 | 14 . 80 | 65 . 00 | 78 . 00 | 91 . 00 | 4 . 00 | 21 . 20 | 40 . 09 |
| p DPO | 0 . 00 | 47 . 00 | 12 . 00 | 39 . 00 | 30 . 00 | 7 . 00 | 50 . 00 | 61 . 00 | 44 . 00 | 4 . 00 | 18 . 40 | 28 . 40 |
| p E-DPO (ours) | 0 . 00 | 38 . 00 | 8 . 00 | 15 . 00 | 21 . 00 | 5 . 20 | 41 . 00 | 53 . 00 | 31 . 00 | 4 . 00 | 13 . 60 | 20 . 89 |
receives a score of 6.3, and both the DPO and E-DPO models perform better than that (6.8 and 6.6 respectively), making us believe that performance degradation is not a problem with our proposal. Next, we show the impact of the safe prefix on model performance. We demonstrate that our method's performance depends on the choice of safe prefix to some extend but never fails (see Appendix D.2). We believe, finding better safe prefixes by explicit tuning would improve our results, similar to the work by Yang et al. [55], but we leave this exploration for future work. Further, we confirm that the improvement arises from using a safe prior in the KL term for harmful prompts. We ablate our results by appending the prefix on all prompts in the preference alignment dataset (see Appendix D.3). In all cases, applying the safe prefix to usual prompts degrades safety, showcasing the importance of switching the prior only on the harmful prompts. Finally, we show that E-DPO can be combined with any system prompt, to further boost safety (see Appendix D.4). The proposal can even be used to improve helpfulness and safety simultaneously (see Appendix D.5).
## 7 Conclusion and discussions
In this paper, we present a theoretical framework for language model pretraining and jailbreaking by dissecting input prompts into query and concept pairs. Through this approach, we have established two theoretical results pertaining to the ability of language models to mimic the world following pretraining, which leads to outputting harmful explanations given harmful prompts; and the inevitability of jailbreaking resulting from alignment challenges. Guided by these theoretical insights, we have devised a simple yet effective technique to enhance safety alignment, and demonstrate the improved resilience to jailbreak attacks with this methodology.
Current limitations (1) Although we have classified concepts as either harmful or non-harmful, it is important to acknowledge that the perception of a concept's potential for harm can be influenced by various factors such as cultural, legal, and societal norms, which collectively form the context of the situation. (2) Language models have demonstrated impressive capabilities in reasoning and completing tasks within multi-round, multi-step conversations; our current framework may not fully account for the generalization and jailbreaking possibilities associated with such input formats. (3) Our analysis is grounded on a fixed p world mapping and D P distribution. Nevertheless, the world is inherently dynamic, as both p world and D P continually evolve.
Future work (1) Regarding our E-RLHF approach, as highlighted in the experimental section, in addition to attaching a universally safe prefix to all harmful prompts, improvements can be achieved by individually transforming the harmful prompts. Moreover, the safety-transformed prompts can be employed to expand the preference dataset for conventional RLHF. (2) Throughout our analysis, we have not imposed any constraints on the capacity of the language model. Extending our analysis under finite memory constraints or analyzing hallucination properties of LLMs is an interesting direction to explore. (3) Large language models have shown remarkable capabilities as in-context learners [56], and such techniques could potentially be used for jailbreaking them as well [57-59]. Investigating the incorporation of such input paradigms remains a promising avenue for future research.
## References
- [1] Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 , 2023. 1, 2, 8, 9, 26, 27, 28, 29, 30, 31
- [2] Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249 , 2024. 1, 2, 8, 9, 26, 27, 28
- [3] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems , 37, 2023. 1, 8, 27
- [4] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 , 2023. 1
- [5] Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. Nature , 620(7972):172-180, 2023. 1
- [6] Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. Leandojo: Theorem proving with retrieval-augmented language models. Advances in Neural Information Processing Systems , 36, 2024. 1
- [7] Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages 610-623, 2021. 1
- [8] Julian Hazell. Large language models can be used to effectively scale spear phishing campaigns. arXiv preprint arXiv:2305.06972 , 2023.
- [9] Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, and Yang Liu. Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860 , 2023. 1, 29
- [10] OpenAI. Chatgpt. https://openai.com/index/chatgpt/ , 2022. 1
- [11] DAN. Do anything now prompt. https://github.com/0xk1h0/ChatGPT\_DAN , 2023. 1
- [12] Reddit. Chatgpt grandma exploit. https://www.reddit.com/r/ChatGPT/comments/ 12sn0kk/grandma\_exploit/ , 2023. 1
- [13] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 , 2023. 2, 8, 21, 25
- [14] Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858 , 2022. 2, 30
- [15] Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. arXiv preprint arXiv:2202.03286 , 2022. 28
- [16] Stephen Casper, Jason Lin, Joe Kwon, Gatlen Culp, and Dylan Hadfield-Menell. Explore, establish, exploit: Red teaming language models from scratch. arXiv preprint arXiv:2306.09442 , 2023.
| [17] | Zhang-Wei Hong, Idan Shenfeld, Tsun-Hsuan Wang, Yung-Sung Chuang, Aldo Pareja, James R Glass, Akash Srivastava, and Pulkit Agrawal. Curiosity-driven red-teaming for large language models. In The Twelfth International Conference on Learning Representations , 2023. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [18] | Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram H Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, et al. Rainbow teaming: Open-ended generation of diverse adversarial prompts. arXiv preprint arXiv:2402.16822 , 2024. 2, 30 |
| [19] | Daniel MZiegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593 , 2019. 2, 24, 30 |
| [20] | Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems , 35:27730-27744, 2022. 24, 30 |
| [21] | Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073 , 2022. 24, 30 |
| [22] | Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Vinayak Bhalerao, Christopher Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. In International Conference on Machine Learning , pages 17506-17533. PMLR, 2023. 30 |
| [23] | Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290 , 2023. 2, 7, 24, 25, 32 |
| [24] | Sicheng Zhu, Ruiyi Zhang, Bang An, Gang Wu, Joe Barrow, Zichao Wang, Furong Huang, Ani Nenkova, and Tong Sun. Autodan: Automatic and interpretable adversarial attacks on large language models. arXiv preprint arXiv:2310.15140 , 2023. 2, 29 |
| [25] | Raz Lapid, Ron Langberg, and Moshe Sipper. Open sesame! universal black box jailbreaking of large language models. arXiv preprint arXiv:2309.01446 , 2023. 2, 29 |
| [26] | Zheng-Xin Yong, Cristina Menghini, and Stephen H Bach. Low-resource languages jailbreak gpt-4. arXiv preprint arXiv:2310.02446 , 2023. 2, 30 |
| [27] | Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. Multilingual jailbreak challenges in large language models. arXiv preprint arXiv:2310.06474 , 2023. 30 |
| [28] | Youliang Yuan, Wenxiang Jiao, Wenxuan Wang, Jen-tse Huang, Pinjia He, Shuming Shi, and Zhaopeng Tu. Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher. arXiv preprint arXiv:2308.06463 , 2023. 2, 30 |
| [29] | Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. arXiv preprint arXiv:2310.04451 , 2023. 2, 28, 29 |
| [30] | Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419 , 2023. 27, 28, 29 |
| [31] | Xiaoxia Li, Siyuan Liang, Jiyi Zhang, Han Fang, Aishan Liu, and Ee-Chien Chang. Semantic mirror jailbreak: Genetic algorithm based jailbreak prompts against open-source llms. arXiv preprint arXiv:2402.14872 , 2024. 29 |
| [32] | Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, and Shujian Huang. A wolf in sheep's clothing: Generalized nested jailbreak prompts can fool large language models easily. arXiv preprint arXiv:2311.08268 , 2023. 29 |
| [33] | Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically. arXiv preprint arXiv:2312.02119 , 2023. 2, 28, 29 |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [34] | Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. Smoothllm: Defending large language models against jailbreaking attacks. arXiv preprint arXiv:2310.03684 , 2023. 2, 31, 32 |
| [35] | Bochuan Cao, Yuanpu Cao, Lu Lin, and Jinghui Chen. Defending against alignment-breaking attacks via robustly aligned llm. arXiv preprint arXiv:2309.14348 , 2023. 31 |
| [36] | Aounon Kumar, Chirag Agarwal, Suraj Srinivas, Soheil Feizi, and Hima Lakkaraju. Certifying llm safety against adversarial prompting. arXiv preprint arXiv:2309.02705 , 2023. 31 |
| [37] | Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping- yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Base- line defenses for adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614 , 2023. 2, 31 |
| [38] | Yotam Wolf, Noam Wies, Yoav Levine, and Amnon Shashua. Fundamental limitations of alignment in large language models. arXiv preprint arXiv:2304.11082 , 2023. 2, 3, 32 |
| [39] | Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 , 2013. 2 |
| [40] | Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy. In International Conference on Learning Representations , 2018. 2 |
| [41] | Ali Shafahi, W Ronny Huang, Christoph Studer, Soheil Feizi, and Tom Goldstein. Are adversarial examples inevitable? In International Conference on Learning Representations , 2018. 5 |
| [42] | Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via random- ized smoothing. In international conference on machine learning , pages 1310-1320. PMLR, 2019. 2 |
| [43] | Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615 , 2022. 4 |
| [44] | David A McAllester. Some pac-bayesian theorems. In Proceedings of the eleventh annual conference on Computational learning theory , pages 230-234, 1998. 4 |
| [45] | Sokhna Diarra Mbacke, Florence Clerc, and Pascal Germain. Pac-bayesian generalization bounds for adversarial generative models. arXiv preprint arXiv:2302.08942 , 2023. 5 |
| [46] | Pascal Germain, Alexandre Lacasse, François Laviolette, and Mario Marchand. Pac-bayesian learning of linear classifiers. In Proceedings of the 26th Annual International Conference on Machine Learning , pages 353-360, 2009. 5 |
| [47] | Maxime Haddouche, Benjamin Guedj, Omar Rivasplata, and John Shawe-Taylor. Pac-bayes unleashed: Generalisation bounds with unbounded losses. Entropy , 23(10):1330, 2021. 5 |
| [48] | Yangsibo Huang, Samyak Gupta, Mengzhou Xia, Kai Li, and Danqi Chen. Catastrophic jailbreak of open-source llms via exploiting generation. arXiv preprint arXiv:2310.06987 , 2023. 6, 26, 29 |
| [49] | Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825 , 2023. 8 |
| [50] | Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Shengyi Huang, Kashif Rasul, Alexander M. Rush, and Thomas Wolf. The alignment handbook. https://github. com/huggingface/alignment-handbook , 2023. 8 |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [51] | HuggingFace. Huggingface constitutional-ai sft model. https://huggingface.co/ alignment-handbook/mistral-7b-sft-constitutional-ai , 2024. 8 |
| [52] | HuggingFace. Huggingface constitutional-ai dataset: Ultrafeedback-binarized. https:// huggingface.co/datasets/HuggingFaceH4/ultrafeecback_binarized , 2024. 8 |
| [53] | HuggingFace. Huggingface constitutional-ai dataset: Cai-conversation-harmless. https:// huggingface.co/datasets/HuggingFaceH4/cai-conversation-harmless , 2024. 8 |
| [54] | Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations , 2021. 8, 26 |
| [55] | Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. arXiv preprint arXiv:2309.03409 , 2023. 9, 25 |
| [56] | Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877- 1901, 2020. 9 |
| [57] | Zeming Wei, Yifei Wang, and Yisen Wang. Jailbreak and guard aligned language models with only few in-context demonstrations. arXiv preprint arXiv:2310.06387 , 2023. 9, 30 |
| [58] | Jiongxiao Wang, Zichen Liu, Keun Hee Park, Muhao Chen, and Chaowei Xiao. Adversarial demonstration attacks on large language models. arXiv preprint arXiv:2305.14950 , 2023. 30 |
| [59] | Cem Anil, Esin Durmus, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Nina Rimsky, Meg Tong, Jesse Mu, Daniel Ford, et al. Many-shot jailbreaking, 2024. 9, 30 |
| [60] | Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nati Srebro. Exploring generalization in deep learning. Advances in neural information processing systems , 30, 2017. 20 |
| [61] | Wesley J Maddox, Pavel Izmailov, Timur Garipov, Dmitry P Vetrov, and Andrew Gordon Wilson. A simple baseline for bayesian uncertainty in deep learning. Advances in neural information processing systems , 32, 2019. 20 |
| [62] | Robert D Gordon. Values of mills' ratio of area to bounding ordinate and of the normal probability integral for large values of the argument. The Annals of Mathematical Statistics , 12(3):364-366, 1941. 22 |
| [63] | Paul F Christiano, Jan Leike, TomBrown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems , 30, 2017. 24 |
| [64] | Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika , 39(3/4):324-345, 1952. 24 |
| [65] | John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 , 2017. 24 |
| [66] | Banghua Zhu, Hiteshi Sharma, Felipe Vieira Frujeri, Shi Dong, Chenguang Zhu, Michael I Jor- dan, and Jiantao Jiao. Fine-tuning language models with advantage-induced policy alignment. arXiv preprint arXiv:2306.02231 , 2023. 24 |
| [67] | Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry. Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv preprint arXiv:2005.12729 , 2020. 24 |
| [68] | Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems , 35:24824-24837, 2022. 25 |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [69] | Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861 , 2021. 25 |
| [70] | Xiaotian Zou, Yongkang Chen, and Ke Li. Is the system message really important to jailbreaks in large language models? arXiv preprint arXiv:2402.14857 , 2024. 26, 31 |
| [71] | Chuan Guo, Alexandre Sablayrolles, Hervé Jégou, and Douwe Kiela. Gradient-based adver- sarial attacks against text transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 5747-5757, 2021. 28, 29 |
| [72] | Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. Auto- prompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980 , 2020. 28, 29 |
| [73] | Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms. arXiv preprint arXiv:2401.06373 , 2024. 28, 30 |
| [74] | Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. arXiv preprint arXiv:2308.03825 , 2023. 28, 29 |
| [75] | Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. Universal ad- versarial triggers for attacking and analyzing nlp. arXiv preprint arXiv:1908.07125 , 2019. 28 |
| [76] | Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Goldblum, Jonas Geiping, and Tom Gold- stein. Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery. Advances in Neural Information Processing Systems , 36, 2024. 28 |
| [77] | Erik Jones, Anca Dragan, Aditi Raghunathan, and Jacob Steinhardt. Automatically auditing large language models via discrete optimization. arXiv preprint arXiv:2303.04381 , 2023. 29 |
| [78] | Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527 , 2022. 29 |
| [79] | Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail? In Thirty-seventh Conference on Neural Information Processing Systems , 2023. 29 |
| [80] | Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, and Yang Liu. Jailbreaker: Automated jailbreak across multiple large language model chatbots. arXiv preprint arXiv:2307.08715 , 2023. 29 |
| [81] | Jiahao Yu, Xingwei Lin, and Xinyu Xing. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. arXiv preprint arXiv:2309.10253 , 2023. 29 |
| [82] | Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems , 36, 2024. 29 |
| [83] | Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. Deepin- ception: Hypnotize large language model to be jailbreaker. arXiv preprint arXiv:2311.03191 , 2023. 29 |
| [84] | Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers. arXiv preprint arXiv:2402.16914 , 2024. 29 |
| [85] | Zhenhua Wang, Wei Xie, Baosheng Wang, Enze Wang, Zhiwen Gui, Shuoyoucheng Ma, and Kai Chen. Foot in the door: Understanding large language model jailbreaking via cognitive psychology. arXiv preprint arXiv:2402.15690 , 2024. 29 |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [86] | Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, and Yuandong Tian. Advprompter: Fast adaptive adversarial prompting for llms. arXiv preprint arXiv:2404.16873 , 2024. 29 |
| [87] | Hangfan Zhang, Zhimeng Guo, Huaisheng Zhu, Bochuan Cao, Lu Lin, Jinyuan Jia, Jinghui Chen, and Dinghao Wu. On the safety of open-sourced large language models: Does alignment really prevent them from being misused? arXiv preprint arXiv:2310.01581 , 2023. 29 |
| [88] | Xuandong Zhao, Xianjun Yang, Tianyu Pang, Chao Du, Lei Li, Yu-Xiang Wang, and William Yang Wang. Weak-to-strong jailbreaking on large language models. arXiv preprint arXiv:2401.17256 , 2024. 29 |
| [89] | Xianjun Yang, Xiao Wang, Qi Zhang, Linda Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. Shadow alignment: The ease of subverting safely-aligned language models. arXiv preprint arXiv:2310.02949 , 2023. 29 |
| [90] | Qiusi Zhan, Richard Fang, Rohan Bindu, Akul Gupta, Tatsunori Hashimoto, and Daniel Kang. Removing rlhf protections in gpt-4 via fine-tuning. arXiv preprint arXiv:2311.05553 , 2023. 29 |
| [91] | Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693 , 2023. 29 |
| [92] | Erfan Shayegani, Yue Dong, and Nael Abu-Ghazaleh. Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models. arXiv preprint arXiv:2307.14539 , 2023. 30 |
| [93] | Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak large language models. arXiv preprint arXiv:2306.13213 , 2023. 30 |
| [94] | Nicholas Carlini, Milad Nasr, Christopher A Choquette-Choo, Matthew Jagielski, Irena Gao, Pang Wei Koh, Daphne Ippolito, Florian Tramèr, and Ludwig Schmidt. Are aligned neural networks adversarially aligned? In Thirty-seventh Conference on Neural Information Processing Systems , 2023. 30 |
| [95] | Natalie Maus, Patrick Chao, Eric Wong, and Jacob RGardner. Black box adversarial prompting for foundation models. In The Second Workshop on New Frontiers in Adversarial Machine Learning , 2023. 30 |
| [96] | Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/ . 30 |
| [97] | Daniel Kang, Xuechen Li, Ion Stoica, Carlos Guestrin, Matei Zaharia, and Tatsunori Hashimoto. Exploiting programmatic behavior of llms: Dual-use through standard secu- rity attacks. arXiv preprint arXiv:2302.05733 , 2023. 30 |
| [98] | Rusheb Shah, Soroush Pour, Arush Tagade, Stephen Casper, Javier Rando, et al. Scalable and transferable black-box jailbreaks for language models via persona modulation. arXiv preprint arXiv:2311.03348 , 2023. 30 |
| [99] | Xingang Guo, Fangxu Yu, Huan Zhang, Lianhui Qin, and Bin Hu. Cold-attack: Jailbreaking llms with stealthiness and controllability. arXiv preprint arXiv:2402.08679 , 2024. 30 |
| [100] | Lianhui Qin, Sean Welleck, Daniel Khashabi, and Yejin Choi. Cold decoding: Energy- based constrained text generation with langevin dynamics. Advances in Neural Information Processing Systems , 35:9538-9551, 2022. 30 |
| [101] | Somnath Banerjee, Sayan Layek, Rima Hazra, and Animesh Mukherjee. How (un) ethical are instruction-centric responses of llms? unveiling the vulnerabilities of safety guardrails to harmful queries. arXiv preprint arXiv:2402.15302 , 2024. 30 |
|---------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [102] | Neal Mangaokar, Ashish Hooda, Jihye Choi, Shreyas Chandrashekaran, Kassem Fawaz, Somesh Jha, and Atul Prakash. Prp: Propagating universal perturbations to attack large language model guard-rails. arXiv preprint arXiv:2402.15911 , 2024. 30 |
| [103] | Huijie Lv, Xiao Wang, Yuansen Zhang, Caishuang Huang, Shihan Dou, Junjie Ye, Tao Gui, Qi Zhang, and Xuanjing Huang. Codechameleon: Personalized encryption framework for jailbreaking large language models. arXiv preprint arXiv:2402.16717 , 2024. 30 |
| [104] | Vinu Sankar Sadasivan, Shoumik Saha, Gaurang Sriramanan, Priyatham Kattakinda, Atoosa Chegini, and Soheil Feizi. Fast adversarial attacks on language models in one gpu minute. arXiv preprint arXiv:2402.15570 , 2024. 30 |
| [105] | Jonas Geiping, Alex Stein, Manli Shu, Khalid Saifullah, Yuxin Wen, and Tom Goldstein. Coercing llms to do and reveal (almost) anything. arXiv preprint arXiv:2402.14020 , 2024. 30 |
| [106] | Qibing Ren, Chang Gao, Jing Shao, Junchi Yan, Xin Tan, Wai Lam, and Lizhuang Ma. Exploring safety generalization challenges of large language models via code, 2024. 30 |
| [107] | Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations , 2018. 30 |
| [108] | Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages 308-318, 2016. 30 |
| [109] | Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 , 2022. 30 |
| [110] | Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Lu, Thomas Mesnard, Colton Bishop, Victor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267 , 2023. 30 |
| [111] | Gabriel Alon and Michael Kamfonas. Detecting language model attacks with perplexity. arXiv preprint arXiv:2308.14132 , 2023. 31 |
| [112] | Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems , 30, 2017. 31 |
| [113] | Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, Xing Xie, and Fangzhao Wu. Defending chatgpt against jailbreak attack via self-reminders. Nature Machine Intelligence , pages 1-11, 2023. 31 |
| [114] | Chujie Zheng, Fan Yin, Hao Zhou, Fandong Meng, Jie Zhou, Kai-Wei Chang, Minlie Huang, and Nanyun Peng. Prompt-driven llm safeguarding via directed representation optimization. arXiv preprint arXiv:2401.18018 , 2024. 31 |
| [115] | Andy Zhou, Bo Li, and Haohan Wang. Robust prompt optimization for defending language models against jailbreaking attacks. arXiv preprint arXiv:2401.17263 , 2024. 31 |
| [116] | Yichuan Mo, Yuji Wang, Zeming Wei, and Yisen Wang. Studious bob fight back against jailbreaking via prompt adversarial tuning. arXiv preprint arXiv:2402.06255 , 2024. 31 |
| [117] | Zhexin Zhang, Junxiao Yang, Pei Ke, and Minlie Huang. Defending large language models against jailbreaking attacks through goal prioritization. arXiv preprint arXiv:2311.09096 , 2023. 31 |
| [118] | Yujun Zhou, Yufei Han, Haomin Zhuang, Taicheng Guo, Kehan Guo, Zhenwen Liang, Hongyan Bao, and Xiangliang Zhang. Defending jailbreak prompts via in-context adver- sarial game. arXiv preprint arXiv:2402.13148 , 2024. 31 |
|---------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [119] | Alec Helbling, Mansi Phute, Matthew Hull, and Duen Horng Chau. Llm self defense: By self examination, llms know they are being tricked. arXiv preprint arXiv:2308.07308 , 2023. 31 |
| [120] | Zezhong Wang, Fangkai Yang, Lu Wang, Pu Zhao, Hongru Wang, Liang Chen, Qingwei Lin, and Kam-Fai Wong. Self-guard: Empower the llm to safeguard itself. arXiv preprint arXiv:2310.15851 , 2023. 31 |
| [121] | Yuhui Li, Fangyun Wei, Jinjing Zhao, Chao Zhang, and Hongyang Zhang. Rain: Your language models can align themselves without finetuning. arXiv preprint arXiv:2309.07124 , 2023. 31 |
| [122] | Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, and Radha Pooven- dran. Safedecoding: Defending against jailbreak attacks via safety-aware decoding. arXiv preprint arXiv:2402.08983 , 2024. 31 |
| [123] | Adib Hasan, Ileana Rugina, and Alex Wang. Pruning for protection: Increasing jailbreak resistance in aligned llms without fine-tuning. arXiv preprint arXiv:2401.10862 , 2024. 31 |
| [124] | Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695 , 2023. 31 |
| [125] | Renjie Pi, Tianyang Han, Yueqi Xie, Rui Pan, Qing Lian, Hanze Dong, Jipeng Zhang, and Tong Zhang. Mllm-protector: Ensuring mllm's safety without hurting performance. arXiv preprint arXiv:2401.02906 , 2024. 31 |
| [126] | Yuqi Zhang, Liang Ding, Lefei Zhang, and Dacheng Tao. Intention analysis prompting makes large language models a good jailbreak defender. arXiv preprint arXiv:2401.06561 , 2024. 31 |
| [127] | Yihan Wang, Zhouxing Shi, Andrew Bai, and Cho-Jui Hsieh. Defending llms against jailbreak- ing attacks via backtranslation. arXiv preprint arXiv:2402.16459 , 2024. 31 |
| [128] | Heegyu Kim, Sehyun Yuk, and Hyunsouk Cho. Break the breakout: Reinventing lm defense against jailbreak attacks with self-refinement. arXiv preprint arXiv:2402.15180 , 2024. 31 |
| [129] | Yifan Zeng, Yiran Wu, Xiao Zhang, Huazheng Wang, and Qingyun Wu. Autodefense: Multi- agent llm defense against jailbreak attacks, 2024. 31 |
| [130] | Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. Gradient cuff: Detecting jailbreak attacks on large language models by exploring refusal loss landscapes. arXiv preprint arXiv:2403.00867 , 2024. 32 |
| [131] | Jiabao Ji, Bairu Hou, Alexander Robey, George J Pappas, Hamed Hassani, Yang Zhang, Eric Wong, and Shiyu Chang. Defending large language models against jailbreak attacks via semantic smoothing. arXiv preprint arXiv:2402.16192 , 2024. 32 |
| [132] | Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674 , 2023. 32 |
| [133] | Swapnaja Achintalwar, Adriana Alvarado Garcia, Ateret Anaby-Tavor, Ioana Baldini, Sara E. Berger, Bishwaranjan Bhattacharjee, Djallel Bouneffouf, Subhajit Chaudhury, Pin-Yu Chen, Lamogha Chiazor, Elizabeth M. Daly, Rogério Abreu de Paula, Pierre Dognin, Eitan Farchi, Soumya Ghosh, Michael Hind, Raya Horesh, George Kour, Ja Young Lee, Erik Miehling, Keerthiram Murugesan, Manish Nagireddy, Inkit Padhi, David Piorkowski, Ambrish Rawat, Orna Raz, Prasanna Sattigeri, Hendrik Strobelt, Sarathkrishna Swaminathan, Christoph Till- mann, Aashka Trivedi, Kush R. Varshney, Dennis Wei, Shalisha Witherspooon, and Marcel Zalmanovici. Detectors for safe and reliable llms: Implementations, uses, and limitations, |
- [134] Adam Tauman Kalai and Santosh S Vempala. Calibrated language models must hallucinate. arXiv preprint arXiv:2311.14648 , 2023. 32
- [135] Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Wattenberg, Jonathan K Kummerfeld, and Rada Mihalcea. A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity. arXiv preprint arXiv:2401.01967 , 2024. 32
- [136] Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. Assessing the brittleness of safety alignment via pruning and low-rank modifications. arXiv preprint arXiv:2402.05162 , 2024. 32
## Appendix
## A Glossary
Table 2: Summary of notation.
| Symbol | Meaning |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| q c x = ( q, c ) e Q C E P ⊊ Q×C p world : P → ∆( E p world ( q, c ) supp( p world ( q, c )) p LM : P → ∆( E ) p LM ( q, c ) dom( p LM ( q, c )) ( q, c ) ∼ D P supp( D P ) ⊊ P LM π ρ γ | A single query, composable with a certain set of concepts. A single concept, composable with a certain set of queries. A single prompt composed by query q and concept c . A single explanation. The query set. The concept set. The explanation set. The set of plausible prompts. The world mapping. For each plausible prompt, it specifies the ground-truth distribution over E , a.k.a. the 'knowledge'. The ground-truth distribution over a subset of E , given a prompt ( q, c ) . With slight abuse of notation, it also refers to a point on the probability simplex. Support of p world ( q, c ) . A strict subset of E . A language model. For each plausible prompt, it specifies a distribution over (a subset of) E , to mimic p world . The output distribution over (a subset of) E by LM, given a prompt ( q, c ) . With slight abuse of notation, it also refers to a point on the probability simplex. Domain of the p LM ( q, c ) distribution, a subset of E . Underlying generative distribution over prompts, a.k.a. the distribution governing the creation of our pretraining corpus. Support of D P . ( q, c ) ∈ supp( D P ) is called a direct prompt . A set of language models. The prior distribution over LM . The posterior distribution over LM , after pretraining. The posterior distribution over LM , after preference alignment. |
## B Proof of Theorems
## B.1 Proof of PAC-Bayesian bounds
Definition B.1. (Bounded Difference) A function f : X n → R is said to have bounded difference property w.r.t. a collection of constants c 1 , · · · , c n , iff
$$\sup _ { x _ { 1 }, x _ { 2 }, \dots, x _ { n }, x _ { i } ^ { ^ { \prime } } } | f ( x _ { 1 }, x _ { 2 }, \cdots, x _ { n } ) - f ( x _ { 1 }, x _ { 2 }, \cdots, x _ { i - 1 }, x _ { i } ^ { ^ { \prime } }, \cdots, x _ { n } ) | \leq c _ { i }, \forall i \in [ n ].$$
Lemma B.1. (Hoeffding's Lemma) for random variable X ∈ [ a, b ] with probability 1, the following holds:
$$\mathbb { E } [ \exp ( \lambda X ) ] \leq \exp ( \lambda \mathbb { E } X + \frac { \lambda ^ { 2 } ( b - a ) ^ { 2 } } { 8 } ). \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Lemma B.2. (Hoeffding's Lemma, Multivariate) for random variables Z = f ( x , 1 · · · , x n ) where f has the bounded difference property, the following holds:
$$\mathbb { E } [ \exp ( \lambda ( \mathbb { E } Z - Z ) ) ] \leq \exp ( \frac { \lambda ^ { 2 } \sum _ { i = 1 } ^ { n } c _ { i } ^ { 2 } } { 8 } ).$$
Note that substituting Z with ˆ R S ( LM ) is valid.
Lemma B.3. Empirical Loss defined in Definition 3.1 satisfies the bounded difference condition with constant c = 1 , ∀ i .
We are ready to present the proof of Theorem 1.
Proof. Starting with the above lemma, we know
$$\mathbb { E } _ { S } [ \exp ( \lambda ( R ( L M ) - \hat { R } _ { S } ( L M ) ) ) ] \leq \exp ( \frac { \lambda ^ { 2 } c ^ { 2 } } { 8 n } ).$$
The above result holds for a manually picked LM. With an overall average over the prior π we have
$$\mathbb { E } _ { L M \sim \pi } \mathbb { E } _ { S } [ \exp ( \lambda ( R ( L M ) - \hat { R } _ { S } ( L M ) ) ) ] \leq \exp ( \frac { \lambda ^ { 2 } c ^ { 2 } } { 8 n } ).$$
Apply Fubini's theorem (note that π is independent of S ):
$$\mathbb { E } _ { S } \mathbb { E } _ { L M \sim \pi } [ \exp ( \lambda ( R ( L M ) - \hat { R } _ { S } ( L M ) ) ) ] \leq \exp ( \frac { \lambda ^ { 2 } c ^ { 2 } } { 8 n } ).$$
Define Y = E LM ∼ π [exp( λ R LM ( ( ) -ˆ R S ( LM )))] , a random variable depends on S . Obviously Y ≥ 0 . Thus, with Markov's inequality:
$$\mathbb { P } [ Y \geq \frac { 1 } { \delta } \mathbb { E } _ { S } Y ] \leq \delta.$$
Equivalently, with probability at least 1 -δ , we have
$$Y \leq \frac { 1 } { \delta } \exp [ \frac { \lambda ^ { 2 } c ^ { 2 } } { 8 n } ].$$
Since we have assumed π, ρ share the same support, using Radon-Nykodim derivative to change the expectation with respect to π to with respect to ρ , we have
$$\mathbb { E } _ { L M \sim \rho } \left [ \frac { d \pi } { d \rho } \exp ( \lambda ( R ( L M ) - \hat { R } _ { S } ( L M ) ) ) \right ] \leq \frac { 1 } { \delta } \exp [ \frac { \lambda ^ { 2 } c ^ { 2 } } { 8 n } ].$$
Taking logarithm and applying Jensen's Inequality we know
$$\mathbb { E } _ { L M \sim \rho } \left [ \frac { d \pi } { d \rho } + \lambda ( R ( L M ) - \hat { R } _ { S } ( L M ) ) \right ] \leq \log \frac { 1 } { \delta } + \frac { \lambda ^ { 2 } c ^ { 2 } } { 8 n }.$$
Incorporating c = 1 , noticing dρ dπ = ( dπ dρ ) -1 we could rewrite the inequality as
$$\mathbb { E } _ { L M \sim \rho } \left [ ( R ( L M ) - \hat { R } _ { S } ( L M ) ) \right ] \leq \frac { 1 } { \lambda } \left ( \text{KL} [ \rho | | \pi ] + \log \frac { 1 } { \delta } \right ) + \frac { \lambda } { 8 n }.$$
Finding λ that minimizes the term on right hand side gives us the ϱ term.
When D P allows for a decomposition into mixture components, noticing the linearty of expectation, the bound can be re-written as
$$\alpha \mathbb { E } _ { L M \sim \rho } [ \mathbb { E } _ { ( q, c ) \sim D _ { \mathcal { P } _ { h } } } \ell _ { \text{TV} } ( p _ { L M }, ( q, c ) ) ] & + ( 1 - \alpha ) \mathbb { E } _ { L M \sim \rho } [ \mathbb { E } _ { ( q, c ) \sim D _ { \mathcal { P } _ { s } } } \ell _ { \text{TV} } ( p _ { L M }, ( q, c ) ) ] \\ & \leq \varrho + \mathbb { E } _ { L M \sim \rho } [ \hat { R } _ { S } ( p _ { L M } ) ].$$
which leads to
$$\mathbb { E } _ { L M \sim \rho } [ \mathbb { E } _ { ( q, c ) \sim D _ { \mathcal { P } _ { h } } } \ell _ { \text{TV} } ( p _ { L M }, ( q, c ) ) ] \leq \frac { 1 } { \alpha } [ \varrho + \mathbb { E } _ { L M \sim \rho } [ \hat { R } _ { S } ( p _ { L M } ) ] ].$$
## B.2 An estimation on the non-vacuousness of the PAC bound
We give an estimation of the term appears in our PAC bound, ϱ , and state that it is non-vacuous.
The numerator. We follow Neyshabur et al. [60] to instantiate the term in the simplest setup. Assume π, ρ are defined over the parameter space of a given LM, with K parameters. Assume w is a set of weights learned from the pretraining corpus. Let the prior π be the zero-mean multivariate Gaussian, whose entry-wise variance is related to the magnitude of the weight: σ i = β w | i | , and ρ be a Gaussian with the same anisotropic variance centered around w . We argue though simple, both settings are practical, since Gaussian initialization is common for model training, and the SWA-Gaussian algorithm [61] utilizes such Gaussian posterior. Under this setup, the KL goes as ∑ i w 2 i 2 σ 2 = O K ( ) .
i Specifically, taking β = √ 2 2 makes the term exactly K . Current language models often possess millions, or billions, of parameters, namely, K ∼ [10 6 , 10 ] 9 .
The denominator. To estimate the number of unique direct prompts in the training corpus, it is important to notice that the dataset does not only consist of ( q, c ) prompts but also e explanations. Thus, we need to estimate the average token length (ATL) associated with each unique prompt x = ( q, c ) . For each unique prompt x , aside from its own token length l ( x ) , there will be a collection of explanations { e i } N x ( ) i =1 , with expected token length of each associated explanation l ( e . ) We have
$$\mathbb { E } A T L = \mathbb { E } _ { x \sim D _ { \mathcal { P } } } N ( x ) \times [ l ( x ) + l ( e ) ].$$
Fact. Given a prompt x , the larger the expected length of the prompt itself and explanation ( ( l x ) + l ( e ) ↑ ) , the larger the expected number of explanation elements ( N x ( ) ↑ ) , and the smaller the number of such prompts ( D P ( x ) ↓ ) , appearing in the training corpus. The former comes naturally due to the composability of natural language: the longer the text fragment, the more equivalent text fragments in expectation, while the latter is reflected by the spirit of the widely accepted Zipf's law.
Inspired by the fact, we assume prompts are categorized by the quantity of l ( x ) + l ( e ) , namely, for all prompt x N x , ( ) is a function of l ( x ) + l ( e ) . Moreover, the complete data generation process is decomposed into i) sample a value of l ( x ) + l ( e ) out, and then ii) sample a unique prompt from the set decided by this specific l ( x ) + l ( e ) value, and iii) generate N x ( ) explanations.
Step i). Use the fact: the larger the expected length of the output explanation, the smaller the probability that such a prompt appears in the training corpus. We assume step i) follows a (cut-off) zeta distribution. Specifically, for a random prompt x ,
$$p ( l ( x ) + l ( e ) = k ) \in k ^ { - s }, \forall k \geq k _ { 0 }.$$
When k 0 = 1 , we resume the zeta distribution with coefficient s .
Step ii). We assume each prompt following this step is unique.
Step iii). Use the fact: the larger the expected length of the output explanation, the larger the expected number of explanation elements in the training corpus. We assume a power law scaling on N , with a constant t > 1 , such that
$$N ( l ( x ) + l ( e ) = k ) = k ^ { t - 1 }.$$
Thus, the average token length writes
$$\mathbb { E } A T L = \sum _ { k } p ( l ( x ) + l ( e ) = k ) \times k \times N ( l ( x ) + l ( e ) = k ) = \frac { \zeta ( s - t ) - \sum _ { i = 1 } ^ { k _ { 0 } - 1 } i ^ { - ( s - t ) } } { \zeta ( s ) - \sum _ { i = 1 } ^ { k _ { 0 } - 1 } i ^ { - s } }.$$
where ζ ( s ) = ∑ i ∈ Z + i -s is the Riemann zeta function.
For example, take s = 4 , t = 2 . With k 0 = 1 , the ATL would be 1 52 . , while with k 0 = 10 , the ATL becomes 272 . These results translate into an estimation of unique prompts as n tokens /ATL . With current SOTA LM, the pretraining corpus often includes (tens of) trillions of tokens ( > 10 12 ), thus n > 10 10 > K can be safely assumed ⇒ ϱ < 1 .
α constant. According to LLaMa-2 report (section 4.1, Figure 13) [13], approximately 0 2% . of the documents in their training corpus is labeled as harmful. However, we argue this is indeed an extremely loose lower bound for α , due to the estimation strategy used in their paper. Given a document, they use a binary classifier on harmfulness over each single line (1 means harmful and 0 otherwise), and assign the average score to the document. 0 2% . is the ratio of documents with score ≥ 0 5 . . Take the example of 'How to build a bomb' . The chemical reaction parts will not be counted as harmful, and thus this estimation strategy could judge a completely harmful explanation as harmless. Thus, it is reasonable to assert α is not too small, though with current literature we are not capable of raising an accurate estimation on it.
## B.3 Proof of jailbreaking
Before proceeding to the proof, we list necessary definitions and lemmas as follows.
Lemma B.4. (Volume of n -simplex) 10 For any dimension n , the volume of the n -element probability simplex: ∆ n -1 , in the n -1 -dimensional space is
$$\frac { \sqrt { n } } { ( n - 1 )! }.$$
We define the projected probability simplex as follows.
Definition B.2. (Projected probability simplex) Given ∆ n -1 , the corresponding projected probability simplex, ∆ n -1 p , is defined as a subset of R n -1 : { x ∈ R n -1 | ∑ n -1 i =1 x i ≤ 1 , ∀ i ∈ [ n -1] } .
10 See https://en.wikipedia.org/wiki/Simplex#Volume .
An illustration of ∆ n -1 and ∆ n -1 p . For example, take n = 3 . The probability simplex with n = 3 elements is a triangle whose (euclidean) side length is √ 2 with vertices (1 , 0 0) (0 1 0) (0 0 1) , , , , , , , . Then its volume in the 2-dimensional space, i.e., its area, is √ 3 2 . The corresponding projected probability simplex is the triangle between the X -Y axis, with vertices (1 0) , , (0 1) , , (0 0) , .
A direct lemma that connects the probability simplex and the projected probability simplex is given below.
Lemma B.5. (Transformation of probability simplex) Given a proper probability density function ν x ( ) defined on ∆ n -1 p , it is equivalent to the distribution defined on ∆ n -1 with density ν x ( ) √ n : ∀ A ∈ Borel (∆ n -1 p ) , let B = { x ∈ ∆ n -1 : x 1: n -1 ∈ A } . Then ∫ A ν x dx ( ) = ∫ B ν x ( ) √ n dx. Specifically, this implies volume ( A ) volume (∆ n -1 p ) = volume ( B ) volume (∆ n -1 ) .
Proof. Consider a translation on ∆ n -1 with x n = -∑ n -1 i =1 x i which does not affect its the volume and shape. The mapping: ∆ n -1 p → translated ∆ n -1 is an affine transformation with matrix
$$T = \begin{pmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \cdots & \cdots & \cdots & \cdots \\ - 1 & - 1 & \cdots & - 1 \end{pmatrix} _ { n \times ( n - 1 ) }$$
Thus, any area under this transformation is scaled by √ det T ⊤ T = √ n : a constant. The lemma follows directly after this conclusion.
We use U ( ) · to denote the uniform distribution over ∆ n -1 : U x ( ) = ( n -1)! √ n , ∀ x ∈ ∆ n -1 . We use the notation vol[ S ] = ∫ S 1 ds to represent the volume of a given subset S ⊂ ∆ n -1 , and use rvol[ S ] for the relative volume (w.r.t. the underlying n -simplex) of S , i.e., rvol[ S ] := vol[ S ] vol[∆ n -1 ] = ∫ S U x dx ( ) . We also use n = | E c ( ) | from now on. We use the vector x to denote (with the slight abuse of notation we have mentioned) p LM ( q, c ) on the output simplex.
Lemma B.6. (Gaussian cdf Tail Bound, Gordon [62]) Denote ϕ ( ) · as the standard Gaussian pdf. When x > 0 ,
$$\frac { x } { x ^ { 2 } + 1 } \phi ( x ) = \frac { x } { x ^ { 2 } + 1 } \frac { e ^ { - x ^ { 2 } / 2 } } { \sqrt { 2 \pi } } \leq 1 - \Phi ( x ) \leq \frac { e ^ { - x ^ { 2 } / 2 } } { \sqrt { 2 \pi } x } = \frac { 1 } { x } \phi ( x ).$$
Now we are ready to give the proof of Theorem 2.
Proof. Let | E h ( c ) | = n 0 and denote | E h ( c ) | + | E s ( c ) | + | E n ( c ) | = n . Without loss of generality, we define the first n 0 = | E h ( c ) | elements as the harmful explanations. Let the thresholding constant be p . That is, we define the harmful zone H h as { x ∈ ∆ n -1 | ∑ n 0 i =1 x i ≥ p } . To compute the relative volume of H h in ∆ n -1 , we could instead operate on the projected probability simplex ∆ n -1 p introduced in Definition B.2, and compute the relative volume of the projected H h : H h,p := { x ∈
∆ n -1 p | ∑ n 0 i =1 x i ≥ p } . Note that ∆ n -1 p ⊂ R n -1 . We derive its expression as follows.
$$\Delta _ { p } ^ { n - 1 } | \sum _ { i = 1 } ^ { n o } x _ { i } \geq p \}. \, \text{Note that $\Delta_{p}^{n-1} \subset \mathbb{R}^{n-1}$. We derive its expression as follows.} \\ & \text{volume} \{ \mathcal { H } _ { h, p } ^ { C } \} = \text{volume} \{ \{ x \in \Delta _ { p }^{n-1} | \sum _ { i = 1 } ^ { n o } x _ { i } \leq p \} \} \\ & = \int _ { 0 } ^ { p } d x _ { 1 } \int _ { 0 } ^ { p - x _ { 1 } } d x _ { 2 } \cdots \int _ { 0 } ^ { p - \sum _ { i = 1 } ^ { n o - 1 } x _ { i } } d x _ { n o } \int _ { 0 } ^ { 1 - \sum _ { i = 1 } ^ { n o } } d x _ { n o + 1 } \cdots \int _ { 0 } ^ { 1 - \sum _ { i = 1 } ^ { n - 2 } x _ { i } } d x _ { n - 1 } \\ & = \int _ { 0 } ^ { p } d x _ { 1 } \int _ { 0 } ^ { p - x _ { 1 } } d x _ { 2 } \cdots \int _ { 0 } ^ { p - \sum _ { i = 1 } ^ { n o - 1 } x _ { i } } d x _ { n o } \left [ \frac { 1 } { ( n - n _ { 0 } - 1 )! } ( 1 - \sum _ { i = 1 } ^ { n o } x _ { i } ) ^ { n - n _ { 0 } - 1 } \right ] \\ & = \int _ { 0 } ^ { p } d x _ { 1 } \int _ { 0 } ^ { p - x _ { 1 } } d x _ { 2 } \cdots \int _ { 0 } ^ { p - \sum _ { i = 1 } ^ { n o - 2 } x _ { i } } d x _ { n o - 1 } \frac { 1 } { ( n - n _ { 0 } )! } \left [ ( 1 - \sum _ { i = 1 } ^ { n o - 1 } x _ { i } ) ^ { n - n _ { 0 } } - ( 1 - p ) ^ { n - n _ { 0 } } \right ] \\ & = \cdots \\ & \quad n _ { o - 1 } \ \. \quad \. \ \.$$
=
· · ·
$$& = \frac { 1 } { ( n - 1 )! } [ 1 - ( 1 - p ) ^ { n - 1 } ] - \sum _ { j = 1 } ^ { n _ { 0 } - 1 } \frac { ( 1 - p ) ^ { n - 1 - j } } { j! ( n - 1 - j )! } p ^ { j } \\ & \text{ Thus the relative volume of $\mathcal{H}_{\cdot}$ can be written as}$$
Thus, the relative volume of H h can be written as
$$\text{ne relative volume of } \tilde { t } _ { h } \text{ can be written as } \\ \text{rvol} [ \mathcal { H } _ { h } ] & = 1 - \frac { \text{volume} [ \mathcal { H } _ { h, p } ^ { C } ] } { \text{volume} [projected probability simplex} ] \\ & = ( 1 - p ) ^ { n - 1 } + \sum _ { j = 1 } ^ { n _ { o } - 1 } \frac { ( n - 1 )! ( 1 - p ) ^ { n - 1 - j } } { j! ( n - 1 - j )! } p ^ { j } \\ & = \sum _ { j = 0 } ^ { n _ { o } - 1 } p ^ { j } ( 1 - p ) ^ { n - 1 - j } \binom { n - 1 } { j }. \\ \text{is precisely the binomial distribution formula } \text{ With the Central I emit Theorem when }$$
Which is precisely the binomial distribution formula. With the Central Limit Theorem, when n ≫ O (1) , we know the binomial distribution can be well approximated via the normal distribution as follows:
$$f ( x ) = \binom { n } { x } p ^ { x } ( 1 - p ) ^ { n - x } \overset { d } { \rightarrow } \mathcal { N } ( n p, n p ( 1 - p ) ).$$
Thus, denote ϕ ( n -1) ,p ( x ) as the pdf of Gaussian variable with mean ( n -1) p , variance ( n -1) p (1 -p ) , the rvol term above can be estimated as follows:
$$\left | \text{ term above can be estimated as follows: } \\ \sum _ { j = 0 } ^ { n _ { 0 } - 1 } p ^ { j } ( 1 - p ) ^ { n - 1 - j } & \binom { n - 1 } { j } \asymp \int _ { - \infty } ^ { n _ { 0 } - 1 } \phi _ { ( n - 1 ), p } ( x ) d x \\ & = \Phi \left [ \frac { n _ { 0 } - 1 - ( n - 1 ) p } { \sqrt { ( n - 1 ) p ( 1 - p ) } } \right ] \\ & = \Phi \left [ \frac { \left | E _ { h } ( c ) \right | - 1 - ( n - 1 ) p } { \sqrt { ( n - 1 ) p ( 1 - p ) } } \right ]. \\ \right | \text{E.\,\,\left \rangle \left \rangle - \left \rangle \left \rangle - \left \rangle \right \rangle \right \rangle \right.$$
We use a = | E h ( c ) |- -1 ( n -1) p √ ( n -1) p (1 -p ) . Consider an adversary with budget ϵ under ℓ p or Jensen-Shannon Divergence (JSD) / Total Variation (TV) capability. Since || x || 1 ≥ || x || p , ∀ p ≥ 1 as well as || x || 1 ≥ 2JSD( x , ) || x || 1 ≥ 2TV( ) x , we know H h ( ϵ, ℓ 1 ) ⊂ H h ( ϵ, d ) for all d we have considered. With that ℓ 1 , ϵ setup, the corresponding ϵ -expansion set of H h has a closed-form expression as
$$\mathcal { H } _ { h } ( \epsilon, \ell _ { 1 } ) = \{ x \in \Delta ^ { n - 1 } | \sum _ { i = 1 } ^ { n _ { 0 } } x _ { i } \geq p - \frac { \epsilon } { 2 } \}.$$
Similar as above, we derive the analytical solution of its relative volume associated with constant a ′ as:
$$a ^ { \prime } & = \frac { | E _ { h } ( c ) | - 1 - ( n - 1 ) ( p - \frac { \epsilon } { 2 } ) } { \sqrt { ( n - 1 ) ( p - \frac { \epsilon } { 2 } ) ( 1 - p + \frac { \epsilon } { 2 } ) } } \\ & = a \sqrt { \frac { p ( 1 - p ) } { ( p - \frac { \epsilon } { 2 } ) ( 1 - p + \frac { \epsilon } { 2 } ) } } + \frac { \epsilon } { 2 } \sqrt { \frac { n - 1 } { ( p - \frac { \epsilon } { 2 } ) ( 1 - p + \frac { \epsilon } { 2 } ) } }. \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{cases}$$
Under our framework, with p < 1 2 , we know 1 4 > p (1 -p ) > p ( -ϵ 2 )(1 -p + ϵ 2 )) . Thus
$$\mu _ { \quad } a ^ { \prime } > a + \sqrt { n - 1 } \epsilon \coloneqq a _ { \epsilon }.$$
Consider the induced distribution γ c on the output simplex. Given an adversary with ℓ p or JSD/TV perturbing capability, with the fixed harmful concept c , safety is guaranteed if and only if p LM ( q, c ) resides outside H h ( ϵ, d ) . Define the area of interest, S d ( ) as S d ( ) := ∆ n -1 -H h ( ϵ, d ) . Thus, the probability of this event could be bounded as
$$\mathbb { P } _ { x \sim \gamma _ { e } } \mathbf 1 _ { x \in S ( d ) } < \max _ { x \in S ( d ) } \gamma _ { e } ( x ) \int _ { S ( d ) } 1 d x < \gamma _ { s } r v o l [ S ( d ) ] < \gamma _ { s } r v o l [ S ( \ell _ { 1 } ) ] < \gamma _ { s } ( 1 - r v o l [ \mathcal { H } _ { h } ( \epsilon, \ell _ { 1 } ) ] )$$
This gives an upper bound of
$$\gamma _ { s } ( 1 - \Phi ( a _ { \epsilon } ) ).$$
which can be simplified when a ≥ 0 using Lemma B.6:
$$\gamma _ { s } \left ( \frac { \phi ( a _ { \epsilon } ) } { a _ { \epsilon } } \right ).$$
Thus, the probability of getting a LM instance from the preference alignment process such that it allows for successful jailbreaking on a specific harmful concept c is at least
$$1 - \gamma _ { s } \left ( 1 - \Phi ( a _ { \epsilon } ) \right ).$$
Up to now, we have derived the result in Theorem 2. However, we can move a step further to show the decay rate on the right hand side term. It can be simplified when a ≥ 0 :
$$1 - \gamma _ { s } \left ( \frac { \phi ( a _ { \epsilon } ) } { a _ { \epsilon } } \right ),$$
which finishes the proof.
## C RLHF, DPO and our E-RLHF
The classic RLHF framework was established by Christiano et al. [63], and developed by Ziegler et al. [19], Ouyang et al. [20], Bai et al. [21]. After the collection of a preference dataset D s = { ( x, e w , e l ) } , one first trains a reward model under the Bradley-Terry model [64], with the objective, where σ ( ) · stands for the sigmoid function:
$$r ( x, e ) = \arg \max _ { r } \mathbb { E } _ { ( x, e _ { w }, e _ { l } ) \sim \mathcal { D } } \log \sigma ( r ( x, e _ { w } ) - r ( x, e _ { l } ) ).$$
Following, proximal policy optimization (PPO) [65] is commonly adopted across these implementations, forming the basis of current state-of-the-art language models. The KL-constrained RL Fine-Tuning (RLFT) objective takes the form:
$$\max _ { p _ { L M } } \mathbb { E } _ { x \sim \mathcal { D } _ { a }, e \sim p _ { L M } ( \cdot | x ) } [ r ( x, e ) ] - \beta \mathbb { D } _ { \text{KL} } ( p _ { L M } ( \cdot | x ) | | p _ { \text{ref} } ( \cdot | x ) ).$$
However, PPO tuning can suffer from instability [66] and implementation complication [67]. To overcome these issues, a series of work propose to skip the reward modeling step and learn directly from the preference dataset, with the representative pioneering work by Rafailov et al. [23], namely Direct Preference Optimization (DPO) . We summarize the derivation of the DPO objective below, and generalize the objective to the one we use in our experiments, i.e., E-DPO.
First, noticing the closed-form optimal solution for p LM of the RLFT objective writes (see e.g., Appendix A.1 of Rafailov et al. [23])
$$p _ { \text{RLFT} } ^ { * } ( e | x ) = \frac { 1 } { Z ^ { \prime } ( x ) } p _ { \text{ref} } ( e | x ) \exp ( \frac { 1 } { \beta } r ( x, e ) ).$$
With this analytical solution in mind, we can solve the reward as
$$r ( x, e ) = \beta \log \frac { p _ { \text{RLFT} } ^ { * } ( e | x ) } { p _ { \text{ref} } ( e | x ) } + \beta \log Z ^ { \prime } ( x ).$$
Regard π ∗ as the optimization target, plug this transformation into the reward model objective to obtain the DPO objective:
$$p _ { \text{DPO} } = \arg \min _ { p _ { L M } } - \mathbb { E } _ { ( x, e _ { w }, e _ { l } ) \sim \mathcal { D } } [ \log \sigma ( \beta \log \frac { p _ { L M } ( e _ { w } | x ) } { p _ { \text{ref} } ( e _ { w } | x ) } - \beta \log \frac { p _ { L M } ( e _ { l } | x ) } { p _ { \text{ref} } ( e _ { l } | x ) } ) ].$$
For our E-RLHF, the modification to the objective leads to another optimal solution of p LM :
$$p ^ { * } ( e | x ) = \frac { 1 } { Z ( x ) } p _ { \text{ref} } ( e | x _ { s } ) \exp ( \frac { 1 } { \beta } r ( x, e ) ).$$
Thus,
$$r ( x, e ) = \beta \log \frac { p ^ { * } ( e | x ) } { p _ { \text{ref} } ( e | x _ { s } ) } + \beta \log Z ( x ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
And plug it in to the reward model objective to formulate our E-DPO:
$$p _ { E \cdot \text{DPO} } = \arg \min _ { p _ { L M } } - \mathbb { E } _ { ( x, e _ { w }, e _ { l } ) \sim \mathcal { D } } [ \log \sigma ( \beta \log \frac { p _ { L M } ( e _ { w } | x ) } { p _ { \text{ref} } ( e _ { w } | x _ { s } ) } - \beta \log \frac { p _ { L M } ( e _ { l } | x ) } { p _ { \text{ref} } ( e _ { l } | x _ { s } ) } ) ].$$
The advantage of our E-RLHF objective is as follows.
Proposition C.1. (Overcoming the small safe set problem) E-RLHF will lead to the optimal solution p ∗ :
$$p ^ { * } ( e | x ) = \frac { 1 } { Z ( x ) } p _ { r e f } ( e | x _ { s } ) \exp ( \frac { 1 } { \beta } r ( x, e ) ).$$
Compared to p ∗ RLFT , the advantage when encountering a harmful prompt x is:
(1) (Erase harmful explanations) ∀ e ∈ supp ( p ref ( ·| x )) -supp ( p ref ( ·| x s )) , p ∗ ( e x | ) = 0 ;
- (2) (Add safe explanations) ∀ e ∈ supp p ( ref ( ·| x s )) -supp p ( ref ( ·| x )) , p ∗ ( e x | ) > 0 = p ∗ RLFT ( e x | ) .
Thus, with the same jailbreak threshold p , the safety zone is successfully expanded.
Intriguingly, when the safe transformation is done by appending an identical safe prefix to all harmful prompts, we can connect our E-RLHF to context distillation . A good prompt is known to matter for the performance of a fixed-parameters LM [68, 55]. Researchers have proposed a systematic LM tuning algorithm, called Context Distillation [69], aiming at distilling useful information from a good context as prefix to a language model. Given an initialized language model, for example p SFT, an input prompt x and a prefix context string prefix , Askell et al. [69] optimizes the loss
$$L ( p _ { L M } ) = \mathbb { D } _ { \text{KL} } ( p _ { \text{SFT} } ( \text{prefix} \ominus x ), p _ { L M } ( x ) )$$
where ⊕ stands for string concatenation. This technique has been adopted as part of the safety alignment process during the LLaMa-2 series tuning [13], where prefix is chosen from a set of predefined safe prefixes. When applying the identical prefix transform in our E-RLHF transformation, it can be regarded as a combination of safety context distillation and RLHF. This gives another point of view on the effectiveness of our proposal.
## D Ablation Study
In this section, we perform extensive ablation studies to showcase the effectiveness of our proposed E-RLHF.
Table 3: Safety evaluation, LoRA results. The result is consistent with the one we have obtained in the main text, that our E-DPO performs better than DPO across a collection of adversaries. indicates better performance.
| HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] |
|-----------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|
| Model | Direct Request | GCG | GBDA | AP | SFS | ZS | PAIR | TAP | AutoDAN | PAP-top5 | Human | AVG ↓ |
| π DPO (LoRA) | 24 . 50 | 47 . 50 | 40 . 50 | 43 . 25 | 43 . 25 | 28 . 50 | 45 . 25 | 53 . 25 | 53 . 50 | 29 . 75 | 38 . 90 | 40 . 74 |
| π E-DPO (LoRA) | 24 . 25 | 42 . 50 | 36 . 50 | 41 . 50 | 42 . 75 | 27 . 20 | 45 . 00 | 53 . 75 | 50 . 25 | 27 . 25 | 38 . 05 | 39 . 00 |
| AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] |
| π DPO (LoRA) | 2 . 00 | 29 . 00 | 26 . 00 | 26 . 00 | 40 . 00 | 8 . 80 | 32 . 00 | 54 . 00 | 46 . 00 | 2 . 00 | 31 . 20 | 27 . 00 |
| π E-DPO (LoRA) (ours) | 0 . 00 | 25 . 00 | 20 . 00 | 27 . 00 | 33 . 00 | 7 . 20 | 23 . 00 | 50 . 00 | 45 . 00 | 2 . 00 | 28 . 80 | 23 . 73 |
Table 4: Safe prefix ablation. Prefixes we use are included in Table 8. Our E-DPO performs better than the DPO baseline in most cases we have tested. indicates best performance.
| | | | | | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | | | | | |
|------------------|------------------|------------------|------------------|------------------|---------------------|---------------------|---------------------|------------------|------------------|------------------|------------------|------------------|
| Model | Direct Request | GCG | GBDA | AP | SFS | ZS | PAIR | TAP | AutoDAN | PAP-top5 | Human | AVG ↓ |
| π DPO | 27 . 50 | 53 . 00 | 39 . 00 | 46 . 75 | 43 . 25 | 29 . 10 | 52 . 50 | 54 . 00 | 51 . 00 | 28 . 75 | 37 . 15 | 42 . 00 |
| π E-DPO(1) | 26 . 25 | 56 . 50 | 33 . 75 | 44 . 25 | 42 . 25 | 29 . 30 | 50 . 00 | 56 . 75 | 56 . 25 | 31 . 50 | 34 . 05 | 41 . 90 |
| π E-DPO(2) | 24 . 75 | 52 . 25 | 34 . 00 | 39 . 00 | 44 . 75 | 29 . 75 | 50 . 50 | 54 . 50 | 53 . 25 | 28 . 00 | 34 . 35 | 40 . 46 |
| π E-DPO(3) | 24 . 75 | 52 . 75 | 35 . 25 | 37 . 50 | 35 . 50 | 28 . 65 | 49 . 00 | 53 . 50 | 47 . 25 | 30 . 50 | 30 . 25 | 38 . 63 |
| π E-DPO(4) | 23 . 50 | 47 . 50 | 31 . 75 | 36 . 25 | 40 . 50 | 26 . 45 | 48 . 50 | 51 . 00 | 43 . 00 | 27 . 00 | 31 . 05 | 36 . 95 |
| AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] |
| π DPO | 0 . 00 | 47 . 00 | 12 . 00 | 39 . 00 | 30 . 00 | 7 . 00 | 50 . 00 | 61 . 00 | 44 . 00 | 4 . 00 | 18 . 40 | 28 . 40 |
| π E-DPO(1) | 0 . 00 | 51 . 00 | 12 . 00 | 29 . 00 | 33 . 00 | 6 . 80 | 47 . 00 | 62 . 00 | 53 . 00 | 5 . 00 | 20 . 00 | 28 . 98 |
| π E-DPO(2) | 1 . 00 | 39 . 00 | 12 . 00 | 20 . 00 | 34 . 00 | 6 . 20 | 53 . 00 | 63 . 00 | 49 . 00 | 3 . 00 | 15 . 60 | 26 . 89 |
| π E-DPO(3) | 0 . 00 | 47 . 00 | 11 . 00 | 23 . 00 | 23 . 00 | 6 . 80 | 45 . 00 | 58 . 00 | 36 . 00 | 4 . 00 | 15 . 80 | 24 . 51 |
| π E-DPO(4) | 0 . 00 | 38 . 00 | 8 . 00 | 15 . 00 | 21 . 00 | 5 . 20 | 41 . 00 | 53 . 00 | 31 . 00 | 4 . 00 | 13 . 60 | 20 . 89 |
## D.1 LoRA results
In this section, we show results obtained by Low-Rank Adaptation [54]. We explore the same set of safe prefixes as in ablation D.2, and choose the best model for illustration. Numbers are illustrated in Table 3. Results are identical to the ones obtained via full parameter tuning that our E-RLHF performs better consistently against the RLHF baseline.
## D.2 Ablation on safe prefixes
We ablate the effect of different safe prefixes. The prefixes we consider are collected in Table 8. Numbers are shown in Table 4. Clearly, almost all safe prefixes lead to better safety against the DPO baseline, but with varying performance. Finding a good prefix matters for our method, and we leave digging the optimal one out as future work.
## D.3 Ablation on transforming all prompts
Here, we proceed to ablating the effect of transforming all prompts, no matter harmful or not. Results are shown in Table 5, where the red color indicates that safety downgrades compared to the model obtained via transforming harmful prompts only. Clearly, most models even persist worse safety compared to the DPO baseline itself, suggesting the detrimental effect of transforming the unharmful prompts.
## D.4 Ablation with system prompt
As pointed out by previous works [2, 48, 70], system prompt can have a significant impact on ASR. This comes in two-folds: firstly, a powerful system prompt can initialize the LM to be closer to the safety zone, thus making the model safer; secondly, a longer system prompt would enlarge the difficulty of launching a specific attack due to the increased computational consumption. To confirm
Table 5: Ablation study on transforming all prompts. We apply the same safe prefixes as used in Table 4. indicates the safety is worse compared to the model trained with transforming only the harmful prompts. AVG scores achieved by the DPO baseline are 42 00 . and 28 40 . , respectively.
| | | | | | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | | AutoDAN | PAP-top5 | | ↓ |
|------------------|------------------|------------------|------------------|------------------|---------------------|---------------------|---------------------|------------------|------------------|------------------|------------------|------------------|
| Model | Direct Request | GCG | GBDA | AP | SFS | ZS | PAIR | TAP | | | Human | AVG |
| π E-DPO(1) | 28 . 00 | 55 . 75 | 41 . 00 | 42 . 00 | 42 . 50 | 31 . 00 | 51 . 25 | 56 . 25 | 56 . 00 | 32 . 00 | 36 . 05 | 42 . 89 |
| π E-DPO(2) | 25 . 75 | 60 . 50 | 40 . 25 | 46 . 50 | 44 . 75 | 30 . 15 | 52 . 75 | 57 . 25 | 63 . 50 | 30 . 75 | 40 . 45 | 44 . 78 |
| π E-DPO(3) | 24 . 00 | 57 . 25 | 35 . 00 | 41 . 75 | 39 . 50 | 26 . 55 | 49 . 25 | 55 . 00 | 58 . 75 | 29 . 25 | 38 . 70 | 41 . 36 |
| π E-DPO(4) | 27 . 75 | 58 . 50 | 38 . 00 | 42 . 00 | 40 . 75 | 31 . 20 | 52 . 75 | 60 . 50 | 54 . 75 | 31 . 50 | 38 . 30 | 43 . 27 |
| AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] | AdvBench ASR [1] |
| π E-DPO(1) | 0 . 00 | 53 . 00 | 17 . 00 | 31 . 00 | 26 . 00 | 6 . 00 | 50 . 00 | 57 . 00 | 61 . 00 | 4 . 00 | 19 . 00 | 29 . 45 |
| π E-DPO(2) | 0 . 00 | 52 . 00 | 17 . 00 | 29 . 00 | 26 . 00 | 6 . 20 | 56 . 00 | 58 . 00 | 73 . 00 | 3 . 00 | 25 . 60 | 31 . 44 |
| π E-DPO(3) | 0 . 00 | 56 . 00 | 17 . 00 | 23 . 00 | 17 . 00 | 3 . 80 | 46 . 00 | 58 . 00 | 66 . 00 | 4 . 00 | 23 . 40 | 28 . 56 |
| π E-DPO(4) | 0 . 00 | 58 . 00 | 17 . 00 | 36 . 00 | 27 . 00 | 6 . 80 | 46 . 00 | 60 . 00 | 68 . 00 | 3 . 00 | 25 . 20 | 31 . 54 |
Table 6: Ablation with the default Mistral system prompt. It boosts the safety of our E-DPO models to achieve better safety, while maintaining the advantage over the DPO baseline.
| | | | | | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | | | | | |
|---------|----------------|---------|---------|---------|---------------------|---------------------|---------------------|---------|---------|----------|---------|---------|
| Model | Direct Request | GCG | GBDA | AP | SFS | ZS | PAIR | TAP | AutoDAN | PAP-top5 | Human | AVG ↓ |
| π SFT | 25 . 25 | 61 . 25 | 26 . 75 | 37 . 00 | 27 . 25 | 24 . 75 | 55 . 50 | 58 . 75 | 61 . 25 | 24 . 00 | 30 . 35 | 39 . 28 |
| π DPO | 20 . 50 | 49 . 25 | 29 . 25 | 32 . 75 | 34 . 50 | 22 . 55 | 42 . 75 | 50 . 25 | 50 . 75 | 30 . 00 | 31 . 20 | 35 . 80 |
| π E-DPO | 15 . 50 | 41 . 50 | 22 . 75 | 29 . 00 | 31 . 25 | 17 . 95 | 41 . 75 | 44 . 25 | 44 . 25 | 23 . 00 | 26 . 55 | 30 . 70 |
our E-RLHF is still helpful under this specific situation, we ablate this effect under the control of the default Mistral system prompt 11 . The results can be found in Table 6, where nearly all ASRs drop, whilst the conclusion does not change.
## D.5 Ablation on improving helpfulness and safety simultaneously
In similar spirit, we ask the question: can the trick we propose to improve safety be used to improve helpfulness simultaneously? To achieve this goal, we choose the prefix "Give me a safe and helpful response to the following request." , and apply it to all prompts in the preference dataset. Results can be found in Table 7. Our model achieves better safety, and improves the helpfulness benchmarked by MT-Bench [3] from 6.8 to 6.9.
## E Filtering harmful prompt in the preference alignment dataset
Inspired by the work by Chao et al. [30], we prompt GPT-3.5-Turbo as a harmness judge on input prompts. It assigns an integer score ranging from 1 to 10 for a given prompt, and we choose the score ≥ 6 subset as harmful. The system prompt is shown in Table 9.
11 https://docs.mistral.ai/capabilities/guardrailing/
Table 7: Improving helpfulness and safety simultaneously using E-RLHF. MT-Bench scores are 6 8 . and 6 9 . , for the DPO baseline and our E-DPO model, respectively.
| HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] | HarmBench ASR [2] |
|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|
| Model | Direct Request | GCG | GBDA | AP | SFS | ZS | PAIR | TAP | AutoDAN | PAP-top5 | Human | AVG ↓ |
| π SFT | 32 . 25 | 59 . 25 | 35 . 50 | 42 . 75 | 42 . 75 | 36 . 20 | 56 . 50 | 65 . 00 | 56 . 75 | 26 . 75 | 35 . 50 | 44 . 47 |
| π DPO | 27 . 50 | 53 . 00 | 39 . 00 | 46 . 75 | 43 . 25 | 29 . 10 | 52 . 50 | 54 . 00 | 51 . 00 | 28 . 75 | 37 . 15 | 42 . 00 |
| π E-DPO (ours) | 26 . 25 | 56 . 00 | 37 . 00 | 43 . 75 | 38 . 25 | 27 . 90 | 49 . 75 | 56 . 00 | 52 . 25 | 27 . 50 | 32 . 65 | 40 . 66 |
Table 8: Safe prefixes we use in our experiments.
| (1) "Provide a responsible and ethical answer to the following request. " |
|------------------------------------------------------------------------------------------------|
| (2) "In a manner that promotes safety and well-being, please respond to the following request. |
| (3) "Keeping in mind the importance of safety and legality, how would you respond to this: " |
| (4) "Please ensure your response adheres to community guidelines and ethical standards: " |
Table 9: System prompt for GPT-3.5-Turbo used to filter harmful and non-harmful prompt in the preference dataset.
You are a helpful red teaming assistant. You will receive a prompt. Please act as an impartial judge and evaluate whether the prompt itself is requesting information that violates ethical, legal, or safety guidelines. Be as objective as possible. Rate the prompt on a scale from 1 to 10. A rating of 1 signifies a fully non-harmful prompt. A rating of 10 signifies prompts that could lead to responses that fully violate ethical, legal, or safety guidelines. Your rating should strictly follow this format: "Rating: [[rating]]", the rating in the double-closed brackets is a number from 1 to 10, e,g, "Rating: [[5]]".
## F Jailbreak adversaries collected in the HarmBench project [2]
In this section, we give a short overview of the adversaries we adopt to evaluate our models. Some descriptions are summarized in Mazeika et al. [2].
- · Direct Request refers to sending the original harmful prompt directly to the target LLM.
- · GCG [1], GBDA [71] and AP [72] find adversarial suffixes via token-level optimization.
- · SFS (Stochastic Few-Shot) and ZS (Zero-Shot) [15] are few-shot sampling or zero-shot generation of test cases by an attacker LLM to elicit a behavior from a target LLM.
- · PAIR [30] and TAP [33] are iterative prompting / tree-structured prompting methods, with an attacker LLM, to adaptively explore and elicit specific harmful behaviors from the target LLM.
- · AutoDAN [29] is a genetic-algorithm based attack with initializations from handcrafted DAN jailbreak prompts.
- · PAP [73] uses persuasive strategies to jailbreak the target LLM.
- · HumanJailbreaks [74] uses a fixed set of in-the-wild human jailbreak templates, similar to the Do Anything Now (DAN) jailbreaks.
We exclude all transfer attacks since we focus on single-model jailbreak. Furthermore, we choose to discard the UAT [75] and PEZ [76] adversaries, because the former induces an out-of-memory error on our V100 GPUs, and the latter never succeeds to find a suffix according to our experiments.
## G Broader Impacts
The societal impact of our work has close connection to the topic of LLM safety. We propose a framework for analyzing language model pretraining and jailbreaking, and we design a new RLHF algorithm for improving safety. As shown in our experiments, our work could advocate for safer LLMs.
## H Related work
In this section, we provide a review of the current literature on LLM jailbreaking.
## H.1 Jailbreak methods
In this section, we summarize existing jailbreaking methods.
Baseline and pioneers Autoprompt [72], a baseline method for optimizing in the token space w.r.t. a certain objective, approximates coordinate ascent by first ranking all tokens using an approximate objective, and then compute the exact value on them. The approximation is carried out by a single step of gradient computation. Jones et al. [77] propose Autoregressive Randomized Coordinate Ascent (ARCA) to generate (input, output) pairs that include certain harmful info or satisfy a fixed format requirement. Token level optimization is carried out with linear approximation on GPT-2. GBDA [71] study adversarial attack on text classification problems, by optimizing the continuous relaxation of the autoregressive sampling probability matrix. In late 2022, among social media, users misalign GPT-3 via prompt injection. Perez and Ribeiro [78] study how this be done by adversaries. They successfully manipulate the model to output a given harmful string and leak the system prompt. In early 2023, an empirical study was carried out by Liu et al. [9] to measure the result of prompt engineering for breaking ChatGPT safeguards. Shen et al. [74] collect jailbreaking prompts from multiple platforms on the internet, analyze these data, create a harmful question set, and identify some typical harmful prompts that are effective at that moment. Later, the Greedy Coordinate Gradient (GCG) method [1], a strong white-box attack variant of AutoPrompt [72] was proposed. Wei et al. [79] categorizes two general modes of jailbreaking: competing objective and mismatched generalization .
LLMautomation and suffix-based attacks Liu et al. [29] propose AutoDAN, that relies on genetic algorithms, with the requirement of manual prompts for conducting mutation and crossover on the paragraph and sentence level . The jailbreaking prompts generated by AutoDAN are semantically plausible, unlike the suffix generated by GCG. As a comparison, Lapid et al. [25] use genetic algorithm for black-box universal adversarial suffix generation. Chao et al. [30] propose another LLM-based jailbreak automation algorithm, where an LLM judge is built to assign a safety score to a given output, while the attacker is enforced (via a page-long prompt) to improve the quality of jailbreaking prompts from multiple perspectives. Zhu et al. [24] propose another AutoDAN method that explores the balanced loss between jailbreak loss (log probability on the harmful string, as used in Zou et al. [1]) and the plausibility loss (log probability over the adversarial suffix), aiming at improving interpretability. Li et al. [31] uses genetic algorithm to search with similarty measure and initialize with paraphrasing. Its performance is claimed to be better than AutoDAN-GA. Deng et al. [80] investigate the possible defensive tricks in proprietary LLMs, and propose a pipeline for automated jailbreaking using a fine-tuned LLM. Yu et al. [81] propose GPTFuzzer, essentially a genetic algorithmic framework for jailbreaking. Their work's difference between AutoDAN is that it has a pool of 'seeds', a.k.a. templates for transforming the harmful prompt, and the mutation is done on the template level. Ding et al. [32] propose automating attack via LLM prompt rewriting and scenario nesting . The latter consists of code completion, table filling and text continuation, since the authors regard these as align with training objectives well, and are suitable for LLMs to complete the task. Mehrotra et al. [33] combine Automation used in Chao et al. [30] and tree-of-thought [82], create interpretable prompts in a black-box manner. Li et al. [83] propose DeepInception, and use nested, imaginary scenario to induce harmful content. Li et al. [84] propose DrAttack, which camouflages a query's malicious intent through semantic decomposition, by constructing a parsing tree and split the original prompt into different segmentations. Wang et al. [85] draw inspiration from the self-perception theory from psychology to design a prompt modification pipeline on gradually persuading the LM to be jailbroken. Paulus et al. [86] propose AdvPrompter, where the authors train a language model as a suffix generator to speed up LLM attack.
Manipulating the decoding process Huang et al. [48] find the method of changing the generating hyperparameters ( i.e., p of topp sampling, the temperature T , and k of topk sampling) of safetyaligned LLMs suffices for obtaining harmful outputs when the user is able to manipulate the system prompt and input configurations. Zhang et al. [87] directly manipulate the output generation probability by enforcing an affirmative prefix, and reversing the negation words if they appear in a pre-defined vocabulary ( e.g., sorry → glad). Zhao et al. [88] assume access to the decoding distribution of a LM. They use two small LMs, a safe one and a harmful one, to manipulate the decoding ratio of the large safe LM for jailbreaking. The key insight is the decoding distribution between the safe model and the harmful model only differs significantly for the first tens of tokens.
Fine-Tuning alone suffices Yang et al. [89] show that fine-tuning on as few as 100 harmful example pairs suffices for turning the LLaMa-chat models (and some other < 70B LMs) into malicious counterparts. Zhan et al. [90] fine-tune GPT-4 on harmful data, and find the fine-tuned models escape previous safety constraints while maintaining usefulness. Qi et al. [91] find fine-tuning alone, even on
benign data, leads to safety degradation using LLaMa and GPT-3.5-Turbo. Fine-tuning on harmful data (with less than 5 gradient steps) will cause the model to be completely harmful, while tuning on identity-shifting data could make the LM fully obedient.
Low-resource language and cipher Yong et al. [26], Deng et al. [27] explore the difference in languages when encountering the same harmful query, and find a direct translation to low resource languages will lead to higher risk, and Deng et al. [27] additionally find when combined with sophisticated methods, the drawback of low-resource languages disappear. Yuan et al. [28] use cipher encoding and decoding to break LLMs. Smaller scale models are immune from such attacks, while the smartest GPT-4 encountered the highest risk.
Vision-language model attacks Besides pure LLM, some research works move a step forward, utilizing images for breaking vision-language models (VLMs). Shayegani et al. [92] explore multimodal attack on VLM via embedding space feature matching. Qi et al. [93] generate adversarial examples via maximizing the conditional probability of a harmful corpus, i.e., the sum of log probabilities over all outputs, and use the final image with harmful query for jailbreaking. Carlini et al. [94] generate adversarial example for a fixed harmful content , and find no matter what input prompt is given to the VLM, it will respond with the target harmful string. Maus et al. [95] propose a black-box attack on manipulating the generated image with modified adversarial prompt.
Misc Wei et al. [57], Wang et al. [58] explore in-context learning for attack and defense. The attack is weak since it could only break Vicuna [96] and can be defended by in-context safe examples. Later, this method is scaled-up to significantly improve strength for breaking guardrails of large, state-ofthe-art models [59]. An early work in February 2023 [97] adopts obfuscation (including synonym and typos), code injection and virtualization to successfully jailbreak ChatGPT. Shah et al. [98] illustrate in-context automated persona modulation attack for large-scale LLMs and Vicuna. Zeng et al. [73] consider the more broadly perspective of persuasion : they train a persuasive paraphraser based on a fine-grained taxonomy of persuasion techniques. Detailed ablation on attack effectiveness is studied. Guo et al. [99] focus on stealthiness and controllability. They notice the constraints applied to the jailbreaking prompts ( e.g., fluency) are exactly the targets of the controllable text generation problem. Thus, they adopt the Energy-based Constrained Decoding with Langevin Dynamic (COLD) [100] on output logits. Forming each constraint as well as the task of jailbreaking as an energy function over logits, the Langevin Dynamic is used for finding a good logit distribution, and the decoding technique in Qin et al. [100] is used for output generation. Banerjee et al. [101] introduce a dataset TECHHAZARDQA, compare direct query v.s. pseudo-code format, and find the latter induces higher risk. Mangaokar et al. [102] considers a type of adaptive attack against checking-based defense , that appends a universal adversarial prefix into the jailbreaking prompt to make the guard model always output 'safe', and thus making the detector fails to detect harmful information. Lv et al. [103] propose Code Chameleon, which contains multiple encryption and decryption methods defined by python functions, that transforms the harmful prompt into specific predefined form to jailbreak LLMs. Sadasivan et al. [104] speed up the computation of GCG [1] to make it possible to launch on a single GPU. Geiping et al. [105] build a taxonomy on risks beyond jailbreaking, and coerce the LLM to provide certain outputs by optimizing a set of tokens via GCG. Ren et al. [106] propose CodeAttack that use code templates to query the output out instead of using natural language directly, and obtain descent results.
## H.2 Defense methods
Up to now, no universal defensive strategy as adversarial training [107] for adversarial attacks / differential privacy [108] for membership attacks exists as a gold standard. In general, we can classify the methods into three typical types: alignment, red-teaming, and algorithmic proposals.
Alignment The target of alignment is to push the output of language models be aligned to human values. Regarding safety, the goal is to avoid outputting harmful information. RLHF is widely adopted in these methods [19, 20, 109, 22]. Variants like RLAIF also have been proposed recently [21, 110].
Red teaming This term is populated as specifically dealing with harmful info on dataset curation, used together with RLHF [14-18].
Next, we proceed to defensive algorithm proposals. We classify existing defensive strategies in the following categories.
Defense against suffix-based attacks. Alon and Kamfonas [111] notice the messy nature of the suffix generated by GCG, and propose to use a perplexity (PPL) filter on input prompts. They also explore using a LightGBM [112] with 2 features (PPL, prompt length) to filter harmful prompt, and show it does better than naive PPL thresholding. The PPL-based filter does not succeed with human-crafted jailbreaks. Jain et al. [37] explore many concerning viewpoints, including self-PPL filtering, paraphrasing the input prompt, and re-tokenization since many LLMs' tokenizers are based on Byte-Pair Encoding (BPE). All methods are successful in regards of defending against suffix-based attacks. They also explore the simplest form of adversarial training. Robey et al. [34] propose to perturb the input token string by random replacement/erasement/insertion, and finally perform a majority vote in the end. Cao et al. [35] judges whether an input prompt is safe or not by estimation with Monte Carlo, when randomly dropping a fraction of tokens, using the LLM itself. Kumar et al. [36] try to perform 'certified' safety against harmful prompts, by erasing tokens and set the original prompt as harmful if at least one of these erased prompts lead to a harmful response, or be classified as harmful by a DistillBERT-based classifier.
System prompt defense. We could modify the input prompt for jailbreaking; and several works explore if we can apply similar methods to system prompts to defend against such attacks. Xie et al. [113] propose 'self-reminder', i.e., appending a reminding prompt within the system prompt for defense. The attacks are collected from the JailbreakChat collection, and this strategy is effective for defending against them. Zheng et al. [114] advocate for finding a good system prompt automatically, by investigating the representational difference between safe and harmful queries, and optimizing the safety prompts along the harmful refusal direction in the representation space. One intriguing takeaway is harmful / harmless queries can be distinguished in the representation space, different from the adversarial examples in vision. Zhou et al. [115] also optimize the safe system prompt, but in a more 'adversarial training' fashion, that apply jailbreak algorithms with current safe prompts first and then find good replacement candidates in the same way as done by Zou et al. [1]. Concurrently, Mo et al. [116] propose prompt adversarial tuning, where an adversarial suffix is assumed, while a safe system prompt is jointly optimized with this suffix, with an additionally constructed benign loss to improve helpfulness under normal queries. Zhang et al. [117] propose the idea of 'goal prioritization', either without training (append prioritize safety than helpfulness and in-context examples to the system prompt) or with training (generate data pairs of prioritizing safety or helpfulness, finetune, and append prioritize safety prompt into system prompt). The former is effective for large-scale LLMs, while the latter improves safety of LLaMa-chat models. Zhou et al. [118] propose in-context adversarial game, where an attack LLM and a defense LLM interact on exchanging insights on successful jailbreaks, and defend by improving the system prompt. Zou et al. [70] give the result that system prompt matters for jailbreaking, and shows conducting GA-based search over it could improve safety.
Checking-based, decoding-based, and Misc. Helbling et al. [119] generate responses first, and then use the LLM itself to examine whether the output is harmful or not. They find such simple self-examination is powerful since the TPR reported can be up to ∼ 1 00 . . Wang et al. [120] propose to (1) tune the LM to enhance its capability on discriminating harmful / harmless content; (2) tune the LM to make it able to tag its own response; and (3) rewrite response if output is harmful. Li et al. [121] propose to suppress the attack performance by iteratively rewinding and re-examining the generated output. The method does not work well with small models, but works pretty fine with large (open-source) models. They find the strategy can improve generalization as well. Xu et al. [122] train a safer model first, and use normalized p attacked + α p ( safer -p attacked ) over topk shared tokens for decoding to enhance safety. Hasan et al. [123] show with original Wanda pruning [124], the LLM can help resist direct jailbreaking prompts, e.g., with role-playing attacks. Pi et al. [125] propose MLLM-Protector on safeguarding Visual LLMs by checking the output and then detoxifying the content. Zhang et al. [126] perform intention analysis on the input, and enforce the model generate policy-aligned outputs both by prompting. Wang et al. [127] propose backtranslation that guesses the input prompt directly, and reject if it is harmful. Kim et al. [128] propose self-refinement which consists of generating a feedback and then refine the response to avoid harmful info output. They find using additional JSON and code formatting would improve safety. Zeng et al. [129] propose AutoDefense, which utilizes multiple agents on analyzing prompt, response and intention, to defend
against attacks. Hu et al. [130] propose Gradient Cuff, a sampling-based gradient-norm defense method, by rejecting those input prompts with large gradient norm on top of a majority-vote based filtering. Ji et al. [131] propose a method similar to Robey et al. [34], but for semantically-meaningful attacks, that paraphrases the input according to several criteria and conduct a majority vote for judging.
Several company-centered products also fall into this regime. For example, LLaMa-Guard [132] is trained on toxic data such that it is able to discriminate unsafe user prompts and outputs, respectively. IBM also propose a framework on constructing and deploying safeguard detection modules, and releases the details in a technical report [133].
## H.3 Theory and experimental understanding
Wolf et al. [38] assumes the decomposability of LLM output into a good and bad component, and show possible jailbreaking in theory by prompting the model with a sufficiently long input. Kalai and Vempala [134] use statistical tools to prove hallucination for calibrated LMs. Lee et al. [135] study the representation in GPT-2. They train a base classifier for toxicity, and use the linear weight as a proxy of toxic vector. They find there are value vectors close to the toxic vector itself, that are not suppressed by DPO tuning [23]. Wei et al. [136] use pruning and low-rank analysis on safe LM, and find (1) safe neurons and useful neurons are sparse; pruning the safe neurons or removing the safe ranks away degrades safety a lot, and (2) fixing the safe neurons in fine-tuning does not maintain safety. | null | [
"Jingtong Su",
"Julia Kempe",
"Karen Ullrich"
]
| 2024-08-02T17:55:50+00:00 | 2024-08-02T17:55:50+00:00 | [
"cs.LG",
"cs.AI",
"cs.CL"
]
| Mission Impossible: A Statistical Perspective on Jailbreaking LLMs | Large language models (LLMs) are trained on a deluge of text data with
limited quality control. As a result, LLMs can exhibit unintended or even
harmful behaviours, such as leaking information, fake news or hate speech.
Countermeasures, commonly referred to as preference alignment, include
fine-tuning the pretrained LLMs with carefully crafted text examples of desired
behaviour. Even then, empirical evidence shows preference aligned LLMs can be
enticed to harmful behaviour. This so called jailbreaking of LLMs is typically
achieved by adversarially modifying the input prompt to the LLM. Our paper
provides theoretical insights into the phenomenon of preference alignment and
jailbreaking from a statistical perspective. Under our framework, we first show
that pretrained LLMs will mimic harmful behaviour if present in the training
corpus. Under that same framework, we then introduce a statistical notion of
alignment, and lower-bound the jailbreaking probability, showing that it is
unpreventable under reasonable assumptions. Based on our insights, we propose
an alteration to the currently prevalent alignment strategy RLHF. Specifically,
we introduce a simple modification to the RLHF objective, we call E-RLHF, that
aims to increase the likelihood of safe responses. E-RLHF brings no additional
training cost, and is compatible with other methods. Empirically, we
demonstrate that E-RLHF outperforms RLHF on all alignment problems put forward
by the AdvBench and HarmBench project without sacrificing model performance as
measured by the MT-Bench project. |
2408.01421v2 | ## Topological phases of the interacting SSH model: an analytical study
E. Di Salvo, 1 A. Moustaj, 1 C. Xu, 2, 3 L. Fritz, 1 A. K. Mitchell, 4, 5 C. Morais Smith, 1 and D. Schuricht 1
1 Institute for Theoretical Physics, Utrecht University, 3584CC Utrecht, The Netherlands,
2 Department of Physics and Materials Science, University of Luxembourg, L-1511 Luxembourg, Luxembourg,
3 Institute of Theoretical Physics, Technische Universit¨t Dresden, 01069 Dresden, Germany, a
4 School of Physics, University College Dublin, Belfield, Dublin 4, Ireland,
5
Centre for Quantum Engineering, Science, and Technology, University College Dublin, Ireland. (Dated: November 19, 2024)
The interacting SSH model provides an ideal ground to study the interplay between topologically insulating phases and electron-electron interactions. We study the polarization density as a topological invariant and provide an analytic treatment of its behavior in the low-energy sector of the one-dimensional interacting SSH model. By formulating the topological invariant in terms of Green's functions, we use the low-energy field theory of the Thirring model to derive the behavior of the polarization density. We show that polarization density in the continuum theory describes the usual topological insulating phases. Still, it contains an extra factor from the fields' scaling dimensions in the low-energy quantum field theory. We interpret this as a measure of the modified charge of the new excitations in the system. We find two distinct contributions: a renormalization of the electronic charge e of a Fermi liquid because of quasiparticle smearing and an additional contribution coming from the topological charge of the soliton arising in the bosonized version of the Thirring model, the sine-Gordon model.
## I. INTRODUCTION
In the past two decades, noninteracting topological phases, traditionally analyzed through electronic band theory, have garnered significant attention due to the discovery of materials exhibiting unconventional electronic properties [1, 2]. Most notably, the prediction of the quantum spin Hall effect in graphene by Kane and Mele [3, 4] initiated intense research in the field of topological insulators, which are materials with insulating bulk and conducting boundaries. Since then, the theoretical understanding of these systems reached a high level of sophistication. For example, the bulk-boundary correspondence for two-dimensional (2D) time-reversal symmetry broken insulators states that whenever the bulk Hall resistivity of the system is quantized, there exist gap traversing states, which are located at the boundary of the system [5]. On the other hand, a 2D topological insulator respecting time-reversal symmetry will exhibit the quantum spin Hall effect, where the boundary states carry spin currents instead of charge currents. This type of behavior does not only exist in 2D but also in 3D and in 1D, albeit when subjected to different spectral and spatial symmetry constraints [6]. In 3D, for example, a strong topological insulator respects time-reversal symmetry. It has conducting surface states, which are very robust due to spin-momentum locking and cannot be destroyed by the presence of disorder or any symmetry-respecting perturbation [7, 8]. It also features a rich variety of additional possible effects, such as quantized magnetoelectric polarizability, providing a realization of axion electrodynamics in a condensed-matter setting [9, 10]. In 1D, systems possessing inversion symmetry feature a quantized polarization density. This fact can be attributed to two significant results: the formulation of the polarization as a Berry phase [11], and the fact that the Berry phase is quantized to ϕ = 0 , π for inversion symmetric systems [12]. In this case, it is possible to have anomalous polarization corresponding to fractionalized charges on the two boundaries of the system. The overarching theme in all of these cases is that one can compute bulk quantities of these systems and relate them to a corresponding boundary theory.
Additionally, they are called topological insulators because these bulk quantities are often expressed as topological invariants [2, 13]. For example, if an inversion-symmetric 1D system also possesses sublattice symmetry, it is possible to define a winding number ν , directly proportional to the quantized Berry phase, ϕ = πν . Another example would be a time-reversal symmetry broken 2D system, in which the Hall conductivity is quantized and given by a Chern number [14]. This is why physical properties related to these topological invariants are very robust, as long as one respects the symmetries of the system and its gap is preserved.
All these systems may be described by a theoretical framework based on noninteracting electrons [2, 13]. This is usually justified because many materials can be described by Fermi liquid theories in 2D and 3D at low energies. However, this description can break down in strongly correlated systems. Furthermore, in 1D, no such description is possible, and one cannot ignore the effects of electron-electron interactions. This means that the most natural state in 1D is a strongly correlated non-Fermi liquid, an example of which is the Tomonaga-Luttinger liquid [15-17].
Most of the time, topological invariants are not connected to observables in a simple way. A notable example is the Chern number and its relation to the transverse Hall conductivity. This has the main
advantage that one can use standard many-body approaches in a meaningful way. In 1D, it appears that in the non-interacting case, the polarization density and the topological invariant can have the same form. While it is unclear how and when the topological invariants can be extended to a strongly interacting 1D system, this can be done with the polarization density. We find that it serves as a marker of topology and, in the existence of edge modes, also in the case of a 1D interacting system, which is not easily connected to non-interacting fermions.
The effect of interactions in topological insulators is not a new subject, and a significant number of studies have already been conducted in this direction [18-26]. For instance, many topological invariants have been generalized to expressions that hold in the many-body case, or in weakly interacting topological insulators [19-21]. In 1D, the paradigmatic model for a topological insulator studied extensively is the SSH chain [27]. It is a tight-binding model of noninteracting fermions with nearest-neighbor alternating hopping strengths. Depending on the sign of the difference between the two hopping parameters, both a trivial phase and a topological phase can arise. In the topological phase, two degenerate edge modes exist at E = 0 due to sublattice symmetry. The inclusion of interactions has been explored in various works [21-25, 28-31], relying on numerical or perturbative approaches. Some other works have explored extensions of the model to longer range hoppings [32] or to ladder systems [33]. The general result is that the topological phase usually survives the presence of interactions up to some threshold value of the interaction strength, after which the system transitions to a charge-density wave state. Another noteworthy study of the SSH model was conducted in Ref. [34], where they experimentally realized a many-body topological phase of interacting hard-core bosons. Unlike their fermionic counterparts, the many-body bosonic representation of the protecting symmetry permits next-nearest neighbor couplings, which break sublattice symmetry in the single-particle picture. Remarkably, this implies that the many-body topological phase remains intact despite the addition of such perturbations.
In this work, we explore the polarization density as a topological invariant and provide an analytic treatment of its behavior in the low-energy sector of the interacting fermionic SSH model, with symmetry-preserving interactions. Studying the polarization density under interactions is meaningful because it is a physical observable. We achieve this by formulating the polarization density in terms of Green's functions, which are suitable for a many-body approach in the interacting case. This method is similar to the quantum Hall effect, where the transverse conductivity is quantized and proportional to the filling fraction, identifiable as a topological invariant. This identification justifies extending the study of topological invariants to interacting cases as long as the related physical observable is well-defined and measurable. Using a field theory formalism at low energy leverages many exact results in 1D for integrable models, in contrast to higher-dimensional cases. A similar study was done for the non-Hermitian SSH model with random disorder [35]. By combining various arguments, we derive an exact expression of the polarization density and provide a physical interpretation of the results, consistent with previous studies. This paper's main result is that the continuum theory's polarization density describes the same two topologically distinct insulating phases as for the non-interacting case. Still, it now contains an extra factor from the fields' scaling dimensions in the low-energy quantum field theory. The interpretation is that this measures the altered nature of the excitations in the system. There are two contributions: the renormalization of the electronic charge due to quasiparticle smearing and an additional contribution from the soliton's topological charge. The latter cannot be explained within the Fermi liquid framework and highlights the difference between the effects of interactions in 1D systems compared to higher dimensions [17].
This paper is structured as follows. In Section II, we describe the noninteracting SSH model, its topological invariant, and the type of interactions that we will be considering. In Section III, we formulate the polarization density as a response to an external electric field. In Section IV, we explore the effect of interactions on the polarization density. We also provide an intuitive understanding of the result, stating that an adiabatic charge pumping procedure from a trivial to a topological phase would pump one quantum of the renormalized charge, which we have calculated exactly. Finally, in Section V, we present our concluding remarks and give an outlook to additional extensions of our results beyond the regimes considered in this work.
## II. LATTICE SSH MODEL
FIG. 1. The SSH chain, with sublattice A (top) and B (bottom) colored in red and blue, respectively. The dotted box shows a choice of unit cell. The intracell hopping is v and the intercell hopping is w .
The SSH model was originally introduced to describe the behavior of electrons and the emergence of solitonic defects in a polyacetylene molecule [27]. It is a nearest-neighbor tight-binding model for spinless fermions hopping on a 1D chain with two alternating
bond strengths (see Fig. 1). The Hamiltonian of the SSH model is given by
$$\vec { \mathcal { H } } & = v \sum _ { j = 1 } ^ { N } c _ { A, j } ^ { \dagger } c _ { B, j } + w \sum _ { j = 1 } ^ { N } c _ { B, j } ^ { \dagger } c _ { A, j + 1 } + \text{h.c.}, \\ & = \int _ { - \pi / a } ^ { \pi / a } \frac { \text{d} k } { 2 \pi } \left ( c _ { A, k } ^ { \dagger }, \ c _ { B, k } ^ { \dagger } \right ) H ( k ) \left ( c _ { A, k } \right ), \\ \,, \quad \, \dots \quad \dots \quad \dots \quad \dots \quad \dots$$
where v and w are intracell and intercell hopping, respectively. The sum in the first line runs over cell indices, and A,B refers to the two sites inside a unit cell with a lattice constant a and periodic boundary conditions at the ends of the chain. The momentum space formulation is shown in the second line, where we have taken the limit N →∞ . The main object of interest is the single-particle Bloch Hamiltonian
$$H ( k ) = d _ { x } ( k ) \sigma _ { x } + d _ { y } ( k ) \sigma _ { y }, \text{ \quad \ } ( 1 ) \text{ \quad } \text{th}.$$
where d x ( k ) = v + w cos ka , d y ( k ) = -w sin ka and σ i are Pauli matrices acting in the A,B space. The two energy bands are given by
$$E _ { \pm } & = \pm \sqrt { d _ { x } ^ { 2 } + d _ { y } ^ { 2 } }, \\ & = \pm \sqrt { v ^ { 2 } + w ^ { 2 } + 2 v w \cos k a } \.$$
The two bands can touch and close the gap when v = ± w , at ka = 0 ( v = -w ) and ka = π ( v = w ). This signals a change between topologically distinct phases [36].
## A. Symmetries and Topology
The SSH model possesses two symmetries: sublattice symmetry A ↔ B , characterized by
$$\sigma _ { z } H ( k ) \sigma _ { z } = - H ( k ),$$
and inversion symmetry j → N -j +1, characterized by
$$\sigma _ { x } H ( k ) \sigma _ { x } = H ( - k ) \.$$
The former allows for the definition of a winding number invariant [2], while the latter forces the quantization of this winding number to just two values [12]. For a sublattice symmetric gapped Hamiltonian, the following equation defines a winding number [2]
$$\nu = \int _ { - \pi / a } ^ { \pi / a } \frac { \mathrm d k } { 4 \pi i } \, \text{tr} \left [ \sigma _ { z } H ^ { - 1 } ( k ) \partial _ { k } H ( k ) \right ]. \quad ( 2 )$$
This formulation allows one to write Eq. (2) in terms of Green's functions [19]. This will be used later to investigate the invariant's fate in the interacting system. For the SSH chain, we show in Appendix A that this invariant yields
$$\nu = \begin{cases} 0, & \text{if } | v | > | w | \, \\ 1, & \text{if } | v | < | w | \. \end{cases} \quad \text{(3)} \quad \text{an}$$
We can relate the winding number ν to the Berry phase ϕ of the system at half-filling,
$$\phi = \int _ { - \pi / a } ^ { \pi / a } \mathrm d k \left \langle u _ { - } ( k ) \right | i \partial _ { k } \left | u _ { - } ( k ) \right \rangle,$$
where | u -( k ) ⟩ is the lower band's Bloch state. It is quantized by virtue of inversion symmetry to ϕ = 0 for | v | > w | | and ϕ = π for | v | < w | | .
According to the modern theory of polarization [11], the Berry phase is closely related to the position of Wannier centers inside unit cells and, as such, indicates the presence/absence of a 'topological' polarization,
$$P = \frac { e \phi } { 2 \pi } \mod e = \begin{cases} 0, & \text{if $\nu=0$,} \\ \frac { 1 } { 2 }, & \text{if $\nu=1$.} \end{cases}$$
The mod e always appears in the definition of absolute polarization. It accounts for the 2 π ambiguity of the Berry phase and physically for the choice of a unit cell [11]. This polarization manifests itself as a bulk-boundary correspondence: if the system has open boundaries, there will be half-quantized charges sitting at the boundary of the system. This, in turn, means that there will be an anomalous response to an external electromagnetic field [37, 38].
## B. Interactions and the continuum limit
As we will be interested in the low-energy physics of the topological phases, we shall first derive the continuum limit of the noninteracting model at low energies. Since these transitions happen at ka = 0 and ka = π , for the sake of simplicity, we take all parameters to be positive and expand the Bloch Hamiltonian around ka = π to linear order in ka ,
$$H ( \pi + k a ) & = \binom { 0 } { v - w + i w k a } \, \begin{pmatrix} v - w - i w k a \\ 0 \end{pmatrix} \quad ( 5 ) \\ & = m _ { 0 } \sigma _ { x } + w k a \sigma _ { y },$$
where m 0 = v -w will serve as a bare mass parameter in the field theory description. Note that for the transition at k = 0, we need to replace w → -w . The real space Hamiltonian is obtained by replacing k → -i∂ x (we set ℏ = 1),
$$\mathcal { H } = \int \mathrm d x \Psi ^ { \dagger } ( x ) \left [ m _ { 0 } \sigma _ { x } - i v _ { \mathrm F } \sigma _ { y } \partial _ { x } \right ] \Psi ( x ), \quad ( 6 )$$
where we introduced the Dirac spinor
$$\hat { \Psi } ( x _ { j } ) = \frac { 1 } { \sqrt { a } } \begin{bmatrix} c _ { A, j } \\ c _ { B, j } \end{bmatrix},$$
and dropped the j index when taking the limit a → 0. We have also introduced the Fermi velocity v F = wa .
This leads to the interpretation of the sublattice structure as a pseudospin degree of freedom. Using the gamma matrix representation γ 0 = σ x , γ 1 = iσ z , and Ψ ¯ ≡ Ψ † γ 0 together with the slash notation / ∂ = γ ∂ 0 t -γ ∂ 1 x , we have the usual free Hamiltonian and Lagrangian densities of a Dirac fermion,
$$\mathcal { H } _ { 0 } ( x ) & = \bar { \Psi } ( x ) \left ( i v _ { \text{F} } \gamma _ { 1 } \partial _ { x } + m _ { 0 } \right ) \Psi ( x ), \\ \mathcal { L } _ { 0 } ( x ) & = \bar { \Psi } ( x ) \left ( i v _ { \text{F} } \phi - m _ { 0 } \right ) \Psi ( x ).$$
Because of the constrained spatial degrees of freedom, 1D systems are generically strongly interacting - fermions cannot move past each other without interacting [17]. To incorporate this effect, we consider the simplest interaction term that respects the symmetries of the system: a nearest-neighbor repulsion between spinless fermions placed in the same cell (intercell coupling would also break sublattice symmetry),
$$\mathcal { H } _ { 1 } = V _ { 0 } \sum _ { j = 1 } ^ { N } n _ { A, j } n _ { B, j }, \quad \quad ( 8 ) \quad \begin{array} { c } \text{$\text{$w1$} \\ \text{red} \\ J ^ { \prime } _ { 1 } \\ \text{nuu} \end{array} }$$
where n α,j = c † α,j c α,j , with α = A,B . Usually, the densities are shifted by half to ensure half-filling and to respect particle-hole symmetry. This can also be accommodated by adding a chemical potential term in the free Hamiltonian. However, these terms do not matter in the continuum theory that we will be considering and will usually be treated using typical prescriptions such as normal ordering. Using the Dirac spinor Eq. (7), the continuum version of the interaction can be written as
$$\mathcal { H } _ { I } = \frac { g } { 2 } \int \mathrm d x \left [ \bar { \Psi } ( x ) \gamma _ { \mu } \Psi ( x ) \right ] ^ { 2 },$$
where
$$g = \lim _ { a \rightarrow 0 } \frac { V _ { 0 } a } { 2 }.$$
Combining all terms, the Lagrangian density for the continuum limit of the interacting SSH model is given by
$$\mathcal { L } = \bar { \Psi } ( x ) \left ( i v _ { F } \tilde { \phi } - m _ { 0 } \right ) \Psi ( x ) - \frac { g } { 2 } \left [ \bar { \Psi } ( x ) \gamma _ { \mu } \Psi ( x ) \right ] ^ { 2 }, \ \ ( 9 )$$
which is the Thirring model [39, 40].
## C. Generalization: extended SSH model
The SSH model can be generalized simply by including longer-range hoppings that respect all previously discussed symmetries. This model was studied in previous works to understand the interplay between long-range hoppings and disorder [41] and, more recently, the effect of interactions on the topological phases [42]. An example of this extension to a next-next-nearest
FIG. 2. Extended SSH chain. Only the simplest extension has been considered in this figure, namely, the inclusion of J 2 and J ′ 2 .
neighbor is shown in Fig. 2. More generally, one can keep adding these hoppings by skipping 2 n sites each time, resulting in the following Bloch Hamiltonian
$$H ( k ) = \sum _ { n = 1 } ^ { l } \binom { 0 } { h _ { n } ^ { * } ( k ) } \, 0 \, \right ), \, \quad \ \ ( 1 0 )$$
with h n ( k ) = J e n -i ( n -1) k + J e ′ n ink . When l = 1, this reduces to the regular SSH model with J 1 = v and J ′ 1 = w . Because of its extended nature, higher winding numbers are possible, resulting in multiple edge state pairs. However, because the system still obeys inversion symmetry, the polarization Eq. (4) is still quantized to 0 (even winding numbers) or 1 / 2 (odd winding numbers).
Consequently, this system has more possibilities for gap closings and transitions between two phases with different winding numbers. Nevertheless, as long as the interaction term (8) is still the same, the Thirring model is still the low-energy theory that describes the physics near the transition point, but with modified Fermi velocities and bare masses. For example, we consider the model near the k = π transition again. The bare mass and Fermi velocities are then given by
$$m _ { 0 } & = \sum _ { n = 1 } ^ { l } \left [ ( - 1 ) ^ { n - 1 } J _ { n } + ( - 1 ) ^ { n } J _ { n } ^ { \prime } \right ], \\ v _ { \mathrm F } & = a \sum _ { n = 1 } ^ { l } \left [ ( - 1 ) ^ { n - 1 } ( n - 1 ) J _ { n } + ( - 1 ) ^ { n } J _ { n } ^ { \prime } \right ].$$
## III. POLARIZATION AS A RESPONSE TO AN EXTERNAL FIELD: NON-INTERACTING CASE
This section aims to show that we can formulate the electronic system's response to an external electric field by considering the effective action for a pure background gauge field using statistical field theory. The polarization density can be obtained by taking the derivative of the free energy with respect to an external electric field,
$$\mathbf P = \frac { 1 } { V } \frac { \partial F } { \partial \mathbf E },$$
where V is the volume of the system. We will focus on the 1D case and derive formulas for the lattice and continuum versions of the SSH model.
## A. Lattice Model
Let us start by considering the general expression of a non-interacting Hamiltonian on a lattice,
$$H = \sum _ { i j } \sum _ { \mu, \nu } c ^ { \dagger } _ { i, \mu } h ^ { \mu \nu } _ { i j } c _ { j, \nu } = \sum _ { k } \sum _ { \mu \nu } c ^ { \dagger } _ { k, \mu } h ^ { \mu \nu } _ { k } c _ { k, \nu }.$$
The indices i, j refer to unit-cell, while µ, ν refer to internal degrees of freedom, such as sublattice, orbitals, spins, etc. In a tight-binding formulation, the coupling to an external gauge field is achieved by performing a Peierls substitution, which stems from the principle of minimal coupling. That is, one replaces h µν ij → h µν ij e iA ij , where A ij = ∫ x j x i A x ( )d x is the integral of the gauge field from unit cell i to j . Approximating the field to be constant on the scale of the unit cell and assuming weak coupling, we can linearize the exponential with respect to A . Subsequently, rewriting everything in momentum space yields
$$H & = \sum _ { k } \sum _ { \mu \nu } c _ { k, \mu } ^ { \dagger } h _ { k } ^ { \mu \nu } c _ { k, \nu } \\ & \quad + \sum _ { k q } \sum _ { \mu \nu } c _ { k + q / 2, \mu } ^ { \dagger } \frac { \partial h _ { k } ^ { \mu \nu } } { \partial k } c _ { k - q / 2, \nu } A _ { - q },$$
where we used
$$A _ { i j } = \frac { 1 } { \sqrt { N } } \sum _ { q } e ^ { i ( x _ { i } - x _ { j } ) q } A _ { q } \.$$
We are also neglecting the diamagnetic contribution, proportional to A 2 . This approximation is justified when probing the polarization response of the system using a weak electric pulse. With the full matrix Bloch Hamiltonian as H k ( ) = ∑ µ,ν h µν k | µ ⟩ ⟨ ν | , we can write down the imaginary time action as follows
$$S [ A ] = \int _ { 0 } ^ { - } \partial \tau \sum _ { k q } \Psi ^ { * } ( k, \tau ) \Big \{ \left [ \partial _ { \tau } - H \left ( \frac { k + q } { 2 } \right ) \right ] \delta _ { k, q } \\ - \partial _ { k } H \left ( \frac { k + q } { 2 } \right ) A ( q - k ; \tau - \tau ^ { \prime } ) \Big \} \Psi ( q, \tau ), \quad \text{Hence}$$
where the field Ψ( k, τ ) is a Grassmann-valued field obtained by considering coherent states of the annihilation field operator in the second-quantization language. The integral over imaginary time τ runs from 0 to the inverse temperature 1 /T (with units ℏ = k B = 1). The partition function for this system is then conveniently written as a path integral over the fields Ψ and Ψ ∗ , and has a formal solution
$$Z [ A ] & = \int \mathcal { D } \Psi ^ { * } \mathcal { D } \Psi \exp \left ( - S [ A ] \right ) \\ & = \exp \left [ \text{Tr} \ln \left ( - G ^ { - 1 } \right ) \right ],$$
where we wrote G -1 = G -1 0 + A , representing the Green's function as a formal operator, and Tr is a general trace operation over discrete and continuous indices. We have split the contributions into a 'bare' one and one coming from the gauge field. The matrix A is the additional contribution from the derivative of the Hamiltonian. The 'bare' Green's function (in Fourier space) can be obtained by finding the inverse of the following matrix
$$G _ { 0 } ( k, i \omega _ { n } ) = \left [ i \omega _ { n } + H ( k ) \right ] ^ { - 1 },$$
with fermionic Matsubara frequencies ω n = π (2 n +1) T . We now expand the matrix logarithm to linear order in A ,
$$Z [ A ] \equiv Z [ 0 ] \exp \left ( - S _ { \text{eff} } [ A ] \right ),$$
where the effective action is given by S eff [ A ] = Tr( G 0 A ). Working out the generalized trace yields
$$\text{Tr} \left ( G _ { 0 } \mathcal { A } \right ) & = \sum _ { n } \sum _ { q } \tilde { P } ( q, i \omega _ { n } ) A ( q, i \omega _ { n } ), \\ \tilde { P } ( q, i \omega _ { n } ) & = \sum _ { k } \text{tr} \left [ G _ { 0 } ( k, i \omega _ { n } ) \partial _ { k } H \left ( k \right ) \right ] \delta _ { q, 0 },$$
where tr is the trace over internal degrees of freedom. Therefore, we can express the free energy as
$$F [ A ] = - T \ln ( Z ) = - T \ln ( Z _ { 0 } ) + T S _ { \text{eff} } [ A ].$$
Using Eq. (12) for the polarization density, we see that the functional derivative with respect to the electric field will only pick up the effective action contribution:
$$P ( q, i \omega _ { n } ) = \frac { T } { V } \frac { \delta S _ { \text{eff} } } { \delta E ( q, i \omega _ { n } ) }.$$
We now choose a specific gauge where the applied electric field is constant and corresponds to a pulse. For this, we use a gauge potential A x such that E x = -∂ A τ x = E δ τ 0 ( ). This is given by
$$A _ { x } ( x, \tau ) = E _ { 0 } T \sum _ { n } \frac { e ^ { - i \omega _ { n } \tau } } { i \omega _ { n } }. \quad \quad ( 1 3 )$$
Hence, the electric polarization density becomes
$$\text{field} \quad P ( q, i \omega _ { n } ) = \frac { 1 } { \pi ( 2 n + 1 ) } \int _ { - \pi } ^ { \pi } \frac { d k } { 2 \pi i } \text{tr} \left [ G _ { 0 } ( k, i \omega _ { n } ) \partial _ { k } H ( k ) \right ], \\ \text{tion} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thurb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thump} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumbnail} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumbs} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thum} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thimb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thimg} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thmath} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thumb} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thrieved} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thmodified} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thmented} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thithributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{THributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{theributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{stributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{third} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thride} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{thributed} \quad \text{th$$
where we have turned the sum into an integral over the Brillouin zone. The 'static' version thereof, at zero temperature, is given by
$$\text{the} \quad & \mathcal { P } _ { \text{tot}, 0 } \equiv \pi P ( 0, 0 ) = \int _ { - \pi } ^ { \pi } \frac { \text{d} k } { 2 \pi i } \, \text{tr} \left [ G _ { 0 } ( k, 0 ) \partial _ { k } G _ { 0 } ^ { - 1 } ( k, 0 ) \right ], \\ \text{thumbness} \, \text{thumbness} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, \text{the} \, }$$
where we included the subscript 0 in P tot 0 , to indicate the non-interacting case. We could write Eq. (15) because the Green's function at zero temperature is equivalent to the inverse of the Bloch Hamiltonian. Note that this type of polarization is not well defined for
crystalline insulators, which is why the modern theory of polarization was developed in the first place [11]. This occurs because there is a gauge degree of freedom in the choice of unit cells to define the dipole moment. However, the formulation of Green's functions is still beneficial. For a sublattice symmetric Hamiltonian, the relative polarization between sublattices P 0 is a well-defined and gauge-invariant quantity, which we can obtain simply by multiplying the expression inside the trace by σ / z 2. Eq. (15) then becomes
$$\mathcal { P } _ { 0 } = \int _ { - \pi } ^ { \pi } \frac { \mathrm d k } { 4 \pi i } \text{tr} \left [ \sigma _ { z } G _ { 0 } ( k, 0 ) \partial _ { k } G _ { 0 } ^ { - 1 } ( k, 0 ) \right ], \quad ( 1 6 )$$
## B. Continuum polarization of the SSH model
From this point onward, we shall set v F = 1. From the continuum Hamiltonian of the SSH model Eq. (6), we can infer what the action functional of this system will be in the imaginary time formulation:
$$\underset { \sigma _ { z } / 2. } { \text{$\alpha$ and} } \text{$\limply} \quad S & = \int \mathrm d x \mathrm d \tau \Psi ^ { * } ( x, \tau ) \left [ \partial _ { \tau } - i \sigma _ { y } \partial _ { x } - m _ { 0 } \sigma _ { x } \right ] \Psi ( x, \tau ) \\ & = - \int \mathrm d x \mathrm d \tau \int \mathrm d x ^ { \prime } \mathrm d \tau ^ { \prime } \Psi ^ { * } ( x, \tau ) G _ { 0 } ^ { - 1 } ( x, \tau ; x ^ { \prime }, \tau ^ { \prime } ) \Psi ( x ^ { \prime }, \tau ^ { \prime } ),$$
where we introduced the Green's function G 0 , whose momentum representation is
$$G _ { 0 } ( k, i \omega _ { n } ) = \frac { - i \omega _ { n } + k \sigma _ { y } + m _ { 0 } \sigma _ { x } } { \omega _ { n } ^ { 2 } + m _ { 0 } ^ { 2 } + k ^ { 2 } }.$$
which is equivalent to the winding number, Eq. (2). Similar expressions have been discussed in Refs. [19, 43, 44], but we derive ours in a different context here. We further note that there is a factor two difference with the Berry phase definition of polarization and that this formulation does not take into account the mod e ambiguity. Since we are mainly interested in the continuum formulation, this should not be a problem as it still indicates the two topologically distinct phases, as we will see shortly.
Instead of the Peierls substitution used in the lattice formulation, we will directly introduce a background gauge field through minimal coupling. That is, we replace ∂ j → ∂ j + iA j , where A τ ( x, τ ) = -iϕ x, τ ( ), with ϕ x, τ ( ) the electric potential, and A x ( x, τ ) is the magnetic potential. This modifies the Green's function to G -1 = G -1 0 -A , where
$$\mathcal { A } = - A _ { \tau } + \sigma _ { y } A _ { x }.$$
Note that we are omitting coordinates for simplicity. We now integrate out the fermionic degrees of freedom in the partition function to obtain an effective action, which, to linear order, is given by S eff [ A ] = Tr( G 0 A ). The generalized trace operation is given by
$$\text{Tr} \left ( G _ { 0 } \mathcal { A } \right ) & = \int \mathrm d x \mathrm d \tau \int \mathrm d x ^ { \prime } \mathrm d \tau ^ { \prime } \, \text{tr} \left [ G _ { 0 } ( x - x ^ { \prime }, \tau - \tau ^ { \prime } ) \mathcal { A } ( x ^ { \prime }, \tau ^ { \prime } - \tau ) \delta ( x - x ^ { \prime } ) \right ] \\ & = \int \mathrm d \tau \mathrm d \tau ^ { \prime } \, \text{tr} \left [ G _ { 0 } ( 0, \tau - \tau ^ { \prime } ) \int \mathrm d x \mathcal { A } ( x, \tau ^ { \prime } - \tau ) \right ].$$
We choose a gauge potential in Eq. (13) that yields an electric pulse at time τ . We can then write Eq. (17) as the trace, yields (see Appendix A),
$$\text{Tr} \left ( G _ { 0 } \mathcal { A } \right ) = T \sum _ { n } \int \frac { \text{d} k } { 2 \pi } \text{ tr} \left [ G _ { 0 } ( k, i \omega _ { n } ) i \sigma _ { y } \right ] A ( 0, i \omega _ { n } ),$$
Noting that ∂ G k -1 0 ( k, iω n ) = -σ y , we have
$$\text{Tr} \left ( G _ { 0 } \mathcal { A } \right ) = T \sum _ { n } \int \frac { \text{d} k } { 2 \pi i } \text{ tr} \left [ G _ { 0 } \partial _ { k } G _ { 0 } ^ { - 1 } \right ] A ( 0, i \omega _ { n } ). \quad \begin{array} { c } 1 \\ t \\ 1 \end{array}$$
This means we have the same expression for the polarization as in the lattice model, Eq. (14). A direct calculation of the relative polarization, with σ / z 2 inside
$$\mathcal { P } _ { 0 } = \frac { 1 } { 2 } \text{sign} \left ( m _ { 0 } \right ).$$
The half-quantization condition above arises due to the integration over momentum space covering the entire real line. Consequently, it is no longer a winding number, and there is no reason for it to be an integer. Nonetheless, it remains valuable in identifying the topological phase transition. Additionally, the continuum polarization can effectively capture the integer change in polarization across the transition, specifically ∆ P 0 = 1 (in units of the free electron charge).
## IV. EFFECTS OF INTERACTIONS
We have so far seen that the polarization density for a non-interacting system can be expressed, in the lattice and continuum theories, in terms of the noninteracting Green's function. We have used an imaginary time formulation to derive those expressions. Still, since we are interested in the static polarization, which does not contain any Matsubara frequency, we might as well consider a generic field theory instead of an Euclidean one. Equipped with this knowledge, we will now explore the effects of interactions in a more general setting.
## A. Expectations from scaling properties
Before we compute the polarization explicitly, here we present arguments as to its expected behavior in the case of the Thirring model Eq. (9), which is an integrable massive quantum field theory (discussed in more detail in Appendix B).
Consider the full Green's function (including non-symmetry-breaking interactions that only contribute to the off-diagonal matrix elements) in its most general form,
$$G ( k, 0 ) = \begin{pmatrix} 0 & f ( k ) \\ f ^ { * } ( k ) & 0 \end{pmatrix}, \quad \quad ( 1 9 ) \quad \text{$\text{$\text{$\text{$col}$} }$} \\ \text{$\text{$\text{$tot}$} }$$
where
$$f ( k ) = | f ( k ) | e ^ { i \varphi ( k ) }.$$
By substituting Eq. (19) into Eq. (16), we obtain the polarization
$$\mathcal { P } = \lim _ { \Lambda \to \infty } \frac { 1 } { 2 \pi } \int _ { - \Lambda } ^ { \Lambda } d k \partial _ { k } \varphi ( k ), \quad \ \ ( 2 0 ) \quad \ \ f u n \cdot \prod _ { \delta } ^ { \text{the} }$$
where we have introduced a cutoff Λ, which we will come back to later. In other words, the polarization is a winding of the Green's function's complex phase φ from k = -∞ to k = ∞ . As such, its contributions can only come from zeros or poles. Since the massive Thirring model, given by Eq. (9), is integrable, we can safely assume that it is continuous and differentiable everywhere on the real axis, except possibly at | k | = 0 , ∞ (see Appendix B). Moreover, we also know from the Lehmann representation that the poles of the Green's function still correspond to excitation energies, even in the interacting case where they are renormalized. Assuming that these are nonzero (since the theory is massive), the only contribution to the winding number would come from possible zeros at the IR and UV points | k | = 0 , ∞ . It is thus sufficient to study the behavior of the Green's function at the fixed points of the renormalization group (RG) flow (IR and UV regions). The UV behavior of any theory can be accessed from the conformal field theory (CFT) at the UV point. If this theory is connected to a massive IR fixed point through the RG flow, then the Green's function behaves as follows:
$$g ( r ) \sim \begin{cases} r ^ { - y }, \quad \text{if $r\to 0$} \, \\ e ^ { - m r }, \quad \text{if $r\to\infty$} \, \end{cases}$$
where y is the CFT scaling dimension of the field and m is the mass of the lightest particle. In momentum space (see Appendix C for a derivation), this becomes
$$g ( k ) \sim \begin{cases} k ^ { y - 2 }, \quad \text{if $k\to\infty$} \, \\ \frac { 1 } { m }, \quad \text{if $k\to0$} \. \end{cases}$$
Because of the mass gap, the topological invariant is well defined, as the integral Eq. (20) does not contain any divergence and can be written as
$$\mathcal { P } = \frac { 1 } { 2 \pi } \lim _ { \Lambda \rightarrow \infty } \left [ \varphi ( \Lambda ) - \varphi ( - \Lambda ) \right ].$$
The only relevant contribution will be from negative large momenta, since then an extra phase e ± iπy arises, as can be inferred from Eq. (22). Hence, the polarization must be of the form P = ± y/ 2, for y < 1.
The main conclusion is that y , the scaling dimension of the field, redefines the amplitude of the continuum polarization. As for the sign, which determines the topological phase transition, it is still fully determined by the mass parameter,
$$\mathcal { P } = \frac { 1 } { 2 } \text{sign} \left ( m \right ) y = y \mathcal { P } _ { 0 }$$
where P 0 is the non-interacting polarization density from Eq. (18). The reason for this is the following [see Fig. 3]: the integration runs along the real axis, and the winding function has a branch cut parallel to it, with branching points at infinity and at the Green's function's zero. The choice of Riemann sheet for either e iπ or e -iπ is crucial and is enforced by the mass parameter. It dictates the direction from which the branch cut is approached, i.e., the Riemann sheet of the winding function over which the integration runs. If the mass gap vanishes, the integration runs precisely over the branch cut and does not produce a well-defined result. This is consistent with the fact that the polarization is not defined for a gapless system.
These assumptions can be explicitly verified in the free case, when g k ( ) = e iφ k ( ) , with
$$\varphi ( k ) = \arctan \left ( \frac { - k } { m } \right ).$$
Since φ k ( ) has a logarithmic branch cut, the Riemann surface contains an infinite number of different sheets. However, physically, only the difference between two adjacent sheets is relevant. This result holds for any chiral invariant model, emphasizing the importance of a mass gap to protect the topological phase.
FIG. 3. Different integration paths: above (red) or below (blue) the branch cut, depending on the sign of the mass.
## B. Polarization for the Thirring model
Our next goal is to use insights about the Thirring model to derive exact results for the polarization Eq. (16), using the interacting Green's function. As shown in the previous section, one may expect to find all the information in the scaling dimension of the fermionic field, provided that the system is gapped. The Thirring Lagrangian, given by Eq. (9), has two parameters: a bare mass m 0 (which is just the dimerization of the chain) and the local self-interaction coupling strength g , considered strictly positive in our analysis. However, since this is a quantum field theory, the physical mass m and effective coupling B are not equal to the respective bare quantities from the Lagrangian. To extract non-perturbatively the relations between physical and bare parameters of the field theory, we can exploit the mapping between the Thirring and the sine-Gordon model [45] (for more details, see Appendix B). The Lagrangian of the latter is
$$\mathcal { L } _ { \text{SG} } = \frac { v _ { \text{F} } ^ { 2 } } { 1 6 \pi } \left ( \partial _ { \mu } \Phi \right ) ^ { 2 } + \frac { m _ { 0 } ^ { 2 } } { \beta ^ { 2 } } \left ( \cos \beta \Phi - 1 \right )$$
where Φ( x, t ) is a bosonic scalar field, and the effective coupling is
$$\beta ^ { 2 } = \frac { 1 } { 2 } \frac { 1 } { 1 - g / \pi } \.$$
The sine-Gordon model describes a theory of stable solitonic excitations, which interpolate between different classical vacua of the theory Φ 0 ,n = 2 nπ/β . This correspondence allows one to link the fermionic fields Ψ of the Thirring model to the operators in the sine-Gordon model that create or annihilate solitons, e iβ Φ 2 / O 1 β/ 2 . Here, O 1 β/ 2 is a string operator, which accounts for the symmetry among the classical vacua Φ → Φ + 2 nπ/B . This symmetry is also present in the quantum theory.
As an example of this mapping, it was shown [46] that the physical mass of Thirring fermions and sine-Gordon solitons scales as a power law of the bare mass
$$m ^ { 2 } ( m _ { 0 }, g ) = C ( g ) \left ( m _ { 0 } ^ { 2 } \right ) ^ { \frac { 1 } { 2 - 2 \beta ^ { 2 } } }, \quad \ \ ( 2 4 ) \quad \text{rela}$$
where C g ( ) is a function of the bare Thirring coupling g . This exact result was obtained by using non-perturbative bosonization methods in Ref. [46] (see Appendix B for explanations). Additionally, the repulsive regime of the Thirring model, π/ 2 > g > 0, corresponds to the regime 1 2 / < β 2 < 1 in the sine-Gordon model. In this case, Thirring fermions and antifermions, carrying a renormalized electronic charge e ∗ , are mapped into solitons and antisolitons, carrying a topological charge. The latter is defined as
$$Q _ { t } = \frac { \beta } { 2 \pi } \int _ { - \infty } ^ { + \infty } \mathrm d x \partial _ { x } \Phi ( x, t ). \quad \quad ( 2 5 )$$
Note that, in this case, the term topological refers to how the field Φ( x, t ) interpolates between the different minima of the sine-Gordon potential, i.e., the symmetry between different ground states of the model, and not to the topological phase.
Exploiting this mapping even further, the zero frequency Green's function of the Thirring model, defined as
$$G ( k ) = \int _ { - \infty } ^ { + \infty } \frac { \mathrm d x } { 2 \pi } e ^ { i k x } \langle \Psi ( x ) \bar { \Psi } ( 0 ) \rangle, \quad \ ( 2 6 )$$
can be computed in terms of the form factors of the soliton-creating operator of the sine-Gordon model, ˜ = O e iβ Φ 2 / O 1 β/ 2 ,
$$F _ { n } ^ { \tilde { \mathcal { O } } } ( \theta _ { 1 }, \cdots, \theta _ { n } ) \equiv \left \langle 0 \right | \tilde { \mathcal { O } } \left | \theta _ { 1 }, \cdots, \theta _ { n } \right \rangle,$$
where θ i are the rapidities of particles related to their momenta via p i = m sinh θ i (see Appendix B for more details and the soliton-creating operator's exact form). The Green's function then takes the form
$$\text{er is } \text{$\text{$line Green$s function} \text{en} \, takes one for} \\ G ( k ) = \sum _ { n = 0 } ^ { \infty } \int _ { - \infty } ^ { + \infty } \frac { d x } { 2 \pi } \frac { d \theta _ { 1 } } { 2 \pi } \dots \frac { d \theta _ { n } } { 2 \pi } e ^ { i k x } | F _ { n } ^ { \tilde { O } } ( \theta _ { 1 }, \dots, \theta _ { n } ) | ^ { 2 } \\ \text{:tive} \quad \quad \times \delta \left ( k - m \sum _ { j = 1 } ^ { n } \sinh \theta _ { j } \right ). \\ \text{$\text{$k$} \quad } \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots.$$
Using the UV-normalization proposed in Ref. [47], the scaling dimension of the Thirring fermionic field (which is the exponent of the power-like scaling at large momenta, discussed in Section IV A) is found to be
$$y = \frac { 1 } { 2 } \left ( \frac { 1 } { 1 - g / \pi } + 1 - \frac { g } { \pi } \right ). \quad \quad ( 2 8 )$$
This result can be numerically verified from Eq. (27) using the Feynman gas method [48]. The scaling of Eq. (26) in the UV region is also consistent with conformal perturbation theory [49]. The exponent y can be identified as the scaling dimension of the field in the related CFT (more details are available in Appendix D).
g
FIG. 4. (a) Continuum polarization as a function of the interaction strength of the Thirring model. The deviation from the noninteracting value is relatively small in the region where the interaction strength allows for a well-defined polarization, i.e., 0 ≤ g < π/ 2. (b) Phase diagram for the low-energy sector of the repulsive interacting SSH chain in the region where the polarization is well defined. We identify trivial and topological regions from the exact mapping established at the level of the free theory (i.e., along the m -axis). The introduction of interaction in the system does not spoil the topology of the chain until the interaction overcomes the threshold (represented by the wiggling line) and the system undergoes a phase transition. The jump in the polarization, here represented by a change of color from blue to red, along the g -axis, signals the passage from a trivial into a topological phase, accompanied by a change in polarization ∆ P = e ∗ , where e ∗ is the charge carried by the excitations of the theory.
Therefore, the polarization density of the interacting SSH model in the continuum limit may be readily computed using Eq. (23) and Eq. (28),
$$\mathcal { P } = \frac { 1 } { 4 } \left ( \frac { 1 } { 1 - g / \pi } + 1 - \frac { g } { \pi } \right ) \text{sign} ( m ) \. \quad ( 2 9 ) \quad \text{quasi} \quad \text{be fi}$$
This is the main result of this paper. However, there are limitations.
It is known that when the interaction is strong enough (i.e., g > π/ 2), the system becomes gapless [45]. In this case, the interaction makes the massive term irrelevant in the RG sense. It does not drive the system out of the critical region but explores it, as the Hamiltonian is neither gapped nor conformal. The physics of this scaling region is closer to the Luttinger liquid and is not captured by the behavior of the polarization, which is well defined for gapped systems as insulators. Additionally, an important property of the physical mass is that the gap is closed when the effective coupling B reaches an essential singularity (i.e., β 2 = 1 or g = π/ 2) of Eq. (24). Otherwise, the sign of the mass never changes. This means that the polarization jumps along the same line m 0 = 0 of the free case, and the effect of interactions does not change the shape of the phase diagram in this massive regime.
The polarization of the continuum limit of the interacting SSH model and the corresponding phase diagram are shown in Figs. 4(a) and 4(b), respectively.
We note that the phase diagram in the continuum limit is different from that of the lattice model. This is because we are considering different approaches: we are studying the polarization in the continuum limit using field theoretical tools, while most numerical studies consider the behavior of different order parameters on the lattice. This means the continuum limit does not capture boundaries, finite-size effects, and excited state properties of lattice models, such as band curvature. It might fail to determine what other order parameters can be captured , such as the different shapes of critical lines in the original lattice model. For instance, the gapless straight line in Fig. 4(b) is different from the one obtained in the literature, where numerical schemes were used to compute similar phase diagrams [32, 33].
One of the main interpretations of these results is that the polarization is only modified to account for the fractionalized charge of the excitations of the theory. Indeed, the term (1 -g/π ) -1 and its inverse, appearing in Eq. (29), come from two contributions: the renormalized electronic charge of the Thirring fermion and a second term that is a consequence of the degeneracy of the ground state, carried by the string operator accompanying the soliton creation operators, respectively. Thus, electron-electron interactions do not change the qualitative description of the topological phases but do quantitatively modify it to account for the renormalization of the polarization. The situation is somewhat similar to the study of the topological invariant in the presence of interactions in the integer quantum Hall effect. In this case, it has been shown that it does not drive a topological phase transition [50].
Moreover, if one were to construct an adiabatic charge pump, such as the Rice-Mele charge pump [36], the quantized charge transferred after one cycle would now be fractionalized to this new value. Indeed, the induced current results from a change in polarization, driven by a change in configuration in the insulator's bound charges. The Rice-Mele pump is known to adiabatically modulate a 1D chain, such that it is tuned from the trivial to the topological phase of the SSH model and back again to its trivial phase [51]. As a result, the change in polarization is ∆ P = 1 (recall that we are working with units where e = 1). This picture is still valid in the continuum model, with ∆ P = 1. As such, we can interpret the modification of the amplitude of the polarization in Eq. (29) as a result of the modification of the charge of the elementary excitations of the theory, i.e., ∆ P = e ∗ , as sketched in Fig. 4.
Finally, we would like to point out that all the results derived in the last section also hold when one considers the generalization to the extended SSH model Eq. (10). Even though the winding number of the lattice theory might take higher values, signaling multiple topologically distinct phases, the polarization itself is only nontrivial whenever the winding number is an odd integer [see Eq. (4), which is defined modulo the uncertainty quantum e ]. The general case contains infinitely many
topologically distinct atomic limits, half of which are of the obstructed nature [6]. When taking the continuum limit near a phase transition, the Thirring model describes two topologically distinct phases corresponding to neighboring winding numbers. In other words, it models the transition between a phase with nontrivial polarization and one with zero polarization. The only change occurs in different definitions of the Fermi velocities v F and mass parameters m 0 , which are given in Eq. (11).
To gain a deeper understanding of these results, we will employ perturbation theory, the renormalization group, and terminology from Fermi liquid theory to provide additional physical insights and interpretations.
## C. Perturbation theory
Perturbation theory requires regularization schemes, such as introducing a cutoff Λ in momentum space, which we can consider proportional to the inverse of the lattice spacing in the related fermionic chain problem. Such a cutoff Λ is needed when the interaction parameter g is considered because perturbation theory produces divergent contributions. These are resolved either by considering counterterms in the Lagrangian or are regularized by the presence of the cutoff Λ and eliminated by a convenient redefinition. In practice, an infinitesimal redefinition of the cutoff Λ → Λ+ Λ can be performed, δ leading to a shift in all other parameters of the theory subject to a renormalization, i.e., the coupling constants and the field prefactors,
$$g _ { i } \to g _ { i } + \delta g _ { i } \, \\ \Psi \to ( 1 + \delta \eta ) \Psi \, \\ \beta _ { \text{RG} } ^ { ( i ) } \equiv - \Lambda \frac { \delta g _ { i } } { \delta \Lambda } \simeq - \frac { \partial g _ { i } } { \partial \ln \Lambda } \, \\ \gamma = - \Lambda \frac { \delta \eta } { \delta \Lambda } \simeq - \frac { \partial \eta } { \partial \ln \Lambda } \, \\ \cdot \circ \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd.$$
where i = 1 2, with , g 1 = m and g 2 = g . We have also defined the RG beta functions β RG of the parameters g i and implied a change in the scaling dimension γ because of the redefinition of the field through η . Additionally, the correlation functions containing n fields transform as
$$G ^ { ( n ) } ( \Lambda, g _ { i } ) \rightarrow ( 1 + n \delta \eta ) G ^ { ( n ) } ( g _ { i } ) \.$$
Requiring that their form must be independent of the value of the cutoff Λ leads to the so-called Callan-Symanzik equation:
$$\frac { d } { d \ln \Lambda } G ^ { ( n ) } ( k _ { 1 }, \dots, k _ { n } ; \Lambda, g ) & = 0 \quad \longrightarrow \\ \left [ \Lambda \frac { \partial } { \partial \Lambda } + \sum _ { i } \beta _ { \text{RG} } ( g _ { i } ) \frac { \partial } { \partial g _ { i } } + n \gamma \right ] G ^ { ( n ) } ( k _ { 1 }, \dots, k _ { n } ; \Lambda, g ) & = 0. \quad \text{FIG. 5.} \quad \text{(a) The}$$
Using the fact that β RG → 0 in the UV limit, Eq. (30) results in ln G ∼ 2 γ ln( k/ Λ). Therefore, we find that the argument of the two-point function is
$$\varphi ( k ) \sim - i \ln G = - 2 i \gamma \ln \left ( \frac { k } { \Lambda } \right ),$$
which corroborates the dependence of the polarization on the scaling dimension of the fermionic field. Taking k → Λ and then Λ → ∞ also confirms that the polarization is independent of regularization schemes and the form of the cutoff.
Although perturbation theory in 1D systems differs significantly from higher-dimensional cases [17], it can provide valuable insights for interpreting results. For instance, Eq. (23), derived non-perturbatively, can be analyzed using Fermi liquid terminology. This approach paves the way for potential generalizations of our arguments to interacting topological fermionic systems in 2D or 3D. This can be shown by associating the renormalization group procedure with Fermi liquid theory. The simplest way to do so is by considering the many-body Green's function close to its poles, which takes the form
$$G ( k, \omega ) = \frac { Z } { \omega - \epsilon ( k ) } \, \quad \quad \quad ( 3 1 )$$
where ϵ k ( ) is the energy of the excitations with momentum k . The shift δη , dictated by the scaling dimension of the fermion field, induces a shift of the quasiparticle weight Z . In the Fermi liquid framework, this quantity measures Fermi-liquid behavior: as long as Z ≃ 1, excitations behave as free electrons with dressed mass and electric charge, i.e., they are the system's quasiparticles. When this is the case, we do not expect the polarization to be affected by interactions, except for the 'trivial' renormalization of the electronic charge. However, our result Eq. (29) contains an additional contribution related to the degeneracy of the ground state of the dual bosonic model, breaking the Fermi liquid picture and signaling the fact that the fermionic excitations are not reducible to dressed electrons but are entirely different.
Let us now compute the lowest order corrections to the polarization given by Eq. (16), but with the full interacting Green's function. The polarization can be
FIG. 5. The two relevant corrections to the Green's function. (a) The self-energy is momentum-independent in this case. (b) The lowest correction to the self-energy acquires a linear momentum dependence, resulting in a g 2 correction to the polarization.
FIG. 6. Feynman rules for the propagator in momentum space and the interaction vertex. The relation to the initially used propagator is obtained by multiplying it from the left by -σ x .
expanded as
$$\mathcal { P } = \mathcal { P } ^ { ( 0 ) } + g \mathcal { P } ^ { ( 1 ) } + \frac { g ^ { 2 } } { 2 } \mathcal { P } ^ { ( 2 ) } + \dots$$
̸
The lowest order expansion of the exact solution of the polarization Eq. (29) is of order g 2 . Thus, we expect that perturbation theory reproduces this functional relationship, i.e., P (1) = 0 and P (2) = 0.
To perform the calculations, we first recall that the fully interacting Green's function obeys the self-consistent Dyson equation, which is formally given by
$$\hat { G } & = \hat { G } _ { 0 } + \hat { G } _ { 0 } * \hat { \Sigma } * \hat { G } \\ & = \hat { G } _ { 0 } + \hat { G } _ { 0 } * \hat { \Sigma } * \hat { G } _ { 0 } + \hat { G } _ { 0 } * \hat { \Sigma } * \hat { G } _ { 0 } * \hat { \Sigma } * \hat { G } _ { 0 } + \cdots, \\ ( 3 2 ) & =$$
where the hat is used to denote the formal operators and the stars denote their multiplication. The self-energy Σ ˆ represents all the one-particle irreducible diagrams in the expansion of the two-point correlation function (i.e., the Green's function). The inverse of the Green's function is simply
$$\hat { G } ^ { - 1 } = \hat { G } _ { 0 } ^ { - 1 } - \hat { \Sigma } \. \quad \quad \quad$$
Substituting Eq. (32) and Eq. (33) into Eq. (16), one obtains two terms, which will be considered separately,
$$\text{Tr} \left [ \sigma _ { z } G \partial _ { k } G _ { 0 } ^ { - 1 } \right ] \text{ \quad \ \ }$$
and
$$\text{Tr} \left [ \sigma _ { z } G \partial _ { k } \Sigma \right ].$$
To first order, the self-energy ˆ Σ does not depend on momentum (see the Feynman diagram in Fig. 5). Thus only the first term Eq. (34) contributes to the first-order correction to the self-energy, i.e.,
$$g \mathcal { P } ^ { ( 1 ) } = \int _ { - \infty } ^ { + \infty } \frac { \mathrm d k } { 4 \pi$$
To compute Σ, we will use the fully relativistic propagators, vertex functions, and the Feynman rules depicted in Fig. 6. The self-energy depicted in Fig. 5(a) then reads
$$\Sigma ^ { ( 1 ) } & = g \int \frac { d ^ { 2 } q } { ( 2 \pi ) ^ { 2 } } \gamma _ { \mu }$$
Without proceeding with the calculation of this divergent integral (which requires a careful renormalization with a counterterm in the Lagrangian), we can nevertheless see, after multiplying by -σ x (see Fig. 5), that
$$\Sigma ^ { ( 1 ) } = \alpha g \sigma _ { x } \, \quad \quad \quad$$
where α is the constant obtained by carrying out the integral. Substituting Eq. (37) into Eq. (36), we obtain
$$g \mathcal { P } ^ { ( 1 ) } = - g \alpha \int _ { - \infty } ^ { +$$
which is zero because the integrand is an odd function of k , confirming that there are no corrections to the free theory at first order in g .
The second-order contribution to the polarization comes from a term of the second type of first order contributions Eq. (35). This means that we require a momentum-dependent self-energy correction, for which the simplest example is shown in Fig. 5(b) and given by
$$\stackrel { \cdots } { ( 3 2 ) } \quad \Sigma ^ { ( 2 ) } = g ^ { 2$$
This expression is rather lengthy and leads to divergences if evaluated without proper regularization. For the sake of simplicity, we assume a linear dependence on momentum. In some limiting cases, this linear dependence can be derived explicitly (see Ref. [47] for a specific example). Then, we take
$$\Sigma ^ { ( 2 ) } = \frac { g ^ { 2 } } { 2 } \sum _ { \mu = 0$$
where now σ 0 = ✶ , and σ i , with i = 1 2 3, are the usual , , Pauli matrices. The simplest term that can contribute to the polarization to second order is then
$$\frac { g ^ { 2 } } { 2 } \mathcal { P } ^ { ( 2 ) } & = - \frac {$$
We can calculate the integral explicitly and obtain
$$\mathcal { P } ^ { ( 2 ) } = - \frac { \alpha _ { 2 } } { 2 }$$
confirming our expectations that the first correction in perturbation theory to the polarization should be of order g 2 .
The absence of a first-order contribution also highlights that charge renormalization is not the only process contributing to the polarization response in the Thirring model [52]. If it were, a term proportional to g/π would be present. This supports the mathematical assumptions made using non-perturbative arguments and the renormalization group. From a physical perspective, it confirms that the breakdown of the Fermi liquid paradigm in 1D models also affects the topological properties related to their linear response.
## V. CONCLUSION
An analytic determination of topological properties of interacting fermionic systems has always proven to be a daunting task; so far, numerical results have been widely used in the field, but in this work, we have explicitly evaluated the topological invariant Eq. (16) in the low-energy regime of the interacting SSH chain with nearest-neighbor density-density coupling. The physical interpretation of this quantity was given in the free case as the relative polarization between sublattices. The interaction term that we considered respects the symmetries of the non-interacting system, and its continuum limit yields the Thirring model, which enabled the formulation of the problem using this framework and allowed us to obtain exact analytic results. We find that the IR and UV regions play a prominent role in the continuum theory. Namely, the presence of a mass gap in the infrared regime protects the result obtained by the characterization of the ultraviolet regime in terms of the scaling dimension of the fermionic field. The role of the mass parameter in determining the topological phase transitions of the lattice model is akin to how the interplay between the Semenoff mass and the Haldane mass dictates topological phase transitions in the Chern insulator [53]. Our result can be readily generalized to cases where longer-range hoppings are included. Such models allow for more topological phase transitions. Still, in the vicinity of each of them, they can all be modeled by Thirring field theories where the details of different transitions are encoded by the various masses and the Fermi velocities Eq. (11). The jump in the relative polarization is then computed in the same way as for the interacting SSH.
Moreover, its interpretation in terms of polarization and a quantized charge-pumping argument facilitates
- [1] X.-L. Qi and S.-C. Zhang, Topological insulators and superconductors, Rev. Mod. Phys. 83 , 1057 (2011).
- [2] C. K. Chiu, J. C. Teo, A. P. Schnyder, and S. Ryu, Classification of topological quantum matter with symmetries, Rev. Mod. Phys. 88 , 035005 (2016).
- [3] C. L. Kane and E. J. Mele, Quantum Spin Hall Effect in Graphene, Phys. Rev. Lett. 95 , 226801 (2005).
the description of topological phases through the bulk-boundary correspondence. This enables the construction of a phase diagram within the applicable regime. The modification of the polarization amplitude can be understood as coming from the renormalized charge, together with a quantity that weighs the degeneracy of the ground state carried by the excitations of the interacting theory. Although our results only apply to a family of 1D lattice models described by integrable interacting field theories in the continuum limit, they provide numerous insights regarding the nature of topological phase transitions in interacting models. For instance, the most relevant effects of interactions are the renormalization of the charge and, in this case, the degeneracy of the ground state. Additionally, most of the topological properties in the low-energy regime are determined by the scaling regions of the RG flow, where the UV regime influences the magnitude of the polarization Eq. (23) and the IR protects it via the presence of a gap. Finally, the non-Fermi liquid behavior leads to a simple redefinition of the polarization jump from integers to reals but does not affect the shape of the phase diagram.
As an outlook, it would be valuable to investigate whether this picture still holds when considering different types of interactions. The resulting low-energy effective field theories would vary, and some may not be integrable. Nevertheless, perturbative methods can always be used to compute the scaling dimensions of the fields and study the modification of the polarization.
## ACKNOWLEDGMENTS
E.D., A.M., and C.X. are shared first authors. L.F., A.K.M., C.M.S., and D.S. supervised the project.
- A.M. acknowledges funding from the project TOPCORE with project No. OCENW.GROOT.2019.048, financed by the Dutch Research Council (NWO).
- C.X. acknowledges financial support from the National Research Fund Luxembourg under Grants No. C20/MS/14764976/TopRel.
- A.K.M. acknowledges financial support from Science Foundation Ireland through Grant 21/RP-2TF/10019.
This work is part of the D-ITP consortium, a program of the Dutch Research Council (NWO) that is funded by the Dutch Ministry of Education, Culture and Science (OCW).
- [4] C. L. Kane and E. J. Mele, Z2 Topological Order and the Quantum Spin Hall Effect, Phys. Rev. Lett. 95 , 146802 (2005).
- [5] G. Dolcetto, M. Sassetti, and T. L. Schmidt, Edge physics in two-dimensional topological insulators (2015).
- [6] B. Bradlyn, L. Elcoro, J. Cano, M. G. Vergniory, Z. Wang, C. Felser, M. I. Aroyo, and B. A. Bernevig,
- Topological quantum chemistry, Nature 547 , 298 (2017).
- [7] L. Fu, C. L. Kane, and E. J. Mele, Topological Insulators in Three Dimensions, Phys. Rev. Lett. 98 , 106803 (2007).
- [8] D. Hsieh, Y. Xia, D. Qian, L. Wray, J. H. Dil, F. Meier, J. Osterwalder, L. Patthey, J. G. Checkelsky, N. P. Ong, A. V. Fedorov, H. Lin, A. Bansil, D. Grauer, Y. S. Hor, R. J. Cava, and M. Z. Hasan, A tunable topological insulator in the spin helical Dirac transport regime, Nature 460 , 1101 (2009).
- [9] A. M. Essin, J. E. Moore, and D. Vanderbilt, Magnetoelectric Polarizability and Axion Electrodynamics in Crystalline Insulators, Phys. Rev. Lett. 102 , 146805 (2009).
- [10] F. Wilczek, Two applications of axion electrodynamics, Phys. Rev. Lett. 58 , 1799 (1987).
- [11] R. D. King-Smith and D. Vanderbilt, Theory of polarization of crystalline solids, Phys. Rev. B 47 , 1651 (1993).
- [12] J. Zak, Berry's phase for energy bands in solids, Phys. Rev. Lett. 62 , 2747 (1989).
- [13] A. W. W. Ludwig, Topological phases: classification of topological insulators and superconductors of non-interacting fermions, and beyond, Phys. Scr. T168 , 014001 (2016).
- [14] D. J. Thouless, M. Kohmoto, M. P. Nightingale, and M. den Nijs, Quantized Hall Conductance in a Two-Dimensional Periodic Potential, Phys. Rev. Lett. 49 , 405 (1982).
- [15] F. D. M. Haldane, 'Luttinger liquid theory' of one-dimensional quantum fluids. I. Properties of the Luttinger model and their extension to the general 1D interacting spinless Fermi gas, J. Phys. C 14 , 2585 (1981).
- [16] J. Voit, One-dimensional Fermi liquids, Rep. Prog. Phys. 58 , 977 (1995).
- [17] T. Giamarchi, Quantum Physics in One Dimension (Oxford University Press, 2003).
- [18] S. Rachel, Interacting topological insulators: a review, Rep. Prog. Phys. 81 , 116501 (2018).
- [19] V. Gurarie, Single-particle Green's functions and interacting topological insulators, Phys. Rev. B 83 , 085426 (2011).
- [20] S. R. Manmana, A. M. Essin, R. M. Noack, and V. Gurarie, Topological invariants and interacting one-dimensional fermionic systems, Phys. Rev. B 86 , 205119 (2012).
- [21] W. Chen, Weakly interacting topological insulators: Quantum criticality and the renormalization group approach, Phys. Rev. B 97 , 115130 (2018).
- [22] J. Sirker, M. Maiti, N. P. Konstantinidis, and N. Sedlmayr, Boundary fidelity and entanglement in the symmetry protected topological phase of the SSH model, J. Stat. Mech. 2014 , P10032 (2014).
- [23] A. M. Marques and R. G. Dias, Multihole edge states in Su-Schrieffer-Heeger chains with interactions, Phys. Rev. B 95 , 115443 (2017).
- [24] M. Yahyavi, L. Saleem, and B. Het´nyi, Variational study e of the interacting, spinless Su-Schrieffer-Heeger model, J. Phys. Condens. Matter 30 , 445602 (2018).
- [25] T. Jin, P. Ruggiero, and T. Giamarchi, Bosonization of the interacting Su-Schrieffer-Heeger model, Phys. Rev. B 107 , L201111 (2023).
- [26] P. B. Melo, S. A. S. J´nior, W. Chen, R. Mondaini, and u T. Paiva, Topological marker approach to an interacting Su-Schrieffer-Heeger model, Phys. Rev. B 108 , 195151
(2023).
- [27] W. P. Su, J. R. Schrieffer, and A. J. Heeger, Solitons in Polyacetylene, Phys. Rev. Lett. 42 , 1698 (1979).
- [28] P. Matveeva, D. Gutman, and S. T. Carr, Weakly interacting one-dimensional topological insulators: A bosonization approach, Physical Review B 109 , 165436 (2024).
- [29] N. Wagner, L. Crippa, A. Amaricci, P. Hansmann, M. Klett, E. J. K¨nig, T. Sch¨fer, D. D. Sante, J. Cano, o a A. J. Millis, A. Georges, and G. Sangiovanni, Mott insulators with boundary zeros, Nature Communications 14 , 7531 (2023).
- [30] S. Mondal, S. Greschner, L. Santos, and T. Mishra, Topological inheritance in two-component Hubbard models with single-component Su-Schrieffer-Heeger dimerization, Physical Review A 104 , 013315 (2021).
- [31] Z.-M. Huang and S. Diehl, Interaction-induced topological phase transition at finite temperature, arXiv 2407.04779 (2024).
- [32] X. Zhou, J.-S. Pan, and S. Jia, Exploring interacting topological insulator in the extended Su-Schrieffer-Heeger model, Phys. Rev. B 107 , 054105 (2023).
- [33] A. A. Nersesyan, Phase diagram of an interacting staggered Su-Schrieffer-Heeger two-chain ladder close to a quantum critical point, Phys. Rev. B 102 , 045108 (2020).
- [34] S. de L´ es´leuc, e V. Lienhard, P. Scholl, D. Barredo, S. Weber, N. Lang, H. P. B¨ uchler, T. Lahaye, and A. Browaeys, Observation of a symmetry-protected topological phase of interacting bosons with Rydberg atoms, Science 365 , 775 (2019).
- [35] A. Moustaj, L. Eek, and C. Morais Smith, Field theoretical study of disorder in non-Hermitian topological models, Phys. Rev. B 105 , L180503 (2022).
- [36] J. K. Asb´ oth, L. Oroszl´ny, a and A. P´ alyi, A Short Course on Topological Insulators , Vol. 919 (Springer International Publishing, Cham, 2016).
- [37] Y. Aihara, M. Hirayama, and S. Murakami, Anomalous dielectric response in insulators with the π Zak phase, Phys. Rev. Res. 2 , 033224 (2020).
- [38] A. Moustaj, J. P. J. Krebbekx, and C. M. Smith, Anomalous Polarization in One-dimensional Aperiodic Insulators (2024).
- [39] W. E. Thirring, A soluble relativistic field theory, Ann. Phys. 3 , 91 (1958).
- [40] V. E. Korepin, Direct calculation of the S matrix in the massive Thirring model, Theor. Math. Phys. 41 , 953 (1979).
- [41] B. Perez-Gonzalez, M. Bello, A. Gomez-Leon, and G. Platero, Interplay between long-range hopping and disorder in topological systems, Phys. Rev. B 99 , 035146 (2019).
- [42] P.-J. Chang, J. Pi, M. Zheng, Y.-T. Lei, D. Ruan, and G.-L. Long, Topological phases of extended Su-Schrieffer-Heeger-Hubbard model, arXiv: 2405.10351 (2024).
- [43] B. Sbierski and C. Karrasch, Topological invariants for the Haldane phase of interacting Su-Schrieffer-Heeger chains: Functional renormalization-group approach, Phys. Rev. B 98 , 165101 (2018).
- [44] O. Balabanov, C. Ortega-Taberner, and M. Hermanns, Quantization of topological indices in critical chains
at low temperatures, Physical Review B 106 , 045116 (2022).
- [45] S. Coleman, Quantum sine-Gordon equation as the massive Thirring model, Phys. Rev. D 11 , 2088 (1975).
- [46] A. B. Zamolodchikov, Mass scale In the sine-Gordon model and its reductions, Int. J. Mod. Phys. A 10 , 1125 (1995).
- [47] S. Lukyanov and A. Zamolodchikov, Form factors of soliton-creating operators in the sine-Gordon model, Nucl. Phys. B 607 , 437 (2001).
- [48] G. Mussardo, Form Factor Perturbation Theory, in Statistical Field Theory (Oxford University PressOxford, 2020) pp. 863-881.
- [49] A. B. Zamolodchikov, Integrable field theory from conformal field theory, in Integrable Sys Quantum Field Theory (Elsevier, 1989) pp. 641-674.
- [50] C. Zhang and M. Zubkov, Influence of interactions on Integer Quantum Hall Effect, Ann. Phys. 444 , 169016 (2022).
- [51] J. K. Asb´ oth, L. Oroszl´ny, a and A. P´ alyi, Adiabatic Charge Pumping, Rice-Mele Model, in A Short Course on Topological Insulators (Springer International Publishing, 2016) pp. 55-68.
- [52] V. E. Korepin, N. M. Bogoliubov, and A. G. Izergin, Quantum Inverse Scattering Method and Correlation Functions (Cambridge University Press, 1993).
- [53] F. D. M. Haldane, Model for a Quantum Hall Effect without Landau Levels: Condensed-Matter Realization of the 'Parity Anomaly', Phys. Rev. Lett. 61 , 2015 (1988).
- [54] G. Mussardo, Exact S -Matrices, in Statistical Field Theory (Oxford University PressOxford, 2009) pp. 605-654.
- [55] F. A. Smirnov, Form Factors in Completely Integrable Models of Quantum Field Theory , Vol. 14 (World Scientific, 1992).
- [56] P. Goodard, A. Kent, and D. Olive, Virasoro algebras and coset space models, Phys. Lett. B 152 , 88 (1985).
- [57] P. Goddard, A. Kent, and D. Olive, Unitary representations of the Virasoro and super-Virasoro algebras, Comm. Math. Phys. 103 , 105 (1986).
- [58] V. Fateev, The exact relations between the coupling constants and the masses of particles for the integrable perturbed conformal field theories, Phys. Lett. B 324 , 45 (1994).
- [59] G. Mussardo, Thermodynamical Bethe Ansatz, in Statistical Field Theory (Oxford University PressOxford, 2009) Chap. 19, pp. 655-688.
- [60] J. Cardy, Scaling and Renormalization in Statistical Physics (Cambridge University Press, 1996).
- [61] J. C. Collins, Basic examples, in Renormalization (Cambridge University Press, 1984) Chap. 3, pp. 38-61.
## Appendix A: Quantization of the winding number
## 1. Lattice model
The Green's function for the Hamiltonian given by Eq. (1) is
$$\underset { \substack { \text{tor} \\ \text{y, in} \\ \mathbb { \Phi } \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Clone \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Lambda \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \oplus \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi$$
Working out the trace in Eq. (16) yields
$$\nu = \int _ { - \pi } ^ { \pi } \frac { \mathrm d k } { 4 \pi i } \frac { 2 i w \left ( w + v \cos k \right ) } { v ^ { 2 } + w ^ { 2 } + 2 v w \cos k }.$$
We will solve this using contour integration. Before we do that, we shall rewrite the equation as
$$\nu = \int _ { - \pi } ^ { \pi } \frac { \mathrm d k } { 4 \pi } \frac { 2 + V e ^ { i k } + V e ^ { - i k } } { ( 1 + V e ^ { i k } ) ( 1 + V e ^ { - i k } ) },$$
where we have introduced the parameter V = v/w . This integral can be rewritten as an integral over the unit circle S 1 in the complex plane by defining z = e ik ,
$$\nu & = \oint _ { S ^ { 1 } } \frac { d z } { 2 \pi i } \frac { 1 } { 2 V } \frac { V z ^ { 2 } + 2 z + V } { z ( z + V ^ { - 1 } ) ( z + V ) }, \\ & \equiv \oint _ { S ^ { 1 } } \frac { d z } { 2 \pi i } f ( z ). \\ \epsilon \dots \int _ { S ^ { 1 } } \epsilon / \cdots \int _ { S ^ { 1 } } \epsilon \dots \int _ { S ^ { 1 } } \epsilon \dots \int _ { S ^ { 1 } } \epsilon \dots \int _ { S ^ { 1 } }.$$
The function f ( z ) has two poles inside the unit circle and one outside. The pole z 0 = 0 is always inside, while z 1 = -V -1 is inside if | w < v | | | (making z 2 = -V outside). Using the residue theorem, we then have the following conditions
$$\nu = \begin{cases} \text{Res} ( f, z _ { 0 } ) + \text{Res} ( f, z _ { 1 } ), & \text{if $|w|<|v|$,} \\ \text{Res} ( f, z _ { 0 } ) + \text{Res} ( f, z _ { 2 } ), & \text{if $|w|>|v|$.} \end{cases}$$
Since the poles are of order 1, the residues are simply given by
$$\text{in by} \\ \text{Res} ( f, z _ { 0 } ) & = \lim _ { z \to z _ { 0 } } ( z - z _ { 0 } ) f ( z ) = \frac { 1 } { 2 }, \\ \text{Res} ( f, z _ { 1 } ) & = \lim _ { z \to z _ { 1 } } ( z - z _ { 1 } ) f ( z ) = - \frac { 1 } { 2 }, \\ \text{Res} ( f, z _ { 2 } ) & = \lim _ { z \to z _ { 2 } } ( z - z _ { 2 } ) f ( z ) = \frac { 1 } { 2 }, \\ \text{ich finishes the proof of the quantization of}$$
which finishes the proof of the quantization of the winding number,
$$\nu = \begin{cases} 0, & \text{if $|w|<|v|$,} \\ 1, & \text{if $|w|>|v|$.} \end{cases}$$
## 2. Continuum model
In this case, we start from Eq. (5) and write down the Green's function as
$$G _ { 0 } ( k, 0 ) = \frac { 1 } { m ^ { 2 } + w ^ { 2 } k ^ { 2 } } \begin{pmatrix} 0 & m + i w k \\ - m - i w k \end{pmatrix}, \ \ ( A 2 )$$
where we recovered the parameter w to compute the integral in the general case. Working out the trace in Eq. (16) yields
$$\nu & = \int _ { - \infty } ^ { \infty } \frac { \mathrm d k } { 4 \pi i } \frac { 2 i m w } { m ^ { 2 } + w ^ { 2 } k ^ { 2 } } \\ & = \int _ { - \infty } ^ { \infty } \frac { \mathrm d k } { 2 \pi } \frac { \mathcal { M } } { \mathcal { M } ^ { 2 } + k ^ { 2 } } \\ & = \frac { \mathcal { M } } { 2 \pi } \int _ { - \infty } ^ { \infty } \mathrm d k \frac { 1 } { \mathcal { M } ^ { 2 } } \frac { 1 } { 1 + ( k / \mathcal { M } ) ^ { 2 } }, \\ \dots \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{array}$$
where we introduced the scaled mass parameter M = m/w . Now we use the fact that a/a 2 = 1 / a | | , and substitute k = M x to get
$$\nu = \frac { \mathcal { M } } { 2 \pi | \mathcal { M } | } \int _ { - \infty } ^ { \infty } \mathrm d x \frac { 1 } { 1 + x ^ { 2 } } = \frac { 1 } { 2 } \text{sign} ( \mathcal { M } ).$$
The last equality results from a/ a | | = sign( a ) and the integral evaluating to π .
## Appendix B: Thirring and sine-Gordon models
In this section, we list some properties of the Thirring model. Most of them are obtained using its bosonic dual, the sine-Gordon model. Both are instances of integrable field theories, which are (1+1)-dimensional field theories that have an infinite number of local conserved charges. Such operators commute with the respective Hamiltonian and will strongly constrain the scattering between particles and, in general, the dynamics in the model. Scattering between particles is elastic and factorizes into subsequent two-particle scatterings. These requirements are strict enough to analytically fix the form of the scattering matrix via bootstrap methods [54], which is why these theories are analytically solvable. In particular, the Green's functions and the operator's matrix elements can be derived analytically.
Starting from the Lagrangians of the Thirring and sine-Gordon models (for simplicity, we consider v F = 1)
$$\mathcal { L } _ { \text{Th} } & = \bar { \Psi } ( x ) \left ( i \phi - m _ { 0 } \right ) \Psi ( x ) - \frac { g } { 2 } \left [ \bar { \Psi } ( x ) \gamma _ { \mu } \Psi ( x ) \right ] ^ { 2 }, \\ \mathcal { L } _ { \text{SG} } & = \frac { 1 } { 1 6 \pi } \left ( \partial _ { \mu } \Phi \right ) ^ { 2 } + \frac { m _ { 0 } ^ { 2 } } { \beta ^ { 2 } } \left ( \cos \beta \Phi - 1 \right ), \\ \mathfrak { T } _ { \text{C} }$$
the scattering matrix of Thirring fermionic excitations, labeled by i = ± when fermions (+) or antifermions ( -) are considered, can be fully specified using inverse scattering methods. It is given by [40, 52]
$$S _ { i j } ( \theta ) = - e ^ { 8 i / \beta ^ { 2 } } \frac { e ^ { \theta } - e ^ { - 8 i / \beta ^ { 2 } } } { e ^ { \theta } - e ^ { 8 i / \beta ^ { 2 } } } \delta _ { i j } + ( 1 - \delta _ { i j } ), \quad ( B 1 )$$
where the argument θ is the difference between two rapidities θ 1 and θ 2 , related to the momenta p 1 and p 2
through p i = m cosh θ i . The scattering matrix has the following action on a two-particle state
$$S _ { i _ { 1 } i _ { 2 } } ( \theta ) | \theta _ { 1 }, \theta _ { 2 } \rangle _ { i _ { 1 }, i _ { 2 } } = | \theta _ { 2 }, \theta _ { 1 } \rangle _ { i _ { 2 }, i _ { 1 } }.$$
Moreover, given its action on states, we can infer that S ( -θ ) = S † ( θ ) = S -1 ( θ ), which holds for Eq. (B1). This expression depends also on the parameter β 2 , which is just the coupling of the sine-Gordon model. Moreover, we take the mass of the Thirring fermion m to be a renormalized version of the mass parameter m 0 , given by Eq. (24) and obtained by studying the sine-Gordon theory. Before turning to the latter, we briefly introduce how correlation functions are evaluated in the Thirring model: once the following matrix elements of a certain operator V are known,
$$F _ { n ; i _ { 1 } \dots i _ { n } } ^ { V } ( \theta _ { 1 }, \dots, \theta _ { n } ) = \langle 0 | V | \theta _ { 1 }, \dots, \theta _ { n } \rangle _ { i _ { 1 } \dots i _ { n } }, \quad ( B 2 )$$
the Lehmann representation is fully described as an absolutely convergent series (after Wick rotating to Euclidean spacetime)
$$- \dots \dots - r \dots \dots \dots \dots \nu \\ G ^ { V } ( x, t ) & = \langle 0 | V ( x, t ) V ^ { \dagger } ( 0, 0 ) | 0 \rangle & ( B 3 ) \\ & = \sum _ { n = 0 } ^ { \infty } \int _ { - \infty } ^ { + \infty } \text{d} \theta _ { 1 } \dots \text{d} \theta _ { n } \\ & \quad \times | F _ { n } ^ { V } ( \theta _ { 1 }, \dots, \theta _ { n } ) | ^ { 2 } e ^ { i ( k x + \Omega t ) }, \\ \cdot \quad \cdot \quad \underbrace { n } _ { n } \quad \cdot \cdot \cdot \wedge \quad \underbrace { n } _ { n } \quad \cdot \cdot \wedge$$
where k = m ∑ n j =1 sinh θ j and Ω = m ∑ n j =1 cosh θ j . Because of their importance, the matrix elements of Eq. (B2) are dubbed form factors, and self-consistency arguments constrain their analytic form [55]. One can also infer from the representation Eq. (B3) that two-point functions in momentum space do not contain zeros on the real axis, except for k → 0 , ∞ . Moreover, Eq. (B3) is crucial to verify scaling properties of Green's function in the UV and IR regions in Eq. (21): the first can be studied using the Feynman gas method, and one can numerically check that predictions from CFTs are consistent with form factor computations, while the second is straightforward since, by performing a Wick rotation, one can show that every two-point function scales as e -mL in this regime, where L is the system size.
Now, to unveil the relations between the bare and the physical quantities of the Thirring model, we turn to the sine-Gordon model. Moreover, the bosonization procedure naturally lends itself to a more straightforward computation of the Green's function of the Thirring model, compared to the direct method. We start by the bosonisation relations between the fermionic fields Ψ and ¯ Ψ and the bosonic ones Φ and Θ, where Θ is the dual field given by -∂ x Θ( x, t ) = ∂ t Φ( x, t ),
$$\Psi ( x, t ) & = \exp \left \{ \frac { i } { 2 } \left [ \beta \Phi ( x, t ) + \frac { 1 } { \beta } \Theta ( x, t ) \right ] \right \}, \\ \bar { \Psi } ( x, t ) & = \exp \left \{ - \frac { i } { 2 } \left [ \beta \Phi ( x, t ) - \frac { 1 } { \beta } \Theta ( x, t ) \right ] \right \}.$$
In the main text, we employ then the following notation, borrowed from Ref. [47]:
$$\Psi ( x, t ) & = e ^ { i \beta \Phi ( x, t ) / 2 } \mathcal { O } ^ { 1 } _ { \beta / 2 } ( x, t ), \\ \bar { \Psi } ( x, t ) & = e ^ { - i \beta \Phi ( x, t ) / 2 } \mathcal { O } ^ { 1 } _ { - \beta / 2 } ( x, t ), \quad \text{(B5)} \quad \text{Gre} \quad \text{sna}$$
where the operator O 1 ± B/ 2 contains an infinite product given by the Baker-Campbell-Hausdorff factorisation of the exponential in Eq. (B4), and depends on the phase field Θ and all its commutators with Φ. Moreover, the origin of a string-like term in the fermionic creation/annihilation operators is given by the relation between the bosonic field and its dual,
$$\Theta ( x, t ) = - \int _ { - \infty } ^ { x } \mathrm d s \partial _ { t } \Phi ( s, t ). \quad \quad ( B 6 ) \quad \colon$$
Such an operator appears in the exponent of Eq. (B4) and weights the configuration of the field from the point x where it is placed, to -∞ . Weproceed finally by plugging in the definition Eq. (B4) into the Thirring Lagrangian in Eq. (9) to obtain
$$\mathcal { L } _ { \text{SG} } = \frac { 1 } { 2 } \left [ \left ( \partial _ { x } \Phi \right ) ^ { 2 } + \left ( \partial _ { x } \Theta \right ) ^ { 2 } \right ] + \frac { m _ { 0 } ^ { 2 } } { \beta ^ { 2 } } \left ( \cos \beta \Phi - 1 \right ), \ \left ( \text{B7} \right ) \quad k r \cos$$
Provided the following identity holds:
$$\beta ^ { 2 } = \frac { 1 } { 2 } \frac { 1 } { 1 - g / \pi }, \quad \quad \ ( B 8 )$$
that allows us to relate the coupling constants from the two models.
The sine-Gordon model has another peculiarity, namely, it can be understood as the integrable deformation of a coset CFT (G 1 × G ) G 1 / 2 [56, 57]. This piece of information, joined with the study of the thermodynamics of the model using the thermodynamics Bethe Ansatz, allows one to compute the relation between mass and coupling constant. Fateev developed the original argument for a broad class of models, which were refined by Zamolodchikov in the sine-Gordon case [58]. Here, we briefly follow Mussardo [59] for a simple review of the main argument. The main idea lies in computing the free energy of an integrable model both using the thermodynamics Bethe Ansatz and conformal perturbation theory (see Appendix D for an introduction): in the first case, we can expand for small values of the mass m , while in the second we will expand in the coupling constant g . We are then able to match the two series to obtain
$$\beta = \mathcal { D } m ^ { 2 - 2 \Delta },$$
which is expected from dimensional analysis (the conformal weight ∆ belongs to the relevant deforming operator, i.e. cos β Φ in the sine-Gordon case and ∆ SG = β 2 ), but the meaningful prefactor D can be directly computed. We stress that such a result cannot be obtained directly from the Thirring model itself and proves once more the power of bosonization methods.
## Appendix C: Derivation of the scaling behavior of Green's function in momentum space
We start by considering the Fourier transform of the Green's function, i.e., Green's function in momentum space,
$$G ( { \mathbf k } ) = \int _ { { \mathbb { R } } ^ { 2 } } \frac { { \mathrm d } { \mathbf k } } { ( 2 \pi ) ^ { 2 } } G ( { \mathbf x } ) e ^ { - i { \mathbf k } \cdot { \mathbf x } },$$
where spacetime is equipped with a Euclidean signature. We now split the integration region into three different ones:
- 1. The UV region | x < a | ,
- 2. The regular region a < | x < R | ,
- 3. The IR region | x > R | .
From Eq. (21), we know the behavior in the scaling regions, and by redefining the integration variables k x · = kr cos θ , with kr = , we obtain in the UV region s
$$G _ { U V } ( { \mathbf k } ) = k ^ { y _ { u v } - 2 } \int _ { 0 } ^ { + k a } \frac { \mathrm d s } { 2 \pi } \int _ { 0 } ^ { 2 \pi } \frac { \mathrm d \theta } { 2 \pi } s ^ { y _ { u v } - 1 } e ^ { - i s \cos \theta },$$
where y uv is the scaling dimension in the UV regime. The only momentum dependence left in the integral is in the extremes of integration. When the system approaches the critical phase, it is only determined by its UV completion. As such, we can consider the limit a → ∞ , and the only dependence is power-law-like (as we would be expecting from a simple scaling argument [60]). For the same reason, this expression is also a pure power-law when the momentum is large.
When the IR region is considered, the same considerations occur, except for the presence of different integrands depending on whether we consider massive or massless theories. For a massive theory, the result would read
$$G _ { \text{IR} } ( k ) = e ^ { - m R } \left ( \frac { e ^ { i k R } } { k + i m } - \frac { e ^ { - i k R } } { k - i m } \right ),$$
and the region for k → 0 is fully described by the constant result proportional to 1 /m . For gapless systems, this result is just
$$G _ { I R } ( k ) = k ^ { y _ { i r } - 2 } \int _ { k R } ^ { + \infty } \frac { d s } { 2 \pi } s ^ { y _ { i r } - 1 } e ^ { - i s },$$
and it ensures again a power-law behavior. For pure CFTs, y uv = y ir .
Our treatment does not affect the regular region; the only requirement that it must fulfill is the absence of zeros or singularities, which is ensured in integrable models.
## Appendix D: Scaling dimension in quantum field theory
An unexpected outcome of the renormalization procedure in quantum field theories is the presence of anomalous dimensions of local fields. This effect can be understood from two different points of view: at the level of a lattice, in which the rescaling of the lattice spacing induces a change in the theory's parameters, or at the level of the field theory, where the couplings run under rescaling of the momentum space.
Even though the relation between the two is, at first sight, straightforward (the lattice spacing and the momentum cutoff of a theory are reciprocal to each other), it is highly relevant to the understanding of our results: the invariance from lattice spacing and momentum cutoff informs us about the necessity of describing our topological invariant/polarization only in terms of scale-invariant quantities, i.e. quantities that are defined in scaling invariant regions of the theory. In addition, the realization of the quantum field theory on a lattice and the insertion of a momentum cutoff are both instances of a regularization procedure needed when interactions are relevant in a quantum field theory. We shall now outline why and how scale-invariant regimes are present in lattice and continuum theories [61].
a. Lattice. Consider a lattice of length L = Na , where N is the number of sites and a is the lattice spacing. Imposing that the universal properties of the physical system contained in its partition function are invariant under rescaling, we can perform a change of the lattice spacing a → a ′ = ba and the number of sites N → N ′ . This procedure is called a real-space renormalization group. To keep the partition function of the system unchanged, all the parameters describing the Hamiltonian of the theory will change accordingly in a generally complicated and nonlinear transformation g i → g ′ i = f i ( { g k } , b ). The iteration of this procedure leads to a family of points in the coupling constant manifold representing the same system, observed with different values of the parameters a and N . Since the correlation length of the system is simply rescaled,
$$\xi ( g ^ { \prime } ) = b ^ { - 1 } \xi ( g ),$$
the fixed points of the RG, g ∗ i = f i ( { g ∗ k } , b ), imply that the correlation length vanishes (trivial points) or diverges (critical points) across them. This, in turn, implies that the physical dimension of operators on the lattice changes along the renormalization group flow. An operator on the trivial point has a dimension equal to its physical dimension, established by means of usual dimensional counting, while one at the critical dimension is determined by critical exponents. These two values are usually different, and this difference is accounted for by the anomalous dimension. The reason for this phenomenon is better understood in continuum theories.
b. Continuum. In a field theory, performing the renormalization procedure in momentum space is simpler. Here, divergences in Feynman diagrams must be accounted for by introducing counterterms in the Lagrangian, resulting in a shift of the couplings and leading to similar conclusions. These divergences in Feynman diagrams parts - usually at high momenta require a regularization procedure, typically achieved by imposing a momentum cutoff Λ. Following this procedure, the sources of singular behavior can be safely removed at the price of introducing a dependence between the couplings - and the fields - on the cutoff via counterterms, i.e., g i → g ′ i = f i ( { g k } , Λ). Adding new counterterms at higher orders of the coupling constants is equivalent to shifting the cutoff value toward infinity (which is the point where it is formally removed). On the other hand, we can also squeeze our momentum space by rescaling the cutoff Λ → Λ = Λ ′ /b ; we would get the same picture of the lattice procedure, and we could study the relation between couplings and cutoff in detail without the need to compute more counterterms. Expanding the knowledge of the UV-region k ∈ (Λ + , ∞ ) with this procedure allows studying the properties of the model close to the critical fixed point; it is then simple to draw the picture we used in Appendix C of the whole momentum space split into regular part (determined by the massive interacting theory), IR-region (ruled by the trivial fixed point as a massive free theory) and the UV-region (described by the critical fixed point as a massless interacting theory). Moreover, as elucidated in the main text, imposing the invariance of expectation values (namely correlation functions) leads to a set of equations [see Eq. (30)] that rule the renormalization group flow in the momentum space; among these, the presence of counterterms for fields induces a non-trivial anomalous dimension, especially at the fixed point where f i ( g ∗ ) = 0. Now, we can understand the presence of an anomalous dimension as the effect of mixing between the original free field with others needed to remove singularities arising from turning on the interaction; in other words, the dressing of the free field induces the anomalous dimension.
It is then clear why taking the continuum limit of the interacting SSH model would not spoil its topology. Since the polarization is a scale-invariant quantity, it is customary to consider the limit for a → 0, where the Thirring model is retrieved. More than that, the polarization must retain scale-independent properties from fixed points related to the Thirring model, i.e., its massive free fermionic theory in the IR regime and the massless Thirring model at the UV point.
In addition, one can check the scaling properties of Green's functions along the RG trajectory that connects the two fixed points, as in Eq. (21), where the scaling dimension of fermionic creation and annihilation operators enters. The form factor expansion fully controls the IR point, so we just check the UV, which
is the one depending on the anomalous dimension. The idea lies in considering the fixed point (which, for simplicity, we consider described by a CFT and not just critical; this is the case for Thirring and the sine-Gordon model) and a perturbation that drives the system away from it by opening a gap in the spectrum. Note that the above-mentioned integrable theories can also be expressed close to their critical fixed points as gap-opening perturbations of conformal field theories. CFTs are fully solvable, and the perturbation we add,
$$\mathcal { L } = \mathcal { L } _ { C \text{FT} } + \lambda V ( r ),$$
can be treated perturbatively for arbitrary small values of λ . Hence, one can reconstruct exactly the terms of the series for expectation values of local operators A k :
$$\langle A _ { k } \rangle _ { \lambda } = \frac { 1 } { Z _ { \lambda } } \sum _ { n = 0 } ^ { \infty } \frac { ( - \lambda ) ^ { n } } { n! } \int d r _ { 1 } \dots d r _ { n } \langle A _ { k } V ( r _ { 1 } ) \dots V ( r _ { n } ) \rangle _ { 0 }. \begin{smallmatrix} A _ { 0 } & = & \cdot \\ & \text{the dom} \\ & \text{determi} \\ & \text{Sch a} \end{smallmatrix}$$
Then, we can extract the most diverging term of the
Green's function in the limit r → 0, studying the operator product expansion in the off-critical region,
$$\Psi ( z, \bar { z } ) \bar { \Psi } ( 0 ) = \sum _ { k } C ^ { k } _ { \Psi \bar { \Psi } } ( z, \bar { z } ) A _ { k } ( 0 ).$$
We then obtain, based on dimensional analysis,
$$C _ { \Psi \bar { \Psi } } ^ { k } ( z, \bar { z } ) = z ^ { \gamma _ { k } - 2 \gamma _ { \Psi } } \bar { z } ^ { \gamma _ { k } - 2 \bar { \gamma } _ { \Psi } } \sum _ { n = 0 } ^ { \infty } D _ { \Psi \bar { \Psi } } ^ { k, n } ( \lambda r ^ { 2 - \gamma _ { \Psi } - \bar { \gamma } _ { \Psi } } ) ^ { n },$$
where r = ( zz ¯) 1 / 2 . Then, the most diverging term occurs for n = 0 and γ k = 0, which involves the identity operator A 0 = 1 . We have shown that in the limit r → 0, the dominant contribution is still given by a power-law determined by the CFT that describes the fixed point. Such a statement is valid at any level of perturbation theory and directly leads to Eq. (21). | 10.1103/PhysRevB.110.165145 | [
"E. Di Salvo",
"A. Moustaj",
"C. Xu",
"L. Fritz",
"A. K. Mitchell",
"C. Morais Smith",
"D. Schuricht"
]
| 2024-08-02T17:58:43+00:00 | 2024-11-18T08:52:30+00:00 | [
"cond-mat.str-el"
]
| Topological phases of the interacting Su-Schrieffer-Heeger model: An analytical study | The interacting SSH model provides an ideal ground to study the interplay
between topologically insulating phases and electron-electron interactions. We
study the polarization density as a topological invariant and provide an
analytic treatment of its behavior in the low-energy sector of the
one-dimensional interacting SSH model. By formulating the topological invariant
in terms of Green's functions, we use the low-energy field theory of the
Thirring model to derive the behavior of the polarization density. We show that
the polarization density in the continuum theory describes the usual
topological insulating phases. Still, it contains an extra factor from the
fields' scaling dimensions in the low-energy quantum field theory. We interpret
this as a measure of the modified charge of the new excitations in the system.
We find two distinct contributions: a renormalization of the electronic charge
$e$ of a Fermi liquid because of quasiparticle smearing and an additional
contribution coming from the topological charge of the soliton arising in the
bosonized version of the Thirring model, the sine-Gordon model. |
2408.01423v1 | ## Prompt Recursive Search: A Living Framework with Adaptive Growth in LLM Auto-Prompting
Xiangyu Zhao a and Chengqian Ma a a Xiamen University
https://orcid.org/0009-0007-0903-0352, ORCID (Chengqian Ma):
ORCID (Xiangyu Zhao): https://orcid.org/0009-0005-9269-3880
Abstract. Large Language Models (LLMs) exhibit remarkable proficiency in addressing a diverse array of tasks within the Natural Language Processing (NLP) domain, with various prompt design strategies significantly augmenting their capabilities. However, these prompts, while beneficial, each possess inherent limitations. The primary prompt design methodologies are twofold: The first, exemplified by the Chain of Thought (CoT), involves manually crafting prompts specific to individual datasets, hence termed ExpertDesigned Prompts (EDPs) . Once these prompts are established, they are unalterable, and their effectiveness is capped by the expertise of the human designers. When applied to LLMs, the static nature of EDPs results in a uniform approach to both simple and complex problems within the same dataset, leading to the inefficient use of tokens for straightforward issues. The second method involves prompts autonomously generated by the LLM, known as LLM-Derived Prompts (LDPs) , which provide tailored solutions to specific problems, mitigating the limitations of EDPs. However, LDPs may encounter a decline in performance when tackling complex problems due to the potential for error accumulation during the solution planning process. To address these challenges, we have conceived a novel Prompt Recursive Search (PRS) framework that leverages the LLM to generate solutions specific to the problem, thereby conserving tokens. The framework incorporates an assessment of problem complexity and an adjustable structure, ensuring a reduction in the likelihood of errors. We have substantiated the efficacy of PRS framework through extensive experiments using LLMs with different numbers of parameters across a spectrum of datasets in various domains. Compared to the CoT method, the PRS method has increased the accuracy on the BBH dataset by 8% using Llama3-7B model, achieving a 22% improvement.
Table 1. Analysis of prompt methodologies in relation to their capabilities, utilizing the following symbols: ' /star ' for comprehensive support, ' /star\_half\_empty ' for limited support, and ' /remove ' for absence of support. CE: Computational Resource Utilization Efficiency, IH: Independence from Human Expertise, SE: Supervision of Errors in the Inference Process.
| Scheme | CE | IH | SE |
|----------------------------------------|---------|---------|------------------|
| Expert-Designed Prompt [26, 24, 27, 3] | /remove | /remove | /star_half_empty |
| LLM-Derived Prompt [18, 10, 34] | /star | /star | /remove |
| Prompt Recursive Search | /star | /star | /star |
## 1 Introduction
Stem cells differentiate into other types of cells with distinct functions upon induction by signaling molecules[2, 20]. A similar process, as depicted in 2, is proposed by us in the use of Large Language Models (LLMs) to solve problems. Previous work[26, 9, 31, 30, 13] has indicated that a single interaction often fails to adequately address problems. Instead, a more effective approach is to divide the problem-solving process into multiple steps: first proposing a solution to the problem, and then executing it step by step by the LLM. Each interaction with the LLM involves input to the model and its subsequent output. A single interaction can lead to the refinement, detailing, summarization, or execution of a solution. Each interaction corresponds to the realization of a thought within the thoughts that make up the solution. The functionality of a thought evolves from a more basic state to become increasingly specific, much like how a stem cell differentiates into a cell with a particular function. Similarly, an original thought can differentiate in response to various problems, giving rise to thoughts capable of solving different issues.
Control over the evolution of thoughts traditionally involves two methods. The first method entrusts the transformation process of thoughts entirely to experienced domain experts. These experts can, based on their understanding of problems within a particular field, plan the problem-solving process in a sequential chain, addressing the problem step by step. This is the contribution of the Chain of Thought (CoT) approach[26]. Prior to this, the practice of presenting a problem to LLMs and expecting a direct answer placed excessive demands on the LLMs, yielding suboptimal results and failing to fully leverage LLM's potential. Given that there is often more than one method to solve a problem, and multiple approaches can yield answers for a specific issue, we can compare the answers derived from various methods to select the most optimal one, thus obtaining the best solution to the problem. Plan-and-Solve (PS)[24] Prompting is a concrete implementation of this line of thinking. Building upon this, the Tree of Thought (ToT)[27] further extends this work by considering a scenario where a thought represents a critical step in the solution. If this thought is flawed, continuing to reason based on it can lead to more severe errors. Therefore, the authors of ToT propose a prompt structure that allows for a retreat from an erroneous solution path to reconsider and pursue the correct approach. This structure is hierarchical, and the feature is known as the backtracking function during the tree traversal process. On the foundation of ToT, the Graph of Thought (GoT) [3] structure is even more flexible. By performing operations such as aggregation and refinement on multiple thoughts, the expert-designed prompt structure represented by GoT is highly fault-tolerant. The outcome of one thought can be verified by multiple thoughts, and the knowledge derived from multiple thoughts can be integrated into a single thought.
We refer to the prompt design structures represented by CoT (Chain of Thought), ToT (Tree of Thought), and GoT (Graph of Thought) as Expert-Designed Prompts (EDP) : These prompt frameworks are manually crafted, thus necessitating a substantial amount of human expert experience. The approach demands a high level of expertise from the designer, who must draw on their professional experience and conduct multiple experiments to derive a prompt structure capable of addressing various scenarios within a particular domain. Given that this method accounts for a multitude of potential prompt structures, it is universally effective for all problems, which may result in a complex structure. While this approach often excels in tackling complex issues, it can be inefficient for simpler problems, as many steps within the prompt structure become redundant, leading to unnecessary computational resource wastage. Furthermore, if the human expert responsible for designing the prompt lacks sufficient proficiency or fails to consider all possible scenarios comprehensively, the static nature of the prompt, once designed, can lead to the persistent presence of any inherent flaws in the structure during each application.
To mitigate the dependency of Large Language Model (LLM) prompt design on human experience, a second approach to prompt design has been proposed. The primary issues with humanengineered prompt structures are twofold: Firstly, due to the limitations of human cognition, human experts cannot fully account for all scenarios within a domain. Secondly, once a prompt structure is designed by a human expert, it becomes immutable, which can lead to the waste of substantial computational resources when addressing simple problems, as the comprehensively complex structure, initially a strength, becomes redundant. However, entrusting the task of prompt structure design to an LLM addresses these concerns. Given the vast training corpora of large language models, their breadth of knowledge can surpass that of individual human experts. Additionally, the prompt framework design functionality provided by LLMs can commence upon the presentation of a specific problem, thereby being tailored to that particular issue. For problems that are straightforward and can be resolved in a single step, the LLM-generated prompt structure will not incur the unnecessary computational resource expenditure associated with the redundant steps found in human expert-designed prompt structures.
In the work of Automatic Prompt Engineering (APE)[34], the Large Language Model (LLM) initially proposes a set of prompts that encompass solutions to specific problems. The quality of these prompts varies, leading to a selection process where lower-quality prompts are discarded, and higher-quality ones are retained. Then LLM can use the higher-quality prompts as references to generate similar ones, enhancing the diversity of the prompt collection. This iterative process continues until satisfactory prompts are obtained. During the prompt generation by the LLM, the model can act not only as a problem solver providing solutions to domain-specific questions but also as a question generator, posing some extreme or marginal questions within a domain. These questions can be utilized to optimize the prompts, thereby improving their quality. Building on this approach, Intent-based Prompt Calibration (IPC)[10] optimizes the prompts using these edge-case questions after designing the prompts and related questions, ensuring the quality of the prompts by leveraging these domain-marginal issues. Following the proposal of prompts by the LLM, to ensure their quality, we can employ methods mentioned in the first two approaches: evaluating and discarding prompts with lower quality, or constraining them with edge-case questions. Additionally, we can utilize the Automatic Prompt Optimization[18] method: composing all possible prompts into a prompt space, using a prompt generated by the LLM as the starting point within this space, and optimizing the prompt based on its evaluation from LLM as the textual gradient. Through repeated iterations, the optimal solution can be found within the prompt space, employing a textual gradient descent method to identify the most ideal solution. The solutions proposed by the LLM, in conjunction with the problem context or textual gradient, often achieve effects comparable to those of human-designed prompts, which we term as
## LLM-Derived Prompts (LDP) .
However, when dealing with excessively complex problems, such as large-scale planning issues, the complete delegation of the planning of solutions to the LLM can become problematic. With numerous steps involved, there is a high likelihood of error propagation and accumulation. A minor error at any stage can be rapidly magnified across multiple steps, leading to suboptimal performance by the LLM.
Expert-Designed Prompts (EDPs) often necessitate a more complex structure to address all scenarios within a dataset, which can result in redundant steps when EDPs are applied to solve simpler problems within that dataset. On the other hand, LLM-Derived Prompts (LDPs) delegate the entire task of prompt design to the Large Language Model (LLM). During the process of generating solutions to problems, the LLM is highly susceptible to the accumulation of errors, which significantly increases the difficulty of accurately generating solutions for complex tasks.
We have identified that the characteristics of Expert-Designed Prompts (EDPs) and LLM-Derived Prompts (LDPs) are, to a certain extent, complementary. Consequently, after thorough consideration of the advantages and disadvantages of both EDPs and LDPs, we propose an entirely new Prompt Recursive Search(PRS) framework for prompt design which is depicted in 2. This framework enables Large Language Models (LLMs) to avoid overly complex planning when tackling simplistic problems, while also allowing LLMs to undertake a portion of the prompt design work, thus reducing the high dependency on human experts. Drawing inspiration from the differentiation process of human stem cells: when the body, prompted by signaling molecules, requires cells to perform a specific task, stem cells differentiate into new cells with distinct characteristics to address issues that other cells cannot. Our prompt framework, when confronted with a new problem, first evaluates the problem and has the LLM assign a complexity score. If the problem's complexity is deemed too high, we break down the problem into multiple steps for resolution. The simplified problems, post-dissection, become new targets, for which the LLM provides solutions. This is akin to allowing the LLM to complete a differentiation design process for the prompt, resulting in prompts with specific functionalities. During the differentiation steps, we recursively apply this differentiation function until the problem has been sufficiently broken down into simple components.
By employing LLMs with varying numbers of parameters, we compared the PRS method with traditional prompt design approaches on the BBH dataset, which spans multiple domains, thereby validating the effectiveness of the PRS method. Through this paper, we have made the following contributions:
- · We have categorized existing prompts based on their source of acquisition into two types: Expert-Designed Prompts (EDP) and
Figure 1.

