
Jet-Nemotron
Collection
2 items
•
Updated
•
15




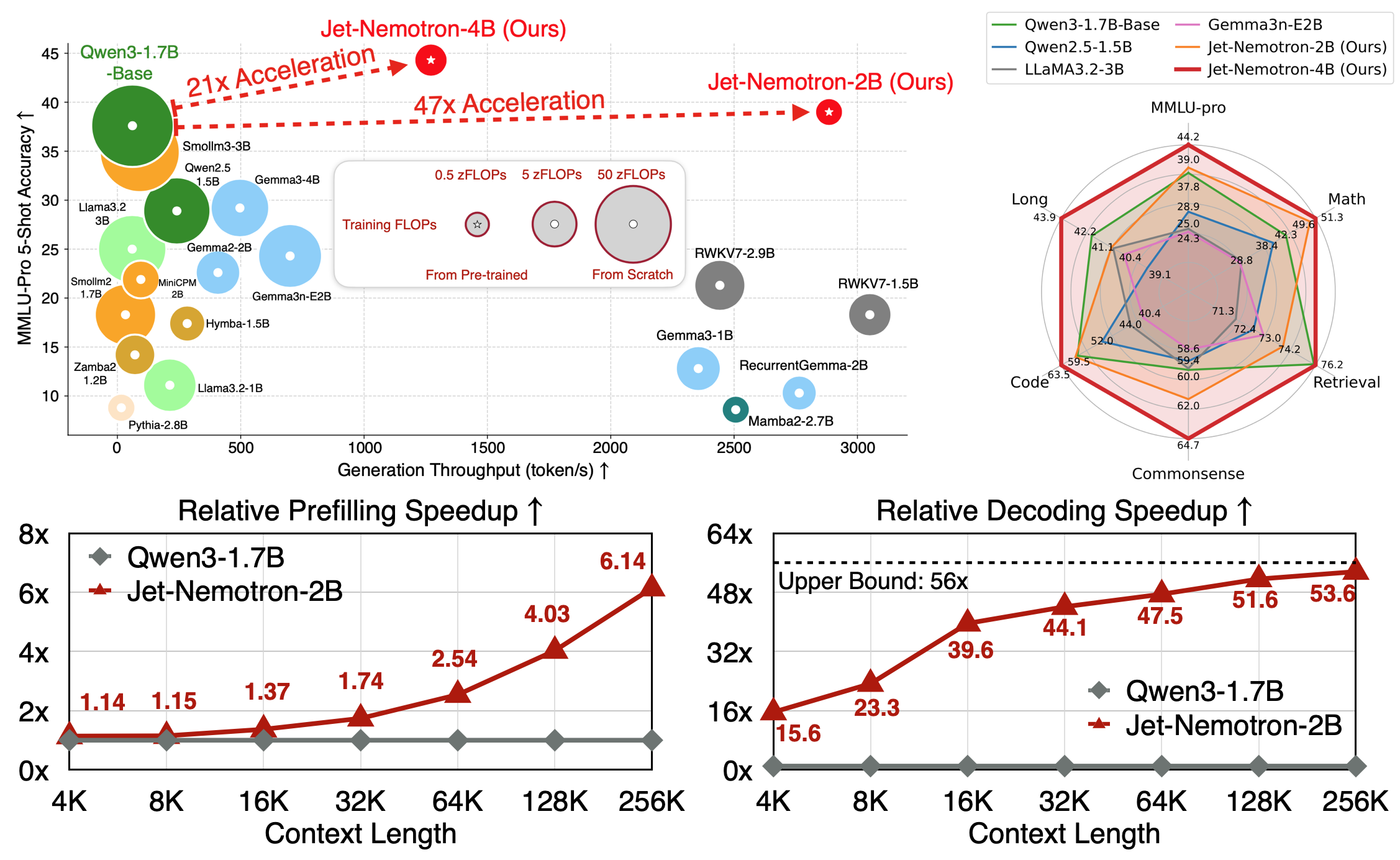
Jet-Nemotron is a new family of hybrid-architecture language models that surpass state-of-the-art open-source full-attention language models such as Qwen3, Qwen2.5, Gemma3, and Llama3.2, while achieving significant efficiency gains—up to 53.6× speedup in generation throughput on H100 GPUs (256K context length, maximum batch size). It is built upon two core innovations:
flash-attn
torch<=2.7.1
transformers<=4.53.0
flash-attn
accelerate
datasets==4.0.0
jieba
fuzzywuzzy
rouge
python-Levenshtein
flash-linear-attention@git+https://github.com/jet-ai-projects/flash-linear-attention.git@jetai
lm_eval@git+https://github.com/jet-ai-projects/lm-evaluation-harness.git@jetai
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "jet-ai/Jet-Nemotron-4B"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = model.eval().cuda()
input_str = "Hello, I'm Jet-Nemotron from NVIDIA."
input_ids = tokenizer(input_str, return_tensors="pt").input_ids.cuda()
output = model.generate(input_ids, max_new_tokens=50, do_sample=False)
output_str = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_str)
| Jet-Nemotron-4B | Jet-Nemotron-2B | Qwen3-1.7B-Base | Llama3-3B | Gemma3n-E2B | ||
|---|---|---|---|---|---|---|
| General | MMLU | 65.2 | 60.8 | 60.3 | 54.9 | 53.9 |
| MMLU-pro | 44.2 | 39.0 | 37.8 | 25.0 | 24.3 | |
| BBH | 65.0 | 58.3 | 54.2 | 47.1 | 45.1 | |
| ARC-C | 51.7 | 48.6 | 44.9 | 46.6 | 29.4 | |
| BoolQ | 83.0 | 81.2 | 79.0 | 73.9 | 76.0 | |
| Winogrande | 70.5 | 65.8 | 63.8 | 69.3 | 60.8 | |
| Math | GSM8K | 78.7 | 76.2 | 62.8 | 25.8 | 24.9 |
| Math | 25.2 | 23.3 | 16.7 | 8.6 | 10.1 | |
| MMLU-Stem | 65.6 | 62.7 | 50.8 | 45.3 | 45.7 | |
| Code | EvalPlus | 65.6 | 60.8 | 62.8 | 35.5 | 29.6 |
| CruXEval-I-Cot | 65.9 | 61.1 | 60.4 | 54.7 | 49.9 | |
| CruXEval-O-Cot | 59.0 | 56.7 | 53.4 | 41.7 | 41.6 | |
| Long-Context | LongBench | 43.9 | 41.1 | 42.2 | 39.9 | 40.4 |
| Efficiency | Cache Size (64k) | 258 | 154 | 7,168 | 7,168 | 768 |
| Max Throughput | 1,271 | 2,885 | 61 | 60 | 701 |
@article{gu2025jet,
title={Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search},
author={Gu, Yuxian and Hu, Qinghao and Yang, Shang and Xi, Haocheng and Chen, Junyu and Han, Song and Cai, Han},
journal={arXiv preprint arXiv:2508.15884},
year={2025}
}