
SecureBERT: A Domain-Specific Language Model for Cybersecurity
SecureBERT is a RoBERTa-based, domain-specific language model trained on a large cybersecurity-focused corpus. It is designed to represent and understand cybersecurity text more effectively than general-purpose models.
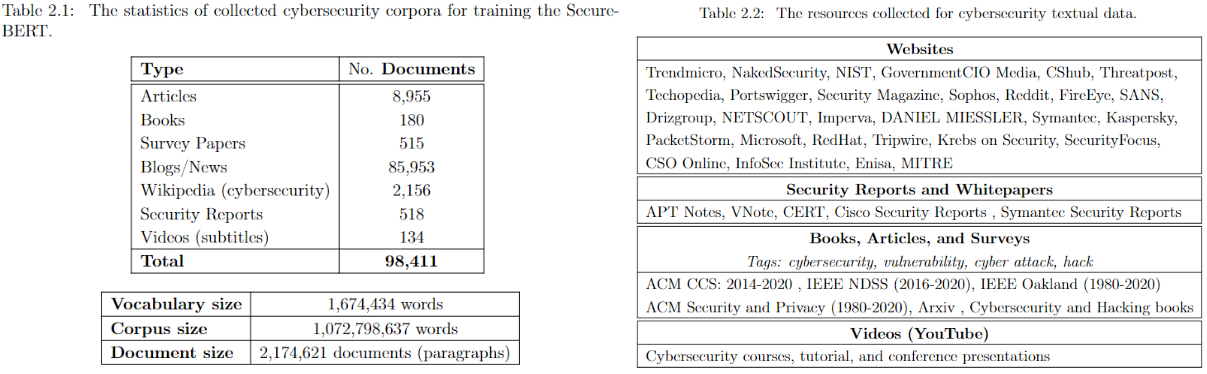
SecureBERT was trained on extensive in-domain data crawled from diverse online resources. It has demonstrated strong performance in a range of cybersecurity NLP tasks.
👉 See the presentation on YouTube.
👉 Explore details on the GitHub repository.
Applications
SecureBERT can be used as a base model for downstream NLP tasks in cybersecurity, including:
- Text classification
- Named Entity Recognition (NER)
- Sequence-to-sequence tasks
- Question answering
Key Results
- Outperforms baseline models such as RoBERTa (base/large), SciBERT, and SecBERT in masked language modeling tasks within the cybersecurity domain.
- Maintains strong performance in general English language understanding, ensuring broad usability beyond domain-specific tasks.
Using SecureBERT
The model is available on Hugging Face.
Load the Model
from transformers import RobertaTokenizer, RobertaModel
import torch
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT")
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT")
inputs = tokenizer("This is SecureBERT!", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
Masked Language Modeling Example
SecureBERT is trained with Masked Language Modeling (MLM). Use the following example to predict masked tokens:
#!pip install transformers torch tokenizers
import torch
import transformers
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT")
model = transformers.RobertaForMaskedLM.from_pretrained("ehsanaghaei/SecureBERT")
def predict_mask(sent, tokenizer, model, topk=10, print_results=True):
token_ids = tokenizer.encode(sent, return_tensors='pt')
masked_pos = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero().tolist()
words = []
with torch.no_grad():
output = model(token_ids)
for pos in masked_pos:
logits = output.logits[0, pos]
top_tokens = torch.topk(logits, k=topk).indices
predictions = [tokenizer.decode(i).strip().replace(" ", "") for i in top_tokens]
words.append(predictions)
if print_results:
print(f"Mask Predictions: {predictions}")
return words
Limitations & Risks
Domain-Specific Bias: SecureBERT is trained primarily on cybersecurity-related text. It may underperform on tasks outside this domain compared to general-purpose models.
Data Quality: The training data was collected from online sources. As such, it may contain inaccuracies, outdated terminology, or biased representations of cybersecurity threats and behaviors.
Potential Misuse: While the model is intended for defensive cybersecurity research, it could potentially be misused to generate malicious text (e.g., obfuscating malware descriptions or aiding adversarial tactics).
Not a Substitute for Expertise: Predictions made by the model should not be considered authoritative. Cybersecurity professionals must validate results before applying them in critical systems or operational contexts.
Evolving Threat Landscape: Cyber threats evolve rapidly, and the model may become outdated without continuous retraining on fresh data.
Users should apply SecureBERT responsibly, keeping in mind its limitations and the need for human oversight in all security-critical applications.
Reference
@inproceedings{aghaei2023securebert,
title={SecureBERT: A Domain-Specific Language Model for Cybersecurity},
author={Aghaei, Ehsan and Niu, Xi and Shadid, Waseem and Al-Shaer, Ehab},
booktitle={Security and Privacy in Communication Networks:
18th EAI International Conference, SecureComm 2022, Virtual Event, October 2022, Proceedings},
pages={39--56},
year={2023},
organization={Springer}
}
- Downloads last month
- 4,116