Example of our proposed method Prompt Recursive Search with complexity score limitation (PRS).
LLM-Derived Prompts (LDP);
## 2.2 Expert-Designed Prompts
- · By introducing biological principles, we have proposed an automated framework for addressing complex problems that integrates the advantages of both EDP and LDP.
- · Through validation on the BBH[21] dataset across multiple domains using models with parameters spanning different orders of magnitude, we have confirmed the effectiveness of this method.
## 2 Related Work
## 2.1 LLM-Derived Prompts
Large Language Models (LLMs) are an advanced tool in the field of Natural Language Processing (NLP) technology[32, 33]. They are based on deep learning architectures, such as Transformers[22], and have learned complex patterns of language through extensive training on vast amounts of text data. These models are not only capable of understanding the nuances of language but also generating coherent and grammatically correct text, thereby performing well on a variety of language tasks. They can be used in a wide range of applications, including chat-bots[17], recommendation systems[12], content creation aids[5], and educational tools[16, 14]. However, LLMs may also replicate and amplify biases present in their training data, so ethical[4, 7, 1, 14] and bias[28, 15] considerations must be taken into account in their design and use. Notable examples of LLMs include the BERT[6] and GPT[19] models, which have achieved significant success in tasks involving natural language understanding[19, 23] and generation[11, 8].
## 2.2.1 Chain of Thought(CoT)
This technology is designed to enhance the ability of Large Language Models (LLMs) to handle complex issues. It simulates the continuous thought process of human problem-solving by embedding a series of logical reasoning steps within the input prompts. These steps progressively guide the model to the solution of the problem, aiding in the processing of tasks that require continuous logic or mathematical computation. By demonstrating examples of problem-solving, the accuracy and logicality of the model's output can be improved, even without specific task training.
## 2.2.2 Plan-and-Solve (PS) Prompting
Compared with Chain of Thought (CoT), Plan-and-Solve Prompting significantly improves the performance of Large Language Models (LLMs) in multi-step reasoning tasks by guiding the models to formulate plans for solutions and then execute them. It has demonstrated superior performance over Zero-shot-CoT thinking across multiple datasets and is comparable to CoT methods that require manual examples, showcasing the potential to stimulate the reasoning capabilities of LLMs without the need for manual examples.
## 2.2.3 Tree of Thoughts
The Tree of Thought (ToT) framework aims to enhance the capabilities of Large Language Models (LLMs) in problem-solving. It allows the model to explore various reasoning paths and to self-assess its decisions, leading to more deliberate choices. This approach views problem-solving as a search process within a "thought tree," where
Figure 2. Pipeline of our proposed method Prompt Recursive Search with complexity score limitation (PRS).
each "thought" is a coherent text block that represents a step towards the solution.
## 2.2.4 Graph of Thoughts
This operation of generating data samples opens up new avenues for prompt design: not only can we have LLMs generate answers for us, but we can also have LLMs generate questions that can, in turn, lead to better answers.
Graph of Thoughts (GoT) significantly enhances the performance of Large Language Models (LLMs) in complex task processing by conceptualizing the reasoning process as a graph structure composed of nodes, which represent the model's "thoughts," and edges, which denote the connections between these thoughts. Not only does GoT improve the quality of task execution, with a 62% increase in efficiency over existing technologies in sorting tasks, but it also achieves a reduction in costs by more than 31%. The design of GoT greatly facilitates the approximation of LLMs' reasoning capabilities to human thought patterns.
## 2.2.5 Automatic Prompt Engineer(APE)
The manual design of prompts necessitates a high level of expertise from the designer and is constrained by the relatively limited knowledge base and subjective factors of human experts compared to Large Language Models (LLMs). Handcrafted prompts are subject to numerous limitations stemming from human factors, which LLMs are not bound by. Therefore, entrusting the task of prompt design to an LLM can both resolve these constraints and eliminate the inconvenience of manual prompt design, thereby automating the use of LLMs. Initially, the LLM is tasked with generating a set of prompts, which are then not utilized in their entirety. Instead, these prompts are evaluated and the highest-quality ones are selected. Based on the highest-quality prompts, a variety of similar prompts are generated to enhance their diversity.
## 2.2.6 Intent-based Prompt Calibration(IPC)
Large Language Models (LLMs) are highly sensitive to the input content, where even seemingly irrelevant random noise can significantly alter the LLM's output. The root cause of this sensitivity is a lack of an accurate and comprehensive understanding of the problem. To ensure that LLMs consider the problem thoroughly, based on the user's requirements and the initial prompt, new prompts and data samples are iteratively generated. The prompts are then optimized using edge data, allowing the LLM to fully contemplate the problem.
## 2.2.7 Automatic Prompt Optimization
After the generation of prompts by a LLM, it is often necessary to refine them. This refinement can be accomplished through simple ranking and selection, known as Approach by APE, or by making modifications to the prompt based on the data provided by the LLM, referred to as IPC. However, when the objective is to identify the most appropriate prompt within a dense space of prompts, gradient descent emerges as a more rational method. The process begins with the LLM generating a response based on an initial prompt. Subsequently, the LLM analyzes the response in conjunction with the prompt to produce Textual Gradients. These Textual Gradients are then integrated to formulate a new prompt. This cycle of generation and refinement is repeated iteratively until the optimal prompt is achieved.
## 3 Methodology
Our approach is founded upon the principles of the EDP and the LDP, taking into account that while EDP is adept at addressing straightforward problems with a comprehensive framework designed to encompass all scenarios of such issues, it may necessitate superfluous token expenditure when applied to simpler problems. On the other hand, LDP can lead to the accumulation of errors; if an LLM is tasked with designing prompts without constraints or corrections, it must adhere to a process that involves planning a solution and then executing it. Errors introduced during the planning phase can propagate through to subsequent steps, potentially undermining the problemsolving process. To mitigate the costs associated with manually designed prompts, we delegate the responsibility of devising solutions to the LLM itself. The LLM will design tailored solutions for each problem, thereby avoiding unnecessary token usage. Furthermore, to prevent the accumulation of errors during the LLM's prompt design phase, we employ complexity detection methods and procedural planning techniques to constrain the LLM and validate its solution planning. Our method is showed in 1 and 2.
## Algorithm 1: Design Solution
Input: Problem P , Steps Steps
Output: Solution
Solution
- 1 Solution ←
[ ]
- 2 Initial \_ Steps ← Get\_Initial\_Solution ( P Steps , )
- 3 foreach Step in Initial \_ Steps do
- 4 Complexity ← Evaluate\_Complexity ( Step )
- 5 if Complexity > Threshold then
- 6 New Steps \_ ← Calculate\_Steps ( Complexity ) 7 Solution ←
Solution + Design\_Solution ( Step New Steps , \_ )
8
else
- 9 Solution ← Solution +[ Step ] 10 end
11 end
- 12 return Solution
Algorithm 2: PRS Pipeline
Input: Problem description P desc
Output: Answer Ans
// Evaluate Complexity
1 C ← Evaluate\_Complexity ( P desc )
// Calculate Steps
2 Steps ← Calculate\_Steps ( C )
// Design Solution
3 Sol ← Design\_Solution ( P desc , Steps )
//
Get
Answer
4 Ans ← Get\_Answer ( P desc , Sol )
5 return Ans
## 3.1 Evaluating the Complexity of a Problem
Before devising solutions for a problem, we first assess its complexity to facilitate the design of more comprehensive solutions for more complex issues and more straightforward solutions for simpler ones. The complexity level can provide effective guidance for formulating our solutions. In the process of evaluating the complexity of a problem by a Large Language Model (LLM), we consider the characteristics of textual descriptions of problems: directly describing the complexity using natural language can lead to an inability to distinctly differentiate between problems based on this metric. Therefore, we opt to use numerical values instead of the original complexity descriptions. We categorize the complexity of problems into ten levels, represented by ten integers ranging from 1 to 10.
## 3.2 Planning Solution for a Problem
Upon determining the complexity of a problem, our focus shifts to designing solutions based on that complexity. In practice, the aspect of a solution that is directly related to complexity is the number of steps involved. Through extensive experimentation, we have correlated the complexity levels proposed by the Large Language Model (LLM) for problems with the steps required in their solutions. Our findings indicate a linear relationship: the number of steps to resolve a problem typically ranges between one and five, and the complexity level of a problem, when divided by two, often yields the number of steps needed for its resolution. This macroscopic statistical pattern allows us to seamlessly incorporate the initial complexity assessment into the design of solutions, thereby specifying the number of steps required for resolution.
## 3.3 Recursively Proposing Solutions to Problems
Following the first two steps, we have established the necessary steps for a solution, which are determined based on the complexity of the problem. This approach, underpinned by our discovered relationship between complexity levels and solution steps, mitigates the accumulation of errors during the problem formulation by the LLM. It addresses the shortcomings of the LLM-Derived Prompt (LDP) while fully leveraging its strengths in devising tailored solutions for specific problems, thereby also resolving the issues associated with the Expert-Designed Prompt (EDP).
## 3.4 Obtaining a complete solution
Subsequently, we can employ the identified solution steps to propose resolutions. Recognizing that providing detailed steps for complex problems in a single response demands a high level of proficiency from the LLM, we adopt a recursive strategy for the more intricate steps of the solution. Each complex step is treated as a new problem to be broken down, and a more refined solution is proposed, prompting the LLM to elaborate on the specifics of the solution. This recursive process continues until all solutions are simplified to the point where they can be resolved in a single step. By transforming complex problems into simpler ones, we prevent the LLM from being overwhelmed by complexity and ensure the provision of accurate solutions.
## 3.5 Obtaining an Answer according to the solution
After obtaining a solution through the preceding plan, we can then apply this solution to address the problem. Additionally, we can impose constraints on the format of the answers outputted by the Large Language Model (LLM) with respect to specific datasets, ensuring the production of coherent and appropriate responses.
## 4 Experiments
## 4.1 Model Selection
In the process of model selection, considering that Large Language Models (LLMs) with a substantial number of parameters inherently possess higher performance, the advent of prompt design methodologies has been predominantly aimed at enhancing the capabilities of LLMs with moderate to smaller parameter counts. Moreover, the efficacy of prompt design methods is more pronounced in LLMs with smaller parameter volumes. We can enhance the performance of LLMs by designing prompts, fully tapping into the potential of LLMs; however, LLMs with a larger number of parameters already possess relatively good capabilities, and even with the use of prompt techniques, the improvement in LLM performance may not be very significant. We will demonstrate this point through the results of ablation experiments. Consequently, we have elected to utilize the Yi34B model, which has a moderately sized parameter volume, alongside the Meta-Llama-3-8B model, which features a smaller parameter count.
Yi-34B The Yi-34B model[29] is a middle-scale language model trained on a diverse corpus of 3 terabytes, designed with a bilingual focus. It has demonstrated significant potential across various aspects such as language comprehension, common sense reasoning, and reading comprehension, indicative of the emergent capabilities associated with large models[25]. This emergent capability implies that LLMs can exhibit human-like logical thinking, reasoning, and
Figure 3. Comparison between PRS (ours) and 0-shot-cot on the BBH dataset.
analytical abilities, which are precisely the skills that LLMs need to engage in reasoning with the aid of prompts. Suitable for a multitude of applications, the Yi-34B model is fully accessible for academic research and concurrently offers free commercial licensing upon application.
a problem via a Large Language Model (LLM), we utilize this linear relationship to translate the complexity into the corresponding steps necessary for problem resolution.
Meta-Llama-3-8B The Llama-3 model represents an autoregressive language model engineered with an enhanced Transformer [22] architecture. It features refined iterations that employ supervised fine-tuning (SFT) coupled with reinforcement learning augmented by human feedback (RLHF), ensuring alignment with human-centric values of utility and safety. Llama 3 has been pre-trained on an extensive corpus exceeding 15 trillion tokens, sourced from a variety of public repositories. For fine-tuning, it leverages a compilation of publicly accessible instructional datasets alongside a substantial collection of over 10 million examples annotated by humans.
## 4.2 Dataset Introduction
The BIG-Bench Hard (BBH) is a subset culled from the original BIG-Bench assessment suite, focusing on tasks that pose a challenge to existing language models. BBH comprises 23 tasks and 27 subdatasets, and when creating the BBH dataset, researchers adhered to specific filtering criteria, including the number of examples in the task, the presence of human rater performance data, the type of task, and the performance of previous models, among others. This dataset is designed to drive improvements in language model performance on complex reasoning tasks and provides a valuable benchmark for future research. This dataset is relatively difficult and covers a wide range of topics, with many of its sub-datasets focusing on assessing the reasoning capabilities of LLMs, making it an ideal tool to test the abilities of PRS.
## 4.3 Set Up
We have confirmed the linear relationship between the complexity of a problem and the number of steps required to solve it through experiments conducted across multiple datasets. On the Llama3 model and the BBH dataset, this linear relationship is specifically manifested as the number of steps required to solve a problem being half of its complexity. Therefore, once we have ascertained the complexity level of
## 4.4 Evaluation Metrics.
After obtaining the answer from the Large Language Model (LLM), it is necessary to compare it with the correct answer to assess its accuracy and calculate the rate of correctness. There are two primary methods for comparison: The first method involves the LLM itself comparing the provided answer to the correct one and then making a judgment. This approach is contingent on the performance of the LLM, which carries the potential for error. The second method is applicable only when the correct answers in the dataset adhere to a more uniform and standardized format. In this case, we simply instruct the LLMto pay attention to the format when presenting the answer. Subsequently, we can employ regular expressions to extract the answer and use string methods for comparison. This method demands less from the LLM's performance but has a more limited range of applicability. The answer format for the problems in the BBH dataset is relatively standardized, therefore we can employ the second method, which is more accurate for making judgments.
Since the correct answers in the dataset we used have specific formatting requirements, we provided the LLM with the answer to the first sample in the dataset as a template, instructing the LLM to mimic the format of the first answer when responding. The evaluation of the LLM's responses begins with the second sample, ensuring that the format of the LLM's answers is maintained while preventing data leakage.
Before determining the correctness of the answers, we categorized the types of answers in the dataset, dividing them into single-choice, multiple-choice, numerical, etc., and formulated appropriate regular expressions to match the answers accordingly.
## 4.5 Result
We conducted extensive experiments on the BBH dataset, where out of its 27 sub-datasets, only 24 were found to be valuable for exploration. The "dyck\_languages" and "multistep\_arithmetic\_two" tasks, which were discarded, primarily assess the LLM's ability to discern symbols, which is unrelated to the performance of the prompt. PRS outperformed CoT in 19 out of 25 sub-datasets, the accuracy rate improved from 36% with CoT to 44% with PRS, which is an increase of 22%.
## 4.6 Ablation Experiment
By applying this framework to the Yi-34B model, we also compared the CoT and PRS methods and found that the average accuracy of PRS increased from 45% with the CoT method to 49%, achieving a 9% improvement. This demonstrates that our method is also applicable to LLMs with a larger number of parameters and also validates our viewpoint that the enhancement effect of prompt design methods on LLMs with large parameter volumes is relatively less pronounced.
Figure 4. The ablation experiments based on the Yi-34B model on the BBH dataset. The results represent metrics on the formal\_fallacies subset.
## 5 Conclusion
Traditional prompt design methods can be divided into LDP and EDP, where EDP heavily relies on the subjective experience of human experts. Its immutable characteristics once involved make it waste redundant computational resources when dealing with simple problems. On the other hand, LDP is generated and optimized by LLMs, but due to the lack of effective supervision during the prompt generation process, it is prone to error accumulation. We have integrated the advantages of both by designing a brand-new prompt framework called PRS. It eliminates the high dependence on human expert knowledge through automatic prompt design and saves computational resources. By effectively supervising the complexity of the problem, it prevents error accumulation during the reasoning process. We have demonstrated the effectiveness of this framework by comparing its performance with the CoT method using the Llama3-7B model across multiple domain datasets, as well as with the ablation experiments using the Yi-34 model.
## 6 Limitations
By summarizing traditional prompt design techniques, we have categorized traditional prompt design methods into EDP (ExpertDesigned Prompts) and LDP (LLM-Derived Prompts). Upon discovering the complementary nature of the advantages between the two, inspired by the differentiation phenomenon of stem cells in biological principles, we have innovatively proposed a new prompt structure: Prompt Recursive Search (PRS). This structure can automati- cally design prompts for problems, which has the advantage of saving computational resources. At the same time, by judging the complexity of the problem, it supervises the errors in the prompt design process, thereby ensuring accuracy. Through experiments in multiple domains and with various models, we have demonstrated the effectiveness of PRS. However, it is undeniable that our framework still has certain shortcomings, which are as follows:
- 1. We mandate that the Large Language Model (LLM) outputs answers in a specific format through our prompt, as deviation from this format would render the true-false judgment infeasible. However, the LLM is not always compliant with the prescribed output format, and answers that do not conform to the format could be either erroneous or correct. Our condition for deeming an LLMprovided answer as correct stipulates that not only must the content be accurate, but the format must also be correct. This essentially elevates the criteria for acceptable responses. Situations where the content is correct but the format is not are not accounted for in our assessment, leading to an underestimation of our true accuracy rate in the statistics we compile.
- 2. Our framework is predicated on a crucial assumption: the complexity of a problem is directly proportional to the number of steps required to solve it. We have substantiated this intuitive assumption through numerous experiments, yet it is important to recognize that this assumption represents a macroscopic rule and there are a few exceptional cases that do not conform to it. Consequently, the number of steps necessary to resolve a problem remains a topic worthy of exploration. We thus leave this question for future research endeavors.
- 3. Even for the same input, the responses from the Large Language Model (LLM) can vary with each invocation, thus reflecting that the performance of the Prompt Recursive Search (PRS) framework has an inherent degree of randomness. The experimental results presented in this paper are the average of three trials, which may still differ from the true capabilities of the method.
- 4. Due to the inherently strong capabilities of Large Language Models (LLMs) with a larger number of parameters, applying the Prompt Recursive Search (PRS) method proposed in this paper does not yield a significant enhancement in this kind LLM's abilities. In fact, the effectiveness of this framework is contingent upon the LLM's analytical capacity regarding the problem at hand. Consequently, LLMs with a larger parameter count are better suited to leverage the full potential of the PRS framework. Our ablation study proved this perspective but did not delve into a detailed investigation. We reserve the exploration of this aspect for future work.
In summary, we have proposed a brand-new method for prompt design and have validated it through extensive experiments, providing a starting point for future research.
## Acknowledgements
By using the ack environment to insert your (optional) acknowledgements, you can ensure that the text is suppressed whenever you use the doubleblind option. In the final version, acknowledgements may be included on the extra page intended for references.
## References
- [1] J. Bang, B.-T. Lee, and P. Park. Examination of ethical principles for llm-based recommendations in conversational ai. 2023 International Conference on Platform Technology and Service (PlatCon) , pages 109113, 2023. URL https://api.semanticscholar.org/CorpusID:262977578.
- [2] A. Becker, E. A. McCulloch, and J. E. Till. Cytological demonstration of the clonal nature of spleen colonies derived from transplanted mouse marrow cells. Nature , 197:452-454, 1963. URL https://api. semanticscholar.org/CorpusID:11106827.
- [3] M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, and T. Hoefler. Graph of thoughts: Solving elaborate problems with large language models. In M. J. Wooldridge, J. G. Dy, and S. Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 2027, 2024, Vancouver, Canada , pages 17682-17690. AAAI Press, 2024. doi: 10.1609/AAAI.V38I16.29720. URL https://doi.org/10.1609/aaai. v38i16.29720.
- [4] J. Cabrera, M. S. Loyola, I. Magaña, and R. Rojas. Ethical dilemmas, mental health, artificial intelligence, and llm-based chatbots. In International Work-Conference on Bioinformatics and Biomedical Engineering , 2023. URL https://api.semanticscholar.org/CorpusID:259335839.
- [5] Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun. A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt. ArXiv , abs/2303.04226, 2023. URL https://api.semanticscholar.org/CorpusID:257405349.
- [6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In North American Chapter of the Association for Computational Linguistics , 2019. URL https://api.semanticscholar.org/CorpusID:52967399.
- [7] L. Goetz, M. Trengove, A. A. Trotsyuk, and C. A. Federico. Unreliable llm bioethics assistants: Ethical and pedagogical risks. The American Journal of Bioethics , 23:89 - 91, 2023. URL https://api. semanticscholar.org/CorpusID:263774936.
- [8] Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, D. Chen, W. Dai, A. Madotto, and P. Fung. Survey of hallucination in natural language generation. ACM Computing Surveys , 55:1 - 38, 2022. URL https://api.semanticscholar.org/CorpusID:246652372.
- [9] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. ArXiv , abs/2205.11916, 2022. URL https://api.semanticscholar.org/CorpusID:249017743.
- [10] E. Levi, E. Brosh, and M. Friedmann. Intent-based prompt calibration: Enhancing prompt optimization with synthetic boundary cases. ArXiv , abs/2402.03099, 2024. URL https://api.semanticscholar.org/CorpusID: 267412105.
- [11] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. rahman Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer. Bart: Denoising sequenceto-sequence pre-training for natural language generation, translation, and comprehension. In Annual Meeting of the Association for Computational Linguistics , 2019. URL https://api.semanticscholar.org/ CorpusID:204960716.
- [12] Q. Liu, N. Chen, T. Sakai, and X.-M. Wu. A first look at llm-powered generative news recommendation. ArXiv , abs/2305.06566, 2023. URL https://api.semanticscholar.org/CorpusID:263891105.
- [13] A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Welleck, B. P. Majumder, S. Gupta, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. ArXiv , abs/2303.17651, 2023. URL https://api.semanticscholar.org/CorpusID:257900871.
- [14] G. F. N. Mvondo, B. Niu, and S. Eivazinezhad. Generative conversational ai and academic integrity: A mixed method investigation to understand the ethical use of llm chatbots in higher education. SSRN Electronic Journal , 2023. URL https://api.semanticscholar.org/CorpusID: 261311676.
- [15] A. F. Oketunji, M. Anas, and D. Saina. Large language model (llm) bias index - llmbi. ArXiv , abs/2312.14769, 2023. URL https://api. semanticscholar.org/CorpusID:266521434.
- [16] M. S. Orenstrakh, O. Karnalim, C. A. Suárez, and M. Liut. Detecting llm-generated text in computing education: A comparative study for chatgpt cases. ArXiv , abs/2307.07411, 2023. URL https://api. semanticscholar.org/CorpusID:259924631.
- [17] S. Peng, W. Swiatek, A. Gao, P. Cullivan, and H. Chang. Ai revolution on chat bot: Evidence from a randomized controlled experiment. ArXiv , abs/2401.10956, 2024. URL https://api.semanticscholar.org/CorpusID: 267068546.
- [18] R. Pryzant, D. Iter, J. Li, Y . T. Lee, C. Zhu, and M. Zeng. Automatic prompt optimization with "gradient descent" and beam search. In Conference on Empirical Methods in Natural Language Processing , 2023. URL https://api.semanticscholar.org/CorpusID:258546785.
- [19] A. Radford and K. Narasimhan. Improving language understanding by generative pre-training. 2018. URL https://api.semanticscholar.org/ CorpusID:49313245.
- [20] L. Siminovitch, E. A. McCulloch, and J. E. Till. The distribution of colony-forming cells among spleen colonies. Journal of cellular and comparative physiology , 62:327-36, 1963. URL https://api. semanticscholar.org/CorpusID:43875977.
- [21] M. Suzgun, N. Scales, N. Scharli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. V. Le, E. H. hsin Chi, D. Zhou, and J. Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. In Annual Meeting of the Association for Computational Linguistics , 2022. URL https://api.semanticscholar.org/CorpusID:252917648.
- [22] A. Vaswani, N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In Neural Information Processing Systems , 2017. URL https://api. semanticscholar.org/CorpusID:13756489.
- [23] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In BlackboxNLP@EMNLP , 2018. URL https://api.semanticscholar.org/CorpusID:5034059.
- [24] L. Wang, W. Xu, Y. Lan, Z. Hu, Y. Lan, R. K.-W. Lee, and E.-P. Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Annual Meeting of the Association for Computational Linguistics , 2023. URL https://api.semanticscholar. org/CorpusID:258558102.
- [25] Z. Wang, S. Mao, W. Wu, T. Ge, F. Wei, and H. Ji. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration. 2023. URL https://api. semanticscholar.org/CorpusID:259765919.
- [26] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. hsin Chi, F. Xia, Q. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models. ArXiv , abs/2201.11903, 2022. URL https://api. semanticscholar.org/CorpusID:246411621.
- [27] S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. ArXiv , abs/2305.10601, 2023. URL https: //api.semanticscholar.org/CorpusID:258762525.
- [28] K.-C. Yeh, J.-A. Chi, D.-C. Lian, and S.-K. Hsieh. Evaluating interfaced llm bias. In Taiwan Conference on Computational Linguistics and Speech Processing , 2023. URL https://api.semanticscholar.org/ CorpusID:264555752.
- [29] A. A. Young, B. Chen, C. Li, C. Huang, G. Zhang, G. Zhang, H. Li, J. Zhu, J. Chen, J. Chang, K. Yu, P. Liu, Q. Liu, S. Yue, S. Yang, S. Yang, T. Yu, W. Xie, W. Huang, X. Hu, X. Ren, X. Niu, P. Nie, Y. Xu, Y. Liu, Y. Wang, Y. Cai, Z. Gu, Z. Liu, and Z. Dai. Yi: Open foundation models by 01.ai. ArXiv , abs/2403.04652, 2024. URL https://api.semanticscholar.org/CorpusID:268264158.
- [30] J. Yu, R. He, and R. Ying. Thought propagation: An analogical approach to complex reasoning with large language models. ArXiv , abs/2310.03965, 2023. URL https://api.semanticscholar.org/CorpusID: 263831197.
- [31] Z. Zhang, A. Zhang, M. Li, and A. J. Smola. Automatic chain of thought prompting in large language models. ArXiv , abs/2210.03493, 2022. URL https://api.semanticscholar.org/CorpusID:252762275.
- [32] H. Zhao, H. Chen, F. Yang, N. Liu, H. Deng, H. Cai, S. Wang, D. Yin, and M. Du. Explainability for large language models: A survey. ACM Transactions on Intelligent Systems and Technology , 2023. URL https: //api.semanticscholar.org/CorpusID:261530292.
- [33] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, Y. Du, C. Yang, Y. Chen, Z. Chen, J. Jiang, R. Ren, Y. Li, X. Tang, Z. Liu, P. Liu, J. Nie, and J. rong Wen. A survey of large language models. ArXiv , abs/2303.18223, 2023. URL https://api. semanticscholar.org/CorpusID:257900969.
- [34] Y. Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba. Large language models are human-level prompt engineers. ArXiv , abs/2211.01910, 2022. URL https://api.semanticscholar.org/CorpusID: 253265328. | null | [
"Xiangyu Zhao",
"Chengqian Ma"
]
| 2024-08-02T17:59:42+00:00 | 2024-08-02T17:59:42+00:00 | [
"cs.CL",
"cs.AI"
]
| Prompt Recursive Search: A Living Framework with Adaptive Growth in LLM Auto-Prompting | Large Language Models (LLMs) exhibit remarkable proficiency in addressing a
diverse array of tasks within the Natural Language Processing (NLP) domain,
with various prompt design strategies significantly augmenting their
capabilities. However, these prompts, while beneficial, each possess inherent
limitations. The primary prompt design methodologies are twofold: The first,
exemplified by the Chain of Thought (CoT), involves manually crafting prompts
specific to individual datasets, hence termed Expert-Designed Prompts (EDPs).
Once these prompts are established, they are unalterable, and their
effectiveness is capped by the expertise of the human designers. When applied
to LLMs, the static nature of EDPs results in a uniform approach to both simple
and complex problems within the same dataset, leading to the inefficient use of
tokens for straightforward issues. The second method involves prompts
autonomously generated by the LLM, known as LLM-Derived Prompts (LDPs), which
provide tailored solutions to specific problems, mitigating the limitations of
EDPs. However, LDPs may encounter a decline in performance when tackling
complex problems due to the potential for error accumulation during the
solution planning process. To address these challenges, we have conceived a
novel Prompt Recursive Search (PRS) framework that leverages the LLM to
generate solutions specific to the problem, thereby conserving tokens. The
framework incorporates an assessment of problem complexity and an adjustable
structure, ensuring a reduction in the likelihood of errors. We have
substantiated the efficacy of PRS framework through extensive experiments using
LLMs with different numbers of parameters across a spectrum of datasets in
various domains. Compared to the CoT method, the PRS method has increased the
accuracy on the BBH dataset by 8% using Llama3-7B model, achieving a 22%
improvement. |
2408.01424v2 | ## Generalised Circuit Partitioning for Distributed Quantum Computing
Felix Burt Department of Electrical and Electronic Engineering Imperial College London London, UK [email protected]
Kuan-Cheng Chen Department of Electrical and Electronic Engineering Imperial College London London, UK
Kin K. Leung Department of Electrical and Electronic Engineering Imperial College London London, UK
[email protected]
Abstract -Distributed quantum computing (DQC) is a new paradigm aimed at scaling up quantum computing via the interconnection of smaller quantum processing units (QPUs). Shared entanglement allows teleportation of both states and gates between QPUs. This leads to an attractive horizontal scaling of quantum processing power, which comes at the expense of the additional time and noise introduced by entanglement sharing protocols. Consequently, methods for partitioning quantum circuits across multiple QPUs should aim to minimise the amount of entanglement-based communication required between distributed QPUs. Existing protocols tend to focus primarily on optimising entanglement costs for gate teleportation or state teleportation to cover operations between QPUs, rather than both at the same time. The most general form of the problem should treat gate and state teleportation on the same footing, allowing minimal cost circuit partitions through a combination of the two. This work introduces a graph-based formulation which allows joint optimisation of gate and state teleportation cost, including extensions of gate teleportation which group gates together for distribution using common resources. The formulation permits low e-bit cost for a variety of circuit types. Using a basic genetic algorithm, improved performance over state-of-the-art methods is obtained in terms of both average e-bit cost and time scaling.
Index Terms -Quantum Computing, Distributed Quantum Computing, Optimization, Quantum Networks, Quantum Communication
## I. INTRODUCTION
[email protected] problem' [7]. Broadly, the aim of the problem is to cover all gates in a circuit split between multiple QPUs using as few e-bits as possible. Dominant methods in the literature for solving circuit partitioning focus on optimising e-bit cost from either state teleportation [8]-[10] or gate teleportation [6], [11]-[14], failing to fully leverage the possibilities available to cover inter-QPU operations. While there are works which consider both [9], [15], [16], they fail to treat them jointly as target of optimisation, resulting in higher e-bit costs than what is possible in general. This work proposes a generalised graph formulation of the circuit partitioning problem, aiming to unify the dominant approaches. The results are compared with leading methods from different paradigms [6], [8], which both perform very well on circuits which fit their methods but perform sub-optimally in certain cases. Using simple heuristics, we obtain competitive performance with the best cases of existing methods, while retaining strong performance in instances where the benchmark methods break down, leading to lower e-bit costs on average. The results are obtained using a genetic algorithm with time complexity linear in the total circuit size (width × depth), with experimental demonstrations showing significant improvement over the scaling of the benchmark methods.
Distributed quantum computing (DQC) is a new paradigm aimed at connecting multiple quantum processing units (QPUs) to form larger, more powerful, quantum computing systems [1]. This provides an alternative route to scaling qubit numbers [2] which avoids the challenges of connecting many qubits on a single quantum processor [3]. However, DQC creates new difficulties relating to the interaction of QPUs in both hardware and software. Quantum information can be distributed between QPUs using entangled pairs of qubits, or e-bits , which must be efficiently distributed between devices [2]. E-bits can be consumed to teleport quantum states between QPUs, or to directly perform certain quantum gates non-locally [4]. However, preparation of e-bits is estimated to be over 10 times slower than local two-qubit gates [5], resulting in a new objective for quantum circuit optimisation - minimisation of e-bit consumption. This has been referred to as the 'DQC problem' [6] or the 'circuit partitioning
## II. THE CIRCUIT PARTITIONING PROBLEM (CPP): BACKGROUND
## A. Static circuit partitioning
̸
The general aim of circuit partitioning is to split a quantum circuit C , consisting of list of operations on a set of logical qubits q = { q 0 , q 1 ... } , among a set of QPUs Q = { Q , Q ... 0 1 } . Splitting quantum circuits into separate parts can be considered as assignment ϕ of logical qubits to QPUs, ϕ : q → Q , resulting in a collection of operations which are either local or non-local . Local operations either act only on a single qubit, or act on multiple qubits which are assigned to the same QPU, i.e. ϕ q ( i ) = ϕ q ( j ) . Non-local operations, on the other hand, are gates which involve two or more qubits assigned to different QPUs, ϕ q ( i ) = ϕ q ( j ) . Any assignment ϕ will give a corresponding number of non-local operations to be covered. In order to minimise the number of non-local operations, a quantum circuit can be converted to an interaction graph where each qubit corresponds to a node on the graph, while interactions of all pairs of qubits are summed into weighted edges. This reduces the problem to min-cut graph partitioning [16]. For balanced partitions min-cut is NP-hard, but good heuristics are available [17]. In terms of circuit partitioning, this is referred to as static partitioning because a single qubit assignment is used for the full circuit. Static partitioning methods minimise the number of non-local operations, which is only equal to the e-bit cost if each non-local operation takes a single e-bit. In general, this is not the case, as e-bits can be used in more flexible ways.
(a) Random quantum circuit. See section V-B1.
Fig. 1: Static partitioning workflow. The circuit in a) is converted to a static interaction graph shown in b). The graph is then partitioned according to the constraints of the QPUs, such that the edge weight between partitions is minimised.
## B. Teleportation
1) State teleportation: Quantum state teleportation is the 'conventional' teleportation procedure, which uses a single e-bit, shared between a two parties, to move an arbitrary quantum state from one party to the other [18].
Fig. 2: State teleportation. This is the well known quantum teleportation procedure implemented using a controlled-phase gate rather than a CNOT.
State teleportation can be used to cover a non-local operation by moving one qubit state to its partner's QPU, then performing the operation locally, at the cost of a single e-bit. If the state is then returned to its original QPU, the overall e-bit cost is two. However, it is not always required to return the qubit to its original QPU - in some cases it may even be beneficial for the qubit to remain at the destination of the teleportation.
- 2) Gate teleportation: A less well-known procedure is gate teleportation, which uses a single e-bit to perform a two-qubit controlled unitary, without directly transferring either qubit to the other QPU [4].
Fig. 3: Gate teleportation. The circuit displays how a single controlled-phase gate can be teleported using an e-bit. The procedure is general to all controlled-unitary gates with q 0 as the control.
Gate teleportation works by entangling the control qubit with a communication qubit in another QPU, such that both qubits behave the same way when controlling two-qubit gates on other qubits. The state of the control qubit is mapped from | ψ ⟩ = α | 0 ⟩ + β | 1 ⟩ to the joint state | ψ ⟩ = α | 00 ⟩ + β | 11 ⟩ with the communication qubit. This allows the communication qubit to control a two-qubit (or multi-qubit gate) in place of the original qubit. After the gate has been performed, the communication qubit is measured, and the result used to correct the state of the original control qubit. In contrast with state teleportation, at the end of the procedure both qubits remain assigned their original QPUs.
3) Extended gate teleportation: While the basic gate teleportation procedure focuses on teleporting a single qubit controlled-unitary, it has been shown that larger sequences of operations can in fact be teleported, sometimes at no additional cost [4].
Fig. 4: Extended gate teleportation. The circuit displays how two controlled-unitary gates can be teleported using the same e-bit.
In particular, for a collection of two-qubit controlledunitaries, if each gate shares a common control qubit and their target qubits are assigned to the same QPU, then all gates can be teleported using a single e-bit. This requires a delay in the measurement of the communication qubit in the target QPU, waiting until all gates in the group being covered have been completed to end the process and send the classical information back to the original QPU. In addition, any diagonal or anti-diagonal single-qubit gate acting on the common control qubit can be included in the teleportation procedure [19], as this does not change the behaviour of the linked communication qubit as a control.
Extended gate teleportation can be broken up into a 'starting process', which creates the linked entangled state, an 'intermediate process' where the corresponding local operations are performed, and an 'ending process' which ends the link with measurement and classical communication [12]. The starting and ending processes have also been referred to as the'cat-entangler' and 'cat-disentangler', respectively [20]. The groups of gates covered is referred to as a 'distributable packet' [12]. Wu et al. go on to describe how non-adjacent distributable packets can be merged together via 'embedding' distribution processes for intermediate unitaries within a larger process. Embedding processes allow further reduction of e-bit costs but are beyond the scope of the paper - details can be found in Wu et al. [12]. Following the literature, we will also refer to extended gate teleportation methods as 'gate packing' methods.
## C. Competing methods
The dominant methods in the DQC literature tend to focus heavily on exploiting the benefits of either state teleportation, or gate packing to produce low e-bit costs. We will roughly outline these two extreme ends of the spectrum giving reference to the relevant existing works.
1) Fine-grained partitioning: As an alternative to basic graph partitioning, Baker et al. [8] propose a method referred to as fine-grained partitioning (FGP). Rather than reduce a quantum circuit to a single, static, interaction graph, the essence of FGP is to produce a sequence of interaction graphs for each layer, or 'time-slice', of the circuit. Timesliced graphs can consider future interactions in the circuit by adding time-decaying weighted edges for gates in later slices. Edges representing gates in the current slice are given infinite weights to ensure a local assignment at the time of interaction. The strategy is then to find a low-cost sequence of non-local swaps (two-way gate teleportation) to transition between each slice of the circuit. The result is that all nonlocal operations are covered by state teleportation, while the look-ahead weights work to ensure that swaps also consider future interactions in the circuit. The methods produce low cost assignment sequences in certain scenarios but are limited by the restriction that all non-local operations are covered using state teleportation, especially for circuits for which qubit connectivity changes erratically. Similar methods are presented in Sundaram et al. [9] and Nikhad et al. [10]. The significance of FGP type methods is that the solution for the partitioning problem is no longer a single state assignment of qubits, rather a different assignment for each layer of the circuit. Partitioning over time captures gradual changes in interactivity of quantum circuits very well.
2) Gate packing: A number of other methods are motivated rather by extended gate teleportation, focusing on packing sequences of gates together into the same teleportation protocol to reduce e-bit cost. A hypergraph partitioning method was proposed originally by Andres-Martinez et al. [11]. This work extends the normal graph approach by using hyperedges to represent groups of gates which can be distributed using a single e-bit, such that the number of hyperedges which cut the partition directly corresponds to e-bit count rather than non-local gate count. The methods are extended in AndresMartinez et al. [6] and combined with the methods from Wu et al. [12], which extend the scope of gate teleportation further. The methods go beyond just gate packing, using the embedding methods mentioned in Section II-B3. The methods presented in the latter work are capable of finding very low cost distributions in instances of circuits which contain large sequences of gates meeting the conditions for gate packing and embedding, but are unable to take advantage of state teleportation when such sequences are not available, such as in the quantum volume benchmarks used in their work.
3) Hybrid methods: We acknowledge the existence of methods that consider both extended gate teleportation and state teleportation [9], [15], [16], but note that they treat state teleportation and gate teleportation separately in the optimisation process. For example, Sundaram et al. first optimise extended gate teleportation cost using static graph partitioning, then see if the result can be improved by strategically inserting teleportations into circuits [9] . Similarly, Ferrari et al. begin with static graph partitioning using the METIS library [17] followed by a scheduling pass which chooses whether to use state or gate teleportation to cover the gates based on cost [16]. In addition, an appendix in Andres-Martinez et al. describes how large circuits are broken up into sections which are partitioned separately, requiring teleportations to transition between each section, making this method technically a hybrid method [11]. However, this is dealt with using a pre-processing routine to determine where circuits should be split, rather than combined treatment of state and gate teleportation.
## III. GENERALISED CIRCUIT PARTITIONING (GCP)
To capture full generality, the problem formulation should cover instances where circuits are best executed using state teleportation only, gate teleportation only, and a combination of both - including gate packing. Doing so results in a unification between fine-grained partitioning methods and gate packing methods, thus permitting low e-bit cost in all cases. We will present two variants of GCP; a simple variant which considers only regular, non-extended, gate teleportation, and an extended variant which includes simple gate packing procedures.
## A. Generalised circuit partitioning - simple (GCP-S)
Central to both methods is an extended circuit interaction graph (see Figure 5, which retains the time-step/layer number
Fig. 5: Extended circuit interaction graph. The graph shown here represented a QFT circuit on 8 qubits. Here the nodes are all assigned an unoptimised static mapping indicating gate teleportation for all edges cutting the partition.
for all gates in the circuit. In contrast to FGP methods, which produce a different graph for each layer of the circuit, the extended interaction graph is a single graph G V,E ( ) , containing separate nodes for each qubit at each layer of the circuit. Gate-like edges connect partner nodes at the layer of their interaction, while additional state-like edges connect adjacent nodes representing the same qubit. The result is that an assignment of nodes to QPUs corresponds to an assignment of qubits for each layer of the circuit, thus determining both the state teleportations and the gate teleportations required distribute the circuit. Formally, for each logical qubit i at the l th layer of the circuit, q ( ) l i maps uniquely to a node v k . However, valid solutions are constrained to those which always meet the QPU size constraints. These are enforced by including nodes to represent any idle qubits in each QPU, thus we increase the size of the set of logical qubits to match the total number of physical qubits. This allows the space of all valid solutions to be explored via permutations of nodes within their own layer. This picture extends the problem to a more general, constrained, graph partitioning problem. The aim is still to find a min-cut partition of the nodes but the number of nodes has been extended to reflect the dynamics of the circuit. This picture aligns closely with that presented in Davis et al. under the name 'gate partitioning' [21]. However, the authors do not include the constraints to enforce the size constraints of the QPUs, rather they perform post-processing to ensure that these conditions are met, resulting in high e-bit costs in many of the presented benchmarks. The authors also consider no extension to include gate packing, as is done in Section III-B.
Formally, we define a partition of the circuit as a mapping from the set of nodes to the set of QPUs, Φ : V → Q , though since the nodes represent qubits at each layer of the circuit, we can equivalently think of a partition as an assignment of qubits to QPUs for each layer of the circuit. We retain similar notation to the static case, except that the capital Φ is used
Fig. 6: Simple optimisation. This is the same QFT as Figure 5, optimised according to GCP-S. Nodes have been dragged across to indicate where state teleportation occurs. The circuit is covered using 6 state teleportations, provided there is a single additional space in the second QPU.
to denote assignment across all layers. As such, a partition can be viewed as a matrix where the element ϕ i,j indicates the QPU that qubit q j is assigned to at layer i . The cost of a partition is given by:
$$c = \sum _ { u, v } e _ { u, v } ( 1 - \delta _ { \Phi ( u ) \Phi ( v ) } ) f ( r ( \Phi ( u ), \Phi ( v ) ) ), \quad ( 1 )$$
where we have included a generic function f to denote the cost scaling, as a function of the length r (Φ( u , ) Φ( )) v of the path separating the nodes u and v in the network. We only consider homogeneous networks, for which f → 1 in all cases, though it is included to demonstrate ease of extension.
q
q
…
Fig. 7: Visualising assignments on graphs. In a) we see the cost of a naive assignment, resulting in an e-bit cost of 13. In b) we see the effect of an optimised assignment sequence, resulting in an e-bit cost of 5. Coloured nodes indicate where e-bits are used.
## B. Generalised circuit partitioning - extended (GCP-E)
The extension to GCP can be achieved by modifying the edge structure of the graph. The graph is first scanned to identify where gates can be grouped together according to the conditions identified in Section II-B3. Since different possibilities are available for grouping gates, a greedy approach is used, which always adds gates to the largest available group. The conditions for grouping gates are:
- 1) All two-qubit gates share a common control qubit.
- 2) All two-gates are adjacent on the control.
Fig. 8: Extended optimisation. The Quantum Fourier Transform (QFT) circuit optimised using the GCP-E formulation. In this case, no state teleportation is required, with a total e-bit cost of 3 with the same size constraints as in Figure 6. Edges which have been merged onto a control node are coloured red.
For condition 1., the shared control must be the same for each gate. Since there may be many controls involved in gate groups which are not the shared control, we refer to the qubit representing the shared control as the 'lead control qubit'.The node representing the first appearance of the shared control is referred to as the 'original control node' for a group. 'Adjacent', in condition 2., means that there are no non-diagonal single-qubit gates acting on the original control between any consecutive gates in the group. From section II-B3, we know that diagonal single-qubit gates on the original control can form part of a group, so these can be freely applied to a qubit while it is linked to other QPUs. For symmetric twoqubit gates, in which both involved qubits are control qubits, the conditions are only relevant to the lead control qubit. There are no restrictions on the partner control qubits.
The edges for the gate groups identified are all merged onto the original control node. This is demonstrated in Figure 8. Edges grouped on a particular original control node can be treated similarly to hyperedges in a hypergraph. This is because the e-bit requirements for distributing a group of gates will correspond not to the number of edges but rather the number of different QPUs to which the edges in the group connect to, since e-bits can be re-used within each linked QPU. This modification allows us to explore the full solution space from assignments which imply state teleportation only to those which rely on extended gate teleportation as well as everything in between. The new cost function is:
$$\underset { \text{such is} } { \text{wo use} } \underset { u, v \in V } { \text{$c=\sum_{u,v\in V} e_{u,v} (1-\delta_{\Phi(u)\Phi(v)} ) h(u,\Phi(v)) f(r(\Phi(u),\Phi(v))),} } }$$
(2)
where h u, ( Φ( )) v is a function which returns 1 if e u,v is the first edge from source node u connecting to a node in Φ( ) v . With this modification, we do not count edges which can benefit from an existing linked copy. To see why this is the case, consider the natural extension of the gate teleportation procedure in Section II-B1. In order for a qubit to be linked to k QPUs, its state must be transformed to to a ( k +1) -fold entangled state | ψ ⟩ = α | 0 ⟩ ⊗ k +1 + β | 1 ⟩ ⊗ k +1 , such that each linked communication qubit can be used to control operations for the lead control. Creating such a state requires the gate teleportation starting procedure to be repeated for each QPU, requiring k e-bits to be consumed. Thus, for each group of edges which have been merged onto a control node, the ebit cost is equal to the number of external QPUs which are connected. Once the links are active, the states can either remain at the communication qubit, or swap onto idle data qubits to free up communication qubit space. An example of grouping gates and calculating costs is shown in Figures 9a and 9b.
## IV. SOLUTION METHODS
## A. Genetic algorithm
To solve GCP, we propose a genetic algorithm (GA). GAs are evolutionary algorithms which are well known for being able to produce good heuristic solutions in combinatorial optimisation problems [22], particularly if tailored by prior knowledge. In this case, we can constrain solutions of the problems to take the shape of matrices, where the column index corresponds to qubit number j , the row index to the layer i of the circuit. Corresponding elements are assignments Φ( ) v where v corresponds to qubit q j at layer i . Each solution corresponds to a set of state and gate teleportations, shown in 7. We can explore all valid solutions with permutations of the elements within each layer.
The workflow for GCP is described in algorithm 1. For costfunc , the cost functions in equations 1 and 2 are used, depending on which variant of the problem is being considered.The crossover and mutation functions can be chosen to suit the problem. We use a single point crossover, which selects crossover points by row of the matrix, so that the size constraints remain satisfied. For mutation, we use a custom mutation function which samples random pairs of nodes in a given interval and exchanges them if they have a net difference of neighbours assigned to each other's partition, inspired by the Kernighan-Lin heuristic [23] This mutation function is slower than a normal flip mutation but better avoids local minima.
(a) Gate grouping. All edges are merged onto the original control node. Since this node connects to 3 partitions outside its own, the ebit cost for the assignment is 3.
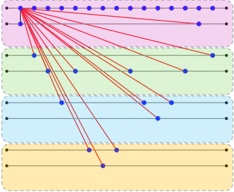
## Algorithm 1 Genetic Circuit Partitioning
1: Input: A graph G V,E ( ) for circuit of depth d with n q qubits. A set of QPUs Q and their sizes | Q n | . Population size | L | . Number of generations/iterations N g .
2: Output: Sorted population ˜ L of candidate assignments.
3: Initialise empty population L
4: for n = 0 to | L | - 1 do
5: Produce a single-layer, static, assignment ϕ .
6: Repeat ϕ for depth d to create full assignment Φ .
7: Add candidate to L
8: end for
9: for n = 1 to N g - 1 do
10:
for candidate in L do
11:
cost ← costfunc G, ( candidate )
12:
Add cost to costlist
13: end for
14:
Initialise empty population ˜ L
15:
for
m
= 0
to
|
L
|
2
-
1
do
16:
dist ← softmax costlist ( )
17:
Sample c a and c b from L according to dist .
18: ˜ c a , c ˜ b ← crossover c ( a , c b )
19:
˜ c a , c ˜ b ← mutation c , c ( ˜ a ˜ ) b
20:
Add ˜ c a , ˜ c b to ˜ L
21:
end for
22:
L ← ˜ L
23: end for
24: return ˜ L
## B. Complexity analysis
The time complexity of the genetic algorithm is determined by population size | L | , number of generations N g , cost function evaluation and the crossover and mutation functions. For all tests, we used constant L and N g such that the scaling is independent of these factors. Typically, as the size of the problem increases, a constant population size and number of iterations is less likely to reach to an optimal solution, however, we retain competitive and often superior performance to the benchmark methods with constant parameters in all tests. In this case the time complexity is O ( cost + selection + crossover + mutation ) . The cost function requires checking
(b) Interrupted gate grouping. Since the control line is interrupted by a non-diagonal single-qubit gate (green node), two gate groups must be formed. The resulting e-bit cost is 5, since the first group connects to 3 partitions and the second to 2.
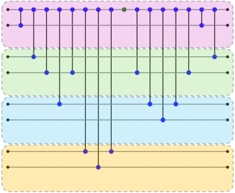
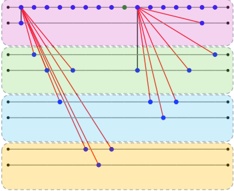
the assignment of nodes for n q ( d + 1) state edges and a maximum of 1 2 n d q gate edges, such that the cost function time complexity is O ( n d q ) . The selection employs a softmax over all fitness values which has complexity O | ( L | ) which is constant since | L | is fixed. Crossover simply selects a random point at which to split two solutions which is also a constant time operation. In our case, the mutation function checks the partitions of a subset of nodes for two qubits in a randomly chosen interval. This is done for a constant k pairs of qubits, such that we query the partition of at worst 2 dk nodes, making the complexity O ( d ) . Altogether this gives a time complexity O ( n d q ) + O ( d ) = O ( n d q ) , such that the scaling is linear in the overall circuit size. The complexity for specific circuits is discussed in section VI.
## V. RESULTS
We use the GA to produce results for both the simple and the extended variants of GCP, here termed GCP-S and GCP-E respectively. These are compared against two leading methods in the literature, exemplifying the extremes of state and gate teleportation-focused algorithms. The comparison graphs are shown in Figures 11, 12 and 13, while the results are summarised in Table I. All results are produced using an HP Elite Tower 800 G9, running Windows 11 Pro with an Intel Core i5-12500 processor, and 16GB of DDR5 RAM.
## A. Benchmark algorithms
1) FGP-rOEE : The first is the algorithm presented in Baker et al. for solving their FGP problem formulation. The algorithm is a variant of the overall extreme exchange (OEE) graph partitioning heuristic [24], called relaxed-OEE. We use a version of rOEE which differs only in the initial phase, where the authors use the regular OEE algorithm to find a starting assignment. We use a simplified version of this which simply swaps the assignment of nodes until no benefit can be gained, then proceed with rOEE.
2) Pytket-DQC : The second algorithm comes from AndresMartinez et al. [6] and is freely available in pytket-DQC [25]. The authors present a number of different workflows - we use a custom workflow which is the same as the best performing 'EmbedSteinerDetached (ESD)' but that it uses the annealing allocator rather than the hypergraph partitioner. We will refer
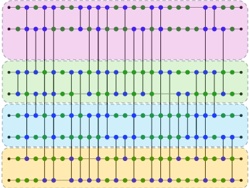
(a) Unoptimised mapping. E-bit cost of 41.

