
XEUS Model and Data
Collection
Data and models used for EMNLP 2024 Best Paper "Towards Robust Speech Representation Learning for Thousands of Languages" • 5 items • Updated
XEUS - A Cross-lingual Encoder for Universal Speech
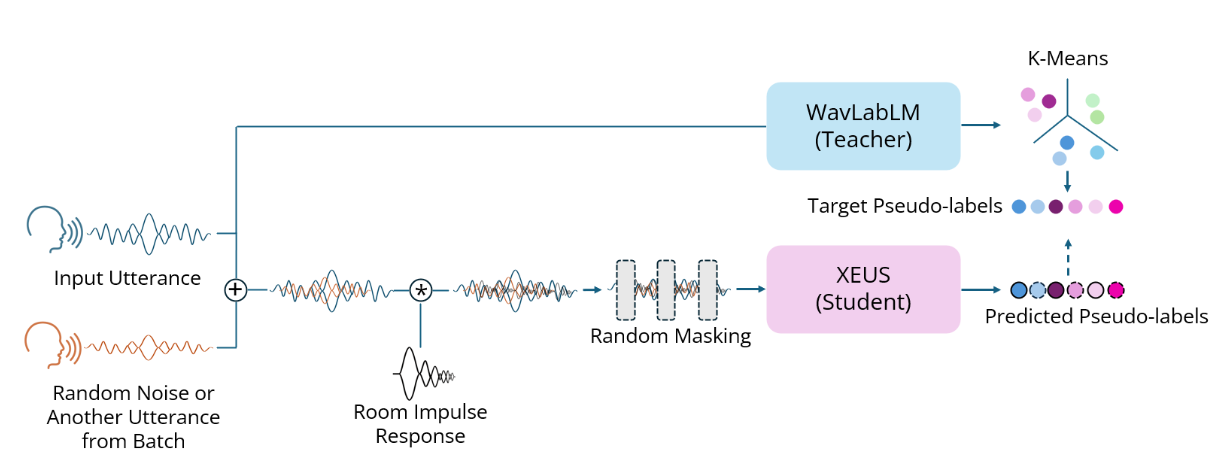
XEUS is a large-scale multilingual speech encoder by Carnegie Mellon University's WAVLab that covers over 4000 languages. It is pre-trained on over 1 million hours of publicly available speech datasets. It requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation. Its hidden states can also be used with k-means for semantic Speech Tokenization. XEUS uses the E-Branchformer architecture and is trained using HuBERT-style masked prediction of discrete speech tokens extracted from WavLabLM. During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
XEUS tops the ML-SUPERB multilingual speech recognition leaderboard, outperforming MMS, w2v-BERT 2.0, and XLS-R. XEUS also sets a new state-of-the-art on 4 tasks in the monolingual SUPERB benchmark.
More information about XEUS, including download links for our crawled 4000-language dataset, can be found in the project page and paper.
The code for XEUS is still in progress of being merged into the main ESPnet repo. It can instead be used from the following fork:
pip install 'espnet @ git+https://github.com/wanchichen/espnet.git@ssl'
git lfs install
git clone https://huggingface.co/espnet/XEUS
XEUS supports Flash Attention, which can be installed as follows:
pip install flash-attn --no-build-isolation
from torch.nn.utils.rnn import pad_sequence
from espnet2.tasks.ssl import SSLTask
import soundfile as sf
device = "cuda" if torch.cuda.is_available() else "cpu"
xeus_model, xeus_train_args = SSLTask.build_model_from_file(
None,
'/path/to/checkpoint/here/checkpoint.pth',
device,
)
wavs, sampling_rate = sf.read('/path/to/audio.wav') # sampling rate should be 16000
wav_lengths = torch.LongTensor([len(wav) for wav in [wavs]]).to(device)
wavs = pad_sequence(torch.Tensor([wavs]), batch_first=True).to(device)
# we recommend use_mask=True during fine-tuning
feats = xeus_model.encode(wavs, wav_lengths, use_mask=False, use_final_output=False)[0][-1] # take the output of the last layer -> batch_size x seq_len x hdim
With Flash Attention:
[layer.use_flash_attn = True for layer in xeus_model.encoder.encoders]
with torch.cuda.amp.autocast(dtype=torch.bfloat16):
feats = xeus_model.encode(wavs, wav_lengths, use_mask=False, use_final_output=False)[0][-1]
Tune the masking settings:
xeus_model.masker.mask_prob = 0.65 # default 0.8
xeus_model.masker.mask_length = 20 # default 10
xeus_model.masker.mask_selection = 'static' # default 'uniform'
xeus_model.train()
feats = xeus_model.encode(wavs, wav_lengths, use_mask=True, use_final_output=False)[0][-1]


@misc{chen2024robustspeechrepresentationlearning,
title={Towards Robust Speech Representation Learning for Thousands of Languages},
author={William Chen and Wangyou Zhang and Yifan Peng and Xinjian Li and Jinchuan Tian and Jiatong Shi and Xuankai Chang and Soumi Maiti and Karen Livescu and Shinji Watanabe},
year={2024},
eprint={2407.00837},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.00837},
}