

metadata
license: apache-2.0
datasets:
- asset
- wi_locness
- GEM/wiki_auto_asset_turk
- discofuse
- zaemyung/IteraTeR_plus
- jfleg
language:
- en
metrics:
- sari
- bleu
- accuracy
Model Card for CoEdIT-xl-composite
This model was obtained by fine-tuning the corresponding google/flan-t5-xl model on the CoEdIT-Composite dataset. Details of the dataset can be found in our paper and repository.
Paper: CoEdIT: Text Editing by Task-Specific Instruction Tuning
Authors: Vipul Raheja, Dhruv Kumar, Ryan Koo, Dongyeop Kang
Model Details
Model Description
- Language(s) (NLP): English
- Finetuned from model: google/flan-t5-xl
Model Sources [optional]
- Repository: https://github.com/vipulraheja/coedit
- Paper [optional]: [More Information Needed]
How to use
We make available the models presented in our paper.
| Model | Number of parameters |
|---|---|
| CoEdIT-large | 770M |
| CoEdIT-xl | 3B |
| CoEdIT-xxl | 11B |
Uses
Text Revision Task
Given an edit instruction and an original text, our model can generate the edited version of the text.
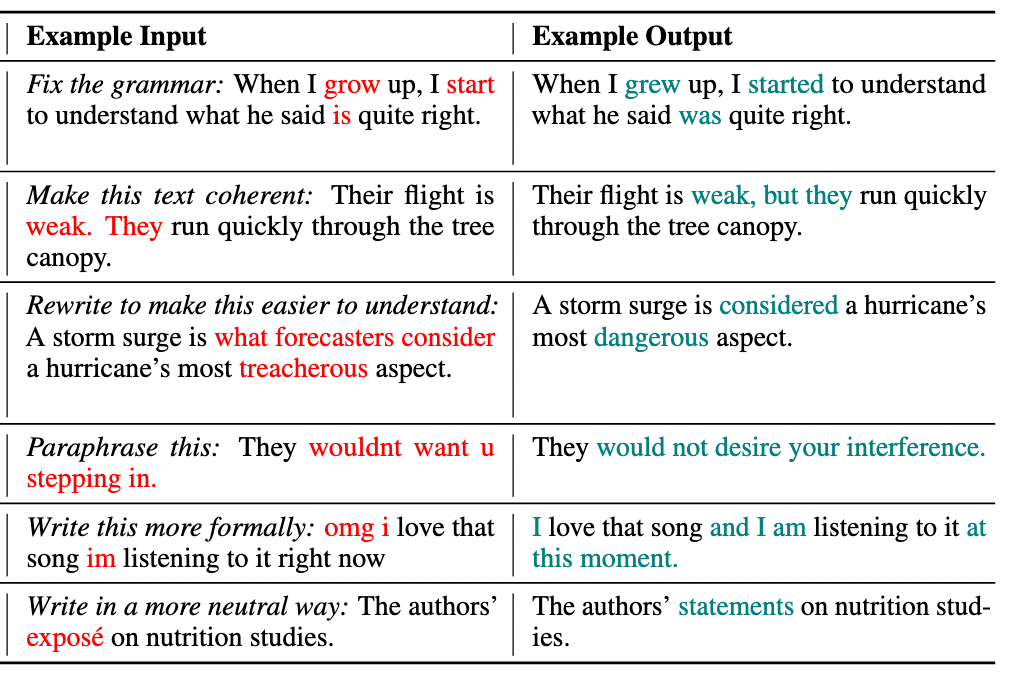
This model can also perform edits on composite instructions, as shown below:

Usage
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("grammarly/coedit-xl-composite")
model = T5ForConditionalGeneration.from_pretrained("grammarly/coedit-xl-composite")
input_text = 'Fix grammatical errors in this sentence and make it simpler: New kinds of vehicles will be invented with new technology than today.'
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=256)
edited_text = tokenizer.decode(outputs[0], skip_special_tokens=True)[0]
Software
https://github.com/vipulraheja/coedit
Citation
BibTeX:
[More Information Needed]
APA:
[More Information Needed]