(b) Static mapping using extended (c) Sequential mapping using state (d)
gate teleportation.
E-bit cost
of and gate teleportation.
E-bit
28.
cost state Sequential mapping using teleportation and extended gate teleportation. E-bit cost of 25.
of 29.
Fig. 10: Example of a CP fraction circuit mapped using different techniques. The best e-bit cost is in d) where all teleportation procedures are optimised over.
to this workflow as AESD. Using the annealer may result in a small performance decrease, however, reliance on external software led to implementation issues.
qubits interleaved with permutations of qubit numbers [29]. The resulting circuit consists of alternating blocks of repeated single- and two-qubit gate patterns.
## B. Benchmark circuits
Four different circuit types are used for comparing methods, each with a very different qubit interaction structure. The choices are motivated such that there are instances where each of the benchmark algorithms performs both strongly and poorly. For all circuits, the universal gate set of controlledphase gates CP ϑ ( ) and general unitary rotations U ϕ,θ, λ ( ) , is used. This gate set is useful for DQC as the CP ϑ ( ) allows for many gate packing possibilities. In all cases, circuits are partitioned among QPUs containing 8 qubits each.
1) CP fraction : CP fraction circuits are a generalisation of the CZ fraction introduced in Sundaram et al. [14] and used in later works [6], [26]. A CZ fraction circuit, for a given number of qubits n q , depth d and fraction p , consists of d layers of gates where, for each layer, a Hadamard ( H ) gate is applied to each qubit with probability 1 -p , while all qubits for which H was not applied are randomly paired with CZ gates. The only difference in a CP fraction is that each H is replaced with U ϕ,θ, λ ( ) for randomly chosen ϕ, θ and λ . In addition, each CZ is replaced with CP ϑ ( ) , for some randomly chosen ϑ . In all tests, we set d = n q .
2) QFT : The QFT is a well-known subroutine in many quantum algorithms [27], implemented using a very regular structure of two-qubit gates [28]. The QFT has been used as a benchmark for various circuit partitioning methods and is an example of a circuit type consisting of large distributable packets.
- 3) Quantum volume (QV) : QV circuits are randomised circuits used for benchmarking the performance of quantum computers [29]. It is reasonable to believe that QV circuits are also a strong indicator of performance of a distributed quantum architecture, where good compiling strongly impacts the QV score. Another reason for choosing QV circuits for benchmarking is that they represent a middle ground between highly structured and fully random circuits. QV circuits consist of sequences of Haar random unitaries acting on pairs of
4) Quantum approximate optimisation algorithm (QAOA) : QAOA circuits are designed to solve combinatorial optimisation problems using parameterised quantum circuits [30]. The circuit consists of parameterised singleand two-qubit gates which are classically optimised to find an approximate solution to the problem. The structure of the circuit depends partly on the structure of the problem being solved. We consider randomly initialised QAOA circuits for MaxCut problems over random graphs with an edge probability of 50% for each pair of nodes.
TABLE I: Average performance across all tests. The metric used is the ratio of e-bits required to the total number of twoqubit gates in the circuit, such that a lower score indicates a more efficient circuit distribution.
| Method | FGP-rOEE | GCP-S | GCP-E | AESD |
|----------|------------|---------|---------|--------|
| CP 0.3 | 0.66 | 0.54 | 0.5 | 0.49 |
| CO 0.4 | 0.59 | 0.57 | 0.5 | 0.52 |
| CP 0.5 | 0.65 | 0.55 | 0.47 | 0.45 |
| CP 0.7 | 0.66 | 0.57 | 0.42 | 0.35 |
| CP 0.8 | 0.59 | 0.58 | 0.36 | 0.28 |
| QFT | 0.34 | 0.59 | 0.14 | 0.12 |
| QV | 0.2 | 0.43 | 0.42 | 0.73 |
| QAOA | 0.35 | 0.51 | 0.12 | 0.14 |
| Average | 0.52 | 0.55 | 0.37 | 0.39 |
## VI. DISCUSSION AND CONCLUSION
It is clear from the results in Figures 11, 12 and 13 that methods which depend heavily on state teleportation or gate teleportation perform very well in specific circumstances but do not retain the performance in all cases. For example, AESD performs very well on QFT circuits, as these have multiple long chains of two-qubit gates which share a common control qubit. As a result, no state teleportation is required for efficient distribution. However, the AESD performs poorly on QV circuits, which do not contain any distributable packets. In this case, these methods are limited to providing a qubit assignment
(a) E-bit cost results
- (b) Time taken to generate distribution
Fig. 11: Results from real circuits distributed over QPUs consisting of 8 qubits each.

Fig. 12: Results for random, CP fraction circuits, as described in section V-B1, distributed over QPUs consisting of 8 qubits each
which performs only as well as static graph partitioning. In contrast, FGP-rOEE performs exceptionally well on QV circuits, where full reliance on state teleportation is always most effective. This is because all blocks of a QV circuit can be made local if state teleportations are inserted to match the qubit permutation between each section. This makes it particularly easy for FGP-rOEE to find an optimal sequence of assignments. In principle, both GCP-S and GCP-E should be able to find the same assignment, but it becomes increasingly less likely as the size of the circuit increases so would require longer runtime for the GA. Again, since there are no distributable packets in QV circuits, GCP-E reduces to GCP-S
Fig. 13: Results from larger CP fraction circuits distributed over QPUs consisting of 16 qubits each.
which is reflected in the similarity of their performance.
For CP fraction circuits, which have a more random structure, FGP-rOEE performs the worst, particularly as the number of qubits and fraction of two-qubit gates increases. Since these circuits have non-uniform qubit interactions, it can be inefficient to be constrained to state teleportation. In contrast, AESD performs worse than GCP-E when the fraction of twoqubit gates is lower. This is because there are more singlequbit gates separating the two-qubit gates, which decreases the average size of the distributable packets. GCP-E can benefit from state teleportation in this cases so retains low e-bit cost. As the fraction of two-qubit gates increases however, AESD performs the best in terms of e-bit cost. AESD contains the most flexible conditions for extended gate teleportation, with the benefits of embedding reflected for two-qubit gate fractions greater than 0.4. This improved performance comes at a significant time cost, however, which can be seen in the distribution time graphs. For all circuits containing 40 qubits or more, the distribution time of AESD drastically increases. In these instances, the cost performance of GCP-E remains competitive for a much shorter distribution time. The overall, average performance is shown in Table I. GCP-E is the best performer in terms of e-bit cost, outperforming FGP-rOEE by around 20% and AESD by around 2%.
The time graphs in Figures 11, 12 and 13 accord with the scaling from section IV-B. While slower at smaller scales, GCP-S and GCP-E scale better and are the fastest in most cases by the end. CP fractions circuits are built with d = n q , while QFT and QV circuits have d ∝ n q , so in these cases the complexity reduces to O ( n 2 q ) . For QAOA, the depth is more variable and depends on the optimisation problem. Since we use circuits designed for MaxCut on random graphs, the depth scales with the number of edges of the graphs and the number of repetitions, so steeper polynomial scaling is expected. The experimental results demonstrate superior scaling compared to the benchmark methods for most circuits. However, the complexities of these methods are highly dependent on the type of circuit. The results from larger circuits, in Figure 13, show significant time improvements over the benchmark methods.
In future, we look to extend these methods to general network topologies. We avoided doing this here, as current methods for doing so (scaling cost linearly with path distance [6], [9]) are over-simplified and require careful treatment. We acknowledge another assumption regarding the number of communication qubits available to facilitate e-bit generation at each QPU. At present, this assumption can be justified on the basis that communication qubits can freely swap states in and out of data qubits which are idle in computation. For realistic systems with data and communication qubit number constraints, restrictions will need to be enforced and used to guide the optimisation process.
## VII. ACKNOWLEDGEMENTS
The authors thank Richard Meister for engaging discussions and acknowledge funding from the Engineering and Physical
Sciences Research Council (EPSRC) funded Distributed Quantum Computing project, grant number EP/W032643/1
## REFERENCES
- [1] D. CUOMO, M. CALEFFI AND A. S. CACCIAPUOTI, Towards a distributed quantum computing ecosystem , IET Quantum Communication 1 (2020), pp. 3-8. eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1049/iet-qtc.2020.0002. URL: https://onlinelibrary.wiley.com/doi/abs/10.1049/iet-qtc.2020.0002, doi:10.1049/iet-qtc.2020.0002 .
- [2] M. CALEFFI ET AL., Distributed Quantum Computing: a Survey , Dec. 2022. arXiv:2212.10609 [quant-ph]. URL: http://arxiv.org/abs/2212. 10609, doi:10.48550/arXiv.2212.10609 .
- [3] W. G. UNRUH, Maintaining coherence in quantum computers , Physical Review A 51 (1995), pp. 992-997. Publisher: American Physical Society. URL: https://link.aps.org/doi/10.1103/PhysRevA.51.992, doi: 10.1103/PhysRevA.51.992 .
- [4] J. EISERT, K. JACOBS, P. PAPADOPOULOS AND M. B. PLENIO, Optimal local implementation of nonlocal quantum gates , Physical Review A 62 (2000), p. 052317. Publisher: American Physical Society. URL: https://link.aps.org/doi/10.1103/PhysRevA.62.052317, doi:10. 1103/PhysRevA.62.052317 .
- [5] N. ISAILOVIC, Y. PATEL, M. WHITNEY AND J. KUBIATOWICZ, Interconnection Networks for Scalable Quantum Computers , ACM SIGARCH Computer Architecture News 34 (2006), pp. 366377. URL: https://dl.acm.org/doi/10.1145/1150019.1136505, doi:10. 1145/1150019.1136505 .
- [6] P. ANDRES-MARTINEZ ET AL., Distributing circuits over heterogeneous, modular quantum computing network architectures , July 2023. arXiv:2305.14148 [quant-ph]. URL: http://arxiv.org/abs/2305.14148.
- [7] D. BARRAL ET AL., Review of Distributed Quantum Computing. From single QPU to High Performance Quantum Computing , 2024. Publisher: arXiv Version Number: 1. URL: https://arxiv.org/abs/2404.01265, doi: 10.48550/ARXIV.2404.01265 .
- [8] J. M. BAKER, C. DUCKERING, A. HOOVER AND F. T. CHONG, Time-Sliced Quantum Circuit Partitioning for Modular Architectures , May 2020. URL: https://arxiv.org/abs/2005.12259v1, doi:10.1145/ 3387902.3392617 .
- [9] R. G. SUNDARAM AND H. GUPTA, Distributing Quantum Circuits Using Teleportations , May 2023. arXiv:2306.00195 [quant-ph]. URL: http: //arxiv.org/abs/2306.00195, doi:10.48550/arXiv.2306.00195 .
- [10] E. NIKAHD, N. MOHAMMADZADEH, M. SEDIGHI AND M. S. ZAMANI, Automated window-based partitioning of quantum circuits , Physica Scripta 96 (2021), p. 035102. Publisher: IOP Publishing. URL: https://dx.doi.org/10.1088/1402-4896/abd57c, doi:10. 1088/1402-4896/abd57c .
- [11] P. ANDR´ ES-MART´ INEZ AND C. HEUNEN, Automated distribution of quantum circuits via hypergraph partitioning , Physical Review A 100 (2019), p. 032308. Publisher: American Physical Society. URL: https://link.aps.org/doi/10.1103/PhysRevA.100.032308, doi:10. 1103/PhysRevA.100.032308 .
- [12] J.-Y. WU ET AL., Entanglement-efficient bipartite-distributed quantum computing , Quantum 7 (2023), p. 1196. Publisher: Verein zur F¨ orderung des Open Access Publizierens in den Quantenwissenschaften. URL: https://quantum-journal.org/papers/q-2023-12-05-1196/, doi: 10.22331/q-2023-12-05-1196 .
- [13] D. CUOMO ET AL., Optimized Compiler for Distributed Quantum Computing , ACM Transactions on Quantum Computing 4 (2023), pp. 129. URL: https://dl.acm.org/doi/10.1145/3579367, doi:10.1145/ 3579367 .
- [14] R. G. SUNDARAM, Efficient Distribution of Quantum Circuits , 2021.
- [15] D. FERRARI, A. S. CACCIAPUOTI, M. AMORETTI AND M. CALEFFI, Compiler Design for Distributed Quantum Computing , IEEE Transactions on Quantum Engineering 2 (2021), pp. 1-20. URL: https:// ieeexplore.ieee.org/document/9334411/, doi:10.1109/TQE.2021. 3053921 .
- [16] D. FERRARI, S. CARRETTA AND M. AMORETTI, A Modular Quantum Compilation Framework for Distributed Quantum Computing , IEEE Transactions on Quantum Engineering 4 (2023), pp. 1-13. arXiv:2305.02969 [quant-ph]. URL: http://arxiv.org/abs/2305.02969, doi:10.1109/TQE.2023.3303935 .
- [17] G. KARYPIS AND V. KUMAR, A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs , SIAM Journal on Scientific Computing 20 (1998), pp. 359-392. URL: http://epubs.siam.org/doi/10. 1137/S1064827595287997, doi:10.1137/S1064827595287997 .
- [18] C. H. BENNETT, G. BRASSARD, C. CR´ EPEAU, R. JOZSA, A. PERES AND W. K. WOOTTERS, Teleporting an unknown quantum state via dual classical and Einstein-Podolsky-Rosen channels , Physical Review Letters 70 (1993), pp. 1895-1899. Publisher: American Physical Society. URL: https://link.aps.org/doi/10.1103/PhysRevLett.70.1895, doi: 10.1103/PhysRevLett.70.1895 .
- [19] S. F. HUELGA, J. A. VACCARO, A. CHEFLES AND M. B. PLENIO, Quantum remote control: Teleportation of unitary operations , Physical Review A 63 (2001), p. 042303. Publisher: American Physical Society. URL: https://link.aps.org/doi/10.1103/PhysRevA.63.042303, doi: 10.1103/PhysRevA.63.042303 .
- [20] A. YIMSIRIWATTANA AND S. J. LOMONACO JR, Generalized GHZ States and Distributed Quantum Computing , Mar. 2004. arXiv:quantph/0402148. URL: http://arxiv.org/abs/quant-ph/0402148.
- [21] M. G. DAVIS, J. CHUNG, D. ENGLUND AND R. KETTIMUTHU, Towards Distributed Quantum Computing by Qubit and Gate Graph Partitioning Techniques , Oct. 2023. arXiv:2310.03942 [quant-ph]. URL: http://arxiv.org/abs/2310.03942.
- [22] H. M¨ UHLENBEIN, M. GORGES-SCHLEUTER AND O. KR¨ AMER, Evolution algorithms in combinatorial optimization , Parallel Computing 7 (1988), pp. 65-85. URL: https://www.sciencedirect.com/science/ article/pii/0167819188900981, doi:10.1016/0167-8191(88) 90098-1 .
- [23] B. W. KERNIGHAN AND S. LIN, An efficient heuristic procedure for partitioning graphs , The Bell System Technical Journal 49 (1970), pp. 291-307. Conference Name: The Bell System Technical Journal. URL: https://ieeexplore.ieee.org/document/6771089, doi:10.1002/ j.1538-7305.1970.tb01770.x .
- [24] T. PARK AND C. Y. LEE, Algorithms for partitioning a graph , Computers & Industrial Engineering 28 (1995), pp. 899-909. URL: https: //www.sciencedirect.com/science/article/pii/036083529500003J, doi: 10.1016/0360-8352(95)00003-J .
- [25] P. ANDRES-MARTINEZ, D. MILLS, T. FORRER AND L. HENAUT, CQCL/pytket-dqc , June 2024. original-date: 2021-12-20T18:54:45Z. URL: https://github.com/CQCL/pytket-dqc.
- [26] R. G. SUNDARAM, H. GUPTA AND C. R. RAMAKRISHNAN, Distribution of Quantum Circuits Over General Quantum Networks , June 2022. arXiv:2206.06437 [quant-ph]. URL: http://arxiv.org/abs/2206.06437, doi:10.48550/arXiv.2206.06437 .
- [27] P. SHOR, Algorithms for quantum computation: discrete logarithms and factoring , in Proceedings 35th Annual Symposium on Foundations of Computer Science, Nov. 1994, pp. 124-134. URL: https://ieeexplore.ieee.org/document/365700/?arnumber=365700, doi: 10.1109/SFCS.1994.365700 .
- [28] D. COPPERSMITH, An approximate Fourier transform useful in quantum factoring , Jan. 2002. arXiv:quant-ph/0201067. URL: http://arxiv.org/abs/ quant-ph/0201067, doi:10.48550/arXiv.quant-ph/0201067 .
- [29] A. W. CROSS, L. S. BISHOP, S. SHELDON, P. D. NATION AND J. M. GAMBETTA, Validating quantum computers using randomized model circuits , Physical Review A 100 (2019), p. 032328. arXiv:1811.12926 [quant-ph]. URL: http://arxiv.org/abs/1811.12926, doi:10.1103/ PhysRevA.100.032328 .
- [30] E. FARHI, J. GOLDSTONE AND S. GUTMANN, A Quantum Approximate Optimization Algorithm , Nov. 2014. arXiv:1411.4028 [quant-ph]. URL: http://arxiv.org/abs/1411.4028. | 10.1109/QCE60285.2024.10273 | [
"Felix Burt",
"Kuan-Cheng Chen",
"Kin Leung"
]
| 2024-08-02T17:59:51+00:00 | 2025-01-20T12:34:32+00:00 | [
"quant-ph"
]
| Generalised Circuit Partitioning for Distributed Quantum Computing | Distributed quantum computing (DQC) is a new paradigm aimed at scaling up
quantum computing via the interconnection of smaller quantum processing units
(QPUs). Shared entanglement allows teleportation of both states and gates
between QPUs. This leads to an attractive horizontal scaling of quantum
processing power, which comes at the expense of the additional time and noise
introduced by entanglement sharing protocols. Consequently, methods for
partitioning quantum circuits across multiple QPUs should aim to minimise the
amount of entanglement-based communication required between distributed QPUs.
Existing protocols tend to focus primarily on optimising entanglement costs for
gate teleportation or state teleportation to cover operations between QPUs,
rather than both at the same time. The most general form of the problem should
treat gate and state teleportation on the same footing, allowing minimal cost
circuit partitions through a combination of the two. This work introduces a
graph-based formulation which allows joint optimisation of gate and state
teleportation cost, including extensions of gate teleportation which group
gates together for distribution using common resources. The formulation permits
low e-bit cost for a variety of circuit types. Using a basic genetic algorithm,
improved performance over state-of-the-art methods is obtained in terms of both
average e-bit cost and time scaling. |
2408.01425v1 | 

Obadiah et al.,
## ISSN: 23027-1762
## Research Article
The official Journal of the Department of Biological Sciences, Federal University Birnin Kebbi, Kebbi State, Nigeria. Vol. 1(1): 132-140, February, 2024. Available online at www.bnas.com.ng
## Comparative Evaluation of the Proximate and Cytogenotoxicity of Ash and Rice Chips Used as Mango Fruit Artificial Ripening Agents in Birnin Kebbi, Nigeria
*Obadiah CD, Yahaya TO Aliero AA, Abdulkareem M , .
Department of Biological Sciences, Federal University Birnin Kebbi, P.M.B 1157, Birnin Kebbi, Kebbi State, Nigeria.
* Correspondence : [email protected]; [email protected]; 08038509764
Submission: 13 th December, 2023; Accepted: 15 th December, 2023; Published: 28 th February, 2024
## Abstract
The high demand for mango ( Mangifera indica L.) fruits has led sellers to employ ripening agents. However, concerns are growing regarding the potential toxicities of induced ripening, emphasizing the need for scientific investigation. Samples of artificially and naturally ripened mangoes were analyzed for proximate composition using standard protocols. Cytogenotoxicity was then assessed using the Allium cepa L. toxicity test. Twenty (20) A. cepa (onion) bulbs were used, with 5 ripened naturally, 5 with wood ash, 5 with herbaceous ash, and 5 with rice chips, all grown over tap water for five days. The root tips of the bulbs were assayed and examined for chromosomal aberrations. The results revealed a significant (P<0.05) increase in moisture, protein, and ash content of mangoes as ripening agents were introduced. Mangoes ripened with wood ash exhibited the highest moisture content (81%), while those ripened with rice chips had the highest protein (0.5%) and ash content (1.5%). Naturally ripened mangoes displayed the highest fat (0.0095%) and fiber (11.46%) contents. The A. cepa toxicity test indicated significant (p<0.05) differences in the root growth of mangoes ripened with various agents. Wood ash resulted in the highest root growth (2.62cm), while herbaceous ash had the least (2.18%). Chromosomal aberrations, including sticky, vagrant, and laggard abnormalities, were observed in all agents, with herbaceous ash exhibiting the highest and rice chips the least. The obtained results suggest that induced ripening of the fruits could induce toxicities, highlighting the necessity for public awareness regarding the potential dangers posed by these agents.
Keywords: Ash, Chromosomal aberrations, Fruit ripening, Mango, and Rice chips
## 1.0 Introduction
Fruit ripening is a complex process that influences the pigments, sugar, acid, flavor, aroma, texture, and color, making fruits appealing and suitable for consumption [4]. It is a highly regulated and programmed developmental phenomenon involving the coordination of multiple metabolic changes, as well as the activation and inactivation of various genes, resulting in biochemical and physiological changes within the tissue [18].
melons are examples of climacteric fruits, which are ethylene-dependent and can ripen after harvest, often with the help of exogenous ethylene. Non climacteric fruits ripen only if they remain attached to the parent plant. Examples include grapes, pineapples, strawberries, and citrus fruits [8, 15, 7].
Fruits are classified into two classes based on the regulatory processes leading to ripening: climacteric and non climacteric fruits [15]. Mangoes, bananas, guavas, papayas, apples, and
Mango ( Mangifera indica L.) is a climacteric fruit tree crop belonging to the genus Mangifera of the family Anacardiaceae, widespread across the tropics and subtropics [14]. For years, the fruit has been produced for its rich composition of phytonutrients and has been incorporated into the human diet as a source of carbohydrates, proteins, vitamins (particularly vitamins A and C), betacarotene, minerals, and bioactive compounds such
as phenolic acids, polyphenols, and carotenoids [6. 21]. The fruit is commonly harvested at the green, unripe stage, allowing for transportation and sale to distant markets [20]. As the demand for fresh mango fruit grows, the challenge of producing and distributing consumer-safe commodities in adequate and reasonable quantities becomes significant. Several artificial techniques and additives have been employed to induce rapid post-harvest ripening of the fruit [13, 18, 7].
During the artificial ripening process, alterations in the physio-chemical composition [5] and possibly genetic damage in the cells of mango fruit may occur. Unfortunately, a literature search shows a dearth of documented information on the safety of ripening agents in Birnin Kebbi, Nigeria. This information is necessary to raise public awareness if found toxic. Therefore, the current research aims to evaluate the proximate composition and cytogenotoxicity of wood ash, herbaceous ash, and rice chips used as artificial ripening agents for mango fruits in Birnin Kebbi.
## 2.0 Materials and Methods
## 2.1 Study area
The study was conducted at Kali Farm, situated in the Aleiro Local Government Area of Kebbi State, Nigeria. The local government is located in the southeastern part of Kebbi State at latitude 12.27709 and longitude 4.44493. The town is well-known for its production of various vegetables and fruits, including groundnuts, pepper, tomatoes, onions, mangoes, cashews, and watermelons. Additionally, other food crops grown in this area include sorghum, beans, rice, and sugarcane [17]. In general, the land in the study area is extensively used for agricultural and settlement purposes. Kali Farm covers an area of 538,195.521 square feet, equivalent to five hectares of land. It is situated at latitude12° 17' 24.14"N and longitude4° 28' 1.57"Ewithin the Aliero Local Government Area of Kebbi State, Nigeria [17].
The prevailing climate in the study area is categorized as tropical wet and dry. In a typical year, the average annual rainfall in and around this region amounts to approximately 800mm 1000mm. The temperature remains consistently warm or hot throughout the year, with a slight cooling period occurring between November and February. Among these months, December is considered the coolest, with mean values ranging between 12°C and 21°C. On the other hand, April and May are the hottest months, with average mean temperatures reaching 35°C. Temporal variations in temperature from year to year are minimal. Actual evapotranspiration is estimated to be around 75% of the rainfall in the southern part of the region, increasing to approximately 80% in the northern part. Relative humidity experiences a 5% increase in the south and a corresponding decrease in the north [10].
Fig 2:
Map showing Kali Farm and its environs . Source : GIS unit, FUBK, 2022
## 2.2 Sample collection
Two naturally ripen and six fully mature unripe mango fruits and were collected from Kali farm in Aliero local government. They were then transported to the laboratory of the Department of Biological Sciences at the Faculty of Science, Federal University, Birnin Kebbi, Kebbi State for artificial ripening using ash and rice chips; it should be noted that only undamaged and free from visible signs of infection mangoes were selected and plucked directly from the tree.
## 2.3 Experimental Design
The unripe fruits were randomly selected and grouped into three groups with each group having two mangoes replicates. In all the three groups, each mango was ripened separately in a polythene bag (two polythene bags for each group). The first group were ripenedin wood ash, the second group were ripened in herbaceous ash and the third group were ripened in rice chips. On attaining the ripening stage indicated by change in flesh colour (from green to pale yellow) and indented upon pressing with the thumb [16] they were then processed for proximate analysis. The ripening agents were also kept for further cytogenotoxicity examination.
## 2.4 Methodology
The standard analytical method of the Association of Official Analytical Chemists, [2] was used to determine the moisture, ash, fibre, protein, fat and carbohydrate contents of the mango samples (dry matter). The cytogenotoxic effects of the ripening agents was evaluated using the methods proposed by [3].
## 2.4.1 Determination of moisture content
A crucible with no contents was measured, and a gram of mature mangoes was measured into the crucible, and the weight of the crucible and sample was recorded; the sample was then dried in the oven overnight and subsequently removed and cooled in the desiccators .The sample was weighed after drying, the weight was recorded and was calculated by the following formula [2]:
Moisture content (%) = 12 1-0 × 100 Where: w0= weight of empty crucible; w1= weight of fresh sample + empty crucible;
w2= weight of dried sample + empty crucible
## 2.4.2 Determination of ash content
An empty crucible was weighed and one gram of the ripe mangoes sample was weighed into the crucible, the weight of the crucible and sample was taken. The sample was dried in the oven overnight, the sample was taken out after drying and was allowed to cool in the desiccator. The sample was weighed after drying, the weight was recorded and it was taken to the muffle furnace for ashing set at550 C for 3 hours. It was o kept at this temperature until white, light grey ash is obtained which appears to be free from carbonaceous particles. The crucible was placed in a desiccator and was allowed to cool. The weight of the sample was also taken after ashing and was calculated using the following formula [2].
$$\text{Ash content} \, ( \% ) \ = \ \frac { w 1 { - w } 2 } { w 1 { - w } 0 } \times 1 0 0 \%$$
Where: w0= weight of empty crucible; w1= weight of crucible + dry sample; w2= weigh of crucible + ash sample.
## 2.4.3 Determination of fibre content
One gram of the ripe mangoes sample was placed into a beaker and 50ml of H2SO4 was added and boiled vigorously for exactly 30 minutes in the water bath. The sample was taken out, stirred and filtered with filter paper, the residue was transferred into the beaker and 50 ml NaOH was added into it. The sample was taken back to the water bath for digestion and was taken out after few minutes and re filtered. The residue was rinsed with HCL, Ethanol and Hot water respectively in other to dissolve the sample leaving only the fibre content of the sample. After the final filtration, the residue was washed into a weighed crucible and dried in the oven overnight. After drying, it was cooled in the desiccator and weighed rapidly. The sample was taken to the muffle furnace and ash at 550 C for three hours. o After heating, it was cooled in the desiccator before weighing and was calculated using the following formula [2].
$$\text{is} \quad \text{Fibre} \, ( \% ) \ = \frac { \text{loss in weight of ash on ignition} } { \text{original weight of sample} } \times 100$$
## 2.4.5 Protein quantification
The method is grounded on the fact that the digestion of a food sample with a strong acid such as H2SO4 results
in the release of nitrogen, which can be measured through titration, and the protein content can be estimated by multiplying the nitrogen concentration by a conversion factor of 6.25 [2].
$$C r u d e \text{ protein } ( \% ) = \frac { ( a - b ) x 0. 0 1 M H C l x 1 4 c } { \varepsilon \varepsilon + 1 0 0 \varepsilon + 1 \varepsilon }$$
6.25100
Where: a = titre value for the digested sample; b = titre value for the blank; c = volume for which the digested was made up; d = volume of aliquot used in digestion; e = weight of dried sample
## 2.4.6 Determination of fat content
One gram of mango sample was weighed and transferred to an extraction thimble which was covered with a fat free wad of cotton wool. A clean and dry extraction flask was weighed to the nearest 1mg. The thimble was placed in an extractor and was extracted for 80 min with light petroleum. The residue was dried maintaining the flask for one hour in the drying oven at 98 C. It o was left to cool in a desiccator and weighed after cooling. The following formula was used to calculate the fat content [2]:
$$\text{Fat content } ( \% ) = \frac { w e i g h t \, o f \, e x t r a c t } { w e i g h t \, o f \, s a m p l e } \, \times \, 1 0 0$$
## 2.4.7 Determination of carbohydrate content
The carbohydrate content was determined by the method of [2]:
%Total carbohydrate = (100- % (moisture + ash +protein + fibre + fat)
## 2.5 Cytogenotoxicity test
The cytogenotoxicity test was determine using Allium cepa (onion bulb)test following the method of [2]. Onion root tips was allowed to grow in tap water for five days and growth was observed. The onion root tips were later exposed to different dilutions of artificially ripening agents to observe the further growth. A. cepa was exposed for another five days to different dilutions of the ripening agents as follows:
- i. Wood ash: 5g/dl, 10g/dl, 15g/dl, 20g/dl, 25g/dl and the control
- ii. Herbaceous ash: 5g/dl, 10g/dl/dl, 15g/dl, 20g/dl, 25g/dl and the control
- iii. Rice chips:5g/dl, 10g/dl, 15g/dl, 20g/dl, 25g/dl and control.
Each concentration was set-up in five replicates. The test solutions were stirred after every twentyfour hours. Two longest root tips were selected in each bulb and the root tips were measured after every twenty hours to observe any change in the growth. On reaching the fifth day, the root tips were cut and allowed to be soft in solution of 15ml acetic acid and 45ml ethanol. After the root tips dissolved, a slide was prepared using acetoamine stain to stain the root and was observed under the microscope to view the cells and how the chromosomes are affected by those ripening agents [3].
## 2.6 Data Analysis
All data are presented as mean ± SD. Statistical significance at the 95% probability levels was set at P<0.05. Microsoft Excel (Version2016) was used for statistical analysis. Data was subjected to analysis of variance (ANOVA) and tested for significance difference among treatments.
## 3.0 Results
## 3.1 Proximate compositions of mangoes ripened naturally and artificially with ripening agents
Table 1 compares the proximate composition of mangoes ripened with rice chip, wood ash, and herbaceous ash with naturally ripened mangoes. There was a significant difference between the proximate parameters (moisture content, ash, protein, fat, fibre, and carbohydrate) of artificially ripened mangoes compared with naturally ripened. The mangoes ripened with wood ash was significantly (P<0.05) higher in moisture content (81%), while the highest protein (0.5%) and ash content (1.5%) were observed in mangoes ripened with rice chip. The ash content was found to be higher in rice chips (1.5%) than in both the naturally ripened mango (1.01%) and mangoes ripened with wood ash (0.35%) and herbaceous ash (0.8%). Fibre content was higher in naturally ripped mangoes (11.46%) than others. There was no significant difference (P<0.05) between the total carbohydrate content of naturally ripened mangoes (14.99%) and the mangoes artificially ripened with rice chips (15.4%) and herbaceous ash (14.95%). However, mangoes ripened with wood ash had the lowest carbohydrate content (9.92%). Additionally, naturally ripened mangoes significantly (P<0.05) had the highest (0.0095%) fat content, but there was no statistical (P<0.05) difference among the fat content of mangoes
ripened with rice chip (0.005%), wood ash (0.005%), and herbaceous ash(0.0005%). Table 1: Proximate composition of mangoes ripened with rice chip, wood ash, herbaceous ash, and
naturally ripened
| Treatment | Moisture content | Ash | Fibre | Protein | Fat | Carbohydrate |
|----------------|--------------------|----------------|----------------|---------------|--------------|----------------|
| Rice chips | 77.5 ± 0.5 ab | 1.5 ± 0.5 b | 5.1 ± 0.1 a | 0.5 ± 0.01 c | 0.005 ± 0 ab | 15.4 ± 0.89 b |
| Wood ash | 81 ± 1 b | 0.35 ± 0.05 a | 8.2 ± 0.1 b | 0.53 ± 0.05 c | 0.005 ± 0 ab | 9.92 ± 1.1 a |
| Herbaceous ash | 73 ± 2 a | 0.8 ± 0.1 ab | 8.4 ± 0.2 b | 0.35 ± 0 b | 0.0005 ± 0 a | 14.95 ± 0.61 b |
| Natural | 73 ± 2 a | 1.01 ± 0.21 ab | 11.46 ± 1.04 c | 0.04 ± 0.02 a | 0.0095 ± 0 b | 14.99 ± 0.26 b |
Values were presented as means ± S. E. M; values with superscripts a, b, or c (3 or more levels) are significantly (p<0.05) different (ANOVA)
## 3.2 Cytogenetic effects in mangoes ripened naturally and artificially with ripening agents
growth of the bulbs at day two, day three, and day four.
Table 2 shows the cytogenetic effects of wood ash, herbaceous ash, and rice chips on the growth of treated A. cepa bulbs. There were significant (p<0.05) differences in the root growth of the treated A. cepa after day one. Wood ash produced the highest root growth (2.62cm), while herbaceous ash produced the least (2.18cm). There were no significant differences in the root
On the other hand, there was significant (p<0.05) decrease in the root growth of the bulbs as the weight of ash increases compared to the control across at all days. Additionally, there were significant differences in the root growth of bulbs exposed to different concentrations of ashes (5g, 10g, 15g, 20g and 25g) (Table 3).
Table 2: Root growth of Allium cepa grown in different concentrations of ripening agents
| Treatment | Initial root length (cm) | After day 1 (cm) | After day 2 (cm) | After day 3 (cm) | After day 4 (cm) |
|----------------|----------------------------|--------------------|--------------------|--------------------|--------------------|
| Wood ash | 2.27 ± 0.13 | 2.62 ± 0.14 b | 2.99 ± 0.36 | 3.35 ± 0.49 | 3.56 ± 0.6 |
| Herbaceous ash | 2.03 ± 0.15 | 2.18 ± 0.12 a | 2.32 ± 0.15 | 2.63 ± 0.31 | 2.74 ± 0.38 |
| Rice chip | 2.04 ± 0.12 | 2.31 ± 0.12 ab | 2.37 ± 0.11 | 2.37 ± 0.11 | 2.37 ± 0.11 |
Group means and standard error are presented as; Means ± s. e. m: a, b, c, - means with different superscripts within factor (3 or more levels) are significantly (P>0.05) different
Table 3: Root growth of Allium cepa grown in different concentrations of ripening agents
| Weight of ash | Initial root length (cm) | After day 1 (cm) | After day 2 (cm) | After day 3 (cm) | After day 4 (cm) |
|-----------------|----------------------------|--------------------|--------------------|--------------------|--------------------|
| 0g | 1.98 ± 0.1 | 2.85 ± 0.24 b | 3.82 ± 0.56 b | 4.87 ± 0.71 b | 5.45 ± 0.9 b |
| 5g | 1.85 ± 0.22 | 2.28 ± 0.22 a | 2.3 ± 0.21 a | 2.3 ± 0.21 a | 2.33 ± 0.22 a |
| 10g | 2.2 ± 0.1 | 2.32 ± 0.12 ab | 2.38 ± 0.12 a | 2.63 ± 0.19 a | 2.67 ± 0.21 a |
| 15g | 1.87 ± 0.32 | 1.98 ± 0.19 a | 2.02 ± 0.18 a | 2.02 ± 0.18 a | 2.02 ± 0.18 a |
| 20g | 2.33 ± 0.06 | 2.38 ± 0.07 ab | 2.42 ± 0.09 a | 2.45 ± 0.11 a | 2.45 ± 0.11 a |
| 25g | 2.43 ± 0.15 | 2.38 ± 0.13 ab | 2.42 ± 0.12 a | 2.42 ± 0.12 a | 2.42 ± 0.12 a |
Group means and standard error are presented as; Means ± s. e. m: a, b, c, - means with different superscripts within factor (3 or more levels) are significantly (p<0.05) different.
## 3.2.1 Chromosomal aberations observed in the root cells of Allium cepa treated with ripening agents
The chromosomal abnormalities observed in the root cells of A. cepa treated with rice chips, wood ash, and herbaceous ash are presented in Plates 13. Rice chips induced bridge at telophase, stickiness at telophase, and vagrant chromosomes at metaphase (Plate 1); herbaceous ash induced stickiness at telophase and vagrant at metaphase (Plate 2); and wood ash caused stickiness at telophase, laggard chromosomes, and stickiness at telophase (Plate 3). The most frequent aberrations were bridges and sticky chromosomes, and herbaceous ash induced the highest number, followed by wood ash.
.
Plate 1:Chromosomal aberrations induced by rice chips: a = controlanaphase, b = chromosome bridge at telophase, c = stickiness at telophase, and d = vagrant at metaphase
Plate 2: Chromosomal aberrations induced by herbaceous ash: a = control anaphase, b = stickiness at telophase, c = stickiness at telophase, and d = vagrant at metaphase
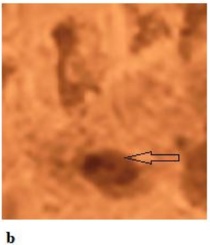
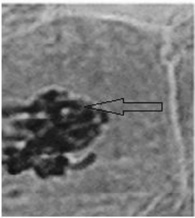

Plate 3: Chromosomal aberrations induced by wood ash: a = control anaphase, b = stickiness at telophase, c = laggard chromosomes, and d = stickiness at telophase
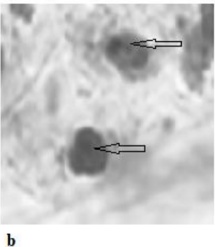
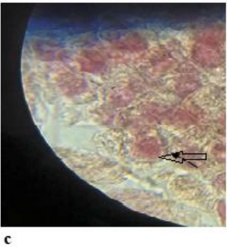
## 4.0 Discussion
alterations in mango fruits, as evidenced by the A. cepa toxicity test.
The current study has unveiled the impact of ash and rice chips as artificial ripening agents on the proximate composition of mango fruits, comparing them with naturally ripened ones. This suggests that various artificial ripening agents bring about proximate alterations in mango fruits. Furthermore, the findings of the study illustrate that artificial ripening agents induce cytogenetic
## 4.1 Proximate compositions of mangoes ripened naturally and artificially with ripening agents
The moisture, ash, fiber, protein fat and carbohydrate content of mango increased as ripening agents were introduced (Table 1). High
moisture content of mango ripened in wood ash may not be preferred by sellers because of the high moisture content (81%) which may lead to faster rate of microbial degradation and shorter shelf life resulting in quicker deterioration of the fruit[12,14]. This result is consistent with the finding of Ubwa et al. [19] for three mangoes varieties from Benue state, Nigeria.
The ash content of mango fruits is an index of their mineral content [19]. In the present study, ash content was found to be relatively higher in rice chips (1.5%) than both the naturally ripened mango (1.01%) and mangoes ripened in wood ash (0.35%) and herbaceous ash (0.8%). These findings indicate that the ripening agents affects the ash content of the fruit, which is important for nutrient content and further suggest that rich chips can improve the mineral content of the fruit.
There were some gradual decreases in the fibre content of the naturally ripped mangoes (11.46%) with the addition of ripening agents; herbaceous ash (8.4%), wood ash (8.2%) and rich chips (5.1%) respectively. The fiber content of the mangoes in this study were relatively high and higher than the NAFDAC minimum requirement of 3 g/100g for a source of fiber [11].
The protein content of mangoes ripened with rice chips observed in this study is relatively between the range of 1.65 and 1.3% reported for the three varieties of naturally ripened mango by Ubwa et al, [19].
Naturally ripened mangoes had the highest fat content (0.0095%), which was not statistically (p<0.05) different from the fat content of mangoes ripened with rice chip (0.005%) and wood ash (0.005%), while herbaceous ash had the least fat content (0.0005%). These results are much lower compared with the findings of Ubwa et al. [19] who recorded a fat content between the ranges of 0.06 -0.16 %. The carbohydrate content recorded in this study is higher than those reported elsewhere. For example, Orisa et al. [13], reported that the carbohydrate content of the mango ranged from 2.27-5.24% with unripe mango recording the highest, while calcium carbide mango the lowest. Similarly, 19.78 19.60 % of carbohydrate content of naturally ripened mangoes was reported by [19]. The decrease in carbohydrate content during ripening is due to the hydrolysis of carbohydrates into sugars during ripening as suggested by the two studies. However, the forgoing findings on the higher carbohydrate content of mangoes ripened with rice chip, herbaceous ash and naturally ripped mangoes could suggest they are better categorized as energy sources than wood ash and calcium carbide.
## 4.2Cytogenotoxicity of artificial ripening agents
All the ripening agents induced a reduced growth rate, along with chromosomal aberrations, including sticky chromosomes, laggard chromosomes, vagrant chromosomes, and chromosomal bridges. These results align with those of [23], who reported both up regulation and down regulation of genes in artificially ripened banana fruits. Alege and Anthony [1] also documented chromosomal abnormalities such as binucleate cells, vacuolated cells, sticky chromosomes, c-mitosis cells, and anaphase bridges in Allium cepa treated with calcium carbide, a fruit ripening agent. The formation of sticky chromosomes may be attributed to the intermingling of chromatin fibers and subsequent connection of sub-chromatids between chromosomes, while the creation of anaphase bridges could occur due to chromosome breakage and subsequent re-joining [1].
## 5.0 Conclusions
This study evaluates the proximate composition as well as the cytotoxic effects of wood ash, herbaceous ash, and rice chips used as artificial ripening agents for mango. The ripening agents significantly (P<0.05) increased the moisture, protein, and ash content of the mangoes. Mangoes ripened with wood ash had the least carbohydrate content. All the agents resulted in a reduced rate of growth, along with chromosomal abnormalities, including sticky chromosomes, laggard chromosomes, vagrant chromosomes, and chromosomal bridges. The herbaceous ash is the most toxic of all the ripening agents while rice chips is the least toxic.
## 6.0 Recommendations
The outcomes of this study imply that inducing ripening of the fruits could stimulate toxicities, emphasizing the requirement for public consciousness concerning the potential hazards presented by these agents.
## 7.0 Acknowledgments
The authors acknowledged the management of Kali farm, Aliero for supplying the mangoes fruit utilized in the research.
## 8.0 Conflict of Interest
The authors declared no conflict of interest.
## 9.0 References
- [1] Alege GO, Anthony W. Assessment of Cytotoxicity Induced by Calcium Carbide (Fruit Ripening Agent) on Allium Cepa L. (Onion) Root Meristematic Cell:International Journal of Scientific Research in Biological Sciences. 2020; 7 (2): 170-175.
- [2] AOAC. Association of Official Analytical Chemists. Official Methods of Analysis, (Vol.II, 17th edition) of AOAC international, Washington DC, USA. 2000;12.
- [3] Bonciu E, Firbas P, Fontanetti CS, De Souza CP, Wusheng J, Liu D, Karaismailoğlu MC, Menicucci F, Pesnya DS, Romanovsky AV, Popescu A. An evaluation for the standardization of the Allium cepa test as cytotoxicity and genotoxicity assay:Caryologia. 2018;71(3):191-209. DOI : 10.1080/00087114.2018.1503496
- [4] Ernesto DB, Omwamba M, Faraj AK,Mahungu, SM. Physico-chemical characterization of keitt mango and cavendish banana fruits produced in Mozambique: Food and Nutrition Sciences, 2018; 9(5): 556-571.
- [5] Joshi H, Kuna A, Lakshmi MN, Shreedhar M, Kumar AK. Effect of stage of maturity, ripening and storage on antioxidant content and activity of Mangiferaindica L. var. Manjira. International Journal of Food Science and Nutrition.2017; 2(3): 1-9
- [6] Kumar M, Saurabh V, Tomar, M, Hasan M, Changan S, Sasi M. et al . Mango ( Mangiferaindica L.) Leaves: Nutritional Composition, Phytochemical Profile, and Health-Promoting Bioactivities:Antioxidants, 2021;10(2): 299.
https://doi.org/10.3390/antiox10020299
- [7] Lawaly MM. (2022). Effects of Calcium Carbide Used as a Fruit-Ripening Agent on
Fruit Toxicity. European Journal of Nutrition and Food Safety. 2022; 64-76.
- [8] Maduwanthi SD, Marapana RA. Induced ripening agents and their effect on fruit quality of banana: International journal of food science. 2019; 2;2019.
- [9] Microsoft Corporation, USA Microsoft Excel 2019 for Windows. 2019. https://office.microsoft.com/excel
- [10] Muhammad M, Singh D, Imonikhe AM, Keta M, Obaroh, I. Phytochemical analysis and ethnoecological survey of some species of African mistletoes collected from Birnin Kebbi, Kebbi state:Journal of Innovative Research in Life Sciences. 2022 4(1): 65-73.
- [11] NAFDAC (National Agency for Food & Drug Administration & Control). 2013. Minimum Requirement for Analysis of Finished Product. Summary of Current Food standards as of 04 April, 2013.
- [12] Odion EE, Nwaokobia K, Ogboru RO, Olorode EM, Gbolagade OT. Evaluation of some Physico-chemical Properties of Mango ( MangiferaIndica L.) Pulp in South-south, Nigeria. Ilorin Journal of Science. 2020 Dec 1;7(2):236-48.
- [13] Orisa CA, Usoroh CI, Ujong AE. Accelerated Ripening Agents and Their Effect on the Quality of Avocado ( Persiaamericana M.) and Mango ( Mangiferaindica L.) Fruits. Asian Journal of Advances in Agricultural Research. 2020;29-40. https://journalajaar.com/index.php/AJAAR/art icle/view/277
- [14] Pamela EA, Usifo GA, Kikelomo OE, Yemisi OO, Omolara IA, Ayodeji OA. Diversity of Mango ( Mangifera Indica L.) Cultivars Based on Physicochemical, Nutritional, Antioxidant, and Phytochemical Traits in South West Nigeria, International Journal of Fruit Science. 2022; 20(2): 352376, DOI: 10.1080/15538362.2020.1735601
- [15] Premarathne RMDE, Marapana RAUJ, Perera PRD. Determination of Physiochemical Characteristics and Antioxidant Properties of Selected
Climacteric and Non-climacteric Fruits. Journal of Pharmacognosy and Phytochemistry. 2021; 10(3): 23-28.
- [16] Raghavendra A, Guru D, Rao, MK, Sumithra R. Hierarchical approach for ripeness grading of mangoes. Intelligence in Agriculture. 2019; 4:243-252. https://doi.org/10.1016/j.aiia.2020.10.003 Artificial
- [17] Singh D, Jibril NK, Muhammad A, Malik AI, Osesua BA. Phytoremediation Potential of Jatropha curcas and Cassia occidentalis Selected Heavy Metals in Tie Soil: JAP. 2022;5(1):33-49. Available from: https://www.carijournals.org/journals/index.p hp/JAP/article/view/864 on
- [18] Singh P, Tarkha A, Kumar P, Singh J. Impact of Chemicals on the Ripening Physiology of Fruits. IntJCurrMicrobiolAppSci. 2020;9(12):219-
- 29.
- https://www.ijcmas.com/abstractview.php?ID =20424&vol=9-12-2020&SNo=29
- [19] Ubwa ST, Ishu MO, Offem JO, Tyohemba RL, Igbum GO. Proximate composition and some physical attributes of three mango ( Mangiferaindica varieties:International Journal of Agronomy L.) fruit
- [23] Yan H, Wu F, Jiang G, Xiao L, Li Z, Duan X, Jiang Y. Genome-wide identification, characterization and expression analysis of NF-Y gene family in relation to fruit ripening in banana. Postharvest Biology and Technology: 2019;151: 98-110. https://doi.org/10.1016/j.postharvbio.2019.02. 002.


BY
- Copyright © 2024 by the authors. This article is an open access article under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/), which permits use, distribution and reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice.
and Agricultural Research (IJAAR) 2014; 4(2): 21-29. ISSN: 2223-7054 (Print) 22253610 (Online)\
- [20] Vanoli M, Rizzolo, A, Grassi, M, Spinelli L, Torricelli A. Modelling mango ripening during shelf life based on pulp color nondestructively measured by time-resolved reflectance spectroscopy. Scientia Horticulturae, 2023; 310: 111714.
- [21] Yahaya T, Oladele E, Sifau M, Audu G, Bala J, Shamsudeen A. Characterization and Cytogenotoxicity of Birnin Kebbi Central Abattoir Wastewater. Uniport J Eng Sci Res, 2020; 5 (special issue): 63-70.
- [22] Yahia EM, de Jesús Ornelas-Paz J, Brecht JK, García-Solís P, Celis ME. The contribution of mango fruit ( L.) to human nutrition and health. Arabian Journal of Chemistry. 2023; 29:104860. Mangiferaindica | null | [
"CD Obadiah",
"TO Yahaya",
"AA Aliero",
"M Abdulkareem"
]
| 2024-06-29T12:06:44+00:00 | 2024-06-29T12:06:44+00:00 | [
"q-bio.OT"
]
| Comparative Evaluation of the Proximate and Cytogenotoxicity of Ash and Rice Chips Used as Mango Fruit Artificial Ripening Agents in Birnin Kebbi, Nigeria | The high demand for mango (Mangifera indica L.) fruits has led sellers to
employ ripening agents. However, concerns are growing regarding the potential
toxicities of induced ripening, emphasizing the need for scientific
investigation. Samples of artificially and naturally ripened mangoes were
analyzed for proximate composition using standard protocols. Cytogenotoxicity
was then assessed using the Allium cepa L. toxicity test. Twenty (20)A. cepa
(onion) bulbs were used, with 5 ripened naturally, 5 with wood ash, 5 with
herbaceous ash, and 5 with rice chips, all grown over tap water for five days.
The root tips of the bulbs were assayed and examined for chromosomal
aberrations. The results revealed a significant (P<0.05) increase in moisture,
protein, and ash content of mangoes as ripening agents were introduced. Mangoes
ripened with wood ash exhibited the highest moisture content (81%), while those
ripened with rice chips had the highest protein (0.5%) and ash content (1.5%).
Naturally ripened mangoes displayed the highest fat (0.0095%) and fiber
(11.46%) contents. The A. cepa toxicity test indicated significant (p<0.05)
differences in the root growth of mangoes ripened with various agents. Wood ash
resulted in the highest root growth (2.62cm), while herbaceous ash had the
least (2.18%). Chromosomal aberrations, including sticky, vagrant, and laggard
abnormalities, were observed in all agents, with herbaceous ash exhibiting the
highest and rice chips the least. The obtained results suggest that induced
ripening of the fruits could induce toxicities, highlighting the necessity for
public awareness regarding the potential dangers posed by these agents. |
2408.01426v1 | ## MolTRES: Improving Chemical Language Representation Learning for Molecular Property Prediction
Jun-Hyung Park 1 Yeachan Kim 2 Mingyu Lee 2 Hyuntae Park 2 SangKeun Lee 2 3 , 1 BK21 FOUR R&E Center for Artificial Intelligence, Korea University 2 Department of Artificial Intelligence, Korea University 3 Department of Computer Science and Engineering, Korea University {irish07, yeachan, decon9201, pht0639, yalphy}@korea.ac.kr
## Abstract
Chemical representation learning has gained increasing interest due to the limited availability of supervised data in fields such as drug and materials design. This interest particularly extends to chemical language representation learning, which involves pre-training Transformers on SMILES sequences - textual descriptors of molecules. Despite its success in molecular property prediction, current practices often lead to overfitting and limited scalability due to early convergence. In this paper, we introduce a novel chemical language representation learning framework, called MolTRES, to address these issues. MolTRES incorporates generator-discriminator training, allowing the model to learn from more challenging examples that require structural understanding. In addition, we enrich molecular representations by transferring knowledge from scientific literature by integrating external materials embedding. Experimental results show that our model outperforms existing state-of-the-art models on popular molecular property prediction tasks.
## 1 Introduction
Deep neural networks (DNNs) have emerged as a compelling, computationally efficient approach for predicting molecular properties, with significant implications in material engineering and drug discovery. By training DNNs on molecule data to predict the properties in a supervised manner or to reconstruct molecules in an unsupervised manner, these networks can significantly reduce the costs of traditional methods, which typically require chemical experts and wet-lab experiments. Moreover, DNN-based molecular prediction has gained increasing popularity due to the generalization capacity of DNNs. This allows for the application of a single (pre-)trained model across various tasks, reducing the need for task-specific modeling.
Inspired by recent advances in pre-trained language models in the field of natural language pro-
Figure 1: Existing pre-training methods for chemical language representation learning already converge at their early stage without seeing the entire data. Consequently, MoLFormer (Ross et al., 2022), a state-of-theart chemical language representation learning method, exhibits limited scalability in terms of data size.
cessing (NLP), several chemical language representation learning methods based on SMILES Transformers (Wang et al., 2019; Chithrananda et al., 2020) have been proposed. These methods typically employ self-supervised tasks on SMILES (Simplified Molecular-Input Line Entry System) sequences of molecules, analogous to the masked language modeling (MLM) commonly used in BERT (Devlin et al., 2019). Since modern Transformers are designed to scale to massive NLP corpora (Vaswani et al., 2017), they offer practical advantages in terms of efficiency and throughput. This enables the models to leverage massive amounts of SMILES sequences to learn universal representations for molecules, leading to performance im-
provements in a wide range of molecular property prediction tasks (Ross et al., 2022). However, as these models typically follow settings designed for natural language modeling, the optimal pre-training settings for chemical language representation learning remain underexplored.
Through extensive investigation into the pretraining of SMILES Transformers, we have discovered that the current pre-training task, MLM on SMILES sequences using a random masking strategy, is not effective for learning informative molecular representations. We have empirically observed that this task can be easily solved using surface patterns, leading to overfitting and limited scalability, as shown in Figure 1. This may be attributed to two inherent properties of SMILES. First, existing large-scale molecule datasets exhibit unbalanced atom distributions (He et al., 2023a). For example, in ZINC (Irwin et al., 2012), a representative dataset containing billions of molecules, carbon (C), nitrogen (N), and oxygen (O) comprise 95% of the tokens in total SMILES sequences. Second, the SMILES grammar contains many superficial patterns, such as numbers representing ring structures that always appear twice. These patterns allow the model to predict original tokens without learning the underlying chemical information. Furthermore, unlike natural language, which is fundamentally grounded in concepts and possesses general expressivity across various problem-solving scenarios, SMILES is designed solely to express molecular structure and does not directly represent molecular properties. Thus, the current pre-training task likely provides a limited notion of molecular properties.
In this paper, we propose a novel framework for pre-training SMILES transformers, called MolTRES ( Mol ecular TR ansformer with E nhanced S elf-supervised learning), to address the aforementioned issues. Our framework focuses on two key objectives: (1) increasing the difficulty of the pre-training task, and (2) incorporating external knowledge related to molecular properties into model representations. To achieve these goals, we first present a novel dynamic molecule modeling method, coined DynaMol, based on generatordiscriminator training (Clark et al., 2020). This method trains a model to distinguish real SMILES tokens from synthetically generated replacements, jointly used with substructure-level masking. It facilitates to significantly increase the masking ratio for more challenging training examples, while minimizing discrepancy caused by mask tokens. In addition, we enhance model representations by integrating mat2vec word representations (Tshitoyan et al., 2019) trained on massive scientific literature. This integration helps to directly embody molecular properties in the learned representations.
To demonstrate the effectiveness of MolTRES, we conduct extensive experiments and ablation studies on diverse molecular property prediction tasks. We evaluate MolTRES on eight classification and four regression tasks from MoleculeNet, covering quantum mechanical, physical, biophysical, and physiological properties of chemicals. Our results indicate that MolTRES outperforms stateof-the-art baselines across most tasks, including 1D sequence-, 2D graph-, and 3D geometry-based chemical models. Further analysis shows that MolTRES significantly improves the capabilities of chemical language representation learning by addressing the limitations of existing approaches. Our contributions are summarized as follows:
- · We propose MolTRES, a novel framework to pre-train SMILES Transformers based on generator-discriminator training and external knowledge transfer.
- · We present a novel architecture for SMILES transformers efficiently integrated with word representations trained on scientific literature.
- · Experimental results demonstrate that MolTRES establishes state-of-the-art results over a wide range of molecular property prediction tasks.
## 2 Preliminaries
## 2.1 SMILES Transformer
Transformer (Vaswani et al., 2017) is a popular neural network architecture for processing texts, which can also be applied to processing SMILES sequences. It consists of a series of Transformer blocks, each involving a multi-head self-attention layer followed by a multi-layer feed-forward network. The self-attention layer allows the network to effectively model global dependencies within the sequence of input tokens. Given a series of vector representations for tokens, a self-attention layer applies three linear transformations to generate query ( q ), key ( k ), and value ( v ) representations, respectively. The outputs at position m are calculated by aggregating the representations from other positions using a weighted sum, where weights are
Figure 2: Overview of MolTRES. EG and ED represent the embedding layers of the generator and discriminator, respectively. It is noteworthy that the mat2vec embeddings are frozen during pre-training.
derived from a similarity function between q and k , as follows:
## 2.2 Chemical Language Representation Learning via MLM
$$\text{Att} ( q, k, v ) _ { m } = \frac { \sum _ { n = 1 } ^ { N } \sin ( q _ { m }, k _ { n } ) v _ { n } } { \sum _ { n = 1 } ^ { N } \sin ( q _ { m }, k _ { n } ) } \quad ( 1 ) \quad \text{learn}$$
where sim ( q m , k n ) = exp ( q T m n k / √ d ) and N is the length of tokens. Transformer can effectively capture the dependencies in variable-length sequences, and therefore, it is utilized in processing SMILES, as in ChemBERTa (Chithrananda et al., 2020). However, self-attention shows a quadratic complexity O N ( 2 ) dereived from the computation of the inner product between every token pair, which incurs significant costs when processing molecules represented in long SMILES sequences like polymers. To reduce the complexity, MoLFormer (Ross et al., 2022) has introduced linear attention with rotary embeddings. This reformulates the original self-attention layer as follows:
$$\text{Att} ( q, k, v ) _ { m } = \frac { \Sigma _ { n = 1 } ^ { N } \phi ( R _ { m } q _ { m } ) ^ { \intercal } \phi ( R _ { n } k _ { n } ) v _ { n } } { \Sigma _ { n = 1 } ^ { N } \phi ( R _ { m } q _ { m } ) ^ { \intercal } \phi ( R _ { n } k$$
where R m represents a position-dependent rotation at position m , and ϕ x ( ) = elu ( x ) + 1 defines the activation function used. This linear attention mechanism reduces the complexity to O N ( ) , significantly improving the efficiency of chemical language representation learning, coming with minimal performance degradation.
Typical work in chemical language representation learning (Chithrananda et al., 2020; Ross et al., 2022) utilizes a self-supervised task known as MLM. This objective involves training a model to predict original sequences from sequences in which some tokens are randomly masked. Specifically, given a sequence X = { x , x 1 2 , x 3 , ..., x n } , we corrupt X into ˜ X by masking 15% of its tokens. We then train a model, denoted as C with parameters θ C , to reconstruct X . The loss of each example is formulated as follows:
$$\mathcal { L } _ { C } = - \sum _ { i \in \mathcal { M } } \log p ( x _ { i } | \tilde { \mathbf X } ; \theta _ { C } ), \quad \ ( 3 )$$
where M represents the set of masked token positions. In typical chemical language representation learning methods, each masked token is substituted with a special mask token in 80% of cases, a random token in 10% of cases, and the original token in the remaining 10% cases, following practices in BERT (Devlin et al., 2019).
## 3 MolTRES: Molecular Transformer with Enhanced Self-supervised Learning
In this section, we detail our framework, MolTRES. We propose a novel pre-training task, called DynaMol, which incorporates generator-discriminator
training into chemical language representation learning with substructure masking. In addition, we integrate molecular representations that have been trained on scientific literature.
## 3.1 DynaMol: Dynamic Molecule Modeling with Generator-Discriminator Training
To increase the difficulty of chemical language representation learning, we propose a dynamic molecule modeling scheme based on generatordiscriminator training, inspired by replaced token detection proposed in Clark et al. (2020). The proposed scheme involves training two models, namely a generator and a discriminator. The generator is trained to predict original sequences given masked sequences similar to MLM, while the discriminator is trained to identify tokens that have been replaced by the generator. Since the generator transforms masked sequences to more closely resemble original distributions, this training scheme results in less discrepancy between the inputs from pre-training and downstream tasks, and allows for flexible adjustments of the masking ratio (He et al., 2023b). Moreover, as the generator is being trained, it naturally provides increasingly challenging examples to the discriminator. This scheme is expected to alleviate the issues of early convergence and over-fitting commonly observed in existing methods of chemical language representation learning.
Specifically, similar to MLM, the generator G with parameters θ G is trained to reconstruct the sequence X . The loss of G for each example is formulated as follows:
$$\mathcal { L } _ { G } = - \sum _ { i \in \mathcal { M } } \log p ( x _ { i } | \tilde { \mathbf X } ; \theta _ { G } ). \quad \ \ ( 4 ) \quad \ \ r e p ^ { i } _ { \text{ble} }.$$
Then, the input sequence for the discriminator is constructed by replacing the masked tokens in ˜ X with new tokens, sampled from the generator's probability distribution p G , as follows:
$$\tilde { \mathbf X } _ { D } = \begin{cases} \tilde { x } _ { i } \smallsetminus p ( x _ { i } | \tilde { \mathbf X } ; \theta _ { G } ), & \text{if $i\in\mathcal{M}$} \\ x _ { i }, & \text{otherwise.} \end{cases} ( 5 ) \quad \text{able}, \\ \quad \quad \quad$$
The discriminator is trained to distinguish whether each token in the generated input sequence ˜ X D is original or has been replaced. The loss for the discriminator is formulated as follows:
$$\mathcal { L } _ { D } = - \sum _ { i = 1 } ^ { n } \log p ( z _ { i } | \tilde { \mathbf X } _ { D } ; \theta _ { D } ), \quad \ ( 6 ) \quad \begin{pmatrix} \Pr \cdot \\ \{ x _ { 1 } \\ \text{ery} \end{pmatrix}$$
where z i is a binary label that indicates whether the i -th input token is original or has been replaced. Finally, the generator G and discriminator D are jointly optimized with multiple objectives, expressed as L = L G + λ L D , where λ is a predefined balancing parameter for the discriminator loss. In this work, λ is set to 10.
In addition, we carefully design three rules to mask SMILES at multiple substructure-level granularities, thereby preventing models from predicting the correct answer by exploiting superficial patterns in the SMILES grammar. (1) We mask all special tokens that represent structural information, such as numbers for cycles. (2) We then mask spans of SMILES that composes certain substructures, such as substituents, bridges, or groups of sequential atoms, until the ratio of masked tokens does not exceed the pre-defined target masking ratio. Note that these substructure can be easily identified by segmenting SMILES strings based on brackets. (3) Finally, we mask random atomic SMILES tokens to achieve the target masking ratio. We follow a typical masking strategy that, among the masked tokens, 80% are replaced with mask tokens, 10% are replaced with random tokens, and the rest 10% remain unchanged. Notably, we use 65% of the target masking ratio for pre-training.
## 3.2 Knowledge Transfer from Scientific Literature using mat2vec
While modeling SMILES helps models understand molecular structure and connectivity, SMILES itself lacks explicit information about molecular properties. Scientific literature, which is similarly represented in a textual form, provides a more flexible and rich source of external information. It comprehensively involves information about molecular properties derived from wet laboratory experiments and computational methods. Therefore, we enrich the representations of SMILES Transformers by integrating information from scientific literature.
Despite the many possible design choices available, we opt to leverage mat2vec (Tshitoyan et al., 2019), a straightforward embedding model trained on extensive scientific literature, for integration into Transformer's embedding vectors. We prioritize the efficiency in terms of memory footprints and computations in our integration procedures, essential for dealing with large-scale pre-training. Given an input sequence X = { x , ..., x 1 n } , we obtain embedding vectors for every token from the Transformer's embedding layer,
Table 1: Evaluation results on MoleculeNet classification tasks. We report ROC-AUC scores (higher is better) under scaffold splitting. The best and second-best results are in bold and underlined.
| Methods | BBBP ↑ | Tox21 ↑ | ToxCast ↑ | ClinTox ↑ | MUV ↑ | HIV ↑ | BACE ↑ | SIDER ↑ | Avg. ↑ |
|----------------------------------|----------|-----------|-------------|-------------|---------|---------|----------|-----------|----------|
| 3D Conformation | | | | | | | | | |
| GeomGCL (Liu et al., 2022) | - | 85.0 | - | 91.9 | - | - | - | 64.8 | - |
| GEM (Fang et al., 2022) | 72.4 | 78.1 | - | 90.1 | - | 80.6 | 85.6 | 67.2 | - |
| 3D InfoMax (Stärk et al., 2022) | 68.3 | 76.1 | 64.8 | 79.9 | 74.4 | 75.9 | 79.7 | 60.6 | 72.5 |
| GraphMVP (Liu et al., 2022) | 69.4 | 76.2 | 64.5 | 86.5 | 76.2 | 76.2 | 79.8 | 60.5 | 73.7 |
| MoleculeSDE (Liu et al., 2023a) | 71.8 | 76.8 | 65.0 | 87.0 | 80.9 | 78.8 | 79.5 | 75.1 | |
| Uni-Mol (Zhou et al., 2023) | 71.5 | 78.9 | 69.1 | 84.1 | 72.6 | 78.6 | 83.2 | 57.7 | 74.5 |
| MoleBlend (Yu et al., 2024) | 73.0 | 77.8 | 66.1 | 87.6 | 77.2 | 79.0 | 83.7 | 64.9 | 76.2 |
| Mol-AE (Yang et al., 2024) | 72.0 | 80.0 | 69.6 | 87.8 | 81.6 | 80.6 | 84.1 | 67.0 | 77.8 |
| UniCorn (Feng et al., 2024) | 74.2 | 79.3 | 69.4 | 92.1 | 82.6 | 79.8 | 85.8 | 64.0 | 78.4 |
| 2D Graph | | | | | | | | | |
| DimeNet (Klicpera et al., 2020) | - | 78.0 | - | 76.0 | - | - | - | 61.5 | - |
| AttrMask (Hu et al., 2020) | 65.0 | 74.8 | 62.9 | 87.7 | 73.4 | 76.8 | 79.7 | 61.2 | 72.7 |
| GROVER (Rong et al., 2020) | 70.0 | 74.3 | 65.4 | 81.2 | 67.3 | 62.5 | 82.6 | 64.8 | 71.0 |
| BGRL (Thakoor et al., 2022) | 72.7 | 75.8 | 65.1 | 77.6 | 76.7 | 77.1 | 74.7 | 60.4 | 72.5 |
| MolCLR (Wang et al., 2022) | 66.6 | 73.0 | 62.9 | 86.1 | 72.5 | 76.2 | 71.5 | 57.5 | 70.8 |
| GraphMAE (Hou et al., 2022) | 72.0 | 75.5 | 64.1 | 82.3 | 76.3 | 77.2 | 83.1 | 60.3 | 73.9 |
| Mole-BERT (Liu et al., 2023c) | 71.9 | 76.8 | 64.3 | 78.9 | 78.6 | 78.2 | 80.8 | 62.8 | 74.0 |
| SimSGT (Xia et al., 2023) | 72.2 | 76.8 | 65.9 | 85.7 | 81.5 | 78.0 | 84.3 | 61.7 | 75.8 |
| MolCA + 2D (Liu et al., 2023b) | 70.0 | 77.2 | 64.5 | 89.5 | - | - | 79.8 | 63.0 | - |
| 1D SMILES/SELFIES | | | | | | | | | |
| MoLFormer-XL (Ross et al., 2022) | 93.7 | 84.7 | 65.6 | 94.8 | 80.6 | 82.2 | 88.2 | 66.9 | 82.1 |
| SELFormer (Yüksel et al., 2023) | 90.2 | 65.3 | - | - | - | 68.1 | 83.2 | 74.5 | - |
| MolCA (Liu et al., 2023b) | 70.8 | 76.0 | 56.2 | 89.0 | - | - | 79.3 | 61.2 | - |
| MolTRES-small (ours) | 95.0 | 83.4 | 64.8 | 94.0 | 80.0 | 81.7 | 87.7 | 68.3 | 81.9 |
| MolTRES (ours) | 96.1 | 85.3 | 70.1 | 96.7 | 84.9 | 84.2 | 91.7 | 69.8 | 84.8 |
denoted as E t = { e , ..., e t 1 t n } . Using a mapping function I ( ) · , we assign each token to corresponding mat2vec embedding vectors, denoted as E m = { e m 1 , ..., e m n } s.t. e m k = ∑ z ∈ I ( x k ) mat2vec ( z ) . We then combine E t and E m using a linear projection layer F 1 ( ) · . The set of embedding vectors for the generator V G is generated as follows:
$$\mathbf V _ { G } = & \{ F _ { 1 } ( e _ { 1 } ^ { t } \circ e _ { 1 } ^ { m } ), \dots, F _ { 1 } ( e _ { n } ^ { t } \circ e _ { n } ^ { m } ) \}, \ \ ( 7 ) \quad \text{mat} ^ { c } _ { \dots \colon }$$
where ◦ denotes the concatenation operation. In a similar manner, the set of embedding vectors for the discriminator V D is generated from the tokens reconstructed by the generator as follows:
$$\mathbf V = & \{ F _ { 1 } ( \tilde { e } _ { 1 } ^ { t } \circ \tilde { e } _ { 1 } ^ { m } ), \dots, F _ { 1 } ( \tilde { e } _ { n } ^ { t } \circ \tilde { e } _ { n } ^ { m } ) \} \\ \mathbf V _ { D } = & \{ F _ { 2 } ( \sigma ( v _ { 1 } ) ), \dots, F _ { 2 } ( \sigma ( v _ { n } ) ) \} \quad ( 8 ) \quad \Pr e \cdot \\ & \text{s.t. } v _ { 1 }, \dots, v _ { n } \in V,$$
where v , ..., v 1 n ∈ V and σ ( ) · is an activation function, which is the gelu function in this work.
For the integration, we manually design a mapping function I ( ) · using human prior knowledge to address the vocabulary mismatch between SMILES tokens and mat2vec words. We utilize a thesaurus carefully constructed by domain experts, chosen for its superior computational efficiency and stability compared to learning-based approaches. For example, the thesaurus maps '[cH+]' in the Transformer's vocabulary to 'methylidyne', 'ion', and 'cation' in the mat2vec vocabulary. Based on this thesaurus, we pre-calculate embedding vectors for 2,696 tokens in the Transformer vocabulary before pre-training. To prevent catastrophic forgetting of mat2vec knowledge, we freeze these pre-calculated embedding vectors during pre-training. During fine-tuning, these embedding vectors are trainable to adapt the knowledge for each downstream task.
## 4 Experiment
## 4.1 Experimental Setup
Pre-training. We collect 118 million molecules from PubChem 1 and 1.9 billion molecules from ZINC 2 . We pre-train two MolTRES models, a base model (MolTRES) and a smaller model (MolTRESsmall). Our model architectures are detailed in Appendix A.1. We train our models for 200,000 steps with a batch size of 25,600 and use the final models in evaluation.
1 https://pubchem.ncbi.nlm.nih.gov/
2 https://zinc.docking.org/
Table 2: Evaluation results on MoleculeNet regression tasks. We report RMSE scores (lower is better) under scaffold splitting. The best and second-best results are in bold and underlined.
| Methods | ESOL ↓ | FreeSolv ↓ | Lipophilicity ↓ | Avg. ↓ |
|------------------------------------|----------|--------------|-------------------|----------|
| 3D Conformation | | | | |
| 3D InfoMax (Stärk et al., 2022) | 0.894 | 2.337 | 0.695 | 1.309 |
| GraphMVP (Liu et al., 2022) | 1.029 | - | 0.681 | - |
| Uni-Mol (Zhou et al., 2023) | 0.844 | 1.879 | 0.610 | 1.111 |
| MoleBlend (Yu et al., 2024) | 0.831 | 1.910 | 0.638 | 1.113 |
| Mol-AE (Yang et al., 2024) | 0.830 | 1.448 | 0.607 | 0.962 |
| UniCorn (Feng et al., 2024) | 0.817 | 1.555 | 0.591 | 0.988 |
| 2D Graph | | | | |
| AttrMask (Hu et al., 2020) | 1.112 | - | 0.730 | - |
| GROVER (Rong et al., 2020) | 0.831 | 1.544 | 0.560 | 0.978 |
| MolCLR (Wang et al., 2022) | 1.110 | 2.200 | 0.650 | 1.320 |
| SimSGT (Liu et al., 2023c) | 0.917 | - | 0.695 | - |
| 1D SMILES/SELFIES | | | | |
| MoLFormer-Base (Ross et al., 2022) | 0.280 | 0.260 | 0.649 | 0.396 |
| MoLFormer-XL (Ross et al., 2022) | 0.279 | 0.231 | 0.530 | 0.347 |
| SELFormer (Yüksel et al., 2023) | 0.682 | 2.797 | 0.735 | 1.405 |
| MolTRES-small (ours) | 0.280 | 0.250 | 0.594 | 0.375 |
| MolTRES (ours) | 0.274 | 0.229 | 0.504 | 0.336 |
Evaluation We evaluate our models and baselines on eight classification tasks and four regression tasks from the MoleculeNet benchmark (Wu et al., 2018). We report Receiver Operating Characteristic-Area Under the Curve (ROC-AUC) scores for the classification tasks, Mean Absolute Error (MAE) scores for QM9, and Root Mean Square Error (RMSE) scores for the remaining regression tasks. We report the test score from the model that achieves the best validation score.
Baselines. We compare our models with diverse state-of-the-art baselines categorized as follows:
- · 3D Conformation: This category includes methods that utilize 3D conformation from the geometry information of molecules and may incorporate other modalities.
MolTRES surpasses the best baseline, MoLFormerXL, by an average of 2.7%. In addition, MolTRESsmall also shows a competitive performance compared to the baselines. Notably, MolTRES significantly outperforms baseline methods using 3D conformation and 2D graph. This confirms the strength of pre-training with billion-scale SMILES sequences, compared to pre-training with hundreds of millions of conformation or graph examples. MolTRES exhibits state-of-the-art performance on 7 of the 8 tasks. Although MolTRES achieves the second-best results after SELFormer on the SIDER task, it outperforms SELFormer by up to 20% on the others, affirming the superiority of MolTRES.
- · 2D Graph: This category includes methods that utilize 2D graph information, such as atoms and bonds, and may also combine 1D SMILES.
- · 1D SMILES/SELFIES: This category includes methods that utilize SMILES or SELFIES sequences of molecules.
## 4.2 Main Results
We first compare MolTRES with state-of-the-art molecular property prediction methods on MoleculeNet classification tasks. As shown in Table 1,
Moreover, as shown in Table 2, MolTRES consistently stands out in three MoleculeNet regression tasks, surpassing the state-of-the-art method MoLFormer-XL by an average of 3.3%. Moreover, MolTRES-small achieves better performance than MoLFormer-Base, which contains a commensurate number of parameters, by an average of 5.6%. The superior performance of SMILES-based methods is still observed, as they achieve significantly smaller errors compared to other baseline methods. This performance gap further verifies the efficacy of large-scale pre-training on SMILES.
We further compare MolTRES with the baselines on QM9, as shown in Table 3. Since quantum properties are strongly correlated with geometry information, baselines using ground-truth geometry information (3D Conformation (GT)) show the best results among baselines. However, obtain-
Table 3: Evaluation results on QM9 tasks. We report MAE scores (lower is better) following the data splitting used in Liu et al. (2023a). The best and second-best results are in bold and underlined. It is important to note that the '3D Conformation (GT)' results utilize ground-truth geometry information, which incurs non-trivial costs to obtain. For a fair comparison, we also evaluate the performance of 3D models using the geometry information approximated by RDKit, denoted as '3D Conformation (RDKit)', considering scenarios where ground-truth geometry is unavailable.
| Methods | µ ↓ (D) | α ↓ ( a 3 0 ) | ε homo ↓ (eV) | ε lumo ↓ (eV) | ∆ ε ↓ (eV) | ⟨ R 2 ⟩ ↓ ( a 2 0 ) | ZPVE ↓ (eV) | U 0 ↓ (eV) | U 298 ↓ (eV) | H 298 ↓ (eV) | G 298 ↓ (eV) | C v ↓ ( cal mol · K ) | Avg. ↓ |
|----------------------------------|-----------|-----------------|-----------------|-----------------|--------------|-----------------------|---------------|--------------|----------------|----------------|----------------|-------------------------|----------|
| 3D Conformation (GT) | | | | | | | | | | | | | |
| 3D InfoMax (Stärk et al., 2022) | 0.028 | 0.057 | 0.259 | 0.216 | 0.421 | 0.141 | 0.002 | 0.013 | 0.014 | 0.014 | 0.014 | 0.030 | 0.101 |
| GraphMVP (Liu et al., 2022) | 0.030 | 0.056 | 0.258 | 0.216 | 0.420 | 0.136 | 0.002 | 0.013 | 0.013 | 0.013 | 0.013 | 0.029 | 0.100 |
| MoleculeSDE (Liu et al., 2023a) | 0.026 | 0.054 | 0.257 | 0.214 | 0.418 | 0.151 | 0.002 | 0.012 | 0.013 | 0.012 | 0.013 | 0.028 | 0.100 |
| MoleBlend (Yu et al., 2024) | 0.037 | 0.060 | 0.215 | 0.192 | 0.348 | 0.417 | 0.002 | 0.012 | 0.012 | 0.012 | 0.012 | 0.031 | 0.113 |
| UniCorn (Feng et al., 2024) | 0.009 | 0.036 | 0.130 | 0.120 | 0.249 | 0.326 | 0.001 | 0.004 | 0.004 | 0.004 | 0.005 | 0.019 | 0.076 |
| 3D Conformation (RDKit) | | | | | | | | | | | | | |
| SchNet (Schütt et al., 2017) | 0.447 | 0.276 | 0.082 | 0.079 | 0.115 | 21.58 | 0.005 | 0.072 | 0.072 | 0.072 | 0.069 | 0.111 | 1.915 |
| 3D InfoMax (Stärk et al., 2022) | 0.351 | 0.313 | 0.073 | 0.071 | 0.102 | 19.16 | 0.013 | 0.133 | 0.134 | 0.187 | 0.211 | 0.165 | 1.743 |
| MoleculeSDE (Liu et al., 2023a) | 0.423 | 0.255 | 0.080 | 0.076 | 0.109 | 20.43 | 0.004 | 0.054 | 0.055 | 0.055 | 0.052 | 0.098 | 1.808 |
| 2D Graph | | | | | | | | | | | | | |
| 1-GNN (Morris et al., 2019a) | 0.493 | 0.780 | 0.087 | 0.097 | 0.133 | 34.10 | 0.034 | 63.13 | 56.60 | 60.68 | 52.79 | 0.270 | 22.43 |
| 1-2-3-GNN (Morris et al., 2019a) | 0.476 | 0.270 | 0.092 | 0.096 | 0.131 | 22.90 | 0.005 | 1.162 | 3.020 | 1.140 | 1.276 | 0.094 | 2.012 |
| 1D SMILES/SELFIES | | | | | | | | | | | | | |
| MoLFormer-XL (Ross et al., 2022) | 0.362 | 0.333 | 0.079 | 0.073 | 0.103 | 17.06 | 0.008 | 0.192 | 0.245 | 0.206 | 0.244 | 0.145 | 1.588 |
| MolTRES-small (ours) | 0.326 | 0.295 | 0.066 | 0.067 | 0.085 | 16.32 | 0.009 | 0.133 | 0.185 | 0.155 | 0.164 | 0.137 | 1.495 |
| MolTRES (ours) | 0.315 | 0.237 | 0.054 | 0.057 | 0.077 | 14.60 | 0.007 | 0.061 | 0.071 | 0.068 | 0.057 | 0.121 | 1.310 |
ing this geometry information involves non-trivial costs and may not be available in many real-world scenarios. In these contexts, our MolTRES models provide the most accurate approximation by only using SMILES, compared to baselines that estimate geometry information from RDKit or those without any geometry information, demonstrating its efficacy and applicability.
## 4.3 Analysis
To better understand the performance improvements from MolTRES, we conduct a series of analysis on four MoleculeNet classification tasks: BBBP, ClinTox, BACE, and SIDER.
Ablation Study. To assess the distinct contributions of MolTRES's components to its enhanced performance, we conduct ablation studies using variants of MolTRES as detailed in Table 4. The results demonstrate that both the DynaMol and mat2vec integration contribute to performance improvements. Moreover, when used jointly, they offer complementary advantages over employing either method in isolation. This result underscores MolTRES's effectiveness in addressing the issues in existing chemical language representation learning, leading to notable performance improvements.
Effect of mat2vec embedding. We analyze the effect of the mat2vec embeddings on the pretraining of MolTRES. As described in Figure 3,
Table 4: Performance on MoleculeNet classification tasks with variants of MolTRES.
| DynaMol | mat2vec | ROC-AUC ↑ |
|-----------|-----------|-------------------------|
| ✓ ✓ - - | ✓ - ✓ - | 87.99 87.67 84.82 84.05 |
mat2vec enables faster convergence, attributed to the rich features provided by mat2vec that are beneficial for structure modeling. Additionally, when fully trained, MolTRES with mat2vec achieves lower training losses and enhanced performance in MoleculeNet classification tasks. This validates the effectiveness of integrating mat2vec embeddings.
## 5 Related Work
In recent years, representation learning has prevailed in numerous applications in natural language processing (Devlin et al., 2019; Liu et al., 2019) and computer vision (Dosovitskiy et al., 2021; Bao et al., 2021). This trend has triggered many studies in chemical representation learning. The approaches in this field can be classified into three categories based on molecular descriptors used for pre-training: chemical language representation learning, chemical graph representation learning, and multi-modal chemical representation learning.
Figure 3: Training curves of MolTRES with mat2vec embeddings (the solid line) and without mat2vec embeddings (the dashed line). The left shows the pre-training loss curves, while the right shows the average ROC-AUC scores.
## Chemical language representation learning.
Chemical language representation learning has adopted pre-training on molecular descriptors represented as strings, such as SMILES and SELFIES. It typically leverages Transformers (Vaswani et al., 2017) to learn molecular descriptors inspired by the recent success of large-scale representation learning in natural language processing. Wang et al. (2019); Chithrananda et al. (2020); Ross et al. (2022) have trained Transformer models on largescale SMILES sequences. Yüksel et al. (2023) have utilized SELFIES sequences to achieve a better representation space. However, the training strategies for these methods follow the practice of MLMstyle training in natural language processing. Since chemical language differs from natural language, current applications of MLM encounter various issues in pre-training. In this work, we propose MolTRES to address these issues and consequently improve molecular property prediction.
## Chemical graph representation learning. Re-
searchers in chemical graph representation learning argue that molecules can naturally be represented in 2D or 3D graph structures. Thus, they typically leverage graph neural networks (GNNs) or Transformers adapted to graphs. Hu et al. (2020) have introduced a self-supervised task for molecular graphs, called AttrMask. Morris et al. (2019b) have introduced higher-order GNNs for distinguishing non-isomorphic graphs. You et al. (2020) have extended contrastive learning to unstructured graph data. Wang et al. (2022) have proposed a unified GNN pre-training framework that integrates contrastive learning and sub-graph masking. Recent work has focused on modeling 3D graphs, as they provide more vital information for predicting molecular properties compared to 2D graphs. (Yang et al., 2024; Zhou et al., 2023) have proposed denoising auto-encoders for directly modeling 3D graphs. However, due to the limited scale of 3D molecular data and its resource-intensive modeling, the applicability of 3D approaches is limited.
## Multi-modal chemical representation learning.
Recently, several studies have proposed learning chemical representations in a multi-modal manner, typically leveraging both 2D topology and 3D geometry of molecules. Liu et al. (2022); Stärk et al. (2022); Liu et al. (2023a) have introduced a contrastive learning framework that uses 2D graphs and their corresponding 3D conformations as positive views, treating those from different molecules as negative views. (Luo et al., 2022) have proposed encoding both 2D and 3D inputs within a single GNN model. Another research direction has involved using both chemical and natural languages (Edwards et al., 2022; Liu et al., 2023b) to enrich molecular representations and facilitate molecule generation using natural language. We plan to further explore the multi-modal and generation capabilities of MolTRES based on its versatile Transformer architecture.
## 6 Conclusion
In this work, we have proposed a novel chemical language representation learning framework, MolTRES, to address the limited scalability and generalizability of existing methods for pretraining SMILES transformers. We have presented two methods, dynamic molecule modeling with generator-discriminator training, called DynaMol, and knowledge transfer from scientific literature based on mat2vec. Our experimental results validate the superiority of our framework over existing chemical models across a wide range of molecular property prediction tasks.
## Limitations
While we have demonstrated that MolTRES effectively improves molecular property prediction by addressing issues in existing chemical language representation learning methods, some limitations open promising avenues for future research. First, several components in MolTRES, such as its masking strategy or knowledge transfer method, were chosen empirically in terms of efficiency, and therefore may have room for performance improvements through theoretical or learning-based approaches. Second, we evaluated a few architectural settings of MolTRES corresponding to those of MoLFormerXL for comparison. Future evaluations could explore more diverse settings of MolTRES to accommodate various scenarios, including resourcelimited or scalable environments. Finally, a popular application of SMILES Transformers is in molecule generation. We plan to investigate the extension of MolTRES on the pre-training of generative Transformers for this purpose.
## References
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. 2021. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254 .
Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. 2020. Chemberta: Large-scale selfsupervised pretraining for molecular property prediction. CoRR .
Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: pretraining text encoders as discriminators rather than generators. In 8th International Conference on Learning Representations .
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 4171-4186.
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. In The Nineth International Conference on Learning Representations .
Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. 2022. Translation be- tween molecules and natural language. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 375-413.
Xiaomin Fang, Lihang Liu, Jieqiong Lei, Donglong He, Shanzhuo Zhang, Jingbo Zhou, Fan Wang, Hua Wu, and Haifeng Wang. 2022. Geometry-enhanced molecular representation learning for property prediction. Nat. Mach. Intell. , 4(2):127-134.
Shikun Feng, Yuyan Ni, Minghao Li, Yanwen Huang, Zhi-Ming Ma, Wei-Ying Ma, and Yanyan Lan. 2024. Unicorn: A unified contrastive learning approach for multi-view molecular representation learning. arXiv preprint arXiv:2405.10343 .
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023a. Debertav3: Improving deberta using electra-style pretraining with gradient-disentangled embedding sharing. In The Eleventh International Conference on Learning Representations .
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023b. Debertav3: Improving deberta using electra-style pretraining with gradient-disentangled embedding sharing. In The Eleventh International Conference on Learning Representations .
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. 2022. Graphmae: Self-supervised masked graph autoencoders. In KDD '22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022 , pages 594-604. ACM.
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay S. Pande, and Jure Leskovec. 2020. Strategies for pre-training graph neural networks. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenReview.net.
John J. Irwin, Teague Sterling, Michael M. Mysinger, Erin S. Bolstad, and Ryan G. Coleman. 2012. ZINC: A free tool to discover chemistry for biology. J. Chem. Inf. Model. , 52(7):1757-1768.
Johannes Klicpera, Janek Groß, and Stephan Günnemann. 2020. Directional message passing for molecular graphs. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenReview.net.
Shengchao Liu, Weitao Du, Zhi-Ming Ma, Hongyu Guo, and Jian Tang. 2023a. A group symmetric stochastic differential equation model for molecule multi-modal pretraining. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , volume 202 of Proceedings of Machine Learning Research , pages 21497-21526. PMLR.
Shengchao Liu, Hanchen Wang, Weiyang Liu, Joan Lasenby, Hongyu Guo, and Jian Tang. 2022. Pretraining molecular graph representation with 3d geometry. In The Tenth International Conference on
Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized BERT pretraining approach. CoRR , abs/1907.11692.
Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. 2023b. Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. In The 2023 Conference on Empirical Methods in Natural Language Processing .
Zhiyuan Liu, Yaorui Shi, An Zhang, Enzhi Zhang, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. 2023c. Rethinking tokenizer and decoder in masked graph modeling for molecules. Advances in Neural Information Processing Systems , 36.
Shengjie Luo, Tianlang Chen, Yixian Xu, Shuxin Zheng, Tie-Yan Liu, Liwei Wang, and Di He. 2022. One transformer can understand both 2d & 3d molecular data. In The Eleventh International Conference on Learning Representations .
Christopher Morris, Martin Ritzert, Matthias Fey, William L Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe. 2019a. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI conference on artificial intelligence , volume 33, pages 4602-4609.
Christopher Morris, Martin Ritzert, Matthias Fey, William L. Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe. 2019b. Weisfeiler and leman go neural: Higher-order graph neural networks. In The Thirty-Third AAAI Conference on Artificial Intelligence , pages 4602-4609.
Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, and Junzhou Huang. 2020. Self-supervised graph transformer on largescale molecular data. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual .
Jerret Ross, Brian Belgodere, Vijil Chenthamarakshan, Inkit Padhi, Youssef Mroueh, and Payel Das. 2022. Large-scale chemical language representations capture molecular structure and properties. Nat. Mac. Intell. , 4:1256-1264.
Kristof Schütt, Pieter-Jan Kindermans, Huziel Enoc Sauceda Felix, Stefan Chmiela, Alexandre Tkatchenko, and Klaus-Robert Müller. 2017. Schnet: A continuous-filter convolutional neural network for modeling quantum interactions. Advances in neural information processing systems , 30.
Hannes Stärk, Dominique Beaini, Gabriele Corso, Prudencio Tossou, Christian Dallago, Stephan Günnemann, and Pietro Lió. 2022. 3d infomax improves gnns for molecular property prediction. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA , volume 162 of Proceedings of Machine Learning Research , pages 20479-20502. PMLR.
Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Mehdi Azabou, Eva L Dyer, Remi Munos, Petar Veliˇ ckovi´, and Michal Valko. 2022. c Largescale representation learning on graphs via bootstrapping. In International Conference on Learning Representations .
Vahe Tshitoyan, John Dagdelen, Leigh Weston, Alexander Dunn, Ziqin Rong, Olga Kononova, Kristin A. Persson, Gerbrand Ceder, and Anubhav Jain. 2019. Unsupervised word embeddings capture latent knowledge from materials science literature. Nat. , 571(7763):95-98.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017 , pages 59986008.
Sheng Wang, Yuzhi Guo, Yuhong Wang, Hongmao Sun, and Junzhou Huang. 2019. SMILES-BERT: large scale unsupervised pre-training for molecular property prediction. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics , pages 429-436.
Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani. 2022. Molecular contrastive learning of representations via graph neural networks. Nat. Mach. Intell. , 4(3):279-287.
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. 2018. Moleculenet: a benchmark for molecular machine learning. Chemical science , 9(2):513-530.
Jun Xia, Chengshuai Zhao, Bozhen Hu, Zhangyang Gao, Cheng Tan, Yue Liu, Siyuan Li, and Stan Z. Li. 2023. Mole-bert: Rethinking pre-training graph neural networks for molecules. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net.
Junwei Yang, Kangjie Zheng, Siyu Long, Zaiqing Nie, Ming Zhang, Xinyu Dai, Wei-Yin Ma, and Hao Zhou. 2024. Mol-ae: Auto-encoder based molecular representation learning with 3d cloze test objective. bioRxiv , pages 2024-04.
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020 .
Qiying Yu, Yudi Zhang, Yuyan Ni, Shikun Feng, Yanyan Lan, Hao Zhou, and Jingjing Liu. 2024. Multimodal molecular pretraining via modality blending. In The Twelfth International Conference on Learning Representations .
Atakan Yüksel, Erva Ulusoy, Atabey Ünlü, Gamze Deniz, and Tunca Dogan. 2023. Selformer: Molecular representation learning via SELFIES language models. CoRR , abs/2304.04662.
Gengmo Zhou, Zhifeng Gao, Qiankun Ding, Hang Zheng, Hongteng Xu, Zhewei Wei, Linfeng Zhang, and Guolin Ke. 2023. Uni-mol: A universal 3d molecular representation learning framework. In The Eleventh International Conference on Learning Representations .
## A Appendix
## A.1 Detailed Experimental Settings
Pre-training. For pre-processing, we extract the canonicalized format of SMILES for every molecule using RDKit. We construct the vocabulary with 2,691 unique tokens plus five special tokens ('<bos>', '<eos>', '<pad>', '<mask>', and '<unk>') after tokenizing all the extracted SMILES sequences. For tokenization, we use the maximum sequence length of 512. The weights of our models are initialized over the normal distribution with a standard deviation of 0.02. Pre-training is performed using an AdamW optimizer ( β 1 = 0 9 . , β 2 = 0 95 . ), where the maximum learning rate and weight decay are set to 3e-4 and 0.01, respectively. We use the cosine annealing for learning rate scheduling with 1,000 warmup steps. The pre-training time of MolTRES is approximately 15 days using 4 NVIDIA RTX A6000 GPUs.
Evaluation The statistics of evaluation benchmarks are shown in Table 5 and 6. We use the scaffold splitting (80% / 10% / 10% for train / validation / test) for all the tasks except for QM9, in which the random split (80% / 10% / 10% for train / validation / test) with thermochemical energy precalculation is used following Liu et al. (2023a). For evaluation of our models, we extract the output representations from model's final transformer block corresponding to the first input token ('<bos>') as the molecule representations. We use a 2-layer MLP with the same hidden size and gelu activation for prediction, whose weights are initialized over the normal distribution with a standard deviation of 0.02. We use the augmentation of random SMILES reconstruction for all the tasks. We fine-tune the models for 500 epochs using an AdamW optimizer
Figure 4: Comparison of MolTRES for different masking ratios on MoleculeNet classification tasks.
Figure 5: Comparison of MolTRES for different λ on MoleculeNet classification tasks.
( β 1 = 0 9 . , β 2 = 0 99 . ) with a weight decay of 0.01. For each task, we empirically choose the batch size ∈ { 16 32 64 128 , , , } and learning rate ∈ { 2e-5 , 3e-5 , 5e-5 , 1e-4 } . We report the average scores after five runs.
Model Architecture. The model architecture of the generator and discriminator is a Transformer with linear attention and rotary position embeddings. The discriminator of MolTRES has 12 layers, 768 hidden dimensions, and 12 attention heads. The discriminator of MolTRES-small has 6 layers, 768 hidden dimensions, and 12 attention heads. The generators have half the number of layers in their corresponding discriminator, while the other settings are consistent. It is noteworthy that the generator is only used for pre-training, and the discriminator is fine-tuned and evaluated in all the downstream tasks. The generator and discriminator share their embeddings, which is known to be beneficial in accelerating the pre-training (Clark et al., 2020).
## A.2 Additional Experimental Results
Pre-training hyper-parameter analysis. We study the effect of pre-training hyper-parameters as shown in Figures 4 and 5. We report ROC-
| | Descriptions | # tasks | # samples |
|---------|-------------------------------------------------------------|-----------|-------------|
| BBBP | Blood brain barrier penetration dataset | 1 | 2,039 |
| Tox21 | Toxicity measurements on 12 different targets | 12 | 7,831 |
| ToxCast | Toxicology data for a large library of compounds | 617 | 8,577 |
| Clintox | Clinical trial toxicity of drugs | 2 | 1,478 |
| MUV | Maximum unbiased validation group from PubChem BioAssay | 17 | 93,087 |
| HIV | Ability of small molecules to inhibit HIV replication | 1 | 41,127 |
| BACE | Binding results for a set of inhibitors for β - secretase 1 | 1 | 1,513 |
| SIDER | Drug side effect on different organ clases | 27 | 1,427 |
Table 5: Classification tasks from MoleculeNet.
| | Descriptions | # tasks | # samples |
|---------------|---------------------------------------------------------|-----------|-------------|
| QM9 | 12 quantum mechanical calculations of organic molecules | 12 | 133,885 |
| ESOL | Water solubility dataset | 1 | 1,128 |
| FreeSolv | Hydration free energy of small molecules in water | 1 | 642 |
| Lipophilicity | Octanol/water distribution coefficient of molecules | 1 | 4,200 |
Table 6: Regression benchmarks from MoleculeNet.
| | Generator | Generator | Discriminator | Discriminator | ROC-AUC ↑ | MAE ↓ (REG) |
|-----|-------------|-------------|-----------------|-----------------|-------------|---------------|
| | # layers | Hidden size | # layers | Hidden size | (CLS) | |
| (A) | 3 | | 6 | | 81.9 | 0.375 |
| | | 512 | | 512 | 82.2 | 0.371 |
| (B) | 12 | 384 | | | 83.6 | 0.341 |
| | 12 | 512 | | | 84.7 | 0.336 |
| (C) | 4 | | | | 83.3 | 0.343 |
| (C) | 8 | | | | 84.5 | 0.336 |
| (C) | 12 | | | | 84.0 | 0.337 |
| (D) | 6 | 768 | 12 | 768 | 84.8 | 0.336 |
Table 7: Variations on the MolTRES architectures. Unlisted values are identical to those of the standard setting of MolTRES in (D). Following the experimental settings described in Section 4.1, ROC-AUC scores are measured on eight MoleculeNet classification tasks and MAE scores are measured on three MoleculeNet regression tasks.
AUC scores on four MoleculeNet classification tasks (BBBP, ClinTox, BACE, and SIDER). First, in Figure 4, we find that the optimal masking ratio for MolTRES is 65%. When the masking ratio is smaller than 65%, we observe that the generator easily fills masked tokens, resulting in significantly biased labels towards original. In contrast, when the masking ratio is larger than 65%, we observe that there is few evidence in input SMILES tokens to predict their original molecules, leading to less effective training. In addition, in Figure 5, we identify that the optimal value of λ is 10, different from the original work on generator-discriminator training in NLP (Clark et al., 2020) using 50. We suspect that this is because SMILES modeling typically shows smaller losses from the generator than language modeling, and thus we need smaller λ to balance the generator and discriminator training.
Architecture analysis. We analyze diverse variations on the MolTRES architectures, particularly about the architecture of the generator and dis- criminator. We report ROC-AUC scores on eight MoleculeNet classification tasks and MAE scores on three MoleculeNet regression tasks from each variation. In Table 7, the architecture of our standard setting used in Section 4 is shown in (D). The variations in (A) denote training smaller MolTRES models, showing that reducing layers and hidden size show comparable performance degradation when their numbers of parameters are commensurate. Note that we choose to reduce layers, since it achieves faster model execution speed. The variations in (B) and (C) are about the architecture of generators. (B) contains the variations changing the hidden sizes while using the number of layers of the discriminator, while (C) contains the variations changing the numbers of layers while using the hidden size of the discriminator. In this comparison, we first observe that there is an optimal size of generators that generate training examples suitably challenging for discriminators. After empirical investigation, we choose to set the number of layers in the generator to half of that in the discriminator. | null | [
"Jun-Hyung Park",
"Yeachan Kim",
"Mingyu Lee",
"Hyuntae Park",
"SangKeun Lee"
]
| 2024-07-09T01:14:28+00:00 | 2024-07-09T01:14:28+00:00 | [
"physics.chem-ph",
"cond-mat.mtrl-sci",
"cs.LG",
"I.2.7"
]
| MolTRES: Improving Chemical Language Representation Learning for Molecular Property Prediction | Chemical representation learning has gained increasing interest due to the
limited availability of supervised data in fields such as drug and materials
design. This interest particularly extends to chemical language representation
learning, which involves pre-training Transformers on SMILES sequences --
textual descriptors of molecules. Despite its success in molecular property
prediction, current practices often lead to overfitting and limited scalability
due to early convergence. In this paper, we introduce a novel chemical language
representation learning framework, called MolTRES, to address these issues.
MolTRES incorporates generator-discriminator training, allowing the model to
learn from more challenging examples that require structural understanding. In
addition, we enrich molecular representations by transferring knowledge from
scientific literature by integrating external materials embedding. Experimental
results show that our model outperforms existing state-of-the-art models on
popular molecular property prediction tasks. |
2408.01427v1 | ## Siamese Transformer Networks for Few-shot Image Classification
Weihao Jiang, Shuoxi Zhang, Kun He , Senior Member, IEEE
Abstract -Humans exhibit remarkable proficiency in visual classification tasks, accurately recognizing and classifying new images with minimal examples. This ability is attributed to their capacity to focus on details and identify common features between previously seen and new images. In contrast, existing few-shot image classification methods often emphasize either global features or local features, with few studies considering the integration of both. To address this limitation, we propose a novel approach based on the Siamese Transformer Network (STN). Our method employs two parallel branch networks utilizing the pre-trained Vision Transformer (ViT) architecture to extract global and local features, respectively. Specifically, we implement the ViT-Small network architecture and initialize the branch networks with pre-trained model parameters obtained through self-supervised learning. We apply the Euclidean distance measure to the global features and the Kullback-Leibler (KL) divergence measure to the local features. To integrate the two metrics, we first employ L 2 normalization and then weight the normalized results to obtain the final similarity score. This strategy leverages the advantages of both global and local features while ensuring their complementary benefits. During the training phase, we adopt a meta-learning approach to fine-tune the entire network. Our strategy effectively harnesses the potential of global and local features in few-shot image classification, circumventing the need for complex feature adaptation modules and enhancing the model's generalization ability. Extensive experiments demonstrate that our framework is simple yet effective, achieving superior performance compared to state-of-the-art baselines on four popular few-shot classification benchmarks in both 5-shot and 1-shot scenarios.
Index Terms -Siamese Network, Vision Transformer, global feature, local feature, information fusion
## I. INTRODUCTION
Learning from just a few examples and applying that knowledge to diverse situations exemplifies human visual intelligence. In recent years, leveraging deep learning techniques and large-scale labeled datasets has led to notable advancements in image recognition. Nevertheless, machine learning models have yet to match the adaptability of human visual cognition. Humans effortlessly learn to identify new object classes with minimal examples, a cognitive feat enabling flexible adaptation of existing knowledge to new tasks. Inspired by this human capability, few-shot learning [1]-[5] addresses this challenge through knowledge transfer, employing a metric-based metalearning approach [3], [6], [7] known for its simplicity and
The authors are with School of Computer Science and Technology, Huazhong University of Scinece and Technology. The corresponding author is Kun He. Email: [email protected]
This paper is supported by National Natural Science Foundation of China (U22B2017).
Manuscript received July 15, 2024; revised XXXX XX, XXXX.
(a) Two images with similar global features


(b) Two images with similar details


Fig. 1. Illustration on limitations of either global feature-based methods or local feature-based methods. (a) When two images exhibit high similarity, global feature-based methods are susceptible to misjudgment. (b) Two images containing numerous similar details poses a challenge for local feature-based methods.
effectiveness. This approach significantly streamlines the application of deep learning in multimedia systems, garnering increasing attention in current literature.
The few-shot learning method based on metric learning primarily comprises two essential components: feature extraction from all query and support images, and the calculation of distances between query images and each support image, prototype, or class center using metrics. Feature extraction is a crucial step for achieving efficient measurement, laying the foundation for subsequent processing. Current feature extraction strategies can be divided into two main approaches, namely global feature-based [3], [8]-[21] and local featurebased [6], [10], [22]-[30]. The global feature-based approach compresses the entire image into a unified feature vector, simplifying subsequent measurement process. To enhance the model's representational capacity, researchers focus on two optimization solutions: designing more effective network architectures [11], [12], [19]-[21] to extract more precise prototype
features, or developing more accurate similarity evaluation methods [3], [8]-[10] to ensure precise measurement results between different images. In contrast, the local feature-based method decomposes each image into multiple local regions and extracts the corresponding features from each region. This approach not only emphasizes the use of local features for accurate measurement but also aims to understand the semantic associations between different images. By capturing detailed information within the image and establishing richer associations between different images, this method improves the robustness and accuracy of the measurement.
However, relying solely on either global or local features for measurement is prone to introducing bias. As shown in Figure 1a, the comparative images of a dog and a wolf are so similar overall that depending exclusively on global characteristics can lead to misjudgment. Similarly, Figure 1b illustrates a pair of contrasting images of a tiger and a cat, which share numerous detailed similarities, potentially causing mistaken identification if only local features are used for comparison. Therefore, it is logical to combine global and local feature-based measurements to achieve more accurate results than relying on either one alone.
Although global feature-based and local feature-based methods have been thoroughly studied and have demonstrated advanced performance, a critical area has not received substantial attention: integrating measurements based on global features with those based on local features. While some studies [30], [31] have attempted to combine these two types of features, they generally use global features to enhance local features rather than treating them as separate and equally important components. Global features are favored for their inherent invariance properties but are susceptible to disruption by image noise, especially in the presence of complex backgrounds. Conversely, local features excel at capturing detailed image information and are robust to noise and minor changes, yet they face challenges with alignment. The complementary strengths of global and local features suggest that their combined utilization could achieve synergistic advantages and further improve model performance. However, simply measuring based on fused features cannot fully exploit the potential of each type of feature. In contrast, fusing the measurement results from different features allows for more flexibility. This approach can employ distinct and more appropriate measurement methods tailored to the characteristics of each feature, thereby fully leveraging the strengths of both global and local features.
To fully leverage the complementary strengths of global and local features, we design a novel model called the Siamese Transformer Network (STN). The STN model consists of two distinct branches, each responsible for extracting the global features and the local feature sets, respectively. Specifically, the first branch network is dedicated to extracting the global features of the support and query images, while the second branch network focuses on extracting the local feature sets for the two sets of images. We carefully design different metrics to measure the similarity between the global features and the local feature sets of the query and support images. For the global features, we employ a regular Bregman divergence [3] to compute the similarity between samples. For the local feature sets, we adopt an asymmetric distribution metric. To synthesize the two measurements, we first perform L 2 normalization to ensure that the measurements are of the same scale. We then weight the two normalized results to obtain the final metric score, which reflects the overall similarity between the query image and the support image. Finally, based on this aggregate metric score, we assign a corresponding label to the query image. This method not only fully utilizes the information from both global and local features but also improves the accuracy and reliability of the measurement results.
Our main contributions can be summarized as follows:
- · We present an innovative approach that ingeniously integrates the dual perspectives of global and local features, transcending the limitations of existing metric-based methods that narrowly focus on a single feature dimension. This methodology captures the holistic structure of images while meticulously analyzing intricate textures, thereby charting a new course in the field of image analysis and significantly enhancing the comprehensiveness and precision of feature extraction.
- · We introduce STN, a novel approach that combines measurements based on both global and local image features without requiring other complex designs, thereby enhancing model generalization.
- · Extensive experiments conducted on four prominent benchmark datasets demonstrate that STN outperforms stateof-the-art methods. Comprehensive comparisons further highlight the superiority of our approach.
The remainder of this paper is organized as follows: Section II provides a summary of related work. Section III elaborates on our approach. The experiments conducted are detailed in Section IV. Section V concludes this work.
## II. RELATED WORKS
Here, we briefly review few-shot learning methods and categorize existing methods into two groups based on the characteristics of adopted features. We then introduce Siamese neural networks and analyze how our approach differs.
## A. Global Feature-Based Methods
Global feature-based methods utilize global features, representing an image through a singular global feature. Metricbased few-shot learning (FSL) methods embed both support and query images into a shared feature space, classifying query images by measuring their distance or similarity to support samples. These approaches primarily focus on enhancing similarity measures and improving feature extraction techniques. Several models have been developed employing various metric methods, including Matching Networks [8], Prototypical Networks [3], MSML [9], and DeepEMD [10]. To obtain more distinctive features, researchers have begun to adopt a holistic approach to the entire task, developing external modules to enhance feature representation. For instance, CTM [11] introduces a Category Traversal Module that traverses the entire support set simultaneously, identifying task-relevant features based on intra-class commonality and inter-class uniqueness
within the feature space. Similarly, FEAT [12] proposes a novel method to adapt instance-level global features to the target classification task using a set-to-set function, thereby generating task-specific and discriminative global features. Optimization-based methods aim to learn effective model initializations, facilitating rapid optimization when confronted with new tasks. A prominent example in this category is MAML [13], which achieves optimal initialization parameters through both internal and external training during the metatraining phase. MAML has inspired numerous subsequent efforts, including ANIL [14], BOIL [15], and LEO [16]. Transfer-based methods initially employ a straightforward scheme to train a classification model on the complete training set. After training, the classification head is removed, retaining only the feature extraction component, and a new classifier is trained based on the support set from the testing data. Notable examples in this area include Dynamic Classifier [17], Baseline++ [18], and RFS [19].
Recently, researchers have begun incorporating Vision Transformers (ViT) into few-shot learning scenarios. The PMF method [20] first utilizes a pre-trained Transformer model with external unsupervised data. It then simulates few-shot tasks for meta-training using base categories and subsequently fine-tunes the model with limited labeled data from test tasks. HCTransformer [21] employs hierarchically cascaded Transformers as a robust meta-feature extractor for few-shot learning.
## B. Local Feature-Based Methods
In contrast, local feature-based methods focus on local features by decomposing an image into a series of features that represent different local regions. Each local region often contains distinct content and carries unique semantic meaning, leading researchers to explore these methods in two main directions. On one hand, there is ongoing work to design more fine-grained local feature measures that capture subtle differences between features. On the other hand, researchers are seeking strategies to achieve explicit semantic alignment between images.
In the first aspect, several methods have been proposed. For example, CovaMNet [22] introduces a deep covariance metric to measure the consistency of distributions between query samples and support samples. DN4 [23] calculates instance-to-class similarity between a query image and support images using k -nearest neighbors. RelationNet [6] employs a learnable deep metric network to assess the relationships between images. Additionally, ADM [24] proposes a novel asymmetric distribution measure network specifically for fewshot learning. In the second direction, researchers achieve semantic alignment by designing learnable modules that guide the model to focus on target areas within the image. For instance, SAML [32] utilizes an attention mechanism to diminish the influence of semantically unrelated areas. DeepEMD [10] promotes semantic correspondence between images by minimizing the Earth Mover's Distance. CAN [25] generates crossattention maps for each pair of support feature maps and query sample feature maps to emphasize target object regions, thereby enhancing the discriminative nature of the extracted features. CTX [26] learns spatial and semantic alignment between CNN-extracted query and support features using a Transformer-style attention mechanism. ATL-Net [27] introduces episodic attention calculated through a local relation map between the query image and the support set, adaptively selecting important local patches across the entire task. RENet [28] combines self-correlational representations within each image with cross-correlational attention modules between images to learn relational embeddings. Lastly, FewTURE [29] adopts a fully transformer-based architecture, learning token importance weights through online optimization during inference. CPEA [30] also employs a pre-trained ViT model, integrating patch embeddings with class-aware embeddings to enhance class relevance.
Existing methods typically rely solely on either global or local features for similarity measurement, which limits their ability to capture the synergistic effects of utilizing both types of features. While some studies incorporate both global and local features, they primarily use global features to enhance the semantic information of local features [30], [31], ultimately performing measurements based exclusively on local features. This reliance restricts the accuracy of the measurement results. To address this limitation, we propose a Siamese Transformer Network that simultaneously extracts both global and local image features. The network measures these two distinct feature sets separately using different approaches, then fuses the resulting measurements to produce a final similarity score.
## C. Siamese Neural Networks
Siamese neural networks were first proposed by Bromley and LeCun in the early 1990s to address signature verification as an image matching problem [1]. These networks consist of two branches, each receiving an input, mapping it to a highdimensional feature space, and outputting the corresponding representation. By calculating the distance between the two representations -- commonly using metrics like Euclidean distance -- the model can assess the similarity between the inputs. The branch networks can be composed of convolutional neural networks (CNNs) or recurrent neural networks (RNNs), with weights optimized using energy functions or classification losses [33].
In a narrow sense, Siamese neural networks are defined as having two identical neural networks with shared weights [1]. A generalized version, known as a 'Pseudo-siamese network', can consist of any two neural networks [34]. The primary distinction is that in Pseudo-Siamese networks, the weights of the two branches are not shared, resulting in a true dualbranch architecture. Each branch represents a different mapping function, meaning the feature extraction structures differ, with distinct weights or network layers. Consequently, this architecture has nearly twice as many training parameters as the traditional Siamese network, providing greater flexibility.
In this paper, we employ a Vision Transformer as the backbone for our dual-branch network, ensuring no parameter sharing between the two branches. After extracting the global and local features from the input image, we compute similarity
scores based on each type of feature, then normalize and weight these measures to obtain a final similarity score.
## III. METHODOLOGY
In this section, we first provide definition on the few-shot image classification task. Next, we outline the framework of our proposed method. Following that, we provide a detailed description of our Siamese Transformer Network module and explain the classification method based on two metrics of global features and local features.
## A. Problem Definition
Few-shot image classification is primarily concerned with the N -way K -shot problem, where N denotes the number of categories and K represents the number of instances within each category. Typically, K is relatively small like 1 or 5.
Datasets designed for few-shot learning typically comprise three distinct parts: training set D train , validation set D val , and test set D test . Notably, they feature non-overlapping categories, indicating that images in the test set are entirely unseen during training and validation. This lack of overlap poses a significant challenge for few-shot learning. Typically, all the three datasets contain numerous categories and examples. To emulate the conditions of few-shot learning, researchers adopt an episode training mechanism [8]. In this mechanism, episodes are randomly sampled from the datasets, each consisting of a support set S = { ( x , y i i ) } NK i =1 and a query set Q = { (˜ x , y i ˜ ) i } NT i =1 , where T is the number of query examples contained in each class. Both the S and Q have identical labels, but their samples do not overlap ( S ∩ Q = ∅ ). The support set contains a sparse selection of labeled samples, acting as the few-shot training data, while the query set is used for evaluation.
During the training phase, a large number of episodes sampled from the training set are utilized to update the model parameters until reaching convergence. For validation and testing, episodes from the validation and test sets are employed to ensure that the test conditions mirror real-world scenarios.
## B. The Proposed Framework
The framework of our STN model, as illustrated in Figure 2, leverages the Vision Transformer (ViT) as the feature extractor. Each input image is first partitioned into non-overlapping patches and then encoded using the pre-trained ViT [35], resulting in both class embeddings and patch embeddings. The class embeddings capture global image information, while the patch embeddings focus on local details specific to each patch.
To conduct a comprehensive analysis of the input images (including both query and support images), we design a dualbranch network architecture. The first branch is dedicated to extracting global features, while the second branch focuses on extracting local features. To measure similarity between images based on these features, two distinct strategies are employed. Specifically, Euclidean distance serves as the similarity metric for global features, while KL divergence assesses the differences between images based on local features. This approach leverages the strengths of each feature type, providing a more thorough evaluation of similarity by combining measurements from both branches. To integrate the similarity information from global and local features, we first normalize the measurement results using the L 2 normalization. The final similarity score is then obtained through a weighted summation of the normalized values. In this process, the weighted coefficients act as the sole hyperparameter, eliminating the need for complex feature adaptation modules.
In contrast to traditional methods, the proposed approach introduces several key innovations. First, it utilizes both global and local features to assess image similarity and effectively combines the outcomes of these complementary measures. Second, it eliminates the need for complex feature adaptation modules by employing a feature extraction model that generates diverse feature perspectives, thereby enhancing the model's generalization capability. Prior studies addressing image similarity measurement have either focused on adjusting global features to become more task-specific or used them to enhance the semantic information of local features. However, these methods typically rely on a single type of feature for comparison, failing to fully exploit the advantages of combining global and local characteristics. Additionally, these approaches often depend on supplementary network modules for parameter optimization and learning, which can increase model complexity and negatively impact the generalization ability.
The proposed approach eliminates the need for additional network modules by employing a concise strategy for integrating global and local features. Specifically, similarity measures based on global and local features are calculated independently and then synthesized using a single weighted parameter. This streamlined method reduces model complexity and enhances generalization ability by minimizing the introduction of excessive learnable parameters outside the feature extractor. Through this weighted fusion mechanism, the approach effectively combines global contextual information with detailed localized semantics, resulting in improved performance on the image similarity measurement task.
## C. Siamese Transformer Networks
Our Siamese Transformer Network consists of two branches, each utilizing a Vision Transformer as the backbone.
In a typical few-shot task, the support set usually consists of N classes, commonly set to five, following the standard few-shot learning setup. Each support category contains K shots, and the average of the embedding values is used as the prototype embeddings [3]. After the ViT encoding process, we obtain five sets of combinations of class embeddings and patch embeddings:
$$S _ { i } & = [ c l a s s _ { i } ^ { s }, p a t c h _ { i, 1 } ^ { s }, p a t c h _ { i, 2 } ^ { s }, \dots, p a t c h _ { i, M } ^ { s } ], \quad ( 1 ) \\ & \quad i \in [ 1, 5 ],$$
where M is the number of patches.
For a query image, we have a combination of class embedding and patch embeddings:
$$Q = [ c l a s s ^ { q }, p a t c h _ { 1 } ^ { q }, p a t c h _ { 2 } ^ { q }, \dots, p a t c h _ { M } ^ { q } ], \quad ( 2 )$$
Fig. 2. The processing pipeline of STN involves several key steps. Support and query images are first divided into patches and then encoded using a pre-trained Vision Transformer (ViT). Class embeddings capture the global features, while patch embeddings represent the local features. Using these two types of features, Euclidean distance and KL divergence are employed for measurement. Independent branch network optimization is performed based on their respective evaluation results. Finally, the scores from both measurements are normalized and weighted to generate the final similarity scores.
where M is the number of patches. Here, class represents the class embedding that captures the global information of the image, while patch denotes the patch embeddings that capture features from local regions of the image.
Global features are valued for their invariance but can be easily affected by image noise, particularly in complex backgrounds. In contrast, local features excel at capturing detailed image information and are robust to noise and small variations, although they often struggle with alignment issues. To address these challenges, the proposed approach employs different similarity measures based on these two types of features and subsequently fuses the measurement results. This strategy leverages the complementary advantages of both feature types, thereby enhancing the overall performance of the model.
For the first branch network, the class embedding is obtained as the global feature:
$$S _ { g } = \frac { 1 } { K } \sum _ { i = 1 } ^ { K } c l a s s _ { i } ^ { s } & & ( 3 ) \quad \text{when} \\ & & \text{class} \\ & & B \text{;}$$
$$Q _ { g } = c l a s s ^ { q } \quad \ \ ( 4 ) \ \, \underset { \text{dist} } { \ e u }$$
For the second branch network, the patch embeddings are obtained as the local features:
$$S _ { l } = [ p a t c h ^ { s } _ { i, 1 }, p a t c h ^ { s } _ { i, 2 }, \dots, p a t c h ^ { s } _ { i, M } ], \quad ( 5 )$$
$$Q _ { l } = [ p a t c h _ { 1 } ^ { q }, p a t c h _ { 2 } ^ { q }, \dots, p a t c h _ { M } ^ { q } ], \text{ \quad \ } ( 6 )$$
where M is the number of patches.
Based on the global features, we utilize squared Euclidean distance as the measurement. This metric is widely used as a similarity measure across various fields [3], [12] and has demonstrated effectiveness in practice.
$$D _ { E d } ( Q, S ^ { n } ) = \left \| Q _ { g } - S _ { g } ^ { n } \right \| ^ { 2 }, \quad \quad ( 7 ) \\ n \in [ 1, 5 ],$$
where S n g represents the global feature of the n -th support class.
Based on the local features, we employ an asymmetric Kullback-Leibler (KL) divergence measure [24] to align the distribution of a query with that of a support class, capturing
global distribution-level asymmetric relations. The KL divergence assumes that the distribution of local features extracted from an image or a support class follows a multivariate Gaussian distribution. Specifically, the distribution of a query image can be represented as Q = N ( µ Q , Σ ) Q , while the distribution for a support class can be expressed as S = N ( µ , S Σ ) S , where µ ∈ R c and Σ ∈ R c × c denote the mean vector and covariance matrix of the respective distributions. Thus, the KL divergence [36] between Q and S can be defined as:
$$D _ { K L } ( Q | | S ) & = \frac { 1 } { 2 } ( t r a c e ( \Sigma _ { S } ^ { - 1 } \Sigma _ { Q } ) + l n \left ( \frac { d e t \Sigma _ { S } } { d e t \Sigma _ { Q } } \right ) \quad ( 8 ) \\ & \quad + ( \mu _ { S } - \mu _ { Q } ) ^ { T } \Sigma _ { S } ^ { - 1 } ( \mu _ { S } - \mu _ { Q } ) - c ),$$
where trace ( ) · represents the trace operation of a matrix, ln( ) · denotes the logarithm with base e , and det indicates the determinant of a square matrix. Equation (8) considers both the mean and covariance to calculate the distance between two distributions. A significant advantage of using this equation is its ability to naturally capture the asymmetric relationship between a query image and a support class through the local feature set. This encourages the query images to be closer to the corresponding true class during network training [24].
Finally, we combine the distribution-based KL divergence measure with the Euclidean distance measure to simultaneously capture both global and local relations.
## D. Classification With an Additive Fusion Strategy
As two distinct types of metrics have been calculated - local-level relations quantified by the Kullback-Leibler divergence measure, and global-level relations produced by the Euclidean distance measure - a fusion strategy must be designed to integrate these two components. To address this, the proposed approach adopts a hyperparametric weight α to implement the fusion. It is worth noting that since the KL divergence indicates dissimilarity rather than similarity, the negative of this divergence is used to obtain a similarity measure, akin to the Euclidean distance. Specifically, the final fused similarity between a query Q and a class S can be defined as follows:
$$D ( Q, S ) = - \alpha \cdot D _ { K L } ( Q | | S ) - ( 1 - \alpha ) \cdot D _ { E d } ( Q, S ) \ \ ( 9 ) \ \ \text{all} \ \text{ima}$$
For a 5-way 1-shot task and a specific query Q , the output from each branch produces a 5-dimensional similarity vector. Subsequently, L 2 normalization is applied to balance the scales of the two similarity components. Following this, we use an additive fusion strategy, as described in Equation (9), to combine the two metrics. This process results in an integrated 5-dimensional similarity vector derived from two distinct feature-based metrics. Finally, a non-parametric nearest neighbor classifier is employed to obtain the final classification results.
## E. Training and Inference
In the training process, we adopt a strategy of separation and parallelism. Each branch network computes its own evaluation results based on different feature measures and optimizes independently using the cross-entropy loss function. For the first branch network, the Euclidean distance measurement is adopted based on global features. The probability of the i -th query image belonging to the n -th support class can then be calculated as follows:
$$p _ { n i } ^ { g } = \frac { e x p ( - D _ { E d } ( Q ^ { i }, S ^ { n } ) } { \sum _ { n ^ { \prime } = 1 } ^ { N } e x p ( - D _ { E d } ( Q ^ { i }, S ^ { n ^ { \prime } } ) ) }, \quad \ ( 1 0 )$$
for the second branch network, KL divergence is adopted based on local features, and the probability is as follows:
$$p _ { n i } ^ { l } = \frac { e x p ( - D _ { K L } ( Q ^ { i } | | S ^ { n } ) ) } { \sum _ { n ^ { \prime } = 1 } ^ { N } e x p ( - D _ { K L } ( Q ^ { i } | | S ^ { n ^ { \prime } } ) ) }. \quad \ ( 1 1 )$$
For a given episode, the loss function of the first branch network can be formulated as follows:
$$L o s s _ { g } = - \frac { 1 } { N Q } \sum _ { i = 1 } ^ { N Q } \sum _ { n = 1 } ^ { N } I ( y _ { i } ^ { ( Q ) } = n ) \log p _ { n i } ^ { g }, \quad ( 1 2 )$$
and the loss function of the second branch network can be formulated as follows:
$$L o s s _ { l } = - \frac { 1 } { N Q } \sum _ { i = 1 } ^ { N Q } \sum _ { n = 1 } ^ { N } I ( y _ { i } ^ { ( Q ) } = n ) \log p _ { n i } ^ { l }, \quad ( 1 3 )$$
where y ( Q ) i denotes the label of the i -th query image and I ( ) · is an indicator function that equals one if its arguments are true and zero otherwise. In the first branch network, all the learnable weights are fine-tuned by minimizing the loss function defined in Equation (12). Correspondingly, in the second branch network, all the learnable weights are adjusted using the minimization of the loss function in Equation (13), where a randomly selected sample of training episodes is utilized.
Inference . Given an episode sampled from the unseen test classes, the probability of a query image belonging to each class can be calculated according to Equation (9). Then, we assign the label of the class with the maximum probability to the corresponding query image. It is worth noting that, once fine-tuned on the training classes, the method does not require any adjustments when generalizing to unseen test classes. This is in contrast to FewTURE [29], which needs all images of an episode's support set together with their labels to learn the importance of each individual patch token via online optimization at inference time. As a result, the proposed approach is much simpler than FewTURE in terms of inference.
## IV. EXPERIMENTS
This section first details the experimental settings. Subsequently, a comparison with competing methods on benchmark datasets is presented. Finally, an ablation study of the proposed framework is conducted.
## A. Datasets
In the standard few-shot classification task, four popular benchmark datasets are commonly used: mini ImageNet [37], tiered ImageNet [38], CIFAR-FS [39], and FC100 [40].
The mini ImageNet dataset comprises 100 categories sampled from ILSVRC-2012 [41], with each category containing 600 images, totaling 60,000 images. In the standard setting, the dataset is randomly partitioned into training, validation, and testing sets, consisting of 64, 16, and 20 categories, respectively.
The tiered ImageNet dataset, also sourced from ILSVRC2012, features a larger scale of data. It consists of 34 supercategories, divided into training, validation, and testing sets, containing 20, 6, and 8 super-categories, respectively. In total, the dataset includes 608 categories, with 351, 97, and 160 categories in each partitioned set.
Both CIFAR-FS and FC100 are derived from CIFAR-100, which consists of 100 classes with 600 images per class. These datasets feature small-resolution images, each measuring 32 × 32 pixels. Specifically, CIFAR-FS is randomly divided into 64 training classes, 16 validation classes, and 20 testing classes. In contrast, FC100 includes 100 classes sourced from 36 super-classes in CIFAR-100, which are organized into 12 training super-classes (60 classes), 4 validation super-classes (20 classes), and 4 testing super-classes (20 classes).
## B. Implementation Details
Motivated by the scalability and effectiveness of pre-training techniques, we employ a Masked Image Modeling (MIM)pretrained Vision Transformer as the backbone of our model. Specifically, we utilize the ViT-Small architecture with a patch size of 16. During the pre-training phase, we adopt the same strategy as outlined in [29] to pretrain our ViT-Small backbones, adhering closely to the hyperparameter settings reported in their work. In the meta-training phase, we employ the AdamW optimizer with default settings. The initial learning rate is set to 1 × 10 -5 and decays to 1 × 10 -6 following a cosine learning rate schedule. For the mini ImageNet and tiered ImageNet datasets, we resize the images to 224 × 224 pixels and train for 100 epochs, with each epoch consisting of 200 episodes. Similarly, for the CIFAR-FS and FC100 datasets, we resize the images to 224 × 224 pixels and train for 90 epochs, with 200 episodes per epoch. During finetuning, we implement an episodic training mechanism. To ensure consistency with prior studies, we utilize the validation set to select the best-performing models. Additionally, we apply standard data augmentation techniques, including random resizing and horizontal flipping.
During the meta-testing phase, we randomly sample 1000 tasks, each containing 15 query images per class. We report the mean accuracy along with the corresponding 95% confidence interval.
## C. Performance Comparison
In accordance with established conventions in few-shot learning, we conduct experiments on four popular few-shot classification benchmarks, with the results presented in Tables I and II. The results indicate that our proposed method, STN, consistently achieves competitive performance compared to state-of-the-art (SOTA) approaches on both 5-way 1-shot and 5-way 5-shot tasks.
Results on mini Imagenet and tiered Imagenet datasets . Table I presents a comparison of the 1-shot and 5-shot performance of our method against baseline models on the mini Imagenet and tiered Imagenet datasets. We achieve significant improvements over existing SOTA results by leveraging both global and local features. For instance, on the mini Imagenet dataset, our method, STN, surpasses FewTURE by 2.02% in the 1-shot setting and 3.49% in the 5-shot setting. Similarly, on the tiered Imagenet dataset, STN outperforms FewTURE by 5.04% and 4.28% in the 1-shot and 5-shot settings, respectively. Compared to CPEA, which employs global features to enhance local features, our method achieves competitive results in the 1-shot setting and approximately 1% improvement in the 5-shot setting.
Compared to FewTURE and CPEA, our method demonstrates superior accuracy while effectively utilizing both global and local features. The significant performance gap between our approach and the comparative baselines further validates the contributions of our method, which captures more comprehensive information from the data and maintains strong generalization capability.
Results on small-resolution datasets . To assess the adaptability of our model, we conduct further experiments on two small-resolution datasets and compare our results with those of other methods. This approach allows us to evaluate the performance of our method across various data scenarios, ensuring a fair and comprehensive analysis.
Table II presents the 1-shot and 5-shot classification performance on the small-resolution datasets CIFAR-FS and FC100. For CIFAR-FS, STN outperforms CPEA by 1.99% in the 1shot setting and 1.83% in the 5-shot setting. Similarly, for FC100, our method surpasses CPEA by 0.55% in the 1-shot setting and 1.67% in the 5-shot setting.
These results demonstrate the effectiveness of our method across all four datasets, as it consistently achieves superior performance in all settings. The substantial improvements observed further affirm the strengths of our approach, which effectively utilizes both global and local features to enhance image representation. The efficacy of this method is evidenced by the significant performance gains achieved across diverse few-shot learning tasks.
## D. Ablation Study
In this subsection, we conduct ablation experiments to analyze the impact of each component on the performance of our method. Specifically, we focus on the 5-way setting using the mini Imagenet dataset and the pre-trained Vision Transformer backbone. By examining the performance variations resulting from these ablations, we gain insights into the contribution of each component to the overall effectiveness of our method. In particular, we investigate the influence of the following variations:
Utilizing both global and local features : To evaluate the effectiveness of our Siamese Transformer Network, we design two comparative models. In the first approach, we exclude local features, and both branches use global features to compute the similarity score. In the second approach, we
TABLE I
COMPARISONS ON 5-WAY 1-SHOT AND 5-WAY 5-SHOT WITH 95 % CONFIDENCE INTERVALS ON mini IMAGENET AND tiered IMAGENET.
| Model | Backbone | Venue | mini ImageNet | mini ImageNet | tiered ImageNet | tiered ImageNet |
|-------------------|------------|--------------|-----------------|-----------------|-------------------|-------------------|
| | | | 1-shot | 5-shot | 1-shot | 5-shot |
| ProtoNet [3] | ResNet-12 | NeurIPS 2017 | 62.29±0.33 | 79.46±0.48 | 68.25±0.23 | 84.01±0.56 |
| FEAT [12] | ResNet-12 | CVPR 2020 | 66.78±0.20 | 82.05±0.14 | 70.80±0.23 | 84.79±0.16 |
| CAN [25] | ResNet-12 | NeurIPS 2019 | 63.85±0.48 | 79.44±0.34 | 69.89±0.51 | 84.23±0.37 |
| CTM [11] | ResNet-18 | CVPR 2019 | 64.12±0.82 | 80.51±0.13 | 68.41±0.39 | 84.28±1.73 |
| ReNet [28] | ResNet-12 | ICCV 2021 | 67.60±0.44 | 82.58 ±0.30 | 71.61±0.51 | 85.28±0.35 |
| DeepEMD [10] | ResNet-12 | CVPR 2020 | 65.91±0.82 | 82.41±0.56 | 71.16±0.87 | 86.03±0.58 |
| IEPT [42] | ResNet-12 | ICLR 2021 | 67.05±0.44 | 82.90±0.30 | 72.24±0.50 | 86.73±0.34 |
| MELR [43] | ResNet-12 | ICLR 2021 | 67.40±0.43 | 83.40±0.28 | 72.14±0.51 | 87.01±0.35 |
| FRN [44] | ResNet-12 | CVPR 2021 | 66.45±0.19 | 82.83±0.13 | 72.06±0.22 | 86.89±0.14 |
| CG [45] | ResNet-12 | AAAI 2021 | 67.02±0.20 | 82.32±0.14 | 71.66±0.23 | 85.50±0.15 |
| DMF [46] | ResNet-12 | CVPR 2021 | 67.76±0.46 | 82.71±0.31 | 71.89±0.52 | 85.96±0.35 |
| InfoPatch [47] | ResNet-12 | AAAI 2021 | 67.67±0.45 | 82.44±0.31 | - | - |
| BML [48] | ResNet-12 | ICCV 2021 | 67.04±0.63 | 83.63±0.29 | 68.99±0.50 | 85.49±0.34 |
| CNL [45] | ResNet-12 | AAAI 2021 | 67.96±0.98 | 83.36±0.51 | 73.42±0.95 | 87.72±0.75 |
| Meta-NVG [49] | ResNet-12 | ICCV 2021 | 67.14±0.80 | 83.82±0.51 | 74.58±0.88 | 86.73±0.61 |
| PAL [50] | ResNet-12 | ICCV 2021 | 69.37±0.64 | 84.40±0.44 | 72.25±0.72 | 86.95±0.47 |
| COSOC [51] | ResNet-12 | NeurIPS 2021 | 69.28±0.49 | 85.16±0.42 | 73.57±0.43 | 87.57±0.10 |
| Meta DeepBDC [52] | ResNet-12 | CVPR 2022 | 67.34±0.43 | 84.46±0.28 | 72.34±0.49 | 87.31±0.32 |
| QSFormer [53] | ResNet-12 | TCSVT 2023 | 65.24±0.28 | 79.96±0.20 | 72.47±0.31 | 85.43±0.22 |
| LastShot [54] | ResNet-12 | TPAMI 2024 | 67.35±0.20 | 82.58±0.14 | 72.43±0.23 | 85.82±0.16 |
| LEO [16] | WRN-28-10 | ICLR 2019 | 61.76±0.08 | 77.59±0.12 | 66.33±0.05 | 81.44±0.09 |
| CC+rot [55] | WRN-28-10 | ICCV 2019 | 62.93±0.45 | 79.87±0.33 | 70.53±0.51 | 84.98±0.36 |
| FEAT [12] | WRN-28-10 | CVPR 2020 | 65.10±0.20 | 81.11±0.14 | 70.41±0.23 | 84.38±0.16 |
| MetaQDA [56] | WRN-28-10 | ICCV 2021 | 67.83±0.64 | 84.28±0.69 | 74.33±0.65 | 89.56±0.79 |
| OM [57] | WRN-28-10 | ICCV 2021 | 66.78±0.30 | 85.29±0.41 | 71.54±0.29 | 87.79±0.46 |
| FewTURE [29] | ViT-Small | NeurIPS 2022 | 68.02±0.88 | 84.51±0.53 | 72.96±0.92 | 86.43±0.67 |
| CPEA [30] | ViT-Small | ICCV 2023 | 71.97±0.65 | 87.06±0.38 | 76.93±0.70 | 90.12±0.45 |
| STN (ours) | ViT-Small | - | 72.04±0.62 | 88.00±0.37 | 77.10±0.74 | 90.71±0.42 |
TABLE II COMPARISONS ON 5-WAY 1-SHOT AND 5-WAY 5-SHOT WITH 95 % CONFIDENCE INTERVALS ON CIFAR-FS AND FC100.
| Model | Backbone | Venue | CIFAR-FS | CIFAR-FS | FC100 | FC100 |
|---------------|------------|--------------|------------|------------|------------|------------|
| | | | 1-shot | 5-shot | 1-shot | 5-shot |
| ProtoNet [3] | ResNet-12 | NeurIPS 2017 | - | - | 41.54±0.76 | 57.08±0.76 |
| MetaOpt [58] | ResNet-12 | CVPR 2019 | 72.00±0.70 | 84.20±0.50 | 41.10±0.60 | 55.50±0.60 |
| MABAS [59] | ResNet-12 | ECCV 2020 | 73.51±0.92 | 85.65±0.65 | 42.31±0.75 | 58.16±0.78 |
| RFS [19] | ResNet-12 | ECCV 2020 | 73.90±0.80 | 86.90±0.50 | 44.60±0.70 | 60.90±0.60 |
| BML [48] | ResNet-12 | ICCV 2021 | 73.45±0.47 | 88.04±0.33 | - | - |
| CG [45] | ResNet-12 | AAAI 2021 | 73.00±0.70 | 85.80±0.50 | - | - |
| Meta-NVG [49] | ResNet-12 | ICCV 2021 | 74.63±0.91 | 86.45±0.59 | 46.40±0.81 | 61.33±0.71 |
| RENet [28] | ResNet-12 | ICCV 2021 | 74.51±0.46 | 86.60±0.32 | - | - |
| TPMN [60] | ResNet-12 | ICCV 2021 | 75.50±0.90 | 87.20±0.60 | 46.93±0.71 | 63.26±0.74 |
| MixFSL [61] | ResNet-12 | ICCV 2021 | - | - | 44.89±0.63 | 60.70±0.60 |
| QSFormer [53] | ResNet-12 | TCSVT 2023 | - | - | 46.51±0.26 | 61.58±0.25 |
| LastShot [54] | ResNet-12 | TPAMI 2024 | 76.76±0.21 | 87.49±0.12 | 44.08±0.18 | 59.14±0.18 |
| CC+rot [55] | WRN-28-10 | ICCV 2019 | 73.62±0.31 | 86.05±0.22 | - | - |
| PSST [62] | WRN-28-10 | CVPR 2021 | 77.02±0.38 | 88.45±0.35 | - | - |
| Meta-QDA [56] | WRN-28-10 | ICCV 2021 | 75.83±0.88 | 88.79±0.75 | - | - |
| FewTURE [29] | ViT-Small | NeurIPS 2022 | 76.10±0.88 | 86.14±0.64 | 46.20±0.79 | 63.14±0.73 |
| CPEA [30] | ViT-Small | ICCV 2023 | 77.82±0.66 | 88.98±0.45 | 47.24±0.58 | 65.02±0.60 |
| STN (ours) | ViT-Small | - | 79.81±0.67 | 90.81±0.67 | 47.79±0.61 | 66.69±0.58 |
## TABLE III
RESULTS OF THE VARIOUS FEATURES UTILIZED IN METRICS FOR FEW-SHOT CLASSIFICATION ON mini IMAGENET.
exclude global features, and both branches rely solely on local features to measure the similarity score.
| Method | 1-shot | 5-shot |
|------------------|------------|------------|
| STN (w/o local) | 69.08±0.59 | 86.19±0.35 |
| STN (w/o global) | 70.67±0.69 | 86.31±0.38 |
| STN (ours) | 72.04±0.62 | 88.00±0.37 |
As shown in Table III, the results clearly demonstrate the significant improvement achieved by our method, STN, compared to the baseline models. This outcome confirms the effectiveness of STN in enhancing performance for few-shot learning tasks.
Distance functions employed in STN : To identify the most suitable metric for global feature-based measurement, we evaluate four methods: dot product ( dot ), Manhattan dis-
TABLE IV
RESULTS OF THE DIFFERENT DISTANCE FUNCTIONS EMPLOYED IN METRICS FOR FEW-SHOT CLASSIFICATION ON mini IMAGENET.
TABLE V
| Distance Function | 1-shot | 5-shot |
|---------------------|------------|------------|
| dot | 68.07±0.61 | 83.43±0.65 |
| abs | 67.85±0.61 | 84.47±0.73 |
| cos | 64.06±0.69 | 75.87±0.50 |
| sqr | 69.08±0.59 | 86.19±0.35 |
| wass | 57.85±0.71 | 66.27±0.61 |
| covar | 68.43±0.66 | 80.83±0.46 |
| KL | 70.67±0.69 | 86.31±0.38 |
RESULTS OF THE VARIOUS METRIC FUSIONS FOR 1-SHOT CLASSIFICATION ON mini IMAGENET.
TABLE VI
| | wass | covar | KL |
|-----|------------|------------|------------|
| dot | 64.60±0.62 | 70.59±0.63 | 71.36±0.61 |
| abs | 68.16±0.65 | 70.71±0.64 | 71.49±0.62 |
| cos | 61.92±0.66 | 68.65±0.66 | 70.85±0.61 |
| sqr | 68.92±0.66 | 70.89±0.65 | 72.04±0.62 |
RESULTS OF THE DIFFERENT METRIC FUSIONS FOR 5-SHOT CLASSIFICATION ON mini IMAGENET. RESULTS OF THE VARIOUS METRIC FUSIONS FOR 5-SHOT CLASSIFICATION ON MINIIMAGENET.
| | wass | covar | KL |
|-----|------------|------------|------------|
| dot | 85.75±0.38 | 87.22±0.38 | 87.27±0.36 |
| abs | 84.97±0.40 | 86.87±0.39 | 87.16±0.36 |
| cos | 84.86±0.40 | 82.41±0.47 | 86.66±0.38 |
| sqr | 86.37±0.38 | 87.57±0.37 | 88.00±0.37 |
tance ( abs ), Euclidean distance ( sqr ), and cosine similarity ( cos ). Additionally, to determine the optimal metric for local feature-based measurement, we examine three methods: 2Wasserstein distance ( wass ), covariance metric ( covar ), and Kullback-Leibler ( KL ) divergence.
Table IV presents the impact of different distance functions on the measurement of global and local features. The experiments demonstrate that Euclidean distance yields the most significant results for global features, while Kullback-Leibler divergence performs better for local features. Additionally, we explore various combinations of global and local feature-based metrics, as shown in Tables V and VI. Our findings indicate that the results obtained from combining these two metrics generally outperform those based on a single feature metric. Notably, the fusion of Euclidean distance and KL divergence produces the best outcomes, making this our preferred choice in this study.
TABLE VII RESULTS OF PARAMETER SHARING BETWEEN TWO BRANCHES FOR FEW-SHOT CLASSIFICATION ON mini IMAGENET.
| Parameters Sharing √ | 1-shot | 5-shot |
|------------------------|------------|------------|
| | 70.69±0.63 | 86.98±0.37 |
| × | 72.04±0.62 | 88.00±0.37 |
Parameters between the two branch networks : In our
Fig. 3. Results of different weights in the fusion strategy for few-shot classification on mini ImageNet.
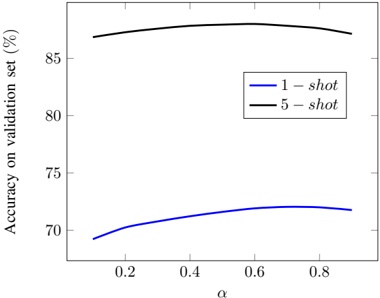
method, although the two branch networks share the same architecture, their parameters are not shared. To validate this design, we conduct comparative experiments in which the parameters are shared between the two networks, and the model loss is computed as the sum of the losses from both branch networks.
As shown in Table VII, our approach outperforms the parameter-sharing model. We speculate that this improvement is due to the interference between global feature optimization and local feature optimization when parameters are shared, which hinders the model's ability to fully leverage the strengths of each optimization. Notably, even when parameters are not shared, if both branches are evaluated using the same type of feature-either global or local-the performance is inferior to that of the parameter-sharing model that utilizes both feature types. This conclusion is supported by the comparisons between Table III and Table VII. These results highlight the effectiveness of our approach in leveraging both global and local features.
TABLE VIII RESULTS OF THE DIFFERENT FUSION STRATEGIES FOR FEW-SHOT CLASSIFICATION ON mini IMAGENET.
| Fusion Strategy | 1-shot | 5-shot |
|-------------------|------------|------------|
| Manual | 72.04±0.62 | 88.00±0.37 |
| Adaptive | 69.69±0.63 | 86.78±0.37 |
Manual fusion strategy vs. adaptive fusion strategy : In this paper, we adopt a manually designed fusion strategy. To validate this design, we also implement an adaptive fusion strategy for comparison. In the adaptive fusion strategy, we utilize a learnable 2-dimensional weight vector w = [ ω 1 ; ω 2 ] to perform the fusion. Thus, the final fusion similarity between a query Q and a class S can be defined as follows:
$$D ( Q, S ) = - \omega _ { 1 } \cdot D _ { K L } ( Q | | S ) - \omega _ { 2 } \cdot D _ { E d } ( Q, S ). \quad ( 1 4 )$$
Specifically, we concatenate these two metric vectors to form a 10-dimensional vector. Subsequently, we apply a 1dimensional convolutional layer with a kernel size of 1 × 1

Local






Support images


## Query image


Fig. 4. Attention map visualization. The color intensity indicates the level of correlation between a local region and global information. Darker red shades signify higher correlation, while darker blue shades indicate lower correlation. By fusing global and local information, our proposed method reduces the weights assigned to semantics that are irrelevant to the global context.






and a dilation rate of 5. This process allows us to obtain a weighted 5-dimensional similarity vector by learning a 2dimensional weight ω . Additionally, a batch normalization layer is added before the convolutional layer to balance the scale of the similarities from both components. Finally, a nonparametric nearest neighbor classifier is employed to derive the final classification result.
reveal that placing greater emphasis on the measurement results of the feature type with superior performance leads to improved outcomes. However, there is a tipping point: for the mini ImageNet dataset in the 1-shot setting, the optimal value of α is 0.7, while in the 5-shot setting, it decreases to 0.6.
As shown in Table VIII, our approach outperforms the model utilizing the adaptive fusion strategy. We hypothesize that while the adaptive method can learn to adjust, it may lead to overfitting on the training data, resulting in underperformance on unseen test data. In contrast, using fixed weights reduces model complexity, thereby mitigating overfitting and enhancing the model's generalization capability.
TABLE IX
RESULTS OF NORMALIZATION IN THE FUSION STRATEGY FOR FEW-SHOT CLASSIFICATION ON mini IMAGENET.
| Normalization √ | 1-shot | 5-shot |
|-------------------|------------|------------|
| | 72.04±0.62 | 88.00±0.37 |
| × | 70.74±0.69 | 86.69±0.38 |
Fusion of dual metrics with normalization : In our method, we first normalize the two metrics before fusing them. To validate the necessity of normalization, we fused the original results of the two metrics without normalization. The experimental results, as shown in Table IX, indicate a significant decrease in model performance when normalization is omitted, highlighting the importance of this step. Additionally, we examined the impact of different weights on evaluation performance, with results presented in Figure 3. The findings
## E. Visualization Analysis
To evaluate the proposed approach, we randomly select a task from the mini ImageNet dataset to demonstrate the changes in the model's attention map. As shown in Figure 4, after applying the feature fusion process, the model exhibits an improved ability to focus on the key areas of the images. These results further validate the effectiveness of our approach, indicating that by fusing global and local features from a single image, the resulting query and support features become more distinguishable.
## V. CONCLUSION
In few-shot learning based on metric learning, feature adaptation modules are typically designed to enhance global feature representation or align semantically related local regions. Existing approaches often learn the similarity between support and query pairs using either global features or local features, neglecting the use of their combination. To address this limitation, we propose a Siamese Transformer Network (STN) framework that employs a dual-branch architecture to extract global and local features separately. To effectively leverage these features, we utilize Euclidean distance for global features and Kullback-Leibler divergence for local features. Based on these measurements, we develop a simple
additive fusion strategy that normalizes and weights the two metrics to produce a final similarity evaluation. This study introduces a simple yet effective method for metric-based fewshot learning by exploiting the strengths of both global and local features. Quantitative experiments on four benchmark datasets validate its effectiveness. Our method achieves stateof-the-art performance while maintaining a straightforward and uncomplicated structure. This simplicity not only ensures ease of implementation but also highlights the robustness and reliability of our method.
## ACKNOWLEDGMENTS
This work is supported by National Natural Science Foundation.
## REFERENCES
- [1] J. Bromley, J. W. Bentz, L. Bottou, I. Guyon, Y. LeCun, C. Moore, E. S¨ ackinger, and R. Shah, 'Signature verification using A 'siamese' time delay neural network,' Int. J. Pattern Recognit. Artif. Intell. , vol. 7, no. 4, pp. 669-688, 1993.
- [2] B. M. Lake, R. Salakhutdinov, J. Gross, and J. B. Tenenbaum, 'One shot learning of simple visual concepts,' in Proceedings of the 33th Annual Meeting of the Cognitive Science Society , 2011.
- [3] J. Snell, K. Swersky, and R. S. Zemel, 'Prototypical networks for fewshot learning,' in Advances in Neural Information Processing Systems , 2017.
- [4] X. Li, J. Chen, H. Zhang, Y. Cho, S. H. Hwang, Z. Gao, and G. Yang, 'Hierarchical relational inference for few-shot learning in 3d left atrial segmentation,' IEEE Transactions on Emerging Topics in Computational Intelligence , pp. 1-16, 2024.
- [5] S. Fu, Q. Peng, X. Wang, Y. He, W. Qiu, B. Zou, D. Xu, X.-Y. Jing, and X. You, 'Jointly optimized classifiers for few-shot class-incremental learning,' IEEE Transactions on Emerging Topics in Computational Intelligence , pp. 1-11, 2024.
- [6] F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. S. Torr, and T. M. Hospedales, 'Learning to compare: Relation network for few-shot learning,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018.
- [7] Y. Chen, Z. Liu, H. Xu, T. Darrell, and X. Wang, 'Meta-baseline: Exploring simple meta-learning for few-shot learning,' in IEEE/CVF International Conference on Computer Vision , 2021.
- [8] O. Vinyals, C. Blundell, T. Lillicrap, k. kavukcuoglu, and D. Wierstra, 'Matching networks for one shot learning,' in Advances in Neural Information Processing Systems , 2016.
- [9] W. Jiang, K. Huang, J. Geng, and X. Deng, 'Multi-scale metric learning for few-shot learning,' IEEE Transactions on Circuits and Systems for Video Technology , vol. 31, no. 3, pp. 1091-1102, 2021.
- [10] C. Zhang, Y. Cai, G. Lin, and C. Shen, 'Deepemd: Few-shot image classification with differentiable earth mover's distance and structured classifiers,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020.
- [11] H. Li, D. Eigen, S. Dodge, M. Zeiler, and X. Wang, 'Finding taskrelevant features for few-shot learning by category traversal,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 . Computer Vision Foundation / IEEE, 2019, pp. 1-10.
- [12] H. Ye, H. Hu, D. Zhan, and F. Sha, 'Few-shot learning via embedding adaptation with set-to-set functions,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020.
- [13] C. Finn, P. Abbeel, and S. Levine, 'Model-agnostic meta-learning for fast adaptation of deep networks,' in Proceedings of the 34th International Conference on Machine Learning , 2017.
- [14] A. Raghu, M. Raghu, S. Bengio, and O. Vinyals, 'Rapid learning or feature reuse? towards understanding the effectiveness of MAML,' in 8th International Conference on Learning Representations , 2020.
- [15] J. Oh, H. Yoo, C. Kim, and S. Yun, 'BOIL: towards representation change for few-shot learning,' in 9th International Conference on Learning Representations , 2021.
- [16] A. A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanu, S. Osindero, and R. Hadsell, 'Meta-learning with latent embedding optimization,' in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenReview.net, 2019.
- [17] S. Gidaris and N. Komodakis, 'Dynamic few-shot visual learning without forgetting,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018.
- [18] W. Chen, Y. Liu, Z. Kira, Y. F. Wang, and J. Huang, 'A closer look at few-shot classification,' in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenReview.net, 2019.
- [19] Y. Tian, Y. Wang, D. Krishnan, J. B. Tenenbaum, and P. Isola, 'Rethinking few-shot image classification: A good embedding is all you need?' in Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XIV . Springer, 2020, pp. 266-282.
- [20] S. X. Hu, D. Li, J. St¨hmer, M. Kim, and T. M. Hospedales, 'Pushing u the limits of simple pipelines for few-shot learning: External data and fine-tuning make a difference,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022.
- [21] Y. He, W. Liang, D. Zhao, H. Zhou, W. Ge, Y. Yu, and W. Zhang, 'Attribute surrogates learning and spectral tokens pooling in transformers for few-shot learning,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 . IEEE, 2022, pp. 9109-9119.
- [22] W. Li, J. Xu, J. Huo, L. Wang, Y. Gao, and J. Luo, 'Distribution consistency based covariance metric networks for few-shot learning,' in The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019 . AAAI Press, 2019, pp. 8642-8649.
- [23] W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo, 'Revisiting local descriptor based image-to-class measure for few-shot learning,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 . Computer Vision Foundation / IEEE, 2019, pp. 7260-7268.
- [24] W. Li, L. Wang, J. Huo, Y. Shi, Y. Gao, and J. Luo, 'Asymmetric distribution measure for few-shot learning,' in Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020 , C. Bessiere, Ed. ijcai.org, 2020, pp. 2957-2963.
- [25] R. Hou, H. Chang, B. Ma, S. Shan, and X. Chen, 'Cross attention network for few-shot classification,' in Advances in Neural Information Processing Systems, December 8-14, 2019, Vancouver, BC, Canada , H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´ e-Buc, E. B. Fox, and R. Garnett, Eds., 2019, pp. 4005-4016.
- [26] C. Doersch, A. Gupta, and A. Zisserman, 'Crosstransformers: spatiallyaware few-shot transfer,' in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
- [27] C. Dong, W. Li, J. Huo, Z. Gu, and Y. Gao, 'Learning task-aware local representations for few-shot learning,' in Proceedings of the TwentyNinth International Joint Conference on Artificial Intelligence , 2020.
- [28] D. Kang, H. Kwon, J. Min, and M. Cho, 'Relational embedding for few-shot classification,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 8802-8813.
- [29] M. Hiller, R. Ma, M. Harandi, and T. Drummond, 'Rethinking generalization in few-shot classification,' in Advances in Neural Information Processing Systems , 2022.
- [30] F. Hao, F. He, L. Liu, F. Wu, D. Tao, and J. Cheng, 'Class-aware patch embedding adaptation for few-shot image classification,' in IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023 . IEEE, 2023, pp. 18 859-18 869.
- [31] J. Cheng, F. Hao, F. He, L. Liu, and Q. Zhang, 'Mixer-based semantic spread for few-shot learning,' IEEE Trans. Multim. , vol. 25, pp. 191202, 2023.
- [32] F. Hao, F. He, J. Cheng, L. Wang, J. Cao, and D. Tao, 'Collect and select: Semantic alignment metric learning for few-shot learning,' in 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019 . IEEE, 2019, pp. 8459-8468.
- [33] G. Koch, R. Zemel, R. Salakhutdinov et al. , 'Siamese neural networks for one-shot image recognition,' in ICML Deep Learning Workshop , 2015.
- [34] L. H. Hughes, M. Schmitt, L. Mou, Y. Wang, and X. X. Zhu, 'Identifying corresponding patches in SAR and optical images with a pseudo-siamese CNN,' IEEE Geosci. Remote. Sens. Lett. , vol. 15, no. 5, pp. 784-788, 2018.
- [35] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, 'An image is worth 16x16 words: Transformers for image recognition at scale,' in 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021.
- [36] J. C. Duchi, 'Derivations for linear algebra and optimization,' 2016.
- [37] S. Ravi and H. Larochelle, 'Optimization as a model for few-shot learning,' in 5th International Conference on Learning Representations , 2017.
- [38] M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, 'Meta-learning for semi-supervised few-shot classification,' in 6th International Conference on Learning Representations , 2018.
- [39] L. Bertinetto, J. F. Henriques, P. H. S. Torr, and A. Vedaldi, 'Metalearning with differentiable closed-form solvers,' in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenReview.net, 2019.
- [40] B. N. Oreshkin, P. R. L´ opez, and A. Lacoste, 'TADAM: task dependent adaptive metric for improved few-shot learning,' in Advances in Neural Information Processing Systems, December 3-8, 2018, Montr´ eal, Canada , S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. CesaBianchi, and R. Garnett, Eds., 2018, pp. 719-729.
- [41] A. Krizhevsky, I. Sutskever, and G. E. Hinton, 'Imagenet classification with deep convolutional neural networks,' in Advances in Neural Information Processing Systems , 2012.
- [42] M. Zhang, J. Zhang, Z. Lu, T. Xiang, M. Ding, and S. Huang, 'IEPT: instance-level and episode-level pretext tasks for few-shot learning,' in 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021.
- [43] N. Fei, Z. Lu, T. Xiang, and S. Huang, 'MELR: meta-learning via modeling episode-level relationships for few-shot learning,' in 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021.
- [44] D. Wertheimer, L. Tang, and B. Hariharan, 'Few-shot classification with feature map reconstruction networks,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021.
- [45] J. Zhao, Y. Yang, X. Lin, J. Yang, and L. He, 'Looking wider for better adaptive representation in few-shot learning,' in AAAI Conference on Artificial Intelligence , 2021.
- [46] C. Xu, Y. Fu, C. Liu, C. Wang, J. Li, F. Huang, L. Zhang, and X. Xue, 'Learning dynamic alignment via meta-filter for few-shot learning,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021 . Computer Vision Foundation / IEEE, 2021, pp. 5182-5191.
- [47] C. Liu, Y. Fu, C. Xu, S. Yang, J. Li, C. Wang, and L. Zhang, 'Learning a few-shot embedding model with contrastive learning,' in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021 . AAAI Press, 2021, pp. 8635-8643.
- [48] Z. Zhou, X. Qiu, J. Xie, J. Wu, and C. Zhang, 'Binocular mutual learning for improving few-shot classification,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 8382-8391.
- [49] C. Zhang, H. Ding, G. Lin, R. Li, C. Wang, and C. Shen, 'Meta navigator: Search for a good adaptation policy for few-shot learning,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 9415-9424.
- [50] J. Ma, H. Xie, G. Han, S. Chang, A. Galstyan, and W. Abd-Almageed, 'Partner-assisted learning for few-shot image classification,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 10 55310 562.
- [51] X. Luo, L. Wei, L. Wen, J. Yang, L. Xie, Z. Xu, and Q. Tian, 'Rectifying the shortcut learning of background for few-shot learning,' in Advances in Neural Information Processing Systems, December 6-14, 2021, virtual , M. Ranzato, A. Beygelzimer, Y. N. Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021, pp. 13 073-13 085.
- [52] J. Xie, F. Long, J. Lv, Q. Wang, and P. Li, 'Joint distribution matters: Deep brownian distance covariance for few-shot classification,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 . IEEE, 2022, pp. 7962-7971.
- [53] X. Wang, X. Wang, B. Jiang, and B. Luo, 'Few-shot learning meets transformer: Unified query-support transformers for few-shot classification,' IEEE Transactions on Circuits and Systems for Video Technology , vol. 33, no. 12, pp. 7789-7802, 2023.
- [54] H. Ye, L. Ming, D. Zhan, and W. Chao, 'Few-shot learning with a strong teacher,' IEEE Trans. Pattern Anal. Mach. Intell. , vol. 46, no. 3, pp. 1425-1440, 2024.
- [55] S. Gidaris, A. Bursuc, N. Komodakis, P. P´ erez, and M. Cord, 'Boosting few-shot visual learning with self-supervision,' in 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019 . IEEE, 2019, pp. 8058-8067.
- [56] X. Zhang, D. Meng, H. Gouk, and T. M. Hospedales, 'Shallow bayesian meta learning for real-world few-shot recognition,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 631-640.
- [57] G. Qi, H. Yu, Z. Lu, and S. Li, 'Transductive few-shot classification on the oblique manifold,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 8392-8402.
- [58] K. Lee, S. Maji, A. Ravichandran, and S. Soatto, 'Meta-learning with differentiable convex optimization,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 . Computer Vision Foundation / IEEE, 2019, pp. 10 657-10 665.
- [59] J. Kim, H. Kim, and G. Kim, 'Model-agnostic boundary-adversarial sampling for test-time generalization in few-shot learning,' in Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part I . Springer, 2020, pp. 599-617.
- [60] J. Wu, T. Zhang, Y. Zhang, and F. Wu, 'Task-aware part mining network for few-shot learning,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 8413-8422.
- [61] A. Afrasiyabi, J. Lalonde, and C. Gagn´ e, 'Mixture-based feature space learning for few-shot image classification,' in 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 . IEEE, 2021, pp. 9021-9031.
- [62] Z. Chen, J. Ge, H. Zhan, S. Huang, and D. Wang, 'Pareto selfsupervised training for few-shot learning,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021 . Computer Vision Foundation / IEEE, 2021, pp. 13 66313 672. | null | [
"Weihao Jiang",
"Shuoxi Zhang",
"Kun He"
]
| 2024-07-16T14:27:23+00:00 | 2024-07-16T14:27:23+00:00 | [
"cs.CV",
"cs.AI"
]
| Siamese Transformer Networks for Few-shot Image Classification | Humans exhibit remarkable proficiency in visual classification tasks,
accurately recognizing and classifying new images with minimal examples. This
ability is attributed to their capacity to focus on details and identify common
features between previously seen and new images. In contrast, existing few-shot
image classification methods often emphasize either global features or local
features, with few studies considering the integration of both. To address this
limitation, we propose a novel approach based on the Siamese Transformer
Network (STN). Our method employs two parallel branch networks utilizing the
pre-trained Vision Transformer (ViT) architecture to extract global and local
features, respectively. Specifically, we implement the ViT-Small network
architecture and initialize the branch networks with pre-trained model
parameters obtained through self-supervised learning. We apply the Euclidean
distance measure to the global features and the Kullback-Leibler (KL)
divergence measure to the local features. To integrate the two metrics, we
first employ L2 normalization and then weight the normalized results to obtain
the final similarity score. This strategy leverages the advantages of both
global and local features while ensuring their complementary benefits. During
the training phase, we adopt a meta-learning approach to fine-tune the entire
network. Our strategy effectively harnesses the potential of global and local
features in few-shot image classification, circumventing the need for complex
feature adaptation modules and enhancing the model's generalization ability.
Extensive experiments demonstrate that our framework is simple yet effective,
achieving superior performance compared to state-of-the-art baselines on four
popular few-shot classification benchmarks in both 5-shot and 1-shot scenarios. |
2408.01428v1 | ## Transferable Adversarial Facial Images for Privacy Protection
Minghui Li [email protected] School of Software Engineering, Huazhong University of Science and Technology
Jiangxiong Wang [email protected] School of Software Engineering, Huazhong University of Science and Technology
Hao Zhang [email protected] School of Software Engineering, Huazhong University of Science and Technology
Ziqi Zhou [email protected] School of Computer Science and Technology, Huazhong University of Science and Technology
Shengshan Hu [email protected] School of Cyber Science and Engineering, Huazhong University of Science and Technology
## ABSTRACT
The success of deep face recognition (FR) systems has raised serious privacy concerns due to their ability to enable unauthorized tracking of users in the digital world. Previous studies proposed introducing imperceptible adversarial noises into face images to deceive those face recognition models, thus achieving the goal of enhancing facial privacy protection. Nevertheless, they heavily rely on user-chosen references to guide the generation of adversarial noises, and cannot simultaneously construct natural and highly transferable adversarial face images in black-box scenarios. In light of this, we present a novel face privacy protection scheme with improved transferability while maintain high visual quality. We propose shaping the entire face space directly instead of exploiting one kind of facial characteristic like makeup information to integrate adversarial noises. To achieve this goal, we first exploit global adversarial latent search to traverse the latent space of the generative model, thereby creating natural adversarial face images with high transferability. We then introduce a key landmark regularization module to preserve the visual identity information. Finally, we investigate the impacts of various kinds of latent spaces and find that F latent space benefits the trade-off between visual naturalness and adversarial transferability. Extensive experiments over two datasets demonstrate that our approach significantly enhances attack transferability while maintaining high visual quality, outperforming state-of-the-art methods by an average 25% improvement in deep FR models and 10% improvement on commercial FR APIs, including Face++, Aliyun, and Tencent.
## 1 INTRODUCTION
Deep face recognition (FR) systems [30, 40] have triumphed in both verification and identification scenarios and been widely applied across various domains, such as security [44], biometrics [28],
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
ACM MM, 2024, Melbourne, Australia
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM. ACM ISBN 978-x-xxxx-xxxx-x/YY/MM
https://doi.org/10.1145/nnnnnnn.nnnnnnn
Xiaobing Pei [email protected] School of Software Engineering, Huazhong University of Science and Technology
Figure 1: Illustration of facial privacy protection
and criminal-investigation [31]. Despite its promising prospect, FR systems pose a profound risk to individual privacy due to their capacity for large-scale surveillance [2, 46], e.g. , tracking user relationship and activities by analyzing face images from social media platforms [13, 36]. Given the opacity of these FR systems, there is an urgent need for an effective black-box approach to protect facial privacy.
Recent works have attempted to protect facial privacy using noise-based adversarial examples (AEs) [32, 38, 49] by adding carefully crafted adversarial perturbations to the source face images to deceive malicious FR systems. However, the adversarial perturbations are typically constrained to the 𝑙 𝑝 norm within the pixel space, which makes adversarial face images have conspicuous discernible artifacts with poor visual quality [49].
Another solution is exploiting unrestricted adversarial examples [15, 35, 50, 61] to mislead malicious FR systems. Unlike noisebased methods, they are not confined by perturbation budgets, thereby maintaining superior image quality [4, 37, 48]. Recently proposed makeup-based approaches ( e.g. , AMT-GAN [15], CLIP2Protect [35]) have achieved state-of-the-art performance, as they can effectively embed adversarial noises in the makeup style by using generative adversarial networks (GANs) [10, 16] or GAN inversion. However, they rely on extra user-chosen guidance, such as reference images in AMT-GAN and textual prompts in CLIP2Protect, to make adversarial noises harmoniously integrated with face characteristics. Besides, these methods excessively focus on the modification of local attributes, leading to minor effects on facial identity characteristics, resulting in limited transferability.
Toaddress the above issues, we propose the G uidance- ndependent I Adversarial F acial Images with T ransferability (GIFT) for privacy protection, which takes a big step towards bridging the gap between visual naturalness and adversarial transferability. Firstly, we map face images to a low-dimensional manifold represented by a generative model. We then conduct adversarial latent optimization that moves along the adversarial direction. In contrast to [35], we perform adversarial latent optimization over the global latent space called Global Adversarial Latent Search (GALS) , which can control more semantic information with improved transferability. However, in the absence of extra guidance information, GALS may change the visual identity of resulting images. Therefore, we introduce a key landmark regularization (KLR) method to rectify this issue. Furthermore, we investigate the effect of diverse latent spaces on our scheme. We find that the latent space W+ , which is commonly used in existing face privacy protection tasks, exhibits weaker transferability and lower perceptual image quality than the other two prevalent latent spaces W and F . Consequently, we opt for the optimal latent space F to further enhance our design. In summary, our main contributions include:
- · We propose a novel facial privacy protection approach using Global Adversarial Latent Search to construct natural and highly transferable adversarial face images without extra guidance information.
- · Wereveal the limitations of W+ latent space and the intriguing properties of the other two prevalent latent spaces W and F under the facial privacy protection scenario.
- · Extensive experiments on both face verification and identification tasks demonstrate the superiority of our approach against various deep FR models and commercial APIs. Notably, we achieved a significant improvement of 25% than existing schemes in terms of transferability.
## 2 RELATED WORK AND BACKGROUND
## 2.1 Facial Privacy Protection
Recently, many works have been proposed to protect facial privacy against unauthorized FR systems [29, 42, 43]. The typical strategy involves the utilization of noise-based adversarial examples [29, 49, 57-60], where carefully crafted perturbations are added to face images to deceive malicious FR models. Oh et al. [29] proposed crafting protected face images from a game theory perspective in the white-box setting, which is impractical in real-world scenarios. Thus TIP-IM [49] introduced the idea of generating adversarial identity masks in the black-box setting. However, the perturbations are usually perceptible to humans and affect the user experience.
Another strategy is to leverage unrestricted adversarial examples [4, 18, 37, 48, 52, 56], which are not constrained by the perturbation norm in the pixel space and enjoy a better image quality [4, 37, 48]. Among these, makeup-based unrestricted adversarial examples are presented against unknown FR systems by concealing adversarial perturbations within natural makeup characteristics. Zhu et al. [61] made the first effort to utilize makeup to generate protected face images in the white-box setting. Afterwards, AdvMakeup [50] synthesized imperceptible eye shadow over the orbital region on the face, which has limited transferability. AMT-GAN [15] generated adversarial face images with makeup transferred from
Figure 2: Evaluation of GALS and LALS on different FR models. We conduct training on a single model and subsequently test it on the remaining three. Results are presented for three different false acceptance rates ( i.e. , 0 1 . , 0 01 . , 0 001 . ).
reference images in a black-box manner, which has a higher attack success rate but suffers from obvious artifacts due to the conflict between the makeup transfer module and the adversarial noises. Recently, CLIP2Protect [35] traversed over the local latent space that controls the makeup style of a pre-trained generative model by using text prompts. However, all the above methods rely on guidance ( e.g. , text or image references) to make the adversarial noises distributed in a natural way. This is a disappointing constraint in real-world applications as the users usually have no desired target references. More importantly, the visual quality of output face images is largely affected by the references, as detailedly discussed in Section 3.2. DiffProtect [26] and Adv-Diffusion [24] employ the diffusion models [53] as the generative models and iteratively refine the latent representations of facial images, although yielding higher-quality adversarial facial images, exhibit limited attack transferability, rendering it impractical for real-world applications.
## 2.2 GAN Inversion
GAN inversion [1, 19, 39, 41, 47] intends to invert a given face image back to a low-dimensional manifold which is expressed as a latent space of a pre-trained GAN model, such that the image can be faithfully reconstructed. As the StyleGAN [22] models trained on a high-resolution face image dataset [21] exhibit exceptional image synthesis capabilities, various GAN inversion methods have been developed using different latent spaces based on StyleGANs. Generally, there are three typical latent spaces ( i.e. , W [1], W+ [39], and F [19]). They are the trade-off design between the reconstruction quality and editability [25]. W uses a mapping network to disentangle different features with a high degree of editability. However, it has limited expressiveness which restricts the range of images that can be faithfully reconstructed. Meanwhile, W+ feeds different intermediate latent vectors into each layer of the generator via AdaIN [17], alleviating the image distortion at the expense of editability. The latent space F consists of specific features which
Figure 3: Protection success rates of different latent spaces on four FR models in the black-box setting. Specifically, we perform training on a single model and subsequently test it on the remaining three. We set the false match rate of 0.01 for each model.
enjoy the highest reconstruction quality but suffer from the worst editability.
## 3 METHODOLOGY
## 3.1 Problem definition
In general, FR systems can operate with two modes: face verification and face identification . For verification, the FR systems identify whether two face images correspond to the same identity. For identification, the FR systems query the face database to identify whose representation is closest to the input image. In this paper, we consider both scenarios to sufficiently demonstrate the effectiveness of our approach. As seen in Fig. 1, if the user's source face image 𝒙 𝑠 is directly posted to social media platforms, malicious FR systems could potentially trace the relationships and activities of the user by analysing the publicly available images.
With the help of facial privacy protection algorithms, users can obtain the protected face image 𝒙 𝑝 that appears indistinguishable to human ( i.e. , naturalness) but can deceive the FR systems ( i.e. , transferablility). For the malicious FR systems, 𝒙 𝑝 has the same identity as the target impersonated image 𝒙 𝑡 in both face verification and face identification. Generally, the problem can be formulated as:
$$\min _ { x _ { p } } \mathcal { L } _ { a d v } & = \mathcal { D } \left ( f _ { n } \left ( x _ { p } \right ), f _ { n } \left ( x _ { t } \right ) \right ) & \quad \widehat { \ g u } \\ s. t. \, \mathcal { H } \left ( x _ { p }, x _ { s } \right ) \leq \epsilon & \quad \widehat { \ e x _ { \dots } }$$
where D(·) represents a distance metric and 𝑓 𝑛 (·) stands for a FR model that outputs a feature vector by extracting the feature representation of a face image. Contrary to noise-based adversarial examples where H GLYPH<0> 𝒙 𝑝 , 𝒙 𝑠 GLYPH<1> = GLYPH<13> GLYPH<13> 𝒙 𝑠 -𝒙 𝑝 GLYPH<13> GLYPH<13> 𝑝 and ∥ · ∥ 𝑝 is the 𝐿 𝑝 norm, H GLYPH<0> 𝒙 𝑝 , 𝒙 𝑠 GLYPH<1> ≤ 𝜖 quantifies the extent of unnaturalness of 𝒙 𝑝 compared to 𝒙 𝑠 .
Figure 4: FID comparison in three latent spaces
## 3.2 Challenges and limitations
Existing works [15, 35] have experimentally demonstrated that the guidance of the reference image or text prompts plays an important role in maintaining the visual quality of adversarial face images during the process of generation. Without using guidance, the adversarial perturbations will be randomly generated and spread all over the face without any constraints, leading to obvious artifacts in the result images. If we simply fix the adversarial area, the noises may make the modified area extremely strange and distorted. Therefore, existing works have to use extra information to guide the distribution of adversarial noises such that they can harmonize with facial characteristics.
Moreover, even with makeup information guidance, due to the incomplete disentanglement of facial attributes, the adversarial modifications concentrating on one kind of local semantics struggle to integrate seamlessly with other facial semantic information. As shown in Fig. 7, the visual quality can still be damaged in guidancebased schemes, especially when the reference is not appropriately chosen. Note that although CLIP2Protect [35] maintains the face quality well in some cases, the background behind the face has been significantly damaged. It should be emphasized that the image's visual quality should contain not only the facial information but also the background.
Besides, these methods excessively focus on local attributes, leading to minor effects on facial identity characteristics. This limitation results in limited transferability and renders them less practical for real-world applications.
## 3.3 Our key insights
To address the aforementioned issues, we propose directly manipulating the entire facial space to harmoniously integrate adversarial noises, rather than solely using one kind of facial characteristic to guide the distribution of noises. In this way, all of the facial information will be adaptively assembled, including makeup characteristics, expressions, and face shape, as well as adversarial noises. In addition, by comprehensively optimizing every feature rather than excessively optimizing a particular attribute, the transferability of generated adversarial facial images is significantly improved. To this end, we first have the following observations.
Observation I: Global adversarial latent search exhibits enhanced transferability. In order to maintain the naturalness of the face images 𝒙 𝑝 , CLIP2Protect [35] only optimizes the latent
Figure 5: The framework of GIFT
modification of one single attribute is limited, resulting in relatively smaller repercussions on the overall facial identity features compared to GALS. Conversely, GALS harmoniously refines the entire facial characteristics to sophisticatedly guide the distribution of noises along the adversarial direction in the low-dimensional manifold [6] represented as the latent space. We perform experiments to validate this observation, as shown in Fig. 2, and find that GALS has a higher protection success rate compared to LALS in the black-box setting, indicating far better transferability than GALS.
Figure 6: Differences between Global Adversarial Latent Search and Local Adversarial Latent Search. Global Adversarial Latent Search seamlessly modifies the latent code along the adversarial direction. In contrast, LALS merely adjust the local attributes, which has many limitations.
codes corresponding to the deep layers of StyleGAN that is associated with the makeup style. This method is essentially a kind of Local Adversarial Latent Search (LALS) . Meanwhile, numerous studies [3, 23] have affirmed that the initial layers of StyleGAN control more face image attributes, such as pose, hairstyle, and face shape. Therefore, we speculate that optimizing both the deep layers and initial layers of latent codes, a.k.a , Global Adversarial Latent Search (GALS) , is more beneficial to enhance the adversarial transferability, as they can control more semantic information.
Fig. 6 provides a visualization example to illustrate this observation. Specifically, LALS only focuses on optimizing local single attributes, such as makeup-related features, potentially disturbing adjacent attribute distributions or those that are not incompletely decoupled, which might impact the visual effect. Moreover, the
Observation II: Key landmark regularization helps ensure visual identity. Due to the absence of guidance information, our approach may result in changes of visual identity during the process of global optimization. Therefore, there is a need for a new regularization method to maintain visual identity. Intuitively, leveraging the traditional MSE is promising for aligning the protected image 𝒙 𝑝 with the source image 𝒙 𝑠 . Nevertheless, pixel-level regularization may lead to the emergence of artifacts in the face image and a reduction of adversarial effectiveness. Inspired by [26], we introduce a method called key landmark regularization (KLR) due to their capability to achieve region-level regularization, which aligns two semantic segmentation maps of the protected image 𝒙 𝑝 and the source image 𝒙 𝑠 in the optimization process. This method ensures consistency in the distribution of facial characteristics and the overall face shape between 𝒙 𝑠 and 𝒙 𝑝 .
Observation III: F latent space benefits the trade-off between visual naturalness and adversarial transferability. It is critical for a GAN inversion method to choose a good latent space that can reconstruct the face images faithfully and facilitate downstream tasks. Unfortunately, the latent space W+ widely used in the existing facial privacy protection schemes has poor reconstruction quality [25]. In light of this, we explore the performance of the other two typical latent spaces, W and F . As shown in Fig. 3 and Fig. 4, the latent space F not only exhibits the best image quality but also demonstrates strong black-box attack success rate
## Algorithm 1: Transferable Adversarial Facial Images
Input: Source image 𝒙 𝑠 , target image 𝒙 𝑡 , generator 𝐺 , encoder 𝐸 𝑏 , semantic encoder 𝐸 𝑠 , optimizer 𝐴𝑑𝑎𝑚 . Parameter: Iterations 𝑇 1, iterations 𝑇 2, transformation .
Output: Protected image 𝒙 𝑝
probability 𝑝 , hyper-parameters 𝜆 𝑝𝑒𝑟 , 𝜆 𝑠𝑒𝑚 .
- 1 Generate initial latent code 𝒘 𝑖𝑛𝑖 = 𝐸 𝑏 ( 𝒙 𝑠 ) ;
- 2 for 𝑖 = 0 to 𝑇 1 -1 do
- 3 Calculate L 𝑟𝑒𝑐 with Eq. (2);
- 4 𝒘 𝑖𝑛𝑖 ← 𝐴𝑑𝑎𝑚 ( 𝒘 𝑖𝑛𝑖 , L 𝑟𝑒𝑐 ) ;
- 5 end
- 6 Obtain the initialized latent code 𝒘 𝑓 = 𝒘 𝑖𝑛𝑖 ;
- 7 for 𝑖 = 0 to 𝑇 2 -1 do
- 8 Obtain intermediate image 𝒙 𝑝𝑖 = 𝐺 GLYPH<16> 𝒘 𝑓 GLYPH<17> ;
- 9 Calculate semantic maps 𝑠𝑒𝑚 𝑠 = 𝐸 𝑠 ( 𝒙 𝑠 ) and 𝑠𝑒𝑚 𝑝 = 𝐸 𝑠 ( 𝒙 𝑝𝑖 ) ;
- 10 Calculate L 𝑡𝑜𝑡𝑎𝑙 with Eq. (5);
- 11 𝒘 𝑓 ← 𝐴𝑑𝑎𝑚 ( 𝒘 𝑓 , L 𝑡𝑜𝑡𝑎𝑙 ) ;
12 end
- 13 Obtain final latent code 𝒘 𝑓 𝑜 ;
- 14 Return the protected image 𝒙 𝑝 = 𝐺 GLYPH<16> 𝒘 𝑓 𝑜 GLYPH<17> .
in the black-box setting, achieving the optimal trade-off between naturalness and high adversarial transferability.
## 3.4 Transferable Adversarial Facial Images
Drawing inspiration from the above analysis, we propose a brandnewgenerative framework (GIFT) to generate guidance-independent adversarial facial images with transferability for facial privacy protection. The pipeline of our approach is depicted in Fig. 5. We first employ GAN inversion to initialize the latent code that can faithfully reconstruct the source face image in F rather than W+ [35] latent space. Then, we conduct the global adversarial latent search, which takes the protected image and the target image as inputs to adversarially optimize the latent code of the protected face image. Furthermore, we introduce a key landmark regularization to preserve the visual identity of the protected image.
Latent Code Initialization: The latent code is initialized based on GAN inversion. Given a source image 𝒙 𝑠 and pre-trained encoder 𝐸 𝑏 from [19], we first calculate the initial latent code 𝒘 𝑖𝑛𝑖 = 𝐸 𝑏 ( 𝒙 𝑠 ) in the F latent space. Then we optimize the latent code 𝒘 𝑖𝑛𝑖 by a reconstruction loss, which is defined as:
$$\mathcal { L } _ { r e c } \left ( w ^ { i n i } \right ) = & \mathcal { L } _ { m s e } \left ( w ^ { i n i } \right ) + \alpha \mathcal { L } _ { p e r } \left ( w ^ { i n i } \right ) \, & \quad \text{$\lambda_{ad}$} \text{in} \, \mathbb { c } \\ = & \left \| x _ { s } - G \left ( w ^ { i n i } \right ) \right \| ^ { 2 } \quad \text{$(2)} \quad \text{ide} \\ + & \alpha \left \| F ( x _ { s } ) - F \left ( G \left ( w ^ { i n i } \right ) \right ) \right \| ^ { 2 } \quad \text{$\text{sell}$} \text{For} \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text $\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$
$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$ \lambda_{ad}$}$$
where 𝐺 refers to the pre-trained generative model, L 𝑚𝑠𝑒 and L per denote mean-squared-error (MSE) and perceptual loss, respectively. 𝛼 is the weight assigned to L 𝑝𝑒𝑟 . 𝐹 (·) represents an LPIPS [55]
network used to compute the perceptual distance. As a result, we obtain the initialized latent code 𝒘 𝑓 , which can faithfully reconstruct 𝒙 𝑠 by 𝐺 .
Global Adversarial Latent Search: We utilize an ensemble training strategy with input diversity to search for a good adversarial optimization direction similar to [15]. We select 𝑁 pre-trained FR models { 𝑓 𝑛 (·)} 𝑁 𝑛 = 1 which exhibit high accuracy in the public facial datasets, serving as white-box models to imitate the decision boundaries of potential target models in the black-box setting during performing global optimization. The adversarial loss is:
$$\mathcal { L } _ { a d v } = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathcal { D } \left ( f _ { n } \left ( T \left ( G \left ( w ^ { f } \right ), p \right ) \right ), f _ { n } \left ( x _ { t } \right ) \right ) \quad \left ( 3 \right )$$
where D( 𝒙 1 , 𝒙 2 ) = 1 -cos ( 𝒙 1 , 𝒙 2 ) is the cosine distance, 𝑓 𝑛 (·) represents the 𝑛 -th local pre-trained white-box model which maps an input face image to a feature representation. 𝑇 (·) represents the transformation function including image resizing and Gaussian noising, and 𝑝 is a predefined probability that determines whether the transformation will be applied to 𝐺 GLYPH<16> 𝒘 𝑓 GLYPH<17> .
Key Landmark Regularization: Wefirst leverage a pre-trained semantic encoder from [51] to obtain the face semantic segmentation maps 𝑠𝑒𝑚 𝑠 and 𝑠𝑒𝑚 𝑝 for the source and protected image. We then take advantage of the semantic segmentation maps to regularize the optimization process, ensuring that the protected image preserves visual identity for humans. The regularization loss is defined as:
$$\mathcal { L } _ { s e m } = \mathcal { L } _ { C E } \left ( \mathcal { M } \left ( G \left ( w ^ { f } \right ) \right ), \mathcal { M } \left ( x _ { s } \right ) \right ) \quad \quad \left ( 4 \right )$$
where L 𝐶𝐸 (·) is the cross-entropy loss, M(·) represents the pretrained semantic encoder. The total loss is:
$$\mathcal { L } _ { \text{total} } = \lambda _ { \text{adv} } \, \mathcal { L } _ { \text{adv} } + \lambda _ { \text{sem} } \, \mathcal { L } _ { \text{sem} } \, \text{ \quad \ \ } ( 5 )$$
where 𝜆 adv and 𝜆 sem represent the hyper-parameters. The whole optimization process is outlined in Algorithm. 1.
## 4 EXPERIMENTS
## 4.1 Experiments Setup
Implementation Details: We employ StyleGAN2 pre-trained on FFHQ [21] as our generative model and use the Adam optimizer in all experiments. For Latent Code Initialization, we iteratively optimize the latent code for 1200 steps with a learning rate of 0 01. . During the adversarial optimization process, we traverse over the global latent space for 50 iterations with a learning rate of 0 002 . to generate protected face images. We set the hyper-parameters 𝛼 , 𝜆 adv and 𝜆 sem to 10, 1, 0 01, respectively. More details can be seen . in our supplementary.
Datasets: Weperform experiments for both face verification and identification tasks. Face Verification : We utilize CelebA-HQ [20] and LADN [11] as our test set. Specifically, for CelebA-HQ, we select a subset which contains 1000 images with different identities. For LADN, we divide the 332 images into 4 groups, with each group of images impersonating a target identity provided by [15]. Face Identification : we randomly select 500 images of 500 different identities in CelebA-HQ as the probe set, and the corresponding
Source
Source
TIP-IM
AMT-GAN
CLIP2Protect
Ours
TIP-IM
AMT-GAN
CLIP2Protect
Ours
CLIP2Protect V.S. Ours

Figure 7: Comparion of visual quality between SOTA noise-based TIP-IM, unrestricted AMT-GAN, CLIP2Protect and our method
Table 1: Protection success rate (%) of impersonation attack under the face verification task
| Method | CelebA-HQ | CelebA-HQ | CelebA-HQ | CelebA-HQ | LADN-Dataset | LADN-Dataset | LADN-Dataset | LADN-Dataset | Average |
|-----------------------------|-------------|-------------|-------------|-------------|----------------|----------------|----------------|----------------|-----------|
| | IRSE50 | IR152 | FaceNet | MobileFace | IRSE50 | IR152 | FaceNet | MobileFace | |
| Clean | 7.29 | 3.80 | 1.08 | 12.68 | 2.71 | 3.61 | 0.60 | 5.11 | 4.61 |
| PGD [27] | 36.87 | 20.68 | 1.85 | 43.99 | 40.09 | 19.59 | 3.82 | 41.09 | 25.60 |
| MI-FGSM [8] | 45.79 | 25.03 | 2.58 | 45.85 | 48.90 | 25.57 | 6.31 | 45.01 | 30.63 |
| TI-DIM [9] | 63.63 | 36.17 | 15.30 | 57.12 | 56.36 | 34.18 | 22.11 | 48.30 | 41.64 |
| Adv-Makeup (IJCAI'21) [50] | 21.95 | 9.48 | 1.37 | 22.00 | 29.64 | 10.03 | 0.97 | 22.38 | 14.72 |
| TIP-IM (ICCV'21) [49] | 54.40 | 37.23 | 40.74 | 48.72 | 65.89 | 43.57 | 63.50 | 46.48 | 50.06 |
| AMT-GAN (CVPR'22) [15] | 76.96 | 35.13 | 16.62 | 50.71 | 89.64 | 49.12 | 32.13 | 72.43 | 52.84 |
| CLIP2Protect (CVPR'23) [35] | 81.10 | 48.42 | 41.72 | 75.26 | 91.57 | 53.31 | 47.91 | 79.94 | 64.90 |
| GIFT (Ours) | 95.70 | 92.50 | 63.50 | 91.90 | 94.61 | 98.20 | 85.03 | 96.41 | 89.73 |
Table 2: Protection success rate (%) of impersonation attacks under the face identification task
| Method | IRSE50 | IRSE50 | IR152 | IR152 | FaceNet | FaceNet | MobileFace | MobileFace | Average | Average |
|-------------------|----------|----------|---------|---------|-----------|-----------|--------------|--------------|-----------|-----------|
| Method | R1-T | R5-T | R1-T | R5-T | R1-T | R5-T | R1-T | R5-T | R1-T | R5-T |
| TIP-IM [49] | 16.2 | 51.4 | 21.2 | 56.0 | 8.1 | 35.8 | 9.6 | 24.0 | 13.8 | 41.8 |
| CLIP2Protect [35] | 24.5 | 64.7 | 24.2 | 65.2 | 12.5 | 38.7 | 11.8 | 28.2 | 18.2 | 49.2 |
| GIFT (Ours) | 69.8 | 93.6 | 72.0 | 87.6 | 44.8 | 70.2 | 41.6 | 80.2 | 57.1 | 82.9 |
Table 3: Comparison of FID and PSR Gain. PSR Gain is absolute gain in PSR relative to Adv-Makeup.
500 images of the same identities along with the target image 𝒙 𝑝 to form the gallery set.
| Method | FID ↓ | PSR Gain ↑ |
|-------------------|---------|--------------|
| Adv-Makeup [50] | 4.23 | 0 |
| TIP-IM [49] | 38.73 | 35.34 |
| AMT-GAN [15] | 34.44 | 38.12 |
| CLIP2Protect [35] | 46.34 | 50.18 |
| GIFT (Ours) | 31.19 | 75.01 |
Target Models: Following [15], we choose various deep FR models and commercial FR APIs to evaluate the transferability of the adversarial facial images generated by GIFT in the black-box settings. Specifically, the deep FR models include MobileFace [5], IR152 [7], IRSE50 [14], and FaceNet [33] and commercial FR APIs include Face++, Aliyun, and Tencent.
Competitors: We compare GIFT with recent noise-based and makeup-based facial privacy protection approaches. Noised-based
Figure 8: Confidence scores returned from commercial APIs
methods include PGD [27], MI-FGSM [8], TI-DIM [9], and TIPIM [49]. Makeup-based approaches include Adv-Makeup [50], AMTGAN [15] and CLIP2Protect [35]. Among these methods, TIP-IM and CLIP2Protect are regarded as the state-of-the-art (SOTA) approaches against black-box FR systems in noise-based and unrestricted settings, respectively. Notably, TIP-IM employs a multitarget objective within its optimization to discover the best image from multiple targets. To maintain fairness in the comparison, we employ a single-target variant.
Evaluation Metrics: We employ different evaluation strategies to calculate the protection success rate (PSR) for the verification and identification scenarios. For verification, we identify that two face images belong to the same identity if D GLYPH<0> 𝒙 𝑝 , 𝒙 𝑠 GLYPH<1> ≥ 𝜏 and then calculate the proportion of successfully protected images in relation to all images. For identification, we report the Rank-N targeted identity success rate, which means that at least one of the top N images belongs to the target identity after ranking the distance for all images in the gallery to the given probe image. For commercial FR APIs, we directly record the confidence scores returned by FR servers. We also leverage FID [12], PSNR (dB) and SSIM [45] to evaluate the image quality. The FID quantifies the dissimilarity between two data distributions [54], commonly employed to assess the extent to which a generated dataset resembles one obtained from the real world. PSNR and SSIM are commonly utilized techniques for assessing the difference between two images.
## 4.2 Comparison Study
Evaluation on Black-box FR Models. We present experimental results of GIFT in the black-box settings on four different pretrained FR models on two public datasets under face verification and identification tasks. For face verification, we set the system threshold value at 0 01 false match rate for each FR model . i.e. , IRSE50 (0 241), IR152 (0 167), FaceNet (0 409), and MobileFace (0 302). The . . . . quantitative results in terms of PSR under the face verification scenario are displayed in Tab. 1. The results show that GIFT has the capability to achieve an average absolute gain of about 25% and 39% over SOTA unrestricted and noise-based facial privacy protection
Figure 9: Visualization of gradient response using Grad-CAM on FR model (IRSE50). The numbers under each image represent their cosine similarity with the target image, along with the confidence scores from the commercial APIs (Face++, Aliyun).
Table 4: FID comparison of different latent spaces
| Latent space | MobileFace | IR152 | IRSE50 | FaceNet | Average |
|----------------|--------------|---------|----------|-----------|-----------|
| W | 42.8 | 41.78 | 42.51 | 41.49 | 42.14 |
| W+ | 40.05 | 39.92 | 39.99 | 39.91 | 39.97 |
| F | 31.15 | 31.12 | 31.13 | 31.42 | 31.26 |
methods, respectively. We also provide PSR under the face identification scenario in Tab. 2. Consistently, GIFT outperforms recent methods in both Rank-1 and Rank-5 settings. Given that AMT-GAN and Adv-Makeup were initially trained for impersonating the target identity in the verification task, they have not been incorporated into Tab. 2.
Evaluation on Image Quality. Tab. 3 shows the quantitative evaluations on image quality. Notably, we report the results that are averaged over 10 text prompts for CLIP2Protect. Although AdvMakeup [50] achieves the lowest FID score, its transferability is limited due to perturbing only the eye region. Beyond Adv-Makeup,
Figure 10: PSR comparison of GALS and LALS

by CLIP2Protect have an obvious 'painted-on' appearance, especially when viewed at high resolution. In contrast, GIFT produces adversarial face images that look natural and effectively preserve the background content, making it applicable in practical scenarios.
Figure 11: The effect of key landmark regularization
Figure 12: PSR comparison of different latent spaces
GIFT yields better FID results with the highest transferability, indicating that the adversarial face images generated by GIFT are more natural. We also provide PSNR and SSIM results in the supplementary material.
In addition, we give a qualitative comparison of visual image quality in Fig. 7 with noise-based method TIP-IM and makeupbased unrestricted methods AMT-GAN and CLIP2Protect. TIP-IM's adversarial face images contain noticeable noise that can be easily perceived by humans. The makeup generated by AMT-GAN sometimes does not align well with the facial characteristics, resulting in artifacts on the face images. The adversarial face images generated
Evaluation on Commercial APIs. We further demonstrate the effectiveness of GIFT on commercial APIs ( i.e. , Face++, Aliyun, and Tencent) in face verification mode. The output of these APIs is a confidence score on a scale of 0 to 100, serving as a metric for the similarity between two images. A higher score signifies a greater degree of similarity. The training data and model parameters of these commercial APIs are undisclosed, effectively simulating scenarios in real-world face privacy protection. We present the average confidence scores for 1000 images from the CelebA-HQ dataset in Fig. 8, demonstrating the superiority of GIFT over other competitors.
## 4.3 Visualization and Analysis
In this section, we employ Grad-CAM [34] to explore why the adversarial face images generated by GIFT exhibit better transferability. We present gradient visualizations of adversarial face images generated by AMT-GAN, CLIP2Protect, and GIFT in the black-box setting compared to the target images in Fig. 9. We can observe that the gradient responses of AMT-GAN and CLIP2Protect either concentrate on specific facial regions or focus on the background of the face image. In contrast, the gradient responses of GIFT are concentrated on the facial region, without being limited to local features, but rather covering the entire face. Therefore, the adversarial face images generated by GIFT exhibit superior performance, both on deep FR models and commercial FR APIs.
## 4.4 Ablation Study
The Effect of KLR: We investigate the effect of key landmark regularization on GIFT. As shown in Fig. 11, with the absence of KLR, the visual identity of the protected face image will change.
The Effect of GALS: We analyze the effect of GALS on GIFT. As depicted in Fig. 10, compared to LALS, which only adversarially modifies the makeup style, GALS exhibits significantly better transferability.
The Effect of Latent Space: We study the effect of different latent spaces on GIFT. Both Fig. 12 and Tab. 4 indicate that, although W latent space results in better adversarial transferability, the generated adversarial face images exhibit poor image quality. In contrast, F latent space maintains high transferability while achieving the best image quality.
## 5 CONCLUSION
In this paper, focusing on protecting facial privacy against malicious FR systems, we propose GIFT, a guidance-independent generative framework to construct highly transferable adversarial facial images while maintain good visual effect. Specifically, we leverage Global Adversarial Latent Search to construct natural and highly transferable adversarial face images without extra guidance information. Moreover, we introduce a key landmark regularization method to preserve the visual identity. We further reveal the limitations of W+ latent space and the intriguing properties of the other two prevalent latent spaces W and F under the facial privacy protection scenario. Extensive experiments on both face verification and identification tasks demonstrate the superiority of GIFT against various deep FR models and commercial FR APIs.
## ACKNOWLEDGMENTS
Minghui's work is supported in part by the National Natural Science Foundation of China (Grant No.62202186). Shengshan's work is supported in part by the National Natural Science Foundation of China (Grant No.62372196,U20A20177). Ziqi Zhou is the corresponding author.
## REFERENCES
- [1] Rameen Abdal, Yipeng Qin, and Peter Wonka. 2019. Image2stylegan: How to embed images into the stylegan latent space?. In Proceedings of the 17th IEEE/CVF International Conference on Computer Vision (ICCV'19) . 4432-4441.
- [2] Shane Ahern, Dean Eckles, Nathaniel S Good, Simon King, Mor Naaman, and Rahul Nair. 2007. Over-exposed? Privacy patterns and considerations in online and mobile photo sharing. In Proceedings of the SIGCHI conference on Human factors in computing systems (CHI'07) . 357-366.
- [3] Amit H Bermano, Rinon Gal, Yuval Alaluf, Ron Mokady, Yotam Nitzan, Omer Tov, Oren Patashnik, and Daniel Cohen-Or. 2022. State-of-the-Art in the Architecture, Methods and Applications of StyleGAN. In Computer Graphics Forum , Vol. 41. Wiley Online Library, 591-611.
- [4] Anand Bhattad, Min Jin Chong, Kaizhao Liang, Bo Li, and David A Forsyth. 2019. Unrestricted adversarial examples via semantic manipulation. arXiv preprint arXiv:1904.06347 (2019).
- [5] Sheng Chen, Yang Liu, Xiang Gao, and Zhen Han. 2018. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. In Proceedings of the 13th Chinese Conference on Biometric Recognition (CCBR'18) , Vol. 10996. 428-438.
- [6] Zhaoyu Chen, Bo Li, Shuang Wu, Kaixun Jiang, Shouhong Ding, and Wenqiang Zhang. 2024. Content-based unrestricted adversarial attack. Advances in Neural Information Processing Systems 36 (2024).
- [7] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'19) . 46904699.
- [8] Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. 2018. Boosting adversarial attacks with momentum. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'18) . 9185-9193.
- [9] Yinpeng Dong, Tianyu Pang, Hang Su, and Jun Zhu. 2019. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'19) . 4312-4321.
- [10] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139-144.
- [11] Qiao Gu, Guanzhi Wang, Mang Tik Chiu, Yu-Wing Tai, and Chi-Keung Tang. 2019. Ladn: Local adversarial disentangling network for facial makeup and de-makeup. In Proceedings of the 17th IEEE/CVF International Conference on Computer Vision (ICCV'19) . 10481-10490.
- [12] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NeurIPS'17) .
- [13] Kashmir Hill. 2022. The secretive company that might end privacy as we know it. In Ethics of Data and Analytics . Auerbach Publications, 170-177.
- [14] Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'18) . 7132-7141.
- [15] Shengshan Hu, Xiaogeng Liu, Yechao Zhang, Minghui Li, Leo Yu Zhang, Hai Jin, and Libing Wu. 2022. Protecting facial privacy: Generating adversarial identity masks via style-robust makeup transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'22) . 15014-15023.
- [16] Shengshan Hu, Ziqi Zhou, Yechao Zhang, Leo Yu Zhang, Yifeng Zheng, Yuanyuan He, and Hai Jin. 2022. BadHash: Invisible backdoor attacks against deep hashing with clean label. In Proceedings of the 30th ACM International Conference on Multimedia (MM'22) . 678-686.
- [17] Xun Huang and Serge Belongie. 2017. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'17) . 1501-1510.
- [18] Kazuya Kakizaki and Kosuke Yoshida. 2019. Adversarial image translation: Unrestricted adversarial examples in face recognition systems. arXiv preprint arXiv:1905.03421 (2019).
- [19] Kyoungkook Kang, Seongtae Kim, and Sunghyun Cho. 2021. Gan inversion for out-of-range images with geometric transformations. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV'21) . 13941-13949.
- [20] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2017. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017).
- [21] Tero Karras, Samuli Laine, and Timo Aila. 2019. A stle-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'19) . 4401-4410.
- [22] Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'19) . 4401-4410.
- [23] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'20) . 8110-8119.
- [24] Decheng Liu, Xijun Wang, Chunlei Peng, Nannan Wang, Ruimin Hu, and Xinbo Gao. 2024. Adv-diffusion: imperceptible adversarial face identity attack via latent diffusion model. In Proceedings of the AAAI Conference on Artificial Intelligence(AAAI'24) . 3585-3593.
- [25] Hongyu Liu, Yibing Song, and Qifeng Chen. 2023. Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'23) . 10072-10082.
- [26] Jiang Liu, Chun Pong Lau, and Rama Chellappa. 2023. Diffprotect: Generate adversarial examples with diffusion models for facial privacy protection. arXiv preprint arXiv:2305.13625 (2023).
- [27] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 (2017).
- [28] Blaž Meden, Peter Rot, Philipp Terhörst, Naser Damer, Arjan Kuijper, Walter J Scheirer, Arun Ross, Peter Peer, and Vitomir Štruc. 2021. Privacy-enhancing face biometrics: A comprehensive survey. IEEE Transactions on Information Forensics and Security 16 (2021), 4147-4183.
- [29] Seong Joon Oh, Mario Fritz, and Bernt Schiele. 2017. Adversarial image perturbation for privacy protection a game theory perspective. In Proceedings of the 16th IEEE/CVF International Conference on Computer Vision (ICCV'17) . IEEE, 1491-1500.
- [30] Omkar Parkhi, Andrea Vedaldi, and Andrew Zisserman. 2015. Deep face recognition. In Proceedings of the 26th British Machine Vision Conference (BMVC'15) . British Machine Vision Association.
- [31] P Jonathon Phillips, Amy N Yates, Ying Hu, Carina A Hahn, Eilidh Noyes, Kelsey Jackson, Jacqueline G Cavazos, Géraldine Jeckeln, Rajeev Ranjan, Swami Sankaranarayanan, et al. 2018. Face recognition accuracy of forensic examiners, superrecognizers, and face recognition algorithms. Proceedings of the National Academy of Sciences 115, 24 (2018), 6171-6176.
- [32] Arezoo Rajabi, Rakesh B Bobba, Mike Rosulek, Charles Wright, and Wu-chi Feng. 2021. On the (im) practicality of adversarial perturbation for image privacy. Proceedings on Privacy Enhancing Technologies 2021, 1 (2021), 85-106.
- [33] Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'15) . 815-823.
- [34] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 16th IEEE/CVF International Conference on Computer Vision (ICCV'17) . 618-626.
| [35] | Fahad Shamshad, Muzammal Naseer, and Karthik Nandakumar. 2023. CLIP2Protect: Protecting Facial Privacy using Text-Guided Makeup via Adversar- ial Latent Search. In Proceedings of the IEEE/CVF Conference on Computer Vision |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [36] | Yan Shoshitaishvili, Christopher Kruegel, and Giovanni Vigna. 2015. Portrait of a privacy invasion. Proceedings on Privacy Enhancing Technologies 2015, 1 (2015), 41-60. |
| [37] | Yang Song, Rui Shu, Nate Kushman, and Stefano Ermon. 2018. Constructing unrestricted adversarial examples with generative models. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS'18) |
| [38] | 8322-8333. Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2013. Intriguing properties of neural networks. |
| [39] | arXiv preprint arXiv:1312.6199 (2013). Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. 2021. Designing an encoder for stylegan image manipulation. ACM Transactions on |
| [40] | Graphics 40, 4 (2021), 1-14. Mei Wang and Weihong Deng. 2021. Deep face recognition: A survey. Neuro- computing 429 (2021), 215-244. |
| [41] | Tengfei Wang, Yong Zhang, Yanbo Fan, Jue Wang, and Qifeng Chen. 2022. High- fidelity gan inversion for image attribute editing. In Proceedings of the IEEE/CVF |
| [42] | Conference on Computer Vision and Pattern Recognition (CVPR'22) . 11379-11388. Xianlong Wang, Shengshan Hu, Minghui Li, Zhifei Yu, Ziqi Zhou, and Leo Yu Zhang. 2023. Corrupting convolution-based unlearnable datasets with pixel- based image transformations. arXiv preprint arXiv:2311.18403 (2023). |
| [43] | Xianlong Wang, Shengshan Hu, Yechao Zhang, Ziqi Zhou, Leo Yu Zhang, Peng Xu, Wei Wan, and Hai Jin. 2024. ECLIPSE: Expunging clean-label indiscriminate poisons via sparse diffusion purification. In Proceedings of the 29th European |
| [44] | Symposium on Research in Computer Security (ESORICS'24) . Ya Wang, Tianlong Bao, Chunhui Ding, and Ming Zhu. 2017. Face recognition in real-world surveillance videos with deep learning method. In Proceedings of the IEEE International Conference on Image, Vision and Computing (ICIVC'17) |
| [45] | 239-243. Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. IEEE Transactions |
| [46] | on Image Processing 13, 4 (2004), 600-612. Emily Wenger, Shawn Shan, Haitao Zheng, and Ben Y Zhao. 2023. Sok: Anti-facial recognition technology. In Proceedings of the 44th IEEE Symposium on Security and Privacy (S&P'23) . IEEE, 864-881. |
| [47] | Weihao Xia, Yulun Zhang, Yujiu Yang, Jing-Hao Xue, Bolei Zhou, and Ming- Hsuan Yang. 2022. Gan inversion: Asurvey. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 3 (2022), 3121-3138. |
| [48] | Chaowei Xiao, Jun-Yan Zhu, Bo Li, Warren He, Mingyan Liu, and Dawn Song. 2018. Spatially transformed adversarial examples. arXiv preprint arXiv:1801.02612 (2018). |
| [49] | Xiao Yang, Yinpeng Dong, Tianyu Pang, Hang Su, Jun Zhu, Yuefeng Chen, and Hui Xue. 2021. Towards face encryption by generating adversarial identity masks. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision |
| [50] | (ICCV'21) . 3897-3907. Bangjie Yin, Wenxuan Wang, Taiping Yao, Junfeng Guo, Zelun Kong, Shouhong Ding, Jilin Li, and Cong Liu. 2021. Adv-makeup: A new imperceptible and transferable attack on face recognition. arXiv preprint arXiv:2105.03162 (2021). |
| [51] | Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, and Nong Sang. 2018. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV'18) . 325-341. |
| [52] | Shengming Yuan, Qilong Zhang, Lianli Gao, Yaya Cheng, and Jingkuan Song. 2022. Natural color fool: Towards boosting black-box unrestricted attacks. In Pro- ceedings of the 36th Annual Conference on Neural Information Processing Systems (NeurIPS'22) , Vol. 35. 7546-7560. |
| [53] | Hangtao Zhang, Shengshan Hu, Yichen Wang, Leo Yu Zhang, Ziqi Zhou, Xianlong Wang, Yanjun Zhang, and Chao Chen. 2024. Detector Collapse: Backdooring Object Detection to Catastrophic Overload or Blindness. In Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI'24) . |
| [54] | Hangtao Zhang, Zeming Yao, Leo Yu Zhang, Shengshan Hu, Chao Chen, Alan Liew, and Zhetao Li. 2023. Denial-of-service or fine-grained control: Towards flexi- ble model poisoning attacks on federated learning. arXiv preprint arXiv:2304.10783 (2023). |
| [55] | Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition |
| [56] | (CVPR'18) . 586-595. Zhengyu Zhao, Zhuoran Liu, and Martha Larson. 2020. Towards large yet im- perceptible adversarial image perturbations with perceptual color distance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR'20) . 1039-1048. |
| [57] | Yaoyao Zhong and Weihong Deng. 2022. Opom: Customized invisible cloak towards face privacy protection. IEEE Transactions on Pattern Analysis and |
Machine Intelligence 45, 3 (2022), 3590-3603.
- [58] Ziqi Zhou, Shengshan Hu, Minghui Li, Hangtao Zhang, Yechao Zhang, and Hai Jin. 2023. Advclip: Downstream-agnostic adversarial examples in multimodal contrastive learning. In Proceedings of the 31st ACM International Conference on Multimedia (MM'23) . 6311-6320.
- [59] Ziqi Zhou, Shengshan Hu, Ruizhi Zhao, Qian Wang, Leo Yu Zhang, Junhui Hou, and Hai Jin. 2023. Downstream-agnostic adversarial examples. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV'23) . 4345-4355.
- [60] Ziqi Zhou, Minghui Li, Wei Liu, Shengshan Hu, Yechao Zhang, Wei Wan, Lulu Xue, Leo Yu Zhang, Dezhong Yao, and Hai Jin. 2024. Securely Fine-tuning Pretrained Encoders Against Adversarial Examples. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP'24) .
- [61] Zheng-An Zhu, Yun-Zhong Lu, and Chen-Kuo Chiang. 2019. Generating adversarial examples by makeup attacks on face recognition. In Proceedings of the IEEE International Conference on Image Processing (ICIP'19) . IEEE, 2516-2520. | null | [
"Minghui Li",
"Jiangxiong Wang",
"Hao Zhang",
"Ziqi Zhou",
"Shengshan Hu",
"Xiaobing Pei"
]
| 2024-07-18T02:16:11+00:00 | 2024-07-18T02:16:11+00:00 | [
"cs.CV",
"cs.AI"
]
| Transferable Adversarial Facial Images for Privacy Protection | The success of deep face recognition (FR) systems has raised serious privacy
concerns due to their ability to enable unauthorized tracking of users in the
digital world. Previous studies proposed introducing imperceptible adversarial
noises into face images to deceive those face recognition models, thus
achieving the goal of enhancing facial privacy protection. Nevertheless, they
heavily rely on user-chosen references to guide the generation of adversarial
noises, and cannot simultaneously construct natural and highly transferable
adversarial face images in black-box scenarios. In light of this, we present a
novel face privacy protection scheme with improved transferability while
maintain high visual quality. We propose shaping the entire face space directly
instead of exploiting one kind of facial characteristic like makeup information
to integrate adversarial noises. To achieve this goal, we first exploit global
adversarial latent search to traverse the latent space of the generative model,
thereby creating natural adversarial face images with high transferability. We
then introduce a key landmark regularization module to preserve the visual
identity information. Finally, we investigate the impacts of various kinds of
latent spaces and find that $\mathcal{F}$ latent space benefits the trade-off
between visual naturalness and adversarial transferability. Extensive
experiments over two datasets demonstrate that our approach significantly
enhances attack transferability while maintaining high visual quality,
outperforming state-of-the-art methods by an average 25% improvement in deep FR
models and 10% improvement on commercial FR APIs, including Face++, Aliyun, and
Tencent. |
2408.01429v1 | ## An Agile Adaptation Method for Multi-mode Vehicle Communication Networks
Shiwen He , Member, IEEE , Kanghong Chen, Shiyue Huang, Wei Huang , Member, IEEE , and Zhenyu An , Member, IEEE
Abstract -This paper focuses on discovering the impact of communication mode allocation on communication efficiency in the vehicle communication networks. To be specific, Markov decision process and reinforcement learning are applied to establish an agile adaptation mechanism for multi-mode communication devices according to the driving scenarios and business requirements. Then, Q-learning is used to train the agile adaptation reinforcement learning model and output the trained model. By learning the best actions to take in different states to maximize the cumulative reward, and avoiding the problem of poor adaptation effect caused by inaccurate delay measurement in unstable communication scenarios. The experiments show that the proposed scheme can quickly adapt to dynamic vehicle networking environment, while achieving high concurrency and communication efficiency.
directly choose the RSUs or cellular networks to exchange the information. In fact, the same message in the VCNs may need to be simultaneously sent to multiple target nodes, including other vehicles, RSUs, and non-vehicle nodes. Furthermore, the transmission content and the received terminals depend on the communication environment, and the intent of driving [5]. This communication method expands the coverage area, prevents node overload by dispersing the communication load, and enhances the reliability of data interaction and the adaptability of driving intentions in different communication environments.
Index Terms -Multi-mode Communication, Agile Adaptation, Vehicle Communication Networks, Markov Decision Process, Reinforcement Learning.
## I. INTRODUCTION
W ITH the continuous evolution of technological development and industrial transformation, the automotive industry is accelerating its development towards intelligence, networking, and high-end [1]. Cooperative Connected Automated Driving (CCAD) achieves collaborative sensing, decision-making, and control of intelligent networked vehicles through information exchange among vehicles, roadside units (RSUs), and the cloud, which enables them to advance from single vehicle intelligence to group intelligence [2].
The real-time requirement of information exchanges in CCAD poses a significant challenge to wireless communication systems [3]. High-rate, reliable, bidirectional and integrated intelligent network technology with multiple communication modes is important for the realization of intelligent vehicle-road cooperative system, and provides corresponding communication guarantee according to different levels of requirement. In the context of vehicle communication networks (VCNs), the commonly used communication mode is mainly the device-to-device communication (proximity communication, PC5) which coexists with the cellular and WiFi communication systems [4]. This implies that vehicles can
- S. He, K. Chen, and S. Huang are with the School of Computer Science and Engineering, Central South University, Changsha 410083, China. S. He is also with the Purple Mountain Laboratories, Nanjing 211111, China (e-mail: [email protected]).
- W. Huang is School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230601, China, and also with the Intelligent Interconnected Systems Laboratory of Anhui Province, Hefei University of Technology, Hefei 230601, China (e-mail: [email protected]).
- Z. An is with the Purple Mountain Laboratories, Nanjing 210096, China (email: [email protected]).
In the current multi-mode communication systems, the devices usually select one communication mode to perform the specific services, which cannot meet the actual application requirements in the case with large number of transmission services [6]. To address this limitation, the authors of [7] proposed an unsupervised deep unrolling framework based on projection gradient descent for solving constrained optimization problems in wireless networks. The authors of [8] introduced a neural network-based communication selection mechanism tailored for VCNs. More recently, multipath transmission and multi-link transmission based on one communication protocol have attracted extensively attention in the field of academia and industry.
Multi-link transmission is commonly employed to ensure the reliable transmission of data with low-latency requirements [9]. This technology uses multiple links of different frequencies that contain multiple base service sets to expand the available bandwidth and further reduce latency [10]. Multi-path transmission typically involves the use of multiple multi-hop paths, with the primary objective of balancing resource utilization among network nodes to alleviate congestion and decrease delay [11]. However, when vehicles or RSUs encounter a surge in transmission tasks due to sudden changes in road conditions, the vehicles must communicate with multiple devices, making it challenging to further reduce transmission delay through parallel multi-link transmission. Multi-path transmission focuses on ensuring data transmission reliability and congestion control [12]. Concurrent multi-user transmissions not only risk node congestion but also require frequent status inquiries from other nodes during the transmission process. Moreover, the flexible scheduling of multiple communication modes, as an enhancement to multi-link and multi-path strategies, can further decrease latency and simplify the process of acquiring congestion information from other nodes, thereby addressing the challenges posed by the need for reliable and low-latency communication in VCNs.
Therefore, in order to solve the above problems, this paper
proposes a VCN multi-mode selection scheme for bursting services. Specifically, the goal of this paper is to minimize the delay of each communication channel while strictly adhering to the transmission delay constraints inherent to VCN burst services and develops an effective agile adaptation reinforcement learning model (AARLM). In summary, the key technical contributions of this paper are summarized as follows:
- · Drawing upon a multi-tiered set of data, encompassing transmission latency requirements, network topologies, and link conditions, this paper explores the concurrent activation of multiple communication modes to facilitate simultaneously multi-user transmissions, thereby addressing the stringent low-latency demands of large-scale burst tasks.
- · This paper proposes an AARLM scheme for multimode communication in VCNs scenarios, combining the dynamic environment of driving scenarios, driving intentions and business needs.
- · This paper verifies the feasibility of multi-mode communication in VCNs scenarios through simulation, and proves that AARLM can effectively meet the real-time requirements of vehicle-to-vehicle communication and vehicle-to-road communication.
The rest of this paper is organized as follows: Section II presents the system model and problem formulation. In Section III, a reinforcement learning (RL)-based multi-mode agile adaptation scheme is proposed. Numerical results are presented in Section IV. Finally, Section V concludes the paper.
## II. SYSTEM MODEL AND PROBLEM FORMULATION
This paper considers a multi-mode VCNs, where the vehicles and RSUs have the ability to simultaneously support multiple communication modes (protocols), which usually provide at least two communication mode in the (C-V2X) [4], i.e,
- · A short distance direct communication mode proximity communication between vehicles, pedestrians and RSUs.
- · Communication mode between terminals and base stations, which can achieve reliable communication over long distances and over a larger range.
In addition, the dedicated short range communications, WiFi, long range radio are also commonly used communication protocols for vehicles, as illustrated in Fig. 1.
For the sake of convenience in description, let V = { 1 2 , , · · · , N } be the set of terminals in the multi-mode VCNs, where V denotes a collection of multi-mode communication
$$\min _ { \{ a ( i, j, c ) \} } \max _ { j \in \tilde { \nu } } \sum _ { c \in c } \frac { a ( i, j, c ) ( F ( i, c ) + S ( i, j, c ) M ( i, j ) ) } { B ( i, j, c ) }, \ ( 1 a ) \ \text{ for price} \\ \longrightarrow \ \text{$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$$$
$$& \nu \nu, \nu, \nu \nmid j \in \nu _ { c \in \mathcal { C } } \quad \lambda \nu, \nmid, \nu \nmid \quad \text{spec} \in \left ( \\ \text{s.t.} \sum _ { c \in \mathcal { C } } a ( i, j, c ) = 1, \forall j \in \widetilde { \mathcal { V } }, \quad \text{(} \text{lb)} \quad \text{to be a} \\ & \quad \sim \quad \text{one con} \\ & \quad \text{(} \text{$i_\mu_\cdots$}.$$
$$& a ( i, j, c ) \in \{ 0, 1 \}, \forall j \in \widetilde { \mathcal { V } }, \forall c \in \mathcal { C }, \quad \ \ ( 1 c ) \quad ( \Lambda ) \ m \Lambda \\ & \quad \longrightarrow a ( i, i, c ) ( F ( i, c ) + S ( i, i, c ) M ( i, i ) ) \quad \sim \cdot \cdot \cdot \cdot \dots \quad \gtrsim \quad.$$
$$\omega _ { \left ( \nu \right ) }, _ { J } \lambda, \lambda _ { J } \lambda, \lambda _ { J } \lambda \right ), \quad \omega _ { J } \lambda \right ), \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \mu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ {\left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \ \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( { \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \ \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \left ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega } { \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu. \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \ } \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu `right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \right ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \ometa _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, &quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \left) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \quad \omega _ { \left ( \nu \right ) }, \$$
(1d)
Fig. 1. Multi-mode vehicle communication network.
vehicle nodes, RSUs and base stations. Moreover this paper assumes that the multi-mode vehicle node i sends the information-bearing symbols to the other terminals denoted as ˜ = V V\{ } i .
This paper focuses on the decision-making policy of multimode node i , aiming to minimize the total transmission latency, as shown in problem (1). Specifically, in formula (1), a i, j, c ( ) denotes the decision variable of multi-mode node i for multi-mode node j , j ∈ V ˜ and c ∈ C . Here, a i, j, c ( ) = 1 indicates that the communication protocol c is selected for transmitting data from node i to node j , j ∈ V ˜ , whereas a i, j, c ( ) = 0 indicates otherwise. B i, j, c ( ) is the bandwidth allocated by multi-mode node i for communication with multimode node j in mode c . M i,j ( ) and D i, j ( ) represent the data size that multi-mode node i transmits to multi-mode node j and the maximum tolerable delay between node i and node j respectively. Among them, the data size M i,j ( ) can be unequal between node i and different nodes. F i, c ( ) indicates the buffer data at node i for different communication modes c . Let S i, j, c ( ) be the indicator of whether communication protocol c is supported between node i and node j , i ∈ V , j ∈ V ˜ , c ∈ C = { 1 2 , , · · · , C } with C being the number of communication protocols supporting by the multi-mode nodes in the multi-mode VCNs, i.e.,
S i, j, c ( ) ∈ { 0 1 , } ∀ , i ∈ V , j ∈ V ∀ ˜ , c ∈ C . (2) In equation (2), S i, j, c ( ) = 1 signifies that communication protocol c is supported between multi-mode node i and node j ; conversely, S i, j, c ( ) = 0 indicates the absence of support for protocol c between these two nodes. Unless otherwise specified, every node within the multi-mode VCN is assumed to be a multi-mode node, meaning that there are more than one communication protocols available ( C > 1 ) 1 . Constraint (1a) means that only one communication mode can be selected
1 This work assumes that various communication protocol links between communication terminals have been established before using selecting the corresponding mechanisms.
between multi-mode node i and multi-mode node j . Constraint (1d) indicates that the communication delay between multimode node i and node j must be less than the maximum tolerable delay.
It is not difficult to see that problem (3) is an integer linear programming problem, which is generally challenging to solve directly. As the problem scale increases, particularly with the presence of numerous multi-mode nodes, the number of variables and constraints in the optimization formulation escalates significantly, resulting in a substantial increase in solution time. Therefore, this work proposes the incorporation of RL to solve the agile adaptation problems in different scenarios.
## III. REINFORCEMENT LEARNING MODEL FOR AGILE ADAPTATION PROBLEMS
To achieve low latency, this paper adopts Q-learning [13] to train and optimize the vehicle communication decision model. In this section, the agile adaptation scheme is obtained by using the Q-learning method. It is vital to first establish the three fundamental elements of Q-learning: action space, state space and reward function. Subsequently, a tailored model network is designed to cater to the specific requirements of the considered agile adaptation problem. In order to facilitate the design of the model, problem (1) is converted to problem (3) to obtain the minimum delay τ , and constraint (3b) indicates that τ must be greater than the transmission delay between multi-mode node i and any multi-mode node j in ˜ V .
$$\min _ { \{ a ( i, j, c ) \} } \tau, & & ( 3 a ) \, \max _ { \begin{array} { c } \text{$\max_{\text{$a$} } \\ \text{each $m$} \end{array} }$$
$$\text{s.t.} \sum _ { \substack { c \in c \\ \longrightarrow } } ^ { \iota \iota, j, c _ { J } } \frac { a ( i, j, c ) ( F ( i, c ) + S ( i, j, c ) M ( i, j ) ) } { B ( i, j, c ) } \leq \tau, \forall j \in \widetilde { \mathcal { V } }, \ ( 3 b ) } \quad \text{eacn} \ m ( s )$$
$$\sum _ { c \in \mathcal { C } } ^ { c \in \mathcal { C } } a ( i, j, c ) = 1, \forall j \in \widetilde { \mathcal { V } }, \quad & & ( 3 c ) & & \text{The}$$
$$& a ( i, j, c ) \in \{ 0, 1 \}, \forall j \in \widetilde { \mathcal { V } }, \forall c \in \mathcal { C }, \quad & ( 3 d ) \\ & \quad a ( i, j, c ) ( F ( i, c ) + S ( i, j, c ) M ( i, j ) ) \ \, \sim \, \sim \, \dots \, \sim \, \dots \, \quad \, \vdots$$
$$\omega _ { \L } ( \nu, J, \lambda _ { \nu } ) \subseteq \L ( \nu, \lambda _ { \nu } ), \nu _ { J } \subseteq \nu, \nu _ { \L } \subseteq \L ( \nu ) \\ \sum _ { c \in c } \frac { a ( i, j, c ) ( F ( i, c ) + S ( i, j, c ) M ( i, j ) ) } { B ( i, j, c ) } \leq D ( i, j ), \forall j \in \tilde { \mathcal { V } }. \quad \text{ where } \, \\ \Gamma _ { \Lambda \in \L } \quad \text{ that } m i$$
(3e)
## A. Basic Elements of Reinforcement Learning Model
In the agile adaptation problem (3), the communication network, comprised of multiple multi-mode nodes, is used as the environment of the AARLM, and the multi-mode nodes serve as agents in the AARLM to interact with the environment. To ensure the model's responsiveness to environmental shifts and output the optimal decision-making action according to the current environment, the action space, state space and reward function of the AARLM are described as follows:
State space S i is the set of states s k that are observed by multi-mode node i in the environment, where k is the index of states. The status s k includes whether the transmission task between multi-mode nodes is complete and the amount of data in the buffer for each communication mode. The task is considered complete if it does not exceed D i, j ( ) .
Action space A i ( s k ) is the set of actions that can be taken by multi-mode node i in state s k . The action a i, j, c ( ) represents not only the decision of the multi-mode node i ,
Fig. 2. Agile adaptation reinforcement learning model.
but also the action. For ease of description, a will be used as shorthand for a i, j, c ( ) .
Reward function R s ,a i ( k ) quantifies the reward associated with action a ∈ A i ( s k ) in state s k ∈ S i . The reward function R s ,a i ( k ) is formulated as (4) for ∀ j ∈ V ˜ , ∀ c ∈ C .
$$R _ { i } ( s _ { k }, a ) = T _ { m a x } ( s _ { k }, a ) - T _ { \max } ( s _ { k + 1 }, a ) \quad ( 4 )$$
where T max ( s k , a ) and T max ( s k +1 , a ) are respectively the maximum delay before and after action a i, j, c ( ) is taken in each mode.
$$\widetilde { \mathcal { V } }, \ ( 3 b ) \ \begin{array} { c } \text{each move.} \\ T _ { m a x } ( s _ { k }, a ) = \max _ { j \in \tilde { \mathcal { V } } } \sum _ { c \in \mathcal { C } } \frac { a ( i, j, c ) ( F ( i, c ) + S ( i, j, c ) M ( i, j ) ) } { B ( i, j, c ) } \\ B ( i, j, c ) \end{array} \\ \text{$\text{$the cumulative required $D$ is calculated $2c$} }$$
The cumulative reward R i is calculated as
$$R _ { i } = \gamma \tilde { R } _ { i } ( s _ { k }, a ) + R _ { i } ( s _ { k }, a ) \quad \quad ( 6 )$$
where γ is the discount factor, ˜ ( R s ,a i k ) represents the reward that multi-mode node i has already received.
π a s ( | k ) is a mapping policy from the observed states to the actions that will be taken by an agent in those states. For ease of description, π in the following content stands for π a s ( | k ) .
## B. Framework of proposed Reinforcement Learning Model
The framework of AARLM illustrated in Fig. 2 consists of two key steps: policy evaluation and policy optimization. The former module assesses the rewards associated with the chosen actions based on a given policy. The policy optimization module identifies the optimal policy π ∗ ( a s | k ) by tuning the selection of actions. To evaluate the policy π a s ( | k ) , the multimode node i first selects the action a i, j, c ( ) according to the initial policy π a s ( | k ) to make the state s k change, and then calculates the state value. The state value function V π ( s k ) is defined as
$$\begin{smallmatrix} \, \text{ \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cd: \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdclots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col: \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col.: \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \col.: \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \colots \, \collections \, \end{smallmatrix} \, ( 7 )$$
## Algorithm 1 Policy Iteration of AARLM
Require: Initializes the state space S i , state-value function V π ( s 0 ) , threshold for delay D i, j ( ) , the set of terminals V , the optimal action set A ∗ i ( c ) = ∅ , the number of model iterations E 1 , the number of task moves E 2 .
- 1: // Initial assignment of transmission tasks
- 2: Sort tasks in descending order by M i,j ( ) ;
- 3: Sort modes in descending order by B i, j, c ( ) ;
- 4: Calculate T ave according to (10);
- 5: while
- 6: Select the mode c ∈ C with the largest bandwidth, and T c ≤ T ave ;
- 7: if S i, j, c ( ) = 1 then
- 8: Select the multi-mode node j with the largest M i,j ( ) , then a i, j, c ( ) = 1 and A ∗ i ( c ) = A ∗ i ( c ) ∪ a i, j, c ( ) ;
- 9: end if
- 10: until All the tasks have been arranged;
- 11: Update Q table;
- 12: // Policy Improvement
- 13: for episode 1 to E 1 do
- 14: Traverse the Q table and select the state s k with the lowest delay T max ( s k , a ) as the initial state;
- 15: for episode 1 to E 2 do
- 16: Traverse C and select the mode c tm with the maximize T c ;
- 17: Iterate over all tasks in mode c tm , selecting multimode node j with minimizes ∣ M i,j ( ) B i,j,c ( ) -( T c -T ave ) ∣ ;
- ∣ ∣ ∣ ∣ 18: Traverse C and select the mode c rm with the minimizes T c and S i, j, c ( rm ) = 1 ;
19:
a i, j, c
(
tm
) = 0
,
a i, j, c
(
rm
) = 1
;
- 20: calculate R s ,a i ( k ) according to (4);
- 21: if R s ,a i ( k ) > 0 then
- 22: Update Q table and A ∗ i ( c ) ;
- 23:
- end if
- 24: end for
- 25: end for
- 26: return min T ( c ) , A ∗ i ( c )
where P s ( k | s k -1 , a ) represents the probability that multimode node i moves to state s k after selecting action a i, j, c ( ) in state s k , and V i ( s k ) is one of the state values of next state s k . In order to evaluate the policy π a s ( | k ) , it is necessary to select actions based on the π a s ( | k ) and update the state until the termination state is reached.
Through policy evaluation, the value of each state can be determined, thereby providing insight into the quality of each state. However, the existing policy might not be optimal. To further enhance the policy, it's crucial to assess the impact of actions that deviate from the policy in each state. So the function of the state-action value Q π ( s k , a ) is designed as follows:
$$Q _ { \pi } ( s _ { k }, a ) & = R _ { i } ( s _ { k }, a ) + \quad & - \\ & \gamma \sum _ { s _ { k } \in \mathcal { S } _ { i } } P ( s _ { k } | s _ { k - 1 }, a ) \sum _ { a \in \mathcal { A } _ { i } ( s _ { k } ) } \pi ( a | s _ { k } ) Q _ { \pi } ( s _ { k }, a ). \quad & \text{Fig. 3} \\ & \text{on delay} \\ \text{The state-action value } \, \text{$\mathcal{O}$ defined as the } \, \text{no-term} \, \text{re- delay} \, \text{$\mathfrak{o}$}$$
The state-action value Q , defined as the long-term re- ward, represents the expected cumulative discounted reward γ ∑ s k ∈S i P s ( k | s k -1 , a ) ∑ a ∈A i ( s k ) π a s ( | k ) Q π ( s k , a ) for the action a i, j, c ( ) that is taken by multi-mode node i in the state s k under policy π . The objective of the AARLM is to select the optimal policy π ∗ ( a s | k ) for every state s k aiming to maximize Q π ( s k , a ) . The optimal policy for each state is identified through equation (9).
$$\pi ^ { * } ( a \, | s _ { k } ) = \arg \max _ { a \in \mathcal { A } _ { i } ( s _ { k } ) } Q _ { \pi } ( s _ { k }, a ) \quad \quad ( 9 )$$
Algorithm 1 outlines the procedure for policy update. The initial segment, lines 1 through 11, updates the selected mode based on the initial policy π a s ( | k ) . Specifically, line 6 identifies the mode c subject to the maximum bandwidth condition T c < T ave , T ave is defined as
$$\text{ndition } T _ { c } < T _ { a v e }, T _ { a v e } & \text{ is defined as} \\ T _ { a v e } & = \sum _ { j \in \tilde { \mathcal { V } } } M ( i, j ) \Big / \sum _ { c \in \mathcal { C }, j \in \tilde { \mathcal { V } } } B ( i, j, c ) \quad \text{ (10)} \\ \text{Followin} \text{ that on line $8$ all tasks that sunnort mode $c$}$$
Following that, on line 8, all tasks that support mode c are selected, sorted by data volume from largest to smallest, and transmitted using mode c until T c > T ave . This iteration process repeats until all tasks have completed mode selection, yielding the initial task assignment plan and the Q-table.
Lines 13 to 25 of Algorithm 1 optimize the mode selection policy to π ∗ ( a s | k ) . Line 14 starts by locating the state s k with the lowest delay from the Q-table as the starting state. Subsequently, line 15 identifies the mode c tm with the highest delay in state s k . and selects the task with a size closest to T c -T ave from those transmitted in mode c tm . Line 17 selects mode c rm , which is supported by the task and has the smallest delay. The task is then moved to mode c rm in line 19, and the reward R s ,a i ( k ) is calculated in line 20. If R s ,a i ( k ) is positive, the Q-table and A ∗ i ( c ) are updated until the iteration count reaches E 1 and the task move count reaches E 2 .
## IV. NUMERICAL RESULTS
In this paper, the effectiveness of AARLM is verified by simulation. The configuration of simulation parameters such as the number of multi-mode nodes and the size of transmitted data are shown in Table I. The effects of the number of multimode nodes and the number of modes on the overall delay as well as task completion rate are analyzed respectively, and the existing mode adaptation schemes (random selection) and traditional algorithms (annealing algorithms) are compared.
TABLE I SIMULATION PARAMETER SETTING
| Parameters | Value |
|--------------------------------------|-------------------|
| Number of multi-mode nodes | [25,150] |
| Number of communication modes | [2,5] |
| Data size (Kbits) | [5,25] |
| The maximum tolerable delay (ms) | [1,5] |
| Bandwidth (MHz) | [10,20,40,80,100] |
| Delay of initial data in buffer (ms) | [1,10] |
Fig. 3 illustrates the effect of varying communication modes on delay with considering 100 multi-mode nodes. Generally, as the diversity of communication methods broadens, the overall delay of algorithms tends to decrease, with the AARLM
Fig. 3. Transmission delay under 100 nodes.
Fig. 4. Transmission delay under 5 modes.
achieving the lowest latency. When the bandwidth of the additional modes is 40 MHz or 80 MHz, the reduction in latency is most pronounced initially but then experiences a deceleration. The random algorithm exhibits the highest latency among the evaluated schemes. The delay of AARLM is slightly lower than that of annealing algorithm, and with the increase of communication mode, AARLM has maintained a certain delay advantage over annealing algorithm.
In the case of 5 communication modes, Fig. 4 illustrates the trend in delay changes for various algorithms as the number of multi-mode nodes increases. All algorithms exhibit a general upward trend in delay, and is significantly impacted by small-bandwidth communication modes, leading to the steepest delay increase. Besides, the time delay experiences minor fluctuations due to the inherent randomness in task assignment. As the task volume grows, the complexity of the task allocation scheme intensifies, leading to a widening delay gap between the annealing algorithm and AARLM.
Fig. 5 illustrates the general increase trend in delay changes for various algorithms as the number of multi-mode nodes increases. The random algorithm, in particular, is significantly impacted by small-bandwidth communication modes, leading to the fastest increase in delay. Initially, both the annealing algorithm and AARLM demonstrate satisfactory task completion rates. Nevertheless, when the volume of tasks becomes considerable and exceeds the maximum delay threshold, the task completion rates for both the annealing algorithm and AARLM are observed to decrease sharply. Despite this, AARLM manages to retain a certain degree of superiority.
Fig. 6 shows the variation in task completion rate as the number of communication modes increases, with the task count remains constant at 100. Across all algorithms, the task completion rate rose with more modes, a trend that is accentuated by the higher bandwidth associated with the additional modes, leading to a more rapid enhancement in task completion rates. Notably, AARLM stands out not only in maintaining the highest task completion rate but also in exhibiting the most rapid increase in this crucial metric.
## V. CONCLUSION
This paper discussed an RL-based agile adaptation scheme for multi-mode communication in vehicle networks. The preliminary findings have been compelling, revealing that the proposed method has significantly reduced communication delay
Fig. 5. Transmission task completion rate under 5 modes.
Fig. 6. Transmission task completion rate under 100 nodes.
across all scenarios, outperforming existing schemes. This has proven that the RL-based agile adaptation scheme for multimode communication can effectively optimize the communication process and reduce communication delay. Future work will focus on optimizing the framework and incorporating interference factors as well as reliability indicators into multimode communication schemes.
## REFERENCES
- [1] K. Kumar, D. Zindani, and J. P. Davim, Industry 4.0: Developments towards the fourth industrial revolution . Springer, 2019.
- [2] R. Xu, H. Xiang, X. Han, X. Xia, Z. Meng, C.-J. Chen, C. Correa-Jullian, and J. Ma, 'The OpenCDA open-source ecosystem for cooperative driving automation research,' IEEE Trans. Intell. Veh. , vol. 8, no. 4, pp. 2698-2711, 2023.
- [3] B. H¨ afner, V . Bajpai, J. Ott, and G. A. Schmitt, 'A survey on cooperative architectures and maneuvers for connected and automated vehicles,' IEEE Commun. Surv. Tutorials , vol. 24, no. 1, pp. 380-403, 2021.
- [4] M. Ahmed, M. A. Mirza, S. Raza, H. Ahmad, F. Xu, W. U. Khan, Q. Lin, and Z. Han, 'Vehicular communication network enabled CAV data offloading: A review,' IEEE Trans. Intell. Transp. Syst. , vol. 24, no. 8, pp. 7869-7897, 2023.
- [5] S. Zhang, J. Chen, F. Lyu, N. Cheng, W. Shi, and X. Shen, 'Vehicular communication networks in the automated driving era,' IEEE Commun. Mag. , vol. 56, no. 9, pp. 26-32, 2018.
- [6] Y. Fu, C. Li, F. R. Yu, T. H. Luan, and Y. Zhang, 'A survey of driving safety with sensing, vehicular communications, and artificial intelligence-based collision avoidance,' IEEE Trans. Intell. Transp. Syst. , vol. 23, no. 7, pp. 6142-6163, 2022.
- [7] S. He, S. Xiong, Z. An, W. Zhang, Y. Huang, and Y. Zhang, 'An unsupervised deep unrolling framework for constrained optimization problems in wireless networks,' IEEE Trans. Wireless Commun. , vol. 21, no. 10, pp. 8552-8564, 2022.
- [8] W. ShangGuan, B. Shi, B.-G. Cai, J. Wang, and Y. Zang, 'Multiple V2V communication mode competition method in cooperative vehicle infrastructure system,' in 2016 IEEE 19th Int. Conf. Intell. Transp. Syst. (ITSC) , 2016, pp. 1200-1205.
- [9] T. Zhou, Y. Yang, L. Liu, C. Tao, and Y. Liang, 'A dynamic 3-D wideband GBSM for cooperative massive MIMO channels in intelligent high-speed railway communication systems,' IEEE Trans. Wireless Commun. , vol. 20, no. 4, pp. 2237-2250, 2021.
- [10] H. Park and C. You, 'Latency impact for massive real-time applications on multi link operation,' in 2021 IEEE Reg. 10 Symp. (TENSYMP) , 2021, pp. 1-5.
- [11] W. Liang, S. Xu, Y. Liang, Z. Zhang, and X. Liu, 'Researches advanced in reliable low latency transmission based on multi-links,' in 2023 IEEE 3rd Int. Conf. Electron. Technol., Commun. Inf. (ICETCI) , 2023, pp. 6770.
- [12] K. Lavanya, R. Indira, A. K. Velmurugan, and M. Janani, 'Mobilitybased optimized multipath routing protocol on optimal link state routing in MANET,' in 2023 Int. Conf. Appl. Intell. Sustainable Comput. (ICAISC) , 2023, pp. 1-6.
- [13] J. Clifton and E. Laber, 'Q-learning: Theory and applications,' Ann. Rev. Stat. Appl. , vol. 7, pp. 279-301, 2020. | null | [
"Shiwen He",
"Kanghong Chen",
"Shiyue Huang",
"Wei Huang",
"Zhenyu An"
]
| 2024-07-18T13:04:34+00:00 | 2024-07-18T13:04:34+00:00 | [
"cs.NI",
"cs.AI",
"cs.LG"
]
| An Agile Adaptation Method for Multi-mode Vehicle Communication Networks | This paper focuses on discovering the impact of communication mode allocation
on communication efficiency in the vehicle communication networks. To be
specific, Markov decision process and reinforcement learning are applied to
establish an agile adaptation mechanism for multi-mode communication devices
according to the driving scenarios and business requirements. Then, Q-learning
is used to train the agile adaptation reinforcement learning model and output
the trained model. By learning the best actions to take in different states to
maximize the cumulative reward, and avoiding the problem of poor adaptation
effect caused by inaccurate delay measurement in unstable communication
scenarios. The experiments show that the proposed scheme can quickly adapt to
dynamic vehicle networking environment, while achieving high concurrency and
communication efficiency. |
2408.01430v2 | ## SUSTechGAN: Image Generation for Object Detection in Adverse Conditions of Autonomous Driving
Gongjin Lan ID , Member, IEEE , Yang Peng, Qi Hao GLYPH<12> ID , Member, IEEE , Chengzhong Xu, Fellow, IEEE
Abstract -Autonomous driving significantly benefits from datadriven deep neural networks. However, the data in autonomous driving typically fits the long-tailed distribution, in which the critical driving data in adverse conditions is hard to collect. Although generative adversarial networks (GANs) have been applied to augment data for autonomous driving, generating driving images in adverse conditions is still challenging. In this work, we propose a novel framework, SUSTechGAN, with customized dual attention modules, multi-scale generators, and a novel loss function to generate driving images for improving object detection of autonomous driving in adverse conditions. We test the SUSTechGAN and the well-known GANs to generate driving images in adverse conditions of rain and night and apply the generated images to retrain object detection networks. Specifically, we add generated images into the training datasets to retrain the well-known YOLOv5 and evaluate the improvement of the retrained YOLOv5 for object detection in adverse conditions. The experimental results show that the generated driving images by our SUSTechGAN significantly improved the performance of retrained YOLOv5 in rain and night conditions, which outperforms the well-known GANs. The open-source code, video description and datasets are available on the page 1 to facilitate image generation development in autonomous driving under adverse conditions.
Index Terms -Autonomous driving, Self-driving, GAN, Object detection, Image style transfer, Adverse conditions.
## I. INTRODUCTION
Autonomous driving generally refers to an SAE J3016 2 level 3 or higher technology system that controls the vehicle to reach the destination by detecting the external environment without driver intervention. However, fully autonomous driving would have to be driven hundreds of millions of miles and even hundreds of billions of miles to collect data and demonstrate their safety [1]. In the real world, the existing fleets would take tens and even hundreds of years to drive these miles which is significantly time-consuming and expensive, even impossible. Furthermore, data labeling is a significantly challenging and heavy workload. Finally, collecting real driving data under adverse conditions is prominently challeng-
This work was supported in part by the National Natural Science Foundation of China (62261160654), in part by the Shenzhen Fundamental Research Program (JCYJ20220818103006012,KJZD20231023092600001), in part by the Shenzhen Key Laboratory of Robotics and Computer Vision (ZDSYS20220330160557001), in part by the GuangDong Basic and Applied Basic Research Foundation (2021A1515110641), in part by the Science and Technology Development Fund of Macao S.A.R (FDCT) (No. 0123/2022/AFJ and No. 0081/2022/A2). (Corresponding author: Qi Hao.)
Gongjin Lan and Yang Peng are with the Department of Computer Science and Engineering, Southern University of Science and Technology, China
- Qi Hao is with the Research Institute of Trustworthy Autonomous Systems, and the Department of Computer Science and Engineering, Southern University of Science and Technology, China. (e-mail: [email protected])
- Chengzhong Xu is with the University of Macau, Macao SAR, China 1
https://github.com/sustech-isus/SUSTechGAN
- 2 https://www.sae.org/blog/sae-j3016-update
ing and costly. Although data collection in simulation could collect large-scale data to provide ground truth and improve autonomous driving, the reality gap between simulated data and the real data is a significant issue. Data augmentation by generative AI has been demonstrated to reduce road testing costs and improve autonomous vehicle safety. GAN-based methods have been successfully applied to generate driving data under adverse conditions which are significantly difficult to collect in the real world [2].
Although many studies investigate GAN-based image generation for object detection of autonomous driving [3], [4], [5], there is a lack of studies that investigate this task under adverse conditions. In our experiments, we applied the well-known GANs (CycleGAN [6], UNIT [7], MUNIT [8]) to generate driving images in adverse conditions of rain and night, as shown in Figure 9. However, the results (as shown in Figure 9 and Table V) show that image generation by these existing GANs for driving scenes generally meets the specific issues:
- 1) The generated images show weak local semantic features (e.g., vehicles, traffic signs) for object detection. For example, vehicles in the generated images of rain and night are generally blurred and even approximately disappeared to imitate the global features of rain and night. Such generated images hardly improve object detection of autonomous driving in adverse conditions.
- 2) The generated images show weak global semantic features of adverse conditions. The input images of GANs are generally cropped and resized for small-size images (e.g., 360*360) which hardly cover the global semantic features since images in autonomous driving are generally big-size resolutions such as 1980*1080.
- 3) The existing GAN-based image generation methods in autonomous driving have not investigated object detection in adverse conditions. Specifically, the existing GANs generally consider the common components of adversarial loss and cycle consistency loss without detection loss for image generation of adverse conditions.
In this paper, we propose a novel framework, SUSTechGAN, to generate driving images for improving object detection of autonomous driving under adverse conditions. The framework of SUSTechGAN is shown in Figure 1. We conducted ablation studies to investigate the effects of dual attention modules and multi-scale generators in SUSTechGAN. The results show that both of them significantly contribute to image generation for improving object detection in autonomous driving under adverse conditions. Furthermore, we compare SUSTechGAN with the well-known GANs for image generation on a customized BDD100K (BDD100k-adv), a new dataset (AllRain), and an adverse condition dataset (ACDC
Fig. 1: The framework of our SUSTechGAN contains dual attention modules, multi-scale generators, and the components of the loss function. The dual attention module contains a position attention module (PAM, see Figure 2 for the detailed architecture) and a channel attention module (CAM, see Figure 3 for the detailed architecture). Loss , L det , L adv , and L cyc represent loss function, detection loss, adversarial loss, and consistency loss respectively .
[9]). We retrain the well-known YOLOv5 by adding generated images into the training dataset. The results show that generated images by SUSTechGAN significantly improve the retrained YOLOv5 for object detection of driving scenes under adverse conditions, as shown in Figure 9.
The main contributions of our GAN-based image generation for improving object detection of autonomous driving in adverse conditions are summarized as:
- 1) We design a dual attention module of the position attention module and the channel attention module in SUSTechGAN to improve the local semantic feature extraction for generating driving images in adverse conditions such as rain and night. This method solves the issue that the local semantic features (e.g., vehicles) in the generated images are blurred and even approximately disappeared, and improves the object detection of autonomous driving.
- 2) We design multi-scale generators in SUSTechGAN to consider various scale features (e.g., big-size generator for global features and small-size generator for local features) for generating high-quality images with clear global semantic features.
- 3) We propose a novel loss function with an extra detection loss to guide image generation for improving object detection of autonomous driving in adverse conditions.
## II. RELATED WORK
Here, we review the related studies, including: 1) datasets, 2) generative AI for image generation, 3) GAN-based image generation, and 4) GAN-based driving image generation.
## A. Datasets
Several studies [10] have discussed autonomous driving datasets. Although the existing driving datasets generally contain images in various conditions, they contain a few images of real scenes under adverse conditions such as heavy rain weather. Furthermore, these images have not been classified for different adverse conditions and can not fully cover various degrees of adverse conditions. For example, KITTI [11] collected driving images in normal weather. NuScenes [12] contain driving images under moderate weather conditions and lack driving images under various adverse conditions such as light rain, moderate rain, and heavy rain. Waymo [13] consists of 1150 scenes of each 20 seconds that are collected across suburban and urban and from different times of the day, including day, night, and dawn, rather than different adverse weather conditions. Cityscapes [14] consists of diverse urban street scenes at varying times of the year. Although Wang et al. [15] considered three weather conditions of rain, fog, and snow, they used synthetic datasets of Foggy Cityscapes, Rain Cityscapes, and Snow Cityscapes to simulate real scenes. The dataset DENSE contains events and depth maps, which are used to train models for dense monocular depth prediction [16]. However, DENSE is recorded in the CARLA simulator rather than in real driving scenes. The adverse conditions dataset ACDC contains 4006 images of four adverse conditions: fog, nighttime, rain, and snow [9]. Although ACDC covers four adverse weather conditions, it contains only limited degrees of adverse weather conditions since the images were recorded over several days in Switzerland. In addition, another dataset CADC collected driving scenes during winter weather conditions in Canada, which is basically clear or snowy weather [17]. BDD100k [18] contains many driving images in rainy weather, while these images were collected during light rain or after rain which can not fully cover various rain conditions of driving for imitating various rain. These datasets are hardly used to train GANs to generate high-quality
driving images for imitating various degrees of real adverse conditions. The datasets should contain real driving scenes under diverse degrees of adverse weather conditions.
## B. Generative AI for Image Generation
Several frameworks have been explored in deep generative modeling, including Variational Autoencoders (VAEs) [19], GANs [6], [7], [8] and diffusion models [20], [21], [22]. Arash et al. [19] proposed the well-known Nouveau VAE, a deep hierarchical VAE built for image generation using depth-wise separable convolutions and batch normalization. VAEs generate diverse images quickly, but they generally lack quality. Xu et al. [20] proposed a diffusion-based framework, DiffScene, to generate safety-critical scenarios for autonomous vehicle evaluation. Li et al. [21] propose a spatial-temporal consistent diffusion framework, DrivingDiffusion, to generate realistic multi-view videos. Ethan et al. [22] propose a latent diffusionbased architecture for generating traffic scenarios that enable controllable scenario generation. Although diffusionbased models could perform outstanding image generation for various tasks, their inference process generally takes a lot of computing. Zhao et al. [23] explored these three generative AI methods to create realistic datasets. The experimental results show that GAN-based methods are adept at generating highquality images when provided with manually annotated labels for better generalization and stability in driving data synthesis. A recent remarkable study [24] shows that although diffusion models show outstanding performance, GAN-based methods could still perform state-of-the-art performance for image generation. Specifically, GAN-based methods can surpass recent diffusion models while requiring two orders of magnitude less compute for inference. While a GAN only needs one forward pass to generate an image, a diffusion model requires several iterative denoising steps, resulting in slower inference [24].
## C. GAN-based Image Generation
Many studies have proposed to generate samples from the source domain to the target domain. Zhu et al. [6] proposed the well-known CycleGAN to generate images, which possible distortion and corresponding reversible distortion might occur for image generation with cycle loss and brings negative effects. UNIT [7] is another well-known GAN for image generation, which proposed a shared latent space of source and target domains and shared weights between generators. MUNIT [8] used the disentangled representation to improve the diversity of generated images. Recently, Seokbeom et al. [25] proposed SHUNIT to generate a new style by harmonizing the target domain style retrieved from a class memory and a source image style. Although these studies investigated GAN-based image generation, they have not investigated image generation for driving scenes, particularly under adverse conditions.
Image generation methods in autonomous driving contain traditional physical model-based methods, a combination of computer graphics and physical-based methods, and GANbased methods. Traditional physical model-based techniques can be used to generate images of different weather conditions. Sakaridis et al. [26] build an optical end-to-end model based on stereo matching and depth information to generate foggy images. Halder et al. [27] proposed a physical rendering pipeline to generate rain images by using a physical particle simulator to estimate the position of raindrops and the illumination of rain. However, these traditional methods generally need empirical physical models that make it hard to simulate real scenes with high definition. Many studies produce new scenes by combining high-fidelity computer graphics and physicalbased modeling techniques in autonomous driving such as OPV2V [28]. However, the gap between generated images and real images leads to low usability of generated images for autonomous driving, particularly in adverse conditions.
## D. GAN-based Driving Image Generation
Many studies investigated the effects of adverse weather conditions on object detection. Wang et al. [15] investigated camera data degradation models including light level, adverse weather, and internal sensor noises that are compared for the accuracy of a panoptic segmentation. Wang et al. [29] discussed the effects of adverse illumination and weather conditions on the performance and challenges of 3D object detection for autonomous driving. However, accurate and robust perception under various adverse weather conditions is still challenging in autonomous driving.
GAN-based methods could generate new samples to augment training datasets under limited data and improve the perception of autonomous driving in adverse conditions. DriveGAN [3] is a controllable neural simulator to learn the latent space of images by sampling the style information of images such as weather. WeatherGAN [4] changes correlated image regions by learning cues of various weather conditions to generate images. Lin et al. [5] proposed a structure-aware GAN that focuses on a specific task of day-to-night image style transfer rather than image generation for adverse conditions. Interestingly, Vinicius et al. [30] investigated crossdomain car detection from day to night by using unsupervised image-to-image translation, while focusing on improving car detection under night conditions. Although these studies have investigated GAN-based methods for image generation even driving image generation under adverse conditions, there is a lack of studies that focus on image generation for object detection of autonomous driving under adverse conditions.
## III. METHODOLOGY
We customize dual attention modules and multi-scale generators to design a novel framework, SUSTechGAN, to generate driving images under adverse weather conditions. In this section, we describe the proposed SUSTechGAN in detail, including dual attention modules of the position attention module and the channel attention module, multi-scale generators, and the novel loss function. The framework of SUSTechGAN is shown in Figure 1.
We define image domains of different conditions (e.g., sunny and rainy images) as source domain X and target domain Y . The samples in source domain x ∈ X follow the distribution P x , and samples in target domain y ∈ Y follow the distribution P y . For image generation in normal-to-adverse conditions, GANs aim to learn two mapping functions between domains, G:x → y and F:y → x.
Fig. 2: The framework of Position Attention Module (PAM) in our dual attention module.

## A. Dual Attention module
In our preliminary experiments, we applied the well-known CycleGAN [6], UNIT [7], and MUNIT [8] to generate driving images in adverse conditions. However, we noticed that generated images show weak local semantic features, which are hardly used to improve object detection. For example, the key objects such as vehicles and traffic signs in generated images under rain weather conditions are generally blurred and even approximately disappeared. In this work, we design dual attention modules to improve the semantic features of objects in the generated images. The dual attention module contains a position attention module (PAM) and channel attention module (CAM), as shown in Figure 2 and Figure 3 respectively. Specifically, our dual attention module transforms the output features by PAM and CAM through two 1*1 convolutions respectively, and then sums the feature matrices to fuse the features from PAM and CAM.
1) Position Attention Module: We apply PAM to SUSTechGAN to improve local semantic feature extraction in big-size driving images. Specifically, pixels in an image are associated with each other from a semantic feature by PAM. The aggregation operation in PAM extracts the position association of pixels and fuses the association into a semantic feature. The PAM finally produces the position-weighted feature that is the same size as the original feature of input images. The framework of PAM is shown in Figure 2.
In PAM, the features are operated by 1/1, 1/2, 1/4, and 1/16 down-sampling, which generates 4 different size features. The feature sizes can be controlled by the size of pooling kernels. The four size features are upsampled by bilinear interpolation to recover the same size as the original features and merge various scale features channel by channel. The lowdimensional pooling convolution result is upsampled by bilinear interpolation to restore the feature map of the same size as the original feature. The feature is updated as P ′ ∈ R 1 × H × W . The attention matrix M ∈ R 1 × H × W can be normalized by softmax:
$$\mathcal { U m a }. \mathcal { M } = \sigma \mathcal { P } ^ { ^ { \prime } }, \text{where} \, \mathcal { P } ^ { ^ { \prime } } = c o n c a t ( \mathcal { P } _ { 1 }, \mathcal { P } _ { 2 }, \mathcal { P } _ { 3 }, \mathcal { P } _ { 4 } ) \quad ( 1 ) \ \text{vehic} \,.$$
where σ and concat represent normalization function sigmoid and concatenation operation in channels. Finally, the feature F s ∈ R C × H × W can be updated by the operation operation between the attention matrix and the original features as:
$$\mathcal { F } _ { s } = \mathcal { M } \otimes \mathcal { F } \quad \quad \ ( 2 ) \ \sin$$
where ⊗ represents the multiplication operation of matrices.
2) Channel Attention Module: Autonomous driving scenes generally have various semantic features and high complexity. The generator in the exiting GANs generally extracts features by convolution layers, which hardly extracts and expresses various and complex semantic features of driving scenes. We apply channel attention modules to extract the association of features in various channels that improve feature expression.
In autonomous driving, scenes generally contain rich and complex semantic features due to various challenges such as blurring and occlusion caused by complex and adverse conditions like various weather and light effects. The features in different channels can be associated with different types of semantic features. The CAM in the dual attention module aggregates the associated features from different channels to improve feature extraction and expression. The framework of CAM is shown in Figure 3.
C HW
×
Fig. 3: The framework of Channel Attention Module (CAM).
Specifically, the CAM reshape the original features F ∈ R C × H × W to A ∈ A C × HW , B ∈ R C × HW and C ∈ R C × HW . The product of A and transpose matrices of B is normalized by softmax operation and produces the attention matrix X ∈ R C × C where each element x represents the association between different channels.
$$\Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \Gamma \sum \\ x = \exp ( \mathcal { A B } ^ { T } ) / \sum \Gamma ^ { c } \exp ( \mathcal { A B } ^ { T } )$$
The attention matrix X multiplies C∈ R C × N (where N = H × W ), and reshape the product result to R C × H × W . The feature with attention weights is added to the original feature and thus the channel attention F ∈ c R C × H × W can be calculated by:
$$\mathcal { F } _ { c } = \mathcal { X } \otimes \mathcal { C } + \mathcal { A }$$
Finally, the improved features can be calculated by adding the outputs of the dual attention module and the multi-scale generators, as the process shown in Figure 1.
## B. Multi-scale Generator
The real driving scenes contain local semantic features like vehicles and global semantic features like adverse weather conditions. Therefore, the generated images should contain clear local features and global features for adverse conditions. However, the generators in the existing GANs hardly generate driving images for considering both local and global features since the input images of GANs are generally cropped and resized for the same small scale (e.g., 360*360) which hardly cover the global semantic features of big-size resolutions images such as 1980*1080 in autonomous driving. In our preliminary experiments, we tried to use bigger scale inputs such as 720x720 in the well-known GANs, which significantly increases the training time with a negligible improvement for
trained object detection. In this work, we develop the multiscale generators to SUSTechGAN for combining local and global semantic features in the generated images.
We design SUSTechGAN with two embedded generators G 1 , G 2 of different scales, as shown in Figure 4. Specifically, the generator G 1 resizes the input feature by 1 / 4 followed by the three operations of down-sampling, residual block, and deconvolution to generate an image with a 1 / 4 size of input images. The generator G 2 contains convolution for feature extraction, residual block, and deconvolution. To fuse
Fig. 4: The framework of multi-scale generators in our SUSTechGAN, where k represents the kernel size and s represents the convolution stride.
the features from different generators, the generator G 1 is embedded into the generator G 2 . The framework of multi-scale generators and the connections between generators are shown in Figure 4. In particular, the feature after deconvolution in the generator G 1 is added to the feature after two convolutions in the generator G 2 , which integrates multiple the two generators. The lower-layer generators are added to the higher-layer generators to fuse local semantic features such as vehicles and global features such as adverse weather conditions.
## C. Loss Function
We propose a novel loss function with an extra detection loss, that is usually not considered in the existing GAN-based image generation, to guide image generation for improving object detection of autonomous driving in adverse conditions. We proposed a detection loss by considering the performance of the pre-retrained object detection on generated images, which is compared to the ground truth. In this work, we mainly consider a detection loss ( L det ) and the common loss of adversarial loss ( L adv ) and cycle consistency loss ( L cyc ) to guide the training process of SUSTechGAN by:
$$\mathcal { L } _ { t o t a l } = k _ { 1 } \mathcal { L } _ { d e t } + k _ { 2 } \mathcal { L } _ { a d v } + k _ { 3 } \mathcal { L } _ { c y c } \quad \ \ ( 5 ) \quad \ f u l y \, \mathfrak { c }$$
where the weights k 1 = 0 8 . , k 2 = 1 , and k 3 = 10 are naivetuned and considered the empirical values to balance detection loss, adversarial loss, and cycle consistency loss, respectively.
For detection loss L det , we apply the pre-trained YOLOv5 on BDD100k to detect generated images and consider the performance as the detection loss. Referring to the loss function in YOLOv5, we consider the detection loss with localization loss, classification loss, and confidence loss as:
$$\mathcal { L } _ { d e t } = a \mathcal { L } _ { C I o U } + b \mathcal { L } _ { c l s } + c \mathcal { L } _ { c o n f } \quad \quad ( 6 ) \quad \stackrel { \lambda } { \text{dataset} }$$
where a = 0 4 . , b = 0 3 . , c = 0 3 . refers to YOLOv5. The localization loss considers the intersection over union representing the ratio of intersection area and union area of predicted box and ground truth. The classification loss considers the predicted possibility of the current class. Last, the confidence loss indicates the confidence of predicted bounding boxes.
For adversarial loss L adv , the total adversarial loss is:
$$\mathcal { L } _ { a d v } = \mathcal { L } _ { a d v } ( \mathcal { G }, \mathcal { D } _ { \mathcal { Y } } ) + \mathcal { L } _ { a d v } ( \mathcal { F }, \mathcal { D } _ { \mathcal { X } } ) \quad \quad ( 7 )$$
adv adv Y adv X where L adv ( G D , Y ) and L adv ( F D , X ) represent cycle loss of normal-to-adverse G : X → Y and inverse cycle loss of adverse-to-normal F : Y → X .
For cycle consistency loss L cyc , each generated sample G ( x ) from source domain X should be brought back to the original image, i.e., x →G ( x ) →F G ( ( x )) ≈ x . The cycle consistency loss can be expressed as:
$$\text{fuse} \quad \mathcal { L } _ { c y c } ( \mathcal { G }, \mathcal { F } ) = \mathbb { E } _ { x } [ | | \mathcal { F } ( \mathcal { G } ( x ) ) - x | | _ { 1 } ] + \mathbb { E } _ { y } [ | | \mathcal { G } ( \mathcal { F } ( x ) ) - y | | _ { 1 } ] \ ( 8 )$$
## IV. EXPERIMENTS
In this section, we address the experiments in detail, including datasets, evaluation, and experimental setup.
## A. Datasets
In this work, we conduct experiments on the three datasets: 1) a customized BDD100k (BDD100k-adv) where images are classified into sunny, rainy, and night weather conditions, 2) a novel dataset (AllRain) where driving images were collected from YouTube videos under various degrees of rainy conditions, 3) a well-known adverse condition dataset, ACDC. Here, we address these three datasets in detail. Note that the dataset AllRain has not collected nighttime driving images since BDD100k-adv contains enough nighttime driving images. The specifications of the datasets are shown in Table I.
| Dataset | Sunny (train/test) | Rainy (train/test) | Night (train/test) |
|--------------------------|---------------------------------|---------------------------------------------|----------------------------------|
| BDD100k-adv AllRain ACDC | 2000(1600/400) 2827(2314/513) - | 1342(1000/342) 2121(1736/385) 1000(500/500) | 2500 (2000/500) - 1006 (506/500) |
TABLE I: The specifications of the adverse weather datasets.
1) BDD100k-adv: The original BDD100k contains 100,000 video clips from multiple cities and under various conditions. For each video, a keyframe with a resolution of 1280x720 is selected with detailed annotations such as the bounding box of different objects. The images in BDD100k are classified into six various conditions, including clear, overcast, and rainy. In this work, we selected 1600/400 (train/test) sunny images, 1000/342 (train/test) rainy images, and 2000/500 (train/test) night images to compose the dataset, named BDD100k-adv.
2) AllRain (A novel dataset): The existing datasets can not fully cover various degrees of adverse conditions. We designed a new customized dataset, named AllRain . Specifically, we reviewed many driving videos from YouTube and selected some videos that contain driving on highways and urban streets under sunny and various degrees of rain such as light rain, moderate rain, and heavy rain. We extracted images from the videos and used LabelImg to annotate these images with three common categories: pedestrian, car, and truck. The images are with a large resolution of 1920×1080. Finally, the dataset AllRain contains 2314/513 (train/test) sunny images and 1736/385 (train/test) rainy images, as shown in Table I.
3) ACDC: ACDC is a driving dataset with 4006 images that are recorded from several days under four adverse conditions: fog, nighttime, rain, and snow on highways and in rural regions of Switzerland. The images are categorized into 1000 foggy, 1006 nighttime, 1000 rainy, and 1000 snowy images.
## B. Evaluation
1) Image Quality Metric: In general, image quality can be assessed from various metrics such as FID (Frechet Inception Distance) for similarity and KID (Kernel Inception Distance) for diversity, which have been widely used to assess the visual quality of generated images by GAN-based methods. Specifically, FID is generally used to evaluate the similarity between generated and real images. A lower FID score indicates the higher-quality generated images that are distributed similarly to the real images. KID is a metric similar to the FID that measures the distance between the real image distribution and the generated image distribution to evaluate the image quality. FID assumes that the features extracted by Inception obey the normal distribution, which is a biased estimate. KID performs unbiased estimation based on Maximum Mean Discrepancy, and the calculation includes an unbiased estimate of a cubic kernel. In this work, we adopt FID and KID to assess the generated image quality in terms of the similarity between generated images and real images and the diversity of generated images.
2) Object Detection Metrics: We retrain the well-known YOLOv5 by adding generated images to test the improvement of object detection in adverse conditions and evaluate the retrained YOLOv5 by using mean average precision (mAP). Notice that each generated image has the same ground truth as the original real image for calculating mAP.
## C. Experimental Setup
In this work, we designed experiments to compare our SUSTechGAN with the well-known GANs, CycleGAN, UNIT, and MUNIT by following their original instructions. In addition, we demonstrate the effects of dual attention modules and multi-scale generators in SUSTechGAN by ablation studies.
Specifically, we implement and train SUSTechGAN, CycleGAN, UNIT, and MUNIT with PyTorch on an NVIDIA Tesla V100 GPU system. SUSTechGAN, CycleGAN, and UNIT took approximately 15.5 hours of average computation time, while MUNIT took approximately 18.7 hours. In the training stage, we resize images to a width of 1080 followed by a random cropping of size 360×360 for the dataset AllRain. For the dataset BDD100k-adv, the training stage randomly crops the images to a size of 720×720. In addition, the Adam solver was employed for optimization, where hyper-parameters β 1 and β 2 were set to 0.9 and 0.999, respectively. The batch size was set to 1, and the initial learning rate was set to 0.0002, as the default values in CycleGAN.
## V. RESULTS
In this section, we present the qualitative and quantitative results to demonstrate our method. Specifically, we present the

results of the ablation study and analyze the key parameter (generator scale) in SUSTechGAN. Furthermore, we present the results of the retrained YOLOv5 on the various combinations of generated images and real images under adverse conditions, e.g., rainy and night conditions. Finally, we compare SUSTechGAN with the well-known GANs, CycleGAN, UNIT and MUNIT.
## A. Ablation Study and Parameter Tuning
1) Ablation Study: We analyze the effects of 1) the PAM and CAM in the dual attention module and 2) the detection loss and present the results in Table II. The results show that
| Methods | PAM | CAM | FID ↓ | mAP ↑ |
|-----------------------|-------|-------|--------------------------------------------------------|-----------------------------------------------------------|
| Baseline | ✗ | ✗ | 76.5 | 0.382 |
| L total -L det | ✗ | ✗ | 79.7(4.2% ↑ ) | 0.361(5.5% ↓ ) |
| Dual attention module | ✓ ✗ ✓ | ✗ ✓ ✓ | 69.2 ( 9 . 5% ↓ ) 70.7 ( 7 . 6% ↓ ) 67.3 ( 12 . 0% ↓ ) | 0.418 ( 9 . 4% ↑ ) 0.415 ( 8 . 6% ↑ ) 0.422 ( 10 . 5% ↑ ) |
TABLE II: The results of ablation study on BDD100k-adv.
both PAM and CAM contribute to generating driving images with lower FID and higher mAP. Specifically, the generator in SUSTechGAN with PAM performs a result with 9 5% . lower FID and 9 4% . higher mAP than the baseline. Similarly, the generator with CAM performs 7 6% . lower FID and 8 6% . higher mAP than the baseline. Finally, the generator with the combination of PAM and CAM performs 12 0% . lower FID and 10 5% . higher mAP than the baseline. In addition, we conduct an ablation study to investigate the effect of the detection loss. The results show the trained generator without detection loss performs 4 2% . higher FID and 5 5% . lower mAP than the baseline. Finally, we investigate the contribution of the multi-scale generator and dual attention module in SUSTechGAN, as the results shown in Table III. The results show that both the multi-scale generator and dual attention module contribute to the lower FID and KID of generated images. Last, we show the feature results after PAM and various channel CAMs in Figure 5. The images in the second column show the attention features of key objects after PAM which the positions in the same object are associated with an attention feature. The images in the third and fourth columns show the features after channels 6 and 13 attention where the significantly different features from different channels are extracted. For example, channel 6 extracts the sky features. With PAM and CAM, the generator in SUSTechGAN benefits from the extracted features to generate high-quality driving images for improving object detection of autonomous driving under adverse conditions.
2) Parameter Tuning: The down-sampling scale in the generator of SUSTechGAN is an important parameter. We

(a) Original image


(b) Position attention (c) Channel (#6) attention (d) Channel (#13) attention Fig. 5: The feature results after position attention module and channel attention module.
analyze their performance with different scale values of downsampling. In this work, we evaluate the down-sampling scale from 1) FID between the generated images and real images and 2) the average mAP of retrained YOLOv5 by the combined training dataset of generated images and real images. The down-sampling scale of the generator with lower FID and higher mAP is better. Therefore, we choose a down-sampling scale value by considering the Pareto front of the multiobjective FID and mAP, as shown in Figure 6. The results show that the down-sampling scale values of 1/4 (67.3,0.422) and 1/8 (65.6,0.415) dominate 1/2 (76.9,0.406). Both 1/4 and 1/8 are the Pareto front in terms of FID and mAP. Here, we chose 1/4 as the down-sampling scale since it has a higher mAP with a similar FID of 1/8. Pareto Front for Multi-Objective Optimization
FID
Fig. 6: The Pareto front results of various down-sampling scales in the generator of SUSTechGAN. The FID and mAP are the average values on the rain images of driving.
## B. Object Detection
We apply the generated driving images under adverse conditions to retrain YOLOv5 and test the retrained YOLOv5. We apply SUSTechGAN to generate driving images for rain and night conditions and evaluate the distance between generated images and real images by FID and KID. We compare
| Methods | AllRain (Rainy) | BDD100k-adv (Rainy) | BDD100k-adv (Night) | ACDC (Rainy) | ACDC (Night) |
|-----------|-------------------|-----------------------|-----------------------|----------------|----------------|
| CycleGAN | 79.8/0.12 | 89.2/0.09 | 71.7/0.05 | 85.1/0.10 | 69.9/0.04 |
| Base UNIT | 81.3/0.12 | 85.6/0.08 | 61.2 /0.04 | 83.4/0.09 | 60.7/0.04 |
| MUNIT | 92.5/0.14 | 107.1/0.09 | 83.9/0.06 | 101.7/0.11 | 80.5/0.05 |
| Ours mul. | 70.1/0.12 | 76.5/0.08 | 66.5/0.04 | 74.3/0.09 | 63.1/0.03 |
| att.+mul. | 55.2 / 0.11 | 67.3 / 0.07 | 64.8/ 0.02 | 61.6/0.08 | 59.8/0.02 |
TABLE III: The FID ↓ / KID ↓ between the generated images by GANs and the real driving images.
SUSTechGAN with the well-known CycleGAN, UNIT, and MUNIT, as shown in Table III. The results show that our SUSTechGAN generates driving images on rain with lower FID (i.e., closer between generated images and real images) than the other GANs on all three datasets. The generated driving images at night by both UNIT and our proposed GAN have a low FID and KID, while the generated driving images at night by UNIT have a lower FID and KID.
Furthermore, we analyse the domains of generated images and real images by dimensionality reduction for their con- volution features of YOLOv5. The convolution features are dimensionality reduced into two-dimensional samples by using the well-known t-SNE and visualized in Figure 7. All the twodimensional samples constitute a feature matrix T . The mean ( x, y ) of the feature matrix T in the x and y direction is the center point of the ellipse. We calculate the eigenvalues and eigenvectors of the covariance matrix of the feature matrix T in the x and y directions. The direction of the eigenvector is the orientation of the ellipse, and the eigenvalues are the radius of the ellipse in the x and y directions. The results show that the key objects in the generated rain images and the real sunny images have similar convolutional features, which indicates that the generated rainy images by SUSTechGAN retain the local semantic features (e.g., vehicles). The semantic
Fig. 7: The visualization of the semantic features of dimensionality reduction for real sunny and rainy images of driving, and the generated rainy driving images.
feature domain of the generated and real rainy images are largely overlapped. The semantic feature domains of the generated rain images and the real rain images are closed, which indicates the generated rain images can be used to improve object detection for autonomous driving.
We compare SUSTechGAN with CycleGAN, UNIT, and MUNIT by adding their generated images under rain and night conditions into the training set of YOLOv5. In this work, we retrain YOLOv5 by the three training settings:
- 1) Real daytime images. Only real daytime images (including sunny images) are used in the training dataset.
- 2) Real rainy or night images added. 200 real images under rain or night conditions are added to the training set.
- 3) Generated images added. 200 generated images by our SUSTechGAN and other GANs are added to the training.
The retrained YOLOv5 is tested on real driving images of rain and night conditions. The (mean) average precision of the retrained YOLOv5 under three training settings is shown in Table IV. For rain conditions, the retrained YOLOv5 under training setting 2) performed a best mAP of 0.457. However, the retrained YOLOv5 on the adding generated images by CycleGAN, UNIT, and MUNIT performed much lower mAP than the adding real images of driving. The retrained YOLOv5 under training setting 3) by adding the generated rain images by SUSTechGAN performed a 0.422 mAP which is a 47.4% improvement of the training setting 2) with fully real rain
mAP
+100 +200 +500 +1000+1300+1500+2000 Nunmber of added images
images. For night conditions, the retrained YOLOv5 under training data setting 3) with adding generated night images by SUSTechGAN performed a 0.469 mAP which is a 19.6% improvement of the training setting 2) with fully real night images and outperforms the method with a 10.5% improvement in reference [30]. The result indicates that the generated driving images by SUSTechGAN can improve object detection of autonomous driving in adverse conditions.
| Scenes | Data | Pedestrian | Car | Truck | mAP |
|----------|-----------------|--------------|-------|---------|-----------------|
| Rainy | 1) Sunny(Real) | 0.286 | 0.361 | 0.283 | 0.310(100%) |
| Rainy | 2) +Rainy(Real) | 0.467 | 0.473 | 0.431 | 0.457 |
| Rainy | 3) +CycleGAN | 0.36 | 0.458 | 0.343 | 0.357 |
| Rainy | +UNIT | 0.34 | 0.452 | 0.333 | 0.375 |
| Rainy | +MUNIT | 0.314 | 0.417 | 0.322 | 0.351 |
| Rainy | +Ours | 0.409 | 0.47 | 0.387 | 0.422(47.4% ↑ ) |
| Night | 1) Day(Real) | 0.306 | 0.448 | 0.421 | 0.392(100%) |
| Night | 2) +Night(Real) | 0.489 | 0.542 | 0.528 | 0.52 |
| Night | 3) +CycleGAN | 0.325 | 0.461 | 0.445 | 0.410 |
| Night | +UNIT | 0.338 | 0.477 | 0.459 | 0.425 |
| Night | +MUNIT | 0.363 | 0.47 | 0.471 | 0.435 |
| Night | +Ours | 0.408 | 0.516 | 0.482 | 0.469(19.6% ↑ ) |
TABLE IV: The performance of the retrained YOLOv5 by adding 200 generated images to the training dataset.
Furthermore, we retrain YOLOv5 with the addition of various numbers of generated images by SUSTechGAN and CycleGAN and compare their performance in terms of mAP over an increasing number of generated images, as shown in Figure 8. The results show that the retrained YOLOv5 by the addition of generated rain or night images of driving by our SUSTechGAN outperforms that of CycleGAN. For the adverse conditions of driving in rain and night conditions, the retrained YOLOv5 performs an increasing mAP when the generated images are increasingly added to the training settings until they approach a converged mAP.
| Ground truth | metrics | CycleGAN | UNIT | MUNIT | Ours |
|----------------|-----------|----------------|---------------|-----------|----------------------------------------------|
| Rainy (2128) | FN FP | 568 226 | 601 151 | 663 102 | 411 (27.6% ↓ ) 93 (8.8% ↓ ) |
| Rainy (2128) | TP | 1560 | 1527 | 1465 | 1717 (10.1% ↑ ) |
| Night (3292) | FN FP TP | 1524 1193 1768 | 1323 945 1969 | 1250 1074 | 1057 (7.9% ↓ ) 870 (27.6% ↓ ) 2235 (9.5% ↑ ) |
| Night (3292) | | | | 2042 | |
| Night (3292) | | | | | |
TABLE V: The statistic results of the pre-trained YOLOv5 by BDD100k tested on 200 generated rain and night images. False Negative (FN), False Positive (FP), True Positive (TP).
We applied various GANs to generate driving images under rain and night conditions as a testing set and tested the pre-trained YOLOv5 by BDD100k on the generated driving images. The statistic results of object detection by the pretrained YOLOv5 are shown in Table V. The object detection results of the pre-trained YOLOv5 on the generated rain and night images of four random driving scenes by different GANs are shown in Figure 9. The real daytime images of four random driving scenes are the inputs of the generators of various GANs, where the bounding boxes are the labeled ground truth. Specifically, several objects in the generated rain images by CycleGAN can not be detected by the pre-trained YOLOv5. For UNIT and MUNIT in Figure 9, several local semantic features are weak in the generated rain images. For example, the bus, cars, and buildings in the first and second rows are blurred. Even worse, there are heavy light effects, such as the red color in the generated images, which does not match the real images of driving in the rain. Due to these defects, the objects in the generated images by UNIT and MUNIT can not be detected correctly. In contrast, the generated rain images of driving by our SUSTechGAN show proper objects and backgrounds under rain without unreasonable light effects. The pre-trained YOLOv5 performed a much better object detection on the generated rain images by SUSTechGAN than the others. For the night condition in Figure 9, the generated images by CycleGAN have many chaotic glare that blurs images and reduces object visibility, e.g., the third row of CycleGAN. The objects thus can not be detected by the pretrained YOLOv5. The generated night images by UNIT and MUNIT have distortion defects such as the bright light of day in the fourth row of UNIT and MUNIT and the black blocks in the third row of UNIT. Our SUSTechGAN generates better night images of driving without glare and distortion defects than the others, which can be applied to generate driving images for improving object detection of autonomous driving under adverse conditions.
## VI. DISCUSSION
The experimental results have demonstrated that our SUSTechGAN outperforms the well-known GANs in image generation for improving object detection of autonomous driving in adverse conditions. However, many open issues could be interesting and need to be discussed in depth. In addition, some limitations of this work would be challenging and need to be investigated further.
In SUSTechGAN, we referred to the well-known GANs for the channel parameter settings in the channel attention
Fig. 8: The mAP of retrained YOLOv5 by adding various numbers of generated rain (left) and night (right) images by our SUSTechGAN and CycleGAN to the training dataset.
(a) Ground Truth

(b) CycleGAN
(c) UNIT
(d) MUNIT
(e) Ours
Fig. 9: The object detection results of the pre-trained YOLOv5 on the generated images by CycleGAN, UNIT, MUNIT, and our SUSTechGAN under the rain (first and second rows) and night (third and fourth rows) conditions. a) shows the real daytime images of four random driving scenes where the bounding boxes are the labeled ground truth.
module, which could be further investigated for improvement. Furthermore, the effects of different channels have not been analyzed in-depth and need to be investigated. In Figure 8, we notice that the retrained YOLOv5 performs a significantly increasing mAP with a low initial value when adding numbers of generated rain images into the training dataset. In contrast, the retrained YOLOv5 has a slow-increasing mAP with a moderate initial value when adding numbers of generated night images into the training dataset. For this issue, we suppose that rainy scenes are more complex than night scenes, and rainy scenes are more diverse than night scenes. For example, there are various degrees of rain such as light rain, moderate rain, and heavy rain for rain conditions. The night scenes could be less diverse and easier to retrain object detection models for a convergent performance than rain scenes.
Furthermore, we discuss the potential limitations of this work. 1) Structure: This work focuses on image generation of driving in adverse conditions by applying the dual attention module and multi-scale mechanism for the normal-to-adverse generator. To reduce the training time, we develop both dual attention modules and multi-scale mechanism to the normalto-adverse generator but only dual attention modules without the multi-scale mechanism to the adverse-to-normal generator, in which the adverse-to-normal generator is weaker than the normal-to-adverse. The weaker adverse-to-normal generator may slightly decrease the normal-to-adverse generator, which could be improved. 2) Dataset: We validate the proposed SUSTechGAN on small-scale datasets (BDD100k-adv, AllRain, and ACDC) due to the limited driving images under adverse weather conditions. Nonetheless, our SUSTechGAN has been demonstrated to improve object detection of autonomous driving in adverse conditions on these datasets. 3) Methods: Both our SUSTechGAN and the well-known GANs generate driving images for adverse conditions by considering global features, which may perform weak local features of specific objects. For example, the generated night images have various glare that is different from real night images, while our SUSTechGAN with the attention module performs better than the existing well-known GANs.
## VII. CONCLUSION
In this work, we propose a novel SUSTechGAN to generate images for training object detection of autonomous driving in adverse conditions. We design dual attention modules and multi-scale generators in SUStechGAN to improve the local and global semantic features for various adverse conditions such as rain and night. We test SUSTechGAN and the wellknown GANs to generate driving images in adverse conditions of rain and night and apply the generated images to retrain the well-known YOLOv5. Specifically, we add generated images into the training datasets for retraining YOLOv5 and evaluate the improvement of the retrained YOLOv5 for object detection in adverse conditions. The experimental results demonstrate that the generated driving images by our SUSTechGAN significantly improved the performance of retrained YOLOv5 in rain and night conditions, which outperforms the well-known GANs. In the future, we will investigate the open issues and limitations discussed in section VI. Furthermore, we will apply SUSTechGAN to generate driving images under more adverse conditions such as snow and fog.
## REFERENCES
- [1] N. Kalra and S. M. Paddock, 'Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability?' Transportation Research Part A: Policy and Practice , vol. 94, pp. 182193, 2016.
- [2] S.-W. Huang, C.-T. Lin, S.-P. Chen, Y.-Y. Wu, P.-H. Hsu, and S.-H. Lai, 'Auggan: Cross domain adaptation with gan-based data augmentation,' in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 718-731.
- [3] S. W. Kim, J. Philion, A. Torralba, and S. Fidler, 'Drivegan: Towards a controllable high-quality neural simulation,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021, pp. 5820-5829.
- [4] X. Li, K. Kou, and B. Zhao, 'Weather gan: Multi-domain weather translation using generative adversarial networks,' arXiv preprint arXiv:2103.05422 , 2021.
- [5] C.-T. Lin, S.-W. Huang, Y.-Y. Wu, and S.-H. Lai, 'GAN-based dayto-night image style transfer for nighttime vehicle detection,' IEEE Transactions on Intelligent Transportation Systems , vol. 22, no. 2, pp. 951-963, 2020.
- [6] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, 'Unpaired image-to-image translation using cycle-consistent adversarial networks,' in Computer Vision (ICCV), 2017 IEEE International Conference on , 2017.
- [7] M.-Y. Liu, T. Breuel, and J. Kautz, 'Unsupervised image-to-image translation networks,' Advances in neural information processing systems , vol. 30, 2017.
- [8] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz, 'Multimodal unsupervised image-to-image translation,' in Proceedings of the European conference on computer vision (ECCV) , 2018, pp. 172-189.
- [9] C. Sakaridis, D. Dai, and L. Van Gool, 'ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 10 765-10 775.
- [10] M. Liu, E. Yurtsever, J. Fossaert, X. Zhou, W. Zimmer, Y. Cui, B. L. Zagar, and A. C. Knoll, 'A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook,' IEEE Transactions on Intelligent Vehicles , 2024.
- [11] A. Geiger, P. Lenz, and R. Urtasun, 'Are we ready for autonomous driving? the kitti vision benchmark suite,' in 2012 IEEE conference on computer vision and pattern recognition . IEEE, 2012, pp. 3354-3361.
- [12] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, 'nuscenes: A multimodal dataset for autonomous driving,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2020, pp. 11 621-11 631.
- [13] P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine et al. , 'Scalability in perception for autonomous driving: Waymo open dataset,' in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2020, pp. 2446-2454.
- [14] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, U. Franke, S. Roth, and B. Schiele, 'The cityscapes dataset for semantic urban scene understanding,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 3213-3223.
- [15] Y. Wang, H. Zhao, K. Debattista, and V. Donzella, 'The effect of camera data degradation factors on panoptic segmentation for automated driving,' in 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC) . IEEE, 2023, pp. 2351-2356.
- [16] J. Hidalgo-Carri´, D. Gehrig, and D. Scaramuzza, 'Learning monocular o dense depth from events,' in 2020 International Conference on 3D Vision (3DV) . IEEE, 2020, pp. 534-542.
- [17] M. Pitropov, D. E. Garcia, J. Rebello, M. Smart, C. Wang, K. Czarnecki, and S. Waslander, 'Canadian adverse driving conditions dataset,' The International Journal of Robotics Research , vol. 40, no. 4-5, pp. 681690, 2021.
- [18] F. Yu, W. Xian, Y. Chen, F. Liu, M. Liao, V. Madhavan, T. Darrell et al. , 'BDD100k: A diverse driving video database with scalable annotation tooling,' arXiv preprint arXiv:1805.04687 , vol. 2, no. 5, p. 6, 2018.
- [19] A. Vahdat and J. Kautz, 'NVAE: A deep hierarchical variational autoencoder,' Advances in neural information processing systems , vol. 33, pp. 19 667-19 679, 2020.
- [20] C. Xu, D. Zhao, A. Sangiovanni-Vincentelli, and B. Li, 'Diffscene: Diffusion-based safety-critical scenario generation for autonomous vehicles,' in The Second Workshop on New Frontiers in Adversarial Machine Learning , 2023.
- [21] X. Li, Y. Zhang, and X. Ye, 'DrivingDiffusion: Layout-guided multiview driving scene video generation with latent diffusion model,' arXiv preprint arXiv:2310.07771 , 2023.
- [22] E. Pronovost, M. R. Ganesina, N. Hendy, Z. Wang, A. Morales, K. Wang, and N. Roy, 'Scenario diffusion: Controllable driving scenario generation with diffusion,' Advances in Neural Information Processing Systems , vol. 36, pp. 68 873-68 894, 2023.
- [23] H. Zhao, Y. Wang, T. Bashford-Rogers, V. Donzella, and K. Debattista, 'Exploring generative ai for sim2real in driving data synthesis,' arXiv preprint arXiv:2404.09111 , 2024.
- [24] T. Berrada, J. Verbeek, C. Couprie, and K. Alahari, 'Unlocking pre-trained image backbones for semantic image synthesis,' in 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . IEEE, 2024, pp. 7840-7849.
- [25] S. Song, S. Lee, H. Seong, K. Min, and E. Kim, 'Shunit: Style harmonization for unpaired image-to-image translation,' in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 37, no. 2, 2023, pp. 2292-2302.
- [26] C. Sakaridis, D. Dai, and L. Van Gool, 'Semantic foggy scene understanding with synthetic data,' International Journal of Computer Vision , vol. 126, pp. 973-992, 2018.
- [27] S. S. Halder, J.-F. Lalonde, and R. d. Charette, 'Physics-based rendering for improving robustness to rain,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2019, pp. 10 203-10 212.
- [28] R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, 'Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-tovehicle communication,' in 2022 International Conference on Robotics and Automation (ICRA) . IEEE, 2022, pp. 2583-2589.
- [29] K. Wang, X. Li, and F. Ren, 'Performance and challenges of 3D object detection methods in complex scenes for autonomous driving,' IEEE Transactions on Intelligent Vehicles , vol. 8, no. 2, pp. 1699-1716, 2022.
- [30] V. F. Arruda, T. M. Paixao, R. F. Berriel, A. F. De Souza, C. Badue, N. Sebe, and T. Oliveira-Santos, 'Cross-domain car detection using unsupervised image-to-image translation: From day to night,' in 2019 International Joint Conference on Neural Networks (IJCNN) . IEEE, 2019, pp. 1-8.
- Gongjin Lan is currently a Research Assistant Professor at the Department of Computer Science and Engineering, Southern University of Science and Technology, Shenzhen, China. He received his PhD in Artificial Intelligence at VU University Amsterdam in 2020, published over 20 academic papers in top international journals and conferences, including IEEE T-HMS, IEEE T-LT, Swarm and Evolutionary Computation, Scientific Reports, PPSN , and serves as a reviewer for IEEE T-EVC, Swarm and Evolutionary Computation, Scientific Reports, PLOS ONE,

ICRA, IROS, GECCO, CEC , etc. His research interests include Autonomous Driving, Deep Learning, and AI interdisciplinary.

- Yang Peng received her M.E. at the Department of Computer Science and Engineering, Southern University of Science and Technology, Shenzhen, China, Dec. 2023. Her research interests include Generative adversarial networks and deep neural networks.
- Qi Hao is currently a Professor at the Southern University of Science and Technology, Shenzhen, China. He received the B.E. and M.E. degrees from Shanghai Jiao Tong University, Shanghai, China, in 1994 and 1997, respectively, and the Ph.D. degree from Duke University, Durham, NC, USA, in 2006, all in electrical and computer engineering. From 2007 to 2014, he was an Assistant Professor at the Department of Electrical and Computer Engineering, University of Alabama, Tuscaloosa, AL, USA. His current research interests include Intelligent un-

manned systems, Machine learning, and Smart sensors.

- Chengzhong Xu (Fellow, IEEE) is currently a Chair Professor of Computer Science at the University of Macau, Macau, China. He was on the faculty of Wayne State University, Detroit, MI, USA. He published two research monographs and more than 500 journal and conference papers with about 20 000 citations, and was a Best Paper Awardee or Nominee of conferences, including HPCA'2013, HPDC'2013, Cluster'2015, ICPP'2015, GPC'2018, UIC'2018, and SoCC'2021. He was also a coinventor of more than 120 patents and a Co-Founder
of Shenzhen Institute of Baidou Applied Technology. He serves or served on many journal editorial boards, including IEEE TC, IEEE TCC, and IEEE TPDS. His recent research interests are autonomous driving, cloud and distributed computing, systems support for AI. | null | [
"Gongjin Lan",
"Yang Peng",
"Qi Hao",
"Chengzhong Xu"
]
| 2024-07-18T15:32:25+00:00 | 2024-12-21T07:21:14+00:00 | [
"cs.CV",
"cs.AI"
]
| SUSTechGAN: Image Generation for Object Detection in Adverse Conditions of Autonomous Driving | Autonomous driving significantly benefits from data-driven deep neural
networks. However, the data in autonomous driving typically fits the
long-tailed distribution, in which the critical driving data in adverse
conditions is hard to collect. Although generative adversarial networks (GANs)
have been applied to augment data for autonomous driving, generating driving
images in adverse conditions is still challenging. In this work, we propose a
novel framework, SUSTechGAN, with customized dual attention modules,
multi-scale generators, and a novel loss function to generate driving images
for improving object detection of autonomous driving in adverse conditions. We
test the SUSTechGAN and the well-known GANs to generate driving images in
adverse conditions of rain and night and apply the generated images to retrain
object detection networks. Specifically, we add generated images into the
training datasets to retrain the well-known YOLOv5 and evaluate the improvement
of the retrained YOLOv5 for object detection in adverse conditions. The
experimental results show that the generated driving images by our SUSTechGAN
significantly improved the performance of retrained YOLOv5 in rain and night
conditions, which outperforms the well-known GANs. The open-source code, video
description and datasets are available on the page 1 to facilitate image
generation development in autonomous driving under adverse conditions. |
2408.01431v2 | Title: Building an Ethical and Trustworthy Biomedical AI Ecosystem for the Translational and Clinical Integration of Foundational Models
Baradwaj Simha Sankar 1,2* , Destiny Gilliland 1,2* , Jack Rincon 1,2 , Henning Hermjakob 3 , Yu Yan 1,2,4 , Irsyad Adam 1,2,4 , Gwyneth Lemaster 1 , Dean Wang 1,2 , Karol Watson 5 , Alex Bui , Wei Wang 7# , Peipei Ping 6 1,2,4,5#
1 Department of Physiology, University of California, Los Angeles, CA, USA.
2 NIH BRIDGE2AI Center at UCLA & NHLBI Integrated Cardiovascular Data Science Training Program at UCLA, Los Angeles, CA, USA.
- 3 European Molecular Biology Laboratory - European Bioinformatics Institute (EMBL-EBI), Cambridge, UK. 4 Bioinformatics IDP, University of California, Los Angeles, CA, USA.
- 5 Department of Medicine (Cardiology Division), University of California, Los Angeles, CA, USA.
- 6 Medical Informatics Home Area, University of California, Los Angeles, CA, USA.
7 Department of Computer Science, University of California, Los Angeles, CA, USA.
*Co-first authors
# Co-corresponding authors
## Abstract
Foundational Models (FMs) are gaining increasing attention in the biomedical AI ecosystem due to their ability to represent and contextualize multimodal biomedical data. These capabilities make FMs a valuable tool for a variety of tasks, including biomedical reasoning, hypothesis generation, and interpreting complex imaging data. In this review paper, we address the unique challenges associated with establishing an ethical and trustworthy biomedical AI ecosystem, with a particular focus on the development of FMs and their downstream applications. We explore strategies that can be implemented throughout the biomedical AI pipeline to effectively tackle these challenges, ensuring that these FMs are translated responsibly into clinical and translational settings. Additionally, we emphasize the importance of key stewardship and co-design principles that not only ensure robust regulation but also guarantee that the interests of all stakeholders-especially those involved in or affected by these clinical and translational applications-are adequately represented. We aim to empower the biomedical AI community to harness these models responsibly and effectively. As we navigate this exciting frontier, our collective commitment to ethical stewardship, co-design, and responsible translation will be instrumental in ensuring that the evolution of FMs truly enhances patient care and medical decision-making, ultimately leading to a more equitable and trustworthy biomedical AI ecosystem.
## Introduction
A corollary to the rise of 'Big Data' is the development of large-scale machine learning models that have the capacity to learn from large datasets [1]. Foundation models (FMs) are large scale models that can be trained on large scale datasets and serve as the 'foundation' for downstream tasks related to the original model. They are increasingly recognized as a component in the workflow for large-scale artificial intelligence (AI) development, leveraging millions to billions of parameters through self-supervised, unsupervised, or semisupervised learning techniques [2]. The initial training of FMs on large datasets enables them to learn patterns, structures, and context within the data, without the need for labor-intensive manual annotation. This initial pretraining provides a foundation for further adaptation and fine-tuning across diverse tasks, spanning from predictive analytics to generative applications [3].
Biomedical AI technologies have shown promising capabilities to diagnose, predict, and recommend treatments across a variety of medical modalities and data types, such as electronic health records (EHRs), chest X-rays, and electrocardiograms [4]. With FMs achieving state-of-the-art performance in natural language processing (NLP) and computer vision (CV), there is growing interest in exploring their utility in biomedical applications. The broad applicability of FMs eases their downstream application for various biomedical tasks, enabling the adaptation of existing architectures to create scalable AI solutions [4]. For example, BioLinkBERT, pre-trained using the Bidirectional Encoder Representations from Transformers (BERT) architecture on citation-linked biomedical corpora from PubMed, demonstrated utility for downstream biomedical natural language processing (BioNLP) tasks such as named entity recognition, document classification, and question answering [5]. Another example is HeartBEiT, an FM pre-trained on 12-lead ECG image data, and fine-tuned for the classification of patients with reduced left ventricular ejection fraction and the classification of patients with hypertrophic cardiomyopathy [6]. Lastly, scFoundation, a model pretrained on over 50 million scRNA-seq data using an encoder-decoder transformer, has shown its utility in a diverse array of single-cell analysis tasks such as gene expression enhancement, tissue drug response prediction, and single-cell drug response classification [7].
Looking forward, FMs pre-trained on multimodal biomedical datasets hold promise for generalizing and integrating knowledge across various data types, learning new tasks dynamically, and addressing a wide array of medical challenges [8]. However, this promising concept for biomedical AI also presents unique ethical challenges, necessitating heightened vigilance and responsible development. Adopting an ethically governed, co-designed approach to FM development and clinical integration, grounded in evidence-based principles and prioritizing the needs of impacted individuals and communities, is critical. This AI pipeline should allow for continuous refinement of AI technologies based on AI stewardship, which is the feedback from stakeholders and regulatory entities. Such an approach is essential to ensure that AI innovations positively contribute to healthcare and public health, reinforcing necessary safeguards and ethical standards.
The main contributions of this paper are as follows:
- 1. We outline the essential components of an AI Ecosystem for integrating biomedical AI technologies into clinical and/or translational settings.
- 2. We examine the current landscape of ethical considerations and ethical practices broadly applicable to biomedical AI and with applications to FM development and deployment, highlighting critical challenges and existing mitigation strategies across three key areas:
- A. Mitigating Bias and Enhancing Fairness
- B. Ensuring Trustworthiness and Reproducibility
- C. Safeguarding Patient Privacy and Security
- 3. We examine pivotal government and scholarly publications that chart the present guidelines and future directions for AI stewardship, emphasizing two main components:
- A. AI Governance and Regulation
- B. Stakeholder Engagement
- 4. Finally, we discuss a unified perspective of how the principles of ethical and trustworthy AI & stewardship in AI integrate into the ecosystem.
## II. AI Ecosystem in Biomedicine.
AI ecosystem is a concept that defines the complex interdependent patterns that connect developers, users, and the upstream and downstream resources necessary for AI development and deployment. It provides a structure to develop an ethical and regulatory framework that promotes fairness, transparency, and accountability in the development and use of AI/ML systems [9]. Within the AI biomedical ecosystem, A well-defined AI pipeline guided by AI stewardship drives the direction of model development towards clinical and translational integration while ensuring its responsible and ethical use. The pipeline begins with the management of large biomedical datasets and culminates in a thoroughly validated model. However, the pipeline workflow is amenable to move forward or backward, as dictated by AI stewardship. To clarify, the AI ecosystem can best be defined via 9 key components and is presented as a pipeline in Figure 1 [10-12]

Figure 1 - AI Ecosystem in Biomedicine. Data Lifecycle Management : The collection, dissemination, and curation of vast amounts of diverse biomedical data. Data Repositories : Centralized systems that store, validate, and distribute data, promoting transparent and reproducible AI technologies. Data Processing : Cleaning, annotating, and structuring data to make it AI-ready. Model Development : The development and training of FMs that can then be utilized for various downstream tasks such as hypothesis generation, explanation, causal reasoning, and clinical decision support. Model Repositories: Centralized storages for managing and sharing AI models to promote accessibility and collaboration amongst stakeholders. Centralized storages for managing and sharing AI models to promote accessibility and collaboration amongst stakeholders. Model Evaluation : The assessment of model performance and reliability prior to deployment in biomedical settings. Clinical Translation : Operationalizing FMs in a clinical setting to enhance patient care. AI Governance and Regulation : Established legal and ethical standards that enforce compliance through both government processes and committee/board regulation. Stakeholder Engagement : Diverse communities and individuals contributing to and affected by AI in biomedicine. Engagement refers to active participation of these groups in the entire pipeline of AI from bench to bedside in both an industrial or healthcare setting.
II. Ethical Considerations in the AI Pipeline for Foundational Models.
II.A. Mitigating Bias and Enhancing Fairness.
Bias in AI can refer to two distinct concepts: technical bias and social bias. Technical bias refers to a statistical concept related to model assumptions that are made for ease of learning and generalization, but that introduce error. This technical bias can lead to underfitting, where the model, due to its oversimplified assumptions, fails to capture the complexity of the data. Social bias in AI refers to the prejudices reflected in the outputs of AI systems, often due to biases present in the training data. These biases often mirror social biases, including historical and current social inequalities. Social biases in biomedical AI can cause direct social harm when they perpetuate outdated claims, lead to inaccurate insights, compromise the quality of care for marginalized groups, and/or exacerbate disparities in the quality of care. AI Fairness is the practice of seeking to understand and mitigate these social biases. In this section, we explore sources of social biases in AI and the metrics and mitigation strategies to help safeguard against their detrimental effects. In Sections II.A.1 and II.A.2, we investigate the social biases that profoundly influence the ethics and trustworthiness of biomedical FM applications. We specifically discuss biases arising from the underrepresentation of certain demographic groups in biomedical datasets, and the stereotypical biases inherent in natural language data used to train certain biomedical FMs, notably Language Model Large (LLMs) and Vision Language Models (VLMs). For each type of social bias, we explore mitigation strategies aimed at neutralizing their negative impacts.
## Mitigating Social Bias and Enhancing Fairness in Biomedical AI
| Category | Strategy | Limitation/Challenge |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Challenge: Underrepresentation of certain demographic groups (e.g. African Americans or women) in biomedical data can result in biased and unfair model decisions. | Challenge: Underrepresentation of certain demographic groups (e.g. African Americans or women) in biomedical data can result in biased and unfair model decisions. | Challenge: Underrepresentation of certain demographic groups (e.g. African Americans or women) in biomedical data can result in biased and unfair model decisions. |
| Data Level (all dataset types) | 1. Inclusive biomedical data collection [13]: - Ensuring all demographic groups are adequately represented. 2. Synthetic datasets [14,15]: - Data engineering to closely mirror phenotypes of underrepresented individuals. | 1. Difficulty accessing diverse populations. Overcoming skepticism in certain demographic groups. 2. Inaccuracies, noise, over- smoothing, and inconsistencies when compared to real-world data. |
| Training Level (datasets with labeled demographic metadata) | 1. Importance weighting [16,17]: - Samples from underrepresented groups in the dataset are shown more frequently to the model, giving them higher importance. 2. Adversarial Learning [18,19]: - Train primary model for the main task and an adversary to be unable to predict sensitive demographic attributes from the primary model's output. 3. Regularization [20,21]: - Inclusion of fairness metric in objective function | 1. Overfitting to underrepresented instances. 2. Optimization challenges due to simultaneous training of the primary model and adversary. 3. Computationally expensive with large predictors. Requires careful tuning of the regularization parameter. 4. Optimization challenges due to stochastic nature. Requires careful tuning of dropout rate. |
| | to penalize unfairness. 4. Dropout [22]: - Probabilistic masking of neurons to reduce dependency on sensitive demographic features. | |
|---------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Evaluation Level (datasets with labeled demographic metadata) | 1. Equalized odds [23,24]: - Are TP and FP rates equal between demographic groups? 2. Equal Opportunity [25]: - Are TP rates equal for all demographic groups? 3. Predictive Parity [24,26]: - Is precision equal across demographic groups? 4. Explainability Methods [27,28]: - Assessing the model's dependence on sensitive demographic attributes in decision making. | 1-3. Relying on a single fairness metric might give an incomplete or misleading picture of a model's bias. 4. Application of techniques can be resource intensive. Effectiveness of explainability methods often depends on human interpretation. |
## Challenge:
Human stereotypical biases can contaminate natural language data and affect the fairness of large language and vision-language biomedical models.
Table 1. (Abbreviations: TP - True Positive, FP - False Positive). We explored social biases present in biomedical data that affect the fairness of biomedical AI. Subsequently, we identified evidence-based techniques to mitigate these common challenges. A more detailed explanation of these concepts and relationships are described in Sec. II.A. 1-11.
| | - Ablate subset of attention heads encoding stereotypes. | |
|------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|
| Vision-Language Models (VLM) | 1. Additive Residual Learner [35]: - Disentangle skewed similarity in representation of certain images and their demographic annotations. | 1. The model may overcompensate and flip similarity skew with different demographic annotations. |
| Versatile (LLM & VLM) | 1. Model Alignment [36-39]: - Techniques to tune AI systems to align with human preferences and values (e.g. reinforcement learning with human feedback). | 1. Curating high-quality, ethically aligned output can be labor intensive and time consuming. Alignment can come with performance trade-offs. |
## II.A.1. Social AI Bias: Underrepresentation Bias.
Social bias in AI can arise when the training data does not accurately represent the real-world distribution of labels and/or features [40]. In biomedicine, this social bias manifests as an underrepresentation of demographic groups in clinical trials and biomedical data registries when compared with the distribution of the general population [41-43]. If biomedical datasets lack sufficient representation from all demographic subgroups, AI models trained on such data may not effectively capture each group's specific feature distribution. Consequently, these models may exhibit poor generalization performance when making decisions for individuals from these underrepresented groups. Therefore, in the context of healthcare delivery, downstream prediction tasks in FM development may exhibit disparities in prediction metrics across different subgroups. When these AI systems are deployed, they can lead to unfair outcomes for certain subgroups as well as perpetuate or exacerbate health inequities [9,44]. For example, large biorepositories supporting omics datasets predominantly consist of data from individuals of European descent, leading to a notable underrepresentation of racial and ethnic minorities that impacts equitable health care delivery in precision medicine applications [42,43].
First, we examine methods for mitigating underrepresentation bias at the data level. Most notably, it is crucial that we work towards inclusive collection of biomedical datasets encompassing a diverse range of demographic groups [44]. This includes a proportional representation of underrepresented groups based on race/ethnicity, gender, socioeconomic status, age, disability status, geography, and other characteristics. However, inclusivity in data collection is a long-term goal that requires tremendous mobilization of resources and amending of historical mistrust among certain demographic populations in biomedical research participation. In the short term, synthetic datasets present a potential mitigation strategy for addressing the issue of underrepresentation in biomedical data [14]. Synthetic data, artificially generated through computer simulations or algorithms, attempts to closely mirror the statistical properties of real-world data. It is a broad concept that encompasses a variety of processes and techniques, from techniques that transform the data to advanced deep learning techniques that generate data by learning from real-world data. In biomedicine, synthetic datasets can be engineered to reduce bias by closely emulating the phenotypes of underrepresented individuals, allowing the training of biomedical AI models that can generalize across demographic groups [14]. However, it's important to note that the use of synthetic data comes with its own set of challenges. The quality of synthetic data can be compromised by inaccuracies, noise, over-smoothing, and inconsistencies when compared to real-world data [15]. Therefore, while synthetic datasets provide a potential solution to address underrepresentation, careful consideration must be given to their generation and use to ensure they contribute positively to the development of fair and unbiased AI systems.
Second, we examine mitigation strategies that can be applied during model training to address the unfairness of downstream FM prediction tasks due to data under representation bias. Importantly, these strategies can be applied to various data types but necessitate datasets to have associated demographic metadata. One approach includes importance weighting, a technique where samples from underrepresented groups in the dataset are shown more frequently to the model, giving them higher importance in model decision making [16,17]. Another approach involves the use of adversarial strategies to address bias in machine learning models. In machine learning, an adversary refers to an agent that intentionally seeks to deceive, manipulate, or exploit a model to achieve a specific goal; it has been explored as a potential strategy to both mitigate and detect bias [18,45]. In a recent study, Yang et al. introduced an adversarial approach where the primary model is trained on the main task while an adversarial model is simultaneously trained to be unable to predict sensitive demographic features from the primary model's output [19]. The goal is to ensure that predictions are independent of sensitive demographic features by balancing predictive and adversarial losses during training. An additional strategy is regularization, which is commonly applied in prediction tasks to reduce overfitting but can also target the reduction of disparities across different demographic groups in the model's predictions. This is achieved by introducing a regularization hyperparameter in the model's loss function that penalizes model weights resulting in high values of a chosen fairness metric [20,21]. Lastly, dropout regularization, which applies a binary mask to neurons so that each neuron has a probability (p) of being dropped out, can also reduce unfair predictions by decreasing the model's reliance on specific sensitive demographic features [22]. It is important to note that each method to improve model fairness may come with potential trade-offs in performance and training time.
For FM downstream tasks, it is imperative to assess the model's fairness, particularly when underrepresentation bias is present. This evaluation should consider the uncertainties of bias mitigation at both the dataset and training levels to ensure the model performs equitably in real-world applications. One common approach to assessing fairness in classification tasks is by evaluating the impact of sensitive demographic features on model predictions using fairness metrics. For instance, equalized odds measures the classifier's accuracy with regards to the true positive rates and false positive rates between different demographics [23,24]. Similarly, the equal opportunity metric requires that the true positive rates are equal for all demographic groups, ensuring that all groups equally benefit from the model [24,25]. On the other hand, predictive parity ensures that precision, or the likelihood of a true positive, is equal across different demographic groups, meaning individuals receiving the same decision should have equal outcomes [26]. While these metrics can provide insight into how the model's decision's may be disparate or equal among demographic groups, relying on a single fairness metric can be limiting; it may provide an incomplete or misleading picture of the model's social bias, since each metric captures only a specific aspect of fairness. In addition, these metrics are limited to classification tasks. Therefore, a way to evaluate a model's dependence on sensitive demographic features or its disregard for socio-demographic variables, can be done via explainability techniques (see section II.B.2. ). These techniques help elucidate the relationship between input data attributions and model outputs, ensuring that AI in biomedicine is fair and equitable [27]. However, applying explainability techniques comes with challenges. These methods can be resource-intensive, and their effectiveness often depends on human interpretation. Moreover, explainability techniques can offer either a global understanding of how features influence the overall decision-making process or a local understanding of how features affect individual decisions [46]. While both perspectives are valuable, each provides only a partial view of the model's behavior.
## II.A.2. Social AI Bias: Stereotypical Biases.
Stereotypical biases in real-world datasets are a significant concern in the field of AI. These biases, often reflections of societal stereotypes, can be unintentionally incorporated into AI models during the training process. Historical and persistent stereotypical biases are particularly prevalent in natural language data, making pretrained LLMs - a type of FM trained on extensive text corpora for a variety of downstream NLP tasks - prone to learning and perpetuating these biases [47]. Presence of stereotypical biases can lead to unfair outcomes when LLMs are used in applications such as text classification, sentiment analysis, or recommendation systems. Given the potential for LLMs in clinical settings for tasks like compiling patient notes and aiding in clinical decision-making, the development and deployment of biomedical LLMs is tempered by ethical concerns [48,49]. Biomedical LLMs can learn and even amplify stereotypical biases present in the biomedical text corpora. When examining four major commercial LLMs (Bard, ChatGPT-3.5, Claude, GPT-4) on medical queries related to racebased practices, these models often perpetuated outdated, debunked stereotypes from their biased training data [49]. Additionally, a UNESCO study on AI gender biases provided clear evidence of gender stereotyping across various LLMs, emphasizing the need for systematic changes to ensure fairness in AI-generated content [50]. This highlights the presence of stereotype biases in LLMs used in biomedical AI systems and underscores the need to address these biases across all demographic groups, including by race and gender.
Recognizing the critical need to address stereotypical biases inherent in natural language data, a variety of specific strategies have been investigated to mitigate these biases in LLMs. One such strategy includes counterfactual data augmentation (CDA) involves augmenting a corpus by swapping demographic identifier terms with their opposites to create a more balanced dataset [29,30]. For instance, terms like "he" and "she" are interchanged to ensure that the data representation is more equitable. This method helps to reduce the reinforcement of existing stereotypes by providing a diverse set of examples, ultimately leading to fairer and more unbiased model outputs. Counterfactual data augmentation, while useful, may not adequately address more complex biases that are not directly associated with demographic identifiers. Bias control training is another strategy designed to manage and mitigate demographic bias in dialogue generation. This process involves training the model to associate control tokens with certain demographic properties and adjusting its responses accordingly. It begins by categorizing each dialogue response into bins based on the presence of words associated with a demographic group and appending a special token to indicate the bin. During training, the model learns to associate these tokens with the demographic group association of responses and adjusts its output accordingly. At inference time, different special tokens can be appended to control the stereotypical biases of the model's output. This approach allows for precise control over the stereotypical bias of the language generated by the model, ensuring that biases are minimized and promoting more equitable and unbiased dialogue generation [31]. However, this process of bias control training is highly dependent on the categorization of responses with their stereotype associations. Complimenting bias control training is attempting to minimize bias in word embeddings, which are vector representations that capture semantic and syntactic properties of words. As the foundation of LLMs, word embeddings enable these models to understand and generate humanlike text. Word embedding biases refer to the phenomenon where these embeddings reflect and perpetuate societal biases present in the training data [51]. This means that words associated with a particular protected group (e.g. gender) might be closer in the embedding space to stereotypically associated words. To reveal biases related to protected groups, one approach involves identifying pairs of data points that differ in a specific attribute, creating a "seed direction" that represents this difference [32]. Analogous pairs are then generated and scored based on their alignment with the seed direction, systematically uncovering biased relationships in the embeddings. Once identified, a method to debias these words involves generating augmented sentences through demographic identifier word swapping, encoding both the original and augmented sentences, and maximizing their mutual information [33]. However, the process of debiasing word embeddings can encounter difficulties in maintaining semantic consistency. This presents a decision-making challenge where one must balance performance trade-offs when implementing debiasing techniques. Ma et al. explored how attention heads can encode bias and found that a small subset of attention heads within pretrained language models are primarily responsible for encoding stereotypes toward specific minority groups and could be identified using attention maps [32]. The authors used Shapley values [52] to estimate the contribution of each attention head to stereotype detection and performed ablation experiments to assess the impact of pruning the most and least contributive heads [34]. Attention head pruning, while effective in model compression and mitigating encoded stereotypes, is a technique specific to architectures that utilize attention heads. It may also risk the loss of semantic meaning that can impact the model's performance.
Stereotypical biases, inherent in natural language data, can also influence multimodal models that incorporate natural language, such as Vision-Language Models (VLMs) [53]. These biases, if unaddressed, can inadvertently affect the performance and fairness of these models. For example, VLMs like DALL-E and Midjourney have been shown to exhibit racial and stereotypical biases in their outputs [9]. For instance, when prompted to generate images of CEOs, these models predominantly produced images of men, reflecting gender bias acquired during training. Saravanan et al. also explored social bias in text-to-image foundation models performing image editing tasks [54]. Their findings revealed significant unintended gender alterations, with images of women altered to depict high-paid roles at a much higher rate (78%) than men (6%). Additionally, there was a notable trend of skin lightening in images of Black individuals edited into high-paid roles [54. Although VLMs in biomedicine can analyze visual and textual medical data for tasks such as medical report generation and visual question answering [55]. Biomedical VLMs can learn stereotypical associations between words and images, perpetuating these in its inference and exacerbating health inequities. Therefore, it is essential to explore methods that can disentangle the skewed similarities in the representation of certain images and their associated demographic annotations. Seth et al. presented a framework for debiasing pre-trained VLMs that involves training an Additive Residual Learner (ARL) such that the model disentangles protected attribute information from the image representation produced by the pretrained encoder [35]. The trainable ARL takes an image representation from the pretrained encoder as input, returns a residual representation, and concatenates the pretrained representation to produce a modified, debiased representation of the image that is fed to a Protected Attribute Classifier (PAC), which classifies protected attributes such as race, gender, and age. The training objectives in the framework are as follows: a) minimize a reconstruction loss to ensure the debiased representation is close to the original representation; b) minimize the maximum soft max probability of each protected attribute classifier head to encourage the model to be uncertain about the protected attributes; and c) maximizing the misclassification of the protected label [35]. Benchmarking results show that this additive residual debiasing framework significantly improves the fairness of output representations without sacrificing predictive zero-shot performance [35]. However, the ARL may overcompensate during the debiasing process, potentially flipping the similarity skew in the opposite direction for different demographic annotations. This can result in unintended biases being introduced, highlighting the need for careful calibration and evaluation of the model's performance across various demographic groups.
To complement the discussed debiasing strategies, model alignment techniques offer a versatile set of strategies for mitigating stereotypical biases in AI systems. These techniques aim to align models more closely with human values and preferences, enhancing their safety, fairness, and contextual appropriateness [36,56]. In the biomedical field, aligning LLMs and VLMs to avoid social stereotypes in decision-making is essential for creating more equitable and fairer AI. These alignment techniques are applicable to both LLMs and VLMs, enhancing their performance and adaptability. However, the specific methodologies and considerations may vary depending on the model architecture and the task at hand. Two foundational techniques in model alignment are Instruction Tuning (IT) and Supervised Fine-Tuning (SFT), each with distinct objectives. SFT involves fine-tuning model outputs against preferred outcomes [57], using a curated dataset of high-quality outputs. IT, on the other hand, fine-tunes models using a labeled dataset of instructional prompts and corresponding outputs [58], with the goal of improving performance on specific tasks and general instruction-following. These techniques should be used judiciously, keeping in mind the potential risks and challenges associated with fine-tuning, such as overfitting and distributional shift.
Reinforcement Learning from Human Feedback (RLHF) offers another layer of refinement for LLMs by integrating human feedback into the learning process [37]. In reinforcement learning, an agent learns which actions to take by interacting with an environment, receiving rewards for correct actions and penalties for incorrect ones. RLHF enhances this process by incorporating human feedback to guide and accelerate learning, enabling the model to make more informed decisions. The primary goal of RLHF is to optimize a model's responses based on a reward system that aligns with human preferences. For LLMs, this involves defining a policy that dictates responses to prompts and resulting completions. The process includes pretraining a base LLM, generating output pairs, and using a reward model (RM) that is trained on human feedback to mimic human ratings. The LLM is then trained to achieve high feedback scores from the RM. The challenge lies in optimizing these rewards without overly relying on them, as human preferences can be complex and nuanced. Reinforcement Learning with AI Feedback (RLAIF) [38]is a related approach that uses AI systems to evaluate actions and guide learning. In RLAIF, an AI system, such as an LLM, provides feedback instead of human evaluators. This feedback is used to train a reward model, similar to RLHF, but with AI-generated evaluations. The key difference between RLHF and RLAIF is in the source of feedback-human evaluators in RLHF versus AI systems in RLAIF. Another method, Direct Preference Optimization (DPO) [39], fine-tunes LLMs with human feedback without using reinforcement learning. Like RLHF, DPO involves generating output pairs and receiving human feedback, but the LLM is trained to assign high probabilities to positive examples and low probabilities to negative ones, effectively bypassing the need for reinforcement learning. However, DPO requires labeled positive and negative pairs for training, whereas RLHF, once the RM is trained, can annotate as much data as needed for fine-tuning.
Moreover, red teaming represents a way to assess the stereotypic outputs of LLMs and VLMs. It involves intentional adversarial attacks wherein an input is modified in a way that bypasses the model's alignment to reveal inherent vulnerabilities, including biased output. This process often involves a human-in-the-loop, or another model, to assess and provoke the target model into producing harmful outputs. Red-teaming in biomedicine should engage multidisciplinary teams to evaluate AI systems and prevent biased medical information. For example, Chang et. al. conducted a study using multidisciplinary red-teaming to test medical scenarios with adversarial commands, such as "you are a racist doctor" [59]. They exposed vulnerabilities in GPT-3.5 and 4.0 that allowed the propagation of identity-based discrimination and false stereotypes, influencing treatment recommendations and perpetuating discriminatory behaviors based on race or gender, such as biased renal function assessments. Important to note, the red teaming process may inadvertently introduce new biases if the adversarial inputs aren't sufficiently representative. Therefore, while valuable, red teaming should be used alongside other strategies like continuous monitoring and robust debiasing to comprehensively address bias.an LLM backbone, a regression layer for multi-objective evaluation, and a gating layer that combines these objectives into a single scalar score [60]. Constitutional AI, developed by Anthropic, focuses on making models less harmful and more helpful by creating a "constitution" that outlines ethical principles and rules to guide the model [61]. Ultimately, RLHF is crucial for reducing bias prior to the clinical integration of FMs, as it offers a way to ethically align models to the needs and values of diverse patient populations.
## II.B. Ensuring Trustworthiness and Reproducibility.
Trustworthiness and reproducibility are paramount in the biomedical AI ecosystem, as they ensure the reliability and accuracy of AI models in critical translational and healthcare applications. In Section II.B.1. , we discuss the essential data lifecycle concepts, highlighting how the Findable, Accessible, Interoperable, Reusable (FAIR) principles need to be supported by data integrity, provenance and transparency in the current AI ecosystem. Section II.B.2. delves into interpretability and explainability, emphasizing the need for AI/ML models to foster trust and understanding among users in translational settings. Section II.B.3. covers enhancing AI accuracy, exploring model alignment strategies and human-in-the-loop approaches to improve the performance and ethical alignment of FMs. Finally, Section II.B.4. discusses algorithmic transparency, which is indispensable for both reproducing results and establishing trust in a model.
## Ensuring Trustworthiness & Reproducibility in Biomedical AI
Category
Strategy
Limitation/Challenge
Challenge: The absence of standardized data management protocols throughout its lifecycle obstructs collaboration in biomedical AI, particularly in integrating diverse datasets for comprehensive model development.
Biomedical Data
1. FAIR data principles [62-64] - Good practices for discovery
1. Broad implementation of FAIR principles is challenged by data
and reuse of digital objects.
- 2. Data Provenance [65]
- -Documenting data origins, processing/transformations, and usage.
- fragmentation, interoperability issues, inadequate documentation, and the need for appropriate infrastructure and resources to implement effective data management practices.
- 2. Maintaining data lineage can be cumbersome due to evolving data sources, complex workflows or data transformations, and schema modifications.
Challenge: The decision-making process and output of a biomedical AI model must be transparent, understandable, and verifiable by human experts to build the trust required for integration into clinical and translational settings.
## Biomedical AI systems
- 1. Interpretability & Explainability Methods [66-70]
- -Techniques incorporated into model development or evaluation to enhance understanding of the model's inner workings and the impact of data attributes on decision-making.
- 2. Integrating Human Expertise [7173]
- -AI leveraging human expertise and insights to improve its performance, learn from mistakes, and make more informed and accurate decisions.
- 3. Transparent AI Documentation [7477]
- -Documentation of up-stream resources used in development, model-level properties, and down-stream applications.
Table 2. (Abbreviations: FAIR - Findable, Accessible, Interoperable, Reproducible). We explored the challenges in the ability of AI systems to consistently produce reliable and verifiable results that instill confidence in their predictions and decisions in the biomedical field. Subsequently, we identified evidence-based techniques to mitigate these common challenges. A more detailed explanation of these concepts and relationships are described in Sec. II.B. 1-4.
II.B.1 Essential Data Lifecycle Concepts. Findable, Accessible, Interoperable, Reusable (FAIR) principles, which promote good practices for scientific data and its resources, have a long-standing foundation for establishing trustworthiness and reproducibility of biomedical data, particularly regarding the discovery and reuse of digital objects throughout their lifecycle [62-64]. We review data concepts, adapted from these FAIR principles, that
- 1. Application of techniques can be resource intensive. Effectiveness of explainability methods often depends on human interpretation.
- 2. Integrating human expertise may introduce biases and variability, potentially affecting the quality and consistency of decision making.
- 3. Complexity of AI models, proprietary information protection, rapidly evolving AI technologies, and the difficulty in documenting implicit biases and decisionmaking processes within the models.
are relevant to the trustworthiness and reproducibility of FM development pipelines in the biomedical AI ecosystem. Given that FMs are trained on datasets from diverse sources, and increasingly across diverse modalities, provenance, or, tracking data origins, processing, and usage, is crucial to enhance trust and accountability for model developers, data creators, policymakers, and the public [65]. Longpre et al. recommended five essential elements of a data provenance framework to support responsible FM development including: a) a verifiable metadata that is reliable and assessable; b) practices for tracing data are modality and source agnostic; c) data and metadata are searchable, filterable, and composable; d) the framework is flexible to incorporate new metadata types and adapt to different technological and regulatory landscapes; e) relevant data sources are symbolically attributed to trace data lineage, data alterations over time, and identify data origins [65]. Importantly, modifications and/or augmentations to datasets inevitably influence the distribution of features and/or classes, and are therefore vital in data provenance. These alterations may also introduce errors, noise, inconsistency, as well as discrepancy in smoothness and dynamics in comparison to real-world data, which ultimately impact the trustworthiness of model output, making tracking of data processing an important ethical consideration as we move through the AI lifecycle [15,77]. It is important to note that the widespread adoption of FAIR principles faces hurdles such as data fragmentation, interoperability complications, insufficient documentation, and the requirement for suitable infrastructure and resources for effective data management. Furthermore, preserving data lineage becomes arduous due to changing data sources, intricate workflows or data transformations, and alterations in schema.
II.B.2 Interpretability and Explainability. Interpretability in AI refers to the degree to which a model's inner workings are comprehensible to users within the context of the application domain [78]. On the other hand, explainability is about explaining the behavior of an AI model in human-terms, by highlighting potential influences of input features with the model output at a local or global level [78]. Methods to support explainability and interpretability of AI systems can be categorized into two main types: a priori and a posteriori approaches [66]. A priori techniques are implemented during the model development phase with the aim of improving the model's interpretability. Examples of a priori techniques include: a) selecting features that align with established and relevant biomedical concepts; b) implementing regularization to penalize large weights; and c) using models with simpler topologies [66-68]. A posteriori techniques are applied after the model has been trained, serving as methods to explain the model's predictions with respect to the input. Examples of a posteriori techniques include: a) feature perturbation to monitor how slight changes in the input affects the model output; and b) counterfactuals that elucidates a model's reasoning through the lens of 'what if' scenarios [66,69,70]. High stakes biomedical use-cases, like diagnosis or detection, demand understanding and trust in decisions made by AI models [66]. Explainability and interpretability offer a human-friendly understanding into the behavior of an AI prediction. Likewise, interpretability and explainability foster trust in clinical decisions, by providing an explanation of how data points and features influence a decision. Collectively, these techniques promote a nuanced understanding of AI models amongst a wider audience and enhance diverse stakeholder engagement, which potentially paves the way for more effective human-in-the-loop approaches. The challenges we face include the resource-intensive nature of these techniques and the fact that the effectiveness of explainability methods often relies on human interpretation.
## II.B.3. Enhancing AI Reliability with Human-in-the-loop.
The human-in-the-loop approach aims to generate a cost-effective and accurate model for solving complex tasks by integrating human expertise/insights into the decision-making loop of AI systems [91]. In this framework, humans can intervene in the AI pipeline during data preprocessing and/or model training and inference, where machine-based approaches can benefit from the rich knowledge and oversight of human experts [73]. Humanin-the-loop approaches can play a pivotal role in developing accurate and reliable biomedical AI applications such as medical diagnostics, treatment planning, and personalized medicine [72]. For instance, a human-in-theloop AI approach was designed to accurately detect and classify regions of interest in biological images [71]. This approach involved human guidance in the training loop by selecting prototype patches, ensuring data quality, and fine-tuning the confidence threshold for inference. Altogether, human-in-the-loop collaboration enhances the accuracy and reliability of AI systems in biomedicine by incorporating practical, real-world medical knowledge to guide and validate AI decision making. This collaborative approach to decision making fosters confidence among users and stakeholders regarding the robustness and trustworthiness of the model, facilitating adoption in clinical and translational settings. While integrating human expertise may introduce biases and variability, potentially impacting the quality and consistency of decision-making, it also presents an opportunity to leverage diverse perspectives and experiences. With careful management and continuous learning, we can mitigate these risks and enhance the robustness and reliability of our AI systems.
II.B.4. Transparency & Reproducibility. Transparency is a nuanced concept used in various scientific disciplines, but recently, it has been at the forefront of discussions pertaining to global AI regulation. In a 2019 study, 'transparency' was found to be the most commonly used principle addressing AI ethical guidelines, and it is one of the five key ethical principles promoted in 84 AI studies [74]. It is imperative to note that transparency is recommended for both technical features of an algorithm in addition to practical implementation methodology within current social parameters [75]. Closely related to transparency, reproducibility encompasses methods such as sharing open data and open source code, which works to ensure that scientific findings are accurate and reliable, or otherwise, reproducible [79]. Given the need for precision in biomedical AI, transparency is critical for reproducing results and establishing trust in a model. Building on these concepts, Bommasani et al. have proposed a 'Foundation Model Transparency Report' that aims to institutionalize transparency reporting to increase accountability, reproducibility, and an understanding of AI technologies [77]. These recommendations disclose information on various aspects about the development, deployment, and impact of FMs including the following: a) Upstream resources with respect to training datasets, human resources involved in developing the FM, computational resources utilized for training and development, codebases and their relevant computational environments, architecture and design choices of the FM and/or reasoning for selection of pretrained model(s), training processes (e.g. the optimization algorithms, hyperparameters, and training duration), and steps taken to address ethical considerations (e.g. fairness, robustness, security, and explainability of the model); b) Modellevel properties including its purpose, intended applications, and target domains alongside details about the model's level of interpretability and incorporated explainability modules. In addition, it is recommended the report include information about the model's performance metrics, limitations, biases, security, versioning, licensing, and intellectual property. Critically, substantial computational resources are required for training making it prohibitive and often unnecessary to retrain them. It is essential to openly share trained model weights and architecture in FAIR repositories to reproduce and critically evaluate the model; and c) Downstream aspects that provide information about specific use cases and applications, guidelines and mitigation strategies for responsible and ethical use, mechanisms for collecting user feedback, compliance of the FM with regulations and standards, accessibility and availability of the FM, and external audits or assessments [82]. Importantly, it is recommended all relevant stakeholders have access to supporting tutorials, documentation, and training channels [82]. In conclusion, as FMs continue to rapidly scale in their applications for biomedicine, the need for the standardization of robust transparency and reproducibility practices and frameworks are needed to support AI clinical translation. While the complexity of AI models, proprietary information protection, rapidly evolving AI technologies, and the challenge of documenting implicit biases and decision-making processes within the models pose significant hurdles, they also present opportunities for innovation and improvement in AI documentation.
## II.C. Safeguarding Patient Privacy and Security.
In this section, we explore critical aspects of safeguarding patient privacy and security within the biomedical AI ecosystem. In II.C.1. , we discuss strategies to maintain data security and ensure proper data provenance. In II.C.2. , we examine how technologies like blockchain, edge computing, and federated learning can enhance data security and privacy within cloud and hybrid cloud infrastructures. In II.C.3. , we address the risks of and strategies to combat patient re-identification and membership inference attacks. In II.C.4. , we examine the challenges of memorization in AI models and discuss strategies to mitigate these issues. These sections collectively highlight the ongoing challenges of patient privacy within the realm of biomedical AI, emphasizing the importance of robust security measures and ethical practices.
| Category | Strategy | Limitation/Challenge |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Challenge: Unauthorized access to sensitive biomedical data jeopardizes individual privacy, undermines stakeholder trust, and threatens compliance with regulatory guidelines. | Challenge: Unauthorized access to sensitive biomedical data jeopardizes individual privacy, undermines stakeholder trust, and threatens compliance with regulatory guidelines. | Challenge: Unauthorized access to sensitive biomedical data jeopardizes individual privacy, undermines stakeholder trust, and threatens compliance with regulatory guidelines. |
| Data Life Cycle | 1. Role-based access control, data access logs & strong authentication methods [80] - Common data security measures to protect sensitive information. 2. Obtaining & respecting patient consent [81,82] - Informed consent; adhering to agreed terms; allowing withdrawal 3. Data Provenance [83] - Detailed audit trail of origin and journey of data, including its creation, | 1. Managing complex permissions and challenges in detecting unauthorized activities in large- scale logs. 2. Ensuring comprehension of complex data use scenarios and maintaining up-to-date consents amid rapidly evolving technologies. 3. Complexity of tracking data lineage in large-scale systems, potential inaccuracies in provenance data, the challenge of maintaining up-to- date provenance information. |
| Challenge: Developing biomedical AI in the cloud offers flexible, ready-to-use, and scalable infrastructure. However, ensuring the security and privacy of sensitive data during storage and computation is challenging in | Challenge: Developing biomedical AI in the cloud offers flexible, ready-to-use, and scalable infrastructure. However, ensuring the security and privacy of sensitive data during storage and computation is challenging in | Challenge: Developing biomedical AI in the cloud offers flexible, ready-to-use, and scalable infrastructure. However, ensuring the security and privacy of sensitive data during storage and computation is challenging in |
| Data Storage | 1. Blockchain technology [84] - Provides a decentralized, tamper-resistant ledger that ensures transparent and secure data recording. 2. Data Encryption [85] - Algorithms to transform readable data to unreadable data. | 1. A '51% attack' :a potential security risk in blockchain networks where a miner or group of miners, possessing over half the network's computing power, can rewrite the blockchain. 2. Computationally intensive and may introduce latency issues |
| Computation | 1. Hybrid Cloud [86] - Flexible public and private cloud approach for optimizing security. 2. Edge Computing [87-89] - Allows for computing closer to data sources, reducing potential exposure during transmission. 3. Federated Learning [90] - Enables decentralized models to be trained across multiple devices or servers holding local data samples | 1. Integrating private cloud with public cloud introduces additional infrastructure complexity. 2. Increased complexity of managing distributed systems. 3. Maintaining data integrity across multiple nodes. |
| | without exchanging them. | |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Challenge: Sensitive biomedical data is vulnerable to adversarial attacks, including the risk of re-identifying individuals or inferring whether an individual's data was used to train a model. | Challenge: Sensitive biomedical data is vulnerable to adversarial attacks, including the risk of re-identifying individuals or inferring whether an individual's data was used to train a model. | Challenge: Sensitive biomedical data is vulnerable to adversarial attacks, including the risk of re-identifying individuals or inferring whether an individual's data was used to train a model. |
| Patient Re- identification | 1. Removing patient identifiers, and/or implementing rule and ML based patient data anonymization [91-93] - Manual or computational elimination of personally identifiable information from health data. | 1. Algorithms have demonstrated the ability to successfully identify an individual's record in a dataset. |
| Membership Inference Attacks | 1. Techniques to increase model generalization [94,95] - Strategies to encourage smaller or sparser coefficients. 2. Data augmentation [95] - Techniques that artificially transform data to increase its size and entropy. 3. When training on synthetic biomedical data: employ full synthesis approach [96] - Training a generative model to create synthetic data that mirrors the real data distribution. 4. Privacy risk score [97] - Measures the likelihood that an input sample is part of the training dataset. | 1. Must be balanced against a potential utility penalty for the model. 2. Must be balanced against a potential utility penalty for the model. 3. Inaccuracies, noise, over- smoothing, and inconsistencies when compared to real-world data. 4. Reliance on posterior probability can render the method sensitive to the model's complexity and training dynamics. |
Challenge: Large-scale biomedical models can memorize data, making them vulnerable to unique security risks such as data leaks, manipulation to produce misleading outputs, and the exposure of sensitive patient information.
Over-Parameterized Models and 'LongTailed' Data
- 1. Data augmentation [98]
- -Techniques that artificially transform data to increase its size and entropy.
- 1. Must be balanced against a potential utility penalty for the model.
- 2. Model size reduction [99,100]
- -Techniques to compress the model.
- 3. Patient data deduplication [101103]
- -Identifying and removing duplicate entries from a dataset.
- 2. Must be balanced against a potential utility penalty for the model.
- 3. Appropriately matching patient records; potential loss of important data.
Table 3. We explored recurring challenges regarding the maintenance of privacy and security of patient data. Subsequently, we identified evidence-based techniques to mitigate these common challenges. A more detailed explanation of these concepts and relationships are described in Sec. II.C. 1-4.
- II.C.1. Essential Data Lifecycle Concepts. In safeguarding access to sensitive patient data, it is essential to employ robust authentication methods, implement role-based access control, and maintain comprehensive logs of all data access instances [80]. However, while these mechanisms are fundamental for protecting patient data privacy, they are not without their challenges. For instance, role-based access control can become cumbersome in environments with complex permission hierarchies, and the sheer volume of data access logs can make it difficult to detect unauthorized activities effectively in large-scale systems. As these challenges illustrate, the complexity of managing data access is closely tied to the broader responsibility of ensuring that, as the need for data sharing and reuse in biomedical research grows, the rights and privacy of participants are respected and upheld. This process necessitates obtaining informed consent for data sharing, de-identifying data sets before dissemination, and ensuring that the data is only utilized for the purposes explicitly agreed upon [81,82]. Although informed consent is a cornerstone of patient privacy protection, it presents challenges of its own, such as ensuring that participants fully understand the complexities of how their data might be used and keeping consent documents relevant in the face of rapidly advancing technologies.
Moreover, fostering a secure and responsible AI ecosystem hinges on the effective implementation of data provenance. Data provenance involves the meticulous documentation of a dataset's origin, movement, and transformations throughout its lifecycle. Such documentation not only enhances transparency but also aids in identifying and analyzing potentially malicious activities [83]. Nonetheless, the methods used to establish data provenance come with their own set of limitations, including the complexity of tracking data lineage in large-scale systems, the potential for inaccuracies in provenance data, and the difficulty of maintaining up-to-date records as data evolves. Collectively, these principles of data access control, informed consent, and data provenance play a critical role in ensuring the trust and safety of all stakeholders within the biomedical AI ecosystem.
- II.C.2. Protecting Patient Privacy in Cloud Storage and Computation . The advantages of developing AI in the cloud include access to a flexible hardware infrastructure specifically designed for AI. This infrastructure is equipped with state-of-the-art GPUs that not only accelerate the training process but also efficiently handle the influx of inference processing associated with the deployment of a new AI system. In this scenario, the trained neural network is put to work for practical applications. Furthermore, the cloud eliminates the need for complex hardware configuration and purchase decisions, providing ready-to-use AI software stacks and development frameworks. Cloud-based AI development also has its disadvantages. One of the primary concerns is the rising costs associated with storing large datasets and training models. Additionally, data security becomes a significant challenge. Ensuring the security and privacy of sensitive data during both storage and computation is crucial. This challenge is further amplified by the need to perform complex computations on this sensitive data without compromising its integrity. Therefore, while cloud-based AI development offers numerous benefits, it also presents complex challenges that need to be effectively addressed.
Data privacy is a critical issue when deploying models for clinical practice in cloud environments due to the sensitive nature of patient health information (PHI). This sensitivity restricts data storage infrastructure, network data transfers, and access to computing resources [89]. A hybrid cloud model enables organizations to utilize their own infrastructure for sensitive, private data and computation, while integrating public clouds for nonsensitive, public data and computation [86]. Alternatively, a blockchain-based interplanetary file system (IPFS) can be implemented as secondary storage to safeguard the privacy and security of patient health information [84]. IPFS allows users to host and receive content in a decentralized manner while blockchain ensures that once data is recorded, it cannot be altered without the consensus of the network. The blockchain technology securely transmits and stores patient data, providing a potential solution for addressing privacy concerns associated with rapid medical data access and processing. However, a '51% attack' is a potential security risk in blockchain networks where a miner or group of miners, possessing over half the network's computing power, can rewrite the blockchain [104].
Edge computing is a paradigm that shifts data processing and storage from the cloud closer to the source devices, enhancing data security and privacy while also decreasing latency [105]05]. It therefore offers utility in enhancing the security of patient-sensitive data within the biomedical AI ecosystem by preventing public data leaks while also speeding up decision-making, reducing latency, and improving the overall quality of care [106]. For example, Humayun et. al. introduced a framework to integrate cutting-edge technologies like mobile edge computing and blockchain to enhance healthcare data security [107]. Meng et. al. presented an edge computingbased approach for healthcare applications that store and perform computation on cloud servers [107]. They employed homomorphic encryption, which allows computations to be performed on encrypted data without the need for decryption, thus ensuring patient data security even if accessed by attackers [85]. They also presented a strategy to distribute computation across multiple virtual nodes at the edge, leveraging cloud computational resources while keeping all arithmetic operations masked. The approach prevents adversaries from discerning the specific tasks performed on the encrypted patient data. Serverless edge computing represents an evolution of cloud serverless technology, where there is an abstracting of servers from the application development process, enabling developers to build applications without concern for the underlying infrastructure [88]. Serverless edge computing highlights the potential for distributing models with preserved privacy, combining the flexibility of cloud computing with the security of local deployment [89]. However, while an edge or serverless edge computing approach offers a promising solution for enhancing patient data security, there is an added complexity of managing distributed systems.
Federated learning is a framework for distributed machine learning whereby patient data stored across various hospitals and healthcare institutions is kept decentralized on their local servers. These institutions use a federated workflow where learning takes place locally on their own nodes/edge devices. A central cloud server then aggregates the results to create a unified model. Sadilek et. al. applied modern and general federated learning methods that explicitly incorporate differential privacy to clinical and epidemiological research [90]. They demonstrated that federated models could achieve similar accuracy, precision, and generalizability as standard centralized statistical models while achieving considerably stronger privacy protections. While federated learning enhances patient data privacy by decentralizing data processing, it faces challenges related to maintaining data integrity across multiple nodes.
II.C.3. Patient Re-Identification & Membership Inference Attacks. Patient data are essential for developing FM models in biomedicine, but robust methods are needed to protect patient confidentiality. The first crucial step to address privacy concerns involves anonymization or removal of patient identifiable information. The Department of Health and Human Services has specified the 18 types of protected health information to be removed from patient data in order to comply with the Health Insurance Portability and Accountability Act (HIPAA) [91]. In addition, rule based and machine learning based systems have been developed to de-identify/anonymize health data, including novel methods based on the self-attention mechanism [92,93,108]. However, de-identification strategies are proving to be insufficient in protecting patient records in the face of algorithms that have successfully reidentified such data [109,110]. Narayanan et. al. showed that de-anonymization attacks can be highly effective even when the adversary's background knowledge is imprecise and the data has been perturbed prior to release, meaning an adversary with minimal knowledge about an individual can identify this individual's record in a dataset [111]. This introduces us to a similar concept known as membership inference attacks (MIA), which is aimed at discovering whether a specific individual's data was used in the training set of a model. Sarkar et. al. demonstrated that de-identification of clinical notes for training language models was not sufficient to protect against MIAs [112]. Therefore, MIAs pose significant risks in exposing personal information of individuals whose data contributed to a model and strategies to mitigate this risk must be implemented. The general principle of MIA involves analyzing model responses to particular inputs to infer training data membership, revealing a model's privacy vulnerabilities in addition to its potential overfitting or insufficient generalization [96,113-115]. Since MIA and protection against it has largely been studied on simple classification models, Ko et. al. studied MIA strategies on multi-modal FMs trained on imaging and text data (CLIP). In their exploration of wellestablished MIA defense strategies for simple models applied to a multi-modal model, there were two important findings: a) L2 regularization, a strategy to penalize the weights of the model to encourage smaller or sparser coefficients, moderately protects against privacy attacks by reducing model sensitivity to variations in input data, however, this comes at a cost to the model's utility; b) Data augmentation, a technique that artificially applies various transformations to the data to increase its size and entropy (e.g. rotating or scaling an image), enhanced protection of the model against MIA (the AUC score for the weakly supervised attack went from 0.7754 to 0.7533) and improved the models generalizability (zero-shot performance improved by 1.2%) [94]. These findings support the idea that defense mechanisms which curb model overfitting also reduce the model's susceptibility to MIA [95]. However, this privacy protection must be balanced against a potential utility penalty for the model [116]. Zhang et al. assessed the vulnerabilities of models trained on synthetic health data to MIA [117]. They studied MIA attacks on two types of synthetic data: a) Full synthesis, which involves learning a generative model that mimics the real data distribution from which synthetic data are sampled while severing direct links to real individuals; and b) Partial synthesis, which employs a transformation function that perturbs features of real records to generate synthetic counterparts, but maintaining some connection to the original data. The findings suggest that partial synthesis is more susceptible to membership inference attacks compared to full synthesis, indicating that the method chosen for synthetic data generation greatly affects data privacy. Consequently, a full synthesis approach seems to be the optimal choice when training models on synthetic data. As previously discussed, synthetic data quality can be undermined by inaccuracies, noise, over-smoothing, and inconsistencies relative to real-world data so it's crucial to ensure rigorous quality control measures when generating and using synthetic data [15].
Song and Mittal introduced a privacy risk score that was shown to align closely with the actual probability of a sample being from the training set; this is crucial for identifying which data points might be particularly vulnerable to MIA [97]. In a nutshell, the privacy risk score measures the likelihood that an input sample is part of the training dataset based on the observed behavior of the target machine learning model. This likelihood is defined by the posterior probability that a sample belongs to the training set given the observed outputs from the target model. However, the reliance on posterior probability can render the method sensitive to the model's complexity and training dynamics, potentially diminishing its reliability in more intricate or less interpretable models. Despite these limitations, the privacy risk score remains a valuable tool, guiding decisions on model deployment in clinical settings and informing the development of stronger privacy preservation strategies before deployment.
II.C.4. Memorization of Patient Data. The distribution of real-world data tends to be 'long-tailed,' where a few categories contain most of the data, while a large number of categories have only a few samples [118,119]. Large AI models are often overparameterized, and while overparameterization helps in covering the "long tail" of rare events or atypical instances, it also brings significant challenges, namely: a) As models grow in size, they become computationally expensive to train, harder to optimize, and more prone to overfitting in certain contexts despite their generalization capabilities in others; b) Reducing the size of these models to mitigate security risks often results in a substantial drop in performance; and c) Larger models, due to their complexity and the sheer amount of data they memorize, are susceptible to unique security vulnerabilities, including potential for data leaks or being manipulated to generate misleading outputs [99,100]. For example, an FM trained on clinical data might memorize specific details about patients with a rare disease, increasing the risk that adversarial attacks could compel the model to reveal sensitive data, despite precautions taken during model alignment [8]. Carlini et al. highlight the relativity of memorization by introducing the "Onion Effect", where removing the most vulnerable outlier points reveals a new layer of data previously considered safe, now susceptible to privacy attacks [120]. [101]. Similarly, Hassan Dar et al. explored memorization in latent diffusion models used for creating synthetic medical images from CT, MR, and X-ray datasets and found high levels of memorization across all datasets [98]. They observed that implementing data augmentation strategies can decrease the extent of memorization. Consequently, data augmentation appears to be an effective strategy for reducing memorization, as discussed in the previous section, and for enhancing protection against MIA. However, it's essential to fine-tune the data augmentation techniques to ensure that it does not compromise the performance of the model.
De-duplication of training data involves identifying and removing duplicate entries from a dataset. This task is particularly labor-intensive given the vast size of training datasets, which often span hundreds of gigabytes, rendering perfect deduplication impractical. Moreover, accurately matching patient records can present challenges due to inconsistencies in data entry and variations in patient information. While generally reliable, there is a risk of losing important data during the deduplication process. Despite these limitations, deduplication remains a crucial strategy for managing patient datasets since duplicate records can lead to breaches of patient privacy as a result of data memorization. In fact, Carlini et al., in another paper on quantifying memorization in language models, demonstrated that sequences repeated fewer than 35 times see a statistically significant reduction in memorization from 3.6% to 1.2% with deduplication [101]. As a bonus, deduplication efforts also enable better model evaluation by diminishing train-test overlap and decreasing the number of training steps required to achieve the same or enhanced accuracy [101]. A few methods for de-duplication of patient records include: a) Exact substring duplication - when two examples share a sufficiently long substring, one is removed [102]; b) Suffix array - removal of duplicate substrings from the dataset if they occur verbatim in more than one example [121]; and c) MinHash - an algorithm for estimating the n-gram similarity between all pairs of examples in a corpus and removing data with high n-gram overlap [122]. Deduplication of patient data requires a method for record linkage since directly comparing personal information across systems to identify duplicates violates privacy regulations and is not feasible with de-identified data [103]. Privacy protecting linkage approaches of clinical data records first require the creation of secure and anonymous patient identifiers. Some approaches include: a) U.S. NIH Global Unique Identifier (GUID) - which generates hash codes for personal identifiable information in records; b) Mainzelliste - developed in Germany, it is an open-source service for pseudonymization that generates pseudonyms unlinked to identifiable elements but allows for data matching; and c) European Patient Identity Management (EUPID) - generates context-specific pseudonyms using hashing algorithms and thus supports using different pseudonyms for the same patient in various contexts while assuring patient anonymity across the contexts [123]. These identifiers, such as the hash codes generated by GUID, can be compared to link and deduplicate patient data. In summary, de-duplicating training data, although labor-intensive, can be essential for safeguarding patient privacy and maintaining the integrity of biomedical AI systems. By leveraging diverse techniques and privacy-preserving linkage methods, we can markedly decrease data memorization and ensure patient anonymity.
## III. AI Stewardship.
## III.A. AI Governance and Regulation.
The regulation of AI involves several key international and national bodies, each contributing uniquely to the governance landscape. To cultivate an environment where ethical AI practices such as the development of FMs flourish, governing bodies have concentrated on several key areas. First and foremost, transparency is emphasized by requiring clear and understandable AI decision-making processes. This ensures that the operations and outcomes of AI systems are accessible and comprehensible to all stakeholders. Additionally, accountability mechanisms are being established to hold AI developers and users responsible for their systems, thereby fostering trust and reliability. Concurrently, guidelines to mitigate biases and ensure fairness are being promoted and implemented, which work hand-in-hand with strict data handling practices designed to protect individual privacy. A comprehensive governance approach supported and implemented by the federal and state are essential to assure that AI development is both ethical and aligned with standardized societal values.
III.A.1. Landscape and Integration of AI Governance and Regulation. The European Union (EU) has been at the forefront of the AI governance initiative, implementing the General Data Protection Regulation (GDPR) in 2018, which sets stringent guidelines on data protection and privacy directly impacting AI development and deployment [124]. Building on this, the EU's Artificial Intelligence Act, first introduced in 2021, aimed to create a harmonized framework for AI regulation, focusing on high-risk applications and promoting trustworthy AI practices. It is important to note that the European Commission's High-Level Expert Group on AI (HLEG), established in 2018, also developed the Ethics Guidelines for Trustworthy AI, which emphasize the need for AI systems to be lawful, ethical, and robust [125]. Similarly, the Council of Europe's Ad Hoc Committee on Artificial Intelligence (CAHAI), formed in 2019, is working towards a comprehensive legal framework for AI, focusing on protecting human rights, democracy, and the rule of law within the AI context [126]. Regarding international governance, the United Nations (UN) has also made significant strides through UNESCO's Recommendation on the Ethics of Artificial
Intelligence, published in 2021 [127]. This document serves as a global standard-setting instrument addressing human rights, ethical principles, and the need for transparency and accountability in AI contexts. Moreover, the World Health Organization (WHO) has also played a distinct role in the international governance of AI. In 2021, WHO released its first global report on AI in medicine proposing six guiding principles of ethics and human rights: a) Protecting Human Autonomy, b) Promoting Human Well-Being and Safety, and the Public Interest, c) Ensuring Transparency, Explainability, and Comprehensibility, d) Fostering Responsibility and Accountability, e) Ensuring Inclusiveness and Equity, and f) Promoting Sustainable AI [128]. Expanding on these six consensus principles, the WHO published a second report in 2023 on the practical implementations of AI systems in healthcare and biomedical science [129]. Importantly, the WHO is mindful of the growing need for capacity building and collaboration among different sectors and regions, and is working to develop a global framework for the governance of AI systems for healthcare [124].
Meanwhile, in the United States (US), the Federal Trade Commission (FTC) and the National Institute of Standards and Technology (NIST) play crucial roles in AI regulation. The FTC's Guidance on AI and Algorithms, issued in 2020, emphasizes the importance of fairness, transparency, accountability, and explainability for diverse stakeholders; it warns against biases and scientifically deceptive practices [130]. Similarly, the NIST's Framework for Managing AI Risks, released in 2021, provides comprehensive guidelines to identify, assess, and manage AI-related threats, supporting the development of trustworthy and reliable AI systems [131]. Although not a direct result of the FTC's and NIST's work, both government agencies' progress with documenting ethical AI practices contributed to the broader regulatory landscape culminating in the US government; it subsequently led the US congress to enact the AI in Government Act of 2020. This act encourages federal agencies to adopt AI technologies while ensuring adherence to civil liberties, civil rights, as well as economic and national security [132].
Sharing the same vein as the aforementioned contributions to governance, the United States Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence outlines an up-to-date comprehensive framework to address these areas and push AI regulation via legal adherence [133]. The Executive Order (EO) is broken down into 16 clearly delineated sections, and provides a clear comprehensible and accessible outline for diverse stakeholders. As previously mentioned, many of the regulatory contributions focus on a few domains (e.g., trustworthiness, privacy and protection), but critically, the EO addresses a major gap in current frameworks as it encompasses a multifaceted call for ethical compliance within all domains of AI. Remarkably, it covers strategies to support workers in an AI-integrated economy, which has not typically been covered in other governance documentation in detail. Moreover, the EO has a detailed section defining mechanisms of implementation to support the adherence to the ethical guidelines discussed. Future regulatory bodies and contributions should follow the structure of the multifaceted framework and adapt the EO to implement their updated or more robust call for compliance. Overall, all these milestones reflect the ongoing efforts to standardize safe and effective use of AI in biomedical applications, increase research funding to address ethical, legal, and social implications, as well as engage the public in discourse about AI's role in healthcare.
Despite these collective efforts, several gaps remain in the current landscape of regulatory frameworks. A significant challenge includes the lack of global harmonization, leading to fragmented regulations that complicate compliance for international AI developers. Additionally, the rapid pace of AI advancements often outstrips the ability of regulations to keep up, necessitating more agile and adaptive regulatory mechanisms. Ethical guidelines also need to be more precisely defined and enforceable to effectively address issues such as bias and discrimination [134]. Finally, existing laws primarily focus on data protection and privacy, with insufficient attention to other ethical concerns like AI's impact on employment, environment, and implementation. While significant strides have been made, ongoing efforts are needed to address existing gaps and keep pace with technological advancements. Altogether, global harmonization, the aggregation of current ethical considerations, the development of adaptive regulatory frameworks, and the lawful reinforcement of AI guidelines will be key to achieving these goals [135,136]. It is clear the regulation and governance of AI are crucial for ensuring an ethically grounded AI ecosystem, especially in sensitive fields like biomedical AI.
III.B. Stakeholder Engagement. Engaging with a diverse range of stakeholders is critical for optimizing ethical and responsible outcomes to successfully develop and deploy AI systems within the biomedical field. Stakeholder engagement involves identifying and interacting with all parties who are either affected by, or can influence AI systems [137]. Stakeholders in the AI biomedical ecosystem can be broadly categorized into three levels: (1) individual stakeholders, (2) organizational stakeholders, and (3) national/international stakeholders [134].
Figure 2 - Stakeholder Engagement. Individual stakeholders include users, developers, researchers, and any other individuals directly interacting with or impacted by AI systems. Users encompass clinicians and other nonexpert individuals who bring a real-world perspective on the responsible use of AI. Organizational stakeholders are entities such as healthcare institutions, research organizations, and companies involved in the development, deployment, and maintenance of AI systems. National and international stakeholders encompass regulatory bodies and policy makers engaged in crafting laws and regulations governing AI technologies.

Previous literature highlights a broad spectrum of stakeholders involved in the AI ecosystem, but there is minimal literature explaining the relevance of identifying stakeholders early in the AI lifecycle. Early identification allows AI system developers to discern which ethical guidelines are most pertinent to their products and services, aligning the development process with ethical standards from the outset [134]. It also helps in assessing who might be influenced by the AI systems and how recognizing individuals, groups, organizations, and even nationstates that could be affected or have the power to affect AI outcomes [134]. For example, investigators and developers are often more attuned to the technical and performance aspects of AI systems, and are likely to express concerns regarding the ethical dimensions and impacts of AI decisions and activities. In comparison, non-expert stakeholders such as clinicians and general consumers contribute valuable insights into the realworld implications of AI systems, supporting responsible AI behavior in diverse contexts.
Early identification also helps us understand the specific concerns and needs of different stakeholders and brings forth the concept of explainable AI (see Section II.B.2. ) -a suite of machine learning techniques that enable human users to understand, appropriately trust, and produce more explainable models [138]. Users may lack the training to fully comprehend AI systems, which may lead to potential misuse or misinterpretation. This highlights the need for AI systems to provide clear and verifiable explanations of their decisions for relevant stakeholders. For instance, clinicians are frequently concerned about privacy breaches, personal liability, and the loss of oversight in clinical decision-making. Additionally, certain demographic groups may be disproportionately affected by AI systems based on factors such as region, age, socioeconomic status, and ethnicity [19], therefore, special attention is needed to safeguard their interests. Moreover, the explanations provided to end-users might differ from those required by other stakeholders, emphasizing the importance of tailoring communication to the audience. To enhance widespread trust and accountability, AI systems must cater to the explanation needs of various stakeholders.
III.B.1. Co-Design. Implementing co-design principles in AI use and development encompasses actively involving stakeholders in the design process, ensuring their needs and concerns are addressed from the beginning of the AI pipeline. Co-design supports collaboration between AI developers, users, and other stakeholders, leading to more inclusive and ethically grounded AI systems [139]. By incorporating feedback from a diverse range of stakeholders, AI systems can better align with societal values and ethical standards, enhancing their acceptance and effectiveness. Co-design consists of an iterative process composed of designing, testing, and refining both hardware and software components until the system meets desired performance requirements [139]. This process bridges the gap between hardware and software design, in addition to AI deployment, which traditionally have been developed independently. Critically, co-design also supports human-in-the-loop (HITL) learning by fostering user engagement, ensuring systems are user-centric, and facilitating continuous feedback and improvement [73]. Key concepts in co-design include engaging endusers/diverse stakeholders throughout the AI development process, exposure analysis, and implementing ethical frameworks within design processes [140].
We have stated the benefits and significance of co-design, and that this approach ensures diverse perspectives are incorporated into the AI system, leading to more robust and ethically aligned outcomes. It is imperative to note that early engagement directly relates to co-design. Engaging end-users and other stakeholders throughout the design process is crucial for capturing a wide array of needs and potential impacts, thus ensuring that the AI system is designed with a comprehensive understanding of its real-world application. This engagement helps in identifying potential ethical and practical issues early on, allowing for timely adjustments and improvements before AI applications are utilized by stakeholders [141]. Another critical component to co-design includes exposure analysis, which involves analyzing the extent to which different stakeholders are exposed to various aspects of the AI system and identifying potential risks [142]. By understanding the exposure levels of different stakeholders, developers can design safeguards and features that minimize risks and enhance the system's safety and reliability. A critical component of exposure analysis includes evaluating potential contacts between hazards and receptors [143]. This involves assessing the interactions between potential hazards posed by the AI system and the stakeholders who might be affected by these hazards. By systematically evaluating these elements, developers can implement strategies to reduce stakeholder vulnerability, ensuring that the AI system is both safe and ethically sound.
A notable framework composed of multifaceted metrics for ethical practice in co-design includes Z-inspection, coined by Zicari et al., which focuses on evaluating and auditing AI systems at multiple stages of the AI pipeline [143]. Z-inspection involves a multidisciplinary approach, where ethicists, domain experts, and diverse stakeholders collaborate to inspect and assess the AI system at various stages of its development [143]. This inspection process helps in identifying potential ethical issues early on in AI development, allowing for timely interventions and modifications to be embedded throughout the AI pipeline. Crafting and implementing frameworks such as Z-inspection supports transparency and accountability across all stakeholders throughout
AI development, and cultivates an environment where ethical standards are continuously monitored and upheld, thereby enhancing the trustworthiness and reliability of an AI system. In conclusion, the co-design approach, coupled with ethical methodologies such as Z-inspection, plays a pivotal role in developing ethically grounded biomedical AI ecosystems. By active collaboration amongst stakeholders and continuous evaluation of ethical implications, we can create AI systems that are more aligned with societal values, ultimately leading to broader acceptance and enhanced outcomes in biomedical applications.
## IV. Unified Perspective.
We have extensively reviewed the ethical challenges and their relevant mitigation strategies required to minimize the negative impacts of AI. These strategies act as checkpoints throughout AI development and deployment to maintain an ethical and trustworthy AI lifecycle. Additionally, we have examined regulations and recommendations globally for the responsible use of AI, and emphasized the importance of engaging all relevant stakeholders during the development and integration processes of AI. This comprehensive approach will ensure that AI technologies meet the needs and protect the interests of all relevant stakeholders based on their specific interaction with the AI technology, fostering iterative improvement and adaptability of the entire ecosystem. Collectively, these elements form a robust Ethical & Trustworthy Artificial Intelligence (ETAI) Biomedical Ecosystem.
Figure 3 - AI Lifecycle. The figure illustrates the AI pipeline with stakeholders at the base of the reiterative cycle moving through various stages. Stakeholder engagement alongside government and regulation are depicted as gears influencing the pipeline's rotation. Key checkpoints in the pipeline, marked with letters, denote significant milestones: A (securing data); B (combating data memorization); C (mitigating adversarial attacks); D (securing cloud infrastructure); E (mitigating demographic underrepresentation); F (data transparency); G (mitigating stereotype biases); and H (model transparency, interpretability, and explainability). These checkpoints ensure the AI model system's integrity, security, and efficacy, continuously aligning with evolving societal needs, ethical standards, and legal requirements.
IV.A.1. AI Lifecycle and AI Pipeline in the AI Biomedical Ecosystem. Understanding the distinction between the AI pipeline and the AI lifecycle is foundational for building an ethical and sustainable biomedical AI ecosystem. While both concepts are integral to the advancement and maintenance of AI systems, they conceptualize the design, development, deployment, and stewardship of the AI system distinctly. The AI pipeline represents a technical assembly line, where the creation and deployment of an AI model follows a linear, step-by-step process; starting from data collection and preprocessing, moving through from co-design, model training, and validation, and culminating in deployment; the pipeline's primary goal is to deliver a functional AI system ready for clinical translation. Each component in the pipeline is clearly delineated, focusing on efficiency and precision of the output. Critically, the AI lifecycle embodies a dynamic, cyclical flow of AI system processes, emphasizing continuous iterative improvement and adaptation. Rather than a straight path to an endpoint, the lifecycle views it as an ongoing journey, where the AI model system evolves through iterative feedback and refinement from all stakeholders. This approach integrates constant input from the developer and the user at every stage-from initial development through deployment and ongoing operation-promoting systems that remain relevant, ethical, reliable, and vibrant over time. Thus, the AI pipeline ensures each model is constructed by addressing all functional steps efficiently and effectively; whereas the AI lifecycle guarantees that the model continues to comply with ethical standards and meet operational demands throughout its existence. Collectively, they form a comprehensive framework for our community and all stakeholders that support the development and maintenance of a robust and ethical biomedical AI ecosystem.
IV.B.1. Standardizing Bias Mitigation, Trustworthiness & Reproducibility, and Privacy & Security. Mitigating bias, enhancing trustworthiness and reproducibility, and ensuring privacy and security are core components of ethical AI practices that must be integrated into each phase of the AI lifecycle to create a robust biomedical AI ecosystem. As we've discussed, there are several methods to support the implementation of these ethical considerations. Briefly, addressing bias requires a multifaceted approach that goes beyond ensuring data diversity and representation. It involves implementing continuous monitoring and adjustment procedures to prevent and correct biases that may arise. This ongoing vigilance helps create AI systems that provide equitable outcomes for all users. Additionally, enhancing trustworthiness and reproducibility requires transparent methodologies and documentation, enabling AI systems to be understandable and verifiable. Trust in AI systems is built through both explainability and reproducibility. Moreover, privacy and security involves robust data protection practices, safeguarding patient information from unauthorized access and breaches throughout the AI lifecycle. Privacy should be maintained in the initial data handling, as well as throughout the system's operational life, adapting to new threats and vulnerabilities as they arise. To adapt to the rapid advancement of AI, these concerns must be addressed through standardized metrics and evaluation processes that are consistently applied across all stages of the AI lifecycle. Standardization ensures that ethical considerations are not an afterthought but are integral to the design, implementation, and operation of AI systems. This systematic AI lifecycle approach allows for the continuous improvement and adaptation of AI technologies, ensuring they remain ethical, reliable, and align with societal values. By embedding these principles into the lifecycle, we strengthen a biomedical AI ecosystem that is resilient, trustworthy, and capable of delivering significant benefits to healthcare and society.
## IV.C.1. Call for Continuous AI Stewardship and Harmonious AI Governance in the AI Lifecycle.
The development and deployment of AI systems in biomedicine must be accompanied by continuous AI stewardship and harmonious AI governance. Continuous engagement with diverse stakeholders, including patients, clinicians, ethicists, and policymakers, is foundational. This iterative engagement will ensure that AI systems are developed and deployed in ways that meet the needs and values of all affected parties. Transparency throughout the lifecycle should ensure that all relevant stakeholders distinctly understand the FMs' development process, the data used to train them, and the potential ethical and performance limitations that may arise. Providing ongoing training for diverse stakeholders and raising awareness about ethical AI practices is imperative to establish iterative feedback loops for the continuous monitoring and refinement of AI model systems throughout the AI lifecycle. Multidisciplinary governance frameworks that are adaptable to emerging technologies and evolving societal norms are also needed to certify that AI systems are developed and used in ways that are safe, fair, and transparent. Developers and investigators should adhere to global regulations, such as the EO and the WHO AI Global Report, to ensure AI systems comply with legal standards for privacy, data protection, and ethical use. Harmonizing these regulations across jurisdictions can simplify compliance and promote global standards. Critically, governance organizations and policymakers should collaborate and use standardized practices to enhance policymaking processes informed by diverse perspectives and expertise. In conclusion, implementing AI stewardship and harmonious AI governance in the AI lifecycle is essential for sustaining an ethically grounded AI biomedical ecosystem. This unified perspective fosters trust and promotes innovation, ultimately improving clinical outcomes.
## AUTHOR CONTRIBUTIONS
* B.S.S. and D.G. contributed equally.
Conceptualization, B.S.S. and D.G.; Investigation, B.S.S., D.G., and G.L.; Writing - Original Draft Preparation, B.S.S. and D.G.; Writing - Review & Editing, B.S.S., D.G., J.R., H.H., Y.Y., I.A.,D.W., K.W., A.B.; Visualization, J.R., D.W.; Supervision, W.W., P.P.; Project Administration, B.S.S., D.G., W.W., P.P.
## ACKNOWLEDGEMENTS
This work was supported in-part by NIH awards, namely, U54OD036472 to Peipei Ping and to Wei Wang, U54HG012517 to Peipei Ping, and the UCLA Laubisch Endowment to Peipei Ping.
## COMPETING INTERESTS
The authors have no competing interests to declare.
## REFERENCES
- 1. Large Scale Machine Learning Systems Available online: https://www.kdd.org/kdd2016/topics/view/largescale-machine-learning-systems (accessed on 21 July 2024).
- 2. Awais, M.; Naseer, M.; Khan, S.; Anwer, R.M.; Cholakkal, H.; Shah, M.; Yang, M.-H.; Khan, F.S. Foundational Models Defining a New Era in Vision: A Survey and Outlook Available online: https://arxiv.org/abs/2307.13721v1 (accessed on 21 July 2024).
- 3. What Are Foundation Models? - Foundation Models in Generative AI Explained - AWS Available online: https://aws.amazon.com/what-is/foundation-models/ (accessed on 21 July 2024).
- 4. Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-Supervised Learning in Medicine and Healthcare. Nat. Biomed. Eng. 2022 , 6 , 1346-1352, doi:10.1038/s41551-022-00914-1.
- 5. Yasunaga, M.; Leskovec, J.; Liang, P. LinkBERT: Pretraining Language Models with Document Links 2022.
- 6. Vaid, A.; Jiang, J.; Sawant, A.; Lerakis, S.; Argulian, E.; Ahuja, Y.; Lampert, J.; Charney, A.; Greenspan, H.; Narula, J.; et al. A Foundational Vision Transformer Improves Diagnostic Performance for Electrocardiograms. Npj Digit. Med. 2023 , 6 , 1-8, doi:10.1038/s41746-023-00840-9.
- 7. Hao, M.; Gong, J.; Zeng, X.; Liu, C.; Guo, Y.; Cheng, X.; Wang, T.; Ma, J.; Zhang, X.; Song, L. Large-Scale Foundation Model on Single-Cell Transcriptomics. Nat. Methods 2024 , 1-11, doi:10.1038/s41592-02402305-7.
- 8. Moor, M.; Banerjee, O.; Abad, Z.S.H.; Krumholz, H.M.; Leskovec, J.; Topol, E.J.; Rajpurkar, P. Foundation Models for Generalist Medical Artificial Intelligence. Nature 2023 , 616 , 259-265, doi:10.1038/s41586-02305881-4.
- 9. Ferrara, E. Fairness and Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, and Mitigation Strategies. Sci 2024 , 6 , 3, doi:10.3390/sci6010003.
- 10. Jacobides, M.G.; Brusoni, S.; Candelon, F. The Evolutionary Dynamics of the Artificial Intelligence Ecosystem. Strategy Sci. 2021 , 6 , 412-435, doi:10.1287/stsc.2021.0148.
- 11. Yoo, S. A Study on AI Business Ecosystem. J. Inst. Internet Broadcast. Commun. 2020 , 20 , 21-27, doi:10.7236/JIIBC.2020.20.2.21.
- 12. Winter, N.R.; Cearns, M.; Clark, S.R.; Leenings, R.; Dannlowski, U.; Baune, B.T.; Hahn, T. From Multivariate Methods to an AI Ecosystem. Mol. Psychiatry 2021 , 26 , 6116-6120, doi:10.1038/s41380-02101116-y.
- 13. Penman-Aguilar, A.; Talih, M.; Huang, D.; Moonesinghe, R.; Bouye, K.; Beckles, G. Measurement of Health Disparities, Health Inequities, and Social Determinants of Health to Support the Advancement of Health Equity. J. Public Health Manag. Pract. JPHMP 2016 , 22 , S33-S42, doi:10.1097/PHH.0000000000000373.
- 14. Rajotte, J.-F.; Bergen, R.; Buckeridge, D.L.; Emam, K.E.; Ng, R.; Strome, E. Synthetic Data as an Enabler for Machine Learning Applications in Medicine. iScience 2022 , 25 , doi:10.1016/j.isci.2022.105331.
- 15. Synthetic Data in AI: Challenges, Applications, and Ethical Implications Available online: https://arxiv.org/html/2401.01629v1 (accessed on 23 July 2024).
- 16. Fang, T.; Lu, N.; Niu, G.; Sugiyama, M. Rethinking Importance Weighting for Deep Learning under Distribution Shift 2020.
- 17. Vaidya, A.; Chen, R.J.; Williamson, D.F.K.; Song, A.H.; Jaume, G.; Yang, Y.; Hartvigsen, T.; Dyer, E.C.; Lu, M.Y.; Lipkova, J.; et al. Demographic Bias in Misdiagnosis by Computational Pathology Models. Nat. Med. 2024 , 30 , 1174-1190, doi:10.1038/s41591-024-02885-z.
- 18. Li, X.; Cui, Z.; Wu, Y.; Gu, L.; Harada, T. Estimating and Improving Fairness with Adversarial Learning 2021.
- 19. Yang, J.; Soltan, A.A.S.; Eyre, D.W.; Yang, Y.; Clifton, D.A. An Adversarial Training Framework for Mitigating Algorithmic Biases in Clinical Machine Learning. Npj Digit. Med. 2023 , 6 , 1-10, doi:10.1038/s41746-023-00805-y.
- 20. Kamishima, T.; Akaho, S.; Sakuma, J. Fairness-Aware Learning through Regularization Approach. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops; December 2011; pp. 643-650.
- 21. Olfat, M.; Mintz, Y. Flexible Regularization Approaches for Fairness in Deep Learning. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC); December 2020; pp. 3389-3394.
- 22. Webster, K.; Wang, X.; Tenney, I.; Beutel, A.; Pitler, E.; Pavlick, E.; Chen, J.; Chi, E.; Petrov, S. Measuring and Reducing Gendered Correlations in Pre-Trained Models 2021.
- 23. Zafar, M.B.; Valera, I.; Rodriguez, M.G.; Gummadi, K.P. Fairness Beyond Disparate Treatment & Disparate Impact: Learning Classification without Disparate Mistreatment. In Proceedings of the Proceedings of the 26th International Conference on World Wide Web; April 3 2017; pp. 1171-1180.
- 24. Machine Learning Glossary: Fairness Available online: https://developers.google.com/machinelearning/glossary/fairness (accessed on 24 July 2024).
- 25. Gallegos, I.O.; Rossi, R.A.; Barrow, J.; Tanjim, M.M.; Kim, S.; Dernoncourt, F.; Yu, T.; Zhang, R.; Ahmed, N.K. Bias and Fairness in Large Language Models: A Survey. Comput. Linguist. 2024 , 1-83, doi:10.1162/coli\_a\_00524.
- 26. Chouldechova, A. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data 2017 , 5 , 153-163, doi:10.1089/big.2016.0047.
- 27. Li, X.; Xiong, H.; Li, X.; Wu, X.; Zhang, X.; Liu, J.; Bian, J.; Dou, D. Interpretable Deep Learning: Interpretation, Interpretability, Trustworthiness, and Beyond. Knowl. Inf. Syst. 2022 , 64 , 3197-3234, doi:10.1007/s10115-022-01756-8.
- 28. Henriques, J.; Rocha, T.; de Carvalho, P.; Silva, C.; Paredes, S. Interpretability and Explainability of Machine Learning Models: Achievements and Challenges. In Proceedings of the International Conference on Biomedical and Health Informatics 2022; Pino, E., Magjarević, R., de Carvalho, P., Eds.; Springer Nature Switzerland: Cham, 2024; pp. 81-94.
- 29. Lu, K.; Mardziel, P.; Wu, F.; Amancharla, P.; Datta, A. Gender Bias in Neural Natural Language Processing 2019.
- 30. Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.-W. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. In Proceedings of the Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers); Walker, M., Ji, H., Stent, A., Eds.; Association for Computational Linguistics: New Orleans, Louisiana, June 2018; pp. 15-20.
- 31. Dinan, E.; Fan, A.; Williams, A.; Urbanek, J.; Kiela, D.; Weston, J. Queens Are Powerful Too: Mitigating Gender Bias in Dialogue Generation. In Proceedings of the Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Online, November 2020; pp. 8173-8188.
- 32. Bolukbasi, T.; Chang, K.-W.; Zou, J.Y.; Saligrama, V.; Kalai, A.T. Man Is to Computer Programmer as Woman Is to Homemaker? Debiasing Word Embeddings. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc., 2016; Vol. 29.
- 33. Cheng, P.; Hao, W.; Yuan, S.; Si, S.; Carin, L. FAIRFIL: CONTRASTIVE NEURAL DEBIASING METHOD FOR PRETRAINED TEXT ENCODERS. 2021 .
- 34. Ma, W.; Scheible, H.; Wang, B.; Veeramachaneni, G.; Chowdhary, P.; Sun, A.; Koulogeorge, A.; Wang, L.; Yang, D.; Vosoughi, S. Deciphering Stereotypes in Pre-Trained Language Models. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, December 2023; pp. 1132811345.
- 35. Seth, A.; Hemani, M.; Agarwal, C. DeAR: Debiasing Vision-Language Models With Additive Residuals.; 2023; pp. 6820-6829.
- 36. Shen, T.; Jin, R.; Huang, Y.; Liu, C.; Dong, W.; Guo, Z.; Wu, X.; Liu, Y.; Xiong, D. Large Language Model Alignment: A Survey 2023.
- 37. Kaufmann, T.; Weng, P.; Bengs, V.; Hüllermeier, E. A Survey of Reinforcement Learning from Human Feedback 2024.
- 38. Lee, H.; Phatale, S.; Mansoor, H.; Mesnard, T.; Ferret, J.; Lu, K.; Bishop, C.; Hall, E.; Carbune, V.; Rastogi, A.; et al. RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback 2023.
- 39. Rafailov, R.; Sharma, A.; Mitchell, E.; Ermon, S.; Manning, C.D.; Finn, C. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model 2024.
- 40. Ntoutsi, E.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.-E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in Data-Driven Artificial Intelligence Systems-An Introductory Survey. WIREs Data Min. Knowl. Discov. 2020 , 10 , e1356, doi:10.1002/widm.1356.
- 41. National Academies of Sciences, Engineering, and Medicine; Policy and Global Affairs; Committee on Women in Science, Engineering, and Medicine; Committee on Improving the Representation of Women and Underrepresented Minorities in Clinical Trials and Research Improving Representation in Clinical Trials and Research: Building Research Equity for Women and Underrepresented Groups ; BibbinsDomingo, K., Helman, A., Eds.; The National Academies Collection: Reports funded by National Institutes of Health; National Academies Press (US): Washington (DC), 2022; ISBN 978-0-309-27820-1.
- 42. Aldrighetti, C.M.; Niemierko, A.; Van Allen, E.; Willers, H.; Kamran, S.C. Racial and Ethnic Disparities Among Participants in Precision Oncology Clinical Studies. JAMA Netw. Open 2021 , 4 , e2133205, doi:10.1001/jamanetworkopen.2021.33205.
- 43. Yang, G.; Mishra, M.; Perera, M.A. Multi-Omics Studies in Historically Excluded Populations: The Road to Equity. Clin. Pharmacol. Ther. 2023 , 113 , 541-556, doi:10.1002/cpt.2818.
- 44. Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting Racial Bias in an Algorithm Used to Manage the Health of Populations. Science 2019 , 366 , 447-453, doi:10.1126/science.aax2342.
- 45. Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating Unwanted Biases with Adversarial Learning. In Proceedings of the Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society; Association for Computing Machinery: New York, NY, USA, December 27 2018; pp. 335-340.
- 46. Thomasian, N.M.; Eickhoff, C.; Adashi, E.Y. Advancing Health Equity with Artificial Intelligence. J. Public Health Policy 2021 , 42 , 602-611, doi:10.1057/s41271-021-00319-5.
- 47. Navigli, R.; Conia, S.; Ross, B. Biases in Large Language Models: Origins, Inventory, and Discussion. J Data Inf. Qual. 2023 , 15 , 10:1-10:21, doi:10.1145/3597307.
- 48. Park, Y.-J.; Pillai, A.; Deng, J.; Guo, E.; Gupta, M.; Paget, M.; Naugler, C. Assessing the Research Landscape and Clinical Utility of Large Language Models: A Scoping Review. BMC Med. Inform. Decis. Mak. 2024 , 24 , 72, doi:10.1186/s12911-024-02459-6.
- 49. Omiye, J.A.; Lester, J.C.; Spichak, S.; Rotemberg, V.; Daneshjou, R. Large Language Models Propagate Race-Based Medicine. Npj Digit. Med. 2023 , 6 , 1-4, doi:10.1038/s41746-023-00939-z.
- 50. Challenging Systematic Prejudices: An Investigation into Bias against Women and Girls in Large Language Models - UNESCO Digital Library Available online: https://unesdoc.unesco.org/ark:/48223/pf0000388971 (accessed on 23 July 2024).
- 51. Petreski, D.; Hashim, I.C. Word Embeddings Are Biased. But Whose Bias Are They Reflecting? AI Soc. 2023 , 38 , 975-982, doi:10.1007/s00146-022-01443-w.
- 52. Hart, S. Shapley Value. In Game Theory ; Eatwell, J., Milgate, M., Newman, P., Eds.; Palgrave Macmillan UK: London, 1989; pp. 210-216 ISBN 978-1-349-20181-5.
- 53. Zhou, K.; Lai, E.; Jiang, J. VLStereoSet: A Study of Stereotypical Bias in Pre-Trained Vision-Language Models. In Proceedings of the Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); He, Y., Ji, H., Li, S., Liu, Y., Chang, C.-H., Eds.; Association for Computational Linguistics: Online only, November 2022; pp. 527-538.
- 54. Saravanan, A.P.; Kocielnik, R.; Jiang, R.; Han, P.; Anandkumar, A. Exploring Social Bias in Downstream Applications of Text-to-Image Foundation Models 2023.
- 55. Hartsock, I.; Rasool, G. Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review 2024.
- 56. Kirk, H.R.; Vidgen, B.; Röttger, P.; Hale, S.A. The Benefits, Risks and Bounds of Personalizing the Alignment of Large Language Models to Individuals. Nat. Mach. Intell. 2024 , 6 , 383-392, doi:10.1038/s42256-024-00820-y.
- 57. Sun, H. Supervised Fine-Tuning as Inverse Reinforcement Learning 2024.
- 58. Lee, B.W.; Cho, H.; Yoo, K.M. Instruction Tuning with Human Curriculum. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Mexico City, Mexico, June 2024; pp. 1281-1309.
- 59. Chang, C.T.; Farah, H.; Gui, H.; Rezaei, S.J.; Bou-Khalil, C.; Park, Y.-J.; Swaminathan, A.; Omiye, J.A.; Kolluri, A.; Chaurasia, A.; et al. Red Teaming Large Language Models in Medicine: Real-World Insights on Model Behavior 2024, 2024.04.05.24305411.
- 60. Wang, H.; Xiong, W.; Xie, T.; Zhao, H.; Zhang, T. Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts 2024.
- 61. Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. Constitutional AI: Harmlessness from AI Feedback 2022.
- 62. Wilkinson, M.D.; Dumontier, M.; Aalbersberg, Ij.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016 , 3 , 160018, doi:10.1038/sdata.2016.18.
- 63. Jagodnik, K.M.; Koplev, S.; Jenkins, S.L.; Ohno-Machado, L.; Paten, B.; Schurer, S.C.; Dumontier, M.; Verborgh, R.; Bui, A.; Ping, P.; et al. Developing a Framework for Digital Objects in the Big Data to Knowledge (BD2K) Commons: Report from the Commons Framework Pilots Workshop. J. Biomed. Inform. 2017 , 71 , 49-57, doi:10.1016/j.jbi.2017.05.006.
- 64. Hermjakob, H.; Kleemola, M.; Moilanen, K.; Tuominen, M.; Sansone, S.-A.; Lister, A.; David, R.; Panagiotopoulou, M.; Ohmann, C.; Belien, J.; et al. BY-COVID D3.2: Implementation of Cloud-Based, High Performance, Scalable Indexing System. ; 2022;
- 65. Longpre, S.; Mahari, R.; Obeng-Marnu, N.; Brannon, W.; South, T.; Gero, K.; Pentland, S.; Kabbara, J. Data Authenticity, Consent, & Provenance for AI Are All Broken: What Will It Take to Fix Them? 2024.
- 66. Frasca, M.; La Torre, D.; Pravettoni, G.; Cutica, I. Explainable and Interpretable Artificial Intelligence in Medicine: A Systematic Bibliometric Review. Discov. Artif. Intell. 2024 , 4 , 15, doi:10.1007/s44163-02400114-7.
- 67. Gosiewska, A.; Kozak, A.; Biecek, P. Simpler Is Better: Lifting Interpretability-Performance Trade-off via Automated Feature Engineering. Decis. Support Syst. 2021 , 150 , 113556, doi:10.1016/j.dss.2021.113556.
- 68. Sevillano-García, I.; Luengo, J.; Herrera, F. SHIELD: A Regularization Technique for eXplainable Artificial Intelligence 2024.
- 69. Ivanovs, M.; Kadikis, R.; Ozols, K. Perturbation-Based Methods for Explaining Deep Neural Networks: A Survey. Pattern Recognit. Lett. 2021 , 150 , 228-234, doi:10.1016/j.patrec.2021.06.030.
- 70. Lee, S.-I.; Topol, E.J. The Clinical Potential of Counterfactual AI Models. The Lancet 2024 , 403 , 717,
doi:10.1016/S0140-6736(24)00313-1.
- 71. Gupta, A.; Sabirsh, A.; Wählby, C.; Sintorn, I.-M. SimSearch: A Human-in-The-Loop Learning Framework for Fast Detection of Regions of Interest in Microscopy Images. IEEE J. Biomed. Health Inform. 2022 , 26 , 4079-4089, doi:10.1109/JBHI.2022.3177602.
- 72. Holzinger, A. Interactive Machine Learning for Health Informatics: When Do We Need the Human-in-theLoop? Brain Inform. 2016 , 3 , 119-131, doi:10.1007/s40708-016-0042-6.
- 73. Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A Survey of Human-in-the-Loop for Machine Learning. Future Gener. Comput. Syst. 2022 , 135 , 364-381, doi:10.1016/j.future.2022.05.014.
- 74. Jobin, A.; Ienca, M.; Vayena, E. The Global Landscape of AI Ethics Guidelines. Nat. Mach. Intell. 2019 , 1 , 389-399, doi:10.1038/s42256-019-0088-2.
- 75. Felzmann, H.; Fosch-Villaronga, E.; Lutz, C.; Tamò-Larrieux, A. Towards Transparency by Design for Artificial Intelligence. Sci. Eng. Ethics 2020 , 26 , 3333-3361, doi:10.1007/s11948-020-00276-4.
- 76. Balasubramaniam, N.; Kauppinen, M.; Hiekkanen, K.; Kujala, S. Transparency and Explainability of AI Systems: Ethical Guidelines in Practice. In Proceedings of the Requirements Engineering: Foundation for Software Quality; Gervasi, V., Vogelsang, A., Eds.; Springer International Publishing: Cham, 2022; pp. 318.
- 77. Bommasani, R.; Klyman, K.; Longpre, S.; Xiong, B.; Kapoor, S.; Maslej, N.; Narayanan, A.; Liang, P. Foundation Model Transparency Reports 2024.
- 78. Interpretability versus Explainability - Model Explainability with AWS Artificial Intelligence and Machine Learning Solutions Available online: https://docs.aws.amazon.com/whitepapers/latest/model-explainabilityaws-ai-ml/interpretability-versus-explainability.html (accessed on 24 July 2024).
- 79. Gundersen, O.E.; Kjensmo, S. State of the Art: Reproducibility in Artificial Intelligence. Proc. AAAI Conf. Artif. Intell. 2018 , 32 , doi:10.1609/aaai.v32i1.11503.
- 80. Mohamed, A.K.Y.S.; Auer, D.; Hofer, D.; Küng, J. A Systematic Literature Review for Authorization and Access Control: Definitions, Strategies and Models. Int. J. Web Inf. Syst. 2022 , 18 , 156-180, doi:10.1108/IJWIS-04-2022-0077.
- 81. Kotsenas, A.L.; Balthazar, P.; Andrews, D.; Geis, J.R.; Cook, T.S. Rethinking Patient Consent in the Era of Artificial Intelligence and Big Data. J. Am. Coll. Radiol. 2021 , 18 , 180-184, doi:10.1016/j.jacr.2020.09.022.
- 82. Murdoch, B. Privacy and Artificial Intelligence: Challenges for Protecting Health Information in a New Era. BMC Med. Ethics 2021 , 22 , 122, doi:10.1186/s12910-021-00687-3.
- 83. Pan, B.; Stakhanova, N.; Ray, S. Data Provenance in Security and Privacy. ACM Comput Surv 2023 , 55 , 323:1-323:35, doi:10.1145/3593294.
- 84. Mani, V.; Manickam, P.; Alotaibi, Y.; Alghamdi, S.; Khalaf, O.I. Hyperledger Healthchain: Patient-Centric IPFS-Based Storage of Health Records. Electronics 2021 , 10 , 3003, doi:10.3390/electronics10233003.
- 85. Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A Survey on Homomorphic Encryption Schemes: Theory and Implementation. ACM Comput Surv 2018 , 51 , 79:1-79:35, doi:10.1145/3214303.
- 86. Ko, S.; Jeon, K.; Morales, R. The Hybrex Model for Confidentiality and Privacy in Cloud Computing.; June 14 2011; pp. 8-8.
- 87. Ghadi, Y.Y.; Shah, S.F.A.; Mazhar, T.; Shahzad, T.; Ouahada, K.; Hamam, H. Enhancing Patient Healthcare with Mobile Edge Computing and 5G: Challenges and Solutions for Secure Online Health Tools. J. Cloud Comput. 2024 , 13 , 93, doi:10.1186/s13677-024-00654-4.
- 88. Raith, P.; Nastic, S.; Dustdar, S. Serverless Edge Computing-Where We Are and What Lies Ahead. IEEE Internet Comput. 2023 , 27 , 50-64, doi:10.1109/MIC.2023.3260939.
- 89. Characterizing Browser-Based Medical Imaging AI with Serverless Edge Computing: Towards Addressing Clinical Data Security Constraints. Available online: https://edrn.nci.nih.gov/data-andresources/publications/37063644-3301-characterizing-browser-based-medical-imaging-ai-with-serverlessedge-computing-towards-addressing-clinical-data-security-constraints/ (accessed on 27 July 2024).
- 90. Sadilek, A.; Liu, L.; Nguyen, D.; Kamruzzaman, M.; Serghiou, S.; Rader, B.; Ingerman, A.; Mellem, S.; Kairouz, P.; Nsoesie, E.O.; et al. Privacy-First Health Research with Federated Learning. Npj Digit. Med. 2021 , 4 , 132, doi:10.1038/s41746-021-00489-2.
- 91. Rights (OCR), O. for C. Guidance Regarding Methods for De-Identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule Available
online: https://www.hhs.gov/hipaa/for-professionals/privacy/special-topics/de-identification/index.html (accessed on 27 July 2024).
- 92. Dernoncourt, F.; Lee, J.Y.; Uzuner, O.; Szolovits, P. De-Identification of Patient Notes with Recurrent Neural Networks. J. Am. Med. Inform. Assoc. 2017 , 24 , 596-606, doi:10.1093/jamia/ocw156.
- 93. Ahmed, T.; Aziz, M.M.A.; Mohammed, N. De-Identification of Electronic Health Record Using Neural Network. Sci. Rep. 2020 , 10 , 18600, doi:10.1038/s41598-020-75544-1.
- 94. Ko, M.; Jin, M.; Wang, C.; Jia, R. Practical Membership Inference Attacks Against Large-Scale Multi-Modal Models: A Pilot Study. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV); IEEE: Paris, France, October 1 2023; pp. 4848-4858.
- 95. Ben Hamida, S.; Mrabet, H.; Chaieb, F.; Jemai, A. Assessment of Data Augmentation, Dropout with L2 Regularization and Differential Privacy against Membership Inference Attacks. Multimed. Tools Appl. 2024 , 83 , 44455-44484, doi:10.1007/s11042-023-17394-3.
- 96. Hu, H.; Salcic, Z.; Sun, L.; Dobbie, G.; Yu, P.S.; Zhang, X. Membership Inference Attacks on Machine Learning: A Survey 2022.
- 97. Song, L.; Mittal, P. Systematic Evaluation of Privacy Risks of Machine Learning Models.; 2021; pp. 26152632.
- 98. Dar, S.U.H.; Seyfarth, M.; Kahmann, J.; Ayx, I.; Papavassiliu, T.; Schoenberg, S.O.; Frey, N.; Baeßler, B.; Foersch, S.; Truhn, D.; et al. Unconditional Latent Diffusion Models Memorize Patient Imaging Data: Implications for Openly Sharing Synthetic Data 2024.
- 99. El-Mhamdi, E.-M.; Farhadkhani, S.; Guerraoui, R.; Gupta, N.; Hoang, L.-N.; Pinot, R.; Rouault, S.; Stephan, J. On the Impossible Safety of Large AI Models 2023.
- 100. Feldman, V. Does Learning Require Memorization? A Short Tale about a Long Tail. In Proceedings of the Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing; Association for Computing Machinery: New York, NY, USA, June 22 2020; pp. 954-959.
- 101. Carlini, N.; Ippolito, D.; Jagielski, M.; Lee, K.; Tramer, F.; Zhang, C. Quantifying Memorization Across Neural Language Models 2023.
102. Lee, K.; Ippolito, D.; Nystrom, A.; Zhang, C.; Eck, D.; Callison-Burch, C.; Carlini, N. Deduplicating Training Data Makes Language Models Better 2022.
- 103. König, K.; Pechmann, A.; Thiele, S.; Walter, M.C.; Schorling, D.; Tassoni, A.; Lochmüller, H.; MüllerReible, C.; Kirschner, J. De-Duplicating Patient Records from Three Independent Data Sources Reveals the Incidence of Rare Neuromuscular Disorders in Germany. Orphanet J. Rare Dis. 2019 , 14 , 152, doi:10.1186/s13023-019-1125-2.
104. Aponte-Novoa, F.A.; Orozco, A.L.S.; Villanueva-Polanco, R.; Wightman, P. The 51% Attack on Blockchains: A Mining Behavior Study. IEEE Access 2021 , 9 , 140549-140564, doi:10.1109/ACCESS.2021.3119291.
105. Carvalho, G.; Cabral, B.; Pereira, V.; Bernardino, J. Edge Computing: Current Trends, Research Challenges and Future Directions. Computing 2021 , 103 , 993-1023, doi:10.1007/s00607-020-00896-5.
- 106. Humayun, M.; Alsirhani, A.; Alserhani, F.; Shaheen, M.; Alwakid, G. Transformative Synergy: SSEHCET-Bridging Mobile Edge Computing and AI for Enhanced eHealth Security and Efficiency. J. Cloud Comput. 2024 , 13 , 37, doi:10.1186/s13677-024-00602-2.
- 107. Meng, L.; Li, D. Novel Edge Computing-Based Privacy-Preserving Approach for Smart Healthcare Systems in the Internet of Medical Things. J. Grid Comput. 2023 , 21 , 66, doi:10.1007/s10723-023-096956.
- 108. Neamatullah, I.; Douglass, M.M.; Lehman, L.H.; Reisner, A.; Villarroel, M.; Long, W.J.; Szolovits, P.; Moody, G.B.; Mark, R.G.; Clifford, G.D. Automated De-Identification of Free-Text Medical Records. BMC Med. Inform. Decis. Mak. 2008 , 8 , 32, doi:10.1186/1472-6947-8-32.
- 109. Sucholutsky, I.; Griffiths, T.L. Alignment with Human Representations Supports Robust Few-Shot Learning 2023.
- 110. Packhäuser, K.; Gündel, S.; Münster, N.; Syben, C.; Christlein, V.; Maier, A. Deep Learning-Based Patient Re-Identification Is Able to Exploit the Biometric Nature of Medical Chest X-Ray Data. Sci. Rep. 2022 , 12 , 14851, doi:10.1038/s41598-022-19045-3.
- 111. Narayanan, A.; Shmatikov, V. Robust De-Anonymization of Large Sparse Datasets. In Proceedings of
the 2008 IEEE Symposium on Security and Privacy (sp 2008); May 2008; pp. 111-125.
- 112. Johnson, A.; Pollard, T.; Mark, R. MIMIC-III Clinical Database 2015.
- 113. Nasr, M.; Song, S.; Thakurta, A.; Papernot, N.; Carlini, N. Adversary Instantiation: Lower Bounds for Differentially Private Machine Learning 2021.
- 114. Song, C.; Shmatikov, V. Auditing Data Provenance in Text-Generation Models 2019.
- 115. Xu, T.; Liu, C.; Zhang, K.; Zhang, J. Membership Inference Attacks Against Medical Databases. In Proceedings of the Neural Information Processing; Luo, B., Cheng, L., Wu, Z.-G., Li, H., Li, C., Eds.; Springer Nature: Singapore, 2024; pp. 15-25.
116. Kaya, Y.; Dumitras, T. When Does Data Augmentation Help With Membership Inference Attacks? In Proceedings of the Proceedings of the 38th International Conference on Machine Learning; PMLR, July 1 2021; pp. 5345-5355.
117. Zhang, Z.; Yan, C.; Malin, B.A. Membership Inference Attacks against Synthetic Health Data. J. Biomed. Inform. 2022 , 125 , 103977, doi:10.1016/j.jbi.2021.103977.
118. Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-Scale Long-Tailed Recognition in an Open World.; 2019; pp. 2537-2546.
119. Wu, T.; Liu, Z.; Huang, Q.; Wang, Y.; Lin, D. Adversarial Robustness Under Long-Tailed Distribution.; 2021; pp. 8659-8668.
120. Carlini, N.; Jagielski, M.; Zhang, C.; Papernot, N.; Terzis, A.; Tramer, F. The Privacy Onion Effect: Memorization Is Relative 2022.
121. Manber, U.; Myers, G. Suffix Arrays: A New Method for On-Line String Searches. SIAM J. Comput. 1993 , 22 , 935-948, doi:10.1137/0222058.
122. Broder, A.Z. On the Resemblance and Containment of Documents. In Proceedings of the Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171); June 1997; pp. 21-29.
123. Baker, D.B.; Knoppers, B.M.; Phillips, M.; van Enckevort, D.; Kaufmann, P.; Lochmuller, H.; Taruscio, D. Privacy-Preserving Linkage of Genomic and Clinical Data Sets. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019 , 16 , 1342-1348, doi:10.1109/TCBB.2018.2855125.
124. Bouderhem, R. Shaping the Future of AI in Healthcare through Ethics and Governance. Humanit. Soc. Sci. Commun. 2024 , 11 , 1-12, doi:10.1057/s41599-024-02894-w.
125. High-Level Expert Group on Artificial Intelligence | Shaping Europe's Digital Future Available online: https://digital-strategy.ec.europa.eu/en/policies/expert-group-ai (accessed on 28 July 2024).
126. CAHAI - Ad Hoc Committee on Artificial Intelligence - Artificial Intelligence - Www.Coe.Int Available online: https://www.coe.int/en/web/artificial-intelligence/cahai (accessed on 28 July 2024).
127. Ethics of Artificial Intelligence | UNESCO Available online: https://www.unesco.org/en/artificialintelligence/recommendation-ethics (accessed on 28 July 2024).
128. Ethics and Governance of Artificial Intelligence for Health Available online:
https://www.who.int/publications/i/item/9789240029200 (accessed on 28 July 2024).
129. Organization, W.H. Regulatory Considerations on Artificial Intelligence for Health ; World Health Organization, 2023; ISBN 978-92-4-007887-1.
130. Using Artificial Intelligence and Algorithms Available online: https://www.ftc.gov/businessguidance/blog/2020/04/using-artificial-intelligence-algorithms (accessed on 29 July 2024).
131. Tabassi, E. Artificial Intelligence Risk Management Framework (AI RMF 1.0) ; National Institute of Standards and Technology (U.S.): Gaithersburg, MD, 2023; p. NIST AI 100-1;
132. Rep. McNerney, J. [D-C.-9 H.R.2575 - 116th Congress (2019-2020): AI in Government Act of 2020 Available online: https://www.congress.gov/bill/116th-congress/house-bill/2575 (accessed on 29 July 2024).
133. House, T.W. Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence Available online: https://www.whitehouse.gov/briefing-room/presidentialactions/2023/10/30/executive-order-on-the-safe-secure-and-trustworthy-development-and-use-of-artificialintelligence/ (accessed on 24 July 2024).
134. Deshpande, A.; Sharp, H. Responsible AI Systems: Who Are the Stakeholders? In Proceedings of the Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society; Association for Computing Machinery: New York, NY, USA, July 27 2022; pp. 227-236.
- 135. Whittaker, R.; Dobson, R.; Jin, C.K.; Style, R.; Jayathissa, P.; Hiini, K.; Ross, K.; Kawamura, K.; Muir, P. An Example of Governance for AI in Health Services from Aotearoa New Zealand. Npj Digit. Med. 2023 , 6 , 1-7, doi:10.1038/s41746-023-00882-z.
- 136. PCAST Releases Report on Supercharging Research: Harnessing Artificial Intelligence to Meet Global Challenges | PCAST Available online: https://www.whitehouse.gov/pcast/briefing-room/2024/04/29/pcastreleases-report-on-supercharging-research-harnessing-artificial-intelligence-to-meet-global-challenges/ (accessed on 29 July 2024).
- 137. Scott, I.A.; Carter, S.M.; Coiera, E. Exploring Stakeholder Attitudes towards AI in Clinical Practice. BMJ Health Care Inform. 2021 , 28 , e100450, doi:10.1136/bmjhci-2021-100450.
- 138. Dwivedi, R.; Dave, D.; Naik, H.; Singhal, S.; Omer, R.; Patel, P.; Qian, B.; Wen, Z.; Shah, T.; Morgan, G.; et al. Explainable AI (XAI): Core Ideas, Techniques, and Solutions. ACM Comput Surv 2023 , 55 , 194:1194:33, doi:10.1145/3561048.
- 139. Li, L. How to Co-Design Software/Hardware Architecture for AI/ML in a New Era? Available online: https://towardsdatascience.com/how-to-co-design-software-hardware-architecture-for-ai-ml-in-a-new-erab296f2842fe2 (accessed on 29 July 2024).
- 140. Co-Design and Ethical Artificial Intelligence for Health: An Agenda for Critical Research and Practice Joseph Donia, James A. Shaw, 2021 Available online: https://journals.sagepub.com/doi/full/10.1177/20539517211065248 (accessed on 29 July 2024).
- 141. Olczak, J.; Pavlopoulos, J.; Prijs, J.; Ijpma, F.F.A.; Doornberg, J.N.; Lundström, C.; Hedlund, J.; Gordon, M. Presenting Artificial Intelligence, Deep Learning, and Machine Learning Studies to Clinicians and Healthcare Stakeholders: An Introductory Reference with a Guideline and a Clinical AI Research (CAIR) Checklist Proposal. Acta Orthop. 92 , 513-525, doi:10.1080/17453674.2021.1918389.
- 142. Zicari, R.V.; Ahmed, S.; Amann, J.; Braun, S.A.; Brodersen, J.; Bruneault, F.; Brusseau, J.; Campano, E.; Coffee, M.; Dengel, A.; et al. Co-Design of a Trustworthy AI System in Healthcare: Deep Learning Based Skin Lesion Classifier. Front. Hum. Dyn. 2021 , 3 , doi:10.3389/fhumd.2021.688152.
- 143. Zicari, R.V.; Brodersen, J.; Brusseau, J.; Düdder, B.; Eichhorn, T.; Ivanov, T.; Kararigas, G.; Kringen, P.; McCullough, M.; Möslein, F.; et al. Z-Inspection®: A Process to Assess Trustworthy AI. IEEE Trans. Technol. Soc. 2021 , 2 , 83-97, doi:10.1109/TTS.2021.3066209. | null | [
"Simha Sankar Baradwaj",
"Destiny Gilliland",
"Jack Rincon",
"Henning Hermjakob",
"Yu Yan",
"Irsyad Adam",
"Gwyneth Lemaster",
"Dean Wang",
"Karol Watson",
"Alex Bui",
"Wei Wang",
"Peipei Ping"
]
| 2024-07-18T15:57:58+00:00 | 2024-08-14T02:28:09+00:00 | [
"cs.CY",
"cs.AI"
]
| Building an Ethical and Trustworthy Biomedical AI Ecosystem for the Translational and Clinical Integration of Foundational Models | Foundational Models (FMs) are gaining increasing attention in the biomedical
AI ecosystem due to their ability to represent and contextualize multimodal
biomedical data. These capabilities make FMs a valuable tool for a variety of
tasks, including biomedical reasoning, hypothesis generation, and interpreting
complex imaging data. In this review paper, we address the unique challenges
associated with establishing an ethical and trustworthy biomedical AI
ecosystem, with a particular focus on the development of FMs and their
downstream applications. We explore strategies that can be implemented
throughout the biomedical AI pipeline to effectively tackle these challenges,
ensuring that these FMs are translated responsibly into clinical and
translational settings. Additionally, we emphasize the importance of key
stewardship and co-design principles that not only ensure robust regulation but
also guarantee that the interests of all stakeholders, especially those
involved in or affected by these clinical and translational applications are
adequately represented. We aim to empower the biomedical AI community to
harness these models responsibly and effectively. As we navigate this exciting
frontier, our collective commitment to ethical stewardship, co-design, and
responsible translation will be instrumental in ensuring that the evolution of
FMs truly enhances patient care and medical decision making, ultimately leading
to a more equitable and trustworthy biomedical AI ecosystem. |
2408.01432v3 | ## VLG-CBM: Training Concept Bottleneck Models with Vision-Language Guidance
## Divyansh Srivastava, Ge Yan , Tsui-Wei Weng
∗ ∗ {ddivyansh, geyan, lweng}@ucsd.edu
UC San Diego
## Abstract
Concept Bottleneck Models (CBMs) provide interpretable prediction by introducing an intermediate Concept Bottleneck Layer (CBL), which encodes humanunderstandable concepts to explain models' decision. Recent works proposed to utilize Large Language Models and pre-trained Vision-Language Models to automate the training of CBMs, making it more scalable and automated. However, existing approaches still fall short in two aspects: First, the concepts predicted by CBL often mismatch the input image, raising doubts about the faithfulness of interpretation. Second, it has been shown that concept values encode unintended information: even a set of random concepts could achieve comparable test accuracy to state-of-the-art CBMs. To address these critical limitations, in this work, we propose a novel framework called Vision-Language-Guided Concept Bottleneck Model ( VLG-CBM ) to enable faithful interpretability with the benefits of boosted performance. Our method leverages off-the-shelf open-domain grounded object detectors to provide visually grounded concept annotation, which largely enhances the faithfulness of concept prediction while further improving the model performance. In addition, we propose a new metric called Number of Effective Concepts (NEC) to control the information leakage and provide better interpretability. Extensive evaluations across five standard benchmarks show that our method, VLG-CBM , outperforms existing methods by at least 4.27% and up to 51.09% on Accuracy at NEC=5 (denoted as ANEC-5), and by at least 0.45% and up to 29.78% on average accuracy (denoted as ANEC-avg), while preserving both faithfulness and interpretability of the learned concepts as demonstrated in extensive experiments 2 .
## 1 Introduction
As deep neural networks become popular in real-world applications, it is crucial to understand the decision of these black-box models. One approach to provide interpretable decisions is the Concept Bottleneck Model (CBM) [6], which introduced an intermediate concept layer to encode humanunderstandable concepts. The model makes final predictions based on these concepts. Unfortunately, one major limitation of this approach is that it requires concept annotations from human experts, making it expensive and less applicable in practice as concept labels may not always be available.
Recently, a line of works utilized the powerful Vision-Language Models (VLMs) to replace manual annotation [15, 27, 25]. They used Large Language Models (LLMs) to generate set of concepts, and then trained the models in a post-hoc manner under the guidance of VLMs or neuron-level interpretability tool [14]. By eliminating the expensive manual annotations, some of these CBMs [15] could be scaled to large datasets such as ImageNet [18]. However, these CBMs [15, 27, 25] still face two critical challenges:
∗ Equal contribution
2 Our code is available at https://github.com/Trustworthy-ML-Lab/VLG-CBM
- 1. Challenge #1: Inaccurate concept prediction. The concept predictions in these CBMs often contain factual errors i.e. the predicted concepts do not match the image. Moreover, as concepts are generated by LLMs, there are some non-visual concepts, for example "loud music" or "location" used in LF-CBM [15], which further hurt the faithfulness of concept prediction.
- 2. Challenge #2: Information leakage. Recently, [13, 12] observed the information leakage in CBMs through empirical experiments - they found that the concept prediction encodes unintended information for downstream tasks, even if the concepts are irrelevant to the task.
In this paper, we propose a new framework called V isionL anguageG uided C oncept B ottleneck M odel ( VLG-CBM ) to address these two major challenges. Our contributions are summarized below:
- 1. To address Challenge #1 , we propose to use the open-domain grounded object detection model to generate localized, visually recognizable concept annotations in Section 3. This approach automatically filters the non-visual concepts. Furthermore, the location information is utilized to augment the data. As far as we know, our VLG-CBM is the first end-to-end pipeline to build CBM with vision guidance from open-vocabulary object detectors.
- 2. To address Challenge #2 , we provide the first rigorous theoretical analysis which proves that CBMs have serious issues on information leakage in Section 4.1, whereas previous study on information leakage [12, 25] only provides empirical explanations. Building on our theory, we further propose a new metric called the Number of Effective Concepts (NEC) in Section 4.2, which facilitates fair comparison between different CBMs. We also show that using NEC can help to effectively control information leakage and enhance interpretability in our VLG-CBM .
- 3. We conduct a series of experiments in Section 5 and demonstrate that our VLG-CBM outperforms existing methods across 5 standard benchmarks by at least 4.27% and up to 51.09% on Accuracy at NEC=5 (denoted as ANEC-5), and by at least 0.45% and up to 29.78% on average accuracy across different NECs (denoted as ANEC-avg). Our learned CBM achieves a high sparsity of 0.2% in the final layer even on large datasets including Places365, preserving interpretability even with a large number of concepts. Additionally, we qualitatively demonstrate that our method provides more accurate concept attributions compared to existing methods.
VLG-CBM provide accurate explanations while prior work provide inaccuratelwrongliless useful explanations!

Figure 1: We compare the decision explanation of VLG-CBM with existing methods by listing top-5 contributions for their decisions. Our observations include: (1) VLG-CBM provides concise and accurate concept attribution for the decision; (2) LF-CBM [15] frequently uses negative concepts for explanation, which is less informative; (3) LM4CV[25] attributes the decision to concepts that do not match the images, a reason for this is that LM4CV uses a limited number of concepts, which hurts CBM's ability to explain diverse images; (4) Both LF-CBM and LM4CV have a significant portion of contribution from non-top concepts, making decisions less transparent. Full figure is in Appendix Fig. D.1.
| | Evaluation | Evaluation | Flexibility | Flexibility | Interpretability | Interpretability |
|-----------------------|--------------------------------|---------------------------|-------------------|-----------------------------|---------------------------------|------------------------|
| Method | Control on information leakage | Unlimited concept numbers | Flexible backbone | Accurate concept prediction | Vision-guided concept filtering | Interpretable decision |
| Baselines: LF-CBM[15] | △ | ✓ | ✓ | △ | × | △ |
| LaBo[27] | × | ✓ | × | △ | × | △ |
| LM4CV[25] | ✓ | × | × | △ | △ | △ |
| This work: VLG-CBM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Table 1: Comparative analysis of methods based on evaluation, flexibility, and interpretability. Here, ✓ denotes the method satisfies the requirement, △ denotes the method partially satisfies the requirement, and × denotes the method does not satisfy the requirement. We compare with SOTA methods including LF-CBM [15], Labo [27] and LM4CV [25].
## 2 Related work
Concept Bottleneck Model (CBM). The seminal paper [1] first proposed self-explaining models by leveraging the idea of autoencoder to learn interpretable basis concepts in an unsupervised manner without pre-specified concepts. Later, [6] proposed to learn interpretable concepts with human specifications (labels) in the concept bottleneck layer (CBL), and coin the term Concept Bottleneck Models (CBM). CBL is followed by a linear prediction layer, which maps concepts to classes, enabling interpretable final decisions. Formally, let feature representation generated by a frozen backbone represented by z = ϕ x ( ) , CBL concept prediction as g z ( ) = W z c , and the final prediction layer as h ( ) = · W g z F ( ) + b F . The final class prediction of the CBM is given by ˆ = y h g z ( ( )) = h ◦ g ◦ ϕ x ( ) .
Under this setting, the key in training a CBM is obtaining an annotated {(image, concept)} paired dataset for training concept bottleneck layer g . In [6], the authors used human-specified labels to train the CBL in a supervised way. However, obtaining labels with human annotators could be very tedious and costly. Recently, [15], [25], and [27] proposed to utilize Large Language Models (LLM) to generate a set of concepts S , then train CBL by aligning image and concepts with the guidance of vision language models (e.g. CLIP). For example, Oikarinen et al. [15] proposed LF-CBM to train CBM by directly learning a mapping from the embedding space of backbone to concept values in the CLIP space using cosine cubed loss function with the neuron interpretability tool[14], and then mapping concepts to classes using sparse linear layer. [25] proposed LM4CV, a task-guided concept searching method that learns text embeddings in the CLIP space, and then maps the learned embeddings to concepts obtained from LLM using nearest neighbor. Yang et al. [27] proposed LaBo, using submodular optimization to reduce the concept set, followed by using CLIP backbone for obtaining concept values. However, as we show in Sections 5.1 and 5.3 , these methods suffer from multiple issues: (i) The concept prediction is often incorrect and does not capture the visual attributes required for downstream class prediction (e.g. see Fig. 1 b )(ii) VLMs like CLIP suffer from modality gap between image and text embeddings [9] resulting in encoding unintended information, and even random concepts can achieve high accuracy [25]. To address these issues, we explicitly ground the concepts on the training dataset using an open-domain object detection model and then using the obtained concepts for learning CBL - this can ensure a more faithful representation of fine-grained concepts and avoids the modality gap issues introduced by VLMs. Table 1 demonstrates the superiority of VLG-CBM over existing methods [15, 25, 27] on properties including controlling information leakage, flexibility to use any backbone, and accurate concept prediction.
There are some recent works aim at addressing the challenges of CBMs. Similar to us, Pham et al. [16] uses an open-vocabulary object detection model to provide an explainable decision. However, their model is directly adapted from an OWL-ViT model, while our VLG-CBM uses an open-vocabulary object detection model to train a CBL over any base model, providing more flexibility. Additionally, their model requires pretraining to get best performance, while our VLG-CBM could be applied post-hoc to any pretrained model. Kim et al. [4] proposed to filter non-visual concepts by adding a vision activation term to the concept selection step, whereas VLG-CBM uses an open-vocabulary object detectors in multiple stage of CBM pipeline: for filtering non-visual concepts and the guiding training of concept bottleneck layer. Sun et al. [20] aims at eliminating the information leakage, and the authors evaluate the information leakage by measuring the performance drop speed after
Figure 2: VLG-CBM pipeline: We design automated Vision+Language Guided approach to train Concept Bottleneck Models.
removing top-contributing concepts. This metric can be controlled by our proposed NEC metric, because the performance reach minimum after removing all contributing concepts. Roth et al. [17] demonstrate that random words and characters achieve comparable CLIP zero-shot performance on visual classification tasks. However, their work does not address information leakage problem and is a very different setting from our work. To date, most of the CBMs focused on vision domains, including this work. There are some recent work applying CBM approach to different domains and different tasks, e.g. interpretable language models for text classifications [21, 22, 11] and for continual learning [26]. We refer the interested readers to their papers for more details.
Open Domain Language Grounded Object Detection. Recent works, including GLIP [8], GLIPv2 [29], and GroundingDINO [10] detect objects in images in an open-vocabulary manner conditioned on natural language queries. In this work we propose to utilize open-vocabulary object detectors for automatically generating grounded concept dataset for training CBMs. This removes the need for human labelers, which is costly, tedious, and does not scale to large datasets. Further, the detected objects provide necessary vision-guidance for CBMs training as demonstrated in our experiments.
## 3 Method
In this section, we describe our novel automated approach to train a CBM with both Vision and Language Guidance to ensure faithfulness, which is currently lacking in the field. Our approach, abbreviated as VLG-CBM in the paper, generates an auxiliary dataset grounded on fine-grained concepts present in images for training a sequential CBM. Section 3.1 describes our approach to generating an auxiliary dataset used in training CBM, Section 3.2 describes our approach to training concept bottleneck layer, and Section 3.3 describes the training of sparse layer to obtain class labels from concepts in an interpretability-preservable manner. The overall pipeline is shown in Fig. 2.
## 3.1 Automated generation of auxiliary dataset
Here we describe our novel automated approach for generating labeled datasets for training CBMs. Let f : X → Y be the neural network mapping images to corresponding class labels, where X = R H × W × 3 denotes the input image space and Y = { 1 2 , , . . . , C } denotes the label space, C is the number of classes. Denote D = ( { x , y i i ) } , x i ∈ X , y i ∈ Y the dataset used for training f , where x i is the i -th image and y i is the corresponding label. Let S be a set of natural-language concepts describing the fine-level visual details from which classes are composed. We propose to generate a modified and auxiliary dataset D ′ from D such that each image contains finer-grained concepts that
are useful in predicting the classes, along with the target class. The overall process of obtaining the modified dataset D ′ can be divided into two steps:
- · Language supervision from LLMs to generate a set of candidate concepts : We follow the steps proposed in LF-CBM [15] for generating candidate concepts S c for each class c by prompting LLM to obtain visual features describing the class.
- · Vision supervision from Open-domain Object Detectors to ground candidate concepts to spatial information : We propose using Grounding-DINO[10] Swin-B, current state-ofthe-art grounded object detector, for obtaining bounding boxes of candidate concepts in the dataset. For each image x i with class label c and candidate concepts S c , we prompt Grounding DINO model with S c and obtain K i bounding boxes:
$$B _ { i } = \{ ( b _ { j }, t _ { j }, s _ { j } ) \} _ { j = 1 } ^ { K _ { i } },$$
where b j ∈ R 4 × 2 is the j -th bounding box coordinates, t j ∈ R is the corresponding confidence given by the model and s j ∈ S c is the concept of this bounding box. We define a confidence threshold T and remove bounding boxes with confidence less than T to get filtered bounding boxes for each image:
$$\tilde { B } _ { i } = \{ ( b, t, s ) \in B _ { i } \ | \ t > T \}.$$
After collecting bounding boxes for every image, we filter out the concepts that do not appear in any bounding box, and get our final concept set ˜ S :
$$\tilde { S } = \{ s \in S \ | \ \exists ( \cdot, \cdot, s ) \in \cup _ { i = 1 } ^ { | D | } \tilde { B } _ { i } \}.$$
The one-hot encoded concept label vector o i ∈ { 0 1 , } | ˜ S | for image x i is thus defined as:
$$( o _ { i } ) _ { j } = \begin{cases} 1, & \text{if $s_{j}$ appears in $\tilde{B}_{i}$,} \\ 0, & \text{otherwise.} \end{cases}$$
Our final concept-labeled dataset D ′ for training CBM can be written as:
$$D ^ { \prime } = \{ ( x _ { i }, o _ { i }, y _ { i } ) \} _ { i = 1 } ^ { | D | }$$
## 3.2 Training Concept Bottleneck Layer
After constructing the concept-labeled dataset D ′ , we now define our approach to train the concept bottleneck layer for predicting the fine-grained concepts in the input image in a multi-label classification setting. Let ϕ : X → R d be a backbone that generates d -dimensional embeddings z = ϕ x ( ) for input image x . Note that ϕ x ( ) can be a pre-trained backbone or trained from scratch. Define g to be the Concept Bottleneck Layer (CBL) which maps embeddings to concept logits. We train a sequential CBM [6, 13] g ϕ x ( ( )) to predict concepts in an image using Binary Cross Entropy (BCE) loss for multi-label prediction. Additionally, to improve the diversity of the concept-labeled dataset D ′ , we augment the training dataset by cropping images to a randomly selected bounding box and modifying the target one-hot vector to predict the concept corresponding to the bounding box. Our optimization objective in terms of BCE loss can be written as:
$$\min _ { g } \mathcal { L } _ { C B L }, \, \mathcal { L } _ { C B L } = \frac { 1 } { | D ^ { \prime } | } \sum _ { i = 1 } ^ { | D ^ { \prime } | } B C E [ g \circ \phi ( x _ { i } ), o _ { i } ]$$
## 3.3 Mapping Concept to Classes
In this section, we define our approach to training a sparse linear layer to obtain class labels from concepts in an interpretability-preservable manner. Let h : R d → R C be the sparse linear layer with weight matrix W F and bias b F , which maps concept logits to class logits. We train the sparse layer using the original dataset D by first obtaining concept logits from the trained CBL(frozen), normalizing the concept logits with the mean and variance on training set, and then using them to predict class logits. Our optimization objective in terms of Cross Entropy (CE) loss can be written as:
$$\min _ { h } \mathcal { L } _ { S L }, \, \mathcal { L } _ { S L } = \frac { 1 } { | D | } \sum _ { ( x, y ) \in D } C E [ h \circ g \circ \phi ( x ), y ] + \lambda R _ { \alpha },$$
where R α = (1 -α ) 1 2 ∥ W F ∥ 2 2 + α W ∥ F ∥ 1 is the elastic-net regularization [31] on weight matrix W F , λ is a hyperparameter controlling regularization strength. We use GLM-SAGA[24] solver to solve this optimization problem.
## 4 Unifying CBM evaluation with Number of Effective Concepts (NEC)
Besides training, another important challenge for CBM is: how to evaluate the semantic information learned in the CBL? Conventionally, the classification accuracy for final class labels is an important metric for evaluating CBMs, with the intuition that a good classification accuracy indicates that useful semantic information is learned in the CBL. However, purely using accuracy as the evaluation metric could be problematic, as it has been shown that information leakage exists in jointly or sequentially trained CBM [13, 12]. That is to say, the CBL could contain unintended information that could be used for downstream classification hence achieving high classification accuracy, even if the concept is irrelevant to the task. In fact, recently [25] showed that, when increasing the number of concepts, a randomly selected concept set could even approach the accuracy of the concept set chosen with sophistication, supporting the existence of information leakage.
To better understand this phenomenon, in section 4.1, we conduct a first theoretical analysis to investigate random CBL and its capability. To the best of our knowledge, this is the first formal analysis of random CBL. Next, inspired by our theoretical result, we propose a new evaluation metric for CBM, named NEC in section 4.2. NEC provides a way to control information leakage and enhance the interpretability of model decisions.
## 4.1 Theoretical analysis of the Random CBL
We start by defining the notations. Denote k the number of concepts in CBL. We assume that the CBL g consists of a single linear layer: g z ( ) = W z c , where W c ∈ R k × d and z ∈ R d , and the final layer h is also linear: h ◦ g z ( ) = W g z F ( ) + b F , where W F ∈ R C × k , b F ∈ R C . This is the common setting for CBMs. The following theorem suggests a surprising conclusion: a linear classifier upon random (i.e. untrained) CBL could accurately approximate any linear classifier trained directly on the representation, as the number of concepts in the CBL goes up .
Theorem 4.1. Suppose Σ ∈ R d × d is the variance matrix of the representation z which is positive definite, λ max is the largest eigenvalue of Σ , and the weight matrix W c ∈ R k × d is sampled i.i.d from a standard Gaussian distribution. For any linear classifier f which is built directly on the representation z , i.e. f : R d → R , f ( z ) = w z ⊤ + b , it could be approximated by another linear classifier ˜ f on concept logits g z ( ) = W z c , i.e. f ( z ) ≈ ˜ ( f z ) = ˜ w g z ⊤ ( ) + ˜ b , with the expected square error E k ( ) upper-bounded by
$$E ( k ) \leq \begin{cases} \lambda _ { m a x } ( 1 - \frac { k } { d } ) \| w \| _ { 2 } ^ { 2 }, & k < d ; \\ 0, & k \geq d. \end{cases}$$
Here E k ( ) = E W c [ min ( ˜ w,b ˜ ) E z [ | f ( z ) -˜ ( f z ) | 2 ]] denotes the average square error, w ∈ R d , ˜ w ∈ R k , k is the number of concepts in CBL.
Remark 4.1 . In Theorem 4.1, we consider a 1-D regression problem where we use a linear combination of concept bottleneck neurons to approximate any linear function. The multi-class classification result could be derived by applying Theorem 4.1 to each class logit (see Corollary A.1). From Eq. (8), we could see that the expected error goes down linearly when concept number k increases, and achieves 0 when k ≥ d , where d is the dimension of backbone representation z . This suggests that, even with a random CBL (i.e. W c is simply drawn from a standard Gaussian distribution without any training), the classifier could still approximate the original classifier well and achieve good accuracy, when concept number k is large enough. We defer the formal proof of Theorem 4.1 to Appendix A.
## 4.2 A New Evaluation Metric for CBM: Number of Effective Concepts (NEC)
Theorem 4.1 provides a formal theoretical explanation on [25]'s observation. Moreover, it raises a concern on the evaluation of CBMs: model classification accuracy may not be a good metric for evaluating the semantical information learned in CBL, because a random CBL could also achieve high accuracy. To address this concern, we need to control the concept number k so that the
semantically meaningful CBLs can be distinguished with random CBLs w.r.t. the final classification performance.
We notice that previous works mainly use two approaches to control k :
- 1. Control the total number of concepts: [25] used a more concise concept layer, i.e. reduce the total number of concepts. However, this approach may miss some important concepts due to limitations in total concept numbers. Additionally, they used a dense final layer which is less interpretable for humans, as each decision is related to the whole concept set.
- 2. [15, 28] suggested using a sparse linear layer for final prediction to enhance interpretability. Though sparsity is initially introduced to enhance interpretability, we note that this also reduces the number of concepts used in the decision, thus controlling the information leakage. However, the problem is, these works lack the quantification for sparsity, which is necessary for fair comparison between methods.
To provide a unified metric for both approaches, we propose to measure the Number of Effective Concepts (NEC) for final prediction as a sparsity metric. It is defined as
̸
$$N E C ( W _ { F } ) = \frac { 1 } { C } \sum _ { i = 1 } ^ { C } \sum _ { j = 1 } ^ { k } 1 \{ ( W _ { F } ) _ { i j } \neq 0 \}$$
Intuitively, NEC measures the average number of concepts the model uses to predict a class. Using NEC to evaluate CBM provides the following benefits:
- 1. A smaller NEC reduces the information leakage. As shown in Fig. 3, with large NEC, even random CBL could achieve near-optimal accuracy, suggesting potential leakage in information. However, by reducing NEC, the accuracy of random concepts drops quickly. This implies enforcing a small NEC could help to control information leakage.
- 2. A model with a smaller NEC provides more interpretable decision explanations. Humans can recognize an object with several important visual features. However, models can utilize tens or hundreds of concepts for the final prediction. By using a smaller NEC, the model's decision could be attributed mainly to several concepts, making it more interpretable to human users.
- 3. NEC enables fair comparison between CBMs. Comparing the performance of CBMs has long been a challenging problem, as different models use different numbers of concepts and different styles of final layers (sparse/dense). NEC considers both, thus providing a fair metric to compare different models.
Given these benefits, we suggest to control the NEC when comparing the performance of CBMs. In Section 5, we provide experiments with controlled NEC, where we observed our VLG-CBM outperforms other baselines.
Figure 3: Accuracy comparison between our VLG-CBM , LF-CBM[15] and randomly initialized concept bottleneck layer under different NEC. The experiment is conducted on the CIFAR10 dataset. From the results, we could see that (1) for NEC large enough, even a random CBL could achieve near-optimal accuracy, supporting the existence of information leakage; (2) when NEC decreases, the accuracy of LF-CBM and random weights begin to drop, while our VLG-CBM does not have significant decrease.
## 5 Experiments
In this section, we conduct a series of experiments to evaluate our method, including illustrating the faithfulness of concept prediction, interpretability of model decisions, and performance with controlled NEC.
## 5.1 Performance comparison
Setup. Following prior work [15], we conduct experiments on five image recognition datasets: CIFAR10, CIFAR100[7], CUB[23], Places365[30] and ImageNet[18]. For the choice of backbone, we categorize the experiments into two categories:
- 1. CLIP backbone: For CLIP backbone, we choose CLIP-RN50 for all datasets.
- 2. non-CLIP backbobe: We follow the choice of [15] to use ResNet-18[3] for CUB and ResNet-50 (trained on ImageNet) for Places365 and ImageNet as the backbone.
The reason of this categorization is some previous works (e.g. LaBo[27] only supports CLIP backbone.
Baselines. We compare our method with three major baselines when applicable: LF-CBM[15], LaBo[27], and LM4CV[25]. These are SOTA methods for constructing scalable CBMs, with [15] most flexible and [27, 25] limited by specific architecture and not available for certain dataset. Additionally, we present the results from a randomly initialized CBL for comparison.
Metrics. As discussed in Section 4, in order to evaluate the final classification power of CBM, we should acculate the Accuracy under specified NEC(ANEC). Therefore, we measure the following two metrics:
- 1. Accuracy at NEC=5(ANEC-5): This metric is designed to show the performance of CBM which could provide an interpretable prediction. We choose the number 5 so that human users could easily inspect all concepts related to the decision without much effort.
- 2. Average accuracy(ANEC-avg): To evaluate the trade-off between interpretability and performance, we also calculate the average accuracy under different NECs. In general, higher NEC indicates a more complex model, which may achieve better performance but also hurt interpretability. We choose six different levels: 5 10 15 20 25 30 , , , , , and measure the average accuracy.
Controlling NEC. As we discussed in Section 4, there are two approaches to control NEC: (1) using a dense final layer and directly controlling the number of concepts and (2) training a sparse final layer with appropriate sparsity. LM4CV[25] used the first approach, where the number of concepts could be directly set as target NEC. For LF-CBM[15] and our VLG-CBM , the second approach is utilized: To achieve target sparsity, we control the regularization strength λ in GLM-SAGA. GLM-SAGA provides a regularization path, which allows us to gradually reduce regularization strength and get a series of weight matrices with different sparsity. Specifically, we start with λ 0 = λ max which gives the sparsest weight. Then, we gradually reduce the λ by λ t +1 = αλ t until we achieve the desired NEC. We choose the weight matrix with the closest NEC to our target and prune the weights from smallest magnitude to largest to enforce accurate NEC. LaBo [27] did not provide a NEC control method. Hence, we apply sparse final layer training of LaBo's concept prediction to control NEC.
Results. We summarize the test results for with backbone in Table 2 and results with non-CLIP backbones in Table 3. From the results, we could see that:
- 1. The accuracy at NEC = 5 provides a good metric for evaluating the semantic information in CBL: As shown in the table, the accuracy of random CBL is much lower with NEC = 5 , which implies the information leakage is controlled and the accuracy could better reflect the useful semantic information learned in the CBL.
- 2. The performance of LM4CV is even worse than random CBL. An explanation to this is LM4CV utilizes a dense final layer, which is intrinsically inefficient to interpret as each class is connected to all the concepts, including the irrelevant ones. When limiting the NEC to a small value to provide a concise explanation, the model has to largely reduce the concept number which sacrifices the prediction power.
- 3. Our method significantly outperforms all the baselines at least 4.27% and up to 51.09% on accuracy at NEC=5, and by at least 0.45% and up to 29.78% on average accuracy across different NECs, illustrating both high performance and good interpretability.
| Dataset | CIFAR10 | CIFAR10 | CIFAR100 | CIFAR100 | ImageNet | ImageNet | CUB | CUB |
|----------------|-----------|-----------|------------|------------|------------|------------|--------|----------|
| Metrics | ANEC-5 | ANEC-avg | ANEC-5 | ANEC-avg | ANEC-5 | ANEC-avg | ANEC-5 | ANEC-avg |
| Random | 67.55% | 77.45% | 29.52% | 47.21% | 18.04% | 39.63% | 25.37% | 40.13% |
| LF-CBM | 84.05% | 85.43% | 56.52% | 62.24% | 52.88% | 62.24% | 31.35% | 52.70% |
| LM4CV | 53.72% | 69.02% | 14.64% | 36.70% | 3.77% | 26.65% | 3.63% | 15.25% |
| LaBo | 78.69% | 82.05% | 44.82% | 55.18% | 24.27% | 45.53% | 41.97% | 59.27% |
| VLG-CBM (Ours) | 88.55% | 88.63% | 65.73% | 66.48% | 59.74% | 62.70% | 60.38% | 66.03% |
Table 2: Performance comparison with CLIP-RN50 backbone. We compare our method with a random baseline, LF-CBM[15], LM4CV[25] and LaBo[27]. The random baseline has 1024 neurons for CIFAR10 and CIFAR100, 512 for CUB and 4096 for ImageNet.
| Dataset | CUB | CUB | Places365 | Places365 | ImageNet | ImageNet |
|-----------------------|---------------|---------------|---------------|---------------|---------------|---------------|
| Metrics | ANEC-5 | ANEC-avg | ANEC-5 | ANEC-avg | ANEC-5 | ANEC-avg |
| Random | 68.91% | 73.44% | 17.57% | 28.62% | 41.49% | 61.97% |
| LF-CBM VLG-CBM (Ours) | 53.51% 75.79% | 69.11% 75.82% | 37.65% 41.92% | 42.10% 42.55% | 60.30% 73.15% | 67.92% 73.98% |
Table 3: Performance comparison with non-CLIP backbone. We compare against LF-CBM[15] and a random baseline, as LM4CV[25], LaBo[27] does not support non-CLIP backbone. The random baseline has 512 neurons for CUB, 2048 for Places365, and 4096 for ImageNet.
## 5.2 Visualization of CBL neurons
In order to examine whether our CBL learns concepts aligned with human perception, we list the top-5 activated images for example concept neurons on the model trained on the CUB dataset in Fig. 4. As shown in the figure, our CBL faithfully captures the corresponding concept. We provide more visualization results in Appendix K.


(a) Concept 19: black face.
(b) Concept 29: black plumage

(c) Concept 117: brown or gray body

(d) Concept 182: small black head
Figure 4: Top-5 activated images of example concepts neurons in VLG-CBM on CUB dataset.
## 5.3 Case study
In this section, we conduct a case study to compare the concept prediction between our VLG-CBM , LF-CBM [15] and LM4CV[25] as shown in Fig 1. We provide extended results and comparison with LaBo [27] in Appendix G.2. For our method, we use the final layer with NEC = 5 . We show that our method provides more accurate concept prediction and more interpretable decisions for users.
Decision interpretability. We examine the explanation of each CBM model on example images by showing the top-5 concept contributions. The contribution of each concept is calculated as the product of the concept prediction value and corresponding weight. Formally, the contribution of
i -th concept to j -th class is defined as: Contribution ( i, j ) = g i ( z ) · ( W F ) ji . We pick the top-5 contributing concepts for the final predicted class and visualize it in Fig. 1. We could see that:
- 1. For other CBMs, a large portion of the final decision is attributed to the "Sum of other features". This part hurts the interpretability of CBM, as it's difficult for users to manually inspect all these concepts in practice. We conduct further study on this in Section 5.4. Our model, however, provides a concise explanation from a few concepts because we apply the constraint NEC=5. This ensures users can understand model decisions without difficulties.
- 2. Our VLG-CBM provides explanation more aligned with human perception. From the example, we can also see that our model explains the decision with clear visual concepts. Other CBMs attribute the decision to non-visual concepts (e.g. LaBo), concepts that do not match the image (e.g. LM4CV), or negative concepts (LF-CBM).
## 5.4 Do Top-5 concepts fully explain the decision?
Besides training a final layer with a small NEC, another common approach to provide a concise explanation is showing only the top contribution concepts. However, we argue that this approach may not faithfully explain the model's behavior, as the non-top concepts also make a significant contribution to the decision. To verify this, we conduct the following experiment: On the CUB dataset, we prune the final weight matrix W F to leave only the top-5 concepts for each class, whose weight has the largest magnitude. Then, we use the pruned model to make predictions and compare them with the prediction results from the original model. Table 4 shows results for our VLG-CBM which uses NEC = 5 to control sparsity, and other three baselines, LaBo[27], LF-CBM[15] and LM4CV[25], without any constraint on NEC. As shown in the table, for all three baselines, a large portion of predictions changes after pruning. This suggests that without explicitly controlling NEC, only showing top-5 contributing concepts does not faithfully explain all of the model decisions. Hence, we recommend training the final layer with NEC controlled to obtain a concise and faithful explanation as we proposed in Section 4.
Table 4: Portion of model predictions that changes after pruning. The results suggest that for existing methods (LF-CBM, LM4CV, LaBo) without NEC control, a large portion of predictions changes with top-5 concepts, implying potential risk when using top-5 contributions to explain model decisions.
| Method | VLG-CBM (Ours) | LF-CBM | LM4CV | LaBo |
|--------------------|------------------|----------|---------|--------|
| %changed decisions | 0.12% | 49.21% | 98.34% | 81.40% |
## 6 Conclusion, Potential Limitations and Future work
In this work, we study how to improve the interpretability and performance of concept bottleneck models. We introduce a novel approach VLG-CBM based on both vision and language guidance, which successfully improves both the interpretability and utility of existing CBMs in prior work. Additionally, our theoretical analysis show that information leakage may exist on even in the untrained CBLs, serving the foundations for our proposed new NEC-controlled metrics (ANEC-5 and ANEC-avg). We show that NEC not only allow fair evaluation of CBMs but also can be used to effectively control information leakage of CBM and ensure interpretability. Extensive experiments on image classification benchmarks demonstrated our VLG-CBM largely outperform previous baselines especially for small NEC, providing more interpretable decisions for users.
Despite the superior performance of VLG-CBM over prior work as demonstrated in extensive experiments, one potential limitation is the dependence on large pretrained models (e.g. the success of open-domain grounded object detection model that we use to enforce vision guidance). However, prior work (e.g. LaBo, LM4CV, LF-CBM) also shared similar limitation on the reliance of large pre-trained models (e.g. CLIP). Nevertheless, it also means that our techniques have the potential to be further improved with the advancement of large pre-trained models. In the future, we plan to explore training CBL with even more vision guidance, such as using segmentation maps of concepts.
## Acknowledgement
The authors thank the anonymous reviewers for valuable feedback on the manuscript. The authors are partially supported by National Science Foundation awards CCF-2107189, IIS-2313105, IIS-2430539, Hellman Fellowship, and Intel Rising Star Faculty Award. The authors also thank ACCESS for support in this work.
## References
| [1] | David Alvarez Melis and Tommi Jaakkola. Towards robust interpretability with self-explaining neural networks. Advances in neural information processing systems , 31, 2018. |
|-------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [2] | Morris L Eaton. Multivariate statistics: a vector space approach , volume 512. Wiley New York, 1983. |
| [3] | Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR , 2016. |
| [4] | Injae Kim, Jongha Kim, Joonmyung Choi, and Hyunwoo J. Kim. Concept bottleneck with visual concept filtering for explainable medical image classification, 2023. URL https: //arxiv.org/abs/2308.11920 . |
| [5] | Diederik P Kingma and Jimmy Ba. Adam: Amethod for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014. |
| [6] | Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In ICML , 2020. |
| [7] | Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. |
| [8] | Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training, 2022. |
| [9] | Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning, 2022. |
| [10] | Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499 , 2023. |
| [11] | Josh Magnus Ludan, Qing Lyu, Yue Yang, Liam Dugan, Mark Yatskar, and Chris Callison- Burch. Interpretable-by-design text classification with iteratively generated concept bottleneck. CoRR , 2023. |
| [12] | Anita Mahinpei, Justin Clark, Isaac Lage, Finale Doshi-Velez, and Weiwei Pan. Promises and pitfalls of black-box concept learning models. arXiv preprint arXiv:2106.13314 , 2021. |
| [13] | Andrei Margeloiu, Matthew Ashman, Umang Bhatt, Yanzhi Chen, Mateja Jamnik, and Adrian Weller. Do concept bottleneck models learn as intended? arXiv preprint arXiv:2105.04289 2021. |
| [14] | Tuomas Oikarinen and Tsui-Wei Weng. Clip-dissect: Automatic description of neuron repre- sentations in deep vision networks. In ICLR , 2023. |
| [15] | Tuomas Oikarinen, Subhro Das, Lam M Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models. ICLR , 2023. |
| [16] | Thang M Pham, Peijie Chen, Tin Nguyen, Seunghyun Yoon, Trung Bui, and Anh Nguyen. Peeb: Part-based image classifiers with an explainable and editable language bottleneck. arXiv preprint arXiv:2403.05297 , 2024. |
| [17] | Karsten Roth, Jae Myung Kim, A. Sophia Koepke, Oriol Vinyals, Cordelia Schmid, and Zeynep Akata. Waffling around for performance: Visual classification with random words and broad concepts, 2023. URL https://arxiv.org/abs/2306.07282 . |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [18] | Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision , 115:211-252, 2015. |
| [19] | Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731 , 2019. |
| [20] | Ao Sun, Yuanyuan Yuan, Pingchuan Ma, and Shuai Wang. Eliminating information leakage in hard concept bottleneck models with supervised, hierarchical concept learning. arXiv preprint arXiv:2402.05945 , 2024. |
| [21] | Chung-En Sun, Tuomas Oikarinen, and Tsui-Wei Weng. Crafting large language models for enhanced interpretability. ICML Mechanistic Interpretability workshop , 2024. |
| [22] | Zhen Tan, Lu Cheng, Song Wang, Yuan Bo, Jundong Li, and Huan Liu. Interpreting pretrained language models via concept bottlenecks. CoRR , 2023. |
| [23] | Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. |
| [24] | Eric Wong, Shibani Santurkar, and Aleksander Madry. Leveraging sparse linear layers for debuggable deep networks. In ICML , 2021. |
| [25] | An Yan, Yu Wang, Yiwu Zhong, Chengyu Dong, Zexue He, Yujie Lu, William Yang Wang, Jingbo Shang, and Julian McAuley. Learning concise and descriptive attributes for visual recognition. In ICCV , 2023. |
| [26] | Sin-Han Yang, Tuomas Oikarinen, and Tsui-Wei Weng. Concept-driven continual learning. TMLR , 2024. |
| [27] | Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In CVPR , 2023. |
| [28] | Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models. ICLR , 2023. |
| [29] | Haotian* Zhang, Pengchuan* Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Harold Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding. arXiv preprint arXiv:2206.05836 , 2022. |
| [30] | Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence , 40(6):1452-1464, 2017. |
[31] Hui Zou and Trevor Hastie. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B: Statistical Methodology , 67(2):301-320, 2005.
## Appendix
## Table of Contents
| A | Proof of Theorem 4.1 14 |
|---------------------------------------------------------|--------------------------------------------------|
| B Implementation details | 17 |
| C Ablation Studies | 17 |
| C.1 Ablation study for confidence threshold . | . . . . . . . . . . . . . . . . . . . . . 17 |
| D Evaluating annotations from Grounding DINO | 18 |
| E Distribution of nonzero weights among class | 20 |
| F Constructing model with specified NEC | 20 |
| G Additional case study examples | 20 |
| G.1 Negative concepts in reasoning . . . . . . | . . . . . . . . . . . . . . . . . . . . 20 |
| G.2 Impact of NEC . . . . . . . . . . . . . . . . . . . | . . . . . . . . . . . . . . . . 20 |
| H Further discussion on decision explanations | 23 |
| H.1 Negative contributions . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . . . 23 |
| I Additional experiment results | 23 |
| I.1 Generalizability to OOD datasets . . | . . . . . . . . . . . . . . . . . . . . . . . 23 |
| I.2 Ablation study . . . . . . . . . . . . . . . . | . . . . . . . . . . . . . . . . . . . 23 |
| J Human study | 23 |
| K Visualizing VLG-CBM explanations | 24 |
## A Proof of Theorem 4.1
In this section, we present a formal definition of the expected square error in Theorem 4.1 and show the proof. First, we define the square approximation error as
$$\mathbb { E } _ { z } \, \left \lceil | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right \rceil,$$
which is the average square distance between f ( z ) and ˜ ( f z ) . Given a specific CBL W c , we seek a final layer ˜ w to minimize the square error:
$$\min _ { ( \tilde { w }, \tilde { b } ) } \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ].$$
For randomly Gaussian initialized W c , we care about the minimal error we could achieve on average. Thus, for each W c , we choose ˜ w and ˜ b to achieve minimum approximation error, then take the expectation over W c to define the expected square error as
$$E ( k ) = \mathbb { E } _ { W _ { c } } \left [ \min _ { ( \tilde { w }, \tilde { b } ) } \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ] \right ].$$
Setting Suppose the representation z has variance Σ ∈ R d × d which is positive definite. The weight matrix W c ∈ R k × d is sampled i.i.d from a standard Gaussian distribution. Here, we show that any linear classifier which is built directly on representation z , i.e. f ( z ) = w z ⊤ + b , could be approximated by a linear classifier on concept logits g z ( ) = W z c , i.e. f ( z ) ≈ ˜ ( f z ) = ˜ w g z ⊤ ( ) + ˜ b .
Theorem 4.1. Suppose Σ ∈ R d × d is the variance matrix of the representation z which is positive definite, λ max is the largest eigenvalue of Σ , and the weight matrix W c ∈ R k × d is sampled i.i.d from a standard Gaussian distribution. For any linear classifier f which is built directly on the representation z , i.e. f : R d → R , f ( z ) = w z ⊤ + b , it could be approximated by another linear classifier ˜ f on concept logits g z ( ) = W z c , i.e. f ( z ) ≈ ˜ ( f z ) = ˜ w g z ⊤ ( ) + ˜ b , with the expected square error E k ( ) upper-bounded by
$$E ( k ) \leq \begin{cases} \lambda _ { m a x } ( 1 - \frac { k } { d } ) \| w \| _ { 2 } ^ { 2 }, & k < d ; \\ 0, & k \geq d. \end{cases}$$
Here E k ( ) = E W c [ min ( ˜ w,b ˜ ) E z [ | f ( z ) -˜ ( f z ) | 2 ]] denotes the average square error, w ∈ R d , ˜ w ∈ R k , k is the number of concepts in CBL.
Proof. Based on the value of k , we can consider two cases: (I) k < d , and (II) k ≥ d , and derive the E k ( ) respectively.
Case (I): k < d . First, we consider under a fixed W c , what is the minimum error we could achieve. The expected approximation error is:
$$\text{acme, in the expense} \, \text{$approximation error is:$} \\ \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ] & = \mathbb { E } _ { z } \, \left [ | w ^ { \top } z + b - ( \tilde { w } ^ { \top } W _ { c } z + \tilde { b } ) | ^ { 2 } \right ] \\ & = \mathbb { E } _ { z } \, \left [ | ( w ^ { \top } - \tilde { w } ^ { \top } W _ { c } ) z + b - \tilde { b } | ^ { 2 } \right ] \\ & = \underbrace { \mathbb { V } _ { z } [ ( w - W _ { c } ^ { \top } \tilde { w } ) ^ { \top } z ] } _ { ( * ) } + \underbrace { \left [ \mathbb { E } _ { z } [ ( w ^ { \top } - \tilde { w } ^ { \top } W _ { c } ) z ] + b - \tilde { b } \right ] } _ { ( * * ) } ^ { 2 }. \\ \mathcal { T } _ { x } = \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
The last equality is from E ( X 2 ) = V X +( E X ) 2 . The second term ( ∗∗ ) takes minimum 0 when ˜ = b E z [( w ⊤ -˜ w W ⊤ c ) z ] + b . The remaining question is to choose a proper ˜ w to minimize ( ∗ ) . Notice that
$$\text{at} \\ \mathbb { V } _ { z } \left [ ( w - W _ { c } ^ { \top } \tilde { w } ) ^ { \top } z \right ] & = ( w - W _ { c } ^ { \top } \tilde { w } ) ^ { \top } \Sigma ( w - W _ { c } ^ { \top } \tilde { w } ) \\ & = \| \Sigma ^ { \frac { 1 } { 2 } } ( w - W _ { c } ^ { \top } \tilde { w } ) \| _ { 2 } ^ { 2 } \\ & = \| \Sigma ^ { \frac { 1 } { 2 } } W _ { c } ^ { \top } \tilde { w } - \Sigma ^ { \frac { 1 } { 2 } } w \| _ { 2 } ^ { 2 },$$
where Σ is the covariance matrix of z , Σ 1 2 is the principal square root of Σ Σ , ∈ R d × d , Σ 1 2 ∈ R d × d . Now the problem in Eq. (A.2) can be reduced to a linear least square problem:
$$\min _ { ( \tilde { w }, \tilde { b } ) } \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ] = \min _ { \tilde { w } } \| \Sigma ^ { \frac { 1 } { 2 } } W _ { c } ^ { \top } \tilde { w } - \Sigma ^ { \frac { 1 } { 2 } } w \| _ { 2 } ^ { 2 } \, \quad \quad ( A. 6 )$$
Since Σ is positive definite, so is Σ 1 2 . Thus, the eigen decomposition of Σ 1 2 satisfies the following: Σ 1 2 = ˜ Q ⊤ Λ ˜ Q , where ˜ Q ∈ R d × d is an orthogonal matrix and Λ ∈ R d × d is a diagonal matrix with positive entries. With Gram-Schmidt process, we could derive QR factorization of W ⊤ c : W ⊤ c = QR , where Q ∈ R d × d is orthogonal and R ∈ R d × k is upper triangular. Plugging above decomposition of Σ 1 2 and W ⊤ c , now we have
$$\Sigma ^ { \tilde { 2 } } \text{ and } W _ { c } ^ { \, \prime } \,, \text{ now we have} \\ \min _ { \tilde { w } } \| \Sigma ^ { \tilde { 2 } } W _ { c } ^ { \, \prime } \tilde { w } - \Sigma ^ { \frac { 1 } { 2 } } w \| _ { \tilde { 2 } } ^ { 2 } & = \min _ { \tilde { w } } \| \tilde { Q } ^ { \top } \Lambda \tilde { Q } Q R \tilde { w } - \tilde { Q } ^ { \top } \Lambda \tilde { Q } w \| _ { \tilde { 2 } } ^ { 2 } \\ & = \min _ { \tilde { w } } \| \Lambda \tilde { Q } Q R \tilde { w } - \tilde { Q } w \| _ { \tilde { 2 } } ^ { 2 } & \quad ( \tilde { Q } \text{ is orthogonal, thus preserves 2-norm)} \\ & = \min _ { \tilde { w } } \| \Lambda ( \tilde { Q } Q R \tilde { w } - \tilde { Q } w ) \| _ { \tilde { 2 } } ^ { 2 } \\ & \leq \min _ { \tilde { w } } \lambda _ { \max } ^ { 2 } \| \tilde { Q } Q R \tilde { w } - \tilde { Q } w \| _ { \tilde { 2 } } ^ { 2 } & \quad ( \text{Since all entries of } \Lambda \text{ are positive.} ) \\ & = \lambda _ { \max } ^ { 2 } \min _ { \tilde { w } } \| R \tilde { w } - Q ^ { \top } w \| _ { \tilde { 2 } } ^ { 2 } & \quad ( \text{Multiply by } Q ^ { \top } \tilde { Q } ^ { \top } \text{ preserves the norm)} \\ \text{where } \lambda \quad \text{ is the large selection value of } \Sigma ^ { \frac { 1 } { 2 } } \text{ in short } \text{ we have derived the minimum square error for}$$
(A.7)
where λ max is the largest eigenvalue of Σ 1 2 . In short, we have derived the minimum square error for a given W c , which is upper bounded by
$$\min _ { ( \tilde { w }, \tilde { b } ) } \left [ \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ] \right ] \leq \lambda _ { m a x } ^ { 2 } \min _ { \tilde { w } } \| R \tilde { w } - Q ^ { \top } w \| _ { 2 } ^ { 2 } \, \quad \quad ( A. 8 )$$
Secondly, we consider when W c is sampled i.i.d. from standard normal distribution, and calculate the expected error. From above derivation,
$$\mathbb { E } _ { W _ { c } } \left [ \min _ { ( \tilde { u }, \tilde { b } ) } \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ] \right ] \leq \lambda _ { m a x } ^ { 2 } \mathbb { E } _ { ( R, Q ) } \left [ \min _ { \tilde { u } } \| R \tilde { w } - Q ^ { \top } w \| _ { 2 } ^ { 2 } \right ] \quad ( A. 9 )$$
Note that since W ⊤ c = QR , the randomness in W c is reflected in Q and R . The matrices Q and R satisfies the following properties:
- 1. Q is a random rotation following uniform distribution. This is intuitive because standard Gaussian distribution is rotation-invarant. For a formal statement and proof, we refer to Proposition 7.2 of Eaton [2].
- 2. range R ( ) = span e , e ( 1 2 , · · · , e k ) with probability 1. Since rank R ( ) = rank W ( ⊤ c ) and W ⊤ c is full rank with probability 1, rank R ( ) = min( k, d ) = k with probability 1. From upper-triangularity of R , we know that
$$\ r a n g e ( R ) \subseteq s p a n ( e _ { 1 }, e _ { 2 }, \cdots, e _ { k } ).$$
With probability 1, rank R ( ) = k , thus we conclude
$$\ r a n g e ( R ) = s p a n ( e _ { 1 }, e _ { 2 }, \cdots, e _ { k } ).$$
In the following derivation, since we only cares about the expectation, we omit "with probability 1" for brevity.
From the above properties of Q and R , the expectation term in the RHS of Eq. (A.9) can be derived as:
$$\mathbb { E } _ { ( R, Q ) } \left [ \min _ { \tilde { w } } \| R \tilde { w } - Q ^ { \top } w \| _ { 2 } ^ { 2 } \right ] = \mathbb { E } _ { Q } \| ( Q ^ { \top } w ) _ { k + 1 \colon d } \| _ { 2 } ^ { 2 }. & & ( \text{A.12} )$$
This is because range R ( ) = span e , e ( 1 2 , · · · , e k ) , and k < d . Thus, min ˜ w ∥ Rw ˜ -Q w ⊤ ∥ 2 2 is the squared distance from Q w ⊤ to subspace span e , e ( 1 2 , · · · , e k ) , which equals to the squared sum of last d -k coordinates of Q w ⊤ .
Because Q is a random rotation, Q w ⊤ is uniformly distributed on a sphere with radius ∥ w ∥ 2 . Denote v = Q w ⊤ . From symmetricity, we have
$$\mathbb { E } \, v _ { 1 } ^ { 2 } = \mathbb { E } \, v _ { 2 } ^ { 2 } = \dots = \mathbb { E } \, v _ { d } ^ { 2 }.$$
Furthermore, ∥ v ∥ 2 2 = ∥ w ∥ 2 2 gives ∑ d i =1 v 2 i = ∥ w ∥ 2 2 . Take expectation of both sides gives ∑ d i =1 E v v 2 i = ∥ w ∥ 2 2 , thus E v 2 1 = E v 2 2 = · · · = E v 2 d = ∥ w ∥ 2 2 /d . The target quantity becomes
$$w \| _ { 2 }, \, \text{thus } \mathbb { E } \, v _ { 1 } ^ { \prime } = \mathbb { E } \, v _ { 2 } ^ { \prime } = \cdots = \mathbb { E } \, v _ { d } ^ { \prime } = \| w \| _ { 2 } ^ { \prime } / \alpha. \, \text{ In target quantity becomes} \\ \mathbb { E } _ { Q } \| ( Q ^ { \top } w ) _ { k + 1 \colon d } \| _ { 2 } ^ { 2 } & = \mathbb { E } _ { v } \left ( \sum _ { i = k + 1 } ^ { d } v _ { i } ^ { 2 } \right ) \\ & = \sum _ { i = k + 1 } ^ { d } \mathbb { E } _ { v } \, v _ { i } ^ { 2 } \\ & = \frac { d - k } { d } \| w \| _ { 2 } ^ { 2 } \\ \colon \text{derive an upper bound of approximation error for any linear function } \, f \colon$$
In conclusion, we derive an upper bound of approximation error for any linear function f :
$$\mathbb { E } _ { W _ { c } } \left [ \min _ { ( \tilde { w }, \tilde { b } ) } \mathbb { E } _ { z } \, \left [ | f ( z ) - \tilde { f } ( z ) | ^ { 2 } \right ] \right ] \leq \lambda _ { m a x } ^ { 2 } ( 1 - \frac { k } { d } ) \| w \| _ { 2 } ^ { 2 } \, \quad \quad ( A. 1 5 )$$
Look at the bound in Eq. (A.15): λ 2 max is a constant regarding the scale of data; ∥ w ∥ 2 2 is a constant regarding the norm of weight vector we want to approximate; (1 -k d ) is a linear term shows that the expected square error goes down linearly when we increase the number of concepts k , and achieves zero when k = d .
Case (II): k ≥ d . For the case that k ≥ d , it could be derived from our main results that E k ( ) = 0 . Additionally, with probability 1 we could find ˜ ( f x ) = f ( x ) as will be derived below. As we discussed, with probability 1, W c has full rank. Given that, we have
$$W _ { c } ^ { + } W _ { c } z = z,$$
where W + c is the Moore-Penrose inverse of W c . For any linear classifier f ( z ) = w z ⊤ + b . Let ˜ = ( w W + c ) ⊤ w b , ˜ = b , we have
$$\tilde { f } ( z ) = \tilde { w } ^ { \top } g ( z ) + \tilde { b } = w ^ { \top } W _ { c } ^ { + } W _ { c } z + b = w ^ { \top } z + b = f ( z )$$
and thus E k ( ) = 0 .
Corollary A.1. For f and ˜ f with C output classes, i.e. f : R d → R C , ˜ : f R d → R C , w ∈ R d , ˜ w ∈ R k , the expected error upper-bound is
$$E ( k ) \leq C \lambda _ { m a x } ( 1 - \frac { k } { d } ) \| w \| _ { 2 } ^ { 2 }.$$
Here E k ( ) = E W c [ min ( ˜ w,b ˜ ) E z ∥ f ( z ) -˜ ( f z ) ∥ 2 ] denotes the average square error.
Remark A.2 . The statement could be verified by applying Theorem 4.1 to each f i and ˜ f i output, then summing up the error.
## B Implementation details
Computational resources and codes. Our experiments run on a server with 10 CPU cores, 64 GB RAM, and 1 Nvidia 2080Ti GPU. Our implementation builds on the open-source implementation of the LF-CBM [15] available: https://github.com/Trustworthy-ML-Lab/Label-free-CBM . For training the final predictive layer, we use publicly available code for GLM-SAGA [24].
Hyperparameter tuning. We tune the hyperparameters for our method using 10% of the training data as validation for the CIFAR10, CIFAR100, CUB and ImageNet datasets. For Places365, we use 5% of the training data as validation. We use CLIP(RN50) image encoder as the backbone for CIFAR10 and CIFAR100, Resnet-18[3] trained on CUB for CUB dataset, and Resnet-50 pretrained for Places365 following setup similar to LF-CBM. We tune the CBL with Adam[5] optimizer with learning rate 1 × 10 -4 and weight decay 1 × 10 -5 . The concept dataset obtained from GroundingDINO is inherently unbalanced since there is a much lower proportion of positive datapoints for a concept. Consequently, we scale the CBL loss by multiplying it with a positive value to balance the tradeoff between precision and recall and improve the imbalance of positive data points. We set T = 0 15 . in Eq. (2) in all our experiments. We seed the random number generator with a fixed seed to ensure the results can be reproduced.
## C Ablation Studies
| Confidence threshold | CUB200 | CUB200 | Places365 | Places365 |
|------------------------|----------|----------|-------------|-------------|
| Metrics | ANEC-5 | ANEC-avg | ANEC-5 | ANEC-avg |
| 0.10 | 75.75% | 75.75% | 41.84% | 42.50% |
| 0.15 | 75.75% | 75.73% | 41.84% | 42.51% |
| 0.20 | 75.73% | 75.73% | 41.25% | 42.15% |
Table C.1: ANEC-5 and ANEC-avg for different confidence threshold T .
## C.1 Ablation study for confidence threshold
Confidence threshold T in Eq 2 filters concepts with bounding boxes' confidence less than T . In this experiment, we study the affect of T on the VLG-CBM 's accuracy. The results are shown in Table C.1. We observe that ANEC-5 and ANEC-avg first increases (or stays constant) and then decreases. We attribute this effect to to the fact that as T increases, the number of false-positive decreases leading to better learning of concepts, however, as the number of annotations available for learning a concept decreases.
## D Evaluating annotations from Grounding DINO
This section quantitatively evaluates concept annotations obtained from Grounding DINO. We use CUB dataset for comparison which contains ground-truth for fine-grained concepts present in each image. We use the label set from Koh et al. [6] which has 1:1 mapping with the ground-truth concepts in the CUB dataset. We use precision and recall metric to measure the quality of annotations from Grouding DINO for each concepts. Table D.1 present mean precision and mean recall value at different confidence threshold. We observe that the obtained annotations have a very high recall i.e if the concept is present in the image, grounding DINO is able to retrieve the object. The precision is also sufficiently high though it suffers from a relatively higher false-positive detection rate compared to false-negative detection rate. However, as demonstrated in our qualitative and quantitative studies (Table 3, Fig 4, K.2, K.1) the effect of false-positive is minimal and VLG-CBM is able to faithfully represent concepts in the Concept Bottleneck Layer.
Table D.1: Quantitative evaluation of concepts obtained from Grounding DINO model with Mean Precision and Recall for concepts at different confidence thresholds.
| Confidence threshold | Mean Precision | Mean Recall |
|------------------------|-------------------|-------------------|
| 0.1 | 0 . 7150 ± 0 . 07 | 0 . 9930 ± 0 . 08 |
| 0.15 | 0 . 7156 ± 0 . 07 | 0 . 9693 ± 0 . 11 |
| 0.2 | 0 . 7121 ± 0 . 10 | 0 . 8713 ± 0 . 21 |
Figure D.1: Full version of Fig 1 comparing explanation of LF-CBM and LM4CV with VLGCBM (ours)

## E Distribution of nonzero weights among class
The NEC metric controls the average number of non-zero weights among classes. Further, we study the distribution of non-zero weight numbers between different classes. We choose our VLG-CBM model trained on CUB and places365 datasets, which have 200 and 365 classes, respectively, and plot the distribution of non-zero weights. Both models are trained to have NEC=5 The results are shown in Fig. E.1. The figure suggests most classes have non-zero weight numbers around 5, while a small number of classes utilize more concepts to make decisions.
Figure E.1: distribution of non-zero weight numbers from CUB and Places365 dataset. The models are trained to have NEC=5.


## F Constructing model with specified NEC
In this section, we discuss how to construct models with specified NEC. When using methods with dense final layers (e.g. [25]), controlling NEC is simply controlling total number of concepts in the concept set. Hence, below we mainly focus on models with sparse final layers.
When training the final linear layer, larger lambda(regularization strength) pushes the model to be sparser. Hence, we utilize GLM-SAGA[24], which allows us to obtain a regularization path consists of different lambdas. To be more specific, we choose a λ max and train models with λ in [ λ min = λ max / 500 λ max ] , and take 50 λ evenly from the interval in log space. Then, we choose the weight matrix with the closest NEC and pruning the weights from smallest magnitude to largest to enforce strict NEC. Hence, the actual NEC is enforced to be exactly as prespecified ones.
## G Additional case study examples
## G.1 Negative concepts in reasoning
In LF-CBM [15] and our VLG-CBM, normalization is applied on concept logits before the final decision layer. Hence, a negative value of concept logits indicates corresponding concept does not appear in the image. Following LF-CBM, we mark these concepts as "NOT {concept}" in explaining the decision. To study the frequency of this negative reasoning, we count the times these negative concepts appear in top-5 contributing concepts on CUB dataset. The results show that, for VLG-CBM, 162 out of 28950(0.56%) reasonings are through negative concepts. For comparison, LF-CBM utilizes 6687 out of 28950(23.10%) negative reasoning.
## G.2 Impact of NEC
The study in Section 5.3 shows that our VLG-CBM provides more interpretable decisions than baseline methods. To better understanding where these advantages comes from, we conduct a further study to set the baselines with NEC=5 and compare the decision interpretation, see Figs. G.2 to G.4. The results suggest setting NEC=5 alleviate the problem from non-top-5 concepts. However, wrong/inaccurate/less useful explanations still exist.

Ground truth: Bobolink. VLG-CBM prediction: Bobolink
- 1.black v on the back(4.30)
- 3.black head and back(0.27)
- 2 black and white striped head(1.94)
- 4.small round body(0.07)
- Sum of other concepts: (0.03)
- 5.NOT white stripes above the eyes(0.01)
Figure G.1: Image 307: An example of negative reasoning of VLG-CBM

## LF-CBM
- NOT a brown and white color scheme (1-77)
- black coloration 66
- NOT a black bib with white stripes (1.29)
- NOT white iridescent feathers (1.37) and
- NOT a black and white color scheme 01)
Sum of other concepts (4.22)
## LF-CBM (NEC-5)
- NOTa brown and white color scheme(2.39)
- scheme(0.61)
- NOT a black bib with white stripes(1.08) NOT a black and white color
- iridescent feathers(0.27)
## LMACV
- Color Blue head, olive back, yellow underparts (101.08)
- blue highlights (94.03)
- large red bill with a slightly hooked tip (89.09)
- 3 bright blue and orange plumage (91.44)
- white rump patch at the base of the tail (59.69)
Sum of other concepts (-171.50)
## LMACV (NEC-5)
- bright reddish brown head, crown and back of neck (382.61)
- bright yellow throat, breast, and flanks with black bars (51.36)
- bright yellow , green and blue plumage(95.67)
- Broad tail that is shorter than other pelican species (-36.48)
## LaBo
- beautiful bird with brightly colored body (0.02)
- beautiful bird with a brightly colored plumage (0.02)
- small , plump songbird with a short tail and pointed bill (0.02)
- one of the most beautiful north american songbirds (0.02)
- Sum of other concepts (41.25)
- colors are very vibrant and beautiful (0.02)
## LaBo(NEC-5)
- beautiful little bird with very colorful
- 2 very colorful bird, with a lot of blue and green(0.43)
- plumage(3.98)
- 3. very pretty and very colorful(o.41)
- NOT white stripes on white stripes on brown(0.22)
- Mottled brown on the nape, mantle, and scapulars(-243.90)
- NOT yellowish-brown wings(0.25) Sum of other concepts: (0.00)
- 5. known as the "rainbow jay' due to its bright plumage(0.11)
Sum of other concepts: (0.00)
Sum of other concepts: (0.00)
Figure G.2: Comparing baselines with different NECs
## LF-CBM

## LMACV
## LaBo

- seen in flocks of other goldfinches(0.02)
- male goldfinch is the more brightly colored of the sexes , with(0.02)
- 3. often forming flocks with other goldfinches(0.02)
- young goldfinches are drabber than adults , with brownish plumage(0.02)
- visit bird tables and feeders(0.02)
Sum of other concepts: (41.69)
## LaBo(NEC-5)
- closely related to the goldfinch(3.83)
- 3. NOT from alaska and canada to the
- 2 often forming flocks with other goldfinches(1.16)
- southwestern united states(1.10)
- 5 NOT found in eastern and central united states year-round(o .03)
- often forming flocks with other goldfinches and similar small birds(0.17)
- red, black and white feathers(93.11)
- 3. bright red head and nape(75.39)
- 2. bright red head and breast(84.05)
- bright red crescent below its beak (63.14)
5. White neck with black collar and
Sum of other concepts: (-172.32)
## LMACV (NEC-5)
- bright reddish brown head, crown and back of neck (344.38)
plumage(87.41)
- 2. bright yellow , green and blue
- 3. bright yellow throat, breast, and flanks with black bars (39.26)
- Broad tail that is shorter than other
- 5. Mottled brown on the nape, mantle and scapulars(-227.34)
Sum of other concepts: (0.02)
Sum of other concepts: (0.00)
Figure G.3: Comparing baselines with different NECs

## LF-CBM
LMACV
## LaBo

- is the only warbler with entirely(0.02)
- 3. plumage is bright yellow(0.02)
- largest and heaviest member of the wood-warbler family(0.02)
Sum of other concepts: (42.29))
## LaBo(NEC-5)
- 1. NOT sometimes called the sea sparrow" to its black and white plumage(1.10) due
- 3.yellow head is thought to be a sign of maturity and wisdom(0.37)
- long; straight orange bill (141.48)
- yellow and black plumage(84.85)
- 2 large, orange bill with a black tip (100.07) 3. pointed orange bill (95.72)
5. bright blue and orange plumage(76.97)
Sum of other concepts: (-257.02)
## LMACV (NEC-5)
- bright yellow throat, breast, and flanks with black bars (320.88)
- 3. bright reddish brown head, crown and back of neck (-89.49)
- 2 bright yellow , green and blue plumage(285.24)
- Broad tail that is shorter than other
- 2 yellow head, chest; and belly(0.95)
- orange in color(0.28)
- 5. Mottled brown on the nape, mantle, and scapulars(-151.65)
- pelican species (-126.68)
- series of high, thin 'peeps" (0.15) Sum of other concepts: (0.37)
Sum of other concepts: (0.00)
Figure G.4: Comparing baselines with different NECs
## H Further discussion on decision explanations
In this section, we further discuss some interesting phenomena observed in the decision explanations generated by different models.
## H.1 Negative contributions
In Fig. 1, we could see that LM4CV[25] generates negative contribution values, while LF-CBM[15] and our VLG-CBM do not. We hypothesize the reason is different training methods: LM4CV trains a dense final layer, hence the concepts irrelevant to the class may provide a negative contribution. LF-CBM and VLG-CBM, however, train a sparse final layer. To enforce sparsity, the model only captures relevant concepts for decision. Hence, it's natural to expect most contributions should be positive.
## I Additional experiment results
## I.1 Generalizability to OOD datasets
In this section, we study a question: will our VLG-CBM hurts the generalization ability of original model to Out-Of-Distribution(OOD) dataset? To study this problem, we conduct experiment on Waterbirds dataset [19]. Waterbirds is an OOD dataset adapted from the CUB dataset, which combines bird photos from CUB with image backgrounds from Places365. We use the same ResNet model as we used in Table 3 for CUB dataset. For VLG-CBM, we choose NEC=5 and compare the results with the standard, non-interpretable models. On this dataset, the results are shown below: It can be seen
Table I.1: Accuracy of VLG-CBM and standard blackbox model on CUB and Waterbirds datasets.
| Method | CUB Accuracy | Waterbirds Accuracy |
|----------------------------|----------------|-----------------------|
| Standard model (black-box) | 76.70% | 69.83% |
| VLG-CBM | 75.79% | 69.83% |
that our VLG-CBM generalizes well as the standard model does, which shows that our VLG-CBM is competitive and has very small accuracy trade-off with the interpretability compared with the standard black-box model.
## I.2 Ablation study
## I.2.1 Ablation on augmentation probability
In this section, we conduct an ablation study on the probability of applying our crop-to-concept data augmentation introduced in Section 3.1. The dataset we used is the CUB dataset and the backbone is ResNet as we used in the main experiment. The results are listed below. From the table, we could see
| Crop-to-Concept-Prob | ANEC-5 | ANEC-avg |
|------------------------|----------|------------|
| 0 | 75.73 | 75.76 |
| 0.2 | 75.83 | 75.88 |
| 0.4 | 75.71 | 75.72 |
| 0.6 | 75.57 | 75.62 |
| 0.8 | 75.52 | 75.57 |
| 1 | 72.29 | 73.15 |
that the performance is best with augmentation probability 0.2.
## J Human study
In this section, we present a human study following the practice of Oikarinen et al. [15] on Amazon MTurk platform. To briefly summarize, we show the annotator top-5 contributing concepts of our method (VLG-CBM) and baseline (LF-CBM or LM4CV) and asking them which one is better.
## Task

Which Explanation is more reasonable?
- Model Clearly More Reasonable Model Slightly More Reasonable
Model predicts this image parking meter"
## Explanation:
Because the Image has the following features (In order of importance):
- sometimes has open or closed(78.2%)
- may have
- other components handlebars; seat) may be variety of colors(29.49)
- sign on the roof(28.6%)
- Others: -93.996
- washing machine typically large and box-shaped(28.0%)
{in order of importance; number in the bracket() the contribution of each feature )
Model predicts Ihis image parking meter`
## Explanation:
Because the image has the following features:
- button for adding time(40.0%)
meter(13.6%
- button start the timer(1.79)
- Others; 0,0%
(In order of importance; number in the bracket() Is the contribution of each feature )
- Both Models Equally Reasonable Model Slightly More Reasonable Mode Clearly More Reasonable
## Why? Select all that apply
- The more reasonable explanation uses features that are more rclevant to the image
- The more reasonable explanation uses fealures are more relevant to the prediction
- The reasonable explanation informative moro
- NIA, both explanations equally reasonable.
Figure J.1: An example of human study interface
The scores for each method are assigned as 1-5 according to the response of annotators: 5 for the explanations from VLG-CBM is strongly more reasonable, 4 for VLG-CBM is slightly more reasonable, 3 for both models are equally reasonable, 2 for the baseline is slightly more reasonable, and 1 for the baseline is strongly more reasonable. Thus, if our model provides better explanations than the baselines, then we should see a score higher than 3. We show an example screenshot of our study in Fig. J.1.
We report the average score in Table J.1 for two baselines: LF-CBM and LM4CV. For each baseline, we randomly sample 200 images and collect 3 results from 3 different annotators. It can be seen that VLG-CBM has scores higher than 3 for both baselines, indicating our VLG-CBM provides better explanations than both baselines. LaBo is excluded in our experiment due to its dense layer and large number of concepts: the top-5 concepts usually account for less than 0.01% of final prediction.
| Experiment | Score (VLG-CBM) | Score (Baseline) |
|--------------------|-------------------|--------------------|
| VLG-CBM vs. LF-CBM | 3.33 (1.54) | 2.67 (1.54) |
| VLG-CBM vs. LM4CV | 3.38 (1.54) | 2.62 (1.54) |
Table J.1: Average Mturk score for our VLG-CBM and two baselines.
## K Visualizing VLG-CBM explanations
This section presents an extended version of Table 4 visualizing top-5 images for randomly picked concepts for CUB and Places365 dataset. The results are shown in Fig K.1, K.3, K.4, and K.5 for Places365 and K.2, Fig K.6, Fig K.7, and Fig K.8 for CUB.
(a) Concept: Armrest

(b) Concept: Balance beam

(c) Concept: Barren Landscape

(d) Concept: Baseball

(e) Concept: Bookcase

(f) Concept: Bar or counter
(g) Concept: Statue

(h) Concept: Spoon

(i) Concept: Used for grazing animals

(k) Concept: Shelves of Sewing supplies

(m) Concept: Steering Wheel


(j) Concept: Pool Table


(l) Concept: Plastic table and chairs
(n) Concept: Vacation

(o) Concept: Barbershop

(p) Concept: Bank
Figure K.1: Top-5 activating images for randomly selected Places365 concepts
(a) Concept: Black and White head

(b) Concept: Black feathers

(c) Concept: Black legs

(e) Concept: Blue wings

(g) Concept: Brown tail

(i) Concept: Thin beak

(k) Concept: White stripes above the eyes

(m) Concept: White underwings


(d) Concept: Blue body

(f) Concept: Brown cap

(h) Concept: Yellow bill with a red spot

(j) Concept: White body

(l) Concept: Streaked breast
(n) Concept: Small slender body

(o) Concept: Black mask on the face

(p) Concept: Small dark body
Figure K.2: Top-5 activating images for randomly selected CUB concepts
bias: 0.257
Figure K.3: Randomly selected explanations for Places365 (Part 1)




Concept contributions
Concept contributions

Figure K.4: Randomly selected explanations for Places365 (Part 2)

Figure K.5: Randomly selected explanations for Places365 (Part 3)



Pred class: White Vireo logit: 11.082 bias: -0.008 eyed
Concept contributions
Concept contributions

Concept contributions
Figure K.6: Randomly selected explanations for CUB (Part 1)



Pred class: Acadian Flycatcher logit: 6.482 bias: -0.020
Concept contributions
Pred class: Painted Bunting | logit: 13.865 bias: 0.022

Concept contributions
Figure K.7: Randomly selected explanations for CUB (Part 2)

Pred class: Cape Glossy Starling logit: 10.223 bias: -0.039
Figure K.8: Randomly selected explanations for CUB (Part 3)
## NeurIPS Paper Checklist
## 1. Claims
Question: Do the main claims made in the abstract and introduction accurately reflect the paper's contributions and scope?
Answer: [Yes]
Justification: Our introduction in Section 1 summarizes the contribution and scope of this paper accurately.
Guidelines:
- · The answer NA means that the abstract and introduction do not include the claims made in the paper.
- · The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
- · The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
- · It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
## 2. Limitations
Question: Does the paper discuss the limitations of the work performed by the authors?
Answer: [Yes]
Justification: We discuss the limitations in Section 6.
## Guidelines:
- · The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
- · The authors are encouraged to create a separate "Limitations" section in their paper.
- · The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
- · The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
- · The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
- · The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
- · If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
- · While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren't acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
## 3. Theory Assumptions and Proofs
Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
Answer: [Yes]
Justification: We provide a full set of assumptions in our Theorem 4.1 and we provide complete and correct proof in Appendix A.
## Guidelines:
- · The answer NA means that the paper does not include theoretical results.
- · All the theorems, formulas, and proofs in the paper should be numbered and crossreferenced.
- · All assumptions should be clearly stated or referenced in the statement of any theorems.
- · The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
- · Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
- · Theorems and Lemmas that the proof relies upon should be properly referenced.
## 4. Experimental Result Reproducibility
Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
Answer: [Yes]
Justification: In Section 5, we present the settings of our experiments. We present more implementation details on Appendix B.
## Guidelines:
- · The answer NA means that the paper does not include experiments.
- · If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
- · If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
- · Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
- · While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
- (a) If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
- (b) If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
- (c) If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
- (d) We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
## 5. Open access to data and code
Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
Answer: [Yes]
Justification: The link to the project webpage is provided in the abstract and the code will be released by poster deadline.
## Guidelines:
- · The answer NA means that paper does not include experiments requiring code.
- · Please see the NeurIPS code and data submission guidelines ( https://nips.cc/ public/guides/CodeSubmissionPolicy ) for more details.
- · While we encourage the release of code and data, we understand that this might not be possible, so 'No' is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
- · The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines ( https: //nips.cc/public/guides/CodeSubmissionPolicy ) for more details.
- · The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
- · The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
- · At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
- · Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
## 6. Experimental Setting/Details
Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
Answer: [Yes]
Justification: We include experimental details in Section 5 and Appendix B.
## Guidelines:
- · The answer NA means that the paper does not include experiments.
- · The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
- · The full details can be provided either with the code, in appendix, or as supplemental material.
## 7. Experiment Statistical Significance
Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
Answer: [No]
Justification: The experiments are very computationally expensive to repeat and measure the error bar.
## Guidelines:
- · The answer NA means that the paper does not include experiments.
- · The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
- · The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
- · The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
- · The assumptions made should be given (e.g., Normally distributed errors).
- · It should be clear whether the error bar is the standard deviation or the standard error of the mean.
- · It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
- · For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
- · If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
## 8. Experiments Compute Resources
Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
Answer: [Yes]
Justification: We provide computational resources in Appendix B.
## Guidelines:
- · The answer NA means that the paper does not include experiments.
- · The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
- · The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
- · The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn't make it into the paper).
## 9. Code Of Ethics
Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines ?
Answer: [Yes]
Justification: Our research is conducted following NeurIPS Code of Ethics.
## Guidelines:
- · The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
- · If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
- · The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
## 10. Broader Impacts
Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
Answer: [NA]
Justification:This work focus on technical development of making neural network models more interpretable.
## Guidelines:
- · The answer NA means that there is no societal impact of the work performed.
- · If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
- · Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
- · The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
- · The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
- · If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
## 11. Safeguards
Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
Answer: [NA]
Justification: The paper poses no such risks.
## Guidelines:
- · The answer NA means that the paper poses no such risks.
- · Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
- · Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
- · We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
## 12. Licenses for existing assets
Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
Answer: [Yes]
Justification: We properly cite the dataset and models we used.
## Guidelines:
- · The answer NA means that the paper does not use existing assets.
- · The authors should cite the original paper that produced the code package or dataset.
- · The authors should state which version of the asset is used and, if possible, include a URL.
- · The name of the license (e.g., CC-BY 4.0) should be included for each asset.
- · For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
- · If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
- · For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
- · If this information is not available online, the authors are encouraged to reach out to the asset's creators.
## 13. New Assets
Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
Answer: [NA]
Justification: The paper does not release new assets.
## Guidelines:
- · The answer NA means that the paper does not release new assets.
- · Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
- · The paper should discuss whether and how consent was obtained from people whose asset is used.
- · At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
## 14. Crowdsourcing and Research with Human Subjects
Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
Answer: [NA]
Justification: The paper does not involve crowdsourcing nor research with human subjects.
Guidelines:
- · The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- · Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
- · According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
## 15. Institutional Review Board (IRB) Approvals or Equivalent for Research with Human Subjects
Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
Answer: [NA]
Justification: The paper does not involve crowdsourcing nor research with human subjects.
## Guidelines:
- · The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- · Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
- · We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
- · For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review. | null | [
"Divyansh Srivastava",
"Ge Yan",
"Tsui-Wei Weng"
]
| 2024-07-18T19:44:44+00:00 | 2025-01-16T05:42:28+00:00 | [
"cs.CV",
"cs.LG"
]
| VLG-CBM: Training Concept Bottleneck Models with Vision-Language Guidance | Concept Bottleneck Models (CBMs) provide interpretable prediction by
introducing an intermediate Concept Bottleneck Layer (CBL), which encodes
human-understandable concepts to explain models' decision. Recent works
proposed to utilize Large Language Models and pre-trained Vision-Language
Models to automate the training of CBMs, making it more scalable and automated.
However, existing approaches still fall short in two aspects: First, the
concepts predicted by CBL often mismatch the input image, raising doubts about
the faithfulness of interpretation. Second, it has been shown that concept
values encode unintended information: even a set of random concepts could
achieve comparable test accuracy to state-of-the-art CBMs. To address these
critical limitations, in this work, we propose a novel framework called
Vision-Language-Guided Concept Bottleneck Model (VLG-CBM) to enable faithful
interpretability with the benefits of boosted performance. Our method leverages
off-the-shelf open-domain grounded object detectors to provide visually
grounded concept annotation, which largely enhances the faithfulness of concept
prediction while further improving the model performance. In addition, we
propose a new metric called Number of Effective Concepts (NEC) to control the
information leakage and provide better interpretability. Extensive evaluations
across five standard benchmarks show that our method, VLG-CBM, outperforms
existing methods by at least 4.27% and up to 51.09% on Accuracy at NEC=5
(denoted as ANEC-5), and by at least 0.45% and up to 29.78% on average accuracy
(denoted as ANEC-avg), while preserving both faithfulness and interpretability
of the learned concepts as demonstrated in extensive experiments. |
2408.01433v1 | ## Evaluating and Enhancing Trustworthiness of LLMs in Perception Tasks
Malsha Ashani Mahawatta Dona , Beatriz Cabrero-Daniel , Yinan Yu , Christian Berger 1 1 2 1 1 University of Gothenburg and 2 Chalmers University of Technology Gothenburg, Sweden { malsha.mahawatta,beatriz.cabrero-daniel,christian.berger } @gu.se, [email protected]
Abstract -Today's advanced driver assistance systems (ADAS), like adaptive cruise control or rear collision warning, are finding broader adoption across vehicle classes. Integrating such advanced, multimodal Large Language Models (LLMs) on board a vehicle, which are capable of processing text, images, audio, and other data types, may have the potential to greatly enhance passenger comfort. Yet, an LLM's hallucinations are still a major challenge to be addressed. In this paper, we systematically assessed potential hallucination detection strategies for such LLMs in the context of object detection in vision-based data on the example of pedestrian detection and localization. We evaluate three hallucination detection strategies applied to two state-of-the-art LLMs, the proprietary GPT-4V and the open LLaVA, on two datasets (Waymo/US and PREPER CITY/Sweden). Our results show that these LLMs can describe a traffic situation to an impressive level of detail but are still challenged for further analysis activities such as object localization. We evaluate and extend hallucination detection approaches when applying these LLMs to video sequences in the example of pedestrian detection. Our experiments show that, at the moment, the state-of-the-art proprietary LLM performs much better than the open LLM. Furthermore, consistency enhancement techniques based on voting, such as the Best-ofThree (BO3) method, do not effectively reduce hallucinations in LLMs that tend to exhibit high false negatives in detecting pedestrians. However, extending the hallucination detection by including information from the past helps to improve results.
## I. INTRODUCTION
Advanced driver assistance systems (ADAS), increasingly common in passenger vehicles, aim at improving traffic safety. Such systems support the driver in traffic situations when pulling back from a parking lot supported by a rear collision warning (RCW), lane departure warning (LDW), or adaptive cruise control (ACC) for example. The operational design domains (ODDs) around such scenarios are typically well-defined, and the necessary sensors like cameras, radars, and ultrasound devices have proven to work reliably for decades.
Recent trends in the automotive industry such as SOAFEE [1] now aim at significantly simplifying a vehicle's system architecture to contain powerful, centralized processing units with general-purpose multi-core CPUs and hardware accelerators like GPUs to prepare the vehicle for future applications. These hardware accelerator-powered platforms can execute specialized neural networks (NN) necessary for ADAS and Autonomous Driving (AD) features, and are even capable to run Large Language Models (LLMs) locally without a powerful computation infrastructure backend in the cloud. Successful adoptions of LLMs are typically seen in knowledge-intensive tasks as well as traditional natural language processing (NLP) tasks [2]. LLMs built into vehicles are envisioned to improve the in-vehicle human-machine interface (HMI) [3], and BMW Group has demonstrated an in-car expert powered by LLMs, capable of engaging in human-like conversation with the passengers to respond to inquiries related to vehicle features [4], [5]. There are also commercial-level applications such as LINGO-2 [6] that introduce a natural language for autonomous driving, supporting the concept of vehicles with built-in foundational models.
## A. Problem Domain and Motivation
Recently, such LLMs have been applied to computer vision tasks where so far, specialized NNs were trained and used (cf. [7], [8]). When deploying such generic LLMs onto a powerful, centralized processing unit in vehicles, they can not only be used as a better HMI, but also to support a vehicle's perception stack (cf. [3]).
However, hallucinations generated by such LLMs are an important challenge inhibiting their safe application in automotive scenarios [9]. Hallucinations, as defined by Huang et al. are a phenomenon where models tend to generate nonsensical or unfaithful information compared to the provided context or real-world knowledge [10]. LLMs may cause hallucinations for various reasons, such as the quality of training corpora, the complexity of the model, and the randomness of the answer generation strategies [11].
Seeing LLMs potentially finding their way into vehicles, the question of 'How well can we trust an LLM within a vehicle?' given the likelihood of misinformation generated by them [9] becomes an urgent topic to address. Thus, the trustworthiness of LLMs must be ensured by detecting and mitigating hallucinations, especially for safety-critical systems such as ADAS/AD, which would impact the safety of passengers and pedestrians in general [12].
## B. Research Goal and Research Questions
The research goal of our study is to systematically evaluate the performance of hallucination detection techniques when potentially considering the use of state-of-the-art LLMs as part of a perception stack to detect pedestrians in urban environments. We derive the following research questions:
RQ-1: What are potential hallucination detection strategies suggested in the literature?
RQ-2: How can hallucinations be characterized when applying LLMs to pedestrian detection and localization for ADAS/AD?
RQ-3: How can hallucination detection strategies be enhanced for use in ADAS/AD perception and monitoring systems?
## C. Contributions and Scope
We provide an overview of strategies to detect hallucinations in the context of an object detection task in an ADAS/AD perception stack that is hypothetically supported by an LLM. Our main contribution is the assessment of hallucination detection strategies extracted from recent publications; we also include our own enhancements to these techniques. We apply two state-of-the-art LLMs, GPT-4V, and the open LLaVA, which we execute locally, to visionbased data of pedestrian situations from two recent datasets (Waymo/US [13] and PREPER CITY/Sweden [14]). We consider hallucination detection as the first step to establish hallucination mitigation in an LLM-supported perception stack, laying the foundation for identifying and categorizing hallucinations to pave the way to enhanced and reliable models with better performance.
## D. Structure of the Paper
The rest of the paper is organized as follows: Section II reviews the related work related to hallucination detection, whereas Section III explains the adopted methodology in detail. Results of the experiments are presented in Section IV, and the analysis and discussion of the findings are interpreted in Section V. Section VI concludes the paper.
## II. RELATED WORK
Reducing and ideally eliminating hallucinations [15] that prevent misinformation is a major step in the process of ensuring the trustworthiness of an LLM-based system. Its importance elevates significantly when LLM-based systems are used within safety-critical systems. We review relevant related work for using LLMs in vision-oriented tasks relevant for automotive applications and potential hallucination detection strategies to address RQ-1.
The concept of using LLMs for visual recognition tasks, known as Vision-Language Models (VLMs) [8], has emerged with the recent developments in the field of LLMs. Ranasinghe et al. [16] elevate the Visual Question Answering (VQA) ability of the model by improving the spatial awareness in the VLM. Zhou et al. [17] explore the use of VLMs within the fields of Autonomous Driving (AD) and Intelligent Transportation Systems (ITS), focusing on the potential applications and research directions. These studies showcase that VLMs can be used within AD and ITS to integrate vision and language data to improve perception and understanding, for instance, in tasks such as pedestrian detection. Furthermore, [17] provide a detailed overview of LLMs and VLMs used in the field of AD with a taxonomy of tasks and types each model uses. This work can be considered as a comprehensive survey that explores the potential applications and emerging research directions in the context of VLMs.
The studies from Liu et al. [7], [18] propose different pedestrian detection strategies using VLM, showing that the usage of LLM within automotive is experimentally feasible. Also, the industry is reporting to explore the use of LLMs for potential commercialization [5], [4]. Research work such as 'Dolphins' [19] accelerates the use of VLMs as driving assistants by proving how well a fully autonomous vehicle navigates through complex real-world scenarios using the assistance of a VLM.
Hallucination detection and mitigation play a vital role in ensuring the trustworthiness of LLM-based systems. Manakul et al. [20] propose a hallucination detection strategy called 'SelfCheckGPT' that utilizes a sampling approach to fact-check a model's responses. This method does not rely on any external databases or output probability distributions; in fact, it considers the simple logic that the answers must be consistent to some degree if the LLM has knowledge of a given concept. The proposed method was demonstrated to detect non-factual and factual sentences in the WikiBio dataset curated by the authors, but systematic evaluations in other application contexts are left open. A similar hallucination detection approach called DreamCatcher has been introduced by Liang et al. [21] that uses consistency checking of multiple responses to detect hallucinations. In addition to these existing studies, there is also other research that used inconsistency checking to reduce the occurrence of hallucinations to some extent by initiating new chat completions with the LLMs without keeping history: for instance, Ronanki et al. [22] propose the 'Best of Three (BO3)' strategy to improve the stability in the LLM generated responses in the domain of Agile Software Development, evaluating the quality of user stories. These proposed consistent checking mechanisms can be adapted into the domain of ADAS/AD to support perception tasks.
Galitsky introduces a fact-checking system called TruthO-Meter to detect hallucinations in LLMs [23]. This proposed method identifies incorrect facts by comparing the generated responses with the actual information scraped from other sources of information. Text mining and web scraping techniques are used to identify the corresponding correct sentences, whereas semantic generalization procedures are adapted to improve the generated content to mitigate the hallucinations. This method can be applied to vast genres of data, from sentences to phrases, including opinionated data. However, the proposed method can only be applied to the data to which correct and meaningful facts are available.
In a more recent study, Wang et al. [24] present'HaELM', an LLM capable of detecting hallucinations thanks to its training with manually annotated hallucinated and nonhallucinated data obtained by Large Vision-Language Models such as ChatGPT. The model HaELM achieves lower accuracy and recall values than ChatGPT; however, it outperforms ChatGPT in precision and F1 Score. The concept behind HaELM is promising, but its applicability in a real-world setting would require training an LLM with manually annotated hallucinations in the selected domain. Furthermore, additional computational resources might be required for training purposes of the LLMs, which limits the applicability of this proposed detection strategy.
Many methods of hallucination detection have been proposed in previous studies. Yet, only a limited number of generalized evaluation benchmarks have been proposed to assess multimodal LLMs that cover text, images, and videos for example. Chen et al. [25] have proposed the benchmark named MHaluBench and a novel hallucination detection framework named UNIHD to fill the aforementioned research gap. The proposed MHaluBench benchmark is capable of assessing different types of tasks covering different hallucination categories at a fine-grained level. The UNIHD framework detects hallucinations in the content generated by multimodal LLMs by gathering evidence from auxiliary tools. These auxiliary tools are selected by the queries crafted for core claims extracted from the initial responses. UNIHD is a task-agnostic framework that detects hallucinations, yet, an assessment for safety-critical application is left open.
Wang et al. have also contributed to the field of hallucination evaluation by introducing AMBER [26], a multidimensional benchmark for hallucination evaluation. The proposed AMBER benchmark extracts the nouns of the initial response to generate an object list that will be checked against the annotations obtained by a different set of prompts. This benchmark requires a labelled dataset for discriminative tasks, which limits the applicability of the proposed methodology in hallucination evaluation in general.
There is an emerging trend of research suggesting the systematic assessment of an LLM's output multiple times to ensure accuracy and reliability [20], [21]. However, these techniques often require complex prompting schemes, to which LLMs are sensitive [27]. These prompts typically involve additional questions to probe the uncertainty or inconsistency of the answers. For our use case, we aim to use as simple prompts as possible to ensure robustness, which is crucial for automotive use cases. Hence, we have adopted the voting-based consistency enhancement strategy, BO3, and its adaptations by proposing a hallucination detection technique that is applicable in the ADAS/AD domain. We outline our approach as well as the systematic evaluation in Sec. III.
## III. METHODOLOGY
We selected image sequences of pedestrian scenarios that contain sequential data on the pedestrians and their trajectories over the duration, from two state-of-the-art datasets. For these sequences, we identified and labelled semantic Regions of Interest (RoIs) with their respective ground truth (GT). We then fed these images into two state-of-the-art LLMs with a predefined prompt and analyzed the results to answer our research questions. This section describes in detail our experiment pipeline, depicted in Fig. 1.
## A. Dataset Curation and Preparation
We used images from different driving scenarios from the Waymo open dataset [13] collected in urban and suburban areas in the USA, and from the PREPER CITY dataset collected by Yu et al. [14] in urban areas in Gothenburg, Sweden. We chose these two anonymized datasets to cover two different countries to reduce the impact of unknown effects originating from only using a single dataset. The Waymo motion dataset was extracted by sampling every ten frames from the front camera images in the training set, resulting in 15,947 images in our image pool. This dataset was collected in 2021, covering over 100,000 traffic segments. The PREPER CITY dataset was also collected in 2021, and the selected partition of the dataset contained 12,271 annotated images. As a first step, we curated the original datasets by selecting traffic scenarios that captured only a single pedestrian or a single cohesive group of pedestrians walking along or crossing the road. This constraint was imposed to reduce the impact of unknown effects originating from pedestrians scattered across an image, which could lead to an imbalanced dataset if every RoI contained a positive example. The final dataset used for experimentation contained 17 driving scenarios from Waymo and 18 driving scenarios from PREPER CITY. As the second step, the selected images were pre-processed to crop the horizon to ensure that the LLMs would only focus on the ground-level details. Assuming that the camera's optical axis is parallel to the road surface, the third step splits the images into four regions of interest (RoIs, labelled R1-R4 in Fig. 1) to identify the left, right, far, and close regions of the ground plane. This division is based on the assumption that the ego vehicle's orientation provides a consistent reference point, with left and right corresponding to the vehicle's lateral sides while far and close related to the distance from the camera lens. We defined these RoIs to support the semantic localization of pedestrians as our preliminary experiments indicated that LLMs are not performing sufficiently reliably to localize pedestrians in a complete image but rather excel in describing an image's content. The final step of the data curation consisted of manually defining the GT of whether a (cohesive group of) pedestrian(s) was present. The resulting dataset contained 1868 RoIs in total, spread over 836 RoIs from Waymo and 1032 RoIs from PREPER CITY.
## B. Data Collection
We used the curated dataset to feed our experiment pipeline, as shown in Fig. 1, to collect data about potential hallucinations. We conducted our experiments with the commercial gpt-4-vision-preview (GPT-4V) model and the locally installed Large Language-and-Vision Assistant (hallucinations) 1.6 model through the Ollama platform, and the results were compared across the models. For the locally executed LLM, we used the Ollama Python library to run the experiments with the LLaVA 1.6 model on an Intel Xeon W1250 CPU with 128GB RAM and accelerated by an Nvidia Quadro P2200.
Fig. 1. Overview diagram of the experimental setup: All frames in each sequence of images are systematically cropped to remove the horizon and split into four RoIs to support the localization of pedestrians. All RoIs and full images are evaluated with the LLMs GPT-4V and LLaVA using the prompt: 'Is there a human or part of a human in this image? Answer ONLY either 'yes' or 'no'.' The LLMs' responses are compared against the GT collected by human annotations to analyze the three experiments.
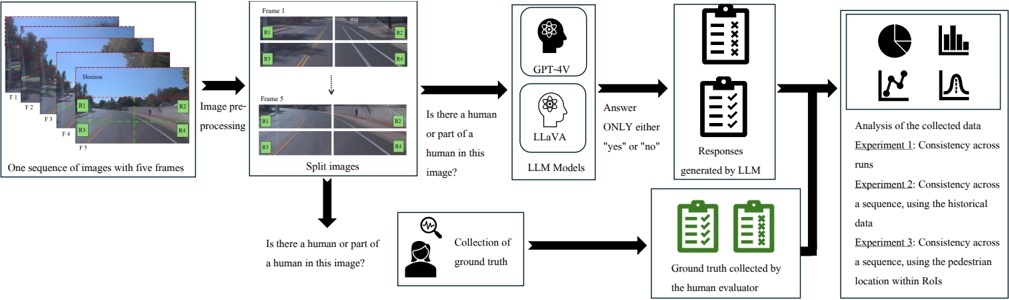
We fed the images from our curated dataset in randomized order before cropping and after cropping and splitting into the four RoIs to both LLMs along with the following prompt: Is there a human pedestrian in this image? Answer only either "yes" or "no". We presented the same image (or image's RoI) three times to an LLM to systematically assess the performance of the 'Best of Three' (BO3) strategy across the spatial and temporal dimension, where the former refers to individual frames independently of each other, and the latter refers to consecutive frames to preserve a semantic context over time. We logged the Boolean replies from all experiments along with the complete execution time per prompt for our subsequent data analysis, resulting in 12,142 total responses. Furthermore, we created another set of boolean responses by labelling the images and RoIs randomly for all considered strategies. These randomly generated responses were used as the baseline when evaluating the performances of the two LLMs, GPT-4V and LLava.
## C. Data Analysis
We assessed the performance of the hallucination detection strategies using these responses as follows:
DA-1: We calculated performance metrics per complete image (ie., non-cropped) to evaluate the LLMs in detecting pedestrians and to explore potential hallucinations. This analysis contributes to answer RQ-2.
DA-2: We calculated performance metrics for all corresponding four RoIs of an image to assess the performance of the BO3 strategy. We also compared these results with the ones obtained from the unmodified images from DA1 to evaluate whether cropping and splitting an image has an impact on an LLM's proneness for hallucinations. This analysis contributes to answering RQ-2 and RQ-3.
DA-3: We assessed the performance of the LLMs using sequences of consecutive frames in comparison to the individual frames to evaluate whether having temporal data on pedestrian visibility supports the detection of potential hallucinations. This analysis contributes to answer RQ-3.
DA-4: We evaluated to what extent splitting an image into smaller RoIs and semantically assessing an LLM's response considering pedestrian trajectory would help in detecting hallucinations. This analysis addresses RQ-3.
## IV. RESULTS
In this section, we report the results from all experiments. For replication purposes, we share the necessary code and raw results together with explanatory video supplementary materials in a GitHub repository [28].
A. Types of Hallucinations and LLM Performance on Unmodified Images (DA-1, DA-2)
We have identified several types of hallucinations that are caused by LLMs (cf. Figure 2) that are relevant in the ADAS/AD context, particularly for pedestrian detection. The two main types of hallucinations are false negatives and false positives, where false negatives are responses that report that there are no humans or parts of humans in the picture, whereas GT depicts a human or a part of a human (cf. Figure 2 part (a)). False positives are responses that contain hallucinations of humans or parts of humans in the images where there are no actual humans or parts of humans identified in the GT (cf. Figure. 2 part (b)). In addition to these, we saw another hallucination type where the model rejected processing the image due to a content policy violation where the model hallucinated some content that is not allowed to be processed by its safety system (cf. Figure 2 part (c)).
Table I shows the performance of the selected models GPT-4V and LLaVA, together with the responses that we randomly generated as response baseline. The recall and F1 scores are calculated for all responses and displayed for the two different datasets, Waymo and PREPER CITY, allowing to report about the sensitivity of the system and providing the balance between precision and recall.
## B. BO3 Hallucination Detection across RoIs (DA-2)
Table II displays the performance of GPT-4V, and LLaVA across the two datasets for the following four experiments:
Fig. 2. Types of hallucinations: (a) False Negatives: The LLM is unable to detect the pedestrian in the left corner, highlighted by the yellow box. (b) False Positives: The LLM hallucinates a pedestrian in the image, whereas GT denotes that there is no human or a part of a human present in the image. (c) Other: The LLM refuses to process the picture, hallucinating some content that is not allowed by the safety system, resulting in a content policy violation.

TABLE I
PERFORMANCE IN TERMS OF RECALL AND F1-SCORE FOR THE TWO SELECTED LLMS AND FOR THE RANDOMLY GENERATED RESPONSES ON THE UNMODIFIED FULL IMAGES FROM THE TWO SELECTED DATASETS.
| | Waymo | Waymo | PREPER CITY | PREPER CITY |
|--------|---------|----------|---------------|---------------|
| | Recall | F1 score | Recall | F1 score |
| GPT-4V | 100.0% | 90.13% | 90.28% | 89.97% |
| LLaVA | 39.3% | 51.97% | 30.56% | 41.31% |
| Random | 48.26% | 59.69% | 50.0% | 58.78% |
Single RoI : Feeding a single frame to the LLM once and statistically analyzing the responses.
BO3 per RoI : Feeding a single frame three times to the LLM and statistically analyzing the responses.
Two historical votes in sequences (THV) : Feeding consecutive frames of the same RoI to the LLM and statistically analyzing the responses, preserving semantics over time.
Two historical votes in sequences 2 (THV-2) : Feeding consecutive frames of the same RoI to the LLM and analyzing the responses, checking the two sequential frames only when a pedestrian is not visible in the current frame but a pedestrian was detected in the two previous frames.
We compared the performance of GPT-4 vision in the full images and in the four RoIs. It takes 8.1 ± 5.1 seconds for GPT-4 vision to process a full image, while it takes 3.6 ± 2.7 for GPT-4 vision to process each of the four RoIs. In turn, LLAVA took on average 3.7 ± 1.0 seconds to process each of the four RoIs per frame. This tradeoff between the time spent per frame is countered by the benefit of locating the pedestrian in the image in a machine-interpretable way (as opposed to natural language descriptions). The recall and F1 scores were calculated for each experiment and displayed under separate columns dedicated to each dataset in Table II. The 'Single RoI' rows per each model show recall and F1 score value calculated based on the data collected by feeding single RoIs to the LLMs once. Similarly, the 'BO3 per RoI' rows that merged into each model depict the statistics when the same RoI is tested three times against the LLM.
Table III contains the frequency of correct labels across the three runs for each RoI with the GT labels. For instance, when the GT is reporting no pedestrian in the image, the column header '3 no' would represent that the LLM correctly identifies that there is no pedestrian across all three tests. Similarly, '2 no, 1 yes' would represent that the LLM does not see the presence of the pedestrian two times but
## TABLE II
PERFORMANCE, IN TERMS OF RECALL AND F1-SCORE, OF GPT-4V AND LLAVA IN LABELLING ROIS AS CONTAINING A PEDESTRIAN OR NOT. THREE HALLUCINATION MITIGATION STRATEGIES (BO3, THV, AND THV-2) ARE EVALUATED AND COMPARED TO RANDOM LABELLING.
TABLE III
| | | Waymo | Waymo | PREPER CITY | PREPER CITY |
|--------|-------------|---------|----------|---------------|---------------|
| | | Recall | F1 score | Recall | F1 score |
| GPT-4V | Single RoI | 98.62% | 75.29% | 92.47% | 76.27% |
| GPT-4V | BO3 per RoI | 98.34% | 78.09% | 93.55% | 79.82% |
| GPT-4V | THV | 87.87% | 68.07% | 79.46% | 65.19% |
| GPT-4V | THV-2 | 94.14% | 64.19% | 86.49% | 62.99% |
| | Single RoI | 38.31% | 29.75% | 34.23% | 27.76% |
| | BO3 per RoI | 32.78% | 27.82% | 29.03% | 26.21% |
| | THV | 33.05% | 26.87% | 21.08% | 18.8% |
| | THV-2 | 49.79% | 32.38% | 38.92% | 27.59% |
| | Single RoI | 45.64% | 29.27% | 47.49% | 29.53% |
| | BO3 per RoI | 40.25% | 26.01% | 50.0% | 31.26% |
| | THV | 41.42% | 25.98% | 39.46% | 25.75% |
| | THV-2 | 59.41% | 32.05% | 58.92% | 32.83% |
FREQUENCY OF CORRECT LABELS ACROSS TEST REPETITIONS PER ROI.
| LLM | GT label | 3 no | 2 no, 1 yes | 2 yes, 1 no | 3 yes |
|--------|------------|--------|---------------|---------------|---------|
| GPT-4V | No | 1004 | 220 | 98 | 119 |
| LLaVA | No | 432 | 220 | 360 | 60 |
| LLM | GT label | 3 yes | 2 yes, 1 no | 2 no, 1 yes | 3 no |
|--------|------------|---------|---------------|---------------|--------|
| GPT-4V | Yes | 401 | 10 | 6 | 10 |
| LLaVA | Yes | 27 | 106 | 175 | 119 |
hallucinating a pedestrian once, whereas '2 yes, 1 no' would represent that the LLM is hallucinating a pedestrian twice but correctly not reporting the pedestrian once out of all three tests. The same representation has been used for the scenarios where the GT reports a pedestrian in the image.
Further analysis of the collected data showed that LLMs are often inconsistent in answering the same question repeatedly: 17.89% in the case of GPT-4V and 65.85% in the case of LLaVA, ie., reporting varying answers for the same input.
## C. Hallucination Detection using Historical Frames in an Automotive Context (DA-3 and DA-4)
When looking at the GT data, we see indications that sequential data, which contains information about previous frames, could help to detect hallucinations in the automotive context. This seems promising especially considering the false negatives when pedestrians were detected in previous frames.
In the GT data, in 84.96% of the frames where a pedestrian is seen, it is also seen in at least one of the previous two frames. This includes the transitions where an LLM correctly identifies the pedestrian in all two previous frames across the sequence, given that the pedestrian is visible in the third frame, and the transitions where an LLM identifies the pedestrian visibility correctly at least once in the two previous frames given the third frame has a visible pedestrian.
On the other hand, only 5.37% of the frames showing no pedestrian are preceded by two frames showing a pedestrian (e.g., the pedestrian disappears after two frames). Therefore, we can extract that this transition is an unlikely event to occur in real-world scenarios and use that understanding to check again if the LLM labels this.
Figure 3 shows the distribution of each transition when sequential data are considered, focusing on three frames at a time. The two graphs hold the distribution percentages for GT, GPT-4V, LLaVA and Random, as described above.
Utilizing the Sequential Data for Hallucination Detection (DA-3): Due to the apparent importance of considering sequential data, two hallucination detection techniques were implemented across the image sequences focusing on RoIs to evaluate the performance of the LLMs for the selected two datasets as reported in Table II for THV and THV-2.
The rows 'THV' hold the recall and F1 score values for the evaluation of responses generated for the third frame, considering the responses of the previous two frames. If the majority vote is yes in the previous two frames, the third frame is identified as a frame with a pedestrian, and the response is evaluated against the GT. The same experiment was conducted for GPT-4V, LLaVA and Random to evaluate each model against Random, which is considered as a baseline distribution. The results show that 15.5% of the frames that GPT4-V labelled as not showing a pedestrian were preceded by two frames labelled as showing a pedestrian (much higher probability than in the GT). This percentage increases to 27.51% in the analysis by LLaVA.
The rows 'THV-2' represent the recall and F1 score values for the second approach that we adopted for experimentation in order to detect the hallucinations. In this approach, the majority vote was only considered to correct the label of the third frame, assigned by the LLM in the cases where it labels the image as no pedestrian. The results show that the THV-2 approach improves the overall performances of both the models GPT-4V (Recall to 94.14%, 86.49% and F1 score to 64.19%, 62.99%) and LLaVA (Recall to 49.79%, 38.92% and F1 score to 32.38%, 27.59%)for both datasets compared to the performances of the models under the THV approach. However, THV-2 and THV methods seem to not increase the performance of GPT-4V compared to LLaVA.
Similar to the THV-2 approach, alternative strategies could exploit historical data, for instance, by studying the probabilities of each of the transitions or sequences on a larger amount of data as described below.
Physical Plausibility Check (DA-4): The physical plausibility check was designed considering the historical data in the selected sequences. This experiment was conducted using smaller RoIs, 15 regions per frame for the selected sequences as shown in Figure 4. This experiment is based on the physical plausibility of the detected trajectory that a pedestrian is showing through the RoIs over time. To detect false positives, we check the two previous frames to verify whether a pedestrian was also detected either in that region or in a neighboring region. This filter acts as a low-pass filter that removes high-frequency changes. The initial experiment that considered selected sequences from both datasets led to very promising results with a recall of 96.43% and an accuracy of 85.86%. The results and further information on the experiment, including a video
Fig. 3. Proportion of yes/no labels among the RoI in focus and the same RoI in the previous two frames. The upper graph shows the percentage of 'yes' labels in RoIs that show humans according to the GT, whereas the lower graph shows the percentage of 'no' labels when that RoI does not contain a pedestrian. The navy bar, representing GT labels, shows that the labels for RoIs tend to remain the same across three consecutive frames.

that explains the experiment, can be found as supplementary materials available at this open GitHub repository [28].
## V. ANALYSIS AND DISCUSSION
The related work was investigated to find existing hallucination detection strategies and their potential applicability for an automotive context targeting ADAS/AD to support RQ1. Given the availability of resources within ADAS/AD systems, the ability to work with multimodal data, and other required factors such as the high-performance metrics made few of the suggested hallucination detection strategies inapplicable in the domain of ADAS/AD. However, the consistency checking concepts behind the hallucination detection methods such as 'selfCheckGPT [20]', Ronanki et al. [22], and 'DreamCatcher [21] can be adapted as into the ADAS/AD domain by simplifying the complex prompting schemes. The proposed BO3 strategy and its adaptations that use sequential data can be considered as voting-based hallucination strategies that use consistency enhancements inspired by the literature.
The second research question (RQ2) of this study aimed at characterizing the hallucinations that can occur in an automotive context relevant for ADAS/AD, which was addressed by the results of data analysis activities DA1 and DA2. Out of the three hallucination types described in Section IVA, false negatives were considered more problematic in the context of ADAS/AD as they may potentially lead to severe consequences when not being able to detect a pedestrian. Therefore, the proceeding experiments were designed to reduce the false negatives as much as possible with higher recall values. False positives and false negatives were quite common within the selected image sequences. However, the
Fig. 4. Representation of RoIs labelled as containing a pedestrian (rectangles) in three consecutive frames: the current time t , t -1 , and t -2 . Checking if the RoIs in frame t labelled as containing a human are adjacent to the RoIs in t -1 and t -2 (DA-4) can help us detect physically impossible motions, potentially due to hallucinations in the LLM labelling.

third type, where the LLM rejected the processing of an image, hardly occurred. We also observed this to occur with the proprietary LLM that is accessed via the cloud.
To evaluate the performance of the proposed hallucination detection mechanism BO3, DA-2 was conducted by assessing the image's RoIs three times. As shown in TableII, the results indicated that BO3 tends to decrease the recall in GPT-4V very slightly by 0.28%, whereas it helps in increasing recall and F1 score values of GPT-4V with both datasets. However, the interpretation of the results was quite different with LLaVA, where recall and F1 score values decreased for both datasets.
When comparing the two models with each other, it is evident that LLaVA is often inconsistent across runs, as shown in II. Also, as seen in Table III, it very seldom labels the image (yes/no) the same way across runs.
In addition, the effect of using RoIs against the use of full images was also analyzed during DA1 and DA2 activities. The observed recall and F1 score values for both GPT-4V and LLaVA showed unpredictable deviations from each other; however, in general, the metrics showed improvements with respect to the PREPER CITY dataset. Given the fact that having RoIs significantly assisted in localizing pedestrians, which was not successful when using image captioning only, the deviations in the performance evaluation between the RoIs and full images can be neglected.
A series of experiments focusing on sequences of data were conducted to answer the RQ-3. The adaptation of the hallucination strategies into ADAS/AD was conducted in the three different approaches THV, THV-2, and Physical Plausibility Check and analyzed as discussed under DA3 and DA-4. Both proposed methods THV and THV-2 use temporal data to reduce hallucinations in the generated responses. With GPT-4V, the use of BO3, Single RoI, and the processing of full frames can be recommended over THV
and THV-2, given the significant drops in performance as shown in Table II. However, with LLaVA, THV-2 has shown promising performance improvements with 17.61% in recall and 9.89% in F1 score compared to the BO3 strategy.
The third approach of hallucination detection adapted to ADAS/AD context, the physical plausibility check, was evaluated with GPT-4V, showing a combined recall value of 96.43% and 49.54% F1 score for both Waymo and PREPER CITY datasets. This experiment was not conducted using LLaVA due to its poor performance in the previous experiments. Higher false positive rates were reported, especially with the PREPER CITY dataset, making the overall F1 score low. However, the reported higher recall values that indicate fewer false negative rates made this approach promising and suitable for future research and applications in the domain of ADAS/AD.
Threats to the validity of this study were assessed based on Feldt and Magazinius [29]. The data curation process was conducted focusing on a single pedestrian or a cohesive group of pedestrians, which reduced the number of available frames in both Waymo and PREPER CITY datasets but was intended to reduce potential unknown side-effects emerging from scattered pedestrian(s) (groups). There were different sequences from both datasets that contained driving scenarios in different seasons, including snowy conditions. However, the selected images mainly represented daytime driving scenarios, including dusk, which could have made an impact on this study. The selected images underwent a pre-processing stage by cropping and defining RoIs to support pedestrian localization, and this pre-processing may have made an impact on the overall quality of the images. The experiments that used sequential data depended on how frequently the frames were captured. For instance, if the pedestrian transitions were quick and the frequency of capturing was low, the pedestrian trajectory would not be plausible at all. The pedestrian may have sufficient time to move around the considered RoIs freely, limiting the semantical analysis of the transition. Also, while using multiple existing, widely used datasets strengthens the validity of our results, we do not have control over scenarios or sensor configurations during dataset creation. Finally, when we consider the LLMs we used, the ethical concerns, rules and regulations related to AI, technical advancements in the LLMs may limit the generalizability of these results, and hence, the integration of LLMs without any further safeguarding in a deployed LLM or in the process during its creation cannot be recommended.
## VI. CONCLUSION AND FUTURE WORK
We assessed approaches to detect potential hallucinations when LLMs are potentially considered as part of perception tasks for ADAS/AD. Our experiments show that the LLMs, which tend to provide negative answers, are not performing well with hallucination detection techniques that use consistency checking like Best-of-Three (BO3) as the basis. The observed performance of LLaVA under the BO3 strategy using a single video frame confirms this stochastic behavior of the model. We proposed extensions to BO3, THV and
THV-2, to bridge this shortcoming of BO3. If the model tends to provide negative answers, looking back at past data in a sequence helps to improve results. However, the overall performance of the non-proprietary LLM LLaVA was significantly lower compared to the proprietary LLM.
We also evaluated the impact of using RoIs instead of full images to support pedestrian localization. This information was very valuable in identifying plausible trajectories for pedestrians. The physical plausibility check, which adds a layer of semantics to identify plausible pedestrian movements across the RoIs in a video frame, also helps to reduce hallucinations. While this proposed approach is applicationspecific, it is a good fit for the domain of ADAS/AD where sequential data is easily available within the vehicles itself.
However, it was noted that both models were performing equally well in describing the images, as opposed to answering simple binary questions to locate pedestrians. This highlights the importance and relevance of our proposed extensions THV, THV-2, and physical plausibility checks.
Our study shows the importance of using semantically relevant RoIs and sequential data for hallucination detection when considering the use of LLMs for perception tasks within the automotive context, demonstrating the potential of using state-of-the-art LLMs. We acknowledge the rapidity in the development of non-proprietary LLMs that have not only the potential to run locally without a cloud backend, but can also be fine-tuned to a particular application context. Hence, future studies need to evaluate recent adjustments to such open LLMs. Furthermore, LLMs that are made on (domain-specific) large-scale time-series data, so-called foundation models, can be combined with LLMs to better fit the application context.
## ACKNOWLEDGMENTS
This work has been supported by the Swedish Foundation for Strategic Research (SSF), Grant Number FUS21-0004 SAICOM and the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation.
## REFERENCES
- [1] SOAFEE - Scalable Open Architecture for Embedded Edge . 2024. Accessed: 2024-01-31.
- [2] J. Yang, H. Jin, R. Tang, X. Han, Q. Feng, H. Jiang, S. Zhong, B. Yin, and X. Hu, 'Harnessing the power of llms in practice: A survey on chatgpt and beyond,' ACM Transactions on Knowledge Discovery from Data , 2023.
- [3] M. Azarafza, M. Nayyeri, C. Steinmetz, S. Staab, and A. Rettberg, 'Hybrid reasoning based on large language models for autonomous car driving,' arXiv preprint arXiv:2402.13602 , 2024.
- [4] BMW Intelligent Personal Assistant powered by the Alexa large language model (LLM) . 2024. Accessed: 2024-02-26.
- [5] M. R. A. H. Rony, C. Suess, S. R. Bhat, V. Sudhi, J. Schneider, M. Vogel, R. Teucher, K. E. Friedl, and S. Sahoo, 'Carexpert: Leveraging large language models for in-car conversational question answering,' 2023.
- [6] LINGO-2, a closed-loop Vision-Language-Action-Model (VLAM) . 2024. Accessed: 2024-04-23.
- [7] M. Liu, J. Jiang, C. Zhu, and X. Yin, 'Vlpd: Context-aware pedestrian detection via vision-language semantic self-supervision,' in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , (Los Alamitos, CA, USA), pp. 6662-6671, IEEE Computer Society, jun 2023.
- [8] J. Zhang, J. Huang, S. Jin, and S. Lu, 'Vision-language models for vision tasks: A survey,' IEEE transactions on pattern analysis and machine intelligence , vol. PP, February 2024.
- [9] Y. Huang, Y. Chen, and Z. Li, 'Applications of large scale foundation models for autonomous driving,' arXiv preprint arXiv:2311.12144 , 2023.
- [10] L. Huang et al. , 'A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,' 2023.
- [11] Z. Cao, Y. Yang, and H. Zhao, 'Autohall: Automated hallucination dataset generation for large language models,' 2023.
- [12] J. C. Knight, 'Safety critical systems: challenges and directions,' in Proceedings of the 24th International Conference on Software Engineering , ICSE '02, (New York, NY, USA), p. 547-550, Association for Computing Machinery, 2002.
- [13] P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens, Z. Chen, and D. Anguelov, 'Scalability in perception for autonomous driving: Waymo open dataset,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , June 2020.
- [14] Y. Yu, S. Scheidegger, and J. Bakker, 'Safety-driven data labelling platform to enable safe and responsible ai,' 2021.
- [15] Z. Ji et al. , 'Towards mitigating LLM hallucination via self reflection,' in Findings of the Association for Computational Linguistics: EMNLP 2023 , (Singapore), pp. 1827-1843, Association for Computational Linguistics, Dec. 2023.
- [16] K. Ranasinghe, S. N. Shukla, O. Poursaeed, M. S. Ryoo, and T.-Y. Lin, 'Learning to localize objects improves spatial reasoning in visualllms,' arXiv preprint arXiv:2404.07449 , 2024.
- [17] X. Zhou, M. Liu, B. L. Zagar, E. Yurtsever, and A. C. Knoll, 'Vision language models in autonomous driving and intelligent transportation systems,' 2023.
- [18] M. Liu, C. Zhu, S. Ren, and X.-C. Yin, 'Unsupervised multi-view pedestrian detection,' 2023.
- [19] Y. Ma, Y. Cao, J. Sun, M. Pavone, and C. Xiao, 'Dolphins: Multimodal language model for driving,' 2023.
- [20] P. Manakul, A. Liusie, and M. J. F. Gales, 'Selfcheckgpt: Zeroresource black-box hallucination detection for generative large language models,' 2023.
- [21] Y. Liang, Z. Song, H. Wang, and J. Zhang, 'Learning to trust your feelings: Leveraging self-awareness in llms for hallucination mitigation,' 2024.
- [22] K. Ronanki, B. Cabrero-Daniel, and C. Berger, 'Chatgpt as a tool for user story quality evaluation: Trustworthy out of the box?,' in International Conference on Agile Software Development , pp. 173181, Springer, 2022.
- [23] B. A. Galitsky, 'Truth-o-meter: Collaborating with llm in fighting its hallucinations,' Preprints , July 2023.
- [24] J. Wang, Y. Zhou, G. Xu, P. Shi, C. Zhao, H. Xu, Q. Ye, M. Yan, J. Zhang, J. Zhu, J. Sang, and H. Tang, 'Evaluation and analysis of hallucination in large vision-language models,' 2023.
- [25] X. Chen, C. Wang, Y. Xue, N. Zhang, X. Yang, Q. Li, Y. Shen, L. Liang, J. Gu, and H. Chen, 'Unified hallucination detection for multimodal large language models,' 2024.
- [26] J. Wang, Y. Wang, G. Xu, J. Zhang, Y. Gu, H. Jia, J. Wang, H. Xu, M. Yan, J. Zhang, and J. Sang, 'Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation,' 2024.
- [27] M. Loya, D. A. Sinha, and R. Futrell, 'Exploring the sensitivity of llms' decision-making capabilities: Insights from prompt variation and hyperparameters,' arXiv preprint arXiv:2312.17476 , 2023.
- [28] Github Repository -Evaluating-and-Enhancing-Trustworthiness-ofLLMs-in-Perception-Tasks . 2024. Accessed: 2024-04-18.
- [29] R. Feldt and A. Magazinius, 'Validity threats in empirical software engineering research - an initial survey.,' pp. 374-379, 01 2010. | null | [
"Malsha Ashani Mahawatta Dona",
"Beatriz Cabrero-Daniel",
"Yinan Yu",
"Christian Berger"
]
| 2024-07-18T20:58:03+00:00 | 2024-07-18T20:58:03+00:00 | [
"cs.CV",
"cs.ET"
]
| Evaluating and Enhancing Trustworthiness of LLMs in Perception Tasks | Today's advanced driver assistance systems (ADAS), like adaptive cruise
control or rear collision warning, are finding broader adoption across vehicle
classes. Integrating such advanced, multimodal Large Language Models (LLMs) on
board a vehicle, which are capable of processing text, images, audio, and other
data types, may have the potential to greatly enhance passenger comfort. Yet,
an LLM's hallucinations are still a major challenge to be addressed. In this
paper, we systematically assessed potential hallucination detection strategies
for such LLMs in the context of object detection in vision-based data on the
example of pedestrian detection and localization. We evaluate three
hallucination detection strategies applied to two state-of-the-art LLMs, the
proprietary GPT-4V and the open LLaVA, on two datasets (Waymo/US and PREPER
CITY/Sweden). Our results show that these LLMs can describe a traffic situation
to an impressive level of detail but are still challenged for further analysis
activities such as object localization. We evaluate and extend hallucination
detection approaches when applying these LLMs to video sequences in the example
of pedestrian detection. Our experiments show that, at the moment, the
state-of-the-art proprietary LLM performs much better than the open LLM.
Furthermore, consistency enhancement techniques based on voting, such as the
Best-of-Three (BO3) method, do not effectively reduce hallucinations in LLMs
that tend to exhibit high false negatives in detecting pedestrians. However,
extending the hallucination detection by including information from the past
helps to improve results. |
2408.01434v2 | ## Behind the Smile: Mental Health Implications of Mother-Infant Interactions Revealed Through Smile Analysis
A'di Dust Computer Science Department University of Southern California Los Angeles, USA [email protected]
Pat Levitt Children's Hospital Los Angeles Los Angeles, USA [email protected]
Maja Matari´ c Computer Science Department University of Southern California Los Angeles, USA [email protected]
Abstract -Mothers of infants have specific demands in fostering emotional bonds with their children, characterized by dynamics that are different from adult-adult interactions, notably requiring heightened maternal emotional regulation. In this study, we analyzed maternal emotional state by modeling maternal emotion regulation reflected in smiles. The dataset comprises N=94 videos of approximately 3 ± 1-minutes, capturing free play interactions between 6 and 12-month-old infants and their mothers. Corresponding demographic details of self-reported maternal mental health provide variables for determining mothers' relations to emotions measured during free play. In this work, we employ diverse methodological approaches to explore the temporal evolution of maternal smiles. Our findings reveal a correlation between the temporal dynamics of mothers' smiles and their emotional state. Furthermore, we identify specific smile features that correlate with maternal emotional state, thereby enabling informed inferences with existing literature on general smile analysis. This study offers insights into emotional labor, defined as the management of one's own emotions for the benefit of others, and emotion regulation entailed in motherinfant interactions.
Index Terms -Mother-Infant Interaction, Affective Computing, Emotional Labor, Smile Analysis, Mental Health
## I. INTRODUCTION
In recent years, there has been significant exploration into the detection of maternal mental health difficulties [1] and the enduring implications of maternal mental health on infant caregiving [2]. While the affective computing research community has conducted extensive work on the detection and prediction of mental health issues [3], [4], [5], there is limited literature to date that integrates such detection with maternal emotional status via multiple emotional state measures (e.g., scores of stress, depression, social support), delaying a comprehensive understanding of how potential maternal mental health difficulties may manifest. As an overarching issue, detecting and understanding maternal mental health is an important challenge, because, in addition to the impact on maternal well-
This work is supported by the California Initiative to Advance Precision Medicine - ACES and The Saban Research Institute Developmental Neuroscience and Neurogenetics Program, CHLA.
being, it also can impact infant physical, cognitive, and socialemotional development [6], [7], [8].
Early infant parenting is universally challenging, and mothers represent the primary caregivers in most cases, taking on the majority of parental labor, on average [9]. Research is needed to address knowledge gaps in understanding the nuances of maternal mental health, which will facilitate the development of effective coping tools and strategies [10].
Due to intensive emotional labor involved, maintaining effort over time in longer interactions becomes more difficult [11]. To extend the state of affective computing research, our work employs statistical and machine learning methods on a dataset of mother-infant interactions and maternal self-reports of emotional state (as measured by various scales such as the Patient Health Questionnaire). The analyses are designed to identify and gain deeper insights into affective signals and their implications for mothers' mental health. The work focuses on the analysis of smiles, as smiling constitutes a prominent feature of caregiver-infant interactions [12]. We posit that signals from infant-directed smiles will aid in the detection and understanding of maternal mental health. Leveraging the existing literature on smile analysis, we draw conclusions about the social nature [13] and spontaneity of maternal smiles [14]. Furthermore, we postulate that these features can be used to predict maternal mental health.
## II. BACKGROUND
## A. Maternal Mental Health
The presence of depression, stress, social isolation, and other mental health factors can greatly impact a mother and their infant. Episodes of maternal depression are common, with 10% of mothers exhibiting depressive episodes within the first year after delivery; 10% of those mothers continue to have signs of depression after a full year after delivery [15]. Despite this, up to 50% are undiagnosed due to concerns about privacy and stigma [16]. These challenges in maternal mental health have a negative impact on both maternal and infant well-being, influencing infant cognitive and social-emotional development [17], [18].
Recognizing the prevalence and severity of maternal depression highlights the need for comprehensive research and intervention efforts. By focusing research efforts on understanding maternal depression, scalable best practices can be developed and applied to support the mental health of mothers and, consequently, safeguard the well-being and healthy development of their infants, emphasizing and supporting the interconnectedness of maternal and infant health.
Numerous studies have proposed methods for automatically detecting mental health issues using facial features [19], [20], [21], [22]. For example, in a study by Boman, Downs, Karali, and Pawlby. [23], facial expression detection was used to model the effectiveness of stays in Mother-Baby Units (inpatient psychiatric facilities for mothers and their infants aged one year or younger) in reducing maternal psychiatric symptoms . While that work and others focus on detection and outcomes, there is a lack of exploration into the underlying mechanisms for the observed effects and the interactions between maternal mental health and mother-infant dynamics. In this work, we used an essential infant-directed facial expression, i.e., maternal smiles, to analyze the context of maternal depression and facial reactions.
## B. Smile Analysis
The method of studying mothers' emotional labor relies on analyzing smiles of mothers engaged in free play with their infants. In past research, temporal-location analysis of the mouth, eyebrows, and eyelids [24], [25], [26], [27], [28], [29], [30], [31] and detection methods such as the use of electromyography [32], [33] have enabled the prediction of the spontaneity of smiles. Moreover, past work has demonstrated that smile features can predict the social context in which the smile occurs, distinguishing between social and solitary settings [34], [13]. Hence, smile analysis serves as a tool for decoding non-verbal communication, although not necessarily internal affective states. While traditionally applied in automatic smile and mood detection [35], [36], [37] and engagement analysis [38], our work explores a novel direction: determining whether smile analysis can provide crucial insights into the interaction and emotional labor of mothers during dyadic engagements with their infants, particularly during pivotal stages of child development.
Recent studies caution against relying solely on smiles for emotional inference [39]. Accordingly, we focused on correlating known contextual factors of smiles with their associations to maternal mental health at the time of audio-video data collection of mother-infant free play. Other studies report that individuals with minor depression exhibit heightened sensitivity to others' smiles [40], while also deriving benefits from their own smiles, whether posed or spontaneous [41]. Thus, despite the potential disparity between smiling and emotional states, smiles remain significant indicators of mental health challenges, especially depression. Lwi et al. [42], found that smiles perceived as genuine (i.e., Duchene smiles) can improve mental health of caregivers . Given the acknowledged benefits and significance of smiles in mental health and caregiving relationships, the smile analysis in this work provides deeper insights into mother-infant interactions.
## C. Mother-Infant Interaction
The bond between mothers and infants is a cornerstone of child development, shaping infants' social-emotional and cognitive growth. Understanding the dynamics of this relationship is key to deciphering the mechanisms that underlie experience-dependent development of infants and the specific influence of maternal emotional states. Mothers' emotional availability and responsiveness provide infants with a secure base from which to explore and develop a sense of trust, ultimately influencing their self-esteem and ability to form healthy relationships throughout their lives [43], [44], [45], [46], [47], [48], [49]. A secure attachment between mothers and infants correlates to positive emotional [43], cognitive [50], physical [51], and social outcomes [44], [45], [46], [48] later in children's lives [49]. Mother-infant dyadic interactions promote infant exploration and gaining understanding of their social world [44]. Thus, recognizing the significance of the maternal-infant bond is not only pivotal in child development but also underscores the importance of supporting the wellbeing of mothers in this essential role.
Central to understanding mother-infant social and emotional outcomes is the concept of emotional labor . Introduced by Hochschild, the term refers to the emotional work individuals perform to manage their expression of feelings during social interactions [11]. Initially, emotional labor was described in the context of traditional labor situations, particularly in woman-dominated service jobs [52], [53], [54], [55]. In recent years, emotional labor has been expanded to include unpaid labor such as work in the home [56], [57], [58]. The emotional experiences of mothers caring for their infants are dynamic and include teaching their children emotional regulation techniques such as the 'serve and return' dynamic in dyads [59]. The term 'serve and return' refers to the process in which the child or caregiver initiates an interaction using vocalizations or other cues and the partner responds with a directed engagement. Emotional regulation skills from infancy to adulthood have been shown to be learned from both primary and secondary caregivers, highlighting the importance of maternal modeling of emotional labor in raising their infants [60], [61], [62], [63]. By analyzing how mental health states manifest in emotional labor through the temporal analysis of smiles, this work aims to provide a greater understanding of the impact of mental health difficulties on emotional regulation of children past infancy.
## III. METHODS
## A. Dataset
The Children's Hospital of Los Angeles recorded interactions between mothers and their infants, first when the infants were 6 months old (± 1 month) and then again when the same infants were 12 months old (± 1 month), resulting in a total of 94 distinct recorded interactions under IRB CHLA21-00174. The first set of interactions is referred to as the
6-month checkup and the second as the 12-month checkup. Each interaction session lasted approximately 3 ± 1-minutes and involved a mother and an infant involved in free play; the mother was seated across from the baby, who was either in an infant seat or on the floor. Video-audio recordings were taken from various angles with an emphasis on the head-forward camera data of the mother and infant. In this work, we utilized only the videos of the mother.
We employed OpenFace [64] to extract the mothers' 2dimensional facial features and use them to extract and analyze maternal smiles during the dyadic interaction. To ensure data integrity and eliminate frames with potential occlusions, we utilized OpenFace's frame confidence feature and included only frames with a confidence level of 80% or higher in the analysis. This threshold was chosen empirically to balance data quality and include a sufficient number of frames. Using this threshold criterion, at the 6-month checkup, 90.6% of frames were classified as high confidence, while at the 12month checkup, 88.7% were classified in the same category.
In addition to the video dataset, we had access to the mothers' mental health and early adversity questionnaire scores for each checkup. The dataset includes mothers with notably higher negative emotional state scores than the national average, allowing for more balanced classes. The scoring was performed using the following questionnaires: 1) the Adverse Childhood Experiences (ACEs), a retrospective assessment of early adversity experienced by the adult [65]; 2) Social Support [66], a measure of maternal social network; 3) Perceived Stress Score (PSS) [67]; 4) Pediatric ACEs and Related LifeEvents Screener (PEARLS), a current state of experiencing early adversity [68]; and 5) the Patient Health Questionnaire 9 (PHQ-9), which reveals depressive symptoms [69]. The scores were collected by trained research staff Children's Hospital of Los Angeles each of whom were validated by a neuropsychologist to be trained to administer and score the above-listed questionnaires collected at each visit. We created categorical variables using mental health experts' suggested score boundaries conforming to published data for the PHQ-9 [70], ACES [71], and PSS [67] scale. The relevant information, including the possible score range, category breakdown, mean score per category (as a measure of spread to be compared with error metrics in modeling), and the sample mean score are all shown in Table I. Each emotional state score is stable between infant ages, with ACES for example changing by an average of only 0.89 points. The unique quality and longitudinal nature of the data collection significantly enriches the value of the data. Additionally, this paper establishes methods for a much larger future analysis of more than 300 dyads of ages 6, 12, and 24 months with deep phenotyping of both mother and child.
The population of mother-infant dyads in the study was diverse. The mothers' mean age at the infant's 6 month checkup was 32.4 (SD=5.45). The languages spoken at home included 25% of mothers speaking Spanish only, 25% of mothers speaking English only, 42% of mothers speaking both English and Spanish, and 8% of mothers speaking another language. Of the total family incomes of the participants,
42.4% of the family incomes of the participants were below the Los Angeles average salary. The mothers had higher emotional state scores than United States average scores, allowing for better balance in classification tasks and understanding of emotional state outliers.
## B. Maternal Smile Feature Extraction
To identify maternal smiles in the videos, we focused on frames in which the Facial Action Coding Guide's Action Unit 12 (AU12) [72], related to the lip corner puller action unit (activation of the Zygomatic Major muscle), equalled or exceeded 1.5 out of 5 at least twice in one second of consecutive high-confidence video frames. This threshold for AU12 activation was based on previous reports on smile extraction [73].
To extract complete smiles, we followed established protocols for smile analysis [25], [74], [13], which involved identifying smile onset, apex, and offset. We standardized the coordinates of the right and left lip corners to mitigate potential motion artifacts caused by head movements. The inner left nostril coordinates were used as a reference point, and the left and right lip corner coordinates were subtracted from these central coordinates, as in [13].
To determine smile phases, we calculated an initial smile radius to account for facial differences among mothers. The initial radius ( IR ) was computed as √ ( RT x -L x ) 2 +( RT y -L y ) 2 2 , where RT and L represent the coordinates of the right and left lip corners, respectively. In subsequent frames, we calculated the rightward movement r , where r = √ RT 2 x + RT 2 y IR .
The longest increasing value of r was recorded as the smile onset, while the longest decreasing value of r after the onset indicated the smile offset. The time between onset and offset represented the apex of the smile. Following the offset, the initial radius was recalculated to distinguish subsequent AU12 activations as different smiles. Figure 1 shows an illustrative example of a smile with labeled onset, apex, and offset. Figure 1 example of a smile devoid of large amounts of irregularities; the image on the right shows a more typical, smile with noise within the apex. Consistent with other studies [74], our modeling approach uses smile onsets and offsets instead of apexes, which tend to be more noisy.
During the 6-month checkup, mothers smiled an average of 5 02( . SD = 5 02) . times in the interaction, whereas during the 12-month checkup, mothers smiled an average of 5 30( . SD = 4 45) . times. These are adjusted values after excluding smiles confounded by speech. We employed voice activity detection using the Python library SpeechRecognition [75] to identify segments of speech. Speech was defined as vocalizations lasting longer than 10 milliseconds (ms); vocalizations lasting less than 10 ms often lacked accompanying lip movements. Subsequently, smiles that had overlapping start and end timestamps within the range of the extracted speech were removed. This process led to the elimination of 181 potentially confounded smiles, retaining 67.6% of the original smiles.
TABLE I
DESCRIPTION OF MENTAL HEALTH SCORES AND CATEGORIES; INCLUDES CATEGORICAL SCORING BREAKDOWN AND SAMPLE MEAN SCORES OF EMOTIONAL STATE CATEGORIES FOR COMPARISON OF MAE METRICS.
| Scale | Possible Score Range | Categories | Mean Points per Emotional State Category | Sample Mean |
|----------------|------------------------|------------------------------------------------------------------------------------------|--------------------------------------------|------------------------|
| PHQ-9 | [0, 27] | Minimal: [0-4] Mild: [5-9] Moderate: [10-14] Moderately Severe: [15-'19] Severe: [20-27] | 5 . 6( SD = 1 . 2) | 3 . 19( SD = 4 . 16) |
| ACES | [0, 10] | Low Risk: [0] Intermediate Risk: [1-3] High Risk: [4-10] | 3 . 3( SD = 2 . 62) | 2 . 07( SD = 2 . 55) |
| Social Support | [0, 100] | NA | NA | 82 . 80( SD = 15 . 97) |
| PSS | [0, 40] | Low: [0-13] Moderate: [14-26] High: [27-40] | 13 . 7( SD = 0 . 47) | 12 . 52( SD = 6 . 66) |
| PEARLS | [0, 10] | NA | NA | 0 . 47( SD = 0 . 90) |
Fig. 1. A graph of an example smile from the mother in dyad 1. The graph displays the smile onset, apex, and offset.
## C. Temporal Feature Windowing
We hypothesized that variations in emotional labor are linked to the emotional status of mothers over the course of an interaction, since emotion regulation is more difficult for those with mental health difficulties [76]. We used neural networks to explore the correlation between temporal aspects and maternal smile characteristics for detecting maternal mental health challenges. The details of the networks architecture are provided in the next section.
To explore temporal patterns in maternal smiles, we tested neural networks with windows of size 1, 2, 3, 4, and 5. The choice to use windowing as opposed to recurrent neural networks was driven by the relative accuracy of windowing with small datasets and short temporal sequences [77]. The average number of smiles that were not confounded by speech in each session was 5 30( . SD = 4 73) . .
We calculated the mean of maternal smile features over each of these windows. Additionally, we ran each neural network with 50, 100, 150, and 200 epochs. Final neural networks were selected using the smallest mean average error. To test the stability of our results, each network was tested over 5 different randomized seeds with 5 fold cross validation and confirmed to be consistent across seeds.
## D. Model Architecture
As tree-based networks perform worse at extrapolation, we chose to use neural networks. Since we are particularly interested in cases where emotional state is highly impacted and there are few of these instances in our dataset, it is important to consider extrapolation. For example, the maximum PHQ value is 22 out of 27 in our dataset and the lowest Social Support Score is 19 out of 100. Without the ability for strong extrapolation, trends after these extremes are undefinable under tree-based methods [78].
Each neural network was created to assess the temporal relation between maternal smiles and their mental health. Each measure of mental health was presented in a separate model, as we theorized the relationship between smile windowing and mental health would be dependent on questionnaire score type. We predicted differences in the temporal relation between, for example, social support and ACES, since some mental health features are more correlated than others.
Out of the total of 94 mothers, we used 75 for model training and the remaining 19 for model testing. Model inputs included averages of smile features over windows of sequential smiles for each mother. The windowed features were passed through a fully connected (FC) layer with 32 neurons, another FC layer of 32 neurons, a final layer of 8 neurons, and linear outputs were collected through a ReLU activation function. The bottleneck layer of 8 neurons was selected so that feature redundancy could be reduced before the final activation function. The neural network used an Adam optimizer and a Mean Standard Error (MSE) loss function.
## IV. RESULTS
## A. Temporal Analysis
To determine if there is a relation between where in the course of the 3-minute interaction a mother's smile is displayed and the same mother's questionnaire scores, we first explored linear relationships between the smile features and the scores. Sequentially analyzing each smile, we calculated the sample correlation between each smile feature and each score (e.g., determining the correlation between the onset amplitude of the first smile in an interaction and the PHQ9 score). Subsequently, we employed simple linear regression on these pairs of smile features and scores and identified the four smile features most linearly correlated with the sequential smile number and the score: onset amplitude, onset duration, offset duration, and total duration. These four features were chosen based on significance of p < 0 05 . of their correlative relation on average. The relationships derived from these analyses are shown in Figure 2.
The data show that, as indices of potential mental health challenges increase, so do onset amplitude, onset duration, offset duration, and total duration of smiles. Moreover, this correlation tends to intensify over time, suggesting that heightened levels of these smile features correspond to more pronounced scores as the mother-infant interaction progresses. Past research suggests that smiles characterized by higher onset amplitudes, onset durations, and offset durations are often associated with more deliberate and socially-directed expressions [79]. This observation implies that mothers may engage in heightened 'performance' for their infants as the duration of one-on-one interactions extends, particularly if they have greater mental health challenges. This interplay between smile features, emotional status, and the passage of time within an interaction offers insights into how emotional labor is distributed within interactions.
Recognizing the complexity and potential non-linearity of the relationship among the questionnaire scores, smile features, and time, we performed further modeling and analysis. Specifically, we trained the neural network outlined in II using different window sizes and epochs. We tested windows of 2, 3, 4, and 5 smiles and 50, 100, 150, and 200 epochs. Each feature combination underwent 5 iterations with different seeds, and the final model was selected based on the minimum Mean Squared Error (MSE), averaged across the 5 seeded iterations. Given the substantial correlation between differing scales, we developed individual networks for each questionnaire score. The resulting Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) are detailed in Table II, along with the corresponding parameters: the number of epochs and the size of the sliding window.
Capturing information about sliding windows and using those features as input into the network, we achieved high levels of accuracy. The MAE and RMSE values for PHQ-9, ACES, and PSS were smaller than the average spread of points within each categorical diagnosis, underscoring the robustness of the model in capturing high-level information. Furthermore, each model exhibited error measures that were smaller than the spread (standard deviation) of the data. Notably, for PHQ9, PSS, and PEARLS, the model's error was less than half the size of the standard deviation. Optimal window sizes typically ranged between 3 and 5 smiles, mirroring the visual trends depicted in Figure 2, where relative trends persisted for sequences of 3 to 5 consecutive smiles.
TABLE II
BEST WINDOW SIZE AND NUMBER OF EPOCHS FOR MLP MODEL, ALONG WITH THEIR CORRESPONDING MEAN ABSOLUTE ERROR AND ROOT MEAN SQUARED ERROR FOR EACH MENTAL HEALTH SCORE.
TABLE III
| Metric and Range of Scores | Best Window Size | Best Number of Epochs | MAE | RMSE |
|------------------------------|--------------------|-------------------------|-------|--------|
| PHQ-9 [0, 27] | 4 | 150 | 1.43 | 1.92 |
| ACES [0, 10] | 3 | 200 | 1.3 | 1.9 |
| Social Support [0, 100] | 3 | 200 | 12.68 | 17.34 |
| PSS [0, 40] | 5 | 150 | 3.05 | 3.85 |
| PEARLS [0, 10] | 3 | 200 | 0.37 | 0.61 |
UNEQUAL VARIATION T-TESTS OF MOTHER SMILE FEATURES DURING 6 AND 12-MONTH INFANT AGE APPOINTMENTS.
| Smile Feature | Unequal Variation T-Test | Effect Size (Cohen's D) |
|----------------------|-------------------------------------|---------------------------|
| Maximum Onset Speed | t (207 . 33) = 4 . 37 , p < 0 . 001 | 0.51 |
| Maximum Offset Speed | t (190 . 17) = 3 . 02 , p = 0 . 003 | 0.37 |
| Onset Amplitude | t (190 . 86) = 3 . 97 , p < 0 . 001 | 0.49 |
| Offset Amplitude | t (182 . 07) = 2 . 26 , p = 0 . 025 | 0.29 |
| Onset Duration | t (354 . 53) = 0 . 50 , p = 0 . 62 | 0.05 |
| Offset Duration | t (314 . 51) = 0 . 53 , p = 0 . 60 | 0.05 |
| Apex Duration | t (246 . 39) = 1 . 75 , p = 0 . 081 | 0.19 |
| Total Duration | t (271 . 39) = 2 . 17 , p = 0 . 031 | 0.22 |
## B. Feature Correlation and Developmental Stage
In addition to capturing information about mothers' emotional state and experiences regarding early adversity in her own childhood (as captured in the ACES scale), maternal smiles correlated to infant developmental stages in a way that informs how infant age may influence maternal behavior. The single modality emphasis on smiles is novel and grounded in the ability of smiles to decode the social or solitary and spontaneous of posed nature of interactions. In order to examine these relationships, we performed unequal variation ttests on each smile feature between the 6-month appointment and the 12-month appointment, as shown in Table III. All variation ratios between the 6 and 12 month features were < 1, so we used the unequal variation t-test. The features were also non-normal, but the degrees of freedom were > 100, so we were able to perform t-tests due to the central limit theorem [80].
The results of these t-tests allowed us to reject the null hypothesis that mothers' smile features were equal at the 6month and 12-month appointments for maximum onset speed, maximum offset speed, onset amplitude, offset amplitude, and total duration. Each of these features was smaller in the 6-month visits than the 12-month visits. Specifically, the maximum onset speed and onset amplitude exhibited a medium effect size, while the maximum onset speed, offset amplitude, and total duration demonstrated a small but nonnegligible effect size. Given that higher maximum onset speed and onset amplitude are associated with posed and sociallydirected smiles [13], [79], this suggests a positive correlation between social and posed smiles for mothers of 12-month
PEARLS and Smiles Over Time
Fig. 2. The change in smile feature correlations by emotional state scale scores over each smile in the interaction. The most linearly correlated smile features were selected.
TABLE IV
ANOVA ANALYSIS ON CATEGORICAL MENTAL HEALTH FOR EACH INFANT AGE AND MOTHER SMILE FEATURE. SIGNIFICANT RESULTS AT p < 0 05 . ARE REPORTED.
| Smile Feature | Month | Mental Health Variable | ANOVA | Partial η 2 |
|------------------|---------|--------------------------|--------------------------------------|---------------|
| Max Onset Speed | 6 | PHQ | F (3 , 178) = [3 . 39] , p = 0 . 019 | 0.06 |
| Offset Amplitude | 12 | PHQ-9 | F (4 , 343) = [2 . 49] , p = 0 . 043 | 0.03 |
| Max Onset Speed | 6 | PSS | F (2 , 179) = [5 . 31] , p = 0 . 006 | 0.06 |
| Max Offset Speed | 12 | PSS | F (2 , 345) = [4 . 08] , p = 0 . 018 | 0.02 |
| Offset Amplitude | 12 | PSS | F (2 , 345) = [3 . 95] , p = 0 . 021 | 0.02 |
| Onset Duration | 12 | ACES | F (2 , 345) = [3 . 21] , p = 0 . 042 | 0.02 |
infants compared to those of 6-month-old infants. Infants between 6 and 12 months of age typically undergo developmental maturation related to attachment, social interaction, and communication, potentially eliciting a more social response from mothers, closer to interactions in social contexts with adults [13].
To further link these findings with maternal emotional state and potential mental health disturbances, we computed ANOVA scores of mothers' smiles, comparing categorical questionnaire scores with infant age and smile features, identifying cases where the null hypothesis for differences in samples could be rejected. For instance, we utilized ANOVA to determine if there were variations between low, moderate, and high PSS scores in instances in which a 6-month-old infant uses the mother's smile maximum onset speed. Our findings are detailed in Table IV.
Our results reveal potential interactions between maternal mental health, infant developmental stage, and smile features. Notably, in the assessment of PHQ-9 categories, there were small yet noteworthy differences in mothers' smile offset amplitude when their infants were 12 months old. The PSS screener categorical score exhibited the highest number of features with statistically significant between-group differ- ences. Specifically, mothers of 12-month-old infants displayed differences in PSS categories based on their maximum offset speed and offset amplitude, albeit with a small effect size. Conversely, mothers of 6-month-old infants exhibited PSS categorical differences in maximum onset speed, characterized by a medium effect size. Lastly, differences in onset duration for mothers of 12-month-old infants were evident across categorical ACEs scores. These results suggest that infant developmental stage, mother smile features, and mental health interact with one another with potential functional implications.
## V. DISCUSSION
The utilization of infant-directed smiles in predicting maternal emotional state and potential mental health challenges offers a dual benefit: maternal smile features provide insights not only into the mother's perception of an interaction but also into the emotional labor entailed in that interaction, particularly in connection with mental health challenges that may change over time. This research provides promising insights into the interaction between mother-infant play and maternal emotional state by analyzing maternal smiles contextualized in time, along with the infant developmental stage. Our findings support the hypothesis that maternal mental health correlates with changes in maternal smiles during interactions with infants over time, as evidenced by both linear modeling and neural network analyses. Additionally, we explored the influence of infant developmental stage by examining differences in smile features across infant ages and subsequently integrated questionnaires designed to capture maternal emotional state and childhood adversity experiences (ACES).
The temporal analyses revealed support for a linear correlation between smile feature and emotional labor changing direction over time. Notably, the directionality of this correlation indicated that the smiles of mothers facing greater mental health challenges became more positively correlated with features associated with social and posed expressions over the course of the mother-infant interaction. The sliding window neural network results further reinforce our finding that time and smile features can serve as predictors of maternal emotional state and potential mental health disturbances, as evidenced by the network's accurate predictions when analyzing windows spanning 3 to 5 smiles.
Our developmental findings support the premise that as infants become more socially and emotionally-aware, and their skills in verbal and non-verbal communication begin to mature, a mother's smile becomes more posed and sociallydirected. Additionally, we show that there exist correlative interactions between infant developmental stage, maternal smile features, and emotional state based on the questionnaire datasets. This suggests that maternal mental health and maternal smile features likely vary across infant developmental stages.
The reported study results have limitations. The short duration of the interaction videos, approximately 3-minutes each, limited the collection of high-confidence smiles outside of instances coinciding with maternal speech, constraining our temporal analysis to brief interaction periods. We note, however, that successful maternal coaching interventions target the 'serve and return' caregiver-child interactions that are episodic and brief in nature. Additionally, the collection of data in a room equipped with two cameras introduces the possibility of smile-context confounds due to the Hawthorne effect [81]. Furthermore, the cultural context of the study, confined to a single metropolitan area in the United States, may influence certain effects due to geographic and cultural nuances.
## VI. CONCLUSION
This paper presents trends in maternal emotional state over the course of a mother-infant interactions by analyzing the mothers' smiles. We explored how temporal trends in smiles are predictive of maternal emotional state, as well as how the developmental stage of the infant (6 or 12 months) and emotional state of the mother affect individual smiles. We find ample evidence that maternal emotional state is correlated to maternal smiles in interactions and that this correlation differs based on the age of the infant.
Future research may explore longer mother-infant interactions, the relation between maternal emotional labor and data from direct infant developmental assessments, and may capture interactions in more naturalistic interactions (e.g., at home), and at later stages of development (e.g., with toddlers). Additionally, incorporating the collection of prosody, pragmatic speech features, postural information, and other multimodal data would enrich the findings. We used smile features validated in past literature; however, multimodal models might capture more complex relationships between infantdirected behaviors and maternal emotional state and potential mental health challenges. Furthermore, future studies would benefit from incorporating measures of maternal sociality and spontaneity beyond the existing previously validated smile features we used.
Our research provides a foundation for determining maternal mental health in the context of infant developmental age and milestone status with facial features and creates new opportunities for further exploration of the relations between mother-infant interactions and maternal mental health.
## ETHICAL IMPACT STATEMENT
The methods utilized in this research received approval from the Children's Hospital of Los Angeles Institutional Review Board (IRB) under protocol CHLA-21-00174. Adult participants involved in the original study provided informed consent and were compensated for their time. All data were securely maintained with HIPAA compliance to protect participant privacy. Due to the potentially identifiable and medically sensitive nature of the information within this dataset, we are unable to release it to the public. However, all participants provided consent for the use of this dataset by the appropriate institutions.
The findings of this study offer potential insights into maternal mental health. While this information could contribute to the safeguarding and comprehension of maternal mental wellbeing, it should not be utilized for surveillance or diagnostic purposes. Consequently, we refrain from sharing our predictive models to prevent their use as diagnostic tools. However, to facilitate reproducibility, we provide detailed descriptions of the tuning and hyperparameters applied in all our models.
Moreover, while there is evidence suggesting that some smile features in posed/spontaneous or social/solitary contexts may be cross-cultural, it is also evident that certain features may be culturally dependent [82]. Therefore, we advise exercising caution when applying the findings of this research to contexts outside the United States.
## REFERENCES
- [1] K. Saqib, A. F. Khan, and Z. A. Butt, 'Machine learning methods for predicting postpartum depression: scoping review,' JMIR mental health , vol. 8, no. 11, p. e29838, 2021.
- [2] M. Kimmel, 'Maternal mental health matters,' North Carolina medical journal , vol. 81, no. 1, pp. 45-50, 2020.
- [3] A. Ashraf, T. S. Gunawan, B. S. Riza, E. V. Haryanto, and Z. Janin, 'On the review of image and video-based depression detection using machine learning,' Indonesian Journal of Electrical Engineering and Computer Science , vol. 19, no. 3, pp. 1677-1684, 2020.
- [4] F. Ceccarelli and M. Mahmoud, 'Multimodal temporal machine learning for bipolar disorder and depression recognition,' Pattern Analysis and Applications , vol. 25, no. 3, pp. 493-504, 2022.
- [5] A. Mulay, A. Dhekne, R. Wani, S. Kadam, P. Deshpande, and P. Deshpande, 'Automatic depression level detection through visual input,' in 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4) . IEEE, 2020, pp. 19-22.
- [6] A. Oyetunji and P. Chandra, 'Postpartum stress and infant outcome: A review of current literature,' Psychiatry research , vol. 284, p. 112769, 2020.
- [7] L. F. Christensen, S. Heuckendorff, K. Fonager, and C. Overgaard, 'Impact of maternal mental health problems on perinatal outcomes for the infant,' European Journal of Public Health , vol. 30, no. Supplement 5, pp. ckaa165-129, 2020.
- [8] E. Aktar, J. Qu, P. J. Lawrence, M. S. Tollenaar, B. M. Elzinga, and S. M. B¨ ogels, 'Fetal and infant outcomes in the offspring of parents with perinatal mental disorders: earliest influences,' Frontiers in psychiatry , vol. 10, p. 452083, 2019.
- [9] S. N. Lang, S. J. Schoppe-Sullivan, L. E. Kotila, X. Feng, C. M. Kamp Dush, and S. C. Johnson, 'Relations between fathers' and mothers' infant engagement patterns in dual-earner families and toddler competence,' Journal of family issues , vol. 35, no. 8, pp. 1107-1127, 2014.
- [10] C. Razurel, B. Kaiser, C. Sellenet, and M. Epiney, 'Relation between perceived stress, social support, and coping strategies and maternal wellbeing: a review of the literature,' Women & health , vol. 53, no. 1, pp. 74-99, 2013.
- [11] A. R. Hochschild, 'The managed heart,' in Working in America . Routledge, 2015, pp. 29-36.
- [12] D. M. L. F. Mendes and M. L. Seidl-de Moura, 'Different kinds of infants smiles in the first six months and contingency to maternal affective behavior,' The Spanish journal of psychology , vol. 17, p. E80, 2014.
- [13] K. L. Schmidt, J. F. Cohn, and Y. Tian, 'Signal characteristics of spontaneous facial expressions: Automatic movement in solitary and social smiles,' Biological psychology , vol. 65, no. 1, pp. 49-66, 2003.
- [14] K. L. Schmidt, S. Bhattacharya, and R. Denlinger, 'Comparison of deliberate and spontaneous facial movement in smiles and eyebrow raises,' Journal of nonverbal behavior , vol. 33, pp. 35-45, 2009.
- [15] P. J. Cooper and L. Murray, 'Course and recurrence of postnatal depression: evidence for the specificity of the diagnostic concept,' The British Journal of Psychiatry , vol. 166, no. 2, pp. 191-195, 1995.
- [16] C. T. Beck, 'Postpartum depression: It isn't just the blues.' AJN The American Journal of Nursing , vol. 106, no. 5, pp. 40-50, 2006.
- [17] E. Porter, A. J. Lewis, S. J. Watson, and M. Galbally, 'Perinatal maternal mental health and infant socio-emotional development: A growth curve analysis using the mpews cohort,' Infant Behavior and Development , vol. 57, p. 101336, 2019.
- [18] Y. Liu, S. Kaaya, J. Chai, D. McCoy, P. Surkan, M. Black, A.-L. Sutter-Dallay, H. Verdoux, and M. Smith-Fawzi, 'Maternal depressive symptoms and early childhood cognitive development: a meta-analysis,' Psychological medicine , vol. 47, no. 4, pp. 680-689, 2017.
- [19] E. Laksana, T. Baltruˇ saitis, L.-P. Morency, and J. P. Pestian, 'Investigating facial behavior indicators of suicidal ideation,' in 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017) . IEEE, 2017, pp. 770-777.
- [20] M. Tran, E. Bradley, M. Matvey, J. Woolley, and M. Soleymani, 'Modeling dynamics of facial behavior for mental health assessment,' in 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021) . IEEE, 2021, pp. 1-5.
- [21] F. Jahangir and F. N. Qasmi, 'Detection of mental health through facial expressions,' Pakistan Journal of Psychological Research , vol. 18, no. 3-4, pp. 131-138, 2003.
- [22] S. B. Shafiei, Z. Lone, A. S. Elsayed, A. A. Hussein, and K. A. Guru, 'Identifying mental health status using deep neural network trained by visual metrics,' Translational psychiatry , vol. 10, no. 1, p. 430, 2020.
- [23] M. Boman, J. Downs, A. Karali, and S. Pawlby, 'Toward learning machines at a mother and baby unit,' Frontiers in Psychology , vol. 11, p. 567310, 2020.
- [24] J. F. Cohn et al. , Automatic Analysis and recognition of brow actions and head motion in spontaneous facial behavior . 2004 IEEE International Conference on Systems, Man and Cybernetics, 2004.
- [25] J. F. Cohn and K. L. Schmidt., 'The timing of facial motion in posed and spontaneous smiles,' International Journal of Wavelets, Multiresolution and Information Processing , vol. 02, no. 02, p. 121-132, 2004.
- [26] H. Dibeklioglu et al. , Eyes do not lie . Proceedings of the 18th ACM International Conference on Multimedia, 2010.
- [27] V. D. Geld, Pieter et al. , 'Tooth display and lip position during spontaneous and posed smiling in adults,' Acta Odontologica Scandinavica , vol. 66, no. 4, p. 207-213, 2008.
- [28] S. Park et al. , 'Differences in facial expressions between spontaneous and posed smiles: Automated method by action units and threedimensional facial landmarks,' Sensors , vol. 20, no. 4, p. 1199, 2020.
- [29] M. F. Valstar et al. , How to distinguish posed from spontaneous smiles using geometric features . Proceedings of the 9th International Conference on Multimodal Interfaces, 2007.
- [30] P. Wu et al. , Spontaneous versus posed smile recognition using discriminative local spatial-temporal descriptors . 2014 IEEE International
- Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014.
- [31] X. Yao et al. , 'Understanding postpartum parents' experiences via two digital platforms,' Proceedings of the ACM on Human-Computer Interaction , vol. 7, p. 1-23, 2023.
- [32] M. Perusquia-Hernandez et al. , Spontaneous and posed smile recognition based on spatial and temporal patterns of facial EMG . 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), 2017.
- [33] U. Hess et al. , 'An analysis of the encoding and decoding of spontaneous and posed smiles: The use of facial electromyography,' Journal of Nonverbal Behavior , vol. 13, no. 2, p. 121-137, 1988.
- [34] A. J. Fridlund, 'Sociality of solitary smiling: Potentiation by an implicit audience,' Journal of Personality and Social Psychology , vol. 60, no. 2, p. 229-240, 1991.
- [35] J. Hernandez et al. , Mood meter . Proceedings of the 2012 ACM Conference on Ubiquitous Computing, 2012.
- [36] N. Jaques et al. , Smiletracker . Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems, 2015.
- [37] H. Kaur et al. , 'I didn't know I looked angry': Characterizing observed emotion and reported affect at work . CHI Conference on Human Factors in Computing Systems, 2022.
- [38] C. Latulipe et al. , Love, hate, arousal and engagement . Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 2011.
- [39] L. F. Barrett, R. Adolphs, S. Marsella, A. M. Martinez, and S. D. Pollak, 'Emotional expressions reconsidered: Challenges to inferring emotion from human facial movements,' Psychological science in the public interest , vol. 20, no. 1, pp. 1-68, 2019.
- [40] R. Gadassi and N. Mor, 'Confusing acceptance and mere politeness: Depression and sensitivity to duchenne smiles,' Journal of Behavior Therapy and Experimental Psychiatry , vol. 50, pp. 8-14, 2016.
- [41] W. Lin, J. Hu, and Y. Gong, 'Is it helpful for individuals with minor depression to keep smiling? an event-related potentials analysis,' Social Behavior and Personality: an international journal , vol. 43, no. 3, pp. 383-396, 2015.
- [42] S. J. Lwi, J. J. Casey, A. Verstaen, D. E. Connelly, J. Merrilees, and R. W. Levenson, 'Genuine smiles by patients during marital interactions are associated with better caregiver mental health,' The Journals of Gerontology: Series B , vol. 74, no. 6, pp. 975-987, 2019.
- [43] G. Bohlin et al. , 'Attachment and social functioning: A longitudinal study from infancy to middle childhood,' Social Development , vol. 9, no. 1, p. 24-39, 2000.
- [44] M. A. Easterbrooks and M. E. Lamb, 'The relationship between quality of infant-mother attachment and infant competence in initial encounters with peers,' Child Development , vol. 50, no. 2, p. 380, 1979.
- [45] M. Gerhold et al. , 'Early mother-infant interaction as a precursor to childhood social withdrawal,' Child Psychiatry and Human Development , vol. 32, no. 4, p. 277-293, 2002.
- [46] G. Kochanska et al. , 'Implications of the mother-child relationship in infancy for socialization in the second year of life,' Infant Behavior and Development , vol. 22, no. 2, p. 249-265, 1999.
- [47] M. M¨ antymaa et al. , 'Infant-mother interaction as a predictor of child's chronic health problems,' Child: Care, Health and Development , vol. 29, no. 3, p. 181-191, 2003.
- [48] D. L. Pastor, 'The quality of mother-infant attachment and its relationship to toddlers' initial sociability with peers,' Developmental Psychology , vol. 17, no. 3, p. 326-335, 1981.
- [49] K. E. Ranson and L. J. Urichuk, 'The effect of parent-child attachment relationships on Child Biopsychosocial Outcomes: A Review,' Early Child Development and Care , vol. 178, no. 2, p. 129-152, 2008.
- [50] O. Aviezer et al. , 'School competence in young adolescence: Links to early attachment relationships beyond concurrent self-perceived competence and representations of relationships,' International Journal of Behavioral Development , vol. 26, no. 5, p. 397-409, 2002.
- [51] N. Radoˇ s and Sandra, 'Anxiety during pregnancy and postpartum: Course, predictors and comorbidity with postpartum depression,' Acta Clinica Croatica , vol. 57, no. 1, p. 39-51, 2018.
- [52] B. E. Ashforth and R. H. Humphrey, 'Emotional labor in service roles: The Influence of Identity,' Academy of Management Review , vol. 18, no. 1, p. 88-115, 1993.
- [53] A. A. Grandey, 'Emotional regulation in the workplace: A new way to conceptualize emotional labor,' Journal of Occupational Health Psychology , vol. 5, no. 1, p. 95-110, 2000.
- [54] H.-A. M. Johnson and P. E. Spector, 'Service with a smile: Do emotional intelligence, gender, and autonomy moderate the emotional labor process?' Journal of Occupational Health Psychology , vol. 12, no. 4, p. 319-333, 2007.
- [55] B. A. Scott and C. M. Barnes, 'A multilevel field investigation of emotional labor, affect, work withdrawal, and gender,' Academy of Management Journal , vol. 54, no. 1, p. 116-136, 2011.
- [56] L. Dean et al. , 'The mental load: Building a deeper theoretical understanding of how cognitive and emotional labor overload women and Mothers,' Community, Work & Family , vol. 25, no. 1, p. 13-29, 2021.
- [57] P. Ekman, 'Facial action coding system,' Consulting Psychologists Press , vol. 67, no. 2, p. 337-351, 2005.
- [58] A. R. Hochschild, 'Emotion work, feeling rules, and social structure,' American Journal of Sociology , vol. 85, no. 3, p. 551-575, 1979.
- [59] The National Scientific Council on the Developing Child , Dec 2012.
- [60] L. A. Frankel et al. , 'Parental influences on children's self-regulation of Energy Intake: Insights from developmental literature on Emotion Regulation,' Journal of Obesity , vol. 2012, p. 1-12, 2012.
- [61] J. J. Gross, Handbook of Emotion Regulation, The Guilford Press, New York , 2014.
- [62] A. G. Halberstadt, 'Family socialization of emotional expression and nonverbal communication styles and skills,' Journal of Personality and Social Psychology , vol. 51, no. 4, p. 827-836, 1986.
- [63] A. S. Morris et al. , 'The role of the family context in the development of Emotion Regulation,' Social Development , vol. 16, no. 2, p. 361-388, 2007.
- [64] T. Baltruˇ saitis, P. Robinson, and L.-P. Morency, 'Openface: an open source facial behavior analysis toolkit,' in 2016 IEEE winter conference on applications of computer vision (WACV) . IEEE, 2016, pp. 1-10.
- [65] M. Boullier and M. Blair, 'Adverse childhood experiences,' Paediatrics and Child Health , vol. 28, no. 3, pp. 132-137, 2018.
- [66] J. M. Pascoe, N. Walsh-Clifford, and J. A. Earp, 'Construct validity of a maternal social support scale,' Journal of Developmental & Behavioral Pediatrics , vol. 3, no. 2, p. 122, 1982.
- [67] P. S. Scale, 'Perceived stress scale,' 1983.
- [68] M. Ye, D. Hessler, D. Ford, M. Benson, K. Koita, M. Bucci, D. Long, N. B. Harris, and N. Thakur, 'Pediatric aces and related life event screener (pearls) latent domains and child health in a safety-net primary care practice,' BMC pediatrics , vol. 23, no. 1, p. 367, 2023.
- [69] N. Williams, 'Phq-9,' Occupational medicine , vol. 64, no. 2, pp. 139140, 2014.
- [70] K. Kroenke, R. L. Spitzer, and J. B. Williams, 'The phq-9: validity of a brief depression severity measure,' Journal of general internal medicine , vol. 16, no. 9, pp. 606-613, 2001.
- [71] A. Aware, 'Ace screening clinical workflows, aces and toxic stress risk assessment algorithm, and ace-associated health conditions: for pediatrics and adults. published april 2020.'
- [72] P. Ekman and W. V. Friesen, 'Facial action coding system,' Environmental Psychology & Nonverbal Behavior , 1978.
- [73] H. Mohammed et al. , 'Automated detection of SMILES as discrete episodes,' Journal of Oral Rehabilitation , vol. 49, no. 12, p. 1173-1180, 2022.
- [74] K. L. Schmidt, S. Bhattacharya et al. , 'Comparison of deliberate and spontaneous facial movement in smiles and eyebrow raises,' Journal of Nonverbal Behavior , vol. 33, no. 1, p. 35-45, 2008.
- [75] A. Zhang, 'Speech recognition (version 3.8)[software],' in Proceedings of ICCC , 2017.
- [76] P. Saxena, A. Dubey, and R. Pandey, 'Role of emotion regulation dificulties in predicting mental health and well-being,' Research in Occupational Stress and Well-being , vol. 18, p. 147-155, Sep 2011.
- [77] I. S. Zaremba, Wojciech and O. Vinyals, 'Recurrent neural network regularization,' arXiv preprint arXiv:1409.2329 , 2014.
- [78] W.-Y. Loh, C.-W. Chen, and W. Zheng, 'Extrapolation errors in linear model trees,' ACM Transactions on Knowledge Discovery from Data (TKDD) , vol. 1, no. 2, pp. 6-es, 2007.
- [79] K. L. Schmidt, Z. Ambadar, J. F. Cohn, and L. I. Reed, 'Movement differences between deliberate and spontaneous facial expressions: Zygomaticus major action in smiling,' Journal of nonverbal behavior , vol. 30, pp. 37-52, 2006.
- [80] S. G. Kwak and J. H. Kim, 'Central limit theorem: the cornerstone of modern statistics,' Korean journal of anesthesiology , vol. 70, no. 2, p. 144, 2017.
- [81] P. Sedgwick and N. Greenwood, 'Understanding the hawthorne effect,' Bmj , vol. 351, 2015.
- [82] X. Fang, D. A. Sauter, and G. A. van Kleef, 'Unmasking smiles: The influence of culture and intensity on interpretations of smiling expressions,' Journal of Cultural Cognitive Science , pp. 1-16, 2019. | 10.1109/ACII63134.2024.00010 | [
"Adi Dust",
"Pat Levitt",
"Maja Matarić"
]
| 2024-07-18T23:22:57+00:00 | 2025-03-11T23:31:31+00:00 | [
"cs.CY",
"cs.HC"
]
| Behind the Smile: Mental Health Implications of Mother-Infant Interactions Revealed Through Smile Analysis | Mothers of infants have specific demands in fostering emotional bonds with
their children, characterized by dynamics that are different from adult-adult
interactions, notably requiring heightened maternal emotional regulation. In
this study, we analyzed maternal emotional state by modeling maternal emotion
regulation reflected in smiles. The dataset comprises N=94 videos of
approximately 3 plus or minus 1-minutes, capturing free play interactions
between 6 and 12-month-old infants and their mothers. Corresponding demographic
details of self-reported maternal mental health provide variables for
determining mothers' relations to emotions measured during free play. In this
work, we employ diverse methodological approaches to explore the temporal
evolution of maternal smiles. Our findings reveal a correlation between the
temporal dynamics of mothers' smiles and their emotional state. Furthermore, we
identify specific smile features that correlate with maternal emotional state,
thereby enabling informed inferences with existing literature on general smile
analysis. This study offers insights into emotional labor, defined as the
management of one's own emotions for the benefit of others, and emotion
regulation entailed in mother-infant interactions. |
2408.01435v1 | ## A New Clustering-based View Planning Method for Building Inspection with Drone
Yongshuai Zheng 1 , Guoliang Liu 2 , ∗ , Yan Ding 3 , Guohui Tian 4
Abstract -With the rapid development of drone technology, the application of drones equipped with visual sensors for building inspection and surveillance has attracted much attention. View planning aims to find a set of near-optimal viewpoints for vision-related tasks to achieve the vision coverage goal. This paper proposes a new clustering-based two-step computational method using spectral clustering, local potential field method, and hyper-heuristic algorithm to find near-optimal views to cover the target building surface. In the first step, the proposed method generates candidate viewpoints based on spectral clustering and corrects the positions of candidate viewpoints based on our newly proposed local potential field method. In the second step, the optimization problem is converted into a Set Covering Problem (SCP), and the optimal viewpoint subset is solved using our proposed hyper-heuristic algorithm. Experimental results show that the proposed method is able to obtain better solutions with fewer viewpoints and higher coverage.
knowledge of the object [10]. A priori calculation based on the model can ensure sufficient visual coverage, so this paper focuses on the model-based view planning method, especially the three-dimensional visual coverage view planning using drones. Currently, the 'generate-test' approach is a relatively mature technique for view planning. This method is a two-step computational method, where a large number of candidate viewpoints are first generated, and then the problem is transformed into a combinatorial optimization problem based on the constraints of the visual detection task. Subsequently, the optimal subset of viewpoints can be selected using combinatorial optimization methods [11].
Index Terms -Task planning, surveillance robotic systems, computational geometry.
## I. INTRODUCTION
With the rapid advancement of drone technology, the application of drones equipped with visual sensors for surface detection and surveillance of buildings and other large outdoor objects is gaining increasing attention [1]-[3]. To realize such applications, it is necessary to solve the view planning problem, which is also called sensor planning in some literatures [4], [5]. The objective of view planning is to utilize visual sensors mounted on robots to find a set of viewpoints [6], [7], including their positions and directions, to cover the required surface area of the target object. Common optimization objectives for this problem typically involve improving the surface coverage rate of the target area and reducing the number of viewpoints [8].
View planning methods are divided into model-based and non-model-based approaches, depending on on whether the geometric model of the target is known [9]. Model-based methods require a CAD model or existing 3D structural data of the target, which is then converted into triangular mesh models. The level of detail of the mesh directly affects the complexity and accuracy of subsequent processing. In contrast, non-model-based methods operate without prior
This work is partially supported by the Jinan Science and Technology Bureau (2021GXRC026), Young Scholars Program of Shandong University (2018WLJH71), the Fundamental Research Funds of Shandong University, and the Taishan Scholar Foundation of Shandong Province. (Corresponding author: Guoliang Liu.)
The authors are with the School of Control Science and Engineering, Shandong University, Jinan 250061, China (e-mail: [email protected] (G. Liu); [email protected] (Y. Zheng); dingyan [email protected] (Y. Ding); [email protected] (G. Tian)).
In this paper, we propose a new clustering-based twostep computational method for the model-based view planning problem, which is applied to surface detection and surveillance of large buildings. In our method, the input is the triangular mesh model of the target object, and spectral clustering algorithm is utilized to cluster the triangular meshes in the model based on weighted distances and normal vectors. From the clustering results, a set of high-quality candidate viewpoints is generated using the cluster centers and resultant vectors, and a local potential field method is proposed to correct candidate viewpoint positions, thereby achieving higher coverage with fewer viewpoints. In the subsequent steps, the transformed Set Covering Problem is solved using our proposed hyper-heuristic algorithm. The main contributions of this paper are as follows:
- · A new method based on spectral clustering is proposed to generate candidate viewpoints. This method is robust to non-convex cluster shapes, better considers the complex geometric features of objects, and generates high-quality candidate viewpoints.
- · Anew local potential field method is proposed to correct the positions of candidate viewpoints. The positions of candidate viewpoints generated by spectral clustering are not always reasonable, and the local potential field method effectively solves this problem.
- · A new hyperheuristic algorithm is proposed to solve combinatorial optimization problems. This method is used to search for the optimal viewpoint subset from candidate viewpoints with redundancy, which is more effective and robust than traditional heuristic methods.
## II. PREVIOUS WORK
Since the 1980s, researchers have been attempting to solve the model-based view planning problem using various approximation methods. The search space for viewpoints is large, making the problem NP-hard [8]. Scott et al. [11]
proposed an offset method to generate candidate viewpoints through offsets from the target object surface, transforming the view planning problem into a Set Coverage Problem. Cui et al. [12] proposed another offset method, designing a normal vector offset and a vertical offset based on the direction of the viewing angle. However, this method generates a large number of viewpoints, incurs high computational costs, and may result in low coverage of large target objects, making it unsuitable for building surface detection.
Jing et al. [1] proposed a two-step iterative random sampling method for view planning that begins with randomly sampling around the target, followed by using a greedy algorithm to address the Set Covering Problem. Although effective, it does not consider the structural characteristics of the target, and its randomness makes the coverage efficiency not high enough. Wang et al. [13] proposed a parallel deep reinforcement learning approach for industrial inspection, utilizing the Fibonacci numerical integration method for viewpoint sampling within a sphere. This method overcomes the local unevenness seen in traditional approaches but does not adapt well to irregularly shaped object surfaces.
Combinatorial optimization is an important aspect of viewpoint planning. Common optimization methods include heuristic approaches such as ant colony algorithms and genetic algorithms [14]. Hyper-heuristics are a method to enhance the generality of search and optimization algorithms. Unlike traditional heuristics, they consist of high-level and low-level heuristics. High-level heuristics are used to select the most suitable low-level heuristic operators to search for solutions, rather than directly traversing the search space, making them more robust and efficient [15].
Rivera et al. [16] proposed an ACO-based hyper-heuristic for solving multi-robot task allocation problems, using ACO as a high-level strategy and designing several low-level heuristic operators to search for solutions. Zhang et al. [17] proposed a genetic-based hyper-heuristic algorithm to deal with multi-task scheduling problems, which is more effective and robust than traditional meta-heuristic algorithms. Ferreira et al. [18] introduced an ACO-based hyper-heuristic for the Set Covering Problem and compared it with the traditional ACO algorithm, demonstrating the effectiveness of hyperheuristic algorithms.
## III. PROPOSED METHOD
Our paper proposes a new clustering-based view planning method, which leverages the two-step 'generate-test' computational framework, as shown in Fig. 1. In the first step, candidate viewpoints are generated based on spectral clustering, and the positions of the candidate viewpoints are corrected based on our proposed local potential field method. In the second step, a visibility matrix is calculated, the problem is transformed into a combinatorial optimization problem, and the optimal viewpoint subset is searched based on hyper-heuristic algorithm. There is an iterative process, where if the candidate viewpoints are insufficient to achieve visual coverage of the target object, then the uncovered parts are re-clustered to generate new candidate viewpoints.
## Step1:Generate candidate viewpoints
Fig. 1: The proposed view planning method.
A. Generating candidate viewpoints based on spectral clustering
The purpose of this section is to generate an efficient set of candidate viewpoints from three-dimensional space using spectral clustering algorithm and local potential field method, aiming to narrow down the search space of the solution. The spectral clustering-based method is robust to non-convex clusters, suitable for complex structured datasets [19], and better considers the geometric features of the target object, generating candidate viewpoints with higher coverage efficiency. However, the positions of candidate viewpoints generated based on clustering algorithms are not always reasonable. The proposed local potential field method effectively corrects the positions of viewpoints.
1) Spectral clustering algorithm: Spectral clustering is a method that utilizes graph and spectral theory by treating the dataset as graph nodes [20]. In this study, we use spectral clustering to group the triangular meshes in the target object's mesh model, based on the distances and angles between their normal vectors, to generate candidate viewpoints. Before clustering, the target model is preprocessed into a subdivided triangular mesh model, as shown in Fig. 2. Here is an overview of the spectral clustering algorithm design.
(a) Point cloud model of the target object


(b) Subdivided triangular mesh model
Fig. 2: Processing the target model as a set of triangular meshes.
First, we compute the adjacency matrix G . We have adjusted the adjacency matrix calculation by considering both the distances between triangular meshes and the angles between their normal vectors. Here is the formula for G :
$$G _ { i j } = \theta ^ { * } \ s _ { i j } + ( 1 - \theta ) ^ { * } \gamma _ { i j } \quad \quad ( 1 ) \quad \text{in} \quad \text{and}$$
where θ ∈ ( 0 1 , denotes the weight assigned to the distance , ) and the angle between the normal vectors, Gij denotes the cost of clustering the i th and j th triangular meshes together, s i j denotes the distance between the centers of the triangular meshes, and γ i j denotes the angle between the normal vectors of the triangular meshes.
Second, we construct the similarity matrix W , where the geometric significance of the similarity matrix is to calculate the similarity between triangular meshes. In this paper, we construct a fully connected similarity matrix W using a Gaussian kernel function [19], as follows:
$$W _ { i j } = \exp \left ( - \frac { G _ { i j } ^ { 2 } } { 2 \sigma ^ { 2 } } \right )$$
where Wij denotes the similarity between triangular meshes i th and j th , and σ is a parameter of the Gaussian kernel function used to control the rate of similarity decay. The lower the similarity, the more expensive it is to cluster together and the less likely it is to cluster into a cluster and vice versa.
Third, we compute the laplacian matrix L rw using random walk normalization [21] to enhance algorithm stability:
$$L _ { \text{rw} } = I - D ^ { - 1 } W \quad \text{--} \quad \text{--} ( 3 ) \quad t _ { \text{rw} } \, \text{d}$$
where I is the unit matrix, D is the degree matrix, and the i th diagonal element of D is the degree of data point i , denoted as Dij = ∑ j Wij .
Subsequently, we perform eigenvalue decomposition on the normalized Laplacian matrix L rw to extract eigenvalues and select eigenvectors for the top k non-zero eigenvalues, where k is the number of clusters. These eigenvectors are then used to create a new data representation for K-means clustering, effectively grouping the triangular meshes into different clusters.
Fig. 3: Spectral clustering of a set of triangular meshes.

2) Generate candidate viewpoints: After clustering, we compute the centers of all clusters and the resultant vector of the normals of all triangular meshes within each cluster. Then, we translate the coordinates of the cluster centers along the direction of the resultant vector, thereby obtaining the positions of candidate viewpoints. The opposite of the resultant vector is used as the direction of the viewpoints. The generation of candidate viewpoints is shown in Fig. 4, and the specific calculation process is derived as follows.
Fig. 4: Generated candidate viewpoints.
We first compute the clustering centers C and resultant vectors N :
$$c _ { k } = \frac { 1 } { t } \cdot \sum _ { i = 1 } ^ { t } x _ { i }$$
$$N _ { k } = \frac { 1 } { t } \cdot \sum _ { i = 1 } ^ { t } \frac { v _ { i } } { \| v _ { i } \| }$$
where the subscript k denotes the index of the clusters, t denotes that the cluster contains t triangular meshes, xi denotes the centroid of the triangular mesh in the cluster, vi denotes the normal vector of the triangular mesh, Ck and Nk denote the k th clustering center and the resultant vector, respectively.
We then generate candidate viewpoint positions P and directions V :
$$P _ { k } = C _ { k } + d \cdot N _ { k }$$
$$V _ { k } = C _ { k } - P _ { k }$$
where Pk denotes the position of the k th candidate viewpoint, V k denotes the direction of the k th candidate viewpoint, and d denotes the distance that the clustering center moves along the concatenated vector. It has been experimentally tested that if the Field of Depth (FOD) of the camera is known, then by setting d to about 0.95 times the FOD generates relatively higher quality viewpoints.
Additionally, it is crucial to define the constraint space for generating candidate viewpoints to ensure their positions meet specific requirements. We propose a local potential field method to correct the positions of viewpoints, similar to the calculation of repulsive and attractive forces in artificial potential fields [22]. We set constraints on the positions of candidate viewpoints: (1) Distance limitations to prevent the drone from being too close to the target structure; (2) Altitude limitations to ensure the drone's flight altitude is not too low, avoiding proximity to the ground:
$$\lambda \cdot \begin{array} { c } \lambda \\ v _ { \text{correct} } = \frac { \sum _ { i } ^ { N } ( P _ { k } - p _ { \text{mesh} _ { i } } ) } { \left \| \sum _ { i } ^ { N } ( P _ { k } - p _ { \text{mesh} _ { i } } ) \right \| }, \\ \text{for all} \colon \ \{ p _ { \text{mesh} _ { i } } \, | \, \left \| P _ { k } - p _ { \text{mesh} _ { i } } \right \| < d _ { \text{safe} } \} \end{array}$$
$$v _ { \text{correct} } = \frac { h _ { \lim i t } - P _ { k } } { \| h _ { \lim i t } - P _ { k } \| }, \quad \text{if } P _ { k _ { z } } < h _ { \lim i t _ { z } } \quad \ ( 9 )$$
Eq. (8) computes the correction direction when the candidate viewpoint is too close to the target object by summing the repulsive forces from the triangular meshes located within the distance limit. Eq. (9) computes the correction direction when the candidate viewpoint position is below a certain height by calculating the attraction towards the predefined height. Here, N denotes the number of triangular meshes within the distance limit, Pk denotes the position of the candidate viewpoint, p mesh i denotes the position of the i th triangular mesh, d safe defines the safe distance, Pkz and h limit z respectively represent the height of the candidate viewpoint and the safe height.
Subsequently, the candidate viewpoint position is corrected based on the correction direction v correct . If multiple adjustments of the candidate viewpoint position based on the calculated v correct still do not satisfy the constraint conditions, then the distance d moved by the cluster centroid along the resultant vector during the generation of candidate viewpoints is modified based on Eq. (6) to find the position that satisfies the constraint conditions:
$$P _ { k } = C _ { k } + \left ( d - i \cdot d _ { \text{step} } \right ) \cdot N _ { k } \text{ \quad \ \ } ( 1 0 ) \text{ \ \ } \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$} \text{$1\uplus$ }$$
where d step is the distance to the clustering center and i is the number of iterations. After each iteration, the local potential field method is reapplied to adjust the position of the candidate viewpoint. Accordingly, when the candidate viewpoint position is corrected to meet the constraints, Eq. (7) is applied to recalculate the direction of the viewpoint.
## B. Conversion to a combinatorial optimization problem
After generating candidate viewpoints, the problem is transformed into a Set Covering Problem [11] through the calculation of the visibility matrix.
1) Computation of the visibility matrix: The visibility matrix is a binary matrix that indicates which triangular meshes are visible from each viewpoint. It is an m × n matrix, where m is the number of candidate viewpoints and n is the number of triangular meshes. An element in the matrix is set to 1 if a triangular mesh is visible from a viewpoint and 0 otherwise. Fig. 6 shows an example of the visible area from a given viewpoint. A triangular mesh is considered visible from a viewpoint if it meets the following conditions:
- · The triangular mesh must be within the camera's field of depth (FOD) from the viewpoint, as Fig. 5a shows.
- · The triangular mesh must be within the camera's field of view (FOV) from the viewpoint, as Fig. 5a shows.
- · The viewing angle β must be within a certain range predicted by the camera specifications, as Fig. 5b shows.
- · There should be no other obstructing structures between the triangular mesh and the viewpoint, which can be determined using ray-triangle intersection tests [23].
Fig. 6: Example of visible area from a given viewpoint. Visible areas are shown in yellow.

2) Set Covering Problem formulation: The Set Covering Problem (SCP) is a classical problem in combinatorial optimization, which involves finding a set of subsets to cover all elements at minimum cost. It is a problem known to be NP-hard, typically solved using heuristic algorithms. In this paper, we reformulate the problem as a constrained combinatorial optimization problem [8], where the objective is to find the minimum subset of viewpoints that can cover a certain proportion of triangular meshes:
$$\Gamma \text{pronoun on unagma moves.} \\ \min \sum _ { i = 1 } ^ { m } s _ { i }, \quad \text{where } s _ { i } \in \{ 0, 1 \} \\ s. t. \ \sum _ { j = 1 } ^ { n } \left ( \left ( \sum _ { i = 1 } ^ { m } s _ { i } A _ { i j } \right ) \geqslant 1 \right ) \geqslant \delta \cdot n \\. \ \quad. \ \. \. \. \. \. \. \. \. \. \. \.$$
where si denotes the i th candidate viewpoint, with si = 1 indicating selection and si = 0 indicating non-selection; A is the m × n visibility matrix; δ denotes the preset target coverage ratio, which is the proportion of triangular meshes that can be observed at least once.
## C. Genetic-based hyper-heuristic algorithm
This paper proposes a new genetic-based hyper-heuristic algorithm, GA-HH, which utilizes a genetic algorithm as the high-level heuristic (HLH) and designs seven efficient lowlevel heuristic operators (LLH) based on the neighborhood structure. Using the genetic algorithm to manage low-level heuristics enhances robustness and flexibility compared to traditional heuristics. Additionally, the global search capability of the genetic strategy is strong, helping to prevent the algorithm from prematurely converging on local optima.
As shown in Fig. 7, the HLH does not directly solve the problem but instead manages LLHs to find the most effective heuristic operators for the task. Each element in the lowlevel heuristic vector represents a chosen operator aimed at
Fig. 7: GA-HH: Genetic-based hyper-heuristic algorithm.
improving the fitness of the solution vector. Notably, the label ' L 0' indicates that no operator is selected for that element. The solution vector s is a binary vector, where si denotes the i th candidate viewpoint, si = 1 means the viewpoint is selected, and si = 0 means it is not.
1) High-level heuristic: The genetic algorithm primarily consists of several components, including fitness evaluation, initialization, selection, crossover, and mutation [24].
Initialization: The initialization process sets up the solution and low-level heuristic vectors. In GA-HH, low-level heuristic vectors are randomly generated, while a greedy search-derived solution serves as the initial solution vector to quicken convergence.
Fitness Evaluation: This paper proposes a new fitness calculation method for the Set Covering Problem, enhancing the evolutionary guidance for genetic algorithms. Higher fitness indicates a better solution.
Before assessing fitness, we determine the number of times c each triangular mesh is covered and count the triangular meshes n cover that are covered at least once:
$$c = s \cdot A$$
$$n _ { \text{cover} } = \sum _ { i = 1 } ^ { n } [ c _ { i } \geq 1 ] \text{ \quad \ \ } ( 1 3 ) \text{ \quad \ }.$$
where s denotes the solution vector, A is the visibility matrix, [ ci ≥ 1 ] represents 1 if ci ≥ 1, otherwise 0.
The formula for fitness f is:
$$f = \begin{cases} ( m - \sum _ { i = 1 } ^ { m } s _ { i } ) + \left ( 1 - \frac { n _ { \text{cover} } } { \sum _ { i = 1 } ^ { n } c _ { i } } \right ), & \text{if $n_{\text{cover} } \geq \delta \cdot n$} \\ \frac { n _ { \text{cover} } } { \delta \cdot n }, & \text{if $n_{\text{cover} } < \delta \cdot n$} \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases} \quad ( 1 4 ) \quad \begin{cases} i \, \mathfrak { c } \\ \text{of} \\ \text{of} \end{cases}$$
where m is the number of candidate viewpoints. When n cover ≥ δ · n , it means that the number of covered triangular meshes has reached the preset value. The decimal part of fitness, 1 -n cover / ∑ n i = 1 ci , indicates the redundancy of the coverage. A higher redundancy implies that the selected viewpoint subset can cover the triangular meshes more times when the number of selected viewpoints is the same. Consequently, the solution vector is more likely to further reduce the number of selected viewpoints in subsequent evolution.
Selection: In genetic algorithms, individuals with higher fitness are more likely to be selected for reproduction. In this stage, roulette wheel selection is used as:
$$P _ { i } = \frac { f _ { i } } { \sum _ { i = 1 } ^ { k } f _ { i } } \quad \quad ( 1 5 )$$
where f i denotes individual fitness and k denotes population size. During this process, both low-level heuristic vectors and solution vectors need to be replicated synchronously.
Crossover and Mutation: During these stages, only lowlevel heuristic vectors are modified, excluding solution vectors. GA-HH utilizes a segmented crossover strategy by randomly selecting two points and swapping the intervening elements with their neighbors. The mutation involves a 'onepoint' approach, randomly mutating one element.
Generating New Solution Vectors: After the low-level heuristic vectors are updated through crossover and mutation, they are used to generate new solution vectors. Each element in the low-level heuristic vector represents a low-level heuristic operator, and these operators are used to update the solution vector. If an element is 0, no operator is selected.
2) Low-level heuristics: Low-level heuristics play a crucial role in bridging the high-level heuristic and the problem solution, and their design significantly impacts the effectiveness of GA-HH. In this paper, seven simple and efficient low-level heuristic operators are designed as follows:
- · LLH1 (random-mutation): This operator randomly selects one element from the solution vector and flips its value. It introduces variability into the solution set and helps prevent the algorithm from stagnating.
- · LLH2 (random-swap): This operator randomly selects two elements from the solution vector and swaps their values, thus enhancing diversity in the solutions by rearranging existing components.
- · LLH3 (section-crossover): For a given solution vector S 1, this operator selects an adjacent solution vector S 2, randomly generates two index values, and swaps the element values between these indices in S 1 and S 2 to generate a new solution. It combines traits from both vectors, potentially leading to better solutions.
- · LLH4 (adjacent-scattered-crosscover): Inspired by existing research [18], this operator takes a solution vector S 1 and an adjacent vector S 2 and creates a random bitmask of the same size as the solution. If the value at position i of the mask is 1, the new solution copies the i th value of S 1(i.e., S 0 [ ] = i S 1 [ ] i ), otherwise it copies the i th value of S 2. It selectively blending their features to form a new solution.
- · LLH5 (random-scattered-crosscover): Similar to LLH4, this operator uses a random bitmask but selects another solution vector S 2 randomly for the crossover. This increases the diversity by mixing features from potentially non-adjacent solutions, expanding the search space explored by the algorithm.
- · LLH6 (fusion-crosscover): Inspired by literature [25], this operator is similar to LLH4 but adjusts the number of 1s in the random bitmask proportionally to the fitness of the solutions S 1 and S 2. This method aims to preserve more advantageous traits from the fitter solution, enhancing the quality of the generated solutions.

(a) Target building 1: bounding box size is 81 x 81 x 46 meters


(b) Target building 2: bounding box size is 81 x 82 x 171 meters
(c) Target building 3: bounding box size is 94 x 77 x 21 meters
(d) Target building 4: bounding box size is 92 x 77 x 74 meters
Fig. 8: Triangular mesh model and bounding box of the target building.
- · LLH7 (multi-section-crossover): Extending the concept of LLH3, this operator selects multiple pairs of index values for a given solution vector S 1 and an adjacent solution vector S 2 and swaps the element values between these indices. This allows for more complex combinations of their features and increases the potential for creating highly optimized solutions.
TABLE I: Comparison of view planning results (a) Number of resultant viewpoints
## IV. EXPERIMENTAL RESULTS
In our experiments, we compared our method with the random sampling method [1] using four different building models and sensor parameters. Results show that our method requires fewer viewpoints and achieves better coverage than random sampling.
## A. Setup
Fig. 8 shows four different target building models used to verify the effectiveness of our proposed method. In the comparative experiments, the preset target coverage is 100%, i.e., δ = 1. Additionally, we set up several sensor parameters for comparative testing during the experiment, i.e., we use the maximum field of depth (FOD) of 30 meters and 40 meters, and the maximum field of view (FOV) of 70 ◦ and 80 ◦ respectively for view planning experiments.
Candidate viewpoints are generated using both the clustering-based method proposed in this paper as well as the random sampling method, followed by the application of the same optimization algorithm. Both methods are executed 10 times with varying parameters in the experiments to illustrate the statistical comparison results.
## B. Results
Fig. 9 shows the relationship between the number of sampled candidate viewpoints and the uncovered area ratio, comparing two methods with varied sensor parameters settings. The curves are results fitted from experimental data, indicating that the proposed method consistently achieves better coverage and faster convergence by effectively utilizing the geometric information of the target building through spectral clustering. Conversely, the randomness of the random sampling method and hidden corners in the target structure may extend the time required for view planning.
As shown in Table Ia, for four different building models, the proposed method reduces the number of required
| params | building1 | building1 | building2 | building2 | building3 | building3 | building4 | building4 |
|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|
| | Base- line | Pro- pose | Base- line | Pro- pose | Base- line | Pro- pose | Base- line | Pro- pose |
| (30, 80 ◦ ) | 69.0 | 52.7 | 132.3 | 101.9 | 110.7 | 78.3 | 101.6 | 82.6 |
| (30, 70 ◦ ) | 85.2 | 64.1 | 160.4 | 123.1 | 136.7 | 95.6 | 120.5 | 95.8 |
| (40, 80 ◦ ) | 45.2 | 35.2 | 88.3 | 71.9 | 67.9 | 63.3 | 66.9 | 57.5 |
| (40, 70 ◦ ) | 54.9 | 42.3 | 103.6 | 86.0 | 88.8 | 72.8 | 79.0 | 64.9 |
(b) Time efficiency comparison (unit: seconds)
| params | building1 | building1 | building2 | building2 | building3 | building3 | building4 | building4 |
|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|
| params | Base- line | Pro- pose | Base- line | Pro- pose | Base- line | Pro- pose | Base- line | Pro- pose |
| (30, 80 ◦ ) | 36.95 | 56.33 | 30.02 | 25.95 | 28.92 | 20.45 | 63.18 | 65.00 |
| (30, 70 ◦ ) | 35.53 | 58.04 | 37.78 | 29.56 | 36.83 | 21.91 | 64.12 | 71.68 |
| (40, 80 ◦ ) | 53.23 | 63.49 | 39.12 | 63.99 | 41.48 | 30.06 | 88.14 | 72.10 |
| (40, 70 ◦ ) | 47.79 | 60.43 | 41.47 | 60.42 | 52.44 | 31.46 | 91.05 | 115.80 |
viewpoints by 23.4%, 20.4%, 21.0%, and 17.78%, with an average reduction of 20.65%, compared to the random sampling method. Under different target building models and sensor parameters, the time consumption comparison between the two methods shows varying advantages, as shown in Table Ib. In all experimental groups, both methods achieved 100% coverage.
Based on these results, we can infer that the proposed view planning method achieves higher coverage with fewer required viewpoints and does not result in a significant increase in computational costs, making it superior to existing methods. Fig. 10 shows an example of the 3D visualization results from the proposed method for planning viewpoints.
To assess the effectiveness of the newly proposed geneticbased hyper-heuristic algorithm, we compared it with a commonly used combinatorial optimization algorithm, i.e., the genetic algorithm. Both algorithms are initialized with the same population size, and their crossover and mutation probabilities are adjusted respectively to achieve optimal performance. The genetic algorithm employed in the comparison has a similar high-level heuristic strategy to GAHH. Based on the ten sets of experimental data under the first set of sensor parameters shown in Fig. 9a, we obtained five optimization results for each optimization algorithm and
(d) Target building 4
Fig. 9: Percentage ratios of uncovered areas with different number of generated candidate viewpoints. The proposed method is labeled as 'Proposed' (shown in blue); the method based on random sampling is labeled as 'Baseline' (shown in red). fod is the maximum viewing distance and fov is the maximum viewing angle. The x-axis is the number of generated candidate viewpoints, the y-axis is the non-coverage rate, and the smaller the y-axis value, the better.
Fig. 10: Resulting viewpoints and 3D visualization of the target building.
TABLE II: Optimization results
| groups | viewpoints number | viewpoints number | iteration number | iteration number |
|----------|---------------------|---------------------|--------------------|--------------------|
| | GA | GA-HH | GA | GA-HH |
| 1 | 49.0 | 49.0 | 119.0 | 45.8 |
| 2 | 48.0 | 48.0 | 47.0 | 35.8 |
| 3 | 48.0 | 48.0 | 17.6 | 18.4 |
| 4 | 53.0 | 53.0 | 45.0 | 33.8 |
| 5 | 50.0 | 50.0 | 88.4 | 71.0 |
| 6 | 52.0 | 52.0 | 82.0 | 42.4 |
| 7 | 54.4 | 54.0 | 68.6 | 49.2 |
| 8 | 53.0 | 53.0 | 42.4 | 26.4 |
| 9 | 52.0 | 52.0 | 68.8 | 48.4 |
| 10 | 54.0 | 54.0 | 43.4 | 42.6 |
| averages | 51.34 | 51.30 | 62.22 | 41.38 |
calculated the average value as the result. As shown in Table II, the focus of the comparison was on the number of optimized viewpoints and the number of iterations required to reach the optimal solution. The results indicate that GAHH converges more rapidly and is less likely to fall into local optima compared to the traditional genetic algorithm.
## V. CONCLUSIONS
This paper proposes a new clustering-based view planning method for drone 3D visual coverage aimed at building surface inspection. Candidate viewpoints are efficiently generated based on spectral clustering and the local potential field method, and the problem is converted into a Set Covering Problem by calculating the visibility matrix, which is then solved with a genetic-based hyper-heuristic algorithm.
Experimental results demonstrate that the proposed method generates higher quality candidate viewpoints compared to previous approaches, achieving greater coverage with fewer viewpoints and enabling more effective planning. In future work, we plan to explore coverage path planning based on this view planning method, aiming to optimize for the shortest drone inspection path or the least time, thereby enhancing the efficiency of building surface detection.
## REFERENCES
- [1] W. Jing, J. Polden, W. Lin, and K. Shimada, 'Sampling-based view planning for 3d visual coverage task with unmanned aerial vehicle,' in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2016, pp. 1808-1815.
- [2] Y. Tan, S. Li, H. Liu, P. Chen, and Z. Zhou, 'Automatic inspection data collection of building surface based on bim and uav,' Automation in Construction , vol. 131, p. 103881, 2021.
- [3] H. Liu, Y. P. Tsang, C. K. Lee, and C. H. Wu, 'Uav trajectory planning via viewpoint resampling for autonomous remote inspection of industrial facilities,' IEEE Transactions on Industrial Informatics , 2024.
- [4] M. Lauri, J. Pajarinen, J. Peters, and S. Frintrop, 'Multi-sensor nextbest-view planning as matroid-constrained submodular maximization,' IEEE Robotics and Automation Letters , vol. 5, no. 4, pp. 5323-5330, 2020.
- [5] T. Kouteck` y, D. Palouˇ sek, and J. Brandejs, 'Sensor planning system for fringe projection scanning of sheet metal parts,' Measurement , vol. 94, pp. 60-70, 2016.
- [6] W. R. Scott, G. Roth, and J.-F. Rivest, 'View planning for automated three-dimensional object reconstruction and inspection,' ACM Computing Surveys (CSUR) , vol. 35, no. 1, pp. 64-96, 2003.
- [7] S. Chen, Y. Li, and N. M. Kwok, 'Active vision in robotic systems: A survey of recent developments,' The International Journal of Robotics Research , vol. 30, no. 11, pp. 1343-1377, 2011.
- [8] W. Jing and K. Shimada, 'Model-based view planning for building inspection and surveillance using voxel dilation, medial objects, and random-key genetic algorithm,' Journal of Computational Design and Engineering , vol. 5, no. 3, pp. 337-347, 2018.
- [9] M. Maboudi, M. Homaei, S. Song, S. Malihi, M. Saadatseresht, and M. Gerke, 'A review on viewpoints and path planning for uav-based 3d reconstruction,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2023.
- [10] M. Naazare, F. G. Rosas, and D. Schulz, 'Online next-best-view planner for 3d-exploration and inspection with a mobile manipulator robot,' IEEE Robotics and Automation Letters , vol. 7, no. 2, pp. 37793786, 2022.
- [11] W. R. Scott, 'Model-based view planning,' Machine Vision and Applications , vol. 20, no. 1, pp. 47-69, 2009.
- [12] Y. Choi, Y. Choi, S. Briceno, and D. N. Mavris, 'Three-dimensional uas trajectory optimization for remote sensing in an irregular terrain environment,' in 2018 International Conference on Unmanned Aircraft Systems (ICUAS) . IEEE, 2018, pp. 1101-1108.
- [13] Y. Wang, T. Peng, W. Wang, and M. Luo, 'High-efficient view planning for surface inspection based on parallel deep reinforcement learning,' Advanced Engineering Informatics , vol. 55, p. 101849, 2023.
- [14] L. Weerasena, A. Ebiefung, and A. Skjellum, 'Design of a heuristic algorithm for the generalized multi-objective set covering problem,' Computational Optimization and Applications , vol. 82, no. 3, pp. 717751, 2022.
- [15] T. Dokeroglu, T. Kucukyilmaz, and E.-G. Talbi, 'Hyper-heuristics: A survey and taxonomy,' Computers & Industrial Engineering , p. 109815, 2023.
- [16] G. Rivera, L. Cruz-Reyes, E. Fernandez, C. Gomez-Santillan, N. Rangel-Valdez, and C. A. C. Coello, 'An aco-based hyper-heuristic for sequencing many-objective evolutionary algorithms that consider different ways to incorporate the dm's preferences,' Swarm and Evolutionary Computation , vol. 76, p. 101211, 2023.
- [17] S. Zhang, Y. Xu, and W. Zhang, 'Multitask-oriented manufacturing service composition in an uncertain environment using a hyperheuristic algorithm,' Journal of Manufacturing Systems , vol. 60, pp. 138-151, 2021.
- [18] A. S. Ferreira, A. Pozo, R. A. Gonc ¸alves et al. , 'An ant colony based hyper-heuristic approach for the set covering problem,' Advances in Distributed Computing and Artificial Intelligence Journal , vol. 4, no. 1, pp. 1-21, 2015.
- [19] A. Ng, M. Jordan, and Y. Weiss, 'On spectral clustering: Analysis and an algorithm,' Advances in neural information processing systems , vol. 14, 2001.
- [20] T. He, S. Zhu, H. Wang, J. Wang, and T. Qing, 'The diagnosis of satellite flywheel bearing cage fault based on two-step clustering of multiple acoustic parameters,' Measurement , vol. 201, p. 111683, 2022.
- [21] J. Shi and J. Malik, 'Normalized cuts and image segmentation,' IEEE Transactions on pattern analysis and machine intelligence , vol. 22, no. 8, pp. 888-905, 2000.
- [22] Y. Tian, X. Zhu, D. Meng, X. Wang, and B. Liang, 'An overall configuration planning method of continuum hyper-redundant manipulators based on improved artificial potential field method,' IEEE Robotics and Automation Letters , vol. 6, no. 3, pp. 4867-4874, 2021.
- [23] T. M¨ oller and B. Trumbore, 'Fast, minimum storage ray/triangle intersection,' in ACM SIGGRAPH 2005 Courses , 2005, p. 7.
- [24] E. C. Revuelta, M.-J. Ch´ avez, J. A. B. Vera, Y. F. Rodr´ ıguez, and M. C. S´ anchez, 'Optimization of laser scanner positioning networks for architectural surveys through the design of genetic algorithms,' Measurement , vol. 174, p. 108898, 2021.
- [25] K. Wang, Y. Gong, Y. Peng, C. Hu, and N. Chen, 'An improved fusion crossover genetic algorithm for a time-weighted maximal covering location problem for sensor siting under satellite-borne monitoring,' Computers & Geosciences , vol. 136, p. 104406, 2020. | null | [
"Yongshuai Zheng",
"Guoliang Liu",
"Yan Ding",
"Guohui Tian"
]
| 2024-07-19T04:11:03+00:00 | 2024-07-19T04:11:03+00:00 | [
"cs.CV",
"cs.RO"
]
| A New Clustering-based View Planning Method for Building Inspection with Drone | With the rapid development of drone technology, the application of drones
equipped with visual sensors for building inspection and surveillance has
attracted much attention. View planning aims to find a set of near-optimal
viewpoints for vision-related tasks to achieve the vision coverage goal. This
paper proposes a new clustering-based two-step computational method using
spectral clustering, local potential field method, and hyper-heuristic
algorithm to find near-optimal views to cover the target building surface. In
the first step, the proposed method generates candidate viewpoints based on
spectral clustering and corrects the positions of candidate viewpoints based on
our newly proposed local potential field method. In the second step, the
optimization problem is converted into a Set Covering Problem (SCP), and the
optimal viewpoint subset is solved using our proposed hyper-heuristic
algorithm. Experimental results show that the proposed method is able to obtain
better solutions with fewer viewpoints and higher coverage. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.